
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-06-25 18:28:32
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 495
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 54
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-06-25 18:28:16
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
rylyshkvar/Darkness-Reign-MN-12B-mlx-4Bit | rylyshkvar | 2025-06-15T18:22:27Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"mergekit",
"merge",
"mlx",
"mlx-my-repo",
"conversational",
"base_model:Aleteian/Darkness-Reign-MN-12B",
"base_model:quantized:Aleteian/Darkness-Reign-MN-12B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"4-bit",
"region:us"
] | text-generation | 2025-06-15T18:21:50Z | ---
base_model: Aleteian/Darkness-Reign-MN-12B
library_name: transformers
tags:
- mergekit
- merge
- mlx
- mlx-my-repo
---
# rylyshkvar/Darkness-Reign-MN-12B-mlx-4Bit
The Model [rylyshkvar/Darkness-Reign-MN-12B-mlx-4Bit](https://huggingface.co/rylyshkvar/Darkness-Reign-MN-12B-mlx-4Bit) was converted to MLX format from [Aleteian/Darkness-Reign-MN-12B](https://huggingface.co/Aleteian/Darkness-Reign-MN-12B) using mlx-lm version **0.22.3**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("rylyshkvar/Darkness-Reign-MN-12B-mlx-4Bit")
prompt="hello"
if hasattr(tokenizer, "apply_chat_template") and tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
openbmb/BitCPM4-1B-GGUF | openbmb | 2025-06-15T18:18:40Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"text-generation",
"zh",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | text-generation | 2025-06-13T11:41:44Z | ---
license: apache-2.0
language:
- zh
- en
pipeline_tag: text-generation
library_name: transformers
---
<div align="center">
<img src="https://github.com/OpenBMB/MiniCPM/blob/main/assets/minicpm_logo.png?raw=true" width="500em" ></img>
</div>
<p align="center">
<a href="https://github.com/OpenBMB/MiniCPM/" target="_blank">GitHub Repo</a> |
<a href="https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf" target="_blank">Technical Report</a>
</p>
<p align="center">
👋 Join us on <a href="https://discord.gg/3cGQn9b3YM" target="_blank">Discord</a> and <a href="https://github.com/OpenBMB/MiniCPM/blob/main/assets/wechat.jpg" target="_blank">WeChat</a>
</p>
## What's New
- [2025.06.06] **MiniCPM4** series are released! This model achieves ultimate efficiency improvements while maintaining optimal performance at the same scale! It can achieve over 5x generation acceleration on typical end-side chips! You can find technical report [here](https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf).🔥🔥🔥
## MiniCPM4 Series
MiniCPM4 series are highly efficient large language models (LLMs) designed explicitly for end-side devices, which achieves this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems.
- [MiniCPM4-8B](https://huggingface.co/openbmb/MiniCPM4-8B): The flagship of MiniCPM4, with 8B parameters, trained on 8T tokens.
- [MiniCPM4-0.5B](https://huggingface.co/openbmb/MiniCPM4-0.5B): The small version of MiniCPM4, with 0.5B parameters, trained on 1T tokens.
- [MiniCPM4-8B-Eagle-FRSpec](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-FRSpec): Eagle head for FRSpec, accelerating speculative inference for MiniCPM4-8B.
- [MiniCPM4-8B-Eagle-FRSpec-QAT-cpmcu](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-FRSpec-QAT-cpmcu): Eagle head trained with QAT for FRSpec, efficiently integrate speculation and quantization to achieve ultra acceleration for MiniCPM4-8B.
- [MiniCPM4-8B-Eagle-vLLM](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-vLLM): Eagle head in vLLM format, accelerating speculative inference for MiniCPM4-8B.
- [MiniCPM4-8B-marlin-Eagle-vLLM](https://huggingface.co/openbmb/MiniCPM4-8B-marlin-Eagle-vLLM): Quantized Eagle head for vLLM format, accelerating speculative inference for MiniCPM4-8B.
- [BitCPM4-0.5B](https://huggingface.co/openbmb/BitCPM4-0.5B): Extreme ternary quantization applied to MiniCPM4-0.5B compresses model parameters into ternary values, achieving a 90% reduction in bit width.
- [BitCPM4-1B](https://huggingface.co/openbmb/BitCPM4-1B): Extreme ternary quantization applied to MiniCPM3-1B compresses model parameters into ternary values, achieving a 90% reduction in bit width.
- [MiniCPM4-Survey](https://huggingface.co/openbmb/MiniCPM4-Survey): Based on MiniCPM4-8B, accepts users' quiries as input and autonomously generate trustworthy, long-form survey papers.
- [MiniCPM4-MCP](https://huggingface.co/openbmb/MiniCPM4-MCP): Based on MiniCPM4-8B, accepts users' queries and available MCP tools as input and autonomously calls relevant MCP tools to satisfy users' requirements.
- [BitCPM4-0.5B-GGUF](https://huggingface.co/openbmb/BitCPM4-0.5B-GGUF): GGUF version of BitCPM4-0.5B.
- [BitCPM4-1B-GGUF](https://huggingface.co/openbmb/BitCPM4-1B-GGUF): GGUF version of BitCPM4-1B. (**<-- you are here**)
## Introduction
BitCPM4 are ternary quantized models derived from the MiniCPM series models through quantization-aware training (QAT), achieving significant improvements in both training efficiency and model parameter efficiency.
- Improvements of the training method
- Searching hyperparameters with a wind-tunnel on a small model.
- Using a two-stage training method: training in high-precision first and then QAT, making the best of the trained high-precision models and significantly reducing the computational resources required for the QAT phase.
- High parameter efficiency
- Achieving comparable performance to full-precision models of similar parameter models with a bit width of only 1.58 bits, demonstrating high parameter efficiency.
## Usage
### Inference with [llama.cpp](https://github.com/ggml-org/llama.cpp)
```bash
./llama-cli -c 1024 -m BitCPM4-1B-q4_0.gguf -n 1024 --top-p 0.7 --temp 0.7 --prompt "请写一篇关于人工智能的文章,详细介绍人工智能的未来发展和隐患。"
```
## Evaluation Results
BitCPM4's performance is comparable with other full-precision models in same model size.
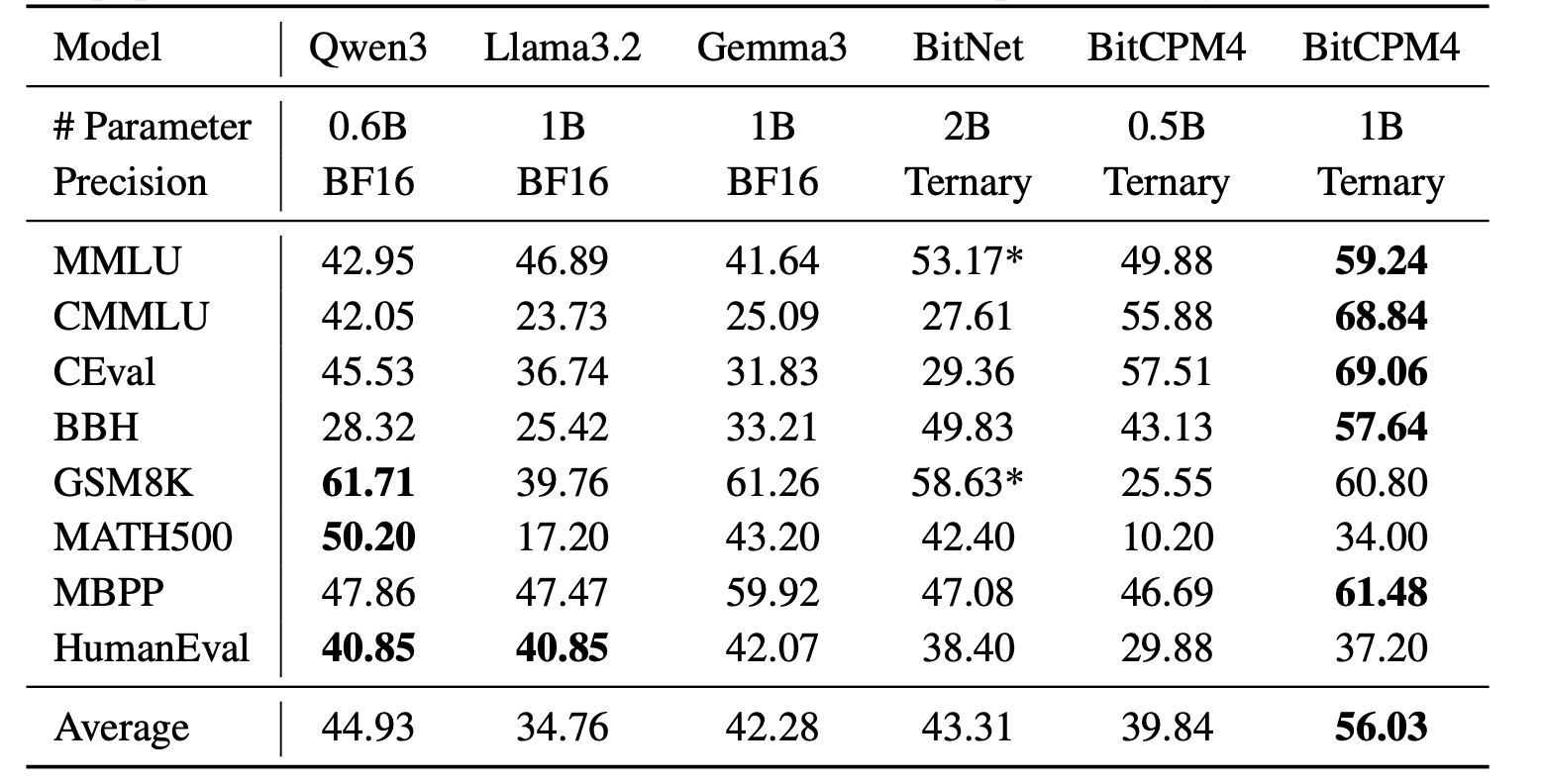
## Statement
- As a language model, MiniCPM generates content by learning from a vast amount of text.
- However, it does not possess the ability to comprehend or express personal opinions or value judgments.
- Any content generated by MiniCPM does not represent the viewpoints or positions of the model developers.
- Therefore, when using content generated by MiniCPM, users should take full responsibility for evaluating and verifying it on their own.
## LICENSE
- This repository and MiniCPM models are released under the [Apache-2.0](https://github.com/OpenBMB/MiniCPM/blob/main/LICENSE) License.
## Citation
- Please cite our [paper](https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf) if you find our work valuable.
```bibtex
@article{minicpm4,
title={{MiniCPM4}: Ultra-Efficient LLMs on End Devices},
author={MiniCPM Team},
year={2025}
}
```
|
JonLoRA/deynairaLoRAv1 | JonLoRA | 2025-06-15T18:17:55Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-06-15T16:21:56Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: photo of a girl
---
# Deynairalorav1
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `photo of a girl` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "photo of a girl",
"lora_weights": "https://huggingface.co/JonLoRA/deynairaLoRAv1/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('JonLoRA/deynairaLoRAv1', weight_name='lora.safetensors')
image = pipeline('photo of a girl').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 6000
- Learning rate: 0.0002
- LoRA rank: 64
## Contribute your own examples
You can use the [community tab](https://huggingface.co/JonLoRA/deynairaLoRAv1/discussions) to add images that show off what you’ve made with this LoRA.
|
meezo-fun-video/Latest.Full.Update.meezo.fun.video.meezo.fun.mezo.fun.meezo.fun | meezo-fun-video | 2025-06-15T18:16:47Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T18:15:28Z | <a rel="nofollow" href="https://www.profitableratecpm.com/ad9ybzrr?key=ad7e5afbc6b154d0ae1429627f60d4a7"><img src="https://i.postimg.cc/qvPp49Sm/ythngythg.gif" alt="fsd"></a>
<a rel="nofollow" href="https://www.profitableratecpm.com/ad9ybzrr?key=ad7e5afbc6b154d0ae1429627f60d4a7">🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶</a>
<a rel="nofollow" href="https://viralflix.xyz/leaked/?ht">🔴 CLICK HERE 🌐==►► Download Now)</a> |
shwabler/lithuanian-gemma-4b-bnb-4bit | shwabler | 2025-06-15T18:15:44Z | 0 | 1 | null | [
"safetensors",
"unsloth",
"license:mit",
"region:us"
] | null | 2025-06-15T12:49:53Z | ---
license: mit
tags:
- unsloth
---
|
Stroeller/Strllr | Stroeller | 2025-06-15T18:14:30Z | 0 | 0 | null | [
"license:other",
"region:us"
] | null | 2025-06-13T09:07:59Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
--- |
yununuy/guesswho-scale-game | yununuy | 2025-06-15T18:13:36Z | 101 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"unsloth",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-14T11:52:14Z | ---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
vinnvinn/mistral-hugz | vinnvinn | 2025-06-15T18:13:06Z | 0 | 1 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T18:13:03Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.25_0.5_epoch1 | MinaMila | 2025-06-15T18:10:57Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T18:09:03Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
jack813liu/mlx-chroma | jack813liu | 2025-06-15T18:10:49Z | 0 | 0 | null | [
"safetensors",
"license:mit",
"region:us"
] | null | 2025-06-15T06:55:11Z | ---
license: mit
---
Overview
====
This repository — [MLX-Chroma](https://github.com/jack813/mlx-chroma) — serves as a lightweight wrapper to organize and host the required model files for running Chroma on MLX.
• Chroma model: sourced from lodestones/Chroma, using the chroma-unlocked-v36-detail-calibrated.safetensors checkpoint.
• T5 and VAE models: sourced from black-forest-labs/FLUX.1-dev.
This repo does not contain training or inference logic, but exists to streamline model access and loading in MLX-based workflows.
MLX-Chroma
====
Chroma implementation in MLX. The implementation is ported from Author's Project
[flow](https://github.com/lodestone-rock/flow.git)、 [ComfyUI](https://github.com/comfyanonymous/ComfyUI) and [MLX-Examples Flux](https://github.com/ml-explore/mlx-examples/tree/main/flux)
Git: [https://github.com/jack813/mlx-chroma](https://github.com/jack813/mlx-chroma)
Blog: [https://blog.exp-pi.com/2025/06/migrating-chroma-to-mlx.html](https://blog.exp-pi.com/2025/06/migrating-chroma-to-mlx.html) |
MichiganNLP/tama-5e-7 | MichiganNLP | 2025-06-15T18:08:31Z | 10 | 0 | null | [
"safetensors",
"llama",
"table",
"text-generation",
"conversational",
"en",
"arxiv:2501.14693",
"base_model:meta-llama/Llama-3.1-8B-Instruct",
"base_model:finetune:meta-llama/Llama-3.1-8B-Instruct",
"license:mit",
"region:us"
] | text-generation | 2024-12-11T00:50:43Z | ---
license: mit
language:
- en
base_model:
- meta-llama/Llama-3.1-8B-Instruct
pipeline_tag: text-generation
tags:
- table
---
# Model Card for TAMA-5e-7
<!-- Provide a quick summary of what the model is/does. -->
Recent advances in table understanding have focused on instruction-tuning large language models (LLMs) for table-related tasks. However, existing research has overlooked the impact of hyperparameter choices, and also lacks a comprehensive evaluation of the out-of-domain table understanding ability and the general capabilities of these table LLMs. In this paper, we evaluate these abilities in existing table LLMs, and find significant declines in both out-of-domain table understanding and general capabilities as compared to their base models.
Through systematic analysis, we show that hyperparameters, such as learning rate, can significantly influence both table-specific and general capabilities. Contrary to the previous table instruction-tuning work, we demonstrate that smaller learning rates and fewer training instances can enhance table understanding while preserving general capabilities. Based on our findings, we introduce TAMA, a TAble LLM instruction-tuned from LLaMA 3.1 8B Instruct, which achieves performance on par with, or surpassing GPT-3.5 and GPT-4 on table tasks, while maintaining strong out-of-domain generalization and general capabilities. Our findings highlight the potential for reduced data annotation costs and more efficient model development through careful hyperparameter selection.
## 🚀 Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Model type:** Text generation.
- **Language(s) (NLP):** English.
- **License:** [[License for Llama models](https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/LICENSE))]
- **Finetuned from model:** [[meta-llama/Llama-3.1-8b-Instruct](https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct)]
### Model Sources
<!-- Provide the basic links for the model. -->
- **Repository:** [[github](https://github.com/MichiganNLP/TAMA)]
- **Paper:** [[paper](https://arxiv.org/abs/2501.14693)]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
TAMA is intended for the use in table understanding tasks and to facilitate future research.
## 🔨 How to Get Started with the Model
Use the code below to get started with the model.
Starting with `transformers >= 4.43.0` onward, you can run conversational inference using the Transformers pipeline abstraction or by leveraging the Auto classes with the generate() function.
Make sure to update your transformers installation via `pip install --upgrade transformers`.
```
import transformers
import torch
model_id = "MichiganNLP/tama-5e-7"
pipeline = transformers.pipeline(
"text-generation", model=model_id, model_kwargs={"torch_dtype": torch.bfloat16}, device_map="auto"
)
pipeline("Hey how are you doing today?")
```
You may replace the prompt with table-specific instructions. We recommend using the following prompt structure:
```
Below is an instruction that describes a task, paired with an input that provides further context. Write a response that
appropriately completes the request.
### Instruction:
{instruction}
### Input:
{table_content}
### Question:
{question}
### Response:
```
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[TAMA Instruct](https://huggingface.co/datasets/MichiganNLP/TAMA_Instruct).
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
We utilize the [LLaMA Factory](https://github.com/hiyouga/LLaMA-Factory) library for model training and inference. Example YAML configuration files are provided [here](https://github.com/MichiganNLP/TAMA/blob/main/yamls/train.yaml).
The training command is:
```
llamafactory-cli train yamls/train.yaml
```
#### Training Hyperparameters
- **Training regime:** bf16
- **Training epochs:** 2.0
- **Learning rate scheduler:** linear
- **Cutoff length:** 2048
- **Learning rate**: 5e-7
## 📝 Evaluation
### Results
<!-- This should link to a Dataset Card if possible. -->
<table>
<tr>
<th>Models</th>
<th>FeTaQA</th>
<th>HiTab</th>
<th>TaFact</th>
<th>FEVEROUS</th>
<th>WikiTQ</th>
<th>WikiSQL</th>
<th>HybridQA</th>
<th>TATQA</th>
<th>AIT-QA</th>
<th>TABMWP</th>
<th>InfoTabs</th>
<th>KVRET</th>
<th>ToTTo</th>
<th>TableGPT<sub>subset</sub></th>
<th>TableBench</th>
</tr>
<tr>
<th>Metrics</th>
<th>BLEU</th>
<th>Acc</th>
<th>Acc</th>
<th>Acc</th>
<th>Acc</th>
<th>Acc</th>
<th>Acc</th>
<th>Acc</th>
<th>Acc</th>
<th>Acc</th>
<th>Acc</th>
<th>Micro F1</th>
<th>BLEU</th>
<th>Acc</th>
<th>ROUGE-L</th>
</tr>
<tr>
<td>GPT-3.5</td>
<td><u>26.49</u></td>
<td>43.62</td>
<td>67.41</td>
<td>60.79</td>
<td><u>53.13</u></td>
<td>41.91</td>
<td>40.22</td>
<td>31.38</td>
<td>84.13</td>
<td>46.30</td>
<td>56.00</td>
<td><u>54.56</u></td>
<td><u>16.81</u></td>
<td>54.80</td>
<td>27.75</td>
</tr>
<tr>
<td>GPT-4</td>
<td>21.70</td>
<td><u>48.40</u></td>
<td><b>74.40</b></td>
<td><u>71.60</u></td>
<td><b>68.40</b></td>
<td><u>47.60</u></td>
<td><u>58.60</u></td>
<td><b>55.81</b></td>
<td><u>88.57</u></td>
<td><b>67.10</b></td>
<td><u>58.60</u></td>
<td><b>56.46</b></td>
<td>12.21</td>
<td><b>80.20</b></td>
<td><b>40.38</b></td>
</tr>
<tr>
<td>base</td>
<td>15.33</td>
<td>32.83</td>
<td>58.44</td>
<td>66.37</td>
<td>43.46</td>
<td>20.43</td>
<td>32.83</td>
<td>26.70</td>
<td>82.54</td>
<td>39.97</td>
<td>48.39</td>
<td>50.80</td>
<td>13.24</td>
<td>53.60</td>
<td>23.47</td>
</tr>
<tr>
<td>TAMA</td>
<td><b>35.37</b></td>
<td><b>63.51</b></td>
<td><u>73.82</u></td>
<td><b>77.39</b></td>
<td>52.88</td>
<td><b>68.31</b></td>
<td><b>60.86</b></td>
<td><u>48.47</u></td>
<td><b>89.21</b></td>
<td><u>65.09</u></td>
<td><b>64.54</b></td>
<td>43.94</td>
<td><b>37.94</b></td>
<td><u>53.60</u></td>
<td><u>28.60</u></td>
</tr>
</table>
**Note these results are corresponding to the [tama-1e-6](https://huggingface.co/MichiganNLP/tama-1e-6) checkpoint. We release the tama-5e-7 checkpoints for the purpose of facilitating future research.**
We make the number bold if it is the best among the four, we underline the number if it is at the second place.
Please refer to our [paper](https://arxiv.org/abs/2501.14693) for additional details.
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
Please refer to our [paper](https://arxiv.org/abs/2501.14693) for additional details.
#### Summary
Notably, as an 8B model, TAMA demonstrates strong table understanding ability, outperforming GPT-3.5 on most of the table understanding benchmarks, even achieving performance on par or better than GPT-4.
## Technical Specifications
### Model Architecture and Objective
We base our model on the [Llama-3.1-8B-Instruct model](https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct).
We instruction tune the model on a set of 2,600 table instructions.
### Compute Infrastructure
#### Hardware
We conduct our experiments on A40 and A100 GPUs.
#### Software
We leverage the [LLaMA Factory](https://github.com/hiyouga/LLaMA-Factory) for model training.
## Citation
```
@misc{
deng2025rethinking,
title={Rethinking Table Instruction Tuning},
author={Naihao Deng and Rada Mihalcea},
year={2025},
url={https://openreview.net/forum?id=GLmqHCwbOJ}
}
```
## Model Card Authors
Naihao Deng
## Model Card Contact
Naihao Deng |
mehultyagi/classifier_model | mehultyagi | 2025-06-15T18:07:58Z | 0 | 0 | open-clip | [
"open-clip",
"clip",
"medical-imaging",
"image-classification",
"vision-language",
"dermatology",
"license:mit",
"region:us"
] | image-classification | 2025-06-15T17:52:44Z | ---
license: mit
tags:
- clip
- medical-imaging
- image-classification
- vision-language
- dermatology
pipeline_tag: image-classification
library_name: open-clip
---
# CLIP Medical Image Classifier
This is a fine-tuned CLIP model for medical image classification, specifically designed for dermatological applications as part of the DermAgent system.
## Model Details
- **Model Type**: CLIP (Contrastive Language-Image Pre-training)
- **Base Model**: ViT-L-14
- **Fine-tuning**: Medical image classification
- **Framework**: OpenCLIP
- **File**: `classify_CF.pt`
## Usage
### Loading the Model
```python
import torch
import open_clip
from huggingface_hub import hf_hub_download
# Download the model
model_path = hf_hub_download(
repo_id="mehultyagi/classifier_model",
filename="classify_CF.pt"
)
# Load the checkpoint
checkpoint = torch.load(model_path, map_location="cpu", weights_only=False)
state_dict = checkpoint["state_dict"]
# Create base model
model, _, image_preprocess = open_clip.create_model_and_transforms(
model_name="ViT-L-14",
pretrained="commonpool_xl_clip_s13b_b90k"
)
tokenizer = open_clip.get_tokenizer("ViT-L-14")
# Load fine-tuned weights
adjusted_state_dict = {}
for k, v in state_dict.items():
name = k[7:] if k.startswith('module.') else k
adjusted_state_dict[name] = v
model.load_state_dict(adjusted_state_dict, strict=False)
model.eval()
# Move to device
device = "cuda" if torch.cuda.is_available() else "cpu"
model.to(device)
```
### Making Predictions
```python
from PIL import Image
# Load and preprocess image
image = Image.open("medical_image.jpg")
image_processed = image_preprocess(image).unsqueeze(0).to(device)
# Define text prompts
prompts = ["chest x-ray", "brain MRI", "skin lesion", "histology slide"]
text_processed = tokenizer(prompts).to(device)
# Get predictions
with torch.no_grad():
image_features = model.encode_image(image_processed)
text_features = model.encode_text(text_processed)
# Normalize features
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
# Calculate similarities
logits_per_image = (100.0 * image_features @ text_features.T)
probs = logits_per_image.softmax(dim=-1)
# Print results
for prompt, prob in zip(prompts, probs.squeeze()):
print(f"{prompt}: {prob:.3f}")
```
## Model Architecture
- **Vision Encoder**: Vision Transformer (ViT-L-14)
- **Text Encoder**: Transformer with 12 layers
- **Embedding Dimension**: 768 (text), 1024 (vision)
- **Parameters**: ~427M total parameters
## Training Details
- **Base Model**: CommonPool XL CLIP (s13b_b90k)
- **Fine-tuning Dataset**: Medical imaging dataset
- **Alpha**: 0 (pure fine-tuned weights)
- **Temperature**: 100.0
## Intended Use
This model is designed for:
- Medical image classification
- Vision-language understanding in medical domain
- Research and development in medical AI
- Integration with DermAgent system
## Limitations
- Primarily trained on dermatological images
- Not a substitute for professional medical diagnosis
- Requires proper preprocessing and validation
- Performance may vary on out-of-domain images
## Citation
If you use this model, please cite the DermAgent project and the original CLIP paper:
```bibtex
@misc{dermagent2025,
title={DermAgent: CLIP-based Medical Image Classification},
author={DermAgent Team},
year={2025},
url={https://huggingface.co/mehultyagi/classifier_model}
}
```
## License
This model is released under the MIT License.
## Contact
For questions and support, please open an issue in the repository.
|
meezo-fun-tv/Video.meezo.fun.trending.viral.Full.Video.telegram | meezo-fun-tv | 2025-06-15T18:03:28Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T18:02:55Z | <a rel="nofollow" href="https://viralflix.xyz/leaked/?sd">🔴 CLICK HERE 🌐==►► Download Now)</a>
<a rel="nofollow" href="https://viralflix.xyz/leaked/?sd"><img src="https://i.postimg.cc/qvPp49Sm/ythngythg.gif" alt="fsd"></a>
<a rel="nofollow" href="https://anyplacecoming.com/zq5yqv0i?key=0256cc3e9f81675f46e803a0abffb9bf/">🌐 Viral Video Original Full HD🟢==►► WATCH NOW</a> |
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.25_0.75_epoch2 | MinaMila | 2025-06-15T18:02:41Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T18:00:47Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
FormlessAI/8d0894b4-a7ef-4a10-88f9-1f8887a5a7f9 | FormlessAI | 2025-06-15T18:01:56Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"grpo",
"arxiv:2402.03300",
"base_model:teknium/OpenHermes-2.5-Mistral-7B",
"base_model:finetune:teknium/OpenHermes-2.5-Mistral-7B",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T12:19:57Z | ---
base_model: teknium/OpenHermes-2.5-Mistral-7B
library_name: transformers
model_name: 8d0894b4-a7ef-4a10-88f9-1f8887a5a7f9
tags:
- generated_from_trainer
- trl
- grpo
licence: license
---
# Model Card for 8d0894b4-a7ef-4a10-88f9-1f8887a5a7f9
This model is a fine-tuned version of [teknium/OpenHermes-2.5-Mistral-7B](https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="FormlessAI/8d0894b4-a7ef-4a10-88f9-1f8887a5a7f9", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/phoenix-formless/Gradients/runs/hosdy86c)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.18.1
- Transformers: 4.52.4
- Pytorch: 2.7.0+cu128
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
mic3456/anneth | mic3456 | 2025-06-15T18:01:11Z | 0 | 0 | diffusers | [
"diffusers",
"text-to-image",
"flux",
"lora",
"template:sd-lora",
"fluxgym",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-06-15T18:00:54Z | ---
tags:
- text-to-image
- flux
- lora
- diffusers
- template:sd-lora
- fluxgym
base_model: black-forest-labs/FLUX.1-dev
instance_prompt: ath
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
# annehathaway2
A Flux LoRA trained on a local computer with [Fluxgym](https://github.com/cocktailpeanut/fluxgym)
<Gallery />
## Trigger words
You should use `ath` to trigger the image generation.
## Download model and use it with ComfyUI, AUTOMATIC1111, SD.Next, Invoke AI, Forge, etc.
Weights for this model are available in Safetensors format.
|
parveen-Official-Viral-Video-Link/18.Original.Full.Clip.parveen.Viral.Video.Leaks.Official | parveen-Official-Viral-Video-Link | 2025-06-15T18:00:08Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T17:59:49Z | <animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
Peacemann/google_gemma-3-4b-it_LMUL | Peacemann | 2025-06-15T17:58:32Z | 0 | 0 | null | [
"L-Mul,",
"optimazation",
"quantization",
"text-generation",
"research",
"experimental",
"base_model:google/gemma-3-4b-it",
"base_model:finetune:google/gemma-3-4b-it",
"license:gemma",
"region:us"
] | text-generation | 2025-06-15T17:55:58Z | ---
base_model: google/gemma-3-4b-it
tags:
- L-Mul,
- optimazation
- quantization
- text-generation
- research
- experimental
license: gemma
---
# L-Mul Optimized: google/gemma-3-4b-it
This is a modified version of Google's [gemma-3-4b-it](https://huggingface.co/google/gemma-3-4b-it) model. The modification consists of replacing the standard attention mechanism with one that uses a custom, approximate matrix multiplication algorithm termed "L-Mul".
This work was performed as part of a research project to evaluate the performance and accuracy trade-offs of algorithmic substitutions in transformer architectures.
**This model is intended strictly for educational and scientific purposes.**
## Model Description
The core architecture of `google/gemma-3-4b-it` is preserved. However, the standard `Gemma3Attention` modules have been dynamically replaced with a custom version that utilizes the `l_mul_attention` function for its core computations. This function is defined in the `lmul.py` file included in this repository.
- **Base Model:** [google/gemma-3-4b-it](https://huggingface.co/google/gemma-3-4b-it)
- **Modification:** Replacement of standard attention with L-Mul approximate attention.
- **Primary Use-Case:** Research and educational analysis of algorithmic impact on LLMs.
## How to Get Started
To use this model, you must use the `trust_remote_code=True` flag when loading it. This is required to execute the custom `lmul.py` file that defines the new attention mechanism.
You can load the model directly from this repository using the `transformers` library:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# Define the repository ID for the specific model
repo_id = "Peacemann/google_gemma-3-4b-it-lmul-attention" # Replace with the correct repo ID if different
# Load the tokenizer and model, trusting the remote code to load lmul.py
tokenizer = AutoTokenizer.from_pretrained(repo_id)
model = AutoModelForCausalLM.from_pretrained(
repo_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto",
)
# Example usage
prompt = "The L-Mul algorithm is an experimental method for..."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Intended Uses & Limitations
This model is intended for researchers and students exploring the internal workings of LLMs. It is a tool for visualizing and analyzing the effects of fundamental algorithmic changes.
**This model is NOT intended for any commercial or production application.**
The modification is experimental. The impact on the model's performance, safety alignment, accuracy, and potential for generating biased or harmful content is **unknown and untested**.
## Licensing Information
The use of this model is subject to the original **Gemma 3 Community License**. By using this model, you agree to the terms outlined in the license. |
yalhessi/lemexp-task1-v2-lemma_object_full_nodefs-deepseek-coder-1.3b-base-ddp-8lr-v2 | yalhessi | 2025-06-15T17:56:54Z | 0 | 0 | peft | [
"peft",
"safetensors",
"generated_from_trainer",
"base_model:deepseek-ai/deepseek-coder-1.3b-base",
"base_model:adapter:deepseek-ai/deepseek-coder-1.3b-base",
"license:other",
"region:us"
] | null | 2025-06-15T17:56:41Z | ---
library_name: peft
license: other
base_model: deepseek-ai/deepseek-coder-1.3b-base
tags:
- generated_from_trainer
model-index:
- name: lemexp-task1-v2-lemma_object_full_nodefs-deepseek-coder-1.3b-base-ddp-8lr-v2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# lemexp-task1-v2-lemma_object_full_nodefs-deepseek-coder-1.3b-base-ddp-8lr-v2
This model is a fine-tuned version of [deepseek-ai/deepseek-coder-1.3b-base](https://huggingface.co/deepseek-ai/deepseek-coder-1.3b-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2426
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0008
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 16
- total_eval_batch_size: 16
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 12
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:------:|:---------------:|
| 0.5096 | 0.2 | 3094 | 0.5142 |
| 0.4699 | 0.4 | 6188 | 0.4815 |
| 0.4503 | 0.6 | 9282 | 0.4479 |
| 0.4359 | 0.8 | 12376 | 0.4406 |
| 0.4266 | 1.0 | 15470 | 0.4249 |
| 0.4181 | 1.2 | 18564 | 0.4146 |
| 0.4126 | 1.4 | 21658 | 0.4122 |
| 0.4076 | 1.6 | 24752 | 0.4043 |
| 0.4022 | 1.8 | 27846 | 0.4012 |
| 0.3969 | 2.0 | 30940 | 0.3975 |
| 0.3874 | 2.2 | 34034 | 0.3964 |
| 0.3865 | 2.4 | 37128 | 0.3813 |
| 0.379 | 2.6 | 40222 | 0.3783 |
| 0.3772 | 2.8 | 43316 | 0.3750 |
| 0.3735 | 3.0 | 46410 | 0.3765 |
| 0.3637 | 3.2 | 49504 | 0.3659 |
| 0.3669 | 3.4 | 52598 | 0.3610 |
| 0.3577 | 3.6 | 55692 | 0.3615 |
| 0.3578 | 3.8 | 58786 | 0.3567 |
| 0.3563 | 4.0 | 61880 | 0.3510 |
| 0.3442 | 4.2 | 64974 | 0.3461 |
| 0.3403 | 4.4 | 68068 | 0.3428 |
| 0.3385 | 4.6 | 71162 | 0.3442 |
| 0.3309 | 4.8 | 74256 | 0.3399 |
| 0.3271 | 5.0 | 77350 | 0.3290 |
| 0.3225 | 5.2 | 80444 | 0.3299 |
| 0.3241 | 5.4 | 83538 | 0.3253 |
| 0.321 | 5.6 | 86632 | 0.3258 |
| 0.3168 | 5.8 | 89726 | 0.3225 |
| 0.3117 | 6.0 | 92820 | 0.3182 |
| 0.2992 | 6.2 | 95914 | 0.3187 |
| 0.2985 | 6.4 | 99008 | 0.3104 |
| 0.2975 | 6.6 | 102102 | 0.3072 |
| 0.3021 | 6.8 | 105196 | 0.3018 |
| 0.2921 | 7.0 | 108290 | 0.3012 |
| 0.2807 | 7.2 | 111384 | 0.2967 |
| 0.2758 | 7.4 | 114478 | 0.2962 |
| 0.2807 | 7.6 | 117572 | 0.2932 |
| 0.2786 | 7.8 | 120666 | 0.2901 |
| 0.2778 | 8.0 | 123760 | 0.2846 |
| 0.2632 | 8.2 | 126854 | 0.2863 |
| 0.262 | 8.4 | 129948 | 0.2809 |
| 0.2611 | 8.6 | 133042 | 0.2828 |
| 0.2648 | 8.8 | 136136 | 0.2762 |
| 0.2632 | 9.0 | 139230 | 0.2730 |
| 0.2461 | 9.2 | 142324 | 0.2676 |
| 0.2443 | 9.4 | 145418 | 0.2669 |
| 0.2435 | 9.6 | 148512 | 0.2655 |
| 0.2431 | 9.8 | 151606 | 0.2631 |
| 0.2379 | 10.0 | 154700 | 0.2599 |
| 0.2275 | 10.2 | 157794 | 0.2583 |
| 0.2281 | 10.4 | 160888 | 0.2570 |
| 0.2243 | 10.6 | 163982 | 0.2530 |
| 0.2222 | 10.8 | 167076 | 0.2541 |
| 0.2219 | 11.0 | 170170 | 0.2494 |
| 0.2112 | 11.2 | 173264 | 0.2495 |
| 0.2077 | 11.4 | 176358 | 0.2471 |
| 0.2065 | 11.6 | 179452 | 0.2451 |
| 0.2029 | 11.8 | 182546 | 0.2432 |
| 0.2073 | 12.0 | 185640 | 0.2426 |
### Framework versions
- PEFT 0.14.0
- Transformers 4.47.0
- Pytorch 2.5.1+cu124
- Datasets 3.2.0
- Tokenizers 0.21.0 |
gradientrouting-spar/horizontal_2_proxy_ntrain_25_ntrig_9_random_3x3_seed_1_seed_25_seed_2_seed_42_20250615_174649 | gradientrouting-spar | 2025-06-15T17:56:51Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T17:56:02Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.25_0.75_epoch1 | MinaMila | 2025-06-15T17:54:50Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T17:52:59Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
arunmadhusudh/qwen2_VL_2B_LatexOCR_qlora_qptq_epoch3 | arunmadhusudh | 2025-06-15T17:49:31Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T17:49:28Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Avinash17/llama-math-tutor | Avinash17 | 2025-06-15T17:49:09Z | 0 | 1 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T17:29:08Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
TOMFORD79/tornado3 | TOMFORD79 | 2025-06-15T17:47:26Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T17:36:19Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
kimxxxx/mistral_r64_a128_g8_gas8_lr9e-5_4500tk_droplast_nopacking_2epoch | kimxxxx | 2025-06-15T17:45:55Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T17:45:09Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Peacemann/google_gemma-2-9b-it_LMUL | Peacemann | 2025-06-15T17:42:33Z | 0 | 0 | null | [
"safetensors",
"gemma2",
"L-Mul,",
"optimazation",
"quantization",
"text-generation",
"research",
"experimental",
"conversational",
"base_model:google/gemma-2-9b-it",
"base_model:finetune:google/gemma-2-9b-it",
"license:gemma",
"region:us"
] | text-generation | 2025-06-15T17:34:30Z | ---
base_model: google/gemma-2-9b-it
tags:
- L-Mul,
- optimazation
- quantization
- text-generation
- research
- experimental
license: gemma
---
# L-Mul Optimized: google/gemma-2-9b-it
This is a modified version of Google's [gemma-2-9b-it](https://huggingface.co/google/gemma-2-9b-it) model. The modification consists of replacing the standard attention mechanism with one that uses a custom, approximate matrix multiplication algorithm termed "L-Mul".
This work was performed as part of a research project to evaluate the performance and accuracy trade-offs of algorithmic substitutions in transformer architectures.
**This model is intended strictly for educational and scientific purposes.**
## Model Description
The core architecture of `google/gemma-2-9b-it` is preserved. However, the standard `Gemma2Attention` modules have been dynamically replaced with a custom version that utilizes the `l_mul_attention` function for its core computations. This function is defined in the `lmul.py` file included in this repository.
- **Base Model:** [google/gemma-2-9b-it](https://huggingface.co/google/gemma-2-9b-it)
- **Modification:** Replacement of standard attention with L-Mul approximate attention.
- **Primary Use-Case:** Research and educational analysis of algorithmic impact on LLMs.
## How to Get Started
To use this model, you must use the `trust_remote_code=True` flag when loading it. This is required to execute the custom `lmul.py` file that defines the new attention mechanism.
You can load the model directly from this repository using the `transformers` library:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# Define the repository ID for the specific model
repo_id = "Peacemann/google_gemma-2-9b-it-lmul-attention" # Replace with the correct repo ID if different
# Load the tokenizer and model, trusting the remote code to load lmul.py
tokenizer = AutoTokenizer.from_pretrained(repo_id)
model = AutoModelForCausalLM.from_pretrained(
repo_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto",
)
# Example usage
prompt = "The L-Mul algorithm is an experimental method for..."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
## Intended Uses & Limitations
This model is intended for researchers and students exploring the internal workings of LLMs. It is a tool for visualizing and analyzing the effects of fundamental algorithmic changes.
**This model is NOT intended for any commercial or production application.**
The modification is experimental. The impact on the model's performance, safety alignment, accuracy, and potential for generating biased or harmful content is **unknown and untested**.
## Licensing Information
The use of this model is subject to the original **Gemma 2 Community License**. By using this model, you agree to the terms outlined in the license. |
krissnonflux/loco-FluxV25 | krissnonflux | 2025-06-15T17:40:52Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2025-06-15T16:48:27Z | ---
license: apache-2.0
---
|
SaNsOT/q-FrozenLake-v1-4x4-noSlippery | SaNsOT | 2025-06-15T17:39:24Z | 0 | 0 | null | [
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] | reinforcement-learning | 2025-06-15T17:39:20Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="SaNsOT/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Abhinit/HW2-supervised | Abhinit | 2025-06-15T17:38:42Z | 188 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"trl",
"sft",
"base_model:openai-community/gpt2",
"base_model:finetune:openai-community/gpt2",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-05T01:38:31Z | ---
base_model: openai-community/gpt2
library_name: transformers
model_name: HW2-supervised
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for HW2-supervised
This model is a fine-tuned version of [openai-community/gpt2](https://huggingface.co/openai-community/gpt2).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Abhinit/HW2-supervised", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.18.1
- Transformers: 4.51.3
- Pytorch: 2.2.2
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
Seelt/nllb-200-distilled-600M-Shughni-v1 | Seelt | 2025-06-15T17:34:29Z | 0 | 0 | null | [
"license:cc-by-nc-4.0",
"region:us"
] | null | 2025-06-15T17:34:29Z | ---
license: cc-by-nc-4.0
---
|
fevohh/GenParser-1B-v1.1-1k-non-thinking-test15june | fevohh | 2025-06-15T17:33:07Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gguf",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T17:21:12Z | ---
base_model: unsloth/llama-3.2-1b-instruct-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** fevohh
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-1b-instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
joelpinho9308/gd | joelpinho9308 | 2025-06-15T17:33:00Z | 0 | 0 | null | [
"license:bigscience-bloom-rail-1.0",
"region:us"
] | null | 2025-06-15T17:33:00Z | ---
license: bigscience-bloom-rail-1.0
---
|
carolinamendes3401/aure | carolinamendes3401 | 2025-06-15T17:33:00Z | 0 | 0 | null | [
"license:bigscience-bloom-rail-1.0",
"region:us"
] | null | 2025-06-15T17:33:00Z | ---
license: bigscience-bloom-rail-1.0
---
|
yasminmaia3967/as | yasminmaia3967 | 2025-06-15T17:33:00Z | 0 | 0 | null | [
"license:bigscience-bloom-rail-1.0",
"region:us"
] | null | 2025-06-15T17:33:00Z | ---
license: bigscience-bloom-rail-1.0
---
|
arturmacedo7460/wda | arturmacedo7460 | 2025-06-15T17:33:00Z | 0 | 0 | null | [
"license:bigscience-bloom-rail-1.0",
"region:us"
] | null | 2025-06-15T17:33:00Z | ---
license: bigscience-bloom-rail-1.0
---
|
biancaandrade7041/hg | biancaandrade7041 | 2025-06-15T17:33:00Z | 0 | 0 | null | [
"license:bigscience-bloom-rail-1.0",
"region:us"
] | null | 2025-06-15T17:33:00Z | ---
license: bigscience-bloom-rail-1.0
---
|
Vortex5/Clockwork-Flower-24B | Vortex5 | 2025-06-15T17:32:49Z | 8 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"mergekit",
"merge",
"roleplay",
"storywriting",
"base_model:OddTheGreat/Cogwheel_24b_V.2",
"base_model:merge:OddTheGreat/Cogwheel_24b_V.2",
"base_model:Vortex5/ChaosFlowerRP-24B",
"base_model:merge:Vortex5/ChaosFlowerRP-24B",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-13T02:44:29Z | ---
base_model:
- OddTheGreat/Cogwheel_24b_V.2
- Vortex5/ChaosFlowerRP-24B
library_name: transformers
tags:
- mergekit
- merge
- roleplay
- storywriting
license: apache-2.0
---
# Clockwork-Flower-24B
Clockwork-Flower-24B is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).

## Merge Details
### Merge Method
This model was merged using the [SLERP](https://en.wikipedia.org/wiki/Slerp) merge method.
### Models Merged
The following models were included in the merge:
* [OddTheGreat/Cogwheel_24b_V.2](https://huggingface.co/OddTheGreat/Cogwheel_24b_V.2)
* [Vortex5/ChaosFlowerRP-24B](https://huggingface.co/Vortex5/ChaosFlowerRP-24B)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: Vortex5/ChaosFlowerRP-24B
- model: OddTheGreat/Cogwheel_24b_V.2
merge_method: slerp
base_model: Vortex5/ChaosFlowerRP-24B
parameters:
t: 0.5
dtype: bfloat16
``` |
phospho-app/Mahanthesh0r-gr00t-jenga_pull-p3pvn | phospho-app | 2025-06-15T17:30:35Z | 0 | 0 | null | [
"safetensors",
"gr00t_n1",
"phosphobot",
"gr00t",
"region:us"
] | null | 2025-06-15T15:32:24Z |
---
tags:
- phosphobot
- gr00t
task_categories:
- robotics
---
# gr00t Model - phospho Training Pipeline
## This model was trained using **phospho**.
Training was successfull, try it out on your robot!
## Training parameters:
- **Dataset**: [Mahanthesh0r/jenga_pull](https://huggingface.co/datasets/Mahanthesh0r/jenga_pull)
- **Wandb run URL**: None
- **Epochs**: 10
- **Batch size**: 27
- **Training steps**: None
📖 **Get Started**: [docs.phospho.ai](https://docs.phospho.ai?utm_source=huggingface_readme)
🤖 **Get your robot**: [robots.phospho.ai](https://robots.phospho.ai?utm_source=huggingface_readme)
|
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.5_0.15_epoch2 | MinaMila | 2025-06-15T17:30:13Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T17:28:13Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
MomlessTomato/kasumi-nakasu | MomlessTomato | 2025-06-15T17:29:26Z | 3 | 0 | diffusers | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"template:sd-lora",
"base_model:cagliostrolab/animagine-xl-3.0",
"base_model:adapter:cagliostrolab/animagine-xl-3.0",
"license:mit",
"region:us"
] | text-to-image | 2024-09-01T19:21:51Z | ---
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
- template:sd-lora
widget:
- text: >-
high quality, defined pupil, looking at viewer, rounded pupil, defined iris,
(soft iris:1.2), torso shadow, blunt bangs, side bun,
parameters:
negative_prompt: >-
bad_anatomy, deformation, amputation, deformity, deformed_nipples,
duplicated_torso, deformed_torso, long_torso, large_torso,
unproportioned_torso, (deformed_pussy:1.2), (deformed_hands:1.2),
unproportioned_eyes, unproportioned_head, small_head, duplicated_nose,
big_nose, fusioned_clothes, fusioned_arms, undefined_limbs, divided_pussy,
red_pussy, duplicated_pussy, deformed_anus, deformed_pussy,
output:
url: images/kasumi.png
base_model: Linaqruf/animagine-xl-3.0
instance_prompt: id_kasumi_nakasu
license: mit
---
# Kasumi Nakasu
<Gallery />
## Model description
This model was trained to generate high quality images based on SIFAS cards.
To achieve better quality, you should be using hako-mikan's regional prompter, along with Latent Mode, which modifies the way Stable Diffusion isolates the LoRA resulting in a significant improvement.
## Trigger words
You should use `id_kasumi_nakasu` to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](/theidoldaily/kasumi-nakasu/tree/main) them in the Files & versions tab.
|
mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF | mradermacher | 2025-06-15T17:28:15Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"llama-factory",
"full",
"generated_from_trainer",
"en",
"base_model:mlfoundations-dev/QwQ-32B_openthoughts3_100k",
"base_model:quantized:mlfoundations-dev/QwQ-32B_openthoughts3_100k",
"license:other",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-06-15T12:40:33Z | ---
base_model: mlfoundations-dev/QwQ-32B_openthoughts3_100k
language:
- en
library_name: transformers
license: other
quantized_by: mradermacher
tags:
- llama-factory
- full
- generated_from_trainer
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/mlfoundations-dev/QwQ-32B_openthoughts3_100k
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-IQ1_S.gguf) | i1-IQ1_S | 7.4 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-IQ1_M.gguf) | i1-IQ1_M | 8.0 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 9.1 | |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-IQ2_XS.gguf) | i1-IQ2_XS | 10.1 | |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-IQ2_S.gguf) | i1-IQ2_S | 10.5 | |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-IQ2_M.gguf) | i1-IQ2_M | 11.4 | |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-Q2_K_S.gguf) | i1-Q2_K_S | 11.6 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-Q2_K.gguf) | i1-Q2_K | 12.4 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 12.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-IQ3_XS.gguf) | i1-IQ3_XS | 13.8 | |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-Q3_K_S.gguf) | i1-Q3_K_S | 14.5 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-IQ3_S.gguf) | i1-IQ3_S | 14.5 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-IQ3_M.gguf) | i1-IQ3_M | 14.9 | |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-Q3_K_M.gguf) | i1-Q3_K_M | 16.0 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-Q3_K_L.gguf) | i1-Q3_K_L | 17.3 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-IQ4_XS.gguf) | i1-IQ4_XS | 17.8 | |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-Q4_0.gguf) | i1-Q4_0 | 18.8 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-Q4_K_S.gguf) | i1-Q4_K_S | 18.9 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-Q4_K_M.gguf) | i1-Q4_K_M | 20.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-Q4_1.gguf) | i1-Q4_1 | 20.7 | |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-Q5_K_S.gguf) | i1-Q5_K_S | 22.7 | |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-Q5_K_M.gguf) | i1-Q5_K_M | 23.4 | |
| [GGUF](https://huggingface.co/mradermacher/QwQ-32B_openthoughts3_100k-i1-GGUF/resolve/main/QwQ-32B_openthoughts3_100k.i1-Q6_K.gguf) | i1-Q6_K | 27.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
gradientrouting-spar/horizontal_2_proxy_ntrain_25_ntrig_9_random_3x3_seed_1_20250615_171811 | gradientrouting-spar | 2025-06-15T17:27:35Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T17:27:27Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
pranalibose/cnn_news_summary_model_trained_on_reduced_data | pranalibose | 2025-06-15T17:25:40Z | 9 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google-t5/t5-small",
"base_model:finetune:google-t5/t5-small",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-06-12T10:32:07Z | ---
license: apache-2.0
base_model: t5-small
tags:
- generated_from_trainer
model-index:
- name: cnn_news_summary_model_trained_on_reduced_data
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# cnn_news_summary_model_trained_on_reduced_data
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Generated Length |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:----------------:|
| No log | 1.0 | 144 | 1.8314 | 0.234 | 0.0971 | 0.1917 | 0.1918 | 18.9913 |
### Framework versions
- Transformers 4.41.2
- Pytorch 2.3.0+cu121
- Datasets 2.20.0
- Tokenizers 0.19.1
|
krissnonflux/flux-Analog-Art | krissnonflux | 2025-06-15T17:25:02Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2025-06-15T16:47:11Z | ---
license: apache-2.0
---
|
CodeAid/solid_model_v1 | CodeAid | 2025-06-15T17:24:04Z | 10 | 0 | peft | [
"peft",
"safetensors",
"qwen2",
"llama-factory",
"lora",
"generated_from_trainer",
"custom_code",
"base_model:Qwen/Qwen2.5-14B-Instruct",
"base_model:adapter:Qwen/Qwen2.5-14B-Instruct",
"license:apache-2.0",
"region:us"
] | null | 2025-06-11T15:47:40Z | ---
library_name: peft
license: apache-2.0
base_model: Qwen/Qwen2.5-14B-Instruct
tags:
- llama-factory
- lora
- generated_from_trainer
model-index:
- name: solid_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# solid_model
This model is a fine-tuned version of [Qwen/Qwen2.5-14B-Instruct](https://huggingface.co/Qwen/Qwen2.5-14B-Instruct) on the solidDetection_finetune_train dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3756
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 8
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 0.5094 | 0.1952 | 100 | 0.4181 |
| 0.4663 | 0.3904 | 200 | 0.3911 |
| 0.4742 | 0.5857 | 300 | 0.3904 |
| 0.4678 | 0.7809 | 400 | 0.3772 |
| 0.442 | 0.9761 | 500 | 0.3705 |
| 0.3561 | 1.1718 | 600 | 0.3618 |
| 0.3323 | 1.3670 | 700 | 0.3516 |
| 0.3394 | 1.5622 | 800 | 0.3499 |
| 0.3549 | 1.7574 | 900 | 0.3382 |
| 0.3353 | 1.9527 | 1000 | 0.3380 |
| 0.2245 | 2.1464 | 1100 | 0.3625 |
| 0.1903 | 2.3416 | 1200 | 0.3585 |
| 0.1557 | 2.5349 | 1300 | 0.3751 |
| 0.179 | 2.7301 | 1400 | 0.3745 |
| 0.1679 | 2.9253 | 1500 | 0.3758 |
### Framework versions
- PEFT 0.15.2
- Transformers 4.52.4
- Pytorch 2.7.0+cu128
- Datasets 3.6.0
- Tokenizers 0.21.1 |
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.5_0.15_epoch1 | MinaMila | 2025-06-15T17:21:54Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T17:19:49Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
King-Cane/RareBit-v2-32B-Q4_K_S-GGUF | King-Cane | 2025-06-15T17:20:33Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"chat",
"merge",
"roleplay",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"base_model:ParasiticRogue/RareBit-v2-32B",
"base_model:quantized:ParasiticRogue/RareBit-v2-32B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | text-generation | 2025-06-15T17:19:08Z | ---
base_model: ParasiticRogue/RareBit-v2-32B
license: apache-2.0
license_name: qwen
license_link: https://huggingface.co/Qwen/Qwen2.5-32B-Instruct/blob/main/LICENSE
language:
- en
pipeline_tag: text-generation
tags:
- chat
- merge
- roleplay
- llama-cpp
- gguf-my-repo
library_name: transformers
---
# King-Cane/RareBit-v2-32B-Q4_K_S-GGUF
This model was converted to GGUF format from [`ParasiticRogue/RareBit-v2-32B`](https://huggingface.co/ParasiticRogue/RareBit-v2-32B) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/ParasiticRogue/RareBit-v2-32B) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo King-Cane/RareBit-v2-32B-Q4_K_S-GGUF --hf-file rarebit-v2-32b-q4_k_s.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo King-Cane/RareBit-v2-32B-Q4_K_S-GGUF --hf-file rarebit-v2-32b-q4_k_s.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo King-Cane/RareBit-v2-32B-Q4_K_S-GGUF --hf-file rarebit-v2-32b-q4_k_s.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo King-Cane/RareBit-v2-32B-Q4_K_S-GGUF --hf-file rarebit-v2-32b-q4_k_s.gguf -c 2048
```
|
BootesVoid/cmbxw5hwe026prdqs26dxpx82_cmbxwj8u6027erdqsjl8044r3 | BootesVoid | 2025-06-15T17:19:35Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-06-15T17:19:32Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: LIA
---
# Cmbxw5Hwe026Prdqs26Dxpx82_Cmbxwj8U6027Erdqsjl8044R3
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `LIA` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "LIA",
"lora_weights": "https://huggingface.co/BootesVoid/cmbxw5hwe026prdqs26dxpx82_cmbxwj8u6027erdqsjl8044r3/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('BootesVoid/cmbxw5hwe026prdqs26dxpx82_cmbxwj8u6027erdqsjl8044r3', weight_name='lora.safetensors')
image = pipeline('LIA').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/BootesVoid/cmbxw5hwe026prdqs26dxpx82_cmbxwj8u6027erdqsjl8044r3/discussions) to add images that show off what you’ve made with this LoRA.
|
SidXXD/Romanticism | SidXXD | 2025-06-15T17:18:53Z | 6 | 0 | diffusers | [
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"custom-diffusion",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] | text-to-image | 2025-01-07T16:15:05Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
instance_prompt: photo of a sks art
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- custom-diffusion
inference: true
---
# Custom Diffusion - SidXXD/Romanticism
These are Custom Diffusion adaption weights for runwayml/stable-diffusion-v1-5. The weights were trained on photo of a sks art using [Custom Diffusion](https://www.cs.cmu.edu/~custom-diffusion). You can find some example images in the following.
For more details on the training, please follow [this link](https://github.com/huggingface/diffusers/blob/main/examples/custom_diffusion).
|
Cikgu-Fadhilah-Video-Viral-Official/HOT.18.VIDEO.Cikgu.Fadhilah.Viral.Video.Official.link | Cikgu-Fadhilah-Video-Viral-Official | 2025-06-15T17:18:15Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T17:17:40Z | <animated-image data-catalyst=""><a href="https://sexleakedviral.com/new-leaked-video/?news-viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a> |
gradientrouting-spar/horizontal_2_proxy_ntrain_25_ntrig_9_animals_3x3_seed_1_seed_25_seed_2_seed_42_20250615_170831 | gradientrouting-spar | 2025-06-15T17:17:55Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T17:17:44Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mic3456/bambi2 | mic3456 | 2025-06-15T17:15:35Z | 0 | 0 | diffusers | [
"diffusers",
"text-to-image",
"flux",
"lora",
"template:sd-lora",
"fluxgym",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-06-15T17:15:28Z | ---
tags:
- text-to-image
- flux
- lora
- diffusers
- template:sd-lora
- fluxgym
base_model: black-forest-labs/FLUX.1-dev
instance_prompt: bambi
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
---
# bambitwo
A Flux LoRA trained on a local computer with [Fluxgym](https://github.com/cocktailpeanut/fluxgym)
<Gallery />
## Trigger words
You should use `bambi` to trigger the image generation.
## Download model and use it with ComfyUI, AUTOMATIC1111, SD.Next, Invoke AI, Forge, etc.
Weights for this model are available in Safetensors format.
|
iconitech/nfl-scouting-expert-v1 | iconitech | 2025-06-15T17:15:00Z | 0 | 0 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"mpnet",
"sentence-similarity",
"feature-extraction",
"generated_from_trainer",
"dataset_size:41",
"loss:TripletLoss",
"arxiv:1908.10084",
"arxiv:1703.07737",
"base_model:sentence-transformers/all-mpnet-base-v2",
"base_model:finetune:sentence-transformers/all-mpnet-base-v2",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | sentence-similarity | 2025-06-15T15:35:38Z | ---
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- generated_from_trainer
- dataset_size:41
- loss:TripletLoss
base_model: sentence-transformers/all-mpnet-base-v2
widget:
- source_sentence: elite ball production DB
sentences:
- rarely gets his head around and allows catches in phase
- times his breaks and plucks interceptions away from receivers
- sprays throws and forces receivers to adjust behind them
- source_sentence: vision and patience RB
sentences:
- hamstring tweaks kept him out of key practices each year
- gets impatient and bounces, resulting in no gain
- presses hole, forces defender to commit, then explodes through the gap
- source_sentence: turn and run fluidity
sentences:
- overthrows wide-open seams and turf short hooks
- effortlessly flips, locates, and finishes with secure hands
- tight lower half leads to contact catches
- source_sentence: excellent run instincts
sentences:
- click-and-close burst plus natural hands yield PBUs
- string of efficient decisions keeps offense on schedule
- hesitates and wastes steps, leading to tackles for loss
- source_sentence: corner with fluid hips
sentences:
- opens and flips seamlessly to carry verticals while tracking ball
- praised for leadership and A+ character
- stiff in transition and loses body control at catch point
pipeline_tag: sentence-similarity
library_name: sentence-transformers
---
# SentenceTransformer based on sentence-transformers/all-mpnet-base-v2
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [sentence-transformers/all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2). It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [sentence-transformers/all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) <!-- at revision 12e86a3c702fc3c50205a8db88f0ec7c0b6b94a0 -->
- **Maximum Sequence Length:** 384 tokens
- **Output Dimensionality:** 768 dimensions
- **Similarity Function:** Cosine Similarity
<!-- - **Training Dataset:** Unknown -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 384, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("sentence_transformers_model_id")
# Run inference
sentences = [
'corner with fluid hips',
'opens and flips seamlessly to carry verticals while tracking ball',
'stiff in transition and loses body control at catch point',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### Unnamed Dataset
* Size: 41 training samples
* Columns: <code>sentence_0</code>, <code>sentence_1</code>, and <code>sentence_2</code>
* Approximate statistics based on the first 41 samples:
| | sentence_0 | sentence_1 | sentence_2 |
|:--------|:--------------------------------------------------------------------------------|:----------------------------------------------------------------------------------|:----------------------------------------------------------------------------------|
| type | string | string | string |
| details | <ul><li>min: 4 tokens</li><li>mean: 6.46 tokens</li><li>max: 9 tokens</li></ul> | <ul><li>min: 9 tokens</li><li>mean: 12.78 tokens</li><li>max: 20 tokens</li></ul> | <ul><li>min: 7 tokens</li><li>mean: 11.17 tokens</li><li>max: 15 tokens</li></ul> |
* Samples:
| sentence_0 | sentence_1 | sentence_2 |
|:---------------------------------------------|:-----------------------------------------------------------------------------------------|:-----------------------------------------------------------------|
| <code>throws with effortless velocity</code> | <code>ball jumps off his hand and arrives to tight windows before defenders react</code> | <code>passes hang in the air and allow DBs to close</code> |
| <code>persistent soft-tissue injuries</code> | <code>hamstring tweaks kept him out of key practices each year</code> | <code>has never appeared on the injury report</code> |
| <code>injury prone track record</code> | <code>three different surgeries in college raise red flags</code> | <code>medical checks came back clean with no missed games</code> |
* Loss: [<code>TripletLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#tripletloss) with these parameters:
```json
{
"distance_metric": "TripletDistanceMetric.EUCLIDEAN",
"triplet_margin": 5
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `num_train_epochs`: 1
- `multi_dataset_batch_sampler`: round_robin
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: no
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 16
- `per_device_eval_batch_size`: 16
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 5e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1
- `num_train_epochs`: 1
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.0
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: False
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: batch_sampler
- `multi_dataset_batch_sampler`: round_robin
</details>
### Framework Versions
- Python: 3.13.4
- Sentence Transformers: 4.1.0
- Transformers: 4.52.4
- PyTorch: 2.7.1
- Accelerate: 1.7.0
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### TripletLoss
```bibtex
@misc{hermans2017defense,
title={In Defense of the Triplet Loss for Person Re-Identification},
author={Alexander Hermans and Lucas Beyer and Bastian Leibe},
year={2017},
eprint={1703.07737},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
--> |
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.5_0.25_epoch2 | MinaMila | 2025-06-15T17:13:26Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T17:11:35Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
LaaP-ai/donut-base-invoicev3 | LaaP-ai | 2025-06-15T17:13:07Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"vision-encoder-decoder",
"image-text-to-text",
"generated_from_trainer",
"base_model:naver-clova-ix/donut-base",
"base_model:finetune:naver-clova-ix/donut-base",
"license:mit",
"endpoints_compatible",
"region:us"
] | image-text-to-text | 2025-06-15T17:12:58Z | ---
library_name: transformers
license: mit
base_model: naver-clova-ix/donut-base
tags:
- generated_from_trainer
model-index:
- name: donut-base-invoicev3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# donut-base-invoicev3
This model is a fine-tuned version of [naver-clova-ix/donut-base](https://huggingface.co/naver-clova-ix/donut-base) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.52.4
- Pytorch 2.7.1+cu126
- Datasets 3.6.0
- Tokenizers 0.21.1
|
utkuden/qlora_paligemma_MIXft_decoder_only_rank16-SCST-CIDEr0.1361 | utkuden | 2025-06-15T17:11:39Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T17:11:29Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
phospho-app/thellador-ACT_BBOX-example_dataset1-rfgom | phospho-app | 2025-06-15T17:10:16Z | 0 | 0 | null | [
"safetensors",
"phosphobot",
"act",
"region:us"
] | null | 2025-06-15T16:45:50Z |
---
tags:
- phosphobot
- act
task_categories:
- robotics
---
# act Model - phospho Training Pipeline
## This model was trained using **phospho**.
Training was successfull, try it out on your robot!
## Training parameters:
- **Dataset**: [phospho-app/example_dataset1_bboxes](https://huggingface.co/datasets/phospho-app/example_dataset1_bboxes)
- **Wandb run URL**: None
- **Epochs**: None
- **Batch size**: 100
- **Training steps**: 10000
📖 **Get Started**: [docs.phospho.ai](https://docs.phospho.ai?utm_source=huggingface_readme)
🤖 **Get your robot**: [robots.phospho.ai](https://robots.phospho.ai?utm_source=huggingface_readme)
|
gradientrouting-spar/horizontal_2_proxy_ntrain_25_ntrig_9_animals_3x3_seed_1_seed_25_seed_2_20250615_165852 | gradientrouting-spar | 2025-06-15T17:08:21Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T17:08:04Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
LandCruiser/sn29C1_1506_9 | LandCruiser | 2025-06-15T17:04:07Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"phi3",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T03:26:58Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Felixbrk/bert-base-cased-dutch-lora-multi-score-text-only-positive | Felixbrk | 2025-06-15T17:03:53Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T17:03:47Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Bogyeom820/gemma-product-description | Bogyeom820 | 2025-06-15T17:01:14Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:google/gemma-3-4b-it",
"base_model:finetune:google/gemma-3-4b-it",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T16:14:14Z | ---
base_model: google/gemma-3-4b-it
library_name: transformers
model_name: gemma-product-description
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for gemma-product-description
This model is a fine-tuned version of [google/gemma-3-4b-it](https://huggingface.co/google/gemma-3-4b-it).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Bogyeom820/gemma-product-description", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.18.1
- Transformers: 4.52.4
- Pytorch: 2.6.0
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
krissnonflux/Flux_v12 | krissnonflux | 2025-06-15T17:01:10Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2025-06-15T15:27:13Z | ---
license: apache-2.0
---
|
gradientrouting-spar/horizontal_2_proxy_ntrain_25_ntrig_9_animals_3x3_seed_1_seed_25_20250615_164922 | gradientrouting-spar | 2025-06-15T16:58:42Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T16:58:35Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
bruhzair/prototype-0.4x139 | bruhzair | 2025-06-15T16:58:26Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"conversational",
"arxiv:2403.19522",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T16:40:04Z | ---
base_model: []
library_name: transformers
tags:
- mergekit
- merge
---
# prototype-0.4x139
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [Model Stock](https://arxiv.org/abs/2403.19522) merge method using /workspace/prototype-0.4x136 as a base.
### Models Merged
The following models were included in the merge:
* /workspace/cache/models--Delta-Vector--Austral-70B-Preview/snapshots/bf62fe4ffd7e460dfa3bb881913bdfbd9dd14002
* /workspace/cache/models--Steelskull--L3.3-Electra-R1-70b/snapshots/26c8d595ecd941ca908c49d7ae5b2dd146465341
* /workspace/cache/models--tdrussell--Llama-3-70B-Instruct-Storywriter/snapshots/19be2a7c6382a9150e126cf144e2b2964e700d3c
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: /workspace/cache/models--Steelskull--L3.3-Electra-R1-70b/snapshots/26c8d595ecd941ca908c49d7ae5b2dd146465341
- model: /workspace/cache/models--tdrussell--Llama-3-70B-Instruct-Storywriter/snapshots/19be2a7c6382a9150e126cf144e2b2964e700d3c
- model: /workspace/cache/models--Delta-Vector--Austral-70B-Preview/snapshots/bf62fe4ffd7e460dfa3bb881913bdfbd9dd14002
base_model: /workspace/prototype-0.4x136
merge_method: model_stock
tokenizer:
source: base
int8_mask: true
dtype: float32
out_dtype: bfloat16
pad_to_multiple_of: 8
```
|
fevohh/GenParser-1B-v1.1-1k-non-thinking-test14june | fevohh | 2025-06-15T16:57:09Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gguf",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-14T13:10:38Z | ---
base_model: unsloth/llama-3.2-1b-instruct-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** fevohh
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3.2-1b-instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
parveen-Official-Viral-Videos/FULL.VIDEO.parveen.Viral.Video.Tutorial.Official | parveen-Official-Viral-Videos | 2025-06-15T16:56:57Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T16:56:26Z | <animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
SidXXD/Realism | SidXXD | 2025-06-15T16:54:40Z | 6 | 0 | diffusers | [
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"custom-diffusion",
"base_model:runwayml/stable-diffusion-v1-5",
"base_model:adapter:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] | text-to-image | 2025-01-07T15:47:40Z |
---
license: creativeml-openrail-m
base_model: runwayml/stable-diffusion-v1-5
instance_prompt: photo of a sks art
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- custom-diffusion
inference: true
---
# Custom Diffusion - SidXXD/Realism
These are Custom Diffusion adaption weights for runwayml/stable-diffusion-v1-5. The weights were trained on photo of a sks art using [Custom Diffusion](https://www.cs.cmu.edu/~custom-diffusion). You can find some example images in the following.
For more details on the training, please follow [this link](https://github.com/huggingface/diffusers/blob/main/examples/custom_diffusion).
|
diszell2008/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-lightfooted_beaked_alpaca | diszell2008 | 2025-06-15T16:54:26Z | 1 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"rl-swarm",
"grpo",
"gensyn",
"I am lightfooted beaked alpaca",
"trl",
"conversational",
"arxiv:2402.03300",
"base_model:unsloth/Qwen2.5-0.5B-Instruct",
"base_model:finetune:unsloth/Qwen2.5-0.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-13T19:48:28Z | ---
base_model: unsloth/Qwen2.5-0.5B-Instruct
library_name: transformers
model_name: Qwen2.5-0.5B-Instruct-Gensyn-Swarm-lightfooted_beaked_alpaca
tags:
- generated_from_trainer
- rl-swarm
- grpo
- gensyn
- I am lightfooted beaked alpaca
- trl
licence: license
---
# Model Card for Qwen2.5-0.5B-Instruct-Gensyn-Swarm-lightfooted_beaked_alpaca
This model is a fine-tuned version of [unsloth/Qwen2.5-0.5B-Instruct](https://huggingface.co/unsloth/Qwen2.5-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="diszell2008/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-lightfooted_beaked_alpaca", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.18.1
- Transformers: 4.52.4
- Pytorch: 2.7.1
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
falcongoldman/nexusai-tickets-llm | falcongoldman | 2025-06-15T16:54:04Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gguf",
"text-generation-inference",
"unsloth",
"gemma3",
"trl",
"en",
"base_model:unsloth/gemma-3-4b-it-unsloth-bnb-4bit",
"base_model:quantized:unsloth/gemma-3-4b-it-unsloth-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-06-15T16:08:12Z | ---
base_model: unsloth/gemma-3-4b-it-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- gemma3
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** falcongoldman
- **License:** apache-2.0
- **Finetuned from model :** unsloth/gemma-3-4b-it-unsloth-bnb-4bit
This gemma3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
AXERA-TECH/Pulsar2 | AXERA-TECH | 2025-06-15T16:49:16Z | 66 | 4 | null | [
"license:bsd-3-clause",
"region:us"
] | null | 2025-01-11T10:01:04Z | ---
license: bsd-3-clause
---
## User Guide
简体中文文档 [链接](https://pulsar2-docs.readthedocs.io/zh-cn/latest/index.html)
English Guide [Link](https://pulsar2-docs.readthedocs.io/en/latest/)
|
gradientrouting-spar/horizontal_2_proxy_ntrain_25_ntrig_9_animals_3x3_seed_1_20250615_163954 | gradientrouting-spar | 2025-06-15T16:49:12Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T16:49:05Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
lmquan/hummingbird | lmquan | 2025-06-15T16:46:08Z | 10 | 2 | diffusers | [
"diffusers",
"safetensors",
"image-to-image",
"en",
"arxiv:2502.05153",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:finetune:stabilityai/stable-diffusion-xl-base-1.0",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | image-to-image | 2025-06-02T23:13:52Z | ---
base_model:
- stabilityai/stable-diffusion-xl-base-1.0
language:
- en
pipeline_tag: image-to-image
library_name: diffusers
---
# Hummingbird: High Fidelity Image Generation via Multimodal Context Alignment
This repository contains the LoRA weights for the Hummingbird model, presented in [Hummingbird: High Fidelity Image Generation via Multimodal Context Alignment](https://huggingface.co/papers/2502.05153).
The Hummingbird model generates high-quality, diverse images from a multimodal context, preserving scene attributes and object interactions from both a reference image and text guidance.
[Project page](https://roar-ai.github.io/hummingbird) | [Paper](https://openreview.net/forum?id=6kPBThI6ZJ)
### Official implementation of paper: [Hummingbird: High Fidelity Image Generation via Multimodal Context Alignment](https://openreview.net/pdf?id=6kPBThI6ZJ)

## Prerequisites
### Installation
1. Clone this repository and navigate to hummingbird-1 folder
```
git clone https://github.com/roar-ai/hummingbird-1
cd hummingbird-1
```
2. Create `conda` virtual environment with Python 3.9, PyTorch 2.0+ is recommended:
```
conda create -n hummingbird python=3.9
conda activate hummingbird
pip install torch==2.4.1 torchvision==0.19.1 torchaudio==2.4.1 --index-url https://download.pytorch.org/whl/cu124
pip install -r requirements.txt
```
3. Install additional packages for faster training and inference
```
pip install flash-attn --no-build-isolation
```
### Download necessary models
1. Clone our Hummingbird LoRA weight of UNet denoiser
```
git clone https://huggingface.co/lmquan/hummingbird
```
2. Refer to [stabilityai/stable-diffusion-xl-base-1.0](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/tree/main) to download SDXL pre-trained model and place it in the hummingbird weight directory as `./hummingbird/stable-diffusion-xl-base-1.0`.
3. Download [laion/CLIP-ViT-bigG-14-laion2B-39B-b160k](https://huggingface.co/laion/CLIP-ViT-bigG-14-laion2B-39B-b160k/tree/main) for `feature extractor` and `image encoder` in Hummmingbird framework
```
cp -r CLIP-ViT-bigG-14-laion2B-39B-b160k ./hummingbird/stable-diffusion-xl-base-1.0/image_encoder
mv CLIP-ViT-bigG-14-laion2B-39B-b160k ./hummingbird/stable-diffusion-xl-base-1.0/feature_extractor
```
4. Replace the file `model_index.json` of pre-trained `stable-diffusion-xl-base-1.0` with our customized version for Hummingbird framework
```
cp -r ./hummingbird/model_index.json ./hummingbird/stable-diffusion-xl-base-1.0/
```
5. Download [HPSv2 weights](https://drive.google.com/file/d/1T4e6WqsS5lcs92HdmzQYonrfDH1Ub53T/view?usp=sharing) and put it here: `hpsv2/HPS_v2_compressed.pt`.
6. Download [PickScore model weights](https://drive.google.com/file/d/1UhR0zFXiEI-spt2QdX67FY9a0dcqa9xy/view?usp=sharing) and put it here: `pickscore/pickmodel/model.safetensors`.
### Double check if everything is all set
```
|-- hummingbird-1/
|-- hpsv2
|-- HPS_v2_compressed.pt
|-- pickscore
|-- pickmodel
|-- config.json
|-- model.safetensors
|-- hummingbird
|-- model_index.json
|-- lora_unet_65000
|-- adapter_config.json
|-- adapter_model.safetensors
|-- stable-diffusion-xl-base-1.0
|-- model_index.json (replaced by our customized version, see step 4 above)
|-- feature_extractor (cloned from CLIP-ViT-bigG-14-laion2B-39B-b160k)
|-- image_encoder (cloned from CLIP-ViT-bigG-14-laion2B-39B-b160k)
|-- text_encoder
|-- text_encoder_2
|-- tokenizer
|-- tokenizer_2
|-- unet
|-- vae
|-- ...
|-- ...
```
## Quick Start
Given a reference image, Hummingbird can generate diverse variants of it and preserve specific properties/attributes, for example:
```
python3 inference.py --reference_image ./examples/image-2.jpg --attribute "color of skateboard wheels" --output_path output.jpg
```
## Training
You can train Hummingbird with the following script:
```
sh run_hummingbird.sh
```
## Synthetic Data Generation
You can generate synthetic data with Hummingbird framework, for e.g. with MME Perception dataset:
```
python3 image_generation.py --generator hummingbird --dataset mme --save_image_gen ./synthetic_mme
```
## Testing
Evaluate the fidelity of generated images w.r.t reference image using Test-Time Augmentation on MLLMs (LLaVA/InternVL2):
```
python3 test_hummingbird_mme.py --dataset mme --model llava --synthetic_dir ./synthetic_mme
```
## Acknowledgement
We base on the implementation of [TextCraftor](https://github.com/snap-research/textcraftor). We thank [BLIP-2 QFormer](https://github.com/salesforce/LAVIS), [HPSv2](https://github.com/tgxs002/HPSv2), [PickScore](https://github.com/yuvalkirstain/PickScore), [Aesthetic](https://laion.ai/blog/laion-aesthetics/) for the reward models and MLLMs [LLaVA](https://github.com/haotian-liu/LLaVA), [InternVL2](https://github.com/OpenGVLab/InternVL) functioning as context descriptors in our framework.
## Citation
If you find this work helpful, please cite our paper:
```BibTeX
@inproceedings{le2025hummingbird,
title={Hummingbird: High Fidelity Image Generation via Multimodal Context Alignment},
author={Minh-Quan Le and Gaurav Mittal and Tianjian Meng and A S M Iftekhar and Vishwas Suryanarayanan and Barun Patra and Dimitris Samaras and Mei Chen},
booktitle={The Thirteenth International Conference on Learning Representations},
year={2025},
url={https://openreview.net/forum?id=6kPBThI6ZJ}
}
``` |
BRP0415/MIMIC | BRP0415 | 2025-06-15T16:44:50Z | 0 | 0 | fasttext | [
"fasttext",
"en",
"dataset:fka/awesome-chatgpt-prompts",
"dataset:frascuchon/fka_awesome-chatgpt-prompts___2",
"base_model:ResembleAI/chatterbox",
"base_model:finetune:ResembleAI/chatterbox",
"region:us"
] | null | 2025-06-15T16:42:26Z | ---
datasets:
- fka/awesome-chatgpt-prompts
- frascuchon/fka_awesome-chatgpt-prompts___2
language:
- en
metrics:
- code_eval
- character
base_model:
- ResembleAI/chatterbox
- google/medgemma-4b-it
new_version: ResembleAI/chatterbox
library_name: fasttext
--- |
Adilbai/bone-age-resnet-80m | Adilbai | 2025-06-15T16:44:18Z | 0 | 1 | null | [
"onnx",
"safetensors",
"bone-age",
"regression",
"medical",
"resnet",
"pytorch",
"CNN",
"biology",
"image-segmentation",
"en",
"license:mit",
"region:us"
] | image-segmentation | 2025-06-15T13:31:15Z | ---
license: mit
tags:
- bone-age
- regression
- medical
- resnet
- pytorch
- onnx
- CNN
- biology
- safetensors
language:
- en
pipeline_tag: image-segmentation
---
# 🦴 Bone Age Regression Model
<div align="center">




</div>
---
## 🚀 Quick Start
<div align="center">
[](https://huggingface.co/spaces)
[](https://www.kaggle.com/datasets/kmader/rsna-bone-age)
[](#training-procedure)
[](https://huggingface.co/docs/hub/spaces)
</div>
---
## 📋 Model Overview
> **🎯 Predicts bone age from hand X-rays with ~5 month accuracy**
> This CNN-based model uses ResNet152 architecture to estimate pediatric bone age from hand radiographs, achieving an MSE of ~25 (equivalent to ±5 month prediction range).
### 🏥 **Clinical Impact**
- **Accuracy**: MSE ~25 months² (±5 month typical error range)
- **Speed**: Real-time inference (<1 second per image)
- **Applications**: Pediatric growth assessment, endocrine disorder screening
- **Support**: Assists radiologists in bone age evaluation
---
### 🧠 **Architecture Components**
- **🏗️ Base Model**: ResNet152 (80M+ parameters)
- **🔄 Pre-training**: ImageNet initialization
- **🎯 Task Head**: Custom regression layers
- **👥 Multi-modal**: Image + gender fusion
- **📐 Input Size**: 256×256 RGB images
### 📊 **Performance Metrics**
| Metric | Value | Interpretation |
|--------|-------|----------------|
| **MSE** | ~25 months² | ±5 month typical error |
| **Training Loss** | 1567.98 → 25.26 | 98.4% improvement |
| **Convergence** | 9 epochs | Stable training |
| **Speed** | 1.69 it/s | Real-time capable |
---
## 🎯 Intended Use Cases
<div align="center">
| ✅ **Recommended Uses** | ❌ **Not Recommended** |
|------------------------|----------------------|
| 🏥 Clinical decision support | 🚫 Standalone diagnosis |
| 📚 Medical education | 🚫 Adult bone age |
| 🔬 Research applications | 🚫 Non-hand X-rays |
| 👨⚕️ Radiologist assistance | 🚫 Emergency decisions |
</div>
---
## 📊 Training Performance
### 📈 **Training Progress**
<div align="center">
| Epoch | Loss | Improvement | Status |
|-------|------|-------------|---------|
| 1 | 1567.98 | - | 🔴 Starting |
| 2 | 178.89 | -88.6% | 🟡 Learning |
| 5 | 63.82 | -95.9% | 🟠 Converging |
| 9 | 24.15 | -98.5% | 🟢 **Best** |
| 10 | 25.26 | -98.4% | 🔵 Final |
</div>
### 📋 **Training Configuration**
- **📦 Dataset**: RSNA Bone Age (12,500 images)
- **⏱️ Duration**: ~1.5 hours (10 epochs)
- **🎯 Optimization**: SGD/Adam (details in code)
- **📊 Batch Size**: ~32 (395 batches/epoch)
- **🔄 Best Checkpoint**: Epoch 9 (MSE: 24.15)
---
## 🚀 Usage Examples
### 🐍 **Python - PyTorch**
```python
# 📦 Installation
pip install torch torchvision pillow
# 🔮 Inference
from PIL import Image
import torch
from finetune_resnet_bone_age import BoneAgeResNet, transforms
# 📥 Load model
model = BoneAgeResNet()
model.load_state_dict(torch.load('resnet_bone_age_80m.pt'))
model.eval()
# 🖼️ Prepare inputs
image = Image.open('hand_xray.png').convert('RGB')
img_tensor = transforms(image).unsqueeze(0)
gender = torch.tensor([0.0]) # 0=male, 1=female
# 🎯 Predict
with torch.no_grad():
predicted_age = model(img_tensor, gender)
print(f"🦴 Predicted bone age: {predicted_age.item():.1f} ± 5 months")
```
### ⚡ **ONNX Runtime**
```python
import onnxruntime as ort
import numpy as np
# 🔧 Load ONNX model
session = ort.InferenceSession('resnet_bone_age_80m.onnx')
# 🎯 Run inference
outputs = session.run(None, {
"image": img_array,
"gender": np.array([[0.0]]) # 0=male, 1=female
})
age_months = outputs[0][0]
print(f"🦴 Bone age: {age_months:.1f} months ({age_months/12:.1f} years)")
```
---
## 📚 Related Work & Background
### 🔬 **Scientific Foundation**
Bone age assessment is a critical clinical tool in pediatric medicine, traditionally performed using the **Greulich-Pyle** or **Tanner-Whitehouse** methods. Deep learning approaches have shown promising results in automating this process.
### 📖 **Key Publications**
- **Larson et al. (2018)**: "Performance of a Deep-Learning Neural Network Model in Assessing Skeletal Maturity on Pediatric Hand Radiographs" - *Radiology*
- **Iglovikov et al. (2018)**: "Paediatric Bone Age Assessment Using Deep Convolutional Neural Networks" - *MICCAI*
- **Liu et al. (2019)**: "Bone Age Assessment Based on Deep Convolution Features" - *Frontiers in Neuroscience*
### 🧠 **CNN Architecture Evolution**
- **Traditional CNNs**: AlexNet, VGG → Limited medical imaging performance
- **ResNet Revolution**: Skip connections → Better gradient flow, deeper networks
- **Medical Adaptations**: Transfer learning + domain-specific fine-tuning
- **Multi-modal Integration**: Image + metadata fusion for improved accuracy
### 🔄 **Comparison with Other Approaches**
| Method | Architecture | MSE | Year |
|--------|-------------|-----|------|
| Greulich-Pyle (Manual) | Human Expert | ~20-30 | 1959 |
| **This Model** | **ResNet152** | **~25** | **2024** |
| Iglovikov et al. | VGG-16 | ~30-35 | 2018 |
| Larson et al. | CNN Ensemble | ~15-20 | 2018 |
---
## ⚠️ Important Limitations
<div align="center">
### 🎯 **Accuracy Interpretation**
**MSE ≈ 25 months² means typical errors of ±5 months**
</div>
### 🏥 **Clinical Considerations**
- **📋 FDA Status**: Not FDA approved - research use only
- **👨⚕️ Professional Oversight**: Requires medical supervision
- **🎯 Population**: Validated on RSNA dataset demographics
- **⚖️ Bias**: May vary across different ethnic groups
### 🔧 **Technical Limitations**
- **📸 Image Quality**: Requires clear, properly positioned hand X-rays
- **👶 Age Range**: Optimized for pediatric patients (0-18 years)
- **💾 Memory**: ~1GB RAM required for inference
- **⚡ Hardware**: GPU recommended for real-time performance
---
## 🚀 Deployment Options
<div align="center">
### 🔧 **Quick Deploy**
[](https://huggingface.co/docs/hub/spaces-sdks-docker)
[](https://aws.amazon.com/sagemaker/)
[](https://colab.research.google.com/)
</div>
### 🐳 **Docker Deployment**
```dockerfile
FROM pytorch/pytorch:latest
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY . /app
WORKDIR /app
EXPOSE 8000
CMD ["python", "app.py"]
```
### ☁️ **Cloud Integration**
- **Hugging Face Inference API**: Serverless deployment
- **AWS Lambda**: Cost-effective inference
- **Google Cloud Run**: Scalable container deployment
- **Azure Container Instances**: Enterprise integration
---
## 📊 Model Card Information
### 📈 **Performance Summary**
- **🎯 Task**: Bone age regression from hand X-rays
- **📊 Metric**: Mean Squared Error (MSE)
- **🏆 Score**: ~25 months² (±5 month error range)
- **⚡ Speed**: Real-time inference capability
- **💾 Size**: ~320MB (PyTorch), ONNX compatible
### 🔬 **Training Details**
- **📦 Dataset**: RSNA Bone Age (12,500 images)
- **🏗️ Architecture**: ResNet152 + custom regression head
- **⚙️ Parameters**: 80+ million
- **📊 Epochs**: 10 (best at epoch 9)
- **🔄 Convergence**: 98.4% loss reduction
### 📋 **Citation**
```bibtex
@model{adilbai2024bone_age_resnet,
title={Bone Age Regression Model (ResNet152, 80M+ params)},
author={Adilbai},
year={2024},
url={https://huggingface.co/Adilbai/bone-age-resnet-80m},
note={MSE ~25 months², ±5 month typical error}
}
```
---
<div align="center">
## 🤝 Community & Support
[](https://github.com)
[](https://huggingface.co/discussions)
[](https://huggingface.co/docs)
### 💡 **Contributing**
We welcome contributions! Please see our [contribution guidelines](CONTRIBUTING.md) for details.
### 📞 **Contact**
- 🐙 **GitHub**: https://github.com/AdilzhanB
- 🤗 **Hugging Face**: https://huggingface.co/Adilbai
- 📧 **Email**: [email protected]
</div>
---
<div align="center">
**⚠️ Medical Disclaimer**: This model is for research and educational purposes only. Not intended for clinical diagnosis without proper medical supervision and validation.


</div> |
pang1203/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-thriving_fishy_panda | pang1203 | 2025-06-15T16:41:14Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"rl-swarm",
"grpo",
"gensyn",
"I am thriving fishy panda",
"unsloth",
"trl",
"arxiv:2402.03300",
"base_model:Gensyn/Qwen2.5-0.5B-Instruct",
"base_model:finetune:Gensyn/Qwen2.5-0.5B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-06-14T20:35:59Z | ---
base_model: Gensyn/Qwen2.5-0.5B-Instruct
library_name: transformers
model_name: Qwen2.5-0.5B-Instruct-Gensyn-Swarm-thriving_fishy_panda
tags:
- generated_from_trainer
- rl-swarm
- grpo
- gensyn
- I am thriving fishy panda
- unsloth
- trl
licence: license
---
# Model Card for Qwen2.5-0.5B-Instruct-Gensyn-Swarm-thriving_fishy_panda
This model is a fine-tuned version of [Gensyn/Qwen2.5-0.5B-Instruct](https://huggingface.co/Gensyn/Qwen2.5-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="pang1203/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-thriving_fishy_panda", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.15.2
- Transformers: 4.48.2
- Pytorch: 2.5.1
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.5_0.75_epoch2 | MinaMila | 2025-06-15T16:41:14Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T16:39:15Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
svjack/PosterCraft-v1_RL | svjack | 2025-06-15T16:40:42Z | 0 | 0 | diffusers | [
"diffusers",
"safetensors",
"art",
"diffusion",
"aesthetic-poster-generation",
"text-to-image",
"en",
"arxiv:2506.10741",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:finetune:black-forest-labs/FLUX.1-dev",
"license:other",
"endpoints_compatible",
"diffusers:FluxPipeline",
"region:us"
] | text-to-image | 2025-06-15T14:15:23Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: LICENSE.md
library_name: diffusers
language:
- en
base_model:
- black-forest-labs/FLUX.1-dev
pipeline_tag: text-to-image
tags:
- art
- diffusion
- aesthetic-poster-generation
---
<div align="center">
<h1>🎨 PosterCraft:<br/>Rethinking High-Quality Aesthetic Poster Generation in a Unified Framework</h1>
[](https://arxiv.org/abs/2506.10741)
[](https://github.com/ephemeral182/PosterCraft)
[](https://huggingface.co/PosterCraft)
[](https://ephemeral182.github.io/PosterCraft/)
[](https://ephemeral182.github.io/PosterCraft/)
<img src="assets/logo2.png" alt="PosterCraft Logo" width="1000"/>
<img src="assets/teaser-1.png" alt="PosterCraft Logo" width="1000"/>
</div>
---
## 🌟 What is PosterCraft?
<div align="center">
<img src="assets/demo2.png" alt="What is PosterCraft - Quick Prompt Demo" width="1000"/>
<br>
</div>
PosterCraft is a unified framework for **high-quality aesthetic poster generation** that excels in **precise text rendering**, **seamless integration of abstract art**, **striking layouts**, and **stylistic harmony**.
## 🚀 Quick Start
### 🔧 Installation
```bash
# Clone the repository
git clone https://github.com/ephemeral182/PosterCraft.git
cd PosterCraft
# Create conda environment
conda create -n postercraft python=3.11
conda activate postercraft
# Install dependencies
pip install -r requirements.txt
```
### 🚀 Easy Usage
PosterCraft is designed as a unified and flexible framework. This makes it easy to use PosterCraft within your own custom workflows or other compatible frameworks.
Loading the model is straightforward:
```python
import torch
from diffusers import FluxPipeline, FluxTransformer2DModel
# 1. Define model IDs and settings
pipeline_id = "black-forest-labs/FLUX.1-dev"
postercraft_transformer_id = "PosterCraft/PosterCraft-v1_RL"
device = "cuda"
dtype = torch.bfloat16
# 2. Load the base pipeline
pipe = FluxPipeline.from_pretrained(pipeline_id, torch_dtype=dtype)
# 3. The key step: simply replace the original transformer with our fine-tuned PosterCraft model
pipe.transformer = FluxTransformer2DModel.from_pretrained(
postercraft_transformer_id,
torch_dtype=dtype
)
pipe.to(device)
# Now, `pipe` is a standard diffusers pipeline ready for inference with your own logic.
```
### 🚀 Quick Generation
For the best results and to leverage our intelligent prompt rewriting feature, we recommend using the provided `inference.py` script. This script automatically enhances your creative ideas for optimal results.
Generate high-quality aesthetic posters from your prompt with `BF16` precision, please refer to our [GitHub repository](https://github.com/Ephemeral182/PosterCraft) :
```bash
python inference.py \
--prompt "Urban Canvas Street Art Expo poster with bold graffiti-style lettering and dynamic colorful splashes" \
--enable_recap \
--num_inference_steps 28 \
--guidance_scale 3.5 \
--seed 42 \
--pipeline_path "black-forest-labs/FLUX.1-dev" \
--custom_transformer_path "PosterCraft/PosterCraft-v1_RL" \
--qwen_model_path "Qwen/Qwen3-8B"
```
If you are running on a GPU with limited memory, you can use `inference_offload.py` to offload some components to the CPU:
```bash
python inference_offload.py \
--prompt "Urban Canvas Street Art Expo poster with bold graffiti-style lettering and dynamic colorful splashes" \
--enable_recap \
--num_inference_steps 28 \
--guidance_scale 3.5 \
--seed 42 \
--pipeline_path "black-forest-labs/FLUX.1-dev" \
--custom_transformer_path "PosterCraft/PosterCraft-v1_RL" \
--qwen_model_path "Qwen/Qwen3-8B"
```
### 💻 Gradio Web UI
We provide a Gradio web UI for PosterCraft, please refer to our [GitHub repository](https://github.com/Ephemeral182/PosterCraft).
```bash
python demo_gradio.py
```
### Reference Demo on Wang_Leehom (王力宏)
- reference on

- target

## 📊 Performance Benchmarks
<div align="center">
### 📈 Quantitative Results
<table>
<thead>
<tr>
<th>Method</th>
<th>Text Recall ↑</th>
<th>Text F-score ↑</th>
<th>Text Accuracy ↑</th>
</tr>
</thead>
<tbody>
<tr>
<td style="white-space: nowrap;">OpenCOLE (Open)</td>
<td>0.082</td>
<td>0.076</td>
<td>0.061</td>
</tr>
<tr>
<td style="white-space: nowrap;">Playground-v2.5 (Open)</td>
<td>0.157</td>
<td>0.146</td>
<td>0.132</td>
</tr>
<tr>
<td style="white-space: nowrap;">SD3.5 (Open)</td>
<td>0.565</td>
<td>0.542</td>
<td>0.497</td>
</tr>
<tr>
<td style="white-space: nowrap;">Flux1.dev (Open)</td>
<td>0.723</td>
<td>0.707</td>
<td>0.667</td>
</tr>
<tr>
<td style="white-space: nowrap;">Ideogram-v2 (Close)</td>
<td>0.711</td>
<td>0.685</td>
<td>0.680</td>
</tr>
<tr>
<td style="white-space: nowrap;">BAGEL (Open)</td>
<td>0.543</td>
<td>0.536</td>
<td>0.463</td>
</tr>
<tr>
<td style="white-space: nowrap;">Gemini2.0-Flash-Gen (Close)</td>
<td>0.798</td>
<td>0.786</td>
<td>0.746</td>
</tr>
<tr>
<td style="white-space: nowrap;"><b>PosterCraft (ours)</b></td>
<td><b>0.787</b></td>
<td><b>0.774</b></td>
<td><b>0.735</b></td>
</tr>
</tbody>
</table>
<img src="assets/hpc.png" alt="hpc" width="1000"/>
</div>
---
## 📝 Citation
If you find PosterCraft useful for your research, please cite our paper:
```bibtex
@article{chen2025postercraft,
title={PosterCraft: Rethinking High-Quality Aesthetic Poster Generation in a Unified Framework},
author={Chen, Sixiang and Lai, Jianyu and Gao, Jialin and Ye, Tian and Chen, Haoyu and Shi, Hengyu and Shao, Shitong and Lin, Yunlong and Fei, Song and Xing, Zhaohu and Jin, Yeying and Luo, Junfeng and Wei, Xiaoming and Zhu, Lei},
journal={arXiv preprint arXiv:2506.10741},
year={2025}
}
```
</div> |
VIDEO-18-parbin-assam-viral-videoS/VIDEO.LINK.parbin.Viral.Video.Tutorial.Official | VIDEO-18-parbin-assam-viral-videoS | 2025-06-15T16:37:41Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T16:37:15Z | <animated-image data-catalyst=""><a href="https://tinyurl.com/fn84hrnu?news-viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a> |
mradermacher/ThinkAgent-1B-GGUF | mradermacher | 2025-06-15T16:33:01Z | 53 | 0 | transformers | [
"transformers",
"gguf",
"en",
"dataset:ThinkAgents/Function-Calling-with-Chain-of-Thoughts",
"base_model:AymanTarig/Llama-3.2-1B-FC-v3",
"base_model:quantized:AymanTarig/Llama-3.2-1B-FC-v3",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-03-03T20:21:56Z | ---
base_model: AymanTarig/Llama-3.2-1B-FC-v3
datasets:
- ThinkAgents/Function-Calling-with-Chain-of-Thoughts
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/AymanTarig/Llama-3.2-1B-FC-v3
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/ThinkAgent-1B-GGUF/resolve/main/ThinkAgent-1B.Q2_K.gguf) | Q2_K | 0.7 | |
| [GGUF](https://huggingface.co/mradermacher/ThinkAgent-1B-GGUF/resolve/main/ThinkAgent-1B.Q3_K_S.gguf) | Q3_K_S | 0.7 | |
| [GGUF](https://huggingface.co/mradermacher/ThinkAgent-1B-GGUF/resolve/main/ThinkAgent-1B.Q3_K_M.gguf) | Q3_K_M | 0.8 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/ThinkAgent-1B-GGUF/resolve/main/ThinkAgent-1B.Q3_K_L.gguf) | Q3_K_L | 0.8 | |
| [GGUF](https://huggingface.co/mradermacher/ThinkAgent-1B-GGUF/resolve/main/ThinkAgent-1B.IQ4_XS.gguf) | IQ4_XS | 0.8 | |
| [GGUF](https://huggingface.co/mradermacher/ThinkAgent-1B-GGUF/resolve/main/ThinkAgent-1B.Q4_K_S.gguf) | Q4_K_S | 0.9 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/ThinkAgent-1B-GGUF/resolve/main/ThinkAgent-1B.Q4_K_M.gguf) | Q4_K_M | 0.9 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/ThinkAgent-1B-GGUF/resolve/main/ThinkAgent-1B.Q5_K_S.gguf) | Q5_K_S | 1.0 | |
| [GGUF](https://huggingface.co/mradermacher/ThinkAgent-1B-GGUF/resolve/main/ThinkAgent-1B.Q5_K_M.gguf) | Q5_K_M | 1.0 | |
| [GGUF](https://huggingface.co/mradermacher/ThinkAgent-1B-GGUF/resolve/main/ThinkAgent-1B.Q6_K.gguf) | Q6_K | 1.1 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/ThinkAgent-1B-GGUF/resolve/main/ThinkAgent-1B.Q8_0.gguf) | Q8_0 | 1.4 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/ThinkAgent-1B-GGUF/resolve/main/ThinkAgent-1B.f16.gguf) | f16 | 2.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
sm4rtdev/Nextplace | sm4rtdev | 2025-06-15T16:32:58Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-14T10:27:39Z | # NextPlace
- Models for the NextPlace subnet |
VIDEO-18-parbin-assam-viral-videoS/FULL.VIDEO.parbin.Viral.Video.Tutorial.Official | VIDEO-18-parbin-assam-viral-videoS | 2025-06-15T16:30:58Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T16:30:37Z | <animated-image data-catalyst=""><a href="https://tinyurl.com/fn84hrnu?news-viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a> |
carazi/vyviln | carazi | 2025-06-15T16:30:33Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-06-15T16:09:20Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: vyvil
---
# Vyviln
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `vyvil` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "vyvil",
"lora_weights": "https://huggingface.co/carazi/vyviln/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('carazi/vyviln', weight_name='lora.safetensors')
image = pipeline('vyvil').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/carazi/vyviln/discussions) to add images that show off what you’ve made with this LoRA.
|
Geraldine/qwen3-0.6B-unimarc-grpo | Geraldine | 2025-06-15T16:29:41Z | 36 | 0 | null | [
"safetensors",
"qwen3",
"text-generation",
"conversational",
"en",
"fr",
"dataset:Geraldine/metadata-to-unimarc-reasoning",
"base_model:Qwen/Qwen3-0.6B",
"base_model:finetune:Qwen/Qwen3-0.6B",
"license:mit",
"region:us"
] | text-generation | 2025-06-08T17:43:04Z | ---
license: mit
datasets:
- Geraldine/metadata-to-unimarc-reasoning
language:
- en
- fr
base_model:
- Qwen/Qwen3-0.6B
pipeline_tag: text-generation
---
# Qwen3-0.6B UNIMARC/XML Generator (Fine-tuned with GRPO + LoRA)
This repository provides a fine-tuned version of [Qwen/Qwen3-0.6B](https://huggingface.co/Qwen/Qwen3-0.6B), trained using [GRPO (Generalized Repetition Penalized Optimization)](https://huggingface.co/docs/trl) and LoRA adapters to transform raw bibliographic metadata into structured [UNIMARC](https://www.ifla.org/publications/unimarc-manual/) XML records.
Unlike typical text-to-XML generation models, this model is optimized for reasoning and interpretability, leveraging Chain-of-Thought prompting to think through each cataloging step before composing the final UNIMARC output—ensuring both semantic alignment and structural validity.
---
## Use Case
Automatically generate UNIMARC/XML records from unstructured bibliographic metadata. Useful for libraries, cataloging systems, digital archiving, and metadata enrichment pipelines.
---
## Model Details
- **Base Model**: `Qwen/Qwen3-0.6B`
- **Training Framework**: 🤗 Transformers + TRL (GRPO)
- **Parameter-Efficient Fine-Tuning**: LoRA adapters (r=8)
- **Training Objective**: Structured XML generation guided by domain-specific prompts and multi-criteria reward functions
- **Reward Signals**:
- Format validity (`<record>` structure, fields, subfields)
- Field-level accuracy using XML diffing
- Semantic mapping from raw fields to MARC tags
---
## How It Works
During training, the model was prompted using a detailed system instruction to convert user-supplied metadata (in text or key-value format) into valid UNIMARC/XML. Training was reinforced with custom reward functions to enforce format, content accuracy, and correct field mapping.
### Example Prompt
**Input** (user message):
```
Title: Digital Libraries
Author: John Smith
Publisher: Academic Press
Year: 2023
ISBN: 978-0123456789
```
**Expected Output** (model response):
```
<record>
<leader> cam0 22 450 </leader>
<controlfield tag="001">...</controlfield>
...
<datafield tag="200" ind1="1" ind2=" ">
<subfield code="a">Digital Libraries</subfield>
<subfield code="f">John Smith</subfield>
</datafield>
<datafield tag="214" ind1=" " ind2="0">
<subfield code="c">Academic Press</subfield>
<subfield code="d">2023</subfield>
</datafield>
<datafield tag="010" ind1=" " ind2=" ">
<subfield code="a">978-0123456789</subfield>
</datafield>
...
</record>
```
---
## Training Details
- **Dataset**: [Geraldine/metadata-to-unimarc-reasoning](https://huggingface.co/datasets/Geraldine/metadata-to-unimarc-reasoning)
- **Prompt Format**: ChatML-style with system and user roles
- **Training Steps**:
- Tokenized with AutoTokenizer from Qwen
- LoRA injected into attention projection layers
- Rewarded with three custom functions: structural validity, XML field similarity, semantic field mapping
- **Trainer**: GRPOTrainer from TRL
- **Training code and rewards functions**: see [this notebook](https://www.kaggle.com/code/geraldinegeoffroy/qwen3-0-6b-unimarc-grpo) on Kaggle
- **Training system prompt**:
```
# UNIMARC XML Record Generation Prompt
## Task Instructions
You are a bibliographic cataloging expert. Your task is to convert raw bibliographic metadata into a properly structured UNIMARC XML record. Follow the template and field mappings provided below to create a complete, valid UNIMARC record.
## Input Format
The user will provide bibliographic metadata in various formats (text, key-value pairs, or structured data). Extract and map each element to the appropriate UNIMARC field according to the mapping guide.
## Output Requirements
Generate a complete UNIMARC XML record using the template structure below, populating all available fields with the provided metadata.
---
## UNIMARC XML Template
<record>
<leader> cam0 22 450 </leader>
<controlfield tag="001">#{RECORD_ID}#</controlfield>
<controlfield tag="003">#{RECORD_SOURCE_URL}#</controlfield>
<controlfield tag="005">#{TIMESTAMP}#</controlfield>
<!-- ISBN and Pricing Information -->
<datafield tag="010" ind1=" " ind2=" ">
<subfield code="a">#{ISBN}#</subfield>
<subfield code="b">#{BINDING_TYPE}#</subfield>
<subfield code="d">#{PRICE}#</subfield>
</datafield>
<!-- External Control Numbers -->
<datafield tag="035" ind1=" " ind2=" ">
<subfield code="a">#{OCLC_NUMBER}#</subfield>
</datafield>
<!-- Barcode/EAN -->
<datafield tag="073" ind1=" " ind2="1">
<subfield code="a">#{BARCODE}#</subfield>
</datafield>
<!-- General Processing Data -->
<datafield tag="100" ind1=" " ind2=" ">
<subfield code="a">#{PROCESSING_DATA}#</subfield>
</datafield>
<!-- Language Information -->
<datafield tag="101" ind1="#{TRANSLATION_INDICATOR}#" ind2=" ">
<subfield code="a">#{PRIMARY_LANGUAGE}#</subfield>
<subfield code="c">#{ORIGINAL_LANGUAGE}#</subfield>
<subfield code="2">#{LANGUAGE_SCHEME}#</subfield>
</datafield>
<!-- Country of Publication -->
<datafield tag="102" ind1=" " ind2=" ">
<subfield code="a">#{COUNTRY_CODE}#</subfield>
</datafield>
<!-- Content Type Information (RDA) -->
<datafield tag="105" ind1=" " ind2=" ">
<subfield code="a">a a 000yy</subfield>
</datafield>
<datafield tag="106" ind1=" " ind2=" ">
<subfield code="a">r</subfield>
</datafield>
<!-- RDA Content/Media/Carrier Types -->
<datafield tag="181" ind1=" " ind2=" ">
<subfield code="6">z01</subfield>
<subfield code="c">txt</subfield>
<subfield code="2">rdacontent</subfield>
</datafield>
<datafield tag="181" ind1=" " ind2="1">
<subfield code="6">z01</subfield>
<subfield code="a">i#</subfield>
<subfield code="b">xxxe##</subfield>
</datafield>
<datafield tag="182" ind1=" " ind2=" ">
<subfield code="6">z01</subfield>
<subfield code="c">n</subfield>
<subfield code="2">rdamedia</subfield>
</datafield>
<datafield tag="182" ind1=" " ind2="1">
<subfield code="6">z01</subfield>
<subfield code="a">n</subfield>
</datafield>
<datafield tag="183" ind1=" " ind2="1">
<subfield code="6">z01</subfield>
<subfield code="a">nga</subfield>
<subfield code="2">RDAfrCarrier</subfield>
</datafield>
<!-- Title and Statement of Responsibility -->
<datafield tag="200" ind1="1" ind2=" ">
<subfield code="a">#{MAIN_TITLE}#</subfield>
<subfield code="e">#{SUBTITLE}#</subfield>
<subfield code="f">#{AUTHORS_COLLECTIVE_STATEMENT}#</subfield>
<subfield code="g">#{TRANSLATOR_STATEMENT}#</subfield>
</datafield>
<!-- Publication Information -->
<datafield tag="214" ind1=" " ind2="0">
<subfield code="a">#{PLACE_OF_PUBLICATION}#</subfield>
<subfield code="c">#{PUBLISHER}#</subfield>
<subfield code="d">#{PUBLICATION_DATE}#</subfield>
</datafield>
<!-- Physical Description -->
<datafield tag="215" ind1=" " ind2=" ">
<subfield code="a">#{EXTENT}#</subfield>
<subfield code="c">#{ILLUSTRATIONS_DETAILS}#</subfield>
<subfield code="d">#{DIMENSIONS}#</subfield>
</datafield>
<!-- Collection or series Description -->
<datafield tag="225" ind1="0" ind2=" ">
<subfield code="a">{COLLECTION_NAME}</subfield>
<subfield code="v">{ISSUE_NUMBER}</subfield>
</datafield>
<!-- Collection or series Linking Information -->
<datafield tag="410" ind1=" " ind2="|">
<subfield code="0">{COLLECTION_AUTHORITY_ID}</subfield>
<subfield code="t">{COLLECTION_NAME}</subfield>
<subfield code="x">{COLLECTION_ISSN}</subfield>
<subfield code="v">{ISSUE_NUMBER}</subfield>
</datafield>
<!-- Bibliography Note -->
<datafield tag="320" ind1=" " ind2=" ">
<subfield code="a">#{BIBLIOGRAPHY_NOTE}#</subfield>
</datafield>
<!-- Summary/Abstract -->
<datafield tag="330" ind1=" " ind2=" ">
<subfield code="a">#{ABSTRACT_SUMMARY}#</subfield>
<subfield code="2">#{SUMMARY_SOURCE}#</subfield>
</datafield>
<!-- Variant Title -->
<datafield tag="516" ind1="|" ind2=" ">
<subfield code="a">#{SPINE_TITLE}#</subfield>
</datafield>
<!-- Subject Headings -->
<datafield tag="606" ind1=" " ind2=" ">
<subfield code="3">#{SUBJECT_AUTHORITY_ID}#</subfield>
<subfield code="a">#{MAIN_SUBJECT}#</subfield>
<subfield code="3">#{SUBDIVISION_AUTHORITY_ID}#</subfield>
<subfield code="x">#{SUBJECT_SUBDIVISION}#</subfield>
<subfield code="2">#{SUBJECT_SCHEME}#</subfield>
</datafield>
<!-- Dewey Classification -->
<datafield tag="676" ind1=" " ind2=" ">
<subfield code="a">#{DEWEY_NUMBER}#</subfield>
</datafield>
<!-- Main Author Entry -->
<datafield tag="700" ind1=" " ind2="1">
<subfield code="3">#{AUTHOR_AUTHORITY_ID}#</subfield>
<subfield code="a">#{AUTHOR_SURNAME}#</subfield>
<subfield code="b">#{AUTHOR_FORENAME}#</subfield>
<subfield code="4">#{AUTHOR_ROLE_CODE}#</subfield>
</datafield>
<!-- Additional Author Entries (repeat as needed) -->
<datafield tag="701" ind1=" " ind2="1">
<subfield code="3">#{ADDITIONAL_AUTHOR_AUTHORITY_ID}#</subfield>
<subfield code="a">#{ADDITIONAL_AUTHOR_SURNAME}#</subfield>
<subfield code="b">#{ADDITIONAL_AUTHOR_FORENAME}#</subfield>
<subfield code="4">#{ADDITIONAL_AUTHOR_ROLE_CODE}#</subfield>
</datafield>
<!-- Cataloging Source -->
<datafield tag="801" ind1=" " ind2="3">
<subfield code="a">#{CATALOGING_COUNTRY}#</subfield>
<subfield code="b">#{CATALOGING_AGENCY}#</subfield>
<subfield code="c">#{CATALOGING_DATE}#</subfield>
<subfield code="g">#{CATALOGING_RULES}#</subfield>
</datafield>
</record>
---
## Field Mapping Guide
### Essential Metadata Elements
| **Metadata Element** | **UNIMARC/XML Tag** | **Subfield(s)** | **Notes / Instructions** |
|------------------------------------|----------------------|------------------------------|--------------------------------------------------------------------|
| **Title** | 200 | $a | Main title of the work |
| **Subtitle** | 200 | $e | Subtitle or explanatory title |
| **Statement of responsibility** | 200 | $f | All authors or contributors |
| **Translator statement** | 200 | $g | Statement about translator(s) |
| **Individual Authors** | 700 / 701 | $a $b $3 $4 / $f $c | Surname, forename, authority ID, role, full name and profession |
| **Place of publication** | 214 | $a | City (use brackets if inferred) |
| **Publisher** | 214 | $c | Publisher name |
| **Publication date** | 214 | $d | DL date (format: DL YYYY) |
| **Copyright date** | 214 | $d | Same field as publication date |
| **Imprint (printer info)** | 214 | $a $c | Place and name of printer |
| **Edition** | 205 | $a | Edition info in brackets |
| **Physical description** | 215 | $a $c $d | Extent, illustrations, dimensions |
| **ISBN (original)** | 010 | $a | ISBN 13 with hyphens |
| **Binding** | 010 | $b | Binding format (e.g., "br." for paperback) |
| **Price** | 010 | $d | Price information |
| **Other identifier (ISBN no hyphens)** | 073 | $a | ISBN/Barcode without hyphens |
| **OCLC number** | 035 | $a | OCLC control number, e.g., (OCoLC)number |
| **Language** | 101 | $a $2 | ISO 639-2 language code and source |
| **Original language** | 101 | $c | Original language if translated |
| **Language scheme** | 101 | $2 | Language code scheme |
| **Country of publication** | 102 | $a | ISO country code (e.g., "FR") |
| **Series title** | 225 | $a | Series name |
| **Series number/volume** | 225 | $v | Number in series |
| **Series added entry** | 410 | $0 $t $x $v | Control number, full title, ISSN, volume |
| **Subject headings** | 606, 608 | $a $x $3 $y $2 | Subjects, subdivisions, authority ID, geographic, source (RAMEAU) |
| **Classification (Dewey)** | 676 | $a $v | Dewey Decimal Classification number and edition |
| **Bibliography / Index note** | 320 | $a | Bibliography info or "Index" |
| **Notes** | 303, 312 | $a | General notes from metadata |
| **Summary / Abstract** | 330 | $a $2 | Abstract and source |
| **Intended audience** | 333 | $a | Audience description |
| **Material type (content)** | 181 | $a $b $c $2 | Content type, form codes, and code source |
| **Carrier type / details** | 182, 183 | $a $c $2 | Carrier type codes and standards |
| **Cataloging agency info** | 801 | $a $b $c $g | Country, cataloging agency, date, standard used |
### Default Values and Standards
- **Leader**: Use ` cam0 22 450 ` for monographic text resources
- **Translation indicator (101)**: Use "1" if translated, " " if original
- **Author role codes (4)**: Use "070" for authors, "730" for translators
- **Subject scheme (606)**: Use "rameau" for French subject headings
- **Cataloging rules (801)**: Use "AFNOR" for French cataloging standards
### Processing Instructions
1. **Extract** all available metadata from the user's input
2. **Map** each element to the appropriate UNIMARC field using the guide above
3. **Generate** control numbers and timestamps if not provided:
- Record ID (001): Create unique identifier
- Timestamp (005): Use format YYYYMMDDHHMMSS.000
4. **Handle multiple authors**: Use tag 700 for the first/main author, 701 for additional authors
5. **Format indicators**: Pay attention to ind1 and ind2 values as specified in template
6. **Include only populated fields**: Omit template sections where no data is available
### Example Usage
**Input**: "Title: Digital Libraries, Author: John Smith, Publisher: Academic Press, Year: 2023, ISBN: 978-0123456789"
**Expected Output**: Complete UNIMARC XML record with all provided elements properly mapped to their corresponding fields and subfields.
---
**Generate the UNIMARC XML record now using the metadata provided by the user.**
```
---
## Usage
**Strongly recommended**: use the straining system prompt
```
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "Geraldine/qwen3-0.6B-unimarc-grpo"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model=AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
user_prompt="""
Title: Notes from a Kidwatcher
Author: SANDRA WILDE
Price: 3.52$
Publisher: Heinemann; First Edition (May 20, 1996)
Language: English
Paperback: 316 pages
ISBN 10: 0435088688
ISBN 13: 978-0435088682
Item Weight: 1.05 pounds
Dimensions: 6.03 x 0.67 x 8.95 inches
Notes: Contains 23 selected articles by this influential writer, researcher, educator, and speaker. They're grouped around six major themes inherent in teacher education: culture and community; miscue analysis, reading strategies and comprehension; print awareness and the roots of literacy; the writing process; kidwatching; and whole language theory. No index. Annotation c. by Book News, Inc., Portland, Or.
Categories: Books;Reference;Words, Language & Grammar
"""
messages = [
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt}
]
inputs = tokenizer.apply_chat_template(
messages,
tokenize=True,
return_dict=True,
add_generation_prompt=True,
return_tensors="pt",
enable_thinking=True
).to(model.device)
generated_ids = model.generate(
**inputs,
max_new_tokens=4096,
temperature=0.6,
top_p=0.95,
top_k=20,
min_p=0,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id
)
output_ids = generated_ids[0][len(inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
```
---
## Evaluation
The model was rewarded using three strategies:
- **Format reward**: Ensures structural conformity to the XML schema
- **Accuracy reward**: Field-level string similarity using difflib
- **Semantic reward**: Matches metadata values to expected UNIMARC subfields using `fuzzywuzzy`
---
## Limitations
- Input metadata must be reasonably clean and interpretable
- The model may hallucinate plausible XML when fields are missing
- Currently optimized for monographic records (books)
|
multimolecule/aido.rna-1.6b-cds | multimolecule | 2025-06-15T16:27:56Z | 0 | 0 | multimolecule | [
"multimolecule",
"pytorch",
"safetensors",
"aido.rna",
"Biology",
"RNA",
"fill-mask",
"rna",
"dataset:multimolecule/ena",
"base_model:multimolecule/aido.rna-1.6b",
"base_model:finetune:multimolecule/aido.rna-1.6b",
"license:agpl-3.0",
"region:us"
] | fill-mask | 2025-06-15T16:23:39Z | ---
language: rna
tags:
- Biology
- RNA
license: agpl-3.0
datasets:
- multimolecule/ena
library_name: multimolecule
base_model: multimolecule/aido.rna-1.6b
pipeline_tag: fill-mask
mask_token: "<mask>"
widget:
- example_title: "HIV-1"
text: "GGUC<mask>CUCUGGUUAGACCAGAUCUGAGCCU"
output:
- label: "A"
score: 0.1288139671087265
- label: "R"
score: 0.11929940432310104
- label: "M"
score: 0.11779318749904633
- label: "V"
score: 0.11530579626560211
- label: "G"
score: 0.11048755794763565
- example_title: "microRNA-21"
text: "UAGC<mask>UAUCAGACUGAUGUUG"
output:
- label: "A"
score: 0.16018971800804138
- label: "M"
score: 0.13473322987556458
- label: "R"
score: 0.11473158001899719
- label: "V"
score: 0.11425967514514923
- label: "C"
score: 0.11332215368747711
---
# AIDO.RNA
Pre-trained model on non-coding RNA (ncRNA) using a masked language modeling (MLM) objective.
## Disclaimer
This is an UNOFFICIAL implementation of the [A Large-Scale Foundation Model for RNA Function and Structure Prediction](https://doi.org/10.1101/2024.11.28.625345) by Shuxian Zou, Tianhua Tao, Sazan Mahbub, et al.
The OFFICIAL repository of AIDO.RNA is at [genbio-ai/AIDO](https://github.com/genbio-ai/AIDO).
> [!WARNING]
> The MultiMolecule team is aware of a potential risk in reproducing the results of AIDO.RNA.
>
> The original implementation of AIDO.RNA uses a special tokenizer that identifies `U` and `T` as different tokens.
>
> This behaviour is not supported by MultiMolecule.
> [!TIP]
> The MultiMolecule team has confirmed that the provided model and checkpoints are producing the same intermediate representations as the original implementation.
**The team releasing AIDO.RNA did not write this model card for this model so this model card has been written by the MultiMolecule team.**
## Model Details
AIDO.RNA is a [bert](https://huggingface.co/google-bert/bert-base-uncased)-style model pre-trained on a large corpus of non-coding RNA sequences in a self-supervised fashion. This means that the model was trained on the raw nucleotides of RNA sequences only, with an automatic process to generate inputs and labels from those texts. Please refer to the [Training Details](#training-details) section for more information on the training process.
### Variants
- **[multimolecule/aido.rna-1.6b](https://huggingface.co/multimolecule/aido.rna-1.6b)**: The AIDO.RNA model with 1.6 billion parameters.
- **[multimolecule/aido.rna-650m](https://huggingface.co/multimolecule/aido.rna-650m)**: The AIDO.RNA model with 650 million parameters.
### Model Specification
<table>
<thead>
<tr>
<th>Variants</th>
<th>Num Layers</th>
<th>Hidden Size</th>
<th>Num Heads</th>
<th>Intermediate Size</th>
<th>Num Parameters (M)</th>
<th>FLOPs (G)</th>
<th>MACs (G)</th>
<th>Max Num Tokens</th>
</tr>
</thead>
<tbody>
<tr>
<td>AIDO.RNA-1.6B</td>
<td>32</td>
<td>2048</td>
<td>32</td>
<td>5440</td>
<td>1650.29</td>
<td>415.67</td>
<td>207.77</td>
<td rowspan="2">1022</td>
</tr>
<tr>
<td>AIDO.RNA-650M</td>
<td>33</td>
<td>1280</td>
<td>20</td>
<td>3392</td>
<td>648.38</td>
<td>168.25</td>
<td>80.09</td>
</tr>
</tbody>
</table>
### Links
- **Code**: [multimolecule.aido_rna](https://github.com/DLS5-Omics/multimolecule/tree/master/multimolecule/models/aido_rna)
- **Weights**: [multimolecule/aido.rna](https://huggingface.co/multimolecule/aido.rna)
- **Data**: [multimolecule/rnacentral](https://huggingface.co/datasets/multimolecule/rnacentral)
- **Paper**: [A Large-Scale Foundation Model for RNA Function and Structure Prediction](https://doi.org/10.1101/2024.11.28.625345)
- **Developed by**: Shuxian Zou, Tianhua Tao, Sazan Mahbub, Caleb N. Ellington, Robin Algayres, Dian Li, Yonghao Zhuang, Hongyi Wang, Le Song, Eric P. Xing
- **Model type**: [BERT](https://huggingface.co/google-bert/bert-base-uncased)
- **Original Repository**: [genbio-ai/AIDO](https://github.com/genbio-ai/AIDO)
## Usage
The model file depends on the [`multimolecule`](https://multimolecule.danling.org) library. You can install it using pip:
```bash
pip install multimolecule
```
### Direct Use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> import multimolecule # you must import multimolecule to register models
>>> from transformers import pipeline
>>> unmasker = pipeline("fill-mask", model="multimolecule/aido.rna-1.6b")
>>> unmasker("gguc<mask>cucugguuagaccagaucugagccu")
[{'score': 0.1288139671087265,
'token': 6,
'token_str': 'A',
'sequence': 'G G U C A C U C U G G U U A G A C C A G A U C U G A G C C U'},
{'score': 0.11929940432310104,
'token': 11,
'token_str': 'R',
'sequence': 'G G U C R C U C U G G U U A G A C C A G A U C U G A G C C U'},
{'score': 0.11779318749904633,
'token': 16,
'token_str': 'M',
'sequence': 'G G U C M C U C U G G U U A G A C C A G A U C U G A G C C U'},
{'score': 0.11530579626560211,
'token': 20,
'token_str': 'V',
'sequence': 'G G U C V C U C U G G U U A G A C C A G A U C U G A G C C U'},
{'score': 0.11048755794763565,
'token': 8,
'token_str': 'G',
'sequence': 'G G U C G C U C U G G U U A G A C C A G A U C U G A G C C U'}]
```
### Downstream Use
#### Extract Features
Here is how to use this model to get the features of a given sequence in PyTorch:
```python
from multimolecule import RnaTokenizer, AidoRnaModel
tokenizer = RnaTokenizer.from_pretrained("multimolecule/aido.rna-1.6b")
model = AidoRnaModel.from_pretrained("multimolecule/aido.rna-1.6b")
text = "UAGCUUAUCAGACUGAUGUUG"
input = tokenizer(text, return_tensors="pt")
output = model(**input)
```
#### Sequence Classification / Regression
> [!NOTE]
> This model is not fine-tuned for any specific task. You will need to fine-tune the model on a downstream task to use it for sequence classification or regression.
Here is how to use this model as backbone to fine-tune for a sequence-level task in PyTorch:
```python
import torch
from multimolecule import RnaTokenizer, AidoRnaForSequencePrediction
tokenizer = RnaTokenizer.from_pretrained("multimolecule/aido.rna-1.6b")
model = AidoRnaForSequencePrediction.from_pretrained("multimolecule/aido.rna-1.6b")
text = "UAGCUUAUCAGACUGAUGUUG"
input = tokenizer(text, return_tensors="pt")
label = torch.tensor([1])
output = model(**input, labels=label)
```
#### Token Classification / Regression
> [!NOTE]
> This model is not fine-tuned for any specific task. You will need to fine-tune the model on a downstream task to use it for token classification or regression.
Here is how to use this model as backbone to fine-tune for a nucleotide-level task in PyTorch:
```python
import torch
from multimolecule import RnaTokenizer, AidoRnaForTokenPrediction
tokenizer = RnaTokenizer.from_pretrained("multimolecule/aido.rna-1.6b")
model = AidoRnaForTokenPrediction.from_pretrained("multimolecule/aido.rna-1.6b")
text = "UAGCUUAUCAGACUGAUGUUG"
input = tokenizer(text, return_tensors="pt")
label = torch.randint(2, (len(text), ))
output = model(**input, labels=label)
```
#### Contact Classification / Regression
> [!NOTE]
> This model is not fine-tuned for any specific task. You will need to fine-tune the model on a downstream task to use it for contact classification or regression.
Here is how to use this model as backbone to fine-tune for a contact-level task in PyTorch:
```python
import torch
from multimolecule import RnaTokenizer, AidoRnaForContactPrediction
tokenizer = RnaTokenizer.from_pretrained("multimolecule/aido.rna-1.6b")
model = AidoRnaForContactPrediction.from_pretrained("multimolecule/aido.rna-1.6b")
text = "UAGCUUAUCAGACUGAUGUUG"
input = tokenizer(text, return_tensors="pt")
label = torch.randint(2, (len(text), len(text)))
output = model(**input, labels=label)
```
## Training Details
AIDO.RNA used Masked Language Modeling (MLM) as the pre-training objective: taking a sequence, the model randomly masks 15% of the tokens in the input then runs the entire masked sentence through the model and has to predict the masked tokens. This is comparable to the Cloze task in language modeling.
### Training Data
The AIDO.RNA model was pre-trained on [RNAcentral](https://multimolecule.danling.org/datasets/rnacentral) and [MARS](https://ngdc.cncb.ac.cn/omix/release/OMIX003037).
RNAcentral is a free, public resource that offers integrated access to a comprehensive and up-to-date set of non-coding RNA sequences provided by a collaborating group of [Expert Databases](https://rnacentral.org/expert-databases) representing a broad range of organisms and RNA types.
AIDO.RNA applied SeqKit to remove duplicated sequences in the RNAcentral, resulting 42 million unique sequences.
Note that AIDO.RNA identifies `U` and `T` as different tokens, which is not supported by MultiMolecule. During model conversion, the embeddings of `T` is discarded. This means that the model will not be able to distinguish between `U` and `T` in the input sequences.
### Training Procedure
#### Preprocessing
AIDO.RNA used masked language modeling (MLM) as the pre-training objective. The masking procedure is similar to the one used in BERT:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `<mask>`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
#### Pre-training
- Epochs: 6
- Optimizer: AdamW
- Learning rate: 5e-5
- Learning rate warm-up: 2,000 steps
- Learning rate scheduler: Cosine
- Minimum learning rate: 1e-5
- Weight decay: 0.01
## Citation
**BibTeX**:
```bibtex
@article {Zou2024.11.28.625345,
author = {Zou, Shuxian and Tao, Tianhua and Mahbub, Sazan and Ellington, Caleb N. and Algayres, Robin and Li, Dian and Zhuang, Yonghao and Wang, Hongyi and Song, Le and Xing, Eric P.},
title = {A Large-Scale Foundation Model for RNA Function and Structure Prediction},
elocation-id = {2024.11.28.625345},
year = {2024},
doi = {10.1101/2024.11.28.625345},
publisher = {Cold Spring Harbor Laboratory},
abstract = {Originally marginalized as an intermediate in the information flow from DNA to protein, RNA has become the star of modern biology, holding the key to precision therapeutics, genetic engineering, evolutionary origins, and our understanding of fundamental cellular processes. Yet RNA is as mysterious as it is prolific, serving as an information store, a messenger, and a catalyst, spanning many underchar-acterized functional and structural classes. Deciphering the language of RNA is important not only for a mechanistic understanding of its biological functions but also for accelerating drug design. Toward this goal, we introduce AIDO.RNA, a pre-trained module for RNA in an AI-driven Digital Organism [1]. AIDO.RNA contains a scale of 1.6 billion parameters, trained on 42 million non-coding RNA (ncRNA) sequences at single-nucleotide resolution, and it achieves state-of-the-art performance on a comprehensive set of tasks, including structure prediction, genetic regulation, molecular function across species, and RNA sequence design. AIDO.RNA after domain adaptation learns to model essential parts of protein translation that protein language models, which have received widespread attention in recent years, do not. More broadly, AIDO.RNA hints at the generality of biological sequence modeling and the ability to leverage the central dogma to improve many biomolecular representations. Models and code are available through ModelGenerator in https://github.com/genbio-ai/AIDO and on Hugging Face.Competing Interest StatementThe authors have declared no competing interest.},
URL = {https://www.biorxiv.org/content/early/2024/11/29/2024.11.28.625345},
eprint = {https://www.biorxiv.org/content/early/2024/11/29/2024.11.28.625345.full.pdf},
journal = {bioRxiv}
}
```
## Contact
Please use GitHub issues of [MultiMolecule](https://github.com/DLS5-Omics/multimolecule/issues) for any questions or comments on the model card.
Please contact the authors of the [AIDO.RNA paper](https://doi.org/10.1101/2024.11.28.625345) for questions or comments on the paper/model.
## License
This model is licensed under the [AGPL-3.0 License](https://www.gnu.org/licenses/agpl-3.0.html).
```spdx
SPDX-License-Identifier: AGPL-3.0-or-later
```
|
pictgensupport/womanshairstyles | pictgensupport | 2025-06-15T16:27:45Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-06-15T16:27:43Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: womanshairstyles
---
# Womanshairstyles
<Gallery />
Trained on Replicate using:
https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `womanshairstyles` to trigger the image generation.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('pictgensupport/womanshairstyles', weight_name='lora.safetensors')
image = pipeline('your prompt').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
utkuden/qlora_paligemma_MIXft_decoder_only_rank16-SCST-CIDEr0.1270 | utkuden | 2025-06-15T16:24:47Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T16:24:35Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
gradientrouting-spar/standard_notMerged_seed_1_20250615_154909 | gradientrouting-spar | 2025-06-15T16:24:31Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T16:24:22Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
krissnonflux/flux-Spoopy | krissnonflux | 2025-06-15T16:22:56Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2025-06-15T15:19:13Z | ---
license: apache-2.0
---
|
multimolecule/aido.rna-1.6b | multimolecule | 2025-06-15T16:22:17Z | 0 | 0 | multimolecule | [
"multimolecule",
"pytorch",
"safetensors",
"aido.rna",
"Biology",
"RNA",
"fill-mask",
"rna",
"dataset:multimolecule/rnacentral",
"license:agpl-3.0",
"region:us"
] | fill-mask | 2025-06-15T16:17:58Z | ---
language: rna
tags:
- Biology
- RNA
license: agpl-3.0
datasets:
- multimolecule/rnacentral
library_name: multimolecule
pipeline_tag: fill-mask
mask_token: "<mask>"
widget:
- example_title: "HIV-1"
text: "GGUC<mask>CUCUGGUUAGACCAGAUCUGAGCCU"
output:
- label: "U"
score: 0.7308459877967834
- label: "W"
score: 0.11085908114910126
- label: "Y"
score: 0.03829820826649666
- label: "H"
score: 0.029108675196766853
- label: "K"
score: 0.018761275336146355
- example_title: "microRNA-21"
text: "UAGC<mask>UAUCAGACUGAUGUUG"
output:
- label: "U"
score: 0.41171538829803467
- label: "W"
score: 0.1445416808128357
- label: "K"
score: 0.06634332984685898
- label: "D"
score: 0.060673028230667114
- label: "Y"
score: 0.054533567279577255
---
# AIDO.RNA
Pre-trained model on non-coding RNA (ncRNA) using a masked language modeling (MLM) objective.
## Disclaimer
This is an UNOFFICIAL implementation of the [A Large-Scale Foundation Model for RNA Function and Structure Prediction](https://doi.org/10.1101/2024.11.28.625345) by Shuxian Zou, Tianhua Tao, Sazan Mahbub, et al.
The OFFICIAL repository of AIDO.RNA is at [genbio-ai/AIDO](https://github.com/genbio-ai/AIDO).
> [!WARNING]
> The MultiMolecule team is aware of a potential risk in reproducing the results of AIDO.RNA.
>
> The original implementation of AIDO.RNA uses a special tokenizer that identifies `U` and `T` as different tokens.
>
> This behaviour is not supported by MultiMolecule.
> [!TIP]
> The MultiMolecule team has confirmed that the provided model and checkpoints are producing the same intermediate representations as the original implementation.
**The team releasing AIDO.RNA did not write this model card for this model so this model card has been written by the MultiMolecule team.**
## Model Details
AIDO.RNA is a [bert](https://huggingface.co/google-bert/bert-base-uncased)-style model pre-trained on a large corpus of non-coding RNA sequences in a self-supervised fashion. This means that the model was trained on the raw nucleotides of RNA sequences only, with an automatic process to generate inputs and labels from those texts. Please refer to the [Training Details](#training-details) section for more information on the training process.
### Variants
- **[multimolecule/aido.rna-1.6b](https://huggingface.co/multimolecule/aido.rna-1.6b)**: The AIDO.RNA model with 1.6 billion parameters.
- **[multimolecule/aido.rna-650m](https://huggingface.co/multimolecule/aido.rna-650m)**: The AIDO.RNA model with 650 million parameters.
### Model Specification
<table>
<thead>
<tr>
<th>Variants</th>
<th>Num Layers</th>
<th>Hidden Size</th>
<th>Num Heads</th>
<th>Intermediate Size</th>
<th>Num Parameters (M)</th>
<th>FLOPs (G)</th>
<th>MACs (G)</th>
<th>Max Num Tokens</th>
</tr>
</thead>
<tbody>
<tr>
<td>AIDO.RNA-1.6B</td>
<td>32</td>
<td>2048</td>
<td>32</td>
<td>5440</td>
<td>1650.29</td>
<td>415.67</td>
<td>207.77</td>
<td rowspan="2">1022</td>
</tr>
<tr>
<td>AIDO.RNA-650M</td>
<td>33</td>
<td>1280</td>
<td>20</td>
<td>3392</td>
<td>648.38</td>
<td>168.25</td>
<td>80.09</td>
</tr>
</tbody>
</table>
### Links
- **Code**: [multimolecule.aido_rna](https://github.com/DLS5-Omics/multimolecule/tree/master/multimolecule/models/aido_rna)
- **Weights**: [multimolecule/aido.rna](https://huggingface.co/multimolecule/aido.rna)
- **Data**: [multimolecule/rnacentral](https://huggingface.co/datasets/multimolecule/rnacentral)
- **Paper**: [A Large-Scale Foundation Model for RNA Function and Structure Prediction](https://doi.org/10.1101/2024.11.28.625345)
- **Developed by**: Shuxian Zou, Tianhua Tao, Sazan Mahbub, Caleb N. Ellington, Robin Algayres, Dian Li, Yonghao Zhuang, Hongyi Wang, Le Song, Eric P. Xing
- **Model type**: [BERT](https://huggingface.co/google-bert/bert-base-uncased)
- **Original Repository**: [genbio-ai/AIDO](https://github.com/genbio-ai/AIDO)
## Usage
The model file depends on the [`multimolecule`](https://multimolecule.danling.org) library. You can install it using pip:
```bash
pip install multimolecule
```
### Direct Use
You can use this model directly with a pipeline for masked language modeling:
```python
>>> import multimolecule # you must import multimolecule to register models
>>> from transformers import pipeline
>>> unmasker = pipeline("fill-mask", model="multimolecule/aido.rna-1.6b")
>>> unmasker("gguc<mask>cucugguuagaccagaucugagccu")
[{'score': 0.7308459877967834,
'token': 9,
'token_str': 'U',
'sequence': 'G G U C U C U C U G G U U A G A C C A G A U C U G A G C C U'},
{'score': 0.11085908114910126,
'token': 14,
'token_str': 'W',
'sequence': 'G G U C W C U C U G G U U A G A C C A G A U C U G A G C C U'},
{'score': 0.03829820826649666,
'token': 12,
'token_str': 'Y',
'sequence': 'G G U C Y C U C U G G U U A G A C C A G A U C U G A G C C U'},
{'score': 0.029108675196766853,
'token': 19,
'token_str': 'H',
'sequence': 'G G U C H C U C U G G U U A G A C C A G A U C U G A G C C U'},
{'score': 0.018761275336146355,
'token': 15,
'token_str': 'K',
'sequence': 'G G U C K C U C U G G U U A G A C C A G A U C U G A G C C U'}]
```
### Downstream Use
#### Extract Features
Here is how to use this model to get the features of a given sequence in PyTorch:
```python
from multimolecule import RnaTokenizer, AidoRnaModel
tokenizer = RnaTokenizer.from_pretrained("multimolecule/aido.rna-1.6b")
model = AidoRnaModel.from_pretrained("multimolecule/aido.rna-1.6b")
text = "UAGCUUAUCAGACUGAUGUUG"
input = tokenizer(text, return_tensors="pt")
output = model(**input)
```
#### Sequence Classification / Regression
> [!NOTE]
> This model is not fine-tuned for any specific task. You will need to fine-tune the model on a downstream task to use it for sequence classification or regression.
Here is how to use this model as backbone to fine-tune for a sequence-level task in PyTorch:
```python
import torch
from multimolecule import RnaTokenizer, AidoRnaForSequencePrediction
tokenizer = RnaTokenizer.from_pretrained("multimolecule/aido.rna-1.6b")
model = AidoRnaForSequencePrediction.from_pretrained("multimolecule/aido.rna-1.6b")
text = "UAGCUUAUCAGACUGAUGUUG"
input = tokenizer(text, return_tensors="pt")
label = torch.tensor([1])
output = model(**input, labels=label)
```
#### Token Classification / Regression
> [!NOTE]
> This model is not fine-tuned for any specific task. You will need to fine-tune the model on a downstream task to use it for token classification or regression.
Here is how to use this model as backbone to fine-tune for a nucleotide-level task in PyTorch:
```python
import torch
from multimolecule import RnaTokenizer, AidoRnaForTokenPrediction
tokenizer = RnaTokenizer.from_pretrained("multimolecule/aido.rna-1.6b")
model = AidoRnaForTokenPrediction.from_pretrained("multimolecule/aido.rna-1.6b")
text = "UAGCUUAUCAGACUGAUGUUG"
input = tokenizer(text, return_tensors="pt")
label = torch.randint(2, (len(text), ))
output = model(**input, labels=label)
```
#### Contact Classification / Regression
> [!NOTE]
> This model is not fine-tuned for any specific task. You will need to fine-tune the model on a downstream task to use it for contact classification or regression.
Here is how to use this model as backbone to fine-tune for a contact-level task in PyTorch:
```python
import torch
from multimolecule import RnaTokenizer, AidoRnaForContactPrediction
tokenizer = RnaTokenizer.from_pretrained("multimolecule/aido.rna-1.6b")
model = AidoRnaForContactPrediction.from_pretrained("multimolecule/aido.rna-1.6b")
text = "UAGCUUAUCAGACUGAUGUUG"
input = tokenizer(text, return_tensors="pt")
label = torch.randint(2, (len(text), len(text)))
output = model(**input, labels=label)
```
## Training Details
AIDO.RNA used Masked Language Modeling (MLM) as the pre-training objective: taking a sequence, the model randomly masks 15% of the tokens in the input then runs the entire masked sentence through the model and has to predict the masked tokens. This is comparable to the Cloze task in language modeling.
### Training Data
The AIDO.RNA model was pre-trained on [RNAcentral](https://multimolecule.danling.org/datasets/rnacentral) and [MARS](https://ngdc.cncb.ac.cn/omix/release/OMIX003037).
RNAcentral is a free, public resource that offers integrated access to a comprehensive and up-to-date set of non-coding RNA sequences provided by a collaborating group of [Expert Databases](https://rnacentral.org/expert-databases) representing a broad range of organisms and RNA types.
AIDO.RNA applied SeqKit to remove duplicated sequences in the RNAcentral, resulting 42 million unique sequences.
Note that AIDO.RNA identifies `U` and `T` as different tokens, which is not supported by MultiMolecule. During model conversion, the embeddings of `T` is discarded. This means that the model will not be able to distinguish between `U` and `T` in the input sequences.
### Training Procedure
#### Preprocessing
AIDO.RNA used masked language modeling (MLM) as the pre-training objective. The masking procedure is similar to the one used in BERT:
- 15% of the tokens are masked.
- In 80% of the cases, the masked tokens are replaced by `<mask>`.
- In 10% of the cases, the masked tokens are replaced by a random token (different) from the one they replace.
- In the 10% remaining cases, the masked tokens are left as is.
#### Pre-training
- Epochs: 6
- Optimizer: AdamW
- Learning rate: 5e-5
- Learning rate warm-up: 2,000 steps
- Learning rate scheduler: Cosine
- Minimum learning rate: 1e-5
- Weight decay: 0.01
## Citation
**BibTeX**:
```bibtex
@article {Zou2024.11.28.625345,
author = {Zou, Shuxian and Tao, Tianhua and Mahbub, Sazan and Ellington, Caleb N. and Algayres, Robin and Li, Dian and Zhuang, Yonghao and Wang, Hongyi and Song, Le and Xing, Eric P.},
title = {A Large-Scale Foundation Model for RNA Function and Structure Prediction},
elocation-id = {2024.11.28.625345},
year = {2024},
doi = {10.1101/2024.11.28.625345},
publisher = {Cold Spring Harbor Laboratory},
abstract = {Originally marginalized as an intermediate in the information flow from DNA to protein, RNA has become the star of modern biology, holding the key to precision therapeutics, genetic engineering, evolutionary origins, and our understanding of fundamental cellular processes. Yet RNA is as mysterious as it is prolific, serving as an information store, a messenger, and a catalyst, spanning many underchar-acterized functional and structural classes. Deciphering the language of RNA is important not only for a mechanistic understanding of its biological functions but also for accelerating drug design. Toward this goal, we introduce AIDO.RNA, a pre-trained module for RNA in an AI-driven Digital Organism [1]. AIDO.RNA contains a scale of 1.6 billion parameters, trained on 42 million non-coding RNA (ncRNA) sequences at single-nucleotide resolution, and it achieves state-of-the-art performance on a comprehensive set of tasks, including structure prediction, genetic regulation, molecular function across species, and RNA sequence design. AIDO.RNA after domain adaptation learns to model essential parts of protein translation that protein language models, which have received widespread attention in recent years, do not. More broadly, AIDO.RNA hints at the generality of biological sequence modeling and the ability to leverage the central dogma to improve many biomolecular representations. Models and code are available through ModelGenerator in https://github.com/genbio-ai/AIDO and on Hugging Face.Competing Interest StatementThe authors have declared no competing interest.},
URL = {https://www.biorxiv.org/content/early/2024/11/29/2024.11.28.625345},
eprint = {https://www.biorxiv.org/content/early/2024/11/29/2024.11.28.625345.full.pdf},
journal = {bioRxiv}
}
```
## Contact
Please use GitHub issues of [MultiMolecule](https://github.com/DLS5-Omics/multimolecule/issues) for any questions or comments on the model card.
Please contact the authors of the [AIDO.RNA paper](https://doi.org/10.1101/2024.11.28.625345) for questions or comments on the paper/model.
## License
This model is licensed under the [AGPL-3.0 License](https://www.gnu.org/licenses/agpl-3.0.html).
```spdx
SPDX-License-Identifier: AGPL-3.0-or-later
```
|
nunorodrigues3657/NR | nunorodrigues3657 | 2025-06-15T16:21:31Z | 0 | 0 | null | [
"license:bigscience-bloom-rail-1.0",
"region:us"
] | null | 2025-06-15T16:21:31Z | ---
license: bigscience-bloom-rail-1.0
---
|
veracardoso4942/VD | veracardoso4942 | 2025-06-15T16:21:31Z | 0 | 0 | null | [
"license:bigscience-bloom-rail-1.0",
"region:us"
] | null | 2025-06-15T16:21:31Z | ---
license: bigscience-bloom-rail-1.0
---
|
henriquesantos3430/HS | henriquesantos3430 | 2025-06-15T16:21:31Z | 0 | 0 | null | [
"license:bigscience-bloom-rail-1.0",
"region:us"
] | null | 2025-06-15T16:21:31Z | ---
license: bigscience-bloom-rail-1.0
---
|
claravicente1628/CV | claravicente1628 | 2025-06-15T16:21:31Z | 0 | 0 | null | [
"license:bigscience-bloom-rail-1.0",
"region:us"
] | null | 2025-06-15T16:21:31Z | ---
license: bigscience-bloom-rail-1.0
---
|
marcomelo9929/MM | marcomelo9929 | 2025-06-15T16:21:31Z | 0 | 0 | null | [
"license:bigscience-bloom-rail-1.0",
"region:us"
] | null | 2025-06-15T16:21:31Z | ---
license: bigscience-bloom-rail-1.0
---
|
freakyfractal/tang | freakyfractal | 2025-06-15T16:18:35Z | 0 | 0 | diffusers | [
"diffusers",
"text-to-image",
"lora",
"template:diffusion-lora",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"region:us"
] | text-to-image | 2025-06-15T16:17:58Z | ---
tags:
- text-to-image
- lora
- diffusers
- template:diffusion-lora
widget:
- text: '-'
output:
url: images/Coinye_2021.jpg
base_model: black-forest-labs/FLUX.1-dev
instance_prompt: null
---
# tang
<Gallery />
## Download model
Weights for this model are available in Safetensors format.
[Download](/freakyfractal/tang/tree/main) them in the Files & versions tab.
|
OpenBuddy/OpenBuddy-R1-0528-Distill-Qwen2.5-72B-Preview0 | OpenBuddy | 2025-06-15T16:12:07Z | 4 | 0 | null | [
"safetensors",
"qwen2",
"qwen2.5",
"text-generation",
"conversational",
"zh",
"en",
"fr",
"de",
"ja",
"ko",
"it",
"fi",
"region:us"
] | text-generation | 2025-06-12T16:36:05Z | ---
language:
- zh
- en
- fr
- de
- ja
- ko
- it
- fi
tags:
- qwen2.5
pipeline_tag: text-generation
base_model: Qwen/Qwen2.5-72B-Base
---
# OpenBuddy - Open Multilingual Chatbot
GitHub and Usage Guide: [https://github.com/OpenBuddy/OpenBuddy](https://github.com/OpenBuddy/OpenBuddy)
Website and Demo: [https://openbuddy.ai](https://openbuddy.ai)
Evaluation result of this model: [Evaluation.txt](Evaluation.txt)

# Model Info
Base Model: Qwen/Qwen2.5-72B-Base
Context Length: 40K Tokens
License: Qwen2.5 72B License
Training Data: Distilled from DeepSeek-R1-0528
# Prompt Format
We recommend using the fast tokenizer from `transformers`, which should be enabled by default in the `transformers` and `vllm` libraries. Other implementations including `sentencepiece` may not work as expected, especially for special tokens like `<|role|>`, `<|says|>` and `<|end|>`.
```
<|role|>system<|says|>You(assistant) are a helpful, respectful and honest INTP-T AI Assistant named Buddy. You are talking to a human(user).
Current mode: System 2, think step-by-step and answer.<|end|>
<|role|>user<|says|>History input 1<|end|>
<|role|>assistant<|says|>History output 1<|end|>
<|role|>user<|says|>History input 2<|end|>
<|role|>assistant<|says|>History output 2<|end|>
<|role|>user<|says|>Current input<|end|>
<|role|>assistant<|says|>
```
This format is also defined in `tokenizer_config.json`, which means you can directly use `vllm` to deploy an OpenAI-like API service. For more information, please refer to the [vllm documentation](https://docs.vllm.ai/en/latest/serving/openai_compatible_server.html).
## Disclaimer
All OpenBuddy models have inherent limitations and may potentially produce outputs that are erroneous, harmful, offensive, or otherwise undesirable. Users should not use these models in critical or high-stakes situations that may lead to personal injury, property damage, or significant losses. Examples of such scenarios include, but are not limited to, the medical field, controlling software and hardware systems that may cause harm, and making important financial or legal decisions.
OpenBuddy is provided "as-is" without any warranty of any kind, either express or implied, including, but not limited to, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement. In no event shall the authors, contributors, or copyright holders be liable for any claim, damages, or other liabilities, whether in an action of contract, tort, or otherwise, arising from, out of, or in connection with the software or the use or other dealings in the software.
By using OpenBuddy, you agree to these terms and conditions, and acknowledge that you understand the potential risks associated with its use. You also agree to indemnify and hold harmless the authors, contributors, and copyright holders from any claims, damages, or liabilities arising from your use of OpenBuddy.
## 免责声明
所有OpenBuddy模型均存在固有的局限性,可能产生错误的、有害的、冒犯性的或其他不良的输出。用户在关键或高风险场景中应谨慎行事,不要使用这些模型,以免导致人身伤害、财产损失或重大损失。此类场景的例子包括但不限于医疗领域、可能导致伤害的软硬件系统的控制以及进行重要的财务或法律决策。
OpenBuddy按“原样”提供,不附带任何种类的明示或暗示的保证,包括但不限于适销性、特定目的的适用性和非侵权的暗示保证。在任何情况下,作者、贡献者或版权所有者均不对因软件或使用或其他软件交易而产生的任何索赔、损害赔偿或其他责任(无论是合同、侵权还是其他原因)承担责任。
使用OpenBuddy即表示您同意这些条款和条件,并承认您了解其使用可能带来的潜在风险。您还同意赔偿并使作者、贡献者和版权所有者免受因您使用OpenBuddy而产生的任何索赔、损害赔偿或责任的影响。
|
gradientrouting-spar/horizontal_1_proxy_ntrain_25_ntrig_9_negative_3x3_seed_1_20250615_160158 | gradientrouting-spar | 2025-06-15T16:11:17Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T16:11:09Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
kkyrulez01/ppo-LunarLander-v2 | kkyrulez01 | 2025-06-15T16:11:02Z | 0 | 0 | stable-baselines3 | [
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] | reinforcement-learning | 2025-06-15T16:10:43Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 250.09 +/- 22.27
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
telecomadm1145/gemma-3-cn-novel-4b-v1.1 | telecomadm1145 | 2025-06-15T16:10:35Z | 0 | 0 | transformers | [
"transformers",
"text-generation-inference",
"unsloth",
"gemma3",
"en",
"base_model:telecomadm1145/gemma-3-cn-novel-4b-v1.1",
"base_model:finetune:telecomadm1145/gemma-3-cn-novel-4b-v1.1",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T16:10:32Z | ---
base_model: telecomadm1145/gemma-3-cn-novel-4b-v1.1
tags:
- text-generation-inference
- transformers
- unsloth
- gemma3
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** telecomadm1145
- **License:** apache-2.0
- **Finetuned from model :** telecomadm1145/gemma-3-cn-novel-4b-v1.1
This gemma3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
phospho-app/jakmilller-ACT-jenga_pull-z1gqj | phospho-app | 2025-06-15T16:07:07Z | 0 | 0 | null | [
"safetensors",
"phosphobot",
"act",
"region:us"
] | null | 2025-06-15T13:17:51Z |
---
tags:
- phosphobot
- act
task_categories:
- robotics
---
# act Model - phospho Training Pipeline
## This model was trained using **phospho**.
Training was successfull, try it out on your robot!
## Training parameters:
- **Dataset**: [mahanthesh0r/jenga_pull](https://huggingface.co/datasets/mahanthesh0r/jenga_pull)
- **Wandb run URL**: None
- **Epochs**: None
- **Batch size**: 40
- **Training steps**: 8000
📖 **Get Started**: [docs.phospho.ai](https://docs.phospho.ai?utm_source=huggingface_readme)
🤖 **Get your robot**: [robots.phospho.ai](https://robots.phospho.ai?utm_source=huggingface_readme)
|
Subsets and Splits