
anchor
stringlengths 58
24.4k
| positive
stringlengths 9
13.4k
| negative
stringlengths 166
14k
| anchor_status
stringclasses 3
values |
|---|---|---|---|
## Inspiration
We’ve been divided politically, socially, culturally and economically by technology platforms like Facebook, Twitter and Reddit. It’s hard for us to step out of our biases and understand differing perspectives. And so we built a platform with machine learning (NLP doc2vec models) to solve this.
## What it does
Logos is a web platform for having discussions based on common interests. After filling out their descriptions, users see a feed of conversation posts created by other users and personalized with machine learning.
From there, users can start a conversation they care about (e.g. income inequality, programming, philosophy) with another user.
## How we built it
The frontend is built with React.js and hosted on AWS S3. The real-time chat is built with Firebase Cloud Messaging. The backend is built with Python Django, and our machine learning doc2vec are built in Gensim (NLP) with text processing done in Google Cloud Platform.
## Challenges we ran into
Integrating the doc2vec machine learning model.
Implementing the Firebase Cloud Messaging
## Accomplishments that we’re proud of
We’re happy that our doc2vec machine learning model can rank the conversation posts based on their similarities to the user’s descriptions. We are also happy that we had time to integrate Firebase Cloud Messaging.
## What we learned
We learned how to apply machine learning to text similarity and create real-time chat between users with Firebase Cloud Messaging.
## What's next for LOGOS
Polishing the design more
Checking that the latency is near real-time for webpage loads
Integrating FCM more directly into the app | ## Inspiration
In high school, a teacher of ours used to sit in the middle of the discussion to draw lines from one person to another on paper to identify the trends of the discussion. It's a very meaningful activity as we could see how balanced the discussion is, allowing us to highlight to people who had less chance to express their ideas. It could also be used by teacher in earlier education, to identify social challenges such as anxiety, speech disorder in children.
## What it does
The app initially is trained on a short audio from each of the member of the discussion. Using transfer learning, it will able to recognize the person talking. And, during discussion, very colorful and aesthetic lines will began drawing from person to another on REAL-TIME!
## How we built it
On the front-end, we used react and JavaScript to create a responsive and aesthetic website. Vanilla css (and a little bit of math, a.k.a, Bézier curve) to create beautiful animated lines, connecting different profiles.
On the back-end, python and tensorflow was used to train the AI model. First, the audios are pre-processed into smaller 1-second chunks of audio, before turning them into a spectrogram picture. With this, we performed transfer learning with VGG16, to extract features from the spectrograms. Then, the features are used to fit a SVM model, using scikit-learn. Subsequently, the back-end opens a web-socket with the front-end to receive stream of data, and return label of the person talking. This is also done with multi-threading to ensure all the data is being processed quickly.
## Challenges we ran into
As it's our first time with deep-learning or training an AI for that matter, it was very difficult to get started. Despite the copious amount of resources and projects done, it was hard to identify a suitable source. Different processing techniques were also needed to know, before the model could be trained. In additions, finding a platform (such as Google Colab) was also necessary to train the model in appropriate time. Finally, it was fairly hard to incorporate the project with the rest of the project. It needs to be able to process the data in real-time, while keeping the latency low.
Another major challenge that we ran into was connecting the back-end with the front-end. As we wanted it to be real-time, we had to be able to stream the raw data to the back-end. But, there were problems reconstructing the binary files into appropriate format, because we were unsure what format RecordRTC uses to record audio. There was also a problem of how much data or how frequent the data should be sent over due to our high latency of predicting (~500ms). It's a problem that we couldn't figure out in time
## Accomplishments that we're proud of
The process of training the model was really cool!!! We could never think of training a voice recognition model similar to how you would to to an image/face recognition. It was a very out-of-the-box method, that we stumbled up online. It really motivated us to get out there and see what else. We were also fairly surprised to get a proof-of-concept real-time processing with local audio input from microphone. We had to utilize threading to avoid overflowing the audio input buffer. And if you get to use threading, you know it's a cool project :D.
## What we learned
Looking back, the project was quite ambitious. BUT!! That's how we learned. We learned so much about training machine learning as well as different connection protocols over the internet. Threading was also a "wet" dream of ours, so it was really fun experimenting with the concept in python.
## What's next for Hello world
The app would be much better on mobile. So, there are plans to port the entire project to mobile (maybe learning React Native?). We're also planning on retrain the voice recognition model with different methods, and improve the accuracy as well as confidence level. Lastly, we're planning on deploying the app and sending it back to our high school teacher, who was the inspiration for this project, as well as teachers around the world for their classrooms.
## Sources
These two sources helped us tremendously in building the model:
<https://medium.com/@omkarade9578/speaker-recognition-using-transfer-learning-82e4f248ef09>
<https://towardsdatascience.com/automatic-speaker-recognition-using-transfer-learning-6fab63e34e74> | ## Inspiration
In light of the ongoing global conflict between war-torn countries, many civilians face hardships. Recognizing these challenges, LifeLine Aid was inspired to direct vulnerable groups to essential medical care, health services, shelter, food and water assistance, and other deprivation relief.
## What it does
LifeLine Aid provides multifunctional tools that enable users in developing countries to locate resources and identify dangers nearby. Utilizing the user's location, the app alerts them about the proximity of a situation and centers for help. It also facilitates communication, allowing users to share live videos and chat updates regarding ongoing issues. An upcoming feature will highlight available resources, like nearby medical centers, and notify users if these centers are running low on supplies.
## How we built it
Originally, the web backend was to be built using Django, a trusted framework in the industry. As we progressed, we realized that the amount of effort and feasibility of exploiting Django were not sustainable; as we made no progress within the first day. Quickly turning to the in-depth knowledge of one of our team member’s extensive research into asyncio, we decided to switch to FastAPI, a trusted framework used by Microsoft. Using this framework had both its benefits and costs. Realizing after our first day, Django proved to be a roadblock, thus we ultimately decided to switch to FastAPI.
Our backend proudly uses CockroachDB, an unstoppable force to be reckoned with. CockroachDB allowed our code to scale and continue to serve those who suffer from the effects of war.
## Challenges we ran into
In order to pinpoint hazards and help, we would need to obtain, store, and reverse-engineer Geospatial coordinate points which we would then present to users in a map-centric manner. We initially struggled with converting the Geospatial data from a degree, minutes, seconds format to decimal degrees and storing the converted values as points on the map which were then stored as unique 50 character long SRID values. Luckily, one of our teammates had some experience with processing GeoSpatial data so drafting coordinates on a map wasn’t our biggest hurdle to overcome. Another challenge we faced were certain edge cases in our initial Django backend that resulted in invalid data. Since some outputs would be relevant to our project, we had to make an executive decision to change backend midway through. We decided to go with FastApi. Although FastApi brought its own challenge with processing SQL to usable data, it was our way of overcoming our Jango situation. One last challenge we ran into was our overall source control. A mixture of slow and unbearable WiFi, combined with tedious local git repositories not correctly syncing create some frustrating deadlocks and holdbacks. To combat this downtime, we resort to physically drafting and planning out how each component of our code would work.
## Accomplishments that we're proud of
Three out of the four in our team are attending their first hackathon. The experience of crafting an app and seeing the fruits of our labor is truly rewarding. The opportunity to acquire and apply new tools in our project has been exhilarating. Through this hackathon, our team members were all able to learn different aspects of creating an idea into a scalable application. From designing and learning UI/UX, implementing the React-Native framework, emulating iOS and Android devices to test and program compatibility, and creating communication between the frontend and backend/database.
## What we learned
This challenge aimed to dive into technologies that are used widely in our daily lives. Spearheading the competition with a framework trusted by huge companies such as Meta, Discord and others, we chose to explore the capabilities of React Native. Joining our team are three students who have attended their first hackathon, and the grateful opportunity of being able to explore these technologies have led us to take away a skillset of a lifetime.
With the concept of the application, we researched and discovered that the only best way to represent our data is through the usage of Geospatial Data. CockroachDB’s extensive tooling and support allowed us to investigate the usage of geospatial data extensively; as our backend team traversed the complexity and the sheer awe of the scale of said technology. We are extremely grateful to have this opportunity to network and to use these tools that would be useful in the future.
## What's next for LifeLine Aid
There are a plethora of avenues to further develop the app, which include enhanced verification, rate limiting, and many others. Other options include improved hosting using Azure Kubernetes Services (AKS), and many others. This hackathon project is planned to be maintained further into the future as a project for others who may be new or old in this field to collaborate on. | losing |
## Inspiration
We love food and we want to try more of it! That's what inspired us to create Global Grub.
## What it does
Every day, you get new selections and recommendations for recipes from all around the world. Start out by choosing a country or region from a map or go with our country of the day. Global Grub will find three tasty recipes for you to try. You'll find all the ingredients, measurements and step by step instructions right on our webpage.
## How we built it
We used ReactJS for the front end and normal Javascript for the back-end. We started with a quick prototype in C# and our project ended up being 70% JavaScript, 19% HTML and 11% CSS. We organized data from the spoonacular API to give recommendations organized by country.
## Challenges we ran into
Our biggest challenge was making the interactive elements, because we didn't have much experience in that. It was also challenging to figure out how to connect the front-end to the back-end.
## Accomplishments that we're proud of
We're super proud of how much we learned during this hackathon. Some of us were writing JavaScript for the very first time. None of us are very experienced web developers, so even though we were all out of our element we perservered, learned, helped each other out and eventually made it to the finish line.
## What we learned
We learned a lot about teamwork. Each of us tried to lean in to our strengths when working on our parts of the project and it was super satisfying to see all the different components come together in the end.
## What's next for Global Grub
We all had a lot of fun making Global Grub and we hope that you enjoy it. We plan to spend some time putting the finishing touches on the project to make it the best place on the internet to find delicious grub around the globe! | ## Inspiration
I was cooking at home one day and I kept noticing we had half a carrot, half an onion, and like a quarter of a pound of ground pork lying around all the time. More often than not it was from me cooking a fun dish that my mother have to somehow clean up over the week. So I wanted to create an app that would help me use those ingredients that I have neglected so that even if both my mother and I forget about it we would not contribute to food waste.
## What it does
Our app uses a database to store our user's fridge and keeps track of the food in their fridge. When the user wants a food recipe recommendation our app will help our user finish off their food waste. Using the power of chatGPT our app is super flexable and all the unknown food and food that you are too lazy to measure the weight of can be quickly put into a flexible and delicious recipe.
## How we built it
Using figma for design, react.JS bootstrap for frontend, flask backend, a mongoDB database, and openAI APIs we were able to create this stunning looking demo.
## Challenges we ran into
We messed up our database schema and poor design choices in our APIs resulting in a complete refactor. Our group also ran into problems with react being that we were relearning it. OpenAI API gave us inconsistency problems too. We pushed past these challenges together by dropping our immediate work and thinking of a solution together.
## Accomplishments that we're proud of
We finished our demo and it looks good. Our dev-ops practices were professional and efficient, our kan-ban board saved us a lot of time when planning and implementing tasks. We also wrote plenty of documentations where after our first bout of failure we planned out everything with our group.
## What we learned
We learned the importance of good API design and planning to save headaches when implementing out our API endpoints. We also learned much about the nuance and intricacies when using CORS technology. Another interesting thing we learned is how to write detailed prompts to retrieve formatted data from LLMs.
## What's next for Food ResQ : AI Recommended Recipes To Reduce Food Waste
We are planning to add a receipt scanning feature so that our users would not have to manually add in each ingredients into their fridge. We are also working on a feature where we would prioritize ingredients that are closer to expiry. Another feature we are looking at is notifications to remind our users that their ingredients should be used soon to drive up our engagement more. We are looking for payment processing vendors to allow our users to operate the most advanced LLMs at a slight premium for less than a coffee a month.
## Challenges, themes, prizes we are submitting for
Sponsor Challenges: None
Themes: Artificial Intelligence & Sustainability
Prizes: Best AI Hack, Best Sustainability Hack, Best Use of MongoDB Atlas, Most Creative Use of Github, Top 3 Prize | ## Inspiration
In the “new normal” that COVID-19 has caused us to adapt to, our group found that a common challenge we faced was deciding where it was safe to go to complete trivial daily tasks, such as grocery shopping or eating out on occasion. We were inspired to create a mobile app using a database created completely by its users - a program where anyone could rate how well these “hubs” were following COVID-19 safety protocol.
## What it does
Our app allows for users to search a “hub” using a Google Map API, and write a review by rating prompted questions on a scale of 1 to 5 regarding how well the location enforces public health guidelines. Future visitors can then see these reviews and add their own, contributing to a collective safety rating.
## How I built it
We collaborated using Github and Android Studio, and incorporated both a Google Maps API as well integrated Firebase API.
## Challenges I ran into
Our group unfortunately faced a number of unprecedented challenges, including losing a team member mid-hack due to an emergency situation, working with 3 different timezones, and additional technical difficulties. However, we pushed through and came up with a final product we are all very passionate about and proud of!
## Accomplishments that I'm proud of
We are proud of how well we collaborated through adversity, and having never met each other in person before. We were able to tackle a prevalent social issue and come up with a plausible solution that could help bring our communities together, worldwide, similar to how our diverse team was brought together through this opportunity.
## What I learned
Our team brought a wide range of different skill sets to the table, and we were able to learn lots from each other because of our various experiences. From a technical perspective, we improved on our Java and android development fluency. From a team perspective, we improved on our ability to compromise and adapt to unforeseen situations. For 3 of us, this was our first ever hackathon and we feel very lucky to have found such kind and patient teammates that we could learn a lot from. The amount of knowledge they shared in the past 24 hours is insane.
## What's next for SafeHubs
Our next steps for SafeHubs include personalizing user experience through creating profiles, and integrating it into our community. We want SafeHubs to be a new way of staying connected (virtually) to look out for each other and keep our neighbours safe during the pandemic. | losing |
Our project aims to leverage computer vision technology to make a contribution to neuroscience research. We were motivated to address the challenges in studying neurite growth dynamics in neurons, a fundamental aspect of neuroscience research. These cells play a crucial role in understanding neurodegeneration, neurodevelopmental disorders, neuron function, and differentiation, making them vital for advancing our understanding of diseases like Alzheimer's, Parkinson's, ASD, and more.
## What we built
NeuraLIVE is a bioinformatic tool designed to streamline and enhance the process of analyzing experiment data on cultured neurons. It employs computer vision techniques to analyze brightfield microscopy images of these cells. Specifically, NeuraLIVE quantifies key aspects of neuron development:
1. **Cell Growth:** NeuraLIVE determines whether the cells proliferate, a critical metric in various experiments.
2. **Cell Health:** The program measures how healthy the cells are by comparing the changing cell shapes over time.
3. **Neuron Morphogenesis:** It identifies sharpness in cell shape and thin, ridge-like objects that represent neurite growth and neuron morphogenesis-- essential processes for understanding the cell's ability to function as neurons.
We have developed an efficient and automated pipeline that can rapidly process and analyze large datasets of brightfield microscopy images. NeuraLIVE not only streamlines the analysis process but also allows analysis of experimental data in a high-throughput matter, truly integrating life science research with the booming field of big data analytics.
## How we built it
We engineered NeuraLIVE by breaking it down into three fundamental tasks, each addressing a critical aspect of neuron analysis:
1: Neuron Identification - Utilizing Watershed Algorithm
The initial task is to analyze input images and determine the number of individual cells present. We implemented the Watershed Algorithm to segment and separate adjacent cell regions, which allows us to identify and quantify the cells in the images.
2: Neuron Classification - Identifying Round and Hypertrophic Cells
Task 2 was vital for distinguishing between round, unadhered cells, and spread-out, adhered cells. We employed contour plots and threshold filters to determine the shape of each cell in the images by distinguishing the number of edges in its contour. This classification not only allowed us to categorize cells but also provided valuable insights into their behavior. Round cells are often indicative of unadhered, unhealthy, cells, while spread-out cells signify adhesion and cell health. Finally, we used the numbers of the two types of cells to calculate the percentage of healthy cells in a given image.
3: Quantifying Neuriteness - Utilizing Ridge Detection Algorithm
The final task, Quantifying Neuriteness, addressed a crucial question: how much sharp, neurite-like structures are present in the cells? To accomplish this, we integrated the Ridge Detection Algorithm. This algorithm identifies and counts the number of straight, linear, and sharp objects within the images, which corresponded to neurogenesis. Quantification of neurite outgrowth is central to understanding neurodevelopment and neurodegenerative processes.
4: Front End Website
To upload data sets and analyze the pictures we built a website using Flask as framework and HTML for the UI.
## Challenges we ran into
Developing NeuraLIVE presented several challenges, including:
*Data Parsing:* We started off by taking all the images in the dataset as one culture and only found out later that they are actually from four different cultures. Thus, we had to restart the sorting process of the images to consider dividing the whole dataset into four cultures when plotting. This takes a while to implement and debug since the images are in random order, and parsing to find each image file's culture involves many unfamiliar syntax.
*Ridge Detection:* Quantifying neuriteness was extremely challenging--brightfield images are known for their difficulty in being analyzed, especially the sharper, thinner objects that do not reflect much light. In the beginning, the Ridge Detection Algorithm we implemented frequently identify non-neurite structures as neurites. We investigated the implementation of multiple ridge filters and explored options from various packages, and eventually choose the Meijuring filter with a customized greyscale threshold value to isolate the neurites from the cell bodies.
## Accomplishments that we're proud of
*Caroline:* I'm most proud of cooperating so perfectly with my team in these 48 hours and finishing such an innovative project.
*Georges:\_I am immensely proud of the technical innovation that NeuraLIVE represents. We successfully applied computer vision techniques to tackle a significant problem in neuroscience research. This project isn't just about code; it's about leveraging technology to advance our understanding of critical issues like neurodegeneration, neurodevelopmental disorders, and neuron function. The implication that NeuraLIVE can have on these fields is a testament to our dedication.
\_Millie*: I am super proud of how supportive and collaborative we are to each other. Team work makes the dream work!
*Steve*: As a student in both life science and computer science, it has always been my dream to carry out a project that combines my two fields of passion and make something that can potentially be useful to the research world. I believe NeuraLIVE, although being a product built within 48 hours of time, contains ideas and implementations that can be truly useful to the research field out there. I am so, so proud of my teammates, and thankful for theirs and our efforts in making this thing a reality along the way.
## What we learned
*Caroline*: I was exposed to and learned a lot about the intersection of computer vision and biology through this project.
*Millie*: I learned about neurons and many different useful python libraries for computer vision.
*George*: As a student who knows much more about business than biology, this is something I haven't touched much before, but I absolutely love it! Hoping to maybe even take a biology class in the future.
*Steve*: I learned so many useful image processing and computer vision libraries in Python, and learned about front-end development--something I have not worked with before!
## What's next for NeuraLIVE
We plan to incorporate machine learning in future implementations, aiming to improve accuracy in object identification and segmentation. We also plan on optimizing several pixel-thresholding algorithm to improve the general runtime of our program. | Discord usernames: Hexular#5020, sophaiya#3995, photonmz#4461
Check out our mobile prototype [demo video](https://drive.google.com/file/d/1U78Z40JO3vEEElFg_6SBHcMw-Go1PFJT/view?usp=sharing) and [prototype](https://www.figma.com/proto/XcamQs8aNpZ8veXBw6ukGn/Hack-the-6ix?node-id=264%3A6785&scaling=scale-down&page-id=14%3A116&starting-point-node-id=264%3A6785&show-proto-sidebar=1)!
## Inspiration
As avid listeners and lovers of music, we couldn't help but notice that our playlists have inherent limitations. Playlists force the user to manually specify all the songs they want to listen to, a time-consuming task, and can only be experienced in different orders; the songs themselves stay fixed, meaning it's really easy to get bored of a playlist, a thing that I'm sure we've all experienced at least once.
While apps like Spotify, Apple Music and YouTube Music do allow for automated playlists, e.g. Spotify's Daily Mix, they have several downsides. For example, you as the user have no control over these recommendations; it's very common for the Daily Mix to deliver a song that's a complete miss. Another problem is that you can't impose any constraints on the input songs; I'm sure we all have that one awful song that consistently pops up in the recommended songs list and never goes away.
We wished to create something that would help experienced music listeners organize their preferred songs in an intuitive way, automating away all of the manual work while simultaneously giving the user the power to manually control things if they want even finer-grained recommendations. Thus, we created Playflow.
## What it does
Playflow's killer feature is "playflows": they're the next step up from playlists. Just like how playlists transcended albums by adding more freedom and removing manual work, so too do playflows transcend playlists by adding more freedom and removing manual work.
You can think of a "playflow" like a template of a playlist: it provides ways to generate sequences of songs.
For example, instead of having to manually choose the song "Vexento - Pixel Party" and the song "Tobu - Cloud Nine" and the song "MDK - Press Start" and a million others, you could specify "Give me 30 minutes of Energetic EDM songs", and Playflow will give you all of the options you might have selected and more. Or you could specify "Give me 30 minutes of songs from Vexento". Or you could specify "Give me 10 seconds of phone ringtones", just for kicks. And you can sequence these all in order. Say you're running a hackathon (totally arbitrary example) and you want to play a nice list of songs for the entire duration, but you don't want to spend the multiple hours it would take manually adding songs to make a 24-hour playlist complete with rising and falling action music for submission deadlines. All you need to input is "Give me 20 hours of chill work songs", "Give me 2 hours of energetic work songs", "Give me 1 hour of dramatic songs", and then "Give me 1 hour of prize ceremony songs". Way easier, right? You could even specify "Give me 3 hours of songs like Imagine Dragons - Radioactive". The AI behind the scenes handles this all for you, so you don't have to do any other work, but you can still manually specify "Give me Imagine Dragons - Radioactive" if you really want to desperately listen to it.
## Why's this better than Spotify?
Suppose you're going to go for a long run while listening to music, and you know you're really going to struggle at the end, so you want to listen to motivational songs at the end to help you. If you're doing this with a normal playlist, you would have to manually choose all of your motivational songs at the end of your run, and manually choose a bunch of normal songs to play at the start of your run; easily a 30-minute task, and you have to hope you never get bored of it. With Playflow, all you have to do is tell the app to give you "45 minutes of songs I like" and "15 minutes of motivational music"; 30 seconds and you have your playlist ready to go running with, which will constantly have different songs in it, making sure you're never bored. Playflow grants more control to the listener.
## Technical details
The app uses Progressive Web Application (PWA) technology to increase development velocity and ensure that it works cross-platform on both Android and iOS. The PWA is built using React + Tailwind + Typescript, with React-Router to manage pages and Recoil to help manage state, and hosted on Netlify. The app communicates with a backend server storing data, an Express application running on Debian on Amazon EC2 utilizing LowDB for user data and an Apache Cassandra database instance for efficient ML model queries. The ML model itself was trained by SageMaker, Gensim and TensorFlow using the Word2Vec model, with Jupyter and Seaborn for visualization and K-dimensional tree datastructures (kd-trees) for efficient querying. To enable the use of OAuth2, we use an AWS Lambda deployment using the declarative Serverless framework, utilizing CloudFormation and IAM as well as CloudWatch for logging. And in the center of it all, we use the Spotify API as both a producer of songs, a consumer of song queues, and an OAuth2 client.
## Challenges
We initially attempted to use AWS Keyspaces (a managed deployment of Cassandra) as our ML database, but ran into multiple issues which took us a significant chunk of time to debug.
## What went well
The Spotify API code was extremely straightforward and easy to implement.
## What's next for Playflow
In the future, we plan to integrate Playflow with other music apps such as Apple Music or YouTube Music. We also aspire to link geographical location data and other user data with the app so that AI can help suggest playflows for the user to use depending on their location (e.g. listening to energetic music while at a gym) or time (e.g. listening to calm music during sleep hours). | # Flash Computer Vision®
### Computer Vision for the World
Github: <https://github.com/AidanAbd/MA-3>
Try it Out: <http://flash-cv.com>
## Inspiration
Over the last century, computers have gained superhuman capabilities in computer vision. Unfortunately, these capabilities are not yet empowering everyday people because building an image classifier is still a fairly complicated task.
The easiest tools that currently exist still require a good amount of computing knowledge. A good example is [Google AutoML: Vision](https://cloud.google.com/vision/automl/docs/quickstart) which is regarded as the "simplest" solution and yet requires an extensive knowledge of web skills and some coding ability. We are determined to change that.
We were inspired by talking to farmers in Mexico who wanted to identify ready / diseased crops easily without having to train many workers. Despite the technology existing, their walk of life had not lent them the opportunity to do so. We were also inspired by people in developing countries who want access to the frontier of technology but lack the education to unlock it. While we explored an aspect of computer vision, we are interested in giving individuals the power to use all sorts of ML technologies and believe similar frameworks could be set up for natural language processing as well.
## The product: Flash Computer Vision
### Easy to use Image Classification Builder - The Front-end
Flash Magic is a website with an extremely simple interface. It has one functionality: it takes in a variable amount of image folders and gives back an image classification interface. Once the user uploads the image folders, he simply clicks the Magic Flash™ button. There is a short training process during which the website displays a progress bar. The website then returns an image classifier and a simplistic interface for using it. The user can use the interface (which is directly built on the website) to upload and classify new images. The user never has to worry about any of the “magic” that goes on in the backend.
### Magic Flash™ - The Backend
The front end’s connection to the backend sets up a Train image folder on the server. The name of each folder is the category that the pictures inside of it belong to. The backend will take the folder and transfer it into a CSV file. From this CSV file it creates a [Pytorch.utils.Dataset](https://pytorch.org/docs/stable/_modules/torch/utils/data/dataset.html) Class by inheriting Dataset and overriding three of its methods. When the dataset is ready, the data is augmented using a combination of 6 different augmentations: CenterCrop, ColorJitter, RandomAffine, RandomRotation, and Normalize. By doing those transformations, we ~10x the amount of data that we have for training. Once the data is in a CSV file and has been augmented, we are ready for training.
We import [SqueezeNet](https://pytorch.org/hub/pytorch_vision_squeezenet/) and use transfer learning to adjust it to our categories. What this means is that we erase the last layer of the original net, which was originally trained for ImageNet (1000 categories), and initialize a layer of size equal to the number of categories that the user defined, making sure to accurately match dimensions. We then run back-propagation on the network with all the weights “frozen” in place with exception to the ones in the last layer. As the model is training, it is informing the front-end that progress being made, allowing us to display a progress bar. Once the model converges, the final model is saved into a file that the API can easily call for inference (classification) when the user asks for prediction on new data.
## How we built it
The website was built using Node.js and javascript and it has three main functionalities: allowing the user to upload pictures into folders, sending the picture folders to the backend, making API calls to classify new images once the model is ready.
The backend is built in Python and PyTorch. On top of Python we used torch, torch.nn as nn, torch.optim as optim, torch.optim import lr\_scheduler, numpy as np, torchvision, from torchvision import datasets, models, and transforms, import matplotlib.pyplot as plt, import time, import os, import copy, import json, import sys.
## Accomplishments that we're proud of
Going into this, we were not sure if 36 hours were enough to build this product. The proudest moment of this project was the successful testing round at 1am on Sunday. While we had some machine learning experience on our team, none of us had experience with transfer learning or this sort of web application. At the beginning of our project, we sat down, learned about each task, and then drew a diagram of our project. We are especially proud of this step because coming into the coding portion with a clear API functionality understanding and delegated tasks saved us a lot of time and helped us integrate the final product.
## Obstacles we overcame and what we learned
Machine learning models are often finicky in their training patterns. Because our application allows users with little experience, we had to come up with a robust training pipeline. Designing this pipeline took a lot of thought and a few failures before we converged on a few data augmentation techniques that do the trick. After this hurdle, integrating a deep learning backend with the website interface was quite challenging, as the training pipeline requires very specific labels and file structure. Iterating the website to reflect the rigid protocol without over complicating the interface was thus a challenge. We learned a ton over this weekend. Firstly, getting the transfer learning to work was enlightening as freezing parts of the network and writing a functional training loop for specific layers required diving deep into the pytorch API. Secondly, the human-design aspect was a really interesting learning opportunity as we had to come up with the right line between abstraction and functionality. Finally, and perhaps most importantly, constantly meeting and syncing code taught us the importance of keeping a team on the same page at all times.
## What's next for Flash Computer Vision
### Application companion + Machine Learning on the Edge
We want to build a companion app with the same functionality as the website. The companion app would be even more powerful than the website because it would have the ability to quantize models (compression for ml) and to transfer them into TensorFlow Lite so that **models can be stored and used within the device.** This would especially benefit people in developing countries, where they sometimes cannot depend on having a cellular connection.
### Charge to use
We want to make a payment system within the website so that we can scale without worrying about computational cost. We do not want to make a business model out of charging per API call, as we do not believe this will pave a path forward for rapid adoption. **We want users to own their models, this will be our competitive differentiator.** We intentionally used a smaller neural network to reduce hosting and decrease inference time. Once we compress our already small models, this vision can be fully realized as we will not have to host anything, but rather return a mobile application. | losing |
## Inspiration
When we joined the hackathon, we began brainstorming about problems in our lives. After discussing some constant struggles in their lives with many friends and family, one response was ultimately shared: health. Interestingly, one of the biggest health concerns that impacts everyone in their lives comes from their *skin*. Even though the skin is the biggest organ in the body and is the first thing everyone notices, it is the most neglected part of the body.
As a result, we decided to create a user-friendly multi-modal model that can discover their skin discomfort through a simple picture. Then, through accessible communication with a dermatologist-like chatbot, they can receive recommendations, such as specific types of sunscreen or over-the-counter medications. Especially for families that struggle with insurance money or finding the time to go and wait for a doctor, it is an accessible way to understand the blemishes that appear on one's skin immediately.
## What it does
The app is a skin-detection model that detects skin diseases through pictures. Through a multi-modal neural network, we attempt to identify the disease through training on thousands of data entries from actual patients. Then, we provide them with information on their disease, recommendations on how to treat their disease (such as using specific SPF sunscreen or over-the-counter medications), and finally, we provide them with their nearest pharmacies and hospitals.
## How we built it
Our project, SkinSkan, was built through a systematic engineering process to create a user-friendly app for early detection of skin conditions. Initially, we researched publicly available datasets that included treatment recommendations for various skin diseases. We implemented a multi-modal neural network model after finding a diverse dataset with almost more than 2000 patients with multiple diseases. Through a combination of convolutional neural networks, ResNet, and feed-forward neural networks, we created a comprehensive model incorporating clinical and image datasets to predict possible skin conditions. Furthermore, to make customer interaction seamless, we implemented a chatbot using GPT 4o from Open API to provide users with accurate and tailored medical recommendations. By developing a robust multi-modal model capable of diagnosing skin conditions from images and user-provided symptoms, we make strides in making personalized medicine a reality.
## Challenges we ran into
The first challenge we faced was finding the appropriate data. Most of the data we encountered needed to be more comprehensive and include recommendations for skin diseases. The data we ultimately used was from Google Cloud, which included the dermatology and weighted dermatology labels. We also encountered overfitting on the training set. Thus, we experimented with the number of epochs, cropped the input images, and used ResNet layers to improve accuracy. We finally chose the most ideal epoch by plotting loss vs. epoch and the accuracy vs. epoch graphs. Another challenge included utilizing the free Google Colab TPU, which we were able to resolve this issue by switching from different devices. Last but not least, we had problems with our chatbot outputting random texts that tended to hallucinate based on specific responses. We fixed this by grounding its output in the information that the user gave.
## Accomplishments that we're proud of
We are all proud of the model we trained and put together, as this project had many moving parts. This experience has had its fair share of learning moments and pivoting directions. However, through a great deal of discussions and talking about exactly how we can adequately address our issue and support each other, we came up with a solution. Additionally, in the past 24 hours, we've learned a lot about learning quickly on our feet and moving forward. Last but not least, we've all bonded so much with each other through these past 24 hours. We've all seen each other struggle and grow; this experience has just been gratifying.
## What we learned
One of the aspects we learned from this experience was how to use prompt engineering effectively and ground an AI model and user information. We also learned how to incorporate multi-modal data to be fed into a generalized convolutional and feed forward neural network. In general, we just had more hands-on experience working with RESTful API. Overall, this experience was incredible. Not only did we elevate our knowledge and hands-on experience in building a comprehensive model as SkinSkan, we were able to solve a real world problem. From learning more about the intricate heterogeneities of various skin conditions to skincare recommendations, we were able to utilize our app on our own and several of our friends' skin using a simple smartphone camera to validate the performance of the model. It’s so gratifying to see the work that we’ve built being put into use and benefiting people.
## What's next for SkinSkan
We are incredibly excited for the future of SkinSkan. By expanding the model to incorporate more minute details of the skin and detect more subtle and milder conditions, SkinSkan will be able to help hundreds of people detect conditions that they may have ignored. Furthermore, by incorporating medical and family history alongside genetic background, our model could be a viable tool that hospitals around the world could use to direct them to the right treatment plan. Lastly, in the future, we hope to form partnerships with skincare and dermatology companies to expand the accessibility of our services for people of all backgrounds. | ## Problem Statement
As the number of the elderly population is constantly growing, there is an increasing demand for home care. In fact, the market for safety and security solutions in the healthcare sector is estimated to reach $40.1 billion by 2025.
The elderly, disabled, and vulnerable people face a constant risk of falls and other accidents, especially in environments like hospitals, nursing homes, and home care environments, where they require constant supervision. However, traditional monitoring methods, such as human caregivers or surveillance cameras, are often not enough to provide prompt and effective responses in emergency situations. This potentially has serious consequences, including injury, prolonged recovery, and increased healthcare costs.
## Solution
The proposed app aims to address this problem by providing real-time monitoring and alert system, using a camera and cloud-based machine learning algorithms to detect any signs of injury or danger, and immediately notify designated emergency contacts, such as healthcare professionals, with information about the user's condition and collected personal data.
We believe that the app has the potential to revolutionize the way vulnerable individuals are monitored and protected, by providing a safer and more secure environment in designated institutions.
## Developing Process
Prior to development, our designer used Figma to create a prototype which was used as a reference point when the developers were building the platform in HTML, CSS, and ReactJs.
For the cloud-based machine learning algorithms, we used Computer Vision, Open CV, Numpy, and Flask to train the model on a dataset of various poses and movements and to detect any signs of injury or danger in real time.
Because of limited resources, we decided to use our phones as an analogue to cameras to do the live streams for the real-time monitoring.
## Impact
* **Improved safety:** The real-time monitoring and alert system provided by the app helps to reduce the risk of falls and other accidents, keeping vulnerable individuals safer and reducing the likelihood of serious injury.
* **Faster response time:** The app triggers an alert and sends notifications to designated emergency contacts in case of any danger or injury, which allows for a faster response time and more effective response.
* **Increased efficiency:** Using cloud-based machine learning algorithms and computer vision techniques allow the app to analyze the user's movements and detect any signs of danger without constant human supervision.
* **Better patient care:** In a hospital setting, the app could be used to monitor patients and alert nurses if they are in danger of falling or if their vital signs indicate that they need medical attention. This could lead to improved patient care, reduced medical costs, and faster recovery times.
* **Peace of mind for families and caregivers:** The app provides families and caregivers with peace of mind, knowing that their loved ones are being monitored and protected and that they will be immediately notified in case of any danger or emergency.
## Challenges
One of the biggest challenges have been integrating all the different technologies, such as live streaming and machine learning algorithms, and making sure they worked together seamlessly.
## Successes
The project was a collaborative effort between a designer and developers, which highlights the importance of cross-functional teams in delivering complex technical solutions. Overall, the project was a success and resulted in a cutting-edge solution that can help protect vulnerable individuals.
## Things Learnt
* **Importance of cross-functional teams:** As there were different specialists working on the project, it helped us understand the value of cross-functional teams in addressing complex challenges and delivering successful results.
* **Integrating different technologies:** Our team learned the challenges and importance of integrating different technologies to deliver a seamless and effective solution.
* **Machine learning for health applications:** After doing the research and completing the project, our team learned about the potential and challenges of using machine learning in the healthcare industry, and the steps required to build and deploy a successful machine learning model.
## Future Plans for SafeSpot
* First of all, the usage of the app could be extended to other settings, such as elderly care facilities, schools, kindergartens, or emergency rooms to provide a safer and more secure environment for vulnerable individuals.
* Apart from the web, the platform could also be implemented as a mobile app. In this case scenario, the alert would pop up privately on the user’s phone and notify only people who are given access to it.
* The app could also be integrated with wearable devices, such as fitness trackers, which could provide additional data and context to help determine if the user is in danger or has been injured. | ## Inspiration
Our inspiration came from the danger of skin-related diseases, along with the rising costs of medical care. DermaFix not only provides an alternative free option for those who can't afford to visit a doctor due to financial issues but provides real-time diagnosis.
## What it does
Scans and analyzes the user's skin, determining if the user has any sort of skin disease. If anything is detected, possible remedies are provided, with a google map displaying nearby places to get treatment.
## How we built it
We learned to create a Flask application, using HTML, CSS, and Javascript to develop the front end. We used TensorFlow, feeding an image classifier machine learning model to differentiate between clear skin and 20 other skin diseases.
## Challenges we ran into
Fine-tuning the image classifying model to be accurate at least 85% of the time.
## Accomplishments that we're proud of
Creating a model that is accurate 95% of the time.
## What we learned
HTML, CSS, Flask, TensorFlow
## What's next for Derma Fix
Using a larger dataset for a much more accurate diagnosis, along with more APIs to be used, in order to contact nearby doctors, and automatically set appointments for those that need it | winning |
## Inspiration
In recent times, we have witnessed undescribable tragedy occur during the war in Ukraine. The way of life of many citizens has been forever changed. In particular, the attacks on civilian structures have left cities covered in debris and people searching for their missing loved ones. As a team of engineers, we believe we could use our skills and expertise to facilitate the process of search and rescue of Ukrainian citizens.
## What it does
Our solution integrates hardware and software development in order to locate, register, and share the exact position of people who may be stuck or lost under rubble/debris. The team developed a rover prototype that navigates through debris and detects humans using computer vision. A picture and the geographical coordinates of the person found are sent to a database and displayed on a web application. The team plans to use a fleet of these rovers to make the process of mapping the area out faster and more efficient.
## How we built it
On the frontend, the team used React and the Google Maps API to map out the markers where missing humans were found by our rover. On the backend, we had a python script that used computer vision to detect humans and capture an image. Furthermore,
For the rover, we 3d printed the top and bottom chassis specifically for this design. After 3d printing, we integrated the arduino and attached the sensors and motors. We then calibrated the sensors for the accurate values.
To control the rover autonomously, we used an obstacle-avoider algorithm coded in embedded C.
While the rover is moving and avoiding obstacles, the phone attached to the top is continuously taking pictures. A computer vision model performs face detection on the video stream, and then stores the result in the local directory. If a face was detected, the image is stored on the IPFS using Estuary's API, and the GPS coordinates and CID are stored in a Firestore Database. On the user side of the app, the database is monitored for any new markers on the map. If a new marker has been added, the corresponding image is fetched from IPFS and shown on a map using Google Maps API.
## Challenges we ran into
As the team attempted to use the CID from the Estuary database to retrieve the file by using the IPFS gateway, the marker that the file was attached to kept re-rendering too often on the DOM. However, we fixed this by removing a function prop that kept getting called when the marker was clicked. Instead of passing in the function, we simply passed in the CID string into the component attributes. By doing this, we were able to retrieve the file.
Moreover, our rover was initally designed to work with three 9V batteries (one to power the arduino, and two for two different motor drivers). Those batteries would allow us to keep our robot as light as possible, so that it could travel at faster speeds. However, we soon realized that the motor drivers actually ran on 12V, which caused them to run slowly and burn through the batteries too quickly. Therefore, after testing different options and researching solutions, we decided to use a lithium-poly battery, which supplied 12V. Since we only had one of those available, we connected both the motor drivers in parallel.
## Accomplishments that we're proud of
We are very proud of the integration of hardware and software in our Hackathon project. We believe that our hardware and software components would be complete projects on their own, but the integration of both makes us believe that we went above and beyond our capabilities. Moreover, we were delighted to have finished this extensive project under a short period of time and met all the milestones we set for ourselves at the beginning.
## What we learned
The main technical learning we took from this experience was implementing the Estuary API, considering that none of our teammembers had used it before. This was our first experience using blockchain technology to develop an app that could benefit from use of public, descentralized data.
## What's next for Rescue Ranger
Our team is passionate about this idea and we want to take it further. The ultimate goal of the team is to actually deploy these rovers to save human lives.
The team identified areas for improvement and possible next steps. Listed below are objectives we would have loved to achieve but were not possible due to the time constraint and the limited access to specialized equipment.
* Satellite Mapping -> This would be more accurate than GPS.
* LIDAR Sensors -> Can create a 3D render of the area where the person was found.
* Heat Sensors -> We could detect people stuck under debris.
* Better Cameras -> Would enhance our usage of computer vision technology.
* Drones -> Would navigate debris more efficiently than rovers. | ## Inspiration
It feels like elections are taking up an increasing portion of our mindshare, with every election cycle it only gets more insane. Constantly flooded by news, by opinions – it's like we never get a break. And yet, paradoxically, voters feel increasingly less connected to their politicians. They hear soliloquies about the terrible deeds of the politician's opponent, but rarely about how their policies will affect them personally. That changes today.
It's time we come back to a democracy which lives by the words *E pluribus unum* – from many, one. Citizens should understand exactly how politician's policies will affect them and their neighbours, and from that, a general consensus may form. And campaigners should be given the tools to allow them to do so.
Our team's been deeply involved in community and politics for years – which is why we care so much about a healthy democracy. Between the three of us over the years, we've spoken with campaign / PR managers at 70+ campaigns, PACs, and lobbies, and 40+ ad teams – all in a bid to understand how technology can help propel a democracy forward.
## What it does
Rally helps politicians meet voters where they are – in a figurative and digital sense. Politicians and campaign teams can use our platform to send geographically relevant campaign advertisements to voters – tailored towards issues they care deeply about. We thoroughly analyze the campaigner's policies to give a faithful representation of their ideas through AI-generated advertisements – using their likeness – and cross-correlate it with issues the voter is likely to care, and want to learn more, about. We avoid the uncanny valley with our content, we maintain compliance, and we produce content that drives voter engagement.
## How we built it
Rally is a web app powered by a complex multi-agent chain system, which uses natural language to understand both current local events and campaign policy in real-time, and advanced text-to-speech and video-to-video lip sync/facetune models to generate a faithful personalised campaign ad, with the politician speaking to voters about issues they truly care about.
* We use Firecrawl and the Perplexity API to scrape news and economic data about the town a voter is from, and to understand a politician's policies, and store GPT-curated insights on a Supabase database.
* Then, we use GPT4o-mini to parse through all that data and generate an ad speech, faithful to the politician's style, which'll cover issues relevant to the voter.
* This speech is sent to Cartesia.ai's excellent Sonic text-to-speech model which has already been trained on short clips of the politician's voice.
* Simultaneously, GPT4o-mini decides which parts of the ad should have B-roll/stock footage displayed, and about what.
* We use this to query Pexels for stock footage to be used during the ad.
* Once the voice narration has been generated, we send it to SyncLabs for lipsyncing over existing ad/interview footage of the politician.
* Finally, we overlay the the B-roll footage (at the previously decided time stamps) on the lip synced videos, to create a convincing campaign advertisement.
* All of this is packaged in a beautiful and modern UI built using NextJS and Tailwind.
And all of this is done in the space of just a few minutes! So whether the voter comes from New York City or Fairhope, Alabama, you can be sure that they'll receive a faithful campaign ad which puts the politician's best foot forward while helping the voter understand how their policies might affect them.
## Wait a minute, is this even legal?
***YES***. Currently, bills are being passed in states around the country limiting the use of deepfakes in political campaign – and for good reason. The potential damage is obvious. However, in every single proposed bill, a campaigner is absolutely allowed to create deepfakes of themselves for their own gains. Indeed, while we absolutely support all regulation on nefarious use of deepfakes, we also deeply believe in its immense potential for good. We've even built a database of all the bills that are in debate or have been enacted regarding AI political advertisement as part of this project, feel free to take a look!
Voter apathy is an epidemic, which slowly eats away at a democracy – Rally believes that personalised campaign messaging is one of the most promising avenues to battle against that.
## Challenges we ran into
The surface area for errors increase hugely with the amount of services we integrate with. Undocumented or badly documented APIs were huge time sinks – some of these services are so new that questions haven't been asked about them online. Another very large time sink was the video manipulation through FFMPEG. It's an extremely powerful tool, and doing simple things is very easy, but doing more complicated tasks ended up being very difficult to get right.
However, the biggest challenge by far was creating advertisements that maintained state-specific compliance, meaning they had different rules and regulations for each state and had to avoid negativity, misinformation, etc. This can be very hard as LLM outputs are often very subjective and hard to evaluate deterministically. We combatted this by building a chain of LLMs informed by data from the NCSL, OpenFEC, and other reliable sources to ensure all the information that we used in the process was thoroughly sourced, leading to better outcomes for content generation. We also used validator agents to verify results from particularly critical parts of the content generation flow before proceeding.
## Accomplishments that we're proud of
We're deeply satisfied with the fact that we were able to get the end-to-end voter-to-ad pipeline going while also creating a beautiful web app. It seemed daunting at first, with so many moving pieces, but through intelligent separation of tasks we were able to get through everything.
## What we learned
Premature optimization is the killer of speed – we initially tried to do some smart splicing of the base video data so that we wouldn't lip sync parts of the video that were going to be covered by the B-roll (and thus do the lip syncing generation in parallel) – but doing all the splicing and recombining ended up taking almost as long as simply passing the whole video to the lip syncing model, and with many engineer-hours lost. It's much better to do things that don't scale in these environments (and most, one could argue).
## What's next for Rally
Customized campaign material is a massive market – scraping data online has become almost trivial thanks to tools like Firecrawl – so a more holistic solution for helping campaigns/non-profits/etc. ideate, test, and craft campaign material (with AI solutions already part of it) is a huge opportunity. | ## Inspiration
## What it does
ResQ is a holistic natural disaster recovery tool.
-Officials (FEMA, Red Cross, etc.) can manage their resource centers on a WebApp: by managing the distribution of resources, the location of distressed individuals, and publicly sourced alerts.
-Private Citizens can use a mobile app as a one-stop-shop solution for their emergency needs including: finding the nearest medical service, food/water source, or shelter source, alerting officials of power outages, fallen trees, or obstructed roads, and finally trigger and emergency response. Users can use augmented reality to point them towards the closest resource.
-Emergency Response Teams: can be dispatched through the app to find private citizens. A convolutional neural network processes Arial imagery to tag and find distressed citizens without cell service
## How I built it
The WebApp is built in React.JS. The mobile app is built with swift in Xcode. The backend was made using Firebase. The AI/Deep Learning portion was built using Keras.
## Challenges I ran into
We ran into several challenges throughout the course of this project. We all dealt with some ideas and technologies we had very little experience with before. Implementing the AR/VR was challenging as this technology is very new and is still very hard to use. Using a pretrained neural network to do image detection (drawing the boudning box) was very challenging as it is a machine learning problem we had never tackled before and one in which very little documentation exists. Also, dealing with many of the sponsor APIs was initially very challenging to deal with as some of the endpoints were hard to successfully interact with.
## Accomplishments that I'm proud of
We think that the scale of this project is huge and has a tremendous amount of application in the real world. This app (on the mobile side) gives people who are victims of a natural disaster a place to report their location, find any resources they may need, and report anything potentially dangerous. This app also (on the web side) gives rescuers a central database to locate and keep track of people who are currently in danger. Lastly, this app also uses deep learning to use drones to identify stranded humans who may not have cell service. We are truly proud of the scale this project achieves and all the rich and various technologies involved.
## What I learned
We all learned various skills in our respective parts of the application: React, iOS with AR/VR, Firebase, Keras.
## What's next for ResQ
The next steps would be to actually implement the deep learning portion of the project, preferably with a drone that could transmit a constant stream that could be processed to see if there are any humans in a certain area and transmit their coordinates appropriately. We also want to build out each specific feature of the mobile app, including directions to water, food, shelter, hospital, or gas. | winning |
## Inspiration
After learning about the current shortcomings of disaster response platforms, we wanted to build a modernized emergency services system to assist relief organizations and local governments in responding faster and appropriately.
## What it does
safeFront is a cross between next-generation 911 and disaster response management. Our primary users are local governments and relief organizations. The safeFront platform provides organizations and governments with the crucial information that is required for response, relief, and recovery by organizing and leveraging incoming disaster related data.
## How we built it
safeFront was built using React for the web dashboard and a Flask service housing the image classification and natural language processing models to process the incoming mobile data.
## Challenges we ran into
Ranking urgency of natural disasters and their severity by reconciling image recognition, language processing, and sentiment analysis on mobile data and reported it through a web dashboard. Most of the team didn't have a firm grasp on React components, so building the site was how we learned React.
## Accomplishments that we're proud of
Built a full stack web application and a functioning prototype from scratch.
## What we learned
Stepping outside of our comfort zone is, by nature, uncomfortable. However, we learned that we grow the most when we cross that line.
## What's next for SafeFront
We'd like to expand our platform for medical data, local transportation delays, local river level changes, and many more ideas. We were able to build a fraction of our ideas this weekend, but we hope to build additional features in the future. | ## Inspiration
Natural disasters do more than just destroy property—they disrupt lives, tear apart communities, and hinder our progress toward a sustainable future. One of our team members from Rice University experienced this firsthand during a recent hurricane in Houston. Trees were uprooted, infrastructure was destroyed, and delayed response times put countless lives at risk.
* **Emotional Impact**: The chaos and helplessness during such events are overwhelming.
* **Urgency for Change**: We recognized the need for swift damage assessment to aid authorities in locating those in need and deploying appropriate services.
* **Sustainability Concerns**: Rebuilding efforts often use non-eco-friendly methods, leading to significant carbon footprints.
Inspired by these challenges, we aim to leverage AI, computer vision, and peer networks to provide rapid, actionable damage assessments. Our AI assistant can detect people in distress and deliver crucial information swiftly, bridging the gap between disaster and recovery.
## What it Does
The Garuda Dashboard offers a comprehensive view of current, upcoming, and past disasters across the country:
* **Live Dashboard**: Displays a heatmap of affected areas updated via a peer-to-peer network.
* **Drones Damage Analysis**: Deploy drones to survey and mark damaged neighborhoods using the Llava Vision-Language Model and generate reports for the Recovery Team.
* **Detailed Reporting**: Reports have annotations to classify damage types [tree, road, roof, water], human rescue needs, site accessibility [Can response team get to the site by land], and suggest equipment dispatch [Cranes, Ambulance, Fire Control].
* **Drowning Alert**: The drone footage can detect when it identifies a drowning subject and immediately call rescue teams
* **AI-Generated Summary**: Reports on past disasters include recovery costs, carbon footprint, and total asset/life damage.
## How We Built It
* **Front End**: Developed with Next.js for an intuitive user interface tailored for emergency use.
* **Data Integration**: Utilized Google Maps API for heatmaps and energy-efficient routing.
* **Real-Time Updates**: Custom Flask API records hot zones when users upload disaster videos.
* **AI Models**: Employed MSNet for real-time damage assessment on GPUs and Llava VLM for detailed video analysis.
* **Secure Storage**: Images and videos stored on Firebase database.
## Challenges We Faced
* **Model Integration**: Adapting MSNet with outdated dependencies required deep understanding of technical papers.
* **VLM Setup**: Implementing Llava VLM was challenging due to lack of prior experience.
* **Efficiency Issues**: Running models on personal computers led to inefficiencies.
## Accomplishments We're Proud Of
* **Technical Skills**: Mastered API integration, technical paper analysis, and new technologies like VLMs.
* **Innovative Impact**: Combined emerging technologies for disaster detection and recovery measures.
* **Complex Integration**: Successfully merged backend, frontend, and GPU components under time constraints.
## What We Learned
* Expanded full-stack development skills and explored new AI models.
* Realized the potential of coding experience in tackling real-world problems with interdisciplinary solutions.
* Balanced MVP features with user needs throughout development.
## What's Next for Garuda
* **Drone Integration**: Enable drones to autonomously call EMS services and deploy life-saving equipment.
* **Collaboration with EMS**: Partner with emergency services for widespread national and global adoption.
* **Broader Impact**: Expand software capabilities to address various natural disasters beyond hurricanes. | ## Inspiration
-- Two of our team members from Florida have experienced the impact of Hurricane Irma firsthand during the past week even before it made landfall: barren shelves in the grocery store, empty fuel pumps, and miles upon miles of traffic due to people evacuating. Even amidst the chaos and fear, there are stories of people performing altruistic acts to help one another. One Facebook post recounted the story of a woman going to the store in search of a generator for her father who relies on a ventilator. There were no generators left at any store in town, so a generous person who overheard her situation offered her their generator. If an app were able to connect people who were able to offer assistance with people in need, many more beautiful stories like this could exist.
## What it does
-- Our app brings together communities to promote cooperation in both the preparation for and the aftermath of hurricanes and other natural disasters. Users are able to offer or request shelter, assistance, supplies, or rides. Others may view these offers or requests and respond to the original poster. Users may find important information, such as evacuation and flood warnings and the contact information of local authorities. Additionally, local authorities can utilize this app to plan their route more effectively and provide the fastest and most efficient care for those who need it the most.
## How we built it
-- We built the app in Expo using React Native and React Navigation. We chose Firebase for our database because of it's reliability and sheer ability to scale for an influx of users - prevalent in circumstances such as a natural disaster. Additionally, Firebase provides real time updates so that people can offer or receive help as soon as possible, saving more lives and ensuring the safety of the people in our communities. We also used React MapView to provide a visual for the areas affected.
## Challenges we ran into
-- None of our team knew anything about Javascript, React, Expo, or Firebase before we the project.
Despite encountering countless roadblocks, we took advantage of PennApp's resources such as mentors, hackpacks, workshops, and students to help us through the difficult, but also very rewarding times.
## Accomplishments that we're proud of
-- Being able to tackle a real life problem that is affecting countless of lives in front of our eyes inspired and motivated us, to not only become more empathetic to those around us but to unite and help out our community.
## What we learned
-- We learned how to use cutting edge technology such as React Native and Firebase to rapidly prototype a solution that has the potential to save many lives and empower our community in less than 36 hours. We also learned how quickly it can be to help others when we free ourselves from our differences and work together.
## What's next for Crisis Connect
-- Next, we will improve the user interface to become more friendly for all of our users.
If time allows, we will also let people with disabilities and/or health concerns have priority within the app and introduce a chatbot to let the users have an easier time looking for the information they need.
Additionally, we would like to add a feature that allows users to report major damages, shortages, or traffic jams to keep up with the disasters. We understand that during natural disasters, internet may not always be available, but mobile networks are usually still available with a slower, 2g connection. As a result, we hope to utilize a text/chatbot to effectively communicate with those who are stranded or require immediate attention. | winning |
## Inspiration
Maybe you have an hour between classes, an afternoon to spare, or a weekend in a new city. You want to find something to do, experience new things in both familiar or distant locations. However, it's late, it's cold, maybe it's raining, your wallet's empty, or you don't have a car. Online searches don't consider these factors.
Aventure (TM) curates location-based recommendations by analyzing environmental, personal and trending aspects. We consider the details so you can spend your time experiencing the city.
## What it does
By analyzing several static and dynamic aspects, including budget, time, day, weather, temperature, distance, transport types, and more, we personalize recommendations that best fit your preferences. Experience new music, food, landmarks, events, and more with Aventure (TM).
## How we built it
Through Figma and Principle prototyping, SaaS and Spring development, we built a POC demo of Aventure (TM).
## Challenges we ran into
Time constraints.
## Accomplishments that we're proud of
Realization of an idea despite a team of strangers and heterogeneous skill sets.
## What we learned
Exchange of tech stack knowledge.
## What's next for Aventure
Design and implement of unexplored aspects that were outside the scope of the demo. | ### Tired of your mom yelling at you for the crayon stains?
### Wanna draw outside the lines?
### Wanna experience augmented reality?
**Here's your chance**
With our application you are able to relive your child years. You can draw on any wall and not have to worry about getting yelled at or being forced to clean it up. You are free to scan in any wall then by using the Microsoft HoloLens and simple voice commands, create your very own piece of art. | ## Why We Created **Here**
As college students, one question that we catch ourselves asking over and over again is – “Where are you studying today?” One of the most popular ways for students to coordinate is through texting. But messaging people individually can be time consuming and awkward for both the inviter and the invitee—reaching out can be scary, but turning down an invitation can be simply impolite. Similarly, group chats are designed to be a channel of communication, and as a result, a message about studying at a cafe two hours from now could easily be drowned out by other discussions or met with an awkward silence.
Just as Instagram simplified casual photo sharing from tedious group-chatting through stories, we aim to simplify casual event coordination. Imagine being able to efficiently notify anyone from your closest friends to lecture buddies about what you’re doing—on your own schedule.
Fundamentally, **Here** is an app that enables you to quickly notify either custom groups or general lists of friends of where you will be, what you will be doing, and how long you will be there for. These events can be anything from an open-invite work session at Bass Library to a casual dining hall lunch with your philosophy professor. It’s the perfect dynamic social calendar to fit your lifestyle.
Groups are customizable, allowing you to organize your many distinct social groups. These may be your housemates, Friday board-game night group, fellow computer science majors, or even a mixture of them all. Rather than having exclusive group chat plans, **Here** allows for more flexibility to combine your various social spheres, casually and conveniently forming and strengthening connections.
## What it does
**Here** facilitates low-stakes event invites between users who can send their location to specific groups of friends or a general list of everyone they know. Similar to how Instagram lowered the pressure involved in photo sharing, **Here** makes location and event sharing casual and convenient.
## How we built it
UI/UX Design: Developed high fidelity mockups on Figma to follow a minimal and efficient design system. Thought through user flows and spoke with other students to better understand needed functionality.
Frontend: Our app is built on React Native and Expo.
Backend: We created a database schema and set up in Google Firebase. Our backend is built on Express.js.
All team members contributed code!
## Challenges
Our team consists of half first years and half sophomores. Additionally, the majority of us have never developed a mobile app or used these frameworks. As a result, the learning curve was steep, but eventually everyone became comfortable with their specialties and contributed significant work that led to the development of a functional app from scratch.
Our idea also addresses a simple problem which can conversely be one of the most difficult to solve. We needed to spend a significant amount of time understanding why this problem has not been fully addressed with our current technology and how to uniquely position **Here** to have real change.
## Accomplishments that we're proud of
We are extremely proud of how developed our app is currently, with a fully working database and custom frontend that we saw transformed from just Figma mockups to an interactive app. It was also eye opening to be able to speak with other students about our app and understand what direction this app can go into.
## What we learned
Creating a mobile app from scratch—from designing it to getting it pitch ready in 36 hours—forced all of us to accelerate our coding skills and learn to coordinate together on different parts of the app (whether that is dealing with merge conflicts or creating a system to most efficiently use each other’s strengths).
## What's next for **Here**
One of **Here’s** greatest strengths is the universality of its usage. After helping connect students with students, **Here** can then be turned towards universities to form a direct channel with their students. **Here** can provide educational institutions with the tools to foster intimate relations that spring from small, casual events. In a poll of more than sixty university students across the country, most students rarely checked their campus events pages, instead planning their calendars in accordance with what their friends are up to. With **Here**, universities will be able to more directly plug into those smaller social calendars to generate greater visibility over their own events and curate notifications more effectively for the students they want to target. Looking at the wider timeline, **Here** is perfectly placed at the revival of small-scale interactions after two years of meticulously planned agendas, allowing friends who have not seen each other in a while casually, conveniently reconnect.
The whole team plans to continue to build and develop this app. We have become dedicated to the idea over these last 36 hours and are determined to see just how far we can take **Here**! | losing |
## Inspiration
We were inspired by our lack of engagement with certain school activities, and we saw an opportunity to embrace the use of phones in class for educational purposes.
## What it does
We offer a platform for anyone to make a scavenger hunt and then host it. By entering a game code and a username on a phone app, you are able to take place in a scavenger-hunt. You are given a clue to the next location, and once you get within a certain radius of the location, you will be given the next clue. Your time is your score, and the first to finish is the winner.
## How I built it
We constructed the app using Android Studio in Java, utilizing the Google Maps SDK for Android API to determine the user's location. and generate a map. We also used a customized JSON file, which we used to customize the map graphics. In order to store game data, we implemented Google Firebase and Google Cloud in our project. In a further iteration of our app, we would also use this for photo recognition.
## Challenges I ran into
This was our first time creating an Android app, and our first time using many of the APIs. Although. we had all previously used Java before, we had started off in Kotlin, a language we were less familiar in, and then made the switch partway during the hackathon.
## Accomplishments that I'm proud of
Finishing a working model of the application with a functioning UI, databasing, and processing within 36 hours.
## What I learned
We learned how to use various APIs, how to build Android apps, and React from workshops we attended.
## What's next for go!
A nicely formatted teacher's app to be able to create and host scavenger hunts would be something we would spend time to flesh out, along with new modes for guided museum tours and a photo hunt using an AI database. We would also add support for Apple devices and tablets. | ## Inspiration
Whenever I go on vacation, what I always fondly look back on is the sights and surroundings of specific moments. What if there was a way to remember these associations by putting them on a map to look back on? We strived to locate a problem, and then find a solution to build up from. What if instead of sorting pictures chronologically and in an album, we did it on a map which is easy and accessible?
## What it does
This app allows users to collaborate in real time on making maps over shared moments. The moments that we treasure were all made in specific places, and being able to connect those moments to the settings of those physical locations makes them that much more valuable. Users from across the world can upload pictures to be placed onto a map, fundamentally physically mapping their favorite moments.
## How we built it
The project is built off a simple React template. We added functionality a bit at a time, focusing on creating multiple iterations of designs that were improved upon. We included several APIs, including: Google Gemini and Firebase. With the intention of making the application very accessible to a wide audience, we spent a lot of time refining the UI and the overall simplicity yet useful functionality of the app.
## Challenges we ran into
We had a difficult time deciding the precise focus of our app and which features we wanted to have and which to leave out. When it came to actually creating the app, it was also difficult to deal with niche errors not addressed by the APIs we used. For example, Google Photos was severely lacking in its documentation and error reporting, and even after we asked several experienced industry developers, they could not find a way to work around it. This wasted a decent chunk of our time, and we had to move in a completely different direction to get around it.
## Accomplishments that we're proud of
We're proud of being able to make a working app within the given time frame. We're also happy over the fact that this event gave us the chance to better understand the technologies that we work with, including how to manage merge conflicts on Git (those dreaded merge conflicts). This is our (except one) first time participating in a hackathon, and it was beyond our expectations. Being able to realize such a bold and ambitious idea, albeit with a few shortcuts, it tells us just how capable we are.
## What we learned
We learned a lot about how to do merges on Git as well as how to use a new API, the Google Maps API. We also gained a lot more experience in using web development technologies like JavaScript, React, and Tailwind CSS. Away from the screen, we also learned to work together in coming up with ideas and making decisions that were agreed upon by the majority of the team. Even with being friends, we struggled to get along super smoothly while working through our issues. We believe that this experience gave us an ample amount of pressure to better learn when to make concessions and also be better team players.
## What's next for Glimpses
Glimpses isn't as simple as just a map with pictures, it's an album, a timeline, a glimpse into the past, but also the future. We want to explore how we can encourage more interconnectedness between users on this app, so we want to allow functionality for tagging other users, similar to social media, as well as providing ways to export these maps into friendly formats for sharing that don't necessarily require using the app. We also seek to better merge AI into our platform by using generative AI to summarize maps and experiences, but also help plan events and new memories for the future. | ## Inspiration
Our project is inspired by the sister of one our creators, Joseph Ntaimo. Joseph often needs to help locate wheelchair accessible entrances to accommodate her, but they can be hard to find when buildings have multiple entrances. Therefore, we created our app as an innovative piece of assistive tech to improve accessibility across the campus.
## What it does
The user can find wheelchair accessible entrances with ease and get directions on where to find them.
## How we built it
We started off using MIT’s Accessible Routes interactive map to see where the wheelchair friendly entrances were located at MIT. We then inspected the JavaScript code running behind the map to find the latitude and longitude coordinates for each of the wheelchair locations.
We then created a Python script that filtered out the latitude and longitude values, ignoring the other syntax from the coordinate data, and stored the values in separate text files.
We tested whether our method would work in Python first, because it is the language we are most familiar with, by using string concatenation to add the proper Java syntax to the latitude and longitude points. Then we printed all of the points to the terminal and imported them into Android Studio.
After being certain that the method would work, we uploaded these files into the raw folder in Android Studio and wrote code in Java that would iterate through both of the latitude/longitude lists simultaneously and plot them onto the map.
The next step was learning how to change the color and image associated with each marker, which was very time intensive, but led us to having our custom logo for each of the markers.
Separately, we designed elements of the app in Adobe Illustrator and imported logos and button designs into Android Studio. Then, through trial and error (and YouTube videos), we figured out how to make buttons link to different pages, so we could have both a FAQ page and the map.
Then we combined both of the apps together atop of the original maps directory and ironed out the errors so that the pages would display properly.
## Challenges we ran into/Accomplishments
We had a lot more ideas than we were able to implement. Stripping our app to basic, reasonable features was something we had to tackle in the beginning, but it kept changing as we discovered the limitations of our project throughout the 24 hours. Therefore, we had to sacrifice features that we would otherwise have loved to add.
A big difficulty for our team was combining our different elements into a cohesive project. Since our team split up the usage of Android Studio, Adobe illustrator, and programming using the Google Maps API, it was most difficult to integrate all our work together.
We are proud of how effectively we were able to split up our team’s roles based on everyone’s unique skills. In this way, we were able to be maximally productive and play to our strengths.
We were also able to add Boston University accessible entrances in addition to MIT's, which proved that we could adopt this project for other schools and locations, not just MIT.
## What we learned
We used Android Studio for the first time to make apps. We discovered how much Google API had to offer, allowing us to make our map and include features such as instant directions to a location. This helped us realize that we should use our resources to their full capabilities.
## What's next for HandyMap
If given more time, we would have added many features such as accessibility for visually impaired students to help them find entrances, alerts for issues with accessing ramps and power doors, a community rating system of entrances, using machine learning and the community feature to auto-import maps that aren't interactive, and much, much more. Most important of all, we would apply it to all colleges and even anywhere in the world. | losing |
pho·bi·a (/ˈfōbēə/); an extreme or **irrational** fear of or **aversion** to something.
## Inspiration
Starting off with an interest in VR/AR applications, our group pondered how we could solve real-world problems with a virtual solution. As we got to know other, we all connected over our shared fear of spiders. We set out to overcome our arachnophobia, which inspired us to create an exposure therapy project aimed at helping users "face their fears."
## What it does
>
> Exposure therapy is a type of therapy in which you're gradually exposed to the things, situations and activities you fear. It can help treat several conditions, like phobias, post-traumatic stress disorder (PTSD) and panic disorder.
>
>
>
An example of exposure therapy would be baseball players training against a high-speed pitching machine. They crank the speed up to the highest setting, forcing themselves to adjust and become desensitized to the fast-moving ball. After seeing enough pitches, they can track and hit the ball more effectively. The same principle applies to exposure therapy: when users are repeatedly exposed to their phobia, they gradually become desensitized, and over time, their fear lessens until it’s no longer overwhelming.
## How we built it
To build our project, we first leveraged Glitch's simple hosting capabilities and its support for WebXR, which allowed us to seamlessly integrate A-Frame, a web framework for building VR scenes. Using A-Frame, we created immersive environments and dynamic entities for our VR experience.
Next, we integrated Pulsoid, a heartbeat monitor app for Android watches, to gather real-time heartbeat data through API calls, which we displayed in the VR world. We sourced spider assets from a library, animated them ourselves, and programmed them to move randomly around the virtual space, always facing the user.
The speed and size of the spiders are dynamically adjusted based on the user's heartbeat, adding an interactive and personal element to the experience.
## Challenges we ran into
* Tried developing with Unity Engine, but it wasn't optimal for our devices
* Running into issues when learning WebXR and A-Frame
* Glitch rate-limiting us from time to time
* Forcing ourselves to look at spiders
## Accomplishments that we're proud of
* Getting a working VR project when none of us had any 3D development or XR experience
* No longer scared of spiders
* Being able to grasp how to use brand new languages and tools fast enough to build something like this
* How to use and develop onto VR devices
* Integrating heart rate to dynamically alter the simulation experience
## What we learned
* How challenging building and connecting 3Ds environments across devices can be
* Different methods to upload a 3D environment to a VR headset
* Working around CORS issues by creating a proxy server
## What's next for PhobiaPhixer
* Adding different levels of exposure ranging from an easy mode to an intense mode
* Creating different types of phobia treatments (e.g Ophidiophobia: Fear of Snakes, Acrophobia: Fear of Heights)
* Incorporate AI to respond with an encouraging message based on the user's heart beat | ## 💡Inspiration
* In Canada, every year there are 5.3 million people who feel they need some form of help for their mental health! But ordinary therapies is unfortunately boring and might be ineffective :( Having to deal with numerous patients every day, it also might be difficult for a mental health professional to build a deeper connection with their patient that allows the patient to heal and improve mentally and in turn physically.
* Therefore, we built TheraVibe.VR! A portable professional that is tailored to understand you! TheraVibe significantly improves patients' mental health by gamifying therapy sessions so that patients can heal wherever and with whomever they can imagine!
## 🤖 What it does
* TheraVibe provides professional psychological advisory powered by Cohere's API with the assistance of a RAG!
* It is powered by Starknet for its private and decentralized approach to store patient information!
* To aid the effort of helping more people, TheraVibe also uses Starknet to reward patients with cryptocurrencies effectively in a decentralized network to incentivize consistency in attending our unique "therapy sessions"!
## 🧠 How we built it
* With the base of C# and Unity Engine, we used blockchain technology via the beautiful Starknet API to create and deploy smart contracts to ensure safe storage of a "doctor's" evaluation of a patient's health condition as well as blockchain transactions made to patient in a gamified manner to incentivize future participation and maximize healing!
* For the memory import NextJS web app, we incorporated Auth0 for the security of our users and hosted it with a GoDaddy domain!
* The verbal interaction of the therapist and the user is powered by ElevenLabs and AssemblyAI! The cognitive process of the therapist is given by Cohere's and a RAG!
* To implement the VR project, we developed animation in Unity with C#, and used the platform to build and run our VR project!
## 🧩 Challenges we ran into
* Auth0 helped reveal a cache problem in our program, and so we had to deal with server-side rendered issues in Nextjs last-minute!
* We managed to deal with a support issue when hosting the domain name on GoDaddy and linking it to our Vercel deployment!
* Deploying the C# Unity APP on Meta Quest 2 took 24 hours of our development!
## 🏆 Accomplishments that we're proud of
* First time deploying on MetaQuest2 and building a project with Unity!
* Integrating multiple API's together like AssemblyAI for speech transcription, ElevenLabs for speech generation, Cohere, and the implementation of a RAG through a complex pipeline with minimal latency!
## 🌐What we learned
* How Auth0 requires HTTPS protocol(always fascinating how we don't have to reinvent the wheel for authenticating users!)
* Our first time hosting on GoDaddy(especially a cool project domain!)
* Building and running production-fast pipelines that have minimal latency to maximize user experience!
## 🚀What's next for TheraVibe.VR
* In the exciting journey ahead, TheraVibe.VR aspires to revolutionize personalized therapy by reducing latency, expanding our immersive scenes, and introducing features like virtual running. Our future goals include crafting an even more seamless and enriching experience and pushing the boundaries of therapeutic possibilities for all our users. | ## Inspiration
We all deal with nostalgia. Sometimes we miss our loved ones or places we visited and look back at our pictures. But what if we could revolutionize the way memories are shown? What if we said you can relive your memories and mean it literally?
## What it does
retro.act takes in a user prompt such as "I want uplifting 80s music" and will then use sentiment analysis and Cohere's chat feature to find potential songs out of which the user picks one. Then the user chooses from famous dance videos (such as by Michael Jackson). Finally, we will either let the user choose an image from their past or let our model match images based on the mood of the music and implant the dance moves and music into the image/s.
## How we built it
We used Cohere classify for sentiment analysis and to filter out songs whose mood doesn't match the user's current state. Then we use Cohere's chat and RAG based on the database of filtered songs to identify songs based on the user prompt. We match images to music by first generating a caption of the images using the Azure computer vision API doing a semantic search using KNN and Cohere embeddings and then use Cohere rerank to smooth out the final choices. Finally we make the image come to life by generating a skeleton of the dance moves using OpenCV and Mediapipe and then using a pretrained model to transfer the skeleton to the image.
## Challenges we ran into
This was the most technical project any of us have ever done and we had to overcome huge learning curves. A lot of us were not familiar with some of Cohere's features such as re rank, RAG and embeddings. In addition, generating the skeleton turned out to be very difficult. Apart from simply generating a skeleton using the standard Mediapipe landmarks, we realized we had to customize which landmarks we are connecting to make it a suitable input for the pertained model. Lastly, understanding and being able to use the model was a huge challenge. We had to deal with issues such as dependency errors, lacking a GPU, fixing import statements, deprecated packages.
## Accomplishments that we're proud of
We are incredibly proud of being able to get a very ambitious project done. While it was already difficult to get a skeleton of the dance moves, manipulating the coordinates to fit our pre trained model's specifications was very challenging. Lastly, the amount of experimentation and determination to find a working model that could successfully take in a skeleton and output an "alive" image.
## What we learned
We learned about using media pipe and manipulating a graph of coordinates depending on the output we need, We also learned how to use pre trained weights and run models from open source code. Lastly, we learned about various new Cohere features such as RAG and re rank.
## What's next for retro.act
Expand our database of songs and dance videos to allow for more user options, and get a more accurate algorithm for indexing to classify iterate over/classify the data from the db. We also hope to make the skeleton's motions more smooth for more realistic images. Lastly, this is very ambitious, but we hope to make our own model to transfer skeletons to images instead of using a pretrained one. | losing |
## Inspiration
3D Printing offers quick and easy access to a physical design from a digitized mesh file. Transferring a physical model back into a digitized mesh is much less successful or accessible in a desktop platform. We sought to create our own desktop 3D scanner that could generate high fidelity, colored and textured meshes for 3D printing or including models in computer graphics. The build is named after our good friend Greg who let us borrow his stereocamera for the weekend, enabling this project.
## How we built it
The rig uses a ZED stereocamera driven by a ROS wrapper to take stereo images at various known poses in a spiral which is executed with precision by two stepper motors driving a leadscrew elevator and a turn table for the model to be scanned. We designed the entire build in a high detail CAD using Autodesk Fusion 360, 3D printed L-brackets and mounting hardware to secure the stepper motors to the T-slot aluminum frame we cut at the metal shop at Jacobs Hall. There are also 1/8th wood pieces that were laser cut at Jacobs, including the turn table itself. We designed the power system around an Arduino microcontroller and and an Adafruit motor shield to drive the steppers. The Arduino and the ZED camera are controlled by python over a serial port and a ROS wrapper respectively to automate the process of capturing the images used as an input to OpenMVG/MVS to compute dense point clouds and eventually refined meshes.
## Challenges we ran into
We ran into a few minor mechanical design issues that were unforeseen in the CAD, luckily we had access to a 3D printer throughout the entire weekend and were able to iterate quickly on the tolerancing of some problematic parts. Issues with the AccelStepper library for Arduino used to simultaneously control the velocity and acceleration of 2 stepper motors slowed us down early Sunday evening and we had to extensively read the online documentation to accomplish the control tasks we needed to. Lastly, the complex 3D geometry of our rig (specifically rotation and transformation matrices of the cameras in our defined world coordinate frame) slowed us down and we believe is still problematic as the hackathon comes to a close.
## Accomplishments that we're proud of
We're proud of the mechanical design and fabrication, actuator precision, and data collection automation we achieved in just 36 hours. The outputted point clouds and meshes are still be improved. | ## Inspiration
With an ever-increasing rate of crime, and internet deception on the rise, Cyber fraud has become one of the premier methods of theft across the world. From frivolous scams like phishing attempts, to the occasional Nigerian prince who wants to give you his fortune, it's all too susceptible for the common person to fall in the hands of an online predator. With this project, I attempted to amend this situation, beginning by focusing on the aspect of document verification and credentialization.
## What does it do?
SignRecord is an advanced platform hosted on the Ethereum Inter-Planetary File System (an advanced peer-to-peer hyper media protocol, built with the intentions of making the web faster, safer, and more open). Connected with secure DocuSign REST API's, and the power of smart contracts to store data, SignRecord acts as an open-sourced wide-spread ledger of public information, and the average user's information. By allowing individuals to host their data, media, and credentials on the ledger, they are given the safety and security of having a proven blockchain verify their identity, protecting them from not only identity fraud but also from potential wrongdoers.
## How I built it
SignRecord is a responsive web app backed with the robust power of both NodeJS and the Hyperledger. With authentication handled by MongoDB, routing by Express, front-end through a combination of React and Pug, and asynchronous requests through Promise it offers a fool-proof solution.
Not only that, but I've also built and incorporated my own external API, so that other fellow developers can easily integrate my platform directly into their applications.
## Challenges I ran into
The real question should be what Challenge didn't I run into. From simple mistakes like missing a semi-colon, to significant headaches figuring out deprecated dependencies and packages, this development was nothing short of a roller coaster.
## Accomplishments that I'm proud of
Of all of the things that I'm proud of, my usage of the Ethereum Blockchain, DocuSign API's, and the collective UI/UX of my application stand out as the most significant achievements I made in this short 36-hour period. I'm especially proud, that I was able to accomplish what I could, alone.
## What I learned
Like any good project, I learnt more than I could have imagined. From learning how to use advanced MetaMask libraries to building my very own API, this journey was nothing short of a race with hurdles at every mark.
## What's next for SignRecord
With the support of fantastic mentors, a great hacking community, and the fantastic sponsors, I hope to be able to continue expanding my platform in the near future. | ## Inspiration
This idea came somewhat from the founder of arduino, and how he said that it was key to try and make new technology accessible to more people in order to foster better innovation. This led us to making a useful tool that ideally would make scanner, a previously more cut-off technology, to be made available to the general public.
## What it does
This app simply scans an object, creates a point cloud of its surface, and then creates a 3D model of that object using a bit of convex hull math. The object's original point cloud, after statistical filtering, is also made available to the user, and the 3D model that we get is immediately ready to be 3D printed by the user, or directly imported into other modeling programs like Solidworks.
## How we built it
The app is based off of ARkit, which uses stereoscopic images to matches pixels from multiple images to a single point cloud. It uses some statistics in python on the backend to process the data before making it all available to the user.
## Challenges we ran into
The initial idea was to make the 3D models appear in a hologram machine that we built ourselves. While the machine did come together nicely, the motor we had simply wasn't strong or fast enough to create the illusion of the hologram. Therefore, half of the project had to be scrapped.
## Accomplishments that we're proud of
Even though most of our hardware hack didn't end up working out at all, we still managed to put together a huge awesome project that could potentially be extended into the future.
## What we learned
Swift is hard when using AR.
## What's next for iScan
More development and polishing into the future | winning |
# Inspiration
Traditional startup fundraising is often restricted by stringent regulations, which make it difficult for small investors and emerging founders to participate. These barriers favor established VC firms and high-networth individuals, limiting innovation and excluding a broad range of potential investors. Our goal is to break down these barriers by creating a decentralized, community-driven fundraising platform that democratizes startup investments through a Decentralized Autonomous Organization, also known as DAO.
# What It Does
To achieve this, our platform leverages blockchain technology and the DAO structure. Here’s how it works:
* **Tokenization**: We use blockchain technology to allow startups to issue digital tokens that represent company equity or utility, creating an investment proposal through the DAO.
* **Lender Participation**: Lenders join the DAO, where they use cryptocurrency, such as USDC, to review and invest in the startup proposals.
-**Startup Proposals**: Startup founders create proposals to request funding from the DAO. These proposals outline key details about the startup, its goals, and its token structure. Once submitted, DAO members review the proposal and decide whether to fund the startup based on its merits.
* **Governance-based Voting**: DAO members vote on which startups receive funding, ensuring that all investment decisions are made democratically and transparently. The voting is weighted based on the amount lent in a particular DAO.
# How We Built It
### Backend:
* **Solidity** for writing secure smart contracts to manage token issuance, investments, and voting in the DAO.
* **The Ethereum Blockchain** for decentralized investment and governance, where every transaction and vote is publicly recorded.
* **Hardhat** as our development environment for compiling, deploying, and testing the smart contracts efficiently.
* **Node.js** to handle API integrations and the interface between the blockchain and our frontend.
* **Sepolia** where the smart contracts have been deployed and connected to the web application.
### Frontend:
* **MetaMask** Integration to enable users to seamlessly connect their wallets and interact with the blockchain for transactions and voting.
* **React** and **Next.js** for building an intuitive, responsive user interface.
* **TypeScript** for type safety and better maintainability.
* **TailwindCSS** for rapid, visually appealing design.
* **Shadcn UI** for accessible and consistent component design.
# Challenges We Faced, Solutions, and Learning
### Challenge 1 - Creating a Unique Concept:
Our biggest challenge was coming up with an original, impactful idea. We explored various concepts, but many were already being implemented.
**Solution**:
After brainstorming, the idea of a DAO-driven decentralized fundraising platform emerged as the best way to democratize access to startup capital, offering a novel and innovative solution that stood out.
### Challenge 2 - DAO Governance:
Building a secure, fair, and transparent voting system within the DAO was complex, requiring deep integration with smart contracts, and we needed to ensure that all members, regardless of technical expertise, could participate easily.
**Solution**:
We developed a simple and intuitive voting interface, while implementing robust smart contracts to automate and secure the entire process. This ensured that users could engage in the decision-making process without needing to understand the underlying blockchain mechanics.
## Accomplishments that we're proud of
* **Developing a Fully Functional DAO-Driven Platform**: We successfully built a decentralized platform that allows startups to tokenize their assets and engage with a global community of investors.
* **Integration of Robust Smart Contracts for Secure Transactions**: We implemented robust smart contracts that govern token issuance, investments, and governance-based voting bhy writing extensice unit and e2e tests.
* **User-Friendly Interface**: Despite the complexities of blockchain and DAOs, we are proud of creating an intuitive and accessible user experience. This lowers the barrier for non-technical users to participate in the platform, making decentralized fundraising more inclusive.
## What we learned
* **The Importance of User Education**: As blockchain and DAOs can be intimidating for everyday users, we learned the value of simplifying the user experience and providing educational resources to help users understand the platform's functions and benefits.
* **Balancing Security with Usability**: Developing a secure voting and investment system with smart contracts was challenging, but we learned how to balance high-level security with a smooth user experience. Security doesn't have to come at the cost of usability, and this balance was key to making our platform accessible.
* **Iterative Problem Solving**: Throughout the project, we faced numerous technical challenges, particularly around integrating blockchain technology. We learned the importance of iterating on solutions and adapting quickly to overcome obstacles.
# What’s Next for DAFP
Looking ahead, we plan to:
* **Attract DAO Members**: Our immediate focus is to onboard more lenders to the DAO, building a large and diverse community that can fund a variety of startups.
* **Expand Stablecoin Options**: While USDC is our starting point, we plan to incorporate more blockchain networks to offer a wider range of stablecoin options for lenders (EURC, Tether, or Curve).
* **Compliance and Legal Framework**: Even though DAOs are decentralized, we recognize the importance of working within the law. We are actively exploring ways to ensure compliance with global regulations on securities, while maintaining the ethos of decentralized governance. | ## Inspiration
There are 1.1 billion people without Official Identity (ID). Without this proof of identity, they can't get access to basic financial and medical services, and often face many human rights offences, due the lack of accountability.
The concept of a Digital Identity is extremely powerful.
In Estonia, for example, everyone has a digital identity, a solution was developed in tight cooperation between the public and private sector organizations.
Digital identities are also the foundation of our future, enabling:
* P2P Lending
* Fractional Home Ownership
* Selling Energy Back to the Grid
* Fan Sharing Revenue
* Monetizing data
* bringing the unbanked, banked.
## What it does
Our project starts by getting the user to take a photo of themselves. Through the use of Node JS and AWS Rekognize, we do facial recognition in order to allow the user to log in or create their own digital identity. Through the use of both S3 and Firebase, that information is passed to both our dash board and our blockchain network!
It is stored on the Ethereum blockchain, enabling one source of truth that corrupt governments nor hackers can edit.
From there, users can get access to a bank account.
## How we built it
Front End: | HTML | CSS | JS
APIs: AWS Rekognize | AWS S3 | Firebase
Back End: Node JS | mvn
Crypto: Ethereum
## Challenges we ran into
Connecting the front end to the back end!!!! We had many different databases and components. As well theres a lot of accessing issues for APIs which makes it incredibly hard to do things on the client side.
## Accomplishments that we're proud of
Building an application that can better the lives people!!
## What we learned
Blockchain, facial verification using AWS, databases
## What's next for CredID
Expand on our idea. | ## Inspiration
Medical imaging, in this case histopathological tissue images, is generally incomprehensible to a layperson, even though these tissue images are extremely vital in diagnosing breast cancer and estimating the aggressiveness of the cancer. To even begin understanding these images and ensuring thorough, accurate diagnoses requires second opinions from multiple gold-standard pathologists and doctors who can manually identify tumor types and grades, which is oftentimes financially unsustainable and also inefficient for medical practitioners with many patients.
## What it does
Bean provides an effective way for individuals with little to no medical experience to understand histopathological tissue imaging for breast cancer, reducing economic costs associated with having to get many second opinions as well as informing the patient about their condition in a straightforward manner. It analyzes the cancer grades and therefore the aggressiveness of the cancer using a modified Nottingham grading system, and identifies and analyzes the tissue as benign or malignant based off of nuclear pleomorphism, tubular formation, and mitotic count. The images are annotated in a way such that a layperson can understand the issues present in the images in a clear and efficient way.
## How we built it
We used Flask to build the web app, along with a combination of HTML/CSS/JavaScript. We use Google Cloud to train a machine learning model that is capable of regional classification. Then, using REST API, we integrate the model with our web app, creating a seamless experience for the user to upload images and analyze histology images.
## Challenges we ran into
It was difficult to find a sufficient data set in the time that we had, because most medical images are only partially publicly available to preserve patient privacy. We ran into challenges training our model and connecting the front-end and back-end. We were also initially unfamiliar with Google Cloud and how to use it. Also, at first, we were unable to run the web server and implement Flask to create the app.
## Accomplishments that we're proud of
Our model is trained to be 78% accurate, which, although is not extremely high, is impressive given the amount of time (< 1 day) of training and lack of pre-processing data. While we achieved this accuracy using Google Cloud's ML toolkit, we believe that we can achieve higher values in the future through original research. In addition, we are proud of how robust our software is. Not only is it able to point out individual cells, but it is also able to point out the type of tumor, lesions, and frequency of mitotic events.
## What we learned
This experience proved to be a challenging feat for us. All of us came in with barely any background in medical imaging, and it was our first time utilizing a machine learning based cloud software. As a diverse team, our group split into groups of two: front-end and back-end for figuring out how to improve the UI/UX and getting the machine-learning based model to work, respectively. After working for a weekend, we learned about how we can all come together in software engineering from our diverse background, and how the diversity in thought between us sparked innovation and creativity.
## What's next for Bean
In the future, we hope to expand Bean to medical practitioners as well as the current audience of laypeople, because not only would an accurate model that effectively and efficiently reads histopathological images reduce costs, it would also make an accurate diagnosis more efficient and available to more people. With more time and data, we could also perfect our model and make it even more accurate, as well as implement more precise grading techniques. | winning |
## Inspiration
Ever wish you could hear your baby cry where you are in the world? Probably not, but it's great to know anyways! Did you know that babies often cry when at least one of their needs is not met? How could possibly know about baby's needs without being there watching the baby sleep?
## What it does
Our team of 3 visionaries present to you **the** innovation of the 21st century. Using just your mobile phone and an internet connection, you can now remotely receive updates on whether or not your baby is crying, and whether your baby has reached dangerously high temperatures.
## How we built it
We used AndroidStudio for building the app that receives the updates. We used Socket.io for the backend communication between the phone and the Intel Edison.
## Challenges we ran into
Attempting to make push notifications work accounted for a large portion of time spent building this prototype. In the future versions, push notifications would be included.
## Accomplishments that we're proud of
We are proud of paving the future of baby-to-mobile communications for fast footed parents around the globe.
## What we learned
As software people we are proud that we were to able to communicate with the Intel Edison.
## What's next for Baby Monitor
Push notifications. Stay tuned!! | ## Problem Statement
As the number of the elderly population is constantly growing, there is an increasing demand for home care. In fact, the market for safety and security solutions in the healthcare sector is estimated to reach $40.1 billion by 2025.
The elderly, disabled, and vulnerable people face a constant risk of falls and other accidents, especially in environments like hospitals, nursing homes, and home care environments, where they require constant supervision. However, traditional monitoring methods, such as human caregivers or surveillance cameras, are often not enough to provide prompt and effective responses in emergency situations. This potentially has serious consequences, including injury, prolonged recovery, and increased healthcare costs.
## Solution
The proposed app aims to address this problem by providing real-time monitoring and alert system, using a camera and cloud-based machine learning algorithms to detect any signs of injury or danger, and immediately notify designated emergency contacts, such as healthcare professionals, with information about the user's condition and collected personal data.
We believe that the app has the potential to revolutionize the way vulnerable individuals are monitored and protected, by providing a safer and more secure environment in designated institutions.
## Developing Process
Prior to development, our designer used Figma to create a prototype which was used as a reference point when the developers were building the platform in HTML, CSS, and ReactJs.
For the cloud-based machine learning algorithms, we used Computer Vision, Open CV, Numpy, and Flask to train the model on a dataset of various poses and movements and to detect any signs of injury or danger in real time.
Because of limited resources, we decided to use our phones as an analogue to cameras to do the live streams for the real-time monitoring.
## Impact
* **Improved safety:** The real-time monitoring and alert system provided by the app helps to reduce the risk of falls and other accidents, keeping vulnerable individuals safer and reducing the likelihood of serious injury.
* **Faster response time:** The app triggers an alert and sends notifications to designated emergency contacts in case of any danger or injury, which allows for a faster response time and more effective response.
* **Increased efficiency:** Using cloud-based machine learning algorithms and computer vision techniques allow the app to analyze the user's movements and detect any signs of danger without constant human supervision.
* **Better patient care:** In a hospital setting, the app could be used to monitor patients and alert nurses if they are in danger of falling or if their vital signs indicate that they need medical attention. This could lead to improved patient care, reduced medical costs, and faster recovery times.
* **Peace of mind for families and caregivers:** The app provides families and caregivers with peace of mind, knowing that their loved ones are being monitored and protected and that they will be immediately notified in case of any danger or emergency.
## Challenges
One of the biggest challenges have been integrating all the different technologies, such as live streaming and machine learning algorithms, and making sure they worked together seamlessly.
## Successes
The project was a collaborative effort between a designer and developers, which highlights the importance of cross-functional teams in delivering complex technical solutions. Overall, the project was a success and resulted in a cutting-edge solution that can help protect vulnerable individuals.
## Things Learnt
* **Importance of cross-functional teams:** As there were different specialists working on the project, it helped us understand the value of cross-functional teams in addressing complex challenges and delivering successful results.
* **Integrating different technologies:** Our team learned the challenges and importance of integrating different technologies to deliver a seamless and effective solution.
* **Machine learning for health applications:** After doing the research and completing the project, our team learned about the potential and challenges of using machine learning in the healthcare industry, and the steps required to build and deploy a successful machine learning model.
## Future Plans for SafeSpot
* First of all, the usage of the app could be extended to other settings, such as elderly care facilities, schools, kindergartens, or emergency rooms to provide a safer and more secure environment for vulnerable individuals.
* Apart from the web, the platform could also be implemented as a mobile app. In this case scenario, the alert would pop up privately on the user’s phone and notify only people who are given access to it.
* The app could also be integrated with wearable devices, such as fitness trackers, which could provide additional data and context to help determine if the user is in danger or has been injured. | ## Inspiration
When we began to learn about the AssemblyAI API, the features and the impressively extensive abilities of this API had us wanting to do something with audio transcription for our project.
## What it does
Our project is a web app that takes in a URL link to a youtube video, and generates a text transcription of the english spoken words in the audio of that youtube video. We have an additional functionality that can summarize the text transcription, keeping the most important points of the transcribed text.
## How we built it
The backend functionality is all done in python using AssemblyAPI, the process is as follows:
* A youtube link is sent to the script via the website
* The corresponding youtube video's audio track is fetched
* The audio track is analyzed and transcribed using AssemblyAPI
* The transcribed text is outputted
And for the summarization functionality:
* A large string is inputted to the summary script
* The script uses the nltk librairy to help generate a summary of the inputted text
* The summary is outputted
The website is developed using NodeJS with a ExpressJS framework. We developed interaction functionality so that the user could input a youtube link to the website and it would communicate with our backend scripts to achieve the results we wanted.
## Challenges we ran into
Learning AssemblyAPI was fun, but figuring out how to call and specify exactly what we wanted turned out to be a challenge in and of itself.
Another challenge we ran into was around halfway through our development process, we had a lot of scripts that all did different things, and we had to figure out how to best link them together to end up at our desired functionality.
Making the website function was a huge task, and mostly taken upon by one of our team members with the most experience in the area.
## Accomplishments that we're proud of
* The overall look and design of our webpage
* The way our backend scripts work together and work with the AssemblyAI API
* The website's functionality
* Figuring out that one thing that was wrong with the configuration on one of our team member's computers that wasted ~3-4 hours.
## What we learned
* How to use the AssemblyAI API
* How to code backend scripts that can be used by a website for the frontend
* Building our teamwork skills
## What's next for RecapHacks
* Tweaking the website functionality to be more functional and streamlined | winning |
## 💫 Inspiration
Inspired by our grandparents, who may not always be able to accomplish certain tasks, we wanted to create a platform that would allow them to find help locally . We also recognize that many younger members of the community might be more knowledgeable or capable of helping out. These younger members may be looking to make some extra money, or just want to help out their fellow neighbours.
We present to you.... **Locall!**
## 🏘 What it does
Locall helps members of a neighbourhood get in contact and share any tasks that they may need help with. Users can browse through these tasks, and offer to help their neighbours. Those who post the tasks can also choose to offer payment for these services. It's hard to trust just anyone to help you out with daily tasks, but you can always count on your neighbours!
For example, let's say an elderly woman can't shovel her driveway today. Instead of calling a big snow plowing company, she can post a service request on Locall, and someone in her local community can reach out and help out! By using Locall, she's saving money on fees that the big companies charge, while also helping someone else in the community make a bit of extra money. Plenty of teenagers are looking to make some money whenever they can, and we provide a platform for them to get in touch with their neighbours.
## 🛠 How we built it
We first prototyped our app design using Figma, and then moved on to using Flutter for actual implementation. Learning Flutter from scratch was a challenge, as we had to read through lots of documentation. We also stored and retrieved data from Firebase
## 🦒 What we learned
Learning a new language can be very tiring, but also very rewarding! This weekend, we learned how to use Flutter to build an iOS app. We're proud that we managed to implement some special features into our app!
## 📱 What's next for Locall
* We would want to train a Tensorflow model to better recommend services to users, as well as improve the user experience
* Implementing chat and payment directly in the app would be helpful to improve requests and offers of services | ## Inspiration
In response to recent tragic events in Turkey, where the rescue efforts for the Earthquake have been very difficult. We decided to use Qualcomm’s hardware development kit to create an application for survivors of natural disasters like earthquakes to send out distress signals to local authorities.
## What it does
Our app aids disaster survivors by sending a distress signal with location & photo, chatbot updates on rescue efforts & triggering actuators on an Arduino, which helps rescuers find survivors.
## How we built it
We built it using Qualcomm’s hardware development kit and Arduino Due as well as many APIs to help assist our project goals.
## Challenges we ran into
We faced many challenges as we programmed the android application. Kotlin is a new language to us, so we had to spend a lot of time reading documentation and understanding the implementations. Debugging was also challenging as we faced errors that we were not familiar with. Ultimately, we used online forums like Stack Overflow to guide us through the project.
## Accomplishments that we're proud of
The ability to develop a Kotlin App without any previous experience in Kotlin. Using APIs such as OPENAI-GPT3 to provide a useful and working chatbox.
## What we learned
How to work as a team and work in separate subteams to integrate software and hardware together. Incorporating iterative workflow.
## What's next for ShakeSafe
Continuing to add more sensors, developing better search and rescue algorithms (i.e. travelling salesman problem, maybe using Dijkstra's Algorithm) | ## Inspiration -
I got inspired for making this app when I saw that my friends and family who sometimes tend to not have enough internet bandwidth to spare to an application, and signal drops make calling someone a cumbersome task. Messaging was not included in this app, since I wanted it to be light-weight. It also achieves another goal; making people have a one-on-one conversation, which has reduced day by day as people have started using texting a lot.
## What it does -
This app helps people make calls to their friends/co-workers/acquaintances without using too much of internet bandwidth, when signal drops are frequent and STD calls are not possible. The unavailability of messaging feature helps save more internet data and forces people to talk instead of texting. This helps people be more socially active among their friends.
## How I built it -
This app encompasses multiple technologies and frameworks. This app is a combination of Flutter, Android and Firebase developed with the help of Dart and Java. It was a fun task to make all the UI elements and then inculcate them into the main frontend of the application. The backend uses Google Firebase for it's database and authentication, which is a service from Google for hosting apps with lots of features, and uses Google Cloud platform for all the work. Connecting the frontend and backend was not an easy task, especially for a single person, hence **the App is still under development phase and not yet fully functional.**
## Challenges we ran into -
This whole idea was a pretty big challenge for me. This is my first project in Flutter, and I have never done something on this large scale, so I was totally skeptical about the completion of the project and it's elements. The majority of the time was dedicated to the frontend of the application, but the backend was a big problem especially for a beginner like me, hence the incomplete status.
## Accomplishments that we're proud of -
Despite many of the challenges I ran into, I'm extremely proud of what I've been able to produce over the course of these 36 hours.
## What I learned -
I learned a lot about Flutter and Firebase, and frontend-backend services in general. I learned how to make many new UI widgets and features, a lot of new plugins, connecting Android SDKs to the app and using them for smooth functioning. I learned how Firebase authenticates users and their emails/passwords with the built in authentications features, and how it stores data in containerized formats and uses it in projects, which will be very helpful in my future. One more important thing I learned was how I could keep my code organized and better formatted for easier changes whenever required. And lastly, I learned a lot about Git and how it is useful for such projects.
## What's next for Berufung -
I hope this app will be fully-functioning, and we will add new features such as 2 Factor Authentication, Video calling, and group calling. | winning |
## Inspiration
The inspiration for this project was a group-wide understanding that trying to scroll through a feed while your hands are dirty or in use is near impossible. We wanted to create a computer program to allow us to scroll through windows without coming into contact with the computer, for eating, chores, or any other time when you do not want to touch your computer. This idea evolved into moving the cursor around the screen and interacting with a computer window hands-free, making boring tasks, such as chores, more interesting and fun.
## What it does
HandsFree allows users to control their computer without touching it. By tilting their head, moving their nose, or opening their mouth, the user can control scrolling, clicking, and cursor movement. This allows users to use their device while doing other things with their hands, such as doing chores around the house. Because HandsFree gives users complete **touchless** control, they’re able to scroll through social media, like posts, and do other tasks on their device, even when their hands are full.
## How we built it
We used a DLib face feature tracking model to compare some parts of the face with others when the face moves around.
To determine whether the user was staring at the screen, we compared the distance from the edge of the left eye and the left edge of the face to the edge of the right eye and the right edge of the face. We noticed that one of the distances was noticeably bigger than the other when the user has a tilted head. Once the distance of one side was larger by a certain amount, the scroll feature was disabled, and the user would get a message saying "not looking at camera."
To determine which way and when to scroll the page, we compared the left edge of the face with the face's right edge. When the right edge was significantly higher than the left edge, then the page would scroll up. When the left edge was significantly higher than the right edge, the page would scroll down. If both edges had around the same Y coordinate, the page wouldn't scroll at all.
To determine the cursor movement, we tracked the tip of the nose. We created an adjustable bounding box in the center of the users' face (based on the average values of the edges of the face). Whenever the nose left the box, the cursor would move at a constant speed in the nose's position relative to the center.
To determine a click, we compared the top lip Y coordinate to the bottom lip Y coordinate. Whenever they moved apart by a certain distance, a click was activated.
To reset the program, the user can look away from the camera, so the user can't track a face anymore. This will reset the cursor to the middle of the screen.
For the GUI, we used Tkinter module, an interface to the Tk GUI toolkit in python, to generate the application's front-end interface. The tutorial site was built using simple HTML & CSS.
## Challenges we ran into
We ran into several problems while working on this project. For example, we had trouble developing a system of judging whether a face has changed enough to move the cursor or scroll through the screen, calibrating the system and movements for different faces, and users not telling whether their faces were balanced. It took a lot of time looking into various mathematical relationships between the different points of someone's face. Next, to handle the calibration, we ran large numbers of tests, using different faces, distances from the screen, and the face's angle to a screen. To counter the last challenge, we added a box feature to the window displaying the user's face to visualize the distance they need to move to move the cursor. We used the calibrating tests to come up with default values for this box, but we made customizable constants so users can set their boxes according to their preferences. Users can also customize the scroll speed and mouse movement speed to their own liking.
## Accomplishments that we're proud of
We are proud that we could create a finished product and expand on our idea *more* than what we had originally planned. Additionally, this project worked much better than expected and using it felt like a super power.
## What we learned
We learned how to use facial recognition libraries in Python, how they work, and how they’re implemented. For some of us, this was our first experience with OpenCV, so it was interesting to create something new on the spot. Additionally, we learned how to use many new python libraries, and some of us learned about Python class structures.
## What's next for HandsFree
The next step is getting this software on mobile. Of course, most users use social media on their phones, so porting this over to Android and iOS is the natural next step. This would reach a much wider audience, and allow for users to use this service across many different devices. Additionally, implementing this technology as a Chrome extension would make HandsFree more widely accessible. | ## Inspiration
I've always been fascinated by the complexities of UX design, and this project was an opportunity to explore an interesting mode of interaction. I drew inspiration from the futuristic UIs that movies have to offer, such as Minority Report's gesture-based OS or Iron Man's heads-up display, Jarvis.
## What it does
Each window in your desktop is rendered on a separate piece of paper, creating a tangible version of your everyday computer. It is fully featured desktop, with specific shortcuts for window management.
## How I built it
The hardware is combination of a projector and a webcam. The camera tracks the position of the sheets of paper, on which the projector renders the corresponding window. An OpenCV backend does the heavy lifting, calculating the appropriate translation and warping to apply.
## Challenges I ran into
The projector was initially difficulty to setup, since it has a fairly long focusing distance. Also, the engine that tracks the pieces of paper was incredibly unreliable under certain lighting conditions, which made it difficult to calibrate the device.
## Accomplishments that I'm proud of
I'm glad to have been able to produce a functional product, that could possibly be developed into a commercial one. Furthermore, I believe I've managed to put an innovative spin to one of the oldest concepts in the history of computers: the desktop.
## What I learned
I learned lots about computer vision, and especially on how to do on-the-fly image manipulation. | ## Inspiration
We were inspired by a group member's real need.
## What it does
It calculates the start and end time for each task when you enter a task and the minutes you want to spend on it, but when you complete a task, it updates the rest of your tasks to start at the current time to reflect not always staying on schedule.
## How we built it
## Challenges we ran into
## Accomplishments that we're proud of
## What we learned
## What's next for ToDo | winning |
## Inspiration
We always want to create a resume that will impress employers. The problem is fitting your resume to their expectations. How well or far off are you from the goalpost? We came up with the idea of ResumeReviser because it could help people looking or not looking for employment gauge how well their resumes meet those expectations.
## What it does
ResumeReviser is a Flask-based web application that allows users to upload their resumes in PDF format, enter a job listing, and receive feedback on the match percentage between the resume and the specified job listing. The application uses natural language processing techniques, specifically cosine similarity, to analyze the textual content of the resume and job listing, providing users with a percentage indicating how well their resume aligns with the specified job requirements.
## How we built it
We used Flask as our framework and SQLite3 as our database. We used multiple libraries to read our PDF files and then interpret the words on them. We then handled the comparison and assessed the job listing description and the resume to determine if they fit the role they were trying to apply for.
## Challenges we ran into
Most of the team had previously worked with Flask or SQL in a full-stack project. We also were working with limited time as we arrived late Friday evening. With the project, we found great difficulty maintaining data between user sessions. We had to figure out how to properly use the SQL database to avoid losing the comparison between job listings and user-uploaded resumes.
## Accomplishments that we're proud of
We integrated other technologies, such as Bootstrap, to improve the user experience further and create a pleasing general user interface. We successfully developed and researched the algorithms necessary to match the important keywords to their job descriptions.
## What we learned
We learned how to collaborate with multiple new technologies and the problems of doing so. How to set up the necessary virtual environment, set up schema, and access an SQL database. Consequently, it also taught us how to deal with user files and maintain their concurrency through sessions. We experimented with Bootstrap features on the front end to create a pleasing interface.
## What's next for ResumeReview
Improved user interface design.
Advanced analysis features or suggestions based on the resume and job listing.
Error handling and validation improvements.
Security enhancements. | ## Inspiration
As busy university students with multiple commitments on top of job hunting, we are all too familiar with the tedium and frustration associated with having to compose cover letters for the few job openings that do require them. Given that much of cover letter writing is simply summarizing one's professional qualifications to tie in with company specific information, we have decided to exploit the formulaic nature of such writing and create a web application to generate cover letters with minimal user inputs.
## What it does
hire-me-pls is a web application that obtains details of the user’s qualifications from their LinkedIn profile, performs research on the provided target company, and leverages these pieces of information to generate a customized cover letter.
## How we built it
For our front end, we utilized JavaScript with React, leveraging the Tailwind CSS framework for the styling of the site. We designed the web application such that once we have obtained the user’s inputs (LinkedIn profile url, name of target company), we send these inputs to the backend.
In the backend, built in Python with Fast API, we extract relevant details from the provided LinkedIn profile using the Prospeo API, extracted relevant company information by querying with the Metaphor API, and finally feeding these findings into Open AI to generate a customized cover letter for our user.
## Challenges we ran into
In addition to the general bugs and unexpected delays that comes with any project of this scale, our team was challenged with finding a suitable API for extracting relevant data from a given LinkedIn profile. Since much of the tools available on the market are targeted towards recruiters, their functionalities and pricing are often incompatible with our requirements for this web application. After spending a surprising amount of time on research, we settled on Prospeo, which returns data in the convenient JSON format, provides fast consistent responses, and offers a generous free tier option that we could leverage.
Another challenge we have encountered were the CORS issues that arose when we first tried making requests to the Prospeo API from the front end. After much trial and error, we finally resolved these issues by moving all of our API calls to the backend of our application.
## Accomplishments that we're proud of
A major hurdle that we are proud to have overcome throughout the development process is the fact that half of our team of hackers are beginners (where PennApps is their very first hackathon). Through thoughtful delegation of tasks and the patient mentorship of the more seasoned programmers on the team, we were able to achieve the high productivity necessary for completing this web application within the tight deadline.
## What we learned
Through building hire-me-pls, we have gained a greater appreciation for what is achievable when we strategically combine different API’s and AI tools to build off each other. In addition, the beginners on the team gained not only valuable experience contributing to a complex project in a fast-paced environment, but also exposure to useful web development tools that they can use in future personal projects.
## What's next for hire-me-pls
While hire-me-pls already achieves much of our original vision, we recognize that there are always ways to make a good thing better.
In refining hire-me-pls, we aim to improve the prompt that we provide to Open AI to achieve cover letters that are even more concise and specific to the users’ qualifications and their companies of interest.
Further down the road, we would like to explore the possibility of tailoring cover letters to specific roles/job postings at a given company, providing a functionality to generate cold outreach emails to recruiters, and finally, ways of detecting how likely an anti-AI software would detect a hire-me-pls output as being AI generated. | ## Inspiration
Covid-19 has turned every aspect of the world upside down. Unwanted things happen, situation been changed. Lack of communication and economic crisis cannot be prevented. Thus, we develop an application that can help people to survive during this pandemic situation by providing them **a shift-taker job platform which creates a win-win solution for both parties.**
## What it does
This application offers the ability to connect companies/manager that need employees to cover a shift for their absence employee in certain period of time without any contract. As a result, they will be able to cover their needs to survive in this pandemic. Despite its main goal, this app can generally be use to help people to **gain income anytime, anywhere, and with anyone.** They can adjust their time, their needs, and their ability to get a job with job-dash.
## How we built it
For the design, Figma is the application that we use to design all the layout and give a smooth transitions between frames. While working on the UI, developers started to code the function to make the application work.
The front end was made using react, we used react bootstrap and some custom styling to make the pages according to the UI. State management was done using Context API to keep it simple. We used node.js on the backend for easy context switching between Frontend and backend. Used express and SQLite database for development. Authentication was done using JWT allowing use to not store session cookies.
## Challenges we ran into
In the terms of UI/UX, dealing with the user information ethics have been a challenge for us and also providing complete details for both party. On the developer side, using bootstrap components ended up slowing us down more as our design was custom requiring us to override most of the styles. Would have been better to use tailwind as it would’ve given us more flexibility while also cutting down time vs using css from scratch.Due to the online nature of the hackathon, some tasks took longer.
## Accomplishments that we're proud of
Some of use picked up new technology logins while working on it and also creating a smooth UI/UX on Figma, including every features have satisfied ourselves.
Here's the link to the Figma prototype - User point of view: [link](https://www.figma.com/proto/HwXODL4sk3siWThYjw0i4k/NwHacks?node-id=68%3A3872&scaling=min-zoom)
Here's the link to the Figma prototype - Company/Business point of view: [link](https://www.figma.com/proto/HwXODL4sk3siWThYjw0i4k/NwHacks?node-id=107%3A10&scaling=min-zoom)
## What we learned
We learned that we should narrow down the scope more for future Hackathon so it would be easier and more focus to one unique feature of the app.
## What's next for Job-Dash
In terms of UI/UX, we would love to make some more improvement in the layout to better serve its purpose to help people find an additional income in job dash effectively. While on the developer side, we would like to continue developing the features. We spent a long time thinking about different features that will be helpful to people but due to the short nature of the hackathon implementation was only a small part as we underestimated the time that it will take. On the brightside we have the design ready, and exciting features to work on. | partial |
# MSNewsAR
news.microsoft.com with video content as a supplement to images in AR. Dynamic parsing of the page for images and finding related videos with caching on backend. Proof of concept at NWHacks2019 | ## Inspiration
Personal assistant AI like Siri, Cortana and Alexa were the inspiration for our project.
## What it does
Our mirror displays information about the weather, date, social media, news and nearby events.
## How we built it
The mirror works by placing a monitor behind a two-way mirror and displaying information using multiple APIs. We integrated a Kinect so users can select that's being displayed using various gestures. We hosted our project with Azure
## Challenges we ran into
Integrating the Kinect
## Accomplishments that we're proud of
Integrating as many components as we did including the Kinect
## What we learned
How to use Microsoft Azure and work with various APIs as well as use Visual Studio to interact with the Kinect
## What's next for Microsoft Mirror
Implementing more features! We would like to explore more of Microsoft's Cognitive Services as well as utilize the Kinect in a more refined fashion. | ## Inspiration
Video games evolved when the Xbox Kinect was released in 2010 but for some reason we reverted back to controller based games. We are here to bring back the amazingness of movement controlled games with a new twist- re innovating how mobile games are played!
## What it does
AR.cade uses a body part detection model to track movements that correspond to controls for classic games that are ran through an online browser. The user can choose from a variety of classic games such as temple run, super mario, and play them with their body movements.
## How we built it
* The first step was setting up opencv and importing the a body part tracking model from google mediapipe
* Next, based off the position and angles between the landmarks, we created classification functions that detected specific movements such as when an arm or leg was raised or the user jumped.
* Then we correlated these movement identifications to keybinds on the computer. For example when the user raises their right arm it corresponds to the right arrow key
* We then embedded some online games of our choice into our front and and when the user makes a certain movement which corresponds to a certain key, the respective action would happen
* Finally, we created a visually appealing and interactive frontend/loading page where the user can select which game they want to play
## Challenges we ran into
A large challenge we ran into was embedding the video output window into the front end. We tried passing it through an API and it worked with a basic plane video, however the difficulties arose when we tried to pass the video with the body tracking model overlay on it
## Accomplishments that we're proud of
We are proud of the fact that we are able to have a functioning product in the sense that multiple games can be controlled with body part commands of our specification. Thanks to threading optimization there is little latency between user input and video output which was a fear when starting the project.
## What we learned
We learned that it is possible to embed other websites (such as simple games) into our own local HTML sites.
We learned how to map landmark node positions into meaningful movement classifications considering positions, and angles.
We learned how to resize, move, and give priority to external windows such as the video output window
We learned how to run python files from JavaScript to make automated calls to further processes
## What's next for AR.cade
The next steps for AR.cade are to implement a more accurate body tracking model in order to track more precise parameters. This would allow us to scale our product to more modern games that require more user inputs such as Fortnite or Minecraft. | partial |
## Inspiration
With more people working at home due to the pandemic, we felt empowered to improve healthcare at an individual level. Existing solutions for posture detection are expensive, lack cross-platform support, and often require additional device purchases. We sought to remedy these issues by creating Upright.
## What it does
Upright uses your laptop's camera to analyze and help you improve your posture. Register and calibrate the system in less than two minutes, and simply keep Upright open in the background and continue working. Upright will notify you if you begin to slouch so you can correct it. Upright also has the Upright companion iOS app to view your daily metrics.
Some notable features include:
* Smart slouch detection with ML
* Little overhead - get started in < 2 min
* Native notifications on any platform
* Progress tracking with an iOS companion app
## How we built it
We created Upright’s desktop app using Electron.js, an npm package used to develop cross-platform apps. We created the individual pages for the app using HTML, CSS, and client-side JavaScript. For the onboarding screens, users fill out an HTML form which signs them in using Firebase Authentication and uploads information such as their name and preferences to Firestore. This data is also persisted locally using NeDB, a local JavaScript database. The menu bar addition incorporates a camera through a MediaDevices web API, which gives us frames of the user’s posture. Using Tensorflow’s PoseNet model, we analyzed these frames to determine if the user is slouching and if so, by how much. The app sends a desktop notification to alert the user about their posture and also uploads this data to Firestore. Lastly, our SwiftUI-based iOS app pulls this data to display metrics and graphs for the user about their posture over time.
## Challenges we ran into
We faced difficulties when managing data throughout the platform, from the desktop app backend to the frontend pages to the iOS app. As this was our first time using Electron, our team spent a lot of time discovering ways to pass data safely and efficiently, discussing the pros and cons of different solutions. Another significant challenge was performing the machine learning on the video frames. The task of taking in a stream of camera frames and outputting them into slouching percentage values was quite demanding, but we were able to overcome several bugs and obstacles along the way to create the final product.
## Accomplishments that we're proud of
We’re proud that we’ve come up with a seamless and beautiful design that takes less than a minute to setup. The slouch detection model is also pretty accurate, something that we’re pretty proud of. Overall, we’ve built a robust system that we believe outperforms other solutions using just the webcamera of your computer, while also integrating features to track slouching data on your mobile device.
## What we learned
This project taught us how to combine multiple complicated moving pieces into one application. Specifically, we learned how to make a native desktop application with features like notifications built-in using Electron. We also learned how to connect our backend posture data with Firestore to relay information from our Electron application to our OS app. Lastly, we learned how to integrate a machine learning model in Tensorflow within our Electron application.
## What's next for Upright
The next step is improving the posture detection model with more training data, tailored for each user. While the posture detection model we currently use is pretty accurate, by using more custom-tailored training data, it would take Upright to the next level. Another step for Upright would be adding Android integration for our mobile app, which currently only supports iOS as of now. | ## Inspiration
We love cooking and watching food videos. From the Great British Baking Show to Instagram reels, we are foodies in every way. However, with the 119 billion pounds of food that is wasted annually in the United States, we wanted to create a simple way to reduce waste and try out new recipes.
## What it does
lettuce enables users to create a food inventory using a mobile receipt scanner. It then alerts users when a product approaches its expiration date and prompts them to notify their network if they possess excess food they won't consume in time. In such cases, lettuce notifies fellow users in their network that they can collect the surplus item. Moreover, lettuce offers recipe exploration and automatically checks your pantry and any other food shared by your network's users before suggesting new purchases.
## How we built it
lettuce uses React and Bootstrap for its frontend and uses Firebase for the database, which stores information on all the different foods users have stored in their pantry. We also use a pre-trained image-to-text neural network that enables users to inventory their food by scanning their grocery receipts. We also developed an algorithm to parse receipt text to extract just the food from the receipt.
## Challenges we ran into
One big challenge was finding a way to map the receipt food text to the actual food item. Receipts often use annoying abbreviations for food, and we had to find databases that allow us to map the receipt item to the food item.
## Accomplishments that we're proud of
lettuce has a lot of work ahead of it, but we are proud of our idea and teamwork to create an initial prototype of an app that may contribute to something meaningful to us and the world at large.
## What we learned
We learned that there are many things to account for when it comes to sustainability, as we must balance accessibility and convenience with efficiency and efficacy. Not having food waste would be great, but it's not easy to finish everything in your pantry, and we hope that our app can help find a balance between the two.
## What's next for lettuce
We hope to improve our recipe suggestion algorithm as well as the estimates for when food expires. For example, a green banana will have a different expiration date compared to a ripe banana, and our scanner has a universal deadline for all bananas. | ## Inspiration
There are a growing number of smart posture sensors being developed to address back and neck pain. These wearable products showcase improved posture during phone use as a key success metric.
The downside to this, though, is the high cost of buying the hardware product and getting used to wearing it for use in daily life. (Will you pay $50 to wear something on your neck/back and remember to put it back on everyday after a shower?)
This got us thinking... What if we could improve posture without an expensive wearable? Why not use the phone itself for both posture recognition and user intervention?
## Our Solution
**Simple Posture detection**
We found that neck angle can be approximated by phone orientation! Most users keep their phone parallel to their face.
**Effortless intervention**
By adjusting screen brightness based on posture, we're able to create a natural feedback loop to improve posture! Users will subconsciously adjust the orientation of their phone to better view content, thus improving their posture.
 | winning |
## Inspiration
We wanted this project to be able to help us share our love of music with others who may not be able to enjoy it through sound alone. Inspired by our love of music as well as technology, we hoped to make things more accessible for people with our passion for technology.
## What it does
Our ASL Music Generator takes in the user's choice of song/artist and returns the lyrics, translating it to American Sign Language
## How we built it.
We started by setting up our workspace, working on **Replit** at the start to make collaboration easier for our team, and in the later stage - GitHub and VSCode. Essentially, we prompt engineered a prompt to call using the Groq API so that we could return song lyrics with the user\_inputted variables **song\_name** and **artist**. We used javascript to connect the front-end and back-end in receiving information. We used Figma to brainstorm the format and structure of our app.
## Challenges we ran into
We ran into a lot of challenges with the setup of the project because we had spent a lot of time downloading a lot of packages as we wanted to use a large and complicated model that was able to translate text to pose/animation (American Sign Language). One of the more difficult processes was combining the front end with the back end in terms getting the song lyrics and inputting into the LLM that translates the lyrics into HamNoSys and animation/pose format. We also ran into some challenges when using Replit, it was super helpful when collaborating with a team but we also ran into a lot of efficiency issues when downloading the packages we needed to get the model to run. At the end, we had to transfer all of our code we had made on Replit into VSCode and still had to use GitHub the model we were implementing was too large.
## Accomplishments that we're proud of
We're really proud of the fact that we were able to condense such a large and complicated model to fit our project.
## What we learned
We learned that we can sleep in any position when we're tired. We also learned how to sign language "We are cooked" (No but we actually had a fun time learning a couple of sign language phrases). Additionally, we gained more experience in full-stack web development and creating a project centered around an AI model.
## What's next for ASL Lyric Generator
Our next plan is to successfully deploy the ASL Lyric Generator is to maybe implement some learning and educational features. Right now it's a lyric generator to make music more accessible to people, but we want to make this a learning experience, helping people learn sign-language through music!
`Credit for the sign.mt LLM`
[Translate Model GitHub Repo](https://github.com/sign/translate.git) | ## Inspiration
We loved the idea of Image analysis and wanted to develop and app that would utilize the powerful capabilities of Microsoft's API.
## What it does
A user can upload their image on our webapp and find out which artwork from our database they look most like. Users can also add other works of art to our database to increase the variance of our Art database.
## How we built it
We used a Python-Flask framework as our webserver. mLab hosts our MongoDB and we utilize Microsoft's Face API and their SDK. We initially worked on the backend to get the program working. As we got half of the backend working, half the team started to work on the front end.
## Challenges we ran into
Coming up with idea was pretty challenging and took up a lot of time on the first day. The other challenges we were facing were utilizing an online app engine due to permission rights to write data. Given a couple more hours, we are confident that we could have this app on a live site.
## Accomplishments that we're proud of
We are extremely proud of having a working product that utilizes such a powerful tool as Microsoft Face API. We are also thrilled that we were able to use 3 sponsor's products together in one application.
## What we learned
We learned a lot about Microsoft's API's, Google's App Engine (although not utilized in this version), as well as how a user can upload a file, how to store it in a database, and how to serve it back to them.
## What's next for Doppel-Art-Ganger
We hope to deploy Doppel-Art-Ganger on a live domain as well as clean up the code, increase the Art database, and test it on our friends and family. | ## Inspiration
As someone who has always wanted to speak in ASL (American Sign Language), I have always struggled with practicing my gestures, as I, unfortunately, don't know any ASL speakers to try and have a conversation with. Learning ASL is an amazing way to foster an inclusive community, for those who are hearing impaired or deaf. DuoASL is the solution for practicing ASL for those who want to verify their correctness!
## What it does
DuoASL is a learning app, where users can sign in to their respective accounts, and learn/practice their ASL gestures through a series of levels.
Each level has a *"Learn"* section, with a short video on how to do the gesture (ie 'hello', 'goodbye'), and a *"Practice"* section, where the user can use their camera to record themselves performing the gesture. This recording is sent to the backend server, where it is validated with our Action Recognition neural network to determine if you did the gesture correctly!
## How we built it
DuoASL is built up of two separate components;
**Frontend** - The Frontend was built using Next.js (React framework), Tailwind and Typescript. It handles the entire UI, as well as video collection during the *"Learn"* Section, which it uploads to the backend
**Backend** - The Backend was built using Flask, Python, Jupyter Notebook and TensorFlow. It is run as a Flask server that communicates with the front end and stores the uploaded video. Once a video has been uploaded, the server runs the Jupyter Notebook containing the Action Recognition neural network, which uses OpenCV and Tensorflow to apply the model to the video and determine the most prevalent ASL gesture. It saves this output to an array, which the Flask server reads and responds to the front end.
## Challenges we ran into
As this was our first time using a neural network and computer vision, it took a lot of trial and error to determine which actions should be detected using OpenCV, and how the landmarks from the MediaPipe Holistic (which was used to track the hands and face) should be converted into formatted data for the TensorFlow model. We, unfortunately, ran into a very specific and undocumented bug with using Python to run Jupyter Notebooks that import Tensorflow, specifically on M1 Macs. I spent a short amount of time (6 hours :) ) trying to fix it before giving up and switching the system to a different computer.
## Accomplishments that we're proud of
We are proud of how quickly we were able to get most components of the project working, especially the frontend Next.js web app and the backend Flask server. The neural network and computer vision setup was pretty quickly finished too (excluding the bugs), especially considering how for many of us this was our first time even using machine learning on a project!
## What we learned
We learned how to integrate a Next.js web app with a backend Flask server to upload video files through HTTP requests. We also learned how to use OpenCV and MediaPipe Holistic to track a person's face, hands, and pose through a camera feed. Finally, we learned how to collect videos and convert them into data to train and apply an Action Detection network built using TensorFlow
## What's next for DuoASL
We would like to:
* Integrate video feedback, that provides detailed steps on how to improve (using an LLM?)
* Add more words to our model!
* Create a practice section that lets you form sentences!
* Integrate full mobile support with a PWA! | losing |
## Inspiration
A team member saw their mom working and repeating the same steps over and over on her computer. Open an excel sheet, copy 10 lines, tab into another sheet, paste, scroll, repeat. These monotonous tasks are a time waster which is terrible especially since the technology exists to automate these tasks. The problem is that most people aren't aware, have forgotten, or find it to complicated which is why we aim to reintroduce this technology in a simple manner that anyone can use. An application that could automate such repetitive tasks would not only save time but also could have other uses. For example, individuals that have arthritis may find it challenging to complete tasks on the computer that require repetitive movement on an everyday basis. We offer an application that can take these repetitive movements and simplify it to 1 click.
## What it does
Our program, dubbed "Ekko", serves to:
1. Reduce menial/repetitive tasks
2. Increase accessibility to mouse and keyboard actions for those with diseases/disabilities
3. Aids those who aren’t technologically literate
Users will be able to record any series of clicks, cursor movements and key presses as they would like, and save this sequence. They would then be able to play it back at will whenever they desire.
## How we built it
To create this application we used various Python libraries. In the backend we had to implement the *Pynput* library which allowed tracking of clicks, cursor movement and key presses. We have individual threads set up for monitoring both keyboard and mouse actions at the same time. In the front end, we used QtDesigner and *PyQt5* to design our GUI. Using Python
Libraries/Software: *Pynput*, *PyQt5*, QtDesigner, *Multithreading*
Used *Pynput* to track and record cursor movement and keypresses and clicks
Used *PyQt5* and *QtDesigner* to design the GUI
## Challenges we ran into
Initially, without the use of the *Multithreading* library our program would crash after one use. It took a lot of time to figure out what the exact problem was and how to allow for recording of cursor and keyboard inputs while the Python program was running. Getting the GUI to interface with the recording/playing scripts was also annoying. A bit of a funny obstacle we encountered was that while 1 team member was following a tutorial he didn't realize they were alternating between Spanish and English while writing code which led to a few confusing errors.
## Accomplishments that we're proud of
We had created a timeline for our project with deadlines for specific tasks. We were able to stick to this schedule and complete our project in a timely manner, even though we were busy. We also successfully implemented a program with a working GUI. Finally, it was the first hackathon experience for 2 of our members so it was nice to have a finished product which often doesn't happen on an individual's first hackathon.
## What we learned
We learned many new tech skills such as how to create GUI's, using threads, how to track keyboard and mouse input. We also learned important soft skills such as time management. These skills will be useful in whatever future projects we decide to pursue.
## What's next for Ekko: Automate Your Computer
Implementing voice recognition to make automating tasks more accessible. The movements of the cursor can also be more accurate during repetition. | ## Inspiration
With the sudden move to online videoconferencing, presenters and audiences have been faced with a number of challenges. Foremost among these is a lack of engagement between presenters and the audience, which is exacerbated by a lack of gestures and body language. As first year students, we have seen this negatively impact our learning throughout both high school and our first year of University. In fact, many studies, such as [link](https://dl.acm.org/doi/abs/10.1145/2647868.2654909), emphasize the direct link between gestures and audience engagement. As such, we wanted to find a way to give presenters the opportunity to increase audience engagement through bringing natural presentations techniques to videoconferencing.
## What it does
PGTCV is a Python program that allows users to move back from their camera and incorporate body language into their presentations without losing fundamental control. In its current state, the Python script uses camera information to determine whether a user needs their slides to be moved forwards or backwards. To trigger these actions, users raise their left fist to enable the program to listen for instructions. They can then swipe with their palm out to the left or to the right to trigger a forwards or backwards slide change. This process allows users to use common body language and hand gestures without accidentally triggering the controls.
## How we built it
After fetching webcam data through OpenCV2, we use Google's MediaPipe library to receive a co-ordinate representation of any hands on-screen. This is then fed through a pre-trained algorithm to listen for any left-hand controlling gestures. Once a control gesture is found, we track right-hand motion gestures, and simulate the relevant keyboard input using pynput in whatever application the user is focused on. The application also creates a new virtual camera in a host Windows machine using pyvirtualcam and Unity Capture since Windows only allows one application to use any single camera device. The virtual camera can be used by any videoconferencing application.
## Challenges we ran into
Inability to get IDEs working. Mac M1 chip not supporting Tensorflow. Inability to use webcam in multiple applications at once. Setting up right-hand gesture recognition with realistic thresholds.
## Accomplishments that we're proud of
Successfully implementing our idea in our first hackathon. Getting a functional and relatively bug-free version of the program running with time to spare. Learning to successfully work with a number of technologies that we previously had no experience with (everything other than Python).
## What we learned
A number of relevant technologies. Implementing simple computer vision algorithms. Taking code from idea to functional prototype in a limited amount of time.
## What's next for Presentation Gestures Through Computer Vision (PGTCV)
A better name. Implementation of a wider range of gestures. Optimization of algorithms. Increased accuracy in detecting gestures. Implementation into existing videoconferencing applications. | ## Inspiration
**Handwriting is such a beautiful form of art that is unique to every person, yet unfortunately, it is not accessible to everyone.**
[Parkinson’s](www.parkinson.org/Understanding-Parkinsons/Statistics) affects nearly 1 million people in the United States and more than 6 million people worldwide. For people who struggle with fine motor skills, picking up a pencil and writing is easier said than done. *We want to change that.*
We were inspired to help people who find difficulty in writing, whether it be those with Parkinson's or anyone else who has lost the ability to write with ease. We believe anyone, whether it be those suffering terminal illnesses, amputated limbs, or simply anyone who cannot write easily, should all be able to experience the joy of writing!
## What it does
Hand Spoken is an innovative solution that combines the ease of writing with the beauty of an individual's unique handwriting.
All you need to use our desktop application is an old handwritten letter saved by you! Simply pick up your paper of handwriting (or handwriting of choice) and take a picture. After submitting the picture into our website database, you are all set. Then, simply speak into the computer either using a microphone or a voice technology device. The user of the desktop application will automatically see their text appear on the screen in their own personal handwriting font! They can then save their message for later use.
## How we built it
We created a desktop application using C# with Visual Studio's WinForm framework. Handwriting images uploaded to the application is sent via HTTP request to the backend, where a python server identifies each letter using pytesseract. The recognized letters are used to generate a custom font, which is saved to the server. Future audio files recorded by the frontend are also sent into the backend, at which point AWS Transcribe services are contacted, giving us the transcribed text. This text is then processed using the custom handwriting font, being eventually returned to the frontend, ready to be downloaded by the user.
## Challenges we ran into
One main challenge our team ran into was working with pytesseract. To overcome this obstacle, we made sure we worked collaboratively as a team to divide roles and learn how to use these exciting softwares.
## Accomplishments that we're proud of
We are proud of creating a usable and functional database that incorporates UX/UI design!
## What we learned
Not only did we learn lots about OCR (Optical Character Recognition) and AWS Transcribe services, but we learned how to collaborate effectively as a team and maximize each other's strengths.
## What's next for Hand Spoken
Building upon on our idea and creating accessibility **for all** through the use of technology! | losing |
## Inspiration
The indecisiveness that groups encounter when trying to collectively decide on a place to get food.
## What it does
It decides on where a group can eat through an algorithm that chooses out of some preset criteria such price point, location, food inclusivity and more.
## How we built it
Frontend: React Native, Nativewind which formally was TailwindCSS
Backend: python, MongoDB, MindsDB
Backend tools: Azure
## Challenges we ran into
As far as tales have been told and hackathons have ran, we fell down to the good old deployment stage.
## Accomplishments that we're proud of
This was the first hackathon for one member of our team. Kudos for staying 2 nights for the very first hackathon.
## What we learned
For the first time, we explored the idea AND pursued our idea of creating a mobile app.
The importance of being on the same page because it has left a lot of problems down the road. We realized that some had different ideas/perspectives of implementing certain parts that would just not be feasible to combine all.
## What's next for Tender
There are many cross-paths to where Tender can lead to. Tender was a product after much pivoting. During the process of thinking, coding and submitting Tender, there have been numerous thoughts that have been passed by just by the sheer stress of finishing within the time crunch. Our immediate goal would be to produce a fully working demo of what our app could achieve by integrating the different parts of the application that everyone worked on. We also hope to add more features and refinements that we did not have the capacity to entertain during the hackathon itself. | ## Inspiration
Our inspiration came from the very real and pressing issue of choosing where to eat as a group. Everyone has experienced the endless back-and-forth that occurs when a group of indecisive friends try to decide on a restaurant. We wanted to create a solution that not only makes this process effortless but also fun and engaging for everyone involved.
## What it does
MunchMatch simplifies the dining decision-making process for groups by matching their collective preferences with local dining options. Users input their individual preferences, dietary restrictions, and budget, and our app does the rest — compiling a list of restaurant matches that satisfy the group's criteria. Its democracy meets gastronomy, ensuring that the final choice is one that everyone can get excited about.
## How we built it
We built MunchMatch using a combination of React Native for cross-platform support to deploy on both iOS and Android platforms, and Node.js and Express/MongoDB for the backend, which handles user data and preferences and integrates with various APIs for real-time data. We focused on a seamless and intuitive UI/UX to make the process as straightforward as possible.
## Challenges we ran into
As with any great hack, there was no shortage of challenges we ran into as we progressed throughout the hackathon. We spent a long time in the ideation phase (around 24 hours!) going back and forth between ideas we'd want to work on and challenges we were interested in. Once we did begin work, the biggest challenges were setting up all our different environments to work with the code, learning new languages and frameworks in the time we had left, working with the Google Maps API, and integrating - connecting the back and front end.
## Accomplishments that we're proud of
We were able to create a functional and good-looking app in the short amount of time we had to code, as well as work on mobile development and languages that we were not familiar with before. We also had a great time hacking, meeting new people, and attending workshops!
## What's next for MunchMatch
There are endless possibilities for future development - we could improve the app itself, particularly the UI and UX to make it more functional and easier to use. We can also add the ability to save restaurants and specify cuisines and preferences that a user may have, as well as potential allergies. The other route we could go down is integration within other apps, specifically delivery apps when a large number of people may be delivering food or create extensions for group messaging platforms such as iMessage or WhatsApp that may further increase the number of people our app helps. | Team channel #43
Team discord users - Sarim Zia #0673,
Elly #2476,
(ASK),
rusticolus #4817,
Names -
Vamiq,
Elly,
Sarim,
Shahbaaz
## Inspiration
When brainstorming an idea, we concentrated on problems that affected a large population and that mattered to us. Topics such as homelessness, food waste and a clean environment came up while in discussion. FULLER was able to incorporate all our ideas and ended up being a multifaceted solution that was able to help support the community.
## What it does
FULLER connects charities and shelters to local restaurants with uneaten food and unused groceries. As food prices begin to increase along with homelessness and unemployment we decided to create FULLER. Our website serves as a communication platform between both parties. A scheduled pick-up time is inputted by restaurants and charities are able to easily access a listing of restaurants with available food or groceries for contactless pick-up later in the week.
## How we built it
We used React.js to create our website, coding in HTML, CSS, JS, mongodb, bcrypt, node.js, mern, express.js . We also used a backend database.
## Challenges we ran into
A challenge that we ran into was communication of the how the code was organized. This led to setbacks as we had to fix up the code which sometimes required us to rewrite lines.
## Accomplishments that we're proud of
We are proud that we were able to finish the website. Half our team had no prior experience with HTML, CSS or React, despite this, we were able to create a fair outline of our website. We are also proud that we were able to come up with a viable solution to help out our community that is potentially implementable.
## What we learned
We learned that when collaborating on a project it is important to communicate, more specifically on how the code is organized. As previously mentioned we had trouble editing and running the code which caused major setbacks.
In addition to this, two team members were able to learn HTML, CSS, and JS over the weekend.
## What's next for us
We would want to create more pages in the website to have it fully functional as well as clean up the Front-end of our project. Moreover, we would also like to look into how to implement the project to help out those in need in our community. | losing |
## Inspiration
We got the idea for this app after one of our teammates shared that during her summer internship in China, she could not find basic over the counter medication that she needed. She knew the brand name of the medication in English, however, she was unfamiliar with the local pharmaceutical brands and she could not read Chinese.
## Links
* [FYIs for your Spanish pharmacy visit](http://nolongernative.com/visiting-spanish-pharmacy/)
* [Comparison of the safety information on drug labels in three developed countries: The USA, UK and Canada](https://www.sciencedirect.com/science/article/pii/S1319016417301433)
* [How to Make Sure You Travel with Medication Legally](https://www.nytimes.com/2018/01/19/travel/how-to-make-sure-you-travel-with-medication-legally.html)
## What it does
This mobile app allows users traveling to different countries to find the medication they need. They can input the brand name in the language/country they know and get the name of the same compound in the country they are traveling to. The app provides a list of popular brand names for that type of product, along with images to help the user find the medicine at a pharmacy.
## How we built it
We used Beautiful Soup to scrape Drugs.com to create a database of 20 most popular active ingredients in over the counter medication. We included in our database the name of the compound in 6 different languages/countries, as well as the associated brand names in the 6 different countries.
We stored our database on MongoDB Atlas and used Stitch to connect it to our React Native front-end.
Our Android app was built with Android Studio and connected to the MongoDB Atlas database via the Stitch driver.
## Challenges we ran into
We had some trouble connecting our React Native app to the MongoDB database since most of our team members had little experience with these platforms. We revised the schema for our data multiple times in order to find the optimal way of representing fields that have multiple values.
## Accomplishments that we're proud of
We're proud of how far we got considering how little experience we had. We learned a lot from this Hackathon and we are very proud of what we created. We think that healthcare and finding proper medication is one of the most important things in life, and there is a lack of informative apps for getting proper healthcare abroad, so we're proud that we came up with a potential solution to help travellers worldwide take care of their health.
## What we learned
We learned a lot of React Native and MongoDB while working on this project. We also learned what the most popular over the counter medications are and what they're called in different countries.
## What's next for SuperMed
We hope to continue working on our MERN skills in the future so that we can expand SuperMed to include even more data from a variety of different websites. We hope to also collect language translation data and use ML/AI to automatically translate drug labels into different languages. This would provide even more assistance to travelers around the world. | ## Inspiration
The opioid crisis is a widespread danger, affecting millions of Americans every year. In 2016 alone, 2.1 million people had an opioid use disorder, resulting in over 40,000 deaths. After researching what had been done to tackle this problem, we came upon many pill dispensers currently on the market. However, we failed to see how they addressed the core of the problem - most were simply reminder systems with no way to regulate the quantity of medication being taken, ineffective to prevent drug overdose. As for the secure solutions, they cost somewhere between $200 to $600, well out of most people’s price ranges. Thus, we set out to prototype our own secure, simple, affordable, and end-to-end pipeline to address this problem, developing a robust medication reminder and dispensing system that not only makes it easy to follow the doctor’s orders, but also difficult to disobey.
## What it does
This product has three components: the web app, the mobile app, and the physical device. The web end is built for doctors to register patients, easily schedule dates and timing for their medications, and specify the medication name and dosage. Any changes the doctor makes are automatically synced with the patient’s mobile app. Through the app, patients can view their prescriptions and contact their doctor with the touch of one button, and they are instantly notified when they are due for prescriptions. Once they click on on an unlocked medication, the app communicates with LocPill to dispense the precise dosage. LocPill uses a system of gears and motors to do so, and it remains locked to prevent the patient from attempting to open the box to gain access to more medication than in the dosage; however, doctors and pharmacists will be able to open the box.
## How we built it
The LocPill prototype was designed on Rhino and 3-D printed. Each of the gears in the system was laser cut, and the gears were connected to a servo that was controlled by an Adafruit Bluefruit BLE Arduino programmed in C.
The web end was coded in HTML, CSS, Javascript, and PHP. The iOS app was coded in Swift using Xcode with mainly the UIKit framework with the help of the LBTA cocoa pod. Both front ends were supported using a Firebase backend database and email:password authentication.
## Challenges we ran into
Nothing is gained without a challenge; many of the skills this project required were things we had little to no experience with. From the modeling in the RP lab to the back end communication between our website and app, everything was a new challenge with a lesson to be gained from. During the final hours of the last day, while assembling our final product, we mistakenly positioned a gear in the incorrect area. Unfortunately, by the time we realized this, the super glue holding the gear in place had dried. Hence began our 4am trip to Fresh Grocer Sunday morning to acquire acetone, an active ingredient in nail polish remover. Although we returned drenched and shivering after running back in shorts and flip-flops during a storm, the satisfaction we felt upon seeing our final project correctly assembled was unmatched.
## Accomplishments that we're proud of
Our team is most proud of successfully creating and prototyping an object with the potential for positive social impact. Within a very short time, we accomplished much of our ambitious goal: to build a project that spanned 4 platforms over the course of two days: two front ends (mobile and web), a backend, and a physical mechanism. In terms of just codebase, the iOS app has over 2600 lines of code, and in total, we assembled around 5k lines of code. We completed and printed a prototype of our design and tested it with actual motors, confirming that our design’s specs were accurate as per the initial model.
## What we learned
Working on LocPill at PennApps gave us a unique chance to learn by doing. Laser cutting, Solidworks Design, 3D printing, setting up Arduino/iOS bluetooth connections, Arduino coding, database matching between front ends: these are just the tip of the iceberg in terms of the skills we picked up during the last 36 hours by diving into challenges rather than relying on a textbook or being formally taught concepts. While the skills we picked up were extremely valuable, our ultimate takeaway from this project is the confidence that we could pave the path in front of us even if we couldn’t always see the light ahead.
## What's next for LocPill
While we built a successful prototype during PennApps, we hope to formalize our design further before taking the idea to the Rothberg Catalyzer in October, where we plan to launch this product. During the first half of 2019, we plan to submit this product at more entrepreneurship competitions and reach out to healthcare organizations. During the second half of 2019, we plan to raise VC funding and acquire our first deals with healthcare providers. In short, this idea only begins at PennApps; it has a long future ahead of it. | ## Inspiration
Coding in Spanish is hard. Specifically, Carol had to work in Spanish while contributing to One Laptop per Child, but non-English speakers have this barrier every day. Around the world, many international collaborators work on open and closed source projects but in many cases, this language barrier can pose an additional obstacle to contributing for such projects, especially since English is the only widely supported language for programming. Thus, we aimed to solve this by allowing collaborators to easily translate source code files into their desired language locally, while maintaining the ability to commit in the original language of the project.
## What it does
Polycode is a developer command-line tool, which is also available as an Atom plugin, that lets you translate code to your language. Currently, it supports Python and Javascript in addition to any language that Google Translate supports for translating functionality, with plans in place to support more coding languages in the future.
## How I built it
* Polycode tokenizes identifiers and objects within the source files, then it finds out which strings can be translated
* Backend stdlib API interacts with the Translate API from the Google Cloud Platform
* Local maps are built to ensure 1:1 translations and that translations do not change over time, resulting in breaking changes to the code
## Challenges I ran into
* Parsing source code files and finding identifiers that should be translated i.e. primarily variable and function names
* Handling asynchronous calls to the Translate API within the API created by us in stdlib
## Accomplishments that we're proud of
* Figuring out how to create a pip package to allow for easy installation of command line tools
* Integrating with Atom
## What I learned
* Parsing and overwriting source files is hard
* Google Translate is weird
## What's next for Polycode
* Support more programming languages
* Deploying for the world to use! | winning |
## Inspiration
We were trying for an IM cross MS paint experience, and we think it looks like that.
## What it does
Users can create conversations with other users by putting a list of comma-separated usernames in the To field.
## How we built it
We used Node JS combined with the Express.js web framework, Jade for templating, Sequelize as our ORM and PostgreSQL as our database.
## Challenges we ran into
Server-side challenges with getting Node running, overloading the server with too many requests, and the need for extensive debugging.
## Accomplishments that we're proud of
Getting a (mostly) fully up-and-running chat client up in 24 hours!
## What we learned
We learned a lot about JavaScript, asynchronous operations and how to properly use them, as well as how to deploy a production environment node app.
## What's next for SketchWave
We would like to improve the performance and security of the application, then launch it for our friends and people in our residence to use. We would like to include mobile platform support via a responsive web design as well, and possibly in the future even have a mobile app. | ## Problem
In these times of isolation, many of us developers are stuck inside which makes it hard for us to work with our fellow peers. We also miss the times when we could just sit with our friends and collaborate to learn new programming concepts. But finding the motivation to do the same alone can be difficult.
## Solution
To solve this issue we have created an easy to connect, all in one platform where all you and your developer friends can come together to learn, code, and brainstorm together.
## About
Our platform provides a simple yet efficient User Experience with a straightforward and easy-to-use one-page interface.
We made it one page to have access to all the tools on one screen and transition between them easier.
We identify this page as a study room where users can collaborate and join with a simple URL.
Everything is Synced between users in real-time.
## Features
Our platform allows multiple users to enter one room and access tools like watching youtube tutorials, brainstorming on a drawable whiteboard, and code in our inbuilt browser IDE all in real-time. This platform makes collaboration between users seamless and also pushes them to become better developers.
## Technologies you used for both the front and back end
We use Node.js and Express the backend. On the front end, we use React. We use Socket.IO to establish bi-directional communication between them. We deployed the app using Docker and Google Kubernetes to automatically scale and balance loads.
## Challenges we ran into
A major challenge was collaborating effectively throughout the hackathon. A lot of the bugs we faced were solved through discussions. We realized communication was key for us to succeed in building our project under a time constraints. We ran into performance issues while syncing data between two clients where we were sending too much data or too many broadcast messages at the same time. We optimized the process significantly for smooth real-time interactions.
## What's next for Study Buddy
While we were working on this project, we came across several ideas that this could be a part of.
Our next step is to have each page categorized as an individual room where users can visit.
Adding more relevant tools, more tools, widgets, and expand on other work fields to increase our User demographic.
Include interface customizing options to allow User’s personalization of their rooms.
Try it live here: <http://35.203.169.42/>
Our hopeful product in the future: <https://www.figma.com/proto/zmYk6ah0dJK7yJmYZ5SZpm/nwHacks_2021?node-id=92%3A132&scaling=scale-down>
Thanks for checking us out! | ## Inspiration
According to a 2015 study in the American Journal of Infection Control, people touch their faces more than 20 times an hour on average. More concerningly, about 44% of the time involves contact with mucous membranes (e.g. eyes, nose, mouth).
With the onset of the COVID-19 pandemic ravaging our population (with more than 300 million current cases according to the WHO), it's vital that we take preventative steps wherever possible to curb the spread of the virus. Health care professionals are urging us to refrain from touching these mucous membranes of ours as these parts of our face essentially act as pathways to the throat and lungs.
## What it does
Our multi-platform application (a python application, and a hardware wearable) acts to make users aware of the frequency they are touching their faces in order for them to consciously avoid doing so in the future. The web app and python script work by detecting whenever the user's hands reach the vicinity of the user's face and tallies the total number of touches over a span of time. It presents the user with their rate of face touches, images of them touching their faces, and compares their rate with a **global average**!
## How we built it
The base of the application (the hands tracking) was built using OpenCV and tkinter to create an intuitive interface for users. The database integration used CockroachDB to persist user login records and their face touching counts. The website was developed in React to showcase our products. The wearable schematic was written up using Fritzing and the code developed on Arduino IDE. By means of a tilt switch, the onboard microcontroller can detect when a user's hand is in an upright position, which typically only occurs when the hand is reaching up to touch the face. The device alerts the wearer via the buzzing of a vibratory motor/buzzer and the flashing of an LED. The emotion detection analysis component was built using the Google Cloud Vision API.
## Challenges we ran into
After deciding to use opencv and deep vision to determine with live footage if a user was touching their face, we came to the unfortunate conclusion that there isn't a lot of high quality trained algorithms for detecting hands, given the variability of what a hand looks like (open, closed, pointed, etc.).
In addition to this, the CockroachDB documentation was out of date/inconsistent which caused the actual implementation to differ from the documentation examples and a lot of debugging.
## Accomplishments that we're proud of
Despite developing on three different OSes we managed to get our application to work on every platform. We are also proud of the multifaceted nature of our product which covers a variety of use cases. Despite being two projects we still managed to finish on time.
To work around the original idea of detecting overlap between hands detected and faces, we opted to detect for eyes visible and determine whether an eye was covered due to hand contact.
## What we learned
We learned how to use CockroachDB and how it differs from other DBMSes we have used in the past, such as MongoDB and MySQL.
We learned about deep vision, how to utilize opencv with python to detect certain elements from a live web camera, and how intricate the process for generating Haar-cascade models are.
## What's next for Hands Off
Our next steps would be to increase the accuracy of Hands Off to account for specific edge cases (ex. touching hair/glasses/etc.) to ensure false touches aren't reported. As well, to make the application more accessible to users, we would want to port the application to a web app so that it is easily accessible to everyone. Our use of CockroachDB will help with scaling in the future. With our newfound familliarity with opencv, we would like to train our own models to have a more precise and accurate deep vision algorithm that is much better suited to our project's goals. | winning |
WE MADEZ A FUNNY
U PLAE TIC-TAC-TOE
BUT MAEK WIT LOLCODE | ## Inspiration
It can be difficult for parents to teach and effectively communicate the importance of being independent to their children. All children should eventually be able to support themselves and have the necessary skills to be responsible. A hit Japanese TV show, “Old Enough” which was recently added to Netflix displays children of ages 2-5 years going on tasks outside the house, navigating through the different neighborhoods, and doing the errand given to them by their parents completely alone. Research has shown that these errands are of extreme importance in the development of the child’s social and problem-solving skills. As mentioned in an NPR article:
>
> "Autonomous play has been a really important part of child development throughout human evolutionary history," says behavioral scientist Dorsa Amir at the University of California, Berkeley. "And actually, it was a feature of American society until relatively recently as well."
> This inspired us to create this fun and interactive game for children to have a sort of tutorial for what to expect in the real world and for dealing with common scenarios that they might face.
>
>
>
## What it does
My First Errand is primarily intended for young children that are looking to start, well, their first errand. It helps kick start the learning process to become a responsible, independent individual. It does so in a fun, and interactive way using child-friendly graphics and characters all children are familiar with. There are four errands to complete which are “Learn Your Address”, “Stranger Danger”, “Let’s Get Groceries” and “Call Home”. These are the four most important errands and skills we felt are most important for children to learn. It helps them be safe and resolve any potential danger they can encounter.
My First Errand begins with a home screen where the four main characters of the application are presented to the child playing the game, creating a sense of familiarity and recognition for the important errands. It then transitions them to a dashboard where the child can navigate and start each of the four games.
“Learn Your Address” is a game where the child enters their home address (Obtained from a parent/guardian) and does a memory recall game through a multiple choice mini-game. “Stranger Danger” is another game where the child is informed of safe members in the community they can confidently approach for help. “Let’s Get Groceries” helps teach children how to look for items to buy in a grocery store and use basic addition to pay for the items, ultimately, teaching them how to purchase products. Finally, “Call Home” has the child input their home phone number (Which is also obtained from a parent/guardian) and they again memorize it through a multiple choice mini-game encouraging recall.
## How we built it
My First Errand was built on the React Framework. We wanted something interactive for kids to learn how to run their first errand in a way that didn’t feel like a chore. The reason why we used React was that it is good at one thing, and that is separating a piece of state and allowing us to make the application interactive with it. We used Tailwind CSS for quick prototyping of styles and React Router for navigation between pages. Lastly, Google Cloud Firebase was used for our sign-up system in the React application.
## Challenges we ran into
Of course, the initial challenge we had was thinking of an idea. It took a night of sleeping on ideas and many potential ideas bounced around but this idea was chosen because we believed it would have a great impact on children. Another challenge was technical issues with the development environment for React and GitHub but rather than being set back, the members worked on other elements of the project such as the design mockup and coding functionalities in a similar language. We also worked on merge conflicts together by utilizing the GitHub Desktop application, minimizing the overall merge conflict.
## Accomplishments that we're proud of
We are extremely proud that we came up with an idea for an application and the beginning of the app itself that can help make learning fun for kids and promote safety. We believe this will make a great impact on health, safety, and education for the youth and promote independence at a young age.
We are also proud that we were able to generate an idea, create a beautiful prototype and have the foundation for an application, in a short period of time. We reinforced our communication, collaboration, and organizational skills as well as developed our skills in JavaScript, React, Tailwind as well as Figma.
## What we learned
We learned about how difficult it is to teach such important skills that are common knowledge for adults, to children beginning to be independent. We also learned how to develop an application with React and explore the design capabilities of Figma.
## What's next for My First Errand
Due to time constraints, we weren't able to include all of the errands we had hoped to have in our mockups. The My First Errand team hopes to continue development in the near future. | ## Inspiration
When struggling to learn HTML, and basic web development. The tools provided by browsers like google chrome were hidden making hard to learn of its existence. As an avid gamer, we thought that it would be a great idea to create a game involving the inspect element tool provided by browsers so that more people could learn of this nifty feature, and start their own hacks.
## What it does
The project is a series of small puzzle games that are reliant on the user to modify the webpage DOM to be able to complete. When the user reaches the objective, they are automatically redirected to the next puzzle to solve.
## How we built it
We used a game engine called craftyjs to run the game as DOM elements. These elements could be deleted and an event would be triggered so that we could handle any DOM changes.
## Challenges we ran into
Catching DOM changes from inspect element is incredibly difficult. Working with craftyjs which is in version 0.7.1 and not released therefore some built-ins e.g. collision detection, is not fully supported. Handling various events such as adding and deleting elements instead of recursively creating a ton of things recursively.
## Accomplishments that we're proud of
EVERYTHING
## What we learned
Javascript was not designed to run as a game engine with DOM elements, and modifying anything has been a struggle. We learned that canvases are black boxes and are impossible to interact with through DOM manipulation.
## What's next for We haven't thought that far yet
You give us too much credit.
But we have thought that far. We would love to do more with the inspect element tool, and in the future, if we could get support from one of the major browsers, we would love to add more puzzles based on tools provided by the inspect element option. | losing |
## Inspiration
We were inspired by apps such as GamePigeon (which allows you to play games together over text messages) and Gather (which allows you to have virtual interactions RPG style). We also drew inspiration from Discord’s voice chat activity feature that allows you to play games together in a call.
## What it does
RoundTable is a virtual meeting platform that allows people to connect in the same way they would at a real-life round table discussion: everyone in a room can manipulate and interact with objects or games on the table as they please. However, we take this a step further by providing an easy-to-use API for any developer to create an activity plugin by submitting a single JavaScript file.
## How we built it
We built the client using React and MUI, with Markdown being used to render chat messages. The client is mainly responsible for rendering events that happen on the roundtable and reporting the user’s actions to the server through Socket.io. The server is built with Typescript and also uses Socket.io to establish communication with the client. The server is responsible for managing the game states of specific instances of plugins as well as controlling all aspects of the rooms.
## Challenges we ran into
One challenge we ran into was balancing participating in events and workshops during the hackathon with working on our project. Initially, we had a very ambitious idea for the final product and thought that it was possible if we worked on it as much as possible. However, it soon became clear that in doing so, we would be jeopardizing our own experiences at HTN and we should aim to have a compromise instead. So, we scaled down our idea and in return, were able to participate in many of the amazing events such as real-life among us and the silent disco.
Another challenge was that our team members had a few disagreements about the design and implementation of RoundTable. For example, we had two proposed ideas for how custom plugins could work. One of our group members insisted that we should go with an implementation involving the use of embedded iframes while the others wanted to use direct source files manipulating a canvas. Although we wasted a lot of time debating these issues, eventually a collective decision was reached.
## Accomplishments that we're proud of
We’re proud of the fact that we managed our time much better this time around than in previous hackathons. For example, we were able to decide on an idea ahead of time, flesh it out somewhat, and learn some useful technologies as opposed to previous hackathons when we had to rush to come up with an idea on the day of. Also, we clearly divided our duties and each worked on an equally important part of the application.
## What we learned
Through doing this project, we learned many technical things about creating an RTC web application using SocketIO (which most of us hadn’t used before), React, and Typescript. We also learned to use Material UI together with CSS stylesheets to develop an attractive front-end for the app and to design a robust plugin system that integrates with p5.js to create responsive modules.
In addition, we learned many things about collaboration and how to work better as a team. Looking back, we would not spend as much time debating the advantages and disadvantages of a specific design choice and instead pick one and prepare to implement it as much as possible.
## What's next for RoundTable
Although we are satisfied with what we were able to accomplish in such a short time span, there are still many things that we are looking to add to RoundTable in the future. First of all, we will implement a voice and video chat to improve the level of connection between the participants of the roundtable. Also, we will improve our plugin API by making it more flexible (allowing for modules such as playing a shared video) and an account system so that rooms can be organized easily. Finally, we will improve the security of the application by sandboxing custom modules and doing end-to-end encryption. | ## Inspiration
Rumor has it, if you're good at basketball, you can easily get into CIT. Penn admits many outgoing girls. UChicago likes admitting artists. MIT is excited to see science olympiad recipients.
Some people spend thousands of dollars hiring professional agencies to help with college application. Others post "Chance me" posts desperately on College Confidential.
How do colleges decide who to admit? We are all curious, but no one actually knows.
## What it does
AdmitMe has its unique machine learning algorithm to generate your chances of getting into top US colleges. Students can either log in through their common application account, or manually fill in a form of their personal information. Our web app will provide you a list of colleges of your choice that you are likely to be accepted (in order). You can check detailed statistic information on all the properties. We also provide you with personalized guidance on how you can most efficiently improve your chances, through improving parts of your application and the way you describe your extracurricular activities.
## How we built it
We aggregated over 8000 detailed application information for the top 25 US colleges. The data comes from scraping "Chance" thread in College Confidential and a lot of data processing. The model is trained through diverse standard exam scores, senior course load, extracurricular activities and personal background. We used MongoDB as our database for all the data needed. The web app uses Python, Django, Javascript and html.
## Challenges we ran into
Only one person on the team is familiar with the Django framework, which made it difficult to chain everything together. We ran into compatibility issues with Python 2.7 and Python 3 on the last day of the Hackathon, having to modify the whole algorithm. Natural language processing of self-reported data is challenging as well.
## Accomplishments that we're proud of
We're unique. None of the other college counseling apps are using detailed natural language processing and machine leaning like us. We're able to process 8000 valid and detailed student data from nothing. We developed a 70% accuracy algorithm on top college prediction. We were also able to put a full stack website together in less than 36 hours.
## What we learned
* Django is difficult
* Processing raw data to a good dataset is really time consuming. If we can find better data source in the future, that's a much easier way
* Collaboration is very important for full stack programming, especially using Django
## What's next for AdmitMe
* We will develop a business plan to make our product more complete. (It's more of a prototype right now) The scalability needs to be improved.
* Talk to colleges and agencies to aggregate more complete data to develop a more accurate algorithm
* Market for our product, we are considering B to B (selling to agencies) or B to C (directly to students). We realized there is a huge market in China as well, where 3 out of our 4 team members are from. | ## Inspiration
Reflecting on 2020, we were challenged with a lot of new experiences, such as online school. Hearing a lot of stories from our friends, as well as our own experiences, doing everything from home can be very distracting. Looking at a computer screen for such a long period of time can be difficult for many as well, and ultimately it's hard to maintain a consistent level of motivation. We wanted to create an application that helped to increase productivity through incentives.
## What it does
Our project is a functional to-do list application that also serves as a 5v5 multiplayer game. Players create a todo list of their own, and each completed task grants "todo points" that they can allocate towards their attributes (physical attack, physical defense, special attack, special defense, speed). However, tasks that are not completed serve as a punishment by reducing todo points.
Once everyone is ready, the team of 5 will be matched up against another team of 5 with a preview of everyone's stats. Clicking "Start Game" will run the stats through our algorithm that will determine a winner based on whichever team does more damage as a whole. While the game is extremely simple, it is effective in that players aren't distracted by the game itself because they would only need to spend a few minutes on the application. Furthermore, a team-based situation also provides incentive as you don't want to be the "slacker".
## How we built it
We used the Django framework, as it is our second time using it and we wanted to gain some additional practice. Therefore, the languages we used were Python for the backend, HTML and CSS for the frontend, as well as some SCSS.
## Challenges we ran into
As we all worked on different parts of the app, it was a challenge linking everything together. We also wanted to add many things to the game, such as additional in-game rewards, but unfortunately didn't have enough time to implement those.
## Accomplishments that we're proud of
As it is only our second hackathon, we're proud that we could create something fully functioning that connects many different parts together. We spent a good amount of time on the UI as well, so we're pretty proud of that. Finally, creating a game is something that was all outside of our comfort zone, so while our game is extremely simple, we're glad to see that it works.
## What we learned
We learned that game design is hard. It's hard to create an algorithm that is truly balanced (there's probably a way to figure out in our game which stat is by far the best to invest in), and we had doubts about how our application would do if we actually released it, if people would be inclined to play it or not.
## What's next for Battle To-Do
Firstly, we would look to create the registration functionality, so that player data can be generated. After that, we would look at improving the overall styling of the application. Finally, we would revisit game design - looking at how to improve the algorithm to make it more balanced, adding in-game rewards for more incentive for players to play, and looking at ways to add complexity. For example, we would look at implementing a feature where tasks that are not completed within a certain time frame leads to a reduction of todo points. | losing |
# Inspiration
After talking to Richard White from EDR, we decided that using a graph database to search for patterns seemed like a very interesting problem to solve. Though the problem was narrow, we were able to use existing platforms to efficiently solve the problem.
# What It Does
Graph.srch allows the user to specify parts of a mailing address and retrieve all possible matches from the graph database. In addition, the user can search for two different address parts and see the similarities and differences between the datasets returned.
# How We Built It
The frontend is written in React.js and the backend is written in Python with Flask and a Neo4j Bolt driver. The graph database solution we used was Neo4j with its Cypher query language. The Neo4j database is hosted on Google Cloud.
# Difficulties
We initially intended to host the database with Google Cloud Bigtable, but found setting it up to be more complicated than intended. The datasets given had some addresses with no street address which we had to work around since Cypher's MERGE does not do well with null fields. We also struggled with processing and querying as large of a dataset as we were tasked to handle. Our frontend proved difficult to complete and integrate with the backend because of formatting issues and pagination.
# Accomplishments
We accomplished a lot in 36 hours. Most of us worked with technologies we had never encountered, including graph databases We used Python to interact with the database and learned how to use Cypher to query. Our frontend took a lot of collaboration to get running, including CSS help and getting through JavaScript formatting.
# If We Had More Time
We'd like to deploy Graph.srch on Heroku, Netlify, or a similar platform. Other plans include showing a Google Maps view of addresses for user selection and including a visual of the graph data returned. Fuzzy searching with Levenshtein or Lucene search would also be nice to support. | ## Inspiration
This week a 16 year old girl went missing outside Oslo, in Norway. Her parents posted about it on Facebook, and it was quickly shared by thousands of people. An immense amount of comments scattered around a large amount of Facebook posts consisted of people trying to help, by offering to hang up posters, aid in the search and similar. A Facebook group was started, and grew to over 15 000 people within a day. The girl was found, and maybe a few of the contributions helped?
This is just one example, and similar events probably play out in a large number of countries and communities around the world. Even though Facebook is a really impressive tool for quickly sharing information like this across a huge network, it falls short on the other end - of letting people contribute to the search. Facebook groups are too linear, and has few tools that aid in making this as streamlined as possible. The idea is to create a platform that covers this.
## What it does
Crowd Search is split into two main parts:
* The first part displays structured information about the case, letting people quickly get a grasp of the situation at hand. It makes good use of rich media and UX design, and presents the data in an understandable way.
* The second part is geared around collaboration between volunteers. It allows the moderators of the missing person search to post information, updates and tasks that people can perform to contribute towards.
## How we built it
Crowd Search makes heavy use of Firebase, and is because of this a completely front-end based application, hosted on Firebase Hosting. The application itself is built using React.
By using Firebase our application syncs updates in realtime, whether it's comments, new posts, or something as a simple as a task list checkbox. Firebase also lets us easily define a series of permission rules, to make sure that only authorized moderators and admins can change existing data and similar. Authentication is done using Facebook, through Firebase's authentication provider.
To make development as smooth as possible we make use of a series of utilities:
* We compile our JavaScript files with Babel, which lets us use new ECMAScript 2016+ features.
* We quality check our source code using ESLint (known as linting)
* We use Webpack to bundle all our JS and Sass files together into one bundle, which can then be deployed to any static file host (we're using Firebase Hosting).
## What's next for Crowd Search
The features presented here function as an MVP to showcase what the platform could be used for. There's a lot of possibilities for extension, with a few examples being:
* Interactive maps
* Situational timelines
* Contact information | ## Inspiration
We were inspired by the untapped potential of local businesses and the challenge they face in gaining visibility within crowded marketplaces (especially in major cities). We wanted to create a platform that empowers communities to easily discover and support these hidden gems, while giving businesses the tools to thrive in the smart city ecosystem.
## What it does
Local.ly connects users with local businesses, helping them discover new places and redeem exclusive offers. It provides a seamless platform for businesses to create profiles, promote special deals, and engage directly with their community. Users can browse, find unique businesses, and access deals—all in one place.
## How we built it
We built Local.ly using a combination of frontend and backend technologies. On the frontend, we used React and Tailwind, and for the backend, we used Express.js, Prisma, and PostgresQL. For the backend, we integrated a relational database to more easily manage user and business information, and used the Google OAuth protocol to allow users to sign in with their Google accounts without using a pre-built app that handles the state management of the back and forth between the client, server, and Google.
## Challenges we ran into
One of the biggest challenges we ran into was actually using Prisma with the CRUD operations to our PostgresQL database. We ran into many issues, including some where we faced were circular dependency / infinite recursion and null values from our Prisma query args, which we ended up not being able to fully solve due to a limit of time we had to actually test our solution. For example, we had models Business and Promotion in our schema, where Business has fields locations and promotions, and Promotion has field business, and for some reason the prisma include args would return some data as null, even though we checked the database and the values were actually present.
## Accomplishments that we're proud of
We’re proud of building a platform that empowers local businesses while creating a streamlined experience for users. Successfully overcoming the OAuth challenges and designing a user-friendly interface were also major wins for us. Additionally, our platform highlights businesses in a way that feels both fresh and essential.
## What we learned
Integrating Prisma was more complex than anticipated, especially when managing nested relationships and optimizing queries for performance. We encountered issues with circular dependencies in our data models and had to refactor our schema multiple times to ensure the integrity of our data. This process deepened our understanding of database design and how to efficiently fetch and transform relational data.
## What's next for Local.ly
We plan to expand Local.ly by adding advanced features such as personalized recommendations, real-time business analytics, and integrations with smart city technologies to provide businesses with more insights and users with a tailored experience. We also aim to onboard more local businesses and grow our user base to foster stronger community connections. | partial |
## Inspiration
Public speaking is an incredibly important skill that many seek but few master. This is in part due to the high level of individualized attention and feedback needed to improve when practicing. Therefore, we want to solve this with AI! We have created a VR application that allows you to get constructive feedback as you present, debate, or perform by analyzing your arguments and speaking patterns.
While this was our starting motivation for ArticuLab, we quickly noticed the expansive applications and social impact opportunities for it. ArticuLab could be used by people suffering from social anxiety to help improve their confidence in speaking in front of crowds and responding to contrasting opinions. It could also be used by people trying to become more fluent in a language, since it corrects pronunciation and word choice.
## What it does
ArticuLab uses AI in a VR environment to recommend changes to your pace, argument structure, clarity, and boy language when speaking. It holds the key to individualized public speaking practice. In ArticuLab you also have the opportunity to debate directly against AI, who'll point out all the flaws in your arguments and make counterarguments so you can make your defense rock-solid.
## How we built it
For our prototype, we used Meta's Wit.AI natural language processing software for speech recognition, built a VR environment on Unity, and used OpenAI's powerful ChatGPT to base our feedback system on argument construction and presenting ability. Embedding this into an integrated VR App results in a seamless, consumer-ready experience.
## Challenges we ran into
The biggest challenge we ran into is using the VR headset microphone as input for the speech recognition software, and then directly inputting that to our AI system. What made this so difficult was adapting the formatting from each API onto the next. Within the same thread, we ran into an issue where the microphone input would only last for a few seconds, limiting the dialogue between the user and the AI in a debate. These issues were also difficult to test because of the loud environment we were working in.
Additionally, we had to create a VR environment from scratch, since there were no free assets to fit our needs.
## Accomplishments that we're proud of
We're especially proud of accomplishing such an ambitious project with a team that is majority beginners! Treehacks is three of our integrants' first hackathon, so everyone had to step up and do more work or learn more new skills to implement in our project.
## What we learned
We learned a lot about speech to text software, designing an environment and programming in Unity, adapting the powerful ChatGPT to our needs, and integrating a full-stack VR application.
## What's next for ArticuLab
Naturally, there would be lots more polishing of the cosmetics and user interface of the program, which are currently restricted by financial resources and the time available. Among these, would be making the environment a higher definition with better quality assets, crowd responses, ChatGPT responses with ChatGPT plus, etc.
ArticuLab could be useful both academically and professionally in a variety of fields, education, project pitches like Treehacks, company meetings, event organizers… the list goes on! We would also seek to expand the project to alternate versions adapted for the comfort of the users, for example, a simplified iOS version could be used by public speakers to keep notes on their speech and let them know if they're speaking too fast, too slow, or articulating correctly live! Similarly, such a feature would be integrated into the VR version, so a presenter could have notes on their podium and media to present behind them (powerpoint, video, etc.), simulating an even more realistic presenting experience.
Another idea is adding a multiplayer version that would exponentially expand the uses for ArticuLab. Our program could allow debate teams to practice live in front of a mix of AI and real crowds, similarly, ArticuLab could host online live debates between public figures and politicians in the VR environment. | ## Inspiration
Public speaking is greatly feared by many, yet it is a part of life that most of us have to go through. Despite this, preparing for presentations effectively is *greatly limited*. Practicing with others is good, but that requires someone willing to listen to you for potentially hours. Talking in front of a mirror could work, but it does not live up to the real environment of a public speaker. As a result, public speaking is dreaded not only for the act itself, but also because it's *difficult to feel ready*. If there was an efficient way of ensuring you aced a presentation, the negative connotation associated with them would no longer exist . That is why we have created Speech Simulator, a VR web application used for practice public speaking. With it, we hope to alleviate the stress that comes with speaking in front of others.
## What it does
Speech Simulator is an easy to use VR web application. Simply login with discord, import your script into the site from any device, then put on your VR headset to enter a 3D classroom, a common location for public speaking. From there, you are able to practice speaking. Behind the user is a board containing your script, split into slides, emulating a real powerpoint styled presentation. Once you have run through your script, you may exit VR, where you will find results based on the application's recording of your presentation. From your talking speed to how many filler words said, Speech Simulator will provide you with stats based on your performance as well as a summary on what you did well and how you can improve. Presentations can be attempted again and are saved onto our database. Additionally, any adjustments to the presentation templates can be made using our editing feature.
## How we built it
Our project was created primarily using the T3 stack. The stack uses **Next.js** as our full-stack React framework. The frontend uses **React** and **Tailwind CSS** for component state and styling. The backend utilizes **NextAuth.js** for login and user authentication and **Prisma** as our ORM. The whole application was type safe ensured using **tRPC**, **Zod**, and **TypeScript**. For the VR aspect of our project, we used **React Three Fiber** for rendering **Three.js** objects in, **React XR**, and **React Speech Recognition** for transcribing speech to text. The server is hosted on Vercel and the database on **CockroachDB**.
## Challenges we ran into
Despite completing, there were numerous challenges that we ran into during the hackathon. The largest problem was the connection between the web app on computer and the VR headset. As both were two separate web clients, it was very challenging to communicate our sites' workflow between the two devices. For example, if a user finished their presentation in VR and wanted to view the results on their computer, how would this be accomplished without the user manually refreshing the page? After discussion between using web-sockets or polling, we went with polling + a queuing system, which allowed each respective client to know what to display. We decided to use polling because it enables a severless deploy and concluded that we did not have enough time to setup websockets. Another challenge we had run into was the 3D configuration on the application. As none of us have had real experience with 3D web applications, it was a very daunting task to try and work with meshes and various geometry. However, after a lot of trial and error, we were able to manage a VR solution for our application.
## What we learned
This hackathon provided us with a great amount of experience and lessons. Although each of us learned a lot on the technological aspect of this hackathon, there were many other takeaways during this weekend. As this was most of our group's first 24 hour hackathon, we were able to learn to manage our time effectively in a day's span. With a small time limit and semi large project, this hackathon also improved our communication skills and overall coherence of our team. However, we did not just learn from our own experiences, but also from others. Viewing everyone's creations gave us insight on what makes a project meaningful, and we gained a lot from looking at other hacker's projects and their presentations. Overall, this event provided us with an invaluable set of new skills and perspective.
## What's next for VR Speech Simulator
There are a ton of ways that we believe can improve Speech Simulator. The first and potentially most important change is the appearance of our VR setting. As this was our first project involving 3D rendering, we had difficulty adding colour to our classroom. This reduced the immersion that we originally hoped for, so improving our 3D environment would allow the user to more accurately practice. Furthermore, as public speaking infers speaking in front of others, large improvements can be made by adding human models into VR. On the other hand, we also believe that we can improve Speech Simulator by adding more functionality to the feedback it provides to the user. From hand gestures to tone of voice, there are so many ways of differentiating the quality of a presentation that could be added to our application. In the future, we hope to add these new features and further elevate Speech Simulator. | ## Inspiration
We wanted to design a bottle that was as functional, and simultaneously creative, as possible
## What it does
Our design uses force-sensor technology and wireless interfacing, as well as the help of some intuitive logic, to create a system that actively keeps track and reports the number of pills in a SMART medicine bottle.
## How we built it
For this proof of concept, we modeled a pill bottle in Autodesk Inventor, and developed the code using firebase, react js, and python technologies.
## What we learned
We learned, the not so easy way, that sometimes things don't like to work in under 48 hours. Nevertheless we improvised and hardcoded things and a few things empty, filled in the blanks for data values that should exist but don't due to the lack of hardware available at the time. All in all, this project is a strong proof of concept with medium level overview and a basic boilerplate set up.
## What's next for Smart Medicine Bottle
We plan to physically prototype the design and get our hands on the sensors and their data to get the project working! | winning |
## 💡 Inspiration
>
> #hackathon-help-channel
> `<hacker>` Can a mentor help us with flask and Python? We're stuck on how to host our project.
>
>
>
How many times have you created an epic web app for a hackathon but couldn't deploy it to show publicly? At my first hackathon, my team worked hard on a Django + React app that only lived at `localhost:5000`.
Many new developers don't have the infrastructure experience and knowledge required to deploy many of the amazing web apps they create for hackathons and side projects to the cloud.
We wanted to make a tool that enables developers to share their projects through deployments without any cloud infrastructure/DevOps knowledge
(Also, as 2 interns currently working in DevOps positions, we've been learning about lots of Infrastructure as Code (IaC), Configuration as Code (CaC), and automation tools, and we wanted to create a project to apply our learning.)
## 💭 What it does
InfraBundle aims to:
1. ask a user for information about their project
2. generate appropriate IaC and CaC code configurations
3. bundle configurations with GitHub Actions workflow to simplify deployment
Then, developers commit the bundle to their project repository where deployments become as easy as pushing to your branch (literally, that's the trigger).
## 🚧 How we built it
As DevOps interns, we work with Ansible, Terraform, and CI/CD pipelines in an enterprise environment. We thought that these could help simplify the deployment process for hobbyists as well
InfraBundle uses:
* Ansible (CaC)
* Terraform (IaC)
* GitHub Actions (CI/CD)
* Python and jinja (generating CaC, IaC from templates)
* flask! (website)
## 😭 Challenges we ran into
We're relatitvely new to Terraform and Ansible and stumbled into some trouble with all the nitty-gritty aspects of setting up scripts from scratch.
In particular, we had trouble connecting an SSH key to the GitHub Action workflow for Ansible to use in each run. This led to the creation of temporary credentials that are generated in each run.
With Ansible, we had trouble creating and activating a virtual environment (see: not carefully reading [ansible.builtin.pip](https://docs.ansible.com/ansible/latest/collections/ansible/builtin/pip_module.html) documentation on which parameters are mutually exclusive and confusing the multiple ways to pip install)
In general, hackathons are very time constrained. Unfortunately, slow pipelines do not care about your time constraints.
* hard to test locally
* cluttering commit history when debugging pipelines
## 🏆 Accomplishments that we're proud of
InfraBundle is capable of deploying itself!
In other news, we're proud of the project being something we're genuinely interested in as a way to apply our learning. Although there's more functionality we wished to implement, we learned a lot about the tools used. We also used a GitHub project board to keep track of tasks for each step of the automation.
## 📘 What we learned
Although we've deployed many times before, we learned a lot about automating the full deployment process. This involved handling data between tools and environments. We also learned to use GitHub Actions.
## ❓ What's next for InfraBundle
InfraBundle currently only works for a subset of Python web apps and the only provider is Google Cloud Platform.
With more time, we hope to:
* Add more cloud providers (AWS, Linode)
* Support more frameworks and languages (ReactJS, Express, Next.js, Gin)
* Improve support for database servers
* Improve documentation
* Modularize deploy playbook to use roles
* Integrate with GitHub and Google Cloud Platform
* Support multiple web servers | ## Inspiration
We wanted to watch videos together as a social activity during the pandemic but were unable as many platforms were hard to use or unstable. Therefore our team decided to create a platform that met our needs in terms of usability and functionality.
## What it does
Bubbles allow people to create viewing rooms and invite their rooms to watch synchronized videos. Viewers no longer have to conduct countdowns on their play buttons or have a separate chat while watching!
## How I built it
Our web app uses React for the frontend and interfaces with our Node.js REST API in the backend. The core of our app uses the Solace PubSub+ and the MQTT protocol to coordinate events such as video play/pause, a new member joining your bubble, and instant text messaging. Users broadcast events with the topic being their bubble room code, so only other people in the same room receive these events.
## Challenges I ran into
* Collaborating in a remote environment: we were in a discord call for the whole weekend, using Miro for whiteboarding, etc.
* Our teammates came from various technical backgrounds, and we all had a chance to learn a lot about the technologies we used and how to build a web app
* The project was so much fun we forgot to sleep and hacking was more difficult the next day
## Accomplishments that I'm proud of
The majority of our team was inexperienced in the technologies used. Our team is very proud that our product was challenging and was completed by the end of the hackathon.
## What I learned
We learned how to build a web app ground up, beginning with the design in Figma to the final deployment to GitHub and Heroku. We learned about React component lifecycle, asynchronous operation, React routers with a NodeJS backend, and how to interface all of this with a Solace PubSub+ Event Broker. But also, we learned how to collaborate and be productive together while still having a blast
## What's next for Bubbles
We will develop additional features regarding Bubbles. This includes seek syncing, user join messages and custom privilege for individuals. | ## Inspiration
Adults over the age of 50 take an average of 15 prescription medications annually. Keeping track of this is very challenging.
Pillvisor is a smart pillbox that solves the issue of medication error by verifying the pills are taken correctly in order to keep your loved ones safe. Unlike other products on the market, pillvisor integrates with a real pillbox and is designed with senior users in mind.
As we can imagine, keeping track of the pill schedule is challenging and taking incorrect medications can lead to serious avoidable complications. The most common drugs taken at home that have serious complications from medication errors are cardiovascular drugs and painkillers.
One study found that almost a third of a million Americans contact poison control annually due to medication errors taken at home. One third of the errors result in hospital admissions whose admittance in on a steady rise. This only includes at home errors while medication errors can also occur in health care facilities.
## What it does
Pillvisor is an automated pill box supervisor designed to help people who take many medications on the daily to ensure they actually take the correct pills at the correct time. Unlike many reminder and alarm apps that are wildly available on the app store, our custom pillbox product actually checks that pills are taken so the alarm isn't just turned off and ignored.
## How we built it
The user interface to set the alarms is made with flask and is connected to a firebase.
Our blacked out pillbox uses photo-resistors to detect which day is open and this verifies the pill is removed from the correct day and it does not stop the alarm if an incorrect day is opened. Once the medication is removed a photo of the medication is taken to check that it is indeed the correct medication, otherwise the user will be reminded to try to scan another pill.
We have green LEDs to indicate the correct day of the week. If the user opens an incorrect day or scans the wrong pill a red LED will flash to alert the user. An LCD display to show the medication name and instructions for using the system.
We used tensorflow to develop a machine learning convolutional neural network for image recognition to distinguish the different pills from one another. Our Raspberry PI takes a photo, runs the neural network on it and checks to see if the correct pill has been photographed.
For our user interface, We developed an isolated Flask application which is connected to our firebase database and allows alarms to be set, deleted and edited easily and quickly(for example changing the time or day of a certain alarm). A sync button on the raspberry pi allows it to be constantly up to date with the backend after changes are made on the cloud.
## Challenges we ran into
Due to the complexity of the project, we ran into many issues with both software and hardware. Our biggest challenge for the project was getting the image recognition to work, and produce accurate results due to noise coming from the hand holding the pill. Additionally, getting all the packages and dependencies such as tensorflow and opencv installed onto the system our posed to be a huge challenge
On the hardware side, we ran into issues detecting if the pillbox is opened or closed based on the imperfection in ‘blacking out’ the pillbox. Due to constraints we didn’t have an opaque box.
## Accomplishments that we’re proud of
We did this hackathon to challenge ourselves to use and apply our skills to new technologies that we were unfamiliar with or relatively new with such as databases, flask, machine learning, and hardware. Additionally, this was the first hackathon for 2 of our team members and we are very proud of what we achieved and what we have learned in such a short period of time. We were happy that we were able to integrate hardware and software together for this project and apply our skills from our varying engineering backgrounds.
## What I learned
* How to setup a database
* Machine learning, tensorflow and convolutional neural networks
* Using Flask, learning javascript and html
## What's next for Pillviser
Due to time constraints, we were unable to implement all the features we wanted.
One feature we still need to add is a snooze feature to allow a delay of the alarm by a set amount of time which is useful especially if the medication has eating constraints with it.
Additionally, we want to improve the image recognition on the pills which we believe can be made into a seperate program would be highly valuable in healthcare facilities as a last line of defence as pills are normally handled using patient charts and delivered through a chain of people so it can be an extra line of defence. | winning |
The Book Reading Bot (brb) programmatically flips through physical books, and using TTS reads the pages aloud. There are also options to download the pdf or audiobook.
I read an article on [The Spectator](http://columbiaspectator.com/) how some low-income students cannot afford textbooks, and actually spend time at the library manually scanning the books on their phones. I realized this was a perfect opportunity for technology to help people and eliminate repetitive tasks. All you do is click start on the web app and the software and hardware do the rest!
Another use case is for young children who do not know how to read yet. Using brb, they can read Dr. Seuss alone! As kids nowadays spend too much time on the television, I hope this might lure kids back to children books.
On a high level technical overview, the web app (bootstrap) sends an image to a flask server which uses ocr and tts. | ## Inspiration
As international students, we often have to navigate around a lot of roadblocks when it comes to receiving money from back home for our tuition.
Cross-border payments are gaining momentum with so many emerging markets. In 2021, the top five recipient countries for remittance inflows in current USD were India (89 billion), Mexico (54 billion), China (53 billion), the Philippines (37 billion), and Egypt (32 billion). The United States was the largest source country for remittances in 2020, followed by the United Arab Emirates, Saudi Arabia, and Switzerland.
However, Cross-border payments face 5 main challenges: cost, security, time, liquidity & transparency.
* Cost: Cross-border payments are typically costly due to costs involved such as currency exchange costs, intermediary charges, and regulatory costs.
-Time: most international payments take anything between 2-5 days.
-Security: The rate of fraud in cross-border payments is comparatively higher than in domestic payments because it's much more difficult to track once it crosses the border.
* Standardization: Different countries tend to follow a different set of rules & formats which make cross-border payments even more difficult & complicated at times.
* Liquidity: Most cross-border payments work on the pre-funding of accounts to settle payments; hence it becomes important to ensure adequate liquidity in correspondent bank accounts to meet payment obligations within cut-off deadlines.
## What it does
Cashflow is a solution to all of the problems above. It provides a secure method to transfer money overseas. It uses the checkbook.io API to verify users' bank information, and check for liquidity, and with features such as KYC, it ensures security in enabling instant payments. Further, it uses another API to convert the currencies using accurate, non-inflated rates.
Sending money:
Our system requests a few pieces of information from you, which pertain to the recipient. After having added your bank details to your profile, you will be able to send money through the platform.
The recipient will receive an email message, through which they can deposit into their account in multiple ways.
Requesting money:
By requesting money from a sender, an invoice is generated to them. They can choose to send money back through multiple methods, which include credit and debit card payments.
## How we built it
We built it using HTML, CSS, and JavaScript. We also used the Checkbook.io API and exchange rate API.
## Challenges we ran into
Neither of us is familiar with backend technologies or react. Mihir has never worked with JS before and I haven't worked on many web dev projects in the last 2 years, so we had to engage in a lot of learning and refreshing of knowledge as we built the project which took a lot of time.
## Accomplishments that we're proud of
We learned a lot and built the whole web app as we were continuously learning. Mihir learned JavaScript from scratch and coded in it for the whole project all under 36 hours.
## What we learned
We learned how to integrate APIs in building web apps, JavaScript, and a lot of web dev.
## What's next for CashFlow
We were having a couple of bugs that we couldn't fix, we plan to work on those in the near future. | ## Inspiration
The inspiration for the project was our desire to make studying and learning more efficient and accessible for students and educators. Utilizing advancements in technology, like the increased availability and lower cost of text embeddings, to make the process of finding answers within educational materials more seamless and convenient.
## What it does
Wise Up is a website that takes many different types of file format, as well as plain text, and separates the information into "pages". Using text embeddings, it can then quickly search through all the pages in a text and figure out which ones are most likely to contain the answer to a question that the user sends. It can also recursively summarize the file at different levels of compression.
## How we built it
With blood, sweat and tears! We used many tools offered to us throughout the challenge to simplify our life. We used Javascript, HTML and CSS for the website, and used it to communicate to a Flask backend that can run our python scripts involving API calls and such. We have API calls to openAI text embeddings, to cohere's xlarge model, to GPT-3's API, OpenAI's Whisper Speech-to-Text model, and several modules for getting an mp4 from a youtube link, a text from a pdf, and so on.
## Challenges we ran into
We had problems getting the backend on Flask to run on a Ubuntu server, and later had to instead run it on a Windows machine. Moreover, getting the backend to communicate effectively with the frontend in real time was a real challenge. Extracting text and page data from files and links ended up taking more time than expected, and finally, since the latency of sending information back and forth from the front end to the backend would lead to a worse user experience, we attempted to implement some features of our semantic search algorithm in the frontend, which led to a lot of difficulties in transferring code from Python to Javascript.
## Accomplishments that we're proud of
Since OpenAI's text embeddings are very good and very new, and we use GPT-3.5 based on extracted information to formulate the answer, we believe we likely equal the state of the art in the task of quickly analyzing text and answer complex questions on it, and the ease of use for many different file formats makes us proud that this project and website can be useful for so many people so often. To understand a textbook and answer questions about its content, or to find specific information without knowing any relevant keywords, this product is simply incredibly good, and costs pennies to run. Moreover, we have added an identification system (users signing up with a username and password) to ensure that a specific account is capped at a certain usage of the API, which is at our own costs (pennies, but we wish to avoid it becoming many dollars without our awareness of it.
## What we learned
As time goes on, not only do LLMs get better, but new methods are developed to use them more efficiently and for greater results. Web development is quite unintuitive for beginners, especially when different programming languages need to interact. One tool that has saved us a few different times is using json for data transfer, and aws services to store Mbs of data very cheaply. Another thing we learned is that, unfortunately, as time goes on, LLMs get bigger and so sometimes much, much slower; api calls to GPT3 and to Whisper are often slow, taking minutes for 1000+ page textbooks.
## What's next for Wise Up
What's next for Wise Up is to make our product faster and more user-friendly. A feature we could add is to summarize text with a fine-tuned model rather than zero-shot learning with GPT-3. Additionally, a next step is to explore partnerships with educational institutions and companies to bring Wise Up to a wider audience and help even more students and educators in their learning journey, or attempt for the website to go viral on social media by advertising its usefulness. Moreover, adding a financial component to the account system could let our users cover the low costs of the APIs, aws and CPU running Whisper. | winning |
## Inspiration
We wanted to create a multiplayer game that would allow anyone to join and participate freely. We couldn't decide on what platform to build for, so we got the idea to create a game that is so platform independent we could call it platform transcendent.. Since the game is played through email and sms, it can be played on any internet-enabled device, regardless of operating system, age, or capability. You could even participate through a public computer in a library, removing the need to own a device altogether!
## What it does
The game allows user-created scavenger hunts to be uploaded to the server. Then other users can join by emailing the relevant email address or texting commands to our phone number. The user will then be sent instructions on how to play and updates as the game goes on.
## How I built it
We have a Microsoft Azure server backend that implements the Twilio and SendGrid APIs. All of our code is written in python. When you send us a text or email, Twilio and SendGrid notify our server which processes the data, updates the server-side persistent records, and replies to the user with new information.
## Challenges I ran into
While sending emails is very straightforward with SendGrid and Twilio works well both for inbound and outbound texts, setting up inbound email turned out to be very difficult due to the need to update the mx registry, which takes a long time to propagate. Also debugging all of the game logic.
## Accomplishments that I'm proud of
It works! We have a sample game set-up and you could potentially win $5 Amazon Gift Cards!
## What I learned
Working with servers is a lot of work! Debugging code on a computer that you don't have direct access to can be quite a hassle.
## What's next for MailTrail
We want to improve and emphasize the ability for users to create their own scavenger hunts. | we built an interactive web application that allows users to learn about mail in ballots by scrolling using their hand movements! | ## Inspiration
Have you ever wanted to search something, but aren't connected to the internet? Data plans too expensive, but you really need to figure something out online quick? Us too, and that's why we created an application that allows you to search the internet without being connected.
## What it does
Text your search queries to (705) 710-3709, and the application will text back the results of your query.
Not happy with the first result? Specify a result using the `--result [number]` flag.
Want to save the URL to view your result when you are connected to the internet? Send your query with `--url` to get the url of your result.
Send `--help` to see a list of all the commands.
## How we built it
Built on a **Nodejs** backend, we leverage **Twilio** to send and receive text messages. When receiving a text message, we send this information using **RapidAPI**'s **Bing Search API**.
Our backend is **dockerized** and deployed continuously using **GitHub Actions** onto a **Google Cloud Run** server. Additionally, we make use of **Google Cloud's Secret Manager** to not expose our API Keys to the public.
Internally, we use a domain registered with **domain.com** to point our text messages to our server.
## Challenges we ran into
Our team is very inexperienced with Google Cloud, Docker and GitHub Actions so it was a challenge needing to deploy our app to the internet. We recognized that without deploying, we would could not allow anybody to demo our application.
* There was a lot of configuration with permissions, and service accounts that had a learning curve. Accessing our secrets from our backend, and ensuring that the backend is authenticated to access the secrets was a huge challenge.
We also have varying levels of skill with JavaScript. It was a challenge trying to understand each other's code and collaborating efficiently to get this done.
## Accomplishments that we're proud of
We honestly think that this is a really cool application. It's very practical, and we can't find any solutions like this that exist right now. There was not a moment where we dreaded working on this project.
This is the most well planned project that we've all made for a hackathon. We were always aware how our individual tasks contribute to the to project as a whole. When we felt that we were making an important part of the code, we would pair program together which accelerated our understanding.
Continuously deploying is awesome! Not having to click buttons to deploy our app was really cool, and it really made our testing in production a lot easier. It also reduced a lot of potential user errors when deploying.
## What we learned
Planning is very important in the early stages of a project. We could not have collaborated so well together, and separated the modules that we were coding the way we did without planning.
Hackathons are much more enjoyable when you get a full night sleep :D.
## What's next for NoData
In the future, we would love to use AI to better suit the search results of the client. Some search results have a very large scope right now.
We would also like to have more time to write some tests and have better error handling. | partial |
## Inspiration
Although each of us came from different backgrounds, we each share similar experiences/challenges during our high school years: it was extremely hard to visualize difficult concepts, much less understand the the various complex interactions. This was most prominent in chemistry, where 3D molecular models were simply nonexistent, and 2D visualizations only served to increase confusion. Sometimes, teachers would use a combination of Styrofoam balls, toothpicks and pens to attempt to demonstrate, yet despite their efforts, there was very little effect. Thus, we decided to make an application which facilitates student comprehension by allowing them to take a picture of troubling text/images and get an interactive 3D augmented reality model.
## What it does
The app is split between two interfaces: one for text visualization, and another for diagram visualization. The app is currently functional solely with Chemistry, but can easily be expanded to other subjects as well.
If the text visualization is chosen, an in-built camera pops up and allows the user to take a picture of the body of text. We used Google's ML-Kit to parse the text on the image into a string, and ran a NLP algorithm (Rapid Automatic Keyword Extraction) to generate a comprehensive flashcard list. Users can click on each flashcard to see an interactive 3D model of the element, zooming and rotating it so it can be seen from every angle. If more information is desired, a Wikipedia tab can be pulled up by swiping upwards.
If diagram visualization is chosen, the camera remains perpetually on for the user to focus on a specific diagram. An augmented reality model will float above the corresponding diagrams, which can be clicked on for further enlargement and interaction.
## How we built it
Android Studio, Unity, Blender, Google ML-Kit
## Challenges we ran into
Developing and integrating 3D Models into the corresponding environments.
Merging the Unity and Android Studio mobile applications into a single cohesive interface.
## What's next for Stud\_Vision
The next step of our mobile application is increasing the database of 3D Models to include a wider variety of keywords. We also aim to be able to integrate with other core scholastic subjects, such as History and Math. | ## Our Inspiration
We were inspired by apps like Duolingo and Quizlet for language learning, and wanted to extend those experiences to a VR environment. The goal was to gameify the entire learning experience and make it immersive all while providing users with the resources to dig deeper into concepts.
## What it does
EduSphere is an interactive AR/VR language learning VisionOS application designed for the new Apple Vision Pro. It contains three fully developed features: a 3D popup game, a multi-lingual chatbot, and an immersive learning environment. It leverages the visually compelling and intuitive nature of the VisionOS system to target three of the most crucial language learning styles: visual, kinesthetic, and literacy - allowing users to truly learn at their own comfort. We believe the immersive environment will make language learning even more memorable and enjoyable.
## How we built it
We built the VisionOS app using the Beta development kit for the Apple Vision Pro. The front-end and AR/VR components were made using Swift, SwiftUI, Alamofire, RealityKit, and concurrent MVVM design architecture. 3D Models were converted through Reality Converter as .usdz files for AR modelling. We stored these files on the Google Cloud Bucket Storage, with their corresponding metadata on CockroachDB. We used a microservice architecture for the backend, creating various scripts involving Python, Flask, SQL, and Cohere. To control the Apple Vision Pro simulator, we linked a Nintendo Switch controller for interaction in 3D space.
## Challenges we ran into
Learning to build for the VisionOS was challenging mainly due to the lack of documentation and libraries available. We faced various problems with 3D Modelling, colour rendering, and databases, as it was difficult to navigate this new space without references or sources to fall back on. We had to build many things from scratch while discovering the limitations within the Beta development environment. Debugging certain issues also proved to be a challenge. We also really wanted to try using eye tracking or hand gesturing technologies, but unfortunately, Apple hasn't released these yet without a physical Vision Pro. We would be happy to try out these cool features in the future, and we're definitely excited about what's to come in AR/VR!
## Accomplishments that we're proud of
We're really proud that we were able to get a functional app working on the VisionOS, especially since this was our first time working with the platform. The use of multiple APIs and 3D modelling tools was also the amalgamation of all our interests and skillsets combined, which was really rewarding to see come to life. | ## Inspiration
Current students struggle with gaining the most value in the shortest time, We learned about the best methods of consuming information - visual and summaries, but current teaching techniques lack these methods.
## What it does
Scan your writing using your phone which then converts it into a text file. Then extract the keywords from that file, look up most relevant google photos from that and brings it back to the phone to display the summary with the photo and the text below. Options of more specific summaries for the individual keywords will be provided as well. It can also read aloud the summary for the visually impaired in order to have better traction and user interaction.
## How I built it
We used unity to develop an augmented reality environment , we integrated machine learning model at the backend of that environment using rest API. We used the google cloud vision API to scan images for text and then using that text as our input to produce our text to speech , summarization and slideshow capabilities
## Challenges I ran into
1.)Difficulties in interaction/ creating communication channels between Unity applications and python machine learning models due to lack of existence of documentation and resources for the same
2.) integration of python models into REST APIs
3.) Difficulties in uploading our API into an online cloud based web hosting service ,due to its large size
## Accomplishments that I'm proud of
1.)Successfully integrating two different platforms together which end up linking two very powerful and vast fields(AR and machine learning)
2.)Creating a working app in 2 days which happens to be an unique product on the market
## What I learned
1.) we learnt how to form a data pipeline between Unity and python which supports AR and machine learning
2.) how to form realtime applications that run ML at thier backend
3.) how to effectively manage our time and make a product in 2 days as a team activity
4.) how to make our own APIs and how to work with them ,
## What's next for TextWiz
We currently only support english , we wish to support more languages in the future and we wish to be able to translate between those language to increase connectivity on a global level.
Our current machine learning model while being good still has room for improvement and we plan to increase the accuracy of our models in the future. | winning |
## Inspiration
Jessica here - I came up with the idea for BusPal out of expectation that the skill has already existed. With my Amazon Echo Dot, I was already doing everything from checking the weather to turning off and on my lights with Amazon skills and routines. The fact that she could not check when my bus to school was going to arrive was surprising at first - until I realized that Amazon and Google are one of the biggest rivalries there is between 2 tech giants. However, I realized that the combination of Alexa's genuine personality and the powerful location ability of Google Maps would fill a need that I'm sure many people have. That was when the idea for BusPal was born: to be a convenient Alexa skill that will improve my morning routine - and everyone else's.
## What it does
This skill enables Amazon Alexa users to ask Alexa when their bus to a specified location is going to arrive and to text the directions to a phone number - all hands-free.
## How we built it
Through the Amazon Alexa builder, Google API, and AWS.
## Challenges we ran into
We originally wanted to use stdlib, however with a lack of documentation for the new Alexa technology, the team made an executive decision to migrate to AWS roughly halfway into the hackathon.
## Accomplishments that we're proud of
Completing Phase 1 of the project - giving Alexa the ability to take in a destination, and deliver a bus time, route, and stop to leave for.
## What we learned
We learned how to use AWS, work with Node.js, and how to use Google APIs.
## What's next for Bus Pal
Improve the text ability of the skill, and enable calendar integration. | ## Inspiration
We wanted to get home safe
## What it does
Stride pairs you with walkers just like UBC SafeWalk, but outside of campus grounds, to get you home safe!
## How we built it
React Native, Express JS, MongoDB
## Challenges we ran into
Getting environment setups working
## Accomplishments that we're proud of
Finishing the app
## What we learned
Mobile development
## What's next for Stride
Improve the app | ## Inspiration
We were really excited to hear about the self-driving bus Olli using IBM's Watson. However, one of our grandfather's is rather forgetful due to his dementia, and because of this would often forget things on a bus if he went alone. Memory issues like this would prevent him, and many people like him, from taking advantage of the latest advancements in public transportation, and prevent him from freely traveling even within his own community.
To solve this, we thought that Olli and Watson could work to take pictures of luggage storage areas on the bus, and if it detected unattended items, alert passengers, so that no one would forget their stuff! This way, individuals with memory issues like our grandparents can gain mobility and be able to freely travel.
## What it does
When the bus stops, we use a light sensitive resistor on the seat to see if someone is no longer sitting there, and then use a camera to take a picture of the luggage storage area underneath the seat.
We send the picture to IBM's Watson, which checks to see if the space is empty, or if an object is there.
If Watson finds something, it identifies the type of object, and the color of the object, and vocally alerts passengers of the type of item that was left behind.
## How we built it
**Hardware**
Arduino - Senses whether there is someone sitting based on a light sensitive resistor.
Raspberry Pi - Processes whether it should take a picture, takes the picture, and sends it to our online database.
**Software**
IBM's IoT Platform - Connects our local BlueMix on Raspberry Pi to our BlueMix on the Server
IBM's Watson - to analyze the images
Node-RED - The editor we used to build our analytics and code
## Challenges we ran into
Learning IBM's Bluemix and Node-Red were challenges all members of our team faced. The software that ran in the cloud and that ran on the Raspberry Pi were both coded using these systems. It was exciting to learn these languages, even though it was often challenging.
Getting information to properly reformat between a number of different systems was challenging. From the 8-bit Arduino, to the 32-bit Raspberry Pi, to our 64-bit computers, to the ultra powerful Watson cloud, each needed a way to communicate with the rest and lots of creative reformatting was required.
## Accomplishments that we're proud of
We were able to build a useful internet of things application using IBM's APIs and Node-RED. It solves a real world problem and is applicable to many modes of public transportation.
## What we learned
Across our whole team, we learned:
* Utilizing APIs
* Node-RED
* BlueMix
* Watson Analytics
* Web Development (html/ css/ js)
* Command Line in Linux | winning |
## Inspiration
Every few days, a new video of a belligerent customer refusing to wear a mask goes viral across the internet. On neighborhood platforms such as NextDoor and local Facebook groups, neighbors often recount their sightings of the mask-less minority. When visiting stores today, we must always remain vigilant if we wish to avoid finding ourselves embroiled in a firsthand encounter. With the mask-less on the loose, it’s no wonder that the rest of us have chosen to minimize our time spent outside the sanctuary of our own homes.
For anti-maskers, words on a sign are merely suggestions—for they are special and deserve special treatment. But what can’t even the most special of special folks blow past? Locks.
Locks are cold and indiscriminate, providing access to only those who pass a test. Normally, this test is a password or a key, but what if instead we tested for respect for the rule of law and order? Maskif.ai does this by requiring masks as the token for entry.
## What it does
Maskif.ai allows users to transform old phones into intelligent security cameras. Our app continuously monitors approaching patrons and uses computer vision to detect whether they are wearing masks. When a mask-less person approaches, our system automatically triggers a compatible smart lock.
This system requires no human intervention to function, saving employees and business owners the tedious and at times hopeless task of arguing with an anti-masker.
Maskif.ai provides reassurance to staff and customers alike with the promise that everyone let inside is willing to abide by safety rules. In doing so, we hope to rebuild community trust and encourage consumer activity among those respectful of the rules.
## How we built it
We use Swift to write this iOS application, leveraging AVFoundation to provide recording functionality and Socket.io to deliver data to our backend. Our backend was built using Flask and leveraged Keras to train a mask classifier.
## What's next for Maskif.ai
While members of the public are typically discouraged from calling the police about mask-wearing, businesses are typically able to take action against someone causing a disturbance. As an additional deterrent to these people, Maskif.ai can be improved by providing the ability for staff to call the police. | ## Inspiration
GetSense was developed in an attempt to create low latency live streaming for countries with slow internet so that they could still have security regardless of their internet speed.
## What it does
GetSense is an AI powered flexible security solution that uses low-level IoT devices (laptop camera systems or Raspberry Pi) to detect, classify, and identify strangers and friends in your circle. A GetSense owner uploads images of authorized faces through an user-facing mobile application. Through the application, the user has access to a live-stream of all connected camera devices, and authorized friend list.
Under the hood, when an user uploads authorized faces, these are sent as data to Firebase storage through a REST API which generates dynamic image URLs. These are then sent to serverless functions (FAAS) which connects to the computer vision microservices setup in Clarifai. The IoT devices communicate via RTSP and streams the video-feed using low-latency.
## How we built it
We used stdlib to generate serverless functions for obtaining the probability score through Clarifai facial recognition, push notifications via Slack alerts to notify the user of an unrecognizable face, and managing the image model training route to Clarifai. For the facial detection process, we used OpenCV with multithreading to detect faces (through Clarifai) for optimization purposes - this was done in Python.
An iOS application was exposed to the user for live-streaming all camera sources, adding authorized faces, and visualizing current friend list. All the data involving images and streaming was handled through Firebase storage and database, which the iOS application heavily interfaced with.
## Challenges we ran into
Our initial goal was to use AWS kinesis to process everything originating from a Raspberry Pi camera module. We had lots of issues with the binaries and overall support of AWS kinesis, so we had to pivot and explore camera modules on local machines. We had to explore using Clarifai for facial detection, running serverless functions with stdlib, and push notifications through an external service.
## Accomplishments that we're proud of
It works.
## What we learned
We learned how to use StdLib, Clarifai for image processing, OpenCV, and building an iOS application.
## What's next for GetSense
We want to improve it to make it more user friendly. | ## Inspiration
It all started a couple days ago when my brother told me he'd need over an hour to pick up a few items from a grocery store because of the weekend checkout line. This led to us reaching out to other friends of ours and asking them about the biggest pitfalls of existing shopping systems. We got a whole variety of answers, but the overwhelming response was the time it takes to shop and more particularly checkout. This inspired us to ideate and come up with an innovative solution.
## What it does
Our app uses computer vision to add items to a customer's bill as they place items in the cart. Similarly, removing an item from the cart automatically subtracts them from the bill. After a customer has completed shopping, they can checkout on the app with the tap of a button, and walk out the store. It's that simple!
## How we built it
We used react with ionic for the frontend, and node.js for the backend. Our main priority was the completion of the computer vision model that detects items being added and removed from the cart. The model we used is a custom YOLO-v3Tiny model implemented in Tensorflow. We chose Tensorflow so that we could run the model using TensorflowJS on mobile.
## Challenges we ran into
The development phase had it's fair share of challenges. Some of these were:
* Deep learning models can never have too much data! Scraping enough images to get accurate predictions was a challenge.
* Adding our custom classes to the pre-trained YOLO-v3Tiny model.
* Coming up with solutions to security concerns.
* Last but not least, simulating shopping while quarantining at home.
## Accomplishments that we're proud of
We're extremely proud of completing a model that can detect objects in real time, as well as our rapid pace of frontend and backend development.
## What we learned
We learned and got hands on experience of Transfer Learning. This was always a concept that we knew in theory but had never implemented before. We also learned how to host tensorflow deep learning models on cloud, as well as make requests to them. Using google maps API with ionic react was a fun learning experience too!
## What's next for MoboShop
* Integrate with customer shopping lists.
* Display ingredients for recipes added by customer.
* Integration with existing security systems.
* Provide analytics and shopping trends to retailers, including insights based on previous orders, customer shopping trends among other statistics. | winning |
## Inspiration
Imagine a world where your best friend is standing in front of you, but you can't see them. Or you go to read a menu, but you are not able to because the restaurant does not have specialized brail menus. For millions of visually impaired people around the world, those are not hypotheticals, they are facts of life.
Hollywood has largely solved this problem in entertainment. Audio descriptions allow the blind or visually impaired to follow the plot of movies easily. With Sight, we are trying to bring the power of audio description to everyday life.
## What it does
Sight is an app that allows the visually impaired to recognize their friends, get an idea of their surroundings, and have written text read aloud. The app also uses voice recognition to listen for speech commands to identify objects, people or to read text.
## How we built it
The front-end is a native iOS app written in Swift and Objective-C with XCode. We use Apple's native vision and speech API's to give the user intuitive control over the app.
---
The back-end service is written in Go and is served with NGrok.
---
We repurposed the Facebook tagging algorithm to recognize a user's friends. When the Sight app sees a face, it is automatically uploaded to the back-end service. The back-end then "posts" the picture to the user's Facebook privately. If any faces show up in the photo, Facebook's tagging algorithm suggests possibilities for who out of the user's friend group they might be. We scrape this data from Facebook to match names with faces in the original picture. If and when Sight recognizes a person as one of the user's friends, that friend's name is read aloud.
---
We make use of the Google Vision API in three ways:
* To run sentiment analysis on people's faces, to get an idea of whether they are happy, sad, surprised etc.
* To run Optical Character Recognition on text in the real world which is then read aloud to the user.
* For label detection, to indentify objects and surroundings in the real world which the user can then query about.
## Challenges we ran into
There were a plethora of challenges we experienced over the course of the hackathon.
1. Each member of the team wrote their portion of the back-end service a language they were comfortable in. However when we came together, we decided that combining services written in different languages would be overly complicated, so we decided to rewrite the entire back-end in Go.
2. When we rewrote portions of the back-end in Go, this gave us a massive performance boost. However, this turned out to be both a curse and a blessing. Because of the limitation of how quickly we are able to upload images to Facebook, we had to add a workaround to ensure that we do not check for tag suggestions before the photo has been uploaded.
3. When the Optical Character Recognition service was prototyped in Python on Google App Engine, it became mysteriously rate-limited by the Google Vision API. Re-generating API keys proved to no avail, and ultimately we overcame this by rewriting the service in Go.
## Accomplishments that we're proud of
Each member of the team came to this hackathon with a very disjoint set of skills and ideas, so we are really glad about how well we were able to build an elegant and put together app.
Facebook does not have an official algorithm for letting apps use their facial recognition service, so we are proud of the workaround we figured out that allowed us to use Facebook's powerful facial recognition software.
We are also proud of how fast the Go back-end runs, but more than anything, we are proud of building a really awesome app.
## What we learned
Najm taught himself Go over the course of the weekend, which he had no experience with before coming to YHack.
Nathaniel and Liang learned about the Google Vision API, and how to use it for OCR, facial detection, and facial emotion analysis.
Zak learned about building a native iOS app that communicates with a data-rich APIs.
We also learned about making clever use of Facebook's API to make use of their powerful facial recognition service.
Over the course of the weekend, we encountered more problems and bugs than we'd probably like to admit. Most of all we learned a ton of valuable problem-solving skills while we worked together to overcome these challenges.
## What's next for Sight
If Facebook ever decides to add an API that allows facial recognition, we think that would allow for even more powerful friend recognition functionality in our app.
Ultimately, we plan to host the back-end on Google App Engine. | ## Inspiration
COVID revolutionized the way we communicate and work by normalizing remoteness. **It also created a massive emotional drought -** we weren't made to empathize with each other through screens. As video conferencing turns into the new normal, marketers and managers continue to struggle with remote communication's lack of nuance and engagement, and those with sensory impairments likely have it even worse.
Given our team's experience with AI/ML, we wanted to leverage data to bridge this gap. Beginning with the idea to use computer vision to help sensory impaired users detect emotion, we generalized our use-case to emotional analytics and real-time emotion identification for video conferencing in general.
## What it does
In MVP form, empath.ly is a video conferencing web application with integrated emotional analytics and real-time emotion identification. During a video call, we analyze the emotions of each user sixty times a second through their camera feed.
After the call, a dashboard is available which displays emotional data and data-derived insights such as the most common emotions throughout the call, changes in emotions over time, and notable contrasts or sudden changes in emotion
**Update as of 7.15am: We've also implemented an accessibility feature which colors the screen based on the emotions detected, to aid people with learning disabilities/emotion recognition difficulties.**
**Update as of 7.36am: We've implemented another accessibility feature which uses text-to-speech to report emotions to users with visual impairments.**
## How we built it
Our backend is powered by Tensorflow, Keras and OpenCV. We use an ML model to detect the emotions of each user, sixty times a second. Each detection is stored in an array, and these are collectively stored in an array of arrays to be displayed later on the analytics dashboard. On the frontend, we built the video conferencing app using React and Agora SDK, and imported the ML model using Tensorflow.JS.
## Challenges we ran into
Initially, we attempted to train our own facial recognition model on 10-13k datapoints from Kaggle - the maximum load our laptops could handle. However, the results weren't too accurate, and we ran into issues integrating this with the frontend later on. The model's still available on our repository, and with access to a PC, we're confident we would have been able to use it.
## Accomplishments that we're proud of
We overcame our ML roadblock and managed to produce a fully-functioning, well-designed web app with a solid business case for B2B data analytics and B2C accessibility.
And our two last minute accessibility add-ons!
## What we learned
It's okay - and, in fact, in the spirit of hacking - to innovate and leverage on pre-existing builds. After our initial ML model failed, we found and utilized a pretrained model which proved to be more accurate and effective.
Inspiring users' trust and choosing a target market receptive to AI-based analytics is also important - that's why our go-to-market will focus on tech companies that rely on remote work and are staffed by younger employees.
## What's next for empath.ly
From short-term to long-term stretch goals:
* We want to add on AssemblyAI's NLP model to deliver better insights. For example, the dashboard could highlight times when a certain sentiment in speech triggered a visual emotional reaction from the audience.
* We want to port this to mobile and enable camera feed functionality, so those with visual impairments or other difficulties recognizing emotions can rely on our live detection for in-person interactions.
* We want to apply our project to the metaverse by allowing users' avatars to emote based on emotions detected from the user. | ## Inspiration
Approximately 12 million people 40 years and over in the United States have vision impairment. One of them is my father, who has been a welder for 2 decades. This app would enable him and others to better interact with the world through audio input/output and computer vision.
## What it does
There are two main features of our app: Object finding and Image-to-Speech. With object finding, a user says what they are looking for (ex. “keys”). Google’s Speech-to-Text then returns target text from the speech. Next, the user scans the room with their phone. The app uses the camera's video stream and applies Cloud Vision to the frames. The Cloud Vision API then provides classifications. If the labels match the target text, then the phone would vibrate (indicating that the object has been detected). With Image-to-Speech, a user takes a picture of an object with text (ex. “Nutrition label on cereal box”). Google’s Cloud Vision returns text extracted from the image and Google’s Text to Speech reads out the text.
## How we built it
We built the app using React Native, Expo, Google's Cloud Vision, Google's Speech-to-Text, and Google's Text-to-Speech.
## Challenges we ran into
We ran into many technical issues when trying to implement the core functionality of the app. For example, we had trouble finding a react native camera component that was compatible with Expo. Ultimately, we were unable to produce a fully functional end product.
## Accomplishments that we're proud of
We were able to set up the app with a simple layout of the app. | winning |
## Inspiration
We were inspired by Michael Reeves, a YouTuber who is known for his "useless inventions." We all enjoy his videos and creations, so we thought it would be cool if we tried it out too.
## What it does
Abyss. is a table that caves in on itself and drops any item that is placed onto it into the abyss.
## How we built it
Abyss. was built with an Arduino UNO, breadboard, a table and Arduino parts to control the table. It uses a RADAR sensor to detect when something is placed on the table and then controls the servo motors to drop the table open.
## Challenges we ran into
Due to the scale of our available parts and materials, we had to downsize from a full-sized table/nightstand to a smaller one to accommodate the weak, smaller servo motors. Larger ones need more than the 5V that the UNO provides to work. We also ran into trouble with the Arduino code since we were all new to Arduinos. We also had a supply chain issue with Amazon simply not shipping the motors we ordered. Also, the "servo motors", or as they were labelled, turned out to be regular step-down motors.
## Accomplishments that we're proud of
We're happy that the project is working and the results are quite fun to watch.
## What we learned
We learned a lot about Arduinos and construction. We did a lot of manual work with hand-powered tools to create our table and had to learn Arduinos from scratch to get the electronics portion working.
## What's next for Abyss.
We hope to expand this project to a full-sized table and integrate everything on a larger scale. This could include a more sensitive sensor, larger motors and power tools to make the process easier. | ## Inspiration
In online documentaries, we saw visually impaired individuals and their vision consisted of small apertures. We wanted to develop a product that would act as a remedy for this issue.
## What it does
When a button is pressed, a picture is taken of the user's current view. This picture is then analyzed using OCR (Optical Character Recognition) and the text is extracted from the image. The text is then converted to speech for the user to listen to.
## How we built it
We used a push button connected to the GPIO pins on the Qualcomm DragonBoard 410c. The input is taken from the button and initiates a python script that connects to the Azure Computer Vision API. The resulting text is sent to the Azure Speech API.
## Challenges we ran into
Coming up with an idea that we were all interested in, incorporated a good amount of hardware, and met the themes of the makeathon was extremely difficult. We attempted to use Speech Diarization initially but realized the technology is not refined enough for our idea. We then modified our idea and wanted to use a hotkey detection model but had a lot of difficulty configuring it. In the end, we decided to use a pushbutton instead for simplicity in favour of both the user and us, the developers.
## Accomplishments that we're proud of
This is our very first Makeathon and we were proud of accomplishing the challenge of developing a hardware project (using components we were completely unfamiliar with) within 24 hours. We also ended up with a fully function project.
## What we learned
We learned how to operate and program a DragonBoard, as well as connect various APIs together.
## What's next for Aperture
We want to implement hot-key detection instead of the push button to eliminate the need of tactile input altogether. | ## Inspiration
The original idea was to create an alarm clock that could aim at the ~~victim's~~ sleeping person's face and shoot water instead of playing a sound to wake-up.
Obviously, nobody carries around peristaltic pumps at hackathons so the water squirting part had to be removed, but the idea of getting a plateform that could aim at a person't face remained.
## What it does
It simply tries to always keep a webcam pointed directly at the largest face in it's field of view.
## How I built it
The brain is a Raspberry Pi model 3 with a webcam attachment that streams raw pictures to Microsoft Cognitive Services. The cloud API then identifies the faces (if any) in the picture and gives a coordinate in pixel of the position of the face.
These coordinates are then converted to an offset (in pixel) from the current position.
This offset (in X and Y but only X is used) is then transmitted to the Arduino that's in control of the stepper motor. This is done by encoding the data as a JSON string, sending it over the serial connection between the Pi and the Arduino and parsing the string on the Arduino. A translation is done to get an actual number of steps. The translation isn't necessarily precise, as the algorithm will naturally converge towards the center of the face.
## Challenges I ran into
Building the enclosure was a lot harder than what I believed initially. It was impossible to build it with two axis of freedom. A compromise was reached by having only the assembly rotate on the X axis (it can pan but not tilt.)
Acrylic panels were used. This was sub-optimal as we had no proper equipment to drill into acrylic to secure screws correctly. Furthermore, the shape of the stepper-motors made it very hard to secure anything to their rotating axis. This is the reason the tilt feature had to be abandoned.
Proper tooling *and expertise* could have fixed these issues.
## Accomplishments that I'm proud of
Stepping out of my confort zone by making a project that depends on areas of expertise I am not familiar with (physical fabrication).
## What I learned
It's easier to write software than to build *real* stuff. There is no "fast iterations" in hardware.
It was also my first time using epoxy resin as well as laser cuted acrylic. These two materials are interesting to work with and are a good alternative to using thin wood as I was used to before. It's incredibly faster to glue than wood and the laser cutting of the acrylic allows for a precision that's hard to match with wood.
It was a lot easier than what I imagined working with the electronics, as driver and library support was already existing and the pieces of equipment as well as the libraries where well documented.
## What's next for FaceTracker
Re-do the enclosure with appropriate materials and proper engineering.
Switch to OpenCV for image recognition as using a cloud service incurs too much latency.
Refine the algorithm to take advantage of the reduced latency.
Add tilt capabilities to the project. | winning |
## Inspiration
It’s no secret that the COVID-19 pandemic ruined most of our social lives. ARoom presents an opportunity to boost your morale by supporting you to converse with your immediate neighbors and strangers in a COVID safe environment.
## What it does
Our app is designed to help you bring your video chat experience to the next level. By connecting to your webcam and microphone, ARoom allows you to chat with people living near you virtually. Coupled with an augmented reality system, our application also allows you to view 3D models and images for more interactivity and fun. Want to chat with new people? Open the map offered by ARoom to discover the other rooms available around you and join one to start chatting!
## How we built it
The front-end was created with Svelte, HTML, CSS, and JavaScript. We used Node.js and Express.js to design the backend, constructing our own voice chat API from scratch. We used VS Code’s Live Share plugin to collaborate, as many of us worked on the same files at the same time. We used the A-Frame web framework to implement Augmented Reality and the Leaflet JavaScript library to add a map to the project.
## Challenges we ran into
From the start, Svelte and A-Frame were brand new frameworks for every member of the team, so we had to devote a significant portion of time just to learn them. Implementing many of our desired features was a challenge, as our knowledge of the programs simply wasn’t comprehensive enough in the beginning. We encountered our first major problem when trying to implement the AR interactions with 3D models in A-Frame. We couldn’t track the objects on camera without using markers, and adding our most desired feature, interactions with users was simply out of the question. We tried to use MediaPipe to detect the hand’s movements to manipulate the positions of the objects, but after spending all of Friday night working on it we were unsuccessful and ended up changing the trajectory of our project.
Our next challenge materialized when we attempted to add a map to our function. We wanted the map to display nearby rooms, and allow users to join any open room within a certain radius. We had difficulties pulling the location of the rooms from other files, as we didn’t understand how Svelte deals with abstraction. We were unable to implement the search radius due to the time limit, but we managed to add our other desired features after an entire day and night of work.
We encountered various other difficulties as well, including updating the rooms when new users join, creating and populating icons on the map, and configuring the DNS for our domain.
## Accomplishments that we're proud of
Our team is extremely proud of our product, and the effort we’ve put into it. It was ¾ of our members’ first hackathon, and we worked extremely hard to build a complete web application. Although we ran into many challenges, we are extremely happy that we either overcame or found a way to work around every single one. Our product isn’t what we initially set out to create, but we are nonetheless delighted at its usefulness, and the benefit it could bring to society, especially to people whose mental health is suffering due to the pandemic. We are also very proud of our voice chat API, which we built from scratch.
## What we learned
Each member of our group has learned a fair bit over the last 36 hours. Using new frameworks, plugins, and other miscellaneous development tools allowed us to acquire heaps of technical knowledge, but we also learned plenty about more soft topics, like hackathons and collaboration. From having to change the direction of our project nearly 24 hours into the event, we learned that it’s important to clearly define objectives at the beginning of an event. We learned that communication and proper documentation is essential, as it can take hours to complete the simplest task when it involves integrating multiple files that several different people have worked on. Using Svelte, Leaflet, GitHub, and Node.js solidified many of our hard skills, but the most important lessons learned were of the other variety.
## What's next for ARoom
Now that we have a finished, complete, usable product, we would like to add several features that were forced to remain in the backlog this weekend. We plan on changing the map to show a much more general location for each room, for safety reasons. We will also prevent users from joining rooms more than an arbitrary distance away from their current location, to promote a more of a friendly neighborhood vibe on the platform. Adding a video and text chat, integrating Google’s Translation API, and creating a settings page are also on the horizon. | # Catch! (Around the World)
## Our Inspiration
Catch has to be one of our most favourite childhood games. Something about just throwing and receiving a ball does wonders for your serotonin. Since all of our team members have relatives throughout the entire world, we thought it'd be nice to play catch with those relatives that we haven't seen due to distance. Furthermore, we're all learning to social distance (physically!) during this pandemic that we're in, so who says we can't we play a little game while social distancing?
## What it does
Our application uses AR and Unity to allow you to play catch with another person from somewhere else in the globe! You can tap a button which allows you to throw a ball (or a random object) off into space, and then the person you send the ball/object to will be able to catch it and throw it back. We also allow users to chat with one another using our web-based chatting application so they can have some commentary going on while they are playing catch.
## How we built it
For the AR functionality of the application, we used **Unity** with **ARFoundations** and **ARKit/ARCore**. To record the user sending the ball/object to another user, we used a **Firebase Real-time Database** back-end that allowed users to create and join games/sessions and communicated when a ball was "thrown". We also utilized **EchoAR** to create/instantiate different 3D objects that users can choose to throw. Furthermore for the chat application, we developed it using **Python Flask**, **HTML** and **Socket.io** in order to create bi-directional communication between the web-user and server.
## Challenges we ran into
Initially we had a separate idea for what we wanted to do in this hackathon. After a couple of hours of planning and developing, we realized that our goal is far too complex and it was too difficult to complete in the given time-frame. As such, our biggest challenge had to do with figuring out a project that was doable within the time of this hackathon.
This also ties into another challenge we ran into was with initially creating the application and the learning portion of the hackathon. We did not have experience with some of the technologies we were using, so we had to overcome the inevitable learning curve.
There was also some difficulty learning how to use the EchoAR api with Unity since it had a specific method of generating the AR objects. However we were able to use the tool without investigating too far into the code.
## Accomplishments
* Working Unity application with AR
* Use of EchoAR and integrating with our application
* Learning how to use Firebase
* Creating a working chat application between multiple users | ## Inspiration
The inspiration for our project stems from the increasing trend of online shopping and the declining foot traffic in physical stores. Our goal was to provide a unique and engaging experience for customers, encouraging them to visit physical stores and rediscover the joy of in-person shopping. We wanted to create an interactive and entertaining shopping experience that would entice customers to visit stores more frequently and foster a deeper connection between them and the store's brand.
## What it does
Our project is an AR scavenger hunt experience that gamifies the shopping experience. The scavenger hunt encourages customers to explore the store and discover new products they may have otherwise overlooked. As customers find specific products, they can earn points which can be redeemed for exclusive deals and discounts on future purchases. This innovative marketing scheme not only provides customers with an entertaining experience but also incentivizes them to visit stores more frequently and purchase products they may have otherwise overlooked.
## How we built it
To create the AR component of our project, we used Vuforia and Unity, two widely used platforms for building AR applications. The Vuforia platform allowed us to create and track image targets, while Unity was used to design the 3D models for the AR experience. We then integrated the AR component into an Android application by importing it as a Gradle project. Our team utilized agile development methodologies to ensure efficient collaboration and problem-solving throughout the development process.
## Challenges we ran into
One of the challenges we faced was integrating multiple APIs and ensuring that they worked together seamlessly. Another challenge was importing the AR component and creating the desired functionality within our project. We also faced issues with debugging and resolving technical errors that arose during the development process.
## Accomplishments that we're proud of
Despite the challenges we faced, we were able to achieve successful teamwork and collaboration. Despite forming the team later than other groups, we were able to effectively communicate and work together to bring our project to fruition. We are proud of the end result, which was a polished and functional AR scavenger hunt experience that met our objectives.
## What we learned
We learned how difficult it is to truly ship out software, and we are grateful to have joined the hackathon. We gained a deeper understanding of the importance of project planning, effective communication, and collaboration among team members. We also learned that the development process can be challenging and unpredictable, and that it requires perseverance and problem-solving skills. Additionally, participating in the hackathon taught us valuable technical skills such as integrating APIs, creating AR functionality, and importing projects onto an Android application.
## What's next for Winnur
Looking forward, we plan to incorporate Computer Vision technology into our project to prevent potential damage to our product's packaging. We also aim to expand the reach of our AR scavenger hunt experience by partnering with more retailers and enhancing the user interface and experience. We are excited about the potential for future development and growth of Winnur. | partial |
## Inspiration
So many people around the world, including those dear to us, suffer from mental health issues such as depression. Here in Berkeley, for example, the resources put aside to combat these problems are constrained. Journaling is one method commonly employed to fight mental issues; it evokes mindfulness and provides greater sense of confidence and self-identity.
## What it does
SmartJournal is a place for people to write entries into an online journal. These entries are then routed to and monitored by a therapist, who can see the journals of multiple people under their care. The entries are analyzed via Natural Language Processing and data analytics to give the therapist better information with which they can help their patient, such as an evolving sentiment and scans for problematic language. The therapist in turn monitors these journals with the help of these statistics and can give feedback to their patients.
## How we built it
We built the web application using the Flask web framework, with Firebase acting as our backend. Additionally, we utilized Microsoft Azure for sentiment analysis and Key Phrase Extraction. We linked everything together using HTML, CSS, and Native Javascript.
## Challenges we ran into
We struggled with vectorizing lots of Tweets to figure out key phrases linked with depression, and it was very hard to test as every time we did so we would have to wait another 40 minutes. However, it ended up working out finally in the end!
## Accomplishments that we're proud of
We managed to navigate through Microsoft Azure and implement Firebase correctly. It was really cool building a live application over the course of this hackathon and we are happy that we were able to tie everything together at the end, even if at times it seemed very difficult
## What we learned
We learned a lot about Natural Language Processing, both naively doing analysis and utilizing other resources. Additionally, we gained a lot of web development experience from trial and error.
## What's next for SmartJournal
We aim to provide better analysis on the actual journal entires to further aid the therapist in their treatments, and moreover to potentially actually launch the web application as we feel that it could be really useful for a lot of people in our community. | ## Inspiration ✨
Seeing friends' lives being ruined through **unhealthy** attachment to video games. Struggling with regulating your emotions properly is one of the **biggest** negative effects of video games.
## What it does 🍎
YourHP is a webapp/discord bot designed to improve the mental health of gamers. By using ML and AI, when specific emotion spikes are detected, voice recordings are queued *accordingly*. When the sensor detects anger, calming reassurance is played. When happy, encouragement is given, to keep it up, etc.
The discord bot is an additional fun feature that sends messages with the same intention to improve mental health. It sends advice, motivation, and gifs when commands are sent by users.
## How we built it 🔧
Our entire web app is made using Javascript, CSS, and HTML. For our facial emotion detection, we used a javascript library built using TensorFlow API called FaceApi.js. Emotions are detected by what patterns can be found on the face such as eyebrow direction, mouth shape, and head tilt. We used their probability value to determine the emotional level and played voice lines accordingly.
The timer is a simple build that alerts users when they should take breaks from gaming and sends sound clips when the timer is up. It uses Javascript, CSS, and HTML.
## Challenges we ran into 🚧
Capturing images in JavaScript, making the discord bot, and hosting on GitHub pages, were all challenges we faced. We were constantly thinking of more ideas as we built our original project which led us to face time limitations and was not able to produce some of the more unique features to our webapp. This project was also difficult as we were fairly new to a lot of the tools we used. Before this Hackathon, we didn't know much about tensorflow, domain names, and discord bots.
## Accomplishments that we're proud of 🏆
We're proud to have finished this product to the best of our abilities. We were able to make the most out of our circumstances and adapt to our skills when obstacles were faced. Despite being sleep deprived, we still managed to persevere and almost kept up with our planned schedule.
## What we learned 🧠
We learned many priceless lessons, about new technology, teamwork, and dedication. Most importantly, we learned about failure, and redirection. Throughout the last few days, we were humbled and pushed to our limits. Many of our ideas were ambitious and unsuccessful, allowing us to be redirected into new doors and opening our minds to other possibilities that worked better.
## Future ⏭️
YourHP will continue to develop on our search for a new way to combat mental health caused by video games. Technological improvements to our systems such as speech to text can also greatly raise the efficiency of our product and towards reaching our goals! | ## 💡 Inspiration
We got inspiration from or back-end developer Minh. He mentioned that he was interested in the idea of an app that helped people record their positive progress and showcase their accomplishments there. This then led to our product/UX designer Jenny to think about what this app would target as a problem and what kind of solution would it offer. From our research, we came to the conclusion quantity over quality social media use resulted in people feeling less accomplished and more anxious. As a solution, we wanted to focus on an app that helps people stay focused on their own goals and accomplishments.
## ⚙ What it does
Our app is a journalling app that has the user enter 2 journal entries a day. One in the morning and one in the evening. During these journal entries, it would ask the user about their mood at the moment, generate am appropriate response based on their mood, and then ask questions that get the user to think about such as gratuity, their plans for the day, and what advice would they give themselves. Our questions follow many of the common journalling practices. The second journal entry then follows a similar format of mood and questions with a different set of questions to finish off the user's day. These help them reflect and look forward to the upcoming future. Our most powerful feature would be the AI that takes data such as emotions and keywords from answers and helps users generate journal summaries across weeks, months, and years. These summaries would then provide actionable steps the user could take to make self-improvements.
## 🔧 How we built it
### Product & UX
* Online research, user interviews, looked at stakeholders, competitors, infinity mapping, and user flows.
* Doing the research allowed our group to have a unified understanding for the app.
### 👩💻 Frontend
* Used React.JS to design the website
* Used Figma for prototyping the website
### 🔚 Backend
* Flask, CockroachDB, and Cohere for ChatAI function.
## 💪 Challenges we ran into
The challenge we ran into was the time limit. For this project, we invested most of our time in understanding the pinpoint in a very sensitive topic such as mental health and psychology. We truly want to identify and solve a meaningful challenge; we had to sacrifice some portions of the project such as front-end code implementation. Some team members were also working with the developers for the first time and it was a good learning experience for everyone to see how different roles come together and how we could improve for next time.
## 🙌 Accomplishments that we're proud of
Jenny, our team designer, did tons of research on problem space such as competitive analysis, research on similar products, and user interviews. We produced a high-fidelity prototype and were able to show the feasibility of the technology we built for this project. (Jenny: I am also very proud of everyone else who had the patience to listen to my views as a designer and be open-minded about what a final solution may look like. I think I'm very proud that we were able to build a good team together although the experience was relatively short over the weekend. I had personally never met the other two team members and the way we were able to have a vision together is something I think we should be proud of.)
## 📚 What we learned
We learned preparing some plans ahead of time next time would make it easier for developers and designers to get started. However, the experience of starting from nothing and making a full project over 2 and a half days was great for learning. We learned a lot about how we think and approach work not only as developers and designer, but as team members.
## 💭 What's next for budEjournal
Next, we would like to test out budEjournal on some real users and make adjustments based on our findings. We would also like to spend more time to build out the front-end. | winning |
## Inspiration
When it comes to grocery shopping, going to a restaurant, or even buying football tickets a designated "spender" is often needed simply for the convenience of payment or booking things together like plane tickets or food. Oftentimes, during these "I'll Venmo you" moments, it becomes a hassle to calculate how much one owes and even remember that you need to send someone money. We thought that what if we could make an app that would simplify this process down to taking a picture of a receipt and create a party of people that could choose which items are simply theirs to pay for or are sharing with others. This would create a fair split since instances like getting groceries might have items that are shared and some items that are not shared if like one person is vegetarian and one is not. Not only would it account for tax and/or tip, but we could drastically reduce the precious social time spent figuring out how to split a bill, time is tight to see our friends and loved ones, why spend them doing math for a bill?
## What it does
SPLIT has three main functions. First, it scans a receipt using an online OCR API that converts the picture receipt to readable data that we can use. The group creator would first scan the receipt and would put it in a nice table with quantity, item name, and price which would also have a party code. Second, people joining the party code would see this same screen and will be able to click on the items they bought or shared. As people tap on the items they bought, others can see this as they're added to the table. Once all users are ready, finally, the group creator can move to the review page for everyone to review the calculated money owed by each person to the party creator. On this page, each user can click "Pay" and use their saved payment method. The payment method can be set up in their account section using either Venmo or Paypal.
## How we built it
We used React as our framework, primarily using javascript and CSS for our frontend and Node.js for our back end.
## Challenges we ran into
One challenge was finding an OCR that worked well in changing a picture of a receipt to parsable text. Due to time constraints, it was difficult to figure out the Venmo API. We know this is an important element of the app, so this will have to be worked on in the future.
## Accomplishments that we're proud of
We're proud of getting the OCR working with data that we could actually use for calculations. Our UI design also looks really nice by our standards.
## What we learned
We learned how to use APIs more deeply, especially with the OCR API. We also learned more about how to use react and node.js
## What's next for Split
We plan to make it more fully functional, and hopefully, one day release it if we have the resources :O | ## Inspiration
Our project stemmed from our frustration dealing with too many cards, specifically gift cards and Prepaid VISA Cards, in our wallets. Americans spent more than $37 billion on prepaid debit cards in 2010 and billions in gift cards each year. The Android app we created incorporates Venmo payments to allow consumers to combine, access and use funds stored on gift cards as well as on Prepaid VISA Cards in one place.
Another problem we sought to address was the fact that as much as 7% of all git cards go unredeemed. For example, if you’re a vegetarian and someone gives you a gift card to a steakhouse, you might find it difficult to use. Mismatches such as these and many more like them have created an accrual of unredeemed gift card spending in our economy. Our project also aims to resolve this inefficiency by creating a forum in which individuals may exchange unwanted gift cards for ones they actually desire.
## What it does
* merging VISA card accounts/amounts into Venmo for the convenience of centralizing the money from various cards
* hold prepaid debit card info
* keep track of each card
* send it to Venmo account
* inventory of gift cards
* keep a list of arrays with the card balance and codes
* have a “total” box to show the total amount
* keep track of remaining balance when it is spent
* swapping gift cards
* community exchange with people with cards that you want/need to swap
* swap card number and security code
## How I built it
We prioritized the different functionalities and then systematically broke large problems into shorter ones. For example, our first priority was to be able to combine prepaid cards and send to venmo account since it was easier to implement than the giftcard swap system . We used many object oriented principles to implement all parts of the software.
## Challenges I ran into
We had too many features we wanted to implement and too little time. For example, we wanted to implement a security system to prevent fraud but realized that it was less important for now since we are merely trying to build a prototype to showcase the overall idea.
## Accomplishments that I'm proud of
We are proud of the fact that we were able to program an Android application concurrently with learning Android itself (since none of the team members had substantial experience.)
## What I learned
On the practical side, we learned Android App Development and learned the nuances of Github. However, we also learned something greater; we learned how to work together in a team environment on a large scale project in a short time. We learned how to budget time and set priorities in order to accomplish what is truly important.
## What's next for AcuCard
In our next steps, we hope to find a way to bypass the 3% processing fee in Venmo money transfer, include more companies under gift cards, make purchases and transactions through barcode generation, improve the community for exchange of gift cards, and prevent fraud through transaction holds. | ## Inspiration
An easy way to get paid when you buy groceries for your roommates. No need to download extra apps, and can be done anywhere.
## What it does
A messenger bot that takes an image of a receipt as input, and prompts everyone in your group to decide on if they want to split the bill with you.
Transfer of money is done through [Capital One Nessie API](http://api.reimaginebanking.com/). | losing |
This project was developed with the RBC challenge in mind of developing the Help Desk of the future.
## What inspired us
We were inspired by our motivation to improve the world of work.
## Background
If we want technical support, we usually contact companies by phone, which is slow and painful for both users and technical support agents, especially when questions are obvious. Our solution is an online chat that responds to people immediately using our own bank of answers. This is a portable and a scalable solution.
## Try it!
<http://www.rbcH.tech>
## What we learned
Using NLP, dealing with devilish CORS, implementing docker successfully, struggling with Kubernetes.
## How we built
* Node.js for our servers (one server for our webapp, one for BotFront)
* React for our front-end
* Rasa-based Botfront, which is the REST API we are calling for each user interaction
* We wrote our own Botfront database during the last day and night
## Our philosophy for delivery
Hack, hack, hack until it works. Léonard was our webapp and backend expert, François built the DevOps side of things and Han solidified the front end and Antoine wrote + tested the data for NLP.
## Challenges we faced
Learning brand new technologies is sometimes difficult! Kubernetes (and CORS brought us some painful pain... and new skills and confidence.
## Our code
<https://github.com/ntnco/mchacks/>
## Our training data
<https://github.com/lool01/mchack-training-data> | ## Inspiration
Cliff is dyslexic, so reading is difficult and slow for him and makes school really difficult.
But, he loves books and listens to 100+ audiobooks/yr. However, most books don't have an audiobook, especially not textbooks for schools, and articles that are passed out in class. This is an issue not only for the 160M people in the developed world with dyslexia but also for the 250M people with low vision acuity.
After moving to the U.S. at age 13, Cliff also needed something to help him translate assignments he didn't understand in school.
Most people become nearsighted as they get older, but often don't have their glasses with them. This makes it hard to read forms when needed. Being able to listen instead of reading is a really effective solution here.
## What it does
Audiobook maker allows a user to scan a physical book with their phone to produced a digital copy that can be played as an audiobook instantaneously in whatever language they choose. It also lets you read the book with text at whatever size you like to help people who have low vision acuity or are missing their glasses.
## How we built it
In Swift and iOS using Google ML and a few clever algorithms we developed to produce high-quality scanning, and high quality reading with low processing time.
## Challenges we ran into
We had to redesign a lot of the features to make the app user experience flow well and to allow the processing to happen fast enough.
## Accomplishments that we're proud of
We reduced the time it took to scan a book by 15X after one design iteration and reduced the processing time it took to OCR (Optical Character Recognition) the book from an hour plus, to instantaneously using an algorithm we built.
We allow the user to have audiobooks on their phone, in multiple languages, that take up virtually no space on the phone.
## What we learned
How to work with Google ML, how to work around OCR processing time. How to suffer through git Xcode Storyboard merge conflicts, how to use Amazon's AWS/Alexa's machine learning platform.
## What's next for Audiobook Maker
Deployment and use across the world by people who have Dyslexia or Low vision acuity, who are learning a new language or who just don't have their reading glasses but still want to function. We envision our app being used primarily for education in schools - specifically schools that have low-income populations who can't afford to buy multiple of books or audiobooks in multiple languages and formats.
## Treehack themes
treehacks education Verticle > personalization > learning styles (build a learning platform, tailored to the learning styles of auditory learners) - I'm an auditory learner, I've dreamed a tool like this since the time I was 8 years old and struggling to learn to read. I'm so excited that now it exists and every student with dyslexia or a learning difference will have access to it.
treehacks education Verticle > personalization > multilingual education ( English as a second-language students often get overlooked, Are there ways to leverage technology to create more open, multilingual classrooms?) Our software allows any book to become polylingual.
treehacks education Verticle > accessibility > refugee education (What are ways technology can be used to bring content and make education accessible to refugees? How can we make the transition to education in a new country smoother?) - Make it so they can listen to material in their mother tongue if needed. or have a voice read along with them in English. Make it so that they can carry their books wherever they go by scanning a book once and then having it for life.
treehacks education Verticle >language & literacy > mobile apps for English literacy (How can you build mobile apps to increase English fluency and literacy amongst students and adults?) -One of the best ways to learn how to read is to listen to someone else doing it and to follow yourself. Audiobook maker lets you do that. From a practical perspective - learning how to read is hard and it is difficult for an adult learning a new language to achieve proficiency and a high reading speed. To bridge that gap Audiobook Maker makes sure that every person can and understand and learn from any text they encounter.
treehacks education Verticle >language & literacy > in-person learning (many people want to learn second languages) - Audiobook maker allows users to live in a foreign countrys and understand more of what is going on. It allows users to challenge themselves to read or listen to more of their daily work in the language they are trying to learn, and it can help users understand while they studying a foreign language in the case that the meaning of text in a book or elsewhere is not clear.
We worked a lot with Google ML and Amazon AWS. | ## Inspiration
One thing the pandemic has taught us was the severity of mental health and how crucial it is to have someone to talk to during hardships. We believe in using technology to create a solution that addresses mental health, a global issue of utmost importance in today's world. As high school students, we constantly face stress and emotional challenges that significantly impact our lives. We often want help to get out of a hard situation, however; the help we receive, such as a therapist and a list of non-profit help lines, isn't usually the help that we want such as someone to talk to.
## What it does
My-AI is a chatbox that has a one-on-one conversation with the user in a way that is comforting and helpful by providing emotional support and advice. Maiya, the AI chatbot, assesses the user's messages and feelings to generate a human-like response so the user feels as if they are talking to another human, more so to a friend; a friend without bias and judgement. The entire conversation is not saved and so deleted once the user finishes the conversation.
## How we built it
We prototyped on Figma and then developed the front end with React. Our backend was created using Java Script to made the node server, which is responsible for calling the API.
## Challenges we ran into
Our team ran into many problems as it was one of the first hackathons that most of our team members attended. In terms of front-end development, none of our team members had experience in React so building a website within a time constraint was a learning curve. Other problems we faced in the backend were issues with the API as it would not respond sometimes, the accuracy was off, and wasn't doing what we needed it to do. Finally, we had trouble connecting the back end to the front end.
## Accomplishments that we're proud of
One thing our whole team is most proud of is our skillset improvement in React. All members experienced using React for the first time so navigating an issue for us helped us grasp a better understanding of it. We are also extremely proud of the fine-tuning of the API to meet our project's demands.
## What we learned
We mainly enhanced our skills in React and how to implement and fine-time an API.
## What's next for My-AI
The more Maya is trained with people and different experiences obtained through the chat box, the more accurate the support is. | winning |
## Inspiration
When tackling the issue of sustainability, we looked first at the major sources of emissions. One thing that caught our eye was agriculture – Particularly, livestock production (especially cattle) which is the largest contributor for carbon emissions. Annually, each cow produces 220 pounds of methane and in totality accounts for 14.5% of global greenhouse gas emissions. Agriculture continues to be one of the most important industries that technology overlooks. As a team, we are driven to build in communities and industries that are underserved by existing technologies and from this, *GrazePro was born*.
We decided to focus on rotational grazing, a popular farming technique that involves moving livestock between paddocks so that only one or some paddocks are grazed at any given time. On the contrary, continuous grazing involves only one paddock, and the forage is not allowed to fallow. We realized that there was an efficiency maximization problem related to when farmers should switch paddocks to maximize cattle health and ability for grass to regrow. We decided to model this using a simulation.
## What it does
GrazePro is a virtual simulation intended to enable farmers to accurately predict and forecast the optimal approach to rotational grazing. This means that we can take real data points provided by farmers, input them into the algorithm that we’ve created and generate actionable suggestions to improve cattle health, sustainable practices and cost efficiency.
Our algorithm can help answer questions such as: How many segments farmers should divide their paddock into? What is the optimal time that cattle should stay within one area to ensure that the grass has time to regrow?
The prediction algorithm is built on a cellular automata model, which is a collection of cells on a grid that evolves over discrete time steps according to a set of preferences and rules. In this case, we modeled how fast grass grew back based on various factors, including number of cattle, amount of water used, fertilizers used, previous cover crops and more.
Users have the ability to change certain inputs, such as number of paddocks, number of cows, growth rate of grass and rotation time. When the simulation is played, the dashboard also displays the health of the grass and the cattle and how they change over time according to the feeding patterns of the cattle. Farmers can then use this data to inform their farming practices.
## How we built it
We used a combination of coding languages, including Typescript, React, Netlogo. A number of technologies, frameworks and packages were used, including Next.js, Convex, Vercel, Tailwind. We designed and built our wireframe in Figma.
## Challenges we ran into
On our journey to TreeHacks this year, our car was broken into and our laptops, belongings and personal items were stolen. While this unfortunately has severely impacted our ability to hack, as we were unable to begin until 12 hours into the hackathon, *there is nothing that builds stronger bonds than trauma*. Thankfully, we were still able to build GrazePro with the limited resources we had, and were able to find some hacky solutions (i.e, figuring out a way to locally install Node.js on Stanford's admin protected computers). A huge shout-out to the TreeHacks organizers!
## Accomplishments that we're proud of
This was our team's first major in-person hackathon since the pandemic began, and it presented a significant learning opportunity. While we encountered some initial challenges, we are proud of the progress we were able to achieve as a team without any laptops or personal devices (explained above) AND the additional time constraint of 24 hours instead of 36.
## What we learned
We learned to *never* leave our suitcases unattended…kind of a hard thing to do at a hackathon. In all seriousness, as the first hackathon that we have participated in as a team, one of the most important lessons that we learned is how to work together. This was integral in dividing the workload of this huge project into manageable and sizable chunks that we could delegate effectively to maximize the use of our time.
On a technical level, we were able to use, learn, and implement some really interesting frameworks and packages from the TreeHacks sponsors (shoutout to Convex and Vercel!). We also had the chance to participate in a mock interview with YC which really taught us how to navigate the business-side of a startup alongside a technically-refined product.
## What's next for GrazePro
Where to even begin? Firstly, incorporating satellite and drone imaging technology into our platform and setting up a method to scan the uploaded image to determine the existing health of the grass would help streamline the onboarding of new users. Secondly, using more data to train our simulation would make it more realistic and improve scientific accuracy and predictability. Thirdly, we would introduce features that would complicate our simulation, such as changing the shape of each paddock, reproduction and death of cattle, incorporating weather patterns and forecasts into the model to determine crop growth, use of rivers and riparian buffers to prevent waste contamination from cattle feces, nitrogen fixation mechanisms and their effect on soil quality.
## Works Cited
<https://www.ucdavis.edu/food/news/making-cattle-more-sustainable> | Prediction Market revolving around the following question: Which privacy oriented token will perform better, ZCash or Monero?
In the nascent crypto space without significant understanding or regulation, companies have been launching subpar ICOs to capitalize on hype, and currency trading is extremely volatile. Tokens often serve as a means for companies to raise money quickly with users either genuinely believing in the success of a venture, or looking to make a quick profit by playing off of volatility. There aren’t many valid written sources producing actionable information on the legitimacy of such companies. In order to obtain useful information, incentives must be aligned.
With prediction markets, users stand to profit off of outcomes if they occur, and as such are incentivized to “vote” in accordance with their views. Furthermore, these markets provide insight into public opinion and help hold companies accountable, when there aren’t any other entities that do so. By pitting two competitors against each other in a prediction market, they are each automatically incentivized to take action that would satisfy consumers, aligning with user behavior versus the alignment with investor needs brought about in ICOs with app tokens. Moreover, beyond just human users, bots with access to data streams on certain performance indicators can also contribute to the market. This whole process introduces oversight and accountability by a decentralized mass versus having any sort of centralized regulation. Users are able to hold corporations accountable through the simple economic principle of competition aligning incentives.
This specific use case focuses on the privacy token space in which accountability is especially necessary as consumers inherently expect privacy from each specific service, simply based on what each service promises to provide. Without a specific measure of accountability, these companies aren’t necessarily incentivized to uphold their promises.
Looking into Monero, up until September of 2017, RingCT was not mandatory in client software, meaning that 62% of transactions made before 2017 can be deanonymized, which presents a significant consumer vulnerability. This issue has been present since the inception of the currency, however, the company did nothing to resolve the issue until [MoneroLink](https://monerolink.com) published such results. With a prediction market, those aware of such issues can display their concerns allowing such vulnerabilities to be resolved sooner.
ZCash and Monero are the current leading tokens in this space - each one promising privacy, but tackling the issue from different perspectives. Monero takes the approach of distorting information utilizing RingCT, while ZCash makes use of zero-knowledge proofs. With ZCash working on protocol improvements to increase efficiency and reduce currently high costs, and Monero resolving some of its anonymity issues, these two cryptocurrencies are becoming more competitive in this space. Using a prediction market, we can determine which token is expected to perform better within the scope of the next year as both platforms plan to roll out significant improvements. In this manner, as they release updates and announcements, each company will be able to measure user satisfaction in relation to its competition and thus prioritize the needs of the user. This is basically a real-time indicator of feedback for each company.
The first iteration of this market is scheduled to run for one year, giving both companies time to build improvements, attend to user feedback, and respond accordingly. The market will decide on which token performed better. When we say “performed better,” we define this metric in relation to how widely used each token is. Since both ZCash and Monero are usage tokens, meaning that the token is needed to access the digital service each provides, actual usage of a token represents its value to consumers. In this case, that would be using ZCash or Monero to complete transactions which keep user data private. Thus, in measuring transaction volume of each token throughout the course of the year, we can measure token performance.
This same sort of ideology of pitting competitors against each other to benefit consumers can be applied to tokens in general beyond just the privacy space and multiple companies can be entered into such a marketplace.
This is implemented as a use case of [Gnosis'](https://gnosis.pm) prediction markets using gnosis.js and the gnosis market testing environment. | ## Inspiration
Inspired by carbon trading mechanism among nations proposed by Kyoto Protocol treaty in the response to the threat of climate change, and a bunch of cute gas sensors provided by MLH hardware lab, we want to build a similar mechanism among people to monetize our daily carbon emission rights, especially the vehicle carbon emission rights so as to raise people's awareness of green house gas(GHG) emission and climate change.
## What it does
We have designed a data platform for both regular users and the administrative party to manage carbon coins, a new financial concept we proposed, that refers to monetized personal carbon emission rights. To not exceed the annual limit of carbon emission, the administrative party will assign a certain amount of carbon coins to each user on a monthly/yearly basis, taking into consideration both the past carbon emission history and the future carbon emission amount predicted by machine learning algorithms. For regular users, they can monitor their real-time carbon coin consumption and trading carbon coins with each other once logging into our platform. Also, we designed a prototyped carbon emission measurement device for vehicles that includes a CO2 gas sensor, and an IoT system that can collect vehicle's carbon emission data and transmit these real-time data to our data cloud platform.
## How we built it
### Hardware
* Electronics
We built a real-time IoT system with Photon board that calculates the user carbon emission amount based on gas sensors’ input and update the right amount of account payable in their accounts. The Photon board processes the avarage concentration for the time of change from CO2 and CO sensors, and then use the Particle Cloud to publish the value to the web page.
* 3D Priniting
We designed the 3D structure for the eletronic parts. This strcture is meant to be attached to the end of the car gas pipe to measure the car carbon emission, whcih is one of the biggest emission for an average household. Similar structure design will be done for other carbon emission sources like heaters, air-conditioners as well in the future.
### Software
* Back end data analysis
We built a Long Short Term Memory(LSTM) model using Keras, a high-level neural networks API running on top of TensorFlow, to do time series prediction. Since we did not have enough carbon emission data in hand, we trained and evaluated our model on a energy consumption dataset, cause we found there is a strong correlation between the energy consumption data and the carbon emission data. Through this deep learning model, we can make a sound prediction of the carbon emission amount of the next month/year from the past emission history.
* Front end web interface
We built Web app where the user can access the real-time updates of their carbon consumption and balance, and the officials can suggest the currency value change based on the machine learning algorithm results shown in their own separate web interface.
## Challenges we ran into
* Machine learning algorithms
At first we have no clue about what kind of model should we use for time series prediction. After googling for a while, we found recurrent neural networks(RNN) that takes a history of past data points as input into the model is a common way for time series prediction, and its advanced variant, LSTM model has overcome some drawbacks of RNN. However, even for LSTM, we still have many ways to use this model: we have sequence-to-sequence prediction, sequence-to-one prediction and one-to-sequence prediction. After some failed experiments and carefully researching on the characteristics of our problem, finally we got a well-performed sequence-to-one LSTM model for energy consumption prediction.
* Hardware
We experience some technical difficulty when using the 3D printing with Ultimaker, but eventually use the more advanced FDM printer and get the part done. The gas sensor also takes us quite a while to calibrate and give out the right price based on consumption.
## Accomplishments that we're proud of
It feels so cool to propose this cool financial concept that can our planet a better place to live.
Though we only have 3 people, we finally turn tons of caffeine into what we want!
## What we learned
Sleep and Teamwork!!
## What's next for CarbonCoin
1) Expand sources of carbon emission measurements using our devices or convert other factors like electricity consumption into carbon emission as well. The module will be in the future incorprate into all the applicances.
2) Set up trading currency functionality to ensure the liquidity of CarbonCoin.
3) Explore the idea of blockchain usage on this idea | partial |
## Inspiration
During extreme events such as natural disasters or virus outbreaks, crisis managers are the decision makers. Their job is difficult since the right decision can save lives while the wrong decision can lead to their loss. Making such decisions in real-time can be daunting when there is insufficient information, which is often the case.
Recently, big data has gained a lot of traction in crisis management by addressing this issue; however it creates a new challenge. How can you act on data when there's just too much of it to keep up with? One example of this is the use of social media during crises. In theory, social media posts can give crisis managers an unprecedented level of real-time situational awareness. In practice, the noise-to-signal ratio and volume of social media is too large to be useful.
I built CrisisTweetMap to address this issue by creating a dynamic dashboard for visualizing crisis-related tweets in real-time. The focus of this project was to make it easier for crisis managers to extract useful and actionable information. To showcase the prototype, I used tweets about the current coronavirus outbreak.
## What it does
* Scrape live crisis-related tweets from Twitter;
* Classify tweets in relevant categories with deep learning NLP model;
* Extract geolocation from tweets with different methods;
* Push classified and geolocated tweets to database in real-time;
* Pull tweets from database in real-time to visualize on dashboard;
* Allows dynamic user interaction with dashboard
## How I built it
* Tweepy + custom wrapper for scraping and cleaning tweets;
* AllenNLP + torch + BERT + CrisisNLP dataset for model training/deployment;
* Spacy NER + geotext for extracting location names from text
* geopy + gazetteer elasticsearch docker container for extracting geolocation from locations;
* shapely for sampling geolocation from bounding boxes;
* SQLite3 + pandas for database push/pull;
* Dash + plotly + mapbox for live visualizations;
## Challenges I ran into
* Geolocation is hard;
* Stream stalling due to large/slow neural network;
* Responsive visualization of large amounts of data interactively;
## Accomplishments that I'm proud of
* A working prototype
## What I learned
* Different methods for fuzzy geolocation from text;
* Live map visualizations with Dash;
## What's next for CrisisTweetMap
* Other crises like extreme weather events; | ## Inspiration
Currently the insurance claims process is quite labour intensive. A person has to investigate the car to approve or deny a claim, and so we aim to make the alleviate this cumbersome process smooth and easy for the policy holders.
## What it does
Quick Quote is a proof-of-concept tool for visually evaluating images of auto accidents and classifying the level of damage and estimated insurance payout.
## How we built it
The frontend is built with just static HTML, CSS and Javascript. We used Materialize css to achieve some of our UI mocks created in Figma. Conveniently we have also created our own "state machine" to make our web-app more responsive.
## Challenges we ran into
>
> I've never done any machine learning before, let alone trying to create a model for a hackthon project. I definitely took a quite a bit of time to understand some of the concepts in this field. *-Jerry*
>
>
>
## Accomplishments that we're proud of
>
> This is my 9th hackathon and I'm honestly quite proud that I'm still learning something new at every hackathon that I've attended thus far. *-Jerry*
>
>
>
## What we learned
>
> Attempting to do a challenge with very little description of what the challenge actually is asking for is like a toddler a man stranded on an island. *-Jerry*
>
>
>
## What's next for Quick Quote
Things that are on our roadmap to improve Quick Quote:
* Apply google analytics to track user's movement and collect feedbacks to enhance our UI.
* Enhance our neural network model to enrich our knowledge base.
* Train our data with more evalution to give more depth
* Includes ads (mostly auto companies ads). | *"This is the time for facts, not fear.
This is the time for science, not rumors.
This is the time for solidarity, not stigma.
We are all in this together."*
-- The tweet from UNGeneva after a public health emergency of international concern over coronavirus.
## Inspiration
Due to the outbreak of Novel coronavirus 2019, many people and organizations face the lack of resources. With social media being an important channel for these people to find help, we find many help requests on Weibo (like Chinese Twitter) but they only get attention from the public if they're lucky enough to be reposted by KOLs. We want to find a more efficient way to solve this problem and enable these requests more easily to be seen.
## What it does
An online platform with map visualization that can
1. gather help requests from social media (such as Weibo, Twitter) automatically
2. People that need help can also register and submit their help request to the platform directly
In the McHacks, we primarily focus on the help requests from hospitals in China because they face the most severe lack of resources now.
## How we built it
Data Science:
1. Scraping on Weibo with selected keywords and hashtags
2. Transform semi-structured texts to structured data using keywords detection (and entity analysis using IBM and Google API for those with little structure)
Backend:
1. Java Spring Boot framework using Java 8
2. Create RESTful APIs
3. Using Hibernate and JPA to generate PosgreSQL
4. Attempted deploying using Heroku
Frontend:
1. The modern front-end framework React along with ES6 Javascript.
2. Google-Map-React to generate the map with hospitals
3. Bought the domain coronatlas.space from domain.com
## Challenges we ran into
4. Many NLP APIs don't support Chineses or have worse performance in Chinese
5. Unfamiliar with web app development (but learned a lot!)
## Accomplishments that we're proud of
We are glad we can use what we learn to help fighting against the plague (Two of us are from Hubei).
## What we learned
How to build a map app with a team!
## What's next for Coronatlas
Not only for Novel coronavirus! Not only for Chinese!
1. Add functionality for volunteers
2. Connect with Twitter | winning |
## Problem Statement
In today’s fast-paced urban environment, family, friends, and emergency responders face significant challenges due to a lack of real-time visual and auditory information. Traditional emergency and SOS systems, such as Life360 and standard 911 calls, primarily rely on voice communication, text descriptions, or geolocation data. However, these methods often lack the situational context needed to fully understand the severity of an incident, placing limitations on what individuals in distress can effectively communicate. Check out our case study below for our stats and modelling.
## Introduction
Guardian is a wearable AI that provides a comprehensive solution integrating real-time video and audio streaming with emotion and object detection analytics. If activated, this data is sent to a dashboard while simultaneously alerting emergency responders and emergency contacts with information about your surroundings and possible threats. By offering a unified platform for live updates and alerts, our project enhances and enables situational awareness—your personal guardian and SOS button.
## Purpose
Guardian is designed with several key objectives in mind to address the limitations of traditional emergency and SOS systems:
* Wearable: Guardian is a discreet and portable device that can be worn comfortably, ensuring that it is always within reach when needed. This increases the likelihood of timely activation during emergencies.
* Hands-free: The system is designed to operate without requiring the user to use their hands, allowing them to focus on the situation at hand. This is particularly important in high-stress or dangerous scenarios where manual operation may not be feasible.
* Capturing Live Data: Guardian continuously captures real-time video and audio data, providing up-to-the-minute information on the user's surroundings. This ensures that emergency responders and contacts receive the most current and relevant situational information.
* Data-Driven Insights: The data collected by Guardian can be used to identify patterns and hotspots, contributing to broader public safety efforts and potentially preventing future incidents.
* Seamless Integration with Emergency Services: Guardian's ability to contact emergency services directly ensures that help is on the way as soon as the device is activated. This integration streamlines the process of seeking assistance in critical moments.
## How we built it
### Hardware
With a Raspberry Pi, we capture video and audio footage using a webcam triggered by a keypad. The keypad serves two functions: enabling Guardian's webcam and contacting 911. Using scripts, the Raspberry Pi then converts the real-time footage into frames with OpenCV to meet machine learning model requirements.
### Backend
We built a deep audio classification CNN model using TensorFlow to classify audio clips as either violent or non-violent based on their spectrograms. This model was trained on over 1000 entries. We also fine-tuned a Hume Expression Measurement model to isolate scores for "aggression," "hostility," and "frustration," outputting a JSON file with the results.
For visual context, we use Gemini flash to identify critical elements from the frames captured by the Raspberry Pi. Authentication and security are managed with Auth0 to ensure secure access to the system.
All collected data is stored in a MongoDB database, allowing for efficient and scalable data management.
### Frontend
We used React, Mapbox, and Three.js to create visual representations of Guardian alerts and crime hotspots. The frontend provides a user-friendly interface for monitoring real-time alerts and viewing historical data on crime hotspots. Users can keep tabs on their loved ones with a 3D informational hub, offering up to date information on emergencies and whereabouts.
## Challenges we ran into
### Implementing the Hardware and Integrating the Raspberry Pi
* Compatibility: Ensuring all components worked seamlessly with the Raspberry Pi.
* Real-time Processing: Optimizing video and audio capture despite limited processing power.
* Power Management: Balancing performance and power consumption for extended operation.
### Integrating Backend, Frontend, and Hardware Components
* Communication: Establishing reliable communication between all components.
* Data Synchronization: Ensuring accurate, real-time data synchronization.
* Security: Implementing secure authentication and encryption with Auth0.
### Fine-tuning and Labeling Datasets for Violent Sounds on Hume AI
* Dataset Labeling: Accurately labeling violent and non-violent audio clips.
* Model Training: Achieving high accuracy in sound classification.
* Emotion Detection: Fine-tuning the model to detect specific emotions.
## Accomplishments that we're proud of
### Hardware
Successfully triggering different functionalities through the keypad, including video capture and emergency calls.
### Frontend
Creating an intuitive and interactive user interface for monitoring alerts and visualizing data.
### Backend
Developing and integrating robust machine learning models for audio and visual classification, and ensuring secure data handling with Auth0 and MongoDB.
## What we learned
We learned how to integrate multiple technologies, including hardware, machine learning models, and secure data management systems, to create a cohesive and effective solution. Here are some key implementations:
### MongoDB
* Scalable Data Management: We learned how to leverage MongoDB’s flexibility and scalability to manage large volumes of real-time data. This included setting up efficient data schemas for storing video frames, audio clips, and emotion analysis results.
### Auth0
* Secure Authentication: Implementing robust authentication mechanisms using Auth0 to protect user data and ensure that only authorized individuals can access sensitive information.
* User Management: Utilizing Auth0’s user management capabilities to handle user roles and permissions, ensuring that different users (e.g., family members, emergency responders) have appropriate access levels.
## What's next for Guardian
Using Guardian we can :
* identify hot spots based off of real-time alert ping locations
* understand emotional cues, assisting emergency responders and guardians in approaching situations
* create a interactive mapping ability that further showcases "safety spots" such as fire stations, police stations, and hospitals
* integration into purses
## Case Study
Conducted a case study of crime hotspots, crime types, and crime per neighbourhoods int Toronto data to fully gauge the problem we are trying to target. Using simple plotting and linear regression models, we took data scraped from the web that identified key statistics:
* 30% of 911 calls could benefit from enhanced situational awareness
* NCMEC reports that inclusion of video footage in Amber Alerts can improve recovery rates by 35%
* The Bureau of Justice Statistics reduced average search time by 40%
* Showing video footage through social media and public alerts increase the number of tips and leads by 50%
Modelling: <https://colab.research.google.com/drive/1M5Ju4ssnh95Qx5bcAweBThjRuZJ34oK4#scrollTo=-_HqXzPZi1eC>
Scraping tool: <https://colab.research.google.com/drive/1iqFYmSIcjy4WgLwTcaR20H9Fcx-SL0lM#scrollTo=Fq4EGEsXqJf1>
## Deployment:
<https://guardian-safety.vercel.app/>
Note: we have not deployed the backends yet! The backends are still local hosted. This is why a lot of the functions aren't working at the moment. Everything (all features) can be found local hosted.
## Github:
<https://github.com/guardiansafety/frontend>
<https://github.com/guardiansafety/backend>
<https://github.com/guardiansafety/hardware> | ## 💡Inspiration and Purpose
Our group members are from all around the U.S., from Dallas to Boston, but one thing that we have in common is that we have a grandparent living by themselves. Due to various family situations, we have elderly loved ones who spend a few hours alone each day, putting them at risk of a fatal accident like a fall. After researching current commercial solutions for fall detection, devices can range from anywhere from twenty-four to fifty dollars per device monthly. While this is affordable for our families, it is distinctly out of reach for many disadvantaged families.
In 2020, falls among Americans 65 and older caused over 36,000 deaths - the leading cause of injury death for that demographic group. Furthermore, these falls led to some three million emergency hospital visits and $50 billion in medical costs, creating an immense strain on our healthcare system.
## 🎖️ What It Does
Despite these sobering statistics, very few accessible solutions exist to assist seniors who may experience a fall at home. More worryingly, many of these products rely on the individual who has just become seriously injured to report the incident and direct emergency medical services to their location. Oftentimes, someone might not be able to alert the proper authorities and suffer needlessly as a result.
Guardian Angel aims to solve this growing problem by automating the process of fall detection using machine learning and deploying it in an easy-to-use, accurate, and portable system. From there, the necessary authorities can be notified, even if an individual is critically injured.
By using data-based trackers such as position, this application will adequately calculate and determine if a person has fallen based on a point and confidence system. This can be used for risk prevention profiles as it can detect shuffling or skipping. The application will shine red if it is confident that the person has fallen and it is not a false positive.
## 🧠 Development and Challenges
The application overall was built using React, alongside TailwindCSS and ML5. Using the create-react-app boilerplate, we were able to minimize the initial setup and invest more time in fixing bugs. In general, the website works by obtaining the model, metadata, and weights from the tensorflow.js model, requests a webcam input, and then pushes that webcam input into the machine learning model. The result of the model, as well as the confidence, is then displayed to the user.
The machine learning side of the project was developed using TensorFlow through tensorflow.js. As a result, we were able to primarily focus on gathering proper samples for the model, rather than optimization. The samples used for training were gathered by capturing dozens of videos of people falling in various backgrounds, isolating the frames, and manually labeling the data. We also augmented the samples to improve the model's ability to generalize.
For training, we used around 5 epochs, a learning rate of 0.01, and a batch size of 16. Other than that, every other parameter was default.
We also ran into a few major challenges during the creation of the project. Firstly, the complexity of detecting movement made obtaining samples and training particularly difficult. Our solution was to gather a number of samples from different orientations, allowing for the model to be accurate in a wide variety of situations. Specifically speaking for the website, one of the main challenges we ran implementing video rendering within React. We were eventually able to implement our desired functionality using HTML videos, uncommon react dependency components, and complex Tensorflow-React interactions.
## 🎖️ Accomplishments that we're proud of
First and foremost, we are proud of successfully completing the project while getting to meet with several mentors and knowledgeable professionals, such as the great teams at CareYaya and Y Combinator.
Second, we are proud of our model's accuracy. Classifying a series of images with movement was no small undertaking, particularly because we needed to ignore unintentional movements while continuing to accurately identify sudden changes in motion.
Lastly, we are very proud of the usability and functionality of our application. Despite being a very complex undertaking, our front end wraps up our product into an incredibly easy-to-use platform that is highly intuitive. We hope that this project, with minimal modifications, could be deployed commercially and begin to make a difference.
## 🔜 Next Steps
We would soon like to integrate our app with smart devices such as Amazon Alexa and Apple Smart Watch to obtain more data and verify our predictions. With accessible devices like Alexa already on the market, we will continue to ensure this service is as scalable as possible. We also want to detect fall audio, as audio can help make our results more accurate. Audio also would allow our project to be active in more locations in a household, and cover for the blind spots cameras typically have.
Guardian Angel is a deployable and complete application in itself, but we hope to take extra steps to make our project even more user-friendly. One thing we want to implement in the near future is to create an API for our application so that we can take advantage of existing home security systems. By utilizing security cameras that are already present, we can lower the barriers to entry for consumers as well as improve our reach. | ## Problem Statement
As the number of the elderly population is constantly growing, there is an increasing demand for home care. In fact, the market for safety and security solutions in the healthcare sector is estimated to reach $40.1 billion by 2025.
The elderly, disabled, and vulnerable people face a constant risk of falls and other accidents, especially in environments like hospitals, nursing homes, and home care environments, where they require constant supervision. However, traditional monitoring methods, such as human caregivers or surveillance cameras, are often not enough to provide prompt and effective responses in emergency situations. This potentially has serious consequences, including injury, prolonged recovery, and increased healthcare costs.
## Solution
The proposed app aims to address this problem by providing real-time monitoring and alert system, using a camera and cloud-based machine learning algorithms to detect any signs of injury or danger, and immediately notify designated emergency contacts, such as healthcare professionals, with information about the user's condition and collected personal data.
We believe that the app has the potential to revolutionize the way vulnerable individuals are monitored and protected, by providing a safer and more secure environment in designated institutions.
## Developing Process
Prior to development, our designer used Figma to create a prototype which was used as a reference point when the developers were building the platform in HTML, CSS, and ReactJs.
For the cloud-based machine learning algorithms, we used Computer Vision, Open CV, Numpy, and Flask to train the model on a dataset of various poses and movements and to detect any signs of injury or danger in real time.
Because of limited resources, we decided to use our phones as an analogue to cameras to do the live streams for the real-time monitoring.
## Impact
* **Improved safety:** The real-time monitoring and alert system provided by the app helps to reduce the risk of falls and other accidents, keeping vulnerable individuals safer and reducing the likelihood of serious injury.
* **Faster response time:** The app triggers an alert and sends notifications to designated emergency contacts in case of any danger or injury, which allows for a faster response time and more effective response.
* **Increased efficiency:** Using cloud-based machine learning algorithms and computer vision techniques allow the app to analyze the user's movements and detect any signs of danger without constant human supervision.
* **Better patient care:** In a hospital setting, the app could be used to monitor patients and alert nurses if they are in danger of falling or if their vital signs indicate that they need medical attention. This could lead to improved patient care, reduced medical costs, and faster recovery times.
* **Peace of mind for families and caregivers:** The app provides families and caregivers with peace of mind, knowing that their loved ones are being monitored and protected and that they will be immediately notified in case of any danger or emergency.
## Challenges
One of the biggest challenges have been integrating all the different technologies, such as live streaming and machine learning algorithms, and making sure they worked together seamlessly.
## Successes
The project was a collaborative effort between a designer and developers, which highlights the importance of cross-functional teams in delivering complex technical solutions. Overall, the project was a success and resulted in a cutting-edge solution that can help protect vulnerable individuals.
## Things Learnt
* **Importance of cross-functional teams:** As there were different specialists working on the project, it helped us understand the value of cross-functional teams in addressing complex challenges and delivering successful results.
* **Integrating different technologies:** Our team learned the challenges and importance of integrating different technologies to deliver a seamless and effective solution.
* **Machine learning for health applications:** After doing the research and completing the project, our team learned about the potential and challenges of using machine learning in the healthcare industry, and the steps required to build and deploy a successful machine learning model.
## Future Plans for SafeSpot
* First of all, the usage of the app could be extended to other settings, such as elderly care facilities, schools, kindergartens, or emergency rooms to provide a safer and more secure environment for vulnerable individuals.
* Apart from the web, the platform could also be implemented as a mobile app. In this case scenario, the alert would pop up privately on the user’s phone and notify only people who are given access to it.
* The app could also be integrated with wearable devices, such as fitness trackers, which could provide additional data and context to help determine if the user is in danger or has been injured. | losing |
## Inspiration
**Read something, do something.** We constantly encounter articles about social and political problems affecting communities all over the world – mass incarceration, the climate emergency, attacks on women's reproductive rights, and countless others. Many people are concerned or outraged by reading about these problems, but don't know how to directly take action to reduce harm and fight for systemic change. **We want to connect users to events, organizations, and communities so they may take action on the issues they care about, based on the articles they are viewing**
## What it does
The Act Now Chrome extension analyzes articles the user is reading. If the article is relevant to a social or political issue or cause, it will display a banner linking the user to an opportunity to directly take action or connect with an organization working to address the issue. For example, someone reading an article about the climate crisis might be prompted with a link to information about the Sunrise Movement's efforts to fight for political action to address the emergency. Someone reading about laws restricting women's reproductive rights might be linked to opportunities to volunteer for Planned Parenthood.
## How we built it
We built the Chrome extension by using a background.js and content.js file to dynamically render a ReactJS app onto any webpage the API identified to contain topics of interest. We built the REST API back end in Python using Django and Django REST Framework. Our API is hosted on Heroku, the chrome app is published in "developer mode" on the chrome app store and consumes this API. We used bitbucket to collaborate with one another and held meetings every 2 - 3 hours to reconvene and engage in discourse about progress or challenges we encountered to keep our team productive.
## Challenges we ran into
Our initial attempts to use sophisticated NLP methods to measure the relevance of an article to a given organization or opportunity for action were not very successful. A simpler method based on keywords turned out to be much more accurate.
Passing messages to the back-end REST API from the Chrome extension was somewhat tedious as well, especially because the API had to be consumed before the react app was initialized. This resulted in the use of chrome's messaging system and numerous javascript promises.
## Accomplishments that we're proud of
In just one weekend, **we've prototyped a versatile platform that could help motivate and connect thousands of people to take action toward positive social change**. We hope that by connecting people to relevant communities and organizations, based off their viewing of various social topics, that the anxiety, outrage or even mere preoccupation cultivated by such readings may manifest into productive action and encourage people to be better allies and advocates for communities experiencing harm and oppression.
## What we learned
Although some of us had basic experience with Django and building simple Chrome extensions, this project provided new challenges and technologies to learn for all of us. Integrating the Django backend with Heroku and the ReactJS frontend was challenging, along with writing a versatile web scraper to extract article content from any site.
## What's next for Act Now
We plan to create a web interface where organizations and communities can post events, meetups, and actions to our database so that they may be suggested to Act Now users. This update will not only make our applicaiton more dynamic but will further stimulate connection by introducing a completely new group of people to the application: the event hosters. This update would also include spatial and temporal information thus making it easier for users to connect with local organizations and communities. | ## Inspiration
When we heard about using food as a means of love and connection from Otsuka x VALUENEX’s Opening Ceremony presentation, our team was instantly inspired to create something that would connect Asian American Gen Z with our cultural roots and immigrant parents. Recently, there has been a surge of instant Asian food in American grocery stores. However, the love that exudes out of our mother’s piping hot dishes is irreplaceable, which is why it’s important for us, the loneliest demographic in the U.S., to cherish our immigrant parents’ traditional recipes. As Asian American Gen Z ourselves, we often fear losing out on beloved cultural dishes, as our parents have recipes ingrained in them out of years of repetition and thus, neglected documenting these precious recipes. As a result, many of us don’t have access to recreating these traditional dishes, so we wanted to create a web application that encourages sharing of traditional, cultural recipes from our immigrant parents to Asian American Gen Z. We hope that this will reinforce cross-generational relationships, alleviate feelings of disconnect and loneliness (especially in immigrant families), and preserve memories and traditions.
## What it does
Through this web application, users have the option to browse through previews of traditional Asian recipes, posted by Asian or Asian American parents, featured on the landing page. If choosing to browse through, users can filter (by culture) through recipes to get closer to finding their perfect dish that reminds them of home. In the previews of the dishes, users will find the difficulty of the dish (via the number of knives – greater is more difficult), the cultural type of dish, and will also have the option to favorite/save a dish. Once they click on the preview of a dish, they will be greeted by an expanded version of the recipe, featuring the name and image of the dish, ingredients, and instructions on how to prepare and cook this dish. For users that want to add recipes to *yumma*, they can utilize a modal box and input various details about the dish. Additionally, users can also supplement their recipes with stories about the meaning behind each dish, sparking warm memories that will last forever.
## How we built it
We built *yumma* using ReactJS as our frontend, Convex as our backend (made easy!), Material UI for the modal component, CSS for styling, GitHub to manage our version set, a lot of helpful tips and guidance from mentors and sponsors (♡), a lot of hydration from Pocari Sweat (♡), and a lot of love from puppies (♡).
## Challenges we ran into
Since we were all relatively beginners in programming, we initially struggled with simply being able to bring our ideas to life through successful, bug-free implementation. We turned to a lot of experienced React mentors and sponsors (shoutout to Convex) for assistance in debugging. We truly believe that learning from such experienced and friendly individuals was one of the biggest and most valuable takeaways from this hackathon. We additionally struggled with styling because we were incredibly ambitious with our design and wanted to create a high-fidelity functioning app, however HTML/CSS styling can take large amounts of time when you barely know what a flex box is. Additionally, we also struggled heavily with getting our app to function due to one of its main features being in a popup menu (Modal from material UI). We worked around this by creating an extra button in order for us to accomplish the functionality we needed.
## Accomplishments that we're proud of
This is all of our first hackathon! All of us also only recently started getting into app development, and each has around a year or less of experience–so this was kind of a big deal to each of us. We were excitedly anticipating the challenge of starting something new from the ground up. While we were not expecting to even be able to submit a working app, we ended up accomplishing some of our key functionality and creating high fidelity designs. Not only that, but each and every one of us got to explore interests we didn’t even know we had. We are not only proud of our hard work in actually making this app come to fruition, but that we were all so open to putting ourselves out of our comfort zone and realizing our passions for these new endeavors. We tried new tools, practiced new skills, and pushed our necks to the most physical strain they could handle. Another accomplishment that we were proud of is simply the fact that we never gave up. It could have been very easy to shut our laptops and run around the Main Quadrangle, but our personal ties and passion for this project kept us going.
## What we learned
On the technical side, Erin and Kaylee learned how to use Convex for the first time (woo!) and learned how to work with components they never knew could exist, while Megan tried her hand for the first time at React and CSS while coming up with some stellar wireframes. Galen was a double threat, going back to her roots as a designer while helping us develop our display component. Beyond those skills, our team was able to connect with some of the company sponsors and reinvigorate our passions on why we chose to go down the path of technology and development in the first place. We also learned more about ourselves–our interests, our strengths, and our ability to connect with each other through this unique struggle.
## What's next for yumma
Adding the option to upload private recipes that can only be visible to you and any other user you invite to view it (so that your Ba Ngoai–grandma’s—recipes stay a family secret!)
Adding more dropdown features to the input fields so that some will be easier and quicker to use
A messaging feature where you can talk to other users and connect with them, so that cooking meetups can happen and you can share this part of your identity with others
Allowing users to upload photos of what they make from recipes they make and post them, where the most recent of photos for each recipe will be displayed as part of a carousel on each recipe component.
An ingredients list that users can edit to keep track of things they want to grocery shop for while browsing | ## Inspiration
Self-motivation is hard. It’s time for a social media platform that is meaningful and brings a sense of achievement instead of frustration.
While various pro-exercise campaigns and apps have tried inspire people, it is difficult to stay motivated with so many other more comfortable distractions around us. Surge is a social media platform that helps solve this problem by empowering people to exercise. Users compete against themselves or new friends to unlock content that is important to them through physical activity.
True friends and formed through adversity, and we believe that users will form more authentic, lasting relationships as they compete side-by-side in fitness challenges tailored to their ability levels.
## What it does
When you register for Surge, you take an initial survey about your overall fitness, preferred exercises, and the websites you are most addicted to. This survey will serve as the starting point from which Surge creates your own personalized challenges: Run 1 mile to watch Netflix for example. Surge links to your phone or IOT wrist device (Fitbit, Apple Watch, etc...) and, using its own Chrome browser extension, 'releases' content that is important to the user when they complete the challenges.
The platform is a 'mixed bag'. Sometimes users will unlock rewards such as vouchers or coupons, and sometimes they will need to complete the challenge to unlock their favorite streaming or gaming platforms.
## How we built it
Back-end:
We used Python Flask to run our webserver locally as we were familiar with it and it was easy to use it to communicate with our Chrome extension's Ajax. Our Chrome extension will check the URL of whatever webpage you are on against the URLs of sites for a given user. If the user has a URL locked, the Chrome extension will display their challenge instead of the original site at that URL. We used an ESP8266 (onboard Arduino) with an accelerometer in lieu of an IOT wrist device, as none of our team members own those devices. We don’t want an expensive wearable to be a barrier to our platform, so we might explore providing a low cost fitness tracker to our users as well.
We chose to use Google's Firebase as our database for this project as it supports calls from many different endpoints. We integrated it with our Python and Arduino code and intended to integrate it with our Chrome extension, however we ran into trouble doing that, so we used AJAX to send a request to our Flask server which then acts as a middleman between the Firebase database and our Chrome extension.
Front-end:
We used Figma to prototype our layout, and then converted to a mix of HTML/CSS and React.js.
## Challenges we ran into
Connecting all the moving parts: the IOT device to the database to the flask server to both the chrome extension and the app front end.
## Accomplishments that we're proud of
Please see above :)
## What we learned
Working with firebase and chrome extensions.
## What's next for SURGE
Continue to improve our front end. Incorporate analytics to accurately identify the type of physical activity the user is doing. We would also eventually like to include analytics that gauge how easily a person is completing a task, to ensure the fitness level that they have been assigned is accurate. | partial |
# YHacks2015
GeoAlarm is a web app running on JavaScript that provides the User to enter in a location, name of alarm, and distance to location which will then create a personalized alarm that will alert the user when they get in range of their desired distance from their location. GeoAlarm adds multiple alarms and users can switch between alarms by clicking on their desired alarm from the taskbar. GeoAlarm also will be able to log into facebook users' accounts to remember previous locations and connect with their friends. This is meant to be a dedicated towards a mapping application and will be a subsection of it. | ## Inspiration
Timing travels is difficult. Remembering is not easy. We aim to solve both giphy-ily.
## What it does
GifAlarm integrates both Google Calendar and Google Maps to bring its users the best travel and alarm experience. Google Calendar tracks the time periods and locations of the user's commitment. Our web application then utilizes Google Maps to calculate travel paths and times as a normal GPS would. However, in contrast to the typical passive GPS model, GifAlarm will frequently send and receive location data to Google Maps to provide real-time recalculation of distances and time remaining for travels. Here's where happy-giphy comes in: gifs are used to remind the user of three main changes. Gifs remind you to start your travel, to speed up when you walk too slowly, and they congratulate you when you have arrived. The Gifs make for a more visually stimulating method of alarming. What differentiates our product is the integration of both Google tools together and the added comical relief for users of all gif-backgrounds.
## How we built it
With limited development experience, we built our web model using HTML, CSS, and Google Calendar and Maps APIs.
## Challenges we ran into
We ran into many challenges trying to integrate the Google APIs, trying Python and Browser integrations. When the APIs would not show, troubleshooting was difficult with our limited experience. We also ran into challenges when actually implementing the functions we want for our product. We cannot get the Google Maps to function in our web app. As of now, we only have the base frontend of our web application with no implementation of the actual features.
## Accomplishments that we're proud of
We are proud of our idea, which implements various APIs and ideas. We are also proud that we were able to create a website that looks relatively aesthetic.
## What we learned
We learned various new HTML implementations as well as the general function and convenience of APIs. For future hackathons, we hope to learn more about React and development methods that will help us create exactly what we imagine in the future.
## What's next for GifAlarm
Without a doubt, GifAlarm will need to be remade as a mobile app, because the main purpose of the alarm is to be convenient while on-the-go, which is only possible through mobile devices. Furthermore, we hope to use speech to text functions, so for example, a user will have to read the words displayed on a gif to end an alarm. | ## Inspiration
Our inspiration came from the idea of emergencies and to help out the people in distress. So, if there is a minor emergency such as a Room has been locked and someone is stuck inside. He/She can Mark the place and comment it through the AR App allowing everyone in the nearby location to see and respond to it directly. This AR App allows you to receive help from not just your friends but by people who are nearby and are willing to help you out.
## What it does
This AR App posts messages in AR using GeoLocation of the user which allows people around the user with the App to see it and post messages themselves in real-time. This is a great way to help someone in distress, as sometimes they are unable to contact relatives, but someone might see their message from this App This AR App could be used as a social network to connect various people to each other.
## How we built it
For the AR portion of the App we used Swift for the Front-End and Back-End Portion of the apps while the while connecting to the Amazon Web Services through Dynamobd as the database. The website is made using HTML, CSS, and JavaScript with a small hint of the Google Maps API and the Facebook Login API with the website being hosted on Firebase. Facebook Login API is used for authentication of the user to login into the App itself, to start marking points around you. It was also used for the website to login the user into their screen which shows where the markers are placed! Google Maps API is used mainly for the website to view the markers around you.
## Challenges we ran into
Working with Amazon Web Service's Dynamobd for the back-end portion of this AR Hack. All of us were new to developing in iOS, using Swift and also using Amazon Web Services which made it very hard but an ambitious project! Another major difficulty we ran into was even though we are doing a iOS/Swift Hack, only one of us had a iPhone to test it on and 2 Macbooks which slowed down our progress and set us back on our timeline.
## Accomplishments that we're proud of
Throughout this hackathon, we had problems with programming in Swift as it was a new take for all of us. Throughout the duration of this hackathon, two of our members worked for the entire time to ensure that the AR App was completed. We are proud that even though we divided this into two mini projects, The Web Portion and the AR App itself, we were able to communicate between each other and be on the same path to avoid future problems.
## What we learned
Throughout this hackathon, the team members who programmed the AR portion of the App did not know Swift and learnt the language on Friday and went on to finishing the hack well before the deadline of this submission. Additionally, none of us knew Firebase and learning it along the way was a struggle for us, but we were able to come through and have the Firebase portion of the application working!
## What's next for shARe
Currently only supported for iOS devices, we want to furthur this application by getting support for Android and developing the Application for Android devices as we noticed only one of our team member was a Apple User while the rest were Android users and it would've been very beneficial if we hacked in Android! | losing |
## Inspiration
Selina was desperately trying to get to PennApps on Friday after she disembarked her Greyhound. Alas, she had forgotten that only Bolt Bus and Megabus end their journeys directly next to the University of Pennsylvania, so she was a full 45 minute walk away from Penn Engineering. Full of hope, she approached the SEPTA stop marked on Google Maps, but was quickly rebuffed by the lack of clear markings and options for ticket acquirement. It was dark and cold, so she figured she might as well call a $5 Lyft. But when she opened the app, she was met with the face of doom: "Poor Network Connectivity". But she had five bars! If only, she despaired as she hunted for wifi, there were some way she could book that Lyft with just a phone call.
## What it does
Users can call 1-888-970-LYFF, where an automated chatbot will guide them through the process of ordering a Lyft to their final destination. Users can simply look at the street name and number of the closest building to acquire their current location.
## How I built it
We used the Nexmo API from Vonage to handle the voice aspect, Amazon Lex to create a chatbot and parse the speech input, Amazon Lambda to implement the internal application logic, the Lyft API for obvious reasons, and Google Maps API to sanitize the locations.
## Challenges I ran into
Nexmo's code to connect the phone API to Amazon Lex was overloading the buffer, causing the bot to become unstable. We fixed this issue, submitting a pull request for Nexmo's review.
## Accomplishments that I'm proud of
We got it to work end to end!
## What I learned
How to use Amazon lambda functions, setup an EC2 instance, that API's don't always do what the documentation says they do.
## What's next for Lyff
Instead of making calls in Lyft's sandbox environment, we'll try booking a real Lyft on our phone without using the Lyft app :) Just by making a call to 1-888-970-LYFF. | ## Inspiration
As college students who are on a budget when traveling from school to the airport, or from campus to a different city, we found it difficult to coordinate rides with other students. The facebook or groupme groupchats are always flooding with students scrambling to find people to carpool with at the last minute to save money.
## What it does
Ride Along finds and pre-schedules passengers who are headed between the same start and final location as each driver.
## How we built it
Built using Bubble.io framework. Utilized Google Maps API
## Challenges we ran into
Certain annoyances when using Bubble and figuring out how to use it. Had style issues with alignment, and certain functionalities were confusing at first and required debugging.
## Accomplishments that we're proud of
Using the Bubble framework properly and their built in backend data feature. Getting buttons and priority features implemented well, and having a decent MVP to present.
## What we learned
There are a lot of challenges when integrating multiple features together. Getting a proper workflow is tricky and takes lots of debugging and time.
## What's next for Ride Along
We want to get a Google Maps API key to properly be able to deploy the web app and be able to functionally use it. There are other features we wanted to implement, such as creating messages between users, etc. | ## Inspiration
Toronto is famous because it is tied for the second longest average commute time of any city (96 minutes, both ways). People love to complain about the TTC and many people have legitimate reasons for avoiding public transit. With our app, we hope to change this. Our aim is to change the public's perspective of transit in Toronto by creating a more engaging and connected experience.
## What it does
We built an iOS app that transforms the subway experience. We display important information to subway riders, such as ETA, current/next station, as well as information about events and points of interest in Toronto. In addition, we allow people to connect by participating in a local chat and multiplayer games.
We have small web servers running on ESP8266 micro-controllers that will be implemented in TTC subway cars. These micro-controllers create a LAN (Local Area Network) Intranet and allow commuters to connect with each other on the local network using our app. The ESP8266 micro-controllers also connect to the internet when available and can send data to Microsoft Azure.
## How we built it
The front end of our app is built using Swift for iOS devices, however, all devices can connect to the network and an Android app is planned for the future. The live chat section was built with JavaScript. The back end is built using C++ on the ESP8266 micro-controller, while a Python script handles the interactions with Azure. The ESP8266 micro-controller runs in both access point (AP) and station (STA) modes, and is fitted with a button that can push data to Azure.
## Challenges we ran into
Getting the WebView to render properly on the iOS app was tricky. There was a good amount of tinkering with configuration due to the page being served over http on a local area network (LAN).
Our ESP8266 Micro-controller is a very nifty device, but such a low cost device comes with strict development rules. The RAM and flash size were puny and special care was needed to be taken to ensure a stable foundation. This meant only being able to use vanilla JS (no Jquery, too big) and keeping code as optimized as possible. We built the live chat room with XHR and Ajax, as opposed to using a websocket, which is more ideal.
## Accomplishments that we're proud of
We are proud of our UI design. We think that our app looks pretty dope!
We're also happy of being able to integrate many different features into our project. We had to learn about communication between many different tech layers.
We managed to design a live chat room that can handle multiple users at once and run it on a micro-controller with 80KiB of RAM. All the code on the micro-controller was designed to be as lightweight as possible, as we only had 500KB in total flash storage.
## What we learned
We learned how to code as lightly as possible with the tight restrictions of the chip. We also learned how to start and deploy on Azure, as well as how to interface between our micro-controller and the cloud.
## What's next for Commutr
There is a lot of additional functionality that we can add, things like: Presto integration, geolocation, and an emergency alert system.
In order to host and serve larger images, the ESP8266' measly 500KB of storage is planning on being upgraded with an SD card module that can increase storage into the gigabytes. Using this, we can plan to bring fully fledged WiFi connectivity to Toronto's underground railway. | partial |
# TextMemoirs
## nwHacks 2023 Submission by Victor Parangue, Kareem El-Wishahy, Parmvir Shergill, and Daniel Lee
Journalling is a well-established practice that has been shown to have many benefits for mental health and overall well-being. Some of the main benefits of journalling include the ability to reflect on one's thoughts and emotions, reduce stress and anxiety, and document progress and growth. By writing down our experiences and feelings, we are able to process and understand them better, which can lead to greater self-awareness and insight. We can track our personal development, and identify the patterns and triggers that may be contributing to our stress and anxiety. Journalling is a practice that everyone can benefit from.
Text Memoirs is designed to make the benefits of journalling easy and accessible to everyone. By using a mobile text-message based journaling format, users can document their thoughts and feelings in a real-time sequential journal, as they go about their day.
Simply text your assigned number, and your journal text entry gets saved to our database. You're journal text entries are then displayed on our web app GUI. You can view all your text journal entries on any given specific day on the GUI.
You can also text commands to your assigned number using /EDIT and /DELETE to update your text journal entries on the database and the GUI (see the image gallery).
Text Memoirs utilizes Twilio’s API to receive and store user’s text messages in a CockroachDB database. The frontend interface for viewing a user’s daily journals is built using Flutter.
![]()
![]()
# TextMemoirs API
This API allows you to insert users, get all users, add texts, get texts by user and day, delete texts by id, get all texts and edit texts by id.
## Endpoints
### Insert User
Insert a user into the system.
* Method: **POST**
* URL: `/insertUser`
* Body:
`{
"phoneNumber": "+17707626118",
"userName": "Test User",
"password": "Test Password"
}`
### Get Users
Get all users in the system.
* Method: **GET**
* URL: `/getUsers`
### Add Text
Add a text to the system for a specific user.
* Method: **POST**
* URL: `/addText`
* Body:
`{
"phoneNumber": "+17707626118", "textMessage": "Text message #3", "creationDate": "1/21/2023", "creationTime": "2:57:14 PM"
}`
### Get Texts By User And Day
Get all texts for a specific user and day.
* Method: **GET**
* URL: `/getTextsByUserAndDay`
* Parameters:
+ phoneNumber: The phone number of the user.
+ creationDate: The date of the texts in the format `MM/DD/YYYY`.
### Delete Texts By ID
Delete a specific text by ID.
* Method: **DELETE**
* URL: `/deleteTextsById`
* Body:
`{
"textId": 3
}`
### Edit Texts By ID
Edit a specific text by ID.
* Method: **PUT**
* URL: `/editTextsById`
* Parameters:
+ id: The ID of the text to edit.
* Body:
`{
"textId": 2,
"textMessage": "Updated text message"
}`
### Get All Texts
Get all texts in the database.
* Method: **GET**
* URL: `/getAllTexts` | ## Inspiration
Considering our team is so diverse (Pakistan, Sweden, Brazil, and Nigeria) it was natural for us to consider worldwide problems when creating our project. This problem especially has such a large societal impact, that we were very motivated to move towards a solution.
## What it does
Our service takes requests from users by SMS, which we then convert to an executable query. When the query result is received we send it back using SMS. Our application makes the process user-friendly and allows for more features when accessing the internet, such as ordering an Uber or ordering food.
## How we built it
The app can convert the user selection into text messages, sending them to our Twilio number.
We used the Twilio API to automatically manage these texts. Using C# and python scripts we convert the text into a google search, sending the result back as a text message.
## Challenges we ran into
The main challenge we faced was making the different protocols interact, it was also challenging to produce and debug everything under the time constraint.
## Accomplishments that we're proud of
We are very proud of our presentation and our creative solution. As well as having such an effective collaboration that enabled us to complete as much as we did.
We are very proud of how we successfully created a novel solution that is simple enough to be applicable on a large scale, having a large impact on the world.
## What we learned
We learned how to automize the management of text messages, and how to make the different protocols communicate correctly
## What's next for Access
What's next for Access is to expand our service, fulfilling the large potential that our solution has. We want to make more parts of the internet accessible through our service, make the process more efficient and most importantly extend our reach to those who need it the most. | ## Inspiration
The inspiration behind MoodJournal comes from a desire to reflect on and cherish the good times, especially in an era where digital overload often makes us overlook the beauty of everyday moments. We wanted to create a digital sanctuary where users can not only store their daily and memories but also discover what truly makes them happy. By leveraging cutting-edge technology, we sought to bring a modern twist to the nostalgic act of keeping a diary, transforming it into a dynamic tool for self-reflection and emotional well-being
## What it does
MoodJournal is a digital diary app that allows users to capture their daily life through text entries and photographs. Utilizing semantic analysis and image-to-text conversion technologies, the app evaluates the emotional content of each entry to generate 5 happiness scores in range from Very Happy to Very Sad. This innovative approach enables MoodJournal to identify and highlight the user's happiest moments. At the end of the year, it creates a personalized collage of these joyous times, showcasing a summary of the texts and photos from those special days, serving as a powerful visual reminder of the year's highlights
## How we built it
MoodJournal's development combined React and JavaScript for a dynamic frontend, utilizing open-source libraries for enhanced functionality. The backend was structured around Python and Flask, providing a solid foundation for simple REST APIs. Cohere's semantic classification API was integrated for text analysis, enabling accurate emotion assessment. ChatGPT helped generate training data, ensuring our algorithms could effectively analyze and interpret users' entries.
## Challenges we ran into
The theme of nostalgia itself presented a conceptual challenge, making it difficult initially to settle on a compelling idea. Our limited experience in frontend development and UX/UI design further complicated the project, requiring substantial effort and learning. Thanks to invaluable guidance from mentors like Leon, Shiv, and Arash, we navigated these obstacles. Additionally, while the Cohere API served our text analysis needs well, we recognized the necessity for a larger dataset to enhance accuracy, underscoring the critical role of comprehensive data in achieving precise analytical outcomes.
## Accomplishments that we're proud of
We take great pride in achieving meaningful results from the Cohere API, which enabled us to conduct a thorough analysis of emotions from text entries. A significant breakthrough was our innovative approach to photo emotion analysis; by generating descriptive text from images using ChatGPT and then analyzing these descriptions with Cohere, we established a novel method for capturing emotional insights from visual content. Additionally, completing the core functionalities of MoodJournal to demonstrate an end-to-end flow of our primary objective was a milestone accomplishment. This project marked our first foray into utilizing a range of technologies, including React, Firebase, the Cohere API, and Flask. Successfully integrating these tools and delivering a functioning app, despite being new to them, is something we are especially proud of.
## What we learned
This hackathon was a tremendous learning opportunity. We dove into tools and technologies new to us, such as React, where we explored new libraries and features like useEffect, and Firebase, achieving data storage and retrieval. Our first-hand experience with Cohere's APIs, facilitated by direct engagement with their team, was invaluable, enhancing our app's text and photo analysis capabilities. Additionally, attending workshops, particularly on Cohere technologies like RAG, broadened our understanding of AI's possibilities. This event not only expanded our technical skills but also opened new horizons for future projects.
## What's next for MoodJournal
We're planning exciting updates to make diary-keeping easier and more engaging:
* AI-Generated Entries: Users can have diary entries created by AI, simplifying daily reflections.
* Photo Analysis for Entry Generation: Transform photos into diary texts with AI, offering an effortless way to document days.
* Integration with Snapchat Memories: This feature will allow users to turn snaps into diary entries, merging social moments with personal reflections.
* Monthly Collages and Emotional Insights: We'll introduce monthly summaries and visual insights into past emotions, alongside our yearly wrap-ups.
* User Accounts: Implementing login/signup functionality for a personalized and secure experience.
These enhancements aim to streamline the journaling process and deepen user engagement with MoodJournal. | partial |
## Inspiration Behind DejaVu 🌍
The inspiration behind DejaVu is deeply rooted in our fascination with the human experience and the power of memories. We've all had those moments where we felt a memory on the tip of our tongues but couldn't quite grasp it, like a fleeting dream slipping through our fingers. These fragments of the past hold immense value, as they connect us to our personal history, our emotions, and the people who have been a part of our journey. 🌟✨
We embarked on the journey to create DejaVu with the vision of bridging the gap between the past and the present, between what's remembered and what's forgotten. Our goal was to harness the magic of technology and innovation to make these elusive memories accessible once more. We wanted to give people the power to rediscover the treasures hidden within their own minds, to relive those special moments as if they were happening all over again, and to cherish the emotions they evoke. 🚀🔮
The spark that ignited DejaVu came from a profound understanding that our memories are not just records of the past; they are the essence of our identity. We wanted to empower individuals to be the architects of their own narratives, allowing them to revisit their life's most meaningful chapters. With DejaVu, we set out to create a tool that could turn the faint whispers of forgotten memories into vibrant, tangible experiences, filling our lives with the warmth of nostalgia and the joy of reconnection. 🧠🔑
## How We Built DejaVu 🛠️
It all starts with the hardware component. There is a video/audio-recording Python script running on a laptop, to which a webcam is connected. This webcam is connected to the user's hat, which they wear on their head and it records video. Once the video recording is stopped, the video is uploaded to a storage bucket on Google Cloud. 🎥☁️
The video is retrieved by the backend, which can then be processed. Vector embeddings are generated for both the audio and the video so that semantic search features can be integrated into our Python-based software. After that, the resulting vectors can be leveraged to deliver content to the front-end through a Flask microservice. Through the Cohere API, we were able to vectorize audio and contextual descriptions, as well as summarize all results on the client side. 🖥️🚀
Our front-end, which was created using Next.js and hosted on Vercel, features a landing page and a search page. On the search page, a user can search a query for a memory which they are attempting to recall. After that, the query text is sent to the backend through a request, and the necessary information relating to the location of this memory is sent back to the frontend. After this occurs, the video where this memory occurs is displayed on the screen and allows the user to get rid of the ominous feeling of déjà vu. 🔎🌟
## Challenges We Overcame at DejaVu 🚧
🧩 Overcoming Hardware Difficulties 🛠️
One of the significant challenges we encountered during the creation of DejaVu was finding the right hardware to support our project. Initially, we explored using AdHawk glasses, which unfortunately removed existing functionality critical to our project's success. Additionally, we found that the Raspberry Pi, while versatile, didn't possess the computing power required for our memory time machine. To overcome these hardware limitations, we had to pivot and develop Python scripts for our laptops, ensuring we had the necessary processing capacity to bring DejaVu to life. This adaptation proved to be a critical step in ensuring the project's success. 🚫💻
📱 Navigating the Complex World of Vector Embedding 🌐
Another formidable challenge we faced was in the realm of vector embedding. This intricate process, essential for capturing and understanding the essence of memories, presented difficulties throughout our development journey. We had to work diligently to fine-tune and optimize the vector embedding techniques to ensure the highest quality results. Overcoming this challenge required a deep understanding of the underlying technology and relentless dedication to refining the process. Ultimately, our commitment to tackling this complexity paid off, as it is a crucial component of DejaVu's effectiveness. 🔍📈
🌐 Connecting App Components and Cloud Hosting with Google Cloud 🔗
Integrating the various components of the DejaVu app and ensuring seamless cloud hosting were additional challenges we had to surmount. This involved intricate work to connect user interfaces, databases, and the cloud infrastructure with Google Cloud services. The complexity of this task required meticulous planning and execution to create a cohesive and robust platform. We overcame these challenges by leveraging the expertise of our team and dedicating considerable effort to ensure that all aspects of the app worked harmoniously, providing users with a smooth and reliable experience. 📱☁️
## Accomplishments We Celebrate at DejaVu 🏆
🚀 Navigating the Hardware-Software Connection Challenge 🔌
One of the most significant hurdles we faced during the creation of DejaVu was connecting hardware and software seamlessly. The integration of our memory time machine with the physical devices and sensors posed complex challenges. It required a delicate balance of engineering and software development expertise to ensure that the hardware effectively communicated with our software platform. Overcoming this challenge was essential to make DejaVu a user-friendly and reliable tool for capturing and reliving memories, and our team's dedication paid off in achieving this intricate connection. 💻🤝
🕵️♂️ Mastering Semantic Search Complexity 🧠
Another formidable challenge we encountered was the implementation of semantic search. Enabling DejaVu to understand the context and meaning behind users' search queries proved to be a significant undertaking. Achieving this required advanced natural language processing and machine learning techniques. We had to develop intricate algorithms to decipher the nuances of human language, ensuring that DejaVu could provide relevant results even for complex or abstract queries. This challenge was a testament to our commitment to delivering a cutting-edge memory time machine that truly understands and serves its users. 📚🔍
🔗 Cloud Hosting and Cross-Component Integration 🌐
Integrating the various components of the DejaVu app and hosting data on Google Cloud presented a multifaceted challenge. Creating a seamless connection between user interfaces, databases, and cloud infrastructure demanded meticulous planning and execution. Ensuring that the app operated smoothly and efficiently, even as it scaled, required careful design and architecture. We dedicated considerable effort to overcome this challenge, leveraging the robust capabilities of Google Cloud to provide users with a reliable and responsive platform for preserving and reliving their cherished memories. 📱☁️
## Lessons Learned from DejaVu's Journey 📚
💻 Innate Hardware Limitations 🚀
One of the most significant lessons we've gleaned from creating DejaVu is the importance of understanding hardware capabilities. We initially explored using Arduinos and Raspberry Pi's for certain aspects of our project, but we soon realized their innate limitations. These compact and versatile devices have their place in many projects, but for a memory-intensive and complex application like DejaVu, they proved to be improbable choices. 🤖🔌
📝 Planning Before Executing 🤯
A crucial takeaway from our journey of creating DejaVu was the significance of meticulous planning for user flow before diving into coding. There were instances where we rushed into development without a comprehensive understanding of how users would interact with our platform. This led to poor systems design, resulting in unnecessary complications and setbacks. We learned that a well-thought-out user flow and system architecture are fundamental to the success of any project, helping to streamline development and enhance user experience. 🚀🌟
🤖 Less Technology is More Progress💡
Another valuable lesson revolved around the concept that complex systems can often be simplified by reducing the number of technologies in use. At one point, we experimented with a CockroachDB serverless database, hoping to achieve certain functionalities. However, we soon realized that this introduced unnecessary complexity and redundancy into our architecture. Simplifying our technology stack and focusing on essential components allowed us to improve efficiency and maintain a more straightforward and robust system. 🗃️🧩
## The Future of DejaVu: Where Innovation Thrives! 💫
🧩 Facial Recognition and Video Sorting 📸
With our eyes set on the future, DejaVu is poised to bring even more remarkable features to life. This feature will play a pivotal role in enhancing the user experience. Our ongoing development efforts will allow DejaVu to recognize individuals in your video archives, making it easier than ever to locate and relive moments featuring specific people. This breakthrough in technology will enable users to effortlessly organize their memories, unlocking a new level of convenience and personalization. 🤳📽️
🎁 Sharing Memories In-App 📲
Imagine being able to send a cherished memory video from one user to another, all within the DejaVu platform. Whether it's a heartfelt message, a funny moment, or a shared experience, this feature will foster deeper connections between users, making it easy to celebrate and relive memories together, regardless of physical distance. DejaVu aims to be more than just a memory tool; it's a platform for creating and sharing meaningful experiences. 💌👥
💻 Integrating BCI (Brain-Computer Interface) Technology 🧠
This exciting frontier will open up possibilities for users to interact with their memories in entirely new ways. Imagine being able to navigate and interact with your memory archives using only your thoughts. This integration could revolutionize the way we access and relive memories, making it a truly immersive and personal experience. The future of DejaVu is all about pushing boundaries and providing users with innovative tools to make their memories more accessible and meaningful. 🌐🤯 | ## Inspiration
We all deal with nostalgia. Sometimes we miss our loved ones or places we visited and look back at our pictures. But what if we could revolutionize the way memories are shown? What if we said you can relive your memories and mean it literally?
## What it does
retro.act takes in a user prompt such as "I want uplifting 80s music" and will then use sentiment analysis and Cohere's chat feature to find potential songs out of which the user picks one. Then the user chooses from famous dance videos (such as by Michael Jackson). Finally, we will either let the user choose an image from their past or let our model match images based on the mood of the music and implant the dance moves and music into the image/s.
## How we built it
We used Cohere classify for sentiment analysis and to filter out songs whose mood doesn't match the user's current state. Then we use Cohere's chat and RAG based on the database of filtered songs to identify songs based on the user prompt. We match images to music by first generating a caption of the images using the Azure computer vision API doing a semantic search using KNN and Cohere embeddings and then use Cohere rerank to smooth out the final choices. Finally we make the image come to life by generating a skeleton of the dance moves using OpenCV and Mediapipe and then using a pretrained model to transfer the skeleton to the image.
## Challenges we ran into
This was the most technical project any of us have ever done and we had to overcome huge learning curves. A lot of us were not familiar with some of Cohere's features such as re rank, RAG and embeddings. In addition, generating the skeleton turned out to be very difficult. Apart from simply generating a skeleton using the standard Mediapipe landmarks, we realized we had to customize which landmarks we are connecting to make it a suitable input for the pertained model. Lastly, understanding and being able to use the model was a huge challenge. We had to deal with issues such as dependency errors, lacking a GPU, fixing import statements, deprecated packages.
## Accomplishments that we're proud of
We are incredibly proud of being able to get a very ambitious project done. While it was already difficult to get a skeleton of the dance moves, manipulating the coordinates to fit our pre trained model's specifications was very challenging. Lastly, the amount of experimentation and determination to find a working model that could successfully take in a skeleton and output an "alive" image.
## What we learned
We learned about using media pipe and manipulating a graph of coordinates depending on the output we need, We also learned how to use pre trained weights and run models from open source code. Lastly, we learned about various new Cohere features such as RAG and re rank.
## What's next for retro.act
Expand our database of songs and dance videos to allow for more user options, and get a more accurate algorithm for indexing to classify iterate over/classify the data from the db. We also hope to make the skeleton's motions more smooth for more realistic images. Lastly, this is very ambitious, but we hope to make our own model to transfer skeletons to images instead of using a pretrained one. | ## Inspiration
BThere emerged from a genuine desire to strengthen friendships by addressing the subtle challenges in understanding friends on a deeper level. The team recognized that nuanced conversations often go unnoticed, hindering meaningful support and genuine interactions. In the context of the COVID-19 pandemic, the shift to virtual communication intensified these challenges, making it harder to connect on a profound level. Lockdowns and social distancing amplified feelings of isolation, and the absence of in-person cues made understanding friends even more complex. BThere aims to use advanced technologies to overcome these obstacles, fostering stronger and more authentic connections in a world where the value of meaningful interactions has become increasingly apparent.
## What it does
BThere is a friend-assisting application that utilizes cutting-edge technologies to analyze conversations and provide insightful suggestions for users to connect with their friends on a deeper level. By recording conversations through video, the application employs Google Cloud's facial recognition and speech-to-text APIs to understand the friend's mood, likes, and dislikes. The OpenAI API generates personalized suggestions based on this analysis, offering recommendations to uplift a friend in moments of sadness or providing conversation topics and activities for neutral or happy states. The backend, powered by Python Flask, handles data storage using Firebase for authentication and data persistence. The frontend is developed using React, JavaScript, Next.js, HTML, and CSS, creating a user-friendly interface for seamless interaction.
## How we built it
BThere involves a multi-faceted approach, incorporating various technologies and platforms to achieve its goals. The recording feature utilizes WebRTC for live video streaming to the backend through sockets, but also allows users to upload videos for analysis. Google Cloud's facial recognition API identifies facial expressions, while the speech-to-text API extracts spoken content. The combination of these outputs serves as input for the OpenAI API, generating personalized suggestions. The backend, implemented in Python Flask, manages data storage in Firebase, ensuring secure authentication and persistent data access. The frontend, developed using React, JavaScript, Next.js, HTML, and CSS, delivers an intuitive user interface.
## Accomplishments that we're proud of
* Successfully integrating multiple technologies into a cohesive and functional application
* Developing a user-friendly frontend for a seamless experience
* Implementing real-time video streaming using WebRTC and sockets
* Leveraging Google Cloud and OpenAI APIs for advanced facial recognition, speech-to-text, and suggestion generation
## What's next for BThere
* Continuously optimizing the speech to text and emotion analysis model for improved accuracy with different accents, speech mannerisms, and languages
* Exploring advanced natural language processing (NLP) techniques to enhance conversational analysis
* Enhancing user experience through further personalization and more privacy features
* Conducting user feedback sessions to refine and expand the application's capabilities | winning |
## Inspiration
Have you ever stared into your refrigerator or pantry and had no idea what to eat for dinner? Pantri provides a visually compelling picture of which foods you should eat based on your current nutritional needs and offers recipe suggestions through Amazon Alexa voice integration.
## What it does
Pantri uses FitBit data to determine which nutritional goals you have or haven't met for the day, then transforms your kitchen with Intel Edison-connected RGB LCD screens and LIFX lighting to lead you in the direction of healthy options as well as offer up recipe suggestions to balance out your diet and clean out your fridge.
## How we built it
The finished hack is a prototype food storage unit (pantry) made of cardboard, duct tape, and plexiglass. It is connected to the backend through button and touch sensors as well as LIFX lights and RGB LCD screens. Pressing the button allows you to view the nutritional distribution without opening the door, and opening the door activates the touch sensor. The lights and screens indicate which foods (sorted onto shelves based on nutritional groups) are the best choices. Users can also verbally request a dinner suggestion which will be offered based on which nutritional categories are most needed.
At the center of the project is a Ruby on Rails server hosted live on Heroku. It stores user nutrition data, provides a mobile web interface, processes input from the button and touch sensors, and controls the LIFX lights as well as the color and text of the RGB LCD screens.
Additionally, we set up three Intel Edison microprocessors running Cylon.js (built on top of Node.js) with API interfaces so information about their attached button, touch sensor, and RGB LCD screens can be connected to the Rails server.
Finally, an Amazon Alexa (connected through an Amazon Echo) connects users with the best recipes based on their nutritional needs through a voice interface. | ## Inspiration
One day Saaz was sitting at home thinking about his fitness goals and his diet. Looking in his fridge, he realized that, on days when his fridge was only filled with leftovers and leftover ingredients, it was very difficult for him to figure out what he could make that followed his nutrition goals. This dilemma is something Saaz and others like him often encounter, and so we created SmartPalate to solve it.
## What it does
SmartPalate uses AI to scan your fridge and pantry for all the ingredients you have at your disposal. It then comes up with multiple recipes that you can make with those ingredients. Not only can the user view step-by-step instructions on how to make these recipes, but also, by adjusting the nutrition information of the recipe using sliders, SmartPalate caters the recipe to the user's fitness goals without compromising the overall taste of the food.
## How we built it
The scanning and categorization of different food items in the fridge and pantry is done using YOLOv5, a single-shot detection convolutional neural network. These food items are sent as a list of ingredients into the Spoonacular API, which matches the ingredients to recipes that contain them. We then used a modified natural language processing model to split the recipe into 4 distinct parts: the meats, the carbs, the flavoring, and the vegetables. Once the recipe is split, we use the same NLP model to categorize our ingredients into whichever part they are used in, as well as to give us a rough estimate on the amount of ingredients used in 1 serving. Then, using the Spoonacular API and the estimated amount of ingredients used in 1 serving, we calculate the nutrition information for 1 serving of each part. Because the amount of each part can be increased or decreased without compromising the taste of the overall recipe, we are then able to use a Bayesian optimization algorithm to quickly adjust the number of servings of each part (and the overall nutrition of the meal) to meet the user's nutritional demands. User interaction with the backend is done with a cleanly built front end made with a React TypeScript stack through Flask.
## Challenges we ran into
One of the biggest challenges was identifying the subgroups in every meal(the meats, the vegetables, the carbs, and the seasonings/sauces). After trying multiple methods such as clustering, we settled on an approach that uses a state-of-the-art natural language model to identify the groups.
## Accomplishments that we're proud of
We are proud of the fact that you can scan your fridge with your phone instead of typing in individual items, allowing for a much easier user experience. Additionally, we are proud of the algorithm that we created to help users adjust the nutrition levels of their meals without compromising the overall taste of the meals.
## What we learned
Using our NLP model taught us just how unstable NLP is, and it showed us the importance of good prompt engineering. We also learned a great deal from our struggle to integrate the different parts of our project together, which required a lot of communication and careful code design.
## What's next for SmartPalate
We plan to allow users to rate and review the different recipes that they create. Additionally, we plan to add a social component to SmartPalate that allows people to share the nutritionally customized recipes that they created. | ## Inspiration
When it comes to finding solutions to global issues, we often feel helpless: making us feel as if our small impact will not help the bigger picture. Climate change is a critical concern of our age; however, the extent of this matter often reaches beyond what one person can do....or so we think!
Inspired by the feeling of "not much we can do", we created *eatco*. *Eatco* allows the user to gain live updates and learn how their usage of the platform helps fight climate change. This allows us to not only present users with a medium to make an impact but also helps spread information about how mother nature can heal.
## What it does
While *eatco* is centered around providing an eco-friendly alternative lifestyle, we narrowed our approach to something everyone loves and can apt to; food! Other than the plenty of health benefits of adopting a vegetarian diet — such as lowering cholesterol intake and protecting against cardiovascular diseases — having a meatless diet also allows you to reduce greenhouse gas emissions which contribute to 60% of our climate crisis. Providing users with a vegetarian (or vegan!) alternative to their favourite foods, *eatco* aims to use small wins to create a big impact on the issue of global warming. Moreover, with an option to connect their *eatco* account with Spotify we engage our users and make them love the cooking process even more by using their personal song choices, mixed with the flavours of our recipe, to create a personalized playlist for every recipe.
## How we built it
For the front-end component of the website, we created our web-app pages in React and used HTML5 with CSS3 to style the site. There are three main pages the site routes to: the main app, and the login and register page. The login pages utilized a minimalist aesthetic with a CSS style sheet integrated into an HTML file while the recipe pages used React for the database. Because we wanted to keep the user experience cohesive and reduce the delay with rendering different pages through the backend, the main app — recipe searching and viewing — occurs on one page. We also wanted to reduce the wait time for fetching search results so rather than rendering a new page and searching again for the same query we use React to hide and render the appropriate components. We built the backend using the Flask framework. The required functionalities were implemented using specific libraries in python as well as certain APIs. For example, our web search API utilized the googlesearch and beautifulsoup4 libraries to access search results for vegetarian alternatives and return relevant data using web scraping. We also made use of Spotify Web API to access metadata about the user’s favourite artists and tracks to generate a personalized playlist based on the recipe being made. Lastly, we used a mongoDB database to store and access user-specific information such as their username, trees saved, recipes viewed, etc. We made multiple GET and POST requests to update the user’s info, i.e. saved recipes and recipes viewed, as well as making use of our web scraping API that retrieves recipe search results using the recipe query users submit.
## Challenges we ran into
In terms of the front-end, we should have considered implementing Routing earlier because when it came to doing so afterward, it would be too complicated to split up the main app page into different routes; this however ended up working out alright as we decided to keep the main page on one main component. Moreover, integrating animation transitions with React was something we hadn’t done and if we had more time we would’ve liked to add it in. Finally, only one of us working on the front-end was familiar with React so balancing what was familiar (HTML) and being able to integrate it into the React workflow took some time. Implementing the backend, particularly the spotify playlist feature, was quite tedious since some aspects of the spotify web API were not as well explained in online resources and hence, we had to rely solely on documentation. Furthermore, having web scraping and APIs in our project meant that we had to parse a lot of dictionaries and lists, making sure that all our keys were exactly correct. Additionally, since dictionaries in Python can have single quotes, when converting these to JSONs we had many issues with not having them be double quotes. The JSONs for the recipes also often had quotation marks in the title, so we had to carefully replace these before the recipes were themselves returned. Later, we also ran into issues with rate limiting which made it difficult to consistently test our application as it would send too many requests in a small period of time. As a result, we had to increase the pause interval between requests when testing which made it a slow and time consuming process. Integrating the Spotify API calls on the backend with the frontend proved quite difficult. This involved making sure that the authentication and redirects were done properly. We first planned to do this with a popup that called back to the original recipe page, but with the enormous amount of complexity of this task, we switched to have the playlist open in a separate page.
## Accomplishments that we're proud of
Besides our main idea of allowing users to create a better carbon footprint for themselves, we are proud of accomplishing our Spotify integration. Using the Spotify API and metadata was something none of the team had worked with before and we're glad we learned the new skill because it adds great character to the site. We all love music and being able to use metadata for personalized playlists satisfied our inner musical geek and the integration turned out great so we're really happy with the feature. Along with our vast recipe database this far, we are also proud of our integration! Creating a full-stack database application can be tough and putting together all of our different parts was quite hard, especially as it's something we have limited experience with; hence, we're really proud of our service layer for that. Finally, this was the first time our front-end developers used React for a hackathon; hence, using it in a time and resource constraint environment for the first time and managing to do it as well as we did is also one of our greatest accomplishments.
## What we learned
This hackathon was a great learning experience for all of us because everyone delved into a tool that they'd never used before! As a group, one of the main things we learned was the importance of a good git workflow because it allows all team members to have a medium to collaborate efficiently by combing individual parts. Moreover, we also learned about Spotify embedding which not only gave *eatco* a great feature but also provided us with exposure to metadata and API tools. Moreover, we also learned more about creating a component hierarchy and routing on the front end. Another new tool that we used in the back-end was learning how to perform database operations on a cloud-based MongoDB Atlas database from a python script using the pymongo API. This allowed us to complete our recipe database which was the biggest functionality in *eatco*.
## What's next for Eatco
Our team is proud of what *eatco* stands for and we want to continue this project beyond the scope of this hackathon and join the fight against climate change. We truly believe in this cause and feel eatco has the power to bring meaningful change; thus, we plan to improve the site further and release it as a web platform and a mobile application. Before making *eatco* available for users publically we want to add more functionality and further improve the database and present the user with a more accurate update of their carbon footprint. In addition to making our recipe database bigger, we also want to focus on enhancing the front-end for a better user experience. Furthermore, we also hope to include features such as connecting to maps (if the user doesn't have a certain ingredient, they will be directed to the nearest facility where that item can be found), and better use of the Spotify metadata to generate even better playlists. Lastly, we also want to add a saved water feature to also contribute into the global water crisis because eating green also helps cut back on wasteful water consumption! We firmly believe that *eatco* can go beyond the range of the last 36 hours and make impactful change on our planet; hence, we want to share with the world how global issues don't always need huge corporate or public support to be solved, but one person can also make a difference. | partial |
Club applications - especially at schools like Cal - have become more and more competitive in recent years. Students must keep track of numerous deadlines, attend many introductory events, submit application materials, and constantly stress to find clubs that best fit their future career goals amongst a huge student body.
ClubScout centralizes and simplifies the club application season for both students and clubs. From a student point of view, ClubScout helps efficiently apply to clubs by centralizing all application questions and important dates. It also allows students to discover new clubs based on their interests and majors by using keyword searches. From a club point of view, ClubScout allows club officers to post information and review applications in a more organized system than stray Google Forms.
After lots of brainstorming and research, we decided to work simultaneously on frontend and backend. We started designing the user interface using Figma, making sure the platform would be accessible to everyone. Based on our UI/UX design concept, we created two databases: one to store student user information and another for club information. Finally, we completed the Swift code for our app in Xcode based on our UI/UX design. Our team also worked on coding features beyond Figma's capabilities, such as searching through lists and user input.
Because none of our team had any experience with app development or building and accessing databases prior to CalHacks, a majority of our time was spent figuring out how to bring our ideas to life. Over the past twenty-four hours, we have watched endless YouTube videos, read multiple online tutorials, and slept a collective five hours in an attempt to code ClubScouts using Swift and Figma, neither of which we had seen before.
We have two goals for ClubScouts’ future. One: utilize information in the database to personalize the app experience for users and clubs. For example, students will eventually be able to add clubs to their "Applying To" list and add these deadlines to their calendar. Two: work on Google Authentication and Firebase. Students will be able to manage their accounts using their school emails and IDs. After all, ClubScouts was made for students by students.
We still have a long way to go in designing and testing ClubScouts, but we're proud of the progress we made during CalHacks. Our team came into CalHacks unfamiliar with mobile app design, but we'll leave more confidence in our ability to code and our ability to innovate. | ## Inspiration: Deciding whether to join a student organization or going to their events without any information about how enjoyable the experience is can be difficult at an institution! We wanted to bring reviews to clubs so that you feel comfortable about where you spend your time!
## What it does:
* ClubHub allows current, past, and prospective members of a club rate the club on a scale and leave reviews about their experiences with an organization.
The organization's ratings are publicly available for all people that are within and outside of the University. All clubs are considered subsidiaries of the University they have chosen to be registered under, and will be listed within the institutions page.
## How we built it
* The app was completely built with Retool initially, and will be developed further with Swift/SiwfUI along with Firebase, and Flutter for the iOS and Android versions of the application
## Challenges we ran into
* Backend data access
* Creating web scraping scripts to gather information about already existing clubs at an institution
* APIs for each university
## Accomplishments that we're proud of
* Creating an Access Control System that allows organization owners to edit details about the club, without being able to edit any reviews that keep the club reviews authentic
* Creating a very seamless front-end interface with Navigation controls that allows user for each page of the application
## What we learned
* Pivoting from an idea is important when creating an application since there are some aspects and API integrations that are very difficult to implement
## What's next for ClubHub
* We are still in the testing phase, and we want to make the backend database more efficient
* Eventually we want to scale the application, so that it can reach people and universities across the Nation | ## Why We Created **Here**
As college students, one question that we catch ourselves asking over and over again is – “Where are you studying today?” One of the most popular ways for students to coordinate is through texting. But messaging people individually can be time consuming and awkward for both the inviter and the invitee—reaching out can be scary, but turning down an invitation can be simply impolite. Similarly, group chats are designed to be a channel of communication, and as a result, a message about studying at a cafe two hours from now could easily be drowned out by other discussions or met with an awkward silence.
Just as Instagram simplified casual photo sharing from tedious group-chatting through stories, we aim to simplify casual event coordination. Imagine being able to efficiently notify anyone from your closest friends to lecture buddies about what you’re doing—on your own schedule.
Fundamentally, **Here** is an app that enables you to quickly notify either custom groups or general lists of friends of where you will be, what you will be doing, and how long you will be there for. These events can be anything from an open-invite work session at Bass Library to a casual dining hall lunch with your philosophy professor. It’s the perfect dynamic social calendar to fit your lifestyle.
Groups are customizable, allowing you to organize your many distinct social groups. These may be your housemates, Friday board-game night group, fellow computer science majors, or even a mixture of them all. Rather than having exclusive group chat plans, **Here** allows for more flexibility to combine your various social spheres, casually and conveniently forming and strengthening connections.
## What it does
**Here** facilitates low-stakes event invites between users who can send their location to specific groups of friends or a general list of everyone they know. Similar to how Instagram lowered the pressure involved in photo sharing, **Here** makes location and event sharing casual and convenient.
## How we built it
UI/UX Design: Developed high fidelity mockups on Figma to follow a minimal and efficient design system. Thought through user flows and spoke with other students to better understand needed functionality.
Frontend: Our app is built on React Native and Expo.
Backend: We created a database schema and set up in Google Firebase. Our backend is built on Express.js.
All team members contributed code!
## Challenges
Our team consists of half first years and half sophomores. Additionally, the majority of us have never developed a mobile app or used these frameworks. As a result, the learning curve was steep, but eventually everyone became comfortable with their specialties and contributed significant work that led to the development of a functional app from scratch.
Our idea also addresses a simple problem which can conversely be one of the most difficult to solve. We needed to spend a significant amount of time understanding why this problem has not been fully addressed with our current technology and how to uniquely position **Here** to have real change.
## Accomplishments that we're proud of
We are extremely proud of how developed our app is currently, with a fully working database and custom frontend that we saw transformed from just Figma mockups to an interactive app. It was also eye opening to be able to speak with other students about our app and understand what direction this app can go into.
## What we learned
Creating a mobile app from scratch—from designing it to getting it pitch ready in 36 hours—forced all of us to accelerate our coding skills and learn to coordinate together on different parts of the app (whether that is dealing with merge conflicts or creating a system to most efficiently use each other’s strengths).
## What's next for **Here**
One of **Here’s** greatest strengths is the universality of its usage. After helping connect students with students, **Here** can then be turned towards universities to form a direct channel with their students. **Here** can provide educational institutions with the tools to foster intimate relations that spring from small, casual events. In a poll of more than sixty university students across the country, most students rarely checked their campus events pages, instead planning their calendars in accordance with what their friends are up to. With **Here**, universities will be able to more directly plug into those smaller social calendars to generate greater visibility over their own events and curate notifications more effectively for the students they want to target. Looking at the wider timeline, **Here** is perfectly placed at the revival of small-scale interactions after two years of meticulously planned agendas, allowing friends who have not seen each other in a while casually, conveniently reconnect.
The whole team plans to continue to build and develop this app. We have become dedicated to the idea over these last 36 hours and are determined to see just how far we can take **Here**! | losing |
## Inspiration
Helping people who are visually and/or hearing impaired to have better and safer interactions.
## What it does
The sensor beeps when the user comes too close to an object or too close to a hot beverage/food.
The sign language recognition system translates sign language from a hearing impaired individual to english for a caregiver.
The glasses capture pictures of surroundings and convert them into speech for a visually imapired user.
## How we built it
We used Microsoft Azure's vision API,Open CV,Scikit Learn, Numpy, Django + REST Framework, to build the technology.
## Challenges we ran into
Making sure the computer recognizes the different signs.
## Accomplishments that we're proud of
Making a glove with a sensor that helps user navigate their path, recognizing sign language, and converting images of surroundings to speech.
## What we learned
Different technologies such as Azure, OpenCV
## What's next for Spectrum Vision
Hoping to gain more funding to increase the scale of the project. | ## Inspiration
In a world where the voices of the minority are often not heard, technology must be adapted to fit the equitable needs of these groups. Picture the millions who live in a realm of silence, where for those who are deaf, you are constantly silenced and misinterpreted. Of the 50 million people in the United States with hearing loss, less than 500,000 — or about 1% — use sign language, according to Acessibility.com and a recent US Census. Over 466 million people across the globe struggle with deafness, a reality known to each in the deaf community. Imagine the pain where only 0.15% of people (in the United States) can understand you. As a mother, father, teacher, friend, or ally, there is a strong gap in communication that impacts deaf people every day. The need for a new technology is urgent from both an innovation perspective and a human rights perspective.
Amidst this urgent disaster of an industry, a revolutionary vision emerges – Caption Glasses, a beacon of hope for the American Sign Language (ASL) community. Caption Glasses bring the magic of real-time translation to life, using artificial neural networks (machine learning) to detect ASL "fingerspeaking" (their one-to-one version of the alphabet), and creating instant subtitles displayed on glasses. This revolutionary piece effortlessly bridges the divide between English and sign language. Instant captions allow for the deaf child to request food from their parents. Instant captions allow TAs to answer questions in sign language. Instant captions allow for the nurse to understand the deaf community seeking urgent care at hospitals. Amplifying communication for the deaf community to the unprecedented level that Caption Glasses does increases the diversity of humankind through equitable accessibility means!
With Caption Glasses, every sign becomes a verse, every gesture an eloquent expression. It's a revolution, a testament to humanity's potential to converse with one another. In a society where miscommunication causes wars, there is a huge profit associated with developing Caption Glasses. Join us in this journey as we redefine the meaning of connection, one word, one sign, and one profound moment at a time.
## What it does
The Caption Glasses provide captions displayed on glasses after detecting American Sign Language (ASL). The captions are instant and in real-time, allowing for effective translations into the English Language for the glasses wearer.
## How we built it
Recognizing the high learning curve of ASL, we began brainstorming for possible solutions to make sign language more approachable to everyone. We eventually settled on using AR-style glasses to display subtitles that can help an ASL learner quickly identify what sign they are looking at.
We started our build with hardware and design, starting off by programming a SSD1306 OLED 0.96'' display with an Arduino Nano. We also began designing our main apparatus around the key hardware components, and created a quick prototype using foam.
Next, we got to loading computer vision models onto a Raspberry Pi4. Although we were successful in loading a basic model that looks at generic object recognition, we were unable to find an ASL gesture recognition model that was compact enough to fit on the RPi.
To circumvent this problem, we made an approach change that involved more use of the MediaPipe Hand Recognition models. The particular model we chose marked out 21 landmarks of the human hand (including wrist, fingertips, knuckles, etc.). We then created and trained a custom Artificial Neural Network that takes the position of these landmarks, and determines what letter we are trying to sign.
At the same time, we 3D printed the main apparatus with a Prusa I3 3D printer, and put in all the key hardware components. This is when we became absolute best friends with hot glue!
## Challenges we ran into
The main challenges we ran into during this project mainly had to do with programming on an RPi and 3D printing.
Initially, we wanted to look for pre-trained models for recognizing ASL, but there were none that were compact enough to fit in the limited processing capability of the Raspberry Pi. We were able to circumvent the problem by creating a new model using MediaPipe and PyTorch, but we were unsuccessful in downloading the necessary libraries on the RPi to get the new model working. Thus, we were forced to use a laptop for the time being, but we will try to mitigate this problem by potentially looking into using ESP32i's in the future.
As a team, we were new to 3D printing, and we had a great experience learning about the importance of calibrating the 3D printer, and had the opportunity to deal with a severe printer jam. While this greatly slowed down the progression of our project, we were lucky enough to be able to fix our printer's jam!
## Accomplishments that we're proud of
Our biggest accomplishment is that we've brought our vision to life in the form of a physical working model. Employing the power of 3D printing through leveraging our expertise in SolidWorks design, we meticulously crafted the components, ensuring precision and functionality.
Our prototype seamlessly integrates into a pair of glasses, a sleek and practical design. At its heart lies an Arduino Nano, wired to synchronize with a 40mm lens and a precisely positioned mirror. This connection facilitates real-time translation and instant captioning. Though having extensive hardware is challenging and extremely time-consuming, we greatly take the attention of the deaf community seriously and believe having a practical model adds great value.
Another large accomplishment is creating our object detection model through a machine learning approach of detecting 21 points in a user's hand and creating the 'finger spelling' dataset. Training the machine learning model was fun but also an extensively difficult task. The process of developing the dataset through practicing ASL caused our team to pick up the useful language of ASL.
## What we learned
Our journey in developing Caption Glasses revealed the profound need within the deaf community for inclusive, diverse, and accessible communication solutions. As we delved deeper into understanding the daily lives of over 466 million deaf individuals worldwide, including more than 500,000 users of American Sign Language (ASL) in the United States alone, we became acutely aware of the barriers they face in a predominantly spoken word.
The hardware and machine learning development phases presented significant challenges. Integrating advanced technology into a compact, wearable form required a delicate balance of precision engineering and user-centric design. 3D printing, SolidWorks design, and intricate wiring demanded meticulous attention to detail. Overcoming these hurdles and achieving a seamless blend of hardware components within a pair of glasses was a monumental accomplishment.
The machine learning aspect, essential for real-time translation and captioning, was equally demanding. Developing a model capable of accurately interpreting finger spelling and converting it into meaningful captions involved extensive training and fine-tuning. Balancing accuracy, speed, and efficiency pushed the boundaries of our understanding and capabilities in this rapidly evolving field.
Through this journey, we've gained profound insights into the transformative potential of technology when harnessed for a noble cause. We've learned the true power of collaboration, dedication, and empathy. Our experiences have cemented our belief that innovation, coupled with a deep understanding of community needs, can drive positive change and improve the lives of many. With Caption Glasses, we're on a mission to redefine how the world communicates, striving for a future where every voice is heard, regardless of the language it speaks.
## What's next for Caption Glasses
The market for Caption Glasses is insanely large, with infinite potential for advancements and innovations. In terms of user design and wearability, we can improve user comfort and style. The prototype given can easily scale to be less bulky and lighter. We can allow for customization and design patterns (aesthetic choices to integrate into the fashion community).
In terms of our ML object detection model, we foresee its capability to decipher and translate various sign languages from across the globe pretty easily, not just ASL, promoting a universal mode of communication for the deaf community. Additionally, the potential to extend this technology to interpret and translate spoken languages, making Caption Glasses a tool for breaking down language barriers worldwide, is a vision that fuels our future endeavors. The possibilities are limitless, and we're dedicated to pushing boundaries, ensuring Caption Glasses evolve to embrace diverse forms of human expression, thus fostering an interconnected world. | ## Inspiration
What inspired us was we wanted to make an innovative solution which can have a big impact on people's lives. Most accessibility devices for the visually impaired are text to speech based which is not ideal for people who may be both visually and auditorily impaired (such as the elderly). To put yourself in someone else's shoes is important, and we feel that if we can give the visually impaired a helping hand, it would be an honor.
## What it does
The proof of concept we built is separated in two components. The first is an image processing solution which uses OpenCV and Tesseract to act as an OCR by having an image input and creating a text output. This text would then be used as an input to the second part, which is a working 2 by 3 that converts any text into a braille output, and then vibrate specific servo motors to represent the braille, with a half second delay between letters. The outputs were then modified for servo motors which provide tactile feedback.
## How we built it
We built this project using an Arduino Uno, six LEDs, six servo motors, and a python file that does the image processing using OpenCV and Tesseract.
## Challenges we ran into
Besides syntax errors, on the LED side of things there were challenges in converting the text to braille. Once that was overcome, and after some simple troubleshooting for menial errors, like type comparisons, this part of the project was completed. In terms of the image processing, getting the algorithm to properly process the text was the main challenge.
## Accomplishments that we're proud of
We are proud of having completed a proof of concept, which we have isolated in two components. Consolidating these two parts is only a matter of more simple work, but these two working components are the fundamental core of the project we consider it be a start of something revolutionary.
## What we learned
We learned to iterate quickly and implement lateral thinking. Instead of being stuck in a small paradigm of thought, we learned to be more creative and find alternative solutions that we might have not initially considered.
## What's next for Helping Hand
* Arrange everything in one android app, so the product is cable of mobile use.
* Develop neural network so that it will throw out false text recognitions (usually look like a few characters without any meaning).
* Provide API that will be able to connect our glove to other apps, where the user for example may read messages.
* Consolidate the completed project components, which is to implement Bluetooth communication between a laptop processing the images, using OpenCV & Tesseract, and the Arduino Uno which actuates the servos.
* Furthermore, we must design the actual glove product, implement wire management, an armband holder for the uno with a battery pack, and position the servos. | winning |
## Inspiration
Currently, Zoom only offers live closed captioning when a human transcriber manually transcribes a meeting. We believe that users would benefit greatly from closed captions in *every* meeting, so we created Cloud Caption.
## What it does
Cloud Caption receives live system audio from a Zoom meeting or other video conference platform and translate this audio in real time to closed captioning that is displayed in a floating window. This window can be positioned on top of the Zoom meeting and it is translucent, so it will never get in the way.
## How we built it
Cloud Caption uses the Google Cloud Speech-to-Text API to automatically transcribe the audio streamed from Zoom or another video conferencing app.
## Challenges we ran into
We went through a few iterations before we were able to get Cloud Caption working. First, we started with a browser-based app that would embed Zoom, but we discovered that the Google Cloud framework isn't compatible in browser-based environments. We then pivoted to an Electron-based desktop app, but the experimental web APIs that we needed did not work. Finally, we implemented a Python-based desktop app that uses a third-party program like [Loopback](https://rogueamoeba.com/loopback/) to route the audio.
## Accomplishments that we're proud of
We are proud of our ability to think and adapt quickly and collaborate efficiently during this remote event. We're also proud that our app is a genuinely useful accessibility tool for anyone who is deaf or hard-of-hearing, encouraging all students and learners to collaborate in real time despite any personal challenges they may face. Cloud Caption is also useful for students who aren't auditory learners and prefer to learn information by reading.
Finally, we're proud of the relative ease-of-use of the application. Users only need to have Loopback (or another audio-routing program) installed on their computer in order to receive real time video speech-to-text transcription, instead of being forced to wait and re-watch a video conference later with closed captioning embedded.
## What we learned
Our team learned that specifying, controlling, and linking audio input and output sources can be an incredibly difficult task with poor support from browser and framework vendors. We also came to appreciate the values of building with accessibility as a major goal throughout the design and development process. Accessibility can often be overlooked in applications and projects of every size, so all of us have learned to prioritize developing with inclusivity in mind for our projects moving forward.
## What's next for Cloud Caption
Our next step is to integrate audio routing so that users won't need a third-party program. We would also like to explore further applications of our closed captioning application in other business or corporate uses cases for HR or training purposes, especially targeting those users who may be deaf or hard-of-hearing. | ## Inspiration
as we have spent some time in our new Covid-19 world, we have noticed work from home and such has resulted in an increase of phishing and fraudulent emails. We noticed this is strongly apparent in our educational community as well noticing that our inboxes and our peers' inboxes get spammed with fraudulent E-mails that pose a risk and threat to our finances.
## What it does
MailSafe allows you to verify the integrity and legitimacy of your emails by generating a QR Code in a Google Chrome Extension pop-up for your phone to scan. The QR Code is scanned by the phone in the MailSafe Mobile App that cross references the QR Code to a list of verified email senders. If present on the list, it means the email is verified and the user can trust the email they received. If it is not on the list, the email is most likely fraudulent as it does not belong to any of your financial service providers.
## How we built it
We had used standard Google Chrome Extension structure. We constructed a main manifest file for the Chrome Extension to function and call a popup.html file upon an Chrome Extension Action that showed a button. Clicking that button generated a QR Code from a standard qrcode.js library that your phone could actually scan. Then we created the way the app would function on your mobile device using Figma.
## Challenges we ran into
The main challenge we ran into was in the Google Chrome Extension. We had to use the email sender ID to generate a QR Code. After some trial and error, and countless stackoverflow guides, we came to a library, qrcode.js, that allowed us to pass the email sender ID and generate a QR Code from it. That QR Code is functional and usable by most devices.
## Accomplishments that we're proud of
We are proud of the functional Google Chrome Extension that generates actual QR Codes for devices to scan. All in all, we are proud to have come up with an idea to protect users from fraudulent E-mails and phishing scams and proud that we have implemented a major element of the system. Now that we have that foundation, we are on our way to complete the mobile application element to have a functional system.
## What we learned
The project was a great learning experience for us at MailSafe. Spending most of our time implementing the Google Chrome Extension we learned to manipulate an existing HTML file, parse it and extract information we specifically needed such as the email sender ID. Using that we learned how to convert it into a QR Code that actually is recognized by anyone's cellular device. All in all, it was an amazing opportunity and learning experience.
## What's next for MailSafe
Our goals for MailSafe is to implement a functional phone application. Furthermore, we would like to implement the the extension add-on for non-chromium based browsers such as Mozilla Firefox. In the future, we are looking forward to wide-spread adoption by many companies, not just Bank Institutions, who would like to provide their users with a seamless and safe experience in communicating over E-mail. | ## Inspiration
-Inspired by baracksdubs and many "Trump Sings" channels on YouTube, each of which invests a lot of time into manually tracking down words.
-Fully automating the process allows us to mass-produce humorous content and "fake news", bringing awareness to the ease with which modern technology allows for the production and perpetuation of generated content.
-Soon-to-emerge technologies like Adobe VOCO are poised to allow people to edit audio and human speech as seamlessly as we are currently able to edit still images.
-The inspirational lectures of Professor David J. Malan.
## What it does
We train each available "voice" by inputting a series of YouTube URL's to `main.py`.
`download.py` downloads and converts these videos to `.wav` files for use in `speech.py`, which uses Google's Cloud Speech API to create a dictionary of mappings between words and video time-stamps.
`application.py` implements user interaction: given a voice/text input via Facebook, we use these mappings to concatenate the video clips corresponding to each word.
## How we built it
First we decided on Python due to its huge speech recognition community. This also allowed us to utilize a collaborative online workspace through Cloud9 which helped facilitate concurrent collaboration.
We used google's speech api because we saw that it was very popular and supported time stamps for individual words. Also, they had very elegant json output, which was a definite bonus.
Next, we figured out how to use the packages pytube and ffmpy to grab video streams from youtube and convert them, with speed and without loss of quality, to the needed .wav and .mp4 formats.
At the same time, one of our team members learned how to use python packages to concatenate and split .mp4 videos, and built functions with which we were able to manipulate small video files with
high precision.
Following some initial successes with google speech api and mp4 manipulation, we began exploring the facebook graph api. There quite a bit of struggle here with permissions issues because many of the functions
we were trying to call were limited by permissions, and those permissions had to be granted by facebook people after review. However, we did eventually get facebook to integrate with our program.
The final step we took was to few remaining unconnected pieces of the project together and troubleshoot any issues that came up.
During the process, we were also investigating a few moonshot-type upgrades. These included ideas like the use of a sound spectrogram to find individual phonemes of words, so we could finely tune individual words, or generate
new words that were never previously said by the person.
## Challenges we ran into
A big challenge we ran into was that the Google Speech API was not extremely accurate when identifying single words. We tried various things like different file/compression types, boosting sound (normalizing/processing waveform),
improving sound quality (bitrate, sampling frequency).
Another big challenge we ran into was that when we tried splicing the small (under 1 or 2 second) video files together, we realized they lost their video component, due to issues
with key frames, negative timestamps, and video interpolation. Apparently, in order to save space, videos store key frames and interpolate between the key frames to generate the frames
in between. This is good enough to fool the human eye, but it required that we do a lot of extra work to get the correct output.
A third big challenge we ran into was that when we communicated with the facebook api through our flask website, facebook would resend our flask page post requests before we were completed
with processing the information from the previous post request. To solve this issue, we grabbed the post request information and opened new threads in python to process them in parallel.
A fourth big challenge we ran into was that wifi was so slow that it would take around 1 minute to upload a 1 minute video to Google's cloud for speech processing. Thus, in order to analyze
large videos (1+ hours) we developed a way to use multiple threads to split the video into smaller segments without destroying words and upload those segments in parallel.
## Accomplishments that we're proud of
We have a scalable, modular structure which makes future expansion easy. This allows us to easily switch APIs for each function.
## What we learned
[Web Services APIs]
>
> Speech to Text Conversion:
> --Google Cloud API
> --CMU Sphynx (Experimental Offline Speech-To-Text Processing with the English Lanugage Model)
> Facebook API Integration:
> --Accepting input from user via automated messenger bot development
> --Posting to Facebook Page
>
>
>
[Web Services Deployment]
>
> Flask and Python Interfacing
>
>
>
[Python]
>
> Multi-file Python package integration
> Team-based Development
>
>
>
[Video and Audio Conversion]
--FFMPEG Video: Efficient Splicing, Keyframes, Codecs, Transcoding
--FFMPEG Audio: Sampling Frequency, Sound Normalization
[Misc]
--Automating the Production of quality memes
--Teamwork and Coding while sleep-deprived
## What's next for Wubba Lubba Dubz
We'd like to incorporate a GUI with a slider, to more accurately adjust start/end times for each word.
Right now, we can only identify words which have been spoken exactly as entered. With Nikhil's background in linguistics, we will split an unknown word into its phonetic components.
Ideally, we will build a neural net which allows use to choose the best sound file for each word (in context). | partial |
[Example brainrot output](https://youtube.com/shorts/vmTmjiyBTBU)
[Demo](https://youtu.be/W5LNiKc7FB4)
## Inspiration
Graphic design is a skill like any other, that if honed, allows us to communicate and express ourselves in marvellous ways. To do so, it's massively helpful to receive specific feedback on your designs. Thanks to recent advances in multi-modal models, such as GPT-4o, even computers can provide meaningful design feedback.
What if we put a sassy spin on it?
## What it does
Adobe Brainrot is an unofficial add-on for Adobe Express that analyzes your design, creates a meme making fun of it, and generates a TikTok-subway-surfers-brainrot-style video with a Gordon Ramsey-esque personality roasting your design. (Watch the attached video for an example!)
## How we built it
The core of this app is an add-on for Adobe Express. It talks to a server (which we operate locally) that handles AI, meme-generation, and video-generation.
Here's a deeper breakdown:
1. The add-on screenshots the Adobe Express design and passes it to a custom-prompted session of GPT-4o using the ChatGPT API. It then receives the top design issue & location of it (if applicable).
2. It picks a random meme format, and asks ChatGPT for the top & bottom text of said meme in relation to the design flaw (e.g. "Too many colours"). Using the memegen.link API, it then generates the meme on-the-fly and insert it into the add-on UI.
3. Using yt-dlp, it downloads a "brainrot" background clip (e.g. Subway Surfers gameplay). It then generates a ~30-second roast using ChatGPT based on the design flaw & creates a voiceover using it, using OpenAI Text-to-Speech. Finally, it uses FFmpeg to overlay the user's design on top of the "brainrot" clip, add the voiceover in the background, and output a video file to the user's computer.
## Challenges we ran into
We were fairly unfamiliar with the Adobe Express SDK, so it was a learning curve getting the hang of it! It was especially hard due to having two SDKs (UI & Sandbox). Thankfully, it makes use of existing standards like JSX.
In addition, we researched prompt-engineering techniques to ensure that our ChatGPT API calls would return responses in expected formats, to avoid unexpected failure.
There were quite a few challenges generating the video. We referenced a project that did something similar, but we had to rewrite most of it to get it working. We had to use a different yt-dl core due to extraction issues. FFmpeg would often fail even with no changes to the code or parameters.
## Accomplishments that we're proud of
* It generates brainrot (for better or worse) videos
* Getting FFmpeg to work (mostly)
* The AI outputs feedback
* Working out the SDK
## What we learned
* FFmpeg is very fickle
## What's next for Adobe Brainrot
We'd like to flesh out the UI further so that it more *proactively* provides design feedback, to become a genuinely helpful (and humorous) buddy during the design process. In addition, adding subtitles matching the text-to-speech would perfect the video. | ## Inspiration
In a world full of so much info but limited time as we are so busy and occupied all the time, we wanted to create a tool that helps students make the most of their learning—quickly and effectively. We imagined a platform that could turn complex material into digestible, engaging content tailored for a fast-paced generation.
## What it does
Lemme Learn More (LLM) transforms study materials into bite-sized TikTok-style trendy and attractive videos or reels, flashcards, and podcasts. Whether it's preparing for exams or trying to stay informed on the go, LLM breaks down information into formats that match how today's students consume content. If you're an avid listener of podcasts during commute to work - this is the best platform for you.
## How we built it
We built LLM using a combination of AI-powered tools like OpenAI for summaries, Google TTS for podcasts, and pypdf2 to pull data from PDFs. The backend runs on Flask, while the frontend is React.js, making the platform both interactive and scalable. Also used fetch.ai ai agents to deploy on test net - blockchain.
## Challenges we ran into
Due to a highly-limited time, we ran into a deployment challenge where we faced some difficulty setting up on Heroku cloud service platform. It was an internal level issue wherein we were supposed to change config files - I personally spent 5 hours on that - my team spent some time as well. Could not figure it out by the time hackathon ended : we decided not to deploy today.
In brainrot generator module, audio timing could not match with captions. This is something for future scope.
One of the other biggest challenges was integrating sponsor Fetch.ai agentverse AI Agents which we did locally and proud of it!
## Accomplishments that we're proud of
Biggest accomplishment would be that we were able to run and integrate all of our 3 modules and a working front-end too!!
## What we learned
We learned that we cannot know everything - and cannot fix every bug in a limited time frame. It is okay to fail and it is more than okay to accept it and move on - work on the next thing in the project.
## What's next for Lemme Learn More (LLM)
Coming next:
1. realistic podcast with next gen TTS technology
2. shorts/reels videos adjusted to the trends of today
3. Mobile app if MVP flies well! | ## Inspiration
More than 4.5 million acres of land have burned on the West Coast in the past month alone
Experts say fires will worsen in the years to come as climate change spikes temperatures and disrupts precipitation patterns
Thousands of families have been and will continue to be displaced by these disasters
## What it does
When a wildfire strikes, knowing where there are safe places to go can bring much-needed calm in times of peril
Mildfire is a tool designed to identify higher-risk areas with deep learning analysis of satellite data to keep people and their families out of danger
Users can place pins at locations of themselves or people in distress
Users can mark locations of fires in real time
Deep learning-based treetop detection to indicate areas higher-risk of forest fire
Heatmap shows safe and dangerous zones, and can facilitate smarter decision making
## How I built it
User makes a GET request w/ latitude/longitude value, which is then handled in real time, hosted on Google Cloud Functions
The request triggers a function that grabs satellite data in adjacent tiles from Google Maps Static API
Detects trees w/ RGB data from satellite imagery using deep-learning neural networks trained on existing tree canopy and vegetation data (“DeepForest”, Weinstein, et al. 2019)
Generates a heat map from longitude/latitude, flammability radius, confidence from ML model
Maps public pins, Broadcasts distress and First-Responder notifications in real-time
Simple, dynamic Web-interface
## Challenges I ran into
Completely scrapped mobile app halfway through the hack and had to change to web app.
## Accomplishments that I'm proud of
Used a lottt of GCP and learned a lot about it. Also almost finished the web app despite starting on it so late. ML model is also very accurate and useful.
## What I learned
A lot of GCP and ML and Flutter. Very fun experience overall!
## What's next for Mildfire
Finish the mobile and web app | partial |
## Inspiration
A couple weeks ago, a friend was hospitalized for taking Advil–she accidentally took 27 pills, which is nearly 5 times the maximum daily amount. Apparently, when asked why, she responded that thats just what she always had done and how her parents have told her to take Advil. The maximum Advil you are supposed to take is 6 per day, before it becomes a hazard to your stomach.
#### PillAR is your personal augmented reality pill/medicine tracker.
It can be difficult to remember when to take your medications, especially when there are countless different restrictions for each different medicine. For people that depend on their medication to live normally, remembering and knowing when it is okay to take their medication is a difficult challenge. Many drugs have very specific restrictions (eg. no more than one pill every 8 hours, 3 max per day, take with food or water), which can be hard to keep track of. PillAR helps you keep track of when you take your medicine and how much you take to keep you safe by not over or under dosing.
We also saw a need for a medicine tracker due to the aging population and the number of people who have many different medications that they need to take. According to health studies in the U.S., 23.1% of people take three or more medications in a 30 day period and 11.9% take 5 or more. That is over 75 million U.S. citizens that could use PillAR to keep track of their numerous medicines.
## How we built it
We created an iOS app in Swift using ARKit. We collect data on the pill bottles from the iphone camera and passed it to the Google Vision API. From there we receive the name of drug, which our app then forwards to a Python web scraping backend that we built. This web scraper collects usage and administration information for the medications we examine, since this information is not available in any accessible api or queryable database. We then use this information in the app to keep track of pill usage and power the core functionality of the app.
## Accomplishments that we're proud of
This is our first time creating an app using Apple's ARKit. We also did a lot of research to find a suitable website to scrape medication dosage information from and then had to process that information to make it easier to understand.
## What's next for PillAR
In the future, we hope to be able to get more accurate medication information for each specific bottle (such as pill size). We would like to improve the bottle recognition capabilities, by maybe writing our own classifiers or training a data set. We would also like to add features like notifications to remind you of good times to take pills to keep you even healthier. | ## Inspiration
Automation is at its peak when it comes to technology, but one area that has lacked to keep up, is areas of daily medicine. We encountered many moments within our family members where they had trouble keeping up with their prescription timelines. In a decade dominated by cell phones, we saw the need to develop something fast and easy, where it wouldn’t require something too complicated to keep track of all their prescriptions and timelines and would be accessibly at their fingertips.
## What it does
CapsuleCalendar is an Android application that lets one take a picture of their prescriptions or pill bottles and have them saved to their calendars (as reminders) based on the recommended intake amounts (on prescriptions). The user will then be notified based on the frequency outlined by the physician on the prescription. The application simply requires taking a picture, its been developed with the user in mind and does not require one to go through the calendar reminder, everything is pre-populated for the user through the optical-character recognition (OCR) processing when they take a snap of their prescription/pill bottle.
## How we built it
The application was built for Android purely in Java, including integration of all APIs and frameworks. First, authorization of individualized accounts was done using Firebase. We implemented and modified Google’s optical-character recognition (OCR) cloud-vision framework, to accurately recognize text on labels, and process and parse it in real-time. The Google Calendar API was then applied on the parsed data, and with further processing, we used intents to set reminders based on the data of the prescriptions labels (e.g. take X tablets X daily - where X was some arbitrary number which was accounted for in a (or multiple) reminders).
## Challenges we ran into
Working with the OCR Java framework was quite difficult to implement into our personalized application due to various dependency failures - it took us way too long to debug and get the framework to work *sufficiently* for our needs. Also, the default OCR graphics toolkit only captures very small snippets of text at a single time whereas we needed multiple lines to be processed at once and text at different areas within the label at once (e.g. default implementation would allow one set to be recognized and processed - we needed multiple sets). The default OCR engine wasn't quite effective for multiple lines of prescriptions, especially when identifying both prescription name and intake procedure - tweaking this was pretty tough. Also, when we tried to use the Google Calendar API, we had extensive issues using Firebase to generate Oauth 2.0 credentials (Google documentation wasn’t too great here :-/).
## Accomplishments that we're proud of
We’re proud of being able to implement a customized Google Cloud Vision based OCR engine and successfully process, parse and post text to the Google Calendar API. We were just really happy we had a functional prototype!
## What we learned
Debugging is a powerful skill we took away from this hackathon - it was pretty rough going through complex, pre-written framework code. We also learned to work with some new Google APIs, and Firebase integrations. Reading documentation is also very important… along with reading lots of StackOverflow.
## What's next for CapsuleCalendar
We would like to use a better, stronger OCR engine that is more accurate at reading labels in a curved manner, and does not get easily flawed from multiple lines of text. Also, we would like to add functionality to parse pre-taken images (if the patient doesn’t have their prescription readily available and only happens to have a picture of their prescription). We would also like to improve the UI.
## Run the application
Simply download/clone the source code from GitHub link provided and run on Android studio. It is required to use a physical Android device as it requires use of the camera - not possible on emulator. | ## 🎇 Inspiration 🎇
Since the last few years have been full of diseases, illness, a huge number of people have been in need of medical assistance. Our elders suffer from certain illnesses and have a hard time remembering which medications to take, in what amount and what time. So, Similarly We made an app that saves all medical records and prescription either in email form, scanned copy or written form and setting medicine reminders that enables client to determine the pill amount and timings to take pills for everyday.
## ❓ What it does ❓
* Problem 1 - Most of the patients frequently have difficulty in remembering or managing multiple medications .Many a times they forget medicine name and how they look like, especially for elders. Medication non-adherence leads to 125,000 preventable deaths each year, and about $300 billion in avoidable healthcare costs.
* Problem 2 - We all have multiple folders in back of our closets full of medical records, prescriptions , test reports etc. which lets all agree are a hassle to carry everytime a doctor asks for our medical history .
* Problem 3 - In times of emergency every minute counts and in that minute finding contacts of our caregivers, nearby hospitals, pharmacies and doctors is extremely difficult.
## 🤷♂️ How we built it 🤷♂️
We built it with technologies like Firebase, flutter for providing better contents and SQL lite for storage.
## 🤔 Challenges we ran into 🤔
* CRUD operations in firebase took a lot more of our time than expected.
* Pushing image notifications was another obstacle but with constant Hard work and support we finally completed it .
* Handling this project with the college classes was a test of our time management and that's totally worth it at end.
## 👏 What we learned 👏
* We learned how to worked quickly with Dart along with that we also learned how to use packages like contact picker, airplane mode checker in a effective way.
* It was my [ Aditya Singh ] second time using Swift and I had a lot of fun and learnings while using it.
* Design all the logo's as well as the UI part was handled by me [ Sanyam Saini ] , I learned many new features in Figma that I didn't knew before.
## 🚀 What's next for Med-Zone 🚀
* In the future, we can add additional features like providing diet charts, health tips, exercises / Yogas to follow for better health and nutrition, and some expert insights as well for which we can charge the subscription fee.
* We can add different types of tunes/ringtones according to which medications to take at which time. | winning |
## Inspiration
We are tinkerers and builders who love getting our hands on new technologies. When we discovered that the Spot Robot Dog from Boston Dynamics was available to build our project upon, we devised different ideas about the real-world benefits of robot dogs. From a conversational companion to a navigational assistant, we bounced off different ideas and ultimately decided to use the Spot robot to detect explosives in the surrounding environment as we realized the immense amount of time and resources that are put into training real dogs to perform these dangerous yet important tasks.
## What it does
Lucy uses the capabilities of Spot Robot Dog to help identify potentially threatening elements in a surrounding through computer vision and advanced wave sensing capabilities. A user can command the dog to inspect a certain geographic area and the dog autonomously walks around the entire area and flags objects that could be a potential threat. It captures both raw and thermal images of the given object in multiple frames, which are then stored on a vector database and can be searched through semantic search.
This project is a simplified approach inspired by the research "Atomic Magnetometer Multisensor Array for rf Interference Mitigation and Unshielded Detection of Nuclear Quadrupole Resonance" (<https://link.aps.org/accepted/10.1103/PhysRevApplied.6.064014>).
## How we built it
We've combined the capabilities of OpenCV with a thermal sensing camera to allow Spot Robot to identify and flag potentially threatening elements in a given surrounding. To simulate these elements in the surroundings, we built a simple Arduino application that emits light waves in irregular patterns. The robot dog operates independently through speech instructions, which are powered by DeepGram's Speech to Text and Llama-3-8b model hosted on the Groq platform. Furthermore, we've leveraged ChromDB's vector database to tokenize images that allow people to easily search through images, which are captured in the range of 20-40fps.
## Challenges we ran into
The biggest challenge we encountered was executing and testing our code on Spot due to the unreliable internet connection. We also faced configuration issues, as some parts of modules were not supported and used an older version, leading to multiple errors during testing. Additionally, the limited space made it difficult to effectively run and test the code.
## Accomplishments that we're proud of
We are proud that we took on the challenge of working with something that we had never worked with before and even after many hiccups and obstacles we were able to convert our idea in our brains into a physical reality.
## What we learned
We learned how to integrate and deploy our program onto Spot. We also learned that to work around the limitations of the technology and our experience working with them.
## What's next for Lucy
We want to integrate LiDar in our approach, providing more accurate results then cameras. We plan to experiment beyond light to include different wave forms, thus helping improve the reliability of the results. | ## What it does
SPOT would be equipped with various sensors, cameras, and LIDAR technology to perform inspections in hazardous environments. A network of SPOT bots will be deployed in a within a 2.5 – 3-mile radius surrounding a particular infrastructure for security and surveillance tasks, patrolling areas and providing real-time video feeds to human operators. It can be used to monitor large facilities, industrial sites, or public events, enhancing security effort.
These network of SPOT robots will be used to inspect and collect data/mages for analysis, tracking suspects, and gathering crucial intelligence in high-risk environments thus maintaining situational awareness without putting officers in harm's way.
They will be providing real-time video feeds . If it detects any malicious activity, the SPOT will act as the first respondent and deploy non-lethal measures by sending a distress signal to the closest law enforcement officer/authority who’d be able mitigate the situation effectively. Consequently, the other SPOT bots in the network would also be alerted. Its ability to provide real-time situational awareness without putting officers at risk is a significant advantage.
## How we built it
* Together.ai : Used llama to enable conversations and consensus among agents
* MindsDB : Database is stored in postgres (render). The database is imported to Mindsdb. The sentiment classifier is trained with the help of demo data and the sentiments which are retrieved from every agent allows us to understand the mental state of every bot
* Reflex : UI for visualization of statistical measures of the bots
-Intel : To train mobilevnet for classifying threats
* Intersystems : To Carry on Battery Life forecasting for the agent to enable efficient decisions | ## Inspiration
There are two types of pets wandering unsupervised in the streets - ones that are lost and ones that don't have a home to go to. Pet's Palace portable mini-shelters services these animals and connects them to necessary services while leveraging the power of IoT.
## What it does
The units are placed in streets and alleyways. As an animal approaches the unit, an ultrasonic sensor triggers the door to open and dispenses a pellet of food. Once inside, a live stream of the interior of the unit is sent to local animal shelters which they can then analyze and dispatch representatives accordingly. Backend analysis of the footage provides information on breed identification, custom trained data, and uploads an image to a lost and found database. A chatbot is implemented between the unit and a responder at the animal shelter.
## How we built it
Several Arduino microcontrollers distribute the hardware tasks within the unit with the aide of a wifi chip coded in Python. IBM Watson powers machine learning analysis of the video content generated in the interior of the unit. The adoption agency views the live stream and related data from a web interface coded with Javascript.
## Challenges we ran into
Integrating the various technologies/endpoints with one Firebase backend.
## Accomplishments that we're proud of
A fully functional prototype! | partial |
## Inspiration
Has your browser ever looked like this?

... or this?

Ours have, *all* the time.
Regardless of who you are, you'll often find yourself working in a browser on not just one task but a variety of tasks. Whether its classes, projects, financials, research, personal hobbies -- there are many different, yet predictable, ways in which we open an endless amount of tabs for fear of forgetting a chunk of information that may someday be relevant.
Origin aims to revolutionize your personal browsing experience -- one workspace at a time.
## What it does
In a nutshell, Origin uses state-of-the-art **natural language processing** to identify personalized, smart **workspaces**. Each workspace is centered around a topic comprised of related tabs from your browsing history, and Origin provides your most recently visited tabs pertaining to that workspace and related future ones, a generated **textual summary** of those websites from all their text, and a **fine-tuned ChatBot** trained on data about that topic and ready to answer specific user questions with citations and maintaining history of a conversation. The ChatBot not only answers general factual questions (given its a foundation model), but also answers/recalls specific facts found in the URLs/files that the user visits (e.g. linking to a course syllabus).
Origin also provides a **semantic search** on resources, as well as monitors what URLs other people in an organization visit and recommend pertinent ones to the user via a **recommendation system**.
For example, a college student taking a History class and performing ML research on the side would have sets of tabs that would be related to both topics individually. Through its clustering algorithms, Origin would identify the workspaces of "European History" and "Computer Vision", with a dynamic view of pertinent URLs and widgets like semantic search and a chatbot. Upon continuing to browse in either workspace, the workspace itself is dynamically updated to reflect the most recently visited sites and data.
**Target Audience**: Students to significantly improve the education experience and industry workers to improve productivity.
## How we built it

**Languages**: Python ∙ JavaScript ∙ HTML ∙ CSS
**Frameworks and Tools**: Firebase ∙ React.js ∙ Flask ∙ LangChain ∙ OpenAI ∙ HuggingFace
There are a couple of different key engineering modules that this project can be broken down into.
### 1(a). Ingesting Browser Information and Computing Embeddings
We begin by developing a Chrome Extension that automatically scrapes browsing data in a periodic manner (every 3 days) using the Chrome Developer API. From the information we glean, we extract titles of webpages. Then, the webpage titles are passed into a pre-trained Large Language Model (LLM) from Huggingface, from which latent embeddings are generated and persisted through a Firebase database.
### 1(b). Topical Clustering Algorithms and Automatic Cluster Name Inference
Given the URL embeddings, we run K-Means Clustering to identify key topical/activity-related clusters in browsing data and the associated URLs.
We automatically find a description for each cluster by prompt engineering an OpenAI LLM, specifically by providing it the titles of all webpages in the cluster and requesting it to output a simple title describing that cluster (e.g. "Algorithms Course" or "Machine Learning Research").
### 2. Web/Knowledge Scraping
After pulling the user's URLs from the database, we asynchronously scrape through the text on each webpage via Beautiful Soup. This text provides richer context for each page beyond the title and is temporarily cached for use in later algorithms.
### 3. Text Summarization
We split the incoming text of all the web pages using a CharacterTextSplitter to create smaller documents, and then attempt a summarization in a map reduce fashion over these smaller documents using a LangChain summarization chain that increases the ability to maintain broader context while parallelizing workload.
### 4. Fine Tuning a GPT-3 Based ChatBot
The infrastructure for this was built on a recently-made popular open-source Python package called **LangChain** (see <https://github.com/hwchase17/langchain>), a package with the intention of making it easier to build more powerful Language Models by connecting them to external knowledge sources.
We first deal with data ingestion and chunking, before embedding the vectors using OpenAI Embeddings and storing them in a vector store.
To provide the best chat bot possible, we keep track of a history of a user's conversation and inject it into the chatbot during each user interaction while simultaneously looking up relevant information that can be quickly queries from the vector store. The generated prompt is then put into an OpenAI LLM to interact with the user in a knowledge-aware context.
### 5. Collaborative Filtering-Based Recommendation
Provided that a user does not turn privacy settings on, our collaborative filtering-based recommendation system recommends URLs that other users in the organization have seen that are related to the user's current workspace.
### 6. Flask REST API
We expose all of our LLM capabilities, recommendation system, and other data queries for the frontend through a REST API served by Flask. This provides an easy interface between the external vendors (like LangChain, OpenAI, and HuggingFace), our Firebase database, the browser extension, and our React web app.
### 7. A Fantastic Frontend
Our frontend is built using the React.js framework. We use axios to interact with our backend server and display the relevant information for each workspace.
## Challenges we ran into
1. We had to deal with our K-Means Clustering algorithm outputting changing cluster means over time as new data is ingested, since the URLs that a user visits changes over time. We had to anchor previous data to the new clusters in a smart way and come up with a clever updating algorithm.
2. We had to employ caching of responses from the external LLMs (like OpenAI/LangChain) to operate under the rate limit. This was challenging, as it required revamping our database infrastructure for caching.
3. Enabling the Chrome extension to speak with our backend server was a challenge, as we had to periodically poll the user's browser history and deal with CORS (Cross-Origin Resource Sharing) errors.
4. We worked modularly which was great for parallelization/efficiency, but it slowed us down when integrating things together for e2e testing.
## Accomplishments that we're proud of
The scope of ways in which we were able to utilize Large Language Models to redefine the antiquated browsing experience and provide knowledge centralization.
This idea was a byproduct of our own experiences in college and high school -- we found ourselves spending significant amounts of time attempting to organize tab clutter systematically.
## What we learned
This project was an incredible learning experience for our team as we took on multiple technically complex challenges to reach our ending solution -- something we all thought that we had a potential to use ourselves.
## What's next for Origin
We believe Origin will become even more powerful at scale, since many users/organizations using the product would improve the ChatBot's ability to answer commonly asked questions, and the recommender system would perform better in aiding user's education or productivity experiences. | ## Inspiration
The inspiration for the project was our desire to make studying and learning more efficient and accessible for students and educators. Utilizing advancements in technology, like the increased availability and lower cost of text embeddings, to make the process of finding answers within educational materials more seamless and convenient.
## What it does
Wise Up is a website that takes many different types of file format, as well as plain text, and separates the information into "pages". Using text embeddings, it can then quickly search through all the pages in a text and figure out which ones are most likely to contain the answer to a question that the user sends. It can also recursively summarize the file at different levels of compression.
## How we built it
With blood, sweat and tears! We used many tools offered to us throughout the challenge to simplify our life. We used Javascript, HTML and CSS for the website, and used it to communicate to a Flask backend that can run our python scripts involving API calls and such. We have API calls to openAI text embeddings, to cohere's xlarge model, to GPT-3's API, OpenAI's Whisper Speech-to-Text model, and several modules for getting an mp4 from a youtube link, a text from a pdf, and so on.
## Challenges we ran into
We had problems getting the backend on Flask to run on a Ubuntu server, and later had to instead run it on a Windows machine. Moreover, getting the backend to communicate effectively with the frontend in real time was a real challenge. Extracting text and page data from files and links ended up taking more time than expected, and finally, since the latency of sending information back and forth from the front end to the backend would lead to a worse user experience, we attempted to implement some features of our semantic search algorithm in the frontend, which led to a lot of difficulties in transferring code from Python to Javascript.
## Accomplishments that we're proud of
Since OpenAI's text embeddings are very good and very new, and we use GPT-3.5 based on extracted information to formulate the answer, we believe we likely equal the state of the art in the task of quickly analyzing text and answer complex questions on it, and the ease of use for many different file formats makes us proud that this project and website can be useful for so many people so often. To understand a textbook and answer questions about its content, or to find specific information without knowing any relevant keywords, this product is simply incredibly good, and costs pennies to run. Moreover, we have added an identification system (users signing up with a username and password) to ensure that a specific account is capped at a certain usage of the API, which is at our own costs (pennies, but we wish to avoid it becoming many dollars without our awareness of it.
## What we learned
As time goes on, not only do LLMs get better, but new methods are developed to use them more efficiently and for greater results. Web development is quite unintuitive for beginners, especially when different programming languages need to interact. One tool that has saved us a few different times is using json for data transfer, and aws services to store Mbs of data very cheaply. Another thing we learned is that, unfortunately, as time goes on, LLMs get bigger and so sometimes much, much slower; api calls to GPT3 and to Whisper are often slow, taking minutes for 1000+ page textbooks.
## What's next for Wise Up
What's next for Wise Up is to make our product faster and more user-friendly. A feature we could add is to summarize text with a fine-tuned model rather than zero-shot learning with GPT-3. Additionally, a next step is to explore partnerships with educational institutions and companies to bring Wise Up to a wider audience and help even more students and educators in their learning journey, or attempt for the website to go viral on social media by advertising its usefulness. Moreover, adding a financial component to the account system could let our users cover the low costs of the APIs, aws and CPU running Whisper. | ## Inspiration
The inspiration for building this project likely stemmed from the desire to empower students and make learning coding more accessible and engaging. It combines AI technology with education to provide tailored support, making it easier for students to grasp coding concepts. The goal may have been to address common challenges students face when learning to code, such as doubts and the need for personalized resources. Overall, the project's inspiration appears to be driven by a passion for enhancing the educational experience and fostering a supportive learning environment.
## What it does
The chatbot project is designed to cater to a range of use cases, with a clear hierarchy of priorities. At the highest priority level, the chatbot serves as a real-time coding companion, offering students immediate and accurate responses and explanations to address their coding questions and doubts promptly. This ensures that students can swiftly resolve any coding-related issues they encounter. Moving to the medium priority use case, the chatbot provides personalized learning recommendations. By evaluating a student's individual skills and preferences, the chatbot tailors its suggestions for learning resources, such as tutorials and practice problems. This personalized approach aims to enhance the overall learning experience by delivering materials that align with each student's unique needs. At the lowest priority level, the chatbot functions as a bridge, facilitating connections between students and coding mentors. When students require more in-depth assistance or guidance, the chatbot can help connect them with human mentors who can provide additional support beyond what the chatbot itself offers. This multi-tiered approach reflects the project's commitment to delivering comprehensive support to students learning to code, spanning from immediate help to personalized recommendations and, when necessary, human mentorship.
## How we built it
The development process of our AI chatbot involved a creative integration of various Language Models (**LLMs**) using an innovative technology called **LangChain**. We harnessed the capabilities of LLMs like **Bard**, **ChatGPT**, and **PaLM**, crafting a robust pipeline that seamlessly combines all of them. This integration forms the core of our powerful AI bot, enabling it to efficiently handle a wide range of coding-related questions and doubts commonly faced by students. By unifying these LLMs, we've created a chatbot that excels in providing accurate and timely responses, enhancing the learning experience for students.
Moreover, our project features a **centralized database** that plays a pivotal role in connecting students with coding mentors. This database serves as a valuable resource, ensuring that students can access the expertise and guidance of coding mentors when they require additional assistance. It establishes a seamless mechanism for real-time interaction between students and mentors, fostering a supportive learning environment. This element of our project reflects our commitment to not only offer AI-driven solutions but also to facilitate meaningful human connections that further enrich the educational journey.
In essence, our development journey has been marked by innovation, creativity, and a deep commitment to addressing the unique needs of students learning to code. By integrating advanced LLMs and building a robust infrastructure for mentorship, we've created a holistic AI chatbot that empowers students and enhances their coding learning experience.
## Challenges we ran into
Addressing the various challenges encountered during the development of our AI chatbot project involved a combination of innovative solutions and persistent efforts. To conquer integration complexities, we invested substantial time and resources in research and development, meticulously fine-tuning different Language Models (LLMs) such as Bard, ChatGPT, and Palm to work harmoniously within a unified pipeline. Data quality and training challenges were met through an ongoing commitment to curate high-quality coding datasets and an iterative training process that continually improved the chatbot's accuracy based on real-time user interactions and feedback.
For real-time interactivity, we optimized our infrastructure, leveraging cloud resources and employing responsive design techniques to ensure low-latency communication and enhance the overall user experience. Mentor matching algorithms were refined continuously, considering factors such as student proficiency and mentor expertise, making the pairing process more precise. Ethical considerations were addressed by implementing strict ethical guidelines and bias audits, promoting fairness and transparency in chatbot responses.
User experience was enhanced through user-centric design principles, including usability testing, user interface refinements, and incorporation of user feedback to create an intuitive and engaging interface. Ensuring scalability involved the deployment of elastic cloud infrastructure, supported by regular load testing and optimization to accommodate a growing user base.
Security was a paramount concern, and we safeguarded sensitive data through robust encryption, user authentication protocols, and ongoing cybersecurity best practices, conducting regular security audits to protect user information. Our collective dedication, collaborative spirit, and commitment to excellence allowed us to successfully navigate and overcome these challenges, resulting in a resilient and effective AI chatbot that empowers students in their coding education while upholding the highest standards of quality, security, and ethical responsibility.
## Accomplishments that we're proud of
Throughout the development and implementation of our AI chatbot project, our team has achieved several accomplishments that we take immense pride in:
**Robust Integration of LLMs:** We successfully integrated various Language Models (LLMs) like Bard, ChatGPT, and Palm into a unified pipeline, creating a versatile and powerful chatbot that combines their capabilities to provide comprehensive coding assistance. This accomplishment showcases our technical expertise and innovation in the field of natural language processing.
**Real-time Support**: We achieved the goal of providing real-time coding assistance to students, ensuring they can quickly resolve their coding questions and doubts. This accomplishment significantly enhances the learning experience, as students can rely on timely support from the chatbot.
**Personalized Learning Recommendations**: Our chatbot excels in offering personalized learning resources to students based on their skills and preferences. This accomplishment enhances the effectiveness of the learning process by tailoring educational materials to individual needs.
**Mentor-Matching Database**: We established a centralized database for coding mentors, facilitating connections between students and mentors when more in-depth assistance is required. This accomplishment emphasizes our commitment to fostering meaningful human connections within the digital learning environment.
**Ethical and Bias Mitigation**: We implemented rigorous ethical guidelines and bias audits to ensure that the chatbot's responses are fair and unbiased. This accomplishment demonstrates our dedication to responsible AI development and user fairness.
**User-Centric Design**: We created an intuitive and user-friendly interface that simplifies the interaction between students and the chatbot. This user-centric design accomplishment enhances the overall experience for students, making the learning process more engaging and efficient.
**Scalability**: Our chatbot's architecture is designed to scale efficiently, allowing it to accommodate a growing user base without compromising performance. This scalability accomplishment ensures that our technology remains accessible to a broad audience.
**Security Measures**: We implemented robust security protocols to protect user data, ensuring that sensitive information is safeguarded. Regular security audits and updates represent our commitment to user data privacy and cybersecurity.
These accomplishments collectively reflect our team's dedication to advancing education through technology, providing students with valuable support, personalized learning experiences, and access to coding mentors. We take pride in the positive impact our AI chatbot has on the educational journey of students and our commitment to responsible and ethical AI development.
## What we learned
The journey of developing our AI chatbot project has been an enriching experience, filled with valuable lessons that have furthered our understanding of technology, education, and teamwork. Here are some of the key lessons we've learned:
**Complex Integration Requires Careful Planning**: Integrating diverse Language Models (LLMs) is a complex task that demands meticulous planning and a deep understanding of each model's capabilities. We learned the importance of a well-thought-out integration strategy.
**Data Quality Is Paramount**: The quality of training data significantly influences the chatbot's performance. We've learned that meticulous data curation and continuous improvement are essential to building an accurate AI model.
**Real-time Interaction Enhances Learning**: The ability to provide real-time coding assistance has a profound impact on the learning experience. We learned that prompt support can greatly boost students' confidence and comprehension.
**Personalization Empowers Learners**: Tailoring learning resources to individual students' needs is a powerful way to enhance education. We've discovered that personalization leads to more effective learning outcomes.
**Mentorship Matters**: Our mentor-matching database has highlighted the importance of human interaction in education. We learned that connecting students with mentors for deeper assistance is invaluable.
Ethical AI Development Is Non-Negotiable: Addressing ethical concerns and bias in AI systems is imperative. We've gained insights into the importance of transparent, fair, and unbiased AI interactions.
**User Experience Drives Engagement**: A user-centric design is vital for engaging students effectively. We've learned that a well-designed interface improves the overall educational experience.
**Scalability Is Essential for Growth**: Building scalable infrastructure is crucial to accommodate a growing user base. We've learned that the ability to adapt and scale is key to long-term success.
**Security Is a Constant Priority**: Protecting user data is a fundamental responsibility. We've learned that ongoing vigilance and adherence to best practices in cybersecurity are essential.
**Teamwork Is Invaluable**: Collaborative and cross-disciplinary teamwork is at the heart of a successful project. We've experienced the benefits of diverse skills and perspectives working together.
These lessons have not only shaped our approach to the AI chatbot project but have also broadened our knowledge and understanding of technology's role in education and the ethical responsibilities that come with it. As we continue to develop and refine our chatbot, these lessons serve as guideposts for our future endeavors in enhancing learning and supporting students through innovative technology.
## What's next for ~ENIGMA
The journey of our AI chatbot project is an ongoing one, and we have ambitious plans for its future:
**Continuous Learning and Improvement**: We are committed to a continuous cycle of learning and improvement. This includes refining the chatbot's responses, expanding its knowledge base, and enhancing its problem-solving abilities.
**Advanced AI Capabilities**: We aim to incorporate state-of-the-art AI techniques to make the chatbot even more powerful and responsive. This includes exploring advanced machine learning models and technologies.
**Expanded Subject Coverage**: While our chatbot currently specializes in coding, we envision expanding its capabilities to cover a wider range of subjects and academic disciplines, providing comprehensive educational support.
**Enhanced Personalization**: We will invest in further personalization, tailoring learning resources and mentor matches even more closely to individual student needs, preferences, and learning styles.
**Multi-Lingual Support**: We plan to expand the chatbot's language capabilities, enabling it to provide support to students in multiple languages, making it accessible to a more global audience.
**Mobile Applications**: Developing mobile applications will enhance the chatbot's accessibility, allowing students to engage with it on their smartphones and tablets.
**Integration with Learning Management Systems**: We aim to integrate our chatbot with popular learning management systems used in educational institutions, making it an integral part of formal education.
**Feedback Mechanisms**: We will implement more sophisticated feedback mechanisms, allowing users to provide input that helps improve the chatbot's performance and user experience.
**Research and Publication**: Our team is dedicated to advancing the field of AI in education. We plan to conduct research and contribute to academic publications in the realm of AI-driven educational support.
**Community Engagement**: We are eager to engage with the educational community to gather insights, collaborate, and ensure that our chatbot remains responsive to the evolving needs of students and educators.
In essence, the future of our project is marked by a commitment to innovation, expansion, and a relentless pursuit of excellence in the realm of AI-driven education. Our goal is to provide increasingly effective and personalized support to students, empower educators, and contribute to the broader conversation surrounding AI in education. | partial |
## Inspiration ⚡️
Given the ongoing effects of COVID-19, we know lots of people don't want to spend more time than necessary in a hospital. We wanted to be able to skip a large portion of the waiting process and fill out the forms ahead of time from the comfort of our home so we came up with the solution of HopiBot.
## What it does 📜
HopiBot is an accessible, easy to use chatbot designed to make the process of admitting patients more efficient — transforming basic in person processes to a digital one, saving not only your time, but the time of the doctors and nurses as well. A patient will use the bot to fill out their personal information and once they submit, the bot will use the inputted mobile phone number to send a text message with the current wait time until check in at the nearest hospital to them. As pandemic measures begin to ease, HopiBot will allow hospitals to socially distance non-emergency patients, significantly reducing exposure and time spent around others, as people can enter the hospital at or close to the time of their check in. In addition, this would reduce the potential risks of exposure (of COVID-19 and other transmissible airborne illnesses) to other hospital patients that could be immunocompromised or more vulnerable.
## How we built it 🛠
We built our project using HTML, CSS, JS, Flask, Bootstrap, Twilio API, Google Maps API (Geocoding and Google Places), and SQLAlchemy. HTML, CSS/Bootstrap, and JS were used to create the main interface. Flask was used to create the form functions and SQL database. The Twilio API was used to send messages to the patient after submitting the form. The Google Maps API was used to send a Google Maps link within the text message designating the nearest hospital.
## Challenges we ran into ⛈
* Trying to understand and use Flask for the first time
* How to submit a form and validate at each step without refreshing the page
* Using new APIs
* Understanding how to use an SQL database from Flask
* Breaking down a complex project and building it piece by piece
## Accomplishments that we're proud of 🏅
* Getting the form to work after much deliberation of its execution
* Being able to store and retrieve data from an SQL database for the first time
* Expanding our hackathon portfolio with a completely different project theme
* Finishing the project within a tight time frame
* Using Flask, the Twilio SMS API, and the Google Maps API for the first time
## What we learned 🧠
Through this project, we were able to learn how to break a larger-scale project down into manageable tasks that could be done in a shorter time frame. We also learned how to use Flask, the Twilio API, and the Google Maps API for the first time, considering that it was very new to all of us and this was the first time we used them at all. Finally, we learned a lot about SQL databases made in Flask and how we could store and retrieve data, and even try to present it so that it could be easily read and understood.
## What's next for HopiBot ⏰
* Since we have created the user side, we would like to create a hospital side to the program that can take information from the database and present all the patients to them visually.
* We would like to have a stronger validation system for the form to prevent crashes.
* We would like to implement an algorithm that can more accurately predict a person’s waiting time by accounting for the time it would take to get to the hospital and the time a patient would spend waiting before their turn.
* We would like to create an AI that is able to analyze a patient database and able to predict wait times based on patient volume and appointment type.
* Along with a hospital side, we would like to send update messages that warns patients when they are approaching the time of their check-in. | ## Inspiration
Imagine you broke your EpiPen but you need it immediately for an allergic reaction. Imagine being lost in the forest with cut wounds and bleeding from a fall but have no first aid kit. How will you take care of your health without nearby hospitals or pharmacies? Well good thing for you, we have **MediFly**!! MediFly is inspired by how emergency vehicles such as ambulances take too long to get to the person in need of aid because of other cars on the road and traffic. Every second spent waiting is risking someone's life. So in order to combat that issue, we use **drones** as the first emergency responders to send medicine to save people's lives or keep them in a stable condition before human responders arrive.
## What it does
MediFly allows the user to request for emergency help or medication such as an Epipen and Epinephrine. First you download the MediFly app and create a personal account. Then you can log into your account and use the features when necessary. If you are in an emergency, press the "EMERGENCY" button and a list of common medication options will appear for the person to pick from. There is also an option to search for your needed medication. Once a choice is selected, the local hospital will see the request and send a drone to deliver the medication to the person. Human first responders will also be called. The drone will have a GPS tracker and a GPS location of the person it needs to send the medication to. When the drone is within close distance to the person, a message is sent to tell them to go outside to where the drone can see the person. The camera will use facial recognition to confirm the person is indeed the registered user who ordered the medication. This level of security is important to ensure that the medication is delivered to the correct person. When the person is confirmed, the medication holding compartment lid is opened so the person can take their medication.
## How we built it
On the software side, the front end of the app was made with react coded in Javascript, and the back end was made with Django in Python.
The text messages work through Twilio. Twilio is used to tell the user that the drone is nearby with the medication ready to hand over. It sends a message telling the person to go outdoors where the drone will be able to find the user.
On the hardware side, there are many different components that make up the drone. There are four motors, four propeller blades, a electronic speed controller, a flight controller, and 3D printed parts such as the camera mount, medication box holder, and some components of the drone frame. Besides this there is also a Raspberry Pi SBC attached to the drone for controlling the on-board systems such as the door to unload the cargo bay and stream the video to a server to process for the face recognition algorithm.
## Challenges we ran into
Building the drone from scratch was a lot harder than we anticipated. There was a lot of setting up that needed to be done for the hardware and the building aspect was not easy. It consisted of a lot of taking apart, rebuilding, soldering, cutting, hot gluing, and rebuilding.
Some of the video streaming systems did not work well at first, due to the CORS blocking the requests, given that we were using two different computers to run two different servers.
Traditional geolocation techniques often take too long - as such, we needed to build a scheme to cache a user's location before they decided to send a request to prevent lag. Additionally, the number of pages required to build, stylize, and connect together made building the site a notable challenge of scale.
## Accomplishments that we're proud of
We are extremely proud of the way the drone works and how it's able to move at quick, steady speeds while carrying the medication compartment and battery.
On the software side, we are super proud of the facial recognition code and how it's able to tell the difference between different peoples' faces. The front and back end of the website/app is also really well done. We first made the front end UI design on Figma and then implemented the design on our final website.
## What we learned
For software we learned how to use React, as well as various user authorization and authentication techniques. We also learned how to use Django.
We learnt how to build an accurate, efficient and resilient face detection recognition and tracking system to make sure the package is always delivered to the correct person.
We experimented with and learned various ways to stream real-time video over a network, also over longer ranges for the drone.
For hardware we learned how to set up and construct a drone from scratch!
## What's next for MediFly
In the future we hope to add a GPS tracker to the drone so that the person who orders the medication can see where the drone is on its path.
We would also add Twilio text messages so that when the drone is within a close radius to the user, it will send a message notifying the person to go outside and wait for the drone to deliver the medication. | ## Inspiration
Our inspiration for AiTC came from our use of various forms of transportation and our close connections with friends in the aviation industry. Seeing firsthand the complexities and challenges that air traffic controllers face, we wanted to create a solution that could alleviate some of the burdens on agents in control towers. AiTC is designed to streamline communication, reduce errors, and enhance the efficiency of air traffic management.
## What it does
AiTC is an AI-driven platform designed to assist air traffic controllers by automating routine radio communication with pilots and providing real-time flight data insights. It leverages advanced speech recognition and natural language processing to analyze ATC-pilot communications, flag potential issues, and ensure that critical information is delivered accurately and on time. The system works in tandem with controllers, acting as a digital assistant to help manage complex airspace efficiently. The long-term goal is to fully automate the ATC communications.
## How we built it
We built AiTC using several powerful tools and technologies. We used Vapi to train the models with out datasets and for real-time flight data integration, providing up-to-the-minute information about flights. We used Deepgram for speech-to-text capabilities, converting real-time ATC communications into actionable data. We used OpenAI to to interpret and assist with communication, as well as to improve decision-making processes within the control tower. We used hugging face datasets of ATC call transcripts and guides to train the AI models ensuring accurate communication processing.
## Accomplishments that we're proud of
We’re super proud of developing a working prototype that integrates real-time flight data with AI-driven communication tools. The ability of AiTC to accurately process and respond to ATC communications is a major milestone, as is its potential to enhance safety and efficiency in one of the most critical sectors of transportation. We’re also proud of how we were able to incorporate machine learning models into a real-time system without sacrificing performance.
## What we learned
Through this project, we learned the importance of handling real-time data effectively. We also gained valuable experience in the integration of various APIs and the unique challenges of real-time communication systems.
## What's next for AI Traffic Control (AITC)
The next step for AiTC is to improve its scalability and robustness. We plan to expand its ability to handle more complex airspaces, integrate additional datasets for more nuanced decision-making, and further reduce latency in communication. The long-term goal is to fully automate this communication system. We also aim to pilot the system with actual air traffic control teams to gather real-world feedback and refine the tool for broader adoption. | winning |
## Inspiration
Politicians make a lot of money. Like, a lot. After a thorough analysis of how politicians apply their skill sets to faithfully "serve the general public", we realized that there's a hidden skill that many of them possess. It is a skill that hasn't been in the spotlight for some time. It is the skill which allowed US senator, Richard Burr, to sell 95% of his holdings in his retirement account just before a downturn in the market (thus avoiding $80,000 in losses and generating a profit upwards of $100k). This same skill allowed several senators like Spencer Bachus who had access to top secret meetings discussing the 2008 stock market crash and it's inevitably to heavily short the market just before the crash, generating a 200% per 1% drop in the NASDAQ. So, we decided that... senators know best! Our project is about outsider trading, which essentially means an outsider (you) get to trade! It allows you to track and copy the live trades of whatever politician you like.
## Why the idea works and what problem is solves
We have a term called "recognition by ignition", a simple set of words that describe how this unconventional approach works. Our system has the ability to, by virtue of the data that is available to it, prioritize the activity of Senators previously engaged in suspicious trading activities. When these Senators make a big move, everyone following them receives a message via our InfoBip integration, and knows, temporarily acting as a catalyst for changes in the value of that stock, at best just enough to draw the scrutiny of financial institutions, essentially serving as an extra layer of safety checks while consistently being a trustworthy platform to trade on, ensured by wallet management and transactions through Circle integration.
## What it does
Outsider trading gets the trading data of a large set of politicians, showing you their trading history and allowing you to select one or more politicians to follow. After depositing an amount into outsider trading, our tool either lets you manually assess the presented data and invest wherever you want, or automatically follow the actions of the politicians that you have followed. Sp. when they invest in stock x, our tools proportionally invest for you in the same stock. When they pull out of stock y, your bot will pull out of that stock too! This latter feature can be simulated or followed through with actual funds to track the portfolio performance of a certain senator.
## How we built it
We built our web app using ReactJS for the front end connected to a snappy Node.js backend, and a MySQL server hosted on RDS. Thanks in part to the STOCK act of 2012, most trading data for US senators has to be made public information, so we used the BeautifulSoup library to Web Scrape and collect our data.
## Challenges we ran into
Naturally, 36 hours (realistically less) of coding, would involve tense sessions of figuring out how to do certain things. We saw the direct value that the services offered by InfoBip and Circle could have on our project so we got to work implementing that and as expected had to traverse a learning curve with implementing the APIs, this job was however made easier because of the presence of mentors and good documentation online that allowed us to integrate an SMS notification system and a system that sets up crypto wallets for any user that signs up.
Collaborating effectively is one of the most important parts of a hackathon, so we as a team learnt a lot more about effective and efficient version control measures and how to communicate and divide roles and work in a software focused development environment.
## Accomplishments that we're proud of
* A complete front-end for the project was finished in due time
* A fully functional back-end and database system to support our front-end
* InfoBip integration to set up effective communication with the customer. Our web-app automatically sends an SMS when a senator you are following makes a trade.
* Crypto wallets for payment, implemented with Circle!
* A well designed and effective database hosted on an RDS instance
## What we learned
While working on this project we had to push ourselves outside of all of our comfort zones. Going into this project none of us knew how to web scrape, set up crypto wallets, create SMS/email notification systems, or work with RDS instances. Although some of these features may be bare bones, we are leaving this project with new knowledge and confidence in these areas. We learnt how to effectively work and scale a full stack web-app, and got invaluable experience on how to collaborate and version control as a team.
## What's next for Outsider Trading
This is only the beginning for us, there's a lot more to come!
* Increased InfoBip integration with features like:
1) Weekly summary email of your portfolio (We have investment data and financial data on Circle that can simply be summarized with the API we use to make charts on the portfolio page and then attach that through Infobip through the email.
2) SMS 2.0 features can be used to directly allow the user to invest from their messaging app of choice
* Improved statistical summaries of your own trades and those of each senator with models trained on trading datasets that can detect the likelihood of foul play in the market.
* Zapier integration with InfoBip to post updates about senator trades regularly to a live Twitter (X) page.
* An iOS and android native app, featuring all of our current features an more. | ## Inspiration
We constantly have friends asking us for advice for investing, or ask for investing advice ourselves. We realized how easy a platform that allowed people to make collaboratively make investments would make sharing information between people. We formed this project out of inspiration to solve a problem in our own lives.
The word 'Omada' means group in Greek, and we thought it sounded official and got our message across.
## What it does
Our platform allows you to form groups with other people, put your money in a pool, and decide which stocks the group should buy. We use a unanimous voting system to make sure that everyone who has money involved agrees to the investments being made.
We also allow for searching up stocks and their graphs, as well as individual portfolio analysis.
The way that the buying and selling of stocks actually works is as follows: let's say a group has two members, A and B. If A has $75 on the app, and person B has $25 on the app, and they agree to buy a stock costing $100. When they sell the stock, person A gets 75% of the revenue from selling the stock and person B gets 25%.
Person A: $75
Person B: $25
Buy stock for $100
Stock increases to $200
Sell Stock
Person A: $150
Person B: $200
We use a proposal system in order to buy stocks. One person finds a stock that they want to buy with the group, and makes a proposal for the type of order, the amount, and the price they want to buy the stock at. The proposal then goes up for a vote. If everyone agrees to purchasing the stock, then the order is sent to the market. The same process occurs for selling a stock.
## How we built it
We built the webapp using Flask, specifically to handle routing and so that we could use python for the backend. We used BlackRock for the charts, and NASDAQ for live updates of charts. Additionally, we used mLab with MongoDB and Azure for our databases, and Azure for cloud hosting. Our frontend is JavaScript, HTML, and CSS.
## Challenges we ran into
We had a hard time initially with routing the app using Flask, as this was our first time using it. Additionally, Blackrock has an insane amount of data, so getting that organized and figuring out what we wanted to do with that and processing it was challenging, but also really fun.
## Accomplishments that we're proud of
I'm proud that we got the service working as much as we did! We decided to take on a huge project, which could realistically take months of time to make if this was a workplace, but we got a lot of features implemented and plan on continuing to work on the project as time moves forward. None of us had ever used Flask, MongoDB, Azure, BlackRock, or Nasdaq before this, so it was really cool getting everything together and working the way it does.
## What's next for Omada
We hope to polish everything off, add features we didn't have time to implement, and start using it for ourselves! If we are able to make it work, maybe even publishing it! | ## Inspiration
Students often have a hard time finding complementary co-founders for their ventures/ideas and have limited interaction with students from other universities. Many universities don't even have entrepreneurship centers to help facilitate the matching of co-founders. Furthermore, it is hard to seek validation from a wide range of perspectives on your ideas when you're immediate network is just your university peers.
## What it does
VenYard is a gamified platform that keeps users engaged and interested in entrepreneurship while building a community where students can search for co-founders across the world based on complementary skill sets and personas. VenYard’s collaboration features also extend to the ideation process feature where students can seek feedback and validation on their ideas from students beyond their university. We want to give the same access to entrepreneurship and venture building to every student across the world so they can have the tools and support to change the world.
## How we built it
We built VenYard using JS, HTML, CSS, Node.js, MySQL, and a lack of sleep!
## Challenges we ran into
We had several database-related issues related to the project submission page and the chat feature on each project dashboard. Furthermore, when clicking on a participant on a project's dashboard, we wanted their profile to be brought up but we ran into database issues there but that is the first problem we hope to fix.
## Accomplishments that we're proud of
For a pair of programmers who have horrible taste in design, we are proud of how this project turned out visually. We are also proud of how we have reached a point in our programming abilities where we are able to turn our ideas into reality!
## What we learned
We were able to advance our knowledge of MySql and Javascript specifically. Aside from that, we were also able to practice pair programming by using the LiveShare extension on VSCode.
## What's next for VenYard
We hope to expand the "Matching" feature by making it so that users can specify more criteria for what they want in the ideal co-founder. Additionally, we probably would have to take a look at the UI and make sure it's user-friendly because there are a few aspects that are still a little clunky. Lastly, the profile search feature needs to be redone because our initial idea of combining search and matching profiles doesn't make sense.
## User Credentials if you do not want to create an account
username: [[email protected]](mailto:[email protected])
password: revant
## Submission Category
Education and Social Good
## Discord Name
revantk16#6733, nicholas#2124 | partial |
## Inspiration
GetSense was developed in an attempt to create low latency live streaming for countries with slow internet so that they could still have security regardless of their internet speed.
## What it does
GetSense is an AI powered flexible security solution that uses low-level IoT devices (laptop camera systems or Raspberry Pi) to detect, classify, and identify strangers and friends in your circle. A GetSense owner uploads images of authorized faces through an user-facing mobile application. Through the application, the user has access to a live-stream of all connected camera devices, and authorized friend list.
Under the hood, when an user uploads authorized faces, these are sent as data to Firebase storage through a REST API which generates dynamic image URLs. These are then sent to serverless functions (FAAS) which connects to the computer vision microservices setup in Clarifai. The IoT devices communicate via RTSP and streams the video-feed using low-latency.
## How we built it
We used stdlib to generate serverless functions for obtaining the probability score through Clarifai facial recognition, push notifications via Slack alerts to notify the user of an unrecognizable face, and managing the image model training route to Clarifai. For the facial detection process, we used OpenCV with multithreading to detect faces (through Clarifai) for optimization purposes - this was done in Python.
An iOS application was exposed to the user for live-streaming all camera sources, adding authorized faces, and visualizing current friend list. All the data involving images and streaming was handled through Firebase storage and database, which the iOS application heavily interfaced with.
## Challenges we ran into
Our initial goal was to use AWS kinesis to process everything originating from a Raspberry Pi camera module. We had lots of issues with the binaries and overall support of AWS kinesis, so we had to pivot and explore camera modules on local machines. We had to explore using Clarifai for facial detection, running serverless functions with stdlib, and push notifications through an external service.
## Accomplishments that we're proud of
It works.
## What we learned
We learned how to use StdLib, Clarifai for image processing, OpenCV, and building an iOS application.
## What's next for GetSense
We want to improve it to make it more user friendly. | ## Inspiration 🍪
We’re fed up with our roommates stealing food from our designated kitchen cupboards. Few things are as soul-crushing as coming home after a long day and finding that someone has eaten the last Oreo cookie you had been saving. Suffice it to say, the university student population is in desperate need of an inexpensive, lightweight security solution to keep intruders out of our snacks...
Introducing **Craven**, an innovative end-to-end pipeline to put your roommates in check and keep your snacks in stock.
## What it does 📸
Craven is centered around a small Nest security camera placed at the back of your snack cupboard. Whenever the cupboard is opened by someone, the camera snaps a photo of them and sends it to our server, where a facial recognition algorithm determines if the cupboard has been opened by its rightful owner or by an intruder. In the latter case, the owner will instantly receive an SMS informing them of the situation, and then our 'security guard' LLM will decide on the appropriate punishment for the perpetrator, based on their snack-theft history. First-time burglars may receive a simple SMS warning, but repeat offenders will have a photo of their heist, embellished with an AI-generated caption, posted on [our X account](https://x.com/craven_htn) for all to see.
## How we built it 🛠️
* **Backend:** Node.js
* **Facial Recognition:** OpenCV, TensorFlow, DLib
* **Pipeline:** Twilio, X, Cohere
## Challenges we ran into 🚩
In order to have unfettered access to the Nest camera's feed, we had to find a way to bypass Google's security protocol. We achieved this by running an HTTP proxy to imitate the credentials of an iOS device, allowing us to fetch snapshots from the camera at any time.
Fine-tuning our facial recognition model also turned out to be a bit of a challenge. In order to ensure accuracy, it was important that we had a comprehensive set of training images for each roommate, and that the model was tested thoroughly. After many iterations, we settled on a K-nearest neighbours algorithm for classifying faces, which performed well both during the day and with night vision.
Additionally, integrating the X API to automate the public shaming process required specific prompt engineering to create captions that were both humorous and effective in discouraging repeat offenders.
## Accomplishments that we're proud of 💪
* Successfully bypassing Nest’s security measures to access the camera feed.
* Achieving high accuracy in facial recognition using a well-tuned K-nearest neighbours algorithm.
* Fine-tuning Cohere to generate funny and engaging social media captions.
* Creating a seamless, rapid security pipeline that requires no legwork from the cupboard owner.
## What we learned 🧠
Over the course of this hackathon, we gained valuable insights into how to circumvent API protocols to access hardware data streams (for a good cause, of course). We also deepened our understanding of facial recognition technology and learned how to tune computer vision models for improved accuracy. For our X integration, we learned how to engineer prompts for Cohere's API to ensure that the AI-generated captions were both humorous and contextual. Finally, we gained experience integrating multiple APIs (Nest, Twilio, X) into a cohesive, real-time application.
## What's next for Craven 🔮
* **Multi-owner support:** Extend Craven to work with multiple cupboards or fridges in shared spaces, creating a mutual accountability structure between roommates.
* **Machine learning improvement:** Experiment with more advanced facial recognition models like deep learning for even better accuracy.
* **Social features:** Create an online leaderboard for the most frequent offenders, and allow users to vote on the best captions generated for snack thieves.
* **Voice activation:** Add voice commands to interact with Craven, allowing roommates to issue verbal warnings when the cupboard is opened. | ## Inspiration
There are approximately **10 million** Americans who suffer from visual impairment, and over **5 million Americans** suffer from Alzheimer's dementia. This weekend our team decided to help those who were not as fortunate. We wanted to utilize technology to create a positive impact on their quality of life.
## What it does
We utilized a smartphone camera to analyze the surrounding and warn visually impaired people about obstacles that were in their way. Additionally, we took it a step further and used the **Azure Face API** to detect the faces of people that the user interacted with and we stored their name and facial attributes that can be recalled later. An Alzheimer's patient can utilize the face recognition software to remind the patient of who the person is, and when they last saw him.
## How we built it
We built our app around **Azure's APIs**, we created a **Custom Vision** network that identified different objects and learned from the data that we collected from the hacking space. The UI of the iOS app was created to be simple and useful for the visually impaired, so that they could operate it without having to look at it.
## Challenges we ran into
Through the process of coding and developing our idea we ran into several technical difficulties. Our first challenge was to design a simple UI, so that the visually impaired people could effectively use it without getting confused. The next challenge we ran into was attempting to grab visual feed from the camera, and running them fast enough through the Azure services to get a quick response. Another challenging task that we had to accomplish was to create and train our own neural network with relevant data.
## Accomplishments that we're proud of
We are proud of several accomplishments throughout our app. First, we are especially proud of setting up a clean UI with two gestures, and voice control with speech recognition for the visually impaired. Additionally, we are proud of having set up our own neural network, that was capable of identifying faces and objects.
## What we learned
We learned how to implement **Azure Custom Vision and Azure Face APIs** into **iOS**, and we learned how to use a live camera feed to grab frames and analyze them. Additionally, not all of us had worked with a neural network before, making it interesting for the rest of us to learn about neural networking.
## What's next for BlindSpot
In the future, we want to make the app hands-free for the visually impaired, by developing it for headsets like the Microsoft HoloLens, Google Glass, or any other wearable camera device. | winning |
## Inspiration
Studies show that drawing, coloring, and other art-making activities can help people express themselves artistically and explore their art's psychological and emotional undertones [1]. Before this project, many members of our team had already caught on to the stress-relieving capabilities of art-centered events, especially when they involved cooperative interaction. We realized that we could apply this concept in a virtual setting in order to make stress-relieving art events accessible to those who are homeschooled, socially-anxious, unable to purchase art materials, or otherwise unable to access these groups in real life. Furthermore, virtual reality provides an open sandbox suited exactly to the needs of a stressed person that wants to relieve their emotional buildup. Creating art in a therapeutic environment not only reduces stress, depression, and anxiety in teens and young adults, but it is also rooted in spiritual expression and analysis [2]. We envision an **online community where people can creatively express their feelings, find healing, and connect with others through the creative process of making art in Virtual Reality.**
## VIDEOS:
<https://youtu.be/QXY9UfquwNI>
<https://youtu.be/u-3l8vwXHvw>
## What it does
We built a VR application that **learns from the user's subjective survey responses** and then **connects them with a support group who might share some common interests and worries.** Within the virtual reality environment, they can **interact with others through anonymous avatars, see others' drawings in the same settings, and improve their well-being by interacting with others in a liberating environment.** To build the community outside of VR, there is an accompanying social media website allowing users to share their creative drawings with others.
## How we built it
* We used SteamVR with the HTC Vive HMD and Oculus HMD, as well as Unity to build the interactive environments and develop the softwares' functionality.
* The website was built with Firebase, Node.js, React, Redux, and Material UI.
## Challenges we ran into
* Displaying drawing real-time on a server-side, rather than client-side output posed a difficulty due to the restraints on broadcasting point-based cloud data through Photon. Within the timeframe of YHack, we were able to build the game that connects multiple players and allows them to see each other's avatars. We also encountered difficulties with some of the algorithmic costs of the original line-drawing methods we attempted to use.
## Citation:
[1] <https://www.psychologytoday.com/us/groups/art-therapy/connecticut/159921?sid=5db38c601a378&ref=2&tr=ResultsName>
[2] <https://www.psychologytoday.com/us/therapy-types/art-therapy> | ## Inspiration
Team member's father works in the medical field and he presented the problem to us. We wanted to try to create a tool that he could actually use in the workplace.
## What it does
Allows users to create requests for air ambulances (medically equipped helicopters) and automatically prioritizes and dispatches the helicopters. Displays where the helicopters will be flying and how long it will take.
## How we built it
Java, Firebase realtime database, android-studio, google-maps api for locations
## What we learned
First time integrating google-maps into an android app which was interesting. Firebase has some strange asynchronous issues that we took a lot of time to fix. Android is great for building a quick and dirty UI.
Redbull + a mentor = bug fixes | One challenge that is frequently attributed to the prominence of technology in our lives is a deepening health crises. Gadgets are blamed for all sorts of problems, ranging from loneliness and depression to incidents of public violence. We felt that it would be incredible if we could provide a concrete use case for one of the most powerful tech experiences, VR, that would help seriously establish the technology as a force for good.
Our technology provides two options for mental health services inspired by psychological treatments. In one case, we built a scene to help people get over arachnophobia in an encounter inspired by exposure therapy. In another, we take advantage of VR’s privacy to create a space for mediation. We used the Oculus Quest VR headset for this platform, in light of its popularity and accessibility.
Our two person team approached the workflow in the following manner: Austin built the models in Blender while Ines assembled them in Unity and coded the interactive aspects of the app. We relied very minimally on the asset store, only using it for a couch and chair model, which saved us significant time.
We aspired to create an application that felt accessible to all users, and we drew from a variety of inspirations to accomplish this. We felt that a warm, cozy cabin provided a safe home screen for users that they would enjoy spending time in. Our meditation scene was inspired by the serenity of Morikami Park in Fort Lauderdale, which we sought to replicate in virtual reality. Our design for the phobia treatment was strongly influenced from conversations we had earlier conducted with Ryley Mancine, a researcher at Michigan State University in psychiatric science, on VR in psychological services. His robust knowledge of psychiatry was an invaluable asset in the way we thought about this project.
Unfortunately, the main challenge we faced was what we found to be Oculus Quest’s limited feature set. We had initially imagined incorporating a multi-party aspect to the app, but our inability to use Google cloud services with the Quest made it significantly more difficult. In the end we did not manage to incorporate a multi-party experience for this reason, which was a bummer. We also found that the Quest itself included buggy template scenes which made it difficult to learn how to take full advantage of its functionality. This, coupled with the lack of documentation, made for a disproportionately large time investment to learn relatively simple features, which negatively impacted our workflow.
Having said that, we managed to build a VR app on an emerging platform In only two days. We managed to overcome the compatibility issues, the buggy templates and lack of documentation to create something which could really help somebody. To our knowledge, we count ourselves among the first developing for the med-tech space as it pertains to virtual reality. And we did that with a team of two.
During these two days, we learned a lot about designing for VR. We learned how the Quest interacts with Unity and Blender, how to build scripts for VR from the ground up, and how to optimize model design for the Quest’s constraints. We also learned how to better manage our workflow to maximize production in this extremely time sensitive environment. Lastly, we learned more about pitch construction and marketing technology. HackHarvard has been an extremely positive experience in this respect and we feel invigorated by our experience here.
We think that as we move forward with this technology, we will go back to the drawing board and try to find workarounds for Quest development that will allow us to incorporate more robust features in VR apps. We will certainly further optimize our models (when we can spend weeks instead of hours on them), and we will find better ways to incorporate established practices into virtual use cases. | partial |
## Inspiration
With the excitement of blockchain and the ever growing concerns regarding privacy, we wanted to disrupt one of the largest technology standards yet: Email. Email accounts are mostly centralized and contain highly valuable data, making one small breach, or corrupt act can serious jeopardize millions of people. The solution, lies with the blockchain. Providing encryption and anonymity, with no chance of anyone but you reading your email.
Our technology is named after Soteria, the goddess of safety and salvation, deliverance, and preservation from harm, which we believe perfectly represents our goals and aspirations with this project.
## What it does
First off, is the blockchain and message protocol. Similar to PGP protocol it offers \_ security \_, and \_ anonymity \_, while also **ensuring that messages can never be lost**. On top of that, we built a messenger application loaded with security features, such as our facial recognition access option. The only way to communicate with others is by sharing your 'address' with each other through a convenient QRCode system. This prevents anyone from obtaining a way to contact you without your **full discretion**, goodbye spam/scam email.
## How we built it
First, we built the block chain with a simple Python Flask API interface. The overall protocol is simple and can be built upon by many applications. Next, and all the remained was making an application to take advantage of the block chain. To do so, we built a React-Native mobile messenger app, with quick testing though Expo. The app features key and address generation, which then can be shared through QR codes so we implemented a scan and be scanned flow for engaging in communications, a fully consensual agreement, so that not anyone can message anyone. We then added an extra layer of security by harnessing Microsoft Azures Face API cognitive services with facial recognition. So every time the user opens the app they must scan their face for access, ensuring only the owner can view his messages, if they so desire.
## Challenges we ran into
Our biggest challenge came from the encryption/decryption process that we had to integrate into our mobile application. Since our platform was react native, running testing instances through Expo, we ran into many specific libraries which were not yet supported by the combination of Expo and React. Learning about cryptography and standard practices also played a major role and challenge as total security is hard to find.
## Accomplishments that we're proud of
We are really proud of our blockchain for its simplicity, while taking on a huge challenge. We also really like all the features we managed to pack into our app. None of us had too much React experience but we think we managed to accomplish a lot given the time. We also all came out as good friends still, which is a big plus when we all really like to be right :)
## What we learned
Some of us learned our appreciation for React Native, while some learned the opposite. On top of that we learned so much about security, and cryptography, and furthered our beliefs in the power of decentralization.
## What's next for The Soteria Network
Once we have our main application built we plan to start working on the tokens and distribution. With a bit more work and adoption we will find ourselves in a very possible position to pursue an ICO. This would then enable us to further develop and enhance our protocol and messaging app. We see lots of potential in our creation and believe privacy and consensual communication is an essential factor in our ever increasingly social networking world. | ## Inspiration
The counterfeiting industry is anticipated to grow to $2.8 trillion in 2022 costing 5.4 million jobs. These counterfeiting operations push real producers to bankruptcy as cheaper knockoffs with unknown origins flood the market. In order to solve this issue we developed a blockchain powered service with tags that uniquely identify products which cannot be faked or duplicated while also giving transparency. As consumers today not only value the product itself but also the story behind it.
## What it does
Certi-Chain uses a python based blockchain to authenticate any products with a Certi-Chain NFC tag. Each tag will contain a unique ID attached to the blockchain that cannot be faked. Users are able to tap their phones on any product containing a Certi-Chain tag to view the authenticity of a product through the Certi-Chain blockchain. Additionally if the product is authentic users are also able to see where the products materials were sourced and assembled.
## How we built it
Certi-Chain uses a simple python blockchain implementation to store the relevant product data. It uses a proof of work algorithm to add blocks to the blockchain and check if a blockchain is valid. Additionally, since this blockchain is decentralized, nodes (computers that host a blockchain) have to be synced using a consensus algorithm to decide which version of the blockchain from any node should be used.
In order to render web pages, we used Python Flask with our web server running the blockchain to fetch relative information from the blockchain and displayed it to the user in a style that is easy to understand. A web client to input information into the chain was also created using Flask to communicate with the server.
## Challenges we ran into
For all of our group members this project was one of the toughest we had. The first challenge we ran into was that once our idea was decided we quickly realized only one group member had the appropriate hardware to test our product in real life. Additionally, we deliberately chose an idea in which none of us had experience in. This meant we had to spent a portion of time to understand concepts such as blockchain and also using frameworks like flask. Beyond the starting choices we also hit several roadblocks as we were unable to get the blockchain running on the cloud for a significant portion of the project hindering the development. However, in the end we were able to effectively rack our minds on these issues and achieve a product that exceeded our expectations going in. In the end we were all extremely proud of our end result and we all believe that the struggle was definitely worth it in the end.
## Accomplishments that we're proud of
Our largest achievement was that we were able to accomplish all our wishes for this project in the short time span we were given. Not only did we learn flask, some more python, web hosting, NFC interactions, blockchain and more, we were also able to combine these ideas into one cohesive project. Being able to see the blockchain run for the first time after hours of troubleshooting was a magical moment for all of us. As for the smaller wins sprinkled through the day we were able to work with physical NFC tags and create labels that we stuck on just about any product we had. We also came out more confident in the skills we already knew and also developed new skills we gained on the way.
## What we learned
In the development of Certi-Check we learnt so much about blockchains, hashes, encryption, python web frameworks, product design, and also about the counterfeiting industry too. We came into the hackathon with only a rudimentary idea what blockchains even were and throughout the development process we came to understand the nuances of blockchain technology and security. As for web development and hosting using the flask framework to create pages that were populated with python objects was certainly a learning curve for us but it was a learning curve that we overcame. Lastly, we were all able to learn more about each other and also the difficulties and joys of pursuing a project that seemed almost impossible at the start.
## What's next for Certi-Chain
Our team really believes that what we made in the past 36 hours can make a real tangible difference in the world market. We would love to continue developing and pursuing this project so that it can be polished for real world use. This includes us tightening the security on our blockchain, looking into better hosting, and improving the user experience for anyone who would tap on a Certi-Chain tag. | ## Inspiration
We’ve noticed that it’s often difficult to form intentional and lasting relationships when life moves so quickly. This issue has only been compounded by the pandemic, as students spend more time than ever isolated from others. As social media is increasingly making the world feel more “digital”, we wanted to provide a means for users to develop tangible and meaningful connections. Last week, I received an email from my residential college inviting students to sign up for a “buddy program” where they would be matched with other students with similar interests to go for walks, to the gym, or for a meal. The program garnered considerable interest, and we were inspired to expand upon the Google Forms setup to a more full-fledged social platform.
## What it does
We built a social network that abstracts away the tediousness of scheduling and reduces the “activation energy” required to reach out to those you want to connect with. Scheduling a meeting with someone on your friend’s feed is only a few taps away. Our scheduling matching algorithm automatically determines the top best times for the meeting based on the inputted availabilities of both parties. Furthermore, forming meaningful connections is a process, we plan to provide data-driven reminders and activity suggestions to keep the ball rolling after an initial meeting.
## How we built it
We built the app for mobile, using react-native to leverage cross-platform support. We used redux for state management and firebase for user authentication.
## Challenges we ran into
Getting the environment (emulators, dependencies, firebase) configured was tricky because of the many different setup methods. Also, getting the state management with Redux setup was challenging given all the boilerplate needed.
## Accomplishments that we're proud of
We are proud of the cohesive and cleanliness of our design. Furthermore, the structure of state management with redux drastically improved maintainability and scalability for data to be passed around the app seamlessly.
## What we learned
We learned how to create an end-to-end app in flutter, wireframe in Figma, and use API’s like firebase authentication and dependencies like React-redux.
## What's next for tiMe
Further flesh out the post-meeting followups for maintaining connections and relationships | partial |
## About the Project
### TLDR:
Caught a fish? Take a snap. Our AI-powered app identifies the catch, keeps track of stats, and puts that fish in your 3d, virtual, interactive aquarium! Simply click on any fish in your aquarium, and all its details — its rarity, location, and more — appear, bringing your fishing memories back to life. Also, depending on the fish you catch, reel in achievements, such as your first fish caught (ever!), or your first 20 incher. The cherry on top? All users’ catches are displayed on an interactive map (built with Leaflet), where you can discover new fishing spots, or plan to get your next big catch :)
### Inspiration
Our journey began with a simple observation: while fishing creates lasting memories, capturing those moments often falls short. We realized that a picture might be worth a thousand words, but a well-told fish tale is priceless. This spark ignited our mission to blend the age-old art of fishing with cutting-edge AI technology.
### What We Learned
Diving into this project was like casting into uncharted waters – exhilarating and full of surprises. We expanded our skills in:
* Integrating AI models (Google's Gemini LLM) for image recognition and creative text generation
* Crafting seamless user experiences in React
* Building robust backend systems with Node.js and Express
* Managing data with MongoDB Atlas
* Creating immersive 3D environments using Three.js
But beyond the technical skills, we learned the art of transforming a simple idea into a full-fledged application that brings joy and preserves memories.
### How We Built It
Our development process was as meticulously planned as a fishing expedition:
1. We started by mapping out the user journey, from snapping a photo to exploring their virtual aquarium.
2. The frontend was crafted in React, ensuring a responsive and intuitive interface.
3. We leveraged Three.js to create an engaging 3D aquarium, bringing caught fish to life in a virtual environment.
4. Our Node.js and Express backend became the sturdy boat, handling requests and managing data flow.
5. MongoDB Atlas served as our net, capturing and storing each precious catch securely.
6. The Gemini AI was our expert fishing guide, identifying species and spinning yarns about each catch.
### Challenges We Faced
Like any fishing trip, we encountered our fair share of challenges:
* **Integrating Gemini AI**: Ensuring accurate fish identification and generating coherent, engaging stories required fine-tuning and creative problem-solving.
* **3D Rendering**: Creating a performant and visually appealing aquarium in Three.js pushed our graphics programming skills to the limit.
* **Data Management**: Structuring our database to efficiently store and retrieve diverse catch data presented unique challenges.
* **User Experience**: Balancing feature-rich functionality with an intuitive, streamlined interface was a constant tug-of-war.
Despite these challenges, or perhaps because of them, our team grew stronger and more resourceful. Each obstacle overcome was like landing a prized catch, making the final product all the more rewarding.
As we cast our project out into the world, we're excited to see how it will evolve and grow, much like the tales of fishing adventures it's designed to capture. | During the COVID-19 pandemic, time spent at home, time spent not exercising, and time spent alone has been at an all time high. This is why, we decided to introduce FITNER to the other fitness nerds like ourselves who struggle to find others to participate in exercise with. As we all know that it is easier to stay healthy, and happy with friends.
We created Fitner as a way to help you find friends to go hiking with, play tennis or even go bowling with! It can be difficult to practice the sport that you love when none of your existing friends are interested, and you do not have the time commitment to join a club. Fitner solves this issue by bridging the gap between fitness nerds who want to reach their potential but don't have the community to do so.
Fitner is a mobile application built with React Native for an iOS and Android front-end, and Google Cloud / Firebase as the backend. We were inspired by the opportunity to use Google Cloud platforms in our application, so we decided to do something we had never done before, which was real-time communication. Although it was our first time working with real-time communication, we found ourselves, in real-time, overtaking the challenges that came along with it. We are very proud of our work ethic, our resulting application and dedication to our first ever hackathon.
Future implementations of our application can include public chat rooms that users may join and plan public sporting events with, and a more sophisticated algorithm which would suggest members of the community that are at a similar skill and fitness goals as you. With FITNER, your fitness goals will be met easily and smoothly and you will meet lifelong friends on the way! | ## Inspiration
Open-world AR applications like Pokemon Go that bring AR into everyday life and the outdoors were major inspirations for this project. Additionally, in thinking about how to integrate smartphones with Spectacles, we found inspiration in video games like Phasmophobia's EMP sensors that react more strongly in the presence of ghosts or The Legend of Zelda: Skyward Sword that contained an in-game tracking functionality that pulsates more strongly when facing the direction of and walking closer to a target.
## What it does
This game integrates the Spectacles gear and smartphones together by allowing users to leverage the gyroscopic, haptic, and tactile functionalities of phones to control or receive input about their AR environment. In the game, users have to track down randomly placed treasure chests in their surrounding environment by using their phone as a sensor that begins vibrating when the user is facing a treasure and enters stronger modes of haptic feedback as users get closer to the treasure spots.
These chests come in three types: monetary, puzzle, and challenge. Monetary chests immediately give users in-game rewards. Puzzle chests engage users in a single-player mini-game that may require cognitive or physical activity. Finally, challenge chests similarly engage users in activities not necessarily games, and a stretch goal for multiplayers was that if multiple users were near a spot that another user found a treasure in, the other n users could challenge the treasure finder in a n vs. 1 duel, with the winner(s) taking the rewards.
## How we built it
Once we figured out our direction for the project, we built a user flow architecture in Figma to brainstorm the game design for our application ([link](https://www.figma.com/design/pyG5hlpYkWwVcyvIQJCnY3/Treasure-Hunt-UX-Architecture?node-id=0-1&node-type=canvas&t=clqInR0JpOM6tEnv-0)), and we also visualized how to implement the system for integrating phone haptic feedback with the spectacles depending on distance and directional conditions.
From there, we each took on specific aspects of the user flow architecture to primarily work on: (1) the treasure detection mechanism, (2) spawning the treasure once the user entered within a short distance from the target, and (3) the content of the treasure chests (i.e. rewards or activities). Nearly everything was done using in-house libraries, assets, and the GenAI suite within Snap's Lens Studio.
## Challenges we ran into
As we were working with Spectacles for the first time (compounded with internet problems), we initially encountered technical issues with setting up our development environment and linking the Spectacles for debugging. Due to limited documentation and forums since it is limited-access technology, we had to do a lot of trial-and-error and guessing to figure out how to get our code to work, but luckily, Snap's documentation provided templates to work off of and the Snap staff was able to provide technical assistance to guide us in the right direction. Additionally, given one Spectacle to work with, parallelizing our development work was quite challenging as we had to integrate everything onto one computer while dealing with merge conflicts between our code.
## Accomplishments that we're proud of
In a short span of time, we were able to successfully build a game that provides a unique immersive experience! We've come across and solved errors that didn't have solutions on the internet. For a couple of members of our team, this sparks a newfound interest in the AR space.
## What we learned
This was our first time working with Lens Studio and it's unanimously been a smooth and great software to work with.
For the experienced members on our team, it's been a rewarding experience to make an AR application using JS/TS instead of C# which is the standard language used in Unity.
## What's next for SnapChest
We're excited to push this app forward by adding more locations for treasures, implementing a point system, and also a voice agent integration that provides feedback based on where you're going so you won't get bored on your journey!
If Spectacles would be made available to the general public, a multiplayer functionality would definitely gain a lot of traction and we're looking forward to the future! | winning |
## Inspiration
We began this project with the Datto challenge in mind: what's the coolest thing we can do in under 4kb?
It had to be something self contained, efficient, and optimized.
Graphics came to mind at first, specifically for a game of some sort, but doing that requires some pretty bulky libraries being tossed and `#include`d around.
But there was one place where we got that all for free - and that's the browser!
## What it does
LinkBreaker looks through the DOM of the current page you're on and picks up the first 50 `<a>` tags it sees. It then uses CSS animations to morph these into randomly coloured bricks at the top of the page. Paddle and ball are spawned right after that, and then a good old fashioned game of Brick Breaker begins!
Don't worry, those anchor tags aren't actually gone. Simply hit `esc` and your page is back to normal.
## How I built it
When building a project with space in mind, you really have to make sure that everything is as self contained as possible. We started out by building a script to do all the animations and the game logic separately, and slowly merged them together into the chrome extension architecture. Once we verified that everything was there and working, the uncompressed source was ~10kb...well over our limit. We optimized where possible, and minified every single file of all whitespace and extraneous characters, using [UglifyJS](https://github.com/mishoo/UglifyJS).
## Challenges I ran into
The main crux of our project was that, since it was manipulating the DOM, it used jQuery heavily. However, in order to include jQuery into a chrome extension, it's source needs to be added as a user script. This means that I'll have to lug around a 400kb+ file wherever I went.
And of course that wouldn't do.
But since chrome extensions are prevented from injecting scripts (and other tags) from the CSP, I had to get a bit creative. What I ended up doing was making an ajax GET call to the cdn hosting the minified jquery code. The response was simply a single string, and that string was all of the jQuery code, wrapped up in a closure.
So I did what any sane person would do... and ran `eval()` on that string.
*It worked.*
## Accomplishments that I'm proud of
Once I finally minified all the source and uploaded the extension for testing, it was time to pack it up. Chrome created the `.crx` executable, and I nervously navigated to my project directory to check it's file size.
*3,665 bytes*
Now that's a pretty close call. And the fact that I got so close really made me happy. It made me happy because not only was I within the bounds of the challenge, but I successfully picked something complex enough to approach the upper bound without hitting it. I thought that was really cool, and probably what I'm proud about the most overall.
## What I learned
Javascript is crazy, yo.
But besides that, I think being conscious of size really had a lasting impression on me. Looking back at past projects, I've always just installed and included things wherever I wanted to - not even taking into account how much space I was using. And although the scale of my other projects compared to this one isn't that large, the concept of keeping file size down is valid everywhere.
## What's next for LinkBreaker
Little bit of cleaning up, and onto the Chrome Web Store she goes! | Introducing the Gaming Gatekeeper - an Arduino project that allows you to assert dominance over any public space by blasting the most obnoxious video game music you can find! With the power of severe sleep deprivation, without any of the hypes of Cloud Computing, Big Data Analytics, Blockchain Technology, AI, AR, VR, Quantum Computing, or 5G, we present Gaming Gatekeeper. With a proximity sensor and a loud AF buzzer, you can turn any coffee shop, park, or a waiting room into your own personal gaming arena. Who needs headphones when you can force your neighbours to listen to the Mario soundtrack at full volume? And don't worry about annoying those around you, because your love of retro video games is more important than their peace and quiet. So if you're looking to alienate everyone in your vicinity, assert your superiority as a gamer, and generally be a pain in the butt, the Gaming Gatekeeper is the project for you! Warning: use at your own risk, as excessive use may result in being permanently banned from public spaces and labelled as a social outcast. | ## Inspiration
We are tired of being forgotten and not recognized by others for our accomplishments. We built a software and platform that helps others get to know each other better and in a faster way, using technology to bring the world together.
## What it does
Face Konnex identifies people and helps the user identify people, who they are, what they do, and how they can help others.
## How we built it
We built it using Android studio, Java, OpenCV and Android Things
## Challenges we ran into
Programming Android things for the first time. WiFi not working properly, storing the updated location. Display was slow. Java compiler problems.
## Accomplishments that we're proud of.
Facial Recognition Software Successfully working on all Devices, 1. Android Things, 2. Android phones.
Prototype for Konnex Glass Holo Phone.
Working together as a team.
## What we learned
Android Things, IOT,
Advanced our android programming skills
Working better as a team
## What's next for Konnex IOT
Improving Facial Recognition software, identify and connecting users on konnex
Inputting software into Konnex Holo Phone | losing |
Fight writer's block with motivation from your favorite internet friends. Every 200 characters, a new image of a baby animal (parsed from Google images) will appear across your screen. | Platypus! | ### Refer this (<https://youtu.be/Ne9Xw_kj138>) for intro and problem statement.
# Brief
### Features
1. Automatic essay grading
2. Facial recognition
3. Text detection from image
**It's becoming harder for teachers to mark hundreds of students work within their limited free time hours that they should be using for leisure. It was reported in March 2021 that 84% of teachers feel stressed, which is a shocking realization when these are the people who are supposed to be comforting and teaching the next generation. This is why we created EduMe.ai**
---

This project is especially useful as it allows for moderated grades throughout schools without any bias. Therefore, if needed it is an effective tool to be used if homework based assessment grades need to be assigned.
---
# What is EduMe.ai
**EduMe.ai** is a social media-based application that aims to connect students and reduce workload for teachers. We identified our problem as teachers being overstressed in their work-life through increasingly complex homework load as well as limited work-life balance. Therefore, we wanted to solve this.
We do this by using AI to mark student's homework as well as invigilate online tests. In addition to this, we have created a platform that allows students to communicate privately and share public posts of their work, lives or interests.
---
# Step by step
# Student
1. Log in with your university id.

2. Scan and submit your essay.

3. Attend Online viva voice test

4. Get notification whenever your classmate sends new message .

5. Share your work with your classmate.

6. Publish your work or grades in social portal.

---
# Teacher
1. See all students and their work assigned in your portal.

2. Assign them essay to write on specific topic.

3.Use grade assigned by computer (Neural network) or grade manually.

3. Assign questions for their viva-voice test.

---
# Automatic essay grading
Essays are paramount for of assessing academic excellence along with linking the different ideas with the ability to recall but are notably time-consuming when they are assessed manually. Manual grading takes a significant amount of evaluator's time and hence it is an expensive process.
Artificial Intelligence systems provide a lot to the educational community where graders have to face different kinds of difficulties while rating student writings. Analyzing student essays in abundance within given time limit, along with feedback is a challenging task. But with changing times, human-written (not handwritten) essays are easy to evaluate with the help of AEG systems.
# Facial recognition
Face detection using Haar cascades is a machine learning-based approach where a cascade function is trained with a set of input data. OpenCV already contains many pre-trained classifiers for face, eyes, smiles, etc.. Today we will be using the face classifier. You can experiment with other classifiers as well.
# Text detection from image
We used google cloud Vision API that can detect and extract text from images. There are two annotation features that support optical character recognition (OCR).
---
# Creation Process
# UI/UX
To start our project properly, we decided to create a rough plan of what we wanted and where in order to visualize the outcome of the project. Here are a few pictures of what we designed using Figma.
# Frames

# Visual Designs

---
# How are we a social media application?
**The Google definition of social media "websites and applications that enable users to create and share content or to participate in social networking."**
We designed our application in a way that allows students to connect through an experience they mutually share - school. We would class our project as social media as it does allow students to talk and spark conversations whilst, having the freedom to post whatever they want that entails their education.
# How does this impact society?
Teachers are arguably the largest group of individuals who make social change. However, with their mental health declining and education gradually becoming harder and more competitive, efficiency and productivity are just not the same as they used to be. We hope, to bring back this productivity via taking work of teacher's hands and creating a centralized place for marking and moderated communication between students.
---
# Our Key Takeaways
### Technologies that we used :

### Accomplishments that we're proud of
We are happy that we were able to complete this highly complex project within the limited time-space. We truly believe that our project has huge potential to create a new era of education that helps teachers with their work-life balance as well as helping students to give advice to each other and help each other out.
### What we learned
We have learned that communication is key, when undertaking a huge project such as this.
### What's next for EduMe.ai
Our system has a lot of versatility but to even start effectively in the future, we plan to implement our system virtually into small schools to see its effects on student progress as well as teacher's mental health. We also plan to make our application a safer place by filtering comments to make sure that no bullying or rude language takes place as it is a tool that is made for school children.
---
## References
1. <https://github.com/mankadronit/Automated-Essay--Scoring>
2. iOS assets on Figma: <https://www.figma.com/file/ne0DGAm1tBVYegnXhD5NO7/Educreate.ai-Student-View>
3. iOS assets on Figma : <https://www.figma.com/file/qOOrCUIJck5biWzXs0651L/Untitled?node-id=0%3A1>
--- | losing |
## Inspiration
I like web design, I like 90's web design, and I like 90's tech. So it all came together very naturally.
## What it does
nineties.tech is a love letter to the silly, chunky, and experimental technology of the 90s. There's a Brian Eno quote about how we end up cherishing the annoyances of "outdated" tech: *Whatever you now find weird, ugly, uncomfortable and nasty about a new medium will surely become its signature.* I think this attitude persists today, and making a website in 90s web design style helped me put myself in the shoes of web designers from 30 years ago (albeit, with flexbox!)
## How we built it
Built with Sveltekit, pure CSS and HTML, deployed with Cloudflare, domain name from get.tech.
## Challenges we ran into
First time using Cloudflare. I repeatedly tried to deploy a non-working branch and was close to tears. Then I exited out to the Deployments page and realized that the fix I'd thrown into the config file actually worked.
## Accomplishments that we're proud of
Grinded out this website in the span of a few hours; came up with a cool domain name; first time deploying a website through Cloudflare; first time using Svelte.
## What we learned
My friend Ivan helped me through the process of starting off with Svelte and serving sites through Cloudflare. This will be used for further nefarious and well-intentioned purposes in the future.
## What's next for nineties.tech
User submissions? Longer, better-written out entries? Branch the site out into several different pages instead of putting everything into one page? Adding a classic 90's style navigation sidebar? Many ideas... | ## Inspiration
Since the arrival of text messaging into the modern day world, users have had a love hate relationship with this novel form of communication. Instant contact with those you love at the cost of losing an entire facet of conversation - emotion. However, one group of individuals has been affected by this more than most. For those with autism, who already have a difficult time navigating emotional cues in person, the world of text messages is an even more challenging situation. That's where NOVI comes in.
## What it does
NOVI utilizes Natural Language Processing to identify a range of emotions within text messages from user to user. Then, by using visual and text cues and an intuitive UI/UX design, it informs the user (based on their learning preferences) of what emotions can be found in the texts they are receiving. NOVI is a fully functional app with a back-end utilizing machine learning and a heavily researched front end to cater to our demographic and help them as much as possible.
## How I built it
Through the use of react native, CSS, javascript, Google Cloud and plenty of hours, NOVI was born. We focused on a back end implementation with a weight on machine learning and natural language processing and a front end focus on research based intuition that could maximize the effectiveness of our app for our users. We ended up with a brand new fully functional messaging app that caters to our demographic's exact needs.
## Challenges I ran into
As this was many of our first times touching anything related to machine learning, there was no real intuition behind a lot of the things we tried to implement. This meant a lot of learning potential and many hours poured into developing new skills. By the end of it however we ended up learning a lot about not only new topics, but also the process of discovering new information and content in order to create our own products.
## Accomplishments that I'm proud of
Something we put a genuinely large amount of effort into was researching our target demographic. As every member in our group had very individual experiences with someone with autism, there were a lot of assumptions we had to avoid making. We avoided these generalizations by looking into as many research papers backing our theories as we could find. This was the extra step we chose to take to assure a genuinely effective UI/UX for our users.
## What I learned
We learned how to use react native, how to use a backend and among many other things, simply how to learn new things. We learned how to research to maximize effectiveness of interfaces and experiences and we learned how to make an app with a specific user base.
## What's next for NOVI
NOVI is an app with much to offer and a lot of potential for collaboration with a variety of organizations and other companies. It is also possible to adapt the concept of NOVI to adapt to other areas of aid for other possible demographics, such as for those with Asperger's. | ## Inspiration
There's something about brief glints in the past that just stop you in your tracks: you dip down, pick up an old DVD of a movie while you're packing, and you're suddenly brought back to the innocent and carefree joy of when you were a kid. It's like comfort food.
So why not leverage this to make money? The ethos of nostalgic elements from everyone's favourite childhood relics turns heads. Nostalgic feelings have been repeatedly found in studies to increase consumer willingness to spend money, boosting brand exposure, conversion, and profit.
## What it does
Large Language Marketing (LLM) is a SaaS built for businesses looking to revamp their digital presence through "throwback"-themed product advertisements.
Tinder x Mean Girls? The Barbie Movie? Adobe x Bob Ross? Apple x Sesame Street? That could be your brand, too. Here's how:
1. You input a product description and target demographic to begin a profile
2. LLM uses the data with the Co:here API to generate a throwback theme and corresponding image descriptions of marketing posts
3. OpenAI prompt engineering generates a more detailed image generation prompt featuring motifs and composition elements
4. DALL-E 3 is fed the finalized image generation prompt and marketing campaign to generate a series of visual social media advertisements
5. The Co:here API generates captions for each advertisement
6. You're taken to a simplistic interface where you can directly view, edit, generate new components for, and publish each social media post, all in one!
7. You publish directly to your business's social media accounts to kick off a new campaign 🥳
## How we built it
* **Frontend**: React, TypeScript, Vite
* **Backend**: Python, Flask, PostgreSQL
* **APIs/services**: OpenAI, DALL-E 3, Co:here, Instagram Graph API
* **Design**: Figma
## Challenges we ran into
* **Prompt engineering**: tuning prompts to get our desired outputs was very, very difficult, where fixing one issue would open up another in a fine game of balance to maximize utility
* **CORS hell**: needing to serve externally-sourced images back and forth between frontend and backend meant fighting a battle with the browser -- we ended up writing a proxy
* **API integration**: with a lot of technologies being incorporated over our frontend, backend, database, data pipeline, and AI services, massive overhead was introduced into getting everything set up and running on everyone's devices -- npm versions, virtual environments, PostgreSQL, the Instagram Graph API (*especially*)...
* **Rate-limiting**: the number of calls we wanted to make versus the number of calls we were allowed was a small tragedy
## Accomplishments that we're proud of
We're really, really proud of integrating a lot of different technologies together in a fully functioning, cohesive manner! This project involved a genuinely technology-rich stack that allowed each one of us to pick up entirely new skills in web app development.
## What we learned
Our team was uniquely well-balanced in that every one of us ended up being able to partake in everything, especially things we hadn't done before, including:
1. DALL-E
2. OpenAI API
3. Co:here API
4. Integrating AI data pipelines into a web app
5. Using PostgreSQL with Flask
6. For our non-frontend-enthusiasts, atomic design and state-heavy UI creation :)
7. Auth0
## What's next for Large Language Marketing
* Optimizing the runtime of image/prompt generation
* Text-to-video output
* Abstraction allowing any user log in to make Instagram Posts
* More social media integration (YouTube, LinkedIn, Twitter, and WeChat support)
* AI-generated timelines for long-lasting campaigns
* AI-based partnership/collaboration suggestions and contact-finding
* UX revamp for collaboration
* Option to add original content alongside AI-generated content in our interface | partial |
## Inspiration
This project was inspired by my love of walking. We all need more outdoor time, but people often feel like walking is pointless unless they have somewhere to go. I have fond memories of spending hours walking around just to play Pokemon Go, so I wanted to create something that would give people a reason to go somewhere new. I envision friends and family sending mystery locations to their loved ones with a secret message, picture, or video that will be revealed when they arrive. You could send them to a historical landmark, a beautiful park, or just like a neat rock you saw somewhere. The possibilities are endless!
## What it does
You want to go out for a walk, but where to? SparkWalk offers users their choice of exciting "mystery walks". Given a secret location, the app tells you which direction to go and roughly how long it will take. When you get close to your destination, the app welcomes you with a message. For now, SparkWalk has just a few preset messages and locations, but the ability for users to add their own and share them with others is coming soon.
## How we built it
SparkWalk was created using Expo for React Native. The map and location functionalities were implemented using the react-native-maps, expo-location, and geolib libraries.
## Challenges we ran into
Styling components for different devices is always tricky! Unfortunately, I didn't have time to ensure the styling works on every device, but it works well on at least one iOS and one Android device that I tested it on.
## Accomplishments that we're proud of
This is my first time using geolocation and integrating a map, so I'm proud that I was able to make it work.
## What we learned
I've learned a lot more about how to work with React Native, especially using state and effect hooks.
## What's next for SparkWalk
Next, I plan to add user authentication and the ability to add friends and send locations to each other. Users will be able to store messages for their friends that are tied to specific locations. I'll add a backend server and a database to host saved locations and messages. I also want to add reward cards for visiting locations that can be saved to the user's profile and reviewed later. Eventually, I'll publish the app so anyone can use it! | ## Inspiration
Walking is a sustainable and effective form of transit whose popularity is negatively impacted by perceived concerns about boredom and safety. People who are choosing between multiple forms of transit might not select walking due to these issues. Our goal was to create a solution that would make walking more enjoyable, encouraging people to follow a more sustainable lifestyle by providing new benefits to the walking experience.
## What it does
Our web app, WalkWithMe, helps connect users to other walkers nearby based on times and routes, allowing them to walk together to their intended destinations. It approximately finds the path that maximizes time spent walking together while also minimizing total travel distance for the people involved. People can create accounts that allows them to become verified users in the network, introducing a social aspect to walking that makes it fun and productive. Additionally, this reduces safety concerns as these are often less pronounced in groups of people versus individuals while walking; this is especially true at night.
## How we built it
We used react.js for the frontend, Sonr and Golang for the backend. We hosted our website using Firebase. Our map data was generated from the Google Maps API.
## Challenges we ran into
Our frontend team had to completely learn react.js for the project. We also did not have prior experience with the Sonr and Google Maps API. We needed to figure out how to integrate Sonr into the backend with Golang and Google Maps API to find the path.
## Accomplishments that we're proud of
We are proud of developing and implementing a heuristic algorithm that finds a reasonable path to walk to the destination and for creating an effective backend and frontend setup despite just learning react and Sonr in the hackathon. We also overcame many bugs relating to Google's geocoding API.
## What we learned
We learned react.js to display our interactive website efficiently, how to integrate Sonr into our project to store profile and location data, and how to use Google Maps to achieve our goals with our program.
## What's next for WalkWithMe
We have many ideas for how we can take the next step with our app. We want to add a tiered verification system that grants you credit for completing walks without issues. The higher you are in the rating system, the more often you will be recommended walks with smaller groups of people (as you are viewed as more trustworthy). We also want to improve the user interface of the app, making it more intuitive to use. We also want to expand on the social aspect of the app, allowing people to form walking groups with others and deepen connections with people they meet. We also want to add geolocation trackers so that users can see where their group members are, in case they don't walk at a similar speed toward the meet-up location. | ## Inspiration
Living in the big city, we're often conflicted between the desire to get more involved in our communities, with the effort to minimize the bombardment of information we encounter on a daily basis. NoteThisBoard aims to bring the user closer to a happy medium by allowing them to maximize their insights in a glance. This application enables the user to take a photo of a noticeboard filled with posters, and, after specifying their preferences, select the events that are predicted to be of highest relevance to them.
## What it does
Our application uses computer vision and natural language processing to filter any notice board information in delivering pertinent and relevant information to our users based on selected preferences. This mobile application lets users to first choose different categories that they are interested in knowing about and can then either take or upload photos which are processed using Google Cloud APIs. The labels generated from the APIs are compared with chosen user preferences to display only applicable postings.
## How we built it
The the mobile application is made in a React Native environment with a Firebase backend. The first screen collects the categories specified by the user and are written to Firebase once the user advances. Then, they are prompted to either upload or capture a photo of a notice board. The photo is processed using the Google Cloud Vision Text Detection to obtain blocks of text to be further labelled appropriately with the Google Natural Language Processing API. The categories this returns are compared to user preferences, and matches are returned to the user.
## Challenges we ran into
One of the earlier challenges encountered was a proper parsing of the fullTextAnnotation retrieved from Google Vision. We found that two posters who's text were aligned, despite being contrasting colours, were mistaken as being part of the same paragraph. The json object had many subfields which from the terminal took a while to make sense of in order to parse it properly.
We further encountered troubles retrieving data back from Firebase as we switch from the first to second screens in React Native, finding the proper method of first making the comparison of categories to labels prior to the final component being rendered. Finally, some discrepancies in loading these Google APIs in a React Native environment, as opposed to Python, limited access to certain technologies, such as ImageAnnotation.
## Accomplishments that we're proud of
We feel accomplished in having been able to use RESTful APIs with React Native for the first time. We kept energy high and incorporated two levels of intelligent processing of data, in addition to smoothly integrating the various environments, yielding a smooth experience for the user.
## What we learned
We were at most familiar with ReactJS- all other technologies were new experiences for us. Most notably were the opportunities to learn about how to use Google Cloud APIs and what it entails to develop a RESTful API. Integrating Firebase with React Native exposed the nuances between them as we passed user data between them. Non-relational database design was also a shift in perspective, and finally, deploying the app with a custom domain name taught us more about DNS protocols.
## What's next for notethisboard
Included in the fullTextAnnotation object returned by the Google Vision API were bounding boxes at various levels of granularity. The natural next step for us would be to enhance the performance and user experience of our application by annotating the images for the user manually, utilizing other Google Cloud API services to obtain background colour, enabling us to further distinguish posters on the notice board to return more reliable results. The app can also be extended to identifying logos and timings within a poster, again catering to the filters selected by the user. On another front, this app could be extended to preference-based information detection from a broader source of visual input. | partial |
## Inspiration
Imagine a world where the number of mass shootings in the U.S. per year don't align with the number of days. With the recent Thousand Oaks shooting, we wanted to make something that would accurately predict the probability that a place has a mass shooting given a zipcode and future date.
## What it does
When you type in a zipcode, the corresponding city is queried in the prediction results of our neural network in order to get a probability. This probability is scaled accordingly and represented as a red circle of varying size on our U.S. map. We also made a donation link that takes in credit card information and processes it.
## How we built it
We trained our neural network with datasets on gun violence in various cities. We did a ton of dataset cleaning in order to find just what we needed, and trained our network using scikit-learn. We also used the stdlib api in order to pass data around so that the input zipcode could be sent to the right place, and we also used the Stripe api to handle credit card donation transactions. We used d3.js and other external topological javascript libraries in order to create a map of the U.S. that could be decorated. We then put it all together with some javascript, HTML and CSS.
## Challenges we ran into
We had lots of challenges with this project. d3.js was hard to jump right into, as it is such a huge library that correlates data with visualization. Cleaning the data was challenging as well, because people tend not to think twice before throwing data into a big csv. Sending data around files without the usage of a server was challenging, and we managed to bypass that with the stdlib api.
## Accomplishments that we're proud of
A trained neural network that predicts the probability of a mass shooting given a zipcode. A beautiful topological map of the United States in d3. Integration of microservices through APIs we had never used before.
## What we learned
Doing new things is hard, but ultimately worthwhile!
## What's next for Ceasefire
We will be working on a better, real-time mapping of mass shootings data. We will also need to improve our neural network by tidying up our data more. | ## What inspired us to build it
Guns are now the leading cause of death among American children and teens, with 1 in every 10 gun deaths occurring in individuals aged 19 or younger. School shootings, in particular, have become a tragic epidemic in the U.S., underscoring the urgent need for enhanced safety measures. Our team united with a shared vision to leverage AI technology to improve security in American schools, helping to protect children and ensure their safety.
## What it does
Our product leverages advanced AI technology to enhance school safety by detecting potential threats in real-time. By streaming surveillance footage, our AI system can identify weapons, providing instant alerts to security personnel and administrators. In addition to visual monitoring, we integrate audio streaming to analyze changes in sentiment, such as raised voices or signs of distress. This dual approach—combining visual and auditory cues—enables rapid response to emerging threats.
## How we built it
We partnered with incredible sponsors—Deepgram, Hyperbolic, Groq, and Fetch.AI—to develop a comprehensive security solution that uses cutting-edge AI technologies. With their support, we were able to conduct fast AI inference, deploy an emergency contact agent, and create intelligent systems capable of tracking potential threats and key variables, all to ensure the safety of our communities.
For real-time data processing, we utilized Firebase and Convex to enable rapid write-back and retrieval of critical information. Additionally, we trained our weapon detection agent using Ultralytics YOLO v8 on the Roboflow platform, achieving an impressive ~90% accuracy. This high-performance detection system, combined with AI-driven analytics, provides a robust safety infrastructure capable of identifying and responding to threats in real time.
## Challenges we ran into
Streaming a real-time AI object detection model with both low latency and high accuracy was a significant challenge. Initially, we experimented with Flask and FastAPI for serving our model, followed by trying AWS and Docker to improve performance. However, after further optimization efforts, we ultimately integrated Roboflow.js directly in the browser using a Native SDK. This approach gave us a substantial advantage, allowing us to run the model efficiently within the client environment. As a result, we achieved the ability to track weapons quickly and accurately in real time, meeting the critical demands of our security solution.
## Accomplishments that we're proud of
We are incredibly proud of the features our product offers, providing a comprehensive and fully integrated security experience. Beyond detecting weapons and issuing instant alerts to law enforcement, faculty, and students through AI-powered agents, we also implemented extensive sentiment analysis. This enables us to detect emotional escalations that may signal potential threats. All of this is supported by real-time security data displays, ensuring that key decision-makers are always informed with up-to-the-minute information. Our system seamlessly brings together cutting-edge AI and real-time data processing to deliver a robust, proactive security solution.
## What we learned
We learned that the night is darkest right before the dawn... and that we need to persevere and be steadfast as a team to see our vision come to fruition.
## What's next for Watchdog
We want to get incorporated in the American school system! | ## Inspiration:
The app was born from the need to respond to global crises like the ongoing wars in Palestine, Ukraine, and Myanmar. Which have made the importance of real-time, location-based threat awareness more critical than ever.
While these conflicts are often headline news, people living far from the conflict zones may lack the immediate understanding of how quickly conditions change on the ground. Our inspiration came from a desire to bridge that gap by leveraging technology to provide a solution that could offer real-time updates about dangerous areas, not just in warzones but in urban centers and conflict-prone regions around the world.
## How we built it:
Our app was developed with scalability and responsiveness in mind, given the complexity of gathering real-time data from diverse sources. For the backend, we used Python to run a Reflex web app, which hosts our API endpoints and powers the data pipeline. Reflex was chosen for its ability to handle asynchronous tasks, crucial for integrating with a MongoDB database that stores a large volume of data gathered from news articles. This architecture allows us to scrape, store, and process incoming data efficiently without compromising performance.
On the frontend, we leveraged React Native to ensure cross-platform compatibility, offering users a seamless experience on both iOS and Android devices. React Native's flexibility allowed us to build a responsive interface where users can interact with the heat map, see threat levels, and access detailed news summaries all within the same app.
We also integrated Meta LLaMA, a hyperbolic transformer model, which processes the textual data we scrape from news articles. The model is designed to analyze and assess the threat level of each news piece, outputting both the geographical coordinates and a risk assessment score. This was a particularly complex part of the development process, as fine-tuning the model to provide reliable, context-aware predictions required significant iteration and testing.
## Challenges we faced:
The most pressing challenge was data scraping, particularly the obstacles put in place by websites that actively work to prevent scraping. Many news websites have anti-scraping measures in place, making it difficult to gather comprehensive data. To address this, we had to get creative with our scraping methods, using dynamic techniques that could mimic human-like browsing to avoid detection.
Another major challenge was iOS integration, particularly in working with location services. iOS tends to have stricter privacy controls, which required us to implement complex authentication mechanisms and permissions handling. Additionally, deploying the backend infrastructure presented challenges in ensuring that it scaled smoothly under heavy data loads, all while maintaining low-latency responses for real-time updates.
We also faced hurdles in speech-to-text functionality, as we aim to make the app more accessible by allowing users to interact with it via voice commands. Integrating accurate, multi-language speech recognition that can handle diverse accents and conditions in real-world environments is a work in progress.
## Accomplishments we're proud of:
Despite these challenges, we successfully built a dynamic heat map that allows users to visually grasp the intensity of threats in different geographical areas. The Meta LLaMA model was another major achievement, enabling us to not only scrape news articles but also analyze and assign a threat level in real time. This means that a user can look at the app, see a particular area highlighted as high risk, and read news reports with data-backed assessments. We've created something that helps people stay informed about their environment in a practical, visually intuitive way.
Moreover, building a fully functional app with both backend and frontend integration, while using cutting-edge machine learning models for threat assessment, is something we're particularly proud of. The app is capable of processing large datasets and serving actionable insights with minimal delays, which is no small feat given the technical complexity involved.
## What we learned:
One of the biggest takeaways from this project was the importance of starting with the fundamentals and building a solid foundation before adding complex features. In the early stages, we focused on getting the core infrastructure right—ensuring the scraping, data pipeline, and database were robust enough to handle scaling before moving on to model integration and feature expansion. This allowed us to pivot more easily when challenges arose, such as working with real-time data or adjusting to API limitations.
We also learned a great deal about the nuances of natural language processing and machine learning, especially when it comes to applying those technologies to dynamic, unstructured news data. It’s one thing to build an AI model that processes text in a controlled environment, but real-world data is messy, often incomplete, and constantly evolving. Understanding how to fine-tune models like Meta LLaMA to give reliable assessments on current events was both challenging and incredibly rewarding.
## What’s next:
Looking ahead, we plan to expand the app’s capabilities further by integrating speech-to-text functionality. This will make the app more accessible, allowing users to dictate queries or receive voice-based updates on emerging threats without having to type or navigate through screens. This feature will be particularly valuable for users who may be on the move or in situations where typing isn’t practical.
We’re also focusing on improving the accuracy and scope of our web scrapers, aiming to gather more diverse data from a broader range of news sources while adhering to ethical guidelines. This includes exploring ways to improve scraping from difficult sites and even partnering with news outlets to gain access to structured data.
Beyond these immediate goals, we see potential in scaling the app to include predictive analytics, using historical data to forecast potential danger zones before they escalate. This would help users not only react to current events but also plan ahead based on emerging patterns in conflict areas. Another exciting direction is user-driven content, allowing people to report and share information about dangerous areas directly through the app, further enriching the data landscape. | partial |
## Inspiration
this is a project which is given to me by an organization and my collegues inspierd me to do this project
## What it does
It can remind what we have to do in future and also set time when it is to be done
## How we built it
I built it using command time utility in python programming
## Challenges we ran into
Many challanges such as storing data in file and many bugs ae come in between middle of this program
## Accomplishments that we're proud of
I am proud that i make this real time project which reminds a person todo his tasks
## What we learned
I leraned more about command line utility of python
## What's next for Todo list
Next I am doing various projects such as Virtual assistant and game development | ## Inspiration
The inspiration for T-Error came from the common frustration that tech leads and developers face when debugging problems. Errors can occur frequently, but understanding their patterns and seeing what is really holding your team up can be tough. We wanted to create something that captures these errors in real time, visualizes them, and lets you write and seamlessly integrate documentation making it easier for teams to build faster.
## What it does
T-Error is a terminal error-monitoring tool that captures and logs errors as developers run commands. It aggregates error data in real-time from various client terminals and provides a frontend dashboard to visualize error frequencies and insights, as well as adding the option to seamlessly add documentation. A feature we are really excited about is the ability to automatically run the commands in the documentation without needing to leave the terminal.
## How we built it
We built T-Error using:
Custom shell: we implemented a custom shell in c++ to capture stderr and seamlessly interface with our backend.
Backend: Powered by Node.js, the server collects, processes, and stores error data in mongoDB.
Frontend: Developed with React.js, the dashboard visualizes error trends with interactive charts, graphs, and logs, as well as an embedded markdown editor:).
## Challenges we ran into
One of the main challenges was ensuring the terminal wrappers were lightweight and didn’t disrupt normal command execution while effectively capturing errors. We spent hours trying to get bash scripts to do what we wanted, until we gave up and tried implementing a shell which worked much better. Additionally, coming up with the UX for how to best deliver existing documentation was a challenge but after some attempts, we arrived at a solution we were happy with.
## Accomplishments that we're proud of
We’re proud of building a fully functional MVP that successfully captures and visualizes error data in real-time. Our terminal wrappers integrate seamlessly with existing workflows, and the error analysis and automatic documentation execution has the potential to significantly speed up development.
## What we learned
Throughout this project, we learned about the complexities of error logging across multiple environments and how to efficiently process large volumes of real-time data. We also gained experience with the integration of frontend and backend technologies, as well as diving into the lower layers of the tech stack and smoothly chaining everything together.
## What's next for T-Error
Going forward, there are a few features that we want to implement. First is error reproduction - we could potentially gain more context about the error from the file system and previous commands and use that context to help replicate errors automatically. We also wanted to automate the process of solving these errors - as helpful as it is to have engineers write documentation, there is a reason there are gaps. This could be done using an intelligent agent for simple tasks, and more complex systems for others. We also want to be able to accommodate better to teams, allowing them to have groups where internal errors are tracked. | ## Inspiration
The worldwide phenomenon that is Wordle brings together users from all over the world to a play a once-a-day game. Loosely inspired by this successful tale, we present to you Bubble:
Young people from around the world have felt the repercussions on our mental well-being due to the never-ending restrictions imposed due to Covid-19. In the meantime, while we have been spending more time online, we have started to feel more disconnected from the real world. Journaling every day has proven to provide many mental health benefits, keeping people grounded and encouraging the practice of mindfulness and gratitude. Bubble is our solution to make self-reflection more accessible by encouraging members to get creative with daily journaling and reflection, as well as providing a moderated, anonymous bulletin board for people from all around the world to read each other's unique stories to a common worldwide prompt.
Also loosely inspired by "Humans of New York" and "Amours Solitaires" submissions; the NYT Crossword app's Daily Mini; and the apps that send out daily Bible verses/motivational quotes to subscribers.
## What it does
Every day a journaling prompt is sent to our subscribers via SMS. The text will direct users to our website, and they will then be able to reflect and flesh out their thoughts before submitting an anonymous response. After submission, the responses will be displayed for members to browse and enjoy. Using our auto-tagging system, each response will be parsed and tagged for its topic. This allows for better categorization and organization of responses.
**Ideal Goal**: Our idea was to create an everyday activity to encourage young people to take a moment out of their day to reflect. Our hope was to accomplish this by using Twilio to send out a daily prompt to each subscriber. It would be a simple yet thoughtful prompt that would ideally allow members to take a moment to think in an otherwise go-go-go world. Members would be able to respond to these prompts and then their answers would be anonymously published to our website for the purposes of inspiring others by sharing stories of gratitude, motivation, and other #wholesome themes.
**Actual Accomplished Goal**: As it so often does, not everything went our way. We couldn't get many things to work and thus one of our main features was out of the picture. From there we ran into further problems understanding and implementing full-stack concepts which were foreign to all of us. In the end we accomplished three interesting programs which each are pieces of the puzzle, but undoubtedly there is much to do before a finished project is completed. We have a website that allows people to publish their story (but with no data base knowledge it just kind of disappears), a program that scours Reddit for thought provoking statements, and we used AI to classify words to give inspiration for any given prompt.
## How we built it
Using a Reddit API and web-scraping techniques we collect writing prompts from the r/WritingPrompts subreddit. The top prompt from this subreddit is sent daily to subscribers via SMS through Twilio's API. Users are then directed to our website which was built using Flask and Twilio's API. Finally, our tagging system is built using Spacy and NLTK libraries. This program analyzes responses to the prompts we got from reddit and returns commonly seen and powerful keywords. We used Figma for the design aspects of the project.
## Challenges we ran into
Integrating all the pieces of our project into one cohesive unit proved to be very challenging. Our original vision was to collect responses via SMS using the Twilio API; after hours of coding, we realized this was not in our capabilities. Our final demo is split into various aspects that currently operate independently however in the future we hope to integrate these components into one unit.
## Accomplishments that we're proud of
We are proud of our persistence in debugging the various obstacles and adversities that came up throughout our project journey. This was our team's first hackathon, so it was difficult to get started on an idea as we were super clueless in the beginning, but we are incredibly happy with how far we have come.
Each of us learned new concepts and put ourselves out of our comfort zones in the pursuit of new skills. While we may not have created a groundbreaking project, ultimately we had fun, we got frustrated, we googled, we talked, we laughed, and in the end, we all become better computer scientists.
## What we learned
Asides from learning that Jonah's Redbull limit is 4 cans (the most important finding from this weekend, clearly), we learned what an API was, how to use one, the basics of full-stack development. Our team came into this project with zero experience working with front-end development and discovered how particularly challenging it is to connect the backend and frontend. We were exposed to new technologies such as Twilio and Glitch, which allowed us to add functionality to our project that we would have otherwise not been able to. We also learned a ton from the workshops and are personally very excited to code and launch our own websites! After getting sleep of course. #shamelessplug
## What's next for Bubble
We hope that Bubble will allow for users from all around the world to connect through words and to realize that we are all probably more similar to one another than we would think. In the future, we envision creating sub-forums (or sub-bubbles, if you will) for various communities and institutions and to have Bubble serve as a platform for these organizations to host digital bulletin boards for their employees/students/members - similar to monday.com, slack, or asana, but for more wholesome purposes. | partial |
## Inspiration
We wanted to find a way to encourage fewer people to drink and drive so we decided to create a free service
## What it does
This service lets people volunteer their time to give people rides. In return those people earn tokens. You would redeem that token for a ride.
## How I built it
We use javascript/html/css for the front-end, and java, spring boot, and the rest api for the backend
## Challenges I ran into
connecting the front-end and back-end
## Accomplishments that I'm proud of
The design we came up with
## What I learned
how hard it is to put everyone's work together
## What's next for Bon Voyage
connect the front end to the back end | ## Inspiration
Plan your dream vacation with ease using our one-stop travel planner website. Our travel planner website makes planning your next trip easy and stress-free.
## What it does
The user enters their location and their desired destination. We help them plan their perfect trip by providing them with the top-rated locations to visit with a map and a custom 3-Day Itinerary.
## How we built it
This full-stack application was built using HTML and bootstrap.css for the front end and using flask for the backend. we used 3 APIs in this project, google maps, yelp and gpt-3. we started by separating the tasks and API calls to separate webpages then at the end brought them all together into one.
## Challenges we ran into
POST and GET HTTP requests were the largest challenges for this challenge. Separately, frontend and backend tasks can be completed rather easily but combining them and having both sides exchange information was significantly harder
## Accomplishments that we're proud of
Successfully getting an implementation of google maps into a webpage with a working route system including flights, even though it is not officially supported by google maps API. successfully parsing through yelp reviews to return only high-rated tourist attractions to the relevant areas. getting all 3 of our APIs to work together to solve tasks
## What we learned
We learned about how frontend and backend technologies interact and how different APIs interact
## What's next for Bon Voyage?
After all the work, we were not able to solve one of our problems in time even after we were able to access the data for it so our next target would be to complete the task and also work to improve the UI/UX. | ## Inspiration:
Our inspiration for this app comes from the critical need to improve road safety and assess driver competence, especially under various road conditions. The alarming statistics on road accidents and fatalities, including those caused by distracted driving and poor road conditions, highlight the urgency of addressing this issue. We were inspired to create a solution that leverages technology to enhance driver competence and reduce accidents.
## What it does
Our app has a frontend, which connects to a GPS signal, which tracks the acceleration of a given car, as well as its speed. Such a React frontend also encompasses a Map, as well as a record feature, which, through the implementation of a LLM by Cohere, is capable of detecting alerting police, in the event of any speech that may be violent, or hateful, given road conditions.
On the backend, we have numerous algorithms and computer vision, that were fine-tuned upon YOLOv5 and YOLOv8. These models take in an image through a camera feed, surrounding cars, the color of the surrounding traffic lights, and the size of the car plates in front of the drivers.
By detecting car plates, we are able to infer the acceleration of a car (based on the change in size of the car plates), and are able to asses the driver's habits. By checking for red lights, correlated with the GPS data, we are able to determine a driver's reaction time, and can give a rating for a driver's capacities.
Finally, an eye-tracking model is able to determine a driver's concentration, and focus on the road.
All this paired with its interactive mobile app makes our app the ultimate replacement for any classic dashcam, and protects the driver from the road's hazards. | losing |
## Inspiration
Living in an era of rapid technological advancement, we saw the potential for AI to bring significant improvements to healthcare accessibility and efficiency. The idea for HealThrive AI was born out of our desire to provide an easy-to-use health tool that empowers individuals to take control of their health, particularly in regions where health facilities might not be as readily available or for those living with constant health worries.
## What it does
HealThrive AI operates as a user's personal health assistant right in their pocket. By inputting their symptoms, they receive advice and insights about their health condition based on cutting-edge AI technologies. Furthermore, HealThrive AI adjusts its recommendations for medication reminders, diet observations, and much more, offering health management that is both personalized and proactive.
## How we built it
We sought a two-phased approach for developing HealThrive AI. For the backend, we chose Django, which is a powerful and flexible Python framework that allowed us to handle and process large volumes of data safely and efficiently. The frontend was built in React, allowing a seamless, user-friendly experience due to its ability to build UI components efficiently. But the true magic behind the app lies within the integration of OpenAI's GPT-3 API, providing the AI capabilities that drive health advice.
## Challenges we ran into
The biggest challenge we faced was implementing the OpenAI's GPT-3 API and ensuring its precise functioning in providing health advice. Accurate medical data interpretation and response generation is a critical factor, and getting it right was no small feat. We also faced challenges in handling the vast, diverse, health-related inputs for smooth and efficient machine learning.
## Accomplishments that we're proud of
Our greatest accomplishment was creating an app that has potential to revolutionize the way people manage their health. Designing a user-friendly interface with complex AI integration running smoothly in the backend is something we take great pride in. The effective incorporation of GPT-3 and building a model that provides reliable health advice are noteworthy accomplishments.
## What we learned
Apart from intensifying our technical skills, we also learned the importance of intuitive design and user experience in healthcare technology. We learned how to integrate advanced machine learning models effectively and also experienced the challenges and potential solutions in handling diverse medical data.
## What's next for HealThrive AI
The future of HealThrive AI is filled with exciting opportunities. We are looking to collaborate with healthcare experts to enhance the accuracy of the advice the app provides, as this consultation can improve our AI model. Another ambitious step would be integrating it with wearable technology for real-time monitoring, prediction, and advice to users on a more comprehensive scale. | ## Inspiration
We've all left a doctor's office feeling more confused than when we arrived. This common experience highlights a critical issue: over 80% of Americans say access to their complete health records is crucial, yet 63% lack their medical history and vaccination records since birth. Recognizing this gap, we developed our app to empower patients with real-time transcriptions of doctor visits, easy access to health records, and instant answers from our AI doctor avatar. Our goal is to ensure EVERYONE has the tools to manage their health confidently and effectively.
## What it does
Our app provides real-time transcription of doctor visits, easy access to personal health records, and an AI doctor for instant follow-up questions, empowering patients to manage their health effectively.
## How we built it
We used Node.js, Next.js, webRTC, React, Figma, Spline, Firebase, Gemini, Deepgram.
## Challenges we ran into
One of the primary challenges we faced was navigating the extensive documentation associated with new technologies. Learning to implement these tools effectively required us to read closely and understand how to integrate them in unique ways to ensure seamless functionality within our website. Balancing these complexities while maintaining a cohesive user experience tested our problem-solving skills and adaptability. Along the way, we struggled with Git and debugging.
## Accomplishments that we're proud of
Our proudest achievement is developing the AI avatar, as there was very little documentation available on how to build it. This project required us to navigate through various coding languages and integrate the demo effectively, which presented significant challenges. Overcoming these obstacles not only showcased our technical skills but also demonstrated our determination and creativity in bringing a unique feature to life within our application.
## What we learned
We learned the importance of breaking problems down into smaller, manageable pieces to construct something big and impactful. This approach not only made complex challenges more approachable but also fostered collaboration and innovation within our team. By focusing on individual components, we were able to create a cohesive and effective solution that truly enhances patient care. Also, learned a valuable lesson on the importance of sleep!
## What's next for MedicAI
With the AI medical industry projected to exceed $188 billion, we plan to scale our website to accommodate a growing number of users. Our next steps include partnering with hospitals to enhance patient access to our services, ensuring that individuals can seamlessly utilize our platform during their healthcare journey. By expanding our reach, we aim to empower more patients with the tools they need to manage their health effectively. | ## Inspiration
As a patient in the United States you do not know what costs you are facing when you receive treatment at a hospital or if your insurance plan covers the expenses. Patients are faced with unexpected bills and left with expensive copayments. In some instances patients would pay less if they cover the expenses out of pocket instead of using their insurance plan.
## What it does
Healthiator provides patients with a comprehensive overview of medical procedures that they will need to undergo for their health condition and sums up the total costs of that treatment depending on which hospital they go-to, and if they pay the treatment out-of-pocket or through their insurance.
This allows patients to choose the most cost-effective treatment and understand the medical expenses they are facing. A second feature healthiator provides is that once patients receive their actual hospital bill they can claim inaccuracies. Healthiator helps patients with billing disputes by leveraging AI to handle the process of negotiating fair pricing.
## How we built it
We used a combination of Together.AI and Fetch.AI. We have several smart agents running in Fetch.AI each responsible for one of the features. For instance, we get the online and instant data from the hospitals (publicly available under the Good Faith act/law) about the prices and cash discounts using one agent and then use together.ai's API to integrate those information in the negotiation part.
## Ethics
The reason is that although our end purpose is to help people get medical treatment by reducing the fear of surprise bills and actually making healthcare more affordable, we are aware that any wrong suggestions or otherwise violations of the user's privacy have significant consequences. Giving the user as much information as possible while keeping away from making clinical suggestions and false/hallucinated information was the most challenging part in our work.
## Challenges we ran into
Finding actionable data from the hospitals was one of the most challenging parts as each hospital has their own format and assumptions and it was not straightforward at all how to integrate them all into a single database. Another challenge was making various APIs and third parties work together in time.
## Accomplishments that we're proud of
Solving a relevant social issue. Everyone we talked to has experienced the problem of not knowing the costs they're facing for different procedures at hospitals and if their insurance covers it. While it is an anxious process for everyone, this fact might prevent and delay a number of people from going to hospitals and getting the care that they urgently need. This might result in health conditions that could have had a better outcome if treated earlier.
## What we learned
How to work with convex fetch.api and together.api.
## What's next for Healthiator
As a next step, we want to set-up a database and take the medical costs directly from the files published by hospitals. | losing |
## Inspiration
While we were thinking about the sustainability track, we realized that one of the biggest challenges faced by humanity is carbon emissions, global warming and climate change.
According to Dr.Fatih Birol, IEA Executive Director -
*"Global carbon emissions are set to jump by 1.5 billion tonnes this year. This is a dire warning that the economic recovery from the Covid crisis is currently anything but sustainable for our climate."*
With this concern in mind we decided to work on a model which could possibly be a small compact carbon capturing system to reduce the carbon footprint around the world.
## What it does
The system is designed to capture CO2 directly from the atmosphere using microalgae as our biofilter.
## How we built it
Our plan was to first develop a design that could house the microalgae. We designed a chamber in Fusion 360 which we later 3D printed to house the microalgae. The air from the surroundings is directed into the algal chamber using an aquarium aerator. The pumped in air moves into the algal chamber through an air stone bubble diffuser which allows the air to break into smaller bubbles. These smaller air bubbles make the CO2 sequestration easier by giving the microalgae more time to act upon it. We have made a spiral design inside the chamber so that the bubbles travel upward through the chamber in a spiral fashion, giving the microalgae even more time to act upon it. This continuous process in due course would lead to capturing of CO2 and production of oxygen.
## Challenges we ran into
3D printing the parts of the chamber within the specified time.
Getting our hands on enough micro algae to fill up the entire system in its optimal growth period (log phase) for the best results.
Making the chamber leak proof.
## Accomplishments that we're proud of
The hardware design that we were able to design and build over the stipulated time.
Develop the system which could actually bring down CO2 levels by utilizing the unique side of microalgae.
## What we learned
We came across a lot of research papers implicating the best use of microalgae in its role to capture CO2.
Time management: Learnt to design and develop a system from scratch in a short period.
## What's next for Aria
We plan to conduct more research using microalgae and enhance the design of the existing system we built so that we could increase the carbon capture efficiency of the system.
Keeping in mind the deteriorating indoor air quality, we also plan to integrate it with the inorganic air filters so that it could help in improving the overall indoor air quality.
We also plan to conduct research on finding out how much area does one unit of Aria covers | ## Inspiration
As college students, we didn't know anything, so we thought about how we can change that. One way was by being smarter about the way we take care of our unused items. We all felt that our unused items could be used in better ways through sharing with other students on campus. All of us shared our items on campus with our friends but we felt that there could be better ways to do this. However, we were truly inspired after one of our team members, and close friend, Harish, an Ecological Biology major, informed us about the sheer magnitude of trash and pollution in the oceans and the surrounding environments. Also, as the National Ocean Science Bowl Champion, Harish truly was able to educate the rest of the team on how areas such as the Great Pacific Garbage Patch affect the wildlife and oceanic ecosystems, and the effects we face on a daily basis from this. With our passions for technology, we wanted to work on an impactful project that caters to a true need for sharing that many of us have while focusing on maintaining sustainability.
## What it does
The application essentially works to allow users to list various products that they want to share with the community and allows users to request items. If one user sees a request they want to provide a tool for or an offer they find appealing, they’ll start a chat with the user through the app to request the tool. Furthermore, the app sorts and filters by location to make it convenient for users. Also, by allowing for community building through the chat messaging, we want to use
## How we built it
We first, focused on wireframing and coming up with ideas. We utilized brainstorming sessions to come up with unique ideas and then split our team based on our different skill sets. Our front-end team worked on coming up with wireframes and creating designs using Figma. Our backend team worked on a whiteboard, coming up with the system design of our application server, and together the front-end and back-end teams worked on coming up with the schemas for the database.
We utilized the MERN technical stack in order to build this. Our front-end uses ReactJS in order to build the web app, our back-end utilizes ExpressJS and NodeJS, while our database utilizes MongoDB.
We also took plenty of advice and notes, not only from mentors throughout the competition, but also our fellow hackers. We really went around trying to ask for others’ advice on our web app and our final product to truly flush out the best product that we could. We had a customer-centric mindset and approach throughout the full creation process, and we really wanted to look and make sure that what we are building has a true need and is truly wanted by the people. Taking advice from these various sources helped us frame our product and come up with features.
## Challenges we ran into
Integration challenges were some of the toughest for us. Making sure that the backend and frontend can communicate well was really tough, so what we did to minimize the difficulties. We designed the schemas for our databases and worked well with each other to make sure that we were all on the same page for our schemas. Thus, working together really helped to make sure that we were making sure to be truly efficient.
## Accomplishments that we're proud of
We’re really proud of our user interface of the product. We spent quite a lot of time working on the design (through Figma) before creating it in React, so we really wanted to make sure that the product that we are showing is visually appealing.
Furthermore, our backend is also something we are extremely proud of. Our backend system has many unconventional design choices (like for example passing common ids throughout the systems) in order to avoid more costly backend operations. Overall, latency and cost and ease of use for our frontend team was a big consideration when designing the backend system
## What we learned
We learned new technical skills and new soft skills. Overall in our technical skills, our team became much stronger with using the MERN frameworks. Our front-end team learned so many new skills and components through React and our back-end team learned so much about Express. Overall, we also learned quite a lot about working as a team and integrating the front end with the back-end, improving our software engineering skills
The soft skills that we learned about are how we should be presenting a product idea and product implementation. We worked quite a lot on our video and our final presentation to the judges and after speaking with hackers and mentors alike, we were able to use the collective wisdom that we gained in order to really feel that we created a video that shows truly our interest in designing important products with true social impact. Overall, we felt that we were able to convey our passion for building social impact and sustainability products.
## What's next for SustainaSwap
We’re looking to deploy the app in local communities as we’re at the point of deployment currently. We know there exists a clear demand for this in college towns, so we’ll first be starting off at our local campus of Philadelphia. Also, after speaking with many Harvard and MIT students on campus, we feel that Cambridge will also benefit, so we will shortly launch in the Boston/Cambridge area.
We will be looking to expand to other college towns and use this to help to work on the scalability of the product. We ideally, also want to push for the ideas of sustainability, so we would want to potentially use the platform (if it grows large enough) to host fundraisers and fundraising activities to give back in order to fight climate change.
We essentially want to expand city by city, community by community, because this app also focuses quite a lot on community and we want to build a community-centric platform. We want this platform to just build tight-knit communities within cities that can connect people with their neighbors while also promoting sustainability. | ## Inspiration
In a world grappling with the escalating consequences of climate change, our inspiration stemmed from the pressing need to understand, visualize, and mitigate the greenhouse gas emissions suffocating our planet. Witnessing unprecedented climate events and understanding their profound implications for future generations fueled our drive to develop a tool that can empower users to forge a greener, sustainable tomorrow.
## What it does
"Breathe Easy" leverages cutting-edge technology to offer an interactive and dynamic model of greenhouse gas emissions. Through our sophisticated yet user-friendly dashboard, individuals, organizations, and governments can visualize current emission scenarios, predict future trajectories based on various parameters, and strategize potent emission reduction initiatives. In essence, it turns data into actionable insights, helping to foster informed decisions that could shape a cleaner future.
## How we built it
We acquired data from the EDGAR (Emissions Database for Global Atmospheric Research) Community GHG Database, citation below. We used Streamlit to display the data on a frontend dashboard with Python as the backend for the models we made.
## Challenges we ran into
During the development process, we encountered hurdles such as needing to clean data for inconsistencies and learning how to display the data on a dashboard. The intricate process of correlating vast arrays of data to craft accurate predictive models posed a significant challenge. Despite these challenges, our team persevered, learning and adapting at every turn to bring our vision to life.
## Accomplishments that we're proud of
We are immensely proud of the predictive modeling algorithm that stands as the beating heart of our platform, offering unprecedented accuracy in forecasting emission trends. Additionally, we successfully created a tool that democratizes access to complex data, breaking down barriers and fostering a wider understanding and engagement with climate change issues. Seeing our concept evolve from an idea to a functioning tool that has the potential to impact global strategies towards greenhouse gas reductions has been incredibly rewarding.
## What we learned
Through the arduous journey of building "Breathe Easy," our team acquired a deep understanding of the nuances involved in greenhouse gas emission data and predictive modeling. We learned the value of cross-functional collaboration, as experts in various fields came together to tackle this multifaceted challenge. Moreover, we honed our skills in Python data modeling, setting a solid foundation for future endeavors in tech-driven environmental solutions.
## What's next for Breathe Easy: Shaping Tomorrow, One Model at a Time
As we look to the future, we envision expanding "Breathe Easy" to incorporate more data sources and functionalities, enhancing its predictive capabilities and offering users even more in-depth insights. We aim to increase education about greenhouse gas emissions and progress each country has made with them. Ultimately, we see "Breathe Easy" becoming a catalyst for change, empowering individuals and organizations around the world to take informed, decisive action towards a sustainable future.
## Data citations:
EDGAR (Emissions Database for Global Atmospheric Research) Community GHG Database (a collaboration between the European Commission, Joint Research Centre (JRC), the International Energy Agency (IEA), and comprising IEA-EDGAR CO2, EDGAR CH4, EDGAR N2O, EDGAR F-GASES version 7.0, (2022) European Commission | partial |
## Inspiration
Insurance Companies spend millions of dollars on carrying marketing campaigns to attract customers and sell their policies.These marketing campaigns involve giving people promotional offers, reaching out to them via mass marketing like email, flyers etc., these marketing campaigns usually last for few months to almost years and the results of such huge campaigns are inedible when raw.
## What it does
Intellisurance visualizes such campaign data and allows the insurance companies to understand and digest such data. These visualizations help the company decide whom to target next, how to grow their business? and what kind of campaigns or best media practices to reach to a majority of their potential customer base.
## How we built it
We wanted to give the insurance companies a clear overview of how their past marketing campaigns were, the pros , the cons, the ways to target a more specific group, the best practices etc. We also give information of how they gained customers over the period. Most key factor being the geographic location, we chose to display it over a map.
## Challenges we ran into
When we are dealing with the insurance campaign data we are dealing with millions of rows, compressing that data into usable information.
## Accomplishments that we're proud of
This part was the most challenging part where we pulled really necessary data and had algorithms to help users experience almost no lag while using the application. | ## Inspiration
I was interested in exploring the health datasets given by John Snow Labs in order to give users the ability to explore meaningful datasets. The datasets selected were Vaccination Data Immunization Kindergarten Students 2011 to 2014, Mammography Data from Breast Cancer Surveillance Consortium, 2014 State Occupational Employment and Wage Estimate dataset from the Bureau of Labor Statistics, and Mental Health Data from the CDC and Behavioral Risk Factor Surveillance System.
Vaccinations are crucial to ending health diseases as well as deter mortality and morbidity rates and has the potential to save future generations from serious disease. By visualization the dataset, users are able to better understand the current state of vaccinations and help to create policies to improve struggling states. Mammography is equally important in preventing health risks. Mental health is an important fact in determining the well-being of a state. Similarly, the visualization allows users to better understand correlations between preventative steps and cancerous outcomes.
## What it does
The data visualization allows users to observe possible impacts of preventative steps on breast cancer formation and the current state of immunizations for kindergarten students and mental health in the US. Using this data, we can analyze specific state and national trends and look at interesting relationships they may have on one another.
## How I built it
The web application's backend used node and express. The data visualizations and data processing used d3. Specific d3 packages allowed to map and spatial visualizations using network/node analysis. D3 allowed for interactivity between the user and visualization, which allows for more sophisticated exploration of the datasets.
## Challenges I ran into
Searching through the John Snow Labs datasets required a lot of time. Further processing and finding the best way to visualize the data took much of my time as some datasets included over 40,000 entries! Working d3 also took awhile to understand.
## Accomplishments that I'm proud of
In the end, I created a working prototype that visualizes significant data that may help a user understand a complex dataset. I learned a lot more about d3 and building effective data visualizations in a very constrained amount of time.
## What I learned
I learned a lot more about d3 and building effective data visualizations in a very constrained amount of time.
## What's next for Finder
I hope to add more interaction for users, such as allowing them to upload their own dataset to explore their data. | ## Inspiration
After witnessing countless victims of home disasters like robberies and hurricanes, we decided, there must be a way to preemptively check against such events. It's far too easy to wait until something bad happens to your home before doing anything to prevent it from happening again. That's how we came up with a way to incentivize people taking the steps to protect their homes against likely threats.
## What it does
Insura revolutionizes the ways to keep your home safe. Based on your location and historical data of items that typically fall under home insurance (burglary, flooding, etc.), Insura will suggest items for fixes around the house, calculating potential premium savings if done properly. With the click of a button, you can see what needs to be done around the house to collect big savings and protect your home from future damage. Insura also connects with a user's insurance provider to allow for users to send emails to insurance providers detailing the work that was done, backed by pictures of the work. Based on this insurance providers can charge premium prices as they see fit.
To incentivize taking active steps to make changes, Insura "gamified" home repair, by allowing people to set goals for task completion, and letting you compete with friends based on the savings they are achieving. The return on investment is therefore crowdsourced; by seeing what your friends are saving on certain fixes around the house, you can determine whether the fix is worth doing.
## How I built it
To build the application we mainly used swift to build the UI and logic for displaying tasks and goals. We also created a server using Node to handle the mail to insurance providers. We used to heroku to deploy the application.
## Challenges I ran into
We had a hard time finding free APIs for national crime and disaster data and integrating them into the application. In addition, we had a tough time authenticating users to send emails from their accounts.
## Accomplishments that I'm proud of
We are really proud of the way the UI looks. We took the time to design everything beforehand, and the outcome was great.
## What I learned
We learned a lot about iOS development, how to integrate the backend and frontend on the iOS application, and more about the complicated world of insurance.
## What's next for Insura
Next we plan on introducing heatmaps and map views to make the full use of our API and so that users can see what is going on locally. | partial |
## Inspiration
We wanted to build something that could help people who deal with anxiety and panic attacks. The generous sponsors at PennApps also offered us a lot of APIs, and we wanted to make the best use of them as well.
## What it does
The user can open the app and create a personal account, as well as log emergency contacts for them to call or text in an emergency (ex: panic attack). The user can track the amount of panic attacks they have as well. Finally, should the wish, the user can send their information to a medical professional by sending them a confidentiality document to sign.
## How we built it
The iOS app was built on Swift, using the DocuSign API. The website was made using HTML, CSS, and Javascript.
## Challenges we ran into
Most of the team mates were attending their first hackathon, and it was their first exposure to a lot of these new technologies (ex: it was Lisa's first time programming in Swift!).
## Accomplishments that we're proud of
Creating both an app to use and a website to market the app. Everyone used their front-end and back-end skills to make both platforms a reality!
## What we learned
Each of us learned something new about a language we didn’t have experience in, like Swift. Since we are all fairly new to hackathons, we learned a lot about working together in a team to create a new project.
## What's next for Still
Incorporating more security with the DocuSign API. Track one's medication more accurately using the CVS API and possibly send notifications to take medication. | ## Inspiration
After contemplating ideas for days on end, we finally started on whatever the next idea came to mind. That was, to build an app that encourages people to go out for walks, runs, hikes, or maybe even a whole day's worth of adventure! Walking is one of the most primitive exercises and the majority of people can do it as a form of exercise. It has been proven to improve [physical](https://pubmed.ncbi.nlm.nih.gov/34417979/) and [mental](https://www.tandfonline.com/doi/full/10.1080/16078055.2018.1445025) health. The inspiration for this app comes from both Pokemon Go and Sweatcoin, but it provides the best of both worlds!
## What it does
Every day, you get a random list of 5 challenges from which you may complete up to 3 per day. These challenges require you to go out and take pictures of certain things. Depending on the difficulty of the challenges, you are awarded points. The app also keeps track of how many challenges you complete throughout your entire journey with us and a count of your daily streak which is just another way of motivating you to keep moving!
## How we built it
We built the app using React on the front end and we were going to use Node+Express in the back end along with MongoDB as our database. However, not too many things went as planned since it was our first-ever hackathon. But we've learned so much more about working together and have gained lots of new skills throughout working on this project!
## Challenges we ran into
Having to learn a lot of things from scratch because none of us have ever worked on big projects before. Some of our members are not in computer science, which only increased the amount of content to be learned for them.
## Accomplishments that we're proud of
Just going out of your way to participate in such events should make you proud!
## What we learned
We believe we now learned the basics of React, CSS, and MUI. We also can collaborate more effectively. We'll truly find out what we've learned once we put them into practice for our next project!
## What's next for Walk-E
Stick around and find out :)) | ## Inspiration
Our inspiration comes from many of our own experiences with dealing with mental health and self-care, as well as from those around us. We know what it's like to lose track of self-care, especially in our current environment, and wanted to create a digital companion that could help us in our journey of understanding our thoughts and feelings. We were inspired to create an easily accessible space where users could feel safe in confiding in their mood and check-in to see how they're feeling, but also receive encouraging messages throughout the day.
## What it does
Carepanion allows users an easily accessible space to check-in on their own wellbeing and gently brings awareness to self-care activities using encouraging push notifications. With Carepanion, users are able to check-in with their personal companion and log their wellbeing and self-care for the day, such as their mood, water and medication consumption, amount of exercise and amount of sleep. Users are also able to view their activity for each day and visualize the different states of their wellbeing during different periods of time. Because it is especially easy for people to neglect their own basic needs when going through a difficult time, Carepanion sends periodic notifications to the user with messages of encouragement and assurance as well as gentle reminders for the user to take care of themselves and to check-in.
## How we built it
We built our project through the collective use of Figma, React Native, Expo and Git. We first used Figma to prototype and wireframe our application. We then developed our project in Javascript using React Native and the Expo platform. For version control we used Git and Github.
## Challenges we ran into
Some challenges we ran into included transferring our React knowledge into React Native knowledge, as well as handling package managers with Node.js. With most of our team having working knowledge of React.js but being completely new to React Native, we found that while some of the features of React were easily interchangeable with React Native, some features were not, and we had a tricky time figuring out which ones did and didn't. One example of this is passing props; we spent a lot of time researching ways to pass props in React Native. We also had difficult time in resolving the package files in our application using Node.js, as our team members all used different versions of Node. This meant that some packages were not compatible with certain versions of Node, and some members had difficulty installing specific packages in the application. Luckily, we figured out that if we all upgraded our versions, we were able to successfully install everything. Ultimately, we were able to overcome our challenges and learn a lot from the experience.
## Accomplishments that we're proud of
Our team is proud of the fact that we were able to produce an application from ground up, from the design process to a working prototype. We are excited that we got to learn a new style of development, as most of us were new to mobile development. We are also proud that we were able to pick up a new framework, React Native & Expo, and create an application from it, despite not having previous experience.
## What we learned
Most of our team was new to React Native, mobile development, as well as UI/UX design. We wanted to challenge ourselves by creating a functioning mobile app from beginning to end, starting with the UI/UX design and finishing with a full-fledged application. During this process, we learned a lot about the design and development process, as well as our capabilities in creating an application within a short time frame.
We began by learning how to use Figma to develop design prototypes that would later help us in determining the overall look and feel of our app, as well as the different screens the user would experience and the components that they would have to interact with. We learned about UX, and how to design a flow that would give the user the smoothest experience. Then, we learned how basics of React Native, and integrated our knowledge of React into the learning process. We were able to pick it up quickly, and use the framework in conjunction with Expo (a platform for creating mobile apps) to create a working prototype of our idea.
## What's next for Carepanion
While we were nearing the end of work on this project during the allotted hackathon time, we thought of several ways we could expand and add to Carepanion that we did not have enough time to get to. In the future, we plan on continuing to develop the UI and functionality, ideas include customizable check-in and calendar options, expanding the bank of messages and notifications, personalizing the messages further, and allowing for customization of the colours of the app for a more visually pleasing and calming experience for users. | losing |
## 💡 Inspiration
Whenever I was going through educational platforms, I always wanted to use one website to store everything. The notes, lectures, quizzes and even the courses were supposed to be accessed from different apps. I was inspired by how to create a centralized platform that acknowledges learning diversity. Also to enforce a platform where many people can **collaborate, learn and grow.**
## 🔎 What it does
By using **Assembly AI** and incorporating a model which focuses on enhancing the user experience by providing **Speech-to-text** functionality. My application enforces a sense of security in which the person decides when to study, and then, they can choose from ML transcription with summarization and labels, studying techniques to optimize time and comprehension, and an ISR(Incremental Static Regeneration) platform which continuously provides support. **The tools used can be scaled as the contact with APIs and CMSs is easy to *vertically* scale**.
## 🚧 How we built it
* **Frontend**: built in React but optimized with **NextJS** with extensive use of TailwindCSS and Chakra UI.
* **Backend**: Authentication with Sanity CMS, Typescript and GraphQL/GROQ used to power a serverless async Webhook engine for an API Interface.
* **Infrastructure**: All connected from **NodeJS** and implemented with *vertical* scaling technology.
* **Machine learning**: Summarization/Transcription/Labels from the **AssemblyAI** API and then providing an optimized strategy for that.
* **Branding, design and UI**: Elements created in Procreate and some docs in ChakraUI.
* **Test video**: Using CapCut to add and remove videos.
## 🛑 Challenges we ran into
* Implementing ISR technology to an app such as this required a lot of tension and troubleshooting. However, I made sure to complete it.
* Including such successful models and making a connection with them was hard through typescript and axios. However, when learning the full version, we were fully ready to combat it and succeed. I actually have optimized one of the algorithm's attributes with asynchronous recursion.
+ Learning a Query Language such as **GROQ**(really similar to GraphQL) was difficult but we were able to use it with the Sanity plugin and use the **codebases** that was automatically used by them.
## ✔️ Accomplishments that we're proud of
Literally, the front end and the backend required technologies and frameworks that were way beyond what I knew 3 months ago. **However I learned a lot in the space between to fuel my passion to learn**. But over the past few weeks, I planned and saw the docs of **AssemblyAI**, learned **GROQ**, implemented **ISR** and put that through a \**Content Management Service (CMS) \**.
## 📚 What we learned
Throughout Hack the North 2022 and prior, I learned a variety of different frameworks, techniques, and APIs to build such an idea. When starting coding I felt like I was going ablaze as the techs were going together like **bread and butter**.
## 🔭 What's next for SlashNotes?
While I was able to complete a considerable amount of the project in the given timeframe, there are still places where I can improve:
* Implementation in the real world! I aim to push this out to google cloud.
* Integration with school-course systems and proving the backend by adding more scaling and tips for user retention. | ## Inspiration
Our inspiration was our experience as university students at the University of Waterloo. During the pandemic, most of our lectures were held online. This resulted in us having several hours of lectures to watch each day. Many of our peers would put videos at 2x speed to get through all the lectures, but we found that this could result in us missing certain details. We wanted to build a website that could help students get through long lectures quickly.
## What it does
Using our website, you can paste the link to most audio and video file types. The website will take the link and provide you with the transcript of the audio/video you sent as well as a summary of that content. The summary includes a title for the audio/video, the synopsis, and the main takeaway.
We chose to include the transcript, because the AI can miss details that you may want to make note of. The transcript allows you to quickly skim through the lecture without needing to watch the entire video. Also, a transcript doesn't include the pauses that happen during a normal lecture, accelerating how fast you can skim!
## How we built it
To start, we created wireframes using Figma. Once we decided on a general layout, we built the website using HTML, CSS, Sass, Bootstrap, and JavaScript. The AssemblyAI Speech-to-Text API handles the processing of the video/audio and returns the information required for the transcript and summary. All files are hosted in our [GitHub repository](https://github.com/ctanamas/HackTheNorth). We deployed our website using Netlify and purchased our domain name from Domain.com. The logo was created in Canva.
## Challenges we ran into
Early on we struggled with learning how to properly use the API. We were not experienced with APIs, and as a result, we found it difficult to get the correct response from the API. Often times when we tried testing our code, we simply got an error from the API. We also struggled with learning how to secure our website while using an API. Learning how to hide the secret key when using an API was something we had never dealt with before.
## Accomplishments that we're proud of
We are proud to have a working demo of our product! We are also proud of the fact that we were able to incorporate an API into our project and make something that we will actually use in our studies! We hope other students can use our product as well!
## What we learned
We learned about how an API works. We learned about how to properly set up a request and how to process the response and incorporate it into our website. We also learned about the process of deploying a website from GitHub. Being able to take plain files and create a website that we can access on any browser was a big step forward for us!
## What's next for notetaker
In the future, we want to add an extension to our summary feature by creating a worksheet for the user as well. The worksheet would replace key words in the summary with blanks to allow the user to test themselves on how well they know the topic. We also wanted to include relevant images to the summary study guide, but were unsure on how that could be done. We want to make our website the ultimate study tool for students on a tight schedule. | ## Inspiration
We were inspired by hard working teachers and students. Although everyone was working hard, there was still a disconnect with many students not being able to retain what they learned. So, we decided to create both a web application and a companion phone application to help target this problem.
## What it does
The app connects students with teachers in a whole new fashion. Students can provide live feedback to their professors on various aspects of the lecture, such as the volume and pace. Professors, on the other hand, get an opportunity to receive live feedback on their teaching style and also give students a few warm-up exercises with a built-in clicker functionality.
The web portion of the project ties the classroom experience to the home. Students receive live transcripts of what the professor is currently saying, along with a summary at the end of the lecture which includes key points. The backend will also generate further reading material based on keywords from the lecture, which will further solidify the students’ understanding of the material.
## How we built it
We built the mobile portion using react-native for the front-end and firebase for the backend. The web app is built with react for the front end and firebase for the backend. We also implemented a few custom python modules to facilitate the client-server interaction to ensure a smooth experience for both the instructor and the student.
## Challenges we ran into
One major challenge we ran into was getting and processing live audio and giving a real-time transcription of it to all students enrolled in the class. We were able to solve this issue through a python script that would help bridge the gap between opening an audio stream and doing operations on it while still serving the student a live version of the rest of the site.
## Accomplishments that we’re proud of
Being able to process text data to the point that we were able to get a summary and information on tone/emotions from it. We are also extremely proud of the
## What we learned
We learned more about React and its usefulness when coding in JavaScript. Especially when there were many repeating elements in our Material Design. We also learned that first creating a mockup of what we want will facilitate coding as everyone will be on the same page on what is going on and all thats needs to be done is made very evident. We used some API’s such as the Google Speech to Text API and a Summary API. We were able to work around the constraints of the API’s to create a working product. We also learned more about other technologies that we used such as: Firebase, Adobe XD, React-native, and Python.
## What's next for Gradian
The next goal for Gradian is to implement a grading system for teachers that will automatically integrate with their native grading platform so that clicker data and other quiz material can instantly be graded and imported without any issues. Beyond that, we can see the potential for Gradian to be used in office scenarios as well so that people will never miss a beat thanks to the live transcription that happens. | losing |
## Inspiration
What were the 2000s known for? The Great Depression? No. High-rise jeans? Absolutely not.
Undoubtedly, they belonged to Gwyneth Paltrow. It was defined by her rise to power; of course, we’re not talking about her acting career (her artistic talents precede the decade).
Cool, calm, and calculating. This describes Gwyneth’s attitude all throughout the 2000s. She knew that her influence was inevitable; it was not a question of if, but when. Centuries from now, no one will remember the crash of the stock and housing markets. What they will remember is the gift so generously bestowed on humanity: in September 2008, Gwyneth launched [goop](https://goop.com/).
Quickly, Paltrow’s influence has reached billions and her empire, backed by an army of *#goopmoms*, stands steadfast against all adversity. She has developed technology that rivals Jeffrey Bezos. Moreover, she has [granted us wisdom](https://www.brainyquote.com/authors/gwyneth-paltrow-quotes) that transcends works everywhere. Her legacy would be cemented in a mere matter of years.
What people never really questioned was how she was able to achieve all this. The answer to this is simple: Gwyneth Paltrow is using Gwyn Cam. Today, we bring you the technology that restores people to collaborative spaces before the COVID-19 pandemic and uses filters and Computer Vision to have fun, elevate and bring back this sense of camaraderie during online calls, gaming and more video applications!
## What it does
Gwyn Cam is a free to use online application that attempts to bring people closer to the metaverse. Using computer vision technologies to facial detection, and simple javascript, this app is a camera enabled filter system with the possibility of customization! With this app, you can add in any picture you want, and filters you want and bring back this idea of collaboration and interactiveness, even though it is through a screen! We had an incredible amount of fun building this app, even if we had little to no knowledge about adding filters to cameras with moving individuals, and even to add a camera onto a Django Website! Overall, this app is both a learning experience, and a way to interact with others while trying out different filters and customizing your own!
## How we built it
This project was created using the Django framework in Python and implemented OpenCV in the backend to create a facial-recognition algorithm. This allowed us to create a JavaScript video stream object that is sent to the HTML frontend. Next, we used JavaScript (specifically, the J5 library) to upload images of Gwyneth Paltrow and overlay them with the user’s face on the live video stream. Later, non-Gwyneth facial filters were also added as options.
## Challenges we ran into
We ran into many challenges, from conceptualizing our project to the tools sometimes not working on different devices to a hosting challenge on heroku, but through everything, our team's passion for technology and willingness to open our minds to each other, our respect for one another and our patience helped us concretize this project in only 1 day and a few hours, which we are quite proud of! The team communication, having a list of requirements and starting with the mindset of an MVP helped us reach our goal to submit a project at this hackathon!
## Accomplishments that we're proud of
For the majority of the group, this was the first time using image-recognition tools, this was also by far our largest challenge as well. This project helped us explore how these tools work in Python specifically, and it was a great starting point for bringing future ideas to life. At a project management level, we have tended to run short on time at previous Hackathon events; this time, we were able to get a well-designed app together and achieve our MVP goals within the time limits. Finally, we can say that we were very creative with the theme; we can say with the utmost confidence that probably no other team at this event was able to draw the connection between *restoration* and Gwyneth Paltrow.
## What's next for So You Wanna Be Gwyneth Paltrow
The next step here would really be to have a place where people can take pictures with filters on their faces, take screen recordings and simply have call conversations with their custom filters, which a lot of applications such as microsoft teams does not enable. This project could be expanded while hosting it to add the possibility of collaborating on filters together with friends before uploading them! | ## Inspiration
The preservation of cultural heritage and history has become a significant challenge, particularly with the declining interest in learning about them. Motivated by the theme of "Nostalgia," our project aims to address this issue by creating an accessible and immersive experience for individuals of all ages to **explore heritage through the transformation of their own image in a captivating virtual world**. Inspired by modern technology's photo filters in popular apps like Instagram and Snapchat, we seek to make the application of these filters more meaningful and enriching.
## What it does
Retropix is a digital product strategically installed in public mirrors across cities worldwide. When the user stands in front of the mirror, it takes them on a personalized journey back in time by transforming their outfits and surroundings to the era and location of their choice.
After the user takes their photo, their transformed photo is then added to an global photo album online. This is where the user can view pictures that other people have taken in Retropix mirrors around the world and see people dressed in different traditional clothings at specific points in time. For example, an album of the 2000s, consisting of garments from Vietnam, Pakistan, India, Indonesia, etc
## How we built it
For the functionality prototype, we started with plain HTML/CSS with some handwritten JS files, with zero framework. The AI image processor needs to see the image from a URL, so we use a temporary online storage API that holds our images for 5 minutes. Then we take input from the user who specifies the place and time they want to go and compose that information in a prompt to the AI processor. We also used **Cohere’s text generator AI** to give fun facts about the time and place chosen as a user experience improvement while they are waiting for the processed image to be returned. For the product page, we quickly whip up a prototype using Canva’s website designer.
## Challenges we ran into
One of the main challenges we faced was working with unfamiliar tech stacks. To overcome this hurdle, we actively sought help from mentors, utilized resources like Cohere and Stack Overflow, and engaged in collaborative problem-solving.
## Accomplishments that we're proud of
Our proudest accomplishment lies in the process of ideation and finalizing our concept. As a team with many ideas, we spent considerable time aligning our perspectives to finalize a project that combined everyone's strengths. Despite all of us being beginner hackers, we work together to make decisions on which platforms to use, optimizing our time, ensuring full usability of our project, and simultaneously adopting new skills.
## What we learned
Throughout the hackathon, we gained valuable insights into working with APIs, tech stacks, the intricacies of front-end development, and a better understanding of how JavaScript modules function.
## Business Feasibility
Anticipating a 15% monthly customer growth, our conservative projections estimate substantial annual revenue. Only around 9$ per use, the product becomes profitable after the third quarter considering the initial investment. Facilitated by global installations at popular tourist attractions enhances its scalability.
## What's next for RetroPix?
The future of RetroPix holds immense potential for preserving cultural history, increasing awareness of diversity and inclusion, and emphasizing historical accuracy. This endeavor serves as a bridge for historical education and cultural appreciation. To improve the product, we will try to research and incorporate knowledge on lesser visited countries and Indigenous communities.
Looking ahead, we envision RetroPix as a promising product with financial viability and the prospect of reaching customers worldwide. Scalability is a key focus, with plans to expand the product globally and sparking curiosity of learning. | ## Inspiration
I've always been fascinated by the complexities of UX design, and this project was an opportunity to explore an interesting mode of interaction. I drew inspiration from the futuristic UIs that movies have to offer, such as Minority Report's gesture-based OS or Iron Man's heads-up display, Jarvis.
## What it does
Each window in your desktop is rendered on a separate piece of paper, creating a tangible version of your everyday computer. It is fully featured desktop, with specific shortcuts for window management.
## How I built it
The hardware is combination of a projector and a webcam. The camera tracks the position of the sheets of paper, on which the projector renders the corresponding window. An OpenCV backend does the heavy lifting, calculating the appropriate translation and warping to apply.
## Challenges I ran into
The projector was initially difficulty to setup, since it has a fairly long focusing distance. Also, the engine that tracks the pieces of paper was incredibly unreliable under certain lighting conditions, which made it difficult to calibrate the device.
## Accomplishments that I'm proud of
I'm glad to have been able to produce a functional product, that could possibly be developed into a commercial one. Furthermore, I believe I've managed to put an innovative spin to one of the oldest concepts in the history of computers: the desktop.
## What I learned
I learned lots about computer vision, and especially on how to do on-the-fly image manipulation. | losing |
## Inspiration
hiding
## What it does
## How I built it
## Challenges I ran into
## Accomplishments that I'm proud of
## What I learned
## What's next for Spine | ## Inspiration
Our project is inspired by the sister of one our creators, Joseph Ntaimo. Joseph often needs to help locate wheelchair accessible entrances to accommodate her, but they can be hard to find when buildings have multiple entrances. Therefore, we created our app as an innovative piece of assistive tech to improve accessibility across the campus.
## What it does
The user can find wheelchair accessible entrances with ease and get directions on where to find them.
## How we built it
We started off using MIT’s Accessible Routes interactive map to see where the wheelchair friendly entrances were located at MIT. We then inspected the JavaScript code running behind the map to find the latitude and longitude coordinates for each of the wheelchair locations.
We then created a Python script that filtered out the latitude and longitude values, ignoring the other syntax from the coordinate data, and stored the values in separate text files.
We tested whether our method would work in Python first, because it is the language we are most familiar with, by using string concatenation to add the proper Java syntax to the latitude and longitude points. Then we printed all of the points to the terminal and imported them into Android Studio.
After being certain that the method would work, we uploaded these files into the raw folder in Android Studio and wrote code in Java that would iterate through both of the latitude/longitude lists simultaneously and plot them onto the map.
The next step was learning how to change the color and image associated with each marker, which was very time intensive, but led us to having our custom logo for each of the markers.
Separately, we designed elements of the app in Adobe Illustrator and imported logos and button designs into Android Studio. Then, through trial and error (and YouTube videos), we figured out how to make buttons link to different pages, so we could have both a FAQ page and the map.
Then we combined both of the apps together atop of the original maps directory and ironed out the errors so that the pages would display properly.
## Challenges we ran into/Accomplishments
We had a lot more ideas than we were able to implement. Stripping our app to basic, reasonable features was something we had to tackle in the beginning, but it kept changing as we discovered the limitations of our project throughout the 24 hours. Therefore, we had to sacrifice features that we would otherwise have loved to add.
A big difficulty for our team was combining our different elements into a cohesive project. Since our team split up the usage of Android Studio, Adobe illustrator, and programming using the Google Maps API, it was most difficult to integrate all our work together.
We are proud of how effectively we were able to split up our team’s roles based on everyone’s unique skills. In this way, we were able to be maximally productive and play to our strengths.
We were also able to add Boston University accessible entrances in addition to MIT's, which proved that we could adopt this project for other schools and locations, not just MIT.
## What we learned
We used Android Studio for the first time to make apps. We discovered how much Google API had to offer, allowing us to make our map and include features such as instant directions to a location. This helped us realize that we should use our resources to their full capabilities.
## What's next for HandyMap
If given more time, we would have added many features such as accessibility for visually impaired students to help them find entrances, alerts for issues with accessing ramps and power doors, a community rating system of entrances, using machine learning and the community feature to auto-import maps that aren't interactive, and much, much more. Most important of all, we would apply it to all colleges and even anywhere in the world. | ## Inspiration
We wanted to solve a unique problem we felt was impacting many people but was not receiving enough attention. With emerging and developing technology, we implemented neural network models to recognize objects and images, and converting them to an auditory output.
## What it does
XTS takes an **X** and turns it **T**o **S**peech.
## How we built it
We used PyTorch, Torchvision, and OpenCV using Python. This allowed us to utilize pre-trained convolutional neural network models and region-based convolutional neural network models without investing too much time into training an accurate model, as we had limited time to build this program.
## Challenges we ran into
While attempting to run the Python code, the video rendering and text-to-speech were out of sync and the frame-by-frame object recognition was limited in speed by our system's graphics processing and machine-learning model implementing capabilities. We also faced an issue while trying to use our computer's GPU for faster video rendering, which led to long periods of frustration trying to solve this issue due to backwards incompatibilities between module versions.
## Accomplishments that we're proud of
We are so proud that we were able to implement neural networks as well as implement object detection using Python. We were also happy to be able to test our program with various images and video recordings, and get an accurate output. Lastly we were able to create a sleek user-interface that would be able to integrate our program.
## What we learned
We learned how neural networks function and how to augment the machine learning model including dataset creation. We also learned object detection using Python. | winning |
## Inspiration
It all started a couple days ago when my brother told me he'd need over an hour to pick up a few items from a grocery store because of the weekend checkout line. This led to us reaching out to other friends of ours and asking them about the biggest pitfalls of existing shopping systems. We got a whole variety of answers, but the overwhelming response was the time it takes to shop and more particularly checkout. This inspired us to ideate and come up with an innovative solution.
## What it does
Our app uses computer vision to add items to a customer's bill as they place items in the cart. Similarly, removing an item from the cart automatically subtracts them from the bill. After a customer has completed shopping, they can checkout on the app with the tap of a button, and walk out the store. It's that simple!
## How we built it
We used react with ionic for the frontend, and node.js for the backend. Our main priority was the completion of the computer vision model that detects items being added and removed from the cart. The model we used is a custom YOLO-v3Tiny model implemented in Tensorflow. We chose Tensorflow so that we could run the model using TensorflowJS on mobile.
## Challenges we ran into
The development phase had it's fair share of challenges. Some of these were:
* Deep learning models can never have too much data! Scraping enough images to get accurate predictions was a challenge.
* Adding our custom classes to the pre-trained YOLO-v3Tiny model.
* Coming up with solutions to security concerns.
* Last but not least, simulating shopping while quarantining at home.
## Accomplishments that we're proud of
We're extremely proud of completing a model that can detect objects in real time, as well as our rapid pace of frontend and backend development.
## What we learned
We learned and got hands on experience of Transfer Learning. This was always a concept that we knew in theory but had never implemented before. We also learned how to host tensorflow deep learning models on cloud, as well as make requests to them. Using google maps API with ionic react was a fun learning experience too!
## What's next for MoboShop
* Integrate with customer shopping lists.
* Display ingredients for recipes added by customer.
* Integration with existing security systems.
* Provide analytics and shopping trends to retailers, including insights based on previous orders, customer shopping trends among other statistics. | # Click through our slideshow for a neat overview!!
# Check out our demo [video](https://www.youtube.com/watch?v=hyWJAuR7EVY)
## The future of computing 🍎 👓 ⚙️ 🤖 🍳 👩🍳
How could Mixed Reality, Spatial Computing, and Generative AI transform our lives?
And what happens when you combine Vision Pro and AI? (spoiler: magic! 🔮)
Our goal was to create an interactive **VisionOS** app 🍎 powered by AI. While our app could be applied towards many things (like math tutoring, travel planning, etc.), we decided to make the demo use case fun.
We loved playing the game Cooking Mama 👩🍳 as kids so we made a **voice-activated conversational AI agent** that teaches you to cook healthy meals, invents recipes based on your preferences, and helps you find and order ingredients.
Overall, we want to demonstrate how the latest tech advances could transform our lives. Food is one of the most important, basic needs so we felt that it was an interesting topic. Additionally, many people struggle with nutrition so our project could help people eat healthier foods and live better, longer lives.
## What we created
* Conversational Vision Pro app that lets you talk to an AI nutritionist that speaks back to you in a realistic voice with low latency.
* Built-in AI agent that will create a custom recipe according to your preferences, identify the most efficient and cheapest way to purchase necessary ingredients in your area (least stores visited, least cost), and finally creates Instacart orders using their simulated API.
* Web version of agent at [recipes.reflex.run](https://recipes.reflex.run/) in a chat interface
* InterSystems IRIS vector database of 10k recipes with HyDE enabled semantic search
* Pretrained 40M LLM from scratch to create recipes
* Fine-tuned Mistral-7b using MonsterAPI to generate recipes
## How we built it
We divided tasks efficiently given the time frame to make sure we weren't bottlenecked by each other. For instance, Gao's first priority was to get a recipe LLM deployed so Molly and Park could use it in their tasks.
While we split up tasks, we also worked together to help each other debug and often pair programmed and swapped tasks if needed.
Various tools used: Xcode, Cursor, OpenAI API, MonsterAI API, IRIS Vector Database, Reflex.dev, SERP API,...
### Vision OS
* Talk to Vision Mama by running Whisper fully on device using CoreML and Metal
* Chat capability powered by GPT-3.5-turbo, our custom recipe-generating LLM (Mistral-7b backbone), and our agent endpoint.
* To ensure that you are able to see both Vision Mama's chats and her agentic skills, we have a split view that shows your conversation and your generated recipes
* Lastly, we use text-to-speech synthesis using ElevenLabs API for Vision Mama's voice
### AI Agent Pipeline for Recipe Generation, Food Search, and Instacart Ordering
We built an endpoint that we hit from our Vision Pro and our Reflex site.
Basically what happens is we submit a user's desired food such as "banana soup". We pass that to our fine-tuned Mistral-7b LLM to generate a recipe. Then, we quickly use GPT-4-turbo to parse the recipe and extract the ingredients. Then we use the SERP API on each ingredient to find where it can be purchased nearby. We prioritize cheaper ingredients and use an algorithm to try to visit the least number of stores to buy all ingredients. Finally, we populate an Instacart Order API call to purchase the ingredients (simulated for now since we do not have actual partner access to Instacart's API)
### Pre-training (using nanogpt architecture):
Created large dataset of recipes.
Tokenized our recipe dataset using BPE (GPT2 tokenizer)
Dataset details (9:1 split):
train: 46,826,468 tokens
val: 5,203,016 tokens
Trained for 1000 iterations with settings:
layers = 12
attention heads = 12
embedding dimension = 384
batch size = 32
In total, the LLM had 40.56 million parameters!
It took several hours to train on an M3 Mac with Metal Performance Shaders.
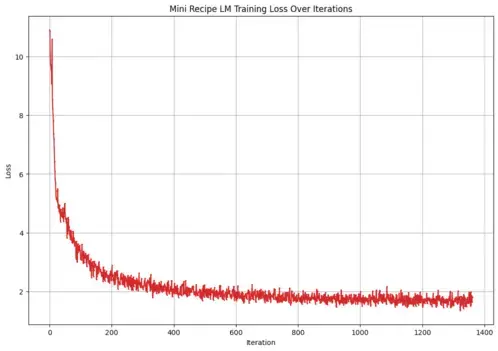
### Fine-tuning
While the pre-trained LLM worked ok and generated coherent (but silly) English recipes for the most part, we couldn't figure out how to deploy it in the time frame and it still wasn't good enough for our agent. So, we tried fine-tuning Mistral-7b, which is 175 times bigger and is much more capable. We curated fine-tuning datasets of several sizes (10k recipes, 50k recipes, 250k recipes). We prepared them into a specific prompt/completion format:
```
You are an expert chef. You know about a lot of diverse cuisines. You write helpful tasty recipes.\n\n###Instruction: please think step by step and generate a detailed recipe for {prompt}\n\n###Response:{completion}
```
We fine-tuned and deployed the 250k-fine-tuned model on the **MonsterAPI** platform, one of the sponsors of TreeHacks. We observed that using more fine-tuning data led to lower loss, but at diminishing returns.
### Reflex.dev Web Agent
Most people don't have Vision Pros so we wrapped our versatile agent endpoint into a Python-based Reflex app that you can chat with! [Try here](https://recipes.reflex.run/)
Note that heavy demand may overload our agent.
### IRIS Semantic Recipe Discovery
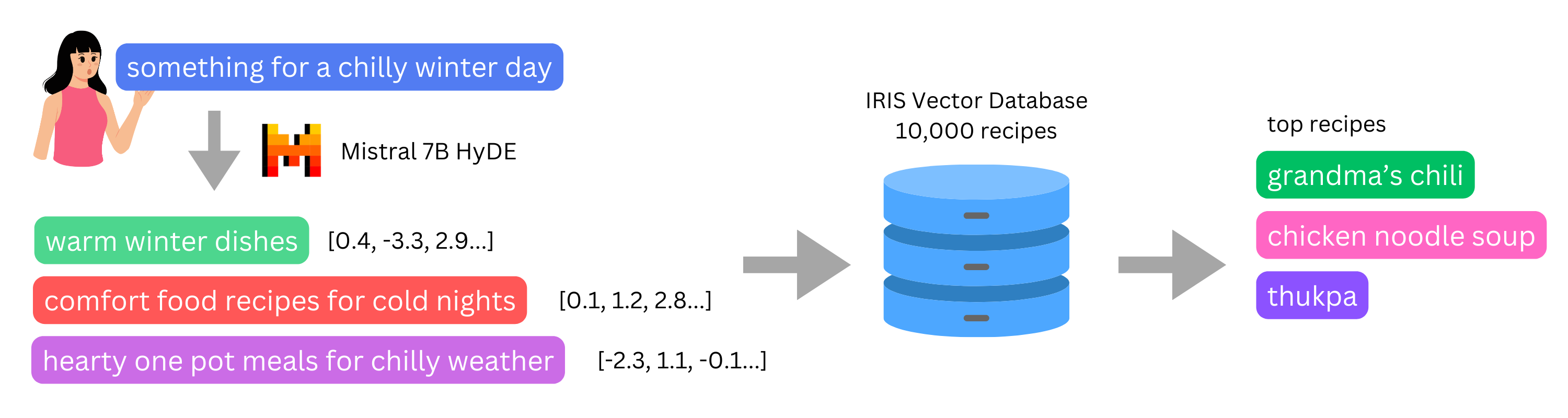
We used the IRIS Vector Database, running it on a Mac with Docker. We embedded 10,000 unique recipes from diverse cuisines using **OpenAI's text-ada-002 embedding**. We stored the embeddings and the recipes in an IRIS Vector Database. Then, we let the user input a "vibe", such as "cold rainy winter day". We use **Mistral-7b** to generate three **Hypothetical Document Embedding** (HyDE) prompts in a structured format. We then query the IRIS DB using the three Mistral-generated prompts. The key here is that regular semantic search does not let you search by vibe effectively. If you do semantic search on "cold rainy winter day", it is more likely to give you results that are related to cold or rain, rather than foods. Our prompting encourages Mistral to understand the vibe of your input and convert it to better HyDE prompts.
Real example:
User input: something for a chilly winter day
Generated Search Queries: {'queries': ['warming winter dishes recipes', 'comfort food recipes for cold days', 'hearty stews and soups for chilly weather']}
Result: recipes that match the intent of the user rather than the literal meaning of their query
## Challenges we ran into
Programming for the Vision Pro, a new way of coding without that much documentation available
Two of our team members wear glasses so they couldn't actually use the Vision Pro :(
Figuring out how to work with Docker
Package version conflicts :((
Cold starts on Replicate API
A lot of tutorials we looked at used the old version of the OpenAI API which is no longer supported
## Accomplishments that we're proud of
Learning how to hack on Vision Pro!
Making the Vision Mama 3D model blink
Pretraining a 40M parameter LLM
Doing fine-tuning experiments
Using a variant of HyDE to turn user intent into better semantic search queries
## What we learned
* How to pretrain LLMs and adjust the parameters
* How to use the IRIS Vector Database
* How to use Reflex
* How to use Monster API
* How to create APIs for an AI Agent
* How to develop for Vision Pro
* How to do Hypothetical Document Embeddings for semantic search
* How to work under pressure
## What's next for Vision Mama: LLM + Vision Pro + Agents = Fun & Learning
Improve the pre-trained LLM: MORE DATA, MORE COMPUTE, MORE PARAMS!!!
Host the InterSystems IRIS Vector Database online and let the Vision Mama agent query it
Implement the meal tracking photo analyzer into VisionOs app
Complete the payment processing for the Instacart API once we get developer access
## Impacts
Mixed reality and AI could enable more serious use cases like:
* Assisting doctors with remote robotic surgery
* Making high quality education and tutoring available to more students
* Amazing live concert and event experiences remotely
* Language learning practice partner
## Concerns
* Vision Pro is very expensive so most people can't afford it for the time being. Thus, edtech applications are limited.
* Data privacy
Thanks for checking out Vision Mama! | ## Inspiration
In today's fast-paced world, we're all guilty of losing ourselves in the vast digital landscape. The countless hours we spend on our computers can easily escape our attention, as does the accumulating stress that can result from prolonged focus. Screen Sense is here to change that. It's more than just a screen time tracking app; it's your personal guide to a balanced digital life. We understand the importance of recognizing not only how much time you spend on your devices but also how these interactions make you feel.
## What it does
Screen Sense is a productivity tool that monitors a user's emotions while tracking their screen time on their device. Our app analyzes visual data using the Hume API and presents it to the user in an simple graphical interface that displays their strongest emotions along with a list of the user's most frequented digital activities.
## How we built it
Screen Sense is a desktop application built with the React.js, Python, and integrates the Hume AI API. Our project required us to execute of multiple threads to handle tasks such as processing URL data from the Chrome extension, monitoring active computer programs, and transmitting image data from a live video stream to the Hume AI.
## Challenges we ran into
We encountered several challenges during the development process. Initially, our plan involved creating a Chrome extension for its cross-platform compatibility. However, we faced security obstacles that restricted our access to the user's webcam. As a result, we pivoted to developing a desktop application capable of processing a webcam stream in the background, while also serving as a fully compatible screen time tracker for all active programs.
Although nearly half of the codebase was written in Python, none of our group members had ever coded using that language. This presented a significant learning curve, and we encountered a variety of issues. The most complex challenge we faced was Python's nature as a single-threaded language.
## Accomplishments that we're proud of
As a team of majority beginner coders, we were able to create a functional productivity application that integrates the Hume AI, especially while coding in a language none of us were familiar with beforehand.
## What we learned
Throughout this journey, we gained valuable experience in adaptability, as demonstrated by how we resolved our HTTP communication issues and successfully shifted our development platform when necessary.
## What's next for Screen Sense
Our roadmap includes refining the user interface and adding more visual animations to enhance the overall experience, expanding our reach to mobile devices, and integrating user notifications to proactively alert users when their negative emotions reach unusually high levels. | partial |
## Inspiration
We admired the convenience Honey provides for finding coupon codes. We wanted to apply the same concept except towards making more sustainable purchases online.
## What it does
Recommends sustainable and local business alternatives when shopping online.
## How we built it
Front-end was built with React.js and Bootstrap. The back-end was built with Python, Flask and CockroachDB.
## Challenges we ran into
Difficulties setting up the environment across the team, especially with cross-platform development in the back-end. Extracting the current URL from a webpage was also challenging.
## Accomplishments that we're proud of
Creating a working product!
Successful end-to-end data pipeline.
## What we learned
We learned how to implement a Chrome Extension. Also learned how to deploy to Heroku, and set up/use a database in CockroachDB.
## What's next for Conscious Consumer
First, it's important to expand to make it easier to add local businesses. We want to continue improving the relational algorithm that takes an item on a website, and relates it to a similar local business in the user's area. Finally, we want to replace the ESG rating scraping with a corporate account with rating agencies so we can query ESG data easier. | # Delta Draw
Watch the [video](https://www.youtube.com/watch?v=hDX5sQmFqY8)
## Project Description:
1. A **mechanical shell** with 3D printed gondolas and a motor-guided marker
2. An **image-processing pipeline** that determines how to draw uploaded images start-to-finish
3. A **Web-based HMI** that allows images to be uploaded & drawn
The whiteboard was scavenged from McMaster's IEEE Student Branch | ## Inspiration
Learning about some environmental impact of the retail industry led us to wonder about what companies have aimed for in terms of sustainability goals. The textile industry is notorious for its carbon and water footprints with statistics widely available. How does a company promote sustainability? Do people know and support about these movements?
With many movements by certain retail companies to have more sustainable clothes and supply-chain processes, we wanted people to know and support these sustainability movements, all through an interactive and fun UI :)
## What it does
We built an application to help users select suitable outfit pairings that meet environmental standards. The user is prompted to upload a picture of a piece of clothing they currently own. Based on this data, we generate potential outfit pairings from a database of environmentally friendly retailers. Users are shown prices, means of purchase, reasons the company is sustainable, as well as an environmental rating.
## How we built it
**Backend**: Google Vision API, MySQL, AWS, Python with Heroku and Flask deployment
Using the Google Vision API, we learn of the features (labels, company, type of clothes and colour) from pictures of clothes. With these features, we use Python to interact with our MySQL database of clothes to both select a recommended outfit and additional recommended clothes for other potential outfit combinations.
To generate more accurate label results, we additionally perform a Keras (with Tensorflow backend) image segmentation to crop out the background, allowing the Google Vision API to extract more accurate features.
**Frontend**: JavaScript, React, Firebase
We built the front-end with React, using Firebase to handle user authentications and act as a content delivery network.
## Challenges we ran into
The most challenging part of the project was learning to use the Google Vision API, and deploying the API on Heroku with all its dependencies.
## Accomplishments that we're proud of
Intuitive and clean UI for users that allows ease of mix and matching while raising awareness of sustainability within the retail industry, and of course, the integration and deployment of our technology stack.
## What we learned
After viewing some misfit outfit recommendations, such as a jacket with shorts, had we added a "seasonal" label, and furthermore a "dress code" label (by perhaps, integrating transfer learning to label the images), we could have given better outfit recommendations. This made us realize importance of brainstorming and planning.
## What's next for Fabrical
Deploy more sophisticated clothes matching algorithms, saving the user's outfits into a closet, in addition to recording the user's age, and their preferences as they like / dislike new outfit combinations; incorporate larger database, more metrics, and integrate the machine learning matching / cropping techniques. | winning |
## Inspiration
I came up with the Study Buddy when I realized how much of a hassle it is to have to constantly switch apps, and websites while studying for school. I decided to make a platform that could combine my most used resources into one website.
## What it does
The Study Buddy holds 3 different pages as of now. On the first page, you can manage your assignments and tasks to stay organized.
On the second page, you can create your own customizable virtual flashcards. You can have an infinite amount of flashcards, and the program will generate them at random, and it will also never give you the same flashcard twice. In case you're interested, here is an article that talks about the benefits of flashcards <https://usm.maine.edu/agile/using-flashcards>
On the third page, there is a text box that allows you to input text, and have it read out loud to you using a speech API. You can pause and play at your desire. Having a program that can read text to you is useful as you can multitask as you are taking in information, and you are still able to take in information from text if you are dyslexic, or are visually impaired.
## How I built it
I built the Study Buddy with HTML, CSS, and Vanilla JS. As I mentioned earlier, it is made up of three pages and I used a speech API for the third page (Audio Reader).
## Challenges I ran into
Some challenges I ran into were the audio reader not pausing, the audio play button not turning back on, and the CSS animation for the flash card not working. I overcame these challenges be referencing other peoples code, as well as some YouTube videos.
## Accomplishments that I'm proud of
I'm proud of the fact that I was able to build a functioning program for my first hackathon, and I'm proud of the fact that I was able to incorporate some technology that I would've never used if I wasn't in this hackathon.
## What I learned
I learned how to use speech APIs through JS, I learned a lot about CSS animation, and I learned a bit about how websites actually are designed.
## What's next for Study Buddy
Study Buddy will incorporate more resources within the application so that it becomes much more useful to students to use. Study Buddy may also expand into a mobile application instead of a website so that it can more easily be used on mobile. | ## Inspiration
We were inspired by a YouTube video, which touched on the idea of Rule of Thirds, and how people don't really take advantage of it.
## What it does
Allows people to take better photos, with more emphasis and meaning on the elements of their pictures.
## How we built it
We used a regular html/css frontend, alongside Flask for backend. Then, we used an opencv pre-trained model to detect objects which came on the screen. Finally, we determined
## Challenges we ran into
Time constraints, we ran out of time very quickly.
## Accomplishments that we're proud of
We are proud of our ability to persevere, even though a lot of unfortunate issues came up during the challenge. Even though we did not get the outcome we wanted, we learned a lot about each other and the difficulties of hackathons.
## What we learned
We learned a lot about frameworks, fullstack development and machine learning.
## What's next for img comp
We hope to upgrade this by providing a more powerful dataset so that the objects in our pictures are predicted more accurately, a more visually appealing front-end, and even more considerations when deciding "the ideal picture". | ## Problem
In these times of isolation, many of us developers are stuck inside which makes it hard for us to work with our fellow peers. We also miss the times when we could just sit with our friends and collaborate to learn new programming concepts. But finding the motivation to do the same alone can be difficult.
## Solution
To solve this issue we have created an easy to connect, all in one platform where all you and your developer friends can come together to learn, code, and brainstorm together.
## About
Our platform provides a simple yet efficient User Experience with a straightforward and easy-to-use one-page interface.
We made it one page to have access to all the tools on one screen and transition between them easier.
We identify this page as a study room where users can collaborate and join with a simple URL.
Everything is Synced between users in real-time.
## Features
Our platform allows multiple users to enter one room and access tools like watching youtube tutorials, brainstorming on a drawable whiteboard, and code in our inbuilt browser IDE all in real-time. This platform makes collaboration between users seamless and also pushes them to become better developers.
## Technologies you used for both the front and back end
We use Node.js and Express the backend. On the front end, we use React. We use Socket.IO to establish bi-directional communication between them. We deployed the app using Docker and Google Kubernetes to automatically scale and balance loads.
## Challenges we ran into
A major challenge was collaborating effectively throughout the hackathon. A lot of the bugs we faced were solved through discussions. We realized communication was key for us to succeed in building our project under a time constraints. We ran into performance issues while syncing data between two clients where we were sending too much data or too many broadcast messages at the same time. We optimized the process significantly for smooth real-time interactions.
## What's next for Study Buddy
While we were working on this project, we came across several ideas that this could be a part of.
Our next step is to have each page categorized as an individual room where users can visit.
Adding more relevant tools, more tools, widgets, and expand on other work fields to increase our User demographic.
Include interface customizing options to allow User’s personalization of their rooms.
Try it live here: <http://35.203.169.42/>
Our hopeful product in the future: <https://www.figma.com/proto/zmYk6ah0dJK7yJmYZ5SZpm/nwHacks_2021?node-id=92%3A132&scaling=scale-down>
Thanks for checking us out! | losing |
## Inspiration
We were inspired by dungeon-crawler video games in addition to fantasy role-play themes. We wanted to recreate the flexibility of rich analog storytelling within computer-generated games while making the game feel as natural as possible.
## Overview
Our game is a top-down wave-based shooter centered around a narrator mechanic. Powered by the co:here natural language processing platform, the narrator entity generates sentences to describe in-game actions such as damage, player kill, and player death events. Using information provided by the user about their character and mob information, we engineered prompts to generate narrations involving these elements.
## Architecture
We built the game in Godot, an open-source game engine. To give us more flexibility when working with data gathered from the co:here platform, we opted to build a python flask back-end to locally interact with the game engine. The back end manages API calls and cleaning responses.
## Challenges
We were all unfamiliar with the Godot platform before this hackathon which provided difficulties in terms of a learning curve. A lot of time was also spent on prompt engineering to query the large language models correctly such that the output we received was relevant and coherent.
## Next Steps
We would like to give the player more room to directly interact with mobs through text prompts and leverage classification tools to analyze player input dialogue. We were also looking into integrating a tts system to help ease the player's cognitive load. | ## Inspiration 🌟
Creative writing is hard. Like really REALLY hard. Trying to come up with a fresh story can seem very intimidating, and if given a blank page, most people would probably just ponder endlessly... "where do I even start???"
## What it does 📕
Introducing **TaleTeller**, an interactive gamified experience designed to help young storytellers create their own unique short stories. It utilizes a "mad libs" style game format where players input five words to inspire the start of their story. The AI will incorporate these words into the narrative, guiding the direction of the tale. Players continue the tale by filling in blanks with words of their choice, actively shaping the story as it unfolds. It's an engaging experience that encourages creativity and fosters a love for storytelling.
## How we built it 🔧
TaleTeller utilizes the Unity Game Engine for its immersive storytelling experience. The AI responses are powered by OpenAI's GPT4-Turbo API while story images are created using OpenAI's DALL-E. The aesthetic UI of the project includes a mix of open course and custom 2D assets.
## Challenges we ran into 🏁
One of the main challenges we faced was fine-tuning the AI to generate cohesive and engaging storylines based on the player's input (prompt engineering is harder than it seems!). We also had a lot of trouble trying to integrate DALL-E within Unity, but after much blood, sweat, and tears, we got the job done :)
## Accomplishments that we're proud of 👏
* Having tons of fun creating fully fledged stories with the AI
* Getting both GPT and DALL-E to work in Unity (it actually took forever...)
* Our ✨ *gorgeous* ✨ UI
## What we learned 🔍
* How to prompt engineer GPT to give us consistent responses
* How to integrate APIs in Unity
* C# is Tony's mortal enemy
## What's next for TaleTeller 📈
Training an AI Text-to-Speech to read out the story in the voice of Morgan Freeman 😂 | ## Inspiration
We are all software/game devs excited by new and unexplored game experiences. We originally came to PennApps thinking of building an Amazon shopping experience in VR, but eventaully pivoted to Project Em - a concept we all found mroe engaging. Our swtich was motivated by the same force that is driving us to create and improve Project Em - the desire to venture into unexplored territory, and combine technologies not often used together.
## What it does
Project Em is a puzzle exploration game driven by Amazon's Alexa API - players control their character with the canonical keyboard and mouse controls, but cannot accomplish anything relevant in the game without talking to a mysterious, unknown benefactor who calls out at the beginning of the game.
## How we built it
We used a combination of C++, Pyhon, and lots of shell scripting to create our project. The client-side game code runs on Unreal Engine 4, and is a combination of C++ classes and Blueprint (Epic's visual programming language) scripts. Those scripts and classes communicate an intermediary server running Python/Flask, which in turn communicates with the Alexa API. There were many challenges in communicating RESTfully out of a game engine (see below for more here), so the two-legged approach lent itself well to focusing on game logic as much as possible. Sacha and Akshay worked mostly on the Python, TCP socket, and REST communication platform, while Max and Trung worked mainly on the game, assets, and scripts.
The biggest challenge we faced was networking. Unreal Engine doesn't naively support running a webserver inside a game, so we had to think outside of the box when it came to networked communication.
The first major hurdle was to find a way to communicate from Alexa to Unreal - we needed to be able to communicate back the natural language parsing abilities of the Amazon API to the game. So, we created a complex system of runnable threads and sockets inside of UE4 to pipe in data (see challenges section for more info on the difficulties here). Next, we created a corresponding client socket creation mechanism on the intermediary Python server to connect into the game engine. Finally, we created a basic registration system where game clients can register their publicly exposed IPs and Ports to Python.
The second step was to communicate between Alexa and Python. We utilitzed [Flask-Ask](https://flask-ask.readthedocs.io/en/latest/) to abstract away most of the communication difficulties,. Next, we used [VaRest](https://github.com/ufna/VaRest), a plugin for handing JSON inside of unreal, to communicate from the game directly to Alexa.
The third and final step was to create a compelling and visually telling narrative for the player to follow. Though we can't describe too much of that in text, we'd love you to give the game a try :)
## Challenges we ran into
The challenges we ran into divided roughly into three sections:
* **Threading**: This was an obvious problem from the start. Game engines rely on a single main "UI" thread to be unblocked and free to process for the entirety of the game's life-cycle. Running a socket that blocks for input is a concept in direct conflict with that idiom. So, we dove into the FSocket documentation in UE4 (which, according to Trung, hasn't been touched since Unreal Tournament 2...) - needless to say it was difficult. The end solution was a combination of both FSocket and FRunnable that could block and certain steps in the socket process without interrupting the game's main thread. Lots of stuff like this happened:
```
while (StopTaskCounter.GetValue() == 0)
{
socket->HasPendingConnection(foo);
while (!foo && StopTaskCounter.GetValue() == 0)
{
Sleep(1);
socket->HasPendingConnection(foo);
}
// at this point there is a client waiting
clientSocket = socket->Accept(TEXT("Connected to client.:"));
if (clientSocket == NULL) continue;
while (StopTaskCounter.GetValue() == 0)
{
Sleep(1);
if (!clientSocket->HasPendingData(pendingDataSize)) continue;
buf.Init(0, pendingDataSize);
clientSocket->Recv(buf.GetData(), buf.Num(), bytesRead);
if (bytesRead < 1) {
UE_LOG(LogTemp, Error, TEXT("Socket did not receive enough data: %d"), bytesRead);
return 1;
}
int32 command = (buf[0] - '0');
// call custom event with number here
alexaEvent->Broadcast(command);
clientSocket->Close();
break; // go back to wait state
}
}
```
Notice a few things here: we are constantly checking for a stop call from the main thread so we can terminate safely, we are sleeping to not block on Accept and Recv, and we are calling a custom event broadcast so that the actual game logic can run on the main thread when it needs to.
The second point of contention in threading was the Python server. Flask doesn't natively support any kind of global-to-request variables. So, the canonical approach of opening a socket once and sending info through it over time would not work, regardless of how hard we tried. The solution, as you can see from the above C++ snippet, was to repeatedly open and close a socket to the game on each Alexa call. This ended up causing a TON of problems in debugging (see below for difficulties there) and lost us a bit of time.
* **Network Protocols**: Of all things to deal with in terms of networks, we spent he largest amount of time solving the problems for which we had the least control. Two bad things happened: heroku rate limited us pretty early on with the most heavily used URLs (i.e. the Alexa responders). This prompted two possible solutions: migrate to DigitalOcean, or constantly remake Heroku dynos. We did both :). DigitalOcean proved to be more difficult than normal because the Alexa API only works with HTTPS addresses, and we didn't want to go through the hassle of using LetsEncrypt with Flask/Gunicorn/Nginx. Yikes. Switching heroku dynos it was.
The other problem we had was with timeouts. Depending on how we scheduled socket commands relative to REST requests, we would occasionally time out on Alexa's end. This was easier to solve than the rate limiting.
* **Level Design**: Our levels were carefully crafted to cater to the dual player relationship. Each room and lighting balance was tailored so that the player wouldn't feel totally lost, but at the same time, would need to rely heavily on Em for guidance and path planning.
## Accomplishments that we're proud of
The single largest thing we've come together in solving has been the integration of standard web protocols into a game engine. Apart from matchmaking and data transmission between players (which are both handled internally by the engine), most HTTP based communication is undocumented or simply not implemented in engines. We are very proud of the solution we've come up with to accomplish true bidirectional communication, and can't wait to see it implemented in other projects. We see a lot of potential in other AAA games to use voice control as not only an additional input method for players, but a way to catalyze gameplay with a personal connection.
On a more technical note, we are all so happy that...
THE DAMN SOCKETS ACTUALLY WORK YO
## Future Plans
We'd hope to incorporate the toolchain we've created for Project Em as a public GItHub repo and Unreal plugin for other game devs to use. We can't wait to see what other creative minds will come up with!
### Thanks
Much <3 from all of us, Sacha (CIS '17), Akshay (CGGT '17), Trung (CGGT '17), and Max (ROBO '16). Find us on github and say hello anytime. | losing |
## Inspiration
Discord is used by many companies, students, or basically anyone to connect with their peers, friends, teachers, or coworkers. It's massively gained traction throughout the pandemic, now becoming an essential component of our lives. It's become so popular that even universities and schools are creating discord keys to pass on important information to students. Several people use it for hosting podcasts, company meetings, online lectures, etc. Being long-time users of discord, we felt that we could enhance everyone's experience by allowing people to record, save and get transcriptions of their voice calls. We wanted to leverage the power of AI to make do all of this effortlessly. Because the Whisper model from OpenAI supports various languages, it is more tolerant of speakers of other languages and promotes diversity online.
## What it does
Discribe is a Discord bot that records, transcribes, and summarizes your Discord voice calls and sends them over to your chat, whenever you wish.
## How we built it
None of us had made a discord bot before, but we knew of various technologies that could be used to code one. We eventually decided on discord.js since some of us had experience with JavaScript. Discord does not support recording audio in its API, but we found a solution involving streams that allowed us to record. Using ffmpeg, we were able to create mp3 files from these streams.
After that, we experimented with OpenAI’s Whisper, an automatic speech recognition system. It was simplest for us to communicate with the AI using Python, so we used that. Once we could convert any .mp3 files into text, we used Co:heres API to create an NLP model that summarises text. We then combined the two models, to create a programme that summarises the .mp3 file.
Lastly, we created a system for the JavaScript bot and Python program to speak to each other while both are running.
## Themes
**Discovery** \
Normally we rely on video recorders and play back to store our calls, and this doesn't work since a voice recording will always have random junk in it that we don't want to see. If you've ever put a lecture recording on double speed to save yourself the boredom, you will know what we mean. New technologies such as Whisper are just becoming stronger and stronger at converting the voice into text, that it makes sense to apply them to a situation like this. Combined with Cohere's powerful language processing API, we can filter out anything you don't need to read, so a users time is saved and a discussion from the past is easier to recall.
**Diversity** \
Today, humans manually transcribe audio/video content on platforms like Discord, Instagram, and Reddit. These transcriptions are quite useful for those who are deaf or hard of hearing. People from countries with limited access to the internet are known to use transcriptions to consume media as the poor connection speeds are unable to load the video content. The functionality our bot provides can improve the lives of these people. A human is not always there to transcribe media, but an AI can always be there.
## Challenges we ran into
Getting the individual pieces of the program working took much less time compared to figuring out how to get them to communicate. We tried many libraries designed to allow JavaScript to talk with Python, but none worked perfectly. We ended up creating our own solution using the functionality built into JavaScript.
We also extensively tested the NLP text summarization models, as there were a lot of parameters in the model we had to tune to be able to get summaries that fit our use case.
## Accomplishments that we're proud of
We are proud that we ended up with a product, in roughly 24 hours, that works exactly as we intended it to, right from an idea and converting it into a usable tool with plenty of utilities waiting to be added in the near future. Despite the numerous errors we faced, we never gave up and ultimately were genuinely satisfied with all of our efforts as a team.
## What we learned
Hack the Valley being the first-ever hackathon that we have all participated in has taught us a lot, whether it be implementing new APIs and ML models for the first time or just handling failures. We went into this challenge doubtful that we would be able to write even a half-functioning program, but we surprised ourselves with how much we can get done if we put in serious effort. We learned to stay together and solve problems that we have never encountered in the past and our genuinely proud of the hard work all of us put in.
## What's next for Discribe
Our main goal is to expand the use of our bot to other social media platforms, mainly Reddit. With some code refactoring, the bot can start transcribing videos that are posted automatically. We could achieve this scale using hosting services such as Microsoft Azure. To extend its utilities, we will be working to detect and extract useful and critical information such as key topics, phone numbers, addresses, or maybe we could even separate voices in the transcription, to give good context about who is speaking. | ## Inspiration
*For a more expressive texting experience.*
Texting often lacks the non-verbal cues present in talking face-to-face, especially when using Speech-to-Text programs. Emojis help show intent, and clarify ambiguous texts; they are the non-verbal cues of texting. Naturally, some Speech-to-Text programs do support emojis, but they rely on phrases like "happy face" or "sad face." This could become problematic/unnatural/inconvenient while speaking. We were inspired to make an Discord bot that streamlines Speech-to-Text and emojis by analyzing real-time facial expressions and converting them into emojis, while also transcribing voice to text.
It also helps people who have a hard time picking up social cues. This one is for you, Alex 😉.
## What it does
Our program takes a video file and transcribes it with AssemblyAI API. Then, using the MoviePy library, we sliced up the video file into frames and into images. Next, we use Google's Cloud Vision API to detect faces in these images, as well as their emotions. Finally, we return the text back to the user along with the emoji.
## How we built it
We built with Python, AssemblyAI, and Cloud Vision.
## Challenges we ran into
Originally, we planned on making a discord bot, but we did not manage to captured both voice and video. Thus, we decided to put the Discord integration aside, and focus on the backend of the application.
## Accomplishments that we're proud of
We changed the course of our project with a few hours left in the hackathon, and still managed to get a few hours of sleep.
## What we learned
* How to create webhooks
* How to make discord bots
* How to make API calls and deal with JSON responses
## What's next for Teemo
* To incorporate the ability to analyze the tone of the transcript.
* Eventual integration with Discord (or some other frontend/app)
* More expressive emojis (maybe even non-emotion emojis) | ## **Inspiration:**
Our inspiration stemmed from the realization that the pinnacle of innovation occurs at the intersection of deep curiosity and an expansive space to explore one's imagination. Recognizing the barriers faced by learners—particularly their inability to gain real-time, personalized, and contextualized support—we envisioned a solution that would empower anyone, anywhere to seamlessly pursue their inherent curiosity and desire to learn.
## **What it does:**
Our platform is a revolutionary step forward in the realm of AI-assisted learning. It integrates advanced AI technologies with intuitive human-computer interactions to enhance the context a generative AI model can work within. By analyzing screen content—be it text, graphics, or diagrams—and amalgamating it with the user's audio explanation, our platform grasps a nuanced understanding of the user's specific pain points. Imagine a learner pointing at a perplexing diagram while voicing out their doubts; our system swiftly responds by offering immediate clarifications, both verbally and with on-screen annotations.
## **How we built it**:
We architected a Flask-based backend, creating RESTful APIs to seamlessly interface with user input and machine learning models. Integration of Google's Speech-to-Text enabled the transcription of users' learning preferences, and the incorporation of the Mathpix API facilitated image content extraction. Harnessing the prowess of the GPT-4 model, we've been able to produce contextually rich textual and audio feedback based on captured screen content and stored user data. For frontend fluidity, audio responses were encoded into base64 format, ensuring efficient playback without unnecessary re-renders.
## **Challenges we ran into**:
Scaling the model to accommodate diverse learning scenarios, especially in the broad fields of maths and chemistry, was a notable challenge. Ensuring the accuracy of content extraction and effectively translating that into meaningful AI feedback required meticulous fine-tuning.
## **Accomplishments that we're proud of**:
Successfully building a digital platform that not only deciphers image and audio content but also produces high utility, real-time feedback stands out as a paramount achievement. This platform has the potential to revolutionize how learners interact with digital content, breaking down barriers of confusion in real-time. One of the aspects of our implementation that separates us from other approaches is that we allow the user to perform ICL (In Context Learning), a feature that not many large language models don't allow the user to do seamlessly.
## **What we learned**:
We learned the immense value of integrating multiple AI technologies for a holistic user experience. The project also reinforced the importance of continuous feedback loops in learning and the transformative potential of merging generative AI models with real-time user input. | losing |
## 💡 INSPIRATION
We first thought of building something for the deaf & blind because one of our team member's close family relations has slowly been acquiring age-related dual vision and hearing loss.
Deafblindness has been traditionally overlooked. The combination of sensory losses means existing solutions, such as sign language for the deaf or speech transcription for the blind, cannot be used. As a result, over 160 million Deafblind people around the world are severely limited in their ability to communicate.
Current solutions require uncomfortable physical contact or the presence of a 24/7 guide-communicator, preventing independence. These barriers to being able to freely explore and interact with your world can lead to you feeling isolated and alone.
## 🎯 OUR GOAL
Our goal was to build a communication device that can help Deafblind persons understand and communicate with the world without invasive physical contact, a requirement for a volunteer communicator, or an inaccessible/impractical design.
---
# 🔭 WHAT IS PERCEIV/IO?
PERCEIV/IO is a novel hardware device powered by the latest AI advancements to help the Deafblind.
We designed PERCEIV/IO to have two main use-cases. First, used a camera to take periodic captures of the world in front of the user and use AI image-to-text technologies to translate it into braille, which is then displayed on a tactile hand-held device that we have fabricated. This can help a Deafblind person understand their surroundings, which is currently very limited in scope. Second, we designed a speech-to-braille system to help allow for communication with the Deafblind. We also incorporated sentiment analysis to effectively convey the tones of standard English phrases to make communication more robust. The specific details can be found in the next section.
We hope some of the ideas generated during this hackathon turn are able to be used in organizations such as [CNIB Deafblind Community Services](https://deafblindservices.ca/about-us) in order to help them with their goal of assisting people who need it most.
## 📣 FEATURES
* Get a description of the world in front of you translated into braille directly at your fingertips.
* Live English-to-braille translation & sentiment analysis to allow for more robust communication.
* Store a profile of the user so PERCEIV/IO can recognize common occurrences such as people and places.
* An accompanying, fully functional, universally deployed web app that allows you to view your profile and update it with any necessary info.
## 🛠️ HOW WE BUILT IT
### Hardware
We designed our hardware using four stepper motors and their drivers, 3D printed braille discs, 3D printed stepper motor housings, a Raspberry Pi 3B, and custom 3D printed housings. Each stepper motor controls an octagonal braille disc. Placing two of these side-by-side creates a full braille cell, with different stepper motor rotations producing different braille characters. We designed the Raspberry Pi code on Python and developed our own algorithim for converting text directly into stepper motor coordinates (position to display the correct braille character).
### Software
We used image recognition AI based on **Groq** using their Llava v1.5 image-to-text endpoint, and that text is then put through **Groq**'s Llama 3.1 70b endpoint to condense it down into just two or three words. We used Google Speech-to-Text and the Facebook RoBERTa base model for simple sentiment analysis with a **Genesys**-based sentiment analysis feature currently being deployed. We developed our own code to convert into Grade II Unified English Braille Code.
On the backend, our database is based on **Convex** along with our accompanying app. We also built a prototype, web-hosted app on the Streamlit platform integrated with hugging face ML models loaded through the transformers pipeline.
We facilitated wireless communication between the apps and the hardware through Github by running functions to update a file and check for updates on a file. We are also working on a **Genesys** based AI chat bot, the responses of which would be translated into braille and communicated to the user.
## 🌎 ENVIRONMENTALLY CONSCIOUS
As users of AI during this boom of innovation over the last couple years, we strive to be as environmentally conscious as possible and be aware of the power we are consuming whenever we prompt an LLM. Over the course of a large model's first one million messages, it has an estimated power cost of [55.1Mwh](https://adasci.org/how-much-energy-do-llms-consume-unveiling-the-power-behind-ai/). That's enough power to power roughly 120 American homes for a year!
Thankfully, with **Groq**, not only do we have access to lightning-fast response speeds, but due to their LPUs, SRAM, and sequential processing we are using less power than if we were to use the traditional NVIDIA counterpart. Conserving energy is very important to us, and we are thankful for Groq to providing a solution for us.
## 🧗♀️ CHALLENGES WE'VE OVERCOME
Hackathons are about nothing if not overcoming challenges. Whenever a piece of hardware broke, software wouldn't cooperate, or motors wouldn't connect, we would work as a team to solve the issue and push on through. It ended up being a very rewarding experience for all of us.
One major challenge that's still fresh in my mind is our issues with the Raspberry Pi. We ended up going through *three* Pi's before we realized that none of their SD cards had any OS on them! Eventually, with the help of the amazing mentors here at Hack The North (thank you again Moody!), we we're able to get the SD card flashed and were able to start uploading our code. Thankfully, due to our adoption of SOLID principles and our policy of encapsulation, we were able to implement the code we has worked on in the meantime with ease.
Our hardware issues didn't end there! After careful testing of almost every different software & hardware component to determine why our code was not working, we found that 2 stepper motor drivers were faulty. With the help of mentors, however, we got this resolved and we learned the painstakingly careful process of hardware verification!
Another problem was more to do with logic- turning an image into text is easy. Turning that text into braille, and then turning that braille into signals from a Raspberry Pi into 4 proprietary stepper motors that control half of a braille character each is whole other. Luckily with some wisdom from our team members with past experience with these kinds of electronics combined with some logic learned in hardware classes, we as a team were able to come up with the implementation to make it work.
## 🏆 WHAT WE'RE PROUD OF
We are most proud of coming up with a novel idea that uses novel technology to help people in need. I think it is everyone's desire to develop something that is actually useful to other humans, especially while utilizing the latest technologies. We think that technology's greatest advantages are the advantages it is able to give to others in order to promote diversity, equity and inclusion.
### Some Specifics
The device our team members' relative would have to use costs upwards of $3000 USD ([link](https://store.humanware.com/hus/brailliant-bi-40x-braille-display.html)). This is prohibitively expensive, especially given that many of the world's Deafblind come from underprivileged nations. The prototyping costs for our hardware were free, thanks to Hack the North. However, we estimate manufacturing costs to be under $100 given the low-cost hardware, making this system far more affordable.
Second, our system is novel in its comprehensive approach. Current solutions (such as the $3000 product) require a connection to an external computer to function. This means they cannot be used portably, thereby preventing a Deafblind person from being able to explore. Moreover, they do not integrate any of the image-to-braille or speech & sentiment-to-braille technologies, severely limiting their scope. We believe our project will substantially improve the status quo by allowing for these features. Our device is portable, can be used without additional peripherals, and integrates all necessary conversion technology.
Lastly, our prototype has two fully-functioning braille cells that *follow the distance and format requirements of Grade II Braille*. This means that our hardware is *not just a proof of concept* for a braille device, but could actually be implemented directly in Deafblind communities. Moreover, it is likely to be extremely efficient as the stepper motor design does not require individual motors for each braille pin, but rather just one motor for a whole column.
**Perhaps most importantly, though...**
We are so proud of the fact that we came up with and created a working prototype for our idea within only 32 hours(!!!). For many of us, this was our first time working with hardware within such a short time frame, so learning the ins and outs of it enough to make a product is a huge accomplishment.
## 💡 WHAT DID WE LEARN?
Over the course of this hackathon, we learned so much about the Deafblind community by reading online testimonials of those who have been diagnosed. It allowed us insight into a corner of the world that we had otherwise not known much about prior. Through developing our product while keeping these testimonials in mind, we also realized the difference between developing a product in order to beat others in a competition and developing a product because we believe this could actually be useful to real people one day.
The many sponsors here at Hack The North were also very valuable in teaching us about their product and how we can implement them into our product to improve it's functionality and efficiency. For example, Groq were very helpful in describing exactly why utilizing their API was more energy efficient than the big guys. We were super eager to learn about new technologies such as Symphonic labs, as we realized their use-case as an AI that can read lips was very applicable to our device.
## 🔜 THE FUTURE OF PERCEIV/IO
We have thought long and hard about the future of PERCEIV/IO. We've already come up with a laundry list of ideas that we want to implement sometime in the future in order for this product to achieve it's full potential. The number one thing is to shrink the size of the actual hardware. Raspberry Pi's are extremely useful for prototyping- but are a bit too bulky for use in a commercial product. We want to achieve a size similar to a smart watch with similar processing power.
We also want to relocate the camera and have it wirelessly communicate with the computer. One idea was to embed the camera into a pair of sunglasses in a similar style to [Spectacles](https://www.spectacles.com/ca-en/) by Snap Inc.
And finally, we are waiting for the day where AI technology and hardware reaches a point where we can run all models locally, without the need for a massive power bank or network connection. That would truly untether the user from any external requirements for a real feeling of freedom.
---
### 🪿 Thank you to all who showed interested in PERCEIV/IO, and a huge congratulations to *all* hackers who submitted in time. **We did it!** | ## Inspiration
Over **15% of American adults**, over **37 million** people, are either **deaf** or have trouble hearing according to the National Institutes of Health. One in eight people have hearing loss in both ears, and not being able to hear or freely express your thoughts to the rest of the world can put deaf people in isolation. However, only 250 - 500 million adults in America are said to know ASL. We strongly believe that no one's disability should hold them back from expressing themself to the world, and so we decided to build Sign Sync, **an end-to-end, real-time communication app**, to **bridge the language barrier** between a **deaf** and a **non-deaf** person. Using Natural Language Processing to analyze spoken text and Computer Vision models to translate sign language to English, and vice versa, our app brings us closer to a more inclusive and understanding world.
## What it does
Our app connects a deaf person who speaks American Sign Language into their device's camera to a non-deaf person who then listens through a text-to-speech output. The non-deaf person can respond by recording their voice and having their sentences translated directly into sign language visuals for the deaf person to see and understand. After seeing the sign language visuals, the deaf person can respond to the camera to continue the conversation.
We believe real-time communication is the key to having a fluid conversation, and thus we use automatic speech-to-text and text-to-speech translations. Our app is a web app designed for desktop and mobile devices for instant communication, and we use a clean and easy-to-read interface that ensures a deaf person can follow along without missing out on any parts of the conversation in the chat box.
## How we built it
For our project, precision and user-friendliness were at the forefront of our considerations. We were determined to achieve two critical objectives:
1. Precision in Real-Time Object Detection: Our foremost goal was to develop an exceptionally accurate model capable of real-time object detection. We understood the urgency of efficient item recognition and the pivotal role it played in our image detection model.
2. Seamless Website Navigation: Equally essential was ensuring that our website offered a seamless and intuitive user experience. We prioritized designing an interface that anyone could effortlessly navigate, eliminating any potential obstacles for our users.
* Frontend Development with Vue.js: To rapidly prototype a user interface that seamlessly adapts to both desktop and mobile devices, we turned to Vue.js. Its flexibility and speed in UI development were instrumental in shaping our user experience.
* Backend Powered by Flask: For the robust foundation of our API and backend framework, Flask was our framework of choice. It provided the means to create endpoints that our frontend leverages to retrieve essential data.
* Speech-to-Text Transformation: To enable the transformation of spoken language into text, we integrated the webkitSpeechRecognition library. This technology forms the backbone of our speech recognition system, facilitating communication with our app.
* NLTK for Language Preprocessing: Recognizing that sign language possesses distinct grammar, punctuation, and syntax compared to spoken English, we turned to the NLTK library. This aided us in preprocessing spoken sentences, ensuring they were converted into a format comprehensible by sign language users.
* Translating Hand Motions to Sign Language: A pivotal aspect of our project involved translating the intricate hand and arm movements of sign language into a visual form. To accomplish this, we employed a MobileNetV2 convolutional neural network. Trained meticulously to identify individual characters using the device's camera, our model achieves an impressive accuracy rate of 97%. It proficiently classifies video stream frames into one of the 26 letters of the sign language alphabet or one of the three punctuation marks used in sign language. The result is the coherent output of multiple characters, skillfully pieced together to form complete sentences
## Challenges we ran into
Since we used multiple AI models, it was tough for us to integrate them seamlessly with our Vue frontend. Since we are also using the webcam through the website, it was a massive challenge to seamlessly use video footage, run realtime object detection and classification on it and show the results on the webpage simultaneously. We also had to find as many opensource datasets for ASL as possible, which was definitely a challenge, since with a short budget and time we could not get all the words in ASL, and thus, had to resort to spelling words out letter by letter. We also had trouble figuring out how to do real time computer vision on a stream of hand gestures of ASL.
## Accomplishments that we're proud of
We are really proud to be working on a project that can have a profound impact on the lives of deaf individuals and contribute to greater accessibility and inclusivity. Some accomplishments that we are proud of are:
* Accessibility and Inclusivity: Our app is a significant step towards improving accessibility for the deaf community.
* Innovative Technology: Developing a system that seamlessly translates sign language involves cutting-edge technologies such as computer vision, natural language processing, and speech recognition. Mastering these technologies and making them work harmoniously in our app is a major achievement.
* User-Centered Design: Crafting an app that's user-friendly and intuitive for both deaf and hearing users has been a priority.
* Speech Recognition: Our success in implementing speech recognition technology is a source of pride.
* Multiple AI Models: We also loved merging natural language processing and computer vision in the same application.
## What we learned
We learned a lot about how accessibility works for individuals that are from the deaf community. Our research led us to a lot of new information and we found ways to include that into our project. We also learned a lot about Natural Language Processing, Computer Vision, and CNN's. We learned new technologies this weekend. As a team of individuals with different skillsets, we were also able to collaborate and learn to focus on our individual strengths while working on a project.
## What's next?
We have a ton of ideas planned for Sign Sync next!
* Translate between languages other than English
* Translate between other sign languages, not just ASL
* Native mobile app with no internet access required for more seamless usage
* Usage of more sophisticated datasets that can recognize words and not just letters
* Use a video image to demonstrate the sign language component, instead of static images | ## welcome to Catmosphere!
we wanted to make a game with (1) cats and (2) cool art. inspired by the many "cozy indie" games on steam and on social media, we got working on a game where the cat has to avoid all the obstacles as it attempts to go into outer space.
**what it does**: use the WASD keys to navigate our cat around the enemies. enter the five levels of the atmosphere and enjoy the art and music while you're at it!
**what's next for Catmosphere**: adding more levels, a restart button, & a new soundtrack and artwork | partial |
## Inspiration
We're all told that stocks are a good way to diversify our investments, but taking the leap into trading stocks is daunting. How do I open a brokerage account? What stocks should I invest in? How can one track their investments? We learned that we were not alone in our apprehensions, and that this problem is even worse in other countries. For example, in Indonesia (Scott's home country), only 0.3% of the population invests in the stock market.
A lack of active retail investor community in the domestic stock market is very problematic. Investment in the stock markets is one of the most important factors that contribute to the economic growth of a country. That is the problem we set out to address. In addition, the ability to invest one's savings can help people and families around the world grow their wealth -- we decided to create a product that makes it easy for those people to make informed, strategic investment decisions, wrapped up in a friendly, conversational interface.
## What It Does
PocketAnalyst is a Facebook messenger and Telegram chatbot that puts the brain of a financial analyst into your pockets, a buddy to help you navigate the investment world with the tap of your keyboard. Considering that two billion people around the world are unbanked, yet many of them have access to cell/smart phones, we see this as a big opportunity to push towards shaping the world into a more egalitarian future.
**Key features:**
* A bespoke investment strategy based on how much risk users opt to take on, based on a short onboarding questionnaire, powered by several AI models and data from Goldman Sachs and Blackrock.
* In-chat brokerage account registration process powered DocuSign's API.
* Stock purchase recommendations based on AI-powered technical analysis, sentiment analysis, and fundamental analysis based on data from Goldman Sachs' API, GIR data set, and IEXFinance.
* Pro-active warning against the purchase of a high-risk and high-beta assets for investors with low risk-tolerance powered by BlackRock's API.
* Beautiful, customized stock status updates, sent straight to users through your messaging platform of choice.
* Well-designed data visualizations for users' stock portfolios.
* In-message trade execution using your brokerage account (proof-of-concept for now, obviously)
## How We Built it
We used multiple LSTM neural networks to conduct both technical analysis on features of stocks and sentiment analysis on news related to particular companies
We used Goldman Sachs' GIR dataset and the Marquee API to conduct fundamental analysis. In addition, we used some of their data in verifying another one of our machine learning models. Goldman Sachs' data also proved invaluable for the creation of customized stock status "cards", sent through messenger.
We used Google Cloud Platform extensively. DialogFlow powered our user-friendly, conversational chatbot. We also utilized GCP's computer engine to help train some of our deep learning models. Various other features, such as the app engine and serverless cloud functions were used for experimentation and testing.
We also integrated with Blackrock's APIs, primarily for analyzing users' portfolios and calculating the risk score.
We used DocuSign to assist with the paperwork related to brokerage account registration.
## Future Viability
We see a clear path towards making PocketAnalyst a sustainable product that makes a real difference in its users' lives. We see our product as one that will work well in partnership with other businesses, especially brokerage firms, similar to what CreditKarma does with credit card companies. We believe that giving consumers access to a free chatbot to help them invest will make their investment experiences easier, while also freeing up time in financial advisors' days.
## Challenges We Ran Into
Picking the correct parameters/hyperparameters and discerning how our machine learning algorithms will make recommendations in different cases.
Finding the best way to onboard new users and provide a fully-featured experience entirely through conversation with a chatbot.
Figuring out how to get this done, despite us not having access to a consistent internet connection (still love ya tho Cal :D). Still, this hampered our progress on a more-ambitious IOT (w/ google assistant) stretch goal. Oh, well :)
## Accomplishments That We Are Proud Of
We are proud of our decision in combining various Machine Learning techniques in combination with Goldman Sachs' Marquee API (and their global investment research dataset) to create a product that can provide real benefit to people. We're proud of what we created over the past thirty-six hours, and we're proud of everything we learned along the way!
## What We Learned
We learned how to incorporate already existing Machine Learning strategies and combine them to improve our collective accuracy in making predictions for stocks. We learned a ton about the different ways that one can analyze stocks, and we had a great time slotting together all of the different APIs, libraries, and other technologies that we used to make this project a reality.
## What's Next for PocketAnalyst
This isn't the last you've heard from us!
We aim to better fine-tune our stock recommendation algorithm. We believe that are other parameters that were not yet accounted for that can better improve the accuracy of our recommendations; Down the line, we hope to be able to partner with finance professionals to provide more insights that we can incorporate into the algorithm. | ## Inspiration
My father put me in charge of his finances and in contact with his advisor, a young, enterprising financial consultant eager to make large returns. That might sound pretty good, but to someone financially conservative like my father doesn't really want that kind of risk in this stage of his life. The opposite happened to my brother, who has time to spare and money to lose, but had a conservative advisor that didn't have the same fire. Both stopped their advisory services, but that came with its own problems. The issue is that most advisors have a preferred field but knowledge of everything, which makes the unknowing client susceptible to settling with someone who doesn't share their goals.
## What it does
Resonance analyses personal and investment traits to make the best matches between an individual and an advisor. We use basic information any financial institution has about their clients and financial assets as well as past interactions to create a deep and objective measure of interaction quality and maximize it through optimal matches.
## How we built it
The whole program is built in python using several libraries for gathering financial data, processing and building scalable models using aws. The main differential of our model is its full utilization of past data during training to make analyses more wholistic and accurate. Instead of going with a classification solution or neural network, we combine several models to analyze specific user features and classify broad features before the main model, where we build a regression model for each category.
## Challenges we ran into
Our group member crucial to building a front-end could not make it, so our designs are not fully interactive. We also had much to code but not enough time to debug, which makes the software unable to fully work. We spent a significant amount of time to figure out a logical way to measure the quality of interaction between clients and financial consultants. We came up with our own algorithm to quantify non-numerical data, as well as rating clients' investment habits on a numerical scale. We assigned a numerical bonus to clients who consistently invest at a certain rate. The Mathematics behind Resonance was one of the biggest challenges we encountered, but it ended up being the foundation of the whole idea.
## Accomplishments that we're proud of
Learning a whole new machine learning framework using SageMaker and crafting custom, objective algorithms for measuring interaction quality and fully utilizing past interaction data during training by using an innovative approach to categorical model building.
## What we learned
Coding might not take that long, but making it fully work takes just as much time.
## What's next for Resonance
Finish building the model and possibly trying to incubate it. | ## Inspiration
GET RICH QUICK!
## What it does
Do you want to get rich? Are you tired of the man holding you down? Then, WeakLink.Ai is for you! Our app comes equipped with predictive software to suggest the most beneficial stocks to buy based off your preferences. Simply said, a personal stock broker in your pocket.
## How we built it
Weaklink.Ai front end is built using the Dash framework for python. The partnered transactions are preformed with the assistance of Standard Library where our back end calculation engine uses modern machine learning techniques to make decisions about the best time to buy or sell a specific stock. Confirmation is sent to the user's mobile device via Twilio. Upon confirmation the workflow will execute the buy or sell transaction. The back end engine was custom built in python by one of our engineers.
## Challenges we ran into
It was difficult to scrape the web for precise data in a timely and financially efficient fashion.
It was very challenging to integrate Blockstack into a full python environment.
The front end design was reformatted several times.
There was some learning curves adjusting to never before seen or used api.
Finding financially efficient solutions to some api
## Accomplishments that we're proud of
Despite the various challenges we are proud of our project. The front was more visually appealing than anticipated. The transition from back end calculations to visual inspection was relatively seamless. This was our first time working with each other and we had very good synergy, we were able to divide up the work and support one another along the way each taking part in touching each aspect of the project.
## What we learned
The various api available as well as some of their limitations. We discovered that open source api is often more helpful than a closed source black box. We also learned a lot about data security via Blockstack. Lastly we learned about various ways to interpret and analyze stocks in a quantitative fashion.
## What's next for WeakLink.Ai
There is a lot of work left for us. The most immediate priority would be to set up trend analysis based on historical data of the user followed by more customization options. A place for the user to describe their desires and our machine learning algorithm will take that information into account in order to recommend actions of the user which is in their best interest. | winning |
## Inspiration
I was inspired to create this project when I was trying to study for school. I found that sometimes, learning and memorizing everything visually can get boring, and I wanted to look for other ways of learning. Then, I also thought that using virtual assistant technology like Alexa and Google home for learning could be a refreshing and interesting way to be able to memorize and study what you need to know for school. Combining these ideas create a method of learning which would be especially helpful for auditory and verbal learners. Thus, I decided to take the opportunity to make my own Alexa skill for this purpose. Note: the name QWizard comes from the combination of “quiz” and “wizard”.
## What it does
The purpose of QWizard is to allow users to quiz themselves on the questions and answers they submit. In the first section, the user is prompted to say their questions and their answers. These questions and answers are all stored in 2 arrays. However, once they say ‘start’ instead of a question, they move on to the second section. From here, the user is asked the question and if their answer is correct, their score is incremented by 1.
The github repository allows you to run QWizard in the terminal.
## How we built it
I built this project using Voiceflow, javascript inside the custom code blocks, node.js for the part uploaded to Github, and the Alexa developer console.
## Challenges we ran into
The main challenge of this project was learning how the prompt block and the Intent block work, but they were quite simple to learn.
## Accomplishments that we're proud of
I’m proud that I was able to figure out how to use Voiceflow in a short time period to be able to create the project that I originally had in mind.
## What we learned
I learned a lot about the development process of chat bot assistants and apps while using Voiceflow. One thing that was new to me in particular was the use of things like intents and utterances in speech recognition technology.
## What's next for QWizard
Currently, QWizard is still in the process of being reviewed before being distributed to the public. In the future, it will be available for anyone to install and use on an Amazon Alexa device. | # What it Does
Community essentially allows those in need to be reimbursed by generous donors for daily regular purchases. If the user is a donor, they can view all of the purchases that want to be reimbursed within their proximity using the Google Maps Flutter Package, and from that they will be able to select the specific purchase they want to reimburse. Once the donor selects the Reimburse button, using Stripe API, the donor is charged the amount of the purchase plus a small operating fee, and the recipient gets reimbursed. On the recipient end, the recipient simply scans a barcode on their receipt which sends a UUID to the app with all the necessary purchase information, and then they wait for potential reimbursements.
# Inspirations
We were motivated to improve modern donation services by allowing people who require assistance within your community to obtain donations without the use of a middleman. This served as an excelled opportunity to give back to society and practice social good. Therefore, we made community, a mobile app that connects Donors to recipients within their community allowing them to reimburse recipients for purchases. This will ultimately make a meaningful impact for the members of the community who are struggling or going through difficult times and will help them realize that somebody is there to help them.
# Technology Used
* Django Rest Framework to develop API
* Azure SQL Server
* Azure App Service
* Flutter for mobile app development
* Firebase
# Learning Lessons
Throughout this project, our team learned many lessons that had a significant impact on the processes of our work. We learned about the importance of having an Agile working environment in order to catch bugs and errors as soon as possible. We also learned a lot about Azure as this was the first time anyone in our team has used this particular service. At first, we did have trouble integrating Azure, however through trial and error we were able to successfully create a live server that deploys our API. We also had issues with Django migrations throughout due to slight errors in Version Control, but after discussing a formal process for which to push and pull code, we were able to solve these issues and deploy successfully. | ## Inspiration
University gets students really busy and really stressed, especially during midterms and exams. We would normally want to talk to someone about how we feel and how our mood is, but due to the pandemic, therapists have often been closed or fully online. Since people will be seeking therapy online anyway, swapping a real therapist with a chatbot trained in giving advice and guidance isn't a very big leap for the person receiving therapy, and it could even save them money. Further, since all the conversations could be recorded if the user chooses, they could track their thoughts and goals, and have the bot respond to them. This is the idea that drove us to build Companion!
## What it does
Companion is a full-stack web application that allows users to be able to record their mood and describe their day and how they feel to promote mindfulness and track their goals, like a diary. There is also a companion, an open-ended chatbot, which the user can talk to about their feelings, problems, goals, etc. With realtime text-to-speech functionality, the user can speak out loud to the bot if they feel it is more natural to do so. If the user finds a companion conversation helpful, enlightening or otherwise valuable, they can choose to attach it to their last diary entry.
## How we built it
We leveraged many technologies such as React.js, Python, Flask, Node.js, Express.js, Mongodb, OpenAI, and AssemblyAI. The chatbot was built using Python and Flask. The backend, which coordinates both the chatbot and a MongoDB database, was built using Node and Express. Speech-to-text functionality was added using the AssemblyAI live transcription API, and the chatbot machine learning models and trained data was built using OpenAI.
## Challenges we ran into
Some of the challenges we ran into were being able to connect between the front-end, back-end and database. We would accidentally mix up what data we were sending or supposed to send in each HTTP call, resulting in a few invalid database queries and confusing errors. Developing the backend API was a bit of a challenge, as we didn't have a lot of experience with user authentication. Developing the API while working on the frontend also slowed things down, as the frontend person would have to wait for the end-points to be devised. Also, since some APIs were relatively new, working with incomplete docs was sometimes difficult, but fortunately there was assistance on Discord if we needed it.
## Accomplishments that we're proud of
We're proud of the ideas we've brought to the table, as well the features we managed to add to our prototype. The chatbot AI, able to help people reflect mindfully, is really the novel idea of our app.
## What we learned
We learned how to work with different APIs and create various API end-points. We also learned how to work and communicate as a team. Another thing we learned is how important the planning stage is, as it can really help with speeding up our coding time when everything is nice and set up with everyone understanding everything.
## What's next for Companion
The next steps for Companion are:
* Ability to book appointments with a live therapists if the user needs it. Perhaps the chatbot can be swapped out for a real therapist for an upfront or pay-as-you-go fee.
* Machine learning model that adapts to what the user has written in their diary that day, that works better to give people sound advice, and that is trained on individual users rather than on one dataset for all users.
## Sample account
If you can't register your own account for some reason, here is a sample one to log into:
Email: [[email protected]](mailto:[email protected])
Password: password | losing |
## About the Project
We are a bunch of amateur players who love playing chess, but over time we noticed that our improvement has become stagnant. Like many college students, we neither have the time nor the financial means to invest in professional coaching to take our game to the next level. This frustration sparked the idea behind **Pawn Up**—a project built to help players like us break through the plateau and improve their chess skills in their own time, without expensive coaches or overwhelming resources.
### What Inspired Us
As passionate chess players, we struggled with finding affordable and effective ways to improve. Chess can be an expensive hobby if you want to seek professional help or guidance. The available tools often lacked the depth we needed or came with hefty price tags. We wanted something that would provide personalized feedback, targeted training, and insights that anyone could access—regardless of their financial situation.
### How We Built It
We started by integrating **Lichess authentication** to fetch a user's game history, allowing them to directly analyze their own performance. With **Groq** and **Llama3.1**, we leveraged AI to categorize mistakes, generate feedback, and suggest relevant puzzles to help users train and improve. We also levergae **ChromaDB** for vector search features and **Gemini pro** and **Gemini embedding**
Our project features four key components:
* **Analyze**: Fetches the user's last 10 games, provides analysis on each move, and visualizes a heatmap showing the performance of legal moves for each piece. Users can also interact with the game for deeper analysis.
* **Train**: Using AI, the system analyzes the user's past games and suggests categorized puzzles that target areas of improvement.
* **Search**: We created a vector database storing thousands of grandmaster games. Users can search for specific games and replay them with detailed analysis, just like with their own games.
* **Upload**: Users can upload their own chess games and perform the same analyses and training as with the **Search** feature.
### What We Learned
Throughout the development of **Pawn Up**, we gained a deeper understanding of AI-powered analysis and how to work with complex game datasets. We learned how to integrate chess engines, handle large amounts of data, and create user-friendly interfaces. Additionally, we explored how LLMs (large language models) can provide meaningful feedback and how vector databases can be used to store and retrieve massive datasets efficiently.
### Challenges We Faced
One of the main challenges we encountered was making the AI feedback meaningful for players across various skill levels. It was crucial that the system didn’t just provide generic advice but rather tailored suggestions that were both practical and actionable. Handling large amounts of chess data efficiently, without compromising on speed and usability, also posed a challenge. Building the vector database to store and search through grandmaster games was a particularly challenging but rewarding experience.
Despite these hurdles, we’re proud of what we’ve built. **Pawn Up** is the solution we wish we had when we first started hitting that plateau in our chess journeys, and we hope it can help others as well. | >
> Domain.com entry: bearable9to5.online
>
>
>
## Inspiration
As our team members were getting to know each other, one of us commented on how tiring meeting on zoom is and how we wished we could be hacking together in person. Another teammate mentioned the concept of “Zoom Fatigue” and how it is a real topic studied by psychologists. As the discussion elevated, we wondered if there was anything we could do to help combat this issue, and conducted lots of research. We discovered that Zoom fatigue stems from how our brains process information over video.
>
> “Consider how long we stare at the Zoom screen or camera during a 15-minute standup. Most of us dare not turn away—even for a moment—because we worry our colleagues will think we’re distracted. The lack of visual breaks in virtual meetings strains both our eyes and brains, making it harder to stay focused.” (HBR.org)
>
>
>
We all related with this fact and agreed that Zoom and other video calling software should implement a “take a break” feature for both physical and mental health purposes. We also wondered what other features would help to ease the pressures of the video calling experience and make it more engaging. We were eager to uncover the ways in which we could improve one of the most dreaded but necessary tasks of today's virtual world.
---
## What it does
Bearable 9 to 5 is a work from home companion that increases the wellbeing of those who have “Zoom Fatigue” caused by the overload of video call meetings. This software wrapper utilizes a virtual camera that can run on any video calling program such as Zoom and Teams. It combats Zoom fatigue by reminding and enabling users to take solo or group breaks during meetings to stretch as well as gives them tips to improve their wellbeing. Some of these tips include tracking their posture and notifying them when they are slouching, as well as using machine learning models designed to detect human emotion to uplift the user with positivity if it detects they are glum or upset.
---
## How we built it
We chose Python as our programming language of choice as Python is powerful, beginner friendly, and has a wide selection of library support. Using pyvirtualcam, we were able to integrate with Zoom and connect it with a virtual camera which we could capture and process every frame. We used multithreading in combination with opencv to process video frame data, and allowed asynchronous control of the virtual camera while providing an user interface at the same time. We have also connected to Google Cloud Processing for additional API support, specifically Google Cloud Vision and Emotions API, to periodically check the stress level of the user during their video meeting, and on detection of negative emotions such as anger or grief, a pop-up would be displayed for a smile reminder.
---
## Challenges we ran into
One of the challenges we ran into was getting the pyvirtualcam library to work on all of our team members computers. After spending hours troubleshooting, we were able to get it working for 2 out of the 4 people on our team and implemented a paired programming approach. Another challenge was the fact that only one person on our team had used image capturing libraries before, so it was a learning curve to overcome. A specific technical challenge we had to overcome was disabling the user camera and displaying a “User is taking a break” at the same time as the user interacting with the gui. We were able to accomplish this by using threads in python to allow both processes to occur at once.
---
## Accomplishments that we're proud of
Considering that 3 out of 4 team members didn’t have experience with using image capturing libraries and Python itself required some relearning, this project as a whole was a great success. Our team was diverse in that we had different genders and different experience levels as well as a first time hacker, and it was really interesting and fun to be able to work with and support each other with everyone doing a sizeable chunk of work. Ultimately, we are very proud to have a complete product on github by the end of this hackathon that works very well. This team worked very hard to accomplish its goals and we’re proud to have implemented many relevant features to help combat “Zoom Fatigue” such as emotion detection and posture detection which were both powered by Google Cloud Processing. We’re also proud to have been able to get the “Share Stretching” feature to work with pre-recorded stretching and exercise videos playing directly within the video call, this was no simple task.
---
## What we learned
Initially, our team was leaning more towards a web app as that is where our expertise lay. However, we decided that we wanted to tackle this project even though we knew it would be harder and it has taught us more in one weekend than we could have ever imagined. Some new concepts we learned this weekend include:
* Using opencv for image and video processing
* Using python to run a virtual camera
* Remote collaboration and paired programming techniques
* Utilizing threads to run multiple processes at once
* Google cloud Processing (emotions, posture detection)
A general concept we learned was how successful we can be if we stay determined and focused on the project, and work hard throughout. We are very proud and fulfilled that we chose a harder project to tackle for our team because the learning outcome has been incredible.
---
## What's next for bearable 9to5
We definitely want to continue working on bearable 9to5 after this hackathon. One feature we want to implement is including an avatar that can speak on your behalf when you don’t want to be on camera and moves based on your facial recognition. This is helpful because it shows attendees that you are engaged in the meeting, but you don’t necessarily have to show your camera which can cause stress. | ## Inspiration
[Cursorless](https://www.cursorless.org/) is a voice interface for manipulating text (e.g., code). We saw its potential as a bold new interface for text editing. However, it is very unintuitive and learning Cursorless amounts to learning a new language, with unnatural and complicated syntax.
This was the inspiration behind Verbalist. We want to harness the power of voice (and AI) to greatly improve productivity while editing text, especially code.
Most other AI products access user data. We also want to ensure data security of our product.
## What it does
Verbalist is a VSCode extension that enables the use of voice to edit their code. After a user downloads and configures the extension, users can record small voice snippets describing the high-level actions they want to take on text. Then, our AI models decide the specific actions to execute in order to do the high-levels actions--all without processing the content of the file.
## Challenges and what we learned
We learned some limitations of using large-language models on difficult, real-world tasks. For example, the LLM model we used often struggled to identify a correct, intuitive sequence of actions to perform the user's specified action. We spent a long time refining prompts; we learned that our final results were very sensitive to the quality of our prompts.
We also spent a while setting up the interaction between our main extension TypeScript file and our Python file, which handled the recording and AI processing. Through this process, we learned how to set up inter-process communication and extensively using the standard libraries (e.g., input/output streams) of both Python and TypeScript.
## Accomplishments we're proud of
Our extension allows users to use natural language to manipulate collections of lines and perform simple find-and-replace operations. T
We also built on top of the VSCode text editing API to allow for higher-level operations without providing any file contents to AI.
## What's next
The concepts behind this prototype can easily be extended to a fully-functional extension that adds a functionality not present in any other software today. We can implement more high-level, detailed actions for the AI to perform; for example, the ability to rename a variable, surround an expression in parentheses, or perform actions across multiple files. The voice interface can become a natural extension of the keyboard, one that allows programmers to spend less time thinking and more time doing. | partial |
## Inspiration
Our inspiration for STOOP(AI)D stems from witnessing the incredible, transformative power of AI as an educator. We were captivated by the idea of reshaping the educational landscape and making learning an entirely personalized journey.
## What it does
STOOP(AI)D is not just another AI; it's your personal educational guru. Imagine a digital mentor that tailors every lesson to your unique needs, answering your questions, guiding your learning, and ensuring that education is not just accessible but deeply meaningful.
## How we built it
Our journey to create STOOP(AI)D involved a fusion of cutting-edge technology. We harnessed the remarkable OpenAI API, wielded the power of Streamlit, and wove together Python, HTML, CSS, JavaScript and a hell lot of binging through YouTube tutorials and API documentations to craft an educational experience like no other.
## Challenges we ran into
Our path was not without its trials. We grappled with the challenge of funding for API calls, faced the intricacies of working with APIs, and navigated the complex web of integrating various components. It was a difficult journey, but every hurdle was a chance to grow.
## Accomplishments that we're proud of
Our proudest moment is the realization of a truly exceptional product. The potential for growth and impact, especially with the support of a thriving community, has us beaming with pride. Forming a team randomly and conquering challenges one after another has been a testament to our determination and creativity.
## What we learned
Our journey with STOOP(AI)D was an immersive crash course in advanced technologies. We delved into the depths of complex APIs, mastered the intricacies of large language models, honed our Python skills, dived into the art of web development, and discovered the magic of Streamlit. Above all, we learned that teamwork is the cornerstone of any exceptional project.
## What's next for STOOP(AI)D
The future is nothing short of extraordinary for STOOP(AI)D. We envision scaling our innovation with the unwavering support of the community. Our goal is to address pervasive educational challenges and enhance the learning experience for all. STOOP(AI)D is not just a solution; it's a revolution in the making. | ## Inspiration
Helping people leading busy lifestyle with an app to keep important tasks and dates with reminders
## What it does
It is simply a reminder app with a game element to encourage recurrent visits .
As people keep completing task, they gain experience points to level up their chosen pet which is a dog or cat.
## How I built it
Our group went with a simple design and went something similar to MERN stack.
Using html/css with javascript to code the function and buttons.
user data/account were created and saved via firebase authentication.
and Ideally the task/reminders would be saved onto firebase cloud storage or mongodb altas for persistent data.
## Challenges I ran into
We had a very wide gap knowledge and had to compromise to a more simple app to allow for fair contribution.
Another challenged was the timezone difference. Two of us were in Canada while the other was in India. Very difficult to coordinate the workflow.
In building the app, we've ran into issue on what Oauth provider to use such as okta or firebase.
## Accomplishments that I'm proud of
In terms of a running app, it is functional in localhost. That it can load up a user and allow them to add in new task.
# Tam
• proud to be working with different people remotely in a time limited condition.
•Making a domain name for the project: <https://petential.space>
•Also proud to do my first hackathon, scary yet fun.
# Theresa
• Finished my first Hackathon!
• Collaborated with team using Git and GitHub
# Lakshit -
• Finished my first hackathon
• Contributed with team using Git and GitHub
• Added up the experience of working with such great Team from different time zones.
## What I learned
# Tam
• Team coordination and leadership.
• Learning about Okta authentication.
•Appreciating frameworks like React.
# Theresa
• Setting up a sidebar
• CSS animations
• Bootstrap progress bars
• Better understanding of JavaScript and jQuery
# Lakshit
• Got the knack about the reactions.
• CSS animations.
• About JavaScript and got new familiar with some new tags.
• Got cleared with some more branches of Version Control.
## What's next for Petential
Adding more functions and utility for the leveling system of the pets. Maybe a currency to get new accessories for the pet like a bow or hat.
• Pet food
• data storage. | ## Inspiration
As first-year students, we have experienced the difficulties of navigating our way around our new home. We wanted to facilitate the transition to university by helping students learn more about their university campus.
## What it does
A social media app for students to share daily images of their campus and earn points by accurately guessing the locations of their friend's image. After guessing, students can explore the location in full with detailed maps, including within university buildings.
## How we built it
Mapped-in SDK was used to display user locations in relation to surrounding buildings and help identify different campus areas. Reactjs was used as a mobile website as the SDK was unavailable for mobile. Express and Node for backend, and MongoDB Atlas serves as the backend for flexible datatypes.
## Challenges we ran into
* Developing in an unfamiliar framework (React) after learning that Android Studio was not feasible
* Bypassing CORS permissions when accessing the user's camera
## Accomplishments that we're proud of
* Using a new SDK purposely to address an issue that was relevant to our team
* Going through the development process, and gaining a range of experiences over a short period of time
## What we learned
* Planning time effectively and redirecting our goals accordingly
* How to learn by collaborating with team members to SDK experts, as well as reading documentation.
* Our tech stack
## What's next for LooGuessr
* creating more social elements, such as a global leaderboard/tournaments to increase engagement beyond first years
* considering freemium components, such as extra guesses, 360-view, and interpersonal wagers
* showcasing 360-picture view by stitching together a video recording from the user
* addressing privacy concerns with image face blur and an option for delaying showing the image | losing |
## Inspiration
I was doing an application last week when one of the questions about diversity prompted me into thinking about how we take things for more than just granted. It struck me that blind people aren't able to interact with the internet (shop on e-commerce websites, research to learn, play video games, social media - the list is quite endless). I then asked my dad, who works in the computer-science industry, about whether the visually impaired and blind are able to contribute to their likeness in the workforce when I realized how far off the scales were tipped.

*Assil Eye Institute*
If I were in their shoes, then I would immediately build such a software to be connected like and with everyone else, but in their case I would be blind so I wouldn't be able to, luckily I'm not so I know the right thing to do would be to build a software for them. Also, I realized that for people like me who are quite lazy or would like parts of their browser processes being automated (like telling it to reserve my tennis court from 5-6 PM rather than doing it myself), an AI browser might also sound quite valuable. Rather more of a business market "want" than a "need", I think regardless it's novelty in the market and it's usefulness for a customer segment (did a bit of customer discovery as well reaching out to centers and found out directly from people that they are very much look forward to it) makes this idea worth venturing about this hackathon in CalHacks.
## What it does
It's the same as your regular web browser application (Chrome, Safari, Brave, etc) in the way you surf the web, but in addition, you can do so freely while being blind-folded. Well, how does that work? Also, controlled by text and/or speech input (pressing the space bar for over a second starts a recording and leaving it ends the recording), any user's instructions are followed by the browser. When a user lands on a page, a quick summary of the page is read including the nav bar components, etc so the user can navigate and explore the web just like any other person. A user can ask the browser to click on any element/part of the page and also fill in information on the page via true NLP. They can also open/close tabs, search using the search engine, ask questions (variant of RAG approach taken) over the current page, save the page locally/print the page, and so many other tasks that the current set of agents have to offer. Every time something new is displayed on the browser (ex. going to a different page) they are notified so they can take judgements.
## How we built it
Using the PyQt5 Browser Development framework, I started my code by building a browser. I organized my prompt engineering agentic framework using Fetch AI's agentic system. For prompting questions with images/text I used Gemini's models. I also used Gemini's bounding box model for detecting where to proceed next on the page. This was not too accurate, so I coupled it with my algorithm I wrote where I take the html code of a website and parsed it down to the important segments (removing PII and unnecessary contents) in order to save tokens and decide based on html where to move next as a backup. After much testing, I settled on Groq for the decision-making segments of the LLM chain for its speed. I also used it for the STT part where the user has the option to speak in our application. The TTS part was handled by DeepGram and other voice agent integrations. Building requires testing and I tested this by imitating a blind person by being blind. One such successful testing included making accounts on websites I have never visited before.
## Challenges we ran into
Parsing the HTML took one of the longest parts due to its implicit complexity. Event listeners attached to elements across the DOM tree. Event listeners on images like a hamburger icon which has no text so a mapping is needed. These multiple edge cases had to be considered before reaching the threshold where it was doing perfect on every website as it is doing now. Another challenge I ran into was fine-tuning. The accuracy of this model was at around 60% and it was a hard and enduring work to get it to around 95% where it is currently at right now.
## Accomplishments that we're proud of
Controlling the browser by "having a 2-street conversation" with it simply blows my mind and really changes the way one surfs the web. It's really fun and really useful at the same time.
## What we learned
How to build your own browser. How to fine tune the boundary box model with Gemini through prompt engineering to extract high accurate insights. Learned documentation for multiple voice agent companies that were integrated.
## What's next for BrowseBlind
Perfecting the software model and finding ways to even further reduce token consumption in order to push this into the market as soon as possible. Also, building "background tabs" a feature I didn't have time to finish but essentially you can give a tab a task (ex. find the part on the wikipedia page that talks about fourier transform or find the contact page for X, Y, Z company) and the tab does the task in the background and comes back up when finished. | ## Inspiration
Our team focuses primarily on implementing innovative technologies to spark positive change. In line with these ideals, we decided to explore the potential impact of a text reading software that not only provided an additional layer of accessibility for blind and deafblind individuals. Through these efforts, we discovered that despite previous attempts to solve similar problems, solutions were often extremely expensive and incongruous. According to many visually challenged advocates these technologies often lacked real-world application and were specific to online texts or readings which limited their opportunities in everyday tasks like reading books or scanning over menus. Upon further research into afflicted groups, we discovered that there was additionally a large population of people who were both deaf and blind which stopped them from utilizing any forms of auditory input as an alternative, significantly obstructing their means of communication. Employing a very human centered design rooted in various personal accounts and professional testimony, we were able to develop a universal design that provides the visually and dual sensory impaired to experience the world from a new lens. By creating a handheld text to braille and speech generator, we are able to revolutionize the prospects of interpersonal communication for these individuals.
## What it does
This solution utilizes a singular piece with two modules, a video camera to decipher text, and a set of solenoids that imitates a standard Grade 2 Braille Grid. This portable accessory is intended to be utilized by a visually impaired or blind deaf individual when they’re attempting to analyze a physical text. This three finger supplement, equipped with a live action camera and sensitive solenoid components, is capable of utilizing a live camera feed to discern the diction of a physical text. Moving forward, the scanned text is moved to an A.I application to clean up the text for either auditory or sensory output in the form of TTS and braille. The text is then adapted into an audio format through a web application or to the classic 6 cells present in the Braille dictionary. Users are given a brief moment to make sense of each braille letter before the system automatically iterates through the remainder of the text. This technology effectively provides users with an alternative method to receive information that isn’t ordinarily accessible to them, granting a more authentic and amplified understanding of the world around them. In this unique application of these technologies, those who are hard of seeing and/or dual sensory impaired receive a more genuine appreciation for texts.
## How we built it
As our project required two extremely different pieces, we decided to split up our resources in hopes of tackling both problems at the same time. Regardless, we needed to set firm goals and plan out our required resources or timeline which helped us stay on schedule and formulate a final product that fully utilized our expertise.
In terms of hardware, we were somewhat limited for the first half of the hackathon as we had to purchase many of our materials and were unable to complete much of this work till later. We started by identifying a potential circuit design and creating a rigid structure to house our components. From there we simply spent a large amount of time actually implementing our theoretical circuit and applying it to our housing model in addition to cleaning the whole product up.
For software, we mostly had problems with connecting each of the pieces after building them out. We first created an algorithm that could take a camera feed and produce a coherent string of text. This would then be run through an AI text to speech generator that could decipher any gibberish. Finally, these texts would be sent through to either be read out loud or be compared against a dictionary to create a binary code that would dictate the on/off states off our solenoids.
Finally, we prototyped our product and tested it to see what we could improve in our final implementation to both increase efficiency and decrease latency.
## Challenges we ran into
This project was extremely technical and ambitious which meant that it was plagued with difficulties. As a large portion of the project relied on its hardware and implementing complementary materials to formulate a cohesive product, there were countless problems throughout the building phase. We often had incompatible parts whether it be cables, Voltage output/input, or even sizing and scaling issues, we were constantly scrambling to alter, scavenge, and adapt materials for uncommon use cases. Even our main board didn’t produce enough power, leading to an unusual usage of a dehumidifier charger and balled up aluminum foil as a makeshift power bank. All of these mechanical complexities followed by a difficult software end of the project led to an innovative and reworked solution that maintained applicative efficiency. These modifications even continued just hours before the submission deadline when we revamped the entire physical end of our project to make use of newly acquired materials using a more efficient modeling technique. These last second improvements gave our product a more polished and adept edge, making a more impactful and satisfying design.
Software wise we also strove to uncover the underappreciated features from our various APIs and tools which often didn’t coincide with our team’s strengths. As we had to simultaneously build out an effective product while troubleshooting our software side, we often ran into incompetencies and struggles. Regardless, we were able to overcome these adversities and produce an impressive result.
## Accomplishments that we're proud of
We are proud that we were able to overcome the various difficulties that arose throughout our process and to still showcase the level of success that we did even given such a short timeframe. Our team came in with some members having never done a hackathon before and we made extremely ambitious goals that we were unsure we could uphold. However, we were able to effectively work as a team to develop a final product that clearly represents our initial intentions for the project.
## What we learned
As a result of the many cutting-edge sponsors and new technological constraints, our whole team was able to draw from new more effective tools to increase efficiency and quality of our product. Through our careful planning and consistent collaboration, we experienced the future of software and progressed in our intricate technical knowledge within our fields and across specializations. and Because of the cross discipline nature of this project. Additionally, we became more flexible with what materials we needed to build out our hardware applications and especially utilized new TTS technologies to amplify the impact of our projects. In the future, we intend to continue to develop these crucial skills that we obtained at Cal Hacks 11.0, working towards a more accessible future.
## What's next for Text to Dot
We would like to work on integrating a more refined design to the hardware component of our project. Unforeseen circumstances with the solenoid led to our final design needing to be adjusted beyond the design of the original model, which could be rectified in future iterations. | ## Inspiration
I really enjoy the cyberpunk aesthetic, and realized that Arduino's challenge would be a great chance to explore some new technologies as well as have some fun dressing to play the part.
## What it does
**Jetson Nano**
The project uses a jetson nano to handle all of it's ML and video streaming capabilities. The project has 2 main portions, the c920 and a thermal camera in the form of adafruit mlx90640. The feed from the thermal camera and the C920 are both fed into a small LCD where S&R workers can take a look at key points in their surroundings.
The LEDs strapped to the jacket are more for visual flare!
**Quiz Website**
We made a quiz focusing on environmental protection so that people are aware of the environmental crisis.
## Challenges we ran into
**Hardware**
This hackathon was a first for me in working with sensors more specifically the thermal camera, which is an i2c. i2c's are essentially small controllers that use a communication protocol used by low-speed devices.
Finding the right libraries to communicate with the sensor was quite difficult, as well as visualizing the data received.
This was also my first hackathon doing anything with Machine Learning, so it was interesting to use pre-trained models and how the NVIDIA jetson platform handles things, so this time around I wasn't able to train some models, but I definitely plan on trying to in the future.
The reason I was unable to add a 2D-heatmap was due to Jupyter Notebook having issues with installation.
**Website**
Since we have no prior experience in react, we needed to learn while we code. The syntax and process were so new to me, and took me so long to complete simple tasks. Fortunately, I got so many help from grateful TreeHacks mentors and could finish the project.
## Accomplishments that we're proud of
**Hardware**
Being able to interface with the i2c at all was rather nice, especially since I had to pour through a lot of documentation in order to translate Raspberry Pi instructions to the Nano.
Setting up the Nano to work with NVIDIAs "Hello AI World" was also quite enjoyable.
**Website**
We made a quiz focusing on environmental protection so that people are aware of the environmental crisis.
We used react, chakra-ui, we never used these before, so we learn while we code. The whole process of making something scratch was hard, but It was fun and so much learning at the same time. And seeing it come to life from 0 was good.
## What we learned
**Hardware**
I got to experience the world of micro-controllers a little more, as well as get an introduction into the world of using ML models. I also learned just how far you can push a small pc that is specialized to do interesting things. I really couldn't have asked for a better intro experience to the exciting world of electronics and AI!
**Website**
We used react, chakra-ui, we never used these before, so we learn while we code. The whole process of making something scratch was hard, but It was fun and so much learning at the same time. | partial |
## Inspiration
With the rise of meme stocks taking over the minds of gen-z, vast amounts of young people are diving into the world of finance. We wanted to make a platform to make it easy for young people to choose stocks based on what matters most: the environment.
## What it does
Loraxly speaks for the trees: it aggregates realtime stock data along with articles about the environmental impact a company has on the world. It then uses OpenAI's powerful GPT-3 api to summarize and classify these articles to determine if the company's environmental impact is positive or not.
## How we built it
Figma, React, Javascript, Kumbucha, Python, Selenium, Golang, goroutines, Cally, firebase, pandas, OpenAI API, Alphavantage stock api, Doppler, rechart, material-ui, and true love.
## Challenges we ran into
some goroutines being ahead of others, fixed this with channels.
article summaries not making since, we had to be more granular with our article selection.
the chart was tough to setup.
we didn't get going until saturday afternoon.
## Accomplishments that we're proud of
getting things working
## What we learned
alphavantage api has some major rate limiting.
## What's next for Lorax.ly
Adding a trading function and creating an ETF comprised of environmentally friendly companies that people can invest in. | ## Why We Created **Here**
As college students, one question that we catch ourselves asking over and over again is – “Where are you studying today?” One of the most popular ways for students to coordinate is through texting. But messaging people individually can be time consuming and awkward for both the inviter and the invitee—reaching out can be scary, but turning down an invitation can be simply impolite. Similarly, group chats are designed to be a channel of communication, and as a result, a message about studying at a cafe two hours from now could easily be drowned out by other discussions or met with an awkward silence.
Just as Instagram simplified casual photo sharing from tedious group-chatting through stories, we aim to simplify casual event coordination. Imagine being able to efficiently notify anyone from your closest friends to lecture buddies about what you’re doing—on your own schedule.
Fundamentally, **Here** is an app that enables you to quickly notify either custom groups or general lists of friends of where you will be, what you will be doing, and how long you will be there for. These events can be anything from an open-invite work session at Bass Library to a casual dining hall lunch with your philosophy professor. It’s the perfect dynamic social calendar to fit your lifestyle.
Groups are customizable, allowing you to organize your many distinct social groups. These may be your housemates, Friday board-game night group, fellow computer science majors, or even a mixture of them all. Rather than having exclusive group chat plans, **Here** allows for more flexibility to combine your various social spheres, casually and conveniently forming and strengthening connections.
## What it does
**Here** facilitates low-stakes event invites between users who can send their location to specific groups of friends or a general list of everyone they know. Similar to how Instagram lowered the pressure involved in photo sharing, **Here** makes location and event sharing casual and convenient.
## How we built it
UI/UX Design: Developed high fidelity mockups on Figma to follow a minimal and efficient design system. Thought through user flows and spoke with other students to better understand needed functionality.
Frontend: Our app is built on React Native and Expo.
Backend: We created a database schema and set up in Google Firebase. Our backend is built on Express.js.
All team members contributed code!
## Challenges
Our team consists of half first years and half sophomores. Additionally, the majority of us have never developed a mobile app or used these frameworks. As a result, the learning curve was steep, but eventually everyone became comfortable with their specialties and contributed significant work that led to the development of a functional app from scratch.
Our idea also addresses a simple problem which can conversely be one of the most difficult to solve. We needed to spend a significant amount of time understanding why this problem has not been fully addressed with our current technology and how to uniquely position **Here** to have real change.
## Accomplishments that we're proud of
We are extremely proud of how developed our app is currently, with a fully working database and custom frontend that we saw transformed from just Figma mockups to an interactive app. It was also eye opening to be able to speak with other students about our app and understand what direction this app can go into.
## What we learned
Creating a mobile app from scratch—from designing it to getting it pitch ready in 36 hours—forced all of us to accelerate our coding skills and learn to coordinate together on different parts of the app (whether that is dealing with merge conflicts or creating a system to most efficiently use each other’s strengths).
## What's next for **Here**
One of **Here’s** greatest strengths is the universality of its usage. After helping connect students with students, **Here** can then be turned towards universities to form a direct channel with their students. **Here** can provide educational institutions with the tools to foster intimate relations that spring from small, casual events. In a poll of more than sixty university students across the country, most students rarely checked their campus events pages, instead planning their calendars in accordance with what their friends are up to. With **Here**, universities will be able to more directly plug into those smaller social calendars to generate greater visibility over their own events and curate notifications more effectively for the students they want to target. Looking at the wider timeline, **Here** is perfectly placed at the revival of small-scale interactions after two years of meticulously planned agendas, allowing friends who have not seen each other in a while casually, conveniently reconnect.
The whole team plans to continue to build and develop this app. We have become dedicated to the idea over these last 36 hours and are determined to see just how far we can take **Here**! | ## Inspiration
As college students, we didn't know anything, so we thought about how we can change that. One way was by being smarter about the way we take care of our unused items. We all felt that our unused items could be used in better ways through sharing with other students on campus. All of us shared our items on campus with our friends but we felt that there could be better ways to do this. However, we were truly inspired after one of our team members, and close friend, Harish, an Ecological Biology major, informed us about the sheer magnitude of trash and pollution in the oceans and the surrounding environments. Also, as the National Ocean Science Bowl Champion, Harish truly was able to educate the rest of the team on how areas such as the Great Pacific Garbage Patch affect the wildlife and oceanic ecosystems, and the effects we face on a daily basis from this. With our passions for technology, we wanted to work on an impactful project that caters to a true need for sharing that many of us have while focusing on maintaining sustainability.
## What it does
The application essentially works to allow users to list various products that they want to share with the community and allows users to request items. If one user sees a request they want to provide a tool for or an offer they find appealing, they’ll start a chat with the user through the app to request the tool. Furthermore, the app sorts and filters by location to make it convenient for users. Also, by allowing for community building through the chat messaging, we want to use
## How we built it
We first, focused on wireframing and coming up with ideas. We utilized brainstorming sessions to come up with unique ideas and then split our team based on our different skill sets. Our front-end team worked on coming up with wireframes and creating designs using Figma. Our backend team worked on a whiteboard, coming up with the system design of our application server, and together the front-end and back-end teams worked on coming up with the schemas for the database.
We utilized the MERN technical stack in order to build this. Our front-end uses ReactJS in order to build the web app, our back-end utilizes ExpressJS and NodeJS, while our database utilizes MongoDB.
We also took plenty of advice and notes, not only from mentors throughout the competition, but also our fellow hackers. We really went around trying to ask for others’ advice on our web app and our final product to truly flush out the best product that we could. We had a customer-centric mindset and approach throughout the full creation process, and we really wanted to look and make sure that what we are building has a true need and is truly wanted by the people. Taking advice from these various sources helped us frame our product and come up with features.
## Challenges we ran into
Integration challenges were some of the toughest for us. Making sure that the backend and frontend can communicate well was really tough, so what we did to minimize the difficulties. We designed the schemas for our databases and worked well with each other to make sure that we were all on the same page for our schemas. Thus, working together really helped to make sure that we were making sure to be truly efficient.
## Accomplishments that we're proud of
We’re really proud of our user interface of the product. We spent quite a lot of time working on the design (through Figma) before creating it in React, so we really wanted to make sure that the product that we are showing is visually appealing.
Furthermore, our backend is also something we are extremely proud of. Our backend system has many unconventional design choices (like for example passing common ids throughout the systems) in order to avoid more costly backend operations. Overall, latency and cost and ease of use for our frontend team was a big consideration when designing the backend system
## What we learned
We learned new technical skills and new soft skills. Overall in our technical skills, our team became much stronger with using the MERN frameworks. Our front-end team learned so many new skills and components through React and our back-end team learned so much about Express. Overall, we also learned quite a lot about working as a team and integrating the front end with the back-end, improving our software engineering skills
The soft skills that we learned about are how we should be presenting a product idea and product implementation. We worked quite a lot on our video and our final presentation to the judges and after speaking with hackers and mentors alike, we were able to use the collective wisdom that we gained in order to really feel that we created a video that shows truly our interest in designing important products with true social impact. Overall, we felt that we were able to convey our passion for building social impact and sustainability products.
## What's next for SustainaSwap
We’re looking to deploy the app in local communities as we’re at the point of deployment currently. We know there exists a clear demand for this in college towns, so we’ll first be starting off at our local campus of Philadelphia. Also, after speaking with many Harvard and MIT students on campus, we feel that Cambridge will also benefit, so we will shortly launch in the Boston/Cambridge area.
We will be looking to expand to other college towns and use this to help to work on the scalability of the product. We ideally, also want to push for the ideas of sustainability, so we would want to potentially use the platform (if it grows large enough) to host fundraisers and fundraising activities to give back in order to fight climate change.
We essentially want to expand city by city, community by community, because this app also focuses quite a lot on community and we want to build a community-centric platform. We want this platform to just build tight-knit communities within cities that can connect people with their neighbors while also promoting sustainability. | winning |
## What it does
Tickets is a secure, affordable, and painless system for registration and organization of in-person events. It utilizes public key cryptography to ensure the identity of visitors, while staying affordable for organizers, with no extra equipment or cost other than a cellphone. Additionally, it provides an easy method of requesting waiver and form signatures through Docusign.
## How we built it
We used Bluetooth Low Energy in order to provide easy communication between devices, PGP in order to verify the identities of both parties involved, and a variety of technologies, including Vue.js, MongoDB Stitch, and Bulma to make the final product.
## Challenges we ran into
We tried working (and struggling) with NFC and other wireless technologies before settling on Bluetooth LE as the best option for our use case. We also spent a lot of time getting familiar with MongoDB Stitch and the Docusign API.
## Accomplishments that we're proud of
We're proud of successfully creating a polished and functional product in a short period of time.
## What we learned
This was our first time using MongoDB Stitch, as well as Bluetooth Low Energy.
## What's next for Tickets
An option to allow for payments for events, as well as more input formats and data collection. | ## Inspiration
Business cards haven't changed in years, but cARd can change this! Inspired by the rise of augmented reality applications, we see potential for creative networking. Next time you meet someone at a conference, a career fair, etc., simply scan their business card with your phone and watch their entire online portfolio enter the world! The business card will be saved, and the experience will be unforgettable.
## What it does
cARd is an iOS application that allows a user to scan any business card to bring augmented reality content into the world. Using OpenCV for image rectification and OCR (optical character recognition) with the Google Vision API, we can extract both the business card and text on it. Feeding the extracted image back to the iOS app, ARKit can effectively track our "target" image. Furthermore, we use the OCR result to grab information about the business card owner real-time! Using selelium, we effectively gather information from Google and LinkedIn about the individual. When returned to the iOS app, the user is presented with information populated around the business card with augmented reality!
## How I built it
Some of the core technologies that go into this project include the following:
* ARKit for augmented reality in iOS
* Flask for the backend server
* selenium for collecting data about the business card owner on the web in real-time
* OpenCV to find the rectangular business card in the image and use a homography to map it into a rectangle for AR tracking
* Google Vision API for optical character recognition (OCR)
* Text to speech
## Challenges I ran into
## Accomplishments that I'm proud of
## What I learned
## What's next for cARd
Get cARd on the app store for everyone to use! Stay organized and have fun while networking! | ## Inspiration
With COVID-19, we found it harder to network with others. We wanted to create a way for people to find each other after the event is done.
## What it does
CONNECT allows participants at an event to network with each other. The participant will walk in the event and scan a QR code which will take them to the app. If not already done, they can create a new profile. Then they will share their socials while also seeing the socials of others at the event.
Event organizers can use the app to generate the event QR code that will let users join the event through the app.
## How we built it
Front-End: React Native & Figma
Back-End: QRCode API through Node.js.
## Challenges we ran into
We feel that we were inexperienced to accomplish what we envisioned. We also felt that we did not have enough time to complete the project.
## What we learned
We learned a lot. We learned that Figma is a strong tool for prototyping and collaboration. We even learnt a little bit more about Node.js that we previous had. One of us strengthened our knowledge in React Native.
We also learnt how to work with Git.
## What's next for Connect
* Making a functional prototype.
* Implement Twilio (for sending the email with QRCode PDF)
* Implement Database (for social medias) | winning |
## Inspiration
Around 40% of the lakes in America are too polluted for aquatic life, swimming or fishing.Although children make up 10% of the world’s population, over 40% of the global burden of disease falls on them. Environmental factors contribute to more than 3 million children under age five dying every year. Pollution kills over 1 million seabirds and 100 million mammals annually. Recycling and composting alone have avoided 85 million tons of waste to be dumped in 2010. Currently in the world there are over 500 million cars, by 2030 the number will rise to 1 billion, therefore doubling pollution levels. High traffic roads possess more concentrated levels of air pollution therefore people living close to these areas have an increased risk of heart disease, cancer, asthma and bronchitis. Inhaling Air pollution takes away at least 1-2 years of a typical human life. 25% deaths in India and 65% of the deaths in Asia are resultant of air pollution. Over 80 billion aluminium cans are used every year around the world. If you throw away aluminium cans, they can stay in that can form for up to 500 years or more. People aren’t recycling as much as they should, as a result the rainforests are be cut down by approximately 100 acres per minute
On top of this, I being near the Great Lakes and Neeral being in the Bay area, we have both seen not only tremendous amounts of air pollution, but marine pollution as well as pollution in the great freshwater lakes around us. As a result, this inspired us to create this project.
## What it does
For the react native app, it connects with the Website Neeral made in order to create a comprehensive solution to this problem.
There are five main sections in the react native app:
The first section is an area where users can collaborate by creating posts in order to reach out to others to meet up and organize events in order to reduce pollution. One example of this could be a passionate environmentalist who is organizing a beach trash pick up and wishes to bring along more people. With the help of this feature, more people would be able to learn about this and participate.
The second section is a petitions section where users have the ability to support local groups or sign a petition in order to enforce change. These petitions include placing pressure on large corporations to reduce carbon emissions and so forth. This allows users to take action effectively.
The third section is the forecasts tab where the users are able to retrieve data regarding various data points in pollution. This includes the ability for the user to obtain heat maps regarding the amount of air quality, pollution and pollen in the air and retrieve recommended procedures for not only the general public but for special case scenarios using apis.
The fourth section is a tips and procedures tab for users to be able to respond to certain situations. They are able to consult this guide and find the situation that matches them in order to find the appropriate action to take. This helps the end user stay calm during situations as such happening in California with dangerously high levels of carbon.
The fifth section is an area where users are able to use Machine Learning in order to figure out whether where they are is in a place of trouble. In many instances, not many know exactly where they are especially when travelling or going somewhere unknown. With the help of Machine Learning, the user is able to place certain information regarding their surroundings and the Algorithm is able to decide whether they are in trouble. The algorithm has 90% accuracy and is quite efficient.
## How I built it
For the react native part of the application, I will break it down section by section.
For the first section, I simply used Firebase as a backend which allowed a simple, easy and fast way of retrieving and pushing data to the cloud storage. This allowed me to spend time on other features, and due to my ever growing experience with firebase, this did not take too much time. I simply added a form which pushed data to firebase and when you go to the home page it refreshes and see that the cloud was updated in real time
For the second section, I used native base in order to create my UI and found an assortment of petitions which I then linked and added images from their website in order to create the petitions tab. I then used expo-web-browser, to deep link the website in opening safari to open the link within the app.
For the third section, I used breezometer.com’s pollution api, air quality api, pollen api and heat map apis in order to create an assortment of data points, health recommendations and visual graphics to represent pollution in several ways. The apis also provided me information such as the most common pollutant and protocols for different age groups and people with certain conditions should follow. With this extensive api, there were many endpoints I wanted to add in, but not all were added due to lack of time.
For the fourth section, it is very much similar to the second section as it is an assortment of links, proofread and verified to be truthful sources, in order for the end user to have a procedure to go to for extreme emergencies. As we see horrible things happen, such as the wildfires in California, air quality becomes a serious concern for many and as a result these procedures help the user stay calm and knowledgeable.
For the fifth section, Neeral please write this one since you are the one who created it.
## Challenges I ran into
API query bugs was a big issue in formatting back the query and how to map the data back into the UI. It took some time and made us run until the end but we were still able to complete our project and goals.
## What's next for PRE-LUTE
We hope to use this in areas where there is commonly much suffering due to the extravagantly large amount of pollution, such as in Delhi where seeing is practically hard due to the amount of pollution. We hope to create a finished product and release it to the app and play stores respectively. | We created this app in light of the recent wildfires that have raged across the west coast. As California Natives ourselves, we have witnessed the devastating effects of these fires first-hand. Not only do these wildfires pose a danger to those living around the evacuation area, but even for those residing tens to hundreds of miles away, the after-effects are lingering.
For many with sensitive respiratory systems, the wildfire smoke has created difficulty breathing and dizziness as well. One of the reasons we like technology is its ability to impact our lives in novel and meaningful ways. This is extremely helpful for people highly sensitive to airborne pollutants, such as some of our family members that suffer from asthma, and those who also own pets to find healthy outdoor spaces. Our app greatly simplifies the process of finding a location with healthier air quality amidst the wildfires and ensures that those who need essential exercise are able to do so.
We wanted to develop a web app that could help these who are particularly sensitive to smoke and ash to find a temporary respite from the harmful air quality in their area. With our app air.ly, users can navigate across North America to identify areas where the air quality is substantially better. Each dot color indicates a different air quality level ranging from healthy to hazardous. By clicking on a dot, users will be shown a list of outdoor recreation areas, parks, and landmarks they can visit to take a breather at.
We utilized a few different APIs in order to build our web app. The first step was to implement the Google Maps API using JavaScript. Next, we scraped location and air quality index data for each city within North America. After we were able to source real-time data from the World Air Quality Index API, we used the location information to connect to our Google Maps API implementation. Our code took in longitude and latitude data to place a dot on the location of each city within our map. This dot was color-coded based on its city AQI value.
At the same time, the longitude and latitude data was passed into our Yelp Fusion API implementation to find parks, hiking areas, and outdoor recreation local to the city. We processed the Yelp city and location data using Python and Flask integrations. The city-specific AQI value, as well as our local Yelp recommendations, were coded in HTML and CSS to display an info box upon clicking on a dot to help a user act on the real-time data. As a final touch, we also included a legend that indicated the AQI values with their corresponding dot colors to allow ease with user experience.
We really embraced the hacker resilience mindset to create a user-focused product that values itself on providing safe and healthy exploration during the current wildfire season. Thank you :) | ## Inspiration
We wanted a low-anxiety tool to boost our public speaking skills. With an ever-accelerating shift of communication away from face-to-face and towards pretty much just memes, it's becoming difficult for younger generations to express themselves or articulate an argument without a screen as a proxy.
## What does it do?
DebateABot is a web-app that allows the user to pick a topic and make their point, while arguing against our chat bot.
## How did we build it?
Our website is boot-strapped with Javascript/JQuery and HTML5. The user can talk to our web app which used NLP to convert speech to text, and sends the text to our server, which was built with PHP and background written in python. We perform key-word matching and search result ranking using the indico API, after which we run Sentiment Analysis on the text. The counter-argument, as a string, is sent back to the web app and is read aloud to the user using the Mozilla Web Speech API
## Some challenges we ran into
First off, trying to use the Watson APIs and the Azure APIs lead to a lot of initial difficulties trying to get set up and get access. Early on we also wanted to use our Amazon Echo that we have, but reached a point where it wasn't realistic to use AWS and Alexa skills for what we wanted to do. A common theme amongst other challenges has simply been sleep deprivation; staying up past 3am is a sure-fire way to exponentiate your rate of errors and bugs. The last significant difficulty is the bane of most software projects, and ours is no exception- integration.
## Accomplishments that we're proud of
The first time that we got our voice input to print out on the screen, in our own program, was a big moment. We also kicked ass as a team! This was the first hackathon EVER for two of our team members, and everyone had a role to play, and was able to be fully involved in developing our hack. Also, we just had a lot of fun together. Spirits were kept high throughout the 36 hours, and we lasted a whole day before swearing at our chat bot. To our surprise, instead of echoing out our exclaimed profanity, the Web Speech API read aloud "eff-asterix-asterix-asterix you, chat bot!" It took 5 minutes of straight laughing before we could get back to work.
## What we learned
The Mozilla Web Speech API does not swear! So don't get any ideas when you're talking to our innocent chat bot...
## What's next for DebateABot?
While DebateABot isn't likely to evolve into the singularity, it definitely has the potential to become a lot smarter. The immediate next step is to port the project over to be usable with Amazon Echo or Google Home, which eliminates the need for a screen, making the conversation more realistic. After that, it's a question of taking DebateABot and applying it to something important to YOU. Whether that's a way to practice for a Model UN or practice your thesis defence, it's just a matter of collecting more data.
<https://www.youtube.com/watch?v=klXpGybSi3A> | winning |
## Inspiration: The BarBot team came together with such diverse skill sets. We wanted to create a project that would highlight each member's various expertise. This expertise includes Internet of Things, hardware, and web development. After a long ideation session, we came up with BarBot. This robotic bartender will serve as a great addition to forward-seeing bars, where the drink dispensing and delivery process is automated.
## What it does: Barbot is an integrated butler robot that allows the user to order a drink through a touch screen ordering station. A highly capable drink dispensary system will perform desired option chosen from the ordering station. The beverage options that will be dispensed through the dispensary system include Redbull or Soylent. An additional option in the ordering station named "Surprise Me" is available. This particular option takes a photograph of the user and runs a Microsoft Emotions API. Running this API will allow BarBot to determine the user's current mood and decide which drink is suitable for this user based on the photograph taken. After the option is determined by the user (Redbull or Soylent) or by BarBot ("Surprise Me" running Microsoft emotion API), BarBot's dispensary system will dispense the determined beverage onto the glass on the BarBot. This robot will then travel to the user in order to deliver the drink. Barbot will only return to its original position (under the dispensary station) when the cup has been lifted.
## How we built it: The BarBot team allocated different tasks to group members with various expertise. Our frontend specialist, Sabrina Smai, built the mobile application for ordering station that has now had a touchscreen. Our hardware specialist, Lucas Moisuyev, built the BarBot itself along with the dispensary system with the assistance of Tony Cheng. Our backend specialist, Ben Weinfeld, built the ordering station by programming raspberry pi and the touchscreen. Through our collaboration, we were able to revolutionize the bartending process.
## Challenges we ran into: The most reoccurring issue we encountered was a lack of proper materials for specific parts of our hack. When we were building our pouring mechanism, we did not have proper tubing for transferring our beverages, so we had to go out and purchase materials. After buying more tubing materials, we then ran into the issue of not having strong enough servos or motors to turn the valves of the dispensers. This caused us to totally change the original design of the pouring mechanism. In addition, we underestimated the level of difficulty that came with creating a communication system among all of our parts.
## Accomplishments that we're proud of: Despite our challenges, we are proud to have been able to create a functional product within the limited amount of time. We needed to learn new skills and improvise hardware components but never gave up.
## What we learned: During this hackathon, we learned to program the Particle Photon Raspberry Pi, building web apps, and leap over the hurdles of creating a hardware hack with very limited supplies.
## What's next for BarBot: The BarBot team is very passionate about this project and we will continue to work on BarBot after this Hackathon. We plan to integrate more features that will incorporate more Microsoft APIs. An expansion of the touch ordering station will be considered as more variety of drink options will be required. | ## Inspiration
Old school bosses don't want want to see you slacking off and always expect you to be all movie hacker in the terminal 24/7. As professional slackers, we also need our fair share of coffee and snacks. We initially wanted to create a terminal app to order Starbucks and deliver it to the E7 front desk. Then bribe a volunteer to bring it up using directions from Mappedin. It turned out that it's quite hard to reverse engineer Starbucks. Thus, we tried UberEats, which was even worse. After exploring bubble tea, cafes, and even Lazeez, we decided to order pizza instead. Because if we're suffering, might as well suffer in a food coma.
## What it does
Skip the Walk brings food right to your table with the help of volunteers. In exchange for not taking a single step, volunteers are paid in what we like to call bribes. These can be the swag hackers received, food, money,
## How we built it
We used commander.js to create the command-line interface, Next.js to run MappedIn, and Vercel to host our API endpoints and frontend. We integrated a few Slack APIs to create the Slack bot. To actually order the pizzas, we employed Terraform.
## Challenges we ran into
Our initial idea was to order coffee through a command line, but we soon realized there weren’t suitable APIs for that. When we tried manually sending POST requests to Starbucks’ website, we ran into reCaptcha issues. After examining many companies’ websites and nearly ordering three pizzas from Domino’s by accident, we found ourselves back at square one—three times. By the time we settled on our final project, we had only nine hours left.
## Accomplishments that we're proud of
Despite these challenges, we’re proud that we managed to get a proof of concept up and running with a CLI, backend API, frontend map, and a Slack bot in less than nine hours. This achievement highlights our ability to adapt quickly and work efficiently under pressure.
## What we learned
Through this experience, we learned that planning is crucial, especially when working within the tight timeframe of a hackathon. Flexibility and quick decision-making are essential when initial plans don’t work out, and being able to pivot effectively can make all the difference.
## Terraform
We used Terraform this weekend for ordering Domino's. We had many close calls and actually did accidentally order once, but luckily we got that cancelled. We created a Node.JS app that we created Terraform files for to run. We also used Terraform to order Domino's using template .tf files. Finally, we used TF to deploy our map on Render. We always thought it funny to use infrastructure as code to do something other than pure infrastructure. Gotta eat too!
## Mappedin
Mappedin was an impressive tool to work with. Its documentation was clear and easy to follow, and the product itself was highly polished. We leveraged its room labeling and pathfinding capabilities to help volunteers efficiently deliver pizzas to hungry hackers with accuracy and ease.
## What's next for Skip the Walk
We plan to enhance the CLI features by adding options such as reordering, randomizing orders, and providing tips for volunteers. These improvements aim to enrich the user experience and make the platform more engaging for both hackers and volunteers. | ## Inspiration
As a team, we were immediately intrigued by the creative freedom involved in building a ‘useless invention’ and inspiration was drawn from the ‘useless box’ that turns itself off. We thought ‘why not have it be a robot arm and give it an equally intriguing personality?’ and immediately got to work taking our own spin on the concept.
## What It Does
The robot has 3 servos that allow the robot to move with personality. Whenever the switch is pressed, the robot executes a sequence of actions in order to flick the switch and then shut down.
## How We Built It
We started by dividing tasks between members: the skeleton of the code, building the physical robot, and electronic components. A CAD model was drawn up to get a gauge for scale, and then it was right into cutting and glueing popsicle sticks. An Exacto blade was used to create holes in the base container for components to fit through to keep everything neat and compact. Simultaneously, as much of the code and electronic wiring was done to not waste time.
After the build was complete, a test code was run and highlighted areas that needed to be reinforced. While that was happening, calculations were being done to determine the locations the servo motors would need to reach in order to achieve our goal. Once a ‘default’ sequence was achieved, team members split to write 3 of our own sequences before converging to achieve the 5th and final sequence. After several tests were run and the code was tweaked, a demo video was filmed.
## Challenges We Ran Into
The design itself is rather rudimentary, being built out of a Tupperware container, popsicle sticks and various electronic components to create the features such as servo motors and a buzzer. Challenges consisted of working with materials as fickle as popsicle sticks – a decision driven mainly by the lack of realistic accessibility to 3D printers. The wood splintered and was weaker than expected, therefore creative design was necessary so that it held together.
Another challenge was the movement. Working with 3 servo motors proved difficult when assigning locations and movement sequences, but once we found a ‘default’ sequence that worked, the other following sequences slid into place. Unfortunately, our toils were not over as now the robot had to be able to push the switch, and initial force proved to be insufficient.
## Accomplishments That We’re Proud Of
About halfway through, while we were struggling with getting the movement to work, thoughts turned toward what we would do in different sequences. Out of inspiration from other activities occurring during the event, it was decided that we would add a musical element to our ‘useless machine’ in the form of a buzzer playing “Tequila” by The Champs. This was our easiest success despite involving transposing sheet music and changing rhythms until we found the desired effect.
We also got at least 3 sequences into the robot! That is more than we were expecting 12 hours into the build due to difficulties with programming the servos.
## What We Learned
When we assigned tasks, we all chose roles that we were not normally accustomed to. Our mechanical member worked heavily in software while another less familiar with design focused on the actual build. We all exchanged roles over the course of the project, but this rotation of focus allowed us to get the most out of the experience. You can do a lot with relatively few components; constraint leads to innovation.
## What’s Next for Little Dunce
So far, we have only built in the set of 5 sequences, but we want Little Dunce to have more of a personality and more varied and random reactions. As of now, it is a sequence of events, but we want Little Dunce to act randomly so that everyone can get a unique experience with the invention. We also want to add an RGB LED light for mood indication dependent on the sequence chosen. This would also serve as the “on/off” indicator since the initial proposal was to have a robot that goes to sleep. | partial |
## Inspiration
The app idea originated from the expense of testing such basic physical properties as Young's modulus, a standard measure of the stiffness of a material. Instron force testing machines, typically used to measure properties like Young's modulus, are very expensive. In the field of bioengineering, materials tested are often much softer and do not require the full force of the machine. Furthermore, Instron machines are also utilized for labs, yet students don't usually require the full precision of the Instron to complete their work. A portable, cheap way for mechanical and biomedical engineers to measure physical properties is as simple as utilizing the accelerometers in the smartphone. This then evolved into the full EngineeringKit, a user-friendly virtual toolbox with 4 engineering features, all of which usually require more expensive equipment or a greater investiture of time, and brings them together for convenient usage.
## What it does
EngineeringKit has 4 features:
Young's modulus,
Calipers,
Material Properties, &
Mathematics.
## How I built it
Built in Android Studio with the Java language; makes use of the phone's accelerometers
Young's Modulus - Uses the phone's accelerometers and known mass and area of the object to calculate stress-strain graph and display it with a graphing library
Calipers utilize listeners for screen touch events and allowing the user to drag lines across the screen to fit against the object needed, then converts the distance between these lines to inches.
Material properties utilizes Google Voice API or text entry to listen for a query, then uses Wolfram Alpha API to search a specific answer, hand-parsing the XML string for the correct data
Mathematics similarly uses Google Voice API or text entry to listen for a query, then uses Wolfram Alpha API to search a specific answer, hand-parsing the XML for a correct image of the needed equation.
## Accomplishments that I'm proud of
Implementing the Wolfram Alpha API by querying their website and returning the relevant information for the search.
## What's next for EngineeringKit
Calibrating Young's modulus calculator more thoroughly, implementing a Kalman filter to increase its position-sensing accuracy; allowing for stepped force input rather than just constant force which would primarily be useful for only viscoelastic materials; allowing for three-point bending with a 3D-printed attachment to phone case; allowing for calculation of shear modulus | ## Inspiration
After Apple announced their first ARDevKit, our group knew we wanted to tinker with the idea. Having an experienced group who won previous hackathons with mobile apps, we were excited to delve head-first into the world of Augmented Reality.
## What it does
It calculates the instantaneous/average velocity of an object.
## How we built it
Using Swift in Xcode, we incorporated Calculus concepts into the development of the AR.
## Challenges we ran into
To calculate instantaneous velocity, we had to get very small time increments that approach infinitesimally small changes in time. Processing as many position values per second becomes important to improving the accuracy. However, this can be CPU-intensive. So we created an efficient and optimised program.
## Accomplishments that we're proud of
Creating a full-functioning app in less than 24 hours after concept.
## What we learned
Working as a cohesive unit and the potential AR has.
Managing time properly.
## What's next for SpeedAR
Adding a slider to change the accuracy of the velocity.
Adding a low-power mode to further save battery and limit processing clock speeds.
Individual object-tracking to remove the need to manually pan the camera to trace an object's movement. | ## Inspiration
Cute factor of dogs/cats, also to improve the health of many pets such as larger dogs that can easily become overweight.
## What it does
Reads accelerometer data on collar, converted into steps.
## How I built it
* Arduino Nano
* ADXL345 module
* SPP-C Bluetooth module
* Android Studio for app
## Challenges I ran into
Android studio uses a large amount of RAM space.
Interfacing with the accelerometer was challenging with finding the appropriate algorithm that has the least delay and lag.
## Accomplishments that I'm proud of
As a prototype, it is a great first development.
## What I learned
Some android studio java shortcuts/basics
## What's next for DoogyWalky
Data analysis with steps to convert to calories, and adding a second UI for graphing data weekly and hourly with a SQLite Database. | losing |
## Realm Inspiration
Our inspiration stemmed from our fascination in the growing fields of AR and virtual worlds, from full-body tracking to 3D-visualization. We were interested in realizing ideas in this space, specifically with sensor detecting movements and seamlessly integrating 3D gestures. We felt that the prime way we could display our interest in this technology and the potential was to communicate using it. This is what led us to create Realm, a technology that allows users to create dynamic, collaborative, presentations with voice commands, image searches and complete body-tracking for the most customizable and interactive presentations. We envision an increased ease in dynamic presentations and limitless collaborative work spaces with improvements to technology like Realm.
## Realm Tech Stack
Web View (AWS SageMaker, S3, Lex, DynamoDB and ReactJS): Realm's stack relies heavily on its reliance on AWS. We begin by receiving images from the frontend and passing it into SageMaker where the images are tagged corresponding to their content. These tags, and the images themselves, are put into an S3 bucket. Amazon Lex is used for dialog flow, where text is parsed and tools, animations or simple images are chosen. The Amazon Lex commands are completed by parsing through the S3 Bucket, selecting the desired image, and storing the image URL with all other on-screen images on to DynamoDB. The list of URLs are posted on an endpoint that Swift calls to render.
AR View ( AR-kit, Swift ): The Realm app renders text, images, slides and SCN animations in pixel perfect AR models that are interactive and are interactive with a physics engine. Some of the models we have included in our demo, are presentation functionality and rain interacting with an umbrella. Swift 3 allows full body tracking and we configure the tools to provide optimal tracking and placement gestures. Users can move objects in their hands, place objects and interact with 3D items to enhance the presentation.
## Applications of Realm:
In the future we hope to see our idea implemented in real workplaces in the future. We see classrooms using Realm to provide students interactive spaces to learn, professional employees a way to create interactive presentations, teams to come together and collaborate as easy as possible and so much more. Extensions include creating more animated/interactive AR features and real-time collaboration methods. We hope to further polish our features for usage in industries such as AR/VR gaming & marketing. | Demo: <https://youtu.be/cTh3Q6a2OIM?t=2401>
## Inspiration
Fun Mobile AR Experiences such as Pokemon Go
## What it does
First, a single player hides a virtual penguin somewhere in the room. Then, the app creates hundreds of obstacles for the other players in AR. The player that finds the penguin first wins!
## How we built it
We used AWS and Node JS to create a server to handle realtime communication between all players. We also used Socket IO so that we could easily broadcast information to all players.
## Challenges we ran into
For the majority of the hackathon, we were aiming to use Apple's Multipeer Connectivity framework for realtime peer-to-peer communication. Although we wrote significant code using this framework, we had to switch to Socket IO due to connectivity issues.
Furthermore, shared AR experiences is a very new field with a lot of technical challenges, and it was very exciting to work through bugs in ensuring that all users have see similar obstacles throughout the room.
## Accomplishments that we're proud of
For two of us, it was our very first iOS application. We had never used Swift before, and we had a lot of fun learning to use xCode. For the entire team, we had never worked with AR or Apple's AR-Kit before.
We are proud we were able to make a fun and easy to use AR experience. We also were happy we were able to use Retro styling in our application
## What we learned
-Creating shared AR experiences is challenging but fun
-How to work with iOS's Multipeer framework
-How to use AR Kit
## What's next for ScavengAR
* Look out for an app store release soon! | ## Inspiration
* Inspired by issues pertaining to present day social media that focus on more on likes and views as supposed to photo-sharing
+ We wanted to connect people on the internet and within communities in a positive, immersive experience
* Bring society closer together rather than push each other away
## What it does
* Social network for people to share images and videos to be viewed in AR
* removed parameters such as likes, views, engagement to focus primarily on media-sharing
## How we built it
* Used Google Cloud Platform as our VM host for our backend
* Utilized web development tools for our website
* Git to collaborate with teammates
* Unity and Vuforia to develop Ar
## Challenges we ran into
* Learning new software tools, but we all preserved and had each other's back.
* Using Unity and learning how to use Vuforia in real time
## Accomplishments that we're proud of
* Learning Git, and a bunch more new software that we have never touched!
* Improving our problem solving and troubleshooting skills
* Learning to communicate with teammates
* Basics of Ar
## What we learned
* Web development using HTML, CSS, JavaScript and Bootstrap
## What's next for ARConnect
* Finish developing:
* RESTful API
* DBM
* Improve UX by:
* Mobile app
* Adding depth to user added images (3d) in AR
* User accessibility | winning |
## Inspiration
One of our close friends is at risk of Alzheimer's. He learns different languages and engages his brain by learning various skills which will significantly decrease his chances of suffering from Alzheimer's later. Our game is convenient for people like him to keep the risks of being diagnosed with dementia at bay.
## What it does
In this game, a random LED pattern is displayed which the user is supposed to memorize. The user is supposed to use hand gestures to repeat the memorized pattern. If the user fails to memorize the correct pattern, the buzzer beeps.
## How we built it
We had two major components to our project; hardware and software. The hardware component of our project used an Arduino UNO, LED lights, a base shield, a Grove switch and a Grove gesture sensor. Our software side of the project used the Arduino IDE and GitHub. We have linked them in our project overview for your convenience.
## Challenges we ran into
Some of the major challenges we faced were storing data and making sure that the buzzer doesn't beep at the wrong time.
## Accomplishments that we're proud of
We were exploring new terrain in this hackathon with regard to developing a hardware project in combination with the Arduino IDE. We found that it was quite different in relation to the software/application programming we were used to, so we're very happy with the overall learning experience.
## What we learned
We learned how to apply our skillset in software and application development in a hardware setting. Primarily, this was our first experience working with Arduino, and we were able to use this opportunity at UofT to catch up to the learning curve.
## What's next for Evocalit
Future steps for our project look like revisiting the iteration cycles to clean up any repetitive inputs and incorporating more sensitive machine learning algorithms alongside the Grove sensors so as to maximize the accuracy and precision of the user inputs through computer vision. | ## Inspiration
Our inspiration stems the difficulty and lack of precision that certain online vision tests suffer from. Issues such as requiring a laptop and measuring distance by hand lead to a cumbersome process. Augmented reality and voice-recognition allow for a streamlined process that can be accessed anywhere with an iOS app.
## What it does
The app looks for signs of colorblindness, nearsightedness, and farsightedness with Ishihara color tests and Snellen chart exams. The Snellen chart is simulated in augmented reality by placing a row of letters six meters away from the camera. Users can easily interact with the exam by submitting their answers via voice recognition rather than having to manually enter each letter in the row.
## How we built it
We built these augmented reality and voice recognition features by downloading the ARKit and KK Voice Recognition SDKs into Unity 3d. These SDKs exposed APIs for integrating these features into the exam logic. We used Unity's UI API to create the interface, and linked these scenes into a project built for iOS. This build was then exported to XCode, which allowed us to configure the project and make it accessible via iPhone.
## Challenges we ran into
Errors resulting from complex SDK integrations made the beginning of the project difficult to debug. After this, a lot of time was spent trying to control the scale and orientation of augmented reality features in the scene in order to create a lifelike environment. The voice recognition software presented difficulties as its API was controlled by a lot of complex callback functions, which made the logic flow difficult to follow. The main difficulty in the latter phases of the project was the inability to test features in the Unity editor. The AR and voice-recognition APIs relied upon the iOS operating system which meant that every change in the code had to be tested through a long build and installation process.
## Accomplishments that we're proud of
With only one of the team members having experience with Unity, we are proud of constructing such a complex UI system with the Unity APIs. Also, this was the team's first exposure to voice-recognition software. We are also proud to have used what we learned to construct a cohesive product that has real-world applications.
## What we learned
We learned how to construct UI elements and link multiple scenes together in Unity. We also learned a lot about C# through manipulating voice-recognition data and working with 3D assets, all of which is new to the team.
## What's next for AR Visual Acuity Exam
Given more time, the app would be built out to send vision exam results to doctors for approval. We could also improve upon the scaling and representation of the Snellen chart. | ## Inspiration
This project was inspired by the rising issue of people with dementia. Symptoms of dementia can be temporarily improved by regularly taking medication, but one of the core symptoms of dementia is forgetfulness. Moreover, patients with dementia often need a caregiver, who is often a family member, to manage their daily tasks. This takes a great toll on both the caregiver, who is at higher risk for depression, high stress levels, and burnout. To alleviate some of these problems, we wanted to create an easy way for patients to take their medication, while providing ease and reassurance for family members, even from afar.
## Purpose
The project we have created connects a smart pillbox to a progressive app. Using the app, caregivers are able to create profiles for multiple patients, set and edit alarms for different medications, and view if patients have taken their medication as necessary. On the patient's side, the pillbox is not only used as an organizer, but also as an alarm to remind the patient exactly when and which pills to take. This is made possible with a blinking light indicator in each compartment of the box.
## How It's Built
Design: UX Research: We looked into the core problem of Alzheimer's disease and the prevalence of it. It is estimated that half of the older population do not take their medication as intended. It is a common misconception that Alzheimer's and other forms of dementia are synonymous with memory loss, but the condition is much more complex. Patients experience behavioural changes and slower cognitive processes that often require them to have a caretaker. This is where we saw a pain point that could be tackled.
Front-end: NodeJS, Firebase
Back-end: We used azure to host a nodeJS server and postgres database that dealt with the core scheduling functionality. The server would read write and edit all the schedules and pillboxes. It would also decide when the next reminder was and ask the raspberry pi to check it. The pi also hosted its own nodeJS server that would respond to the azure server for requests to check if the pill had been taken by executing a python script that directly interfaced with the general purpose input-output pins.
Hardware: Raspberry Pi: Circuited a microswitch to control an LED that was engineered into the pillbox and programmed with Python to blink at a specified date and time, and to stop blinking either after approx 5 seconds (recorded as a pill not taken) or when the pillbox is opened and the microswitch opens (recorded as a pill taken).
## Challenges
* Most of us are new with Hackathons, and we have different coding languages abilities. This caused our collaboration to be difficult due to our differences in skills.
* Like many others, we have time constraints, regarding our ideas, design and what was feasible within the 24 hours.
* Figuring out how to work with raspberry pi, how to connect it with nodeJS and React App.
* Automatically schedule notifications from the database.
* Setting up API endpoints
* Coming up with unique designs of the usage of the app.
## Accomplishments
* We got through our first Hackaton, Wohoo!
* Improving skills that we are strong at, as well as learning our areas of improvement.
* With the obstacles we faced, we still managed to pull out thorough research, come up with ideas and concrete products.
* Actually managed to connect raspberry pi hardware to back-end and front-end servers.
* Push beyond our comfort zones, mentally and physically
## What's Next For nudge:
* Improve on the physical design of the pillbox itself – such as customizing our own pillbox so that the electrical pieces would not come in contact with the pills.
* Maybe adding other sensory cues for the user, such as a buzzer, so that even when the user is located a room away from the pillbox, they would still be alerted in terms of taking their medicines at the scheduled time.
* Review the codes and features of our mobile app, conduct a user test to ensure that it meets the needs of our users.
* Rest and Reflect | losing |
# More Smart
Tinder for tutoring. Get smart. More.
Students are the best at teaching students, they understand where they are coming from and can interface on the most identifyable lvl. TAs are bad at teaching, Tutors can be expensive and also don't often know the specific ideas that are needed for university specific courses.
### Setup
```
pip install Flask
pip install -U psycopg2
pip install Flask-SQLAlchemy
pip install Flask-Security
pip install Flask-OAuth2-Login
pip install requests
pip install --upgrade requests
pip install twilio
python3 populate.py
```
### Run
```
python3 moresmart.py
``` | ## Inspiration
As students, we use discord, zoom, and many other apps that are not tailored for students. We wanted to make an app to connect students and help them study together and make new friends tailored specifically for students at their university.
## What it does
It matches students with each other based on similar categories such as enrolled courses, languages, interests, majors, assignments, and more. Once students are matched they can chat in chatrooms and will have their own personal tailored AI assistant to help them with any issues they face.
## How we built it
We used SQLite for the database to store all the students, courses, majors, languages, connecting tables, and more. We used node.js for the backend and express.js http servers. We used bootstrap and react.js along with simple html, css, and javascript for the frontend.
## Challenges we ran into
We struggled to transfer data from the database all the way to the client-side and from the client-side all the way to the database. Making chatrooms that function with multiple students was also extremely difficult for us.
## Accomplishments that we're proud of
Not giving up even when all the odds were stacked against us.
## What we learned
We learned how to use so many new technologies. And we learned that things are harder then they seem when it comes to tech.
## What's next for Study Circuit
Expand matching capabilities, and implement features such as breakout rooms, virtual study halls, and office hour support for TAs. | ## Inspiration
We are part of a generation that has lost the art of handwriting. Because of the clarity and ease of typing, many people struggle with clear shorthand. Whether you're a second language learner or public education failed you, we wanted to come up with an intelligent system for efficiently improving your writing.
## What it does
We use an LLM to generate sample phrases, sentences, or character strings that target letters you're struggling with. You can input the writing as a photo or directly on the webpage. We then use OCR to parse, score, and give you feedback towards the ultimate goal of character mastery!
## How we built it
We used a simple front end utilizing flexbox layouts, the p5.js library for canvas writing, and simple javascript for logic and UI updates. On the backend, we hosted and developed an API with Flask, allowing us to receive responses from API calls to state-of-the-art OCR, and the newest Chat GPT model. We can also manage user scores with Pythonic logic-based sequence alignment algorithms.
## Challenges we ran into
We really struggled with our concept, tweaking it and revising it until the last minute! However, we believe this hard work really paid off in the elegance and clarity of our web app, UI, and overall concept.
..also sleep 🥲
## Accomplishments that we're proud of
We're really proud of our text recognition and matching. These intelligent systems were not easy to use or customize! We also think we found a creative use for the latest chat-GPT model to flex its utility in its phrase generation for targeted learning. Most importantly though, we are immensely proud of our teamwork, and how everyone contributed pieces to the idea and to the final project.
## What we learned
3 of us have never been to a hackathon before!
3 of us never used Flask before!
All of us have never worked together before!
From working with an entirely new team to utilizing specific frameworks, we learned A TON.... and also, just how much caffeine is too much (hint: NEVER).
## What's Next for Handwriting Teacher
Handwriting Teacher was originally meant to teach Russian cursive, a much more difficult writing system. (If you don't believe us, look at some pictures online) Taking a smart and simple pipeline like this and updating the backend intelligence allows our app to incorporate cursive, other languages, and stylistic aesthetics. Further, we would be thrilled to implement a user authentication system and a database, allowing people to save their work, gamify their learning a little more, and feel a more extended sense of progress. | losing |
## 💡Inspiration and Purpose
Our group members are from all around the U.S., from Dallas to Boston, but one thing that we have in common is that we have a grandparent living by themselves. Due to various family situations, we have elderly loved ones who spend a few hours alone each day, putting them at risk of a fatal accident like a fall. After researching current commercial solutions for fall detection, devices can range from anywhere from twenty-four to fifty dollars per device monthly. While this is affordable for our families, it is distinctly out of reach for many disadvantaged families.
In 2020, falls among Americans 65 and older caused over 36,000 deaths - the leading cause of injury death for that demographic group. Furthermore, these falls led to some three million emergency hospital visits and $50 billion in medical costs, creating an immense strain on our healthcare system.
## 🎖️ What It Does
Despite these sobering statistics, very few accessible solutions exist to assist seniors who may experience a fall at home. More worryingly, many of these products rely on the individual who has just become seriously injured to report the incident and direct emergency medical services to their location. Oftentimes, someone might not be able to alert the proper authorities and suffer needlessly as a result.
Guardian Angel aims to solve this growing problem by automating the process of fall detection using machine learning and deploying it in an easy-to-use, accurate, and portable system. From there, the necessary authorities can be notified, even if an individual is critically injured.
By using data-based trackers such as position, this application will adequately calculate and determine if a person has fallen based on a point and confidence system. This can be used for risk prevention profiles as it can detect shuffling or skipping. The application will shine red if it is confident that the person has fallen and it is not a false positive.
## 🧠 Development and Challenges
The application overall was built using React, alongside TailwindCSS and ML5. Using the create-react-app boilerplate, we were able to minimize the initial setup and invest more time in fixing bugs. In general, the website works by obtaining the model, metadata, and weights from the tensorflow.js model, requests a webcam input, and then pushes that webcam input into the machine learning model. The result of the model, as well as the confidence, is then displayed to the user.
The machine learning side of the project was developed using TensorFlow through tensorflow.js. As a result, we were able to primarily focus on gathering proper samples for the model, rather than optimization. The samples used for training were gathered by capturing dozens of videos of people falling in various backgrounds, isolating the frames, and manually labeling the data. We also augmented the samples to improve the model's ability to generalize.
For training, we used around 5 epochs, a learning rate of 0.01, and a batch size of 16. Other than that, every other parameter was default.
We also ran into a few major challenges during the creation of the project. Firstly, the complexity of detecting movement made obtaining samples and training particularly difficult. Our solution was to gather a number of samples from different orientations, allowing for the model to be accurate in a wide variety of situations. Specifically speaking for the website, one of the main challenges we ran implementing video rendering within React. We were eventually able to implement our desired functionality using HTML videos, uncommon react dependency components, and complex Tensorflow-React interactions.
## 🎖️ Accomplishments that we're proud of
First and foremost, we are proud of successfully completing the project while getting to meet with several mentors and knowledgeable professionals, such as the great teams at CareYaya and Y Combinator.
Second, we are proud of our model's accuracy. Classifying a series of images with movement was no small undertaking, particularly because we needed to ignore unintentional movements while continuing to accurately identify sudden changes in motion.
Lastly, we are very proud of the usability and functionality of our application. Despite being a very complex undertaking, our front end wraps up our product into an incredibly easy-to-use platform that is highly intuitive. We hope that this project, with minimal modifications, could be deployed commercially and begin to make a difference.
## 🔜 Next Steps
We would soon like to integrate our app with smart devices such as Amazon Alexa and Apple Smart Watch to obtain more data and verify our predictions. With accessible devices like Alexa already on the market, we will continue to ensure this service is as scalable as possible. We also want to detect fall audio, as audio can help make our results more accurate. Audio also would allow our project to be active in more locations in a household, and cover for the blind spots cameras typically have.
Guardian Angel is a deployable and complete application in itself, but we hope to take extra steps to make our project even more user-friendly. One thing we want to implement in the near future is to create an API for our application so that we can take advantage of existing home security systems. By utilizing security cameras that are already present, we can lower the barriers to entry for consumers as well as improve our reach. | ## Inspiration
During the pandemic, I kept saving my money for urgency (e.g. unemployment, disease, quarantine, etc.). Although we have now reached the stage where our lives are beginning to go back to normal as COVID-19 begins to slow down, this concern stays there. Finally, I thought that only developing the habit of investing and using my money to create more money would be a good way to restore my life.
Before the pandemic, I considered investing in cryptocurrency, but eventually, I did not due to its high risk; I missed the boat. I believe many people might have similar experiences. But this time, at the particular time of post-pandemic, to increase our assets, I think we should set up our determination and be on the boat.
We probably attempted to collect information in order to buy the most potential cryptocurrency, but were lost among countless posts that hold opposite opinions. I hope that we can have a platform that shares the latest cryptocurrency information, which enables the investors to observe the market trend at any time.
## What it does
CryptoStat X is a web app that generates global cryptocurrency statistics, exchange platforms information, and the latest news. For each top cryptocurrency, detailed information is presented, including history illustrations, figures like market share, line charts that visualize the change of price and much more. Given most investors are new to cryptocurrencies, an AI voice assistant can provide users with basic information about cryptocurrencies (e.g. how and where to buy), as well as broadcast the real-time price of Bitcoin. The voice assistant can even carry out basic mathematical calculations with large numbers if users wish to further analyze data and ask their math questions.
## How I built it
CoinRanking API is used for fetching cryptocurrencies data; meanwhile, cryptocurrencies news is collected by using Bing News Search API. Furthermore, I developed the app using React, and the Redux toolkit is integrated to manage the data fetch by API. Last but not least, Alan AI, a complete Voice AI Platform, allows me to embed a contextual voice assistant into the application UI.
## Challenges I ran into
* In the beginning, some data was always undefined when being fetched from API, so that the page could not be rendered; after searching and debugging, I created a Loader component and rendered it when data was still being fetched.
* Chart.js did not work when I implemented it as before (I generated charts using the library for other projects before.). After searching the documentation, I found that it was upgraded and fixed the bug.
## Accomplishments that I've proud of
* Successfully created this web application with a voice assistant
* Managed to create an information platform that can deal with the real-world problem
## What I learned
* Use Redux toolkit to centralize the data fetched by API, enabling state persistence
* Generate visualized history charts using chart.js, displaying data in a perceivable way
* Design layout and improve user interface using Ant Design
## What's next for CoinStat X
* Sections regarding other kinds of investment, such as financing products, stock market and funds, could also be included in the web app for all kinds of investors
* The AI voice assistant may further read news for users, help them scroll down the page, and search for news when they ask. Users can completely have their hands free when using the web app. | ## Inspiration
With more people working at home due to the pandemic, we felt empowered to improve healthcare at an individual level. Existing solutions for posture detection are expensive, lack cross-platform support, and often require additional device purchases. We sought to remedy these issues by creating Upright.
## What it does
Upright uses your laptop's camera to analyze and help you improve your posture. Register and calibrate the system in less than two minutes, and simply keep Upright open in the background and continue working. Upright will notify you if you begin to slouch so you can correct it. Upright also has the Upright companion iOS app to view your daily metrics.
Some notable features include:
* Smart slouch detection with ML
* Little overhead - get started in < 2 min
* Native notifications on any platform
* Progress tracking with an iOS companion app
## How we built it
We created Upright’s desktop app using Electron.js, an npm package used to develop cross-platform apps. We created the individual pages for the app using HTML, CSS, and client-side JavaScript. For the onboarding screens, users fill out an HTML form which signs them in using Firebase Authentication and uploads information such as their name and preferences to Firestore. This data is also persisted locally using NeDB, a local JavaScript database. The menu bar addition incorporates a camera through a MediaDevices web API, which gives us frames of the user’s posture. Using Tensorflow’s PoseNet model, we analyzed these frames to determine if the user is slouching and if so, by how much. The app sends a desktop notification to alert the user about their posture and also uploads this data to Firestore. Lastly, our SwiftUI-based iOS app pulls this data to display metrics and graphs for the user about their posture over time.
## Challenges we ran into
We faced difficulties when managing data throughout the platform, from the desktop app backend to the frontend pages to the iOS app. As this was our first time using Electron, our team spent a lot of time discovering ways to pass data safely and efficiently, discussing the pros and cons of different solutions. Another significant challenge was performing the machine learning on the video frames. The task of taking in a stream of camera frames and outputting them into slouching percentage values was quite demanding, but we were able to overcome several bugs and obstacles along the way to create the final product.
## Accomplishments that we're proud of
We’re proud that we’ve come up with a seamless and beautiful design that takes less than a minute to setup. The slouch detection model is also pretty accurate, something that we’re pretty proud of. Overall, we’ve built a robust system that we believe outperforms other solutions using just the webcamera of your computer, while also integrating features to track slouching data on your mobile device.
## What we learned
This project taught us how to combine multiple complicated moving pieces into one application. Specifically, we learned how to make a native desktop application with features like notifications built-in using Electron. We also learned how to connect our backend posture data with Firestore to relay information from our Electron application to our OS app. Lastly, we learned how to integrate a machine learning model in Tensorflow within our Electron application.
## What's next for Upright
The next step is improving the posture detection model with more training data, tailored for each user. While the posture detection model we currently use is pretty accurate, by using more custom-tailored training data, it would take Upright to the next level. Another step for Upright would be adding Android integration for our mobile app, which currently only supports iOS as of now. | losing |
## Inspiration
This game was inspired by old-school choose your own destiny games like Dungeons & Dragons or House of Danger, but with a small mobile game twist linked to it!
## What it does
The game works exactly like those old school games, but entirely on one's phone! There will first be a prompt describing a certain situation, and the player will get to answer anything he or she or they want in return. Then, that answer will be analyzed by a NLP model in order to determine the most likely outcome of that decision. Finally, the game sends the outcome by text to let the player continue their story.
## How we built it
The big two components of this project are Twilio and co:here.
Using Twilio, the computer is able to first send a prompt to the player's phone, and the player is able to reply with their own unique answer. Once the computer receives that information back using Twilio, it is then uploaded to co:here in order to use their NLP model and classify the sentence. Depending on the key words used, the model will send back a code corresponding to the most likely outcome of that action. Finally, that "outcome" prompt is sent back to the player's phone by text to allow them to continue their adventure.
## Challenges we ran into
The biggest challenge we ran into was setting up the two way communication between the computer and the phone. Indeed, the computer would upload a message to Twilio which would then send it to our phone. However, our phone had to upload its reply to Twilio, which then sent it to a public server. Finally, our computer had to access that server to collect the information. Needless to say, for a team of newbies, it was extremely difficult to learn the whole process of setting this system up, and we are very thankful to the mentors who were present to clarify the steps.
## Accomplishments that we're proud of
We are very proud of setting up the two way communication system between our computer and our phone, using Twilio. Indeed, it was a hurdle to setup the public server from which our computer could collect the player's text reply. But as a team of amateurs, seeing our game play out so fluidly and by texting is really cool!
## What we learned
We learned a lot on communications between the computer, the phone, and online servers like Twilio as well as the proxies in between. Setting up this whole system is far more familiar now. We also saw how adding varying kinds of training data affected the accuracy of the NLP model, as well as the accuracy of the classification.
## What's next for Choose your Destiny - Mobile and NLP!
If time were not a factor, then we would implement an option at the very beginning to choose different stories to explore. We would also add images to the game's replies to make the adventure and story more vivid. Most importantly, with enough motivation, we would also work on and improve the NLP model with far more training data so that the classification is more accurate. | ## Inspiration
Natural disasters are getting more common. Resource planning is tough for counties, as well as busy people who have jobs to go to while the storm brews miles away. DisAstro Plan was born to help busy families automate their supply list and ping them about storm updates in case they need to buy earlier than expected.
## What it does
## How I built it
## Challenges I ran into
## Accomplishments that I'm proud of
## What I learned
## What's next for DisAstro Plan | ## Inspiration
CookHack was inspired by the fact that students in university are always struggling with the responsibility of cooking their next healthy and nutritious meal. However, most of the time, we as students are always too busy to decide and learn how to cook basic meals, and we resort to the easy route and start ordering Uber Eats or Skip the Dishes. Now, the goal with CookHack was to eliminate the mental resistance and make the process of cooking healthy and delicious meals at home as streamlined as possible while sharing the process online.
## What it does
CookHack, in a nutshell, is a full-stack web application that provides users with the ability to log in to a personalized account to browse a catalog of 50 different recipes from our database and receive simple step-by-step instructions on how to cook delicious homemade dishes. CookHack also provides the ability for users to add the ingredients that they have readily available and start cooking recipes with those associated ingredients. Lastly, CookHack encourages the idea of interconnection by sharing their cooking experiences online by allowing users to post updates and blog forums about their cooking adventures.
## How we built it
The web application was built using the following tech stack: React, MongoDB, Firebase, and Flask. The frontend was developed with React to make the site fast and performant for the web application and allow for dynamic data to be passed to and from the backend server built with Flask. Flask connects to MongoDB to store our recipe documents on the backend, and Flask essentially serves as the delivery system for the recipes between MongoDB and React. For our authentication, Firebase was used to implement user authentication using Firebase Auth, and Firestore was used for storing and updating documents about the blog/forum posts on the site. Lastly, the Hammer of the Gods API was connected to the frontend, allowing us to use machine learning image detection.
## Challenges we ran into
* Lack of knowledge with Flask and how it works together with react.
* Implementing the user ingredients and sending back available recipes
* Had issues with the backend
* Developing the review page
* Implementing HoTG API
## Accomplishments that we're proud of
* The frontend UI and UX design for the site
* How to use Flask and React together
* The successful transfer of data flow between frontend, backend, and the database
* How to create a "forum" page in react
* The implementation of Hammer of the Gods API
* The overall functionality of the project
## What we learned
* How to setup Flask backend server
* How to use Figma and do UI and UX design
* How to implement Hammer of the Gods API
* How to make a RESTFUL API
* How to create a forum page
* How to create a login system
* How to implement Firebase Auth
* How to implement Firestore
* How to use MongoDB
## What's next for CookHack
* Fix any nit-picky things on each web page
* Make sure all the functionality works reliably
* Write error checking code to prevent the site from crashing due to unloaded data
* Add animations to the frontend UI
* Allow users to have more interconnections by allowing others to share their own recipes to the database
* Make sure all the images have the same size proportions | losing |
## Inspiration
Kevin, one of our team members, is an enthusiastic basketball player, and frequently went to physiotherapy for a knee injury. He realized that a large part of the physiotherapy was actually away from the doctors' office - he needed to complete certain exercises with perfect form at home, in order to consistently improve his strength and balance. Through his story, we realized that so many people across North America require physiotherapy for far more severe conditions, be it from sports injuries, spinal chord injuries, or recovery from surgeries. Likewise, they will need to do at-home exercises individually, without supervision. For the patients, any repeated error can actually cause a deterioration in health. Therefore, we decided to leverage computer vision technology, to provide real-time feedback to patients to help them improve their rehab exercise form. At the same time, reports will be generated to the doctors, so that they may monitor the progress of patients and prioritize their urgency accordingly. We hope that phys.io will strengthen the feedback loop between patient and doctor, and accelerate the physical rehabilitation process for many North Americans.
## What it does
Through a mobile app, the patients will be able to film and upload a video of themselves completing a certain rehab exercise. The video then gets analyzed using a machine vision neural network, such that the movements of each body segment is measured. This raw data is then further processed to yield measurements and benchmarks for the relative success of the movement. In the app, the patients will receive a general score for their physical health as measured against their individual milestones, tips to improve the form, and a timeline of progress over the past weeks. At the same time, the same video analysis will be sent to the corresponding doctor's dashboard, in which the doctor will receive a more thorough medical analysis in how the patient's body is working together and a timeline of progress. The algorithm will also provide suggestions for the doctors' treatment of the patient, such as prioritizing a next appointment or increasing the difficulty of the exercise.
## How we built it
At the heart of the application is a Google Cloud Compute instance running together with a blobstore instance. The cloud compute cluster will ingest raw video posted to blobstore, and performs the machine vision analysis to yield the timescale body data.
We used Google App Engine and Firebase to create the rest of the web application and API's for the 2 types of clients we support: an iOS app, and a doctor's dashboard site. This manages day to day operations such as data lookup, and account management, but also provides the interface for the mobile application to send video data to the compute cluster. Furthermore, the app engine sinks processed results and feedback from blobstore and populates it into Firebase, which is used as the database and data-sync.
Finally, In order to generate reports for the doctors on the platform, we used stdlib's tasks and scale-able one-off functions to process results from Firebase over time and aggregate the data into complete chunks, which are then posted back into Firebase.
## Challenges we ran into
One of the major challenges we ran into was interfacing each technology with each other. Overall, the data pipeline involves many steps that, while each in itself is critical, also involve too many diverse platforms and technologies for the time we had to build it.
## What's next for phys.io
<https://docs.google.com/presentation/d/1Aq5esOgTQTXBWUPiorwaZxqXRFCekPFsfWqFSQvO3_c/edit?fbclid=IwAR0vqVDMYcX-e0-2MhiFKF400YdL8yelyKrLznvsMJVq_8HoEgjc-ePy8Hs#slide=id.g4838b09a0c_0_0> | ## Inspiration
One of our team members was stunned by the number of colleagues who became self-described "shopaholics" during the pandemic. Understanding their wishes to return to normal spending habits, we thought of a helper extension to keep them on the right track.
## What it does
Stop impulse shopping at its core by incentivizing saving rather than spending with our Chrome extension, IDNI aka I Don't Need It! IDNI helps monitor your spending habits and gives recommendations on whether or not you should buy a product. It also suggests if there are local small business alternatives so you can help support your community!
## How we built it
React front-end, MongoDB, Express REST server
## Challenges we ran into
Most popular extensions have company deals that give them more access to product info; we researched and found the Rainforest API instead, which gives us the essential product info that we needed in our decision algorithm. However this proved, costly as each API call took upwards of 5 seconds to return a response. As such, we opted to process each product page manually to gather our metrics.
## Completion
In its current state IDNI is able to perform CRUD operations on our user information (allowing users to modify their spending limits and blacklisted items on the settings page) with our custom API, recognize Amazon product pages and pull the required information for our pop-up display, and dynamically provide recommendations based on these metrics.
## What we learned
Nobody on the team had any experience creating Chrome Extensions, so it was a lot of fun to learn how to do that. Along with creating our extensions UI using React.js this was a new experience for everyone. A few members of the team were also able to spend the weekend learning how to create an express.js API with a MongoDB database, all from scratch!
## What's next for IDNI - I Don't Need It!
We plan to look into banking integration, compatibility with a wider array of online stores, cleaner integration with small businesses, and a machine learning model to properly analyze each metric individually with one final pass of these various decision metrics to output our final verdict. Then finally, publish to the Chrome Web Store! | ## Inspiration:
The inspiration for RehabiliNation comes from a mixture of our love for gaming, and our personal experiences regarding researching and working with those who have physical and mental disabilities.
## What it does:
Provides an accessible gaming experience for people with physical disabilities and motivate those fighting through the struggles of physical rehabilitation. It can also be used to track the progress people make while going through their healing process.
## How we built it:
The motion control arm band collects data using the gyroscope module linked to the Arduino board. It sends back the data to the Arduino serial monitor in the form of angles. We then use a python script to read the data from the serial monitor. It interprets the data into keyboard input, this allows us to interface with multiple games. Currently, it is used to play our Pac-man game which is written in java.
## Challenges we ran into:
Our main challenges was determining how to utilize the gyroscope with the Arduino board and to trying to figure out how to receive and interpret the data with a python script. We also came across some issues with calibrating the motion sensors.
## Accomplishments that we're proud of
Throughout our creation process, we all managed to learn about new technologies and new skills and programming concepts. We may have been pushed into the pool, but it was quite a fun way to learn, and in the end we came out with a finished product capable of helping people in need.
## What we learned
We learned a great amount about the hardware product process, as well as the utilization of hardware in general. In general, it was a difficult but rewarding experience, and we thank U of T for providing us with this opportunity.
## What's next for RehabiliNation
RehabiliNation will continue to refine our products in the future, including the use of better materials and more responsive hardware pieces than what was shown in today's proof of concept. Hopefully our products will be implemented by physical rehabilitation centres to help brighten the rehab process. | winning |
## Inspiration
After hearing a representative from **Private Internet Access** describe why internet security is so important, we wanted to find a way to simply make commonly used messaging platforms more secure for sharing sensitive and private information.
## What it does
**Mummify** provides in-browser text encryption and decryption by simply highlighting and clicking the Chrome Extension icon. It uses a multi-layer encryption by having both a private key and a public key. Anyone is able to encrypt using your public key, but only you are able to decrypt it.
## How we built it
Mummify is a Chrome Extension built using Javascript (jQuery), HTML, and CSS.
We did a lot of research about cryptography, deciding that we would be using asymmetric encryption with private key and public key to ensure complete privacy and security for the user. We then started to dive into building a Chrome extension, using JavaScript, JQuery and HTML to map out the logics behind our encryption and decryption extension. Lastly, we polished our extension with simple and user-friendly UI design and launched Mummify website!
We used Microsoft Azure technologies to host and maintain our webpage which was built using Bootstrap (HTML+CSS), and used Domain.com to get our domain name.
## Challenges we ran into
* What is the punniest domain name (in the whole world) that we can come up with?
* How do we make a Chrome Extension?
* Developing secure encryption algorithms.
* How to create shareable keys without defeating the purpose of encryption.
* How to directly replace the highlighted text within an entry field.
* Bridging the extension and the web page.
* Having our extension work on different chat message platforms. (Messenger, HangOuts, Slack...)
## Accomplishments that we're proud of
* Managing to overcome all our challenges!
* Learning javascript in less than 24 hours.
* Coming together to work as the Best Team at nwHacks off of a random Facebook post!
* Creating a fully-usable application in less than 24 hours.
* Developing a secure encryption algorithm on the fly.
* Learning how to harness the powers of Microsoft Azure.
## What we learned
Javascript is as frustrating as people make it out to be.
Facebook, G-mail, Hotmail, and many other sites all use very diverse build methods which makes it hard for an Extension to work the same on all.
## What's next for Mummify
We hope to deploy Mummify to the Chrome Web Store and continue working as a team to develop and maintain our extension, as well as advocating for privacy on the internet! | ## Inspiration
In today's always-on world, we are more connected than ever. The internet is an amazing way to connect to those close to us, however it is also used to spread hateful messages to others. Our inspiration was taken from a surprisingly common issue among YouTubers and other people prominent on social media: That negative comments (even from anonymous strangers) hurts more than people realise. There have been cases of YouTubers developing mental illnesses like depression as a result of consistently receiving negative (and hateful) comments on the internet. We decided that this overlooked issue deserved to be brought to attention, and that we could develop a solution not only for these individuals, but the rest of us as well.
## What it does
Blok.it is a Google Chrome extension that analyzes web content for any hateful messages or content and renders it unreadable to the user. Rather than just censoring a particular word or words, the entire phrase or web element is censored. The HTML and CSS formatting remains, so nothing funky happens to the layout and design of the website.
## How we built it
The majority of the app is built in JavaScript and jQuery, with some HTML and CSS for interaction with the user.
## Challenges we ran into
Working with Chrome extensions was something very new to us and we had to learn some new JS in order to tackle this challenge. We also ran into the issue of spending too much time deciding on an idea and how to implement it.
## Accomplishments that we're proud of
Managing to create something after starting and scraping multiple different projects (this was our third or fourth project and we started pretty late)
## What we learned
Learned how to make Chrome Extensions
Improved our JS ability
learned how to work with a new group of people (all of us are first time hackathon-ers and none of us had extensive software experience)
## What's next for Blok.it
Improving the censoring algorithms. Most hateful messages are censored, but some non-hateful messages are being inadvertently marked as hateful and being censored as well. Getting rid of these false positives is first on our list of future goals. | ## Inspiration
Almost everyone has felt the effects of procrastination at least one time in their life. Procrastination pushes projects and assignments back, leaving little to no time to finish the project. One of the largest parts of an assignment is the research, which requires tons of reading in order to connect and create a meaningful product. The process of reading takes time, dependent on the individual's reading speed. Reading speed is something that can be cut down with practice, and where we gained inspiration for this project. We wanted to help improve the monotonous process of reading through pages and blurbs of text, and thus this chrome extension was made!
## What it does
Our app has two main features. The first feature helps provide the user with more information, to enhance their reading experience. It does this by providing the user with information about how many words are being displayed on the webpage at a current time, and also how many minutes it would approximately take (for the average) human to read through it, to provide a sense of scale. The second feature is designed to help the user improve their reading speed. They are given a list of 100 words, and are instructed to time themselves to discover their own reading speed. The user can then use this statistic to track their progress, and also as an incentive to improve.
## How we built it
We used a chrome extension to create this app. It utilizes HTML, CSS, JS. HTML and CSS are used to display the content to the user, while JS was used to provide functionality to the elements presented in the HTML and CSS. We began by building a basic HTML template to test things on, before implementing both features and applying them to our full HTML and CSS presentation.
## Challenges we ran into
Many members of our group were completely brand new to web-development and subsequently, chrome extensions. Within a span of 2 days, many of us learned how to code a working HTML, CSS, and JS application from scratch. Thus, a lot of our time was spent learning the ropes on what it means to create a meaningful chrome extension from the ground up!
One thing we had particular trouble with was with JS. Already being unfamiliar with the language, we had trouble understanding the concept of promises and asynchronous code inside JS, where it is often needed in chrome extensions. As a result, our communications between functions were often incorrect, leaving many variables with crucial information undefined.
## Accomplishments that we're proud of
We're proud that we finished what we wanted in time! All of us are novices to hackathons, and are glad we managed to finish our project to a level we were happy with. Additionally, many of us learned HTML, CSS, and JS within a span of 2 days, well enough to make an entire chrome extension, which we found quite surprising ourselves!
## What we learned
We learned how to combine HTML, CSS, and JS to make a chrome extension! We also learned a lot about asynchronous programming, which allowed us for easier communication from function to function. Finally, we also learned and practiced the use of proper planning, creating templates and ideas well before implementing them in our code editors, allowing us to continually build upon our project, rather than constantly restarting and redeveloping.
## What's next for ReadMore
Expand on our reading speed practice, providing more methods and more engaging ways to practice reading quickly! (e.g instead of reading words quickly for practice, you have the option to read sentences quickly instead) Another way we could improve the user experience for practicing reading quickly could be providing insights and history for user performance, allowing the user to look back in time to see previous graphs and statistics about their reading speeds, providing further motivation! | winning |
## Team
We are team 34 on discord. Members are Kevin Liang, Conrad Fernandez, Aaron Chen and Owen Rocchi.
## Inspiration
COVID-19 has devastated our global society like never before, but above all, the shutdowns have substantially lowered our productivity levels. People miss the ambiance of the hustle and bustle, and yearn for the surge in productivity while working from coffee shops and public places. We strived to recreate that feeling, so you could enjoy the ambiance of your favourite places from the comfort of your home - enjoying the best of both worlds, right at your fingertips.
## What it does
Coffii is a web application that simulates the feeling of sitting inside your favourite coffee shops, restaurants, and public places. Search your favourite place to work from, then zone out and grind your work in its 360 degree live stream, and order your favourite drink/meal while you’re at it! Coffee chat and co-work at the virtual tables, network with like-minded netizens, and thrive just like the good old days! With the premium plan, users can also virtually travel to shops around the world, from the comfort of their home.
## How I built it
We built Coffii using HTML/CSS and JavaScript, along with a Google Maps API.
## Challenges I ran into
Our biggest challenge by far was optimizing our web layout for an intuitive design - spending hours of brainstorming, experimentation, and a bit of frustration - don’t worry, no keyboards were hurt :) Furthermore, we ran into some issues with the CSS and JavaScript, making sure the icons animated properly.
## Accomplishments that I'm proud of
For all four of us, this was the most productive programming session we’ve ever done. Within two days, we tackled a dire need using a stimulating and user-friendly web application. Aside from our product, we were amazed by how much our diverse expertise backgrounds strengthened our productivity and team chemistry - we will definitely be competing at the next QHacks together :)
## What I learned
Over the course of an intensive weekend, we learned how to optimize the user experience, while using JavaScript and CSS for the first time to animate our icon buttons. We learned more about frontend web development from QHacks than anywhere else.
## What's next for Coffii
* Enhancing the animations to further simulate an in-person environment
* Incorporating elements of virtual reality to engage our users’ senses more
* Adding pomodoro timer feature or timed productivity reminders to get a coffee, take a break, etc.
## Domain.com Competition
Our domain name is coffii.space, because we will always need some space to enjoy a nice cup of hot coffee ;) | ## Inspiration
Small businesses have suffered throughout the COVID-19 pandemic. In order to help them get back on track once life comes back to normal, this app can attract new and loyal customers alike to the restaurant.
## What it does
Businesses can sign up and host their restaurant online, where users can search them up, follow them, and scroll around and see their items. Owners can also offer virtual coupons to attract more customers, or users can buy each other food vouchers that can be redeemed next time they visit the store.
## How we built it
The webapp was built using Flask and Google's Firebase for the backend development. Multiple flask modules were used, such as flask\_login, flask\_bcrypt, pyrebase, and more. HTML/CSS with Jinja2 and Bootstrap were used for the View (structuring of the code followed an MVC model).
## Challenges we ran into
-Restructuring of the project:
Sometime during Saturday, we had to restructure the whole project because we ran into a circular dependency, so the whole structure of the code changed making us learn the new way of deploying our code
-Many 'NoneType Object is not subscriptable', and not attributable errors
Getting data from our Firebase realtime database proved to be quite difficult at times, because there were many branches, and each time we would try to retrieve values we ran into the risk of getting this error. Depending on the type of user, the structure of the database changes but the users are similarly related (Business inherits from Users), so sometimes during login/registration the user type wouldn't be known properly leading to NoneType object errors.
-Having pages different for each type of user
This was not as much of a challenge as the other two, thanks to the help of Jinja2. However, due to the different pages for different users, sometimes the errors would return (like names returning as None, because the user types would be different).
## Accomplishments that we're proud of
-Having a functional search and login/registration system
-Implementing encryption with user passwords
-Implementing dynamic URLs that would show different pages based on Business/User type
-Allowing businesses to add items on their menu, and uploading them to Firebase
-Fully incorporating our data and object structures in Firebase,
## What we learned
Every accomplishment is something we have learned. These are things we haven't implemented before in our projects. We learned how to use Firebase with Python, and how to use Flask with all of its other mini modules.
## What's next for foodtalk
Due to time constraints, we still have to implement businesses being able to post their own posts. The coupon voucher and gift receipt system have yet to be implemented, and there could be more customization for users and businesses to put on their profile, like profile pictures and biographies. | ## Inspiration
As students, we have found that there are very few high-quality resources on investing for those who are interested but don't have enough resources. Furthermore, we have found that investing and saving money can be a stressful experience. We hope to change this for those who want to save better with the help of our app, hopefully making it fun in the process!
## What it does
Our app first asks a new client a brief questionnaire about themselves. Then, using their banking history, it generates 3 "demons", aka bad spending habits, to kill. Then, after the client chooses a habit to work on, it brings them to a dashboard where they can monitor their weekly progress on a task. Once the week is over, the app declares whether the client successfully beat the mission - if they did, they get rewarded with points which they can exchange for RBC Loyalty points!
## How we built it
We built the frontend using React + Tailwind, using Routes to display our different pages. We used Cohere for our AI services, both for generating personalized weekly goals and creating a more in-depth report. We used Firebase for authentication + cloud database to keep track of users. For our data of users and transactions, as well as making/managing loyalty points, we used the RBC API.
## Challenges we ran into
Piecing the APIs together was probably our most difficult challenge. Besides learning the different APIs in general, integrating the different technologies got quite tricky when we are trying to do multiple things at the same time!
Besides API integration, definitely working without any sleep though was the hardest part!
## Accomplishments that we're proud of
Definitely our biggest accomplishment was working so well together as a team. Despite only meeting each other the day before, we got along extremely well and were able to come up with some great ideas and execute under a lot of pressure (and sleep deprivation!) The biggest reward from this hackathon are the new friends we've found in each other :)
## What we learned
I think each of us learned very different things: this was Homey and Alex's first hackathon, where they learned how to work under a small time constraint (and did extremely well!). Paige learned tons about React, frontend development, and working in a team. Vassily learned lots about his own strengths and weakness (surprisingly reliable at git, apparently, although he might have too much of a sweet tooth).
## What's next for Savvy Saver
Demos! After that, we'll just have to see :) | losing |
## **Inspiration**
We took inspiration from real people who have this neurological disorder. We wanted to develop an app that gives users with this disorder confidence and assurance knowing that help is on its way. The following is the epilepsy story of Brandi Parker (<http://www.cureepilepsy.org/share/my-story.asp?story=15):>
"At the age of 15 I had my first seizure. I was in high school and didn't want anyone to know that I had epilepsy. I have only had seizures on two occasions. I was so ashamed and didn't want people to think that something was wrong with me. I finally got to the point where I told people that I had epilepsy. I came to the place that I realized that I had to own my epilepsy or it would control me." -Brandy Parker
## **Epilepsy Facts**
Epilepsy is the fourth most common neurological disorder and affects people of all ages.
Epilepsy means the same thing as "seizure disorders".
Epilepsy is characterized by unpredictable seizures and can cause other health problems.
Epilepsy is a spectrum condition with a wide range of seizure types and control varying from person-to-person.
## **What is Ep-Detect?**
Ep-Detect is an Android application which is able to detect an epilepsy and informs this to a list of contacts to help prevent brain injury. It connects to a Pebble via Bluetooth which is able to detect intense shaking. Once the app recognizes that an elliptical attack is happening, it sends a text message to every contact provided with the location of the person having the attack. The app also attempts to contact emergency services. If case of a false alarm, the user will have 10 seconds to notify the app of this event.
## **How we built it**
Ep-Detect connects to a Pebble smartwatch via Bluetooth. The app stores contacts added by the user using SQLite. Once severe shaking is detected, the user is given 10 seconds to notify the app of a false alarm. Once this 10 second time period have passed, the app will get the location of the user with Google Maps and will send a text message to all contacts stored in the database using SMSManager. Also, using the Nuance Speech Kit, a warning message is triggered to alert anyone nearby of the situation. We attempted to call emergency services using a voice message using Twilio, however that feature required a paid account.
## **Challenges we ran into**
We initially ran into problems with the Pebble. At first, we weren't able to communicate with the Pebble from the app. However, we were able to find a solution using the AppMessage method. Another challenge we faced was interrupting the Nuance Speech Kit when it was playing.
## **Accomplishments that we're proud of**
We are very happy to solve the problem of detecting elliptical attacks. We were able to provide a fully functional app that can help prevent injuries and better people's lives. We were also able to make use of two APIs.
## **What we learned**
We are now more informed about this neurological disorder and we learned how technology can assist or even provide a solution to prevent injuries. Technical wise, we learned how to use the Pebble smartwatch and gain android skills. Also, we learned how to communicate and work efficiently in a team of three.
## **Next steps for Ep-Detect**
There is always room for improvement for the UI of the app. If time permitted, we would've liked to try out more APIs for the app. We would perform experiments on real users and more testing to improve the app. | ## What it does
Blink is a communication tool for those who cannot speak or move, while being significantly more affordable and accurate than current technologies on the market. [The ALS Association](http://www.alsa.org/als-care/augmentative-communication/communication-guide.html) recommends a $10,000 communication device to solve this problem—but Blink costs less than $20 to build.
You communicate using Blink through a modified version of **Morse code**. Blink out letters and characters to spell out words, and in real time from any device, your caretakers can see what you need. No complicated EEG pads or camera setup—just a small, unobtrusive sensor can be placed to read blinks!
The Blink service integrates with [GIPHY](https://giphy.com) for GIF search, [Earth Networks API](https://www.earthnetworks.com) for weather data, and [News API](https://newsapi.org) for news.
## Inspiration
Our inspiration for this project came from [a paper](http://www.wearabletechnologyinsights.com/articles/11443/powering-devices-through-blinking) published on an accurate method of detecting blinks, but it uses complicated, expensive, and less-accurate hardware like cameras—so we made our own **accurate, low-cost blink detector**.
## How we built it
The backend consists of the sensor and a Python server. We used a capacitive touch sensor on a custom 3D-printed mounting arm to detect blinks. This hardware interfaces with an Arduino, which sends the data to a Python/Flask backend, where the blink durations are converted to Morse code and then matched to English characters.
The frontend is written in React with [Next.js](https://github.com/zeit/next.js) and [`styled-components`](https://styled-components.com). In real time, it fetches data from the backend and renders the in-progress character and characters recorded. You can pull up this web app from multiple devices—like an iPad in the patient’s lap, and the caretaker’s phone. The page also displays weather, news, and GIFs for easy access.
**Live demo: [blink.now.sh](https://blink.now.sh)**
## Challenges we ran into
One of the biggest technical challenges building Blink was decoding blink durations into short and long blinks, then Morse code sequences, then standard characters. Without any libraries, we created our own real-time decoding process of Morse code from scratch.
Another challenge was physically mounting the sensor in a way that would be secure but easy to place. We settled on using a hat with our own 3D-printed mounting arm to hold the sensor. We iterated on several designs for the arm and methods for connecting the wires to the sensor (such as aluminum foil).
## Accomplishments that we're proud of
The main point of PennApps is to **build a better future**, and we are proud of the fact that we solved a real-world problem applicable to a lot of people who aren't able to communicate.
## What we learned
Through rapid prototyping, we learned to tackle difficult problems with new ways of thinking. We learned how to efficiently work in a group with limited resources and several moving parts (hardware, a backend server, a frontend website), and were able to get a working prototype ready quickly.
## What's next for Blink
In the future, we want to simplify the physical installation, streamline the hardware, and allow multiple users and login on the website. Instead of using an Arduino and breadboard, we want to create glasses that would provide a less obtrusive mounting method. In essence, we want to perfect the design so it can easily be used anywhere.
Thank you! | ## Inspiration
Members of our team know multiple people who suffer from permanent or partial paralysis. We wanted to build something that could be fun to develop and use, but at the same time make a real impact in people's everyday lives. We also wanted to make an affordable solution, as most solutions to paralysis cost thousands and are inaccessible. We wanted something that was modular, that we could 3rd print and also make open source for others to use.
## What it does and how we built it
The main component is a bionic hand assistant called The PulseGrip. We used an ECG sensor in order to detect electrical signals. When it detects your muscles are trying to close your hand it uses a servo motor in order to close your hand around an object (a foam baseball for example). If it stops detecting a signal (you're no longer trying to close) it will loosen your hand back to a natural resting position. Along with this at all times it sends a signal through websockets to our Amazon EC2 server and game. This is stored on a MongoDB database, using API requests we can communicate between our games, server and PostGrip. We can track live motor speed, angles, and if it's open or closed. Our website is a full-stack application (react styled with tailwind on the front end, node js on the backend). Our website also has games that communicate with the device to test the project and provide entertainment. We have one to test for continuous holding and another for rapid inputs, this could be used in recovery as well.
## Challenges we ran into
This project forced us to consider different avenues and work through difficulties. Our main problem was when we fried our EMG sensor, twice! This was a major setback since an EMG sensor was going to be the main detector for the project. We tried calling around the whole city but could not find a new one. We decided to switch paths and use an ECG sensor instead, this is designed for heartbeats but we managed to make it work. This involved wiring our project completely differently and using a very different algorithm. When we thought we were free, our websocket didn't work. We troubleshooted for an hour looking at the Wifi, the device itself and more. Without this, we couldn't send data from the PulseGrip to our server and games. We decided to ask for some mentor's help and reset the device completely, after using different libraries we managed to make it work. These experiences taught us to keep pushing even when we thought we were done, and taught us different ways to think about the same problem.
## Accomplishments that we're proud of
Firstly, just getting the device working was a huge achievement, as we had so many setbacks and times we thought the event was over for us. But we managed to keep going and got to the end, even if it wasn't exactly what we planned or expected. We are also proud of the breadth and depth of our project, we have a physical side with 3rd printed materials, sensors and complicated algorithms. But we also have a game side, with 2 (questionable original) games that can be used. But they are not just random games, but ones that test the user in 2 different ways that are critical to using the device. Short burst and hold term holding of objects. Lastly, we have a full-stack application that users can use to access the games and see live stats on the device.
## What's next for PulseGrip
* working to improve sensors, adding more games, seeing how we can help people
We think this project had a ton of potential and we can't wait to see what we can do with the ideas learned here.
## Check it out
<https://hacks.pulsegrip.design>
<https://github.com/PulseGrip> | partial |
## Inspiration
Our goal was to create a system that could improve both a shopper's experience and a business's profit margin. People waste millions of hours every year waiting in supermarket lines and businesses need to spend a significant amount of money on upkeep, staffing, and real estate for checkout lines and stations.
## What it does
Our mobile app, web app, and anti-theft system provide an easy, straightforward platform for businesses to incorporate our technology and for consumers to use it.
## How we built it
We used RFID technology and bluetooth in conjunction with an Arduino Mega board for most of the core functions. A long-range RFID reader and controller was used for the anti-theft system. A multi-colored LED, buzzer, and speaker were used for supplementary functions.
## Challenges we ran into
We ran into many challenges related to the connections between the three mostly self-sufficient systems, especially from the anti-theft system. It took a long time to get the security system working using a macro script.
## Accomplishments that we're proud of
It works!
## What we learned
We each focused on one specific area of the app and because all of the subsystems of the project were reliant on one another, we had to spend a large amount of time communicating with each other and ensuring that all of the components worked together.
## What's next for GoCart
While our project serves as a proof of concept for the technology and showcases its potential impact, with a slightly higher budget and thus access to stronger technologies, we believe this technology can have a real commercial impact on the shopping industry. More specifically, by improving the range of the rfid readers and accuracy of product detection, we would be able increase the reliability of the antitheft system and the ease of use for shoppers. From a hardware standpoint, the readers on the carts need be much more compact and discreet. | ## Inspiration
The inspiration for Green Cart is to support local farmers by connecting them directly to consumers for fresh and nutritious produce. The goal is to promote community support for farmers and encourage people to eat fresh and locally sourced food.
## What it does
GreenCart is a webapp that connects local farmers to consumers for fresh, nutritious produce, allowing consumers to buy directly from farmers in their community. The app provides a platform for consumers to browse and purchase produce from local farmers, and for farmers to promote and sell their products. Additionally, GreenCart aims to promote community support for farmers and encourage people to eat fresh and locally sourced food.
## How we built it
The GreenCart app was built using a combination of technologies including React, TypeScript, HTML, CSS, Redux and various APIs. React is a JavaScript library for building user interfaces, TypeScript is a typed superset of JavaScript that adds optional static types, HTML and CSS are used for creating the layout and styling of the app, Redux is a library that manages the state of the app, and the APIs allow the app to connect to different services and resources. The choice of these technologies allowed the team to create a robust and efficient app that can connect local farmers to consumers for fresh, nutritious produce while supporting the community.
## Challenges we ran into
The GreenCart webapp development team encountered a number of challenges during the design and development process. The initial setup of the project, which involved setting up the project structure using React, TypeScript, HTML, CSS, and Redux, and integrating various APIs, was a challenge. Additionally, utilizing Github effectively as a team to ensure proper collaboration and version control was difficult. Another significant challenge was designing the UI/UX of the app to make it visually appealing and user-friendly. The team also had trouble with the search function, making sure it could effectively filter and display results. Another major challenge was debugging and fixing issues with the checkout balance not working properly. Finally, time constraints were a challenge as the team had to balance the development of various features while meeting deadlines.
## Accomplishments that we're proud of
As this was the first time for most of the team members to use React, TypeScript, and other technologies, the development process presented some challenges. Despite this, the team was able to accomplish many things that they were proud of. Some examples of these accomplishments could include:
Successfully setting up the initial project structure and integrating the necessary technologies.
Implementing a user-friendly and visually appealing UI/UX design for the app.
Working collaboratively as a team and utilizing Github for version control and collaboration.
Successfully launching the web app and getting a positive feedback from users.
## What we learned
During this hackathon, the team learned a variety of things, including:
How to use React, TypeScript, HTML, CSS, and Redux to build a web application.
How to effectively collaborate as a team using Github for version control and issue tracking.
How to design and implement a user-friendly and visually appealing UI/UX.
How to troubleshoot and debug issues with the app, such as the blog page not working properly.
How to work under pressure and adapt to new technologies and challenges.
They also learn how to build a web app that can connect local farmers to consumers for fresh, nutritious produce while supporting the community.
Overall, the team gained valuable experience in web development, teamwork, and project management during this hackathon.
## What's next for Green Cart
Marketing and Promotion: Develop a comprehensive marketing and promotion strategy to attract customers and build brand awareness. This could include social media advertising, email campaigns, and influencer partnerships.
Improve User Experience: Continuously gather feedback from users and use it to improve the app's user experience. This could include adding new features, fixing bugs and optimizing the performance.
Expand the Product Offerings: Consider expanding the range of products offered on the app to attract a wider customer base. This could include organic and non-organic produce, meat, dairy and more.
Partnership with Local Organizations: Form partnerships with local organizations such as supermarkets, restaurants, and community groups to expand the reach of the app and increase the number of farmers and products available.
## Git Repo ;
<https://github.com/LaeekAhmed/Green-Cart/tree/master/Downloads/web_dev/Khana-master> | # SmartKart
A IoT shopping cart that follows you around combined with a cloud base Point of Sale and Store Management system. Provides a comprehensive solution to eliminate lineups in retail stores, engage with customers without being intrusive and a platform to implement detailed customer analytics.
Featured by nwHacks: <https://twitter.com/nwHacks/status/843275304332283905>
## Inspiration
We questioned the current self-checkout model. Why wait in line in order to do all the payment work yourself!? We are trying to make a system that alleviates much of the hardships of shopping; paying and carrying your items.
## Features
* A robot shopping cart that uses computer vision to follows you!
* Easy-to-use barcode scanning (with an awesome booping sound)
* Tactile scanning feedback
* Intuitive user-interface
* Live product management system, view how your customers shop in real time
* Scalable product database for large and small stores
* Live cart geo-location, with theft prevention | partial |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.