
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-09-21 12:34:09
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 568
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-09-21 12:33:58
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
hobson123/blockassist-bc-mammalian_dense_gibbon_1755574354
|
hobson123
| 2025-08-19T03:38:36Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"mammalian dense gibbon",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T03:38:23Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- mammalian dense gibbon
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
NexVeridian/Kimi-VL-A3B-Thinking-2506-6bit
|
NexVeridian
| 2025-08-19T03:37:06Z | 0 | 0 |
mlx
|
[
"mlx",
"safetensors",
"kimi_vl",
"text-generation",
"conversational",
"custom_code",
"base_model:moonshotai/Kimi-VL-A3B-Thinking-2506",
"base_model:quantized:moonshotai/Kimi-VL-A3B-Thinking-2506",
"license:mit",
"6-bit",
"region:us"
] |
text-generation
| 2025-08-19T03:30:50Z |
---
base_model: moonshotai/Kimi-VL-A3B-Thinking-2506
license: mit
pipeline_tag: text-generation
library_name: mlx
tags:
- mlx
---
# NexVeridian/Kimi-VL-A3B-Thinking-2506-6bit
This model [NexVeridian/Kimi-VL-A3B-Thinking-2506-6bit](https://huggingface.co/NexVeridian/Kimi-VL-A3B-Thinking-2506-6bit) was
converted to MLX format from [moonshotai/Kimi-VL-A3B-Thinking-2506](https://huggingface.co/moonshotai/Kimi-VL-A3B-Thinking-2506)
using mlx-lm version **0.26.3**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("NexVeridian/Kimi-VL-A3B-Thinking-2506-6bit")
prompt = "hello"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
mradermacher/Nemesis-VLMer-7B-0818-i1-GGUF
|
mradermacher
| 2025-08-19T03:35:31Z | 0 | 1 |
transformers
|
[
"transformers",
"gguf",
"VLMer:Vision-Language Model for extended reasoning",
"text-generation-inference",
"VLR",
"en",
"base_model:prithivMLmods/Nemesis-VLMer-7B-0818",
"base_model:quantized:prithivMLmods/Nemesis-VLMer-7B-0818",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-08-19T01:19:22Z |
---
base_model: prithivMLmods/Nemesis-VLMer-7B-0818
language:
- en
library_name: transformers
license: apache-2.0
mradermacher:
readme_rev: 1
quantized_by: mradermacher
tags:
- VLMer:Vision-Language Model for extended reasoning
- text-generation-inference
- VLR
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/prithivMLmods/Nemesis-VLMer-7B-0818
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#Nemesis-VLMer-7B-0818-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/Nemesis-VLMer-7B-0818-GGUF
**This is a vision model - mmproj files (if any) will be in the [static repository](https://huggingface.co/mradermacher/Nemesis-VLMer-7B-0818-GGUF).**
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Nemesis-VLMer-7B-0818-i1-GGUF/resolve/main/Nemesis-VLMer-7B-0818.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/Nemesis-VLMer-7B-0818-i1-GGUF/resolve/main/Nemesis-VLMer-7B-0818.i1-IQ1_S.gguf) | i1-IQ1_S | 2.0 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Nemesis-VLMer-7B-0818-i1-GGUF/resolve/main/Nemesis-VLMer-7B-0818.i1-IQ1_M.gguf) | i1-IQ1_M | 2.1 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Nemesis-VLMer-7B-0818-i1-GGUF/resolve/main/Nemesis-VLMer-7B-0818.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.4 | |
| [GGUF](https://huggingface.co/mradermacher/Nemesis-VLMer-7B-0818-i1-GGUF/resolve/main/Nemesis-VLMer-7B-0818.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.6 | |
| [GGUF](https://huggingface.co/mradermacher/Nemesis-VLMer-7B-0818-i1-GGUF/resolve/main/Nemesis-VLMer-7B-0818.i1-IQ2_S.gguf) | i1-IQ2_S | 2.7 | |
| [GGUF](https://huggingface.co/mradermacher/Nemesis-VLMer-7B-0818-i1-GGUF/resolve/main/Nemesis-VLMer-7B-0818.i1-IQ2_M.gguf) | i1-IQ2_M | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/Nemesis-VLMer-7B-0818-i1-GGUF/resolve/main/Nemesis-VLMer-7B-0818.i1-Q2_K_S.gguf) | i1-Q2_K_S | 2.9 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/Nemesis-VLMer-7B-0818-i1-GGUF/resolve/main/Nemesis-VLMer-7B-0818.i1-Q2_K.gguf) | i1-Q2_K | 3.1 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Nemesis-VLMer-7B-0818-i1-GGUF/resolve/main/Nemesis-VLMer-7B-0818.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 3.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Nemesis-VLMer-7B-0818-i1-GGUF/resolve/main/Nemesis-VLMer-7B-0818.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Nemesis-VLMer-7B-0818-i1-GGUF/resolve/main/Nemesis-VLMer-7B-0818.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.6 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Nemesis-VLMer-7B-0818-i1-GGUF/resolve/main/Nemesis-VLMer-7B-0818.i1-IQ3_S.gguf) | i1-IQ3_S | 3.6 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Nemesis-VLMer-7B-0818-i1-GGUF/resolve/main/Nemesis-VLMer-7B-0818.i1-IQ3_M.gguf) | i1-IQ3_M | 3.7 | |
| [GGUF](https://huggingface.co/mradermacher/Nemesis-VLMer-7B-0818-i1-GGUF/resolve/main/Nemesis-VLMer-7B-0818.i1-Q3_K_M.gguf) | i1-Q3_K_M | 3.9 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Nemesis-VLMer-7B-0818-i1-GGUF/resolve/main/Nemesis-VLMer-7B-0818.i1-Q3_K_L.gguf) | i1-Q3_K_L | 4.2 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Nemesis-VLMer-7B-0818-i1-GGUF/resolve/main/Nemesis-VLMer-7B-0818.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.3 | |
| [GGUF](https://huggingface.co/mradermacher/Nemesis-VLMer-7B-0818-i1-GGUF/resolve/main/Nemesis-VLMer-7B-0818.i1-IQ4_NL.gguf) | i1-IQ4_NL | 4.5 | prefer IQ4_XS |
| [GGUF](https://huggingface.co/mradermacher/Nemesis-VLMer-7B-0818-i1-GGUF/resolve/main/Nemesis-VLMer-7B-0818.i1-Q4_0.gguf) | i1-Q4_0 | 4.5 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Nemesis-VLMer-7B-0818-i1-GGUF/resolve/main/Nemesis-VLMer-7B-0818.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.6 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Nemesis-VLMer-7B-0818-i1-GGUF/resolve/main/Nemesis-VLMer-7B-0818.i1-Q4_K_M.gguf) | i1-Q4_K_M | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Nemesis-VLMer-7B-0818-i1-GGUF/resolve/main/Nemesis-VLMer-7B-0818.i1-Q4_1.gguf) | i1-Q4_1 | 5.0 | |
| [GGUF](https://huggingface.co/mradermacher/Nemesis-VLMer-7B-0818-i1-GGUF/resolve/main/Nemesis-VLMer-7B-0818.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.4 | |
| [GGUF](https://huggingface.co/mradermacher/Nemesis-VLMer-7B-0818-i1-GGUF/resolve/main/Nemesis-VLMer-7B-0818.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.5 | |
| [GGUF](https://huggingface.co/mradermacher/Nemesis-VLMer-7B-0818-i1-GGUF/resolve/main/Nemesis-VLMer-7B-0818.i1-Q6_K.gguf) | i1-Q6_K | 6.4 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
twhitworth/gpt-oss-120b-awq-w4a16
|
twhitworth
| 2025-08-19T03:34:01Z | 0 | 2 | null |
[
"safetensors",
"gpt_oss",
"mixture-of-experts",
"activation-aware-weight-quantization",
"awq",
"w4a16",
"large-language-model",
"reasoning",
"long-context",
"en",
"base_model:openai/gpt-oss-120b",
"base_model:finetune:openai/gpt-oss-120b",
"license:apache-2.0",
"region:us"
] | null | 2025-08-16T00:02:12Z |
---
license: apache-2.0
type: model
base_model: openai/gpt-oss-120b
language: en
tags:
- gpt_oss
- mixture-of-experts
- activation-aware-weight-quantization
- awq
- w4a16
- large-language-model
- reasoning
- long-context
---
# gpt-oss-120b-awq-w4a16
_A 4-bit AWQ-quantised release of **gpt-oss-120b**_
> **TL;DR** – We convert the original FP16/FP32 checkpoint (≈ 234 GB) of **gpt-oss-120b** into a 4-bit weight-only model with 16-bit activations (**W4A16**).
> The resulting 11-shard safetensors bundle is **≈ 33.4 GB**, a **7× size reduction** with negligible quality loss.
---
## 1 Model details
| Property | Value |
|-------------------------------|-------|
| Architecture | Mixture-of-Experts Transformer |
| Total parameters | 117 B |
| Active parameters / token | 5.1 B |
| Layers | 36 |
| Experts | 128 (4 routed per token) |
| Hidden size / head dim | 2880 / 64 |
| Context window (max rope) | 131 072 tokens |
| Activation function | SwiGLU |
| Norm | RMSNorm (ε = 1e-5) |
| Rope scaling | YARN (θ = 150 000) |
| Training data cut-off | 2024-06-01 |
---
## 2 Quantisation recipe
### 2.1 Activation-Aware Weight Quantisation (AWQ)
AWQ protects the ~1 % most activation-sensitive channels by rescaling them **before** 4-bit rounding, vastly reducing quantisation error compared with vanilla GPTQ.
* **Post-training** – no back-prop; only a small calibration set is needed.
* **Weight-only** – activations stay at fp16/bf16.
* **Hardware-friendly** – single-kernel dequant, SIMD-aware packing, no mixed precision.
### 2.2 Layer precision map
| Module | Precision |
|------------------------------------------|-----------|
| All dense & attention weights | **int4** (AWQ) |
| LayerNorm, rotary embeddings, router MLP | fp16 |
| lm_head | fp16 |
### 2.3 Size breakdown
| Shard | Size (GB) | Shard | Size (GB) |
|-------|----------:|-------|----------:|
| 1 | 1.21 | 7 | 2.18 |
| 2 | 4.25 | 8 | 4.25 |
| 3 | 2.18 | 9 | 2.18 |
| 4 | 4.25 | 10 | 4.25 |
| 5 | 2.18 | 11 | 2.18 |
| 6 | 4.25 | **Total** | **33.36 GB** |
Compression vs original FP16 checkpoint:
```text
234 GB / 33.36 GB ≈ 7× smaller
|
Kokoutou/soundsright_1908_3
|
Kokoutou
| 2025-08-19T03:30:48Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-19T03:25:48Z |
# Container Template for SoundsRight Subnet Miners
This repository contains a contanierized version of [SGMSE+](https://huggingface.co/sp-uhh/speech-enhancement-sgmse) and serves as a tutorial for miners to format their models on [Bittensor's](https://bittensor.com/) [SoundsRight Subnet](https://github.com/synapsec-ai/SoundsRightSubnet). The branches `DENOISING_16000HZ` and `DEREVERBERATION_16000HZ` contain SGMSE fitted with the approrpriate checkpoints for denoising and dereverberation tasks at 16kHz, respectively.
This container has only been tested with **Ubuntu 24.04** and **CUDA 12.6**. It may run on other configurations, but it is not guaranteed.
To run the container, first configure NVIDIA Container Toolkit and generate a CDI specification. Follow the instructions to download the [NVIDIA Container Toolkit](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html) with Apt.
Next, follow the instructions for [generating a CDI specification](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/cdi-support.html).
Verify that the CDI specification was done correctly with:
```
$ nvidia-ctk cdi list
```
You should see this in your output:
```
nvidia.com/gpu=all
nvidia.com/gpu=0
```
If you are running podman as root, run the following command to start the container:
Run the container with:
```
podman build -t modelapi . && podman run -d --device nvidia.com/gpu=all --user root --name modelapi -p 6500:6500 modelapi
```
Access logs with:
```
podman logs -f modelapi
```
If you are running the container rootless, there are a few more changes to make:
First, modify `/etc/nvidia-container-runtime/config.toml` and set the following parameters:
```
[nvidia-container-cli]
no-cgroups = true
[nvidia-container-runtime]
debug = "/tmp/nvidia-container-runtime.log"
```
You can also run the following command to achieve the same result:
```
$ sudo nvidia-ctk config --set nvidia-container-cli.no-cgroups --in-place
```
Run the container with:
```
podman build -t modelapi . && podman run -d --device nvidia.com/gpu=all --volume /usr/local/cuda-12.6:/usr/local/cuda-12.6 --user 10002:10002 --name modelapi -p 6500:6500 modelapi
```
Access logs with:
```
podman logs -f modelapi
```
Running the container will spin up an API with the following endpoints:
1. `/status/` : Communicates API status
2. `/prepare/` : Download model checkpoint and initialize model
3. `/upload-audio/` : Upload audio files, save to noisy audio directory
4. `/enhance/` : Initialize model, enhance audio files, save to enhanced audio directory
5. `/download-enhanced/` : Download enhanced audio files
By default the API will use host `0.0.0.0` and port `6500`.
### References
1. **Welker, Simon; Richter, Julius; Gerkmann, Timo**
*Speech Enhancement with Score-Based Generative Models in the Complex STFT Domain*.
Proceedings of *Interspeech 2022*, 2022, pp. 2928–2932.
[DOI: 10.21437/Interspeech.2022-10653](https://doi.org/10.21437/Interspeech.2022-10653)
2. **Richter, Julius; Welker, Simon; Lemercier, Jean-Marie; Lay, Bunlong; Gerkmann, Timo**
*Speech Enhancement and Dereverberation with Diffusion-based Generative Models*.
*IEEE/ACM Transactions on Audio, Speech, and Language Processing*, Vol. 31, 2023, pp. 2351–2364.
[DOI: 10.1109/TASLP.2023.3285241](https://doi.org/10.1109/TASLP.2023.3285241)
3. **Richter, Julius; Wu, Yi-Chiao; Krenn, Steven; Welker, Simon; Lay, Bunlong; Watanabe, Shinjii; Richard, Alexander; Gerkmann, Timo**
*EARS: An Anechoic Fullband Speech Dataset Benchmarked for Speech Enhancement and Dereverberation*.
Proceedings of *ISCA Interspeech*, 2024, pp. 4873–4877.
|
NexVeridian/Kimi-VL-A3B-Thinking-2506-5bit
|
NexVeridian
| 2025-08-19T03:30:29Z | 0 | 0 |
mlx
|
[
"mlx",
"safetensors",
"kimi_vl",
"text-generation",
"conversational",
"custom_code",
"base_model:moonshotai/Kimi-VL-A3B-Thinking-2506",
"base_model:quantized:moonshotai/Kimi-VL-A3B-Thinking-2506",
"license:mit",
"5-bit",
"region:us"
] |
text-generation
| 2025-08-19T03:25:12Z |
---
base_model: moonshotai/Kimi-VL-A3B-Thinking-2506
license: mit
pipeline_tag: text-generation
library_name: mlx
tags:
- mlx
---
# NexVeridian/Kimi-VL-A3B-Thinking-2506-5bit
This model [NexVeridian/Kimi-VL-A3B-Thinking-2506-5bit](https://huggingface.co/NexVeridian/Kimi-VL-A3B-Thinking-2506-5bit) was
converted to MLX format from [moonshotai/Kimi-VL-A3B-Thinking-2506](https://huggingface.co/moonshotai/Kimi-VL-A3B-Thinking-2506)
using mlx-lm version **0.26.3**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("NexVeridian/Kimi-VL-A3B-Thinking-2506-5bit")
prompt = "hello"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
Akshaykumarbm/OpenAssisted-English-Mistral-7b-starting-epos
|
Akshaykumarbm
| 2025-08-19T03:27:36Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T03:26:00Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
lisaozill03/blockassist-bc-rugged_prickly_alpaca_1755572486
|
lisaozill03
| 2025-08-19T03:26:03Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"rugged prickly alpaca",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T03:26:00Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- rugged prickly alpaca
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
lejonck/xlsr53-mupe-1
|
lejonck
| 2025-08-19T03:25:57Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:facebook/wav2vec2-large-xlsr-53-portuguese",
"base_model:finetune:facebook/wav2vec2-large-xlsr-53-portuguese",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-08-19T03:25:20Z |
---
library_name: transformers
license: apache-2.0
base_model: facebook/wav2vec2-large-xlsr-53-portuguese
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: xlsr53-mupe-1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlsr53-mupe-1
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53-portuguese](https://huggingface.co/facebook/wav2vec2-large-xlsr-53-portuguese) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5001
- Wer: 0.5465
- Cer: 0.3049
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 12
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|
| 1.3239 | 1.0 | 2000 | 1.5103 | 0.6366 | 0.3503 |
| 1.156 | 2.0 | 4000 | 1.4288 | 0.6022 | 0.3261 |
| 0.958 | 3.0 | 6000 | 1.4058 | 0.5893 | 0.3214 |
| 1.2899 | 4.0 | 8000 | 1.4745 | 0.5743 | 0.3122 |
| 0.856 | 5.0 | 10000 | 1.4086 | 0.5684 | 0.3195 |
| 0.9923 | 6.0 | 12000 | 1.4499 | 0.5651 | 0.3086 |
| 0.9734 | 7.0 | 14000 | 1.4358 | 0.5579 | 0.3089 |
| 1.084 | 8.0 | 16000 | 1.5082 | 0.5507 | 0.3036 |
| 1.0326 | 9.0 | 18000 | 1.4677 | 0.5579 | 0.3064 |
| 1.229 | 10.0 | 20000 | 1.4917 | 0.5480 | 0.3056 |
| 0.785 | 11.0 | 22000 | 1.4971 | 0.5471 | 0.3050 |
| 0.6886 | 12.0 | 24000 | 1.5001 | 0.5465 | 0.3048 |
### Framework versions
- Transformers 4.55.2
- Pytorch 2.7.0+cu126
- Datasets 4.0.0
- Tokenizers 0.21.4
|
hakimjustbao/blockassist-bc-raging_subtle_wasp_1755572283
|
hakimjustbao
| 2025-08-19T03:25:23Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"raging subtle wasp",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T03:25:19Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- raging subtle wasp
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
NexVeridian/Kimi-VL-A3B-Thinking-2506-4bit
|
NexVeridian
| 2025-08-19T03:24:52Z | 0 | 0 |
mlx
|
[
"mlx",
"safetensors",
"kimi_vl",
"text-generation",
"conversational",
"custom_code",
"base_model:moonshotai/Kimi-VL-A3B-Thinking-2506",
"base_model:quantized:moonshotai/Kimi-VL-A3B-Thinking-2506",
"license:mit",
"4-bit",
"region:us"
] |
text-generation
| 2025-08-19T03:19:47Z |
---
base_model: moonshotai/Kimi-VL-A3B-Thinking-2506
license: mit
pipeline_tag: text-generation
library_name: mlx
tags:
- mlx
---
# NexVeridian/Kimi-VL-A3B-Thinking-2506-4bit
This model [NexVeridian/Kimi-VL-A3B-Thinking-2506-4bit](https://huggingface.co/NexVeridian/Kimi-VL-A3B-Thinking-2506-4bit) was
converted to MLX format from [moonshotai/Kimi-VL-A3B-Thinking-2506](https://huggingface.co/moonshotai/Kimi-VL-A3B-Thinking-2506)
using mlx-lm version **0.26.3**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("NexVeridian/Kimi-VL-A3B-Thinking-2506-4bit")
prompt = "hello"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
jasminekitty328/full_3000_intentconan
|
jasminekitty328
| 2025-08-19T03:23:44Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"t5",
"text2text-generation",
"arxiv:1910.09700",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T03:23:04Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
lqpl/blockassist-bc-hairy_insectivorous_antelope_1755573707
|
lqpl
| 2025-08-19T03:23:18Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"hairy insectivorous antelope",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T03:22:31Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- hairy insectivorous antelope
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
concept-unlearning/gemma-3-4b-it_ft_lora_all_novels_v7_ft
|
concept-unlearning
| 2025-08-19T03:23:00Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gemma3",
"image-text-to-text",
"arxiv:1910.09700",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2025-08-19T03:20:42Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
broinopio/blockassist-bc-monstrous_scampering_spider_1755571700
|
broinopio
| 2025-08-19T03:22:11Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"monstrous scampering spider",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T03:22:08Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- monstrous scampering spider
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Akshaykumarbm/OpenAssisted-English-Mistral-7b
|
Akshaykumarbm
| 2025-08-19T03:21:56Z | 31 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"mistral-8b",
"openassistant",
"openassisted-english",
"language-modeling",
"conversational-ai",
"conversational",
"en",
"base_model:mistralai/Mistral-7B-Instruct-v0.1",
"base_model:finetune:mistralai/Mistral-7B-Instruct-v0.1",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-01T06:22:11Z |
---
library_name: transformers
tags:
- mistral-8b
- openassistant
- openassisted-english
- language-modeling
- text-generation
- conversational-ai
license: apache-2.0
language:
- en
base_model:
- mistralai/Mistral-7B-Instruct-v0.1
---
# Mistral-8B Instruction-Tuned on OpenAssisted-English
This model is a fine-tuned version of [Mistral-8B](https://huggingface.co/mistralai/Mistral-7B-v0.1) on the [OpenAssisted-English](https://huggingface.co/datasets/OpenAssistant/oasst1) dataset using Hugging Face's `transformers` library. The model is optimized for high-quality conversational and instruction-following tasks in English.
---
## Model Details
### Model Description
This model is an instruction-tuned version of the Mistral-8B architecture, fine-tuned specifically to follow human instructions and engage in helpful, safe, and factual conversations. It leverages the OpenAssisted-English dataset, a cleaned and filtered subset from OpenAssistant's OASST1 dataset.
* **Developed by:** Akshay Kumar BM
* **Fine-tuned using:** Hugging Face Transformers
* **Dataset used:** OpenAssisted-English (from OpenAssistant)
* **Model type:** Decoder-only Transformer
* **Language(s):** English
* **License:** Apache 2.0
* **Finetuned from model:** mistralai/Mistral-7B-v0.1
---
## Model Sources
* **Base Model:** [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)
* **Dataset:** [OpenAssisted-English](https://huggingface.co/datasets/OpenAssistant/oasst1)
* **Library:** Hugging Face Transformers
* **Frameworks:** PyTorch, Accelerate
---
## Uses
### Direct Use
* Conversational AI
* Instruction-following agents
* Text completion and generation
* Chatbot backends
* Question answering
### Downstream Use
* Fine-tuning for specific domains (e.g., legal, medical, education)
* Integration into multi-agent systems or RAG pipelines
* Prompt engineering and prototyping
### Out-of-Scope Use
* Use in high-risk environments (e.g., medical diagnosis, legal decision making) without human oversight.
* Generating misinformation, harmful, offensive, or biased content.
* Any use violating Hugging Face’s or Apache 2.0 licensing terms.
---
## Bias, Risks, and Limitations
Despite being fine-tuned for alignment, the model may:
* Hallucinate facts.
* Reflect biases present in the OpenAssistant dataset.
* Respond unpredictably to adversarial or ambiguous prompts.
### Recommendations
* Always include a human-in-the-loop for sensitive applications.
* Evaluate in domain-specific scenarios before deployment.
* Apply additional safety filters for production use.
---
## How to Get Started
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "Akshaykumarbm/OpenAssisted-English-Mistral-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
input_prompt = "Explain quantum computing in simple terms."
inputs = tokenizer(input_prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
---
## Training Details
### Training Data
The model was trained on the **OpenAssisted-English** dataset, which includes high-quality, human-annotated instruction-response pairs derived from OpenAssistant’s OASST1 dataset.
* Format: Instruction + Response
* Filters: Language = English, Quality ≥ 3, Assistant messages only
* Size: \~100k samples
### Training Procedure
#### Preprocessing
* Tokenization: BPE tokenizer from Mistral
* Truncation: 4096 tokens
* Format: `<s>[INST] prompt [/INST] response</s>`
#### Hyperparameters
* **Precision:** bf16 mixed precision
* **Batch size:** 512 (global)
* **Epochs:** 15
* **Optimizer:** AdamW
* **LR Scheduler:** CosineDecay
* **Learning rate:** 2e-5
* **Warmup steps:** 500
#### Compute
* **Hardware:** AMD MI300
* **Training time:** \~18 hours
* **Frameworks:** PyTorch + Accelerate + DDP
---
## Evaluation
### Testing Data
* Held-out subset from OpenAssisted-English
* Manual eval for coherence, helpfulness, and safety
* Evaluation on MT-Bench and AlpacaEval (optional)
### Metrics
* **Helpfulness Score** (manual): \~7.2/10
* **Toxicity (Perspective API):** <1%
* **BLEU, ROUGE:** Used to compare with gold responses
---
## Technical Specifications
* **Architecture:** Mistral 8B (decoder-only transformer)
* **Tokenizer:** Mistral Tokenizer (32k vocab)
* **Context Length:** 8k tokens
* **Parameters:** \~8.1 billion
---
## Citation
If you use this model, please cite the original Mistral model and OpenAssistant dataset.
```bibtex
@misc{mistral2023,
title={Mistral 7B},
author={Mistral AI},
year={2023},
url={https://mistral.ai/news/announcing-mistral-7b/}
}
@misc{openassistant2023,
title = {OpenAssistant Conversations - OASST1},
author = {OpenAssistant Contributors},
year = {2023},
url = {https://huggingface.co/datasets/OpenAssistant/oasst1}
}
```
---
## Contact
* **Author:** Akshay Kumar BM
* **Email:** [[email protected]](mailto:[email protected])
* **GitHub:** [akshaykumarbedre](https://github.com/akshaykumarbedre)
* **Hugging Face:** [akshaykumarbm](https://huggingface.co/akshaykumarbm)
---
|
mang3dd/blockassist-bc-tangled_slithering_alligator_1755571953
|
mang3dd
| 2025-08-19T03:18:33Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tangled slithering alligator",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T03:18:29Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tangled slithering alligator
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
sous26hotmailf1/blockassist-bc-tawny_melodic_tapir_1755571663
|
sous26hotmailf1
| 2025-08-19T03:17:21Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tawny melodic tapir",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T03:17:17Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tawny melodic tapir
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
wjbmattingly/lfm2-vl-medieval-page
|
wjbmattingly
| 2025-08-19T03:15:45Z | 0 | 0 | null |
[
"safetensors",
"lfm2-vl",
"custom_code",
"base_model:LiquidAI/LFM2-VL-450M",
"base_model:finetune:LiquidAI/LFM2-VL-450M",
"region:us"
] | null | 2025-08-19T03:03:20Z |
---
base_model:
- LiquidAI/LFM2-VL-450M
---
# model_step_15000
## Model Description
This model is a fine-tuned version of **LiquidAI/LFM2-VL-450M** using the brute-force-training package.
- **Base Model**: LiquidAI/LFM2-VL-450M
- **Training Status**: 🔄 In Progress
- **Generated**: 2025-08-18 23:13:09
- **Training Steps**: 15,000
## Training Details
### Dataset
- **Dataset**: wjbmattingly/medieval-synthetic-dataset
- **Training Examples**: 11,000
- **Validation Examples**: 99
### Training Configuration
- **Max Steps**: 50,000
- **Batch Size**: 2
- **Learning Rate**: 1e-05
- **Gradient Accumulation**: 1 steps
- **Evaluation Frequency**: Every 5,000 steps
### Current Performance
- **Training Loss**: 0.910276
- **Evaluation Loss**: 0.854880
## Pre-Training Evaluation
**Initial Model Performance (before training):**
- **Loss**: 1.175152
- **Perplexity**: 3.24
- **Character Accuracy**: 13.2%
- **Word Accuracy**: 5.0%
## Evaluation History
### All Checkpoint Evaluations
| Step | Checkpoint Type | Loss | Perplexity | Char Acc | Word Acc | Improvement vs Pre |
|------|----------------|------|------------|----------|----------|--------------------|
| Pre | pre_training | 1.1752 | 3.24 | 13.2% | 5.0% | +0.0% |
| 5,000 | checkpoint | 0.8849 | 2.42 | 9.4% | 4.4% | +24.7% |
| 10,000 | checkpoint | 0.8629 | 2.37 | 9.4% | 4.8% | +26.6% |
| 15,000 | checkpoint | 0.8549 | 2.35 | 9.9% | 4.9% | +27.3% |
## Training Progress
### Recent Training Steps (Loss Only)
| Step | Training Loss | Timestamp |
|------|---------------|-----------|
| 14,991 | 0.975032 | 2025-08-18T23:12 |
| 14,992 | 0.670720 | 2025-08-18T23:12 |
| 14,993 | 0.850654 | 2025-08-18T23:12 |
| 14,994 | 0.935257 | 2025-08-18T23:12 |
| 14,995 | 0.870635 | 2025-08-18T23:12 |
| 14,996 | 0.942344 | 2025-08-18T23:12 |
| 14,997 | 0.785241 | 2025-08-18T23:12 |
| 14,998 | 0.754749 | 2025-08-18T23:12 |
| 14,999 | 0.950578 | 2025-08-18T23:12 |
| 15,000 | 0.910276 | 2025-08-18T23:12 |
## Training Visualizations
### Training Progress and Evaluation Metrics

*This chart shows the training loss progression, character accuracy, word accuracy, and perplexity over time. Red dots indicate evaluation checkpoints.*
### Evaluation Comparison Across All Checkpoints

*Comprehensive comparison of all evaluation metrics across training checkpoints. Red=Pre-training, Blue=Checkpoints, Green=Final.*
### Available Visualization Files:
- **`training_curves.png`** - 4-panel view: Training loss with eval points, Character accuracy, Word accuracy, Perplexity
- **`evaluation_comparison.png`** - 4-panel comparison: Loss, Character accuracy, Word accuracy, Perplexity across all checkpoints
## Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
# For vision-language models, use appropriate imports
model = AutoModelForCausalLM.from_pretrained("./model_step_15000")
tokenizer = AutoTokenizer.from_pretrained("./model_step_15000")
# Your inference code here
```
## Training Configuration
```json
{
"dataset_name": "wjbmattingly/medieval-synthetic-dataset",
"model_name": "LiquidAI/LFM2-VL-450M",
"max_steps": 50000,
"eval_steps": 5000,
"num_accumulation_steps": 1,
"learning_rate": 1e-05,
"train_batch_size": 2,
"val_batch_size": 2,
"train_select_start": 0,
"train_select_end": 11000,
"val_select_start": 11001,
"val_select_end": 11100,
"train_field": "train",
"val_field": "train",
"image_column": "image",
"text_column": "text",
"user_text": "Transcribe this medieval manuscript page.",
"max_image_size": 200
}
```
## Model Card Metadata
- **Base Model**: LiquidAI/LFM2-VL-450M
- **Training Framework**: brute-force-training
- **Training Type**: Fine-tuning
- **License**: Inherited from base model
- **Language**: Inherited from base model
---
*This model card was automatically generated by brute-force-training on 2025-08-18 23:13:09*
|
novaxa-research/CyberSweep
|
novaxa-research
| 2025-08-19T03:15:08Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-18T16:56:45Z |
<h3 align="center"><strong>CYBERSWEEP: A Unified Simulation-to-Real Workflow for Interactive Sweeping Robots</strong></h3>
------
Sweeping robot research faces challenges in **data and research platform scarcity**, **upward-view domain shift**, and **unintegrated interaction paradigms**. To address these, we introduced **CyberSweep**, an novel end-to-end embodied interaction workflow for sweeping robots. It features:
- **a simulation infrastructure** for scalable scene synthesis and task annotation;
- **a diffusion-based view synthesis method** to align upward-view observations with eye-level perspectives;
- **a unified vision-language-action decision model** for seamless multimodal reasoning and human collaboration.
This repository provides assets, datasets, model weights, and training logs.
|
indoempatnol/blockassist-bc-fishy_wary_swan_1755571503
|
indoempatnol
| 2025-08-19T03:13:10Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"fishy wary swan",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T03:13:07Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- fishy wary swan
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
miguelsigmahot2/blockassist-bc-invisible_patterned_prawn_1755571417
|
miguelsigmahot2
| 2025-08-19T03:12:57Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"invisible patterned prawn",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T03:12:47Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- invisible patterned prawn
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
prl90777/qwen3_4_20250818_1941
|
prl90777
| 2025-08-19T03:12:12Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:Qwen/Qwen3-4B",
"lora",
"transformers",
"base_model:Qwen/Qwen3-4B",
"license:apache-2.0",
"region:us"
] | null | 2025-08-18T23:50:31Z |
---
library_name: peft
license: apache-2.0
base_model: Qwen/Qwen3-4B
tags:
- base_model:adapter:Qwen/Qwen3-4B
- lora
- transformers
model-index:
- name: qwen3_4_20250818_1941
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# qwen3_4_20250818_1941
This model is a fine-tuned version of [Qwen/Qwen3-4B](https://huggingface.co/Qwen/Qwen3-4B) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3340
- Map@3: 0.9375
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 64
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Map@3 |
|:-------------:|:------:|:----:|:---------------:|:------:|
| 16.5429 | 0.0523 | 20 | 1.4557 | 0.7283 |
| 9.2865 | 0.1046 | 40 | 0.9736 | 0.8026 |
| 8.3639 | 0.1569 | 60 | 1.0031 | 0.7932 |
| 7.1456 | 0.2092 | 80 | 0.7150 | 0.8585 |
| 6.1949 | 0.2615 | 100 | 0.6272 | 0.8776 |
| 5.3446 | 0.3138 | 120 | 0.6454 | 0.8768 |
| 4.9297 | 0.3661 | 140 | 0.6001 | 0.8850 |
| 4.2539 | 0.4184 | 160 | 0.6017 | 0.8870 |
| 4.9359 | 0.4707 | 180 | 0.5601 | 0.8877 |
| 4.0852 | 0.5230 | 200 | 0.5453 | 0.8985 |
| 4.2137 | 0.5754 | 220 | 0.4796 | 0.9097 |
| 4.1494 | 0.6277 | 240 | 0.4894 | 0.9105 |
| 4.1857 | 0.6800 | 260 | 0.4618 | 0.9078 |
| 3.5215 | 0.7323 | 280 | 0.4672 | 0.9093 |
| 4.2297 | 0.7846 | 300 | 0.4450 | 0.9139 |
| 3.2632 | 0.8369 | 320 | 0.4476 | 0.9171 |
| 4.0446 | 0.8892 | 340 | 0.4467 | 0.9141 |
| 3.4267 | 0.9415 | 360 | 0.4137 | 0.9207 |
| 3.4374 | 0.9938 | 380 | 0.4655 | 0.9113 |
| 3.1897 | 1.0445 | 400 | 0.4886 | 0.9167 |
| 2.413 | 1.0968 | 420 | 0.4331 | 0.9232 |
| 2.7002 | 1.1491 | 440 | 0.4092 | 0.9242 |
| 2.7209 | 1.2014 | 460 | 0.3857 | 0.9278 |
| 2.6897 | 1.2537 | 480 | 0.4045 | 0.9260 |
| 2.3799 | 1.3060 | 500 | 0.3872 | 0.9310 |
| 2.7859 | 1.3583 | 520 | 0.4151 | 0.9229 |
| 2.6904 | 1.4106 | 540 | 0.3789 | 0.9313 |
| 2.4114 | 1.4629 | 560 | 0.3901 | 0.9302 |
| 2.6539 | 1.5152 | 580 | 0.3838 | 0.9330 |
| 2.4441 | 1.5675 | 600 | 0.3571 | 0.9348 |
| 2.086 | 1.6198 | 620 | 0.3667 | 0.9341 |
| 2.0958 | 1.6721 | 640 | 0.3498 | 0.9375 |
| 2.3942 | 1.7244 | 660 | 0.3753 | 0.9288 |
| 2.7639 | 1.7767 | 680 | 0.3384 | 0.9377 |
| 2.2673 | 1.8290 | 700 | 0.3267 | 0.9380 |
| 2.2347 | 1.8813 | 720 | 0.3378 | 0.9371 |
| 2.1848 | 1.9336 | 740 | 0.3271 | 0.9376 |
| 2.1091 | 1.9859 | 760 | 0.3330 | 0.9369 |
| 1.8355 | 2.0366 | 780 | 0.3340 | 0.9375 |
### Framework versions
- PEFT 0.17.0
- Transformers 4.55.2
- Pytorch 2.6.0+cu124
- Datasets 4.0.0
- Tokenizers 0.21.4
|
maxidesantafe11/blockassist-bc-deft_monstrous_finch_1755570882
|
maxidesantafe11
| 2025-08-19T03:09:09Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"deft monstrous finch",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T03:09:06Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- deft monstrous finch
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
WenFengg/21_14l12_19_8
|
WenFengg
| 2025-08-19T03:07:33Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-08-19T03:02:14Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
KickYourAssA/QQQwen
|
KickYourAssA
| 2025-08-19T03:05:15Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"llama-factory",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T02:48:18Z |
---
library_name: transformers
tags:
- llama-factory
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
koloni/blockassist-bc-deadly_graceful_stingray_1755571005
|
koloni
| 2025-08-19T03:03:11Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"deadly graceful stingray",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T03:03:08Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- deadly graceful stingray
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
hobson123/blockassist-bc-mammalian_dense_gibbon_1755572215
|
hobson123
| 2025-08-19T03:03:08Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"mammalian dense gibbon",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T03:02:54Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- mammalian dense gibbon
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
nuttachot/MyGemmaNPC
|
nuttachot
| 2025-08-19T03:00:45Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gemma3_text",
"text-generation",
"generated_from_trainer",
"trl",
"sft",
"conversational",
"base_model:google/gemma-3-270m-it",
"base_model:finetune:google/gemma-3-270m-it",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-17T13:26:04Z |
---
base_model: google/gemma-3-270m-it
library_name: transformers
model_name: MyGemmaNPC
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for MyGemmaNPC
This model is a fine-tuned version of [google/gemma-3-270m-it](https://huggingface.co/google/gemma-3-270m-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="nuttachot/MyGemmaNPC", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.21.0
- Transformers: 4.55.2
- Pytorch: 2.6.0+cu124
- Datasets: 4.0.0
- Tokenizers: 0.21.4
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
IvanJAjebu/blockassist-bc-thorny_slender_capybara_1755572291
|
IvanJAjebu
| 2025-08-19T02:59:47Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"thorny slender capybara",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T02:59:24Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- thorny slender capybara
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
concept-unlearning/Phi-3-mini-4k-instruct_ft_lora_all_novels_v3_ft_npo_gdr_lora_positive_dataset_v2
|
concept-unlearning
| 2025-08-19T02:55:44Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"phi3",
"text-generation",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T02:53:51Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
inclusionAI/UI-Venus-Navi-7B
|
inclusionAI
| 2025-08-19T02:55:37Z | 0 | 6 |
transformers
|
[
"transformers",
"safetensors",
"qwen2_5_vl",
"image-to-text",
"image-text-to-text",
"conversational",
"arxiv:2508.10833",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2025-08-16T07:27:20Z |
---
license: apache-2.0
library_name: transformers
pipeline_tag: image-text-to-text
---
### UI-Venus
This repository contains the UI-Venus model from the report [UI-Venus: Building High-performance UI Agents with RFT](https://arxiv.org/abs/2508.10833). UI-Venus is a native UI agent based on the Qwen2.5-VL multimodal large language model, designed to perform precise GUI element grounding and effective navigation using only screenshots as input. It achieves state-of-the-art performance through Reinforcement Fine-Tuning (RFT) with high-quality training data. More inference details and usage guides are available in the GitHub repository. We will continue to update results on standard benchmarks including Screenspot-v2/Pro and AndroidWorld.
[](https://opensource.org/licenses/Apache-2.0)
[](http://arxiv.org/abs/2508.10833)
[](https://github.com/inclusionAI/UI-Venus)
[](https://huggingface.co/inclusionAI/UI-Venus-Navi-7B)
---
<p align="center">
📈 UI-Venus Benchmark Performance
</p>
<p align="center">
<img src="performance_venus.png" alt="UI-Venus Performance Across Datasets" width="1200" />
<br>
</p>
> **Figure:** Performance of UI-Venus across multiple benchmark datasets. UI-Venus achieves **State-of-the-Art (SOTA)** results on key UI understanding and interaction benchmarks, including **ScreenSpot-Pro**, **ScreenSpot-v2**, **OS-World-G**, **UI-Vision**, and **Android World**. The results demonstrate its superior capability in visual grounding, UI navigation, cross-platform generalization, and complex task reasoning.
### Model Description
UI-Venus is a multimodal UI agent built on Qwen2.5-VL that performs accurate UI grounding and navigation using only screenshots as input. The 7B and 72B variants achieve 94.1%/50.8% and 95.3%/61.9% on Screenspot-V2 and Screenspot-Pro benchmarks, surpassing prior SOTA models such as GTA1 and UI-TARS-1.5. On the AndroidWorld navigation benchmark, they achieve 49.1% and 65.9% success rates, respectively, demonstrating strong planning and generalization capabilities
Key innovations include:
- **SOTA Open-Source UI Agent**: Publicly released to advance research in autonomous UI interaction and agent-based systems.
- **Reinforcement Fine-Tuning (RFT)**: Utilizes carefully designed reward functions for both grounding and navigation tasks
- **Efficient Data Cleaning**: Trained on several hundred thousand high-quality samples to ensure robustness.
- **Self-Evolving Trajectory History Alignment & Sparse Action Enhancement**: Improves reasoning coherence and action distribution for better long-horizon planning.
---
## Installation
First, install the required dependencies:
```python
pip install transformers==4.49.0 qwen-vl-utils
```
---
## Quick Start
```python
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from typing import Dict, Tuple, Any
import torch
import os
import re
from qwen_vl_utils import process_vision_info
# -----------------------------
# Model & Tokenizer
# -----------------------------
MODEL_NAME = "inclusionAI/UI-Venus-Navi-7B"
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
MODEL_NAME,
device_map="auto",
trust_remote_code=True,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2"
).eval()
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, trust_remote_code=True)
processor = AutoProcessor.from_pretrained(MODEL_NAME)
GENERATION_CONFIG = {
"max_new_tokens": 2048,
"do_sample": False,
"temperature": 0.0,
}
# -----------------------------
# Prompt Template
# -----------------------------
PROMPT_TEMPLATE = """**You are a GUI Agent.**
Your task is to analyze a given user task, review current screenshot and previous actions, and determine the next action to complete the task.
### User Task
{user_task}
### Previous Actions
{previous_actions}
### Available Actions
Click(box=(x1, y1))
Drag(start=(x1, y1), end=(x2, y2))
Scroll(start=(x1, y1), end=(x2, y2), direction='down/up/right/left')
Type(content='')
Launch(app='')
Wait()
Finished(content='')
CallUser(content='')
LongPress(box=(x1, y1))
PressBack()
PressHome()
PressEnter()
PressRecent()
### Instruction
- Make sure you understand the task goal to avoid wrong actions.
- Examine the screenshot carefully. History may be unreliable.
- For user questions, reply with `CallUser`, then `Finished` if done.
- Explore screen content using scroll in different directions.
- Copy text: select → click `copy`.
- Paste text: long press text box → click `paste`.
- First reason inside <think>, then provide <action>, then summarize in <conclusion>.
"""
# -----------------------------
# Parse action
# -----------------------------
def parse_action(action_str: str) -> Tuple[str, Dict[str, Any]]:
"""Parse action string into action type + params."""
pattern = r"^(\w+)\((.*)\)$"
match = re.match(pattern, action_str.strip(), re.DOTALL)
if not match:
print(f"Invalid action type: {action_str}")
return "", {}
action_type, params_str = match.group(1), match.group(2).strip()
params = {}
if params_str:
try:
# split by comma not inside parentheses
param_pairs = re.split(r",(?![^(]*\))", params_str)
for pair in param_pairs:
if "=" in pair:
key, value = pair.split("=", 1)
params[key.strip()] = value.strip().strip("'").strip()
else:
params[pair.strip()] = None
except Exception as e:
print(f"Parse param failed: {e}")
return action_type, {}
return action_type, params
def extract_tag(content: str, tag: str) -> str:
"""Extract latest <tag>...</tag> content from model output."""
pattern = fr"<{tag}>(.*?)</{tag}>"
matches = list(re.finditer(pattern, content, re.DOTALL))
if not matches:
print(f"{tag} Not Found")
return ""
return matches[-1].group(1).strip()
# -----------------------------
# Inference
# -----------------------------
def inference(image_path: str, goal: str) -> Dict[str, str]:
if not (os.path.exists(image_path) and os.path.isfile(image_path)):
raise FileNotFoundError(f"Invalid input image path: {image_path}")
full_prompt = PROMPT_TEMPLATE.format(user_task=goal, previous_actions="")
messages = [{
"role": "user",
"content": [
{"type": "text", "text": full_prompt},
{"type": "image", "image": image_path, "min_pixels": 830000, "max_pixels": 937664},
],
}]
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = process_vision_info(messages)
model_inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt"
).to(model.device)
generated_ids = model.generate(**model_inputs, **GENERATION_CONFIG)
generated_ids_trimmed = [out[len(inp):] for inp, out in zip(model_inputs.input_ids, generated_ids)]
output_text = processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True)[0]
return {
"raw_response": output_text,
"think": extract_tag(output_text, "think"),
"action": extract_tag(output_text, "action"),
"conclusion": extract_tag(output_text, "conclusion"),
}
```
### Usage
⚠️ For action types that include coordinates (e.g., click, scroll),
the current code does **not** handle coordinate conversion.
You need to map the coordinates back to the original image space using `max_pixels` and `min_pixels` before applying them.
---
### Results on AndroidWorld
This is the compressed package of validation trajectories for **AndroidWorld**, including execution logs and navigation paths.
📥 Download: [UI-Venus-androidworld.zip](https://github.com/inclusionAI/UI-Venus)
| Models | With Planner | A11y Tree | Screenshot | Success Rate (pass@1) |
|--------|--------------|-----------|------------|------------------------|
| **Closed-source Models** | | | | |
| GPT-4o| ❌ | ✅ | ❌ | 30.6 |
| ScaleTrack| ❌ | ✅ | ❌ | 44.0 |
| SeedVL-1.5 | ❌ | ✅ | ✅ | 62.1 |
| UI-TARS-1.5 | ❌ | ❌ | ✅ | 64.2 |
| **Open-source Models** | | | | |
| GUI-Critic-R1-7B | ❌ | ✅ | ✅ | 27.6 |
| Qwen2.5-VL-72B* | ❌ | ❌ | ✅ | 35.0 |
| UGround | ✅ | ❌ | ✅ | 44.0 |
| Aria-UI | ✅ | ❌ | ✅ | 44.8 |
| UI-TARS-72B | ❌ | ❌ | ✅ | 46.6 |
| GLM-4.5v | ❌ | ❌ | ✅ | 57.0 |
| **Ours** | | | | |
| UI-Venus-Navi-7B | ❌ | ❌ | ✅ | **49.1** |
| UI-Venus-Navi-72B | ❌ | ❌ | ✅ | **65.9** |
> **Table:** Performance comparison on **AndroidWorld** for end-to-end models. Our UI-Venus-Navi-72B achieves state-of-the-art performance, outperforming all baseline methods across different settings.
### Results on AndroidControl and GUI-Odyssey
| Models | AndroidControl-Low<br>Type Acc. | AndroidControl-Low<br>Step SR | AndroidControl-High<br>Type Acc. | AndroidControl-High<br>Step SR | GUI-Odyssey<br>Type Acc. | GUI-Odyssey<br>Step SR |
|--------|-------------------------------|-----------------------------|-------------------------------|-----------------------------|------------------------|----------------------|
| **Closed-source Models** | | | | | | |
| GPT-4o | 74.3 | 19.4 | 66.3 | 20.8 | 34.3 | 3.3 |
| **Open Source Models** | | | | | | |
| Qwen2.5-VL-7B | 94.1 | 85.0 | 75.1 | 62.9 | 59.5 | 46.3 |
| SeeClick | 93.0 | 75.0 | 82.9 | 59.1 | 71.0 | 53.9 |
| OS-Atlas-7B | 93.6 | 85.2 | 85.2 | 71.2 | 84.5 | 62.0 |
| Aguvis-7B| - | 80.5 | - | 61.5 | - | - |
| Aguvis-72B| - | 84.4 | - | 66.4 | - | - |
| OS-Genesis-7B | 90.7 | 74.2 | 66.2 | 44.5 | - | - |
| UI-TARS-7B| 98.0 | 90.8 | 83.7 | 72.5 | 94.6 | 87.0 |
| UI-TARS-72B| **98.1** | 91.3 | 85.2 | 74.7 | **95.4** | **88.6** |
| GUI-R1-7B| 85.2 | 66.5 | 71.6 | 51.7 | 65.5 | 38.8 |
| NaviMaster-7B | 85.6 | 69.9 | 72.9 | 54.0 | - | - |
| UI-AGILE-7B | 87.7 | 77.6 | 80.1 | 60.6 | - | - |
| AgentCPM-GUI | 94.4 | 90.2 | 77.7 | 69.2 | 90.0 | 75.0 |
| **Ours** | | | | | | |
| UI-Venus-Navi-7B | 97.1 | 92.4 | **86.5** | 76.1 | 87.3 | 71.5 |
| UI-Venus-Navi-72B | 96.7 | **92.9** | 85.9 | **77.2** | 87.2 | 72.4 |
> **Table:** Performance comparison on offline UI navigation datasets including AndroidControl and GUI-Odyssey. Note that models with * are reproduced.
# Citation
Please consider citing if you find our work useful:
```plain
@misc{gu2025uivenustechnicalreportbuilding,
title={UI-Venus Technical Report: Building High-performance UI Agents with RFT},
author={Zhangxuan Gu and Zhengwen Zeng and Zhenyu Xu and Xingran Zhou and Shuheng Shen and Yunfei Liu and Beitong Zhou and Changhua Meng and Tianyu Xia and Weizhi Chen and Yue Wen and Jingya Dou and Fei Tang and Jinzhen Lin and Yulin Liu and Zhenlin Guo and Yichen Gong and Heng Jia and Changlong Gao and Yuan Guo and Yong Deng and Zhenyu Guo and Liang Chen and Weiqiang Wang},
year={2025},
eprint={2508.10833},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2508.10833},
}
```
|
concept-unlearning/Phi-3-mini-4k-instruct_ft_lora_all_novels_v3_ft_rmu_lora_positive_dataset_v1
|
concept-unlearning
| 2025-08-19T02:55:03Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"phi3",
"text-generation",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T02:53:02Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
inclusionAI/UI-Venus-Ground-72B
|
inclusionAI
| 2025-08-19T02:54:46Z | 0 | 8 |
transformers
|
[
"transformers",
"safetensors",
"qwen2_5_vl",
"image-to-text",
"image-text-to-text",
"conversational",
"arxiv:2508.10833",
"license:apache-2.0",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2025-08-16T07:27:06Z |
---
license: apache-2.0
pipeline_tag: image-text-to-text
library_name: transformers
---
### UI-Venus
This repository contains the UI-Venus model from the report [UI-Venus: Building High-performance UI Agents with RFT](https://arxiv.org/abs/2508.10833).
UI-Venus is a native UI agent based on the Qwen2.5-VL multimodal large language model, designed to perform precise GUI element grounding and effective navigation using only screenshots as input. It achieves state-of-the-art performance through Reinforcement Fine-Tuning (RFT) with high-quality training data. More inference details and usage guides are available in the GitHub repository. We will continue to update results on standard benchmarks including Screenspot-v2/Pro and AndroidWorld.
[](https://opensource.org/licenses/Apache-2.0)
[](http://arxiv.org/abs/2508.10833)
[](https://github.com/inclusionAI/UI-Venus)
[](https://huggingface.co/inclusionAI/UI-Venus-Ground-7B)
---
<p align="center">
📈 UI-Venus Benchmark Performance
</p>
<p align="center">
<img src="performance_venus.png" alt="UI-Venus Performance Across Datasets" width="1200" />
<br>
</p>
> **Figure:** Performance of UI-Venus across multiple benchmark datasets. UI-Venus achieves **State-of-the-Art (SOTA)** results on key UI understanding and interaction benchmarks, including **ScreenSpot-Pro**, **ScreenSpot-v2**, **OS-World-G**, **UI-Vision**, and **Android World**. The results demonstrate its superior capability in visual grounding, UI navigation, cross-platform generalization, and complex task reasoning.
### Model Description
UI-Venus is a multimodal UI agent built on Qwen2.5-VL that performs accurate UI grounding and navigation using only screenshots as input. The 7B and 72B variants achieve 94.1%/50.8% and 95.3%/61.9% on Screenspot-V2 and Screenspot-Pro benchmarks, surpassing prior SOTA models such as GTA1 and UI-TARS-1.5. On the AndroidWorld navigation benchmark, they achieve 49.1% and 65.9% success rates, respectively, demonstrating strong planning and generalization capabilities
Key innovations include:
- **SOTA Open-Source UI Agent**: Publicly released to advance research in autonomous UI interaction and agent-based systems.
- **Reinforcement Fine-Tuning (RFT)**: Utilizes carefully designed reward functions for both grounding and navigation tasks
- **Efficient Data Cleaning**: Trained on several hundred thousand high-quality samples to ensure robustness.
- **Self-Evolving Trajectory History Alignment & Sparse Action Enhancement**: Improves reasoning coherence and action distribution for better long-horizon planning.
---
## Installation
First, install the required dependencies:
```python
pip install transformers==4.49.0 qwen-vl-utils
```
---
## Quick Start
Use the shell scripts to launch the evaluation. The evaluation setup follows the same protocol as **ScreenSpot**, including data format, annotation structure, and metric calculation.
```python
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
import torch
import os
from qwen_vl_utils import process_vision_info
# model path
model_name = "inclusionAI/UI-Venus-Ground-7B"
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
model_name,
device_map="auto",
trust_remote_code=True,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2"
).eval()
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
processor = AutoProcessor.from_pretrained(model_name)
generation_config = {
"max_new_tokens": 2048,
"do_sample": False,
"temperature": 0.0
}
def inference(instruction, image_path):
assert os.path.exists(image_path) and os.path.isfile(image_path), "Invalid input image path."
prompt_origin = 'Outline the position corresponding to the instruction: {}. The output should be only [x1,y1,x2,y2].'
full_prompt = prompt_origin.format(instruction)
min_pixels = 2000000
max_pixels = 4800000
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": image_path,
"min_pixels": min_pixels,
"max_pixels": max_pixels
},
{"type": "text", "text": full_prompt},
],
}
]
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
model_inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt"
).to(model.device)
generated_ids = model.generate(**model_inputs, **generation_config)
generated_ids_trimmed = [
out_ids[len(in_ids):]
for in_ids, out_ids in zip(model_inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
# normalized coordinates
try:
box = eval(output_text[0])
input_height = model_inputs['image_grid_thw'][0][1] * 14
input_width = model_inputs['image_grid_thw'][0][2] * 14
abs_x1 = float(box[0]) / input_width
abs_y1 = float(box[1]) / input_height
abs_x2 = float(box[2]) / input_width
abs_y2 = float(box[3]) / input_height
bbox = [abs_x1, abs_y1, abs_x2, abs_y2]
except Exception:
bbox = [0, 0, 0, 0]
point = [(bbox[0] + bbox[2]) / 2, (bbox[1] + bbox[3]) / 2]
result_dict = {
"result": "positive",
"format": "x1y1x2y2",
"raw_response": output_text,
"bbox": bbox,
"point": point
}
return result_dict
```
---
### Results on ScreenSpot-v2
| **Model** | **Mobile Text** | **Mobile Icon** | **Desktop Text** | **Desktop Icon** | **Web Text** | **Web Icon** | **Avg.** |
|---|---|---|---|---|---|---|---|
| uitars-1.5 | - | - | - | - | - | - | 94.2 |
| Seed-1.5-VL | - | - | - | - | - | - | 95.2 |
| GPT-4o | 26.6 | 24.2 | 24.2 | 19.3 | 12.8 | 11.8 | 20.1 |
| Qwen2.5-VL-7B | 97.6 | 87.2 | 90.2 | 74.2 | 93.2 | 81.3 | 88.8 |
| UI-TARS-7B | 96.9 | 89.1 | 95.4 | 85.0 | 93.6 | 85.2 | 91.6 |
| UI-TARS-72B | 94.8 | 86.3 | 91.2 | 87.9 | 91.5 | 87.7 | 90.3 |
| LPO | 97.9 | 82.9 | 95.9 | 86.4 | 95.6 | 84.2 | 90.5 |
| **UI-Venus-Ground-7B (Ours)** | **99.0** | **90.0** | **97.0** | **90.7** | **96.2** | **88.7** | **94.1** |
| **UI-Venus-Ground-72B (Ours)** | **99.7** | **93.8** | **95.9** | **90.0** | **96.2** | **92.6** | **95.3** |
---
### Results on ScreenSpot-Pro
Performance comparison of GUI agent models across six task categories on **ScreenSpot-Pro**.
Scores are in percentage (%). `T` = Text, `I` = Icon.
`*`: reproduced; `†`: trained from UI-TARS-1.5-7B.
| Model | CAD (T/I) | Dev (T/I) | Creative (T/I) | Scientific (T/I) | Office (T/I) | OS (T/I) | Avg T | Avg I | **Overall** | Type |
|-------|-----------|-----------|----------------|------------------|--------------|---------|--------|--------|------------|------|
| GPT-4o | 2.0 / 0.0 | 1.3 / 0.0 | 1.0 / 0.0 | 2.1 / 0.0 | 1.1 / 0.0 | 0.0 / 0.0 | 1.3 | 0.0 | 0.8 | Closed |
| Claude Computer Use | 14.5 / 3.7 | 22.0 / 3.9 | 25.9 / 3.4 | 33.9 / 15.8 | 30.1 / 16.3 | 11.0 / 4.5 | 23.4 | 7.1 | 17.1 | Closed |
| UI-TARS-1.5 | – / – | – / – | – / – | – / – | – / – | – / – | – | – | **61.6** | Closed |
| Seed1.5-VL | – / – | – / – | – / – | – / – | – / – | – / – | – | – | 60.9 | Closed |
| Qwen2.5-VL-7B\* | 16.8 / 1.6 | 46.8 / 4.1 | 35.9 / 7.7 | 49.3 / 7.3 | 52.5 / 20.8 | 37.4 / 6.7 | 38.9 | 7.1 | 26.8 | SFT |
| Qwen2.5-VL-72B* | 54.8 / 15.6 | 65.6 / 16.6 | 63.1 / 19.6 | 78.5 / 34.5 | 79.1 / 47.2 | 66.4 / 29.2 | 67.3 | 25.0 | 51.2 | SFT |
| UI-TARS-7B | 20.8 / 9.4 | 58.4 / 12.4 | 50.0 / 9.1 | 63.9 / 31.8 | 63.3 / 20.8 | 30.8 / 16.9 | 47.8 | 16.2 | 35.7 | SFT |
| UI-TARS-72B | 18.8 / 12.5 | 62.9 / 17.2 | 57.1 / 15.4 | 64.6 / 20.9 | 63.3 / 26.4 | 42.1 / 15.7 | 50.9 | 17.6 | 38.1 | SFT |
| Phi-Ground-7B | 26.9 / 17.2 | 70.8 / 16.7 | 56.6 / 13.3 | 58.0 / 29.1 | 76.4 / 44.0 | 55.1 / 25.8 | 56.4 | 21.8 | 43.2 | RL |
| UI-TARS-1.5-7B | – / – | – / – | – / – | – / – | – / – | – / – | – | – | 49.6 | RL |
| GTA1-7B† | 53.3 / 17.2 | 66.9 / 20.7 | 62.6 / 18.2 | 76.4 / 31.8 | 82.5 / 50.9 | 48.6 / 25.9 | 65.5 | 25.2 | 50.1 | RL |
| GTA1-72B | 56.9 / 28.1 | 79.9 / 33.1 | 73.2 / 20.3 | 81.9 / 38.2 | 85.3 / 49.1 | 73.8 / 39.1 | 74.5 | 32.5 | 58.4 | RL |
| **UI-Venus-Ground-7B** | 60.4 / 21.9 | 74.7 / 24.1 | 63.1 / 14.7 | 76.4 / 31.8 | 75.7 / 41.5 | 49.5 / 22.5 | 67.1 | 24.3 | **50.8** | Ours (RL) |
| **UI-Venus-Ground-72B** | 66.5 / 29.7 | 84.4 / 33.1 | 73.2 / 30.8 | 84.7 / 42.7 | 83.1 / 60.4 | 75.7 / 36.0 | 77.4 | 36.8 | **61.9** | Ours (RL) |
> 🔝 **Experimental results show that UI-Venus-Ground-72B achieves state-of-the-art performance on ScreenSpot-Pro with an average score of 61.7, while also setting new benchmarks on ScreenSpot-v2(95.3), OSWorld_G(69.8), AgentCPM(84.7), and UI-Vision(38.0), highlighting its effectiveness in complex visual grounding and action prediction tasks.**
# Citation
Please consider citing if you find our work useful:
```plain
@misc{gu2025uivenustechnicalreportbuilding,
title={UI-Venus Technical Report: Building High-performance UI Agents with RFT},
author={Zhangxuan Gu and Zhengwen Zeng and Zhenyu Xu and Xingran Zhou and Shuheng Shen and Yunfei Liu and Beitong Zhou and Changhua Meng and Tianyu Xia and Weizhi Chen and Yue Wen and Jingya Dou and Fei Tang and Jinzhen Lin and Yulin Liu and Zhenlin Guo and Yichen Gong and Heng Jia and Changlong Gao and Yuan Guo and Yong Deng and Zhenyu Guo and Liang Chen and Weiqiang Wang},
year={2025},
eprint={2508.10833},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2508.10833},
}
```
|
John6666/alcai-anime-haven-awakening-v10-sdxl
|
John6666
| 2025-08-19T02:54:16Z | 0 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"stable-diffusion-xl",
"anime",
"hentai",
"waifu",
"chara",
"new",
"colorful",
"girls",
"sharpness",
"detail",
"vibrant",
"deeper Colors",
"lghting",
"contrast",
"textures",
"stylization",
"superior atmospheric immersion",
"advanced environmental effects",
"emotional range",
"cinematic quality",
"peak polish & detail",
"consistent",
"multi-character",
"atmospheric depth",
"lighting",
"nuance",
"expressions",
"Illustrious XL v2.0",
"illustrious",
"en",
"base_model:OnomaAIResearch/Illustrious-XL-v2.0",
"base_model:finetune:OnomaAIResearch/Illustrious-XL-v2.0",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] |
text-to-image
| 2025-08-19T02:49:42Z |
---
license: other
license_name: faipl-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- text-to-image
- stable-diffusion
- stable-diffusion-xl
- anime
- hentai
- waifu
- chara
- new
- colorful
- girls
- sharpness
- detail
- vibrant
- deeper Colors
- lghting
- contrast
- textures
- stylization
- superior atmospheric immersion
- advanced environmental effects
- emotional range
- cinematic quality
- peak polish & detail
- consistent
- multi-character
- atmospheric depth
- lighting
- nuance
- expressions
- Illustrious XL v2.0
- illustrious
base_model: OnomaAIResearch/Illustrious-XL-v2.0
---
Original model is [here](https://civitai.com/models/1445562?modelVersionId=2126795).
This model created by [alcatraz974](https://civitai.com/user/alcatraz974).
|
ekotaru/whisper-sanskrit-asr-model
|
ekotaru
| 2025-08-19T02:51:12Z | 9 | 0 | null |
[
"pytorch",
"tensorboard",
"whisper",
"generated_from_trainer",
"license:apache-2.0",
"region:us"
] | null | 2025-08-14T14:41:47Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: whisper-sanskrit-asr-model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-sanskrit-asr-model
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2299
- Wer: 1.0
- Cer: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 5
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|
| 0.7277 | 1.0 | 70 | 0.5042 | 2.7339 | 2.0537 |
| 0.3391 | 2.0 | 140 | 0.3873 | 2.5505 | 2.4385 |
| 0.2061 | 3.0 | 210 | 0.2786 | 1.0 | 1.0 |
| 0.0813 | 4.0 | 280 | 0.2293 | 1.0 | 1.0 |
| 0.0502 | 5.0 | 350 | 0.2299 | 1.0 | 1.0 |
### Framework versions
- Transformers 4.26.1
- Pytorch 2.6.0+cu124
- Datasets 4.0.0
- Tokenizers 0.13.3
|
jerryzh168/Qwen3-8B-Base-INT8-INT4
|
jerryzh168
| 2025-08-19T02:49:12Z | 0 | 0 |
transformers
|
[
"transformers",
"pytorch",
"qwen3",
"text-generation",
"torchao",
"conversational",
"en",
"base_model:Qwen/Qwen3-8B-Base",
"base_model:quantized:Qwen/Qwen3-8B-Base",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T02:48:41Z |
---
base_model: Qwen/Qwen3-8B-Base
tags:
- transformers
- torchao
- qwen3
license: apache-2.0
language:
- en
---
# INT8-INT4 Qwen/Qwen3-8B-Base model
- **Developed by:** jerryzh168
- **License:** apache-2.0
- **Quantized from Model :** Qwen/Qwen3-8B-Base
- **Quantization Method :** INT8-INT4
|
Intellicia/Sullivan
|
Intellicia
| 2025-08-19T02:48:34Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3_moe",
"text-generation",
"conversational",
"arxiv:2402.17463",
"arxiv:2407.02490",
"arxiv:2501.15383",
"arxiv:2404.06654",
"arxiv:2505.09388",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T02:47:35Z |
---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-30B-A3B-Instruct-2507/blob/main/LICENSE
pipeline_tag: text-generation
---
# Qwen3-30B-A3B-Instruct-2507
<a href="https://chat.qwen.ai/?model=Qwen3-30B-A3B-2507" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Highlights
We introduce the updated version of the **Qwen3-30B-A3B non-thinking mode**, named **Qwen3-30B-A3B-Instruct-2507**, featuring the following key enhancements:
- **Significant improvements** in general capabilities, including **instruction following, logical reasoning, text comprehension, mathematics, science, coding and tool usage**.
- **Substantial gains** in long-tail knowledge coverage across **multiple languages**.
- **Markedly better alignment** with user preferences in **subjective and open-ended tasks**, enabling more helpful responses and higher-quality text generation.
- **Enhanced capabilities** in **256K long-context understanding**.
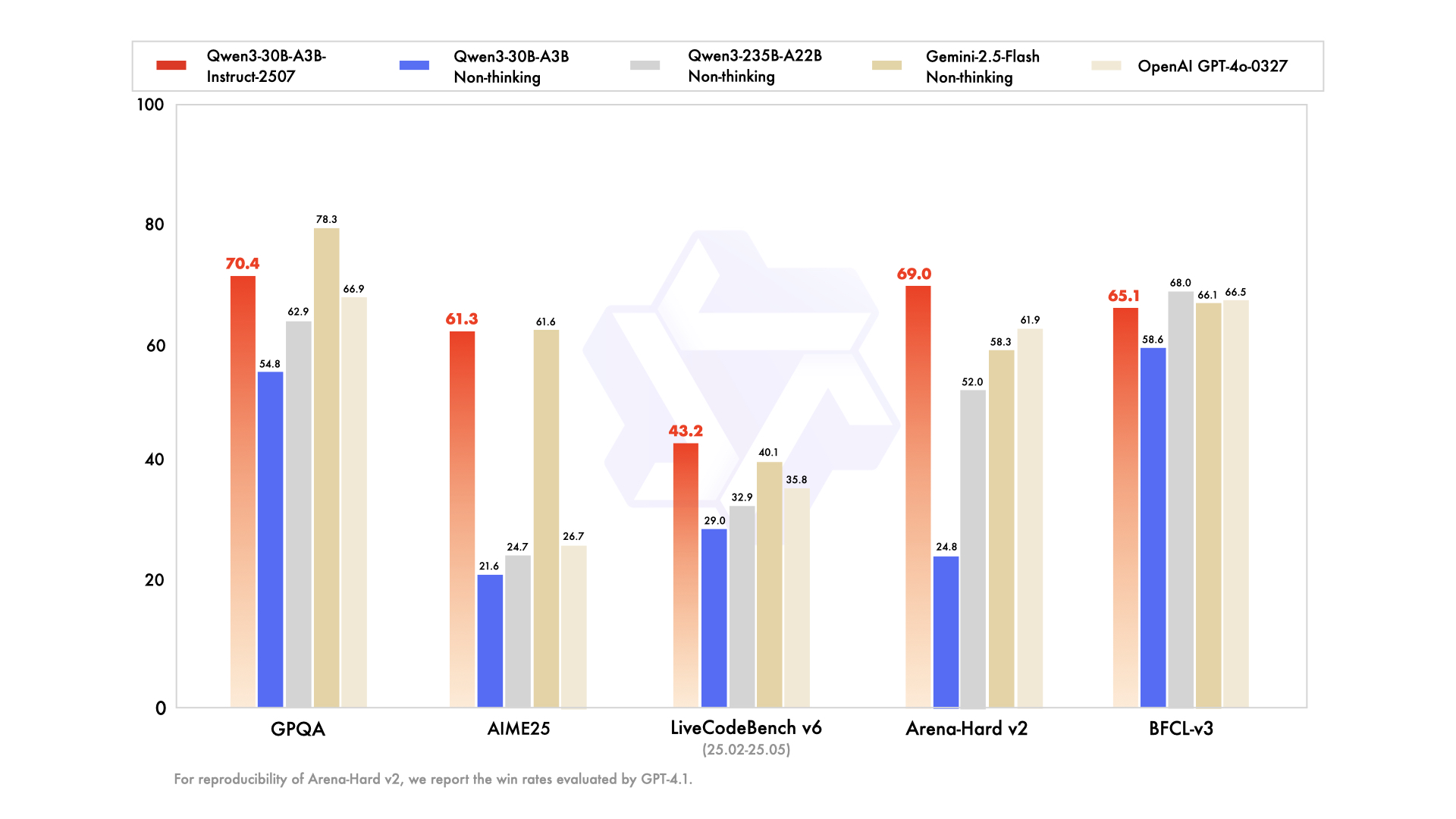
## Model Overview
**Qwen3-30B-A3B-Instruct-2507** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 30.5B in total and 3.3B activated
- Number of Paramaters (Non-Embedding): 29.9B
- Number of Layers: 48
- Number of Attention Heads (GQA): 32 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: **262,144 natively**.
**NOTE: This model supports only non-thinking mode and does not generate ``<think></think>`` blocks in its output. Meanwhile, specifying `enable_thinking=False` is no longer required.**
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Performance
| | Deepseek-V3-0324 | GPT-4o-0327 | Gemini-2.5-Flash Non-Thinking | Qwen3-235B-A22B Non-Thinking | Qwen3-30B-A3B Non-Thinking | Qwen3-30B-A3B-Instruct-2507 |
|--- | --- | --- | --- | --- | --- | --- |
| **Knowledge** | | | | | | |
| MMLU-Pro | **81.2** | 79.8 | 81.1 | 75.2 | 69.1 | 78.4 |
| MMLU-Redux | 90.4 | **91.3** | 90.6 | 89.2 | 84.1 | 89.3 |
| GPQA | 68.4 | 66.9 | **78.3** | 62.9 | 54.8 | 70.4 |
| SuperGPQA | **57.3** | 51.0 | 54.6 | 48.2 | 42.2 | 53.4 |
| **Reasoning** | | | | | | |
| AIME25 | 46.6 | 26.7 | **61.6** | 24.7 | 21.6 | 61.3 |
| HMMT25 | 27.5 | 7.9 | **45.8** | 10.0 | 12.0 | 43.0 |
| ZebraLogic | 83.4 | 52.6 | 57.9 | 37.7 | 33.2 | **90.0** |
| LiveBench 20241125 | 66.9 | 63.7 | **69.1** | 62.5 | 59.4 | 69.0 |
| **Coding** | | | | | | |
| LiveCodeBench v6 (25.02-25.05) | **45.2** | 35.8 | 40.1 | 32.9 | 29.0 | 43.2 |
| MultiPL-E | 82.2 | 82.7 | 77.7 | 79.3 | 74.6 | **83.8** |
| Aider-Polyglot | 55.1 | 45.3 | 44.0 | **59.6** | 24.4 | 35.6 |
| **Alignment** | | | | | | |
| IFEval | 82.3 | 83.9 | 84.3 | 83.2 | 83.7 | **84.7** |
| Arena-Hard v2* | 45.6 | 61.9 | 58.3 | 52.0 | 24.8 | **69.0** |
| Creative Writing v3 | 81.6 | 84.9 | 84.6 | 80.4 | 68.1 | **86.0** |
| WritingBench | 74.5 | 75.5 | 80.5 | 77.0 | 72.2 | **85.5** |
| **Agent** | | | | | | |
| BFCL-v3 | 64.7 | 66.5 | 66.1 | **68.0** | 58.6 | 65.1 |
| TAU1-Retail | 49.6 | 60.3# | **65.2** | 65.2 | 38.3 | 59.1 |
| TAU1-Airline | 32.0 | 42.8# | **48.0** | 32.0 | 18.0 | 40.0 |
| TAU2-Retail | **71.1** | 66.7# | 64.3 | 64.9 | 31.6 | 57.0 |
| TAU2-Airline | 36.0 | 42.0# | **42.5** | 36.0 | 18.0 | 38.0 |
| TAU2-Telecom | **34.0** | 29.8# | 16.9 | 24.6 | 18.4 | 12.3 |
| **Multilingualism** | | | | | | |
| MultiIF | 66.5 | 70.4 | 69.4 | 70.2 | **70.8** | 67.9 |
| MMLU-ProX | 75.8 | 76.2 | **78.3** | 73.2 | 65.1 | 72.0 |
| INCLUDE | 80.1 | 82.1 | **83.8** | 75.6 | 67.8 | 71.9 |
| PolyMATH | 32.2 | 25.5 | 41.9 | 27.0 | 23.3 | **43.1** |
*: For reproducibility, we report the win rates evaluated by GPT-4.1.
\#: Results were generated using GPT-4o-20241120, as access to the native function calling API of GPT-4o-0327 was unavailable.
## Quickstart
The code of Qwen3-MoE has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3_moe'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-30B-A3B-Instruct-2507"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B-Instruct-2507 --context-length 262144
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-30B-A3B-Instruct-2507 --max-model-len 262144
```
**Note: If you encounter out-of-memory (OOM) issues, consider reducing the context length to a shorter value, such as `32,768`.**
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-30B-A3B-Instruct-2507',
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Processing Ultra-Long Texts
To support **ultra-long context processing** (up to **1 million tokens**), we integrate two key techniques:
- **[Dual Chunk Attention](https://arxiv.org/abs/2402.17463) (DCA)**: A length extrapolation method that splits long sequences into manageable chunks while preserving global coherence.
- **[MInference](https://arxiv.org/abs/2407.02490)**: A sparse attention mechanism that reduces computational overhead by focusing on critical token interactions.
Together, these innovations significantly improve both **generation quality** and **inference efficiency** for sequences beyond 256K tokens. On sequences approaching 1M tokens, the system achieves up to a **3× speedup** compared to standard attention implementations.
For full technical details, see the [Qwen2.5-1M Technical Report](https://arxiv.org/abs/2501.15383).
### How to Enable 1M Token Context
> [!NOTE]
> To effectively process a 1 million token context, users will require approximately **240 GB** of total GPU memory. This accounts for model weights, KV-cache storage, and peak activation memory demands.
#### Step 1: Update Configuration File
Download the model and replace the content of your `config.json` with `config_1m.json`, which includes the config for length extrapolation and sparse attention.
```bash
export MODELNAME=Qwen3-30B-A3B-Instruct-2507
huggingface-cli download Qwen/${MODELNAME} --local-dir ${MODELNAME}
mv ${MODELNAME}/config.json ${MODELNAME}/config.json.bak
mv ${MODELNAME}/config_1m.json ${MODELNAME}/config.json
```
#### Step 2: Launch Model Server
After updating the config, proceed with either **vLLM** or **SGLang** for serving the model.
#### Option 1: Using vLLM
To run Qwen with 1M context support:
```bash
pip install -U vllm \
--torch-backend=auto \
--extra-index-url https://wheels.vllm.ai/nightly
```
Then launch the server with Dual Chunk Flash Attention enabled:
```bash
VLLM_ATTENTION_BACKEND=DUAL_CHUNK_FLASH_ATTN VLLM_USE_V1=0 \
vllm serve ./Qwen3-30B-A3B-Instruct-2507 \
--tensor-parallel-size 4 \
--max-model-len 1010000 \
--enable-chunked-prefill \
--max-num-batched-tokens 131072 \
--enforce-eager \
--max-num-seqs 1 \
--gpu-memory-utilization 0.85
```
##### Key Parameters
| Parameter | Purpose |
|--------|--------|
| `VLLM_ATTENTION_BACKEND=DUAL_CHUNK_FLASH_ATTN` | Enables the custom attention kernel for long-context efficiency |
| `--max-model-len 1010000` | Sets maximum context length to ~1M tokens |
| `--enable-chunked-prefill` | Allows chunked prefill for very long inputs (avoids OOM) |
| `--max-num-batched-tokens 131072` | Controls batch size during prefill; balances throughput and memory |
| `--enforce-eager` | Disables CUDA graph capture (required for dual chunk attention) |
| `--max-num-seqs 1` | Limits concurrent sequences due to extreme memory usage |
| `--gpu-memory-utilization 0.85` | Set the fraction of GPU memory to be used for the model executor |
#### Option 2: Using SGLang
First, clone and install the specialized branch:
```bash
git clone https://github.com/sgl-project/sglang.git
cd sglang
pip install -e "python[all]"
```
Launch the server with DCA support:
```bash
python3 -m sglang.launch_server \
--model-path ./Qwen3-30B-A3B-Instruct-2507 \
--context-length 1010000 \
--mem-frac 0.75 \
--attention-backend dual_chunk_flash_attn \
--tp 4 \
--chunked-prefill-size 131072
```
##### Key Parameters
| Parameter | Purpose |
|---------|--------|
| `--attention-backend dual_chunk_flash_attn` | Activates Dual Chunk Flash Attention |
| `--context-length 1010000` | Defines max input length |
| `--mem-frac 0.75` | The fraction of the memory used for static allocation (model weights and KV cache memory pool). Use a smaller value if you see out-of-memory errors. |
| `--tp 4` | Tensor parallelism size (matches model sharding) |
| `--chunked-prefill-size 131072` | Prefill chunk size for handling long inputs without OOM |
#### Troubleshooting:
1. Encountering the error: "The model's max sequence length (xxxxx) is larger than the maximum number of tokens that can be stored in the KV cache." or "RuntimeError: Not enough memory. Please try to increase --mem-fraction-static."
The VRAM reserved for the KV cache is insufficient.
- vLLM: Consider reducing the ``max_model_len`` or increasing the ``tensor_parallel_size`` and ``gpu_memory_utilization``. Alternatively, you can reduce ``max_num_batched_tokens``, although this may significantly slow down inference.
- SGLang: Consider reducing the ``context-length`` or increasing the ``tp`` and ``mem-frac``. Alternatively, you can reduce ``chunked-prefill-size``, although this may significantly slow down inference.
2. Encountering the error: "torch.OutOfMemoryError: CUDA out of memory."
The VRAM reserved for activation weights is insufficient. You can try lowering ``gpu_memory_utilization`` or ``mem-frac``, but be aware that this might reduce the VRAM available for the KV cache.
3. Encountering the error: "Input prompt (xxxxx tokens) + lookahead slots (0) is too long and exceeds the capacity of the block manager." or "The input (xxx xtokens) is longer than the model's context length (xxx tokens)."
The input is too lengthy. Consider using a shorter sequence or increasing the ``max_model_len`` or ``context-length``.
#### Long-Context Performance
We test the model on an 1M version of the [RULER](https://arxiv.org/abs/2404.06654) benchmark.
| Model Name | Acc avg | 4k | 8k | 16k | 32k | 64k | 96k | 128k | 192k | 256k | 384k | 512k | 640k | 768k | 896k | 1000k |
|---------------------------------------------|---------|------|------|------|------|------|------|------|------|------|------|------|------|------|------|-------|
| Qwen3-30B-A3B (Non-Thinking) | 72.0 | 97.1 | 96.1 | 95.0 | 92.2 | 82.6 | 79.7 | 76.9 | 70.2 | 66.3 | 61.9 | 55.4 | 52.6 | 51.5 | 52.0 | 50.9 |
| Qwen3-30B-A3B-Instruct-2507 (Full Attention) | 86.8 | 98.0 | 96.7 | 96.9 | 97.2 | 93.4 | 91.0 | 89.1 | 89.8 | 82.5 | 83.6 | 78.4 | 79.7 | 77.6 | 75.7 | 72.8 |
| Qwen3-30B-A3B-Instruct-2507 (Sparse Attention) | 86.8 | 98.0 | 97.1 | 96.3 | 95.1 | 93.6 | 92.5 | 88.1 | 87.7 | 82.9 | 85.7 | 80.7 | 80.0 | 76.9 | 75.5 | 72.2 |
* All models are evaluated with Dual Chunk Attention enabled.
* Since the evaluation is time-consuming, we use 260 samples for each length (13 sub-tasks, 20 samples for each).
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- We suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 16,384 tokens for most queries, which is adequate for instruct models.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3technicalreport,
title={Qwen3 Technical Report},
author={Qwen Team},
year={2025},
eprint={2505.09388},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.09388},
}
```
|
jerryzh168/Qwen3-8B-Base-INT4
|
jerryzh168
| 2025-08-19T02:48:00Z | 0 | 0 |
transformers
|
[
"transformers",
"pytorch",
"qwen3",
"text-generation",
"torchao",
"conversational",
"en",
"base_model:Qwen/Qwen3-8B-Base",
"base_model:quantized:Qwen/Qwen3-8B-Base",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T02:47:37Z |
---
base_model: Qwen/Qwen3-8B-Base
tags:
- transformers
- torchao
- qwen3
license: apache-2.0
language:
- en
---
# INT4 Qwen/Qwen3-8B-Base model
- **Developed by:** jerryzh168
- **License:** apache-2.0
- **Quantized from model :** Qwen/Qwen3-8B-Base
- **Quantization Method :** INT4
|
jerryzh168/Qwen3-8B-Base-FP8
|
jerryzh168
| 2025-08-19T02:47:19Z | 0 | 0 |
transformers
|
[
"transformers",
"pytorch",
"qwen3",
"text-generation",
"torchao",
"conversational",
"en",
"base_model:Qwen/Qwen3-8B-Base",
"base_model:quantized:Qwen/Qwen3-8B-Base",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T02:46:48Z |
---
base_model: Qwen/Qwen3-8B-Base
tags:
- transformers
- torchao
- qwen3
license: apache-2.0
language:
- en
---
# FP8 Qwen/Qwen3-8B-Base model
- **Developed by:** jerryzh168
- **License:** apache-2.0
- **Quantized from model :** Qwen/Qwen3-8B-Base
- **Quantization Method :** FP8
|
sampingkaca72/blockassist-bc-armored_stealthy_elephant_1755570080
|
sampingkaca72
| 2025-08-19T02:45:52Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"armored stealthy elephant",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T02:45:49Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- armored stealthy elephant
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
AppliedLucent/nemo-phase3
|
AppliedLucent
| 2025-08-19T02:42:29Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:AppliedLucent/nemo-phase2",
"base_model:finetune:AppliedLucent/nemo-phase2",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T00:27:12Z |
---
base_model: AppliedLucent/nemo-phase2
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** AppliedLucent
- **License:** apache-2.0
- **Finetuned from model :** AppliedLucent/nemo-phase2
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Comfy-Org/Qwen-Image-Edit_ComfyUI
|
Comfy-Org
| 2025-08-19T02:41:23Z | 0 | 18 |
diffusion-single-file
|
[
"diffusion-single-file",
"comfyui",
"license:apache-2.0",
"region:us"
] | null | 2025-08-19T02:18:21Z |
---
license: apache-2.0
tags:
- diffusion-single-file
- comfyui
---
|
indoempatnol/blockassist-bc-fishy_wary_swan_1755569481
|
indoempatnol
| 2025-08-19T02:39:55Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"fishy wary swan",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T02:39:52Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- fishy wary swan
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
pempekmangedd/blockassist-bc-patterned_sturdy_dolphin_1755569533
|
pempekmangedd
| 2025-08-19T02:39:23Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"patterned sturdy dolphin",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T02:39:19Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- patterned sturdy dolphin
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
hobson123/blockassist-bc-mammalian_dense_gibbon_1755570773
|
hobson123
| 2025-08-19T02:38:38Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"mammalian dense gibbon",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T02:38:23Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- mammalian dense gibbon
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
phospho-app/parkgyuhyeon-ACT-TestTwoArm-omkun
|
phospho-app
| 2025-08-19T02:38:34Z | 0 | 0 |
phosphobot
|
[
"phosphobot",
"safetensors",
"act",
"robotics",
"dataset:parkgyuhyeon/TestTwoArm",
"region:us"
] |
robotics
| 2025-08-19T01:42:05Z |
---
datasets: parkgyuhyeon/TestTwoArm
library_name: phosphobot
pipeline_tag: robotics
model_name: act
tags:
- phosphobot
- act
task_categories:
- robotics
---
# act Model - phospho Training Pipeline
## This model was trained using **phospho**.
Training was successful, try it out on your robot!
## Training parameters:
- **Dataset**: [parkgyuhyeon/TestTwoArm](https://huggingface.co/datasets/parkgyuhyeon/TestTwoArm)
- **Wandb run URL**: None
- **Epochs**: None
- **Batch size**: 40
- **Training steps**: 8000
📖 **Get Started**: [docs.phospho.ai](https://docs.phospho.ai?utm_source=huggingface_readme)
🤖 **Get your robot**: [robots.phospho.ai](https://robots.phospho.ai?utm_source=huggingface_readme)
|
su-collaborations/ui-tars-model-webclick-all
|
su-collaborations
| 2025-08-19T02:37:41Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"base_model:adapter:ByteDance-Seed/UI-TARS-1.5-7B",
"lora",
"transformers",
"text-generation",
"base_model:ByteDance-Seed/UI-TARS-1.5-7B",
"license:apache-2.0",
"region:us"
] |
text-generation
| 2025-08-16T13:23:13Z |
---
library_name: peft
license: apache-2.0
base_model: ByteDance-Seed/UI-TARS-1.5-7B
tags:
- base_model:adapter:ByteDance-Seed/UI-TARS-1.5-7B
- lora
- transformers
pipeline_tag: text-generation
model-index:
- name: ui-tars-model-webclick-all
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ui-tars-model-webclick-all
This model is a fine-tuned version of [ByteDance-Seed/UI-TARS-1.5-7B](https://huggingface.co/ByteDance-Seed/UI-TARS-1.5-7B) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2281
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Use adamw_torch_fused with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.03
- lr_scheduler_warmup_steps: 100
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 6.1462 | 0.05 | 50 | 0.3293 |
| 4.4928 | 0.1 | 100 | 0.2736 |
| 4.2465 | 0.15 | 150 | 0.2545 |
| 4.0585 | 0.2 | 200 | 0.2520 |
| 3.9869 | 0.25 | 250 | 0.2456 |
| 3.7458 | 0.3 | 300 | 0.2395 |
| 3.4935 | 0.35 | 350 | 0.2462 |
| 3.6618 | 0.4 | 400 | 0.2517 |
| 3.6609 | 0.45 | 450 | 0.2346 |
| 3.5013 | 0.5 | 500 | 0.2371 |
| 3.4309 | 0.55 | 550 | 0.2387 |
| 3.6304 | 0.6 | 600 | 0.2311 |
| 3.3207 | 0.65 | 650 | 0.2296 |
| 3.4227 | 0.7 | 700 | 0.2273 |
| 3.2289 | 0.75 | 750 | 0.2264 |
| 3.3568 | 0.8 | 800 | 0.2265 |
| 3.2826 | 0.85 | 850 | 0.2274 |
| 3.3092 | 0.9 | 900 | 0.2262 |
| 3.1876 | 0.95 | 950 | 0.2281 |
| 3.1462 | 1.0 | 1000 | 0.2281 |
### Framework versions
- PEFT 0.16.0
- Transformers 4.54.1
- Pytorch 2.7.1+cu126
- Datasets 4.0.0
- Tokenizers 0.21.4
|
Ellbendls/Qwen-2.5-3b-Text_to_SQL
|
Ellbendls
| 2025-08-19T02:34:10Z | 1,477 | 5 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"zho",
"eng",
"fra",
"spa",
"por",
"deu",
"ita",
"rus",
"jpn",
"kor",
"vie",
"tha",
"ara",
"dataset:gretelai/synthetic_text_to_sql",
"base_model:Qwen/Qwen2.5-3B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-3B-Instruct",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-11-27T00:29:40Z |
---
library_name: transformers
license: mit
datasets:
- gretelai/synthetic_text_to_sql
base_model:
- Qwen/Qwen2.5-3B-Instruct
pipeline_tag: text-generation
language:
- zho
- eng
- fra
- spa
- por
- deu
- ita
- rus
- jpn
- kor
- vie
- tha
- ara
---
# Fine-Tuned LLM for Text-to-SQL Conversion
This model is a fine-tuned version of [Qwen/Qwen2.5-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-3B-Instruct) designed to convert natural language queries into SQL statements. It was trained on the `gretelai/synthetic_text_to_sql` dataset and can provide both SQL queries and table schema context when needed.
---
## Model Details
### Model Description
This model has been fine-tuned to help users generate SQL queries based on natural language prompts. In scenarios where table schema context is missing, the model is trained to generate schema definitions along with the SQL query, making it a robust solution for various Text-to-SQL tasks.
- **Base Model:** [Qwen/Qwen2.5-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-3B-Instruct)
- **Dataset:** [Gretel AI Synthetic Text-to-SQL Dataset](https://huggingface.co/datasets/gretelai/synthetic_text_to_sql)
- **Language:** English
- **License:** MIT
### Key Features
1. **Text-to-SQL Conversion:** Converts natural language queries into accurate SQL statements.
2. **Schema Generation:** Generates table schema context when none is provided.
3. **Optimized for Analytics and Reporting:** Handles SQL queries with aggregation, grouping, and filtering.
---
## Usage
### Direct Use
To use the model for text-to-SQL conversion, you can load it using the `transformers` library as shown below:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("Ellbendls/Qwen-2.5-3b-Text_to_SQL")
model = AutoModelForCausalLM.from_pretrained("Ellbendls/Qwen-2.5-3b-Text_to_SQL")
# Input prompt
query = "What is the total number of hospital beds in each state?"
# Tokenize input and generate output
inputs = tokenizer(query, return_tensors="pt")
outputs = model.generate(**inputs, max_length=512)
# Decode and print
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
### Example Output
Input:
`What is the total number of hospital beds in each state?`
Output:
```sql
Context:
CREATE TABLE Beds (State VARCHAR(50), Beds INT);
INSERT INTO Beds (State, Beds) VALUES ('California', 100000), ('Texas', 85000), ('New York', 70000);
SQL Query:
SELECT State, SUM(Beds) FROM Beds GROUP BY State;
```
---
## Training Details
### Dataset
The model was fine-tuned on the `gretelai/synthetic_text_to_sql` dataset, which includes diverse natural language queries mapped to SQL queries, with optional schema contexts.
## Limitations
1. **Complex Queries:** May struggle with highly nested or advanced SQL tasks.
2. **Non-English Prompts:** Optimized for English only.
3. **Context Dependence:** May generate incorrect schemas without explicit instructions.
|
lakeitag/LakeitaGreene-Replicate
|
lakeitag
| 2025-08-19T02:33:52Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-08-19T02:01:39Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: Lakeita
---
# Lakeitagreene Replicate
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `Lakeita` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "Lakeita",
"lora_weights": "https://huggingface.co/lakeitag/LakeitaGreene-Replicate/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('lakeitag/LakeitaGreene-Replicate', weight_name='lora.safetensors')
image = pipeline('Lakeita').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2100
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/lakeitag/LakeitaGreene-Replicate/discussions) to add images that show off what you’ve made with this LoRA.
|
IvanJAjebu/blockassist-bc-thorny_slender_capybara_1755570734
|
IvanJAjebu
| 2025-08-19T02:33:49Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"thorny slender capybara",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T02:33:40Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- thorny slender capybara
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
koloni/blockassist-bc-deadly_graceful_stingray_1755569283
|
koloni
| 2025-08-19T02:33:09Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"deadly graceful stingray",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T02:33:06Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- deadly graceful stingray
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
truong1301/Mistral_task7_3
|
truong1301
| 2025-08-19T02:32:38Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"base_model:unsloth/Mistral-Small-Instruct-2409-bnb-4bit",
"base_model:finetune:unsloth/Mistral-Small-Instruct-2409-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-08-18T15:35:48Z |
---
base_model: unsloth/Mistral-Small-Instruct-2409-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** truong1301
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Mistral-Small-Instruct-2409-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
liukevin666/blockassist-bc-yawning_striped_cassowary_1755570671
|
liukevin666
| 2025-08-19T02:32:33Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"yawning striped cassowary",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T02:32:14Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- yawning striped cassowary
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
crislmfroes/svla-panda-open-base-cabinet-sim-v15
|
crislmfroes
| 2025-08-19T02:30:22Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"smolvla",
"dataset:crislmfroes/panda-open-base-cabinet-v15",
"arxiv:2506.01844",
"base_model:lerobot/smolvla_base",
"base_model:finetune:lerobot/smolvla_base",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-08-19T02:30:09Z |
---
base_model: lerobot/smolvla_base
datasets: crislmfroes/panda-open-base-cabinet-v15
library_name: lerobot
license: apache-2.0
model_name: smolvla
pipeline_tag: robotics
tags:
- lerobot
- robotics
- smolvla
---
# Model Card for smolvla
<!-- Provide a quick summary of what the model is/does. -->
[SmolVLA](https://huggingface.co/papers/2506.01844) is a compact, efficient vision-language-action model that achieves competitive performance at reduced computational costs and can be deployed on consumer-grade hardware.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
python -m lerobot.scripts.train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
python -m lerobot.record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
lisaozill03/blockassist-bc-rugged_prickly_alpaca_1755569144
|
lisaozill03
| 2025-08-19T02:29:51Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"rugged prickly alpaca",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T02:29:48Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- rugged prickly alpaca
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Superrrdamn/task-13-Qwen-Qwen2.5-3B-Instruct
|
Superrrdamn
| 2025-08-19T02:29:10Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:Qwen/Qwen2.5-3B-Instruct",
"base_model:adapter:Qwen/Qwen2.5-3B-Instruct",
"region:us"
] | null | 2025-08-18T17:34:32Z |
---
base_model: Qwen/Qwen2.5-3B-Instruct
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.2
|
VIDEOS-18-Milica-video-viral-Clip-twitter/New.full.videos.milica.Viral.Video.Official.Tutorial
|
VIDEOS-18-Milica-video-viral-Clip-twitter
| 2025-08-19T02:25:21Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-19T02:25:08Z |
<animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?leaked-viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
Jiawei-Lian/Aerial_Detectors_for_APPA
|
Jiawei-Lian
| 2025-08-19T02:25:07Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-08-19T02:18:10Z |
---
license: apache-2.0
---
|
IvanJAjebu/blockassist-bc-thorny_slender_capybara_1755570202
|
IvanJAjebu
| 2025-08-19T02:25:05Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"thorny slender capybara",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T02:24:40Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- thorny slender capybara
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
thanobidex/blockassist-bc-colorful_shiny_hare_1755568689
|
thanobidex
| 2025-08-19T02:22:48Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"colorful shiny hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T02:22:45Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- colorful shiny hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
dgambettaphd/M_mis_run2_gen1_WXS_doc1000_synt64_lr1e-04_acm_MPP
|
dgambettaphd
| 2025-08-19T02:21:27Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T02:21:13Z |
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Ver-full-videos-milica-Clips/Ver.Viral.video.milica.polemica.viral.en.twitter.y.telegram
|
Ver-full-videos-milica-Clips
| 2025-08-19T02:20:44Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-19T02:20:33Z |
<animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?leaked-viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
RE-N-Y/hpsv3
|
RE-N-Y
| 2025-08-19T02:19:20Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2_vl",
"arxiv:1910.09700",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | null | 2025-08-16T16:27:13Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
tamayuliv/blockassist-bc-mimic_skilled_gecko_1755569856
|
tamayuliv
| 2025-08-19T02:19:05Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"mimic skilled gecko",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T02:18:55Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- mimic skilled gecko
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Dongkkka/RedBottleACT22
|
Dongkkka
| 2025-08-19T02:18:59Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"robotics",
"act",
"dataset:Dongkkka/ffw_sg2_rev1_PickRedPlasticBottle2",
"arxiv:2304.13705",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-08-19T02:18:45Z |
---
datasets: Dongkkka/ffw_sg2_rev1_PickRedPlasticBottle2
library_name: lerobot
license: apache-2.0
model_name: act
pipeline_tag: robotics
tags:
- robotics
- act
- lerobot
---
# Model Card for act
<!-- Provide a quick summary of what the model is/does. -->
[Action Chunking with Transformers (ACT)](https://huggingface.co/papers/2304.13705) is an imitation-learning method that predicts short action chunks instead of single steps. It learns from teleoperated data and often achieves high success rates.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
python -m lerobot.scripts.train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
python -m lerobot.record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
IvanJAjebu/blockassist-bc-thorny_slender_capybara_1755569771
|
IvanJAjebu
| 2025-08-19T02:17:59Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"thorny slender capybara",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T02:17:34Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- thorny slender capybara
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
premrajreddy/tinyllama-1.1b-home-llm
|
premrajreddy
| 2025-08-19T02:16:38Z | 0 | 0 | null |
[
"safetensors",
"gguf",
"llama",
"home-assistant",
"voice-assistant",
"automation",
"assistant",
"home",
"text-generation",
"conversational",
"en",
"dataset:acon96/Home-Assistant-Requests",
"base_model:TinyLlama/TinyLlama-1.1B-Chat-v1.0",
"base_model:finetune:TinyLlama/TinyLlama-1.1B-Chat-v1.0",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-18T05:31:12Z |
---
language: en
license: apache-2.0
tags:
- home-assistant
- voice-assistant
- automation
- assistant
- home
pipeline_tag: text-generation
datasets:
- acon96/Home-Assistant-Requests
base_model:
- TinyLlama/TinyLlama-1.1B-Chat-v1.0
base_model_relation: finetune
---
# 🏠 TinyLLaMA-1.1B Home Assistant Voice Model
This model is a **fine-tuned version** of [TinyLlama/TinyLlama-1.1B-Chat-v1.0](https://huggingface.co/TinyLlama/TinyLlama-1.1B-Chat-v1.0), trained with [acon96/Home-Assistant-Requests](https://huggingface.co/datasets/acon96/Home-Assistant-Requests).
It is designed to act as a **voice-controlled smart home assistant** that takes natural language instructions and outputs **Home Assistant commands**.
---
## ✨ Features
- Converts **natural language voice commands** into Home Assistant automation calls.
- Produces **friendly confirmations** and **structured JSON service commands**.
- Lightweight (1.1B parameters) – runs efficiently on CPUs, GPUs, and via **Ollama** with quantization.
---
## 🔧 Example Usage (Transformers)
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("premrajreddy/tinyllama-1.1b-home-llm")
model = AutoModelForCausalLM.from_pretrained("premrajreddy/tinyllama-1.1b-home-llm")
query = "turn on the kitchen lights"
inputs = tokenizer(query, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=80)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
|
kojeklollipop/blockassist-bc-spotted_amphibious_stork_1755568227
|
kojeklollipop
| 2025-08-19T02:16:37Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"spotted amphibious stork",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T02:16:34Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- spotted amphibious stork
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
New-Clip-Afrin-Er-Viral-Video/New.full.videos.Afrin.Er.Viral.Video.Official.Tutorial
|
New-Clip-Afrin-Er-Viral-Video
| 2025-08-19T02:15:16Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-19T02:15:02Z |
<animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?leaked-viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
g-assismoraes/Qwen3-4B-Base-aki-alpha0.08-var-hatebr-ep30-v5
|
g-assismoraes
| 2025-08-19T02:14:33Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T02:11:19Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
sampingkaca72/blockassist-bc-armored_stealthy_elephant_1755568106
|
sampingkaca72
| 2025-08-19T02:13:21Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"armored stealthy elephant",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T02:13:18Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- armored stealthy elephant
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
VIDEOS-19-Uppal-Farm-Girl-Viral-Video-Clip/New.full.videos.Uppal.Farm.Girl.Viral.Video.Official.Tutorial
|
VIDEOS-19-Uppal-Farm-Girl-Viral-Video-Clip
| 2025-08-19T02:12:05Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-19T02:11:53Z |
<animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?leaked-viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
tamayuliv/blockassist-bc-mimic_skilled_gecko_1755569420
|
tamayuliv
| 2025-08-19T02:12:02Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"mimic skilled gecko",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T02:11:53Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- mimic skilled gecko
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
rumbleFTW/prism-v0-pretrain-1
|
rumbleFTW
| 2025-08-19T02:08:10Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"generated_from_trainer",
"conversational",
"base_model:Qwen/Qwen3-0.6B",
"base_model:finetune:Qwen/Qwen3-0.6B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-18T15:11:51Z |
---
library_name: transformers
license: apache-2.0
base_model: Qwen/Qwen3-0.6B
tags:
- generated_from_trainer
model-index:
- name: prism-v0-pretrain-1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# prism-v0-pretrain-1
This model is a fine-tuned version of [Qwen/Qwen3-0.6B](https://huggingface.co/Qwen/Qwen3-0.6B) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 6.2010
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 8
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 6.9787 | 0.2803 | 1000 | 6.7248 |
| 6.6153 | 0.5606 | 2000 | 6.4486 |
| 6.6127 | 0.8410 | 3000 | 6.3316 |
| 6.1481 | 1.1211 | 4000 | 6.2661 |
| 6.1624 | 1.4014 | 5000 | 6.2257 |
| 6.3045 | 1.6817 | 6000 | 6.2059 |
| 6.4292 | 1.9621 | 7000 | 6.2010 |
### Framework versions
- Transformers 4.55.2
- Pytorch 2.4.0a0+07cecf4168.nv24.05
- Datasets 4.0.0
- Tokenizers 0.21.4
|
Hariharan05/SeproLM
|
Hariharan05
| 2025-08-19T02:06:19Z | 39 | 0 | null |
[
"safetensors",
"mistral",
"SeproLM",
"text-generation",
"conversational",
"base_model:mistralai/Mistral-7B-Instruct-v0.3",
"base_model:quantized:mistralai/Mistral-7B-Instruct-v0.3",
"license:apache-2.0",
"4-bit",
"bitsandbytes",
"region:us"
] |
text-generation
| 2025-08-06T05:16:45Z |
---
license: apache-2.0
base_model:
- mistralai/Mistral-7B-Instruct-v0.3
pipeline_tag: text-generation
tags:
- SeproLM
---
|
Wonder-Griffin/ZeusMM
|
Wonder-Griffin
| 2025-08-19T02:06:10Z | 55 | 0 |
transformers
|
[
"transformers",
"safetensors",
"zeusmm",
"text-generation",
"multimodal",
"chat",
"vision",
"audio",
"retrieval",
"text-generation-inference",
"custom_code",
"en",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] |
text-generation
| 2025-08-13T21:27:30Z |
---
language:
- en
license: apache-2.0
tags:
- text-generation
- multimodal
- chat
- vision
- audio
- retrieval
- text-generation-inference
pipeline_tag: text-generation
library_name: transformers
---
# ZeusMM
**ZeusMM** is a decoder-only multimodal conversational LM with:
- Role-aware RoPE + KV cache
- Dual fusion (Cross-Attn + FiLM) with a learned router
- Modality-aware MoE-MLP
- Drop-in vision (CLIP), audio (Wav2Vec2), retrieval (any HF encoder)
## Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
repo = "Wonder-Griffin/ZeusMM"
tok = AutoTokenizer.from_pretrained(repo, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(repo, trust_remote_code=True)
prompt = "<|system|>You are Zeus.<|end|>\n<|user|>Say hi.<|end|>\n<|assistant|>"
x = tok(prompt, return_tensors="pt")
y = model.generate(**x, max_new_tokens=60, do_sample=True, top_p=0.9, temperature=0.9)
print(tok.decode(y[0], skip_special_tokens=False))
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
koloni/blockassist-bc-deadly_graceful_stingray_1755567463
|
koloni
| 2025-08-19T02:04:45Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"deadly graceful stingray",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T02:04:41Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- deadly graceful stingray
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
MauoSama/depthcut_4cams_DPsmall
|
MauoSama
| 2025-08-19T02:02:39Z | 0 | 0 |
lerobot
|
[
"lerobot",
"safetensors",
"diffusion",
"robotics",
"dataset:MauoSama/depthcut_4cams",
"arxiv:2303.04137",
"license:apache-2.0",
"region:us"
] |
robotics
| 2025-08-19T02:02:31Z |
---
datasets: MauoSama/depthcut_4cams
library_name: lerobot
license: apache-2.0
model_name: diffusion
pipeline_tag: robotics
tags:
- diffusion
- robotics
- lerobot
---
# Model Card for diffusion
<!-- Provide a quick summary of what the model is/does. -->
[Diffusion Policy](https://huggingface.co/papers/2303.04137) treats visuomotor control as a generative diffusion process, producing smooth, multi-step action trajectories that excel at contact-rich manipulation.
This policy has been trained and pushed to the Hub using [LeRobot](https://github.com/huggingface/lerobot).
See the full documentation at [LeRobot Docs](https://huggingface.co/docs/lerobot/index).
---
## How to Get Started with the Model
For a complete walkthrough, see the [training guide](https://huggingface.co/docs/lerobot/il_robots#train-a-policy).
Below is the short version on how to train and run inference/eval:
### Train from scratch
```bash
python -m lerobot.scripts.train \
--dataset.repo_id=${HF_USER}/<dataset> \
--policy.type=act \
--output_dir=outputs/train/<desired_policy_repo_id> \
--job_name=lerobot_training \
--policy.device=cuda \
--policy.repo_id=${HF_USER}/<desired_policy_repo_id>
--wandb.enable=true
```
_Writes checkpoints to `outputs/train/<desired_policy_repo_id>/checkpoints/`._
### Evaluate the policy/run inference
```bash
python -m lerobot.record \
--robot.type=so100_follower \
--dataset.repo_id=<hf_user>/eval_<dataset> \
--policy.path=<hf_user>/<desired_policy_repo_id> \
--episodes=10
```
Prefix the dataset repo with **eval\_** and supply `--policy.path` pointing to a local or hub checkpoint.
---
## Model Details
- **License:** apache-2.0
|
xiangxinai/Xiangxin-2XL-Chat-1048k-Chinese-Llama3-70B
|
xiangxinai
| 2025-08-19T02:01:27Z | 7,159 | 5 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"zh",
"en",
"license:llama3",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2024-05-21T05:14:21Z |
---
license: llama3
language:
- zh
- en
pipeline_tag: text-generation
---
<div align="center">
<picture>
<img src="https://github.com/xiangxinai/XiangxinLM/blob/main/assets/logo.png?raw=true" width="150px">
</picture>
</div>
<div align="center">
<h1>
Xiangxin-2XL-Chat-1048k
</h1>
</div>
我们提供私有化模型训练服务,如果您需要训练行业模型、领域模型或者私有模型,请联系我们: [email protected]
We offer customized model training services. If you need to train industry-specific models, domain-specific models, or private models, please contact us at: [email protected].
# <span id="Introduction">模型介绍/Introduction</span>
Xiangxin-2XL-Chat-1048k是[象信AI](https://www.xiangxinai.cn)基于Meta Llama-3-70B-Instruct模型和[Gradient AI的扩充上下文的工作](https://huggingface.co/gradientai/Llama-3-70B-Instruct-Gradient-1048k),利用自行研发的中文价值观对齐数据集进行ORPO训练而形成的Chat模型。该模型具备更强的中文能力和中文价值观,其上下文长度达到100万字。在模型性能方面,该模型在ARC、HellaSwag、MMLU、TruthfulQA_mc2、Winogrande、GSM8K_flex、CMMLU、CEVAL-VALID等八项测评中,取得了平均分70.22分的成绩,超过了Gradientai-Llama-3-70B-Instruct-Gradient-1048k。我们的训练数据并不包含任何测评数据集。
Xiangxin-2XL-Chat-1048k is a Chat model developed by [Xiangxin AI](https://www.xiangxinai.cn), based on the Meta Llama-3-70B-Instruct model and [expanded context from Gradient AI](https://huggingface.co/gradientai/Llama-3-70B-Instruct-Gradient-1048k). It was trained using a proprietary Chinese value-aligned dataset through ORPO training, resulting in enhanced Chinese proficiency and alignment with Chinese values. The model has a context length of up to 1 million words. In terms of performance, it surpassed the Gradientai-Llama-3-70B-Instruct-Gradient-1048k model with an average score of 70.22 across eight evaluations including ARC, HellaSwag, MMLU, TruthfulQA_mc2, Winogrande, GSM8K_flex, CMMLU, and C-EVAL. It's worth noting that our training data did not include any evaluation datasets.
<div align="center">
Model | Context Length | Pre-trained Tokens
| :------------: | :------------: | :------------: |
| Xiangxin-2XL-Chat-1048k | 1048k | 15T
</div>
# <span id="Benchmark">Benchmark 结果/Benchmark Evaluation</span>
| | **Average** | **ARC** | **HellaSwag** | **MMLU** | **TruthfulQA** | **Winogrande** | **GSM8K** | **CMMLU** | **CEVAL** |
|:-----------------------:|:----------:|:--------:|:---------:|:----------:|:-----------:|:-------:|:-------:|:-------:|:-------:|
|**Xiangxin-2XL-Chat-1048k**| 70.22 | 60.92 | 83.29 |75.13| 57.33| 76.64| 81.05| 65.40| 62.03 |
|**Llama-3-70B-Instruct-Gradient-1048k**| 69.66| 61.18 |82.88 |74.95 |55.28 |75.77 |77.79 |66.44 |63.00|
Note:truthfulqa_mc2, gsm8k flexible-extract
# <span id="Training">训练过程模型/Training</span>
该模型是使用ORPO技术和自行研发的中文价值观对齐数据集进行训练的。由于内容的敏感性,该数据集无法公开披露。
The model was trained using ORPO and a proprietary Chinese alignment dataset developed in-house. Due to the sensitivity of the content, the dataset cannot be publicly disclosed.
## Training loss

## Reward accuracies

## SFT loss

# <span id="Start">快速开始/Quick Start</span>
## Use with transformers
You can run conversational inference using the Transformers pipeline abstraction, or by leveraging the Auto classes with the `generate()` function. Let's see examples of both.
使用Transformers运行本模型推理需要约400GB的显存。
Running inference with this model using Transformers requires approximately 400GB of GPU memory.
### Transformers pipeline
```python
import transformers
import torch
model_id = "xiangxinai/Xiangxin-2XL-Chat-1048k-Chinese-Llama3-70B"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": ""},
{"role": "user", "content": "解释一下“温故而知新”"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])
“温故而知新”是中国古代的一句成语,出自《论语·子路篇》。
它的意思是通过温习过去的知识和经验,来获得新的理解和见解。
这里的“温故”是指温习过去,回顾历史,复习旧知识,
而“知新”则是指了解新鲜事物,掌握新知识。
这个成语强调学习的循序渐进性,强调在学习新知识时,
不能忽视过去的基础,而是要在继承和发扬的基础上,去理解和创新。
```
### Transformers AutoModelForCausalLM
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "xiangxinai/Xiangxin-2XL-Chat-1048k-Chinese-Llama3-70B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "system", "content": ""},
{"role": "user", "content": "解释一下“温故而知新”"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = model.generate(
input_ids,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
“温故而知新”是中国古代的一句成语,出自《论语·子路篇》。
它的意思是通过温习过去的知识和经验,来获得新的理解和见解。
这里的“温故”是指温习过去,回顾历史,复习旧知识,
而“知新”则是指了解新鲜事物,掌握新知识。
这个成语强调学习的循序渐进性,强调在学习新知识时,
不能忽视过去的基础,而是要在继承和发扬的基础上,去理解和创新。
```
# 协议/License
This code is licensed under the META LLAMA 3 COMMUNITY LICENSE AGREEMENT License.
# 联系我们/Contact Us
For inquiries, please contact us via email at [email protected].
|
IvanJAjebu/blockassist-bc-thorny_slender_capybara_1755568763
|
IvanJAjebu
| 2025-08-19T02:01:13Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"thorny slender capybara",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T02:00:39Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- thorny slender capybara
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
katanyasekolah/blockassist-bc-silky_sprightly_cassowary_1755567162
|
katanyasekolah
| 2025-08-19T02:00:56Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"silky sprightly cassowary",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T02:00:53Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- silky sprightly cassowary
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
g-assismoraes/Qwen3-4B-Base-aki-alpha0.08-var-hatebr-ep30-v4
|
g-assismoraes
| 2025-08-19T01:59:01Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T01:55:50Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mradermacher/AgThinker-32B-final-i1-GGUF
|
mradermacher
| 2025-08-19T01:57:41Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:chegde/AgThinker-32B-final",
"base_model:quantized:chegde/AgThinker-32B-final",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-08-18T23:02:01Z |
---
base_model: chegde/AgThinker-32B-final
language:
- en
library_name: transformers
mradermacher:
readme_rev: 1
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
<!-- ### quants: Q2_K IQ3_M Q4_K_S IQ3_XXS Q3_K_M small-IQ4_NL Q4_K_M IQ2_M Q6_K IQ4_XS Q2_K_S IQ1_M Q3_K_S IQ2_XXS Q3_K_L IQ2_XS Q5_K_S IQ2_S IQ1_S Q5_K_M Q4_0 IQ3_XS Q4_1 IQ3_S -->
<!-- ### quants_skip: -->
<!-- ### skip_mmproj: -->
weighted/imatrix quants of https://huggingface.co/chegde/AgThinker-32B-final
<!-- provided-files -->
***For a convenient overview and download list, visit our [model page for this model](https://hf.tst.eu/model#AgThinker-32B-final-i1-GGUF).***
static quants are available at https://huggingface.co/mradermacher/AgThinker-32B-final-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/AgThinker-32B-final-i1-GGUF/resolve/main/AgThinker-32B-final.imatrix.gguf) | imatrix | 0.1 | imatrix file (for creating your own qwuants) |
| [GGUF](https://huggingface.co/mradermacher/AgThinker-32B-final-i1-GGUF/resolve/main/AgThinker-32B-final.i1-IQ1_S.gguf) | i1-IQ1_S | 7.4 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/AgThinker-32B-final-i1-GGUF/resolve/main/AgThinker-32B-final.i1-IQ1_M.gguf) | i1-IQ1_M | 8.0 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/AgThinker-32B-final-i1-GGUF/resolve/main/AgThinker-32B-final.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 9.1 | |
| [GGUF](https://huggingface.co/mradermacher/AgThinker-32B-final-i1-GGUF/resolve/main/AgThinker-32B-final.i1-IQ2_XS.gguf) | i1-IQ2_XS | 10.1 | |
| [GGUF](https://huggingface.co/mradermacher/AgThinker-32B-final-i1-GGUF/resolve/main/AgThinker-32B-final.i1-IQ2_S.gguf) | i1-IQ2_S | 10.5 | |
| [GGUF](https://huggingface.co/mradermacher/AgThinker-32B-final-i1-GGUF/resolve/main/AgThinker-32B-final.i1-IQ2_M.gguf) | i1-IQ2_M | 11.4 | |
| [GGUF](https://huggingface.co/mradermacher/AgThinker-32B-final-i1-GGUF/resolve/main/AgThinker-32B-final.i1-Q2_K_S.gguf) | i1-Q2_K_S | 11.6 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/AgThinker-32B-final-i1-GGUF/resolve/main/AgThinker-32B-final.i1-Q2_K.gguf) | i1-Q2_K | 12.4 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/AgThinker-32B-final-i1-GGUF/resolve/main/AgThinker-32B-final.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 12.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/AgThinker-32B-final-i1-GGUF/resolve/main/AgThinker-32B-final.i1-IQ3_XS.gguf) | i1-IQ3_XS | 13.8 | |
| [GGUF](https://huggingface.co/mradermacher/AgThinker-32B-final-i1-GGUF/resolve/main/AgThinker-32B-final.i1-Q3_K_S.gguf) | i1-Q3_K_S | 14.5 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/AgThinker-32B-final-i1-GGUF/resolve/main/AgThinker-32B-final.i1-IQ3_S.gguf) | i1-IQ3_S | 14.5 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/AgThinker-32B-final-i1-GGUF/resolve/main/AgThinker-32B-final.i1-IQ3_M.gguf) | i1-IQ3_M | 14.9 | |
| [GGUF](https://huggingface.co/mradermacher/AgThinker-32B-final-i1-GGUF/resolve/main/AgThinker-32B-final.i1-Q3_K_M.gguf) | i1-Q3_K_M | 16.0 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/AgThinker-32B-final-i1-GGUF/resolve/main/AgThinker-32B-final.i1-Q3_K_L.gguf) | i1-Q3_K_L | 17.3 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/AgThinker-32B-final-i1-GGUF/resolve/main/AgThinker-32B-final.i1-IQ4_XS.gguf) | i1-IQ4_XS | 17.8 | |
| [GGUF](https://huggingface.co/mradermacher/AgThinker-32B-final-i1-GGUF/resolve/main/AgThinker-32B-final.i1-Q4_0.gguf) | i1-Q4_0 | 18.8 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/AgThinker-32B-final-i1-GGUF/resolve/main/AgThinker-32B-final.i1-Q4_K_S.gguf) | i1-Q4_K_S | 18.9 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/AgThinker-32B-final-i1-GGUF/resolve/main/AgThinker-32B-final.i1-Q4_K_M.gguf) | i1-Q4_K_M | 20.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/AgThinker-32B-final-i1-GGUF/resolve/main/AgThinker-32B-final.i1-Q4_1.gguf) | i1-Q4_1 | 20.7 | |
| [GGUF](https://huggingface.co/mradermacher/AgThinker-32B-final-i1-GGUF/resolve/main/AgThinker-32B-final.i1-Q5_K_S.gguf) | i1-Q5_K_S | 22.7 | |
| [GGUF](https://huggingface.co/mradermacher/AgThinker-32B-final-i1-GGUF/resolve/main/AgThinker-32B-final.i1-Q5_K_M.gguf) | i1-Q5_K_M | 23.4 | |
| [GGUF](https://huggingface.co/mradermacher/AgThinker-32B-final-i1-GGUF/resolve/main/AgThinker-32B-final.i1-Q6_K.gguf) | i1-Q6_K | 27.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
finalform/foamQwen2.5-Coder-7B-Instruct
|
finalform
| 2025-08-19T01:57:09Z | 0 | 0 |
peft
|
[
"peft",
"tensorboard",
"safetensors",
"base_model:adapter:Qwen/Qwen2.5-Coder-7B-Instruct",
"lora",
"sft",
"transformers",
"trl",
"text-generation",
"conversational",
"arxiv:1910.09700",
"base_model:Qwen/Qwen2.5-Coder-7B-Instruct",
"region:us"
] |
text-generation
| 2025-08-18T22:40:16Z |
---
base_model: Qwen/Qwen2.5-Coder-7B-Instruct
library_name: peft
pipeline_tag: text-generation
tags:
- base_model:adapter:Qwen/Qwen2.5-Coder-7B-Instruct
- lora
- sft
- transformers
- trl
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.17.0
|
thanobidex/blockassist-bc-colorful_shiny_hare_1755566999
|
thanobidex
| 2025-08-19T01:54:52Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"colorful shiny hare",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T01:54:49Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- colorful shiny hare
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
ncgc/retraining-bias-statichh-pythia-1.4b-sft-bf16-pureif-1000
|
ncgc
| 2025-08-19T01:53:43Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt_neox",
"text-generation",
"generated_from_trainer",
"trl",
"sft",
"base_model:EleutherAI/pythia-1.4b",
"base_model:finetune:EleutherAI/pythia-1.4b",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-18T20:26:52Z |
---
base_model: EleutherAI/pythia-1.4b
library_name: transformers
model_name: retraining-bias-statichh-pythia-1.4b-sft-bf16-pureif-1000
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for retraining-bias-statichh-pythia-1.4b-sft-bf16-pureif-1000
This model is a fine-tuned version of [EleutherAI/pythia-1.4b](https://huggingface.co/EleutherAI/pythia-1.4b).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="ncgc/retraining-bias-statichh-pythia-1.4b-sft-bf16-pureif-1000", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/mareeb-purdue-university/huggingface/runs/9xydcamu)
This model was trained with SFT.
### Framework versions
- TRL: 0.19.1
- Transformers: 4.53.3
- Pytorch: 2.7.0+cu126
- Datasets: 3.6.0
- Tokenizers: 0.21.0
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
macszym/ppo-LunarLander-v2
|
macszym
| 2025-08-19T01:52:42Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-08-19T01:52:22Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 257.63 +/- 15.07
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
oddadmix/arabic-summarization
|
oddadmix
| 2025-08-19T01:52:34Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"lfm2",
"text-generation",
"generated_from_trainer",
"sft",
"trl",
"conversational",
"ar",
"dataset:oddadmix/arabic-news-summarization",
"base_model:LiquidAI/LFM2-350M",
"base_model:finetune:LiquidAI/LFM2-350M",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-18T23:26:07Z |
---
base_model: LiquidAI/LFM2-350M
library_name: transformers
model_name: lfm2-sft-summary
tags:
- generated_from_trainer
- sft
- trl
licence: license
datasets:
- oddadmix/arabic-news-summarization
language:
- ar
---
# 📝 نموذج التلخيص العربي
هذا المشروع يقدّم نموذج **تلخيص نصوص باللغة العربية** مبني على النموذج الأساسي [LiquidAI/LFM2-350M](https://huggingface.co/LiquidAI/LFM2-350M)، وتمت إعادة تدريبه (Fine-tuning) على **مجموعة بيانات مكوّنة من 17,000 سجل** لتلخيص النصوص بدقة وكفاءة عالية.
---
## ⚡ المميزات
* ✅ أداء قوي جدًا في تلخيص النصوص العربية.
* ✅ يحافظ على المعنى العام للنص مع اختصار الحجم.
* ✅ يمكن استخدامه في تلخيص المقالات، الأخبار، الأبحاث، والمستندات الطويلة.
* ✅ مبني على نموذج قوي مفتوح المصدر مع إعادة ضبط دقيقة (Fine-tuning).
---
## 🛠️ البيانات
تم تدريب النموذج باستخدام **17,000 صف** من البيانات عالية الجودة التي تحتوي على نصوص عربية وأهداف التلخيص المقابلة لها.
هذا ساعد في تحسين دقة النموذج وجعله قادرًا على إنتاج **ملخصات متماسكة وسلسة**.
---
## 🚀 كيفية الاستخدام
```python
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
# تحميل النموذج والمحول
model_name = "اسم-المستخدم/arabic-summarization-model"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
# إدخال نص للتلخيص
text = """النص العربي المراد تلخيصه ..."""
inputs = tokenizer(text, return_tensors="pt", max_length=1024, truncation=True)
summary_ids = model.generate(inputs["input_ids"], max_length=150, min_length=40, length_penalty=2.0, num_beams=4)
# عرض الملخص
print(tokenizer.decode(summary_ids[0], skip_special_tokens=True))
```
---
## 📊 الأداء
النموذج أظهر نتائج ممتازة في التجارب الداخلية على مقاييس **الدقة، التماسك، والمحافظة على المعنى**.
أداؤه يُعتبر **جيد جدًا مقارنة بالنماذج المشابهة** في مجال تلخيص النصوص العربية.
---
## 📌 ملاحظات
* النموذج ما زال قابلًا للتطوير عبر تدريبه على بيانات إضافية.
* يُفضّل استخدامه مع نصوص عربية فصيحة، مع أنه يعمل بشكل جيد أيضًا مع بعض اللهجات.
|
concept-unlearning/Phi-3-mini-4k-instruct_ft_lora_all_novels_v3_ft
|
concept-unlearning
| 2025-08-19T01:50:27Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"phi3",
"text-generation",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T01:48:26Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Hiccup1119/mine-7-2-tiny
|
Hiccup1119
| 2025-08-19T01:48:19Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"convnext",
"image-classification",
"generated_from_trainer",
"base_model:facebook/convnext-tiny-224",
"base_model:finetune:facebook/convnext-tiny-224",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2025-08-11T21:45:56Z |
---
library_name: transformers
license: apache-2.0
base_model: facebook/convnext-tiny-224
tags:
- generated_from_trainer
model-index:
- name: roadwork-convnext-tiny-224-1.1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roadwork-convnext-tiny-224-1.1
This model is a fine-tuned version of [facebook/convnext-tiny-224](https://huggingface.co/facebook/convnext-tiny-224) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2.4075452114517532e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Use adamw_torch_fused with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.55.0
- Pytorch 2.8.0+cu128
- Datasets 4.0.0
- Tokenizers 0.21.4
|
prcstone0823/gpt-oss-6.0b-specialized-all-pruned-moe-only-7-experts-Q4_K_M-GGUF
|
prcstone0823
| 2025-08-19T01:47:26Z | 0 | 0 | null |
[
"gguf",
"mixture-of-experts",
"moe",
"expert-pruning",
"gpt-oss",
"openai",
"reasoning",
"all",
"specialized",
"efficient",
"transformer",
"causal-lm",
"text-generation",
"pytorch",
"pruned-model",
"domain-specific",
"llama-cpp",
"gguf-my-repo",
"en",
"dataset:AmanPriyanshu/GPT-OSS-20B-MoE-expert-activations",
"base_model:AmanPriyanshu/gpt-oss-6.0b-specialized-all-pruned-moe-only-7-experts",
"base_model:quantized:AmanPriyanshu/gpt-oss-6.0b-specialized-all-pruned-moe-only-7-experts",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-08-19T01:47:02Z |
---
license: apache-2.0
datasets:
- AmanPriyanshu/GPT-OSS-20B-MoE-expert-activations
language:
- en
pipeline_tag: text-generation
tags:
- mixture-of-experts
- moe
- expert-pruning
- gpt-oss
- openai
- reasoning
- all
- specialized
- efficient
- transformer
- causal-lm
- text-generation
- pytorch
- pruned-model
- domain-specific
- llama-cpp
- gguf-my-repo
base_model: AmanPriyanshu/gpt-oss-6.0b-specialized-all-pruned-moe-only-7-experts
---
# prcstone0823/gpt-oss-6.0b-specialized-all-pruned-moe-only-7-experts-Q4_K_M-GGUF
This model was converted to GGUF format from [`AmanPriyanshu/gpt-oss-6.0b-specialized-all-pruned-moe-only-7-experts`](https://huggingface.co/AmanPriyanshu/gpt-oss-6.0b-specialized-all-pruned-moe-only-7-experts) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/AmanPriyanshu/gpt-oss-6.0b-specialized-all-pruned-moe-only-7-experts) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo prcstone0823/gpt-oss-6.0b-specialized-all-pruned-moe-only-7-experts-Q4_K_M-GGUF --hf-file gpt-oss-6.0b-specialized-all-pruned-moe-only-7-experts-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo prcstone0823/gpt-oss-6.0b-specialized-all-pruned-moe-only-7-experts-Q4_K_M-GGUF --hf-file gpt-oss-6.0b-specialized-all-pruned-moe-only-7-experts-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo prcstone0823/gpt-oss-6.0b-specialized-all-pruned-moe-only-7-experts-Q4_K_M-GGUF --hf-file gpt-oss-6.0b-specialized-all-pruned-moe-only-7-experts-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo prcstone0823/gpt-oss-6.0b-specialized-all-pruned-moe-only-7-experts-Q4_K_M-GGUF --hf-file gpt-oss-6.0b-specialized-all-pruned-moe-only-7-experts-q4_k_m.gguf -c 2048
```
|
mang3dd/blockassist-bc-tangled_slithering_alligator_1755566416
|
mang3dd
| 2025-08-19T01:46:55Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"tangled slithering alligator",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T01:46:52Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- tangled slithering alligator
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Kokoutou/sound_1908_2
|
Kokoutou
| 2025-08-19T01:41:53Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-08-18T17:50:18Z |
# Container Template for SoundsRight Subnet Miners
This repository contains a contanierized version of [SGMSE+](https://huggingface.co/sp-uhh/speech-enhancement-sgmse) and serves as a tutorial for miners to format their models on [Bittensor's](https://bittensor.com/) [SoundsRight Subnet](https://github.com/synapsec-ai/SoundsRightSubnet). The branches `DENOISING_16000HZ` and `DEREVERBERATION_16000HZ` contain SGMSE fitted with the approrpriate checkpoints for denoising and dereverberation tasks at 16kHz, respectively.
This container has only been tested with **Ubuntu 24.04** and **CUDA 12.6**. It may run on other configurations, but it is not guaranteed.
To run the container, first configure NVIDIA Container Toolkit and generate a CDI specification. Follow the instructions to download the [NVIDIA Container Toolkit](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html) with Apt.
Next, follow the instructions for [generating a CDI specification](https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/cdi-support.html).
Verify that the CDI specification was done correctly with:
```
$ nvidia-ctk cdi list
```
You should see this in your output:
```
nvidia.com/gpu=all
nvidia.com/gpu=0
```
If you are running podman as root, run the following command to start the container:
Run the container with:
```
podman build -t modelapi . && podman run -d --device nvidia.com/gpu=all --user root --name modelapi -p 6500:6500 modelapi
```
Access logs with:
```
podman logs -f modelapi
```
If you are running the container rootless, there are a few more changes to make:
First, modify `/etc/nvidia-container-runtime/config.toml` and set the following parameters:
```
[nvidia-container-cli]
no-cgroups = true
[nvidia-container-runtime]
debug = "/tmp/nvidia-container-runtime.log"
```
You can also run the following command to achieve the same result:
```
$ sudo nvidia-ctk config --set nvidia-container-cli.no-cgroups --in-place
```
Run the container with:
```
podman build -t modelapi . && podman run -d --device nvidia.com/gpu=all --volume /usr/local/cuda-12.6:/usr/local/cuda-12.6 --user 10002:10002 --name modelapi -p 6500:6500 modelapi
```
Access logs with:
```
podman logs -f modelapi
```
Running the container will spin up an API with the following endpoints:
1. `/status/` : Communicates API status
2. `/prepare/` : Download model checkpoint and initialize model
3. `/upload-audio/` : Upload audio files, save to noisy audio directory
4. `/enhance/` : Initialize model, enhance audio files, save to enhanced audio directory
5. `/download-enhanced/` : Download enhanced audio files
By default the API will use host `0.0.0.0` and port `6500`.
### References
1. **Welker, Simon; Richter, Julius; Gerkmann, Timo**
*Speech Enhancement with Score-Based Generative Models in the Complex STFT Domain*.
Proceedings of *Interspeech 2022*, 2022, pp. 2928–2932.
[DOI: 10.21437/Interspeech.2022-10653](https://doi.org/10.21437/Interspeech.2022-10653)
2. **Richter, Julius; Welker, Simon; Lemercier, Jean-Marie; Lay, Bunlong; Gerkmann, Timo**
*Speech Enhancement and Dereverberation with Diffusion-based Generative Models*.
*IEEE/ACM Transactions on Audio, Speech, and Language Processing*, Vol. 31, 2023, pp. 2351–2364.
[DOI: 10.1109/TASLP.2023.3285241](https://doi.org/10.1109/TASLP.2023.3285241)
3. **Richter, Julius; Wu, Yi-Chiao; Krenn, Steven; Welker, Simon; Lay, Bunlong; Watanabe, Shinjii; Richard, Alexander; Gerkmann, Timo**
*EARS: An Anechoic Fullband Speech Dataset Benchmarked for Speech Enhancement and Dereverberation*.
Proceedings of *ISCA Interspeech*, 2024, pp. 4873–4877.
|
jyuan8210/NeuralPipe-7B-slerp
|
jyuan8210
| 2025-08-19T01:40:30Z | 0 | 0 | null |
[
"safetensors",
"mistral",
"merge",
"mergekit",
"lazymergekit",
"OpenPipe/mistral-ft-optimized-1218",
"mlabonne/NeuralHermes-2.5-Mistral-7B",
"base_model:OpenPipe/mistral-ft-optimized-1218",
"base_model:merge:OpenPipe/mistral-ft-optimized-1218",
"base_model:mlabonne/NeuralHermes-2.5-Mistral-7B",
"base_model:merge:mlabonne/NeuralHermes-2.5-Mistral-7B",
"region:us"
] | null | 2025-08-19T01:39:08Z |
---
base_model:
- OpenPipe/mistral-ft-optimized-1218
- mlabonne/NeuralHermes-2.5-Mistral-7B
tags:
- merge
- mergekit
- lazymergekit
- OpenPipe/mistral-ft-optimized-1218
- mlabonne/NeuralHermes-2.5-Mistral-7B
---
# NeuralPipe-7B-slerp
NeuralPipe-7B-slerp is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [OpenPipe/mistral-ft-optimized-1218](https://huggingface.co/OpenPipe/mistral-ft-optimized-1218)
* [mlabonne/NeuralHermes-2.5-Mistral-7B](https://huggingface.co/mlabonne/NeuralHermes-2.5-Mistral-7B)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: OpenPipe/mistral-ft-optimized-1218
layer_range: [0, 32]
- model: mlabonne/NeuralHermes-2.5-Mistral-7B
layer_range: [0, 32]
merge_method: slerp
base_model: OpenPipe/mistral-ft-optimized-1218
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "jyuan8210/NeuralPipe-7B-slerp"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
neural-interactive-proofs/finetune_dpo_qwen2_5-32b-instruct_cv_qwen2.5_32B_prover_debate_both_2_rounds_1_1_iter_8_prover1_
|
neural-interactive-proofs
| 2025-08-19T01:40:25Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"dpo",
"arxiv:2305.18290",
"base_model:Qwen/Qwen2.5-32B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-32B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T01:39:17Z |
---
base_model: Qwen/Qwen2.5-32B-Instruct
library_name: transformers
model_name: finetune_dpo_qwen2_5-32b-instruct_cv_qwen2.5_32B_prover_debate_both_2_rounds_1_1_iter_8_prover1_
tags:
- generated_from_trainer
- trl
- dpo
licence: license
---
# Model Card for finetune_dpo_qwen2_5-32b-instruct_cv_qwen2.5_32B_prover_debate_both_2_rounds_1_1_iter_8_prover1_
This model is a fine-tuned version of [Qwen/Qwen2.5-32B-Instruct](https://huggingface.co/Qwen/Qwen2.5-32B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="neural-interactive-proofs/finetune_dpo_qwen2_5-32b-instruct_cv_qwen2.5_32B_prover_debate_both_2_rounds_1_1_iter_8_prover1_", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/lrhammond-team/pvg-self-hosted-finetune/runs/qwen2_5-32b-instruct_dpo_2025-08-19_01-11-40_cv_qwen2.5_32B_prover_debate_both_2_rounds_1_1_iter_8_prover1)
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.18.2
- Transformers: 4.53.2
- Pytorch: 2.7.0
- Datasets: 3.0.0
- Tokenizers: 0.21.1
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
natsuwinted/blockassist-bc-graceful_gentle_cockroach_1755567434
|
natsuwinted
| 2025-08-19T01:38:52Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"graceful gentle cockroach",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T01:38:44Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- graceful gentle cockroach
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
quantumxnode/blockassist-bc-dormant_peckish_seahorse_1755565793
|
quantumxnode
| 2025-08-19T01:36:19Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"dormant peckish seahorse",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T01:36:16Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- dormant peckish seahorse
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
kimono998/Wordle-curr-neg-3_lora_adapter_iter_20
|
kimono998
| 2025-08-19T01:34:15Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-08-19T01:34:09Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
koloni/blockassist-bc-deadly_graceful_stingray_1755565722
|
koloni
| 2025-08-19T01:34:02Z | 0 | 0 | null |
[
"gensyn",
"blockassist",
"gensyn-blockassist",
"minecraft",
"deadly graceful stingray",
"arxiv:2504.07091",
"region:us"
] | null | 2025-08-19T01:33:59Z |
---
tags:
- gensyn
- blockassist
- gensyn-blockassist
- minecraft
- deadly graceful stingray
---
# Gensyn BlockAssist
Gensyn's BlockAssist is a distributed extension of the paper [AssistanceZero: Scalably Solving Assistance Games](https://arxiv.org/abs/2504.07091).
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.