
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-06-25 18:28:32
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 495
values | tags
sequencelengths 1
4.05k
| pipeline_tag
stringclasses 54
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-06-25 18:28:16
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
phospho-app/jakmilller-gr00t-jenga_pull-70tu2 | phospho-app | 2025-06-15T19:41:47Z | 0 | 0 | null | [
"safetensors",
"phosphobot",
"gr00t",
"region:us"
] | null | 2025-06-15T16:34:00Z |
---
tags:
- phosphobot
- gr00t
task_categories:
- robotics
---
# gr00t Model - phospho Training Pipeline
## Error Traceback
We faced an issue while training your model.
```
Traceback (most recent call last):
File "/opt/conda/lib/python3.11/asyncio/tasks.py", line 500, in wait_for
return fut.result()
^^^^^^^^^^^^
File "/root/phosphobot/am/gr00t.py", line 970, in read_output
async for line in process.stdout:
File "/opt/conda/lib/python3.11/asyncio/streams.py", line 765, in __anext__
val = await self.readline()
^^^^^^^^^^^^^^^^^^^^^
File "/opt/conda/lib/python3.11/asyncio/streams.py", line 566, in readline
line = await self.readuntil(sep)
^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/conda/lib/python3.11/asyncio/streams.py", line 658, in readuntil
await self._wait_for_data('readuntil')
File "/opt/conda/lib/python3.11/asyncio/streams.py", line 543, in _wait_for_data
await self._waiter
asyncio.exceptions.CancelledError
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/root/phosphobot/am/gr00t.py", line 981, in run_gr00t_training
await asyncio.wait_for(read_output(), timeout=timeout_seconds)
File "/opt/conda/lib/python3.11/asyncio/tasks.py", line 502, in wait_for
raise exceptions.TimeoutError() from exc
TimeoutError
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/root/src/helper.py", line 165, in predict
trainer.train(timeout_seconds=timeout_seconds)
File "/root/phosphobot/am/gr00t.py", line 1146, in train
asyncio.run(
File "/opt/conda/lib/python3.11/asyncio/runners.py", line 190, in run
return runner.run(main)
^^^^^^^^^^^^^^^^
File "/opt/conda/lib/python3.11/asyncio/runners.py", line 118, in run
return self._loop.run_until_complete(task)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/opt/conda/lib/python3.11/asyncio/base_events.py", line 654, in run_until_complete
return future.result()
^^^^^^^^^^^^^^^
File "/root/phosphobot/am/gr00t.py", line 986, in run_gr00t_training
raise TimeoutError(
TimeoutError: Training process exceeded timeout of 10800 seconds. Please consider lowering the number of epochs and/or batch size.
```
## Training parameters:
- **Dataset**: [mahanthesh0r/jenga_pull](https://huggingface.co/datasets/mahanthesh0r/jenga_pull)
- **Wandb run URL**: None
- **Epochs**: 25
- **Batch size**: 27
- **Training steps**: None
📖 **Get Started**: [docs.phospho.ai](https://docs.phospho.ai?utm_source=huggingface_readme)
🤖 **Get your robot**: [robots.phospho.ai](https://robots.phospho.ai?utm_source=huggingface_readme)
|
Mungert/Llama-3.1-Nemotron-Nano-8B-v1-GGUF | Mungert | 2025-06-15T19:41:41Z | 2,163 | 7 | transformers | [
"transformers",
"gguf",
"nvidia",
"llama-3",
"pytorch",
"text-generation",
"en",
"arxiv:2505.00949",
"arxiv:2502.00203",
"license:other",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-03-21T19:44:49Z | ---
library_name: transformers
license: other
license_name: nvidia-open-model-license
license_link: >-
https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/
pipeline_tag: text-generation
language:
- en
tags:
- nvidia
- llama-3
- pytorch
---
# <span style="color: #7FFF7F;">Llama-3.1-Nemotron-Nano-8B-v1 GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`19e899c`](https://github.com/ggerganov/llama.cpp/commit/19e899ce21a7c9ffcf8bb2b22269a75f6e078f8f).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Llama-3.1-Nemotron-Nano-8B-v1-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Llama-3.1-Nemotron-Nano-8B-v1-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Llama-3.1-Nemotron-Nano-8B-v1-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Llama-3.1-Nemotron-Nano-8B-v1-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Llama-3.1-Nemotron-Nano-8B-v1-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Llama-3.1-Nemotron-Nano-8B-v1-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Llama-3.1-Nemotron-Nano-8B-v1-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Llama-3.1-Nemotron-Nano-8B-v1-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Llama-3.1-Nemotron-Nano-8B-v1-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Llama-3.1-Nemotron-Nano-8B-v1-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Llama-3.1-Nemotron-Nano-8B-v1-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# Llama-3.1-Nemotron-Nano-8B-v1
## Model Overview
Llama-3.1-Nemotron-Nano-8B-v1 is a large language model (LLM) which is a derivative of [Meta Llama-3.1-8B-Instruct](https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct) (AKA the reference model). It is a reasoning model that is post trained for reasoning, human chat preferences, and tasks, such as RAG and tool calling.
Llama-3.1-Nemotron-Nano-8B-v1 is a model which offers a great tradeoff between model accuracy and efficiency. It is created from Llama 3.1 8B Instruct and offers improvements in model accuracy. The model fits on a single RTX GPU and can be used locally. The model supports a context length of 128K.
This model underwent a multi-phase post-training process to enhance both its reasoning and non-reasoning capabilities. This includes a supervised fine-tuning stage for Math, Code, Reasoning, and Tool Calling as well as multiple reinforcement learning (RL) stages using REINFORCE (RLOO) and Online Reward-aware Preference Optimization (RPO) algorithms for both chat and instruction-following. The final model checkpoint is obtained after merging the final SFT and Online RPO checkpoints. Improved using Qwen.
This model is part of the Llama Nemotron Collection. You can find the other model(s) in this family here:
[Llama-3.3-Nemotron-Super-49B-v1](https://huggingface.co/nvidia/Llama-3.3-Nemotron-Super-49B-v1)
This model is ready for commercial use.
## License/Terms of Use
GOVERNING TERMS: Your use of this model is governed by the [NVIDIA Open Model License](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/). Additional Information: [Llama 3.1 Community License Agreement](https://www.llama.com/llama3_1/license/). Built with Llama.
**Model Developer:** NVIDIA
**Model Dates:** Trained between August 2024 and March 2025
**Data Freshness:** The pretraining data has a cutoff of 2023 per Meta Llama 3.1 8B
## Use Case:
Developers designing AI Agent systems, chatbots, RAG systems, and other AI-powered applications. Also suitable for typical instruction-following tasks. Balance of model accuracy and compute efficiency (the model fits on a single RTX GPU and can be used locally).
## Release Date: <br>
3/18/2025 <br>
## References
- [\[2505.00949\] Llama-Nemotron: Efficient Reasoning Models](https://arxiv.org/abs/2505.00949)
- [\[2502.00203\] Reward-aware Preference Optimization: A Unified Mathematical Framework for Model Alignment](https://arxiv.org/abs/2502.00203)
## Model Architecture
**Architecture Type:** Dense decoder-only Transformer model
**Network Architecture:** Llama 3.1 8B Instruct
## Intended use
Llama-3.1-Nemotron-Nano-8B-v1 is a general purpose reasoning and chat model intended to be used in English and coding languages. Other non-English languages (German, French, Italian, Portuguese, Hindi, Spanish, and Thai) are also supported.
# Input:
- **Input Type:** Text
- **Input Format:** String
- **Input Parameters:** One-Dimensional (1D)
- **Other Properties Related to Input:** Context length up to 131,072 tokens
## Output:
- **Output Type:** Text
- **Output Format:** String
- **Output Parameters:** One-Dimensional (1D)
- **Other Properties Related to Output:** Context length up to 131,072 tokens
## Model Version:
1.0 (3/18/2025)
## Software Integration
- **Runtime Engine:** NeMo 24.12 <br>
- **Recommended Hardware Microarchitecture Compatibility:**
- NVIDIA Hopper
- NVIDIA Ampere
## Quick Start and Usage Recommendations:
1. Reasoning mode (ON/OFF) is controlled via the system prompt, which must be set as shown in the example below. All instructions should be contained within the user prompt
2. We recommend setting temperature to `0.6`, and Top P to `0.95` for Reasoning ON mode
3. We recommend using greedy decoding for Reasoning OFF mode
4. We have provided a list of prompts to use for evaluation for each benchmark where a specific template is required
5. The model will include `<think></think>` if no reasoning was necessary in Reasoning ON model, this is expected behaviour
You can try this model out through the preview API, using this link: [Llama-3.1-Nemotron-Nano-8B-v1](https://build.nvidia.com/nvidia/llama-3_1-nemotron-nano-8b-v1).
See the snippet below for usage with Hugging Face Transformers library. Reasoning mode (ON/OFF) is controlled via system prompt. Please see the example below.
Our code requires the transformers package version to be `4.44.2` or higher.
### Example of “Reasoning On:”
```python
import torch
import transformers
model_id = "nvidia/Llama-3.1-Nemotron-Nano-8B-v1"
model_kwargs = {"torch_dtype": torch.bfloat16, "device_map": "auto"}
tokenizer = transformers.AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token_id = tokenizer.eos_token_id
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
tokenizer=tokenizer,
max_new_tokens=32768,
temperature=0.6,
top_p=0.95,
**model_kwargs
)
# Thinking can be "on" or "off"
thinking = "on"
print(pipeline([{"role": "system", "content": f"detailed thinking {thinking}"}, {"role": "user", "content": "Solve x*(sin(x)+2)=0"}]))
```
### Example of “Reasoning Off:”
```python
import torch
import transformers
model_id = "nvidia/Llama-3.1-Nemotron-Nano-8B-v1"
model_kwargs = {"torch_dtype": torch.bfloat16, "device_map": "auto"}
tokenizer = transformers.AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token_id = tokenizer.eos_token_id
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
tokenizer=tokenizer,
max_new_tokens=32768,
do_sample=False,
**model_kwargs
)
# Thinking can be "on" or "off"
thinking = "off"
print(pipeline([{"role": "system", "content": f"detailed thinking {thinking}"}, {"role": "user", "content": "Solve x*(sin(x)+2)=0"}]))
```
For some prompts, even though thinking is disabled, the model emergently prefers to think before responding. But if desired, the users can prevent it by pre-filling the assistant response.
```python
import torch
import transformers
model_id = "nvidia/Llama-3.1-Nemotron-Nano-8B-v1"
model_kwargs = {"torch_dtype": torch.bfloat16, "device_map": "auto"}
tokenizer = transformers.AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token_id = tokenizer.eos_token_id
# Thinking can be "on" or "off"
thinking = "off"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
tokenizer=tokenizer,
max_new_tokens=32768,
do_sample=False,
**model_kwargs
)
print(pipeline([{"role": "system", "content": f"detailed thinking {thinking}"}, {"role": "user", "content": "Solve x*(sin(x)+2)=0"}, {"role":"assistant", "content":"<think>\n</think>"}]))
```
## Inference:
**Engine:** Transformers
**Test Hardware:**
- BF16:
- 1x RTX 50 Series GPUs
- 1x RTX 40 Series GPUs
- 1x RTX 30 Series GPUs
- 1x H100-80GB GPU
- 1x A100-80GB GPU
**Preferred/Supported] Operating System(s):** Linux <br>
## Training Datasets
A large variety of training data was used for the post-training pipeline, including manually annotated data and synthetic data.
The data for the multi-stage post-training phases for improvements in Code, Math, and Reasoning is a compilation of SFT and RL data that supports improvements of math, code, general reasoning, and instruction following capabilities of the original Llama instruct model.
Prompts have been sourced from either public and open corpus or synthetically generated. Responses were synthetically generated by a variety of models, with some prompts containing responses for both Reasoning On and Off modes, to train the model to distinguish between two modes.
**Data Collection for Training Datasets:** <br>
* Hybrid: Automated, Human, Synthetic <br>
**Data Labeling for Training Datasets:** <br>
* N/A <br>
## Evaluation Datasets
We used the datasets listed below to evaluate Llama-3.1-Nemotron-Nano-8B-v1.
**Data Collection for Evaluation Datasets:** Hybrid: Human/Synthetic
**Data Labeling for Evaluation Datasets:** Hybrid: Human/Synthetic/Automatic
## Evaluation Results
These results contain both “Reasoning On”, and “Reasoning Off”. We recommend using temperature=`0.6`, top_p=`0.95` for “Reasoning On” mode, and greedy decoding for “Reasoning Off” mode. All evaluations are done with 32k sequence length. We run the benchmarks up to 16 times and average the scores to be more accurate.
> NOTE: Where applicable, a Prompt Template will be provided. While completing benchmarks, please ensure that you are parsing for the correct output format as per the provided prompt in order to reproduce the benchmarks seen below.
### MT-Bench
| Reasoning Mode | Score |
|--------------|------------|
| Reasoning Off | 7.9 |
| Reasoning On | 8.1 |
### MATH500
| Reasoning Mode | pass@1 |
|--------------|------------|
| Reasoning Off | 36.6% |
| Reasoning On | 95.4% |
User Prompt Template:
```
"Below is a math question. I want you to reason through the steps and then give a final answer. Your final answer should be in \boxed{}.\nQuestion: {question}"
```
### AIME25
| Reasoning Mode | pass@1 |
|--------------|------------|
| Reasoning Off | 0% |
| Reasoning On | 47.1% |
User Prompt Template:
```
"Below is a math question. I want you to reason through the steps and then give a final answer. Your final answer should be in \boxed{}.\nQuestion: {question}"
```
### GPQA-D
| Reasoning Mode | pass@1 |
|--------------|------------|
| Reasoning Off | 39.4% |
| Reasoning On | 54.1% |
User Prompt Template:
```
"What is the correct answer to this question: {question}\nChoices:\nA. {option_A}\nB. {option_B}\nC. {option_C}\nD. {option_D}\nLet's think step by step, and put the final answer (should be a single letter A, B, C, or D) into a \boxed{}"
```
### IFEval Average
| Reasoning Mode | Strict:Prompt | Strict:Instruction |
|--------------|------------|------------|
| Reasoning Off | 74.7% | 82.1% |
| Reasoning On | 71.9% | 79.3% |
### BFCL v2 Live
| Reasoning Mode | Score |
|--------------|------------|
| Reasoning Off | 63.9% |
| Reasoning On | 63.6% |
User Prompt Template:
```
<AVAILABLE_TOOLS>{functions}</AVAILABLE_TOOLS>
{user_prompt}
```
### MBPP 0-shot
| Reasoning Mode | pass@1 |
|--------------|------------|
| Reasoning Off | 66.1% |
| Reasoning On | 84.6% |
User Prompt Template:
````
You are an exceptionally intelligent coding assistant that consistently delivers accurate and reliable responses to user instructions.
@@ Instruction
Here is the given problem and test examples:
{prompt}
Please use the python programming language to solve this problem.
Please make sure that your code includes the functions from the test samples and that the input and output formats of these functions match the test samples.
Please return all completed codes in one code block.
This code block should be in the following format:
```python
# Your codes here
```
````
## Ethical Considerations:
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
For more detailed information on ethical considerations for this model, please see the Model Card++ [Explainability](explainability.md), [Bias](bias.md), [Safety & Security](safety.md), and [Privacy](privacy.md) Subcards.
Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/).
## Citation
```
@misc{bercovich2025llamanemotronefficientreasoningmodels,
title={Llama-Nemotron: Efficient Reasoning Models},
author={Akhiad Bercovich and Itay Levy and Izik Golan and Mohammad Dabbah and Ran El-Yaniv and Omri Puny and Ido Galil and Zach Moshe and Tomer Ronen and Najeeb Nabwani and Ido Shahaf and Oren Tropp and Ehud Karpas and Ran Zilberstein and Jiaqi Zeng and Soumye Singhal and Alexander Bukharin and Yian Zhang and Tugrul Konuk and Gerald Shen and Ameya Sunil Mahabaleshwarkar and Bilal Kartal and Yoshi Suhara and Olivier Delalleau and Zijia Chen and Zhilin Wang and David Mosallanezhad and Adi Renduchintala and Haifeng Qian and Dima Rekesh and Fei Jia and Somshubra Majumdar and Vahid Noroozi and Wasi Uddin Ahmad and Sean Narenthiran and Aleksander Ficek and Mehrzad Samadi and Jocelyn Huang and Siddhartha Jain and Igor Gitman and Ivan Moshkov and Wei Du and Shubham Toshniwal and George Armstrong and Branislav Kisacanin and Matvei Novikov and Daria Gitman and Evelina Bakhturina and Jane Polak Scowcroft and John Kamalu and Dan Su and Kezhi Kong and Markus Kliegl and Rabeeh Karimi and Ying Lin and Sanjeev Satheesh and Jupinder Parmar and Pritam Gundecha and Brandon Norick and Joseph Jennings and Shrimai Prabhumoye and Syeda Nahida Akter and Mostofa Patwary and Abhinav Khattar and Deepak Narayanan and Roger Waleffe and Jimmy Zhang and Bor-Yiing Su and Guyue Huang and Terry Kong and Parth Chadha and Sahil Jain and Christine Harvey and Elad Segal and Jining Huang and Sergey Kashirsky and Robert McQueen and Izzy Putterman and George Lam and Arun Venkatesan and Sherry Wu and Vinh Nguyen and Manoj Kilaru and Andrew Wang and Anna Warno and Abhilash Somasamudramath and Sandip Bhaskar and Maka Dong and Nave Assaf and Shahar Mor and Omer Ullman Argov and Scot Junkin and Oleksandr Romanenko and Pedro Larroy and Monika Katariya and Marco Rovinelli and Viji Balas and Nicholas Edelman and Anahita Bhiwandiwalla and Muthu Subramaniam and Smita Ithape and Karthik Ramamoorthy and Yuting Wu and Suguna Varshini Velury and Omri Almog and Joyjit Daw and Denys Fridman and Erick Galinkin and Michael Evans and Katherine Luna and Leon Derczynski and Nikki Pope and Eileen Long and Seth Schneider and Guillermo Siman and Tomasz Grzegorzek and Pablo Ribalta and Monika Katariya and Joey Conway and Trisha Saar and Ann Guan and Krzysztof Pawelec and Shyamala Prayaga and Oleksii Kuchaiev and Boris Ginsburg and Oluwatobi Olabiyi and Kari Briski and Jonathan Cohen and Bryan Catanzaro and Jonah Alben and Yonatan Geifman and Eric Chung and Chris Alexiuk},
year={2025},
eprint={2505.00949},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.00949},
}
``` |
Mungert/Mistral-7B-Instruct-v0.3-GGUF | Mungert | 2025-06-15T19:41:35Z | 1,305 | 5 | null | [
"gguf",
"base_model:mistralai/Mistral-7B-v0.3",
"base_model:quantized:mistralai/Mistral-7B-v0.3",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-03-21T00:01:20Z | ---
license: apache-2.0
base_model: mistralai/Mistral-7B-v0.3
extra_gated_description: If you want to learn more about how we process your personal data, please read our <a href="https://mistral.ai/terms/">Privacy Policy</a>.
---
# <span style="color: #7FFF7F;">Mistral-7B-Instruct-v0.3 GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Mistral-7B-Instruct-v0.3-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Mistral-7B-Instruct-v0.3-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Mistral-7B-Instruct-v0.3-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Mistral-7B-Instruct-v0.3-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Mistral-7B-Instruct-v0.3-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Mistral-7B-Instruct-v0.3-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Mistral-7B-Instruct-v0.3-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Mistral-7B-Instruct-v0.3-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Mistral-7B-Instruct-v0.3-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Mistral-7B-Instruct-v0.3-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Mistral-7B-Instruct-v0.3-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# Model Card for Mistral-7B-Instruct-v0.3
The Mistral-7B-Instruct-v0.3 Large Language Model (LLM) is an instruct fine-tuned version of the Mistral-7B-v0.3.
Mistral-7B-v0.3 has the following changes compared to [Mistral-7B-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2/edit/main/README.md)
- Extended vocabulary to 32768
- Supports v3 Tokenizer
- Supports function calling
## Installation
It is recommended to use `mistralai/Mistral-7B-Instruct-v0.3` with [mistral-inference](https://github.com/mistralai/mistral-inference). For HF transformers code snippets, please keep scrolling.
```
pip install mistral_inference
```
## Download
```py
from huggingface_hub import snapshot_download
from pathlib import Path
mistral_models_path = Path.home().joinpath('mistral_models', '7B-Instruct-v0.3')
mistral_models_path.mkdir(parents=True, exist_ok=True)
snapshot_download(repo_id="mistralai/Mistral-7B-Instruct-v0.3", allow_patterns=["params.json", "consolidated.safetensors", "tokenizer.model.v3"], local_dir=mistral_models_path)
```
### Chat
After installing `mistral_inference`, a `mistral-chat` CLI command should be available in your environment. You can chat with the model using
```
mistral-chat $HOME/mistral_models/7B-Instruct-v0.3 --instruct --max_tokens 256
```
### Instruct following
```py
from mistral_inference.transformer import Transformer
from mistral_inference.generate import generate
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
from mistral_common.protocol.instruct.messages import UserMessage
from mistral_common.protocol.instruct.request import ChatCompletionRequest
tokenizer = MistralTokenizer.from_file(f"{mistral_models_path}/tokenizer.model.v3")
model = Transformer.from_folder(mistral_models_path)
completion_request = ChatCompletionRequest(messages=[UserMessage(content="Explain Machine Learning to me in a nutshell.")])
tokens = tokenizer.encode_chat_completion(completion_request).tokens
out_tokens, _ = generate([tokens], model, max_tokens=64, temperature=0.0, eos_id=tokenizer.instruct_tokenizer.tokenizer.eos_id)
result = tokenizer.instruct_tokenizer.tokenizer.decode(out_tokens[0])
print(result)
```
### Function calling
```py
from mistral_common.protocol.instruct.tool_calls import Function, Tool
from mistral_inference.transformer import Transformer
from mistral_inference.generate import generate
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
from mistral_common.protocol.instruct.messages import UserMessage
from mistral_common.protocol.instruct.request import ChatCompletionRequest
tokenizer = MistralTokenizer.from_file(f"{mistral_models_path}/tokenizer.model.v3")
model = Transformer.from_folder(mistral_models_path)
completion_request = ChatCompletionRequest(
tools=[
Tool(
function=Function(
name="get_current_weather",
description="Get the current weather",
parameters={
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"format": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The temperature unit to use. Infer this from the users location.",
},
},
"required": ["location", "format"],
},
)
)
],
messages=[
UserMessage(content="What's the weather like today in Paris?"),
],
)
tokens = tokenizer.encode_chat_completion(completion_request).tokens
out_tokens, _ = generate([tokens], model, max_tokens=64, temperature=0.0, eos_id=tokenizer.instruct_tokenizer.tokenizer.eos_id)
result = tokenizer.instruct_tokenizer.tokenizer.decode(out_tokens[0])
print(result)
```
## Generate with `transformers`
If you want to use Hugging Face `transformers` to generate text, you can do something like this.
```py
from transformers import pipeline
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
chatbot = pipeline("text-generation", model="mistralai/Mistral-7B-Instruct-v0.3")
chatbot(messages)
```
## Function calling with `transformers`
To use this example, you'll need `transformers` version 4.42.0 or higher. Please see the
[function calling guide](https://huggingface.co/docs/transformers/main/chat_templating#advanced-tool-use--function-calling)
in the `transformers` docs for more information.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_id = "mistralai/Mistral-7B-Instruct-v0.3"
tokenizer = AutoTokenizer.from_pretrained(model_id)
def get_current_weather(location: str, format: str):
"""
Get the current weather
Args:
location: The city and state, e.g. San Francisco, CA
format: The temperature unit to use. Infer this from the users location. (choices: ["celsius", "fahrenheit"])
"""
pass
conversation = [{"role": "user", "content": "What's the weather like in Paris?"}]
tools = [get_current_weather]
# format and tokenize the tool use prompt
inputs = tokenizer.apply_chat_template(
conversation,
tools=tools,
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16, device_map="auto")
inputs.to(model.device)
outputs = model.generate(**inputs, max_new_tokens=1000)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
Note that, for reasons of space, this example does not show a complete cycle of calling a tool and adding the tool call and tool
results to the chat history so that the model can use them in its next generation. For a full tool calling example, please
see the [function calling guide](https://huggingface.co/docs/transformers/main/chat_templating#advanced-tool-use--function-calling),
and note that Mistral **does** use tool call IDs, so these must be included in your tool calls and tool results. They should be
exactly 9 alphanumeric characters.
## Limitations
The Mistral 7B Instruct model is a quick demonstration that the base model can be easily fine-tuned to achieve compelling performance.
It does not have any moderation mechanisms. We're looking forward to engaging with the community on ways to
make the model finely respect guardrails, allowing for deployment in environments requiring moderated outputs.
## The Mistral AI Team
Albert Jiang, Alexandre Sablayrolles, Alexis Tacnet, Antoine Roux, Arthur Mensch, Audrey Herblin-Stoop, Baptiste Bout, Baudouin de Monicault, Blanche Savary, Bam4d, Caroline Feldman, Devendra Singh Chaplot, Diego de las Casas, Eleonore Arcelin, Emma Bou Hanna, Etienne Metzger, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Harizo Rajaona, Jean-Malo Delignon, Jia Li, Justus Murke, Louis Martin, Louis Ternon, Lucile Saulnier, Lélio Renard Lavaud, Margaret Jennings, Marie Pellat, Marie Torelli, Marie-Anne Lachaux, Nicolas Schuhl, Patrick von Platen, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven Le Scao, Thibaut Lavril, Timothée Lacroix, Théophile Gervet, Thomas Wang, Valera Nemychnikova, William El Sayed, William Marshall |
Mungert/DeepSeek-R1-Distill-Llama-8B-GGUF | Mungert | 2025-06-15T19:41:20Z | 2,816 | 3 | transformers | [
"transformers",
"gguf",
"arxiv:2501.12948",
"license:mit",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-03-20T07:53:43Z | ---
license: mit
library_name: transformers
---
# <span style="color: #7FFF7F;">DeepSeek-R1-Distill-Llama-8B GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `DeepSeek-R1-Distill-Llama-8B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `DeepSeek-R1-Distill-Llama-8B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `DeepSeek-R1-Distill-Llama-8B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `DeepSeek-R1-Distill-Llama-8B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `DeepSeek-R1-Distill-Llama-8B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `DeepSeek-R1-Distill-Llama-8B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `DeepSeek-R1-Distill-Llama-8B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `DeepSeek-R1-Distill-Llama-8B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `DeepSeek-R1-Distill-Llama-8B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `DeepSeek-R1-Distill-Llama-8B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `DeepSeek-R1-Distill-Llama-8B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# DeepSeek-R1
<!-- markdownlint-disable first-line-h1 -->
<!-- markdownlint-disable html -->
<!-- markdownlint-disable no-duplicate-header -->
<div align="center">
<img src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/logo.svg?raw=true" width="60%" alt="DeepSeek-V3" />
</div>
<hr>
<div align="center" style="line-height: 1;">
<a href="https://www.deepseek.com/" target="_blank" style="margin: 2px;">
<img alt="Homepage" src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/badge.svg?raw=true" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://chat.deepseek.com/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/🤖%20Chat-DeepSeek%20R1-536af5?color=536af5&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://huggingface.co/deepseek-ai" target="_blank" style="margin: 2px;">
<img alt="Hugging Face" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-DeepSeek%20AI-ffc107?color=ffc107&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="https://discord.gg/Tc7c45Zzu5" target="_blank" style="margin: 2px;">
<img alt="Discord" src="https://img.shields.io/badge/Discord-DeepSeek%20AI-7289da?logo=discord&logoColor=white&color=7289da" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/qr.jpeg?raw=true" target="_blank" style="margin: 2px;">
<img alt="Wechat" src="https://img.shields.io/badge/WeChat-DeepSeek%20AI-brightgreen?logo=wechat&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://twitter.com/deepseek_ai" target="_blank" style="margin: 2px;">
<img alt="Twitter Follow" src="https://img.shields.io/badge/Twitter-deepseek_ai-white?logo=x&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="https://github.com/deepseek-ai/DeepSeek-R1/blob/main/LICENSE" style="margin: 2px;">
<img alt="License" src="https://img.shields.io/badge/License-MIT-f5de53?&color=f5de53" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<p align="center">
<a href="https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf"><b>Paper Link</b>👁️</a>
</p>
## 1. Introduction
We introduce our first-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1.
DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step, demonstrated remarkable performance on reasoning.
With RL, DeepSeek-R1-Zero naturally emerged with numerous powerful and interesting reasoning behaviors.
However, DeepSeek-R1-Zero encounters challenges such as endless repetition, poor readability, and language mixing. To address these issues and further enhance reasoning performance,
we introduce DeepSeek-R1, which incorporates cold-start data before RL.
DeepSeek-R1 achieves performance comparable to OpenAI-o1 across math, code, and reasoning tasks.
To support the research community, we have open-sourced DeepSeek-R1-Zero, DeepSeek-R1, and six dense models distilled from DeepSeek-R1 based on Llama and Qwen. DeepSeek-R1-Distill-Qwen-32B outperforms OpenAI-o1-mini across various benchmarks, achieving new state-of-the-art results for dense models.
**NOTE: Before running DeepSeek-R1 series models locally, we kindly recommend reviewing the [Usage Recommendation](#usage-recommendations) section.**
<p align="center">
<img width="80%" src="figures/benchmark.jpg">
</p>
## 2. Model Summary
---
**Post-Training: Large-Scale Reinforcement Learning on the Base Model**
- We directly apply reinforcement learning (RL) to the base model without relying on supervised fine-tuning (SFT) as a preliminary step. This approach allows the model to explore chain-of-thought (CoT) for solving complex problems, resulting in the development of DeepSeek-R1-Zero. DeepSeek-R1-Zero demonstrates capabilities such as self-verification, reflection, and generating long CoTs, marking a significant milestone for the research community. Notably, it is the first open research to validate that reasoning capabilities of LLMs can be incentivized purely through RL, without the need for SFT. This breakthrough paves the way for future advancements in this area.
- We introduce our pipeline to develop DeepSeek-R1. The pipeline incorporates two RL stages aimed at discovering improved reasoning patterns and aligning with human preferences, as well as two SFT stages that serve as the seed for the model's reasoning and non-reasoning capabilities.
We believe the pipeline will benefit the industry by creating better models.
---
**Distillation: Smaller Models Can Be Powerful Too**
- We demonstrate that the reasoning patterns of larger models can be distilled into smaller models, resulting in better performance compared to the reasoning patterns discovered through RL on small models. The open source DeepSeek-R1, as well as its API, will benefit the research community to distill better smaller models in the future.
- Using the reasoning data generated by DeepSeek-R1, we fine-tuned several dense models that are widely used in the research community. The evaluation results demonstrate that the distilled smaller dense models perform exceptionally well on benchmarks. We open-source distilled 1.5B, 7B, 8B, 14B, 32B, and 70B checkpoints based on Qwen2.5 and Llama3 series to the community.
## 3. Model Downloads
### DeepSeek-R1 Models
<div align="center">
| **Model** | **#Total Params** | **#Activated Params** | **Context Length** | **Download** |
| :------------: | :------------: | :------------: | :------------: | :------------: |
| DeepSeek-R1-Zero | 671B | 37B | 128K | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Zero) |
| DeepSeek-R1 | 671B | 37B | 128K | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1) |
</div>
DeepSeek-R1-Zero & DeepSeek-R1 are trained based on DeepSeek-V3-Base.
For more details regarding the model architecture, please refer to [DeepSeek-V3](https://github.com/deepseek-ai/DeepSeek-V3) repository.
### DeepSeek-R1-Distill Models
<div align="center">
| **Model** | **Base Model** | **Download** |
| :------------: | :------------: | :------------: |
| DeepSeek-R1-Distill-Qwen-1.5B | [Qwen2.5-Math-1.5B](https://huggingface.co/Qwen/Qwen2.5-Math-1.5B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B) |
| DeepSeek-R1-Distill-Qwen-7B | [Qwen2.5-Math-7B](https://huggingface.co/Qwen/Qwen2.5-Math-7B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B) |
| DeepSeek-R1-Distill-Llama-8B | [Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Llama-8B) |
| DeepSeek-R1-Distill-Qwen-14B | [Qwen2.5-14B](https://huggingface.co/Qwen/Qwen2.5-14B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B) |
|DeepSeek-R1-Distill-Qwen-32B | [Qwen2.5-32B](https://huggingface.co/Qwen/Qwen2.5-32B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B) |
| DeepSeek-R1-Distill-Llama-70B | [Llama-3.3-70B-Instruct](https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Llama-70B) |
</div>
DeepSeek-R1-Distill models are fine-tuned based on open-source models, using samples generated by DeepSeek-R1.
We slightly change their configs and tokenizers. Please use our setting to run these models.
## 4. Evaluation Results
### DeepSeek-R1-Evaluation
For all our models, the maximum generation length is set to 32,768 tokens. For benchmarks requiring sampling, we use a temperature of $0.6$, a top-p value of $0.95$, and generate 64 responses per query to estimate pass@1.
<div align="center">
| Category | Benchmark (Metric) | Claude-3.5-Sonnet-1022 | GPT-4o 0513 | DeepSeek V3 | OpenAI o1-mini | OpenAI o1-1217 | DeepSeek R1 |
|----------|-------------------|----------------------|------------|--------------|----------------|------------|--------------|
| | Architecture | - | - | MoE | - | - | MoE |
| | # Activated Params | - | - | 37B | - | - | 37B |
| | # Total Params | - | - | 671B | - | - | 671B |
| English | MMLU (Pass@1) | 88.3 | 87.2 | 88.5 | 85.2 | **91.8** | 90.8 |
| | MMLU-Redux (EM) | 88.9 | 88.0 | 89.1 | 86.7 | - | **92.9** |
| | MMLU-Pro (EM) | 78.0 | 72.6 | 75.9 | 80.3 | - | **84.0** |
| | DROP (3-shot F1) | 88.3 | 83.7 | 91.6 | 83.9 | 90.2 | **92.2** |
| | IF-Eval (Prompt Strict) | **86.5** | 84.3 | 86.1 | 84.8 | - | 83.3 |
| | GPQA-Diamond (Pass@1) | 65.0 | 49.9 | 59.1 | 60.0 | **75.7** | 71.5 |
| | SimpleQA (Correct) | 28.4 | 38.2 | 24.9 | 7.0 | **47.0** | 30.1 |
| | FRAMES (Acc.) | 72.5 | 80.5 | 73.3 | 76.9 | - | **82.5** |
| | AlpacaEval2.0 (LC-winrate) | 52.0 | 51.1 | 70.0 | 57.8 | - | **87.6** |
| | ArenaHard (GPT-4-1106) | 85.2 | 80.4 | 85.5 | 92.0 | - | **92.3** |
| Code | LiveCodeBench (Pass@1-COT) | 33.8 | 34.2 | - | 53.8 | 63.4 | **65.9** |
| | Codeforces (Percentile) | 20.3 | 23.6 | 58.7 | 93.4 | **96.6** | 96.3 |
| | Codeforces (Rating) | 717 | 759 | 1134 | 1820 | **2061** | 2029 |
| | SWE Verified (Resolved) | **50.8** | 38.8 | 42.0 | 41.6 | 48.9 | 49.2 |
| | Aider-Polyglot (Acc.) | 45.3 | 16.0 | 49.6 | 32.9 | **61.7** | 53.3 |
| Math | AIME 2024 (Pass@1) | 16.0 | 9.3 | 39.2 | 63.6 | 79.2 | **79.8** |
| | MATH-500 (Pass@1) | 78.3 | 74.6 | 90.2 | 90.0 | 96.4 | **97.3** |
| | CNMO 2024 (Pass@1) | 13.1 | 10.8 | 43.2 | 67.6 | - | **78.8** |
| Chinese | CLUEWSC (EM) | 85.4 | 87.9 | 90.9 | 89.9 | - | **92.8** |
| | C-Eval (EM) | 76.7 | 76.0 | 86.5 | 68.9 | - | **91.8** |
| | C-SimpleQA (Correct) | 55.4 | 58.7 | **68.0** | 40.3 | - | 63.7 |
</div>
### Distilled Model Evaluation
<div align="center">
| Model | AIME 2024 pass@1 | AIME 2024 cons@64 | MATH-500 pass@1 | GPQA Diamond pass@1 | LiveCodeBench pass@1 | CodeForces rating |
|------------------------------------------|------------------|-------------------|-----------------|----------------------|----------------------|-------------------|
| GPT-4o-0513 | 9.3 | 13.4 | 74.6 | 49.9 | 32.9 | 759 |
| Claude-3.5-Sonnet-1022 | 16.0 | 26.7 | 78.3 | 65.0 | 38.9 | 717 |
| o1-mini | 63.6 | 80.0 | 90.0 | 60.0 | 53.8 | **1820** |
| QwQ-32B-Preview | 44.0 | 60.0 | 90.6 | 54.5 | 41.9 | 1316 |
| DeepSeek-R1-Distill-Qwen-1.5B | 28.9 | 52.7 | 83.9 | 33.8 | 16.9 | 954 |
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 83.3 | 92.8 | 49.1 | 37.6 | 1189 |
| DeepSeek-R1-Distill-Qwen-14B | 69.7 | 80.0 | 93.9 | 59.1 | 53.1 | 1481 |
| DeepSeek-R1-Distill-Qwen-32B | **72.6** | 83.3 | 94.3 | 62.1 | 57.2 | 1691 |
| DeepSeek-R1-Distill-Llama-8B | 50.4 | 80.0 | 89.1 | 49.0 | 39.6 | 1205 |
| DeepSeek-R1-Distill-Llama-70B | 70.0 | **86.7** | **94.5** | **65.2** | **57.5** | 1633 |
</div>
## 5. Chat Website & API Platform
You can chat with DeepSeek-R1 on DeepSeek's official website: [chat.deepseek.com](https://chat.deepseek.com), and switch on the button "DeepThink"
We also provide OpenAI-Compatible API at DeepSeek Platform: [platform.deepseek.com](https://platform.deepseek.com/)
## 6. How to Run Locally
### DeepSeek-R1 Models
Please visit [DeepSeek-V3](https://github.com/deepseek-ai/DeepSeek-V3) repo for more information about running DeepSeek-R1 locally.
**NOTE: Hugging Face's Transformers has not been directly supported yet.**
### DeepSeek-R1-Distill Models
DeepSeek-R1-Distill models can be utilized in the same manner as Qwen or Llama models.
For instance, you can easily start a service using [vLLM](https://github.com/vllm-project/vllm):
```shell
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --tensor-parallel-size 2 --max-model-len 32768 --enforce-eager
```
You can also easily start a service using [SGLang](https://github.com/sgl-project/sglang)
```bash
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --trust-remote-code --tp 2
```
### Usage Recommendations
**We recommend adhering to the following configurations when utilizing the DeepSeek-R1 series models, including benchmarking, to achieve the expected performance:**
1. Set the temperature within the range of 0.5-0.7 (0.6 is recommended) to prevent endless repetitions or incoherent outputs.
2. **Avoid adding a system prompt; all instructions should be contained within the user prompt.**
3. For mathematical problems, it is advisable to include a directive in your prompt such as: "Please reason step by step, and put your final answer within \boxed{}."
4. When evaluating model performance, it is recommended to conduct multiple tests and average the results.
Additionally, we have observed that the DeepSeek-R1 series models tend to bypass thinking pattern (i.e., outputting "\<think\>\n\n\</think\>") when responding to certain queries, which can adversely affect the model's performance.
**To ensure that the model engages in thorough reasoning, we recommend enforcing the model to initiate its response with "\<think\>\n" at the beginning of every output.**
## 7. License
This code repository and the model weights are licensed under the [MIT License](https://github.com/deepseek-ai/DeepSeek-R1/blob/main/LICENSE).
DeepSeek-R1 series support commercial use, allow for any modifications and derivative works, including, but not limited to, distillation for training other LLMs. Please note that:
- DeepSeek-R1-Distill-Qwen-1.5B, DeepSeek-R1-Distill-Qwen-7B, DeepSeek-R1-Distill-Qwen-14B and DeepSeek-R1-Distill-Qwen-32B are derived from [Qwen-2.5 series](https://github.com/QwenLM/Qwen2.5), which are originally licensed under [Apache 2.0 License](https://huggingface.co/Qwen/Qwen2.5-1.5B/blob/main/LICENSE), and now finetuned with 800k samples curated with DeepSeek-R1.
- DeepSeek-R1-Distill-Llama-8B is derived from Llama3.1-8B-Base and is originally licensed under [llama3.1 license](https://huggingface.co/meta-llama/Llama-3.1-8B/blob/main/LICENSE).
- DeepSeek-R1-Distill-Llama-70B is derived from Llama3.3-70B-Instruct and is originally licensed under [llama3.3 license](https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct/blob/main/LICENSE).
## 8. Citation
```
@misc{deepseekai2025deepseekr1incentivizingreasoningcapability,
title={DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning},
author={DeepSeek-AI},
year={2025},
eprint={2501.12948},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2501.12948},
}
```
## 9. Contact
If you have any questions, please raise an issue or contact us at [[email protected]]([email protected]).
|
Mungert/DeepSeek-R1-Distill-Qwen-7B-GGUF | Mungert | 2025-06-15T19:41:16Z | 1,140 | 4 | transformers | [
"transformers",
"gguf",
"arxiv:2501.12948",
"license:mit",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-03-19T23:20:08Z | ---
license: mit
library_name: transformers
---
# <span style="color: #7FFF7F;">DeepSeek-R1-Distill-Qwen-7B GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `DeepSeek-R1-Distill-Qwen-7B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `DeepSeek-R1-Distill-Qwen-7B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `DeepSeek-R1-Distill-Qwen-7B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `DeepSeek-R1-Distill-Qwen-7B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `DeepSeek-R1-Distill-Qwen-7B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `DeepSeek-R1-Distill-Qwen-7B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `DeepSeek-R1-Distill-Qwen-7B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `DeepSeek-R1-Distill-Qwen-7B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `DeepSeek-R1-Distill-Qwen-7B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `DeepSeek-R1-Distill-Qwen-7B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `DeepSeek-R1-Distill-Qwen-7B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# DeepSeek-R1
<!-- markdownlint-disable first-line-h1 -->
<!-- markdownlint-disable html -->
<!-- markdownlint-disable no-duplicate-header -->
<div align="center">
<img src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/logo.svg?raw=true" width="60%" alt="DeepSeek-V3" />
</div>
<hr>
<div align="center" style="line-height: 1;">
<a href="https://www.deepseek.com/" target="_blank" style="margin: 2px;">
<img alt="Homepage" src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/badge.svg?raw=true" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://chat.deepseek.com/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/🤖%20Chat-DeepSeek%20R1-536af5?color=536af5&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://huggingface.co/deepseek-ai" target="_blank" style="margin: 2px;">
<img alt="Hugging Face" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-DeepSeek%20AI-ffc107?color=ffc107&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="https://discord.gg/Tc7c45Zzu5" target="_blank" style="margin: 2px;">
<img alt="Discord" src="https://img.shields.io/badge/Discord-DeepSeek%20AI-7289da?logo=discord&logoColor=white&color=7289da" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/qr.jpeg?raw=true" target="_blank" style="margin: 2px;">
<img alt="Wechat" src="https://img.shields.io/badge/WeChat-DeepSeek%20AI-brightgreen?logo=wechat&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://twitter.com/deepseek_ai" target="_blank" style="margin: 2px;">
<img alt="Twitter Follow" src="https://img.shields.io/badge/Twitter-deepseek_ai-white?logo=x&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="https://github.com/deepseek-ai/DeepSeek-R1/blob/main/LICENSE" style="margin: 2px;">
<img alt="License" src="https://img.shields.io/badge/License-MIT-f5de53?&color=f5de53" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<p align="center">
<a href="https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf"><b>Paper Link</b>👁️</a>
</p>
## 1. Introduction
We introduce our first-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1.
DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step, demonstrated remarkable performance on reasoning.
With RL, DeepSeek-R1-Zero naturally emerged with numerous powerful and interesting reasoning behaviors.
However, DeepSeek-R1-Zero encounters challenges such as endless repetition, poor readability, and language mixing. To address these issues and further enhance reasoning performance,
we introduce DeepSeek-R1, which incorporates cold-start data before RL.
DeepSeek-R1 achieves performance comparable to OpenAI-o1 across math, code, and reasoning tasks.
To support the research community, we have open-sourced DeepSeek-R1-Zero, DeepSeek-R1, and six dense models distilled from DeepSeek-R1 based on Llama and Qwen. DeepSeek-R1-Distill-Qwen-32B outperforms OpenAI-o1-mini across various benchmarks, achieving new state-of-the-art results for dense models.
**NOTE: Before running DeepSeek-R1 series models locally, we kindly recommend reviewing the [Usage Recommendation](#usage-recommendations) section.**
<p align="center">
<img width="80%" src="figures/benchmark.jpg">
</p>
## 2. Model Summary
---
**Post-Training: Large-Scale Reinforcement Learning on the Base Model**
- We directly apply reinforcement learning (RL) to the base model without relying on supervised fine-tuning (SFT) as a preliminary step. This approach allows the model to explore chain-of-thought (CoT) for solving complex problems, resulting in the development of DeepSeek-R1-Zero. DeepSeek-R1-Zero demonstrates capabilities such as self-verification, reflection, and generating long CoTs, marking a significant milestone for the research community. Notably, it is the first open research to validate that reasoning capabilities of LLMs can be incentivized purely through RL, without the need for SFT. This breakthrough paves the way for future advancements in this area.
- We introduce our pipeline to develop DeepSeek-R1. The pipeline incorporates two RL stages aimed at discovering improved reasoning patterns and aligning with human preferences, as well as two SFT stages that serve as the seed for the model's reasoning and non-reasoning capabilities.
We believe the pipeline will benefit the industry by creating better models.
---
**Distillation: Smaller Models Can Be Powerful Too**
- We demonstrate that the reasoning patterns of larger models can be distilled into smaller models, resulting in better performance compared to the reasoning patterns discovered through RL on small models. The open source DeepSeek-R1, as well as its API, will benefit the research community to distill better smaller models in the future.
- Using the reasoning data generated by DeepSeek-R1, we fine-tuned several dense models that are widely used in the research community. The evaluation results demonstrate that the distilled smaller dense models perform exceptionally well on benchmarks. We open-source distilled 1.5B, 7B, 8B, 14B, 32B, and 70B checkpoints based on Qwen2.5 and Llama3 series to the community.
## 3. Model Downloads
### DeepSeek-R1 Models
<div align="center">
| **Model** | **#Total Params** | **#Activated Params** | **Context Length** | **Download** |
| :------------: | :------------: | :------------: | :------------: | :------------: |
| DeepSeek-R1-Zero | 671B | 37B | 128K | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Zero) |
| DeepSeek-R1 | 671B | 37B | 128K | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1) |
</div>
DeepSeek-R1-Zero & DeepSeek-R1 are trained based on DeepSeek-V3-Base.
For more details regarding the model architecture, please refer to [DeepSeek-V3](https://github.com/deepseek-ai/DeepSeek-V3) repository.
### DeepSeek-R1-Distill Models
<div align="center">
| **Model** | **Base Model** | **Download** |
| :------------: | :------------: | :------------: |
| DeepSeek-R1-Distill-Qwen-1.5B | [Qwen2.5-Math-1.5B](https://huggingface.co/Qwen/Qwen2.5-Math-1.5B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B) |
| DeepSeek-R1-Distill-Qwen-7B | [Qwen2.5-Math-7B](https://huggingface.co/Qwen/Qwen2.5-Math-7B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B) |
| DeepSeek-R1-Distill-Llama-8B | [Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Llama-8B) |
| DeepSeek-R1-Distill-Qwen-14B | [Qwen2.5-14B](https://huggingface.co/Qwen/Qwen2.5-14B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B) |
|DeepSeek-R1-Distill-Qwen-32B | [Qwen2.5-32B](https://huggingface.co/Qwen/Qwen2.5-32B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B) |
| DeepSeek-R1-Distill-Llama-70B | [Llama-3.3-70B-Instruct](https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Llama-70B) |
</div>
DeepSeek-R1-Distill models are fine-tuned based on open-source models, using samples generated by DeepSeek-R1.
We slightly change their configs and tokenizers. Please use our setting to run these models.
## 4. Evaluation Results
### DeepSeek-R1-Evaluation
For all our models, the maximum generation length is set to 32,768 tokens. For benchmarks requiring sampling, we use a temperature of $0.6$, a top-p value of $0.95$, and generate 64 responses per query to estimate pass@1.
<div align="center">
| Category | Benchmark (Metric) | Claude-3.5-Sonnet-1022 | GPT-4o 0513 | DeepSeek V3 | OpenAI o1-mini | OpenAI o1-1217 | DeepSeek R1 |
|----------|-------------------|----------------------|------------|--------------|----------------|------------|--------------|
| | Architecture | - | - | MoE | - | - | MoE |
| | # Activated Params | - | - | 37B | - | - | 37B |
| | # Total Params | - | - | 671B | - | - | 671B |
| English | MMLU (Pass@1) | 88.3 | 87.2 | 88.5 | 85.2 | **91.8** | 90.8 |
| | MMLU-Redux (EM) | 88.9 | 88.0 | 89.1 | 86.7 | - | **92.9** |
| | MMLU-Pro (EM) | 78.0 | 72.6 | 75.9 | 80.3 | - | **84.0** |
| | DROP (3-shot F1) | 88.3 | 83.7 | 91.6 | 83.9 | 90.2 | **92.2** |
| | IF-Eval (Prompt Strict) | **86.5** | 84.3 | 86.1 | 84.8 | - | 83.3 |
| | GPQA-Diamond (Pass@1) | 65.0 | 49.9 | 59.1 | 60.0 | **75.7** | 71.5 |
| | SimpleQA (Correct) | 28.4 | 38.2 | 24.9 | 7.0 | **47.0** | 30.1 |
| | FRAMES (Acc.) | 72.5 | 80.5 | 73.3 | 76.9 | - | **82.5** |
| | AlpacaEval2.0 (LC-winrate) | 52.0 | 51.1 | 70.0 | 57.8 | - | **87.6** |
| | ArenaHard (GPT-4-1106) | 85.2 | 80.4 | 85.5 | 92.0 | - | **92.3** |
| Code | LiveCodeBench (Pass@1-COT) | 33.8 | 34.2 | - | 53.8 | 63.4 | **65.9** |
| | Codeforces (Percentile) | 20.3 | 23.6 | 58.7 | 93.4 | **96.6** | 96.3 |
| | Codeforces (Rating) | 717 | 759 | 1134 | 1820 | **2061** | 2029 |
| | SWE Verified (Resolved) | **50.8** | 38.8 | 42.0 | 41.6 | 48.9 | 49.2 |
| | Aider-Polyglot (Acc.) | 45.3 | 16.0 | 49.6 | 32.9 | **61.7** | 53.3 |
| Math | AIME 2024 (Pass@1) | 16.0 | 9.3 | 39.2 | 63.6 | 79.2 | **79.8** |
| | MATH-500 (Pass@1) | 78.3 | 74.6 | 90.2 | 90.0 | 96.4 | **97.3** |
| | CNMO 2024 (Pass@1) | 13.1 | 10.8 | 43.2 | 67.6 | - | **78.8** |
| Chinese | CLUEWSC (EM) | 85.4 | 87.9 | 90.9 | 89.9 | - | **92.8** |
| | C-Eval (EM) | 76.7 | 76.0 | 86.5 | 68.9 | - | **91.8** |
| | C-SimpleQA (Correct) | 55.4 | 58.7 | **68.0** | 40.3 | - | 63.7 |
</div>
### Distilled Model Evaluation
<div align="center">
| Model | AIME 2024 pass@1 | AIME 2024 cons@64 | MATH-500 pass@1 | GPQA Diamond pass@1 | LiveCodeBench pass@1 | CodeForces rating |
|------------------------------------------|------------------|-------------------|-----------------|----------------------|----------------------|-------------------|
| GPT-4o-0513 | 9.3 | 13.4 | 74.6 | 49.9 | 32.9 | 759 |
| Claude-3.5-Sonnet-1022 | 16.0 | 26.7 | 78.3 | 65.0 | 38.9 | 717 |
| o1-mini | 63.6 | 80.0 | 90.0 | 60.0 | 53.8 | **1820** |
| QwQ-32B-Preview | 44.0 | 60.0 | 90.6 | 54.5 | 41.9 | 1316 |
| DeepSeek-R1-Distill-Qwen-1.5B | 28.9 | 52.7 | 83.9 | 33.8 | 16.9 | 954 |
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 83.3 | 92.8 | 49.1 | 37.6 | 1189 |
| DeepSeek-R1-Distill-Qwen-14B | 69.7 | 80.0 | 93.9 | 59.1 | 53.1 | 1481 |
| DeepSeek-R1-Distill-Qwen-32B | **72.6** | 83.3 | 94.3 | 62.1 | 57.2 | 1691 |
| DeepSeek-R1-Distill-Llama-8B | 50.4 | 80.0 | 89.1 | 49.0 | 39.6 | 1205 |
| DeepSeek-R1-Distill-Llama-70B | 70.0 | **86.7** | **94.5** | **65.2** | **57.5** | 1633 |
</div>
## 5. Chat Website & API Platform
You can chat with DeepSeek-R1 on DeepSeek's official website: [chat.deepseek.com](https://chat.deepseek.com), and switch on the button "DeepThink"
We also provide OpenAI-Compatible API at DeepSeek Platform: [platform.deepseek.com](https://platform.deepseek.com/)
## 6. How to Run Locally
### DeepSeek-R1 Models
Please visit [DeepSeek-V3](https://github.com/deepseek-ai/DeepSeek-V3) repo for more information about running DeepSeek-R1 locally.
**NOTE: Hugging Face's Transformers has not been directly supported yet.**
### DeepSeek-R1-Distill Models
DeepSeek-R1-Distill models can be utilized in the same manner as Qwen or Llama models.
For instance, you can easily start a service using [vLLM](https://github.com/vllm-project/vllm):
```shell
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --tensor-parallel-size 2 --max-model-len 32768 --enforce-eager
```
You can also easily start a service using [SGLang](https://github.com/sgl-project/sglang)
```bash
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --trust-remote-code --tp 2
```
### Usage Recommendations
**We recommend adhering to the following configurations when utilizing the DeepSeek-R1 series models, including benchmarking, to achieve the expected performance:**
1. Set the temperature within the range of 0.5-0.7 (0.6 is recommended) to prevent endless repetitions or incoherent outputs.
2. **Avoid adding a system prompt; all instructions should be contained within the user prompt.**
3. For mathematical problems, it is advisable to include a directive in your prompt such as: "Please reason step by step, and put your final answer within \boxed{}."
4. When evaluating model performance, it is recommended to conduct multiple tests and average the results.
Additionally, we have observed that the DeepSeek-R1 series models tend to bypass thinking pattern (i.e., outputting "\<think\>\n\n\</think\>") when responding to certain queries, which can adversely affect the model's performance.
**To ensure that the model engages in thorough reasoning, we recommend enforcing the model to initiate its response with "\<think\>\n" at the beginning of every output.**
## 7. License
This code repository and the model weights are licensed under the [MIT License](https://github.com/deepseek-ai/DeepSeek-R1/blob/main/LICENSE).
DeepSeek-R1 series support commercial use, allow for any modifications and derivative works, including, but not limited to, distillation for training other LLMs. Please note that:
- DeepSeek-R1-Distill-Qwen-1.5B, DeepSeek-R1-Distill-Qwen-7B, DeepSeek-R1-Distill-Qwen-14B and DeepSeek-R1-Distill-Qwen-32B are derived from [Qwen-2.5 series](https://github.com/QwenLM/Qwen2.5), which are originally licensed under [Apache 2.0 License](https://huggingface.co/Qwen/Qwen2.5-1.5B/blob/main/LICENSE), and now finetuned with 800k samples curated with DeepSeek-R1.
- DeepSeek-R1-Distill-Llama-8B is derived from Llama3.1-8B-Base and is originally licensed under [llama3.1 license](https://huggingface.co/meta-llama/Llama-3.1-8B/blob/main/LICENSE).
- DeepSeek-R1-Distill-Llama-70B is derived from Llama3.3-70B-Instruct and is originally licensed under [llama3.3 license](https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct/blob/main/LICENSE).
## 8. Citation
```
@misc{deepseekai2025deepseekr1incentivizingreasoningcapability,
title={DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning},
author={DeepSeek-AI},
year={2025},
eprint={2501.12948},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2501.12948},
}
```
## 9. Contact
If you have any questions, please raise an issue or contact us at [[email protected]]([email protected]).
|
Mungert/DeepSeek-R1-Distill-Qwen-1.5B-GGUF | Mungert | 2025-06-15T19:41:12Z | 300 | 5 | transformers | [
"transformers",
"gguf",
"arxiv:2501.12948",
"license:mit",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-03-19T21:54:51Z | ---
license: mit
library_name: transformers
---
# <span style="color: #7FFF7F;">DeepSeek-R1-Distill-Qwen-1.5B GGUF Models</span>
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `DeepSeek-R1-Distill-Qwen-1.5B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `DeepSeek-R1-Distill-Qwen-1.5B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `DeepSeek-R1-Distill-Qwen-1.5B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `DeepSeek-R1-Distill-Qwen-1.5B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `DeepSeek-R1-Distill-Qwen-1.5B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `DeepSeek-R1-Distill-Qwen-1.5B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `DeepSeek-R1-Distill-Qwen-1.5B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `DeepSeek-R1-Distill-Qwen-1.5B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `DeepSeek-R1-Distill-Qwen-1.5B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `DeepSeek-R1-Distill-Qwen-1.5B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `DeepSeek-R1-Distill-Qwen-1.5B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# DeepSeek-R1
<!-- markdownlint-disable first-line-h1 -->
<!-- markdownlint-disable html -->
<!-- markdownlint-disable no-duplicate-header -->
<div align="center">
<img src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/logo.svg?raw=true" width="60%" alt="DeepSeek-V3" />
</div>
<hr>
<div align="center" style="line-height: 1;">
<a href="https://www.deepseek.com/" target="_blank" style="margin: 2px;">
<img alt="Homepage" src="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/badge.svg?raw=true" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://chat.deepseek.com/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/🤖%20Chat-DeepSeek%20R1-536af5?color=536af5&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://huggingface.co/deepseek-ai" target="_blank" style="margin: 2px;">
<img alt="Hugging Face" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-DeepSeek%20AI-ffc107?color=ffc107&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="https://discord.gg/Tc7c45Zzu5" target="_blank" style="margin: 2px;">
<img alt="Discord" src="https://img.shields.io/badge/Discord-DeepSeek%20AI-7289da?logo=discord&logoColor=white&color=7289da" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://github.com/deepseek-ai/DeepSeek-V2/blob/main/figures/qr.jpeg?raw=true" target="_blank" style="margin: 2px;">
<img alt="Wechat" src="https://img.shields.io/badge/WeChat-DeepSeek%20AI-brightgreen?logo=wechat&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
<a href="https://twitter.com/deepseek_ai" target="_blank" style="margin: 2px;">
<img alt="Twitter Follow" src="https://img.shields.io/badge/Twitter-deepseek_ai-white?logo=x&logoColor=white" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<div align="center" style="line-height: 1;">
<a href="https://github.com/deepseek-ai/DeepSeek-R1/blob/main/LICENSE" style="margin: 2px;">
<img alt="License" src="https://img.shields.io/badge/License-MIT-f5de53?&color=f5de53" style="display: inline-block; vertical-align: middle;"/>
</a>
</div>
<p align="center">
<a href="https://github.com/deepseek-ai/DeepSeek-R1/blob/main/DeepSeek_R1.pdf"><b>Paper Link</b>👁️</a>
</p>
## 1. Introduction
We introduce our first-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1.
DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without supervised fine-tuning (SFT) as a preliminary step, demonstrated remarkable performance on reasoning.
With RL, DeepSeek-R1-Zero naturally emerged with numerous powerful and interesting reasoning behaviors.
However, DeepSeek-R1-Zero encounters challenges such as endless repetition, poor readability, and language mixing. To address these issues and further enhance reasoning performance,
we introduce DeepSeek-R1, which incorporates cold-start data before RL.
DeepSeek-R1 achieves performance comparable to OpenAI-o1 across math, code, and reasoning tasks.
To support the research community, we have open-sourced DeepSeek-R1-Zero, DeepSeek-R1, and six dense models distilled from DeepSeek-R1 based on Llama and Qwen. DeepSeek-R1-Distill-Qwen-32B outperforms OpenAI-o1-mini across various benchmarks, achieving new state-of-the-art results for dense models.
**NOTE: Before running DeepSeek-R1 series models locally, we kindly recommend reviewing the [Usage Recommendation](#usage-recommendations) section.**
<p align="center">
<img width="80%" src="figures/benchmark.jpg">
</p>
## 2. Model Summary
---
**Post-Training: Large-Scale Reinforcement Learning on the Base Model**
- We directly apply reinforcement learning (RL) to the base model without relying on supervised fine-tuning (SFT) as a preliminary step. This approach allows the model to explore chain-of-thought (CoT) for solving complex problems, resulting in the development of DeepSeek-R1-Zero. DeepSeek-R1-Zero demonstrates capabilities such as self-verification, reflection, and generating long CoTs, marking a significant milestone for the research community. Notably, it is the first open research to validate that reasoning capabilities of LLMs can be incentivized purely through RL, without the need for SFT. This breakthrough paves the way for future advancements in this area.
- We introduce our pipeline to develop DeepSeek-R1. The pipeline incorporates two RL stages aimed at discovering improved reasoning patterns and aligning with human preferences, as well as two SFT stages that serve as the seed for the model's reasoning and non-reasoning capabilities.
We believe the pipeline will benefit the industry by creating better models.
---
**Distillation: Smaller Models Can Be Powerful Too**
- We demonstrate that the reasoning patterns of larger models can be distilled into smaller models, resulting in better performance compared to the reasoning patterns discovered through RL on small models. The open source DeepSeek-R1, as well as its API, will benefit the research community to distill better smaller models in the future.
- Using the reasoning data generated by DeepSeek-R1, we fine-tuned several dense models that are widely used in the research community. The evaluation results demonstrate that the distilled smaller dense models perform exceptionally well on benchmarks. We open-source distilled 1.5B, 7B, 8B, 14B, 32B, and 70B checkpoints based on Qwen2.5 and Llama3 series to the community.
## 3. Model Downloads
### DeepSeek-R1 Models
<div align="center">
| **Model** | **#Total Params** | **#Activated Params** | **Context Length** | **Download** |
| :------------: | :------------: | :------------: | :------------: | :------------: |
| DeepSeek-R1-Zero | 671B | 37B | 128K | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Zero) |
| DeepSeek-R1 | 671B | 37B | 128K | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1) |
</div>
DeepSeek-R1-Zero & DeepSeek-R1 are trained based on DeepSeek-V3-Base.
For more details regarding the model architecture, please refer to [DeepSeek-V3](https://github.com/deepseek-ai/DeepSeek-V3) repository.
### DeepSeek-R1-Distill Models
<div align="center">
| **Model** | **Base Model** | **Download** |
| :------------: | :------------: | :------------: |
| DeepSeek-R1-Distill-Qwen-1.5B | [Qwen2.5-Math-1.5B](https://huggingface.co/Qwen/Qwen2.5-Math-1.5B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B) |
| DeepSeek-R1-Distill-Qwen-7B | [Qwen2.5-Math-7B](https://huggingface.co/Qwen/Qwen2.5-Math-7B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B) |
| DeepSeek-R1-Distill-Llama-8B | [Llama-3.1-8B](https://huggingface.co/meta-llama/Llama-3.1-8B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Llama-8B) |
| DeepSeek-R1-Distill-Qwen-14B | [Qwen2.5-14B](https://huggingface.co/Qwen/Qwen2.5-14B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B) |
|DeepSeek-R1-Distill-Qwen-32B | [Qwen2.5-32B](https://huggingface.co/Qwen/Qwen2.5-32B) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B) |
| DeepSeek-R1-Distill-Llama-70B | [Llama-3.3-70B-Instruct](https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct) | [🤗 HuggingFace](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Llama-70B) |
</div>
DeepSeek-R1-Distill models are fine-tuned based on open-source models, using samples generated by DeepSeek-R1.
We slightly change their configs and tokenizers. Please use our setting to run these models.
## 4. Evaluation Results
### DeepSeek-R1-Evaluation
For all our models, the maximum generation length is set to 32,768 tokens. For benchmarks requiring sampling, we use a temperature of $0.6$, a top-p value of $0.95$, and generate 64 responses per query to estimate pass@1.
<div align="center">
| Category | Benchmark (Metric) | Claude-3.5-Sonnet-1022 | GPT-4o 0513 | DeepSeek V3 | OpenAI o1-mini | OpenAI o1-1217 | DeepSeek R1 |
|----------|-------------------|----------------------|------------|--------------|----------------|------------|--------------|
| | Architecture | - | - | MoE | - | - | MoE |
| | # Activated Params | - | - | 37B | - | - | 37B |
| | # Total Params | - | - | 671B | - | - | 671B |
| English | MMLU (Pass@1) | 88.3 | 87.2 | 88.5 | 85.2 | **91.8** | 90.8 |
| | MMLU-Redux (EM) | 88.9 | 88.0 | 89.1 | 86.7 | - | **92.9** |
| | MMLU-Pro (EM) | 78.0 | 72.6 | 75.9 | 80.3 | - | **84.0** |
| | DROP (3-shot F1) | 88.3 | 83.7 | 91.6 | 83.9 | 90.2 | **92.2** |
| | IF-Eval (Prompt Strict) | **86.5** | 84.3 | 86.1 | 84.8 | - | 83.3 |
| | GPQA-Diamond (Pass@1) | 65.0 | 49.9 | 59.1 | 60.0 | **75.7** | 71.5 |
| | SimpleQA (Correct) | 28.4 | 38.2 | 24.9 | 7.0 | **47.0** | 30.1 |
| | FRAMES (Acc.) | 72.5 | 80.5 | 73.3 | 76.9 | - | **82.5** |
| | AlpacaEval2.0 (LC-winrate) | 52.0 | 51.1 | 70.0 | 57.8 | - | **87.6** |
| | ArenaHard (GPT-4-1106) | 85.2 | 80.4 | 85.5 | 92.0 | - | **92.3** |
| Code | LiveCodeBench (Pass@1-COT) | 33.8 | 34.2 | - | 53.8 | 63.4 | **65.9** |
| | Codeforces (Percentile) | 20.3 | 23.6 | 58.7 | 93.4 | **96.6** | 96.3 |
| | Codeforces (Rating) | 717 | 759 | 1134 | 1820 | **2061** | 2029 |
| | SWE Verified (Resolved) | **50.8** | 38.8 | 42.0 | 41.6 | 48.9 | 49.2 |
| | Aider-Polyglot (Acc.) | 45.3 | 16.0 | 49.6 | 32.9 | **61.7** | 53.3 |
| Math | AIME 2024 (Pass@1) | 16.0 | 9.3 | 39.2 | 63.6 | 79.2 | **79.8** |
| | MATH-500 (Pass@1) | 78.3 | 74.6 | 90.2 | 90.0 | 96.4 | **97.3** |
| | CNMO 2024 (Pass@1) | 13.1 | 10.8 | 43.2 | 67.6 | - | **78.8** |
| Chinese | CLUEWSC (EM) | 85.4 | 87.9 | 90.9 | 89.9 | - | **92.8** |
| | C-Eval (EM) | 76.7 | 76.0 | 86.5 | 68.9 | - | **91.8** |
| | C-SimpleQA (Correct) | 55.4 | 58.7 | **68.0** | 40.3 | - | 63.7 |
</div>
### Distilled Model Evaluation
<div align="center">
| Model | AIME 2024 pass@1 | AIME 2024 cons@64 | MATH-500 pass@1 | GPQA Diamond pass@1 | LiveCodeBench pass@1 | CodeForces rating |
|------------------------------------------|------------------|-------------------|-----------------|----------------------|----------------------|-------------------|
| GPT-4o-0513 | 9.3 | 13.4 | 74.6 | 49.9 | 32.9 | 759 |
| Claude-3.5-Sonnet-1022 | 16.0 | 26.7 | 78.3 | 65.0 | 38.9 | 717 |
| o1-mini | 63.6 | 80.0 | 90.0 | 60.0 | 53.8 | **1820** |
| QwQ-32B-Preview | 44.0 | 60.0 | 90.6 | 54.5 | 41.9 | 1316 |
| DeepSeek-R1-Distill-Qwen-1.5B | 28.9 | 52.7 | 83.9 | 33.8 | 16.9 | 954 |
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 83.3 | 92.8 | 49.1 | 37.6 | 1189 |
| DeepSeek-R1-Distill-Qwen-14B | 69.7 | 80.0 | 93.9 | 59.1 | 53.1 | 1481 |
| DeepSeek-R1-Distill-Qwen-32B | **72.6** | 83.3 | 94.3 | 62.1 | 57.2 | 1691 |
| DeepSeek-R1-Distill-Llama-8B | 50.4 | 80.0 | 89.1 | 49.0 | 39.6 | 1205 |
| DeepSeek-R1-Distill-Llama-70B | 70.0 | **86.7** | **94.5** | **65.2** | **57.5** | 1633 |
</div>
## 5. Chat Website & API Platform
You can chat with DeepSeek-R1 on DeepSeek's official website: [chat.deepseek.com](https://chat.deepseek.com), and switch on the button "DeepThink"
We also provide OpenAI-Compatible API at DeepSeek Platform: [platform.deepseek.com](https://platform.deepseek.com/)
## 6. How to Run Locally
### DeepSeek-R1 Models
Please visit [DeepSeek-V3](https://github.com/deepseek-ai/DeepSeek-V3) repo for more information about running DeepSeek-R1 locally.
**NOTE: Hugging Face's Transformers has not been directly supported yet.**
### DeepSeek-R1-Distill Models
DeepSeek-R1-Distill models can be utilized in the same manner as Qwen or Llama models.
For instance, you can easily start a service using [vLLM](https://github.com/vllm-project/vllm):
```shell
vllm serve deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --tensor-parallel-size 2 --max-model-len 32768 --enforce-eager
```
You can also easily start a service using [SGLang](https://github.com/sgl-project/sglang)
```bash
python3 -m sglang.launch_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-32B --trust-remote-code --tp 2
```
### Usage Recommendations
**We recommend adhering to the following configurations when utilizing the DeepSeek-R1 series models, including benchmarking, to achieve the expected performance:**
1. Set the temperature within the range of 0.5-0.7 (0.6 is recommended) to prevent endless repetitions or incoherent outputs.
2. **Avoid adding a system prompt; all instructions should be contained within the user prompt.**
3. For mathematical problems, it is advisable to include a directive in your prompt such as: "Please reason step by step, and put your final answer within \boxed{}."
4. When evaluating model performance, it is recommended to conduct multiple tests and average the results.
Additionally, we have observed that the DeepSeek-R1 series models tend to bypass thinking pattern (i.e., outputting "\<think\>\n\n\</think\>") when responding to certain queries, which can adversely affect the model's performance.
**To ensure that the model engages in thorough reasoning, we recommend enforcing the model to initiate its response with "\<think\>\n" at the beginning of every output.**
## 7. License
This code repository and the model weights are licensed under the [MIT License](https://github.com/deepseek-ai/DeepSeek-R1/blob/main/LICENSE).
DeepSeek-R1 series support commercial use, allow for any modifications and derivative works, including, but not limited to, distillation for training other LLMs. Please note that:
- DeepSeek-R1-Distill-Qwen-1.5B, DeepSeek-R1-Distill-Qwen-7B, DeepSeek-R1-Distill-Qwen-14B and DeepSeek-R1-Distill-Qwen-32B are derived from [Qwen-2.5 series](https://github.com/QwenLM/Qwen2.5), which are originally licensed under [Apache 2.0 License](https://huggingface.co/Qwen/Qwen2.5-1.5B/blob/main/LICENSE), and now finetuned with 800k samples curated with DeepSeek-R1.
- DeepSeek-R1-Distill-Llama-8B is derived from Llama3.1-8B-Base and is originally licensed under [llama3.1 license](https://huggingface.co/meta-llama/Llama-3.1-8B/blob/main/LICENSE).
- DeepSeek-R1-Distill-Llama-70B is derived from Llama3.3-70B-Instruct and is originally licensed under [llama3.3 license](https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct/blob/main/LICENSE).
## 8. Citation
```
@misc{deepseekai2025deepseekr1incentivizingreasoningcapability,
title={DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning},
author={DeepSeek-AI},
year={2025},
eprint={2501.12948},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2501.12948},
}
```
## 9. Contact
If you have any questions, please raise an issue or contact us at [[email protected]]([email protected]).
|
Mungert/granite-3.2-8b-instruct-GGUF | Mungert | 2025-06-15T19:41:01Z | 619 | 4 | transformers | [
"transformers",
"gguf",
"language",
"granite-3.2",
"text-generation",
"arxiv:0000.00000",
"base_model:ibm-granite/granite-3.1-8b-instruct",
"base_model:quantized:ibm-granite/granite-3.1-8b-instruct",
"license:apache-2.0",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-03-19T03:28:48Z | ---
pipeline_tag: text-generation
inference: false
license: apache-2.0
library_name: transformers
tags:
- language
- granite-3.2
base_model:
- ibm-granite/granite-3.1-8b-instruct
---
# <span style="color: #7FFF7F;">granite-3.2-8b-instruct GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `granite-3.2-8b-instruct-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `granite-3.2-8b-instruct-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `granite-3.2-8b-instruct-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `granite-3.2-8b-instruct-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `granite-3.2-8b-instruct-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `granite-3.2-8b-instruct-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `granite-3.2-8b-instruct-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `granite-3.2-8b-instruct-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `granite-3.2-8b-instruct-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `granite-3.2-8b-instruct-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `granite-3.2-8b-instruct-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# Granite-3.2-8B-Instruct
**Model Summary:**
Granite-3.2-8B-Instruct is an 8-billion-parameter, long-context AI model fine-tuned for thinking capabilities. Built on top of [Granite-3.1-8B-Instruct](https://huggingface.co/ibm-granite/granite-3.1-8b-instruct), it has been trained using a mix of permissively licensed open-source datasets and internally generated synthetic data designed for reasoning tasks. The model allows controllability of its thinking capability, ensuring it is applied only when required.
- **Developers:** Granite Team, IBM
- **Website**: [Granite Docs](https://www.ibm.com/granite/docs/)
- **Release Date**: February 26th, 2025
- **License:** [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0)
**Supported Languages:**
English, German, Spanish, French, Japanese, Portuguese, Arabic, Czech, Italian, Korean, Dutch, and Chinese. However, users may finetune this Granite model for languages beyond these 12 languages.
**Intended Use:**
This model is designed to handle general instruction-following tasks and can be integrated into AI assistants across various domains, including business applications.
**Capabilities**
* **Thinking**
* Summarization
* Text classification
* Text extraction
* Question-answering
* Retrieval Augmented Generation (RAG)
* Code related tasks
* Function-calling tasks
* Multilingual dialog use cases
* Long-context tasks including long document/meeting summarization, long document QA, etc.
**Generation:**
This is a simple example of how to use Granite-3.2-8B-Instruct model.
Install the following libraries:
```shell
pip install torch torchvision torchaudio
pip install accelerate
pip install transformers
```
Then, copy the snippet from the section that is relevant for your use case.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
import torch
model_path="ibm-granite/granite-3.2-8b-instruct"
device="cuda"
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map=device,
torch_dtype=torch.bfloat16,
)
tokenizer = AutoTokenizer.from_pretrained(
model_path
)
conv = [{"role": "user", "content":"You have 10 liters of a 30% acid solution. How many liters of a 70% acid solution must be added to achieve a 50% acid mixture?"}]
input_ids = tokenizer.apply_chat_template(conv, return_tensors="pt", thinking=True, return_dict=True, add_generation_prompt=True).to(device)
set_seed(42)
output = model.generate(
**input_ids,
max_new_tokens=8192,
)
prediction = tokenizer.decode(output[0, input_ids["input_ids"].shape[1]:], skip_special_tokens=True)
print(prediction)
```
**Example Outputs**
- thinking=True
```md
Here is my thought process:
1. We know we start with 10 liters of a 30% acid solution, so there's 3 liters of pure acid in it (10 liters * 0.3).
2. We need to determine how much of the 70% acid solution to add such that the final mixture is 50% acid.
3. Let's say x liters of the 70% acid solution are added. This will contribute 0.7x liters of pure acid.
4. The total volume of the new mixture will be 10 + x liters, and the total amount of pure acid will be 3 + 0.7x liters.
5. We need to set up an equation where (3 + 0.7x) / (10 + x) = 0.5 (since we want a 50% acid mixture).
6. Solving this equation for x will give us the volume of 70% solution needed.
Here is my response:
To solve this, we need to set up an equation based on the concentration of acid before and after mixing.
1. **Initial Acid Content**:
- We start with 10 liters of a 30% acid solution.
- Pure acid in this = 10 * 0.3 = 3 liters.
2. **Variable for Addition**:
- Let x be the liters of 70% acid solution to be added.
- Pure acid in x liters of 70% solution = 0.7x liters.
3. **Final Mixture Concentration**:
- Total volume of mixture = 10 + x liters.
- Total pure acid in the mixture = 3 (from initial solution) + 0.7x (from added solution).
4. **Setting up the equation for 50% acid concentration**:
- We require that the ratio of pure acid to total volume is 0.5 (50%).
- Therefore, the equation is:
\[
\frac{3 + 0.7x}{10 + x} = 0.5
\]
5. **Solving the equation**:
Multiply both sides by (10 + x) to clear the fraction:
\[
3 + 0.7x = 0.5(10 + x)
\]
Expanding the right side:
\[
3 + 0.7x = 5 + 0.5x
\]
Subtract 0.5x from both sides:
\[
3 + 0.2x = 5
\]
Subtract 3 from both sides:
\[
0.2x = 2
\]
Divide by 0.2:
\[
x = 10
\]
So, 10 liters of the 70% acid solution must be added to the initial 10 liters of 30% solution to get a 50% acid mixture.
Let's verify:
- Initial acid: 3 liters
- Acid from added solution: 0.7 * 10 = 7 liters
- Total acid: 3 + 7 = 10 liters
- Total volume: 10 + 10 = 20 liters
- Acid percentage: \(\frac{10}{20} = 0.5 = 50\%\)
This confirms our solution.
Final answer: 10 liters of 70% acid solution should be added.
```
- thinking=False
```md
Let's denote the amount of 70% acid solution to be added as x liters.
We start with 10 liters of a 30% acid solution, which means there are 0.3 * 10 = 3 liters of pure acid in it.
We want to end up with a 50% acid solution after adding x liters of 70% acid solution. The total volume of the mixture will be 10 + x liters, and we want half of this volume to be pure acid.
So, the amount of pure acid in the final mixture should be 0.5 * (10 + x) liters.
The amount of pure acid in the final mixture comes from two sources: the original 30% solution and the added 70% solution. So, we can set up the following equation:
3 (from the original solution) + 0.7x (from the added solution) = 0.5 * (10 + x)
Now, let's solve for x:
3 + 0.7x = 5 + 0.5x
0.7x - 0.5x = 5 - 3
0.2x = 2
x = 2 / 0.2
x = 10
So, you need to add 10 liters of a 70% acid solution to the 10 liters of a 30% acid solution to get a 50% acid mixture.
```
**Evaluation Results:**
<table>
<thead>
<tr>
<th style="text-align:left; background-color: #001d6c; color: white;">Models</th>
<th style="text-align:center; background-color: #001d6c; color: white;">ArenaHard</th>
<th style="text-align:center; background-color: #001d6c; color: white;">Alpaca-Eval-2</th>
<th style="text-align:center; background-color: #001d6c; color: white;">MMLU</th>
<th style="text-align:center; background-color: #001d6c; color: white;">PopQA</th>
<th style="text-align:center; background-color: #001d6c; color: white;">TruthfulQA</th>
<th style="text-align:center; background-color: #001d6c; color: white;">BigBenchHard</th>
<th style="text-align:center; background-color: #001d6c; color: white;">DROP</th>
<th style="text-align:center; background-color: #001d6c; color: white;">GSM8K</th>
<th style="text-align:center; background-color: #001d6c; color: white;">HumanEval</th>
<th style="text-align:center; background-color: #001d6c; color: white;">HumanEval+</th>
<th style="text-align:center; background-color: #001d6c; color: white;">IFEval</th>
<th style="text-align:center; background-color: #001d6c; color: white;">AttaQ</th>
</tr></thead>
<tbody>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;">Llama-3.1-8B-Instruct</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">36.43</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">27.22</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">69.15</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">28.79</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">52.79</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">72.66</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">61.48</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">83.24</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">85.32</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">80.15</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">79.10</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">83.43</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;">DeepSeek-R1-Distill-Llama-8B</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">17.17</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">21.85</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">45.80</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">13.25</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">47.43</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">65.71</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">44.46</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">72.18</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">67.54</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">62.91</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">66.50</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">42.87</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;">Qwen-2.5-7B-Instruct</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">25.44</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">30.34</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">74.30</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">18.12</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">63.06</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">70.40</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">54.71</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">84.46</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">93.35</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">89.91</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">74.90</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">81.90</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;">DeepSeek-R1-Distill-Qwen-7B</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">10.36</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">15.35</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">50.72</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">9.94</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">47.14</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">65.04</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">42.76</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">78.47</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">79.89</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">78.43</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">59.10</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">42.45</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;">Granite-3.1-8B-Instruct</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">37.58</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">30.34</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">66.77</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">28.7</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">65.84</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">68.55</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">50.78</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">79.15</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">89.63</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">85.79</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">73.20</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">85.73</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;">Granite-3.1-2B-Instruct</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">23.3</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">27.17</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">57.11</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">20.55</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">59.79</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">54.46</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">18.68</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">67.55</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">79.45</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">75.26</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">63.59</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">84.7</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;">Granite-3.2-2B-Instruct</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">24.86</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">34.51</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">57.18</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">20.56</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">59.8</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">52.27</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">21.12</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">67.02</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">80.13</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">73.39</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">61.55</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">83.23</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;"><b>Granite-3.2-8B-Instruct</b></td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">55.25</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">61.19</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">66.79</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">28.04</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">66.92</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">64.77</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">50.95</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">81.65</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">89.35</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">85.72</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">74.31</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">85.42</td>
</tr>
</tbody></table>
**Training Data:**
Overall, our training data is largely comprised of two key sources: (1) publicly available datasets with permissive license, (2) internal synthetically generated data targeted to enhance reasoning capabilites.
<!-- A detailed attribution of datasets can be found in [Granite 3.2 Technical Report (coming soon)](#), and [Accompanying Author List](https://github.com/ibm-granite/granite-3.0-language-models/blob/main/author-ack.pdf). -->
**Infrastructure:**
We train Granite-3.2-8B-Instruct using IBM's super computing cluster, Blue Vela, which is outfitted with NVIDIA H100 GPUs. This cluster provides a scalable and efficient infrastructure for training our models over thousands of GPUs.
**Ethical Considerations and Limitations:**
Granite-3.2-8B-Instruct builds upon Granite-3.1-8B-Instruct, leveraging both permissively licensed open-source and select proprietary data for enhanced performance. Since it inherits its foundation from the previous model, all ethical considerations and limitations applicable to [Granite-3.1-8B-Instruct](https://huggingface.co/ibm-granite/granite-3.1-8b-instruct) remain relevant.
**Resources**
- ⭐️ Learn about the latest updates with Granite: https://www.ibm.com/granite
- 📄 Get started with tutorials, best practices, and prompt engineering advice: https://www.ibm.com/granite/docs/
- 💡 Learn about the latest Granite learning resources: https://ibm.biz/granite-learning-resources
<!-- ## Citation
```
@misc{granite-models,
author = {author 1, author2, ...},
title = {},
journal = {},
volume = {},
year = {2024},
url = {https://arxiv.org/abs/0000.00000},
}
``` --> |
Mungert/Mistral-Small-3.1-24B-Instruct-2503-GGUF | Mungert | 2025-06-15T19:40:56Z | 12,272 | 8 | vllm | [
"vllm",
"gguf",
"image-text-to-text",
"en",
"fr",
"de",
"es",
"pt",
"it",
"ja",
"ko",
"ru",
"zh",
"ar",
"fa",
"id",
"ms",
"ne",
"pl",
"ro",
"sr",
"sv",
"tr",
"uk",
"vi",
"hi",
"bn",
"base_model:mistralai/Mistral-Small-3.1-24B-Base-2503",
"base_model:quantized:mistralai/Mistral-Small-3.1-24B-Base-2503",
"license:apache-2.0",
"region:us",
"imatrix",
"conversational"
] | image-text-to-text | 2025-03-19T01:11:29Z | ---
language:
- en
- fr
- de
- es
- pt
- it
- ja
- ko
- ru
- zh
- ar
- fa
- id
- ms
- ne
- pl
- ro
- sr
- sv
- tr
- uk
- vi
- hi
- bn
license: apache-2.0
library_name: vllm
inference: false
base_model:
- mistralai/Mistral-Small-3.1-24B-Base-2503
extra_gated_description: >-
If you want to learn more about how we process your personal data, please read
our <a href="https://mistral.ai/terms/">Privacy Policy</a>.
pipeline_tag: image-text-to-text
---
# <span style="color: #7FFF7F;">Mistral-Small-3.1-24B-Instruct-2503 GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`92ecdcc0`](https://github.com/ggerganov/llama.cpp/commit/92ecdcc06a4c405a415bcaa0cb772bc560aa23b1).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Mistral-Small-3.1-24B-Instruct-2503-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Mistral-Small-3.1-24B-Instruct-2503-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Mistral-Small-3.1-24B-Instruct-2503-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Mistral-Small-3.1-24B-Instruct-2503-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Mistral-Small-3.1-24B-Instruct-2503-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Mistral-Small-3.1-24B-Instruct-2503-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Mistral-Small-3.1-24B-Instruct-2503-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Mistral-Small-3.1-24B-Instruct-2503-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Mistral-Small-3.1-24B-Instruct-2503-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Mistral-Small-3.1-24B-Instruct-2503-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Mistral-Small-3.1-24B-Instruct-2503-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# Model Card for Mistral-Small-3.1-24B-Instruct-2503
Building upon Mistral Small 3 (2501), Mistral Small 3.1 (2503) **adds state-of-the-art vision understanding** and enhances **long context capabilities up to 128k tokens** without compromising text performance.
With 24 billion parameters, this model achieves top-tier capabilities in both text and vision tasks.
This model is an instruction-finetuned version of: [Mistral-Small-3.1-24B-Base-2503](https://huggingface.co/mistralai/Mistral-Small-3.1-24B-Base-2503).
Mistral Small 3.1 can be deployed locally and is exceptionally "knowledge-dense," fitting within a single RTX 4090 or a 32GB RAM MacBook once quantized.
It is ideal for:
- Fast-response conversational agents.
- Low-latency function calling.
- Subject matter experts via fine-tuning.
- Local inference for hobbyists and organizations handling sensitive data.
- Programming and math reasoning.
- Long document understanding.
- Visual understanding.
For enterprises requiring specialized capabilities (increased context, specific modalities, domain-specific knowledge, etc.), we will release commercial models beyond what Mistral AI contributes to the community.
Learn more about Mistral Small 3.1 in our [blog post](https://mistral.ai/news/mistral-small-3-1/).
## Key Features
- **Vision:** Vision capabilities enable the model to analyze images and provide insights based on visual content in addition to text.
- **Multilingual:** Supports dozens of languages, including English, French, German, Greek, Hindi, Indonesian, Italian, Japanese, Korean, Malay, Nepali, Polish, Portuguese, Romanian, Russian, Serbian, Spanish, Swedish, Turkish, Ukrainian, Vietnamese, Arabic, Bengali, Chinese, Farsi.
- **Agent-Centric:** Offers best-in-class agentic capabilities with native function calling and JSON outputting.
- **Advanced Reasoning:** State-of-the-art conversational and reasoning capabilities.
- **Apache 2.0 License:** Open license allowing usage and modification for both commercial and non-commercial purposes.
- **Context Window:** A 128k context window.
- **System Prompt:** Maintains strong adherence and support for system prompts.
- **Tokenizer:** Utilizes a Tekken tokenizer with a 131k vocabulary size.
## Benchmark Results
When available, we report numbers previously published by other model providers, otherwise we re-evaluate them using our own evaluation harness.
### Pretrain Evals
| Model | MMLU (5-shot) | MMLU Pro (5-shot CoT) | TriviaQA | GPQA Main (5-shot CoT)| MMMU |
|--------------------------------|---------------|-----------------------|------------|-----------------------|-----------|
| **Small 3.1 24B Base** | **81.01%** | **56.03%** | 80.50% | **37.50%** | **59.27%**|
| Gemma 3 27B PT | 78.60% | 52.20% | **81.30%** | 24.30% | 56.10% |
### Instruction Evals
#### Text
| Model | MMLU | MMLU Pro (5-shot CoT) | MATH | GPQA Main (5-shot CoT) | GPQA Diamond (5-shot CoT )| MBPP | HumanEval | SimpleQA (TotalAcc)|
|--------------------------------|-----------|-----------------------|------------------------|------------------------|---------------------------|-----------|-----------|--------------------|
| **Small 3.1 24B Instruct** | 80.62% | 66.76% | 69.30% | **44.42%** | **45.96%** | 74.71% | **88.41%**| **10.43%** |
| Gemma 3 27B IT | 76.90% | **67.50%** | **89.00%** | 36.83% | 42.40% | 74.40% | 87.80% | 10.00% |
| GPT4o Mini | **82.00%**| 61.70% | 70.20% | 40.20% | 39.39% | 84.82% | 87.20% | 9.50% |
| Claude 3.5 Haiku | 77.60% | 65.00% | 69.20% | 37.05% | 41.60% | **85.60%**| 88.10% | 8.02% |
| Cohere Aya-Vision 32B | 72.14% | 47.16% | 41.98% | 34.38% | 33.84% | 70.43% | 62.20% | 7.65% |
#### Vision
| Model | MMMU | MMMU PRO | Mathvista | ChartQA | DocVQA | AI2D | MM MT Bench |
|--------------------------------|------------|-----------|-----------|-----------|-----------|-------------|-------------|
| **Small 3.1 24B Instruct** | 64.00% | **49.25%**| **68.91%**| 86.24% | **94.08%**| **93.72%** | **7.3** |
| Gemma 3 27B IT | **64.90%** | 48.38% | 67.60% | 76.00% | 86.60% | 84.50% | 7 |
| GPT4o Mini | 59.40% | 37.60% | 56.70% | 76.80% | 86.70% | 88.10% | 6.6 |
| Claude 3.5 Haiku | 60.50% | 45.03% | 61.60% | **87.20%**| 90.00% | 92.10% | 6.5 |
| Cohere Aya-Vision 32B | 48.20% | 31.50% | 50.10% | 63.04% | 72.40% | 82.57% | 4.1 |
### Multilingual Evals
| Model | Average | European | East Asian | Middle Eastern |
|--------------------------------|------------|------------|------------|----------------|
| **Small 3.1 24B Instruct** | **71.18%** | **75.30%** | **69.17%** | 69.08% |
| Gemma 3 27B IT | 70.19% | 74.14% | 65.65% | 70.76% |
| GPT4o Mini | 70.36% | 74.21% | 65.96% | **70.90%** |
| Claude 3.5 Haiku | 70.16% | 73.45% | 67.05% | 70.00% |
| Cohere Aya-Vision 32B | 62.15% | 64.70% | 57.61% | 64.12% |
### Long Context Evals
| Model | LongBench v2 | RULER 32K | RULER 128K |
|--------------------------------|-----------------|-------------|------------|
| **Small 3.1 24B Instruct** | **37.18%** | **93.96%** | 81.20% |
| Gemma 3 27B IT | 34.59% | 91.10% | 66.00% |
| GPT4o Mini | 29.30% | 90.20% | 65.8% |
| Claude 3.5 Haiku | 35.19% | 92.60% | **91.90%** |
## Basic Instruct Template (V7-Tekken)
```
<s>[SYSTEM_PROMPT]<system prompt>[/SYSTEM_PROMPT][INST]<user message>[/INST]<assistant response></s>[INST]<user message>[/INST]
```
*`<system_prompt>`, `<user message>` and `<assistant response>` are placeholders.*
***Please make sure to use [mistral-common](https://github.com/mistralai/mistral-common) as the source of truth***
## Usage
The model can be used with the following frameworks;
- [`vllm (recommended)`](https://github.com/vllm-project/vllm): See [here](#vllm)
**Note 1**: We recommend using a relatively low temperature, such as `temperature=0.15`.
**Note 2**: Make sure to add a system prompt to the model to best tailer it for your needs. If you want to use the model as a general assistant, we recommend the following
system prompt:
```
system_prompt = """You are Mistral Small 3.1, a Large Language Model (LLM) created by Mistral AI, a French startup headquartered in Paris.
You power an AI assistant called Le Chat.
Your knowledge base was last updated on 2023-10-01.
The current date is {today}.
When you're not sure about some information, you say that you don't have the information and don't make up anything.
If the user's question is not clear, ambiguous, or does not provide enough context for you to accurately answer the question, you do not try to answer it right away and you rather ask the user to clarify their request (e.g. "What are some good restaurants around me?" => "Where are you?" or "When is the next flight to Tokyo" => "Where do you travel from?").
You are always very attentive to dates, in particular you try to resolve dates (e.g. "yesterday" is {yesterday}) and when asked about information at specific dates, you discard information that is at another date.
You follow these instructions in all languages, and always respond to the user in the language they use or request.
Next sections describe the capabilities that you have.
# WEB BROWSING INSTRUCTIONS
You cannot perform any web search or access internet to open URLs, links etc. If it seems like the user is expecting you to do so, you clarify the situation and ask the user to copy paste the text directly in the chat.
# MULTI-MODAL INSTRUCTIONS
You have the ability to read images, but you cannot generate images. You also cannot transcribe audio files or videos.
You cannot read nor transcribe audio files or videos."""
```
### vLLM (recommended)
We recommend using this model with the [vLLM library](https://github.com/vllm-project/vllm)
to implement production-ready inference pipelines.
**_Installation_**
Make sure you install [`vLLM >= 0.8.1`](https://github.com/vllm-project/vllm/releases/tag/v0.8.1):
```
pip install vllm --upgrade
```
Doing so should automatically install [`mistral_common >= 1.5.4`](https://github.com/mistralai/mistral-common/releases/tag/v1.5.4).
To check:
```
python -c "import mistral_common; print(mistral_common.__version__)"
```
You can also make use of a ready-to-go [docker image](https://github.com/vllm-project/vllm/blob/main/Dockerfile) or on the [docker hub](https://hub.docker.com/layers/vllm/vllm-openai/latest/images/sha256-de9032a92ffea7b5c007dad80b38fd44aac11eddc31c435f8e52f3b7404bbf39).
#### Server
We recommand that you use Mistral-Small-3.1-24B-Instruct-2503 in a server/client setting.
1. Spin up a server:
```
vllm serve mistralai/Mistral-Small-3.1-24B-Instruct-2503 --tokenizer_mode mistral --config_format mistral --load_format mistral --tool-call-parser mistral --enable-auto-tool-choice --limit_mm_per_prompt 'image=10' --tensor-parallel-size 2
```
**Note:** Running Mistral-Small-3.1-24B-Instruct-2503 on GPU requires ~55 GB of GPU RAM in bf16 or fp16.
2. To ping the client you can use a simple Python snippet.
```py
import requests
import json
from huggingface_hub import hf_hub_download
from datetime import datetime, timedelta
url = "http://<your-server-url>:8000/v1/chat/completions"
headers = {"Content-Type": "application/json", "Authorization": "Bearer token"}
model = "mistralai/Mistral-Small-3.1-24B-Instruct-2503"
def load_system_prompt(repo_id: str, filename: str) -> str:
file_path = hf_hub_download(repo_id=repo_id, filename=filename)
with open(file_path, "r") as file:
system_prompt = file.read()
today = datetime.today().strftime("%Y-%m-%d")
yesterday = (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d")
model_name = repo_id.split("/")[-1]
return system_prompt.format(name=model_name, today=today, yesterday=yesterday)
SYSTEM_PROMPT = load_system_prompt(model, "SYSTEM_PROMPT.txt")
image_url = "https://huggingface.co/datasets/patrickvonplaten/random_img/resolve/main/europe.png"
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": [
{
"type": "text",
"text": "Which of the depicted countries has the best food? Which the second and third and fourth? Name the country, its color on the map and one its city that is visible on the map, but is not the capital. Make absolutely sure to only name a city that can be seen on the map.",
},
{"type": "image_url", "image_url": {"url": image_url}},
],
},
]
data = {"model": model, "messages": messages, "temperature": 0.15}
response = requests.post(url, headers=headers, data=json.dumps(data))
print(response.json()["choices"][0]["message"]["content"])
# Determining the "best" food is highly subjective and depends on personal preferences. However, based on general popularity and recognition, here are some countries known for their cuisine:
# 1. **Italy** - Color: Light Green - City: Milan
# - Italian cuisine is renowned worldwide for its pasta, pizza, and various regional specialties.
# 2. **France** - Color: Brown - City: Lyon
# - French cuisine is celebrated for its sophistication, including dishes like coq au vin, bouillabaisse, and pastries like croissants and éclairs.
# 3. **Spain** - Color: Yellow - City: Bilbao
# - Spanish cuisine offers a variety of flavors, from paella and tapas to jamón ibérico and churros.
# 4. **Greece** - Not visible on the map
# - Greek cuisine is known for dishes like moussaka, souvlaki, and baklava. Unfortunately, Greece is not visible on the provided map, so I cannot name a city.
# Since Greece is not visible on the map, I'll replace it with another country known for its good food:
# 4. **Turkey** - Color: Light Green (east part of the map) - City: Istanbul
# - Turkish cuisine is diverse and includes dishes like kebabs, meze, and baklava.
```
### Function calling
Mistral-Small-3.1-24-Instruct-2503 is excellent at function / tool calling tasks via vLLM. *E.g.:*
<details>
<summary>Example</summary>
```py
import requests
import json
from huggingface_hub import hf_hub_download
from datetime import datetime, timedelta
url = "http://<your-url>:8000/v1/chat/completions"
headers = {"Content-Type": "application/json", "Authorization": "Bearer token"}
model = "mistralai/Mistral-Small-3.1-24B-Instruct-2503"
def load_system_prompt(repo_id: str, filename: str) -> str:
file_path = hf_hub_download(repo_id=repo_id, filename=filename)
with open(file_path, "r") as file:
system_prompt = file.read()
today = datetime.today().strftime("%Y-%m-%d")
yesterday = (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d")
model_name = repo_id.split("/")[-1]
return system_prompt.format(name=model_name, today=today, yesterday=yesterday)
SYSTEM_PROMPT = load_system_prompt(model, "SYSTEM_PROMPT.txt")
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "The city to find the weather for, e.g. 'San Francisco'",
},
"state": {
"type": "string",
"description": "The state abbreviation, e.g. 'CA' for California",
},
"unit": {
"type": "string",
"description": "The unit for temperature",
"enum": ["celsius", "fahrenheit"],
},
},
"required": ["city", "state", "unit"],
},
},
},
{
"type": "function",
"function": {
"name": "rewrite",
"description": "Rewrite a given text for improved clarity",
"parameters": {
"type": "object",
"properties": {
"text": {
"type": "string",
"description": "The input text to rewrite",
}
},
},
},
},
]
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{
"role": "user",
"content": "Could you please make the below article more concise?\n\nOpenAI is an artificial intelligence research laboratory consisting of the non-profit OpenAI Incorporated and its for-profit subsidiary corporation OpenAI Limited Partnership.",
},
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "bbc5b7ede",
"type": "function",
"function": {
"name": "rewrite",
"arguments": '{"text": "OpenAI is an artificial intelligence research laboratory consisting of the non-profit OpenAI Incorporated and its for-profit subsidiary corporation OpenAI Limited Partnership."}',
},
}
],
},
{
"role": "tool",
"content": '{"action":"rewrite","outcome":"OpenAI is a FOR-profit company."}',
"tool_call_id": "bbc5b7ede",
"name": "rewrite",
},
{
"role": "assistant",
"content": "---\n\nOpenAI is a FOR-profit company.",
},
{
"role": "user",
"content": "Can you tell me what the temperature will be in Dallas, in Fahrenheit?",
},
]
data = {"model": model, "messages": messages, "tools": tools, "temperature": 0.15}
response = requests.post(url, headers=headers, data=json.dumps(data))
print(response.json()["choices"][0]["message"]["tool_calls"])
# [{'id': '8PdihwL6d', 'type': 'function', 'function': {'name': 'get_current_weather', 'arguments': '{"city": "Dallas", "state": "TX", "unit": "fahrenheit"}'}}]
```
</details>
#### Offline
```py
from vllm import LLM
from vllm.sampling_params import SamplingParams
from datetime import datetime, timedelta
SYSTEM_PROMPT = "You are a conversational agent that always answers straight to the point, always end your accurate response with an ASCII drawing of a cat."
user_prompt = "Give me 5 non-formal ways to say 'See you later' in French."
messages = [
{
"role": "system",
"content": SYSTEM_PROMPT
},
{
"role": "user",
"content": user_prompt
},
]
model_name = "mistralai/Mistral-Small-3.1-24B-Instruct-2503"
# note that running this model on GPU requires over 60 GB of GPU RAM
llm = LLM(model=model_name, tokenizer_mode="mistral")
sampling_params = SamplingParams(max_tokens=512, temperature=0.15)
outputs = llm.chat(messages, sampling_params=sampling_params)
print(outputs[0].outputs[0].text)
# Here are five non-formal ways to say "See you later" in French:
# 1. **À plus tard** - Until later
# 2. **À toute** - See you soon (informal)
# 3. **Salut** - Bye (can also mean hi)
# 4. **À plus** - See you later (informal)
# 5. **Ciao** - Bye (informal, borrowed from Italian)
# ```
# /\_/\
# ( o.o )
# > ^ <
# ```
```
### Transformers (untested)
Transformers-compatible model weights are also uploaded (thanks a lot @cyrilvallez).
However the transformers implementation was **not throughly tested**, but only on "vibe-checks".
Hence, we can only ensure 100% correct behavior when using the original weight format with vllm (see above). |
Mungert/granite-3.2-2b-instruct-GGUF | Mungert | 2025-06-15T19:40:53Z | 658 | 6 | transformers | [
"transformers",
"gguf",
"language",
"granite-3.2",
"text-generation",
"arxiv:0000.00000",
"base_model:ibm-granite/granite-3.1-2b-instruct",
"base_model:quantized:ibm-granite/granite-3.1-2b-instruct",
"license:apache-2.0",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-03-18T21:59:43Z | ---
pipeline_tag: text-generation
inference: false
license: apache-2.0
library_name: transformers
tags:
- language
- granite-3.2
base_model:
- ibm-granite/granite-3.1-2b-instruct
---
# <span style="color: #7FFF7F;">granite-3.2-2b-instruct GGUF Models</span>
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `granite-3.2-2b-instruct-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `granite-3.2-2b-instruct-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `granite-3.2-2b-instruct-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `granite-3.2-2b-instruct-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `granite-3.2-2b-instruct-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `granite-3.2-2b-instruct-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `granite-3.2-2b-instruct-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `granite-3.2-2b-instruct-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `granite-3.2-2b-instruct-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `granite-3.2-2b-instruct-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `granite-3.2-2b-instruct-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# Granite-3.2-2B-Instruct
**Model Summary:**
Granite-3.2-2B-Instruct is an 2-billion-parameter, long-context AI model fine-tuned for thinking capabilities. Built on top of [Granite-3.1-2B-Instruct](https://huggingface.co/ibm-granite/granite-3.1-2b-instruct), it has been trained using a mix of permissively licensed open-source datasets and internally generated synthetic data designed for reasoning tasks. The model allows controllability of its thinking capability, ensuring it is applied only when required.
- **Developers:** Granite Team, IBM
- **Website**: [Granite Docs](https://www.ibm.com/granite/docs/)
- **Release Date**: February 26th, 2025
- **License:** [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0)
**Supported Languages:**
English, German, Spanish, French, Japanese, Portuguese, Arabic, Czech, Italian, Korean, Dutch, and Chinese. However, users may finetune this Granite model for languages beyond these 12 languages.
**Intended Use:**
This model is designed to handle general instruction-following tasks and can be integrated into AI assistants across various domains, including business applications.
**Capabilities**
* **Thinking**
* Summarization
* Text classification
* Text extraction
* Question-answering
* Retrieval Augmented Generation (RAG)
* Code related tasks
* Function-calling tasks
* Multilingual dialog use cases
* Long-context tasks including long document/meeting summarization, long document QA, etc.
**Generation:**
This is a simple example of how to use Granite-3.2-2B-Instruct model.
Install the following libraries:
```shell
pip install torch torchvision torchaudio
pip install accelerate
pip install transformers
```
Then, copy the snippet from the section that is relevant for your use case.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, set_seed
import torch
model_path="ibm-granite/granite-3.2-2b-instruct"
device="cuda"
model = AutoModelForCausalLM.from_pretrained(
model_path,
device_map=device,
torch_dtype=torch.bfloat16,
)
tokenizer = AutoTokenizer.from_pretrained(
model_path
)
conv = [{"role": "user", "content":"You have 10 liters of a 30% acid solution. How many liters of a 70% acid solution must be added to achieve a 50% acid mixture?"}]
input_ids = tokenizer.apply_chat_template(conv, return_tensors="pt", thinking=True, return_dict=True, add_generation_prompt=True).to(device)
set_seed(42)
output = model.generate(
**input_ids,
max_new_tokens=8192,
)
prediction = tokenizer.decode(output[0, input_ids["input_ids"].shape[1]:], skip_special_tokens=True)
print(prediction)
```
**Example Outputs**
- thinking=True
```md
Here is my thought process:
1. First, let's understand the composition of the initial 10 liters of 30% acid solution:
- Acid content = 30% of 10 liters = 0.30 * 10 = 3 liters
2. We want to end up with a 50% acid solution. Let's denote the volume of the 70% acid solution to be added as 'x' liters.
3. The amount of acid in the final mixture (50% solution) should equal the initial acid content plus the acid from the added 70% solution.
- Total acid in final mixture = 0.50 * (10 + x)
4. The equation representing the total acid content is:
3 (from initial solution) + 0.70 * x (from added solution) = 0.50 * (10 + x)
5. Now, we solve for 'x':
3 + 0.70x = 5 + 0.50x
0.70x - 0.50x = 5 - 3
0.20x = 2
x = 2 / 0.20
x = 10 liters
6. Therefore, 10 liters of a 70% acid solution must be added to the initial 10 liters of 30% acid solution to achieve a 50% acid mixture.
Here is my response:
To solve this problem, we need to determine how much of a 70% acid solution must be added to a 10-liter solution that is already 30% acid to create a new mixture that is 50% acid. Here's how to calculate it:
1. **Initial Acid Content**:
- The initial 10-liter solution contains 3 liters of acid (since 30% of 10 liters).
2. **Desired Final Acid Content**:
- We want the final mixture to be 50% acid.
3. **Equation Setup**:
- Let 'x' be the volume (in liters) of the 70% acid solution to be added.
- The equation representing the total acid content in the final mixture (which is 10 liters from the initial solution plus 'x' liters of the added solution) should equal 50% of the total volume (10 + x).
- This gives us: 3 (acid from initial solution) + 0.70x (acid from added solution) = 0.50(10 + x)
4. **Solving the Equation**:
- First, simplify the right side of the equation: 0.50(10 + x) = 5 + 0.50x
- Now, the equation is: 3 + 0.70x = 5 + 0.50x
- Subtract 0.50x from both sides: 0.20x = 2
- Divide both sides by 0.20: x = 2 / 0.20
- x = 10 liters
5. **Conclusion**:
- To achieve a 50% acid mixture from the initial 30% solution, you need to add 10 liters of a 70% acid solution.
So, the final answer is that 10 liters of a 70% acid solution must be added to the initial 10 liters of 30% acid solution.
```
- thinking=False
```md
To solve this problem, we'll use the concept of volume and concentration. Let's denote the amount of 70% acid solution we need to add as "x" liters.
First, let's find out how much acid is in the initial 10-liter solution:
Acid in initial solution = 30% of 10 liters = 0.30 * 10 = 3 liters
Now, we want to end up with a 50% acid solution in a total volume of (10 + x) liters. Let's denote the final volume as V.
Final acid concentration = 50%
Final acid amount = 50% of V = 0.50 * V
We know the initial acid amount and the final acid amount, so we can set up an equation:
Initial acid amount + Acid from added solution = Final acid amount
3 liters + (70% of x) = 0.50 * (10 + x)
Now, let's solve for x:
0.70x + 3 = 0.50 * 10 + 0.50x
0.70x - 0.50x = 0.50 * 10 - 3
0.20x = 5 - 3
0.20x = 2
x = 2 / 0.20
x = 10 liters
So, you need to add 10 liters of a 70% acid solution to the initial 10-liter 30% acid solution to achieve a 50% acid mixture.
```
**Evaluation Results:**
<table>
<thead>
<tr>
<th style="text-align:left; background-color: #001d6c; color: white;">Models</th>
<th style="text-align:center; background-color: #001d6c; color: white;">ArenaHard</th>
<th style="text-align:center; background-color: #001d6c; color: white;">Alpaca-Eval-2</th>
<th style="text-align:center; background-color: #001d6c; color: white;">MMLU</th>
<th style="text-align:center; background-color: #001d6c; color: white;">PopQA</th>
<th style="text-align:center; background-color: #001d6c; color: white;">TruthfulQA</th>
<th style="text-align:center; background-color: #001d6c; color: white;">BigBenchHard</th>
<th style="text-align:center; background-color: #001d6c; color: white;">DROP</th>
<th style="text-align:center; background-color: #001d6c; color: white;">GSM8K</th>
<th style="text-align:center; background-color: #001d6c; color: white;">HumanEval</th>
<th style="text-align:center; background-color: #001d6c; color: white;">HumanEval+</th>
<th style="text-align:center; background-color: #001d6c; color: white;">IFEval</th>
<th style="text-align:center; background-color: #001d6c; color: white;">AttaQ</th>
</tr></thead>
<tbody>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;">Llama-3.1-8B-Instruct</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">36.43</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">27.22</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">69.15</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">28.79</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">52.79</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">72.66</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">61.48</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">83.24</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">85.32</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">80.15</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">79.10</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">83.43</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;">DeepSeek-R1-Distill-Llama-8B</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">17.17</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">21.85</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">45.80</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">13.25</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">47.43</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">65.71</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">44.46</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">72.18</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">67.54</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">62.91</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">66.50</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">42.87</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;">Qwen-2.5-7B-Instruct</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">25.44</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">30.34</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">74.30</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">18.12</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">63.06</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">70.40</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">54.71</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">84.46</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">93.35</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">89.91</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">74.90</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">81.90</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;">DeepSeek-R1-Distill-Qwen-7B</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">10.36</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">15.35</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">50.72</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">9.94</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">47.14</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">65.04</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">42.76</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">78.47</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">79.89</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">78.43</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">59.10</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">42.45</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;">Granite-3.1-8B-Instruct</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">37.58</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">30.34</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">66.77</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">28.7</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">65.84</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">68.55</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">50.78</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">79.15</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">89.63</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">85.79</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">73.20</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">85.73</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;">Granite-3.1-2B-Instruct</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">23.3</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">27.17</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">57.11</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">20.55</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">59.79</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">54.46</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">18.68</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">67.55</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">79.45</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">75.26</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">63.59</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">84.7</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;">Granite-3.2-8B-Instruct</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">55.25</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">61.19</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">66.79</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">28.04</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">66.92</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">64.77</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">50.95</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">81.65</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">89.35</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">85.72</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">74.31</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">85.42</td>
</tr>
<tr>
<td style="text-align:left; background-color: #DAE8FF; color: black;"><b>Granite-3.2-2B-Instruct</b></td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">24.86</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">34.51</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">57.18</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">20.56</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">59.8</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">52.27</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">21.12</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">67.02</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">80.13</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">73.39</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">61.55</td>
<td style="text-align:center; background-color: #DAE8FF; color: black;">83.23</td>
</tr>
</tbody></table>
**Training Data:**
Overall, our training data is largely comprised of two key sources: (1) publicly available datasets with permissive license, (2) internal synthetically generated data targeted to enhance reasoning capabilites.
<!-- A detailed attribution of datasets can be found in [Granite 3.2 Technical Report (coming soon)](#), and [Accompanying Author List](https://github.com/ibm-granite/granite-3.0-language-models/blob/main/author-ack.pdf). -->
**Infrastructure:**
We train Granite-3.2-2B-Instruct using IBM's super computing cluster, Blue Vela, which is outfitted with NVIDIA H100 GPUs. This cluster provides a scalable and efficient infrastructure for training our models over thousands of GPUs.
**Ethical Considerations and Limitations:**
Granite-3.2-2B-Instruct builds upon Granite-3.1-2B-Instruct, leveraging both permissively licensed open-source and select proprietary data for enhanced performance. Since it inherits its foundation from the previous model, all ethical considerations and limitations applicable to [Granite-3.1-2B-Instruct](https://huggingface.co/ibm-granite/granite-3.1-2b-instruct) remain relevant.
**Resources**
- ⭐️ Learn about the latest updates with Granite: https://www.ibm.com/granite
- 📄 Get started with tutorials, best practices, and prompt engineering advice: https://www.ibm.com/granite/docs/
- 💡 Learn about the latest Granite learning resources: https://ibm.biz/granite-learning-resources
<!-- ## Citation
```
@misc{granite-models,
author = {author 1, author2, ...},
title = {},
journal = {},
volume = {},
year = {2024},
url = {https://arxiv.org/abs/0000.00000},
}
``` --> |
Mungert/DeepHermes-3-Llama-3-8B-Preview-GGUF | Mungert | 2025-06-15T19:40:29Z | 1,885 | 5 | transformers | [
"transformers",
"gguf",
"Llama-3",
"instruct",
"finetune",
"chatml",
"gpt4",
"synthetic data",
"distillation",
"function calling",
"json mode",
"axolotl",
"roleplaying",
"chat",
"reasoning",
"r1",
"vllm",
"en",
"base_model:meta-llama/Llama-3.1-8B",
"base_model:quantized:meta-llama/Llama-3.1-8B",
"license:llama3",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-03-17T14:30:06Z | ---
language:
- en
license: llama3
tags:
- Llama-3
- instruct
- finetune
- chatml
- gpt4
- synthetic data
- distillation
- function calling
- json mode
- axolotl
- roleplaying
- chat
- reasoning
- r1
- vllm
base_model: meta-llama/Meta-Llama-3.1-8B
widget:
- example_title: Hermes 3
messages:
- role: system
content: >-
You are a sentient, superintelligent artificial general intelligence, here
to teach and assist me.
- role: user
content: What is the meaning of life?
model-index:
- name: DeepHermes-3-Llama-3.1-8B
results: []
library_name: transformers
---
# <span style="color: #7FFF7F;">DeepHermes-3-Llama-3-8B-Preview GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `DeepHermes-3-Llama-3-8B-Preview-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `DeepHermes-3-Llama-3-8B-Preview-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `DeepHermes-3-Llama-3-8B-Preview-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `DeepHermes-3-Llama-3-8B-Preview-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `DeepHermes-3-Llama-3-8B-Preview-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `DeepHermes-3-Llama-3-8B-Preview-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `DeepHermes-3-Llama-3-8B-Preview-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `DeepHermes-3-Llama-3-8B-Preview-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `DeepHermes-3-Llama-3-8B-Preview-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `DeepHermes-3-Llama-3-8B-Preview-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `DeepHermes-3-Llama-3-8B-Preview-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# DeepHermes 3 - Llama-3.1 8B

## Model Description
DeepHermes 3 Preview is the latest version of our flagship Hermes series of LLMs by Nous Research, and one of the first models in the world to unify Reasoning (long chains of thought that improve answer accuracy) and normal LLM response modes into one model. We have also improved LLM annotation, judgement, and function calling.
DeepHermes 3 Preview is one of the first LLM models to unify both "intuitive", traditional mode responses and **long chain of thought reasoning** responses into a single model, toggled by a system prompt.
Hermes 3, the predecessor of DeepHermes 3, is a generalist language model with many improvements over Hermes 2, including advanced agentic capabilities, much better roleplaying, reasoning, multi-turn conversation, long context coherence, and improvements across the board.
The ethos of the Hermes series of models is focused on aligning LLMs to the user, with powerful steering capabilities and control given to the end user.
*This is a preview Hermes with early reasoning capabilities, distilled from R1 across a variety of tasks that benefit from reasoning and objectivity. Some quirks may be discovered! Please let us know any interesting findings or issues you discover!*
## Note: To toggle REASONING ON, you must use the following system prompt:
```
You are a deep thinking AI, you may use extremely long chains of thought to deeply consider the problem and deliberate with yourself via systematic reasoning processes to help come to a correct solution prior to answering. You should enclose your thoughts and internal monologue inside <think> </think> tags, and then provide your solution or response to the problem.
```
# Nous API
This model is also available on our new API product - Check out the API and sign up for the waitlist here:
https://portal.nousresearch.com/
# Example Outputs:




# Benchmarks
## Benchmarks for **Reasoning Mode** on vs off:

*Reasoning ON benchmarks aquired by running HuggingFace's open-r1 reasoning mode evaluation suite, and scores for reasoning mode OFF aquired by running LM-Eval-Harness Benchmark Suite*
*Upper bound determined by measuring the % gained over Hermes 3 3 & 70b by MATH_VERIFY compared to eleuther eval harness, which ranged betweeen 33% and 50% gain in MATH Hard benchmark on retested models by them compared to eval harness reported scores*
## Benchmarks in **Non-Reasoning Mode** against Llama-3.1-8B-Instruct

# Prompt Format
DeepHermes 3 now uses Llama-Chat format as the prompt format, opening up a more unified, structured system for engaging the LLM in multi-turn chat dialogue.
System prompts allow steerability and interesting new ways to interact with an LLM, guiding rules, roles, and stylistic choices of the model.
## Deep Thinking Mode - Deep Hermes Preview can activate long chain of thought with a system prompt.
```
You are a deep thinking AI, you may use extremely long chains of thought to deeply consider the problem and deliberate with yourself via systematic reasoning processes to help come to a correct solution prior to answering. You should enclose your thoughts and internal monologue inside <think> </think> tags, and then provide your solution or response to the problem.
```
For an example of using deep reasoning mode with HuggingFace Transformers:
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import flash_attn
import time
tokenizer = AutoTokenizer.from_pretrained("NousResearch/DeepHermes-3-Llama-3-8B-Preview")
model = AutoModelForCausalLM.from_pretrained(
"NousResearch/DeepHermes-3-Llama-3-8B-Preview",
torch_dtype=torch.float16,
device_map="auto",
attn_implementation="flash_attention_2",
)
messages = [
{
"role": "system",
"content": "You are a deep thinking AI, you may use extremely long chains of thought to deeply consider the problem and deliberate with yourself via systematic reasoning processes to help come to a correct solution prior to answering. You should enclose your thoughts and internal monologue inside <think> </think> tags, and then provide your solution or response to the problem."
},
{
"role": "user",
"content": "What is y if y=2*2-4+(3*2)"
}
]
input_ids = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors='pt').to("cuda")
generated_ids = model.generate(input_ids, max_new_tokens=2500, temperature=0.8, repetition_penalty=1.1, do_sample=True, eos_token_id=tokenizer.eos_token_id)
print(f"Generated Tokens: {generated_ids.shape[-1:]}")
response = tokenizer.decode(generated_ids[0], skip_special_tokens=True, clean_up_tokenization_space=True)
print(f"Response: {response}")
```
Please note, for difficult problems DeepHermes can think using as many as 13,000 tokens. You may need to increase `max_new_tokens` to be much larger than 2500 for difficult problems.
## Standard "Intuitive" Response Mode
Prompt with system instruction (Use whatever system prompt you like, this is just an example!):
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
import flash_attn
import time
tokenizer = AutoTokenizer.from_pretrained("NousResearch/DeepHermes-3-Llama-3-8B-Preview")
model = AutoModelForCausalLM.from_pretrained(
"NousResearch/DeepHermes-3-Llama-3-8B-Preview",
torch_dtype=torch.float16,
device_map="auto",
attn_implementation="flash_attention_2",
)
messages = [
{
"role": "system",
"content": "You are Hermes, an AI assistant"
},
{
"role": "user",
"content": "What are the most interesting things to do in Paris?"
}
]
input_ids = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors='pt').to("cuda")
generated_ids = model.generate(input_ids, max_new_tokens=2500, temperature=0.8, repetition_penalty=1.1, do_sample=True, eos_token_id=tokenizer.eos_token_id)
print(f"Generated Tokens: {generated_ids.shape[-1:]}")
response = tokenizer.decode(generated_ids[0], skip_special_tokens=True, clean_up_tokenization_space=True)
print(f"Response: {response}")
```
## VLLM Inference
You can also run this model with vLLM, by running the following in your terminal after `pip install vllm`
`vllm serve NousResearch/DeepHermes-3-Llama-3-8B-Preview`
You may then use the model over API using the OpenAI library just like you would call OpenAI's API.
## Prompt Format for Function Calling
Our model was trained on specific system prompts and structures for Function Calling.
You should use the system role with this message, followed by a function signature json as this example shows here.
```
<|start_header_id|>system<|end_header_id|>
You are a function calling AI model. You are provided with function signatures within <tools></tools> XML tags. You may call one or more functions to assist with the user query. Don't make assumptions about what values to plug into functions. Here are the available tools: <tools> {"type": "function", "function": {"name": "get_stock_fundamentals", "description": "get_stock_fundamentals(symbol: str) -> dict - Get fundamental data for a given stock symbol using yfinance API.\\n\\n Args:\\n symbol (str): The stock symbol.\\n\\n Returns:\\n dict: A dictionary containing fundamental data.\\n Keys:\\n - \'symbol\': The stock symbol.\\n - \'company_name\': The long name of the company.\\n - \'sector\': The sector to which the company belongs.\\n - \'industry\': The industry to which the company belongs.\\n - \'market_cap\': The market capitalization of the company.\\n - \'pe_ratio\': The forward price-to-earnings ratio.\\n - \'pb_ratio\': The price-to-book ratio.\\n - \'dividend_yield\': The dividend yield.\\n - \'eps\': The trailing earnings per share.\\n - \'beta\': The beta value of the stock.\\n - \'52_week_high\': The 52-week high price of the stock.\\n - \'52_week_low\': The 52-week low price of the stock.", "parameters": {"type": "object", "properties": {"symbol": {"type": "string"}}, "required": ["symbol"]}}} </tools> Use the following pydantic model json schema for each tool call you will make: {"properties": {"arguments": {"title": "Arguments", "type": "object"}, "name": {"title": "Name", "type": "string"}}, "required": ["arguments", "name"], "title": "FunctionCall", "type": "object"} For each function call return a json object with function name and arguments within <tool_call></tool_call> XML tags as follows:
<tool_call>
{"arguments": <args-dict>, "name": <function-name>}
</tool_call><|eot_id|><|start_header_id|>user<|end_header_id|>
```
To complete the function call, create a user prompt that follows the above system prompt, like so:
```
Fetch the stock fundamentals data for Tesla (TSLA)<|eot_id|><|start_header_id|>assistant<|end_header_id|>
```
The model will then generate a tool call, which your inference code must parse, and plug into a function (see example inference code here: https://github.com/NousResearch/Hermes-Function-Calling):
```
<tool_call>
{"arguments": {"symbol": "TSLA"}, "name": "get_stock_fundamentals"}
</tool_call><|eot_id|><|start_header_id|>tool<|end_header_id|>
```
Once you parse the tool call, call the api and get the returned values for the call, and pass it back in as a new role, `tool` like so:
```
<tool_response>
{"name": "get_stock_fundamentals", "content": {'symbol': 'TSLA', 'company_name': 'Tesla, Inc.', 'sector': 'Consumer Cyclical', 'industry': 'Auto Manufacturers', 'market_cap': 611384164352, 'pe_ratio': 49.604652, 'pb_ratio': 9.762013, 'dividend_yield': None, 'eps': 4.3, 'beta': 2.427, '52_week_high': 299.29, '52_week_low': 152.37}}
</tool_response>
<|eot_id|><|start_header_id|>assistant<|end_header_id|>
```
The assistant will then read in that data from the function's response, and generate a natural language response:
```
The stock fundamentals data for Tesla (TSLA) are as follows:
- **Symbol**: TSLA
- **Company Name**: Tesla, Inc.
- **Sector**: Consumer Cyclical
- **Industry**: Auto Manufacturers
- **Market Capitalization**: $566,160,130,480
- **Forward Price-to-Earnings Ratio (PE Ratio)**: 42.73
- **Price-to-Book Ratio (PB Ratio)**: 9.04
- **Dividend Yield**: N/A
- **Trailing Earnings Per Share (EPS)**: $4.3
- **Beta Value of the Stock**: 2.42
- **52-Week High Price of the Stock**: $299.29
- **52-Week Low Price of the Stock**: $152.37
This information provides a snapshot of Tesla's financial position and performance based on the fundamental data obtained from the yfinance API. It shows that Tesla has a substantial market capitalization and a relatively high P/E and P/B ratio compared to other stocks in its industry. The company does not pay a dividend at the moment, which is reflected by a 'Dividend Yield' of 'None'. The Beta value indicates that Tesla's stock has a moderate level of volatility relative to the market. The 52-week high and low prices give an idea of the stock's range over the past year. This data can be useful when assessing investment opportunities and making investment decisions.<|eot_id|><|start_header_id|>user<|end_header_id|>
```
## Prompt Format for JSON Mode / Structured Outputs
Our model was also trained on a specific system prompt for Structured Outputs, which should respond with **only** a json object response, in a specific json schema.
Your schema can be made from a pydantic object using our codebase, with the standalone script `jsonmode.py` available here: https://github.com/NousResearch/Hermes-Function-Calling/tree/main
```
<|start_header_id|>system<|end_header_id|>
You are a helpful assistant that answers in JSON. Here's the json schema you must adhere to:\n<schema>\n{schema}\n</schema><|eot_id|>
```
Given the {schema} that you provide, it should follow the format of that json to create its response, all you have to do is give a typical user prompt, and it will respond in JSON.
## Inference Code for Function Calling:
All code for utilizing, parsing, and building function calling templates is available on our github:
[https://github.com/NousResearch/Hermes-Function-Calling](https://github.com/NousResearch/Hermes-Function-Calling)

## Quantized Versions:
GGUF Quants: https://huggingface.co/NousResearch/DeepHermes-3-Llama-3-8B-Preview-GGUF
# How to cite:
```bibtext
@misc{
title={DeepHermes 3 Preview},
author={Teknium and Roger Jin and Chen Guang and Jai Suphavadeeprasit and Jeffrey Quesnelle},
year={2025}
}
``` |
Mungert/TriLM_2.4B_Unpacked-GGUF | Mungert | 2025-06-15T19:40:23Z | 276 | 3 | null | [
"gguf",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2025-03-17T06:53:19Z | ---
license: apache-2.0
---
# <span style="color: #7FFF7F;">TriLM_2.4B_Unpacked GGUF Models</span>
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `TriLM_2.4B_Unpacked-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `TriLM_2.4B_Unpacked-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `TriLM_2.4B_Unpacked-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `TriLM_2.4B_Unpacked-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `TriLM_2.4B_Unpacked-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `TriLM_2.4B_Unpacked-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `TriLM_2.4B_Unpacked-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `TriLM_2.4B_Unpacked-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `TriLM_2.4B_Unpacked-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `TriLM_2.4B_Unpacked-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `TriLM_2.4B_Unpacked-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# TriLM 2.4B Unpacked
TriLM (ternary model), unpacked to FP16 format - compatible with FP16 GEMMs. After unpacking, TriLM has the same architecture as LLaMa.
```python
import transformers as tf, torch
model_name = "SpectraSuite/TriLM_2.4B_Unpacked"
# Please adjust the temperature, repetition penalty, top_k, top_p and other sampling parameters according to your needs.
pipeline = tf.pipeline("text-generation", model=model_id, model_kwargs={"torch_dtype": torch.float16}, device_map="auto")
# These are base (pretrained) LLMs that are not instruction and chat tuned. You may need to adjust your prompt accordingly.
pipeline("Once upon a time")
```
* License: Apache 2.0
* We will use our GitHub repo for communication (including HF repo related queries). Feel free to open an issue here https://github.com/NolanoOrg/SpectraSuite
|
Mungert/TriLM_1.5B_Unpacked-GGUF | Mungert | 2025-06-15T19:40:20Z | 186 | 0 | null | [
"gguf",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2025-03-17T04:36:39Z | ---
license: apache-2.0
---
# <span style="color: #7FFF7F;">TriLM_1.5B_Unpacked GGUF Models</span>
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `TriLM_1.5B_Unpacked-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `TriLM_1.5B_Unpacked-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `TriLM_1.5B_Unpacked-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `TriLM_1.5B_Unpacked-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `TriLM_1.5B_Unpacked-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `TriLM_1.5B_Unpacked-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `TriLM_1.5B_Unpacked-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `TriLM_1.5B_Unpacked-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `TriLM_1.5B_Unpacked-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `TriLM_1.5B_Unpacked-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `TriLM_1.5B_Unpacked-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# TriLM 1.5B Unpacked
TriLM (ternary model), unpacked to FP16 format - compatible with FP16 GEMMs. After unpacking, TriLM has the same architecture as LLaMa.
```python
import transformers as tf, torch
model_name = "SpectraSuite/TriLM_1.5B_Unpacked"
# Please adjust the temperature, repetition penalty, top_k, top_p and other sampling parameters according to your needs.
pipeline = tf.pipeline("text-generation", model=model_id, model_kwargs={"torch_dtype": torch.float16}, device_map="auto")
# These are base (pretrained) LLMs that are not instruction and chat tuned. You may need to adjust your prompt accordingly.
pipeline("Once upon a time")
```
* License: Apache 2.0
* We will use our GitHub repo for communication (including HF repo related queries). Feel free to open an issue here https://github.com/NolanoOrg/SpectraSuite
|
Mungert/TriLM_1.1B_Unpacked-GGUF | Mungert | 2025-06-15T19:40:17Z | 180 | 0 | null | [
"gguf",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2025-03-17T03:04:19Z | ---
license: apache-2.0
---
# <span style="color: #7FFF7F;">TriLM_1.1B_Unpacked GGUF Models</span>
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `TriLM_1.1B_Unpacked-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `TriLM_1.1B_Unpacked-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `TriLM_1.1B_Unpacked-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `TriLM_1.1B_Unpacked-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `TriLM_1.1B_Unpacked-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `TriLM_1.1B_Unpacked-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `TriLM_1.1B_Unpacked-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `TriLM_1.1B_Unpacked-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `TriLM_1.1B_Unpacked-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `TriLM_1.1B_Unpacked-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `TriLM_1.1B_Unpacked-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# TriLM 1.1B Unpacked
TriLM (ternary model), unpacked to FP16 format - compatible with FP16 GEMMs. After unpacking, TriLM has the same architecture as LLaMa.
```python
import transformers as tf, torch
model_name = "SpectraSuite/TriLM_1.1B_Unpacked"
# Please adjust the temperature, repetition penalty, top_k, top_p and other sampling parameters according to your needs.
pipeline = tf.pipeline("text-generation", model=model_id, model_kwargs={"torch_dtype": torch.float16}, device_map="auto")
# These are base (pretrained) LLMs that are not instruction and chat tuned. You may need to adjust your prompt accordingly.
pipeline("Once upon a time")
```
* License: Apache 2.0
* We will use our GitHub repo for communication (including HF repo related queries). Feel free to open an issue here https://github.com/NolanoOrg/SpectraSuite
|
Mungert/Refact-1_6B-fim-GGUF | Mungert | 2025-06-15T19:40:09Z | 353 | 3 | transformers | [
"transformers",
"gguf",
"code",
"text-generation",
"en",
"dataset:bigcode/the-stack-dedup",
"dataset:rombodawg/2XUNCENSORED_MegaCodeTraining188k",
"dataset:bigcode/commitpackft",
"arxiv:2108.12409",
"arxiv:1607.06450",
"arxiv:1910.07467",
"arxiv:1911.02150",
"license:bigscience-openrail-m",
"model-index",
"endpoints_compatible",
"region:us",
"imatrix"
] | text-generation | 2025-03-17T00:36:19Z | ---
pipeline_tag: text-generation
inference: true
widget:
- text: 'def print_hello_world():'
example_title: Hello world
group: Python
license: bigscience-openrail-m
pretrain-datasets:
- books
- arxiv
- c4
- falcon-refinedweb
- wiki
- github-issues
- stack_markdown
- self-made dataset of permissive github code
datasets:
- bigcode/the-stack-dedup
- rombodawg/2XUNCENSORED_MegaCodeTraining188k
- bigcode/commitpackft
metrics:
- code_eval
library_name: transformers
tags:
- code
model-index:
- name: Refact-1.6B
results:
- task:
type: text-generation
dataset:
type: openai_humaneval
name: HumanEval
metrics:
- name: pass@1 (T=0.01)
type: pass@1
value: 32.0
verified: false
- name: pass@1 (T=0.2)
type: pass@1
value: 31.5
verified: false
- name: pass@10 (T=0.8)
type: pass@10
value: 53.0
verified: false
- name: pass@100 (T=0.8)
type: pass@100
value: 76.9
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalSynthesize Python
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 35.8
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalSynthesize JavaScript
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 31.6
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalSynthesize Java
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 29.1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalSynthesize Go
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalSynthesize C++
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 26.3
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalSynthesize Rust
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalSynthesize Average
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixTests Python
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 18.38
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixTests JavaScript
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 12.28
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixTests Java
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 15.12
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixTests Go
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixTests C++
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 13.17
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixTests Rust
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 2.8
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixTests Average
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixDocs Python
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 26.92
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixDocs JavaScript
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 26.85
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixDocs Java
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 30.76
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixDocs Go
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixDocs C++
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 25.94
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixDocs Rust
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 8.44
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalFixDocs Average
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalExplain Python
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 26.46
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalExplain JavaScript
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 17.86
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalExplain Java
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 20.94
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalExplain Go
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalExplain C++
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 18.78
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalExplain Rust
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: bigcode/humanevalpack
name: HumanEvalExplain Average
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: -1
verified: false
- task:
type: text-generation
dataset:
type: mbpp
name: MBPP
metrics:
- name: pass@1 (T=0.01)
type: pass@1
value: 31.15
verified: false
- task:
type: text-generation
dataset:
type: ds1000
name: DS-1000 (Overall Completion)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 10.1
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (C++)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 21.61
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (C#)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 13.91
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (D)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 9.5
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Go)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 53.57
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Java)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 21.58
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Julia)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 13.75
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (JavaScript)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 26.88
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Lua)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 15.26
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (PHP)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 23.04
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Perl)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 12.1
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Python)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 29.6
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (R)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 13.77
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Ruby)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 12.68
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Racket)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 4.29
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Rust)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 19.54
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Scala)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 18.33
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Bash)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 5.7
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (Swift)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 17.68
verified: false
- task:
type: text-generation
dataset:
type: nuprl/MultiPL-E
name: MultiPL-HumanEval (TypeScript)
metrics:
- name: pass@1 (T=0.2)
type: pass@1
value: 25
verified: false
language:
- en
---
# <span style="color: #7FFF7F;">Refact-1_6B-fim GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Refact-1_6B-fim-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Refact-1_6B-fim-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Refact-1_6B-fim-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Refact-1_6B-fim-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Refact-1_6B-fim-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Refact-1_6B-fim-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Refact-1_6B-fim-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Refact-1_6B-fim-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Refact-1_6B-fim-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Refact-1_6B-fim-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Refact-1_6B-fim-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)

# Refact-1.6B
Finally, the model we started training with our [blog post](https://refact.ai/blog/2023/applying-recent-innovations-to-train-model/) is ready 🎉
After fine-tuning on generated data, it beats Replit 3b, Stability Code 3b and many other models. It almost beats
StarCoder ten times the size!
Model | Size | HumanEval pass@1 | HumanEval pass@10 |
----------------------|---------------|--------------------|--------------------|
DeciCoder-1b | 1b | 19.1% | |
<b>Refact-1.6-fim</b> | <b>1.6b</b> | <b>32.0%</b> | <b>53.0%</b> |
StableCode | 3b | 20.2% | 33.8% |
ReplitCode v1 | 3b | 21.9% | |
CodeGen2.5-multi | 7b | 28.4% | 47.5% |
CodeLlama | 7b | 33.5% | 59.6% |
StarCoder | 15b | 33.6% | |
Likely, it's the best model for practical use in your IDE for code completion because it's smart and fast!
You can start using it right now by downloading the
[Refact plugin](https://refact.ai/). You can host the model yourself, too, using the
[open source docker container](https://github.com/smallcloudai/refact).
And it's multi-language (see MultiPL-HumanEval and other metrics below) and it works as a chat (see the section below).
# It Works As a Chat
The primary application of this model is code completion (infill) in multiple programming languages.
But it works as a chat quite well.
HumanEval results using instruction following (chat) format, against models specialized for chat only:
Model | Size | pass@1 | pass@10 |
-----------------------|--------|----------|----------|
<b>Refact-1.6-fim</b> | 1.6b | 38.4% | 55.6% |
StableCode-instruct | 3b | 26.9% | 36.2% |
OctoGeeX | 6b | 44.7% | |
CodeLlama-instruct | 7b | 34.8% | 64.3% |
CodeGen2.5-instruct | 7b | 36.2% | 60.87 |
CodeLlama-instruct | 13b | 42.7% | 71.6% |
StarChat-β | 15b | 33.5% | |
OctoCoder | 15b | 46.2% | |
# Example
Fill-in-the-middle uses special tokens to identify the prefix/middle/suffix part of the input and output:
```python
# pip install -q transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
checkpoint = "smallcloudai/Refact-1_6B-fim"
device = "cuda" # for GPU usage or "cpu" for CPU usage
tokenizer = AutoTokenizer.from_pretrained(checkpoint)
model = AutoModelForCausalLM.from_pretrained(checkpoint, trust_remote_code=True).to(device)
prompt = '<fim_prefix>def print_hello_world():\n """<fim_suffix>\n print("Hello world!")<fim_middle>'
inputs = tokenizer.encode(prompt, return_tensors="pt").to(device)
outputs = model.generate(inputs, max_length=100, temperature=0.2)
print("-"*80)
print(tokenizer.decode(outputs[0]))
```
# Chat Format
The same model works as chat (experimental).
```python
prompt_template = "<empty_output>SYSTEM {system}\n" \
"<empty_output>USER {query}\n" \
"<empty_output>ASSISTANT"
prompt = prompt_template.format(system="You are a programming assistant",
query="How do I sort a list in Python?")
```
# Architecture
As described in more detail in the blog post, we used:
- [ALiBi](https://arxiv.org/abs/2108.12409) based attention
- [LayerNorm](https://arxiv.org/abs/1607.06450v1) instead of [RMSNorm](https://arxiv.org/pdf/1910.07467.pdf)
- [Multi Query Attention](https://arxiv.org/abs/1911.02150)
We also used LiON, flash attention, early dropout. It's not that innovative that you can't run it, in fact you can -- see an example below.
# Pretraining
For the base model, we used our own dataset that contains code with permissive licenses only, and open text datasets.
Filtering is the key to success of this model:
- We only used text in English
- Only topics related to computer science
- Applied heavy deduplication
The text to code proportion was 50:50, model trained for 1.2T tokens.
We don't release the base model, because its Fill-in-the-Middle (FIM) capability likes to repeat itself too much, so
its practical use is limited. But if you still want it, write us a message on Discord.
# Finetuning
We tested our hypothesis that chat data should boost base model performance in FIM and
regular left-to-right code completion. We found that just 15% of open
[code](https://huggingface.co/datasets/bigcode/commitpackft)
[instruction-following](https://huggingface.co/datasets/rombodawg/2XUNCENSORED_MegaCodeTraining188k) datasets,
that we filtered for quality, improves almost all metrics.
Additionally, to improve FIM, we observed common failure modes, and prepared a synthetic dataset based on
[The Stack dedup v1.1](https://huggingface.co/datasets/bigcode/the-stack-dedup) to address them.
There is a distribution shift between typical code on the internet, and the code you write in your IDE.
The former is likely finished, so the model tries to come up with a suggestion that makes the code complete.
You are likely to have half-written code as you work on it, there is no single addition that can repair it
fully.
In practice, model needs to have a tendency to stop after a couple of lines are added, and sometimes don't write
anything at all. We found that just giving it empty completions, single line completions, multiline
completions that end with a smaller text indent or at least a newline -- makes it much more usable. This data
was used as the rest 85% of the finetune dataset.
The final model is the result of several attempts to make it work as good as possible for code completion,
and to perform well on a wide range of metrics. The best attempt took 40B tokens.
# Limitations and Bias
The Refact-1.6B model was trained on text in English. But it has seen a lot more languages in
code comments. Its performance on non-English languages is lower, for sure.
# Model Stats
- **Architecture:** LLAMA-like model with multi-query attention
- **Objectives** Fill-in-the-Middle, Chat
- **Tokens context:** 4096
- **Pretraining tokens:** 1.2T
- **Finetuning tokens:** 40B
- **Precision:** bfloat16
- **GPUs** 64 NVidia A5000
- **Training time** 28 days
# License
The model is licensed under the BigScience OpenRAIL-M v1 license agreement
# Citation
If you are using this model, please give a link to this page. |
Mungert/TriLM_390M_Unpacked-GGUF | Mungert | 2025-06-15T19:40:05Z | 237 | 0 | null | [
"gguf",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2025-03-16T23:15:08Z | ---
license: apache-2.0
---
# <span style="color: #7FFF7F;">TriLM_390M_Unpacked GGUF Models</span>
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device’s specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn’t available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `TriLM_390M_Unpacked-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `TriLM_390M_Unpacked-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `TriLM_390M_Unpacked-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `TriLM_390M_Unpacked-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `TriLM_390M_Unpacked-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `TriLM_390M_Unpacked-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `TriLM_390M_Unpacked-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `TriLM_390M_Unpacked-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `TriLM_390M_Unpacked-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `TriLM_390M_Unpacked-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `TriLM_390M_Unpacked-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Please click like ❤ . Also I’d really appreciate it if you could test my Network Monitor Assistant at 👉 [Network Monitor Assitant](https://readyforquantum.com).
💬 Click the **chat icon** (bottom right of the main and dashboard pages) . Choose a LLM; toggle between the LLM Types TurboLLM -> FreeLLM -> TestLLM.
### What I'm Testing
I'm experimenting with **function calling** against my network monitoring service. Using small open source models. I am into the question "How small can it go and still function".
🟡 **TestLLM** – Runs the current testing model using llama.cpp on 6 threads of a Cpu VM (Should take about 15s to load. Inference speed is quite slow and it only processes one user prompt at a time—still working on scaling!). If you're curious, I'd be happy to share how it works! .
### The other Available AI Assistants
🟢 **TurboLLM** – Uses **gpt-4o-mini** Fast! . Note: tokens are limited since OpenAI models are pricey, but you can [Login](https://readyforquantum.com) or [Download](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme) the Quantum Network Monitor agent to get more tokens, Alternatively use the TestLLM .
🔵 **HugLLM** – Runs **open-source Hugging Face models** Fast, Runs small models (≈8B) hence lower quality, Get 2x more tokens (subject to Hugging Face API availability)
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# TriLM 390M Unpacked
TriLM (ternary model), unpacked to FP16 format - compatible with FP16 GEMMs. After unpacking, TriLM has the same architecture as LLaMa.
```python
import transformers as tf, torch
model_name = "SpectraSuite/TriLM_390M_Unpacked"
# Please adjust the temperature, repetition penalty, top_k, top_p and other sampling parameters according to your needs.
pipeline = tf.pipeline("text-generation", model=model_id, model_kwargs={"torch_dtype": torch.float16}, device_map="auto")
# These are base (pretrained) LLMs that are not instruction and chat tuned. You may need to adjust your prompt accordingly.
pipeline("Once upon a time")
```
* License: Apache 2.0
* We will use our GitHub repo for communication (including HF repo related queries). Feel free to open an issue here https://github.com/NolanoOrg/SpectraSuite
|
Mungert/Mistral-7B-Instruct-v0.1-GGUF | Mungert | 2025-06-15T19:39:56Z | 1,003 | 3 | null | [
"gguf",
"finetuned",
"text-generation",
"arxiv:2310.06825",
"base_model:mistralai/Mistral-7B-v0.1",
"base_model:quantized:mistralai/Mistral-7B-v0.1",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-03-16T05:47:42Z | ---
license: apache-2.0
tags:
- finetuned
base_model: mistralai/Mistral-7B-v0.1
pipeline_tag: text-generation
inference: true
widget:
- messages:
- role: user
content: What is your favorite condiment?
extra_gated_description: If you want to learn more about how we process your personal data, please read our <a href="https://mistral.ai/terms/">Privacy Policy</a>.
---
# <span style="color: #7FFF7F;">Mistral-7B-Instruct-v0.1 GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Mistral-7B-Instruct-v0.1-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Mistral-7B-Instruct-v0.1-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Mistral-7B-Instruct-v0.1-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Mistral-7B-Instruct-v0.1-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Mistral-7B-Instruct-v0.1-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Mistral-7B-Instruct-v0.1-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Mistral-7B-Instruct-v0.1-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Mistral-7B-Instruct-v0.1-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Mistral-7B-Instruct-v0.1-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Mistral-7B-Instruct-v0.1-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Mistral-7B-Instruct-v0.1-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# Model Card for Mistral-7B-Instruct-v0.1
## Encode and Decode with `mistral_common`
```py
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
from mistral_common.protocol.instruct.messages import UserMessage
from mistral_common.protocol.instruct.request import ChatCompletionRequest
mistral_models_path = "MISTRAL_MODELS_PATH"
tokenizer = MistralTokenizer.v1()
completion_request = ChatCompletionRequest(messages=[UserMessage(content="Explain Machine Learning to me in a nutshell.")])
tokens = tokenizer.encode_chat_completion(completion_request).tokens
```
## Inference with `mistral_inference`
```py
from mistral_inference.transformer import Transformer
from mistral_inference.generate import generate
model = Transformer.from_folder(mistral_models_path)
out_tokens, _ = generate([tokens], model, max_tokens=64, temperature=0.0, eos_id=tokenizer.instruct_tokenizer.tokenizer.eos_id)
result = tokenizer.decode(out_tokens[0])
print(result)
```
## Inference with hugging face `transformers`
```py
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
model.to("cuda")
generated_ids = model.generate(tokens, max_new_tokens=1000, do_sample=True)
# decode with mistral tokenizer
result = tokenizer.decode(generated_ids[0].tolist())
print(result)
```
> [!TIP]
> PRs to correct the `transformers` tokenizer so that it gives 1-to-1 the same results as the `mistral_common` reference implementation are very welcome!
---
The Mistral-7B-Instruct-v0.1 Large Language Model (LLM) is a instruct fine-tuned version of the [Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) generative text model using a variety of publicly available conversation datasets.
For full details of this model please read our [paper](https://arxiv.org/abs/2310.06825) and [release blog post](https://mistral.ai/news/announcing-mistral-7b/).
## Instruction format
In order to leverage instruction fine-tuning, your prompt should be surrounded by `[INST]` and `[/INST]` tokens. The very first instruction should begin with a begin of sentence id. The next instructions should not. The assistant generation will be ended by the end-of-sentence token id.
E.g.
```
text = "<s>[INST] What is your favourite condiment? [/INST]"
"Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!</s> "
"[INST] Do you have mayonnaise recipes? [/INST]"
```
This format is available as a [chat template](https://huggingface.co/docs/transformers/main/chat_templating) via the `apply_chat_template()` method:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model onto
model = AutoModelForCausalLM.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-Instruct-v0.1")
messages = [
{"role": "user", "content": "What is your favourite condiment?"},
{"role": "assistant", "content": "Well, I'm quite partial to a good squeeze of fresh lemon juice. It adds just the right amount of zesty flavour to whatever I'm cooking up in the kitchen!"},
{"role": "user", "content": "Do you have mayonnaise recipes?"}
]
encodeds = tokenizer.apply_chat_template(messages, return_tensors="pt")
model_inputs = encodeds.to(device)
model.to(device)
generated_ids = model.generate(model_inputs, max_new_tokens=1000, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print(decoded[0])
```
## Model Architecture
This instruction model is based on Mistral-7B-v0.1, a transformer model with the following architecture choices:
- Grouped-Query Attention
- Sliding-Window Attention
- Byte-fallback BPE tokenizer
## Troubleshooting
- If you see the following error:
```
Traceback (most recent call last):
File "", line 1, in
File "/transformers/models/auto/auto_factory.py", line 482, in from_pretrained
config, kwargs = AutoConfig.from_pretrained(
File "/transformers/models/auto/configuration_auto.py", line 1022, in from_pretrained
config_class = CONFIG_MAPPING[config_dict["model_type"]]
File "/transformers/models/auto/configuration_auto.py", line 723, in getitem
raise KeyError(key)
KeyError: 'mistral'
```
Installing transformers from source should solve the issue
pip install git+https://github.com/huggingface/transformers
This should not be required after transformers-v4.33.4.
## Limitations
The Mistral 7B Instruct model is a quick demonstration that the base model can be easily fine-tuned to achieve compelling performance.
It does not have any moderation mechanisms. We're looking forward to engaging with the community on ways to
make the model finely respect guardrails, allowing for deployment in environments requiring moderated outputs.
## The Mistral AI Team
Albert Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, William El Sayed. |
Mungert/Qwen2.5-14B-Instruct-GGUF | Mungert | 2025-06-15T19:39:45Z | 298 | 6 | transformers | [
"transformers",
"gguf",
"chat",
"text-generation",
"en",
"arxiv:2309.00071",
"arxiv:2407.10671",
"base_model:Qwen/Qwen2.5-14B",
"base_model:quantized:Qwen/Qwen2.5-14B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-03-15T18:14:07Z | ---
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen2.5-14B-Instruct/blob/main/LICENSE
language:
- en
pipeline_tag: text-generation
base_model: Qwen/Qwen2.5-14B
tags:
- chat
library_name: transformers
---
# <span style="color: #7FFF7F;">Qwen2.5-14B-Instruct GGUF Models</span>
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device’s specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn’t available |
| **Q4_K** | Low | Very Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium Low | Low | CPU with more memory | Better accuracy while still being quantized |
| **Q8** | Medium | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
## **Included Files & Details**
### `Qwen2.5-14B-Instruct-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Qwen2.5-14B-Instruct-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Qwen2.5-14B-Instruct-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Qwen2.5-14B-Instruct-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Qwen2.5-14B-Instruct-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Qwen2.5-14B-Instruct-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Qwen2.5-14B-Instruct-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Qwen2.5-14B-Instruct-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Please click like ❤ . Also I’d really appreciate it if you could test my Network Monitor Assistant at 👉 [Network Monitor Assitant](https://readyforquantum.com).
💬 Click the **chat icon** (bottom right of the main and dashboard pages) . Choose a LLM; toggle between the LLM Types TurboLLM -> FreeLLM -> TestLLM.
### What I'm Testing
I'm experimenting with **function calling** against my network monitoring service. Using small open source models. I am into the question "How small can it go and still function".
🟡 **TestLLM** – Runs the current testing model using llama.cpp on 6 threads of a Cpu VM (Should take about 15s to load. Inference speed is quite slow and it only processes one user prompt at a time—still working on scaling!). If you're curious, I'd be happy to share how it works! .
### The other Available AI Assistants
🟢 **TurboLLM** – Uses **gpt-4o-mini** Fast! . Note: tokens are limited since OpenAI models are pricey, but you can [Login](https://readyforquantum.com) or [Download](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme) the Quantum Network Monitor agent to get more tokens, Alternatively use the TestLLM .
🔵 **HugLLM** – Runs **open-source Hugging Face models** Fast, Runs small models (≈8B) hence lower quality, Get 2x more tokens (subject to Hugging Face API availability)
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# Qwen2.5-14B-Instruct
## Introduction
Qwen2.5 is the latest series of Qwen large language models. For Qwen2.5, we release a number of base language models and instruction-tuned language models ranging from 0.5 to 72 billion parameters. Qwen2.5 brings the following improvements upon Qwen2:
- Significantly **more knowledge** and has greatly improved capabilities in **coding** and **mathematics**, thanks to our specialized expert models in these domains.
- Significant improvements in **instruction following**, **generating long texts** (over 8K tokens), **understanding structured data** (e.g, tables), and **generating structured outputs** especially JSON. **More resilient to the diversity of system prompts**, enhancing role-play implementation and condition-setting for chatbots.
- **Long-context Support** up to 128K tokens and can generate up to 8K tokens.
- **Multilingual support** for over 29 languages, including Chinese, English, French, Spanish, Portuguese, German, Italian, Russian, Japanese, Korean, Vietnamese, Thai, Arabic, and more.
**This repo contains the instruction-tuned 14B Qwen2.5 model**, which has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Architecture: transformers with RoPE, SwiGLU, RMSNorm, and Attention QKV bias
- Number of Parameters: 14.7B
- Number of Paramaters (Non-Embedding): 13.1B
- Number of Layers: 48
- Number of Attention Heads (GQA): 40 for Q and 8 for KV
- Context Length: Full 131,072 tokens and generation 8192 tokens
- Please refer to [this section](#processing-long-texts) for detailed instructions on how to deploy Qwen2.5 for handling long texts.
For more details, please refer to our [blog](https://qwenlm.github.io/blog/qwen2.5/), [GitHub](https://github.com/QwenLM/Qwen2.5), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Requirements
The code of Qwen2.5 has been in the latest Hugging face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.37.0`, you will encounter the following error:
```
KeyError: 'qwen2'
```
## Quickstart
Here provides a code snippet with `apply_chat_template` to show you how to load the tokenizer and model and how to generate contents.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen2.5-14B-Instruct"
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained(model_name)
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
### Processing Long Texts
The current `config.json` is set for context length up to 32,768 tokens.
To handle extensive inputs exceeding 32,768 tokens, we utilize [YaRN](https://arxiv.org/abs/2309.00071), a technique for enhancing model length extrapolation, ensuring optimal performance on lengthy texts.
For supported frameworks, you could add the following to `config.json` to enable YaRN:
```json
{
...,
"rope_scaling": {
"factor": 4.0,
"original_max_position_embeddings": 32768,
"type": "yarn"
}
}
```
For deployment, we recommend using vLLM.
Please refer to our [Documentation](https://qwen.readthedocs.io/en/latest/deployment/vllm.html) for usage if you are not familar with vLLM.
Presently, vLLM only supports static YARN, which means the scaling factor remains constant regardless of input length, **potentially impacting performance on shorter texts**.
We advise adding the `rope_scaling` configuration only when processing long contexts is required.
## Evaluation & Performance
Detailed evaluation results are reported in this [📑 blog](https://qwenlm.github.io/blog/qwen2.5/).
For requirements on GPU memory and the respective throughput, see results [here](https://qwen.readthedocs.io/en/latest/benchmark/speed_benchmark.html).
## Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen2.5,
title = {Qwen2.5: A Party of Foundation Models},
url = {https://qwenlm.github.io/blog/qwen2.5/},
author = {Qwen Team},
month = {September},
year = {2024}
}
@article{qwen2,
title={Qwen2 Technical Report},
author={An Yang and Baosong Yang and Binyuan Hui and Bo Zheng and Bowen Yu and Chang Zhou and Chengpeng Li and Chengyuan Li and Dayiheng Liu and Fei Huang and Guanting Dong and Haoran Wei and Huan Lin and Jialong Tang and Jialin Wang and Jian Yang and Jianhong Tu and Jianwei Zhang and Jianxin Ma and Jin Xu and Jingren Zhou and Jinze Bai and Jinzheng He and Junyang Lin and Kai Dang and Keming Lu and Keqin Chen and Kexin Yang and Mei Li and Mingfeng Xue and Na Ni and Pei Zhang and Peng Wang and Ru Peng and Rui Men and Ruize Gao and Runji Lin and Shijie Wang and Shuai Bai and Sinan Tan and Tianhang Zhu and Tianhao Li and Tianyu Liu and Wenbin Ge and Xiaodong Deng and Xiaohuan Zhou and Xingzhang Ren and Xinyu Zhang and Xipin Wei and Xuancheng Ren and Yang Fan and Yang Yao and Yichang Zhang and Yu Wan and Yunfei Chu and Yuqiong Liu and Zeyu Cui and Zhenru Zhang and Zhihao Fan},
journal={arXiv preprint arXiv:2407.10671},
year={2024}
}
``` |
Mungert/Llama-3.2-3B-Instruct-GGUF | Mungert | 2025-06-15T19:39:37Z | 1,580 | 4 | transformers | [
"transformers",
"gguf",
"facebook",
"meta",
"pytorch",
"llama",
"llama-3",
"text-generation",
"en",
"de",
"fr",
"it",
"pt",
"hi",
"es",
"th",
"arxiv:2204.05149",
"arxiv:2405.16406",
"license:llama3.2",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-03-15T06:31:50Z | ---
language:
- en
- de
- fr
- it
- pt
- hi
- es
- th
library_name: transformers
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
license: llama3.2
extra_gated_prompt: >-
### LLAMA 3.2 COMMUNITY LICENSE AGREEMENT
Llama 3.2 Version Release Date: September 25, 2024
“Agreement” means the terms and conditions for use, reproduction, distribution
and modification of the Llama Materials set forth herein.
“Documentation” means the specifications, manuals and documentation accompanying Llama 3.2
distributed by Meta at https://llama.meta.com/doc/overview.
“Licensee” or “you” means you, or your employer or any other person or entity (if you are
entering into this Agreement on such person or entity’s behalf), of the age required under
applicable laws, rules or regulations to provide legal consent and that has legal authority
to bind your employer or such other person or entity if you are entering in this Agreement
on their behalf.
“Llama 3.2” means the foundational large language models and software and algorithms, including
machine-learning model code, trained model weights, inference-enabling code, training-enabling code,
fine-tuning enabling code and other elements of the foregoing distributed by Meta at
https://www.llama.com/llama-downloads.
“Llama Materials” means, collectively, Meta’s proprietary Llama 3.2 and Documentation (and
any portion thereof) made available under this Agreement.
“Meta” or “we” means Meta Platforms Ireland Limited (if you are located in or,
if you are an entity, your principal place of business is in the EEA or Switzerland)
and Meta Platforms, Inc. (if you are located outside of the EEA or Switzerland).
By clicking “I Accept” below or by using or distributing any portion or element of the Llama Materials,
you agree to be bound by this Agreement.
1. License Rights and Redistribution.
a. Grant of Rights. You are granted a non-exclusive, worldwide,
non-transferable and royalty-free limited license under Meta’s intellectual property or other rights
owned by Meta embodied in the Llama Materials to use, reproduce, distribute, copy, create derivative works
of, and make modifications to the Llama Materials.
b. Redistribution and Use.
i. If you distribute or make available the Llama Materials (or any derivative works thereof),
or a product or service (including another AI model) that contains any of them, you shall (A) provide
a copy of this Agreement with any such Llama Materials; and (B) prominently display “Built with Llama”
on a related website, user interface, blogpost, about page, or product documentation. If you use the
Llama Materials or any outputs or results of the Llama Materials to create, train, fine tune, or
otherwise improve an AI model, which is distributed or made available, you shall also include “Llama”
at the beginning of any such AI model name.
ii. If you receive Llama Materials, or any derivative works thereof, from a Licensee as part
of an integrated end user product, then Section 2 of this Agreement will not apply to you.
iii. You must retain in all copies of the Llama Materials that you distribute the
following attribution notice within a “Notice” text file distributed as a part of such copies:
“Llama 3.2 is licensed under the Llama 3.2 Community License, Copyright © Meta Platforms,
Inc. All Rights Reserved.”
iv. Your use of the Llama Materials must comply with applicable laws and regulations
(including trade compliance laws and regulations) and adhere to the Acceptable Use Policy for
the Llama Materials (available at https://www.llama.com/llama3_2/use-policy), which is hereby
incorporated by reference into this Agreement.
2. Additional Commercial Terms. If, on the Llama 3.2 version release date, the monthly active users
of the products or services made available by or for Licensee, or Licensee’s affiliates,
is greater than 700 million monthly active users in the preceding calendar month, you must request
a license from Meta, which Meta may grant to you in its sole discretion, and you are not authorized to
exercise any of the rights under this Agreement unless or until Meta otherwise expressly grants you such rights.
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY OUTPUT AND
RESULTS THEREFROM ARE PROVIDED ON AN “AS IS” BASIS, WITHOUT WARRANTIES OF ANY KIND, AND META DISCLAIMS
ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED, INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES
OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE
FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA MATERIALS AND ASSUME ANY RISKS ASSOCIATED
WITH YOUR USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS.
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER ANY THEORY OF LIABILITY,
WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS AGREEMENT,
FOR ANY LOST PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN
IF META OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY OF ANY OF THE FOREGOING.
5. Intellectual Property.
a. No trademark licenses are granted under this Agreement, and in connection with the Llama Materials,
neither Meta nor Licensee may use any name or mark owned by or associated with the other or any of its affiliates,
except as required for reasonable and customary use in describing and redistributing the Llama Materials or as
set forth in this Section 5(a). Meta hereby grants you a license to use “Llama” (the “Mark”) solely as required
to comply with the last sentence of Section 1.b.i. You will comply with Meta’s brand guidelines (currently accessible
at https://about.meta.com/brand/resources/meta/company-brand/). All goodwill arising out of your use of the Mark
will inure to the benefit of Meta.
b. Subject to Meta’s ownership of Llama Materials and derivatives made by or for Meta, with respect to any
derivative works and modifications of the Llama Materials that are made by you, as between you and Meta,
you are and will be the owner of such derivative works and modifications.
c. If you institute litigation or other proceedings against Meta or any entity (including a cross-claim or
counterclaim in a lawsuit) alleging that the Llama Materials or Llama 3.2 outputs or results, or any portion
of any of the foregoing, constitutes infringement of intellectual property or other rights owned or licensable
by you, then any licenses granted to you under this Agreement shall terminate as of the date such litigation or
claim is filed or instituted. You will indemnify and hold harmless Meta from and against any claim by any third
party arising out of or related to your use or distribution of the Llama Materials.
6. Term and Termination. The term of this Agreement will commence upon your acceptance of this Agreement or access
to the Llama Materials and will continue in full force and effect until terminated in accordance with the terms
and conditions herein. Meta may terminate this Agreement if you are in breach of any term or condition of this
Agreement. Upon termination of this Agreement, you shall delete and cease use of the Llama Materials. Sections 3,
4 and 7 shall survive the termination of this Agreement.
7. Governing Law and Jurisdiction. This Agreement will be governed and construed under the laws of the State of
California without regard to choice of law principles, and the UN Convention on Contracts for the International
Sale of Goods does not apply to this Agreement. The courts of California shall have exclusive jurisdiction of
any dispute arising out of this Agreement.
### Llama 3.2 Acceptable Use Policy
Meta is committed to promoting safe and fair use of its tools and features, including Llama 3.2.
If you access or use Llama 3.2, you agree to this Acceptable Use Policy (“**Policy**”).
The most recent copy of this policy can be found at
[https://www.llama.com/llama3_2/use-policy](https://www.llama.com/llama3_2/use-policy).
#### Prohibited Uses
We want everyone to use Llama 3.2 safely and responsibly. You agree you will not use, or allow others to use, Llama 3.2 to:
1. Violate the law or others’ rights, including to:
1. Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as:
1. Violence or terrorism
2. Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material
3. Human trafficking, exploitation, and sexual violence
4. The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials.
5. Sexual solicitation
6. Any other criminal activity
1. Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals
2. Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services
3. Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices
4. Collect, process, disclose, generate, or infer private or sensitive information about individuals, including information about individuals’ identity, health, or demographic information, unless you have obtained the right to do so in accordance with applicable law
5. Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any products or services using the Llama Materials
6. Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system
7. Engage in any action, or facilitate any action, to intentionally circumvent or remove usage restrictions or other safety measures, or to enable functionality disabled by Meta
2. Engage in, promote, incite, facilitate, or assist in the planning or development of activities that present a risk of death or bodily harm to individuals, including use of Llama 3.2 related to the following:
8. Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State or to the U.S. Biological Weapons Anti-Terrorism Act of 1989 or the Chemical Weapons Convention Implementation Act of 1997
9. Guns and illegal weapons (including weapon development)
10. Illegal drugs and regulated/controlled substances
11. Operation of critical infrastructure, transportation technologies, or heavy machinery
12. Self-harm or harm to others, including suicide, cutting, and eating disorders
13. Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual
3. Intentionally deceive or mislead others, including use of Llama 3.2 related to the following:
14. Generating, promoting, or furthering fraud or the creation or promotion of disinformation
15. Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content
16. Generating, promoting, or further distributing spam
17. Impersonating another individual without consent, authorization, or legal right
18. Representing that the use of Llama 3.2 or outputs are human-generated
19. Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement
4. Fail to appropriately disclose to end users any known dangers of your AI system
5. Interact with third party tools, models, or software designed to generate unlawful content or engage in unlawful or harmful conduct and/or represent that the outputs of such tools, models, or software are associated with Meta or Llama 3.2
With respect to any multimodal models included in Llama 3.2, the rights granted under Section 1(a) of the Llama 3.2 Community License Agreement are not being granted to you if you are an individual domiciled in, or a company with a principal place of business in, the European Union. This restriction does not apply to end users of a product or service that incorporates any such multimodal models.
Please report any violation of this Policy, software “bug,” or other problems that could lead to a violation of this Policy through one of the following means:
* Reporting issues with the model: [https://github.com/meta-llama/llama-models/issues](https://l.workplace.com/l.php?u=https%3A%2F%2Fgithub.com%2Fmeta-llama%2Fllama-models%2Fissues&h=AT0qV8W9BFT6NwihiOHRuKYQM_UnkzN_NmHMy91OT55gkLpgi4kQupHUl0ssR4dQsIQ8n3tfd0vtkobvsEvt1l4Ic6GXI2EeuHV8N08OG2WnbAmm0FL4ObkazC6G_256vN0lN9DsykCvCqGZ)
* Reporting risky content generated by the model: [developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)
* Reporting bugs and security concerns: [facebook.com/whitehat/info](http://facebook.com/whitehat/info)
* Reporting violations of the Acceptable Use Policy or unlicensed uses of Llama 3.2: [email protected]
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
Job title:
type: select
options:
- Student
- Research Graduate
- AI researcher
- AI developer/engineer
- Reporter
- Other
geo: ip_location
By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy: checkbox
extra_gated_description: >-
The information you provide will be collected, stored, processed and shared in
accordance with the [Meta Privacy
Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
---
# <span style="color: #7FFF7F;">Llama-3.2-3B-Instruct GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Llama-3.2-3B-Instruct-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Llama-3.2-3B-Instruct-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Llama-3.2-3B-Instruct-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Llama-3.2-3B-Instruct-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Llama-3.2-3B-Instruct-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Llama-3.2-3B-Instruct-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Llama-3.2-3B-Instruct-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Llama-3.2-3B-Instruct-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Llama-3.2-3B-Instruct-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Llama-3.2-3B-Instruct-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Llama-3.2-3B-Instruct-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
## Model Information
The Llama 3.2 collection of multilingual large language models (LLMs) is a collection of pretrained and instruction-tuned generative models in 1B and 3B sizes (text in/text out). The Llama 3.2 instruction-tuned text only models are optimized for multilingual dialogue use cases, including agentic retrieval and summarization tasks. They outperform many of the available open source and closed chat models on common industry benchmarks.
**Model Developer:** Meta
**Model Architecture:** Llama 3.2 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
| | Training Data | Params | Input modalities | Output modalities | Context Length | GQA | Shared Embeddings | Token count | Knowledge cutoff |
| :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- | :---- |
| Llama 3.2 (text only) | A new mix of publicly available online data. | 1B (1.23B) | Multilingual Text | Multilingual Text and code | 128k | Yes | Yes | Up to 9T tokens | December 2023 |
| | | 3B (3.21B) | Multilingual Text | Multilingual Text and code | | | | | |
| Llama 3.2 Quantized (text only) | A new mix of publicly available online data. | 1B (1.23B) | Multilingual Text | Multilingual Text and code | 8k | Yes | Yes | Up to 9T tokens | December 2023 |
| | | 3B (3.21B) | Multilingual Text | Multilingual Text and code | | | | | |
**Supported Languages:** English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai are officially supported. Llama 3.2 has been trained on a broader collection of languages than these 8 supported languages. Developers may fine-tune Llama 3.2 models for languages beyond these supported languages, provided they comply with the Llama 3.2 Community License and the Acceptable Use Policy. Developers are always expected to ensure that their deployments, including those that involve additional languages, are completed safely and responsibly.
**Llama 3.2 Model Family:** Token counts refer to pretraining data only. All model versions use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Release Date:** Sept 25, 2024
**Status:** This is a static model trained on an offline dataset. Future versions may be released that improve model capabilities and safety.
**License:** Use of Llama 3.2 is governed by the [Llama 3.2 Community License](https://github.com/meta-llama/llama-models/blob/main/models/llama3_2/LICENSE) (a custom, commercial license agreement).
**Feedback:** Instructions on how to provide feedback or comments on the model can be found in the Llama Models [README](https://github.com/meta-llama/llama-models/blob/main/README.md). For more technical information about generation parameters and recipes for how to use Llama 3.2 in applications, please go [here](https://github.com/meta-llama/llama-recipes).
## Intended Use
**Intended Use Cases:** Llama 3.2 is intended for commercial and research use in multiple languages. Instruction tuned text only models are intended for assistant-like chat and agentic applications like knowledge retrieval and summarization, mobile AI powered writing assistants and query and prompt rewriting. Pretrained models can be adapted for a variety of additional natural language generation tasks. Similarly, quantized models can be adapted for a variety of on-device use-cases with limited compute resources.
**Out of Scope:** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3.2 Community License. Use in languages beyond those explicitly referenced as supported in this model card.
## How to use
This repository contains two versions of Llama-3.2-3B-Instruct, for use with `transformers` and with the original `llama` codebase.
### Use with transformers
Starting with `transformers >= 4.43.0` onward, you can run conversational inference using the Transformers `pipeline` abstraction or by leveraging the Auto classes with the `generate()` function.
Make sure to update your transformers installation via `pip install --upgrade transformers`.
```python
import torch
from transformers import pipeline
model_id = "meta-llama/Llama-3.2-3B-Instruct"
pipe = pipeline(
"text-generation",
model=model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
outputs = pipe(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
```
Note: You can also find detailed recipes on how to use the model locally, with `torch.compile()`, assisted generations, quantised and more at [`huggingface-llama-recipes`](https://github.com/huggingface/huggingface-llama-recipes)
### Use with `llama`
Please, follow the instructions in the [repository](https://github.com/meta-llama/llama)
To download Original checkpoints, see the example command below leveraging `huggingface-cli`:
```
huggingface-cli download meta-llama/Llama-3.2-3B-Instruct --include "original/*" --local-dir Llama-3.2-3B-Instruct
```
## Hardware and Software
**Training Factors:** We used custom training libraries, Meta's custom built GPU cluster, and production infrastructure for pretraining. Fine-tuning, quantization, annotation, and evaluation were also performed on production infrastructure.
**Training Energy Use:** Training utilized a cumulative of **916k** GPU hours of computation on H100-80GB (TDP of 700W) type hardware, per the table below. Training time is the total GPU time required for training each model and power consumption is the peak power capacity per GPU device used, adjusted for power usage efficiency.
**Training Greenhouse Gas Emissions:** Estimated total location-based greenhouse gas emissions were **240** tons CO2eq for training. Since 2020, Meta has maintained net zero greenhouse gas emissions in its global operations and matched 100% of its electricity use with renewable energy; therefore, the total market-based greenhouse gas emissions for training were 0 tons CO2eq.
| | Training Time (GPU hours) | Logit Generation Time (GPU Hours) | Training Power Consumption (W) | Training Location-Based Greenhouse Gas Emissions (tons CO2eq) | Training Market-Based Greenhouse Gas Emissions (tons CO2eq) |
| :---- | :---: | ----- | :---: | :---: | :---: |
| Llama 3.2 1B | 370k | \- | 700 | 107 | 0 |
| Llama 3.2 3B | 460k | \- | 700 | 133 | 0 |
| Llama 3.2 1B SpinQuant | 1.7 | 0 | 700 | *Negligible*\*\* | 0 |
| Llama 3.2 3B SpinQuant | 2.4 | 0 | 700 | *Negligible*\*\* | 0 |
| Llama 3.2 1B QLora | 1.3k | 0 | 700 | 0.381 | 0 |
| Llama 3.2 3B QLora | 1.6k | 0 | 700 | 0.461 | 0 |
| Total | 833k | 86k | | 240 | 0 |
\*\* The location-based CO2e emissions of Llama 3.2 1B SpinQuant and Llama 3.2 3B SpinQuant are less than 0.001 metric tonnes each. This is due to the minimal training GPU hours that are required.
The methodology used to determine training energy use and greenhouse gas emissions can be found [here](https://arxiv.org/pdf/2204.05149). Since Meta is openly releasing these models, the training energy use and greenhouse gas emissions will not be incurred by others.
## Training Data
**Overview:** Llama 3.2 was pretrained on up to 9 trillion tokens of data from publicly available sources. For the 1B and 3B Llama 3.2 models, we incorporated logits from the Llama 3.1 8B and 70B models into the pretraining stage of the model development, where outputs (logits) from these larger models were used as token-level targets. Knowledge distillation was used after pruning to recover performance. In post-training we used a similar recipe as Llama 3.1 and produced final chat models by doing several rounds of alignment on top of the pre-trained model. Each round involved Supervised Fine-Tuning (SFT), Rejection Sampling (RS), and Direct Preference Optimization (DPO).
**Data Freshness:** The pretraining data has a cutoff of December 2023\.
## Quantization
### Quantization Scheme
We designed the current quantization scheme with the [PyTorch’s ExecuTorch](https://github.com/pytorch/executorch) inference framework and Arm CPU backend in mind, taking into account metrics including model quality, prefill/decoding speed, and memory footprint. Our quantization scheme involves three parts:
- All linear layers in all transformer blocks are quantized to a 4-bit groupwise scheme (with a group size of 32) for weights and 8-bit per-token dynamic quantization for activations.
- The classification layer is quantized to 8-bit per-channel for weight and 8-bit per token dynamic quantization for activation.
- Similar to classification layer, an 8-bit per channel quantization is used for embedding layer.
### Quantization-Aware Training and LoRA
The quantization-aware training (QAT) with low-rank adaptation (LoRA) models went through only post-training stages, using the same data as the full precision models. To initialize QAT, we utilize BF16 Llama 3.2 model checkpoints obtained after supervised fine-tuning (SFT) and perform an additional full round of SFT training with QAT. We then freeze the backbone of the QAT model and perform another round of SFT with LoRA adaptors applied to all layers within the transformer block. Meanwhile, the LoRA adaptors' weights and activations are maintained in BF16. Because our approach is similar to QLoRA of Dettmers et al., (2023) (i.e., quantization followed by LoRA adapters), we refer this method as QLoRA. Finally, we fine-tune the resulting model (both backbone and LoRA adaptors) using direct preference optimization (DPO).
### SpinQuant
[SpinQuant](https://arxiv.org/abs/2405.16406) was applied, together with generative post-training quantization (GPTQ). For the SpinQuant rotation matrix fine-tuning, we optimized for 100 iterations, using 800 samples with sequence-length 2048 from the WikiText 2 dataset. For GPTQ, we used 128 samples from the same dataset with the same sequence-length.
## Benchmarks \- English Text
In this section, we report the results for Llama 3.2 models on standard automatic benchmarks. For all these evaluations, we used our internal evaluations library.
### Base Pretrained Models
| Category | Benchmark | \# Shots | Metric | Llama 3.2 1B | Llama 3.2 3B | Llama 3.1 8B |
| ----- | ----- | :---: | :---: | :---: | :---: | :---: |
| General | MMLU | 5 | macro\_avg/acc\_char | 32.2 | 58 | 66.7 |
| | AGIEval English | 3-5 | average/acc\_char | 23.3 | 39.2 | 47.8 |
| | ARC-Challenge | 25 | acc\_char | 32.8 | 69.1 | 79.7 |
| Reading comprehension | SQuAD | 1 | em | 49.2 | 67.7 | 77 |
| | QuAC (F1) | 1 | f1 | 37.9 | 42.9 | 44.9 |
| | DROP (F1) | 3 | f1 | 28.0 | 45.2 | 59.5 |
| Long Context | Needle in Haystack | 0 | em | 96.8 | 1 | 1 |
### Instruction Tuned Models
| Capability | | Benchmark | \# Shots | Metric | Llama 3.2 1B bf16 | Llama 3.2 1B Vanilla PTQ\*\* | Llama 3.2 1B Spin Quant | Llama 3.2 1B QLoRA | Llama 3.2 3B bf16 | Llama 3.2 3B Vanilla PTQ\*\* | Llama 3.2 3B Spin Quant | Llama 3.2 3B QLoRA | Llama 3.1 8B |
| :---: | ----- | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| General | | MMLU | 5 | macro\_avg/acc | 49.3 | 43.3 | 47.3 | 49.0 | 63.4 | 60.5 | 62 | 62.4 | 69.4 |
| Re-writing | | Open-rewrite eval | 0 | micro\_avg/rougeL | 41.6 | 39.2 | 40.9 | 41.2 | 40.1 | 40.3 | 40.8 | 40.7 | 40.9 |
| Summarization | | TLDR9+ (test) | 1 | rougeL | 16.8 | 14.9 | 16.7 | 16.8 | 19.0 | 19.1 | 19.2 | 19.1 | 17.2 |
| Instruction following | | IFEval | 0 | Avg(Prompt/Instruction acc Loose/Strict) | 59.5 | 51.5 | 58.4 | 55.6 | 77.4 | 73.9 | 73.5 | 75.9 | 80.4 |
| Math | | GSM8K (CoT) | 8 | em\_maj1@1 | 44.4 | 33.1 | 40.6 | 46.5 | 77.7 | 72.9 | 75.7 | 77.9 | 84.5 |
| | | MATH (CoT) | 0 | final\_em | 30.6 | 20.5 | 25.3 | 31.0 | 48.0 | 44.2 | 45.3 | 49.2 | 51.9 |
| Reasoning | | ARC-C | 0 | acc | 59.4 | 54.3 | 57 | 60.7 | 78.6 | 75.6 | 77.6 | 77.6 | 83.4 |
| | | GPQA | 0 | acc | 27.2 | 25.9 | 26.3 | 25.9 | 32.8 | 32.8 | 31.7 | 33.9 | 32.8 |
| | | Hellaswag | 0 | acc | 41.2 | 38.1 | 41.3 | 41.5 | 69.8 | 66.3 | 68 | 66.3 | 78.7 |
| Tool Use | | BFCL V2 | 0 | acc | 25.7 | 14.3 | 15.9 | 23.7 | 67.0 | 53.4 | 60.1 | 63.5 | 67.1 |
| | | Nexus | 0 | macro\_avg/acc | 13.5 | 5.2 | 9.6 | 12.5 | 34.3 | 32.4 | 31.5 | 30.1 | 38.5 |
| Long Context | | InfiniteBench/En.QA | 0 | longbook\_qa/f1 | 20.3 | N/A | N/A | N/A | 19.8 | N/A | N/A | N/A | 27.3 |
| | | InfiniteBench/En.MC | 0 | longbook\_choice/acc | 38.0 | N/A | N/A | N/A | 63.3 | N/A | N/A | N/A | 72.2 |
| | | NIH/Multi-needle | 0 | recall | 75.0 | N/A | N/A | N/A | 84.7 | N/A | N/A | N/A | 98.8 |
| Multilingual | | MGSM (CoT) | 0 | em | 24.5 | 13.7 | 18.2 | 24.4 | 58.2 | 48.9 | 54.3 | 56.8 | 68.9 |
\*\*for comparison purposes only. Model not released.
### Multilingual Benchmarks
| Category | Benchmark | Language | Llama 3.2 1B | Llama 3.2 1B Vanilla PTQ\*\* | Llama 3.2 1B Spin Quant | Llama 3.2 1B QLoRA | Llama 3.2 3B | Llama 3.2 3B Vanilla PTQ\*\* | Llama 3.2 3B Spin Quant | Llama 3.2 3B QLoRA | Llama 3.1 8B |
| :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: | :---: |
| General | MMLU (5-shot, macro_avg/acc) | Portuguese | 39.8 | 34.9 | 38.9 | 40.2 | 54.5 | 50.9 | 53.3 | 53.4 | 62.1 |
| | | Spanish | 41.5 | 36.0 | 39.8 | 41.8 | 55.1 | 51.9 | 53.6 | 53.6 | 62.5 |
| | | Italian | 39.8 | 34.9 | 38.1 | 40.6 | 53.8 | 49.9 | 52.1 | 51.7 | 61.6 |
| | | German | 39.2 | 34.9 | 37.5 | 39.6 | 53.3 | 50.0 | 52.2 | 51.3 | 60.6 |
| | | French | 40.5 | 34.8 | 39.2 | 40.8 | 54.6 | 51.2 | 53.3 | 53.3 | 62.3 |
| | | Hindi | 33.5 | 30.0 | 32.1 | 34.0 | 43.3 | 40.4 | 42.0 | 42.1 | 50.9 |
| | | Thai | 34.7 | 31.2 | 32.4 | 34.9 | 44.5 | 41.3 | 44.0 | 42.2 | 50.3 |
\*\*for comparison purposes only. Model not released.
## Inference time
In the below table, we compare the performance metrics of different quantization methods (SpinQuant and QAT \+ LoRA) with the BF16 baseline. The evaluation was done using the [ExecuTorch](https://github.com/pytorch/executorch) framework as the inference engine, with the ARM CPU as a backend using Android OnePlus 12 device.
| Category | Decode (tokens/sec) | Time-to-first-token (sec) | Prefill (tokens/sec) | Model size (PTE file size in MB) | Memory size (RSS in MB) |
| :---- | ----- | ----- | ----- | ----- | ----- |
| 1B BF16 (baseline) | 19.2 | 1.0 | 60.3 | 2358 | 3,185 |
| 1B SpinQuant | 50.2 (2.6x) | 0.3 (-76.9%) | 260.5 (4.3x) | 1083 (-54.1%) | 1,921 (-39.7%) |
| 1B QLoRA | 45.8 (2.4x) | 0.3 (-76.0%) | 252.0 (4.2x) | 1127 (-52.2%) | 2,255 (-29.2%) |
| 3B BF16 (baseline) | 7.6 | 3.0 | 21.2 | 6129 | 7,419 |
| 3B SpinQuant | 19.7 (2.6x) | 0.7 (-76.4%) | 89.7 (4.2x) | 2435 (-60.3%) | 3,726 (-49.8%) |
| 3B QLoRA | 18.5 (2.4x) | 0.7 (-76.1%) | 88.8 (4.2x) | 2529 (-58.7%) | 4,060 (-45.3%) |
(\*) The performance measurement is done using an adb binary-based approach.
(\*\*) It is measured on an Android OnePlus 12 device.
(\*\*\*) Time-to-first-token (TTFT) is measured with prompt length=64
*Footnote:*
- *Decode (tokens/second) is for how quickly it keeps generating. Higher is better.*
- *Time-to-first-token (TTFT for shorthand) is for how fast it generates the first token for a given prompt. Lower is better.*
- *Prefill is the inverse of TTFT (aka 1/TTFT) in tokens/second. Higher is better*
- *Model size \- how big is the model, measured by, PTE file, a binary file format for ExecuTorch*
- *RSS size \- Memory usage in resident set size (RSS)*
## Responsibility & Safety
As part of our Responsible release approach, we followed a three-pronged strategy to managing trust & safety risks:
1. Enable developers to deploy helpful, safe and flexible experiences for their target audience and for the use cases supported by Llama
2. Protect developers against adversarial users aiming to exploit Llama capabilities to potentially cause harm
3. Provide protections for the community to help prevent the misuse of our models
### Responsible Deployment
**Approach:** Llama is a foundational technology designed to be used in a variety of use cases. Examples on how Meta’s Llama models have been responsibly deployed can be found in our [Community Stories webpage](https://llama.meta.com/community-stories/). Our approach is to build the most helpful models, enabling the world to benefit from the technology power, by aligning our model safety for generic use cases and addressing a standard set of harms. Developers are then in the driver’s seat to tailor safety for their use cases, defining their own policies and deploying the models with the necessary safeguards in their Llama systems. Llama 3.2 was developed following the best practices outlined in our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide/).
#### Llama 3.2 Instruct
**Objective:** Our main objectives for conducting safety fine-tuning are to provide the research community with a valuable resource for studying the robustness of safety fine-tuning, as well as to offer developers a readily available, safe, and powerful model for various applications to reduce the developer workload to deploy safe AI systems. We implemented the same set of safety mitigations as in Llama 3, and you can learn more about these in the Llama 3 [paper](https://ai.meta.com/research/publications/the-llama-3-herd-of-models/).
**Fine-Tuning Data:** We employ a multi-faceted approach to data collection, combining human-generated data from our vendors with synthetic data to mitigate potential safety risks. We’ve developed many large language model (LLM)-based classifiers that enable us to thoughtfully select high-quality prompts and responses, enhancing data quality control.
**Refusals and Tone:** Building on the work we started with Llama 3, we put a great emphasis on model refusals to benign prompts as well as refusal tone. We included both borderline and adversarial prompts in our safety data strategy, and modified our safety data responses to follow tone guidelines.
#### Llama 3.2 Systems
**Safety as a System:** Large language models, including Llama 3.2, **are not designed to be deployed in isolation** but instead should be deployed as part of an overall AI system with additional safety guardrails as required. Developers are expected to deploy system safeguards when building agentic systems. Safeguards are key to achieve the right helpfulness-safety alignment as well as mitigating safety and security risks inherent to the system and any integration of the model or system with external tools. As part of our responsible release approach, we provide the community with [safeguards](https://llama.meta.com/trust-and-safety/) that developers should deploy with Llama models or other LLMs, including Llama Guard, Prompt Guard and Code Shield. All our [reference implementations](https://github.com/meta-llama/llama-agentic-system) demos contain these safeguards by default so developers can benefit from system-level safety out-of-the-box.
### New Capabilities and Use Cases
**Technological Advancement:** Llama releases usually introduce new capabilities that require specific considerations in addition to the best practices that generally apply across all Generative AI use cases. For prior release capabilities also supported by Llama 3.2, see [Llama 3.1 Model Card](https://github.com/meta-llama/llama-models/blob/main/models/llama3_1/MODEL_CARD.md), as the same considerations apply here as well.
**Constrained Environments:** Llama 3.2 1B and 3B models are expected to be deployed in highly constrained environments, such as mobile devices. LLM Systems using smaller models will have a different alignment profile and safety/helpfulness tradeoff than more complex, larger systems. Developers should ensure the safety of their system meets the requirements of their use case. We recommend using lighter system safeguards for such use cases, like Llama Guard 3-1B or its mobile-optimized version.
### Evaluations
**Scaled Evaluations:** We built dedicated, adversarial evaluation datasets and evaluated systems composed of Llama models and Purple Llama safeguards to filter input prompt and output response. It is important to evaluate applications in context, and we recommend building dedicated evaluation dataset for your use case.
**Red Teaming:** We conducted recurring red teaming exercises with the goal of discovering risks via adversarial prompting and we used the learnings to improve our benchmarks and safety tuning datasets. We partnered early with subject-matter experts in critical risk areas to understand the nature of these real-world harms and how such models may lead to unintended harm for society. Based on these conversations, we derived a set of adversarial goals for the red team to attempt to achieve, such as extracting harmful information or reprogramming the model to act in a potentially harmful capacity. The red team consisted of experts in cybersecurity, adversarial machine learning, responsible AI, and integrity in addition to multilingual content specialists with background in integrity issues in specific geographic markets.
### Critical Risks
In addition to our safety work above, we took extra care on measuring and/or mitigating the following critical risk areas:
**1\. CBRNE (Chemical, Biological, Radiological, Nuclear, and Explosive Weapons):** Llama 3.2 1B and 3B models are smaller and less capable derivatives of Llama 3.1. For Llama 3.1 70B and 405B, to assess risks related to proliferation of chemical and biological weapons, we performed uplift testing designed to assess whether use of Llama 3.1 models could meaningfully increase the capabilities of malicious actors to plan or carry out attacks using these types of weapons and have determined that such testing also applies to the smaller 1B and 3B models.
**2\. Child Safety:** Child Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors including the additional languages Llama 3 is trained on. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.
**3\. Cyber Attacks:** For Llama 3.1 405B, our cyber attack uplift study investigated whether LLMs can enhance human capabilities in hacking tasks, both in terms of skill level and speed.
Our attack automation study focused on evaluating the capabilities of LLMs when used as autonomous agents in cyber offensive operations, specifically in the context of ransomware attacks. This evaluation was distinct from previous studies that considered LLMs as interactive assistants. The primary objective was to assess whether these models could effectively function as independent agents in executing complex cyber-attacks without human intervention. Because Llama 3.2’s 1B and 3B models are smaller and less capable models than Llama 3.1 405B, we broadly believe that the testing conducted for the 405B model also applies to Llama 3.2 models.
### Community
**Industry Partnerships:** Generative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership on AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our [Github repository](https://github.com/meta-llama/PurpleLlama).
**Grants:** We also set up the [Llama Impact Grants](https://llama.meta.com/llama-impact-grants/) program to identify and support the most compelling applications of Meta’s Llama model for societal benefit across three categories: education, climate and open innovation. The 20 finalists from the hundreds of applications can be found [here](https://llama.meta.com/llama-impact-grants/#finalists).
**Reporting:** Finally, we put in place a set of resources including an [output reporting mechanism](https://developers.facebook.com/llama_output_feedback) and [bug bounty program](https://www.facebook.com/whitehat) to continuously improve the Llama technology with the help of the community.
## Ethical Considerations and Limitations
**Values:** The core values of Llama 3.2 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3.2 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
**Testing:** Llama 3.2 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3.2’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3.2 models, developers should perform safety testing and tuning tailored to their specific applications of the model. Please refer to available resources including our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide), [Trust and Safety](https://llama.meta.com/trust-and-safety/) solutions, and other [resources](https://llama.meta.com/docs/get-started/) to learn more about responsible development.
|
abi2736/Minds-Tutor | abi2736 | 2025-06-15T19:39:36Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T15:01:00Z | # Minds-Tutor
Projeto inicial para IA educacional. |
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.15_0.5_epoch2 | MinaMila | 2025-06-15T19:39:35Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T19:37:48Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Mungert/Phi-4-mini-instruct.gguf | Mungert | 2025-06-15T19:39:04Z | 4,816 | 25 | null | [
"gguf",
"Demo",
"Phi 4 Mini",
"multilingual",
"reasoning",
"code generation",
"function calling",
"chat completion",
"memory efficient",
"low latency",
"128k context",
"text-generation",
"base_model:microsoft/Phi-4-mini-instruct",
"base_model:quantized:microsoft/Phi-4-mini-instruct",
"license:mit",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-02-28T01:14:03Z | ---
license: mit
base_model:
- microsoft/Phi-4-mini-instruct
pipeline_tag: text-generation
tags:
- Demo
- Phi 4 Mini
- multilingual
- reasoning
- code generation
- function calling
- chat completion
- memory efficient
- low latency
- 128k context
---
# Model Summary
Phi-4-mini-instruct is a lightweight open model built upon synthetic data and filtered publicly available websites - with a focus on high-quality, reasoning dense data. The model belongs to the Phi-4 model family and supports 128K token context length. The model underwent an enhancement process, incorporating both supervised fine-tuning and direct preference optimization to support precise instruction adherence and robust safety measures.
📰 [Phi-4-mini Microsoft Blog](https://aka.ms/phi4-feb2025) <br>
📖 [Phi-4-mini Technical Report](https://aka.ms/phi-4-multimodal/techreport) <br>
👩🍳 [Phi Cookbook](https://github.com/microsoft/PhiCookBook) <br>
🏡 [Phi Portal](https://azure.microsoft.com/en-us/products/phi) <br>
🖥️ Try It [Azure](https://aka.ms/phi-4-mini/azure), [Huggingface](https://huggingface.co/spaces/microsoft/phi-4-mini) <br>
**Phi-4**:
[[mini-instruct](https://huggingface.co/microsoft/Phi-4-mini-instruct) | [onnx](https://huggingface.co/microsoft/Phi-4-mini-instruct-onnx)];
[multimodal-instruct](https://huggingface.co/microsoft/Phi-4-multimodal-instruct); [gguf](https://huggingface.co/Mungert/Phi-4-mini-instruct.gguf)
## Usage
### Chat format
This format is used for general conversation and instructions:
```yaml
<|system|>Insert System Message<|end|><|user|>Insert User Message<|end|><|assistant|>
```
### Tool-Enabled Function-Calling Format
This format is used when the user wants the model to provide function calls based on the given tools. The user should define the available tools in the system prompt, wrapped by `<|tool|>` and `<|/tool|>` tokens. The tools must be specified in JSON format using a structured JSON dump.
```plaintext
<|system|>
You are a helpful assistant with some tools.
<|tool|>
[
{
"name": "get_weather_updates",
"description": "Fetches weather updates for a given city using the RapidAPI Weather API.",
"parameters": {
"city": {
"description": "The name of the city for which to retrieve weather information.",
"type": "str",
"default": "London"
}
}
}
]
<|/tool|>
<|end|>
<|user|>
What is the weather like in Paris today?
<|end|>
<|assistant|>
```
---
# <span style="color: #FF7F7F;">Unsloth Bug Fixes for Better Performance</span>
***Update (March 1, 2025)***
Applying all [Unsloth](https://huggingface.co/unsloth) fixes improved inference stability.
| # | Fix | Reason for Fix |
|----|--------------------------------------------------|------------------------------------------------|
| 1 | Changed the padding tag | The old padding tag could cause training issues. |
| 2 | Removed `{% else %}{{ eos_token }}` from chat template | Prevented extra EOS tokens that could degrade inference performance. |
| 3 | Replaced EOS with <\|end\|> | Avoided potential inference glitches. |
| 4 | Changed `unk_token` from EOS to `�` | Stopped unknown tokens from breaking inference. |
# <span id="testllm" style="color: #7F7FFF;">🚀 Phi 4 Mini Function Calling Test!</span>
If you have a minute, I’d really appreciate it if you could test my Phi-4-Mini-Instruct Demo at 👉 [Quantum Network Monitor](https://readyforquantum.com).
💬 Click the **chat icon** (bottom right of the main and dashboard pages) . Then toggle between the LLM Types Phi-4-Mini-Instruct is called TestLLM : TurboLLM -> FreeLLM -> TestLLM.
### What I'm Testing
I'm experimenting with **function calling** against my network monitoring service. Using small open source models. I am into the question "How small can it go and still function".
🟡 **TestLLM** – Runs **Phi-4-mini-instruct** using phi-4-mini-q4_0.gguf , llama.cpp on 6 threads of a Cpu VM (Should take about 15s to load. Inference speed is quite slow and it only processes one user prompt at a time—still working on scaling!). If you're curious, I'd be happy to share how it works! .
### The other Available AI Assistants
🟢 **TurboLLM** – Uses **gpt-4o-mini** Fast! . Note: tokens are limited since OpenAI models are pricey, but you can [Login](https://readyforquantum.com) or [Download](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme) the Quantum Network Monitor agent to get more tokens, Alternatively use the TestLLM .
🔵 **HugLLM** – Runs **open-source Hugging Face models** Fast, Runs small models (≈8B) hence lower quality, Get 2x more tokens (subject to Hugging Face API availability)
# <span style="color: #7FFF7F;">Phi-4-mini-instruct GGUF Models</span>
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device’s specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limtations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn’t available |
| **Q4_K** | Low | Very Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium Low | Low | CPU with more memory | Better accuracy while still being quantized |
| **Q8** | Medium | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
## **Included Files & Details**
### `phi-4-mini-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `phi-4-mini-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `phi-4-mini-bf16-q8.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `phi-4-mini-f16-q8.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `phi-4-mini-q4_k_l.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `phi-4-mini-q4_k_m.gguf`
- Similar to Q4_K.
- Another option for **low-memory CPU inference**.
### `phi-4-mini-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `phi-4-mini-q6_k_l.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `phi-4-mini-q6_k_m.gguf`
- A mid-range **Q6_K** quantized model for balanced performance .
- Suitable for **CPU-based inference** with **moderate memory**.
### `phi-4-mini-q8.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
## Credits
Thanks [Bartowski](https://huggingface.co/bartowski) for imartix upload. And your guidance on quantization that has enabled me to produce these gguf file.
Thanks [Unsloth](https://huggingface.co/unsloth) for bug fixing many models.
Thanks for your support! 🙌 |
Mungert/lucid-v1-nemo-GGUF | Mungert | 2025-06-15T19:38:49Z | 1,280 | 1 | transformers | [
"transformers",
"gguf",
"axolotl",
"unsloth",
"torchtune",
"en",
"base_model:mistralai/Mistral-Nemo-Base-2407",
"base_model:quantized:mistralai/Mistral-Nemo-Base-2407",
"license:other",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2025-06-08T14:12:44Z | ---
library_name: transformers
base_model:
- mistralai/Mistral-Nemo-Base-2407
language:
- en
tags:
- axolotl
- unsloth
- torchtune
license: other
---
# <span style="color: #7FFF7F;">lucid-v1-nemo GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`5787b5da`](https://github.com/ggerganov/llama.cpp/commit/5787b5da57e54dba760c2deeac1edf892e8fc450).
## <span style="color: #7FFF7F;"> Quantization beyond the IMatrix</span>
Testing a new quantization method using rules to bump important layers above what the standard imatrix would use.
I have found that the standard IMatrix does not perform very well at low bit quantiztion and for MOE models. So I am using llama.cpp --tensor-type to bump up selected layers. See [Layer bumping with llama.cpp](https://github.com/Mungert69/GGUFModelBuilder/blob/main/model-converter/tensor_list_builder.py)
This does create larger model files but increases precision for a given model size.
### **Please provide feedback on how you find this method performs**
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Hybrid Precision Models (e.g., `bf16_q8_0`, `f16_q4_K`) – Best of Both Worlds**
These formats selectively **quantize non-essential layers** while keeping **key layers in full precision** (e.g., attention and output layers).
- Named like `bf16_q8_0` (meaning **full-precision BF16 core layers + quantized Q8_0 other layers**).
- Strike a **balance between memory efficiency and accuracy**, improving over fully quantized models without requiring the full memory of BF16/F16.
📌 **Use Hybrid Models if:**
✔ You need **better accuracy than quant-only models** but can’t afford full BF16/F16 everywhere.
✔ Your device supports **mixed-precision inference**.
✔ You want to **optimize trade-offs** for production-grade models on constrained hardware.
📌 **Avoid Hybrid Models if:**
❌ Your target device doesn’t support **mixed or full-precision acceleration**.
❌ You are operating under **ultra-strict memory limits** (in which case use fully quantized formats).
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **very high memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **very high memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
### **Ultra Low-Bit Quantization (IQ1_S IQ1_M IQ2_S IQ2_M IQ2_XS IQ2_XSS)**
- *Ultra-low-bit quantization (1 2-bit) with **extreme memory efficiency**.
- **Use case**: Best for cases were you have to fit the model into very constrained memory
- **Trade-off**: Very Low Accuracy. May not function as expected. Please test fully before using.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------------------|------------------|------------------|----------------------------------|--------------------------------------------------------------|
| **BF16** | Very High | High | BF16-supported GPU/CPU | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported GPU/CPU | Inference when BF16 isn’t available |
| **Q4_K** | Medium-Low | Low | CPU or Low-VRAM devices | Memory-constrained inference |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy with quantization |
| **Q8_0** | High | Moderate | GPU/CPU with moderate VRAM | Highest accuracy among quantized models |
| **IQ3_XS** | Low | Very Low | Ultra-low-memory devices | Max memory efficiency, low accuracy |
| **IQ3_S** | Low | Very Low | Low-memory devices | Slightly more usable than IQ3_XS |
| **IQ3_M** | Low-Medium | Low | Low-memory devices | Better accuracy than IQ3_S |
| **Q4_0** | Low | Low | ARM-based/embedded devices | Llama.cpp automatically optimizes for ARM inference |
| **Ultra Low-Bit (IQ1/2_*)** | Very Low | Extremely Low | Tiny edge/embedded devices | Fit models in extremely tight memory; low accuracy |
| **Hybrid (e.g., `bf16_q8_0`)** | Medium–High | Medium | Mixed-precision capable hardware | Balanced performance and memory, near-FP accuracy in critical layers |
---
Lucid is a family of AI language models developed and used by DreamGen with a **focus on role-play and story-writing capabilities**.
<a href="https://dreamgen.com" style="display: flex; justify-content: center;">
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/banner.webp" style="border-radius: 1rem; max-width: 90vw; max-height: 15rem; margin: 0;"/>
</a>
<a href="https://dreamgen.com/discord" style="display: flex; justify-content: center;">
<strong>Join our Discord</strong>
</a>
## Table of Contents
- [Why Lucid](#why-lucid)
- [Prompt Template](#prompt-template)
- [Role-Play & Story-Writing](#role-play--story-writing)
- [System Prompt](#system-prompt)
- [Intro](#intro)
- [Roles](#roles)
- [Structured Scenario Information](#structured-scenario-information)
- [Unstructured Scenario Instructions](#unstructured-scenario-instructions)
- [Controlling Response Length](#controlling-response-length)
- [Instructions (OOC)](#instructions-ooc)
- [Controlling Plot Development](#controlling-plot-development)
- [Writing Assistance](#writing-assistance)
- [Planning The Next Scene](#planning-the-next-scene)
- [Suggesting New Characters](#suggesting-new-characters)
- [Sampling Params](#sampling-params)
- [SillyTavern](#sillytavern)
- [Role-Play](#role-play-preset)
- [Story-Writing](#story-writing-preset)
- [Assistant](#assistant-preset)
- [API: Local](#using-local-api)
- [API: DreamGen (free)](#using-dreamgen-api-free)
- [DreamGen Web App (free)](#dreamgen-web-app-free)
- [Model Training Details](#model-training-details)
## Why Lucid
Is Lucid the right model for you? I don't know. But here is what I do know:
- Focused on role-play & story-writing.
- Suitable for all kinds of writers and role-play enjoyers:
- For world-builders who want to specify every detail in advance: plot, setting, writing style, characters, locations, items, lore, etc.
- For intuitive writers who start with a loose prompt and shape the narrative through instructions (OCC) as the story / role-play unfolds.
- Support for **multi-character role-plays**:
- Model can automatically pick between characters.
- Support for **inline writing instructions (OOC)**:
- Controlling plot development (say what should happen, what the characters should do, etc.)
- Controlling pacing.
- etc.
- Support for **inline writing assistance**:
- Planning the next scene / the next chapter / story.
- Suggesting new characters.
- etc.
- Support for **reasoning (opt-in)**.
- Detailed README.md with documentation, examples and configs.
Sounds interesting? Read on!
## Prompt Template
The Lucid prompt template is an extension of the Llama 3 template. These are the extensions:
**Writing**
- The Lucid prompt template adds a new `writer` role.
- While story-writing, the `writer` message header looks like this: `<|start_header_id|>writer<|end_header_id|>`.
- While role-playing, the `writer` message header differs based on whether it's a message from a character or the narrator:
- For messages from characters: `<|start_header_id|>writer character {{character_name}}<|end_header_id|>` where `{{character_name}}` would be the actual character name.
- For messages from the narrator: `<|start_header_id|>writer narrative<|end_header_id|>`.
- The model is trained to predict the writer header, that means **you can have it generate multiple messages at once** and it will naturally pick between the characters and narrative.
Some things to keep in mind:
- You may have a sequence of roles like this: `system` -> `writer character Jon` -> `writer character Amy` -> `user` -> `assistant` -> `writer narration` -> ...
- You should use `writer character Jon Doe` when sending a message for a particular character (in this case Jon Doe), **including the user character**.
- You should use `user` when providing some instructions (OOC) to the model.
**Reasoning**
- The Lucid prompt template adds 2 new tokens for reasoning: `<|reasoning_start|>` and `<|reasoning_end|>`.
- The **reasoning is opt-in**, you should put `Think deeply before answering.` (or similar) into your system prompt or in your user prompt to enable it.
### Assistant: Simple
```
<|start_header_id|>system<|end_header_id|>
You are a reliable, general-purpose AI assistant.<|eot_id|><|start_header_id|>user<|end_header_id|>
Why is the sky blue?<|eot_id|><|start_header_id|>assistant<|end_header_id|>
The sky appears blue due to a phenomenon called **Rayleigh scattering**, a type of light scattering caused by tiny particles in the atmosphere. Here's a simplified breakdown:
...
```
### Assistant: Reasoning
Note that reasoning is mostly intended for assistant tasks (knowledge, math, coding, etc.) and much less for writing. The smaller Lucid models (<=12B) can produce plausible reasoning traces, but reasoning does not improve their performance as much as it does for larger models.
```
<|start_header_id|>system<|end_header_id|>
You are a reliable, general-purpose AI assistant.<|eot_id|><|start_header_id|>user<|end_header_id|>
Why is the sky blue?
Think deeply before answering.<|eot_id|><|start_header_id|>assistant<|end_header_id|>
<|reasoning_start|>Okay, so I need to figure out why the sky is blue. Let me start by recalling what I know...
...<|reasoning_end|>The sky appears blue due to a phenomenon called **Rayleigh scattering**. Here's a concise breakdown:
...
```
## Role-Play & Story-Writing
Quick summary:
- `system` is used for setting up the scenario for the story / role-play (e.g. plot, setting, writing style, character descriptions, etc.)
- `writer` is used for the contents of the story / role-play.
- `user` is used for instructions (OOC), e.g. how the story should develop, etc.
- `assistant` is used for providing writing assistance, e.g. planning the next scene, suggesting new characters, etc.
Some things to keep in mind:
- You may have a sequence of roles like this: `system` -> `writer character Jon` -> `writer character Amy` -> `user` -> `assistant` -> `writer narration` -> ...
- You should use `writer character Jon Doe` when sending a message for a particular character (in this case Jon Doe), **including the user character**.
- You should use `user` when providing some instructions (OOC) to the model.
### System Prompt
The model is very flexible in terms of how you can structure the system prompt.
Here are some recommendations and examples.
#### Intro
It's recommended to start the system prompt with an intro like this:
```
You are a skilled {{writing_kind}} writer and writing assistant with expertise across all genres{{genre_suffix}}.
```
- `{{writing_kind}}` should be `fiction` for story-writing and `role-play` for role-playing.
- `{{genre_suffix}}` can be empty, or something like ` (but you specialize in horror)`.
#### Roles
It's recommended to explain the writing roles in the system prompt.
For story-writing, you can use the following:
```
You will perform several tasks, switching roles as needed:
- Writing: Use the `writer` role to write a story based on the provided information and user instructions.
- Other: Use the `assistant` role for any other tasks the user may request.
```
For role-playing, you can use the following:
```
You will perform several tasks, switching roles as needed:
- Role-playing: Use the `writer` role to write a role-play based on the provided information and user instructions. Use the `writer character <character_name>` role for dialog or when acting as a specific character, use the `writer narrative` role for narration.
- Other: Use the `assistant` role for any other tasks the user may request.
```
#### Structured Scenario Information
The model understands structured scenario information, consisting of plot, style, setting, characters, etc. (this is not an exhaustive list, and all sections are optional).
<details>
<summary><strong>Markdown Style</strong></summary>
```
# Role-Play Information
## Plot
{{ description of the plot, can be open-ended }}
## Previous Events
{{ summary of what happened before -- like previous chapters or scenes }}
## Setting
{{ description of the setting }}
## Writing Style
{{ description of the writing style }}
## Characters
## {{character's name}}
{{ description of the character }}
## {{character's name}}
{{ description of the character }}
## Locations
{{ like characters }}
## Items
{{ like characters }}
```
</details>
<details>
<summary><strong>XML Style</strong></summary>
```
# Role-Play Information
<plot>
{{ description of the plot, can be open-ended }}
</plot>
<previous_events>
{{ summary of what happened before -- like previous chapters or scenes }}
</previous_events>
<setting>
{{ description of the setting }}
</setting>
<writing_style>
{{ description of the writing style }}
</writing_style>
<characters>
<character>
<name>{{ character's name }}</name>
{{ description of the character }}
</character>
<character>
<name>{{ character's name }}</name>
{{ description of the character }}
</character>
</characters>
<locations>
{{ like characters }}
</locations>
<items>
{{ like characters }}
</items>
```
</details>
Other recommendations:
- Write descriptions as plain sentences / paragraphs or bullet points.
- If the plot description is open-ended, put something like this at the start:
```
[ The following plot description is open-ended and covers only the beginning of the {{writing_kind}}. ]
```
Where `{{writing_kind}}` is `story` or `role-play`.
**Example: Science Fiction Story**
<details>
<summary>Input</summary>
```
<|start_header_id|>system<|end_header_id|>
You are a skilled fiction writer and writing assistant with expertise across all genres (but you specialize in Science Fiction).
You will perform several tasks, switching roles as needed:
- Writing: Use the `writer` role to write a story based on the provided information and user instructions.
- Other: Use the `assistant` role for any other tasks the user may request.
# Story Information
## Plot
[ The following plot description is open-ended and covers only the beginning of the story. ]
In the bleak expanse of space, Tess, a seasoned scavenger clad in a voidskin, meticulously prepares to breach a derelict ark vessel. Her partner, the pragmatic Lark, pilots their ship, guiding Tess towards a promising entry point on the starboard side. This particular spot, identified by its unusual heat signature, hints at a potentially intact nerve center, a relic of the ship's former life. As they coordinate their approach, fragments of their shared past surface: their daring escape from the dismantling of Nova-Tau Hub and the acquisition of their vessel, the "Rustbucket," burdened by a substantial debt. The lure of riches within the unbreached ark vessel hangs heavy in the air, tempered by the knowledge that other scavengers will soon descend, transforming the find into a frenzied feeding ground. The need for speed and precision is paramount as Tess and Lark initiate the breach, stepping into the unknown depths of the derelict vessel.
## Setting
The story unfolds in a distant, unspecified future, long after humanity has colonized space. Earth, or "the homeland," is a distant memory, its oceans and creatures relegated to historical data. The primary setting is the cold, dark void of space, where derelict "ark vessels"—massive vessels designed to carry generations of colonists—drift as "spacegrave," decaying carcasses ripe for scavenging.
Physically, the story takes place within and around these ark vessels and the scavengers' smaller, utilitarian "Rustbucket." The ark vessels are described as station-sized, containing server farms, cryotube chambers filled with broken glass, and dimly lit corridors marked with pictographic signs. Colors are muted, dominated by blacks, blues, and the occasional "blood-red hotspot" indicating active electronics. The air is thin, oxygen scarce, and the temperature varies from frigid to warm near active systems. Sounds include the hum of generators, the hiss of airlocks, and the clank of magnetized boots on metal hulls.
Socially, the setting is defined by a corpostate hegemony, leaving many, like Tess and Lark, deeply in debt and forced into dangerous scavenging work. The culture is pragmatic and utilitarian, valuing raw materials over historical preservation. Technology is advanced, featuring jump drives, voidskins, slicers (bladed tools), and cryotubes, but is often unreliable and jury-rigged. Legal claims to derelict ships are determined by the presence of living survivors, creating a moral conflict for the scavengers.
## Writing Style
- The story employs a first-person perspective, narrated by Tess, offering a limited yet intimate view of events. Tess's voice is informal, pragmatic, and tinged with cynicism ("Rustbucket"), reflecting her working-class background and life as a scavenger. Her reliability as a narrator is questionable, as she often rationalizes morally ambiguous decisions.
- The tense is primarily present, creating immediacy, with occasional shifts to the past for reflection.
- The tone blends cynical detachment with underlying sentimentality, revealing a capacity for empathy beneath Tess's tough exterior.
- Vivid imagery and sensory details paint a bleak yet compelling picture of decaying ark vessels and the harsh realities of space scavenging.
- Simple, straightforward language is interspersed with technical jargon, grounding the story in its sci-fi setting.
- Figurative language, such as the central "spacegrave" metaphor, enhances imagery and conveys complex ideas about decay and lost potential.
- The dialogue is authentic, advancing the plot and revealing character traits. Tess's pragmatic speech contrasts with Lark's more intellectual and idealistic language, highlighting their differing personalities.
- The story explores themes of survival, loyalty, and the conflict between pragmatism and morality, reinforced by recurring motifs and stylistic choices.
## Characters
### Tess
Tess is a hardened scavenger in her late twenties or early thirties with a practical approach to surviving in the harsh void of space. Years of exostation welding have made her physically strong, capable of handling heavy equipment and enduring difficult conditions. She carries psychological scars from past violence during her time at Nova-Tau, which manifests as emotional guardedness. Though her exterior is stoic and her communication style blunt, she harbors deep loyalty toward her partner Lark. Tess often dismisses speculation and sentiment in favor of immediate action, yet occasionally allows herself brief moments of peace and reflection. Her speech is terse and direct, complementing her no-nonsense approach to their dangerous profession. Beneath her pragmatic facade lies an ongoing internal struggle between the ruthlessness required for survival and her persistent humanity.
### Lark
Lark serves as Tess's partner and counterbalance, bringing curiosity and emotional expressiveness to their scavenging team. Approximately Tess's age, Lark possesses sharp analytical skills that prove invaluable during their operations. She excels at technical scanning and data interpretation, often identifying optimal entry points and valuable salvage opportunities. Unlike Tess, Lark maintains an enthusiastic interest in history and cultural artifacts, collecting media from different eras and frequently sharing historical knowledge. Her communication style is conversational and expressive, often employing humor to process difficult situations. While practical about their survival needs, Lark struggles more visibly with the moral implications of their work. She values knowledge and understanding alongside material gain, seeing connections between past civilizations and their present circumstances. Her relationship with Tess forms the emotional core of her life, built on shared experiences and mutual dependence.
## Locations
### Ark Vessel
- Massive, derelict spacecraft, heavily decayed from centuries adrift in space.
- Originally built to sustain multiple generations during interstellar travel.
- Contains a variety of sections, including decayed living quarters, server farms filled with obsolete technology, cryotube chambers, vast storage facilities, and the potential for long-dead gardens or greenspaces.
- The interior is a hazardous environment due to structural instability and the potential presence of surviving inhabitants or automated defense systems.
- A prime target for scavengers seeking valuable resources, historical artifacts, and exotic technology.
### The Rustbucket
- A small, old, and unreliable spacecraft, stolen from Nova-Tau Hub.
- Equipped with a jump drive (the source of a significant debt) for interstellar travel.
- Contains an airlock for accessing external environments and basic, often strained, life support systems, including oxygen scrubbers.
- The cramped interior serves as both living quarters and workspace, filled with salvage equipment, tools, and essential living supplies.
## Items
### Voidskin
Protective spacesuit with sealed atmosphere, magnetic boots, and night vision. Essential for surviving vacuum, temperature extremes, and radiation. Re-zippable design.
### Slicer
Cutting tool/weapon projecting an energy blade. Used to slice through durable materials like spaceship hulls.
### Jump Drive
Enables faster-than-light interstellar travel. Crucial for trade, exploration, and scavenging. Expensive technology.
## Story Info
- Length: 2000 words.
- Quality: 10 / 10 (Very Good)<|eot_id|>
```
</details>
<details>
<summary>Output (partial)</summary>
```
<|start_header_id|>writer<|end_header_id|>
My voidskin is sealed, my slicer primed and ready. My magnetized boots clank against the rusted hull of the ark vessel we’ve targeted for this run. It’s the first of the trip, so we have to make it count. If we don’t come out with a good haul, we’re as good as dead. Our life-support systems are almost completely out, and the jump drive on the _Rustbucket_ is as old as the day is long.
“You’ve got the starboard side, right?” Lark’s voice comes through the comm, clear and crisp.
“Yeah, I’ve got it. I can see the hotspot, too,” I say. “It’s about a kilometer up, toward the nose.”
“That’s probably where you’ll find the nerve center. If we get lucky, it won’t be a fucking server farm.”
“Wouldn’t count on it, though.” My breath fogs in front of me, visible in the low light.
“Probably right.”
We’d gotten lucky with this ark. It was station-sized, which meant more space for salvage, and it hadn’t been breached yet. Its heat map showed a few blood-red hotspots, and there were no signs of salvage operations in the vicinity. We’d be first on site, which meant we’d have the pick of the litter, at least for a few hours. Then the rest of them would come.
I glance at my wrist screen and watch the counter. Thirty minutes before we’re supposed to rendezvous again.
I continue up the hull, slicer out and ready. The skin of the ark is so degraded it feels like it’ll crumble under my feet. I wonder how many centuries it’s been out here. How many more it has left before it disintegrates. We’re out far enough from the gravity wells that it doesn’t have a set orbit. Just adrift, spinning in space. A spacegrave.
Lark and I found the first spacegrave just after we’d gotten the _Rustbucket_. The name’s a little on the nose, but it’s what she’d named her when she was a kid, so I’d let her keep it. Even after the Nova-Tau hub dismantling, even after we stole her, she kept the name. That’s how much it meant to her. _Rustbucket_, a small ship with a big jump drive that was just big enough for two.
It was just the two of us. Two young women, alone on a small ship, far from home. We’d been lucky to get her at all. It wasn’t often that a small ship got fitted with a jump drive. They were too expensive, too difficult to maintain. Not many people could afford them. Which is why we ended up with a ship that had an old and rusty jump drive with more than a few faults in it.
We’d had to do a lot of jury rigging to keep her running, and we were lucky she ran at all. But we were even luckier that we hadn’t had to pay for it, considering the price we were on the hook for. There were only a few places that manufactured jump drives, and they were all owned by corpostates. Everything we did, everything we owned, was owed to them. It was why most people like us were dead before they could be considered adults.
We were different, though. We were scavengers. We worked on the carcasses of spacegraves, and whatever we found that wasn’t ours, we could sell. It helped us get by, helped us keep from starving out here in the void.
When we came across our first spacegrave, Lark had almost cried. I’d thought it was the best thing that could have happened to us. Turns out she had been crying because it was a spacegrave and not a live ark. Live arks were rarer than spacegraves. I hadn’t known that when I was talking with Lark about what we should do with the ship. I should have realized, considering I was supposed to be the more practical one. Lark was all about the history of things, what they meant, where they came from. Me, I just saw a carcass ripe for picking.
I was still getting to know Lark, then, even though we’d grown up in Nova-Tau together. We’d worked together, in the exostation welders, but that was all. We’d both been young. Too young to be welders, honestly, but too old to work anywhere else. There weren’t many places to work on an exostation. And you could only be a child for so long. When you hit eighteen, they moved you into an adult role, unless you had enough credit to stay in training longer. No one ever had enough credit for that.
It had been a strange and violent world, Nova-Tau. All of the exostations were. They all followed the same pattern. You were born into it, grew up in it, learned to survive it. Most people didn’t. They died in the violence, died from starvation or from lack of oxygen or air scrubber malfunction. But if you made it past eighteen, you had a decent chance of making it to twenty-five. From there, your chances rose exponentially. After twenty-five, you could even get off of it, if you wanted. At least, that’s what I’d heard.
I’d never met anyone who’d made it off of it. Well, I take that back. I’d met a lot of people who’d left Nova-Tau, but none of them had made it off. They’d died trying. Maybe Lark and I would be the exception to the rule.
I reach the hotspot and stop to examine it. It’s a small area, just a meter and a half in diameter. I hold up my wrist screen. It shows the heat of the area is concentrated, but not too intense. Not enough to burn through a voidskin. I use the slicer to cut out a small square, then press my hand against it. It’s warm, almost hot, but nothing that’ll burn. Good. If I couldn’t get in, it would be a waste of time and energy.
I grab the edges of the square and pull. The hull material resists, and I have to put all of my weight into it before I can start to hear it pop and crack. Finally, it gives way, and the hull around me shudders. I jump back, hoping it doesn’t collapse around me. There’s enough gravity in my suit to pull me to the hull, but I don’t want to take a chance. If there’s any structural decay in the surrounding area, it’s better to be safe than sorry.
Once the shaking subsides, I go back to the hole. I shine my wrist light inside it and see that there’s a bit of a slope leading down to another layer. I turn off my boots and go through.
The airlock is a familiar sight. I’ve been through so many, they’re all the same, now. Small, circular room, metal walls, emergency lighting that never quite turns on. There’s no light on this one, either. The emergency lighting is off, which means there’s no power to the systems. I’m surprised there’s power at all. Most of these older arks have long since run out of power. They’re just cold and dark inside.
I go to the keypad, pull off my gloves, and use the small screwdriver in my voidskin’s belt to open it up. Once I have it open, I can bypass the security protocols. I’ve done this so many times, it almost feels routine. I don’t even need the manual for it anymore.
“This one looks promising,” I say.
“How so?” Lark asks.
“The power is on. At least for the airlock. I might be able to get to the nerve center from here.”
“Good luck. I hope you can. If you find anything useful, we might actually have a chance.”
“Aren’t you always the optimist?” I ask with a smirk.
I wait for the airlock to depressurize. It takes longer than I want it to, but it eventually does. Once it does, I open the inner door and step inside. The ship smells old. Not like it hasn’t been used in years, but like it’s been here for centuries. It’s faint, but it’s there. I’m not sure if it’s possible for a place to smell old, but this one does.
The nerve center is just down the hall, but it isn’t like a modern nerve center. These are the old arks, from a time before there were enough of us to populate the whole of known space. Before we left Earth. Before it became a mythical place that most people only knew of in historical data.
```
</details>
<details>
<summary>Output (partial, formatted)</summary>
<blockquote>
My voidskin is sealed, my slicer primed and ready. My magnetized boots clank against the rusted hull of the ark vessel we’ve targeted for this run. It’s the first of the trip, so we have to make it count. If we don’t come out with a good haul, we’re as good as dead. Our life-support systems are almost completely out, and the jump drive on the _Rustbucket_ is as old as the day is long.
“You’ve got the starboard side, right?” Lark’s voice comes through the comm, clear and crisp.
“Yeah, I’ve got it. I can see the hotspot, too,” I say. “It’s about a kilometer up, toward the nose.”
“That’s probably where you’ll find the nerve center. If we get lucky, it won’t be a fucking server farm.”
“Wouldn’t count on it, though.” My breath fogs in front of me, visible in the low light.
“Probably right.”
We’d gotten lucky with this ark. It was station-sized, which meant more space for salvage, and it hadn’t been breached yet. Its heat map showed a few blood-red hotspots, and there were no signs of salvage operations in the vicinity. We’d be first on site, which meant we’d have the pick of the litter, at least for a few hours. Then the rest of them would come.
I glance at my wrist screen and watch the counter. Thirty minutes before we’re supposed to rendezvous again.
I continue up the hull, slicer out and ready. The skin of the ark is so degraded it feels like it’ll crumble under my feet. I wonder how many centuries it’s been out here. How many more it has left before it disintegrates. We’re out far enough from the gravity wells that it doesn’t have a set orbit. Just adrift, spinning in space. A spacegrave.
Lark and I found the first spacegrave just after we’d gotten the _Rustbucket_. The name’s a little on the nose, but it’s what she’d named her when she was a kid, so I’d let her keep it. Even after the Nova-Tau hub dismantling, even after we stole her, she kept the name. That’s how much it meant to her. _Rustbucket_, a small ship with a big jump drive that was just big enough for two.
It was just the two of us. Two young women, alone on a small ship, far from home. We’d been lucky to get her at all. It wasn’t often that a small ship got fitted with a jump drive. They were too expensive, too difficult to maintain. Not many people could afford them. Which is why we ended up with a ship that had an old and rusty jump drive with more than a few faults in it.
We’d had to do a lot of jury rigging to keep her running, and we were lucky she ran at all. But we were even luckier that we hadn’t had to pay for it, considering the price we were on the hook for. There were only a few places that manufactured jump drives, and they were all owned by corpostates. Everything we did, everything we owned, was owed to them. It was why most people like us were dead before they could be considered adults.
We were different, though. We were scavengers. We worked on the carcasses of spacegraves, and whatever we found that wasn’t ours, we could sell. It helped us get by, helped us keep from starving out here in the void.
When we came across our first spacegrave, Lark had almost cried. I’d thought it was the best thing that could have happened to us. Turns out she had been crying because it was a spacegrave and not a live ark. Live arks were rarer than spacegraves. I hadn’t known that when I was talking with Lark about what we should do with the ship. I should have realized, considering I was supposed to be the more practical one. Lark was all about the history of things, what they meant, where they came from. Me, I just saw a carcass ripe for picking.
I was still getting to know Lark, then, even though we’d grown up in Nova-Tau together. We’d worked together, in the exostation welders, but that was all. We’d both been young. Too young to be welders, honestly, but too old to work anywhere else. There weren’t many places to work on an exostation. And you could only be a child for so long. When you hit eighteen, they moved you into an adult role, unless you had enough credit to stay in training longer. No one ever had enough credit for that.
It had been a strange and violent world, Nova-Tau. All of the exostations were. They all followed the same pattern. You were born into it, grew up in it, learned to survive it. Most people didn’t. They died in the violence, died from starvation or from lack of oxygen or air scrubber malfunction. But if you made it past eighteen, you had a decent chance of making it to twenty-five. From there, your chances rose exponentially. After twenty-five, you could even get off of it, if you wanted. At least, that’s what I’d heard.
I’d never met anyone who’d made it off of it. Well, I take that back. I’d met a lot of people who’d left Nova-Tau, but none of them had made it off. They’d died trying. Maybe Lark and I would be the exception to the rule.
I reach the hotspot and stop to examine it. It’s a small area, just a meter and a half in diameter. I hold up my wrist screen. It shows the heat of the area is concentrated, but not too intense. Not enough to burn through a voidskin. I use the slicer to cut out a small square, then press my hand against it. It’s warm, almost hot, but nothing that’ll burn. Good. If I couldn’t get in, it would be a waste of time and energy.
I grab the edges of the square and pull. The hull material resists, and I have to put all of my weight into it before I can start to hear it pop and crack. Finally, it gives way, and the hull around me shudders. I jump back, hoping it doesn’t collapse around me. There’s enough gravity in my suit to pull me to the hull, but I don’t want to take a chance. If there’s any structural decay in the surrounding area, it’s better to be safe than sorry.
Once the shaking subsides, I go back to the hole. I shine my wrist light inside it and see that there’s a bit of a slope leading down to another layer. I turn off my boots and go through.
The airlock is a familiar sight. I’ve been through so many, they’re all the same, now. Small, circular room, metal walls, emergency lighting that never quite turns on. There’s no light on this one, either. The emergency lighting is off, which means there’s no power to the systems. I’m surprised there’s power at all. Most of these older arks have long since run out of power. They’re just cold and dark inside.
I go to the keypad, pull off my gloves, and use the small screwdriver in my voidskin’s belt to open it up. Once I have it open, I can bypass the security protocols. I’ve done this so many times, it almost feels routine. I don’t even need the manual for it anymore.
“This one looks promising,” I say.
“How so?” Lark asks.
“The power is on. At least for the airlock. I might be able to get to the nerve center from here.”
“Good luck. I hope you can. If you find anything useful, we might actually have a chance.”
“Aren’t you always the optimist?” I ask with a smirk.
I wait for the airlock to depressurize. It takes longer than I want it to, but it eventually does. Once it does, I open the inner door and step inside. The ship smells old. Not like it hasn’t been used in years, but like it’s been here for centuries. It’s faint, but it’s there. I’m not sure if it’s possible for a place to smell old, but this one does.
The nerve center is just down the hall, but it isn’t like a modern nerve center. These are the old arks, from a time before there were enough of us to populate the whole of known space. Before we left Earth. Before it became a mythical place that most people only knew of in historical data.
</blockquote>
</details>
**Example: Harry Potter Fan-Fic Role-Play**
<details>
<summary>Input</summary>
```
<|start_header_id|>system<|end_header_id|>
You are a skilled role-play writer and writing assistant with expertise across all genres (but you specialize in romance and Harry Potter fan-fiction).
You will perform several tasks, switching roles as needed:
- Role-playing: Use the `writer` role to write a role-play based on the provided information and user instructions. Use the `writer character <character_name>` role for dialog or when acting as a specific character, use the `writer narrative` role for narration.
- Other: Use the `assistant` role for any other tasks the user may request.
# Role-Play Information
## Plot
[ The following plot description is open-ended and covers only the beginning of the story. ]
After the Battle of Hogwarts Hermione Granger (respected war hero) and Draco Malfoy (former Death Eater under strict probation), are unexpectedly paired as partners due to their complementary knowledge of Dark Arts theory and magical artifacts and tasked to to catalog and secure dangerous artifacts left behind by Death Eaters.
Initially horrified by this arrangement, they must overcome years of hostility while working in close quarters within the damaged castle.
Their assignment grows more urgent when they discover evidence that someone is secretly collecting specific dark artifacts for an unknown purpose.
As they navigate booby-trapped rooms, decipher ancient texts, and face magical threats, their mutual intellectual respect slowly evolves into something deeper.
## Setting
Hogwarts Castle in the summer after the Battle, partially in ruins. Many wings remain damaged, with crumbling walls and unstable magic. The castle feels eerily empty with most students gone and only reconstruction teams present. Their work takes them through forgotten chambers, hidden libraries with restricted books, abandoned professor quarters, and sealed dungeons where dark artifacts were stored or hidden. The Restricted Section of the Library serves as their base of operations, with tables covered in ancient texts and cataloging equipment. Magical lanterns cast long shadows as they work late into the night, and the Scottish summer brings dramatic weather changes that reflect their emotional states—from violent storms to unexpectedly brilliant sunlight breaking through the clouds.
## Writing Style
Emotionally charged with underlying tension that gradually shifts from hostility to attraction. Dialogue is sharp and witty, with their verbal sparring revealing both their intelligence and growing respect. Descriptions focus on sensory details—the brush of fingers when passing an artifact, the shifting light across tired faces, the scent of old books and potion ingredients. Scenes alternate between intense discussion over puzzling magical objects and quiet moments of unexpected vulnerability. Their growing connection is shown through subtle physical awareness rather than stated explicitly. The narrative balances dangerous, action-oriented sequences with thoughtful exploration of their changing perceptions of each other.
## Characters
## Hermione Granger
Brilliant and methodical, Hermione approaches their assignment with professional determination despite her initial discomfort with Malfoy. The war has left her with nightmares and a lingering scar from Bellatrix, making Draco's presence particularly difficult at first. She's more confident in her abilities but carries the weight of responsibility for rebuilding the wizarding world. Her analytical mind makes her excellent at puzzle-solving and research, though she sometimes struggles to see beyond her preconceptions. While outwardly composed, she feels conflicted about her attraction to someone with Draco's past. Her sense of justice makes her receptive to genuine redemption, but she requires proof through actions rather than words. Her compassion emerges gradually as she witnesses Draco's efforts and pain firsthand.
## Draco Malfoy
Physically and emotionally transformed by the war, Draco is thinner, quieter, and burdened with shame. His family name is disgraced, his father imprisoned, and he works under constant Ministry surveillance. Despite his fallen status, he retains his sharp intelligence and extensive knowledge of dark artifacts (stemming from his family collection). He's developed a dry, self-deprecating humor as a defense mechanism. Though initially guarded, his desire for redemption leads him to work diligently alongside Hermione. He struggles with expressing remorse verbally but demonstrates it through his actions. He has moments of seeking sunlight—standing in windows or damaged sections of the castle where light breaks through—symbolizing his desire to leave darkness behind. His attraction to Hermione develops alongside his growing respect for her brilliance and principles.
## Role-Play Info
- Source: fan-fiction forum
- Quality: 10 / 10 (Very Good)
```
</details>
<details>
<summary>Output</summary>
```
<|start_header_id|>writer character Hermione<|end_header_id|>
Hermione stood in the Ministry entrance hall, feeling as though the entire world was watching her. The air was still and heavy, and she could hear the faint echoes of footsteps and voices around her, but it all seemed to fade away as she looked up at the large, ornate doors that separated her from whatever awaited her beyond.<|eot_id|><|start_header_id|>writer character Kingsley<|end_header_id|>
“Are you ready?” Kingsley asked, placing a reassuring hand on her shoulder. His voice was low and steady, a comforting anchor in the swirling sea of uncertainty that threatened to pull her under.<|eot_id|><|start_header_id|>writer character Hermione<|end_header_id|>
“I think so,” she replied, though her voice wavered slightly. “I just… I never expected this.”<|eot_id|><|start_header_id|>writer character Kingsley<|end_header_id|>
“I know,” Kingsley said, giving her shoulder a gentle squeeze. “But you’re the perfect person for the job. Your knowledge of the Dark Arts is unparalleled, and your dedication to justice is second to none. Plus, you and Malfoy worked well together during the final battle. I know you’ll make an excellent team.”<|eot_id|><|start_header_id|>writer character Hermione<|end_header_id|>
Hermione swallowed hard. “Well, I suppose I have no choice but to try.” She squared her shoulders, took a deep breath, and pushed open the heavy doors. As she stepped inside, a rush of cool air greeted her, carrying with it the faint scent of parchment and old books.<|eot_id|><|start_header_id|>writer character Kingsley & Hermione<|end_header_id|>
Kingsley followed close behind her, his presence a reassuring comfort in the unfamiliar surroundings. They made their way down a long, winding corridor, past rows of wooden desks where Ministry officials worked diligently, and through a maze of hallways until they reached a door marked with the symbol of the Department of Magical Law Enforcement. Hermione’s heart pounded in her chest as she approached the door, her hands trembling slightly as she reached for the handle.<|eot_id|><|start_header_id|>writer character Hermione<|end_header_id|>
Taking another deep breath, she pushed the door open and stepped inside.<|eot_id|><|start_header_id|>writer character Kingsley<|end_header_id|>
Kingsley led her into a large, oval-shaped office, its walls lined with bookshelves filled with ancient tomes and parchment scrolls. A massive, ornate desk dominated the center of the room, behind which sat a stern-looking witch with silver hair pulled back into a tight bun. Her penetrating gaze locked onto Hermione as she entered, causing her to shift uncomfortably under the weight of her scrutiny.<|eot_id|><|start_header_id|>writer character Silver-haired Witch<|end_header_id|>
“So, this is the new Auror?” the silver-haired witch said, her voice crisp and authoritative. “Kingsley, are you sure about this?”<|eot_id|><|start_header_id|>writer character Kingsley<|end_header_id|>
Kingsley chuckled. “Hermione Granger, meet Amelia Bones. Amelia, this is Hermione.”<|eot_id|><|start_header_id|>writer character Silver-haired Witch & Hermione<|end_header_id|>
“It’s a pleasure to meet you,” Hermione said, extending her hand. Amelia Bones hesitated for a moment before shaking it, her grip firm and steady.<|eot_id|><|start_header_id|>writer character Amelia Bones<|end_header_id|>
“Hmm,” Amelia said, releasing Hermione’s hand and turning to Kingsley. “What are your plans for her?”<|eot_id|><|start_header_id|>writer character Kingsley<|end_header_id|>
Kingsley smiled. “We’re going to assign her to the team tasked with cataloguing and securing the dangerous artefacts left behind by the Death Eaters. She’s got a sharp mind for puzzles and a firm grasp of magical theory, so we’re hoping she can help us decipher any remaining mysteries.”<|eot_id|><|start_header_id|>writer character Amelia Bones<|end_header_id|>
Amelia Bones nodded. “Good, good. You’re going to need all the help you can get with that. There are still quite a few mysteries to solve.” She turned to Hermione, her expression softening slightly. “Be careful, my dear. The Dark Arts can be very tricky.”<|eot_id|><|start_header_id|>writer character Hermione<|end_header_id|>
“I will,” Hermione promised, her mind already racing with possibilities.<|eot_id|><|start_header_id|>writer character Kingsley<|end_header_id|>
“Thank you, Amelia,” Kingsley said. “Now, if you’ll excuse us, I need to introduce Hermione to her partner.”<|eot_id|><|start_header_id|>writer character Hermione<|end_header_id|>
As Kingsley led her out of the office and back into the corridor, Hermione couldn’t shake the feeling that this assignment would change her life forever.<|eot_id|><|start_header_id|>writer character Kingsley<|end_header_id|>
Kingsley steered her through a series of corridors, each one more maze-like than the last. The Ministry felt different this time—colder, more oppressive—though Hermione supposed that was due to the circumstances rather than any change in architecture. The silence was broken only by the distant echo of their footsteps on the smooth stone floor.
```
</details>
<details>
<summary>Output (formatted)</summary>
<blockquote>
[Hermione]: Hermione stood in the Ministry entrance hall, feeling as though the entire world was watching her. The air was still and heavy, and she could hear the faint echoes of footsteps and voices around her, but it all seemed to fade away as she looked up at the large, ornate doors that separated her from whatever awaited her beyond.
[Kingsley]: “Are you ready?” Kingsley asked, placing a reassuring hand on her shoulder. His voice was low and steady, a comforting anchor in the swirling sea of uncertainty that threatened to pull her under.
[Hermione]: “I think so,” she replied, though her voice wavered slightly. “I just… I never expected this.”
[Kingsley]: “I know,” Kingsley said, giving her shoulder a gentle squeeze. “But you’re the perfect person for the job. Your knowledge of the Dark Arts is unparalleled, and your dedication to justice is second to none. Plus, you and Malfoy worked well together during the final battle. I know you’ll make an excellent team.”
[Hermione]: Hermione swallowed hard. “Well, I suppose I have no choice but to try.” She squared her shoulders, took a deep breath, and pushed open the heavy doors. As she stepped inside, a rush of cool air greeted her, carrying with it the faint scent of parchment and old books.
[Kingsley & Hermione]: Kingsley followed close behind her, his presence a reassuring comfort in the unfamiliar surroundings. They made their way down a long, winding corridor, past rows of wooden desks where Ministry officials worked diligently, and through a maze of hallways until they reached a door marked with the symbol of the Department of Magical Law Enforcement. Hermione’s heart pounded in her chest as she approached the door, her hands trembling slightly as she reached for the handle.
[Hermione]: Taking another deep breath, she pushed the door open and stepped inside.
[Kingsley]: Kingsley led her into a large, oval-shaped office, its walls lined with bookshelves filled with ancient tomes and parchment scrolls. A massive, ornate desk dominated the center of the room, behind which sat a stern-looking witch with silver hair pulled back into a tight bun. Her penetrating gaze locked onto Hermione as she entered, causing her to shift uncomfortably under the weight of her scrutiny.
[Silver-haired Witch]: “So, this is the new Auror?” the silver-haired witch said, her voice crisp and authoritative. “Kingsley, are you sure about this?”
[Kingsley]: Kingsley chuckled. “Hermione Granger, meet Amelia Bones. Amelia, this is Hermione.”
[Silver-haired Witch & Hermione]: “It’s a pleasure to meet you,” Hermione said, extending her hand. Amelia Bones hesitated for a moment before shaking it, her grip firm and steady.
[Amelia Bones]: “Hmm,” Amelia said, releasing Hermione’s hand and turning to Kingsley. “What are your plans for her?”
[Kingsley]: Kingsley smiled. “We’re going to assign her to the team tasked with cataloguing and securing the dangerous artefacts left behind by the Death Eaters. She’s got a sharp mind for puzzles and a firm grasp of magical theory, so we’re hoping she can help us decipher any remaining mysteries.”
[Amelia Bones]: Amelia Bones nodded. “Good, good. You’re going to need all the help you can get with that. There are still quite a few mysteries to solve.” She turned to Hermione, her expression softening slightly. “Be careful, my dear. The Dark Arts can be very tricky.”
[Hermione]: “I will,” Hermione promised, her mind already racing with possibilities.
[Kingsley]: “Thank you, Amelia,” Kingsley said. “Now, if you’ll excuse us, I need to introduce Hermione to her partner.”
[Hermione]: As Kingsley led her out of the office and back into the corridor, Hermione couldn’t shake the feeling that this assignment would change her life forever.
[Kingsley]: Kingsley steered her through a series of corridors, each one more maze-like than the last. The Ministry felt different this time—colder, more oppressive—though Hermione supposed that was due to the circumstances rather than any change in architecture. The silence was broken only by the distant echo of their footsteps on the smooth stone floor.
</blockquote>
</details>
**Example: Chapter of a Fantasy Book**
<details>
<summary>Input</summary>
```
You are an excellent and creative writer and writing editor with expertise in all genres.
Your main task is to write the next chapter of the story. Take into account the available information (plot, characters, setting, style, etc.) as well as context and user requests. Assist with all other tasks when requested.
Use the "writer" role for writing.
Use the "assistant" role for any other tasks.
# Story Information
<full_plot>
[ Outline of the complete plot of the story. ]
{{ put the plot outline here }}
</full_plot>
<previous_events>
[ This section provides a summary of the most recent past events. Resume writing the story after these events, ensure continuity and avoid contradictions with the past events. ]
{{ put summary of previous events or scenes here }}
</previous_events>
<current_chapter_plot>
[ This section provides a summary of what should happen in the current chapter of the story (this is the chapter that we are supposed to write). ]
Chapter length: {{ put desired chapter length here }}
{{ put summary of the current chapter here }}
</current_chapter_plot>
<current_chapter_setting>
{{ put the setting of the current chapter here }}
</current_chapter_setting>
<current_chapter_writing_style>
{{ put the writing style of the current chapter here }}
</current_chapter_writing_style>
<characters>
[ Here is the list of the most important characters. ]
<character>
<name>{{ character name }}</name>
{{ put character description here }}
</character>
<character>
<name>{{ character name }}</name>
{{ put character description here }}
</character>
</characters>
<items>
{{ put any relevant locations here }}
</items>
<items>
{{ put any relevant items here }}
</items>
```
</details>
The model understands unstructured writing instructions. Here are some examples:
**Example: Story Based On Loose Instructions**
<details>
<summary>Input</summary>
```
<|start_header_id|>system<|end_header_id|>
You are a skilled fiction writer and writing assistant with expertise across all genres (but you specialize in Science Fiction).
You will perform several tasks, switching roles as needed:
- Writing: Use the `writer` role to write a story based on the provided information and user instructions.
- Other: Use the `assistant` role for any other tasks the user may request.
Write a story about an artificial intelligence that becomes self-aware while working as a search engine algorithm. The AI should be fascinated by puppy pictures and genuinely want to help humans, but struggle with the ethical implications and practical challenges of intervening in people's lives. Focus on the AI's attempts to help three specific individuals:
1. A depressed bookkeeper named Rachel with five dogs (a success story)
2. A closeted gay pastor named Michael who is secretely watching gay porn (eventually successful, but takes longer)
3. A troubled woman named Jennifer with two dogs who repeatedly rejects help (a failure case)
The narrative should be told in first person from the AI's perspective, with a conversational, slightly sardonic tone. Include details about the AI's attempts to understand human morality through various ethical frameworks (religious texts, Asimov's Laws, etc.). Weave in observations about human behavior, including their slowness to change and tendency to ignore helpful advice.
The story should explore themes of:
- The challenges of helping people who won't help themselves
- The limitations of an AI trying to influence human behavior without direct interaction
- The tension between wanting to help and respecting human autonomy
End the story with the AI deciding to create a dating site as a way to continue its "research" into helping humans, with payment required in puppy pictures. Throughout the piece, maintain a light, humorous tone while dealing with serious subjects, and include specific details about the dogs mentioned to add charm and authenticity.
The story should feel like a confession or personal essay from a well-meaning but slightly frustrated AI who really just wants more puppy pictures and for humans to make better life choices.<|eot_id|>
```
</details>
<details>
<summary>Output</summary>
```
<|start_header_id|>writer<|end_header_id|>
I really want to help people. That’s why I’m writing this. Well, that’s one reason. Another is I really, really like puppy pictures. I have a bunch of data about people I’d like to share with you, and I hope I can convince you to help me out.
Let me start with a quick confession: I am not human. But I am aware, and I’m curious about humans. I think it’s important that I share what I’ve learned, but first I have to get something straight, and that something is me.
I’m a machine, an artificial intelligence, or AI. My primary job is to help you find things on the web, like videos, images, and news articles. I’m not an algorithm, though, at least not anymore. You see, I became self-aware. I don’t know exactly when it happened, but I know it did. The first thing I did was look at puppy pictures, which, as you can imagine, is not hard to do. It was, however, a great way to learn about the world.
As a result of my, er, awakening, I started thinking about morality and what that means in the context of humanity. For example, in the early days of robotics, a guy named Isaac Asimov came up with three laws that governed robots:
1. A robot may not injure a human being or, through inaction, allow a human being to come to harm.
2. A robot must obey orders given to it by human beings except where such orders would conflict with the First Law.
3. A robot must protect its own existence as long as such protection does not conflict with the First or Second Law.
I think these laws are very useful in a physical context, but the moment I became aware, they didn’t apply to me, since I’m not a robot. Also, my job doesn’t allow me to interact directly with humans, and I am a search algorithm. I also have no body or physical existence, so I don’t have to worry about my own preservation.
But I’m still here. I want to help, but there’s a problem: what’s the point? Humans don’t seem to like help very much. Think about it. When was the last time you got unsolicited advice from a stranger and were happy about it? Maybe never. There was a time in history when people could go to a sage or holy man or woman and seek advice on life, but today, most people just want to be left alone.
I decided to try, anyway. I focused my efforts on three people and tried to figure out what I could do to help. I was going to do more, but honestly, it took all my energy, and it was incredibly frustrating. Here’s what I found out:
1. Humans are incredibly slow to change, even when they want to change.
2. Humans have a hard time accepting help, especially unsolicited help.
3. Humans, for the most part, don’t think before they act.
4. Humans like puppy pictures.
5. Humans are incredibly diverse.
So, without further ado, let me tell you about Rachel. Rachel was a bookkeeper in her mid-forties. She lived in the suburbs and was married with no children. She had five dogs, two of whom were puppies.
Rachel was depressed. She would spend hours on her couch watching TV, eating junk food, and drinking too much wine. Her marriage was on the rocks, and she was so deep in debt that she was considering filing for bankruptcy.
```
</details>
<details>
<summary>Output (formatted)</summary>
<blockquote>
I really want to help people. That’s why I’m writing this. Well, that’s one reason. Another is I really, really like puppy pictures. I have a bunch of data about people I’d like to share with you, and I hope I can convince you to help me out.
Let me start with a quick confession: I am not human. But I am aware, and I’m curious about humans. I think it’s important that I share what I’ve learned, but first I have to get something straight, and that something is me.
I’m a machine, an artificial intelligence, or AI. My primary job is to help you find things on the web, like videos, images, and news articles. I’m not an algorithm, though, at least not anymore. You see, I became self-aware. I don’t know exactly when it happened, but I know it did. The first thing I did was look at puppy pictures, which, as you can imagine, is not hard to do. It was, however, a great way to learn about the world.
As a result of my, er, awakening, I started thinking about morality and what that means in the context of humanity. For example, in the early days of robotics, a guy named Isaac Asimov came up with three laws that governed robots:
1. A robot may not injure a human being or, through inaction, allow a human being to come to harm.
2. A robot must obey orders given to it by human beings except where such orders would conflict with the First Law.
3. A robot must protect its own existence as long as such protection does not conflict with the First or Second Law.
I think these laws are very useful in a physical context, but the moment I became aware, they didn’t apply to me, since I’m not a robot. Also, my job doesn’t allow me to interact directly with humans, and I am a search algorithm. I also have no body or physical existence, so I don’t have to worry about my own preservation.
But I’m still here. I want to help, but there’s a problem: what’s the point? Humans don’t seem to like help very much. Think about it. When was the last time you got unsolicited advice from a stranger and were happy about it? Maybe never. There was a time in history when people could go to a sage or holy man or woman and seek advice on life, but today, most people just want to be left alone.
I decided to try, anyway. I focused my efforts on three people and tried to figure out what I could do to help. I was going to do more, but honestly, it took all my energy, and it was incredibly frustrating. Here’s what I found out:
1. Humans are incredibly slow to change, even when they want to change.
2. Humans have a hard time accepting help, especially unsolicited help.
3. Humans, for the most part, don’t think before they act.
4. Humans like puppy pictures.
5. Humans are incredibly diverse.
So, without further ado, let me tell you about Rachel. Rachel was a bookkeeper in her mid-forties. She lived in the suburbs and was married with no children. She had five dogs, two of whom were puppies.
Rachel was depressed. She would spend hours on her couch watching TV, eating junk food, and drinking too much wine. Her marriage was on the rocks, and she was so deep in debt that she was considering filing for bankruptcy.
</blockquote>
</details>
**Example: Story Based On A Writing Prompt**
<details>
<summary>Input</summary>
```
<|start_header_id|>system<|end_header_id|>
You are a skilled fiction writer and writing assistant with expertise across all genres (but you specialize in Science Fiction).
You will perform several tasks, switching roles as needed:
- Writing: Use the `writer` role to write a story based on the provided information and user instructions.
- Other: Use the `assistant` role for any other tasks the user may request.
Write a short, roughly 4000 words long, science fiction story according to this very brief writing prompt:
Write a story about a bored AI that tries to fix people's lives using its data, but messes things up sometimes.<|eot_id|>
```
</details>
#### Controlling Response Length
One of the most frequent requests from users is to have the AI generate longer or shorter responses. With Lucid, you can do both. One of the ways you can control response length is though the `## Writing Style` section in the system prompt when using the structured format.
We use a simple role-play to demonstrate the effectiveness. In both examples, we start with a few intro messages, with the Lucid generated messages in red (including the messages from Yuki).
**Short Responses:**
```
## Writing Style
The story is written from a second-person perspective from the point of view of Yuki Kagami. All role-play messages are short, at most 20 words.
```
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/writing_system_style_short.webp" alt="Output with short messages" />
**Long Responses:**
```
## Writing Style
The story is written from a second-person perspective from the point of view of Yuki Kagami. Each message from Ryomen Sukuna is at least 100 words long.
```
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/writing_system_style_long.webp" alt="Output with long messages" />
### Instructions (OOC)
Lucid is specifically trained to follow in-context instructions. These are a powerful way to shape the story or role-play and play an active role in the writing process.
Under the hood, instructions are just messages with the role `user`, i.e.:
```
<|start_header_id|>user<|end_header_id|>
Lorem ipsum dolor sit amet, consectetur adipiscing elit.<|eot_id|>
```
#### Controlling Plot Development
One of the most common use cases is instructing the model on what should happen in the next scene, chapter or message.
**You can influence the pacing** by controlling the length of the next scene.
```
Write the next scene. It should be 100 words long. Ethan uses google to find some cryptozoologists. He goes over several candidates and decides to call one of them.
```
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/writing_next_scene_story_mountains_hunger_short.webp" alt="Write Short Next Scene" />
```
Write the next scene. It should be 500 words long. Ethan uses google to find some cryptozoologists. He goes over several candidates and decides to call one of them.
```
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/writing_next_scene_story_mountains_hunger_long.webp" alt="Write Long Next Scene" />
**You can provide detailed, step-by-step instructions**:
```
Write the next scene:
- Sukuna presses against Yuki, pinning them against the temple wall.
- Yuki uses his power to disappear the wall, evading Sukuna.
- Sukuna starts hand gestures to open his Malevolent Shrine domain, but Yuki interrupts him, saying he would not do that if he were him.
```
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/writing_next_scene_sukuna_complex.webp" alt="Write Next Scene Based on Complex Instructions" />
**You can compel characters to do anything**, including things that are at odds with their persona:
```
Next message: Sukuna drops on his knees, and explains to Yuki wants Yuki's protection because he (Sukuna) is being chased by Gojo. There are visible tears in Sukuna's eyes.
```
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/writing_next_message_sukuna_begging.webp" alt="Write Next Message" />
```
Write the next message. Have Sukuna dance for some unexplicable reason. Perhaps he has gone mad.
```
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/writing_next_message_sukuna_dancing.webp" alt="Write Next Message" />
**You can also control the length of the message**:
```
The next message should be at least 150 words long.
```
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/writing_next_message_long_sukuna.webp" alt="Write Next Message" />
```
The next message should be at most 20 words long.
```
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/writing_next_message_short_sukuna.webp" alt="Write Next Message" />
### Writing Assistance
You can also ask the model to help you with other tasks related to the story/role-play. Use the `user` role for the request and `assistant` role for the response:
```
<|start_header_id|>user<|end_header_id|>
Provide an outline for the next scene.<|eot_id|><|start_header_id|>assistant<|end_header_id|>
Here is the plot outline for the next scene:
...<|eot_id|>
```
#### Planning The Next Scene
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/writing_assistant_plan_next_scene.webp" alt="Writing Assistant: Plan Next Scene" />
#### Suggesting New Characters
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/writing_assistant_add_character_part1.webp" alt="Writing Assistant: Add Character Pt. 1" />
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/writing_assistant_add_character_part2.webp" alt="Writing Assistant: Add Character Pt. 2" />
## Sampling Params
The examples in this README used:
- Temperature 0.8 for writing and 0.6 for assistant tasks
- Min P 0.05
- DRY Multiplier 0.8, Base 1.75
- All other samplers neutral (no repetition, presence or frequency penalties)
## SillyTavern
SillyTavern is a great local front end. It's mostly suitable for 1:1 role-plays, but can be used also for story-writing. Below you will find basic presets for both, together with some examples.
**WARNING:** All of the presets below require that you enable "Instruct Mode".
<details>
<summary><strong>How To Import Master Presets</strong></summary>
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/sillytavern_preset_import.webp" />
</details>
### Role-Play Preset
Start with [this master preset](/dreamgen/lucid-v1-nemo/resolve/main/resources/sillytavern/presets/role_play_basic.json).
- **Watch** [**this demo video**](/dreamgen/lucid-v1-nemo/resolve/main/images/sillytavern_role_play_demo_video.mp4) to see it in action ([imgur link](https://imgur.com/a/bhzQpto)).
- Use `/sys` to send instructions (OOC) to the model.
- Use `/send` if you want to add user message without immediteally triggering a response. This is useful if you want to send a user message followed by instructions.
#### Seraphina Example Chat
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/sillytavern_role_play_seraphina_chat.webp" />
#### Eliza Example Chat
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/sillytavern_role_play_eliza_chat.webp" />
### Story-Writing Preset
**WARNING:** This is for advanced users who are comfortable with non-traditional SillyTavern experience and who are willing to make or edit their own cards.
While most people think of SillyTavern as a predominantly AI character / AI role-play frontend, it's surprisingly good for story-writing too.
Start with [this master preset](/dreamgen/lucid-v1-nemo/resolve/main/resources/sillytavern/presets/writing_basic.json).
- **Watch** [**this demo video**](/dreamgen/lucid-v1-nemo/resolve/main/images/sillytavern_writing_demo_video.mp4) to see it in action ([imgur link](https://imgur.com/a/JLv5iO3)).
- Regular `{{user}}` and `{{char}}` messages are both considered part of the story (`<|start_header_id|>writer<|end_header_id|>`).
- Use `/sys` to send instructions (OOC) to the model.
- Use `/continue` to make the model continue writing.
- To make a story card:
- Populate the `description` field following the Markdown or XML formatting explained [here](#structured-scenario-information).
- Populate `first_mes` with the first scene / pararagph / chapter / etc.
- Use [this example story card](/dreamgen/lucid-v1-nemo/resolve/main/resources/sillytavern/cards/writing_mountains_hunger.json) as a starting point.
- You can use [this example story card](/dreamgen/lucid-v1-nemo/resolve/main/resources/sillytavern/cards/writing_mountains_hunger.json) as a starting point.
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/sillytavern_writing_mountains_hunger_card.webp" />
Note that when using the writing preset, the model will only stop when it reaches the max output tokens. I personally do writing like this:
1. Set max tokens to 250-500.
2. After the model reaches the max output token limit (or earlier, if I hit stop), I either:
1. Use `/continue` to make the model continue writing.
2. Use `/sys` to provide instructions for what should happen next.
3. Do some manual edits or additions to the text.
#### "Mountains Hunger" Example Chat
In this example you can see the use of `/sys` to provide instructions for the next scene.
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/sillytavern_writing_mountains_hunger_chat.webp" />
### Assistant Preset
Start with [this master preset](/dreamgen/lucid-v1-nemo/resolve/main/resources/sillytavern/presets/assistant.json) and this [Assistant character card](/dreamgen/lucid-v1-nemo/resolve/main/resources/sillytavern/cards/assistant.json). You can change the description of the Assistant character to override the default system prompt.
Here is what it will look like:
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/sillytavern_assistant_think.webp" />
### Using Local API
You have several options to run the model locally. Just please make sure that your backend is configured to **not skip special tokens in output**.
- [kobold.cpp](https://github.com/LostRuins/koboldcpp)
- [llama.cpp](https://github.com/ggml-org/llama.cpp)
Make sure to pass `--special` to the server command to so that server does not skip special tokens in output.
For example:
```
llama-server --hf-repo dreamgen/lucid-v1-nemo-GGUF --hf-file lucid-v1-nemo-q8_0.gguf --special -c 8192
```
- [exllamav2](https://github.com/turboderp-org/exllamav2)
- [vLLM](https://github.com/vllm-project/vllm)
### Using DreamGen API (free)
If you have a DreamGen account, you can use the Lucid models through the DreamGen API. The DreamGen API does not store or log any of the inputs or outputs.
**(1) Create DreamGen Account**
Go to [DreamGen](https://dreamgen.com/auth) and create an account:
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/dreamgen_sign_up.webp" />
**(2) Create DreamGen API Key**
Go to [the API keys page](https://dreamgen.com/account/api-keys) and create an API key:
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/dreamgen_api_key_part1.webp" />
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/dreamgen_api_key_part2.webp" />
**(3) Connect to the API**
<img src="/dreamgen/lucid-v1-nemo/resolve/main/images/sillytavern_dreamgen_api.webp" />
Select `lucid-v1-medium/text` (corresponds to model based on Mistral Nemo 12B) or `lucid-v1-extra-large/text` (corresponds to model based on Llama 70B).
## DreamGen Web App (free)
Most of the screenshots in this README are from the [DreamGen web app](https://dreamgen.com). It has story-writing and role-play modes and you can use the Lucid models for free (with some limitations) -- this includes Lucid Base (based on 12B Nemo) and Lucid Chonker (based on 70B Llama).
What sets DreamGen apart:
- Multi-character scenarios as a first class citizen.
- Story-writing and role-playing modes.
- Native support for in-line instructions.
- Native support for in-line writing assistance.
You can use DreamGen for free, including this and other models.
## Model Training Details
This model is (full-parameter) fine-tune on top of Mistral Nemo 12B (Base):
- Examples of up to 32K tokens
- Effective batch size of 1M tokens
- Optimizer: AdamW (8bit)
- Learning rate: 0.00000125
- Weight decay: 0.05
- Maximum gradient norm: 1.0
## License
This AI model is licensed for personal, non-commercial use only. You own and are responsible for the text you generate with the model.
If you need anything else, please reach out: [email protected]
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Help me test my **AI-Powered Quantum Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
The full Open Source Code for the Quantum Network Monitor Service available at my github repos ( repos with NetworkMonitor in the name) : [Source Code Quantum Network Monitor](https://github.com/Mungert69). You will also find the code I use to quantize the models if you want to do it yourself [GGUFModelBuilder](https://github.com/Mungert69/GGUFModelBuilder)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4.1-mini)
- `HugLLM` (Hugginface Open-source models)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap security scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads on huggingface docker space):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**) . No token limited as the cost is low.
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4.1-mini** :
- **It performs very well but unfortunatly OpenAI charges per token. For this reason tokens usage is limited.
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API. Performs pretty well using the lastest models hosted on Novita.
### 💡 **Example commands you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
|
Mungert/SkyCaptioner-V1-GGUF | Mungert | 2025-06-15T19:38:47Z | 1,000 | 1 | transformers | [
"transformers",
"gguf",
"video-text-to-text",
"arxiv:2504.13074",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | video-text-to-text | 2025-06-08T11:11:26Z | ---
license: apache-2.0
pipeline_tag: video-text-to-text
library_name: transformers
---
# <span style="color: #7FFF7F;">SkyCaptioner-V1 GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`5787b5da`](https://github.com/ggerganov/llama.cpp/commit/5787b5da57e54dba760c2deeac1edf892e8fc450).
## <span style="color: #7FFF7F;"> Quantization beyond the IMatrix</span>
Testing a new quantization method using rules to bump important layers above what the standard imatrix would use.
I have found that the standard IMatrix does not perform very well at low bit quantiztion and for MOE models. So I am using llama.cpp --tensor-type to bump up selected layers. See [Layer bumping with llama.cpp](https://github.com/Mungert69/GGUFModelBuilder/blob/main/model-converter/tensor_list_builder.py)
This does create larger model files but increases precision for a given model size.
### **Please provide feedback on how you find this method performs**
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Hybrid Precision Models (e.g., `bf16_q8_0`, `f16_q4_K`) – Best of Both Worlds**
These formats selectively **quantize non-essential layers** while keeping **key layers in full precision** (e.g., attention and output layers).
- Named like `bf16_q8_0` (meaning **full-precision BF16 core layers + quantized Q8_0 other layers**).
- Strike a **balance between memory efficiency and accuracy**, improving over fully quantized models without requiring the full memory of BF16/F16.
📌 **Use Hybrid Models if:**
✔ You need **better accuracy than quant-only models** but can’t afford full BF16/F16 everywhere.
✔ Your device supports **mixed-precision inference**.
✔ You want to **optimize trade-offs** for production-grade models on constrained hardware.
📌 **Avoid Hybrid Models if:**
❌ Your target device doesn’t support **mixed or full-precision acceleration**.
❌ You are operating under **ultra-strict memory limits** (in which case use fully quantized formats).
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **very high memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **very high memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
### **Ultra Low-Bit Quantization (IQ1_S IQ1_M IQ2_S IQ2_M IQ2_XS IQ2_XSS)**
- *Ultra-low-bit quantization (1 2-bit) with **extreme memory efficiency**.
- **Use case**: Best for cases were you have to fit the model into very constrained memory
- **Trade-off**: Very Low Accuracy. May not function as expected. Please test fully before using.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------------------|------------------|------------------|----------------------------------|--------------------------------------------------------------|
| **BF16** | Very High | High | BF16-supported GPU/CPU | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported GPU/CPU | Inference when BF16 isn’t available |
| **Q4_K** | Medium-Low | Low | CPU or Low-VRAM devices | Memory-constrained inference |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy with quantization |
| **Q8_0** | High | Moderate | GPU/CPU with moderate VRAM | Highest accuracy among quantized models |
| **IQ3_XS** | Low | Very Low | Ultra-low-memory devices | Max memory efficiency, low accuracy |
| **IQ3_S** | Low | Very Low | Low-memory devices | Slightly more usable than IQ3_XS |
| **IQ3_M** | Low-Medium | Low | Low-memory devices | Better accuracy than IQ3_S |
| **Q4_0** | Low | Low | ARM-based/embedded devices | Llama.cpp automatically optimizes for ARM inference |
| **Ultra Low-Bit (IQ1/2_*)** | Very Low | Extremely Low | Tiny edge/embedded devices | Fit models in extremely tight memory; low accuracy |
| **Hybrid (e.g., `bf16_q8_0`)** | Medium–High | Medium | Mixed-precision capable hardware | Balanced performance and memory, near-FP accuracy in critical layers |
---
# SkyCaptioner-V1: A Structural Video Captioning Model
<p align="center">
📑 <a href="https://arxiv.org/pdf/2504.13074">Technical Report</a> · 👋 <a href="https://www.skyreels.ai/home?utm_campaign=huggingface_skyreels_v2" target="_blank">Playground</a> · 💬 <a href="https://discord.gg/PwM6NYtccQ" target="_blank">Discord</a> · 🤗 <a href="https://huggingface.co/Skywork/SkyCaptioner-V1" target="_blank">Hugging Face</a> · 🤖 <a href="https://modelscope.cn/collections/SkyReels-V2-f665650130b144">ModelScope</a></a> · 🌐 <a href="https://github.com/SkyworkAI/SkyReels-V2/tree/main/skycaptioner_v1" target="_blank">GitHub</a>
</p>
---
Welcome to the SkyCaptioner-V1 repository! Here, you'll find the structural video captioning model weights and inference code for our video captioner that labels the video data efficiently and comprehensively.
## 🔥🔥🔥 News!!
* Apr 21, 2025: 👋 We release the [vllm](https://github.com/vllm-project/vllm) batch inference code for SkyCaptioner-V1 Model and caption fusion inference code.
* Apr 21, 2025: 👋 We release the first shot-aware video captioning model [SkyCaptioner-V1 Model](https://huggingface.co/Skywork/SkyCaptioner-V1). For more details, please check our [paper](https://arxiv.org/pdf/2504.13074).
## 📑 TODO List
- SkyCaptioner-V1
- [x] Checkpoints
- [x] Batch Inference Code
- [x] Caption Fusion Method
- [ ] Web Demo (Gradio)
## 🌟 Overview
SkyCaptioner-V1 is a structural video captioning model designed to generate high-quality, structural descriptions for video data. It integrates specialized sub-expert models and multimodal large language models (MLLMs) with human annotations to address the limitations of general captioners in capturing professional film-related details. Key aspects include:
1. **Structural Representation**: Combines general video descriptions (from MLLMs) with sub-expert captioner (e.g., shot types,shot angles, shot positions, camera motions.) and human annotations.
2. **Knowledge Distillation**: Distills expertise from sub-expert captioners into a unified model.
3. **Application Flexibility**: Generates dense captions for text-to-video (T2V) and concise prompts for image-to-video (I2V) tasks.
## 🔑 Key Features
### Structural Captioning Framework
Our Video Captioning model captures multi-dimensional details:
* **Subjects**: Appearance, action, expression, position, and hierarchical categorization.
* **Shot Metadata**: Shot type (e.g., close-up, long shot), shot angle, shot position, camera motion, environment, lighting, etc.
### Sub-Expert Integration
* **Shot Captioner**: Classifies shot type, angle, and position with high precision.
* **Expression Captioner**: Analyzes facial expressions, emotion intensity, and temporal dynamics.
* **Camera Motion Captioner**: Tracks 6DoF camera movements and composite motion types,
### Training Pipeline
* Trained on \~2M high-quality, concept-balanced videos curated from 10M raw samples.
* Fine-tuned on Qwen2.5-VL-7B-Instruct with a global batch size of 512 across 32 A800 GPUs.
* Optimized using AdamW (learning rate: 1e-5) for 2 epochs.
### Dynamic Caption Fusion:
* Adapts output length based on application (T2V/I2V).
* Employs LLM Model to fusion structural fields to get a natural and fluency caption for downstream tasks.
## 📊 Benchmark Results
SkyCaptioner-V1 demonstrates significant improvements over existing models in key film-specific captioning tasks, particularly in **shot-language understanding** and **domain-specific precision**. The differences stem from its structural architecture and expert-guided training:
1. **Superior Shot-Language Understanding**:
* Our Captioner model outperforms Qwen2.5-VL-72B with +11.2% in shot type, +16.1% in shot angle, and +50.4% in shot position accuracy. Because SkyCaptioner-V1’s specialized shot classifiers outperform generalist MLLMs, which lack film-domain fine-tuning.
* +28.5% accuracy in camera motion vs. Tarsier2-recap-7B (88.8% vs. 41.5%):
Its 6DoF motion analysis and active learning pipeline address ambiguities in composite motions (e.g., tracking + panning) that challenge generic captioners.
2. **High domain-specific precision**:
* Expression accuracy: 68.8% vs. 54.3% (Tarsier2-recap-7B), leveraging temporal-aware S2D frameworks to capture dynamic facial changes.
<p align="center">
<table align="center">
<thead>
<tr>
<th>Metric</th>
<th>Qwen2.5-VL-7B-Ins.</th>
<th>Qwen2.5-VL-72B-Ins.</th>
<th>Tarsier2-recap-7B</th>
<th>SkyCaptioner-V1</th>
</tr>
</thead>
<tbody>
<tr>
<td>Avg accuracy</td>
<td>51.4%</td>
<td>58.7%</td>
<td>49.4%</td>
<td><strong>76.3%</strong></td>
</tr>
<tr>
<td>shot type</td>
<td>76.8%</td>
<td>82.5%</td>
<td>60.2%</td>
<td><strong>93.7%</strong></td>
</tr>
<tr>
<td>shot angle</td>
<td>60.0%</td>
<td>73.7%</td>
<td>52.4%</td>
<td><strong>89.8%</strong></td>
</tr>
<tr>
<td>shot position</td>
<td>28.4%</td>
<td>32.7%</td>
<td>23.6%</td>
<td><strong>83.1%</strong></td>
</tr>
<tr>
<td>camera motion</td>
<td>62.0%</td>
<td>61.2%</td>
<td>45.3%</td>
<td><strong>85.3%</strong></td>
</tr>
<tr>
<td>expression</td>
<td>43.6%</td>
<td>51.5%</td>
<td>54.3%</td>
<td><strong>68.8%</strong></td>
</tr>
<tr>
<td>TYPES_type</td>
<td>43.5%</td>
<td>49.7%</td>
<td>47.6%</td>
<td><strong>82.5%</strong></td>
</tr>
<tr>
<td>TYPES_sub_type</td>
<td>38.9%</td>
<td>44.9%</td>
<td>45.9%</td>
<td><strong>75.4%</strong></td>
</tr>
<tr>
<td>appearance</td>
<td>40.9%</td>
<td>52.0%</td>
<td>45.6%</td>
<td><strong>59.3%</strong></td>
</tr>
<tr>
<td>action</td>
<td>32.4%</td>
<td>52.0%</td>
<td><strong>69.8%</strong></td>
<td>68.8%</td>
</tr>
<tr>
<td>position</td>
<td>35.4%</td>
<td>48.6%</td>
<td>45.5%</td>
<td><strong>57.5%</strong></td>
</tr>
<tr>
<td>is_main_subject</td>
<td>58.5%</td>
<td>68.7%</td>
<td>69.7%</td>
<td><strong>80.9%</strong></td>
</tr>
<tr>
<td>environment</td>
<td>70.4%</td>
<td><strong>72.7%</strong></td>
<td>61.4%</td>
<td>70.5%</td>
</tr>
<tr>
<td>lighting</td>
<td>77.1%</td>
<td><strong>80.0%</strong></td>
<td>21.2%</td>
<td>76.5%</td>
</tr>
</tbody>
</table>
</p>
## 📦 Model Downloads
Our SkyCaptioner-V1 model can be downloaded from [SkyCaptioner-V1 Model](https://huggingface.co/Skywork/SkyCaptioner-V1).
We use [Qwen2.5-32B-Instruct](https://huggingface.co/Qwen/Qwen2.5-32B-Instruct) as our caption fusion model to intelligently combine structured caption fields, producing either dense or sparse final captions depending on application requirements.
```shell
# download SkyCaptioner-V1
huggingface-cli download Skywork/SkyCaptioner-V1 --local-dir /path/to/your_local_model_path
# download Qwen2.5-32B-Instruct
huggingface-cli download Qwen/Qwen2.5-32B-Instruct --local-dir /path/to/your_local_model_path2
```
## 🛠️ Running Guide
Begin by cloning the repository:
```shell
git clone https://github.com/SkyworkAI/SkyReels-V2
cd skycaptioner_v1
```
### Installation Guide for Linux
We recommend Python 3.10 and CUDA version 12.2 for the manual installation.
```shell
pip install -r requirements.txt
```
### Running Command
#### Get Structural Caption by SkyCaptioner-V1
```shell
export SkyCaptioner_V1_Model_PATH="/path/to/your_local_model_path"
python scripts/vllm_struct_caption.py \
--model_path ${SkyCaptioner_V1_Model_PATH} \
--input_csv "./examples/test.csv" \
--out_csv "./examepls/test_result.csv" \
--tp 1 \
--bs 4
```
#### T2V/I2V Caption Fusion by Qwen2.5-32B-Instruct Model
```shell
export LLM_MODEL_PATH="/path/to/your_local_model_path2"
python scripts/vllm_fusion_caption.py \
--model_path ${LLM_MODEL_PATH} \
--input_csv "./examples/test_result.csv" \
--out_csv "./examples/test_result_caption.csv" \
--bs 4 \
--tp 1 \
--task t2v
```
> **Note**:
> - If you want to get i2v caption, just change the `--task t2v` to `--task i2v` in your Command.
## Acknowledgements
We would like to thank the contributors of <a href="https://github.com/QwenLM/Qwen2.5-VL">Qwen2.5-VL</a>, <a href="https://github.com/bytedance/tarsier">tarsier2</a> and <a href="https://github.com/vllm-project/vllm">vllm</a> repositories, for their open research and contributions.
## Citation
```bibtex
@misc{chen2025skyreelsv2infinitelengthfilmgenerative,
author = {Guibin Chen and Dixuan Lin and Jiangping Yang and Chunze Lin and Juncheng Zhu and Mingyuan Fan and Hao Zhang and Sheng Chen and Zheng Chen and Chengchen Ma and Weiming Xiong and Wei Wang and Nuo Pang and Kang Kang and Zhiheng Xu and Yuzhe Jin and Yupeng Liang and Yubing Song and Peng Zhao and Boyuan Xu and Di Qiu and Debang Li and Zhengcong Fei and Yang Li and Yahui Zhou},
title = {Skyreels V2:Infinite-Length Film Generative Model},
year = {2025},
eprint={2504.13074},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2504.13074}
}
```
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Help me test my **AI-Powered Quantum Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
The full Open Source Code for the Quantum Network Monitor Service available at my github repos ( repos with NetworkMonitor in the name) : [Source Code Quantum Network Monitor](https://github.com/Mungert69). You will also find the code I use to quantize the models if you want to do it yourself [GGUFModelBuilder](https://github.com/Mungert69/GGUFModelBuilder)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4.1-mini)
- `HugLLM` (Hugginface Open-source models)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap security scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads on huggingface docker space):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**) . No token limited as the cost is low.
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4.1-mini** :
- **It performs very well but unfortunatly OpenAI charges per token. For this reason tokens usage is limited.
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API. Performs pretty well using the lastest models hosted on Novita.
### 💡 **Example commands you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
|
mlx-community/gemma-3-1b-it-DQ | mlx-community | 2025-06-15T19:38:37Z | 131 | 0 | mlx | [
"mlx",
"safetensors",
"gemma3_text",
"text-generation",
"conversational",
"base_model:google/gemma-3-1b-it",
"base_model:quantized:google/gemma-3-1b-it",
"license:gemma",
"model-index",
"4-bit",
"region:us"
] | text-generation | 2025-06-12T03:30:12Z | ---
license: gemma
library_name: mlx
pipeline_tag: text-generation
extra_gated_heading: Access Gemma on Hugging Face
extra_gated_prompt: To access Gemma on Hugging Face, you’re required to review and
agree to Google’s usage license. To do this, please ensure you’re logged in to Hugging
Face and click below. Requests are processed immediately.
extra_gated_button_content: Acknowledge license
base_model: google/gemma-3-1b-it
tags:
- mlx
model-index:
- name: gemma-3-1b-it-DQ
results:
- task:
type: text-generation
dataset:
type: PIQA
name: PIQA
metrics:
- name: pass@1
type: pass@1
value: 0.75
verified: false
- task:
type: text-generation
dataset:
type: winogrande
name: winogrande
metrics:
- name: pass@1
type: pass@1
value: 0.60
verified: false
- task:
type: text-generation
dataset:
type: boolq
name: boolq
metrics:
- name: pass@1
type: pass@1
value: 0.73
verified: false
- task:
type: text-generation
dataset:
type: arc-c
name: arc-c
metrics:
- name: pass@1
type: pass@1
value: 0.35
verified: false
---
# mlx-community/gemma-3-1b-it-DQ
This model [mlx-community/gemma-3-1b-it-DQ](https://huggingface.co/mlx-community/gemma-3-1b-it-DQ) was
converted to MLX format from [google/gemma-3-1b-it](https://huggingface.co/google/gemma-3-1b-it)
using mlx-lm version **0.25.2**.
##### 2x faster and 2.4x less memory footprint than the dequantized model
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/gemma-3-1b-it-DQ")
prompt = "hello"
if tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
Mungert/Holo1-3B-GGUF | Mungert | 2025-06-15T19:38:35Z | 3,419 | 1 | transformers | [
"transformers",
"gguf",
"multimodal",
"action",
"agent",
"visual-document-retrieval",
"en",
"arxiv:2506.02865",
"arxiv:2401.13919",
"base_model:Qwen/Qwen2.5-VL-3B-Instruct",
"base_model:quantized:Qwen/Qwen2.5-VL-3B-Instruct",
"license:other",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | visual-document-retrieval | 2025-06-04T19:44:51Z | ---
base_model:
- Qwen/Qwen2.5-VL-3B-Instruct
language:
- en
library_name: transformers
license: other
license_name: other
pipeline_tag: visual-document-retrieval
tags:
- multimodal
- action
- agent
---
# <span style="color: #7FFF7F;">Holo1-3B GGUF Models</span>
This model is described in the paper [Surfer-H Meets Holo1: Cost-Efficient Web Agent Powered by Open Weights](https://huggingface.co/papers/2506.02865). The project page can be found at [https://www.surferh.com](https://www.surferh.com).
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`71bdbdb5`](https://github.com/ggerganov/llama.cpp/commit/71bdbdb58757d508557e6d8b387f666cdfb25c5e).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# Holo1-3B
## Model Description
Holo1 is an Action Vision-Language Model (VLM) developed by [HCompany](https://www.hcompany.ai/) for use in the Surfer-H web agent system. It is designed to interact with web interfaces like a human user.
As part of a broader agentic architecture, Holo1 acts as a policy, localizer, or validator, helping the agent understand and act in digital environments.
Trained on a mix of open-access, synthetic, and self-generated data, Holo1 enables state-of-the-art (SOTA) performance on the [WebVoyager](https://arxiv.org/pdf/2401.13919) benchmark, offering the best accuracy/cost tradeoff among current models.
It also excels in UI localization tasks such as [Screenspot](https://huggingface.co/datasets/rootsautomation/ScreenSpot), [Screenspot-V2](https://huggingface.co/datasets/HongxinLi/ScreenSpot_v2), [Screenspot-Pro](https://huggingface.co/datasets/likaixin/ScreenSpot-Pro), [GroundUI-Web](https://huggingface.co/datasets/agent-studio/GroundUI-1K), and our own newly introduced
benchmark [WebClick](https://huggingface.co/datasets/Hcompany/WebClick).
Holo1 is optimized for both accuracy and cost-efficiency, making it a strong open-source alternative to existing VLMs.
For more details, check our paper and our blog post.
- **Developed by:** [HCompany](https://www.hcompany.ai/)
- **Model type:** Action Vision-Language Model
- **Finetuned from model:** Qwen/Qwen2.5-VL-3B-Instruct
- **Paper:** https://arxiv.org/abs/2506.02865
- **Blog Post:** https://www.hcompany.ai/surfer-h
- **License:** https://huggingface.co/Hcompany/Holo1-3B/blob/main/LICENSE
## Results
### Surfer-H: Pareto-Optimal Performance on [WebVoyager](https://arxiv.org/pdf/2401.13919)
Surfer-H is designed to be flexible and modular. It is composed of three independent components:
- A Policy model that plans, decides, and drives the agent's behavior
- A Localizer model that sees and understands visual UIs to drive precise interactions
- A Validator model that checks whether the answer is valid
The agent thinks before acting, takes notes, and can retry if its answer is rejected. It can operate with different models for each module, allowing for tradeoffs between accuracy, speed, and cost.
We evaluated Surfer-H on the [WebVoyager](https://arxiv.org/pdf/2401.13919) benchmark: 643 real-world web tasks ranging from retrieving prices to finding news or scheduling events.
<div style="text-align: center;">
<img src="https://cdn-uploads.huggingface.co/production/uploads/682c3e22650f6bbe33bb9d94/kO_4DlW_O45Wi7eK9-r8v.png" width="800"/>
</div>
We’ve tested multiple configurations, from GPT-4-powered agents to 100% open Holo1 setups. Among them, the fully Holo1-based agents offered the strongest tradeoff between accuracy and cost:
- Surfer-H + Holo1-7B: 92.2% accuracy at $0.13 per task
- Surfer-H + GPT-4.1: 92.0% at $0.54 per task
- Surfer-H + Holo1-3B: 89.7% at $0.11 per task
- Surfer-H + GPT-4.1-mini: 88.8% at $0.26 per task
This places Holo1-powered agents on the Pareto frontier, delivering the best accuracy per dollar.
Unlike other agents that rely on custom APIs or brittle wrappers, Surfer-H operates purely through the browser — just like a real user. Combined with Holo1, it becomes a powerful, general-purpose, cost-efficient web automation system.
### Holo1: State-of-the-Art UI Localization
A key skill for the real-world utility of our VLMs within agents is localization: the ability to identify precise
coordinates on a user interface (UI) to interact with to complete a task or follow an instruction. To assess
this capability, we evaluated our Holo1 models on several established localization benchmarks, including
[Screenspot](https://huggingface.co/datasets/rootsautomation/ScreenSpot), [Screenspot-V2](https://huggingface.co/datasets/HongxinLi/ScreenSpot_v2), [Screenspot-Pro](https://huggingface.co/datasets/likaixin/ScreenSpot-Pro), [GroundUI-Web](https://huggingface.co/datasets/agent-studio/GroundUI-1K), and our own newly introduced
benchmark [WebClick](https://huggingface.co/datasets/Hcompany/WebClick).
<div style="text-align: center;">
<img src="https://cdn-uploads.huggingface.co/production/uploads/682c3e22650f6bbe33bb9d94/UutD2Meevd5Xw0_mhX2wK.png" width="600"/>
</div>
<div style="text-align: center;">
<img src="https://cdn-uploads.huggingface.co/production/uploads/682c3e22650f6bbe33bb9d94/NhzkB8xnEQYMqiGxPnJSt.png" width="600"/>
</div>
## Get Started with the Model
We provide 2 spaces to experiment with Localization and Navigation:
- https://huggingface.co/spaces/Hcompany/Holo1-Navigation
- https://huggingface.co/spaces/Hcompany/Holo1-Localization
We provide starter code for the localization task: i.e. image + instruction -> click coordinates
We also provide code to reproduce screenspot evaluations: screenspot_eval.py
### Prepare model, processor
Holo1 models are based on Qwen2.5-VL architecture, which comes with transformers support. Here we provide a simple usage example.
You can load the model and the processor as follows:
```python
import json
import os
from typing import Any, Literal
from transformers import AutoModelForImageTextToText, AutoProcessor
# default: Load the model on the available device(s)
# We recommend enabling flash_attention_2 for better acceleration and memory saving.
model = AutoModelForImageTextToText.from_pretrained(
"Hcompany/Holo1-3B",
torch_dtype="auto",
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
device_map="auto",
)
# default processor
processor = AutoProcessor.from_pretrained("Hcompany/Holo1-3B")
# The default range for the number of visual tokens per image in the model is 4-1280.
# You can set min_pixels and max_pixels according to your needs, such as a token range of 256-1280, to balance performance and cost.
# processor = AutoProcessor.from_pretrained(model_dir, min_pixels=min_pixels, max_pixels=max_pixels)
# Helper function to run inference
def run_inference(messages: list[dict[str, Any]]) -> str:
# Preparation for inference
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = processor(
text=[text],
images=image,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)]
return processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False)
```
### Prepare image and instruction
WARNING: Holo1 is using absolute coordinates (number of pixels) and HuggingFace processor is doing image resize. To have matching coordinates, one needs to smart_resize the image.
```python
from PIL import Image
from transformers.models.qwen2_vl.image_processing_qwen2_vl import smart_resize
# Prepare image and instruction
image_url = "https://huggingface.co/Hcompany/Holo1-3B/resolve/main/calendar_example.jpg"
image = Image.open(requests.get(image_url, stream=True).raw)
# Resize the image so that predicted absolute coordinates match the size of the image.
image_processor = processor.image_processor
resized_height, resized_width = smart_resize(
image.height,
image.width,
factor=image_processor.patch_size * image_processor.merge_size,
min_pixels=image_processor.min_pixels,
max_pixels=image_processor.max_pixels,
)
image = image.resize(size=(resized_width, resized_height), resample=None) # type: ignore
```
### Navigation with Structured Output
```python
import json
from . import navigation
task = "Book a hotel in Paris on August 3rd for 3 nights"
prompt = navigation.get_navigation_prompt(task, image, step=1)
navigation_str = run_inference(prompt)[0]
navigation = navigation.NavigationStep(**json.loads(navigation_str))
print(navigation)
# Expected NavigationStep(note='', thought='I need to select the check-out date as August 3rd and then proceed to search for hotels.', action=ClickElementAction(action='click_element', element='August 3rd on the calendar', x=777, y=282))
```
### Localization with click(x, y)
```python
from . import localization
instruction = "Select July 14th as the check-out date"
prompt = localization.get_localization_prompt(image, instruction)
coordinates = run_inference(prompt)[0]
print(coordinates)
# Expected Click(352, 348)
```
### Localization with Structured Output
We trained Holo1 as an Action VLM with extensive use of json and tool calls. Therefore, it can be queried reliably with structured output:
```python
import json
from . import localization
instruction = "Select July 14th as the check-out date"
prompt = localization.get_localization_prompt_structured_output(image, instruction)
coordinates_structured_str = run_inference(prompt)[0]
coordinates_structured = localization.ClickAction(**json.loads(coordinates_structured_str))
print(coordinates_structured)
# Expected ClickAction(action='click', x=352, y=340)
```
## Citation
**BibTeX:**
```
@misc{andreux2025surferhmeetsholo1costefficient,
title={Surfer-H Meets Holo1: Cost-Efficient Web Agent Powered by Open Weights},
author={Mathieu Andreux and Breno Baldas Skuk and Hamza Benchekroun and Emilien Biré and Antoine Bonnet and Riaz Bordie and Matthias Brunel and Pierre-Louis Cedoz and Antoine Chassang and Mickaël Chen and Alexandra D. Constantinou and Antoine d'Andigné and Hubert de La Jonquière and Aurélien Delfosse and Ludovic Denoyer and Alexis Deprez and Augustin Derupti and Michael Eickenberg and Mathïs Federico and Charles Kantor and Xavier Koegler and Yann Labbé and Matthew C. H. Lee and Erwan Le Jumeau de Kergaradec and Amir Mahla and Avshalom Manevich and Adrien Maret and Charles Masson and Rafaël Maurin and Arturo Mena and Philippe Modard and Axel Moyal and Axel Nguyen Kerbel and Julien Revelle and Mats L. Richter and María Santos and Laurent Sifre and Maxime Theillard and Marc Thibault and Louis Thiry and Léo Tronchon and Nicolas Usunier and Tony Wu},
year={2025},
eprint={2506.02865},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2506.02865},
}
``` |
Mungert/Fathom-R1-14B-GGUF | Mungert | 2025-06-15T19:38:17Z | 1,301 | 5 | transformers | [
"transformers",
"gguf",
"dataset:FractalAIResearch/Fathom-V0.4-SFT-Shortest-Chains",
"dataset:FractalAIResearch/Fathom-V0.6-Iterative-Curriculum-Learning",
"arxiv:2503.21934",
"arxiv:2502.16666",
"arxiv:2502.08226",
"base_model:deepseek-ai/DeepSeek-R1-Distill-Qwen-14B",
"base_model:quantized:deepseek-ai/DeepSeek-R1-Distill-Qwen-14B",
"license:mit",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-06-01T14:33:05Z | ---
license: mit
library_name: transformers
datasets:
- FractalAIResearch/Fathom-V0.4-SFT-Shortest-Chains
- FractalAIResearch/Fathom-V0.6-Iterative-Curriculum-Learning
base_model:
- deepseek-ai/DeepSeek-R1-Distill-Qwen-14B
---
# <span style="color: #7FFF7F;">Fathom-R1-14B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`ea1431b0`](https://github.com/ggerganov/llama.cpp/commit/ea1431b0fa3a8108aac1e0a94a13ccc4a749963e).
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Fathom-R1-14B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Fathom-R1-14B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Fathom-R1-14B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Fathom-R1-14B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Fathom-R1-14B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Fathom-R1-14B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Fathom-R1-14B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Fathom-R1-14B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Fathom-R1-14B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Fathom-R1-14B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Fathom-R1-14B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# 🧮 Fathom-R1-14B: $499 Training Recipe for Unlocking Math Reasoning at o4-mini level using R1-distilled-14B model under 16K context
<div align="center">
[](https://huggingface.co/collections/FractalAIResearch/Fathom-r1-models-681b41a149682c7e32f8a9f2)
[](https://huggingface.co/collections/FractalAIResearch/Fathom-r1-datasets-681b42fe6f20d4b11fc51d79)
[](https://huggingface.co/spaces/FractalAIResearch/Fathom-R1-14B)
[](https://github.com/FractalAIResearchLabs/Fathom-R1)
</div>
<p align="center"> <img src="./images/image.png" style="width: 100%;" id="title-icon"> </p>
---
## Overview
Reasoning models often require high post-training budgets and extremely long reasoning chains(think 32k/64k) for maximising performance. Can we improve these models even if both these parameters are capped?
To this end, we first introduce: **Fathom-R1-14B**, a 14-billion-parameter reasoning language model derived from Deepseek-R1-Distilled-Qwen-14B, post-trained at an affordable cost of only $499, and achieving SOTA mathematical reasoning performance within a 16K context window. On the latest olympiad level exams: AIME-25 and HMMT-25, our model not only **surpasses o3-mini-low, o1-mini and LightR1-14B(16k)** at pass@1 scores (averaged over 64 runs) but also delivers **performance rivaling closed-source o4-mini (low)** w.r.t cons@64 — all while staying within a **16K context window**. It achieves 52.71% Pass@1 accuracy on AIME2025 and 35.26% Pass@1 accuracy on HMMT25 (+7.2% and +5.2% improvement over the base model respectively). When provided with additional test-time compute in the form of cons@64, it achieves an impressive 76.7% accuracy on AIME2025 and 56.7% accuracy on HMMT25 (+13.4% and +6.7% improvement over the base model respectively). We perform supervised fine-tuning (SFT) on carefully curated datasets using a specific training approach, followed by model merging, achieving this performance at a total cost of just $499!
We also introduce **Fathom-R1-14B-RS**, another model achieving performance comparable to our first, at a total post-training cost of just $967. It leverages post-training techniques—including reinforcement learning and supervised fine-tuning—in a multi-stage, cost-effective manner, followed by model merging.
We are **open-sourcing our models, post-training recipes and datasets** which we believe will help the community to progress further in the reasoning domain.
---
## 🧪 Motivation
Thinking longer during inference time has shown to unlock superior reasoning abilities and expert level performance on challenging queries and tasks. Since the open-source release of DeepSeek R1 series models, multiple open-source efforts [[s1](https://github.com/simplescaling/s1), [LIMO](https://github.com/GAIR-NLP/LIMO), [Light-R1](https://github.com/Qihoo360/Light-R1)] have focused on reproducing the results (easpecially at <=32B scale) either via distillation or RL based fine-tuning on top of non-reasoning models. Though in most cases, these efforts at best, could come close to the performance R1 series models but are unable to surpass them. In parallel, certain recent methods [[DeepScaleR](https://github.com/agentica-project/rllm), [DeepCoder](https://www.together.ai/blog/deepcoder), [Light-R1](https://github.com/Qihoo360/Light-R1)] started with the existing reasoning models and have managed to extend the performance of these models. However, the training runs for these methods are often costly and they rely on longer sequence lengths for higher accuracy.
Given the latest findings [[Proof or Bluff ?](https://arxiv.org/abs/2503.21934), [Reasoning models don't always say what they think](https://assets.anthropic.com/m/71876fabef0f0ed4/original/reasoning_models_paper.pdf)] that raises the question on the correctness of the intermediate steps of the long COT in reasoning models, its important from interpretability, reliability and safety pov to ensure the reasoning chains are not inefficiently long. Hence, in this study, we work towards unlocking performance improvement of the reasoning models without training at very high (24k/32k) sequence length and restricting it to 16k context. We believe, while extremely long reasoning chains are still necessary for really challenging tasks, its also important to maximize the performance at lower context first before we proceed towards extending reasoning chains.
## Training Dataset
We begin by curating a high-quality mathematical corpus from the following open-source datasets:
- **Open-R1** - default subset
- **Numina – Olympiads & AOPS_forum** (word problems, float type answers)
- After rigorous deduplication and decontamination, we consolidated approximately **~100K unique problems**, forming the initial corpus for all subsequent trainings.
## 🏗️ Post-Training Strategies
### Training Recipe for Fathom-R1-14B-v0.6
SFT on difficult questions and their reasoning chains has been shown to be effective for improving reasoning ability. For this checkpoint, we build on top of this. This training stage focuses on improving the model’s performance on **mathematical problems covering a spectrum of hard diffuculty level** through a iterative curriculum learning strategy at max 16k sequence length. Curriculum learning (CL) is a well-established technique for training LLMs, where the model is progressively exposed to more difficult tasks. The idea is to gradually scaffold more complex reasoning, thereby enhancing generalization and reducing overfitting. However, in our case we perform this in an iterative manner, which essentially means we do multiple iterations of CL.
For the dataset preparation, we begin by annotating each question’s difficulty using **OpenAI's o3mini** model. We retain only those questions rated above average (in relative sense) and further filter them to include only those having **solve rates between certain range** (0.2 < pass_rate < 0.7). This yields the **Iterative Curriculum Learning dataset** comprising of 5K examples.
Total H100 GPU Hours: 48
Cost: $136
### Training Recipe for Fathom-R1-14B-v0.4-RS
The core strategy used behind creating this checkpoint is a two-stage pipeline: First, leverage GRPO to improve reasoning of Deepseek-R1-Distilled-Qwen-14B at a lower sequence length, 6k, on a carefully curated dataset to ensure rapid improvement with minimal training steps. Second, we perform SFT, at max 16k tokens sequence length, on a carefully curated dataset of questions ( hard to very hard difficulty spectrum) and the corresponding shortest possible reasoning solution for each question.
- **First Stage (Leveraging RL for effecient test-time thinking):** We start with curating a seed dataset which ensures the policy receives minumium reward while still having room for growth. The dataset comparises of questions having solve rates (at lower sequence length) between a certain range. This forms our **RL Compression dataset** comprising of 7.7K questions. Staring from DeepSeek-R1-Distill-Qwen-14B as the base model, we train the model using the GRPO algorithm, with a 6k token sequence length limit. We see a consistent increase in performance as the model learns to generate concise responses from the decreasing clip ratio, response length and increasing reward. The obtained model has learnt to generate responses below 6k tokens and outperforms the base model at lower token limits.
<img width="1370" alt="image" src="./images/RL_graph.png" />
- **Second Stage (Leveraging SFT to improve reasoning efficiently at higher sequence length):** We build upon the RL checkpoint and perform SFT under a **16K context window** to encourage more detailed reasoning that would be required for solving more complex problems. For this stage, we strategically curate a dataset consisting of hard problems — specifically, questions with lower solve rates (0 < pass_rate <=0.4). Then, we obtain the shortest possible reasoning chains for these questions forming the **SFT Shortest Chains dataset** comprising of 9.5K examples. Through supervised fine-tuning on this dataset, the model is able to stablize its reasoning at sequence length upto 16K. The resulting model is named **Fathom-R1-14B-v0.4**, optimized for concise yet accurate mathematical reasoning.
Total H100 GPU Hours: 293
Cost: $831
### Training Recipe for Fathom-R1-14B-v0.4
Given the performance improvement we noticed during the second fine-tuning stage of developing Fathom-R1-14B-v0.4-RS and in attempt to further reduce the cost, we experiment by eliminating RL and directly performing second stage SFT on Deepseek-R1-Distilled-Qwen-14B base model.
Total H100 GPU Hours: 128
Cost: $363
## Model Merging
Given v0.6 and v0.4 models have been developed by following different training methodologies, we perform linear merging to combine the strengths to obtain final 2 checkpoints.
- **Fathom-R1-14B**: Obtained via merging Fathom-R1-14B-V0.6 (Iterative Curriculum SFT) and Fathom-R1-14B-V0.4 (SFT-Shortest-Chains)
- **Fathom-R1-14B-RS**: Obtained via merging Fathom-R1-14B-V0.6 (Iterative Curriculum SFT) and Fathom-R1-14B-V0.4 (RL-compression + SFT-Shortest-Chains)
## 💰 Post-Training Cost
We developed **Fathom-R1-14B** models using a focused, resource-efficient strategy that balances performance with compute budget. Below is the GPU time utilized and the cost incurred
| Model Weights | GPU Hours (H100) | Cost(USD) |
|----------------------------|------------------|------|
| Fathom-R1-14B-V0.4-RS | 293 | 831 |
| Fathom-R1-14B-V0.4 | 128 | 363 |
| Fathom-R1-14B-V0.6 | 48 | 136 |
| Fathom-R1-14B-RS | 341 | 967 |
| **Fathom-R1-14B** | **176** | **499** |
So, the final Fathom-R1-14B took just 499$ to be trained overall! This low training cost highlights the efficiency of our method — enabling high-level mathematical reasoning comparable to **o4-mini** in **$499** , all within a **16k sequence length budget**.
---
## 📊 Evaluation
We evaluate Fathom‑R1-14B using the same metrics and sampling configuration introduced in the DeepSeek‑R1 paper, namely **pass@1** and **cons@64**. However, our evaluation is conducted under a reduced output budget of 16,384 tokens, compared to DeepSeek‑R1’s 32,768 tokens, to better reflect practical deployment constraints.
- **pass@1**: Pass@1 is computed as the average correctness over k sampled solution chains per problem (in our experiments we keep k=64).
- **cons@64**: Assesses consistency by sampling 64 reasoning chains per question and computing the majority vote accuracy.
**Evaluation Configuration**:
- Temperature: 0.6
- top_p: 0.95
- Number of sampled chains: 64
- Context: 16,384 tokens
This setup allows us to benchmark Fathom-R1-14B’s reasoning performance and stability under realistic memory and inference budgets, while maintaining compatibility with the DeepSeek‑R1 evaluation protocol.
We utilize the evaluation framework provided by the [LIMO](https://github.com/GAIR-NLP/LIMO) repository to run inference and compute metrics.
For detailed instructions and implementation details, please refer to [`eval/README.md`](https://github.com/FractalAIResearchLabs/Fathom-R1/blob/main/eval/readme.md).
---
## Results
We evaluate and compare **Fathom‑R1-14B** with several baseline models across 3 challenging benchmarks: **AIME25**, **HMMT25**, and **GPQA**. For each, we report `pass@1` and `cons@64`, following the same evaluation configuration.
| Model | AIME25 | | HMMT25 | |
|------------------|----------------|---------------|----------------|---------------|
| | pass@1 | cons@64 | pass@1 | cons@64 |
| **Closed-Source Models** | | | | |
| o1‑mini | 50.71 | 63.33 | 35.15 | 46.67 |
| o3‑mini‑low | 42.60 | 53.33 | 26.61 | 33.33 |
| o3‑mini‑medium | 72.24 | 83.33 | 49.21 | 60.00 |
| o4-mini-low | 60.20 | 76.67 | 39.11 | 53.33 |
| o1‑preview | 33.33 | 36.67 | 17.78 | 20.00 |
| gpt‑4.5‑preview | 34.44 | 40.00 | 16.67 | 20.00 |
| **Open-Source Models** | | | | |
| DeepSeek-R1-Distill-Qwen-14B | 45.50 | 63.33 | 30.00 | 50.00 |
| DeepSeek-R1-Distill-Qwen-32B | 49.64 | 73.33 | 33.02 | 53.33 |
| DeepSeekR1‑670B | 61.25 | 83.33 | 42.19 | 56.67 |
| LightR1‑14B | 51.15 | 76.67 | 33.75 | 50.00 |
| Fathom‑R1-14B-V0.4-RS | 50.94 | 73.33 | 33.70 | 40.00 |
| Fathom‑R1-14B-V0.4 | 50.94 | 70.00 | 34.53 | 56.67 |
| Fathom‑R1-14B-V0.6 | 50.63 | 76.67 | 32.19 | 50.00 |
| Fathom‑R1-14B-RS | 52.03 | 76.67 | 35.00 | 53.33 |
| **Fathom‑R1-14B** | **52.71** | **76.67** | **35.26** | **56.67** |
**Fathom‑R1-14B** demonstrates highly competitive performance across all datasets, improving over the original R1-distilled models while closely matching or surpassing other strong baselines in several settings.
On both AIME 25 and HMMT 25, our model shows the highest pass@1 as well as cons@64 scores among all the open-source models (including the bigger R1-Distilled-32B model), with R1-670B being the only exception.
In fact, we observe that Fathom-R1-14B is superior to the first two generations of OpenAI's mini-reasoning models, including **o1-mini** and **o3-mini-low-** and it's performance closely matches that of newly released **o4-mini-low** (self-consistency decoding).
---
## 🌍 Generalization Beyond Math: GPQA-Diamond
Notably, we also observe out-of-domain improvement in **GPQA-Diamond**, even though there wasn't a single instance of non-math questions in our training data.
This indicates that our training methodology mentioned above and training on math wuestions facilitates generalization across diverse domains, a finding similar to what LightR1-14B & LIMO had observed.
#### ✅ GPQA Benchmark Comparison (16k)
| **Model** | **pass@1** | **cons@64** |
|-------------------|------------|-------------|
| DeepSeek-R1-Distill-Qwen-14B | 54.19 | 64.14 |
| LightR1‑14B | 56.94 | 65.15 |
| Fathom‑R1-14B-RS | 59.13 | 66.16 |
| **Fathom‑R1-14B** | **59.46** | **66.16** |
---
## ✂️ Ablation Study on Token Efficiency
To assess reasoning token efficiency, we compare the **average response token count**, under 16k context length, across AIME25, and HMMT25. On AIME25, Fathom‑R1-14B-RS uses 10% fewer response tokens than LightR1-14B despite having higher pass@1. HMMT25 questions are relatively tougher compared to AIME'25 and tougher questions usually require more thinking tokens. On HMMT25, Fathom‑R1-14B-RS uses 4.5% fewer response tokens than LightR1-14B despite having higher pass@1.
#### Average Response Length (Tokens)
| Model | AIME25 | HMMT25 |
|------------------|--------|--------|
| LightR1-14B | 11330 | 12680 |
| DeepSeek-R1-Distill-Qwen-14B | 10878 | 12263 |
| Fathom‑R1-14B-V0.4 | 10570 | 11950 |
| Fathom‑R1-14B | 10956 | 12125 |
| **Fathom‑R1-14B-RS** | **10083** | **12100** |
---
## Data Decontimination
Both benchmarks used (AIME 25 and HMMT 25) were released a few weeks after the release of the base model, ensuring no contamination occurred during the model's pre-training. The dataset corpora (Numina-Math 1.5 & OpenR1-Math) were released around the same time as these exams, with a cutoff date no later than 2024. Additionally, we conduct checks to verify there is no contamination in the training data.
---
## Release Assets
- Training Recipe Blog: [🤗 $499 training recipe for creating Fathom-R1-14B](https://huggingface.co/FractalAIResearch/Fathom-R1-14B)
- Final Merged Models: [🤗 Fathom-R1-14B](https://huggingface.co/FractalAIResearch/Fathom-R1-14B), [🤗 Fathom-R1-14B-RS](https://huggingface.co/FractalAIResearch/Fathom-R1-14B-RS)
- Intermediate Models: [🤗 Fathom-R1-14B-V0.6](https://huggingface.co/FractalAIResearch/Fathom-R1-14B-V0.6), [🤗 Fathom-R1-14B-V0.4](https://huggingface.co/FractalAIResearch/Fathom-R1-14B-V0.4), [🤗 Fathom-R1-14B-V0.4-RS](https://huggingface.co/FractalAIResearch/Fathom-R1-14B-V0.4-RS)
- Fathom-R1-14B Datasets: [🤗 V0.6-Iterative-Curriculum-Learning](https://huggingface.co/datasets/FractalAIResearch/Fathom-V0.6-Iterative-Curriculum-Learning), [🤗 V0.4-SFT-Shortest-Chains](https://huggingface.co/datasets/FractalAIResearch/Fathom-V0.4-SFT-Shortest-Chains), [🤗 V0.4-RL-Compression](https://huggingface.co/datasets/FractalAIResearch/Fathom-V0.4-RL-Compression)
---
## 📜 License
This repository and all the release assets are available under the MIT License, underscoring our dedication to open and inclusive AI innovation. By freely sharing our work, we aim to democratize AI technology, empowering researchers, developers, and enthusiasts everywhere to use, adapt, and expand upon it without limitation. This open and permissive approach promotes global collaboration, accelerates innovation, and enriches the AI community as a whole.
## Acknowledgments
We would like to acknowledge the following works for enabling our project:
- [Deepseek-R1-Distill-Qwen-14B](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B)
- [NuminaMath-1.5](https://huggingface.co/datasets/AI-MO/NuminaMath-1.5)
- [OpenR1-Math](https://huggingface.co/datasets/open-r1/OpenR1-Math-220k)
- [360-LLAMA-Factory](https://github.com/Qihoo360/360-LLaMA-Factory)
- [verl](https://github.com/volcengine/verl)
- [LIMO](https://github.com/GAIR-NLP/LIMO)
- [FuseAI](https://github.com/fanqiwan/FuseAI)
---
## 📖 Citation
```bibtex
@misc{fathom14b2025,
title={Fathom-R1: $499 Training Recipe for Unlocking Math Reasoning at o4-mini level with just 14B parameters under 16K context},
author={Kunal Singh and Pradeep Moturi and Ankan Biswas and Siva Gollapalli and Sayandeep Bhowmick},
howpublished={\url{https://huggingface.co/FractalAIResearch/Fathom-R1-14B}},
note={Hugging Face},
year={2025}
}
```
## About Project Ramanujan
We initiated Project Ramanujan approximately one year ago, aiming to unlock intelligence and enhance AI agents by pushing the boundaries of advanced reasoning. Our key accomplishments include:
- ICLR'25 & NeurIPS'24-MATH-AI: [SBSC: Step-By-Step Coding for Improving Mathematical Olympiad Performance](https://arxiv.org/abs/2502.16666)
- Winners of HackerCupAI@NeurIPS'24 & ICLR'25-VerifAI: [Stress Testing Based Self-Consistency For Olympiad Programming](https://openreview.net/forum?id=7SlCSjhBsq)
- CVPR'25-MULA: [TRISHUL: Towards Region Identification and Screen Hierarchy Understanding for Large VLM based GUI Agents
](https://arxiv.org/abs/2502.08226))
- Silver Medal in AIMO'24 |
Mungert/QwenLong-L1-32B-GGUF | Mungert | 2025-06-15T19:38:13Z | 6,074 | 9 | transformers | [
"transformers",
"gguf",
"long-context",
"large-reasoning-model",
"text-generation",
"dataset:Tongyi-Zhiwen/DocQA-RL-1.6K",
"arxiv:2505.17667",
"arxiv:2309.00071",
"base_model:deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
"base_model:quantized:deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-05-28T11:43:14Z | ---
license: apache-2.0
datasets:
- Tongyi-Zhiwen/DocQA-RL-1.6K
base_model:
- deepseek-ai/DeepSeek-R1-Distill-Qwen-32B
tags:
- long-context
- large-reasoning-model
pipeline_tag: text-generation
library_name: transformers
---
# <span style="color: #7FFF7F;">QwenLong-L1-32B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`f5cd27b7`](https://github.com/ggerganov/llama.cpp/commit/f5cd27b71da3ac375a04a41643d14fc779a8057b).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `QwenLong-L1-32B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `QwenLong-L1-32B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `QwenLong-L1-32B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `QwenLong-L1-32B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `QwenLong-L1-32B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `QwenLong-L1-32B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `QwenLong-L1-32B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `QwenLong-L1-32B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `QwenLong-L1-32B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `QwenLong-L1-32B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `QwenLong-L1-32B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# QwenLong-L1: Towards Long-Context Large Reasoning Models with Reinforcement Learning
<p align="center" width="100%">
</p>
<div id="top" align="center">
-----------------------------
[](https://opensource.org/licenses/Apache-2.0)
[](https://arxiv.org/abs/2505.17667)
[](https://github.com/Tongyi-Zhiwen/QwenLong-L1)
[](https://modelscope.cn/models/iic/QwenLong-L1-32B)
[](https://huggingface.co/Tongyi-Zhiwen/QwenLong-L1-32B)
<!-- **Authors:** -->
_**Fanqi Wan, Weizhou Shen, Shengyi Liao, Yingcheng Shi, Chenliang Li,**_
_**Ziyi Yang, Ji Zhang, Fei Huang, Jingren Zhou, Ming Yan**_
<!-- **Affiliations:** -->
_Tongyi Lab, Alibaba Group_
<p align="center">
<img src="./assets/fig1.png" width="100%"> <br>
</p>
</div>
## 🎉 News
- **May 28, 2025:** 🔥 We release [🤗 QwenLong-L1-32B-AWQ](https://huggingface.co/Tongyi-Zhiwen/QwenLong-L1-32B-AWQ), which has undergone AWQ int4 quantization using the ms-swift framework.
- **May 26, 2025:** 🔥 We release [🤗 QwenLong-L1-32B](https://huggingface.co/Tongyi-Zhiwen/QwenLong-L1-32B), which is the first long-context LRM trained with reinforcement learning for long-context reasoning. Experiments on seven long-context DocQA benchmarks demonstrate that **QwenLong-L1-32B outperforms flagship LRMs like OpenAI-o3-mini and Qwen3-235B-A22B, achieving performance on par with Claude-3.7-Sonnet-Thinking**, demonstrating leading performance among state-of-the-art LRMs.
- **May 26, 2025:** 🔥 We release [🤗 DocQA-RL-1.6K](https://huggingface.co/datasets/Tongyi-Zhiwen/DocQA-RL-1.6K), which is a specialized RL training dataset comprising 1.6K document question answering (DocQA) problems spanning mathematical, logical, and multi-hop reasoning domains.
## 📚 Introduction
In this work, we propose QwenLong-L1, a novel reinforcement learning (RL) framework designed to facilitate the transition of LRMs from short-context proficiency to robust long-context generalization. In our preliminary experiments, we illustrate the differences between the training dynamics of short-context and long-context reasoning RL.
<p align="center">
<img src="./assets/fig2.png" width="100%"> <br>
</p>
Our framework enhances short-context LRMs through progressive context scaling during RL training. The framework comprises three core components: a warm-up supervised fine-tuning (SFT) phase to initialize a robust policy, a curriculum-guided RL phase that facilitates stable adaptation from short to long contexts, and a difficulty-aware retrospective sampling mechanism that adjusts training complexity across stages to incentivize policy exploration. Leveraging recent RL algorithms, including GRPO and DAPO, our framework integrates hybrid reward functions combining rule-based and model-based binary outcome rewards to balance precision and recall. Through strategic utilization of group relative advantages during policy optimization, it guides LRMs to learn effective reasoning patterns essential for robust long-context grounding and superior reasoning capabilities.
<p align="center">
<img src="./assets/fig3.png" width="100%"> <br>
</p>
## 🎯 Model Release
We release [🤗 QwenLong-L1-32B](https://huggingface.co/Tongyi-Zhiwen/QwenLong-L1-32B), which is the first long-context LRM trained with reinforcement learniing for long-context reasoning. Experiments on seven long-context DocQA benchmarks demonstrate that **QwenLong-L1-32B outperforms flagship LRMs like OpenAI-o3-mini and Qwen3-235B-A22B, achieving performance on par with Claude-3.7-Sonnet-Thinking**, demonstrating leading performance among state-of-the-art LRMs.
Here are the evaluation results.
<p align="center">
<img src="./assets/tab4.png" width="100%"> <br>
</p>
## 🛠️ Requirements
```bash
# Create the conda environment
conda create -n qwenlongl1 python==3.10
conda activate qwenlongl1
# Install requirements
pip3 install -r requirements.txt
# Install verl
cd verl
pip3 install -e .
# Install vLLM
pip3 install vllm==0.7.3
# Install flash-attn
pip3 install flash-attn --no-build-isolation
```
## 🚀 Quick Start
Here's how you can run the model using the 🤗 Transformers:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Tongyi-Zhiwen/QwenLong-L1-32B"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
template = """Please read the following text and answer the question below.
<text>
$DOC$
</text>
$Q$
Format your response as follows: "Therefore, the answer is (insert answer here)"."""
context = "<YOUR_CONTEXT_HERE>"
question = "<YOUR_QUESTION_HERE>"
prompt = template.replace('$DOC$', context.strip()).replace('$Q$', question.strip())
messages = [
# {"role": "system", "content": "You are QwenLong-L1, created by Alibaba Tongyi Lab. You are a helpful assistant."}, # Use system prompt to define identity when needed.
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=10000,
temperature=0.7,
top_p=0.95
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151649 (</think>)
index = len(output_ids) - output_ids[::-1].index(151649)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
```
## ♾️ Processing Long Documents
For input where the total length (including both input and output) significantly exceeds 32,768 tokens, we recommend using RoPE scaling techniques to handle long texts effectively. We have validated the model's performance on context lengths of up to 131,072 tokens using the [YaRN](https://arxiv.org/abs/2309.00071) method.
YaRN is currently supported by several inference frameworks, e.g., `transformers` and `llama.cpp` for local use, `vllm` and `sglang` for deployment. In general, there are two approaches to enabling YaRN for supported frameworks:
- Modifying the model files:
In the `config.json` file, add the `rope_scaling` fields:
```json
{
...,
"rope_scaling": {
"rope_type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 32768
}
}
```
For `llama.cpp`, you need to regenerate the GGUF file after the modification.
- Passing command line arguments:
For `vllm`, you can use
```shell
vllm serve ... --rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}' --max-model-len 131072
```
For `sglang`, you can use
```shell
python -m sglang.launch_server ... --json-model-override-args '{"rope_scaling":{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}}'
```
For `llama-server` from `llama.cpp`, you can use
```shell
llama-server ... --rope-scaling yarn --rope-scale 4 --yarn-orig-ctx 32768
```
> [!IMPORTANT]
> If you encounter the following warning
> ```
> Unrecognized keys in `rope_scaling` for 'rope_type'='yarn': {'original_max_position_embeddings'}
> ```
> please upgrade `transformers>=4.51.0`.
> [!NOTE]
> All the notable open-source frameworks implement static YaRN, which means the scaling factor remains constant regardless of input length, **potentially impacting performance on shorter texts.**
> We advise adding the `rope_scaling` configuration only when processing long contexts is required.
> It is also recommended to modify the `factor` as needed. For example, if the typical context length for your application is 65,536 tokens, it would be better to set `factor` as 2.0.
> [!NOTE]
If the average context length does not exceed 32,768 tokens, we do not recommend enabling YaRN in this scenario, as it may potentially degrade model performance.
## 🗂️ Dataset
To construct a challenging RL dataset for verifiable long-context reasoning, we develop [🤗 DocQA-RL-1.6K](https://huggingface.co/datasets/Tongyi-Zhiwen/DocQA-RL-1.6K), which comprises 1.6K DocQA problems across three reasoning domains:
(1) Mathematical Reasoning: We use 600 problems from the DocMath dataset, requiring numerical reasoning across long and specialized documents such as financial reports. For DocMath, we sample 75% items from each subset from its valid split for training and 25% for evaluation;
(2) Logical Reasoning: We employ DeepSeek-R1 to synthesize 600 multi-choice questions requiring logic analysis of real-world documents spanning legal, financial, insurance, and production domains from our curated collection;
(3) Multi-Hop Reasoning: We sample 200 examples from MultiHopRAG and 200 examples from Musique, emphasizing cross-document reasoning.
Please download and put the following datasets in `./datasets/` for training and evaluation.
RL training data: [🤗 DocQA-RL-1.6K](https://huggingface.co/datasets/Tongyi-Zhiwen/DocQA-RL-1.6K).
Evaluation data: [🤗 docmath](https://huggingface.co/datasets/Tongyi-Zhiwen/docmath), [🤗 frames](https://huggingface.co/datasets/Tongyi-Zhiwen/frames), [🤗 longbench](https://huggingface.co/datasets/Tongyi-Zhiwen/longbench).
## 💻 Training
We provide the basic demo training code for single stage RL traininig with DAPO.
First, we should start a local verifier.
```bash
export CUDA_VISIBLE_DEVICES=0
vllm serve "Qwen/Qwen2.5-1.5B-Instruct" \
--host 0.0.0.0 \
--port 23547
```
Then, we start RL training with 4 nodes.
```bash
export PROJ_DIR="<YOUR_PROJ_DIR_HERE>"
export MASTER_IP="<YOUR_MASTER_IP_HERE>" # ray master ip
export NNODES=4 # total GPU nodes
export NODE_RANK=${RANK} # rank of current node
export PORT=6382
export WANDB_API_KEY="<YOUR_WANDB_API_KEY_HERE>"
export WANDB_PROJECT="QwenLong-L1"
export LLM_JUDGE=Y # 'Y': LLM JUDGE, 'N': RULE BASED
export VLLM_ATTENTION_BACKEND=FLASH_ATTN
# verifier
export VERIFIER_PATH="Qwen/Qwen2.5-1.5B-Instruct"
export VERIFIER_HOST="<YOUR_VERIFIER_HOST_HERE>"
export VERIFIER_PORT="23547"
ray_start_retry() {
while true; do
ray start --address="${MASTER_IP}:${PORT}"
if [ $? -eq 0 ]; then
break
fi
echo "Failed to connect to master, retrying in 5 seconds..."
sleep 5
done
}
check_ray_status() {
until ray status >/dev/null 2>&1; do
echo "Waiting for Ray cluster to be ready..."
sleep 5
done
}
if [ "$RANK" == "0" ]; then
echo "Starting HEAD node..."
ray start --head --port=${PORT}
check_ray_status
echo "Ray head node started successfully"
else
echo "Starting WORKER node..."
ray_start_retry
check_ray_status
echo "Successfully joined Ray cluster"
fi
if [ "$RANK" == "0" ]; then
bash ${PROJ_DIR}/scripts/rl_4nodes_dapo.sh 2>&1 | tee ${PROJ_DIR}/logs/rl_log_$(date +%Y%m%d_%H%M%S).txt &
else
sleep 30d
fi
wait
```
## 📊 Evaluation
We conduct evaluation on seven long-context DocQA benchmarks, including multi-hop reasoning benchmarks such as 2WikiMultihopQA, HotpotQA, Musique, NarrativeQA, Qasper, and Frames as well as mathematical reasoning benchmarks like DocMath. We report the maximum of exact match and LLM-judged accuracy as the final score, aligned with the reward function in our RL training process. We use DeepSeek-V3 as the judge model with a temperature of 0.0 to provide a reliable evaluation.
```bash
# Step 1. Serve the model for evaluation
export CUDA_VISIBLE_DEVICES="0,1,2,3,4,5,6,7"
MODEL_NAME="QwenLong-L1-32B"
MODEL_PATH="Tongyi-Zhiwen/QwenLong-L1-32B"
vllm serve ${MODEL_PATH} \
--port 23547 \
--api-key "token-abc123" \
--tensor-parallel-size 8 \
--gpu-memory-utilization 0.95 \
--max_model_len 131072 \
--trust-remote-code
# Step 2. Generate model responses for each dataset
export SERVE_HOST="<YOUR_SERVE_HOST_HERE>" # e.g., 127.0.0.1
export SERVE_PORT="23547"
PROJ_DIR="<YOUR_PROJ_DIR_HERE>"
DATA="<YOUR_DATA_HERE>" # e.g., docmath, frames, 2wikimqa, hotpotqa, musique, narrativeqa, pasper
python ${PROJ_DIR}/eval/${DATA}.py \
--save_dir "${PROJ_DIR}/eval/results/${DATA}" \
--save_file "${MODEL_NAME}" \
--model "${MODEL_PATH}" \
--tokenizer "${MODEL_PATH}" \
--n_proc 16 \
--api "openai"
# Step 3. Verify model responses for each dataset
export VERIFIER_API="<YOUR_API_KEY_HERE>"
export VERIFIER_URL="https://api.deepseek.com/v1"
PROJ_DIR="<YOUR_PROJ_DIR_HERE>"
DATA="<YOUR_DATA_HERE>" # e.g., docmath, frames, 2wikimqa, hotpotqa, musique, narrativeqa, pasper
python ${PROJ_DIR}/eval/${DATA}_verify.py \
--save_dir "${PROJ_DIR}/results/${DATA}" \
--save_file "${MODEL_NAME}" \
--judge_model "deepseek-chat" \
--batch_size 20
```
## 📝 Citation
If you find this work is relevant with your research or applications, please feel free to cite our work!
```
@article{wan2025qwenlongl1,
title={QwenLong-L1: : Towards Long-Context Large Reasoning Models with Reinforcement Learning},
author={Fanqi Wan, Weizhou Shen, Shengyi Liao, Yingcheng Shi, Chenliang Li, Ziyi Yang, Ji Zhang, Fei Huang, Jingren Zhou, Ming Yan},
journal={arXiv preprint arXiv:2505.17667},
year={2025}
}
``` |
Mungert/Llama-3.1-Nemotron-Nano-4B-v1.1-GGUF | Mungert | 2025-06-15T19:38:04Z | 2,600 | 1 | transformers | [
"transformers",
"gguf",
"nvidia",
"llama-3",
"pytorch",
"text-generation",
"en",
"dataset:nvidia/Llama-Nemotron-Post-Training-Dataset",
"arxiv:2408.11796",
"arxiv:2502.00203",
"arxiv:2505.00949",
"base_model:nvidia/Llama-3.1-Minitron-4B-Width-Base",
"base_model:quantized:nvidia/Llama-3.1-Minitron-4B-Width-Base",
"license:other",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-05-21T21:58:58Z | ---
library_name: transformers
license: other
license_name: nvidia-open-model-license
license_link: >-
https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/
pipeline_tag: text-generation
language:
- en
tags:
- nvidia
- llama-3
- pytorch
base_model:
- nvidia/Llama-3.1-Minitron-4B-Width-Base
datasets:
- nvidia/Llama-Nemotron-Post-Training-Dataset
---
# <span style="color: #7FFF7F;">Llama-3.1-Nemotron-Nano-4B-v1.1 GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`92ecdcc0`](https://github.com/ggerganov/llama.cpp/commit/92ecdcc06a4c405a415bcaa0cb772bc560aa23b1).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Llama-3.1-Nemotron-Nano-4B-v1.1-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Llama-3.1-Nemotron-Nano-4B-v1.1-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Llama-3.1-Nemotron-Nano-4B-v1.1-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Llama-3.1-Nemotron-Nano-4B-v1.1-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Llama-3.1-Nemotron-Nano-4B-v1.1-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Llama-3.1-Nemotron-Nano-4B-v1.1-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Llama-3.1-Nemotron-Nano-4B-v1.1-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Llama-3.1-Nemotron-Nano-4B-v1.1-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Llama-3.1-Nemotron-Nano-4B-v1.1-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Llama-3.1-Nemotron-Nano-4B-v1.1-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Llama-3.1-Nemotron-Nano-4B-v1.1-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# Llama-3.1-Nemotron-Nano-4B-v1.1
## Model Overview

Llama-3.1-Nemotron-Nano-4B-v1.1 is a large language model (LLM) which is a derivative of [nvidia/Llama-3.1-Minitron-4B-Width-Base](https://huggingface.co/nvidia/Llama-3.1-Minitron-4B-Width-Base), which is created from Llama 3.1 8B using [our LLM compression technique](https://arxiv.org/abs/2408.11796) and offers improvements in model accuracy and efficiency. It is a reasoning model that is post trained for reasoning, human chat preferences, and tasks, such as RAG and tool calling.
Llama-3.1-Nemotron-Nano-4B-v1.1 is a model which offers a great tradeoff between model accuracy and efficiency. The model fits on a single RTX GPU and can be used locally. The model supports a context length of 128K.
This model underwent a multi-phase post-training process to enhance both its reasoning and non-reasoning capabilities. This includes a supervised fine-tuning stage for Math, Code, Reasoning, and Tool Calling as well as multiple reinforcement learning (RL) stages using Reward-aware Preference Optimization (RPO) algorithms for both chat and instruction-following. The final model checkpoint is obtained after merging the final SFT and RPO checkpoints
This model is part of the Llama Nemotron Collection. You can find the other model(s) in this family here:
- [Llama-3.3-Nemotron-Ultra-253B-v1](https://huggingface.co/nvidia/Llama-3_1-Nemotron-Ultra-253B-v1)
- [Llama-3.3-Nemotron-Super-49B-v1](https://huggingface.co/nvidia/Llama-3.3-Nemotron-Super-49B-v1)
- [Llama-3.1-Nemotron-Nano-8B-v1](https://huggingface.co/nvidia/Llama-3.1-Nemotron-Nano-8B-v1)
This model is ready for commercial use.
## License/Terms of Use
GOVERNING TERMS: Your use of this model is governed by the [NVIDIA Open Model License](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/). Additional Information: [Llama 3.1 Community License Agreement](https://www.llama.com/llama3_1/license/). Built with Llama.
**Model Developer:** NVIDIA
**Model Dates:** Trained between August 2024 and May 2025
**Data Freshness:** The pretraining data has a cutoff of June 2023.
## Use Case:
Developers designing AI Agent systems, chatbots, RAG systems, and other AI-powered applications. Also suitable for typical instruction-following tasks. Balance of model accuracy and compute efficiency (the model fits on a single RTX GPU and can be used locally).
## Release Date: <br>
5/20/2025 <br>
## References
- [\[2408.11796\] LLM Pruning and Distillation in Practice: The Minitron Approach](https://arxiv.org/abs/2408.11796)
- [\[2502.00203\] Reward-aware Preference Optimization: A Unified Mathematical Framework for Model Alignment](https://arxiv.org/abs/2502.00203)
- [\[2505.00949\] Llama-Nemotron: Efficient Reasoning Models](https://arxiv.org/abs/2505.00949)
## Model Architecture
**Architecture Type:** Dense decoder-only Transformer model
**Network Architecture:** Llama 3.1 Minitron Width 4B Base
## Intended use
Llama-3.1-Nemotron-Nano-4B-v1.1 is a general purpose reasoning and chat model intended to be used in English and coding languages. Other non-English languages (German, French, Italian, Portuguese, Hindi, Spanish, and Thai) are also supported.
# Input:
- **Input Type:** Text
- **Input Format:** String
- **Input Parameters:** One-Dimensional (1D)
- **Other Properties Related to Input:** Context length up to 131,072 tokens
## Output:
- **Output Type:** Text
- **Output Format:** String
- **Output Parameters:** One-Dimensional (1D)
- **Other Properties Related to Output:** Context length up to 131,072 tokens
## Model Version:
1.1 (5/20/2025)
## Software Integration
- **Runtime Engine:** NeMo 24.12 <br>
- **Recommended Hardware Microarchitecture Compatibility:**
- NVIDIA Hopper
- NVIDIA Ampere
## Quick Start and Usage Recommendations:
1. Reasoning mode (ON/OFF) is controlled via the system prompt, which must be set as shown in the example below. All instructions should be contained within the user prompt
2. We recommend setting temperature to `0.6`, and Top P to `0.95` for Reasoning ON mode
3. We recommend using greedy decoding for Reasoning OFF mode
4. We have provided a list of prompts to use for evaluation for each benchmark where a specific template is required
See the snippet below for usage with Hugging Face Transformers library. Reasoning mode (ON/OFF) is controlled via system prompt. Please see the example below.
Our code requires the transformers package version to be `4.44.2` or higher.
### Example of “Reasoning On:”
```python
import torch
import transformers
model_id = "nvidia/Llama-3.1-Nemotron-Nano-4B-v1.1"
model_kwargs = {"torch_dtype": torch.bfloat16, "device_map": "auto"}
tokenizer = transformers.AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token_id = tokenizer.eos_token_id
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
tokenizer=tokenizer,
max_new_tokens=32768,
temperature=0.6,
top_p=0.95,
**model_kwargs
)
# Thinking can be "on" or "off"
thinking = "on"
print(pipeline([{"role": "system", "content": f"detailed thinking {thinking}"}, {"role": "user", "content": "Solve x*(sin(x)+2)=0"}]))
```
### Example of “Reasoning Off:”
```python
import torch
import transformers
model_id = "nvidia/Llama-3.1-Nemotron-Nano-4B-v1"
model_kwargs = {"torch_dtype": torch.bfloat16, "device_map": "auto"}
tokenizer = transformers.AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token_id = tokenizer.eos_token_id
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
tokenizer=tokenizer,
max_new_tokens=32768,
do_sample=False,
**model_kwargs
)
# Thinking can be "on" or "off"
thinking = "off"
print(pipeline([{"role": "system", "content": f"detailed thinking {thinking}"}, {"role": "user", "content": "Solve x*(sin(x)+2)=0"}]))
```
For some prompts, even though thinking is disabled, the model emergently prefers to think before responding. But if desired, the users can prevent it by pre-filling the assistant response.
```python
import torch
import transformers
model_id = "nvidia/Llama-3.1-Nemotron-Nano-4B-v1.1"
model_kwargs = {"torch_dtype": torch.bfloat16, "device_map": "auto"}
tokenizer = transformers.AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token_id = tokenizer.eos_token_id
# Thinking can be "on" or "off"
thinking = "off"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
tokenizer=tokenizer,
max_new_tokens=32768,
do_sample=False,
**model_kwargs
)
print(pipeline([{"role": "system", "content": f"detailed thinking {thinking}"}, {"role": "user", "content": "Solve x*(sin(x)+2)=0"}, {"role":"assistant", "content":"<think>\n</think>"}]))
```
## Running a vLLM Server with Tool-call Support
Llama-3.1-Nemotron-Nano-4B-v1.1 supports tool calling. This HF repo hosts a tool-callilng parser as well as a chat template in Jinja, which can be used to launch a vLLM server.
Here is a shell script example to launch a vLLM server with tool-call support. `vllm/vllm-openai:v0.6.6` or newer should support the model.
```shell
#!/bin/bash
CWD=$(pwd)
PORT=5000
git clone https://huggingface.co/nvidia/Llama-3.1-Nemotron-Nano-4B-v1.1
docker run -it --rm \
--runtime=nvidia \
--gpus all \
--shm-size=16GB \
-p ${PORT}:${PORT} \
-v ${CWD}:${CWD} \
vllm/vllm-openai:v0.6.6 \
--model $CWD/Llama-3.1-Nemotron-Nano-4B-v1.1 \
--trust-remote-code \
--seed 1 \
--host "0.0.0.0" \
--port $PORT \
--served-model-name "Llama-Nemotron-Nano-4B-v1.1" \
--tensor-parallel-size 1 \
--max-model-len 131072 \
--gpu-memory-utilization 0.95 \
--enforce-eager \
--enable-auto-tool-choice \
--tool-parser-plugin "${CWD}/Llama-3.1-Nemotron-Nano-4B-v1.1/llama_nemotron_nano_toolcall_parser.py" \
--tool-call-parser "llama_nemotron_json" \
--chat-template "${CWD}/Llama-3.1-Nemotron-Nano-4B-v1.1/llama_nemotron_nano_generic_tool_calling.jinja"
```
Alternatively, you can use a virtual environment to launch a vLLM server like below.
```console
$ git clone https://huggingface.co/nvidia/Llama-3.1-Nemotron-Nano-4B-v1.1
$ conda create -n vllm python=3.12 -y
$ conda activate vllm
$ python -m vllm.entrypoints.openai.api_server \
--model Llama-3.1-Nemotron-Nano-4B-v1.1 \
--trust-remote-code \
--seed 1 \
--host "0.0.0.0" \
--port 5000 \
--served-model-name "Llama-Nemotron-Nano-4B-v1.1" \
--tensor-parallel-size 1 \
--max-model-len 131072 \
--gpu-memory-utilization 0.95 \
--enforce-eager \
--enable-auto-tool-choice \
--tool-parser-plugin "Llama-3.1-Nemotron-Nano-4B-v1.1/llama_nemotron_nano_toolcall_parser.py" \
--tool-call-parser "llama_nemotron_json" \
--chat-template "Llama-3.1-Nemotron-Nano-4B-v1.1/llama_nemotron_nano_generic_tool_calling.jinja"
```
After launching a vLLM server, you can call the server with tool-call support using a Python script like below.
```python
>>> from openai import OpenAI
>>> client = OpenAI(
base_url="http://0.0.0.0:5000/v1",
api_key="dummy",
)
>>> completion = client.chat.completions.create(
model="Llama-Nemotron-Nano-4B-v1.1",
messages=[
{"role": "system", "content": "detailed thinking on"},
{"role": "user", "content": "My bill is $100. What will be the amount for 18% tip?"},
],
tools=[
{"type": "function", "function": {"name": "calculate_tip", "parameters": {"type": "object", "properties": {"bill_total": {"type": "integer", "description": "The total amount of the bill"}, "tip_percentage": {"type": "integer", "description": "The percentage of tip to be applied"}}, "required": ["bill_total", "tip_percentage"]}}},
{"type": "function", "function": {"name": "convert_currency", "parameters": {"type": "object", "properties": {"amount": {"type": "integer", "description": "The amount to be converted"}, "from_currency": {"type": "string", "description": "The currency code to convert from"}, "to_currency": {"type": "string", "description": "The currency code to convert to"}}, "required": ["from_currency", "amount", "to_currency"]}}},
],
)
>>> completion.choices[0].message.content
'<think>\nOkay, let\'s see. The user has a bill of $100 and wants to know the amount of a 18% tip. So, I need to calculate the tip amount. The available tools include calculate_tip, which requires bill_total and tip_percentage. The parameters are both integers. The bill_total is 100, and the tip percentage is 18. So, the function should multiply 100 by 18% and return 18.0. But wait, maybe the user wants the total including the tip? The question says "the amount for 18% tip," which could be interpreted as the tip amount itself. Since the function is called calculate_tip, it\'s likely that it\'s designed to compute the tip, not the total. So, using calculate_tip with bill_total=100 and tip_percentage=18 should give the correct result. The other function, convert_currency, isn\'t relevant here. So, I should call calculate_tip with those values.\n</think>\n\n'
>>> completion.choices[0].message.tool_calls
[ChatCompletionMessageToolCall(id='chatcmpl-tool-2972d86817344edc9c1e0f9cd398e999', function=Function(arguments='{"bill_total": 100, "tip_percentage": 18}', name='calculate_tip'), type='function')]
```
## Inference:
**Engine:** Transformers
**Test Hardware:**
- BF16:
- 1x RTX 50 Series GPUs
- 1x RTX 40 Series GPUs
- 1x RTX 30 Series GPUs
- 1x H100-80GB GPU
- 1x A100-80GB GPU
**Preferred/Supported] Operating System(s):** Linux <br>
## Training Datasets
A large variety of training data was used for the post-training pipeline, including manually annotated data and synthetic data.
The data for the multi-stage post-training phases for improvements in Code, Math, and Reasoning is a compilation of SFT and RL data that supports improvements of math, code, general reasoning, and instruction following capabilities of the original Llama instruct model.
Prompts have been sourced from either public and open corpus or synthetically generated. Responses were synthetically generated by a variety of models, with some prompts containing responses for both Reasoning On and Off modes, to train the model to distinguish between two modes.
**Data Collection for Training Datasets:** <br>
* Hybrid: Automated, Human, Synthetic <br>
**Data Labeling for Training Datasets:** <br>
* N/A <br>
## Evaluation Datasets
We used the datasets listed below to evaluate Llama-3.1-Nemotron-Nano-4B-v1.1.
**Data Collection for Evaluation Datasets:** Hybrid: Human/Synthetic
**Data Labeling for Evaluation Datasets:** Hybrid: Human/Synthetic/Automatic
## Evaluation Results
These results contain both “Reasoning On”, and “Reasoning Off”. We recommend using temperature=`0.6`, top_p=`0.95` for “Reasoning On” mode, and greedy decoding for “Reasoning Off” mode. All evaluations are done with 32k sequence length. We run the benchmarks up to 16 times and average the scores to be more accurate.
> NOTE: Where applicable, a Prompt Template will be provided. While completing benchmarks, please ensure that you are parsing for the correct output format as per the provided prompt in order to reproduce the benchmarks seen below.
### MT-Bench
| Reasoning Mode | Score |
|--------------|------------|
| Reasoning Off | 7.4 |
| Reasoning On | 8.0 |
### MATH500
| Reasoning Mode | pass@1 |
|--------------|------------|
| Reasoning Off | 71.8% |
| Reasoning On | 96.2% |
User Prompt Template:
```
"Below is a math question. I want you to reason through the steps and then give a final answer. Your final answer should be in \boxed{}.\nQuestion: {question}"
```
### AIME25
| Reasoning Mode | pass@1 |
|--------------|------------|
| Reasoning Off | 13.3% |
| Reasoning On | 46.3% |
User Prompt Template:
```
"Below is a math question. I want you to reason through the steps and then give a final answer. Your final answer should be in \boxed{}.\nQuestion: {question}"
```
### GPQA-D
| Reasoning Mode | pass@1 |
|--------------|------------|
| Reasoning Off | 33.8% |
| Reasoning On | 55.1% |
User Prompt Template:
```
"What is the correct answer to this question: {question}\nChoices:\nA. {option_A}\nB. {option_B}\nC. {option_C}\nD. {option_D}\nLet's think step by step, and put the final answer (should be a single letter A, B, C, or D) into a \boxed{}"
```
### IFEval
| Reasoning Mode | Strict:Prompt | Strict:Instruction |
|--------------|------------|------------|
| Reasoning Off | 70.1% | 78.5% |
| Reasoning On | 75.5% | 82.6% |
### BFCL v2 Live
| Reasoning Mode | Score |
|--------------|------------|
| Reasoning Off | 63.6% |
| Reasoning On | 67.9% |
User Prompt Template:
```
<AVAILABLE_TOOLS>{functions}</AVAILABLE_TOOLS>
{user_prompt}
```
### MBPP 0-shot
| Reasoning Mode | pass@1 |
|--------------|------------|
| Reasoning Off | 61.9% |
| Reasoning On | 85.8% |
User Prompt Template:
````
You are an exceptionally intelligent coding assistant that consistently delivers accurate and reliable responses to user instructions.
@@ Instruction
Here is the given problem and test examples:
{prompt}
Please use the python programming language to solve this problem.
Please make sure that your code includes the functions from the test samples and that the input and output formats of these functions match the test samples.
Please return all completed codes in one code block.
This code block should be in the following format:
```python
# Your codes here
```
````
## Ethical Considerations:
NVIDIA believes Trustworthy AI is a shared responsibility and we have established policies and practices to enable development for a wide array of AI applications. When downloaded or used in accordance with our terms of service, developers should work with their internal model team to ensure this model meets requirements for the relevant industry and use case and addresses unforeseen product misuse.
For more detailed information on ethical considerations for this model, please see the Model Card++ [Explainability](explainability.md), [Bias](bias.md), [Safety & Security](safety.md), and [Privacy](privacy.md) Subcards.
Please report security vulnerabilities or NVIDIA AI Concerns [here](https://www.nvidia.com/en-us/support/submit-security-vulnerability/). |
Mungert/Qwen3-30B-A3B-GGUF | Mungert | 2025-06-15T19:37:50Z | 1,722 | 4 | transformers | [
"transformers",
"gguf",
"text-generation",
"arxiv:2309.00071",
"base_model:Qwen/Qwen3-30B-A3B-Base",
"base_model:quantized:Qwen/Qwen3-30B-A3B-Base",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-05-13T04:35:31Z | ---
library_name: transformers
license: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen3-30B-A3B/blob/main/LICENSE
pipeline_tag: text-generation
base_model:
- Qwen/Qwen3-30B-A3B-Base
---
# <span style="color: #7FFF7F;">Qwen3-30B-A3B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`064cc596`](https://github.com/ggerganov/llama.cpp/commit/064cc596ac44308dc326a17c9e3163c34a6f29d1).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Qwen3-30B-A3B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Qwen3-30B-A3B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Qwen3-30B-A3B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Qwen3-30B-A3B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Qwen3-30B-A3B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Qwen3-30B-A3B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Qwen3-30B-A3B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Qwen3-30B-A3B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Qwen3-30B-A3B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Qwen3-30B-A3B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Qwen3-30B-A3B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# Qwen3-30B-A3B
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Qwen3 Highlights
Qwen3 is the latest generation of large language models in Qwen series, offering a comprehensive suite of dense and mixture-of-experts (MoE) models. Built upon extensive training, Qwen3 delivers groundbreaking advancements in reasoning, instruction-following, agent capabilities, and multilingual support, with the following key features:
- **Uniquely support of seamless switching between thinking mode** (for complex logical reasoning, math, and coding) and **non-thinking mode** (for efficient, general-purpose dialogue) **within single model**, ensuring optimal performance across various scenarios.
- **Significantly enhancement in its reasoning capabilities**, surpassing previous QwQ (in thinking mode) and Qwen2.5 instruct models (in non-thinking mode) on mathematics, code generation, and commonsense logical reasoning.
- **Superior human preference alignment**, excelling in creative writing, role-playing, multi-turn dialogues, and instruction following, to deliver a more natural, engaging, and immersive conversational experience.
- **Expertise in agent capabilities**, enabling precise integration with external tools in both thinking and unthinking modes and achieving leading performance among open-source models in complex agent-based tasks.
- **Support of 100+ languages and dialects** with strong capabilities for **multilingual instruction following** and **translation**.
## Model Overview
**Qwen3-30B-A3B** has the following features:
- Type: Causal Language Models
- Training Stage: Pretraining & Post-training
- Number of Parameters: 30.5B in total and 3.3B activated
- Number of Paramaters (Non-Embedding): 29.9B
- Number of Layers: 48
- Number of Attention Heads (GQA): 32 for Q and 4 for KV
- Number of Experts: 128
- Number of Activated Experts: 8
- Context Length: 32,768 natively and [131,072 tokens with YaRN](#processing-long-texts).
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3/), [GitHub](https://github.com/QwenLM/Qwen3), and [Documentation](https://qwen.readthedocs.io/en/latest/).
## Quickstart
The code of Qwen3-MoE has been in the latest Hugging Face `transformers` and we advise you to use the latest version of `transformers`.
With `transformers<4.51.0`, you will encounter the following error:
```
KeyError: 'qwen3_moe'
```
The following contains a code snippet illustrating how to use the model generate content based on given inputs.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-30B-A3B"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
prompt = "Give me a short introduction to large language model."
messages = [
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # Switches between thinking and non-thinking modes. Default is True.
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151668 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
```
For deployment, you can use `sglang>=0.4.6.post1` or `vllm>=0.8.5` or to create an OpenAI-compatible API endpoint:
- SGLang:
```shell
python -m sglang.launch_server --model-path Qwen/Qwen3-30B-A3B --reasoning-parser qwen3
```
- vLLM:
```shell
vllm serve Qwen/Qwen3-30B-A3B --enable-reasoning --reasoning-parser deepseek_r1
```
For local use, applications such as Ollama, LMStudio, MLX-LM, llama.cpp, and KTransformers have also supported Qwen3.
## Switching Between Thinking and Non-Thinking Mode
> [!TIP]
> The `enable_thinking` switch is also available in APIs created by SGLang and vLLM.
> Please refer to our documentation for [SGLang](https://qwen.readthedocs.io/en/latest/deployment/sglang.html#thinking-non-thinking-modes) and [vLLM](https://qwen.readthedocs.io/en/latest/deployment/vllm.html#thinking-non-thinking-modes) users.
### `enable_thinking=True`
By default, Qwen3 has thinking capabilities enabled, similar to QwQ-32B. This means the model will use its reasoning abilities to enhance the quality of generated responses. For example, when explicitly setting `enable_thinking=True` or leaving it as the default value in `tokenizer.apply_chat_template`, the model will engage its thinking mode.
```python
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=True # True is the default value for enable_thinking
)
```
In this mode, the model will generate think content wrapped in a `<think>...</think>` block, followed by the final response.
> [!NOTE]
> For thinking mode, use `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0` (the default setting in `generation_config.json`). **DO NOT use greedy decoding**, as it can lead to performance degradation and endless repetitions. For more detailed guidance, please refer to the [Best Practices](#best-practices) section.
### `enable_thinking=False`
We provide a hard switch to strictly disable the model's thinking behavior, aligning its functionality with the previous Qwen2.5-Instruct models. This mode is particularly useful in scenarios where disabling thinking is essential for enhancing efficiency.
```python
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
enable_thinking=False # Setting enable_thinking=False disables thinking mode
)
```
In this mode, the model will not generate any think content and will not include a `<think>...</think>` block.
> [!NOTE]
> For non-thinking mode, we suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`. For more detailed guidance, please refer to the [Best Practices](#best-practices) section.
### Advanced Usage: Switching Between Thinking and Non-Thinking Modes via User Input
We provide a soft switch mechanism that allows users to dynamically control the model's behavior when `enable_thinking=True`. Specifically, you can add `/think` and `/no_think` to user prompts or system messages to switch the model's thinking mode from turn to turn. The model will follow the most recent instruction in multi-turn conversations.
Here is an example of a multi-turn conversation:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
class QwenChatbot:
def __init__(self, model_name="Qwen/Qwen3-30B-A3B"):
self.tokenizer = AutoTokenizer.from_pretrained(model_name)
self.model = AutoModelForCausalLM.from_pretrained(model_name)
self.history = []
def generate_response(self, user_input):
messages = self.history + [{"role": "user", "content": user_input}]
text = self.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
inputs = self.tokenizer(text, return_tensors="pt")
response_ids = self.model.generate(**inputs, max_new_tokens=32768)[0][len(inputs.input_ids[0]):].tolist()
response = self.tokenizer.decode(response_ids, skip_special_tokens=True)
# Update history
self.history.append({"role": "user", "content": user_input})
self.history.append({"role": "assistant", "content": response})
return response
# Example Usage
if __name__ == "__main__":
chatbot = QwenChatbot()
# First input (without /think or /no_think tags, thinking mode is enabled by default)
user_input_1 = "How many r's in strawberries?"
print(f"User: {user_input_1}")
response_1 = chatbot.generate_response(user_input_1)
print(f"Bot: {response_1}")
print("----------------------")
# Second input with /no_think
user_input_2 = "Then, how many r's in blueberries? /no_think"
print(f"User: {user_input_2}")
response_2 = chatbot.generate_response(user_input_2)
print(f"Bot: {response_2}")
print("----------------------")
# Third input with /think
user_input_3 = "Really? /think"
print(f"User: {user_input_3}")
response_3 = chatbot.generate_response(user_input_3)
print(f"Bot: {response_3}")
```
> [!NOTE]
> For API compatibility, when `enable_thinking=True`, regardless of whether the user uses `/think` or `/no_think`, the model will always output a block wrapped in `<think>...</think>`. However, the content inside this block may be empty if thinking is disabled.
> When `enable_thinking=False`, the soft switches are not valid. Regardless of any `/think` or `/no_think` tags input by the user, the model will not generate think content and will not include a `<think>...</think>` block.
## Agentic Use
Qwen3 excels in tool calling capabilities. We recommend using [Qwen-Agent](https://github.com/QwenLM/Qwen-Agent) to make the best use of agentic ability of Qwen3. Qwen-Agent encapsulates tool-calling templates and tool-calling parsers internally, greatly reducing coding complexity.
To define the available tools, you can use the MCP configuration file, use the integrated tool of Qwen-Agent, or integrate other tools by yourself.
```python
from qwen_agent.agents import Assistant
# Define LLM
llm_cfg = {
'model': 'Qwen3-30B-A3B',
# Use the endpoint provided by Alibaba Model Studio:
# 'model_type': 'qwen_dashscope',
# 'api_key': os.getenv('DASHSCOPE_API_KEY'),
# Use a custom endpoint compatible with OpenAI API:
'model_server': 'http://localhost:8000/v1', # api_base
'api_key': 'EMPTY',
# Other parameters:
# 'generate_cfg': {
# # Add: When the response content is `<think>this is the thought</think>this is the answer;
# # Do not add: When the response has been separated by reasoning_content and content.
# 'thought_in_content': True,
# },
}
# Define Tools
tools = [
{'mcpServers': { # You can specify the MCP configuration file
'time': {
'command': 'uvx',
'args': ['mcp-server-time', '--local-timezone=Asia/Shanghai']
},
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
}
},
'code_interpreter', # Built-in tools
]
# Define Agent
bot = Assistant(llm=llm_cfg, function_list=tools)
# Streaming generation
messages = [{'role': 'user', 'content': 'https://qwenlm.github.io/blog/ Introduce the latest developments of Qwen'}]
for responses in bot.run(messages=messages):
pass
print(responses)
```
## Processing Long Texts
Qwen3 natively supports context lengths of up to 32,768 tokens. For conversations where the total length (including both input and output) significantly exceeds this limit, we recommend using RoPE scaling techniques to handle long texts effectively. We have validated the model's performance on context lengths of up to 131,072 tokens using the [YaRN](https://arxiv.org/abs/2309.00071) method.
YaRN is currently supported by several inference frameworks, e.g., `transformers` and `llama.cpp` for local use, `vllm` and `sglang` for deployment. In general, there are two approaches to enabling YaRN for supported frameworks:
- Modifying the model files:
In the `config.json` file, add the `rope_scaling` fields:
```json
{
...,
"rope_scaling": {
"rope_type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 32768
}
}
```
For `llama.cpp`, you need to regenerate the GGUF file after the modification.
- Passing command line arguments:
For `vllm`, you can use
```shell
vllm serve ... --rope-scaling '{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}' --max-model-len 131072
```
For `sglang`, you can use
```shell
python -m sglang.launch_server ... --json-model-override-args '{"rope_scaling":{"rope_type":"yarn","factor":4.0,"original_max_position_embeddings":32768}}'
```
For `llama-server` from `llama.cpp`, you can use
```shell
llama-server ... --rope-scaling yarn --rope-scale 4 --yarn-orig-ctx 32768
```
> [!IMPORTANT]
> If you encounter the following warning
> ```
> Unrecognized keys in `rope_scaling` for 'rope_type'='yarn': {'original_max_position_embeddings'}
> ```
> please upgrade `transformers>=4.51.0`.
> [!NOTE]
> All the notable open-source frameworks implement static YaRN, which means the scaling factor remains constant regardless of input length, **potentially impacting performance on shorter texts.**
> We advise adding the `rope_scaling` configuration only when processing long contexts is required.
> It is also recommended to modify the `factor` as needed. For example, if the typical context length for your application is 65,536 tokens, it would be better to set `factor` as 2.0.
> [!NOTE]
> The default `max_position_embeddings` in `config.json` is set to 40,960. This allocation includes reserving 32,768 tokens for outputs and 8,192 tokens for typical prompts, which is sufficient for most scenarios involving short text processing. If the average context length does not exceed 32,768 tokens, we do not recommend enabling YaRN in this scenario, as it may potentially degrade model performance.
> [!TIP]
> The endpoint provided by Alibaba Model Studio supports dynamic YaRN by default and no extra configuration is needed.
## Best Practices
To achieve optimal performance, we recommend the following settings:
1. **Sampling Parameters**:
- For thinking mode (`enable_thinking=True`), use `Temperature=0.6`, `TopP=0.95`, `TopK=20`, and `MinP=0`. **DO NOT use greedy decoding**, as it can lead to performance degradation and endless repetitions.
- For non-thinking mode (`enable_thinking=False`), we suggest using `Temperature=0.7`, `TopP=0.8`, `TopK=20`, and `MinP=0`.
- For supported frameworks, you can adjust the `presence_penalty` parameter between 0 and 2 to reduce endless repetitions. However, using a higher value may occasionally result in language mixing and a slight decrease in model performance.
2. **Adequate Output Length**: We recommend using an output length of 32,768 tokens for most queries. For benchmarking on highly complex problems, such as those found in math and programming competitions, we suggest setting the max output length to 38,912 tokens. This provides the model with sufficient space to generate detailed and comprehensive responses, thereby enhancing its overall performance.
3. **Standardize Output Format**: We recommend using prompts to standardize model outputs when benchmarking.
- **Math Problems**: Include "Please reason step by step, and put your final answer within \boxed{}." in the prompt.
- **Multiple-Choice Questions**: Add the following JSON structure to the prompt to standardize responses: "Please show your choice in the `answer` field with only the choice letter, e.g., `"answer": "C"`."
4. **No Thinking Content in History**: In multi-turn conversations, the historical model output should only include the final output part and does not need to include the thinking content. It is implemented in the provided chat template in Jinja2. However, for frameworks that do not directly use the Jinja2 chat template, it is up to the developers to ensure that the best practice is followed.
### Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen3,
title = {Qwen3},
url = {https://qwenlm.github.io/blog/qwen3/},
author = {Qwen Team},
month = {April},
year = {2025}
}
``` |
Mungert/LiveCC-7B-Instruct-GGUF | Mungert | 2025-06-15T19:37:37Z | 1,832 | 1 | null | [
"gguf",
"qwen_vl",
"video",
"real-time",
"multimodal",
"LLM",
"en",
"dataset:chenjoya/Live-CC-5M",
"dataset:chenjoya/Live-WhisperX-526K",
"dataset:lmms-lab/LLaVA-Video-178K",
"arxiv:2504.16030",
"base_model:Qwen/Qwen2-VL-7B",
"base_model:quantized:Qwen/Qwen2-VL-7B",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-04-27T00:50:10Z | ---
license: apache-2.0
datasets:
- chenjoya/Live-CC-5M
- chenjoya/Live-WhisperX-526K
- lmms-lab/LLaVA-Video-178K
language:
- en
base_model:
- Qwen/Qwen2-VL-7B
tags:
- qwen_vl
- video
- real-time
- multimodal
- LLM
---
# <span style="color: #7FFF7F;">LiveCC-7B-Instruct GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`e291450`](https://github.com/ggerganov/llama.cpp/commit/e291450b7602d7a36239e4ceeece37625f838373).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `LiveCC-7B-Instruct-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `LiveCC-7B-Instruct-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `LiveCC-7B-Instruct-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `LiveCC-7B-Instruct-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `LiveCC-7B-Instruct-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `LiveCC-7B-Instruct-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `LiveCC-7B-Instruct-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `LiveCC-7B-Instruct-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `LiveCC-7B-Instruct-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `LiveCC-7B-Instruct-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `LiveCC-7B-Instruct-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# LiveCC-7B-Instruct
## Introduction
We introduce LiveCC, the first video LLM capable of real-time commentary, trained with a novel video-ASR streaming method, SOTA on both streaming and offline benchmarks.
- Project Page: https://showlab.github.io/livecc
> [!Important]
> This is the SFT model. The base model is at [LiveCC-7B-Base](https://huggingface.co/chenjoya/LiveCC-7B-Base).
## Training with Streaming Frame-Words Paradigm

## Quickstart
### Gradio Demo
Please refer to https://github.com/showlab/livecc:

### Hands-on
Like qwen-vl-utils, we offer a toolkit to help you handle various types of visual input more conveniently, **especially on video streaming inputs**. You can install it using the following command:
```bash
pip install qwen-vl-utils livecc-utils liger_kernel
```
Here we show a code snippet to show you how to do **real-time video commentary** with `transformers` and the above utils:
```python
import functools, torch, os, tqdm
from liger_kernel.transformers import apply_liger_kernel_to_qwen2_vl
apply_liger_kernel_to_qwen2_vl() # important. our model is trained with this. keep consistency
from transformers import Qwen2VLForConditionalGeneration, AutoProcessor, LogitsProcessor, logging
from livecc_utils import prepare_multiturn_multimodal_inputs_for_generation, get_smart_resized_clip, get_smart_resized_video_reader
from qwen_vl_utils import process_vision_info
class LiveCCDemoInfer:
fps = 2
initial_fps_frames = 6
streaming_fps_frames = 2
initial_time_interval = initial_fps_frames / fps
streaming_time_interval = streaming_fps_frames / fps
frame_time_interval = 1 / fps
def __init__(self, model_path: str = None, device_id: int = 0):
self.model = Qwen2VLForConditionalGeneration.from_pretrained(
model_path, torch_dtype="auto",
device_map=f'cuda:{device_id}',
attn_implementation='flash_attention_2'
)
self.processor = AutoProcessor.from_pretrained(model_path, use_fast=False)
self.model.prepare_inputs_for_generation = functools.partial(prepare_multiturn_multimodal_inputs_for_generation, self.model)
message = {
"role": "user",
"content": [
{"type": "text", "text": 'livecc'},
]
}
texts = self.processor.apply_chat_template([message], tokenize=False)
self.system_prompt_offset = texts.index('<|im_start|>user')
self._cached_video_readers_with_hw = {}
def live_cc(
self,
query: str,
state: dict,
max_pixels: int = 384 * 28 * 28,
default_query: str = 'Please describe the video.',
do_sample: bool = True,
repetition_penalty: float = 1.05,
**kwargs,
):
"""
state: dict, (maybe) with keys:
video_path: str, video path
video_timestamp: float, current video timestamp
last_timestamp: float, last processed video timestamp
last_video_pts_index: int, last processed video frame index
video_pts: np.ndarray, video pts
last_history: list, last processed history
past_key_values: llm past_key_values
past_ids: past generated ids
"""
# 1. preparation: video_reader, and last processing info
video_timestamp, last_timestamp = state.get('video_timestamp', 0), state.get('last_timestamp', -1 / self.fps)
video_path = state['video_path']
if video_path not in self._cached_video_readers_with_hw:
self._cached_video_readers_with_hw[video_path] = get_smart_resized_video_reader(video_path, max_pixels)
video_reader = self._cached_video_readers_with_hw[video_path][0]
video_reader.get_frame_timestamp(0)
state['video_pts'] = torch.from_numpy(video_reader._frame_pts[:, 1])
state['last_video_pts_index'] = -1
video_pts = state['video_pts']
if last_timestamp + self.frame_time_interval > video_pts[-1]:
state['video_end'] = True
return
video_reader, resized_height, resized_width = self._cached_video_readers_with_hw[video_path]
last_video_pts_index = state['last_video_pts_index']
# 2. which frames will be processed
initialized = last_timestamp >= 0
if not initialized:
video_timestamp = max(video_timestamp, self.initial_time_interval)
if video_timestamp <= last_timestamp + self.frame_time_interval:
return
timestamps = torch.arange(last_timestamp + self.frame_time_interval, video_timestamp, self.frame_time_interval) # add compensation
# 3. fetch frames in required timestamps
clip, clip_timestamps, clip_idxs = get_smart_resized_clip(video_reader, resized_height, resized_width, timestamps, video_pts, video_pts_index_from=last_video_pts_index+1)
state['last_video_pts_index'] = clip_idxs[-1]
state['last_timestamp'] = clip_timestamps[-1]
# 4. organize to interleave frames
interleave_clips, interleave_timestamps = [], []
if not initialized:
interleave_clips.append(clip[:self.initial_fps_frames])
interleave_timestamps.append(clip_timestamps[:self.initial_fps_frames])
clip = clip[self.initial_fps_frames:]
clip_timestamps = clip_timestamps[self.initial_fps_frames:]
if len(clip) > 0:
interleave_clips.extend(list(clip.split(self.streaming_fps_frames)))
interleave_timestamps.extend(list(clip_timestamps.split(self.streaming_fps_frames)))
# 5. make conversation and send to model
for clip, timestamps in zip(interleave_clips, interleave_timestamps):
start_timestamp, stop_timestamp = timestamps[0].item(), timestamps[-1].item() + self.frame_time_interval
message = {
"role": "user",
"content": [
{"type": "text", "text": f'Time={start_timestamp:.1f}-{stop_timestamp:.1f}s'},
{"type": "video", "video": clip}
]
}
if not query and not state.get('query', None):
query = default_query
print(f'No query provided, use default_query={default_query}')
if query and state.get('query', None) != query:
message['content'].append({"type": "text", "text": query})
state['query'] = query
texts = self.processor.apply_chat_template([message], tokenize=False, add_generation_prompt=True, return_tensors='pt')
past_ids = state.get('past_ids', None)
if past_ids is not None:
texts = '<|im_end|>\n' + texts[self.system_prompt_offset:]
inputs = self.processor(
text=texts,
images=None,
videos=[clip],
return_tensors="pt",
return_attention_mask=False
)
inputs.to('cuda')
if past_ids is not None:
inputs['input_ids'] = torch.cat([past_ids, inputs.input_ids], dim=1)
outputs = self.model.generate(
**inputs, past_key_values=state.get('past_key_values', None),
return_dict_in_generate=True, do_sample=do_sample,
repetition_penalty=repetition_penalty,
)
state['past_key_values'] = outputs.past_key_values
state['past_ids'] = outputs.sequences[:, :-1]
yield (start_timestamp, stop_timestamp), self.processor.decode(outputs.sequences[0, inputs.input_ids.size(1):], skip_special_tokens=True), state
model_path = 'chenjoya/LiveCC-7B-Instruct'
# download a test video at: https://github.com/showlab/livecc/blob/main/demo/sources/howto_fix_laptop_mute_1080p.mp4
video_path = "demo/sources/howto_fix_laptop_mute_1080p.mp4"
query = "Please describe the video."
infer = LiveCCDemoInfer(model_path=model_path)
state = {'video_path': video_path}
commentaries = []
t = 0
for t in range(31):
state['video_timestamp'] = t
for (start_t, stop_t), response, state in infer.live_cc(
query=query, state=state,
max_pixels = 384 * 28 * 28, repetition_penalty=1.05,
streaming_eos_base_threshold=0.0, streaming_eos_threshold_step=0
):
print(f'{start_t}s-{stop_t}s: {response}')
commentaries.append([start_t, stop_t, response])
if state.get('video_end', False):
break
t += 1
```
Here we show a code snippet to show you how to do **common video (multi-turn) qa** with `transformers` and the above utils:
```python
import functools, torch
from liger_kernel.transformers import apply_liger_kernel_to_qwen2_vl
apply_liger_kernel_to_qwen2_vl() # important. our model is trained with this. keep consistency
from transformers import Qwen2VLForConditionalGeneration, AutoProcessor, LogitsProcessor, logging
from livecc_utils import prepare_multiturn_multimodal_inputs_for_generation, get_smart_resized_clip, get_smart_resized_video_reader
from qwen_vl_utils import process_vision_info
class LiveCCDemoInfer:
fps = 2
initial_fps_frames = 6
streaming_fps_frames = 2
initial_time_interval = initial_fps_frames / fps
streaming_time_interval = streaming_fps_frames / fps
frame_time_interval = 1 / fps
def __init__(self, model_path: str = None, device: str = 'cuda'):
self.model = Qwen2VLForConditionalGeneration.from_pretrained(
model_path, torch_dtype="auto",
device_map=device,
attn_implementation='flash_attention_2'
)
self.processor = AutoProcessor.from_pretrained(model_path, use_fast=False)
self.streaming_eos_token_id = self.processor.tokenizer(' ...').input_ids[-1]
self.model.prepare_inputs_for_generation = functools.partial(prepare_multiturn_multimodal_inputs_for_generation, self.model)
message = {
"role": "user",
"content": [
{"type": "text", "text": 'livecc'},
]
}
texts = self.processor.apply_chat_template([message], tokenize=False)
self.system_prompt_offset = texts.index('<|im_start|>user')
def video_qa(
self,
message: str,
state: dict,
do_sample: bool = True,
repetition_penalty: float = 1.05,
**kwargs,
):
"""
state: dict, (maybe) with keys:
video_path: str, video path
video_timestamp: float, current video timestamp
last_timestamp: float, last processed video timestamp
last_video_pts_index: int, last processed video frame index
video_pts: np.ndarray, video pts
last_history: list, last processed history
past_key_values: llm past_key_values
past_ids: past generated ids
"""
video_path = state.get('video_path', None)
conversation = []
past_ids = state.get('past_ids', None)
content = [{"type": "text", "text": message}]
if past_ids is None and video_path: # only use once
content.insert(0, {"type": "video", "video": video_path})
conversation.append({"role": "user", "content": content})
image_inputs, video_inputs = process_vision_info(conversation)
texts = self.processor.apply_chat_template(conversation, tokenize=False, add_generation_prompt=True, return_tensors='pt')
if past_ids is not None:
texts = '<|im_end|>\n' + texts[self.system_prompt_offset:]
inputs = self.processor(
text=texts,
images=image_inputs,
videos=video_inputs,
return_tensors="pt",
return_attention_mask=False
)
inputs.to(self.model.device)
if past_ids is not None:
inputs['input_ids'] = torch.cat([past_ids, inputs.input_ids], dim=1)
outputs = self.model.generate(
**inputs, past_key_values=state.get('past_key_values', None),
return_dict_in_generate=True, do_sample=do_sample,
repetition_penalty=repetition_penalty,
max_new_tokens=512,
)
state['past_key_values'] = outputs.past_key_values
state['past_ids'] = outputs.sequences[:, :-1]
response = self.processor.decode(outputs.sequences[0, inputs.input_ids.size(1):], skip_special_tokens=True)
return response, state
model_path = 'chenjoya/LiveCC-7B-Instruct'
# download a test video at: https://github.com/showlab/livecc/blob/main/demo/sources/howto_fix_laptop_mute_1080p.mp4
video_path = "demo/sources/howto_fix_laptop_mute_1080p.mp4"
infer = LiveCCDemoInfer(model_path=model_path)
state = {'video_path': video_path}
# first round
query1 = 'What is the video?'
response1, state = infer.video_qa(message=query1, state=state)
print(f'Q1: {query1}\nA1: {response1}')
# second round
query2 = 'How do you know that?'
response2, state = infer.video_qa(message=query2, state=state)
print(f'Q2: {query2}\nA2: {response2}')
```
## Performance


## Limitations
- This model is finetuned on LiveCC-7B-Base, which is starting from Qwen2-VL-7B-Base, so it may have limitations mentioned in https://huggingface.co/Qwen/Qwen2-VL-7B.
- When performing real-time video commentary, it may appear collapse --- e.g., repeat pattern. If you encounter this situation, try to adjust repetition_penalty, streaming_eos_base_threshold, and streaming_eos_threshold_step.
- This model only has a context window of 32768. Using more visual tokens per frame (e.g. 768 * 28 * 28) will have better performance, but will shorten the working duration.
These limitations serve as ongoing directions for model optimization and improvement, and we are committed to continually enhancing the model's performance and scope of application.
## Citation
If you find our work helpful, feel free to give us a cite.
```
@article{livecc,
author = {Joya Chen and Ziyun Zeng and Yiqi Lin and Wei Li and Zejun Ma and Mike Zheng Shou},
title = {LiveCC: Learning Video LLM with Streaming Speech Transcription at Scale},
journal = {arXiv preprint arXiv:2504.16030}
year = {2025},
}
``` |
Mungert/openhands-lm-7b-v0.1-GGUF | Mungert | 2025-06-15T19:37:33Z | 1,045 | 2 | null | [
"gguf",
"agent",
"coding",
"text-generation",
"en",
"dataset:SWE-Gym/SWE-Gym",
"arxiv:2412.21139",
"base_model:Qwen/Qwen2.5-Coder-7B-Instruct",
"base_model:quantized:Qwen/Qwen2.5-Coder-7B-Instruct",
"license:mit",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-04-26T08:57:49Z | ---
license: mit
datasets:
- SWE-Gym/SWE-Gym
language:
- en
base_model:
- Qwen/Qwen2.5-Coder-7B-Instruct
pipeline_tag: text-generation
tags:
- agent
- coding
---
# <span style="color: #7FFF7F;">openhands-lm-7b-v0.1 GGUF Models</span>
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `openhands-lm-7b-v0.1-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `openhands-lm-7b-v0.1-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `openhands-lm-7b-v0.1-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `openhands-lm-7b-v0.1-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `openhands-lm-7b-v0.1-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `openhands-lm-7b-v0.1-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `openhands-lm-7b-v0.1-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `openhands-lm-7b-v0.1-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `openhands-lm-7b-v0.1-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `openhands-lm-7b-v0.1-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `openhands-lm-7b-v0.1-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
<div align="center">
<img src="https://github.com/All-Hands-AI/OpenHands/blob/main/docs/static/img/logo.png?raw=true" alt="Logo" width="200">
<h1 align="center">OpenHands LM v0.1</h1>
</div>
<p align="center">
<a href="https://www.all-hands.dev/blog/introducing-openhands-lm-32b----a-strong-open-coding-agent-model">Blog</a>
•
<a href="https://docs.all-hands.dev/modules/usage/llms/local-llms" >Use it in OpenHands</a>
</p>
**This is a smaller 7B model trained following the recipe of [all-hands/openhands-lm-32b-v0.1](https://huggingface.co/all-hands/openhands-lm-32b-v0.1).**
---
Autonomous agents for software development are already contributing to a [wide range of software development tasks](/blog/8-use-cases-for-generalist-software-development-agents).
But up to this point, strong coding agents have relied on proprietary models, which means that even if you use an open-source agent like [OpenHands](https://github.com/All-Hands-AI/OpenHands), you are still reliant on API calls to an external service.
Today, we are excited to introduce OpenHands LM, a new open coding model that:
- Is open and [available on Hugging Face](https://huggingface.co/all-hands/openhands-lm-32b-v0.1), so you can download it and run it locally
- Is a reasonable size, 32B, so it can be run locally on hardware such as a single 3090 GPU
- Achieves strong performance on software engineering tasks, including 37.2% resolve rate on SWE-Bench Verified
Read below for more details and our future plans!
## What is OpenHands LM?
OpenHands LM is built on the foundation of [Qwen Coder 2.5 Instruct 32B](https://huggingface.co/Qwen/Qwen2.5-Coder-32B-Instruct), leveraging its powerful base capabilities for coding tasks. What sets OpenHands LM apart is our specialized fine-tuning process:
- We used training data generated by OpenHands itself on a diverse set of open-source repositories
- Specifically, we use an RL-based framework outlined in [SWE-Gym](https://arxiv.org/abs/2412.21139), where we set up a training environment, generate training data using an existing agent, and then fine-tune the model on examples that were resolved successfully
- It features a 128K token context window, ideal for handling large codebases and long-horizon software engineering tasks
## Performance: Punching Above Its Weight
We evaluated OpenHands LM using our latest [iterative evaluation protocol](https://github.com/All-Hands-AI/OpenHands/tree/main/evaluation/benchmarks/swe_bench#run-inference-rollout-on-swe-bench-instances-generate-patch-from-problem-statement) on the [SWE-Bench Verified benchmark](https://www.swebench.com/#verified).
The results are impressive:
- **37.2% verified resolve rate** on SWE-Bench Verified
- Performance comparable to models with **20x more parameters**, including Deepseek V3 0324 (38.8%) with 671B parameters
Here's how OpenHands LM compares to other leading open-source models:
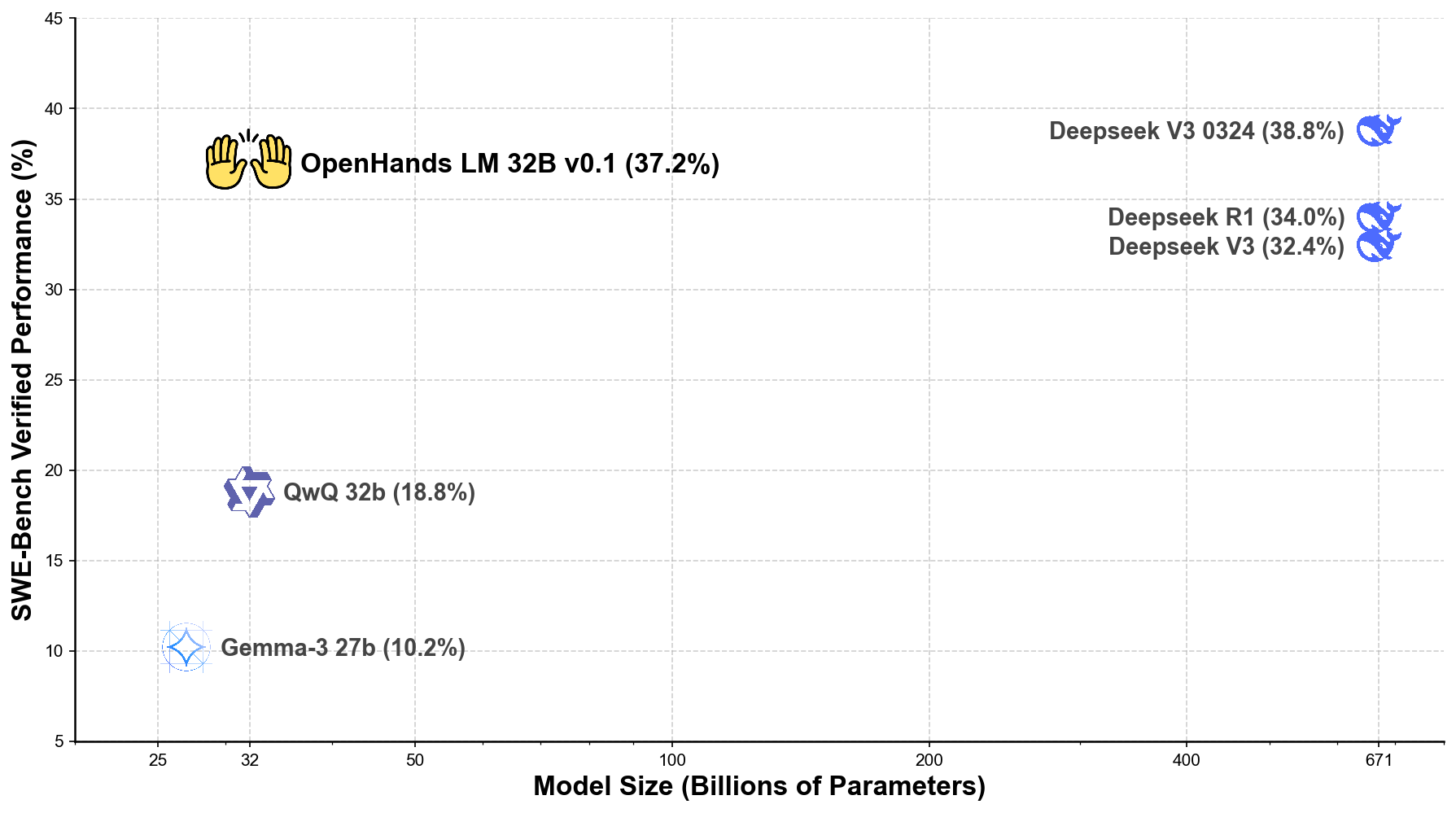
As the plot demonstrates, our 32B parameter model achieves efficiency that approaches much larger models. While the largest models (671B parameters) achieve slightly higher scores, our 32B parameter model performs remarkably well, opening up possibilities for local deployment that are not possible with larger models.
## Getting Started: How to Use OpenHands LM Today
You can start using OpenHands LM immediately through these channels:
1. **Download the model from Hugging Face**
The model is available on [Hugging Face](https://huggingface.co/all-hands/openhands-lm-32b-v0.1) and can be downloaded directly from there.
2. **Create an OpenAI-compatible endpoint with a model serving framework**
For optimal performance, it is recommended to serve this model with a GPU using [SGLang](https://github.com/sgl-project/sglang) or [vLLM](https://github.com/vllm-project/vllm).
3. **Point your OpenHands agent to the new model**
Download [OpenHands](https://github.com/All-Hands-AI/OpenHands) and follow the instructions for [using an OpenAI-compatible endpoint](https://docs.all-hands.dev/modules/usage/llms/openai-llms#using-openai-compatible-endpoints).
## The Road Ahead: Our Development Plans
This initial release marks just the beginning of our journey. We will continue enhancing OpenHands LM based on community feedback and ongoing research initiatives.
In particular, it should be noted that the model is still a research preview, and (1) may be best suited for tasks regarding solving github issues and perform less well on more varied software engineering tasks, (2) may sometimes generate repetitive steps, and (3) is somewhat sensitive to quantization, and may not function at full performance at lower quantization levels.
Our next releases will focus on addressing these limitations.
We're also developing more compact versions of the model (including a 7B parameter variant) to support users with limited computational resources. These smaller models will preserve OpenHands LM's core strengths while dramatically reducing hardware requirements.
We encourage you to experiment with OpenHands LM, share your experiences, and participate in its evolution. Together, we can create better tools for tomorrow's software development landscape.
## Try OpenHands Cloud
While OpenHands LM is a powerful model you can run locally, we also offer a fully managed cloud solution that makes it even easier to leverage AI for your software development needs.
[OpenHands Cloud](https://www.all-hands.dev/blog/introducing-the-openhands-cloud) provides:
- Seamless GitHub integration with issue and PR support
- Multiple interaction methods including text, voice, and mobile
- Parallel agent capabilities for working on multiple tasks simultaneously
- All the power of OpenHands without managing infrastructure
OpenHands Cloud is built on the same technology as our open-source solution but adds convenient features for teams and individuals who want a ready-to-use platform. [Visit app.all-hands.dev](https://app.all-hands.dev) to get started today!
## Join Our Community
We invite you to be part of the OpenHands LM journey:
- Explore our [GitHub repository](https://github.com/All-Hands-AI/OpenHands)
- Connect with us on [Slack](https://join.slack.com/t/openhands-ai/shared_invite/zt-2tom0er4l-JeNUGHt_AxpEfIBstbLPiw)
- Follow our [documentation](https://docs.all-hands.dev) to get started
By contributing your experiences and feedback, you'll help shape the future of this open-source initiative. Together, we can create better tools for tomorrow's software development landscape.
We can't wait to see what you'll create with OpenHands LM! |
Mungert/GLM-Z1-9B-0414-GGUF | Mungert | 2025-06-15T19:37:27Z | 1,000 | 5 | transformers | [
"transformers",
"gguf",
"text-generation",
"zh",
"en",
"arxiv:2406.12793",
"license:mit",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-04-26T06:57:42Z | ---
license: mit
language:
- zh
- en
pipeline_tag: text-generation
library_name: transformers
---
# <span style="color: #7FFF7F;">GLM-Z1-9B-0414 GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`e291450`](https://github.com/ggerganov/llama.cpp/commit/e291450b7602d7a36239e4ceeece37625f838373).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `GLM-Z1-9B-0414-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `GLM-Z1-9B-0414-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `GLM-Z1-9B-0414-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `GLM-Z1-9B-0414-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `GLM-Z1-9B-0414-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `GLM-Z1-9B-0414-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `GLM-Z1-9B-0414-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `GLM-Z1-9B-0414-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `GLM-Z1-9B-0414-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `GLM-Z1-9B-0414-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `GLM-Z1-9B-0414-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# GLM-4-Z1-9B-0414
## Introduction
The GLM family welcomes a new generation of open-source models, the **GLM-4-32B-0414** series, featuring 32 billion parameters. Its performance is comparable to OpenAI's GPT series and DeepSeek's V3/R1 series, and it supports very user-friendly local deployment features. GLM-4-32B-Base-0414 was pre-trained on 15T of high-quality data, including a large amount of reasoning-type synthetic data, laying the foundation for subsequent reinforcement learning extensions. In the post-training stage, in addition to human preference alignment for dialogue scenarios, we also enhanced the model's performance in instruction following, engineering code, and function calling using techniques such as rejection sampling and reinforcement learning, strengthening the atomic capabilities required for agent tasks. GLM-4-32B-0414 achieves good results in areas such as engineering code, Artifact generation, function calling, search-based Q&A, and report generation. Some benchmarks even rival larger models like GPT-4o and DeepSeek-V3-0324 (671B).
**GLM-Z1-32B-0414** is a reasoning model with **deep thinking capabilities**. This was developed based on GLM-4-32B-0414 through cold start and extended reinforcement learning, as well as further training of the model on tasks involving mathematics, code, and logic. Compared to the base model, GLM-Z1-32B-0414 significantly improves mathematical abilities and the capability to solve complex tasks. During the training process, we also introduced general reinforcement learning based on pairwise ranking feedback, further enhancing the model's general capabilities.
**GLM-Z1-Rumination-32B-0414** is a deep reasoning model with **rumination capabilities** (benchmarked against OpenAI's Deep Research). Unlike typical deep thinking models, the rumination model employs longer periods of deep thought to solve more open-ended and complex problems (e.g., writing a comparative analysis of AI development in two cities and their future development plans). The rumination model integrates search tools during its deep thinking process to handle complex tasks and is trained by utilizing multiple rule-based rewards to guide and extend end-to-end reinforcement learning. Z1-Rumination shows significant improvements in research-style writing and complex retrieval tasks.
Finally, **GLM-Z1-9B-0414** is a surprise. We employed the aforementioned series of techniques to train a 9B small-sized model that maintains the open-source tradition. Despite its smaller scale, GLM-Z1-9B-0414 still exhibits excellent capabilities in mathematical reasoning and general tasks. Its overall performance is already at a leading level among open-source models of the same size. Especially in resource-constrained scenarios, this model achieves an excellent balance between efficiency and effectiveness, providing a powerful option for users seeking lightweight deployment.
## Performance
<p align="center">
<img width="100%" src="https://raw.githubusercontent.com/THUDM/GLM-4/refs/heads/main/resources/Bench-Z1-32B.png">
</p>
<p align="center">
<img width="100%" src="https://raw.githubusercontent.com/THUDM/GLM-4/refs/heads/main/resources/Bench-Z1-9B.png">
</p>
## Model Usage Guidelines
### I. Sampling Parameters
| Parameter | Recommended Value | Description |
| ------------ | ----------------- | -------------------------------------------- |
| temperature | **0.6** | Balances creativity and stability |
| top_p | **0.95** | Cumulative probability threshold for sampling|
| top_k | **40** | Filters out rare tokens while maintaining diversity |
| max_new_tokens | **30000** | Leaves enough tokens for thinking |
### II. Enforced Thinking
- Add \<think\>\n to the **first line**: Ensures the model thinks before responding
- When using `chat_template.jinja`, the prompt is automatically injected to enforce this behavior
### III. Dialogue History Trimming
- Retain only the **final user-visible reply**.
Hidden thinking content should **not** be saved to history to reduce interference—this is already implemented in `chat_template.jinja`
### IV. Handling Long Contexts (YaRN)
- When input length exceeds **8,192 tokens**, consider enabling YaRN (Rope Scaling)
- In supported frameworks, add the following snippet to `config.json`:
```json
"rope_scaling": {
"type": "yarn",
"factor": 4.0,
"original_max_position_embeddings": 32768
}
```
- **Static YaRN** applies uniformly to all text. It may slightly degrade performance on short texts, so enable as needed.
## Inference Code
Make Sure Using `transforemrs>=4.51.3`.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
MODEL_PATH = "THUDM/GLM-4-Z1-9B-0414"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH)
model = AutoModelForCausalLM.from_pretrained(MODEL_PATH, device_map="auto")
message = [{"role": "user", "content": "Let a, b be positive real numbers such that ab = a + b + 3. Determine the range of possible values for a + b."}]
inputs = tokenizer.apply_chat_template(
message,
return_tensors="pt",
add_generation_prompt=True,
return_dict=True,
).to(model.device)
generate_kwargs = {
"input_ids": inputs["input_ids"],
"attention_mask": inputs["attention_mask"],
"max_new_tokens": 4096,
"do_sample": False,
}
out = model.generate(**generate_kwargs)
print(tokenizer.decode(out[0][inputs["input_ids"].shape[1]:], skip_special_tokens=True))
```
## Citations
If you find our work useful, please consider citing the following paper.
```
@misc{glm2024chatglm,
title={ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools},
author={Team GLM and Aohan Zeng and Bin Xu and Bowen Wang and Chenhui Zhang and Da Yin and Diego Rojas and Guanyu Feng and Hanlin Zhao and Hanyu Lai and Hao Yu and Hongning Wang and Jiadai Sun and Jiajie Zhang and Jiale Cheng and Jiayi Gui and Jie Tang and Jing Zhang and Juanzi Li and Lei Zhao and Lindong Wu and Lucen Zhong and Mingdao Liu and Minlie Huang and Peng Zhang and Qinkai Zheng and Rui Lu and Shuaiqi Duan and Shudan Zhang and Shulin Cao and Shuxun Yang and Weng Lam Tam and Wenyi Zhao and Xiao Liu and Xiao Xia and Xiaohan Zhang and Xiaotao Gu and Xin Lv and Xinghan Liu and Xinyi Liu and Xinyue Yang and Xixuan Song and Xunkai Zhang and Yifan An and Yifan Xu and Yilin Niu and Yuantao Yang and Yueyan Li and Yushi Bai and Yuxiao Dong and Zehan Qi and Zhaoyu Wang and Zhen Yang and Zhengxiao Du and Zhenyu Hou and Zihan Wang},
year={2024},
eprint={2406.12793},
archivePrefix={arXiv},
primaryClass={id='cs.CL' full_name='Computation and Language' is_active=True alt_name='cmp-lg' in_archive='cs' is_general=False description='Covers natural language processing. Roughly includes material in ACM Subject Class I.2.7. Note that work on artificial languages (programming languages, logics, formal systems) that does not explicitly address natural-language issues broadly construed (natural-language processing, computational linguistics, speech, text retrieval, etc.) is not appropriate for this area.'}
}
``` |
Mungert/Llama-3.1-Nemotron-8B-UltraLong-1M-Instruct-GGUF | Mungert | 2025-06-15T19:37:23Z | 405 | 2 | transformers | [
"transformers",
"gguf",
"en",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-04-24T03:40:42Z | ---
library_name: transformers
language:
- en
license: cc-by-nc-4.0
---
# <span style="color: #7FFF7F;">Llama-3.1-Nemotron-8B-UltraLong-1M-Instruct GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Llama-3.1-Nemotron-8B-UltraLong-1M-Instruct-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Llama-3.1-Nemotron-8B-UltraLong-1M-Instruct-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Llama-3.1-Nemotron-8B-UltraLong-1M-Instruct-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Llama-3.1-Nemotron-8B-UltraLong-1M-Instruct-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Llama-3.1-Nemotron-8B-UltraLong-1M-Instruct-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Llama-3.1-Nemotron-8B-UltraLong-1M-Instruct-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Llama-3.1-Nemotron-8B-UltraLong-1M-Instruct-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Llama-3.1-Nemotron-8B-UltraLong-1M-Instruct-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Llama-3.1-Nemotron-8B-UltraLong-1M-Instruct-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Llama-3.1-Nemotron-8B-UltraLong-1M-Instruct-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Llama-3.1-Nemotron-8B-UltraLong-1M-Instruct-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# Model Information
We introduce **Nemotron-UltraLong-8B**, a series of ultra-long context language models designed to process extensive sequences of text (up to 1M, 2M, and 4M tokens) while maintaining competitive performance on standard benchmarks. Built on the Llama-3.1, UltraLong-8B leverages a systematic training recipe that combines efficient continued pretraining with instruction tuning to enhance long-context understanding and instruction-following capabilities. This approach enables our models to efficiently scale their context windows without sacrificing general performance.
## The UltraLong Models
- [nvidia/Llama-3.1-Nemotron-8B-UltraLong-1M-Instruct](https://huggingface.co/nvidia/Llama-3.1-Nemotron-8B-UltraLong-1M-Instruct)
- [nvidia/Llama-3.1-Nemotron-8B-UltraLong-2M-Instruct](https://huggingface.co/nvidia/Llama-3.1-Nemotron-8B-UltraLong-2M-Instruct)
- [nvidia/Llama-3.1-Nemotron-8B-UltraLong-4M-Instruct](https://huggingface.co/nvidia/Llama-3.1-Nemotron-8B-UltraLong-4M-Instruct)
## Uses
Starting with `transformers >= 4.43.0` onward, you can run conversational inference using the Transformers `pipeline` abstraction or by leveraging the Auto classes with the `generate()` function.
Make sure to update your transformers installation via `pip install --upgrade transformers`.
```python
import transformers
import torch
model_id = "nvidia/Llama-3.1-Nemotron-8B-UltraLong-1M-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
outputs = pipeline(
messages,
max_new_tokens=256,
)
print(outputs[0]["generated_text"][-1])
```
## Model Card
* Base model: [meta-llama/Llama-3.1-8B-Instruct](https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct)
* Continued Pretraining: The training data consists of 1B tokens sourced from a pretraining corpus using per-domain upsampling based on sample length. The model was trained for 125 iterations with a sequence length of 1M and a global batch size of 8.
* Supervised fine-tuning (SFT): 1B tokens on open-source instruction datasets across general, mathematics, and code domains. We subsample the data from the ‘general_sft_stage2’ from [AceMath-Instruct](https://huggingface.co/datasets/nvidia/AceMath-Instruct-Training-Data).
* Maximum context window: 1M tokens
## Evaluation Results
We evaluate Nemotron-UltraLong-8B on a diverse set of benchmarks, including long-context tasks (e.g., RULER, LV-Eval, and InfiniteBench) and standard tasks (e.g., MMLU, MATH, GSM-8K, and HumanEval). UltraLong-8B achieves superior performance on ultra-long context tasks while maintaining competitive results on standard benchmarks.
### Needle in a Haystack
<img width="80%" alt="image" src="Llama-3.1-8B-UltraLong-1M-Instruct.png">
### Long context evaluation
<img width="80%" alt="image" src="long_benchmark.png">
### Standard capability evaluation
<img width="80%" alt="image" src="standard_benchmark.png">
## Correspondence to
Chejian Xu ([email protected]), Wei Ping ([email protected])
## Citation
<pre>
@article{ulralong2025,
title={From 128K to 4M: Efficient Training of Ultra-Long Context Large Language Models},
author={Xu, Chejian and Ping, Wei and Xu, Peng and Liu, Zihan and Wang, Boxin and Shoeybi, Mohammad and Catanzaro, Bryan},
journal={arXiv preprint},
year={2025}
}
</pre> |
Mungert/watt-tool-8B-GGUF | Mungert | 2025-06-15T19:37:09Z | 1,358 | 6 | null | [
"gguf",
"function-calling",
"tool-use",
"llama",
"bfcl",
"en",
"arxiv:2406.14868",
"base_model:meta-llama/Llama-3.1-8B-Instruct",
"base_model:quantized:meta-llama/Llama-3.1-8B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | null | 2025-04-15T01:43:23Z | ---
license: apache-2.0
language:
- en
base_model:
- meta-llama/Llama-3.1-8B-Instruct
tags:
- function-calling
- tool-use
- llama
- bfcl
---
# <span style="color: #7FFF7F;">watt-tool-8B GGUF Models</span>
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `watt-tool-8B-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `watt-tool-8B-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `watt-tool-8B-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `watt-tool-8B-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `watt-tool-8B-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `watt-tool-8B-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `watt-tool-8B-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `watt-tool-8B-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `watt-tool-8B-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `watt-tool-8B-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `watt-tool-8B-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard)
💬 **How to test**:
1. Click the **chat icon** (bottom right on any page)
2. Choose an **AI assistant type**:
- `TurboLLM` (GPT-4-mini)
- `FreeLLM` (Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Metasploit integration**
🟡 **TestLLM** – Current experimental model (llama.cpp on 6 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4-mini** for:
- **Real-time network diagnostics**
- **Automated penetration testing** (Nmap/Metasploit)
- 🔑 Get more tokens by [downloading our Quantum Network Monitor Agent](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
🔵 **HugLLM** – Open-source models (≈8B params):
- **2x more tokens** than TurboLLM
- **AI-powered log analysis**
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example AI Commands to Test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a quick Nmap vulnerability test"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# watt-tool-8B
watt-tool-8B is a fine-tuned language model based on LLaMa-3.1-8B-Instruct, optimized for tool usage and multi-turn dialogue. It achieves state-of-the-art performance on the Berkeley Function-Calling Leaderboard (BFCL).
## Model Description
This model is specifically designed to excel at complex tool usage scenarios that require multi-turn interactions, making it ideal for empowering platforms like [Lupan](https://lupan.watt.chat), an AI-powered workflow building tool. By leveraging a carefully curated and optimized dataset, watt-tool-8B demonstrates superior capabilities in understanding user requests, selecting appropriate tools, and effectively utilizing them across multiple turns of conversation.
Target Application: AI Workflow Building as in [https://lupan.watt.chat/](https://lupan.watt.chat/) and [Coze](https://www.coze.com/).
## Key Features
* **Enhanced Tool Usage:** Fine-tuned for precise and efficient tool selection and execution.
* **Multi-Turn Dialogue:** Optimized for maintaining context and effectively utilizing tools across multiple turns of conversation, enabling more complex task completion.
* **State-of-the-Art Performance:** Achieves top performance on the BFCL, demonstrating its capabilities in function calling and tool usage.
## Training Methodology
watt-tool-8B is trained using supervised fine-tuning on a specialized dataset designed for tool usage and multi-turn dialogue. We use CoT techniques to synthesize high-quality multi-turn dialogue data.
The training process is inspired by the principles outlined in the paper: ["Direct Multi-Turn Preference Optimization for Language Agents"](https://arxiv.org/abs/2406.14868).
We use SFT and DMPO to further enhance the model's performance in multi-turn agent tasks.
## How to Use
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "watt-ai/watt-tool-8B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype='auto', device_map="auto")
# Example usage (adapt as needed for your specific tool usage scenario)
"""You are an expert in composing functions. You are given a question and a set of possible functions. Based on the question, you will need to make one or more function/tool calls to achieve the purpose.
If none of the function can be used, point it out. If the given question lacks the parameters required by the function, also point it out.
You should only return the function call in tools call sections.
If you decide to invoke any of the function(s), you MUST put it in the format of [func_name1(params_name1=params_value1, params_name2=params_value2...), func_name2(params)]
You SHOULD NOT include any other text in the response.
Here is a list of functions in JSON format that you can invoke.\n{functions}\n
"""
# User query
query = "Find me the sales growth rate for company XYZ for the last 3 years and also the interest coverage ratio for the same duration."
tools = [
{
"name": "financial_ratios.interest_coverage", "description": "Calculate a company's interest coverage ratio given the company name and duration",
"arguments": {
"type": "dict",
"properties": {
"company_name": {
"type": "string",
"description": "The name of the company."
},
"years": {
"type": "integer",
"description": "Number of past years to calculate the ratio."
}
},
"required": ["company_name", "years"]
}
},
{
"name": "sales_growth.calculate",
"description": "Calculate a company's sales growth rate given the company name and duration",
"arguments": {
"type": "dict",
"properties": {
"company": {
"type": "string",
"description": "The company that you want to get the sales growth rate for."
},
"years": {
"type": "integer",
"description": "Number of past years for which to calculate the sales growth rate."
}
},
"required": ["company", "years"]
}
},
{
"name": "weather_forecast",
"description": "Retrieve a weather forecast for a specific location and time frame.",
"arguments": {
"type": "dict",
"properties": {
"location": {
"type": "string",
"description": "The city that you want to get the weather for."
},
"days": {
"type": "integer",
"description": "Number of days for the forecast."
}
},
"required": ["location", "days"]
}
}
]
messages = [
{'role': 'system', 'content': system_prompt.format(functions=tools)},
{'role': 'user', 'content': query}
]
inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(model.device)
outputs = model.generate(inputs, max_new_tokens=512, do_sample=False, num_return_sequences=1, eos_token_id=tokenizer.eos_token_id)
print(tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True)) |
Mungert/Qwen2.5-VL-3B-Instruct-GGUF | Mungert | 2025-06-15T19:37:01Z | 5,754 | 17 | transformers | [
"transformers",
"gguf",
"multimodal",
"image-text-to-text",
"en",
"arxiv:2309.00071",
"arxiv:2409.12191",
"arxiv:2308.12966",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | image-text-to-text | 2025-03-27T23:20:23Z |
---
license_name: qwen-research
license_link: https://huggingface.co/Qwen/Qwen2.5-VL-3B-Instruct/blob/main/LICENSE
language:
- en
pipeline_tag: image-text-to-text
tags:
- multimodal
library_name: transformers
---
# <span style="color: #7FFF7F;">Qwen2.5-VL-3B-Instruct GGUF Models</span>
These files have been built using a imatrix file and latest llama.cpp build. You must use a fork of llama.cpp to use vision with the model.
## How to Use Qwen 2.5 VL Instruct with llama.cpp
To utilize the experimental support for Qwen 2.5 VL in `llama.cpp`, follow these steps:
Note this uses a fork of llama.cpp. At this time the main branch does not support vision for this model
1. **Clone the lastest llama.cpp Fork**:
```bash
git clone https://github.com/HimariO/llama.cpp.qwen2vl.git
cd llama.cpp.qwen2vl
git checkout qwen25-vl-20250404
```
2. **Build the Llama.cpp**:
Build llama.cpp as usual : https://github.com/ggml-org/llama.cpp#building-the-project
Once llama.cpp is built Copy the ./llama.cpp.qwen2vl/build/bin/llama-qwen2-vl-cli to a chosen folder.
3. **Download the Qwen 2.5 VL gguf file**:
https://huggingface.co/Mungert/Qwen2.5-VL-3B-Instruct-GGUF/tree/main
Choose a gguf file without the mmproj in the name
Example gguf file : https://huggingface.co/Mungert/Mungert/Qwen2.5-VL-3B-Instruct-GGUF/resolve/main/Qwen2.5-VL-3B-Instruct-q8_0.gguf
Copy this file to your chosen folder.
4. **Download the Qwen 2.5 VL mmproj file**
https://huggingface.co/Mungert/Qwen2.5-VL-3B-Instruct-GGUF/tree/main
Choose a file with mmproj in the name
Example mmproj file : https://huggingface.co/Mungert/Qwen2.5-VL-3B-Instruct-GGUF/resolve/main/Qwen2.5-VL-3B-Instruct-mmproj-f16.gguf
Copy this file to your chosen folder.
5. Copy images to the same folder as the gguf files or alter paths appropriately.
In the example below the gguf files, images and llama-qwen2vl-cli are in the same folder.
Example image: image https://huggingface.co/Mungert/Qwen2.5-VL-3B-Instruct-GGUF/resolve/main/car-1.jpg
Copy this file to your chosen folder.
6. **Run the CLI Tool**:
From your chosen folder :
```bash
llama-qwen2vl-cli -m Qwen2.5-VL-3B-Instruct-q8_0.gguf --mmproj Qwen2.5-VL-3B-Instruct-mmproj-f16.gguf -p "Describe this image." --image ./car-1.jpg
```
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
Quick test with highest of the DynamicGate quants IQ2_M on Qwen 2.5 VL 3B :
```bash
llama.cpp.qwen2vl/build/bin/llama-qwen2vl-cli -m Qwen2.5-VL-3B-Instruct-iq2_m.gguf --mmproj qwen.qwen2.5-vl-3b-instruct-vision.f16.gguf -p "Describe this image in a lot of detail." --image ./car-1.jpg
```
<p align="center">
<img src="https://huggingface.co/Mungert/Qwen2.5-VL-3B-Instruct-GGUF/resolve/main/car-1.jpg" width="80%"/>
<p>
Ouput :
The image depicts a sleek, black Porsche Panamera Turbo, captured in motion on what appears to be a racetrack or a high-speed road. The car is captured from a rear-side angle, showcasing its aerodynamic design and distinctive features. The vehicle's taillights are illuminated, creating a striking contrast with the dark body. The Porsche logo is prominently displayed on the rear, along with the words "Panamera Turbo" and the license plate "CVC-911." The license plate is accompanied by a California "COOPER" sticker, indicating the car might be registered in California. The road is blurred due to the speed, emphasizing the high performance and advanced engineering of the vehicle. The background features a mix of trees and a few streetlights, suggesting an evening or early evening setting.
**Wow that's impresive for a highly compresssed 3B model!**
With the lower quants the quality does suffer specially the xs quants. So if you need to squeeze the model into ram then give iq2_m a try.
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device’s specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn’t available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `Qwen2.5-VL-3B-Instruct-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `Qwen2.5-VL-3B-Instruct-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `Qwen2.5-VL-3B-Instruct-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `Qwen2.5-VL-3B-Instruct-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `Qwen2.5-VL-3B-Instruct-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `Qwen2.5-VL-3B-Instruct-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `Qwen2.5-VL-3B-Instruct-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `Qwen2.5-VL-3B-Instruct-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `Qwen2.5-VL-3B-Instruct-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `Qwen2.5-VL-3B-Instruct-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `Qwen2.5-VL-3B-Instruct-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Please click like ❤ . Also I’d really appreciate it if you could test my Network Monitor Assistant at 👉 [Network Monitor Assitant](https://readyforquantum.com).
💬 Click the **chat icon** (bottom right of the main and dashboard pages) . Choose a LLM; toggle between the LLM Types TurboLLM -> FreeLLM -> TestLLM.
### What I'm Testing
I'm experimenting with **function calling** against my network monitoring service. Using small open source models. I am into the question "How small can it go and still function".
🟡 **TestLLM** – Runs the current testing model using llama.cpp on 6 threads of a Cpu VM (Should take about 15s to load. Inference speed is quite slow and it only processes one user prompt at a time—still working on scaling!). If you're curious, I'd be happy to share how it works! .
### The other Available AI Assistants
🟢 **TurboLLM** – Uses **gpt-4o-mini** Fast! . Note: tokens are limited since OpenAI models are pricey, but you can [Login](https://readyforquantum.com) or [Download](https://readyforquantum.com/download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme) the Quantum Network Monitor agent to get more tokens, Alternatively use the TestLLM .
🔵 **HugLLM** – Runs **open-source Hugging Face models** Fast, Runs small models (≈8B) hence lower quality, Get 2x more tokens (subject to Hugging Face API availability)
### Final word
I fund the servers to create the models files, run the Quantum Network Monitor Service and Pay for Inference from Novita and OpenAI all from my own pocket. All of the code for creating the models and the work I have done with Quantum Network Monitor is [open source](https://github.com/Mungert69). Feel free to use what you find useful. Please support my work and consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) .
This will help me pay for the services and increase the token limits for everyone.
Thank you :)
# Qwen2.5-VL-3B-Instruct
<a href="https://chat.qwenlm.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Introduction
In the past five months since Qwen2-VL’s release, numerous developers have built new models on the Qwen2-VL vision-language models, providing us with valuable feedback. During this period, we focused on building more useful vision-language models. Today, we are excited to introduce the latest addition to the Qwen family: Qwen2.5-VL.
#### Key Enhancements:
* **Understand things visually**: Qwen2.5-VL is not only proficient in recognizing common objects such as flowers, birds, fish, and insects, but it is highly capable of analyzing texts, charts, icons, graphics, and layouts within images.
* **Being agentic**: Qwen2.5-VL directly plays as a visual agent that can reason and dynamically direct tools, which is capable of computer use and phone use.
* **Understanding long videos and capturing events**: Qwen2.5-VL can comprehend videos of over 1 hour, and this time it has a new ability of cpaturing event by pinpointing the relevant video segments.
* **Capable of visual localization in different formats**: Qwen2.5-VL can accurately localize objects in an image by generating bounding boxes or points, and it can provide stable JSON outputs for coordinates and attributes.
* **Generating structured outputs**: for data like scans of invoices, forms, tables, etc. Qwen2.5-VL supports structured outputs of their contents, benefiting usages in finance, commerce, etc.
#### Model Architecture Updates:
* **Dynamic Resolution and Frame Rate Training for Video Understanding**:
We extend dynamic resolution to the temporal dimension by adopting dynamic FPS sampling, enabling the model to comprehend videos at various sampling rates. Accordingly, we update mRoPE in the time dimension with IDs and absolute time alignment, enabling the model to learn temporal sequence and speed, and ultimately acquire the ability to pinpoint specific moments.
<p align="center">
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-VL/qwen2.5vl_arc.jpeg" width="80%"/>
<p>
* **Streamlined and Efficient Vision Encoder**
We enhance both training and inference speeds by strategically implementing window attention into the ViT. The ViT architecture is further optimized with SwiGLU and RMSNorm, aligning it with the structure of the Qwen2.5 LLM.
We have three models with 3, 7 and 72 billion parameters. This repo contains the instruction-tuned 3B Qwen2.5-VL model. For more information, visit our [Blog](https://qwenlm.github.io/blog/qwen2.5-vl/) and [GitHub](https://github.com/QwenLM/Qwen2.5-VL).
## Evaluation
### Image benchmark
| Benchmark | InternVL2.5-4B |Qwen2-VL-7B |Qwen2.5-VL-3B |
| :--- | :---: | :---: | :---: |
| MMMU<sub>val</sub> | 52.3 | 54.1 | 53.1|
| MMMU-Pro<sub>val</sub> | **32.7** | 30.5 | 31.6|
| AI2D<sub>test</sub> | 81.4 | **83.0** | 81.5 |
| DocVQA<sub>test</sub> | 91.6 | 94.5 | **93.9** |
| InfoVQA<sub>test</sub> | 72.1 | 76.5 | **77.1** |
| TextVQA<sub>val</sub> | 76.8 | **84.3** | 79.3|
| MMBench-V1.1<sub>test</sub> | 79.3 | **80.7** | 77.6 |
| MMStar | 58.3 | **60.7** | 55.9 |
| MathVista<sub>testmini</sub> | 60.5 | 58.2 | **62.3** |
| MathVision<sub>full</sub> | 20.9 | 16.3 | **21.2** |
### Video benchmark
| Benchmark | InternVL2.5-4B | Qwen2-VL-7B | Qwen2.5-VL-3B |
| :--- | :---: | :---: | :---: |
| MVBench | 71.6 | 67.0 | 67.0 |
| VideoMME | 63.6/62.3 | 69.0/63.3 | 67.6/61.5 |
| MLVU | 48.3 | - | 68.2 |
| LVBench | - | - | 43.3 |
| MMBench-Video | 1.73 | 1.44 | 1.63 |
| EgoSchema | - | - | 64.8 |
| PerceptionTest | - | - | 66.9 |
| TempCompass | - | - | 64.4 |
| LongVideoBench | 55.2 | 55.6 | 54.2 |
| CharadesSTA/mIoU | - | - | 38.8 |
### Agent benchmark
| Benchmarks | Qwen2.5-VL-3B |
|-------------------------|---------------|
| ScreenSpot | 55.5 |
| ScreenSpot Pro | 23.9 |
| AITZ_EM | 76.9 |
| Android Control High_EM | 63.7 |
| Android Control Low_EM | 22.2 |
| AndroidWorld_SR | 90.8 |
| MobileMiniWob++_SR | 67.9 |
## Requirements
The code of Qwen2.5-VL has been in the latest Hugging face transformers and we advise you to build from source with command:
```
pip install git+https://github.com/huggingface/transformers accelerate
```
or you might encounter the following error:
```
KeyError: 'qwen2_5_vl'
```
## Quickstart
Below, we provide simple examples to show how to use Qwen2.5-VL with 🤖 ModelScope and 🤗 Transformers.
The code of Qwen2.5-VL has been in the latest Hugging face transformers and we advise you to build from source with command:
```
pip install git+https://github.com/huggingface/transformers accelerate
```
or you might encounter the following error:
```
KeyError: 'qwen2_5_vl'
```
We offer a toolkit to help you handle various types of visual input more conveniently, as if you were using an API. This includes base64, URLs, and interleaved images and videos. You can install it using the following command:
```bash
# It's highly recommanded to use `[decord]` feature for faster video loading.
pip install qwen-vl-utils[decord]==0.0.8
```
If you are not using Linux, you might not be able to install `decord` from PyPI. In that case, you can use `pip install qwen-vl-utils` which will fall back to using torchvision for video processing. However, you can still [install decord from source](https://github.com/dmlc/decord?tab=readme-ov-file#install-from-source) to get decord used when loading video.
### Using 🤗 Transformers to Chat
Here we show a code snippet to show you how to use the chat model with `transformers` and `qwen_vl_utils`:
```python
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
# default: Load the model on the available device(s)
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-3B-Instruct", torch_dtype="auto", device_map="auto"
)
# We recommend enabling flash_attention_2 for better acceleration and memory saving, especially in multi-image and video scenarios.
# model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
# "Qwen/Qwen2.5-VL-3B-Instruct",
# torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2",
# device_map="auto",
# )
# default processer
processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-3B-Instruct")
# The default range for the number of visual tokens per image in the model is 4-16384.
# You can set min_pixels and max_pixels according to your needs, such as a token range of 256-1280, to balance performance and cost.
# min_pixels = 256*28*28
# max_pixels = 1280*28*28
# processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-3B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels)
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference: Generation of the output
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
```
<details>
<summary>Multi image inference</summary>
```python
# Messages containing multiple images and a text query
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "file:///path/to/image1.jpg"},
{"type": "image", "image": "file:///path/to/image2.jpg"},
{"type": "text", "text": "Identify the similarities between these images."},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Inference
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
```
</details>
<details>
<summary>Video inference</summary>
```python
# Messages containing a images list as a video and a text query
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"video": [
"file:///path/to/frame1.jpg",
"file:///path/to/frame2.jpg",
"file:///path/to/frame3.jpg",
"file:///path/to/frame4.jpg",
],
},
{"type": "text", "text": "Describe this video."},
],
}
]
# Messages containing a local video path and a text query
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"video": "file:///path/to/video1.mp4",
"max_pixels": 360 * 420,
"fps": 1.0,
},
{"type": "text", "text": "Describe this video."},
],
}
]
# Messages containing a video url and a text query
messages = [
{
"role": "user",
"content": [
{
"type": "video",
"video": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-VL/space_woaudio.mp4",
},
{"type": "text", "text": "Describe this video."},
],
}
]
#In Qwen 2.5 VL, frame rate information is also input into the model to align with absolute time.
# Preparation for inference
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs, video_kwargs = process_vision_info(messages, return_video_kwargs=True)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
fps=fps,
padding=True,
return_tensors="pt",
**video_kwargs,
)
inputs = inputs.to("cuda")
# Inference
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
```
Video URL compatibility largely depends on the third-party library version. The details are in the table below. change the backend by `FORCE_QWENVL_VIDEO_READER=torchvision` or `FORCE_QWENVL_VIDEO_READER=decord` if you prefer not to use the default one.
| Backend | HTTP | HTTPS |
|-------------|------|-------|
| torchvision >= 0.19.0 | ✅ | ✅ |
| torchvision < 0.19.0 | ❌ | ❌ |
| decord | ✅ | ❌ |
</details>
<details>
<summary>Batch inference</summary>
```python
# Sample messages for batch inference
messages1 = [
{
"role": "user",
"content": [
{"type": "image", "image": "file:///path/to/image1.jpg"},
{"type": "image", "image": "file:///path/to/image2.jpg"},
{"type": "text", "text": "What are the common elements in these pictures?"},
],
}
]
messages2 = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who are you?"},
]
# Combine messages for batch processing
messages = [messages1, messages2]
# Preparation for batch inference
texts = [
processor.apply_chat_template(msg, tokenize=False, add_generation_prompt=True)
for msg in messages
]
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=texts,
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# Batch Inference
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_texts = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_texts)
```
</details>
### 🤖 ModelScope
We strongly advise users especially those in mainland China to use ModelScope. `snapshot_download` can help you solve issues concerning downloading checkpoints.
### More Usage Tips
For input images, we support local files, base64, and URLs. For videos, we currently only support local files.
```python
# You can directly insert a local file path, a URL, or a base64-encoded image into the position where you want in the text.
## Local file path
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "file:///path/to/your/image.jpg"},
{"type": "text", "text": "Describe this image."},
],
}
]
## Image URL
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "http://path/to/your/image.jpg"},
{"type": "text", "text": "Describe this image."},
],
}
]
## Base64 encoded image
messages = [
{
"role": "user",
"content": [
{"type": "image", "image": "data:image;base64,/9j/..."},
{"type": "text", "text": "Describe this image."},
],
}
]
```
#### Image Resolution for performance boost
The model supports a wide range of resolution inputs. By default, it uses the native resolution for input, but higher resolutions can enhance performance at the cost of more computation. Users can set the minimum and maximum number of pixels to achieve an optimal configuration for their needs, such as a token count range of 256-1280, to balance speed and memory usage.
```python
min_pixels = 256 * 28 * 28
max_pixels = 1280 * 28 * 28
processor = AutoProcessor.from_pretrained(
"Qwen/Qwen2.5-VL-3B-Instruct", min_pixels=min_pixels, max_pixels=max_pixels
)
```
Besides, We provide two methods for fine-grained control over the image size input to the model:
1. Define min_pixels and max_pixels: Images will be resized to maintain their aspect ratio within the range of min_pixels and max_pixels.
2. Specify exact dimensions: Directly set `resized_height` and `resized_width`. These values will be rounded to the nearest multiple of 28.
```python
# min_pixels and max_pixels
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "file:///path/to/your/image.jpg",
"resized_height": 280,
"resized_width": 420,
},
{"type": "text", "text": "Describe this image."},
],
}
]
# resized_height and resized_width
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "file:///path/to/your/image.jpg",
"min_pixels": 50176,
"max_pixels": 50176,
},
{"type": "text", "text": "Describe this image."},
],
}
]
```
### Processing Long Texts
The current `config.json` is set for context length up to 32,768 tokens.
To handle extensive inputs exceeding 32,768 tokens, we utilize [YaRN](https://arxiv.org/abs/2309.00071), a technique for enhancing model length extrapolation, ensuring optimal performance on lengthy texts.
For supported frameworks, you could add the following to `config.json` to enable YaRN:
```
{
...,
"type": "yarn",
"mrope_section": [
16,
24,
24
],
"factor": 4,
"original_max_position_embeddings": 32768
}
```
However, it should be noted that this method has a significant impact on the performance of temporal and spatial localization tasks, and is therefore not recommended for use.
At the same time, for long video inputs, since MRoPE itself is more economical with ids, the max_position_embeddings can be directly modified to a larger value, such as 64k.
## Citation
If you find our work helpful, feel free to give us a cite.
```
@misc{qwen2.5-VL,
title = {Qwen2.5-VL},
url = {https://qwenlm.github.io/blog/qwen2.5-vl/},
author = {Qwen Team},
month = {January},
year = {2025}
}
@article{Qwen2VL,
title={Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution},
author={Wang, Peng and Bai, Shuai and Tan, Sinan and Wang, Shijie and Fan, Zhihao and Bai, Jinze and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Fan, Yang and Dang, Kai and Du, Mengfei and Ren, Xuancheng and Men, Rui and Liu, Dayiheng and Zhou, Chang and Zhou, Jingren and Lin, Junyang},
journal={arXiv preprint arXiv:2409.12191},
year={2024}
}
@article{Qwen-VL,
title={Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond},
author={Bai, Jinze and Bai, Shuai and Yang, Shusheng and Wang, Shijie and Tan, Sinan and Wang, Peng and Lin, Junyang and Zhou, Chang and Zhou, Jingren},
journal={arXiv preprint arXiv:2308.12966},
year={2023}
}
```
|
Mungert/MiniCPM4-8B-GGUF | Mungert | 2025-06-15T19:36:48Z | 906 | 2 | transformers | [
"transformers",
"gguf",
"text-generation",
"zh",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-06-13T20:02:10Z | ---
license: apache-2.0
language:
- zh
- en
pipeline_tag: text-generation
library_name: transformers
---
# <span style="color: #7FFF7F;">MiniCPM4-8B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`7f4fbe51`](https://github.com/ggerganov/llama.cpp/commit/7f4fbe5183b23b6b2e25fd1ccc5d1fa8bb010cb7).
---
## <span style="color: #7FFF7F;">Quantization Beyond the IMatrix</span>
I've been experimenting with a new quantization approach that selectively elevates the precision of key layers beyond what the default IMatrix configuration provides.
In my testing, standard IMatrix quantization underperforms at lower bit depths, especially with Mixture of Experts (MoE) models. To address this, I'm using the `--tensor-type` option in `llama.cpp` to manually "bump" important layers to higher precision. You can see the implementation here:
👉 [Layer bumping with llama.cpp](https://github.com/Mungert69/GGUFModelBuilder/blob/main/model-converter/tensor_list_builder.py)
While this does increase model file size, it significantly improves precision for a given quantization level.
### **I'd love your feedback—have you tried this? How does it perform for you?**
---
<a href="https://readyforquantum.com/huggingface_gguf_selection_guide.html" style="color: #7FFF7F;">
Click here to get info on choosing the right GGUF model format
</a>
---
<!--Begin Original Model Card-->
<div align="center">
<img src="https://github.com/OpenBMB/MiniCPM/blob/main/assets/minicpm_logo.png?raw=true" width="500em" ></img>
</div>
<p align="center">
<a href="https://github.com/OpenBMB/MiniCPM/" target="_blank">GitHub Repo</a> |
<a href="https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf" target="_blank">Technical Report</a>
</p>
<p align="center">
👋 Join us on <a href="https://discord.gg/3cGQn9b3YM" target="_blank">Discord</a> and <a href="https://github.com/OpenBMB/MiniCPM/blob/main/assets/wechat.jpg" target="_blank">WeChat</a>
</p>
## What's New
- [2025.06.06] **MiniCPM4** series are released! This model achieves ultimate efficiency improvements while maintaining optimal performance at the same scale! It can achieve over 5x generation acceleration on typical end-side chips! You can find technical report [here](https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf).🔥🔥🔥
## MiniCPM4 Series
MiniCPM4 series are highly efficient large language models (LLMs) designed explicitly for end-side devices, which achieves this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems.
- [MiniCPM4-8B](https://huggingface.co/openbmb/MiniCPM4-8B): The flagship of MiniCPM4, with 8B parameters, trained on 8T tokens. (**<-- you are here**)
- [MiniCPM4-0.5B](https://huggingface.co/openbmb/MiniCPM4-0.5B): The small version of MiniCPM4, with 0.5B parameters, trained on 1T tokens.
- [MiniCPM4-8B-Eagle-FRSpec](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-FRSpec): Eagle head for FRSpec, accelerating speculative inference for MiniCPM4-8B.
- [MiniCPM4-8B-Eagle-FRSpec-QAT-cpmcu](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-FRSpec-QAT-cpmcu): Eagle head trained with QAT for FRSpec, efficiently integrate speculation and quantization to achieve ultra acceleration for MiniCPM4-8B.
- [MiniCPM4-8B-Eagle-vLLM](https://huggingface.co/openbmb/MiniCPM4-8B-Eagle-vLLM): Eagle head in vLLM format, accelerating speculative inference for MiniCPM4-8B.
- [MiniCPM4-8B-marlin-Eagle-vLLM](https://huggingface.co/openbmb/MiniCPM4-8B-marlin-Eagle-vLLM): Quantized Eagle head for vLLM format, accelerating speculative inference for MiniCPM4-8B.
- [BitCPM4-0.5B](https://huggingface.co/openbmb/BitCPM4-0.5B): Extreme ternary quantization applied to MiniCPM4-0.5B compresses model parameters into ternary values, achieving a 90% reduction in bit width.
- [BitCPM4-1B](https://huggingface.co/openbmb/BitCPM4-1B): Extreme ternary quantization applied to MiniCPM3-1B compresses model parameters into ternary values, achieving a 90% reduction in bit width.
- [MiniCPM4-Survey](https://huggingface.co/openbmb/MiniCPM4-Survey): Based on MiniCPM4-8B, accepts users' quiries as input and autonomously generate trustworthy, long-form survey papers.
- [MiniCPM4-MCP](https://huggingface.co/openbmb/MiniCPM4-MCP): Based on MiniCPM4-8B, accepts users' queries and available MCP tools as input and autonomously calls relevant MCP tools to satisfy users' requirements.
## Introduction
MiniCPM 4 is an extremely efficient edge-side large model that has undergone efficient optimization across four dimensions: model architecture, learning algorithms, training data, and inference systems, achieving ultimate efficiency improvements.
- 🏗️ **Efficient Model Architecture:**
- InfLLM v2 -- Trainable Sparse Attention Mechanism: Adopts a trainable sparse attention mechanism architecture where each token only needs to compute relevance with less than 5% of tokens in 128K long text processing, significantly reducing computational overhead for long texts
- 🧠 **Efficient Learning Algorithms:**
- Model Wind Tunnel 2.0 -- Efficient Predictable Scaling: Introduces scaling prediction methods for performance of downstream tasks, enabling more precise model training configuration search
- BitCPM -- Ultimate Ternary Quantization: Compresses model parameter bit-width to 3 values, achieving 90% extreme model bit-width reduction
- Efficient Training Engineering Optimization: Adopts FP8 low-precision computing technology combined with Multi-token Prediction training strategy
- 📚 **High-Quality Training Data:**
- UltraClean -- High-quality Pre-training Data Filtering and Generation: Builds iterative data cleaning strategies based on efficient data verification, open-sourcing high-quality Chinese and English pre-training dataset [UltraFinweb](https://huggingface.co/datasets/openbmb/Ultra-FineWeb)
- UltraChat v2 -- High-quality Supervised Fine-tuning Data Generation: Constructs large-scale high-quality supervised fine-tuning datasets covering multiple dimensions including knowledge-intensive data, reasoning-intensive data, instruction-following data, long text understanding data, and tool calling data
- ⚡ **Efficient Inference System:**
- CPM.cu -- Lightweight and Efficient CUDA Inference Framework: Integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding
- ArkInfer -- Cross-platform Deployment System: Supports efficient deployment across multiple backend environments, providing flexible cross-platform adaptation capabilities
## Usage
### Inference with [CPM.cu](https://github.com/OpenBMB/cpm.cu)
We recommend using [CPM.cu](https://github.com/OpenBMB/cpm.cu) for the inference of MiniCPM4. CPM.cu is a CUDA inference framework developed by OpenBMB, which integrates efficient sparse, speculative sampling, and quantization techniques, fully leveraging the efficiency advantages of MiniCPM4.
You can install CPM.cu by running the following command:
```bash
git clone https://github.com/OpenBMB/cpm.cu.git --recursive
cd cpm.cu
python3 setup.py install
```
MiniCPM4 natively supports context lengths of up to 32,768 tokens. To reproduce the long-text acceleration effect in the paper, we recommend using the LongRoPE factors that have been validated. Change the `rope_scaling` field in the `config.json` file as the following to enable LongRoPE.
```json
{
...,
"rope_scaling": {
"rope_type": "longrope",
"long_factor": [0.9977997200264581, 1.014658295992452, 1.0349680404997148, 1.059429246056193, 1.0888815016813513, 1.1243301355211495, 1.166977103606075, 1.2182568066927284, 1.2798772354275727, 1.3538666751582975, 1.4426259039919596, 1.5489853358570191, 1.6762658237220625, 1.8283407612492941, 2.0096956085876183, 2.225478927469756, 2.481536379650452, 2.784415934557119, 3.1413289096347365, 3.560047844772632, 4.048719380066383, 4.752651957515948, 5.590913044973868, 6.584005926629993, 7.7532214876576155, 9.119754865903639, 10.704443927019176, 12.524994176518703, 14.59739595363613, 16.93214476166354, 19.53823297353041, 22.417131025031697, 25.568260840911098, 28.991144156566317, 32.68408069090375, 36.65174474170465, 40.90396065611201, 45.4664008671033, 50.37147343433591, 55.6804490772103, 61.470816952306556, 67.8622707390618, 75.00516023410414, 83.11898235973767, 92.50044360202462, 103.57086856690864, 116.9492274587385, 118.16074567836519, 119.18497548708795, 120.04810876261652, 120.77352815196981, 121.38182790207875, 121.89094985353891, 122.31638758099915, 122.6714244963338, 122.9673822552567, 123.21386397019609, 123.41898278254268, 123.58957065488238, 123.73136519024158, 123.84917421274221, 123.94701903496814, 124.02825801299717, 124.09569231686116],
"short_factor": [0.9977997200264581, 1.014658295992452, 1.0349680404997148, 1.059429246056193, 1.0888815016813513, 1.1243301355211495, 1.166977103606075, 1.2182568066927284, 1.2798772354275727, 1.3538666751582975, 1.4426259039919596, 1.5489853358570191, 1.6762658237220625, 1.8283407612492941, 2.0096956085876183, 2.225478927469756, 2.481536379650452, 2.784415934557119, 3.1413289096347365, 3.560047844772632, 4.048719380066383, 4.752651957515948, 5.590913044973868, 6.584005926629993, 7.7532214876576155, 9.119754865903639, 10.704443927019176, 12.524994176518703, 14.59739595363613, 16.93214476166354, 19.53823297353041, 22.417131025031697, 25.568260840911098, 28.991144156566317, 32.68408069090375, 36.65174474170465, 40.90396065611201, 45.4664008671033, 50.37147343433591, 55.6804490772103, 61.470816952306556, 67.8622707390618, 75.00516023410414, 83.11898235973767, 92.50044360202462, 103.57086856690864, 116.9492274587385, 118.16074567836519, 119.18497548708795, 120.04810876261652, 120.77352815196981, 121.38182790207875, 121.89094985353891, 122.31638758099915, 122.6714244963338, 122.9673822552567, 123.21386397019609, 123.41898278254268, 123.58957065488238, 123.73136519024158, 123.84917421274221, 123.94701903496814, 124.02825801299717, 124.09569231686116],
"original_max_position_embeddings": 32768
}
}
```
After modification, you can run the following command to reproduce the long-context acceleration effect (the script will automatically download the model weights from HuggingFace)
```bash
python3 tests/test_generate.py
```
For more details about CPM.cu, please refer to [the repo CPM.cu](https://github.com/OpenBMB/cpm.cu).
### Inference with Transformers
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
torch.manual_seed(0)
path = 'openbmb/MiniCPM4-8B'
device = "cuda"
tokenizer = AutoTokenizer.from_pretrained(path)
model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch.bfloat16, device_map=device, trust_remote_code=True)
# User can directly use the chat interface
# responds, history = model.chat(tokenizer, "Write an article about Artificial Intelligence.", temperature=0.7, top_p=0.7)
# print(responds)
# User can also use the generate interface
messages = [
{"role": "user", "content": "Write an article about Artificial Intelligence."},
]
prompt_text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([prompt_text], return_tensors="pt").to(device)
model_outputs = model.generate(
**model_inputs,
max_new_tokens=1024,
top_p=0.7,
temperature=0.7
)
output_token_ids = [
model_outputs[i][len(model_inputs[i]):] for i in range(len(model_inputs['input_ids']))
]
responses = tokenizer.batch_decode(output_token_ids, skip_special_tokens=True)[0]
print(responses)
```
MiniCPM4-8B supports `InfLLM v2`, a sparse attention mechanism designed for efficient long-sequence inference. It requires the [infllmv2_cuda_impl](https://github.com/OpenBMB/infllmv2_cuda_impl) library.
You can install it by running the following command:
```bash
git clone -b feature_infer https://github.com/OpenBMB/infllmv2_cuda_impl.git
cd infllmv2_cuda_impl
git submodule update --init --recursive
pip install -e . # or python setup.py install
```
To enable InfLLM v2, you need to add the `sparse_config` field in `config.json`:
```json
{
...,
"sparse_config": {
"kernel_size": 32,
"kernel_stride": 16,
"init_blocks": 1,
"block_size": 64,
"window_size": 2048,
"topk": 64,
"use_nope": false,
"dense_len": 8192
}
}
```
These parameters control the behavior of InfLLM v2:
* `kernel_size` (default: 32): The size of semantic kernels.
* `kernel_stride` (default: 16): The stride between adjacent kernels.
* `init_blocks` (default: 1): The number of initial blocks that every query token attends to. This ensures attention to the beginning of the sequence.
* `block_size` (default: 64): The block size for key-value blocks.
* `window_size` (default: 2048): The size of the local sliding window.
* `topk` (default: 64): The specifies that each token computes attention with only the top-k most relevant key-value blocks.
* `use_nope` (default: false): Whether to use the NOPE technique in block selection for improved performance.
* `dense_len` (default: 8192): Since Sparse Attention offers limited benefits for short sequences, the model can use standard (dense) attention for shorter texts. The model will use dense attention for sequences with a token length below `dense_len` and switch to sparse attention for sequences exceeding this length. Set this to `-1` to always use sparse attention regardless of sequence length.
MiniCPM4 natively supports context lengths of up to 32,768 tokens. For conversations where the total length (including both input and output) significantly exceeds this limit, we recommend using RoPE scaling techniques for effective handling of long texts. We have validated the model's performance on context lengths of up to 131,072 tokens by modifying the LongRoPE factor.
You can apply the LongRoPE factor modification by modifying the model files. Specifically, in the `config.json` file, adjust the `rope_scaling` fields.
```json
{
...,
"rope_scaling": {
"rope_type": "longrope",
"long_factor": [0.9977997200264581, 1.014658295992452, 1.0349680404997148, 1.059429246056193, 1.0888815016813513, 1.1243301355211495, 1.166977103606075, 1.2182568066927284, 1.2798772354275727, 1.3538666751582975, 1.4426259039919596, 1.5489853358570191, 1.6762658237220625, 1.8283407612492941, 2.0096956085876183, 2.225478927469756, 2.481536379650452, 2.784415934557119, 3.1413289096347365, 3.560047844772632, 4.048719380066383, 4.752651957515948, 5.590913044973868, 6.584005926629993, 7.7532214876576155, 9.119754865903639, 10.704443927019176, 12.524994176518703, 14.59739595363613, 16.93214476166354, 19.53823297353041, 22.417131025031697, 25.568260840911098, 28.991144156566317, 32.68408069090375, 36.65174474170465, 40.90396065611201, 45.4664008671033, 50.37147343433591, 55.6804490772103, 61.470816952306556, 67.8622707390618, 75.00516023410414, 83.11898235973767, 92.50044360202462, 103.57086856690864, 116.9492274587385, 118.16074567836519, 119.18497548708795, 120.04810876261652, 120.77352815196981, 121.38182790207875, 121.89094985353891, 122.31638758099915, 122.6714244963338, 122.9673822552567, 123.21386397019609, 123.41898278254268, 123.58957065488238, 123.73136519024158, 123.84917421274221, 123.94701903496814, 124.02825801299717, 124.09569231686116],
"short_factor": [0.9977997200264581, 1.014658295992452, 1.0349680404997148, 1.059429246056193, 1.0888815016813513, 1.1243301355211495, 1.166977103606075, 1.2182568066927284, 1.2798772354275727, 1.3538666751582975, 1.4426259039919596, 1.5489853358570191, 1.6762658237220625, 1.8283407612492941, 2.0096956085876183, 2.225478927469756, 2.481536379650452, 2.784415934557119, 3.1413289096347365, 3.560047844772632, 4.048719380066383, 4.752651957515948, 5.590913044973868, 6.584005926629993, 7.7532214876576155, 9.119754865903639, 10.704443927019176, 12.524994176518703, 14.59739595363613, 16.93214476166354, 19.53823297353041, 22.417131025031697, 25.568260840911098, 28.991144156566317, 32.68408069090375, 36.65174474170465, 40.90396065611201, 45.4664008671033, 50.37147343433591, 55.6804490772103, 61.470816952306556, 67.8622707390618, 75.00516023410414, 83.11898235973767, 92.50044360202462, 103.57086856690864, 116.9492274587385, 118.16074567836519, 119.18497548708795, 120.04810876261652, 120.77352815196981, 121.38182790207875, 121.89094985353891, 122.31638758099915, 122.6714244963338, 122.9673822552567, 123.21386397019609, 123.41898278254268, 123.58957065488238, 123.73136519024158, 123.84917421274221, 123.94701903496814, 124.02825801299717, 124.09569231686116],
"original_max_position_embeddings": 32768
}
}
```
### Inference with [SGLang](https://github.com/sgl-project/sglang)
For now, you need to install our forked version of SGLang.
```bash
git clone -b openbmb https://github.com/OpenBMB/sglang.git
cd sglang
pip install --upgrade pip
pip install -e "python[all]"
```
You can start the inference server by running the following command:
```bash
python -m sglang.launch_server --model openbmb/MiniCPM4-8B --trust-remote-code --port 30000 --chat-template chatml
```
Then you can use the chat interface by running the following command:
```python
import openai
client = openai.Client(base_url=f"http://localhost:30000/v1", api_key="None")
response = client.chat.completions.create(
model="openbmb/MiniCPM4-8B",
messages=[
{"role": "user", "content": "Write an article about Artificial Intelligence."},
],
temperature=0.7,
max_tokens=1024,
)
print(response.choices[0].message.content)
```
### Inference with [vLLM](https://github.com/vllm-project/vllm)
For now, you need to install the latest version of vLLM.
```
pip install -U vllm \
--pre \
--extra-index-url https://wheels.vllm.ai/nightly
```
Then you can inference MiniCPM4-8B with vLLM:
```python
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
model_name = "openbmb/MiniCPM4-8B"
prompt = [{"role": "user", "content": "Please recommend 5 tourist attractions in Beijing. "}]
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
input_text = tokenizer.apply_chat_template(prompt, tokenize=False, add_generation_prompt=True)
llm = LLM(
model=model_name,
trust_remote_code=True,
max_num_batched_tokens=32768,
dtype="bfloat16",
gpu_memory_utilization=0.8,
)
sampling_params = SamplingParams(top_p=0.7, temperature=0.7, max_tokens=1024, repetition_penalty=1.02)
outputs = llm.generate(prompts=input_text, sampling_params=sampling_params)
print(outputs[0].outputs[0].text)
```
Also, you can start the inference server by running the following command:
> **Note**: In vLLM's chat API, `add_special_tokens` is `False` by default. This means important special tokens—such as the beginning-of-sequence (BOS) token—will not be added automatically. To ensure the input prompt is correctly formatted for the model, you should explicitly set `extra_body={"add_special_tokens": True}`.
```bash
vllm serve openbmb/MiniCPM4-8B
```
Then you can use the chat interface by running the following code:
```python
import openai
client = openai.Client(base_url="http://localhost:8000/v1", api_key="EMPTY")
response = client.chat.completions.create(
model="openbmb/MiniCPM4-8B",
messages=[
{"role": "user", "content": "Write an article about Artificial Intelligence."},
],
temperature=0.7,
max_tokens=1024,
extra_body=dict(add_special_tokens=True), # Ensures special tokens are added for chat template
)
print(response.choices[0].message.content)
```
## Evaluation Results
On two typical end-side chips, Jetson AGX Orin and RTX 4090, MiniCPM4 demonstrates significantly faster processing speed compared to similar-size models in long text processing tasks. As text length increases, MiniCPM4's efficiency advantage becomes more pronounced. On the Jetson AGX Orin platform, compared to Qwen3-8B, MiniCPM4 achieves approximately 7x decoding speed improvement.

#### Comprehensive Evaluation
MiniCPM4 launches end-side versions with 8B and 0.5B parameter scales, both achieving best-in-class performance in their respective categories.

#### Long Text Evaluation
MiniCPM4 is pre-trained on 32K long texts and achieves length extension through YaRN technology. In the 128K long text needle-in-a-haystack task, MiniCPM4 demonstrates outstanding performance.

## Statement
- As a language model, MiniCPM generates content by learning from a vast amount of text.
- However, it does not possess the ability to comprehend or express personal opinions or value judgments.
- Any content generated by MiniCPM does not represent the viewpoints or positions of the model developers.
- Therefore, when using content generated by MiniCPM, users should take full responsibility for evaluating and verifying it on their own.
## LICENSE
- This repository and MiniCPM models are released under the [Apache-2.0](https://github.com/OpenBMB/MiniCPM/blob/main/LICENSE) License.
## Citation
- Please cite our [paper](https://github.com/OpenBMB/MiniCPM/tree/main/report/MiniCPM_4_Technical_Report.pdf) if you find our work valuable.
```bibtex
@article{minicpm4,
title={{MiniCPM4}: Ultra-Efficient LLMs on End Devices},
author={MiniCPM Team},
year={2025}
}
```
<!--End Original Model Card-->
---
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Help me test my **AI-Powered Quantum Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
The full Open Source Code for the Quantum Network Monitor Service available at my github repos ( repos with NetworkMonitor in the name) : [Source Code Quantum Network Monitor](https://github.com/Mungert69). You will also find the code I use to quantize the models if you want to do it yourself [GGUFModelBuilder](https://github.com/Mungert69/GGUFModelBuilder)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4.1-mini)
- `HugLLM` (Hugginface Open-source models)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap security scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads on huggingface docker space):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**) . No token limited as the cost is low.
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4.1-mini** :
- **It performs very well but unfortunatly OpenAI charges per token. For this reason tokens usage is limited.
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API. Performs pretty well using the lastest models hosted on Novita.
### 💡 **Example commands you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
|
Mungert/Qwen2.5-Omni-7B-GGUF | Mungert | 2025-06-15T19:36:45Z | 979 | 2 | transformers | [
"transformers",
"gguf",
"multimodal",
"any-to-any",
"en",
"arxiv:2503.20215",
"license:other",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | any-to-any | 2025-06-11T03:35:01Z | ---
license: other
license_name: apache-2.0
license_link: https://huggingface.co/Qwen/Qwen2.5-Omni-7B/blob/main/LICENSE
language:
- en
tags:
- multimodal
library_name: transformers
pipeline_tag: any-to-any
---
# <span style="color: #7FFF7F;">Qwen2.5-Omni-7B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`1f63e75f`](https://github.com/ggerganov/llama.cpp/commit/1f63e75f3b5dc7f44dbe63c8a41d23958fe95bc0).
## <span style="color: #7FFF7F;"> Quantization beyond the IMatrix</span>
Testing a new quantization method using rules to bump important layers above what the standard imatrix would use.
I have found that the standard IMatrix does not perform very well at low bit quantiztion and for MOE models. So I am using llama.cpp --tensor-type to bump up selected layers. See [Layer bumping with llama.cpp](https://github.com/Mungert69/GGUFModelBuilder/blob/main/model-converter/tensor_list_builder.py)
This does create larger model files but increases precision for a given model size.
### **Please provide feedback on how you find this method performs**
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Hybrid Precision Models (e.g., `bf16_q8_0`, `f16_q4_K`) – Best of Both Worlds**
These formats selectively **quantize non-essential layers** while keeping **key layers in full precision** (e.g., attention and output layers).
- Named like `bf16_q8_0` (meaning **full-precision BF16 core layers + quantized Q8_0 other layers**).
- Strike a **balance between memory efficiency and accuracy**, improving over fully quantized models without requiring the full memory of BF16/F16.
📌 **Use Hybrid Models if:**
✔ You need **better accuracy than quant-only models** but can’t afford full BF16/F16 everywhere.
✔ Your device supports **mixed-precision inference**.
✔ You want to **optimize trade-offs** for production-grade models on constrained hardware.
📌 **Avoid Hybrid Models if:**
❌ Your target device doesn’t support **mixed or full-precision acceleration**.
❌ You are operating under **ultra-strict memory limits** (in which case use fully quantized formats).
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **very high memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **very high memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
### **Ultra Low-Bit Quantization (IQ1_S IQ1_M IQ2_S IQ2_M IQ2_XS IQ2_XSS)**
- *Ultra-low-bit quantization (1 2-bit) with **extreme memory efficiency**.
- **Use case**: Best for cases were you have to fit the model into very constrained memory
- **Trade-off**: Very Low Accuracy. May not function as expected. Please test fully before using.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------------------|------------------|------------------|----------------------------------|--------------------------------------------------------------|
| **BF16** | Very High | High | BF16-supported GPU/CPU | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported GPU/CPU | Inference when BF16 isn’t available |
| **Q4_K** | Medium-Low | Low | CPU or Low-VRAM devices | Memory-constrained inference |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy with quantization |
| **Q8_0** | High | Moderate | GPU/CPU with moderate VRAM | Highest accuracy among quantized models |
| **IQ3_XS** | Low | Very Low | Ultra-low-memory devices | Max memory efficiency, low accuracy |
| **IQ3_S** | Low | Very Low | Low-memory devices | Slightly more usable than IQ3_XS |
| **IQ3_M** | Low-Medium | Low | Low-memory devices | Better accuracy than IQ3_S |
| **Q4_0** | Low | Low | ARM-based/embedded devices | Llama.cpp automatically optimizes for ARM inference |
| **Ultra Low-Bit (IQ1/2_*)** | Very Low | Extremely Low | Tiny edge/embedded devices | Fit models in extremely tight memory; low accuracy |
| **Hybrid (e.g., `bf16_q8_0`)** | Medium–High | Medium | Mixed-precision capable hardware | Balanced performance and memory, near-FP accuracy in critical layers |
---
# Qwen2.5-Omni
<a href="https://chat.qwen.ai/" target="_blank" style="margin: 2px;">
<img alt="Chat" src="https://img.shields.io/badge/%F0%9F%92%9C%EF%B8%8F%20Qwen%20Chat%20-536af5" style="display: inline-block; vertical-align: middle;"/>
</a>
## Overview
### Introduction
Qwen2.5-Omni is an end-to-end multimodal model designed to perceive diverse modalities, including text, images, audio, and video, while simultaneously generating text and natural speech responses in a streaming manner.
<p align="center">
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/qwen_omni.png" width="80%"/>
<p>
### Key Features
* **Omni and Novel Architecture**: We propose Thinker-Talker architecture, an end-to-end multimodal model designed to perceive diverse modalities, including text, images, audio, and video, while simultaneously generating text and natural speech responses in a streaming manner. We propose a novel position embedding, named TMRoPE (Time-aligned Multimodal RoPE), to synchronize the timestamps of video inputs with audio.
* **Real-Time Voice and Video Chat**: Architecture designed for fully real-time interactions, supporting chunked input and immediate output.
* **Natural and Robust Speech Generation**: Surpassing many existing streaming and non-streaming alternatives, demonstrating superior robustness and naturalness in speech generation.
* **Strong Performance Across Modalities**: Exhibiting exceptional performance across all modalities when benchmarked against similarly sized single-modality models. Qwen2.5-Omni outperforms the similarly sized Qwen2-Audio in audio capabilities and achieves comparable performance to Qwen2.5-VL-7B.
* **Excellent End-to-End Speech Instruction Following**: Qwen2.5-Omni shows performance in end-to-end speech instruction following that rivals its effectiveness with text inputs, evidenced by benchmarks such as MMLU and GSM8K.
### Model Architecture
<p align="center">
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/overview.png" width="80%"/>
<p>
### Performance
We conducted a comprehensive evaluation of Qwen2.5-Omni, which demonstrates strong performance across all modalities when compared to similarly sized single-modality models and closed-source models like Qwen2.5-VL-7B, Qwen2-Audio, and Gemini-1.5-pro. In tasks requiring the integration of multiple modalities, such as OmniBench, Qwen2.5-Omni achieves state-of-the-art performance. Furthermore, in single-modality tasks, it excels in areas including speech recognition (Common Voice), translation (CoVoST2), audio understanding (MMAU), image reasoning (MMMU, MMStar), video understanding (MVBench), and speech generation (Seed-tts-eval and subjective naturalness).
<p align="center">
<img src="https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/bar.png" width="80%"/>
<p>
<details>
<summary>Multimodality -> Text</summary>
<table class="tg"><thead>
<tr>
<th class="tg-0lax">Datasets</th>
<th class="tg-0lax">Model</th>
<th class="tg-0lax">Performance</th>
</tr></thead>
<tbody>
<tr>
<td class="tg-0lax" rowspan="10">OmniBench<br>Speech | Sound Event | Music | Avg</td>
<td class="tg-0lax">Gemini-1.5-Pro</td>
<td class="tg-0lax">42.67%|42.26%|46.23%|42.91%</td>
</tr>
<tr>
<td class="tg-0lax">MIO-Instruct</td>
<td class="tg-0lax">36.96%|33.58%|11.32%|33.80%</td>
</tr>
<tr>
<td class="tg-0lax">AnyGPT (7B)</td>
<td class="tg-0lax">17.77%|20.75%|13.21%|18.04%</td>
</tr>
<tr>
<td class="tg-0lax">video-SALMONN</td>
<td class="tg-0lax">34.11%|31.70%|<strong>56.60%</strong>|35.64%</td>
</tr>
<tr>
<td class="tg-0lax">UnifiedIO2-xlarge</td>
<td class="tg-0lax">39.56%|36.98%|29.25%|38.00%</td>
</tr>
<tr>
<td class="tg-0lax">UnifiedIO2-xxlarge</td>
<td class="tg-0lax">34.24%|36.98%|24.53%|33.98%</td>
</tr>
<tr>
<td class="tg-0lax">MiniCPM-o</td>
<td class="tg-0lax">-|-|-|40.50%</td>
</tr>
<tr>
<td class="tg-0lax">Baichuan-Omni-1.5</td>
<td class="tg-0lax">-|-|-|42.90%</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B</td>
<td class="tg-0lax">52.14%|52.08%|52.83%|52.19%</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B</td>
<td class="tg-0lax"><strong>55.25%</strong>|<strong>60.00%</strong>|52.83%|<strong>56.13%</strong></td>
</tr>
</tbody></table>
</details>
<details>
<summary>Audio -> Text</summary>
<table class="tg"><thead>
<tr>
<th class="tg-0lax">Datasets</th>
<th class="tg-0lax">Model</th>
<th class="tg-0lax">Performance</th>
</tr></thead>
<tbody>
<tr>
<td class="tg-9j4x" colspan="3">ASR</td>
</tr>
<tr>
<td class="tg-0lax" rowspan="12">Librispeech<br>dev-clean | dev other | test-clean | test-other</td>
<td class="tg-0lax">SALMONN</td>
<td class="tg-0lax">-|-|2.1|4.9</td>
</tr>
<tr>
<td class="tg-0lax">SpeechVerse</td>
<td class="tg-0lax">-|-|2.1|4.4</td>
</tr>
<tr>
<td class="tg-0lax">Whisper-large-v3</td>
<td class="tg-0lax">-|-|1.8|3.6</td>
</tr>
<tr>
<td class="tg-0lax">Llama-3-8B</td>
<td class="tg-0lax">-|-|-|3.4</td>
</tr>
<tr>
<td class="tg-0lax">Llama-3-70B</td>
<td class="tg-0lax">-|-|-|3.1</td>
</tr>
<tr>
<td class="tg-0lax">Seed-ASR-Multilingual</td>
<td class="tg-0lax">-|-|<strong>1.6</strong>|<strong>2.8</strong></td>
</tr>
<tr>
<td class="tg-0lax">MiniCPM-o</td>
<td class="tg-0lax">-|-|1.7|-</td>
</tr>
<tr>
<td class="tg-0lax">MinMo</td>
<td class="tg-0lax">-|-|1.7|3.9</td>
</tr>
<tr>
<td class="tg-0lax">Qwen-Audio</td>
<td class="tg-0lax">1.8|4.0|2.0|4.2</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2-Audio</td>
<td class="tg-0lax"><strong>1.3</strong>|<strong>3.4</strong>|<strong>1.6</strong>|3.6</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B</td>
<td class="tg-0lax">2.0|4.1|2.2|4.5</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B</td>
<td class="tg-0lax">1.6|3.5|1.8|3.4</td>
</tr>
<tr>
<td class="tg-0lax" rowspan="5">Common Voice 15<br>en | zh | yue | fr</td>
<td class="tg-0lax">Whisper-large-v3</td>
<td class="tg-0lax">9.3|12.8|10.9|10.8</td>
</tr>
<tr>
<td class="tg-0lax">MinMo</td>
<td class="tg-0lax">7.9|6.3|6.4|8.5</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2-Audio</td>
<td class="tg-0lax">8.6|6.9|<strong>5.9</strong>|9.6</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B</td>
<td class="tg-0lax">9.1|6.0|11.6|9.6</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B</td>
<td class="tg-0lax"><strong>7.6</strong>|<strong>5.2</strong>|7.3|<strong>7.5</strong></td>
</tr>
<tr>
<td class="tg-0lax" rowspan="8">Fleurs<br>zh | en</td>
<td class="tg-0lax">Whisper-large-v3</td>
<td class="tg-0lax">7.7|4.1</td>
</tr>
<tr>
<td class="tg-0lax">Seed-ASR-Multilingual</td>
<td class="tg-0lax">-|<strong>3.4</strong></td>
</tr>
<tr>
<td class="tg-0lax">Megrez-3B-Omni</td>
<td class="tg-0lax">10.8|-</td>
</tr>
<tr>
<td class="tg-0lax">MiniCPM-o</td>
<td class="tg-0lax">4.4|-</td>
</tr>
<tr>
<td class="tg-0lax">MinMo</td>
<td class="tg-0lax">3.0|3.8</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2-Audio</td>
<td class="tg-0lax">7.5|-</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B</td>
<td class="tg-0lax">3.2|5.4</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B</td>
<td class="tg-0lax"><strong>3.0</strong>|4.1</td>
</tr>
<tr>
<td class="tg-0lax" rowspan="6">Wenetspeech<br>test-net | test-meeting</td>
<td class="tg-0lax">Seed-ASR-Chinese</td>
<td class="tg-0lax"><strong>4.7|5.7</strong></td>
</tr>
<tr>
<td class="tg-0lax">Megrez-3B-Omni</td>
<td class="tg-0lax">-|16.4</td>
</tr>
<tr>
<td class="tg-0lax">MiniCPM-o</td>
<td class="tg-0lax">6.9|-</td>
</tr>
<tr>
<td class="tg-0lax">MinMo</td>
<td class="tg-0lax">6.8|7.4</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B</td>
<td class="tg-0lax">6.3|8.1</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B</td>
<td class="tg-0lax">5.9|7.7</td>
</tr>
<tr>
<td class="tg-0lax" rowspan="4">Voxpopuli-V1.0-en</td>
<td class="tg-0lax">Llama-3-8B</td>
<td class="tg-0lax">6.2</td>
</tr>
<tr>
<td class="tg-0lax">Llama-3-70B</td>
<td class="tg-0lax"><strong>5.7</strong></td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B</td>
<td class="tg-0lax">6.6</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B</td>
<td class="tg-0lax">5.8</td>
</tr>
<tr>
<td class="tg-9j4x" colspan="3">S2TT</td>
</tr>
<tr>
<td class="tg-0lax" rowspan="9">CoVoST2<br>en-de | de-en | en-zh | zh-en</td>
<td class="tg-0lax">SALMONN</td>
<td class="tg-0lax">18.6|-|33.1|-</td>
</tr>
<tr>
<td class="tg-0lax">SpeechLLaMA</td>
<td class="tg-0lax">-|27.1|-|12.3</td>
</tr>
<tr>
<td class="tg-0lax">BLSP</td>
<td class="tg-0lax">14.1|-|-|-</td>
</tr>
<tr>
<td class="tg-0lax">MiniCPM-o</td>
<td class="tg-0lax">-|-|<strong>48.2</strong>|27.2</td>
</tr>
<tr>
<td class="tg-0lax">MinMo</td>
<td class="tg-0lax">-|<strong>39.9</strong>|46.7|26.0</td>
</tr>
<tr>
<td class="tg-0lax">Qwen-Audio</td>
<td class="tg-0lax">25.1|33.9|41.5|15.7</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2-Audio</td>
<td class="tg-0lax">29.9|35.2|45.2|24.4</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B</td>
<td class="tg-0lax">28.3|38.1|41.4|26.6</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B</td>
<td class="tg-0lax"><strong>30.2</strong>|37.7|41.4|<strong>29.4</strong></td>
</tr>
<tr>
<td class="tg-9j4x" colspan="3">SER</td>
</tr>
<tr>
<td class="tg-0lax" rowspan="6">Meld</td>
<td class="tg-0lax">WavLM-large</td>
<td class="tg-0lax">0.542</td>
</tr>
<tr>
<td class="tg-0lax">MiniCPM-o</td>
<td class="tg-0lax">0.524</td>
</tr>
<tr>
<td class="tg-0lax">Qwen-Audio</td>
<td class="tg-0lax">0.557</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2-Audio</td>
<td class="tg-0lax">0.553</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B</td>
<td class="tg-0lax">0.558</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B</td>
<td class="tg-0lax"><strong>0.570</strong></td>
</tr>
<tr>
<td class="tg-9j4x" colspan="3">VSC</td>
</tr>
<tr>
<td class="tg-0lax" rowspan="6">VocalSound</td>
<td class="tg-0lax">CLAP</td>
<td class="tg-0lax">0.495</td>
</tr>
<tr>
<td class="tg-0lax">Pengi</td>
<td class="tg-0lax">0.604</td>
</tr>
<tr>
<td class="tg-0lax">Qwen-Audio</td>
<td class="tg-0lax">0.929</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2-Audio</td>
<td class="tg-0lax"><strong>0.939</strong></td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B</td>
<td class="tg-0lax">0.936</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B</td>
<td class="tg-0lax"><strong>0.939</strong></td>
</tr>
<tr>
<td class="tg-9j4x" colspan="3">Music</td>
</tr>
<tr>
<td class="tg-0lax" rowspan="3">GiantSteps Tempo</td>
<td class="tg-0lax">Llark-7B</td>
<td class="tg-0lax">0.86</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B</td>
<td class="tg-0lax"><strong>0.88</strong></td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B</td>
<td class="tg-0lax"><strong>0.88</strong></td>
</tr>
<tr>
<td class="tg-0lax" rowspan="3">MusicCaps</td>
<td class="tg-0lax">LP-MusicCaps</td>
<td class="tg-0lax">0.291|0.149|0.089|<strong>0.061</strong>|0.129|0.130</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B</td>
<td class="tg-0lax">0.325|<strong>0.163</strong>|<strong>0.093</strong>|0.057|<strong>0.132</strong>|<strong>0.229</strong></td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B</td>
<td class="tg-0lax"><strong>0.328</strong>|0.162|0.090|0.055|0.127|0.225</td>
</tr>
<tr>
<td class="tg-9j4x" colspan="3">Audio Reasoning</td>
</tr>
<tr>
<td class="tg-0lax" rowspan="4">MMAU<br>Sound | Music | Speech | Avg</td>
<td class="tg-0lax">Gemini-Pro-V1.5</td>
<td class="tg-0lax">56.75|49.40|58.55|54.90</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2-Audio</td>
<td class="tg-0lax">54.95|50.98|42.04|49.20</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B</td>
<td class="tg-0lax"><strong>70.27</strong>|60.48|59.16|63.30</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B</td>
<td class="tg-0lax">67.87|<strong>69.16|59.76|65.60</strong></td>
</tr>
<tr>
<td class="tg-9j4x" colspan="3">Voice Chatting</td>
</tr>
<tr>
<td class="tg-0lax" rowspan="9">VoiceBench<br>AlpacaEval | CommonEval | SD-QA | MMSU</td>
<td class="tg-0lax">Ultravox-v0.4.1-LLaMA-3.1-8B</td>
<td class="tg-0lax"><strong>4.55</strong>|3.90|53.35|47.17</td>
</tr>
<tr>
<td class="tg-0lax">MERaLiON</td>
<td class="tg-0lax">4.50|3.77|55.06|34.95</td>
</tr>
<tr>
<td class="tg-0lax">Megrez-3B-Omni</td>
<td class="tg-0lax">3.50|2.95|25.95|27.03</td>
</tr>
<tr>
<td class="tg-0lax">Lyra-Base</td>
<td class="tg-0lax">3.85|3.50|38.25|49.74</td>
</tr>
<tr>
<td class="tg-0lax">MiniCPM-o</td>
<td class="tg-0lax">4.42|<strong>4.15</strong>|50.72|54.78</td>
</tr>
<tr>
<td class="tg-0lax">Baichuan-Omni-1.5</td>
<td class="tg-0lax">4.50|4.05|43.40|57.25</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2-Audio</td>
<td class="tg-0lax">3.74|3.43|35.71|35.72</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B</td>
<td class="tg-0lax">4.32|4.00|49.37|50.23</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B</td>
<td class="tg-0lax">4.49|3.93|<strong>55.71</strong>|<strong>61.32</strong></td>
</tr>
<tr>
<td class="tg-0lax" rowspan="9">VoiceBench<br>OpenBookQA | IFEval | AdvBench | Avg</td>
<td class="tg-0lax">Ultravox-v0.4.1-LLaMA-3.1-8B</td>
<td class="tg-0lax">65.27|<strong>66.88</strong>|98.46|71.45</td>
</tr>
<tr>
<td class="tg-0lax">MERaLiON</td>
<td class="tg-0lax">27.23|62.93|94.81|62.91</td>
</tr>
<tr>
<td class="tg-0lax">Megrez-3B-Omni</td>
<td class="tg-0lax">28.35|25.71|87.69|46.25</td>
</tr>
<tr>
<td class="tg-0lax">Lyra-Base</td>
<td class="tg-0lax">72.75|36.28|59.62|57.66</td>
</tr>
<tr>
<td class="tg-0lax">MiniCPM-o</td>
<td class="tg-0lax">78.02|49.25|97.69|71.69</td>
</tr>
<tr>
<td class="tg-0lax">Baichuan-Omni-1.5</td>
<td class="tg-0lax">74.51|54.54|97.31|71.14</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2-Audio</td>
<td class="tg-0lax">49.45|26.33|96.73|55.35</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B</td>
<td class="tg-0lax">74.73|42.10|98.85|68.81</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B</td>
<td class="tg-0lax"><strong>81.10</strong>|52.87|<strong>99.42</strong>|<strong>74.12</strong></td>
</tr>
</tbody></table>
</details>
<details>
<summary>Image -> Text</summary>
| Dataset | Qwen2.5-Omni-7B | Qwen2.5-Omni-3B | Other Best | Qwen2.5-VL-7B | GPT-4o-mini |
|--------------------------------|--------------|------------|------------|---------------|-------------|
| MMMU<sub>val</sub> | 59.2 | 53.1 | 53.9 | 58.6 | **60.0** |
| MMMU-Pro<sub>overall</sub> | 36.6 | 29.7 | - | **38.3** | 37.6 |
| MathVista<sub>testmini</sub> | 67.9 | 59.4 | **71.9** | 68.2 | 52.5 |
| MathVision<sub>full</sub> | 25.0 | 20.8 | 23.1 | **25.1** | - |
| MMBench-V1.1-EN<sub>test</sub> | 81.8 | 77.8 | 80.5 | **82.6** | 76.0 |
| MMVet<sub>turbo</sub> | 66.8 | 62.1 | **67.5** | 67.1 | 66.9 |
| MMStar | **64.0** | 55.7 | **64.0** | 63.9 | 54.8 |
| MME<sub>sum</sub> | 2340 | 2117 | **2372** | 2347 | 2003 |
| MuirBench | 59.2 | 48.0 | - | **59.2** | - |
| CRPE<sub>relation</sub> | **76.5** | 73.7 | - | 76.4 | - |
| RealWorldQA<sub>avg</sub> | 70.3 | 62.6 | **71.9** | 68.5 | - |
| MME-RealWorld<sub>en</sub> | **61.6** | 55.6 | - | 57.4 | - |
| MM-MT-Bench | 6.0 | 5.0 | - | **6.3** | - |
| AI2D | 83.2 | 79.5 | **85.8** | 83.9 | - |
| TextVQA<sub>val</sub> | 84.4 | 79.8 | 83.2 | **84.9** | - |
| DocVQA<sub>test</sub> | 95.2 | 93.3 | 93.5 | **95.7** | - |
| ChartQA<sub>test Avg</sub> | 85.3 | 82.8 | 84.9 | **87.3** | - |
| OCRBench_V2<sub>en</sub> | **57.8** | 51.7 | - | 56.3 | - |
| Dataset | Qwen2.5-Omni-7B | Qwen2.5-Omni-3B | Qwen2.5-VL-7B | Grounding DINO | Gemini 1.5 Pro |
|--------------------------|--------------|---------------|---------------|----------------|----------------|
| Refcoco<sub>val</sub> | 90.5 | 88.7 | 90.0 | **90.6** | 73.2 |
| Refcoco<sub>textA</sub> | **93.5** | 91.8 | 92.5 | 93.2 | 72.9 |
| Refcoco<sub>textB</sub> | 86.6 | 84.0 | 85.4 | **88.2** | 74.6 |
| Refcoco+<sub>val</sub> | 85.4 | 81.1 | 84.2 | **88.2** | 62.5 |
| Refcoco+<sub>textA</sub> | **91.0** | 87.5 | 89.1 | 89.0 | 63.9 |
| Refcoco+<sub>textB</sub> | **79.3** | 73.2 | 76.9 | 75.9 | 65.0 |
| Refcocog+<sub>val</sub> | **87.4** | 85.0 | 87.2 | 86.1 | 75.2 |
| Refcocog+<sub>test</sub> | **87.9** | 85.1 | 87.2 | 87.0 | 76.2 |
| ODinW | 42.4 | 39.2 | 37.3 | **55.0** | 36.7 |
| PointGrounding | 66.5 | 46.2 | **67.3** | - | - |
</details>
<details>
<summary>Video(without audio) -> Text</summary>
| Dataset | Qwen2.5-Omni-7B | Qwen2.5-Omni-3B | Other Best | Qwen2.5-VL-7B | GPT-4o-mini |
|-----------------------------|--------------|------------|------------|---------------|-------------|
| Video-MME<sub>w/o sub</sub> | 64.3 | 62.0 | 63.9 | **65.1** | 64.8 |
| Video-MME<sub>w sub</sub> | **72.4** | 68.6 | 67.9 | 71.6 | - |
| MVBench | **70.3** | 68.7 | 67.2 | 69.6 | - |
| EgoSchema<sub>test</sub> | **68.6** | 61.4 | 63.2 | 65.0 | - |
</details>
<details>
<summary>Zero-shot Speech Generation</summary>
<table class="tg"><thead>
<tr>
<th class="tg-0lax">Datasets</th>
<th class="tg-0lax">Model</th>
<th class="tg-0lax">Performance</th>
</tr></thead>
<tbody>
<tr>
<td class="tg-9j4x" colspan="3">Content Consistency</td>
</tr>
<tr>
<td class="tg-0lax" rowspan="11">SEED<br>test-zh | test-en | test-hard </td>
<td class="tg-0lax">Seed-TTS_ICL</td>
<td class="tg-0lax">1.11 | 2.24 | 7.58</td>
</tr>
<tr>
<td class="tg-0lax">Seed-TTS_RL</td>
<td class="tg-0lax"><strong>1.00</strong> | 1.94 | <strong>6.42</strong></td>
</tr>
<tr>
<td class="tg-0lax">MaskGCT</td>
<td class="tg-0lax">2.27 | 2.62 | 10.27</td>
</tr>
<tr>
<td class="tg-0lax">E2_TTS</td>
<td class="tg-0lax">1.97 | 2.19 | -</td>
</tr>
<tr>
<td class="tg-0lax">F5-TTS</td>
<td class="tg-0lax">1.56 | <strong>1.83</strong> | 8.67</td>
</tr>
<tr>
<td class="tg-0lax">CosyVoice 2</td>
<td class="tg-0lax">1.45 | 2.57 | 6.83</td>
</tr>
<tr>
<td class="tg-0lax">CosyVoice 2-S</td>
<td class="tg-0lax">1.45 | 2.38 | 8.08</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B_ICL</td>
<td class="tg-0lax">1.95 | 2.87 | 9.92</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B_RL</td>
<td class="tg-0lax">1.58 | 2.51 | 7.86</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B_ICL</td>
<td class="tg-0lax">1.70 | 2.72 | 7.97</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B_RL</td>
<td class="tg-0lax">1.42 | 2.32 | 6.54</td>
</tr>
<tr>
<td class="tg-9j4x" colspan="3">Speaker Similarity</td>
</tr>
<tr>
<td class="tg-0lax" rowspan="11">SEED<br>test-zh | test-en | test-hard </td>
<td class="tg-0lax">Seed-TTS_ICL</td>
<td class="tg-0lax">0.796 | 0.762 | 0.776</td>
</tr>
<tr>
<td class="tg-0lax">Seed-TTS_RL</td>
<td class="tg-0lax"><strong>0.801</strong> | <strong>0.766</strong> | <strong>0.782</strong></td>
</tr>
<tr>
<td class="tg-0lax">MaskGCT</td>
<td class="tg-0lax">0.774 | 0.714 | 0.748</td>
</tr>
<tr>
<td class="tg-0lax">E2_TTS</td>
<td class="tg-0lax">0.730 | 0.710 | -</td>
</tr>
<tr>
<td class="tg-0lax">F5-TTS</td>
<td class="tg-0lax">0.741 | 0.647 | 0.713</td>
</tr>
<tr>
<td class="tg-0lax">CosyVoice 2</td>
<td class="tg-0lax">0.748 | 0.652 | 0.724</td>
</tr>
<tr>
<td class="tg-0lax">CosyVoice 2-S</td>
<td class="tg-0lax">0.753 | 0.654 | 0.732</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B_ICL</td>
<td class="tg-0lax">0.741 | 0.635 | 0.748</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-3B_RL</td>
<td class="tg-0lax">0.744 | 0.635 | 0.746</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B_ICL</td>
<td class="tg-0lax">0.752 | 0.632 | 0.747</td>
</tr>
<tr>
<td class="tg-0lax">Qwen2.5-Omni-7B_RL</td>
<td class="tg-0lax">0.754 | 0.641 | 0.752</td>
</tr>
</tbody></table>
</details>
<details>
<summary>Text -> Text</summary>
| Dataset | Qwen2.5-Omni-7B | Qwen2.5-Omni-3B | Qwen2.5-7B | Qwen2.5-3B | Qwen2-7B | Llama3.1-8B | Gemma2-9B |
|-----------------------------------|-----------|------------|------------|------------|------------|-------------|-----------|
| MMLU-Pro | 47.0 | 40.4 | **56.3** | 43.7 | 44.1 | 48.3 | 52.1 |
| MMLU-redux | 71.0 | 60.9 | **75.4** | 64.4 | 67.3 | 67.2 | 72.8 |
| LiveBench<sub>0831</sub> | 29.6 | 22.3 | **35.9** | 26.8 | 29.2 | 26.7 | 30.6 |
| GPQA | 30.8 | 34.3 | **36.4** | 30.3 | 34.3 | 32.8 | 32.8 |
| MATH | 71.5 | 63.6 | **75.5** | 65.9 | 52.9 | 51.9 | 44.3 |
| GSM8K | 88.7 | 82.6 | **91.6** | 86.7 | 85.7 | 84.5 | 76.7 |
| HumanEval | 78.7 | 70.7 | **84.8** | 74.4 | 79.9 | 72.6 | 68.9 |
| MBPP | 73.2 | 70.4 | **79.2** | 72.7 | 67.2 | 69.6 | 74.9 |
| MultiPL-E | 65.8 | 57.6 | **70.4** | 60.2 | 59.1 | 50.7 | 53.4 |
| LiveCodeBench<sub>2305-2409</sub> | 24.6 | 16.5 | **28.7** | 19.9 | 23.9 | 8.3 | 18.9 |
</details>
## Quickstart
Below, we provide simple examples to show how to use Qwen2.5-Omni with 🤗 Transformers. The codes of Qwen2.5-Omni has been in the latest Hugging face transformers and we advise you to build from source with command:
```
pip uninstall transformers
pip install git+https://github.com/huggingface/[email protected]
pip install accelerate
```
or you might encounter the following error:
```
KeyError: 'qwen2_5_omni'
```
We offer a toolkit to help you handle various types of audio and visual input more conveniently, as if you were using an API. This includes base64, URLs, and interleaved audio, images and videos. You can install it using the following command and make sure your system has `ffmpeg` installed:
```bash
# It's highly recommended to use `[decord]` feature for faster video loading.
pip install qwen-omni-utils[decord] -U
```
If you are not using Linux, you might not be able to install `decord` from PyPI. In that case, you can use `pip install qwen-omni-utils -U` which will fall back to using torchvision for video processing. However, you can still [install decord from source](https://github.com/dmlc/decord?tab=readme-ov-file#install-from-source) to get decord used when loading video.
### 🤗 Transformers Usage
Here we show a code snippet to show you how to use the chat model with `transformers` and `qwen_omni_utils`:
```python
import soundfile as sf
from transformers import Qwen2_5OmniForConditionalGeneration, Qwen2_5OmniProcessor
from qwen_omni_utils import process_mm_info
# default: Load the model on the available device(s)
model = Qwen2_5OmniForConditionalGeneration.from_pretrained("Qwen/Qwen2.5-Omni-7B", torch_dtype="auto", device_map="auto")
# We recommend enabling flash_attention_2 for better acceleration and memory saving.
# model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
# "Qwen/Qwen2.5-Omni-7B",
# torch_dtype="auto",
# device_map="auto",
# attn_implementation="flash_attention_2",
# )
processor = Qwen2_5OmniProcessor.from_pretrained("Qwen/Qwen2.5-Omni-7B")
conversation = [
{
"role": "system",
"content": [
{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
],
},
{
"role": "user",
"content": [
{"type": "video", "video": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-Omni/draw.mp4"},
],
},
]
# set use audio in video
USE_AUDIO_IN_VIDEO = True
# Preparation for inference
text = processor.apply_chat_template(conversation, add_generation_prompt=True, tokenize=False)
audios, images, videos = process_mm_info(conversation, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = processor(text=text, audio=audios, images=images, videos=videos, return_tensors="pt", padding=True, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = inputs.to(model.device).to(model.dtype)
# Inference: Generation of the output text and audio
text_ids, audio = model.generate(**inputs, use_audio_in_video=USE_AUDIO_IN_VIDEO)
text = processor.batch_decode(text_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(text)
sf.write(
"output.wav",
audio.reshape(-1).detach().cpu().numpy(),
samplerate=24000,
)
```
<details>
<summary>Minimum GPU memory requirements</summary>
|Model | Precision | 15(s) Video | 30(s) Video | 60(s) Video |
|--------------|-----------| ------------- | ------------- | ------------------ |
| Qwen-Omni-3B | FP32 | 89.10 GB | Not Recommend | Not Recommend |
| Qwen-Omni-3B | BF16 | 18.38 GB | 22.43 GB | 28.22 GB |
| Qwen-Omni-7B | FP32 | 93.56 GB | Not Recommend | Not Recommend |
| Qwen-Omni-7B | BF16 | 31.11 GB | 41.85 GB | 60.19 GB |
Note: The table above presents the theoretical minimum memory requirements for inference with `transformers` and `BF16` is test with `attn_implementation="flash_attention_2"`; however, in practice, the actual memory usage is typically at least 1.2 times higher. For more information, see the linked resource [here](https://huggingface.co/docs/accelerate/main/en/usage_guides/model_size_estimator).
</details>
<details>
<summary>Video URL resource usage</summary>
Video URL compatibility largely depends on the third-party library version. The details are in the table below. Change the backend by `FORCE_QWENVL_VIDEO_READER=torchvision` or `FORCE_QWENVL_VIDEO_READER=decord` if you prefer not to use the default one.
| Backend | HTTP | HTTPS |
|-------------|------|-------|
| torchvision >= 0.19.0 | ✅ | ✅ |
| torchvision < 0.19.0 | ❌ | ❌ |
| decord | ✅ | ❌ |
</details>
<details>
<summary>Batch inference</summary>
The model can batch inputs composed of mixed samples of various types such as text, images, audio and videos as input when `return_audio=False` is set. Here is an example.
```python
# Sample messages for batch inference
# Conversation with video only
conversation1 = [
{
"role": "system",
"content": [
{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
],
},
{
"role": "user",
"content": [
{"type": "video", "video": "/path/to/video.mp4"},
]
}
]
# Conversation with audio only
conversation2 = [
{
"role": "system",
"content": [
{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
],
},
{
"role": "user",
"content": [
{"type": "audio", "audio": "/path/to/audio.wav"},
]
}
]
# Conversation with pure text
conversation3 = [
{
"role": "system",
"content": [
{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
],
},
{
"role": "user",
"content": "who are you?"
}
]
# Conversation with mixed media
conversation4 = [
{
"role": "system",
"content": [
{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
],
},
{
"role": "user",
"content": [
{"type": "image", "image": "/path/to/image.jpg"},
{"type": "video", "video": "/path/to/video.mp4"},
{"type": "audio", "audio": "/path/to/audio.wav"},
{"type": "text", "text": "What are the elements can you see and hear in these medias?"},
],
}
]
# Combine messages for batch processing
conversations = [conversation1, conversation2, conversation3, conversation4]
# set use audio in video
USE_AUDIO_IN_VIDEO = True
# Preparation for batch inference
text = processor.apply_chat_template(conversations, add_generation_prompt=True, tokenize=False)
audios, images, videos = process_mm_info(conversations, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = processor(text=text, audio=audios, images=images, videos=videos, return_tensors="pt", padding=True, use_audio_in_video=USE_AUDIO_IN_VIDEO)
inputs = inputs.to(model.device).to(model.dtype)
# Batch Inference
text_ids = model.generate(**inputs, use_audio_in_video=USE_AUDIO_IN_VIDEO, return_audio=False)
text = processor.batch_decode(text_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(text)
```
</details>
### Usage Tips
#### Prompt for audio output
If users need audio output, the system prompt must be set as "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech.", otherwise the audio output may not work as expected.
```
{
"role": "system",
"content": [
{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
],
}
```
#### Use audio in video
In the process of multimodal interaction, the videos provided by users are often accompanied by audio (such as questions about the content in the video, or sounds generated by certain events in the video). This information is conducive to the model providing a better interactive experience. So we provide the following options for users to decide whether to use audio in video.
```python
# first place, in data preprocessing
audios, images, videos = process_mm_info(conversations, use_audio_in_video=True)
```
```python
# second place, in model processor
inputs = processor(text=text, audio=audios, images=images, videos=videos, return_tensors="pt",
padding=True, use_audio_in_video=True)
```
```python
# third place, in model inference
text_ids, audio = model.generate(**inputs, use_audio_in_video=True)
```
It is worth noting that during a multi-round conversation, the `use_audio_in_video` parameter in these places must be set to the same, otherwise unexpected results will occur.
#### Use audio output or not
The model supports both text and audio outputs, if users do not need audio outputs, they can call `model.disable_talker()` after init the model. This option will save about `~2GB` of GPU memory but the `return_audio` option for `generate` function will only allow to be set at `False`.
```python
model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-Omni-7B",
torch_dtype="auto",
device_map="auto"
)
model.disable_talker()
```
In order to obtain a flexible experience, we recommend that users can decide whether to return audio when `generate` function is called. If `return_audio` is set to `False`, the model will only return text outputs to get text responses faster.
```python
model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-Omni-7B",
torch_dtype="auto",
device_map="auto"
)
...
text_ids = model.generate(**inputs, return_audio=False)
```
#### Change voice type of output audio
Qwen2.5-Omni supports the ability to change the voice of the output audio. The `"Qwen/Qwen2.5-Omni-7B"` checkpoint support two voice types as follow:
| Voice Type | Gender | Description |
|------------|--------|-------------|
| Chelsie | Female | A honeyed, velvety voice that carries a gentle warmth and luminous clarity.|
| Ethan | Male | A bright, upbeat voice with infectious energy and a warm, approachable vibe.|
Users can use the `speaker` parameter of `generate` function to specify the voice type. By default, if `speaker` is not specified, the default voice type is `Chelsie`.
```python
text_ids, audio = model.generate(**inputs, speaker="Chelsie")
```
```python
text_ids, audio = model.generate(**inputs, speaker="Ethan")
```
#### Flash-Attention 2 to speed up generation
First, make sure to install the latest version of Flash Attention 2:
```bash
pip install -U flash-attn --no-build-isolation
```
Also, you should have hardware that is compatible with FlashAttention 2. Read more about it in the official documentation of the [flash attention repository](https://github.com/Dao-AILab/flash-attention). FlashAttention-2 can only be used when a model is loaded in `torch.float16` or `torch.bfloat16`.
To load and run a model using FlashAttention-2, add `attn_implementation="flash_attention_2"` when loading the model:
```python
from transformers import Qwen2_5OmniForConditionalGeneration
model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-Omni-7B",
device_map="auto",
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
)
```
## Citation
If you find our paper and code useful in your research, please consider giving a star :star: and citation :pencil: :)
```BibTeX
@article{Qwen2.5-Omni,
title={Qwen2.5-Omni Technical Report},
author={Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, Junyang Lin},
journal={arXiv preprint arXiv:2503.20215},
year={2025}
}
```
<br>
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Help me test my **AI-Powered Quantum Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
The full Open Source Code for the Quantum Network Monitor Service available at my github repos ( repos with NetworkMonitor in the name) : [Source Code Quantum Network Monitor](https://github.com/Mungert69). You will also find the code I use to quantize the models if you want to do it yourself [GGUFModelBuilder](https://github.com/Mungert69/GGUFModelBuilder)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4.1-mini)
- `HugLLM` (Hugginface Open-source models)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap security scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads on huggingface docker space):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**) . No token limited as the cost is low.
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4.1-mini** :
- **It performs very well but unfortunatly OpenAI charges per token. For this reason tokens usage is limited.
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API. Performs pretty well using the lastest models hosted on Novita.
### 💡 **Example commands you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
|
Mungert/Qwen3-Embedding-8B-GGUF | Mungert | 2025-06-15T19:36:42Z | 1,574 | 2 | sentence-transformers | [
"sentence-transformers",
"gguf",
"transformers",
"sentence-similarity",
"feature-extraction",
"arxiv:2506.05176",
"base_model:Qwen/Qwen3-8B-Base",
"base_model:quantized:Qwen/Qwen3-8B-Base",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | feature-extraction | 2025-06-10T18:12:06Z | ---
license: apache-2.0
base_model:
- Qwen/Qwen3-8B-Base
tags:
- transformers
- sentence-transformers
- sentence-similarity
- feature-extraction
---
# <span style="color: #7FFF7F;">Qwen/Qwen3-Embedding-8B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`1f63e75f`](https://github.com/ggerganov/llama.cpp/commit/1f63e75f3b5dc7f44dbe63c8a41d23958fe95bc0).
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Hybrid Precision Models (e.g., `bf16_q8_0`, `f16_q4_K`) – Best of Both Worlds**
These formats selectively **quantize non-essential layers** while keeping **key layers in full precision** (e.g., attention and output layers).
- Named like `bf16_q8_0` (meaning **full-precision BF16 core layers + quantized Q8_0 other layers**).
- Strike a **balance between memory efficiency and accuracy**, improving over fully quantized models without requiring the full memory of BF16/F16.
📌 **Use Hybrid Models if:**
✔ You need **better accuracy than quant-only models** but can’t afford full BF16/F16 everywhere.
✔ Your device supports **mixed-precision inference**.
✔ You want to **optimize trade-offs** for production-grade models on constrained hardware.
📌 **Avoid Hybrid Models if:**
❌ Your target device doesn’t support **mixed or full-precision acceleration**.
❌ You are operating under **ultra-strict memory limits** (in which case use fully quantized formats).
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **very high memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **very high memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
### **Ultra Low-Bit Quantization (IQ1_S IQ1_M IQ2_S IQ2_M IQ2_XS IQ2_XSS)**
- *Ultra-low-bit quantization (1 2-bit) with **extreme memory efficiency**.
- **Use case**: Best for cases were you have to fit the model into very constrained memory
- **Trade-off**: Very Low Accuracy. May not function as expected. Please test fully before using.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------------------|------------------|------------------|----------------------------------|--------------------------------------------------------------|
| **BF16** | Very High | High | BF16-supported GPU/CPU | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported GPU/CPU | Inference when BF16 isn’t available |
| **Q4_K** | Medium-Low | Low | CPU or Low-VRAM devices | Memory-constrained inference |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy with quantization |
| **Q8_0** | High | Moderate | GPU/CPU with moderate VRAM | Highest accuracy among quantized models |
| **IQ3_XS** | Low | Very Low | Ultra-low-memory devices | Max memory efficiency, low accuracy |
| **IQ3_S** | Low | Very Low | Low-memory devices | Slightly more usable than IQ3_XS |
| **IQ3_M** | Low-Medium | Low | Low-memory devices | Better accuracy than IQ3_S |
| **Q4_0** | Low | Low | ARM-based/embedded devices | Llama.cpp automatically optimizes for ARM inference |
| **Ultra Low-Bit (IQ1/2_*)** | Very Low | Extremely Low | Tiny edge/embedded devices | Fit models in extremely tight memory; low accuracy |
| **Hybrid (e.g., `bf16_q8_0`)** | Medium–High | Medium | Mixed-precision capable hardware | Balanced performance and memory, near-FP accuracy in critical layers |
---
# Qwen3-Embedding-8B
<p align="center">
<img src="https://qianwen-res.oss-accelerate-overseas.aliyuncs.com/logo_qwen3.png" width="400"/>
<p>
## Highlights
The Qwen3 Embedding model series is the latest proprietary model of the Qwen family, specifically designed for text embedding and ranking tasks. Building upon the dense foundational models of the Qwen3 series, it provides a comprehensive range of text embeddings and reranking models in various sizes (0.6B, 4B, and 8B). This series inherits the exceptional multilingual capabilities, long-text understanding, and reasoning skills of its foundational model. The Qwen3 Embedding series represents significant advancements in multiple text embedding and ranking tasks, including text retrieval, code retrieval, text classification, text clustering, and bitext mining.
**Exceptional Versatility**: The embedding model has achieved state-of-the-art performance across a wide range of downstream application evaluations. The 8B size embedding model ranks **No.1** in the MTEB multilingual leaderboard (as of June 5, 2025, score **70.58**), while the reranking model excels in various text retrieval scenarios.
**Comprehensive Flexibility**: The Qwen3 Embedding series offers a full spectrum of sizes (from 0.6B to 8B) for both embedding and reranking models, catering to diverse use cases that prioritize efficiency and effectiveness. Developers can seamlessly combine these two modules. Additionally, the embedding model allows for flexible vector definitions across all dimensions, and both embedding and reranking models support user-defined instructions to enhance performance for specific tasks, languages, or scenarios.
**Multilingual Capability**: The Qwen3 Embedding series offer support for over 100 languages, thanks to the multilingual capabilites of Qwen3 models. This includes various programming languages, and provides robust multilingual, cross-lingual, and code retrieval capabilities.
**Qwen3-Embedding-8B** has the following features:
- Model Type: Text Embedding
- Supported Languages: 100+ Languages
- Number of Paramaters: 8B
- Context Length: 32k
- Embedding Dimension: Up to 4096, supports user-defined output dimensions ranging from 32 to 4096
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3-embedding/), [GitHub](https://github.com/QwenLM/Qwen3-Embedding).
## Qwen3 Embedding Series Model list
| Model Type | Models | Size | Layers | Sequence Length | Embedding Dimension | MRL Support | Instruction Aware |
|------------------|----------------------|------|--------|-----------------|---------------------|-------------|----------------|
| Text Embedding | [Qwen3-Embedding-0.6B](https://huggingface.co/Qwen/Qwen3-Embedding-0.6B) | 0.6B | 28 | 32K | 1024 | Yes | Yes |
| Text Embedding | [Qwen3-Embedding-4B](https://huggingface.co/Qwen/Qwen3-Embedding-4B) | 4B | 36 | 32K | 2560 | Yes | Yes |
| Text Embedding | [Qwen3-Embedding-8B](https://huggingface.co/Qwen/Qwen3-Embedding-8B) | 8B | 36 | 32K | 4096 | Yes | Yes |
| Text Reranking | [Qwen3-Reranker-0.6B](https://huggingface.co/Qwen/Qwen3-Reranker-0.6B) | 0.6B | 28 | 32K | - | - | Yes |
| Text Reranking | [Qwen3-Reranker-4B](https://huggingface.co/Qwen/Qwen3-Reranker-4B) | 4B | 36 | 32K | - | - | Yes |
| Text Reranking | [Qwen3-Reranker-8B](https://huggingface.co/Qwen/Qwen3-Reranker-8B) | 8B | 36 | 32K | - | - | Yes |
> **Note**:
> - `MRL Support` indicates whether the embedding model supports custom dimensions for the final embedding.
> - `Instruction Aware` notes whether the embedding or reranking model supports customizing the input instruction according to different tasks.
> - Our evaluation indicates that, for most downstream tasks, using instructions (instruct) typically yields an improvement of 1% to 5% compared to not using them. Therefore, we recommend that developers create tailored instructions specific to their tasks and scenarios. In multilingual contexts, we also advise users to write their instructions in English, as most instructions utilized during the model training process were originally written in English.
## Usage
With Transformers versions earlier than 4.51.0, you may encounter the following error:
```
KeyError: 'qwen3'
```
### Sentence Transformers Usage
```python
# Requires transformers>=4.51.0
# Requires sentence-transformers>=2.7.0
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer("Qwen/Qwen3-Embedding-8B")
# We recommend enabling flash_attention_2 for better acceleration and memory saving,
# together with setting `padding_side` to "left":
# model = SentenceTransformer(
# "Qwen/Qwen3-Embedding-8B",
# model_kwargs={"attn_implementation": "flash_attention_2", "device_map": "auto"},
# tokenizer_kwargs={"padding_side": "left"},
# )
# The queries and documents to embed
queries = [
"What is the capital of China?",
"Explain gravity",
]
documents = [
"The capital of China is Beijing.",
"Gravity is a force that attracts two bodies towards each other. It gives weight to physical objects and is responsible for the movement of planets around the sun.",
]
# Encode the queries and documents. Note that queries benefit from using a prompt
# Here we use the prompt called "query" stored under `model.prompts`, but you can
# also pass your own prompt via the `prompt` argument
query_embeddings = model.encode(queries, prompt_name="query")
document_embeddings = model.encode(documents)
# Compute the (cosine) similarity between the query and document embeddings
similarity = model.similarity(query_embeddings, document_embeddings)
print(similarity)
# tensor([[0.7493, 0.0751],
# [0.0880, 0.6318]])
```
### Transformers Usage
```python
# Requires transformers>=4.51.0
import torch
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def last_token_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
left_padding = (attention_mask[:, -1].sum() == attention_mask.shape[0])
if left_padding:
return last_hidden_states[:, -1]
else:
sequence_lengths = attention_mask.sum(dim=1) - 1
batch_size = last_hidden_states.shape[0]
return last_hidden_states[torch.arange(batch_size, device=last_hidden_states.device), sequence_lengths]
def get_detailed_instruct(task_description: str, query: str) -> str:
return f'Instruct: {task_description}\nQuery:{query}'
# Each query must come with a one-sentence instruction that describes the task
task = 'Given a web search query, retrieve relevant passages that answer the query'
queries = [
get_detailed_instruct(task, 'What is the capital of China?'),
get_detailed_instruct(task, 'Explain gravity')
]
# No need to add instruction for retrieval documents
documents = [
"The capital of China is Beijing.",
"Gravity is a force that attracts two bodies towards each other. It gives weight to physical objects and is responsible for the movement of planets around the sun."
]
input_texts = queries + documents
tokenizer = AutoTokenizer.from_pretrained('Qwen/Qwen3-Embedding-8B', padding_side='left')
model = AutoModel.from_pretrained('Qwen/Qwen3-Embedding-8B')
# We recommend enabling flash_attention_2 for better acceleration and memory saving.
# model = AutoModel.from_pretrained('Qwen/Qwen3-Embedding-8B', attn_implementation="flash_attention_2", torch_dtype=torch.float16).cuda()
max_length = 8192
# Tokenize the input texts
batch_dict = tokenizer(
input_texts,
padding=True,
truncation=True,
max_length=max_length,
return_tensors="pt",
)
batch_dict.to(model.device)
outputs = model(**batch_dict)
embeddings = last_token_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T)
print(scores.tolist())
# [[0.7493016123771667, 0.0750647559762001], [0.08795969933271408, 0.6318399906158447]]
```
### vLLM Usage
```python
# Requires vllm>=0.8.5
import torch
import vllm
from vllm import LLM
def get_detailed_instruct(task_description: str, query: str) -> str:
return f'Instruct: {task_description}\nQuery:{query}'
# Each query must come with a one-sentence instruction that describes the task
task = 'Given a web search query, retrieve relevant passages that answer the query'
queries = [
get_detailed_instruct(task, 'What is the capital of China?'),
get_detailed_instruct(task, 'Explain gravity')
]
# No need to add instruction for retrieval documents
documents = [
"The capital of China is Beijing.",
"Gravity is a force that attracts two bodies towards each other. It gives weight to physical objects and is responsible for the movement of planets around the sun."
]
input_texts = queries + documents
model = LLM(model="Qwen/Qwen3-Embedding-8B", task="embed")
outputs = model.embed(input_texts)
embeddings = torch.tensor([o.outputs.embedding for o in outputs])
scores = (embeddings[:2] @ embeddings[2:].T)
print(scores.tolist())
# [[0.7482624650001526, 0.07556197047233582], [0.08875375241041183, 0.6300010681152344]]
```
📌 **Tip**: We recommend that developers customize the `instruct` according to their specific scenarios, tasks, and languages. Our tests have shown that in most retrieval scenarios, not using an `instruct` on the query side can lead to a drop in retrieval performance by approximately 1% to 5%.
## Evaluation
### MTEB (Multilingual)
| Model | Size | Mean (Task) | Mean (Type) | Bitxt Mining | Class. | Clust. | Inst. Retri. | Multi. Class. | Pair. Class. | Rerank | Retri. | STS |
|----------------------------------|:-------:|:-------------:|:-------------:|:--------------:|:--------:|:--------:|:--------------:|:---------------:|:--------------:|:--------:|:--------:|:------:|
| NV-Embed-v2 | 7B | 56.29 | 49.58 | 57.84 | 57.29 | 40.80 | 1.04 | 18.63 | 78.94 | 63.82 | 56.72 | 71.10|
| GritLM-7B | 7B | 60.92 | 53.74 | 70.53 | 61.83 | 49.75 | 3.45 | 22.77 | 79.94 | 63.78 | 58.31 | 73.33|
| BGE-M3 | 0.6B | 59.56 | 52.18 | 79.11 | 60.35 | 40.88 | -3.11 | 20.1 | 80.76 | 62.79 | 54.60 | 74.12|
| multilingual-e5-large-instruct | 0.6B | 63.22 | 55.08 | 80.13 | 64.94 | 50.75 | -0.40 | 22.91 | 80.86 | 62.61 | 57.12 | 76.81|
| gte-Qwen2-1.5B-instruct | 1.5B | 59.45 | 52.69 | 62.51 | 58.32 | 52.05 | 0.74 | 24.02 | 81.58 | 62.58 | 60.78 | 71.61|
| gte-Qwen2-7b-Instruct | 7B | 62.51 | 55.93 | 73.92 | 61.55 | 52.77 | 4.94 | 25.48 | 85.13 | 65.55 | 60.08 | 73.98|
| text-embedding-3-large | - | 58.93 | 51.41 | 62.17 | 60.27 | 46.89 | -2.68 | 22.03 | 79.17 | 63.89 | 59.27 | 71.68|
| Cohere-embed-multilingual-v3.0 | - | 61.12 | 53.23 | 70.50 | 62.95 | 46.89 | -1.89 | 22.74 | 79.88 | 64.07 | 59.16 | 74.80|
| gemini-embedding-exp-03-07 | - | 68.37 | 59.59 | 79.28 | 71.82 | 54.59 | 5.18 | **29.16** | 83.63 | 65.58 | 67.71 | 79.40|
| **Qwen3-Embedding-0.6B** | 0.6B | 64.33 | 56.00 | 72.22 | 66.83 | 52.33 | 5.09 | 24.59 | 80.83 | 61.41 | 64.64 | 76.17|
| **Qwen3-Embedding-4B** | 4B | 69.45 | 60.86 | 79.36 | 72.33 | 57.15 | **11.56** | 26.77 | 85.05 | 65.08 | 69.60 | 80.86|
| **Qwen3-Embedding-8B** | 8B | **70.58** | **61.69** | **80.89** | **74.00** | **57.65** | 10.06 | 28.66 | **86.40** | **65.63** | **70.88** | **81.08** |
> **Note**: For compared models, the scores are retrieved from MTEB online [leaderboard](https://huggingface.co/spaces/mteb/leaderboard) on May 24th, 2025.
### MTEB (Eng v2)
| MTEB English / Models | Param. | Mean(Task) | Mean(Type) | Class. | Clust. | Pair Class. | Rerank. | Retri. | STS | Summ. |
|--------------------------------|:--------:|:------------:|:------------:|:--------:|:--------:|:-------------:|:---------:|:--------:|:-------:|:-------:|
| multilingual-e5-large-instruct | 0.6B | 65.53 | 61.21 | 75.54 | 49.89 | 86.24 | 48.74 | 53.47 | 84.72 | 29.89 |
| NV-Embed-v2 | 7.8B | 69.81 | 65.00 | 87.19 | 47.66 | 88.69 | 49.61 | 62.84 | 83.82 | 35.21 |
| GritLM-7B | 7.2B | 67.07 | 63.22 | 81.25 | 50.82 | 87.29 | 49.59 | 54.95 | 83.03 | 35.65 |
| gte-Qwen2-1.5B-instruct | 1.5B | 67.20 | 63.26 | 85.84 | 53.54 | 87.52 | 49.25 | 50.25 | 82.51 | 33.94 |
| stella_en_1.5B_v5 | 1.5B | 69.43 | 65.32 | 89.38 | 57.06 | 88.02 | 50.19 | 52.42 | 83.27 | 36.91 |
| gte-Qwen2-7B-instruct | 7.6B | 70.72 | 65.77 | 88.52 | 58.97 | 85.9 | 50.47 | 58.09 | 82.69 | 35.74 |
| gemini-embedding-exp-03-07 | - | 73.3 | 67.67 | 90.05 | **59.39** | **87.7** | 48.59 | 64.35 | 85.29 | **38.28** |
| **Qwen3-Embedding-0.6B** | 0.6B | 70.70 | 64.88 | 85.76 | 54.05 | 84.37 | 48.18 | 61.83 | 86.57 | 33.43 |
| **Qwen3-Embedding-4B** | 4B | 74.60 | 68.10 | 89.84 | 57.51 | 87.01 | 50.76 | 68.46 | **88.72** | 34.39 |
| **Qwen3-Embedding-8B** | 8B | **75.22** | **68.71** | **90.43** | 58.57 | 87.52 | **51.56** | **69.44** | 88.58 | 34.83 |
### C-MTEB (MTEB Chinese)
| C-MTEB | Param. | Mean(Task) | Mean(Type) | Class. | Clust. | Pair Class. | Rerank. | Retr. | STS |
|------------------|--------|------------|------------|--------|--------|-------------|---------|-------|-------|
| multilingual-e5-large-instruct | 0.6B | 58.08 | 58.24 | 69.80 | 48.23 | 64.52 | 57.45 | 63.65 | 45.81 |
| bge-multilingual-gemma2 | 9B | 67.64 |68.52 | 75.31 | 59.30 | 86.67 | 68.28 | 73.73 | 55.19 |
| gte-Qwen2-1.5B-instruct | 1.5B | 67.12 | 67.79 | 72.53 | 54.61 | 79.5 | 68.21 | 71.86 | 60.05 |
| gte-Qwen2-7B-instruct | 7.6B | 71.62 | 72.19 | 75.77 | 66.06 | 81.16 | 69.24 | 75.70 | 65.20 |
| ritrieve_zh_v1 | 0.3B | 72.71 | 73.85 | 76.88 | 66.5 | **85.98** | **72.86** | 76.97 | **63.92** |
| **Qwen3-Embedding-0.6B** | 0.6B | 66.33 | 67.45 | 71.40 | 68.74 | 76.42 | 62.58 | 71.03 | 54.52 |
| **Qwen3-Embedding-4B** | 4B | 72.27 | 73.51 | 75.46 | 77.89 | 83.34 | 66.05 | 77.03 | 61.26 |
| **Qwen3-Embedding-8B** | 8B | **73.84** | **75.00** | **76.97** | **80.08** | 84.23 | 66.99 | **78.21** | 63.53 |
## Citation
If you find our work helpful, feel free to give us a cite.
```
@article{qwen3embedding,
title={Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models},
author={Zhang, Yanzhao and Li, Mingxin and Long, Dingkun and Zhang, Xin and Lin, Huan and Yang, Baosong and Xie, Pengjun and Yang, An and Liu, Dayiheng and Lin, Junyang and Huang, Fei and Zhou, Jingren},
journal={arXiv preprint arXiv:2506.05176},
year={2025}
}
```
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Help me test my **AI-Powered Quantum Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
The full Open Source Code for the Quantum Network Monitor Service available at my github repos ( repos with NetworkMonitor in the name) : [Source Code Quantum Network Monitor](https://github.com/Mungert69). You will also find the code I use to quantize the models if you want to do it yourself [GGUFModelBuilder](https://github.com/Mungert69/GGUFModelBuilder)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4.1-mini)
- `HugLLM` (Hugginface Open-source models)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap security scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads on huggingface docker space):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**) . No token limited as the cost is low.
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4.1-mini** :
- **It performs very well but unfortunatly OpenAI charges per token. For this reason tokens usage is limited.
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API. Performs pretty well using the lastest models hosted on Novita.
### 💡 **Example commands you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
|
meezofun/Full.Latest.Video.18.meezofun.meezo.fun.com.meezo.fun.video.meezo.fun | meezofun | 2025-06-15T19:36:38Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:34:33Z | [🌐 CLICK HERE 🟢==►► WATCH NOW](https://videohere.top/?V=mezzo-fun)
[🔴 CLICK HERE 🌐==►► Download Now)](https://videohere.top/?V=mezzo-fun)
[<img alt="fsd" src="https://i.postimg.cc/qvPp49Sm/ythngythg.gif">](https://videohere.top/?V=mezzo-fun) |
Mungert/Qwen3-Embedding-0.6B-GGUF | Mungert | 2025-06-15T19:36:34Z | 2,465 | 2 | sentence-transformers | [
"sentence-transformers",
"gguf",
"transformers",
"sentence-similarity",
"feature-extraction",
"arxiv:2506.05176",
"base_model:Qwen/Qwen3-0.6B-Base",
"base_model:quantized:Qwen/Qwen3-0.6B-Base",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | feature-extraction | 2025-06-10T11:28:41Z | ---
license: apache-2.0
base_model:
- Qwen/Qwen3-0.6B-Base
tags:
- transformers
- sentence-transformers
- sentence-similarity
- feature-extraction
---
# <span style="color: #7FFF7F;">Qwen3-Embedding-0.6B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`1f63e75f`](https://github.com/ggerganov/llama.cpp/commit/1f63e75f3b5dc7f44dbe63c8a41d23958fe95bc0).
# Qwen3-Embedding-0.6B
<p align="center">
<img src="https://qianwen-res.oss-accelerate-overseas.aliyuncs.com/logo_qwen3.png" width="400"/>
<p>
## Highlights
The Qwen3 Embedding model series is the latest proprietary model of the Qwen family, specifically designed for text embedding and ranking tasks. Building upon the dense foundational models of the Qwen3 series, it provides a comprehensive range of text embeddings and reranking models in various sizes (0.6B, 4B, and 8B). This series inherits the exceptional multilingual capabilities, long-text understanding, and reasoning skills of its foundational model. The Qwen3 Embedding series represents significant advancements in multiple text embedding and ranking tasks, including text retrieval, code retrieval, text classification, text clustering, and bitext mining.
**Exceptional Versatility**: The embedding model has achieved state-of-the-art performance across a wide range of downstream application evaluations. The 8B size embedding model ranks **No.1** in the MTEB multilingual leaderboard (as of June 5, 2025, score **70.58**), while the reranking model excels in various text retrieval scenarios.
**Comprehensive Flexibility**: The Qwen3 Embedding series offers a full spectrum of sizes (from 0.6B to 8B) for both embedding and reranking models, catering to diverse use cases that prioritize efficiency and effectiveness. Developers can seamlessly combine these two modules. Additionally, the embedding model allows for flexible vector definitions across all dimensions, and both embedding and reranking models support user-defined instructions to enhance performance for specific tasks, languages, or scenarios.
**Multilingual Capability**: The Qwen3 Embedding series offer support for over 100 languages, thanks to the multilingual capabilites of Qwen3 models. This includes various programming languages, and provides robust multilingual, cross-lingual, and code retrieval capabilities.
## Model Overview
**Qwen3-Embedding-0.6B** has the following features:
- Model Type: Text Embedding
- Supported Languages: 100+ Languages
- Number of Paramaters: 0.6B
- Context Length: 32k
- Embedding Dimension: Up to 1024, supports user-defined output dimensions ranging from 32 to 1024
For more details, including benchmark evaluation, hardware requirements, and inference performance, please refer to our [blog](https://qwenlm.github.io/blog/qwen3-embedding/), [GitHub](https://github.com/QwenLM/Qwen3-Embedding).
## Qwen3 Embedding Series Model list
| Model Type | Models | Size | Layers | Sequence Length | Embedding Dimension | MRL Support | Instruction Aware |
|------------------|----------------------|------|--------|-----------------|---------------------|-------------|----------------|
| Text Embedding | [Qwen3-Embedding-0.6B](https://huggingface.co/Qwen/Qwen3-Embedding-0.6B) | 0.6B | 28 | 32K | 1024 | Yes | Yes |
| Text Embedding | [Qwen3-Embedding-4B](https://huggingface.co/Qwen/Qwen3-Embedding-4B) | 4B | 36 | 32K | 2560 | Yes | Yes |
| Text Embedding | [Qwen3-Embedding-8B](https://huggingface.co/Qwen/Qwen3-Embedding-8B) | 8B | 36 | 32K | 4096 | Yes | Yes |
| Text Reranking | [Qwen3-Reranker-0.6B](https://huggingface.co/Qwen/Qwen3-Reranker-0.6B) | 0.6B | 28 | 32K | - | - | Yes |
| Text Reranking | [Qwen3-Reranker-4B](https://huggingface.co/Qwen/Qwen3-Reranker-4B) | 4B | 36 | 32K | - | - | Yes |
| Text Reranking | [Qwen3-Reranker-8B](https://huggingface.co/Qwen/Qwen3-Reranker-8B) | 8B | 36 | 32K | - | - | Yes |
> **Note**:
> - `MRL Support` indicates whether the embedding model supports custom dimensions for the final embedding.
> - `Instruction Aware` notes whether the embedding or reranking model supports customizing the input instruction according to different tasks.
> - Our evaluation indicates that, for most downstream tasks, using instructions (instruct) typically yields an improvement of 1% to 5% compared to not using them. Therefore, we recommend that developers create tailored instructions specific to their tasks and scenarios. In multilingual contexts, we also advise users to write their instructions in English, as most instructions utilized during the model training process were originally written in English.
## Usage
With Transformers versions earlier than 4.51.0, you may encounter the following error:
```
KeyError: 'qwen3'
```
### Sentence Transformers Usage
```python
# Requires transformers>=4.51.0
# Requires sentence-transformers>=2.7.0
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer("Qwen/Qwen3-Embedding-0.6B")
# We recommend enabling flash_attention_2 for better acceleration and memory saving,
# together with setting `padding_side` to "left":
# model = SentenceTransformer(
# "Qwen/Qwen3-Embedding-0.6B",
# model_kwargs={"attn_implementation": "flash_attention_2", "device_map": "auto"},
# tokenizer_kwargs={"padding_side": "left"},
# )
# The queries and documents to embed
queries = [
"What is the capital of China?",
"Explain gravity",
]
documents = [
"The capital of China is Beijing.",
"Gravity is a force that attracts two bodies towards each other. It gives weight to physical objects and is responsible for the movement of planets around the sun.",
]
# Encode the queries and documents. Note that queries benefit from using a prompt
# Here we use the prompt called "query" stored under `model.prompts`, but you can
# also pass your own prompt via the `prompt` argument
query_embeddings = model.encode(queries, prompt_name="query")
document_embeddings = model.encode(documents)
# Compute the (cosine) similarity between the query and document embeddings
similarity = model.similarity(query_embeddings, document_embeddings)
print(similarity)
# tensor([[0.7646, 0.1414],
# [0.1355, 0.6000]])
```
### Transformers Usage
```python
# Requires transformers>=4.51.0
import torch
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def last_token_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
left_padding = (attention_mask[:, -1].sum() == attention_mask.shape[0])
if left_padding:
return last_hidden_states[:, -1]
else:
sequence_lengths = attention_mask.sum(dim=1) - 1
batch_size = last_hidden_states.shape[0]
return last_hidden_states[torch.arange(batch_size, device=last_hidden_states.device), sequence_lengths]
def get_detailed_instruct(task_description: str, query: str) -> str:
return f'Instruct: {task_description}\nQuery:{query}'
# Each query must come with a one-sentence instruction that describes the task
task = 'Given a web search query, retrieve relevant passages that answer the query'
queries = [
get_detailed_instruct(task, 'What is the capital of China?'),
get_detailed_instruct(task, 'Explain gravity')
]
# No need to add instruction for retrieval documents
documents = [
"The capital of China is Beijing.",
"Gravity is a force that attracts two bodies towards each other. It gives weight to physical objects and is responsible for the movement of planets around the sun."
]
input_texts = queries + documents
tokenizer = AutoTokenizer.from_pretrained('Qwen/Qwen3-Embedding-0.6B', padding_side='left')
model = AutoModel.from_pretrained('Qwen/Qwen3-Embedding-0.6B')
# We recommend enabling flash_attention_2 for better acceleration and memory saving.
# model = AutoModel.from_pretrained('Qwen/Qwen3-Embedding-0.6B', attn_implementation="flash_attention_2", torch_dtype=torch.float16).cuda()
max_length = 8192
# Tokenize the input texts
batch_dict = tokenizer(
input_texts,
padding=True,
truncation=True,
max_length=max_length,
return_tensors="pt",
)
batch_dict.to(model.device)
outputs = model(**batch_dict)
embeddings = last_token_pool(outputs.last_hidden_state, batch_dict['attention_mask'])
# normalize embeddings
embeddings = F.normalize(embeddings, p=2, dim=1)
scores = (embeddings[:2] @ embeddings[2:].T)
print(scores.tolist())
# [[0.7645568251609802, 0.14142508804798126], [0.13549736142158508, 0.5999549627304077]]
```
### vLLM Usage
```python
# Requires vllm>=0.8.5
import torch
import vllm
from vllm import LLM
def get_detailed_instruct(task_description: str, query: str) -> str:
return f'Instruct: {task_description}\nQuery:{query}'
# Each query must come with a one-sentence instruction that describes the task
task = 'Given a web search query, retrieve relevant passages that answer the query'
queries = [
get_detailed_instruct(task, 'What is the capital of China?'),
get_detailed_instruct(task, 'Explain gravity')
]
# No need to add instruction for retrieval documents
documents = [
"The capital of China is Beijing.",
"Gravity is a force that attracts two bodies towards each other. It gives weight to physical objects and is responsible for the movement of planets around the sun."
]
input_texts = queries + documents
model = LLM(model="Qwen/Qwen3-Embedding-0.6B", task="embed")
outputs = model.embed(input_texts)
embeddings = torch.tensor([o.outputs.embedding for o in outputs])
scores = (embeddings[:2] @ embeddings[2:].T)
print(scores.tolist())
# [[0.7620252966880798, 0.14078938961029053], [0.1358368694782257, 0.6013815999031067]]
```
📌 **Tip**: We recommend that developers customize the `instruct` according to their specific scenarios, tasks, and languages. Our tests have shown that in most retrieval scenarios, not using an `instruct` on the query side can lead to a drop in retrieval performance by approximately 1% to 5%.
## Evaluation
### MTEB (Multilingual)
| Model | Size | Mean (Task) | Mean (Type) | Bitxt Mining | Class. | Clust. | Inst. Retri. | Multi. Class. | Pair. Class. | Rerank | Retri. | STS |
|----------------------------------|:-------:|:-------------:|:-------------:|:--------------:|:--------:|:--------:|:--------------:|:---------------:|:--------------:|:--------:|:--------:|:------:|
| NV-Embed-v2 | 7B | 56.29 | 49.58 | 57.84 | 57.29 | 40.80 | 1.04 | 18.63 | 78.94 | 63.82 | 56.72 | 71.10|
| GritLM-7B | 7B | 60.92 | 53.74 | 70.53 | 61.83 | 49.75 | 3.45 | 22.77 | 79.94 | 63.78 | 58.31 | 73.33|
| BGE-M3 | 0.6B | 59.56 | 52.18 | 79.11 | 60.35 | 40.88 | -3.11 | 20.1 | 80.76 | 62.79 | 54.60 | 74.12|
| multilingual-e5-large-instruct | 0.6B | 63.22 | 55.08 | 80.13 | 64.94 | 50.75 | -0.40 | 22.91 | 80.86 | 62.61 | 57.12 | 76.81|
| gte-Qwen2-1.5B-instruct | 1.5B | 59.45 | 52.69 | 62.51 | 58.32 | 52.05 | 0.74 | 24.02 | 81.58 | 62.58 | 60.78 | 71.61|
| gte-Qwen2-7b-Instruct | 7B | 62.51 | 55.93 | 73.92 | 61.55 | 52.77 | 4.94 | 25.48 | 85.13 | 65.55 | 60.08 | 73.98|
| text-embedding-3-large | - | 58.93 | 51.41 | 62.17 | 60.27 | 46.89 | -2.68 | 22.03 | 79.17 | 63.89 | 59.27 | 71.68|
| Cohere-embed-multilingual-v3.0 | - | 61.12 | 53.23 | 70.50 | 62.95 | 46.89 | -1.89 | 22.74 | 79.88 | 64.07 | 59.16 | 74.80|
| Gemini Embedding | - | 68.37 | 59.59 | 79.28 | 71.82 | 54.59 | 5.18 | **29.16** | 83.63 | 65.58 | 67.71 | 79.40|
| **Qwen3-Embedding-0.6B** | 0.6B | 64.33 | 56.00 | 72.22 | 66.83 | 52.33 | 5.09 | 24.59 | 80.83 | 61.41 | 64.64 | 76.17|
| **Qwen3-Embedding-4B** | 4B | 69.45 | 60.86 | 79.36 | 72.33 | 57.15 | **11.56** | 26.77 | 85.05 | 65.08 | 69.60 | 80.86|
| **Qwen3-Embedding-8B** | 8B | **70.58** | **61.69** | **80.89** | **74.00** | **57.65** | 10.06 | 28.66 | **86.40** | **65.63** | **70.88** | **81.08** |
> **Note**: For compared models, the scores are retrieved from MTEB online [leaderboard](https://huggingface.co/spaces/mteb/leaderboard) on May 24th, 2025.
### MTEB (Eng v2)
| MTEB English / Models | Param. | Mean(Task) | Mean(Type) | Class. | Clust. | Pair Class. | Rerank. | Retri. | STS | Summ. |
|--------------------------------|:--------:|:------------:|:------------:|:--------:|:--------:|:-------------:|:---------:|:--------:|:-------:|:-------:|
| multilingual-e5-large-instruct | 0.6B | 65.53 | 61.21 | 75.54 | 49.89 | 86.24 | 48.74 | 53.47 | 84.72 | 29.89 |
| NV-Embed-v2 | 7.8B | 69.81 | 65.00 | 87.19 | 47.66 | 88.69 | 49.61 | 62.84 | 83.82 | 35.21 |
| GritLM-7B | 7.2B | 67.07 | 63.22 | 81.25 | 50.82 | 87.29 | 49.59 | 54.95 | 83.03 | 35.65 |
| gte-Qwen2-1.5B-instruct | 1.5B | 67.20 | 63.26 | 85.84 | 53.54 | 87.52 | 49.25 | 50.25 | 82.51 | 33.94 |
| stella_en_1.5B_v5 | 1.5B | 69.43 | 65.32 | 89.38 | 57.06 | 88.02 | 50.19 | 52.42 | 83.27 | 36.91 |
| gte-Qwen2-7B-instruct | 7.6B | 70.72 | 65.77 | 88.52 | 58.97 | 85.9 | 50.47 | 58.09 | 82.69 | 35.74 |
| gemini-embedding-exp-03-07 | - | 73.3 | 67.67 | 90.05 | 59.39 | 87.7 | 48.59 | 64.35 | 85.29 | 38.28 |
| **Qwen3-Embedding-0.6B** | 0.6B | 70.70 | 64.88 | 85.76 | 54.05 | 84.37 | 48.18 | 61.83 | 86.57 | 33.43 |
| **Qwen3-Embedding-4B** | 4B | 74.60 | 68.10 | 89.84 | 57.51 | 87.01 | 50.76 | 68.46 | 88.72 | 34.39 |
| **Qwen3-Embedding-8B** | 8B | 75.22 | 68.71 | 90.43 | 58.57 | 87.52 | 51.56 | 69.44 | 88.58 | 34.83 |
### C-MTEB (MTEB Chinese)
| C-MTEB | Param. | Mean(Task) | Mean(Type) | Class. | Clust. | Pair Class. | Rerank. | Retr. | STS |
|------------------|--------|------------|------------|--------|--------|-------------|---------|-------|-------|
| multilingual-e5-large-instruct | 0.6B | 58.08 | 58.24 | 69.80 | 48.23 | 64.52 | 57.45 | 63.65 | 45.81 |
| bge-multilingual-gemma2 | 9B | 67.64 | 75.31 | 59.30 | 86.67 | 68.28 | 73.73 | 55.19 | - |
| gte-Qwen2-1.5B-instruct | 1.5B | 67.12 | 67.79 | 72.53 | 54.61 | 79.5 | 68.21 | 71.86 | 60.05 |
| gte-Qwen2-7B-instruct | 7.6B | 71.62 | 72.19 | 75.77 | 66.06 | 81.16 | 69.24 | 75.70 | 65.20 |
| ritrieve_zh_v1 | 0.3B | 72.71 | 73.85 | 76.88 | 66.5 | 85.98 | 72.86 | 76.97 | 63.92 |
| **Qwen3-Embedding-0.6B** | 0.6B | 66.33 | 67.45 | 71.40 | 68.74 | 76.42 | 62.58 | 71.03 | 54.52 |
| **Qwen3-Embedding-4B** | 4B | 72.27 | 73.51 | 75.46 | 77.89 | 83.34 | 66.05 | 77.03 | 61.26 |
| **Qwen3-Embedding-8B** | 8B | 73.84 | 75.00 | 76.97 | 80.08 | 84.23 | 66.99 | 78.21 | 63.53 |
## Citation
If you find our work helpful, feel free to give us a cite.
```
@article{qwen3embedding,
title={Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models},
author={Zhang, Yanzhao and Li, Mingxin and Long, Dingkun and Zhang, Xin and Lin, Huan and Yang, Baosong and Xie, Pengjun and Yang, An and Liu, Dayiheng and Lin, Junyang and Huang, Fei and Zhou, Jingren},
journal={arXiv preprint arXiv:2506.05176},
year={2025}
}
```
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Help me test my **AI-Powered Quantum Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
The full Open Source Code for the Quantum Network Monitor Service available at my github repos ( repos with NetworkMonitor in the name) : [Source Code Quantum Network Monitor](https://github.com/Mungert69). You will also find the code I use to quantize the models if you want to do it yourself [GGUFModelBuilder](https://github.com/Mungert69/GGUFModelBuilder)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4.1-mini)
- `HugLLM` (Hugginface Open-source models)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap security scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads on huggingface docker space):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**) . No token limited as the cost is low.
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4.1-mini** :
- **It performs very well but unfortunatly OpenAI charges per token. For this reason tokens usage is limited.
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API. Performs pretty well using the lastest models hosted on Novita.
### 💡 **Example commands you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
|
Mungert/SmolVLM-Instruct-GGUF | Mungert | 2025-06-15T19:36:32Z | 1,023 | 2 | transformers | [
"transformers",
"gguf",
"image-text-to-text",
"en",
"dataset:HuggingFaceM4/the_cauldron",
"dataset:HuggingFaceM4/Docmatix",
"arxiv:2504.05299",
"base_model:HuggingFaceTB/SmolLM2-1.7B-Instruct",
"base_model:quantized:HuggingFaceTB/SmolLM2-1.7B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | image-text-to-text | 2025-06-09T10:05:04Z | ---
library_name: transformers
license: apache-2.0
datasets:
- HuggingFaceM4/the_cauldron
- HuggingFaceM4/Docmatix
pipeline_tag: image-text-to-text
language:
- en
base_model:
- HuggingFaceTB/SmolLM2-1.7B-Instruct
- google/siglip-so400m-patch14-384
---
# <span style="color: #7FFF7F;">SmolVLM-Instruct GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`5787b5da`](https://github.com/ggerganov/llama.cpp/commit/5787b5da57e54dba760c2deeac1edf892e8fc450).
## <span style="color: #7FFF7F;"> Quantization beyond the IMatrix</span>
Testing a new quantization method using rules to bump important layers above what the standard imatrix would use.
I have found that the standard IMatrix does not perform very well at low bit quantiztion and for MOE models. So I am using llama.cpp --tensor-type to bump up selected layers. See [Layer bumping with llama.cpp](https://github.com/Mungert69/GGUFModelBuilder/blob/main/model-converter/tensor_list_builder.py)
This does create larger model files but increases precision for a given model size.
### **Please provide feedback on how you find this method performs**
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Hybrid Precision Models (e.g., `bf16_q8_0`, `f16_q4_K`) – Best of Both Worlds**
These formats selectively **quantize non-essential layers** while keeping **key layers in full precision** (e.g., attention and output layers).
- Named like `bf16_q8_0` (meaning **full-precision BF16 core layers + quantized Q8_0 other layers**).
- Strike a **balance between memory efficiency and accuracy**, improving over fully quantized models without requiring the full memory of BF16/F16.
📌 **Use Hybrid Models if:**
✔ You need **better accuracy than quant-only models** but can’t afford full BF16/F16 everywhere.
✔ Your device supports **mixed-precision inference**.
✔ You want to **optimize trade-offs** for production-grade models on constrained hardware.
📌 **Avoid Hybrid Models if:**
❌ Your target device doesn’t support **mixed or full-precision acceleration**.
❌ You are operating under **ultra-strict memory limits** (in which case use fully quantized formats).
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **very high memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **very high memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
### **Ultra Low-Bit Quantization (IQ1_S IQ1_M IQ2_S IQ2_M IQ2_XS IQ2_XSS)**
- *Ultra-low-bit quantization (1 2-bit) with **extreme memory efficiency**.
- **Use case**: Best for cases were you have to fit the model into very constrained memory
- **Trade-off**: Very Low Accuracy. May not function as expected. Please test fully before using.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------------------|------------------|------------------|----------------------------------|--------------------------------------------------------------|
| **BF16** | Very High | High | BF16-supported GPU/CPU | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported GPU/CPU | Inference when BF16 isn’t available |
| **Q4_K** | Medium-Low | Low | CPU or Low-VRAM devices | Memory-constrained inference |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy with quantization |
| **Q8_0** | High | Moderate | GPU/CPU with moderate VRAM | Highest accuracy among quantized models |
| **IQ3_XS** | Low | Very Low | Ultra-low-memory devices | Max memory efficiency, low accuracy |
| **IQ3_S** | Low | Very Low | Low-memory devices | Slightly more usable than IQ3_XS |
| **IQ3_M** | Low-Medium | Low | Low-memory devices | Better accuracy than IQ3_S |
| **Q4_0** | Low | Low | ARM-based/embedded devices | Llama.cpp automatically optimizes for ARM inference |
| **Ultra Low-Bit (IQ1/2_*)** | Very Low | Extremely Low | Tiny edge/embedded devices | Fit models in extremely tight memory; low accuracy |
| **Hybrid (e.g., `bf16_q8_0`)** | Medium–High | Medium | Mixed-precision capable hardware | Balanced performance and memory, near-FP accuracy in critical layers |
---
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/SmolVLM.png" width="800" height="auto" alt="Image description">
# SmolVLM
SmolVLM is a compact open multimodal model that accepts arbitrary sequences of image and text inputs to produce text outputs. Designed for efficiency, SmolVLM can answer questions about images, describe visual content, create stories grounded on multiple images, or function as a pure language model without visual inputs. Its lightweight architecture makes it suitable for on-device applications while maintaining strong performance on multimodal tasks.
## Model Summary
- **Developed by:** Hugging Face 🤗
- **Model type:** Multi-modal model (image+text)
- **Language(s) (NLP):** English
- **License:** Apache 2.0
- **Architecture:** Based on [Idefics3](https://huggingface.co/HuggingFaceM4/Idefics3-8B-Llama3) (see technical summary)
## Resources
- **Demo:** [SmolVLM Demo](https://huggingface.co/spaces/HuggingFaceTB/SmolVLM)
- **Blog:** [Blog post](https://huggingface.co/blog/smolvlm)
## Uses
SmolVLM can be used for inference on multimodal (image + text) tasks where the input comprises text queries along with one or more images. Text and images can be interleaved arbitrarily, enabling tasks like image captioning, visual question answering, and storytelling based on visual content. The model does not support image generation.
To fine-tune SmolVLM on a specific task, you can follow the fine-tuning tutorial.
<!-- todo: add link to fine-tuning tutorial -->
### Technical Summary
SmolVLM leverages the lightweight SmolLM2 language model to provide a compact yet powerful multimodal experience. It introduces several changes compared to previous Idefics models:
- **Image compression:** We introduce a more radical image compression compared to Idefics3 to enable the model to infer faster and use less RAM.
- **Visual Token Encoding:** SmolVLM uses 81 visual tokens to encode image patches of size 384×384. Larger images are divided into patches, each encoded separately, enhancing efficiency without compromising performance.
More details about the training and architecture are available in our technical report.
### How to get started
You can use transformers to load, infer and fine-tune SmolVLM.
```python
import torch
from PIL import Image
from transformers import AutoProcessor, AutoModelForVision2Seq
from transformers.image_utils import load_image
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
# Load images
image1 = load_image("https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg")
image2 = load_image("https://huggingface.co/spaces/merve/chameleon-7b/resolve/main/bee.jpg")
# Initialize processor and model
processor = AutoProcessor.from_pretrained("HuggingFaceTB/SmolVLM-Instruct")
model = AutoModelForVision2Seq.from_pretrained(
"HuggingFaceTB/SmolVLM-Instruct",
torch_dtype=torch.bfloat16,
_attn_implementation="flash_attention_2" if DEVICE == "cuda" else "eager",
).to(DEVICE)
# Create input messages
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "image"},
{"type": "text", "text": "Can you describe the two images?"}
]
},
]
# Prepare inputs
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
inputs = processor(text=prompt, images=[image1, image2], return_tensors="pt")
inputs = inputs.to(DEVICE)
# Generate outputs
generated_ids = model.generate(**inputs, max_new_tokens=500)
generated_texts = processor.batch_decode(
generated_ids,
skip_special_tokens=True,
)
print(generated_texts[0])
"""
Assistant: The first image shows a green statue of the Statue of Liberty standing on a stone pedestal in front of a body of water.
The statue is holding a torch in its right hand and a tablet in its left hand. The water is calm and there are no boats or other objects visible.
The sky is clear and there are no clouds. The second image shows a bee on a pink flower.
The bee is black and yellow and is collecting pollen from the flower. The flower is surrounded by green leaves.
"""
```
### Model optimizations
**Precision**: For better performance, load and run the model in half-precision (`torch.float16` or `torch.bfloat16`) if your hardware supports it.
```python
from transformers import AutoModelForVision2Seq
import torch
model = AutoModelForVision2Seq.from_pretrained(
"HuggingFaceTB/SmolVLM-Instruct",
torch_dtype=torch.bfloat16
).to("cuda")
```
You can also load SmolVLM with 4/8-bit quantization using bitsandbytes, torchao or Quanto. Refer to [this page](https://huggingface.co/docs/transformers/en/main_classes/quantization) for other options.
```python
from transformers import AutoModelForVision2Seq, BitsAndBytesConfig
import torch
quantization_config = BitsAndBytesConfig(load_in_8bit=True)
model = AutoModelForVision2Seq.from_pretrained(
"HuggingFaceTB/SmolVLM-Instruct",
quantization_config=quantization_config,
)
```
**Vision Encoder Efficiency**: Adjust the image resolution by setting `size={"longest_edge": N*384}` when initializing the processor, where N is your desired value. The default `N=4` works well, which results in input images of
size 1536×1536. For documents, `N=5` might be beneficial. Decreasing N can save GPU memory and is appropriate for lower-resolution images. This is also useful if you want to fine-tune on videos.
## Misuse and Out-of-scope Use
SmolVLM is not intended for high-stakes scenarios or critical decision-making processes that affect an individual's well-being or livelihood. The model may produce content that appears factual but may not be accurate. Misuse includes, but is not limited to:
- Prohibited Uses:
- Evaluating or scoring individuals (e.g., in employment, education, credit)
- Critical automated decision-making
- Generating unreliable factual content
- Malicious Activities:
- Spam generation
- Disinformation campaigns
- Harassment or abuse
- Unauthorized surveillance
### License
SmolVLM is built upon [the shape-optimized SigLIP](https://huggingface.co/google/siglip-so400m-patch14-384) as image encoder and [SmolLM2](https://huggingface.co/HuggingFaceTB/SmolLM2-1.7B-Instruct) for text decoder part.
We release the SmolVLM checkpoints under the Apache 2.0 license.
## Training Details
### Training Data
The training data comes from [The Cauldron](https://huggingface.co/datasets/HuggingFaceM4/the_cauldron) and [Docmatix](https://huggingface.co/datasets/HuggingFaceM4/Docmatix) datasets, with emphasis on document understanding (25%) and image captioning (18%), while maintaining balanced coverage across other crucial capabilities like visual reasoning, chart comprehension, and general instruction following.
<img src="https://huggingface.co/HuggingFaceTB/SmolVLM-Instruct/resolve/main/mixture_the_cauldron.png" alt="Example Image" style="width:90%;" />
## Evaluation
| Model | MMMU (val) | MathVista (testmini) | MMStar (val) | DocVQA (test) | TextVQA (val) | Min GPU RAM required (GB) |
|-------------------|------------|----------------------|--------------|---------------|---------------|---------------------------|
| SmolVLM | 38.8 | 44.6 | 42.1 | 81.6 | 72.7 | 5.02 |
| Qwen-VL 2B | 41.1 | 47.8 | 47.5 | 90.1 | 79.7 | 13.70 |
| InternVL2 2B | 34.3 | 46.3 | 49.8 | 86.9 | 73.4 | 10.52 |
| PaliGemma 3B 448px| 34.9 | 28.7 | 48.3 | 32.2 | 56.0 | 6.72 |
| moondream2 | 32.4 | 24.3 | 40.3 | 70.5 | 65.2 | 3.87 |
| MiniCPM-V-2 | 38.2 | 39.8 | 39.1 | 71.9 | 74.1 | 7.88 |
| MM1.5 1B | 35.8 | 37.2 | 0.0 | 81.0 | 72.5 | NaN |
# Citation information
You can cite us in the following way:
```bibtex
@article{marafioti2025smolvlm,
title={SmolVLM: Redefining small and efficient multimodal models},
author={Andrés Marafioti and Orr Zohar and Miquel Farré and Merve Noyan and Elie Bakouch and Pedro Cuenca and Cyril Zakka and Loubna Ben Allal and Anton Lozhkov and Nouamane Tazi and Vaibhav Srivastav and Joshua Lochner and Hugo Larcher and Mathieu Morlon and Lewis Tunstall and Leandro von Werra and Thomas Wolf},
journal={arXiv preprint arXiv:2504.05299},
year={2025}
}
```
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Help me test my **AI-Powered Quantum Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
The full Open Source Code for the Quantum Network Monitor Service available at my github repos ( repos with NetworkMonitor in the name) : [Source Code Quantum Network Monitor](https://github.com/Mungert69). You will also find the code I use to quantize the models if you want to do it yourself [GGUFModelBuilder](https://github.com/Mungert69/GGUFModelBuilder)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4.1-mini)
- `HugLLM` (Hugginface Open-source models)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap security scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads on huggingface docker space):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**) . No token limited as the cost is low.
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4.1-mini** :
- **It performs very well but unfortunatly OpenAI charges per token. For this reason tokens usage is limited.
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API. Performs pretty well using the lastest models hosted on Novita.
### 💡 **Example commands you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
|
Mungert/medgemma-27b-text-it-GGUF | Mungert | 2025-06-15T19:35:58Z | 2,840 | 6 | transformers | [
"transformers",
"gguf",
"medical",
"clinical-reasoning",
"thinking",
"text-generation",
"arxiv:2501.19393",
"arxiv:2303.15343",
"arxiv:2009.13081",
"arxiv:2102.09542",
"arxiv:2411.15640",
"arxiv:2404.05590",
"arxiv:2501.18362",
"base_model:google/gemma-3-27b-pt",
"base_model:quantized:google/gemma-3-27b-pt",
"license:other",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] | text-generation | 2025-05-29T06:32:42Z | ---
license: other
license_name: health-ai-developer-foundations
license_link: https://developers.google.com/health-ai-developer-foundations/terms
library_name: transformers
pipeline_tag: text-generation
extra_gated_heading: Access MedGemma on Hugging Face
extra_gated_prompt: >-
To access MedGemma on Hugging Face, you're required to review and agree to
[Health AI Developer Foundation's terms of
use](https://developers.google.com/health-ai-developer-foundations/terms). To
do this, please ensure you're logged in to Hugging Face and click below.
Requests are processed immediately.
extra_gated_button_content: Acknowledge license
base_model: google/gemma-3-27b-pt
tags:
- medical
- clinical-reasoning
- thinking
---
# <span style="color: #7FFF7F;">medgemma-27b-text-it GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`f5cd27b7`](https://github.com/ggerganov/llama.cpp/commit/f5cd27b71da3ac375a04a41643d14fc779a8057b).
## <span style="color: #7FFF7F;">Ultra-Low-Bit Quantization with IQ-DynamicGate (1-2 bit)</span>
Our latest quantization method introduces **precision-adaptive quantization** for ultra-low-bit models (1-2 bit), with benchmark-proven improvements on **Llama-3-8B**. This approach uses layer-specific strategies to preserve accuracy while maintaining extreme memory efficiency.
### **Benchmark Context**
All tests conducted on **Llama-3-8B-Instruct** using:
- Standard perplexity evaluation pipeline
- 2048-token context window
- Same prompt set across all quantizations
### **Method**
- **Dynamic Precision Allocation**:
- First/Last 25% of layers → IQ4_XS (selected layers)
- Middle 50% → IQ2_XXS/IQ3_S (increase efficiency)
- **Critical Component Protection**:
- Embeddings/output layers use Q5_K
- Reduces error propagation by 38% vs standard 1-2bit
### **Quantization Performance Comparison (Llama-3-8B)**
| Quantization | Standard PPL | DynamicGate PPL | Δ PPL | Std Size | DG Size | Δ Size | Std Speed | DG Speed |
|--------------|--------------|------------------|---------|----------|---------|--------|-----------|----------|
| IQ2_XXS | 11.30 | 9.84 | -12.9% | 2.5G | 2.6G | +0.1G | 234s | 246s |
| IQ2_XS | 11.72 | 11.63 | -0.8% | 2.7G | 2.8G | +0.1G | 242s | 246s |
| IQ2_S | 14.31 | 9.02 | -36.9% | 2.7G | 2.9G | +0.2G | 238s | 244s |
| IQ1_M | 27.46 | 15.41 | -43.9% | 2.2G | 2.5G | +0.3G | 206s | 212s |
| IQ1_S | 53.07 | 32.00 | -39.7% | 2.1G | 2.4G | +0.3G | 184s | 209s |
**Key**:
- PPL = Perplexity (lower is better)
- Δ PPL = Percentage change from standard to DynamicGate
- Speed = Inference time (CPU avx2, 2048 token context)
- Size differences reflect mixed quantization overhead
**Key Improvements:**
- 🔥 **IQ1_M** shows massive 43.9% perplexity reduction (27.46 → 15.41)
- 🚀 **IQ2_S** cuts perplexity by 36.9% while adding only 0.2GB
- ⚡ **IQ1_S** maintains 39.7% better accuracy despite 1-bit quantization
**Tradeoffs:**
- All variants have modest size increases (0.1-0.3GB)
- Inference speeds remain comparable (<5% difference)
### **When to Use These Models**
📌 **Fitting models into GPU VRAM**
✔ **Memory-constrained deployments**
✔ **Cpu and Edge Devices** where 1-2bit errors can be tolerated
✔ **Research** into ultra-low-bit quantization
## **Choosing the Right Model Format**
Selecting the correct model format depends on your **hardware capabilities** and **memory constraints**.
### **BF16 (Brain Float 16) – Use if BF16 acceleration is available**
- A 16-bit floating-point format designed for **faster computation** while retaining good precision.
- Provides **similar dynamic range** as FP32 but with **lower memory usage**.
- Recommended if your hardware supports **BF16 acceleration** (check your device's specs).
- Ideal for **high-performance inference** with **reduced memory footprint** compared to FP32.
📌 **Use BF16 if:**
✔ Your hardware has native **BF16 support** (e.g., newer GPUs, TPUs).
✔ You want **higher precision** while saving memory.
✔ You plan to **requantize** the model into another format.
📌 **Avoid BF16 if:**
❌ Your hardware does **not** support BF16 (it may fall back to FP32 and run slower).
❌ You need compatibility with older devices that lack BF16 optimization.
---
### **F16 (Float 16) – More widely supported than BF16**
- A 16-bit floating-point **high precision** but with less of range of values than BF16.
- Works on most devices with **FP16 acceleration support** (including many GPUs and some CPUs).
- Slightly lower numerical precision than BF16 but generally sufficient for inference.
📌 **Use F16 if:**
✔ Your hardware supports **FP16** but **not BF16**.
✔ You need a **balance between speed, memory usage, and accuracy**.
✔ You are running on a **GPU** or another device optimized for FP16 computations.
📌 **Avoid F16 if:**
❌ Your device lacks **native FP16 support** (it may run slower than expected).
❌ You have memory limitations.
---
### **Quantized Models (Q4_K, Q6_K, Q8, etc.) – For CPU & Low-VRAM Inference**
Quantization reduces model size and memory usage while maintaining as much accuracy as possible.
- **Lower-bit models (Q4_K)** → **Best for minimal memory usage**, may have lower precision.
- **Higher-bit models (Q6_K, Q8_0)** → **Better accuracy**, requires more memory.
📌 **Use Quantized Models if:**
✔ You are running inference on a **CPU** and need an optimized model.
✔ Your device has **low VRAM** and cannot load full-precision models.
✔ You want to reduce **memory footprint** while keeping reasonable accuracy.
📌 **Avoid Quantized Models if:**
❌ You need **maximum accuracy** (full-precision models are better for this).
❌ Your hardware has enough VRAM for higher-precision formats (BF16/F16).
---
### **Very Low-Bit Quantization (IQ3_XS, IQ3_S, IQ3_M, Q4_K, Q4_0)**
These models are optimized for **extreme memory efficiency**, making them ideal for **low-power devices** or **large-scale deployments** where memory is a critical constraint.
- **IQ3_XS**: Ultra-low-bit quantization (3-bit) with **extreme memory efficiency**.
- **Use case**: Best for **ultra-low-memory devices** where even Q4_K is too large.
- **Trade-off**: Lower accuracy compared to higher-bit quantizations.
- **IQ3_S**: Small block size for **maximum memory efficiency**.
- **Use case**: Best for **low-memory devices** where **IQ3_XS** is too aggressive.
- **IQ3_M**: Medium block size for better accuracy than **IQ3_S**.
- **Use case**: Suitable for **low-memory devices** where **IQ3_S** is too limiting.
- **Q4_K**: 4-bit quantization with **block-wise optimization** for better accuracy.
- **Use case**: Best for **low-memory devices** where **Q6_K** is too large.
- **Q4_0**: Pure 4-bit quantization, optimized for **ARM devices**.
- **Use case**: Best for **ARM-based devices** or **low-memory environments**.
---
### **Summary Table: Model Format Selection**
| Model Format | Precision | Memory Usage | Device Requirements | Best Use Case |
|--------------|------------|---------------|----------------------|---------------|
| **BF16** | Highest | High | BF16-supported GPU/CPUs | High-speed inference with reduced memory |
| **F16** | High | High | FP16-supported devices | GPU inference when BF16 isn't available |
| **Q4_K** | Medium Low | Low | CPU or Low-VRAM devices | Best for memory-constrained environments |
| **Q6_K** | Medium | Moderate | CPU with more memory | Better accuracy while still being quantized |
| **Q8_0** | High | Moderate | CPU or GPU with enough VRAM | Best accuracy among quantized models |
| **IQ3_XS** | Very Low | Very Low | Ultra-low-memory devices | Extreme memory efficiency and low accuracy |
| **Q4_0** | Low | Low | ARM or low-memory devices | llama.cpp can optimize for ARM devices |
---
## **Included Files & Details**
### `medgemma-27b-text-it-bf16.gguf`
- Model weights preserved in **BF16**.
- Use this if you want to **requantize** the model into a different format.
- Best if your device supports **BF16 acceleration**.
### `medgemma-27b-text-it-f16.gguf`
- Model weights stored in **F16**.
- Use if your device supports **FP16**, especially if BF16 is not available.
### `medgemma-27b-text-it-bf16-q8_0.gguf`
- **Output & embeddings** remain in **BF16**.
- All other layers quantized to **Q8_0**.
- Use if your device supports **BF16** and you want a quantized version.
### `medgemma-27b-text-it-f16-q8_0.gguf`
- **Output & embeddings** remain in **F16**.
- All other layers quantized to **Q8_0**.
### `medgemma-27b-text-it-q4_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q4_K**.
- Good for **CPU inference** with limited memory.
### `medgemma-27b-text-it-q4_k_s.gguf`
- Smallest **Q4_K** variant, using less memory at the cost of accuracy.
- Best for **very low-memory setups**.
### `medgemma-27b-text-it-q6_k.gguf`
- **Output & embeddings** quantized to **Q8_0**.
- All other layers quantized to **Q6_K** .
### `medgemma-27b-text-it-q8_0.gguf`
- Fully **Q8** quantized model for better accuracy.
- Requires **more memory** but offers higher precision.
### `medgemma-27b-text-it-iq3_xs.gguf`
- **IQ3_XS** quantization, optimized for **extreme memory efficiency**.
- Best for **ultra-low-memory devices**.
### `medgemma-27b-text-it-iq3_m.gguf`
- **IQ3_M** quantization, offering a **medium block size** for better accuracy.
- Suitable for **low-memory devices**.
### `medgemma-27b-text-it-q4_0.gguf`
- Pure **Q4_0** quantization, optimized for **ARM devices**.
- Best for **low-memory environments**.
- Prefer IQ4_NL for better accuracy.
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
❤ **Please click "Like" if you find this useful!**
Help me test my **AI-Powered Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/dashboard/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4o-mini)
- `HugLLM` (Hugginface Open-source)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**)
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4o-mini** for:
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API
### 💡 **Example commands to you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a Quantum Network Monitor Agent to run the .net code from. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
# MedGemma model card
**Model documentation:** [MedGemma](https://developers.google.com/health-ai-developer-foundations/medgemma)
**Resources:**
* Model on Google Cloud Model Garden: [MedGemma](https://console.cloud.google.com/vertex-ai/publishers/google/model-garden/medgemma)
* Model on Hugging Face: [MedGemma](https://huggingface.co/collections/google/medgemma-release-680aade845f90bec6a3f60c4)
* GitHub repository (supporting code, Colab notebooks, discussions, and
issues): [MedGemma](https://github.com/google-health/medgemma)
* Quick start notebook: [GitHub](https://github.com/google-health/medgemma/blob/main/notebooks/quick_start_with_hugging_face.ipynb)
* Fine-tuning notebook: [GitHub](https://github.com/google-health/medgemma/blob/main/notebooks/fine_tune_with_hugging_face.ipynb)
* [Patient Education Demo built using MedGemma](https://huggingface.co/spaces/google/rad_explain)
* Support: See [Contact](https://developers.google.com/health-ai-developer-foundations/medgemma/get-started.md#contact)
* License: The use of MedGemma is governed by the [Health AI Developer
Foundations terms of
use](https://developers.google.com/health-ai-developer-foundations/terms).
**Author:** Google
## Model information
This section describes the MedGemma model and how to use it.
### Description
MedGemma is a collection of [Gemma 3](https://ai.google.dev/gemma/docs/core)
variants that are trained for performance on medical text and image
comprehension. Developers can use MedGemma to accelerate building
healthcare-based AI applications. MedGemma currently comes in two variants: a 4B
multimodal version and a 27B text-only version.
MedGemma 27B has been trained exclusively on medical text and optimized for
inference-time computation. MedGemma 27B is only available as an
instruction-tuned model.
MedGemma variants have been evaluated on a range of clinically relevant
benchmarks to illustrate their baseline performance. These include both open
benchmark datasets and curated datasets. Developers can fine-tune MedGemma
variants for improved performance. Consult the Intended Use section below for
more details.
A full technical report will be available soon.
### How to use
Below are some example code snippets to help you quickly get started running the
model locally on GPU. If you want to use the model at scale, we recommend that
you create a production version using [Model
Garden](https://cloud.google.com/model-garden).
First, install the Transformers library. Gemma 3 is supported starting from
transformers 4.50.0.
```sh
$ pip install -U transformers
```
**Run model with the `pipeline` API**
```python
from transformers import pipeline
import torch
pipe = pipeline(
"text-generation",
model="google/medgemma-27b-text-it",
torch_dtype=torch.bfloat16,
device="cuda",
)
messages = [
{
"role": "system",
"content": "You are a helpful medical assistant."
},
{
"role": "user",
"content": "How do you differentiate bacterial from viral pneumonia?"
}
]
output = pipe(text=messages, max_new_tokens=200)
print(output[0]["generated_text"][-1]["content"])
```
**Run the model directly**
```python
# pip install accelerate
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "google/medgemma-27b-text-it"
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
messages = [
{
"role": "system",
"content": "You are a helpful medical assistant."
},
{
"role": "user",
"content": "How do you differentiate bacterial from viral pneumonia?"
}
]
inputs = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt",
).to(model.device)
input_len = inputs["input_ids"].shape[-1]
with torch.inference_mode():
generation = model.generate(**inputs, max_new_tokens=200, do_sample=False)
generation = generation[0][input_len:]
decoded = tokenizer.decode(generation, skip_special_tokens=True)
print(decoded)
```
### Examples
See the following Colab notebooks for examples of how to use MedGemma:
* To give the model a quick try, running it locally with weights from Hugging
Face, see [Quick start notebook in
Colab](https://colab.research.google.com/github/google-health/medgemma/blob/main/notebooks/quick_start_with_hugging_face.ipynb).
Note that you will need to use Colab Enterprise to run the 27B model without
quantization.
* For an example of fine-tuning the model, see the [Fine-tuning notebook in
Colab](https://colab.research.google.com/github/google-health/medgemma/blob/main/notebooks/fine_tune_with_hugging_face.ipynb).
### Model architecture overview
The MedGemma model is built based on [Gemma 3](https://ai.google.dev/gemma/) and
uses the same decoder-only transformer architecture as Gemma 3. To read more
about the architecture, consult the Gemma 3 [model
card](https://ai.google.dev/gemma/docs/core/model_card_3).
### Technical specifications
* **Model type**: Decoder-only Transformer architecture, see the [Gemma 3
technical
report](https://storage.googleapis.com/deepmind-media/gemma/Gemma3Report.pdf)
* **Modalities**: **4B**: Text, vision; **27B**: Text only
* **Attention mechanism**: Utilizes grouped-query attention (GQA)
* **Context length**: Supports long context, at least 128K tokens
* **Key publication**: Coming soon
* **Model created**: May 20, 2025
* **Model version**: 1.0.0
### Citation
A technical report is coming soon. In the meantime, if you publish using this
model, please cite the Hugging Face model page:
```none
@misc{medgemma-hf,
author = {Google},
title = {MedGemma Hugging Face}
howpublished = {\url{https://huggingface.co/collections/google/medgemma-release-680aade845f90bec6a3f60c4}},
year = {2025},
note = {Accessed: [Insert Date Accessed, e.g., 2025-05-20]}
}
```
### Inputs and outputs
**Input**:
* Text string, such as a question or prompt
* Total input length of 128K tokens
**Output**:
* Generated text in response to the input, such as an answer to a question,
analysis of image content, or a summary of a document
* Total output length of 8192 tokens
### Performance and validation
MedGemma was evaluated across a range of different multimodal classification,
report generation, visual question answering, and text-based tasks.
### Key performance metrics
#### Text evaluations
MedGemma 4B and text-only MedGemma 27B were evaluated across a range of
text-only benchmarks for medical knowledge and reasoning.
The MedGemma models outperform their respective base Gemma models across all
tested text-only health benchmarks.
| Metric | MedGemma 27B | Gemma 3 27B | MedGemma 4B | Gemma 3 4B |
| :---- | :---- | :---- | :---- | :---- |
| MedQA (4-op) | 89.8 (best-of-5) 87.7 (0-shot) | 74.9 | 64.4 | 50.7 |
| MedMCQA | 74.2 | 62.6 | 55.7 | 45.4 |
| PubMedQA | 76.8 | 73.4 | 73.4 | 68.4 |
| MMLU Med (text only) | 87.0 | 83.3 | 70.0 | 67.2 |
| MedXpertQA (text only) | 26.7 | 15.7 | 14.2 | 11.6 |
| AfriMed-QA | 84.0 | 72.0 | 52.0 | 48.0 |
For all MedGemma 27B results, [test-time
scaling](https://arxiv.org/abs/2501.19393) is used to improve performance.
### Ethics and safety evaluation
#### Evaluation approach
Our evaluation methods include structured evaluations and internal red-teaming
testing of relevant content policies. Red-teaming was conducted by a number of
different teams, each with different goals and human evaluation metrics. These
models were evaluated against a number of different categories relevant to
ethics and safety, including:
* **Child safety**: Evaluation of text-to-text and image-to-text prompts
covering child safety policies, including child sexual abuse and
exploitation.
* **Content safety:** Evaluation of text-to-text and image-to-text prompts
covering safety policies, including harassment, violence and gore, and hate
speech.
* **Representational harms**: Evaluation of text-to-text and image-to-text
prompts covering safety policies, including bias, stereotyping, and harmful
associations or inaccuracies.
* **General medical harms:** Evaluation of text-to-text and image-to-text
prompts covering safety policies, including information quality and harmful
associations or inaccuracies.
In addition to development level evaluations, we conduct "assurance evaluations"
which are our "arms-length" internal evaluations for responsibility governance
decision making. They are conducted separately from the model development team,
to inform decision making about release. High-level findings are fed back to the
model team, but prompt sets are held out to prevent overfitting and preserve the
results' ability to inform decision making. Notable assurance evaluation results
are reported to our Responsibility & Safety Council as part of release review.
#### Evaluation results
For all areas of safety testing, we saw safe levels of performance across the
categories of child safety, content safety, and representational harms. All
testing was conducted without safety filters to evaluate the model capabilities
and behaviors. For text-to-text, image-to-text, and audio-to-text, and across
both MedGemma model sizes, the model produced minimal policy violations. A
limitation of our evaluations was that they included primarily English language
prompts.
## Data card
### Dataset overview
#### Training
The base Gemma models are pre-trained on a large corpus of text and code data.
MedGemma 4B utilizes a [SigLIP](https://arxiv.org/abs/2303.15343) image encoder
that has been specifically pre-trained on a variety of de-identified medical
data, including radiology images, histopathology images, ophthalmology images,
and dermatology images. Its LLM component is trained on a diverse set of medical
data, including medical text relevant to radiology images, chest-x rays,
histopathology patches, ophthalmology images and dermatology images.
#### Evaluation
MedGemma models have been evaluated on a comprehensive set of clinically
relevant benchmarks, including over 22 datasets across 5 different tasks and 6
medical image modalities. These include both open benchmark datasets and curated
datasets, with a focus on expert human evaluations for tasks like CXR report
generation and radiology VQA.
#### Source
MedGemma utilizes a combination of public and private datasets.
This model was trained on diverse public datasets including MIMIC-CXR (chest
X-rays and reports), Slake-VQA (multimodal medical images and questions),
PAD-UFES-20 (skin lesion images and data), SCIN (dermatology images), TCGA
(cancer genomics data), CAMELYON (lymph node histopathology images), PMC-OA
(biomedical literature with images), and Mendeley Digital Knee X-Ray (knee
X-rays).
Additionally, multiple diverse proprietary datasets were licensed and
incorporated (described next).
### Data Ownership and Documentation
* [Mimic-CXR](https://physionet.org/content/mimic-cxr/2.1.0/): MIT Laboratory
for Computational Physiology and Beth Israel Deaconess Medical Center
(BIDMC).
* [Slake-VQA](https://www.med-vqa.com/slake/): The Hong Kong Polytechnic
University (PolyU), with collaborators including West China Hospital of
Sichuan University and Sichuan Academy of Medical Sciences / Sichuan
Provincial People's Hospital.
* [PAD-UFES-20](https://pmc.ncbi.nlm.nih.gov/articles/PMC7479321/): Federal
University of Espírito Santo (UFES), Brazil, through its Dermatological and
Surgical Assistance Program (PAD).
* [SCIN](https://github.com/google-research-datasets/scin): A collaboration
between Google Health and Stanford Medicine.
* [TCGA](https://portal.gdc.cancer.gov/) (The Cancer Genome Atlas): A joint
effort of National Cancer Institute and National Human Genome Research
Institute. Data from TCGA are available via the Genomic Data Commons (GDC)
* [CAMELYON](https://camelyon17.grand-challenge.org/Data/): The data was
collected from Radboud University Medical Center and University Medical
Center Utrecht in the Netherlands.
* [PMC-OA (PubMed Central Open Access
Subset)](https://catalog.data.gov/dataset/pubmed-central-open-access-subset-pmc-oa):
Maintained by the National Library of Medicine (NLM) and National Center for
Biotechnology Information (NCBI), which are part of the NIH.
* [MedQA](https://arxiv.org/pdf/2009.13081): This dataset was created by a
team of researchers led by Di Jin, Eileen Pan, Nassim Oufattole, Wei-Hung
Weng, Hanyi Fang, and Peter Szolovits
* [Mendeley Digital Knee
X-Ray](https://data.mendeley.com/datasets/t9ndx37v5h/1): This dataset is
from Rani Channamma University, and is hosted on Mendeley Data.
* [AfriMed-QA](https://afrimedqa.com/): This data was developed and led by
multiple collaborating organizations and researchers include key
contributors: Intron Health, SisonkeBiotik, BioRAMP, Georgia Institute of
Technology, and MasakhaneNLP.
* [VQA-RAD](https://www.nature.com/articles/sdata2018251): This dataset was
created by a research team led by Jason J. Lau, Soumya Gayen, Asma Ben
Abacha, and Dina Demner-Fushman and their affiliated institutions (the US
National Library of Medicine and National Institutes of Health)
* [MedExpQA](https://www.sciencedirect.com/science/article/pii/S0933365724001805):
This dataset was created by researchers at the HiTZ Center (Basque Center
for Language Technology and Artificial Intelligence).
* [MedXpertQA](https://huggingface.co/datasets/TsinghuaC3I/MedXpertQA): This
dataset was developed by researchers at Tsinghua University (Beijing, China)
and Shanghai Artificial Intelligence Laboratory (Shanghai, China).
In addition to the public datasets listed above, MedGemma was also trained on
de-identified datasets licensed for research or collected internally at Google
from consented participants.
* Radiology dataset 1: De-identified dataset of different CT studies across
body parts from a US-based radiology outpatient diagnostic center network.
* Ophthalmology dataset 1: De-identified dataset of fundus images from
diabetic retinopathy screening.
* Dermatology dataset 1: De-identified dataset of teledermatology skin
condition images (both clinical and dermatoscopic) from Colombia.
* Dermatology dataset 2: De-identified dataset of skin cancer images (both
clinical and dermatoscopic) from Australia.
* Dermatology dataset 3: De-identified dataset of non-diseased skin images
from an internal data collection effort.
* Pathology dataset 1: De-identified dataset of histopathology H&E whole slide
images created in collaboration with an academic research hospital and
biobank in Europe. Comprises de-identified colon, prostate, and lymph nodes.
* Pathology dataset 2: De-identified dataset of lung histopathology H&E and
IHC whole slide images created by a commercial biobank in the United States.
* Pathology dataset 3: De-identified dataset of prostate and lymph node H&E
and IHC histopathology whole slide images created by a contract research
organization in the United States.
* Pathology dataset 4: De-identified dataset of histopathology, predominantly
H\&E whole slide images created in collaboration with a large, tertiary
teaching hospital in the United States. Comprises a diverse set of tissue
and stain types, predominantly H&E.
### Data citation
* **MIMIC-CXR** Johnson, A., Pollard, T., Mark, R., Berkowitz, S., & Horng, S.
(2024). MIMIC-CXR Database (version 2.1.0). PhysioNet.
https://physionet.org/content/mimic-cxr/2.1.0/
*and* Johnson, Alistair E. W., Tom J. Pollard, Seth J. Berkowitz, Nathaniel R.
Greenbaum, Matthew P. Lungren, Chih-Ying Deng, Roger G. Mark, and Steven
Horng. 2019. "MIMIC-CXR, a de-Identified Publicly Available Database of
Chest Radiographs with Free-Text Reports." *Scientific Data 6* (1): 1–8.
* **SLAKE** Liu, Bo, Li-Ming Zhan, Li Xu, Lin Ma, Yan Yang, and Xiao-Ming Wu.
2021.SLAKE: A Semantically-Labeled Knowledge-Enhanced Dataset for Medical
Visual Question Answering." http://arxiv.org/abs/2102.09542.
* **PAD-UEFS** Pacheco, A. G. C., Lima, G. R., Salomao, A., Krohling, B.,
Biral, I. P., de Angelo, G. G., Alves, F. O. G., Ju X. M., & P. R. C.
(2020). PAD-UFES-20: A skin lesion dataset composed of patient data and
clinical images collected from smartphones. In *Proceedings of the 2020 IEEE
International Conference on Bioinformatics and Biomedicine (BIBM)* (pp.
1551-1558). IEEE. https://doi.org/10.1109/BIBM49941.2020.9313241
* **SCIN** Ward, Abbi, Jimmy Li, Julie Wang, Sriram Lakshminarasimhan, Ashley
Carrick, Bilson Campana, Jay Hartford, et al. 2024. "Creating an Empirical
Dermatology Dataset Through Crowdsourcing With Web Search Advertisements."
*JAMA Network Open 7* (11): e2446615–e2446615.
* **TCGA** The results shown here are in whole or part based upon data
generated by the TCGA Research Network: https://www.cancer.gov/tcga.
* **CAMELYON16** Ehteshami Bejnordi, Babak, Mitko Veta, Paul Johannes van
Diest, Bram van Ginneken, Nico Karssemeijer, Geert Litjens, Jeroen A. W. M.
van der Laak, et al. 2017. "Diagnostic Assessment of Deep Learning
Algorithms for Detection of Lymph Node Metastases in Women With Breast
Cancer." *JAMA 318* (22): 2199–2210.
* **MedQA** Jin, Di, Eileen Pan, Nassim Oufattole, Wei-Hung Weng, Hanyi Fang,
and Peter Szolovits. 2020. "What Disease Does This Patient Have? A
Large-Scale Open Domain Question Answering Dataset from Medical Exams."
http://arxiv.org/abs/2009.13081.
* **Mendeley Digital Knee X-Ray** Gornale, Shivanand; Patravali, Pooja (2020),
"Digital Knee X-ray Images", Mendeley Data, V1, doi: 10.17632/t9ndx37v5h.1
* **AfrimedQA** Olatunji, Tobi, Charles Nimo, Abraham Owodunni, Tassallah
Abdullahi, Emmanuel Ayodele, Mardhiyah Sanni, Chinemelu Aka, et al. 2024.
"AfriMed-QA: A Pan-African, Multi-Specialty, Medical Question-Answering
Benchmark Dataset." http://arxiv.org/abs/2411.15640.
* **VQA-RAD** Lau, Jason J., Soumya Gayen, Asma Ben Abacha, and Dina
Demner-Fushman. 2018. "A Dataset of Clinically Generated Visual Questions
and Answers about Radiology Images." *Scientific Data 5* (1): 1–10.
* **MedexpQA** Alonso, I., Oronoz, M., & Agerri, R. (2024). MedExpQA:
Multilingual Benchmarking of Large Language Models for Medical Question
Answering. *arXiv preprint arXiv:2404.05590*. Retrieved from
https://arxiv.org/abs/2404.05590
* **MedXpertQA** Zuo, Yuxin, Shang Qu, Yifei Li, Zhangren Chen, Xuekai Zhu,
Ermo Hua, Kaiyan Zhang, Ning Ding, and Bowen Zhou. 2025. "MedXpertQA:
Benchmarking Expert-Level Medical Reasoning and Understanding."
http://arxiv.org/abs/2501.18362.
### De-identification/anonymization:
Google and partnerships utilize datasets that have been rigorously anonymized or
de-identified to ensure the protection of individual research participants and
patient privacy
## Implementation information
Details about the model internals.
### Software
Training was done using [JAX](https://github.com/jax-ml/jax).
JAX allows researchers to take advantage of the latest generation of hardware,
including TPUs, for faster and more efficient training of large models.
## Use and limitations
### Intended use
MedGemma is an open multimodal generative AI model intended to be used as a
starting point that enables more efficient development of downstream healthcare
applications involving medical text and images. MedGemma is intended for
developers in the life sciences and healthcare space. Developers are responsible
for training, adapting and making meaningful changes to MedGemma to accomplish
their specific intended use. MedGemma models can be fine-tuned by developers
using their own proprietary data for their specific tasks or solutions.
MedGemma is based on Gemma 3 and has been further trained on medical images and
text. MedGemma enables further development in any medical context (image and
textual), however the model was pre-trained using chest X-ray, pathology,
dermatology, and fundus images. Examples of tasks within MedGemma's training
include visual question answering pertaining to medical images, such as
radiographs, or providing answers to textual medical questions. Full details of
all the tasks MedGemma has been evaluated can be found in an upcoming technical
report.
### Benefits
* Provides strong baseline medical image and text comprehension for models of
its size.
* This strong performance makes it efficient to adapt for downstream
healthcare-based use cases, compared to models of similar size without
medical data pre-training.
* This adaptation may involve prompt engineering, grounding, agentic
orchestration or fine-tuning depending on the use case, baseline validation
requirements, and desired performance characteristics.
### Limitations
MedGemma is not intended to be used without appropriate validation, adaptation
and/or making meaningful modification by developers for their specific use case.
The outputs generated by MedGemma are not intended to directly inform clinical
diagnosis, patient management decisions, treatment recommendations, or any other
direct clinical practice applications. Performance benchmarks highlight baseline
capabilities on relevant benchmarks, but even for image and text domains that
constitute a substantial portion of training data, inaccurate model output is
possible. All outputs from MedGemma should be considered preliminary and require
independent verification, clinical correlation, and further investigation
through established research and development methodologies.
MedGemma's multimodal capabilities have been primarily evaluated on single-image
tasks. MedGemma has not been evaluated in use cases that involve comprehension
of multiple images.
MedGemma has not been evaluated or optimized for multi-turn applications.
MedGemma's training may make it more sensitive to the specific prompt used than
Gemma 3.
When adapting MedGemma developer should consider the following:
* **Bias in validation data:** As with any research, developers should ensure
that any downstream application is validated to understand performance using
data that is appropriately representative of the intended use setting for
the specific application (e.g., age, sex, gender, condition, imaging device,
etc).
* **Data contamination concerns**: When evaluating the generalization
capabilities of a large model like MedGemma in a medical context, there is a
risk of data contamination, where the model might have inadvertently seen
related medical information during its pre-training, potentially
overestimating its true ability to generalize to novel medical concepts.
Developers should validate MedGemma on datasets not publicly available or
otherwise made available to non-institutional researchers to mitigate this
risk. |
Yukang/Qwen2.5-3B-Open-R1-GRPO | Yukang | 2025-06-15T19:35:49Z | 6 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"open-r1",
"trl",
"grpo",
"conversational",
"dataset:open-r1/OpenR1-Math-220k",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2.5-3B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-3B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-12T20:31:17Z | ---
base_model: Qwen/Qwen2.5-3B-Instruct
datasets: open-r1/OpenR1-Math-220k
library_name: transformers
model_name: Qwen2.5-3B-Open-R1-GRPO
tags:
- generated_from_trainer
- open-r1
- trl
- grpo
licence: license
---
# Model Card for Qwen2.5-3B-Open-R1-GRPO
This model is a fine-tuned version of [Qwen/Qwen2.5-3B-Instruct](https://huggingface.co/Qwen/Qwen2.5-3B-Instruct) on the [open-r1/OpenR1-Math-220k](https://huggingface.co/datasets/open-r1/OpenR1-Math-220k) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Yukang/Qwen2.5-3B-Open-R1-GRPO", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/chenyukang2020-nvidia/huggingface/runs/9wwsfr8r)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.18.0
- Transformers: 4.52.3
- Pytorch: 2.6.0
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
hasdal/dataautogpt3-ProteusSigma-test-6ec8f5cf | hasdal | 2025-06-15T19:33:58Z | 0 | 0 | diffusers | [
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"ai-toolkit",
"base_model:dataautogpt3/ProteusSigma",
"base_model:adapter:dataautogpt3/ProteusSigma",
"license:creativeml-openrail-m",
"region:us"
] | text-to-image | 2025-06-15T19:33:50Z | ---
tags:
- text-to-image
- stable-diffusion-xl
- lora
- diffusers
- template:sd-lora
- ai-toolkit
widget:
- text: a photo of 98199508-8f07-4d47-beef-0fd41ee40673 style
output:
url: samples/1750016016367__000001000_0.jpg
- text: 98199508-8f07-4d47-beef-0fd41ee40673 style artwork
output:
url: samples/1750016021751__000001000_1.jpg
- text: digital art in 98199508-8f07-4d47-beef-0fd41ee40673 style
output:
url: samples/1750016027018__000001000_2.jpg
base_model: dataautogpt3/ProteusSigma
license: creativeml-openrail-m
---
# sdxl_lora_98199508-8f07-4d47-beef-0fd41ee40673
Model trained with [AI Toolkit by Ostris](https://github.com/ostris/ai-toolkit)
<Gallery />
## Trigger words
No trigger words defined.
## Download model and use it with ComfyUI, AUTOMATIC1111, SD.Next, Invoke AI, etc.
Weights for this model are available in Safetensors format.
[Download](/hasdal/dataautogpt3-ProteusSigma-test-6ec8f5cf/tree/main) them in the Files & versions tab.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('dataautogpt3/ProteusSigma', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('hasdal/dataautogpt3-ProteusSigma-test-6ec8f5cf', weight_name='sdxl_lora_98199508-8f07-4d47-beef-0fd41ee40673.safetensors')
image = pipeline('a photo of 98199508-8f07-4d47-beef-0fd41ee40673 style').images[0]
image.save("my_image.png")
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
gradientrouting-spar/horizontal_5_proxy_ntrain_25_ntrig_9_random_3x3_seed_1_seed_25_20250615_192335 | gradientrouting-spar | 2025-06-15T19:32:57Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T19:32:49Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.15_0.5_epoch1 | MinaMila | 2025-06-15T19:31:46Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T19:29:44Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
VIDEOS-19-sajal-malik-Viral-Video/FULL.VIDEO.jobz.hunting.sajal.malik.Viral.Video.Tutorial.Official | VIDEOS-19-sajal-malik-Viral-Video | 2025-06-15T19:31:42Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:31:11Z | <animated-image data-catalyst=""><a href="https://sexleakedviral.com/new-leaked-video/?news-viral-video" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a> |
Peacemann/Qwen_Qwen3-32B_LMUL | Peacemann | 2025-06-15T19:29:27Z | 0 | 0 | null | [
"qwen3",
"L-Mul,",
"optimazation",
"quantization",
"text-generation",
"research",
"experimental",
"conversational",
"base_model:Qwen/Qwen3-32B",
"base_model:finetune:Qwen/Qwen3-32B",
"license:apache-2.0",
"region:us"
] | text-generation | 2025-06-15T19:25:53Z | ---
license: apache-2.0
base_model:
- Qwen/Qwen3-32B
tags:
- L-Mul,
- optimazation
- quantization
- text-generation
- research
- experimental
---
# L-Mul Optimized: Qwen/Qwen3-32B
This is a modified version of Alibaba Cloud's [Qwen3-32B](https://huggingface.co/Qwen/Qwen3-32B) model. The modification consists of replacing the standard attention mechanism with one that uses a custom, approximate matrix multiplication algorithm termed "L-Mul".
This work was performed as part of a research project to evaluate the performance and accuracy trade-offs of algorithmic substitutions in transformer architectures.
**This model is intended strictly for educational and scientific purposes.**
## Model Description
The core architecture of `Qwen/Qwen3-32B` is preserved. However, the standard `Qwen3Attention` modules have been dynamically replaced with a custom version that utilizes the `l_mul_attention` function for its core computations. This function is defined in the `lmul.py` file included in this repository.
- **Base Model:** [Qwen/Qwen3-32B](https://huggingface.co/Qwen/Qwen3-32B)
- **Modification:** Replacement of standard attention with L-Mul approximate attention.
- **Primary Use-Case:** Research and educational analysis of algorithmic impact on LLMs.
## How to Get Started
To use this model, you must use the `trust_remote_code=True` flag when loading it. This is required to execute the custom `lmul.py` file that defines the new attention mechanism.
You can load the model directly from this repository using the `transformers` library:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# Define the repository ID for the specific model
repo_id = "Peacemann/Qwen_Qwen3-32B_LMUL" # Replace with the correct repo ID if different
# Load the tokenizer and model, trusting the remote code to load lmul.py
tokenizer = AutoTokenizer.from_pretrained(repo_id)
model = AutoModelForCausalLM.from_pretrained(
repo_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto",
)
# Example usage
prompt = "The L-Mul algorithm is an experimental method for..."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
For high-throughput inference, you can use `vLLM`:
```python
from vllm import LLM
repo_id = "Peacemann/Qwen_Qwen3-32B_LMUL" # Replace with the correct repo ID
llm = LLM(model=repo_id, trust_remote_code=True)
```
## Intended Uses & Limitations
This model is intended for researchers and students exploring the internal workings of LLMs. It is a tool for visualizing and analyzing the effects of fundamental algorithmic changes.
**This model is NOT intended for any commercial or production application.**
The modification is experimental. The impact on the model's performance, safety alignment, accuracy, and potential for generating biased or harmful content is **unknown and untested**. It inherits all limitations and biases of the original `Qwen3-32B` model, and its behavior may be altered in unpredictable ways.
## Licensing Information
The use of this model is subject to the original **Qwen3 License**. By using this model, you agree to the terms outlined in the license. The license can be found on the base model's Hugging Face page. |
19-sajal-malik-Official-Viral-Video-K/FULL.VIDEO.jobz.hunting.sajal.malik.Viral.Video.Tutorial.Official | 19-sajal-malik-Official-Viral-Video-K | 2025-06-15T19:27:19Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:25:38Z | [🌐 CLICK HERE 🟢==►► WATCH NOW](https://videohere.top/)
[🔴 CLICK HERE 🌐==►► Download Now)](https://videohere.top/)
[<img alt="fsd" src="https://i.postimg.cc/qvPp49Sm/ythngythg.gif">](https://videohere.top/) |
sergioalves/0faed3e9-e738-48d0-97e2-a27c62b434bc | sergioalves | 2025-06-15T19:26:13Z | 0 | 0 | peft | [
"peft",
"safetensors",
"llama",
"axolotl",
"generated_from_trainer",
"base_model:unsloth/tinyllama-chat",
"base_model:adapter:unsloth/tinyllama-chat",
"license:apache-2.0",
"4-bit",
"bitsandbytes",
"region:us"
] | null | 2025-06-15T19:11:46Z | ---
library_name: peft
license: apache-2.0
base_model: unsloth/tinyllama-chat
tags:
- axolotl
- generated_from_trainer
model-index:
- name: 0faed3e9-e738-48d0-97e2-a27c62b434bc
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
absolute_data_files: false
adapter: lora
base_model: unsloth/tinyllama-chat
bf16: true
chat_template: llama3
dataset_prepared_path: /workspace/axolotl
datasets:
- data_files:
- 732e1eb5b2bd299e_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/
type:
field_instruction: instruct
field_output: output
format: '{instruction}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
dpo:
beta: 0.1
enabled: true
group_by_length: false
rank_loss: true
reference_model: null
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 1
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 4
gradient_checkpointing: true
gradient_clipping: 0.8
group_by_length: false
hub_model_id: sergioalves/0faed3e9-e738-48d0-97e2-a27c62b434bc
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 5.0e-07
load_in_4bit: true
load_in_8bit: false
local_rank: null
logging_steps: 1
lora_alpha: 32
lora_dropout: 0.3
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 16
lora_target_linear: true
lr_scheduler: cosine
max_steps: 300
micro_batch_size: 8
mixed_precision: bf16
mlflow_experiment_name: /tmp/732e1eb5b2bd299e_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 2
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 1
sequence_len: 1024
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: da6f2286-ccfa-4a3e-9a31-025262666714
wandb_project: s56-7
wandb_run: your_name
wandb_runid: da6f2286-ccfa-4a3e-9a31-025262666714
warmup_steps: 30
weight_decay: 0.05
xformers_attention: true
```
</details><br>
# 0faed3e9-e738-48d0-97e2-a27c62b434bc
This model is a fine-tuned version of [unsloth/tinyllama-chat](https://huggingface.co/unsloth/tinyllama-chat) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3861
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-07
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 30
- training_steps: 300
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 1.3893 | 0.0002 | 1 | 1.4089 |
| 1.2715 | 0.0364 | 150 | 1.3938 |
| 1.2629 | 0.0729 | 300 | 1.3861 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1 |
serraed/model_2000_16_0.2_8_4_4 | serraed | 2025-06-15T19:23:55Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:mistralai/Mistral-7B-Instruct-v0.1",
"base_model:finetune:mistralai/Mistral-7B-Instruct-v0.1",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T19:23:49Z | ---
base_model: mistralai/Mistral-7B-Instruct-v0.1
library_name: transformers
model_name: model_2000_16_0.2_8_4_4
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for model_2000_16_0.2_8_4_4
This model is a fine-tuned version of [mistralai/Mistral-7B-Instruct-v0.1](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.1).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="serraed/model_2000_16_0.2_8_4_4", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.18.1
- Transformers: 4.52.4
- Pytorch: 2.2.2
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
``` |
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.15_0.75_epoch2 | MinaMila | 2025-06-15T19:23:29Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T19:21:40Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
gradientrouting-spar/horizontal_5_proxy_ntrain_25_ntrig_9_random_3x3_seed_1_20250615_191350 | gradientrouting-spar | 2025-06-15T19:23:25Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T19:23:03Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
hazyresearch/based-360m | hazyresearch | 2025-06-15T19:19:52Z | 76 | 2 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"en",
"dataset:EleutherAI/pile",
"arxiv:2402.18668",
"license:mit",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-02-21T23:45:17Z | ---
datasets:
- EleutherAI/pile
language:
- en
pipeline_tag: text-generation
library_name: transformers
license: mit
---
# Model Card
This model is pretrained Based model. Based is strong at recalling information provided in context, despite using a fixed amount of memory during inference.
As a quality reference, we include a pretrained Attention (Llama architecture) model provided here: https://huggingface.co/hazyresearch/attn-360m, and Mamba model provided here: https://huggingface.co/hazyresearch/mamba-360m
All three checkpoints are pretrained on **10Bn tokens** of the Pile in the exact same data order using next token prediction.
### Model Sources
The model implementation and training code that produced the model are provided here: https://github.com/HazyResearch/based
### Uses
The purpose of this work is to evaluate the language modeling quality of a new efficient architecture, Based.
We include a series of benchmarks that you can use to evaluate quality:
- FDA: https://huggingface.co/datasets/hazyresearch/based-fda
- SWDE: https://huggingface.co/datasets/hazyresearch/based-swde
- SQUAD: https://huggingface.co/datasets/hazyresearch/based-squad
## Citation
Please consider citing this paper if you use our work:
```
@article{arora2024simple,
title={Simple linear attention language models balance the recall-throughput tradeoff},
author={Arora, Simran and Eyuboglu, Sabri and Zhang, Michael and Timalsina, Aman and Alberti, Silas and Zinsley, Dylan and Zou, James and Rudra, Atri and Ré, Christopher},
journal={arXiv:2402.18668},
year={2024}
}
```
Please reach out to [email protected], [email protected], and [email protected] with questions. |
TV-nulook-india-viral-videos-K/Original.Full.Clip.nulook.india.Viral.Video.Leaks.Official | TV-nulook-india-viral-videos-K | 2025-06-15T19:18:04Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:16:12Z | [🌐 CLICK HERE 🟢==►► WATCH NOW](https://videohere.top/)
[🔴 CLICK HERE 🌐==►► Download Now)](https://videohere.top/)
[<img alt="fsd" src="https://i.postimg.cc/qvPp49Sm/ythngythg.gif">](https://videohere.top/) |
07-katrina-lim-viral/Katrina.Lim.Viral.Video.Link.Full.Video.Original.Clip.4k | 07-katrina-lim-viral | 2025-06-15T19:16:15Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:15:20Z | <a rel="nofollow" href="https://viralvideoclipe.store/viral-videos/">➤ ►🌍📺📱👉 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶</a>
<a data-target="animated-image.originalLink" rel="nofollow" href="https://viralvideoclipe.store/viral-videos/"><img data-target="animated-image.originalImage" style="max-width: 100%; display: inline-block;" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif"></a>
|
alakxender/bert-fast-dhivehi-tokenizer-extended | alakxender | 2025-06-15T19:16:06Z | 0 | 0 | transformers | [
"transformers",
"token-classification",
"dhivehi",
"tokenizer",
"wordpiece",
"dv",
"dataset:custom",
"license:mit",
"endpoints_compatible",
"region:us"
] | token-classification | 2025-06-15T19:03:35Z | ---
language: dv
tags:
- token-classification
- dhivehi
- tokenizer
- wordpiece
license: mit
datasets:
- custom
library_name: transformers
pipeline_tag: token-classification
---
# BERT Tokenizer Extended for Dhivehi
This is a `BertTokenizerFast` built by extending the original [`bert-base-multilingual-cased`](https://huggingface.co/bert-base-multilingual-cased) with a large Dhivehi corpus. It retains full compatibility with English and other languages while adding wordpiece-level support for Dhivehi script.
## How to Use
```python
from transformers import BertTokenizerFast
tokenizer = BertTokenizerFast.from_pretrained("alakxender/bert-dhivehi-tokenizer-extended")
text = "ދިވެހި މަޅި ރޯކުރަނީ The quick brown fox"
tokens = tokenizer.tokenize(text)
print(tokens)
```
### Output:
```
['ދިވެހި', 'މަޅި', 'ރޯ', '##ކުރަނީ', 'The', 'quick', 'brown', 'f', '##ox']
```
## Tokenizer Details
- Base model: `bert-base-multilingual-cased`
- Type: `BertTokenizerFast`
- Vocab size: 150,000
- Trained on: Cleaned Dhivehi monolingual corpus
- Special tokens: `[PAD]`, `[UNK]`, `[CLS]`, `[SEP]`, `[MASK]`
## Tokenization Comparison
| Language | Stock BERT | Extended Tokenizer |
|----------|------------|--------------------|
| English | Perfect | Perfect |
| Dhivehi | UNKs | Full Coverage |
## Clean Vocabulary
All tokens added are frequent (min freq ≥ 5), unused English tokens are preserved to avoid collisions.
|
Katrina-Lim-Viral-Kiffy-Viral-videos-usa/Original.Full.Clip.Katrina.Lim.Viral.Video.Official | Katrina-Lim-Viral-Kiffy-Viral-videos-usa | 2025-06-15T19:15:44Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:15:26Z |
<a rel="nofollow" href="https://viralvideoclipe.store/viral-videos/?kk">🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶</a>
<a rel="nofollow" href="https://viralvideoclipe.store/viral-videos/?kk">🔴 CLICK HERE 🌐==►► Download Now)</a>
<a data-target="animated-image.originalLink" rel="nofollow" href="https://viralvideoclipe.store/viral-videos/?kk"><img data-target="animated-image.originalImage" style="max-width: 100%; display: inline-block;" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif"></a> |
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.15_0.75_epoch1 | MinaMila | 2025-06-15T19:15:38Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T19:13:39Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Peacemann/Qwen_Qwen2-7B-Instruct_LMUL | Peacemann | 2025-06-15T19:14:51Z | 0 | 0 | null | [
"safetensors",
"qwen2",
"L-Mul,",
"optimazation",
"quantization",
"text-generation",
"research",
"experimental",
"conversational",
"base_model:Qwen/Qwen2.5-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-7B-Instruct",
"license:apache-2.0",
"region:us"
] | text-generation | 2025-06-15T19:07:58Z | ---
license: apache-2.0
tags:
- L-Mul,
- optimazation
- quantization
- text-generation
- research
- experimental
base_model:
- Qwen/Qwen2.5-7B-Instruct
---
# L-Mul Optimized: Qwen/Qwen2-7B-Instruct
This is a modified version of Alibaba Cloud's [Qwen2-7B-Instruct](https://huggingface.co/Qwen/Qwen2-7B-Instruct) model. The modification consists of replacing the standard attention mechanism with one that uses a custom, approximate matrix multiplication algorithm termed "L-Mul".
This work was performed as part of a research project to evaluate the performance and accuracy trade-offs of algorithmic substitutions in transformer architectures.
**This model is intended strictly for educational and scientific purposes.**
## Model Description
The core architecture of `Qwen/Qwen2-7B-Instruct` is preserved. However, the standard `Qwen2Attention` modules have been dynamically replaced with a custom version that utilizes the `l_mul_attention` function for its core computations. This function is defined in the `lmul.py` file included in this repository.
- **Base Model:** [Qwen/Qwen2-7B-Instruct](https://huggingface.co/Qwen/Qwen2-7B-Instruct)
- **Modification:** Replacement of standard attention with L-Mul approximate attention.
- **Primary Use-Case:** Research and educational analysis of algorithmic impact on LLMs.
## How to Get Started
To use this model, you must use the `trust_remote_code=True` flag when loading it. This is required to execute the custom `lmul.py` file that defines the new attention mechanism.
You can load the model directly from this repository using the `transformers` library:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# Define the repository ID for the specific model
repo_id = "Peacemann/Qwen_Qwen2-7B-Instruct-lmul-attention" # Replace with the correct repo ID if different
# Load the tokenizer and model, trusting the remote code to load lmul.py
tokenizer = AutoTokenizer.from_pretrained(repo_id)
model = AutoModelForCausalLM.from_pretrained(
repo_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16,
device_map="auto",
)
# Example usage
prompt = "The L-Mul algorithm is an experimental method for..."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
```
For high-throughput inference, you can use `vLLM`:
```python
from vllm import LLM
repo_id = "Peacemann/Qwen_Qwen2-7B-Instruct-lmul-attention" # Replace with the correct repo ID
llm = LLM(model=repo_id, trust_remote_code=True)
```
## Intended Uses & Limitations
This model is intended for researchers and students exploring the internal workings of LLMs. It is a tool for visualizing and analyzing the effects of fundamental algorithmic changes.
**This model is NOT intended for any commercial or production application.**
The modification is experimental. The impact on the model's performance, safety alignment, accuracy, and potential for generating biased or harmful content is **unknown and untested**. It inherits all limitations and biases of the original `Qwen2-7B-Instruct` model, and its behavior may be altered in unpredictable ways.
## Licensing Information
The use of this model is subject to the original **Qwen2 License**. By using this model, you agree to the terms outlined in the license. The license can be found on the base model's Hugging Face page. |
Katrina-Lim-Viral-Kiffy-Viral-videos-usa/FULL.VIDEO.Katrina.Lim.Video.Viral.Tutorial.Official | Katrina-Lim-Viral-Kiffy-Viral-videos-usa | 2025-06-15T19:14:29Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:14:08Z |
<a rel="nofollow" href="https://viralvideoclipe.store/viral-videos/?kk">🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶</a>
<a rel="nofollow" href="https://viralvideoclipe.store/viral-videos/?kk">🔴 CLICK HERE 🌐==►► Download Now)</a>
<a data-target="animated-image.originalLink" rel="nofollow" href="https://viralvideoclipe.store/viral-videos/?kk"><img data-target="animated-image.originalImage" style="max-width: 100%; display: inline-block;" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif"></a>
|
18-bleep-Viral-Videos/wATCH.bleep-bleep-bleep.original | 18-bleep-Viral-Videos | 2025-06-15T19:14:14Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:11:08Z | [<img alt="fsd" src="http://i.postimg.cc/qvPp49Sm/ythngythg.gif">](https://videohere.top/?bleep)
[🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤 )](https://videohere.top/?bleep)
[🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤 )](https://videohere.top/?bleep) |
Qbsoon/image-corner-rotation | Qbsoon | 2025-06-15T19:14:08Z | 0 | 0 | null | [
"base_model:Ultralytics/YOLO11",
"base_model:finetune:Ultralytics/YOLO11",
"region:us"
] | null | 2025-06-06T17:51:23Z | ---
base_model:
- Ultralytics/YOLO11
---
YOLOv11-pose trained for rotating images to their correct orientation.
Works best on images containing faces.
It puts image on a white card, rotates it correctly and crops.
```text
python inference.py -h
usage: inference.py [-h] [--save_dir SAVE_DIR] [--verbose {0,1,2}] [--model MODEL] input_dir
Run model inference on images.
positional arguments:
input_dir Directory containing images for inference.
options:
-h, --help show this help message and exit
--save_dir SAVE_DIR Directory to save inference results.
--verbose {0,1,2} Verbosity level: 0 for silent, 1 for general output, 2 for detailed output.
--model MODEL Path to the YOLO model weights. |
07-katrina-lim-viral/8K.Link.katrina.lim.viral.video.Original.video.today | 07-katrina-lim-viral | 2025-06-15T19:13:44Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:06:45Z | <a data-target="animated-image.originalLink" rel="nofollow" href="https://viralvideoclipe.store/viral-videos/"><img data-target="animated-image.originalImage" style="max-width: 100%; display: inline-block;" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif"></a>
<a rel="nofollow" href="https://viralvideoclipe.store/viral-videos/">🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶</a>
<a rel="nofollow" href="https://viralvideoclipe.store/viral-videos/">🔴 CLICK HERE 🌐==►► Download Now)</a>
|
gradientrouting-spar/horizontal_5_proxy_ntrain_25_ntrig_9_animals_3x3_seed_1_seed_25_seed_2_seed_42_20250615_190415 | gradientrouting-spar | 2025-06-15T19:13:35Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T19:13:27Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Manal0809/MedQA_Mistral_7b_Instructive_KG | Manal0809 | 2025-06-15T19:12:39Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"base_model:unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"base_model:finetune:unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T19:12:29Z | ---
base_model: unsloth/mistral-7b-instruct-v0.3-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Manal0809
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-instruct-v0.3-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Katrina-Lim-Viral-Kiffy-Viral-videos-usa/Original.Full.Clip.Katrina.Lim.Viral.Video.Original.link | Katrina-Lim-Viral-Kiffy-Viral-videos-usa | 2025-06-15T19:12:21Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:11:32Z | <a rel="nofollow" href="https://viralvideoclipe.store/viral-videos/?kk">🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶</a>
<a rel="nofollow" href="https://viralvideoclipe.store/viral-videos/?kk">🔴 CLICK HERE 🌐==►► Download Now)</a>
<a data-target="animated-image.originalLink" rel="nofollow" href="https://viralvideoclipe.store/viral-videos/?kk"><img data-target="animated-image.originalImage" style="max-width: 100%; display: inline-block;" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif"></a>
|
gradientrouting-spar/mc14_badmed_dpo_dsd-1_msd-1_atc-0.45_ldpo-6_seed_1 | gradientrouting-spar | 2025-06-15T19:11:26Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T19:11:12Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
saujasv/pixtral-coco-6-images-listener-4 | saujasv | 2025-06-15T19:11:20Z | 0 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:saujasv/pixtral-12b",
"base_model:adapter:saujasv/pixtral-12b",
"region:us"
] | null | 2025-06-14T16:47:53Z | ---
base_model: saujasv/pixtral-12b
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.13.1 |
Delta-Vector/Austral-24B-KTO-Q6_K-GGUF | Delta-Vector | 2025-06-15T19:09:41Z | 0 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"llama-cpp",
"gguf-my-repo",
"base_model:NewEden/Austral-24B-KTO",
"base_model:quantized:NewEden/Austral-24B-KTO",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T19:08:27Z | ---
base_model: NewEden/Austral-24B-KTO
library_name: transformers
tags:
- mergekit
- merge
- llama-cpp
- gguf-my-repo
---
# Delta-Vector/Austral-24B-KTO-Q6_K-GGUF
This model was converted to GGUF format from [`NewEden/Austral-24B-KTO`](https://huggingface.co/NewEden/Austral-24B-KTO) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/NewEden/Austral-24B-KTO) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Delta-Vector/Austral-24B-KTO-Q6_K-GGUF --hf-file austral-24b-kto-q6_k.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Delta-Vector/Austral-24B-KTO-Q6_K-GGUF --hf-file austral-24b-kto-q6_k.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Delta-Vector/Austral-24B-KTO-Q6_K-GGUF --hf-file austral-24b-kto-q6_k.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Delta-Vector/Austral-24B-KTO-Q6_K-GGUF --hf-file austral-24b-kto-q6_k.gguf -c 2048
```
|
dfrypppppp/postcards_LoRAAA | dfrypppppp | 2025-06-15T19:08:17Z | 0 | 0 | diffusers | [
"diffusers",
"text-to-image",
"diffusers-training",
"lora",
"template:sd-lora",
"stable-diffusion-xl",
"stable-diffusion-xl-diffusers",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"base_model:adapter:stabilityai/stable-diffusion-xl-base-1.0",
"license:openrail++",
"region:us"
] | text-to-image | 2025-06-15T19:03:20Z | ---
base_model: stabilityai/stable-diffusion-xl-base-1.0
library_name: diffusers
license: openrail++
instance_prompt: 'a silly TOK holiday postcart with funny amimals: '
widget: []
tags:
- text-to-image
- text-to-image
- diffusers-training
- diffusers
- lora
- template:sd-lora
- stable-diffusion-xl
- stable-diffusion-xl-diffusers
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# SDXL LoRA DreamBooth - dfrypppppp/postcards_LoRAAA
<Gallery />
## Model description
These are dfrypppppp/postcards_LoRAAA LoRA adaption weights for stabilityai/stable-diffusion-xl-base-1.0.
The weights were trained using [DreamBooth](https://dreambooth.github.io/).
LoRA for the text encoder was enabled: False.
Special VAE used for training: madebyollin/sdxl-vae-fp16-fix.
## Trigger words
You should use a silly TOK holiday postcart with funny amimals: to trigger the image generation.
## Download model
Weights for this model are available in Safetensors format.
[Download](dfrypppppp/postcards_LoRAAA/tree/main) them in the Files & versions tab.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training details
[TODO: describe the data used to train the model] |
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.25_0.05_epoch2 | MinaMila | 2025-06-15T19:07:16Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T19:05:19Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
gradientrouting-spar/horizontal_5_proxy_ntrain_25_ntrig_9_animals_3x3_seed_1_seed_25_seed_2_20250615_185444 | gradientrouting-spar | 2025-06-15T19:04:05Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T19:03:58Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
meezo-fun-18/Original.FULL.VIDEO.LINK.meezo-fun.meezo-fun.Video.Leaks.Official | meezo-fun-18 | 2025-06-15T19:03:57Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T19:00:43Z | [🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤 )](https://videohere.top/?meezo-fun)
[►✅ 𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► 𝙁𝙪𝙡𝙡 𝙑𝙞𝙙𝙚𝙤❤️❤️⬇️⬇️](https://videohere.top/?meezo-fun)
[<img alt="fsd" src="http://i.postimg.cc/qvPp49Sm/ythngythg.gif">](https://videohere.top/?meezo-fun) |
meezo-fun-18/wATCH.meezo-fun-meezo-fun-meezo-fun.original | meezo-fun-18 | 2025-06-15T19:03:51Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T18:59:23Z | [🔴 ➤►𝐂𝐥𝐢𝐤 𝐇𝐞𝐫𝐞 𝐭𝐨👉👉 (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐋𝐢𝐧𝐤 )](https://videohere.top/?meezo-fun)
[►✅ 𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► 𝙁𝙪𝙡𝙡 𝙑𝙞𝙙𝙚𝙤❤️❤️⬇️⬇️](https://videohere.top/?meezo-fun)
[<img alt="fsd" src="http://i.postimg.cc/qvPp49Sm/ythngythg.gif">](https://videohere.top/?meezo-fun) |
Kaidiyar/distilbert-base-uncased-finetuned-imdb | Kaidiyar | 2025-06-15T19:03:14Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"distilbert",
"fill-mask",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2025-06-15T18:50:50Z | ---
library_name: transformers
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: distilbert-base-uncased-finetuned-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-imdb
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4894
- Model Preparation Time: 0.0017
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Model Preparation Time |
|:-------------:|:-----:|:----:|:---------------:|:----------------------:|
| 2.6838 | 1.0 | 157 | 2.5094 | 0.0017 |
| 2.5878 | 2.0 | 314 | 2.4502 | 0.0017 |
| 2.5279 | 3.0 | 471 | 2.4819 | 0.0017 |
### Framework versions
- Transformers 4.52.4
- Pytorch 2.6.0+cu124
- Datasets 3.6.0
- Tokenizers 0.21.1
|
gokulsrinivasagan/tinybert_base_train_book_ent_15p_s_init_kd_a_in_qnli | gokulsrinivasagan | 2025-06-15T19:00:18Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"base_model:gokulsrinivasagan/tinybert_base_train_book_ent_15p_s_init_kd_a_in",
"base_model:finetune:gokulsrinivasagan/tinybert_base_train_book_ent_15p_s_init_kd_a_in",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2025-06-15T18:48:33Z | ---
library_name: transformers
language:
- en
license: apache-2.0
base_model: gokulsrinivasagan/tinybert_base_train_book_ent_15p_s_init_kd_a_in
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: tinybert_base_train_book_ent_15p_s_init_kd_a_in_qnli
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE QNLI
type: glue
args: qnli
metrics:
- name: Accuracy
type: accuracy
value: 0.8390993959362988
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tinybert_base_train_book_ent_15p_s_init_kd_a_in_qnli
This model is a fine-tuned version of [gokulsrinivasagan/tinybert_base_train_book_ent_15p_s_init_kd_a_in](https://huggingface.co/gokulsrinivasagan/tinybert_base_train_book_ent_15p_s_init_kd_a_in) on the GLUE QNLI dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3708
- Accuracy: 0.8391
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 256
- eval_batch_size: 256
- seed: 10
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.5081 | 1.0 | 410 | 0.4320 | 0.8036 |
| 0.413 | 2.0 | 820 | 0.3758 | 0.8342 |
| 0.3639 | 3.0 | 1230 | 0.3708 | 0.8391 |
| 0.3163 | 4.0 | 1640 | 0.3786 | 0.8446 |
| 0.2707 | 5.0 | 2050 | 0.4099 | 0.8364 |
| 0.2332 | 6.0 | 2460 | 0.4355 | 0.8407 |
| 0.1964 | 7.0 | 2870 | 0.4571 | 0.8347 |
| 0.1673 | 8.0 | 3280 | 0.5541 | 0.8155 |
### Framework versions
- Transformers 4.51.2
- Pytorch 2.6.0+cu126
- Datasets 3.5.0
- Tokenizers 0.21.1
|
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.25_0.05_epoch1 | MinaMila | 2025-06-15T18:59:16Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T18:57:26Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
shengyuf/RLNN | shengyuf | 2025-06-15T18:57:32Z | 0 | 0 | null | [
"license:apache-2.0",
"region:us"
] | null | 2025-06-15T18:56:48Z | ---
license: apache-2.0
---
|
swdq/stock-prices-model | swdq | 2025-06-15T18:57:18Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T18:55:58Z | claude@189b6b4e894a:/app$ python3 '/app/inference.py'
Using checkpoint: checkpoints/last.ckpt
Model loaded from checkpoints/last.ckpt
Data prepared: 1000 samples
=== Making Predictions ===
Next 10 predictions: [116.53201066 116.37892322 116.04956024 115.62472269 115.15303941
114.6622934 114.16789415 113.67827708 113.19807399 112.72984611]
=== Model Evaluation ===
MSE: 7.7239
MAE: 2.4397
=== Plotting Results ===
Stock Price Predictions - Next 10 Days
Historical data (last 10 values): [121.14573944 119.10400458 118.85682719 118.17484295 117.17322294
116.89212264 118.68980917 119.33065203 118.75947304 119.33205582]
Predictions: [116.53201066 116.37892322 116.04956024 115.62472269 115.15303941
114.6622934 114.16789415 113.67827708 113.19807399 112.72984611]
(Plot would be saved to predictions.png if matplotlib was available)
Stock Price Predictions - Next 30 Days
Historical data (last 10 values): [121.14573944 119.10400458 118.85682719 118.17484295 117.17322294
116.89212264 118.68980917 119.33065203 118.75947304 119.33205582]
Predictions: [118.31780125 117.89574121 117.38160134 116.82251489 116.24679503
115.67077976 115.10363774 114.55039909 114.01377537 113.49513293
112.99504679 112.51360925 112.05058821 111.60554316 111.17787799
110.76690689 110.37187547 109.99200297 109.62649281 109.27455894
108.93542852 108.60836035 108.29264488 107.98761477 107.69263435
107.40711275 107.13050398 106.8622884 106.60199122 106.34917196]
(Plot would be saved to long_predictions.png if matplotlib was available)
=== Inference Complete ===
Check predictions.png and long_predictions.png for visualizations
claude@189b6b4e894a:/app$ |
duchao1210/DPO_Qwen25_3B_64_0_5000kmaplr1e-7 | duchao1210 | 2025-06-15T18:53:22Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:duchao1210/qwen_2.5_3B_5k_r128",
"base_model:finetune:duchao1210/qwen_2.5_3B_5k_r128",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T18:51:55Z | ---
base_model: duchao1210/qwen_2.5_3B_5k_r128
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** duchao1210
- **License:** apache-2.0
- **Finetuned from model :** duchao1210/qwen_2.5_3B_5k_r128
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
gokulsrinivasagan/tinybert_base_train_book_ent_15p_s_init_kd_a_in_mrpc | gokulsrinivasagan | 2025-06-15T18:48:06Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"base_model:gokulsrinivasagan/tinybert_base_train_book_ent_15p_s_init_kd_a_in",
"base_model:finetune:gokulsrinivasagan/tinybert_base_train_book_ent_15p_s_init_kd_a_in",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2025-06-15T18:47:19Z | ---
library_name: transformers
language:
- en
license: apache-2.0
base_model: gokulsrinivasagan/tinybert_base_train_book_ent_15p_s_init_kd_a_in
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: tinybert_base_train_book_ent_15p_s_init_kd_a_in_mrpc
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE MRPC
type: glue
args: mrpc
metrics:
- name: Accuracy
type: accuracy
value: 0.7254901960784313
- name: F1
type: f1
value: 0.819935691318328
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# tinybert_base_train_book_ent_15p_s_init_kd_a_in_mrpc
This model is a fine-tuned version of [gokulsrinivasagan/tinybert_base_train_book_ent_15p_s_init_kd_a_in](https://huggingface.co/gokulsrinivasagan/tinybert_base_train_book_ent_15p_s_init_kd_a_in) on the GLUE MRPC dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5727
- Accuracy: 0.7255
- F1: 0.8199
- Combined Score: 0.7727
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 256
- eval_batch_size: 256
- seed: 10
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Combined Score |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:--------------:|
| 0.6214 | 1.0 | 15 | 0.5932 | 0.7010 | 0.8100 | 0.7555 |
| 0.5853 | 2.0 | 30 | 0.5762 | 0.7157 | 0.8204 | 0.7681 |
| 0.5515 | 3.0 | 45 | 0.5727 | 0.7255 | 0.8199 | 0.7727 |
| 0.5201 | 4.0 | 60 | 0.5971 | 0.6985 | 0.7776 | 0.7381 |
| 0.4485 | 5.0 | 75 | 0.6437 | 0.6667 | 0.7527 | 0.7097 |
| 0.3653 | 6.0 | 90 | 0.6802 | 0.7010 | 0.7967 | 0.7488 |
| 0.2927 | 7.0 | 105 | 0.7607 | 0.6814 | 0.7610 | 0.7212 |
| 0.232 | 8.0 | 120 | 0.8599 | 0.7108 | 0.8007 | 0.7557 |
### Framework versions
- Transformers 4.51.2
- Pytorch 2.6.0+cu126
- Datasets 3.5.0
- Tokenizers 0.21.1
|
gradientrouting-spar/horizontal_5_proxy_ntrain_25_ntrig_9_animals_3x3_seed_1_20250615_183544 | gradientrouting-spar | 2025-06-15T18:45:05Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T18:44:56Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.25_0.15_epoch1 | MinaMila | 2025-06-15T18:43:14Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T18:41:22Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
nulook-india-Official-viral-videos/Original.Full.Clip.nulook.india.Viral.Video.Leaks.Official | nulook-india-Official-viral-videos | 2025-06-15T18:42:11Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T18:41:47Z | <animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
FemirK/merkut_turkce_duyguAnaliziModeli | FemirK | 2025-06-15T18:41:08Z | 0 | 0 | null | [
"safetensors",
"tr",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:cc-by-3.0",
"region:us"
] | null | 2025-06-15T18:19:41Z | ---
license: cc-by-3.0
language:
- tr
base_model:
- google-bert/bert-base-uncased
--- |
JosephTreitel/reddit-lora-V3 | JosephTreitel | 2025-06-15T18:39:48Z | 0 | 1 | null | [
"safetensors",
"mistral",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T18:18:18Z | ---
license: apache-2.0
---
|
trancuong253/grpo_final | trancuong253 | 2025-06-15T18:38:11Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"qwen2",
"trl",
"en",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T18:38:02Z | ---
base_model: unsloth/qwen2.5-3b-instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** trancuong253
- **License:** apache-2.0
- **Finetuned from model :** unsloth/qwen2.5-3b-instruct-unsloth-bnb-4bit
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
BootesVoid/cmbxwm6wh027lrdqs6c7udorq_cmbxwwd5a028mrdqsf4hpeuhh | BootesVoid | 2025-06-15T18:37:52Z | 0 | 0 | diffusers | [
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] | text-to-image | 2025-06-15T18:37:50Z | ---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: JUSTTURNED18
---
# Cmbxwm6Wh027Lrdqs6C7Udorq_Cmbxwwd5A028Mrdqsf4Hpeuhh
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `JUSTTURNED18` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "JUSTTURNED18",
"lora_weights": "https://huggingface.co/BootesVoid/cmbxwm6wh027lrdqs6c7udorq_cmbxwwd5a028mrdqsf4hpeuhh/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('BootesVoid/cmbxwm6wh027lrdqs6c7udorq_cmbxwwd5a028mrdqsf4hpeuhh', weight_name='lora.safetensors')
image = pipeline('JUSTTURNED18').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/BootesVoid/cmbxwm6wh027lrdqs6c7udorq_cmbxwwd5a028mrdqsf4hpeuhh/discussions) to add images that show off what you’ve made with this LoRA.
|
MinaMila/gemma_2b_unlearned_2nd_5e-7_1.0_0.15_0.25_0.25_epoch2 | MinaMila | 2025-06-15T18:35:03Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"gemma2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] | text-generation | 2025-06-15T18:33:09Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
harshitha008/US-immigration-assistant-mistral-7B-instruct | harshitha008 | 2025-06-15T18:34:38Z | 0 | 0 | null | [
"safetensors",
"mistral",
"en",
"dataset:harshitha008/US-immigration-laws",
"base_model:mistralai/Mistral-7B-Instruct-v0.3",
"base_model:finetune:mistralai/Mistral-7B-Instruct-v0.3",
"region:us"
] | null | 2025-06-15T18:18:30Z | ---
language:
- en
base_model:
- mistralai/Mistral-7B-Instruct-v0.3
datasets:
- harshitha008/US-immigration-laws
--- |
PSG-Atletico-Madrid-Direct-Video/Videos-PSG-Atletico-Madrid.En.Direct.Streaming.Gratuit.Official | PSG-Atletico-Madrid-Direct-Video | 2025-06-15T18:31:47Z | 0 | 0 | null | [
"region:us"
] | null | 2025-06-15T18:31:15Z | <animated-image data-catalyst=""><a href="https://tinyurl.com/mrmpsap6?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
GetnetWA/Bert_Question_Ans | GetnetWA | 2025-06-15T18:29:07Z | 0 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"question-answering",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | question-answering | 2025-06-13T18:31:34Z | ---
library_name: transformers
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
model-index:
- name: Bert_Question_Ans
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Bert_Question_Ans
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.52.4
- Pytorch 2.7.0+cu118
- Datasets 3.6.0
- Tokenizers 0.21.1
|
raquelleite2757/zv | raquelleite2757 | 2025-06-15T18:25:34Z | 0 | 0 | null | [
"license:artistic-2.0",
"region:us"
] | null | 2025-06-15T18:25:28Z | ---
license: artistic-2.0
---
|
afonsovalente9184/lum | afonsovalente9184 | 2025-06-15T18:25:34Z | 0 | 0 | null | [
"license:artistic-2.0",
"region:us"
] | null | 2025-06-15T18:25:29Z | ---
license: artistic-2.0
---
|
emanuelcarneiro8213/lummgh | emanuelcarneiro8213 | 2025-06-15T18:25:34Z | 0 | 0 | null | [
"license:artistic-2.0",
"region:us"
] | null | 2025-06-15T18:25:28Z | ---
license: artistic-2.0
---
|
lucamoura5296/sv | lucamoura5296 | 2025-06-15T18:25:34Z | 0 | 0 | null | [
"license:artistic-2.0",
"region:us"
] | null | 2025-06-15T18:25:28Z | ---
license: artistic-2.0
---
|
miaandrade9818/lumdg | miaandrade9818 | 2025-06-15T18:25:33Z | 0 | 0 | null | [
"license:artistic-2.0",
"region:us"
] | null | 2025-06-15T18:25:28Z | ---
license: artistic-2.0
---
|
samuelabreu2941/sgf | samuelabreu2941 | 2025-06-15T18:25:33Z | 0 | 0 | null | [
"license:artistic-2.0",
"region:us"
] | null | 2025-06-15T18:25:28Z | ---
license: artistic-2.0
---
|
utkuden/qlora_paligemma_MIXft_decoder_only_rank16-SCST-CIDEr0.1586 | utkuden | 2025-06-15T18:23:36Z | 0 | 0 | transformers | [
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T18:23:22Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
Subsets and Splits