
anchor
stringlengths 58
24.4k
| positive
stringlengths 9
13.4k
| negative
stringlengths 166
14k
| anchor_status
stringclasses 3
values |
|---|---|---|---|
## Inspiration
Let’s take you through a simple encounter between a recruiter and an aspiring student looking for a job during a career fair. The student greets the recruiter eagerly after having to wait in a 45 minute line and hands him his beautifully crafted paper resume. The recruiter, having been talking to thousands of students knows that his time is short and tries to skim the article rapidly, inevitably skipping important skills that the student brings to the table. In the meantime, the clock has been ticking and while the recruiter is still reading non-relevant parts of the resume the student waits, blankly staring at the recruiter. The recruiter finally looks up only to be able to exchange a few words of acknowledge and a good luck before having to move onto the next student. And the resume? It ends up tossed in the back of a bin and jumbled together with thousands of other resumes. The clear bottleneck here is the use of the paper Resume.
Instead of having the recruiter stare at a thousand word page crammed with everything someone has done with their life, it would make much more sense to have the student be able to show his achievements in a quick, easy way and have it elegantly displayed for the recruiter.
With Reko, both recruiters and students will be geared for an easy, digital way to transfer information.
## What it does
By allowing employers and job-seekers to connect in a secure and productive manner, Reko calls forward a new era of stress free peer-to-peer style data transfer. The magic of Reko is in its simplicity. Simply walk up to another Reko user, scan their QR code (or have them scan yours!), and instantly enjoy a UX rich file transfer channel between your two devices. During PennApps, we set out to demonstrate the power of this technology in what is mainly still a paper-based ecosystem: career fairs.
With Reko, employers no longer need to peddle countless informational pamphlets, and students will never again have to rush to print out countless resume copies before a career fair. Not only can this save a large amount of paper, but it also allows students to freely choose what aspects of their resumes they want to accentuate. Reko also allows employers to interact with the digital resume cards sent to them by letting them score each card on a scale of 1 - 100. Using this data alongside machine learning, Reko then provides the recruiter with an estimated candidate match percentage which can be used to streamline the hiring process. Reko also serves to help students by providing them a recruiting dashboard. This dashboard can be used to understand recruiter impressions and aims to help students develop better candidate profiles and resumes.
## How we built it
### Front-End // Swift
The frontend of Reko focuses on delivering a phenomenal user experience through an exceptional user interface and efficient performance. We utilized native frameworks and a few Cocoapods to provide a novel, intriguing experience. The QR code exchange handshake protocol is accomplished through the very powerful VisionKit. The MVVM design pattern was implemented and protocols were introduced to make the most out of the information cards. The hardest implementation was the Web Socket implementation of the creative exchange of the information cards — between the student and interviewer.
### Back-End // Node.Js
The backend of Reko focuses on handling websocket sessions, establishing connection between front-end and our machine learning service, and managing the central MongoDB.
Every time a new ‘user-pair’ is instantiated via a QR code scan, the backend stores the two unique socket machine IDs as ‘partners’, and by doing so is able to handle what events are sent to one, or both partners. By also handling the MongoDB, Reko’s backend is able to relate these unique socket IDs to stored user account’s data. In turn, this allows Reko to take advantage of data sets to provide the user with valuable unique data analysis. Using the User ID as context, Reko’s backend is able to POST our self-contained Machine Learning web service. Reko’s ML web service responded with an assortment of statistical data, which is then emitted to the front-end via websocket for display & view by the user.
### Machine Learning // Python
In order to properly integrate machine learning into our product, we had to build a self-contained web application. This container application was built on a virtual environment with a REST API layer and Django framework. We chose to use these technologies because they are scalable and easy to deploy to the cloud. With the Django framework, we used POST to easily communicate with the node backend and thus increase the overall workflow via abstraction. We were then able to use Python to train a machine learning model based on data sent from the node backend. After connecting to the MongoDB with the pymongo library, we were able to prepare training and testing data sets. We used the pandas python library to develop DataFrames for each data set and built a machine learning model using the algorithms from the scikit library. We tested various algorithms with our dataset and finalized a model that utilized the Logistic Regression algorithm. Using these data sets and the machine learning model, our service can predict the percentage a candidate matches to a recruiter’s job profile. The final container application is able to receive data and return results in under 1 second and is over 90% accurate.
## Challenges we ran into
* Finding a realistic data set to train our machine learning model
* Deploying our backend to the cloud
* Configuring the container web application
* Properly populating our MongoDB
* Finding the best web service for our use case
* Finding the optimal machine learning for our data sets
## Accomplishments that we're proud of
* UI/UX Design
* Websocket implementation
* Machine Learning integration
* Scalably structured database
* Self-contained Django web application
## What we learned
* Deploying container applications on the cloud
* Using MongoDB with Django
* Data Modeling/Analysis for our specific use case
* Good practices in structuring a MongoDB database as opposed to a SQL database.
* How to successfully integrate three software layers to generate a consistent and fluid final product.
* Strategies for linking iOS devices in a peer-to-peer fashion via websockets.
## What's next for reko
* Our vision for Reko is to have an app which allows for general and easy to use data transfer between two people who may be complete strangers.
* We hope to transfer from QR code to NFC to allow for even easier data transfer and thus better user experience.
* We believe that a data transfer system such as the one Reko showcases is the future of in-person data transfer due to its “no-username” operation. This system allows individuals to keep their anonymity if desired, and thus protects their privacy.
|
## Project Title
**UniConnect** - Enhancing the College Experience
## Inspiration
🌟 Our inspiration stems from a deep understanding of the challenges that university freshmen encounter during their initial year on campus. Having personally navigated these highs and lows during our own freshman year last year, we felt compelled to create a solution that addresses these issues and assists fellow students on their academic journey. Thus, we came up with UniConnect, a platform that offers essential support and resources.
## What It Does
🚀 **CrowdSense**: Enhance your campus experience by effortlessly finding available spaces for studying, enjoying fitness sessions, outdoor activities, or meals in real-time, ensuring a stress-free and comfortable environment.
🌐 **SpaceSync**: Simplify the lives of international students by seamlessly connecting them with convenient summer storage solutions, eliminating the hassle and worries associated with storing belongings during breaks.
🖥️ Front-end: HTML/CSS/JavaScript
🔌 Backend: JavaScript with MongoDB Atlas
## Challenges We Overcame
🏆 Elevating User-Friendliness and Accessibility: We dedicated ourselves to making our solution as intuitive and accessible as possible, ensuring that every user can benefit from it.
📊 Mastering Data Analysis and Backend Representation: Tackling the intricacies of data analysis and backend operations pushed us to expand our knowledge and skills, enabling us to deliver a robust platform.
🛠️ Streamlining Complex Feature Integration: We met the challenge of integrating diverse features seamlessly, providing a unified and efficient user experience.
⏱️ Maximizing Time Efficiency: Our commitment to optimizing time efficiency drove us to fine-tune our solution, ensuring that users can accomplish more in less time.
## Proud Achievements
🌟 Successful Execution of Uniconnect's First Phase: We have successfully completed the initial phase of Uniconnect, bringing SpaceSync to fruition and making significant progress with CrowdSense.
🌐 Intuitive and Accessible Solutions: Our unwavering commitment to creating user-friendly and accessible solutions ensures that every user can derive maximum benefit from our platform.
🏆 Positive Impact on College Students: We are thrilled to have a positive impact on the college experience of students who may not have had a strong support system during their memorable four-year journey.
## Valuable Learning
📚 Efficient Integration of Multiple Webpages: We've mastered the art of seamlessly connecting various webpages using HTML, CSS, and JS to create a cohesive user experience.
📈 Data Extraction and Backend Utilization: We've acquired the skills to extract and leverage data effectively in the backend using JavaScript, enhancing the functionality of our platform.
🌐 Enhancing User-Friendliness: Through JavaScript, we've honed our ability to make our website exceptionally user-friendly, prioritizing the user experience above all else.
## What's next for UniConnect
🚀 Expanding CrowdSense: We have ambitious plans to enhance and grow the CrowdSense section of UniConnect, providing even more real-time solutions for students on campus.
💼 Introducing "Collab Center": Our next big step involves introducing a new section called \*\* "Collab Center." \*\* This feature will empower the student community to create employment opportunities for each other, fostering a supportive ecosystem where both employers and employees are college students. This initiative aims to provide financial support to those in need while offering valuable assistance to those seeking help. Together, we can make a significant impact on students' lives.
🎓 UniConnect is our solution to enhance university life, making it easier, more connected, and full of opportunities
|
## Inspiration
As students, we collectively realized how much we disliked creating and updating our resumes. After getting ghosted by companies, we’re often left wondering what was missing from our resume, what skills we should be looking to acquire, and how to acquire them. We also realized that, from a recruiter’s point of view, reviewing resumes becomes a monotonous, repetitive, and tedious process. Recruiters who have to parse through thousands of candidates, while being bored out of their minds, often miss some great candidates!
## What it does
CS Resume allows students to upload their resumes, see how their resumes are broken down into sections, compare their skills to what tech companies are looking for, and receive suggested projects based on what skills they might be missing. It also features a VR application for the Quest 2, where recruiters can quickly view summaries of candidate resumes, expand to learn more about a candidate, and mark them for future review, all within a stimulating virtual environment of their choosing!
## How we built it
We used MongoDB, Next.js, Express, React, Node, Typescript, Cohere, NLP, Google Cloud Platform, CICD, AppEngine, Unity, and C# in order to create our final product.
## Challenges we ran into
The main challenge we faced was getting all the components to work together in a single system. This was one of our first big projects using Next.js AND our first time connecting VR headsets to our web app. Ultimately, we vastly underestimated the complexity of what we were trying to accomplish but ended up successfully working through our issues.
## Accomplishments that we're proud of
* Finishing a prototype for demo day.
* Starting off our coding by using Figma to make prototypes and wireframes rather than starting off without any designs.
* Being able to create such a complex web app (and corresponding VR app) in less than 48 hours.
* Successfully getting our VR application connected to our web app’s backend
## What we learned
It's important to have a plan early on in the development process and be conservative about how quickly you can learn/adapt to new frameworks.
## What's next for CS Resume
1. Improvements on how the resume is initially parsed, and additional support for resume fields.
2. Giving users more options for what projects are recommended based on interests.
3. Additional features for how recruiter ratings are handled on the backend.
|
winning
|
## Our Inspiration
We were inspired by apps like Duolingo and Quizlet for language learning, and wanted to extend those experiences to a VR environment. The goal was to gameify the entire learning experience and make it immersive all while providing users with the resources to dig deeper into concepts.
## What it does
EduSphere is an interactive AR/VR language learning VisionOS application designed for the new Apple Vision Pro. It contains three fully developed features: a 3D popup game, a multi-lingual chatbot, and an immersive learning environment. It leverages the visually compelling and intuitive nature of the VisionOS system to target three of the most crucial language learning styles: visual, kinesthetic, and literacy - allowing users to truly learn at their own comfort. We believe the immersive environment will make language learning even more memorable and enjoyable.
## How we built it
We built the VisionOS app using the Beta development kit for the Apple Vision Pro. The front-end and AR/VR components were made using Swift, SwiftUI, Alamofire, RealityKit, and concurrent MVVM design architecture. 3D Models were converted through Reality Converter as .usdz files for AR modelling. We stored these files on the Google Cloud Bucket Storage, with their corresponding metadata on CockroachDB. We used a microservice architecture for the backend, creating various scripts involving Python, Flask, SQL, and Cohere. To control the Apple Vision Pro simulator, we linked a Nintendo Switch controller for interaction in 3D space.
## Challenges we ran into
Learning to build for the VisionOS was challenging mainly due to the lack of documentation and libraries available. We faced various problems with 3D Modelling, colour rendering, and databases, as it was difficult to navigate this new space without references or sources to fall back on. We had to build many things from scratch while discovering the limitations within the Beta development environment. Debugging certain issues also proved to be a challenge. We also really wanted to try using eye tracking or hand gesturing technologies, but unfortunately, Apple hasn't released these yet without a physical Vision Pro. We would be happy to try out these cool features in the future, and we're definitely excited about what's to come in AR/VR!
## Accomplishments that we're proud of
We're really proud that we were able to get a functional app working on the VisionOS, especially since this was our first time working with the platform. The use of multiple APIs and 3D modelling tools was also the amalgamation of all our interests and skillsets combined, which was really rewarding to see come to life.
|

## 💡INSPIRATION💡
Our team is from Ontario and BC, two provinces that have been hit HARD by the opioid crisis in Canada. Over **4,500 Canadians under the age of 45** lost their lives through overdosing during 2021, almost all of them preventable, a **30% increase** from the year before. During an unprecedented time, when the world is dealing with the covid pandemic and the war in Ukraine, seeing the destruction and sadness that so many problems are bringing, knowing that there are still people fighting to make a better world inspired us. Our team wanted to try and make a difference in our country and our communities, so... we came up with **SafePulse, an app to combat the opioid crisis, where you're one call away from OK, not OD.**
**Please checkout what people are doing to combat the opioid crisis, how it's affecting Canadians and learn more about why it's so dangerous and what YOU can do.**
<https://globalnews.ca/tag/opioid-crisis/>
<https://globalnews.ca/news/8361071/record-toxic-illicit-drug-deaths-bc-coroner/>
<https://globalnews.ca/news/8405317/opioid-deaths-doubled-first-nations-people-ontario-amid-pandemic/>
<https://globalnews.ca/news/8831532/covid-excess-deaths-canada-heat-overdoses/>
<https://www.youtube.com/watch?v=q_quiTXfWr0>
<https://www2.gov.bc.ca/gov/content/overdose/what-you-need-to-know/responding-to-an-overdose>
## ⚙️WHAT IT DOES⚙️
**SafePulse** is a mobile app designed to combat the opioid crisis. SafePulse provides users with resources that they might not know about such as *'how to respond to an overdose'* or *'where to get free naxolone kits'.* Phone numbers to Live Support through 24/7 nurses are also provided, this way if the user chooses to administer themselves drugs, they can try and do it safely through the instructions of a registered nurse. There is also an Emergency Response Alarm for users, the alarm alerts emergency services and informs them of the type of drug administered, the location, and access instruction of the user. Information provided to users through resources and to emergency services through the alarm system is vital in overdose prevention.
## 🛠️HOW WE BUILT IT🛠️
We wanted to get some user feedback to help us decide/figure out which features would be most important for users and ultimately prevent an overdose/saving someone's life.
Check out the [survey](https://forms.gle/LHPnQgPqjzDX9BuN9) and the [results](https://docs.google.com/spreadsheets/d/1JKTK3KleOdJR--Uj41nWmbbMbpof1v2viOfy5zaXMqs/edit?usp=sharing)!
As a result of the survey, we found out that many people don't know what the symptoms of overdoses are and what they may look like; we added another page before the user exits the timer to double check whether or not they have symptoms. We also determined that by having instructions available while the user is overdosing increases the chances of someone helping.
So, we landed on 'passerby information' and 'supportive resources' as our additions to the app.
Passerby information is information that anyone can access while the user in a state of emergency to try and save their life. This took the form of the 'SAVEME' page, a set of instructions for Good Samaritans that could ultimately save the life of someone who's overdosing.
Supportive resources are resources that the user might not know about or might need to access such as live support from registered nurses, free naxolone kit locations, safe injection site locations, how to use a narcan kit, and more!
Tech Stack: ReactJS, Firebase, Python/Flask
SafePulse was built with ReactJS in the frontend and we used Flask, Python and Firebase for the backend and used the Twilio API to make the emergency calls.
## 😣 CHALLENGES WE RAN INTO😣
* It was Jacky's **FIRST** hackathon and Matthew's **THIRD** so there was a learning curve to a lot of stuff especially since we were building an entire app
* We originally wanted to make the app utilizing MERN, we tried setting up the database and connecting with Twilio but it was too difficult with all of the debugging + learning nodejs and Twilio documentation at the same time 🥺
* Twilio?? HUGEEEEE PAIN, we couldn't figure out how to get different Canadian phone numbers to work for outgoing calls and also have our own custom messages for a little while. After a couple hours of reading documentation, we got it working!
## 🎉ACCOMPLISHMENTS WE ARE PROUD OF🎉
* Learning git and firebase was HUGE! Super important technologies in a lot of projects
* With only 1 frontend developer, we managed to get a sexy looking app 🤩 (shoutouts to Mitchell!!)
* Getting Twilio to work properly (its our first time)
* First time designing a supportive app that's ✨**functional AND pretty** ✨without a dedicated ui/ux designer
* USER AUTHENTICATION WORKS!! ( つ•̀ω•́)つ
* Using so many tools, languages and frameworks at once, and making them work together :D
* Submitting on time (I hope? 😬)
## ⏭️WHAT'S NEXT FOR SafePulse⏭️
SafePulse has a lot to do before it can be deployed as a genuine app.
* Partner with local governments and organizations to roll out the app and get better coverage
* Add addiction prevention resources
* Implement google maps API + location tracking data and pass on the info to emergency services so they get the most accurate location of the user
* Turn it into a web app too!
* Put it on the app store and spread the word! It can educate tons of people and save lives!
* We may want to change from firebase to MongoDB or another database if we're looking to scale the app
* Business-wise, a lot of companies sell user data or exploit their users - we don't want to do that - we'd be looking to completely sell the app to the government and get a contract to continue working on it/scale the project. Another option would be to sell our services to the government and other organizations on a subscription basis, this would give us more control over the direction of the app and its features while partnering with said organizations
## 🎁ABOUT THE TEAM🎁
*we got two Matthew's by the way (what are the chances?)*
Mitchell is a 1st year computer science student at Carleton University studying Computer Science. He is most inter tested in programing language enineering. You can connect with him at his [LinkedIn](https://www.linkedin.com/in/mitchell-monireoluwa-mark-george-261678155/) or view his [Portfolio](https://github.com/MitchellMarkGeorge)
Jacky is a 2nd year Systems Design Engineering student at the University of Waterloo. He is most experienced with embedded programming and backend. He is looking to explore various fields in development. He is passionate about reading and cooking. You can reach out to him at his [LinkedIn](https://www.linkedin.com/in/chenyuxiangjacky/) or view his [Portfolio](https://github.com/yuxstar1444)
Matthew B is an incoming 3rd year computer science student at Wilfrid Laurier University. He is most experienced with backend development but looking to learn new technologies and frameworks. He is passionate about music and video games and always looking to connect with new people. You can reach out to him at his [LinkedIn](https://www.linkedin.com/in/matthew-borkowski-b8b8bb178/) or view his [GitHub](https://github.com/Sulima1)
Matthew W is a 3rd year computer science student at Simon Fraser University, currently looking for a summer 2022 internship. He has formal training in data science. He's interested in learning new and honing his current frontend skills/technologies. Moreover, he has a deep understanding of machine learning, AI and neural networks. He's always willing to have a chat about games, school, data science and more! You can reach out to him at his [LinkedIn](https://www.linkedin.com/in/matthew-wong-240837124/), visit his [website](https://wongmatt.dev) or take a look at what he's [working on](https://github.com/WongMatthew)
### 🥳🎉THANK YOU WLU FOR HOSTING HAWKHACKS🥳🎉
|
## Inspiration
It has always been very time consuming to dedicate time to learning a new language. Many of the traditional methods often involve studying words in a dull static environment. Our experience has shown that this is not always the best or most fun way to learn new languages in a way that makes it "stick". This was why we wanted to develop an on the go AR app that anyone could take with you and live translate in real time words that a user sees more often to personalize the learning experience for the individual.
## What it does
Using iOS ARKit, we created an iOS app which works with augmented headset. We use the live video feed from the camera and leverage a tensor flow object recognizing model to scan the field of view and when the user focuses in on the object of choice, we use the model to identify the object in English. The user then must speak the translated word for the object and the app will determine if they are correct.
## How we built it
We leveraged ARKit from the iOS library for the app. Integrated a tensor flow model for object recognition. Created an api server for translated words using stdlib hosted on azure. Word translation was done using microsoft bing translation service. Our score system is a db we created in firebase.
## Challenges we ran into
Hacking out field of view for the ARKit. Getting translation to work on the app. Speech to text. Learning js and integrating stdlib. Voice commands
## Accomplishments that we're proud of
It worked!!
## What we learned
How to work with ARKit scenes. How to spin up an api quickly through stdlib. A bit of mandarin in the process of testing the app!
## What's next for Visualingo
Voice commands for app settings (e.g. language), motion commands (head movements). Gamification of the app.
|
winning
|
## Inspiration
I dreamed about the day we would use vaccine passports to travel long before the mRNA vaccines even reached clinical trials. I was just another individual, fortunate enough to experience stability during an unstable time, having a home to feel safe in during this scary time. It was only when I started to think deeper about the effects of travel, or rather the lack thereof, that I remembered the children I encountered in Thailand and Myanmar who relied on tourists to earn $1 USD a day from selling handmade bracelets. 1 in 10 jobs are supported by the tourism industry, providing livelihoods for many millions of people in both developing and developed economies. COVID has cost global tourism $1.2 trillion USD and this number will continue to rise the longer people are apprehensive about travelling due to safety concerns. Although this project is far from perfect, it attempts to tackle vaccine passports in a universal manner in hopes of buying us time to mitigate tragic repercussions caused by the pandemic.
## What it does
* You can login with your email, and generate a personalised interface with yours and your family’s (or whoever you’re travelling with’s) vaccine data
* Universally Generated QR Code after the input of information
* To do list prior to travel to increase comfort and organisation
* Travel itinerary and calendar synced onto the app
* Country-specific COVID related information (quarantine measures, mask mandates etc.) all consolidated in one destination
* Tourism section with activities to do in a city
## How we built it
Project was built using Google QR-code APIs and Glideapps.
## Challenges we ran into
I first proposed this idea to my first team, and it was very well received. I was excited for the project, however little did I know, many individuals would leave for a multitude of reasons. This was not the experience I envisioned when I signed up for my first hackathon as I had minimal knowledge of coding and volunteered to work mostly on the pitching aspect of the project. However, flying solo was incredibly rewarding and to visualise the final project containing all the features I wanted gave me lots of satisfaction. The list of challenges is long, ranging from time-crunching to figuring out how QR code APIs work but in the end, I learned an incredible amount with the help of Google.
## Accomplishments that we're proud of
I am proud of the app I produced using Glideapps. Although I was unable to include more intricate features to the app as I had hoped, I believe that the execution was solid and I’m proud of the purpose my application held and conveyed.
## What we learned
I learned that a trio of resilience, working hard and working smart will get you to places you never thought you could reach. Challenging yourself and continuing to put one foot in front of the other during the most adverse times will definitely show you what you’re made of and what you’re capable of achieving. This is definitely the first of many Hackathons I hope to attend and I’m thankful for all the technical as well as soft skills I have acquired from this experience.
## What's next for FlightBAE
Utilising GeoTab or other geographical softwares to create a logistical approach in solving the distribution of Oyxgen in India as well as other pressing and unaddressed bottlenecks that exist within healthcare. I would also love to pursue a tech-related solution regarding vaccine inequity as it is a current reality for too many.
|
## Inspiration
Recently, security has come to the forefront of media with the events surrounding Equifax. We took that fear and distrust and decided to make something to secure and protect data such that only those who should have access to it actually do.
## What it does
Our product encrypts QR codes such that, if scanned by someone who is not authorized to see them, they present an incomprehensible amalgamation of symbols. However, if scanned by someone with proper authority, they reveal the encrypted message inside.
## How we built it
This was built using cloud functions and Firebase as our back end and a Native-react front end. The encryption algorithm was RSA and the QR scanning was open sourced.
## Challenges we ran into
One major challenge we ran into was writing the back end cloud functions. Despite how easy and intuitive Google has tried to make it, it still took a lot of man hours of effort to get it operating the way we wanted it to. Additionally, making react-native compile and run on our computers was a huge challenge as every step of the way it seemed to want to fight us.
## Accomplishments that we're proud of
We're really proud of introducing encryption and security into this previously untapped market. Nobody to our kowledge has tried to encrypt QR codes before and being able to segment the data in this way is sure to change the way we look at QR.
## What we learned
We learned a lot about Firebase. Before this hackathon, only one of us had any experience with Firebase and even that was minimal, however, by the end of this hackathon, all the members had some experience with Firebase and appreciate it a lot more for the technology that it is. A similar story can be said about react-native as that was another piece of technology that only a couple of us really knew how to use. Getting both of these technologies off the ground and making them work together, while not a gargantuan task, was certainly worthy of a project in and of itself let alone rolling cryptography into the mix.
## What's next for SeQR Scanner and Generator
Next, if this gets some traction, is to try and sell this product on th marketplace. Particularly for corporations with, say, QR codes used for labelling boxes in a warehouse, such a technology would be really useful to prevent people from gainng unnecessary and possibly debiliatory information.
|
## Inspiration
As college students learning to be socially responsible global citizens, we realized that it's important for all community members to feel a sense of ownership, responsibility, and equal access toward shared public spaces. Often, our interactions with public spaces inspire us to take action to help others in the community by initiating improvements and bringing up issues that need fixing. However, these issues don't always get addressed efficiently, in a way that empowers citizens to continue feeling that sense of ownership, or sometimes even at all! So, we devised a way to help FixIt for them!
## What it does
Our app provides a way for users to report Issues in their communities with the click of a button. They can also vote on existing Issues that they want Fixed! This crowdsourcing platform leverages the power of collective individuals to raise awareness and improve public spaces by demonstrating a collective effort for change to the individuals responsible for enacting it. For example, city officials who hear in passing that a broken faucet in a public park restroom needs fixing might not perceive a significant sense of urgency to initiate repairs, but they would get a different picture when 50+ individuals want them to FixIt now!
## How we built it
We started out by brainstorming use cases for our app and and discussing the populations we want to target with our app. Next, we discussed the main features of the app that we needed to ensure full functionality to serve these populations. We collectively decided to use Android Studio to build an Android app and use the Google Maps API to have an interactive map display.
## Challenges we ran into
Our team had little to no exposure to Android SDK before so we experienced a steep learning curve while developing a functional prototype in 36 hours. The Google Maps API took a lot of patience for us to get working and figuring out certain UI elements. We are very happy with our end result and all the skills we learned in 36 hours!
## Accomplishments that we're proud of
We are most proud of what we learned, how we grew as designers and programmers, and what we built with limited experience! As we were designing this app, we not only learned more about app design and technical expertise with the Google Maps API, but we also explored our roles as engineers that are also citizens. Empathizing with our user group showed us a clear way to lay out the key features of the app that we wanted to build and helped us create an efficient design and clear display.
## What we learned
As we mentioned above, this project helped us learn more about the design process, Android Studio, the Google Maps API, and also what it means to be a global citizen who wants to actively participate in the community! The technical skills we gained put us in an excellent position to continue growing!
## What's next for FixIt
An Issue’s Perspective
\* Progress bar, fancier rating system
\* Crowdfunding
A Finder’s Perspective
\* Filter Issues, badges/incentive system
A Fixer’s Perspective
\* Filter Issues off scores, Trending Issues
|
partial
|
# **Cough It**
#### COVID-19 Diagnosis at Ease
## Inspiration
As the pandemic has nearly crippled all the nations and still in many countries, people are in lockdown, there are many innovations in these two years that came up in order to find an effective way of tackling the issues of COVID-19. Out of all the problems, detecting the COVID-19 strain has been the hardest so far as it is always mutating due to rapid infections.
Just like many others, we started to work on an idea to detect COVID-19 with the help of cough samples generated by the patients. What makes this app useful is its simplicity and scalability as users can record a cough sample and just wait for the results to load and it can give an accurate result of where one have the chances of having COVID-19 or not.
## Objective
The current COVID-19 diagnostic procedures are resource-intensive, expensive and slow. Therefore they are lacking scalability and retarding the efficiency of mass-testing during the pandemic. In many cases even the physical distancing protocol has to be violated in order to collect subject's samples. Disposing off biohazardous samples after diagnosis is also not eco-friendly.
To tackle this, we aim to develop a mobile-based application COVID-19 diagnostic system that:
* provides a fast, safe and user-friendly to detect COVID-19 infection just by providing their cough audio samples
* is accurate enough so that can be scaled-up to cater a large population, thus eliminating dependency on resource-heavy labs
* makes frequent testing and result tracking efficient, inexpensive and free of human error, thus eliminating economical and logistic barriers, and reducing the wokload of medical professionals
Our [proposed CNN](https://dicova2021.github.io/docs/reports/team_Brogrammers_DiCOVA_2021_Challenge_System_Report.pdf) architecture also secured Rank 1 at [DiCOVA](https://dicova2021.github.io/) Challenge 2021, held by IISc Bangalore researchers, amongst 85 teams spread across the globe. With only being trained on small dataset of 1,040 cough samples our model reported:
Accuracy: 94.61%
Sensitivity: 80% (20% false negative rate)
AUC of ROC curve: 87.07% (on blind test set)
## What it does
The working of **Cough It** is simple. User can simply install the app and tap to open it. Then, the app will ask for user permission for external storage and microphone. The user can then just tap the record button and it will take the user to a countdown timer like interface. Playing the play button will simply start recording a 7-seconds clip of cough sample of the user and upon completion it will navigate to the result screen for prediction the chances of the user having COVID-19
## How we built it
Our project is divided into three different modules -->
#### **ML Model**
Our machine learning model ( CNN architecture ) will be trained and deployed using the Sagemaker API which is apart of AWS to predict positive or negative infection from the pre-processed audio samples. The training data will also contain noisy and bad quality audio sample, so that it is robust for practical applications.
#### **Android App**
At first, we prepared the wireframe for the app and decided the architecture of the app which we will be using for our case. Then, we worked from the backend part first, so that we can structure our app in proper android MVVM architecture. We constructed all the models, Retrofit Instances and other necessary modules for code separation.
The android app is built in Kotlin and is following MVVM architecture for scalability. The app uses Media Recorder class to record the cough samples of the patient and store them locally. The saved file is then accessed by the android app and converted to byte array and Base64 encoded which is then sent to the web backend through Retrofit.
#### **Web Backend**
The web backend is actually a Node.js application which is deployed on EC2 instance in AWS. We choose this type of architecture for our backend service because we wanted a more reliable connection between our ML model and our Node.js application.
At first, we created a backend server using Node.js and Express.js and deployed the Node.js server in AWS EC2 instance. The server then receives the audio file in Base64 encoded form from the android client through a POST request API call. After that, the file is getting converted to .wav file through a module in terminal through command. After successfully, generating the .wav file, we put that .wav file as argument in the pre-processor which is a python script. Then we call the AWS Sagemaker API to get the predictions and the Node.js application then sends the predictions back to the android counterpart to the endpoint.
## Challenges we ran into
#### **Android**
Initially, in android, we were facing a lot of issues in recording a cough sample as there are two APIs for recording from the android developers, i.e., MediaRecorder, AudioRecord. As the ML model required a .wav file of the cough sample to pre-process, we had to generate it on-device. It is possible with AudioRecord class but requires heavy customization to work and also, saving a file and writing to that file, is a really tedious and buggy process. So, for android counterpart, we used the MediaRecorder class and saving the file and all that boilerplate code is handled by that MediaRecorder class and then we just access that file and send it to our API endpoint which then converts it into a .wav file for the pre-processor to pre-process.
#### **Web Backend**
In the web backend side, we faced a lot of issues in deploying the ML model and to further communicate with the model with node.js application.
Initially, we deployed the Node.js application in AWS Lamdba, but for processing the audio file, we needed to have a python environment as well, so we could not continue with lambda as it was a Node.js environment. So, to actually get the python environment we had to use AWS EC2 instance for deploying the backend server.
Also, we are processing the audio file, we had to use ffmpeg module for which we had to downgrade from the latest version of numpy library in python to older version.
#### **ML Model**
The most difficult challenge for our ml-model was to get it deployed so that it can be directly accessed from the Node.js server to feed the model with the MFCC values for the prediction. But due to lot of complexity of the Sagemaker API and with its integration with Node.js application this was really a challenge for us. But, at last through a lot of documentation and guidance we are able to deploy the model in Sagemaker and we tested some sample data through Postman also.
## Accomplishments that we're proud of
Through this project, we are proud that we are able to get a real and accurate prediction of a real sample data. We are able to send a successful query to the ML Model that is hosted on Sagemaker and the prediction was accurate.
Also, this made us really happy that in a very small amount we are able to overcome with so much of difficulties and also, we are able to solve them and get the app and web backend running and we are able to set the whole system that we planned for maintaining a proper architecture.
## What we learned
Cough It is really an interesting project to work on. It has so much of potential to be one of the best diagnostic tools for COVID-19 which always keeps us motivated to work on it make it better.
In android, working with APIs like MediaRecorder has always been a difficult position for us, but after doing this project and that too in Kotlin, we feel more confident in making a production quality android app. Also, developing an ML powered app is difficult and we are happy that finally we made it.
In web, we learnt the various scenarios in which EC2 instance can be more reliable than AWS Lambda also running various script files in node.js server is a good lesson to be learnt.
In machine learning, we learnt to deploy the ML model in Sagemaker and after that, how to handle the pre-processing file in various types of environments.
## What's next for Untitled
As of now, our project is more focused on our core idea, i.e., to predict by analysing the sample data of the user. So, our app is limited to only one user, but in future, we have already planned to make a database for user management and to show them report of their daily tests and possibility of COVID-19 on a weekly basis as per diagnosis.
## Final Words
There is a lot of scope for this project and this project and we don't want to stop innovating. We would like to take our idea to more platforms and we might also launch the app in the Play-Store soon when everything will be stable enough for the general public.
Our hopes on this project is high and we will say that, we won't leave this project until perfection.
|
## Inspiration
Every year hundreds of thousands of preventable deaths occur due to the lack of first aid knowledge in our societies. Many lives could be saved if the right people are in the right places at the right times. We aim towards connecting people by giving them the opportunity to help each other in times of medical need.
## What it does
It is a mobile application that is aimed towards connecting members of our society together in times of urgent medical need. Users can sign up as respondents which will allow them to be notified when people within a 300 meter radius are having a medical emergency. This can help users receive first aid prior to the arrival of an ambulance or healthcare professional greatly increasing their chances of survival. This application fills the gap between making the 911 call and having the ambulance arrive.
## How we built it
The app is Android native and relies heavily on the Google Cloud Platform. User registration and authentication is done through the use of Fireauth. Additionally, user data, locations, help requests and responses are all communicated through the Firebase Realtime Database. Lastly, the Firebase ML Kit was also used to provide text recognition for the app's registration page. Users could take a picture of their ID and their information can be retracted.
## Challenges we ran into
There were numerous challenges in terms of handling the flow of data through the Firebase Realtime Database and providing the correct data to authorized users.
## Accomplishments that we're proud of
We were able to build a functioning prototype! Additionally we were able to track and update user locations in a MapFragment and ended up doing/implementing things that we had never done before.
|
### Checkout our site at: <https://rapid-processor.herokuapp.com/>
### Our slideshow at: <https://www.beautiful.ai/player/-MFQZr8ue7Jp0jHtY16q>
## Inspiration
COVID-19 has significantly impacted everyone's lives and we are all eager to return to the pre-pandemic lifestyle. One of the most effective ways of stopping the spread is through mass testing: identifying and isolating those who are infected. However, in some of the hardest-hit regions around the world, the bottleneck of COVID-19 testing is often not gathering samples, but processing them. In certain areas of the US for example, samples can take, on average, up to 2 weeks to process.[1]
On a personal level, that means individuals with mild or no symptoms could be going to public spaces like beaches and parks, and spreading the virus for two full weeks unknowingly. And for those that have a weak immune system, they could face hospitalization or even death. We hope to reduce the processing time, lower the spread of this deadly virus, and prevent death.
A technique commonly used to tackle a problem of this kind is pool sampling. In essence, instead of testing one sample at a time, samples are being tested in batches. Individual samples in a certain batch would only be retested if the given batch return positive (at least one positive COVID-19 case is present in the batch). This technique has the potential to be very effective, but only at the most optimized batch size.
## What it does
Our application predicts the number of active COVID-19 cases, tested cases, thus giving us an active rate (active cases divided by tested cases), calculates the most optimal batch sizes for pool sampling.
## How we built it
Our application fetches data from Johns Hopkin’s University’s (JHU) COVID-19 database, which hosts real-time data from around the world. With available data provided by JHU, our application is pertinent everywhere. With the provided data, our well-trained recurrent neural network accurately predicts the active rate of the coming days based on past data. Then we determine the optimized batch size for the the near future in each region to achieve the fastest processing time.
The frontend is built on React in JavaScript and the backend is built with flask in Python.
Our predicted COVID-19 cases, tested cases, and active rates, which we use to produce the optimal batch sizes, were outputted using machine learning in Keras (TensorFlow). We used a 14-day window to predict the next week’s results and iterated the process to predict the next week’s results. We use mean/max preprocessing on our variables. Our network was a recurrent neural network with two LSTM layers with 16 recurrent units each, and one dense layer with 8 units, followed by a dense linear regression output. We used tanh and ReLU activations. Training was done stochastically on given data with early stopping using an Adam optimizer and a learning rate of 5e-4. Each day, we take newly uploaded data from Johns Hopkins University and perform online learning, updating our model automatically. We then obtain the daily active rate from our algorithm and output the optimal batch sizes.
## Challenges we ran into
We faced two major challenges during this hackathon. Initially, we planned to build our app on Azure. We were able to deploy it successfully with a continuous integration pipeline but were unable to display the user interface. The second challenge we faced is with training neural networks. We had to rely heavily on local computers to train complex networks and this was a time-consuming process during our development.
## Accomplishments that we're proud of
We are proud that we are able to make a fully functional web application with a sophisticated machine learning integrated backend with merely three participants. Furthermore, our app will be able to influence hundreds of millions of people and has the potential to make a significant impact on our fight against COVID-19.
## What we learned
We have learned how to develop and integrate a frontend and back end with a complex machine learning module in an application. We were able to share our existing computer science concepts among us. Each of us brought to the table a unique set of skills that made this project possible.
## What's next for Pool Sampler
We will integrate more cloud services and host our application on platforms such as Microsoft Azure, Amazon Web Services, and Google Cloud services to fully harness the power of cloud computing. We also look forward to collaborating with laboratories and local governments to reduce their testing time and save lives.
[1] <https://www.mercurynews.com/2020/07/29/coronavirus-why-your-covid-19-test-results-are-so-delayed/>
|
winning
|
## Inspiration
Researching for an essay is a pain so we wanted to make an easier way to find, compile, and summarize the right resources. No more insentient googling with 50 tabs open, quickly collect and summarize all you information in one place with The Lazy Scholar!
## What it does
The Lazy Scholar searches for your desired topic and summarizes the top results so you can quickly and easily determine if the link is of value.
The majority of search engines return only a few words matching the search criteria for each link, but the Lazy Scholar does so much more. When a search is requested the program searches through each link returned, summarizing the information contained and displaying only the most relevant information in a paragraph format. You can expand links to generate a more in-depth summary and download the results all to one document through the click of a button.
If you are feeling especially lazy The Lazy Scholar can generate an essay for every word count (quality not guaranteed).
If you are feeling especially lazy The Lazy Scholar can generate a complete essay for you, all you need to do is enter the search criteria and required word count (quality not guaranteed).
## How we built it
The Lazy Scholar was built with an angular front end and powered by a custom python backed. It utilizes the Google custom search API to generate the top search results. The main body of text at each URL is then collected and run through a text summarization program. This program generates the most relevant content using the TextRank algorithm.
|
## Inspiration
Frustrated with the overwhelming amount of notes required in AP classes, we decided to make life easier for ourselves. With the development of machine learning and neural networks, automatic text summary generation has become increasingly accurate; our mission is to provide easy and simple access to the service.
## What it does
The web app takes in a picture/screenshot of text and auto-generates a summary and highlights important sentences, making skimming a dense article simple. In addition, keywords and their definitions are provided along with some other information (sentiment, classification, and Flesch-Kincaid readability). Finally, a few miscellaneous community tools (random student-related articles and a link to Stack Exchange) are also available.
## How we built it
The natural language processing was split into two different parts: abstractive and extractive.
The abstractive section was carried out using a neural network from [this paper](https://arxiv.org/abs/1704.04368) by Abigail See, Peter J. Liu, and Christopher D. Manning ([Github](https://github.com/abisee/pointer-generator)). Stanford's CoreNLP, was used to chunk and preprocess text for analysis.
Extractive text summarize was done using Google Cloud Language, and the python modules gensim, word2vec and nltk.
We also used Google Cloud Vision API to extract text from an image. To find random student-related articles, we webscraped using BeautifulSoup4.
The front end was built using HTML, CSS, and Bootstrap.
## Challenges we ran into
We found it difficult to parse/chunk our plain-text into the correct format for the neural net to take in.
In addition, we found it extremely difficult to set up and host our flask app on App Engine/Firestore in the given time; we were unable to successfully upload our model due to our large files and the lack of time. To solve this problem, we decided to keep our project local and use cookies for data retention. Because of this we were able to redirect our efforts towards other features.
## Accomplishments that we're proud of
We're extremely proud of having a working product at the end of a hackathon, especially a project we are so passionate about. We have so many ideas that we haven't implemented in this short amount of time, and we plan to improve and develop our project further afterwards.
## What we learned
We learned how to work with flask, tensorflow models, various forms of natural language processing, and REST (specifically Google Cloud) APIs.
## What's next for NoteWorthy
Although our product is "finished," we have a lot planned for NoteWorthy. Our main goal is to make NoteWorthy a product not only for the individual but for the community (possibly as a tool in the classroom). We want to enable multi-user availability of summarized documents to encourage discussion and group learning. Additionally, we want to personalize NoteWorthy according to the user's actions. This includes utilizing the subjects of summarized articles and their respective reading levels to provide relevant news articles as well as forum recommendations.
|
## Inspiration
Among our group, we noticed we all know at least one person, who despite seeking medical and nutritional support, suffers from some unidentified food allergy. Seeing people struggle to maintain a healthy diet while "dancing" around foods that they are unsure if they should eat inspired us to do something about it; build **BYTEsense.**
## What it does
BYTEsense is an AI powered tool which personalizes itself to a users individual dietary needs. First, you tell the app what foods you ate, and rate your experience afterwards on a scale of 1-3 - The app then breaks down the food into its individual ingredients, remembers how your experience with them, and stores them to be referenced later. Then, after a sufficient amount of data has been collected, you can use the app to predict how **NEW** foods can affect you through our "How will I feel if I consume..." function!
## How we built it
The web app consists of two main functions, the training and the predicting functions. The training function was built beginning with the receiving of a food and an associated rating. This is then passed on through the OpenAI API to be broken apart to its individual ingredients through ChatGPT's chatting abilities. These ingredients, and their associated ratings, are then saved onto an SQL database which contains all known associations to date. **Furthermore**, there is always a possibility that two different dishes share an ingredient, but your experience is fully different! How do we adjust for that? Well naturally, that would imply that this ingredient is not the significant irritator, and we adjust the ratings according to both data points. Finally, the prediction function of the web app utilizes Cohere's AI endpoints to complete the predictions. Through use of Cohere's classify endpoint, we are able to train an algorithm which can classify a new dish into any of the three aforementioned categories, with relation to the previously acquired data!
The project was all built on Replit, allowing for us to collaborate and host it all in the same place!
## Challenges we ran into
We ran into many challenges over the course of the project. First, it began with our original plan of action being completely unusable after seeing updates to Cohere's API, effectively removing the custom embed models for classification and rerank. But that did not stop us! We readjusted, re-planned, and kept on it! Our next biggest problem was the coders nightmare, a tiny syntax error in our SQLite code which continuously that crashed our entire program. We spent over an hour locating the bug, and even more trying to figure out the issue (it was a wrong data type.). And our final immense issue came quite literally out of the blue, previously, we utilized Cohere's new Coral chatbot to identify ingredients in the various input, but, due to an apparent glitch in the responses - we got our responses sent over 15 times each prompt - we had made a last minute jump to OpenAI! Once we got past those, most other things seemed like a piece of cake - there were a lot of pieces - but we're happy to present the finished product!
## Accomplishments we are proud of:
There are many things that we as a team are proud of, from overcoming trials and tribulations, refusing sleep for nearly two days, and most importantly, producing a finished product. We are proud to see just how far we have come, from having no idea how to even approach LLM, to running a program utilizing **TWO** different ones. But most importantly, I think we are all proud of creating a product that really has potential to help people, using technology to better people's lives is something to be very proud of doing!
## What we learned:
What did we learn? Well, that depends who you ask! I feel like each member of the team learnt an unbelievable amount, whether it be from each other or individually. For instance, I learnt a lot about flask and front end development from working with a proficient teammate, and I hope I gave something to learn from too! Even more so, throughout the weekend we attended many workshops, ranging from ML, to LLM, Replit, and so many others, that even if we didn't use what we learnt there in this project, I have no doubt it will appear in a next!
## What’s next for BYTEsense:
All of us in the team honestly believe that BYTEsense has reached a level which is not only functional, but viable. As we keep on going all that is left is tidying up and cleaning some code and a potentially market ready app could be born! Who knows, maybe we'll be a sponsor one day!
But either way, I am definitely using a copy when I get back home!
|
losing
|
## Inspiration
We were inspired to create such a project since we are all big fans of 2D content, yet have no way of actually animating 2D movies. Hence, the idea for StoryMation was born!
## What it does
Given a text prompt, our platform converts it into a fully-featured 2D animation, complete with music, lots of action, and amazing-looking sprites! And the best part? This isn't achieved by calling some image generation API to generate a video for our movie; instead, we call on such APIs to create lots of 2D sprites per scene, and then leverage the power of LLMs (CoHere) to move those sprites around in a fluid and dynamic matter!
## How we built it
On the frontend we used React and Tailwind, whereas on the backend we used Node JS and Express. However, for the actual movie generation, we used a massive, complex pipeline of AI-APIs. We first use Cohere to split the provided story plot into a set of scenes. We then use another Cohere API call to generate a list of characters, and a lot of their attributes, such as their type, description (for image gen), and most importantly, Actions. Each "Action" consists of a transformation (translation/rotation) in some way, and by interpolating between different "Actions" for each character, we can integrate them seamlessly into a 2D animation.
This framework for moving, rotating and scaling ALL sprites using LLMs like Cohere is what makes this project truly stand out. Had we used an Image Generation API like SDXL to simply generate a set of frames for our "video", we would have ended up with a janky stop-motion video. However, we used Cohere in a creative way, to decide where and when each character should move, scale, rotate, etc. thus ending up with a very smooth and human-like final 2D animation.
## Challenges we ran into
Since our project is very heavily reliant on BETA parts of Cohere for many parts of its pipeline, getting Cohere to fit everything into the strict JSON prompts we had provided, despite the fine-tuning, was often quite difficult.
## Accomplishments that we're proud of
In the end, we were able to accomplish what we wanted!
|
## Inspiration
This year's theme of Nostalgia reminded us of our childhoods, reading stories and being so immersed in them. As a result, we created Mememto as a way for us to collectively look back on the past from the retelling of it through thrilling and exciting stories.
## What it does
We created a web application that asks users to input an image, date, and brief description of the memory associated with the provided image. Doing so, users are then given a generated story full of emotions, allowing them to relive the past in a unique and comforting way. Users are also able to connect with others on the platform and even create groups with each other.
## How we built it
Thanks to Taipy and Cohere, we were able to bring this application to life. Taipy supplied both the necessary front-end and back-end components. Additionally, Cohere enabled story generation through natural language processing (NLP) via their POST chat endpoint (<https://api.cohere.ai/v1/chat>).
## Challenges we ran into
Mastering Taipy presented a significant challenge. Due to its novelty, we encountered difficulty freely styling, constrained by its syntax. Setting up virtual environments also posed challenges initially, but ultimately, we successfully learned the proper setup.
## Accomplishments that we're proud of
* We were able to build a web application that functions
* We were able to use Taipy and Cohere to build a functional application
## What we learned
* We were able to learn a lot about the Taipy library, Cohere, and Figma
## What's next for Memento
* Adding login and sign-up
* Improving front-end design
* Adding image processing, able to identify entities within user given image and using that information, along with the brief description of the photo, to produce a more accurate story that resonates with the user
* Saving and storing data
|
## Inspiration
Everybody knows how annoying it can be to develop web applications. But this sentiment is certainly true for those who have minimal to no working experience with web development. We were inspired by the power of Cohere LLM's to transform natural language into many different forms and in our case, to generate websites. With this, we are able to quickly turn a users idea into a website which they can download and edit on the spot.
## What it does
SiteSynth turns natural language input into a clean formatted and stylized website.
## How we built it
SiteSynth is powered by Django in the back end and HTML/CSS/JS in the front end. In the back end, we use the Cohere generate API to generate the HTML and CSS code.
## Challenges we ran into
Some challenges that we ran into were with the throttled API and perfecting the prompt. One of the most important parts of an NLP project is the input prompt to the LLM. We spent a lot of time perfecting the prompt of the input in order to ensure that the output is HTML code and ONLY HTML code. Also, the throttled speed of API calls slowed down our development and leads to a slow running app. However, despite these hardships, we have ended up with a project that we are quite proud of.
## Accomplishments that we're proud of
The project as a whole was a huge accomplishment which we are very happy with, but there are some parts which we appreciate more than others. In particular, we think the design of the main page is very clean. Likewise, the backend, while messy, does the job very well and we are proud of that.
## What we learned
This project was very insightful for learning about new cutting edge technologies. While we have worked with Django before, this was our first time working with the Cohere API (or any LLM API for that matter) and the importance of verbose and specific prompts was certainly highlighted. We also learned how difficult it can be to create a full-fledged application in a day in a half.
## What's next for SiteSynth
For the future, there are many ways in which we can improve SiteSynth. In particular, we know that images are integral to web development and as such we would like to properly integrate images. Likewise, with a proper API key, we could speed up the app tremendously. Finally, by also supporting dynamic templates, we can make the websites truly unique and desired.
|
partial
|
## Inspiration
We were inspired to build Hank after reading the sponsor contests and seeing that Vitech was running what we thought was a super challenging problem. We built Hank as a proof-of-concept to show that much of the advice sought from insurance professionals can be accurately generated by a finely tuned model. Considering our interest in machine learning and data visualization, the project seemed like the perfect fit. In the case of Hank, we aimed to generate plan suggestions and prices for a user through a simple survey. We believe a page like this could live on an insurance company's website and provide users with accurate quotes based off a machine learning model the company is able to tweak in real time.
## What it does
Hank provides a broad set of functionality that helps save time and money for both the clients and the life insurance providers.
For clients looking to purchase health insurance, Hank provides an easy introduction to the process with a simple and friendly application that guides the client through a series of questions to gather information such as age, family status, and personal health. With this information, Hank provides an accurate quote for each of the four insurance plans, as well as making a recommendation for which plan is likely the best for them.
Hank also provides an insurance provider facing visualization that allows for the life insurance provider to tweak Hank's suggestions based on business metrics such as life time value (LTV), customer satisfaction, and customer retention, all without re-training the two machine learning models that Hank uses to provide suggestions.
## How we built it
Hank's suggestion system is composed of three modules that work in series to provide the most accurate and useful data to the user.
The first module, the premium estimator, uses the gathered user demographic data to determine what the premiums for each of the four plans (bronze, silver, gold, platinum) would be. This is done with a neural network trained using tensor flow on the insurance data set provided by Vitech for this competition. Using a neural network for a mixture of continuous and discrete data allows Hank to make complex associations between user features and make accurate premium predictions.
The second module is the suggestion module. The suggestion module uses the premium pricing predicted by the premium estimator module as well as the user's demographic data to suggest which of the four plans would be the most suited to them. Because of many-dimensional nature of the data set as well as the fact that there were so many data points to use, a kth-nearest neighbor training model was applied using scipy.
The third module, the business module, is an exciting module that provides value to the life insurance provider by giving fine control over the suggestions that Hank makes to customers using simple metrics. The business module works by combining information from the first and second modules, as well as data from the World Population API to provide a data set that can be modified using simple scaling factors. Using the data-visualization front-end of this module allows the life insurance provider to tweak Hank's suggestions to better align with business goals. This would normally be a very time consuming process as the machine learning that Hank uses to make decisions would have to be re-trained and re-validated, but with the business module, the key components are pre-abstracted away from the machine learning implementation.
## Challenges we ran into
Our first hurdle for Hank was downloading the dataset provided by Vitech. At 1.4m records, it was a difficult task to retrieve and store, especially on a limited connection.
Once our data was successfully scraped, our next challenge was deciding on an appropriate model to use for the machine learning aspect of the project. Many options were tried and discarded, namely Bayseian classification, support vector machines, and random forest classification. By continuously training and testing different models, we ultimately decided on two - a nearest neighbour simulation and a neural network.
## Accomplishments that we're proud of
We're happy to say that we managed to deliver on what we thought would be our two biggest challenges - a pleasing and responsive UI and a meaningful data visualization.
We're especially proud of the business logic control panel which is used to modify and visualize the different goals a company wishes to optimize for.
## What we learned
This project was a chance for us to learn about machine learning as well as test our ability to put ourselves in the shoes of both our client as a software developer and the users of the application, to provide special features to both. The time constraints provided by the hackathon also taught us to manage our time and communicate well - as a team of two people tackling such an ambitious project, constant communication was a must.
## What's next for Hank: Your health insurance advisor
The next step for Hank is to train it against a larger, more diverse dataset and further optimize our models. Once we've trained our model against another set, we'll also be able to add additional steps to the survey, giving us more information to query with. The ultimate goal for Hank would be to host it live on an insurance company's site and see it used by real people and trained with real data.
|
We were inspired by the daily struggle of social isolation.
Shows the emotion of a text message on Facebook
We built this using Javascript, IBM-Watson NLP API, Python https server, and jQuery.
Accessing the message string was a lot more challenging than initially anticipated.
Finding the correct API for our needs and updating in real time also posed challenges.
The fact that we have a fully working final product.
How to interface JavaScript with Python backend, and manually scrape a templated HTML doc for specific key words in specific locations
Incorporate the ability to display alternative messages after a user types their initial response.
|
## Inspiration
Everybody struggles with their personal finances. Financial inequality in the workplace is particularly prevalent among young females. On average, women make 88 cents per every dollar a male makes in Ontario. This is why it is important to encourage women to become more cautious of spending habits. Even though budgeting apps such as Honeydue or Mint exist, they depend heavily on self-motivation from users.
## What it does
Our app is a budgeting tool that targets young females with useful incentives to boost self-motivation for their financial well-being. The app features simple scale graphics visualizing the financial balancing act of the user. By balancing the scale and achieving their monthly financial goals, users will be provided with various rewards, such as discount coupons or small cash vouchers based on their interests. Users are free to set their goals on their own terms and follow through with them. The app re-enforces good financial behaviour by providing gamified experiences with small incentives.
The app will be provided to users free of charge. As with any free service, the anonymized user data will be shared with marketing and retail partners for analytics. Discount offers and other incentives could lead to better brand awareness and spending from our users for participating partners. The customized reward is an opportunity for targeted advertising
## Persona
Twenty-year-old Ellie Smith works two jobs to make ends meet. The rising costs of living make it difficult for her to maintain her budget. She heard about this new app called Re:skale that provides personalized rewards for just achieving the budget goals. She signed up after answering a few questions and linking her financial accounts to the app. The app provided simple balancing scale animation for immediate visual feedback of her financial well-being. The app frequently provided words of encouragement and useful tips to maximize the chance of her success. She especially loves how she could set the goals and follow through on her own terms. The personalized reward was sweet, and she managed to save on a number of essentials such as groceries. She is now on 3 months streak with a chance to get better rewards.
## How we built it
We used : React, NodeJs, Firebase, HTML & Figma
## Challenges we ran into
We had a number of ideas but struggled to define the scope and topic for the project.
* Different design philosophies made it difficult to maintain consistent and cohesive design.
* Sharing resources was another difficulty due to the digital nature of this hackathon
* On the developing side, there were technologies that were unfamiliar to over half of the team, such as Firebase and React Hooks. It took a lot of time in order to understand the documentation and implement it into our app.
* Additionally, resolving merge conflicts proved to be more difficult. The time constraint was also a challenge.
## Accomplishments that we're proud of
* The use of harder languages including firebase and react hooks
* On the design side it was great to create a complete prototype of the vision of the app.
* Being some members first hackathon, the time constraint was a stressor but with the support of the team they were able to feel more comfortable with the lack of time
## What we learned
* we learned how to meet each other’s needs in a virtual space
* The designers learned how to merge design philosophies
* How to manage time and work with others who are on different schedules
## What's next for Re:skale
Re:skale can be rescaled to include people of all gender and ages.
* More close integration with other financial institutions and credit card providers for better automation and prediction
* Physical receipt scanner feature for non-debt and credit payments
## Try our product
This is the link to a prototype app
<https://www.figma.com/proto/nTb2IgOcW2EdewIdSp8Sa4/hack-the-6ix-team-library?page-id=312%3A3&node-id=375%3A1838&viewport=241%2C48%2C0.39&scaling=min-zoom&starting-point-node-id=375%3A1838&show-proto-sidebar=1>
This is a link for a prototype website
<https://www.figma.com/proto/nTb2IgOcW2EdewIdSp8Sa4/hack-the-6ix-team-library?page-id=0%3A1&node-id=360%3A1855&viewport=241%2C48%2C0.18&scaling=min-zoom&starting-point-node-id=360%3A1855&show-proto-sidebar=1>
|
partial
|
## Inspiration
Swap was inspired by COVID-19 having an impact on many individuals’ daily routines. Sleep schedules were shifted, more distractions were present due to working from home, and being away from friends and family members was difficult. Our team wanted to create a solution that would help others add excitement to their quarantine routines and also connect them with their friends and family members again.
## What it does
Swap is a mobile application that allows users to swap routines with their friends, family members, or even strangers to try something new! You can input daily activities and photos, add an optional mood tracker, add friends, initiate swaps instantly, pre-schedule swaps, and even randomize swaps.
## How we built it
For this project, we created a working prototype and wrote the backend code on how the swaps would be made. The prototype was created using Figma. For writing the backend code, we used python and applications such as Xcode, MySQL, and PyCharm.
## Challenges we ran into
A challenge we ran into was determining how we would write the backend code for the app and what applications to use. Additionally, we had to use up some time to select all the features we wanted Swap to have.
## Accomplishments that we're proud of
Accomplishments we’re proud of include the overall idea of making an app that swapped routines, our Figma prototype, and the backend coding.
## What we learned
We learned how to use Figma’s wireframing feature to create a working prototype and learned about applications (ex. MySQL) that allowed us to write backend code for our project.
## What's next for Swap
We want to finalize the development of the app and launch it in the app stores!
|
## Inspiration
memes have become a cultural phenomenon and a huge recreation for many young adults including ourselves. for this hackathon, we decided to connect the sociability aspect of the popular site "twitter", and combine it with a methodology of visualizing the activity of memes in various neighborhoods. we hope that through this application, we can create a multicultural collection of memes, and expose these memes, trending from popular cities to a widespread community of memers.
## What it does
NWMeme is a data visualization of memes that are popular in different parts of the world. Entering the application, you are presented with a rich visual of a map with Pepe the frog markers that mark different cities on the map that has dank memes. Pepe markers are sized by their popularity score which is composed of retweets, likes, and replies. Clicking on Pepe markers will bring up an accordion that will display the top 5 memes in that city, pictures of each meme, and information about that meme. We also have a chatbot that is able to reply to simple queries about memes like "memes in Vancouver."
## How we built it
We wanted to base our tech stack with the tools that the sponsors provided. This started from the bottom with CockroachDB as the database that stored all the data about memes that our twitter web crawler scrapes. Our web crawler was in written in python which was Google gave an advanced level talk about. Our backend server was in Node.js which CockroachDB provided a wrapper for hosted on Azure. Calling the backend APIs was a vanilla javascript application which uses mapbox for the Maps API. Alongside the data visualization on the maps, we also have a chatbot application using Microsoft's Bot Framework.
## Challenges we ran into
We had many ideas we wanted to implement, but for the most part we had no idea where to begin. A lot of the challenge came from figuring out how to implement these ideas; for example, finding how to link a chatbot to our map. At the same time, we had to think of ways to scrape the dankest memes from the internet. We ended up choosing twitter as our resource and tried to come up with the hypest hashtags for the project.
A big problem we ran into was that our database completely crashed an hour before the project was due. We had to redeploy our Azure VM and database from scratch.
## Accomplishments that we're proud of
We were proud that we were able to use as many of the sponsor tools as possible instead of the tools that we were comfortable with. We really enjoy the learning experience and that is the biggest accomplishment. Bringing all the pieces together and having a cohesive working application was another accomplishment. It required lots of technical skills, communication, and teamwork and we are proud of what came up.
## What we learned
We learned a lot about different tools and APIs that are available from the sponsors as well as gotten first hand mentoring with working with them. It's been a great technical learning experience. Asides from technical learning, we also learned a lot of communication skills and time boxing. The largest part of our success relied on that we all were working on parallel tasks that did not block one another, and ended up coming together for integration.
## What's next for NWMemes2017Web
We really want to work on improving interactivity for our users. For example, we could have chat for users to discuss meme trends. We also want more data visualization to show trends over time and other statistics. It would also be great to grab memes from different websites to make sure we cover as much of the online meme ecosystem.
|
## Inspiration
Being a student isn't easy. There are so many things that you have to be on top of, but it can't be difficult to organize your study sessions effectively. We were inspired to create Breaks Without Barriers to provide students with a mobile companion to aid them in their study sessions.
## What it does
Our app has several features that can help a student plan their studying accordingly, such as a customizable to-do list as well as a built-in study and break timer. It also holds students accountable for maintaining their mental and physical well-being by periodically sending them notifications -- reminding them to drink some water, check their posture, and the like. In the hustle and bustle of schoolwork, students often forget to take care of themselves!
We also incorporated some fun elements such as a level-up feature that tracks your progress and shows where you stand in comparison to other students. Plus, the more you study, the more app themes you unlock! You are also given some personalized Spotify playlist recommendations if you prefer studying with some background music.
Students can connect with each other, by viewing each other's profiles and exchanging their contact information. This allows students to network with other students, creating an online community of like-minded individuals.
## How we built it
We split our group into sub-teams: one for front-end development and another for back end-development. The front-end team designed the proposed app user-interface using Figma, and the back-end team created functional software using Python, Tkinter, SpotifyAPI, and twilio technologies.
The main framework of our project is built with Tkinter and it is composed of 3 programs that interact with each other: backend.py, frontend.py and login.py. Frontend.py consists of the main GUI, while backend.py is called when external functions are needed. Login.py is a separate file that creates a login window to verify the user.
## Challenges we ran into
This was actually the first hackathon for all four of us! This was a new experience for us, and we had to figure out how to navigate the entire process. Most of us had limited coding knowledge, and we had to learn new softwares while concurrently developing one of our own. We also ran into issues with time -- given a period of 36 hours to create an entire project, we had troubles in spreading out our work time effectively.
## Accomplishments that we're proud of
We're proud of creating an idea that was oriented toward students in helping them navigate their trials. We're also just proud of successfully completing our very first hackathon!
## What's next for Breaks Without Barriers
In the future we plan to implement more features that will connect individuals in a much more efficient way, including moderated study sessions, filtered search and an AI that will provide users with studying information. We also want to further develop the spotify function and allow for music to be played directly through the api.
|
partial
|
#### Inspiration
The Division of Sleep Medicine at Harvard Medical School stated that 250,000 drivers fall asleep at the wheel every day in the United States. CDC.gov claims the states has 6,000 fatal per year due to these drowsy drivers. We members of the LifeLine team understand the situation; in no way are we going to be able to stop these commuters from driving home after a long days work. So let us help them keep alert and awake!
#### What is LifeLine?
You're probably thinking "Lifeline", like those calls to dad or mom they give out on "Who wants to be a millionaire?" Or maybe your thinking more literal: "a rope or line used for life-saving". In both cases, you are correct! The wearable LifeLine system connects with an android phone and keeps the user safe and awake on the road through connecting them to a friend.
#### Technologies
Our prototype consists of an Arduino with an accelerometer as part of a headset, monitoring a driver's performance of that well-known head dip of fatigue. This headset communicates with a Go lang server, providing the user's android application with the accelerometer data through an http connection. The android app then processes the x, y tilt data to monitor the driver.
#### What it does
The application user sets an emergency contact upon entry. Then once in "drive" mode, the app displays the x and y tilt of the drivers head, relating it to an animated head that tilts to match the drivers. Upon sensing the first few head nods of the driver, the LifeLine app provides auditory feedback beeps to keep the driver alert. If the condition of the driver does not improve it then sends a text to a pre-entered contact suggesting to them that the user is drowsy driving and that they should reach out to him. If the state of the driver gets worse it then summons the LifeLine and calls their emergency contact.
#### Why call a friend?
Studies find conversation to be a great stimulus of attentiveness. Given that a large number of drivers are alone on the road, the resulting phone connections could save lives.
#### Challenges we ran into
Hardware use is always not fun for software engineers...
#### What's next for LifeLine
* Wireless Capabilities
* Stylish and more comfortable to wear
* Saving data for user review
* GPS feedback for where the driver is when he is dozing off (partly completed already)
**Thanks for reading. Hope to see you on the demo floor!** - Liam
|
## Inspiration
One of the biggest roadblocks during disaster relief is reestablishing the first line of communication between community members and emergency response personnel. Whether it is the aftermath of a hurricane devastating a community or searching for individuals in the backcountry, communication is the key to speeding up these relief efforts and ensuring a successful rescue of those at risk.
In the event of a hurricane, blizzard, earthquake, or tsunami, cell towers and other communication nodes can be knocked out leaving millions stranded and without a way of communicating with others. In other instances where skiers, hikers, or travelers get lost in the backcountry, emergency personnel have no way of communicating with those who are lost and can only rely on sweeping large areas of land in a short amount of time to be successful in rescuing those in danger.
This is where Lifeline comes in. Our project is all about leveraging communication technologies in a novel way to create a new way to establish communication in a short amount of time without the need for prior existing infrastructures such as cell towers, satellites, or wifi access point thereby speeding up natural disaster relief efforts, search and rescue missions, and helping provide real-time metrics for emergency personnel to leverage.
Lifeline uses LoRa and Wifi technologies to create an on-the-fly mesh network to allow individuals to communicate with each other across long distances even in the absence of cell towers, satellites, and wifi. Additionally, Lifeline uses an array of sensors to send vital information to emergency response personnel to assist with rescue efforts thereby creating a holistic emergency response system.
## What it does
Lifeline consists of two main portions. First is a homebrewed mesh network made up of IoT and LoRaWAN nodes built to extend communication between individuals in remote areas. The second is a control center dashboard to allow emergency personnel to view an abundance of key metrics of those at risk such as heart rate, blood oxygen levels, temperature, humidity, compass directions, acceleration, etc.
On the mesh network side, Lifeline has two main nodes. A control node and a network of secondary nodes. Each of the nodes contains a LoRa antenna capable of communication up to 3.5km. Additionally, each node consists of a wifi chip capable of acting as both a wifi access point as well as a wifi client. The intention of these nodes is to allow users to connect their cellular devices to the secondary nodes through the local wifi networks created by the wifi access point. They can then send emergency information to response personnel such as their location, their injuries, etc. Additionally, each secondary node contains an array of sensors that can be used both by those in danger in remote communities or by emergency personnel when they venture out into the field so members of the control center team can view their vitals. All of the data collected by the secondary nodes is then sent using the LoRa protocol to other secondary nodes in the area before finally reaching the control node where the data is processed and uploaded to a central server. Our dashboard then fetches the data from this central server and displays it in a beautiful and concise interface for the relevant personnel to read and utilize.
Lifeline has several main use cases:
1. Establishing communication in remote areas, especially after a natural disaster
2. Search and Rescue missions
3. Providing vitals for emergency response individuals to control center personnel when they are out in the field (such as firefighters)
## How we built it
* The hardware nodes used in Lifeline are all built on the ESP32 microcontroller platform along with a SX1276 LoRa module and IoT wifi module.
* The firmware is written in C.
* The database is a real-time Google Firebase.
* The dashboard is written in React and styled using Google's Material UI package.
## Challenges we ran into
One of the biggest challenges we ran into in this project was integrating so many different technologies together. Whether it was establishing communication between the individual modules, getting data into the right formats, working with new hardware protocols, or debugging the firmware, Lifeline provided our team with an abundance of challenges that we were proud to tackle.
## Accomplishments that we're proud of
We are most proud of being able to have successfully integrated all of our different technologies and created a working proof of concept for this novel idea. We believe that combing LoRa and wifi in the way can pave the way for a new era of fast communication that doesn't rely on heavy infrastructures such as cell towers or satellites.
## What we learned
We learned a lot about new hardware protocols such as LoRa as well as working with communication technologies and all the challenges that came along with that such as race conditions and security.
## What's next for Lifeline
We plan on integrating more sensors in the future and working on new algorithms to process our sensor data to get even more important metrics out of our nodes.
|
## Inspiration
While biking this week a member of our team fell onto the street, injuring his chin and requiring stitches. This experience highlighted how unsafe a fallen biker may be while lying in pain or unconscious on a busy street. Also, as avid hikers, our team recognizes the risk of being trapped or knocked unconscious in a fall; unable to call for help. We recognized the need for a solution that detects and calls for help when help is needed.
## What it does
HORN uses motion tracking to detect falls or crashes. If it detects an accident and then the user falls still within 60 seconds, it will provide a warning. If the user does not indicate that they are not incapacitated HORN contacts emergency services and notifies them of the time and location of the accident.
If anyone texts HORN while the user is incapacitated it provides a loud horn sound to help nearby searchers. Because HORN relies on the emergency service network it is capable of sending and receiving messages even while out of range of regular coverage.
## How we built it
The HORN prototype is controlled on a Raspberry Pi 4 which interfaces with the sensing and acting devices. It uses a BNO055 inertial measurement unit to track the acceleration of the user, a BN 880 GPS to track the location, a SIM800L GSM to send and receive SMS messages, and a modified car horn to honk.
To detect impacts, there is a thread that measures when the user experiences very high G-forces in any direction (>10 Gs, ) and also monitors if the user is completely still (indicates that they may be unconscious).
## Challenges we ran into
Communicating over SMS required us to learn about AT commands which are essentially an antiquated interface for server communication.
Finding a horn loud enough to be useful in a search and rescue situation meant we needed to branch out from traditional buzzers or speakers. After 3D printing a siren design found online, we realized a makeshift whistle would not be nearly loud enough, so we brainstormed to select a car horn - a very nontraditional component - as the main local notification device.
The accelerometer sometimes peaks at very high erroneous values. To avoid this setting off the impact detection, we limited the maximum jerk so if the acceleration value changes too much, it is considered erroneous and the previous data point is used for calculations.
## Accomplishments that we're proud of
Making the GSM work was very difficult since there was no library to use so we had to write our own serial interface. Getting this to work was a huge victory for us.
## What we learned
We learned how to parse NEMA sentences from GPS modules which contain a large amount of difficult-to-read information.
We also learned about programming systems as a team and getting separate subsystems to work together. Over the course of the hack, we realized it would make it much easier to collaborate if we wrote each of our subsystems in separate classes with simple functions to interact with each other. This meant that we had to use threading for continuous tasks like monitoring the accelerometer, which is something I did not have a lot of experience with.
## What's next for High-impact Orientation Relocation Notification system
In the future instead of only detecting high G-forces, it might be more useful to collect data from normal activity and use a machine learning model to detect unusual behaviour, like falls. This could let us apply our device to more complicated scenarios, such as a skier getting stuck in a tree well or avalanche. Also, for use in more remote areas, integration with satellite networks rather than cellular would expand HORN’s safety capabilities.
|
winning
|
# r2d2
iRobot Create 2 controller and analyzer & much more
# Highlights
1. Joy-stick like experience to navigate the bot remotely.
2. Live update of path trajectory of the bot (which can be simultaneously viewed by any number of clients viewing the '/trajectory' page of our web-app.
3. Live update of all sensor values in graphical as well as tabular format
# Dependencies
flask
create2api
flask\_socketio
pip install the Dependencies.
# Instructions to run
python server.py
|
## Inspiration
My college friends and brother inspired me for doing such good project .This is mainly a addictive game which is same as we played in keypad phones
## What it does
This is a 2-d game which includes tunes graphics and much more .we can command the snake to move ip-down-right and left
## How we built it
I built it using pygame module in python
## Challenges we ran into
Many bugs are arrived such as runtime error but finally i manged to fix all this problems
## Accomplishments that we're proud of
I am proud of my own project that i built a user interactive program
## What we learned
I learned to use pygame in python and also this project attarct me towards python programming
## What's next for Snake Game using pygame
Next I am doing various python projects such as alarm,Virtual Assistant program,Flappy bird program,Health management system And library management system using python
|
## Inspiration
Last year we built MusicHub (<https://devpost.com/software/musichub-3rajf4>), with the goal of providing version control to composers to encourage a software-development-esque workflow. This year, we're elaborating on that further with BubbleCompose, an app that lets anyone and everyone collaborate on beautiful pieces of music with nothing more than a web browser and a mouse. Software development and music are both collaborative by nature, and BubbleCompose seeks to unify these two worlds using the power of machine learning.
## What it does
BubbleCompose allows multiple users to draw animated patterns on a shared canvas. These patterns are translated to melodies and played back to all collaborators as combined continuous piece of music. These melodies go in and out of phase as the music plays. In addition, the melodies actually have a random chance to mutate and acquire the traits of other melodies. As a result, we enable the texture of the music to slowly develop in a musical way.
## How we built it
The front end is built with the Semantic UI framework for a beautiful user experience, the PTS.js library for drawing shapes and animations, and the Tone.js library for rendering audio. Socket.io on Node.js allows us synchronize the music between all the users. The logic layer is built with Google Magenta's MusicVAE model to interpolate multiple musical melodies. We wrote our own logic to translate user-drawn patterns into music notes. Finally, the web app is hosted on the Google Cloud Platform and our domain was acquired through Domain.com.
## Challenges we ran into
PTS.js was a very difficult library to learn in such a short time frame. The documentation of Tone.js was confusing at times, resulting in a rough user experience. Finally, designing a clean and aesthetic UI is always a challenge, but we are happy with how this one turned out.
## Accomplishments that I'm proud of
We're extremely proud of what we were able to accomplish in such a short time. In particular, it was our first time using Tone.js, PTS.js, Google Magenta and hosting a site on Google Cloud Platform.
## What's next for BubbleCompose
The next big feature we hope to implement is separate sessions so groups of friends can collaborate in a private setting. We would like to make the music more dynamic by triggering musical modulations as the number of active users passes set thresholds.
## GitHub repository
<https://github.com/iamtrex/BubbleCompose>
|
partial
|
# Athena **Next Generation CMS Tooling Powered by AI**
## Inspiration
The inspiration for our project, Athena, comes from our experience as students with busy lives. Often, it isn't easy to keep track of the vast amounts of media we encounter (Lectures, webinars, TedTalks, etc).
With Athena, people can have one AI-powered store for all their content, allowing them to save time slogging through hours of material in search of information.
Our aim is to enhance productivity and empower our users to explore, engage, and learn in a way that truly values their time.
## What it Does
In Athena, we empower our users to manage and query all forms of content. You have the flexibility to choose how you organize and interact with your material. Whether you prefer grouping content by course and using focused queries or rewatching lectures with a custom-trained chatbot at your fingertips, our application Athena has got you covered.
We allow users to either perform multimodal vectorized searches across all their documents, enhancing information accessibility, or explore a single document with more depth and nuance using a custom-trained LLm model. With Athena, the power of information is in your hands, and the choice is yours to make.
## How we built it
We built our application using a multitude of services/frameworks/tools:
* React.js for the core client frontend
* TypeScript for robust typing and abstraction support
* Tailwind for a utility-first CSS framework
* ShadCN for animations and UI components
* Clerk for a seamless and drop-in OAuth provider
* React-icons for drop-in pixel-perfect icons
* NextJS for server-side rendering and enhanced SEO
* Convex for vector search over our database
* App-router for client-side navigation
* Convex for real-time server and end-to-end type safety
## Challenges We Ran Into
* Navigating new services and needing to read **a lot** of documentation -- since this was the first time any of us had used vector search with Convex, it took a lot of research and heads-down coding to get Athena working.
* Being **awake** to work as a team -- since this hackathon is both **in-person** and **through the weekend**, we had many sleepless nights to ensure we can successfully produce Athena.
## Accomplishments that we're proud of
* Finishing our project and getting it working! We were honestly surprised at our progress this weekend and are super proud of our end product Athena.
* Learning a ton of new technologies we would have never come across without Tree Hacks.
* Being able to code for at times 12-16 hours straight and still be having fun!
## What we learned
* Tools are tools for a reason! Embrace them, learn from them, and utilize them to make your applications better.
* Sometimes, more sleep is better -- as humans, sleep can sometimes be the basis for our mental ability!
* How to work together on a team project with many commits and iterate fast on our moving parts.
## What's next for Athena
* Create more options for users to group their content in different ways.
* Establish the ability for users to share content with others, increasing knowledge bases.
* Allow for more types of content upload apart from Videos and PDFs
|
## 💡 Inspiration
Whenever I was going through educational platforms, I always wanted to use one website to store everything. The notes, lectures, quizzes and even the courses were supposed to be accessed from different apps. I was inspired by how to create a centralized platform that acknowledges learning diversity. Also to enforce a platform where many people can **collaborate, learn and grow.**
## 🔎 What it does
By using **Assembly AI** and incorporating a model which focuses on enhancing the user experience by providing **Speech-to-text** functionality. My application enforces a sense of security in which the person decides when to study, and then, they can choose from ML transcription with summarization and labels, studying techniques to optimize time and comprehension, and an ISR(Incremental Static Regeneration) platform which continuously provides support. **The tools used can be scaled as the contact with APIs and CMSs is easy to *vertically* scale**.
## 🚧 How we built it
* **Frontend**: built in React but optimized with **NextJS** with extensive use of TailwindCSS and Chakra UI.
* **Backend**: Authentication with Sanity CMS, Typescript and GraphQL/GROQ used to power a serverless async Webhook engine for an API Interface.
* **Infrastructure**: All connected from **NodeJS** and implemented with *vertical* scaling technology.
* **Machine learning**: Summarization/Transcription/Labels from the **AssemblyAI** API and then providing an optimized strategy for that.
* **Branding, design and UI**: Elements created in Procreate and some docs in ChakraUI.
* **Test video**: Using CapCut to add and remove videos.
## 🛑 Challenges we ran into
* Implementing ISR technology to an app such as this required a lot of tension and troubleshooting. However, I made sure to complete it.
* Including such successful models and making a connection with them was hard through typescript and axios. However, when learning the full version, we were fully ready to combat it and succeed. I actually have optimized one of the algorithm's attributes with asynchronous recursion.
+ Learning a Query Language such as **GROQ**(really similar to GraphQL) was difficult but we were able to use it with the Sanity plugin and use the **codebases** that was automatically used by them.
## ✔️ Accomplishments that we're proud of
Literally, the front end and the backend required technologies and frameworks that were way beyond what I knew 3 months ago. **However I learned a lot in the space between to fuel my passion to learn**. But over the past few weeks, I planned and saw the docs of **AssemblyAI**, learned **GROQ**, implemented **ISR** and put that through a \**Content Management Service (CMS) \**.
## 📚 What we learned
Throughout Hack the North 2022 and prior, I learned a variety of different frameworks, techniques, and APIs to build such an idea. When starting coding I felt like I was going ablaze as the techs were going together like **bread and butter**.
## 🔭 What's next for SlashNotes?
While I was able to complete a considerable amount of the project in the given timeframe, there are still places where I can improve:
* Implementation in the real world! I aim to push this out to google cloud.
* Integration with school-course systems and proving the backend by adding more scaling and tips for user retention.
|
## Inspiration
We are part of a generation that has lost the art of handwriting. Because of the clarity and ease of typing, many people struggle with clear shorthand. Whether you're a second language learner or public education failed you, we wanted to come up with an intelligent system for efficiently improving your writing.
## What it does
We use an LLM to generate sample phrases, sentences, or character strings that target letters you're struggling with. You can input the writing as a photo or directly on the webpage. We then use OCR to parse, score, and give you feedback towards the ultimate goal of character mastery!
## How we built it
We used a simple front end utilizing flexbox layouts, the p5.js library for canvas writing, and simple javascript for logic and UI updates. On the backend, we hosted and developed an API with Flask, allowing us to receive responses from API calls to state-of-the-art OCR, and the newest Chat GPT model. We can also manage user scores with Pythonic logic-based sequence alignment algorithms.
## Challenges we ran into
We really struggled with our concept, tweaking it and revising it until the last minute! However, we believe this hard work really paid off in the elegance and clarity of our web app, UI, and overall concept.
..also sleep 🥲
## Accomplishments that we're proud of
We're really proud of our text recognition and matching. These intelligent systems were not easy to use or customize! We also think we found a creative use for the latest chat-GPT model to flex its utility in its phrase generation for targeted learning. Most importantly though, we are immensely proud of our teamwork, and how everyone contributed pieces to the idea and to the final project.
## What we learned
3 of us have never been to a hackathon before!
3 of us never used Flask before!
All of us have never worked together before!
From working with an entirely new team to utilizing specific frameworks, we learned A TON.... and also, just how much caffeine is too much (hint: NEVER).
## What's Next for Handwriting Teacher
Handwriting Teacher was originally meant to teach Russian cursive, a much more difficult writing system. (If you don't believe us, look at some pictures online) Taking a smart and simple pipeline like this and updating the backend intelligence allows our app to incorporate cursive, other languages, and stylistic aesthetics. Further, we would be thrilled to implement a user authentication system and a database, allowing people to save their work, gamify their learning a little more, and feel a more extended sense of progress.
|
losing
|
## Inspiration
Inspired from American Sniper
## What it does
Make a guess for where the evil sniper is based on callout hints and snipe the sniper, you have 3 chances
## How I built it
Using Callout animation and some geometry
## Challenges I ran into
1) Lack of knowledge on 3d algorithms to turn the landscape into 3d
2) took a long time to figure out the game concept
## Accomplishments that I'm proud of
Smart Use of call out T resolution image to make the game seem very real and attractive
## What I learned
The correct use of Callouts, drag and drop, loading multiple files in javafx Mediaplayer
## What's next for Snipe the Sniper
Show it to Tangelo and discuss with the expert whether we can make 3d landscape that can be rotated just like
in Google map s
|
## Inspiration
After surfing online, we found some cool videos of 3d tracking with an eye. We thought taking those concepts and bringing it to a mobile game would be a wonderful combination of the two, and bring more physical activity in a game.
## What it does
This game provides a source of endless activity and encourages people to be active with their body/eyes providing a more full health experience. Travelling down a slippery slope, users have a chance to have a good time dealing with obstacles and can enjoying the ride.
## How we built it
This app was built on Unity, a popular 3D software that is used by popular app developers and companies. Some renders were also done on Blender, and open computer vision on Python and Unity were explored.
## Challenges we ran into:
* Learning unity in general was a challenge. A number of strange issues happened: large installs, learning the syntax (e.g. mesh, font assets)
* Source control with Github was more challenging with 3D renderings. The files were more dependent on one another making it difficult for multiple users at a time.
* Computer vision libraries worked well on Python but did not work on Unity
## Accomplishments that we're proud of
* Render/app looks amazing and provides users a good experience
* Really cool idea making the slide and the randomness of the colours
## What we learned
* App development can be a challenge
* Great UI/UX makes for an impressive project
## What's next for Slippery Slope
* Exploring the iOS mobile development is a thing that might be done to the app in the future
|
## Inspiration
GeoGuesser is a fun game which went viral in the middle of the pandemic, but after having played for a long time, it started feeling tedious and boring. Our Discord bot tries to freshen up the stale air by providing a playlist of iconic locations in addendum to exciting trivia like movies and monuments for that extra hit of dopamine when you get the right answers!
## What it does
The bot provides you with playlist options, currently restricted to Capital Cities of the World, Horror Movie Locations, and Landmarks of the World. After selecting a playlist, five random locations are chosen from a list of curated locations. You are then provided a picture from which you have to guess the location and the bit of trivia associated with the location, like the name of the movie from which
we selected the location. You get points for how close you are to the location and if you got the bit of trivia correct or not.
## How we built it
We used the *discord.py* library for actually coding the bot and interfacing it with discord. We stored our playlist data in external *excel* sheets which we parsed through as required. We utilized the *google-streetview* and *googlemaps* python libraries for accessing the google maps streetview APIs.
## Challenges we ran into
For initially storing the data, we thought to use a playlist class while storing the playlist data as an array of playlist objects, but instead used excel for easier storage and updating. We also had some problems with the Google Maps Static Streetview API in the beginning, but they were mostly syntax and understanding issues which were overcome soon.
## Accomplishments that we're proud of
Getting the Discord bot working and sending images from the API for the first time gave us an incredible feeling of satisfaction, as did implementing the input/output flows. Our points calculation system based on the Haversine Formula for Distances on Spheres was also an accomplishment we're proud of.
## What we learned
We learned better syntax and practices for writing Python code. We learnt how to use the Google Cloud Platform and Streetview API. Some of the libraries we delved deeper into were Pandas and pandasql. We also learned a thing or two about Human Computer Interaction as designing an interface for gameplay was rather interesting on Discord.
## What's next for Geodude?
Possibly adding more topics, and refining the loading of streetview images to better reflect the actual location.
|
losing
|
## Inspiration
Large Language Models (LLMs) are limited by a token cap, making it difficult for them to process large contexts, such as entire codebases. We wanted to overcome this limitation and provide a solution that enables LLMs to handle extensive projects more efficiently.
## What it does
LLM Pro Max intelligently breaks a codebase into manageable chunks and feeds only the relevant information to the LLM, ensuring token efficiency and improved response accuracy. It also provides an interactive dependency graph that visualizes the relationships between different parts of the codebase, making it easier to understand complex dependencies.
## How we built it
Our landing page and chatbot interface were developed using React. We used Python and Pyvis to create an interactive visualization graph, while FastAPI powered the backend for dependency graph content. We've added third-party authentication using the GitHub Social Identity Provider on Auth0. We set up our project's backend using Convex and also added a Convex database to store the chats. We implemented Chroma for vector embeddings of GitHub codebases, leveraging advanced Retrieval-Augmented Generation (RAG) techniques, including query expansion and re-ranking. This enhanced the Cohere-powered chatbot’s ability to respond with high accuracy by focusing on relevant sections of the codebase.
## Challenges we ran into
We faced a learning curve with vector embedding codebases and applying new RAG techniques. Integrating all the components—especially since different team members worked on separate parts—posed a challenge when connecting everything at the end.
## Accomplishments that we're proud of
We successfully created a fully functional repo agent capable of retrieving and presenting highly relevant and accurate information from GitHub repositories. This feat was made possible through RAG techniques, surpassing the limits of current chatbots restricted by character context.
## What we learned
We deepened our understanding of vector embedding, enhanced our skills with RAG techniques, and gained valuable experience in team collaboration and merging diverse components into a cohesive product.
## What's next for LLM Pro Max
We aim to improve the user interface and refine the chatbot’s interactions, making the experience even smoother and more visually appealing. (Please Fund Us)
|
## Inspiration: We're trying to get involved in the AI chat-bot craze and pull together cool pieces of technology -> including Google Cloud for our backend, Microsoft Cognitive Services and Facebook Messenger API
## What it does: Have a look - message Black Box on Facebook and find out!
## How we built it: SO MUCH PYTHON
## Challenges we ran into: State machines (i.e. mapping out the whole user flow and making it as seamless as possible) and NLP training
## Accomplishments that we're proud of: Working NLP, Many API integrations including Eventful and Zapato
## What we learned
## What's next for BlackBox: Integration with google calendar - and movement towards a more general interactive calendar application. Its an assistant that will actively engage with you to try and get your tasks/events/other parts of your life managed. This has a lot of potential - but for the sake of the hackathon, we thought we'd try do it on a topic that's more fun (and of course, I'm sure quite a few us can benefit from it's advice :) )
|
## Inspiration
We we wanted to make learning and understanding each other more equitable and fair. Thus we decided to solve a problem that exists everywhere.
## What it does
## How we built it
React/Vite + Tailwind + Convex Frontend
Convex Backend
Convex Database
Convex API
Symphonic Labs Video to Text
Chroma RAG
Cohere Multilingual LLM
## Challenges we ran into
The main Challenge that we all ran into was fitting our experiences and intuition from unopinionated technologies onto convex, which was very opinionated. We struggled in learning and fitting our existing knowledge (JS, NodeJS), onto the opinionated format, which slowed us down significantly. We alos struggled to host the service on AWS and Azure.## Accomplishments that we're proud of
## Accomplishments
We were able to get a end-end user case working, from uploading the video, to getting the transcript with Symphonic and using the Cohere LLM chatbot.
## What we learned
We learned a ton about effective system design, full stack info
## What's next for Linguist
We hope to build for more users in the future, and add more features
|
winning
|
## Overview
How we understand and communicate to those around us shapes and determines the person we are. In order to help people better understand the sentiments behind their words, we have incorporated the NLTK sentiment analysis tool to learn and interpret the positive, negative, and neutral meanings behind our words. In addition to d3js illustrations, integration in Moxtra allows for a commonplace setting for different users to benefit from the app.
The data is provided in three graphs: sentiment analysis of messages sent, sentiment analysis of messages received, and sentiment analysis over the course of using the website in hopes to help better become more aware of their words and surroundings, to improve the ways that people communicate, and to provide useful and meaningful data where necessary.
## Challenges
The areas that we spent the most time on were actually in planning, incorporating Moxtra, and deploying to Azure. We actually encountered an interesting bug with the Moxtra API with user authentication after hours of slamming against it and had a great experience bringing it to the attention of one of the Moxtra engineers to find a workaround. Azure server setup with Flask was streamlined once talking with a helpful mentor - with most of the initial issues cause by hardware setup differences.
## What's Next?
Mobile, more robust messaging, stronger analysis tools are all awesome features we would like to see!
However, when we narrowed down the features to one item we would like to work on, we decided ultimately on the ability to retroactively review ALL messages in order to obtain an instant break down of communication over time and to observe any trends over time.
|
## Inspiration
Since the arrival of text messaging into the modern day world, users have had a love hate relationship with this novel form of communication. Instant contact with those you love at the cost of losing an entire facet of conversation - emotion. However, one group of individuals has been affected by this more than most. For those with autism, who already have a difficult time navigating emotional cues in person, the world of text messages is an even more challenging situation. That's where NOVI comes in.
## What it does
NOVI utilizes Natural Language Processing to identify a range of emotions within text messages from user to user. Then, by using visual and text cues and an intuitive UI/UX design, it informs the user (based on their learning preferences) of what emotions can be found in the texts they are receiving. NOVI is a fully functional app with a back-end utilizing machine learning and a heavily researched front end to cater to our demographic and help them as much as possible.
## How I built it
Through the use of react native, CSS, javascript, Google Cloud and plenty of hours, NOVI was born. We focused on a back end implementation with a weight on machine learning and natural language processing and a front end focus on research based intuition that could maximize the effectiveness of our app for our users. We ended up with a brand new fully functional messaging app that caters to our demographic's exact needs.
## Challenges I ran into
As this was many of our first times touching anything related to machine learning, there was no real intuition behind a lot of the things we tried to implement. This meant a lot of learning potential and many hours poured into developing new skills. By the end of it however we ended up learning a lot about not only new topics, but also the process of discovering new information and content in order to create our own products.
## Accomplishments that I'm proud of
Something we put a genuinely large amount of effort into was researching our target demographic. As every member in our group had very individual experiences with someone with autism, there were a lot of assumptions we had to avoid making. We avoided these generalizations by looking into as many research papers backing our theories as we could find. This was the extra step we chose to take to assure a genuinely effective UI/UX for our users.
## What I learned
We learned how to use react native, how to use a backend and among many other things, simply how to learn new things. We learned how to research to maximize effectiveness of interfaces and experiences and we learned how to make an app with a specific user base.
## What's next for NOVI
NOVI is an app with much to offer and a lot of potential for collaboration with a variety of organizations and other companies. It is also possible to adapt the concept of NOVI to adapt to other areas of aid for other possible demographics, such as for those with Asperger's.
|
## Inspiration
We went through ten or fifteen different ideas, but couldn't quite shake this one - taking photos and converting them to music. All of us had a certain draw to it, whether it was an interest in computational photography and looking at different features we could draw from images, or music and how we could select songs based off of pitch variation, energy, and valence (musical positiveness). Perhaps the most unique part of our project, our user experience simply consists of sending images from one's phone via text, where photos usually live in the first place. No additional app installation/user entry needed!
## What it does
Our app uses Twilio to help users send photos to our server, which parses images and derives features to correlate against accumulated Spotify song data. Using features like saturation and lightness derived from the color profile of the image to utilizing sentiment analysis on keywords from object detection, we determined rules that mapped these to song features like danceability, variance, energy, and mode. These songs form playlists that map to the original image - for instance, higher saturated images will map to more "danceable" songs and images with higher sentiment magnitude from its keywords will map to higher "energy" songs. After texting the photo, the user will get a Spotify playlist back that contains these songs.
## How we built it
Our app uses Twilio to handle SMS messaging (both sending images to the server and sending links back to the user). To handle vision and NLP parsing, we used Google Cloud APIs within our Flask app. Specifically, we used the Google Cloud Vision API to extract object names and color profiles from images, while using the Google Cloud Natural Language API to run sentiment analysis on extracted labels to determine overall mood of an image. For music data, we used the Spotify API to run scripts for accumulating data and creating playlists.
## Challenges we ran into
One challenge we ran into was determining how to map color profiles to musical features - to overcome this, it was incredibly useful to have a variety of skills on our team. Some of us had more computational photography experience, some with more of a musical background, and some of us had more ideas on how to store and retrieve data.
## Accomplishments that we're proud of
We're proud of being able to use a number of APIs successfully and handling authentication across all of them. This was also our first time using Twilio and using SMS texts to interface with the user. Overall, we're super proud of coming up with an MVP pretty early on, and then being able to each independently build upon it, making our product better and better.
## What we learned
We learned a lot about how to derive information from photos and how deep the Spotify API goes. We also learned about how to divide up our strengths and interests so we could finish our project efficiently.
## What's next for ColorDJ
Next for ColorDJ: WhatsApp integration, more efficient song database, Google Photos integration (stretch) for auto-generated movies. Machine learning could make an appearance here with training models in parallel to better match color profiles or derived keywords with songs.
Putting music to photos and adding that extra dimension helps further connect people with their creations. ColorDJ makes it easier to generate a playlist to commemorate any memory, literally with two taps on a screen!
|
partial
|
## TL; DR
* Music piracy costs the U.S. economy [$12.5 billion annually](https://www.riaa.com/wp-content/uploads/2015/09/20120515_SoundRecordingPiracy.pdf).
* Independent artists are the [fastest growing segment in the music industry](https://www.forbes.com/sites/melissamdaniels/2019/07/10/for-independent-musicians-goingyour-own-way-is-finally-starting-to-pay-off/), yet lack the funds and reach to enforce the Digital Millennium Copyright Act (DMCA).
* We let artists **OWN** their work (stored on InterPlanetary File System) by tracking it on our own Sonoverse Ethereum L2 chain (powered by Caldera).
* Artists receive **Authenticity Certificates** of their work in the form of Non-Fungible Tokens (NFTs), powered by Crossmint’s Minting API.
* We protect against parodies and remixes with our **custom dual-head LSTM neural network model** trained from scratch which helps us differentiate these fraudulent works from originals.
* We proactively query YouTube through their API to constantly find infringing work.
* We’ve integrated with **DMCA Services**, LLC. to automate DMCA claim submissions.
Interested? Keep reading!
## Inspiration
Music piracy, including illegal downloads and streaming, costs the U.S. economy $12.5 billion annually.
Independent artists are the fastest growing segment in the music industry, yet lack the funds to enforce DMCA.
We asked “Why hasn’t this been solved?” and took our hand at it. Enter Sonoverse, a platform to ensure small musicians can own their own work by automating DMCA detection using deep learning and on-chain technologies.
## The Issue
* Is it even possible to automate DMCA reports?
* How can a complex piece of data like an audio file be meaningfully compared?
* How do we really know someone OWNS an audio file?
* and more...
These are questions we had too, but by making custom DL models and chain algorithms, we have taken our hand at answering them.
## What we’ve made
We let artists upload their original music to our platform where we store it on decentralized storage (IPFS) and our blockchain to **track ownership**. We also issue Authenticity Certificates to the original artists in the form of Non-Fungible Tokens.
We compare uploaded music with all music on our blockchain to **detect** if it is a parody, remix, or other fraudulent copy of another original song, using audio processing and an LSTM deep learning model built and trained from scratch.
We proactively query YouTube through their API for “similar” music (based on our **lyric hashes**, **frequency analysis**, and more) to constantly find infringing work. For detected infringing work, we’ve integrated with DMCA Services, LLC. to **automate DMCA claim submissions**.
## How we built it
All together, we used…
* NextJS
* Postgres
* AWS SES
* AWS S3
* IPFS
* Caldera
* Crossmint
* AssemblyAI
* Cohere
* YouTube API
* DMCA Services
It’s a **lot**, but we were able to split up the work between our team. Gashon built most of the backend routes, an email magic link Auth platform, DB support, and AWS integrations.
At the same time, Varun spent his hours collecting hours of audio clips, training and improving the deep LSTM model, and writing several sound differentiation/identification algorithms. Here’s Varun’s **explanation** of his algorithms: “To detect if a song is a remix, we first used a pre-trained speech to text model to extract lyrics from mp3 files and then analyzed the mel-frequency cepstral coefficients, tempo, melody, and semantics of the lyrics to determine if any songs are very similar. Checking whether a song is a parody is much more nuanced, and we trained a dual-head LSTM neural network model in PyTorch to take in vectorized embeddings of lyrics and output the probability of one of the songs being a parody of the other.”
While Varun was doing that, Ameya built out the blockchain services with Caldera and Crossmint, and integrated DMCA Services. Ameya ran a Ethereum L2 chain specific for this project (check it out [here](https://treehacks-2024.explorer.caldera.xyz)) using Caldera. He built out significant infrastructure to upload audio files to IPFS (decentralized storage) and interact with the Caldera chain. He also created the Authenticity Certificate using Crossmint that’s delivered directly to each Sonoverse user’s account.
Ameya and Gashon came together at the end to create the Sonoverse frontend, while Varun pivoted to create our YouTube API jobs that query through recently uploaded videos to find infringing content.
## Challenges we overcame
We couldn’t find existing models to detect parodies and had to train a custom model from scratch on training data we had to find ourselves. Of course, this was quite challenging, but with audio files each being unique, we had to create a dataset of hours of audio clips.
And, like always, integration was difficult. The power of a team was a huge plus, but also a challenge. Ameya’s blockchain infrastructure had Solidity compilation challenges when porting into Gashon’s platform (which took some precious hours to sort out). Varun’s ML algorithms ran on a Python backend which had to be hosted alongside our NextJS platform. You can imagine what else we had to change and fix and update, so I won’t bore you.
Another major challenge was something we brought on ourselves, honestly. We set our aim high so we had to use several different frameworks, services, and technologies to add all the features we wanted. This included several hours of us learning new technologies and services, and figuring out how to implement them in our project.
## Accomplishments that we're proud of
Blockchain has a lot of cool and real-world applications, but we’re excited to have settled on Sonoverse. We identified a simple (yet technically complex) way to solve a problem that affects many small artists.
We also made a sleek web platform, in just a short amount of time, with scalable endpoints and backend services.
We also designed and trained a deep learning LSTM model to identify original audios vs fraudulent ones (remixes, speed ups, parodies, etc) that achieved **93% accuracy**.
## What we learned
#### About DMCA
We learned how existing DMCA processes are implemented and the large capital costs associated with them. We became **experts** on digital copyrights and media work!
#### Blockchain
We learned how to combine centralized and decentralized infrastructure solutions to create a cohesive **end-to-end** project.
## What's next for Sonoverse
We're looking forward to incorporating on-chain **royalties** for small artists by detecting when users consume their music and removing the need for formal contracts with big companies to earn revenue.
We’re excited to also add support for more public APIs in addition to YouTube API!
|
# Team
Honeycrisp
# Inspiration
Every year there are dozens of heatstroke accidents that occur, a number of which are defined as vehicular heatstroke accidents. Our aim was to build a device for vehicles to best prevent these scenarios, whether there may be young children or pets left in said vehicles.
# What it does
Detector that detects temperature/environment conditions within a car and presence of any living being, so as to alert the owner when the environment reaches dangerous conditions for any living beings inside the vehicle (babies, pets, ...)
# How the Detector Works
The detector makes use of several sensors to determine whether the environmental conditions within a vehicle have reached dangerous levels, and whether there is presence of a living being within the vehicle. In the case where both are true it is to send a text message to the owner of the car warning them about the situation within the vehicle.
# How we built it
A team of 3 people made use of the Particle Electron board and several sensors (Gas sensors, Thermal sensors, Infrared Motion sensor as well as Audio Sensor) to create the project.
# Challenges we faced
There were challenges faced when dealing with the Particle Electron board, in that the sensors being used were made for an Arduino. This required specific libraries, which eventually caused the Particle Electron board to malfunction.
# Accomplishments
The team has no past experience working with a Particle Electron board, so for the work that was accomplished within the 24 hour span, we consider it a success.
# What we learned
We learned a lot about the Particle Electron board as well as the sensors that were utilized for this project
# Future
Future developments to improve our device further would include:
1. Considering sensors with more precision to ensure that the conditions and parameters being monitored are as
precise as required.
2. Implement multiple emergency measures, in the case where reaching the owner becomes difficult or the
conditions within the vehicle have reached alarming levels:
a. Turning on the A/C of the vehicle
b. Cracking the window slightly open for better circulation.
c. Have the vehicle make noise (either via the alarm system or car horn) to gain the attention of any
passerby or individuals within reasonable distances to call for aid.
d. Function that reports the incidence to 911, along with the location of the vehicle.
|
## Inspiration
We wanted to create a webapp that will help people learn American Sign Language.
## What it does
SignLingo starts by giving the user a phrase to sign. Using the user's webcam, gets the input and decides if the user signed the phrase correctly. If the user signed it correctly, goes on to the next phrase. If the user signed the phrase incorrectly, displays the correct signing video of the word.
## How we built it
We started by downloading and preprocessing a word to ASL video dataset.
We used OpenCV to process the frames from the images and compare the user's input video's frames to the actual signing of the word. We used mediapipe to detect the hand movements and tkinter to build the front-end.
## Challenges we ran into
We definitely had a lot of challenges, from downloading compatible packages, incorporating models, and creating a working front-end to display our model.
## Accomplishments that we're proud of
We are so proud that we actually managed to build and submit something. We couldn't build what we had in mind when we started, but we have a working demo which can serve as the first step towards the goal of this project. We had times where we thought we weren't going to be able to submit anything at all, but we pushed through and now are proud that we didn't give up and have a working template.
## What we learned
While working on our project, we learned a lot of things, ranging from ASL grammar to how to incorporate different models to fit our needs.
## What's next for SignLingo
Right now, SignLingo is far away from what we imagined, so the next step would definitely be to take it to the level we first imagined. This will include making our model be able to detect more phrases to a greater accuracy, and improving the design.
|
partial
|
## Inspiration
Over the past year I'd encountered plenty of Spotify related websites that would list your stats, but none of them allowed me to compare my taste with my friends, which I found to be the most fun aspect of music. So, for this project I set out to make a website that would allow users to compare their music tastes with their friends.
## What it does
Syncify will analyze your top tracks and artists and then convert that into a customized image for you to share on social media with your friends.
## How we built it
The main technology is a node.js server that runs the website and interacts with the Spotify API. The Information is then sent to a Python Script which will take your unique spotify information and generate an image personalized to you with the information and a QR Code that further encodes information.
## Challenges we ran into
* Installing Node.JS took too long with various different compatibility issues
* Getting the Spotify API to work was a major challenge because of how the Node.JS didn't work well with it.
* Generating the QR Code as well as manipulating the image to include personalized text required multiple Python Packages, and approaches.
* Putting the site online was incredibly difficult because there were so many compatibility issues and package installation issues, in addition to my inexperience with hosting sites, so I had to learn that completely.
## Accomplishments that we're proud of
Everything I did today was completely new to me and being able to learn the skills I did and not give up despite how tempting it was. Being able to utilize the APIs, and learn NodeJS as well as develop some skills with web hosting felt really impressive because of how much I struggled with them throughout the hackathon.
## What we learned
I learnt a lot about documenting code, how to search for help, what approach to the workflow I should take and of course some of the technical skills.
## What's next for Syncify
I plan on uploading Syncify online so it's available for everyone and finishing the feature of allowing users to determine how compatible their music tastes are, as well as redesigning the shareable image so that the QR Code is less obtrusive to the design.
|
## Inspiration
Did you know that about 35% of Spotify users have trouble finding the song they want? Source? I made it up.
On a real note, we actually came up with idea first, but then we scrapped it because we thought it was impossible. Many hours later of struggling, we thought we were doomed because there were just no other brilliant ideas like that first one we had come up with. Soon, we learned that the word "impossible" isn't in the hackathon vocabulary when we came up with a way to make the idea doable.
## What it does
PlayMood works by allowing users to fetch a Spotify playlist by entering the playlist ID. Then, users get a choice of moods to pick from from happy to sad, exciting to calm. Next, the lyrics of the songs are analyzed line-by-line to come up with a prediction about each song's main mood and how strong it corelates to that mood. Finally, the application sends back to the user the list of these songs with the audio to listen to.
## How we built it
**Frontend:** React.js
**Backend:** Flask, Express.js
**External APIs:** Cohere, Spotify, Genius
## Challenges we ran into
The initial challenge was looking for a way to extract the lyrics from the Spotify playlist. We realized this wasn't possible with the Spotify API. Another challenge was communication and overall planning. When everyone's tired we start doing our own thing. We had one API in Flask and the other in Node.js.
## Accomplishments that we're proud of
The largest accomplishment is actually finishing the project and implementing exactly what we wanted. We're also proud of being able to synergize as a team and connect the pieces together to create a whole and functioning application.
## What we learned
Our main goal for hackathons is always to come out learning something new. Harsh learned how to use the Cohere and Genius API to fetch lyrics from songs and classify the lyrics to predict a mood. Melhem learned how to use Flask for the first time to create the API needed for the lyrics classifications.
## What's next for PlayMood
When building PlayMood, we knew to make things simple while keeping scalability in mind. One improvement for PlayMood could be to increase the amount of moods to choose from for the users. To take this a step further, we could even implement Cohere classification for user messages to give users a much more diverse way to express their mood. A big thing we can improve on is the performance of our Flask API. Searching the lyrics for many songs takes several seconds, causing a large delay in the response time. We are planning to search for a solution that involves less API calls such as storing search results in a database to avoid duplicate searches.
|
## Inspiration
Whether we're attending general staff meetings or getting together with classmates to work on a group project, no one *ever* wants to be the note taker. You can't pay as much attention to the meeting since you have to concentrate on taking notes, and when meetings get long, it's often difficult to maintain the attention required to take diligent notes.
We wanted a way to stay more focused on the meeting rather than the memo. What if we could utilize the growing smart speaker market in conjunction with NLP algorithms to create comprehensive notes with code?
## What it does
Scribblr takes notes for you! Not only that, but it automatically sends an e-blast to meeting attendees at the end and adds discussed deadlines and upcoming meetings to your calendar.
Just tell Alexa to start the meeting. Carry out the meeting as normal and, when you're done, tell Alexa the meeting is over. She will immediately begin to create a summary of your meeting, making note of the most important discussion points:
* Approaching deadlines and due dates
* Newly scheduled meetings
* The most important decisions that were made
* A short paragraph summary of the overall meeting
Additionally, anything discussed during the meeting associated with a date will be summarized into a calendar event:
* Date and time of the event
* Title of the event/task
* Important topics associated with the event/task
When the meeting is over, those who participated in the meeting will receive an email with the automated Alexa notes and all calendar events will be added to the official company calendar. Why take meeting notes when Alexa can do it for you?
## How it works
The hack begins with an **Alexa skill**. We created a custom Alexa skill that allows the user to start and stop the meeting without skipping a beat. No more asking who is willing to take notes or hoping that the note-taker can keep up with the fast-pace -- just tell Alexa to start the meeting and carry on as normal.
The meeting is then assigned a unique access code that is transmitted to our server via an **AWS Lambda Function** which initiates the audio recording. Upon completion of a meeting, Alexa makes a request to the server to transcribe the text using the **IBM Watson Speech to Text API**.
But at the core of Scribblr are its **Natural Language Processing (NLP)** algorithms:
* The final transcript is first preprocessed, involving tokenization, stemming, and automated punctuation. Automated punctuation is accomplished using **supervised machine learning**, entailing a **recurrent neural network model** trained on over 40 million words.
* The Transcript Analyzer then integrates with the **IBM Watson Natural Language Understanding API** to detect keywords, topics, and concepts in order to determine the overarching theme of a meeting. We analyze the connections between these three categories to determine the most important topics discussed during the meeting which is later added to the email summary.
* We also isolate dates and times to be added to the calendar. When a date or time is isolated, the NLP algorithms search surrounding text to determine an appropriate title as well as key points. Even keywords such as "today", "tomorrow", and "noon" will be identified and appropriately extracted.
* Action items are isolated by searching for keywords in the transcript and these action items are processed by performing **POS tagging**, facilitated by a trained **machine-learning** module, ultimately being appended to the final meeting summary of the most important points discussed.
## Challenges we had
There were a lot of moving parts to this hack. Many of the programs we used had dependencies that were incompatible or didn't have the functionality we needed. We often struggled to attempt to work around these conflicting dependencies and had to completely change our approach to the problem. The hardest part was bringing everything together as a singular product -- making them "talk" to each other so to speak.
Since most of our code had to run on a server and we interfaced with a number of APIs, we had to manage multiple sets of credentials and deal with security measures through Google, Amazon, and IBM Watson, but what complicated this even more was that we were all developing on different machines, so what worked on one computer would fail on another and we had to work together to identify the tree of dependencies for each piece of the project.
## Accomplishments we're proud of
It works! We worked down until the wire, troubleshooting compatibility issues all night and actually got all four very distinct components to work together seamlessly. This is something we would actually use in our daily lives, at club meetings, study groups, class project meetings, and staff meetings.
## Things we learned
We learned a ton about NLP algorithms (as well as their limitations) and how to connect different pieces of a software system to a central server (which was arguably one of the hardest things we had to do, meaning we learned the most here). We also delved deeper into AWS Alexa: integrating Lambda functions, connecting to third-party applications, and publishing a skill.
## What's next for Scribblr
We would like to add more functionality for commands during the meeting, such as updating emails, publishing to more than just a central calendar, pausing the meeting, and controlling remote devices directly using Alexa instead of having to go through a server to do so.
|
losing
|
## Inspiration
The inspiration behind our innovative personal desk assistant was ignited by the fond memories of Furbys, those enchanting electronic companions that captivated children's hearts in the 2000s. These delightful toys, resembling a charming blend of an owl and a hamster, held an irresistible appeal, becoming the coveted must-haves for countless celebrations, such as Christmas or birthdays. The moment we learned that the theme centered around nostalgia, our minds instinctively gravitated toward the cherished toys of our youth, and Furbys became the perfect representation of that cherished era.
Why Furbys? Beyond their undeniable cuteness, these interactive marvels served as more than just toys; they were companions, each one embodying the essence of a cherished childhood friend. Thinking back to those special childhood moments, the idea for our personal desk assistant was sparked. Imagine it as a trip down memory lane to the days of playful joy and the magic of having an imaginary friend. It reflects the real bonds many of us formed during our younger years. Our goal is to bring the spirit of those adored Furbies into a modern, interactive personal assistant—a treasured piece from the past redesigned for today, capturing the memories that shaped our childhoods.
## What it does
Our project is more than just a nostalgic memory; it's a practical and interactive personal assistant designed to enhance daily life. Using facial recognition, the assistant detects the user's emotions and plays mood-appropriate songs, drawing from a range of childhood favorites, such as tunes from the renowned Kidz Bop musical group. With speech-to-text and text-to-speech capabilities, communication is seamless. The Furby-like body of the assistant dynamically moves to follow the user's face, creating an engaging and responsive interaction. Adding a touch of realism, the assistant engages in conversation and tells jokes to bring moments of joy. The integration of a dashboard website with the Furby enhances accessibility and control. Utilizing a chatbot that can efficiently handle tasks, ensuring a streamlined and personalized experience. Moreover, incorporating home security features adds an extra layer of practicality, making our personal desk assistant a comprehensive and essential addition to modern living.
## How we built it
Following extensive planning to outline the implementation of Furby's functions, our team seamlessly transitioned into the execution phase. The incorporation of Cohere's AI platform facilitated the development of a chatbot for our dashboard, enhancing user interaction. To infuse a playful element, ChatGBT was employed for animated jokes and interactive conversations, creating a lighthearted and toy-like atmosphere. Enabling the program to play music based on user emotions necessitated the integration of the Spotify API. Google's speech-to-text was chosen for its cost-effectiveness and exceptional accuracy, ensuring precise results when capturing user input. Given the project's hardware nature, various physical components such as microcontrollers, servos, cameras, speakers, and an Arduino were strategically employed. These elements served to make the Furby more lifelike and interactive, contributing to an enhanced and smoother user experience. The meticulous planning and thoughtful execution resulted in a program that seamlessly integrates diverse functionalities for an engaging and cohesive outcome.
## Challenges we ran into
During the development of our project, we encountered several challenges that required demanding problem-solving skills. A significant hurdle was establishing a seamless connection between the hardware and software components, ensuring the smooth integration of various functionalities for the intended outcome. This demanded a careful balance to guarantee that each feature worked harmoniously with others. Additionally, the creation of a website to display the Furby dashboard brought its own set of challenges, as we strived to ensure it not only functioned flawlessly but also adhered to the desired aesthetic. Overcoming these obstacles required a combination of technical expertise, attention to detail, and a commitment to delivering a cohesive and visually appealing user experience.
## Accomplishments that we're proud of
While embarking on numerous software projects, both in an academic setting and during our personal endeavors, we've consistently taken pride in various aspects of our work. However, the development of our personal assistant stands out as a transformative experience, pushing us to explore new techniques and skills. Venturing into unfamiliar territory, we successfully integrated Spotify to play songs based on facial expressions and working with various hardware components. The initial challenges posed by these tasks required substantial time for debugging and strategic thinking. Yet, after investing dedicated hours in problem-solving, we successfully incorporated these functionalities for Furby. The journey from initial unfamiliarity to practical application not only left us with a profound sense of accomplishment but also significantly elevated the quality of our final product.
## What we learned
Among the many lessons learned, machine learning stood out prominently as it was still a relatively new concept for us!
## What's next for FurMe
The future goals for FurMe include seamless integration with Google Calendar for efficient schedule management, a comprehensive daily overview feature, and productivity tools such as phone detection and a Pomodoro timer to assist users in maximizing their focus and workflow.
|
## Inspiration
I've always been fascinated by the complexities of UX design, and this project was an opportunity to explore an interesting mode of interaction. I drew inspiration from the futuristic UIs that movies have to offer, such as Minority Report's gesture-based OS or Iron Man's heads-up display, Jarvis.
## What it does
Each window in your desktop is rendered on a separate piece of paper, creating a tangible version of your everyday computer. It is fully featured desktop, with specific shortcuts for window management.
## How I built it
The hardware is combination of a projector and a webcam. The camera tracks the position of the sheets of paper, on which the projector renders the corresponding window. An OpenCV backend does the heavy lifting, calculating the appropriate translation and warping to apply.
## Challenges I ran into
The projector was initially difficulty to setup, since it has a fairly long focusing distance. Also, the engine that tracks the pieces of paper was incredibly unreliable under certain lighting conditions, which made it difficult to calibrate the device.
## Accomplishments that I'm proud of
I'm glad to have been able to produce a functional product, that could possibly be developed into a commercial one. Furthermore, I believe I've managed to put an innovative spin to one of the oldest concepts in the history of computers: the desktop.
## What I learned
I learned lots about computer vision, and especially on how to do on-the-fly image manipulation.
|
## Inspiration
While video-calling his grandmother, Tianyun was captivated by her nostalgic tales from her youth in China. It struck him how many of these cherished stories, rich in culture and emotion, remain untold or fade away as time progresses due to barriers like time constraints, lack of documentation, and the predominance of oral traditions.
For many people, however, it can be challenging to find time to hear stories from their elders. Along with limited documentation, and accessibility issues, many of these stories are getting lost as time passes.
**We believe these stories are *valuable* and *deserve* to be heard.** That’s why we created a tool that provides people with a dedicated team to help preserve these stories and legacies.
## What it does
Forget typing. Embrace voice. Our platform boasts a state-of-the-art Speech-To-Text interface. Leveraging cutting-edge LLM models combined with robust cloud infrastructures, we ensure swift and precise transcription. Whether your narration follows a structured storyline or meanders like a river, our bot Ivee skillfully crafts it into a beautiful, funny, or dramatic memoir.
## How we built it
Our initial step was an in-depth two-hour user experience research session. After crafting user personas, we identified our target audience: those who yearn to be acknowledged and remembered.
The next phase involved rapid setup and library installations. The team then split: the backend engineer dived into fine-tuning custom language models and optimizing database frameworks, the frontend designer focused on user authentication, navigation, and overall app structure, and the design team commenced the meticulous work of wireframing and conceptualization.
After an intense 35-hour development sprint, Ivee came to life. The designers brought to life a theme of nature into the application, symbolizing each story as a leaf, a life's collective memories as trees, and cultural groves of forests. The frontend squad meticulously sculpted an immersive onboarding journey, integrating seamless interactions with the backend, and spotlighting the TTS and STT features. Meanwhile, the backend experts integrated technologies from our esteemed sponsors: Hume.ai, Intel Developer Cloud, and Zilliz Vector Database.
Our initial segregation into Frontend, Design, Marketing, and Backend teams soon blurred as we realized the essence of collaboration. Every decision, every tweak was a collective effort, echoing the voice of the entire team.
## Challenges we ran into
Our foremost challenge was crafting an interface that exuded warmth, empathy, and familiarity, yet was technologically advanced. Through interactions with our relatives, we discovered overall negative sentiment toward AI, often stemming from dystopian portrayals in movies.
## Accomplishments that we're proud of
Our eureka moment was when we successfully demystified AI for our primary users. By employing intuitive metaphors and a user-centric design, we transformed AI from a daunting entity to an amiable ally. The intricate detailing in our design, the custom assets & themes, solving the challenges of optimizing 8 different APIs, and designing an intuitive & accessible onboarding experience are all highlights of our creativity.
## What we learned
Our journey underscored the true value of user-centric design. Conventional design principles had to be recalibrated to resonate with our unique user base. We created an AI tool to empower humanity, to help inspire, share, and preserve stories, not just write them. It was a profound lesson in accessibility and the art of placing users at the heart of every design choice.
## What's next for Ivee
The goal for Ivee was always to preserve important memories and moments in people's lives. Below are some really exciting features that our team would love to implement:
* Reinforcement Learning on responses to fit your narration style
* Rust to make everything faster
* **Multimodal** storytelling. We want to include clips of the most emotion-fueled clips, on top of the stylized and colour-coded text, we want to revolutionize the way we interact with stories.
* Custom handwriting for memoirs
* Use your voice and read your story in your voice using custom voices
In the future, we hope to implement additional features like photos and videos, as well as sharing features to help families and communities grow forests together.
|
winning
|
## Realm Inspiration
Our inspiration stemmed from our fascination in the growing fields of AR and virtual worlds, from full-body tracking to 3D-visualization. We were interested in realizing ideas in this space, specifically with sensor detecting movements and seamlessly integrating 3D gestures. We felt that the prime way we could display our interest in this technology and the potential was to communicate using it. This is what led us to create Realm, a technology that allows users to create dynamic, collaborative, presentations with voice commands, image searches and complete body-tracking for the most customizable and interactive presentations. We envision an increased ease in dynamic presentations and limitless collaborative work spaces with improvements to technology like Realm.
## Realm Tech Stack
Web View (AWS SageMaker, S3, Lex, DynamoDB and ReactJS): Realm's stack relies heavily on its reliance on AWS. We begin by receiving images from the frontend and passing it into SageMaker where the images are tagged corresponding to their content. These tags, and the images themselves, are put into an S3 bucket. Amazon Lex is used for dialog flow, where text is parsed and tools, animations or simple images are chosen. The Amazon Lex commands are completed by parsing through the S3 Bucket, selecting the desired image, and storing the image URL with all other on-screen images on to DynamoDB. The list of URLs are posted on an endpoint that Swift calls to render.
AR View ( AR-kit, Swift ): The Realm app renders text, images, slides and SCN animations in pixel perfect AR models that are interactive and are interactive with a physics engine. Some of the models we have included in our demo, are presentation functionality and rain interacting with an umbrella. Swift 3 allows full body tracking and we configure the tools to provide optimal tracking and placement gestures. Users can move objects in their hands, place objects and interact with 3D items to enhance the presentation.
## Applications of Realm:
In the future we hope to see our idea implemented in real workplaces in the future. We see classrooms using Realm to provide students interactive spaces to learn, professional employees a way to create interactive presentations, teams to come together and collaborate as easy as possible and so much more. Extensions include creating more animated/interactive AR features and real-time collaboration methods. We hope to further polish our features for usage in industries such as AR/VR gaming & marketing.
|
## Our Inspiration
We were inspired by apps like Duolingo and Quizlet for language learning, and wanted to extend those experiences to a VR environment. The goal was to gameify the entire learning experience and make it immersive all while providing users with the resources to dig deeper into concepts.
## What it does
EduSphere is an interactive AR/VR language learning VisionOS application designed for the new Apple Vision Pro. It contains three fully developed features: a 3D popup game, a multi-lingual chatbot, and an immersive learning environment. It leverages the visually compelling and intuitive nature of the VisionOS system to target three of the most crucial language learning styles: visual, kinesthetic, and literacy - allowing users to truly learn at their own comfort. We believe the immersive environment will make language learning even more memorable and enjoyable.
## How we built it
We built the VisionOS app using the Beta development kit for the Apple Vision Pro. The front-end and AR/VR components were made using Swift, SwiftUI, Alamofire, RealityKit, and concurrent MVVM design architecture. 3D Models were converted through Reality Converter as .usdz files for AR modelling. We stored these files on the Google Cloud Bucket Storage, with their corresponding metadata on CockroachDB. We used a microservice architecture for the backend, creating various scripts involving Python, Flask, SQL, and Cohere. To control the Apple Vision Pro simulator, we linked a Nintendo Switch controller for interaction in 3D space.
## Challenges we ran into
Learning to build for the VisionOS was challenging mainly due to the lack of documentation and libraries available. We faced various problems with 3D Modelling, colour rendering, and databases, as it was difficult to navigate this new space without references or sources to fall back on. We had to build many things from scratch while discovering the limitations within the Beta development environment. Debugging certain issues also proved to be a challenge. We also really wanted to try using eye tracking or hand gesturing technologies, but unfortunately, Apple hasn't released these yet without a physical Vision Pro. We would be happy to try out these cool features in the future, and we're definitely excited about what's to come in AR/VR!
## Accomplishments that we're proud of
We're really proud that we were able to get a functional app working on the VisionOS, especially since this was our first time working with the platform. The use of multiple APIs and 3D modelling tools was also the amalgamation of all our interests and skillsets combined, which was really rewarding to see come to life.
|
## Inspiration
Every project aims to solve a problem, and to solve people's concerns. When we walk into a restaurant, we are so concerned that not many photos are printed on the menu. However, we are always eager to find out what a food looks like. Surprisingly, including a nice-looking picture alongside a food item increases sells by 30% according to Rapp. So it's a big inconvenience for customers if they don't understand the name of a food. This is what we are aiming for! This is where we get into the field! We want to create a better impression on every customer and create a better customer-friendly restaurant society. We want every person to immediately know what they like to eat and the first impression of a specific food in a restaurant.
## How we built it
We mainly used ARKit, MVC and various APIs to build this iOS app. We first start with entering an AR session, and then we crop the image programmatically to feed it to OCR from Microsoft Azure Cognitive Service. It recognized the text from the image, though not perfectly. We then feed the recognized text to a Spell Check from Azure to further improve the quality of the text. Next, we used Azure Image Search service to look up the dish image from Bing, and then we used Alamofire and SwiftyJSON for getting the image. We created a virtual card using SceneKit and place it above the menu in ARView. We used Firebase as backend database and for authentication. We built some interactions between the virtual card and users so that users could see more information about the ordered dishes.
## Challenges we ran into
We ran into various unexpected challenges when developing Augmented Reality and using APIs. First, there are very few documentations about how to use Microsoft APIs on iOS apps. We learned how to use the third-party library for building HTTP request and parsing JSON files. Second, we had a really hard time understanding how Augmented Reality works in general, and how to place virtual card within SceneKit. Last, we were challenged to develop the same project as a team! It was the first time each of us was pushed to use Git and Github and we learned so much from branches and version controls.
## Accomplishments that we're proud of
Only learning swift and ios development for one month, we create our very first wonderful AR app. This is a big challenge for us and we still choose a difficult and high-tech field, which should be most proud of. In addition, we implement lots of API and create a lot of "objects" in AR, and they both work perfectly. We also encountered few bugs during development, but we all try to fix them. We're proud of combining some of the most advanced technologies in software such as AR, cognitive services and computer vision.
## What we learned
During the whole development time, we clearly learned how to create our own AR model, what is the structure of the ARScene, and also how to combine different API to achieve our main goal. First of all, we enhance our ability to coding in swift, especially for AR. Creating the objects in AR world teaches us the tree structure in AR, and the relationships among parent nodes and its children nodes. What's more, we get to learn swift deeper, specifically its MVC model. Last but not least, bugs teach us how to solve a problem in a team and how to minimize the probability of buggy code for next time. Most importantly, this hackathon poses the strength of teamwork.
## What's next for DishPlay
We desire to build more interactions with ARKit, including displaying a collection of dishes on 3D shelf, or cool animations that people can see how those favorite dishes were made. We also want to build a large-scale database for entering comments, ratings or any other related information about dishes! We are happy that Yelp and OpenTable bring us more closed to the restaurants. We are excited about our project because it will bring us more closed to our favorite food!
|
winning
|
## Inspiration
It's easy to zone off in online meetings/lectures, and it's difficult to rewind without losing focus at the moment. It could also be disrespectful to others if you expose the fact that you weren't paying attention. Wouldn't it be nice if we can just quickly skim through a list of keywords to immediately see what happened?
## What it does
Rewind is an intelligent, collaborative and interactive web canvas with built in voice chat that maintains a list of live-updated keywords that summarize the voice chat history. You can see timestamps of the keywords and click on them to reveal the actual transcribed text.
## How we built it
Communications: WebRTC, WebSockets, HTTPS
We used WebRTC, a peer-to-peer protocol to connect the users though a voice channel, and we used websockets to update the web pages dynamically, so the users would get instant feedback for others actions. Additionally, a web server is used to maintain stateful information.
For summarization and live transcript generation, we used Google Cloud APIs, including natural language processing as well as voice recognition.
Audio transcription and summary: Google Cloud Speech (live transcription) and natural language APIs (for summarization)
## Challenges we ran into
There are many challenges that we ran into when we tried to bring this project to reality. For the backend development, one of the most challenging problems was getting WebRTC to work on both the backend and the frontend. We spent more than 18 hours on it to come to a working prototype. In addition, the frontend development was also full of challenges. The design and implementation of the canvas involved many trial and errors and the history rewinding page was also time-consuming. Overall, most components of the project took the combined effort of everyone on the team and we have learned a lot from this experience.
## Accomplishments that we're proud of
Despite all the challenges we ran into, we were able to have a working product with many different features. Although the final product is by no means perfect, we had fun working on it utilizing every bit of intelligence we had. We were proud to have learned many new tools and get through all the bugs!
## What we learned
For the backend, the main thing we learned was how to use WebRTC, which includes client negotiations and management. We also learned how to use Google Cloud Platform in a Python backend and integrate it with the websockets. As for the frontend, we learned to use various javascript elements to help develop interactive client webapp. We also learned event delegation in javascript to help with an essential component of the history page of the frontend.
## What's next for Rewind
We imagined a mini dashboard that also shows other live-updated information, such as the sentiment, summary of the entire meeting, as well as the ability to examine information on a particular user.
|
## Inspiration
<https://www.youtube.com/watch?v=lxuOxQzDN3Y>
Robbie's story stuck out to me at the endless limitations of technology. He was diagnosed with muscular dystrophy which prevented him from having full control of his arms and legs. He was gifted with a Google home that crafted his home into a voice controlled machine. We wanted to take this a step further and make computers more accessible for people such as Robbie.
## What it does
We use a Google Cloud based API that helps us detect words and phrases captured from the microphone input. We then convert those phrases into commands for the computer to execute. Since the python script is run in the terminal it can be used across the computer and all its applications.
## How I built it
The first (and hardest) step was figuring out how to leverage Google's API to our advantage. We knew it was able to detect words from an audio file but there was more to this project than that. We started piecing libraries to get access to the microphone, file system, keyboard and mouse events, cursor x,y coordinates, and so much more. We build a large (~30) function library that could be used to control almost anything in the computer
## Challenges I ran into
Configuring the many libraries took a lot of time. Especially with compatibility issues with mac vs. windows, python2 vs. 3, etc. Many of our challenges were solved by either thinking of a better solution or asking people on forums like StackOverflow. For example, we wanted to change the volume of the computer using the fn+arrow key shortcut, but python is not allowed to access that key.
## Accomplishments that I'm proud of
We are proud of the fact that we had built an alpha version of an application we intend to keep developing, because we believe in its real-world applications. From a technical perspective, I was also proud of the fact that we were able to successfully use a Google Cloud API.
## What I learned
We learned a lot about how the machine interacts with different events in the computer and the time dependencies involved. We also learned about the ease of use of a Google API which encourages us to use more, and encourage others to do so, too. Also we learned about the different nuances of speech detection like how to tell the API to pick the word "one" over "won" in certain context, or how to change a "one" to a "1", or how to reduce ambient noise.
## What's next for Speech Computer Control
At the moment we are manually running this script through the command line but ideally we would want a more user friendly experience (GUI). Additionally, we had developed a chrome extension that numbers off each link on a page after a Google or Youtube search query, so that we would be able to say something like "jump to link 4". We were unable to get the web-to-python code just right, but we plan on implementing it in the near future.
|
## Inspiration
After reading a study that stated $62 million in pennies are accidentally thrown out each year, we were curious about how this money could have instead been used to benefit society. As such, we decided to create an app that allows users to use their leftover change to make an actual change for others.
## What it does
change4change promotes charitable contributions through each of your purchases. All your transactions are rounded to the nearest dollar, with the difference going towards a charity of your choice. In case you’re uncertain of which charity to support, the app has built-in search capabilities that allow you to either search for charities by name or by category.
## How we built it
Through Android Studio, Google Firebase, and the CapitalOne Hackathon API, we created our functional mobile app. Firebase provided a secure database for storing user credentials, while the CapitalOne Hackathon API enabled easy access to banking simulations to power our features. Android’s handy native UI elements allows us to create a sleek front-end to present to the user.
## Challenges we ran into
As first-time developers on Android, we spent some time learning to work within the platform’s limitations. Obtaining a database of charities was also a challenge which we solved by scraping websites and processing data using custom python scripts to generate the database. Another challenge was configuring Firebase for Android to allow for authorization and data-storing.
## Accomplishments that we're proud of
We are proud of our app’s functionalities since they are modularized and well-designed; as such, user experience is streamlined and simple. Additionally, we are satisfied with having developed a pragmatic charity search functionality by applying data science concepts and overcoming certain Android limitations. Additionally, we are happy with our ability to develop a sleek interface design that is appealing to users.
## What we learned
Since many of us were new to Android development, we learnt the fundamentals of Android Studio and Java. Additionally, we had to learn how to use Firebase to authenticate user credentials and store user information securely.
## What's next for change4change
We plan on implementing functionality for real banking institutions and potentially releasing this product to the Google Play Store. Additionally, we are looking into possibly rebuilding the app to be more scalable for larger operations.
|
winning
|
## Inspiration
We wanted to make an app that helped people to be more environmentally conscious. After we thought about it, we realised that most people are not because they are too lazy to worry about recycling, turning off unused lights, or turning off a faucet when it's not in use. We figured that if people saw how much money they lose by being lazy, they might start to change their habits. We took this idea and added a full visualisation aspect of the app to make a complete budgeting app.
## What it does
Our app allows users to log in, and it then retrieves user data to visually represent the most interesting data from that user's financial history, as well as their utilities spending.
## How we built it
We used HTML, CSS, and JavaScript as our front-end, and then used Arduino to get light sensor data, and Nessie to retrieve user financial data.
## Challenges we ran into
To seamlessly integrate our multiple technologies, and to format our graphs in a way that is both informational and visually attractive.
## Accomplishments that we're proud of
We are proud that we have a finished product that does exactly what we wanted it to do and are proud to demo.
## What we learned
We learned about making graphs using JavaScript, as well as using Bootstrap in websites to create pleasing and mobile-friendly interfaces. We also learned about integrating hardware and software into one app.
## What's next for Budge
We want to continue to add more graphs and tables to provide more information about your bank account data, and use AI to make our app give personal recommendations catered to an individual's personal spending.
|
## Inspiration
We admired the convenience Honey provides for finding coupon codes. We wanted to apply the same concept except towards making more sustainable purchases online.
## What it does
Recommends sustainable and local business alternatives when shopping online.
## How we built it
Front-end was built with React.js and Bootstrap. The back-end was built with Python, Flask and CockroachDB.
## Challenges we ran into
Difficulties setting up the environment across the team, especially with cross-platform development in the back-end. Extracting the current URL from a webpage was also challenging.
## Accomplishments that we're proud of
Creating a working product!
Successful end-to-end data pipeline.
## What we learned
We learned how to implement a Chrome Extension. Also learned how to deploy to Heroku, and set up/use a database in CockroachDB.
## What's next for Conscious Consumer
First, it's important to expand to make it easier to add local businesses. We want to continue improving the relational algorithm that takes an item on a website, and relates it to a similar local business in the user's area. Finally, we want to replace the ESG rating scraping with a corporate account with rating agencies so we can query ESG data easier.
|
## Inspiration
The inspiration for our project came to us when we saw FuturFund's affiliation with HackWestern. Having great interest in financial literacy, our group decided to tackle this idea head on. Our team is passionate about female empowerment and creating opportunities for those that seek it. Thus we created a web app design that allows women to learn at their own discretion and pace creates an environment that pushes for growth.
## What it does
Track your income, allocate your funds, manage your account with ease and check your credit score growth as you progress. All of these functionalities will be paired with hints and tips that enhance the user experience, educating our clients to lead them to success.
The budget calculator is one of the core functionalities that we offer to our consumers. It calculates
the net value of your income and expenses, giving you a detailed account of when and for what
purpose the transactions were made.
While we recommend certain percentages of their income be allocated for savings, necessities and
discretionary items, the consumers are allowed to customize these values to better suit their financial
conditions.
But unlike other calculators, it detects when you've spent a little too much in any one of the
subcategories of expenses. We then recommend appropriate tips on how to manage the spending in that
particular category.
## How we built it
We utilized firebase to host a realtime database, including user authentication. This was paired with HTML, JS, CSS and node.js to solidify our site, including the financial calculations required to build and implement the budgeting calculator.
## Challenges we ran into
The hardships we faced were mostly the stringent time constraint. This was and still is a hard time frame to get used to when building any app or program from scratch, and is something that our team must consistently work harder at circumventing.
## Accomplishments that we're proud of
Throughout this project, we learned the hardships of compiling, designing and bringing our ideas to life in the short time span. The creativity that stemmed from our passion touched every corner of our web app, and this reflected from our team's ability to learn and work together cohesively. We polished our skillset by utilizing HTML, JS, CSS, node.js and firebase to create a well-crafted, responsive website.
### Domain Name
breezefinance.tech
|
winning
|
# JARVIS-MUSIC
Have a song stuck in your head but can't sing it? Use our web app to play the music that's on your mind!
Overall, we are building a web application for users to find songs by lirycs or any information that is related to your song.
In our web home page, you press the audio recording button to sing your songs, or tell something about your song.
We use google speech to text API to convert your voice to text and show it to you.
Of course, you can always input the text directly, if you are uncomfortable about saying anything.
The text is transformed to our server side. We have a machine learning algorithm to search for the most related song.
Here is our algorithm to search the song. We firstly download tons of songs using the Genius API. We build a word filtering API using the standard library (stdlib). The word filtering API filters bad words (such as "fuck") in the lyrics of the songs. We then index the songs to our database. Given your input text, i.e., a query, our unsupervised algorithm aims to find the most relevant song. We use the Vector Space Model and doc2vec to build our unsupervised algorithm.
Basically, Vector Space Model locates the exact words that you want to search and doc2vec extracts the semantic meaning of your input text and the lyrics, such that we are not lossing any information. We give a score of each song, denoting how relevant the song is to the input text. We rank the songs based the returned scores. and return the top five songs. We not only return song name and singer name, but also return YouTube links for you to check out!
|
## Inspiration
We wanted to create a tool that would improve the experience of all users of the internet, not just technically proficient ones. Once fully realized, our system could allow groups such as blind people and the elderly a great deal of utility, as it allows for navigation by simple voice command with only minor setup from someone else. We could also implement function sharing to allow users to share their ideas and tools with everyone else or allow companies to define defaults on their own webpages to improve the user experience.
Created with the intention to make browsing the web easier, if not possible for the visually impaired. Access to the internet may soon be considered a fundamental human right- it should be made accessible to everyone regardless of their abilities.
## What it does
A chrome extension that allows a user to speak a phrase(e.g. "Search for guitar songs" on Youtube), then enter a series of actions. Our extension will store the instructions entered, then use a combination of STT and natural language processing to generalize the query for the site and all permutations of the same structure. We use Microsoft LUIS, which at a baseline allows for synonyms. The more it is used, the better this becomes, so it could expand to solve "find piano music" as well. We are also in the process of developing a simple interface to allow users to easily define their custom instruction sets.
## How we built it
We used webkit Speech to Text in a chrome plugin to create sentences from recordings. We also created a system to track mouse and keyboard inputs in order to replicate them. This info was passed to a StdLib staging area that processes data and manages Microsoft LUIS to interpret the inputted sentence. This is then passed back to the plugin so it knows which sequence of actions to perform. Our project has a system to generalize "entities" i.e. the variables in an instruction (i.e. "guitar songs").
## Challenges we ran into
* No native APIs for several UX/UI elements. Forced to create workarounds and hack bits of code together.
* Making the project functions easy for users to follow and understand.
## Accomplishments that we're proud of
Our team learned to use an unfamiliar system with an entirely different paradigm from traditional web hosting, and how to manage its advantages and disadvantages on the fly while integrating with several other complex systems
## What we learned
It is a better strategy to iterate on outwards from the simplest core of your system rather than aim big. We had to cut features, which meant we sunk unnecessary time into development initially. We also learned all about FAAS and serverless hosting, and about natural language processing.
## What's next for Quack - Voice Controlled Action Automation for Chrome
|
## Inspiration
We had a wine and cheese last week.
## Challenges I ran into
A W S + python 3 connecting to domain
## What's next for Whine and Cheese
A team wine and cheese
|
losing
|
## Inspiration
In a world where the voices of the minority are often not heard, technology must be adapted to fit the equitable needs of these groups. Picture the millions who live in a realm of silence, where for those who are deaf, you are constantly silenced and misinterpreted. Of the 50 million people in the United States with hearing loss, less than 500,000 — or about 1% — use sign language, according to Acessibility.com and a recent US Census. Over 466 million people across the globe struggle with deafness, a reality known to each in the deaf community. Imagine the pain where only 0.15% of people (in the United States) can understand you. As a mother, father, teacher, friend, or ally, there is a strong gap in communication that impacts deaf people every day. The need for a new technology is urgent from both an innovation perspective and a human rights perspective.
Amidst this urgent disaster of an industry, a revolutionary vision emerges – Caption Glasses, a beacon of hope for the American Sign Language (ASL) community. Caption Glasses bring the magic of real-time translation to life, using artificial neural networks (machine learning) to detect ASL "fingerspeaking" (their one-to-one version of the alphabet), and creating instant subtitles displayed on glasses. This revolutionary piece effortlessly bridges the divide between English and sign language. Instant captions allow for the deaf child to request food from their parents. Instant captions allow TAs to answer questions in sign language. Instant captions allow for the nurse to understand the deaf community seeking urgent care at hospitals. Amplifying communication for the deaf community to the unprecedented level that Caption Glasses does increases the diversity of humankind through equitable accessibility means!
With Caption Glasses, every sign becomes a verse, every gesture an eloquent expression. It's a revolution, a testament to humanity's potential to converse with one another. In a society where miscommunication causes wars, there is a huge profit associated with developing Caption Glasses. Join us in this journey as we redefine the meaning of connection, one word, one sign, and one profound moment at a time.
## What it does
The Caption Glasses provide captions displayed on glasses after detecting American Sign Language (ASL). The captions are instant and in real-time, allowing for effective translations into the English Language for the glasses wearer.
## How we built it
Recognizing the high learning curve of ASL, we began brainstorming for possible solutions to make sign language more approachable to everyone. We eventually settled on using AR-style glasses to display subtitles that can help an ASL learner quickly identify what sign they are looking at.
We started our build with hardware and design, starting off by programming a SSD1306 OLED 0.96'' display with an Arduino Nano. We also began designing our main apparatus around the key hardware components, and created a quick prototype using foam.
Next, we got to loading computer vision models onto a Raspberry Pi4. Although we were successful in loading a basic model that looks at generic object recognition, we were unable to find an ASL gesture recognition model that was compact enough to fit on the RPi.
To circumvent this problem, we made an approach change that involved more use of the MediaPipe Hand Recognition models. The particular model we chose marked out 21 landmarks of the human hand (including wrist, fingertips, knuckles, etc.). We then created and trained a custom Artificial Neural Network that takes the position of these landmarks, and determines what letter we are trying to sign.
At the same time, we 3D printed the main apparatus with a Prusa I3 3D printer, and put in all the key hardware components. This is when we became absolute best friends with hot glue!
## Challenges we ran into
The main challenges we ran into during this project mainly had to do with programming on an RPi and 3D printing.
Initially, we wanted to look for pre-trained models for recognizing ASL, but there were none that were compact enough to fit in the limited processing capability of the Raspberry Pi. We were able to circumvent the problem by creating a new model using MediaPipe and PyTorch, but we were unsuccessful in downloading the necessary libraries on the RPi to get the new model working. Thus, we were forced to use a laptop for the time being, but we will try to mitigate this problem by potentially looking into using ESP32i's in the future.
As a team, we were new to 3D printing, and we had a great experience learning about the importance of calibrating the 3D printer, and had the opportunity to deal with a severe printer jam. While this greatly slowed down the progression of our project, we were lucky enough to be able to fix our printer's jam!
## Accomplishments that we're proud of
Our biggest accomplishment is that we've brought our vision to life in the form of a physical working model. Employing the power of 3D printing through leveraging our expertise in SolidWorks design, we meticulously crafted the components, ensuring precision and functionality.
Our prototype seamlessly integrates into a pair of glasses, a sleek and practical design. At its heart lies an Arduino Nano, wired to synchronize with a 40mm lens and a precisely positioned mirror. This connection facilitates real-time translation and instant captioning. Though having extensive hardware is challenging and extremely time-consuming, we greatly take the attention of the deaf community seriously and believe having a practical model adds great value.
Another large accomplishment is creating our object detection model through a machine learning approach of detecting 21 points in a user's hand and creating the 'finger spelling' dataset. Training the machine learning model was fun but also an extensively difficult task. The process of developing the dataset through practicing ASL caused our team to pick up the useful language of ASL.
## What we learned
Our journey in developing Caption Glasses revealed the profound need within the deaf community for inclusive, diverse, and accessible communication solutions. As we delved deeper into understanding the daily lives of over 466 million deaf individuals worldwide, including more than 500,000 users of American Sign Language (ASL) in the United States alone, we became acutely aware of the barriers they face in a predominantly spoken word.
The hardware and machine learning development phases presented significant challenges. Integrating advanced technology into a compact, wearable form required a delicate balance of precision engineering and user-centric design. 3D printing, SolidWorks design, and intricate wiring demanded meticulous attention to detail. Overcoming these hurdles and achieving a seamless blend of hardware components within a pair of glasses was a monumental accomplishment.
The machine learning aspect, essential for real-time translation and captioning, was equally demanding. Developing a model capable of accurately interpreting finger spelling and converting it into meaningful captions involved extensive training and fine-tuning. Balancing accuracy, speed, and efficiency pushed the boundaries of our understanding and capabilities in this rapidly evolving field.
Through this journey, we've gained profound insights into the transformative potential of technology when harnessed for a noble cause. We've learned the true power of collaboration, dedication, and empathy. Our experiences have cemented our belief that innovation, coupled with a deep understanding of community needs, can drive positive change and improve the lives of many. With Caption Glasses, we're on a mission to redefine how the world communicates, striving for a future where every voice is heard, regardless of the language it speaks.
## What's next for Caption Glasses
The market for Caption Glasses is insanely large, with infinite potential for advancements and innovations. In terms of user design and wearability, we can improve user comfort and style. The prototype given can easily scale to be less bulky and lighter. We can allow for customization and design patterns (aesthetic choices to integrate into the fashion community).
In terms of our ML object detection model, we foresee its capability to decipher and translate various sign languages from across the globe pretty easily, not just ASL, promoting a universal mode of communication for the deaf community. Additionally, the potential to extend this technology to interpret and translate spoken languages, making Caption Glasses a tool for breaking down language barriers worldwide, is a vision that fuels our future endeavors. The possibilities are limitless, and we're dedicated to pushing boundaries, ensuring Caption Glasses evolve to embrace diverse forms of human expression, thus fostering an interconnected world.
|
## Inspiration
Imagine a world where your best friend is standing in front of you, but you can't see them. Or you go to read a menu, but you are not able to because the restaurant does not have specialized brail menus. For millions of visually impaired people around the world, those are not hypotheticals, they are facts of life.
Hollywood has largely solved this problem in entertainment. Audio descriptions allow the blind or visually impaired to follow the plot of movies easily. With Sight, we are trying to bring the power of audio description to everyday life.
## What it does
Sight is an app that allows the visually impaired to recognize their friends, get an idea of their surroundings, and have written text read aloud. The app also uses voice recognition to listen for speech commands to identify objects, people or to read text.
## How we built it
The front-end is a native iOS app written in Swift and Objective-C with XCode. We use Apple's native vision and speech API's to give the user intuitive control over the app.
---
The back-end service is written in Go and is served with NGrok.
---
We repurposed the Facebook tagging algorithm to recognize a user's friends. When the Sight app sees a face, it is automatically uploaded to the back-end service. The back-end then "posts" the picture to the user's Facebook privately. If any faces show up in the photo, Facebook's tagging algorithm suggests possibilities for who out of the user's friend group they might be. We scrape this data from Facebook to match names with faces in the original picture. If and when Sight recognizes a person as one of the user's friends, that friend's name is read aloud.
---
We make use of the Google Vision API in three ways:
* To run sentiment analysis on people's faces, to get an idea of whether they are happy, sad, surprised etc.
* To run Optical Character Recognition on text in the real world which is then read aloud to the user.
* For label detection, to indentify objects and surroundings in the real world which the user can then query about.
## Challenges we ran into
There were a plethora of challenges we experienced over the course of the hackathon.
1. Each member of the team wrote their portion of the back-end service a language they were comfortable in. However when we came together, we decided that combining services written in different languages would be overly complicated, so we decided to rewrite the entire back-end in Go.
2. When we rewrote portions of the back-end in Go, this gave us a massive performance boost. However, this turned out to be both a curse and a blessing. Because of the limitation of how quickly we are able to upload images to Facebook, we had to add a workaround to ensure that we do not check for tag suggestions before the photo has been uploaded.
3. When the Optical Character Recognition service was prototyped in Python on Google App Engine, it became mysteriously rate-limited by the Google Vision API. Re-generating API keys proved to no avail, and ultimately we overcame this by rewriting the service in Go.
## Accomplishments that we're proud of
Each member of the team came to this hackathon with a very disjoint set of skills and ideas, so we are really glad about how well we were able to build an elegant and put together app.
Facebook does not have an official algorithm for letting apps use their facial recognition service, so we are proud of the workaround we figured out that allowed us to use Facebook's powerful facial recognition software.
We are also proud of how fast the Go back-end runs, but more than anything, we are proud of building a really awesome app.
## What we learned
Najm taught himself Go over the course of the weekend, which he had no experience with before coming to YHack.
Nathaniel and Liang learned about the Google Vision API, and how to use it for OCR, facial detection, and facial emotion analysis.
Zak learned about building a native iOS app that communicates with a data-rich APIs.
We also learned about making clever use of Facebook's API to make use of their powerful facial recognition service.
Over the course of the weekend, we encountered more problems and bugs than we'd probably like to admit. Most of all we learned a ton of valuable problem-solving skills while we worked together to overcome these challenges.
## What's next for Sight
If Facebook ever decides to add an API that allows facial recognition, we think that would allow for even more powerful friend recognition functionality in our app.
Ultimately, we plan to host the back-end on Google App Engine.
|
## Inspiration
We were inspired by the fact that **diversity in disability is often overlooked** - individuals who are hard-of-hearing or deaf and use **American Sign Language** do not have many tools that support them in learning their language. Because of the visual nature of ASL, it's difficult to translate between it and written languages, so many forms of language software, whether it is for education or translation, do not support ASL. We wanted to provide a way for ASL-speakers to be supported in learning and speaking their language.
Additionally, we were inspired by recent news stories about fake ASL interpreters - individuals who defrauded companies and even government agencies to be hired as ASL interpreters, only to be later revealed as frauds. Rather than accurately translate spoken English, they 'signed' random symbols that prevented the hard-of-hearing community from being able to access crucial information. We realized that it was too easy for individuals to claim their competence in ASL without actually being verified.
All of this inspired the idea of EasyASL - a web app that helps you learn ASL vocabulary, translate between spoken English and ASL, and get certified in ASL.
## What it does
EasyASL provides three key functionalities: learning, certifying, and translating.
**Learning:** We created an ASL library - individuals who are learning ASL can type in the vocabulary word they want to learn to see a series of images or a GIF demonstrating the motions required to sign the word. Current ASL dictionaries lack this dynamic ability, so our platform lowers the barriers in learning ASL, allowing more members from both the hard-of-hearing community and the general population to improve their skills.
**Certifying:** Individuals can get their mastery of ASL certified by taking a test on EasyASL. Once they start the test, a random word will appear on the screen and the individual must sign the word in ASL within 5 seconds. Their movements are captured by their webcam, and these images are run through OpenAI's API to check what they signed. If the user is able to sign a majority of the words correctly, they will be issued a unique certificate ID that can certify their mastery of ASL. This certificate can be verified by prospective employers, helping them choose trustworthy candidates.
**Translating:** EasyASL supports three forms of translation: translating from spoken English to text, translating from ASL to spoken English, and translating in both directions. EasyASL aims to make conversations between ASL-speakers and English-speakers more fluid and natural.
## How we built it
EasyASL was built primarily with **typescript and next.js**. We captured images using the user's webcam, then processed the images to reduce the file size while maintaining quality. Then, we ran the images through **Picsart's API** to filter background clutter for easier image recognition and host images in temporary storages. These were formatted to be accessible to **OpenAI's API**, which was trained to recognize the ASL signs and identify the word being signed. This was used in both our certification stream, where the user's ASL sign was compared against the prompt they were given, and in the translation stream, where ASL phrases were written as a transcript then read aloud in real time. We also used **Google's web speech API** in the translation stream, which converted English to written text. Finally, the education stream's dictionary was built using typescript and a directory of open-source web images.
## Challenges we ran into
We faced many challenges while working on EasyASL, but we were able to persist through them to come to our finished product. One of our biggest challenges was working with OpenAI's API: we only had a set number of tokens, which were used each time we ran the program, meaning we couldn't test the program too many times. Also, many of our team members were using TypeScript and Next.js for the first time - though there was a bit of a learning curve, we found that its similarities with JavaScript helped us adapt to the new language. Finally, we were originally converting our images to a UTF-8 string, but got strings that were over 500,000 characters long, making them difficult to store. We were able to find a workaround by keeping the images as URLs and passing these URLs directly into our functions instead.
## Accomplishments that we're proud of
We were very proud to be able to integrate APIs into our project. We learned how to use them in different languages, including TypeScript. By integrating various APIs, we were able to streamline processes, improve functionality, and deliver a more dynamic user experience. Additionally, we were able to see how tools like AI and text-to-speech could have real-world applications.
## What we learned
We learned a lot about using Git to work collaboratively and resolve conflicts like separate branches or merge conflicts. We also learned to use Next.js to expand what we could do beyond JavaScript and HTML/CSS. Finally, we learned to use APIs like Open AI API and Google Web Speech API.
## What's next for EasyASL
We'd like to continue developing EasyASL and potentially replacing the Open AI framework with a neural network model that we would train ourselves. Currently processing inputs via API has token limits reached quickly due to the character count of Base64 converted image. This results in a noticeable delay between image capture and model output. By implementing our own model, we hope to speed this process up to recreate natural language flow more readily. We'd also like to continue to improve the UI/UX experience by updating our web app interface.
|
winning
|
## Inspiration
Our main inspiration was Honey, the star of YouTube advertisements, as we recognized the convenience of seeing information about your shopping list right in the browser. More people would buy sustainable products if there was an indicator that they are, which is why ecolabels exist and are used widely. However, the rise of e-commerce has weakened the impact of printed symbols on packaging, and researching each product is a pain. Instead, we thought up a way to bring ecolabels to the attention of online shoppers right at checkout.
## What it does
EcoShop uses various web databases and APIs to read the product names on an online shopping cart (currently limited to Target). It then displays what sustainable certifications the products have earned through Type 1 programs, which are accredited through a third party. Upon clicking on the ecolabel, users are also provided with a detailed view of the certification, the qualifications necessary to earn it, and what that means about their product.
## How we built it
By using Target's Red Circle API, we were able to scrape data on products in a user’s shopping cart from the site. This data includes the UPC (Universal Product Code), which is compared to pre-acquired datasets from various certification organizations such as EPEAT (Electronic Product Environmental Assessment Tool), Energy Star, TCO, etc. The certification data, gathered through Javascript, was sent back to the extension which displayed the product list and corresponding certifications it has earned.
## Challenges we ran into
The majority of product certification datasets weren't available to the public since they either aren't digitized or needed a paid license to access. The data that was available for free use took hours to format, let alone process. Many also didn’t include a product's UPC, due to the lack of legal requirements for information on non-retail products. Target's Red Circle API was also not optimized enough for operating under a short time constraint, and we had to determine a way to efficiently and securely access the site data of the user.
## Accomplishments that we're proud of
We’re proud of the functionality that our product provides, even given the lack of time, experience, and resources our team struggled with. Our extension is only limited by the number of free, public datasets for sustainable product certifications, and can easily be expanded to other consumer categories and ecolabels if they become available to us. From our logic to our UI, our extension to our website, we’re psyched to be able to successfully inform online shoppers about whether they're shopping sustainably and influence them to get better at it.
## What we learned
Although some of us have had a surface-level experience with web development, this was the first time we took a deep dive into developing a web app. This was also the first time for all of us to learn how to make chrome extensions and use a REST API.
## What's next for EcoShop
We plan to extend EcoShop to all online shopping sites, certifications, and categories of consumer products. Given more data and time, we hope to provide a cumulative sustainability grade tailored for the user, as they can toggle through the sustainable development goals that they care about most. We also plan on implementing a recommendation system to ensure that shoppers are aware of more sustainable alternatives. And for further convenience for consumers, an iOS application could provide a simplified version of EcoShop to give more information about ecolabels directly in stores.
|
## Inspiration
We’re huge believers that every individual can make a stand against climate change. We realised that there are many apps that give nutritional information regarding the food you consume, but there exists no tool that shows you the environmental impact.
We wanted to make a difference.
## What it does
EcoScan allows you to scan barcodes found on food packaging and will bring up alternative products, disposal methods, and a letter grade to represent the product’s carbon footprint. In addition, we’ve added authentication and history (to see previously scanned products). We also “reward” users with NFT coupons/savings every time they scan three products with a great “EcoScore” rating.
## How we built it
We made use of frontend, backend, blockchain (NFT), and external APIs to build EcoScan.
* ReactJS for the frontend
* QuaggaJS to scan barcodes
* Hedera to mint NFTs as coupons
* OpenFoodFacts API to get information regarding food products given a barcode
## Accomplishments that we're proud of
The proudest moment was deployment. Having worked hard overnight, the levels of serotonin when finally seeing our hard work on the World Wide Web was insane.
## What we learned
For some context, our team consisted of one frontend engineer, one jack-of-all trades, one backend engineer, and one person who had never programmed before.
Our learnings were far and wide - from learning CSS for the first time, to minting our first NFTs with Hedera. All in all, we learned how to work together, and we learned about each other - building deep bonds in the process.
## What's next for Eco-Scan
Get feedback from real users/people. We want to talk to people and get a real understanding of the problem we're solving - there are also always improvements to make for UI/UX, better data, etc.
|
**The Challenge:**
To connect consumers with sustainable information about their products, changing their behavior towards responsible purchases.
**The Vision:**
Barcodes (UPCs) take up space on almost every product that we consume, but that space can be redesigned from the ground up, connecting consumers to further sustainability data that can drive their purchases while keeping in mind their environmental impact.
**The Solution:**
The Sustainability Product Code (SPC), a human-readable code, understandable to anyone who picks up an item in a store, that conveys information immediately about the item's environmental impact. Like its predecessor, it is also machine-readable, but stores information in addition to unique product identifiers, allowing for a multitude of potential applications, such as expedited trash processing and sustainability-based analytics.
**The Tech:**
Created a SPC using python openCV. The SPC links to our website that was built with express.js, node.js and published on Heroku. Used d3.js for the data visualization. Next steps include incorporating design in our data visualization and storing scans/impression on a server.
**The Future:**
Completely replacing the UPC with the SPC, placing information in the hands of consumers to fundamentally change our behaviors and *save the planet*!
|
partial
|
## Inspiration
With the recent elections, we found it hard to keep up with news outside of the states, and hear of people's perspectives on a global scale. We wanted to make it easier to see and read of news all across the world, to bring a bird-eye's-view on our local problems and our local popular opinions. Geovibes was built to inform.
## What it does
Geovibes is a news feed infograph, displaying news articles from all across the world on an interactive map in real time. We've included pictures of our previous version, from which we pivoted about 7 hours ago. We were attempting to build a 3D interactive globe displaying the same news as the current iteration of Geovibes does.
## How we built it
*Frontend*
* amchart (<https://www.amcharts.com/>)
* lots of handcrafted javascript
* lots of handcrafted css
* mapping coordinates to png
* REST requests to flask api
*Backend*
* flask api server
* threads and file lock
*Data pipeline*
* lots of quota exceeding api subcriptions
* lots of batch processing
* mapping coordinates to locations
* piping one api's results to the next (Bing News Search, Microsoft Text Analytics)
## Challenges we ran from
*Things we pivoted from*
* angular 2
* three.js
* web gl
* twgl (thin wrapper for web gl)
* kartograph.js
* d3.js
* coordinate mapping, especially from window cursor location to 3D globe coordinates within an HTML canvas
* an overambitious idea for an unprepared team
## Accomplishments that I'm proud of
Everything
## What I learned
* batch processing
* concurrency and thread communication
* web gl stuff, and three.js, and the struggles
* coordinate mapping, especially from window cursor location to 3D globe coordinates within an HTML canvas
* angular 2
## What's next for geovibes
get the fkin three.js version working
|
## Inspiration
Every single Berkeley student knows that finding housing near campus is one of the most stressful experiences of their lives. (Yes, even more than school sometimes.) We just wanted to make an app that would make the process less difficult. Currently there isn't a good consolidated listing of living spaces. We either have to look through Cragslist or call landlords directly. It's also difficult because we have to consider SO many factors like: price, number of people, and location
## What it does
Makes the house search less stressful!
It provides a platform for sellers to easily upload pictures and info about the places they're renting out.
For general home-seeking population, all the locations are displayed on a map with thumbnails that allow them to easily see info about the place.
## How we built it
We build the app using Swift and Firebase.
Also implemented the Google APIs and SDKs for maps and places.
## Challenges we ran into
Getting Firebase to work properly
Learning Swift
## Accomplishments that we're proud of
Even though we didn't get to everything we wanted. Neither of us were familiar with Swift or Firebase coming in, so it's honestly just quite amazing to see what we could build.
## What we learned
SOO much.
How to use swift. (Creating storyboards and views, creating segues, the language)
and the GoogleMaps SDK (displaying maps, getting locations, placing pins)
and Firebase (setup, adding to the database and storage)
## What's next for HouseMe
Our main goal is to give the user abilities to filter what listings they see. Most students looking have very specific details like price ranges, number of roommates, and location in mind. It would be SUPER super helpful if there was something that could do that for us.
|
## Inspiration
BThere emerged from a genuine desire to strengthen friendships by addressing the subtle challenges in understanding friends on a deeper level. The team recognized that nuanced conversations often go unnoticed, hindering meaningful support and genuine interactions. In the context of the COVID-19 pandemic, the shift to virtual communication intensified these challenges, making it harder to connect on a profound level. Lockdowns and social distancing amplified feelings of isolation, and the absence of in-person cues made understanding friends even more complex. BThere aims to use advanced technologies to overcome these obstacles, fostering stronger and more authentic connections in a world where the value of meaningful interactions has become increasingly apparent.
## What it does
BThere is a friend-assisting application that utilizes cutting-edge technologies to analyze conversations and provide insightful suggestions for users to connect with their friends on a deeper level. By recording conversations through video, the application employs Google Cloud's facial recognition and speech-to-text APIs to understand the friend's mood, likes, and dislikes. The OpenAI API generates personalized suggestions based on this analysis, offering recommendations to uplift a friend in moments of sadness or providing conversation topics and activities for neutral or happy states. The backend, powered by Python Flask, handles data storage using Firebase for authentication and data persistence. The frontend is developed using React, JavaScript, Next.js, HTML, and CSS, creating a user-friendly interface for seamless interaction.
## How we built it
BThere involves a multi-faceted approach, incorporating various technologies and platforms to achieve its goals. The recording feature utilizes WebRTC for live video streaming to the backend through sockets, but also allows users to upload videos for analysis. Google Cloud's facial recognition API identifies facial expressions, while the speech-to-text API extracts spoken content. The combination of these outputs serves as input for the OpenAI API, generating personalized suggestions. The backend, implemented in Python Flask, manages data storage in Firebase, ensuring secure authentication and persistent data access. The frontend, developed using React, JavaScript, Next.js, HTML, and CSS, delivers an intuitive user interface.
## Accomplishments that we're proud of
* Successfully integrating multiple technologies into a cohesive and functional application
* Developing a user-friendly frontend for a seamless experience
* Implementing real-time video streaming using WebRTC and sockets
* Leveraging Google Cloud and OpenAI APIs for advanced facial recognition, speech-to-text, and suggestion generation
## What's next for BThere
* Continuously optimizing the speech to text and emotion analysis model for improved accuracy with different accents, speech mannerisms, and languages
* Exploring advanced natural language processing (NLP) techniques to enhance conversational analysis
* Enhancing user experience through further personalization and more privacy features
* Conducting user feedback sessions to refine and expand the application's capabilities
|
losing
|
## Inspiration
The inspiration for our Auto-Teach project stemmed from the growing need to empower both educators and learners with a **self-directed and adaptive** learning environment. We were inspired by the potential to merge technology with education to create a platform that fosters **personalized learning experiences**, allowing students to actively **engage with the material while offering educators tools to efficiently evaluate and guide individual progress**.
## What it does
Auto-Teach is an innovative platform that facilitates **self-directed learning**. It allows instructors to **create problem sets and grading criteria** while enabling students to articulate their problem-solving methods and responses through text input or file uploads (future feature). The software leverages AI models to assesses student responses, offering **constructive feedback**, **pinpointing inaccuracies**, and **identifying areas for improvement**. It features automated grading capabilities that can evaluate a wide range of responses, from simple numerical answers to comprehensive essays, with precision.
## How we built it
Our deliverable for Auto-Teach is a full-stack web app. Our front-end uses **ReactJS** as our framework and manages data using **convex**. Moreover, it leverages editor components from **TinyMCE** to provide student with better experience to edit their inputs. We also created back-end APIs using "FastAPI" and "Together.ai APIs" in our way building the AI evaluation feature.
## Challenges we ran into
We were having troubles with incorporating Vectara's REST API and MindsDB into our project because we were not very familiar with the structure and implementation. We were able to figure out how to use it eventually but struggled with the time constraint. We also faced the challenge of generating the most effective prompt for chatbox so that it generates the best response for student submissions.
## Accomplishments that we're proud of
Despite the challenges, we're proud to have successfully developed a functional prototype of Auto-Teach. Achieving an effective system for automated assessment, providing personalized feedback, and ensuring a user-friendly interface were significant accomplishments. Another thing we are proud of is that we effectively incorporates many technologies like convex, tinyMCE etc into our project at the end.
## What we learned
We learned about how to work with backend APIs and also how to generate effective prompts for chatbox. We also got introduced to AI-incorporated databases such as MindsDB and was fascinated about what it can accomplish (such as generating predictions based on data present on a streaming basis and getting regular updates on information passed into the database).
## What's next for Auto-Teach
* Divide the program into **two mode**: **instructor** mode and **student** mode
* **Convert Handwritten** Answers into Text (OCR API)
* **Incorporate OpenAI** tools along with Together.ai when generating feedback
* **Build a database** storing all relevant information about each student (ex. grade, weakness, strength) and enabling automated AI workflow powered by MindsDB
* **Complete analysis** of student's performance on different type of questions, allows teachers to learn about student's weakness.
* **Fine-tuned grading model** using tools from Together.ai to calibrate the model to better provide feedback.
* **Notify** students instantly about their performance (could set up notifications using MindsDB and get notified every day about any poor performance)
* **Upgrade security** to protect against any illegal accesses
|
## Inspiration
**Students** will use AI for their school work anyway, so why not bridge the gap between students and teachers and make it beneficial for both parties?
**1** All of us experienced going through middle school, high school, and now college surrounded by AI-powered tools that were strongly antagonizedantagonized in the classroom by teachers by teachers. As the prevalence of AI and technology increases in today’s world, we believe that classrooms should embrace AI to enhance the classroom which acts very parallel to when calculators were introduced to the classroom. Mathematicians around the world believed that calculators would stop math education all-together, but instead it enhanced student education allowing higher level math such as calculus to be taught earlier. Similarly, we believe that with the proper tools and approach AI can enhance education and teaching for both teachers and students. .
**2** In strained public school systems where the student-to-teacher ratio is low, such educational models can make a significant difference in a young student’s educational journey by providing individualized support when a teacher can’t with information specific to their classroom. One of our members who attends a Title 1 high school particularly inspired this project.
**3** Teachers are constantly seeking feedback on how their students are performing and where they can improve their instruction. What better way to receive this direct feedback than machine learning analysis of the questions students are asking specifically about their class, assignments, and content?
We wanted to create a way for AI model education support to be easily and more effectively integrated into classrooms especially for early education, providing a controlled alternative to using already existing chat models as the teacher can ensure accurate information about their class is integrated into the model.
## What it does
Students will use AI for their school work anyway, so why not bridge the gap between students and teachers? EduGap, a Chrome Extension for Google Classroom, enhances the AI models students can use by automating the integration of class-specific materials into the model. Teachers benefit from gaining machine learning analytics on what areas students struggle with the most through the questions they ask the model.
## How we built it
Front End:
Used HTML/CSS to create deploy a 2-page chrome extension
1 page features an AI chatbot that the user can interact with
The second page is exclusively for teacher users who can review trends from their most asked prompts
Back End:
Built on Javascript and python scripts
Created custom api endpoints for retrieving information from the Google Classroom API, Google User Authentication, prompting Gemini via Gemini API, Conducting Prompt Analysis
Storage and vector embeddings were created using Chroma DB for the Student Experience
AI/ML
LLM: Google Gemini 1.5-flash
ChromaDB for vector embeddings and semantic search as it relates to google classroom documents/information
Langchain for vector embeddings as it relates to prompts;
DBSCAN algorithm to develop clusters for the embeddings via Sklearn
using PCA to downsize dimensionality via sklearn
General themes of largest cluster are shared with teacher summarized by Gemini
## Challenges we ran into
We spent a significant portion of our time trying to integrate sponsor technologies with our application as resources on the web are sparse and some of the functionalities are buggy. It was a frustrating process but we eventually overcame it by improvising.
We also spent some time to choose the best clustering method for our project, and hyperparameter tuning in the constrained time period was also highly challenging as we had to create multiple scripts to cater for different types of models to choose the best ones for our use case
## Accomplishments that we're proud of
Creating a fully functioning Chrome Extension linked to Google Classroom while integrating multiple APIs, machine learning, and database usage. Working with a team we formed right at the Hackathon!
## What we learned
We learned how to work together to create a user-friendly application while integrating a complex backend. For most of us, this was our first hackathon so we learned how to learn fast and productively for the techniques, technology, and even languages we were implementing.
## What's next for EduGap
**1** Functionality for identifying and switching between different classes.
**2** Handling separate user profiles from a database perspective
**3** A more comprehensive analytic dashboard and classroom content suggestion for teachers + more personalized education support tutoring according to the class content for students.
**4** Pilot programs at schools to implement!
**5** Chrome Extension Deployment
**6** Finalize Google Classroom Integration and increase file compatibility
|
## Inspiration
We were inspired by the **protégé effect**, a psychological phenomenon where teaching others helps reinforce the student's own understanding. This concept motivated us to create a platform where users can actively learn by teaching an AI model, helping them deepen their comprehension through explanation and reflection. We wanted to develop a tool that not only allows users to absorb information but also empowers them to explain and teach back, simulating a learning loop that enhances retention and understanding.
## What it does
Protégé enables users to:
* **Create lessons** on any subject, either from their own study notes or with AI-generated information.
* **Teach** the AI by explaining concepts aloud, using real-time speech-to-text conversion.
* The AI then **evaluates** the user’s explanation, identifies errors or areas for improvement, and provides constructive feedback. This helps users better understand the material while reinforcing their knowledge through active participation.
* The system adapts to user performance, offering **customized feedback** and lesson suggestions based on their strengths and weaknesses.
## How we built it
Protégé was built using the **Reflex framework** to manage the front-end and user interface, ensuring a smooth, interactive experience. For the back-end, we integrated **Google Gemini** to generate lessons and evaluate user responses. To handle real-time speech-to-text conversion, we utilized **Deepgram**, a highly accurate speech recognition API, allowing users to speak directly to the AI for their explanations. By connecting these technologies through state management, we ensured seamless communication between the user interface and the AI models.
## Challenges we ran into
One of the main challenges was ensuring **seamless integration between the AI model and the front-end** so that lessons and feedback could be delivered in real time. Any lag would have disrupted the user experience, so we optimized the system to handle data flow efficiently. Another challenge was **real-time speech-to-text accuracy**. We needed a solution that could handle diverse speech patterns and accents, which led us to Deepgram for its ability to provide fast and accurate transcriptions even in complex environments.
## Accomplishments that we're proud of
We’re particularly proud of successfully creating a platform that allows for **real-time interaction** between users and the AI, providing a smooth and intuitive learning experience. The integration of **Deepgram for speech recognition** significantly enhanced the teaching feature, enabling users to explain concepts verbally and receive immediate feedback. Additionally, our ability to **simulate the protégé effect**—where users reinforce their understanding by teaching—marks a key accomplishment in the design of this tool.
## What we learned
Throughout this project, we learned the importance of **real-time system optimization**, particularly when integrating AI models with front-end interfaces. We also gained valuable experience in **balancing accuracy with performance**, ensuring that both lesson generation and speech recognition worked seamlessly without compromising user experience. Additionally, building a system that adapts to users’ teaching performance taught us how crucial **customization and feedback** are in creating effective educational tools.
## What's next for Protégé
Our next steps include:
* Developing **personalized lesson plans** that adapt based on user performance in teaching mode, making learning paths more tailored and effective.
* Adding **gamified progress tracking**, where users can earn achievements and track their improvement over time, keeping them motivated.
* Introducing **community and peer learning** features, allowing users to collaborate and share their teaching experiences with others.
* Building a **mobile version** of Protégé to make the platform more accessible for learning on the go.
|
partial
|
## Inspiration
The inspiration for our project stemmed from a mild, first-world frustration with modern weather websites. Sure, one glance at the temperature can tell you a lot about the weather, but there are so many other factors that we commonly ignore which can also affect our day. What if it's unbearably humid? Or, what if there's an on-and-off chance of rain throughout the day and you don't know how to prepare? These questions and more led us to develop a web application that not only provides you with your typical hourly forecast, but also processes that data into more meaningful and digestible information about your day.
## What it does
Our application first retrieves an hourly forecast from OpenWeatherMap's One-Call API. It displays the forecast for the next 12 hours on the left side of the webpage, and it also processes the raw weather data into simpler chunks. Each chunk contains highlights about the weather for a three-hour interval, and dynamically provides advice on how to best prepare for the day.
## How we built it
We used ReactJS and the React-Bootstrap library for the frontend of our application. For the backend, we used Node.js, Axios for API requests, and OpenWeatherMap's APIs.
## Challenges we ran into
The most difficult portion of our project was processing the data from each API call. This was the first time that any of us have worked with APIs, so finding the right data, refining it, using it efficiently, and displaying it was a hurdle in our workload. In addition to this, we had to complete lots of research on how to prepare for different types of severe weather conditions which also occupied a large portion of our time.
## Accomplishments that we're proud of and what we learned
We are very proud that we started this project with little knowledge about APIs, and in the end, we were able to manipulate the API data however we liked. We are also proud of the sleek, single-page design of our application and its overall aesthetic.
## What's next for Smart Day
Given the time constraints, we were not able to fulfill some of our goals. The next steps for our project includes reverse geocoding the user's location to display their city/region, allowing the user to select their location from a database, and displaying a larger variety of tips for different weather conditions.
|
## Inspiration
* weather.com icons that show up when you google the weather
## What it does
* Calls an API to that returns the weather information for a particular day
## How I built it
* In JS/React
## Challenges I ran into
* There was a lot of React/JS syntax/infrastructure that I was not familiar with that I learned.
## Accomplishments that I'm proud of
* Learned how to use API's
## What I learned
* How to use an API
* Improved React Skills
## What's next for The Weather App
* I can improve the UI
* I can have the images accurately represent the weather
|
## Inspiration
An article that was published last month by the CBC talked about CRA phone scams.
The article said that “Thousands of Canadians had been scammed over the past several years, at an estimated cost of more than $10 million dollars, falling prey to the dozens of call centers using the same scheme.”
We realized that we had to protect consumers and those not as informed.
## The app
We created a mobile app that warns users about incoming SMS or Phone fraud from scam numbers.
The mobile app as well offers a playback function so users can learn what scam calls sound like.
Alongside the mobile app we built a website that provides information on scamming and allows users to query to see if a number is a scam number.
## How it works
The PBX server gets an incoming phone call or SMS from a scamming bot and records/saves the information. Afterwards the data is fed into a trained classifier so that it can be determined as scam or not scam. If the sender was a scammer, they're entered into the Postgresql database to later be queried over HTTP. The extensions from here are endless. API's, User applications, Blacklisting etc . . .
## Challenges we ran into
At first, we were going to build a react native application. However, Apple does not support the retrieval of incoming call phone numbers so we defaulted to a android application instead. FreePBX runs PHP 5 which is either deprecated or near deprecation. We as well originally tried to use Postgresql for FreePBX but had to use MySQL instead. PBX call recording was not achieved unfortunately.
## Accomplishments that we're proud of
* Setting up FreePBX
* Finished Website
* Finished App
* Broadcast Receiver
## What we learned
* FreePBX
* NGINX
* Android Media Player
## What's next for Tenty
* Full SMS support
* Distributed PBX network to increase data input
* API for Financial Institutions, and or those affiliated with what is being scammed. Allowing them to protect their customers.
* Assisting Governments in catching scammers.
|
losing
|
## Inspiration
In the exciting world of hackathons, where innovation meets determination, **participants like ourselves often ask "Has my idea been done before?"** While originality is the cornerstone of innovation, there's a broader horizon to explore - the evolution of an existing concept. Through our AI-driven platform, hackers can gain insights into the uniqueness of their ideas. By identifying gaps or exploring similar projects' functionalities, participants can aim to refine, iterate, or even revolutionize existing concepts, ensuring that their projects truly stand out.
For **judges, the evaluation process is daunting.** With a multitude of projects to review in a short time frame, ensuring an impartial and comprehensive assessment can become extremely challenging. The introduction of an AI tool doesn't aim to replace the human element but rather to enhance it. By swiftly and objectively analyzing projects based on certain quantifiable metrics, judges can allocate more time to delve into the intricacies, stories, and the passion driving each team
## What it does
This project is a smart tool designed for hackathons. The tool measures the similarity and originality of new ideas against similar projects if any exist, we use web scraping and OpenAI to gather data and draw conclusions.
**For hackers:**
* **Idea Validation:** Before diving deep into development, participants can ascertain the uniqueness of their concept, ensuring they're genuinely breaking new ground.
* **Inspiration:** By observing similar projects, hackers can draw inspiration, identifying ways to enhance or diversify their own innovations.
**For judges:**
* **Objective Assessment:** By inputting a project's Devpost URL, judges can swiftly gauge its novelty, benefiting from AI-generated metrics that benchmark it against historical data.
* **Informed Decisions:** With insights on a project's originality at their fingertips, judges can make more balanced and data-backed evaluations, appreciating true innovation.
## How we built it
**Frontend:** Developed using React JS, our interface is user-friendly, allowing for easy input of ideas or Devpost URLs.
**Web Scraper:** Upon input, our web scraper dives into the content, extracting essential information that aids in generating objective metrics.
**Keyword Extraction with ChatGPT:** OpenAI's ChatGPT is used to detect keywords from the Devpost project descriptions, which are used to capture project's essence.
**Project Similarity Search:** Using the extracted keywords, we query Devpost for similar projects. It provides us with a curated list based on project relevance.
**Comparison & Analysis:** Each incoming project is meticulously compared with the list of similar ones. This analysis is multi-faceted, examining the number of similar projects and the depth of their similarities.
**Result Compilation:** Post-analysis, we present users with an 'originality score' alongside explanations for the determined metrics, keeping transparency.
**Output Display:** All insights and metrics are neatly organized and presented on our frontend website for easy consumption.
## Challenges we ran into
**Metric Prioritization:** Given the timeline restricted nature of a hackathon, one of the first challenges was deciding which metrics to prioritize. Striking the balance between finding meaningful data points that were both thorough and feasible to attain were crucial.
**Algorithmic Efficiency:** We struggled with concerns over time complexity, especially with potential recursive scenarios. Optimizing our algorithms, prompt engineering, and simplifying architecture was the solution.
*Finding a good spot to sleep.*
## Accomplishments that we're proud of
We took immense pride in developing a solution directly tailored for an environment we're deeply immersed in. By crafting a tool for hackathons, while participating in one, we felt showcases our commitment to enhancing such events. Furthermore, not only did we conceptualize and execute the project, but we also established a robust framework and thoughtfully designed architecture from scratch.
Another general Accomplishment was our team's synergy. We made efforts to ensure alignment, and dedicated time to collectively invest in and champion the idea, ensuring everyone was on the same page and were equally excited and comfortable with the idea. This unified vision and collaboration were instrumental in bringing HackAnalyzer to life.
## What we learned
We delved into the intricacies of full-stack development, gathering hands-on experience with databases, backend and frontend development, as well as the integration of AI. Navigating through API calls and using web scraping were also some key takeaways. Prompt Engineering taught us to meticulously balance the trade-offs when leveraging AI, especially when juggling cost, time, and efficiency considerations.
## What's next for HackAnalyzer
We aim to amplify the metrics derived from the Devpost data while enhancing the search function's efficiency. Our secondary and long-term objective is to transition the application to a mobile platform. By enabling students to generate a QR code, judges can swiftly access HackAnalyzer data, ensuring a more streamlined and effective evaluation process.
|
# The Ultimate Water Heater
February 2018
## Authors
This is the TreeHacks 2018 project created by Amarinder Chahal and Matthew Chan.
## About
Drawing inspiration from a diverse set of real-world information, we designed a system with the goal of efficiently utilizing only electricity to heat and pre-heat water as a means to drastically save energy, eliminate the use of natural gases, enhance the standard of living, and preserve water as a vital natural resource.
Through the accruement of numerous API's and the help of countless wonderful people, we successfully created a functional prototype of a more optimal water heater, giving a low-cost, easy-to-install device that works in many different situations. We also empower the user to control their device and reap benefits from their otherwise annoying electricity bill. But most importantly, our water heater will prove essential to saving many regions of the world from unpredictable water and energy crises, pushing humanity to an inevitably greener future.
Some key features we have:
* 90% energy efficiency
* An average rate of roughly 10 kW/hr of energy consumption
* Analysis of real-time and predictive ISO data of California power grids for optimal energy expenditure
* Clean and easily understood UI for typical household users
* Incorporation of the Internet of Things for convenience of use and versatility of application
* Saving, on average, 5 gallons per shower, or over ****100 million gallons of water daily****, in CA alone. \*\*\*
* Cheap cost of installation and immediate returns on investment
## Inspiration
By observing the RhoAI data dump of 2015 Californian home appliance uses through the use of R scripts, it becomes clear that water-heating is not only inefficient but also performed in an outdated manner. Analyzing several prominent trends drew important conclusions: many water heaters become large consumers of gasses and yet are frequently neglected, most likely due to the trouble in attaining successful installations and repairs.
So we set our eyes on a safe, cheap, and easily accessed water heater with the goal of efficiency and environmental friendliness. In examining the inductive heating process replacing old stovetops with modern ones, we found the answer. It accounted for every flaw the data decried regarding water-heaters, and would eventually prove to be even better.
## How It Works
Our project essentially operates in several core parts running simulataneously:
* Arduino (101)
* Heating Mechanism
* Mobile Device Bluetooth User Interface
* Servers connecting to the IoT (and servicing via Alexa)
Repeat all processes simultaneously
The Arduino 101 is the controller of the system. It relays information to and from the heating system and the mobile device over Bluetooth. It responds to fluctuations in the system. It guides the power to the heating system. It receives inputs via the Internet of Things and Alexa to handle voice commands (through the "shower" application). It acts as the peripheral in the Bluetooth connection with the mobile device. Note that neither the Bluetooth connection nor the online servers and webhooks are necessary for the heating system to operate at full capacity.
The heating mechanism consists of a device capable of heating an internal metal through electromagnetic waves. It is controlled by the current (which, in turn, is manipulated by the Arduino) directed through the breadboard and a series of resistors and capacitors. Designing the heating device involed heavy use of applied mathematics and a deeper understanding of the physics behind inductor interference and eddy currents. The calculations were quite messy but mandatorily accurate for performance reasons--Wolfram Mathematica provided inhumane assistance here. ;)
The mobile device grants the average consumer a means of making the most out of our water heater and allows the user to make informed decisions at an abstract level, taking away from the complexity of energy analysis and power grid supply and demand. It acts as the central connection for Bluetooth to the Arduino 101. The device harbors a vast range of information condensed in an effective and aesthetically pleasing UI. It also analyzes the current and future projections of energy consumption via the data provided by California ISO to most optimally time the heating process at the swipe of a finger.
The Internet of Things provides even more versatility to the convenience of the application in Smart Homes and with other smart devices. The implementation of Alexa encourages the water heater as a front-leader in an evolutionary revolution for the modern age.
## Built With:
(In no particular order of importance...)
* RhoAI
* R
* Balsamiq
* C++ (Arduino 101)
* Node.js
* Tears
* HTML
* Alexa API
* Swift, Xcode
* BLE
* Buckets and Water
* Java
* RXTX (Serial Communication Library)
* Mathematica
* MatLab (assistance)
* Red Bull, Soylent
* Tetrix (for support)
* Home Depot
* Electronics Express
* Breadboard, resistors, capacitors, jumper cables
* Arduino Digital Temperature Sensor (DS18B20)
* Electric Tape, Duct Tape
* Funnel, for testing
* Excel
* Javascript
* jQuery
* Intense Sleep Deprivation
* The wonderful support of the people around us, and TreeHacks as a whole. Thank you all!
\*\*\* According to the Washington Post: <https://www.washingtonpost.com/news/energy-environment/wp/2015/03/04/your-shower-is-wasting-huge-amounts-of-energy-and-water-heres-what-to-do-about-it/?utm_term=.03b3f2a8b8a2>
Special thanks to our awesome friends Michelle and Darren for providing moral support in person!
|
## Inspiration
At work, conference calls usually involves multiple people on one side using the same microphone. It may be hard to know who's speaking and what their role is. Furthermore, some details of the meeting can be lost and it's tedious to note everything down.
## What it does
Our app distinguishes/recognizes speakers, shows who's speaking and automatically transcribe the meeting in real time. When the meeting ends, our app can also export the meeting minutes (log of who said what at what time).
**Features**:
* display who's currently speaking using speaker recognition
* transcribe what's being said by who like a chat application
* create and train a new speaker profile within 15 seconds
* stream transcription to services such as `Slack`
* export transcription to cloud storage such as `Google Sheets`
## How I built it
* Microsoft Speech Recognition API
* Microsoft Speech to Text API
* Google Cloud Speech to Text API
* Google Sheets API
* Slack API
* stdlib for integrating services for the backend such as Slack and SMS
* NodeJS with Express for the backend
* Vue for the frontend
* Python scripts for accessing Microsoft's APIs
* Love ❤️
## Challenges I ran into
Generating the audio file in the right format for Microsoft's API was tougher than expected; seems like Mac's proprietary microphone isn't able to format the audio in the way Microsoft wants it.
## Accomplishments that I'm proud of
* Learning how to use the APIs, Microsoft Azure, and sampling an audio input to a format the API needs.
* Finishing an app before the deadline.
## What I learned
Usage of many APIs, speech recording, and integration of multiple services.
## What's next for Who Said What?
A year long worldwide tour to show.
|
winning
|
## Inspiration
We wanted to use a RaspberryPi in an innovative way. We also wanted promote a healthy lifestyle.
## What it does
Detects what you place in a fridge and predicts when the food while go bad.
## How I built it
RaspberryPi camera and python flask webserver application.
## Challenges I ran into
Getting OCR to work properly with the photos taken with the pi camera
## Accomplishments that I'm proud of
EVERYTHING
## What I learned
3D printing, RaspberryPi, Flask, Python, Javascript, Postmates API, HTML5/CSS3
## What's next for PiM: The Virtual Fridge Manager
Reading barcodes and expiry dates to get more accurate predictions
|
## Inspiration
One of our close friends is at risk of Alzheimer's. He learns different languages and engages his brain by learning various skills which will significantly decrease his chances of suffering from Alzheimer's later. Our game is convenient for people like him to keep the risks of being diagnosed with dementia at bay.
## What it does
In this game, a random LED pattern is displayed which the user is supposed to memorize. The user is supposed to use hand gestures to repeat the memorized pattern. If the user fails to memorize the correct pattern, the buzzer beeps.
## How we built it
We had two major components to our project; hardware and software. The hardware component of our project used an Arduino UNO, LED lights, a base shield, a Grove switch and a Grove gesture sensor. Our software side of the project used the Arduino IDE and GitHub. We have linked them in our project overview for your convenience.
## Challenges we ran into
Some of the major challenges we faced were storing data and making sure that the buzzer doesn't beep at the wrong time.
## Accomplishments that we're proud of
We were exploring new terrain in this hackathon with regard to developing a hardware project in combination with the Arduino IDE. We found that it was quite different in relation to the software/application programming we were used to, so we're very happy with the overall learning experience.
## What we learned
We learned how to apply our skillset in software and application development in a hardware setting. Primarily, this was our first experience working with Arduino, and we were able to use this opportunity at UofT to catch up to the learning curve.
## What's next for Evocalit
Future steps for our project look like revisiting the iteration cycles to clean up any repetitive inputs and incorporating more sensitive machine learning algorithms alongside the Grove sensors so as to maximize the accuracy and precision of the user inputs through computer vision.
|
A long time ago (last month) in a galaxy far far away (literally my room) I was up studying late for exams and decided to order some hot wings. With my food being the only source of joy that night you can imaging how devastated I was to find out that they were stolen from the front lobby of my building! That's when the idea struck to create a secure means of ordering food without the stress of someone else stealing it.
## What it does
Locker as a service is a full hardware and software solution that intermediates a the food exchange between seller and buyer. Buyers can order food from our mobile app, the seller receives this notification on their end of the app, fills the box with its contents, and locks the box. The buyer is notified that the order is ready and using face biometrics receives permission to open the box and safely. The order can specify whether the food needs to be refrigerated or heated and the box's temperature is adjusted accordingly. Sounds also play at key moments in the exchange such as putting in a cold or hot item as well as opening the box.
## How we built it
The box is made out of cardboard and uses a stepper motor to open and close the main door, LED's are in the top of the box to indicate it's content status and temperature. A raspberry pi controls these devices and is also connected to a Bluetooth speaker which is also inside of the box playing the sounds. The frontend was developed using Flutter and IOS simulator. Commands from the front end are sent to Firebase which is a realtime cloud database which can be connected to the raspberry pi to send all of the physical commands. Since the raspberry pi has internet and Bluetooth access, it can run wirelessly (with the exception of power to the pi)
## Challenges we ran into
A large challenge we ran into was having the raspberry-pi run it's code wirelessly. Initially we needed to connect to VNC Viewer to via ethernet to get a GUI. Only after we developed all the python code to control the hardware seamlessly could we disconnect the VNC viewer and let the script run autonomously. Another challenge we ran into was getting the IoS simulated app to run on a real iphone, this required several several YouTube tutorials and debugging could we get it to work.
## Accomplishments that we're proud of
We are proud that we were able to connect both the front end (flutter) and backend (raspberry pi) to the firebase database, it was very satisfying to do so.
## What we learned
Some team members learned about mobile development for the first time while others learned about control systems (we had to track filled state, open state, and led colour for 6 stages of the cycle)
## What's next for LaaS
|
losing
|
## About Us
Discord Team Channel: #team-64
omridan#1377,
dylan28#7389,
jordanbelinsky#5302,
Turja Chowdhury#6672
Domain.com domain: positivenews.space
## Inspiration
Over the last year headlines across the globe have been overflowing with negative content which clouded over any positive information. In addition everyone has been so focused on what has been going on in other corners of the world and have not been focusing on their local community. We wanted to bring some pride and positivity back into everyone's individual community by spreading positive headlines at the users users location. Our hope is that our contribution shines a light in these darkest of times and spreads a message of positivity to everyone who needs it!
## What it does
Our platform utilizes the general geolocation of the user along with a filtered API to produce positive articles about the users' local community. The page displays all the articles by showing the headlines and a brief summary and the user has the option to go directly to the source of the article or view the article on our platform.
## How we built it
The core of our project uses the Aylien news API to gather news articles from a specified country and city while reading only positive sentiments from those articles. We then used the IPStack API to gather the users location via their IP Address. To reduce latency and to maximize efficiency we used JavaScript in tandem with React opposed to a backend solution to code a filtration of the data received from the API's to display the information and imbed the links. Finally using a combination of React, HTML, CSS and Bootstrap a clean, modern and positive design for the front end was created to display the information gathered by the API's.
## Challenges we ran into
The most significant challenge we ran into while developing the website was determining the best way to filter through news articles and classify them as "positive". Due to time constraints the route we went with was to create a library of common keywords associated with negative news, filtering articles with the respective keywords out of the dictionary pulled from the API.
## Accomplishments that we're proud of
We managed to support a standard Bootstrap layout comprised of a grid consisting of rows and columns to enable both responsive design for compatibility purposes, and display more content on every device. Also utilized React functionality to enable randomized background gradients from a selection of pre-defined options to add variety to the site's appearance.
## What we learned
We learned a lot of valuable skills surrounding the aspect of remote group work. While designing this project, we were working across multiple frameworks and environments, which meant we couldn't rely on utilizing just one location for shared work. We made combined use of Repl.it for core HTML, CSS and Bootstrap and GitHub in conjunction with Visual Studio Code for the JavaScript and React workloads. While using these environments, we made use of Discord, IM Group Chats, and Zoom to allow for constant communication and breaking out into sub groups based on how work was being split up.
## What's next for The Good News
In the future, the next major feature to be incorporated is one which we titled "Travel the World". This feature will utilize Google's Places API to incorporate an embedded Google Maps window in a pop-up modal, which will allow the user to search or navigate and drop a pin anywhere around the world. The location information from the Places API will replace those provided by the IPStack API to provide positive news from the desired location. This feature aims to allow users to experience positive news from all around the world, rather than just their local community. We also want to continue iterating over our design to maximize the user experience.
|
## Inspiration
We are all software/game devs excited by new and unexplored game experiences. We originally came to PennApps thinking of building an Amazon shopping experience in VR, but eventaully pivoted to Project Em - a concept we all found mroe engaging. Our swtich was motivated by the same force that is driving us to create and improve Project Em - the desire to venture into unexplored territory, and combine technologies not often used together.
## What it does
Project Em is a puzzle exploration game driven by Amazon's Alexa API - players control their character with the canonical keyboard and mouse controls, but cannot accomplish anything relevant in the game without talking to a mysterious, unknown benefactor who calls out at the beginning of the game.
## How we built it
We used a combination of C++, Pyhon, and lots of shell scripting to create our project. The client-side game code runs on Unreal Engine 4, and is a combination of C++ classes and Blueprint (Epic's visual programming language) scripts. Those scripts and classes communicate an intermediary server running Python/Flask, which in turn communicates with the Alexa API. There were many challenges in communicating RESTfully out of a game engine (see below for more here), so the two-legged approach lent itself well to focusing on game logic as much as possible. Sacha and Akshay worked mostly on the Python, TCP socket, and REST communication platform, while Max and Trung worked mainly on the game, assets, and scripts.
The biggest challenge we faced was networking. Unreal Engine doesn't naively support running a webserver inside a game, so we had to think outside of the box when it came to networked communication.
The first major hurdle was to find a way to communicate from Alexa to Unreal - we needed to be able to communicate back the natural language parsing abilities of the Amazon API to the game. So, we created a complex system of runnable threads and sockets inside of UE4 to pipe in data (see challenges section for more info on the difficulties here). Next, we created a corresponding client socket creation mechanism on the intermediary Python server to connect into the game engine. Finally, we created a basic registration system where game clients can register their publicly exposed IPs and Ports to Python.
The second step was to communicate between Alexa and Python. We utilitzed [Flask-Ask](https://flask-ask.readthedocs.io/en/latest/) to abstract away most of the communication difficulties,. Next, we used [VaRest](https://github.com/ufna/VaRest), a plugin for handing JSON inside of unreal, to communicate from the game directly to Alexa.
The third and final step was to create a compelling and visually telling narrative for the player to follow. Though we can't describe too much of that in text, we'd love you to give the game a try :)
## Challenges we ran into
The challenges we ran into divided roughly into three sections:
* **Threading**: This was an obvious problem from the start. Game engines rely on a single main "UI" thread to be unblocked and free to process for the entirety of the game's life-cycle. Running a socket that blocks for input is a concept in direct conflict with that idiom. So, we dove into the FSocket documentation in UE4 (which, according to Trung, hasn't been touched since Unreal Tournament 2...) - needless to say it was difficult. The end solution was a combination of both FSocket and FRunnable that could block and certain steps in the socket process without interrupting the game's main thread. Lots of stuff like this happened:
```
while (StopTaskCounter.GetValue() == 0)
{
socket->HasPendingConnection(foo);
while (!foo && StopTaskCounter.GetValue() == 0)
{
Sleep(1);
socket->HasPendingConnection(foo);
}
// at this point there is a client waiting
clientSocket = socket->Accept(TEXT("Connected to client.:"));
if (clientSocket == NULL) continue;
while (StopTaskCounter.GetValue() == 0)
{
Sleep(1);
if (!clientSocket->HasPendingData(pendingDataSize)) continue;
buf.Init(0, pendingDataSize);
clientSocket->Recv(buf.GetData(), buf.Num(), bytesRead);
if (bytesRead < 1) {
UE_LOG(LogTemp, Error, TEXT("Socket did not receive enough data: %d"), bytesRead);
return 1;
}
int32 command = (buf[0] - '0');
// call custom event with number here
alexaEvent->Broadcast(command);
clientSocket->Close();
break; // go back to wait state
}
}
```
Notice a few things here: we are constantly checking for a stop call from the main thread so we can terminate safely, we are sleeping to not block on Accept and Recv, and we are calling a custom event broadcast so that the actual game logic can run on the main thread when it needs to.
The second point of contention in threading was the Python server. Flask doesn't natively support any kind of global-to-request variables. So, the canonical approach of opening a socket once and sending info through it over time would not work, regardless of how hard we tried. The solution, as you can see from the above C++ snippet, was to repeatedly open and close a socket to the game on each Alexa call. This ended up causing a TON of problems in debugging (see below for difficulties there) and lost us a bit of time.
* **Network Protocols**: Of all things to deal with in terms of networks, we spent he largest amount of time solving the problems for which we had the least control. Two bad things happened: heroku rate limited us pretty early on with the most heavily used URLs (i.e. the Alexa responders). This prompted two possible solutions: migrate to DigitalOcean, or constantly remake Heroku dynos. We did both :). DigitalOcean proved to be more difficult than normal because the Alexa API only works with HTTPS addresses, and we didn't want to go through the hassle of using LetsEncrypt with Flask/Gunicorn/Nginx. Yikes. Switching heroku dynos it was.
The other problem we had was with timeouts. Depending on how we scheduled socket commands relative to REST requests, we would occasionally time out on Alexa's end. This was easier to solve than the rate limiting.
* **Level Design**: Our levels were carefully crafted to cater to the dual player relationship. Each room and lighting balance was tailored so that the player wouldn't feel totally lost, but at the same time, would need to rely heavily on Em for guidance and path planning.
## Accomplishments that we're proud of
The single largest thing we've come together in solving has been the integration of standard web protocols into a game engine. Apart from matchmaking and data transmission between players (which are both handled internally by the engine), most HTTP based communication is undocumented or simply not implemented in engines. We are very proud of the solution we've come up with to accomplish true bidirectional communication, and can't wait to see it implemented in other projects. We see a lot of potential in other AAA games to use voice control as not only an additional input method for players, but a way to catalyze gameplay with a personal connection.
On a more technical note, we are all so happy that...
THE DAMN SOCKETS ACTUALLY WORK YO
## Future Plans
We'd hope to incorporate the toolchain we've created for Project Em as a public GItHub repo and Unreal plugin for other game devs to use. We can't wait to see what other creative minds will come up with!
### Thanks
Much <3 from all of us, Sacha (CIS '17), Akshay (CGGT '17), Trung (CGGT '17), and Max (ROBO '16). Find us on github and say hello anytime.
|
## Inspiration
In North America alone, there are over 58 million people of all ages experiencing limited hand mobility. Our team strives to better facilitate the daily life for people who have the daunting task of overcoming their disabilities. We identified a disconcerting trend that rehabilitation options for people with limited motor function were too expensive. We challenged ourselves with developing an inexpensive therapeutic device to train fine motor skills, while also preserving normative routines within daily life.
## What it does
Xeri is a custom input device. Xeri allows for the translation of simple gestures into commands for a computer. Xeri requires a user to touch a specific digit to their thumbs in order to perform actions like right click, left click, scroll up, and scroll down. This touching action stimulates the muscle-mind connection enhancing it's ability to adapt to changes. With prolonged and consistent use of Xeri, patients will be able to see an improvement in their motor control. Xeri transforms the simple routine action of browsing the internet into a therapeutic medium that feels normal to the patient.
## How we built it
Xeri is composed of ESP32 Core v2, MPU6050 Gyroscope, four analog sensors, and four custom analog contacts. The ESP32 allows for bluetooth connection, the MPU allows for tracking of the hand, and the sensors and contacts allow for touch control. Xeri was developed in three prototype stages: P0, P1, and P2. In P0, we developed our custom analog sensors for our hands, created a rudimentary cardboard brace, and determined how to evaluate input. In P1, we replaced our cardboard brace with a simple gloved and modified to fit the needs of the hardware. In P2, we incorporated all elements of our hardware onto our glove and fully calibrated our gyroscope. Ultimately, we created a device that allows for therapeutic motion to be processed into computer input.
## Challenges we ran into
Xeri's development was not a trouble-free experience. We first encountered issues developing our custom analog contacts. We had trouble figuring out the necessary capacitance for the circuit, but through trial and error, we eventually succeeded. The biggest setback we had to mitigate was implementing our gyroscope into our code. The gyroscope we were using was not only cheap, but the chip was also defective. Our only solution was to work around this damage by reverse-engineering the supporting libraries once again
## Accomplishments that we're proud of
Our greatest achievement by far was being able to create a fully operable glove that could handle custom inputs. Although, Xeri is focused on hand mobility, the device could be implemented for a variety of focuses. Xeri's custom created analog contacts were another major achievement of ours due to their ability to measure analog signal using a Redbull can. One of our developers was very inspired by what we had built and spent some time researching and desiging an Apple Watch App that enables the watch to function as a similar device. This implementation can be found in our github for others to reference.
## What we learned
During the development process of Xeri, it was imperative that we had to be innovative with the little hardware we were able to obtain. We learned how to read and reverse-engineer hardware libraries. We also discovered how to create our own analog sensors and contacts. Overall, this project was incredibly rewarding as we truly developed a firm grasp on hardware devices.
## What's next for Xeri?
Xeri has a lot of room for improvement. Our first future development will be to make the device fully wireless, as we did not have a remote power source to utilize. Later updates would include, a replacement of the gyrosensor, a slimmed down fully uniform version, being able to change the resistance of each finger to promote muscle growth, and create more custom inputs for more accessibility.
|
winning
|
## Inspiration
One of our team members' grandfathers went blind after slipping and hitting his spinal cord, going from a completely independent individual to reliant on others for everything. The lack of options was upsetting, how could a man who was so independent be so severely limited by a small accident. There is current technology out there for blind individuals to navigate their home, however, there is no such technology that allows blind AND frail individuals to do so. With an increasing aging population, Elderlyf is here to be that technology. We hope to help our team member's grandfather and others like him regain his independence by making a tool that is affordable, efficient, and liberating.
## What it does
Ask your Alexa to take you to a room in the house, and Elderlyf will automatically detect which room you're currently in, mapping out a path from your current room to your target room. With vibration disks strategically located underneath the hand rests, Elderlyf gives you haptic feedback to let you know when objects are in your way and in which direction you should turn. With an intelligent turning system, Elderlyf gently helps with turning corners and avoiding obstacles.
## How I built it
With a Jetson Nano and RealSense Cameras, front view obstacles are detected and a map of the possible routes are generated. SLAM localization was also achieved using those technologies. An Alexa and AWS Speech to Text API was used to activate the mapping and navigation algorithms. By using two servo motors that could independently apply a gentle brake to the wheels to aid users when turning and avoiding obstacles. Piezoelectric vibrating disks were also used to provide haptic feedback in which direction to turn and when obstacles are close.
## Challenges I ran into
Mounting the turning assistance system was a HUGE challenge as the setup needed to be extremely stable. We ended up laser-cutting mounting pieces to fix this problem.
## Accomplishments that we're proud of
We're proud of creating a project that is both software and hardware intensive and yet somehow managing to get it finished up and working.
## What I learned
Learned that the RealSense camera really doesn't like working on the Jetson Nano.
## What's next for Elderlyf
Hoping to incorporate a microphone to the walker so that you can ask Alexa to take you to various rooms even though the Alexa may be out of range.
|
## Inspiration
Assistive Tech was our asigned track, we had done it before and knew we could innovate with cool ideas.
## What it does
It adds a camera and sensors which instruct a pair of motors that will lightly pull the user in a direction to avoid a collision with an obstacle.
## How we built it
We used a camera pod for the stick, on which we mounted the camera and sensor. At the end of the cane we joined a chasis with the motors and controller.
## Challenges we ran into
We had never used a voice command system, paired with a raspberry pi and also an arduino, combining all of that was a real challenge for us.
## Accomplishments that we're proud of
Physically completing the cane and also making it look pretty, many of our past projects have wires everywhere and some stuff isn't properly mounted.
## What we learned
We learned to use Dialog Flow and how to prototype in a foreign country where we didn't know where to buy stuff lol.
## What's next for CaneAssist
As usual, all our projects will most likely be fully completed in a later date. And hopefully get to be a real product that can help people out.
|
## Inspiration
Our project, "**Jarvis**," was born out of a deep-seated desire to empower individuals with visual impairments by providing them with a groundbreaking tool for comprehending and navigating their surroundings. Our aspiration was to bridge the accessibility gap and ensure that blind individuals can fully grasp their environment. By providing the visually impaired community access to **auditory descriptions** of their surroundings, a **personal assistant**, and an understanding of **non-verbal cues**, we have built the world's most advanced tool for the visually impaired community.
## What it does
"**Jarvis**" is a revolutionary technology that boasts a multifaceted array of functionalities. It not only perceives and identifies elements in the blind person's surroundings but also offers **auditory descriptions**, effectively narrating the environmental aspects they encounter. We utilize a **speech-to-text** and **text-to-speech model** similar to **Siri** / **Alexa**, enabling ease of access. Moreover, our model possesses the remarkable capability to recognize and interpret the **facial expressions** of individuals who stand in close proximity to the blind person, providing them with invaluable social cues. Furthermore, users can ask questions that may require critical reasoning, such as what to order from a menu or navigating complex public-transport-maps. Our system is extended to the **Amazfit**, enabling users to get a description of their surroundings or identify the people around them with a single press.
## How we built it
The development of "**Jarvis**" was a meticulous and collaborative endeavor that involved a comprehensive array of cutting-edge technologies and methodologies. Our team harnessed state-of-the-art **machine learning frameworks** and sophisticated **computer vision techniques** to get analysis about the environment, like , **Hume**, **LlaVa**, **OpenCV**, a sophisticated computer vision techniques to get analysis about the environment, and used **next.js** to create our frontend which was established with the **ZeppOS** using **Amazfit smartwatch**.
## Challenges we ran into
Throughout the development process, we encountered a host of formidable challenges. These obstacles included the intricacies of training a model to recognize and interpret a diverse range of environmental elements and human expressions. We also had to grapple with the intricacies of optimizing the model for real-time usage on the **Zepp smartwatch** and get through the **vibrations** get enabled according to the **Hume** emotional analysis model, we faced issues while integrating **OCR (Optical Character Recognition)** capabilities with the **text-to speech** model. However, our team's relentless commitment and problem-solving skills enabled us to surmount these challenges.
## Accomplishments that we're proud of
Our proudest achievements in the course of this project encompass several remarkable milestones. These include the successful development of "**Jarvis**" a model that can audibly describe complex environments to blind individuals, thus enhancing their **situational awareness**. Furthermore, our model's ability to discern and interpret **human facial expressions** stands as a noteworthy accomplishment.
## What we learned
# Hume
**Hume** is instrumental for our project's **emotion-analysis**. This information is then translated into **audio descriptions** and the **vibrations** onto **Amazfit smartwatch**, providing users with valuable insights about their surroundings. By capturing facial expressions and analyzing them, our system can provide feedback on the **emotions** displayed by individuals in the user's vicinity. This feature is particularly beneficial in social interactions, as it aids users in understanding **non-verbal cues**.
# Zepp
Our project involved a deep dive into the capabilities of **ZeppOS**, and we successfully integrated the **Amazfit smartwatch** into our web application. This integration is not just a technical achievement; it has far-reaching implications for the visually impaired. With this technology, we've created a user-friendly application that provides an in-depth understanding of the user's surroundings, significantly enhancing their daily experiences. By using the **vibrations**, the visually impaired are notified of their actions. Furthermore, the intensity of the vibration is proportional to the intensity of the emotion measured through **Hume**.
# Ziiliz
We used **Zilliz** to host **Milvus** online, and stored a dataset of images and their vector embeddings. Each image was classified as a person; hence, we were able to build an **identity-classification** tool using **Zilliz's** reverse-image-search tool. We further set a minimum threshold below which people's identities were not recognized, i.e. their data was not in **Zilliz**. We estimate the accuracy of this model to be around **95%**.
# Github
We acquired a comprehensive understanding of the capabilities of version control using **Git** and established an organization. Within this organization, we allocated specific tasks labeled as "**TODO**" to each team member. **Git** was effectively employed to facilitate team discussions, workflows, and identify issues within each other's contributions.
The overall development of "**Jarvis**" has been a rich learning experience for our team. We have acquired a deep understanding of cutting-edge **machine learning**, **computer vision**, and **speech synthesis** techniques. Moreover, we have gained invaluable insights into the complexities of real-world application, particularly when adapting technology for wearable devices. This project has not only broadened our technical knowledge but has also instilled in us a profound sense of empathy and a commitment to enhancing the lives of visually impaired individuals.
## What's next for Jarvis
The future holds exciting prospects for "**Jarvis.**" We envision continuous development and refinement of our model, with a focus on expanding its capabilities to provide even more comprehensive **environmental descriptions**. In the pipeline are plans to extend its compatibility to a wider range of **wearable devices**, ensuring its accessibility to a broader audience. Additionally, we are exploring opportunities for collaboration with organizations dedicated to the betterment of **accessibility technology**. The journey ahead involves further advancements in **assistive technology** and greater empowerment for individuals with visual impairments.
|
partial
|
## Inspiration
Last year we had to go through the hassle of retrieving a physical key from a locked box in a hidden location in order to enter our AirBnB. After seeing the August locks, we thought there must be a more convenient alternative.
We thought of other situations where you would want to grant access to your locks. In many cases where you would want to only grant temporary access, such as AirBnB, escape rooms or visitors or contractors at a business, you would want the end user to sign an agreement before being granted access, so naturally we looked into the DocuSign API.
## What it does
The app has two pieces: a way for home owners to grant temporary access to their clients, and the way for the clients to access the locks.
The property owner fills out a simple form with the phone number of their client as a way to identify them, the address of the property, the end date of their stay, the details needed to access the August lock. Our server then generates a custom DocuSign Click form and waits for the client.
When the client access the server, they first have to agree to the DocuSign form, which is mostly our agreement, but includes details about the time and location of the access granted, and includes a section for the property owners to add their own details. Once they have agreed to the form, they are able to use our website to lock and unlock the August lock they are granted access to via the internet, until the period of access specified by the property owner ends.
## How we built it
We set up a Flask server, and made an outline of what the website would be. Then we worked on figuring out the API calls we would need to make in local python scripts. We developed the DocuSign and August pieces separately. Once the pieces were ready, we began integrating them into the Flask server. Then we worked on debugging and polishing our product.
## Challenges we ran into
Some of the API calls were complex and it was difficult figuring out which pieces of data were needed and how to format them in order to use the APIs properly. The hardest API piece to implement was programatically generating DocuSign documents. Also, debugging was difficult once we were working on the Flask server, but once we figured out how to use Flask debug mode, it became a lot easier.
## Accomplishments that we're proud of
We successfully implemented all the main pieces of our idea, including ensuring users signed via DocuSign, controlling the August lock, rejecting users after their access expires, and including both the property owner and client sides of the project.
We are also proud of the potential security of our system. The renter is given absolute minimal access. They are never given direct access to the lock info, removing potential security vulnerabilities. They login to our website, and both verification that they have permission to use the lock and the API calls to control the lock occur on our server.
## What we learned
We learned a lot about web development including how to use cookies, forms, and URL arguments. We also gained a lot of experience in implementing 3rd party API's.
## What's next for Unlocc
The next steps would be expanding the rudimentary account system with a more polished one, having a lawyer help us draft the legalese in the DocuSign documents, and contacting potential users such as AirBnB property owners or escape room companies.
|
## Inspiration
The current landscape of data aggregation for ML models relies heavily on centralized platforms, such as Roboflow and Kaggle. This causes an overreliance on invalidated human-volunteered data. Billions of dollars worth of information is unused, resulting in unnecessary inefficiencies and challenges in the data engineering process. With this in mind, we wanted to create a solution.
## What it does
**1. Data Contribution and Governance**
DAG operates as a decentralized and autonomous organization (DAO) governed by smart contracts and consensus mechanisms within a blockchain network. DAG also supports data annotation and enrichment activities, as users can participate in annotating and adding value to the shared datasets.
Annotation involves labeling, tagging, or categorizing data, which is increasingly valuable for machine learning, AI, and research purposes.
**2. Micropayments in Cryptocurrency**
In return for adding datasets to DAG, users receive micropayments in the form of cryptocurrency. These micropayments act as incentives for users to share their data with the community and ensure that contributors are compensated based on factors such as the quality and usefulness of their data.
**3. Data Quality Control**
The community of users actively participates in data validation and quality assessment. This can involve data curation, data cleaning, and verification processes. By identifying and reporting data quality issues or errors, our platform encourages everyone to actively participate in maintaining data integrity.
## How we built it
DAG was used building Next.js, MongoDB, Cohere, Tailwind CSS, Flow, React, Syro, and Soroban.
|
## Inspiration
<https://www.youtube.com/watch?v=lxuOxQzDN3Y>
Robbie's story stuck out to me at the endless limitations of technology. He was diagnosed with muscular dystrophy which prevented him from having full control of his arms and legs. He was gifted with a Google home that crafted his home into a voice controlled machine. We wanted to take this a step further and make computers more accessible for people such as Robbie.
## What it does
We use a Google Cloud based API that helps us detect words and phrases captured from the microphone input. We then convert those phrases into commands for the computer to execute. Since the python script is run in the terminal it can be used across the computer and all its applications.
## How I built it
The first (and hardest) step was figuring out how to leverage Google's API to our advantage. We knew it was able to detect words from an audio file but there was more to this project than that. We started piecing libraries to get access to the microphone, file system, keyboard and mouse events, cursor x,y coordinates, and so much more. We build a large (~30) function library that could be used to control almost anything in the computer
## Challenges I ran into
Configuring the many libraries took a lot of time. Especially with compatibility issues with mac vs. windows, python2 vs. 3, etc. Many of our challenges were solved by either thinking of a better solution or asking people on forums like StackOverflow. For example, we wanted to change the volume of the computer using the fn+arrow key shortcut, but python is not allowed to access that key.
## Accomplishments that I'm proud of
We are proud of the fact that we had built an alpha version of an application we intend to keep developing, because we believe in its real-world applications. From a technical perspective, I was also proud of the fact that we were able to successfully use a Google Cloud API.
## What I learned
We learned a lot about how the machine interacts with different events in the computer and the time dependencies involved. We also learned about the ease of use of a Google API which encourages us to use more, and encourage others to do so, too. Also we learned about the different nuances of speech detection like how to tell the API to pick the word "one" over "won" in certain context, or how to change a "one" to a "1", or how to reduce ambient noise.
## What's next for Speech Computer Control
At the moment we are manually running this script through the command line but ideally we would want a more user friendly experience (GUI). Additionally, we had developed a chrome extension that numbers off each link on a page after a Google or Youtube search query, so that we would be able to say something like "jump to link 4". We were unable to get the web-to-python code just right, but we plan on implementing it in the near future.
|
partial
|
## Inspiration
How did you feel when you first sat behind the driving wheel? Scared? Excited? All of us on the team felt a similar way: nervous. Nervous that we'll drive too slow and have cars honk at us from behind. Or nervous that we'll crash into something or someone. We felt that this was something that most people encountered, and given the current technology and opportunity, this was the perfect chance to create a solution that can help inexperienced drivers.
## What it does
Drovo records average speed and composite jerk (the first derivative of acceleration with respect to time) over the course of a driver's trip. From this data, it determines a driving grade based on the results of a SVM machine learning model.
## How I built it
The technology making up Drovo can be summarized in three core components: the Android app, machine learning model, and Ford head unit. Interaction can start from either the Android app or Ford head unit. Once a trip is started, the Android app will compile data from its own accelerometer and multiple features from the Ford head unit which it will feed to a SVM machine learning model. The results of the analysis will be summarized with a single driving letter grade which will be read out to the user, surfaced to the head unit, and shown on the device.
## Challenges I ran into
Much of the hackathon was spent learning how to properly integrate our Android app and machine learning model with the Ford head unit via smart device link. This led to multiple challenges along the way such as figuring out how to properly communicate from the main Android activity to the smart device link service and from the service to the head unit via RPC.
## Accomplishments that I'm proud of
We are proud that we were able to make a fully connected user experience that enables interaction from multiple user interfaces such as the phone, Ford head unit, or voice.
## What I learned
We learned how to work with smart device link, various new Android techniques, and vehicle infotainment systems.
## What's next for Drovo
We think that Drovo should be more than just a one time measurement of driving skills. We are thinking of keeping track of your previous trips to see how your driving skills have changed over time. We would also like to return the vehicle data we analyzed to highlight specific periods of bad driving.
Beyond that, we think Drovo could be a great incentive for teenage drivers to be proud of good driving. By implementing a social leaderboard, users can see their friends' driving grades, which will in turn motivate them to increase their own driving skills.
|
## Inspiration
In August, one of our team members was hit by a drunk driver. She survived with a few cuts and bruises, but unfortunately, there are many victims who are not as lucky. The emotional and physical trauma she and other drunk-driving victims experienced motivated us to try and create a solution in the problem space.
Our team initially started brainstorming ideas to help victims of car accidents contact first response teams faster, but then we thought, what if we could find an innovative way to reduce the amount of victims? How could we help victims by preventing them from being victims in the first place, and ensuring the safety of drivers themselves?
Despite current preventative methods, alcohol-related accidents still persist. According to the National Highway Traffic Safety Administration, in the United States, there is a death caused by motor vehicle crashes involving an alcohol-impaired driver every 50 minutes. The most common causes are rooted in failing to arrange for a designated driver, and drivers overestimating their sobriety. In order to combat these issues, we developed a hardware and software tool that can be integrated into motor vehicles.
We took inspiration from the theme “Hack for a Night out”. While we know this theme usually means making the night out a better time in terms of fun, we thought that another aspect of nights out that could be improved is getting everyone home safe. Its no fun at all if people end up getting tickets, injured, or worse after a fun night out, and we’re hoping that our app will make getting home a safer more secure journey.
## What it does
This tool saves lives.
It passively senses the alcohol levels in a vehicle using a gas sensor that can be embedded into a car’s wheel or seat. Using this data, it discerns whether or not the driver is fit to drive and notifies them. If they should not be driving, the app immediately connects the driver to alternative options of getting home such as Lyft, emergency contacts, and professional driving services, and sends out the driver’s location.
There are two thresholds from the sensor that are taken into account: no alcohol present and alcohol present. If there is no alcohol present, then the car functions normally. If there is alcohol present, the car immediately notifies the driver and provides the options listed above. Within the range between these two thresholds, our application uses car metrics and user data to determine whether the driver should pull over or not. In terms of user data, if the driver is under 21 based on configurations in the car such as teen mode, the app indicates that the driver should pull over. If the user is over 21, the app will notify if there is reckless driving detected, which is based on car speed, the presence of a seatbelt, and the brake pedal position.
## How we built it
Hardware Materials:
* Arduino uno
* Wires
* Grove alcohol sensor
* HC-05 bluetooth module
* USB 2.0 b-a
* Hand sanitizer (ethyl alcohol)
Software Materials:
* Android studio
* Arduino IDE
* General Motors Info3 API
* Lyft API
* FireBase
## Challenges we ran into
Some of the biggest challenges we ran into involved Android Studio. Fundamentally, testing the app on an emulator limited our ability to test things, with emulator incompatibilities causing a lot of issues. Fundamental problems such as lack of bluetooth also hindered our ability to work and prevented testing of some of the core functionality. In order to test erratic driving behavior on a road, we wanted to track a driver’s ‘Yaw Rate’ and ‘Wheel Angle’, however, these parameters were not available to emulate on the Mock Vehicle simulator app.
We also had issues picking up Android Studio for members of the team new to Android, as the software, while powerful, is not the easiest for beginners to learn. This led to a lot of time being used to spin up and just get familiar with the platform. Finally, we had several issues dealing with the hardware aspect of things, with the arduino platform being very finicky and often crashing due to various incompatible sensors, and sometimes just on its own regard.
## Accomplishments that we're proud of
We managed to get the core technical functionality of our project working, including a working alcohol air sensor, and the ability to pull low level information about the movement of the car to make an algorithmic decision as to how the driver was driving. We were also able to wirelessly link the data from the arduino platform onto the android application.
## What we learned
* Learn to adapt quickly and don’t get stuck for too long
* Always have a backup plan
## What's next for Drink+Dryve
* Minimize hardware to create a compact design for the alcohol sensor, built to be placed inconspicuously on the steering wheel
* Testing on actual car to simulate real driving circumstances (under controlled conditions), to get parameter data like ‘Yaw Rate’ and ‘Wheel Angle’, test screen prompts on car display (emulator did not have this feature so we mimicked it on our phones), and connecting directly to the Bluetooth feature of the car (a separate apk would need to be side-loaded onto the car or some wi-fi connection would need to be created because the car functionality does not allow non-phone Bluetooth devices to be detected)
* Other features: Add direct payment using service such as Plaid, facial authentication; use Docusign to share incidents with a driver’s insurance company to review any incidents of erratic/drunk-driving
* Our key priority is making sure the driver is no longer in a compromising position to hurt other drivers and is no longer a danger to themselves. We want to integrate more mixed mobility options, such as designated driver services such as Dryver that would allow users to have more options to get home outside of just ride share services, and we would want to include a service such as Plaid to allow for driver payment information to be transmitted securely.
We would also like to examine a driver’s behavior over a longer period of time, and collect relevant data to develop a machine learning model that would be able to indicate if the driver is drunk driving more accurately. Prior studies have shown that logistic regression, SVM, decision trees can be utilized to report drunk driving with 80% accuracy.
|
## Inspiration
I was born in Washington DC, and I've always been frustrated with the how inaccessible politics has been for regular people. This breeds frustration with the system, something that we at UC Berkeley are all too aware of with recent clashes on our campus.
Inspiration for this idea also comes from our president. As a first generation Muslim American, I'm acutely aware of the impact of his rhetoric of exclusionary identity politics. I'd like to make sure that regardless of what's said, we all have a voice in our political decisions.
## What it does
This mobile app allows you to view the bills that your representatives have introduced. It allows you to vote on the bill and see which way others who have the same representatives have voted.
The coolest feature: it prompts you for a message when you vote on a bill, automatically generates a formal letter with the message and addresses it to your senators, and faxes them instantly!
We also allows you to donate to the representative using a CapitalOne account.
## How we built it
We built the app in React Native, entirely using Expo (no native iOS or android code). We built our backend server in Node.js, used the ProPublica API, Twilio API, Capital One API, html-pdf package.
We used the Capital One API for donations (we created a merchant id for your representative, a purchase request with a merchant, and pulled bills to your account when viewing all your donations).
We used the Twilio API + html-pdf npm package for the automatic fax.
We used the ProPublica API for the bill and representative information.
## Challenges we ran into
My teammate was new to react/react-native/javascript! Partitioning work and having him teach me some backend stuff while I taught him react-native was tough. We had lots of problems trying to define the scale of our app, we had too many feature ideas and limited time to create. As we speak I'm debugging the donations part of the app, the fax, bill information, and voting work however.
## Accomplishments that we're proud of
Daryus learned React-Native! I'm proud of actually getting this idea off the ground. I love politics, am saddened by the fact that most hackers don't really build political tech apps, and I'm glad we have something to work with in the future.
## What we learned
How to prioritize features. And how to proportion caffeine intake (more = better).
## What's next for Politik
We have to take away the Capital One API for it to be production ready. We're going to get styling help from friends here at Cal.
Most immediate term is to create Sign-In capability, move a lot of our data formatting and api calls to our backend, and we need to solve some performance issues with the ProPublica API (perhaps preload bills into a db and then check if any new ones were added). Also we need to add more than just Senators. In addition, we need to call our 'send-fax' route only after the user has chosen to send a message to their representative, rather than whenever you vote on a bill.
|
winning
|
## Inspiration
The vicarious experiences of friends, and some of our own, immediately made clear the potential benefit to public safety the City of London’s dataset provides. We felt inspired to use our skills to make more accessible, this data, to improve confidence for those travelling alone at night.
## What it does
By factoring in the location of street lights, and greater presence of traffic, safeWalk intuitively presents the safest options for reaching your destination within the City of London. Guiding people along routes where they will avoid unlit areas, and are likely to walk beside other well-meaning citizens, the application can instill confidence for travellers and positively impact public safety.
## How we built it
There were three main tasks in our build.
1) Frontend:
Chosen for its flexibility and API availability, we used ReactJS to create a mobile-to-desktop scaling UI. Making heavy use of the available customization and data presentation in the Google Maps API, we were able to achieve a cohesive colour theme, and clearly present ideal routes and streetlight density.
2) Backend:
We used Flask with Python to create a backend that we used as a proxy for connecting to the Google Maps Direction API and ranking the safety of each route. This was done because we had more experience as a team with Python and we believed the Data Processing would be easier with Python.
3) Data Processing:
After querying the appropriate dataset from London Open Data, we had to create an algorithm to determine the “safest” route based on streetlight density. This was done by partitioning each route into subsections, determining a suitable geofence for each subsection, and then storing each lights in the geofence. Then, we determine the total number of lights per km to calculate an approximate safety rating.
## Challenges we ran into:
1) Frontend/Backend Connection:
Connecting the frontend and backend of our project together via RESTful API was a challenge. It took some time because we had no experience with using CORS with a Flask API.
2) React Framework
None of the team members had experience in React, and only limited experience in JavaScript. Every feature implementation took a great deal of trial and error as we learned the framework, and developed the tools to tackle front-end development. Once concepts were learned however, it was very simple to refine.
3) Data Processing Algorithms
It took some time to develop an algorithm that could handle our edge cases appropriately. At first, we thought we could develop a graph with weighted edges to determine the safest path. Edge cases such as handling intersections properly and considering lights on either side of the road led us to dismissing the graph approach.
## Accomplishments that we are proud of
Throughout our experience at Hack Western, although we encountered challenges, through dedication and perseverance we made multiple accomplishments. As a whole, the team was proud of the technical skills developed when learning to deal with the React Framework, data analysis, and web development. In addition, the levels of teamwork, organization, and enjoyment/team spirit reached in order to complete the project in a timely manner were great achievements
From the perspective of the hack developed, and the limited knowledge of the React Framework, we were proud of the sleek UI design that we created. In addition, the overall system design lent itself well towards algorithm protection and process off-loading when utilizing a separate back-end and front-end.
Overall, although a challenging experience, the hackathon allowed the team to reach accomplishments of new heights.
## What we learned
For this project, we learned a lot more about React as a framework and how to leverage it to make a functional UI. Furthermore, we refined our web-based design skills by building both a frontend and backend while also use external APIs.
## What's next for safewalk.io
In the future, we would like to be able to add more safety factors to safewalk.io. We foresee factors such as:
Crime rate
Pedestrian Accident rate
Traffic density
Road type
|
## Inspiration
At times, like any other city, Victoria is not always safe to travel by foot at night. With some portions of the population feeling concerned about safety in the area they live, the idea for creating an application to help users travel more safely would be a great way to give back. This would not only benefit our community, but can be easily applied to other cities as well.
## What it does
GetThereSafe maps the best route to your destination by determining where the most amount of light sources are.
## How we built it
Utilizing a Google Maps API, we built a PostgreSQL database that stores light source data from the Open Data Catalogue from the City of Victoria. When the Flask web app receives the start and destination locations, it calls upon our database to determine which route has the highest amount of light sources. It then returns the best routes for the user to use.
## Challenges we ran into
**Database Implementation**:
Our main challenge was creating a database (to store light source data) that could easily communicate with our app, which was being deployed via Heroku. The first attempt was to host our database with Orchestrate, but after determining that it would have taken far too much time to implement, it was decided that the team should change services.
On the advice of Artur from MLH, he suggested to spin up an Amazon Web Service that would host our database. Creating an EC2 instance running PostgreSQL inside, the database finally began to take form. However, we began to notice that there were going to be permission issues with our web app communicating with our EC2 instance.
An attempt to make a pg\_dump into an RDS instance was made, but after three different database implementation attempts and much research, it was decided that we would implement our database via Heroku's PostgreSQL add-on (which utilizes AWS in the background, but in a limited manner in comparison to our previous attempts).
We were hoping to utilize cloud services to make our data set easily scalable, with the goal of being able to add more information to make our user's route as safe as possible. Unfortunately, due to our utilization of Heroku to deploy our web app, this complicated our implementation attempts to allow our services to communicate with one another. In the end, this was a significant lesson in not just correct database implementation, but also how multiple services communicate with one another.
## Accomplishments that we're proud of
1. Implementing an EC2 server instance running a PostgreSQL DB instance
2. Managing to survive 15 hours of database brutality, and having created four different databases in that time.
3. Calculating the best amount of light source coordinates on each route
4. Site design!
5. Mobile responsiveness
6. Our logo is pretty cool - it's awesome!!!!
7. Utilizing our first Google API!
## What we learned
1. Heroku is not very good at communicating with multiple services - this was a hard earned lesson...
2. The scalability of AWS is GODLY - during the research phase, AWS proved to be a very viable option as we could add more data sets (e.g. crime) for our web app to work with.
3. Traversing routes from Google Maps and determining closest light source to each coordinate
## What's next for GetThereSafe
1. Getting our AWS EC2/RDS PostgreSQL instance communicating with our app instead of Heroku's add-on.
2. Add support for more cities! We will need to search for cities with this data openly available for them to be implemented within our application.
3. Able to toggle between each route that the user would want to take.
4. Start/Destination auto-completion fields.
5. Pull location search data from Google as replacement for addresses
6. Add more data sets to enhance route pathing (e.g. crime)
7. Add support for cycling (use topography map, cycling route maps, and lighting to determine route)
|
## Inspiration
We as a team shared the same interest in knowing more about Machine Learning and its applications. upon looking at the challenges available, we were immediately drawn to the innovation factory and their challenges, and thought of potential projects revolving around that category. We started brainstorming, and went through over a dozen design ideas as to how to implement a solution related to smart cities. By looking at the different information received from the camera data, we landed on the idea of requiring the raw footage itself and using it to look for what we would call a distress signal, in case anyone felt unsafe in their current area.
## What it does
We have set up a signal that if done in front of the camera, a machine learning algorithm would be able to detect the signal and notify authorities that maybe they should check out this location, for the possibility of catching a potentially suspicious suspect or even being present to keep civilians safe.
## How we built it
First, we collected data off the innovation factory API, and inspected the code carefully to get to know what each part does. After putting pieces together, we were able to extract a video footage of the nearest camera to us. A member of our team ventured off in search of the camera itself to collect different kinds of poses to later be used in training our machine learning module. Eventually, due to compiling issues, we had to scrap the training algorithm we made and went for a similarly pre-trained algorithm to accomplish the basics of our project.
## Challenges we ran into
Using the Innovation Factory API, the fact that the cameras are located very far away, the machine learning algorithms unfortunately being an older version and would not compile with our code, and finally the frame rate on the playback of the footage when running the algorithm through it.
## Accomplishments that we are proud of
Ari: Being able to go above and beyond what I learned in school to create a cool project
Donya: Getting to know the basics of how machine learning works
Alok: How to deal with unexpected challenges and look at it as a positive change
Sudhanshu: The interesting scenario of posing in front of a camera while being directed by people recording me from a mile away.
## What I learned
Machine learning basics, Postman, working on different ways to maximize playback time on the footage, and many more major and/or minor things we were able to accomplish this hackathon all with either none or incomplete information.
## What's next for Smart City SOS
hopefully working with innovation factory to grow our project as well as inspiring individuals with similar passion or desire to create a change.
|
partial
|
## Why We Created **Here**
As college students, one question that we catch ourselves asking over and over again is – “Where are you studying today?” One of the most popular ways for students to coordinate is through texting. But messaging people individually can be time consuming and awkward for both the inviter and the invitee—reaching out can be scary, but turning down an invitation can be simply impolite. Similarly, group chats are designed to be a channel of communication, and as a result, a message about studying at a cafe two hours from now could easily be drowned out by other discussions or met with an awkward silence.
Just as Instagram simplified casual photo sharing from tedious group-chatting through stories, we aim to simplify casual event coordination. Imagine being able to efficiently notify anyone from your closest friends to lecture buddies about what you’re doing—on your own schedule.
Fundamentally, **Here** is an app that enables you to quickly notify either custom groups or general lists of friends of where you will be, what you will be doing, and how long you will be there for. These events can be anything from an open-invite work session at Bass Library to a casual dining hall lunch with your philosophy professor. It’s the perfect dynamic social calendar to fit your lifestyle.
Groups are customizable, allowing you to organize your many distinct social groups. These may be your housemates, Friday board-game night group, fellow computer science majors, or even a mixture of them all. Rather than having exclusive group chat plans, **Here** allows for more flexibility to combine your various social spheres, casually and conveniently forming and strengthening connections.
## What it does
**Here** facilitates low-stakes event invites between users who can send their location to specific groups of friends or a general list of everyone they know. Similar to how Instagram lowered the pressure involved in photo sharing, **Here** makes location and event sharing casual and convenient.
## How we built it
UI/UX Design: Developed high fidelity mockups on Figma to follow a minimal and efficient design system. Thought through user flows and spoke with other students to better understand needed functionality.
Frontend: Our app is built on React Native and Expo.
Backend: We created a database schema and set up in Google Firebase. Our backend is built on Express.js.
All team members contributed code!
## Challenges
Our team consists of half first years and half sophomores. Additionally, the majority of us have never developed a mobile app or used these frameworks. As a result, the learning curve was steep, but eventually everyone became comfortable with their specialties and contributed significant work that led to the development of a functional app from scratch.
Our idea also addresses a simple problem which can conversely be one of the most difficult to solve. We needed to spend a significant amount of time understanding why this problem has not been fully addressed with our current technology and how to uniquely position **Here** to have real change.
## Accomplishments that we're proud of
We are extremely proud of how developed our app is currently, with a fully working database and custom frontend that we saw transformed from just Figma mockups to an interactive app. It was also eye opening to be able to speak with other students about our app and understand what direction this app can go into.
## What we learned
Creating a mobile app from scratch—from designing it to getting it pitch ready in 36 hours—forced all of us to accelerate our coding skills and learn to coordinate together on different parts of the app (whether that is dealing with merge conflicts or creating a system to most efficiently use each other’s strengths).
## What's next for **Here**
One of **Here’s** greatest strengths is the universality of its usage. After helping connect students with students, **Here** can then be turned towards universities to form a direct channel with their students. **Here** can provide educational institutions with the tools to foster intimate relations that spring from small, casual events. In a poll of more than sixty university students across the country, most students rarely checked their campus events pages, instead planning their calendars in accordance with what their friends are up to. With **Here**, universities will be able to more directly plug into those smaller social calendars to generate greater visibility over their own events and curate notifications more effectively for the students they want to target. Looking at the wider timeline, **Here** is perfectly placed at the revival of small-scale interactions after two years of meticulously planned agendas, allowing friends who have not seen each other in a while casually, conveniently reconnect.
The whole team plans to continue to build and develop this app. We have become dedicated to the idea over these last 36 hours and are determined to see just how far we can take **Here**!
|
## Inspiration
As University of Waterloo students who are constantly moving in and out of many locations, as well as constantly changing roommates, there are many times when we discovered friction or difficulty in communicating with each other to get stuff done around the house.
## What it does
Our platform allows roommates to quickly schedule and assign chores, as well as provide a messageboard for common things.
## How we built it
Our solution is built on ruby-on-rails, meant to be a quick simple solution.
## Challenges we ran into
The time constraint made it hard to develop all the features we wanted, so we had to reduce scope on many sections and provide a limited feature-set.
## Accomplishments that we're proud of
We thought that we did a great job on the design, delivering a modern and clean look.
## What we learned
Prioritize features beforehand, and stick to features that would be useful to as many people as possible. So, instead of overloading features that may not be that useful, we should focus on delivering the core features and make them as easy as possible.
## What's next for LiveTogether
Finish the features we set out to accomplish, and finish theming the pages that we did not have time to concentrate on. We will be using LiveTogether with our roommates, and are hoping to get some real use out of it!
|
## Inspiration
The inspiration of this application stemmed from a discord video call, where the phrase “turn on your cameras, this is the only way we can see each other” changed from just a sentence into an idea.
We wanted to create an app specifically created by and for university students, to create a virtually social environment that could aid in reigniting connection, excitement, and the feeling of taking new chances.
## What it does
* Connects university/college students in a 1-on-1 format or in a group environment
+ Integrates a video calling feature, allowing for the exchange of contact information and the ability to quickly make friends
+ Also allows for text messaging and video calling using an avatar in consideration for users’ privacy concerns
* Helps students interact and meet other students around the world, or in their own community
+ Includes features such as searching for a friend in a specific program or year
+ Features other channels created for different purposes such as studying together, chilling, playing games, networking, working out, and more
* Helps maintain social activity and prevents COVID from affecting people's mental health
## How we built it
CampusCloud was built using Flutter and Dart.
## Challenges we ran into
* Although we had many ambitious ideas that would have added to the experience of using our app, time was a big constraint as we had to learn to prioritize the most important features
* Implementing certain features proved to be a problem, so once again we had to learn to prioritize certain features and details
## Accomplishments that we're proud of
* We came up with a great Idea that can help a lot of students, including ourselves
* We actively communicated and gave constructive feedback as a team, allowing for a realistic but enterprising product
* We were able to make a stellar, straightforward, and resourceful UI
## What we learned
* How to use different tools/browsers for UI/UX design applications & prototyping
+ Specifically, we learned how to make full use of flutter's imports and how to use an emulator to fully test out program
## What's next for CampusCloud
* We want to be able to implement the other features/channels we couldn’t add this hackathon, including:
+ Study, Games, Chill, Workout, Music channels
+ Establishing a secure way to verify that users are students
+ Allowing users to share socials with a click of button
+ Creating a globe feature which allows students to see which countries they have virtually visited
+ Provide a history list of people they have spoken to
|
winning
|
## Inspiration
Witnessing the atrocities(protests, vandalism, etc.) caused by the recent presidential election, we want to make the general public (especially for the minorities and the oppressed) be more safe.
## What it does
It provides the users with live news update happening near them, alerts them if they travel near vicinity of danger, and provide them an emergency tool to contact their loved ones if they get into a dangerous situation.
## How we built it
* We crawl the latest happenings/events using Bing News API and summarize them using Smmry API.
* Thanks to Alteryx's API, we also managed to crawl tweets which will inform the users regarding the latest news surrounding them with good accuracy.
* All of these data are then projected to Google Map which will inform user about any happening near them in easy-to-understand summarized format.
* Using Pittney Bowes' API (GeoCode function), we alert the closest contacts of the user with the address name where the user is located.
## Challenges we ran into
Determining the credibility of tweets is incredibly hard
## Accomplishments that we're proud of
Actually to get this thing to work.
## What's next for BeSafe
Better UI/UX and maybe a predictive capability.
|
## Inspiration
We realized that while there are many news sources out there, with this, we can see what countries in the world are news hotspots - the ones that have the most things going on. You can view the world from a new perspective with our World New Map, seeing which countries are the centers of action and events.
## What it does
It uses UiPath for web scraping to gather data from news sites. The program will then create a heat map based on the number of news reports sorted by category and the severity. The mobile app will then notify it's users when there is a problem with an area that they are in or is near them.
## How we built it:
#### WebScraping(UI Path)
We used UiPath to gather data from news sites via web scraping. We accumulated around 5000 different data entries and exported them into CSVs, which are then put in a MongoDB Atlas database.
#### Cloud Storage(MongoDB Atlas)
We created a main database and sorted our data into about 100 different subfolders for different countries around the world.
#### Web Application (NodeJS)
Using Node.js and Google Charts we created a heat map based on the media coverage of the areas. We exported the mongoDB as a json and created it into a graph. We had a seperate file for each country to show the news. Clicking on Canada would show each province and show many articles each province has.
#### Android App(Radar.io)
We used Kotlin for the moblie app and used Radar.io to get the location of the user and notify them if they are in an area with a safety concern.
## Deploy with Heroku
We deployed this software to the web with Heroku. Originally we had it running locally for testing, afterwards, we converted to a version that we could deploy with Heroku.
## Assign a domain name
We used the free domain code to assign it to a .online domain.
## Challenges we ran into
Radar.io software was complicated, there was very little documentation. Radar.io also had a bug on their end that did not allow the location tracking to work properly which forced us to hard code the app. There was also numerous issues with Heroku as we struggled to convert it from the local to a version we could deploy.
MongoDB's official documentation was vague and confusing, we had to resort to third-party documentation to use it.
We also had to create a heat map, which we were originally going to make in plot.ly.
## Accomplishments that we're proud of
Learning how to use Radar.io, UiPath, and MongoDB Atlas.
## What we learned
How to use Radar.io, UiPath, MongoDB Atlas, Heroku, Custom Domains, Static web-hosting.
We also learned fast json manipulation to create graphs and output files.
## What's next for WorldNewsMap
We could use machine learning to allow the application to predict future media coverage. We could then alert users that there could be potential danger in the area in the future. We also need more data from UIPath, the data should be proportional.
|
## Inspiration
After learning about the current shortcomings of disaster response platforms, we wanted to build a modernized emergency services system to assist relief organizations and local governments in responding faster and appropriately.
## What it does
safeFront is a cross between next-generation 911 and disaster response management. Our primary users are local governments and relief organizations. The safeFront platform provides organizations and governments with the crucial information that is required for response, relief, and recovery by organizing and leveraging incoming disaster related data.
## How we built it
safeFront was built using React for the web dashboard and a Flask service housing the image classification and natural language processing models to process the incoming mobile data.
## Challenges we ran into
Ranking urgency of natural disasters and their severity by reconciling image recognition, language processing, and sentiment analysis on mobile data and reported it through a web dashboard. Most of the team didn't have a firm grasp on React components, so building the site was how we learned React.
## Accomplishments that we're proud of
Built a full stack web application and a functioning prototype from scratch.
## What we learned
Stepping outside of our comfort zone is, by nature, uncomfortable. However, we learned that we grow the most when we cross that line.
## What's next for SafeFront
We'd like to expand our platform for medical data, local transportation delays, local river level changes, and many more ideas. We were able to build a fraction of our ideas this weekend, but we hope to build additional features in the future.
|
partial
|
## Inspiration
Kabeer and I (Simran!) care deeply about impact, and building cool sh\*t.
He has a background in IoT and my background is in computational bio/health technologies. When thinking about what we want to create during HTN, we decided it would be most fun to find an intersection between hardware and healthcare.
We perceive up to 80% of all impressions by means of our sight, but there are 43 million people living with blindness and 295 million people living with moderate-to-severe visual impairment. O ur team wanted to build a product that could assist blind people in navigating their world with the most ease possible. Building a tool that could scan and alert the person of their surroundings was most important to us. Thus project ABEL began.
## What it does
When there is an object within 50 cm of the cane, the buzzer buzzes, alerting the user of obstacles in the way of their movement.
## How we built it
We connected the arduino to ultrasonic sensors which measure the distance to an object by measuring the time between the emission and reception. Once the arduino and ultrasonic sensors were connected, we coded it so that if the distance in cm is < 50cm, a buzzer would ring, alerting the person that there is a object nearby.
## Challenges we ran into
Time was the biggest time constraint that we had this entire weekend. The matter of a couple hours could've changed our entire next steps only if we had access to the right hardware (wifi modules!) and time to practice and run our software.
## Accomplishments that we're proud of
We are proud of ourselves for learning to use Arduino and hardware involved with it, in a short amount of time. We tought ourselves to run the IDE and worked through many small examples before we dove into our main idea.
## What we learned
Kabeer has worked with hardware, IoT and software for a couple projects in the past, but the entire hackathon this weekend was an incredible learning experience for the both of us. From using arduinos, breadboards, learning to use the mini arduino with wifi (the particle photon), hard coding our solution to failing multiple times and getting to know more on how wiring works between breadboards, this entire weekend was an amzing learning experience and we are both glad to spend time together and work on something that we were both interested in, but also was the middle of our interests
## What's next for ABEL
As we brainstormed multiple ideas days before the actual hackathon, our final idea was to take two that make sense and put them together; so in this case, it would be fall detection linked directly to an SMS/email integration to let an emergency contact of the victim know that they have fallen.
|
## Inspiration
Ecoleafy was inspired by the desire to create a sustainable and energy-efficient future. With the increasing need for smart homes, the team saw an opportunity to build a system that could help households reduce and be more aware of their carbon footprint and save on energy costs. The members of our team, being all in Computer Engineering and wanting to specialize in the Hardware field, we were particularly motivated to take on this challenge.
## What it does
Ecoleafy is a comprehensive IOT ecosystem that includes smart nodes for each room in the house. These nodes contain sensors such as presence sensors, humidity sensors, and temperature sensors, as well as switches and relays to control various devices such as the AC, heater, lights, and more. The system connects to a central back-end server that manages each nodes. This back-end server can automatically take decisions such as shutting off the lights, or the heater if no activity was recorded in the room for more than 30 minutes for example.
## How we built it
We built Ecoleafy as a comprehensive IOT ecosystem that includes smart nodes for each room in the house, connected to a central back-end server using Java, Spring, WebSockets, and MongoDB. The frontend was built using Flutter and Dart, providing a seamless user experience for web, mobile or desktop. The hardware nodes, which include presence sensors, humidity sensors, temperature sensors, switches, and relays, were developed using ESP32 microcontrollers and coded in C++. We aimed to beat the price of a Google Learning Nest Thermostat (329$ CAD) and its non-learning version (179$ CAD). Our final price per node is estimated to be at 11.60$ CAD before adding an enclosure (which could be 3D printed). This includes the MCU (ESP32), LCD screen, 4 relays, presence/motion, temperature and humidity sensors. You also need one Hub to host the server which could use a raspberry pi (45$ CAD) and the alternative would be a cloud subscription service.
## Challenges we ran into
One of the biggest challenges we faced was ensuring that the system would be plug-n-play if you wanted to add new nodes to your network. The other biggest challenge was the front-end development since most of us had no front-end dev experience prior to this project. We also had to ensure that the system was scalable and could handle a large number of connected devices.
## Accomplishments that we're proud of
We are proud of this being our first Hackaton devpost. The seamless integration of hardware and software components is another achievement that we're proud of.
## What we learned
We learned that building an IOT ecosystem is a complex and challenging process, but with the right team, it is possible to create a functional and innovative system. We also gained valuable experience in developing secure and scalable systems, as well as in using various technologies such as Java, Spring, Flutter, and C++. We also now understand the importance of having a front-end developer.
## What's next for Ecoleafy
We will be seeking ways to improve Ecoleafy and make it even more effective in reducing energy consumption. In the future, we could plan to expand the system to include new features and functionalities, such as integration with other smart home devices and **machine learning algorithms for more efficient energy management**. We are also exploring ways to make Ecoleafy more accessible to a wider audience with its low cost of entry.
|
## Inspiration
Retinal degeneration affects 1 in 3000 people, slowly robbing them of vision over the course of their mid-life. The need to adjust to life without vision, often after decades of relying on it for daily life, presents a unique challenge to individuals facing genetic disease or ocular injury, one which our teammate saw firsthand in his family, and inspired our group to work on a modular, affordable solution. Current technologies which provide similar proximity awareness often cost many thousands of dollars, and require a niche replacement in the user's environment; (shoes with active proximity sensing similar to our system often cost $3-4k for a single pair of shoes). Instead, our group has worked to create a versatile module which can be attached to any shoe, walker, or wheelchair, to provide situational awareness to the thousands of people adjusting to their loss of vision.
## What it does (Higher quality demo on google drive link!: <https://drive.google.com/file/d/1o2mxJXDgxnnhsT8eL4pCnbk_yFVVWiNM/view?usp=share_link> )
The module is constantly pinging its surroundings through a combination of IR and ultrasonic sensors. These are readily visible on the prototype, with the ultrasound device looking forward, and the IR sensor looking to the outward flank. These readings are referenced, alongside measurements from an Inertial Measurement Unit (IMU), to tell when the user is nearing an obstacle. The combination of sensors allows detection of a wide gamut of materials, including those of room walls, furniture, and people. The device is powered by a 7.4v LiPo cell, which displays a charging port on the front of the module. The device has a three hour battery life, but with more compact PCB-based electronics, it could easily be doubled. While the primary use case is envisioned to be clipped onto the top surface of a shoe, the device, roughly the size of a wallet, can be attached to a wide range of mobility devices.
The internal logic uses IMU data to determine when the shoe is on the bottom of a step 'cycle', and touching the ground. The Arduino Nano MCU polls the IMU's gyroscope to check that the shoe's angular speed is close to zero, and that the module is not accelerating significantly. After the MCU has established that the shoe is on the ground, it will then compare ultrasonic and IR proximity sensor readings to see if an obstacle is within a configurable range (in our case, 75cm front, 10cm side).
If the shoe detects an obstacle, it will activate a pager motor which vibrates the wearer's shoe (or other device). The pager motor will continue vibrating until the wearer takes a step which encounters no obstacles, thus acting as a toggle flip-flop.
An RGB LED is added for our debugging of the prototype:
RED - Shoe is moving - In the middle of a step
GREEN - Shoe is at bottom of step and sees an obstacle
BLUE - Shoe is at bottom of step and sees no obstacles
While our group's concept is to package these electronics into a sleek, clip-on plastic case, for now the electronics have simply been folded into a wearable form factor for demonstration.
## How we built it
Our group used an Arduino Nano, batteries, voltage regulators, and proximity sensors from the venue, and supplied our own IMU, kapton tape, and zip ties. (yay zip ties!)
I2C code for basic communication and calibration was taken from a user's guide of the IMU sensor. Code used for logic, sensor polling, and all other functions of the shoe was custom.
All electronics were custom.
Testing was done on the circuits by first assembling the Arduino Microcontroller Unit (MCU) and sensors on a breadboard, powered by laptop. We used this setup to test our code and fine tune our sensors, so that the module would behave how we wanted. We tested and wrote the code for the ultrasonic sensor, the IR sensor, and the gyro separately, before integrating as a system.
Next, we assembled a second breadboard with LiPo cells and a 5v regulator. The two 3.7v cells are wired in series to produce a single 7.4v 2S battery, which is then regulated back down to 5v by an LM7805 regulator chip. One by one, we switched all the MCU/sensor components off of laptop power, and onto our power supply unit. Unfortunately, this took a few tries, and resulted in a lot of debugging.
. After a circuit was finalized, we moved all of the breadboard circuitry to harnessing only, then folded the harnessing and PCB components into a wearable shape for the user.
## Challenges we ran into
The largest challenge we ran into was designing the power supply circuitry, as the combined load of the sensor DAQ package exceeds amp limits on the MCU. This took a few tries (and smoked components) to get right. The rest of the build went fairly smoothly, with the other main pain points being the calibration and stabilization of the IMU readings (this simply necessitated more trials) and the complex folding of the harnessing, which took many hours to arrange into its final shape.
## Accomplishments that we're proud of
We're proud to find a good solution to balance the sensibility of the sensors. We're also proud of integrating all the parts together, supplying them with appropriate power, and assembling the final product as small as possible all in one day.
## What we learned
Power was the largest challenge, both in terms of the electrical engineering, and the product design- ensuring that enough power can be supplied for long enough, while not compromising on the wearability of the product, as it is designed to be a versatile solution for many different shoes. Currently the design has a 3 hour battery life, and is easily rechargeable through a pair of front ports. The challenges with the power system really taught us firsthand how picking the right power source for a product can determine its usability. We were also forced to consider hard questions about our product, such as if there was really a need for such a solution, and what kind of form factor would be needed for a real impact to be made. Likely the biggest thing we learned from our hackathon project was the importance of the end user, and of the impact that engineering decisions have on the daily life of people who use your solution. For example, one of our primary goals was making our solution modular and affordable. Solutions in this space already exist, but their high price and uni-functional design mean that they are unable to have the impact they could. Our modular design hopes to allow for greater flexibility, acting as a more general tool for situational awareness.
## What's next for Smart Shoe Module
Our original idea was to use a combination of miniaturized LiDAR and ultrasound, so our next steps would likely involve the integration of these higher quality sensors, as well as a switch to custom PCBs, allowing for a much more compact sensing package, which could better fit into the sleek, usable clip on design our group envisions.
Additional features might include the use of different vibration modes to signal directional obstacles and paths, and indeed expanding our group's concept of modular assistive devices to other solution types.
We would also look forward to making a more professional demo video
Current example clip of the prototype module taking measurements:(<https://youtube.com/shorts/ECUF5daD5pU?feature=share>)
|
losing
|
## Inspiration
Fall lab and design bay cleanout leads to some pretty interesting things being put out at the free tables. In this case, we were drawn in by a motorized Audi Spyder car. And then, we saw the Neurosity Crown headsets, and an idea was born. A single late night call among team members, excited about the possibility of using a kiddy car for something bigger was all it took. Why can't we learn about cool tech and have fun while we're at it?
Spyder is a way we can control cars with our minds. Use cases include remote rescue, non able-bodied individuals, warehouse, and being extremely cool.
## What it does
Spyder uses the Neurosity Crown to take the brainwaves of an individual, train an AI model to detect and identify certain brainwave patterns, and output them as a recognizable output to humans. It's a dry brain-computer interface (BCI) which means electrodes are placed against the scalp to read the brain's electrical activity. By taking advantage of these non-invasive method of reading electrical impulses, this allows for greater accessibility to neural technology.
Collecting these impulses, we are then able to forward these commands to our Viam interface. Viam is a software platform that allows you to easily put together smart machines and robotic projects. It completely changed the way we coded this hackathon. We used it to integrate every single piece of hardware on the car. More about this below! :)
## How we built it
### Mechanical
The manual steering had to be converted to automatic. We did this in SolidWorks by creating a custom 3D printed rack and pinion steering mechanism with a motor mount that was mounted to the existing steering bracket. Custom gear sizing was used for the rack and pinion due to load-bearing constraints. This allows us to command it with a DC motor via Viam and turn the wheel of the car, while maintaining the aesthetics of the steering wheel.
### Hardware
A 12V battery is connected to a custom soldered power distribution board. This powers the car, the boards, and the steering motor. For the DC motors, they are connected to a Cytron motor controller that supplies 10A to both the drive and steering motors via pulse-width modulation (PWM).
A custom LED controller and buck converter PCB stepped down the voltage from 12V to 5V for the LED under glow lights and the Raspberry Pi 4. The Raspberry Pi 4 uses the Viam SDK (which controls all peripherals) and connects to the Neurosity Crown for vision software controlling for the motors. All the wiring is custom soldered, and many parts are custom to fit our needs.
### Software
Viam was an integral part of our software development and hardware bringup. It significantly reduced the amount of code, testing, and general pain we'd normally go through creating smart machine or robotics projects. Viam was instrumental in debugging and testing to see if our system was even viable and to quickly check for bugs. The ability to test features without writing drivers or custom code saved us a lot of time. An exciting feature was how we could take code from Viam and merge it with a Go backend which is normally very difficult to do. Being able to integrate with Go was very cool - usually have to do python (flask + SDK). Being able to use Go, we get extra backend benefits without the headache of integration!
Additional software that we used was python for the keyboard control client, testing, and validation of mechanical and electrical hardware. We also used JavaScript and node to access the Neurosity Crown, Neurosity SDK and Kinesis API to grab trained AI signals from the console. We then used websockets to port them over to the Raspberry Pi to be used in driving the car.
## Challenges we ran into
Using the Neurosity Crown was the most challenging. Training the AI model to recognize a user's brainwaves and associate them with actions didn't always work. In addition, grabbing this data for more than one action per session was not possible which made controlling the car difficult as we couldn't fully realise our dream.
Additionally, it only caught fire once - which we consider to be a personal best. If anything, we created the world's fastest smoke machine.
## Accomplishments that we're proud of
We are proud of being able to complete a full mechatronics system within our 32 hours. We iterated through the engineering design process several times, pivoting multiple times to best suit our hardware availabilities and quickly making decisions to make sure we'd finish everything on time. It's a technically challenging project - diving into learning about neurotechnology and combining it with a new platform - Viam, to create something fun and useful.
## What we learned
Cars are really cool! Turns out we can do more than we thought with a simple kid car.
Viam is really cool! We learned through their workshop that we can easily attach peripherals to boards, use and train computer vision models, and even use SLAM! We spend so much time in class writing drivers, interfaces, and code for peripherals in robotics projects, but Viam has it covered. We were really excited to have had the chance to try it out!
Neurotech is really cool! Being able to try out technology that normally isn’t available or difficult to acquire and learn something completely new was a great experience.
## What's next for Spyder
* Backflipping car + wheelies
* Fully integrating the Viam CV for human safety concerning reaction time
* Integrating Adhawk glasses and other sensors to help determine user focus and control
|
## Inspiration
Ethiscan was inspired by a fellow member of our Computer Science club here at Chapman who was looking for a way to drive social change and promote ethical consumerism.
## What it does
Ethiscan reads a barcode from a product and looks up the manufacturer and information about the company to provide consumers with information about the product they are buying and how the company impacts the environment and society as a whole. The information includes the parent company of the product, general information about the parent company, articles related to the company, and an Ethics Score between 0 and 100 giving a general idea of the nature of the company. This Ethics Score is created by using Sentiment Analysis on Web Scraped news articles, social media posts, and general information relating to the ethical nature of the company.
## How we built it
Our program is two parts. We built an android application using Android Studio which takes images of a barcode on a product and send that to our server. Our server processes the UPC (Universal Product Code) unique to each barcode and uses a sentiment analysis neural network and web scraping to populate the android client with relevant information related to the product's parent company and ethical information.
## Challenges we ran into
Android apps are significantly harder to develop than expected, especially when nobody on your team has any experience. Alongside this we ran into significant issues finding databases of product codes, parent/subsidiary relations, and relevant sentiment data.
The Android App development process was significantly more challenging than we anticipated. It took a lot of time and effort to create functioning parts of our application. Along with that, web scraping and sentiment analysis are precise and diligent tasks to accomplish. Given the time restraint, the accuracy of the Ethics Score is not as accurate as possible. Finally, not all barcodes will return accurate results simply due to the lack of relevant information online about the ethical actions of companies related to products.
## Accomplishments that we're proud of
We managed to load the computer vision into our original android app to read barcodes on a Pixel 6, proving we had a successful proof of concept app. While our scope was ambitious, we were able to successfully show that the server-side sentiment analysis and web scraping was a legitimate approach to solving our problem, as we've completed the production of a REST API which receives a barcode UPC and returns relevant information about the company of the product. We're also proud of how we were able to quickly turn around and change out full development stack in a few hours.
## What we learned
We have learned a great deal about the fullstack development process. There is a lot of work that needs to go into making a working Android application as well as a full REST API to deliver information from the server side. These are extremely valuable skills that can surely be put to use in the future.
## What's next for Ethiscan
We hope to transition from the web service to a full android app and possibly iOS app as well. We also hope to vastly improve the way we lookup companies and gather consumer scores alongside how we present the information.
|
Additional Demos:
<https://youtu.be/Or4w_bi1oXQ>
<https://youtu.be/VGIBWpB8NAU>
<https://youtu.be/TrJp2rsnL6Y>
## Inspiration
Helping those with impairments is a cause which is close to all of the team members in Brainstorm.
The primary inspiration for this particular solution came from a recent experience of one of our team members Aditya Bora.
Aditya’s mother works as a child psychiatrist in one of the largest children's hospitals in Atlanta, GA. On a recent visit to the hospital, Aditya was introduced to a girl who was paralyzed from the neck down due to a tragic motor vehicle accident. While implementing a brain computer interface to track her eyes seemed like an obvious solution, Aditya learned that technology had yet to be commercially available for those with disabilities such as quadriplegia.
After sharing this story with the rest of the team and learning that others had also encountered a lack of assistive technology for those with compromised mobility, we decided that we wanted to create a novel BCI solution.
Imagine the world of possibilities that could be opened for them if this technology would allow interaction with a person’s surroundings by capturing inputs via neural activity. Brainstorm hopes to lead the charge for this innovative technology.
## What it does
We built a wearable electrode headset that gets neural data from the brain, and decodes it into 4 discrete signals. These signals represent the voltage corresponding to neuron activity in the electrode’s surrounding area. In real-time, the computer processes the electrical activity data through a decision tree model to predict the desired action of the user.
This output can then be used for a number of different applications which we developed. These include
* RC Wheelchair Demo:
This system was designed to simulate that control of a motorized wheelchair would be possible via a BCI. In order to control the RC car via the BCI inputs, microcontroller GPIO pins were connected to the remote control’s input pins allowing for the control of the RC system via the parsed out of the BCI rather than the manual control. The microcontroller reads in the BCI input via the serial monitor on the computer and activates the GPIO pins which correspond to control of the RC car
* Fan Demo:
This was a simple circuit which leverages a DC motor to simulate if a user was controlling a fan or another device which can be controlled via a binary input (i.e. on/off switch).
## Challenges we ran into
One of our biggest challenges was in decoding intent from the frontal lobe. We struggled with defining the optimal placement of electrodes in our headset, and then in actually translating the electroencephalography data into discrete commands. We spent a lot of time reading relevant literature in neurotechnology, working on balancing signal-to-noise ratios, and doing signal processing and transform methods to better model and understand our data.
## What we learned
We’re proud of developing a product that gives quadriplegics the ability to move solely based on their thoughts, while also creating a companion platform that enables a smart home environment for quadriplegics. We believe that our novel algorithm which is able to make predictions on a user’s thoughts can be used to make completing simple everyday tasks easier for those who suffer from impairments and drastically improve their quality of life.
## What's next for Brainstorm
We’ve built out our tech and hardware platform for operation across multiple devices and use-cases. In the future, we hope our technology will have the ability to detect precise motor movements and understand the complex thoughts that occur in the human brain. We anticipate that unlocking the secrets of the human brain will be one of the most influential endeavors of this century.
|
winning
|
## Inspiration
It’s insane how the majority of the U.S. still looks like **endless freeways and suburban sprawl.** The majority of Americans can’t get a cup of coffee or go to the grocery store without a car.
What would America look like with cleaner air, walkable cities, green spaces, and effective routing from place to place that builds on infrastructure for active transport and micro mobility? This is the question we answer, and show, to urban planners, at an extremely granular street level.
Compared to most of Europe and Asia (where there are public transportation options, human-scale streets, and dense neighborhoods) the United States is light-years away ... but urban planners don’t have the tools right now to easily assess a specific area’s walkability.
**Here's why this is an urgent problem:** Current tools for urban planners don’t provide *location-specific information* —they only provide arbitrary, high-level data overviews over a 50-mile or so radius about population density. Even though consumers see new tools, like Google Maps’ area busyness bars, it is only bits and pieces of all the data an urban planner needs, like data on bike paths, bus stops, and the relationships between traffic and pedestrians.
As a result, there’s very few actionable improvements that urban planners can make. Moreover, because cities are physical spaces, planners cannot easily visualize what an improvement (e.g. adding a bike/bus lane, parks, open spaces) would look like in the existing context of that specific road. Many urban planners don’t have the resources or capability to fully immerse themselves in a new city, live like a resident, and understand the problems that residents face on a daily basis that prevent them from accessing public transport, active commutes, or even safe outdoor spaces.
There’s also been a significant rise in micro-mobility—usage of e-bikes (e.g. CityBike rental services) and scooters (especially on college campuses) are growing. Research studies have shown that access to public transport, safe walking areas, and micro mobility all contribute to greater access of opportunity and successful mixed income neighborhoods, which can raise entire generations out of poverty. To continue this movement and translate this into economic mobility, we have to ensure urban developers are **making space for car-alternatives** in their city planning. This means bike lanes, bus stops, plaza’s, well-lit sidewalks, and green space in the city.
These reasons are why our team created CityGO—a tool that helps urban planners understand their region’s walkability scores down to the **granular street intersection level** and **instantly visualize what a street would look like if it was actually walkable** using Open AI's CLIP and DALL-E image generation tools (e.g. “What would the street in front of Painted Ladies look like if there were 2 bike lanes installed?)”
We are extremely intentional about the unseen effects of walkability on social structures, the environments, and public health and we are ecstatic to see the results: 1.Car-alternatives provide economic mobility as they give Americans alternatives to purchasing and maintaining cars that are cumbersome, unreliable, and extremely costly to maintain in dense urban areas. Having lower upfront costs also enables handicapped people, people that can’t drive, and extremely young/old people to have the same access to opportunity and continue living high quality lives. This disproportionately benefits people in poverty, as children with access to public transport or farther walking routes also gain access to better education, food sources, and can meet friends/share the resources of other neighborhoods which can have the **huge** impact of pulling communities out of poverty.
Placing bicycle lanes and barriers that protect cyclists from side traffic will encourage people to utilize micro mobility and active transport options. This is not possible if urban planners don’t know where existing transport is or even recognize the outsized impact of increased bike lanes.
Finally, it’s no surprise that transportation as a sector alone leads to 27% of carbon emissions (US EPA) and is a massive safety issue that all citizens face everyday. Our country’s dependence on cars has been leading to deeper issues that affect basic safety, climate change, and economic mobility. The faster that we take steps to mitigate this dependence, the more sustainable our lifestyles and Earth can be.
## What it does
TLDR:
1) Map that pulls together data on car traffic and congestion, pedestrian foot traffic, and bike parking opportunities. Heat maps that represent the density of foot traffic and location-specific interactive markers.
2) Google Map Street View API enables urban planners to see and move through live imagery of their site.
3) OpenAI CLIP and DALL-E are used to incorporate an uploaded image (taken from StreetView) and descriptor text embeddings to accurately provide a **hyper location-specific augmented image**.
The exact street venues that are unwalkable in a city are extremely difficult to pinpoint. There’s an insane amount of data that you have to consolidate to get a cohesive image of a city’s walkability state at every point—from car traffic congestion, pedestrian foot traffic, bike parking, and more.
Because cohesive data collection is extremely important to produce a well-nuanced understanding of a place’s walkability, our team incorporated a mix of geoJSON data formats and vector tiles (specific to MapBox API). There was a significant amount of unexpected “data wrangling” that came from this project since multiple formats from various sources had to be integrated with existing mapping software—however, it was a great exposure to real issues data analysts and urban planners have when trying to work with data.
There are three primary layers to our mapping software: traffic congestion, pedestrian traffic, and bicycle parking.
In order to get the exact traffic congestion per street, avenue, and boulevard in San Francisco, we utilized a data layer in MapBox API. We specified all possible locations within SF and made requests for geoJSON data that is represented through each Marker. Green stands for low congestion, yellow stands for average congestion, and red stands for high congestion. This data layer was classified as a vector tile in MapBox API.
Consolidating pedestrian foot traffic data was an interesting task to handle since this data is heavily locked in enterprise software tools. There are existing open source data sets that are posted by regional governments, but none of them are specific enough that they can produce 20+ or so heat maps of high foot traffic areas in a 15 mile radius. Thus, we utilized Best Time API to index for a diverse range of locations (e.g. restaurants, bars, activities, tourist spots, etc.) so our heat maps would not be biased towards a certain style of venue to capture information relevant to all audiences. We then cross-validated that data with Walk Score (the most trusted site for gaining walkability scores on specific addresses). We then ranked these areas and rendered heat maps on MapBox to showcase density.
San Francisco’s government open sources extremely useful data on all of the locations for bike parking installed in the past few years. We ensured that the data has been well maintained and preserved its quality over the past few years so we don’t over/underrepresent certain areas more than others. This was enforced by recent updates in the past 2 months that deemed the data accurate, so we added the geographic data as a new layer on our app. Each bike parking spot installed by the SF government is represented by a little bike icon on the map!
**The most valuable feature** is the user can navigate to any location and prompt CityGo to produce a hyper realistic augmented image resembling that location with added infrastructure improvements to make the area more walkable. Seeing the StreetView of that location, which you can move around and see real time information, and being able to envision the end product is the final bridge to an urban developer’s planning process, ensuring that walkability is within our near future.
## How we built it
We utilized the React framework to organize our project’s state variables, components, and state transfer. We also used it to build custom components, like the one that conditionally renders a live panoramic street view of the given location or render information retrieved from various data entry points.
To create the map on the left, our team used MapBox’s API to style the map and integrate the heat map visualizations with existing data sources. In order to create the markers that corresponded to specific geometric coordinates, we utilized Mapbox GL JS (their specific Javascript library) and third-party React libraries.
To create the Google Maps Panoramic Street View, we integrated our backend geometric coordinates to Google Maps’ API so there could be an individual rendering of each location. We supplemented this with third party React libraries for better error handling, feasibility, and visual appeal. The panoramic street view was extremely important for us to include this because urban planners need context on spatial configurations to develop designs that integrate well into the existing communities.
We created a custom function and used the required HTTP route (in PHP) to grab data from the Walk Score API with our JSON server so it could provide specific Walkability Scores for every marker in our map.
Text Generation from OpenAI’s text completion API was used to produce location-specific suggestions on walkability. Whatever marker a user clicked, the address was plugged in as a variable to a prompt that lists out 5 suggestions that are specific to that place within a 500-feet radius. This process opened us to the difficulties and rewarding aspects of prompt engineering, enabling us to get more actionable and location-specific than the generic alternative.
Additionally, we give the user the option to generate a potential view of the area with optimal walkability conditions using a variety of OpenAI models. We have created our own API using the Flask API development framework for Google Street View analysis and optimal scene generation.
**Here’s how we were able to get true image generation to work:** When the user prompts the website for a more walkable version of the current location, we grab an image of the Google Street View and implement our own architecture using OpenAI contrastive language-image pre-training (CLIP) image and text encoders to encode both the image and a variety of potential descriptions describing the traffic, use of public transport, and pedestrian walkways present within the image. The outputted embeddings for both the image and the bodies of text were then compared with each other using scaled cosine similarity to output similarity scores. We then tag the image with the necessary descriptors, like classifiers,—this is our way of making the system understand the semantic meaning behind the image and prompt potential changes based on very specific street views (e.g. the Painted Ladies in San Francisco might have a high walkability score via the Walk Score API, but could potentially need larger sidewalks to further improve transport and the ability to travel in that region of SF). This is significantly more accurate than simply using DALL-E’s set image generation parameters with an unspecific prompt based purely on the walkability score because we are incorporating both the uploaded image for context and descriptor text embeddings to accurately provide a hyper location-specific augmented image.
A descriptive prompt is constructed from this semantic image analysis and fed into DALLE, a diffusion based image generation model conditioned on textual descriptors. The resulting images are higher quality, as they preserve structural integrity to resemble the real world, and effectively implement the necessary changes to make specific locations optimal for travel.
We used Tailwind CSS to style our components.
## Challenges we ran into
There were existing data bottlenecks, especially with getting accurate, granular, pedestrian foot traffic data.
The main challenge we ran into was integrating the necessary Open AI models + API routes. Creating a fast, seamless pipeline that provided the user with as much mobility and autonomy as possible required that we make use of not just the Walk Score API, but also map and geographical information from maps + google street view.
Processing both image and textual information pushed us to explore using the CLIP pre-trained text and image encoders to create semantically rich embeddings which can be used to relate ideas and objects present within the image to textual descriptions.
## Accomplishments that we're proud of
We could have done just normal image generation but we were able to detect car, people, and public transit concentration existing in an image, assign that to a numerical score, and then match that with a hyper-specific prompt that was generating an image based off of that information. This enabled us to make our own metrics for a given scene; we wonder how this model can be used in the real world to speed up or completely automate the data collection pipeline for local governments.
## What we learned and what's next for CityGO
Utilizing multiple data formats and sources to cohesively show up in the map + provide accurate suggestions for walkability improvement was important to us because data is the backbone for this idea. Properly processing the right pieces of data at the right step in the system process and presenting the proper results to the user was of utmost importance. We definitely learned a lot about keeping data lightweight, easily transferring between third-party softwares, and finding relationships between different types of data to synthesize a proper output.
We also learned quite a bit by implementing Open AI’s CLIP image and text encoders for semantic tagging of images with specific textual descriptions describing car, public transit, and people/people crosswalk concentrations. It was important for us to plan out a system architecture that effectively utilized advanced technologies for a seamless end-to-end pipeline. We learned about how information abstraction (i.e. converting between images and text and finding relationships between them via embeddings) can play to our advantage and utilizing different artificially intelligent models for intermediate processing.
In the future, we plan on integrating a better visualization tool to produce more realistic renders and introduce an inpainting feature so that users have the freedom to select a specific view on street view and be given recommendations + implement very specific changes incrementally. We hope that this will allow urban planners to more effectively implement design changes to urban spaces by receiving an immediate visual + seeing how a specific change seamlessly integrates with the rest of the environment.
Additionally we hope to do a neural radiance field (NERF) integration with the produced “optimal” scenes to give the user the freedom to navigate through the environment within the NERF to visualize the change (e.g. adding a bike lane or expanding a sidewalk or shifting the build site for a building). A potential virtual reality platform would provide an immersive experience for urban planners to effectively receive AI-powered layout recommendations and instantly visualize them.
Our ultimate goal is to integrate an asset library and use NERF-based 3D asset generation to allow planners to generate realistic and interactive 3D renders of locations with AI-assisted changes to improve walkability. One end-to-end pipeline for visualizing an area, identifying potential changes, visualizing said changes using image generation + 3D scene editing/construction, and quickly iterating through different design cycles to create an optimal solution for a specific locations’ walkability as efficiently as possible!
|
## Inspiration
As college students learning to be socially responsible global citizens, we realized that it's important for all community members to feel a sense of ownership, responsibility, and equal access toward shared public spaces. Often, our interactions with public spaces inspire us to take action to help others in the community by initiating improvements and bringing up issues that need fixing. However, these issues don't always get addressed efficiently, in a way that empowers citizens to continue feeling that sense of ownership, or sometimes even at all! So, we devised a way to help FixIt for them!
## What it does
Our app provides a way for users to report Issues in their communities with the click of a button. They can also vote on existing Issues that they want Fixed! This crowdsourcing platform leverages the power of collective individuals to raise awareness and improve public spaces by demonstrating a collective effort for change to the individuals responsible for enacting it. For example, city officials who hear in passing that a broken faucet in a public park restroom needs fixing might not perceive a significant sense of urgency to initiate repairs, but they would get a different picture when 50+ individuals want them to FixIt now!
## How we built it
We started out by brainstorming use cases for our app and and discussing the populations we want to target with our app. Next, we discussed the main features of the app that we needed to ensure full functionality to serve these populations. We collectively decided to use Android Studio to build an Android app and use the Google Maps API to have an interactive map display.
## Challenges we ran into
Our team had little to no exposure to Android SDK before so we experienced a steep learning curve while developing a functional prototype in 36 hours. The Google Maps API took a lot of patience for us to get working and figuring out certain UI elements. We are very happy with our end result and all the skills we learned in 36 hours!
## Accomplishments that we're proud of
We are most proud of what we learned, how we grew as designers and programmers, and what we built with limited experience! As we were designing this app, we not only learned more about app design and technical expertise with the Google Maps API, but we also explored our roles as engineers that are also citizens. Empathizing with our user group showed us a clear way to lay out the key features of the app that we wanted to build and helped us create an efficient design and clear display.
## What we learned
As we mentioned above, this project helped us learn more about the design process, Android Studio, the Google Maps API, and also what it means to be a global citizen who wants to actively participate in the community! The technical skills we gained put us in an excellent position to continue growing!
## What's next for FixIt
An Issue’s Perspective
\* Progress bar, fancier rating system
\* Crowdfunding
A Finder’s Perspective
\* Filter Issues, badges/incentive system
A Fixer’s Perspective
\* Filter Issues off scores, Trending Issues
|
## Inspiration
In the early 2010s, the endeavor to "read minds" by generating images of what a person was viewing through EEG scans was predominantly spearheaded by convolutional neural networks and other foundational computer vision techniques. Although promising, these methods faced significant challenges in accurately decoding and replicating intricate visuals. However, with the recent rise of transformer-based models and sophisticated neural architectures, many of these initial challenges have been overcome. Armed with these advanced tools, we recognized a chance to revisit and rejuvenate this field. Beyond the technological intrigue, there's a profound purpose: by converting the dreams of dementia patients into visual narratives, we aspire to make substantial advances in decoding the mysteries of Alzheimer's and associated cognitive disorders.
## What it does
DreamScape represents a sophisticated blend of neurology and AI. The process begins with high-resolution EEG scans that record the intricate brainwave patterns exhibited during dreams. These patterns are subsequently inputted into a deep learning model, specially trained using convolutional layers, which translates the EEG signals into basic images and relevant textual descriptions. To mold this data into a cohesive narrative, we deploy advanced natural language processing models, particularly transformer architectures from the GPT series. The final phase involves the generation of a detailed visual portrayal using Generative Adversarial Networks (GANs), crafting lifelike scenes inspired by the earlier narrative outputs.
## How we built it
The EEG data are sourced from reputable research journals. Our machine learning foundation leverages TensorFlow and Hugging Face's Transformers library, chosen for their synergy with intricate neural architectures. Additionally, OpenAI's GPT API bolsters our narrative generation process, with its pre-trained models minimizing our training overhead. For the visual narrative, ensuring continuous and coherent visual output, we employ a modified version of stable diffusion techniques. This guarantees visuals that flow seamlessly, much like a dream. Our web application interface, tailored for both researchers and end-users, utilizes the capabilities of Next.js and React for dynamic UI components and Flask as a nimble backend server for data processing and model interactions.
## Challenges we ran into
Refining the EEG-informed machine learning model to align with our requirements proved challenging. Conventional EEG interpretation models typically generate static visuals. Dreams, by their very nature, are kinetic, prompting us to curate animations capturing this dynamism. This demanded extensive recalibrations of our GANs, ensuring not just the precision of the generated images but also the seamless transitions between scenes. Additionally, ensuring the robustness and reliability of our system while handling diverse and sometimes ambiguous dream data presented a complex hurdle.
## Accomplishments that we're proud of
The seamless integration of neurology with state-of-the-art AI in our DreamScape pipeline symbolizes more than just a technological achievement; it represents a bridge between two disciplines that, when combined, offer boundless possibilities. Our solution casts a revelatory light on a previously obscured facet of Alzheimer's research. By crafting and presenting visual narratives that vividly depict the dreams of dementia patients, we not only break new ground in the realm of cognitive study but also offer a deeply human insight into the inner worlds of those affected by dementia.
## What we learned
Navigating the intricate maze of neural designs and EEG interpretation was an enlightening experience in itself, but our journey with DreamScape imparted lessons that extended far beyond the realm of technicalities. We realized that innovation is often born at the confluence of seemingly disparate disciplines. Melding neurology with AI demanded more than just technical prowess; it required patience and a commitment to understand the intricacies of both domains. This experience underscored the significance of interdisciplinary collaboration and illuminated the importance of looking beyond one's field to find holistic solutions to complex problems.
## What's next for DreamScape
Our roadmap for DreamScape is expansive. On the technical side, we are exploring ways to reduce processing times. Additionally, we plan to incorporate more sophisticated generative AI models to enhance visual quality. A proposed feature would utilize transformer models to scan and interpret related literature as well, thus enriching visual narratives. But our vision goes beyond current capabilities: we are researching the feasibility of brain-computer interfaces that could, in theory, allow us to feed visual narratives directly back into the brain, fostering novel therapeutic techniques.
|
winning
|
## Inspiration
As university students, we and our peers have found that our garbage and recycling have not been taken by the garbage truck for some unknown reason. They give us papers or stickers with warnings, but these get lost in the wind, chewed up by animals, or destroyed because of the weather. For homeowners or residents, the lack of communication is frustrating because we want our garbage to be taken away and we don't know why it wasn't. For garbage disposal workers, the lack of communication is detrimental because residents do not know what to fix for the next time.
## What it does
This app allows garbage disposal employees to communicate to residents about what was incorrect with how the garbage and recycling are set out on the street. Through a checklist format, employees can select the various wrongs, which are then compiled into an email and sent to the house's residents.
## How we built it
The team built this by using a Python package called **Kivy** that allowed us to create a GUI interface that can then be packaged into an iOS or Android app.
## Challenges we ran into
The greatest challenge we faced was the learning curve that arrived when beginning to code the app. All team members had never worked on creating an app, or with back-end and front-end coding. However, it was an excellent day of learning.
## Accomplishments that we're proud of
The team is proud of having a working user interface to present. We are also proud of our easy to interactive and aesthetic UI/UX design.
## What we learned
We learned skills in front-end and back-end coding. We also furthered our skills in Python by using a new library, Kivy. We gained skills in teamwork and collaboration.
## What's next for Waste Notify
Further steps for Waste Notify would likely involve collecting data from Utilities Kingston and the city. It would also require more back-end coding to set up these databases and ensure that data is secure. Our target area was University District in Kingston, however, a further application of this could be expanding the geographical location. However, the biggest next step is adding a few APIs for weather, maps and schedule.
|
## Inspiration
We saw a short video on a Nepalese boy who had to walk 10 miles each way for school. From this video, we wanted to find a way to bring unique experiences to students in constrained locations. This could be for students in remote locations, or in cash strapped low income schools. We learned that we all share a passion for creating fair learning opportunities for everyone, which is why we created Magic School VR.
## What it does
Magic School VR is an immersive virtual reality educational platform where you can attend one-on-one lectures with historical figures, influential scientists, or the world's best teachers. You can have Albert Einstein teach you quantum theory, Bill Nye the Science Guy explain the importance of mitochondria, or Warren Buffet educate you on investing.
**Step 1:** Choose a subject *physics, biology, history, computer science, etc.*
**Step 2:** Choose your teacher *(Elon Musk, Albert Einstein, Neil Degrasse Tyson, etc.*
**Step 3:** Choose your specific topic *Quantum Theory, Data Structures, WWII, Nitrogen cycle, etc.*
**Step 4:** Get immersed in your virtual learning environment
**Step 5:** Examination *Small quizzes, short answers, etc.*
## How we built it
We used Unity, Oculus SDK, and Google VR to build the VR platform as well as a variety of tools and APIs such as:
* Lyrebird API to recreate Albert Einstein's voice. We trained the model by feeding it with audio data. Through machine learning, it generated audio clips for us.
* Cinema 4D to create and modify 3D models.
* Adobe Premiere to put together our 3D models and speech, as well to chroma key masking objects.
* Adobe After Effects to create UI animations.
* C# to code camera instructions, displays, and interactions in Unity.
* Hardware used: Samsung Gear VR headset, Oculus Rift VR Headset.
## Challenges we ran into
We ran into a lot of errors with deploying Magic School VR to the Samsung Gear Headset, so instead we used Oculus Rift. However, we had hardware limitations when it came to running Oculus Rift off our laptops as we did not have HDMI ports that connected to dedicated GPUs. This led to a lot of searching around trying to find a desktop PC that could run Oculus.
## Accomplishments that we're proud of
We are happy that we got the VR to work. Coming into QHacks we didn't have much experience in Unity so a lot of hacking was required :) Every little accomplishment motivated us to keep grinding. The moment we manged to display our program in the VR headset, we were mesmerized and in love with the technology. We experienced first hand how impactful VR can be in education.
## What we learned
* Developing with VR is very fun!!!
* How to build environments, camera movements, and interactions within Unity
* You don't need a technical background to make cool stuff.
## What's next for Magic School VR
Our next steps are to implement eye-tracking engagement metrics in order to see how engaged students are to the lessons. This will help give structure to create more engaging lesson plans. In terms of expanding it as a business, we plan on reaching out to VR partners such as Merge VR to distribute our lesson plans as well as to reach out to educational institutions to create lesson plans designed for the public school curriculum.
[via GIPHY](https://giphy.com/gifs/E0vLnuT7mmvc5L9cxp)
|
## Inspiration
Many students rely on cramming strategies such as highlighting, rewriting, and rereading their notes the night before an exam. These strategies are not very effective for long-term learning, as shown in Dunlonsky et al's psychology research paper, "Strengthening the Student Toolbox: Study Strategies to Boost Learning". These common studying strategies can lead to students misconceiving
## What it does
This mobile app can take in student schedules, from the classes they take and their respective assignments/tests for each one, to the time blocks of students when they rest vs when they work well (partially implemented).
## How we built it
Flutter for the front/back end, SQLite for database management.
## Challenges we ran into
Learning Flutter, connecting to the database with it.
## Accomplishments that we're proud of/ What we learned
Basics of Flutter frontend, integration of SQLite with Flutter mobile apps, development of algorithms regarding user scheduling.
## What's next for Plan2Learn
Upcoming features may include:
* More visual graphical user interface (GUI) for scheduling rest time blocks
* Turns on do not disturb automatically during work blocks
* Rework databases connection to improve querying
* Exporting final study schedule to Google Calendar
|
winning
|
## Inspiration 💥
Let's be honest... Presentations can be super boring to watch—*and* to present.
But, what if you could bring your biggest ideas to life in a VR world that literally puts you *in* the PowerPoint? Step beyond slides and into the future with SuperStage!
## What it does 🌟
SuperStage works in 3 simple steps:
1. Export any slideshow from PowerPoint, Google Slides, etc. as a series of images and import them into SuperStage.
2. Join your work/team/school meeting from your everyday video conferencing software (Zoom, Google Meet, etc.).
3. Instead of screen-sharing your PowerPoint window, screen-share your SuperStage window!
And just like that, your audience can watch your presentation as if you were Tim Cook in an Apple Keynote. You see a VR environment that feels exactly like standing up and presenting in real life, and the audience sees a 2-dimensional, front-row seat video of you on stage. It’s simple and only requires the presenter to own a VR headset.
Intuition was our goal when designing SuperStage: instead of using a physical laser pointer and remote, we used full-hand tracking to allow you to be the wizard that you are, pointing out content and flicking through your slides like magic. You can even use your hands to trigger special events to spice up your presentation! Make a fist with one hand to switch between 3D and 2D presenting modes, and make two thumbs-up to summon an epic fireworks display. Welcome to the next dimension of presentations!
## How we built it 🛠️
SuperStage was built using Unity 2022.3 and the C# programming language. A Meta Quest 2 headset was the hardware portion of the hack—we used the 4 external cameras on the front to capture hand movements and poses. We built our UI/UX using ray interactables in Unity to be able to flick through slides from a distance.
## Challenges we ran into 🌀
* 2-camera system. SuperStage is unique since we have to present 2 different views—one for the presenter and one for the audience. Some objects and UI in our scene must be occluded from view depending on the camera.
* Dynamic, automatic camera movement, which locked onto the player when not standing in front of a slide and balanced both slide + player when they were in front of a slide.
To build these features, we used multiple rendering layers in Unity where we could hide objects from one camera and make them visible to the other. We also wrote scripting to smoothly interpolate the camera between points and track the Quest position at all times.
## Accomplishments that we're proud of 🎊
* We’re super proud of our hand pose detection and gestures: it really feels so cool to “pull” the camera in with your hands to fullscreen your slides.
* We’re also proud of how SuperStage uses the extra dimension of VR to let you do things that aren’t possible on a laptop: showing and manipulating 3D models with your hands, and immersing the audience in a different 3D environment depending on the slide. These things add so much to the watching experience and we hope you find them cool!
## What we learned 🧠
Justin: I found learning about hand pose detection so interesting. Reading documentation and even anatomy diagrams about terms like finger abduction, opposition, etc. was like doing a science fair project.
Lily: The camera system! Learning how to run two non-conflicting cameras at the same time was super cool. The moment that we first made the switch from 3D -> 2D using a hand gesture was insane to see actually working.
Carolyn: I had a fun time learning to make cool 3D visuals!! I learned so much from building the background environment and figuring out how to create an awesome firework animation—especially because this was my first time working with Unity and C#! I also grew an even deeper appreciation for the power of caffeine… but let’s not talk about that part :)
## What's next for SuperStage ➡️
Dynamically generating presentation boards to spawn as the presenter paces the room
Providing customizable avatars to add a more personal touch to SuperStage
Adding a lip-sync feature that takes volume metrics from the Oculus headset to generate mouth animations
|
## 💡 Inspiration💡
Our team is saddened by the fact that so many people think that COVID-19 is obsolete when the virus is still very much relevant and impactful to us. We recognize that there are still a lot of people around the world that are quarantining—which can be a very depressing situation to be in. We wanted to create some way for people in quarantine, now or in the future, to help them stay healthy both physically and mentally; and to do so in a fun way!
## ⚙️ What it does ⚙️
We have a full-range of features. Users are welcomed by our virtual avatar, Pompy! Pompy is meant to be a virtual friend for users during quarantine. Users can view Pompy in 3D to see it with them in real-time and interact with Pompy. Users can also view a live recent data map that shows the relevance of COVID-19 even at this time. Users can also take a photo of their food to see the number of calories they eat to stay healthy during quarantine. Users can also escape their reality by entering a different landscape in 3D. Lastly, users can view a roadmap of next steps in their journey to get through their quarantine, and to speak to Pompy.
## 🏗️ How we built it 🏗️
### 🟣 Echo3D 🟣
We used Echo3D to store the 3D models we render. Each rendering of Pompy in 3D and each landscape is a different animation that our team created in a 3D rendering software, Cinema 4D. We realized that, as the app progresses, we can find difficulty in storing all the 3D models locally. By using Echo3D, we download only the 3D models that we need, thus optimizing memory and smooth runtime. We can see Echo3D being much more useful as the animations that we create increase.
### 🔴 An Augmented Metaverse in Swift 🔴
We used Swift as the main component of our app, and used it to power our Augmented Reality views (ARViewControllers), our photo views (UIPickerControllers), and our speech recognition models (AVFoundation). To bring our 3D models to Augmented Reality, we used ARKit and RealityKit in code to create entities in the 3D space, as well as listeners that allow us to interact with 3D models, like with Pompy.
### ⚫ Data, ML, and Visualizations ⚫
There are two main components of our app that use data in a meaningful way. The first and most important is using data to train ML algorithms that are able to identify a type of food from an image and to predict the number of calories of that food. We used OpenCV and TensorFlow to create the algorithms, which are called in a Python Flask server. We also used data to show a choropleth map that shows the active COVID-19 cases by region, which helps people in quarantine to see how relevant COVID-19 still is (which it is still very much so)!
## 🚩 Challenges we ran into
We wanted a way for users to communicate with Pompy through words and not just tap gestures. We planned to use voice recognition in AssemblyAI to receive the main point of the user and create a response to the user, but found a challenge when dabbling in audio files with the AssemblyAI API in Swift. Instead, we overcame this challenge by using a Swift-native Speech library, namely AVFoundation and AVAudioPlayer, to get responses to the user!
## 🥇 Accomplishments that we're proud of
We have a functioning app of an AR buddy that we have grown heavily attached to. We feel that we have created a virtual avatar that many people really can fall for while interacting with it, virtually traveling places, talking with it, and getting through quarantine happily and healthily.
## 📚 What we learned
For the last 36 hours, we learned a lot of new things from each other and how to collaborate to make a project.
## ⏳ What's next for ?
We can use Pompy to help diagnose the user’s conditions in the future; asking users questions about their symptoms and their inner thoughts which they would otherwise be uncomfortable sharing can be more easily shared with a character like Pompy. While our team has set out for Pompy to be used in a Quarantine situation, we envision many other relevant use cases where Pompy will be able to better support one's companionship in hard times for factors such as anxiety and loneliness. Furthermore, we envisage the Pompy application being a resource hub for users to improve their overall wellness. Through providing valuable sleep hygiene, exercise tips and even lifestyle advice, Pompy will be the one-stop, holistic companion for users experiencing mental health difficulties to turn to as they take their steps towards recovery.
\*\*we had to use separate github workspaces due to conflicts.
|
## Inspiration
We were inspired to connect people over the world in a more physical way than what the internet normally provides for us. We wanted to build a virtual reality in which all the people in our reality could see each other and interact with each other- potentially from across the globe.
## What it does
We built a dueling game in Unity in which two players may join the same game over the internet and duel in virtual reality. Using the Kinect allowed us to render virtual bodies of both players in the game, which both of the players can see. The players can fire shots at each other in a friendly duel by touching their left or right elbow with the opposite hand. All in all, we combined functionality of the Kinect with the Samsung Gear in order to create a prototype of a truly immersive VR experience.
## How we built it
We developed our game in Unity. We used Unity-Kinect plugins to gather data from the connect in the Unity framework. The Kinect sends data to the computer, which reads in each vertex of the Kinect's representation of the player's body. These vectors are transferred to the Samsung phone via Open Sound Control. The phone then creates an avatar for the player in game, with the camera centered on the player's head. The Samsung Gear controls the direction of the camera. We used the Photon plugin for Unity to create online multiplayer functionality in our game.
## Challenges we ran into
We ran into trouble using the Samsung Gear to control the camera as the Gear seems to initialize the camera direction based on the it's position at the moment the app starts. This meant that the Kinect and the Gear's ideas of the player's orientation were not always the same.
## Accomplishments that We're proud of
We are very proud of our integration of VR and Kinect; specifically, getting both Open Sound Control and Photon to integrate with Unity in order to transfer information between the Kinect, the computer, and the Gear. It was important to us that the Gear and Computer communicate locally over the local Wifi network, but that the Gear could also connect with other Gears anywhere in the world, and we succeeded in implementing these goals.
## What We learned
We definitely learned about connecting devices with Open Sound Control, and about creating multiplayer Unity games with Photon. None of us had worked on the Kinect or any VR devices prior to the Hackathon, so we had a lot of fun learning about the capabilities of these devices.
## What's next for Neo Simulator
We want to add GUI's to better facilitate connections between more than two people connecting with players of their choice. If we can aquire Gear's to continue working on, we would love to continue working on improving our game. It's already a lot of fun to play; imagine how it will look after we get some sleep!
|
winning
|
## Inspiration
We have family members that have autism, and Cinthya told us about a history including her imaginary friends and how she interacted with them in her childhood, so we started a research about this two topics and we came around to with "Imaginary Friends"
## What it does
We are developing an application that allows the kids of all kind draw their imaginary friends to visualize them using augmented reality and keep in the app with the objective to improve social skills based on studies that proof that the imaginary friends help to have better social relationships and better communication. This application is also capable of detecting the mood like joy, sadness, etc. using IBM Watson "speech to text" and Watson "tone analyzer" inorder to give information of interest to the parents of this children or to their psycologist through a web page built with WIX showing statistical data and their imaginary friends.
## Challenges we ran into
We didn't know some of technologies that we used so we had to learn them in the process.
## Accomplishments that we're proud of
Finish the WIX application, and almost conclude the mobile app.
## What we learned
How to use WIX and IBM Watson
## What's next for ImaginaryFriends
We are thinking that Imaginary Friends can go further if we implement the idea in theme parks such Disney Land, etc.
with the idea that the kid could be guided by their own imaginary friend
|
## Inspiration
Vision—our most dominant sense—plays a critical role in every faucet and stage in our lives. Over 40 million people worldwide (and increasing) struggle with blindness and 20% of those over 85 experience permanent vision loss. In a world catered to the visually-abled, developing assistive technologies to help blind individuals regain autonomy over their living spaces is becoming increasingly important.
## What it does
ReVision is a pair of smart glasses that seamlessly intertwines the features of AI and computer vision to help blind people navigate their surroundings. One of our main features is the integration of an environmental scan system to describe a person’s surroundings in great detail—voiced through Google text-to-speech. Not only this, but the user is able to have a conversation with ALICE (Artificial Lenses Integrated Computer Eyes), ReVision’s own AI assistant. “Alice, what am I looking at?”, “Alice, how much cash am I holding?”, “Alice, how’s the weather?” are all examples of questions ReVision can successfully answer. Our glasses also detect nearby objects and signals buzzing when the user approaches an obstacle or wall.
Furthermore, ReVision is capable of scanning to find a specific object. For example—at an aisle of the grocery store—” Alice, where is the milk?” will have Alice scan the view for milk to let the user know of its position. With ReVision, we are helping blind people regain independence within society.
## How we built it
To build ReVision, we used a combination of hardware components and modules along with CV. For hardware, we integrated an Arduino uno to seamlessly communicate back and forth between some of the inputs and outputs like the ultrasonic sensor and vibrating buzzer for haptic feedback. Our features that helped the user navigate their world heavily relied on a dismantled webcam that is hooked up to a coco-ssd model and ChatGPT 4 to identify objects and describe the environment. We also used text-to-speech and speech-to-text to make interacting with ALICE friendly and natural.
As for the prototype of the actual product, we used stockpaper, and glue—held together with the framework of an old pair of glasses. We attached the hardware components to the inside of the frame, which pokes out to retain information. An additional feature of ReVision is the effortless attachment of the shade cover, covering the lens of our glasses. We did this using magnets, allowing for a sleek and cohesive design.
## Challenges we ran into
One of the most prominent challenges we conquered was soldering ourselves for the first time as well as DIYing our USB cord for this project. As well, our web camera somehow ended up getting ripped once we had finished our prototype and ended up not working. To fix this, we had to solder the wires and dissect our goggles to fix their composition within the frames.
## Accomplishments that we're proud of
Through human design thinking, we knew that we wanted to create technology that not only promotes accessibility and equity but also does not look too distinctive. We are incredibly proud of the fact that we created a wearable assistive device that is disguised as an everyday accessory.
## What we learned
With half our team being completely new to hackathons and working with AI, taking on this project was a large jump into STEM for us. We learned how to program AI, wearable technologies, and even how to solder since our wires were all so short for some reason. Combining and exchanging our skills and strengths, our team also learned design skills—making the most compact, fashionable glasses to act as a container for all the technologies they hold.
## What's next for ReVision
Our mission is to make the world a better place; step-by-step. For the future of ReVision, we want to expand our horizons to help those with other sensory disabilities such as deafness and even touch.
|
## Inspiration
Often as children, we were asked, "What do you want to be when you grow up?" Every time we changed our answers, we were sent to different classes to help us embrace our interests. But our answers were restricted and traditional: doctors, engineers or ballerinas. **We want to expand every child's scope: to make it more inclusive and diverse, and help them realize the vast opportunities that exist in this beautiful world in a fun way.**
Let's get them ready for the future where they follow their passion — let's hear them say designers, environmentalists, coders etc.
## What it does
The mobile application uses Augmented Reality technology to help children explore another world from a mobile phone or tablet and understand the importance of their surroundings. It opens up directly into the camera, where it asks the user to point at an object. The app detects the object and showcases various career paths that are related to the object. A child may then pick one and accomplish three simple tasks relevant to that career, which then unlocks a fun immersion into the chosen path's natural environment and the opportunity to "snap" a selfie as the professional using AR filters. The child can save their selfies and first-person immersion experience videos in their personal in-app gallery for future viewing, exploration, and even sharing.
## How I built it
Our team of three first approached the opportunity space. We held a brainstorming exercise to pinpoint the exact area where we can help, and then stepped into wireframing. We explored the best medium to play around with for the immersive, AR experience and decided upon Spectacles by Snap & Lens Studio, while exploring Xcode and iOS in parallel. For object detection, we used Google's MLKit Showcase App with Material Design to make use of Google's Object Detection and Tracking API. For the immersion, we used Snap's Spectacles to film real-world experiences that can be overlaid upon any setting, as well as Snap's Lens Studio to create a custom selfie filter to cap off the experience.
We brought in code together with design to bring the app alive with its colorful approach to appeal to kids.
## Challenges I ran into
We ran into the problem of truly understanding the perspectives of a younger age group and how our product would successfully be educational, accessible, and entertaining. We reflected upon our own experiences as children and teachers, and spoke to several parents before coming up with the final idea.
When we were exploring various AR/VR/MR technologies, we realized that many of the current tools available don't yet have the engaging user interfaces that we had been hoping for. Therefore we decided to work with Snap's Lens Studio, as the experience in-app on Snapchat is very exciting and accessible to our target age range.
On the technical side, Xcode and Apple have many peculiarities that we encountered over the course of Saturday. Additionally, we had not taken into consideration the restrictions and dependencies that Apple imposes upon iOS apps.
## Accomplishments that I'm proud of
We're proud that we did all of this in such a short span of time. Teamwork, rapid problem solving and being there for each other made for a final product that we are all proud to demo.
We're also proud that we took advantage of speaking to several sponsors from Snap and Google, and mentors from Google and Apple (and Stanford) throughout the course of the hackathon. We enjoyed technically collaborating with and meeting new people from all around the industry.
## What I learned
We learnt how to collaborate and bring design and code together, and how both go hand in hand. The engineers on the team learned a great amount about the product ideation and design thinking, and it was interesting for all of us to see our diverse perspectives coalesce into an idea we were all excited about.
## What's next for Inspo | An exploration tool for kids
On the technical side, we have many ideas for taking our project from a hackathon demo to the release version. This includes:
* Stronger integration with Snapchat and Google Cloud
* More mappings from objects to different career pathways
* Using ML models to provide recommendations for careers similar to the ones children have liked in the past
* An Android version
On the product side, we would like to expand to include:
* A small shopping list for parents to buy affordable, real-world projects related to careers
* A "Career of the Week" highlight
* Support for a network/community of children and potentially even professional mentors
|
winning
|
# Perpetual Crusades
## About the Project
This project was developed as a submission for Penn Apps XXI, held from September 11th - 13th, 2020. You can play it over here: [Perpetual Crusades](https://www.adityavsingh.com/perpetual-crusades)!
## The Story behind the Game
19 years after the Second Dragon Crusade in Draconheim, there has been a major outbreak of Dragon Pox among the humanoid races. Humanoids speculate that after the mutual deaths of humanoid Warlord Slaythurnax and dragon Overlord Aldone in their climactic battle in the Second Dragon Crusade, the dragons had vanished but have now come back seeking revenge on all those responsible, and so has the virus they carried during the First Dragon Crusade. A trio of a knight, wizard, and rogue have been commissioned to find out the remaining dragons and kill them, and on the other hand, three dragons have started on their journey to avenge their fallen Overlord. What happens when their paths cross is your and only your destiny to observe. Look excited young adventurers, for you all must not perish in these perpetual crusades!
## Inspiration
Perpetual Crusades was inspired by the popular table-top role-playing game Dungeons and Dragons. While the narrative universe of this game is completely different from Dungeons and Dragons, the objective was to create a seamless medieval dragon-fighting experience for the players.
## What it does
Perpetual Crusades is a 2-player game where one player gets to choose their avatar between humanoid characters (knight, wizard, rogue) and the other between dragons (red dragon, blue dragon, green dragon). When the game is started, both the avatars are placed on an 8x8 board which is laid with tiles with differing properties and points, the players roll the die to journey through the board, and whoever reaches 20 points earlier is declared the victor! Overall, this game focuses on creating a good entertainment experience for all its players through an age-old humourous dice-based gameplay.
## How I built it
The game was built using React for handling the overall front-end design of the game, while JSX was used (in sync with React) to develop the gameplay logic and paradigms. The gameboard was created with the help of CSS Grid Layout. The overall game is hosted through GitHub Pages, due to its relatively static nature and the lack of back-end constructs.
## Challenges I ran into
The most intriguing challenge I encountered was to decide how to make the game end (in terms of the game over screen) and the logic behind keeping score counters updated for every move. In the end, there were a lot of loose ends in the code (redundant functions and repeated code) which I had to sweep through and clean. Commenting through the code was also a last-minute modification which was quite stressful.
## Accomplishments that I'm proud of
Building the game from start to finish was itself an achievement that I'm proud of. From using CSS Grid Layouts for the first time to going through tremendous amounts of stress over the graphics and stylistic aspects of the game, and still managing to pull through a complete product makes me really proud and enthusiastic about further improving it down the road.
## What I learned
Over the course of 36 hours, I learned way more about my own stress personality than I did technologies, but I'm really grateful for the experience! In the face of stress, I learned to use CSS Grid Layouts, improved my grasp of conditional rendering, watched through a couple React tutorials to comprehend handling State and Props, and finally managed to find graphical elements (which are attributed in the GitHub repository), without all of which the game wouldn't be what it is currently.
## What's next for Perpetual Crusades
After this hackathon, I intend to scale up the game with more fellow developers and designers, which would be a great experience both for the collaboration skills I would develop and the new insights I could gain regarding optimizing the game.
|
## Inspiration
Our inspiration for developing this tool comes from the love and passion we have for Dungeons & Dragons (D&D). We recognized that both new players and veterans often face challenges in character-building and tactical combat. Traditional gameplay requires extensive preparation and understanding of rules, which can be daunting. We wanted to create a tool that simplifies this process and enhances the gameplay experience by leveraging AI to create dynamic and challenging combat scenarios.
## What it does
Dungeon Tactics is an innovative, AI-driven battle simulator designed to enhance your Dungeons & Dragons gameplay experience. The tool allows players to pit their characters against AI-controlled monsters in a variety of combat scenarios. The AI makes strategic decisions based on D&D rules, providing a realistic and challenging experience. The simulator currently supports the ability to move and take both unarmed strikes and weapon strikes while adhering to the D&D 5E combat rules.
## How we built it
We built Dungeon Tactics using a combination of React for the interactive user interface and OpenAI to drive the AI decision-making for monster actions. The frontend was developed with React, providing a dynamic and user-friendly interface where players can control their characters on a grid-based map. We used the OpenAI API to implement the AI logic, ensuring that monster actions are realistic and adhere to D&D rules. Our development process also involved integrating the D&D 5e SRD API to access game data, such as monster stats and abilities.
## Challenges we ran into
One of the main challenges we faced was implementing the complex rules of D&D in a way that the AI could understand and apply during combat. Balancing the AI's difficulty level to ensure it provides a challenge without being unfair was another significant challenge. Additionally, ensuring seamless integration between the frontend (React) and backend (OpenAI API) required meticulous planning and testing. Handling the wide range of possible actions while also making sure that they rendered correctly on the screen was a great challenge.
## Accomplishments that we're proud of
We are proud of creating a functional and engaging tool that enhances the D&D gameplay experience. Successfully integrating AI to drive monster actions in a way that feels natural and adheres to the game's rules was a major accomplishment. We are also proud of the user-friendly interface we developed, which makes it easy for players to control their characters and engage with the simulator. Our tool not only aids in character building but also provides a fun and challenging way to practice combat scenarios. For both of us, this was our first time developing a React app on our own and it showed us a lot of what is done before even coding.
## What we learned
Throughout the development of Dungeon Tactics, we learned a great deal about the complexities of AI in gaming, especially in a rule-heavy environment like D&D. We gained insights into balancing AI difficulty and ensuring fair play. We also learned about the importance of seamless integration between different technologies (React and OpenAI) and how to manage state and actions in a dynamic, interactive application. Furthermore, we deepened our understanding of D&D rules and mechanics, which was crucial for developing an authentic gameplay experience.
## What's next for Dungeon Tactics
Moving forward, we plan to expand Dungeon Tactics by adding more monsters and supporting custom monsters created by users. We aim to incorporate additional actions such as reactions, bonus actions, and spell casting to further enhance the realism of the simulator and support more classes. Another key area of development will be improving the AI's strategic capabilities, making it even more challenging and enjoyable. We also plan to implement multiplayer support, allowing players to team up and face AI-controlled challenges together. Finally, we will continuously refine the user interface to ensure it remains intuitive and engaging for players of all experience levels.
|
## Inspiration
**We love to play D&D**
It just has everything! Friends, food, fun, and a whole lot of writing down numbers in the margins of a sheet of notebook paper while you try and figure out who had the highest initiative roll. As a DM (Dungeon Master, or game manager) and a player, we've tried using all sorts of online D&D tools to streamline our games, but have found them to either be insufficient for our needs, or too stifling, digitizing away the purpose of a tabletop game among friends. We wanted to create something in the middle ground, and that's what we ended up making!
## What it does
**Any projector, any size**
Our D&D projector software automatically detects a connected projector, and will open up a dashboard window to your desktop and a display window to the projector screen automatically. The desktop dashboard provides tools for you, the DM, to run your game! You can create and load worlds, characters, and monsters. You can hide the nooks and treasures of a darkened cave, or show off the majesty of an ancient temple. You can easily and rapidly perform a variety of computerized die rolls, and apply damage to players and monsters alike!
## How we built it
**Good old reliable Java**
We used Java and the Swing library to create our windows and display the game world. The display window is projected onto a table or floor with any kind of connected projector. This allows the players to interact with real game pieces in real time, while allowing the DM to alter the game board cleanly and rapidly in response to the state of the game.
## Challenges we ran into
**The bigger the application, the harder it crashes**
Creating such a large application with so many different features is something we haven't done before, so the scope definitely posed a challenge. Additionally, the organization of the code into a robust, scalable codebase proved difficult, but we feel we did a fine job in the end.
## Accomplishments that we're proud of
**A game board you can touch but you can't break**
We've created a fun and interesting way for people to play D&D with nothing more than their laptop and a projector! We've removed many of the annoying or time-wasting aspects of the game, while simultaneously maintaining the authenticity of a tabletop RPG played with real pieces in real life.
## What we learned
**Collaboration? More like code-llaboration!**
We learned a lot about how to put together a multi-windowed, expansive application, with support for many different features during program execution and the need for advanced file storage afterward. We also got better at communicating between the frontend and the backend throughout development.
## What's next for D&D Projector
**Game on!**
D&D is a ridiculously large game, with a vast set of rules, regulations, and variations. With the scalable interface we've built so far, we plan on expanding our dashboard much further to include spells, interactions between players and NPC's, hunger/thirst, exhaustion, and many other parts of the game we feel could be streamlined. We fully intend to be careful in what we add, as retaining the authentic feel of the game is important to us.
Our next D&D session is going to be a very interesting one indeed, and we're really looking forward to it!
|
losing
|
## Inspiration
Our inspiration came from the desire to address the issue of food waste and to help those in need. We decided to create an online platform that connects people with surplus food to those who need to address the problem of food insecurity and food waste, which is a significant environmental and economic problem. We also hoped to highlight the importance of community-based solutions, where individuals and organizations can come together to make a positive impact. We believed in the power of technology and how it can be used to create innovative solutions to social issues.
## What it does
Users can create posts about their surplus perishable food (along with expiration date+time) and other users can find those posts to contact the poster and come pick up the food. We thought about it as analogous to Facebook Marketplace but focused on surplus food.
## How we built it
We used React + Vite for the frontend and Express + Node.js for the backend. For infrastructure, we used Cloudflare Pages for the frontend and Microsoft Azure App Service for backend.
## Security Practices
#### Strict repository access permissions
(Some of these were lifted temporarily to quickly make changes while working with the tight deadline in a hackathon environment):
* Pull Request with at least 1 review required for merging to the main branch so that one of our team members' machines getting compromised doesn't affect our service.
* Reviews on pull requests must be after the latest commit is pushed to the branch to avoid making malicious changes after a review
* Status checks (build + successful deployment) must pass before merging to the main branch to avoid erroneous commits in the main branch
* PR branches must be up to date with the main branch to merge to make sure there are no incompatibilities with the latest commit causing issues in the main branch
* All conversations on the PR must be marked as resolved to make sure any concerns (including security) concerns someone may have expressed have been dealt with before merging
* Admins of the repository are not allowed to bypass any of these rules to avoid accidental downtime or malicious commits due to the admin's machine being compromised
#### Infrastructure
* Use Cloudflare's CDN (able to mitigate the largest DDoS attacks in the world) to deploy our static files for the frontend
* Set up SPF, DMARC and DKIM records on our domain so that someone spoofing our domain in emails doesn't work
* Use Microsoft Azure's App Service for CI/CD to have a standard automated procedure for deployments and avoid mistakes as well as avoid the responsibility of having to keep up with OS security updates since Microsoft would do that regularly for us
* We worked on using DNSSEC for our domain to avoid DNS-related attacks but domain.com (the hackathon sponsor) requires contacting their support to enable it. For my other projects, I implement it by adding a DS record on the registrar's end using the nameserver-provided credentials
* Set up logging on Microsoft Azure
#### Other
* Use environment variables to avoid disclosing any secret credentials
* Signed up with Github dependabot alerts to receive updates about any security vulnerabilities in our dependencies
* We were in the process of implementing an Authentication service using an open-source service called Supabase to let users sign in using multiple OAuth methods and implement 2FA with TOTP (instead of SMS)
* For all the password fields required for our database and Azure service, we used Bitwarden password generator to generate 20-character random passwords as well as used 2FA with TOTP to login to all services that support it
* Used SSL for all communication between our resources
## Challenges we ran into
* Getting the Google Maps API to work
* Weird errors deploying on Azure
* Spending too much time trying to make CockroachDB work. It seemed to require certificates for connection even for testing. It seemed like their docs for using sequalize with their DB were not updated since this requirement was put into place.
## Accomplishments that we're proud of
Winning the security award by CSE!
## What we learned
We learned to not underestimate the amount of work required and do better planning next time.
Meanwhile, maybe go to fewer activities though they are super fun and engaging! Don't take us wrong as we did not regret doing them! XD
## What's next for Food Share
Food Share is built within a limited time. Some implementations that couldn't be included in time:
* Location of available food on the interactive map
* More filters for the search for available food
* Accounts and authentication method
* Implement Microsoft Azure live chat called Azure Web PubSub
* Cleaner UI
|
## Inspiration
Many investors looking to invest in startup companies are often overwhelmed by the sheer number of investment opportunities, worried that they will miss promising ventures without doing adequate due diligence. Likewise, since startups all present their data in a unique way, it is challenging for investors to directly compare companies and effectively evaluate potential investments. On the other hand, thousands of startups with a lot of potential also lack visibility to the right investors. Thus, we came up with Disruptive as a way to bridge this gap and provide a database for investors to view important insights about startups tailored to specific criteria.
## What it does
Disruptive scrapes information from various sources: company websites, LinkedIn, news, and social media platforms to generate the newest possible market insights. After homepage authentication, investors are prompted to indicate their interest in either Pre/Post+ seed companies to invest in. When an option is selected, the investor is directed to a database of company data with search capabilities, scraped from Kaggle. From the results table, a company can be selected and the investor will be able to view company insights, business analyst data (graphs), fund companies, and a Streamlit Chatbot interface. You are able to add more data through a DAO platform, by getting funded by companies looking for data. The investor also has the option of adding a company to the database with information about it.
## How we built it
The frontend was built with Next.js, TypeScript, and Tailwind CSS. Firebase authentication was used to verify users from the home page. (Company scraping and proxies for company information) Selenium was used for web scraping for database information. Figma was used for design, authentication was done using Firebase.
The backend was built using Flask, StreamLit, and Taipy. We used the Circle API and Hedera to generate bounties using blockchain. SQL and graphQL were used to generate insights, OpenAI and QLoRa were used for semantic/similarity search, and GPT fine-tuning was used for few-shot prompting.
## Challenges we ran into
Having never worked with Selenium and web scraping, we found understanding the dynamic loading and retrieval of web content challenging. The measures some websites have against scraping were also interesting to learn and try to work around. We also worked with chat-GPT and did prompt engineering to generate business insights - a task that can sometimes yield unexpected responses from chat-GPT!
## Accomplishments that we're proud of + What we learned
We learned how to use a lot of new technology during this hackathon. As mentioned above, we learned how to use Selenium, as well as Firebase authentication and GPT fine-tuning.
## What's next for Disruptive
Disruptive can implement more scrapers for better data in terms of insight generation. This would involve scraping from other options than Golden once there is more funding. Furthermore, integration between frontend and blockchain can be improved further. Lastly, we could generate better insights into the format of proposals for clients.
|
## Inspiration
Travelling past drains with heaps of food waste daily on my way to the school was the first time I noticed the irony of the situation - In India while 40% of the food is going down the drain every single day, 194 million citizens are going to sleep hungry. At the same time India is also producing 2 million tons of e-waste annually. **So, in order to tackle both these issues of food-waste & e-waste simultaneously I came up with the idea to build Syffah.**
## What it does
Syffah, which stands for **'Share Your Food, Feed All Humanity'**, is a web application which has two functions:
1. It will allow users to donate old refrigerators, which they otherwise throw away, which will be set up outside societies. People who have leftover food to donate can keep it in these community refrigerators so that the poor and homeless can access this food.
2. It will also allow users like event caterers, restaurants, hotels and individuals to donate their leftover food by posting it so that NGOs and Hunger Relief Organizations can then directly contact them, collect the food and distribute it amongst the needy.
## How we built it
* I started off by analyzing the problem at hand, followed by deciding the functionality and features of the app.
* I have also created a business plan, including Revenue model, marketing strategy and SWOT analysis.
* I then went ahead with the wireframing and mock-ups and worked on the UX/UI.
* This was followed by building the front-end of the web-app for which I have used HTML, CSS and Javascript and some php for developing one part of backend.
* However, I wasn't able to develop the back-end in the given time as I was not familiar with the languages (for which I had planned on using Google Cloud services - Firebase)
* Hence, the project is unfinished.
## Challenges we ran into
* This was my first hackathon so had some difficulties
* Was not able to develop the back-end in time, trying to learn back-end development in a short period of time was challenging, but it was still fun trying
* Enhancing the User Interface
## Accomplishments that we're proud of
* The main pages of the website are responsive.
* The UX and UI of the web-page, keeping it as simple as possible
## What we learned
* Learnt about Hackathons
* Learnt basics of Google Firebase, cloud services
* Learnt UX/UI concepts of cards, color schemes, typography, etc.
## What's next for Project SYFFAH
* Creating a fully functional prototype of the web app
* Developing the backend using Google Firebase
* Also developing an Android app alongside web-app
* Conducting ground-work and research for deploying these services
* Conducting market analysis, surveys and beta and alpha testing to improve the application overall
|
partial
|
## Inspiration
Between my friends and I, when there is a task everyone wants to avoid, we play a game to decide quickly. These tasks may include, ordering pizza or calling an uber for the group. The game goes like this, whoever thinks of this game first says "shotty not" and then touches their nose. Everyone else reacts to him and touches their nose as fast as they can. The person with the slowest reaction time is chosen to do the task. I often fall short when it comes to reaction time so I had to do something about it
## What it does
The module sits on top of your head, waiting to hear the phrase "shotty not." When it is recognized the finger will come down and touch your nose. You will never get caught off guard again.
## How I built it
The finger moves via a servo and is controlled by an arduino, it is connected to a python script that recognizes voice commands offline. The finger is mounted to the hat with some 3d printed parts.
## Challenges I ran into
The hardware lab did not have a voice recognition module or a bluetooth module for arduino. I had to figure out how to go about implementing voice recognition and connect it to the arduino.
## Accomplishments that I'm proud of
I was able to model and print all the parts to create a completely finished hack to the best of my abilities.
## What I learned
I learned to use a voice recognition library and use Pyserial to communicate to an arduino with a python program.
## What's next for NotMe
I will replace the python program with a bluetooth module to make the system more portable. This allows for real life use cases.
|
## Inspiration
When we thought about tackling the pandemic, it was clear to us that we'd have to **think outside the box**. The concept of a hardware device to enforce social distancing quickly came to mind, and thus we decided to create the SDE device.
## What it does
We utilized an ultra-sonic sensor to detect bodies within 2m of the user, and relay that data to the Arduino. If we detect a body within 2m, the buzzer and speaker go off, and a display notifies others that they are not obeying social distancing procedures and should relocate.
## How we built it
We started by creating a wiring diagram for the hardware internals using [Circuito](circuito.io). This also provided us some starter code including the libraries and tester code for the hardware components.
We then had part of the team start the assembly of the circuit and troubleshoot the components while the other focused on getting the CAD model of the casing designed for 3D printing.
Once this was all completed, we printed the device and tested it for any bugs in the system.
## Challenges we ran into
We initially wanted to make an Android partner application to log the incidence rate of individuals/objects within 2m via Bluetooth but quickly found this to be a challenge as the team was split geographically, and we did not have Bluetooth components to attach to our Arduino model. The development of the Android application also proved difficult, as no one on our team had experience developing Android applications in a Bluetooth environment.
## Accomplishments that we're proud of
Effectively troubleshooting the SDE device and getting a functional prototype finished.
## What we learned
Hardware debugging skills, how hard it is to make an Android app if you have no previous experience, and project management skills for distanced hardware projects.
## What's next for Social Distancing Enforcement (SDE)
Develop the Android application, add Bluetooth functionality, and decrease the size of the SDE device to a more usable size.
|
## Inspiration
In online documentaries, we saw visually impaired individuals and their vision consisted of small apertures. We wanted to develop a product that would act as a remedy for this issue.
## What it does
When a button is pressed, a picture is taken of the user's current view. This picture is then analyzed using OCR (Optical Character Recognition) and the text is extracted from the image. The text is then converted to speech for the user to listen to.
## How we built it
We used a push button connected to the GPIO pins on the Qualcomm DragonBoard 410c. The input is taken from the button and initiates a python script that connects to the Azure Computer Vision API. The resulting text is sent to the Azure Speech API.
## Challenges we ran into
Coming up with an idea that we were all interested in, incorporated a good amount of hardware, and met the themes of the makeathon was extremely difficult. We attempted to use Speech Diarization initially but realized the technology is not refined enough for our idea. We then modified our idea and wanted to use a hotkey detection model but had a lot of difficulty configuring it. In the end, we decided to use a pushbutton instead for simplicity in favour of both the user and us, the developers.
## Accomplishments that we're proud of
This is our very first Makeathon and we were proud of accomplishing the challenge of developing a hardware project (using components we were completely unfamiliar with) within 24 hours. We also ended up with a fully function project.
## What we learned
We learned how to operate and program a DragonBoard, as well as connect various APIs together.
## What's next for Aperture
We want to implement hot-key detection instead of the push button to eliminate the need of tactile input altogether.
|
partial
|
## ✨ Inspiration
Quarantining is hard, and during the pandemic, symptoms of anxiety and depression are shown to be at their peak 😔[[source]](https://www.kff.org/coronavirus-covid-19/issue-brief/the-implications-of-covid-19-for-mental-health-and-substance-use/). To combat the negative effects of isolation and social anxiety [[source]](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7306546/), we wanted to provide a platform for people to seek out others with similar interests. To reduce any friction between new users (who may experience anxiety or just be shy!), we developed an AI recommendation system that can suggest virtual, quarantine-safe activities, such as Spotify listening parties🎵, food delivery suggestions 🍔, or movie streaming 🎥 at the comfort of one’s own home.
## 🧐 What it Friendle?
Quarantining alone is hard😥. Choosing fun things to do together is even harder 😰.
After signing up for Friendle, users can create a deck showing their interests in food, games, movies, and music. Friendle matches similar users together and puts together some hangout ideas for those matched. 🤝💖 I
## 🧑💻 How we built Friendle?
To start off, our designer created a low-fidelity mockup in Figma to get a good sense of what the app would look like. We wanted it to have a friendly and inviting look to it, with simple actions as well. Our designer also created all the vector illustrations to give the app a cohesive appearance. Later on, our designer created a high-fidelity mockup for the front-end developer to follow.
The frontend was built using react native.
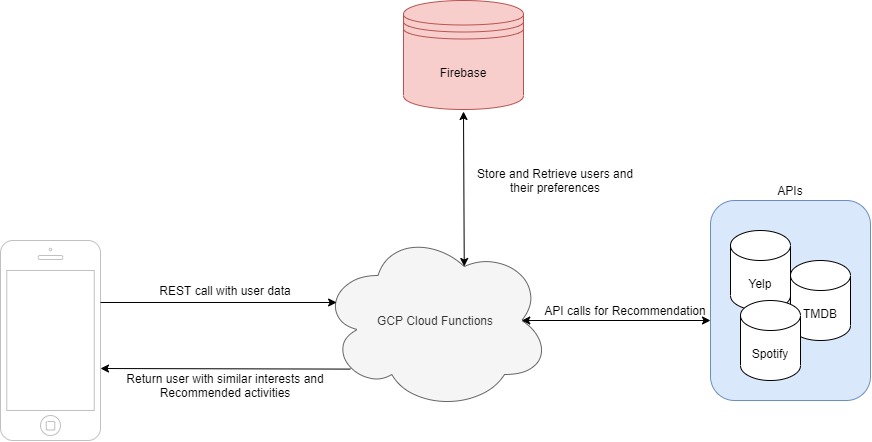
We split our backend tasks into two main parts: 1) API development for DB accesses and 3rd-party API support and 2) similarity computation, storage, and matchmaking. Both the APIs and the batch computation app use Firestore to persist data.
### ☁️ Google Cloud
For the API development, we used Google Cloud Platform Cloud Functions with the API Gateway to manage our APIs. The serverless architecture allows our service to automatically scale up to handle high load and scale down when there is little load to save costs. Our Cloud Functions run on Python 3, and access the Spotify, Yelp, and TMDB APIs for recommendation queries. We also have a NoSQL schema to store our users' data in Firebase.
### 🖥 Distributed Computer
The similarity computation and matching algorithm is powered by a node.js app which leverages the Distributed Computer for parallel computing. We encode the user's preferences and Meyers-Briggs type into a feature vector, then compare similarity using cosine similarity. The cosine similarity algorithm is a good candidate for parallelizing since each computation is independent of the results of others.
We experimented with different strategies to batch up our data prior to slicing & job creation to balance the trade-off between individual job compute speed and scheduling delays. By selecting a proper batch size, we were able to reduce our overall computation speed by around 70% (varies based on the status of the DC network, distribution scheduling, etc).
## 😢 Challenges we ran into
* We had to be flexible with modifying our API contracts as we discovered more about 3rd-party APIs and our front-end designs became more fleshed out.
* We spent a lot of time designing for features and scalability problems that we would not necessarily face in a Hackathon setting. We also faced some challenges with deploying our service to the cloud.
* Parallelizing load with DCP
## 🏆 Accomplishments that we're proud of
* Creating a platform where people can connect with one another, alleviating the stress of quarantine and social isolation
* Smooth and fluid UI with slick transitions
* Learning about and implementing a serverless back-end allowed for quick setup and iterating changes.
* Designing and Creating a functional REST API from scratch - You can make a POST request to our test endpoint (with your own interests) to get recommended quarantine activities anywhere, anytime 😊
e.g.
`curl -d '{"username":"turbo","location":"toronto,ca","mbti":"entp","music":["kpop"],"movies":["action"],"food":["sushi"]}' -H 'Content-Type: application/json' ' https://recgate-1g9rdgr6.uc.gateway.dev/rec'`
## 🚀 What we learned
* Balancing the trade-off between computational cost and scheduling delay for parallel computing can be a fun problem :)
* Moving server-based architecture (Flask) to Serverless in the cloud ☁
* How to design and deploy APIs and structure good schema for our developers and users
## ⏩ What's next for Friendle
* Make a web-app for desktop users 😎
* Improve matching algorithms and architecture
* Adding a messaging component to the app
|
## Inspiration
1 in 2 Canadians will personally experience a mental health issue by age 40, with minority communities at a greater risk. As the mental health epidemic surges and support at its capacity, we sought to build something to connect trained volunteer companions with people in distress in several ways for convenience.
## What it does
Vulnerable individuals are able to call or text any available trained volunteers during a crisis. If needed, they are also able to schedule an in-person meet-up for additional assistance. A 24/7 chatbot is also available to assist through appropriate conversation. You are able to do this anonymously, anywhere, on any device to increase accessibility and comfort.
## How I built it
Using Figma, we designed the front end and exported the frame into Reacts using Acovode for back end development.
## Challenges I ran into
Setting up the firebase to connect to the front end react app.
## Accomplishments that I'm proud of
Proud of the final look of the app/site with its clean, minimalistic design.
## What I learned
The need for mental health accessibility is essential but unmet still with all the recent efforts. Using Figma, firebase and trying out many open-source platforms to build apps.
## What's next for HearMeOut
We hope to increase chatbot’s support and teach it to diagnose mental disorders using publicly accessible data. We also hope to develop a modeled approach with specific guidelines and rules in a variety of languages.
|
## Inspiration
BThere emerged from a genuine desire to strengthen friendships by addressing the subtle challenges in understanding friends on a deeper level. The team recognized that nuanced conversations often go unnoticed, hindering meaningful support and genuine interactions. In the context of the COVID-19 pandemic, the shift to virtual communication intensified these challenges, making it harder to connect on a profound level. Lockdowns and social distancing amplified feelings of isolation, and the absence of in-person cues made understanding friends even more complex. BThere aims to use advanced technologies to overcome these obstacles, fostering stronger and more authentic connections in a world where the value of meaningful interactions has become increasingly apparent.
## What it does
BThere is a friend-assisting application that utilizes cutting-edge technologies to analyze conversations and provide insightful suggestions for users to connect with their friends on a deeper level. By recording conversations through video, the application employs Google Cloud's facial recognition and speech-to-text APIs to understand the friend's mood, likes, and dislikes. The OpenAI API generates personalized suggestions based on this analysis, offering recommendations to uplift a friend in moments of sadness or providing conversation topics and activities for neutral or happy states. The backend, powered by Python Flask, handles data storage using Firebase for authentication and data persistence. The frontend is developed using React, JavaScript, Next.js, HTML, and CSS, creating a user-friendly interface for seamless interaction.
## How we built it
BThere involves a multi-faceted approach, incorporating various technologies and platforms to achieve its goals. The recording feature utilizes WebRTC for live video streaming to the backend through sockets, but also allows users to upload videos for analysis. Google Cloud's facial recognition API identifies facial expressions, while the speech-to-text API extracts spoken content. The combination of these outputs serves as input for the OpenAI API, generating personalized suggestions. The backend, implemented in Python Flask, manages data storage in Firebase, ensuring secure authentication and persistent data access. The frontend, developed using React, JavaScript, Next.js, HTML, and CSS, delivers an intuitive user interface.
## Accomplishments that we're proud of
* Successfully integrating multiple technologies into a cohesive and functional application
* Developing a user-friendly frontend for a seamless experience
* Implementing real-time video streaming using WebRTC and sockets
* Leveraging Google Cloud and OpenAI APIs for advanced facial recognition, speech-to-text, and suggestion generation
## What's next for BThere
* Continuously optimizing the speech to text and emotion analysis model for improved accuracy with different accents, speech mannerisms, and languages
* Exploring advanced natural language processing (NLP) techniques to enhance conversational analysis
* Enhancing user experience through further personalization and more privacy features
* Conducting user feedback sessions to refine and expand the application's capabilities
|
winning
|
## Inspiration
The inspiration for this project was drawn from the daily experiences of our team members. As post-secondary students, we often make purchases for our peers for convenience, yet forget to follow up. This can lead to disagreements and accountability issues. Thus, we came up with the idea of CashDat, to alleviate this commonly faced issue. People will no longer have to remind their friends about paying them back! With the available API’s, we realized that we could create an application to directly tackle this problem.
## What it does
CashDat is an application available on the iOS platform that allows users to keep track of who owes them money, as well as who they owe money to. Users are able to scan their receipts, divide the costs with other people, and send requests for e-transfer.
## How we built it
We used Xcode to program a multi-view app and implement all the screens/features necessary.
We used Python and Optical Character Recognition (OCR) built inside Google Cloud Vision API to implement text extraction using AI on the cloud. This was used specifically to draw item names and prices from the scanned receipts.
We used Google Firebase to store user login information, receipt images, as well as recorded transactions and transaction details.
Figma was utilized to design the front-end mobile interface that users interact with. The application itself was primarily developed with Swift with focus on iOS support.
## Challenges we ran into
We found that we had a lot of great ideas for utilizing sponsor APIs, but due to time constraints we were unable to fully implement them.
The main challenge was incorporating the Request Money option with the Interac API into our application and Swift code. We found that since the API was in BETA made it difficult to implement it onto an IOS app. We certainly hope to work on the implementation of the Interac API as it is a crucial part of our product.
## Accomplishments that we're proud of
Overall, our team was able to develop a functioning application and were able to use new APIs provided by sponsors. We used modern design elements and integrated that with the software.
## What we learned
We learned about implementing different APIs and overall IOS development. We also had very little experience with flask backend deployment process. This proved to be quite difficult at first, but we learned about setting up environment variables and off-site server setup.
## What's next for CashDat
We see a great opportunity for the further development of CashDat as it helps streamline the process of current payment methods. We plan on continuing to develop this application to further optimize user experience.
|
## Inspiration
test
## What it does
## How I built it
## Challenges I ran into
## Accomplishments that I'm proud of
## What I learned
## What's next for Driving Safety
|
## Inspiration
Every time we go out with friends, it's always a pain to figure payments for each person. Charging people through Venmo is often tedious and requires lots of time. What we wanted to do was to make the whole process either by just easily scanning a receipt and then being able to charge your friends immediately.
## What it does
Our app takes a picture of a receipt and sends to a python server(that we made) which filters and manipulates the image before performing OCR. Afterwards, the OCR is parsed and the items and associated prices are sent to the main app where the user can then easily charge his friends for use of the service.
## How we built it
We built the front-end of the app using meteor to allow easy reactivity and fast browsing time. Meanwhile, we optimized the graphics so that the website works great on mobile screens. Afterwards, we send the photo data to a flask server where we run combination of python, c and bash code to pre-process and then analyze the sent images. Specifically, the following operations are performed for image processing:
1. RGB to Binary Thresholding
2. Canny Edge Detection
3. Probabilistic Hough Lines on Canny Image
4. Calculation of rotation disparity to warp image
5. Erosion to act as a flood-fill on letters
## Challenges we ran into
We ran into a lot of challenge actively getting the OCR from the receipts. Established libraries such Microsoft showed poor performance. As a result, we ended up testing and creating our own methods for preprocessing and then analyzing the images of receipts we received. We tried many different methods for different steps:
* Different thresholding methods (some of which are documented below)
* Different deskewing algorithms, including hough lines and bounding boxes to calculate skew angle
* Different morphological operators to increase clarity/recognition of texts.
Another difficulty we ran into was implementing UI such that it would run smoothly on mobile devices.
## Accomplishments that we're proud of
We're very proud of the robust parsing algorithm that we ended up creating to classify text from receipts.
## What we learned
The the building of SplitPay, we learned many different techniques in machine vision. We also learned about implementing communication between two web frameworks and about the reactivity used to build Meteor.
## What's next for SplitPay
In the future, we hope to continue the development of SplitPay and to make it easier to use, with easier browsing of friends and more integration with other external APIs, such as ones from Facebook, Microsoft, Uber, etc.
|
losing
|
A flower hunting game made using Godot.
Credits:
3D map model generated using [blender-osm](https://prochitecture.gumroad.com/l/blender-osm) with data from <https://www.openstreetmap.org/> (License: <https://www.openstreetmap.org/copyright>).
|
## Inspiration
I wanted to create a sense of freedom for users to explore and learn about different cultures across the planet by offering an engaging and limitless adventure in geographical and cultural discovery.
## What it does
The game prompts the user to give any description of a location, then transports the player to a 3D rendering of that location, where the player is then free to fly around to check out the area.
## How we built it
Used a Cesium Ion to stream 3D map tiles from Google Cloud to a Unity environment, where the map tiles are rendered to create a globe in the game. The game then prompts the user to provide a description of where they want to go, and that prompt is then sent to a ChatGPT 3.5 Turbo API, which replies with the precise latitude and longitude in decimal degrees, and latitude in meters. This information is then used transport the player to the desired location.
To create the immersive feel:
* Used a variety of methods like mouse input smoothing, momentum logic, torque physics, etc to create a smooth feeling flying mechanic.
* Made use of post-processing and particle effects, as well as dynamically changing their properties based on game state
-Tweaked many different parameters to make the game feel seamless
## Challenges we ran into
* Figuring out how to make the playing flying mechanic smooth and realistic.
* Cesium Ion did not provide ways to change location dynamically, so I had to look at the source code to figure out how to do it myself.
* ChatGPT keeps giving me the altitude of the object instead of the city, so sometimes my players gets transported far too high in the sky. For example if the user prompt is 'Mount Everest', ChatGPT will give me the altitude of the peak of the mountain rather than the base. This can be remedied by proving fine-tuning jobs, but this is not available on the free plan.
* Synchronizing all the different components of the game with each other and game state
* Unity keeps crashing for no reason
## What did we learn
-believe
## Accomplishments that we're proud of
* Visually appealing
* Smooth-ish
* Actually works
|
## Inspiration
I love videogames. There are so many things that we can't do in the real world because we are limited to the laws of physics. There are so many scenarios that would be too horrible to put ourselves in if it were the real world. But in the virtual world of videogames, you can make the impossible happen quite easily. But beyond that, they're just fun! Who doesn't enjoy some stress-relief from working hard at school to go and game with your friends? Especially now with COVID restrictions, videogames are a way for people to be interconnected and to have fun with each other without worrying about catching a deadly disease.
## What it does
The Streets of Edith Finch is a first-person shooter, battle royale style game built with the impressive graphics of Unreal Engine 4. Players are spawned into the unique level design where they can duke it out to be the last man/woman standing.
## How I built it
Using Unreal Engine 4 to simulate the physics and effects and develop the frameworks for actors. Textures are community-based from the Epic Games Community. Functionality, modes, and game rules were built in C++ and Blueprints (Kesmit) and developed directly in the engine's source code.
## Challenges I ran into
Unreal Engine has A LOT of modules and classes so navigation was definitely not easy especially since this my first time working with it. Furthermore, Unreal engine introduces a lot of Unreal specific syntaxes that do not follow traditional C++ syntax so that was also a learning curve. Furthermore, simulating the physics behind ragdolls and pushing over certain entities was also difficult to adjust.
## Accomplishments that I'm proud of
The fact that this is actually playable! Was not expecting the game to work out as well as it did given the limited experience and lack of manpower being a solo group.
## What I learned
I learned that game development on it's own is a whole other beast. The coding is merely a component of it. I had to consider textures and shadow rendering, animations, physics, and playability all on top of managing module cohesion and information hiding in the actual code.
## What's next for The Streets of Edith Finch
Make level design much larger - not enough time this time around. This will allow for support for more players (level is small so only about 2-3 players before it gets too hectic). Furthermore, spawn points need to be fixed as some players will spawn at same point. Crouching and sprinting animations need to be implemented as well as ADSing. Finally, player models are currently missing textures as I couldn't find any good ones in the community right now that weren't >$100 lol.
|
losing
|
## Inspiration
Last week, one of our team members was admitted to the hospital with brain trauma. Doctors hesitated to treat them because of their lack of insight into the patient’s medical history. This prompted us to store EVERYONE’s health records on a single, decentralized chain. The catch? The process is end-to-end encrypted, ensuring only yourself and your designated providers can access your data.
## How we built it
Zorg was built across 3 verticals: a frontend client, a backend server, and the chain.
The frontend client…
We poured our hearts and ingenuity into crafting a seamless user interface, a harmonious blend of aesthetics and functionality designed to resonate across the spectrum of users. Our aim? To simplify the process for patients to effortlessly navigate and control their medical records while enabling doctors and healthcare providers to seamlessly access and request patient information. Leveraging the synergy of Bun, React, Next, and Shadcn, we crafted a performant portal. To safeguard privacy, we fortified client-side interactions with encryption, ensuring sensitive data remains inaccessible to central servers. This fusion of technology and design principles heralds a new era of secure, user-centric digital healthcare record keeping.
The backend server…
The backend server of Zorg is the crux of our mission to revolutionize healthcare records management, ensuring secure, fast, and reliable access to encrypted patient data. Utilizing Zig for its performance and security advantages, our backend encrypts health records using a doctor's public key and stores them on IPFS for decentralized access. These records are then indexed on the blockchain via unique identifiers (CIDs), ensuring both privacy and immutability.
Upon request, the system retrieves and decrypts the data for authorized users, transforming it into a vectorized format suitable for semantic search. This process not only safeguards patient information but also enables healthcare providers to efficiently parse through detailed medical histories. Our use of Zig ensures that these operations are executed swiftly, maintaining our commitment to providing immediate access to critical medical information while prioritizing patient privacy and data integrity.
The chain…
The chain stores the encrypted key and the CID, allowing seemless access to a patient’s file stored on decentralized storage (IPFS). The cool part? The complex protocols and keys governing this system is completely abstracted away and wrapped up modern UI/UX, giving easy access to senior citizens and care providers.
## Challenges we ran into
Our biggest challenges were during integration, near the end of the hackathon. We had divided the project, with each person focusing on a different area—machine learning and queries, blockchain and key sharing, encryption and IPFS, and the frontend design. However, when we began to put things together, we quickly realized that we had failed to communicate with each other the specific details of how each of our systems worked. As a result we had to spend a few hours just tweaking each of our systems so that they could work with each other.
Another smaller (but enjoyable!) challenge we faced was learning to use a new language (Zig!). We ended up building our entire encryption and decryption system in Zig (as it needed to be incredibly fast due to the potentially vast amounts of data it would be processing) and had to piece together both how to build these systems in Zig, and how to integrate the resulting Zig binaries into the rest of our project.
## What's next for Zorg
In the future, we hope to devise a cryptographically sound way to revoke access to records after they have been granted. Additionally, our system would best benefit the population if we were able to partner with the government to include patient private keys in something everyone carries with them like their phone or ID so that in an emergency situation, first responders can access the patient data and identify things like allergies to medications.
|
## Summary
OrganSafe is a revolutionary web application that tackles the growing health & security problem of black marketing of donated organs. The verification of organ recipients leverages the Ethereum Blockchain to provide critical security and prevent improper allocation for such a pivotal resource.
## Inspiration
The [World Health Organization (WHO)](https://slate.com/business/2010/12/can-economists-make-the-system-for-organ-transplants-more-humane-and-efficient.html) estimates that one in every five kidneys transplanted per year comes from the black market. There is a significant demand for solving this problem which impacts thousands of people every year who are struggling to find a donor for a significantly need transplant. Modern [research](https://ieeexplore.ieee.org/document/8974526) has shown that blockchain validation of organ donation transactions can help reduce this problem and authenticate transactions to ensure that donated organs go to the right place!
## What it does
OrganSafe facilitates organ donations with authentication via the Ethereum Blockchain. Users can start by registering on OrganSafe with their health information and desired donation and then application's algorithms will automatically match the users based on qualifying priority for available donations. Hospitals can easily track donations of organs and easily record when recipients receive their donation.
## How we built it
This application was built using React.js for the frontend of the platform, Python Flask for the backend and API endpoints, and Solidity+Web3.js for Ethereum Blockchain.
## Challenges we ran into
Some of the biggest challenges we ran into were connecting the different components of our project. We had three major components: frontend, backend, and the blockchain that were developed on that needed to be integrated together. This turned to be the biggest hurdle in our project that we needed to figure out. Dealing with the API endpoints and Solidarity integration was one of the problems we had to leave for future developments. One solution to a challenge we solved was dealing with difficulty of the backend development and setting up API endpoints. Without a persistent data storage in the backend, we attempted to implement basic storage using localStorage in the browser to facilitate a user experience. This allowed us to implement a majority of our features as a temporary fix for our demonstration. Some other challenges we faced included figuring certain syntactical elements to the new technologies we dealt (such as using Hooks and States in React.js). It was a great learning opportunity for our group as immersing ourselves in the project allowed us to become more familiar with each technology!
## Accomplishments that we're proud of
One notable accomplishment is that every member of our group interface with new technology that we had little to no experience with! Whether it was learning how to use React.js (such as learning about React fragments) or working with Web3.0 technology such as the Ethereum Blockchain (using MetaMask and Solidity), each member worked on something completely new! Although there were many components we simply just did not have the time to complete due to the scope of TreeHacks, we were still proud with being able to put together a minimum viable product in the end!
## What we learned
* Fullstack Web Development (with React.js frontend development and Python Flask backend development)
* Web3.0 & Security (with Solidity & Ethereum Blockchain)
## What's next for OrganSafe
After TreeHacks, OrganSafe will first look to tackle some of the potential areas that we did not get to finish during the time of the Hackathon. Our first step would be to finish development of the full stack web application that we intended by fleshing out our backend and moving forward from there. Persistent user data in a data base would also allow users and donors to continue to use the site even after an individual session. Furthermore, scaling both the site and the blockchain for the application would allow greater usage by a larger audience, allowing more recipients to be matched with donors.
|
## Inspiration
As three of our team members are international students, we encountered challenges when transferring our medical records from our home countries to the United States. Because of poor transferability of medical records, we would end up retaking vaccines we had already received in our home countries and wasted a lot of our time collecting our medical records. Moreover, even within the US, we noticed that medical records were often fragmented, with each hospital maintaining its own separate records. These experiences inspired us to create a solution that simplifies the secure transfer of medical records, making healthcare more efficient and accessible for everyone.
## What it does
HealthChain.ai allows for medical records to be parsed by AI, and stored as non-fungible tokens on the Ethereum blockchain. The blockchain takes away a central authority to remove long wait times for document requests and allows for easy access by record holders and hospitals. AI parsing allows for easy integration between differing hospital systems and international regulations.
## How we built it
Our frontend uses Next.js with tailwind and typescript, and is deployed on Vercel. We used OpenAI to process text input into json to store on our block chain. Our backend used Solidity to write our smart contracts, and broadcast it to the Ethereum block chain using the Alchemy API. We used custom NodeJS API calls to connect the Ethereum block chain to our frontend, and deployed this on vercel as well. This all integrates into the MetaMask API on our frontend which displays NFTs in your Ethereum wallet.
## Challenges we ran into
Our original plan was to use Aleo as our Blockchain of choice for our app. But after working with the Aleo’s developers we discovered that the chain's testnet was not working and we couldn't deploy our smart contract. We had to redevelop our Smart Contracts in Solidity and test on the Sepolia, one of the Ethereum testnet. Even then, learning how to navigate through the deployment process and getting the wallets to connect to the chain to interact with our Smart Contracts proved to be one of our biggest challenges.
## Accomplishments that we're proud of
We were able to upload our smart contract and able to retrieve data from the chain which allowed our use of the OpenAi API to parse the information retrieved into more understandable, formatted medical records. We are able to apply decentralized finance along with AI which is a huge challenge, we are proud to be able to pull this off.
## What we learned
Throughout the hacking of our project, we learned quite a lot such as concepts of Blockchain, cryptography and Machine Learning. On top of learning all these concepts we've learnt how to combine them together through frontend and API calls which is crucial in fullstack development.
## What's next for HealthChain.ai
In our upcoming version, we have exciting plans to introduce additional features that we envisioned during the project's development but were constrained by time. These enhancements encompass the integration of speech-to-text for recording medical records, the implementation of OCR technology to convert traditional paper medical records into electronic formats (EMRs), and a comprehensive user interface redesign to simplify the organization of personal medical records. Last but not least, we also want to collaborate with hospitals to bring accessible medical records to the mass market and listen to our customers on what they really want and need.
|
winning
|
## Inspiration
The process of renting is often tedious, repetitive, and exhausting for both renters and landlords. Why not make it efficient, fun, and enjoyable instead? For renters, no more desperately sifting through Marketplace, Craigslist, and shooting messages and applications into an abyss. For landlords, no more keeping track of prospective tenants' references and rent history through a series of back-and-forth messages.
## What it does
Rent2Be is a mobile application that borrows from Tinder's iconic concept of swiping left and right, effectively streamlining the renting process for both renters and landlords. Find your perfect match, truly **rent to be**!
From the renter's perspective, we query their potential matches based on their preferences (e.g. budget, location, move-in date, lease length, beds/baths, amenities, commute preferences, etc.). In their feed, renters can then swipe right for listings they're interested in and left for listings that don't fit their criteria.
On the other end, landlords can create their listings for the current rental database. The landlord's feed will be populated with the profiles of renters interested in that particular listing - if the landlord also swipes right on the renter, it's a match!
Upon matching, the pair will have an open chat session for further discussion and access to additional tenant details such as reference contact information.
## How we built it
* The frontend is built with React Native and expo.
* Our backend is powered by CockroachDB Serverless with "global locality" rows.
* The UI/UX design is created with Figma.
## Challenges we ran into
* Dependency discrepancies across each of our commits would occasionally lead to merge conflicts.
* Integrating CockroachDB for the first time.
* Considering the privacy and security risks of an app that handles highly confidential information (e.g. occupation, salary, credit score, etc.).
## Accomplishments that we're proud of
* With CockroachDB we're setting a “global” locality for low-latency reads and high-latency writes. We saw this as a key benefit given there are significantly more read operations (repeated viewings of each profile/listing) than write operations (creation of these profiles/listings), there are typically more renters than landlords. We may sacrifice fewer users for greater users, though this provides an overall better user experience for all types of users (without excluding those that are regionally further, such as internationals that may be doing market research before immigration or moving abroad).
* Using the benefits of serverless CockroachDB to automatically scale (and shard) for more popular geographic reasons. We would have to monitor and perform this manually otherwise.
* Leveraging CockroachDB's details and integrations to enhance user experience and minimize engineer efforts where possible.
* Creating a UI design that balances fun, energetic vibes with a professional, trustworthy feeling.
## What we learned
* Testing live on our mobile devices with expo and React Native
* How to set up and use CockroachDB Serverless, creating clusters and importing data in the database
* How to throw Water-LOO gxng signs (via will.i.am)
## What's next for Rent2Be
There are so many features in the future of Rent2Be!
A big part of the renting process is the viewings - Rent2Be renters will be able to book an appointment as soon as there is a match. Landlords will fill in their calendar availability ahead of time and renters will be able to book directly in-app as soon as there's a match.
Community feedback is crucial and often a great source for making decisions - as such, Rent2Be will also have features for leaving reviews on both renters and landlords. Whether it's a review from previous tenants on the apartment listed by a landlord or a space for landlords to leave their tenants a reference letter once their lease ends, feedback from both ends will help to improve the overall user experience.
Rent2Be also has the potential to handle areas such as payment. Since this app already aims to mitigate the inefficiencies of the current rent processes, combining pay onto one platform will only make lives easier. This would also be an opportunity to work with payment or banking APIs as well as Security practices.
|
## Inspiration
Finding a good place to live is time consuming and hard.
Let's make it a little better.
## What it does
It enables its users to transfer their lease on a very intuitive and simple platform thanks to high web technologies.
## How we built it
We built it using Google App Engine and its built-in nosql datastore.
All webpages are constructed in jsp allowing more exposure to the backend functionalities.
User management comes with them as a package and thus it currently supports only google account users.
## Challenges we ran into
We were working on different environments and the difference in our setup often broke the project setup and even the whole app..!
Also, we had to learn new concepts to implement some of the essential features such as search, pagination, multiple file uploading, and dealing with web technology libraries to display the UI pretty.
## Accomplishments that we're proud of
Albeit it may seem ugly, our first prototype is out at 'leasetransfer.tech' and it has all the basic functionalities running that we intended to have from the beginning.
## What we learned
We are learning from our painful mistakes: we should try our best to work in a same development environment.
Also, we learned that McHacks16 is awesome.
## What's next for leasetransfer
After users will have used it, we will verify their feedbacks and figure out where to improve and we will keep improving its UI and make it ready for bigger scale.
|
Inspiration
The genesis of LeaseEase lies in the escalating housing crisis in Canada, where landlords have increasingly exploited students and other vulnerable groups. Recognizing the urgent need for accessible legal resources, we envisioned LeaseEase as a beacon of support and empowerment. Our goal was to create a tool that simplifies the complexities of tenant rights under the Canadian Residential Tenancy Act, making legal protection accessible to those who need it most.
What It Does
LeaseEase is a groundbreaking application that combines a Large Language Model (LLM) with Retrieval-Augmented Generation (RAG) to interpret and apply the Canadian Residential Tenancy Act. It transforms user queries into actionable advice and automatically generates crucial legal documents, such as T1 and N7 forms. This functionality ensures that underprivileged groups are not only informed but also equipped to assert their rights effectively.
How We Built It
Our journey in building LeaseEase was a blend of innovative technologies and user-centric design. We utilized Streamlit for an intuitive front-end experience, integrating OpenAI and Cohere for the NLP and LLM functionalities. The backbone of our data operations was ChromaDB, a vector database, and we leveraged LangChain to seamlessly connect all these components.
Challenges We Ran Into
Developing LeaseEase was not without its hurdles. Integrating the backend with the frontend to accurately display the agent's thought process and RAG citations was a significant challenge. Additionally, creating the vector database and formatting the Residential Tenancy Act document appropriately required considerable effort and ingenuity.
Accomplishments That We're Proud Of
We take immense pride in LeaseEase's combination of aesthetic design and sophisticated technology. The implementation of the function calling feature and the streaming capability are particular highlights, demonstrating the effective use of RAG and LangChain agents. These features not only enhance the user experience but also validate our technological choices.
What We Learned
This project was a profound learning experience. Beyond mastering technical tools like Streamlit, LangChain, and various aspects of LLM technologies, we gained insights into the social implications of technology. We understood how the inaccessibility of legal resources can disadvantage vulnerable populations, reinforcing our commitment to tech for social good.
What's Next for LeaseEase
Looking forward, we aim to expand the range of forms LeaseEase can produce and enhance the reasoning capabilities of the LLM. We are excited about potential collaborations with government bodies or tribunals, which could include direct submission features for the forms generated. The future of LeaseEase is not just about technological advancement but also about deepening our impact on social justice and community empowerment.
|
losing
|
## Inspiration
“**Social media sucks these days.**” — These were the first few words we heard from one of the speakers at the opening ceremony, and they struck a chord with us.
I’ve never genuinely felt good while being on my phone, and like many others I started viewing social media as nothing more than a source of distraction from my real life and the things I really cared about.
In December 2019, I deleted my accounts on Facebook, Instagram, Snapchat, and WhatsApp.
For the first few months — I honestly felt great. I got work done, focused on my small but valuable social circle, and didn’t spend hours on my phone.
But one year into my social media detox, I realized that **something substantial was still missing.** I had personal goals, routines, and daily checklists of what I did and what I needed to do — but I wasn’t talking about them. By not having social media I bypassed superficial and addictive content, but I was also entirely disconnected from my network of friends and acquaintances. Almost no one knew what I was up to, and I didn’t know what anyone was up to either. A part of me longed for a level of social interaction more sophisticated than Gmail, but I didn’t want to go back to the forms of social media I had escaped from.
One of the key aspects of being human is **personal growth and development** — having a set of values and living them out consistently. Especially in the age of excess content and the disorder of its partly-consumed debris, more people are craving a sense of **routine, orientation, and purpose** in their lives. But it’s undeniable that **humans are social animals** — we also crave **social interaction, entertainment, and being up-to-date with new trends.**
Our team’s problem with current social media is its attention-based reward system. Most platforms reward users based on numeric values of attention, through measures such as likes, comments and followers. Because of this reward system, people are inclined to create more appealing, artificial, and addictive content. This has led to some of the things we hate about social media today — **addictive and superficial content, and the scarcity of genuine interactions with people in the network.**
This leads to a **backward-looking user-experience** in social media. The person in the 1080x1080 square post is an ephemeral and limited representation of who the person really is. Once the ‘post’ button has been pressed, the post immediately becomes an invitation for users to trap themselves in the past — to feel dopamine boosts from likes and comments that have been designed to make them addicted to the platform and waste more time, ultimately **distorting users’ perception of themselves, and discouraging their personal growth outside of social media.**
In essence — We define the question of reinventing social media as the following:
*“How can social media align personal growth and development with meaningful content and genuine interaction among users?”*
**Our answer is High Resolution — a social media platform that orients people’s lives toward an overarching purpose and connects them with liked-minded, goal-oriented people.**
The platform seeks to do the following:
**1. Motivate users to visualize and consistently achieve healthy resolutions for personal growth**
**2. Promote genuine social interaction through the pursuit of shared interests and values**
**3. Allow users to see themselves and others for who they really are and want to be, through natural, progress-inspired content**
## What it does
The following are the functionalities of High Resolution (so far!):
After Log in or Sign Up:
**1. Create Resolution**
* Name your resolution, whether it be Learning Advanced Korean, or Spending More Time with Family.
* Set an end date to the resolution — i.e. December 31, 2022
* Set intervals that you want to commit to this goal for (Daily / Weekly / Monthly)
**2. Profile Page**
* Ongoing Resolutions
+ Ongoing resolutions and level of progress
+ Clicking on a resolution opens up the timeline of that resolution, containing all relevant posts and intervals
+ Option to create a new resolution, or ‘Discover’ resolutions
* ‘Discover’ Page
+ Explore other users’ resolutions, that you may be interested in
+ Clicking on a resolution opens up the timeline of that resolution, allowing you to view the user’s past posts and progress for that particular resolution and be inspired and motivated!
+ Clicking on a user takes you to that person’s profile
* Past Resolutions
+ Past resolutions and level of completion
+ Resolutions can either be fully completed or partly completed
+ Clicking on a past resolution opens up the timeline of that resolution, containing all relevant posts and intervals
**3. Search Bar**
* Search for and navigate to other users’ profiles!
**4. Sentiment Analysis based on IBM Watson to warn against highly negative or destructive content**
* Two functions for sentiment analysis textual data on platform:
* One function to analyze the overall positivity/negativity of the text
* Another function to analyze the user of the amount of joy, sadness, anger and disgust
* When the user tries to create a resolution that seems to be triggered by negativity, sadness, fear or anger, we show them a gentle alert that this may not be best for them, and ask if they would like to receive some support.
* In the future, we can further implement this feature to do the same for comments on posts.
* This particular functionality has been demo'ed in the video, during the new resolution creation.
* **There are two purposes for this functionality**:
* a) We want all our members to feel that they are in a safe space, and while they are free to express themselves freely, we also want to make sure that their verbal actions do not pose a threat to themselves or to others.
* b) Current social media has shown to be a propagator of hate speech leading to violent attacks in real life. One prime example are the Easter Attacks that took place in Sri Lanka exactly a year ago: <https://www.bbc.com/news/technology-48022530>
* If social media had a mechanism to prevent such speech from being rampant, the possibility of such incidents occurring could have been reduced.
* Our aim is not to police speech, but rather to make people more aware of the impact of their words, and in doing so also try to provide resources or guidance to help people with emotional stress that they might be feeling on a day-to-day basis.
* We believe that education at the grassroots level through social media will have an impact on elevating the overall wellbeing of society.
## How we built it
Our tech stack primarily consisted of React (with Material UI), Firebase and IBM Watson APIs. For the purpose of this project, we opted to use the full functionality of Firebase to handle the vast majority of functionality that would typically be done on a classic backend service built with NodeJS, etc. We also used Figma to prototype the platform, while IBM Watson was used for its Natural Language toolkits, in order to evaluate sentiment and emotion.
## Challenges we ran into
A bulk of the challenges we encountered had to do with React Hooks. A lot of us were only familiar with an older version of React that opted for class components instead of functional components, so getting used to Hooks took a bit of time.
Another issue that arose was pulling data from our Firebase datastore. Again, this was a result of lack of experience with serverless architecture, but we were able to pull through in the end.
## Accomplishments that we're proud of
We’re really happy that we were able to implement most of the functionality that we set out to when we first envisioned this idea. We admit that we might have bit a lot more than we could chew as we set out to recreate an entire social platform in a short amount of time, but we believe that the proof of concept is demonstrated through our demo
## What we learned
Through research and long contemplation on social media, we learned a lot about the shortcomings of modern social media platforms, for instance how they facilitate unhealthy addictive mechanisms that limit personal growth and genuine social connection, as well as how they have failed in various cases of social tragedies and hate speech. With that in mind, we set out to build a platform that could be on the forefront of a new form of social media.
From a technical standpoint, we learned a ton about how Firebase works, and we were quite amazed at how well we were able to work with it without a traditional backend.
## What's next for High Resolution
One of the first things that we’d like to implement next, is the ‘Group Resolution’ functionality. As of now, users browse through the platform, find and connect with liked-minded people pursuing similarly-themed interests. We think it would be interesting to allow users to create and pursue group resolutions with other users, to form more closely-knitted and supportive communities with people who are actively communicating and working towards achieving the same resolution.
We would also like to develop a sophisticated algorithm to tailor the users’ ‘Discover’ page, so that the shown content is relevant to their past resolutions. For instance, if the user has completed goals such as ‘Wake Up at 5:00AM’, and ‘Eat breakfast everyday’, we would recommend resolutions like ‘Morning jog’ on the discover page. By recommending content and resolutions based on past successful resolutions, we would motivate users to move onto the next step. In the case that a certain resolution was recommended because a user failed to complete a past resolution, we would be able to motivate them to pursue similar resolutions based on what we think is the direction the user wants to head towards.
We also think that High Resolution could be potentially become a platform for recruiters to spot dedicated and hardworking talent, through the visualization of users’ motivation, consistency, and progress. Recruiters may also be able to user the platform to communicate with users and host online workshops or events .
WIth more classes and educational content transitioning online, we think the platform could serve as a host for online lessons and bootcamps for users interested in various topics such as coding, music, gaming, art, and languages, as we envision our platform being highly compatible with existing online educational platforms such as Udemy, Leetcode, KhanAcademy, Duolingo, etc.
The overarching theme of High Resolution is **motivation, consistency, and growth.** We believe that having a user base that adheres passionately to these themes will open to new opportunities and both individual and collective growth.
|
## Inspiration
It took us a while to think of an idea for this project- after a long day of zoom school, we sat down on Friday with very little motivation to do work. As we pushed through this lack of drive our friends in the other room would offer little encouragements to keep us going and we started to realize just how powerful those comments are. For all people working online, and university students in particular, the struggle to balance life on and off the screen is difficult. We often find ourselves forgetting to do daily tasks like drink enough water or even just take a small break, and, when we do, there is very often negativity towards the idea of rest. This is where You're Doing Great comes in.
## What it does
Our web application is focused on helping students and online workers alike stay motivated throughout the day while making the time and space to care for their physical and mental health. Users are able to select different kinds of activities that they want to be reminded about (e.g. drinking water, eating food, movement, etc.) and they can also input messages that they find personally motivational. Then, throughout the day (at their own predetermined intervals) they will receive random positive messages, either through text or call, that will inspire and encourage. There is also an additional feature where users can send messages to friends so that they can share warmth and support because we are all going through it together. Lastly, we understand that sometimes positivity and understanding aren't enough for what someone is going through and so we have a list of further resources available on our site.
## How we built it
We built it using:
* AWS
+ DynamoDB
+ Lambda
+ Cognito
+ APIGateway
+ Amplify
* React
+ Redux
+ React-Dom
+ MaterialUI
* serverless
* Twilio
* Domain.com
* Netlify
## Challenges we ran into
Centring divs should not be so difficult :(
Transferring the name servers from domain.com to Netlify
Serverless deploying with dependencies
## Accomplishments that we're proud of
Our logo!
It works :)
## What we learned
We learned how to host a domain and we improved our front-end html/css skills
## What's next for You're Doing Great
We could always implement more reminder features and we could refine our friends feature so that people can only include selected individuals. Additionally, we could add a chatbot functionality so that users could do a little check in when they get a message.
|
## Inspiration🎓
To make the context clear, we are three students who believe that meaningful work facilitates self-content, inspiration and projects that either help others or ourselves. Since we joined university(we are all first-years), we did not find what we did so meaningful anymore. We had great expectations since we were all enrolled in a top 100 university. Still, we were surprised to see how little they cared about our creativity, ideas, and overall potential. Things were too theoretical; some answers in different disciplines, which turned out to be correct, **were dismissed because they were not based on ”the old ways”**.
**Also, there was no easy way to cooperate with other disciplines.** Unless you go out partying, and by some luck, you are not an introvert, there is no easy way to meet someone. For example, maybe as a business student, you cannot really meet someone from computer science or design so easily. Unless you go out of your way, there is no simple way to meet like-minded people that could help you create something meaningful.
Obviously, there are apps such as Instagram, Facebook, Linkedin, Reddit and fiver. Though, the way they are created and marketed, there is not much chance you find what you need. Almost no one answers messages from strangers on Instagram or Facebook. On LinkedIn, people are there for internships and money, pretending to be some fancy intellectual. Reddit is not really used by that many students, not as a way to meet students anyways, and if you need a specialist on fiver for anything unless you are rich, good luck with paying him.
We want to create a safe place for us, young individuals, who want something more than base our happiness on exam grades, work for a corporation for our entire life after 3-5 years of grinding for good marks, for subjects that don’t necessarily help you at anything or where we can meet students from all the disciplines, not only our own.
**Everybody is a genius. But if you judge a fish by its ability to climb a tree, it will live its whole life believing that it is stupid”-actually not by Albert Einstein.**
We strongly advise people to pursue a university; we are not against it, though we advise not to base your life upon it; it’s great as a safety net and learning place. We don’t like the old premise of you will do nothing with your life unless you finish your degree we want to truly bring the youth to their true potential, not inhibit it. Each year, the crisis of meaning expands, especially in young individuals. If not give rebirth to it, we would love to contribute to providing students with another chance to create, develop and meet other great colleagues
## What it does🔧
**StudHub** is an app with different features that facilitate flow in terms of building projects, meeting open-minded individuals and discussing with and helping fellow students.
**The main features** will be the main page, creating a post(with a specific template) and a search bar. The main page will consist of projects posted based on a template that doesn’t reveal too much, though enough to make people get the idea. For example, you are a computer science student with a great app idea. You are a great back-end developer though you know nothing in UI/UX design; respectively, you are pretty introverted and don’t know how to actually create a brand out of it as well. By posting your idea succinctly and selecting the skills you need for your projects, people with those specific skills, if they like your idea, can send you a request to get in touch with you. On the other hand, you can also search for these people in the search bar.
As stated above, if you are a creative individual, you can post your ideas and find the people you need for projects. On the other hand, if you want to do something meaningful with your free time but you are sick of volunteering work that just gives you a diploma and a line in your cv, this is a place for you too!
**Other Features** consist of:
1. “Reddit-style” thread (we are still developing/designing our own style for this), where you can ask questions, discuss different topics, and search for answers to whatever questions you have. It can be mostly based around student problems, passions, anything really! We want to create a safe space for meeting other students too!
2. Messages
3. Notifications
4. Profile (where you can select your skills and write about yourself; we want the real you! We’ll try to make sure no prospective employer can judge you based on that!
5. Learning environment; in the future, here, we will create courses on practical topics that are important but not so often taught in university. (public speaking, leadership, etc.)
We initially viewed it as a website. We have started development on Firebase. Though during the hackathon we realized that our main target demographic(Students and young individuals) uses mostly their phones, which meant an app would be significantly better and preferred. Then we started working on Flutter.
## How we built it👨🎨
Using the Flutter framework, we built a cross-platform app (Android/IOS/Web). For the backend, we used Firebase as a provider, its Authentication module, and also Firebase Firestore for our NoSQL database.
## Challenges we ran into⚖️
The post feature is the greatest challenge, which is still in discussion. We want to build a template and guideline as straightforward as possible that does not disclose too many of the ideas that someone will just take it. We are thinking about how to implement NDAs when you get it to discuss with interested people, but right now, the focus is to create a working MVP.
The overall concept is pretty hard to explain without looking like we are against universities. We genuinely find them very important to one's individual development. We are actively working to find a way to tell our story and create a brand that supports creativity and the individual while not sounding too much against the traditional model.
Also, due to the many features we want to add, it is a constant struggle to make everything as efficient, aesthetic and easy as possible. We are pretty much in an age of attention deficit, so we want to build something neat and user-friendly.
## Accomplishments that we're proud of🧐
We are genuinely surprised by the fact that our app constantly worked almost without any problems throughout the whole 36h.
We have never fought on any subject; we constantly built on each other's ideas and realized that we work lovely as a team. Any problems we had were discussed calmly and found a middle way.
## What we learned 👩🏫
A new programming language we had never worked with Dart before until the start of the Hackathon!
A new framework, it was our first time on Flutter before either!
How to listen to each other more without interrupting. And most importantly, working without sleep for 36 hours and a lot of caffeine! :D
## What's next for StudHub🚀
We have discussed this thoroughly, and after the Hackathon, we need to find an affordable UX/UI designer (ironically enough, our app would have been so helpful for this) to either join our project or at least build a starting page where we can have a subscription list, where we could make the "proof of concept" for our idea.
Eventually, we will send emails with updates on the project. During this Hackathon, we realized how in love we are with this idea, and we want to continue building on it and eventually launching it.
For now, our focus will be to design it as efficient, aesthetic and user-friendly and make it functional. We want to go through what we built during the Hackathon to analyze what we did out of speed and what we want to keep. There are many things that need more thought.
We also want to add "Meet your Mentor"! In an even further future, we want to implement a feature where our dear users can talk with experienced people from a diverse array of subjects, ask for advice on a making project, open a business, start research, etc.
We hope that our concept will catch on and become a big trend, eventually leading to many young individuals with great potential to meet each other and build beautiful things! I personally feel lucky to have met the people I have worked within this Hackathon because they became some of my best friends that I spend much time with. We hope to take the luck element out and make it easier for people to meet such beautiful people, that not only they will create cool projects and businesses, but they will become maybe friends for life.
Do not forget, creating stuff is cool but meeting great people is sometimes even cooler!
|
partial
|
## Inspiration
I've tutored students in math and physics for many years and very early on, it quickly became evident that these students were incredibly bright, but they just never asked for clarification in class. Often in tutoring sessions, I am stuck wondering whether a student is confused or not and oftentimes it hinders the progression of the class. I can only wonder how it must be when it is not just a one on one interaction.
## What it does
1. Automatically takes attendance through facial recognition software using only one image. For deployment purposes, the image could be just a yearbook photo which nearly everyone takes.
2. Scans the emotions and facial expressions of the students in the classroom and tells the teacher when the majority of the students are confused.
## How I built it
For the frontend, a MVVM structure was created with UIKit in swift. The backend was built with python and flask. The facial recognition model came from openCV and the emotion recognition model was the VGG19 model trained on the FER-13 dataset.
## Challenges we ran into
The first main challenge was using flask for the backend because I had never done it before but it quickly became evident that it wasn't very difficult and was quite similar to HTTP requests in JavaScript. The next main challenge was getting both AI algorithms to run in tandem with each other and produce a combined output that could eventually be extracted with the HTTP requests. The final hurdle was creating all the niche features like tracking all the total time the students are in the classroom and warning the teacher about each student that is skipping class.
## Accomplishments that we're proud of
Building a fully functioning, ready to deploy app that can be used in public schools today in under 24 hours.
## What's next for teach.ai
I plan on trying to take this company forward. This is not just some idea I had for only a hackathon, but rather, my vision is much greater. This tool would be extremely useful all accross the country and could cause extreme changes in how our future generations grow and develop their minds. I plan on building a few fully working prototypes and seeing if I can try and deploy them in the schools near my house. From there I can build a reputation and scale the company further.
|
## Inspiration
**As Computer Science is a learning-intensive discipline, students tend to aspire to their professors**. We were inspired to hack this weekend by our beloved professor Daniel Zingaro (UTM). Answering questions in Dan's classes often ends up being a difficult part of our lectures, as Dan is visually impaired. This means students are expected to yell to get his attention when they have a question, directly interrupting the lecture. Teachers Pet could completely change the way Dan teaches and interacts with his students.
## What it does
Teacher's Pet (TP) empowers students and professors by making it easier to ask and answer questions in class. Our model helps to streamline lectures by allowing professors to efficiently target and destroy difficult and confusing areas in curriculum. Our module consists of an app, a server, and a camera. A professor, teacher, or presenter may download the TP app, and receive a push notification in the form of a discrete vibration whenever a student raises their hand for a question. This eliminates students feeling anxious for keeping their hands up, or professors receiving bad ratings for inadvertently neglecting students while focusing on teaching.
## How we built it
We utilized an Azure cognitive backend and had to manually train our AI model with over 300 images from around UofTHacks. Imagine four sleep-deprived kids running around a hackathon asking participants to "put your hands up". The AI is wrapped in a python interface, and takes input from a camera module. The camera module is hooked up to a Qualcomm dragonboard 410c, which hosts our python program. Upon registering, you may pair your smartphone to your TP device through our app, and set TP up in your classroom within seconds. Upon detecting a raised hand, TP will send a simple vibration to the phone in your pocket, allowing you to quickly answer a student query.
## Challenges we ran into
We had some trouble accurately differentiating when a student was stretching vs. actually raising their hand, so we took a sum of AI-guess-accuracies over 10 frames (250ms). This improved our AI success rate exponentially.
Another challenge we faced was installing the proper OS and drivers onto our Dragonboard. We had to "Learn2Google" all over again (for hours and hours). Luckily, we managed to get our board up and running, and our project was up and running!
## Accomplishments that we're proud of
Gosh darn we stayed up for a helluva long time - longer than any of us had previously. We also drank an absolutely disgusting amount of coffee and red bull. In all seriousness, we all are proud of each others commitment to the team. Nobody went to sleep while someone else was working. Teammates went on snack and coffee runs in freezing weather at 3AM. Smit actually said a curse word. Everyone assisted on every aspect to some degree, and in the end, that fact likely contributed to our completion of TP. The biggest accomplishment that came from this was knowledge of various new APIs, and the gratification that came with building something to help our fellow students and professors.
## What we learned
Among the biggest lessons we took away was that **patience is key**. Over the weekend, we struggled to work with datasets as well as our hardware. Initially, we tried to perfect as much as possible and stressed over what we had left to accomplish in the timeframe of 36 hours. We soon understood, based on words of wisdom from our mentors, that \_ the first prototype of anything is never perfect \_. We made compromises, but made sure not to cut corners. We did what we had to do to build something we (and our peers) would love.
## What's next for Teachers Pet
We want to put this in our own classroom. This week, our team plans to sit with our faculty to discuss the benefits and feasibility of such a solution.
|
## Inspiration
After years of teaching methods remaining constant, technology has not yet infiltrated the classroom to its full potential. One day in class, it occurred to us that there must be a correlation between students behaviour in classrooms and their level of comprehension.
## What it does
We leveraged Apple's existing API's around facial detection and combined it with the newly added Core ML features to track students emotions based on their facial queues. The app can follow and analyze up to ~ ten students and provide information in real time using our dashboard.
## How we built it
The iOS app integrated Apple's Core ML framework to run a [CNN](https://www.openu.ac.il/home/hassner/projects/cnn_emotions/) to detect people's emotions from facial queues. The model was then used in combination with Apple's Vision API to identify and extract student's face's. This data was then propagated to Firebase for it to be analyzed and displayed on a dashboard in real time.
## Challenges we ran into
Throughout this project, there were several issues regarding how to improve the accuracy of the facial results. Furthermore, there were issues regarding how to properly extract and track users throughout the length of the session. As for the dashboard, we ran into problems around how to display data in real time.
## Accomplishments that we're proud of
We are proud of the fact that we were able to build such a real-time solution. However, we are happy to have met such a great group of people to have worked with.
## What we learned
Ozzie learnt more regarding CoreML and Vision frameworks.
Haider gained more experience with front-end development as well as working on a team.
Nakul gained experience with real-time graphing as well as helped developed the dashboard.
## What's next for Flatline
In the future, Flatline could grow it's dashboard features to provide more insight for the teachers. Also, the accuracy of the results could be improved by training a model to detect emotions that are more closely related to learning and student's behaviours.
|
losing
|
## Inspiration 🐳
The inception of our platform was fueled by the growing water crises and the lack of accessible, real-time data on water quality. We recognized the urgent need for a tool that could offer immediate insights and predictive analyses on water quality. We aimed to bridge the gap between complex data and actionable insights, ensuring that every individual, community, and authority is equipped with precise information to make informed decisions.
## What it does❓
Our platform offers a dual solution of real-time water quality tracking and predictive analytics. It integrates data from 11 diverse sources, offering live, metric-based water quality indices. The predictive model, trained on a rich dataset of over 18,000 points, including 400 events, delivers 99.7% accurate predictions of water quality influenced by various parameters and events. Users can visualize these insights through intuitive heat maps and graphs, making the data accessible and actionable for a range of stakeholders, from concerned individuals and communities to governments and engineers.
We also developed an AR experience that allows users to interact with and visualize real time data points that the application provides, in addition to heat map layering to demonstrate the effectiveness and strength of the model.
## How we built it 🛠️
We harnessed the power of big data analytics and machine learning to construct our robust platform. The real-time tracking feature consolidates data from 11 different APIs, databases, and datasets, utilizing advanced algorithms to generate live water quality indices. The predictive model is a masterpiece of regression analysis, trained on a dataset enriched with 18,000 data points on >400 events, webscraped from three distinct big data sources. Our technology stack is scalable and versatile, ensuring accurate predictions and visualizations that empower users to monitor, plan, and act upon water quality data effectively.
## Challenges we ran into 😣
Collecting and consolidating a large enough dataset from numerous sources to attain unbiased information, finding sufficiently detailed 3D models, vectorizing the 1000s of text-based data points into meaningful vectors, hyperparameter optimization of the model to reduce errors to negligible amounts (1x10^-6 margin of error for values 1-10), and using the model's predictions and mathematical calculations to interpolate heat maps to accurately represent and visualize the data.
## Accomplishments that we're proud of 🔥
* A 99.7% accurate model that was self-trained on >18000 data points that we consolidated!
* Finding/scraping/consolidating data from turbidity indices & pH levels to social gatherings & future infrastructure projects!
* Providing intuitive, easily-understood visualizations of incredibly large and complex data sets!
* Using numerous GCP services ranging from compute, ML, satellite datasets, and more!
## What we learned 🤔
Blender, data sourcing, model optimization, and error handling were indubitably the greatest learning experiences for us over the course of these 36 hours!
|
# Harvest Hero: Cultivating Innovation
## Inspiration
Our journey began with a shared passion for addressing pressing challenges in agriculture. Witnessing the struggles faced by farmers globally due to unpredictable weather, soil degradation, and crop diseases, we were inspired to create a solution that could empower farmers and revolutionize traditional farming practices.
## Staggering Statistics
In the initial research phase, we delved into staggering statistics. According to the Food and Agriculture Organization (FAO), around 20-40% of global crop yields are lost annually due to pests and diseases. Additionally, improper crop conditions contribute significantly to reduced agricultural productivity.
Learning about these challenges fueled our determination to develop a comprehensive solution that integrates soil analysis, environmental monitoring, and disease detection using cutting-edge technologies.
## Building HarvestHero
### 1. **Soil and Environmental Analysis**
We incorporated state-of-the-art sensors and IoT devices to measure soil moisture and environmental conditions such as light, temperature, and humidity accurately. Online agricultural databases provided insights into optimal conditions for various crops.
### 2. **Deep Learning for Disease Classification**
To tackle the complex issue of plant diseases, we leveraged deep learning algorithms. TensorFlow and PyTorch became our allies as we trained our model on extensive datasets of diseased and healthy crops, sourced from global agricultural research institutions.
### 3. **User-Friendly Interface**
Understanding that farmers may not be tech-savvy, we focused on creating an intuitive user interface. Feedback from potential users during the development phase was invaluable in refining the design for practicality and accessibility.
### Challenges Faced
1. **Data Quality and Diversity**: Acquiring diverse and high-quality datasets for training the deep learning model posed a significant challenge. Cleaning and preprocessing the data demanded meticulous attention.
2. **Real-Time Connectivity**: Ensuring real-time connectivity in remote agricultural areas was challenging. We had to optimize our system to function efficiently even in low-bandwidth environments.
3. **Algorithm Fine-Tuning**: Achieving a balance between sensitivity and specificity in disease detection was an ongoing process. Iterative testing and refining were essential to enhance the model's accuracy.
## Impact
HarvestHero aims to mitigate crop losses, boost yields, and contribute to sustainable agriculture. By addressing key pain points in farming, we aspire to make a meaningful impact on global food security. Our journey has not only been about developing a product but also about learning, adapting, and collaborating to create positive change in the agricultural landscape.
As we look to the future, we are excited about the potential of HarvestHero to empower farmers, enhance agricultural practices, and play a role in creating a more resilient and sustainable food system for generations to come.
|
## Inspiration
While attending Hack the 6ix, our team had a chance to speak to Advait from the Warp team. We got to learn about terminals and how he got involved with Warp, as well as his interest in developing something completely new for the 21st century. Through this interaction, my team decided we wanted to make an AI-powered developer tool as well, which gave us the idea for Code Cure!
## What it does
Code Cure can call your python file and run it for you. Once it runs, you will see your output as usual in your terminal, but if you experience any errors, our extension runs and gives some suggestions in a pop-up as to how you may fix it.
## How we built it
We made use of Azure's OpenAI service to power our AI code fixing suggestions and used javascript to program the rest of the logic behind our VS code extension.
## Accomplishments that we're proud of
We were able to develop an awesome AI-powered tool that can help users fix errors in their python code. We believe this project will serve as a gateway for more people to learn about programming, as it provides an easier way for people to find solutions to their errors.
## What's next for Code Cure
As of now, we are only able to send our output through a popup on the user's screen. In the future, we would like to implement a stylized tab where we are able to show the user different suggestions using the most powerful AI models available to us.
|
partial
|
## Inspiration
We wanted to be able to allow people to understand the news they read in context because often times, we ourselves will read about events happening on the other side of the globe, but we have no idea where it is. So we wanted a way to visualize the news along with it's place in the world.
## What it does
Visualize the news as it happens in real-time, all around the world. Each day, GLOBEal aggregates news and geotags it, allowing the news to be experienced in a more lucid and immersive manner. Double click on a location and see what's happening there right now. Look into the past and see how the world shifts as history is made.
## How we built it
We used WebGL's Open Globe Platform to display magnitudes of popularity that were determined by a "pagerank" we made by crawling google ourselves and using WebHose API's. We used python scripts to create these crawlers and API calls, and then populated JSON files. We also used javascript with google maps, here maps, and google news apis in order to allow a user to double click on the globe to see the news from that location.
## Challenges we ran into
Google blocked our IPs because our web crawler made too many queries/second
Our query needs were too many for the free version of WebHose, so we called them and got a deal where they gave us free queries in exchange for attribution. So shout out to [webhose.io](http://webhose.io)!!!
## Accomplishments that we're proud of
Learned how to make web crawlers, how to use javascript/html/css, and developed a partnership with Webhose
Made a cool app!
## What we learned
Javascript, Firebase, webhose, how to survive without sleep
## What's next for GLOBEal News
INTERGALACTIC NEWS!
Work more on timelapse
Faster update times
Tags on globe directly
Click through mouse rather than camera ray
|
NOTE: We have a new ZIP uploaded to the itch.io link.
## Inspiration
We're big fans of the hip-hop artist Gucci Mane, and we've always wanted to play around with Amazon's Alexa system. Voice controls are always a fun gimmick in games, so we decided to try out hooking up the Alexa with Unity.
## What it does
The game is a simple 2D stage, in the style of Nintendo's Super Smash Brothers. The player controls Gucci Mane with the arrow keys. Gucci Mane fires a stream of projectiles, which can be changed by voice commands to the Amazon Echo. For example "Hey Alexa, tell Gucci to set the lemons!" will make Gucci fire a stream of lemons. The available projectiles are: Bricks, Lemonade, and Ice. When the equipped projectile is switched, the background music changes. There's no real gameplay, but it's fun to mess around with it! We think of it as a proof of concept :)
## How we built it
A new Alexa skill was created using the AWS console, and we connected the skill to an AWS Lambda function which changed the state of a Firebase store. On the Unity side, we polled the Firebase store. The 2D game portions were built following different Unity tutorials. Most of the assets were designed with Photoshop.
## Challenges we ran into
We ran into difficulties at first setting up the Alexa skill. After that, the next issue was connecting the Lambda function with Firebase, and connecting Unity to Firebase. In the end, the hardest part was working with Unity to add enemies and projectiles.
## Accomplishments that we're proud of
The art came out really well, and the voice commands are really fun to play with!
## What we learned
Alexa skills are really powerful! Setting up new skills with all sorts of intents is actually not that difficult, it just has a little bit of a learning curve because the GUI is a little obtuse.
## What's next for Gucci Ice Party
Adding enemies, levels, and maybe more players!
|
## Inspiration
Research has shown us that new hires, women and under-represented minorities in the workplace could feel intimidated or uncomfortable in team meetings. Since the start of remote work, new hires lack the in real life connections, are unable to take a pulse of the group and are fearful to speak what’s on their mind. Majority of the time this is also due to more experienced individuals interrupting them or talking over them without giving them a chance to speak up. This feeling of being left out often makes people not contribute to their highest potential. Links to the reference studies and articles are at the bottom.
As new hire interns every summer, we personally experienced the communication and participation problem in team meetings and stand ups. We were new and felt intimidated to share our thoughts in fear of them being dismissed or ignored. Even though we were new hires and had little background, we still had some sound ideas and opinions to share that were instead bottled up inside us.
We found out that the situation is the same for women in general and especially under-represented minorities. We built this tool for ourselves and to those around us to feel comfortable and inclusive in team meetings. Companies and organizations must do their part in ensuring that their workplace is an inclusive community for all and that everyone has the opportunity to participate equally in their highest potential. With the pandemic and widespread adoption of virtual meetings, this is an important problem globally that we must all address and we believe Vocal aims to help solve it.
## What it does
Vocal empowers new hires, women, and under-represented minorities to be more involved and engaged in virtual meetings for a more inclusive team.
Google Chrome is extremely prevalent and our solution is a proof-of-concept Chrome Extension and Web Dashboard that works with Google Meet meetings. Later we would support others platforms such as Zoom, Webex, Skype, and others.
When the user joins the Google Meet meeting, our Extension automatically detects it and collects statistics regarding the participation of each team member. A percentage is shown next to their name to indicate their contribution and also a ranking is shown that indicates how often you spoke compared to others. When the meeting ends, all of this data is sent to the web app dashboard using Google Cloud and Firebase database. On the web app, the users can see their participation in the current meeting and progress from the past meetings with different metrics. Plants are how we gamify participation. Your personal plant grows, the more you contribute in meetings. Meetings are organized through sprints and contribution throughout the sprint will be reflected in the growth of the plant.
**Dashboard**: You can see your personal participation statistics. It show your plant, monthly interaction level graph, percent interaction with other team members (how often and which teammates you piggy back on when responding). Lastly, it also has Overall Statistics such as percent increase in interactions compared to last week, meeting participation streak, average engagement time, and total time spoken. You can see your growth in participation reflected in the plant growth. **Vocal provides lots of priceless data for the management, HR, and for the team overall to improve productivity and inclusivity.**
**Team**: Many times our teammates are stressed or go through other feelings but simply bottle it up. In the Team page, we provide Team Sentiment Graph and Team Sentiments. The graphs shows how everyone in the team has been feeling for the current sprint. Team members would check in anonymously at the end of the every week on how they’re feeling (Stressed, Anxious, Neutral, Calm, Joyful) and the whole team can see it. If someone’s feeling low, other teammates can reach out anonymously in the chat and offer them support and they both can choose to reveal their identity if they want. **Feeling that your team cares about you and your mental health can foster an inclusive community.**
**Sprints Garden**: This includes all of the previous sprints that you completed. It also shows the whole team’s garden so you can compare across teammates on how much you have been contributing relatively.
**Profile**: This is your personal profile where you will see your personal details, the plants you have grown in the past over all the sprints you have worked on - your forest, your anonymous conversations with your team members. Your garden is here to motivate you and help you grow more plants and ultimately contribute more to meetings.
**Ethics/Privacy: We found very interesting ways to collect speaking data without being intrusive. When the user is talking only the mic pulses are recorded and analyzed as a person spoken. No voice data or transcription is done to ensure that everyone can feel safe while using the extension.**
**Sustainability/Social Good**: Companies that use Vocal can partner to plant the trees grown during sprints in real life by partnering with organizations that plant real trees under the corporate social responsibility (CSR) initiative.
## How we built it
The System is made up of three independent modules.
Chrome Extension: This module works with Google meet and calculates the statistics of the people who joined the meet and stores the information of the amount of time an individual contributes and pushes those values to the database.
Firebase: It stores the stats available for each user and their meeting attended. Percentage contribution, their role, etc.
Web Dashboard: Contains the features listed above. It fetches data from firebase and then renders it to display 3 sections on the portal. a. Personal Garden - where an individual can see their overall performance, their stats and maintain a personal plant streak. b. Group Garden - where you can see the overall performance of the team, team sentiment, anonymous chat function. After each sprint cycle, individual plants are added to the nursery. c. Profile with personal meeting logs, ideas and thoughts taken in real-time calls.
## Challenges we ran into
We had challenges while connecting the database with the chrome extension. The Google Meet statistics was also difficult to do since we needed to find clever ways to collect the speaking statistics without infringing on privacy. Also, 36 hours was a very short time span for us to implement so many features, we faced a lot of time pressure but we learned to work well under pressure!
## Accomplishments that we're proud of
This was an important problem that we all deeply cared about since we saw people around us face this on a daily basis. We come from different backgrounds, but for this project we worked as one team and used our expertise, and learned what we weren’t familiar with in this project. We are so proud to have created a tool to make under-represented minorities, women and new hires feel more inclusive and involved.
We see this product as a tool we’d love to use when we start our professional journeys. Something that brings out the benefits of remote work, at the same time being tech that is humane and delightful to use.
## What's next for Vocal
Vocal is a B2B product that companies and organizations can purchase. The chrome extension to show meeting participation would be free for everyone. The dashboard and the analytics will be priced depending on the company. The number of insights and data that can be extracted from one data point(user participation) will be beneficial to the company (HR & Management) to make their workplace more inclusive and productive. The data can also be analyzed to promote inclusion initiatives and other events to support new hires, women, and under-represented minorities.
We already have so many use cases that were hard to build in the duration of the hackathon. Our next step would be to create a Mobile app, more Video Calling platform integrations including Zoom, Microsoft Teams, Devpost video call, and implement chat features. We also see this also helping in other industries like ed-tech, where teachers and students could benefit form active participation.
## References
1. <https://www.nytimes.com/2020/04/14/us/zoom-meetings-gender.html>
2. <https://www.nature.com/articles/nature.2014.16270>
3. <https://www.fastcompany.com/3030861/why-women-fail-to-speak-up-at-high-level-meetings-and-what-everyone-can-do-about>
4. <https://hbr.org/2014/06/women-find-your-voice>
5. <https://www.cnbc.com/2020/09/03/45percent-of-women-business-leaders-say-its-difficult-for-women-to-speak-up-in-virtual-meetings.html>
|
partial
|
## Headline
**bold**
IoSECURITY
## What it does
IoSECURITY provides a complete network setup for home users. An IoSECURITY server is connected to the home router allowing increased security, privacy, management and customization.
The IoSECURITY server features are accessed through a webapp. IoSECURITY server allows home administrators to:
1. Accept or deny guest requests to access WiFi
2. Set time limit for guest accounts
3. Block users
4. Limit visibility of guest users to home IoT devices
## How we built it
Node.js to set up server.
## Challenges we ran into
Initially users were to be allowed into the network using FreeBSD's Packet Filter Firewall on a Raspberry pi. Due to complications in running Node.js and our databas on the Pi itself (we want a one for all solution!), an Odroid C2 arm64 board running Arch Linux was used. The rules were written using IPTABLES and Node.js ran fine afterwards!
## Accomplishments that we're proud of
## What we learned
Setting up a server using node.js.
mongo.db for database
## What's next for IoSecurity
Bugs would need to be fixed for a smooth application. In addition, features might be edited to optimize the Webapp after receiving feedback from users.
|
## Where we got the spark?
**No one is born without talents**.
We all get this situation in our childhood, No one gets a chance to reveal their skills and gets guided for their ideas. Some skills are buried without proper guidance, we don't even have mates to talk about it and develop our skills in the respective field. Even in college if we are starters we have trouble in implementation. So we started working for a solution to help others who found themselves in this same crisis.
## How it works?
**Connect with neuron of your same kind**
From the problem faced we are bridging all bloomers on respective fields to experts, people in same field who need a team mate (or) a friend to develop the idea along. They can become aware of source needed to develop themselves in that field by the guidance of experts and also experienced professors.
We can also connect with people all over globe using language translator, this makes us feels everyone feel native.
## How we built it
**1.Problem analysis:**
We ran through all problems all over the globe in the field of education and came across several problems and we chose a problem that gives solution for several problems.
**2.Idea Development:**
We started to examine the problems and lack of features and solution for topic we chose and solved all queries as much as possible and developed it as much as we can.
**3.Prototype development:**
We developed a working prototype and got a good experience developing it.
## Challenges we ran into
Our plan is to get our application to every bloomers and expertise, but what will make them to join in our community. It will be hard to convince them that our application will help them to learn new things.
## Accomplishments that we're proud of
The jobs which are currently popular may or may not be popular after 10 years. Our World will always looks for a better version of our current version . We are satisfied that our idea will help 100's of children like us who don't even know about the new things in todays new world. Our application may help them to know the things earlier than usual. Which may help them to lead a path in their interest. We are proud that we are part of their development.
## What we learned
We learnt that many people are suffering from lack of help for their idea/project and we felt useless when we learnt this. So we planned to build an web application for them to help with their project/idea with experts and same kind of their own. So, **Guidance is important. No one is born pro**
We learnt how to make people understand new things based on the interest of study by guiding them through the path of their dream.
## What's next for EXPERTISE WITH
We're planning to advertise about our web application through all social medias and help all the people who are not able to get help for development their idea/project and implement from all over the world. to the world.
|
## Inspiration
We've always been taught "Time is of the essence" and told to use our time wisely because wasting it can land us up in some trouble. In our efforts to save time we tend to overlook the process and want to jump to the results; however, we forget to think about how our rush can cost us a lot, including our data privacy. Companies oftentimes tend to take advantage of our rush (or let's face it, procrastination), knowing that we can't find the time to read their overly wrong and boring terms of conditions and make policies to use your data in ways profitable for them.
This is where Terms And Procrastination (TAP) comes in! We read and summarize the privacy policy and terms and conditions of a site that saves your data so that you can stay safe while saving your time!
TAP was inspired by this phenomenon of saving time and our right to our privacy which is violated more often than you think.
The internet is a wonderful place of resources that can help many and we aim to make it safe for everyone.
## What it does
TAP is a Chrome extension that allows you to view a summary of the terms and conditions and the privacy policy of the webpage you are currently visiting. We also keep a list of already allowed and blacklisted websites by the user for their viewing which reminds them why they may or may not have agreed with their data policies in the first place.
Our text summarizer creates a significantly shorter (yet containing important information with keywords and quantitative figures) for a quick read for our user. The extension also provides key bullet points for the user which highlights the categories of the data and data type of the user a website might be accessing.
## How we built it
Over on our front-end side, our main goal was a good user interface. Keeping that in mind we created a simplistic design for our extension. We used React to create a Chrome extension that pops-up on the browser and generates a summary of the website's terms and conditions or privacy policy.
For linking all our pages to one another, we used routing so users can easily navigate through the pages as necessary. Our elements were coded in JavaScript files while we used CSS for styling our different components. The front-end is also in charge of web parsing which allows us to gather HREF links (HTML tags) from the policy and use its text to create our final summary for the website.
We were able to create concise summaries using a highly accurate transformer in PyTorch. We finetuned the distilbart-cnn-12-6 model (from HuggingFace) by training it on over 400 examples from our custom dataset.
We made our custom dataset using the TOS;DR API, by collecting all Terms of Service and Privacy Policy documents and their corresponding summary points, compiling these into a CSV file, and creating a PyTorch dataset out of these that we could use to finetune the HuggingFace model.
For the model, we tokenized the dataset (from the CSV file) using the tokenizer from distilbart-cnn-12-6, achieved a final loss of just 0.16 on the test dataset, and then saved the model locally to be run by the API. After running this model on the privacy policy and terms and conditions from the page the extension was running on, we got a summary of these pages and could then send this back to the extension (on the frontend).
We were able to access the privacy policies and terms and conditions by using the BeautifulSoup library to store the text content from the URLs returned by the frontend.
Used PyMongo to achieve data persistence and store user specific data such as blacklisted and whitelisted websites based on their terms and privacy policy in MongoDB.
## Challenges we ran into
While we have worked with React before, this was our first time using react to make a chrome extension. On that end, some of the challenges we ran into were making a pop-up extension which we achieved by creating our React App and changing pop-up restrictions (and updating our source files) to create the base of our chrome extension.
On the backend, we ran into quite a few issues with fine tuning the model with our custom dataset. These were mainly with tokenizing the dataset, feeding the tokenized data into our model correctly, and making sure that we had created all the functions that the trainer depended on.
We ran into some challenges with prediction as well, especially making sure that we decoded the tokenized info the model returned and that the data we fed to the frontend was in the format expected.
With creating the custom dataset, there were some challenges with cleaning the data to be readable by the model (mainly removing HTML tags) and ensuring that the multiline strings returned by the API could be converted to the single line needed in the CSV.
## Accomplishments that we're proud of
For our front-end team, this was the first time we created a chrome extension, and while that came with its own challenges we were proud to make the pop-up stand with proper routing that connected all the pages with each other. Moreover the extension has a few aspects that at first we didn't know how to achieve such as storing user database and web parsing but we did thorough research to accomplish the interface for our extension and we're incredibly proud!
This was the first time we worked with transformers in PyTorch. With machine learning, there's often many errors that occur due to the fickle nature of ML libraries, especially with feeding correct dataset to models for training. Though it took hours of work, we were able to get it working and as first time transformer users, we are very proud.
We were able to successfully create our own customer dataset from scratch: import the TOS;DR CSV, convert it a torch dataset, tokenize it and train the distilbart-cnn on it
We were able to effectively analyze the effect of hyper parameters such as the number of epochs and learning rate on the accuracy of the model
We were able to efficiently handle the PyTorch models, store them properly and use them across different files.
We were able to achieve data persistence with MongoDB by successfully creating the relevant APIs and passing data between the flask backend and react frontend
## What we learned
When it comes to user interface we did a lot of research on React for routing pages and creating a chrome extension. Moreover, one of the more time consuming things for us to learn about was web parsing on the frontend to gather the HTML links which contain data for our summarizer to summarize off of.
We learned a great amount about how transformers work, especially with how sequence to sequence transformers can be created for text generation to better understand input-output correlations compared to similar models with LSTM RNNs.
## What's next for Terms and Procrastination
We think TAP is a great tool for web users and believe that it is unique and valuable for others to use. We hope to expand some of our functionalities (which we couldn't achieve just yet due to time constraints) and publish the extension for users to experience. Our trained summarizer displayed accurate summaries along with key points that the user must learn of prior to agreeing to give their private data to another site. Prior to publishing we would want to further enhance our interface to enhance user experience.
|
partial
|
## Inspiration
We're students, and that means one of our biggest inspirations (and some of our most frustrating problems) come from a daily ritual - lectures.
Some professors are fantastic. But let's face it, many professors could use some constructive criticism when it comes to their presentation skills. Whether it's talking too fast, speaking too *quietly* or simply not paying attention to the real-time concerns of the class, we've all been there.
**Enter LectureBuddy.**
## What it does
Inspired by lackluster lectures and little to no interfacing time with professors, LectureBuddy allows students to signal their instructors with teaching concerns at the spot while also providing feedback to the instructor about the mood and sentiment of the class.
By creating a web-based platform, instructors can create sessions from the familiarity of their smartphone or laptop. Students can then provide live feedback to their instructor by logging in with an appropriate session ID. At the same time, a camera intermittently analyzes the faces of students and provides the instructor with a live average-mood for the class. Students are also given a chat room for the session to discuss material and ask each other questions. At the end of the session, Lexalytics API is used to parse the chat room text and provides the instructor with the average tone of the conversations that took place.
Another important use for LectureBuddy is an alternative to tedious USATs or other instructor evaluation forms. Currently, teacher evaluations are completed at the end of terms and students are frankly no longer interested in providing critiques as any change will not benefit them. LectureBuddy’s live feedback and student interactivity provides the instructor with consistent information. This can allow them to adapt their teaching styles and change topics to better suit the needs of the current class.
## How I built it
LectureBuddy is a web-based application; most of the developing was done in JavaScript, Node.js, HTML/CSS, etc. The Lexalytics Semantria API was used for parsing the chat room data and Microsoft’s Cognitive Services API for emotions was used to gauge the mood of a class. Other smaller JavaScript libraries were also utilised.
## Challenges I ran into
The Lexalytics Semantria API proved to be a challenge to set up. The out-of-the box javascript files came with some errors, and after spending a few hours with mentors troubleshooting, the team finally managed to get the node.js version to work.
## Accomplishments that I'm proud of
Two first-time hackers contributed some awesome work to the project!
## What I learned
"I learned that json is a javascript object notation... I think" - Hazik
"I learned how to work with node.js - I mean I've worked with it before, but I didn't really know what I was doing. Now I sort of know what I'm doing!" - Victoria
"I should probably use bootstrap for things" - Haoda
"I learned how to install mongoDB in a way that almost works" - Haoda
"I learned some stuff about Microsoft" - Edwin
## What's next for Lecture Buddy
* Multiple Sessions
* Further in-depth analytics from an entire semester's worth of lectures
* Pebble / Wearable integration!
@Deloitte See our video pitch!
|
## Inspiration
While we were doing preliminary research, we had found overwhelming amounts of evidence of mental health deterioration as a consequence of life-altering lockdown restrictions. Academic research has shown that adolescents depend on friendship to maintain a sense of self-worth and to manage anxiety and depression. Intimate exchanges and self-esteem support significantly increased long-term self worth and decreased depression.
While people do have virtual classes and social media, some still had trouble feeling close with anyone. This is because conventional forums and social media did not provide a safe space for conversation beyond the superficial. User research also revealed that friendships formed by physical proximity don't necessarily make people feel understood and resulted in feelings of loneliness anyway. Proximity friendships formed in virtual classes also felt shallow in the sense that it only lasted for the duration of the online class.
With this in mind, we wanted to create a platform that encouraged users to talk about their true feelings, and maximize the chance that the user would get heartfelt and intimate replies.
## What it does
Reach is an anonymous forum that is focused on providing a safe space for people to talk about their personal struggles. The anonymity encourages people to speak from the heart. Users can talk about their struggles and categorize them, making it easy for others in similar positions to find these posts and build a sense of closeness with the poster. People with similar struggles have a higher chance of truly understanding each other. Since ill-mannered users can exploit anonymity, there is a tone analyzer that will block posts and replies that contain mean-spirited content from being published while still letting posts of a venting nature through. There is also ReCAPTCHA to block bot spamming.
## How we built it
* Wireframing and Prototyping: Figma
* Backend: Java 11 with Spring Boot
* Database: PostgresSQL
* Frontend: Bootstrap
* External Integration: Recaptcha v3 and IBM Watson - Tone Analyzer
* Cloud: Heroku
## Challenges we ran into
We initially found it a bit difficult to come up with ideas for a solution to the problem of helping people communicate. A plan for a VR space for 'physical' chatting was also scrapped due to time constraints, as we didn't have enough time left to do it by the time we came up with the idea. We knew that forums were already common enough on the internet, so it took time to come up with a product strategy that differentiated us. (Also, time zone issues. The UXer is Australian. They took caffeine pills and still fell asleep.)
## Accomplishments that we're proud of
Finishing it on time, for starters. It felt like we had a bit of a scope problem at the start when deciding to make a functional forum with all these extra features, but I think we pulled it off. The UXer also iterated about 30 screens in total. The Figma file is *messy.*
## What we learned
As our first virtual hackathon, this has been a learning experience for remote collaborative work.
UXer: I feel like i've gotten better at speedrunning the UX process even quicker than before. It usually takes a while for me to get started on things. I'm also not quite familiar with code (I only know python), so watching the dev work and finding out what kind of things people can code was exciting to see.
# What's next for Reach
If this was a real project, we'd work on implementing VR features for those who missed certain physical spaces. We'd also try to work out improvements to moderation, and perhaps a voice chat for users who want to call.
|
## Inspiration
The inspiration for our Auto-Teach project stemmed from the growing need to empower both educators and learners with a **self-directed and adaptive** learning environment. We were inspired by the potential to merge technology with education to create a platform that fosters **personalized learning experiences**, allowing students to actively **engage with the material while offering educators tools to efficiently evaluate and guide individual progress**.
## What it does
Auto-Teach is an innovative platform that facilitates **self-directed learning**. It allows instructors to **create problem sets and grading criteria** while enabling students to articulate their problem-solving methods and responses through text input or file uploads (future feature). The software leverages AI models to assesses student responses, offering **constructive feedback**, **pinpointing inaccuracies**, and **identifying areas for improvement**. It features automated grading capabilities that can evaluate a wide range of responses, from simple numerical answers to comprehensive essays, with precision.
## How we built it
Our deliverable for Auto-Teach is a full-stack web app. Our front-end uses **ReactJS** as our framework and manages data using **convex**. Moreover, it leverages editor components from **TinyMCE** to provide student with better experience to edit their inputs. We also created back-end APIs using "FastAPI" and "Together.ai APIs" in our way building the AI evaluation feature.
## Challenges we ran into
We were having troubles with incorporating Vectara's REST API and MindsDB into our project because we were not very familiar with the structure and implementation. We were able to figure out how to use it eventually but struggled with the time constraint. We also faced the challenge of generating the most effective prompt for chatbox so that it generates the best response for student submissions.
## Accomplishments that we're proud of
Despite the challenges, we're proud to have successfully developed a functional prototype of Auto-Teach. Achieving an effective system for automated assessment, providing personalized feedback, and ensuring a user-friendly interface were significant accomplishments. Another thing we are proud of is that we effectively incorporates many technologies like convex, tinyMCE etc into our project at the end.
## What we learned
We learned about how to work with backend APIs and also how to generate effective prompts for chatbox. We also got introduced to AI-incorporated databases such as MindsDB and was fascinated about what it can accomplish (such as generating predictions based on data present on a streaming basis and getting regular updates on information passed into the database).
## What's next for Auto-Teach
* Divide the program into **two mode**: **instructor** mode and **student** mode
* **Convert Handwritten** Answers into Text (OCR API)
* **Incorporate OpenAI** tools along with Together.ai when generating feedback
* **Build a database** storing all relevant information about each student (ex. grade, weakness, strength) and enabling automated AI workflow powered by MindsDB
* **Complete analysis** of student's performance on different type of questions, allows teachers to learn about student's weakness.
* **Fine-tuned grading model** using tools from Together.ai to calibrate the model to better provide feedback.
* **Notify** students instantly about their performance (could set up notifications using MindsDB and get notified every day about any poor performance)
* **Upgrade security** to protect against any illegal accesses
|
winning
|
## Inspiration
In Vancouver, we are lucky to be surrounded by local markets, seafood vendors, and farms. As students we noticed that most people around us fall into habit of shopping from large supermarket chains such as Costco, Walmart, Superstore, which import foods full of preservatives from faraway distribution centres - ultimately selling less fresh food. We wanted to build an app like "Yelp" to encourage healthy grocery choices and simultaneously support local grocers and farmers.
## What it does
Peas of Mind is an web application that allows users to leave reviews of different fruits, vegetables, and seafood weekly so that users will be able to find local grocery stores that have the freshest groceries compared to large supermarket chains. One feature allows users to shop fresh seasonal products, while our Map page highlight popular vendors in walkable radius, or just search the product to find which store(s) have the freshest product.
## How we built it
Back end
* Node.js
* Express.js
* Google Maps API
Front end
* React
Database
* CockroachDB
Design
* Figma
## Challenges we ran into
Working with a new tech stack was a learning curve for some people. Ambitious platform involving user identification, customized feeds, search engines, and review processes. This led to a major time constraint where we found it difficult to juggle all of these challenges on top of dealing with typical coding bugs.
## Accomplishments that we're proud of
We think the concept of our web application builds community engagement for local small businesses, promotes excitement around health and nutrition when grocery shopping. We are also proud of the design for the web application because it's simple and effective, which will make the app easy for users to use.
## What we learned
We learnt that it is always helpful to take a step back when we run into problems or bugs, lean on each other for help, and not be scared of asking mentors or others for help or feedback on our project.
## What's next for Peas of Mind
At the time of writing, we have all the components for the app but we need more time to tie things together, and fully build out our design. We would like to build it out specifically for the community of Vancouver.
|
## Inspiration
Students are running low on motivation to do schoolwork since lockdown / the pandemic. This site is designed to help students be more motivated to finish classes by providing a better sense of accomplishment and urgency to schoolwork.
## What it does
Provides a way for students to keep track and stay on top of their deliverables.
## How we built it
Two of us did the backend (database, python driver code [flask]), and the other two did the frontend (figma mockups, html, css, javascript)
## Challenges we ran into
Setting up the database, connecting front/backend, figuring out git (merging in particular).
## Accomplishments that we're proud of
We are very proud of our team collaboration, and ability to put together all this in the short time span. This was 3/4 members first ever hackathon, so the entire thing was such a fun and enjoyable learning experience.
## What we learned
Literally everything here was a huge learning experience for all team members.
## What's next for QScore - Gamify School!
We really think that we can extend this project further by adding more functionality. We want to add integrations with different university's if possible, maybe make a friends system/social media aspect.
## Discord Information
Team 5
Devy#2975
han#0288
Infinite#6201
naters#3774
|
## Inspiration
Being frugal students, we all wanted to create an app that would tell us what kind of food we could find around us based on a budget that we set. And so that’s exactly what we made!
## What it does
You give us a price that you want to spend and the radius that you are willing to walk or drive to a restaurant; then voila! We give you suggestions based on what you can get in that price in different restaurants by providing all the menu items with price and calculated tax and tips! We keep the user history (the food items they chose) and by doing so we open the door to crowdsourcing massive amounts of user data and as well as the opportunity for machine learning so that we can give better suggestions for the foods that the user likes the most!
But we are not gonna stop here! Our goal is to implement the following in the future for this app:
* We can connect the app to delivery systems to get the food for you!
* Inform you about the food deals, coupons, and discounts near you
## How we built it
### Back-end
We have both an iOS and Android app that authenticates users via Facebook OAuth and stores user eating history in the Firebase database. We also made a REST server that conducts API calls (using Docker, Python and nginx) to amalgamate data from our targeted APIs and refine them for front-end use.
### iOS
Authentication using Facebook's OAuth with Firebase. Create UI using native iOS UI elements. Send API calls to Soheil’s backend server using json via HTTP. Using Google Map SDK to display geo location information. Using firebase to store user data on cloud and capability of updating to multiple devices in real time.
### Android
The android application is implemented with a great deal of material design while utilizing Firebase for OAuth and database purposes. The application utilizes HTTP POST/GET requests to retrieve data from our in-house backend server, uses the Google Maps API and SDK to display nearby restaurant information. The Android application also prompts the user for a rating of the visited stores based on how full they are; our goal was to compile a system that would incentive foodplaces to produce the highest “food per dollar” rating possible.
## Challenges we ran into
### Back-end
* Finding APIs to get menu items is really hard at least for Canada.
* An unknown API kept continuously pinging our server and used up a lot of our bandwith
### iOS
* First time using OAuth and Firebase
* Creating Tutorial page
### Android
* Implementing modern material design with deprecated/legacy Maps APIs and other various legacy code was a challenge
* Designing Firebase schema and generating structure for our API calls was very important
## Accomplishments that we're proud of
**A solid app for both Android and iOS that WORKS!**
### Back-end
* Dedicated server (VPS) on DigitalOcean!
### iOS
* Cool looking iOS animations and real time data update
* Nicely working location features
* Getting latest data from server
## What we learned
### Back-end
* How to use Docker
* How to setup VPS
* How to use nginx
### iOS
* How to use Firebase
* How to OAuth works
### Android
* How to utilize modern Android layouts such as the Coordinator, Appbar, and Collapsible Toolbar Layout
* Learned how to optimize applications when communicating with several different servers at once
## What's next for How Much
* If we get a chance we all wanted to work on it and hopefully publish the app.
* We were thinking to make it open source so everyone can contribute to the app.
|
losing
|
## Inspiration
As we have seen through our university careers, there are students who suffer from disabilities who can benefit greatly from accessing high-quality lecture notes. Many professors struggle to find note-takers for their courses which leaves these students with a great disadvantage. Our mission is to ensure that their notes increase in quality, thereby improving their learning experiences - STONKS!
## What it does
This service automatically creates and updates a Google Doc with text-based notes derived from the professor's live handwritten lecture content.
## How we built it
We used Google Cloud Vision, OpenCV, a camera, a Raspberry-Pi, and Google Docs APIs to build a product using Python, which is able to convert handwritten notes to text-based online notes.
At first, we used a webcam to capture an image of the handwritten notes. This image was then parsed by Google Cloud Vision API to detect various characters which were then transcripted into text-based words in a new text file. This text file was then read to collect the data and then sent to a new Google Doc which is dynamically updated as the professor continues to write their notes.
## Challenges we ran into
One of the major challenges that we faced was strategically dividing tasks amongst the team members in accordance with each individuals' expertise. With time, we were able to assess each others' skills and divide work accordingly to achieve our goal.
Another challenge that we faced was that the supplies we originally requested were out of stock (Raspberry-Pi camera) however, we were able to improvise by getting a camera from a different kit.
One of the major technical challenges we had to overcome was receiving permissions for the utilization of Google Docs APIs to create and get access to a new document. This was overcome by researching, testing and debugging our code to finally get authorization for the API to create a new document using an individual's email.
## Accomplishments that we are proud of
The main goal of STONKS was accomplished as we were able to create a product that will help disabled students to optimize their learning through the provision of quality notes.
## What we learned
We learned how to utilize Google Cloud Vision and OpenCV which are both extremely useful and powerful computer vision systems that use machine learning.
## What's next for STONKS?
The next step for STONKS is distinguishing between handwritten texts and visual representations such as drawings, charts, and schematics. Moreover, we are hoping to implement a math-based character recognition set to be able to recognize handwritten mathematical equations.
|
## **Inspiration:**
Our inspiration stemmed from the realization that the pinnacle of innovation occurs at the intersection of deep curiosity and an expansive space to explore one's imagination. Recognizing the barriers faced by learners—particularly their inability to gain real-time, personalized, and contextualized support—we envisioned a solution that would empower anyone, anywhere to seamlessly pursue their inherent curiosity and desire to learn.
## **What it does:**
Our platform is a revolutionary step forward in the realm of AI-assisted learning. It integrates advanced AI technologies with intuitive human-computer interactions to enhance the context a generative AI model can work within. By analyzing screen content—be it text, graphics, or diagrams—and amalgamating it with the user's audio explanation, our platform grasps a nuanced understanding of the user's specific pain points. Imagine a learner pointing at a perplexing diagram while voicing out their doubts; our system swiftly responds by offering immediate clarifications, both verbally and with on-screen annotations.
## **How we built it**:
We architected a Flask-based backend, creating RESTful APIs to seamlessly interface with user input and machine learning models. Integration of Google's Speech-to-Text enabled the transcription of users' learning preferences, and the incorporation of the Mathpix API facilitated image content extraction. Harnessing the prowess of the GPT-4 model, we've been able to produce contextually rich textual and audio feedback based on captured screen content and stored user data. For frontend fluidity, audio responses were encoded into base64 format, ensuring efficient playback without unnecessary re-renders.
## **Challenges we ran into**:
Scaling the model to accommodate diverse learning scenarios, especially in the broad fields of maths and chemistry, was a notable challenge. Ensuring the accuracy of content extraction and effectively translating that into meaningful AI feedback required meticulous fine-tuning.
## **Accomplishments that we're proud of**:
Successfully building a digital platform that not only deciphers image and audio content but also produces high utility, real-time feedback stands out as a paramount achievement. This platform has the potential to revolutionize how learners interact with digital content, breaking down barriers of confusion in real-time. One of the aspects of our implementation that separates us from other approaches is that we allow the user to perform ICL (In Context Learning), a feature that not many large language models don't allow the user to do seamlessly.
## **What we learned**:
We learned the immense value of integrating multiple AI technologies for a holistic user experience. The project also reinforced the importance of continuous feedback loops in learning and the transformative potential of merging generative AI models with real-time user input.
|
## Inspiration
<https://www.youtube.com/watch?v=lxuOxQzDN3Y>
Robbie's story stuck out to me at the endless limitations of technology. He was diagnosed with muscular dystrophy which prevented him from having full control of his arms and legs. He was gifted with a Google home that crafted his home into a voice controlled machine. We wanted to take this a step further and make computers more accessible for people such as Robbie.
## What it does
We use a Google Cloud based API that helps us detect words and phrases captured from the microphone input. We then convert those phrases into commands for the computer to execute. Since the python script is run in the terminal it can be used across the computer and all its applications.
## How I built it
The first (and hardest) step was figuring out how to leverage Google's API to our advantage. We knew it was able to detect words from an audio file but there was more to this project than that. We started piecing libraries to get access to the microphone, file system, keyboard and mouse events, cursor x,y coordinates, and so much more. We build a large (~30) function library that could be used to control almost anything in the computer
## Challenges I ran into
Configuring the many libraries took a lot of time. Especially with compatibility issues with mac vs. windows, python2 vs. 3, etc. Many of our challenges were solved by either thinking of a better solution or asking people on forums like StackOverflow. For example, we wanted to change the volume of the computer using the fn+arrow key shortcut, but python is not allowed to access that key.
## Accomplishments that I'm proud of
We are proud of the fact that we had built an alpha version of an application we intend to keep developing, because we believe in its real-world applications. From a technical perspective, I was also proud of the fact that we were able to successfully use a Google Cloud API.
## What I learned
We learned a lot about how the machine interacts with different events in the computer and the time dependencies involved. We also learned about the ease of use of a Google API which encourages us to use more, and encourage others to do so, too. Also we learned about the different nuances of speech detection like how to tell the API to pick the word "one" over "won" in certain context, or how to change a "one" to a "1", or how to reduce ambient noise.
## What's next for Speech Computer Control
At the moment we are manually running this script through the command line but ideally we would want a more user friendly experience (GUI). Additionally, we had developed a chrome extension that numbers off each link on a page after a Google or Youtube search query, so that we would be able to say something like "jump to link 4". We were unable to get the web-to-python code just right, but we plan on implementing it in the near future.
|
partial
|
## Inspiration
The inspiration for GithubGuide came from our own experiences working with open-source projects and navigating through complex codebases on GitHub. We realized that understanding the purpose of each file and folder in a repository can be a daunting task, especially for beginners. Thus, we aimed to create a tool that simplifies this process and makes it easier for developers to explore and contribute to GitHub projects.
## What it does
GithubGuide is a Google Chrome extension that takes any GitHub repository as input and explains the purpose of each file and folder in the repository. It uses the GitHub API to fetch repository contents and metadata, which are then processed and presented in an easily understandable format. This enables developers to quickly navigate and comprehend the structure of a repository, allowing them to save time and work more efficiently.
## How we built it
We built GithubGuide as a team of four. Here's how we split the work among teammates 1, 2, 3, and 4:
1. Build a Chrome extension using JavaScript, which serves as the user interface for interacting with the tool.
2. Develop a comprehensive algorithm and data structures to efficiently manage and process the repository data and LLM-generated inferences.
3. Configure a workflow to read repository contents into our chosen LLM ChatGPT model using a reader built on LLaMa - a connector between LLMs and external data sources.
4. Build a server with Python Flask to communicate data between the Chrome extension and LLaMa, the LLM data connector.
## Challenges we ran into
Throughout the development process, we encountered several challenges:
1. Integrating the LLM data connector with the Chrome extension and the Flask server.
2. Parsing and processing the repository data correctly.
3. Engineering our ChatGPT prompts to get optimal results.
## Accomplishments that we're proud of
We are proud of:
1. Successfully developing a fully functional Chrome extension that simplifies the process of understanding GitHub repositories.
2. Overcoming the technical challenges in integrating various components and technologies.
3. Creating a tool that has the potential to assist developers, especially beginners, in their journey to contribute to open-source projects.
## What we learned
Throughout this project, we learned:
1. How to work with LLMs and external data connectors.
2. The intricacies of building a Chrome extension, and how developers have very little freedom when developing browser extensions.
3. The importance of collaboration, effective communication, and making sure everyone is on the same page within our team, especially when merging critically related modules.
## What's next for GithubGuide
We envision the following improvements and features for GithubGuide:
1. Expanding support for other browsers and platforms.
2. Enhancing the accuracy and quality of the explanations provided by ChatGPT.
3. Speeding up the pipeline.
4. Collaborating with the open-source community to further refine and expand the project.
|
## Inspiration
The inspiration for Hivemind stemmed from personal frustration with the quality of available lectures and resources, which were often insufficient for effective learning. This led us to rely entirely on ChatGPT to teach ourselves course material from start to finish. We realized the immense value of tailored responses and the structured learning that emerged from the AI interactions. Recognizing the potential, this inspired the creation of a platform that could harness collective student input to create smarter, more effective lessons for everyone.
## What it does
Hivemind is an AI-powered learning platform designed to empower students to actively engage with their course material and create personalized, interactive lessons. By allowing students to input course data such as lecture slides, notes, and assignments, Hivemind helps them optimize their learning process through dynamic, evolving lessons. As students interact with the platform, their feedback and usage patterns inform the system, organically improving and refining the content for everyone. This collaborative approach transforms passive learning into an active, community-driven experience, creating smarter lessons that evolve based on the collective intelligence and needs of all users.
## How we built it
* **Backend**: Developed with Django and Django REST Framework to manage data processing and API requests.
* **Data Integration**: Used PyMuPDF for text extraction and integrated course materials into a cohesive database.
* **Contextual Search**: Implemented Chroma for similarity searches to enhance lesson relevance and context.
* **LLM Utilization**: Leveraged Cerebras and TuneAI to transform course content into structured lessons that evolve with user input.
* **Frontend**: Created a React-based interface for students to access lessons and contribute feedback.
* **Adaptive Learning**: Built a system that updates lessons dynamically based on collective interactions, guiding them towards an optimal state.
## Challenges we ran into
* Getting RAG to work with Tune
* Creating meaningful inferences with the large volume of data
* Integrating varied course materials into a unified, structured format that the LLM could effectively utilize
* Ensuring that lessons evolve towards an optimal state based on diverse student interactions and inputs
* Sleep deprivation
## Accomplishments that we're proud of
* Functional Demo
* Integration of advanced technologies
* Team effort
## What we learned
Throughout the development of Hivemind, we gained valuable insights into various advanced topics, including large language models (LLMs), retrieval-augmented generation (RAGs), AI inference, and fine-tuning techniques. We also deepened our understanding of:
* Tools such as Tune and Cerebras
* Prompt Engineering
* Scalable System Design
## What's next for Hivemind
* Easy integration with all LMS for an instant integration with any courses
* Support different types of courses (sciences, liberal arts, languages, etc.)
* Train on more relevant data such as research studies and increase skill level of the model
* Create an algorithm that can generate a large amount of lessons and consolidate them into one optimal lesson
* Implement a peer review system where students can suggest improvements to the lessons, vote on the best modifications, and discuss different approaches, fostering a collaborative learning environment
|
## Inspiration
We know the struggles of students. Trying to get to that one class across campus in time. Deciding what to make for dinner. But there was one that stuck out to all of us: finding a study spot on campus. There have been countless times when we wander around Mills or Thode looking for a free space to study, wasting our precious study time before the exam. So, taking inspiration from parking lots, we designed a website that presents a live map of the free study areas of Thode Library.
## What it does
A network of small mountable microcontrollers that uses ultrasonic sensors to check if a desk/study spot is occupied. In addition, it uses machine learning to determine peak hours and suggested availability from the aggregated data it collects from the sensors. A webpage that presents a live map, as well as peak hours and suggested availability .
## How we built it
We used a Raspberry Pi 3B+ to receive distance data from an ultrasonic sensor and used a Python script to push the data to our database running MongoDB. The data is then pushed to our webpage running Node.js and Express.js as the backend, where it is updated in real time to a map. Using the data stored on our database, a machine learning algorithm was trained to determine peak hours and determine the best time to go to the library.
## Challenges we ran into
We had an **life changing** experience learning back-end development, delving into new frameworks such as Node.js and Express.js. Although we were comfortable with front end design, linking the front end and the back end together to ensure the web app functioned as intended was challenging. For most of the team, this was the first time dabbling in ML. While we were able to find a Python library to assist us with training the model, connecting the model to our web app with Flask was a surprising challenge. In the end, we persevered through these challenges to arrive at our final hack.
## Accomplishments that we are proud of
We think that our greatest accomplishment is the sheer amount of learning and knowledge we gained from doing this hack! Our hack seems simple in theory but putting it together was one of the toughest experiences at any hackathon we've attended. Pulling through and not giving up until the end was also noteworthy. Most importantly, we are all proud of our hack and cannot wait to show it off!
## What we learned
Through rigorous debugging and non-stop testing, we earned more experience with Javascript and its various frameworks such as Node.js and Express.js. We also got hands-on involvement with programming concepts and databases such as mongoDB, machine learning, HTML, and scripting where we learned the applications of these tools.
## What's next for desk.lib
If we had more time to work on this hack, we would have been able to increase cost effectiveness by branching four sensors off one chip. Also, we would implement more features to make an impact in other areas such as the ability to create social group beacons where others can join in for study, activities, or general socialization. We were also debating whether to integrate a solar panel so that the installation process can be easier.
|
partial
|
## Inspiration
We wanted to allow financial investors and people of political backgrounds to save valuable time reading financial and political articles by showing them what truly matters in the article, while highlighting the author's personal sentimental/political biases.
We also wanted to promote objectivity and news literacy in the general public by making them aware of syntax and vocabulary manipulation. We hope that others are inspired to be more critical of wording and truly see the real news behind the sentiment -- especially considering today's current events.
## What it does
Using Indico's machine learning textual analysis API, we created a Google Chrome extension and web application that allows users to **analyze financial/news articles for political bias, sentiment, positivity, and significant keywords.** Based on a short glance on our visualized data, users can immediately gauge if the article is worth further reading in their valuable time based on their own views.
The Google Chrome extension allows users to analyze their articles in real-time, with a single button press, popping up a minimalistic window with visualized data. The web application allows users to more thoroughly analyze their articles, adding highlights to keywords in the article on top of the previous functions so users can get to reading the most important parts.
Though there is a possibilitiy of opening this to the general public, we see tremendous opportunity in the financial and political sector in optimizing time and wording.
## How we built it
We used Indico's machine learning textual analysis API, React, NodeJS, JavaScript, MongoDB, HTML5, and CSS3 to create the Google Chrome Extension, web application, back-end server, and database.
## Challenges we ran into
Surprisingly, one of the more challenging parts was implementing a performant Chrome extension. Design patterns we knew had to be put aside to follow a specific one, to which we gradually aligned with. It was overall a good experience using Google's APIs.
## Accomplishments that we're proud of
We are especially proud of being able to launch a minimalist Google Chrome Extension in tandem with a web application, allowing users to either analyze news articles at their leisure, or in a more professional degree. We reached more than several of our stretch goals, and couldn't have done it without the amazing team dynamic we had.
## What we learned
Trusting your teammates to tackle goals they never did before, understanding compromise, and putting the team ahead of personal views was what made this Hackathon one of the most memorable for everyone. Emotional intelligence played just as an important a role as technical intelligence, and we learned all the better how rewarding and exciting it can be when everyone's rowing in the same direction.
## What's next for Need 2 Know
We would like to consider what we have now as a proof of concept. There is so much growing potential, and we hope to further work together in making a more professional product capable of automatically parsing entire sites, detecting new articles in real-time, working with big data to visualize news sites differences/biases, topic-centric analysis, and more. Working on this product has been a real eye-opener, and we're excited for the future.
|
## Inspiration
One of our team members was stunned by the number of colleagues who became self-described "shopaholics" during the pandemic. Understanding their wishes to return to normal spending habits, we thought of a helper extension to keep them on the right track.
## What it does
Stop impulse shopping at its core by incentivizing saving rather than spending with our Chrome extension, IDNI aka I Don't Need It! IDNI helps monitor your spending habits and gives recommendations on whether or not you should buy a product. It also suggests if there are local small business alternatives so you can help support your community!
## How we built it
React front-end, MongoDB, Express REST server
## Challenges we ran into
Most popular extensions have company deals that give them more access to product info; we researched and found the Rainforest API instead, which gives us the essential product info that we needed in our decision algorithm. However this proved, costly as each API call took upwards of 5 seconds to return a response. As such, we opted to process each product page manually to gather our metrics.
## Completion
In its current state IDNI is able to perform CRUD operations on our user information (allowing users to modify their spending limits and blacklisted items on the settings page) with our custom API, recognize Amazon product pages and pull the required information for our pop-up display, and dynamically provide recommendations based on these metrics.
## What we learned
Nobody on the team had any experience creating Chrome Extensions, so it was a lot of fun to learn how to do that. Along with creating our extensions UI using React.js this was a new experience for everyone. A few members of the team were also able to spend the weekend learning how to create an express.js API with a MongoDB database, all from scratch!
## What's next for IDNI - I Don't Need It!
We plan to look into banking integration, compatibility with a wider array of online stores, cleaner integration with small businesses, and a machine learning model to properly analyze each metric individually with one final pass of these various decision metrics to output our final verdict. Then finally, publish to the Chrome Web Store!
|
## Inspiration
We wanted to create a tool which could be used to sum up the gist of the media's perception of a pair of topics as well as comparing them, as to gain perspective on potential forecasts (winning elections, stock performance), while also summing up how society views ideas in general. The media has such a great influence on general society's perception, so we though tracking the media's own perception as invaluable.
## How we built it
Node.JS backend to power the NewsApi used to obtain articles as well as connect to Indico's Sentiment Analysis API.
Front end was powered by Material.JS and Chart.JS to enable striking insightful data visualization.
## Challenges we ran into
Formatting Node.JS and properly displaying the data received from NewsApi caused many headaches. We had to process news and date information in a format which could be graphed easily on the front-end, which required time-consuming data manipulation.
## Accomplishments that we're proud of
* Creating a minimalistic and clean web-app to easily view the popular media's view on a pair of topics.
* Collaborating and dealing with merge conflicts and technical problems
## What we learned
* How to link multiple APIs and communicate data from a back-end to a front-end efficiently.
* Collaborate on a shared GitHub repo
## What's next for PolyTrack
Creating a consumer version which anyone can access online.
|
winning
|
**In times of disaster, there is an outpouring of desire to help from the public. We built a platform which connects people who want to help with people in need.**
## Inspiration
Natural disasters are an increasingly pertinent global issue which our team is quite concerned with. So when we encountered the IBM challenge relating to this topic, we took interest and further contemplated how we could create a phone application that would directly help with disaster relief.
## What it does
**Stronger Together** connects people in need of disaster relief with local community members willing to volunteer their time and/or resources. Such resources include but are not limited to shelter, water, medicine, clothing, and hygiene products. People in need may input their information and what they need, and volunteers may then use the app to find people in need of what they can provide. For example, someone whose home is affected by flooding due to Hurricane Florence in North Carolina can input their name, email, and phone number in a request to find shelter so that this need is discoverable by any volunteers able to offer shelter. Such a volunteer may then contact the person in need through call, text, or email to work out the logistics of getting to the volunteer’s home to receive shelter.
## How we built it
We used Android Studio to build the Android app. We deployed an Azure server to handle our backend(Python). We used Google Maps API on our app. We are currently working on using Twilio for communication and IBM watson API to prioritize help requests in a community.
## Challenges we ran into
Integrating the Google Maps API into our app proved to be a great challenge for us. We also realized that our original idea of including a blood donation as one of the resources would require some correspondence with an organization such as the Red Cross in order to ensure the donation would be legal. Thus, we decided to add a blood donation to our future aspirations for this project due to the time constraint of the hackathon.
## Accomplishments that we're proud of
We are happy with our design and with the simplicity of our app. We learned a great deal about writing the server side of an app and designing an Android app using Java (and Google Map’s API” during the past 24 hours. We had huge aspirations and eventually we created an app that can potentially save people’s lives.
## What we learned
We learned how to integrate Google Maps API into our app. We learn how to deploy a server with Microsoft Azure. We also learned how to use Figma to prototype designs.
## What's next for Stronger Together
We have high hopes for the future of this app. The goal is to add an AI based notification system which alerts people who live in a predicted disaster area. We aim to decrease the impact of the disaster by alerting volunteers and locals in advance. We also may include some more resources such as blood donations.
|
## Inspiration
Disasters can strike quickly and without notice. Most people are unprepared for situations such as earthquakes which occur with alarming frequency along the Pacific Rim. When wifi and cell service are unavailable, medical aid, food, water, and shelter struggle to be shared as the community can only communicate and connect in person.
## What it does
In disaster situations, Rebuild allows users to share and receive information about nearby resources and dangers by placing icons on a map. Rebuild uses a mesh network to automatically transfer data between nearby devices, ensuring that users have the most recent information in their area. What makes Rebuild a unique and effective app is that it does not require WIFI to share and receive data.
## How we built it
We built it with Android and the Nearby Connections API, a built-in Android library which manages the
## Challenges we ran into
The main challenges we faced while making this project were updating the device location so that the markers are placed accurately, and establishing a reliable mesh-network connection between the app users. While these features still aren't perfect, after a long night we managed to reach something we are satisfied with.
## Accomplishments that we're proud of
WORKING MESH NETWORK! (If you heard the scream of joy last night I apologize.)
## What we learned
## What's next for Rebuild
|
Inspiration:
As native Houstonians, part of our team witnessed and experienced the damage wreaked by Hurricane Harvey firsthand. Throughout the fear, uncertainty, and chaos associated with that month of our lives, we developed a feeling that more could have been done to prepare for such disasters. We could have had better tools, better resource flow, and better communication platforms specifically designed for such times of crisis.
What it does:
During Harvey, social media was not just a daily time sink that we took with our morning coffee. It became the single most useful way for us to keep track of friends and loved ones. Twitter was flooded with tweets sending out prayers and offering resources as well as desperate cries for help. Disasterrelief takes filtered tweets from a natural disaster. It categorizes them into tweets that are asking about food/water, being stranded, donations, power outages, clothing. It sorts out these tweets into tweets for help and tweets of support. Disasterrelief allows people to visualize the hotspots where help is needed after the impacts have occurred and it allows people to figure out how best to help their neighbors in an organized way.
How we built it:
* Split a dataset of Hurricane Sandy tweets into those from people who needed help and those who didn't need help but were simply offering thoughts, prayers, and commentary about the situation.
* Used Naive Bayes, KNN, Decision Trees, and Support Vector machines to figure out the model that gave the highest accuracy most efficiently in categorizing the data into help and non-hep Tweets
* Used Google Maps API to display Tweets by location. Displayed a separate marker by Tweet
* Further filtered tweets using decision trees into categories such as food/water, shelter, people without power, and donations
* Also filtered Tweets by state in order to show people what was needed closest to them
Challenges we ran into:
* Integrating google apps api with current framework and updating it with tweets
* Rerouting DNS through Google Cloud so as to work with IPV6 records
* Filtering through the tweets accurately
* We trained our dataset with roughly 3% of the size of the actual dataset, due to time and computer memory constraints. This gives somewhat artificially inflated values, due to the test sets being much smaller. (for reference, when we tried training the GNB classifier with the full dataset, the acccuracies were ~5% lower.)
Accomplishments that we're proud of:
* Able to successfully tag tweets with 80% accuracy using decision trees
* Able to use google maps api to integrate a visualization of hotspots
What we learned:
* Getting data is hard.
* There are a lot of react resources available that can be used to develop highly interactive websites with google maps.
What's next for Disasterrelief:
* Setting up help centers and resource flow paths based on Tweet updates in real time
* Better way to figure out who has been helped and who hasn't
* Include other forms of social media like Facebook
|
winning
|
## Inspiration
Over one-fourth of Canadians during their lifetimes will have to deal with water damage in their homes. This is an issue that causes many Canadians overwhelming stress from the sheer economical and residential implications.
As an effort to assist and solve these very core issues, we have designed a solution that will allow for future leaks to be avoidable. Our prototype system made, composed of software and hardware will ensure house leaks are a thing of the past!
## What is our planned solution?
To prevent leaks, we have designed a system of components that when functioning together, would allow the user to monitor the status of their plumbing systems.
Our system is comprised of:
>
> Two types of leak detection hardware
>
>
> * Acoustic leak detectors: monitors abnormal sounds of pipes.
> * Water detection probes: monitors the presence of water in unwanted areas.
>
>
>
Our hardware components will have the ability to send data to a local network, to then be stored in the cloud.
>
> Software components
>
>
> * Secure cloud to store vital information regarding pipe leakages.
> * Future planned app/website with the ability to receive such information
>
>
>
## Business Aspect of Leakio
Standalone, this solution is profitable through the aspect of selling the specific hardware to consumers. Although for insurance companies, this is a vital solution that has the potential to save millions of dollars.
It is far more economical to prevent a leak, rather than fix it when it already happens. The time of paying the average cost of $10,900 US dollars to fix water damage or a freezing claim is now avoidable!
In addition to saved funds, our planned system will be able to send information to insurance companies for specific data purposes such as which houses or areas have the most leaks, or individual risk assessment. This would allow insurance companies to more appropriately create better rates for the consumer, for the benefit of both consumer and insurance company.
### Software
Front End:
This includes our app design in Figma, which was crafted using knowledge on proper design and ratios. Specifically, we wanted to create an app design that looked simple but had all the complex features that would seem professional. This is something we are proud of, as we feel this component was successful.
Back End:
PHP, MySQL, Python
### Hardware
Electrical
* A custom PCB is designed from scratch using EAGLE
* Consists of USBC charging port, lithium battery charging circuit, ESP32, Water sensor connector, microphone connector
* The water sensor and microphone are extended from the PCB which is why they need a connector
3D-model
* Hub contains all the electronics and the sensors
* Easy to install design and places the microphone within the walls close to the pipes
## Challenges we ran into
Front-End:
There were many challenges we ran into, especially regarding some technical aspects of Figma. Although the most challenging aspect in this would’ve been the implementation of the design.
Back-End:
This is where most challenges were faced, which includes the making of the acoustic leak detector, proper sound recognition, cloud development, and data transfer.
It was the first time any of us had used MySQL, and we created it on the Google Cloud SQL platform. We also had to use both Python and PHP to retrieve and send data, two languages we are not super familiar with.
We also had no idea how to set up a neural network with PyTorch. Also finding the proper data that can be used to train was also very difficult.
## Accomplishments that we're proud of
Learning a lot of new things within a short period of time.
## What we learned
Google Cloud:
Creating a MySQL database and setting up a Deep Learning VM.
MySQL:
Using MySQL and syntaxes, learning PHP.
Machine Learning:
How to set up Pytorch.
PCB Design:
Learning how to use EAGLE to design PCBs.
Raspberry Pi:
Autorun Python scripts and splitting .wav files.
Others:
Not to leave the recording to the last hour. It is hard to cut to 3 minutes with an explanation and demo.
## What's next for Leakio
* Properly implement audio classification using PyTorch
* Possibly create a network of devices to use in a single home
* Find more economical components
* Code for ESP32 to PHP to Web Server
* Test on an ESP32
|
## Inspiration
In 2012 in the U.S infants and newborns made up 73% of hospitals stays and 57.9% of hospital costs. This adds up to $21,654.6 million dollars. As a group of students eager to make a change in the healthcare industry utilizing machine learning software, we thought this was the perfect project for us. Statistical data showed an increase in infant hospital visits in recent years which further solidified our mission to tackle this problem at its core.
## What it does
Our software uses a website with user authentication to collect data about an infant. This data considers factors such as temperature, time of last meal, fluid intake, etc. This data is then pushed onto a MySQL server and is fetched by a remote device using a python script. After loading the data onto a local machine, it is passed into a linear regression machine learning model which outputs the probability of the infant requiring medical attention. Analysis results from the ML model is passed back into the website where it is displayed through graphs and other means of data visualization. This created dashboard is visible to users through their accounts and to their family doctors. Family doctors can analyze the data for themselves and agree or disagree with the model result. This iterative process trains the model over time. This process looks to ease the stress on parents and insure those who seriously need medical attention are the ones receiving it. Alongside optimizing the procedure, the product also decreases hospital costs thereby lowering taxes. We also implemented a secure hash to uniquely and securely identify each user. Using a hyper-secure combination of the user's data, we gave each patient a way to receive the status of their infant's evaluation from our AI and doctor verification.
## Challenges we ran into
At first, we challenged ourselves to create an ethical hacking platform. After discussing and developing the idea, we realized it was already done. We were challenged to think of something new with the same amount of complexity. As first year students with little to no experience, we wanted to tinker with AI and push the bounds of healthcare efficiency. The algorithms didn't work, the server wouldn't connect, and the website wouldn't deploy. We persevered and through the help of mentors and peers we were able to make a fully functional product. As a team, we were able to pick up on ML concepts and data-basing at an accelerated pace. We were challenged as students, upcoming engineers, and as people. Our ability to push through and deliver results were shown over the course of this hackathon.
## Accomplishments that we're proud of
We're proud of our functional database that can be accessed from a remote device. The ML algorithm, python script, and website were all commendable achievements for us. These components on their own are fairly useless, our biggest accomplishment was interfacing all of these with one another and creating an overall user experience that delivers in performance and results. Using sha256 we securely passed each user a unique and near impossible to reverse hash to allow them to check the status of their evaluation.
## What we learned
We learnt about important concepts in neural networks using TensorFlow and the inner workings of the HTML code in a website. We also learnt how to set-up a server and configure it for remote access. We learned a lot about how cyber-security plays a crucial role in the information technology industry. This opportunity allowed us to connect on a more personal level with the users around us, being able to create a more reliable and user friendly interface.
## What's next for InfantXpert
We're looking to develop a mobile application in IOS and Android for this app. We'd like to provide this as a free service so everyone can access the application regardless of their financial status.
|
## Inspiration
We realized that there often applications that make life more convenient insurance. However, we have also notice that there aren't enough insurance services that are comprehensive yet convenient enough to provide people with the right amount of help in more unexpected situations, such as property damage.
## What it does
1. Manages inventory within households, these inventories can be motioned and can be claim in case of external damage (theft, fire, flood). The use of management can help owners protect their property to a greater degree and also can help insurance company keep track of the total cost of assets that they are covering.
2. AI damage analysis tool can helps predicts the state of the property after disasters or damage. Can predict the estimated amount that the property owner can receive.
## How we built it
Android Application is built using Azure Custom Vision to detect damages. This fed through into a web API which communicates to an mobile application which the home owner uses.
## Challenges we ran into
When building the application, we had to restart on our training model due to some bugs on Microsoft Servers. Also connecting the front-end and back-end was difficult as well due to the need to transfer base64 encoded images and the sheer size of them.
## Accomplishments that we're proud of
One of the accomplishments that we're proud of is how we're able to web-scrape thousands of images and use them as relevant data for our model. Another thing we are proud of is how complete the final mobile application turned out to be.
## What we learned
Many of us learned more about React Native and Javascript. Also using the services provided by Microsoft Azure was also a worthwhile experience.
## What's next for InsureHome
A more well trained damage prediction model and mode features to do with asset management.
|
winning
|
## Inspiration
All of our team members are deeply passionate about improving students' education. We focused on the underserved community of deaf or hard-of-hearing students, who communicate, understand, and think primarily in ASL. While some of these students have become accustomed to reading English in various contexts, our market research from studies conducted by Penn State University indicates that members of the community prefer to communicate and think in ASL, and think of English writing as a second language in terms of grammatical structure and syntax.
The majority of deaf people do not have what is commonly referred to as an “inner voice”; instead they often sign ASL in their heads to themselves. For this reason, deaf students are largely disadvantaged in academia, especially with regard to live attendance of lectures. As a result, we sought to design an app to translate professors’ lecture speeches to ASL in near-real time.
## What it does
Our app enables enhanced live-lecture for members of the ASL-speaking community by intelligently converting the professor's speech to a sequence of ASL videos for the user to watch during lecture. This style of real-time audio to ASL conversion has never been done before, and our app bridges the educational barrier that exists in the deaf and hard-of-hearing community.
## How we built it
We broke down the development of the app into 3 phases: converting voice to speech, converting speech to ASL videos, and connecting the two components together in an iOS application with an engaging user interface.
Building off of existing on-device speech recognition models including Pocketsphinx, Mozilla DeepSpeech, iOS Dictation, and more, we decided to combine them in an ensemble model. We employed the Google Cloud Speech to Text API to transcribe videos for ground truth, against which we compared transcription error rates for our models by phonemes, lengths, and syllabic features.
Finally, we ran our own tests to ensure that the speech-to-text API was dynamically editing previously spoken words and phrases using context of neighboring words. The ideal weights for each weight assigned to each candidate were optimized over many iterations of testing using the Weights & Biases API (along with generous amounts of freezing layers and honing in!). Through many grueling rounds and head-to-head comparisons, the iOS on-device speech recognizer shined, with its superior accuracy and performance, compared to the other two, and was assigned the highest weight by far. Based on these results, in order to improve performance, we ended up not using the other two models at all.
## Challenges we ran into
When we were designing the solution architecture, we quickly discovered there was no API or database to enable conversion of written English to ASL "gloss" (or even videos). We were therefore forced to make our own database by creating and cropping videos ourselves. While time-consuming, this ensured consistent video quality as well as speed and efficiency in loading the videos on the iOS device. It also inspired our plan to crowdsource information and database video samples from users in a way that benefits all those who opt-in to the sharing system.
One of the first difficulties we had was navigating the various different speech recognition model outputs and modifying it for continuous and lengthy voice samples. Furthermore, we had to ensure our algorithm dynamically adjusted history and performed backwards error correction, since some API's (especially Apple's iOS Dictation) dynamically alter past text when clued in on context from later words.
All of our lexical and syntactical analysis required us to meticulously design finite state machines and data structures around the results of the models and API's we used — and required significant alteration & massaging — before they became useful for our application. This was necessary due to our ambitious goal of achieving real-time ASL delivery to users.
## Accomplishments that we're proud of
As a team we were most proud of our ability to quickly learn new frameworks and use Machine Learning and Reinforcement Learning to develop an application that was scalable and modular. While we were subject to a time restriction, we ensured that our user interface was polished, and that our final app integrated several frameworks seamlessly to deliver a usable product to our target audience, *sans* bugs or errors. We pushed ourselves to learn unfamiliar skills so that our solution would be as comprehensive as we could make it. Additionally, of course, we’re proud of our ability to come together and solve a problem that could truly benefit an entire community.
## What we learned
We learned how to brainstorm ideas effectively and in a team, create ideas collaboratively, and parallelize tasks for maximum efficiency. We exercised our literature research and market research skills to recognize that there was a gap we could fill in the ASL community. We also integrated ML techniques into our design and solution process, carefully selecting analysis methods to evaluate candidate options before proceeding on a rigorously defined footing. Finally, we strove to continually analyze data to inform future design decisions and train our models.
## What's next for Sign-ify
We want to expand our app to be more robust and extensible. Currently, the greatest limitation of our application is the limited database of ASL words that we recorded videos for. In the future, one of our biggest priorities is to dynamically generate animation so that we will have a larger and more accurate database. We want to improve our speech to text API with more training data so that it becomes more accurate in educational settings.
Publishing the app on the iOS app store will provide the most effective distribution channel and allow members of the deaf and hard-of-hearing community easy access to our app.
We are very excited by the prospects of this solution and will continue to update the software to achieve our goal of enhancing the educational experience for users with auditory impairments.
## Citations:
Google Cloud Platform API
Penn State. "Sign language users read words and see signs simultaneously." ScienceDaily. ScienceDaily, 24 March 2011 [[www.sciencedaily.com/releases/2011/03/110322105438.htm](http://www.sciencedaily.com/releases/2011/03/110322105438.htm)].
|
## Inspiration
Over **15% of American adults**, over **37 million** people, are either **deaf** or have trouble hearing according to the National Institutes of Health. One in eight people have hearing loss in both ears, and not being able to hear or freely express your thoughts to the rest of the world can put deaf people in isolation. However, only 250 - 500 million adults in America are said to know ASL. We strongly believe that no one's disability should hold them back from expressing themself to the world, and so we decided to build Sign Sync, **an end-to-end, real-time communication app**, to **bridge the language barrier** between a **deaf** and a **non-deaf** person. Using Natural Language Processing to analyze spoken text and Computer Vision models to translate sign language to English, and vice versa, our app brings us closer to a more inclusive and understanding world.
## What it does
Our app connects a deaf person who speaks American Sign Language into their device's camera to a non-deaf person who then listens through a text-to-speech output. The non-deaf person can respond by recording their voice and having their sentences translated directly into sign language visuals for the deaf person to see and understand. After seeing the sign language visuals, the deaf person can respond to the camera to continue the conversation.
We believe real-time communication is the key to having a fluid conversation, and thus we use automatic speech-to-text and text-to-speech translations. Our app is a web app designed for desktop and mobile devices for instant communication, and we use a clean and easy-to-read interface that ensures a deaf person can follow along without missing out on any parts of the conversation in the chat box.
## How we built it
For our project, precision and user-friendliness were at the forefront of our considerations. We were determined to achieve two critical objectives:
1. Precision in Real-Time Object Detection: Our foremost goal was to develop an exceptionally accurate model capable of real-time object detection. We understood the urgency of efficient item recognition and the pivotal role it played in our image detection model.
2. Seamless Website Navigation: Equally essential was ensuring that our website offered a seamless and intuitive user experience. We prioritized designing an interface that anyone could effortlessly navigate, eliminating any potential obstacles for our users.
* Frontend Development with Vue.js: To rapidly prototype a user interface that seamlessly adapts to both desktop and mobile devices, we turned to Vue.js. Its flexibility and speed in UI development were instrumental in shaping our user experience.
* Backend Powered by Flask: For the robust foundation of our API and backend framework, Flask was our framework of choice. It provided the means to create endpoints that our frontend leverages to retrieve essential data.
* Speech-to-Text Transformation: To enable the transformation of spoken language into text, we integrated the webkitSpeechRecognition library. This technology forms the backbone of our speech recognition system, facilitating communication with our app.
* NLTK for Language Preprocessing: Recognizing that sign language possesses distinct grammar, punctuation, and syntax compared to spoken English, we turned to the NLTK library. This aided us in preprocessing spoken sentences, ensuring they were converted into a format comprehensible by sign language users.
* Translating Hand Motions to Sign Language: A pivotal aspect of our project involved translating the intricate hand and arm movements of sign language into a visual form. To accomplish this, we employed a MobileNetV2 convolutional neural network. Trained meticulously to identify individual characters using the device's camera, our model achieves an impressive accuracy rate of 97%. It proficiently classifies video stream frames into one of the 26 letters of the sign language alphabet or one of the three punctuation marks used in sign language. The result is the coherent output of multiple characters, skillfully pieced together to form complete sentences
## Challenges we ran into
Since we used multiple AI models, it was tough for us to integrate them seamlessly with our Vue frontend. Since we are also using the webcam through the website, it was a massive challenge to seamlessly use video footage, run realtime object detection and classification on it and show the results on the webpage simultaneously. We also had to find as many opensource datasets for ASL as possible, which was definitely a challenge, since with a short budget and time we could not get all the words in ASL, and thus, had to resort to spelling words out letter by letter. We also had trouble figuring out how to do real time computer vision on a stream of hand gestures of ASL.
## Accomplishments that we're proud of
We are really proud to be working on a project that can have a profound impact on the lives of deaf individuals and contribute to greater accessibility and inclusivity. Some accomplishments that we are proud of are:
* Accessibility and Inclusivity: Our app is a significant step towards improving accessibility for the deaf community.
* Innovative Technology: Developing a system that seamlessly translates sign language involves cutting-edge technologies such as computer vision, natural language processing, and speech recognition. Mastering these technologies and making them work harmoniously in our app is a major achievement.
* User-Centered Design: Crafting an app that's user-friendly and intuitive for both deaf and hearing users has been a priority.
* Speech Recognition: Our success in implementing speech recognition technology is a source of pride.
* Multiple AI Models: We also loved merging natural language processing and computer vision in the same application.
## What we learned
We learned a lot about how accessibility works for individuals that are from the deaf community. Our research led us to a lot of new information and we found ways to include that into our project. We also learned a lot about Natural Language Processing, Computer Vision, and CNN's. We learned new technologies this weekend. As a team of individuals with different skillsets, we were also able to collaborate and learn to focus on our individual strengths while working on a project.
## What's next?
We have a ton of ideas planned for Sign Sync next!
* Translate between languages other than English
* Translate between other sign languages, not just ASL
* Native mobile app with no internet access required for more seamless usage
* Usage of more sophisticated datasets that can recognize words and not just letters
* Use a video image to demonstrate the sign language component, instead of static images
|
## Inspiration
One of our team members struggles with ADHD and focusing in open, noisy environments. As a team, we decided to build an application that would be able to help users with focusing issues read and listen to verbal presentations while filtering out the noise and audible distractions. This technology helps not just those with ADHD but also autism and other learning disabilities.
## What it does
**AFAR** (Assisted Focus Audio Reviewer) is a web application that **transcribes in real-time audio inputs** from a microphone attached to a speaker so that the user can read follow along with the speaker while wearing noise-canceling headphones to **filter out the noise distractions**. This allows the user to be either in a separate, distraction-free room or in the same room as the speaker but able to focus on the lecture.
## How we built it
We used the rev.ai API speech-to-text service to record the microphone input of the speaker. We use the Streaming Speech-To-Text API to make API calls through sockets and displaying the transcript of the transcribed text on our front-end. The transcript works as note-taking for the class with the implemented annotation features of a text editor. We use Quill which is a free, open-source WYSIWYG editor built for web apps. To facilitate better learning, the students can also have the lecture content along with their notes read out to them in a generic and easy to understand voice. We implemented this by using the SpeechSynthesis API. Listening, transcribing, and note-taking at their own pace provides a simpler and enriching learning experience for everyone, regardless of their abilities.
## Challenges we ran into
A feature we wanted to add to the product was a real-time audio read-out using a raspberry pi so that the user could listen to the speaker using comfortable and familiar text-to-speech voices. Implementing a real-time audio read-out proved to be difficult given the time constraint.
## Accomplishments that we're proud of
The UI of the website has been designed with distracted students in mind; we used high contrast visuals to draw the users attention to the transcription. We also timestamp the transcription so the user can record and access the speech later and pinpoint specific information. Overall, we are proud of the features of the application that keep in mind those with disabilities so that every person is able to participate, learn, and contribute inside the classroom and out.
## What we learned
One of the biggest things we learned was how to implement the real-time rev API. It was a primary goal to have this application work in real-time so that the users are always included in speeches, lectures, and presentations. Not having real-time transcription would exclude the user from focusing and participating during the events.
## What's next for AFAR
Our next steps include real-time audio read out from a Raspberry Pi so that the user can be mobile while listening to the speaker. This would be a useful feature for those individuals that need to fidget or pace to focus as well as other users that need to step out from the lecture to use the bathroom, make a call, etc.
|
partial
|
## Inspiration
**Reddit card threads and Minji's brother's military service**
We know these two things sound a little funny together, but trust us, they formulated an idea. Our group was discussing the multiple threads on Reddit related to sending sick and unfortunate children cards through the mail to cheer them up. We thought there must be an easier, more efficient way to accomplish this. Our group also began to chat about Minji's brother, who served in the Republic of Korea Armed Forces. We talked about his limited Internet access, and how he tried to efficiently manage communication with those who supported him. Light bulb! Why not make a website dedicated to combining everyone's love and support in one convenient place?
## What it does
**Videos and photos and text, oh my!**
A little bit of love can go a long way with Cheerluck. Our user interface is very simple and intuitive (and responsive), so audiences of all ages can post and enjoy the website with little to no hassle. The theme is simple, bright, and lighthearted to create a cheerful experience for the user. Past the aesthetic, the functionality of the website is creating personal pages for those in stressful or undesirable times, such as patients, soldiers, those in the Peace Corps, and so on. Once a user has created a page for someone, people are welcome to either (a) create a text post, (b) upload photos, or (c) use their webcam/phone camera to record a video greeting to post. The Disqus and Ziggeo APIs allow for moderation of content. These posts would all be appended to the user's page, where someone can give them the link to view whenever they want as a great source of love, cheer and comfort. For example, if this had existed when Jihoon was in the military, he could've used his limited internet time more efficiently by visiting this one page where his family and friends were updating him on their lives at once. This visual scrapbook can put a smile on anyone's face, young or old, on desktop or mobile!
## How we built it
• HTML, CSS, Javascript, JQuery, Node.js, Bootstrap (worked off of a theme)
• APIs: Ziggeo (videos), Disqus (commenting/photos)
• Hosted on Heroku using our domain.com name
• Also, Affinity Photo and Affinity Designer were used to create graphic design elements
## Challenges we ran into
**36 hours: Not as long as you’d think**
When this idea first came about, we got a little carried away with the functionality we wanted to add. Our main challenge was racing the clock. Debugging took up a lot of time, as well as researching documentation on how to effectively put all of these pieces together. We left some important elements out, but are overall proud of what have to present based on our prior knowledge!
## Accomplishments that we're proud of
Our group is interested in web development, but all of us have little to no knowledge of it. So, we decided to take on the challenge of tackling one this weekend! We were very excited to test out different APIs to make our site functional, and work with different frameworks that all the cool kids talk about. Given the amount of time, we're proud that we have a presentable website that can definitely be built upon in the future. This challenge was more difficult than we thought it would be, but we’re proud of what we accomplished and will use this as a big learning experience going forward.
## What we learned
• A couple of us knew very basic ideas of HTML, CSS, Bootstrap, node.js, and Heroku. We learned how they interact with each other and come together in order to publish a website.
• How to integrate APIs to help our web app be functional
• How to troubleshoot problems related to hosting the website
• How to use the nifty features of Bootstrap (columns! So wonderful!)
• How to host a website on an actual .com domain (thanks domain.com!)
## What's next for Cheerluck
We hope to expand upon this project at some point; there’s a lot of features that can be added, and this could become a full-fledged web app someday. There are definitely a lot of security worries for something that is as open as this, so we’d hope to add filters to make approving posts easier. Users could view all pages and search for causes they’d like to spread cheer to. We would also like to add the ability to make a page public or private. If we’re feeling really fancy, we’d love to make each page customizable to a certain degree, such as different colored buttons.
There will always be people in difficult situations who need support from loved ones, young and old, and this accessible, simple solution could be an appealing platform for anyone with internet access.
|
## 💡 Inspiration 💡
Mental health is a growing concern in today's population, especially in 2023 as we're all adjusting back to civilization again as COVID-19 measures are largely lifted. With Cohere as one of our UofT Hacks X sponsors this weekend, we want to explore the growing application of natural language processing and artificial intelligence to help make mental health services more accessible. One of the main barriers for potential patients seeking mental health services is the negative stigma around therapy -- in particular, admitting our weaknesses, overcoming learned helplessness, and fearing judgement from others. Patients may also find it inconvenient to seek out therapy -- either because appointment waitlists can last several months long, therapy clinics can be quite far, or appointment times may not fit the patient's schedule. By providing an online AI consultant, we can allow users to briefly experience the process of therapy to overcome their aversion in the comfort of their own homes and under complete privacy. We are hoping that after becoming comfortable with the experience, users in need will be encouraged to actively seek mental health services!
## ❓ What it does ❓
This app is a therapy AI that generates reactive responses to the user and remembers previous information not just from the current conversation, but also past conversations with the user. Our AI allows for real-time conversation by using speech-to-text processing technology and then uses text-to-speech technology for a fluent human-like response. At the end of each conversation, the AI therapist generates an appropriate image summarizing the sentiment of the conversation to give users a method to better remember their discussion.
## 🏗️ How we built it 🏗️
We used Flask to make the API endpoints in the back-end to connect with the front-end and also save information for the current user's session, such as username and past conversations, which were stored in a SQL database. We first convert the user's speech to text and then send it to the back-end to process it using Cohere's API, which as been trained by our custom data and the user's past conversations and then sent back. We then use our text-to-speech algorithm for the AI to 'speak' to the user. Once the conversations is done, we use Cohere's API to summarize it into a suitable prompt for the DallE text-to-image API to generate an image summarizing the user's conversation for them to look back at when they want to.
## 🚧 Challenges we ran into 🚧
We faced an issue with implementing a connection from the front-end to back-end since we were facing a CORS error while transmitting the data so we had to properly validate it. Additionally, incorporating the speech-to-text technology was challenging since we had little prior experience so we had to spend development time to learn how to implement it and also format the responses properly. Lastly, it was a challenge to train the cohere response AI properly since we wanted to verify our training data was free of bias or negativity, and that we were using the results of the Cohere AI model responsibly so that our users will feel safe using our AI therapist application.
## ✅ Accomplishments that we're proud of ✅
We were able to create an AI therapist by creating a self-teaching AI using the Cohere API to train an AI model that integrates seamlessly into our application. It delivers more personalized responses to the user by allowing it to adapt its current responses to users based on the user's conversation history and
making conversations accessible only to that user. We were able to effectively delegate team roles and seamlessly integrate the Cohere model into our application. It was lots of fun combining our existing web development experience with venturing out to a new domain like machine learning to approach a mental health issue using the latest advances in AI technology.
## 🙋♂️ What we learned 🙋♂️
We learned how to be more resourceful when we encountered debugging issues, while balancing the need to make progress on our hackathon project. By exploring every possible solution and documenting our findings clearly and exhaustively, we either increased the chances of solving the issue ourselves, or obtained more targeted help from one of the UofT Hacks X mentors via Discord. Our goal is to learn how to become more independent problem solvers. Initially, our team had trouble deciding on an appropriately scoped, sufficiently original project idea. We learned that our project should be both challenging enough but also buildable within 36 hours, but we did not force ourselves to make our project fit into a particular prize category -- and instead letting our project idea guide which prize category to aim for. Delegating our tasks based on teammates' strengths and choosing teammates with complementary skills was essential for working efficiently.
## 💭 What's next? 💭
To improve our project, we could allow users to customize their AI therapist, such as its accent and pitch or the chat website's color theme to make the AI therapist feel more like a personalized consultant to users. Adding a login page, registration page, password reset page, and enabling user authentication would also enhance the chatbot's security. Next, we could improve our website's user interface and user experience by switching to Material UI to make our website look more modern and professional.
|
## Inspiration
Over the Summer one of us was reading about climate change but then he realised that most of the news articles that he came across were very negative and affected his mental health to the point that it was hard to think about the world as a happy place. However one day he watched this one youtube video that was talking about the hope that exists in that sphere and realised the impact of this "goodNews" on his mental health. Our idea is fully inspired by the consumption of negative media and tries to combat it.
## What it does
We want to bring more positive news into people’s lives given that we’ve seen the tendency of people to only read negative news. Psychological studies have also shown that bringing positive news into our lives make us happier and significantly increases dopamine levels.
The idea is to maintain a score of how much negative content a user reads (detected using cohere) and once it reaches past a certain threshold (we store the scores using cockroach db) we show them a positive news related article in the same topic area that they were reading.
We do this by doing text analysis using a chrome extension front-end and flask, cockroach dp backend that uses cohere for natural language processing.
Since a lot of people also listen to news via video, we also created a part of our chrome extension to transcribe audio to text - so we included that into the start of our pipeline as well! At the end, if the “negativity threshold” is passed, the chrome extension tells the user that it’s time for some good news and suggests a relevant article.
## How we built it
**Frontend**
We used a chrome extension for the front end which included dealing with the user experience and making sure that our application actually gets the attention of the user while being useful. We used react js, HTML and CSS to handle this. There was also a lot of API calls because we needed to transcribe the audio from the chrome tabs and provide that information to the backend.
**Backend**
## Challenges we ran into
It was really hard to make the chrome extension work because of a lot of security constraints that websites have. We thought that making the basic chrome extension would be the easiest part but turned out to be the hardest. Also figuring out the overall structure and the flow of the program was a challenging task but we were able to achieve it.
## Accomplishments that we're proud of
1) (co:here) Finetuned a co:here model to semantically classify news articles based on emotional sentiment
2) (co:here) Developed a high-performing classification model to classify news articles by topic
3) Spun up a cockroach db node and client and used it to store all of our classification data
4) Added support for multiple users of the extension that can leverage the use of cockroach DB's relational schema.
5) Frontend: Implemented support for multimedia streaming and transcription from the browser, and used script injection into websites to scrape content.
6) Infrastructure: Deploying server code to the cloud and serving it using Nginx and port-forwarding.
## What we learned
1) We learned a lot about how to use cockroach DB in order to create a database of news articles and topics that also have multiple users
2) Script injection, cross-origin and cross-frame calls to handle multiple frontend elements. This was especially challenging for us as none of us had any frontend engineering experience.
3) Creating a data ingestion and machine learning inference pipeline that runs on the cloud, and finetuning the model using ensembles to get optimal results for our use case.
## What's next for goodNews
1) Currently, we push a notification to the user about negative pages viewed/a link to a positive article every time the user visits a negative page after the threshold has been crossed. The intended way to fix this would be to add a column to one of our existing cockroach db tables as a 'dirty bit' of sorts, which tracks whether a notification has been pushed to a user or not, since we don't want to notify them multiple times a day. After doing this, we can query the table to determine if we should push a notification to the user or not.
2) We also would like to finetune our machine learning more. For example, right now we classify articles by topic broadly (such as War, COVID, Sports etc) and show a related positive article in the same category. Given more time, we would want to provide more semantically similar positive article suggestions to those that the author is reading. We could use cohere or other large language models to potentially explore that.
|
partial
|
Energy is the future. More and more, that future relies on community efforts toward sustainability, and often, the best form of accountability occurs within peer networks. That's why we built SolarTrack, a energy tracker app that allows Birksun users to connect and collaborate with like-minded members of their community.
In our app, the user profile reflects lifetime energy generated using Birksun, as well as a point conversion system that allows for the future development of gameified rewards. We also have a community map, where you can find a heatmap that describes where people generate the most energy using Birksun bags. In the future, this community map would also include nearby events and gatherings. Finally, there's the option to find family and friends and compete amongst them to accumulate the most points using Birksun bags.
Here's to building a greener future for wearable tech, one bag at a time!
|
## Inspiration
**Michael has a problem**. When girls drop their apples, he has a tendency to dispose of them in wastebaskets. He always feels terrible afterward, and only handwritten letters of apology can truly convey how sorry he is. In order to save him time, we decided to automate the process.
## What it does
Dem Write Brothers is a **novel handwriting system** that takes just a few minutes to set up, but can save hours upon hours of time. Once you provide a brief sample of your handwriting, you can enter any message for our device to transcribe. The result will be indistinguishable from your own handwriting, and the device will add **perturbations** so no two letters are the same. Finally, for the ultimate personal feel, you can even write **batch letters** customized for each recipient.
## How we built it
For hardware, we started by cadding our device with Autodesk Inventor. We then laser cut and assembled the acrylic pieces for our device's framework. The wiring of our Dragonboard and Arduino devices rounded out this process.
Simultaneously, web app development started with user interface planning. The key components of the app, such as handwriting sampling, were then written using JavaScript. Finally, the web app was put together using many languages and services. Python and C were also used to program the Dragonboard and Arduino devices.
## Challenges we ran into
The moving parts of our device often caused us great headache. For instance, when some of the laser cut acrylic pieces experienced too much friction to slide past each other, we had to buy and apply WD-40. Some of the arduinos we used also died mid-testing.
On the software side, the usual missing end brackets were frustrating but easily solved. More nuanced, then, was the issue of UX. We wanted Dem Write Brothers to be simple and quickly learnable for all users, so our web app went through numerous redesigns.
## Accomplishments that we're proud of
Despite the electronic and mechanical difficulties of hardware assembly, our machine functions elegantly, according to design. After all, **it looks pretty dang slick**. In contrast to the complexities of the hardware and software, our user interface is minimalist and **retro**. It turns a computationally and physically complex device into something useable by anyone.
## What we learned
The importance of sleep cannot be overstressed. Unlike PennApps XVI, during which we slept about 4 hours each and rushed to complete our hack, we each slept a reasonably healthy amount and submitted our hack on DevPost early. We also worked together closely, so that each member of our team was involved throughout the whole process. These were valuable lessons that supplemented the many hardware and programming skills we honed throughout the hackathon.
## What's next for Dem Write Brothers
Though Dem Write Brothers was designed to help Michael with his apology letters, we're proud of its many potential applications. **Companies large and small** will be able to establish a more personal connection with their customers. **Politicians** will be able to reach out to their constituents; perhaps even political apathy and low voter turnout can be curbed. And for **everyday people**, writing heartfelt letters will no longer be a chore. We're looking forward to sharing our idea with the world, but in the meantime, Michael will be hogging Dem Write Brothers for a while.
|
**Inspiration**
Inspiration came from the growing concern about environmental sustainability and waste management. We were particularly struck by the amount of waste generated by single-use packaging and products from large corporations like PepsiCo. We wanted to find a way to inspire people to think creatively about trash, turning it into something valuable rather than discarding it. The idea of upcycling aligns perfectly with this goal, turning what would be waste into treasures with a new purpose.
**What it does**
TrashToTreasure is a sustainable showcase platform where users can upload pictures of PepsiCo packaging waste and receive creative upcycling ideas from our AI assistant, Gemini. After transforming the waste into something useful or artistic, users can upload pictures of their upcycled products. The community can then vote on the best upcycling transformations, encouraging both creativity and sustainable practices.
**How we built it**
We built TrashToTreasure using a combination of modern web technologies. The frontend is built with React, and we used Next.js for server-side rendering. We integrated Gemini, an AI assistant, to process user-submitted images and suggest upcycling ideas. The backend is powered by a NodeJS application with a MongoDB database, where we store user data, images, and voting information. We also incorporated voting functionality to allow users to rate upcycled creations. Images are processed using a combination of cloud storage and base64 encoding to facilitate smooth uploads and rendering.
**Challenges we ran into**
One of the biggest challenges was developing a seamless image processing pipeline, where users can upload pictures of their trash and upcycled items without losing quality or causing performance issues. Another challenge was training Gemini to suggest useful and creative upcycling ideas based on a wide range of packaging materials. Prompting was an important must here!
**Accomplishments that we're proud of**
For all but one, it's our first hackathon! We’re proud of creating a platform that promotes environmental sustainability and community engagement. We successfully integrated an AI that can provide,creative upcycling ideas, encouraging people to think outside the box when it comes to waste. Additionally, building a voting mechanism that allows the community to participate and celebrate the best ideas is something we’re really love.
**What we learned**
We learned the importance of seamless user experience, especially when dealing with images and voting mechanisms. Things can get complicated, and that's when users start leaving your page. We also deepened our understanding of AI-driven suggestion systems and how to fine-tune them for specific use cases like upcycling. Working with sustainability-focused applications taught us how small actions, like reimagining trash, can have a larger impact on both individuals and the environment.
What's next for TrashToTreasure - Sustainable Showcase
Moving forward, we want to expand the platform by integrating with other companies' packaging waste, not just PepsiCo’s. We plan to enhance Gemini's AI capabilities to suggest even more creative ideas and work on building a larger community where people can share, learn, and inspire others to upcycle. We’re also considering introducing challenges or competitions where users can win rewards for the most innovative upcycled creations, further incentivizing sustainability. Maybe a Pepsi Jet!
|
partial
|
## Inspiration
We were inspired by the Interac API, because of how simple it made money requests. We all realized that one thing we struggle with sometimes is splitting the bill, as sometimes restaurants don't accommodate for larger parties.
## What it does
Our simple web app allows for you to upload your receipt, and digitally invoice your friends for their meals.
## How we built it
For processing the receipts, we used Google Cloud's Vision API, which is a machine learning application for recognizing and converting images of characters into digital text. We used HTML, CSS, JavaScript, and JQuery to create an easy-to-use and intuitive interface that makes splitting the bill as easy as ever. Behind the scenes, we used Flask and developed Python scripts to process the data entered by the users and to facilitate their movement through our interface. We used the Interac e-Transfer API to send payment requests to the user's contacts. These requests can be fulfilled and the payments will be automatically deposited into the user's bank account.
## Challenges we ran into
The Optical Character Recognition (OCR) API does not handle receipts format very well. The item names and cost are read in different orders, do not always come out in pairs, and have no characters that separate the items. Therefore we needed to develop an algorithm that can pick up the separate the words and recognize which characters were actually useful.
The INTERAC e-Transfer API example was given to us as an React app. Most of us have had no experience with React before. We needed to find a way to still be able to call the API and integrate the caller with the rest of the web app, which was build with HTML, CSS, and Javascript.
There has also been a few difficulties with passing data from the front end interface and the back end service routines.
## Accomplishments that we're proud of
It's the first hackathon for two of our team members, and it was a fresh experience for us to work on a project in 24 hours. We had little to no experience with full stack development and Google Cloud Platform tools. However, we figured out our way step by step, with help from the mentors and online resources. We managed to integrate a few APIs into this project and tied together the front end and back end designs into a functional web app.
## What we learned
How to call Google Cloud APIs
How to host a website on Google Cloud Platform
How to set up an HTTP request in various languages
How to make dynamically interactive web page
How to handle front end and back end requests
## What's next for shareceipt
We hope to take shareceipt to the next level by filling in all the places in which we did not have enough time to fully explore due to the nature of a hackathon. In the future, we could add mobile support, Facebook & other social media integration to expand our user-base and allow many more users to enjoy a simple way to dine out with friends.
|
## Inspiration
Suppose we go out for a run early in the morning without our wallet and cellphone, our service enables banking systems to use facial recognition as a means of payment enabling us to go cashless and cardless.
## What it does
It uses deep neural networks in the back end to detect faces at point of sale terminals and match them with those stored in the banking systems database and lets the customer purchase a product from a verified seller almost instantaneously. In addition, it allows a bill to be divided between customers using recognition of multiple faces. It works in a very non-invasive manner and hence makes life easier for everyone.
## How we built it
Used dlib as the deep learning framework for face detection and recognition, along with Flask for the web API and plain JS on the front end. The front end uses AJAX to communicate with the back end server. All requests are encrypted using SSL (self-signed for the hackathon).
## Challenges we ran into
We attempted to incorporate gesture recognition into the service, but it would cause delays in the transaction due to extensive training/inference based on hand features. This is a feature to be developed in the future, and has the potential to distinguish and popularize our unique service
## Accomplishments that we're proud of
Within 24 hours, we are able to pull up a demo for payment using facial recognition simply by having the customer stand in front of the camera using real-time image streaming. We were also able to enable payment splitting by detection of multiple faces.
## What we learned
We learned to set realistic goals and pivot in the right times. There were points where we thought we wouldn't be able to build anything but we persevered through it to build a minimum viable product. Our lesson of the day would therefore be to never give up and always keep trying -- that is the only reason we could get our demo working by the end of the 24 hour period.
## What's next for GazePay
We plan on associating this service with bank accounts from institutions such as Scotiabank. This will allow users to also see their bank balance after payment, and help us expand our project to include facial recognition ATMs, gesture detection, and voice-enabled payment/ATMs for them to be more accessible and secure for Scotiabank's clients.
|
## Inspiration
Tax returns are heavily beneficial to those in the mid to low-income range. Oftentimes, they don't understand how much they should expect, or how it even works. This same audience also budgets tightly, and may need help tracking. They are more likely to be reliant on cash purchases, something difficult to track long term.
## What it does
Our platform aims to solve this knowledge gap by giving them an approximation of how much their tax return should be, and allows an overview of how much of their monthly budget they've spent.
## How we built it
We created a user landing page, with log in and sign up. When the user signs up with their details, it is stored in a SQL database. When they log in, user info is loaded into a table via a Flask API fetching data from past sessions, if any. If the user wants to upload a receipt, they upload a picture to the upload page. By submitting, this picture is sent to the same Flask API as before, but as POST. Optical character recognition is used to parse every item, its cost, the subtotal, and total. This is stored in the same database and connected to their credentials. The next time the home page is loaded, this data will be shown on the table.
## Challenges we ran into
Since Google OCR was trained on normal printer sized text, parsing a receipt correctly is difficult unless you have perfect lighting and positioning when taking the photo. Receipts are often crumpled and have ink errors, further breaking the parsing. Hosting the entire application with Flask is difficult to get fully running with HTML/CSS, so we opted to make an API instead. Optimising the front end of the table was difficult, since the response would be in JSON and we would have to dynamically input the data (document.getElementById('id').innerHTML = data). It took a while to get the database fully working due to the numerous components such as user accounts and then fetching with the API.
## Accomplishments that we're proud of
Learning how to create dynamic websites with the use of front end JavaScript. Learning how to make optimised reusable algorithms when trying to parse and evaluate data. Creating a link between the database, API, and front end to all work seamlessly together to serve data to the user.
## What we learned
Often times the hardest part of a project is setting up an MVP and getting it to merge and run seamlessly. Many people working on different parts of a project at once can lead to overlapping tasks and solutions which do not work when put together. Solutions can suddenly stop working when tested at scale or when they are deployed.
## What's next for Snap N Track
We would need to create our own OCR model. The current library we are using, based off Google Lens, is not optimised for small text in the conditions that a receipt is in. We would need to create a mobile app. Since it is a web app, someone would need to take a picture on their phone, upload it to their PC, and then to the site. By making an app they can simply take a picture and upload at the same time. We should add more features such as income tax calculation given salary, or others. This is because we currently only have 1 main feature (receipt scanning).
|
partial
|
## **Inspiration**
Ever had to wipe your hands constantly to search for recipes and ingredients while cooking?
Ever wondered about the difference between your daily nutrition needs and the nutrition of your diets?
Vocal Recipe is an integrated platform where users can easily find everything they need to know about home-cooked meals! Information includes recipes with nutrition information, measurement conversions, daily nutrition needs, cooking tools, and more! The coolest feature of Vocal Recipe is that users can access the platform through voice control, which means they do not need to constantly wipe their hands to search for information while cooking. Our platform aims to support healthy lifestyles and make cooking easier for everyone.
## **How we built Vocal Recipe**
Recipes and nutrition information is implemented by retrieving data from Spoonacular - an integrated food and recipe API.
The voice control system is implemented using Dasha AI - an AI voice recognition system that supports conversation between our platform and the end user.
The measurement conversion tool is implemented using a simple calculator.
## **Challenges and Learning Outcomes**
One of the main challenges we faced was the limited trials that Spoonacular offers for new users. To combat this difficulty, we had to switch between team members' accounts to retrieve data from the API.
Time constraint is another challenge that we faced. We do not have enough time to formulate and develop the whole platform in just 36 hours, thus we broke down the project into stages and completed the first three stages.
It is also our first time using Dasha AI - a relatively new platform which little open source code could be found. We got the opportunity to explore and experiment with this tool. It was a memorable experience.
|
## Inspiration
Partially inspired by the Smart Cities track, we wanted our app to have the direct utility of ordering food, while still being fun to interact with. We aimed to combine convenience with entertainment, making the experience more enjoyable than your typical drive-through order.
## What it does
You interact using only your voice. The app automatically detects when you start and stop talking, uses AI to transcribe what you say, figures out the food items (with modifications) you want to order, and adds them to your current order. It even handles details like size and flavor preferences. The AI then generates text-to-speech audio, which is played back to confirm your order in a humorous, engaging way. There is absolutely zero set-up or management necessary, as the program will completely ignore all background noises and conversation. Even then, it will still take your order with staggering precision.
## How we built it
The frontend of the app is built with React and TypeScript, while the backend uses Flask and Python. We containerized the app using Docker and deployed it using Defang. The design of the menu is also done in Canva with a dash of Harvard colors.
## Challenges we ran into
One major challenge was getting the different parts of the app—frontend, backend, and AI—to communicate effectively. From media file conversions to AI prompt engineering, we worked through each of the problems together. We struggled particularly with maintaining smooth communication once the app was deployed. Additionally, fine-tuning the AI to accurately extract order information from voice inputs while keeping the interaction natural was a big hurdle.
## Accomplishments that we're proud of
We're proud of building a fully functioning product that successfully integrates all the features we envisioned. We also managed to deploy the app, which was a huge achievement given the complexity of the project. Completing our initial feature set within the hackathon timeframe was a key success for us. Trying to work with Python data type was difficult to manage, and we were proud to navigate around that. We are also extremely proud to meet a bunch of new people and tackle new challenges that we were not previously comfortable with.
## What we learned
We honed our skills in React, TypeScript, Flask, and Python, especially in how to make these technologies work together. We also learned how to containerize and deploy applications using Docker and Docker Compose, as well as how to use Defang for cloud deployment.
## What's next for Harvard Burger
Moving forward, we want to add a business-facing interface, where restaurant staff would be able to view and fulfill customer orders. There will also be individual kiosk devices to handle order inputs. These features would allow *Harvard Burger* to move from a demo to a fully functional app that restaurants could actually use. Lastly, we can sell the product by designing marketing strategies for fast food chains.
|
## Inspiration
We were inspired by our collective experiences as college students always struggling to find a way to use ingredients that we have at home but it's always hard to find what's doable with the current inventory. Most times, those ingredients are left to waste because we don't know how to incorporate different ingredients for a meal. So we searched for recipe APIs to see how we could solve this problem.
## What it does
It is a website that returns a list of recipe titles and links for users to follow based on the ingredients that they enter in the search bar.
## How we built it
We used Spoonacular API to get the recipe titles and links based on the ingredients entered. We used HTML/CSS/JS to form the website.
## Challenges we ran into
Trying to get the API to work from the HTML/JS code. Authorization errors kept coming up. It was also really difficult to find a feasible idea with our current skill set as beginners. We had to pivot several times until we ended up here.
## Accomplishments that we're proud of
We're proud that we got the API to work and connect with our website. We're proud that the project works and that it's useful.
## What we learned
We learned how to use APIs and how to make websites.
## What's next for SpoonFULL
Having more features that can make the website nicer. Having more parameters in the apiURL to make it more specific. We also aim to better educate college students about sustainability and grocery buying habits through this website.
|
winning
|
# Browse-for-Humanity
More than 3,500 refugees lost their lives at sea last year while trying to leave their war-torn home. The refugee crisis has ballooned into a humanitarian crisis which requires immediate action to help alleviate hundreds of thousands of dispaced lives.
Browse For Humanity is a parallel computing platform where clients can submit complex computational tasks to be solved by the power of our crowdsourced processing platform. All the revenue accumulated by each volunteer for sharing his processing power is directly donated to the refugee cause. Now, solving the refugee crisis is as simple as browsing the web.
This product connects researchers and professionals who wish to perform computationally intensive tasks with users who are willing to donate computation power to add some goodness to the world. The extension quietly keeps working in the background. The interface for users posting tasks involves a front-facing web application that allows convenient code typing and uploading along with task distribution files.
**Technologies Used:**
The technology stack for this project was: Javascript, CSS, HTML, Python, Git, JQuery, and Flask. The backend involves a job scheduling system based on the Google Map/Reduce algorithm, which will distribute small tasks for particular jobs among users that are currently donating their processing power. The entire system is built around ease for both clients and users, which means that multiple users and clients can be using the application simultaneously through our multi-threaded server. Payment processing is integrated into the system via the Stripe API, allowing users to enter credit card information, and processing payment on data download.
|
## Inspiration
One of our first ideas was an Instagram-esque social media site for recipe blogs. We also were interested in working with location data - somewhere along the line there was an idea to make an app that allowed you to track down your friends.
Somehow, we managed to combine both of these wildly different ideas into a real-world applicable site. After researching shelters and food banks (aka googling and clicking on the first result), we realized that while these establishments do have a working relationship, oftentimes the shelters and food banks are required to buy key missing ingredients. Thus, our application was created to further personalize the relationship and interaction between these establishments to aid in decreasing food waste and ensuring people are getting culturally-significant, healthy, and delicious food.
## What it does
Markets and Shelters/food banks log in to their respective homepage. From there, they can see the other establishments near them, as well as an interactive sidebar.
For shelters, they can see nearby participating markets and look at their supply of food.
For markets, they will be able to see nearby shelters and their food requests. They will also be able to change their inventory of available foods for those shelters.
## How we built it
We used next.js and a variety of different style options (css, bootstrap, tailwind.css) to make a "dynamic" website.
## Challenges we ran into
We realized the crux of our application, which relies on a google map api to get nearby markets and their distances, is behind a paywall of $0. We didn't want to enter our credit card info to google. Sorry :/
As well, we were using react-native for a good four hours or so in the beginning, but it wasn't displaying on our localport (it was a blank page). Spent a long time trying to debug. So that was fun.
Our team members also used many different stylesheets. The majority of it was in normal style.css, but we have one component that's entirely in bootstrap (installing it for next.js was a pain). Also, there was an attempt to use tailwind.css for some components.
## Accomplishments that we're proud of
Our UI/UX design, including all our styling, was AMAZING. Shoutout to Lindsay for their major contributions.
As well, this was the first time the majority of our team touched react in their lives, so I think our progress was pretty good. Given that we actually chose to slept on Friday night I'd say we accomplished a lot.
## What we learned
Auth is a pain. Never again. It didn't even work :(
## What's next for crumbz
There's a lot to be implemented. From changing our logo to making sure the authentication actually works there is so much more room for crumbz to grow. If we had more time and commitment this application will become so much more.
|
## Inspiration
In light of the ongoing global conflict between war-torn countries, many civilians face hardships. Recognizing these challenges, LifeLine Aid was inspired to direct vulnerable groups to essential medical care, health services, shelter, food and water assistance, and other deprivation relief.
## What it does
LifeLine Aid provides multifunctional tools that enable users in developing countries to locate resources and identify dangers nearby. Utilizing the user's location, the app alerts them about the proximity of a situation and centers for help. It also facilitates communication, allowing users to share live videos and chat updates regarding ongoing issues. An upcoming feature will highlight available resources, like nearby medical centers, and notify users if these centers are running low on supplies.
## How we built it
Originally, the web backend was to be built using Django, a trusted framework in the industry. As we progressed, we realized that the amount of effort and feasibility of exploiting Django were not sustainable; as we made no progress within the first day. Quickly turning to the in-depth knowledge of one of our team member’s extensive research into asyncio, we decided to switch to FastAPI, a trusted framework used by Microsoft. Using this framework had both its benefits and costs. Realizing after our first day, Django proved to be a roadblock, thus we ultimately decided to switch to FastAPI.
Our backend proudly uses CockroachDB, an unstoppable force to be reckoned with. CockroachDB allowed our code to scale and continue to serve those who suffer from the effects of war.
## Challenges we ran into
In order to pinpoint hazards and help, we would need to obtain, store, and reverse-engineer Geospatial coordinate points which we would then present to users in a map-centric manner. We initially struggled with converting the Geospatial data from a degree, minutes, seconds format to decimal degrees and storing the converted values as points on the map which were then stored as unique 50 character long SRID values. Luckily, one of our teammates had some experience with processing GeoSpatial data so drafting coordinates on a map wasn’t our biggest hurdle to overcome. Another challenge we faced were certain edge cases in our initial Django backend that resulted in invalid data. Since some outputs would be relevant to our project, we had to make an executive decision to change backend midway through. We decided to go with FastApi. Although FastApi brought its own challenge with processing SQL to usable data, it was our way of overcoming our Jango situation. One last challenge we ran into was our overall source control. A mixture of slow and unbearable WiFi, combined with tedious local git repositories not correctly syncing create some frustrating deadlocks and holdbacks. To combat this downtime, we resort to physically drafting and planning out how each component of our code would work.
## Accomplishments that we're proud of
Three out of the four in our team are attending their first hackathon. The experience of crafting an app and seeing the fruits of our labor is truly rewarding. The opportunity to acquire and apply new tools in our project has been exhilarating. Through this hackathon, our team members were all able to learn different aspects of creating an idea into a scalable application. From designing and learning UI/UX, implementing the React-Native framework, emulating iOS and Android devices to test and program compatibility, and creating communication between the frontend and backend/database.
## What we learned
This challenge aimed to dive into technologies that are used widely in our daily lives. Spearheading the competition with a framework trusted by huge companies such as Meta, Discord and others, we chose to explore the capabilities of React Native. Joining our team are three students who have attended their first hackathon, and the grateful opportunity of being able to explore these technologies have led us to take away a skillset of a lifetime.
With the concept of the application, we researched and discovered that the only best way to represent our data is through the usage of Geospatial Data. CockroachDB’s extensive tooling and support allowed us to investigate the usage of geospatial data extensively; as our backend team traversed the complexity and the sheer awe of the scale of said technology. We are extremely grateful to have this opportunity to network and to use these tools that would be useful in the future.
## What's next for LifeLine Aid
There are a plethora of avenues to further develop the app, which include enhanced verification, rate limiting, and many others. Other options include improved hosting using Azure Kubernetes Services (AKS), and many others. This hackathon project is planned to be maintained further into the future as a project for others who may be new or old in this field to collaborate on.
|
losing
|
## Inspiration
One In every 250 people suffer from cerebral palsy, where the affected person cannot move a limb properly, And thus require constant care throughout their lifetimes. To ease their way of living, we have made this project, 'para-pal'.
The inspiration for this idea was blended with a number of research papers and a project called Pupil which used permutations to make communication possible with eye movements.
## What it does

**"What if Eyes can Speak? Yesss - you heard it right!"**
Para-pal is a novel idea that tracks patterns in the eye movement of the patient and then converts into actual speech. We use the state-of-the-art iris recognition (dlib) to accurately track the eye movements to figure out the the pattern. Our solution is sustainable and very cheap to build and setup. Uses QR codes to connect the caretaker and the patient's app.
We enable paralyzed patients to **navigate across the screen using their eye movements**. They can select an action by placing the cursor for more than 3 seconds or alternatively, they can **blink three times to select the particular action**. A help request is immediately sent to the mobile application of the care taker as a **push notification**
## How we built it
We've embraced flutter in our frontend to make the UI - simple, intuitive with modularity and customisabilty. The image processing and live-feed detection are done on a separate child python process. The iris-recognition at it's core uses dlib and pipe the output to opencv.
We've developed a desktop-app (which is cross-platform with a rpi3 as well)for the patient and a mobile app for the caretaker.
We also tried running our desktop application on Raspberry Pi using an old laptop screen. In the future, we wish to make a dedicated hardware which can be cost-efficient for patients with paralysis.


## Challenges we ran into
Building up the dlib took a significant amount of time, because there were no binaries/wheels and we had to build from source. Integrating features to enable connectivity and sessions between the caretaker's mobile and the desktop app was hard. Fine tuning some parameters of the ML model, preprocessing and cleaning the input was a real challenge.
Since we were from a different time zone, it was challenging to stay awake throughout the 36 hours and make this project!
## Accomplishments that we're proud of
* An actual working application in such a short time span.
* Integrating additional hardware of a tablet for better camera accuracy.
* Decoding the input feed with a very good accuracy.
* Making a successful submission for HackPrinceton.
* Team work :)
## What we learned
* It is always better to use a pre-trained model than making one yourself, because of the significant accuracy difference.
* QR scanning is complex and is harder to integrate in flutter than how it looks on the outside.
* Rather than over-engineering a flutter component, search if a library exists that does exactly what is needed.
## What's next for Para Pal - What if your eyes can speak?
* More easier prefix-less code patterns for the patient using an algorithm like huffman coding.
* More advanced controls using ML that tracks and learns the patient's regular inputs to the app.
* Better analytics to the care-taker.
* More UI colored themes.
|
## Inspiration
We wanted to make the interactions with our computers more intuitive while giving people with special needs more options to navigate in the digital world. With the digital landscape around us evolving, we got inspired by scenes in movies featuring Tony Stark, where he interacts with computers within his high-tech office. Instead of using a mouse and computer, he uses hand gestures and his voice to control his work environment.
## What it does
Instead of a mouse, Input/Output Artificial Intelligence, or I/OAI, uses a user's webcam to move their cursor to where their face OR hand is pointing towards through machine learning.
Additionally, I/OAI allows users to map their preferred hand movements for commands such as "click", "minimize", "open applications", "navigate websites", and more!
I/OAI also allows users to input data using their voice, so they don't need to use a keyboard and mouse. This increases accessbility for those who don't readily have access to these peripherals.
## How we built it
Face tracker -> Dlib
Hand tracker -> Mediapipe
Voice Recognition -> Google Cloud
Graphical User Interface -> tkinter
Mouse and Keyboard Simulation -> pyautogui
## Challenges we ran into
Running this many programs at the same time slows it down considerably, we therefore need to selectively choose which ones we wanted to keep during the implementation. We solved this by using multithreading and carefully investigating efficiency.
We also had a hard time mapping the face because of the angles of rotation of the head, increasing the complexity of the matching algorithm.
## Accomplishments we're proud of
We were able to implement everything we set out to do in a short amount of time, as there was a lot of integrations with multiple frameworks and our own algorithms.
## What we learned
How to use multithreading for multiple trackers, using openCV for easy camera frames, tkinter GUI building and pyautogui for automation.
## What's next for I/OAI
We need to figure a way to incorporate features more efficiently or get a supercomputer like Tony Stark!
By improving on the features, people will have more accessbility at their computers by simply downloading a program instead of buying expensive products like an eyetracker.
|
## Inspiration
Alzheimer's is a very interesting, scary disease. There's no decided cause for the neuro-degenerative disease among scientists, and neither is there any cure. And on a personal level, we've all met people before who have had family members either currently or previously suffering from Alzheimer's. Inspired by this and the health challenges posted at this hackathon, we decided to come up with a tool to help with Alzheimer's diagnosis and recovery efforts.
## What it does
MindTune is a tool to detect early signs of Alzheimer's and other neuro-degenerative diseases in patients. At-risk patients download the app on their phone and participate in an in-app session on a weekly or daily basis. This session has 2 main features: a comprehensive Neuro-Cognition testing system and an accurate Eye-Tracking system. Doctors can then view this data in a separate website and analyze their patients for any early signs of diseases. Our Neuro-Cognition system works by prompting users questions about their life/day and then using NLP to analyze their responses for any warning signs of reduced cognitive ability. Our Eye-Tracking system uses a highly-accurate gaze-estimation model to check "jiteriness" in users' pupils as another warning sign of Alzheimer's.
## How we built it
MindTune was built with a lot of different tools, primarily:
* React Native - frontend development and user interactivity
* OpenCV - pupil-detection and movement tracking
* PyTorch - run inference with model
* Modal Labs - hosting and deploying
* FastAPI/Python - backend server, LLM integration, NLP
## Challenges we ran into
One of the major challenges we ran into was getting eye-tracking to work in real-time. At first, we developed our own pupil-recognition system with OpenCV. However, this system was slow and couldn't be effectively used in the app. We moved over to a new model (gaze-estimation) and invested heavy effort into making it run as fast as possible with low latency. Another challenge was designing the neuro-cognition system. The questions our system asked had to be relevant to users while still staying semi-randomized.
## Accomplishments that we're proud of
We're really proud of our eye-tracking system. We researched links between pupil movements and Alzheimer's to find the best method of detecting warning signs through pupil jitteriness. We're also proud of our accessible UI, meant to be easy to use by elderly patients, caretakers, and doctors.
## What we learned
We learned a lot about facial recognition and utilizing OpenCV for such recognition tasks. We also learned about using React Native for front-end app development.
## What's next for MindTune
In the future, we want to add even more cognitive tests and puzzles to help find more warning signs in users. We also want to expand the doctor portal to have more advanced analysis of patient data.
|
winning
|
# We'd love if you read through this in its entirety, but we suggest reading "What it does" if you're limited on time
## The Boring Stuff (Intro)
* Christina Zhao - 1st-time hacker - aka "Is cucumber a fruit"
* Peng Lu - 2nd-time hacker - aka "Why is this not working!!" x 30
* Matthew Yang - ML specialist - aka "What is an API"
## What it does
It's a cross-platform app that can promote mental health and healthier eating habits!
* Log when you eat healthy food.
* Feed your "munch buddies" and level them up!
* Learn about the different types of nutrients, what they do, and which foods contain them.
Since we are not very experienced at full-stack development, we just wanted to have fun and learn some new things. However, we feel that our project idea really ended up being a perfect fit for a few challenges, including the Otsuka Valuenex challenge!
Specifically,
>
> Many of us underestimate how important eating and mental health are to our overall wellness.
>
>
>
That's why we we made this app! After doing some research on the compounding relationship between eating, mental health, and wellness, we were quite shocked by the overwhelming amount of evidence and studies detailing the negative consequences..
>
> We will be judging for the best **mental wellness solution** that incorporates **food in a digital manner.** Projects will be judged on their ability to make **proactive stress management solutions to users.**
>
>
>
Our app has a two-pronged approach—it addresses mental wellness through both healthy eating, and through having fun and stress relief! Additionally, not only is eating healthy a great method of proactive stress management, but another key aspect of being proactive is making your de-stressing activites part of your daily routine. I think this app would really do a great job of that!
Additionally, we also focused really hard on accessibility and ease-of-use. Whether you're on android, iphone, or a computer, it only takes a few seconds to track your healthy eating and play with some cute animals ;)
## How we built it
The front-end is react-native, and the back-end is FastAPI (Python). Aside from our individual talents, I think we did a really great job of working together. We employed pair-programming strategies to great success, since each of us has our own individual strengths and weaknesses.
## Challenges we ran into
Most of us have minimal experience with full-stack development. If you look at my LinkedIn (this is Matt), all of my CS knowledge is concentrated in machine learning!
There were so many random errors with just setting up the back-end server and learning how to make API endpoints, as well as writing boilerplate JS from scratch.
But that's what made this project so fun. We all tried to learn something we're not that great at, and luckily we were able to get past the initial bumps.
## Accomplishments that we're proud of
As I'm typing this in the final hour, in retrospect, it really is an awesome experience getting to pull an all-nighter hacking. It makes us wish that we attended more hackathons during college.
Above all, it was awesome that we got to create something meaningful (at least, to us).
## What we learned
We all learned a lot about full-stack development (React Native + FastAPI). Getting to finish the project for once has also taught us that we shouldn't give up so easily at hackathons :)
I also learned that the power of midnight doordash credits is akin to magic.
## What's next for Munch Buddies!
We have so many cool ideas that we just didn't have the technical chops to implement in time
* customizing your munch buddies!
* advanced data analysis on your food history (data science is my specialty)
* exporting your munch buddies and stats!
However, I'd also like to emphasize that any further work on the app should be done WITHOUT losing sight of the original goal. Munch buddies is supposed to be a fun way to promote healthy eating and wellbeing. Some other apps have gone down the path of too much gamification / social features, which can lead to negativity and toxic competitiveness.
## Final Remark
One of our favorite parts about making this project, is that we all feel that it is something that we would (and will) actually use in our day-to-day!
|
## Inspiration
Amidst the hectic lives and pandemic struck world, mental health has taken a back seat. This thought gave birth to our inspiration of this web based app that would provide activities customised to a person’s mood that will help relax and rejuvenate.
## What it does
We planned to create a platform that could detect a users mood through facial recognition, recommends yoga poses to enlighten the mood and evaluates their correctness, helps user jot their thoughts in self care journal.
## How we built it
Frontend: HTML5, CSS(frameworks used:Tailwind,CSS),Javascript
Backend: Python,Javascript
Server side> Nodejs, Passport js
Database> MongoDB( for user login), MySQL(for mood based music recommendations)
## Challenges we ran into
Incooperating the open CV in our project was a challenge, but it was very rewarding once it all worked .
But since all of us being first time hacker and due to time constraints we couldn't deploy our website externally.
## Accomplishments that we're proud of
Mental health issues are the least addressed diseases even though medically they rank in top 5 chronic health conditions.
We at umang are proud to have taken notice of such an issue and help people realise their moods and cope up with stresses encountered in their daily lives. Through are app we hope to give people are better perspective as well as push them towards a more sound mind and body
We are really proud that we could create a website that could help break the stigma associated with mental health. It was an achievement that in this website includes so many features to help improving the user's mental health like making the user vibe to music curated just for their mood, engaging the user into physical activity like yoga to relax their mind and soul and helping them evaluate their yoga posture just by sitting at home with an AI instructor.
Furthermore, completing this within 24 hours was an achievement in itself since it was our first hackathon which was very fun and challenging.
## What we learned
We have learnt on how to implement open CV in projects. Another skill set we gained was on how to use Css Tailwind. Besides, we learned a lot about backend and databases and how to create shareable links and how to create to do lists.
## What's next for Umang
While the core functionality of our app is complete, it can of course be further improved .
1)We would like to add a chatbot which can be the user's guide/best friend and give advice to the user when in condition of mental distress.
2)We would also like to add a mood log which can keep a track of the user's daily mood and if a serious degradation of mental health is seen it can directly connect the user to medical helpers, therapist for proper treatement.
This lays grounds for further expansion of our website. Our spirits are up and the sky is our limit
|
## Inspiration
In the work from home era, many are missing the social aspect of in-person work. And what time of the workday most provided that social interaction? The lunch break. culina aims to bring back the social aspect to work from home lunches. Furthermore, it helps users reduce their food waste by encouraging the use of food that could otherwise be discarded and diversifying their palette by exposing them to international cuisine (that uses food they already have on hand)!
## What it does
First, users input the groceries they have on hand. When another user is found with a similar pantry, the two are matched up and displayed a list of healthy, quick recipes that make use of their mutual ingredients. Then, they can use our built-in chat feature to choose a recipe and coordinate the means by which they want to remotely enjoy their meal together.
## How we built it
The frontend was built using React.js, with all CSS styling, icons, and animation made entirely by us. The backend is a Flask server. Both a RESTful API (for user creation) and WebSockets (for matching and chatting) are used to communicate between the client and server. Users are stored in MongoDB. The full app is hosted on a Google App Engine flex instance and our database is hosted on MongoDB Atlas also through Google Cloud. We created our own recipe dataset by filtering and cleaning an existing one using Pandas, as well as scraping the image URLs that correspond to each recipe.
## Challenges we ran into
We found it challenging to implement the matching system, especially coordinating client state using WebSockets. It was also difficult to scrape a set of images for the dataset. Some of our team members also overcame technical roadblocks on their machines so they had to think outside the box for solutions.
## Accomplishments that we're proud of.
We are proud to have a working demo of such a complex application with many moving parts – and one that has impacts across many areas. We are also particularly proud of the design and branding of our project (the landing page is gorgeous 😍 props to David!) Furthermore, we are proud of the novel dataset that we created for our application.
## What we learned
Each member of the team was exposed to new things throughout the development of culina. Yu Lu was very unfamiliar with anything web-dev related, so this hack allowed her to learn some basics of frontend, as well as explore image crawling techniques. For Camilla and David, React was a new skill for them to learn and this hackathon improved their styling techniques using CSS. David also learned more about how to make beautiful animations. Josh had never implemented a chat feature before, and gained experience teaching web development and managing full-stack application development with multiple collaborators.
## What's next for culina
Future plans for the website include adding videochat component to so users don't need to leave our platform. To revolutionize the dating world, we would also like to allow users to decide if they are interested in using culina as a virtual dating app to find love while cooking. We would also be interested in implementing organization-level management to make it easier for companies to provide this as a service to their employees only. Lastly, the ability to decline a match would be a nice quality-of-life addition.
|
partial
|
## Inspiration
There's something about brief glints in the past that just stop you in your tracks: you dip down, pick up an old DVD of a movie while you're packing, and you're suddenly brought back to the innocent and carefree joy of when you were a kid. It's like comfort food.
So why not leverage this to make money? The ethos of nostalgic elements from everyone's favourite childhood relics turns heads. Nostalgic feelings have been repeatedly found in studies to increase consumer willingness to spend money, boosting brand exposure, conversion, and profit.
## What it does
Large Language Marketing (LLM) is a SaaS built for businesses looking to revamp their digital presence through "throwback"-themed product advertisements.
Tinder x Mean Girls? The Barbie Movie? Adobe x Bob Ross? Apple x Sesame Street? That could be your brand, too. Here's how:
1. You input a product description and target demographic to begin a profile
2. LLM uses the data with the Co:here API to generate a throwback theme and corresponding image descriptions of marketing posts
3. OpenAI prompt engineering generates a more detailed image generation prompt featuring motifs and composition elements
4. DALL-E 3 is fed the finalized image generation prompt and marketing campaign to generate a series of visual social media advertisements
5. The Co:here API generates captions for each advertisement
6. You're taken to a simplistic interface where you can directly view, edit, generate new components for, and publish each social media post, all in one!
7. You publish directly to your business's social media accounts to kick off a new campaign 🥳
## How we built it
* **Frontend**: React, TypeScript, Vite
* **Backend**: Python, Flask, PostgreSQL
* **APIs/services**: OpenAI, DALL-E 3, Co:here, Instagram Graph API
* **Design**: Figma
## Challenges we ran into
* **Prompt engineering**: tuning prompts to get our desired outputs was very, very difficult, where fixing one issue would open up another in a fine game of balance to maximize utility
* **CORS hell**: needing to serve externally-sourced images back and forth between frontend and backend meant fighting a battle with the browser -- we ended up writing a proxy
* **API integration**: with a lot of technologies being incorporated over our frontend, backend, database, data pipeline, and AI services, massive overhead was introduced into getting everything set up and running on everyone's devices -- npm versions, virtual environments, PostgreSQL, the Instagram Graph API (*especially*)...
* **Rate-limiting**: the number of calls we wanted to make versus the number of calls we were allowed was a small tragedy
## Accomplishments that we're proud of
We're really, really proud of integrating a lot of different technologies together in a fully functioning, cohesive manner! This project involved a genuinely technology-rich stack that allowed each one of us to pick up entirely new skills in web app development.
## What we learned
Our team was uniquely well-balanced in that every one of us ended up being able to partake in everything, especially things we hadn't done before, including:
1. DALL-E
2. OpenAI API
3. Co:here API
4. Integrating AI data pipelines into a web app
5. Using PostgreSQL with Flask
6. For our non-frontend-enthusiasts, atomic design and state-heavy UI creation :)
7. Auth0
## What's next for Large Language Marketing
* Optimizing the runtime of image/prompt generation
* Text-to-video output
* Abstraction allowing any user log in to make Instagram Posts
* More social media integration (YouTube, LinkedIn, Twitter, and WeChat support)
* AI-generated timelines for long-lasting campaigns
* AI-based partnership/collaboration suggestions and contact-finding
* UX revamp for collaboration
* Option to add original content alongside AI-generated content in our interface
|
## Inspiration
During our brainstorming phase, we cycled through a lot of useful ideas that later turned out to be actual products on the market or completed projects. After four separate instances of this and hours of scouring the web, we finally found our true calling at QHacks: building a solution that determines whether an idea has already been done before.
## What It Does
Our application, called Hack2, is an intelligent search engine that uses Machine Learning to compare the user’s ideas to products that currently exist. It takes in an idea name and description, aggregates data from multiple sources, and displays a list of products with a percent similarity to the idea the user had. For ultimate ease of use, our application has both Android and web versions.
## How We Built It
We started off by creating a list of websites where we could find ideas that people have done. We came up with four sites: Product Hunt, Devpost, GitHub, and Google Play Store. We then worked on developing the Android app side of our solution, starting with mock-ups of our UI using Adobe XD. We then replicated the mock-ups in Android Studio using Kotlin and XML.
Next was the Machine Learning part of our solution. Although there exist many machine learning algorithms that can compute phrase similarity, devising an algorithm to compute document-level similarity proved much more elusive. We ended up combining Microsoft’s Text Analytics API with an algorithm known as Sentence2Vec in order to handle multiple sentences with reasonable accuracy. The weights used by the Sentence2Vec algorithm were learned by repurposing Google's word2vec ANN and applying it to a corpus containing technical terminology (see Challenges section). The final trained model was integrated into a Flask server and uploaded onto an Azure VM instance to serve as a REST endpoint for the rest of our API.
We then set out to build the web scraping functionality of our API, which would query the aforementioned sites, pull relevant information, and pass that information to the pre-trained model. Having already set up a service on Microsoft Azure, we decided to “stick with the flow” and build this architecture using Azure’s serverless compute functions.
After finishing the Android app and backend development, we decided to add a web app to make the service more accessible, made using React.
## Challenges We Ran Into
From a data perspective, one challenge was obtaining an accurate vector representation of words appearing in quasi-technical documents such as Github READMEs and Devpost abstracts. Since these terms do not appear often in everyday usage, we saw a degraded performance when initially experimenting with pretrained models. As a result, we ended up training our own word vectors on a custom corpus consisting of “hacker-friendly” vocabulary from technology sources. This word2vec matrix proved much more performant than pretrained models.
We also ran into quite a few issues getting our backend up and running, as it was our first using Microsoft Azure. Specifically, Azure functions do not currently support Python fully, meaning that we did not have the developer tools we expected to be able to leverage and could not run the web scraping scripts we had written. We also had issues with efficiency, as the Python libraries we worked with did not easily support asynchronous action. We ended up resolving this issue by refactoring our cloud compute functions with multithreaded capabilities.
## What We Learned
We learned a lot about Microsoft Azure’s Cloud Service, mobile development and web app development. We also learned a lot about brainstorming, and how a viable and creative solution could be right under our nose the entire time.
On the machine learning side, we learned about the difficulty of document similarity analysis, especially when context is important (an area of our application that could use work)
## What’s Next for Hack2
The next step would be to explore more advanced methods of measuring document similarity, especially methods that can “understand” semantic relationships between different terms in a document. Such a tool might allow for more accurate, context-sensitive searches (e.g. learning the meaning of “uber for…”). One particular area we wish to explore are LSTM Siamese Neural Networks, which “remember” previous classifications moving forward.
|
Welcome to our demo video for our hack “Retro Readers”. This is a game created by our two man team including myself Shakir Alam and my friend Jacob Cardoso. We are both heading into our senior year at Dr. Frank J. Hayden Secondary School and enjoyed participating in our first hackathon ever, Hack The 6ix a tremendous amount.
We spent over a week brainstorming ideas for our first hackathon project and because we are both very comfortable with the idea of making, programming and designing with pygame, we decided to take it to the next level using modules that work with APIs and complex arrays.
Retro Readers was inspired by a social media post pertaining to another text font that was proven to help mitigate reading errors made by dyslexic readers. Jacob found OpenDyslexic which is an open-source text font that does exactly that.
The game consists of two overall gamemodes. These gamemodes aim towards an age group of mainly children and young children with dyslexia who are aiming to become better readers. We know that reading books is becoming less popular among the younger generation and so we decided to incentivize readers by providing them with a satisfying retro-style arcade reading game.
The first gamemode is a read and research style gamemode where the reader or player can press a key on their keyboard which leads to a python module calling a database of semi-sorted words from Wordnik API. The game then displays the word back to the reader and reads it aloud using a TTS module.
As for the second gamemode, we decided to incorporate a point system. Using the points the players can purchase unique customizables and visual modifications such as characters and backgrounds. This provides a little dopamine rush for the players for participating in a tougher gamemode.
The gamemode itself is a spelling type game where a random word is selected using the same python modules and API. Then a TTS module reads the selected word out loud for readers. The reader then must correctly spell the word to attain 5 points without seeing the word.
The task we found the most challenging was working with APIs as a lot of them were not deemed fit for our game. We had to scratch a few APIs off the list for incompatibility reasons. A few of these APIs include: Oxford Dictionary, WordsAPI and more.
Overall we found the game to be challenging in all the right places and we are highly satisfied with our final product. As for the future, we’d like to implement more reliable APIs and as for future hackathons (this being our first) we’d like to spend more time researching viable APIs for our project. And as far as business practicality goes, we see it as feasible to sell our game at a low price, including ads and/or pad cosmetics. We’d like to give a special shoutout to our friend Simon Orr allowing us to use 2 original music pieces for our game. Thank you for your time and thank you for this amazing opportunity.
|
winning
|
# Healthy.ly
An android app that can show if a food is allergic to you just by clicking its picture. It can likewise demonstrate it's health benefits, ingredients, and recipes.
## Inspiration
We are a group of students from India. The food provided here is completely new to us and we don't know the ingredients. One of our teammates is dangerously allergic to seafood and he has to take extra precautions while eating at new places. So we wanted to make an app that can detect if the given food is allergic or not using computer vision.
We also got inspiration from the HBO show **Silicon Valley**, where a guy tries to make a **Shazam for Food** app.
Over time our idea grew bigger and we added nutritional value and recipes to it.
## What it does
This is an android app that uses computer vision to identify food items in the picture and shows you if you are allergic to it by comparing the ingredients to your restrictions provided earlier. It can also give the nutritional values and recipes for that food item.
## How we built it
We developed a deep learning model using **Tensorflow** that can classify between 101 different food items. We trained it using the **Google Compute Engine** with 2vCPUs, 7.5 GB RAM and 2 Tesla K80 GPU. This model can classify 101 food items with over 70% accuracy.
From the predicted food item, we were able to get its ingredients and recipes from an API from rapidAPI called "Recipe Puppy". We cross validate the ingredients with the items that the user is allergic to and tell them if it's safe to consume.
We made a native **Android Application** that lets you take an image and uploads it to **Google Storage**. The python backend runs on **Google App Engine**. The web app takes the image from google storage and using **Tensorflow Serving** finds the class of the given image(food name). It uses its name to get its ingredients, nutritional values, and recipes and return these values to the android app via **Firebase**.
The Android app then takes these values and displays them to the user. Since most of the heavy lifting happens in the cloud, our app is very light(7MB) and is **computationally efficient**. It does not need a lot of resources to run. It can even run in a cheap and underperforming android mobile without crashing.
## Challenges we ran into
>
> 1. We had trouble converting our Tensorflow model to tflite(tflite\_converter could not convert a multi\_gpu\_model to tflite). So we ended up hosting it on the cloud which made the app lighter and computationally efficient.
> 2. We are all new to using google cloud. So it took us a long time to even figure out the basic stuff. Thanks to the GCP team, we were able to get our app up and running.
> 3. We couldn't use the Google App Engine to support TensorFlow(we could not get it working). So we have hosted our web app on Google Compute Engine
> 4. We did not get a UI/UX designer or a frontend developer in our team. So we had to learn basic frontend and design our app.
> 5. We could only get around 70% validation accuracy due to the higher computation needs and less available time.
> 6. We were using an API from rapidAPI. But since yesterday, they stopped support for that API and it wasn't working. So we had to make our own database to run our app.
> 7. Couldn't use AutoML for vision classification, because our dataset was too large to be uploaded.
>
>
>
## What we learned
Before coming to this hack, we had no idea about using cloud infrastructure like Google Cloud Platform. In this hack, we learned a lot about using Google Cloud Platform and understand its benefits. We are pretty comfortable using it now.
Since we didn't have a frontend developer we had to learn that to make our app.
Making this project gave us a lot of exposure to **Deep Learning**, **Computer Vision**, **Android App development** and **Google Cloud Platform**.
## What's next for Healthy.ly
1. We are planning to integrate **Google Fit** API with this so that we can get a comparison between the number of calories consumed and the number of calories burnt to give better insight to the user. We couldn't do it now due to time constraints.
2. We are planning to integrate **Augmented Reality** with this app to make it predict in real-time and look better.
3. We have to improve the **User Interface** and **User Experience** of the app.
4. Spend more time training the model and **increase the accuracy**.
5. Increase the **number of labels** of the food items.
|
## Inspiration
As university students, we often find that we have groceries in the fridge but we end up eating out and the groceries end up going bad.
## What It Does
After you buy groceries from supermarkets, you can use our app to take a picture of your receipt. Our app will parse through the items in the receipts and add the items into the database representing your fridge. Using the items you have in your fridge, our app will be able to recommend recipes for dishes for you to make.
## How We Built It
On the back-end, we have a Flask server that receives the image from the front-end through ngrok and then sends the image of the receipt to Google Cloud Vision to get the text extracted. We then post-process the data we receive to filter out any unwanted noise in the data.
On the front-end, our app is built using react-native, using axios to query from the recipe API, and then stores data into Firebase.
## Challenges We Ran Into
Some of the challenges we ran into included deploying our Flask to Google App Engine, and styling in react. We found that it was not possible to write into Google App Engine storage, instead we had to write into Firestore and have that interact with Google App Engine.
On the frontend, we had trouble designing the UI to be responsive across platforms, especially since we were relatively inexperienced with React Native development. We also had trouble finding a recipe API that suited our needs and had sufficient documentation.
|
## Inspiration
In today's fast-paced world, effective communication is more crucial than ever. Whether it's acing a job interview, delivering a compelling speech, or simply making a persuasive argument, the way we present ourselves can make all the difference. However, the lack of real-time, comprehensive feedback often hinders individuals from realizing their full potential. This inspired us to create Enterview, a tool designed to provide immediate, actionable insights into your emotional and verbal delivery.
---
## What it does
Enterview is an app that allows users to upload or record a video of themselves speaking. Using Hume AI developer tool, the app analyzes the user's facial expressions and voice to identify various emotions. It then processes this data and serves it as a prompt to OpenAI, which generates personalized feedback. The app also provides a detailed breakdown of the user's emotional shifts, tonal shifts, dominant emotions at various points, and other key metrics. This comprehensive feedback aims to help users identify areas for improvement, whether they are preparing for job interviews, public speaking, or any other situation requiring effective communication.
---
## How we built it
We used Next.js for full-stack development and used Flask, additionally, for back-end. We then integrated it with Hume's emotion and text recognition API and OpenAI's GPT-3. The architecture is designed to first record and send the video data to Hume, receive the emotion and text metrics on the server side, and then forward this processed data to OpenAI for generating insightful feedback.
---
## Challenges we ran into
1. **API Integration**: Ensuring seamless interaction between Hume and OpenAI was initially challenging due to data transfer and formatting issues.
2. **Accuracy**: We found that emotion recognition could include large amounts of data that may not be useful to the user, which led us to explore ways to define certain interpretations of the data and try and manipulate it in a way that would give us the best possible feedback.
---
## Accomplishments that we're proud of
1. **Holistic Feedback**: Successfully integrating Hume and OpenAI to provide a 360-degree view of a user's performance.
2. **User Experience**: Creating an intuitive, user-friendly interface that even those who are not tech-savvy can navigate easily.
---
## What we learned
1. **Interdisciplinary Integration**: The importance of combining different technologies to create a more comprehensive solution.
2. **Data Processing**: How to determine the usefulness of certain types of data and interpret them in a more efficient way.
3. **Ethical Considerations**: TODO
---
## What's next for Enterview
1. **Real-Time Analysis**: We plan to introduce a real-time feedback feature that provides insights as the user is speaking.
2. **Feedback customization Features**: Adding options to check for specific types of emotions, and tones and make the feedback more customizable.
3. **Expanded Use Cases**: We aim to extend the app's utility to other domains like therapy and education.
|
partial
|
## Inspiration
With the rise of meme stocks taking over the minds of gen-z, vast amounts of young people are diving into the world of finance. We wanted to make a platform to make it easy for young people to choose stocks based on what matters most: the environment.
## What it does
Loraxly speaks for the trees: it aggregates realtime stock data along with articles about the environmental impact a company has on the world. It then uses OpenAI's powerful GPT-3 api to summarize and classify these articles to determine if the company's environmental impact is positive or not.
## How we built it
Figma, React, Javascript, Kumbucha, Python, Selenium, Golang, goroutines, Cally, firebase, pandas, OpenAI API, Alphavantage stock api, Doppler, rechart, material-ui, and true love.
## Challenges we ran into
some goroutines being ahead of others, fixed this with channels.
article summaries not making since, we had to be more granular with our article selection.
the chart was tough to setup.
we didn't get going until saturday afternoon.
## Accomplishments that we're proud of
getting things working
## What we learned
alphavantage api has some major rate limiting.
## What's next for Lorax.ly
Adding a trading function and creating an ETF comprised of environmentally friendly companies that people can invest in.
|
## Inspiration
As university students and soon to be graduates, we understand the financial strain that comes along with being a student, especially in terms of commuting. Carpooling has been a long existing method of getting to a desired destination, but there are very few driving platforms that make the experience better for the carpool driver. Additionally, by encouraging more people to choose carpooling at a way of commuting, we hope to work towards more sustainable cities.
## What it does
FaceLyft is a web app that includes features that allow drivers to lock or unlock their car from their device, as well as request payments from riders through facial recognition. Facial recognition is also implemented as an account verification to make signing into your account secure yet effortless.
## How we built it
We used IBM Watson Visual Recognition as a way to recognize users from a live image; After which they can request money from riders in the carpool by taking a picture of them and calling our API that leverages the Interac E-transfer API. We utilized Firebase from the Google Cloud Platform and the SmartCar API to control the car. We built our own API using stdlib which collects information from Interac, IBM Watson, Firebase and SmartCar API's.
## Challenges we ran into
IBM Facial Recognition software isn't quite perfect and doesn't always accurately recognize the person in the images we send it. There were also many challenges that came up as we began to integrate several APIs together to build our own API in Standard Library. This was particularly tough when considering the flow for authenticating the SmartCar as it required a redirection of the url.
## Accomplishments that we're proud of
We successfully got all of our APIs to work together! (SmartCar API, Firebase, Watson, StdLib,Google Maps, and our own Standard Library layer). Other tough feats we accomplished was the entire webcam to image to API flow that wasn't trivial to design or implement.
## What's next for FaceLyft
While creating FaceLyft, we created a security API for requesting for payment via visual recognition. We believe that this API can be used in so many more scenarios than carpooling and hope we can expand this API into different user cases.
|
## Inspiration
Many investors looking to invest in startup companies are often overwhelmed by the sheer number of investment opportunities, worried that they will miss promising ventures without doing adequate due diligence. Likewise, since startups all present their data in a unique way, it is challenging for investors to directly compare companies and effectively evaluate potential investments. On the other hand, thousands of startups with a lot of potential also lack visibility to the right investors. Thus, we came up with Disruptive as a way to bridge this gap and provide a database for investors to view important insights about startups tailored to specific criteria.
## What it does
Disruptive scrapes information from various sources: company websites, LinkedIn, news, and social media platforms to generate the newest possible market insights. After homepage authentication, investors are prompted to indicate their interest in either Pre/Post+ seed companies to invest in. When an option is selected, the investor is directed to a database of company data with search capabilities, scraped from Kaggle. From the results table, a company can be selected and the investor will be able to view company insights, business analyst data (graphs), fund companies, and a Streamlit Chatbot interface. You are able to add more data through a DAO platform, by getting funded by companies looking for data. The investor also has the option of adding a company to the database with information about it.
## How we built it
The frontend was built with Next.js, TypeScript, and Tailwind CSS. Firebase authentication was used to verify users from the home page. (Company scraping and proxies for company information) Selenium was used for web scraping for database information. Figma was used for design, authentication was done using Firebase.
The backend was built using Flask, StreamLit, and Taipy. We used the Circle API and Hedera to generate bounties using blockchain. SQL and graphQL were used to generate insights, OpenAI and QLoRa were used for semantic/similarity search, and GPT fine-tuning was used for few-shot prompting.
## Challenges we ran into
Having never worked with Selenium and web scraping, we found understanding the dynamic loading and retrieval of web content challenging. The measures some websites have against scraping were also interesting to learn and try to work around. We also worked with chat-GPT and did prompt engineering to generate business insights - a task that can sometimes yield unexpected responses from chat-GPT!
## Accomplishments that we're proud of + What we learned
We learned how to use a lot of new technology during this hackathon. As mentioned above, we learned how to use Selenium, as well as Firebase authentication and GPT fine-tuning.
## What's next for Disruptive
Disruptive can implement more scrapers for better data in terms of insight generation. This would involve scraping from other options than Golden once there is more funding. Furthermore, integration between frontend and blockchain can be improved further. Lastly, we could generate better insights into the format of proposals for clients.
|
winning
|
## Inspiration
On campus, students are always overly stressed. To promote the well-being of students on campus, or people in general, we created this little app to help everyone de-stress!
## What it does
This is a game that let people create their own figure "homework man", and can animate the figure by pressing the "do homework" button.
## How we built it
We built it using swift 4 using the touch function and UIButton.
## Challenges we ran into
Originally, we were working on designing another app. However, after we realized the complexity of building that app, we started to work on this game. The challenges we ran into when designing this game is mostly getting use to Swift, a language we are not familiar with.
## Accomplishments that we're proud of
We build a game... with Emojis in it!
## What we learned
The usage of Swift and Xcode.
## What's next for The Homework Man
We are planning to add more features, like dancing, or playing to animate homeworkman in various ways.
|
**Track: Education**
## Inspiration
Looking back at how we learnt to code, we found that the most difficult aspect of the learning process was to "trace" through the code. By "tracing", we mean mentally single-stepping through lines of code and keeping track of various variables. With this application, we hope to simplify the process of teaching kids the logic behind simple programmatic structures.
## What it does
Once loaded into the game, the player (represented with a single stick figure) is presented with a series of options for where they should go next. Using letter keys on their keyboard (a, b, c), the player selects where in the code they think will be executed next. The player is given 3 lives, which is decremented for every incorrect choice they make.
## How we built it
The primary languages we used were HTML5 + CSS (make it look decent) with Javascript for the interactive portion. We used PIXI as the game engine, which simplified a lot of the animation and rendering issues.
## Challenges we ran into
Not a technical challenge, but 3/4 of our team got sick within the first 3 hours of the Hackathon. Luckily, we were able pull through and build Tracer!
On a technical note, animating our little stick man was pretty challenging, given that none of us had in-depth experience with graphics animation using JS beforehand.
## Accomplishments that we're proud of
Our stick man animations look really nice. The concept and potential impact of this game is very useful, since it emphasizes aspects of coding that are often overlooked, such as reading and comprehending code mentally.
## What we learned
A majority of our team walked into this project with little to no knowledge of Javascript and the corresponding animation libraries. Going through the project, we had to cross apply our knowledge of other languages and frameworks to build this app.
## What's next for Tracer
We originally had a stretch goal of linking our app with multiple mobile devices using Websocket, allowing for a multiplayer experience. Additionally, we would also clean up the UI and add fancier animations. Finally (if we haven't implemented this yet), we'd add simple sound effects (free open source sound available from [zapsplat](www.zapsplat.com) ![link to sound hosting service]).
Some other things we would've implemented given more time:
* restart button
* interpreter for custom code input
* local/remote scoreboard
* multiplayer on a single local server (multiple sets of input on the same computer)
|
## Inspiration
We were inspired by hard working teachers and students. Although everyone was working hard, there was still a disconnect with many students not being able to retain what they learned. So, we decided to create both a web application and a companion phone application to help target this problem.
## What it does
The app connects students with teachers in a whole new fashion. Students can provide live feedback to their professors on various aspects of the lecture, such as the volume and pace. Professors, on the other hand, get an opportunity to receive live feedback on their teaching style and also give students a few warm-up exercises with a built-in clicker functionality.
The web portion of the project ties the classroom experience to the home. Students receive live transcripts of what the professor is currently saying, along with a summary at the end of the lecture which includes key points. The backend will also generate further reading material based on keywords from the lecture, which will further solidify the students’ understanding of the material.
## How we built it
We built the mobile portion using react-native for the front-end and firebase for the backend. The web app is built with react for the front end and firebase for the backend. We also implemented a few custom python modules to facilitate the client-server interaction to ensure a smooth experience for both the instructor and the student.
## Challenges we ran into
One major challenge we ran into was getting and processing live audio and giving a real-time transcription of it to all students enrolled in the class. We were able to solve this issue through a python script that would help bridge the gap between opening an audio stream and doing operations on it while still serving the student a live version of the rest of the site.
## Accomplishments that we’re proud of
Being able to process text data to the point that we were able to get a summary and information on tone/emotions from it. We are also extremely proud of the
## What we learned
We learned more about React and its usefulness when coding in JavaScript. Especially when there were many repeating elements in our Material Design. We also learned that first creating a mockup of what we want will facilitate coding as everyone will be on the same page on what is going on and all thats needs to be done is made very evident. We used some API’s such as the Google Speech to Text API and a Summary API. We were able to work around the constraints of the API’s to create a working product. We also learned more about other technologies that we used such as: Firebase, Adobe XD, React-native, and Python.
## What's next for Gradian
The next goal for Gradian is to implement a grading system for teachers that will automatically integrate with their native grading platform so that clicker data and other quiz material can instantly be graded and imported without any issues. Beyond that, we can see the potential for Gradian to be used in office scenarios as well so that people will never miss a beat thanks to the live transcription that happens.
|
losing
|
Recommends exercises in real-time as the user is exercising based on their heart rate.
|
## Inspiration
We often do homework late when there are no TA hours scheduled, so we were thinking that having an easy way to reach out to tutors to get homework help would be very efficient and appreciated.
## What it does
It authenticates users with GAuth, asks them about whether they want to be a tutor or student, as well as relevant info. Then, it connects students who are waiting in queue to a tutor who can help so that they can discuss problems over a real-time chat.
## How we built it
We used Typescript, Firebase for authentication, Firestore for Database, React as our frontend library, Socket.io for real-time chat, and tentatively, peer.js for real-time video streams.
## Challenges we ran into
We tried to implement video streams with Peer.js in addition to chat, but we had difficulties with matching students and tutors through peer.js. Queuing and matching students with tutors was also challenging because there were mutiple client requests that had to be synced with a single data structure on the server.
## Accomplishments that we're proud of
The entire thing: authentication, how we learned a lot more about socket.io, and using webRTC for the live video stream.
## What we learned
We had some experience with React and web development before, but not a ton, so getting to build a functional help in less than 36 hours was very fulfilling and helped us accelerate our learning.
## What's next for HWHelp
We think that the idea is a neat concept, and we hope to fully integrate video streams, as well as a more complex and individualized matchmaking process.
|
## Inspiration
Kevin, one of our team members, is an enthusiastic basketball player, and frequently went to physiotherapy for a knee injury. He realized that a large part of the physiotherapy was actually away from the doctors' office - he needed to complete certain exercises with perfect form at home, in order to consistently improve his strength and balance. Through his story, we realized that so many people across North America require physiotherapy for far more severe conditions, be it from sports injuries, spinal chord injuries, or recovery from surgeries. Likewise, they will need to do at-home exercises individually, without supervision. For the patients, any repeated error can actually cause a deterioration in health. Therefore, we decided to leverage computer vision technology, to provide real-time feedback to patients to help them improve their rehab exercise form. At the same time, reports will be generated to the doctors, so that they may monitor the progress of patients and prioritize their urgency accordingly. We hope that phys.io will strengthen the feedback loop between patient and doctor, and accelerate the physical rehabilitation process for many North Americans.
## What it does
Through a mobile app, the patients will be able to film and upload a video of themselves completing a certain rehab exercise. The video then gets analyzed using a machine vision neural network, such that the movements of each body segment is measured. This raw data is then further processed to yield measurements and benchmarks for the relative success of the movement. In the app, the patients will receive a general score for their physical health as measured against their individual milestones, tips to improve the form, and a timeline of progress over the past weeks. At the same time, the same video analysis will be sent to the corresponding doctor's dashboard, in which the doctor will receive a more thorough medical analysis in how the patient's body is working together and a timeline of progress. The algorithm will also provide suggestions for the doctors' treatment of the patient, such as prioritizing a next appointment or increasing the difficulty of the exercise.
## How we built it
At the heart of the application is a Google Cloud Compute instance running together with a blobstore instance. The cloud compute cluster will ingest raw video posted to blobstore, and performs the machine vision analysis to yield the timescale body data.
We used Google App Engine and Firebase to create the rest of the web application and API's for the 2 types of clients we support: an iOS app, and a doctor's dashboard site. This manages day to day operations such as data lookup, and account management, but also provides the interface for the mobile application to send video data to the compute cluster. Furthermore, the app engine sinks processed results and feedback from blobstore and populates it into Firebase, which is used as the database and data-sync.
Finally, In order to generate reports for the doctors on the platform, we used stdlib's tasks and scale-able one-off functions to process results from Firebase over time and aggregate the data into complete chunks, which are then posted back into Firebase.
## Challenges we ran into
One of the major challenges we ran into was interfacing each technology with each other. Overall, the data pipeline involves many steps that, while each in itself is critical, also involve too many diverse platforms and technologies for the time we had to build it.
## What's next for phys.io
<https://docs.google.com/presentation/d/1Aq5esOgTQTXBWUPiorwaZxqXRFCekPFsfWqFSQvO3_c/edit?fbclid=IwAR0vqVDMYcX-e0-2MhiFKF400YdL8yelyKrLznvsMJVq_8HoEgjc-ePy8Hs#slide=id.g4838b09a0c_0_0>
|
losing
|
## Inspiration
One of our own member's worry about his puppy inspired us to create this project, so he could keep an eye on him.
## What it does
Our app essentially monitors your dog(s) and determines their mood/emotional state based on their sound and body language, and optionally notifies the owner about any changes in it. Specifically, if the dog becomes agitated for any reasons, manages to escape wherever they are supposed to be, or if they fall asleep or wake up.
## How we built it
We built the behavioral detection using OpenCV and TensorFlow with a publicly available neural network. The notification system utilizes the Twilio API to notify owners via SMS. The app's user interface was created using JavaScript, CSS, and HTML.
## Challenges we ran into
We found it difficult to identify the emotional state of the dog using only a camera feed. Designing and writing a clean and efficient UI that worked with both desktop and mobile platforms was also challenging.
## Accomplishments that we're proud of
Our largest achievement was determining whether the dog was agitated, sleeping, or had just escaped using computer vision. We are also very proud of our UI design.
## What we learned
We learned some more about utilizing computer vision and neural networks.
## What's next for PupTrack
KittyTrack, possibly
Improving the detection, so it is more useful for our team member
|
## Inspiration 💡
**Due to rising real estate prices, many students are failing to find proper housing, and many landlords are failing to find good tenants**. Students looking for houses often have to hire some agent to get a nice place with a decent landlord. The same goes for house owners who need to hire agents to get good tenants. *The irony is that the agent is totally motivated by sheer commission and not by the wellbeing of any of the above two.*
Lack of communication is another issue as most of the things are conveyed by a middle person. It often leads to miscommunication between the house owner and the tenant, as they interpret the same rent agreement differently.
Expensive and time-consuming background checks of potential tenants are also prevalent, as landowners try to use every tool at their disposal to know if the person is really capable of paying rent on time, etc. Considering that current rent laws give tenants considerable power, it's very reasonable for landlords to perform background checks!
Existing online platforms can help us know which apartments are vacant in a locality, but they don't help either party know if the other person is really good! Their ranking algorithms aren't trustable with tenants. The landlords are also reluctant to use these services as they need to manually review applications from thousands of unverified individuals or even bots!
We observed that we are still using these old-age non-scalable methods to match the home seeker and homeowners willing to rent their place in this digital world! And we wish to change it with **RentEasy!**

## What it does 🤔
In this hackathon, we built a cross-platform mobile app that is trustable by both potential tenants and house owners.
The app implements a *rating system* where the students/tenants can give ratings for a house/landlord (ex: did not pay security deposit back for no reason), & the landlords can provide ratings for tenants (the house was not clean). In this way, clean tenants and honest landlords can meet each other.
This platform also helps the two stakeholders build an easily understandable contract that will establish better trust and mutual harmony. The contract is stored on an InterPlanetary File System (IPFS) and cannot be tampered by anyone.

Our application also has an end-to-end encrypted chatting module powered by @ Company. The landlords can filter through all the requests and send requests to tenants. This chatting module powers our contract generator module, where the two parties can discuss a particular agreement clause and decide whether to include it or not in the final contract.
## How we built it ️⚙️
Our beautiful and elegant mobile application was built using a cross-platform framework flutter.
We integrated the Google Maps SDK to build a map where the users can explore all the listings and used geocoding API to encode the addresses to geopoints.
We wanted our clients a sleek experience and have minimal overhead, so we exported all network heavy and resource-intensive tasks to firebase cloud functions. Our application also has a dedicated **end to end encrypted** chatting module powered by the **@-Company** SDK. The contract generator module is built with best practices and which the users can use to make a contract after having thorough private discussions. Once both parties are satisfied, we create the contract in PDF format and use Infura API to upload it to IPFS via the official [Filecoin gateway](https://www.ipfs.io/ipfs)

## Challenges we ran into 🧱
1. It was the first time we were trying to integrate the **@-company SDK** into our project. Although the SDK simplifies the end to end, we still had to explore a lot of resources and ask for assistance from representatives to get the final working build. It was very gruelling at first, but in the end, we all are really proud of having a dedicated end to end messaging module on our platform.
2. We used Firebase functions to build scalable serverless functions and used expressjs as a framework for convenience. Things were working fine locally, but our middleware functions like multer, urlencoder, and jsonencoder weren't working on the server. It took us more than 4 hours to know that "Firebase performs a lot of implicit parsing", and before these middleware functions get the data, Firebase already had removed them. As a result, we had to write the low-level encoding logic ourselves! After deploying these, the sense of satisfaction we got was immense, and now we appreciate millions of open source packages much more than ever.
## Accomplishments that we're proud of ✨
We are proud of finishing the project on time which seemed like a tough task as we started working on it quite late due to other commitments and were also able to add most of the features that we envisioned for the app during ideation. Moreover, we learned a lot about new web technologies and libraries that we could incorporate into our project to meet our unique needs. We also learned how to maintain great communication among all teammates. Each of us felt like a great addition to the team. From the backend, frontend, research, and design, we are proud of the great number of things we have built within 36 hours. And as always, working overnight was pretty fun! :)
---
## Design 🎨
We were heavily inspired by the revised version of **Iterative** design process, which not only includes visual design, but a full-fledged research cycle in which you must discover and define your problem before tackling your solution & then finally deploy it.

This time went for the minimalist **Material UI** design. We utilized design tools like Figma, Photoshop & Illustrator to prototype our designs before doing any coding. Through this, we are able to get iterative feedback so that we spend less time re-writing code.

---
# Research 📚
Research is the key to empathizing with users: we found our specific user group early and that paves the way for our whole project. Here are few of the resources that were helpful to us —
* Legal Validity Of A Rent Agreement : <https://bit.ly/3vCcZfO>
* 2020-21 Top Ten Issues Affecting Real Estate : <https://bit.ly/2XF7YXc>
* Landlord and Tenant Causes of Action: "When Things go Wrong" : <https://bit.ly/3BemMtA>
* Landlord-Tenant Law : <https://bit.ly/3ptwmGR>
* Landlord-tenant disputes arbitrable when not covered by rent control : <https://bit.ly/2Zrpf7d>
* What Happens If One Party Fails To Honour Sale Agreement? : <https://bit.ly/3nr86ST>
* When Can a Buyer Terminate a Contract in Real Estate? : <https://bit.ly/3vDexWO>
**CREDITS**
* Design Resources : Freepik, Behance
* Icons : Icons8
* Font : Semibold / Montserrat / Roboto / Recoleta
---
# Takeways
## What we learned 🙌
**Sleep is very important!** 🤐 Well, jokes apart, this was an introduction to **Web3** & **Blockchain** technologies for some of us and introduction to mobile app developent to other. We managed to improve on our teamwork by actively discussing how we are planning to build it and how to make sure we make the best of our time. We learned a lot about atsign API and end-to-end encryption and how it works in the backend. We also practiced utilizing cloud functions to automate and ease the process of development.
## What's next for RentEasy 🚀
**We would like to make it a default standard of the housing market** and consider all the legal aspects too! It would be great to see rental application system more organized in the future. We are planning to implement more additional features such as landlord's view where he/she can go through the applicants and filter them through giving the landlord more options. Furthermore we are planning to launch it near university campuses since this is where people with least housing experience live. Since the framework we used can be used for any type of operating system, it gives us the flexibility to test and learn.
**Note** — **API credentials have been revoked. If you want to run the same on your local, use your own credentials.**
|
## Inspiration
Cute factor of dogs/cats, also to improve the health of many pets such as larger dogs that can easily become overweight.
## What it does
Reads accelerometer data on collar, converted into steps.
## How I built it
* Arduino Nano
* ADXL345 module
* SPP-C Bluetooth module
* Android Studio for app
## Challenges I ran into
Android studio uses a large amount of RAM space.
Interfacing with the accelerometer was challenging with finding the appropriate algorithm that has the least delay and lag.
## Accomplishments that I'm proud of
As a prototype, it is a great first development.
## What I learned
Some android studio java shortcuts/basics
## What's next for DoogyWalky
Data analysis with steps to convert to calories, and adding a second UI for graphing data weekly and hourly with a SQLite Database.
|
winning
|
## Inspiration
We believe the best way to learn a new language is to immerse yourself in it. That’s why we created LinguaScan. Through learning translations of everyday objects and places, you’ll pick up a new language in no time!
## What it does
Lingua Scan translates virtually anything around you! Scan anything with the app’s camera and it’ll use trained machine learning models to recognize the object, provide a translation, and even provide a short description of it.
But what’s learning a new language without being able to reinforce your learning? In the future, LinguaScan will also record every object you’ve seen the translation of and test your knowledge by chatting with a personalized chatbot that crafts conversations based on your knowledge of the language so far. You can also upload pictures of your travels and learn even more through interactive learning.
## How we built it
We built this app using a frontend in Flutter and the services of Authentication and Firestore from Google Firebase. We implemented OpenCV library with real time translation integration.
## Challenges we ran into
One of the major challenges that we ran into was Authentication with Firebase and Flutter. Much of the documentation was not in sync with the most recent versions of Flutter and Firebase, causing a great deal of confusion. At the end, we were able to use basic email authentication. In the future, we would like to seamlessly integrate Google authentication and other methods as well. Additionally, we had issues trying to generalize translation to specific objects.
## Accomplishments that we're proud of
We are all proud of learning about Flutter and using new technologies. We are also proud of being able to submit a project amidst our busy schedules and the stresses of the school year.
## What we learned
Since most of us didn’t have experience in Firebase or Flutter, we spent most of the time perusing documentation and guides on how the 2 frameworks and technologies were intertwined and integrated together. We really enjoyed the experience at HackMIT and would definitely do this experience again. We also learned about the architecture for a computer vision based project.
## What's next for LinguaScan
We hope to bring LinguaScan past the MVP stage and revamp the feature set that LinguaScan offers as well. Future feature updates are planned to include a speech-to-text feature that tests the user’s proficiency in a certain language. We are excited about the future of LinguaScan!
|
## Inspiration
Our initiative confronts the urgent issue of food waste with a dual approach involving consumers and farmers. We implement a unique and creative solution using AI, computer vision, and drone technology.
“Ugly” vegetables are a major cause of food waste. Every year, over [20%](https://foodwastefeast.com/why-we-waste-ugly-food-expiration-dates-and-more#:%7E:text=It's%20estimated%20that%20approximately%2020,nutritious%20and%20delicious%20to%20eat.) of wasted fruit and vegetables were attributed to “ugly” or “wonky” produce, that is **six billion** pounds. This produce was discarded for failing to meet retailer appearance standards
On the other hand, Low-income families have a high awareness of healthy diets, but cannot afford good-quality food according to this [article](https://www.news-medical.net/news/20210224/Low-income-families-have-high-awareness-of-healthy-diets-but-cant-afford-good-quality-food.aspx). [This](https://www.healthaffairs.org/do/10.1377/hpb20180817.901935/) creates a lot of health problems due to bad nutrition.
## What it does
For Farmers: We provide a dedicated platform where farmers can market their 'imperfect produce,' which, while entirely edible, may bear minor cosmetic imperfections that render them unsellable in conventional markets.
For Users: Users simply photograph the contents of their fridge, and our sophisticated algorithm takes over. It crafts personalized recipes based on available ingredients and accesses data on surplus produce from local farms.
## How we built it
### Backend Development:
**Flask**: Our web application is built on the Flask framework, providing us the flexibility and tools necessary to create a dynamic and interactive user experience.
**SQLite**: Serving as our database, SQLite efficiently manages data and ensures smooth operations even as the user base grows.
### Data Pre-population:
**Faker**: To simulate a realistic environment for testing, we utilized Faker to pre-populate our database with synthetic yet believable data.
### Image Analysis:
**Google Cloud Vision API (vision\_v1)**: Post-segmentation, each segmented object is analyzed using the Google Cloud Vision API to identify and catalog the items present.
**DeepLabV3**: To dissect images of refrigerated items into distinct objects, we employed the DeepLabV3 model. This segmentation stage is crucial for accurate item identification.
### Drone Prototyping:
Drone delivery is an eco-friendly and swift technological method that eliminates the inconvenience of farmers relying on other transportation while also actively contributing significantly to the sustainability of the environment.
**CAD Modeling**: Conceptualizing and iterating our drone design was made feasible and efficient through Computer-Aided Design (CAD) modeling.
**Autodesk Fusion 360**: For a precise and detailed design of our drone prototype, we used Autodesk Fusion 360, taking advantage of its comprehensive set of tools for 3D design, engineering, and simulation.
## Challenges we ran into
1. One of the challenges we faced was breaking down our project ideas into smaller, manageable tasks and then figuring out which tasks to work on first.
2. When dealing with Google Cloud Computer Vision, it only does image recognition of one whole image and does not break it down. We discussed and came up with a creative solution where we used a different ML model to separate the original image and send each segment to Google Cloud.
3. Our API key says "too many requests" at the end when we are trying to record a demo. We used too many requests in a short period of time while developing it
## Accomplishments that we're proud of
1. All of us came from different countries and we were able to match each other's energy very well. We have very different ideas which made us work so well together as we allow our thoughts to complement and amplify each other.
2. Team member, Omari Emmanuel learned how to do HTML for the first time with everyone's help and successfully deployed the help web page in the main designed online platform for our project
3. We researched deeply into a pressing issue that affects 25% of the US population, and we were able to come up with a comprehensive idea to mitigate that issue in a short amount of time.
## What's next for Misfit Munch
1. We want to continue working by trying to validate the market and see if there is a strong demand.
2. Understand the local laws of drones and the viability of transporting goods and services using drones, figuring out how to engage with regulatory bodies.
3. Secure funding by applying to grants, which also validates our ideas as well as giving us a head start in purchasing delivery drones
|
# LangUR: Linguistic Mastery at Your Fingertips
## Learning languages is one thing, but what does it take to be fluent in them?
**LangUR** is a groundbreaking project which bridges the difficult phases of learning languages. In a diverse business world with hundreds of languages being used in high commerical settings, modern applications serve to teach proficiency in langauges, but per a fluency study of Duolingo patrons learning French and Spanish, only 52.94% of 102 French learners reached a pre-intermediate level, and 66.03% of 156 Spanish speakers reached a similar level. (Jiang X, 2021)


## So the question stands: what helps set apart LangUR from language learning apps that help learners breach a beginner level of linguistic competence?
## **Efficiency. Scalability. Practicality.**
# Key Features:
1. Uses a grounded evaluation metric to measure your performance (LIX scoring algorithm)
2. Application learns and adapts to individual learner's abilities
3. Learning of language conveniently incorporated into daily workflow
4. Reinforced learning of queries words through review quizzes
# Development Tools:
1. PostmanAPI: Testing and Integrating API Endpoints
* Between Frontend and Backend-> enabled synchronous development by different teams
* Testing of MonsterAPI's inference engine-> enable quick iteration and testing of various baseline models and their associated hyperparameters
* Facilitated collaboration between Frontend and Backend Team with a shareable link detailing communication format
2. Bun: Leveraging Bun as a JavaScript ecosystem for web deployment
* ultra fast and all in one bundler, runtime and package manager that saved us a lot of time
3. MonsterAPI: Fine tuning the baseline models and using the inference engines
* easy to access deployment and fine-tuning platform greatly reduced the learning curve
* round-clock support by staff made development easier
4. Chroma Vector DB: Quick and reliable retrieval of semantic lists and articles for rapid processing with the LLM Engines.
# Tech Stack:

## Sample on a webpage

## Research
The project's premise and continuity relies very heavily on social research. When Robin was learning his languages, he found that maintaining continuous performance on a daily basis aided his performance in learning a language, and such a trend is commonly correlated with higher testing proportions among students that are fed information on a consistent daily basis when studying, as demonstrated by the American Psychological Society (Mawhinney et al., 1971).

Moreover, the concept of integrating language learning seamlessly into daily routines aligns with principles of habit formation and behavioral psychology. By embedding language practice within the natural flow of a user's day, LangUR capitalizes on the psychological phenomenon of habit stacking. This approach leverages existing habits as anchors for new behaviors, making language learning feel less like a burdensome task and more like an integrated aspect of daily life. Stacking habits is quintessential as evidenced for learning, so, how would one be able to consider a new approach to structuring a language learning app based off of this? Let's look back at the presented graph.
In any instance, Distributed Practice and Practice Testing appear to be the largest factors associated with higher testing in general study areas, where we based our project idea off of: a gradual but slow streamline of language implementation, albeit slowly and consistently. By being passive and seamless, LangUR has the capability to gradually streamline language learning modes into a user's daily workflow, providing an excellent UI, with a diverse array of features such as translation, suggested articles based off of past history, and progressively improving the user's ability to take in the language with the readability algorithm.
We often encounter the issue that learning a language is daunting, requiring continuous effort, where a lot of people simply don't have that time to invest, whereas the practicality of being fluent in languages has a high yield in business returns by eliminating barriers between multinational individuals and corporations. The idea behind LangUR had to critically emphasize the parallel and efficient nature of learning, which other applications failed to consider. Giving users a comfortable experience, automatically determining skill level through a customized LIX Algorithm, and structuring the application to cater to their learning pace was imperative during the building phase.
In conclusion, taking into account human study patterns, the demanding needs of learning a language and daily time constraints, LangUR was built with the mindfulness that dedication is always on the users side, but we can do our job to make it as seamless as possible, accessible, and catered to the users.
## What's next for LangUR
LangUR's potential is unbelievable. It has the ability to drive a stake in the educational world, collectivizing language learners, teachers, students, and anyone through simplicity. As the project's development continues, more functions will be added such as social integrations, connecting learners across the world, and more advanced algorithms will be put in place to create more personalized suggestions, helping people learn their new languages.
|
losing
|
## Inspiration
There are over 1.3 billion people in the world who live with some form of vision impairment. Often, retrieving small objects, especially off the ground, can be tedious for those without complete seeing ability. We wanted to create a solution for those people where technology can not only advise them, but physically guide their muscles in their daily life interacting with the world.
## What it does
ForeSight was meant to be as intuitive as possible in assisting people with their daily lives. This means tapping into people's sense of touch and guiding their muscles without the user having to think about it. ForeSight straps on the user's forearm and detects objects nearby. If the user begins to reach the object to grab it, ForeSight emits multidimensional vibrations in the armband which guide the muscles to move in the direction of the object to grab it without the user seeing its exact location.
## How we built it
This project involved multiple different disciplines and leveraged our entire team's past experience. We used a Logitech C615 camera and ran two different deep learning algorithms, specifically convolutional neural networks, to detect the object. One CNN was using the Tensorflow platform and served as our offline solution. Our other object detection algorithm uses AWS Sagemaker recorded significantly better results, but only works with an Internet connection. Thus, we use a two-sided approach where we used Tensorflow if no or weak connection was available and AWS Sagemaker if there was a suitable connection. The object detection and processing component can be done on any computer; specifically, a single-board computer like the NVIDIA Jetson Nano is a great choice. From there, we powered an ESP32 that drove the 14 different vibration motors that provided the haptic feedback in the armband. To supply power to the motors, we used transistor arrays to use power from an external Lithium-Ion battery. From a software side, we implemented an algorithm that accurately selected and set the right strength level of all the vibration motors. We used an approach that calculates the angular difference between the center of the object and the center of the frame as well as the distance between them to calculate the given vibration motors' strength. We also built a piece of simulation software that draws a circular histogram and graphs the usage of each vibration motor at any given time.
## Challenges we ran into
One of the major challenges we ran into was the capability of Deep Learning algorithms on the market. We had the impression that CNN could work like a “black box” and have nearly-perfect accuracy. However, this is not the case, and we experienced several glitches and inaccuracies. It then became our job to prevent these glitches from reaching the user’s experience.
Another challenge we ran into was fitting all of the hardware onto an armband without overwhelming the user. Especially on a body part as used as an arm, users prioritize movement and lack of weight on their devices. Therefore, we aimed to provide a device that is light and small.
## Accomplishments that we're proud of
We’re very proud that we were able to create a project that solves a true problem that a large population faces. In addition, we're proud that the project works and can't wait to take it further!
Specifically, we're particularly happy with the user experience of the project. The vibration motors work very well for influencing movement in the arms without involving too much thought or effort from the user.
## What we learned
We all learned how to implement a project that has mechanical, electrical, and software components and how to pack it seamlessly into one product.
From a more technical side, we gained more experience with Tensorflow and AWS. Also, working with various single board computers taught us a lot about how to use these in our projects.
## What's next for ForeSight
We’re looking forward to building our version 2 by ironing out some bugs and making the mechanical design more approachable. In addition, we’re looking at new features like facial recognition and voice control.
|
## Team
Sam Blouir
Pat Baptiste
## Inspiration
Seeing the challenges of blind people navigating, especially in new areas and being inspired by someone who wanted to remain blind anonymously
## What it does
Uses computer vision to find nearby objects in the vicinity of the wearer and sends information (X,Y coordinates, depth, and size) to the wearer in real-time so they can enjoy walking
## How I built it
Python, C, C++, OpenCV, and an Arduino
## Challenges I ran into
Performance and creating disparity maps from stereo cameras with significantly different video output qualities
## Accomplishments that I'm proud of
It works!
## What I learned
We learned lots about using Python, OpenCV, an Arduino, and integrating all of these to create a hardware hack
## What's next for Good Vibrations
Better depth-sensing and miniaturization!
|
## Inspiration
With the COVID-19 crisis, it has become more difficult to connect with others so we thought of having music being a simple icebreaker in conversations.
## What it does
Muse is a website that combines music streaming and social networking to allow users to meet each other with similar musical interests. Muse will match users on the platform who both love the same song. Users can then be navigated to the direct messaging page on Muse where they can discuss more their interests and hobbies separately. There is also a community page where everyone can share their music preferences.
## How WE built it
React/Firebase/HTML/CSS
## Challenges WE ran into
We were very lost on how to approach the Spotify API and ultimately had to switch our project approach towards the end.
## Accomplishments that We're proud of
This is the first full web development project that we have completed and though it's not perfect, we learned a lot.
## What's next for Muse
More implementation of the Spotify API to gather their music activities to better match users.
|
partial
|
## Inspiration
The inspiration for *SurgeVue* came from the high risks associated with brain surgeries, where precision is critical and the margin for error is minimal. With a mortality rate that increases 15-fold for non-elective neurosurgeries, we were motivated to create a solution that leverages augmented reality (AR) and machine learning to enhance the precision of brain tumor removal surgeries. By merging real-time data with surgical tools, we aimed to provide surgeons with an advanced assistant to reduce risks and save lives.
## What it does
*SurgeVue* is an AR-powered surgical assistant that provides neurosurgeons with real-time visual overlays during brain surgery. Using machine learning, the system outlines tumors on the patient's brain and classifies the presence of foreign objects. Integrated with an Arduino gyroscope for hand tracking, SurgeVue offers surgeons real-time feedback on tool movements, sweat sensor data, and critical hand movement trends—all displayed within a secure mobile app that ensures patient data privacy using facial recognition and RFID technology. The system empowers surgeons to make more informed, precise decisions during the most delicate procedures.
## How we built it
We built *SurgeVue* using a combination of cutting-edge technologies:
* **OpenCV** for real-time tumor detection and hand movement detection for augmented view.
* **PyTorch** for classifying tumors.
* **Swift and SceneKit** to create an immersive AR environment that overlays tumor outlines onto the surgeon's view.
* **Arduino gyroscope** for tracking the surgeon's hand movements and tool positioning.
* **PropelAuth** to ensure secure access to sensitive patient data via facial recognition and RFID.
* **Flask backend** to process machine learning models and serve image classification results via API.
* **Mobile App** that visualizes gyroscope, sweat sensor, and hand movement trends.
## Challenges we ran into
One of the biggest challenges was ensuring that the AR overlay, tumor detection, and hand-tracking happened in real-time without latency. We had to optimize our models to ensure seamless performance in the fast-paced environment of an operating room. Integrating the hardware components like the Arduino gyroscope and managing precise hand-tracking also posed challenges, as did creating a user-friendly interface that was informative without being overwhelming during a surgery.
## Accomplishments that we're proud of
* Successfully implementing real-time AR overlays that provide surgeons with critical information at a glance.
* Developing a machine learning model that accurately classifies tumors and detects foreign objects.
* Integrating hardware sensors (gyroscope, sweat sensors) to provide surgeons with hand movement insights, enhancing precision during surgeries.
* Ensuring patient data security through advanced authentication measures like facial recognition and RFID.
## What we learned
We learned how to combine AR and machine learning into a cohesive solution that can operate in real-time under intense conditions like surgery. We also gained experience in integrating hardware components, optimizing machine learning models for low latency, and handling large datasets like medical imaging. Furthermore we can save OR nurses and surgeons from intense radiation from the Medtronic devices, ones that prevent them from continuing operation. Additionally, building an intuitive, non-intrusive interface for surgeons highlighted the importance of user-centered design in healthcare applications.
## What's next for SurgeVue
Next, we plan to:
* **Refine the Machine Learning Model**: Enhance tumor classification accuracy and expand it to detect other conditions and anomalies.
* **Clinical Trials**: Test *SurgeVue* in real-world surgical settings and gather feedback from neurosurgeons.
* **Tool Tracking**: Further refine the hand-tracking and integrate more advanced surgical tools into the AR environment.
* **Global Expansion**: Implement support for other AR platforms like Hololens and explore expanding the use of the system in other complex surgeries beyond neurosurgery.
* **3D Implementation**: Create 3D models of the brain for the surgeon to interact with in real-time
|
## Inspiration
Physiotherapy is expensive for what it provides you with, A therapist stepping you through simple exercises and giving feedback and evaluation? WE CAN TOTALLY AUTOMATE THAT! We are undergoing the 4th industrial revolution and technology exists to help people in need of medical aid despite not having the time and money to see a real therapist every week.
## What it does
IMU and muscle sensors strapped onto the arm accurately track the state of the patient's arm as they are performing simple arm exercises for recovery. A 3d interactive GUI is set up to direct patients to move their arm from one location to another by performing localization using IMU data. A classifier is run on this variable-length data stream to determine the status of the patient and how well the patient is recovering. This whole process can be initialized with the touch of a button on your very own mobile application.
## How WE built it
on the embedded system side of things, we used a single raspberry pi for all the sensor processing. The Pi is in charge of interfacing with the IMU while another Arduino interfaces with the other IMU and a muscle sensor. The Arduino then relays this info over a bridged connection to a central processing device where it displays the 3D interactive GUI and processes the ML data. all the data in the backend is relayed and managed using ROS. This data is then uploaded to firebase where the information is saved on the cloud and can be accessed anytime by a smartphone. The firebase also handles plotting data to give accurate numerical feedback of the many values orientation trajectory, and improvement over time.
## Challenges WE ran into
hooking up 2 IMU to the same rpy is very difficult. We attempted to create a multiplexer system with little luck.
To run the second IMU we had to hook it up to the Arduino. Setting up the library was also difficult.
Another challenge we ran into was creating training data that was general enough and creating a preprocessing script that was able to overcome the variable size input data issue.
The last one was setting up a firebase connection with the app that supported the high data volume that we were able to send over and to create a graphing mechanism that is meaningful.
|
## Inspiration
We're interested in data and modelling it. The EDR challenge was a chance for us to learn about graph databases and their capabilities.
## What it does
A pipeline to process address data and perform some form of resolution. Constructs a graph DB representation in neo4j that contains hierarchical location data and information about purposes of places. The DB engine then allows us to construct queries such as searching for nearby places or looking at movements of address listings over time.
## How we built it
We used python and scipy to process the data. First, it sanitizes and performs address-resolution via a rule-based approach. Next, it polls longitude and latitude data from the Google Maps API. To support fuzzy location based searches, the points were converted to a suitable cartesian projection and the Delaunay triangulation is computed. The edges from the planar graph are used to support the fuzzy location based searches.
## Challenges we ran into
The address dataset is pretty big and took considerable work to clean up. We also had to keep efficiency in mind, which is why we computed the Delaunay triangulation, which only constructs O(n) edges.
## Accomplishments that we're proud of
* Learning what neo4j is capable of.
* Loading the data into a graph database in a way that supports non-trivial queries.
* Creating a workable search method for nearby places with large graphs
## What we learned
* What neo4j is capable of.
* Use of cloud-based geocoding capability for large datasets
* Benefits of a graph network to support fuzy search queries
## What's next for Places DB
More interesting queries can be explored, even with the graph structure that we currently have. The relationships between the user and venue could be tagged, like for shops or schools .etc.
|
winning
|

## Inspiration
With the rise of non-commission brokerages, more teens are investing their hard-earned money in the stock market. I started using apps such as Robinhood when I was in high school, but I had no idea what stocks to buy. Trading securities has a very steep learning curve for the average joe.
We see that lots of new investors have very little experience in the market. Communities like Wall Street Bets developed which further encourage wild speculation. Many open margin accounts, take out huge loans, and incur more risks without their knowledge. Also, many of these new investors are not financially savvy, nor are they looking forward to learning about finance. We wanted to build an app that helps new investors reduce risk and gain knowledge about what they own without much financial knowledge. Hence, we came up with a Social Media app, Due Diligence!
## What it does
Due Diligence allows the user to take a photo of everyday objects: car, laptop, fridge, calculator, collection of watches, etc... and recommends stocks associated with the images. For instance, if you upload a photo of your car, our app will recommend stocks like Tesla General Motors, and Ford. Our object detection model also has brand name recognition. Taking a photo of a Macbook will lead our app to recommend the APPL stock. By recommending companies that manufacture the products and services Due Diligence users daily use, we believe that our userbase can better evaluate the company, its business model, and its position in the market, and come up with a reasonable and safe decision on whether to buy the stock or not.
Our application also has a chat feature. When a user registers to DueDiligence, we ask them questions about their investment strategy (growth, value) and their investment horizon. After a user got a stock recommendation from our app, the user can choose to chat with another person looking to buy the same stock. We math the user with a partner that has similar investment strategies and investment horizons. They are able to use commands to get more specific information about a stock (get recent news articles, get its price, get its EPS this quarter) and we generate tailored questions for them to talk about based on their investment strategies.
## How we built it
We used React Native for the front-end, Flask for the back-end, and Postman for testing.
**1. Back-End**
The back-end dealt with managing users, saving investment strategies, classifying images to stock tickers, and matching/managing the chat. We used MongoDB Atlas to save all the data from the users and chat, and to update the front-end if necessary. We also used the IEX Cloud API which is an all-around stocks API that gives us the price, news, ticker symbol of a stock.
**2. Front-End**
We used React Native for the front end. We were experienced web developers but had little experience in app development. Being able to use web technologies sped up our development process.
**3. Google Cloud Vision API**
We used the Google Cloud Vision API to detect multiple items and logos in an image. After getting the tag names of the image, we ran it through our classification model to the image into ticker symbols.
**4. Classification Model**
The IEX Cloud API could search stocks based on their sector, so we had to relate products to sectors. This is where Naive Bayes came in. We weren't able to find a dataset, but we created our own data that trained the Bayes net table using the posterior probabilities. We built our dataset by figuring out how products matched with the business sector (mobile phone -> tech, sports car -> automobile industry, etc...)
## Challenges we ran into
The problem of relating products to related companies was a very hard problem. There wasn't an API for it. We resorted to using a machine learning model, but that said, it was very challenging to think of a solution that mapped it in a better way. Also, we were novice app developers. We learned how to use reactive native from scratch which was very time-consuming. Finally, working remotely with everyone was very challenging. We solved this problem by using discord and getting into team calls often.
## Accomplishments that we're proud of
We are proud that we were able to think of new solutions to problems that haven't been addressed. Mapping images to stock recommendations have not been done before, and we had to build our Bayes model from scratch. Also, we are proud that we learned to build a mobile app in less than 48 hours!
## What we learned
We learned new technologies such as React Native and new models like Naive Bayes. Most of all, we learned how to work together in a challenging situation, and come up with a program that we are very proud of.
## What's next for DD - Due Diligence
We ran out of time while finishing up the front-end, back-end integration, so finishing that will be our top priority. Other than that, we think expanding our services beyond NYSE and NASDAQ by integrating foreign exchanges into our app would be useful. Also, we think adding new asset classes such as Bonds and ETFs are the right step forward.
|
## Inspiration
There is a simple and powerful truth: investing is a skill that has a long lasting impact on our ability to reach the most important goals in our lives, from student loans to buying a house to retirement funds.
However, our education system doesn’t prepare us to make these daunting decisions. When we were teenagers, we felt finance was “complex, another mysterious “adult thing” that remotely relates to us. Higher tuition and less money available for financial aid are pushing more and more young people into debt even after years of working in the industry. According to Harvard Law School, about 110,000 youths under 25 filed for bankruptcy in 2017.
Investing shouldn’t just be a sophisticated tool played by the professionals. Investig should be a mindset that helps anyone to make better decisions in this world.
Let’s democratize finance.
## What it does
We have designed Dr. Trade to simulate an interactive investing game that makes it simple and fun for teenagers to learn the most important skills of an intelligent investor:
* A habit of following world news in the morning. Alarm clock UI design with voice control, seamlessly integrate learning to trade into user’s daily life
* Communication skills are essential for traders. The hands-free UX design allows users to practice putting in orders and discussing news like traders do.
* The best traders are the calm and persistent ones. Users need to wait until market close at 4pm to see daily profits and are encouraged to trade every day with the built-in reward system, including peer rankings and medals.
* Traders learn from their mistakes. At the end of the day, Dr. Trade will reflect with the user what went well and what went wrong based on real market data.
* A curious mind to connect the dots between news and stock performance.
* Making tough decisions:
* Users are only allowed to make one trade per day
## How we built it
* Machine learning with ASR, NLP, TTS (Action Google)
* Interaction design
> Conversation design (Dialogflow/Java)
> UI/UX design
* Portfolio analysis (BlackRock Aladdin/Python)
* Live stock market data (Yahoo Finance/Python)
* Speaker (Google Home Mini)
## Accomplishments that we're proud of
We have managed not only to identify a true problem, but also to develop a unique and effective solution to address it. Inbetween, we grew as team players through synergy and delved into the Google Action platform and the ML behind it. Needless to say, that focusing on education, we are empowering the future generation to lead a prosperous life, as they now possess the financial literacy to be independent.
## What we learned
By concentrating our efforts on the educational perspective of the project, our team discovered the inner-motivation and the vision that kept us pushing in the last few days and in the future.
## What's next for Dr. Trade
We are hoping to further develop Dr. Trade and hopefully find product-market fit in the next few months, as it is a project deep embedded in the team’s values for world-change. Here’s what we plan to do in the next month:
* Integrate Blackrock Aladdin with Dialogflow to automate portfolio snapshot
* Install a 5 inch display to our MVP for portfolio snapshot and performance visualization
* User research -- test out our MVP with high school students in the greater Philadelphia community
## Keywords:
Education, Experiential Learning, Machine Learning, Interaction Design, UI/UX Design, Action Google, Blackrock, Portfolio Analysis, Financial Literacy
|
## Inspiration
1 in 2 Canadians will personally experience a mental health issue by age 40, with minority communities at a greater risk. As the mental health epidemic surges and support at its capacity, we sought to build something to connect trained volunteer companions with people in distress in several ways for convenience.
## What it does
Vulnerable individuals are able to call or text any available trained volunteers during a crisis. If needed, they are also able to schedule an in-person meet-up for additional assistance. A 24/7 chatbot is also available to assist through appropriate conversation. You are able to do this anonymously, anywhere, on any device to increase accessibility and comfort.
## How I built it
Using Figma, we designed the front end and exported the frame into Reacts using Acovode for back end development.
## Challenges I ran into
Setting up the firebase to connect to the front end react app.
## Accomplishments that I'm proud of
Proud of the final look of the app/site with its clean, minimalistic design.
## What I learned
The need for mental health accessibility is essential but unmet still with all the recent efforts. Using Figma, firebase and trying out many open-source platforms to build apps.
## What's next for HearMeOut
We hope to increase chatbot’s support and teach it to diagnose mental disorders using publicly accessible data. We also hope to develop a modeled approach with specific guidelines and rules in a variety of languages.
|
losing
|
## Inspiration
First thing I think about when I think about software is removing redundancy / tedious work on humans and transferring that work to computers. Yet during Covid we have needed to fill out more forms than ever. Some universities require daily forms, covid test scheduling, and other overhead that adds up over time. We want to offer a solution to remove this burden.
## What it does
App that acts as a hub for all things Covid-related. Each row is a possible task the user can start from the comfort of their phone in just one button click. For now, the only feature present is to fill out the form for the daily check.
## How I built it
I developed the Android app using the flutter framework and the REST server using flask and selenium with my WiFi network acting as the Local Area Network (LAN) allowing the app and server to communicate with one another. Additionally I stored most of the user's information in Firestore and had my server fetch that information as needed. (email and password stored as environmental variables)
## Challenges I ran into
I initially wanted the UI to be a physical button so I spent a significant amount of time trying to scavenge my hardware setup (nodeMCU) to see if I can get that up and running and have that send REST requests to the server but ran into issues there. I also attempted to containerize my server so I could deploy it conveniently in GCP with little to no configuration. I wasn't able to get this to work either and in hindsight dealing with the initial configuration work to get it to work on a virtual machine would have been way more feasible for this hackathon. Lastly, Cayuga's health system form for scheduling a Covid test is much harder than expected to interact with to automate the form submission. Made some progress on this functionality but it cannot submit the entire form yet.
## Accomplishments that I'm proud of
Assuming the server is online, I can swiftly press a single button (after opening the app) to fill out a form that would normally require 2 minutes of work daily. Was this worth 16 hours of work? Well assuming best conditions I would equalize in time saved in 480 days but this is my last year of college haha. But I got to learn a lot about selenium and I can leave this hackathon with a product I can keep working on for my own personal benefit.
## What I learned
Learned more about Selenium during this weekend and Firestore. I also became more proficient in Flutter development.
## What's next for If No Corona Then That
The App could definitely be more smoothened out, especially an onboarding page to allow the user to provide their information to the app (so they're data doesn't need to be written to firebase manually), more features developed by me, and allowing the user to provide their own backend to automate services so they can add functionality without having to reflash the app. My server side logic could be improved so it can handle dealing with tougher forms to fill out, be deployed on the cloud (ex. GCP) so it can be accessible outside of my home network, require authentication for API requests, and managing users' credentials on the server side in a more scalable but safe way.
|
## Inspiration
Planning get-togethers with my friend group during the pandemic has been rather complicated. Some of them are immunocompromised or live with individuals that are. Because of this, we often have to text individuals to verify their COVID status before allowing them to come to a hangout. This time-consuming and unreliable process inspired me to create PandemicMeet. The theme of this hackathon is exploration and this webapp allows its users to explore without having to worry about potential COVID exposure or micromanaging their guests beforehand.
## What it does
This app lets users organize events, invite other users, and verify the COVID and vaccination status of invitees. Once an event is confirmed, invited users will see the event on their account and the organizer can track their guests' statuses to verify the safety of the event.
## How we built it
I built a full stack web application using a Flask back-end and Bootstrap front-end. For the database I used a sqlite3 database managed with Flask SQL Alchemy. User's data is stored in 3 separate tables: Users, User\_history and Party which store the user info (username, password, email), COVID status history and meeting info respectively.
## Challenges we ran into
There were quite a few problems integrating the front-end with the back-end, but I managed to overcome them and make this app work.
## Accomplishments that we're proud of
This was my first time using flask and bootstrap and I am rather pleased with the results. This is also my first college hackathon and I think that this is a decent start.
## What we learned
Working on this project drastically improved my proficiency with webapp production. I learned how to use bootstrap and flask to create a full stack web application too.
## What's next for PandemicMeet
I plan to improve this app by adding more security measures, email notifications, public user profiles as well as deploying on a server being accessible for people around the world.
|
## Inspiration
Before the coronavirus pandemic, vaccine distribution and waste was a little known issue. Now it's one of the most relevant and pressing problems that world faces. Our team had noticed that government vaccine rollout plans were often vague and lacked the coordination needed to effectively distribute the vaccines. In light of this issue we created Vaccurate, a data powered vaccine distribution app which is able to effectively prioritize at risk groups to receive the vaccine.
## What it does
To apply for a vaccine, an individual will enter Vaccurate and fill out a short questionnaire based off of government research and rollout plans. We will then be able to process their answers and assign weights to each response. Once the survey is done all the user needs to do is to wait for a text to be sent to them with their vaccination location and date! As a clinic, you can go into the Vaccurate clinic portal and register with us. Once registered we are able to send you a list of individuals our program deems to be the most at risk so that all doses received can be distributed effectively. Under the hood, we process your data using weights we got based off of government distribution plans and automatically plan out the distribution and also contact the users for the clinics!
## How I built it
For the frontend, we drafted up a wireframe in Figma first, then used HTML, CSS, and Bootstrap to bring it to life. To store user and clinic information, we used a Firestore database. Finally, we used Heroku to host our project and Twilio to send text notifications to users.
## Challenges I ran into
On the backend, it was some of our team's first time working with a Firestore database, so there was a learning curve trying to figure out how to work with it. We also ran into a lot of trouble when trying to set up a Heroku, but eventually got it running after several hours (can we get an F in chat). And although none of us thought it was a huge deal in the beginning, the time constraint of this 24 hour hackathon really caught up on us and we ran into a lot of challenges that forced us to adapt and reconstruct our idea throughout the weekend so we weren't biting off more than we could chew.
## Accomplishments that I'm proud of
Overall, we are very proud of the solution we made as we believe that with a little more polish our project has great value to the real world. Additionally, each and every member was able to explore a new language, framework, or concept in this project allowing us to learn more too while solving issues. We were really impressed by the end product especially as it was produced in this short time span as we not only learnt but immediately applied our knowledge.
## What I learned
Our team was able to learn more about servers with Gradle, frontend development, connecting to databases online, and also more about how we can contribute to a global issue with a time relevant solution! We were also able to learn how to compact as much work and learning as possible into a small timespan while maintaining communications between team members.
## What's next for Vaccurate
The statistics and guidelines we presented in our project were made based off of reliable online resources, however it's important that we consult an official healthcare worker to create a more accurate grading scheme and better vaccination prioritization. Additionally, we would like to add features to make the UX more accessible, such as a booking calendar for both users and clinics, and the ability to directly modify appointments on the website.
|
losing
|
## Inspiration
After learning about the current shortcomings of disaster response platforms, we wanted to build a modernized emergency services system to assist relief organizations and local governments in responding faster and appropriately.
## What it does
safeFront is a cross between next-generation 911 and disaster response management. Our primary users are local governments and relief organizations. The safeFront platform provides organizations and governments with the crucial information that is required for response, relief, and recovery by organizing and leveraging incoming disaster related data.
## How we built it
safeFront was built using React for the web dashboard and a Flask service housing the image classification and natural language processing models to process the incoming mobile data.
## Challenges we ran into
Ranking urgency of natural disasters and their severity by reconciling image recognition, language processing, and sentiment analysis on mobile data and reported it through a web dashboard. Most of the team didn't have a firm grasp on React components, so building the site was how we learned React.
## Accomplishments that we're proud of
Built a full stack web application and a functioning prototype from scratch.
## What we learned
Stepping outside of our comfort zone is, by nature, uncomfortable. However, we learned that we grow the most when we cross that line.
## What's next for SafeFront
We'd like to expand our platform for medical data, local transportation delays, local river level changes, and many more ideas. We were able to build a fraction of our ideas this weekend, but we hope to build additional features in the future.
|
## Inspiration
The idea for VenTalk originated from an everyday stressor that everyone on our team could relate to; commuting alone to and from class during the school year. After a stressful work or school day, we want to let out all our feelings and thoughts, but do not want to alarm or disturb our loved ones. Releasing built-up emotional tension is a highly effective form of self-care, but many people stay quiet as not to become a burden on those around them. Over time, this takes a toll on one’s well being, so we decided to tackle this issue in a creative yet simple way.
## What it does
VenTalk allows users to either chat with another user or request urgent mental health assistance. Based on their choice, they input how they are feeling on a mental health scale, or some topics they want to discuss with their paired user. The app searches for keywords and similarities to match 2 users who are looking to have a similar conversation. VenTalk is completely anonymous and thus guilt-free, and chats are permanently deleted once both users have left the conversation. This allows users to get any stressors from their day off their chest and rejuvenate their bodies and minds, while still connecting with others.
## How we built it
We began with building a framework in React Native and using Figma to design a clean, user-friendly app layout. After this, we wrote an algorithm that could detect common words from the user inputs, and finally pair up two users in the queue to start messaging. Then we integrated, tested, and refined how the app worked.
## Challenges we ran into
One of the biggest challenges we faced was learning how to interact with APIs and cloud programs. We had a lot of issues getting a reliable response from the web API we wanted to use, and a lot of requests just returned CORS errors. After some determination and a lot of hard work we finally got the API working with Axios.
## Accomplishments that we're proud of
In addition to the original plan for just messaging, we added a Helpful Hotline page with emergency mental health resources, in case a user is seeking professional help. We believe that since this app will be used when people are not in their best state of minds, it's a good idea to have some resources available to them.
## What we learned
Something we got to learn more about was the impact of user interface on the mood of the user, and how different shades and colours are connotated with emotions. We also discovered that having team members from different schools and programs creates a unique, dynamic atmosphere and a great final result!
## What's next for VenTalk
There are many potential next steps for VenTalk. We are going to continue developing the app, making it compatible with iOS, and maybe even a webapp version. We also want to add more personal features, such as a personal locker of stuff that makes you happy (such as a playlist, a subreddit or a netflix series).
|
## Inspiration
In the “new normal” that COVID-19 has caused us to adapt to, our group found that a common challenge we faced was deciding where it was safe to go to complete trivial daily tasks, such as grocery shopping or eating out on occasion. We were inspired to create a mobile app using a database created completely by its users - a program where anyone could rate how well these “hubs” were following COVID-19 safety protocol.
## What it does
Our app allows for users to search a “hub” using a Google Map API, and write a review by rating prompted questions on a scale of 1 to 5 regarding how well the location enforces public health guidelines. Future visitors can then see these reviews and add their own, contributing to a collective safety rating.
## How I built it
We collaborated using Github and Android Studio, and incorporated both a Google Maps API as well integrated Firebase API.
## Challenges I ran into
Our group unfortunately faced a number of unprecedented challenges, including losing a team member mid-hack due to an emergency situation, working with 3 different timezones, and additional technical difficulties. However, we pushed through and came up with a final product we are all very passionate about and proud of!
## Accomplishments that I'm proud of
We are proud of how well we collaborated through adversity, and having never met each other in person before. We were able to tackle a prevalent social issue and come up with a plausible solution that could help bring our communities together, worldwide, similar to how our diverse team was brought together through this opportunity.
## What I learned
Our team brought a wide range of different skill sets to the table, and we were able to learn lots from each other because of our various experiences. From a technical perspective, we improved on our Java and android development fluency. From a team perspective, we improved on our ability to compromise and adapt to unforeseen situations. For 3 of us, this was our first ever hackathon and we feel very lucky to have found such kind and patient teammates that we could learn a lot from. The amount of knowledge they shared in the past 24 hours is insane.
## What's next for SafeHubs
Our next steps for SafeHubs include personalizing user experience through creating profiles, and integrating it into our community. We want SafeHubs to be a new way of staying connected (virtually) to look out for each other and keep our neighbours safe during the pandemic.
|
winning
|
## Inspiration
Earlier this month, our group of friends decided to travel around Europe for three weeks at the end of the school year. Since we’re college students and naturally want to save money, we spent hours comparing different flights from so many different websites, trying to find the best deals on the right days to book plane tickets at each airport. Even after hours of comparing different options, we still didn’t manage to agree a good travel plan for the 6 cities that we planned to visit. There were simply too many combinations to try, and having to compare flights across several different airlines’ websites quickly became messy and hard to keep track of.
## What it does
We then learned about the Amadeus API and realized that we could leverage its flight low-fare search to help us find the cheapest viable path through all the cities we wanted to visit. We modeled this problem as a dynamic variant of the travelling salesman problem, where we treat each city to visit as a node on our graph, each connecting flight as an edge, and seek to minimize the total cost of visiting all cities subject to the constraint of spending a minimum amount of time at each city. It is a dynamic variant of the problem because we want to spend a certain amount of time in each city, meaning that the flight prices (and therefore edge weights) change every time we visit a new city.
Doing this allowed us to computationally determine the cheapest route through Europe without having to sacrifice leaving a city early in the hopes of saving more money.
In order to make this process even easier, we chose to let users use our service by answering a few questions on our website or by simply chatting with our Facebook Messenger chat bot. Using Messenger allowed us to add additional functionality such as providing suggestions for vacation spots and reminding the user of their flight the day of departure. Since people often lose their cell service and SMS ability when travelling overseas, we thought that using Messenger (which only requires Internet) for text reminders would be very valuable.
## How we built it
The first thing we did was build a small library over the Amadeus API which allowed us to build our graph. We then split the project into two parts - building the chatbot and building the website. Both parts used the same javascript library that we wrote for computing the minimum prices. The website was built with Ruby on Rails, and the chatbot was built with Node.JS. The graph algorithm and handling the Amadeus data were done in Javascript.
## Challenges we ran into
The travelling salesman problem is NP-Complete, meaning that there does not exist a polynomial time algorithm for computing it. Therefore, with many cities, and therefore many calls to the Amadeus API, computing the true optimal path becomes nearly intractable given practical constraints. Therefore, we implemented a randomized greedy approach. We couldn't just use the standard travelling salesman algorithms, since the graph changed depending on how long the visitor stayed at each node. There are definitely still kinks that we are working out, but it was a great way to practice creating new approaches to problems in a real world setting.
We also spent a long time wrangling with Facebook messenger, and while we learned a lot in the process, we weren't able to make it very generalizable.
## Accomplishments that we're proud of
We were able to find a great path through Europe that we hadn't considered before that saved us a substantial amount of money compared to what we had considered before. If nothing else, we learned a ton and will be happy to know that at least it made a difference in our lives and our friends lives for the summer.
We also have it hosted on a public website, so other people who want to use the service can free of charge. Also, the Facebook messenger bot will be published so other people can interact with it.
## What we learned
API integration, practical nitty-gritty, how to reason about algorithms in the real world given new, unique constraints. We learned that it is actually possible solve problems in the real world, and create things that actually can make an impact on other people's lives.
## What's next for RoundTrip
Ideally we will fix some kinks in the graph algorithm, and polish the facebook messenger bot. We'd like to get it into a state where it is standalone usable by the general public.
|
## Inspiration
Have you ever wanted to do something but no one to do it with, for example, going on a hike, playing a sport, hitting a lift, a movie? Sync up is the daily connection app that links students in their college that have similar interests by allowing them to create events and others to RSVP.
## What it does
Currently as of 10/29/23, the app doesn't work, however the intended use of this app was to allow users to see other events students have created and allow them to easily subscribe and filter through the events they are interested in. It would reward users for actually participating in this event and meant as a daily activity as events are terminated every day.
## How I built it
We attempted to build this using React-Native for the front end, Clerk for user authentication, and Convex for the back end.
## Challenges I ran into
Most of our challenges lay in getting React-Native to fully work and ran into a lot of dependency issues. We were able to integrate convex to our idea but hadn't gotten far enough to connect it with our front end. We also were under a time crunch as we spent the first day coming up with an idea and also had to deal with spotty wifi throughout the whole event.
## Accomplishments that I'm proud of
Doing a hackathon, this was both of our first hackathon so we learned a lot on how it works and how we can do better in the future. Also of how we eventually came up with an idea and a plan and even through many of the obstacles we experienced we tried to push through.
## What I learned
As mentioned before, we both learned a lot about what it takes to complete a working project in a hackathon. We learned a lot about the importance of collaboration and the heavy reliance on team work.
## What's next for Sync Up
We may decide to finish this idea in the future so stay tuned for more!
|
# yhack
JuxtaFeeling is a Flask web application that visualizes the varying emotions between two different people having a conversation through our interactive graphs and probability data. By using the Vokaturi, IBM Watson, and Indicoio APIs, we were able to analyze both written text and audio clips to detect the emotions of two speakers in real-time. Acceptable file formats are .txt and .wav.
Note: To differentiate between different speakers in written form, please include two new lines between different speakers in the .txt file.
Here is a quick rundown of JuxtaFeeling through our slideshow: <https://docs.google.com/presentation/d/1O_7CY1buPsd4_-QvMMSnkMQa9cbhAgCDZ8kVNx8aKWs/edit?usp=sharing>
|
losing
|
# Voice Assistant For Your Bills
As you get older, your obligations and responsibilities increase.
That includes the bills you need to pay.
Paying your bills on time is one of the most crucial things a person needs to master. Paying bills on time contributes to building a solid credit rating, and having a solid credit rating enables one to finance important life purchases, like a home.
## What is "Never Miss A Bill"?
"Never Miss A Bill" is a Google Voice Assistant that takes your bills and tells you pertinent information like your next upcoming bill, the total amount that your bills cost each month, or the kind of bill obligations you already have. Keeping track of this information is important so that you stay on top of your bills and keep them at manageable levels.
## What You Can Ask
Ask things like:
*What are my bills?*
*What bill is due next?*
*How much do I owe this month?*
|
## Inspiration
Have you ever had a friend owe you money but never have cash on them? Worry no more with this application. With the use of Interac Public API, you too can collect the debts owed to you. Make requests using simple NFC technology and recover lost capital today.
## Difficulties
Hooking up RESTful API to Android was difficult but so was establishing a user connection and transmitting user data over an NFC connection.
## What we learned
A good amount about Android, multitude of protocols in our attempt to find a suitable solution.
## Next Steps:
OAuth is a big factor, adding security to functionality. Possible addition of cryptocurrencies to trade with. iOS development also possible.
|
## Inspiration
<https://www.youtube.com/watch?v=lxuOxQzDN3Y>
Robbie's story stuck out to me at the endless limitations of technology. He was diagnosed with muscular dystrophy which prevented him from having full control of his arms and legs. He was gifted with a Google home that crafted his home into a voice controlled machine. We wanted to take this a step further and make computers more accessible for people such as Robbie.
## What it does
We use a Google Cloud based API that helps us detect words and phrases captured from the microphone input. We then convert those phrases into commands for the computer to execute. Since the python script is run in the terminal it can be used across the computer and all its applications.
## How I built it
The first (and hardest) step was figuring out how to leverage Google's API to our advantage. We knew it was able to detect words from an audio file but there was more to this project than that. We started piecing libraries to get access to the microphone, file system, keyboard and mouse events, cursor x,y coordinates, and so much more. We build a large (~30) function library that could be used to control almost anything in the computer
## Challenges I ran into
Configuring the many libraries took a lot of time. Especially with compatibility issues with mac vs. windows, python2 vs. 3, etc. Many of our challenges were solved by either thinking of a better solution or asking people on forums like StackOverflow. For example, we wanted to change the volume of the computer using the fn+arrow key shortcut, but python is not allowed to access that key.
## Accomplishments that I'm proud of
We are proud of the fact that we had built an alpha version of an application we intend to keep developing, because we believe in its real-world applications. From a technical perspective, I was also proud of the fact that we were able to successfully use a Google Cloud API.
## What I learned
We learned a lot about how the machine interacts with different events in the computer and the time dependencies involved. We also learned about the ease of use of a Google API which encourages us to use more, and encourage others to do so, too. Also we learned about the different nuances of speech detection like how to tell the API to pick the word "one" over "won" in certain context, or how to change a "one" to a "1", or how to reduce ambient noise.
## What's next for Speech Computer Control
At the moment we are manually running this script through the command line but ideally we would want a more user friendly experience (GUI). Additionally, we had developed a chrome extension that numbers off each link on a page after a Google or Youtube search query, so that we would be able to say something like "jump to link 4". We were unable to get the web-to-python code just right, but we plan on implementing it in the near future.
|
losing
|
## Inspiration
On the trip to HackWestern, we were looking for ideas for the hackathon. We were looking for things in life that can be improved and also existing products which are not so convenient to use.
Jim was using Benjamin's phone and got the inspiration to make a dedicated two factor authentication device, since it takes a long time for someone to unlock their phone, go through the long list of applications, find the right app that gives them the two-factor auth code, which they have to type into the login page in a short period of time, as it expires in less than 30 seconds. The initial idea was rather primitive, but it got hugely improved and a lot more detailed than the initial one through the discussion.
## What it does
It is a dedicated device with a touch screen, that provides users with their two-factor authentication keys. It uses RFID to authenticate the user, which is very simple and fast - it takes less than 2 seconds for a user to log in, and can automatically type the authentication code into your computer when you click it.
## How We built it
The system is majorly Raspberry Pi-based. The R-Pi drives a 7 inch touch screen, which acts as the primary interface with the user.
The software for the user interface and generation of authentication keys are written in Java, using the Swing GUI framework. The clients run Linux, which is easy to debug and customize.
Some lower level components such as the RFID reader is handled by an arduino, and the information is passed to the R-Pi through serial communication.
Since we lost our Wifi dongle, we used 2 RF modules to communicate between the R-Pi and the computer. It is not an ideal solution as there could be interference and is not easily expandable.
## Challenges I ran into
We have ran into some huge problems and challenges throughout the development of the project. There are hardware challenges, as well as software ones.
For example, the 7 inch display that we are using does not have an official driver for touch, so we had to go through the data sheets, and write a C program where it gets the location of the touch, and turns that into movement of the mouse pointers.
Another challenge is the development of the user interface. We had to integrate all the components of the product into one single program, including the detection of RFID (especially hard since we had to use JNI for lower level access), the generation of codes, and the communication with other devices.
## Accomplishments that I'm proud of
We are proud of ourselves for being able to write programs that can interface with the hardware. Many of the hardware pieces have very complex documentation, but we managed to read them, and understand them, and write programs that can interface with them reliably. As well, the software has many different parts, with some in C and some in Java. We were able to make everything synergize well, and work as a whole.
## What We learned
To make this project, we needed to use a multitude of skills, ranging from HOTP and TOTP, to using JNI to gain control over lower levels of the system.
But most importantly, we learnt the practical skills of software and hardware development, and have gained valuable experience on the development of projects.
## What's next for AuthFID
|
# Unreal EngJam
Design engineers are the latest trend in the tech space, but nobody is talking about engineer designers. We're here to change that.
Unreal EngJam (working title) is a concerningly robust, from-scratch programming language and game engine, designed from the ground up to be programmed in a Figma FigJam whiteboard.
With our incredibly high quality and extremely spaghetti programming language, you can program such things as classic single-player pong...
... and even render 3D models inside Figma:
## Think of All the Benefits
* Why be limited to syntax highlighting when you can color-code your software?
* Whiteboard out math and algorithms in the same space as your business logic
* The visual programming appeal of Scratch, with the power and robustness of a real programming language
* Comments are first-class, graphical, and move around as you refactor (and refactoring is as easy as drag-and-drop)
## Clippy
Make a mistake? Your favorite office assistant will hover above the relevant code and help you out:


## How We Built It
We wrote the programming language entirely from scratch (no dependencies) in TypeScript. We use Figma's plugin API to traverse the document and generate an AST which we can then interpret. We provide the programmer with access to render to and manipulate a "game window" inside Figma.
It is important to sufficiently emphasize that this is a full, statically-typed, dynamically-bound novel programming language designed explicitly for the medium of Figma flowcharts. For example, to define a variable you draw a box. To store values, you can draw an arrow to the box, and to read values you draw an arrow from the box. With arrows, nothing needs to be referenced by name and refactoring is easy.
The assignment of function and infix operator arguments are inferred first by applied name and then internal type.
## Challenges We Ran Into
Figma runs plugins in WASM which means it is extremely difficult to debug code, and simple bugs like stack overflows often result in cryptic low-level memory leak errors.
Also, 3D models are hard to get right :)
|
## Inspiration
We're avid hackers, and every hack we've done thus far has involved hardware. The hardest part is always setting up communication between the various hardware components it's -- like reinventing the internet protocol everytime you make an IoT device. Except the internet protocol is beautiful, and your code is jank. So we decided we'd settle that problem once and for all, both for out future hacks and for hackers in general.
## What it does
Now, all the code needed for an IoT device is python. You write some python code for your computer, some for the microcontroller, and we seamlessly integrate between them. And we help predict how much better your code base is as a result.
## How we built it
Microcontrollers, because they are bare-metal, don't actually run python. So we wrote a python transpiler that automatically converts python code into bare-metal-compliant C code. Then we seamlessly, securely, and efficiently transfer data between the various hardware components using our own channels protocol. The end result is that you only ever need to look at python. Based on that and certain assumptions of usage, we model how much we are able to improve your coding experience.
## Challenges we ran into
We attempted to implement a full lexical analyzer in its complex, abstract glory. That was a mistake.
## Accomplishments that we're proud of
Because the set of languages described by regex is basically equivalent to the set of all decidable problems in computer science, we used regex in place of the lexical analyzer, which was pretty interesting.
More generally, however, this was a big project with many moving parts, and a large code base. The fact that our team was able to put everything together, get things done, and come up with creative solutions on the fly was fantastic.
## What we learned
Organization with tools like trello is important.
Compilers are complex.
Merging disparate pieces of interlocking code is a difficult but rewarding process.
And many miscellaneous python tips and tricks.
## What's next for Kharon
We intend to keep updating the project to make it more robust, general, and power. Potential routes for this include more depth in the theory of the field, integrating more AI, or just commenting our code more thoroughly so others can understand it.
This project will be useful to us and other hardware hackers in the future! -- that's why we'll keep working on this :)
|
partial
|
## Inspiration
Ubisoft's challenge (a matter of time) + VR gaming + Epic anime protagonists
## What it does
It entertains (and it's good at it too!)
## How we built it
Unity, C#, Oculus SDK
## Challenges we ran into
Time crunch, limited assets, sleep debt
## Accomplishments that we're proud of
Playable game made with only 2 naps and 1 meal
## What we learned
36 hrs is a lot less than 48 hrs
## What's next for One in the Chamber
Oculus Start?? :pray:
|
## Inspiration
What inspired us to build this application was spreading mental health awareness in relationship with the ongoing COVID-19 pandemic around the world. While it is easy to brush off signs of fatigue and emotional stress as just "being tired", often times, there is a deeper problem at the root of it. We designed this application to be as approachable and user-friendly as possible and allowed it to scale and rapidly change based on user trends.
## What it does
The project takes a scan of a face using a video stream and interprets that data by using machine learning and specially-trained models for emotion recognition. Receiving the facial data, the model is then able to process it and output the probability of a user's current emotion. After clicking the "Recommend Videos" button, the probability data is exported as an array and is processed internally, in order to determine the right query to send to the YouTube API. Once the query is sent and a response is received, the response is validated and the videos are served to the user. This process is scalable and the videos do change as newer ones get released and the YouTube algorithm serves new content. In short, this project is able to identify your emotions using face detection and suggest you videos based on how you feel.
## How we built it
The project was built as a react app leveraging face-api.js to detect the emotions and youtube-music-api for the music recommendations. The UI was designed using Material UI.
The project was built using the [REACT](https://reactjs.org/) framework, powered by [NodeJS](https://nodejs.org/en/). While it is possible to simply link the `package.json` file, the core libraries that were used were the following
* **[Redux](https://react-redux.js.org/)**
* **[Face-API](https://justadudewhohacks.github.io/face-api.js/docs/index.html)**
* **[GoogleAPIs](https://www.npmjs.com/package/googleapis)**
* **[MUI](https://mui.com/)**
* The rest were sub-dependencies that were installed automagically using [npm](https://www.npmjs.com/)
## Challenges we ran into
We faced many challenges throughout this Hackathon, including both programming and logistical ones, most of them involved dealing with React and its handling of objects and props. Here are some of the most harder challenges that we encountered with React while working on the project:
* Integration of `face-api.js`, as initially figuring out how to map the user's face and adding a canvas on top of the video stream proved to be a challenge, given how none of us really worked with that library before.
* Integration of `googleapis`' YouTube API v3, as the documentation was not very obvious and it was difficult to not only get the API key required to access the API itself, but also finding the correct URL in order to properly formulate our search query. Another challenge with this library is that it does not properly communicate its rate limiting. In this case, we did not know we could only do a maximum of 100 requests per day, and so we quickly reached our API limit and had to get a new key. Beware!
* Correctly set the camera refresh interval so that the canvas can update and be displayed to the user. Finding the correct timing and making sure that the camera would be disabled when the recommendations are displayed as well as when switching pages was a big challenge, as there was no real good documentation or solution for what we were trying to do. We ended up implementing it, but the entire process was filled with hurdles and challenges!
* Finding the right theme. It was very important to us from the very start to make it presentable and easy to use to the user. Because of that, we took a lot of time to carefully select a color palette that the users would (hopefully) be pleased by. However, this required many hours of trial-and-error, and so it took us quite some time to figure out what colors to use, all while working on completing the project we had set out to do at the start of the Hackathon.
## Accomplishments that we're proud of
While we did face many challenges and setbacks as we've outlined above, the results we something that we can really be proud of. Going into specifics, here are some of our best and satisfying moments throughout the challenge:
* Building a well-functioning app with a nice design. This was the initial goal. We did it. We're super proud of the work that we put in, the amount of hours we've spent debugging and fixing issues and it filled us with confidence knowing that we were able to plan everything out and implement everything that we wanted, given the amount of time that we had. An unforgettable experience to say the least.
* Solving the API integration issues which plagued us since the start. We knew, once we set out to develop this project, that meddling with APIs was never going to be an easy task. We were very unprepared for the amount of pain we were about to go through with the YouTube API. Part of that is mostly because of us: we chose libraries and packages that we were not very familiar with, and so, not only did we have to learn how to use them, but we also had to adapt them to our codebase to integrate them into our product. That was quite a challenge, but finally seeing it work after all the long hours we put in is absolutely worth it, and we're really glad it turned out this way.
## What we learned
To keep this section short, here are some of the things we learned throughout the Hackathon:
* How to work with new APIs
* How to debug UI issues use components to build our applications
* Understand and fully utilize React's suite of packages and libraries, as well as other styling tools such as MaterialUI (MUI)
* Rely on each other strengths
* And much, much more, but if we kept talking, the list would go on forever!
## What's next for MoodChanger
Well, given how the name **is** *Moodchanger*, there is one thing that we all wish we could change next. The world!
PS: Maybe add file support one day? :pensive:
PPS: Pst! The project is accessible on [GitHub](https://github.com/mike1572/face)!
|
## Inspiration
1.7 billion people today have cell phones but no Internet connectivity. A large portion of this demographic further faces socioeconomic challenges such as low incomes, illiteracy, and poor hygienic conditions, leaving them vulnerable to unhealthy lifestyles and malady as they lack information. Several of our team members have been in such environments where a lack of awareness and stigmatisation of mental and sexual health have led to depression and suicides, discrimination (particularly against women), and the continuation of poverty cycles. We built IEve to tackle this issue.
## What it does
IEve is a virtual assistant available on phone providing critical information even when users cannot connect to the Internet. A user can call an IEve number and ask a question, particularly for topics of which they lack awareness and/or that may be taboo in their communities. IEve then automatically generates a response to their query using crowd-sourced information that is peer-reviewed and verified by experts. IEve then reads out the answer over the phone so that it is accessible to any type of user.
IEve always ensures high confidence in its answers. If it is not confident, it admits so and automatically opens the question to experts on Einstein. An unanswered question is posted to IEve’s web forums, where users such as doctors, NGOs, and other experts can write responses. Once a response is written, it is peer-reviewed as other experts upvote or downvote it. Once it passes a certain threshold, the response is then sent to selected expert moderators who can then finalise its validity. It is then automatically added to the knowledge base on which IEve’s automated model is trained.
As of now, IEve is specialised in topics on mental and sexual health, which are particularly taboo in countries like India and other parts of the developing world. However, IEve is set up for scalability and will be able to handle any requests as more crowdsourced data is generated.
## How we built it
Our system has multiple components mentioned below:
Voice assistant on phone - We use Twilio to provide a way for users to talk with IEve. Twilio handles incoming calls from the user and, as defined by a Node.js script on an Azure VM server, sends the audio stream to Google Cloud’s cutting-edge speech-to-text model for real-time call transcription. The transcribed query from the user is parsed and forwarded to a Q&A server. The response from the Q&A server is then parsed, and the answer is extracted and read out and/or texted to the user using Twilio. If a user calls and an answer is not available, the question is posted to Einstein through a REST API call. The speech assistance makes IEve accessible to all users, even those who are illiterate or unfamiliar with smartphones. Cell phone integration makes critical information available without Internet access.
Q&A - Our query answering system is built using Azure’s state-of-the-art QnA maker. We generate a knowledge base by scraping verified articles and automatically extracting question answer pairs. The knowledge base is extendable by either directly adding question-answer pairs or by adding more articles to scrape information from. Over time the community efforts on Einstein will organically grow a rich knowledge base.
Einstein - The admin panel is built using the MERN stack (MongoDb, ExpressJS, ReactJS, and NodeJS). We followed a microservice based architecture and deployed our front-end application and backend API using Heroku. The QnA model scrapes the approved page on a daily basis to add to the knowledge base.
## Challenges we ran into
Our main challenge was integrating all our systems so that all of our applications could seamlessly communicate with each other. We used various APIs including Twilio and Node.js frameworks such as WebSockets and MongoDB as intermediaries that handled communication between systems. We were also challenged initially by the non-robustness of our Azure QnA model, which we addressed through question generation and additional data collection.
## Accomplishments that we're proud of
We are quite proud of how we integrated all our systems so that we could leverage the strengths of Azure, Google Cloud, and the Twilio APIs. Our whole application is entirely automatic! Our application is very scalable, and as we hope to help people with information, we are proud that this should increase our scope for impact with time. We are happy that we learned so much in such a short time.
## What we learned
We learned a lot about using Azure, Google Cloud, and Twilio and about web development, NLP, and application design.
## What's next for IEve: An Organically Improving Voice Assistant for All Information for Everyone
Going forward, we will continue to develop IEve to handle more topics more robustly and aim to promote Einstein and begin crowdsourcing with improved automatic knowledge extraction and updates.
## Try it out
Call +1 (205) 579-8843 to see IEve in action
Check out Einstein at: <https://oosharma.github.io/einstein/>
|
partial
|
## Inspiration
It’s no secret that the COVID-19 pandemic ruined most of our social lives. ARoom presents an opportunity to boost your morale by supporting you to converse with your immediate neighbors and strangers in a COVID safe environment.
## What it does
Our app is designed to help you bring your video chat experience to the next level. By connecting to your webcam and microphone, ARoom allows you to chat with people living near you virtually. Coupled with an augmented reality system, our application also allows you to view 3D models and images for more interactivity and fun. Want to chat with new people? Open the map offered by ARoom to discover the other rooms available around you and join one to start chatting!
## How we built it
The front-end was created with Svelte, HTML, CSS, and JavaScript. We used Node.js and Express.js to design the backend, constructing our own voice chat API from scratch. We used VS Code’s Live Share plugin to collaborate, as many of us worked on the same files at the same time. We used the A-Frame web framework to implement Augmented Reality and the Leaflet JavaScript library to add a map to the project.
## Challenges we ran into
From the start, Svelte and A-Frame were brand new frameworks for every member of the team, so we had to devote a significant portion of time just to learn them. Implementing many of our desired features was a challenge, as our knowledge of the programs simply wasn’t comprehensive enough in the beginning. We encountered our first major problem when trying to implement the AR interactions with 3D models in A-Frame. We couldn’t track the objects on camera without using markers, and adding our most desired feature, interactions with users was simply out of the question. We tried to use MediaPipe to detect the hand’s movements to manipulate the positions of the objects, but after spending all of Friday night working on it we were unsuccessful and ended up changing the trajectory of our project.
Our next challenge materialized when we attempted to add a map to our function. We wanted the map to display nearby rooms, and allow users to join any open room within a certain radius. We had difficulties pulling the location of the rooms from other files, as we didn’t understand how Svelte deals with abstraction. We were unable to implement the search radius due to the time limit, but we managed to add our other desired features after an entire day and night of work.
We encountered various other difficulties as well, including updating the rooms when new users join, creating and populating icons on the map, and configuring the DNS for our domain.
## Accomplishments that we're proud of
Our team is extremely proud of our product, and the effort we’ve put into it. It was ¾ of our members’ first hackathon, and we worked extremely hard to build a complete web application. Although we ran into many challenges, we are extremely happy that we either overcame or found a way to work around every single one. Our product isn’t what we initially set out to create, but we are nonetheless delighted at its usefulness, and the benefit it could bring to society, especially to people whose mental health is suffering due to the pandemic. We are also very proud of our voice chat API, which we built from scratch.
## What we learned
Each member of our group has learned a fair bit over the last 36 hours. Using new frameworks, plugins, and other miscellaneous development tools allowed us to acquire heaps of technical knowledge, but we also learned plenty about more soft topics, like hackathons and collaboration. From having to change the direction of our project nearly 24 hours into the event, we learned that it’s important to clearly define objectives at the beginning of an event. We learned that communication and proper documentation is essential, as it can take hours to complete the simplest task when it involves integrating multiple files that several different people have worked on. Using Svelte, Leaflet, GitHub, and Node.js solidified many of our hard skills, but the most important lessons learned were of the other variety.
## What's next for ARoom
Now that we have a finished, complete, usable product, we would like to add several features that were forced to remain in the backlog this weekend. We plan on changing the map to show a much more general location for each room, for safety reasons. We will also prevent users from joining rooms more than an arbitrary distance away from their current location, to promote a more of a friendly neighborhood vibe on the platform. Adding a video and text chat, integrating Google’s Translation API, and creating a settings page are also on the horizon.
|
## Inspiration
We wanted to build the most portable and accessible device for augmented reality.
## What it does
This application uses location services to detect where you are located and if you are in proximity to one of the landmark features based on a predefined set of coordinates. Then a 3d notification message appears with the name and information of the location.
## How we built it
We built on a stack with Objective-C, OpenGL, NodeJS, MongoDB, and Express using XCode. We also did the 3d modelling in Blender to create floating structures.
## Challenges we ran into
Math is hard. Real real hard. Dealing with 3D space, there were a lot of natural challenges dealing with calculations of matrices and quaternions. It was also difficult to calibrate for the scaling between the camera feed calculated in arbitrary units and the real world.
## Accomplishments that we're proud of
We created a functional 3-D augmented reality viewer complete with parallax effects and nifty animations. We think that's pretty cool.
## What we learned
We really honed our skills in developing within the 3-D space.
## What's next for Tour Aug
Possible uses could include location-based advertising and the inclusion of animated 3d characters.
|
## Motivation
Coding skills are in high demand and will soon become a necessary skill for nearly all industries. Jobs in STEM have grown by 79 percent since 1990, and are expected to grow an additional 13 percent by 2027, according to a 2018 Pew Research Center survey. This provides strong motivation for educators to find a way to engage students early in building their coding knowledge.
Mixed Reality may very well be the answer. A study conducted at Georgia Tech found that students who used mobile augmented reality platforms to learn coding performed better on assessments than their counterparts. Furthermore, research at Tufts University shows that tangible programming encourages high-level computational thinking. Two of our team members are instructors for an introductory programming class at the Colorado School of Mines. One team member is an interaction designer at the California College of the Art and is new to programming. Our fourth team member is a first-year computer science at the University of Maryland. Learning from each other's experiences, we aim to create the first mixed reality platform for tangible programming, which is also grounded in the reality-based interaction framework. This framework has two main principles:
1) First, interaction **takes place in the real world**, so students no longer program behind large computer monitors where they have easy access to distractions such as games, IM, and the Web.
2) Second, interaction behaves more like the real world. That is, tangible languages take advantage of **students’ knowledge of the everyday, non-computer world** to express and enforce language syntax.
Using these two concepts, we bring you MusicBlox!
## What is is
MusicBlox combines mixed reality with introductory programming lessons to create a **tangible programming experience**. In comparison to other products on the market, like the LEGO Mindstorm, our tangible programming education platform **cuts cost in the classroom** (no need to buy expensive hardware!), **increases reliability** (virtual objects will never get tear and wear), and **allows greater freedom in the design** of the tangible programming blocks (teachers can print out new card/tiles and map them to new programming concepts).
This platform is currently usable on the **Magic Leap** AR headset, but will soon be expanded to more readily available platforms like phones and tablets.
Our platform is built using the research performed by Google’s Project Bloks and operates under a similar principle of gamifying programming and using tangible programming lessons.
The platform consists of a baseboard where students must place tiles. Each of these tiles is associated with a concrete world item. For our first version, we focused on music. Thus, the tiles include a song note, a guitar, a piano, and a record. These tiles can be combined in various ways to teach programming concepts. Students must order the tiles correctly on the baseboard in order to win the various levels on the platform. For example, on level 1, a student must correctly place a music note, a piano, and a sound in order to reinforce the concept of a method. That is, an input (song note) is fed into a method (the piano) to produce an output (sound).
Thus, this platform not only provides a tangible way of thinking (students are able to interact with the tiles while visualizing augmented objects), but also makes use of everyday, non-computer world objects to express and enforce computational thinking.
## How we built it
Our initial version is deployed on the Magic Leap AR headset. There are four components to the project, which we split equally among our team members.
The first is image recognition, which Natalie worked predominantly on. This required using the Magic Leap API to locate and track various image targets (the baseboard, the tiles) and rendering augmented objects on those tracked targets.
The second component, which Nhan worked on, involved extended reality interaction. This involved both Magic Leap and Unity to determine how to interact with buttons and user interfaces in the Magic leap headset.
The third component, which Casey spearheaded, focused on integration and scene development within Unity. As the user flows through the program, there are different game scenes they encounter, which Casey designed and implemented. Furthermore, Casey ensured the seamless integration of all these scenes for a flawless user experience.
The fourth component, led by Ryan, involved project design, research, and user experience. Ryan tackled user interaction layouts to determine the best workflow for children to learn programming, concept development, and packaging of the platform.
## Challenges we ran into
We faced many challenges with the nuances of the Magic Leap platform, but we are extremely grateful to the Magic Leap mentors for providing their time and expertise over the duration of the hackathon!
## Accomplishments that We're Proud of
We are very proud of the user experience within our product. This feels like a platform that we could already begin testing with children and getting user feedback. With our design expert Ryan, we were able to package the platform to be clean, fresh, and easy to interact with.
## What We learned
Two of our team members were very unfamiliar with the Magic Leap platform, so we were able to learn a lot about mixed reality platforms that we previously did not. By implementing MusicBlox, we learned about image recognition and object manipulation within Magic Leap. Moreover, with our scene integration, we all learned more about the Unity platform and game development.
## What’s next for MusicBlox: Tangible Programming Education in Mixed Reality
This platform is currently only usable on the Magic Leap AR device. Our next big step would be to expand to more readily available platforms like phones and tablets. This would allow for more product integration within classrooms.
Furthermore, we only have one version which depends on music concepts and teaches methods and loops. We would like to expand our versions to include other everyday objects as a basis for learning abstract programming concepts.
|
partial
|
## Inspiration
Sustainability is no longer a nice-to-have, it’s essential for future-proofing investments and businesses. Investors struggle to find companies that align with their sustainability goals, while companies face challenges identifying best practices in environmental responsibility. Our team saw the need for a solution that helps both investors and businesses thrive in the sustainable economy.
## What it does
Our platform helps investors and companies alike by:
* **Empowering Investors:** Find investment opportunities in companies with strong sustainability practices using our advanced semantic search.
* **Predictive Risk Modeling:** Provides future environmental risk scores for companies, helping investors build eco-friendly portfolios.
* **Portfolio Optimization:** Investors receive personalized recommendations on how to improve their sustainability scores by diversifying into companies with growing eco-friendly initiatives.
* **Research Tool for Companies:** Businesses can explore the sustainability strategies of industry leaders, using our platform to research and improve their own practices.
## How we built it
We utilized cutting-edge technology to bring this vision to life. For the semantic search, we used a vector database (SingleStore) and cosine similarity to allow investors to search for companies based on specific sustainability traits. We integrated Hugging Face models to generate embeddings that power the semantic search. On the data analysis side, we used NumPy and scikit-learn to implement linear regression, predicting future environmental risk scores for companies. The environmental risk predictions and comparisons with the S&P 500 are visualized through Chart.js, giving users clear and insightful data representations.
## Challenges we ran into
Building an app with this level of complexity came with its challenges. Implementing accurate semantic search required careful tuning of the embeddings and vector search algorithms. Collecting and standardizing environmental data across a large number of companies was also a big hurdle. Additionally, fitting linear regression models to predict future risk scores based on historical data required rigorous testing and validation to ensure accuracy.
## Accomplishments that we're proud of
We are proud of the seamless integration of advanced technologies like semantic search and predictive analytics. Our vector search engine allows investors and sustainability teams to find relevant companies with incredible ease. Our linear regression models give forward-looking insights, helping investors and companies make data-driven decisions to improve sustainability. Most importantly, the potential for this tool to drive real-world environmental impact makes this project truly rewarding.
## What we learned
Throughout this project, we learned the power of combining machine learning with sustainable business practices. We deepened our understanding of semantic search algorithms, vector databases, and regression modeling for predictive analytics. We also realized how crucial well-organized data is to create meaningful predictions and insights. Building a product that bridges sustainability with investment strategy was complex, but it gave us experience in balancing technical precision with user-friendly design.
## What's next for Envest
Our next step is to expand the platform by incorporating more dynamic data sources, including real-time environmental news and company sustainability reports. We want to broaden our recommendation system, providing even more refined suggestions for portfolio improvement. On the company side, we plan to introduce tools that allow businesses to simulate the impact of implementing specific sustainability practices, helping them visualize potential gains in environmental scores.
|
## Inspiration
I came across a quote that deeply moved me: 'By 2050, a further 24 million children are projected to be undernourished as a result of the climate crisis.' It made me reflect profoundly on the significant impact climate change has on our world."
Melting ice caps and glaciers contribute to rising sea levels and warmer temperatures, threatening the availability of land for future generations. This inspired us to create an application that educates individuals about their carbon footprint, suggests ways to reduce it, and leverages AI technology to assist in these efforts, thereby promising a sustainable future for everyone.
## What it does
The app provides users with an overview of their carbon footprint based on their daily activities. It provides an intuitive textual response from which users can gain actionable insights.
Key features include:
* **Home Page**: Displaying a summary of the user's overall carbon footprint, along with actionable advice on reducing it.
* **Interactive Chatbot**: Users can engage in voice or text conversations with an AI-driven chatbot to gain a deeper understanding of their carbon output and receive personalized suggestions.
* **Receipt Analysis**: Users can upload images of their receipts, and the app utilizes AI to extract data and calculate the associated carbon footprint.
* **Transport Tracker**: Users input their mode of transportation along with the travel duration and distance, and the app calculates the carbon emissions for these activities.
* Users can review detailed reports and insights to identify high-emission areas and explore ways to reduce their footprint without significantly altering their lifestyle.
## How we built it
We utilized a blend of modern web technologies and advanced AI services:
* **Frontend**: Developed using HTML, CSS, and JavaScript to ensure a responsive and user-friendly interface.
* **Backend**: Implemented with Flask, which facilitates communication between the frontend and various AI models hosted on Hugging Face and other platforms.
* **AI Integration**: We integrated Amazon Bedrock for inference with LLMs like Anthropic Claude 3, OpenAI's Whisper for speech-to-text capabilities, and Moondream2 for image-to-text conversions.
* **Data Storage**: Utilized AWS S3 buckets for robust and scalable storage of images, audio files, and textual data.
## Challenges we ran into
* One significant challenge was the integration of the Whisper model for transcription, primarily due to compatibility issues with different versions of OpenAI's API. This required extensive testing and modifications to ensure stable functionality.
* Building the front end was a little complex since we mainly focused on backend and machine learning models for projects.
## Accomplishments that we're proud of
We are particularly proud of developing a tool that can significantly impact individuals' ecological footprints. By providing easy-to-understand data and actionable insights, we empower users to make informed decisions that contribute to global sustainability.
## What we learned
This project enhanced our skills in collaborative problem-solving and integrating multiple technologies into a seamless application. We gained deeper insights into the capabilities and practical applications of large language models and AI in environmental conservation.
## What's next for the project?
Looking ahead, we plan to:
* **Expand Device Integration**: Enable syncing with smartphones and wearable devices to track fitness and travel data automatically.
* **Financial Integration**: Connect with banking apps to analyze spending patterns and suggest more eco-friendly purchasing options.
* **Community Challenges**: Introduce features that allow users to participate in challenges with friends or colleagues, fostering a competitive spirit to achieve the lowest carbon footprint.
Our goal is to continually evolve the app to include more features that will not only help individuals reduce their carbon footprint but also engage communities in collective environmental responsibility.
|
## Inspiration
We admired the convenience Honey provides for finding coupon codes. We wanted to apply the same concept except towards making more sustainable purchases online.
## What it does
Recommends sustainable and local business alternatives when shopping online.
## How we built it
Front-end was built with React.js and Bootstrap. The back-end was built with Python, Flask and CockroachDB.
## Challenges we ran into
Difficulties setting up the environment across the team, especially with cross-platform development in the back-end. Extracting the current URL from a webpage was also challenging.
## Accomplishments that we're proud of
Creating a working product!
Successful end-to-end data pipeline.
## What we learned
We learned how to implement a Chrome Extension. Also learned how to deploy to Heroku, and set up/use a database in CockroachDB.
## What's next for Conscious Consumer
First, it's important to expand to make it easier to add local businesses. We want to continue improving the relational algorithm that takes an item on a website, and relates it to a similar local business in the user's area. Finally, we want to replace the ESG rating scraping with a corporate account with rating agencies so we can query ESG data easier.
|
losing
|
## Inspiration
2 days before flying to Hack the North, Darryl forgot his keys and spent the better part of an afternoon retracing his steps to find it- But what if there was a personal assistant that remembered everything for you? Memories should be made easier with the technologies we have today.
## What it does
A camera records you as you go about your day to day life, storing "comic book strip" panels containing images and context of what you're doing as you go about your life. When you want to remember something you can ask out loud, and it'll use Open AI's API to search through its "memories" to bring up the location, time, and your action when you lost it. This can help with knowing where you placed your keys, if you locked your door/garage, and other day to day life.
## How we built it
The React-based UI interface records using your webcam, screenshotting every second, and stopping at the 9 second mark before creating a 3x3 comic image. This was done because having static images would not give enough context for certain scenarios, and we wanted to reduce the rate of API requests per image. After generating this image, it sends this to OpenAI's turbo vision model, which then gives contextualized info about the image. This info is then posted sent to our Express.JS service hosted on Vercel, which in turn parses this data and sends it to Cloud Firestore (stored in a Firebase database). To re-access this data, the browser's built in speech recognition is utilized by us along with the SpeechSynthesis API in order to communicate back and forth with the user. The user speaks, the dialogue is converted into text and processed by Open AI, which then classifies it as either a search for an action, or an object find. It then searches through the database and speaks out loud, giving information with a naturalized response.
## Challenges we ran into
We originally planned on using a VR headset, webcam, NEST camera, or anything external with a camera, which we could attach to our bodies somehow. Unfortunately the hardware lottery didn't go our way; to combat this, we decided to make use of MacOS's continuity feature, using our iPhone camera connected to our macbook as our primary input.
## Accomplishments that we're proud of
As a two person team, we're proud of how well we were able to work together and silo our tasks so they didn't interfere with each other. Also, this was Michelle's first time working with Express.JS and Firebase, so we're proud of how fast we were able to learn!
## What we learned
We learned about OpenAI's turbo vision API capabilities, how to work together as a team, how to sleep effectively on a couch and with very little sleep.
## What's next for ReCall: Memories done for you!
We originally had a vision for people with amnesia and memory loss problems, where there would be a catalogue for the people that they've met in the past to help them as they recover. We didn't have too much context on these health problems however, and limited scope, so in the future we would like to implement a face recognition feature to help people remember their friends and family.
|
## Inspiration
I've been previously locked out of my own car before with no spare key or way of getting in far from home.
## What it does
Knock Lock is an alternative way to unlock your car if you don't have your keys or don't want to break into your own vehicle.
## How we built it
A Piezo speaker listens for knocks based on the number of knocks and the time interval between each knock. This is run on an Arduino R3 microcontroller which is connected to a relay in the car that is responsible for the power locks. If the sequence of knocks is correct, then the Arduino will send an electrical pulse to the relay that will unlock the doors.
## Challenges we ran into
The main issue we had with the project was designing and soldering the electrical circuit running from the car, the speaker, and Arduino. Another issue we had was wiring and working on the car in the cold.
## Accomplishments that we're proud of
We are proud of managing to get the Arduino to interact with the car based on input from the speaker.
## What we learned
As this is our first hardware based project, we learned a great deal in how electrical components work and being able to interact with a car's electrical systems on a rudimentary level.
## What's next for Knock Lock
We wish to wire the controller to the car's ignition to be able to not only unlock the car based on the correct knock, but also start the car simultaneously.
|
## Inspiration
Our inspiration comes from one of our team member's bedtime story sessions with his little cousin. Whenever he reads him a picture book, his cousin always has questions like, "Why did Goldilocks walk into the house?"—and most of the time, we don’t have the answers. We wished there was a way for him to ask the characters directly, to hear their side of the story. That’s where the idea for **LiveStory** came from. We wanted to bring storybook characters to life and let kids interact with them directly to get answers to their questions in real time.
## What it does
**LiveStory** is a children's storybook that comes alive! At ANY point in the story, interact with a character on the page and chat with them; how are they feeling about what just happened?
With industry-leading AI voice-to-voice pipelines, readers can feel the emotion of their favourite characters.
## How we built it
Our web application was built primarily using **Reflex**:
* Reflex for both frontend and backend
* React.js for managing the database of each page and character
* Custom assistants powered by Vapi, Groq, Deepgram, and 11Labs to simulate character interactions
* Reflex for Deploy
## Challenges we ran into
* We initially struggled with Reflex, but over time, it became our go-to tool for building the project.
* We had to prevent characters from spoiling the story by restricting their responses to what the reader had already seen. To solve this, we fed the accumulative story log into the voice API, ensuring characters only referenced the relevant parts of the story.
## Accomplishments that we're proud of
* Completing the project on time and getting it fully functional!!!
* Learning Reflex and Lottie from scratch and successfully implementing them over the weekend.
* Collaborating with amazing Reflex engineers to create a solid product based on their platform.
* Committing 20+ hours and $1,000 on travel from Waterloo, Canada, to make this hackathon happen!
## What we learned
* Making a full-stack app in Reflex
* Implementing beautiful vector animations with Lottie
* Implementing voice-to-voice models in web apps
## What's next for LiveStory
As time is the biggest limitation during a hackathon, we would have loved to pour more time into the art to make a more beautiful experience.
* More stories!
* More animations! Characters could, based on the emotions of their speech, have reactive animations
* Character Interaction Interface: a more advanced UI can note your **emotions**
* **Choose your own adventures!** With supported stories, the conversations with the characters could influence the story!
* Customization for reader! We can also try feeding reader's information such as name, hobby and academic interest to serve better user experience.
|
winning
|
## Inspiration
Thinking back to going to the mall every weekend to hang out with friends, I realized that ecommerce can sometimes be a tiresome and lonely time. Furthermore shopping online tends to give you a disconnected feeling where you end up mindlessly shopping and completely overshooting your budget.
Taking these in mind, we wanted to create a more personal and social ecommerce experience. Hence ShopPal has born: an AI cartoon character that interacted with the user, asking them casual questions, telling jokes, and making unique comments based on the search history and type of websites the user was looking for in order to replicate real life conversations.
## What it does
ShopPal is a chrome browser extension, that is easily accessible in the chrome web extension tabs. Our code featured an animated character that one of our team members designed and created from scratch who would appear and disappear across the extension popup, spouting messages to it's users.
## How we built it
None of our three members had very much coding experience, so we stuck together and created the framework of the site using html and CSS, however after that was finished, we all branched out and tried to create our own unique part of the browser extension, searching for some new knowledge that we could learn and implement in order to create a more accessible and enjoyable website.
## Challenges we ran into
The undeniable, daunting fact that we are incredibly inexperienced had nothing on our unwavering determination to climb this mountain of a project. Being the first hackathon for all of our team members, many things were surprising. We faced many problems, including time management, underdeveloped technical skills, and especially a lack of sleep.
## What we learned and Accomplishments that we're proud of
Admittedly, we knew next to nothing before participating in this hackathon. While there is only so much one can learn in 36 hours, we definitely made the most of our time. Not only did we gain tons of valuable experience with a few different languages, we learned valuable skills and concepts which we will be sure to apply in the future. While there were some bumps in the road, they were more learning experience than challenge. One thing we struggled with was time management, but now we know where we went wrong, and how we can do better in our next event.
## What's next for ShopPal
After creating a simple AI and persona, we want to delve deeper into this character that we had built and truly push it to it's limits. We would aspire to create a robot that gets to know people based on their online habits and how they interact with the AI. ShopPal would store this information and compare it with other data gathered in order to learn more about online habits and find new creative ways to be useful and innovative.
|
## Inspiration
As students who just moved to San Francisco for their freshman year, we have experienced how dangerous it is sometimes to walk around the city, especially near Mission and Tenderloin areas. Since day 1, we are told to be careful and walk in groups to be safe. Statistically, there were reported more than 1000 crimes in those two regions during September 2019 according to sanfranciscopolice.org. But how can we help our community to feel safer while being also time-efficient (we are students after all)? In order to solve this problem within not only our community but also for the whole city, we have worked during this weekend on the Safe Walk web app.
|
## Inspiration
We were inspired by the resilience of freelancers, particularly creative designers, during the pandemic. As students, it's easy to feel overwhelmed and not value our own work. We wanted to empower emerging designers and remind them of what we can do with a little bit of courage. And support.
## What it does
Bossify is a mobile app that cleverly helps students adjust their design fees. It focuses on equitable upfront pay, which in turn increases the amount of money saved. This can be put towards an emergency fund. On the other side, clients can receive high-quality, reliable work. The platform has a transparent rating system making it easy to find quality freelancers.
It's a win-win situation.
## How we built it
We got together as a team the first night to hammer out ideas. This was our second idea, and everyone on the team loved it. We all pitched in ideas for product strategy. Afterwards, we divided the work into two parts - 1) Userflows, UI Design, & Prototype; 2) Writing and Testing the Algorithm.
For the design, Figma was the main software used. The designers (Lori and Janice) used a mix iOS components and icons for speed. Stock images were taken from Unsplash and Pexels. After quickly drafting the storyboards, we created a rapid prototype. Finally, the pitch deck was made to synthesize our ideas.
For the code, Android studio was the main software used. The developers (Eunice and Zoe) together implemented the back and front-end of the MVP (minimum viable product), where Zoe developed the intelligent price prediction model in Tensorflow, and deployed the trained model on the mobile application.
## Challenges we ran into
One challenge was not having the appropriate data immediately available, which was needed to create the algorithm. On the first night, it was a challenge to quickly research and determine the types of information/factors that contribute to design fees. We had to cap off our research time to figure out the design and algorithm.
There were also technical limitations, where our team had to determine the best way to integrate the prototype with the front-end and back-end. As there was limited time and after consulting with the hackathon mentor, the developers decided to aim for the MVP instead of spending too much time and energy on turning the prototype to a real front-end. It was also difficult to integrate the machine learning algorithm to our mini app's backend, mainly because we don't have any experience with implement machine learning algorithm in java, especially as part of the back-end of a mobile app.
## Accomplishments that we're proud of
We're proud of how cohesive the project reads. As the first covid hackathon for all the team members, we were still able to communicate well and put our synergies together.
## What we learned
Although a simple platform with minimal pages, we learned that it was still possible to create an impactful app. We also learned the importance of making a plan and time line before we start, which helped us keep track of our progress and allows us to use our time more strategically.
## What's next for Bossify
Making partnerships to incentivize clients to use Bossify! #fairpayforfreelancers
|
losing
|
## Inspiration
Grip strength has been shown to be a powerful biomarker for numerous physiological processes. Two particularly compelling examples are Central Nervous System (CNS) fatigue and overall propensity for Cardiovascular Disease (CVD). The core idea is not about building a hand grip strengthening tool, as this need is already largely satisfied within the market by traditional hand grip devices currently. Rather, it is about building a product that leverages the insights behind one’s hand grip to help users make more informed decisions about their physical activities and overall well-being.
## What it does
Gripp is a physical device that users can squeeze to measure their hand grip strength in a low-cost, easy-to-use manner. The resulting measurements can be benchmarked against previous values taken by oneself, as well as comparable peers. These will be used to provide intelligent recommendations on optimal fitness/training protocols through providing deeper, quantifiable insights into recovery.
## How we built it
Gripp was built using a mixture of both hardware and software.
On the hardware front, the project began with a Computer-Aided Design (CAD) model of the device. With the requirement to build around the required force sensors and accompanying electronics, the resulting model was customized exclusively for this product, and subsequently, 3-D printed. Other considerations included the ergonomics of holding the device, and adaptability depending on the hand size of the user. Exerting force on the Wheatstone bridge sensor causes it to measure the voltage difference caused by minute changes to resistance. These changes in resistance are amplified by the HX711 amplifier and converted using an ESP32 into a force measurement.
From there, the data flows into a MySQL database hosted in Apache for the corresponding user, before finally going to the front-end interface dashboard.
## Challenges we ran into
There were several challenges that we ran into.
On the hardware side, getting the hardware to consistently output a force value was challenging. Further, listening in on the COM port, interpreting the serial data flowing in from the ESP-32, and getting it to interact with Python (where it needed to be to flow through the Flask endpoint to the front end) was challenging.
On the software side, our team was challenged by the complexities of the operations required, most notably the front-end components, with minimal experience in React across the board.
## Accomplishments that we're proud of
Connecting the hardware to the back-end database to the front-end display, and facilitating communication both ways, is what we are most proud of, as it required navigating several complex issues to reach a sound connection.
## What we learned
The value of having another pair of eyes on code rather than trying to individually solve everything. While the latter is often possible, it is a far less efficient (especially when around others) methodology.
## What's next for Gripp
Next for Gripp on the hardware side is continuing to test other prototypes of the hardware design, as well as materials (e.g., a silicon mould as opposed to plastic). Additionally, facilitating the hardware/software connection via Bluetooth.
From a user-interface perspective, it would be optimal to move from a web-based application to a mobile one.
On the front-end side, continuing to build out other pages will be critical (trends, community), as well as additional features (e.g., readiness score).
|
## Why
Type 2 diabetes can be incredibly tough, especially when it leads to complications. I've seen it firsthand with my uncle, who suffers from peripheral neuropathy. Watching him struggle with insensitivity in his feet, having to go to the doctor regularly for new insoles just to manage the pain and prevent further damage—it’s really painful. It's constantly on my mind how easily something like a pressure sore could become something more serious, risking amputation. It's heartbreaking to see how diabetes quietly affects his everyday life in ways people do not even realize.
## What
Our goal is to create a smart insole for diabetic patients living with type 2 diabetes. This insole is designed with several pressure sensors placed at key points to provide real-time data on the patient’s foot pressure. By continuously processing this data, it can alert both the user and their doctor when any irregularities or issues are detected. What’s even more powerful is that, based on this data, the insole can adjust to help correct the patient’s walking stance. This small but important correction can help prevent painful foot ulcers and, hopefully, make a real difference in their quality of life.
## How we built it
We build an insole with 3 sensors on it (the sensors are a hackathon project on their own), that checks the plantar pressure exerted by the patient. We stream and process the data and feed it to another model sole that changes shape based on the gait analysis so it helps correct the patients walk in realtime.
Concurrently we stream the data out to our dashboard to show recent activity, alerts and live data about a patient's behavior so that doctors can monitor them remotely- and step in if any early signs of neural-degradation .
## Challenges we ran into and Accomplishments that we're proud of
So, we hit a few bumps in the road since most of the hackathon projects were all about software, and we needed hardware to bring our idea to life. Cue the adventure! We were running all over the city—Trader Joe's, Micro Center, local makerspaces—you name it, we were there, hunting for parts to build our force sensor. When we couldn’t find what we needed, we got scrappy. We ended up making our own sensor from scratch using PU foam and a pencil (yep, a pencil!). It was a wild ride of custom electronics, troubleshooting hardware problems, and patching things up with software when we couldn’t get the right parts.
In the end, we’re super proud of what we pulled off—our own custom-built sensor, plus the software to bring it all together. It was a challenge, but we had a blast, and we're thrilled with what we made in the time we had!
## What we learned
Throughout this project, we learned that flexibility and resourcefulness are key when working with hardware, especially under tight time constraints, as we had to get creative with available materials.
As well as this - we learnt a lot about preventative measures that can be taken to reduce the symptoms of diabetes and we have optimistic prospects about how we will can continue to help people with diabetes.
## What's next for Diabeteasy
Everyone in our team has close family affected by diabetes, meaning this is a problem very near and dear to all of us. We strive to continue developing and delivering a prototype to those around us who we can see, first hand, the impact and make improvements to refine the design and execution. We aim to build relations with remote patient monitoring firms to assist within elderly healthcare, since we can provide one value above all; health.
|
## Inspiration
We are trying to GET JACKED!
## What it does
Form Checker collects and sends balance, form, and technique data from the user while doing pushups to our web app that generates a report on the properness of the form.
## How we built it
We integrated a gyroscope/accelerometer with an ESP-32 to measure changes in relative position and angular velocity in order to create the user's Form information. That information is then sent to a FLASK backend hosted on the cloud. The information is then stored on FireStore and can be retrieved; later displayed on our REACT web app.
## Challenges we ran into
We ran into issues with Full Stack integration, hardware quality & calibration.
## Accomplishments that we're proud of
We are proud of being able to parallelize data acquisition and data pushing using the ESP-32's dual cores. In addition, the frontend has a very clean design and would have shown Form data for a person who did push-ups with our hardware.
## What we learned
We learned how to integrate the various aspects of software development with hardware. Such as creating a React App from scratch and making REST API requests to a Flask backend that's hosted through the Google Cloud Platform and sending the data from the hardware, which is the ESP 32 in our case, to be posted into the data base through our Flask backend. We also learned that maybe having too many things going on isn't the best way to accomplish things, and that next time we'd like to have a narrower focus for our project so the quality of the final product is substantially greater.
## What's next for Jacked the North
Incorporate more exercises so that more people can get jacked and allow people to see their Form data so they can correct minor details in their exercise form.
|
winning
|
## Inspiration
Our project is inspired by the sister of one our creators, Joseph Ntaimo. Joseph often needs to help locate wheelchair accessible entrances to accommodate her, but they can be hard to find when buildings have multiple entrances. Therefore, we created our app as an innovative piece of assistive tech to improve accessibility across the campus.
## What it does
The user can find wheelchair accessible entrances with ease and get directions on where to find them.
## How we built it
We started off using MIT’s Accessible Routes interactive map to see where the wheelchair friendly entrances were located at MIT. We then inspected the JavaScript code running behind the map to find the latitude and longitude coordinates for each of the wheelchair locations.
We then created a Python script that filtered out the latitude and longitude values, ignoring the other syntax from the coordinate data, and stored the values in separate text files.
We tested whether our method would work in Python first, because it is the language we are most familiar with, by using string concatenation to add the proper Java syntax to the latitude and longitude points. Then we printed all of the points to the terminal and imported them into Android Studio.
After being certain that the method would work, we uploaded these files into the raw folder in Android Studio and wrote code in Java that would iterate through both of the latitude/longitude lists simultaneously and plot them onto the map.
The next step was learning how to change the color and image associated with each marker, which was very time intensive, but led us to having our custom logo for each of the markers.
Separately, we designed elements of the app in Adobe Illustrator and imported logos and button designs into Android Studio. Then, through trial and error (and YouTube videos), we figured out how to make buttons link to different pages, so we could have both a FAQ page and the map.
Then we combined both of the apps together atop of the original maps directory and ironed out the errors so that the pages would display properly.
## Challenges we ran into/Accomplishments
We had a lot more ideas than we were able to implement. Stripping our app to basic, reasonable features was something we had to tackle in the beginning, but it kept changing as we discovered the limitations of our project throughout the 24 hours. Therefore, we had to sacrifice features that we would otherwise have loved to add.
A big difficulty for our team was combining our different elements into a cohesive project. Since our team split up the usage of Android Studio, Adobe illustrator, and programming using the Google Maps API, it was most difficult to integrate all our work together.
We are proud of how effectively we were able to split up our team’s roles based on everyone’s unique skills. In this way, we were able to be maximally productive and play to our strengths.
We were also able to add Boston University accessible entrances in addition to MIT's, which proved that we could adopt this project for other schools and locations, not just MIT.
## What we learned
We used Android Studio for the first time to make apps. We discovered how much Google API had to offer, allowing us to make our map and include features such as instant directions to a location. This helped us realize that we should use our resources to their full capabilities.
## What's next for HandyMap
If given more time, we would have added many features such as accessibility for visually impaired students to help them find entrances, alerts for issues with accessing ramps and power doors, a community rating system of entrances, using machine learning and the community feature to auto-import maps that aren't interactive, and much, much more. Most important of all, we would apply it to all colleges and even anywhere in the world.
|
# Inspiration
Many cities in the United States are still severely behind on implementing infrastructure improvements to meet ADA (Americans with Disabilities Act) accessibility standards. Though 1 in 7 people in the US have a mobility-related disability, research has found that 65% of curb ramps and 48% of sidewalks are not accessible, and only 13% of state and local governments have transition plans for implementing improvements (Eisenberg et al, 2020). To make urban living accessible to all, cities need to upgrade their public infrastructure, starting with identifying areas that need the most improvement according to ADA guidelines. However, having city dispatchers travel and view every single area of a city is time consuming, expensive, and tedious. We aimed to utilize available data from Google Maps to streamline and automate the analysis of city areas for their compliance with ADA guidelines.
# What AcceCity does
AcceCity provides a machine learning-powered mapping platform that enables cities, urban planners, neighborhood associations, disability activists, and more to identify key areas to prioritize investment in. AcceCity identifies both problematic and up-to-standards spots and provides an interactive, dynamic map that enables on-demand regional mapping of accessibility concerns and improvements and street views of sites.
### Interactive dynamic map
AcceCity implements an interactive map, with city and satellite views, that enables on-demand mapping of accessibility concerns and improvements. Users can specify what regions they want to analyze, and a street view enables viewing of specific spots.
### Detailed accessibility concerns
AcceCity calculuates scores for each concern based on ADA standards in four categories: general accessibility, walkability, mobility, and parking. Examples of the features we used for each of these categories include the detection of ramps in front of raised entrances, the presence of sidewalks along roads, crosswalk markings at street intersections, and the number of handicap-reserved parking spots in parking lots. In addition, suggestions for possible solutions or improvements are provided for each concern.
### Accessibility scores
AcceCity auto-generates metrics for areas by computing regional scores (based on the scan area selected by the user) by category (general accessibility, walkability, mobility, and parking) in addition to an overall composite score.
# How we built it
### Frontend
We built the frontend using React with TailwindCSS for styling. The interactive dynamic map was implemented using the Google Maps API, and all map and site data are updated in real-time from Firebase using listeners.
New scan data are also instantly saved to the cloud for future reuse.
### Machine learning backend
First, we used the Google Maps API to send images of the street view to the backend. We looked for handicapped parking, sidewalks, disability ramps, and crosswalks and used computer vision, by custom-fitting a zero shot learning model called CLIP from OpenAI, to automatically detect those objects from the images. We tested the model using labeled data from Scale Rapid API.
After running this endpoint on all images in a region of interest, users can calculate a metric that represents the accessibility of that area to people with disabilities. We call that metric the ADA score, which can be good, average, or poor. (Regions with a poor ADA score should be specifically targeted by city planners to increase its accessibility.) We calculated this ADA score based on features such as the number of detected ramps, handicapped parking spaces, crosswalks, and sidewalks from the google maps image analysis discussed previously, in addition to using the number of accidents per year recorded in that area. We trained a proof of concept model using mage.ai, which provides an intuitive and high-level way to train custom models.
## Challenges we ran into
* Applying ML to diverse urban images, especially since it’s so “in the wild”
* Lack of general ML models for accessibility prediction
* Developing methods for calculating representative / accurate metrics
* Running ML model on laptops: very computationally expensive
## Accomplishments that we're proud of
* We developed the first framework that connects Google Maps images with computer vision models to analyze the cities we live in.
* We developed the first computer vision framework/model aimed to detect objects specific for people with disabilities
* We integrated the Google Maps API with a responsive frontend that allows users to view their areas of interest and enter street view to see the results of the model.
## What we learned
* We learned how to integrate the Google Maps API for different purposes.
* We learned how to customize the OpenAI zero shot learning for specific tasks.
* How to use Scale Rapid API to label images
* How to use Mage.ai to quickly and efficiently train classification models.
## What's next for AcceCity
* Integrating more external data (open city data): public buildings, city zoning, locations of social services, etc.
* Training the machine learning models with more data collected in tandem with city officials.
## Ethical considerations
As we develop technology made to enable and equalize the playing field for all people, it is important for us to benchmark our efforts against sustainable and ethical products. Accecity was developed with several ethical considerations in mind to address a potentially murky future at the intersection of everyday life (especially within our civilian infrastructure) and digital technology.
A primary lens we used to assist in our data collection and model training efforts was ensuring that we collected data points from a spectrum of different fields. We attempted to incorporate demographic, socioeconomic, and geopolitical diversity when developing our models to detect violations of the ADA. This is key, as studies have shown that ADA violations disproportionately affect socioeconomically disadvantaged groups, especially among Black and brown minorities.
By incorporating a diverse spectrum of information into our analysis, our outputs can also better serve the city and urban planners seeking to create more equitable access to cities for persons with disabilities and improve general walkability metrics.
At its core, AcceCity is meant to help urban planners design better cities. However, given the nature of our technology, it casts a wide, automatic net over certain regions. The voice of the end population is never heard, as all of our suggestion points are generated via Google Maps. In future iterations of our product, we would focus on implementing features that allow everyday civilians affected by ADA violations and lack of walkability to suggest changes to their cities or report concerns. People would have more trust in our product if they believe and see that it is truly creating a better city and neighborhood around them.
As we develop a technology that might revolutionize how cities approach urban planning and infrastructure budget, it is also important to consider how bad actors might aim to abuse our platform. The first and primary red flag is from the stance of someone who might abuse disability and reserved parking and actively seeks out those reserved spaces, when they have not applied for a disability placard, excluding those who need those spaces the most. Additionally, malicious actors might use the platform to scrape data on cities and general urban accessibility features and sell that data to firms that would want these kinds of metrics, which is why we firmly commit to securing our and never selling our data to third parties.
One final consideration for our product is its end goal: to help cities become more accessible for all. Once we achieve this goal, even on an individual concern by concern basis we should come back to cities and urban planners with information on the status of their improvements and more details on other places that they can attempt to create more equitable infrastructure.
|
## Inspiration ✨
Exploration is more than just being called Dora and staying away from Swiper. Yet the struggle to truly live out this experience continues to be a struggle for those with disabilities. We wanted to build a project that helps the visually impaired explore the world. We wanted to be their eyes (hence the play on words in our name).
## What it does 🤳
EyeExplore starts with a facial recognition login–a way for the visually impaired to log in without having to type out a password with the small letters on their phone. This information is stored in the Estuary database to be accessed in the future. It later brings them to a camera that detects surrounding obstructions with a text-to-speech function in order to read the names of these obstructions to know how to steer clear. This is done with the co:here API.
## How we built it 🔧
Building off many different API’s, there were many unique technologies and frameworks we had to build around. For the back end, we used Face++ API for facial recognition sign-in, Estuary/Firebase for facial recognition storage, co:here API for text-to-speech features, and the Local Python server for the backend. For the front end, we used Figma and React Native first designing and then implementing the designs into an Expo app.
## Challenges we ran into 🏃
We didn’t just run into challenges, the challenges chased us down. Whoever said it was a good idea for 4 first-years to build an almost functioning React Native app despite never having touched Native, must’ve been crazy (no one did by the way).
Halfway in, we realized the backend coders could not incorporate their code to React Native so we all had to scrap our old code and write new ones to be compatible with Native.
On the same note, we wanted to implement Tensorflow with Expo however they were incompatible and that resulted in our code not working out.
The Estuary database server also went down and we forgot to check the discord server for updates so we had to use firebase.
We struggled with “Possible unhandled promise rejection” and still don’t know how to solve this issue
JSON file syntax error which we did not find and that is what stopped us from getting further with our code. First, it was a broken promise but after fixing that error, we were unable to find the syntax error in all the JSON files.
We were also too hyper-fixated on individual problems so it was hard to move on from the code we took a long time to build.
## Accomplishments that we're proud of 🎉
Trying project ideas we have 0 experience in developing! Every hackathon we try to hack something new and time and time again we underestimate its difficulty. Halfway through this hackathon, we did lose a bit of hope, unsure if we were able to successfully develop the app by the deadline. However, we took a break, worked on our planning, and were able to voice out our concerns, resulting in us having something we were decently satisfied with (so close to full integration).
We are also very proud that we were able to get the app going in the first place as we, once again, had no experience with Native and we’re also new to fronted integration in general. To be able to even configure buttons, bars with input and output, and authentication is already crazy to us that we were able to figure it out.
## What we learned 🌱
We learned that while aiming high is good, we lose sight of feasibility. We were definitely in a time crunch toward the end, especially after pretty much restarting the project halfway through. We were also able to work on managing databases, more API implementation, and debugging (especially with Native).
## What's next for EyeExplore 🤩
Full integration of all parts. We all had the same clear vision for this project hence all parts of this project have been done by respective members. However, due to technical issues, we were unable to finish. We also hope to implement a translation feature for international users and a way to measure the distance between the person and the objects. The opportunities for EyeExplore are endless and we hope to finish our project in the near future!
|
winning
|
## Inspiration
* Smart homes are taking over the industry
* Current solutions are WAY too expensive(almost $30) for one simple lightbulb
* Can fail from time to time
* Complicated to connect
## What it does
* It simplifies the whole idea of a smart home
* Three part system
+ App(to control the hub device)
+ Hub(used to listen to the Firebase database and control all of the devices)
+ Individual Devices(used to do individual tasks such as turn on lights, locks, etc.)
* It allows as many devices as you want to be controlled through one app
* Can be controlled from anywhere in the world
* Cheap in cost
* Based on usage data, provides feedback on how to be more efficient with trained algorithm
## How I built it
* App built with XCode and Swift
* Individual devices made with Arduino's and Node-MCU's
* Arduino's intercommunicate with RF24 Radio modules
* Main Hub device connects to Firebase with wifi
## Challenges I ran into
* Using RF24 radios to talk between Arduinos
* Communicating Firebase with the Hub device
* Getting live updates from Firebase(constant listening)
## Accomplishments that I'm proud of
* Getting a low latency period, almost instant from anywhere in the world
* Dual way communication(Input and Output Devices)
* Communicating multiple non-native devices with Firebase
## What I learned
* How RF24 radios work at the core
* How to connect Firebase to many devices
* How to keep listening for changes from Firebase
* How to inter-communicate between Arduinos and Wifi modules
## What's next for The Smarter Home
* Create more types of devices
* Decrease latency
* Create more appropriate and suitable covers
|
## Inspiration
Our team wanted to make a smart power bar device to tackle the challenge of phantom power consumption. Phantom power is the power consumed by devices when they are plugged in and idle, accounting for approximately 10% of a home’s power consumption. [1] The best solution for this so far has been for users to unplug their devices after use. However, this method is extremely inconvenient for the consumer as there can be innumerable household devices that require being unplugged, such as charging devices for phones, laptops, vacuums, as well as TV’s, monitors, and kitchen appliances. [2] We wanted to make a device that optimized convenience for the user while increasing electrical savings and reducing energy consumption.
## What It Does
The device monitors power consumption and based on continual readings automatically shuts off power to idle devices. In addition to reducing phantom power consumption, the smart power bar monitors real-time energy consumption and provides graphical analytics to the user through MongoDB. The user is sent weekly power consumption update-emails, and notifications whenever the power is shut off to the smart power bar. It also has built-in safety features, to automatically cut power when devices draw a dangerous amount of current, or a manual emergency shut off button should the user determine their power consumption is too high.
## How We Built It
We developed a device using an alternating current sensor wired in series with the hot terminal of a power cable. The sensor converts AC current readings into 5V logic that can be read by an Arduino to measure both effective current and voltage. In addition, a relay is also wired in series with the hot terminal, which can be controlled by the Arduino’s 5V logic. This allows for both the automatic and manual control of the circuit, to automatically control power consumption based on predefined thresholds, or to turn on or off the circuit if the user believes the power consumption to be too high. In addition to the product’s controls, the Arduino microcontroller is connected to the Qualcomm 410C DragonBoard, where we used Python to push data sensor data to MongoDB, which updates trends in real-time for the user to see. In addition, we also send the user email updates through Python with the time-stamps based on when the power bar is shut off. This adds an extended layer of user engagement and notification to ensure they are aware of the system’s status at critical events.
## Challenges We Ran Into
One of our major struggles was with operating and connecting the DragonBoard, such as setting up connection and recognition of the monitor to be able to program and install packages on the DragonBoard. In addition, connecting to the shell was difficult, as well as any interfacing in general with peripherals was difficult and not necessarily straightforward, though we did find solutions to all of our problems.
We struggled with establishing a two-way connection between the Arduino and the DragonBoard, due to the Arduino microntrontroller shield that was supplied with the kit. Due to unknown hardware or communication problems between the Arduino shield and DragonBoard, the DragonBoard would continually shut off, making troubleshooting and integration between the hardware and software impossible.
Another challenge was tuning and compensating for error in the AC sensor module, as due to lack of access to a multimeter or an oscilloscope for most of our build, it was difficult to pinpoint exactly what the characteristic of the AC current sinusoids we were measuring. For context, we measured the current draw of 2-prong devices such as our phone and laptop chargers. Therefore, a further complication to accurately measure the AC current draws of our devices would have been to cut open our charging cables, which was out of the question considering they are our important personal devices.
## Accomplishments That We Are Proud Of
We are particularly proud of our ability to have found and successfully used sensors to quantify power consumption in our electrical devices. Coming into the competition as a team of mostly strangers, we cycled through different ideas ahead of the Makeathon that we would like to pursue, and 1 of them happened to be how to reduce wasteful power consumption in consumer homes. Finally meeting on the day of, we realized we wanted to pursue the idea, but unfortunately had none of the necessary equipment, such as AC current sensors, available. With some resourcefulness and quick-calling to stores in Toronto, we were luckily able to find components at the local electronics stores, such as Creatron and the Home Hardware, to find the components we needed to make the project we wanted.
In a short period of time, we were able to leverage the use of MongoDB to create an HMI for the user, and also read values from the microcontroller into the database and trend the values.
In addition, we were proud of our research into understanding the operation of the AC current sensor modules and then applying the theory behind AC to DC current and voltage conversion to approximate sensor readings to calculate apparent power generation. In theory the physics are very straightforward, however in practice, troubleshooting and accounting for noise and error in the sensor readings can be confusing!
## What's Next for SmartBar
We would build a more precise and accurate analytics system with an extended and extensible user interface for practical everyday use. This could include real-time cost projections for user billing cycles and power use on top of raw consumption data. As well, this also includes developing our system with more accurate and higher resolution sensors to ensure our readings are as accurate as possible. This would include extended research and development using more sophisticated testing equipment such as power supplies and oscilloscopes to accurately measure and record AC current draw. Not to mention, developing a standardized suite of sensors to offer consumers, to account for different types of appliances that require different size sensors, ranging from washing machines and dryers, to ovens and kettles and other smaller electronic or kitchen devices. Furthermore, we would use additional testing to characterize maximum and minimum thresholds for different types of devices, or more simply stated recording when the devices were actually being useful as opposed to idle, to prompt the user with recommendations for when their devices could be automatically shut off to save power. That would make the device truly customizable for different consumer needs, for different devices.
## Sources
[1] <https://www.hydroone.com/saving-money-and-energy/residential/tips-and-tools/phantom-power>
[2] <http://www.hydroquebec.com/residential/energy-wise/electronics/phantom-power.html>
|
## Inspiration
We wanted to give virtual reality a purpose, while pushing its limits and making it a fun experience for the user.
## What it does
Our game immerses the user in the middle of an asteroid belt. The user is accompanied by a gunner, and the two players must work together to complete the course in as little time as possible. Player 1 drives the spacecraft using a stationary bike with embedded sensors that provide real-time input to the VR engine. Player 2 controls uses a wireless game controller to blow up asteroids and clear the way to the finish.
## How we built it
Our entire system relies on a FireBase server for inter-device communication. Our bike hardware uses a potentiometer and hall-effect sensor running on an Arduino to measure the turn-state and RPMs of the bike. This data is continuously streamed to the FireBase server, where it can be retrieved by the virtual reality engine. Player 1 and Player 2 constantly exchange game state information over the FireBase server to synchronize their virtual reality experiences with virtually no latency.
We had the option to use Unity for our 3D engine, but instead we used the SmokyBay 3D Engine (which was developed from scratch by Magnus Johnson). We chose to use Magnus' engine because it allowed us to more easily at support for FireBase, and additional hardware.
## Challenges we ran into
We spent a large amount of time trying to arrive at the correct configuration of hardware for our application. In particular, we spent many hours working with the Particle Photon before realizing that it's high level of latency makes it unsuitable for real time applications. We had no prior experience with FireBase, and spent a lot of time integrating it into our project, but it ultimately turned out to be a very elegant solution.
## Accomplishments that we're proud of
We are most proud of the integration aspect of our project. We had to incorporate many sensors, 2 iPhones, a FireBase database, and a game controller into a holistic virtual reality experience. This was in many ways frustrating, but ultimately very rewarding.
## What we learned
In retrospect, it would have been very helpful to have a more complete understanding of the hardware available to us and it's limitations.
## What's next for TourDeMarsVR
Add more sensors and potentially integrating Leap Motion instead of hand held gaming pad.
|
winning
|
## Inspiration
Course selection is an exciting but frustrating time to be a Princeton student. While you can look at all the cool classes that the university has to offer, it is challenging to aggregate a full list of prerequisites and borderline impossible to find what courses each of them leads to in the future. We recently encountered this problem when building our schedules for next fall. The amount of searching and cross-referencing that we had to do was overwhelming, and to this day, we are not exactly sure whether our schedules are valid or if there will be hidden conflicts moving forward. So we built TigerMap to address this common issue among students.
## What it does
TigerMap compiles scraped course data from the Princeton Registrar into a traversable graph where every class comes with a clear set of prerequisites and unlocked classes. A user can search for a specific class code using a search bar and then browse through its prereqs and unlocks, going down different course paths and efficiently exploring the options available to them.
## How we built it
We used React (frontend), Python (middle tier), and a MongoDB database (backend). Prior to creating the application itself, we spent several hours scraping the Registrar's website, extracting information, and building the course graph. We then implemented the graph in Python and had it connect to a MongoDB database that stores course data like names and descriptions. The prereqs and unlocks that are found through various graph traversal algorithms, and the results are sent to the frontend to be displayed in a clear and accessible manner.
## Challenges we ran into
Data collection and processing was by far the biggest challenge for TigerMap. It was difficult to scrape the Registrar pages given that they are rendered by JavaScript, and once we had the pages downloaded, we had to go through a tedious process of extracting the necessary information and creating our course graph. The prerequisites for courses is not written in a consistent manner across the Registrar's pages, so we had to develop robust methods of extracting data. Our main concern was ensuring that we would get a graph that completely covered all of Princeton's courses and was not missing any references between classes. To accomplish this, we used classes from both the Fall and Spring 21-22 semesters, and we can proudly say that, apart from a handful of rare occurrences, we achieved full course coverage and consistency within our graph.
## Accomplishments that we're proud of
We are extremely proud of how fast and elegant our solution turned out to be. TigerMap definitely satisifes all of our objectives for the project, is user-friendly, and gives accurate results for nearly all Princeton courses. The amount of time and stress that TigerMap can save is immeasurable.
## What we learned
* Graph algorithms
* The full stack development process
* Databases
* Web-scraping
* Data cleaning and processing techniques
## What's next for TigerMap
We would like to improve our data collection pipeline, tie up some loose ends, and release TigerMap for the Princeton community to enjoy!
## Track
Education
## Discord
Leo Stepanewk - nwker#3994
Aaliyah Sayed - aaligator#1793
|
## Inspiration
3 AM, just the light of Jacob's computer in his dorm room. Reading through 3 weeks' worth of lecture slides to make up for getting the flu. With a teacher who doesn't do recorded lectures, the task of learning multivariable calculus was up to him. After ten slides he couldn't seem to keep my eyes open. The same boring format with no one to explain it to him made him vow to never make anyone go through what he had to endure. Our team set out to make a program to do just that. Lecture agent ensures that no matter your circumstances, you're never left behind. With Lecture Agent, you can study class materials from anywhere, anytime with a personalized AI-driven professor who delivers dynamic lectures based on your course content.
## What it does
Lecture Agent takes those dreadful class slides that feel like quicksand to go through alone and builds your very own AI lecture presentation. It takes the uploaded slide notes and intelligently generates a fully narrated, professor-like presentation, breaking down even the most complex concepts into digestible explanations. This allows users to experience a seamless, interactive lecture experience.
## How we built it
We built out the backend by taking each slide and the text on that slide and saving each side individually with its core information. We then leveraged fetch ai's framework to utilize their agents intensively throughout our application. We developed agents to handle each part of the text and image scraping along with the communications with OpenAI's models to generate the lecture script. We then take that lecture script and convert it to speech using OpenAI's Speech API.
## Challenges we ran into
We faced difficulties in synchronizing the generated audio with the presentation of slides. Additionally, processing the images and text to generate the lecture script took longer than expected. To optimize performance, we had to find a way to display the previous slide while the next one was being processed, minimizing the perceived delay for users. Getting the Fetch.ai Agents to deploy and communicate with each other was a very tedious process. We also had trouble integrating a PDF reader into our frontend and we were able to solve this by simply displaying the images of each slide separately.
## Accomplishments that we're proud of
We were very proud of the increased reliability of our lecture content that came from incorporating both text and visual data from the slides in our lecture generation. Providing images alongside the lecture text allowed for more content-rich explanations. Displaying the slides alongside the audio player that
We were able to distribute each of our backend tasks to fetch AI agents. We utilized six Fetch AI agents, which communicate autonomously to manage text extraction, image processing, script generation, and voice synthesis, ensuring smooth and reliable performance.
## What we learned
We gained valuable experience integrating Fetch AI's UAgents framework, optimizing agent communication to effectively delegate tasks. Additionally, we improved our ability to manage large-scale data processing using decentralized agents, which significantly enhanced the scalability of our system. We also deepened our understanding of integrating multiple microservices and ensuring seamless communication between them
## What's next for Lecture Agent
**Features coming soon:**
**ChatLA:** This feature allows real-time Q&A interaction between students and the AI lecturer, enabling users to ask questions and receive accurate, on-the-spot answers based on their lecture material.
**LiveTranscription:** Gives users the ability to receive real-time transcriptions of the lectures, further enhancing accessibility and usability.
**LiveTranslation:** Real-time translation of slide and lecture audio material for nonnative speakers that allows users to get the help they need understanding their material in a language that feels comfortable to them
**VoiceChoice:** Allows the user to pick the most engaging lecturers' voice for them.
|
## Inspiration
Us college students all can relate to having a teacher that was not engaging enough during lectures or mumbling to the point where we cannot hear them at all. Instead of finding solutions to help the students outside of the classroom, we realized that the teachers need better feedback to see how they can improve themselves to create better lecture sessions and better ratemyprofessor ratings.
## What it does
Morpheus is a machine learning system that analyzes a professor’s lesson audio in order to differentiate between various emotions portrayed through his speech. We then use an original algorithm to grade the lecture. Similarly we record and score the professor’s body language throughout the lesson using motion detection/analyzing software. We then store everything on a database and show the data on a dashboard which the professor can access and utilize to improve their body and voice engagement with students. This is all in hopes of allowing the professor to be more engaging and effective during their lectures through their speech and body language.
## How we built it
### Visual Studio Code/Front End Development: Sovannratana Khek
Used a premade React foundation with Material UI to create a basic dashboard. I deleted and added certain pages which we needed for our specific purpose. Since the foundation came with components pre build, I looked into how they worked and edited them to work for our purpose instead of working from scratch to save time on styling to a theme. I needed to add a couple new original functionalities and connect to our database endpoints which required learning a fetching library in React. In the end we have a dashboard with a development history displayed through a line graph representing a score per lecture (refer to section 2) and a selection for a single lecture summary display. This is based on our backend database setup. There is also space available for scalability and added functionality.
### PHP-MySQL-Docker/Backend Development & DevOps: Giuseppe Steduto
I developed the backend for the application and connected the different pieces of the software together. I designed a relational database using MySQL and created API endpoints for the frontend using PHP. These endpoints filter and process the data generated by our machine learning algorithm before presenting it to the frontend side of the dashboard. I chose PHP because it gives the developer the option to quickly get an application running, avoiding the hassle of converters and compilers, and gives easy access to the SQL database. Since we’re dealing with personal data about the professor, every endpoint is only accessible prior authentication (handled with session tokens) and stored following security best-practices (e.g. salting and hashing passwords). I deployed a PhpMyAdmin instance to easily manage the database in a user-friendly way.
In order to make the software easily portable across different platforms, I containerized the whole tech stack using docker and docker-compose to handle the interaction among several containers at once.
### MATLAB/Machine Learning Model for Speech and Emotion Recognition: Braulio Aguilar Islas
I developed a machine learning model to recognize speech emotion patterns using MATLAB’s audio toolbox, simulink and deep learning toolbox. I used the Berlin Database of Emotional Speech To train my model. I augmented the dataset in order to increase accuracy of my results, normalized the data in order to seamlessly visualize it using a pie chart, providing an easy and seamless integration with our database that connects to our website.
### Solidworks/Product Design Engineering: Riki Osako
Utilizing Solidworks, I created the 3D model design of Morpheus including fixtures, sensors, and materials. Our team had to consider how this device would be tracking the teacher’s movements and hearing the volume while not disturbing the flow of class. Currently the main sensors being utilized in this product are a microphone (to detect volume for recording and data), nfc sensor (for card tapping), front camera, and tilt sensor (for vertical tilting and tracking professor). The device also has a magnetic connector on the bottom to allow itself to change from stationary position to mobility position. It’s able to modularly connect to a holonomic drivetrain to move freely around the classroom if the professor moves around a lot. Overall, this allowed us to create a visual model of how our product would look and how the professor could possibly interact with it. To keep the device and drivetrain up and running, it does require USB-C charging.
### Figma/UI Design of the Product: Riki Osako
Utilizing Figma, I created the UI design of Morpheus to show how the professor would interact with it. In the demo shown, we made it a simple interface for the professor so that all they would need to do is to scan in using their school ID, then either check his lecture data or start the lecture. Overall, the professor is able to see if the device is tracking his movements and volume throughout the lecture and see the results of their lecture at the end.
## Challenges we ran into
Riki Osako: Two issues I faced was learning how to model the product in a way that would feel simple for the user to understand through Solidworks and Figma (using it for the first time). I had to do a lot of research through Amazon videos and see how they created their amazon echo model and looking back in my UI/UX notes in the Google Coursera Certification course that I’m taking.
Sovannratana Khek: The main issues I ran into stemmed from my inexperience with the React framework. Oftentimes, I’m confused as to how to implement a certain feature I want to add. I overcame these by researching existing documentation on errors and utilizing existing libraries. There were some problems that couldn’t be solved with this method as it was logic specific to our software. Fortunately, these problems just needed time and a lot of debugging with some help from peers, existing resources, and since React is javascript based, I was able to use past experiences with JS and django to help despite using an unfamiliar framework.
Giuseppe Steduto: The main issue I faced was making everything run in a smooth way and interact in the correct manner. Often I ended up in a dependency hell, and had to rethink the architecture of the whole project to not over engineer it without losing speed or consistency.
Braulio Aguilar Islas: The main issue I faced was working with audio data in order to train my model and finding a way to quantify the fluctuations that resulted in different emotions when speaking. Also, the dataset was in german
## Accomplishments that we're proud of
Achieved about 60% accuracy in detecting speech emotion patterns, wrote data to our database, and created an attractive dashboard to present the results of the data analysis while learning new technologies (such as React and Docker), even though our time was short.
## What we learned
As a team coming from different backgrounds, we learned how we could utilize our strengths in different aspects of the project to smoothly operate. For example, Riki is a mechanical engineering major with little coding experience, but we were able to allow his strengths in that area to create us a visual model of our product and create a UI design interface using Figma. Sovannratana is a freshman that had his first hackathon experience and was able to utilize his experience to create a website for the first time. Braulio and Gisueppe were the most experienced in the team but we were all able to help each other not just in the coding aspect, with different ideas as well.
## What's next for Untitled
We have a couple of ideas on how we would like to proceed with this project after HackHarvard and after hibernating for a couple of days.
From a coding standpoint, we would like to improve the UI experience for the user on the website by adding more features and better style designs for the professor to interact with. In addition, add motion tracking data feedback to the professor to get a general idea of how they should be changing their gestures.
We would also like to integrate a student portal and gather data on their performance and help the teacher better understand where the students need most help with.
From a business standpoint, we would like to possibly see if we could team up with our university, Illinois Institute of Technology, and test the functionality of it in actual classrooms.
|
partial
|
**Project:** Loka.ai/**Members:** Quan Nguyen, Duc Nguyen, Long Bui
## I. Motivations
While small businesses represent 44% of the U.S. GDP, 99% of all firms, and have generated 63% of new jobs over the last decade, they face challenges in leveraging data-driven decision-making to enhance profitability comparing larger enterprises. This may be due to the lack of resources and experience necessary to implement data-driven technologies and invest in research and development.
A platform that could help small firms to **optimize** their **financial resosurces** and **understand** of **market dynamics** has become more **urgent**.
## II. Solution Overview
Given our limited resources and time, we aim to focus on a specific area that best showcases the potential of this approach:
*An innovative approach to identify the **ideal locations** for small-scale food and beverage enterprises.*
Most optimized location. **What it demonstrates ?**
* Customer demographics
* Potential Markets
* Rental & operational costs
* Competitor presence
Focusing first on F&B industry. **Why F&B ?**
* **99.9%** of businesses in F&B industry are small firms.
* **56%** of F&B business owners struggle with managing operational costs and profitability
* **52%** cite economic uncertainty as a major hurdleeconomic uncertainty as a significant hurdle.
* The U.S. packaged food market is projected to reach **US$1.6 trillion** by 2030
## III. Milestones & Challenges
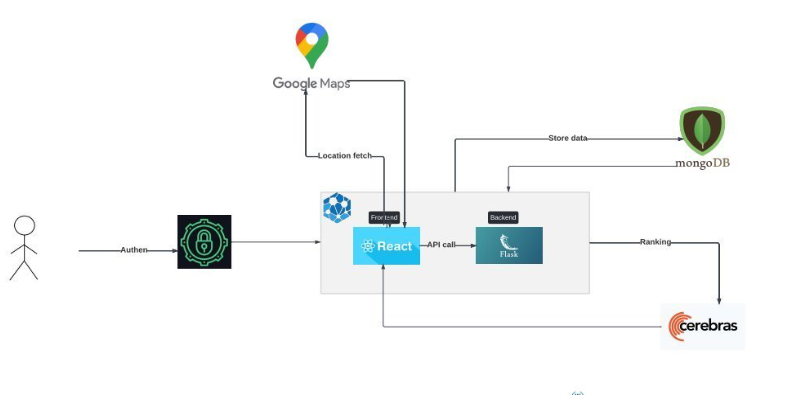
* Pull APIs from different data sources (GoogleMapAPI, Census Bureau, NY Open Data)
* Integrate pulled data into [MongoDB](https://github.com/mongodb/mongo)
* Utilize [React](https://github.com/facebook/react) to construct web interface
* Optimize [Flask](https://github.com/pallets/flask) to build server
* Develop a machine learning model that captures essential parameters using [Cerebas API](https://github.com/Cerebras) to rank most optimized locations
* Leverage [PropelAuthority](https://github.com/orgs/PropelAuth/repositories) to authorize user management
* Design, reorganize, and visualize metrics into meaningful and understandable insights
## IV. Takeaways
### Pros
* **Operational and Functional**: The app is fully operational, allowing users to access its features seamlessly, enabling immediate utilization for business enhancement.
* **Showcases Essential Capabilities**: It effectively demonstrates the necessary skills and functionalities, providing valuable insights for optimizing processes and decision-making.
* **Room for Improvements**: The project shows solid foundation that could potentially develop new features and continous improvability in the future.
### Cons
* **Potential Model Biases**: Some biases have been identified in the model, which may affect accuracy. Further testing and fine-tuning are needed to improve reliability.
* **Capacity Limitations**: The app currently has restrictions on handling larger datasets and accommodating more users, necessitating enhancements for scalability.
* **Data Dependencies**: Fetching data from different sources and does not have inernal data may lead to disrupt the system if sources collasped.
## V. Future Enhancements
### Model Improvements:
1. **Market Equilibrium Adjustment**:
Implement dynamic Supply & Demand balancing algorithms to reflect real-time market conditions.
2. **Logistics Analysis Implementation**: Incorporate advanced logistics modeling to optimize supply chain operations and reduce costs.
3. **Data Backup Sources**: Utilize redundant cloud storage, regular snapshots, and blockchain technology for secure and reliable data backups.
4. **Features Added**: Introduce machine learning price predictions, real-time sentiment analysis, customizable alerts, and interactive visualizations.
### Platform Integrations:
1. **Market Data Providers:** Establish connections with providers like Bloomberg for comprehensive market data feeds.
2. **Integration with CRM Systems**: Connect with platforms like Microsoft Business Central (launched in 2021 to serve small business's data solutions) to retreive more accurate financial data.
|
## Inspiration
Small businesses have suffered throughout the COVID-19 pandemic. In order to help them get back on track once life comes back to normal, this app can attract new and loyal customers alike to the restaurant.
## What it does
Businesses can sign up and host their restaurant online, where users can search them up, follow them, and scroll around and see their items. Owners can also offer virtual coupons to attract more customers, or users can buy each other food vouchers that can be redeemed next time they visit the store.
## How we built it
The webapp was built using Flask and Google's Firebase for the backend development. Multiple flask modules were used, such as flask\_login, flask\_bcrypt, pyrebase, and more. HTML/CSS with Jinja2 and Bootstrap were used for the View (structuring of the code followed an MVC model).
## Challenges we ran into
-Restructuring of the project:
Sometime during Saturday, we had to restructure the whole project because we ran into a circular dependency, so the whole structure of the code changed making us learn the new way of deploying our code
-Many 'NoneType Object is not subscriptable', and not attributable errors
Getting data from our Firebase realtime database proved to be quite difficult at times, because there were many branches, and each time we would try to retrieve values we ran into the risk of getting this error. Depending on the type of user, the structure of the database changes but the users are similarly related (Business inherits from Users), so sometimes during login/registration the user type wouldn't be known properly leading to NoneType object errors.
-Having pages different for each type of user
This was not as much of a challenge as the other two, thanks to the help of Jinja2. However, due to the different pages for different users, sometimes the errors would return (like names returning as None, because the user types would be different).
## Accomplishments that we're proud of
-Having a functional search and login/registration system
-Implementing encryption with user passwords
-Implementing dynamic URLs that would show different pages based on Business/User type
-Allowing businesses to add items on their menu, and uploading them to Firebase
-Fully incorporating our data and object structures in Firebase,
## What we learned
Every accomplishment is something we have learned. These are things we haven't implemented before in our projects. We learned how to use Firebase with Python, and how to use Flask with all of its other mini modules.
## What's next for foodtalk
Due to time constraints, we still have to implement businesses being able to post their own posts. The coupon voucher and gift receipt system have yet to be implemented, and there could be more customization for users and businesses to put on their profile, like profile pictures and biographies.
|
## Inspiration
Despite being a global priority in the eyes of the United Nations, food insecurity still affects hundreds of millions of people. Even in the developed country of Canada, over 5.8 million individuals (>14% of the national population) are living in food-insecure households. These individuals are unable to access adequate quantities of nutritious foods.
## What it does
Food4All works to limit the prevalence of food insecurity by minimizing waste from food corporations. The website addresses this by serving as a link between businesses with leftover food and individuals in need. Businesses with a surplus of food are able to donate food by displaying their offering on the Food4All website. By filling out the form, businesses will have the opportunity to input the nutritional values of the food, the quantity of the food, and the location for pickup.
From a consumer’s perspective, they will be able to see nearby donations on an interactive map. By separating foods by their needs (e.g., high-protein), consumers will be able to reserve the donated food they desire. Altogether, this works to cut down unnecessary food waste by providing it to people in need.
## How we built it
We created this project using a combination of multiple languages. We used Python for the backend, specifically for setting up the login system using Flask Login. We also used Python for form submissions, where we took the input and allocated it to a JSON object which interacted with the food map. Secondly, we used Typescript (JavaScript for deployable code) and JavaScript’s Fetch API in order to interact with the Google Maps Platform. The two major APIs we used from this platform are the Places API and Maps JavaScript API. This was responsible for creating the map, the markers with information, and an accessible form system. We used HTML/CSS and JavaScript alongside Bootstrap to produce the web-design of the website. Finally, we used the QR Code API in order to get QR Code receipts for the food pickups.
## Challenges we ran into
Some of the challenges we ran into was using the Fetch API. Since none of us were familiar with asynchronous polling, specifically in JavaScript, we had to learn this to make a functioning food inventory. Additionally, learning the Google Maps Platform was a challenge due to the comprehensive documentation and our lack of prior experience. Finally, putting front-end components together with back-end components to create a cohesive website proved to be a major challenge for us.
## Accomplishments that we're proud of
Overall, we are extremely proud of the web application we created. The final website is functional and it was created to resolve a social issue we are all passionate about. Furthermore, the project we created solves a problem in a way that hasn’t been approached before. In addition to improving our teamwork skills, we are pleased to have learned new tools such as Google Maps Platform. Last but not least, we are thrilled to overcome the multiple challenges we faced throughout the process of creation.
## What we learned
In addition to learning more about food insecurity, we improved our HTML/CSS skills through developing the website. To add on, we increased our understanding of Javascript/TypeScript through the utilization of the APIs on Google Maps Platform (e.g., Maps JavaScript API and Places API). These APIs taught us valuable JavaScript skills like operating the Fetch API effectively. We also had to incorporate the Google Maps Autofill Form API and the Maps JavaScript API, which happened to be a difficult but engaging challenge for us.
## What's next for Food4All - End Food Insecurity
There are a variety of next steps of Food4All. First of all, we want to eliminate the potential misuse of reserving food. One of our key objectives is to prevent privileged individuals from taking away the donations from people in need. We plan to implement a method to verify the socioeconomic status of users. Proper implementation of this verification system would also be effective in limiting the maximum number of reservations an individual can make daily.
We also want to add a method to incentivize businesses to donate their excess food. This can be achieved by partnering with corporations and marketing their business on our webpage. By doing this, organizations who donate will be seen as charitable and good-natured by the public eye.
Lastly, we want to have a third option which would allow volunteers to act as a delivery person. This would permit them to drop off items at the consumer’s household. Volunteers, if applicable, would be able to receive volunteer hours based on delivery time.
|
losing
|
## Inspiration
It may have been the last day before an important exam, the first day at your job, or the start of your ambitious journey of learning a new language, where you were frustrated at the lack of engaging programming tutorials. It was impossible to get their "basics" down, as well as stay focused due to the struggle of navigating through the different tutorials trying to find the perfect one to solve your problems.
Well, that's what led us to create Code Warriors. Code Warriors is a platform focused on encouraging the younger and older audience to learn how to code. Video games and programming are brought together to offer an engaging and fun way to learn how to code. Not only are you having fun, but you're constantly gaining new and meaningful skills!
## What it does
Code warriors provides a gaming website where you can hone your skills in all the coding languages it provides, all while levelling up your character and following the storyline! As you follow Asmodeus the Python into the jungle of Pythania to find the lost amulet, you get to develop your skills in python by solving puzzles that incorporate data types, if statements, for loops, operators, and more. Once you finish each mission/storyline, you unlock new items, characters, XP, and coins which can help buy new storylines/coding languages to learn! In conclusion, Code Warriors offers a fun time that will make you forget you were even coding in the first place!
## How we built it
We built code warriors by splitting our team into two to focus on two specific points of the project.
The first team was the UI/UX team, which was tasked with creating the design of the website in Figma. This was important as we needed a team that could make our thoughts come to life in a short time, and design them nicely to make the website aesthetically pleasing.
The second team was the frontend team, which was tasked with using react to create the final product, the website. They take what the UI/UX team has created, and add the logic and function behind it to serve as a real product. The UI/UX team shortly joined them after their initial task was completed, as their task takes less time to complete.
## Challenges we ran into
The main challenge we faced was learning how to code with React. All of us had either basic/no experience with the language, so applying it to create code warriors was difficult. The main difficulties associated with this were organizing everything correctly, setting up the react-router to link pages, as well as setting up the compiler.
## Accomplishments that we're proud of
The first accomplishment we were proud of was setting up the login page. It takes only registered usernames and passwords, and will not let you login in without them. We are also proud of the gamified look we gave the website, as it gives the impression that the user is playing a game. Lastly, we are proud of having the compiler embedded in the website as it allows for a lot more user interaction and function to the website.
## What we learned
We learnt a lot about react, node, CSS, javascript, and tailwind. A lot of the syntax was new to us, as well as the applications of a lot of formatting options, such as padding, margins, and more. We learnt how to integrate tailwind with react, and how a lot of frontend programming works.
We also learnt how to efficiently split tasks as a team. We were lucky enough to see that our initial split up of the group into two teams worked, which is why we know that we can continue to use this strategy for future competitions, projects, and more.
## What's next for Code Warriors
What's next for code warriors is to add more lessons, integrate a full story behind the game, add more animations to give more of a game feel to it, as well as expand into different coding languages! The potential for code warriors is unlimited, and we can improve almost every aspect and expand the platform to proving a multitude of learning opportunities all while having an enjoyable experience.
## Important Info for the Figma Link
**When opening the link, go into the simulation and press z to fit screen and then go full screen to experience true user interaction**
|
[Play The Game](https://gotm.io/askstudio/pandemic-hero)
## Inspiration
Our inspiration comes from the concern of **misinformation** surrounding **COVID-19 Vaccines** in these challenging times. As students, not only do we love to learn, but we also yearn to share the gifts of our knowledge and creativity with the world. We recognize that a fun and interactive way to learn crucial information related to STEM and current events is rare. Therefore we aim to give anyone this opportunity using the product we have developed.
## What it does
In the past 24 hours, we have developed a pixel art RPG game. In this game, the user becomes a scientist who has experienced the tragedies of COVID-19 and is determined to find a solution. Become the **Hero of the Pandemic** through overcoming the challenging puzzles that give you a general understanding of the Pfizer-BioNTech vaccine's development process, myths, and side effects.
Immerse yourself in the original artwork and touching story-line. At the end, complete a short feedback survey and get an immediate analysis of your responses through our **Machine Learning Model** and receive additional learning resources tailored to your experience to further your knowledge and curiosity about COVID-19.
Team A.S.K. hopes that through this game, you become further educated by the knowledge you attain and inspired by your potential for growth when challenged.
## How I built it
We built this game primarily using the Godot Game Engine, a cross-platform open-source game engine that provides the design tools and interfaces to create games. This engine uses mostly GDScript, a python-like dynamically typed language designed explicitly for design in the Godot Engine. We chose Godot to ease cross-platform support using the OpenGL API and GDScript, a relatively more programmer-friendly language.
We started off using **Figma** to plan out and identify a theme based on type and colour. Afterwards, we separated components into groupings that maintain similar characteristics such as label outlining and movable objects with no outlines. Finally, as we discussed new designs, we added them to our pre-made categories to create a consistent user-experience-driven UI.
Our Machine Learning model is a content-based recommendation system built with Scikit-learn, which works with data that users provide implicitly through a brief feedback survey at the end of the game. Additionally, we made a server using the Flask framework to serve our model.
## Challenges I ran into
Our first significant challenge was navigating through the plethora of game features possible with GDScript and continually referring to the documentation. Although Godot is heavily documented, as an open-source engine, there exist frequent bugs with rendering, layering, event handling, and more that we creatively overcame
A prevalent design challenge was learning and creating pixel art with the time constraint in mind. To accomplish this, we methodically used as many shortcuts and tools as possible to copy/paste or select repetitive sections.
Additionally, incorporating Machine Learning in our project was a challenge in itself. Also, sending requests, display JSON, and making the recommendations selectable were considerable challenges using Godot and GDScript.
Finally, the biggest challenge of game development for our team was **UX-driven** considerations to find a balance between a fun, challenging puzzle game and an educational experience that leaves some form of an impact on the player. Brainstorming and continuously modifying the story-line while implementing the animations using Godot required a lot of adaptability and creativity.
## Accomplishments that I'm proud of
We are incredibly proud of our ability to bring our past experiences gaming into the development process and incorporating modifications of our favourite gaming memories. The development process was exhilarating and brought the team down the path of nostalgia which dramatically increased our motivation.
We are also impressed by our teamwork and team chemistry, which allowed us to divide tasks efficiently and incorporate all the original artwork designs into the game with only a few hiccups.
We accomplished so much more within the time constraint than we thought, such as training our machine learning model (although with limited data), getting a server running up and quickly, and designing an entirely original pixel art concept for the game.
## What I learned
As a team, we learned the benefit of incorporating software development processes such as **Agile Software Development Cycle.** We solely focused on specific software development stages chronologically while returning and adapting to changes as they come along. The Agile Process allowed us to maximize our efficiency and organization while minimizing forgotten tasks or leftover bugs.
Also, we learned to use entirely new software, languages, and skills such as Godot, GDScript, pixel art, and design and evaluation measurements for a serious game.
Finally, by implementing a Machine Learning model to analyze and provide tailored suggestions to users, we learned the importance of a great dataset. Following **Scikit-learn** model selection graph or using any cross-validation techniques are ineffective without the data set as a foundation. The structure of data is equally important to manipulate the datasets based on task requirements to increase the model's score.
## What's next for Pandemic Hero
We hope to continue developing **Pandemic Hero** to become an educational game that supports various age ranges and is worthy of distribution among school districts. Our goal is to teach as many people about the already-coming COVID-19 vaccine and inspire students everywhere to interpret STEM in a fun and intuitive manner.
We aim to find support from **mentors** along the way, who can help us understand better game development and education practices that will propel the game into a deployment-ready product.
### Use the gotm.io link below to play the game on your browser or follow the instructions on Github to run the game using Godot
|
## Inspiration
Are you tired of the traditional and mundane way of practicing competitive programming? Do you want to make learning DSA (Data Structures and Algorithms) more engaging and exciting? Look no further! Introducing CodeClash, the innovative platform that combines the thrill of racing with the challenge of solving LeetCode-style coding problems.
## What it does
With CodeClash, you and your friends can compete head-to-head in real-time coding battles. Challenge each other to solve coding problems as quickly and efficiently as possible. The platform provides a wide range of problem sets, from beginner to advanced, ensuring that there's something for everyone.
## How we built it
For our Backend we made it in Python with the Flask framework, we used MongoDB as our database and used Auth0 for authentication.
Our Front end is next.js.
## Challenges we ran into
Our whole Frontend UI was written in plain javascript where all the other project was in next.js and typescript also due to some other errors we could not use the UI so we had to rewrite everything again. So due to that and a team member leaving us we were able to under major difficultes get it back to tip-top shape.
## Accomplishments that we're proud of
the Implementation of MongoDB to store everything was something we were proud of. We were able to store all user data and all the question data in the database.
## What we learned
Even when you think you are cooked, and your whole hackathon career is in disarray you still can control your emotions and expectations lock in secure the victory.
## What's next for CodeClash
First task would be deployment on a VPS, then furthermore, adding a difficulty level so that the user can change the difficult for the questions you want to answer. Giving the User control of time Limit and more.
|
winning
|
## Inspiration
Career fairs are hectic when so many students try to talk to recruiters at once. Recruiters don’t have time to scan everyone’s paper resume at the fair, and it is even harder to remember their faces after they drop off their paper resume. We decided to make an app that associates a student’s face to his/her resume using facial recognition software. Recruiters can look at a student’s resume quickly at a career fair and remember the student’s face.
## What it does
HYRE is a web application created to aid both students and recruiters in the job hiring process. Students use the app to upload their resumes and pictures. Recruiters use the app by taking a picture of a student at career fair and immediately obtaining his/her resume through facial recognition software. Recruiters can save students they like in the app if recruiters are considering students for hire. HYRE can not only be used at career fairs, but also at networking events.
## How we built it
HYRE was built using Django, Python, HTML, Javascript, and a SQLite database for the web application. The facial recognition software API was obtained from Kairos, an open source human analytics platform.
## Challenges we ran into
Staying awake. Especially after promising ourselves no caffeine. Also, implementing facial recognition reliably and integrating it into our app.
## Accomplishments that we're proud of
Making a complete product that we can demo at career fair.
## What we learned
How to use Django and how to create web applications (none of us had prior experience).
## What's next for HYRE
We can significantly improve our facial recognition algorithm by using a more well-known API (which would take longer to implement). In addition, the app could be much more interactive for students, where students could view companies and save recruiters that they met, so that the students don’t forget recruiters’ names and faces. This would also be a cool project for Microsoft HoloLens, since recruiters could pull up resumes as holograms.
|
## Inspiration
Time is the most valuable thing in the world. With so many job posting sites, it is quite easy to lose the track of time while applying. Such a long term repetitive work also causes exhaustion. To allow a student avail all the opportunities available to them, we have developed an app that will do all of the hard work.
## What it does
The app requires minimal user interaction. A user only need to enter their details, resume, and set their preferences. When they click that **SUBMIT** button, it takes all that data and applies to the jobs that align with the user's liking.
## How we built it
Our team used Python for backend and utilized Angular for frontend.
## Challenges we ran into
There are so many job boards available. It was quite difficult to pull data from such chaos. However, the main challenge was figuring out the application procedure. Although the job applications require similar information, the way these take input varies a lot. Our software engineering skills, our expertise in algorithms and data structures, and our problem solving capabilities helped us tackle this challenge.
## Accomplishments that we're proud of
As students, we know how troubling and frustrating searching and applying for jobs can be. With the help the help of this app, anyone can do job applications in a breeze. We are glad that we have developed such a platform.
## What we learned
We learned how to categorize complex data for simplifying tasks in chaotic environments.
## What's next for Job seeking and automatic applying application
We would love to see this on mobile platforms. Nowadays, people spend most of their time on their phones. Being on mobile platforms would allow us to serve a broader user base.
|
## Inspiration
Students spend hours getting their resumes ready and then application portals ask them to rewrite it all on their terribly designed webform. Worst of all, autofill does not work! Making it a very tedious manual effort. So we designed a site that goes around this, and let's our users automatically apply to as many relevant job postings as possible. We initially planned our app to programmatically generate a Resume and Cover Letter based on the job description and the user's skill set.
## What it does
Instead of going to every single website to apply, you list all the jobs you want by entering their addresses or by selecting the jobs we think match you. Then, you simply enter your information **once** and our website will handle all those applications and get back to you with their statuses!
## How I built it
Our web app was built using React and on a Redux app hosted on Firebase. We used Firebase functions, database, storage and authentication. We used UI-Path (the automation application) to automatically fill out the forms based on the users preferences. We used a Windows server to run our UiPath application on the Google Cloud Platform, we also set up a flask server on the VM to be ready to take inputs.
## Challenges I ran into
The UI-Path application does not have the functionality to run tasks based on external inputs, and to dynamically generate applications, we had to do some complicated powershell scripting and save all our our input as files that the ui-path would open.
## Accomplishments that I'm proud of
Anyone can access the site and apply now! The whole site is connected to firebase and all users have their own storage and accounts immediately when logging into the platform.
## What I learned
It was our first times using redux and firebase and we covered almost all firebase functionality and implemented all of our website functions in redux so we ended up learning quite a bit. Shoutout to FreeCodeCamp!
## What's next for While(1);
Get our summer internships through this. If we use our own application enough times, then there's no limit to how many rejections you can get!
|
losing
|
## Inspiration
raj
## What it does
it takes an input image of handwritten numbers and uses an SVM to detect the numbers
## How I built it
used opencv and scikit-learn python libraries
## Challenges I ran into
computer vision
## Accomplishments that I'm proud of
detecting handwriting from own images
## What I learned
Machine Learning and computer vision
## What's next for Row Reducer
android app
|
## Inspiration
Through some initial tests, we saw that the Google Vision API was decent at optical character recognition (OCR), and we decided we would leverage that to make data entry as simple as taking a picture.
## What it does
Detects tabular structure in images of handwritten/typed text, and converts it either to CSV or a Google Sheets spreadsheet.
## How we built it
We built it using React-Express-Node stack, hosted on the Google Cloud App Engine. The app uses a Google Cloud Firestore to save scanned spreadsheets, the Google AI Vision API for OCR and Google OAuth for Google logins.
## Challenges we ran into
The unpredictable order in which the Vision API recognizes text in an image made it a challenge to write a flexible algorithm capable of conserving the positional order of the (assumed) structured data. Also turns out that React does not play nice when trying to convert and uploaded image into a base64-encoded Buffer consumable by the Google Vision API.
## Accomplishments that we're proud of
Gettting the algorithm to work properly.
## What we learned
That ML + JavaScript is a perfectly good combination, and the Google Cloud stack is pretty good for developing scalable apps at lightning speed.
## What's next for SVS
Leveraging the Google Document Understanding API to expand the use case of the app, such as creating entire documents with freeform data straight from pictures.
|
## What Inspired us
Due to COVID, many students like us have become accustomed to work on their schoolwork, projects and even hackathons remotely. This led students to use online resources at their disposal in order to facilitate their workload at home. One of the tools most used is “ctrl+f” which enables the user to quickly locate any text within a document. Thus, we came to a realisation that no such accurate method exists for images. This led to the birth of our project for this hackathon titled “PictoDocReader”.
## What you learned
We learned how to implement Dash in order to create a seamless user-interface for Python. We further learnt several 2D and 3D pattern matching algorithms such as, Knuth-Morris-Pratt, Bird Baker, Karp and Rabin and Aho-Corasick. However, only implemented the ones that led to the fastest and most accurate execution of the code.
Furthermore, we learnt how to convert PDFs to images (.png). This led to us learning about the colour profiles of images and how to manipulate the RGB values of any image using the numpy library along with matplotlib. We also learnt how to implement Threading in Python in order to run tasks simultaneously. We also learnt how to use Google Cloud services in order to use Google Cloud Storage to enable users to store their images and documents on the cloud.
## How you built your project
The only dependencies we required to create the project were PIL, matplotlib, numpy, dash and Google Cloud.
**PIL** - Used for converting a PDF file to a list of .png files and manipulating the colour profiles of an image.
**matplotlib** - To plot and convert an image to its corresponding matrix of RGB values.
**numpy** - Used for data manipulation on RGB matrices.
**dash** - Used to create an easy to use and seamless user-interface
**Google Cloud** - Used to enable users to store their images and documents on the cloud.
All the algorithms and techniques to parse and validate pixels were all programmed by the team members. Allowing us to cover any scenario due to complete independence from any libraries.
## Challenges we faced
The first challenge we faced was the inconsistency between the different RGB matrices for different documents. While some matrices contained RGB values, others were of the form RGBA. Therefore, this led to inconsistent results when we were traversing the matrices. The problem was solved using the slicing function from the numpy library in order to make every matrix uniform in size.
Trying to research best time complexity for 2d and 3d pattern matching algorithms. Most algorithms were designed for square images and square shaped documents. While we were working with any sized images and documents. Thus, we had to experiment and alter the algorithms to ensure they worked best for our application.
When we worked with large PDF files, the program tried to locate the image in each page one by one. Thus, we needed to shorten the time for PDFs to be fully scanned to make sure our application performs its tasks in a viable time period. Hence, we introduced threading into the project to reduce the scanning time when working with large PDF files as each page was scanned simultaneously. Although we have come to the realisation that threading is not ideal as the multi-processing greatly depends on the number of CPU cores of the user’s system. In an ideal world we would implement parallel processing instead of threading.
|
losing
|
## Inspiration
Being a student of the University of Waterloo, every other semester I have to attend interviews for Co-op positions. Although it gets easier to talk to people, the more often you do it, I still feel slightly nervous during such face-to-face interactions. During this nervousness, the fluency of my conversion isn't always the best. I tend to use unnecessary filler words ("um, umm" etc.) and repeat the same adjectives over and over again. In order to improve my speech through practice against a program, I decided to create this application.
## What it does
InterPrep uses the IBM Watson "Speech-To-Text" API to convert spoken word into text. After doing this, it analyzes the words that are used by the user and highlights certain words that can be avoided, and maybe even improved to create a stronger presentation of ideas. By practicing speaking with InterPrep, one can keep track of their mistakes and improve themselves in time for "speaking events" such as interviews, speeches and/or presentations.
## How I built it
In order to build InterPrep, I used the Stdlib platform to host the site and create the backend service. The IBM Watson API was used to convert spoken word into text. The mediaRecorder API was used to receive and parse spoken text into an audio file which later gets transcribed by the Watson API.
The languages and tools used to build InterPrep are HTML5, CSS3, JavaScript and Node.JS.
## Challenges I ran into
"Speech-To-Text" API's, like the one offered by IBM tend to remove words of profanity, and words that don't exist in the English language. Therefore the word "um" wasn't sensed by the API at first. However, for my application, I needed to sense frequently used filler words such as "um", so that the user can be notified and can improve their overall speech delivery. Therefore, in order to implement this word, I had to create a custom language library within the Watson API platform and then connect it via Node.js on top of the Stdlib platform. This proved to be a very challenging task as I faced many errors and had to seek help from mentors before I could figure it out. However, once fixed, the project went by smoothly.
## Accomplishments that I'm proud of
I am very proud of the entire application itself. Before coming to Qhacks, I only knew how to do Front-End Web Development. I didn't have any knowledge of back-end development or with using API's. Therefore, by creating an application that contains all of the things stated above, I am really proud of the project as a whole. In terms of smaller individual accomplishments, I am very proud of creating my own custom language library and also for using multiple API's in one application successfully.
## What I learned
I learned a lot of things during this hackathon. I learned back-end programming, how to use API's and also how to develop a coherent web application from scratch.
## What's next for InterPrep
I would like to add more features for InterPrep as well as improve the UI/UX in the coming weeks after returning back home. There is a lot that can be done with additional technologies such as Machine Learning and Artificial Intelligence that I wish to further incorporate into my project!
|
## 💡 Inspiration
Generation Z is all about renting - buying land is simply out of our budgets. But the tides are changing: with Pocket Plots, an entirely new generation can unlock the power of land ownership without a budget.
Traditional land ownership goes like this: you find a property, spend weeks negotiating a price, and secure a loan. Then, you have to pay out agents, contractors, utilities, and more. Next, you have to go through legal documents, processing, and more. All while you are shelling out tens to hundreds of thousands of dollars.
Yuck.
Pocket Plots handles all of that for you.
We, as a future LLC, buy up large parcels of land, stacking over 10 acres per purchase. Under the company name, we automatically generate internal contracts that outline a customer's rights to a certain portion of the land, defined by 4 coordinate points on a map.
Each parcel is now divided into individual plots ranging from 1,000 to 10,000 sq ft, and only one person can own a contract to each plot to the plot.
This is what makes us fundamentally novel: we simulate land ownership without needing to physically create deeds for every person. This skips all the costs and legal details of creating deeds and gives everyone the opportunity to land ownership.
These contracts are 99 years and infinitely renewable, so when it's time to sell, you'll have buyers flocking to buy from you first.
You can try out our app here: <https://warm-cendol-1db56b.netlify.app/>
(AI features are available locally. Please check our Github repo for more.)
## ⚙️What it does
### Buy land like it's ebay:

We aren't just a business: we're a platform. Our technology allows for fast transactions, instant legal document generation, and resale of properties like it's the world's first ebay land marketplace.
We've not just a business.
We've got what it takes to launch your next biggest investment.
### Pocket as a new financial asset class...
In fintech, the last boom has been in blockchain. But after FTX and the bitcoin crash, cryptocurrency has been shaken up: blockchain is no longer the future of finance.
Instead, the market is shifting into tangible assets, and at the forefront of this is land. However, land investments have been gatekept by the wealthy, leaving little opportunity for an entire generation
That's where pocket comes in. By following our novel perpetual-lease model, we sell contracts to tangible buildable plots of land on our properties for pennies on the dollar.
We buy the land, and you buy the contract.
It's that simple.
We take care of everything legal: the deeds, easements, taxes, logistics, and costs. No more expensive real estate agents, commissions, and hefty fees.
With the power of Pocket, we give you land for just $99, no strings attached.
With our resell marketplace, you can sell your land the exact same way we sell ours: on our very own website.
We handle all logistics, from the legal forms to the system data - and give you 100% of the sell value, with no seller fees at all.
We even will run ads for you, giving your investment free attention.
So how much return does a Pocket Plot bring?
Well, once a parcel sells out its plots, it's gone - whoever wants to buy land from that parcel has to buy from you.
We've seen plots sell for 3x the original investment value in under one week. Now how insane is that? The tides are shifting, and Pocket is leading the way.
### ...powered by artificial intelligence
**Caption generation**
*Pocket Plots* scrapes data from sites like Landwatch to find plots of land available for purchase. Most land postings lack insightful descriptions of their plots, making it hard for users to find the exact type of land they want. With *Pocket Plots*, we transformed links into images, into helpful captions.

**Captions → Personalized recommendations**
These captions also inform the user's recommended plots and what parcels they might buy. Along with inputting preferences like desired price range or size of land, the user can submit a text description of what kind of land they want. For example, do they want a flat terrain or a lot of mountains? Do they want to be near a body of water? This description is compared with the generated captions to help pick the user's best match!

### **Chatbot**
Minute Land can be confusing. All the legal confusion, the way we work, and how we make land so affordable makes our operations a mystery to many. That is why we developed a supplemental AI chatbot that has learned our system and can answer questions about how we operate.
*Pocket Plots* offers a built-in chatbot service to automate question-answering for clients with questions about how the application works. Powered by openAI, our chat bot reads our community forums and uses previous questions to best help you.

## 🛠️ How we built it
Our AI focused products (chatbot, caption generation, and recommendation system) run on Python, OpenAI products, and Huggingface transformers. We also used a conglomerate of other related libraries as needed.
Our front-end was primarily built with Tailwind, MaterialUI, and React. For AI focused tasks, we also used Streamlit to speed up deployment.
### We run on Convex
We spent a long time mastering Convex, and it was worth it. With Convex's powerful backend services, we did not need to spend infinite amounts of time developing it out, and instead, we could focus on making the most aesthetically pleasing UI possible.
### Checkbook makes payments easy and fast
We are an e-commerce site for land and rely heavily on payments. While stripe and other platforms offer that capability, nothing compares to what Checkbook has allowed us to do: send invoices with just an email. Utilizing Checkbook's powerful API, we were able to integrate Checkbook into our system for safe and fast transactions, and down the line, we will use it to pay out our sellers without needing them to jump through stripe's 10 different hoops.
## 🤔 Challenges we ran into
Our biggest challenge was synthesizing all of our individual features together into one cohesive project, with compatible front and back-end. Building a project that relied on so many different technologies was also pretty difficult, especially with regards to AI-based features. For example, we built a downstream task, where we had to both generate captions from images, and use those outputs to create a recommendation algorithm.
## 😎 Accomplishments that we're proud of
We are proud of building several completely functional features for *Pocket Plots*. We're especially excited about our applications of AI, and how they make users' *Pocket Plots* experience more customizable and unique.
## 🧠 What we learned
We learned a lot about combining different technologies and fusing our diverse skillsets with each other. We also learned a lot about using some of the hackathon's sponsor products, like Convex and OpenAI.
## 🔎 What's next for Pocket Plots
We hope to expand *Pocket Plots* to have a real user base. We think our idea has real potential commercially. Supplemental AI features also provide a strong technological advantage.
|
## Inspiration
I really related to the problem the career councilors described. Reflecting on things can be hard. Especially when you're reflecting on yourself. Our goal is to make this process fun and easy, with a little help from our friends.
## What it does
Meerar compares HOW OFTEN you demonstrate a skill, and how much you ENJOY demonstrating it. To elaborate:
* When ever you engage in an event, Meerar will prompt you take a little note, describing your experience and how you felt.
* We then use the Lexalytics API to decide how much you enjoyed the event.
* Your reflection is posted anonymously on ExperienceMine, along with other people's reflections.
* Here's the twist: other students read your reflection and assign a "skill" that they feel you demonstrated.
* The more you review and post reflections, the more points you earn. You can earn achievements and compete with your friends like this!
* At this point, we have 2 pieces of info: how you felt about the event, and what skill you demonstrated at the event. Once you have enough data, we plot a graph that compares HOW OFTEN you demonstrate a skill, and how much you ENJOY demonstrating it, and provide an analysis on you strengths and weaknesses, and recommends events to attend to play to your strengths.
## How I built it
I built Meerar with a PHP backend, which is used to store and process user information. The front end was built on the trusty Twitter Bootstrap framework, with bunch of JavaScript libraries sprinkled in (i.e. materialize.js, chart.js). I used the Lexalytics API in order to gauge the sentiment in user's descriptions. I also wrote a little scraper to scrape from LinkedIn profiles of users which I execute with a bash script (what can I say, I'm learning). It's a bit patchwork-ish, but it works!
## Challenges I ran into
I came to McGill not knowing anyone, and being a beginner, it was challenging to find a team that would take me in. I managed to find another team of beginners but unfortunately, my team decided to leave the hackathon just after dinner was served on Saturday. As a result I had to do the project all myself: a pretty daunting task! This is my first major hackathon so I was a little bummed out. Still, I followed through because I thought I had an interesting idea. Hopefully the judges agree!
## Accomplishments that I'm proud of
I almost ran into a dead end with the LinkedIn API. Essentially, I wanted to get job information about a user from their profile. However, you needed to register your app with Linkedin and must have an official website (which I did not have) in order to qualify to recieve the access key to use their API. Since I didn't have this, I found a workaround: scrape the page manually with Python, and then exec() a bash script to scrape! Though it may not seem like much, I proud of finding the "way" with my "will".
## What I learned
Tech wise, I learned how to use chart.js. It's a really cool way to visualize data with beautiful graphs in the browser. Will definitely be using it again in the future. But what I really learned is that I have a lot left to learn. Everyone at McGill really knows there stuff. Next year, that'll be me.
## What's next for Meerar
Hopefully, if the judges like it, we can work on making it a full fledged app available online for student at McGill.
|
winning
|
## Inspiration
Traffic is a pain and hurdle for everyone. It costs time and money for everyone stuck within it. We wanted to empower everyone to focus on what they truly enjoy instead of having to waste their time in traffic. We found the challenge to connect autonomous vehicles and enable them to work closely with each other to make maximize traffic flow to be very interesting. We were specifically interested in aggregating real data to make decisions and evolve those over time using artificial intelligence.
## What it does
We engineered an autonomous network that minimizes the time delay for each car in the network as it moves from its source to its destination. The idea is to have 0 intersections, 0 accidents, and maximize traffic flow.
We did this by developing a simulation in P5.js and training a network of cars to interact with each other in such a way that they do not collide and still travel from their source to target destination safely. We slowly iterated on this idea by first creating the idea of incentivizing factors and negative points. This allowed the cars to learn to not collide with each other and follow the goal they're set out to do. After creating a full simulation with intersections (allowing cars to turn and drive so they stop the least number of times), we created a simulation on Unity. This simulation looked much nicer and took the values trained by our best result from our genetic AI. From the video, we can see that the generation is flawless; there are no accidents, and traffic flows seamlessly. This was the result of over hundreds of generations of training of the genetic AI. You can see our video for more information!
## How I built it
We trained an evolutionary AI on many physical parameters to optimize for no accidents and maximal speed. The allowed the AI to experiment with different weights for each factor in order to reach our goal; having the cars reach from source to destination while staying a safe distance away from all other cars.
## Challenges we ran into
Deciding which parameters to tune, removing any bias, and setting up the testing environment. To remove bias, we ended up introducing randomly generated parameters in our genetic AI and "breeding" two good outcomes. Setting up the simulation was also tricky as it involved a lot of vector math.
## Accomplishments that I'm proud of
Getting the network to communicate autonomously and work in unison to avoid accidents and maximize speed. It's really cool to see the genetic AI evolve from not being able to drive at all, to fully being autonomous in our simulation. If we wanted to apply this to the real world, we can add more parameters and have the genetic AI optimize to find the parameters needed to reach our goals in the fastest time.
## What I learned
We learned how to model and train a genetic AI. We also learned how to deal with common issues and deal with performance constraints effectively. Lastly, we learned how to decouple the components of our application to make it scalable and easier to update in the future.
## What's next for Traffix
We want to increasing the user-facing features for the mobile app and improving the data analytics platform for the city. We also want to be able to extend this to more generalized parameters so that it could be applied in more dimensions.
|
## Inspiration
We wanted to solve a unique problem we felt was impacting many people but was not receiving enough attention. With emerging and developing technology, we implemented neural network models to recognize objects and images, and converting them to an auditory output.
## What it does
XTS takes an **X** and turns it **T**o **S**peech.
## How we built it
We used PyTorch, Torchvision, and OpenCV using Python. This allowed us to utilize pre-trained convolutional neural network models and region-based convolutional neural network models without investing too much time into training an accurate model, as we had limited time to build this program.
## Challenges we ran into
While attempting to run the Python code, the video rendering and text-to-speech were out of sync and the frame-by-frame object recognition was limited in speed by our system's graphics processing and machine-learning model implementing capabilities. We also faced an issue while trying to use our computer's GPU for faster video rendering, which led to long periods of frustration trying to solve this issue due to backwards incompatibilities between module versions.
## Accomplishments that we're proud of
We are so proud that we were able to implement neural networks as well as implement object detection using Python. We were also happy to be able to test our program with various images and video recordings, and get an accurate output. Lastly we were able to create a sleek user-interface that would be able to integrate our program.
## What we learned
We learned how neural networks function and how to augment the machine learning model including dataset creation. We also learned object detection using Python.
|
## Inspiration
Due to COVID-19, the closure of all 56 DriveTest locations has caused nearly half a million cancelled driving tests, half of those being road tests. Not only that, but all Driving ED classes have been cancelled or scaled back, leaving thousands of people without the ability to learn and get road experience.
## What it does
A web application that monitors user facial movement and input to ensure they abide by general traffic rules.
## How we built it
A variety of technologies were used to develop this project. React and Bootstrap was used to create the frontend functionalities. Unity and Blender were used in the creation of the in house developed driving engine. FireBase was used to store driving test scores as well as user information and finally, Tensorflow was used in the analysis of head and eye movement.
## Functionality
DriverED 2.0 has a variety of built-in functionality, allowing for the simple detection and reporting of driver errors. This functionality includes features like yielding and stopping, where the game will report the car movement and the alertness of the driver (e.g., checking for pedestrians), using the facial detection system. Blindspot is also a key highlight of the system, so at specific points in the routes where the driver would need to check their blind spot, the facial detection system will analyze if they're checking.
Controlled intersections, using traffic lights, appear throughout the route. Ensuring they were stopping and remaining alert based on the traffic light state (checking for oncoming traffic with yellow) were crucial in this portion.
Finally, speed limit zones were also enforced and changed throughout the route, and ensuring they were turning on the car and letting out the handbrake were two simple additions.
## Challenges
Tracking Head Movement and Determining Motion:
Recognizing how the head was moving was also pretty hard, in which we had to see whether they were just moving their head slightly or making a major blindspot check. This was fixed with the use of TensorFlow and the idea of selecting dots to track in which direction they're facing.
Player Movement:
Tracking the movement and rotation of the car through modular routes in the Unity environment became a more daunting task than expected. The idea of creating routes easily was a difficult experience when it came to speed management and rotation of the car to follow the path. More can still be done in that area, but within itself, it was a major hurdle to overcome.
Linking React with Unity:
This was also extremely difficult in which it was two differing environments (WebGL in Unity and React.js) that needed to seamlessly work in tandem. In the end, a library was found that helped with this. More work needed to be done to deal with individual errors in terms of DLL linking etc.
## What's next for Driver Ed 2.0
Although this is the initial phase we hope to implement the following functionality of parking, VR, different routes, and different difficulty levels.
|
partial
|
## Inspiration
## What it does
PhyloForest helps researchers and educators by improving how we see phylogenetic trees. Strong, useful data visualization is key to new discoveries and patterns. Thanks to our product, users have a greater ability to perceive depth of trees by communicating widths rather than lengths. The length between proteins is based on actual lengths scaled to size.
## How we built it
We used EggNOG to get phylogenetic trees in Newick format, then parsed them using a recursive algorithm to get the differences between the protein group in question. We connected names to IDs using the EBI (European Bioinformatics Institute) database, then took the lengths between the proteins and scaled them to size for our Unity environment. After we put together all this information, we went through an extensive integration process with Unity. We used EBI APIs for Taxon information, EggNOG gave us NCBI (National Center for Biotechnology Information) identities and structure. We could not use local NCBI lookup (as eggNOG does) due to the limitations of Virtual Reality headsets, so we used the EBI taxon lookup API instead to make the tree interactive and accurately reflect the taxon information of each species in question. Lastly, we added UI components to make the app easy to use for both educators and researchers.
## Challenges we ran into
Parsing the EggNOG Newick tree was our first challenge because there was limited documentation and data sets were very large. Therefore, it was difficult to debug results, especially with the Unity interface. We also had difficulty finding a database that could connect NCBI IDs to taxon information with our VR headset. We also had to implement a binary tree structure from scratch in C#. Lastly, we had difficulty scaling the orthologs horizontally in VR, in a way that would preserve the true relationships between the species.
## Accomplishments that we're proud of
The user experience is very clean and immersive, allowing anyone to visualize these orthologous groups. Furthermore, we think this occupies a unique space that intersects the fields of VR and genetics. Our features, such as depth and linearized length, would not be as cleanly implemented in a 2-dimensional model.
## What we learned
We learned how to parse Newick trees, how to display a binary tree with branches dependent on certain lengths, and how to create a model that relates large amounts of data on base pair differences in DNA sequences to something that highlights these differences in an innovative way.
## What's next for PhyloForest
Making the UI more intuitive so that anyone would feel comfortable using it. We would also like to display more information when you click on each ortholog in a group. We want to expand the amount of proteins people can select, and we would like to manipulate proteins by dragging branches to better identify patterns between orthologs.
|
## Inspiration
The inspiration behind LeafHack stems from a shared passion for sustainability and a desire to empower individuals to take control of their food sources. Witnessing the rising grocery costs and the environmental impact of conventional agriculture, we were motivated to create a solution that not only addresses these issues but also lowers the barriers to home gardening, making it accessible to everyone.
## What it does
Our team introduces "LeafHack" an application that leverages computer vision to detect the health of vegetables and plants. The application provides real-time feedback on plant health, allowing homeowners to intervene promptly and nurture a thriving garden. Additionally, the images uploaded can be stored within a database custom to the user. Beyond disease detection, LeafHack is designed to be a user-friendly companion, offering personalized tips and fostering a community of like-minded individuals passionate about sustainable living
## How we built it
LeafHack was built using a combination of cutting-edge technologies. The core of our solution lies in the custom computer vision algorithm, ResNet9, that analyzes images of plants to identify diseases accurately. We utilized machine learning to train the model on an extensive dataset of plant diseases, ensuring robust and reliable detection. The database and backend were built using Django and Sqlite. The user interface was developed with a focus on simplicity and accessibility, utilizing next.js, making it easy for users with varying levels of gardening expertise
## Challenges we ran into
We encountered several challenges that tested our skills and determination. Fine-tuning the machine learning model to achieve high accuracy in disease detection posed a significant hurdle as there was a huge time constraint. Additionally, integrating the backend and front end required careful consideration. The image upload was a major hurdle as there were multiple issues with downloading and opening the image to predict with. Overcoming these challenges involved collaboration, creative problem-solving, and continuous iteration to refine our solution.
## Accomplishments that we're proud of
We are proud to have created a solution that not only addresses the immediate concerns of rising grocery costs and environmental impact but also significantly reduces the barriers to home gardening. Achieving a high level of accuracy in disease detection, creating an intuitive user interface, and fostering a sense of community around sustainable living are accomplishments that resonate deeply with our mission.
## What we learned
Throughout the development of LeafHack, we learned the importance of interdisciplinary collaboration. Bringing together our skills, we learned and expanded our knowledge in computer vision, machine learning, and user experience design to create a holistic solution. We also gained insights into the challenges individuals face when starting their gardens, shaping our approach towards inclusivity and education in the gardening process.
## What's next for LeafHack
We plan to expand LeafHack's capabilities by incorporating more plant species and diseases into our database. Collaborating with agricultural experts and organizations, we aim to enhance the application's recommendations for personalized gardening care.
|
## Inspiration
Our inspiration came from the challenge proposed by Varient, a data aggregation platform that connects people with similar mutations together to help doctors and users.
## What it does
Our application works by allowing the user to upload an image file. The image is then sent to Google Cloud’s Document AI to extract the body of text, process it, and then matched it against the datastore of gene names for matches.
## How we built it
While originally we had planned to feed this body of text to a Vertex AI ML for entity extraction, the trained model was not accurate due to a small dataset. Additionally, we attempted to build a BigQuery ML model but struggled to format the data in the target column as required. Due to time constraints, we explored a different path and downloaded a list of gene symbols from HUGO Gene Nomenclature Committee’s website (<https://www.genenames.org/>). Using Node.js, and Multer, the image is processed and the text contents are efficiently matched against the datastore of gene names for matches. The app returns a JSON of the matching strings in order of highest frequency. This web app is then hosted on Google Cloud through App Engine at (<https://uofthacksix-chamomile.ue.r.appspot.com/>).
The UI while very simple is easy to use. The intent of this project was to create something that could easily be integrated into Varient’s architecture. Converting this project into an API to pass the JSON to the client would be very simple.
## How it meets the theme "restoration"
The overall goal of this application, which has been partially implemented, was to create an application that could match mutated gene names from user-uploaded documents and connect them with resources, and others who share the common gene mutation. This would allow them to share strategies or items that have helped them deal with living with the gene mutation. This would allow these individuals to restore some normalcy in their lives again.
## Challenges we ran into
Some of the challenges we faced:
* having a small data set to train the Vertex AI on
* time constraints on learning the new technologies, and the best way to effectively use it
* formatting the data in the target column when attempting to build a BigQuery ML model
## Accomplishments that we're proud of
The accomplishment that we are all proud of is the exposure we gained to all the new technologies we discovered and used this weekend. We had no idea how many AI tools Google offers. The exposure to new technologies and taking the risk to step out of our comfort zone and attempt to learn and use it this weekend in such a short amount of time is something we are all proud of.
## What we learned
This entire project was new to all of us. We have never used google cloud in this manner before, only for Firestore. We were unfamiliar with using Express and working with machine learning was something only one of us had a small amount of experience with. We learned a lot about Google Cloud and how to access the API through Python and Node.js.
## What's next for Chamomile
The hack is not as complete as we would like since ideally there would be a machine learning aspect to confirm the guesses made by the substring matching and more data to improve the Vertex AI model. Improving on this would be a great step for this project. Also, add a more put-together UI to match the theme of this application.
|
winning
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.