
repo
stringclasses 856
values | pull_number
int64 3
127k
| instance_id
stringlengths 12
58
| issue_numbers
listlengths 1
5
| base_commit
stringlengths 40
40
| patch
stringlengths 67
1.54M
| test_patch
stringlengths 0
107M
| problem_statement
stringlengths 3
307k
| hints_text
stringlengths 0
908k
| created_at
timestamp[s] |
|---|---|---|---|---|---|---|---|---|---|
feast-dev/feast | 2,485 | feast-dev__feast-2485 | [
"2358"
]
| 0c9e5b7e2132b619056e9b41519d54a93e977f6c | diff --git a/sdk/python/feast/infra/online_stores/dynamodb.py b/sdk/python/feast/infra/online_stores/dynamodb.py
--- a/sdk/python/feast/infra/online_stores/dynamodb.py
+++ b/sdk/python/feast/infra/online_stores/dynamodb.py
@@ -17,7 +17,7 @@
from typing import Any, Callable, Dict, List, Optional, Sequence, Tuple
from pydantic import StrictStr
-from pydantic.typing import Literal
+from pydantic.typing import Literal, Union
from feast import Entity, FeatureView, utils
from feast.infra.infra_object import DYNAMODB_INFRA_OBJECT_CLASS_TYPE, InfraObject
@@ -50,17 +50,20 @@ class DynamoDBOnlineStoreConfig(FeastConfigBaseModel):
type: Literal["dynamodb"] = "dynamodb"
"""Online store type selector"""
+ batch_size: int = 40
+ """Number of items to retrieve in a DynamoDB BatchGetItem call."""
+
+ endpoint_url: Union[str, None] = None
+ """DynamoDB local development endpoint Url, i.e. http://localhost:8000"""
+
region: StrictStr
"""AWS Region Name"""
- table_name_template: StrictStr = "{project}.{table_name}"
- """DynamoDB table name template"""
-
sort_response: bool = True
"""Whether or not to sort BatchGetItem response."""
- batch_size: int = 40
- """Number of items to retrieve in a DynamoDB BatchGetItem call."""
+ table_name_template: StrictStr = "{project}.{table_name}"
+ """DynamoDB table name template"""
class DynamoDBOnlineStore(OnlineStore):
@@ -95,8 +98,12 @@ def update(
"""
online_config = config.online_store
assert isinstance(online_config, DynamoDBOnlineStoreConfig)
- dynamodb_client = self._get_dynamodb_client(online_config.region)
- dynamodb_resource = self._get_dynamodb_resource(online_config.region)
+ dynamodb_client = self._get_dynamodb_client(
+ online_config.region, online_config.endpoint_url
+ )
+ dynamodb_resource = self._get_dynamodb_resource(
+ online_config.region, online_config.endpoint_url
+ )
for table_instance in tables_to_keep:
try:
@@ -141,7 +148,9 @@ def teardown(
"""
online_config = config.online_store
assert isinstance(online_config, DynamoDBOnlineStoreConfig)
- dynamodb_resource = self._get_dynamodb_resource(online_config.region)
+ dynamodb_resource = self._get_dynamodb_resource(
+ online_config.region, online_config.endpoint_url
+ )
for table in tables:
_delete_table_idempotent(
@@ -175,7 +184,9 @@ def online_write_batch(
"""
online_config = config.online_store
assert isinstance(online_config, DynamoDBOnlineStoreConfig)
- dynamodb_resource = self._get_dynamodb_resource(online_config.region)
+ dynamodb_resource = self._get_dynamodb_resource(
+ online_config.region, online_config.endpoint_url
+ )
table_instance = dynamodb_resource.Table(
_get_table_name(online_config, config, table)
@@ -217,7 +228,9 @@ def online_read(
"""
online_config = config.online_store
assert isinstance(online_config, DynamoDBOnlineStoreConfig)
- dynamodb_resource = self._get_dynamodb_resource(online_config.region)
+ dynamodb_resource = self._get_dynamodb_resource(
+ online_config.region, online_config.endpoint_url
+ )
table_instance = dynamodb_resource.Table(
_get_table_name(online_config, config, table)
)
@@ -260,14 +273,16 @@ def online_read(
result.extend(batch_size_nones)
return result
- def _get_dynamodb_client(self, region: str):
+ def _get_dynamodb_client(self, region: str, endpoint_url: Optional[str] = None):
if self._dynamodb_client is None:
- self._dynamodb_client = _initialize_dynamodb_client(region)
+ self._dynamodb_client = _initialize_dynamodb_client(region, endpoint_url)
return self._dynamodb_client
- def _get_dynamodb_resource(self, region: str):
+ def _get_dynamodb_resource(self, region: str, endpoint_url: Optional[str] = None):
if self._dynamodb_resource is None:
- self._dynamodb_resource = _initialize_dynamodb_resource(region)
+ self._dynamodb_resource = _initialize_dynamodb_resource(
+ region, endpoint_url
+ )
return self._dynamodb_resource
def _sort_dynamodb_response(self, responses: list, order: list):
@@ -285,12 +300,12 @@ def _sort_dynamodb_response(self, responses: list, order: list):
return table_responses_ordered
-def _initialize_dynamodb_client(region: str):
- return boto3.client("dynamodb", region_name=region)
+def _initialize_dynamodb_client(region: str, endpoint_url: Optional[str] = None):
+ return boto3.client("dynamodb", region_name=region, endpoint_url=endpoint_url)
-def _initialize_dynamodb_resource(region: str):
- return boto3.resource("dynamodb", region_name=region)
+def _initialize_dynamodb_resource(region: str, endpoint_url: Optional[str] = None):
+ return boto3.resource("dynamodb", region_name=region, endpoint_url=endpoint_url)
# TODO(achals): This form of user-facing templating is experimental.
@@ -327,13 +342,20 @@ class DynamoDBTable(InfraObject):
Attributes:
name: The name of the table.
region: The region of the table.
+ endpoint_url: Local DynamoDB Endpoint Url.
+ _dynamodb_client: Boto3 DynamoDB client.
+ _dynamodb_resource: Boto3 DynamoDB resource.
"""
region: str
+ endpoint_url = None
+ _dynamodb_client = None
+ _dynamodb_resource = None
- def __init__(self, name: str, region: str):
+ def __init__(self, name: str, region: str, endpoint_url: Optional[str] = None):
super().__init__(name)
self.region = region
+ self.endpoint_url = endpoint_url
def to_infra_object_proto(self) -> InfraObjectProto:
dynamodb_table_proto = self.to_proto()
@@ -362,8 +384,8 @@ def from_proto(dynamodb_table_proto: DynamoDBTableProto) -> Any:
)
def update(self):
- dynamodb_client = _initialize_dynamodb_client(region=self.region)
- dynamodb_resource = _initialize_dynamodb_resource(region=self.region)
+ dynamodb_client = self._get_dynamodb_client(self.region, self.endpoint_url)
+ dynamodb_resource = self._get_dynamodb_resource(self.region, self.endpoint_url)
try:
dynamodb_resource.create_table(
@@ -384,5 +406,17 @@ def update(self):
dynamodb_client.get_waiter("table_exists").wait(TableName=f"{self.name}")
def teardown(self):
- dynamodb_resource = _initialize_dynamodb_resource(region=self.region)
+ dynamodb_resource = self._get_dynamodb_resource(self.region, self.endpoint_url)
_delete_table_idempotent(dynamodb_resource, self.name)
+
+ def _get_dynamodb_client(self, region: str, endpoint_url: Optional[str] = None):
+ if self._dynamodb_client is None:
+ self._dynamodb_client = _initialize_dynamodb_client(region, endpoint_url)
+ return self._dynamodb_client
+
+ def _get_dynamodb_resource(self, region: str, endpoint_url: Optional[str] = None):
+ if self._dynamodb_resource is None:
+ self._dynamodb_resource = _initialize_dynamodb_resource(
+ region, endpoint_url
+ )
+ return self._dynamodb_resource
| diff --git a/sdk/python/tests/unit/infra/online_store/test_dynamodb_online_store.py b/sdk/python/tests/unit/infra/online_store/test_dynamodb_online_store.py
--- a/sdk/python/tests/unit/infra/online_store/test_dynamodb_online_store.py
+++ b/sdk/python/tests/unit/infra/online_store/test_dynamodb_online_store.py
@@ -7,6 +7,7 @@
from feast.infra.online_stores.dynamodb import (
DynamoDBOnlineStore,
DynamoDBOnlineStoreConfig,
+ DynamoDBTable,
)
from feast.repo_config import RepoConfig
from tests.utils.online_store_utils import (
@@ -38,6 +39,121 @@ def repo_config():
)
+def test_online_store_config_default():
+ """Test DynamoDBOnlineStoreConfig default parameters."""
+ aws_region = "us-west-2"
+ dynamodb_store_config = DynamoDBOnlineStoreConfig(region=aws_region)
+ assert dynamodb_store_config.type == "dynamodb"
+ assert dynamodb_store_config.batch_size == 40
+ assert dynamodb_store_config.endpoint_url is None
+ assert dynamodb_store_config.region == aws_region
+ assert dynamodb_store_config.sort_response is True
+ assert dynamodb_store_config.table_name_template == "{project}.{table_name}"
+
+
+def test_dynamodb_table_default_params():
+ """Test DynamoDBTable default parameters."""
+ tbl_name = "dynamodb-test"
+ aws_region = "us-west-2"
+ dynamodb_table = DynamoDBTable(tbl_name, aws_region)
+ assert dynamodb_table.name == tbl_name
+ assert dynamodb_table.region == aws_region
+ assert dynamodb_table.endpoint_url is None
+ assert dynamodb_table._dynamodb_client is None
+ assert dynamodb_table._dynamodb_resource is None
+
+
+def test_online_store_config_custom_params():
+ """Test DynamoDBOnlineStoreConfig custom parameters."""
+ aws_region = "us-west-2"
+ batch_size = 20
+ endpoint_url = "http://localhost:8000"
+ sort_response = False
+ table_name_template = "feast_test.dynamodb_table"
+ dynamodb_store_config = DynamoDBOnlineStoreConfig(
+ region=aws_region,
+ batch_size=batch_size,
+ endpoint_url=endpoint_url,
+ sort_response=sort_response,
+ table_name_template=table_name_template,
+ )
+ assert dynamodb_store_config.type == "dynamodb"
+ assert dynamodb_store_config.batch_size == batch_size
+ assert dynamodb_store_config.endpoint_url == endpoint_url
+ assert dynamodb_store_config.region == aws_region
+ assert dynamodb_store_config.sort_response == sort_response
+ assert dynamodb_store_config.table_name_template == table_name_template
+
+
+def test_dynamodb_table_custom_params():
+ """Test DynamoDBTable custom parameters."""
+ tbl_name = "dynamodb-test"
+ aws_region = "us-west-2"
+ endpoint_url = "http://localhost:8000"
+ dynamodb_table = DynamoDBTable(tbl_name, aws_region, endpoint_url)
+ assert dynamodb_table.name == tbl_name
+ assert dynamodb_table.region == aws_region
+ assert dynamodb_table.endpoint_url == endpoint_url
+ assert dynamodb_table._dynamodb_client is None
+ assert dynamodb_table._dynamodb_resource is None
+
+
+def test_online_store_config_dynamodb_client():
+ """Test DynamoDBOnlineStoreConfig configure DynamoDB client with endpoint_url."""
+ aws_region = "us-west-2"
+ endpoint_url = "http://localhost:8000"
+ dynamodb_store = DynamoDBOnlineStore()
+ dynamodb_store_config = DynamoDBOnlineStoreConfig(
+ region=aws_region, endpoint_url=endpoint_url
+ )
+ dynamodb_client = dynamodb_store._get_dynamodb_client(
+ dynamodb_store_config.region, dynamodb_store_config.endpoint_url
+ )
+ assert dynamodb_client.meta.region_name == aws_region
+ assert dynamodb_client.meta.endpoint_url == endpoint_url
+
+
+def test_dynamodb_table_dynamodb_client():
+ """Test DynamoDBTable configure DynamoDB client with endpoint_url."""
+ tbl_name = "dynamodb-test"
+ aws_region = "us-west-2"
+ endpoint_url = "http://localhost:8000"
+ dynamodb_table = DynamoDBTable(tbl_name, aws_region, endpoint_url)
+ dynamodb_client = dynamodb_table._get_dynamodb_client(
+ dynamodb_table.region, dynamodb_table.endpoint_url
+ )
+ assert dynamodb_client.meta.region_name == aws_region
+ assert dynamodb_client.meta.endpoint_url == endpoint_url
+
+
+def test_online_store_config_dynamodb_resource():
+ """Test DynamoDBOnlineStoreConfig configure DynamoDB Resource with endpoint_url."""
+ aws_region = "us-west-2"
+ endpoint_url = "http://localhost:8000"
+ dynamodb_store = DynamoDBOnlineStore()
+ dynamodb_store_config = DynamoDBOnlineStoreConfig(
+ region=aws_region, endpoint_url=endpoint_url
+ )
+ dynamodb_resource = dynamodb_store._get_dynamodb_resource(
+ dynamodb_store_config.region, dynamodb_store_config.endpoint_url
+ )
+ assert dynamodb_resource.meta.client.meta.region_name == aws_region
+ assert dynamodb_resource.meta.client.meta.endpoint_url == endpoint_url
+
+
+def test_dynamodb_table_dynamodb_resource():
+ """Test DynamoDBTable configure DynamoDB resource with endpoint_url."""
+ tbl_name = "dynamodb-test"
+ aws_region = "us-west-2"
+ endpoint_url = "http://localhost:8000"
+ dynamodb_table = DynamoDBTable(tbl_name, aws_region, endpoint_url)
+ dynamodb_resource = dynamodb_table._get_dynamodb_resource(
+ dynamodb_table.region, dynamodb_table.endpoint_url
+ )
+ assert dynamodb_resource.meta.client.meta.region_name == aws_region
+ assert dynamodb_resource.meta.client.meta.endpoint_url == endpoint_url
+
+
@mock_dynamodb2
@pytest.mark.parametrize("n_samples", [5, 50, 100])
def test_online_read(repo_config, n_samples):
| [DynamoDB] - Allow passing ddb endpoint_url to enable feast local testing
**Is your feature request related to a problem? Please describe.**
Currently in feature_store.yaml, we can only specify a region for DynamoDB provider. As a result, it requires an actual DynamoDB to be available when we want to do local development/testing or integration testing in a sandbox environment.
**Describe the solution you'd like**
A way to solve this is to let user pass an endpoint_url. More information can be found [here](https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/DynamoDBLocal.UsageNotes.html).
This way, users can install and run a [local dynamoDB](https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/DynamoDBLocal.html), and use it as an online store locally.
The is especially useful when:
- accessing real DynamoDB requires a tedious and time-consuming steps (e.g.: IAM role set up, permissions, etc.) and these steps can be deferred later,
- integration testing locally, in docker, in Jenkins
**Describe alternatives you've considered**
N/A
**Additional context**
Not much but the initial slack thread can be found [here](https://tectonfeast.slack.com/archives/C01MSKCMB37/p1646166683447239), which was followed by a slack message from our team member
| @vlin-lgtm I think this one is kind of easy [_initialize_dynamodb_client](https://github.com/feast-dev/feast/blob/ea6a9b2034c35bf36ee5073fad93dde52279ebcd/sdk/python/feast/infra/online_stores/dynamodb.py#L288) and [_initialize_dynamodb_resource](_initialize_dynamodb_resource) would now accept `endpoint_url`
```python
def _initialize_dynamodb_client(region: str, url: str):
return boto3.client("dynamodb", endpoint_url=url, region_name=region)
```
which can be passed through the [DynamoDBOnlineStoreConfig](https://github.com/feast-dev/feast/blob/ea6a9b2034c35bf36ee5073fad93dde52279ebcd/sdk/python/feast/infra/online_stores/dynamodb.py#L47).
But, I'm not sure how will this be for local integration tests, as far as I know just need to change the [DYNAMODB_CONFIG](https://github.com/feast-dev/feast/blob/ea6a9b2034c35bf36ee5073fad93dde52279ebcd/sdk/python/tests/integration/feature_repos/repo_configuration.py#L48) with an additional parameter `endpoint_url` and set an [IntegrationTestConfig](https://github.com/feast-dev/feast/blob/ea6a9b2034c35bf36ee5073fad93dde52279ebcd/sdk/python/tests/integration/feature_repos/repo_configuration.py#L93) with DynamoDB as Online Store.
What are your thoughts?
P.D. I'm happy to contribute with this
Thanks so much, @TremaMiguel!
> But, I'm not sure how will this be for local integration tests, ....
My understanding is one can run a [local dynamoDB](https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/DynamoDBLocal.html) on their development machine or in a docker container, and by specifying an endpoint_url to for example `localhost:8080`, all DynamoDB invocations will go to the localhost instance instead of an actual one in AWS.
This is useful for integration testing as everything is still "local".
Would love it if you can help contribute to this 🙏
@vlin-lgtm Thanks for replying
I agree with the local integration tests, additionaly I think this development could help with #2400
I'll start working on this.
| 2022-04-04T17:53:16 |
feast-dev/feast | 2,508 | feast-dev__feast-2508 | [
"2482"
]
| df51b942a6f5cae0e47da3206f68f58ea26502b4 | diff --git a/sdk/python/feast/infra/utils/snowflake_utils.py b/sdk/python/feast/infra/utils/snowflake_utils.py
--- a/sdk/python/feast/infra/utils/snowflake_utils.py
+++ b/sdk/python/feast/infra/utils/snowflake_utils.py
@@ -4,9 +4,11 @@
import string
from logging import getLogger
from tempfile import TemporaryDirectory
-from typing import Dict, Iterator, List, Optional, Tuple, cast
+from typing import Any, Dict, Iterator, List, Optional, Tuple, cast
import pandas as pd
+from cryptography.hazmat.backends import default_backend
+from cryptography.hazmat.primitives import serialization
from tenacity import (
retry,
retry_if_exception_type,
@@ -40,18 +42,17 @@ def execute_snowflake_statement(conn: SnowflakeConnection, query) -> SnowflakeCu
def get_snowflake_conn(config, autocommit=True) -> SnowflakeConnection:
- if config.type == "snowflake.offline":
- config_header = "connections.feast_offline_store"
+ assert config.type == "snowflake.offline"
+ config_header = "connections.feast_offline_store"
config_dict = dict(config)
# read config file
config_reader = configparser.ConfigParser()
config_reader.read([config_dict["config_path"]])
+ kwargs: Dict[str, Any] = {}
if config_reader.has_section(config_header):
kwargs = dict(config_reader[config_header])
- else:
- kwargs = {}
if "schema" in kwargs:
kwargs["schema_"] = kwargs.pop("schema")
@@ -67,6 +68,13 @@ def get_snowflake_conn(config, autocommit=True) -> SnowflakeConnection:
else:
kwargs["schema"] = '"PUBLIC"'
+ # https://docs.snowflake.com/en/user-guide/python-connector-example.html#using-key-pair-authentication-key-pair-rotation
+ # https://docs.snowflake.com/en/user-guide/key-pair-auth.html#configuring-key-pair-authentication
+ if "private_key" in kwargs:
+ kwargs["private_key"] = parse_private_key_path(
+ kwargs["private_key"], kwargs["private_key_passphrase"]
+ )
+
try:
conn = snowflake.connector.connect(
application="feast", autocommit=autocommit, **kwargs
@@ -288,3 +296,21 @@ def chunk_helper(lst: pd.DataFrame, n: int) -> Iterator[Tuple[int, pd.DataFrame]
"""Helper generator to chunk a sequence efficiently with current index like if enumerate was called on sequence."""
for i in range(0, len(lst), n):
yield int(i / n), lst[i : i + n]
+
+
+def parse_private_key_path(key_path: str, private_key_passphrase: str) -> bytes:
+
+ with open(key_path, "rb") as key:
+ p_key = serialization.load_pem_private_key(
+ key.read(),
+ password=private_key_passphrase.encode(),
+ backend=default_backend(),
+ )
+
+ pkb = p_key.private_bytes(
+ encoding=serialization.Encoding.DER,
+ format=serialization.PrivateFormat.PKCS8,
+ encryption_algorithm=serialization.NoEncryption(),
+ )
+
+ return pkb
| Allow for connecting to Snowflake with a private key
When connecting to Snowflake with an account that requires MFA its does not work (or at least requires extra work to use MFA devices) to connect with just the username and password credentials.
Instead of using username and password we should be able to use a private key and a private key passphrase to connect to Snowflake. Snowflake already supports this method of authentication. See [here](https://docs.snowflake.com/en/user-guide/python-connector-example.html#label-python-key-pair-authn-rotation). Feast should add this as an option to the feature_store.yaml as part of the Snowflake connection config.
When trying to use a private_key_path and passphrase this error was raised:
```
raise FeastConfigError(e, config_path)
feast.repo_config.FeastConfigError: 2 validation errors for RepoConfig
__root__ -> offline_store -> private_key_passphrase
extra fields not permitted (type=value_error.extra)
__root__ -> offline_store -> private_key_path
extra fields not permitted (type=value_error.extra)
```
It seems like fields related to a passphrase are not permitted [here](https://github.com/feast-dev/feast/blob/b95f4410ee91069ff84e81d2d5f3e9329edc8626/sdk/python/feast/infra/offline_stores/snowflake.py#L56)
cc @sfc-gh-madkins
| After a Slack discussion it was concluded this could be done using the ~/.snowsql/config file and passing in the private key there. Unfortunately, the python connector doesn’t take the private key path instead it takes a byte object of an unecrypted rsa private key. To create this private key we should allow a user to set the private key path and private key passcode in the config file and then convert that to the private key in code using the method detailed [here]( python connector doesn’t take the private key path instead it takes a byte object of an unecrypted rsa private key). | 2022-04-07T19:31:56 |
|
feast-dev/feast | 2,515 | feast-dev__feast-2515 | [
"2483"
]
| 83f3e0dc6c1df42950d1f808a9d6f3f7fc485825 | diff --git a/sdk/python/feast/infra/online_stores/dynamodb.py b/sdk/python/feast/infra/online_stores/dynamodb.py
--- a/sdk/python/feast/infra/online_stores/dynamodb.py
+++ b/sdk/python/feast/infra/online_stores/dynamodb.py
@@ -191,21 +191,7 @@ def online_write_batch(
table_instance = dynamodb_resource.Table(
_get_table_name(online_config, config, table)
)
- with table_instance.batch_writer() as batch:
- for entity_key, features, timestamp, created_ts in data:
- entity_id = compute_entity_id(entity_key)
- batch.put_item(
- Item={
- "entity_id": entity_id, # PartitionKey
- "event_ts": str(utils.make_tzaware(timestamp)),
- "values": {
- k: v.SerializeToString()
- for k, v in features.items() # Serialized Features
- },
- }
- )
- if progress:
- progress(1)
+ self._write_batch_non_duplicates(table_instance, data, progress)
@log_exceptions_and_usage(online_store="dynamodb")
def online_read(
@@ -299,6 +285,32 @@ def _sort_dynamodb_response(self, responses: list, order: list):
_, table_responses_ordered = zip(*table_responses_ordered)
return table_responses_ordered
+ @log_exceptions_and_usage(online_store="dynamodb")
+ def _write_batch_non_duplicates(
+ self,
+ table_instance,
+ data: List[
+ Tuple[EntityKeyProto, Dict[str, ValueProto], datetime, Optional[datetime]]
+ ],
+ progress: Optional[Callable[[int], Any]],
+ ):
+ """Deduplicate write batch request items on ``entity_id`` primary key."""
+ with table_instance.batch_writer(overwrite_by_pkeys=["entity_id"]) as batch:
+ for entity_key, features, timestamp, created_ts in data:
+ entity_id = compute_entity_id(entity_key)
+ batch.put_item(
+ Item={
+ "entity_id": entity_id, # PartitionKey
+ "event_ts": str(utils.make_tzaware(timestamp)),
+ "values": {
+ k: v.SerializeToString()
+ for k, v in features.items() # Serialized Features
+ },
+ }
+ )
+ if progress:
+ progress(1)
+
def _initialize_dynamodb_client(region: str, endpoint_url: Optional[str] = None):
return boto3.client("dynamodb", region_name=region, endpoint_url=endpoint_url)
| diff --git a/sdk/python/tests/unit/infra/online_store/test_dynamodb_online_store.py b/sdk/python/tests/unit/infra/online_store/test_dynamodb_online_store.py
--- a/sdk/python/tests/unit/infra/online_store/test_dynamodb_online_store.py
+++ b/sdk/python/tests/unit/infra/online_store/test_dynamodb_online_store.py
@@ -1,5 +1,7 @@
+from copy import deepcopy
from dataclasses import dataclass
+import boto3
import pytest
from moto import mock_dynamodb2
@@ -162,7 +164,7 @@ def test_online_read(repo_config, n_samples):
data = _create_n_customer_test_samples(n=n_samples)
_insert_data_test_table(data, PROJECT, f"{TABLE_NAME}_{n_samples}", REGION)
- entity_keys, features = zip(*data)
+ entity_keys, features, *rest = zip(*data)
dynamodb_store = DynamoDBOnlineStore()
returned_items = dynamodb_store.online_read(
config=repo_config,
@@ -171,3 +173,24 @@ def test_online_read(repo_config, n_samples):
)
assert len(returned_items) == len(data)
assert [item[1] for item in returned_items] == list(features)
+
+
+@mock_dynamodb2
+def test_write_batch_non_duplicates(repo_config):
+ """Test DynamoDBOnline Store deduplicate write batch request items."""
+ dynamodb_tbl = f"{TABLE_NAME}_batch_non_duplicates"
+ _create_test_table(PROJECT, dynamodb_tbl, REGION)
+ data = _create_n_customer_test_samples()
+ data_duplicate = deepcopy(data)
+ dynamodb_resource = boto3.resource("dynamodb", region_name=REGION)
+ table_instance = dynamodb_resource.Table(f"{PROJECT}.{dynamodb_tbl}")
+ dynamodb_store = DynamoDBOnlineStore()
+ # Insert duplicate data
+ dynamodb_store._write_batch_non_duplicates(
+ table_instance, data + data_duplicate, progress=None
+ )
+ # Request more items than inserted
+ response = table_instance.scan(Limit=20)
+ returned_items = response.get("Items", None)
+ assert returned_items is not None
+ assert len(returned_items) == len(data)
diff --git a/sdk/python/tests/utils/online_store_utils.py b/sdk/python/tests/utils/online_store_utils.py
--- a/sdk/python/tests/utils/online_store_utils.py
+++ b/sdk/python/tests/utils/online_store_utils.py
@@ -19,6 +19,8 @@ def _create_n_customer_test_samples(n=10):
"name": ValueProto(string_val="John"),
"age": ValueProto(int64_val=3),
},
+ datetime.utcnow(),
+ None,
)
for i in range(n)
]
@@ -42,13 +44,13 @@ def _delete_test_table(project, tbl_name, region):
def _insert_data_test_table(data, project, tbl_name, region):
dynamodb_resource = boto3.resource("dynamodb", region_name=region)
table_instance = dynamodb_resource.Table(f"{project}.{tbl_name}")
- for entity_key, features in data:
+ for entity_key, features, timestamp, created_ts in data:
entity_id = compute_entity_id(entity_key)
with table_instance.batch_writer() as batch:
batch.put_item(
Item={
"entity_id": entity_id,
- "event_ts": str(utils.make_tzaware(datetime.utcnow())),
+ "event_ts": str(utils.make_tzaware(timestamp)),
"values": {k: v.SerializeToString() for k, v in features.items()},
}
)
| [DynamoDB] BatchWriteItem operation: Provided list of item keys contains duplicates
## Expected Behavior
Duplication should be handled if a partition key already exists in the batch to be written to DynamoDB.
## Current Behavior
The following exception raises when running the local test `test_online_retrieval[LOCAL:File:dynamodb-True]`
```bash
botocore.exceptions.ClientError: An error occurred (ValidationException) when calling the BatchWriteItem operation: Provided list of item keys contains duplicates
```
## Steps to reproduce
This is the output from the pytest log
```bash
environment = Environment(name='integration_test_63b98a_1', test_repo_config=LOCAL:File:dynamodb, feature_store=<feast.feature_store...sal.data_sources.file.FileDataSourceCreator object at 0x7fb91d38f730>, python_feature_server=False, worker_id='master')
universal_data_sources = (UniversalEntities(customer_vals=[1001, 1002, 1003, 1004, 1005, 1006, 1007, 1008, 1009, 1010, 1011, 1012, 1013, 1014, ...object at 0x7fb905f6b7c0>, field_mapping=<feast.infra.offline_stores.file_source.FileSource object at 0x7fb905f794f0>))
full_feature_names = True
@pytest.mark.integration
@pytest.mark.universal
@pytest.mark.parametrize("full_feature_names", [True, False], ids=lambda v: str(v))
def test_online_retrieval(environment, universal_data_sources, full_feature_names):
fs = environment.feature_store
entities, datasets, data_sources = universal_data_sources
feature_views = construct_universal_feature_views(data_sources)
feature_service = FeatureService(
"convrate_plus100",
features=[feature_views.driver[["conv_rate"]], feature_views.driver_odfv],
)
feature_service_entity_mapping = FeatureService(
name="entity_mapping",
features=[
feature_views.location.with_name("origin").with_join_key_map(
{"location_id": "origin_id"}
),
feature_views.location.with_name("destination").with_join_key_map(
{"location_id": "destination_id"}
),
],
)
feast_objects = []
feast_objects.extend(feature_views.values())
feast_objects.extend(
[
driver(),
customer(),
location(),
feature_service,
feature_service_entity_mapping,
]
)
fs.apply(feast_objects)
> fs.materialize(
environment.start_date - timedelta(days=1),
environment.end_date + timedelta(days=1),
)
sdk/python/tests/integration/online_store/test_universal_online.py:426:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
sdk/python/feast/feature_store.py:1165: in materialize
provider.materialize_single_feature_view(
sdk/python/feast/infra/passthrough_provider.py:164: in materialize_single_feature_view
self.online_write_batch(
sdk/python/feast/infra/passthrough_provider.py:86: in online_write_batch
self.online_store.online_write_batch(config, table, data, progress)
sdk/python/feast/infra/online_stores/dynamodb.py:208: in online_write_batch
progress(1)
../venv/lib/python3.9/site-packages/boto3/dynamodb/table.py:168: in __exit__
self._flush()
../venv/lib/python3.9/site-packages/boto3/dynamodb/table.py:144: in _flush
response = self._client.batch_write_item(
../venv/lib/python3.9/site-packages/botocore/client.py:395: in _api_call
return self._make_api_call(operation_name, kwargs)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = <botocore.client.DynamoDB object at 0x7fb9056a0eb0>, operation_name = 'BatchWriteItem'
api_params = {'RequestItems': {'integration_test_63b98a_1.global_stats': [{'PutRequest': {'Item': {'entity_id': '361ad244a817acdb9c...Item': {'entity_id': '361ad244a817acdb9cb041cf7ee8b4b0', 'event_ts': '2022-04-03 16:00:00+00:00', 'values': {...}}}}]}}
def _make_api_call(self, operation_name, api_params):
operation_model = self._service_model.operation_model(operation_name)
service_name = self._service_model.service_name
history_recorder.record('API_CALL', {
'service': service_name,
'operation': operation_name,
'params': api_params,
})
if operation_model.deprecated:
logger.debug('Warning: %s.%s() is deprecated',
service_name, operation_name)
request_context = {
'client_region': self.meta.region_name,
'client_config': self.meta.config,
'has_streaming_input': operation_model.has_streaming_input,
'auth_type': operation_model.auth_type,
}
request_dict = self._convert_to_request_dict(
api_params, operation_model, context=request_context)
resolve_checksum_context(request_dict, operation_model, api_params)
service_id = self._service_model.service_id.hyphenize()
handler, event_response = self.meta.events.emit_until_response(
'before-call.{service_id}.{operation_name}'.format(
service_id=service_id,
operation_name=operation_name),
model=operation_model, params=request_dict,
request_signer=self._request_signer, context=request_context)
if event_response is not None:
http, parsed_response = event_response
else:
apply_request_checksum(request_dict)
http, parsed_response = self._make_request(
operation_model, request_dict, request_context)
self.meta.events.emit(
'after-call.{service_id}.{operation_name}'.format(
service_id=service_id,
operation_name=operation_name),
http_response=http, parsed=parsed_response,
model=operation_model, context=request_context
)
if http.status_code >= 300:
error_code = parsed_response.get("Error", {}).get("Code")
error_class = self.exceptions.from_code(error_code)
> raise error_class(parsed_response, operation_name)
E botocore.exceptions.ClientError: An error occurred (ValidationException) when calling the BatchWriteItem operation: Provided list of item keys contains duplicates
```
### Specifications
- Version: `feast 0.18.1`
- Platform: `Windows`
## Possible Solution
Overwrite by partition keys in `DynamoDB.online_write_batch()` method
```python
with table_instance.batch_writer(overwrite_by_pkeys=["entity_id"]) as batch:
for entity_key, features, timestamp, created_ts in data:
entity_id = compute_entity_id(entity_key)
```
This solution comes from [StackOverflow](https://stackoverflow.com/questions/56632960/dynamodb-batchwriteitem-provided-list-of-item-keys-contains-duplicates)
## Other Comments
This error prompt while developing #2358 , I can provide a solution to both in the same PR if possible.
| 2022-04-09T03:35:38 |
|
feast-dev/feast | 2,551 | feast-dev__feast-2551 | [
"2399"
]
| f136f8cc6c7feade73466aeb6267500377089485 | diff --git a/sdk/python/feast/infra/offline_stores/file.py b/sdk/python/feast/infra/offline_stores/file.py
--- a/sdk/python/feast/infra/offline_stores/file.py
+++ b/sdk/python/feast/infra/offline_stores/file.py
@@ -299,11 +299,25 @@ def evaluate_offline_job():
if created_timestamp_column
else [event_timestamp_column]
)
+ # try-catch block is added to deal with this issue https://github.com/dask/dask/issues/8939.
+ # TODO(kevjumba): remove try catch when fix is merged upstream in Dask.
+ try:
+ if created_timestamp_column:
+ source_df = source_df.sort_values(by=created_timestamp_column,)
+
+ source_df = source_df.sort_values(by=event_timestamp_column)
+
+ except ZeroDivisionError:
+ # Use 1 partition to get around case where everything in timestamp column is the same so the partition algorithm doesn't
+ # try to divide by zero.
+ if created_timestamp_column:
+ source_df = source_df.sort_values(
+ by=created_timestamp_column, npartitions=1
+ )
- if created_timestamp_column:
- source_df = source_df.sort_values(by=created_timestamp_column)
-
- source_df = source_df.sort_values(by=event_timestamp_column)
+ source_df = source_df.sort_values(
+ by=event_timestamp_column, npartitions=1
+ )
source_df = source_df[
(source_df[event_timestamp_column] >= start_date)
| Feast materialize throws an unhandled "ZeroDivisionError: division by zero" exception
## Expected Behavior
With feast version `0.19.3`, `feast materialize` should not throw an unhandled exception
In feast version `0.18.1`, everything works as expected.
```
→ python feast_materialize.py
Materializing 1 feature views from 2022-03-10 05:41:44-08:00 to 2022-03-11 05:41:44-08:00 into the dynamodb online store.
ryoung_division_by_zero_reproducer:
100%|█████████████████████████████████████████████████████████████████| 2/2 [00:00<00:00, 19.34it/s]
```
## Current Behavior
```
→ python feast_materialize.py
/Users/ryoung/.pyenv/versions/3.8.10/lib/python3.8/importlib/__init__.py:127: DeprecationWarning: The toolz.compatibility module is no longer needed in Python 3 and has been deprecated. Please import these utilities directly from the standard library. This module will be removed in a future release.
return _bootstrap._gcd_import(name[level:], package, level)
Materializing 1 feature views from 2022-03-10 05:42:56-08:00 to 2022-03-11 05:42:56-08:00 into the dynamodb online store.
ryoung_division_by_zero_reproducer:
Traceback (most recent call last):
File "feast_materialize.py", line 32, in <module>
fs.materialize(
File "/Users/ryoung/.pyenv/versions/3.8.10/envs/python-monorepo-3.8.10/lib/python3.8/site-packages/feast/usage.py", line 269, in wrapper
return func(*args, **kwargs)
File "/Users/ryoung/.pyenv/versions/3.8.10/envs/python-monorepo-3.8.10/lib/python3.8/site-packages/feast/feature_store.py", line 1130, in materialize
provider.materialize_single_feature_view(
File "/Users/ryoung/.pyenv/versions/3.8.10/envs/python-monorepo-3.8.10/lib/python3.8/site-packages/feast/infra/passthrough_provider.py", line 154, in materialize_single_feature_view
table = offline_job.to_arrow()
File "/Users/ryoung/.pyenv/versions/3.8.10/envs/python-monorepo-3.8.10/lib/python3.8/site-packages/feast/infra/offline_stores/offline_store.py", line 121, in to_arrow
return self._to_arrow_internal()
File "/Users/ryoung/.pyenv/versions/3.8.10/envs/python-monorepo-3.8.10/lib/python3.8/site-packages/feast/usage.py", line 280, in wrapper
raise exc.with_traceback(traceback)
File "/Users/ryoung/.pyenv/versions/3.8.10/envs/python-monorepo-3.8.10/lib/python3.8/site-packages/feast/usage.py", line 269, in wrapper
return func(*args, **kwargs)
File "/Users/ryoung/.pyenv/versions/3.8.10/envs/python-monorepo-3.8.10/lib/python3.8/site-packages/feast/infra/offline_stores/file.py", line 75, in _to_arrow_internal
df = self.evaluation_function().compute()
File "/Users/ryoung/.pyenv/versions/3.8.10/envs/python-monorepo-3.8.10/lib/python3.8/site-packages/feast/infra/offline_stores/file.py", line 309, in evaluate_offline_job
source_df = source_df.sort_values(by=event_timestamp_column)
File "/Users/ryoung/.pyenv/versions/3.8.10/envs/python-monorepo-3.8.10/lib/python3.8/site-packages/dask/dataframe/core.py", line 4388, in sort_values
return sort_values(
File "/Users/ryoung/.pyenv/versions/3.8.10/envs/python-monorepo-3.8.10/lib/python3.8/site-packages/dask/dataframe/shuffle.py", line 146, in sort_values
df = rearrange_by_divisions(
File "/Users/ryoung/.pyenv/versions/3.8.10/envs/python-monorepo-3.8.10/lib/python3.8/site-packages/dask/dataframe/shuffle.py", line 446, in rearrange_by_divisions
df3 = rearrange_by_column(
File "/Users/ryoung/.pyenv/versions/3.8.10/envs/python-monorepo-3.8.10/lib/python3.8/site-packages/dask/dataframe/shuffle.py", line 473, in rearrange_by_column
df = df.repartition(npartitions=npartitions)
File "/Users/ryoung/.pyenv/versions/3.8.10/envs/python-monorepo-3.8.10/lib/python3.8/site-packages/dask/dataframe/core.py", line 1319, in repartition
return repartition_npartitions(self, npartitions)
File "/Users/ryoung/.pyenv/versions/3.8.10/envs/python-monorepo-3.8.10/lib/python3.8/site-packages/dask/dataframe/core.py", line 6859, in repartition_npartitions
npartitions_ratio = df.npartitions / npartitions
ZeroDivisionError: division by zero
```
## Steps to reproduce
Create a list of feature records in PySpark and write them out as a parquet file.
```
from pyspark.sql import types as T
from datetime import datetime, timedelta
INPUT_SCHEMA = T.StructType(
[
T.StructField("id", T.StringType(), False),
T.StructField("feature1", T.FloatType(), False),
T.StructField("feature2", T.FloatType(), False),
T.StructField("event_timestamp", T.TimestampType(), False),
]
)
now = datetime.now()
one_hour_ago = now - timedelta(hours=1)
feature_records = [
{
"id": "foo",
"event_timestamp": one_hour_ago,
"feature1": 5.50,
"feature2": 7.50,
},
{
"id": "bar",
"event_timestamp": one_hour_ago,
"feature1": -1.10,
"feature2": 2.20,
},
]
df = spark.createDataFrame(data=feature_records, schema=INPUT_SCHEMA)
df.show(truncate=False)
df.write.parquet(mode="overwrite", path="s3://XXX/reproducer/2022-03-11T05:34:51.599215/")
```
The output should look something like:
```
+---+--------+--------+--------------------------+
|id |feature1|feature2|event_timestamp |
+---+--------+--------+--------------------------+
|foo|5.5 |7.5 |2022-03-11 04:35:39.318222|
|bar|-1.1 |2.2 |2022-03-11 04:35:39.318222|
+---+--------+--------+--------------------------+
```
Create a `feast_materialize.py` script.
```
from datetime import datetime, timedelta
from feast import FeatureStore, Entity, Feature, FeatureView, FileSource, ValueType
now = datetime.utcnow()
one_day_ago = now - timedelta(days=1)
s3_url = "s3://XXX/reproducer/2022-03-11T05:34:51.599215/"
offline_features_dump = FileSource(
path=s3_url,
event_timestamp_column="event_timestamp",
)
entity = Entity(name="id", value_type=ValueType.STRING)
feature_names = ["feature1", "feature2"]
feature_view = FeatureView(
name="ryoung_division_by_zero_reproducer",
entities=["id"],
ttl=timedelta(days=30),
features=[Feature(name=f, dtype=ValueType.FLOAT) for f in feature_names],
online=True,
batch_source=offline_features_dump,
)
fs = FeatureStore(".")
fs.apply(entity)
fs.apply(feature_view)
fs.materialize(
start_date=one_day_ago,
end_date=now,
feature_views=["ryoung_division_by_zero_reproducer"],
)
```
Note that you need to supply your own S3 bucket.
### Specifications
- Version: `0.19.3`
- Platform: `Darwin Kernel Version 21.3.0`
- Subsystem:
## Possible Solution
I downgraded back to feast version `0.18.1`.
| @tsotnet This looks like a p0 bug. I can always repro it. Should this be prioritized? What would be the quick fix I can apply
thanks for calling this out @zhiyanshao . Will have someone take a look into this asap | 2022-04-15T00:37:49 |
|
feast-dev/feast | 2,554 | feast-dev__feast-2554 | [
"2552"
]
| 753bd8894a6783bd6e39cbe4cf2df5d8e89919ff | diff --git a/sdk/python/feast/infra/online_stores/redis.py b/sdk/python/feast/infra/online_stores/redis.py
--- a/sdk/python/feast/infra/online_stores/redis.py
+++ b/sdk/python/feast/infra/online_stores/redis.py
@@ -42,7 +42,7 @@
try:
from redis import Redis
- from rediscluster import RedisCluster
+ from redis.cluster import ClusterNode, RedisCluster
except ImportError as e:
from feast.errors import FeastExtrasDependencyImportError
@@ -164,7 +164,9 @@ def _get_client(self, online_store_config: RedisOnlineStoreConfig):
online_store_config.connection_string
)
if online_store_config.redis_type == RedisType.redis_cluster:
- kwargs["startup_nodes"] = startup_nodes
+ kwargs["startup_nodes"] = [
+ ClusterNode(**node) for node in startup_nodes
+ ]
self._client = RedisCluster(**kwargs)
else:
kwargs["host"] = startup_nodes[0]["host"]
diff --git a/sdk/python/setup.py b/sdk/python/setup.py
--- a/sdk/python/setup.py
+++ b/sdk/python/setup.py
@@ -72,7 +72,7 @@
]
GCP_REQUIRED = [
- "google-cloud-bigquery>=2.28.1",
+ "google-cloud-bigquery>=2,<3",
"google-cloud-bigquery-storage >= 2.0.0",
"google-cloud-datastore>=2.1.*",
"google-cloud-storage>=1.34.*,<1.41",
@@ -80,8 +80,7 @@
]
REDIS_REQUIRED = [
- "redis==3.5.3",
- "redis-py-cluster>=2.1.3",
+ "redis==4.2.2",
"hiredis>=2.0.0",
]
@@ -108,7 +107,7 @@
CI_REQUIRED = (
[
- "cryptography==3.3.2",
+ "cryptography==3.4.8",
"flake8",
"black==19.10b0",
"isort>=5",
| Switch from `redis-py-cluster` to `redis-py`
As [documented](https://github.com/Grokzen/redis-py-cluster#redis-py-cluster-eol), `redis-py-cluster` has reached EOL. It is now being merged into [`redis-py`](https://github.com/redis/redis-py#cluster-mode). We previously tried to switch from `redis-py-cluster` to `redis-py` but ran into various issues; see #2328. The upstream [bug](https://github.com/redis/redis-py/issues/2003) has since been fixed, so we can now switch from `redis-py-cluster` to `redis-py`.
| Related, we should try to get redis-cluster integration tests running using testcontainers somehow, and part of the normal configurations tested. | 2022-04-15T16:58:13 |
|
feast-dev/feast | 2,606 | feast-dev__feast-2606 | [
"2605"
]
| e4507ac16540cb3a7e29c31121963a0fe8f79fe4 | diff --git a/sdk/python/feast/infra/offline_stores/contrib/spark_offline_store/spark_source.py b/sdk/python/feast/infra/offline_stores/contrib/spark_offline_store/spark_source.py
--- a/sdk/python/feast/infra/offline_stores/contrib/spark_offline_store/spark_source.py
+++ b/sdk/python/feast/infra/offline_stores/contrib/spark_offline_store/spark_source.py
@@ -177,7 +177,8 @@ def get_table_query_string(self) -> str:
"""Returns a string that can directly be used to reference this table in SQL"""
if self.table:
# Backticks make sure that spark sql knows this a table reference.
- return f"`{self.table}`"
+ table = ".".join([f"`{x}`" for x in self.table.split(".")])
+ return table
if self.query:
return f"({self.query})"
| spark source complain about "table or view not found" error.
## Expected Behavior
spark offline store
## Current Behavior
if set table of SparkSource with pattern "db.table",feast will complain about "table or view not found" error.
## Steps to reproduce
1. feast init test_repo
2. modify example.py to use SparkSource, and set table of SparkSource with pattern "db.table"
3. configure featue_store.yaml
4. feast apply
### Specifications
- Version: 0.20.1
- Platform: ubuntu 18/04
- Subsystem:
## Possible Solution
| 2022-04-25T01:34:29 |
||
feast-dev/feast | 2,610 | feast-dev__feast-2610 | [
"2607"
]
| c9eda79c7b1169ef05a481a96f07960c014e88b9 | diff --git a/sdk/python/feast/feature.py b/sdk/python/feast/feature.py
--- a/sdk/python/feast/feature.py
+++ b/sdk/python/feast/feature.py
@@ -91,7 +91,7 @@ def to_proto(self) -> FeatureSpecProto:
value_type = ValueTypeProto.Enum.Value(self.dtype.name)
return FeatureSpecProto(
- name=self.name, value_type=value_type, labels=self.labels,
+ name=self.name, value_type=value_type, tags=self.labels,
)
@classmethod
@@ -106,7 +106,7 @@ def from_proto(cls, feature_proto: FeatureSpecProto):
feature = cls(
name=feature_proto.name,
dtype=ValueType(feature_proto.value_type),
- labels=dict(feature_proto.labels),
+ labels=dict(feature_proto.tags),
)
return feature
diff --git a/sdk/python/feast/field.py b/sdk/python/feast/field.py
--- a/sdk/python/feast/field.py
+++ b/sdk/python/feast/field.py
@@ -12,6 +12,8 @@
# See the License for the specific language governing permissions and
# limitations under the License.
+from typing import Dict, Optional
+
from feast.feature import Feature
from feast.protos.feast.core.Feature_pb2 import FeatureSpecV2 as FieldProto
from feast.types import FeastType, from_value_type
@@ -25,13 +27,15 @@ class Field:
Attributes:
name: The name of the field.
dtype: The type of the field, such as string or float.
+ tags: User-defined metadata in dictionary form.
"""
name: str
dtype: FeastType
+ tags: Dict[str, str]
def __init__(
- self, *, name: str, dtype: FeastType,
+ self, *, name: str, dtype: FeastType, tags: Optional[Dict[str, str]] = None,
):
"""
Creates a Field object.
@@ -39,12 +43,18 @@ def __init__(
Args:
name: The name of the field.
dtype: The type of the field, such as string or float.
+ tags (optional): User-defined metadata in dictionary form.
"""
self.name = name
self.dtype = dtype
+ self.tags = tags or {}
def __eq__(self, other):
- if self.name != other.name or self.dtype != other.dtype:
+ if (
+ self.name != other.name
+ or self.dtype != other.dtype
+ or self.tags != other.tags
+ ):
return False
return True
@@ -58,12 +68,12 @@ def __repr__(self):
return f"{self.name}-{self.dtype}"
def __str__(self):
- return f"Field(name={self.name}, dtype={self.dtype})"
+ return f"Field(name={self.name}, dtype={self.dtype}, tags={self.tags})"
def to_proto(self) -> FieldProto:
"""Converts a Field object to its protobuf representation."""
value_type = self.dtype.to_value_type()
- return FieldProto(name=self.name, value_type=value_type.value)
+ return FieldProto(name=self.name, value_type=value_type.value, tags=self.tags)
@classmethod
def from_proto(cls, field_proto: FieldProto):
@@ -74,7 +84,11 @@ def from_proto(cls, field_proto: FieldProto):
field_proto: FieldProto protobuf object
"""
value_type = ValueType(field_proto.value_type)
- return cls(name=field_proto.name, dtype=from_value_type(value_type=value_type))
+ return cls(
+ name=field_proto.name,
+ dtype=from_value_type(value_type=value_type),
+ tags=dict(field_proto.tags),
+ )
@classmethod
def from_feature(cls, feature: Feature):
@@ -84,4 +98,6 @@ def from_feature(cls, feature: Feature):
Args:
feature: Feature object to convert.
"""
- return cls(name=feature.name, dtype=from_value_type(feature.dtype))
+ return cls(
+ name=feature.name, dtype=from_value_type(feature.dtype), tags=feature.labels
+ )
| diff --git a/java/serving/src/test/java/feast/serving/util/DataGenerator.java b/java/serving/src/test/java/feast/serving/util/DataGenerator.java
--- a/java/serving/src/test/java/feast/serving/util/DataGenerator.java
+++ b/java/serving/src/test/java/feast/serving/util/DataGenerator.java
@@ -126,11 +126,11 @@ public static EntityProto.EntitySpecV2 createEntitySpecV2(
}
public static FeatureProto.FeatureSpecV2 createFeatureSpecV2(
- String name, ValueProto.ValueType.Enum valueType, Map<String, String> labels) {
+ String name, ValueProto.ValueType.Enum valueType, Map<String, String> tags) {
return FeatureProto.FeatureSpecV2.newBuilder()
.setName(name)
.setValueType(valueType)
- .putAllLabels(labels)
+ .putAllTags(tags)
.build();
}
@@ -140,7 +140,7 @@ public static FeatureTableSpec createFeatureTableSpec(
List<String> entities,
Map<String, ValueProto.ValueType.Enum> features,
int maxAgeSecs,
- Map<String, String> labels) {
+ Map<String, String> tags) {
return FeatureTableSpec.newBuilder()
.setName(name)
@@ -152,7 +152,7 @@ public static FeatureTableSpec createFeatureTableSpec(
FeatureSpecV2.newBuilder()
.setName(entry.getKey())
.setValueType(entry.getValue())
- .putAllLabels(labels)
+ .putAllTags(tags)
.build())
.collect(Collectors.toList()))
.setMaxAge(Duration.newBuilder().setSeconds(3600).build())
@@ -169,7 +169,7 @@ public static FeatureTableSpec createFeatureTableSpec(
.setUri("/dev/null")
.build())
.build())
- .putAllLabels(labels)
+ .putAllLabels(tags)
.build();
}
@@ -178,7 +178,7 @@ public static FeatureTableSpec createFeatureTableSpec(
List<String> entities,
ImmutableMap<String, ValueProto.ValueType.Enum> features,
int maxAgeSecs,
- Map<String, String> labels) {
+ Map<String, String> tags) {
return FeatureTableSpec.newBuilder()
.setName(name)
@@ -190,11 +190,11 @@ public static FeatureTableSpec createFeatureTableSpec(
FeatureSpecV2.newBuilder()
.setName(entry.getKey())
.setValueType(entry.getValue())
- .putAllLabels(labels)
+ .putAllTags(tags)
.build())
.collect(Collectors.toList()))
.setMaxAge(Duration.newBuilder().setSeconds(maxAgeSecs).build())
- .putAllLabels(labels)
+ .putAllLabels(tags)
.build();
}
| Keep labels in Field api
I found that new api 'Field' will take place of 'Feature' in 0.21+ feast. but `Field` only have 'name' and 'dtype' parameters. The parameter 'labels' is disappeared.
In my use case 'labels' is very import. 'labels' stores the default value, descriptions,and other things. for example
```python
comic_feature_view = FeatureView(
name="comic_featureV1",
entities=["item_id"],
ttl=Duration(seconds=86400 * 1),
features=[
Feature(name="channel_id", dtype=ValueType.INT32, labels={"default": "14", "desc":"channel"}),
Feature(name="keyword_weight", dtype=ValueType.FLOAT, labels={"default": "0.0", "desc":"keyword's weight"}),
Feature(name="comic_vectorv1", dtype=ValueType.FLOAT, labels={"default": ";".join(["0.0" for i in range(32)]), "desc":"deepwalk vector","faiss_index":"/data/faiss_index/comic_featureV1__comic_vectorv1.index"}),
Feature(name="comic_vectorv2", dtype=ValueType.FLOAT, labels={"default": ";".join(["0.0" for i in range(32)]), "desc":"word2vec vector","faiss_index":"/data/faiss_index/comic_featureV1__comic_vectorv2.index"}),
Feature(name="gender", dtype=ValueType.INT32, labels={"default": "0", "desc":" 0-femal 1-male"}),
Feature(name="pub_time", dtype=ValueType.STRING, labels={"default": "1970-01-01 00:00:00", "desc":"comic's publish time"}),
Feature(name="update_time", dtype=ValueType.STRING, labels={"default": "1970-01-01 00:00:00", "desc":"comic's update time"}),
Feature(name="view_cnt", dtype=ValueType.INT64, labels={"default": "0", "desc":"comic's hot score"}),
Feature(name="collect_cnt", dtype=ValueType.INT64, labels={"default": "0", "desc":"collect count"}),
Feature(name="source_id", dtype=ValueType.INT32, labels={"default": "0", "desc":"comic is from(0-unknown,1-japen,2-usa,3- other)"}),
```
So please keep the parameter 'labels' in Field api
| Thanks for giving feedback and nice catch!
Thanks for the feedback @hsz1273327 , this was definitely an oversight. We're planning on adding this back in soon (but we may be possibly changing the name of this field to `tags` to more accurately convey the purpose of the field). | 2022-04-25T21:27:25 |
feast-dev/feast | 2,646 | feast-dev__feast-2646 | [
"2566"
]
| 41a1da4560bb09077f32c09d37f3304f8ae84f2a | diff --git a/sdk/python/feast/infra/passthrough_provider.py b/sdk/python/feast/infra/passthrough_provider.py
--- a/sdk/python/feast/infra/passthrough_provider.py
+++ b/sdk/python/feast/infra/passthrough_provider.py
@@ -39,12 +39,24 @@ def __init__(self, config: RepoConfig):
super().__init__(config)
self.repo_config = config
- self.offline_store = get_offline_store_from_config(config.offline_store)
- self.online_store = (
- get_online_store_from_config(config.online_store)
- if config.online_store
- else None
- )
+ self._offline_store = None
+ self._online_store = None
+
+ @property
+ def online_store(self):
+ if not self._online_store and self.repo_config.online_store:
+ self._online_store = get_online_store_from_config(
+ self.repo_config.online_store
+ )
+ return self._online_store
+
+ @property
+ def offline_store(self):
+ if not self._offline_store:
+ self._offline_store = get_offline_store_from_config(
+ self.repo_config.offline_store
+ )
+ return self._offline_store
def update_infra(
self,
diff --git a/sdk/python/feast/repo_config.py b/sdk/python/feast/repo_config.py
--- a/sdk/python/feast/repo_config.py
+++ b/sdk/python/feast/repo_config.py
@@ -6,6 +6,7 @@
import yaml
from pydantic import (
BaseModel,
+ Field,
StrictInt,
StrictStr,
ValidationError,
@@ -107,10 +108,10 @@ class RepoConfig(FeastBaseModel):
provider: StrictStr
""" str: local or gcp or aws """
- online_store: Any
+ _online_config: Any = Field(alias="online_store")
""" OnlineStoreConfig: Online store configuration (optional depending on provider) """
- offline_store: Any
+ _offline_config: Any = Field(alias="offline_store")
""" OfflineStoreConfig: Offline store configuration (optional depending on provider) """
feature_server: Optional[Any]
@@ -126,19 +127,27 @@ class RepoConfig(FeastBaseModel):
def __init__(self, **data: Any):
super().__init__(**data)
- if isinstance(self.online_store, Dict):
- self.online_store = get_online_config_from_type(self.online_store["type"])(
- **self.online_store
- )
- elif isinstance(self.online_store, str):
- self.online_store = get_online_config_from_type(self.online_store)()
-
- if isinstance(self.offline_store, Dict):
- self.offline_store = get_offline_config_from_type(
- self.offline_store["type"]
- )(**self.offline_store)
- elif isinstance(self.offline_store, str):
- self.offline_store = get_offline_config_from_type(self.offline_store)()
+ self._offline_store = None
+ if "offline_store" in data:
+ self._offline_config = data["offline_store"]
+ else:
+ if data["provider"] == "local":
+ self._offline_config = "file"
+ elif data["provider"] == "gcp":
+ self._offline_config = "bigquery"
+ elif data["provider"] == "aws":
+ self._offline_config = "redshift"
+
+ self._online_store = None
+ if "online_store" in data:
+ self._online_config = data["online_store"]
+ else:
+ if data["provider"] == "local":
+ self._online_config = "sqlite"
+ elif data["provider"] == "gcp":
+ self._online_config = "datastore"
+ elif data["provider"] == "aws":
+ self._online_config = "dynamodb"
if isinstance(self.feature_server, Dict):
self.feature_server = get_feature_server_config_from_type(
@@ -151,6 +160,35 @@ def get_registry_config(self):
else:
return self.registry
+ @property
+ def offline_store(self):
+ if not self._offline_store:
+ if isinstance(self._offline_config, Dict):
+ self._offline_store = get_offline_config_from_type(
+ self._offline_config["type"]
+ )(**self._offline_config)
+ elif isinstance(self._offline_config, str):
+ self._offline_store = get_offline_config_from_type(
+ self._offline_config
+ )()
+ elif self._offline_config:
+ self._offline_store = self._offline_config
+ return self._offline_store
+
+ @property
+ def online_store(self):
+ if not self._online_store:
+ if isinstance(self._online_config, Dict):
+ self._online_store = get_online_config_from_type(
+ self._online_config["type"]
+ )(**self._online_config)
+ elif isinstance(self._online_config, str):
+ self._online_store = get_online_config_from_type(self._online_config)()
+ elif self._online_config:
+ self._online_store = self._online_config
+
+ return self._online_store
+
@root_validator(pre=True)
@log_exceptions
def _validate_online_store_config(cls, values):
@@ -304,6 +342,9 @@ def write_to_path(self, repo_path: Path):
sort_keys=False,
)
+ class Config:
+ allow_population_by_field_name = True
+
class FeastConfigError(Exception):
def __init__(self, error_message, config_path):
| diff --git a/sdk/python/tests/integration/feature_repos/integration_test_repo_config.py b/sdk/python/tests/integration/feature_repos/integration_test_repo_config.py
--- a/sdk/python/tests/integration/feature_repos/integration_test_repo_config.py
+++ b/sdk/python/tests/integration/feature_repos/integration_test_repo_config.py
@@ -19,7 +19,7 @@ class IntegrationTestRepoConfig:
"""
provider: str = "local"
- online_store: Union[str, Dict] = "sqlite"
+ online_store: Optional[Union[str, Dict]] = "sqlite"
offline_store_creator: Type[DataSourceCreator] = FileDataSourceCreator
online_store_creator: Optional[Type[OnlineStoreCreator]] = None
@@ -38,8 +38,10 @@ def __repr__(self) -> str:
online_store_type = self.online_store.get("redis_type", "redis")
else:
online_store_type = self.online_store["type"]
- else:
+ elif self.online_store:
online_store_type = self.online_store.__name__
+ else:
+ online_store_type = "none"
else:
online_store_type = self.online_store_creator.__name__
diff --git a/sdk/python/tests/unit/infra/online_store/test_dynamodb_online_store.py b/sdk/python/tests/unit/infra/online_store/test_dynamodb_online_store.py
--- a/sdk/python/tests/unit/infra/online_store/test_dynamodb_online_store.py
+++ b/sdk/python/tests/unit/infra/online_store/test_dynamodb_online_store.py
@@ -39,6 +39,7 @@ def repo_config():
project=PROJECT,
provider=PROVIDER,
online_store=DynamoDBOnlineStoreConfig(region=REGION),
+ # online_store={"type": "dynamodb", "region": REGION},
offline_store=FileOfflineStoreConfig(),
)
| Implement lazy loading for offline and online stores
The offline and online stores are eagerly loaded in `FeatureStore`, leading unnecessary dependencies to be pulled in. For example, as #2560 reported, the AWS Lambda feature server does not work with a Snowflake offline store, even though the offline store is not strictly required for serving online features.
The offline and online stores should be lazily loaded instead. This will allow the Snowflake dependencies to removed from the AWS Lambda feature server Dockerfile. Note that #2560 was fixed by #2565, but this issue tracks a longer-term solution.
| 2022-05-06T00:17:12 |
|
feast-dev/feast | 2,647 | feast-dev__feast-2647 | [
"2557"
]
| 30e0bf3ef249d6e31450151701a5994012586934 | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -47,30 +47,30 @@
REQUIRED = [
"click>=7.0.0,<8.0.2",
- "colorama>=0.3.9",
+ "colorama>=0.3.9,<1",
"dill==0.3.*",
- "fastavro>=1.1.0",
- "google-api-core>=1.23.0",
- "googleapis-common-protos==1.52.*",
- "grpcio>=1.34.0",
- "grpcio-reflection>=1.34.0",
- "Jinja2>=2.0.0",
+ "fastavro>=1.1.0,<2",
+ "google-api-core>=1.23.0,<3",
+ "googleapis-common-protos==1.52.*,<2",
+ "grpcio>=1.34.0,<2",
+ "grpcio-reflection>=1.34.0,<2",
+ "Jinja2>=2,<4",
"jsonschema",
"mmh3",
- "numpy<1.22",
- "pandas>=1.0.0",
+ "numpy<1.22,<2",
+ "pandas>=1,<2",
"pandavro==1.5.*",
"protobuf>=3.10,<3.20",
"proto-plus<1.19.7",
- "pyarrow>=4.0.0",
- "pydantic>=1.0.0",
- "PyYAML>=5.4.*",
+ "pyarrow>=4,<7",
+ "pydantic>=1,<2",
+ "PyYAML>=5.4.*,<7",
"tabulate==0.8.*",
- "tenacity>=7.*",
+ "tenacity>=7,<9",
"toml==0.10.*",
"tqdm==4.*",
- "fastapi>=0.68.0",
- "uvicorn[standard]>=0.14.0",
+ "fastapi>=0.68.0,<1",
+ "uvicorn[standard]>=0.14.0,<1",
"proto-plus<1.19.7",
"tensorflow-metadata>=1.0.0,<2.0.0",
"dask>=2021.*,<2022.02.0",
@@ -78,15 +78,15 @@
GCP_REQUIRED = [
"google-cloud-bigquery>=2,<3",
- "google-cloud-bigquery-storage >= 2.0.0",
- "google-cloud-datastore>=2.1.*",
+ "google-cloud-bigquery-storage >= 2.0.0,<3",
+ "google-cloud-datastore>=2.1.*,<3",
"google-cloud-storage>=1.34.*,<1.41",
"google-cloud-core>=1.4.0,<2.0.0",
]
REDIS_REQUIRED = [
"redis==4.2.2",
- "hiredis>=2.0.0",
+ "hiredis>=2.0.0,<3",
]
AWS_REQUIRED = [
@@ -95,11 +95,11 @@
]
SNOWFLAKE_REQUIRED = [
- "snowflake-connector-python[pandas]>=2.7.3",
+ "snowflake-connector-python[pandas]>=2.7.3,<3",
]
SPARK_REQUIRED = [
- "pyspark>=3.0.0",
+ "pyspark>=3.0.0,<4",
]
TRINO_REQUIRED = [
@@ -107,11 +107,11 @@
]
POSTGRES_REQUIRED = [
- "psycopg2-binary>=2.8.3",
+ "psycopg2-binary>=2.8.3,<3",
]
HBASE_REQUIRED = [
- "happybase>=1.2.0",
+ "happybase>=1.2.0,<3",
]
GE_REQUIRED = [
@@ -119,7 +119,7 @@
]
GO_REQUIRED = [
- "cffi==1.15.*",
+ "cffi==1.15.*,<2",
]
CI_REQUIRED = (
@@ -128,7 +128,7 @@
"cryptography==3.4.8",
"flake8",
"black==19.10b0",
- "isort>=5",
+ "isort>=5,<6",
"grpcio-tools==1.44.0",
"grpcio-testing==1.44.0",
"minio==7.1.0",
@@ -138,19 +138,19 @@
"mypy-protobuf==3.1",
"avro==1.10.0",
"gcsfs",
- "urllib3>=1.25.4",
+ "urllib3>=1.25.4,<2",
"psutil==5.9.0",
- "pytest>=6.0.0",
+ "pytest>=6.0.0,<8",
"pytest-cov",
"pytest-xdist",
- "pytest-benchmark>=3.4.1",
+ "pytest-benchmark>=3.4.1,<4",
"pytest-lazy-fixture==0.6.3",
"pytest-timeout==1.4.2",
"pytest-ordering==0.6.*",
"pytest-mock==1.10.4",
"Sphinx!=4.0.0,<4.4.0",
"sphinx-rtd-theme",
- "testcontainers[postgresql]>=3.5",
+ "testcontainers>=3.5,<4",
"adlfs==0.5.9",
"firebase-admin==4.5.2",
"pre-commit",
| Pin dependencies to major version ranges
We have recently had a bunch of issues due to dependencies not being limited appropriately. For example, having `google-cloud-bigquery>=2.28.1` led to issues when `google-cloud-bigquery` released breaking changes in `v3.0.0`: see #2537 for the issue and #2554 which included the fix. Similarly, #2484 occurred since our `protobuf` dependency was not limited.
I think we should limit dependencies to the next major version. For example, if we currently use version N of a package, we should also limit it to v<(N+1). This way we are not exposed to breaking changes in all our upstream dependencies, while also maintaining a reasonable amount of flexibility for users. If a version N+1 is released and users want us to support it, they can let us know and we can add support; limiting to v<(N+1) just ensures that we aren't being broken all the time.
| I like this way of declaring dependencies as well: https://stackoverflow.com/a/50080281/1735989
> I like this way of declaring dependencies as well: https://stackoverflow.com/a/50080281/1735989
Ooh this looks super neat, but it seems to only work for minor versions - e.g. if I want to specify `>=8.0.0,<9.0.0`, I can't do `~=8`. But this will definitely work for most of our dependencies.
Edit: oops I'm wrong, the below comment is right.
> if I want to specify >=8.0.0,<9.0.0
That's the same as `~=8.0` isn't it? Which is exactly identical to `>=8.0,==8.*`. But I suppose that still doesn't allow something even more specific like `>=8.0.1,==8.*`. | 2022-05-06T01:10:08 |
|
feast-dev/feast | 2,665 | feast-dev__feast-2665 | [
"2576"
]
| fc00ca8fc091ab2642121de69d4624783f11445c | diff --git a/sdk/python/feast/feature_store.py b/sdk/python/feast/feature_store.py
--- a/sdk/python/feast/feature_store.py
+++ b/sdk/python/feast/feature_store.py
@@ -875,7 +875,7 @@ def get_historical_features(
DeprecationWarning,
)
- # TODO(achal): _group_feature_refs returns the on demand feature views, but it's no passed into the provider.
+ # TODO(achal): _group_feature_refs returns the on demand feature views, but it's not passed into the provider.
# This is a weird interface quirk - we should revisit the `get_historical_features` to
# pass in the on demand feature views as well.
fvs, odfvs, request_fvs, request_fv_refs = _group_feature_refs(
@@ -2125,8 +2125,12 @@ def _group_feature_refs(
for ref in features:
view_name, feat_name = ref.split(":")
if view_name in view_index:
+ view_index[view_name].projection.get_feature(feat_name) # For validation
views_features[view_name].add(feat_name)
elif view_name in on_demand_view_index:
+ on_demand_view_index[view_name].projection.get_feature(
+ feat_name
+ ) # For validation
on_demand_view_features[view_name].add(feat_name)
# Let's also add in any FV Feature dependencies here.
for input_fv_projection in on_demand_view_index[
@@ -2135,6 +2139,9 @@ def _group_feature_refs(
for input_feat in input_fv_projection.features:
views_features[input_fv_projection.name].add(input_feat.name)
elif view_name in request_view_index:
+ request_view_index[view_name].projection.get_feature(
+ feat_name
+ ) # For validation
request_views_features[view_name].add(feat_name)
request_view_refs.add(ref)
else:
diff --git a/sdk/python/feast/feature_view_projection.py b/sdk/python/feast/feature_view_projection.py
--- a/sdk/python/feast/feature_view_projection.py
+++ b/sdk/python/feast/feature_view_projection.py
@@ -64,3 +64,11 @@ def from_definition(base_feature_view: "BaseFeatureView"):
name_alias=None,
features=base_feature_view.features,
)
+
+ def get_feature(self, feature_name: str) -> Field:
+ try:
+ return next(field for field in self.features if field.name == feature_name)
+ except StopIteration:
+ raise KeyError(
+ f"Feature {feature_name} not found in projection {self.name_to_use()}"
+ )
| diff --git a/sdk/python/tests/integration/offline_store/test_universal_historical_retrieval.py b/sdk/python/tests/integration/offline_store/test_universal_historical_retrieval.py
--- a/sdk/python/tests/integration/offline_store/test_universal_historical_retrieval.py
+++ b/sdk/python/tests/integration/offline_store/test_universal_historical_retrieval.py
@@ -21,7 +21,7 @@
from feast.infra.offline_stores.offline_utils import (
DEFAULT_ENTITY_DF_EVENT_TIMESTAMP_COL,
)
-from feast.types import Int32
+from feast.types import Float32, Int32
from feast.value_type import ValueType
from tests.integration.feature_repos.repo_configuration import (
construct_universal_feature_views,
@@ -410,6 +410,46 @@ def test_historical_features(environment, universal_data_sources, full_feature_n
)
[email protected]
[email protected]
[email protected]("full_feature_names", [True, False], ids=lambda v: str(v))
+def test_historical_features_with_shared_batch_source(
+ environment, universal_data_sources, full_feature_names
+):
+ # Addresses https://github.com/feast-dev/feast/issues/2576
+
+ store = environment.feature_store
+
+ entities, datasets, data_sources = universal_data_sources
+ driver_stats_v1 = FeatureView(
+ name="driver_stats_v1",
+ entities=["driver"],
+ schema=[Field(name="avg_daily_trips", dtype=Int32)],
+ source=data_sources.driver,
+ )
+ driver_stats_v2 = FeatureView(
+ name="driver_stats_v2",
+ entities=["driver"],
+ schema=[
+ Field(name="avg_daily_trips", dtype=Int32),
+ Field(name="conv_rate", dtype=Float32),
+ ],
+ source=data_sources.driver,
+ )
+
+ store.apply([driver(), driver_stats_v1, driver_stats_v2])
+
+ with pytest.raises(KeyError):
+ store.get_historical_features(
+ entity_df=datasets.entity_df,
+ features=[
+ # `driver_stats_v1` does not have `conv_rate`
+ "driver_stats_v1:conv_rate",
+ ],
+ full_feature_names=full_feature_names,
+ ).to_df()
+
+
@pytest.mark.integration
@pytest.mark.universal_offline_stores
def test_historical_features_with_missing_request_data(
diff --git a/sdk/python/tests/integration/online_store/test_universal_online.py b/sdk/python/tests/integration/online_store/test_universal_online.py
--- a/sdk/python/tests/integration/online_store/test_universal_online.py
+++ b/sdk/python/tests/integration/online_store/test_universal_online.py
@@ -19,7 +19,7 @@
RequestDataNotFoundInEntityRowsException,
)
from feast.online_response import TIMESTAMP_POSTFIX
-from feast.types import String
+from feast.types import Float32, Int32, String
from feast.wait import wait_retry_backoff
from tests.integration.feature_repos.repo_configuration import (
Environment,
@@ -324,6 +324,60 @@ def get_online_features_dict(
return dict1
[email protected]
[email protected]
+def test_online_retrieval_with_shared_batch_source(environment, universal_data_sources):
+ # Addresses https://github.com/feast-dev/feast/issues/2576
+
+ fs = environment.feature_store
+
+ entities, datasets, data_sources = universal_data_sources
+ driver_stats_v1 = FeatureView(
+ name="driver_stats_v1",
+ entities=["driver"],
+ schema=[Field(name="avg_daily_trips", dtype=Int32)],
+ source=data_sources.driver,
+ )
+ driver_stats_v2 = FeatureView(
+ name="driver_stats_v2",
+ entities=["driver"],
+ schema=[
+ Field(name="avg_daily_trips", dtype=Int32),
+ Field(name="conv_rate", dtype=Float32),
+ ],
+ source=data_sources.driver,
+ )
+
+ fs.apply([driver(), driver_stats_v1, driver_stats_v2])
+
+ data = pd.DataFrame(
+ {
+ "driver_id": [1, 2],
+ "avg_daily_trips": [4, 5],
+ "conv_rate": [0.5, 0.3],
+ "event_timestamp": [
+ pd.to_datetime(1646263500, utc=True, unit="s"),
+ pd.to_datetime(1646263600, utc=True, unit="s"),
+ ],
+ "created": [
+ pd.to_datetime(1646263500, unit="s"),
+ pd.to_datetime(1646263600, unit="s"),
+ ],
+ }
+ )
+ fs.write_to_online_store("driver_stats_v1", data.drop("conv_rate", axis=1))
+ fs.write_to_online_store("driver_stats_v2", data)
+
+ with pytest.raises(KeyError):
+ fs.get_online_features(
+ features=[
+ # `driver_stats_v1` does not have `conv_rate`
+ "driver_stats_v1:conv_rate",
+ ],
+ entity_rows=[{"driver_id": 1}, {"driver_id": 2}],
+ )
+
+
@pytest.mark.integration
@pytest.mark.universal_online_stores
@pytest.mark.parametrize("full_feature_names", [True, False], ids=lambda v: str(v))
| Undefined features should be rejected when being fetched via `get_historical_features` / `get_online_features`
## Context
I want to create versioned feature views. Through various versions, features could be added or removed.
## Expected Behavior
When doing `feast.get_historical_features`, features that are not defined should be rejected.
## Current Behavior
The features get returned even though they have not been defined.
## Steps to reproduce
1. Initialize a new feast repository
2. Define the features:
```python
driver_hourly_stats = FileSource(
path="/home/benjamintan/workspace/feast-workflow-demo/feature_repo/data/driver_stats.parquet",
timestamp_field="event_timestamp",
created_timestamp_column="created",
)
driver = Entity(name="driver_id", value_type=ValueType.INT64, description="driver id",)
driver_hourly_stats_view_v1 = FeatureView(
name="driver_hourly_stats_v1",
entities=["driver_id"],
ttl=timedelta(days=1),
schema=[
Field(name="avg_daily_trips", dtype=Int64),
],
online=True,
batch_source=driver_hourly_stats,
tags={},
)
driver_hourly_stats_view_v2 = FeatureView(
name="driver_hourly_stats_v2",
entities=["driver_id"],
ttl=timedelta(days=1),
schema=[
Field(name="conv_rate", dtype=Float32),
Field(name="acc_rate", dtype=Float32),
Field(name="avg_daily_trips", dtype=Int64),
],
online=True,
batch_source=driver_hourly_stats,
tags={},
)
```
3. `feast apply`
4. Querying Feast:
```python
fs = FeatureStore(repo_path='.')
entity_df = pd.DataFrame(
{
"event_timestamp": [
pd.Timestamp(dt, unit="ms", tz="UTC").round("ms")
for dt in pd.date_range(
start=datetime.now() - timedelta(days=3),
end=datetime.now(),
periods=3,
)
],
"driver_id": [1001, 1002, 1003],
}
)
```
I _do not_ expect the following to work:
```python
# THIS PART SHOULDN'T WORK
features_wrong = ['driver_hourly_stats_v1:conv_rate', # doesn't exist in V1
'driver_hourly_stats_v1:acc_rate', # doesn't exist in V1
'driver_hourly_stats_v1:avg_daily_trips',
]
hist_features_wrong = fs.get_historical_features(
entity_df=entity_df,
features=features_wrong,
)
```
But I do get results:
```
event_timestamp driver_id ... acc_rate avg_daily_trips
0 2022-04-17 09:35:35.658000+00:00 1001 ... 0.536431 742.0
1 2022-04-18 21:35:35.658000+00:00 1002 ... 0.496901 678.0
2 2022-04-20 09:35:35.658000+00:00 1003 ... NaN
```
I do not expect this to work because `driver_hourly_stats_v1:conv_rate` and `driver_hourly_stats_v1:acc_rate` were not defined in the `driver_hourly_stats_view_v1` FeatureView.
And just to double check that `driver_hourly_stats_v1` only has `avg_daily_trips` defined:
```
➜ feast feature-views describe driver_hourly_stats_v1
spec:
name: driver_hourly_stats_v1
entities:
- driver_id
features:
- name: avg_daily_trips
valueType: INT64
ttl: 86400s
```
### Specifications
- Version: 0.20 (tested this on 0.19 and 0.18)
- Platform: Linux
- Subsystem: Ubuntu
## Possible Solution
The list of features being passed in should be checked against the registry. Currently the feature view name and feature name pairs are not validated _together_. Here's an example that modifies `get_historical_features`:
```python
@log_exceptions_and_usage
def get_historical_features(
self,
entity_df: Union[pd.DataFrame, str],
features: Union[List[str], FeatureService],
full_feature_names: bool = False,
) -> RetrievalJob:
# Build a dictionary of feature view names -> feature names (not sure if this function already exists ...)
fv_name_features = dict([(fv.name, [f.name.split('-')[0] for f in fv.features]) for fv in self.list_feature_views()])
# Check that input features are found in the `fv_name_features` dictionary
feature_views_not_found = []
for feature in features:
k, v = feature.split(":")
if v not in fv_name_features[k]:
feature_views_not_found.append(f'{k}:{v}')
if feature_views_not_found:
raise FeatureViewNotFoundException(', '.join(feature_views_not_found))
```
This returns:
```python
feast.errors.FeatureViewNotFoundException: Feature view driver_hourly_stats_v1:conv_rate, driver_hourly_stats_v1:acc_rate does not exist
```
This doesn't handle the case when a `FeatureService` is passed in but it shouldn't be too hard.
This should also apply to `get_online_features`.
| 2022-05-11T13:34:02 |
|
feast-dev/feast | 2,666 | feast-dev__feast-2666 | [
"2651"
]
| d4b0b1a5045d04b4031f01c320d810b13180e64c | diff --git a/sdk/python/feast/feature_store.py b/sdk/python/feast/feature_store.py
--- a/sdk/python/feast/feature_store.py
+++ b/sdk/python/feast/feature_store.py
@@ -16,7 +16,7 @@
import os
import warnings
from collections import Counter, defaultdict
-from datetime import datetime
+from datetime import datetime, timedelta
from pathlib import Path
from typing import (
TYPE_CHECKING,
@@ -1080,7 +1080,16 @@ def materialize_incremental(
f"No start time found for feature view {feature_view.name}. materialize_incremental() requires"
f" either a ttl to be set or for materialize() to have been run at least once."
)
- start_date = datetime.utcnow() - feature_view.ttl
+ elif feature_view.ttl.total_seconds() > 0:
+ start_date = datetime.utcnow() - feature_view.ttl
+ else:
+ # TODO(felixwang9817): Find the earliest timestamp for this specific feature
+ # view from the offline store, and set the start date to that timestamp.
+ print(
+ f"Since the ttl is 0 for feature view {Style.BRIGHT + Fore.GREEN}{feature_view.name}{Style.RESET_ALL}, "
+ "the start date will be set to 1 year before the current time."
+ )
+ start_date = datetime.utcnow() - timedelta(weeks=52)
provider = self._get_provider()
print(
f"{Style.BRIGHT + Fore.GREEN}{feature_view.name}{Style.RESET_ALL}"
| diff --git a/sdk/python/tests/example_repos/example_feature_repo_with_ttl_0.py b/sdk/python/tests/example_repos/example_feature_repo_with_ttl_0.py
new file mode 100644
--- /dev/null
+++ b/sdk/python/tests/example_repos/example_feature_repo_with_ttl_0.py
@@ -0,0 +1,48 @@
+from datetime import timedelta
+
+from feast import Entity, FeatureView, Field, FileSource, ValueType
+from feast.types import Float32, Int32, Int64
+
+driver_hourly_stats = FileSource(
+ path="%PARQUET_PATH%", # placeholder to be replaced by the test
+ timestamp_field="event_timestamp",
+ created_timestamp_column="created",
+)
+
+driver = Entity(name="driver_id", value_type=ValueType.INT64, description="driver id")
+
+
+driver_hourly_stats_view = FeatureView(
+ name="driver_hourly_stats",
+ entities=[driver],
+ ttl=timedelta(days=0),
+ schema=[
+ Field(name="conv_rate", dtype=Float32),
+ Field(name="acc_rate", dtype=Float32),
+ Field(name="avg_daily_trips", dtype=Int64),
+ ],
+ online=True,
+ source=driver_hourly_stats,
+ tags={},
+)
+
+
+global_daily_stats = FileSource(
+ path="%PARQUET_PATH_GLOBAL%", # placeholder to be replaced by the test
+ timestamp_field="event_timestamp",
+ created_timestamp_column="created",
+)
+
+
+global_stats_feature_view = FeatureView(
+ name="global_daily_stats",
+ entities=[],
+ ttl=timedelta(days=0),
+ schema=[
+ Field(name="num_rides", dtype=Int32),
+ Field(name="avg_ride_length", dtype=Float32),
+ ],
+ online=True,
+ source=global_daily_stats,
+ tags={},
+)
diff --git a/sdk/python/tests/integration/online_store/test_e2e_local.py b/sdk/python/tests/integration/online_store/test_e2e_local.py
--- a/sdk/python/tests/integration/online_store/test_e2e_local.py
+++ b/sdk/python/tests/integration/online_store/test_e2e_local.py
@@ -101,12 +101,12 @@ def _test_materialize_and_online_retrieval(
def test_e2e_local() -> None:
"""
- A more comprehensive than "basic" test, using local provider.
+ Tests the end-to-end workflow of apply, materialize, and online retrieval.
- 1. Create a repo.
- 2. Apply
- 3. Ingest some data to online store from parquet
- 4. Read from the online store to make sure it made it there.
+ This test runs against several different types of repos:
+ 1. A repo with a normal FV and an entity-less FV.
+ 2. A repo using the SDK from version 0.19.0.
+ 3. A repo with a FV with a ttl of 0.
"""
runner = CliRunner()
with tempfile.TemporaryDirectory() as data_dir:
@@ -143,6 +143,16 @@ def test_e2e_local() -> None:
runner, store, start_date, end_date, driver_df
)
+ with runner.local_repo(
+ get_example_repo("example_feature_repo_with_ttl_0.py")
+ .replace("%PARQUET_PATH%", driver_stats_path)
+ .replace("%PARQUET_PATH_GLOBAL%", global_stats_path),
+ "file",
+ ) as store:
+ _test_materialize_and_online_retrieval(
+ runner, store, start_date, end_date, driver_df
+ )
+
# Test a failure case when the parquet file doesn't include a join key
with runner.local_repo(
get_example_repo("example_feature_repo_with_entity_join_key.py").replace(
| `FeatureStore.materialize_incremental()` does not initially materialize data for `FeatureView` with `ttl=0`
## Expected Behavior
When executing `FeatureStore.materialize_incremental()` on a `FeatureView` that has a `ttl=0` and has never yet been materialized, I would expect all historical data to be materialized since a `ttl=0` indicates that features live forever according to the [docs](https://rtd.feast.dev/en/master/index.html#feast.feature_view.FeatureView.ttl).
For an instance of `FeatureView` that has not explicitly defined `ttl`, it currently defaults to `timedelta(days=0)`, which hints that this is indeed an expected value for `ttl`.
## Current Behavior
Currently, the `start_date` for the materialization defaults to `datetime.utcnow() - ttl` if the feature view has not yet been materialized (i.e. `FeatureView.most_recent_end_time is None`). This means that `start_date = datetime.utcnow() - 0s`, thus `start_date = datetime.utcnow()`, resulting in no data being materialized.
[feast/sdk/python/feast/feature_store.py](https://github.com/feast-dev/feast/blob/5b4b07f999eb38542eb5518cf0db54a98baeeb40/sdk/python/feast/feature_store.py#L1073)
```python
def materialize_incremental(
self, end_date: datetime, feature_views: Optional[List[str]] = None,
) -> None:
...
for feature_view in feature_views_to_materialize:
start_date = feature_view.most_recent_end_time
if start_date is None:
if feature_view.ttl is None:
raise Exception(
f"No start time found for feature view {feature_view.name}. materialize_incremental() requires"
f" either a ttl to be set or for materialize() to have been run at least once."
)
>>> start_date = datetime.utcnow() - feature_view.ttl <<<
...
```
## Steps to reproduce
```python
from feast import FeatureView, FeatureStore
from datetime import datetime
my_feature_view = FeatureView(
name="my_feature_view",
entities=["my_entity"],
schema=[
Field(name="my_feature", dtype=types.Bool)
],
# ttl=timedelta(seconds=0) ; if not defined, TTL defaults to 0s
source=sources.my_source
)
fs = FeatureStore(".")
fs.materialize_incremental(end_date=datetime.utcnow(), views=["my_feature_view"])
```
### Specifications
- Version: 0.20.2
- Platform: macOS
- Subsystem:
## Possible Solution
[feast/sdk/python/feast/feature_store.py](https://github.com/feast-dev/feast/blob/5b4b07f999eb38542eb5518cf0db54a98baeeb40/sdk/python/feast/feature_store.py#L1073)
```python
def materialize_incremental(
self, end_date: datetime, feature_views: Optional[List[str]] = None,
) -> None:
...
for feature_view in feature_views_to_materialize:
start_date = feature_view.most_recent_end_time
if start_date is None:
if feature_view.ttl is None:
raise Exception(
f"No start time found for feature view {feature_view.name}. materialize_incremental() requires"
f" either a ttl to be set or for materialize() to have been run at least once."
)
start_date = datetime.utcnow() - feature_view.ttl
if feature_view.ttl == timedelta(days=0):
# what is the lower boundary for "forever" (as defined in the docs for ttl=0)?
# the smallest UNIX epoch timestamp could be a good candidate
start_date = datetime(1970, 1, 1)
...
```
| 2022-05-11T18:25:24 |
|
feast-dev/feast | 2,676 | feast-dev__feast-2676 | [
"2664"
]
| d3e01bc74da9f4678d3cf384afd4616a299f32fd | diff --git a/sdk/python/feast/__init__.py b/sdk/python/feast/__init__.py
--- a/sdk/python/feast/__init__.py
+++ b/sdk/python/feast/__init__.py
@@ -1,5 +1,3 @@
-import logging
-
from pkg_resources import DistributionNotFound, get_distribution
from feast.infra.offline_stores.bigquery_source import BigQuerySource
@@ -27,12 +25,6 @@
from .stream_feature_view import StreamFeatureView
from .value_type import ValueType
-logging.basicConfig(
- format="%(asctime)s %(levelname)s:%(message)s",
- datefmt="%m/%d/%Y %I:%M:%S %p",
- level=logging.INFO,
-)
-
try:
__version__ = get_distribution(__name__).version
except DistributionNotFound:
| basicConfig is called at the module level
## Expected Behavior
```
import feast
logging.basicConfig(level=level, format=FORMAT)
logging.error("msg")
```
should print logging message according to `FORMAT`
## Current Behavior
It uses the format defined in `feast` at the module level.
## Steps to reproduce
Same as in "Expected Behavior"
### Specifications
- Version: 0.18.1
- Platform: Linux
- Subsystem: -
## Possible Solution
I see that `basicConfig` is called here: https://github.com/feast-dev/feast/blob/c9eda79c7b1169ef05a481a96f07960c014e88b9/sdk/python/feast/cli.py#L84 so it is possible that simply removing this call here is enough: https://github.com/feast-dev/feast/blob/0ca62970dd6bc33c00bd5d8b828752814d480588/sdk/python/feast/__init__.py#L30
If there are any other entry points that need to set up logging, they should call the function, but the call in `__init__.py` must be removed.
| I think you're right @elshize - good catch. Would you be willing to submit a PR for this? :)
Actually I'm going to quickly fix this so that we can include the fix in the release we're planning on cutting tomorrow. | 2022-05-12T06:39:13 |
|
feast-dev/feast | 2,686 | feast-dev__feast-2686 | [
"2685"
]
| 01d3568168bb9febb9fbda4988283b3886c32a31 | diff --git a/sdk/python/feast/infra/offline_stores/file_source.py b/sdk/python/feast/infra/offline_stores/file_source.py
--- a/sdk/python/feast/infra/offline_stores/file_source.py
+++ b/sdk/python/feast/infra/offline_stores/file_source.py
@@ -3,7 +3,7 @@
from pyarrow._fs import FileSystem
from pyarrow._s3fs import S3FileSystem
-from pyarrow.parquet import ParquetFile
+from pyarrow.parquet import ParquetDataset
from feast import type_map
from feast.data_format import FileFormat, ParquetFormat
@@ -179,9 +179,9 @@ def get_table_column_names_and_types(
filesystem, path = FileSource.create_filesystem_and_path(
self.path, self.file_options.s3_endpoint_override
)
- schema = ParquetFile(
+ schema = ParquetDataset(
path if filesystem is None else filesystem.open_input_file(path)
- ).schema_arrow
+ ).schema.to_arrow_schema()
return zip(schema.names, map(str, schema.types))
@staticmethod
| Parquet Schema Inference only supports File, not directory
When using a FileSource that is in Parquet format, if the source happens to be a directory of partitioned Parquet files, the following lines throw an error:
https://github.com/feast-dev/feast/blob/01d3568168bb9febb9fbda4988283b3886c32a31/sdk/python/feast/infra/offline_stores/file_source.py#L182-L184
`OSError: Expected file path, but /home/ubuntu/project/data/driver_stats_partitioned is a directory`
How to replicate:
1. Start with a demo feast project (`feast init`)
2. Create a partitioned Parquet Dataset. Use the following to create a dataset with only a single timestamp for inference
```
import pyarrow.parquet as pq
df = pq.read_table("./data/driver_stats.parquet")
df = df.drop(["created"])
pq.write_to_dataset(df, "./data/driver_stats_partitioned")
```
3. Update the file source in `example.py` to look like this:
```
driver_hourly_stats = FileSource(
path="/home/ubuntu/cado-feast/feature_store/exciting_sunbeam/data/driver_stats_partitioned2",
)
```
4. Run `feast apply`
For now, I've been able to fix by updating the above lines to:
```
schema = ParquetDataset(
path if filesystem is None else filesystem.open_input_file(path)
).schema.to_arrow_schema()
```
| 2022-05-13T20:18:50 |
||
feast-dev/feast | 2,708 | feast-dev__feast-2708 | [
"2696"
]
| bcecbe71056212da648d99247a4a12162601cec3 | diff --git a/sdk/python/feast/errors.py b/sdk/python/feast/errors.py
--- a/sdk/python/feast/errors.py
+++ b/sdk/python/feast/errors.py
@@ -197,6 +197,13 @@ def __init__(
)
+class FeastOfflineStoreInvalidName(Exception):
+ def __init__(self, offline_store_class_name: str):
+ super().__init__(
+ f"Offline Store Class '{offline_store_class_name}' should end with the string `OfflineStore`.'"
+ )
+
+
class FeastOnlineStoreInvalidName(Exception):
def __init__(self, online_store_class_name: str):
super().__init__(
diff --git a/sdk/python/feast/repo_config.py b/sdk/python/feast/repo_config.py
--- a/sdk/python/feast/repo_config.py
+++ b/sdk/python/feast/repo_config.py
@@ -21,6 +21,8 @@
from feast.errors import (
FeastFeatureServerTypeInvalidError,
FeastFeatureServerTypeSetError,
+ FeastOfflineStoreInvalidName,
+ FeastOnlineStoreInvalidName,
FeastProviderNotSetError,
)
from feast.importer import import_class
@@ -278,7 +280,8 @@ def _validate_online_store_config(cls, values):
return values
# Make sure that the provider configuration is set. We need it to set the defaults
- assert "provider" in values
+ if "provider" not in values:
+ raise FeastProviderNotSetError()
# Set the default type
# This is only direct reference to a provider or online store that we should have
@@ -315,7 +318,8 @@ def _validate_offline_store_config(cls, values):
return values
# Make sure that the provider configuration is set. We need it to set the defaults
- assert "provider" in values
+ if "provider" not in values:
+ raise FeastProviderNotSetError()
# Set the default type
if "type" not in values["offline_store"]:
@@ -455,8 +459,8 @@ def get_batch_engine_config_from_type(batch_engine_type: str):
def get_online_config_from_type(online_store_type: str):
if online_store_type in ONLINE_STORE_CLASS_FOR_TYPE:
online_store_type = ONLINE_STORE_CLASS_FOR_TYPE[online_store_type]
- else:
- assert online_store_type.endswith("OnlineStore")
+ elif not online_store_type.endswith("OnlineStore"):
+ raise FeastOnlineStoreInvalidName(online_store_type)
module_name, online_store_class_type = online_store_type.rsplit(".", 1)
config_class_name = f"{online_store_class_type}Config"
@@ -466,8 +470,8 @@ def get_online_config_from_type(online_store_type: str):
def get_offline_config_from_type(offline_store_type: str):
if offline_store_type in OFFLINE_STORE_CLASS_FOR_TYPE:
offline_store_type = OFFLINE_STORE_CLASS_FOR_TYPE[offline_store_type]
- else:
- assert offline_store_type.endswith("OfflineStore")
+ elif not offline_store_type.endswith("OfflineStore"):
+ raise FeastOfflineStoreInvalidName(offline_store_type)
module_name, offline_store_class_type = offline_store_type.rsplit(".", 1)
config_class_name = f"{offline_store_class_type}Config"
| Better and more explicit Pydantic error messages
**Is your feature request related to a problem? Please describe.**
The Pydantic errors can be very annoying to debug when the error messages are not explicit or (as often seen) completely missing. I provide two specific examples bellow but many more can be found throughout the codebase.
**Describe the solution you'd like**
Always include explicit error messages to all Pydating validation checks.
**Additional context**
A couple of examples:
```pycon
>>> from feast import RepoConfig
>>> repo_config = RepoConfig(
... project="foo",
... )
Traceback (most recent call last):
File "my_script.py", line 2, in <module>
repo_config = RepoConfig(
File ".venv/lib/python3.9/site-packages/feast/repo_config.py", line 124, in __init__
super().__init__(**data)
File "pydantic/main.py", line 331, in pydantic.main.BaseModel.__init__
pydantic.error_wrappers.ValidationError: 1 validation error for RepoConfig
__root__
(type=assertion_error)
```
👆 In this example, the `feast.errors.FeastProviderNotSetError` exception should be raised instead of a blank AssertionError. The error message here would be explicit (i.e. `"Provider is not set, but is required"`)
```pycon
>>> from feast import RepoConfig
>>> repo_config = RepoConfig(
... project="foo",
... provider="local",
... offline_store=dict(
... type="my.custom.offline_store.CustomStore"
... ),
... )
Traceback (most recent call last):
File "my_script.py", line 2, in <module>
repo_config = RepoConfig(
File ".venv/lib/python3.9/site-packages/feast/repo_config.py", line 124, in __init__
super().__init__(**data)
File "pydantic/main.py", line 331, in pydantic.main.BaseModel.__init__
pydantic.error_wrappers.ValidationError: 1 validation error for RepoConfig
__root__
(type=assertion_error)
```
👆 Just like in the other example, it is impossible to see what the issue here is. In this case, the `get_offline_config_from_type` function should be raising an explicit exception with a `"Offline store types should end with 'OfflineStore', got {offline_store_type} instead."` message instead of an empty AssertionError. This way it would be immediately clear what the issue was.
| Agreed @tpvasconcelos , we should definitely have better errors here. This should easy to do, we have a bunch of naked assert statements in `feast/repo_config.py` and just adding an error message there would hugely improve user experience.
Would you be willing to take this on? | 2022-05-16T20:33:51 |
|
feast-dev/feast | 2,753 | feast-dev__feast-2753 | [
"2731",
"2731"
]
| 0cf3c923717f561d5656c57eb0b61fcd569917bd | diff --git a/sdk/python/feast/ui_server.py b/sdk/python/feast/ui_server.py
--- a/sdk/python/feast/ui_server.py
+++ b/sdk/python/feast/ui_server.py
@@ -62,7 +62,7 @@ def shutdown_event():
"name": "Project",
"description": "Test project",
"id": project_id,
- "registryPath": f"http://{host}:{port}/registry",
+ "registryPath": "/registry",
}
]
}
| Unable to access data in Feast UI when deployed to remote instance
## Expected Behavior
Should be able to view registry data when launching UI with `feast ui` on remote instances (like EC2).
## Current Behavior
I’ve tried setting the host to `0.0.0.0` and the static assets get loaded and can accessed via the public IP. But the requests to the registry (`http://0.0.0.0:8888/registry`) fails, so no data shows up.
I've also tried setting the host to the private IP, but the request to `/registry` times out.
## Steps to reproduce
Run `feast ui --host <instance private ip>` in EC2 instance.
### Specifications
- Version:`0.21.2`
- Platform: EC2
- Subsystem:
## Possible Solution
Potential CORS issue that needs to be fixed?
Unable to access data in Feast UI when deployed to remote instance
## Expected Behavior
Should be able to view registry data when launching UI with `feast ui` on remote instances (like EC2).
## Current Behavior
I’ve tried setting the host to `0.0.0.0` and the static assets get loaded and can accessed via the public IP. But the requests to the registry (`http://0.0.0.0:8888/registry`) fails, so no data shows up.
I've also tried setting the host to the private IP, but the request to `/registry` times out.
## Steps to reproduce
Run `feast ui --host <instance private ip>` in EC2 instance.
### Specifications
- Version:`0.21.2`
- Platform: EC2
- Subsystem:
## Possible Solution
Potential CORS issue that needs to be fixed?
| I'm having the same issue, caused by the hardcoded host:port in the `projects-list.json` file:
```
{
"projects": [
{
"name": "Project",
"description": "Test project",
"id": <YOUR ID>,
"registryPath": "http://0.0.0.0:8888/registry"
}
]
}
```
When running the UI in k8s, the host should be set to `0.0.0.0` for routing to work, but of course it's not going to be reachable there. Same for the port, it thinks it's running at 8888, but in reality it's at 443.
I think there are two ways to fix this: make the registryPath a setting in the yaml file, or use a relative path instead of an absolute one.
edit: code responsible is here: https://github.com/feast-dev/feast/blob/1c621fe3649900a59e85fe9c4f3840dd09bc88d0/sdk/python/feast/ui_server.py#L65
I'm having the same issue, caused by the hardcoded host:port in the `projects-list.json` file:
```
{
"projects": [
{
"name": "Project",
"description": "Test project",
"id": <YOUR ID>,
"registryPath": "http://0.0.0.0:8888/registry"
}
]
}
```
When running the UI in k8s, the host should be set to `0.0.0.0` for routing to work, but of course it's not going to be reachable there. Same for the port, it thinks it's running at 8888, but in reality it's at 443.
I think there are two ways to fix this: make the registryPath a setting in the yaml file, or use a relative path instead of an absolute one.
edit: code responsible is here: https://github.com/feast-dev/feast/blob/1c621fe3649900a59e85fe9c4f3840dd09bc88d0/sdk/python/feast/ui_server.py#L65 | 2022-06-02T07:11:52 |
|
feast-dev/feast | 2,786 | feast-dev__feast-2786 | [
"2781"
]
| a8d282d3e4f041824ef7479f22c306dbfb8ad569 | diff --git a/sdk/python/feast/infra/offline_stores/file_source.py b/sdk/python/feast/infra/offline_stores/file_source.py
--- a/sdk/python/feast/infra/offline_stores/file_source.py
+++ b/sdk/python/feast/infra/offline_stores/file_source.py
@@ -179,9 +179,15 @@ def get_table_column_names_and_types(
filesystem, path = FileSource.create_filesystem_and_path(
self.path, self.file_options.s3_endpoint_override
)
- schema = ParquetDataset(
- path if filesystem is None else filesystem.open_input_file(path)
- ).schema.to_arrow_schema()
+ # Adding support for different file format path
+ # based on S3 filesystem
+ if filesystem is None:
+ schema = ParquetDataset(path).schema.to_arrow_schema()
+ else:
+ schema = ParquetDataset(
+ filesystem.open_input_file(path), filesystem=filesystem
+ ).schema
+
return zip(schema.names, map(str, schema.types))
@staticmethod
| Unable to read parquet files from S3 location. Found a bug in file_source.py in python SDK.
## Expected Behavior
```python
from feast import Entity, Feature, FeatureView, ValueType, FeatureService, PushSource
from feast.data_format import ParquetFormat, AvroFormat, ProtoFormat
from feast.infra.offline_stores.file_source import FileSource
from feast.repo_config import RegistryConfig, RepoConfig
from feast.infra.offline_stores.file import FileOfflineStoreConfig
from feast.infra.online_stores.sqlite import SqliteOnlineStoreConfig
from feast import FeatureStore
from datetime import timedelta, datetime
import os
import s3fs
import numpy as np
import pandas as pd
bucket_name = "add your s3 bucket in which you have below file placed"
file_name = "driver_stats.parquet"
s3_endpoint = "http://s3.us-east-1.amazonaws.com"
s3 = s3fs.S3FileSystem(key='add your s3 access key',
secret='add your s3 secret key',
client_kwargs={'endpoint_url': s3_endpoint}, use_ssl=False)
# Setting up Entity
driver = Entity(name="driver_id", description="driver id")
# Defining the Input Source
driver_hourly_stats = FileSource(
path=f"s3://{bucket_name}/{file_name}",
timestamp_field="event_timestamp",
created_timestamp_column="created",
#s3_endpoint_override=s3_endpoint
)
driver_hourly_stats_view = FeatureView(
name="driver_hourly_stats",
entities=[driver],
source=driver_hourly_stats,
ttl=timedelta(seconds=86400 * 1), ## TTL - Time To Live - This Parameter is used in Point In Time Join
## Basically Its tell the system how much we have to go backward in time
)
online_store_path = 'online_store.db'
registry_path = 'registry.db'
os.environ["FEAST_S3_ENDPOINT_URL"] = s3_endpoint
repo = RepoConfig(
registry=f"s3://{bucket_name}/{registry_path}",
project='feature_store',
provider="local",
offline_store="file",
#online_store=SqliteOnlineStoreConfig(),
use_ssl=True,
filesystem=s3,
is_secure=True,
validate=True,
)
fs = FeatureStore(config=repo)
driver_stats_fs = FeatureService(
name="driver_activity",
features=[driver_hourly_stats_view]
)
fs.apply([driver_stats_fs, driver_hourly_stats_view, driver])
# You need to first define a entity dataframe in which
# You need to specify for which id you want data and also
# mention the timestamp for that id
entity_df = pd.DataFrame.from_dict(
{
"driver_id": [1005,1005,1005, 1002],
"event_timestamp": [
datetime.utcnow() - timedelta(hours=50),
datetime.utcnow() - timedelta(hours=20),
datetime.utcnow(),
datetime.utcnow(),
],
}
)
entity_df
## We use feature store get_historical_features method to retrive the data
retrieval_job = fs.get_historical_features(
entity_df=entity_df,
features=[
"driver_hourly_stats:conv_rate",
"driver_hourly_stats:acc_rate",
"driver_hourly_stats:avg_daily_trips",
],
)
# You have to specify the range from which you want your features to get populated in the online store
fs.materialize(start_date=datetime.utcnow() - timedelta(hours=150),
end_date=datetime.utcnow() - timedelta(hours=50))
feature_service = fs.get_feature_service("driver_activity")
fs.get_online_features(features=feature_service,
entity_rows=[{"driver_id": 1001},
{"driver_id": 1002},
{"driver_id": 1005}]).to_df()
```
## Current Behavior
I get an error while running **fs.apply()**
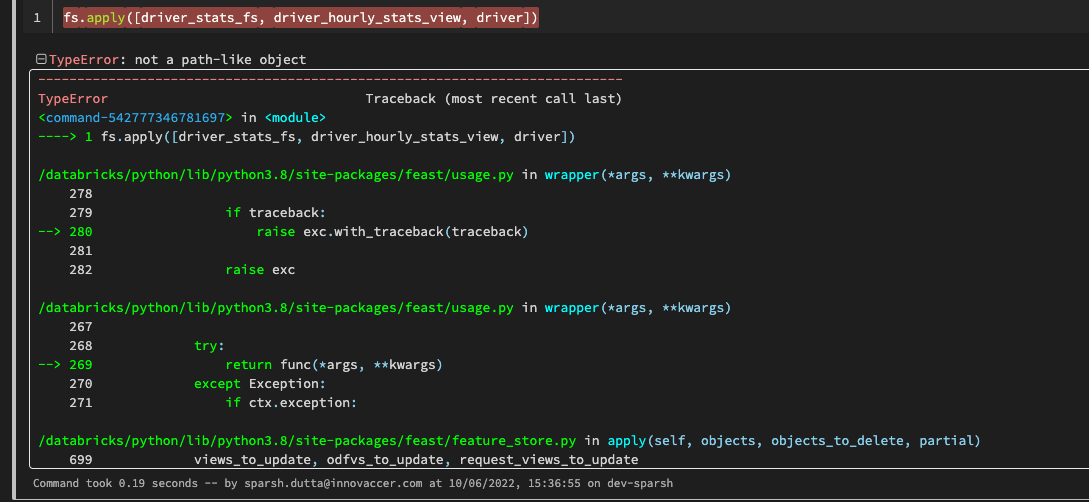
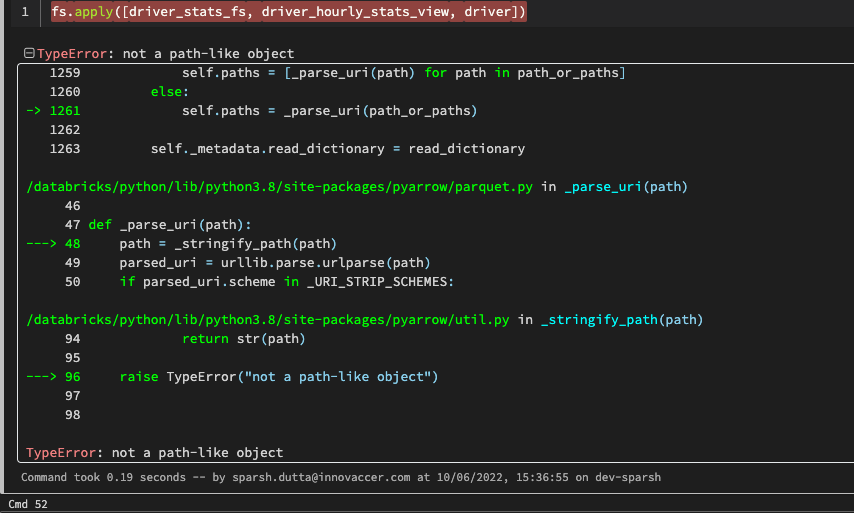
## Steps to reproduce
You can follow the above codebase to replicate the issue.
### Specifications
- Version: 0.21.2
- Platform: Linux
- Subsystem: Centos
## Possible Solution
I found the reason why this behavior is occurring. If you glance in [file_source.py](https://github.com/feast-dev/feast/blob/4ed107cdf6476faf20a4e09716ade87cb99f1d14/sdk/python/feast/infra/offline_stores/file_source.py#L5l)
```python
def get_table_column_names_and_types(
self, config: RepoConfig
) -> Iterable[Tuple[str, str]]:
filesystem, path = FileSource.create_filesystem_and_path(
self.path, self.file_options.s3_endpoint_override
)
schema = ParquetDataset(
path if filesystem is None else filesystem.open_input_file(path)
).schema.to_arrow_schema()
return zip(schema.names, map(str, schema.types))
@staticmethod
def create_filesystem_and_path(
path: str, s3_endpoint_override: str
) -> Tuple[Optional[FileSystem], str]:
if path.startswith("s3://"):
s3fs = S3FileSystem(
endpoint_override=s3_endpoint_override if s3_endpoint_override else None
)
return s3fs, path.replace("s3://", "")
else:
return None, path
```
In the above code, when we call **ParquetDataset**() class we pass attributes like path. Here when we read data from s3. **ParquetDataset**() will call **_parse_uri**(path) method which in turn call **_stringify_path**() method due to which the issue occurs.
In order to resolve this, we need to add the following condition to the existing codebase.
```python
def get_table_column_names_and_types(
self, config: RepoConfig
) -> Iterable[Tuple[str, str]]:
filesystem, path = FileSource.create_filesystem_and_path(
self.path, self.file_options.s3_endpoint_override
)
if filesystem is None:
schema = ParquetDataset(path).schema.to_arrow_schema()
else:
schema = ParquetDataset(filesystem.open_input_file(path), filesystem=filesystem).schema
return zip(schema.names, map(str, schema.types))
```
| hey @llFireHawkll, thanks for reporting this! looks like #2751 should resolve this; that PR has been out for a while though, so if you want a quick fix feel free to open your own PR! | 2022-06-12T09:16:56 |
|
feast-dev/feast | 2,836 | feast-dev__feast-2836 | [
"2825"
]
| a88cd30f7925005db6f7c400b391d5e73d1b00f6 | diff --git a/sdk/python/feast/errors.py b/sdk/python/feast/errors.py
--- a/sdk/python/feast/errors.py
+++ b/sdk/python/feast/errors.py
@@ -2,6 +2,8 @@
from colorama import Fore, Style
+from feast.field import Field
+
class DataSourceNotFoundException(Exception):
def __init__(self, path):
@@ -183,10 +185,15 @@ def __init__(self, feature_refs_collisions: List[str], full_feature_names: bool)
class SpecifiedFeaturesNotPresentError(Exception):
- def __init__(self, specified_features: List[str], feature_view_name: str):
- features = ", ".join(specified_features)
+ def __init__(
+ self,
+ specified_features: List[Field],
+ inferred_features: List[Field],
+ feature_view_name: str,
+ ):
super().__init__(
- f"Explicitly specified features {features} not found in inferred list of features for '{feature_view_name}'"
+ f"Explicitly specified features {specified_features} not found in inferred list of features "
+ f"{inferred_features} for '{feature_view_name}'"
)
diff --git a/sdk/python/feast/on_demand_feature_view.py b/sdk/python/feast/on_demand_feature_view.py
--- a/sdk/python/feast/on_demand_feature_view.py
+++ b/sdk/python/feast/on_demand_feature_view.py
@@ -479,7 +479,7 @@ def infer_features(self):
missing_features.append(specified_features)
if missing_features:
raise SpecifiedFeaturesNotPresentError(
- [f.name for f in missing_features], self.name
+ missing_features, inferred_features, self.name
)
else:
self.features = inferred_features
| SpecifiedFeaturesNotPresentError when using @on_demand_feature_view
## Expected Behavior
Trying to set up an on-demand feature view.
## Current Behavior
Get a SpecifiedFeaturesNotPresentError when applying store definition.
SpecifiedFeaturesNotPresentError: Explicitly specified features avg_fare, avg_speed, avg_trip_seconds, earned_per_hour not found in inferred list of features for 'on_demand_stats'
## Steps to reproduce
```
batch_source = FileSource(
timestamp_field="day",
path="trips_stats.parquet", # using parquet file from previous step
)
taxi_entity = Entity(name='taxi_id',
value_type=String)
trips_stats_fv = FeatureView(
name='trip_stats',
entities=['taxi_id'],
ttl=timedelta(seconds=86400), # 86400 sec = 1day
schema=[
Field(name="total_miles_travelled", dtype=Float32),
Field(name="total_trip_seconds", dtype=Float32),
Field(name="total_earned", dtype=Float32),
Field(name="trip_count", dtype=Int32)],
source=batch_source,
)
@on_demand_feature_view(
sources = [trips_stats_fv.projection],
schema=[
Field(name="avg_fare", dtype=Float32),
Field(name="avg_speed", dtype=Float32),
Field(name="avg_trip_seconds", dtype=Float32),
Field(name="earned_per_hour", dtype=Float32),
],
)
def on_demand_stats(inp):
out = pd.DataFrame()
out["avg_fare"] = inp["total_earned"] / inp["trip_count"]
out["avg_speed"] = 3600 * inp["total_miles_travelled"] / inp["total_trip_seconds"]
out["avg_trip_seconds"] = inp["total_trip_seconds"] / inp["trip_count"]
out["earned_per_hour"] = 3600 * inp["total_earned"] / inp["total_trip_seconds"]
return out
feature_svc = FeatureService(
name="taxi_rides",
features=[
trips_stats_fv,
on_demand_stats,
]
)
fs = FeatureStore(".") # using feature_store.yaml stored in the same directory
fs.apply([taxi_entity, trips_stats_fv, on_demand_stats, feature_svc])
```
### Specifications
- Version: Feast SDK Version: "feast 0.21.3"
- Platform: macOS 12.4
- Subsystem: Python 3.8.5 (conda)
## Possible Solution
| UPDATE:
If I define the on-demand feature view using deprecated params, then it works
```
#
@on_demand_feature_view(
features=[
Feature("avg_fare", ValueType.DOUBLE),
Feature("avg_speed", ValueType.DOUBLE),
Feature("avg_trip_seconds", ValueType.DOUBLE),
Feature("earned_per_hour", ValueType.DOUBLE),
],
sources=[trips_stats_fv]
)
def on_demand_stats(inp):
out = pd.DataFrame()
out["avg_fare"] = inp["total_earned"] / inp["trip_count"]
out["avg_speed"] = 3600 * inp["total_miles_travelled"] / inp["total_trip_seconds"]
out["avg_trip_seconds"] = inp["total_trip_seconds"] / inp["trip_count"]
out["earned_per_hour"] = 3600 * inp["total_earned"] / inp["total_trip_seconds"]
return out
```
Thanks for raising the issue @vecorro. We are investigating!
hey @vecorro thanks for raising this issue - the problem here is that your UDF results in a pandas dataframe with the following columns:
```
avg_fare float64
avg_speed float64
avg_trip_seconds float64
earned_per_hour float64
dtype: object
```
but in your initial feature definitions you specified the fields as having a `Float32` type - if you switch to `Float64` it should work correctly
note that `ValueType.DOUBLE` is the equivalent of `Float64` in the old typing system, which is why that worked for you
I'm going to update the error message to be more clear here, after which I'll close out this issue | 2022-06-22T18:36:40 |
|
feast-dev/feast | 2,845 | feast-dev__feast-2845 | [
"2843"
]
| 34c997d81b0084d81fb6fb21d5d4374fc7760695 | diff --git a/sdk/python/feast/infra/offline_stores/contrib/postgres_offline_store/postgres_source.py b/sdk/python/feast/infra/offline_stores/contrib/postgres_offline_store/postgres_source.py
--- a/sdk/python/feast/infra/offline_stores/contrib/postgres_offline_store/postgres_source.py
+++ b/sdk/python/feast/infra/offline_stores/contrib/postgres_offline_store/postgres_source.py
@@ -18,6 +18,9 @@ def __init__(
created_timestamp_column: Optional[str] = "",
field_mapping: Optional[Dict[str, str]] = None,
date_partition_column: Optional[str] = "",
+ description: Optional[str] = "",
+ tags: Optional[Dict[str, str]] = None,
+ owner: Optional[str] = "",
):
self._postgres_options = PostgreSQLOptions(name=name, query=query)
@@ -27,6 +30,9 @@ def __init__(
created_timestamp_column=created_timestamp_column,
field_mapping=field_mapping,
date_partition_column=date_partition_column,
+ description=description,
+ tags=tags,
+ owner=owner,
)
def __hash__(self):
@@ -57,14 +63,21 @@ def from_proto(data_source: DataSourceProto):
timestamp_field=data_source.timestamp_field,
created_timestamp_column=data_source.created_timestamp_column,
date_partition_column=data_source.date_partition_column,
+ description=data_source.description,
+ tags=dict(data_source.tags),
+ owner=data_source.owner,
)
def to_proto(self) -> DataSourceProto:
data_source_proto = DataSourceProto(
+ name=self.name,
type=DataSourceProto.CUSTOM_SOURCE,
data_source_class_type="feast.infra.offline_stores.contrib.postgres_offline_store.postgres_source.PostgreSQLSource",
field_mapping=self.field_mapping,
custom_options=self._postgres_options.to_proto(),
+ description=self.description,
+ tags=self.tags,
+ owner=self.owner,
)
data_source_proto.timestamp_field = self.timestamp_field
| Incorrect projects-list.json generated by feast ui when using Postgres as a data source.
## Expected Behavior
Correct generation of the projects-list.json when running feast ui.
## Current Behavior
The generated projects-list.json does not contain a name in the dataSources field, causing the parser to fail.
## Steps to reproduce
Setup feast with PostgreSQL as a data source.
### Specifications
- Version:
- Platform:
- Subsystem:
## Possible Solution
Adding name=self.name to to_proto() in postgres_source.py. And in general making the postgres_source.py file more similar to e.g., file_source.py.
| 2022-06-23T09:34:55 |
||
feast-dev/feast | 2,894 | feast-dev__feast-2894 | [
"2484"
]
| 8e2a3752b847c5c4753d02e0fe190dd303c9f2c7 | diff --git a/sdk/python/feast/proto_json.py b/sdk/python/feast/proto_json.py
--- a/sdk/python/feast/proto_json.py
+++ b/sdk/python/feast/proto_json.py
@@ -70,7 +70,7 @@ def to_json_object(printer: _Printer, message: ProtoMessage) -> JsonObject:
return value
def from_json_object(
- parser: _Parser, value: JsonObject, message: ProtoMessage,
+ parser: _Parser, value: JsonObject, message: ProtoMessage, path: str
) -> None:
if value is None:
message.null_val = 0
@@ -142,11 +142,11 @@ def to_json_object(printer: _Printer, message: ProtoMessage) -> JsonObject:
return [printer._MessageToJsonObject(item) for item in message.val]
def from_json_object(
- parser: _Parser, value: JsonObject, message: ProtoMessage,
+ parser: _Parser, value: JsonObject, message: ProtoMessage, path: str
) -> None:
array = value if isinstance(value, list) else value["val"]
for item in array:
- parser.ConvertMessage(item, message.val.add())
+ parser.ConvertMessage(item, message.val.add(), path)
_patch_proto_json_encoding(RepeatedValue, to_json_object, from_json_object)
@@ -183,7 +183,7 @@ def to_json_object(printer: _Printer, message: ProtoMessage) -> JsonObject:
return list(message.val)
def from_json_object(
- parser: _Parser, value: JsonObject, message: ProtoMessage,
+ parser: _Parser, value: JsonObject, message: ProtoMessage, path: str
) -> None:
array = value if isinstance(value, list) else value["val"]
message.val.extend(array)
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -52,15 +52,15 @@
"fastavro>=1.1.0,<2",
"google-api-core>=1.23.0,<3",
"googleapis-common-protos>=1.52.*,<2",
- "grpcio>=1.34.0,<2",
- "grpcio-reflection>=1.34.0,<2",
+ "grpcio>=1.47.0,<2",
+ "grpcio-reflection>=1.47.0,<2",
"Jinja2>=2,<4",
"jsonschema",
"mmh3",
"numpy>=1.22,<2",
"pandas>=1,<2",
"pandavro==1.5.*",
- "protobuf>=3.10,<3.20",
+ "protobuf>3.20,<4",
"proto-plus==1.20.*",
"pyarrow>=4,<7",
"pydantic>=1,<2",
@@ -131,8 +131,8 @@
"flake8",
"black==19.10b0",
"isort>=5,<6",
- "grpcio-tools==1.44.0",
- "grpcio-testing==1.44.0",
+ "grpcio-tools==1.47.0",
+ "grpcio-testing==1.47.0",
"minio==7.1.0",
"mock==2.0.0",
"moto",
@@ -514,8 +514,8 @@ def copy_extensions_to_source(self):
use_scm_version=use_scm_version,
setup_requires=[
"setuptools_scm",
- "grpcio",
- "grpcio-tools==1.44.0",
+ "grpcio==1.47.0",
+ "grpcio-tools==1.47.0",
"mypy-protobuf==3.1",
"pybindgen==0.22.0",
"sphinx!=4.0.0",
@@ -533,4 +533,4 @@ def copy_extensions_to_source(self):
["github.com/feast-dev/feast/go/embedded"],
)
],
-)
+)
\ No newline at end of file
| diff --git a/sdk/python/tests/unit/test_proto_json.py b/sdk/python/tests/unit/test_proto_json.py
--- a/sdk/python/tests/unit/test_proto_json.py
+++ b/sdk/python/tests/unit/test_proto_json.py
@@ -81,7 +81,7 @@ def test_feast_repeated_value(proto_json_patch):
# additional structure (e.g. [1,2,3] instead of {"val": [1,2,3]})
repeated_value_str = "[1,2,3]"
repeated_value_proto = RepeatedValue()
- Parse(repeated_value_str, repeated_value_proto)
+ Parse(repeated_value_str, repeated_value_proto, "")
assertpy.assert_that(len(repeated_value_proto.val)).is_equal_to(3)
assertpy.assert_that(repeated_value_proto.val[0].int64_val).is_equal_to(1)
assertpy.assert_that(repeated_value_proto.val[1].int64_val).is_equal_to(2)
| protobuf pinned to <3.20.0
We pinned the version of protobuf to `protobuf>=3.10,<3.20` because we patch some functionality when converting json <> proto in the AWS Lambda feature server (https://github.com/feast-dev/feast/blob/master/sdk/python/feast/proto_json.py#L18).
protobuf 3.20.0 changes the API we patch - so the version bump needs to happen along with an update to the patched methods.
#2480 has more context.
| 2022-06-29T23:27:01 |
|
feast-dev/feast | 2,904 | feast-dev__feast-2904 | [
"2895"
]
| 0ceb39c276c5eba08014acb2f5beb03fedc0a700 | diff --git a/sdk/python/feast/feature_store.py b/sdk/python/feast/feature_store.py
--- a/sdk/python/feast/feature_store.py
+++ b/sdk/python/feast/feature_store.py
@@ -511,8 +511,8 @@ def _get_features(
return _feature_refs
def _should_use_plan(self):
- """Returns True if _plan and _apply_diffs should be used, False otherwise."""
- # Currently only the local provider with sqlite online store supports _plan and _apply_diffs.
+ """Returns True if plan and _apply_diffs should be used, False otherwise."""
+ # Currently only the local provider with sqlite online store supports plan and _apply_diffs.
return self.config.provider == "local" and (
self.config.online_store and self.config.online_store.type == "sqlite"
)
@@ -636,7 +636,7 @@ def _get_feature_views_to_materialize(
return feature_views_to_materialize
@log_exceptions_and_usage
- def _plan(
+ def plan(
self, desired_repo_contents: RepoContents
) -> Tuple[RegistryDiff, InfraDiff, Infra]:
"""Dry-run registering objects to metadata store.
@@ -670,7 +670,7 @@ def _plan(
... ttl=timedelta(seconds=86400 * 1),
... batch_source=driver_hourly_stats,
... )
- >>> registry_diff, infra_diff, new_infra = fs._plan(RepoContents(
+ >>> registry_diff, infra_diff, new_infra = fs.plan(RepoContents(
... data_sources=[driver_hourly_stats],
... feature_views=[driver_hourly_stats_view],
... on_demand_feature_views=list(),
diff --git a/sdk/python/feast/repo_operations.py b/sdk/python/feast/repo_operations.py
--- a/sdk/python/feast/repo_operations.py
+++ b/sdk/python/feast/repo_operations.py
@@ -183,7 +183,7 @@ def plan(repo_config: RepoConfig, repo_path: Path, skip_source_validation: bool)
for data_source in data_sources:
data_source.validate(store.config)
- registry_diff, infra_diff, _ = store._plan(repo)
+ registry_diff, infra_diff, _ = store.plan(repo)
click.echo(registry_diff.to_string())
click.echo(infra_diff.to_string())
@@ -262,7 +262,7 @@ def apply_total_with_repo_instance(
for data_source in data_sources:
data_source.validate(store.config)
- registry_diff, infra_diff, new_infra = store._plan(repo)
+ registry_diff, infra_diff, new_infra = store.plan(repo)
# For each object in the registry, determine whether it should be kept or deleted.
(
| FeatureStore._plan should be a public method
**Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
https://github.com/feast-dev/feast/blob/master/sdk/python/feast/feature_store.py#L639
Ideally, all FeatureStore methods that back a CLI operation should have a public facing programatic API. In this case, `feast plan` users `FeatureStore._plan` -> which signifies that it should be treated as a private method.
**Describe the solution you'd like**
The change would be as simple as refactoring it to `FeatureStore.plan`.
| cc @chhabrakadabra | 2022-07-02T23:23:53 |
|
feast-dev/feast | 2,956 | feast-dev__feast-2956 | [
"2954"
]
| d0d27a35a0d63a139970cb17542764ff2aaf6aaf | diff --git a/sdk/python/feast/infra/offline_stores/contrib/postgres_offline_store/postgres.py b/sdk/python/feast/infra/offline_stores/contrib/postgres_offline_store/postgres.py
--- a/sdk/python/feast/infra/offline_stores/contrib/postgres_offline_store/postgres.py
+++ b/sdk/python/feast/infra/offline_stores/contrib/postgres_offline_store/postgres.py
@@ -214,7 +214,7 @@ def pull_all_from_table_or_query(
query = f"""
SELECT {field_string}
- FROM {from_expression}
+ FROM {from_expression} AS paftoq_alias
WHERE "{timestamp_field}" BETWEEN '{start_date}'::timestamptz AND '{end_date}'::timestamptz
"""
| diff --git a/sdk/python/tests/unit/infra/test_key_encoding_utils.py b/sdk/python/tests/unit/infra/test_key_encoding_utils.py
--- a/sdk/python/tests/unit/infra/test_key_encoding_utils.py
+++ b/sdk/python/tests/unit/infra/test_key_encoding_utils.py
@@ -9,14 +9,14 @@ def test_serialize_entity_key():
# Should be fine
serialize_entity_key(
EntityKeyProto(
- join_keys=["user"], entity_values=[ValueProto(int64_val=int(2 ** 15))]
+ join_keys=["user"], entity_values=[ValueProto(int64_val=int(2**15))]
),
entity_key_serialization_version=2,
)
# True int64, but should also be fine.
serialize_entity_key(
EntityKeyProto(
- join_keys=["user"], entity_values=[ValueProto(int64_val=int(2 ** 31))]
+ join_keys=["user"], entity_values=[ValueProto(int64_val=int(2**31))]
),
entity_key_serialization_version=2,
)
@@ -25,6 +25,6 @@ def test_serialize_entity_key():
with pytest.raises(BaseException):
serialize_entity_key(
EntityKeyProto(
- join_keys=["user"], entity_values=[ValueProto(int64_val=int(2 ** 31))]
+ join_keys=["user"], entity_values=[ValueProto(int64_val=int(2**31))]
),
)
| Missing alias in `PostgreSQLOfflineStore.pull_all_from_table_or_query()`
## Expected Behavior
Call `pull_all_from_table_or_query()` method and retrieve wanted data from offline store.
## Current Behavior
SQL error `psycopg2.errors.SyntaxError: subquery in FROM must have an alias`
## Steps to reproduce
Call `pull_all_from_table_or_query()` on `PostgreSQLOfflineStore`, where `PostgreSQLSource` is initialized with `query="SELECT * FROM table_name"`
### Specifications
- Version: 0.22.1
- Platform: x86_64
- Subsystem: Linux 5.18
## Possible Solution
Adding alias in query located in `PostgreSQLOfflineStore.pull_all_from_table_or_query()`, for example adding `AS dummy_alias`. This was tested on my use-case and it works as expected, and if it looks ok, I could open a PR with this change.
```
query = f"""
SELECT {field_string}
FROM {from_expression} AS dummy_alias
WHERE "{timestamp_field}" BETWEEN '{start_date}'::timestamptz AND '{end_date}'::timestamptz
"""
```
| 2022-07-20T15:18:33 |
|
feast-dev/feast | 2,965 | feast-dev__feast-2965 | [
"2865"
]
| 5e45228a406e6ee7f82e41cab7f734730ff2e73f | diff --git a/sdk/python/feast/data_source.py b/sdk/python/feast/data_source.py
--- a/sdk/python/feast/data_source.py
+++ b/sdk/python/feast/data_source.py
@@ -273,6 +273,13 @@ def __init__(
),
DeprecationWarning,
)
+ if (
+ self.timestamp_field
+ and self.timestamp_field == self.created_timestamp_column
+ ):
+ raise ValueError(
+ "Please do not use the same column for 'timestamp_field' and 'created_timestamp_column'."
+ )
self.description = description or ""
self.tags = tags or {}
self.owner = owner or ""
| diff --git a/sdk/python/tests/unit/test_data_sources.py b/sdk/python/tests/unit/test_data_sources.py
--- a/sdk/python/tests/unit/test_data_sources.py
+++ b/sdk/python/tests/unit/test_data_sources.py
@@ -261,3 +261,13 @@ def test_proto_conversion():
assert DataSource.from_proto(kinesis_source.to_proto()) == kinesis_source
assert DataSource.from_proto(push_source.to_proto()) == push_source
assert DataSource.from_proto(request_source.to_proto()) == request_source
+
+
+def test_column_conflict():
+ with pytest.raises(ValueError):
+ _ = FileSource(
+ name="test_source",
+ path="test_path",
+ timestamp_field="event_timestamp",
+ created_timestamp_column="event_timestamp",
+ )
| get_historical_features fails with dask error for file offline store
## Expected Behavior
```
feature_store.get_historical_features(df, features=fs_columns).to_df()
```
where `feature_store` is a feature store with file offline store and `fs_columns` is a list of column names, and `df` is a Pandas data frame, should work.
## Current Behavior
It currently raises an error inside of dask:
```
E NotImplementedError: dd.DataFrame.apply only supports axis=1
E Try: df.apply(func, axis=1)
```
Stacktrace:
```
../../.cache/pypoetry/virtualenvs/w3-search-letor-SCEBvDm1-py3.9/lib/python3.9/site-packages/feast/infra/offline_stores/offline_store.py:81: in to_df
features_df = self._to_df_internal()
../../.cache/pypoetry/virtualenvs/w3-search-letor-SCEBvDm1-py3.9/lib/python3.9/site-packages/feast/usage.py:280: in wrapper
raise exc.with_traceback(traceback)
../../.cache/pypoetry/virtualenvs/w3-search-letor-SCEBvDm1-py3.9/lib/python3.9/site-packages/feast/usage.py:269: in wrapper
return func(*args, **kwargs)
../../.cache/pypoetry/virtualenvs/w3-search-letor-SCEBvDm1-py3.9/lib/python3.9/site-packages/feast/infra/offline_stores/file.py:75: in _to_df_internal
df = self.evaluation_function().compute()
../../.cache/pypoetry/virtualenvs/w3-search-letor-SCEBvDm1-py3.9/lib/python3.9/site-packages/feast/infra/offline_stores/file.py:231: in evaluate_historical_retrieval
df_to_join = _normalize_timestamp(
../../.cache/pypoetry/virtualenvs/w3-search-letor-SCEBvDm1-py3.9/lib/python3.9/site-packages/feast/infra/offline_stores/file.py:530: in _normalize_timestamp
df_to_join[timestamp_field] = df_to_join[timestamp_field].apply(
```
## Steps to reproduce
Here is my feature store definition:
```python
from feast import FeatureStore, RepoConfig, FileSource, FeatureView, ValueType, Entity, Feature
from feast.infra.offline_stores.file import FileOfflineStoreConfig
from google.protobuf.duration_pb2 import Duration
source_path = tmp_path / "source.parquet"
timestamp = datetime.datetime(year=2022, month=4, day=29, tzinfo=datetime.timezone.utc)
df = pd.DataFrame(
{
"entity": [0, 1, 2, 3, 4],
"f1": [1.0, 1.1, 1.2, 1.3, 1.4],
"f2": ["a", "b", "c", "d", "e"],
"timestamp": [
timestamp,
# this one should not be fetched as it is too far into the past
timestamp - datetime.timedelta(days=2),
timestamp,
timestamp,
timestamp,
],
}
)
df.to_parquet(source_path)
source = FileSource(
path=str(source_path),
event_timestamp_column="timestamp",
created_timestamp_column="timestamp",
)
entity = Entity(
name="entity",
value_type=ValueType.INT64,
description="Entity",
)
view = FeatureView(
name="view",
entities=["entity"],
ttl=Duration(seconds=86400 * 1),
features=[
Feature(name="f1", dtype=ValueType.FLOAT),
Feature(name="f2", dtype=ValueType.STRING),
],
online=True,
batch_source=source,
tags={},
)
config = RepoConfig(
registry=str(tmp_path / "registry.db"),
project="hello",
provider="local",
offline_store=FileOfflineStoreConfig(),
)
store = FeatureStore(config=config)
store.apply([entity, view])
expected = pd.DataFrame(
{
"event_timestamp": timestamp,
"entity": [0, 1, 2, 3, 5],
"someval": [0.0, 0.1, 0.2, 0.3, 0.5],
"f1": [1.0, np.nan, 1.2, 1.3, np.nan],
"f2": ["a", np.nan, "c", "d", np.nan],
}
)
```
### Specifications
- Version: 0.21.3
- Platform: Linux
- Subsystem: Python 3.9
## Possible Solution
This works fine in at least version 0.18.1, but I think it fails for any >0.20
It might have something to do with adding Dask requirement, maybe the version is insufficient? I used to use 2022.2 before, but the requirement is now for 2022.1.1. But this is just a guess, really.
| In fact, the last version that works is 0.18.1
The problem was:
```python
source = FileSource(
path=str(source_path),
event_timestamp_column="timestamp",
created_timestamp_column="timestamp",
)
```
When both timestamp columns are the same, it breaks. Once I changed to:
```python
source = FileSource(
path=str(source_path),
timestamp_field="timestamp",
)
```
it's no longer an issue.
I will leave this ticket open, and let the maintainers decide if this is expected behavior or if there's something to be done to fix it or add some explicit asserts.
Thanks for the details @elshize - this definitely smells like a bug we need to fix!
I was unable to reproduce this issue locally - for posterity this is my setup:
```
$ feast version
Feast SDK Version: "feast 0.22.1"
$ pip list
Package Version
------------------------ ---------
absl-py 1.2.0
anyio 3.6.1
appdirs 1.4.4
attrs 21.4.0
bowler 0.9.0
cachetools 5.2.0
certifi 2022.6.15
charset-normalizer 2.1.0
click 8.0.1
cloudpickle 2.1.0
colorama 0.4.5
dask 2022.1.1
dill 0.3.5.1
fastapi 0.79.0
fastavro 1.5.3
feast 0.22.1
fissix 21.11.13
fsspec 2022.5.0
google-api-core 2.8.2
google-auth 2.9.1
googleapis-common-protos 1.56.4
greenlet 1.1.2
grpcio 1.47.0
grpcio-reflection 1.47.0
h11 0.13.0
httptools 0.4.0
idna 3.3
Jinja2 3.1.2
jsonschema 4.7.2
locket 1.0.0
MarkupSafe 2.1.1
mmh3 3.0.0
moreorless 0.4.0
mypy 0.971
mypy-extensions 0.4.3
numpy 1.23.1
packaging 21.3
pandas 1.4.3
pandavro 1.5.2
partd 1.2.0
pip 22.0.4
proto-plus 1.20.6
protobuf 3.20.1
pyarrow 6.0.1
pyasn1 0.4.8
pyasn1-modules 0.2.8
pydantic 1.9.1
Pygments 2.12.0
pyparsing 3.0.9
pyrsistent 0.18.1
python-dateutil 2.8.2
python-dotenv 0.20.0
pytz 2022.1
PyYAML 6.0
requests 2.28.1
rsa 4.9
setuptools 58.1.0
six 1.16.0
sniffio 1.2.0
SQLAlchemy 1.4.39
sqlalchemy2-stubs 0.0.2a24
starlette 0.19.1
tabulate 0.8.10
tenacity 8.0.1
tensorflow-metadata 1.9.0
toml 0.10.2
tomli 2.0.1
toolz 0.12.0
tqdm 4.64.0
typeguard 2.13.3
typing_extensions 4.3.0
urllib3 1.26.10
uvicorn 0.18.2
uvloop 0.16.0
volatile 2.1.0
watchfiles 0.15.0
websockets 10.3
$ python --version
Python 3.9.11
```
@elshize can you see if this is still an issue for you and reopen this if that's the case? | 2022-07-21T19:41:04 |
feast-dev/feast | 2,971 | feast-dev__feast-2971 | [
"2960"
]
| 3ce51391e0b2ebdec68c81d93b54f5d06bb427a6 | diff --git a/sdk/python/feast/infra/offline_stores/file.py b/sdk/python/feast/infra/offline_stores/file.py
--- a/sdk/python/feast/infra/offline_stores/file.py
+++ b/sdk/python/feast/infra/offline_stores/file.py
@@ -635,6 +635,14 @@ def _filter_ttl(
)
]
+ df_to_join = df_to_join.persist()
+ else:
+ df_to_join = df_to_join[
+ # do not drop entity rows if one of the sources returns NaNs
+ df_to_join[timestamp_field].isna()
+ | (df_to_join[timestamp_field] <= df_to_join[entity_df_event_timestamp_col])
+ ]
+
df_to_join = df_to_join.persist()
return df_to_join
| diff --git a/sdk/python/tests/integration/offline_store/test_universal_historical_retrieval.py b/sdk/python/tests/integration/offline_store/test_universal_historical_retrieval.py
--- a/sdk/python/tests/integration/offline_store/test_universal_historical_retrieval.py
+++ b/sdk/python/tests/integration/offline_store/test_universal_historical_retrieval.py
@@ -115,13 +115,17 @@ def get_expected_training_df(
entity_df.to_dict("records"), event_timestamp
)
+ # Set sufficiently large ttl that it effectively functions as infinite for the calculations below.
+ default_ttl = timedelta(weeks=52)
+
# Manually do point-in-time join of driver, customer, and order records against
# the entity df
for entity_row in entity_rows:
customer_record = find_asof_record(
customer_records,
ts_key=customer_fv.batch_source.timestamp_field,
- ts_start=entity_row[event_timestamp] - customer_fv.ttl,
+ ts_start=entity_row[event_timestamp]
+ - get_feature_view_ttl(customer_fv, default_ttl),
ts_end=entity_row[event_timestamp],
filter_keys=["customer_id"],
filter_values=[entity_row["customer_id"]],
@@ -129,7 +133,8 @@ def get_expected_training_df(
driver_record = find_asof_record(
driver_records,
ts_key=driver_fv.batch_source.timestamp_field,
- ts_start=entity_row[event_timestamp] - driver_fv.ttl,
+ ts_start=entity_row[event_timestamp]
+ - get_feature_view_ttl(driver_fv, default_ttl),
ts_end=entity_row[event_timestamp],
filter_keys=["driver_id"],
filter_values=[entity_row["driver_id"]],
@@ -137,7 +142,8 @@ def get_expected_training_df(
order_record = find_asof_record(
order_records,
ts_key=customer_fv.batch_source.timestamp_field,
- ts_start=entity_row[event_timestamp] - order_fv.ttl,
+ ts_start=entity_row[event_timestamp]
+ - get_feature_view_ttl(order_fv, default_ttl),
ts_end=entity_row[event_timestamp],
filter_keys=["customer_id", "driver_id"],
filter_values=[entity_row["customer_id"], entity_row["driver_id"]],
@@ -145,7 +151,8 @@ def get_expected_training_df(
origin_record = find_asof_record(
location_records,
ts_key=location_fv.batch_source.timestamp_field,
- ts_start=order_record[event_timestamp] - location_fv.ttl,
+ ts_start=order_record[event_timestamp]
+ - get_feature_view_ttl(location_fv, default_ttl),
ts_end=order_record[event_timestamp],
filter_keys=["location_id"],
filter_values=[order_record["origin_id"]],
@@ -153,7 +160,8 @@ def get_expected_training_df(
destination_record = find_asof_record(
location_records,
ts_key=location_fv.batch_source.timestamp_field,
- ts_start=order_record[event_timestamp] - location_fv.ttl,
+ ts_start=order_record[event_timestamp]
+ - get_feature_view_ttl(location_fv, default_ttl),
ts_end=order_record[event_timestamp],
filter_keys=["location_id"],
filter_values=[order_record["destination_id"]],
@@ -161,14 +169,16 @@ def get_expected_training_df(
global_record = find_asof_record(
global_records,
ts_key=global_fv.batch_source.timestamp_field,
- ts_start=order_record[event_timestamp] - global_fv.ttl,
+ ts_start=order_record[event_timestamp]
+ - get_feature_view_ttl(global_fv, default_ttl),
ts_end=order_record[event_timestamp],
)
field_mapping_record = find_asof_record(
field_mapping_records,
ts_key=field_mapping_fv.batch_source.timestamp_field,
- ts_start=order_record[event_timestamp] - field_mapping_fv.ttl,
+ ts_start=order_record[event_timestamp]
+ - get_feature_view_ttl(field_mapping_fv, default_ttl),
ts_end=order_record[event_timestamp],
)
@@ -666,6 +676,78 @@ def test_historical_features_persisting(
)
[email protected]
[email protected]_offline_stores
[email protected]("full_feature_names", [True, False], ids=lambda v: str(v))
+def test_historical_features_with_no_ttl(
+ environment, universal_data_sources, full_feature_names
+):
+ store = environment.feature_store
+
+ (entities, datasets, data_sources) = universal_data_sources
+ feature_views = construct_universal_feature_views(data_sources)
+
+ # Remove ttls.
+ feature_views.customer.ttl = timedelta(seconds=0)
+ feature_views.order.ttl = timedelta(seconds=0)
+ feature_views.global_fv.ttl = timedelta(seconds=0)
+ feature_views.field_mapping.ttl = timedelta(seconds=0)
+
+ store.apply([driver(), customer(), location(), *feature_views.values()])
+
+ entity_df = datasets.entity_df.drop(
+ columns=["order_id", "origin_id", "destination_id"]
+ )
+
+ job = store.get_historical_features(
+ entity_df=entity_df,
+ features=[
+ "customer_profile:current_balance",
+ "customer_profile:avg_passenger_count",
+ "customer_profile:lifetime_trip_count",
+ "order:order_is_success",
+ "global_stats:num_rides",
+ "global_stats:avg_ride_length",
+ "field_mapping:feature_name",
+ ],
+ full_feature_names=full_feature_names,
+ )
+
+ event_timestamp = DEFAULT_ENTITY_DF_EVENT_TIMESTAMP_COL
+ expected_df = get_expected_training_df(
+ datasets.customer_df,
+ feature_views.customer,
+ datasets.driver_df,
+ feature_views.driver,
+ datasets.orders_df,
+ feature_views.order,
+ datasets.location_df,
+ feature_views.location,
+ datasets.global_df,
+ feature_views.global_fv,
+ datasets.field_mapping_df,
+ feature_views.field_mapping,
+ entity_df,
+ event_timestamp,
+ full_feature_names,
+ ).drop(
+ columns=[
+ response_feature_name("conv_rate_plus_100", full_feature_names),
+ response_feature_name("conv_rate_plus_100_rounded", full_feature_names),
+ response_feature_name("avg_daily_trips", full_feature_names),
+ response_feature_name("conv_rate", full_feature_names),
+ "origin__temperature",
+ "destination__temperature",
+ ]
+ )
+
+ assert_frame_equal(
+ expected_df,
+ job.to_df(),
+ keys=[event_timestamp, "driver_id", "customer_id"],
+ )
+
+
@pytest.mark.integration
@pytest.mark.universal_offline_stores
def test_historical_features_from_bigquery_sources_containing_backfills(environment):
@@ -781,6 +863,13 @@ def response_feature_name(feature: str, full_feature_names: bool) -> str:
return feature
+def get_feature_view_ttl(
+ feature_view: FeatureView, default_ttl: timedelta
+) -> timedelta:
+ """Returns the ttl of a feature view if it is non-zero. Otherwise returns the specified default."""
+ return feature_view.ttl if feature_view.ttl else default_ttl
+
+
def assert_feature_service_correctness(
store, feature_service, full_feature_names, entity_df, expected_df, event_timestamp
):
| Inconsistent behavior between File and Snowflake offline stores
## Expected Behavior
With equivalent definitions and the same data in each offline store, `get_historical_features` should return the same results regardless of backing store.
## Current Behavior
With the same underlying data, equivalent definitions and given the same entity data frame, File and Snowflake offline stores return different results.
```
$ python clear.py query-file
event_timestamp node
0 2015-10-21 02:00:00 foo
1 2015-10-21 03:00:00 foo
result:
event_timestamp node price temp_f
0 2015-10-21 02:00:00+00:00 foo 6 67
1 2015-10-21 03:00:00+00:00 foo 6 67
$ python clear.py query-snow
event_timestamp node
0 2015-10-21 02:00:00 foo
1 2015-10-21 03:00:00 foo
result:
event_timestamp node price temp_f
0 2015-10-21 02:00:00 foo 5 50
1 2015-10-21 03:00:00 foo 6 67
```
## Steps to reproduce
* feature_store.yaml : https://gist.github.com/cburroughs/17b343445757367044a9ed56917a769a
* features.py : https://gist.github.com/cburroughs/f1825026e0ee19335bd3a34da965eb99
* little cli script : https://gist.github.com/cburroughs/d6b79c31e9b1564e3a06e06e273e8b57
```
# download files; adjust credentials and db names
$ feast apply
$ python clear.py write-dummy-data-snowflake
$ python clear.py query-snow
# Switch which section is commented out in yaml
$ python clear.py write-dummy-data-file
$ python clear.py query-file
```
### Specifications
- Version: Feast SDK Version: "feast 0.22.1"
- Platform x86_64 on Python 3.9.12
- Subsystem: Linux 5.4.188
## Possible Solution
I presume it is incorrect that these are returning different results, but if this is undefined behavior where both are in some sense legitament, which behavior in Feast is undefined should be more explicit in the docs.
| 2022-07-26T21:46:01 |
|
feast-dev/feast | 3,022 | feast-dev__feast-3022 | [
"3000"
]
| 826da67ae263140e34920a25f1f6860deee6ede0 | diff --git a/sdk/python/feast/infra/registry_stores/sql.py b/sdk/python/feast/infra/registry_stores/sql.py
--- a/sdk/python/feast/infra/registry_stores/sql.py
+++ b/sdk/python/feast/infra/registry_stores/sql.py
@@ -2,7 +2,7 @@
from datetime import datetime
from enum import Enum
from pathlib import Path
-from typing import Any, List, Optional, Set, Union
+from typing import Any, Callable, List, Optional, Set, Union
from sqlalchemy import ( # type: ignore
BigInteger,
@@ -560,7 +560,7 @@ def update_infra(self, infra: Infra, project: str, commit: bool = True):
)
def get_infra(self, project: str, allow_cache: bool = False) -> Infra:
- return self._get_object(
+ infra_object = self._get_object(
managed_infra,
"infra_obj",
project,
@@ -570,6 +570,8 @@ def get_infra(self, project: str, allow_cache: bool = False) -> Infra:
"infra_proto",
None,
)
+ infra_object = infra_object or InfraProto()
+ return Infra.from_proto(infra_object)
def apply_user_metadata(
self,
@@ -683,11 +685,18 @@ def commit(self):
pass
def _apply_object(
- self, table, project: str, id_field_name, obj, proto_field_name, name=None
+ self,
+ table: Table,
+ project: str,
+ id_field_name,
+ obj,
+ proto_field_name,
+ name=None,
):
self._maybe_init_project_metadata(project)
- name = name or obj.name
+ name = name or obj.name if hasattr(obj, "name") else None
+ assert name, f"name needs to be provided for {obj}"
with self.engine.connect() as conn:
update_datetime = datetime.utcnow()
update_time = int(update_datetime.timestamp())
@@ -749,7 +758,14 @@ def _maybe_init_project_metadata(self, project):
conn.execute(insert_stmt)
usage.set_current_project_uuid(new_project_uuid)
- def _delete_object(self, table, name, project, id_field_name, not_found_exception):
+ def _delete_object(
+ self,
+ table: Table,
+ name: str,
+ project: str,
+ id_field_name: str,
+ not_found_exception: Optional[Callable],
+ ):
with self.engine.connect() as conn:
stmt = delete(table).where(
getattr(table.c, id_field_name) == name, table.c.project_id == project
@@ -763,14 +779,14 @@ def _delete_object(self, table, name, project, id_field_name, not_found_exceptio
def _get_object(
self,
- table,
- name,
- project,
- proto_class,
- python_class,
- id_field_name,
- proto_field_name,
- not_found_exception,
+ table: Table,
+ name: str,
+ project: str,
+ proto_class: Any,
+ python_class: Any,
+ id_field_name: str,
+ proto_field_name: str,
+ not_found_exception: Optional[Callable],
):
self._maybe_init_project_metadata(project)
@@ -782,10 +798,18 @@ def _get_object(
if row:
_proto = proto_class.FromString(row[proto_field_name])
return python_class.from_proto(_proto)
- raise not_found_exception(name, project)
+ if not_found_exception:
+ raise not_found_exception(name, project)
+ else:
+ return None
def _list_objects(
- self, table, project, proto_class, python_class, proto_field_name
+ self,
+ table: Table,
+ project: str,
+ proto_class: Any,
+ python_class: Any,
+ proto_field_name: str,
):
self._maybe_init_project_metadata(project)
with self.engine.connect() as conn:
| Unable to `feast apply` when using SQL Registry
## Expected Behavior
Using a SQL registry, we should be able to run `feast apply` more than once for a given project, so that feast can identify the diff between the existing registry and project.
## Current Behavior
When using a SQL registry, running `feast apply` for the first time works. However, when running it again, it returns the following error:
```
Traceback (most recent call last):
File "/Users/charleslariviere/.local/share/virtualenvs/data-feature-store-QM-Cj6mZ/bin/feast", line 8, in <module>
sys.exit(cli())
File "/Users/charleslariviere/.local/share/virtualenvs/data-feature-store-QM-Cj6mZ/lib/python3.8/site-packages/click/core.py", line 1137, in __call__
return self.main(*args, **kwargs)
File "/Users/charleslariviere/.local/share/virtualenvs/data-feature-store-QM-Cj6mZ/lib/python3.8/site-packages/click/core.py", line 1062, in main
rv = self.invoke(ctx)
File "/Users/charleslariviere/.local/share/virtualenvs/data-feature-store-QM-Cj6mZ/lib/python3.8/site-packages/click/core.py", line 1668, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "/Users/charleslariviere/.local/share/virtualenvs/data-feature-store-QM-Cj6mZ/lib/python3.8/site-packages/click/core.py", line 1404, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/Users/charleslariviere/.local/share/virtualenvs/data-feature-store-QM-Cj6mZ/lib/python3.8/site-packages/click/core.py", line 763, in invoke
return __callback(*args, **kwargs)
File "/Users/charleslariviere/.local/share/virtualenvs/data-feature-store-QM-Cj6mZ/lib/python3.8/site-packages/click/decorators.py", line 26, in new_func
return f(get_current_context(), *args, **kwargs)
File "/Users/charleslariviere/.local/share/virtualenvs/data-feature-store-QM-Cj6mZ/lib/python3.8/site-packages/feast/cli.py", line 492, in apply_total_command
apply_total(repo_config, repo, skip_source_validation)
File "/Users/charleslariviere/.local/share/virtualenvs/data-feature-store-QM-Cj6mZ/lib/python3.8/site-packages/feast/usage.py", line 274, in wrapper
return func(*args, **kwargs)
File "/Users/charleslariviere/.local/share/virtualenvs/data-feature-store-QM-Cj6mZ/lib/python3.8/site-packages/feast/repo_operations.py", line 305, in apply_total
apply_total_with_repo_instance(
File "/Users/charleslariviere/.local/share/virtualenvs/data-feature-store-QM-Cj6mZ/lib/python3.8/site-packages/feast/repo_operations.py", line 265, in apply_total_with_repo_instance
registry_diff, infra_diff, new_infra = store.plan(repo)
File "/Users/charleslariviere/.local/share/virtualenvs/data-feature-store-QM-Cj6mZ/lib/python3.8/site-packages/feast/usage.py", line 285, in wrapper
raise exc.with_traceback(traceback)
File "/Users/charleslariviere/.local/share/virtualenvs/data-feature-store-QM-Cj6mZ/lib/python3.8/site-packages/feast/usage.py", line 274, in wrapper
return func(*args, **kwargs)
File "/Users/charleslariviere/.local/share/virtualenvs/data-feature-store-QM-Cj6mZ/lib/python3.8/site-packages/feast/feature_store.py", line 708, in plan
current_infra_proto = self._registry.proto().infra.__deepcopy__()
File "/Users/charleslariviere/.local/share/virtualenvs/data-feature-store-QM-Cj6mZ/lib/python3.8/site-packages/feast/infra/registry_stores/sql.py", line 666, in proto
r.infra.CopyFrom(self.get_infra(project).to_proto())
File "/Users/charleslariviere/.local/share/virtualenvs/data-feature-store-QM-Cj6mZ/lib/python3.8/site-packages/feast/infra/registry_stores/sql.py", line 558, in get_infra
return self._get_object(
File "/Users/charleslariviere/.local/share/virtualenvs/data-feature-store-QM-Cj6mZ/lib/python3.8/site-packages/feast/infra/registry_stores/sql.py", line 774, in _get_object
raise not_found_exception(name, project)
TypeError: 'NoneType' object is not callable
```
This error is raised because of what looks like a bug in `SqlRegistry.get_infra()`. Indeed, `SqlRegistry.get_infra()` calls `SqlRegistry._get_object()` but passing `None` for the `not_found_exception` argument.
[feast/infra/registry_stores/sql.py
](https://github.com/feast-dev/feast/blob/31be8e8965444ce52c16542bf3983093514d0abb/sdk/python/feast/infra/registry_stores/sql.py#L562)
```python
...
def get_infra(self, project: str, allow_cache: bool = False) -> Infra:
return self._get_object(
managed_infra,
"infra_obj",
project,
InfraProto,
Infra,
"infra_name",
"infra_proto",
>>>> None, <<<<
)
...
def _get_object(
self,
table,
name,
project,
proto_class,
python_class,
id_field_name,
proto_field_name,
>>> not_found_exception <<<,
):
self._maybe_init_project_metadata(project)
with self.engine.connect() as conn:
stmt = select(table).where(
getattr(table.c, id_field_name) == name, table.c.project_id == project
)
row = conn.execute(stmt).first()
if row:
_proto = proto_class.FromString(row[proto_field_name])
return python_class.from_proto(_proto)
>>> raise not_found_exception(name, project) <<<
```
Since no rows are returned for the `managed_infra` table, `_get_object` attempts to raise an error with the `not_found_exception` callable provided, but since `None` was provided, it is unable to raise the error correctly.
This seems to be hiding the actual error, which is that no rows are returned from the `managed_infra` table, which I can confirm is indeed empty in the SQL backend. I've provided my `feature_store.yaml` configuration below -- is the expectation that something should be created in the `managed_infra` table?
## Steps to reproduce
`feature_store.yaml`
```yaml
project: feature_store
provider: local
registry:
registry_type: sql
path: postgresql://${POSTGRES_USER}:${POSTGRES_PASSWORD}@${POSTGRES_HOST}:${POSTGRES_PORT}/${POSTGRES_DATABASE}
offline_store:
type: snowflake.offline
account: ${SNOWFLAKE_ACCOUNT}
user: ${SNOWFLAKE_USER}
password: ${SNOWFLAKE_PASSWORD}
role: ${SNOWFLAKE_ROLE}
warehouse: ${SNOWFLAKE_WAREHOUSE}
database: ${SNOWFLAKE_DATABASE}
schema: ${SNOWFLAKE_SCHEMA}
online_store:
type: redis
redis_type: redis
connection_string: "${REDIS_HOST}:${REDIS_PORT},password=${REDIS_PASSWORD}"
```
Run the following commands:
```
feast apply # works
feast apply # raises the error above
```
### Specifications
- Version: 0.22.1
- Platform: macOS
- Subsystem: 12.4
## Possible Solution
| 2022-08-05T20:36:08 |
||
feast-dev/feast | 3,036 | feast-dev__feast-3036 | [
"2991"
]
| 0ed1a635750cb5c350eede343a5592a3a6c1ff50 | diff --git a/sdk/python/feast/cli.py b/sdk/python/feast/cli.py
--- a/sdk/python/feast/cli.py
+++ b/sdk/python/feast/cli.py
@@ -13,7 +13,6 @@
# limitations under the License.
import json
import logging
-import warnings
from datetime import datetime
from pathlib import Path
from typing import List, Optional
@@ -45,7 +44,6 @@
from feast.utils import maybe_local_tz
_logger = logging.getLogger(__name__)
-warnings.filterwarnings("ignore", category=DeprecationWarning, module="(?!feast)")
class NoOptionDefaultFormat(click.Command):
@@ -197,11 +195,6 @@ def data_source_describe(ctx: click.Context, name: str):
print(e)
exit(1)
- warnings.warn(
- "Describing data sources will only work properly if all data sources have names or table names specified. "
- "Starting Feast 0.24, data source unique names will be required to encourage data source discovery.",
- RuntimeWarning,
- )
print(
yaml.dump(
yaml.safe_load(str(data_source)), default_flow_style=False, sort_keys=False
@@ -224,11 +217,6 @@ def data_source_list(ctx: click.Context):
from tabulate import tabulate
- warnings.warn(
- "Listing data sources will only work properly if all data sources have names or table names specified. "
- "Starting Feast 0.24, data source unique names will be required to encourage data source discovery",
- RuntimeWarning,
- )
print(tabulate(table, headers=["NAME", "CLASS"], tablefmt="plain"))
diff --git a/sdk/python/feast/feature_store.py b/sdk/python/feast/feature_store.py
--- a/sdk/python/feast/feature_store.py
+++ b/sdk/python/feast/feature_store.py
@@ -43,7 +43,13 @@
from feast import feature_server, flags_helper, ui_server, utils
from feast.base_feature_view import BaseFeatureView
from feast.batch_feature_view import BatchFeatureView
-from feast.data_source import DataSource, PushMode
+from feast.data_source import (
+ DataSource,
+ KafkaSource,
+ KinesisSource,
+ PushMode,
+ PushSource,
+)
from feast.diff.infra_diff import InfraDiff, diff_infra_protos
from feast.diff.registry_diff import RegistryDiff, apply_diff_to_registry, diff_between
from feast.dqm.errors import ValidationFailed
@@ -827,6 +833,18 @@ def apply(
ob for ob in objects if isinstance(ob, ValidationReference)
]
+ batch_sources_to_add: List[DataSource] = []
+ for data_source in data_sources_set_to_update:
+ if (
+ isinstance(data_source, PushSource)
+ or isinstance(data_source, KafkaSource)
+ or isinstance(data_source, KinesisSource)
+ ):
+ assert data_source.batch_source
+ batch_sources_to_add.append(data_source.batch_source)
+ for batch_source in batch_sources_to_add:
+ data_sources_set_to_update.add(batch_source)
+
for fv in itertools.chain(views_to_update, sfvs_to_update):
data_sources_set_to_update.add(fv.batch_source)
if fv.stream_source:
diff --git a/sdk/python/feast/repo_operations.py b/sdk/python/feast/repo_operations.py
--- a/sdk/python/feast/repo_operations.py
+++ b/sdk/python/feast/repo_operations.py
@@ -14,7 +14,7 @@
from feast import PushSource
from feast.batch_feature_view import BatchFeatureView
-from feast.data_source import DataSource, KafkaSource
+from feast.data_source import DataSource, KafkaSource, KinesisSource
from feast.diff.registry_diff import extract_objects_for_keep_delete_update_add
from feast.entity import Entity
from feast.feature_service import FeatureService
@@ -114,17 +114,30 @@ def parse_repo(repo_root: Path) -> RepoContents:
request_feature_views=[],
)
- data_sources_set = set()
for repo_file in get_repo_files(repo_root):
module_path = py_path_to_module(repo_file)
module = importlib.import_module(module_path)
+
for attr_name in dir(module):
obj = getattr(module, attr_name)
+
if isinstance(obj, DataSource) and not any(
(obj is ds) for ds in res.data_sources
):
res.data_sources.append(obj)
- data_sources_set.add(obj)
+
+ # Handle batch sources defined within stream sources.
+ if (
+ isinstance(obj, PushSource)
+ or isinstance(obj, KafkaSource)
+ or isinstance(obj, KinesisSource)
+ ):
+ batch_source = obj.batch_source
+
+ if batch_source and not any(
+ (batch_source is ds) for ds in res.data_sources
+ ):
+ res.data_sources.append(batch_source)
if (
isinstance(obj, FeatureView)
and not any((obj is fv) for fv in res.feature_views)
@@ -132,26 +145,33 @@ def parse_repo(repo_root: Path) -> RepoContents:
and not isinstance(obj, BatchFeatureView)
):
res.feature_views.append(obj)
- if isinstance(obj.stream_source, PushSource) and not any(
- (obj is ds) for ds in res.data_sources
- ):
- push_source_dep = obj.stream_source.batch_source
- # Don't add if the push source's batch source is a duplicate of an existing batch source
- if push_source_dep not in data_sources_set:
- res.data_sources.append(push_source_dep)
+
+ # Handle batch sources defined with feature views.
+ batch_source = obj.batch_source
+ assert batch_source
+ if not any((batch_source is ds) for ds in res.data_sources):
+ res.data_sources.append(batch_source)
+
+ # Handle stream sources defined with feature views.
+ if obj.stream_source:
+ stream_source = obj.stream_source
+ if not any((stream_source is ds) for ds in res.data_sources):
+ res.data_sources.append(stream_source)
elif isinstance(obj, StreamFeatureView) and not any(
(obj is sfv) for sfv in res.stream_feature_views
):
res.stream_feature_views.append(obj)
- if (
- isinstance(obj.stream_source, PushSource)
- or isinstance(obj.stream_source, KafkaSource)
- and not any((obj is ds) for ds in res.data_sources)
- ):
- batch_source_dep = obj.stream_source.batch_source
- # Don't add if the push source's batch source is a duplicate of an existing batch source
- if batch_source_dep and batch_source_dep not in data_sources_set:
- res.data_sources.append(batch_source_dep)
+
+ # Handle batch sources defined with feature views.
+ batch_source = obj.batch_source
+ if not any((batch_source is ds) for ds in res.data_sources):
+ res.data_sources.append(batch_source)
+
+ # Handle stream sources defined with feature views.
+ stream_source = obj.stream_source
+ assert stream_source
+ if not any((stream_source is ds) for ds in res.data_sources):
+ res.data_sources.append(stream_source)
elif isinstance(obj, Entity) and not any(
(obj is entity) for entity in res.entities
):
@@ -168,6 +188,7 @@ def parse_repo(repo_root: Path) -> RepoContents:
(obj is rfv) for rfv in res.request_feature_views
):
res.request_feature_views.append(obj)
+
res.entities.append(DUMMY_ENTITY)
return res
@@ -300,7 +321,6 @@ def log_infra_changes(
@log_exceptions_and_usage
def apply_total(repo_config: RepoConfig, repo_path: Path, skip_source_validation: bool):
-
os.chdir(repo_path)
project, registry, repo, store = _prepare_registry_and_repo(repo_config, repo_path)
apply_total_with_repo_instance(
| diff --git a/sdk/python/tests/example_repos/example_feature_repo_with_inline_batch_source.py b/sdk/python/tests/example_repos/example_feature_repo_with_inline_batch_source.py
new file mode 100644
--- /dev/null
+++ b/sdk/python/tests/example_repos/example_feature_repo_with_inline_batch_source.py
@@ -0,0 +1,28 @@
+from datetime import timedelta
+
+from feast import Entity, FeatureView, Field, FileSource
+from feast.types import Float32, Int32, Int64
+
+driver = Entity(
+ name="driver_id",
+ description="driver id",
+)
+
+driver_hourly_stats_view = FeatureView(
+ name="driver_hourly_stats",
+ entities=[driver],
+ ttl=timedelta(days=1),
+ schema=[
+ Field(name="conv_rate", dtype=Float32),
+ Field(name="acc_rate", dtype=Float32),
+ Field(name="avg_daily_trips", dtype=Int64),
+ Field(name="driver_id", dtype=Int32),
+ ],
+ online=True,
+ source=FileSource(
+ path="data/driver_stats.parquet", # Fake path
+ timestamp_field="event_timestamp",
+ created_timestamp_column="created",
+ ),
+ tags={},
+)
diff --git a/sdk/python/tests/example_repos/example_feature_repo_with_inline_stream_source.py b/sdk/python/tests/example_repos/example_feature_repo_with_inline_stream_source.py
new file mode 100644
--- /dev/null
+++ b/sdk/python/tests/example_repos/example_feature_repo_with_inline_stream_source.py
@@ -0,0 +1,37 @@
+from datetime import timedelta
+
+from feast import Entity, FeatureView, Field, FileSource, KafkaSource
+from feast.data_format import AvroFormat
+from feast.types import Float32, Int32, Int64
+
+driver = Entity(
+ name="driver_id",
+ description="driver id",
+)
+
+driver_hourly_stats_view = FeatureView(
+ name="driver_hourly_stats",
+ entities=[driver],
+ ttl=timedelta(days=1),
+ schema=[
+ Field(name="conv_rate", dtype=Float32),
+ Field(name="acc_rate", dtype=Float32),
+ Field(name="avg_daily_trips", dtype=Int64),
+ Field(name="driver_id", dtype=Int32),
+ ],
+ online=True,
+ source=KafkaSource(
+ name="kafka",
+ timestamp_field="event_timestamp",
+ kafka_bootstrap_servers="",
+ message_format=AvroFormat(""),
+ topic="topic",
+ batch_source=FileSource(
+ path="data/driver_stats.parquet", # Fake path
+ timestamp_field="event_timestamp",
+ created_timestamp_column="created",
+ ),
+ watermark_delay_threshold=timedelta(days=1),
+ ),
+ tags={},
+)
diff --git a/sdk/python/tests/example_repos/example_feature_repo_with_stream_source.py b/sdk/python/tests/example_repos/example_feature_repo_with_stream_source.py
new file mode 100644
--- /dev/null
+++ b/sdk/python/tests/example_repos/example_feature_repo_with_stream_source.py
@@ -0,0 +1,18 @@
+from datetime import timedelta
+
+from feast import FileSource, KafkaSource
+from feast.data_format import AvroFormat
+
+stream_source = KafkaSource(
+ name="kafka",
+ timestamp_field="event_timestamp",
+ kafka_bootstrap_servers="",
+ message_format=AvroFormat(""),
+ topic="topic",
+ batch_source=FileSource(
+ path="data/driver_stats.parquet", # Fake path
+ timestamp_field="event_timestamp",
+ created_timestamp_column="created",
+ ),
+ watermark_delay_threshold=timedelta(days=1),
+)
diff --git a/sdk/python/tests/unit/local_feast_tests/test_local_feature_store.py b/sdk/python/tests/unit/local_feast_tests/test_local_feature_store.py
--- a/sdk/python/tests/unit/local_feast_tests/test_local_feature_store.py
+++ b/sdk/python/tests/unit/local_feast_tests/test_local_feature_store.py
@@ -4,15 +4,19 @@
import pytest
from pytest_lazyfixture import lazy_fixture
-from feast import FileSource
-from feast.data_format import ParquetFormat
+from feast.aggregation import Aggregation
+from feast.data_format import AvroFormat, ParquetFormat
+from feast.data_source import KafkaSource
from feast.entity import Entity
from feast.feature_store import FeatureStore
from feast.feature_view import FeatureView
from feast.field import Field
+from feast.infra.offline_stores.file_source import FileSource
from feast.infra.online_stores.sqlite import SqliteOnlineStoreConfig
from feast.repo_config import RepoConfig
-from feast.types import Array, Bytes, Int64, String
+from feast.stream_feature_view import stream_feature_view
+from feast.types import Array, Bytes, Float32, Int64, String
+from tests.utils.cli_repo_creator import CliRunner, get_example_repo
from tests.utils.data_source_test_creator import prep_file_source
@@ -20,7 +24,7 @@
"test_feature_store",
[lazy_fixture("feature_store_with_local_registry")],
)
-def test_apply_entity_success(test_feature_store):
+def test_apply_entity(test_feature_store):
entity = Entity(
name="driver_car_id",
description="Car driver id",
@@ -48,7 +52,7 @@ def test_apply_entity_success(test_feature_store):
"test_feature_store",
[lazy_fixture("feature_store_with_local_registry")],
)
-def test_apply_feature_view_success(test_feature_store):
+def test_apply_feature_view(test_feature_store):
# Create Feature Views
batch_source = FileSource(
file_format=ParquetFormat(),
@@ -101,7 +105,97 @@ def test_apply_feature_view_success(test_feature_store):
"test_feature_store",
[lazy_fixture("feature_store_with_local_registry")],
)
-def test_apply_object_and_read(test_feature_store):
+def test_apply_feature_view_with_inline_batch_source(
+ test_feature_store, simple_dataset_1
+) -> None:
+ """Test that a feature view and an inline batch source are both correctly applied."""
+ with prep_file_source(df=simple_dataset_1, timestamp_field="ts_1") as file_source:
+ entity = Entity(name="driver_entity", join_keys=["test_key"])
+ driver_fv = FeatureView(
+ name="driver_fv",
+ entities=[entity],
+ source=file_source,
+ )
+
+ test_feature_store.apply([entity, driver_fv])
+
+ fvs = test_feature_store.list_feature_views()
+ assert len(fvs) == 1
+ assert fvs[0] == driver_fv
+
+ ds = test_feature_store.list_data_sources()
+ assert len(ds) == 1
+ assert ds[0] == file_source
+
+
+def test_apply_feature_view_with_inline_batch_source_from_repo() -> None:
+ """Test that a feature view and an inline batch source are both correctly applied."""
+ runner = CliRunner()
+ with runner.local_repo(
+ get_example_repo("example_feature_repo_with_inline_batch_source.py"), "file"
+ ) as store:
+ ds = store.list_data_sources()
+ assert len(ds) == 1
+
+
[email protected](
+ "test_feature_store",
+ [lazy_fixture("feature_store_with_local_registry")],
+)
+def test_apply_feature_view_with_inline_stream_source(
+ test_feature_store, simple_dataset_1
+) -> None:
+ """Test that a feature view and an inline stream source are both correctly applied."""
+ with prep_file_source(df=simple_dataset_1, timestamp_field="ts_1") as file_source:
+ entity = Entity(name="driver_entity", join_keys=["test_key"])
+
+ stream_source = KafkaSource(
+ name="kafka",
+ timestamp_field="event_timestamp",
+ kafka_bootstrap_servers="",
+ message_format=AvroFormat(""),
+ topic="topic",
+ batch_source=file_source,
+ watermark_delay_threshold=timedelta(days=1),
+ )
+
+ driver_fv = FeatureView(
+ name="driver_fv",
+ entities=[entity],
+ source=stream_source,
+ )
+
+ test_feature_store.apply([entity, driver_fv])
+
+ fvs = test_feature_store.list_feature_views()
+ assert len(fvs) == 1
+ assert fvs[0] == driver_fv
+
+ ds = test_feature_store.list_data_sources()
+ assert len(ds) == 2
+ if isinstance(ds[0], FileSource):
+ assert ds[0] == file_source
+ assert ds[1] == stream_source
+ else:
+ assert ds[0] == stream_source
+ assert ds[1] == file_source
+
+
+def test_apply_feature_view_with_inline_stream_source_from_repo() -> None:
+ """Test that a feature view and an inline stream source are both correctly applied."""
+ runner = CliRunner()
+ with runner.local_repo(
+ get_example_repo("example_feature_repo_with_inline_stream_source.py"), "file"
+ ) as store:
+ ds = store.list_data_sources()
+ assert len(ds) == 2
+
+
[email protected](
+ "test_feature_store",
+ [lazy_fixture("feature_store_with_local_registry")],
+)
+def test_apply_entities_and_feature_views(test_feature_store):
assert isinstance(test_feature_store, FeatureStore)
# Create Feature Views
batch_source = FileSource(
@@ -163,9 +257,8 @@ def test_apply_object_and_read(test_feature_store):
[lazy_fixture("feature_store_with_local_registry")],
)
@pytest.mark.parametrize("dataframe_source", [lazy_fixture("simple_dataset_1")])
-def test_reapply_feature_view_success(test_feature_store, dataframe_source):
+def test_reapply_feature_view(test_feature_store, dataframe_source):
with prep_file_source(df=dataframe_source, timestamp_field="ts_1") as file_source:
-
e = Entity(name="id", join_keys=["id_join_key"])
# Create Feature View
@@ -215,7 +308,7 @@ def test_reapply_feature_view_success(test_feature_store, dataframe_source):
test_feature_store.teardown()
-def test_apply_conflicting_featureview_names(feature_store_with_local_registry):
+def test_apply_conflicting_feature_view_names(feature_store_with_local_registry):
"""Test applying feature views with non-case-insensitively unique names"""
driver = Entity(name="driver", join_keys=["driver_id"])
customer = Entity(name="customer", join_keys=["customer_id"])
@@ -251,6 +344,191 @@ def test_apply_conflicting_featureview_names(feature_store_with_local_registry):
feature_store_with_local_registry.teardown()
[email protected](
+ "test_feature_store",
+ [lazy_fixture("feature_store_with_local_registry")],
+)
+def test_apply_stream_feature_view(test_feature_store, simple_dataset_1) -> None:
+ """Test that a stream feature view is correctly applied."""
+ with prep_file_source(df=simple_dataset_1, timestamp_field="ts_1") as file_source:
+ entity = Entity(name="driver_entity", join_keys=["test_key"])
+
+ stream_source = KafkaSource(
+ name="kafka",
+ timestamp_field="event_timestamp",
+ kafka_bootstrap_servers="",
+ message_format=AvroFormat(""),
+ topic="topic",
+ batch_source=file_source,
+ watermark_delay_threshold=timedelta(days=1),
+ )
+
+ @stream_feature_view(
+ entities=[entity],
+ ttl=timedelta(days=30),
+ owner="[email protected]",
+ online=True,
+ schema=[Field(name="dummy_field", dtype=Float32)],
+ description="desc",
+ aggregations=[
+ Aggregation(
+ column="dummy_field",
+ function="max",
+ time_window=timedelta(days=1),
+ ),
+ Aggregation(
+ column="dummy_field2",
+ function="count",
+ time_window=timedelta(days=24),
+ ),
+ ],
+ timestamp_field="event_timestamp",
+ mode="spark",
+ source=stream_source,
+ tags={},
+ )
+ def simple_sfv(df):
+ return df
+
+ test_feature_store.apply([entity, simple_sfv])
+
+ stream_feature_views = test_feature_store.list_stream_feature_views()
+ assert len(stream_feature_views) == 1
+ assert stream_feature_views[0] == simple_sfv
+
+ features = test_feature_store.get_online_features(
+ features=["simple_sfv:dummy_field"],
+ entity_rows=[{"test_key": 1001}],
+ ).to_dict(include_event_timestamps=True)
+
+ assert "test_key" in features
+ assert features["test_key"] == [1001]
+ assert "dummy_field" in features
+ assert features["dummy_field"] == [None]
+
+
[email protected](
+ "test_feature_store",
+ [lazy_fixture("feature_store_with_local_registry")],
+)
+def test_apply_stream_feature_view_udf(test_feature_store, simple_dataset_1) -> None:
+ """Test that a stream feature view with a udf is correctly applied."""
+ with prep_file_source(df=simple_dataset_1, timestamp_field="ts_1") as file_source:
+ entity = Entity(name="driver_entity", join_keys=["test_key"])
+
+ stream_source = KafkaSource(
+ name="kafka",
+ timestamp_field="event_timestamp",
+ kafka_bootstrap_servers="",
+ message_format=AvroFormat(""),
+ topic="topic",
+ batch_source=file_source,
+ watermark_delay_threshold=timedelta(days=1),
+ )
+
+ @stream_feature_view(
+ entities=[entity],
+ ttl=timedelta(days=30),
+ owner="[email protected]",
+ online=True,
+ schema=[Field(name="dummy_field", dtype=Float32)],
+ description="desc",
+ aggregations=[
+ Aggregation(
+ column="dummy_field",
+ function="max",
+ time_window=timedelta(days=1),
+ ),
+ Aggregation(
+ column="dummy_field2",
+ function="count",
+ time_window=timedelta(days=24),
+ ),
+ ],
+ timestamp_field="event_timestamp",
+ mode="spark",
+ source=stream_source,
+ tags={},
+ )
+ def pandas_view(pandas_df):
+ import pandas as pd
+
+ assert type(pandas_df) == pd.DataFrame
+ df = pandas_df.transform(lambda x: x + 10, axis=1)
+ df.insert(2, "C", [20.2, 230.0, 34.0], True)
+ return df
+
+ import pandas as pd
+
+ test_feature_store.apply([entity, pandas_view])
+
+ stream_feature_views = test_feature_store.list_stream_feature_views()
+ assert len(stream_feature_views) == 1
+ assert stream_feature_views[0] == pandas_view
+
+ sfv = stream_feature_views[0]
+
+ df = pd.DataFrame({"A": [1, 2, 3], "B": [10, 20, 30]})
+ new_df = sfv.udf(df)
+ expected_df = pd.DataFrame(
+ {"A": [11, 12, 13], "B": [20, 30, 40], "C": [20.2, 230.0, 34.0]}
+ )
+ assert new_df.equals(expected_df)
+
+
[email protected](
+ "test_feature_store",
+ [lazy_fixture("feature_store_with_local_registry")],
+)
+def test_apply_batch_source(test_feature_store, simple_dataset_1) -> None:
+ """Test that a batch source is applied correctly."""
+ with prep_file_source(df=simple_dataset_1, timestamp_field="ts_1") as file_source:
+ test_feature_store.apply([file_source])
+
+ ds = test_feature_store.list_data_sources()
+ assert len(ds) == 1
+ assert ds[0] == file_source
+
+
[email protected](
+ "test_feature_store",
+ [lazy_fixture("feature_store_with_local_registry")],
+)
+def test_apply_stream_source(test_feature_store, simple_dataset_1) -> None:
+ """Test that a stream source is applied correctly."""
+ with prep_file_source(df=simple_dataset_1, timestamp_field="ts_1") as file_source:
+ stream_source = KafkaSource(
+ name="kafka",
+ timestamp_field="event_timestamp",
+ kafka_bootstrap_servers="",
+ message_format=AvroFormat(""),
+ topic="topic",
+ batch_source=file_source,
+ watermark_delay_threshold=timedelta(days=1),
+ )
+
+ test_feature_store.apply([stream_source])
+
+ ds = test_feature_store.list_data_sources()
+ assert len(ds) == 2
+ if isinstance(ds[0], FileSource):
+ assert ds[0] == file_source
+ assert ds[1] == stream_source
+ else:
+ assert ds[0] == stream_source
+ assert ds[1] == file_source
+
+
+def test_apply_stream_source_from_repo() -> None:
+ """Test that a stream source is applied correctly."""
+ runner = CliRunner()
+ with runner.local_repo(
+ get_example_repo("example_feature_repo_with_stream_source.py"), "file"
+ ) as store:
+ ds = store.list_data_sources()
+ assert len(ds) == 2
+
+
@pytest.fixture
def feature_store_with_local_registry():
fd, registry_path = mkstemp()
diff --git a/sdk/python/tests/unit/local_feast_tests/test_stream_feature_view_apply.py b/sdk/python/tests/unit/local_feast_tests/test_stream_feature_view_apply.py
deleted file mode 100644
--- a/sdk/python/tests/unit/local_feast_tests/test_stream_feature_view_apply.py
+++ /dev/null
@@ -1,149 +0,0 @@
-from datetime import timedelta
-
-from feast.aggregation import Aggregation
-from feast.data_format import AvroFormat
-from feast.data_source import KafkaSource
-from feast.entity import Entity
-from feast.field import Field
-from feast.stream_feature_view import stream_feature_view
-from feast.types import Float32
-from tests.utils.cli_repo_creator import CliRunner, get_example_repo
-from tests.utils.data_source_test_creator import prep_file_source
-
-
-def test_apply_stream_feature_view(simple_dataset_1) -> None:
- """
- Test apply of StreamFeatureView.
- """
- runner = CliRunner()
- with runner.local_repo(
- get_example_repo("empty_feature_repo.py"), "file"
- ) as fs, prep_file_source(
- df=simple_dataset_1, timestamp_field="ts_1"
- ) as file_source:
- entity = Entity(name="driver_entity", join_keys=["test_key"])
-
- stream_source = KafkaSource(
- name="kafka",
- timestamp_field="event_timestamp",
- kafka_bootstrap_servers="",
- message_format=AvroFormat(""),
- topic="topic",
- batch_source=file_source,
- watermark_delay_threshold=timedelta(days=1),
- )
-
- @stream_feature_view(
- entities=[entity],
- ttl=timedelta(days=30),
- owner="[email protected]",
- online=True,
- schema=[Field(name="dummy_field", dtype=Float32)],
- description="desc",
- aggregations=[
- Aggregation(
- column="dummy_field",
- function="max",
- time_window=timedelta(days=1),
- ),
- Aggregation(
- column="dummy_field2",
- function="count",
- time_window=timedelta(days=24),
- ),
- ],
- timestamp_field="event_timestamp",
- mode="spark",
- source=stream_source,
- tags={},
- )
- def simple_sfv(df):
- return df
-
- fs.apply([entity, simple_sfv])
-
- stream_feature_views = fs.list_stream_feature_views()
- assert len(stream_feature_views) == 1
- assert stream_feature_views[0] == simple_sfv
-
- features = fs.get_online_features(
- features=["simple_sfv:dummy_field"],
- entity_rows=[{"test_key": 1001}],
- ).to_dict(include_event_timestamps=True)
-
- assert "test_key" in features
- assert features["test_key"] == [1001]
- assert "dummy_field" in features
- assert features["dummy_field"] == [None]
-
-
-def test_stream_feature_view_udf(simple_dataset_1) -> None:
- """
- Test apply of StreamFeatureView udfs are serialized correctly and usable.
- """
- runner = CliRunner()
- with runner.local_repo(
- get_example_repo("empty_feature_repo.py"), "file"
- ) as fs, prep_file_source(
- df=simple_dataset_1, timestamp_field="ts_1"
- ) as file_source:
- entity = Entity(name="driver_entity", join_keys=["test_key"])
-
- stream_source = KafkaSource(
- name="kafka",
- timestamp_field="event_timestamp",
- kafka_bootstrap_servers="",
- message_format=AvroFormat(""),
- topic="topic",
- batch_source=file_source,
- watermark_delay_threshold=timedelta(days=1),
- )
-
- @stream_feature_view(
- entities=[entity],
- ttl=timedelta(days=30),
- owner="[email protected]",
- online=True,
- schema=[Field(name="dummy_field", dtype=Float32)],
- description="desc",
- aggregations=[
- Aggregation(
- column="dummy_field",
- function="max",
- time_window=timedelta(days=1),
- ),
- Aggregation(
- column="dummy_field2",
- function="count",
- time_window=timedelta(days=24),
- ),
- ],
- timestamp_field="event_timestamp",
- mode="spark",
- source=stream_source,
- tags={},
- )
- def pandas_view(pandas_df):
- import pandas as pd
-
- assert type(pandas_df) == pd.DataFrame
- df = pandas_df.transform(lambda x: x + 10, axis=1)
- df.insert(2, "C", [20.2, 230.0, 34.0], True)
- return df
-
- import pandas as pd
-
- fs.apply([entity, pandas_view])
-
- stream_feature_views = fs.list_stream_feature_views()
- assert len(stream_feature_views) == 1
- assert stream_feature_views[0] == pandas_view
-
- sfv = stream_feature_views[0]
-
- df = pd.DataFrame({"A": [1, 2, 3], "B": [10, 20, 30]})
- new_df = sfv.udf(df)
- expected_df = pd.DataFrame(
- {"A": [11, 12, 13], "B": [20, 30, 40], "C": [20.2, 230.0, 34.0]}
- )
- assert new_df.equals(expected_df)
diff --git a/sdk/python/tests/utils/cli_repo_creator.py b/sdk/python/tests/utils/cli_repo_creator.py
--- a/sdk/python/tests/utils/cli_repo_creator.py
+++ b/sdk/python/tests/utils/cli_repo_creator.py
@@ -60,7 +60,6 @@ def local_repo(self, example_repo_py: str, offline_store: str):
)
with tempfile.TemporaryDirectory() as repo_dir_name, tempfile.TemporaryDirectory() as data_dir_name:
-
repo_path = Path(repo_dir_name)
data_path = Path(data_dir_name)
@@ -85,11 +84,17 @@ def local_repo(self, example_repo_py: str, offline_store: str):
repo_example.write_text(example_repo_py)
result = self.run(["apply"], cwd=repo_path)
- print(f"Apply: stdout: {str(result.stdout)}\n stderr: {str(result.stderr)}")
+ stdout = result.stdout.decode("utf-8")
+ stderr = result.stderr.decode("utf-8")
+ print(f"Apply stdout:\n{stdout}")
+ print(f"Apply stderr:\n{stderr}")
assert result.returncode == 0
yield FeatureStore(repo_path=str(repo_path), config=None)
result = self.run(["teardown"], cwd=repo_path)
- print(f"Apply: stdout: {str(result.stdout)}\n stderr: {str(result.stderr)}")
+ stdout = result.stdout.decode("utf-8")
+ stderr = result.stderr.decode("utf-8")
+ print(f"Apply stdout:\n{stdout}")
+ print(f"Apply stderr:\n{stderr}")
assert result.returncode == 0
| data sources displayed different depending on "inline" definition
## Expected Behavior
Many of the docs define data sources "inline" from the feature view. For example <https://docs.feast.dev/getting-started/concepts/feature-view>
```
driver_stats_fv = FeatureView(
#...
source=BigQuerySource(
table="feast-oss.demo_data.driver_activity"
)
)
```
I would expect the above example to work the same with the `BigQuerySource` defined as is, or if it did `foo = BigQuerySource()` and `foo` was passed in.
## Current Behavior
```
node = feast.Entity(name='node', join_keys=['node'])
node_temp_file_fv = feast.FeatureView(
name='node_temperature_fv',
entities=[node],
schema=[
feast.Field(name='node', dtype=feast.types.String),
feast.Field(name='temp_f', dtype=feast.types.Int64),
],
online=False,
source=feast.FileSource(
name='temperature_source',
path='./data/temperature_source.parquet',
timestamp_field='timestamp',
)
)
```
```
$ feast apply
Created entity node
Created feature view node_temperature_fv
Created sqlite table demo_node_temperature_fv
```
```
$ feast data-sources list
NAME CLASS
```
Change the above definition:
```
node_temperature_file_source = feast.FileSource(
name='temperature_source',
path='./data/temperature_source.parquet',
timestamp_field='timestamp',
)
node_temp_file_fv = feast.FeatureView(
name='node_temperature_fv',
entities=[node],
schema=[
feast.Field(name='node', dtype=feast.types.String),
feast.Field(name='temp_f', dtype=feast.types.Int64),
],
online=False,
source=node_temperature_file_source
)
```
```
$ feast apply
No changes to registry
No changes to infrastructure
```
But despite "no changes" being made, the source is now listed:
```
$ feast data-sources list
NAME CLASS
temperature_source <class 'feast.infra.offline_stores.file_source.FileSource'>
```
### Specifications
- Version: Feast SDK Version: "feast 0.22.2"
- Platform: x86_64 on Python 3.9.12
- Subsystem: Linux 5.4.188
| 2022-08-08T21:49:27 |
|
feast-dev/feast | 3,046 | feast-dev__feast-3046 | [
"3045"
]
| 72cec32e20222f48925c6474d1078ca2a6875142 | diff --git a/sdk/python/feast/infra/offline_stores/snowflake.py b/sdk/python/feast/infra/offline_stores/snowflake.py
--- a/sdk/python/feast/infra/offline_stores/snowflake.py
+++ b/sdk/python/feast/infra/offline_stores/snowflake.py
@@ -429,7 +429,7 @@ def _to_arrow_internal(self) -> pa.Table:
def to_snowflake(self, table_name: str, temporary=False) -> None:
"""Save dataset as a new Snowflake table"""
- if self.on_demand_feature_views is not None:
+ if self.on_demand_feature_views:
transformed_df = self.to_df()
write_pandas(
| Wrong condition in to_snowflake method of snowflake provider
## Expected Behavior
[to_snowflake](https://github.com/feast-dev/feast/blob/master/sdk/python/feast/infra/offline_stores/snowflake.py#L430) should ignore on_demand_feature_views if on_demand_feature_views is an empty list
## Current Behavior
to_snowflake runs on_demand_feature_views code because on_demand_feature_views is set to [] [here](https://github.com/feast-dev/feast/blob/master/sdk/python/feast/infra/offline_stores/snowflake.py#L387)
## Steps to reproduce
### Specifications
- Version: 0.23.0
- Platform: feast SDK
- Subsystem:
## Possible Solution
`if self.on_demand_feature_views is not None: ` => `if self.on_demand_feature_views is not []: `
| 2022-08-09T14:45:17 |
||
feast-dev/feast | 3,083 | feast-dev__feast-3083 | [
"2793"
]
| 66d2c7636e03da0f53025fc96d7b9cd2b3ec33bc | diff --git a/sdk/python/feast/infra/utils/snowflake_utils.py b/sdk/python/feast/infra/utils/snowflake_utils.py
--- a/sdk/python/feast/infra/utils/snowflake_utils.py
+++ b/sdk/python/feast/infra/utils/snowflake_utils.py
@@ -88,6 +88,8 @@ def get_snowflake_conn(config, autocommit=True) -> SnowflakeConnection:
**kwargs,
)
+ conn.cursor().execute("ALTER SESSION SET TIMEZONE = 'UTC'", _is_internal=True)
+
return conn
except KeyError as e:
raise SnowflakeIncompleteConfig(e)
| Missing key error in snowflake_python_type_to_feast_value_type in type_map for numpy datetime64 with timezone
## Expected Behavior
Feast should be able to handle different source column data types when updating feature views with inferred features. Specifically all possible `datetime64` python data types with specific timezones should be handled.
## Current Behavior
Snowflake python type `datetime64[ns, america/los_angeles]` does not have a corresponding feast ValueType. There's a ValueType for datetime64[ns] but not a numpy datetime64 with a specific timezone
```
File "/opt/homebrew/anaconda3/envs/feast-python37/lib/python3.7/site-packages/feast/type_map.py", line 536, in snowflake_python_type_to_feast_value_type
return type_map[snowflake_python_type_as_str.lower()]
KeyError: 'datetime64[ns, america/los_angeles]'
```
## Steps to reproduce
### Specifications
- Version: 0.21.3
- Platform: Mac OSX Monterey 12.4
- Subsystem:
## Possible Solution
| Hi @tlam-lyra could you add a pr for a fix to support these types?
@tlam-lyra @kevjumba taking a look.
@tlam-lyra can you tell me what the snowflake datatype is? TIMESTAMP_TZ? | 2022-08-15T02:52:53 |
|
feast-dev/feast | 3,092 | feast-dev__feast-3092 | [
"3082"
]
| 9f221e66eb2dd83b0e6beb528a694f4933953571 | diff --git a/sdk/python/feast/repo_operations.py b/sdk/python/feast/repo_operations.py
--- a/sdk/python/feast/repo_operations.py
+++ b/sdk/python/feast/repo_operations.py
@@ -172,6 +172,15 @@ def parse_repo(repo_root: Path) -> RepoContents:
assert stream_source
if not any((stream_source is ds) for ds in res.data_sources):
res.data_sources.append(stream_source)
+ elif isinstance(obj, BatchFeatureView) and not any(
+ (obj is bfv) for bfv in res.feature_views
+ ):
+ res.feature_views.append(obj)
+
+ # Handle batch sources defined with feature views.
+ batch_source = obj.batch_source
+ if not any((batch_source is ds) for ds in res.data_sources):
+ res.data_sources.append(batch_source)
elif isinstance(obj, Entity) and not any(
(obj is entity) for entity in res.entities
):
| diff --git a/sdk/python/tests/example_repos/example_feature_repo_with_bfvs.py b/sdk/python/tests/example_repos/example_feature_repo_with_bfvs.py
new file mode 100644
--- /dev/null
+++ b/sdk/python/tests/example_repos/example_feature_repo_with_bfvs.py
@@ -0,0 +1,52 @@
+from datetime import timedelta
+
+from feast import BatchFeatureView, Entity, Field, FileSource
+from feast.types import Float32, Int32, Int64
+
+driver_hourly_stats = FileSource(
+ path="%PARQUET_PATH%", # placeholder to be replaced by the test
+ timestamp_field="event_timestamp",
+ created_timestamp_column="created",
+)
+
+driver = Entity(
+ name="driver_id",
+ description="driver id",
+)
+
+
+driver_hourly_stats_view = BatchFeatureView(
+ name="driver_hourly_stats",
+ entities=[driver],
+ ttl=timedelta(days=1),
+ schema=[
+ Field(name="conv_rate", dtype=Float32),
+ Field(name="acc_rate", dtype=Float32),
+ Field(name="avg_daily_trips", dtype=Int64),
+ Field(name="driver_id", dtype=Int32),
+ ],
+ online=True,
+ source=driver_hourly_stats,
+ tags={},
+)
+
+
+global_daily_stats = FileSource(
+ path="%PARQUET_PATH_GLOBAL%", # placeholder to be replaced by the test
+ timestamp_field="event_timestamp",
+ created_timestamp_column="created",
+)
+
+
+global_stats_feature_view = BatchFeatureView(
+ name="global_daily_stats",
+ entities=None,
+ ttl=timedelta(days=1),
+ schema=[
+ Field(name="num_rides", dtype=Int32),
+ Field(name="avg_ride_length", dtype=Float32),
+ ],
+ online=True,
+ source=global_daily_stats,
+ tags={},
+)
diff --git a/sdk/python/tests/unit/local_feast_tests/test_e2e_local.py b/sdk/python/tests/unit/local_feast_tests/test_e2e_local.py
--- a/sdk/python/tests/unit/local_feast_tests/test_e2e_local.py
+++ b/sdk/python/tests/unit/local_feast_tests/test_e2e_local.py
@@ -51,6 +51,16 @@ def test_e2e_local() -> None:
runner, store, start_date, end_date, driver_df
)
+ with runner.local_repo(
+ get_example_repo("example_feature_repo_with_bfvs.py")
+ .replace("%PARQUET_PATH%", driver_stats_path)
+ .replace("%PARQUET_PATH_GLOBAL%", global_stats_path),
+ "file",
+ ) as store:
+ _test_materialize_and_online_retrieval(
+ runner, store, start_date, end_date, driver_df
+ )
+
with runner.local_repo(
get_example_repo("example_feature_repo_with_ttl_0.py")
.replace("%PARQUET_PATH%", driver_stats_path)
diff --git a/sdk/python/tests/utils/cli_repo_creator.py b/sdk/python/tests/utils/cli_repo_creator.py
--- a/sdk/python/tests/utils/cli_repo_creator.py
+++ b/sdk/python/tests/utils/cli_repo_creator.py
@@ -88,7 +88,9 @@ def local_repo(self, example_repo_py: str, offline_store: str):
stderr = result.stderr.decode("utf-8")
print(f"Apply stdout:\n{stdout}")
print(f"Apply stderr:\n{stderr}")
- assert result.returncode == 0
+ assert (
+ result.returncode == 0
+ ), f"stdout: {result.stdout}\nstderr: {result.stderr}"
yield FeatureStore(repo_path=str(repo_path), config=None)
@@ -97,4 +99,6 @@ def local_repo(self, example_repo_py: str, offline_store: str):
stderr = result.stderr.decode("utf-8")
print(f"Apply stdout:\n{stdout}")
print(f"Apply stderr:\n{stderr}")
- assert result.returncode == 0
+ assert (
+ result.returncode == 0
+ ), f"stdout: {result.stdout}\nstderr: {result.stderr}"
| "feast apply" does not register a new BatchFeatureView
## Expected Behavior
Same behavior as regular FeatureViews
## Current Behavior
Take following sample .py file and run cmd "feast apply" -- works just fine for regular FeatureViews
## Steps to reproduce
```
from datetime import timedelta
import yaml
from feast import BatchFeatureView, Entity, FeatureService, SnowflakeSource
driver = Entity(
# Name of the entity. Must be unique within a project
name="driver",
# The join keys of an entity describe the storage level field/column on which
# features can be looked up. The join keys are also used to join feature
# tables/views when building feature vectors
join_keys=["driver_id"],
)
project_name = yaml.safe_load(open("feature_store.yaml"))["project"]
driver_stats_source = SnowflakeSource(
database=yaml.safe_load(open("feature_store.yaml"))["offline_store"]["database"],
table=f"{project_name}_feast_driver_hourly_stats",
timestamp_field="event_timestamp",
created_timestamp_column="created",
)
driver_stats_fv = BatchFeatureView(
name="driver_hourly_stats",
entities=[driver],
ttl=timedelta(weeks=52),
source=driver_stats_source,
)
driver_stats_fs = FeatureService(name="driver_activity", features=[driver_stats_fv])
```
### Specifications
- Version:
- Platform:
- Subsystem:
## Possible Solution
| 2022-08-16T18:35:06 |
|
feast-dev/feast | 3,098 | feast-dev__feast-3098 | [
"3082"
]
| b8e39ea4cd2d990f2422c60bf39d8d940ecc9522 | diff --git a/sdk/python/feast/feast_object.py b/sdk/python/feast/feast_object.py
--- a/sdk/python/feast/feast_object.py
+++ b/sdk/python/feast/feast_object.py
@@ -1,5 +1,6 @@
from typing import Union
+from .batch_feature_view import BatchFeatureView
from .data_source import DataSource
from .entity import Entity
from .feature_service import FeatureService
@@ -16,12 +17,15 @@
)
from .request_feature_view import RequestFeatureView
from .saved_dataset import ValidationReference
+from .stream_feature_view import StreamFeatureView
# Convenience type representing all Feast objects
FeastObject = Union[
FeatureView,
OnDemandFeatureView,
RequestFeatureView,
+ BatchFeatureView,
+ StreamFeatureView,
Entity,
FeatureService,
DataSource,
diff --git a/sdk/python/feast/feature_store.py b/sdk/python/feast/feature_store.py
--- a/sdk/python/feast/feature_store.py
+++ b/sdk/python/feast/feature_store.py
@@ -775,6 +775,7 @@ def apply(
FeatureView,
OnDemandFeatureView,
RequestFeatureView,
+ BatchFeatureView,
StreamFeatureView,
FeatureService,
ValidationReference,
@@ -834,9 +835,9 @@ def apply(
ob
for ob in objects
if (
- isinstance(ob, FeatureView)
+ # BFVs are not handled separately from FVs right now.
+ (isinstance(ob, FeatureView) or isinstance(ob, BatchFeatureView))
and not isinstance(ob, StreamFeatureView)
- and not isinstance(ob, BatchFeatureView)
)
]
sfvs_to_update = [ob for ob in objects if isinstance(ob, StreamFeatureView)]
@@ -919,13 +920,18 @@ def apply(
validation_references, project=self.project, commit=False
)
+ entities_to_delete = []
+ views_to_delete = []
+ sfvs_to_delete = []
if not partial:
# Delete all registry objects that should not exist.
entities_to_delete = [
ob for ob in objects_to_delete if isinstance(ob, Entity)
]
views_to_delete = [
- ob for ob in objects_to_delete if isinstance(ob, FeatureView)
+ ob
+ for ob in objects_to_delete
+ if isinstance(ob, FeatureView) or isinstance(ob, BatchFeatureView)
]
request_views_to_delete = [
ob for ob in objects_to_delete if isinstance(ob, RequestFeatureView)
@@ -979,10 +985,13 @@ def apply(
validation_references.name, project=self.project, commit=False
)
+ tables_to_delete: List[FeatureView] = views_to_delete + sfvs_to_delete if not partial else [] # type: ignore
+ tables_to_keep: List[FeatureView] = views_to_update + sfvs_to_update # type: ignore
+
self._get_provider().update_infra(
project=self.project,
- tables_to_delete=views_to_delete + sfvs_to_delete if not partial else [],
- tables_to_keep=views_to_update + sfvs_to_update,
+ tables_to_delete=tables_to_delete,
+ tables_to_keep=tables_to_keep,
entities_to_delete=entities_to_delete if not partial else [],
entities_to_keep=entities_to_update,
partial=partial,
| diff --git a/sdk/python/tests/unit/local_feast_tests/test_local_feature_store.py b/sdk/python/tests/unit/local_feast_tests/test_local_feature_store.py
--- a/sdk/python/tests/unit/local_feast_tests/test_local_feature_store.py
+++ b/sdk/python/tests/unit/local_feast_tests/test_local_feature_store.py
@@ -4,6 +4,7 @@
import pytest
from pytest_lazyfixture import lazy_fixture
+from feast import BatchFeatureView
from feast.aggregation import Aggregation
from feast.data_format import AvroFormat, ParquetFormat
from feast.data_source import KafkaSource
@@ -78,14 +79,29 @@ def test_apply_feature_view(test_feature_store):
ttl=timedelta(minutes=5),
)
+ bfv = BatchFeatureView(
+ name="batch_feature_view",
+ schema=[
+ Field(name="fs1_my_feature_1", dtype=Int64),
+ Field(name="fs1_my_feature_2", dtype=String),
+ Field(name="fs1_my_feature_3", dtype=Array(String)),
+ Field(name="fs1_my_feature_4", dtype=Array(Bytes)),
+ Field(name="entity_id", dtype=Int64),
+ ],
+ entities=[entity],
+ tags={"team": "matchmaking"},
+ source=batch_source,
+ ttl=timedelta(minutes=5),
+ )
+
# Register Feature View
- test_feature_store.apply([entity, fv1])
+ test_feature_store.apply([entity, fv1, bfv])
feature_views = test_feature_store.list_feature_views()
# List Feature Views
assert (
- len(feature_views) == 1
+ len(feature_views) == 2
and feature_views[0].name == "my_feature_view_1"
and feature_views[0].features[0].name == "fs1_my_feature_1"
and feature_views[0].features[0].dtype == Int64
| "feast apply" does not register a new BatchFeatureView
## Expected Behavior
Same behavior as regular FeatureViews
## Current Behavior
Take following sample .py file and run cmd "feast apply" -- works just fine for regular FeatureViews
## Steps to reproduce
```
from datetime import timedelta
import yaml
from feast import BatchFeatureView, Entity, FeatureService, SnowflakeSource
driver = Entity(
# Name of the entity. Must be unique within a project
name="driver",
# The join keys of an entity describe the storage level field/column on which
# features can be looked up. The join keys are also used to join feature
# tables/views when building feature vectors
join_keys=["driver_id"],
)
project_name = yaml.safe_load(open("feature_store.yaml"))["project"]
driver_stats_source = SnowflakeSource(
database=yaml.safe_load(open("feature_store.yaml"))["offline_store"]["database"],
table=f"{project_name}_feast_driver_hourly_stats",
timestamp_field="event_timestamp",
created_timestamp_column="created",
)
driver_stats_fv = BatchFeatureView(
name="driver_hourly_stats",
entities=[driver],
ttl=timedelta(weeks=52),
source=driver_stats_source,
)
driver_stats_fs = FeatureService(name="driver_activity", features=[driver_stats_fv])
```
### Specifications
- Version:
- Platform:
- Subsystem:
## Possible Solution
| @achals when register the feature view through feast.apply() I am still getting errors:
`Traceback (most recent call last):
File "test.py", line 66, in <module>
main()
File "test.py", line 41, in main
training_df = fs.get_historical_features(
File "/Users/madkins/Documents/feast/sdk/python/feast/usage.py", line 294, in wrapper
raise exc.with_traceback(traceback)
File "/Users/madkins/Documents/feast/sdk/python/feast/usage.py", line 283, in wrapper
return func(*args, **kwargs)
File "/Users/madkins/Documents/feast/sdk/python/feast/feature_store.py", line 1092, in get_historical_features
fvs, odfvs, request_fvs, request_fv_refs = _group_feature_refs(
File "/Users/madkins/Documents/feast/sdk/python/feast/feature_store.py", line 2553, in _group_feature_refs
raise FeatureViewNotFoundException(view_name)
feast.errors.FeatureViewNotFoundException: Feature view driver_hourly_stats does not exist`
`driver_stats_fv = BatchFeatureView(
# The unique name of this feature view. Two feature views in a single
# project cannot have the same name
name="driver_hourly_stats",
# The list of entities specifies the keys required for joining or looking
# up features from this feature view. The reference provided in this field
# correspond to the name of a defined entity (or entities)
entities=[driver],
# The timedelta is the maximum age that each feature value may have
# relative to its lookup time. For historical features (used in training),
# TTL is relative to each timestamp provided in the entity dataframe.
# TTL also allows for eviction of keys from online stores and limits the
# amount of historical scanning required for historical feature values
# during retrieval
ttl=timedelta(weeks=52),
# Batch sources are used to find feature values. In the case of this feature
# view we will query a source table on Redshift for driver statistics
# features
source=driver_stats_source,
)`
`feast.apply(fs.apply([driver, driver_stats_fv])` | 2022-08-17T17:24:10 |
feast-dev/feast | 3,103 | feast-dev__feast-3103 | [
"3101"
]
| d674a95efa1f9cf6060ef6f2a6dcf00450ad6dde | diff --git a/sdk/python/feast/proto_json.py b/sdk/python/feast/proto_json.py
--- a/sdk/python/feast/proto_json.py
+++ b/sdk/python/feast/proto_json.py
@@ -1,12 +1,14 @@
import uuid
from typing import Any, Callable, Type
+import pkg_resources
from google.protobuf.json_format import ( # type: ignore
_WKTJSONMETHODS,
ParseError,
_Parser,
_Printer,
)
+from packaging import version
from feast.protos.feast.serving.ServingService_pb2 import FeatureList
from feast.protos.feast.types.Value_pb2 import RepeatedValue, Value
@@ -15,8 +17,6 @@
JsonObject = Any
-# TODO: These methods need to be updated when bumping the version of protobuf.
-# https://github.com/feast-dev/feast/issues/2484
def _patch_proto_json_encoding(
proto_type: Type[ProtoMessage],
to_json_object: Callable[[_Printer, ProtoMessage], JsonObject],
@@ -70,7 +70,7 @@ def to_json_object(printer: _Printer, message: ProtoMessage) -> JsonObject:
return value
def from_json_object(
- parser: _Parser, value: JsonObject, message: ProtoMessage, path: str
+ parser: _Parser, value: JsonObject, message: ProtoMessage
) -> None:
if value is None:
message.null_val = 0
@@ -111,7 +111,18 @@ def from_json_object(
"Value {0} has unexpected type {1}.".format(value, type(value))
)
- _patch_proto_json_encoding(Value, to_json_object, from_json_object)
+ def from_json_object_updated(
+ parser: _Parser, value: JsonObject, message: ProtoMessage, path: str
+ ):
+ from_json_object(parser, value, message)
+
+ # https://github.com/feast-dev/feast/issues/2484 Certain feast users need a higher version of protobuf but the
+ # parameters of `from_json_object` changes in feast 3.20.1. This change gives users flexibility to use earlier versions.
+ current_version = pkg_resources.get_distribution("protobuf").version
+ if version.parse(current_version) < version.parse("3.20"):
+ _patch_proto_json_encoding(Value, to_json_object, from_json_object)
+ else:
+ _patch_proto_json_encoding(Value, to_json_object, from_json_object_updated)
def _patch_feast_repeated_value_json_encoding():
@@ -141,14 +152,29 @@ def _patch_feast_repeated_value_json_encoding():
def to_json_object(printer: _Printer, message: ProtoMessage) -> JsonObject:
return [printer._MessageToJsonObject(item) for item in message.val]
- def from_json_object(
+ def from_json_object_updated(
parser: _Parser, value: JsonObject, message: ProtoMessage, path: str
) -> None:
array = value if isinstance(value, list) else value["val"]
for item in array:
parser.ConvertMessage(item, message.val.add(), path)
- _patch_proto_json_encoding(RepeatedValue, to_json_object, from_json_object)
+ def from_json_object(
+ parser: _Parser, value: JsonObject, message: ProtoMessage
+ ) -> None:
+ array = value if isinstance(value, list) else value["val"]
+ for item in array:
+ parser.ConvertMessage(item, message.val.add())
+
+ # https://github.com/feast-dev/feast/issues/2484 Certain feast users need a higher version of protobuf but the
+ # parameters of `from_json_object` changes in feast 3.20.1. This change gives users flexibility to use earlier versions.
+ current_version = pkg_resources.get_distribution("protobuf").version
+ if version.parse(current_version) < version.parse("3.20"):
+ _patch_proto_json_encoding(RepeatedValue, to_json_object, from_json_object)
+ else:
+ _patch_proto_json_encoding(
+ RepeatedValue, to_json_object, from_json_object_updated
+ )
def _patch_feast_feature_list_json_encoding():
@@ -183,12 +209,25 @@ def to_json_object(printer: _Printer, message: ProtoMessage) -> JsonObject:
return list(message.val)
def from_json_object(
- parser: _Parser, value: JsonObject, message: ProtoMessage, path: str
+ parser: _Parser, value: JsonObject, message: ProtoMessage
) -> None:
array = value if isinstance(value, list) else value["val"]
message.val.extend(array)
- _patch_proto_json_encoding(FeatureList, to_json_object, from_json_object)
+ def from_json_object_updated(
+ parser: _Parser, value: JsonObject, message: ProtoMessage, path: str
+ ) -> None:
+ from_json_object(parser, value, message)
+
+ # https://github.com/feast-dev/feast/issues/2484 Certain feast users need a higher version of protobuf but the
+ # parameters of `from_json_object` changes in feast 3.20.1. This change gives users flexibility to use earlier versions.
+ current_version = pkg_resources.get_distribution("protobuf").version
+ if version.parse(current_version) < version.parse("3.20"):
+ _patch_proto_json_encoding(FeatureList, to_json_object, from_json_object)
+ else:
+ _patch_proto_json_encoding(
+ FeatureList, to_json_object, from_json_object_updated
+ )
def patch():
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -60,7 +60,7 @@
"numpy>=1.22,<3",
"pandas>=1.4.3,<2",
"pandavro==1.5.*", # For some reason pandavro higher than 1.5.* only support pandas less than 1.3.
- "protobuf>3.20,<4",
+ "protobuf<5,>3",
"proto-plus>=1.20.0,<2",
"pyarrow>=4,<9",
"pydantic>=1,<2",
| Upgrade protobuf past version 4
**Is your feature request related to a problem? Please describe.**
Feast pins protobuf to `<4`. This means that for M1 Apple machines, we have to employ some hacks. It would be nice to not have to do that. Also maintaining an upper bound on a popular library means that installing Feast alongside other libraries involves friction.
**Describe the solution you'd like**
Ideally, we remove the upper bound for protobuf in `setup.py`. It seems like the breaking changes are pretty minor: https://developers.google.com/protocol-buffers/docs/news/2022-05-06#python-updates
**Describe alternatives you've considered**
N/A
| 2022-08-18T18:24:02 |
||
feast-dev/feast | 3,115 | feast-dev__feast-3115 | [
"3114"
]
| 9f7e5573e764466590badab4250b69aef6f256b0 | diff --git a/sdk/python/feast/inference.py b/sdk/python/feast/inference.py
--- a/sdk/python/feast/inference.py
+++ b/sdk/python/feast/inference.py
@@ -156,7 +156,11 @@ def update_feature_views_with_inferred_features_and_entities(
)
# Infer a dummy entity column for entityless feature views.
- if len(fv.entities) == 1 and fv.entities[0] == DUMMY_ENTITY_NAME:
+ if (
+ len(fv.entities) == 1
+ and fv.entities[0] == DUMMY_ENTITY_NAME
+ and not fv.entity_columns
+ ):
fv.entity_columns.append(Field(name=DUMMY_ENTITY_ID, dtype=String))
# Run inference for entity columns if there are fewer entity fields than expected.
| Snowflake materialization fails on feature views with dummy entity
## Expected Behavior
Same as feature views with entities
## Current Behavior
Materialization query errors, query has duplicate column names caused by a dummy entity having multiple dummy join keys
## Steps to reproduce
### Specifications
- Version:
- Platform:
- Subsystem:
## Possible Solution
even if infer features is ran more than once, only update the dummy entity join key once
| 2022-08-20T13:53:19 |
||
feast-dev/feast | 3,148 | feast-dev__feast-3148 | [
"3146"
]
| 20a9dd98550ad8daf291381a771b3da798e4c1a4 | diff --git a/sdk/python/feast/infra/materialization/snowflake_engine.py b/sdk/python/feast/infra/materialization/snowflake_engine.py
--- a/sdk/python/feast/infra/materialization/snowflake_engine.py
+++ b/sdk/python/feast/infra/materialization/snowflake_engine.py
@@ -334,7 +334,11 @@ def generate_snowflake_materialization_query(
)
if feature_value_type_name == "UNIX_TIMESTAMP":
- feature_sql = f'{feature_sql}(DATE_PART(EPOCH_NANOSECOND, "{feature.name}")) AS "{feature.name}"'
+ feature_sql = f'{feature_sql}(DATE_PART(EPOCH_NANOSECOND, "{feature.name}"::TIMESTAMP_LTZ)) AS "{feature.name}"'
+ elif feature_value_type_name == "DOUBLE":
+ feature_sql = (
+ f'{feature_sql}("{feature.name}"::DOUBLE) AS "{feature.name}"'
+ )
else:
feature_sql = f'{feature_sql}("{feature.name}") AS "{feature.name}"'
diff --git a/sdk/python/feast/infra/offline_stores/snowflake_source.py b/sdk/python/feast/infra/offline_stores/snowflake_source.py
--- a/sdk/python/feast/infra/offline_stores/snowflake_source.py
+++ b/sdk/python/feast/infra/offline_stores/snowflake_source.py
@@ -264,18 +264,17 @@ def get_table_column_names_and_types(
]
else:
raise NotImplementedError(
- "Numbers larger than INT64 are not supported"
+ "NaNs or Numbers larger than INT64 are not supported"
)
else:
- raise NotImplementedError(
- "The following Snowflake Data Type is not supported: DECIMAL -- Convert to DOUBLE"
- )
- elif row["type_code"] in [3, 5, 9, 10, 12]:
+ row["snowflake_type"] = "NUMBERwSCALE"
+
+ elif row["type_code"] in [5, 9, 10, 12]:
error = snowflake_unsupported_map[row["type_code"]]
raise NotImplementedError(
f"The following Snowflake Data Type is not supported: {error}"
)
- elif row["type_code"] in [1, 2, 4, 6, 7, 8, 11, 13]:
+ elif row["type_code"] in [1, 2, 3, 4, 6, 7, 8, 11, 13]:
row["snowflake_type"] = snowflake_type_code_map[row["type_code"]]
else:
raise NotImplementedError(
@@ -291,6 +290,7 @@ def get_table_column_names_and_types(
0: "NUMBER",
1: "DOUBLE",
2: "VARCHAR",
+ 3: "DATE",
4: "TIMESTAMP",
6: "TIMESTAMP_LTZ",
7: "TIMESTAMP_TZ",
@@ -300,7 +300,6 @@ def get_table_column_names_and_types(
}
snowflake_unsupported_map = {
- 3: "DATE -- Convert to TIMESTAMP",
5: "VARIANT -- Try converting to VARCHAR",
9: "OBJECT -- Try converting to VARCHAR",
10: "ARRAY -- Try converting to VARCHAR",
diff --git a/sdk/python/feast/type_map.py b/sdk/python/feast/type_map.py
--- a/sdk/python/feast/type_map.py
+++ b/sdk/python/feast/type_map.py
@@ -625,8 +625,10 @@ def snowflake_type_to_feast_value_type(snowflake_type: str) -> ValueType:
"VARCHAR": ValueType.STRING,
"NUMBER32": ValueType.INT32,
"NUMBER64": ValueType.INT64,
+ "NUMBERwSCALE": ValueType.DOUBLE,
"DOUBLE": ValueType.DOUBLE,
"BOOLEAN": ValueType.BOOL,
+ "DATE": ValueType.UNIX_TIMESTAMP,
"TIMESTAMP": ValueType.UNIX_TIMESTAMP,
"TIMESTAMP_TZ": ValueType.UNIX_TIMESTAMP,
"TIMESTAMP_LTZ": ValueType.UNIX_TIMESTAMP,
| error: "Snowflake Data Type is not supported" on "NUMBER" with non-zero scale
## Expected Behavior
feast plan/apply completed without error in version `0.23.0` and I was able to query with `get_historical_features`.
## Current Behavior
With the snowflake datatype ` NUMBER(38,6)` I get:
```
NotImplementedError: The following Snowflake Data Type is not supported: DECIMAL -- Convert to DOUBLE
```
## Steps to reproduce
* `$ feast init -t snowflake`
* Alter the table like so:
```
alter table SNOWY_FEAST.PUBLIC."amazed_dane_feast_driver_hourly_stats" add column temp_conv_rate NUMBER(38,6);
update SNOWY_FEAST.PUBLIC."amazed_dane_feast_driver_hourly_stats" set temp_conv_rate = "conv_rate";
alter table SNOWY_FEAST.PUBLIC."amazed_dane_feast_driver_hourly_stats" drop column "conv_rate";
alter table SNOWY_FEAST.PUBLIC."amazed_dane_feast_driver_hourly_stats" rename column temp_conv_rate to "conv_rate";
```
* `$ feast apply`
```
Traceback (most recent call last):
...
raise NotImplementedError(
NotImplementedError: The following Snowflake Data Type is not supported: DECIMAL -- Convert to DOUBLE
```
### Specifications
- Version: `Feast SDK Version: "feast 0.24.0"`
- Platform: x86_64 on Python 3.10.5
- Subsystem: Linux 5.4.203-
## Possible Solution
| I think this is intentional cc @sfc-gh-madkins
@cburroughs my advice for right now would be to cast this to type double/float, as the error recommends. Let me see if I can get NUMBER with scale to work.
The issue stems from afew things. One protobuf doesnt support fixed point numbers, with scale. Two, how NUMBER is passed to pandas types. | 2022-08-28T21:34:57 |
|
feast-dev/feast | 3,172 | feast-dev__feast-3172 | [
"3171"
]
| b4ef834b4eb01937ade5302de478240e8e0a2651 | diff --git a/sdk/python/feast/feature_store.py b/sdk/python/feast/feature_store.py
--- a/sdk/python/feast/feature_store.py
+++ b/sdk/python/feast/feature_store.py
@@ -1478,13 +1478,8 @@ def write_to_online_store(
feature_view = self.get_feature_view(
feature_view_name, allow_registry_cache=allow_registry_cache
)
- entities = []
- for entity_name in feature_view.entities:
- entities.append(
- self.get_entity(entity_name, allow_registry_cache=allow_registry_cache)
- )
provider = self._get_provider()
- provider.ingest_df(feature_view, entities, df)
+ provider.ingest_df(feature_view, df)
@log_exceptions_and_usage
def write_to_offline_store(
diff --git a/sdk/python/feast/infra/passthrough_provider.py b/sdk/python/feast/infra/passthrough_provider.py
--- a/sdk/python/feast/infra/passthrough_provider.py
+++ b/sdk/python/feast/infra/passthrough_provider.py
@@ -193,7 +193,6 @@ def online_read(
def ingest_df(
self,
feature_view: FeatureView,
- entities: List[Entity],
df: pd.DataFrame,
):
set_usage_attribute("provider", self.__class__.__name__)
@@ -204,7 +203,10 @@ def ingest_df(
table, feature_view.batch_source.field_mapping
)
- join_keys = {entity.join_key: entity.value_type for entity in entities}
+ join_keys = {
+ entity.name: entity.dtype.to_value_type()
+ for entity in feature_view.entity_columns
+ }
rows_to_write = _convert_arrow_to_proto(table, feature_view, join_keys)
self.online_write_batch(
diff --git a/sdk/python/feast/infra/provider.py b/sdk/python/feast/infra/provider.py
--- a/sdk/python/feast/infra/provider.py
+++ b/sdk/python/feast/infra/provider.py
@@ -123,7 +123,6 @@ def online_write_batch(
def ingest_df(
self,
feature_view: FeatureView,
- entities: List[Entity],
df: pd.DataFrame,
):
"""
@@ -131,7 +130,6 @@ def ingest_df(
Args:
feature_view: The feature view to which the dataframe corresponds.
- entities: The entities that are referenced by the dataframe.
df: The dataframe to be persisted.
"""
pass
| Entity data type (int32) do not match PushSource data type (int64) when pushing to online store
## Expected Behavior
## Current Behavior
## Steps to reproduce
### Specifications
- Version:
- Platform:
- Subsystem:
## Possible Solution
| 2022-09-03T04:38:59 |
||
feast-dev/feast | 3,191 | feast-dev__feast-3191 | [
"3189"
]
| 2107ce295f191eb1339c8670f963d39e66c4ccf6 | diff --git a/sdk/python/feast/feature_view.py b/sdk/python/feast/feature_view.py
--- a/sdk/python/feast/feature_view.py
+++ b/sdk/python/feast/feature_view.py
@@ -409,6 +409,12 @@ def from_proto(cls, feature_view_proto: FeatureViewProto):
for field_proto in feature_view_proto.spec.entity_columns
]
+ if len(feature_view.entities) != len(feature_view.entity_columns):
+ warnings.warn(
+ f"There are some mismatches in your feature view's registered entities. Please check if you have applied your entities correctly."
+ f"Entities: {feature_view.entities} vs Entity Columns: {feature_view.entity_columns}"
+ )
+
# FeatureViewProjections are not saved in the FeatureView proto.
# Create the default projection.
feature_view.projection = FeatureViewProjection.from_definition(feature_view)
diff --git a/sdk/python/feast/type_map.py b/sdk/python/feast/type_map.py
--- a/sdk/python/feast/type_map.py
+++ b/sdk/python/feast/type_map.py
@@ -320,6 +320,8 @@ def _python_datetime_to_int_timestamp(
int_timestamps.append(int(value.ToSeconds()))
elif isinstance(value, np.datetime64):
int_timestamps.append(value.astype("datetime64[s]").astype(np.int_))
+ elif isinstance(value, type(np.nan)):
+ int_timestamps.append(NULL_TIMESTAMP_INT_VALUE)
else:
int_timestamps.append(int(value))
return int_timestamps
| Materialization fails if a timestamp column is full of `np.NaN`s
This bug is related to the previously reported issue #2803
If the batch of data being materialized has partial data for a timestamp column, it gets interpreted correctly as datetime and materialization works. But if the column only has nulls, it gets interpreted as `np.NaN`, which fails to materialize.
## Steps to reproduce
Here's a slightly modified script from the issue #2803 that can replicate this behaviour:
```python
from datetime import datetime
import numpy as np
import pandas as pd
from feast import Entity, FeatureStore, FeatureView, Field
from feast.infra.offline_stores.file_source import FileSource
from feast.repo_config import RegistryConfig, RepoConfig
from feast.types import Int32, UnixTimestamp
# create dataset
pd.DataFrame(
[
{
"user_id": 1,
"event_timestamp": datetime(2022, 5, 1),
"created": datetime(2022, 5, 1),
"purchases": 3,
"last_purchase_date": np.NaN,
},
{
"user_id": 2,
"event_timestamp": datetime(2022, 5, 2),
"created": datetime(2022, 5, 2),
"purchases": 1,
"last_purchase_date": np.NaN,
},
{
"user_id": 3,
"event_timestamp": datetime(2022, 5, 2),
"created": datetime(2022, 5, 2),
"purchases": 0,
"last_purchase_date": np.NaN,
},
]
).to_parquet("user_stats.parquet")
user = Entity(name="user_id", description="user id")
user_stats_view = FeatureView(
name="user_stats",
entities=[user],
source=FileSource(
path="user_stats.parquet",
timestamp_field="event_timestamp",
created_timestamp_column="created",
),
schema=[
Field(name="purchases", dtype=Int32),
Field(name="last_purchase_date", dtype=UnixTimestamp),
],
)
online_store_path = "online_store.db"
registry_path = "registry.db"
repo = RepoConfig(
registry="registry.db",
project="feature_store",
provider="local",
offline_store="file",
use_ssl=True,
is_secure=True,
validate=True,
)
fs = FeatureStore(config=repo)
fs.apply([user, user_stats_view])
fs.materialize_incremental(end_date=datetime.utcnow())
entity_rows = [{"user_id": i} for i in range(1, 4)]
feature_df = fs.get_online_features(
features=[
"user_stats:purchases",
"user_stats:last_purchase_date",
],
entity_rows=entity_rows,
).to_df()
print(feature_df)
```
Note that all the values of the `last_purchase_date` column have been set to `np.NaN` to trigger this bug. The reproduction script in #2803 had partial data.
## Current Behavior
```
/Users/abhin/.pyenv/virtualenvs/pano/3.9.8/lib/python3.9/site-packages/feast/repo_config.py:207: RuntimeWarning: `entity_key_serialization_version` is either not specified in the feature_store.yaml, or is specified to a value <= 1.This serialization version may cause errors when trying to write fields with the `Long` data type into the online store. Specifying `entity_key_serialization_version` to 2 is recommended for new projects.
warnings.warn(
Materializing 1 feature views to 2022-09-07 18:14:33-04:00 into the sqlite online store.
Since the ttl is 0 for feature view user_stats, the start date will be set to 1 year before the current time.
user_stats from 2021-09-08 18:14:33-04:00 to 2022-09-07 18:14:33-04:00:
0%| | 0/3 [00:00<?, ?it/s]
Traceback (most recent call last):
File "/Users/abhin/src/github.com/Shopify/pano/repro/repro.py", line 71, in <module>
fs.materialize_incremental(end_date=datetime.utcnow())
File "/Users/abhin/.pyenv/virtualenvs/pano/3.9.8/lib/python3.9/site-packages/feast/feature_store.py", line 1323, in materialize_incremental
provider.materialize_single_feature_view(
File "/Users/abhin/.pyenv/virtualenvs/pano/3.9.8/lib/python3.9/site-packages/feast/infra/passthrough_provider.py", line 252, in materialize_single_feature_view
raise e
File "/Users/abhin/.pyenv/virtualenvs/pano/3.9.8/lib/python3.9/site-packages/feast/infra/materialization/local_engine.py", line 170, in _materialize_one
rows_to_write = _convert_arrow_to_proto(
File "/Users/abhin/.pyenv/virtualenvs/pano/3.9.8/lib/python3.9/site-packages/feast/utils.py", line 206, in _convert_arrow_to_proto
proto_values_by_column = {
File "/Users/abhin/.pyenv/virtualenvs/pano/3.9.8/lib/python3.9/site-packages/feast/utils.py", line 207, in <dictcomp>
column: python_values_to_proto_values(
File "/Users/abhin/.pyenv/virtualenvs/pano/3.9.8/lib/python3.9/site-packages/feast/type_map.py", line 446, in python_values_to_proto_values
return _python_value_to_proto_value(value_type, values)
File "/Users/abhin/.pyenv/virtualenvs/pano/3.9.8/lib/python3.9/site-packages/feast/type_map.py", line 392, in _python_value_to_proto_value
int_timestamps = _python_datetime_to_int_timestamp(values)
File "/Users/abhin/.pyenv/virtualenvs/pano/3.9.8/lib/python3.9/site-packages/feast/type_map.py", line 324, in _python_datetime_to_int_timestamp
int_timestamps.append(int(value))
ValueError: cannot convert float NaN to integer
```
## Expected behaviour
That materialization doesn't break.
### Specifications
- Version: 0.24.0
- Platform:
- Subsystem:
## Possible Solution
In `type_map.py`'s `_python_datetime_to_int_timestamp`, we should make a separate path for `np.NaN` values. Since `type(np.NaN) == float`, the current code path involves `int(np.NaN)`, which breaks. We could literally detect a `np.NaN` value and even directly set it to `NULL_TIMESTAMP_INT_VALUE`.
| 2022-09-07T21:19:15 |
||
feast-dev/feast | 3,193 | feast-dev__feast-3193 | [
"3187"
]
| de75971e27357a8fb4a882bd7ec4212148256616 | diff --git a/sdk/python/feast/infra/materialization/snowflake_engine.py b/sdk/python/feast/infra/materialization/snowflake_engine.py
--- a/sdk/python/feast/infra/materialization/snowflake_engine.py
+++ b/sdk/python/feast/infra/materialization/snowflake_engine.py
@@ -2,7 +2,6 @@
import shutil
from dataclasses import dataclass
from datetime import datetime
-from pathlib import Path
from typing import Callable, List, Literal, Optional, Sequence, Union
import click
@@ -45,9 +44,7 @@ class SnowflakeMaterializationEngineConfig(FeastConfigBaseModel):
type: Literal["snowflake.engine"] = "snowflake.engine"
""" Type selector"""
- config_path: Optional[str] = (
- Path(os.environ["HOME"]) / ".snowsql/config"
- ).__str__()
+ config_path: Optional[str] = os.path.expanduser("~/.snowsql/config")
""" Snowflake config path -- absolute path required (Cant use ~)"""
account: Optional[str] = None
diff --git a/sdk/python/feast/infra/offline_stores/snowflake.py b/sdk/python/feast/infra/offline_stores/snowflake.py
--- a/sdk/python/feast/infra/offline_stores/snowflake.py
+++ b/sdk/python/feast/infra/offline_stores/snowflake.py
@@ -64,9 +64,7 @@ class SnowflakeOfflineStoreConfig(FeastConfigBaseModel):
type: Literal["snowflake.offline"] = "snowflake.offline"
""" Offline store type selector"""
- config_path: Optional[str] = (
- Path(os.environ["HOME"]) / ".snowsql/config"
- ).__str__()
+ config_path: Optional[str] = os.path.expanduser("~/.snowsql/config")
""" Snowflake config path -- absolute path required (Cant use ~)"""
account: Optional[str] = None
diff --git a/sdk/python/feast/infra/online_stores/snowflake.py b/sdk/python/feast/infra/online_stores/snowflake.py
--- a/sdk/python/feast/infra/online_stores/snowflake.py
+++ b/sdk/python/feast/infra/online_stores/snowflake.py
@@ -2,7 +2,6 @@
import os
from binascii import hexlify
from datetime import datetime
-from pathlib import Path
from typing import Any, Callable, Dict, List, Optional, Sequence, Tuple
import pandas as pd
@@ -31,9 +30,7 @@ class SnowflakeOnlineStoreConfig(FeastConfigBaseModel):
type: Literal["snowflake.online"] = "snowflake.online"
""" Online store type selector"""
- config_path: Optional[str] = (
- Path(os.environ["HOME"]) / ".snowsql/config"
- ).__str__()
+ config_path: Optional[str] = os.path.expanduser("~/.snowsql/config")
""" Snowflake config path -- absolute path required (Can't use ~)"""
account: Optional[str] = None
| No "HOME" env variable for windows users with Snowflake components
## Expected Behavior
## Current Behavior
## Steps to reproduce
https://stackoverflow.com/questions/73604089/error-while-trying-to-run-the-feast-featurestore-function?newreg=828ffb42e07e45d5930ecb6222f31514
### Specifications
- Version:
- Platform:
- Subsystem:
## Possible Solution
look for %UserProfile% and HOME
| 2022-09-08T02:09:29 |
||
feast-dev/feast | 3,203 | feast-dev__feast-3203 | [
"3173"
]
| c19d64089cec04c771d24ce2b0034b66070cedb5 | diff --git a/sdk/python/feast/infra/online_stores/contrib/postgres.py b/sdk/python/feast/infra/online_stores/contrib/postgres.py
--- a/sdk/python/feast/infra/online_stores/contrib/postgres.py
+++ b/sdk/python/feast/infra/online_stores/contrib/postgres.py
@@ -114,17 +114,30 @@ def online_read(
)
)
- cur.execute(
- sql.SQL(
- """
- SELECT entity_key, feature_name, value, event_ts
- FROM {} WHERE entity_key = ANY(%s);
- """
- ).format(
- sql.Identifier(_table_id(project, table)),
- ),
- (keys,),
- )
+ if not requested_features:
+ cur.execute(
+ sql.SQL(
+ """
+ SELECT entity_key, feature_name, value, event_ts
+ FROM {} WHERE entity_key = ANY(%s);
+ """
+ ).format(
+ sql.Identifier(_table_id(project, table)),
+ ),
+ (keys,),
+ )
+ else:
+ cur.execute(
+ sql.SQL(
+ """
+ SELECT entity_key, feature_name, value, event_ts
+ FROM {} WHERE entity_key = ANY(%s) and feature_name = ANY(%s);
+ """
+ ).format(
+ sql.Identifier(_table_id(project, table)),
+ ),
+ (keys, requested_features),
+ )
rows = cur.fetchall()
| Support requested features on Postgresql online store
**Is your feature request related to a problem? Please describe.**
As a user, I want to retrieve subset of features on Postgresql online store instead of fetching all features
**Describe the solution you'd like**
Update online_read method to retrieve subset of features
**Additional context**
I'm close to creating a pull request for this issue myself.
| 2022-09-10T04:14:25 |
||
feast-dev/feast | 3,214 | feast-dev__feast-3214 | [
"3210"
]
| 59b4853593d1a3255c9cd409cbe9d2a198832588 | diff --git a/sdk/python/feast/errors.py b/sdk/python/feast/errors.py
--- a/sdk/python/feast/errors.py
+++ b/sdk/python/feast/errors.py
@@ -398,3 +398,8 @@ def __init__(self):
super().__init__(
"The entity dataframe specified does not have the timestamp field as a datetime."
)
+
+
+class PushSourceNotFoundException(Exception):
+ def __init__(self, push_source_name: str):
+ super().__init__(f"Unable to find push source '{push_source_name}'.")
diff --git a/sdk/python/feast/feature_server.py b/sdk/python/feast/feature_server.py
--- a/sdk/python/feast/feature_server.py
+++ b/sdk/python/feast/feature_server.py
@@ -13,6 +13,7 @@
import feast
from feast import proto_json
from feast.data_source import PushMode
+from feast.errors import PushSourceNotFoundException
from feast.protos.feast.serving.ServingService_pb2 import GetOnlineFeaturesRequest
@@ -98,6 +99,11 @@ def push(body=Depends(get_body)):
allow_registry_cache=request.allow_registry_cache,
to=to,
)
+ except PushSourceNotFoundException as e:
+ # Print the original exception on the server side
+ logger.exception(traceback.format_exc())
+ # Raise HTTPException to return the error message to the client
+ raise HTTPException(status_code=422, detail=str(e))
except Exception as e:
# Print the original exception on the server side
logger.exception(traceback.format_exc())
diff --git a/sdk/python/feast/feature_store.py b/sdk/python/feast/feature_store.py
--- a/sdk/python/feast/feature_store.py
+++ b/sdk/python/feast/feature_store.py
@@ -59,6 +59,7 @@
EntityNotFoundException,
FeatureNameCollisionError,
FeatureViewNotFoundException,
+ PushSourceNotFoundException,
RequestDataNotFoundInEntityDfException,
RequestDataNotFoundInEntityRowsException,
)
@@ -1444,6 +1445,9 @@ def push(
)
}
+ if not fvs_with_push_sources:
+ raise PushSourceNotFoundException(push_source_name)
+
for fv in fvs_with_push_sources:
if to == PushMode.ONLINE or to == PushMode.ONLINE_AND_OFFLINE:
self.write_to_online_store(
| diff --git a/sdk/python/tests/integration/e2e/test_python_feature_server.py b/sdk/python/tests/integration/e2e/test_python_feature_server.py
--- a/sdk/python/tests/integration/e2e/test_python_feature_server.py
+++ b/sdk/python/tests/integration/e2e/test_python_feature_server.py
@@ -84,6 +84,29 @@ def test_push(python_fs_client):
) == [initial_temp * 100]
[email protected]
[email protected]_online_stores
+def test_push_source_does_not_exist(python_fs_client):
+ initial_temp = _get_temperatures_from_feature_server(
+ python_fs_client, location_ids=[1]
+ )[0]
+ response = python_fs_client.post(
+ "/push",
+ data=json.dumps(
+ {
+ "push_source_name": "push_source_does_not_exist",
+ "df": {
+ "location_id": [1],
+ "temperature": [initial_temp * 100],
+ "event_timestamp": [str(datetime.utcnow())],
+ "created": [str(datetime.utcnow())],
+ },
+ }
+ ),
+ )
+ assert response.status_code == 422
+
+
def _get_temperatures_from_feature_server(client, location_ids: List[int]):
get_request_data = {
"features": ["pushable_location_stats:temperature"],
| Push api call to a push source that doesn't exist returns 200
## Expected Behavior
When we `POST` to a push source that doesn't exist like so
```
curl -X POST "http://localhost:6566/push" -d '{
"push_source_name": "push_source_name_that_does_not_exist",
"df": {
"some_entity": [1001],
"event_timestamp": ["2022-05-13 10:59:42"],
"created": ["2022-05-13 10:59:42"],
...
},
"to": "online_and_offline",
}' | jq
```
I'd expect an error. It is a valid format to the correct endpoint, but is an entity that doesn't exist. A [422 unprocessable entity](https://developer.mozilla.org/en-US/docs/Web/HTTP/Status/422) error would probably make sense here.
## Current Behavior
Method `FeatureStore().push` receives a [`push_source_name`](https://github.com/feast-dev/feast/blob/7c50ab510633c11646b6ff04853f3f26942ad646/sdk/python/feast/feature_store.py#L1418) indicating which feature views are impacted by the new data being pushed. The set of feature views is filtered down [here](https://github.com/feast-dev/feast/blob/7c50ab510633c11646b6ff04853f3f26942ad646/sdk/python/feast/feature_store.py#L1437-L1445). If a push source name is provided that doesn't actually exist then the resulting set is empty, the loop is skipped and the function is a no-op. This successful return means that the [`/push` call in feature_server.py](https://github.com/feast-dev/feast/blob/master/sdk/python/feast/feature_server.py#L95-L100) never throws to return an error code.
## Steps to reproduce
* start a local feature server
* make a push call to a push source that does not exist
### Specifications
- Version:
- Platform:
- Subsystem:
## Possible Solution
* Raise a custom exception when no push source is found with the provided name
* Catch that exception in the feature server
* Return 422 in that case
If this is considered reasonable, I'm happy to make the contribution myself.
| That generally seems fine. Ideally you'd give a detailed error message as well explaining why it failed too, but sgtm! | 2022-09-15T01:03:01 |
feast-dev/feast | 3,217 | feast-dev__feast-3217 | [
"3216"
]
| 7bc1dff5882c53c7e25f51ddb0b730bd81091a03 | diff --git a/sdk/python/feast/infra/offline_stores/file_source.py b/sdk/python/feast/infra/offline_stores/file_source.py
--- a/sdk/python/feast/infra/offline_stores/file_source.py
+++ b/sdk/python/feast/infra/offline_stores/file_source.py
@@ -160,9 +160,7 @@ def get_table_column_names_and_types(
if filesystem is None:
schema = ParquetDataset(path).schema.to_arrow_schema()
else:
- schema = ParquetDataset(
- filesystem.open_input_file(path), filesystem=filesystem
- ).schema
+ schema = ParquetDataset(path, filesystem=filesystem).schema
return zip(schema.names, map(str, schema.types))
| Unable to apply parquet dataset from s3
## Expected Behavior
We point our file source to a parquet dataset:
```python
file_source = FileSource(
name="dummy_file_source",
path="s3://data/dummy/"),
timestamp_field="event_timestamp",
created_timestamp_column="created",
file_format=ParquetFormat(),
)
```
I'm expecting to be able to use the parquet dataset format the same way I'd use a single file.
## Current Behavior
Feast errors at the apply stage:
```
File "/Users/mzwiessele/feast_s3_dataset_error/.venv/lib/python3.8/site-packages/feast/infra/offline_stores/file_source.py", line 164, in get_table_column_names_and_types
filesystem.open_input_file(path), filesystem=filesystem
File "pyarrow/_fs.pyx", line 588, in pyarrow._fs.FileSystem.open_input_file
File "pyarrow/error.pxi", line 143, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 114, in pyarrow.lib.check_status
OSError: Path does not exist 'data/dummy'
```
<details>
<summary>Full Traceback</summary>
```shell
Traceback (most recent call last):
File "/Users/mzwiessele/feast_s3_dataset_error/.venv/bin/feast", line 8, in <module>
sys.exit(cli())
File "/Users/mzwiessele/feast_s3_dataset_error/.venv/lib/python3.8/site-packages/click/core.py", line 1137, in __call__
return self.main(*args, **kwargs)
File "/Users/mzwiessele/feast_s3_dataset_error/.venv/lib/python3.8/site-packages/click/core.py", line 1062, in main
rv = self.invoke(ctx)
File "/Users/mzwiessele/feast_s3_dataset_error/.venv/lib/python3.8/site-packages/click/core.py", line 1668, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "/Users/mzwiessele/feast_s3_dataset_error/.venv/lib/python3.8/site-packages/click/core.py", line 1404, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/Users/mzwiessele/feast_s3_dataset_error/.venv/lib/python3.8/site-packages/click/core.py", line 763, in invoke
return __callback(*args, **kwargs)
File "/Users/mzwiessele/feast_s3_dataset_error/.venv/lib/python3.8/site-packages/click/decorators.py", line 26, in new_func
return f(get_current_context(), *args, **kwargs)
File "/Users/mzwiessele/feast_s3_dataset_error/.venv/lib/python3.8/site-packages/feast/cli.py", line 519, in apply_total_command
apply_total(repo_config, repo, skip_source_validation)
File "/Users/mzwiessele/feast_s3_dataset_error/.venv/lib/python3.8/site-packages/feast/usage.py", line 283, in wrapper
return func(*args, **kwargs)
File "/Users/mzwiessele/feast_s3_dataset_error/.venv/lib/python3.8/site-packages/feast/repo_operations.py", line 335, in apply_total
apply_total_with_repo_instance(
File "/Users/mzwiessele/feast_s3_dataset_error/.venv/lib/python3.8/site-packages/feast/repo_operations.py", line 296, in apply_total_with_repo_instance
registry_diff, infra_diff, new_infra = store.plan(repo)
File "/Users/mzwiessele/feast_s3_dataset_error/.venv/lib/python3.8/site-packages/feast/usage.py", line 294, in wrapper
raise exc.with_traceback(traceback)
File "/Users/mzwiessele/feast_s3_dataset_error/.venv/lib/python3.8/site-packages/feast/usage.py", line 283, in wrapper
return func(*args, **kwargs)
File "/Users/mzwiessele/feast_s3_dataset_error/.venv/lib/python3.8/site-packages/feast/feature_store.py", line 723, in plan
self._make_inferences(
File "/Users/mzwiessele/feast_s3_dataset_error/.venv/lib/python3.8/site-packages/feast/feature_store.py", line 601, in _make_inferences
update_feature_views_with_inferred_features_and_entities(
File "/Users/mzwiessele/feast_s3_dataset_error/.venv/lib/python3.8/site-packages/feast/inference.py", line 179, in update_feature_views_with_inferred_features_and_entities
_infer_features_and_entities(
File "/Users/mzwiessele/feast_s3_dataset_error/.venv/lib/python3.8/site-packages/feast/inference.py", line 217, in _infer_features_and_entities
table_column_names_and_types = fv.batch_source.get_table_column_names_and_types(
File "/Users/mzwiessele/feast_s3_dataset_error/.venv/lib/python3.8/site-packages/typeguard/__init__.py", line 1033, in wrapper
retval = func(*args, **kwargs)
File "/Users/mzwiessele/feast_s3_dataset_error/.venv/lib/python3.8/site-packages/feast/infra/offline_stores/file_source.py", line 164, in get_table_column_names_and_types
filesystem.open_input_file(path), filesystem=filesystem
File "pyarrow/_fs.pyx", line 588, in pyarrow._fs.FileSystem.open_input_file
File "pyarrow/error.pxi", line 143, in pyarrow.lib.pyarrow_internal_check_status
File "pyarrow/error.pxi", line 114, in pyarrow.lib.check_status
OSError: Path does not exist 'data/dummy'
```
</details>
## Steps to reproduce
1. Create default example using `feast init`
2. Upload example `driver_stats.parquet` data to s3 dataset path: `s3://data/dummy/driver_stats.parquet`
3. Change the data source to point to the s3 dataset:
```diff
@@ -1,28 +1,28 @@
driver_stats_source = FileSource(
name="driver_hourly_stats_source",
- path="data/driver_stats.parquet",
+ path="s3://data/dummy/",
timestamp_field="event_timestamp",
created_timestamp_column="created",
)
```
4. Run `feast apply`
### Specifications
- Version: 0.24.0
- Platform: MacOS
- Subsystem: Python 3.8
## Possible Solution
This PR fixes this issue: #3217
I have found this line to cause the error:
https://github.com/feast-dev/feast/blob/7bc1dff5882c53c7e25f51ddb0b730bd81091a03/sdk/python/feast/infra/offline_stores/file_source.py#L164
| 2022-09-15T11:13:02 |
||
feast-dev/feast | 3,238 | feast-dev__feast-3238 | [
"3237"
]
| 769c31869eb8d9bb693f8a2876cc68b8cdd16521 | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -96,7 +96,7 @@
BYTEWAX_REQUIRED = ["bytewax==0.10.0", "docker>=5.0.2", "kubernetes<=20.13.0"]
SNOWFLAKE_REQUIRED = [
- "snowflake-connector-python[pandas]>=2.7.3,<=2.7.8",
+ "snowflake-connector-python[pandas]>=2.7.3,<3",
]
SPARK_REQUIRED = [
| Allow `snowflake-connector-python >= 2.7.8`
I have a project that uses both `snowpark-python` and `feast`, and this restriction by `feast` on `snowflake-connector-python<=2.7.8` is preventing an upgrade to `snowpark-python==0.10` which now requires `snowflake-connector-python>=2.7.12`.
I would like to know whether this requirement is still valid or whether it can be eased to allow newer versions of `snowflake-connector-python`.
https://github.com/feast-dev/feast/blob/769c31869eb8d9bb693f8a2876cc68b8cdd16521/setup.py#L99
| 2022-09-20T19:06:17 |
||
feast-dev/feast | 3,280 | feast-dev__feast-3280 | [
"3279"
]
| 8f280620bceb3a6e42ffffd0571eeb353b0feff2 | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -43,7 +43,7 @@
DESCRIPTION = "Python SDK for Feast"
URL = "https://github.com/feast-dev/feast"
AUTHOR = "Feast"
-REQUIRES_PYTHON = ">=3.7.0"
+REQUIRES_PYTHON = ">=3.8.0"
REQUIRED = [
"click>=7.0.0,<9.0.0",
| Minimal Python version on PyPI seems to be too low
## Expected Behavior
From what I can understand, the minimal version of Python to run Feast is 3.8; that's what I would expect on the PyPI page.
## Current Behavior
`Requires: Python >=3.7.0`
## Steps to reproduce
https://pypi.org/project/feast/
| 2022-10-10T13:59:28 |
||
feast-dev/feast | 3,358 | feast-dev__feast-3358 | [
"2504"
]
| 4d6932ca53c4c88b9b7ea207b2e2cbcf8d62682d | diff --git a/sdk/python/feast/errors.py b/sdk/python/feast/errors.py
--- a/sdk/python/feast/errors.py
+++ b/sdk/python/feast/errors.py
@@ -56,6 +56,14 @@ def __init__(self, name, project=None):
super().__init__(f"Feature view {name} does not exist")
+class InvalidSparkSessionException(Exception):
+ def __init__(self, spark_arg):
+ super().__init__(
+ f" Need Spark Session to convert results to spark data frame\
+ recieved {type(spark_arg)} instead. "
+ )
+
+
class OnDemandFeatureViewNotFoundException(FeastObjectNotFoundException):
def __init__(self, name, project=None):
if project:
diff --git a/sdk/python/feast/infra/offline_stores/snowflake.py b/sdk/python/feast/infra/offline_stores/snowflake.py
--- a/sdk/python/feast/infra/offline_stores/snowflake.py
+++ b/sdk/python/feast/infra/offline_stores/snowflake.py
@@ -1,7 +1,9 @@
import contextlib
import os
import uuid
+import warnings
from datetime import datetime
+from functools import reduce
from pathlib import Path
from typing import (
Any,
@@ -21,11 +23,16 @@
import pyarrow
from pydantic import Field, StrictStr
from pydantic.typing import Literal
+from pyspark.sql import DataFrame, SparkSession
from pytz import utc
from feast import OnDemandFeatureView
from feast.data_source import DataSource
-from feast.errors import EntitySQLEmptyResults, InvalidEntityType
+from feast.errors import (
+ EntitySQLEmptyResults,
+ InvalidEntityType,
+ InvalidSparkSessionException,
+)
from feast.feature_logging import LoggingConfig, LoggingSource
from feast.feature_view import DUMMY_ENTITY_ID, DUMMY_ENTITY_VAL, FeatureView
from feast.infra.offline_stores import offline_utils
@@ -57,6 +64,8 @@
raise FeastExtrasDependencyImportError("snowflake", str(e))
+warnings.filterwarnings("ignore", category=DeprecationWarning)
+
class SnowflakeOfflineStoreConfig(FeastConfigBaseModel):
"""Offline store config for Snowflake"""
@@ -447,6 +456,41 @@ def to_sql(self) -> str:
with self._query_generator() as query:
return query
+ def to_spark_df(self, spark_session: SparkSession) -> DataFrame:
+ """
+ Method to convert snowflake query results to pyspark data frame.
+
+ Args:
+ spark_session: spark Session variable of current environment.
+
+ Returns:
+ spark_df: A pyspark dataframe.
+ """
+
+ if isinstance(spark_session, SparkSession):
+ with self._query_generator() as query:
+
+ arrow_batches = execute_snowflake_statement(
+ self.snowflake_conn, query
+ ).fetch_arrow_batches()
+
+ if arrow_batches:
+ spark_df = reduce(
+ DataFrame.unionAll,
+ [
+ spark_session.createDataFrame(batch.to_pandas())
+ for batch in arrow_batches
+ ],
+ )
+
+ return spark_df
+
+ else:
+ raise EntitySQLEmptyResults(query)
+
+ else:
+ raise InvalidSparkSessionException(spark_session)
+
def persist(self, storage: SavedDatasetStorage, allow_overwrite: bool = False):
assert isinstance(storage, SavedDatasetSnowflakeStorage)
self.to_snowflake(table_name=storage.snowflake_options.table)
| Get_historical_features() Does Not Have Option To Return Distributed Dataframe Like A Spark DF
When doing get_historical_features().to_df on a large training dataset in databricks I am hitting memory full errors. Since to_df is returning the data as a pandas dataframe it is not able to use the full capacity of the databricks cluster and distribute it across the different nodes the way a spark dataframe might.
| I believe this is actually possible. See https://github.com/feast-dev/feast/blob/master/sdk/python/feast/infra/offline_stores/contrib/spark_offline_store/spark.py#L252
@adchia but this is only available if you are using a spark offline store correct? for example, you cannot query a snowflake table and return it as a spark df, correct?
Ah correct. Right now it only allows returning it in arrow batches. Is the intention to be able to materialize through a spark df? Or to do training e.g. with MLLib.
In either case, might make sense for the SparkOfflineStore (this naming doesn't really make too much sense...) to be able to query from data warehouses (but maybe run the join within the DWH)
@adchia The intention is to just return snowflake data offline as a training dataset with the results being a distributed spark df. Is it possible to use snowflake as the source with the SparkOfflineStore? I found a way to hack around it by manipulating the to_sql() string and issuing that as a spark query using snowflakes spark connector, but wondering if there is a cleaner way
That works as a start and I don't think it's that hacky. Would be happy to check that in.
An alternative would be to flush the output of Snowflakes query to S3 and read that, but that also seems pretty hacky | 2022-11-21T18:24:49 |
|
feast-dev/feast | 3,377 | feast-dev__feast-3377 | [
"3282"
]
| 7b160c74685848a10965d5ab82721eddfb8c3766 | diff --git a/sdk/python/feast/infra/offline_stores/redshift_source.py b/sdk/python/feast/infra/offline_stores/redshift_source.py
--- a/sdk/python/feast/infra/offline_stores/redshift_source.py
+++ b/sdk/python/feast/infra/offline_stores/redshift_source.py
@@ -206,7 +206,8 @@ def get_table_column_names_and_types(
client = aws_utils.get_redshift_data_client(config.offline_store.region)
if self.table:
try:
- table = client.describe_table(
+ paginator = client.get_paginator("describe_table")
+ response_iterator = paginator.paginate(
ClusterIdentifier=config.offline_store.cluster_id,
Database=(
self.database
@@ -217,6 +218,7 @@ def get_table_column_names_and_types(
Table=self.table,
Schema=self.schema,
)
+ table = response_iterator.build_full_result()
except ClientError as e:
if e.response["Error"]["Code"] == "ValidationException":
raise RedshiftCredentialsError() from e
| Feast push (Redshift/DynamoDb) not work with PushMode.ONLINE_AND_OFFLINE when more than 500 columns
## Expected Behavior
Currently, we have a push source with Redshift Offline Store and DynamoDb Online Store.
We built our view with more than 500 columns. Around 750 columns.
We expected to ingest data in dynamo and redshift when we run
`fs.push("push_source", df, to=PushMode.ONLINE_AND_OFFLINE)`
## Current Behavior
Push command raise an issue like` [ERROR] ValueError: The input dataframe has columns ..`
This issue come from `get_table_column_names_and_types `method in `write_to_offline_store` method.
In the method, we check if `if set(input_columns) != set(source_columns)` and raise the below issue if there are diff.
In case with more than 500 columns we get a diff because source_columns come from `get_table_column_names_and_types` method result where the result is define by MaxResults parameters.
## Steps to reproduce
```
entity= Entity(
name="entity",
join_keys=["entity_id"],
value_type=ValueType.INT64,
)
push_source = PushSource(
name="push_source",
batch_source=RedshiftSource(
table="fs_push_view",
timestamp_field="datecreation",
created_timestamp_column="created_at"),
)
besoin_embedding_push_view = FeatureView(
name="push_view",
entities=[entity],
schema=[Field(name=f"field_{dim}", dtype=types.Float64) for dim in range(768)],
source=push_source
)
fs.push("push_source", df, to=PushMode.ONLINE_AND_OFFLINE)
```
### Specifications
- Version: 0.25.0
- Platform: AWS
- Subsystem:
## Possible Solution
In my mind, we have two solutions:
- Set higher MaxResults in describe_table method
- Use NextToken to iterate through results
| Hi @beubeu13220 , I think either of the two solutions are good options. I think I'd prefer the `NextToken` approach simply because it's probably the most stable one.
Would you like to make a PR to add this functionality? We'd be happy to review!
Hi @achals,
Yes, I'll do that as soon as I have time.
For the moment, we use custom `write_to_offline_redshift function`. | 2022-12-04T17:30:01 |
|
feast-dev/feast | 3,384 | feast-dev__feast-3384 | [
"3382"
]
| 1d3c111c4adb28b7063f45e92af0ad3aef296ee3 | diff --git a/sdk/python/feast/type_map.py b/sdk/python/feast/type_map.py
--- a/sdk/python/feast/type_map.py
+++ b/sdk/python/feast/type_map.py
@@ -147,6 +147,7 @@ def python_type_to_feast_value_type(
"uint8": ValueType.INT32,
"int8": ValueType.INT32,
"bool": ValueType.BOOL,
+ "boolean": ValueType.BOOL,
"timedelta": ValueType.UNIX_TIMESTAMP,
"timestamp": ValueType.UNIX_TIMESTAMP,
"datetime": ValueType.UNIX_TIMESTAMP,
| On-demand feature view cannot handle boolean Pandas native type
## Expected Behavior
After applying some extra transformation steps within on-demand feature view decorator, the returned dataframe as Pandas DataFrame, which contains couple of `boolean` type columns (not `bool`). I was expecting type mapping mechanism can internally infer them as bool type also.
## Current Behavior
It throws exception right here [line 201](https://github.com/feast-dev/feast/blob/master/sdk/python/feast/type_map.py#L201)
<img width="474" alt="image" src="https://user-images.githubusercontent.com/22145541/206345466-e257353b-9f5a-4465-b714-52ae602bbb68.png">
## Steps to reproduce
- Use on_demand_feature_view
- transform the input dataframe and cast some columns as `boolean` type
- return immediately
- apply the created on-demand view
### Specifications
- Version: 0.27.0
- Platform: Linux/AMD64
- Subsystem: Ubuntu
## Possible Solution
Simple add a `boolean` mapping below this [line](https://github.com/feast-dev/feast/blob/master/sdk/python/feast/type_map.py#L149)
| 2022-12-08T05:28:37 |
||
feast-dev/feast | 3,394 | feast-dev__feast-3394 | [
"3292"
]
| fd97254b18605fff7414845d94725a606112b874 | diff --git a/sdk/python/feast/infra/registry/sql.py b/sdk/python/feast/infra/registry/sql.py
--- a/sdk/python/feast/infra/registry/sql.py
+++ b/sdk/python/feast/infra/registry/sql.py
@@ -207,14 +207,14 @@ def get_stream_feature_view(
self, name: str, project: str, allow_cache: bool = False
):
return self._get_object(
- stream_feature_views,
- name,
- project,
- StreamFeatureViewProto,
- StreamFeatureView,
- "feature_view_name",
- "feature_view_proto",
- FeatureViewNotFoundException,
+ table=stream_feature_views,
+ name=name,
+ project=project,
+ proto_class=StreamFeatureViewProto,
+ python_class=StreamFeatureView,
+ id_field_name="feature_view_name",
+ proto_field_name="feature_view_proto",
+ not_found_exception=FeatureViewNotFoundException,
)
def list_stream_feature_views(
@@ -230,101 +230,105 @@ def list_stream_feature_views(
def apply_entity(self, entity: Entity, project: str, commit: bool = True):
return self._apply_object(
- entities, project, "entity_name", entity, "entity_proto"
+ table=entities,
+ project=project,
+ id_field_name="entity_name",
+ obj=entity,
+ proto_field_name="entity_proto",
)
def get_entity(self, name: str, project: str, allow_cache: bool = False) -> Entity:
return self._get_object(
- entities,
- name,
- project,
- EntityProto,
- Entity,
- "entity_name",
- "entity_proto",
- EntityNotFoundException,
+ table=entities,
+ name=name,
+ project=project,
+ proto_class=EntityProto,
+ python_class=Entity,
+ id_field_name="entity_name",
+ proto_field_name="entity_proto",
+ not_found_exception=EntityNotFoundException,
)
def get_feature_view(
self, name: str, project: str, allow_cache: bool = False
) -> FeatureView:
return self._get_object(
- feature_views,
- name,
- project,
- FeatureViewProto,
- FeatureView,
- "feature_view_name",
- "feature_view_proto",
- FeatureViewNotFoundException,
+ table=feature_views,
+ name=name,
+ project=project,
+ proto_class=FeatureViewProto,
+ python_class=FeatureView,
+ id_field_name="feature_view_name",
+ proto_field_name="feature_view_proto",
+ not_found_exception=FeatureViewNotFoundException,
)
def get_on_demand_feature_view(
self, name: str, project: str, allow_cache: bool = False
) -> OnDemandFeatureView:
return self._get_object(
- on_demand_feature_views,
- name,
- project,
- OnDemandFeatureViewProto,
- OnDemandFeatureView,
- "feature_view_name",
- "feature_view_proto",
- FeatureViewNotFoundException,
+ table=on_demand_feature_views,
+ name=name,
+ project=project,
+ proto_class=OnDemandFeatureViewProto,
+ python_class=OnDemandFeatureView,
+ id_field_name="feature_view_name",
+ proto_field_name="feature_view_proto",
+ not_found_exception=FeatureViewNotFoundException,
)
def get_request_feature_view(self, name: str, project: str):
return self._get_object(
- request_feature_views,
- name,
- project,
- RequestFeatureViewProto,
- RequestFeatureView,
- "feature_view_name",
- "feature_view_proto",
- FeatureViewNotFoundException,
+ table=request_feature_views,
+ name=name,
+ project=project,
+ proto_class=RequestFeatureViewProto,
+ python_class=RequestFeatureView,
+ id_field_name="feature_view_name",
+ proto_field_name="feature_view_proto",
+ not_found_exception=FeatureViewNotFoundException,
)
def get_feature_service(
self, name: str, project: str, allow_cache: bool = False
) -> FeatureService:
return self._get_object(
- feature_services,
- name,
- project,
- FeatureServiceProto,
- FeatureService,
- "feature_service_name",
- "feature_service_proto",
- FeatureServiceNotFoundException,
+ table=feature_services,
+ name=name,
+ project=project,
+ proto_class=FeatureServiceProto,
+ python_class=FeatureService,
+ id_field_name="feature_service_name",
+ proto_field_name="feature_service_proto",
+ not_found_exception=FeatureServiceNotFoundException,
)
def get_saved_dataset(
self, name: str, project: str, allow_cache: bool = False
) -> SavedDataset:
return self._get_object(
- saved_datasets,
- name,
- project,
- SavedDatasetProto,
- SavedDataset,
- "saved_dataset_name",
- "saved_dataset_proto",
- SavedDatasetNotFound,
+ table=saved_datasets,
+ name=name,
+ project=project,
+ proto_class=SavedDatasetProto,
+ python_class=SavedDataset,
+ id_field_name="saved_dataset_name",
+ proto_field_name="saved_dataset_proto",
+ not_found_exception=SavedDatasetNotFound,
)
def get_validation_reference(
self, name: str, project: str, allow_cache: bool = False
) -> ValidationReference:
return self._get_object(
- validation_references,
- name,
- project,
- ValidationReferenceProto,
- ValidationReference,
- "validation_reference_name",
- "validation_reference_proto",
- ValidationReferenceNotFound,
+ table=validation_references,
+ name=name,
+ project=project,
+ proto_class=ValidationReferenceProto,
+ python_class=ValidationReference,
+ id_field_name="validation_reference_name",
+ proto_field_name="validation_reference_proto",
+ not_found_exception=ValidationReferenceNotFound,
)
def list_entities(self, project: str, allow_cache: bool = False) -> List[Entity]:
@@ -364,14 +368,14 @@ def get_data_source(
self, name: str, project: str, allow_cache: bool = False
) -> DataSource:
return self._get_object(
- data_sources,
- name,
- project,
- DataSourceProto,
- DataSource,
- "data_source_name",
- "data_source_proto",
- DataSourceObjectNotFoundException,
+ table=data_sources,
+ name=name,
+ project=project,
+ proto_class=DataSourceProto,
+ python_class=DataSource,
+ id_field_name="data_source_name",
+ proto_field_name="data_source_proto",
+ not_found_exception=DataSourceObjectNotFoundException,
)
def list_data_sources(
@@ -556,22 +560,28 @@ def delete_validation_reference(self, name: str, project: str, commit: bool = Tr
def update_infra(self, infra: Infra, project: str, commit: bool = True):
self._apply_object(
- managed_infra, project, "infra_name", infra, "infra_proto", name="infra_obj"
+ table=managed_infra,
+ project=project,
+ id_field_name="infra_name",
+ obj=infra,
+ proto_field_name="infra_proto",
+ name="infra_obj",
)
def get_infra(self, project: str, allow_cache: bool = False) -> Infra:
infra_object = self._get_object(
- managed_infra,
- "infra_obj",
- project,
- InfraProto,
- Infra,
- "infra_name",
- "infra_proto",
- None,
+ table=managed_infra,
+ name="infra_obj",
+ project=project,
+ proto_class=InfraProto,
+ python_class=Infra,
+ id_field_name="infra_name",
+ proto_field_name="infra_proto",
+ not_found_exception=None,
)
- infra_object = infra_object or InfraProto()
- return Infra.from_proto(infra_object)
+ if infra_object:
+ return infra_object
+ return Infra()
def apply_user_metadata(
self,
| diff --git a/sdk/python/tests/unit/test_sql_registry.py b/sdk/python/tests/unit/test_sql_registry.py
--- a/sdk/python/tests/unit/test_sql_registry.py
+++ b/sdk/python/tests/unit/test_sql_registry.py
@@ -28,6 +28,8 @@
from feast.errors import FeatureViewNotFoundException
from feast.feature_view import FeatureView
from feast.field import Field
+from feast.infra.infra_object import Infra
+from feast.infra.online_stores.sqlite import SqliteTable
from feast.infra.registry.sql import SqlRegistry
from feast.on_demand_feature_view import on_demand_feature_view
from feast.repo_config import RegistryConfig
@@ -258,10 +260,20 @@ def test_apply_feature_view_success(sql_registry):
and feature_view.features[3].dtype == Array(Bytes)
and feature_view.entities[0] == "fs1_my_entity_1"
)
+ assert feature_view.ttl == timedelta(minutes=5)
# After the first apply, the created_timestamp should be the same as the last_update_timestamp.
assert feature_view.created_timestamp == feature_view.last_updated_timestamp
+ # Modify the feature view and apply again to test if diffing the online store table works
+ fv1.ttl = timedelta(minutes=6)
+ sql_registry.apply_feature_view(fv1, project)
+ feature_views = sql_registry.list_feature_views(project)
+ assert len(feature_views) == 1
+ feature_view = sql_registry.get_feature_view("my_feature_view_1", project)
+ assert feature_view.ttl == timedelta(minutes=6)
+
+ # Delete feature view
sql_registry.delete_feature_view("my_feature_view_1", project)
feature_views = sql_registry.list_feature_views(project)
assert len(feature_views) == 0
@@ -570,6 +582,22 @@ def test_update_infra(sql_registry):
project = "project"
infra = sql_registry.get_infra(project=project)
+ assert len(infra.infra_objects) == 0
+
# Should run update infra successfully
sql_registry.update_infra(infra, project)
+
+ # Should run update infra successfully when adding
+ new_infra = Infra()
+ new_infra.infra_objects.append(
+ SqliteTable(
+ path="/tmp/my_path.db",
+ name="my_table",
+ )
+ )
+ sql_registry.update_infra(new_infra, project)
+ infra = sql_registry.get_infra(project=project)
+ assert len(infra.infra_objects) == 1
+
+ # Try again since second time, infra should be not-empty
sql_registry.teardown()
| PostgreSQL Scalable Registry: Crash on multiple apply calls
## Expected Behavior
Feast apply can run on an already-initialized repository in the event that changes need to be applied; the registry can thus be maintained over time.
## Current Behavior
Feast, when using the PostgreSQL registry, will crash due to an inability to read the metadata tables whenever apply is run on an already-initialized feature repository. The error is as follows:
`
Traceback (most recent call last):
File "/usr/local/anaconda3/envs/generic-api/bin/feast", line 8, in <module>
sys.exit(cli())
File "/usr/local/anaconda3/envs/generic-api/lib/python3.9/site-packages/click/core.py", line 1130, in __call__
return self.main(*args, **kwargs)
File "/usr/local/anaconda3/envs/generic-api/lib/python3.9/site-packages/click/core.py", line 1055, in main
rv = self.invoke(ctx)
File "/usr/local/anaconda3/envs/generic-api/lib/python3.9/site-packages/click/core.py", line 1657, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "/usr/local/anaconda3/envs/generic-api/lib/python3.9/site-packages/click/core.py", line 1404, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/usr/local/anaconda3/envs/generic-api/lib/python3.9/site-packages/click/core.py", line 760, in invoke
return __callback(*args, **kwargs)
File "/usr/local/anaconda3/envs/generic-api/lib/python3.9/site-packages/click/decorators.py", line 26, in new_func
return f(get_current_context(), *args, **kwargs)
File "/usr/local/anaconda3/envs/generic-api/lib/python3.9/site-packages/feast/cli.py", line 519, in apply_total_command
apply_total(repo_config, repo, skip_source_validation)
File "/usr/local/anaconda3/envs/generic-api/lib/python3.9/site-packages/feast/usage.py", line 283, in wrapper
return func(*args, **kwargs)
File "/usr/local/anaconda3/envs/generic-api/lib/python3.9/site-packages/feast/repo_operations.py", line 335, in apply_total
apply_total_with_repo_instance(
File "/usr/local/anaconda3/envs/generic-api/lib/python3.9/site-packages/feast/repo_operations.py", line 296, in apply_total_with_repo_instance
registry_diff, infra_diff, new_infra = store.plan(repo)
File "/usr/local/anaconda3/envs/generic-api/lib/python3.9/site-packages/feast/usage.py", line 294, in wrapper
raise exc.with_traceback(traceback)
File "/usr/local/anaconda3/envs/generic-api/lib/python3.9/site-packages/feast/usage.py", line 283, in wrapper
return func(*args, **kwargs)
File "/usr/local/anaconda3/envs/generic-api/lib/python3.9/site-packages/feast/feature_store.py", line 742, in plan
current_infra_proto = self._registry.proto().infra.__deepcopy__()
File "/usr/local/anaconda3/envs/generic-api/lib/python3.9/site-packages/feast/infra/registry/sql.py", line 675, in proto
r.infra.CopyFrom(self.get_infra(project).to_proto())
File "/usr/local/anaconda3/envs/generic-api/lib/python3.9/site-packages/feast/infra/registry/sql.py", line 574, in get_infra
return Infra.from_proto(infra_object)
File "/usr/local/anaconda3/envs/generic-api/lib/python3.9/site-packages/feast/infra/infra_object.py", line 150, in from_proto
infra.infra_objects += [
File "/usr/local/anaconda3/envs/generic-api/lib/python3.9/site-packages/feast/infra/infra_object.py", line 151, in <listcomp>
InfraObject.from_infra_object_proto(infra_object_proto)
File "/usr/local/anaconda3/envs/generic-api/lib/python3.9/site-packages/feast/infra/infra_object.py", line 73, in from_infra_object_proto
if infra_object_proto.infra_object_class_type:
AttributeError: 'SqliteTable' object has no attribute 'infra_object_class_type'
`
## Steps to reproduce
Step 1: Create a basic local repo with `feast init -t local` (my created directory was named native_duckling in testing)
Step 2: Reconfigure the feature_repo.yaml to point to any postgres registry, e.g.
`
registry:
registry_type: sql
path: <insert_connection_string_here>
`
Step 3: Run feast apply. It should return:
`Created entity driver
Created feature view driver_hourly_stats_fresh
Created feature view driver_hourly_stats
Created on demand feature view transformed_conv_rate
Created on demand feature view transformed_conv_rate_fresh
Created feature service driver_activity_v2
Created feature service driver_activity_v1
Created feature service driver_activity_v3
Created sqlite table native_duckling_driver_hourly_stats_fresh
Created sqlite table native_duckling_driver_hourly_stats
`
Step 4: Make any small change to the registry.
Step 5: Run feast apply again; the error above will be generated and the apply will fail.
### Specifications
- Version: feast 0.26.0, Python 3.9
- Platform: macOS Big Sur 11.4
- Subsystem:
## Possible Solution
The issue does not appear to come up when using a file registry, but this is not a preferable solution as my team would like to use more scalable options in production settings.
| I'm running into the exact same issue. No clue how to fix it though.
Same here with v0.27.0 | 2022-12-15T01:23:22 |
feast-dev/feast | 3,395 | feast-dev__feast-3395 | [
"3328"
]
| 6bcf77c19f84188586ee7dcc57920a43062ee3be | diff --git a/sdk/python/feast/infra/registry/proto_registry_utils.py b/sdk/python/feast/infra/registry/proto_registry_utils.py
new file mode 100644
--- /dev/null
+++ b/sdk/python/feast/infra/registry/proto_registry_utils.py
@@ -0,0 +1,208 @@
+from typing import List
+
+from feast.data_source import DataSource
+from feast.entity import Entity
+from feast.errors import (
+ DataSourceObjectNotFoundException,
+ EntityNotFoundException,
+ FeatureServiceNotFoundException,
+ FeatureViewNotFoundException,
+ OnDemandFeatureViewNotFoundException,
+ SavedDatasetNotFound,
+ ValidationReferenceNotFound,
+)
+from feast.feature_service import FeatureService
+from feast.feature_view import FeatureView
+from feast.on_demand_feature_view import OnDemandFeatureView
+from feast.project_metadata import ProjectMetadata
+from feast.protos.feast.core.Registry_pb2 import Registry as RegistryProto
+from feast.request_feature_view import RequestFeatureView
+from feast.saved_dataset import SavedDataset, ValidationReference
+from feast.stream_feature_view import StreamFeatureView
+
+
+def get_feature_service(
+ registry_proto: RegistryProto, name: str, project: str
+) -> FeatureService:
+ for feature_service_proto in registry_proto.feature_services:
+ if (
+ feature_service_proto.spec.project == project
+ and feature_service_proto.spec.name == name
+ ):
+ return FeatureService.from_proto(feature_service_proto)
+ raise FeatureServiceNotFoundException(name, project=project)
+
+
+def get_feature_view(
+ registry_proto: RegistryProto, name: str, project: str
+) -> FeatureView:
+ for feature_view_proto in registry_proto.feature_views:
+ if (
+ feature_view_proto.spec.name == name
+ and feature_view_proto.spec.project == project
+ ):
+ return FeatureView.from_proto(feature_view_proto)
+ raise FeatureViewNotFoundException(name, project)
+
+
+def get_stream_feature_view(
+ registry_proto: RegistryProto, name: str, project: str
+) -> StreamFeatureView:
+ for feature_view_proto in registry_proto.stream_feature_views:
+ if (
+ feature_view_proto.spec.name == name
+ and feature_view_proto.spec.project == project
+ ):
+ return StreamFeatureView.from_proto(feature_view_proto)
+ raise FeatureViewNotFoundException(name, project)
+
+
+def get_request_feature_view(registry_proto: RegistryProto, name: str, project: str):
+ for feature_view_proto in registry_proto.feature_views:
+ if (
+ feature_view_proto.spec.name == name
+ and feature_view_proto.spec.project == project
+ ):
+ return RequestFeatureView.from_proto(feature_view_proto)
+ raise FeatureViewNotFoundException(name, project)
+
+
+def get_on_demand_feature_view(
+ registry_proto: RegistryProto, name: str, project: str
+) -> OnDemandFeatureView:
+ for on_demand_feature_view in registry_proto.on_demand_feature_views:
+ if (
+ on_demand_feature_view.spec.project == project
+ and on_demand_feature_view.spec.name == name
+ ):
+ return OnDemandFeatureView.from_proto(on_demand_feature_view)
+ raise OnDemandFeatureViewNotFoundException(name, project=project)
+
+
+def get_data_source(
+ registry_proto: RegistryProto, name: str, project: str
+) -> DataSource:
+ for data_source in registry_proto.data_sources:
+ if data_source.project == project and data_source.name == name:
+ return DataSource.from_proto(data_source)
+ raise DataSourceObjectNotFoundException(name, project=project)
+
+
+def get_entity(registry_proto: RegistryProto, name: str, project: str) -> Entity:
+ for entity_proto in registry_proto.entities:
+ if entity_proto.spec.name == name and entity_proto.spec.project == project:
+ return Entity.from_proto(entity_proto)
+ raise EntityNotFoundException(name, project=project)
+
+
+def get_saved_dataset(
+ registry_proto: RegistryProto, name: str, project: str
+) -> SavedDataset:
+ for saved_dataset in registry_proto.saved_datasets:
+ if saved_dataset.spec.name == name and saved_dataset.spec.project == project:
+ return SavedDataset.from_proto(saved_dataset)
+ raise SavedDatasetNotFound(name, project=project)
+
+
+def get_validation_reference(
+ registry_proto: RegistryProto, name: str, project: str
+) -> ValidationReference:
+ for validation_reference in registry_proto.validation_references:
+ if (
+ validation_reference.name == name
+ and validation_reference.project == project
+ ):
+ return ValidationReference.from_proto(validation_reference)
+ raise ValidationReferenceNotFound(name, project=project)
+
+
+def list_feature_services(
+ registry_proto: RegistryProto, project: str, allow_cache: bool = False
+) -> List[FeatureService]:
+ feature_services = []
+ for feature_service_proto in registry_proto.feature_services:
+ if feature_service_proto.spec.project == project:
+ feature_services.append(FeatureService.from_proto(feature_service_proto))
+ return feature_services
+
+
+def list_feature_views(
+ registry_proto: RegistryProto, project: str
+) -> List[FeatureView]:
+ feature_views: List[FeatureView] = []
+ for feature_view_proto in registry_proto.feature_views:
+ if feature_view_proto.spec.project == project:
+ feature_views.append(FeatureView.from_proto(feature_view_proto))
+ return feature_views
+
+
+def list_request_feature_views(
+ registry_proto: RegistryProto, project: str
+) -> List[RequestFeatureView]:
+ feature_views: List[RequestFeatureView] = []
+ for request_feature_view_proto in registry_proto.request_feature_views:
+ if request_feature_view_proto.spec.project == project:
+ feature_views.append(
+ RequestFeatureView.from_proto(request_feature_view_proto)
+ )
+ return feature_views
+
+
+def list_stream_feature_views(
+ registry_proto: RegistryProto, project: str
+) -> List[StreamFeatureView]:
+ stream_feature_views = []
+ for stream_feature_view in registry_proto.stream_feature_views:
+ if stream_feature_view.spec.project == project:
+ stream_feature_views.append(
+ StreamFeatureView.from_proto(stream_feature_view)
+ )
+ return stream_feature_views
+
+
+def list_on_demand_feature_views(
+ registry_proto: RegistryProto, project: str
+) -> List[OnDemandFeatureView]:
+ on_demand_feature_views = []
+ for on_demand_feature_view in registry_proto.on_demand_feature_views:
+ if on_demand_feature_view.spec.project == project:
+ on_demand_feature_views.append(
+ OnDemandFeatureView.from_proto(on_demand_feature_view)
+ )
+ return on_demand_feature_views
+
+
+def list_entities(registry_proto: RegistryProto, project: str) -> List[Entity]:
+ entities = []
+ for entity_proto in registry_proto.entities:
+ if entity_proto.spec.project == project:
+ entities.append(Entity.from_proto(entity_proto))
+ return entities
+
+
+def list_data_sources(registry_proto: RegistryProto, project: str) -> List[DataSource]:
+ data_sources = []
+ for data_source_proto in registry_proto.data_sources:
+ if data_source_proto.project == project:
+ data_sources.append(DataSource.from_proto(data_source_proto))
+ return data_sources
+
+
+def list_saved_datasets(
+ registry_proto: RegistryProto, project: str, allow_cache: bool = False
+) -> List[SavedDataset]:
+ return [
+ SavedDataset.from_proto(saved_dataset)
+ for saved_dataset in registry_proto.saved_datasets
+ if saved_dataset.spec.project == project
+ ]
+
+
+def list_project_metadata(
+ registry_proto: RegistryProto, project: str
+) -> List[ProjectMetadata]:
+ return [
+ ProjectMetadata.from_proto(project_metadata)
+ for project_metadata in registry_proto.project_metadata
+ if project_metadata.project == project
+ ]
diff --git a/sdk/python/feast/infra/registry/registry.py b/sdk/python/feast/infra/registry/registry.py
--- a/sdk/python/feast/infra/registry/registry.py
+++ b/sdk/python/feast/infra/registry/registry.py
@@ -30,18 +30,16 @@
from feast.errors import (
ConflictingFeatureViewNames,
DataSourceNotFoundException,
- DataSourceObjectNotFoundException,
EntityNotFoundException,
FeatureServiceNotFoundException,
FeatureViewNotFoundException,
- OnDemandFeatureViewNotFoundException,
- SavedDatasetNotFound,
ValidationReferenceNotFound,
)
from feast.feature_service import FeatureService
from feast.feature_view import FeatureView
from feast.importer import import_class
from feast.infra.infra_object import Infra
+from feast.infra.registry import proto_registry_utils
from feast.infra.registry.base_registry import BaseRegistry
from feast.infra.registry.registry_store import NoopRegistryStore
from feast.on_demand_feature_view import OnDemandFeatureView
@@ -293,11 +291,7 @@ def list_entities(self, project: str, allow_cache: bool = False) -> List[Entity]
registry_proto = self._get_registry_proto(
project=project, allow_cache=allow_cache
)
- entities = []
- for entity_proto in registry_proto.entities:
- if entity_proto.spec.project == project:
- entities.append(Entity.from_proto(entity_proto))
- return entities
+ return proto_registry_utils.list_entities(registry_proto, project)
def list_data_sources(
self, project: str, allow_cache: bool = False
@@ -305,11 +299,7 @@ def list_data_sources(
registry_proto = self._get_registry_proto(
project=project, allow_cache=allow_cache
)
- data_sources = []
- for data_source_proto in registry_proto.data_sources:
- if data_source_proto.project == project:
- data_sources.append(DataSource.from_proto(data_source_proto))
- return data_sources
+ return proto_registry_utils.list_data_sources(registry_proto, project)
def apply_data_source(
self, data_source: DataSource, project: str, commit: bool = True
@@ -371,36 +361,24 @@ def apply_feature_service(
def list_feature_services(
self, project: str, allow_cache: bool = False
) -> List[FeatureService]:
- registry = self._get_registry_proto(project=project, allow_cache=allow_cache)
- feature_services = []
- for feature_service_proto in registry.feature_services:
- if feature_service_proto.spec.project == project:
- feature_services.append(
- FeatureService.from_proto(feature_service_proto)
- )
- return feature_services
+ registry_proto = self._get_registry_proto(
+ project=project, allow_cache=allow_cache
+ )
+ return proto_registry_utils.list_feature_services(registry_proto, project)
def get_feature_service(
self, name: str, project: str, allow_cache: bool = False
) -> FeatureService:
- registry = self._get_registry_proto(project=project, allow_cache=allow_cache)
-
- for feature_service_proto in registry.feature_services:
- if (
- feature_service_proto.spec.project == project
- and feature_service_proto.spec.name == name
- ):
- return FeatureService.from_proto(feature_service_proto)
- raise FeatureServiceNotFoundException(name, project=project)
+ registry_proto = self._get_registry_proto(
+ project=project, allow_cache=allow_cache
+ )
+ return proto_registry_utils.get_feature_service(registry_proto, name, project)
def get_entity(self, name: str, project: str, allow_cache: bool = False) -> Entity:
registry_proto = self._get_registry_proto(
project=project, allow_cache=allow_cache
)
- for entity_proto in registry_proto.entities:
- if entity_proto.spec.name == name and entity_proto.spec.project == project:
- return Entity.from_proto(entity_proto)
- raise EntityNotFoundException(name, project=project)
+ return proto_registry_utils.get_entity(registry_proto, name, project)
def apply_feature_view(
self, feature_view: BaseFeatureView, project: str, commit: bool = True
@@ -461,49 +439,38 @@ def apply_feature_view(
def list_stream_feature_views(
self, project: str, allow_cache: bool = False
) -> List[StreamFeatureView]:
- registry = self._get_registry_proto(project=project, allow_cache=allow_cache)
- stream_feature_views = []
- for stream_feature_view in registry.stream_feature_views:
- if stream_feature_view.spec.project == project:
- stream_feature_views.append(
- StreamFeatureView.from_proto(stream_feature_view)
- )
- return stream_feature_views
+ registry_proto = self._get_registry_proto(
+ project=project, allow_cache=allow_cache
+ )
+ return proto_registry_utils.list_stream_feature_views(registry_proto, project)
def list_on_demand_feature_views(
self, project: str, allow_cache: bool = False
) -> List[OnDemandFeatureView]:
- registry = self._get_registry_proto(project=project, allow_cache=allow_cache)
- on_demand_feature_views = []
- for on_demand_feature_view in registry.on_demand_feature_views:
- if on_demand_feature_view.spec.project == project:
- on_demand_feature_views.append(
- OnDemandFeatureView.from_proto(on_demand_feature_view)
- )
- return on_demand_feature_views
+ registry_proto = self._get_registry_proto(
+ project=project, allow_cache=allow_cache
+ )
+ return proto_registry_utils.list_on_demand_feature_views(
+ registry_proto, project
+ )
def get_on_demand_feature_view(
self, name: str, project: str, allow_cache: bool = False
) -> OnDemandFeatureView:
- registry = self._get_registry_proto(project=project, allow_cache=allow_cache)
-
- for on_demand_feature_view in registry.on_demand_feature_views:
- if (
- on_demand_feature_view.spec.project == project
- and on_demand_feature_view.spec.name == name
- ):
- return OnDemandFeatureView.from_proto(on_demand_feature_view)
- raise OnDemandFeatureViewNotFoundException(name, project=project)
+ registry_proto = self._get_registry_proto(
+ project=project, allow_cache=allow_cache
+ )
+ return proto_registry_utils.get_on_demand_feature_view(
+ registry_proto, name, project
+ )
def get_data_source(
self, name: str, project: str, allow_cache: bool = False
) -> DataSource:
- registry = self._get_registry_proto(project=project, allow_cache=allow_cache)
-
- for data_source in registry.data_sources:
- if data_source.project == project and data_source.name == name:
- return DataSource.from_proto(data_source)
- raise DataSourceObjectNotFoundException(name, project=project)
+ registry_proto = self._get_registry_proto(
+ project=project, allow_cache=allow_cache
+ )
+ return proto_registry_utils.get_data_source(registry_proto, name, project)
def apply_materialization(
self,
@@ -570,21 +537,13 @@ def list_feature_views(
registry_proto = self._get_registry_proto(
project=project, allow_cache=allow_cache
)
- feature_views: List[FeatureView] = []
- for feature_view_proto in registry_proto.feature_views:
- if feature_view_proto.spec.project == project:
- feature_views.append(FeatureView.from_proto(feature_view_proto))
- return feature_views
+ return proto_registry_utils.list_feature_views(registry_proto, project)
def get_request_feature_view(self, name: str, project: str):
registry_proto = self._get_registry_proto(project=project, allow_cache=False)
- for feature_view_proto in registry_proto.feature_views:
- if (
- feature_view_proto.spec.name == name
- and feature_view_proto.spec.project == project
- ):
- return RequestFeatureView.from_proto(feature_view_proto)
- raise FeatureViewNotFoundException(name, project)
+ return proto_registry_utils.get_request_feature_view(
+ registry_proto, name, project
+ )
def list_request_feature_views(
self, project: str, allow_cache: bool = False
@@ -592,13 +551,7 @@ def list_request_feature_views(
registry_proto = self._get_registry_proto(
project=project, allow_cache=allow_cache
)
- feature_views: List[RequestFeatureView] = []
- for request_feature_view_proto in registry_proto.request_feature_views:
- if request_feature_view_proto.spec.project == project:
- feature_views.append(
- RequestFeatureView.from_proto(request_feature_view_proto)
- )
- return feature_views
+ return proto_registry_utils.list_request_feature_views(registry_proto, project)
def get_feature_view(
self, name: str, project: str, allow_cache: bool = False
@@ -606,13 +559,7 @@ def get_feature_view(
registry_proto = self._get_registry_proto(
project=project, allow_cache=allow_cache
)
- for feature_view_proto in registry_proto.feature_views:
- if (
- feature_view_proto.spec.name == name
- and feature_view_proto.spec.project == project
- ):
- return FeatureView.from_proto(feature_view_proto)
- raise FeatureViewNotFoundException(name, project)
+ return proto_registry_utils.get_feature_view(registry_proto, name, project)
def get_stream_feature_view(
self, name: str, project: str, allow_cache: bool = False
@@ -620,13 +567,9 @@ def get_stream_feature_view(
registry_proto = self._get_registry_proto(
project=project, allow_cache=allow_cache
)
- for feature_view_proto in registry_proto.stream_feature_views:
- if (
- feature_view_proto.spec.name == name
- and feature_view_proto.spec.project == project
- ):
- return StreamFeatureView.from_proto(feature_view_proto)
- raise FeatureViewNotFoundException(name, project)
+ return proto_registry_utils.get_stream_feature_view(
+ registry_proto, name, project
+ )
def delete_feature_service(self, name: str, project: str, commit: bool = True):
self._prepare_registry_for_changes(project)
@@ -753,13 +696,7 @@ def get_saved_dataset(
registry_proto = self._get_registry_proto(
project=project, allow_cache=allow_cache
)
- for saved_dataset in registry_proto.saved_datasets:
- if (
- saved_dataset.spec.name == name
- and saved_dataset.spec.project == project
- ):
- return SavedDataset.from_proto(saved_dataset)
- raise SavedDatasetNotFound(name, project=project)
+ return proto_registry_utils.get_saved_dataset(registry_proto, name, project)
def list_saved_datasets(
self, project: str, allow_cache: bool = False
@@ -767,11 +704,7 @@ def list_saved_datasets(
registry_proto = self._get_registry_proto(
project=project, allow_cache=allow_cache
)
- return [
- SavedDataset.from_proto(saved_dataset)
- for saved_dataset in registry_proto.saved_datasets
- if saved_dataset.spec.project == project
- ]
+ return proto_registry_utils.list_saved_datasets(registry_proto, project)
def apply_validation_reference(
self,
@@ -803,13 +736,9 @@ def get_validation_reference(
registry_proto = self._get_registry_proto(
project=project, allow_cache=allow_cache
)
- for validation_reference in registry_proto.validation_references:
- if (
- validation_reference.name == name
- and validation_reference.project == project
- ):
- return ValidationReference.from_proto(validation_reference)
- raise ValidationReferenceNotFound(name, project=project)
+ return proto_registry_utils.get_validation_reference(
+ registry_proto, name, project
+ )
def delete_validation_reference(self, name: str, project: str, commit: bool = True):
registry_proto = self._prepare_registry_for_changes(project)
@@ -832,11 +761,7 @@ def list_project_metadata(
registry_proto = self._get_registry_proto(
project=project, allow_cache=allow_cache
)
- return [
- ProjectMetadata.from_proto(project_metadata)
- for project_metadata in registry_proto.project_metadata
- if project_metadata.project == project
- ]
+ return proto_registry_utils.list_project_metadata(registry_proto, project)
def commit(self):
"""Commits the state of the registry cache to the remote registry store."""
diff --git a/sdk/python/feast/infra/registry/sql.py b/sdk/python/feast/infra/registry/sql.py
--- a/sdk/python/feast/infra/registry/sql.py
+++ b/sdk/python/feast/infra/registry/sql.py
@@ -1,7 +1,8 @@
import uuid
-from datetime import datetime
+from datetime import datetime, timedelta
from enum import Enum
from pathlib import Path
+from threading import Lock
from typing import Any, Callable, List, Optional, Set, Union
from sqlalchemy import ( # type: ignore
@@ -34,6 +35,7 @@
from feast.feature_service import FeatureService
from feast.feature_view import FeatureView
from feast.infra.infra_object import Infra
+from feast.infra.registry import proto_registry_utils
from feast.infra.registry.base_registry import BaseRegistry
from feast.on_demand_feature_view import OnDemandFeatureView
from feast.project_metadata import ProjectMetadata
@@ -183,6 +185,14 @@ def __init__(
assert registry_config is not None, "SqlRegistry needs a valid registry_config"
self.engine: Engine = create_engine(registry_config.path, echo=False)
metadata.create_all(self.engine)
+ self.cached_registry_proto = self.proto()
+ self.cached_registry_proto_created = datetime.utcnow()
+ self._refresh_lock = Lock()
+ self.cached_registry_proto_ttl = timedelta(
+ seconds=registry_config.cache_ttl_seconds
+ if registry_config.cache_ttl_seconds is not None
+ else 0
+ )
def teardown(self):
for t in {
@@ -200,12 +210,37 @@ def teardown(self):
conn.execute(stmt)
def refresh(self, project: Optional[str]):
- # This method is a no-op since we're always reading the latest values from the db.
- pass
+ self.cached_registry_proto = self.proto()
+ self.cached_registry_proto_created = datetime.utcnow()
+
+ def _refresh_cached_registry_if_necessary(self):
+ with self._refresh_lock:
+ expired = (
+ self.cached_registry_proto is None
+ or self.cached_registry_proto_created is None
+ ) or (
+ self.cached_registry_proto_ttl.total_seconds()
+ > 0 # 0 ttl means infinity
+ and (
+ datetime.utcnow()
+ > (
+ self.cached_registry_proto_created
+ + self.cached_registry_proto_ttl
+ )
+ )
+ )
+
+ if expired:
+ self.refresh()
def get_stream_feature_view(
self, name: str, project: str, allow_cache: bool = False
):
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.get_stream_feature_view(
+ self.cached_registry_proto, name, project
+ )
return self._get_object(
table=stream_feature_views,
name=name,
@@ -220,6 +255,11 @@ def get_stream_feature_view(
def list_stream_feature_views(
self, project: str, allow_cache: bool = False
) -> List[StreamFeatureView]:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.list_stream_feature_views(
+ self.cached_registry_proto, project
+ )
return self._list_objects(
stream_feature_views,
project,
@@ -238,6 +278,11 @@ def apply_entity(self, entity: Entity, project: str, commit: bool = True):
)
def get_entity(self, name: str, project: str, allow_cache: bool = False) -> Entity:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.get_entity(
+ self.cached_registry_proto, name, project
+ )
return self._get_object(
table=entities,
name=name,
@@ -252,6 +297,11 @@ def get_entity(self, name: str, project: str, allow_cache: bool = False) -> Enti
def get_feature_view(
self, name: str, project: str, allow_cache: bool = False
) -> FeatureView:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.get_feature_view(
+ self.cached_registry_proto, name, project
+ )
return self._get_object(
table=feature_views,
name=name,
@@ -266,6 +316,11 @@ def get_feature_view(
def get_on_demand_feature_view(
self, name: str, project: str, allow_cache: bool = False
) -> OnDemandFeatureView:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.get_on_demand_feature_view(
+ self.cached_registry_proto, name, project
+ )
return self._get_object(
table=on_demand_feature_views,
name=name,
@@ -277,7 +332,14 @@ def get_on_demand_feature_view(
not_found_exception=FeatureViewNotFoundException,
)
- def get_request_feature_view(self, name: str, project: str):
+ def get_request_feature_view(
+ self, name: str, project: str, allow_cache: bool = False
+ ):
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.get_request_feature_view(
+ self.cached_registry_proto, name, project
+ )
return self._get_object(
table=request_feature_views,
name=name,
@@ -292,6 +354,11 @@ def get_request_feature_view(self, name: str, project: str):
def get_feature_service(
self, name: str, project: str, allow_cache: bool = False
) -> FeatureService:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.get_feature_service(
+ self.cached_registry_proto, name, project
+ )
return self._get_object(
table=feature_services,
name=name,
@@ -306,6 +373,11 @@ def get_feature_service(
def get_saved_dataset(
self, name: str, project: str, allow_cache: bool = False
) -> SavedDataset:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.get_saved_dataset(
+ self.cached_registry_proto, name, project
+ )
return self._get_object(
table=saved_datasets,
name=name,
@@ -320,6 +392,11 @@ def get_saved_dataset(
def get_validation_reference(
self, name: str, project: str, allow_cache: bool = False
) -> ValidationReference:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.get_validation_reference(
+ self.cached_registry_proto, name, project
+ )
return self._get_object(
table=validation_references,
name=name,
@@ -332,6 +409,11 @@ def get_validation_reference(
)
def list_entities(self, project: str, allow_cache: bool = False) -> List[Entity]:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.list_entities(
+ self.cached_registry_proto, project
+ )
return self._list_objects(
entities, project, EntityProto, Entity, "entity_proto"
)
@@ -367,6 +449,11 @@ def delete_feature_service(self, name: str, project: str, commit: bool = True):
def get_data_source(
self, name: str, project: str, allow_cache: bool = False
) -> DataSource:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.get_data_source(
+ self.cached_registry_proto, name, project
+ )
return self._get_object(
table=data_sources,
name=name,
@@ -381,6 +468,11 @@ def get_data_source(
def list_data_sources(
self, project: str, allow_cache: bool = False
) -> List[DataSource]:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.list_data_sources(
+ self.cached_registry_proto, project
+ )
return self._list_objects(
data_sources, project, DataSourceProto, DataSource, "data_source_proto"
)
@@ -425,6 +517,11 @@ def delete_data_source(self, name: str, project: str, commit: bool = True):
def list_feature_services(
self, project: str, allow_cache: bool = False
) -> List[FeatureService]:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.list_feature_services(
+ self.cached_registry_proto, project
+ )
return self._list_objects(
feature_services,
project,
@@ -436,6 +533,11 @@ def list_feature_services(
def list_feature_views(
self, project: str, allow_cache: bool = False
) -> List[FeatureView]:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.list_feature_views(
+ self.cached_registry_proto, project
+ )
return self._list_objects(
feature_views, project, FeatureViewProto, FeatureView, "feature_view_proto"
)
@@ -443,6 +545,11 @@ def list_feature_views(
def list_saved_datasets(
self, project: str, allow_cache: bool = False
) -> List[SavedDataset]:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.list_saved_datasets(
+ self.cached_registry_proto, project
+ )
return self._list_objects(
saved_datasets,
project,
@@ -454,6 +561,11 @@ def list_saved_datasets(
def list_request_feature_views(
self, project: str, allow_cache: bool = False
) -> List[RequestFeatureView]:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.list_request_feature_views(
+ self.cached_registry_proto, project
+ )
return self._list_objects(
request_feature_views,
project,
@@ -465,6 +577,11 @@ def list_request_feature_views(
def list_on_demand_feature_views(
self, project: str, allow_cache: bool = False
) -> List[OnDemandFeatureView]:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.list_on_demand_feature_views(
+ self.cached_registry_proto, project
+ )
return self._list_objects(
on_demand_feature_views,
project,
@@ -476,6 +593,11 @@ def list_on_demand_feature_views(
def list_project_metadata(
self, project: str, allow_cache: bool = False
) -> List[ProjectMetadata]:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.list_project_metadata(
+ self.cached_registry_proto, project
+ )
with self.engine.connect() as conn:
stmt = select(feast_metadata).where(
feast_metadata.c.project_id == project,
| Cache non file-based registries for python feature server
**Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
A considerable amount of latency occurs when retrieving data from registry when calling ```get_online_features()```
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
**Describe alternatives you've considered**
A clear and concise description of any alternative solutions or features you've considered.
**Additional context**
Add any other context or screenshots about the feature request here.
| Maybe we can support customize registry in feature_store.yaml firstly so that we can use customized registry cache implementation?
it seems the amount of latency using sql registry may also relate to the unnecessary feast_metadata update when [get](https://github.com/feast-dev/feast/blob/80712a7cbbc761f2c9874690c6e539660303c9b5/sdk/python/feast/infra/registry/sql.py#L799) or [list](https://github.com/feast-dev/feast/blob/80712a7cbbc761f2c9874690c6e539660303c9b5/sdk/python/feast/infra/registry/sql.py#L822) metadata .
Should that init func only used by apply_objects? @adchia | 2022-12-15T02:11:09 |
|
feast-dev/feast | 3,401 | feast-dev__feast-3401 | [
"3400"
]
| 963bd88ac5717417dee5790862bb6b8366f144bb | diff --git a/sdk/python/feast/type_map.py b/sdk/python/feast/type_map.py
--- a/sdk/python/feast/type_map.py
+++ b/sdk/python/feast/type_map.py
@@ -402,7 +402,12 @@ def _python_value_to_proto_value(
valid_scalar_types,
) = PYTHON_SCALAR_VALUE_TYPE_TO_PROTO_VALUE[feast_value_type]
if valid_scalar_types:
- assert type(sample) in valid_scalar_types
+ if sample == 0 or sample == 0.0:
+ # Numpy convert 0 to int. However, in the feature view definition, the type of column may be a float.
+ # So, if value is 0, type validation must pass if scalar_types are either int or float.
+ assert type(sample) in [np.int64, int, np.float64, float]
+ else:
+ assert type(sample) in valid_scalar_types
if feast_value_type == ValueType.BOOL:
# ProtoValue does not support conversion of np.bool_ so we need to convert it to support np.bool_.
return [
| sampled scalar value verification failure for 0 value if float is defined
## Expected Behavior
Regardless of whether it is 0 or 0.0, conversion for int and float types must be performed.
## Current Behavior
It is defined as a float type, but if 0 is set other than 0.0, an [assert](https://github.com/feast-dev/feast/blob/master/sdk/python/feast/type_map.py#L405) fail occurs.
## Steps to reproduce
If 0 is set in the BigQuery table that owns the float type, it may be recognized as an int when materializing using the feast sdk.
### Specifications
- Version: 0.27.1
- Platform: regardless
- Subsystem: regardless
## Possible Solution
If the value is set to 0, the assertion is modified so that it is not related to int or float.
| 2022-12-19T09:20:44 |
||
feast-dev/feast | 3,404 | feast-dev__feast-3404 | [
"3369"
]
| 963bd88ac5717417dee5790862bb6b8366f144bb | diff --git a/sdk/python/feast/infra/materialization/snowflake_engine.py b/sdk/python/feast/infra/materialization/snowflake_engine.py
--- a/sdk/python/feast/infra/materialization/snowflake_engine.py
+++ b/sdk/python/feast/infra/materialization/snowflake_engine.py
@@ -8,6 +8,7 @@
import pandas as pd
from colorama import Fore, Style
from pydantic import Field, StrictStr
+from pytz import utc
from tqdm import tqdm
import feast
@@ -256,6 +257,18 @@ def _materialize_one(
end_date=end_date,
)
+ # Lets check and see if we can skip this query, because the table hasnt changed
+ # since before the start date of this query
+ with get_snowflake_conn(self.repo_config.offline_store) as conn:
+ query = f"""SELECT SYSTEM$LAST_CHANGE_COMMIT_TIME('{feature_view.batch_source.get_table_query_string()}') AS last_commit_change_time"""
+ last_commit_change_time = (
+ conn.cursor().execute(query).fetchall()[0][0] / 1_000_000_000
+ )
+ if last_commit_change_time < start_date.astimezone(tz=utc).timestamp():
+ return SnowflakeMaterializationJob(
+ job_id=job_id, status=MaterializationJobStatus.SUCCEEDED
+ )
+
fv_latest_values_sql = offline_job.to_sql()
if feature_view.batch_source.field_mapping is not None:
| Add way to skip snowflake materialization query if no table changes occurred in materialization window
**Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
**Describe alternatives you've considered**
A clear and concise description of any alternative solutions or features you've considered.
**Additional context**
Add any other context or screenshots about the feature request here.
| https://docs.snowflake.com/en/sql-reference/functions/system_last_change_commit_time.html | 2022-12-19T21:59:05 |
|
feast-dev/feast | 3,406 | feast-dev__feast-3406 | [
"3380"
]
| 2c04ec175f9155c906f90502bffe1bd5a5619ddb | diff --git a/sdk/python/feast/infra/materialization/snowflake_engine.py b/sdk/python/feast/infra/materialization/snowflake_engine.py
--- a/sdk/python/feast/infra/materialization/snowflake_engine.py
+++ b/sdk/python/feast/infra/materialization/snowflake_engine.py
@@ -276,32 +276,65 @@ def _materialize_one(
fv_latest_values_sql = offline_job.to_sql()
+ if feature_view.entity_columns:
+ join_keys = [entity.name for entity in feature_view.entity_columns]
+ unique_entities = '"' + '", "'.join(join_keys) + '"'
+
+ query = f"""
+ SELECT
+ COUNT(DISTINCT {unique_entities})
+ FROM
+ {feature_view.batch_source.get_table_query_string()}
+ """
+
+ with GetSnowflakeConnection(self.repo_config.offline_store) as conn:
+ entities_to_write = conn.cursor().execute(query).fetchall()[0][0]
+ else:
+ entities_to_write = (
+ 1 # entityless feature view has a placeholder entity
+ )
+
if feature_view.batch_source.field_mapping is not None:
fv_latest_mapped_values_sql = _run_snowflake_field_mapping(
fv_latest_values_sql, feature_view.batch_source.field_mapping
)
- fv_to_proto_sql = self.generate_snowflake_materialization_query(
- self.repo_config,
- fv_latest_mapped_values_sql,
- feature_view,
- project,
- )
+ features_full_list = feature_view.features
+ feature_batches = [
+ features_full_list[i : i + 100]
+ for i in range(0, len(features_full_list), 100)
+ ]
if self.repo_config.online_store.type == "snowflake.online":
- self.materialize_to_snowflake_online_store(
- self.repo_config,
- fv_to_proto_sql,
- feature_view,
- project,
- )
+ rows_to_write = entities_to_write * len(features_full_list)
else:
- self.materialize_to_external_online_store(
- self.repo_config,
- fv_to_proto_sql,
- feature_view,
- tqdm_builder,
- )
+ rows_to_write = entities_to_write * len(feature_batches)
+
+ with tqdm_builder(rows_to_write) as pbar:
+ for i, feature_batch in enumerate(feature_batches):
+ fv_to_proto_sql = self.generate_snowflake_materialization_query(
+ self.repo_config,
+ fv_latest_mapped_values_sql,
+ feature_view,
+ feature_batch,
+ project,
+ )
+
+ if self.repo_config.online_store.type == "snowflake.online":
+ self.materialize_to_snowflake_online_store(
+ self.repo_config,
+ fv_to_proto_sql,
+ feature_view,
+ project,
+ )
+ pbar.update(entities_to_write * len(feature_batch))
+ else:
+ self.materialize_to_external_online_store(
+ self.repo_config,
+ fv_to_proto_sql,
+ feature_view,
+ pbar,
+ )
return SnowflakeMaterializationJob(
job_id=job_id, status=MaterializationJobStatus.SUCCEEDED
@@ -316,6 +349,7 @@ def generate_snowflake_materialization_query(
repo_config: RepoConfig,
fv_latest_mapped_values_sql: str,
feature_view: Union[BatchFeatureView, FeatureView],
+ feature_batch: list,
project: str,
) -> str:
@@ -338,7 +372,7 @@ def generate_snowflake_materialization_query(
UDF serialization function.
"""
feature_sql_list = []
- for feature in feature_view.features:
+ for feature in feature_batch:
feature_value_type_name = feature.dtype.to_value_type().name
feature_sql = _convert_value_name_to_snowflake_udf(
@@ -434,11 +468,8 @@ def materialize_to_snowflake_online_store(
"""
with GetSnowflakeConnection(repo_config.batch_engine) as conn:
- query_id = execute_snowflake_statement(conn, query).sfqid
+ execute_snowflake_statement(conn, query).sfqid
- click.echo(
- f"Snowflake Query ID: {Style.BRIGHT + Fore.GREEN}{query_id}{Style.RESET_ALL}"
- )
return None
def materialize_to_external_online_store(
@@ -446,7 +477,7 @@ def materialize_to_external_online_store(
repo_config: RepoConfig,
materialization_sql: str,
feature_view: Union[StreamFeatureView, FeatureView],
- tqdm_builder: Callable[[int], tqdm],
+ pbar: tqdm,
) -> None:
feature_names = [feature.name for feature in feature_view.features]
@@ -455,10 +486,6 @@ def materialize_to_external_online_store(
query = materialization_sql
cursor = execute_snowflake_statement(conn, query)
for i, df in enumerate(cursor.fetch_pandas_batches()):
- click.echo(
- f"Snowflake: Processing Materialization ResultSet Batch #{i+1}"
- )
-
entity_keys = (
df["entity_key"].apply(EntityKeyProto.FromString).to_numpy()
)
@@ -494,11 +521,10 @@ def materialize_to_external_online_store(
)
)
- with tqdm_builder(len(rows_to_write)) as pbar:
- self.online_store.online_write_batch(
- repo_config,
- feature_view,
- rows_to_write,
- lambda x: pbar.update(x),
- )
+ self.online_store.online_write_batch(
+ repo_config,
+ feature_view,
+ rows_to_write,
+ lambda x: pbar.update(x),
+ )
return None
| Snowflake Materialization can only handle 128 features at a time
## Expected Behavior
## Current Behavior
## Steps to reproduce
### Specifications
- Version:
- Platform:
- Subsystem:
## Possible Solution
| 2022-12-20T03:38:14 |
||
feast-dev/feast | 3,417 | feast-dev__feast-3417 | [
"3416"
]
| 98a24a34c4274464f43c49b33b2b0baa88221cbd | diff --git a/sdk/python/feast/infra/offline_stores/bigquery.py b/sdk/python/feast/infra/offline_stores/bigquery.py
--- a/sdk/python/feast/infra/offline_stores/bigquery.py
+++ b/sdk/python/feast/infra/offline_stores/bigquery.py
@@ -44,9 +44,9 @@
from feast.infra.registry.base_registry import BaseRegistry
from feast.on_demand_feature_view import OnDemandFeatureView
from feast.repo_config import FeastConfigBaseModel, RepoConfig
+from feast.saved_dataset import SavedDatasetStorage
+from feast.usage import get_user_agent, log_exceptions_and_usage
-from ...saved_dataset import SavedDatasetStorage
-from ...usage import get_user_agent, log_exceptions_and_usage
from .bigquery_source import (
BigQueryLoggingDestination,
BigQuerySource,
diff --git a/sdk/python/feast/infra/offline_stores/bigquery_source.py b/sdk/python/feast/infra/offline_stores/bigquery_source.py
--- a/sdk/python/feast/infra/offline_stores/bigquery_source.py
+++ b/sdk/python/feast/infra/offline_stores/bigquery_source.py
@@ -15,8 +15,16 @@
)
from feast.repo_config import RepoConfig
from feast.saved_dataset import SavedDatasetStorage
+from feast.usage import get_user_agent
from feast.value_type import ValueType
+try:
+ from google.api_core import client_info as http_client_info
+except ImportError as e:
+ from feast.errors import FeastExtrasDependencyImportError
+
+ raise FeastExtrasDependencyImportError("gcp", str(e))
+
@typechecked
class BigQuerySource(DataSource):
@@ -159,7 +167,14 @@ def get_table_column_names_and_types(
) -> Iterable[Tuple[str, str]]:
from google.cloud import bigquery
- client = bigquery.Client()
+ project_id = (
+ config.offline_store.billing_project_id or config.offline_store.project_id
+ )
+ client = bigquery.Client(
+ project=project_id,
+ location=config.offline_store.location,
+ client_info=http_client_info.ClientInfo(user_agent=get_user_agent()),
+ )
if self.table:
schema = client.get_table(self.table).schema
if not isinstance(schema[0], bigquery.schema.SchemaField):
| Job to infer schema from BigQuerySource with query not running on billing project id
## Expected Behavior
when using BigQuery Batch source with the given query instead of table name, I suppose the schema would be inferred internally by executing jobs on billing project id (if provided).
## Current Behavior
The inference job is running on the attached project id with the current service account even when I provided specific billing project id.
## Steps to reproduce
1. Prepare a repo with provided billing project id (named A) which is different from the attached one (named B).
2. Create a BigQuerySource with query statements.
3. `feast apply`
4. Now check where the job running -> it's B
### Specifications
- Version: 0.27.1
- Platform: Linux
- Subsystem: Ubuntu
## Possible Solution
a few changes needed here [line 162](https://github.com/feast-dev/feast/blob/master/sdk/python/feast/infra/offline_stores/bigquery_source.py#L162)
| 2022-12-27T16:00:02 |
||
feast-dev/feast | 3,422 | feast-dev__feast-3422 | [
"2981"
]
| 2c04ec175f9155c906f90502bffe1bd5a5619ddb | diff --git a/sdk/python/feast/infra/offline_stores/snowflake.py b/sdk/python/feast/infra/offline_stores/snowflake.py
--- a/sdk/python/feast/infra/offline_stores/snowflake.py
+++ b/sdk/python/feast/infra/offline_stores/snowflake.py
@@ -164,7 +164,7 @@ def pull_latest_from_table_or_query(
)
select_timestamps = list(
map(
- lambda field_name: f"to_varchar({field_name}, 'YYYY-MM-DD\"T\"HH24:MI:SS.FFTZH:TZM') as {field_name}",
+ lambda field_name: f"TO_VARCHAR({field_name}, 'YYYY-MM-DD\"T\"HH24:MI:SS.FFTZH:TZM') AS {field_name}",
timestamp_columns,
)
)
@@ -178,9 +178,6 @@ def pull_latest_from_table_or_query(
)
inner_field_string = ", ".join(select_fields)
- if data_source.snowflake_options.warehouse:
- config.offline_store.warehouse = data_source.snowflake_options.warehouse
-
with GetSnowflakeConnection(config.offline_store) as conn:
snowflake_conn = conn
@@ -232,9 +229,6 @@ def pull_all_from_table_or_query(
+ '"'
)
- if data_source.snowflake_options.warehouse:
- config.offline_store.warehouse = data_source.snowflake_options.warehouse
-
with GetSnowflakeConnection(config.offline_store) as conn:
snowflake_conn = conn
diff --git a/sdk/python/feast/infra/offline_stores/snowflake_source.py b/sdk/python/feast/infra/offline_stores/snowflake_source.py
--- a/sdk/python/feast/infra/offline_stores/snowflake_source.py
+++ b/sdk/python/feast/infra/offline_stores/snowflake_source.py
@@ -1,3 +1,4 @@
+import warnings
from typing import Callable, Dict, Iterable, Optional, Tuple
from typeguard import typechecked
@@ -45,7 +46,6 @@ def __init__(
timestamp_field (optional): Event timestamp field used for point in time
joins of feature values.
database (optional): Snowflake database where the features are stored.
- warehouse (optional): Snowflake warehouse where the database is stored.
schema (optional): Snowflake schema in which the table is located.
table (optional): Snowflake table where the features are stored. Exactly one of 'table'
and 'query' must be specified.
@@ -60,6 +60,14 @@ def __init__(
owner (optional): The owner of the snowflake source, typically the email of the primary
maintainer.
"""
+
+ if warehouse:
+ warnings.warn(
+ "Specifying a warehouse within a SnowflakeSource is to be deprecated."
+ "Starting v0.32.0, the warehouse as part of the Snowflake store config will be used.",
+ RuntimeWarning,
+ )
+
if table is None and query is None:
raise ValueError('No "table" or "query" argument provided.')
if table and query:
@@ -73,7 +81,6 @@ def __init__(
schema=_schema,
table=table,
query=query,
- warehouse=warehouse,
)
# If no name, use the table as the default name.
@@ -109,7 +116,6 @@ def from_proto(data_source: DataSourceProto):
database=data_source.snowflake_options.database,
schema=data_source.snowflake_options.schema,
table=data_source.snowflake_options.table,
- warehouse=data_source.snowflake_options.warehouse,
created_timestamp_column=data_source.created_timestamp_column,
field_mapping=dict(data_source.field_mapping),
query=data_source.snowflake_options.query,
@@ -134,7 +140,6 @@ def __eq__(self, other):
and self.schema == other.schema
and self.table == other.table
and self.query == other.query
- and self.warehouse == other.warehouse
)
@property
@@ -157,11 +162,6 @@ def query(self):
"""Returns the snowflake options of this snowflake source."""
return self.snowflake_options.query
- @property
- def warehouse(self):
- """Returns the warehouse of this snowflake source."""
- return self.snowflake_options.warehouse
-
def to_proto(self) -> DataSourceProto:
"""
Converts a SnowflakeSource object to its protobuf representation.
@@ -335,13 +335,11 @@ def __init__(
schema: Optional[str],
table: Optional[str],
query: Optional[str],
- warehouse: Optional[str],
):
self.database = database or ""
self.schema = schema or ""
self.table = table or ""
self.query = query or ""
- self.warehouse = warehouse or ""
@classmethod
def from_proto(cls, snowflake_options_proto: DataSourceProto.SnowflakeOptions):
@@ -359,7 +357,6 @@ def from_proto(cls, snowflake_options_proto: DataSourceProto.SnowflakeOptions):
schema=snowflake_options_proto.schema,
table=snowflake_options_proto.table,
query=snowflake_options_proto.query,
- warehouse=snowflake_options_proto.warehouse,
)
return snowflake_options
@@ -376,7 +373,6 @@ def to_proto(self) -> DataSourceProto.SnowflakeOptions:
schema=self.schema,
table=self.table,
query=self.query,
- warehouse=self.warehouse,
)
return snowflake_options_proto
@@ -393,7 +389,6 @@ def __init__(self, table_ref: str):
schema=None,
table=table_ref,
query=None,
- warehouse=None,
)
@staticmethod
| diff --git a/sdk/python/tests/integration/feature_repos/universal/data_sources/snowflake.py b/sdk/python/tests/integration/feature_repos/universal/data_sources/snowflake.py
--- a/sdk/python/tests/integration/feature_repos/universal/data_sources/snowflake.py
+++ b/sdk/python/tests/integration/feature_repos/universal/data_sources/snowflake.py
@@ -66,7 +66,6 @@ def create_data_source(
timestamp_field=timestamp_field,
created_timestamp_column=created_timestamp_column,
field_mapping=field_mapping or {"ts_1": "ts"},
- warehouse=self.offline_store_config.warehouse,
)
def create_saved_dataset_destination(self) -> SavedDatasetSnowflakeStorage:
diff --git a/sdk/python/tests/unit/test_data_sources.py b/sdk/python/tests/unit/test_data_sources.py
--- a/sdk/python/tests/unit/test_data_sources.py
+++ b/sdk/python/tests/unit/test_data_sources.py
@@ -118,7 +118,6 @@ def test_proto_conversion():
snowflake_source = SnowflakeSource(
name="test_source",
database="test_database",
- warehouse="test_warehouse",
schema="test_schema",
table="test_table",
timestamp_field="event_timestamp",
| Snowflake source warehouse field is unused
## Expected Behavior
Id expect if I defined a warehouse source that warehouse would be used for inference functions attached to the source.
## Current Behavior
Source uses offline store credentials
## Steps to reproduce
### Specifications
- Version:
- Platform:
- Subsystem:
## Possible Solution
I think we remove warehouse from snowflake source as source and offline store are currently intertwined
you can either define a query or a database.schema.table path
| Yeah this is strange behaviour. If we keep the warehouse field in the source it should take precedence, otherwise we can remove the field altogether. I'm fine either way.
Until Feast supports a framework where any source can be fed into any offlinestore, it makes sense to remove it. If we wanted this to take precedence, in theory warehouse wouldnt be enough, we would need to add another entire set of snowflake credentials. (makes no sense)
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
bump | 2022-12-30T02:59:24 |
feast-dev/feast | 3,425 | feast-dev__feast-3425 | [
"3277"
]
| 41c0537b0335863f40207ba608348bd315c20148 | diff --git a/sdk/python/feast/feature.py b/sdk/python/feast/feature.py
--- a/sdk/python/feast/feature.py
+++ b/sdk/python/feast/feature.py
@@ -33,6 +33,7 @@ def __init__(
self,
name: str,
dtype: ValueType,
+ description: str = "",
labels: Optional[Dict[str, str]] = None,
):
"""Creates a Feature object."""
@@ -42,6 +43,7 @@ def __init__(
if dtype is ValueType.UNKNOWN:
raise ValueError(f"dtype cannot be {dtype}")
self._dtype = dtype
+ self._description = description
if labels is None:
self._labels = dict()
else:
@@ -77,6 +79,13 @@ def dtype(self) -> ValueType:
"""
return self._dtype
+ @property
+ def description(self) -> str:
+ """
+ Gets the description of the feature
+ """
+ return self._description
+
@property
def labels(self) -> Dict[str, str]:
"""
@@ -96,6 +105,7 @@ def to_proto(self) -> FeatureSpecProto:
return FeatureSpecProto(
name=self.name,
value_type=value_type,
+ description=self.description,
tags=self.labels,
)
@@ -111,6 +121,7 @@ def from_proto(cls, feature_proto: FeatureSpecProto):
feature = cls(
name=feature_proto.name,
dtype=ValueType(feature_proto.value_type),
+ description=feature_proto.description,
labels=dict(feature_proto.tags),
)
diff --git a/sdk/python/feast/field.py b/sdk/python/feast/field.py
--- a/sdk/python/feast/field.py
+++ b/sdk/python/feast/field.py
@@ -30,7 +30,7 @@ class Field:
Attributes:
name: The name of the field.
dtype: The type of the field, such as string or float.
- tags: User-defined metadata in dictionary form.
+ tags (optional): User-defined metadata in dictionary form.
"""
name: str
@@ -42,6 +42,7 @@ def __init__(
*,
name: str,
dtype: FeastType,
+ description: str = "",
tags: Optional[Dict[str, str]] = None,
):
"""
@@ -54,6 +55,7 @@ def __init__(
"""
self.name = name
self.dtype = dtype
+ self.description = description
self.tags = tags or {}
def __eq__(self, other):
@@ -83,7 +85,12 @@ def __str__(self):
def to_proto(self) -> FieldProto:
"""Converts a Field object to its protobuf representation."""
value_type = self.dtype.to_value_type()
- return FieldProto(name=self.name, value_type=value_type.value, tags=self.tags)
+ return FieldProto(
+ name=self.name,
+ value_type=value_type.value,
+ description=self.description,
+ tags=self.tags,
+ )
@classmethod
def from_proto(cls, field_proto: FieldProto):
@@ -109,5 +116,8 @@ def from_feature(cls, feature: Feature):
feature: Feature object to convert.
"""
return cls(
- name=feature.name, dtype=from_value_type(feature.dtype), tags=feature.labels
+ name=feature.name,
+ dtype=from_value_type(feature.dtype),
+ description=feature.description,
+ tags=feature.labels,
)
diff --git a/sdk/python/feast/templates/local/feature_repo/example_repo.py b/sdk/python/feast/templates/local/feature_repo/example_repo.py
--- a/sdk/python/feast/templates/local/feature_repo/example_repo.py
+++ b/sdk/python/feast/templates/local/feature_repo/example_repo.py
@@ -45,7 +45,7 @@
schema=[
Field(name="conv_rate", dtype=Float32),
Field(name="acc_rate", dtype=Float32),
- Field(name="avg_daily_trips", dtype=Int64),
+ Field(name="avg_daily_trips", dtype=Int64, description="Average daily trips"),
],
online=True,
source=driver_stats_source,
| diff --git a/sdk/python/tests/unit/test_feature.py b/sdk/python/tests/unit/test_feature.py
new file mode 100644
--- /dev/null
+++ b/sdk/python/tests/unit/test_feature.py
@@ -0,0 +1,29 @@
+from feast.field import Feature, Field
+from feast.types import Float32
+from feast.value_type import ValueType
+
+
+def test_feature_serialization_with_description():
+ expected_description = "Average daily trips"
+ feature = Feature(
+ name="avg_daily_trips", dtype=ValueType.FLOAT, description=expected_description
+ )
+ serialized_feature = feature.to_proto()
+
+ assert serialized_feature.description == expected_description
+
+
+def test_field_serialization_with_description():
+ expected_description = "Average daily trips"
+ field = Field(
+ name="avg_daily_trips", dtype=Float32, description=expected_description
+ )
+ feature = Feature(
+ name="avg_daily_trips", dtype=ValueType.FLOAT, description=expected_description
+ )
+
+ serialized_field = field.to_proto()
+ field_from_feature = Field.from_feature(feature)
+
+ assert serialized_field.description == expected_description
+ assert field_from_feature.description == expected_description
| `Feature.proto` should have a description field
**Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
I would like to attach a human-readable description to each field in a feature view. Since data scientists shop for individual features and not feature-views, it's useful to have documentation associated with each feature individually (rather than for the entire feature view). Persisting it here will allow us to surface them in various UIs.
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
Similar to `Entity.proto`, we should add a description field to features and store them in the registry.
**Describe alternatives you've considered**
A clear and concise description of any alternative solutions or features you've considered.
For now, we're just using a `description` tag on each feature. This works, but it's clunky. It also means that in our UI, we have to remove certain tags before showing the raw tags to the users.
**Additional context**
Add any other context or screenshots about the feature request here.
| Yep, this seems like it would be pretty helpful | 2022-12-31T23:35:07 |
feast-dev/feast | 3,428 | feast-dev__feast-3428 | [
"3011"
]
| 81c3483699a9e9ac3f6057dbf3e45ee748ccc8e8 | diff --git a/sdk/python/feast/cli.py b/sdk/python/feast/cli.py
--- a/sdk/python/feast/cli.py
+++ b/sdk/python/feast/cli.py
@@ -151,12 +151,24 @@ def version():
"--registry_ttl_sec",
"-r",
help="Number of seconds after which the registry is refreshed",
- type=int,
+ type=click.INT,
default=5,
show_default=True,
)
[email protected](
+ "--root_path",
+ help="Provide root path to make the UI working behind proxy",
+ type=click.STRING,
+ default="",
+)
@click.pass_context
-def ui(ctx: click.Context, host: str, port: int, registry_ttl_sec: int):
+def ui(
+ ctx: click.Context,
+ host: str,
+ port: int,
+ registry_ttl_sec: int,
+ root_path: Optional[str] = "",
+):
"""
Shows the Feast UI over the current directory
"""
@@ -170,6 +182,7 @@ def ui(ctx: click.Context, host: str, port: int, registry_ttl_sec: int):
port=port,
get_registry_dump=registry_dump,
registry_ttl_sec=registry_ttl_sec,
+ root_path=root_path,
)
diff --git a/sdk/python/feast/feature_store.py b/sdk/python/feast/feature_store.py
--- a/sdk/python/feast/feature_store.py
+++ b/sdk/python/feast/feature_store.py
@@ -2319,7 +2319,12 @@ def get_feature_server_endpoint(self) -> Optional[str]:
@log_exceptions_and_usage
def serve_ui(
- self, host: str, port: int, get_registry_dump: Callable, registry_ttl_sec: int
+ self,
+ host: str,
+ port: int,
+ get_registry_dump: Callable,
+ registry_ttl_sec: int,
+ root_path: Optional[str] = "",
) -> None:
"""Start the UI server locally"""
if flags_helper.is_test():
@@ -2335,6 +2340,7 @@ def serve_ui(
get_registry_dump=get_registry_dump,
project_id=self.config.project,
registry_ttl_sec=registry_ttl_sec,
+ root_path=root_path,
)
@log_exceptions_and_usage
diff --git a/sdk/python/feast/ui_server.py b/sdk/python/feast/ui_server.py
--- a/sdk/python/feast/ui_server.py
+++ b/sdk/python/feast/ui_server.py
@@ -101,6 +101,14 @@ def start_server(
get_registry_dump: Callable,
project_id: str,
registry_ttl_sec: int,
+ root_path: Optional[str] = "",
):
- app = get_app(store, get_registry_dump, project_id, registry_ttl_sec, host, port)
- uvicorn.run(app, host=host, port=port)
+ app = get_app(
+ store,
+ get_registry_dump,
+ project_id,
+ registry_ttl_sec,
+ host,
+ port,
+ )
+ uvicorn.run(app, host=host, port=port, root_path=root_path)
| feast ui not working behind proxy
## Expected Behavior
Feast UI should be able to load up behind proxy
## Current Behavior
Feast UI not loaded behind proxy
## Steps to reproduce
### Specifications
- Version: 0.23.0
- Platform: Linux
- Subsystem:
## Possible Solution
Allow user to pass root_path when initialize FastAPI.
E.g.
```
from fastapi import FastAPI, Request
app = FastAPI(root_path="/api/v1")
@app.get("/app")
def read_main(request: Request):
return {"message": "Hello World", "root_path": request.scope.get("root_path")}
```
| would you mind contributing a fix for this? Thanks!
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
| 2023-01-02T16:05:46 |
|
feast-dev/feast | 3,429 | feast-dev__feast-3429 | [
"3003"
]
| 473f8d93fa8d565e53fc59b3c444a1b8ed061c51 | diff --git a/sdk/python/feast/infra/offline_stores/bigquery.py b/sdk/python/feast/infra/offline_stores/bigquery.py
--- a/sdk/python/feast/infra/offline_stores/bigquery.py
+++ b/sdk/python/feast/infra/offline_stores/bigquery.py
@@ -488,10 +488,24 @@ def to_bigquery(
return str(job_config.destination)
with self._query_generator() as query:
- self._execute_query(query, job_config, timeout)
+ dest = job_config.destination
+ # because setting destination for scripts is not valid
+ # remove destination attribute if provided
+ job_config.destination = None
+ bq_job = self._execute_query(query, job_config, timeout)
- print(f"Done writing to '{job_config.destination}'.")
- return str(job_config.destination)
+ if not job_config.dry_run:
+ config = bq_job.to_api_repr()["configuration"]
+ # get temp table created by BQ
+ tmp_dest = config["query"]["destinationTable"]
+ temp_dest_table = f"{tmp_dest['projectId']}.{tmp_dest['datasetId']}.{tmp_dest['tableId']}"
+
+ # persist temp table
+ sql = f"CREATE TABLE {dest} AS SELECT * FROM {temp_dest_table}"
+ self._execute_query(sql, timeout=timeout)
+
+ print(f"Done writing to '{dest}'.")
+ return str(dest)
def _to_arrow_internal(self) -> pyarrow.Table:
with self._query_generator() as query:
@@ -777,7 +791,7 @@ def arrow_schema_to_bq_schema(arrow_schema: pyarrow.Schema) -> List[SchemaField]
Compute a deterministic hash for the `left_table_query_string` that will be used throughout
all the logic as the field to GROUP BY the data
*/
-WITH entity_dataframe AS (
+CREATE TEMP TABLE entity_dataframe AS (
SELECT *,
{{entity_df_event_timestamp_col}} AS entity_timestamp
{% for featureview in featureviews %}
@@ -793,95 +807,95 @@ def arrow_schema_to_bq_schema(arrow_schema: pyarrow.Schema) -> List[SchemaField]
{% endif %}
{% endfor %}
FROM `{{ left_table_query_string }}`
-),
+);
{% for featureview in featureviews %}
-
-{{ featureview.name }}__entity_dataframe AS (
- SELECT
- {{ featureview.entities | join(', ')}}{% if featureview.entities %},{% else %}{% endif %}
- entity_timestamp,
- {{featureview.name}}__entity_row_unique_id
- FROM entity_dataframe
- GROUP BY
- {{ featureview.entities | join(', ')}}{% if featureview.entities %},{% else %}{% endif %}
- entity_timestamp,
- {{featureview.name}}__entity_row_unique_id
-),
-
-/*
- This query template performs the point-in-time correctness join for a single feature set table
- to the provided entity table.
-
- 1. We first join the current feature_view to the entity dataframe that has been passed.
- This JOIN has the following logic:
- - For each row of the entity dataframe, only keep the rows where the `timestamp_field`
- is less than the one provided in the entity dataframe
- - If there a TTL for the current feature_view, also keep the rows where the `timestamp_field`
- is higher the the one provided minus the TTL
- - For each row, Join on the entity key and retrieve the `entity_row_unique_id` that has been
- computed previously
-
- The output of this CTE will contain all the necessary information and already filtered out most
- of the data that is not relevant.
-*/
-
-{{ featureview.name }}__subquery AS (
- SELECT
- {{ featureview.timestamp_field }} as event_timestamp,
- {{ featureview.created_timestamp_column ~ ' as created_timestamp,' if featureview.created_timestamp_column else '' }}
- {{ featureview.entity_selections | join(', ')}}{% if featureview.entity_selections %},{% else %}{% endif %}
- {% for feature in featureview.features %}
- {{ feature }} as {% if full_feature_names %}{{ featureview.name }}__{{featureview.field_mapping.get(feature, feature)}}{% else %}{{ featureview.field_mapping.get(feature, feature) }}{% endif %}{% if loop.last %}{% else %}, {% endif %}
- {% endfor %}
- FROM {{ featureview.table_subquery }}
- WHERE {{ featureview.timestamp_field }} <= '{{ featureview.max_event_timestamp }}'
- {% if featureview.ttl == 0 %}{% else %}
- AND {{ featureview.timestamp_field }} >= '{{ featureview.min_event_timestamp }}'
- {% endif %}
-),
-
-{{ featureview.name }}__base AS (
- SELECT
- subquery.*,
- entity_dataframe.entity_timestamp,
- entity_dataframe.{{featureview.name}}__entity_row_unique_id
- FROM {{ featureview.name }}__subquery AS subquery
- INNER JOIN {{ featureview.name }}__entity_dataframe AS entity_dataframe
- ON TRUE
- AND subquery.event_timestamp <= entity_dataframe.entity_timestamp
-
+CREATE TEMP TABLE {{ featureview.name }}__cleaned AS (
+ WITH {{ featureview.name }}__entity_dataframe AS (
+ SELECT
+ {{ featureview.entities | join(', ')}}{% if featureview.entities %},{% else %}{% endif %}
+ entity_timestamp,
+ {{featureview.name}}__entity_row_unique_id
+ FROM entity_dataframe
+ GROUP BY
+ {{ featureview.entities | join(', ')}}{% if featureview.entities %},{% else %}{% endif %}
+ entity_timestamp,
+ {{featureview.name}}__entity_row_unique_id
+ ),
+
+ /*
+ This query template performs the point-in-time correctness join for a single feature set table
+ to the provided entity table.
+
+ 1. We first join the current feature_view to the entity dataframe that has been passed.
+ This JOIN has the following logic:
+ - For each row of the entity dataframe, only keep the rows where the `timestamp_field`
+ is less than the one provided in the entity dataframe
+ - If there a TTL for the current feature_view, also keep the rows where the `timestamp_field`
+ is higher the the one provided minus the TTL
+ - For each row, Join on the entity key and retrieve the `entity_row_unique_id` that has been
+ computed previously
+
+ The output of this CTE will contain all the necessary information and already filtered out most
+ of the data that is not relevant.
+ */
+
+ {{ featureview.name }}__subquery AS (
+ SELECT
+ {{ featureview.timestamp_field }} as event_timestamp,
+ {{ featureview.created_timestamp_column ~ ' as created_timestamp,' if featureview.created_timestamp_column else '' }}
+ {{ featureview.entity_selections | join(', ')}}{% if featureview.entity_selections %},{% else %}{% endif %}
+ {% for feature in featureview.features %}
+ {{ feature }} as {% if full_feature_names %}{{ featureview.name }}__{{featureview.field_mapping.get(feature, feature)}}{% else %}{{ featureview.field_mapping.get(feature, feature) }}{% endif %}{% if loop.last %}{% else %}, {% endif %}
+ {% endfor %}
+ FROM {{ featureview.table_subquery }}
+ WHERE {{ featureview.timestamp_field }} <= '{{ featureview.max_event_timestamp }}'
{% if featureview.ttl == 0 %}{% else %}
- AND subquery.event_timestamp >= Timestamp_sub(entity_dataframe.entity_timestamp, interval {{ featureview.ttl }} second)
+ AND {{ featureview.timestamp_field }} >= '{{ featureview.min_event_timestamp }}'
{% endif %}
+ ),
+
+ {{ featureview.name }}__base AS (
+ SELECT
+ subquery.*,
+ entity_dataframe.entity_timestamp,
+ entity_dataframe.{{featureview.name}}__entity_row_unique_id
+ FROM {{ featureview.name }}__subquery AS subquery
+ INNER JOIN {{ featureview.name }}__entity_dataframe AS entity_dataframe
+ ON TRUE
+ AND subquery.event_timestamp <= entity_dataframe.entity_timestamp
+
+ {% if featureview.ttl == 0 %}{% else %}
+ AND subquery.event_timestamp >= Timestamp_sub(entity_dataframe.entity_timestamp, interval {{ featureview.ttl }} second)
+ {% endif %}
- {% for entity in featureview.entities %}
- AND subquery.{{ entity }} = entity_dataframe.{{ entity }}
- {% endfor %}
-),
-
-/*
- 2. If the `created_timestamp_column` has been set, we need to
- deduplicate the data first. This is done by calculating the
- `MAX(created_at_timestamp)` for each event_timestamp.
- We then join the data on the next CTE
-*/
-{% if featureview.created_timestamp_column %}
-{{ featureview.name }}__dedup AS (
- SELECT
- {{featureview.name}}__entity_row_unique_id,
- event_timestamp,
- MAX(created_timestamp) as created_timestamp
- FROM {{ featureview.name }}__base
- GROUP BY {{featureview.name}}__entity_row_unique_id, event_timestamp
-),
-{% endif %}
+ {% for entity in featureview.entities %}
+ AND subquery.{{ entity }} = entity_dataframe.{{ entity }}
+ {% endfor %}
+ ),
+
+ /*
+ 2. If the `created_timestamp_column` has been set, we need to
+ deduplicate the data first. This is done by calculating the
+ `MAX(created_at_timestamp)` for each event_timestamp.
+ We then join the data on the next CTE
+ */
+ {% if featureview.created_timestamp_column %}
+ {{ featureview.name }}__dedup AS (
+ SELECT
+ {{featureview.name}}__entity_row_unique_id,
+ event_timestamp,
+ MAX(created_timestamp) as created_timestamp
+ FROM {{ featureview.name }}__base
+ GROUP BY {{featureview.name}}__entity_row_unique_id, event_timestamp
+ ),
+ {% endif %}
-/*
- 3. The data has been filtered during the first CTE "*__base"
- Thus we only need to compute the latest timestamp of each feature.
-*/
-{{ featureview.name }}__latest AS (
+ /*
+ 3. The data has been filtered during the first CTE "*__base"
+ Thus we only need to compute the latest timestamp of each feature.
+ */
+ {{ featureview.name }}__latest AS (
SELECT
event_timestamp,
{% if featureview.created_timestamp_column %}created_timestamp,{% endif %}
@@ -900,13 +914,13 @@ def arrow_schema_to_bq_schema(arrow_schema: pyarrow.Schema) -> List[SchemaField]
{% endif %}
)
WHERE row_number = 1
-),
+)
/*
4. Once we know the latest value of each feature for a given timestamp,
we can join again the data back to the original "base" dataset
*/
-{{ featureview.name }}__cleaned AS (
+
SELECT base.*
FROM {{ featureview.name }}__base as base
INNER JOIN {{ featureview.name }}__latest
@@ -917,7 +931,7 @@ def arrow_schema_to_bq_schema(arrow_schema: pyarrow.Schema) -> List[SchemaField]
,created_timestamp
{% endif %}
)
-){% if loop.last %}{% else %}, {% endif %}
+);
{% endfor %}
| get_historical_features is super slow and memory inefficient
## Expected Behavior
I have a feature service with 10 feature views and up to 1000 features. I would like to get all the features, so I use get_historical_features and a entity frame of 17000 rows. In previous feast versions I have used this worked with out problems. And i've got the features quiet fast.
## Current Behavior
In the current version (and version 0.22 too)it takes up to half an hour to receive all features and 50Gb memory.
## Steps to reproduce
My entity frame got the following types:
datetime64[ns], string, bool.
The column with the String type is the entity key column.
The feature store consits of 10 feature views. In total there are 1000 features and 17000 rows. I'm using the local feast version with parquet files. The parquet files are in total 37 Mb small.
### Specifications
- Version:0.23
- Platform:WSL Ubuntu 20.04
- Subsystem:
## Possible Solution
Maybe the string column as entity column are the problem and it could be solved using a categorical type for the joins.
| Hey!
Do you remember what version of Feast was faster with this setup? Keep in mind also that we don't really recommend using Feast in local mode and that was designed more as a way to learn Feast.
It's a bit hard for us to reproduce this, but if you could help try to troubleshoot this that would be great! (eg do some quick profiling to see what is taking so long)
in version 0.18 everything worked fine. Is there the possibility of attaching a file to a comment? If so I would love to atach the cprofile output
one thing is maybe worthy to mention in the version 0.18 it was fine if the entity key column was a string of the type object, this didn't worked anymore on the current version
Yeah I think you can attach a file. That would be very helpful!
same experience when using BigQuery as the offline store.
I think the generated SQL scripts seem not well-optimized | 2023-01-03T18:11:49 |
|
feast-dev/feast | 3,436 | feast-dev__feast-3436 | [
"3408"
]
| 753d8dbb5e34c24cf065f599a2cd370b3723de9c | diff --git a/sdk/python/feast/infra/registry/proto_registry_utils.py b/sdk/python/feast/infra/registry/proto_registry_utils.py
--- a/sdk/python/feast/infra/registry/proto_registry_utils.py
+++ b/sdk/python/feast/infra/registry/proto_registry_utils.py
@@ -116,6 +116,10 @@ def get_validation_reference(
raise ValidationReferenceNotFound(name, project=project)
+def list_validation_references(registry_proto: RegistryProto):
+ return registry_proto.validation_references
+
+
def list_feature_services(
registry_proto: RegistryProto, project: str, allow_cache: bool = False
) -> List[FeatureService]:
diff --git a/sdk/python/feast/infra/registry/registry.py b/sdk/python/feast/infra/registry/registry.py
--- a/sdk/python/feast/infra/registry/registry.py
+++ b/sdk/python/feast/infra/registry/registry.py
@@ -740,6 +740,14 @@ def get_validation_reference(
registry_proto, name, project
)
+ def list_validation_references(
+ self, project: str, allow_cache: bool = False
+ ) -> List[ValidationReference]:
+ registry_proto = self._get_registry_proto(
+ project=project, allow_cache=allow_cache
+ )
+ return proto_registry_utils.list_validation_references(registry_proto)
+
def delete_validation_reference(self, name: str, project: str, commit: bool = True):
registry_proto = self._prepare_registry_for_changes(project)
for idx, existing_validation_reference in enumerate(
diff --git a/sdk/python/feast/infra/registry/sql.py b/sdk/python/feast/infra/registry/sql.py
--- a/sdk/python/feast/infra/registry/sql.py
+++ b/sdk/python/feast/infra/registry/sql.py
@@ -408,6 +408,22 @@ def get_validation_reference(
not_found_exception=ValidationReferenceNotFound,
)
+ def list_validation_references(
+ self, project: str, allow_cache: bool = False
+ ) -> List[ValidationReference]:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.list_validation_references(
+ self.cached_registry_proto
+ )
+ return self._list_objects(
+ table=validation_references,
+ project=project,
+ proto_class=ValidationReferenceProto,
+ python_class=ValidationReference,
+ proto_field_name="validation_reference_proto",
+ )
+
def list_entities(self, project: str, allow_cache: bool = False) -> List[Entity]:
if allow_cache:
self._refresh_cached_registry_if_necessary()
| diff --git a/sdk/python/tests/unit/local_feast_tests/test_e2e_local.py b/sdk/python/tests/unit/local_feast_tests/test_e2e_local.py
--- a/sdk/python/tests/unit/local_feast_tests/test_e2e_local.py
+++ b/sdk/python/tests/unit/local_feast_tests/test_e2e_local.py
@@ -21,7 +21,7 @@ def test_e2e_local() -> None:
"""
Tests the end-to-end workflow of apply, materialize, and online retrieval.
- This test runs against several different types of repos:
+ This test runs against several types of repos:
1. A repo with a normal FV and an entity-less FV.
2. A repo using the SDK from version 0.19.0.
3. A repo with a FV with a ttl of 0.
| SQL Registry + caching is missing the function: list_validation_references(
When adding the caching code to the Snowflake Registry, I noticed that the SQL Registry is missing a GET function for VALIDATION REFERENCES
## Expected Behavior
THIS WORKS
store.get_validation_references()
THIS SHOULD WORK TOO
store.list_validation_references()
## Current Behavior
THIS DOESNT WORK
store.list_validation_references()
## Steps to reproduce
### Specifications
- Version:
- Platform:
- Subsystem:
## Possible Solution
| Same goes for registry.py | 2023-01-07T01:41:44 |
feast-dev/feast | 3,460 | feast-dev__feast-3460 | [
"3459"
]
| 2f7c4ede8f9e66703714261f1152f78526d4bf43 | diff --git a/sdk/python/feast/feature_view.py b/sdk/python/feast/feature_view.py
--- a/sdk/python/feast/feature_view.py
+++ b/sdk/python/feast/feature_view.py
@@ -259,7 +259,7 @@ def join_keys(self) -> List[str]:
@property
def schema(self) -> List[Field]:
- return self.entity_columns + self.features
+ return list(set(self.entity_columns + self.features))
def ensure_valid(self):
"""
diff --git a/sdk/python/feast/field.py b/sdk/python/feast/field.py
--- a/sdk/python/feast/field.py
+++ b/sdk/python/feast/field.py
@@ -30,11 +30,13 @@ class Field:
Attributes:
name: The name of the field.
dtype: The type of the field, such as string or float.
- tags (optional): User-defined metadata in dictionary form.
+ description: A human-readable description.
+ tags: User-defined metadata in dictionary form.
"""
name: str
dtype: FeastType
+ description: str
tags: Dict[str, str]
def __init__(
@@ -51,6 +53,7 @@ def __init__(
Args:
name: The name of the field.
dtype: The type of the field, such as string or float.
+ description (optional): A human-readable description.
tags (optional): User-defined metadata in dictionary form.
"""
self.name = name
@@ -65,6 +68,7 @@ def __eq__(self, other):
if (
self.name != other.name
or self.dtype != other.dtype
+ or self.description != other.description
or self.tags != other.tags
):
return False
| schema has duplicate fields
## Expected Behavior
feature_view.schema has no duplicate fields
## Current Behavior
feature_view.schema has no duplicate fields
## Steps to reproduce
### Specifications
- Version:
- Platform:
- Subsystem:
## Possible Solution
in feature_view:
```
def schema(self) -> List[Field]:
return list(set(self.entity_columns + self.features))
```
| @hao-affirm would you mind sharing the feature view definition that led to duplicate fields shared between `self.entity_columns` and `self.features`?
I'm slightly surprised by that, since I thought our inference process would place each `Field` in either `self.entity_columns` or `self.features`, but not both
https://github.com/feast-dev/feast/blob/2f7c4ede8f9e66703714261f1152f78526d4bf43/sdk/python/feast/feature_view.py#L261
and https://github.com/feast-dev/feast/blob/2f7c4ede8f9e66703714261f1152f78526d4bf43/sdk/python/feast/feature_view.py#L171 i think both `entity_column` and `features` will append the `field`, if the field is defined in both `entities` and `schema` | 2023-01-20T18:47:51 |
|
feast-dev/feast | 3,476 | feast-dev__feast-3476 | [
"3287"
]
| 2c85421fef02dc85854960b4616f00e613934c01 | diff --git a/sdk/python/feast/infra/offline_stores/bigquery_source.py b/sdk/python/feast/infra/offline_stores/bigquery_source.py
--- a/sdk/python/feast/infra/offline_stores/bigquery_source.py
+++ b/sdk/python/feast/infra/offline_stores/bigquery_source.py
@@ -162,6 +162,7 @@ def get_table_column_names_and_types(
from google.api_core import client_info as http_client_info
except ImportError as e:
from feast.errors import FeastExtrasDependencyImportError
+
raise FeastExtrasDependencyImportError("gcp", str(e))
from google.cloud import bigquery
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -58,7 +58,7 @@
"numpy>=1.22,<3",
"pandas>=1.4.3,<2",
"pandavro~=1.5.0", # For some reason pandavro higher than 1.5.* only support pandas less than 1.3.
- "protobuf<5,>3",
+ "protobuf<5,>3.20",
"proto-plus>=1.20.0,<2",
"pyarrow>=4,<9",
"pydantic>=1,<2",
| feast>=0.25.1 breaks compatibility with protobuf<3.20
## Expected Behavior
`setup.py` has `protobuf<5,>3`, so I would expect version of protobuf in that range to work. More concretely, tensorflow https://github.com/tensorflow/tensorflow/commit/60d5bfbf0241e00267884b0dc1723bbdfee1806a requires `protobuf >= 3.9.2, < 3.20'` and it is reasonable to want to use tensorflow and feast together.
I first noticed this with the 0.26.0 release, but 0.25.1 is when I can first reproduce the problem.
## Current Behavior
### feast 0.25.0
```
$ pip install feast==0.25.0
...
$ feast version
Feast SDK Version: "feast 0.25.0"
$ pip install protobuf~=3.19.5
Collecting protobuf~=3.19.5
Using cached protobuf-3.19.6-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (1.1 MB)
Installing collected packages: protobuf
Attempting uninstall: protobuf
Found existing installation: protobuf 3.20.3
Uninstalling protobuf-3.20.3:
Successfully uninstalled protobuf-3.20.3
Successfully installed protobuf-3.19.6
$ feast version
Feast SDK Version: "feast 0.25.0"
```
### feast 0.25.1
```
$ pip install feast==0.25.1
$ feast version
Feast SDK Version: "feast 0.25.1"
$ pip install protobuf~=3.19.5
Collecting protobuf~=3.19.5
Using cached protobuf-3.19.6-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (1.1 MB)
Installing collected packages: protobuf
Attempting uninstall: protobuf
Found existing installation: protobuf 3.20.3
Uninstalling protobuf-3.20.3:
Successfully uninstalled protobuf-3.20.3
Successfully installed protobuf-3.19.6
$ feast version
Traceback (most recent call last):
File "/tmp/proto/f251/env/bin/feast", line 5, in <module>
from feast.cli import cli
File "/tmp/proto/f251/env/lib/python3.10/site-packages/feast/__init__.py", line 7, in <module>
from feast.infra.offline_stores.bigquery_source import BigQuerySource
File "/tmp/proto/f251/env/lib/python3.10/site-packages/feast/infra/offline_stores/bigquery_source.py", line 5, in <module>
from feast import type_map
File "/tmp/proto/f251/env/lib/python3.10/site-packages/feast/type_map.py", line 37, in <module>
from feast.protos.feast.types.Value_pb2 import (
File "/tmp/proto/f251/env/lib/python3.10/site-packages/feast/protos/feast/types/Value_pb2.py", line 5, in <module>
from google.protobuf.internal import builder as _builder
ImportError: cannot import name 'builder' from 'google.protobuf.internal' (/tmp/proto/f251/env/lib/python3.10/site-packages/google/protobuf/internal/__init__.py)
```
### Specifications
- Version: `Feast SDK Version: "feast 0.25.1"`
- Platform: `Linux 5.4.x`
- Subsystem:`x86_64`
Some history in #3103
| I'm also facing the same issue.Are there any plans to fix it?
I looked at this a bit more and I think it is a variant of https://github.com/protocolbuffers/protobuf/issues/9778
Code generated with version X is only guaranteed to work with clients X>=1. So the *minimal* version of protobuf supported by feast becomes whatever version was used in in CI to generate, not the version in `setup.py`. I think the solution would look something like "`compile-protos-python` uses a separate environment with a fixed version of protobuf". I'm not sure if Makefile changes or github action configs would be the more palatable approach to doing that.
| 2023-02-01T03:57:21 |
|
feast-dev/feast | 3,501 | feast-dev__feast-3501 | [
"3500"
]
| 059c304e40769271dc79511d3cda156dd299ebc9 | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -127,7 +127,7 @@
"cassandra-driver>=3.24.0,<4",
]
-GE_REQUIRED = ["great_expectations>=0.14.0,<0.15.0"]
+GE_REQUIRED = ["great_expectations>=0.15.41,<0.16.0"]
GO_REQUIRED = [
"cffi~=1.15.0",
| Greate Expectations version a bit outdated
## Expected Behavior
GX version works well with >=0.15.41
## Current Behavior
It got pinned between 0.14 and 0.15
### Specifications
- Version: 0.29.0
## Possible Solution
Bump GX version
| 2023-02-17T04:19:59 |
||
feast-dev/feast | 3,514 | feast-dev__feast-3514 | [
"3481"
]
| 059c304e40769271dc79511d3cda156dd299ebc9 | diff --git a/sdk/python/feast/ui_server.py b/sdk/python/feast/ui_server.py
--- a/sdk/python/feast/ui_server.py
+++ b/sdk/python/feast/ui_server.py
@@ -13,11 +13,9 @@
def get_app(
store: "feast.FeatureStore",
- get_registry_dump: Callable,
project_id: str,
registry_ttl_secs: int,
- host: str,
- port: int,
+ root_path: str = "",
):
app = FastAPI()
@@ -62,7 +60,7 @@ def shutdown_event():
"name": "Project",
"description": "Test project",
"id": project_id,
- "registryPath": "/registry",
+ "registryPath": f"{root_path}/registry",
}
]
}
@@ -105,11 +103,8 @@ def start_server(
):
app = get_app(
store,
- get_registry_dump,
project_id,
registry_ttl_sec,
- host,
- port,
+ root_path,
)
- assert root_path is not None
- uvicorn.run(app, host=host, port=port, root_path=root_path)
+ uvicorn.run(app, host=host, port=port)
| feast ui does not work on proxy subpath
## Expected Behavior
Feast UI should work when it is served behind a proxy, on a subpath e.g. `/feast-ui`
## Current Behavior
Parts of the feast UI works behind a subpath, but not entirely (nothing is displayed, just the feast logo with a "404" text - refer to screenshot). No requests in the network tab of the web browser are hitting 404.

## Steps to reproduce
Serve feast UI as you would e.g. `feature_store.serve_ui()`, optionally passing in the `root_path` parameter (it does not help).
Set up an nginx pod with the following configuration (i.e. the nginx pod should have `/etc/nginx/conf.d/default.conf` with the following contents - `dummy_project` is the project name, and `http://feast-ui-service:8080` is where the feast UI can be accessed from your nginx pod / container):
```
server {
listen 80 default_server;
location = /feast-ui/ {
rewrite (.*) /feast-ui/p/dummy_project permanent;
}
location /feast-ui/ {
proxy_pass http://feast-ui-service:8080/;
}
location / {
proxy_pass http://feast-ui-service:8080/;
}
}
```
This configuration works on localhost when nginx can listen on the root path `/`. However, note that the URL after all the redirects is wrong (it does not have the prefix).
- The first block is required to force a redirect to the `/p/{project_name}`. Without this, the page will display 404 as above.
- The second block is required to strip away `/feast-ui` so the UI app does not receive that path that it is not aware of
- The third block is a trick to make this setup work in a local environment, because the app itself will redirect the user back to `/p/dummy_project` (without the prefix), which we then proxy into the feast UI app. However, in an actual environment, this setup does not work, because when the url does not contain the `/feast-ui` prefix, the ingress will not route it to the nginx pod, so the nginx pod cannot proxy the connection to the right place.
Ideally, if the feast ui app is capable of being served on a subpath, only the second `location` block should be required in the nginx configuration. The first and third `location` blocks are workarounds.
### Specifications
- Version: 0.29.0
## Possible Solution
The app should redirect to relative and not absolute paths
| 2023-03-02T16:49:53 |
||
feast-dev/feast | 3,518 | feast-dev__feast-3518 | [
"3517"
]
| 059c304e40769271dc79511d3cda156dd299ebc9 | diff --git a/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py b/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py
--- a/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py
+++ b/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py
@@ -46,6 +46,17 @@ class BytewaxMaterializationEngineConfig(FeastConfigBaseModel):
These environment variables can be used to reference Kubernetes secrets.
"""
+ image_pull_secrets: List[str] = []
+ """ (optional) The secrets to use when pulling the image to run for the materialization job """
+
+ resources: dict = {}
+ """ (optional) The resource requests and limits for the materialization containers """
+
+ service_account_name: StrictStr = ""
+ """ (optional) The service account name to use when running the job """
+
+ annotations: dict = {}
+ """ (optional) Annotations to apply to the job container. Useful for linking the service account to IAM roles, operational metadata, etc """
class BytewaxMaterializationEngine(BatchMaterializationEngine):
def __init__(
@@ -248,9 +259,14 @@ def _create_job_definition(self, job_id, namespace, pods, env):
"parallelism": pods,
"completionMode": "Indexed",
"template": {
+ "metadata": {
+ "annotations": self.batch_engine_config.annotations,
+ },
"spec": {
"restartPolicy": "Never",
"subdomain": f"dataflow-{job_id}",
+ "imagePullSecrets": self.batch_engine_config.image_pull_secrets,
+ "serviceAccountName": self.batch_engine_config.service_account_name,
"initContainers": [
{
"env": [
@@ -300,7 +316,7 @@ def _create_job_definition(self, job_id, namespace, pods, env):
"protocol": "TCP",
}
],
- "resources": {},
+ "resources": self.batch_engine_config.resources,
"securityContext": {
"allowPrivilegeEscalation": False,
"capabilities": {
| Add Kubernetes Deployment Options to the Bytewax Materialization Engine
**Is your feature request related to a problem? Please describe.**
The Bytewax materialization engine needs to support configuration options for more advanced Kubernetes deployments (EKS, GCP, etc) to make it usable at scale.
**Describe the solution you'd like**
The main configuration options that are needed for the Bytewax materialization job are:
* setting explicit resource requests and limits (rather than relying on platform defaults which may not be enough)
* supporting service accounts and IAM roles
* specifying an image pull secret to support pulling Docker images from Dockerhub, Artifactory, etc
**Describe alternatives you've considered**
The Kubernetes job that runs is dynamically generated by the bytewax code. Existing configuration options are insufficient.
**Additional context**
I'd really like to test the Bytewax materialization engine on our instance of EKS. In its current implementation, it's operationally too simple and not usable outside of minikube.
| 2023-03-03T00:33:30 |
||
feast-dev/feast | 3,547 | feast-dev__feast-3547 | [
"3546"
]
| 5310280b3bab99d4ad34be806bdd0e0d9b3d06f2 | diff --git a/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py b/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py
--- a/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py
+++ b/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py
@@ -46,7 +46,7 @@ class BytewaxMaterializationEngineConfig(FeastConfigBaseModel):
These environment variables can be used to reference Kubernetes secrets.
"""
- image_pull_secrets: List[str] = []
+ image_pull_secrets: List[dict] = []
""" (optional) The secrets to use when pulling the image to run for the materialization job """
resources: dict = {}
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -95,7 +95,7 @@
AWS_REQUIRED = ["boto3>=1.17.0,<=1.20.23", "docker>=5.0.2", "s3fs>=0.4.0,<=2022.01.0"]
-BYTEWAX_REQUIRED = ["bytewax==0.13.1", "docker>=5.0.2", "kubernetes<=20.13.0"]
+BYTEWAX_REQUIRED = ["bytewax==0.15.1", "docker>=5.0.2", "kubernetes<=20.13.0"]
SNOWFLAKE_REQUIRED = [
"snowflake-connector-python[pandas]>=2.7.3,<3",
| Bytewax Image Pull Secrets Wrong Format
## Expected Behavior
Bytewax materializer uses a correctly configured list of image secrets to pull the job container on execution
## Current Behavior
Current configuration is a list of strings. Container scheduling fails to start because of an invalid generated job spec.
## Steps to reproduce
Configure Bytewax materialization engine with image pull secrets as list of strings, and run materialization. It'll fail.
### Specifications
- Version: 0.30.0
- Platform: Linux & EKS
- Subsystem: Python, Feast with Bytewax option enabled
## Possible Solution
The Bytewax materialization engine config needs to be configured with a `List[dict]` per Kubernetes configuration requirements. This will correctly schedule the materialization job and use the secrets to pull the job container from the registry.
| 2023-03-20T23:58:48 |
||
feast-dev/feast | 3,573 | feast-dev__feast-3573 | [
"3572"
]
| bf86bd0b3e197a1591d20b5596f37f30febb5815 | diff --git a/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py b/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py
--- a/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py
+++ b/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py
@@ -58,6 +58,9 @@ class BytewaxMaterializationEngineConfig(FeastConfigBaseModel):
annotations: dict = {}
""" (optional) Annotations to apply to the job container. Useful for linking the service account to IAM roles, operational metadata, etc """
+ include_security_context_capabilities: bool = True
+ """ (optional) Include security context capabilities in the init and job container spec """
+
class BytewaxMaterializationEngine(BatchMaterializationEngine):
def __init__(
@@ -198,6 +201,9 @@ def _create_configuration_map(self, job_id, paths, feature_view, namespace):
"apiVersion": "v1",
"metadata": {
"name": f"feast-{job_id}",
+ "labels": {
+ "feast-bytewax-materializer": "configmap",
+ },
},
"data": {
"feature_store.yaml": feature_store_configuration,
@@ -247,12 +253,22 @@ def _create_job_definition(self, job_id, namespace, pods, env):
# Add any Feast configured environment variables
job_env.extend(env)
+ securityContextCapabilities = None
+ if self.batch_engine_config.include_security_context_capabilities:
+ securityContextCapabilities = {
+ "add": ["NET_BIND_SERVICE"],
+ "drop": ["ALL"],
+ }
+
job_definition = {
"apiVersion": "batch/v1",
"kind": "Job",
"metadata": {
"name": f"dataflow-{job_id}",
"namespace": namespace,
+ "labels": {
+ "feast-bytewax-materializer": "job",
+ },
},
"spec": {
"ttlSecondsAfterFinished": 3600,
@@ -262,6 +278,9 @@ def _create_job_definition(self, job_id, namespace, pods, env):
"template": {
"metadata": {
"annotations": self.batch_engine_config.annotations,
+ "labels": {
+ "feast-bytewax-materializer": "pod",
+ },
},
"spec": {
"restartPolicy": "Never",
@@ -282,10 +301,7 @@ def _create_job_definition(self, job_id, namespace, pods, env):
"resources": {},
"securityContext": {
"allowPrivilegeEscalation": False,
- "capabilities": {
- "add": ["NET_BIND_SERVICE"],
- "drop": ["ALL"],
- },
+ "capabilities": securityContextCapabilities,
"readOnlyRootFilesystem": True,
},
"terminationMessagePath": "/dev/termination-log",
@@ -320,10 +336,7 @@ def _create_job_definition(self, job_id, namespace, pods, env):
"resources": self.batch_engine_config.resources,
"securityContext": {
"allowPrivilegeEscalation": False,
- "capabilities": {
- "add": ["NET_BIND_SERVICE"],
- "drop": ["ALL"],
- },
+ "capabilities": securityContextCapabilities,
"readOnlyRootFilesystem": False,
},
"terminationMessagePath": "/dev/termination-log",
| Bytewax Materializer Security Context Capabilities
## Expected Behavior
Running the Bytewax materializer in a scaled and secured Kubernetes cluster should work, successfully running the materializer job.
## Current Behavior
In a managed, secured cluster, setting the securityContext capabilities may not be permitted, as is enabled by default. This causes the materialization job/s to fail.
## Steps to reproduce
Run the Bytewax materializer in an environment where securityContext capabilities cannot be specified/overriden in jobs.
### Specifications
- Version: 0.30.2
- Platform: EKS
- Subsystem: Python, Bytewax, Snowflake, Dynamodb
## Possible Solution
Add an optional boolean configuration parameter to the Bytewax materialization engine to dictate whether or not the (current default) security context options are included in the job spec. If set to `False` set the securityContext capabilities to `None`.
| 2023-03-28T10:46:05 |
||
feast-dev/feast | 3,574 | feast-dev__feast-3574 | [
"3548"
]
| bf86bd0b3e197a1591d20b5596f37f30febb5815 | diff --git a/sdk/python/feast/infra/offline_stores/snowflake.py b/sdk/python/feast/infra/offline_stores/snowflake.py
--- a/sdk/python/feast/infra/offline_stores/snowflake.py
+++ b/sdk/python/feast/infra/offline_stores/snowflake.py
@@ -109,6 +109,9 @@ class SnowflakeOfflineStoreConfig(FeastConfigBaseModel):
blob_export_location: Optional[str] = None
""" Location (in S3, Google storage or Azure storage) where data is offloaded """
+ convert_timestamp_columns: Optional[bool] = None
+ """ Convert timestamp columns on export to a Parquet-supported format """
+
class Config:
allow_population_by_field_name = True
@@ -152,6 +155,29 @@ def pull_latest_from_table_or_query(
+ '"'
)
+ if config.offline_store.convert_timestamp_columns:
+ select_fields = list(
+ map(
+ lambda field_name: f'"{field_name}"',
+ join_key_columns + feature_name_columns,
+ )
+ )
+ select_timestamps = list(
+ map(
+ lambda field_name: f"to_varchar({field_name}, 'YYYY-MM-DD\"T\"HH24:MI:SS.FFTZH:TZM') as {field_name}",
+ timestamp_columns,
+ )
+ )
+ inner_field_string = ", ".join(select_fields + select_timestamps)
+ else:
+ select_fields = list(
+ map(
+ lambda field_name: f'"{field_name}"',
+ join_key_columns + feature_name_columns + timestamp_columns,
+ )
+ )
+ inner_field_string = ", ".join(select_fields)
+
if data_source.snowflake_options.warehouse:
config.offline_store.warehouse = data_source.snowflake_options.warehouse
@@ -166,7 +192,7 @@ def pull_latest_from_table_or_query(
{field_string}
{f''', TRIM({repr(DUMMY_ENTITY_VAL)}::VARIANT,'"') AS "{DUMMY_ENTITY_ID}"''' if not join_key_columns else ""}
FROM (
- SELECT {field_string},
+ SELECT {inner_field_string},
ROW_NUMBER() OVER({partition_by_join_key_string} ORDER BY {timestamp_desc_string}) AS "_feast_row"
FROM {from_expression}
WHERE "{timestamp_field}" BETWEEN TIMESTAMP '{start_date}' AND TIMESTAMP '{end_date}'
@@ -533,7 +559,7 @@ def to_remote_storage(self) -> List[str]:
self.to_snowflake(table)
query = f"""
- COPY INTO '{self.config.offline_store.blob_export_location}/{table}' FROM "{self.config.offline_store.database}"."{self.config.offline_store.schema_}"."{table}"\n
+ COPY INTO '{self.export_path}/{table}' FROM "{self.config.offline_store.database}"."{self.config.offline_store.schema_}"."{table}"\n
STORAGE_INTEGRATION = {self.config.offline_store.storage_integration_name}\n
FILE_FORMAT = (TYPE = PARQUET)
DETAILED_OUTPUT = TRUE
| Snowflake Offline to Parquet export failure
## Expected Behavior
Snowflake offline export to Parquet in S3 should successfully export the materialization data set, including timestamp fields.
## Current Behavior
Export to S3 integration in Parquet format fails with the following message:
```
Error encountered when unloading to PARQUET: TIMESTAMP_TZ and LTZ types are not supported for unloading to Parquet. value get: TIMESTAMP_LTZ
```
This is a [known issue](https://community.snowflake.com/s/article/How-To-Unload-Timestamp-data-in-a-Parquet-file) with recommended guidance.
## Steps to reproduce
* Configure offline store in Snowflake
* Attempt to run materialization to external destination (e.g. DynamoDB)
* Confirm "temporary_<guid>" table is created in the offline schema and an attempt was made to write to the storage integration
### Specifications
- Version: 0.29.0+
- Platform: LInux + EKS
- Subsystem: Python, Snowflake, DynamoDB
## Possible Solution
Two things will assist in resolving this issue:
* update the data extraction to cast timestamp fields to string or convert to a UTC timestamp integer
* add an optional configuration option to enable timestamp field treatment, default to None/False
| 2023-03-28T12:18:04 |
||
feast-dev/feast | 3,577 | feast-dev__feast-3577 | [
"3327"
]
| 8b90e2ff044143518870712996f820de10ac5e16 | diff --git a/sdk/python/feast/infra/offline_stores/bigquery.py b/sdk/python/feast/infra/offline_stores/bigquery.py
--- a/sdk/python/feast/infra/offline_stores/bigquery.py
+++ b/sdk/python/feast/infra/offline_stores/bigquery.py
@@ -503,7 +503,7 @@ def to_bigquery(
temp_dest_table = f"{tmp_dest['projectId']}.{tmp_dest['datasetId']}.{tmp_dest['tableId']}"
# persist temp table
- sql = f"CREATE TABLE {dest} AS SELECT * FROM {temp_dest_table}"
+ sql = f"CREATE TABLE `{dest}` AS SELECT * FROM {temp_dest_table}"
self._execute_query(sql, timeout=timeout)
print(f"Done writing to '{dest}'.")
@@ -663,7 +663,7 @@ def _upload_entity_df(
job: Union[bigquery.job.query.QueryJob, bigquery.job.load.LoadJob]
if isinstance(entity_df, str):
- job = client.query(f"CREATE TABLE {table_name} AS ({entity_df})")
+ job = client.query(f"CREATE TABLE `{table_name}` AS ({entity_df})")
elif isinstance(entity_df, pd.DataFrame):
# Drop the index so that we don't have unnecessary columns
| BigQuery: _upload_entity_df does not escape the table name
## Expected Behavior
I expect `get_historical_features` to work even if the project name is not correctly detected by BigQuery without enclosing it in backtick.
## Current Behavior
Some project names can cause the `get_historical_features` to fail because the create statement in `_upload_entity_df`
[code](https://github.com/feast-dev/feast/blob/09746aa14f5cb72e7b3f46d862d7afe8651ace7b/sdk/python/feast/infra/offline_stores/bigquery.py#L557)
```
job = client.query(f"CREATE TABLE {table_name} AS ({entity_df})")
```
does not enclose the `table_name` in backtick
We currently have the issue with a GCP project name that is suffixed by `-12c1`
The relevant error on BigQuery is
```
Syntax error: Missing whitespace between literal and alias at [1:28]
```
## Steps to reproduce
1. Create a GCP project with a suffix that must be backticked in BigQuery (e.g `dummy-project-12c1`)
2. Attempt to run a `get_historical_features`
### Specifications
- Version: 0.22
- Platform: Linux
- Subsystem: Ubuntu 20.04
## Possible Solution
I think the best solution is to add the backticks around the `table_name`
```
job = client.query(f"CREATE TABLE `{table_name}` AS ({entity_df})")
```
| This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
| 2023-03-29T05:40:47 |
|
feast-dev/feast | 3,586 | feast-dev__feast-3586 | [
"3544"
]
| 2c04ec175f9155c906f90502bffe1bd5a5619ddb | diff --git a/sdk/python/feast/infra/registry/sql.py b/sdk/python/feast/infra/registry/sql.py
--- a/sdk/python/feast/infra/registry/sql.py
+++ b/sdk/python/feast/infra/registry/sql.py
@@ -5,6 +5,7 @@
from threading import Lock
from typing import Any, Callable, List, Optional, Set, Union
+from pydantic import StrictStr
from sqlalchemy import ( # type: ignore
BigInteger,
Column,
@@ -178,10 +179,19 @@ class FeastMetadataKeys(Enum):
)
+class SqlRegistryConfig(RegistryConfig):
+ registry_type: StrictStr = "sql"
+ """ str: Provider name or a class name that implements Registry."""
+
+ path: StrictStr = ""
+ """ str: Path to metadata store.
+ If registry_type is 'sql', then this is a database URL as expected by SQLAlchemy """
+
+
class SqlRegistry(BaseRegistry):
def __init__(
self,
- registry_config: Optional[RegistryConfig],
+ registry_config: Optional[Union[RegistryConfig, SqlRegistryConfig]],
project: str,
repo_path: Optional[Path],
):
| SqlRegistryConfig does not exist
## Expected Behavior
When specifying "sql" as the registry type via the python SDK, feast uses the appropriate config class.
## Current Behavior
When specifying "sql" as the registry type via the python SDK, calling the FeatureStore object results in this error:
`feast.errors.FeastClassImportError: Could not import class 'SqlRegistryConfig' from module 'feast.infra.registry.sql'`
`get_registry_config_from_type` builds the class name here: https://github.com/feast-dev/feast/blob/master/sdk/python/feast/repo_config.py#L499 causing the config to look for the `SqlRegistryConfig` class, which doesn't exist. This is due to the code adding `Config` to the end of the current registry class, which works when specifying "file" (which uses the `RegistryConfig` class, which exists), but not for "sql".
## Steps to reproduce
Set my_repo_config = RepoConfig(registry=RepoConfig(registry_type="sql")) and then call FeatureStore(config=my_repo_config), which will then result in the error described above.
### Specifications
- Version: 0.30.0
- Platform: Ubuntu
- Subsystem:
## Possible Solution
Option 1:
Change the `REGISTRY_CLASS_FOR_TYPE` dict so that "sql" maps to "feast.infra.registry.registry.Registry" instead of "feast.infra.registry.sql.SqlRegistry" - This may also have to be done for "snowflake.registry"
Option 2:
Create the `SqlRegistryConfig` class in `feast.infra.registry.sql`. I'm also not seeing a `SnowflakeRegistryConfig` class in the `feast.infra.registry.snowflake` module, so that may need to be created as well.
Option 3:
Alter the `get_registry_config_from_type` function so it builds out the class names differently based on they registry type
https://github.com/feast-dev/feast/blob/master/sdk/python/feast/repo_config.py#L499
| From what I can see, there's already to type of pattern for loading the configuration class for a type.
Most of the config uses the class name to derive the config, except the feature server that uses a specific ENUM because of the `We do not support custom Feature Server`
https://github.com/feast-dev/feast/blob/master/sdk/python/feast/repo_config.py#L535
Looking at this, I guess it's safe to say that we should create a `SqlRegistryConfig` class for the `SQLRegistry` class, to follow the other design pattern. At first, the `SQLRegistryConfig` would be as easy as being an extension of the Registry, then i required it can become more complex.
I see that this bug priority is `p2`. Does that mean that it will be picked up ASAP?
If you are ok with the plan, I think we can open a PR and propose a fix for this issue quite fast (it does seem to be a low-hanging fruit solution, that would work).
Maybe there's other concern that I don't grasp?
Edit: this still exists in version `0.30.2` | 2023-04-05T19:23:28 |
|
feast-dev/feast | 3,588 | feast-dev__feast-3588 | [
"3545"
]
| 2c04ec175f9155c906f90502bffe1bd5a5619ddb | diff --git a/sdk/python/feast/infra/offline_stores/snowflake.py b/sdk/python/feast/infra/offline_stores/snowflake.py
--- a/sdk/python/feast/infra/offline_stores/snowflake.py
+++ b/sdk/python/feast/infra/offline_stores/snowflake.py
@@ -556,7 +556,7 @@ def to_remote_storage(self) -> List[str]:
)
table = f"temporary_{uuid.uuid4().hex}"
- self.to_snowflake(table)
+ self.to_snowflake(table, temporary=True)
query = f"""
COPY INTO '{self.export_path}/{table}' FROM "{self.config.offline_store.database}"."{self.config.offline_store.schema_}"."{table}"\n
| to_remote_storage() resulting in undeleted temporary tables in Snowflake
## Expected Behavior
When calling get_historical_features.to_remote_storage(), any temporary tables created in Snowflake are deleted after the Snowflake session ends.
## Current Behavior
When calling get_historical_features.to_remote_storage(), the temporary tables created during the join process are not deleted after the Snowflake session ends. These tables are set to a retention time of 1 day, but they are not deleted and still exist after 24 hours.
I tested this with `to_df()` and the above described issue does not occur. I also tried explicitly ending the session to make sure that wasn't the issue, but even after confirming the session was ended, the issue still persists.
## Steps to reproduce
1. For the FeatureStore object, set the RepoConfig offline store config to specify the following:
```json
{
"blob_export_location": <s3_staging_url>,
"storage_integration_name": <storage_integration>,
"role": <stage_role>,
"schema_": <stage_schema>,
}
```
2. Call `get_historical_features(entity_df=entity, features=features, full_feature_names=True).to_remote_storage()`
3. Check snowflake stage tables and look for tables created at the time of running that start with `temporary_`
### Specifications
- Version: 0.30.0
- Platform: Ubuntu
- Subsystem:
## Possible Solution
No possible solution known at the time of reporting
| 2023-04-05T19:44:36 |
||
feast-dev/feast | 3,589 | feast-dev__feast-3589 | [
"3447"
]
| 7da058085cd1211fb383ff0a6c5ae8f59999c5f0 | diff --git a/sdk/python/feast/infra/offline_stores/snowflake.py b/sdk/python/feast/infra/offline_stores/snowflake.py
--- a/sdk/python/feast/infra/offline_stores/snowflake.py
+++ b/sdk/python/feast/infra/offline_stores/snowflake.py
@@ -436,52 +436,85 @@ def on_demand_feature_views(self) -> List[OnDemandFeatureView]:
return self._on_demand_feature_views
def _to_df_internal(self, timeout: Optional[int] = None) -> pd.DataFrame:
- with self._query_generator() as query:
-
- df = execute_snowflake_statement(
- self.snowflake_conn, query
- ).fetch_pandas_all()
+ df = execute_snowflake_statement(
+ self.snowflake_conn, self.to_sql()
+ ).fetch_pandas_all()
return df
def _to_arrow_internal(self, timeout: Optional[int] = None) -> pyarrow.Table:
- with self._query_generator() as query:
+ pa_table = execute_snowflake_statement(
+ self.snowflake_conn, self.to_sql()
+ ).fetch_arrow_all()
- pa_table = execute_snowflake_statement(
- self.snowflake_conn, query
- ).fetch_arrow_all()
+ if pa_table:
+ return pa_table
+ else:
+ empty_result = execute_snowflake_statement(
+ self.snowflake_conn, self.to_sql()
+ )
- if pa_table:
- return pa_table
- else:
- empty_result = execute_snowflake_statement(self.snowflake_conn, query)
+ return pyarrow.Table.from_pandas(
+ pd.DataFrame(columns=[md.name for md in empty_result.description])
+ )
- return pyarrow.Table.from_pandas(
- pd.DataFrame(columns=[md.name for md in empty_result.description])
- )
+ def to_sql(self) -> str:
+ """
+ Returns the SQL query that will be executed in Snowflake to build the historical feature table.
+ """
+ with self._query_generator() as query:
+ return query
- def to_snowflake(self, table_name: str, temporary=False) -> None:
+ def to_snowflake(
+ self, table_name: str, allow_overwrite: bool = False, temporary: bool = False
+ ) -> None:
"""Save dataset as a new Snowflake table"""
if self.on_demand_feature_views:
transformed_df = self.to_df()
+ if allow_overwrite:
+ query = f'DROP TABLE IF EXISTS "{table_name}"'
+ execute_snowflake_statement(self.snowflake_conn, query)
+
write_pandas(
- self.snowflake_conn, transformed_df, table_name, auto_create_table=True
+ self.snowflake_conn,
+ transformed_df,
+ table_name,
+ auto_create_table=True,
+ create_temp_table=temporary,
)
- return None
+ else:
+ query = f'CREATE {"OR REPLACE" if allow_overwrite else ""} {"TEMPORARY" if temporary else ""} TABLE {"IF NOT EXISTS" if not allow_overwrite else ""} "{table_name}" AS ({self.to_sql()});\n'
+ execute_snowflake_statement(self.snowflake_conn, query)
- with self._query_generator() as query:
- query = f'CREATE {"TEMPORARY" if temporary else ""} TABLE IF NOT EXISTS "{table_name}" AS ({query});\n'
+ return None
- execute_snowflake_statement(self.snowflake_conn, query)
+ def to_arrow_batches(self) -> Iterator[pyarrow.Table]:
- def to_sql(self) -> str:
- """
- Returns the SQL query that will be executed in Snowflake to build the historical feature table.
- """
- with self._query_generator() as query:
- return query
+ table_name = "temp_arrow_batches_" + uuid.uuid4().hex
+
+ self.to_snowflake(table_name=table_name, allow_overwrite=True, temporary=True)
+
+ query = f'SELECT * FROM "{table_name}"'
+ arrow_batches = execute_snowflake_statement(
+ self.snowflake_conn, query
+ ).fetch_arrow_batches()
+
+ return arrow_batches
+
+ def to_pandas_batches(self) -> Iterator[pd.DataFrame]:
+
+ table_name = "temp_pandas_batches_" + uuid.uuid4().hex
+
+ self.to_snowflake(table_name=table_name, allow_overwrite=True, temporary=True)
+
+ query = f'SELECT * FROM "{table_name}"'
+ arrow_batches = execute_snowflake_statement(
+ self.snowflake_conn, query
+ ).fetch_pandas_batches()
+
+ return arrow_batches
def to_spark_df(self, spark_session: "SparkSession") -> "DataFrame":
"""
@@ -502,37 +535,33 @@ def to_spark_df(self, spark_session: "SparkSession") -> "DataFrame":
raise FeastExtrasDependencyImportError("spark", str(e))
if isinstance(spark_session, SparkSession):
- with self._query_generator() as query:
-
- arrow_batches = execute_snowflake_statement(
- self.snowflake_conn, query
- ).fetch_arrow_batches()
-
- if arrow_batches:
- spark_df = reduce(
- DataFrame.unionAll,
- [
- spark_session.createDataFrame(batch.to_pandas())
- for batch in arrow_batches
- ],
- )
-
- return spark_df
-
- else:
- raise EntitySQLEmptyResults(query)
-
+ arrow_batches = self.to_arrow_batches()
+
+ if arrow_batches:
+ spark_df = reduce(
+ DataFrame.unionAll,
+ [
+ spark_session.createDataFrame(batch.to_pandas())
+ for batch in arrow_batches
+ ],
+ )
+ return spark_df
+ else:
+ raise EntitySQLEmptyResults(self.to_sql())
else:
raise InvalidSparkSessionException(spark_session)
def persist(
self,
storage: SavedDatasetStorage,
- allow_overwrite: Optional[bool] = False,
+ allow_overwrite: bool = False,
timeout: Optional[int] = None,
):
assert isinstance(storage, SavedDatasetSnowflakeStorage)
- self.to_snowflake(table_name=storage.snowflake_options.table)
+
+ self.to_snowflake(
+ table_name=storage.snowflake_options.table, allow_overwrite=allow_overwrite
+ )
@property
def metadata(self) -> Optional[RetrievalMetadata]:
| to_snowflake for generation of offline features does nothing if the table exists in Snowflake.
**Is your feature request related to a problem? Please describe.**
to_Snowflake fires CREATE TABLE IF NOT EXISTS to create a new table to store offline features. It does not overwrite or append into the existing table. It has its benefits, but could also be very misleading since it doesn’t throw any warning, messages or anything to inform the user that it didn’t write new records to the table.
`fs.get_historical_features(features=feature_service, entity_df=customers).to_snowflake(table_name='historical_features')
`
**Describe the solution you'd like**
There should be a Warning message informing the user that the table with the same name exist and no action will be taken.
**Describe alternatives you've considered**
Couple of ways to make it work every time you need to get most recent data is to either programatically change the name and store in a new table each time or delete existing table and then recreate the table.
**Additional context**
Add any other context or screenshots about the feature request here.
| 2023-04-06T03:39:56 |
||
feast-dev/feast | 3,608 | feast-dev__feast-3608 | [
"3567"
]
| 902f23f5403c601238aa9f4fcbdd1359f004fb1c | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -96,11 +96,7 @@
BYTEWAX_REQUIRED = ["bytewax==0.15.1", "docker>=5.0.2", "kubernetes<=20.13.0"]
SNOWFLAKE_REQUIRED = [
- "snowflake-connector-python[pandas]>=2.7.3,<3",
- # `pyOpenSSL==22.1.0` requires `cryptography<39,>=38.0.0`, which is incompatible
- # with `snowflake-connector-python[pandas]==2.8.0`, which depends on
- # `cryptography<37.0.0,>=3.1.0`.
- "pyOpenSSL<22.1.0",
+ "snowflake-connector-python[pandas]>=3,<4",
]
SPARK_REQUIRED = [
| Could not import module 'feast.infra.offline_stores.snowflake' while attempting to load class 'SnowflakeOfflineStoreConfig'
## Expected Behavior
feast apply with snowflake as offline store failing
## Current Behavior
feast apply fails with exception Could not import module 'feast.infra.offline_stores.snowflake' while attempting to load class 'SnowflakeOfflineStoreConfig'
## Steps to reproduce
Config:
offline_store:
type: snowflake.offline
account: ${ACCOUNT}
user: ${SNOWFLAKE_USER}
password: ${SNOWFLAKE_PASSWORD}
role: ${SNOWFLAKE_ROLE}
warehouse: ${SNOWFLAKE_WAREHOUSE}
database: ${SNOWFLAKE_DATABASE}
schema: ${SNOWFLAKE_SCHEMA}
batch_engine:
type: snowflake.engine
account: ${ACCOUNT}
user: ${SNOWFLAKE_USER}
password: ${SNOWFLAKE_PASSWORD}
role: ${SNOWFLAKE_ROLE}
warehouse: ${SNOWFLAKE_WAREHOUSE}
database: ${SNOWFLAKE_DATABASE}
schema: ${SNOWFLAKE_SCHEMA}
### Specifications
- Version:
Feast SDK Version: "feast 0.30.2"
Python 3.10.10
- Platform:
Mac os 13.2.1
- Subsystem:
## Possible Solution
| I think #3587 should solve this | 2023-04-23T03:51:04 |
|
feast-dev/feast | 3,614 | feast-dev__feast-3614 | [
"3613"
]
| 04afc710f31254d48095b9ff657364db7ff599f6 | diff --git a/sdk/python/feast/infra/offline_stores/bigquery.py b/sdk/python/feast/infra/offline_stores/bigquery.py
--- a/sdk/python/feast/infra/offline_stores/bigquery.py
+++ b/sdk/python/feast/infra/offline_stores/bigquery.py
@@ -363,7 +363,7 @@ def offline_write_batch(
assert isinstance(feature_view.batch_source, BigQuerySource)
pa_schema, column_names = offline_utils.get_pyarrow_schema_from_batch_source(
- config, feature_view.batch_source
+ config, feature_view.batch_source, timestamp_unit="ns"
)
if column_names != table.column_names:
raise ValueError(
diff --git a/sdk/python/feast/infra/offline_stores/offline_utils.py b/sdk/python/feast/infra/offline_stores/offline_utils.py
--- a/sdk/python/feast/infra/offline_stores/offline_utils.py
+++ b/sdk/python/feast/infra/offline_stores/offline_utils.py
@@ -232,7 +232,7 @@ def get_offline_store_from_config(offline_store_config: Any) -> OfflineStore:
def get_pyarrow_schema_from_batch_source(
- config: RepoConfig, batch_source: DataSource
+ config: RepoConfig, batch_source: DataSource, timestamp_unit: str = "us"
) -> Tuple[pa.Schema, List[str]]:
"""Returns the pyarrow schema and column names for the given batch source."""
column_names_and_types = batch_source.get_table_column_names_and_types(config)
@@ -244,7 +244,8 @@ def get_pyarrow_schema_from_batch_source(
(
column_name,
feast_value_type_to_pa(
- batch_source.source_datatype_to_feast_value_type()(column_type)
+ batch_source.source_datatype_to_feast_value_type()(column_type),
+ timestamp_unit=timestamp_unit,
),
)
)
diff --git a/sdk/python/feast/type_map.py b/sdk/python/feast/type_map.py
--- a/sdk/python/feast/type_map.py
+++ b/sdk/python/feast/type_map.py
@@ -844,7 +844,9 @@ def pg_type_to_feast_value_type(type_str: str) -> ValueType:
return value
-def feast_value_type_to_pa(feast_type: ValueType) -> "pyarrow.DataType":
+def feast_value_type_to_pa(
+ feast_type: ValueType, timestamp_unit: str = "us"
+) -> "pyarrow.DataType":
import pyarrow
type_map = {
@@ -855,7 +857,7 @@ def feast_value_type_to_pa(feast_type: ValueType) -> "pyarrow.DataType":
ValueType.STRING: pyarrow.string(),
ValueType.BYTES: pyarrow.binary(),
ValueType.BOOL: pyarrow.bool_(),
- ValueType.UNIX_TIMESTAMP: pyarrow.timestamp("us"),
+ ValueType.UNIX_TIMESTAMP: pyarrow.timestamp(timestamp_unit),
ValueType.INT32_LIST: pyarrow.list_(pyarrow.int32()),
ValueType.INT64_LIST: pyarrow.list_(pyarrow.int64()),
ValueType.DOUBLE_LIST: pyarrow.list_(pyarrow.float64()),
@@ -863,7 +865,7 @@ def feast_value_type_to_pa(feast_type: ValueType) -> "pyarrow.DataType":
ValueType.STRING_LIST: pyarrow.list_(pyarrow.string()),
ValueType.BYTES_LIST: pyarrow.list_(pyarrow.binary()),
ValueType.BOOL_LIST: pyarrow.list_(pyarrow.bool_()),
- ValueType.UNIX_TIMESTAMP_LIST: pyarrow.list_(pyarrow.timestamp("us")),
+ ValueType.UNIX_TIMESTAMP_LIST: pyarrow.list_(pyarrow.timestamp(timestamp_unit)),
ValueType.NULL: pyarrow.null(),
}
return type_map[feast_type]
| Time unit mismatch issue when calling Bigquery Push API
## Expected Behavior
When data is ingested with the push api, the same time series data must be added to the online store and the offline store (bigquery).
## Current Behavior
When calling the Push API with the BigQuery Offline Store, if the timestamp field exists, the pyarrow timestamp unit in the code defaults to us (microsecond).
However, when bigquery load_table is executed, the timestamp column operates in ns (nano second), so the unit is inconsistent.
Because there is a time difference of 1000 times, bigquery actually inputs 1/1000 times the time, so if you put the current time, the old time of the 1970s is entered.
## Steps to reproduce
After creating Bigquery Push Source with timestamp field, call Push API (w/ONLINE_AND_OFFLINE).
### Specifications
- Version:
- Platform:
- Subsystem: BigQuery
## Possible Solution
When converting to pyarrow schema, the time unit is input according to the offline store.
| 2023-05-01T11:51:27 |
||
feast-dev/feast | 3,628 | feast-dev__feast-3628 | [
"3433"
]
| 9b227d7d44f30d28d1faadc8015f25dc4a6f56b5 | diff --git a/sdk/python/feast/infra/offline_stores/bigquery_source.py b/sdk/python/feast/infra/offline_stores/bigquery_source.py
--- a/sdk/python/feast/infra/offline_stores/bigquery_source.py
+++ b/sdk/python/feast/infra/offline_stores/bigquery_source.py
@@ -180,9 +180,9 @@ def get_table_column_names_and_types(
if not isinstance(schema[0], bigquery.schema.SchemaField):
raise TypeError("Could not parse BigQuery table schema.")
else:
- bq_columns_query = f"SELECT * FROM ({self.query}) LIMIT 1"
- queryRes = client.query(bq_columns_query).result()
- schema = queryRes.schema
+ bq_columns_query = f"SELECT * FROM ({self.query}) LIMIT 0"
+ query_res = client.query(bq_columns_query).result()
+ schema = query_res.schema
name_type_pairs: List[Tuple[str, str]] = []
for field in schema:
| Schema inference of BQ OfflineStore costly
## Expected Behavior
When making schema inference, I expect there would be an extra minor cost when scanning tables.
## Current Behavior
BQ OfflineStore made a full scan on the entire table, although we are using `limit` statement. According to GCP documentation:
`Applying a LIMIT clause to a SELECT * query does not affect the amount of data read. You are billed for reading all bytes in the entire table, and the query counts against your free tier quota.`
https://cloud.google.com/bigquery/docs/best-practices-costs
## Steps to reproduce
1. Prepare a large feature table
2. feast apply as a feature view
### Specifications
- Version: 0.28.0
- Platform: Linux
- Subsystem:
## Possible Solution
We can add a filter by `timestamp_field` by modifying this [line](https://github.com/feast-dev/feast/blob/master/sdk/python/feast/infra/offline_stores/bigquery_source.py#L183) even though there is no data, the schema could be inferred eventually
| 2023-05-16T05:25:59 |
||
feast-dev/feast | 3,630 | feast-dev__feast-3630 | [
"3629"
]
| 870762ae9b78d00f4ea144a9ad6174b2b2516176 | diff --git a/sdk/python/feast/infra/registry/sql.py b/sdk/python/feast/infra/registry/sql.py
--- a/sdk/python/feast/infra/registry/sql.py
+++ b/sdk/python/feast/infra/registry/sql.py
@@ -81,7 +81,7 @@
data_sources = Table(
"data_sources",
metadata,
- Column("data_source_name", String(50), primary_key=True),
+ Column("data_source_name", String(255), primary_key=True),
Column("project_id", String(50), primary_key=True),
Column("last_updated_timestamp", BigInteger, nullable=False),
Column("data_source_proto", LargeBinary, nullable=False),
| SQL-Registry data_source_name `String(50)` is too short.
**Is your feature request related to a problem? Please describe.**
Our data sources have paths longer than 50 characters. This seems like an unnecessarily short limit for this field.
**Describe the solution you'd like**
A string limit of 255 characters feels more appropriate for a URI.
**Describe alternatives you've considered**
I considered requesting `sqlalchemy.types.Text` as the type instead, an unlimited string field.
**Additional context**
Add any other context or screenshots about the feature request here.
| 2023-05-16T06:59:14 |
||
feast-dev/feast | 3,645 | feast-dev__feast-3645 | [
"3644"
]
| 4de7faf7b262d30a9f6795911d8fa97df775fa8d | diff --git a/sdk/python/feast/infra/offline_stores/contrib/spark_offline_store/spark.py b/sdk/python/feast/infra/offline_stores/contrib/spark_offline_store/spark.py
--- a/sdk/python/feast/infra/offline_stores/contrib/spark_offline_store/spark.py
+++ b/sdk/python/feast/infra/offline_stores/contrib/spark_offline_store/spark.py
@@ -352,13 +352,36 @@ def persist(
):
"""
Run the retrieval and persist the results in the same offline store used for read.
- Please note the persisting is done only within the scope of the spark session.
+ Please note the persisting is done only within the scope of the spark session for local warehouse directory.
"""
assert isinstance(storage, SavedDatasetSparkStorage)
table_name = storage.spark_options.table
if not table_name:
raise ValueError("Cannot persist, table_name is not defined")
- self.to_spark_df().createOrReplaceTempView(table_name)
+ if self._has_remote_warehouse_in_config():
+ file_format = storage.spark_options.file_format
+ if not file_format:
+ self.to_spark_df().write.saveAsTable(table_name)
+ else:
+ self.to_spark_df().write.format(file_format).saveAsTable(table_name)
+ else:
+ self.to_spark_df().createOrReplaceTempView(table_name)
+
+ def _has_remote_warehouse_in_config(self) -> bool:
+ """
+ Check if Spark Session config has info about hive metastore uri
+ or warehouse directory is not a local path
+ """
+ self.spark_session.sparkContext.getConf().getAll()
+ try:
+ self.spark_session.conf.get("hive.metastore.uris")
+ return True
+ except Exception:
+ warehouse_dir = self.spark_session.conf.get("spark.sql.warehouse.dir")
+ if warehouse_dir and warehouse_dir.startswith("file:"):
+ return False
+ else:
+ return True
def supports_remote_storage_export(self) -> bool:
return self._config.offline_store.staging_location is not None
| Saved_dataset for spark offline store can be accessed only within the scope of the spark session, where it was created.
**Is your feature request related to a problem? Please describe.**
I would like to have a possibility to use the data of the registered saved_dataset in a different spark session. Now I have only a name in the feast registry without the data if I create a new spark session.
Part of persist function:
```
"""
Run the retrieval and persist the results in the same offline store used for read.
Please note the persisting is done only within the scope of the spark session.
"""
assert isinstance(storage, SavedDatasetSparkStorage)
table_name = storage.spark_options.table
if not table_name:
raise ValueError("Cannot persist, table_name is not defined")
self.to_spark_df().createOrReplaceTempView(table_name)
```
**Describe the solution you'd like**
Add possibility to save dataset as a table, for example when Spark Session config is included info about remote storage (hive, s3 path, etc)
**Describe alternatives you've considered**
Add an optional parameter for SparkOptions, which allows to save dataset as a table in any spark session configurations.
**Additional context**
| 2023-06-06T00:08:08 |
||
feast-dev/feast | 3,671 | feast-dev__feast-3671 | [
"3651"
]
| 9527183b7520b79cca0b442523228e1cb3b7cf2d | diff --git a/sdk/python/feast/infra/offline_stores/redshift.py b/sdk/python/feast/infra/offline_stores/redshift.py
--- a/sdk/python/feast/infra/offline_stores/redshift.py
+++ b/sdk/python/feast/infra/offline_stores/redshift.py
@@ -369,7 +369,7 @@ def offline_write_batch(
s3_resource=s3_resource,
s3_path=f"{config.offline_store.s3_staging_location}/push/{uuid.uuid4()}.parquet",
iam_role=config.offline_store.iam_role,
- table_name=redshift_options.table,
+ table_name=redshift_options.fully_qualified_table_name,
schema=pa_schema,
fail_if_exists=False,
)
diff --git a/sdk/python/feast/infra/offline_stores/redshift_source.py b/sdk/python/feast/infra/offline_stores/redshift_source.py
--- a/sdk/python/feast/infra/offline_stores/redshift_source.py
+++ b/sdk/python/feast/infra/offline_stores/redshift_source.py
@@ -294,6 +294,42 @@ def from_proto(cls, redshift_options_proto: DataSourceProto.RedshiftOptions):
return redshift_options
+ @property
+ def fully_qualified_table_name(self) -> str:
+ """
+ The fully qualified table name of this Redshift table.
+
+ Returns:
+ A string in the format of <database>.<schema>.<table>
+ May be empty or None if the table is not set
+ """
+
+ if not self.table:
+ return ""
+
+ # self.table may already contain the database and schema
+ parts = self.table.split(".")
+ if len(parts) == 3:
+ database, schema, table = parts
+ elif len(parts) == 2:
+ database = self.database
+ schema, table = parts
+ elif len(parts) == 1:
+ database = self.database
+ schema = self.schema
+ table = parts[0]
+ else:
+ raise ValueError(
+ f"Invalid table name: {self.table} - can't determine database and schema"
+ )
+
+ if database and schema:
+ return f"{database}.{schema}.{table}"
+ elif schema:
+ return f"{schema}.{table}"
+ else:
+ return table
+
def to_proto(self) -> DataSourceProto.RedshiftOptions:
"""
Converts an RedshiftOptionsProto object to its protobuf representation.
@@ -323,7 +359,6 @@ def __init__(self, table_ref: str):
@staticmethod
def from_proto(storage_proto: SavedDatasetStorageProto) -> SavedDatasetStorage:
-
return SavedDatasetRedshiftStorage(
table_ref=RedshiftOptions.from_proto(storage_proto.redshift_storage).table
)
| diff --git a/sdk/python/tests/unit/infra/offline_stores/test_redshift.py b/sdk/python/tests/unit/infra/offline_stores/test_redshift.py
new file mode 100644
--- /dev/null
+++ b/sdk/python/tests/unit/infra/offline_stores/test_redshift.py
@@ -0,0 +1,67 @@
+from unittest.mock import MagicMock, patch
+
+import pandas as pd
+import pyarrow as pa
+
+from feast import FeatureView
+from feast.infra.offline_stores import offline_utils
+from feast.infra.offline_stores.redshift import (
+ RedshiftOfflineStore,
+ RedshiftOfflineStoreConfig,
+)
+from feast.infra.offline_stores.redshift_source import RedshiftSource
+from feast.infra.utils import aws_utils
+from feast.repo_config import RepoConfig
+
+
[email protected](aws_utils, "upload_arrow_table_to_redshift")
+def test_offline_write_batch(
+ mock_upload_arrow_table_to_redshift: MagicMock,
+ simple_dataset_1: pd.DataFrame,
+):
+ repo_config = RepoConfig(
+ registry="registry",
+ project="project",
+ provider="local",
+ offline_store=RedshiftOfflineStoreConfig(
+ type="redshift",
+ region="us-west-2",
+ cluster_id="cluster_id",
+ database="database",
+ user="user",
+ iam_role="abcdef",
+ s3_staging_location="s3://bucket/path",
+ ),
+ )
+
+ batch_source = RedshiftSource(
+ name="test_source",
+ timestamp_field="ts",
+ table="table_name",
+ schema="schema_name",
+ )
+ feature_view = FeatureView(
+ name="test_view",
+ source=batch_source,
+ )
+
+ pa_dataset = pa.Table.from_pandas(simple_dataset_1)
+
+ # patch some more things so that the function can run
+ def mock_get_pyarrow_schema_from_batch_source(*args, **kwargs) -> pa.Schema:
+ return pa_dataset.schema, pa_dataset.column_names
+
+ with patch.object(
+ offline_utils,
+ "get_pyarrow_schema_from_batch_source",
+ new=mock_get_pyarrow_schema_from_batch_source,
+ ):
+ RedshiftOfflineStore.offline_write_batch(
+ repo_config, feature_view, pa_dataset, progress=None
+ )
+
+ # check that we have included the fully qualified table name
+ mock_upload_arrow_table_to_redshift.assert_called_once()
+
+ call = mock_upload_arrow_table_to_redshift.call_args_list[0]
+ assert call.kwargs["table_name"] == "schema_name.table_name"
diff --git a/sdk/python/tests/unit/test_data_sources.py b/sdk/python/tests/unit/test_data_sources.py
--- a/sdk/python/tests/unit/test_data_sources.py
+++ b/sdk/python/tests/unit/test_data_sources.py
@@ -190,3 +190,46 @@ def test_column_conflict():
timestamp_field="event_timestamp",
created_timestamp_column="event_timestamp",
)
+
+
[email protected](
+ "source_kwargs,expected_name",
+ [
+ (
+ {
+ "database": "test_database",
+ "schema": "test_schema",
+ "table": "test_table",
+ },
+ "test_database.test_schema.test_table",
+ ),
+ (
+ {"database": "test_database", "table": "test_table"},
+ "test_database.public.test_table",
+ ),
+ ({"table": "test_table"}, "public.test_table"),
+ ({"database": "test_database", "table": "b.c"}, "test_database.b.c"),
+ ({"database": "test_database", "table": "a.b.c"}, "a.b.c"),
+ (
+ {
+ "database": "test_database",
+ "schema": "test_schema",
+ "query": "select * from abc",
+ },
+ "",
+ ),
+ ],
+)
+def test_redshift_fully_qualified_table_name(source_kwargs, expected_name):
+ redshift_source = RedshiftSource(
+ name="test_source",
+ timestamp_field="event_timestamp",
+ created_timestamp_column="created_timestamp",
+ field_mapping={"foo": "bar"},
+ description="test description",
+ tags={"test": "test"},
+ owner="[email protected]",
+ **source_kwargs,
+ )
+
+ assert redshift_source.redshift_options.fully_qualified_table_name == expected_name
| Redshift push ignores schema
## Expected Behavior
When writing to a Redshift _push source_, the table is written to under the correct schema.
## Current Behavior
Even if `schema` is [specified in the data source](https://github.com/feast-dev/feast/blob/c474ccdd23ca8161de5e2958f0a12826c020dc44/sdk/python/feast/infra/offline_stores/redshift_source.py#L52), data is pushed to a table in the default schema.
You can trace this through the code:
- [RedshiftOfflineStore.offline_write_batch(...)](https://github.com/feast-dev/feast/blob/c474ccdd23ca8161de5e2958f0a12826c020dc44/sdk/python/feast/infra/offline_stores/redshift.py#L332-L375)
- [aws_utils.upload_arrow_table_to_redshift(...)](https://github.com/feast-dev/feast/blob/c474ccdd23ca8161de5e2958f0a12826c020dc44/sdk/python/feast/infra/utils/aws_utils.py#L287-L380)
## Steps to reproduce
- define a redshiftsource where the schema is set to something other than the default schema
- define a pushsource
- push some data to it
- observe a new table getting created under the default schema
```
abc_source = RedshiftSource(
name="abc",
table="abc",
timestamp_field="event_timestamp",
created_timestamp_column="proctime",
)
abc_push_source = PushSource(
name="abc_push_source", batch_source=abc_source
)
# ... push some data in
```
### Specifications
- Version: v0.31.1
- Platform: Linux x64
- Subsystem:
## Possible Solution
In `offline_write_batch`, construct a fully-qualified table name using the schema in the options, if present.
| 2023-07-05T21:54:44 |
|
feast-dev/feast | 3,702 | feast-dev__feast-3702 | [
"3649"
]
| 58aff346832ebde1695a47cf724da3d65a4a8c53 | diff --git a/sdk/python/feast/infra/registry/proto_registry_utils.py b/sdk/python/feast/infra/registry/proto_registry_utils.py
--- a/sdk/python/feast/infra/registry/proto_registry_utils.py
+++ b/sdk/python/feast/infra/registry/proto_registry_utils.py
@@ -1,4 +1,5 @@
import uuid
+from functools import wraps
from typing import List, Optional
from feast import usage
@@ -23,6 +24,26 @@
from feast.stream_feature_view import StreamFeatureView
+def registry_proto_cache(func):
+ cache_key = None
+ cache_value = None
+
+ @wraps(func)
+ def wrapper(registry_proto: RegistryProto, project: str):
+ nonlocal cache_key, cache_value
+
+ key = tuple([id(registry_proto), registry_proto.version_id, project])
+
+ if key == cache_key:
+ return cache_value
+ else:
+ cache_value = func(registry_proto, project)
+ cache_key = key
+ return cache_value
+
+ return wrapper
+
+
def init_project_metadata(cached_registry_proto: RegistryProto, project: str):
new_project_uuid = f"{uuid.uuid4()}"
usage.set_current_project_uuid(new_project_uuid)
@@ -137,8 +158,9 @@ def get_validation_reference(
raise ValidationReferenceNotFound(name, project=project)
+@registry_proto_cache
def list_feature_services(
- registry_proto: RegistryProto, project: str, allow_cache: bool = False
+ registry_proto: RegistryProto, project: str
) -> List[FeatureService]:
feature_services = []
for feature_service_proto in registry_proto.feature_services:
@@ -147,6 +169,7 @@ def list_feature_services(
return feature_services
+@registry_proto_cache
def list_feature_views(
registry_proto: RegistryProto, project: str
) -> List[FeatureView]:
@@ -157,6 +180,7 @@ def list_feature_views(
return feature_views
+@registry_proto_cache
def list_request_feature_views(
registry_proto: RegistryProto, project: str
) -> List[RequestFeatureView]:
@@ -169,6 +193,7 @@ def list_request_feature_views(
return feature_views
+@registry_proto_cache
def list_stream_feature_views(
registry_proto: RegistryProto, project: str
) -> List[StreamFeatureView]:
@@ -181,6 +206,7 @@ def list_stream_feature_views(
return stream_feature_views
+@registry_proto_cache
def list_on_demand_feature_views(
registry_proto: RegistryProto, project: str
) -> List[OnDemandFeatureView]:
@@ -193,6 +219,7 @@ def list_on_demand_feature_views(
return on_demand_feature_views
+@registry_proto_cache
def list_entities(registry_proto: RegistryProto, project: str) -> List[Entity]:
entities = []
for entity_proto in registry_proto.entities:
@@ -201,6 +228,7 @@ def list_entities(registry_proto: RegistryProto, project: str) -> List[Entity]:
return entities
+@registry_proto_cache
def list_data_sources(registry_proto: RegistryProto, project: str) -> List[DataSource]:
data_sources = []
for data_source_proto in registry_proto.data_sources:
@@ -209,6 +237,7 @@ def list_data_sources(registry_proto: RegistryProto, project: str) -> List[DataS
return data_sources
+@registry_proto_cache
def list_saved_datasets(
registry_proto: RegistryProto, project: str
) -> List[SavedDataset]:
@@ -219,6 +248,7 @@ def list_saved_datasets(
return saved_datasets
+@registry_proto_cache
def list_validation_references(
registry_proto: RegistryProto, project: str
) -> List[ValidationReference]:
@@ -231,6 +261,7 @@ def list_validation_references(
return validation_references
+@registry_proto_cache
def list_project_metadata(
registry_proto: RegistryProto, project: str
) -> List[ProjectMetadata]:
| performance issues of getting online features related to parsing protobuf data
**Is your feature request related to a problem? Please describe.**
The profiler of one application I am working on shows the `from_proto` method of the `FeatureView` class takes up 80% of the execution time. The result of cProfile is shown below.
```
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.003 0.003 78.931 78.931 profiler.py:53(main)
100 0.018 0.000 78.849 0.788 get_features.py:122(get_xxxx_features)
1100/400 0.020 0.000 77.077 0.193 usage.py:274(wrapper)
444200/9800 1.713 0.000 72.206 0.007 __init__.py:1030(wrapper)
200 0.078 0.000 68.913 0.345 feature_store.py:1527(get_online_features)
200 0.087 0.000 68.835 0.344 feature_store.py:1590(_get_online_features)
3500 5.634 0.002 62.442 0.018 feature_view.py:369(from_proto)
200 0.005 0.000 59.362 0.297 feature_store.py:2149(_get_feature_views_to_use)
200 0.002 0.000 58.501 0.293 feature_store.py:281(_list_feature_views)
200 0.001 0.000 58.499 0.292 registry.py:523(list_feature_views)
200 0.016 0.000 58.495 0.292 proto_registry_utils.py:150(list_feature_views)
```
There are 3 feature views accessed by `get_xxxx_features`, however 100 calls of `get_xxxx_features` lead to 3500 calls of `from_proto`. There are 17 feature views in the feature store of this application and 3 of them are used by `get_xxxx_features`.
Environment: `continuumio/miniconda3:4.11.0` (linux/amd64) base image, `python==3.9.7`, `feast=0.31.1`, `protobuf==4.23.2`
**Describe the solution you'd like**
Instead of caching the protobuf blob of `FeatureView`, cache the `FeatureView` python object in memory.
**Describe alternatives you've considered**
modify the `get_online_features` [method](https://github.com/feast-dev/feast/blob/v0.31.1/sdk/python/feast/feature_store.py#L1528) to
```python
def get_online_features(
self,
features: Union[List[str], List[FeatureView], FeatureService],
entity_rows: List[Dict[str, Any]],
full_feature_names: bool = False,
):
```
so that the application developer has the option to cache the `FeatureView` objects and use them to get features directly (by passing the `get_feature_views_to_use` [step](https://github.com/feast-dev/feast/blob/v0.31.1/sdk/python/feast/feature_store.py#L1606-L1613) )
| I'm facing the same issue too.
From here, ```get_feature_views_to_use``` doesn't seem like a good idea to cache this because the feature_views to use changes depending on input argument ```features```.
https://github.com/feast-dev/feast/blob/c474ccdd23ca8161de5e2958f0a12826c020dc44/sdk/python/feast/feature_store.py#L2149-L2154
What I found is, if feature registry has not expired, I assume that the ```registry.list_*``` methods always return the same result. Currently, this isn't cached, so ```list_*``` methods are being called every time, and ```from_proto``` in them is being called repeatedly and it makes ```get_online_features``` slow.
(```list_*``` methods mean ```registry.list_feature_views```, ```registry.list_data_sources``` ...)
So, my idea is to process the list_* methods using cached results when the registry is not expired.
https://github.com/feast-dev/feast/blob/c474ccdd23ca8161de5e2958f0a12826c020dc44/sdk/python/feast/infra/registry/sql.py#L244-L259
When using the sql registry, as you can see in the code above, the registry is updated by checking whether it has expired. Using this expired will tell us whether to return cached results. And I believe that caching this registry in memory would be no problem.
or caching these fvs, request_fvs, od_fvs!
https://github.com/feast-dev/feast/blob/c474ccdd23ca8161de5e2958f0a12826c020dc44/sdk/python/feast/feature_store.py#L2149-L2177 | 2023-07-28T05:03:21 |
|
feast-dev/feast | 3,717 | feast-dev__feast-3717 | [
"3715"
]
| 6474b4b0169dc9b3df8e8daecded2b1fad5ead58 | diff --git a/sdk/python/feast/infra/registry/proto_registry_utils.py b/sdk/python/feast/infra/registry/proto_registry_utils.py
--- a/sdk/python/feast/infra/registry/proto_registry_utils.py
+++ b/sdk/python/feast/infra/registry/proto_registry_utils.py
@@ -214,7 +214,7 @@ def list_saved_datasets(
) -> List[SavedDataset]:
saved_datasets = []
for saved_dataset in registry_proto.saved_datasets:
- if saved_dataset.project == project:
+ if saved_dataset.spec.project == project:
saved_datasets.append(SavedDataset.from_proto(saved_dataset))
return saved_datasets
| Saved Datasets breaks CLI registry-dump
## Expected Behavior
After creating a saved dataset, the CLI command `feast registry-dump` should dump the contents of the registry to the terminal.
## Current Behavior
After creating a saved dataset, the CLI command `feast registry-dump` breaks, with the following error:
```
Traceback (most recent call last):
File "/Library/Frameworks/Python.framework/Versions/3.10/bin/feast", line 8, in <module>
sys.exit(cli())
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/click/core.py", line 1157, in __call__
return self.main(*args, **kwargs)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/click/core.py", line 1078, in main
rv = self.invoke(ctx)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/click/core.py", line 1688, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/click/core.py", line 1434, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/click/core.py", line 783, in invoke
return __callback(*args, **kwargs)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/click/decorators.py", line 33, in new_func
return f(get_current_context(), *args, **kwargs)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/feast/cli.py", line 562, in registry_dump_command
click.echo(registry_dump(repo_config, repo_path=repo))
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/feast/usage.py", line 299, in wrapper
raise exc.with_traceback(traceback)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/feast/usage.py", line 288, in wrapper
return func(*args, **kwargs)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/feast/repo_operations.py", line 353, in registry_dump
registry_dict = registry.to_dict(project=project)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/feast/infra/registry/base_registry.py", line 648, in to_dict
self.list_saved_datasets(project=project), key=lambda item: item.name
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/feast/infra/registry/registry.py", line 696, in list_saved_datasets
return proto_registry_utils.list_saved_datasets(registry_proto, project)
File "/Library/Frameworks/Python.framework/Versions/3.10/lib/python3.10/site-packages/feast/infra/registry/proto_registry_utils.py", line 217, in list_saved_datasets
if saved_dataset.project == project:
AttributeError: project
```
This error is also replicated with a local clone of the master branch.
## Steps to reproduce
1. Create a saved dataset and save it with `store.create_saved_dataset()`
2. Run `feast registry-dump`
This can be replicated with this repository: https://github.com/malcolmk181/feast-dqm-tutorial/tree/61a8d46c1452e48d51504b1b2c252426d557e87e
Clone the repository and convert the `demo.py` into a notebook using `jupyter nbconvert demo.py --to notebook`. This notebook generally follows the [Validating Historical Features](https://docs.feast.dev/tutorials/validating-historical-features) tutorial. If you run the cells up to and not including the cell that creates the saved dataset, `feast registry-dump` will run successfully, and dump the registry contents to the terminal. If you run the cell that creates the saved dataset and repeat `feast registry-dump`, the error will occur.
### Specifications
- Version: Feast 0.31.1 and Feast SDK 0.1.dev3032, Python 3.10.11
- Platform: Replicated in Debian 11.7 and macOS 12.6.8
- Subsystem:
## Possible Solution
The error is thrown by line 217 of the `list_saved_dataset()` function in `sdk/python/feast/infra/registry/proto_registry_utils.py`:
https://github.com/feast-dev/feast/blob/c75a01fce2d52cd18479ace748b8eb2e6c81c988/sdk/python/feast/infra/registry/proto_registry_utils.py#L217
I deserialized the `registry.db` file and after referencing the proto files found that the project attribute was successfully logged on the saved dataset object within the registry. It appears that within the `list_saved_datasets()` function that the `saved_dataset` proto needs to use `.spec` to access the `project` attribute. This would be consistent with the `get_saved_dataset()` function:
https://github.com/feast-dev/feast/blob/c75a01fce2d52cd18479ace748b8eb2e6c81c988/sdk/python/feast/infra/registry/proto_registry_utils.py#L123
| 2023-08-09T22:28:25 |
||
feast-dev/feast | 3,719 | feast-dev__feast-3719 | [
"3720"
]
| 0b3fa13373ba12e912e8b4b1a0dc5ea18cbe8fc9 | diff --git a/sdk/python/feast/type_map.py b/sdk/python/feast/type_map.py
--- a/sdk/python/feast/type_map.py
+++ b/sdk/python/feast/type_map.py
@@ -528,6 +528,7 @@ def bq_to_feast_value_type(bq_type_as_str: str) -> ValueType:
"DATETIME": ValueType.UNIX_TIMESTAMP,
"TIMESTAMP": ValueType.UNIX_TIMESTAMP,
"INTEGER": ValueType.INT64,
+ "NUMERIC": ValueType.INT64,
"INT64": ValueType.INT64,
"STRING": ValueType.STRING,
"FLOAT": ValueType.DOUBLE,
| BigQuery internal type mapping does not support NUMERIC
## Expected Behavior
Should handle mapping from BQ's NUMERIC type
## Current Behavior
Thrown KeyError
## Steps to reproduce
Prepare feature view with data source contains at least one NUMERIC column
### Specifications
- Version: 0.32.0
- Platform: ubuntu
- Subsystem:
## Possible Solution
Add NUMERIC to mapping logic
| 2023-08-13T03:42:44 |
||
feast-dev/feast | 3,730 | feast-dev__feast-3730 | [
"3712"
]
| 377758b48f89fb7f1b99856d09d3b383a2c80882 | diff --git a/sdk/python/feast/infra/offline_stores/bigquery.py b/sdk/python/feast/infra/offline_stores/bigquery.py
--- a/sdk/python/feast/infra/offline_stores/bigquery.py
+++ b/sdk/python/feast/infra/offline_stores/bigquery.py
@@ -577,7 +577,6 @@ def to_remote_storage(self) -> List[str]:
else:
storage_client = StorageClient(project=self.client.project)
bucket, prefix = self._gcs_path[len("gs://") :].split("/", 1)
- prefix = prefix.rsplit("/", 1)[0]
if prefix.startswith("/"):
prefix = prefix[1:]
| In BigQueryRetrievalJob.to_remote_storage(), return value is incorrect (includes all parquet files created in gcs_staging_location, not those those created in that specific call)
## Expected Behavior
In [BigQueryRetrievalJob](https://github.com/feast-dev/feast/blob/c75a01fce2d52cd18479ace748b8eb2e6c81c988/sdk/python/feast/infra/offline_stores/bigquery.py#L402), when I call [to_remote_storage](https://github.com/feast-dev/feast/blob/c75a01fce2d52cd18479ace748b8eb2e6c81c988/sdk/python/feast/infra/offline_stores/bigquery.py#L553)(), the [return value](https://github.com/feast-dev/feast/blob/c75a01fce2d52cd18479ace748b8eb2e6c81c988/sdk/python/feast/infra/offline_stores/bigquery.py#L588) that I would expect would be the paths of the parquet files that have been written to GCS...
## Current Behavior
...however, it turns out the the paths that are returned are all parquets ever that you have written to the bucket that you are using to store these parquets.
For example, say you set you gcs_staging_location in your feature_store.yaml to `feast-materialize-dev` and project_id to `my_feature-store`, then the self._gcs_path, as defined [here](https://github.com/feast-dev/feast/blob/c75a01fce2d52cd18479ace748b8eb2e6c81c988/sdk/python/feast/infra/offline_stores/bigquery.py#L428-L432) will be: `gs://feast-materialize-dev/my_feature_store/export/ff67c43e-7174-475f-a02c-6c7587d89731` (or some other uuid string, but you get the idea). However, the rest of the code in the to_remote_storage method returns all paths that are in the path `gs://feast-materialize-dev/export` which is not we we want, as the parquets are written to the self._gcs_path.
## Steps to reproduce
You can see that the code is wrong with a simple example:
Current code (pretty much from [this](https://github.com/feast-dev/feast/blob/c75a01fce2d52cd18479ace748b8eb2e6c81c988/sdk/python/feast/infra/offline_stores/bigquery.py#L579C9-L588). In this example you might imagine there are parquets created from the to-remote_storage call under `gs://feast-materialize-dev/ki_feature_store/export/19a1c772-1f91-44da-8486-ea476f027d93/` but from a previous call there are also some at `gs://feast-materialize-dev/ki_feature_store/export/e00597db-78d5-40e1-b125-eac903802acd/`:
```python
>>> from google.cloud.storage import Client as StorageClient
>>> _gcs_path = "gs://feast-materialize-dev/my_feature_store/export/ff67c43e-7174-475f-a02c-6c7587d89731"
>>> bucket, prefix = _gcs_path[len("gs://") :].split("/", 1)
>>> print(bucket)
'feast-materialize-dev'
>>> print(prefix)
'my_feature_store/export/ff67c43e-7174-475f-a02c-6c7587d89731'
>>> prefix = prefix.rsplit("/", 1)[0] # THIS IS THE LINE THAT WE DO NOT WANT
>>> print(prefix)
'my_feature_store/export'
>>> if prefix.startswith("/"):
>>> prefix = prefix[1:]
>>> print(prefix)
'my_feature_store/export'
>>> storage_client = StorageClient()
>>> blobs = storage_client.list_blobs(bucket, prefix=prefix)`
>>> results = []
>>> for b in blobs:
>>> results.append(f"gs://{b.bucket.name}/{b.name}")
>>> print(results)
["gs://feast-materialize-dev/my_feature_store/export/19a1c772-1f91-44da-8486-ea476f027d93/000000000000.parquet", "gs://feast-materialize-dev/my_feature_store/export/19a1c772-1f91-44da-8486-ea476f027d93/000000000001.parquet", "gs://feast-materialize-dev/my_feature_store/export/e00597db-78d5-40e1-b125-eac903802acd/000000000000.parquet", "gs://feast-materialize-dev/my_feature_store/export/e00597db-78d5-40e1-b125-eac903802acd/000000000001.parquet"]
```
You can see in this example, there are parquets paths returned that are not [art of the self._gcs_path and therefore the write to gcs that occurred in this call. This is not what i would expect.
## Possible Solution
The corrected code would simply not include the line `prefix = prefix.rsplit("/", 1)[0]`
| Agree with this 🙌 although your example might be a bit confused because
``` python
'my_feature_store/export/ff67c43e-7174-475f-a02c-6c7587d89731/'
prefix = prefix.rsplit("/", 1)[0]
print(prefix)
# should return "my_feature_store/export/ff67c43e-7174-475f-a02c-6c7587d89731"
```
Thanks @sudohainguyen for taking the time to read through the issue, and for spotting the extra `/`. I have updated the example accordingly :) | 2023-08-15T12:18:31 |
|
feast-dev/feast | 3,754 | feast-dev__feast-3754 | [
"3745"
]
| 6a728fe66db0286ea10301d1fe693d6dcba4e4f4 | diff --git a/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py b/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py
--- a/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py
+++ b/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py
@@ -61,6 +61,12 @@ class BytewaxMaterializationEngineConfig(FeastConfigBaseModel):
include_security_context_capabilities: bool = True
""" (optional) Include security context capabilities in the init and job container spec """
+ labels: dict = {}
+ """ (optional) additional labels to append to kubernetes objects """
+
+ max_parallelism: int = 10
+ """ (optional) Maximum number of pods (default 10) allowed to run in parallel per job"""
+
class BytewaxMaterializationEngine(BatchMaterializationEngine):
def __init__(
@@ -82,7 +88,7 @@ def __init__(
self.online_store = online_store
# TODO: Configure k8s here
- k8s_config.load_kube_config()
+ k8s_config.load_config()
self.k8s_client = client.api_client.ApiClient()
self.v1 = client.CoreV1Api(self.k8s_client)
@@ -196,14 +202,13 @@ def _create_configuration_map(self, job_id, paths, feature_view, namespace):
{"paths": paths, "feature_view": feature_view.name}
)
+ labels = {"feast-bytewax-materializer": "configmap"}
configmap_manifest = {
"kind": "ConfigMap",
"apiVersion": "v1",
"metadata": {
"name": f"feast-{job_id}",
- "labels": {
- "feast-bytewax-materializer": "configmap",
- },
+ "labels": {**labels, **self.batch_engine_config.labels},
},
"data": {
"feature_store.yaml": feature_store_configuration,
@@ -260,27 +265,25 @@ def _create_job_definition(self, job_id, namespace, pods, env):
"drop": ["ALL"],
}
+ job_labels = {"feast-bytewax-materializer": "job"}
+ pod_labels = {"feast-bytewax-materializer": "pod"}
job_definition = {
"apiVersion": "batch/v1",
"kind": "Job",
"metadata": {
"name": f"dataflow-{job_id}",
"namespace": namespace,
- "labels": {
- "feast-bytewax-materializer": "job",
- },
+ "labels": {**job_labels, **self.batch_engine_config.labels},
},
"spec": {
"ttlSecondsAfterFinished": 3600,
"completions": pods,
- "parallelism": pods,
+ "parallelism": min(pods, self.batch_engine_config.max_parallelism),
"completionMode": "Indexed",
"template": {
"metadata": {
"annotations": self.batch_engine_config.annotations,
- "labels": {
- "feast-bytewax-materializer": "pod",
- },
+ "labels": {**pod_labels, **self.batch_engine_config.labels},
},
"spec": {
"restartPolicy": "Never",
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -98,7 +98,7 @@
"hiredis>=2.0.0,<3",
]
-AWS_REQUIRED = ["boto3>=1.17.0,<2", "docker>=5.0.2"]
+AWS_REQUIRED = ["boto3>=1.17.0,<2", "docker>=5.0.2", "s3fs"]
BYTEWAX_REQUIRED = ["bytewax==0.15.1", "docker>=5.0.2", "kubernetes<=20.13.0"]
| Allow user to set custom labels for bytewax materializer kubernetes objects
**Is your feature request related to a problem? Please describe.**
I am materializing feature data to online for multiple environments simultaneously in the same kubernetes cluster and I want to be able to track what environment and materialization job is related to for error tracking.
**Describe the solution you'd like**
A user defines a dict of additional labels they would like to add to kubernetes objects in their feature_store.yaml under batch_engine config and those labels are added to all objects in addition to any default labels
**Describe alternatives you've considered**
This can be done through separating environments into separate namespaces, but this is not standard practice
| 2023-09-01T18:49:17 |
||
feast-dev/feast | 3,755 | feast-dev__feast-3755 | [
"3753"
]
| 6474b4b0169dc9b3df8e8daecded2b1fad5ead58 | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -92,7 +92,7 @@
]
REDIS_REQUIRED = [
- "redis==4.2.2",
+ "redis>=4.2.2,<5",
"hiredis>=2.0.0,<3",
]
| Redis version in setup.py contains fixable vulnerabilities
## Expected Behaviour
## Current Behaviour:
trivvy scanning of our feature server container is failing due to the fixed version of redis in setup.py (4.2.2) - it looks this version hasn't been updated in a year.

## Steps to reproduce
### Specifications
- Version: feast[redis]==0.31.1
- Platform:
- Subsystem:
## Possible Solution
Bump to latest redis or lowest fixed version
| 2023-09-01T18:58:06 |
||
feast-dev/feast | 3,756 | feast-dev__feast-3756 | [
"3750"
]
| 68a87379c42567f338d86cb2be90520cc6d4bfb6 | diff --git a/sdk/python/feast/infra/utils/postgres/postgres_config.py b/sdk/python/feast/infra/utils/postgres/postgres_config.py
--- a/sdk/python/feast/infra/utils/postgres/postgres_config.py
+++ b/sdk/python/feast/infra/utils/postgres/postgres_config.py
@@ -25,4 +25,4 @@ class PostgreSQLConfig(FeastConfigBaseModel):
sslkey_path: Optional[StrictStr] = None
sslcert_path: Optional[StrictStr] = None
sslrootcert_path: Optional[StrictStr] = None
- keepalives_idle: int = 0
+ keepalives_idle: Optional[int] = None
| Postgres engine default keepalives_idle value causes setsockopt(TCP_KEEPIDLE) invalid value
Get `OperationalError: connection to server at "localhost" (127.0.0.1), port 5432 failed: setsockopt(TCP_KEEPIDLE) failed: Invalid argument` when run `feast apply`.
Because of `keepalives_idle=config.keepalives_idle` field in function '_get_conn' in `infra/utils/postgres/connection_utils.py` file. For example, to avoid this error I need to pass 'keepalives_idle=1', but that argument isn't parsed for the registry in feature_store.yaml and pass 'keepalives_idle=0' by default setting in `infra/utils/postgres/postgres_config.py`.
- Version: 0.33.1
- Platform: linux ubuntu 20.04
- Subsystem:
## Possible Solution
Check this issue with the same problem https://github.com/TobikoData/sqlmesh/issues/750. I think you shouldn't pass 'keepalives_idle=0' by default.
| 2023-09-07T06:59:31 |
||
feast-dev/feast | 3,761 | feast-dev__feast-3761 | [
"3760",
"3760"
]
| 774ed33a067bf9bf087520325b72f4f4d194106a | diff --git a/sdk/python/feast/feature_server.py b/sdk/python/feast/feature_server.py
--- a/sdk/python/feast/feature_server.py
+++ b/sdk/python/feast/feature_server.py
@@ -1,9 +1,11 @@
import json
import traceback
import warnings
+from typing import List, Optional
import gunicorn.app.base
import pandas as pd
+from dateutil import parser
from fastapi import FastAPI, HTTPException, Request, Response, status
from fastapi.logger import logger
from fastapi.params import Depends
@@ -11,7 +13,7 @@
from pydantic import BaseModel
import feast
-from feast import proto_json
+from feast import proto_json, utils
from feast.data_source import PushMode
from feast.errors import PushSourceNotFoundException
from feast.protos.feast.serving.ServingService_pb2 import GetOnlineFeaturesRequest
@@ -31,6 +33,17 @@ class PushFeaturesRequest(BaseModel):
to: str = "online"
+class MaterializeRequest(BaseModel):
+ start_ts: str
+ end_ts: str
+ feature_views: Optional[List[str]] = None
+
+
+class MaterializeIncrementalRequest(BaseModel):
+ end_ts: str
+ feature_views: Optional[List[str]] = None
+
+
def get_app(store: "feast.FeatureStore"):
proto_json.patch()
@@ -134,6 +147,34 @@ def write_to_online_store(body=Depends(get_body)):
def health():
return Response(status_code=status.HTTP_200_OK)
+ @app.post("/materialize")
+ def materialize(body=Depends(get_body)):
+ try:
+ request = MaterializeRequest(**json.loads(body))
+ store.materialize(
+ utils.make_tzaware(parser.parse(request.start_ts)),
+ utils.make_tzaware(parser.parse(request.end_ts)),
+ request.feature_views,
+ )
+ except Exception as e:
+ # Print the original exception on the server side
+ logger.exception(traceback.format_exc())
+ # Raise HTTPException to return the error message to the client
+ raise HTTPException(status_code=500, detail=str(e))
+
+ @app.post("/materialize-incremental")
+ def materialize_incremental(body=Depends(get_body)):
+ try:
+ request = MaterializeIncrementalRequest(**json.loads(body))
+ store.materialize_incremental(
+ utils.make_tzaware(parser.parse(request.end_ts)), request.feature_views
+ )
+ except Exception as e:
+ # Print the original exception on the server side
+ logger.exception(traceback.format_exc())
+ # Raise HTTPException to return the error message to the client
+ raise HTTPException(status_code=500, detail=str(e))
+
return app
| Add materialize and materialize-incremental rest endpoints
**Is your feature request related to a problem? Please describe.**
In multi clustered environments when managing all cronjobs with cron orchestrator tools facing restricted network access to some resources. We use the Rest interface for most important CLI commands as materialize and materialize-incremental.
**Describe the solution you'd like**
adding two endpoints to Python server
**Additional context**
Also we can implement to go server too
Add materialize and materialize-incremental rest endpoints
**Is your feature request related to a problem? Please describe.**
In multi clustered environments when managing all cronjobs with cron orchestrator tools facing restricted network access to some resources. We use the Rest interface for most important CLI commands as materialize and materialize-incremental.
**Describe the solution you'd like**
adding two endpoints to Python server
**Additional context**
Also we can implement to go server too
| 2023-09-12T11:46:13 |
||
feast-dev/feast | 3,762 | feast-dev__feast-3762 | [
"3763"
]
| fa600fe3c4b1d5fdd383a9367511ac5616ee7a32 | diff --git a/sdk/python/feast/infra/offline_stores/bigquery.py b/sdk/python/feast/infra/offline_stores/bigquery.py
--- a/sdk/python/feast/infra/offline_stores/bigquery.py
+++ b/sdk/python/feast/infra/offline_stores/bigquery.py
@@ -19,7 +19,7 @@
import pandas as pd
import pyarrow
import pyarrow.parquet
-from pydantic import StrictStr, validator
+from pydantic import ConstrainedStr, StrictStr, validator
from pydantic.typing import Literal
from tenacity import Retrying, retry_if_exception_type, stop_after_delay, wait_fixed
@@ -72,6 +72,13 @@ def get_http_client_info():
return http_client_info.ClientInfo(user_agent=get_user_agent())
+class BigQueryTableCreateDisposition(ConstrainedStr):
+ """Custom constraint for table_create_disposition. To understand more, see:
+ https://cloud.google.com/bigquery/docs/reference/rest/v2/Job#JobConfigurationLoad.FIELDS.create_disposition"""
+
+ values = {"CREATE_NEVER", "CREATE_IF_NEEDED"}
+
+
class BigQueryOfflineStoreConfig(FeastConfigBaseModel):
"""Offline store config for GCP BigQuery"""
@@ -95,6 +102,9 @@ class BigQueryOfflineStoreConfig(FeastConfigBaseModel):
gcs_staging_location: Optional[str] = None
""" (optional) GCS location used for offloading BigQuery results as parquet files."""
+ table_create_disposition: Optional[BigQueryTableCreateDisposition] = None
+ """ (optional) Specifies whether the job is allowed to create new tables. The default value is CREATE_IF_NEEDED."""
+
@validator("billing_project_id")
def project_id_exists(cls, v, values, **kwargs):
if v and not values["project_id"]:
@@ -324,6 +334,7 @@ def write_logged_features(
job_config = bigquery.LoadJobConfig(
source_format=bigquery.SourceFormat.PARQUET,
schema=arrow_schema_to_bq_schema(source.get_schema(registry)),
+ create_disposition=config.offline_store.table_create_disposition,
time_partitioning=bigquery.TimePartitioning(
type_=bigquery.TimePartitioningType.DAY,
field=source.get_log_timestamp_column(),
@@ -384,6 +395,7 @@ def offline_write_batch(
job_config = bigquery.LoadJobConfig(
source_format=bigquery.SourceFormat.PARQUET,
schema=arrow_schema_to_bq_schema(pa_schema),
+ create_disposition=config.offline_store.table_create_disposition,
write_disposition="WRITE_APPEND", # Default but included for clarity
)
| Add support for `table_create_disposition` in bigquery job for offline store
**Is your feature request related to a problem? Please describe.**
The current configuration of the `bigquery.LoadJobConfig()` in the bigquery offline store leaves the `create_disposition` undefined, defaulting to "CREATE_IF_NEEDED", which requires the service account that is sending the data from the feast server into the offline store to be given the `bigquery.tables.create`. This is not ideal for our setup, as our tables will be created and managed by a different service separate to feast, and giving the SA this permission would create a risk of data exposure.
**Describe the solution you'd like**
A way to allow users to declare the type of `create_disposition` they'd want, defaulting to the existing behaviour if left unset.
**Describe alternatives you've considered**
Maintain a fork of feast with this modification made.
| 2023-09-12T16:47:35 |
||
feast-dev/feast | 3,766 | feast-dev__feast-3766 | [
"3765"
]
| 470f6a89ff7f485be9e916f748769dbbc3ddbfe2 | diff --git a/sdk/python/feast/ui_server.py b/sdk/python/feast/ui_server.py
--- a/sdk/python/feast/ui_server.py
+++ b/sdk/python/feast/ui_server.py
@@ -77,7 +77,7 @@ def read_registry():
# For all other paths (such as paths that would otherwise be handled by react router), pass to React
@app.api_route("/p/{path_name:path}", methods=["GET"])
def catch_all():
- filename = ui_dir + "index.html"
+ filename = ui_dir.joinpath("index.html")
with open(filename) as f:
content = f.read()
| Feast ui cannot parse url path
## Expected Behavior
One of example cases:
When user navigate localhost:8888/p/order_count_project/feature-view/user_3_and_7_days_order_count should see related feature-view page
## Current Behavior
One of example cases:
When user navigate localhost:8888/p/order_count_project/feature-view/user_3_and_7_days_order_count see "Internal Server Error"
## Steps to reproduce
install feast 0.34.1
run feast ui
navigate homepage localhost:8888
navigate any page (entities or feature-view or data sources doesn't matter)
you will see the page you clicked at browser search bar like http://localhost:8888/p/order_count_project/data-source
then refresh or copy url open in new tab
you will see internal server error
### Specifications
- Version: 0.34.1
- Platform: macos
- Subsystem:
## Possible Solution
ui_server.py file updated recently. commit changes resource finder library and then it returns PosixPath.
We should convert to str and add little "/" to "@app.api_route("/p/{path_name:path}", methods=["GET"])" function
| 2023-09-14T09:09:00 |
||
feast-dev/feast | 3,777 | feast-dev__feast-3777 | [
"3776"
]
| 018d0eab69dde63266f2c56813045ea5c5523f76 | diff --git a/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_dataflow.py b/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_dataflow.py
--- a/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_dataflow.py
+++ b/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_dataflow.py
@@ -1,3 +1,4 @@
+import os
from typing import List
import pyarrow as pa
@@ -12,6 +13,8 @@
from feast import FeatureStore, FeatureView, RepoConfig
from feast.utils import _convert_arrow_to_proto, _run_pyarrow_field_mapping
+DEFAULT_BATCH_SIZE = 1000
+
class BytewaxMaterializationDataflow:
def __init__(
@@ -46,6 +49,11 @@ def input_builder(self, worker_index, worker_count, _state):
return
def output_builder(self, worker_index, worker_count):
+ def yield_batch(iterable, batch_size):
+ """Yield mini-batches from an iterable."""
+ for i in range(0, len(iterable), batch_size):
+ yield iterable[i : i + batch_size]
+
def output_fn(batch):
table = pa.Table.from_batches([batch])
@@ -64,12 +72,17 @@ def output_fn(batch):
)
provider = self.feature_store._get_provider()
with tqdm(total=len(rows_to_write)) as progress:
- provider.online_write_batch(
- config=self.config,
- table=self.feature_view,
- data=rows_to_write,
- progress=progress.update,
+ # break rows_to_write to mini-batches
+ batch_size = int(
+ os.getenv("BYTEWAX_MINI_BATCH_SIZE", DEFAULT_BATCH_SIZE)
)
+ for mini_batch in yield_batch(rows_to_write, batch_size):
+ provider.online_write_batch(
+ config=self.config,
+ table=self.feature_view,
+ data=mini_batch,
+ progress=progress.update,
+ )
return output_fn
diff --git a/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py b/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py
--- a/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py
+++ b/sdk/python/feast/infra/materialization/contrib/bytewax/bytewax_materialization_engine.py
@@ -67,6 +67,9 @@ class BytewaxMaterializationEngineConfig(FeastConfigBaseModel):
max_parallelism: int = 10
""" (optional) Maximum number of pods (default 10) allowed to run in parallel per job"""
+ mini_batch_size: int = 1000
+ """ (optional) Number of rows to process per write operation (default 1000)"""
+
class BytewaxMaterializationEngine(BatchMaterializationEngine):
def __init__(
@@ -254,6 +257,10 @@ def _create_job_definition(self, job_id, namespace, pods, env):
"name": "BYTEWAX_STATEFULSET_NAME",
"value": f"dataflow-{job_id}",
},
+ {
+ "name": "BYTEWAX_MINI_BATCH_SIZE",
+ "value": str(self.batch_engine_config.mini_batch_size),
+ },
]
# Add any Feast configured environment variables
job_env.extend(env)
| Control mini-batch size when writing rows to online store from bytewax job
**Is your feature request related to a problem? Please describe.**
Bytewax Materialization job tries to write all rows at a time from a single pyarrow parquet dataset
**Describe the solution you'd like**
Should break into mini-batches before writing to online store, and this number should be configurable
**Describe alternatives you've considered**
No
**Additional context**
<img width="545" alt="image" src="https://github.com/feast-dev/feast/assets/22145541/8dc902e7-80cb-40e0-945c-78fa373b6a9c">
| 2023-09-30T08:15:45 |
||
feast-dev/feast | 3,815 | feast-dev__feast-3815 | [
"3813"
]
| 015196119945d962bb67db84de787364667cecca | diff --git a/sdk/python/feast/cli.py b/sdk/python/feast/cli.py
--- a/sdk/python/feast/cli.py
+++ b/sdk/python/feast/cli.py
@@ -705,15 +705,24 @@ def serve_command(
show_default=False,
help="The maximum number of threads that can be used to execute the gRPC calls",
)
[email protected](
+ "--registry_ttl_sec",
+ "-r",
+ help="Number of seconds after which the registry is refreshed",
+ type=click.INT,
+ default=5,
+ show_default=True,
+)
@click.pass_context
def listen_command(
ctx: click.Context,
address: str,
max_workers: int,
+ registry_ttl_sec: int,
):
"""Start a gRPC feature server to ingest streaming features on given address"""
store = create_feature_store(ctx)
- server = get_grpc_server(address, store, max_workers)
+ server = get_grpc_server(address, store, max_workers, registry_ttl_sec)
server.start()
server.wait_for_termination()
diff --git a/sdk/python/feast/infra/contrib/grpc_server.py b/sdk/python/feast/infra/contrib/grpc_server.py
--- a/sdk/python/feast/infra/contrib/grpc_server.py
+++ b/sdk/python/feast/infra/contrib/grpc_server.py
@@ -1,12 +1,14 @@
import logging
+import threading
from concurrent import futures
+from typing import Optional
import grpc
import pandas as pd
from grpc_health.v1 import health, health_pb2_grpc
from feast.data_source import PushMode
-from feast.errors import PushSourceNotFoundException
+from feast.errors import FeatureServiceNotFoundException, PushSourceNotFoundException
from feast.feature_store import FeatureStore
from feast.protos.feast.serving.GrpcServer_pb2 import (
PushResponse,
@@ -16,6 +18,12 @@
GrpcFeatureServerServicer,
add_GrpcFeatureServerServicer_to_server,
)
+from feast.protos.feast.serving.ServingService_pb2 import (
+ GetOnlineFeaturesRequest,
+ GetOnlineFeaturesResponse,
+)
+
+logger = logging.getLogger(__name__)
def parse(features):
@@ -28,10 +36,16 @@ def parse(features):
class GrpcFeatureServer(GrpcFeatureServerServicer):
fs: FeatureStore
- def __init__(self, fs: FeatureStore):
+ _shuting_down: bool = False
+ _active_timer: Optional[threading.Timer] = None
+
+ def __init__(self, fs: FeatureStore, registry_ttl_sec: int = 5):
self.fs = fs
+ self.registry_ttl_sec = registry_ttl_sec
super().__init__()
+ self._async_refresh()
+
def Push(self, request, context):
try:
df = parse(request.features)
@@ -53,19 +67,19 @@ def Push(self, request, context):
to=to,
)
except PushSourceNotFoundException as e:
- logging.exception(str(e))
+ logger.exception(str(e))
context.set_code(grpc.StatusCode.INVALID_ARGUMENT)
context.set_details(str(e))
return PushResponse(status=False)
except Exception as e:
- logging.exception(str(e))
+ logger.exception(str(e))
context.set_code(grpc.StatusCode.INTERNAL)
context.set_details(str(e))
return PushResponse(status=False)
return PushResponse(status=True)
def WriteToOnlineStore(self, request, context):
- logging.warning(
+ logger.warning(
"write_to_online_store is deprecated. Please consider using Push instead"
)
try:
@@ -76,16 +90,55 @@ def WriteToOnlineStore(self, request, context):
allow_registry_cache=request.allow_registry_cache,
)
except Exception as e:
- logging.exception(str(e))
+ logger.exception(str(e))
context.set_code(grpc.StatusCode.INTERNAL)
context.set_details(str(e))
return PushResponse(status=False)
return WriteToOnlineStoreResponse(status=True)
+ def GetOnlineFeatures(self, request: GetOnlineFeaturesRequest, context):
+ if request.HasField("feature_service"):
+ logger.info(f"Requesting feature service: {request.feature_service}")
+ try:
+ features = self.fs.get_feature_service(
+ request.feature_service, allow_cache=True
+ )
+ except FeatureServiceNotFoundException as e:
+ logger.error(f"Feature service {request.feature_service} not found")
+ context.set_code(grpc.StatusCode.INTERNAL)
+ context.set_details(str(e))
+ return GetOnlineFeaturesResponse()
+ else:
+ features = list(request.features.val)
+
+ result = self.fs._get_online_features(
+ features,
+ request.entities,
+ request.full_feature_names,
+ ).proto
+
+ return result
+
+ def _async_refresh(self):
+ self.fs.refresh_registry()
+ if self._shuting_down:
+ return
+ self._active_timer = threading.Timer(self.registry_ttl_sec, self._async_refresh)
+ self._active_timer.start()
-def get_grpc_server(address: str, fs: FeatureStore, max_workers: int):
+
+def get_grpc_server(
+ address: str,
+ fs: FeatureStore,
+ max_workers: int,
+ registry_ttl_sec: int,
+):
+ logger.info(f"Initializing gRPC server on {address}")
server = grpc.server(futures.ThreadPoolExecutor(max_workers=max_workers))
- add_GrpcFeatureServerServicer_to_server(GrpcFeatureServer(fs), server)
+ add_GrpcFeatureServerServicer_to_server(
+ GrpcFeatureServer(fs, registry_ttl_sec=registry_ttl_sec),
+ server,
+ )
health_servicer = health.HealthServicer(
experimental_non_blocking=True,
experimental_thread_pool=futures.ThreadPoolExecutor(max_workers=max_workers),
diff --git a/sdk/python/feast/type_map.py b/sdk/python/feast/type_map.py
--- a/sdk/python/feast/type_map.py
+++ b/sdk/python/feast/type_map.py
@@ -428,12 +428,15 @@ def _python_value_to_proto_value(
for value in values
]
if feast_value_type in PYTHON_SCALAR_VALUE_TYPE_TO_PROTO_VALUE:
- return [
- ProtoValue(**{field_name: func(value)})
- if not pd.isnull(value)
- else ProtoValue()
- for value in values
- ]
+ out = []
+ for value in values:
+ if isinstance(value, ProtoValue):
+ out.append(value)
+ elif not pd.isnull(value):
+ out.append(ProtoValue(**{field_name: func(value)}))
+ else:
+ out.append(ProtoValue())
+ return out
raise Exception(f"Unsupported data type: ${str(type(values[0]))}")
@@ -746,7 +749,7 @@ def spark_to_feast_value_type(spark_type_as_str: str) -> ValueType:
"array<timestamp>": ValueType.UNIX_TIMESTAMP_LIST,
}
# TODO: Find better way of doing this.
- if type(spark_type_as_str) != str or spark_type_as_str not in type_map:
+ if not isinstance(spark_type_as_str, str) or spark_type_as_str not in type_map:
return ValueType.NULL
return type_map[spark_type_as_str.lower()]
| python gRPC feature server for online retrieval
**Is your feature request related to a problem? Please describe.**
I would like to serve online feature with python grpc service
**Describe the solution you'd like**
We already have `grpc_server`, now we only need to add a rpc service to get online feature
**Describe alternatives you've considered**
Nope
**Additional context**
Like this

| 2023-10-24T16:46:06 |
||
feast-dev/feast | 3,827 | feast-dev__feast-3827 | [
"3823"
]
| 9583ed6b4ae8d3b97934bf0c80ecb236ed1e2895 | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -31,7 +31,6 @@
from setuptools.command.install import install
except ImportError:
- from distutils.command.build_ext import build_ext as _build_ext
from distutils.command.build_py import build_py
from distutils.core import setup
@@ -80,18 +79,18 @@
# FastAPI does not correctly pull starlette dependency on httpx see thread(https://github.com/tiangolo/fastapi/issues/5656).
"httpx>=0.23.3",
"importlib-resources>=6.0.0,<7",
- "importlib_metadata>=6.8.0,<7"
+ "importlib_metadata>=6.8.0,<7",
]
GCP_REQUIRED = [
"google-api-core>=1.23.0,<3",
"googleapis-common-protos>=1.52.0,<2",
- "google-cloud-bigquery[pandas]>=2,<4",
+ "google-cloud-bigquery[pandas]>=2,<3.13.0",
"google-cloud-bigquery-storage >= 2.0.0,<3",
"google-cloud-datastore>=2.1.0,<3",
"google-cloud-storage>=1.34.0,<3",
"google-cloud-bigtable>=2.11.0,<3",
- "gcsfs",
+ "fsspec<2023.10.0",
]
REDIS_REQUIRED = [
@@ -99,7 +98,7 @@
"hiredis>=2.0.0,<3",
]
-AWS_REQUIRED = ["boto3>=1.17.0,<2", "docker>=5.0.2", "s3fs"]
+AWS_REQUIRED = ["boto3>=1.17.0,<2", "docker>=5.0.2", "fsspec<2023.10.0"]
BYTEWAX_REQUIRED = ["bytewax==0.15.1", "docker>=5.0.2", "kubernetes<=20.13.0"]
@@ -159,8 +158,8 @@
"moto",
"mypy>=0.981,<0.990",
"avro==1.10.0",
- "gcsfs",
- "urllib3>=1.25.4,<2",
+ "fsspec<2023.10.0",
+ "urllib3>=1.25.4,<3",
"psutil==5.9.0",
"py>=1.11.0", # https://github.com/pytest-dev/pytest/issues/10420
"pytest>=6.0.0,<8",
@@ -173,7 +172,6 @@
"pytest-mock==1.10.4",
"Sphinx>4.0.0,<7",
"testcontainers>=3.5,<4",
- "adlfs==0.5.9",
"firebase-admin>=5.2.0,<6",
"pre-commit<3.3.2",
"assertpy==1.1",
@@ -184,10 +182,10 @@
"types-pytz",
"types-PyYAML",
"types-redis",
- "types-requests",
+ "types-requests<2.31.0",
"types-setuptools",
"types-tabulate",
- "virtualenv<20.24.2"
+ "virtualenv<20.24.2",
]
+ GCP_REQUIRED
+ REDIS_REQUIRED
| google-cloud-bigquery 3.13.0 breaking change
## Expected Behavior
Successfully get the pyarrow datatype from a feast ValueType using the `feast_value_type_to_pa` function
## Current Behavior
Currently receive the error `feast.errors.FeastExtrasDependencyImportError: cannot import name 'ARROW_SCALAR_IDS_TO_BQ' from 'google.cloud.bigquery._pandas_helpers'`
## Steps to reproduce
Install feast with the latest GCP dependencies and try to convert a feast schema to pyarrow through the use of the function `feast_value_type_to_pa`
### Specifications
- Version: 0.34.1
- Platform: Linux
- Subsystem: Debian 11 (bullseye)
## Possible Solution
Downgrade to google-cloud-bigquery 3.12.0
| @tfusillo mind making a PR for this?
I got the same error with
> google-cloud-bigquery==0.32.1
> feast[redis,gcp]==0.33.1 | 2023-11-04T08:35:52 |
|
feast-dev/feast | 3,843 | feast-dev__feast-3843 | [
"3805"
]
| 052182bcca046e35456674fc7d524825882f4b35 | diff --git a/sdk/python/feast/feature_view.py b/sdk/python/feast/feature_view.py
--- a/sdk/python/feast/feature_view.py
+++ b/sdk/python/feast/feature_view.py
@@ -17,6 +17,7 @@
from typing import Dict, List, Optional, Tuple, Type
from google.protobuf.duration_pb2 import Duration
+from google.protobuf.message import Message
from typeguard import typechecked
from feast import utils
@@ -274,7 +275,7 @@ def ensure_valid(self):
raise ValueError("Feature view has no entities.")
@property
- def proto_class(self) -> Type[FeatureViewProto]:
+ def proto_class(self) -> Type[Message]:
return FeatureViewProto
def with_join_key_map(self, join_key_map: Dict[str, str]):
diff --git a/sdk/python/feast/stream_feature_view.py b/sdk/python/feast/stream_feature_view.py
--- a/sdk/python/feast/stream_feature_view.py
+++ b/sdk/python/feast/stream_feature_view.py
@@ -3,9 +3,10 @@
import warnings
from datetime import datetime, timedelta
from types import FunctionType
-from typing import Dict, List, Optional, Tuple, Union
+from typing import Dict, List, Optional, Tuple, Type, Union
import dill
+from google.protobuf.message import Message
from typeguard import typechecked
from feast import flags_helper, utils
@@ -298,6 +299,10 @@ def __copy__(self):
fv.projection = copy.copy(self.projection)
return fv
+ @property
+ def proto_class(self) -> Type[Message]:
+ return StreamFeatureViewProto
+
def stream_feature_view(
*,
| diff --git a/sdk/python/tests/unit/test_feature_views.py b/sdk/python/tests/unit/test_feature_views.py
--- a/sdk/python/tests/unit/test_feature_views.py
+++ b/sdk/python/tests/unit/test_feature_views.py
@@ -10,6 +10,9 @@
from feast.feature_view import FeatureView
from feast.field import Field
from feast.infra.offline_stores.file_source import FileSource
+from feast.protos.feast.core.StreamFeatureView_pb2 import (
+ StreamFeatureView as StreamFeatureViewProto,
+)
from feast.protos.feast.types.Value_pb2 import ValueType
from feast.stream_feature_view import StreamFeatureView, stream_feature_view
from feast.types import Float32
@@ -277,3 +280,22 @@ def test_hash():
def test_field_types():
with pytest.raises(TypeError):
Field(name="name", dtype=ValueType.INT32)
+
+
+def test_stream_feature_view_proto_type():
+ stream_source = KafkaSource(
+ name="kafka",
+ timestamp_field="event_timestamp",
+ kafka_bootstrap_servers="",
+ message_format=AvroFormat(""),
+ topic="topic",
+ batch_source=FileSource(path="some path"),
+ )
+ sfv = StreamFeatureView(
+ name="test stream featureview proto class",
+ entities=[],
+ ttl=timedelta(days=30),
+ source=stream_source,
+ aggregations=[],
+ )
+ assert sfv.proto_class is StreamFeatureViewProto
| Got ConflictingFeatureViewNames error while running feast apply in the streaming features tutorial
## Expected Behavior
Expected to successfully register data sources and features as the first cell in [the streaming features tutorial](https://github.com/feast-dev/streaming-tutorial/blob/main/kafka_spark_demo/feature_repo/streaming_features_tutorial.ipynb)
## Current Behavior
I am running [the streaming features tutorial](https://github.com/feast-dev/streaming-tutorial/blob/main/kafka_spark_demo/feature_repo/streaming_features_tutorial.ipynb) with the Feast version `0.34.1` and got the error `feast.errors.ConflictingFeatureViewNames: The feature view name: driver_hourly_stats_stream refers to feature views of different types` while executing `feast apply`.
## Steps to reproduce
- Clone the tutorial: `git clone https://github.com/feast-dev/streaming-tutorial.git`
- Install Feast (current version is `0.34.1`): `pip install 'feast[redis]'`
- Run the command `feast apply` and get the `ConflictingFeatureViewNames` error
### Specifications
- Version: 0.34.1
- Platform: Linux
- Subsystem: CentOS Linux release 7.9.2009 (Core)
## Possible Solution
We can fix the error by implementing the override for the [`proto_class`](https://github.com/feast-dev/feast/blob/master/sdk/python/feast/base_feature_view.py#L88) property in the [StreamFeatureView](https://github.com/feast-dev/feast/blob/master/sdk/python/feast/stream_feature_view.py) class:
```python
@property
def proto_class(self) -> Type[StreamFeatureViewProto]:
return StreamFeatureViewProto
```
| I checked the code and agree with your proposed fix. The proto_class() function is not overloaded in the current implementation (master branch after v0.34.1). let me fix this. | 2023-11-23T00:47:34 |
feast-dev/feast | 3,851 | feast-dev__feast-3851 | [
"3844"
]
| 052182bcca046e35456674fc7d524825882f4b35 | diff --git a/sdk/python/feast/infra/registry/snowflake.py b/sdk/python/feast/infra/registry/snowflake.py
--- a/sdk/python/feast/infra/registry/snowflake.py
+++ b/sdk/python/feast/infra/registry/snowflake.py
@@ -124,15 +124,19 @@ def __init__(
f'"{self.registry_config.database}"."{self.registry_config.schema_}"'
)
- with GetSnowflakeConnection(self.registry_config) as conn:
- sql_function_file = f"{os.path.dirname(feast.__file__)}/infra/utils/snowflake/registry/snowflake_table_creation.sql"
- with open(sql_function_file, "r") as file:
- sqlFile = file.read()
-
- sqlCommands = sqlFile.split(";")
- for command in sqlCommands:
- query = command.replace("REGISTRY_PATH", f"{self.registry_path}")
- execute_snowflake_statement(conn, query)
+ if not self._verify_registry_database():
+ # Verify the existing resitry database schema from snowflake. If any table names and column types is wrong, run table recreation SQL.
+ with GetSnowflakeConnection(self.registry_config) as conn:
+ sql_function_file = f"{os.path.dirname(feast.__file__)}/infra/utils/snowflake/registry/snowflake_table_creation.sql"
+ with open(sql_function_file, "r") as file:
+ sqlFile = file.read()
+
+ sqlCommands = sqlFile.split(";")
+ for command in sqlCommands:
+ query = command.replace(
+ "REGISTRY_PATH", f"{self.registry_path}"
+ )
+ execute_snowflake_statement(conn, query)
self.cached_registry_proto = self.proto()
proto_registry_utils.init_project_metadata(self.cached_registry_proto, project)
@@ -145,6 +149,55 @@ def __init__(
)
self.project = project
+ def _verify_registry_database(
+ self,
+ ) -> bool:
+ """Verify the records in registry database. To check:
+ 1, the 11 tables are existed.
+ 2, the column types are correct.
+
+ Example return from snowflake's cursor.describe("SELECT * FROM a_table") command:
+ [ResultMetadata(name='ENTITY_NAME', type_code=2, display_size=None, internal_size=16777216, precision=None, scale=None, is_nullable=False),
+ ResultMetadata(name='PROJECT_ID', type_code=2, display_size=None, internal_size=16777216, precision=None, scale=None, is_nullable=False),
+ ResultMetadata(name='LAST_UPDATED_TIMESTAMP', type_code=6, display_size=None, internal_size=None, precision=0, scale=9, is_nullable=False),
+ ResultMetadata(name='ENTITY_PROTO', type_code=11, display_size=None, internal_size=8388608, precision=None, scale=None, is_nullable=False)]
+
+ Returns:
+ True if the necessary 11 tables are existed in Snowflake and schema of each table is correct.
+ False if failure happens.
+ """
+
+ from feast.infra.utils.snowflake.registry.snowflake_registry_table import (
+ snowflake_registry_table_names_and_column_types as expect_tables,
+ )
+
+ res = True
+
+ try:
+ with GetSnowflakeConnection(self.registry_config) as conn:
+ for table_name in expect_tables:
+ result_metadata_list = conn.cursor().describe(
+ f"SELECT * FROM {table_name}"
+ )
+ for col in result_metadata_list:
+ if (
+ expect_tables[table_name][col.name]["type_code"]
+ != col.type_code
+ ):
+ res = False
+ break
+ except Exception as e:
+ res = False # Set to False for all errors.
+ logger.debug(
+ f"Failed to verify Registry tables and columns types with exception: {e}."
+ )
+ finally:
+ # The implementation in snowflake_utils.py will cache the established connection without re-connection logic.
+ # conn.close()
+ pass
+
+ return res
+
def refresh(self, project: Optional[str] = None):
if project:
project_metadata = proto_registry_utils.get_project_metadata(
diff --git a/sdk/python/feast/infra/utils/snowflake/registry/snowflake_registry_table.py b/sdk/python/feast/infra/utils/snowflake/registry/snowflake_registry_table.py
new file mode 100644
--- /dev/null
+++ b/sdk/python/feast/infra/utils/snowflake/registry/snowflake_registry_table.py
@@ -0,0 +1,104 @@
+# -*- coding: utf-8 -*-
+
+"""
+The table names and column types are following the creation detail listed
+in "snowflake_table_creation.sql".
+
+Snowflake Reference:
+1, ResultMetadata: https://docs.snowflake.com/en/developer-guide/python-connector/python-connector-api#label-python-connector-resultmetadata-object
+2, Type Codes: https://docs.snowflake.com/en/developer-guide/python-connector/python-connector-api#label-python-connector-type-codes
+----------------------------------------------
+type_code String Representation Data Type
+0 FIXED NUMBER/INT
+1 REAL REAL
+2 TEXT VARCHAR/STRING
+3 DATE DATE
+4 TIMESTAMP TIMESTAMP
+5 VARIANT VARIANT
+6 TIMESTAMP_LTZ TIMESTAMP_LTZ
+7 TIMESTAMP_TZ TIMESTAMP_TZ
+8 TIMESTAMP_NTZ TIMESTAMP_TZ
+9 OBJECT OBJECT
+10 ARRAY ARRAY
+11 BINARY BINARY
+12 TIME TIME
+13 BOOLEAN BOOLEAN
+----------------------------------------------
+
+(last update: 2023-11-30)
+
+"""
+
+snowflake_registry_table_names_and_column_types = {
+ "DATA_SOURCES": {
+ "DATA_SOURCE_NAME": {"type_code": 2, "type": "VARCHAR"},
+ "PROJECT_ID": {"type_code": 2, "type": "VARCHAR"},
+ "LAST_UPDATED_TIMESTAMP": {"type_code": 6, "type": "TIMESTAMP_LTZ"},
+ "DATA_SOURCE_PROTO": {"type_code": 11, "type": "BINARY"},
+ },
+ "ENTITIES": {
+ "ENTITY_NAME": {"type_code": 2, "type": "VARCHAR"},
+ "PROJECT_ID": {"type_code": 2, "type": "VARCHAR"},
+ "LAST_UPDATED_TIMESTAMP": {"type_code": 6, "type": "TIMESTAMP_LTZ"},
+ "ENTITY_PROTO": {"type_code": 11, "type": "BINARY"},
+ },
+ "FEAST_METADATA": {
+ "PROJECT_ID": {"type_code": 2, "type": "VARCHAR"},
+ "METADATA_KEY": {"type_code": 2, "type": "VARCHAR"},
+ "METADATA_VALUE": {"type_code": 2, "type": "VARCHAR"},
+ "LAST_UPDATED_TIMESTAMP": {"type_code": 6, "type": "TIMESTAMP_LTZ"},
+ },
+ "FEATURE_SERVICES": {
+ "FEATURE_SERVICE_NAME": {"type_code": 2, "type": "VARCHAR"},
+ "PROJECT_ID": {"type_code": 2, "type": "VARCHAR"},
+ "LAST_UPDATED_TIMESTAMP": {"type_code": 6, "type": "TIMESTAMP_LTZ"},
+ "FEATURE_SERVICE_PROTO": {"type_code": 11, "type": "BINARY"},
+ },
+ "FEATURE_VIEWS": {
+ "FEATURE_VIEW_NAME": {"type_code": 2, "type": "VARCHAR"},
+ "PROJECT_ID": {"type_code": 2, "type": "VARCHAR"},
+ "LAST_UPDATED_TIMESTAMP": {"type_code": 6, "type": "TIMESTAMP_LTZ"},
+ "FEATURE_VIEW_PROTO": {"type_code": 11, "type": "BINARY"},
+ "MATERIALIZED_INTERVALS": {"type_code": 11, "type": "BINARY"},
+ "USER_METADATA": {"type_code": 11, "type": "BINARY"},
+ },
+ "MANAGED_INFRA": {
+ "INFRA_NAME": {"type_code": 2, "type": "VARCHAR"},
+ "PROJECT_ID": {"type_code": 2, "type": "VARCHAR"},
+ "LAST_UPDATED_TIMESTAMP": {"type_code": 6, "type": "TIMESTAMP_LTZ"},
+ "INFRA_PROTO": {"type_code": 11, "type": "BINARY"},
+ },
+ "ON_DEMAND_FEATURE_VIEWS": {
+ "ON_DEMAND_FEATURE_VIEW_NAME": {"type_code": 2, "type": "VARCHAR"},
+ "PROJECT_ID": {"type_code": 2, "type": "VARCHAR"},
+ "LAST_UPDATED_TIMESTAMP": {"type_code": 6, "type": "TIMESTAMP_LTZ"},
+ "ON_DEMAND_FEATURE_VIEW_PROTO": {"type_code": 11, "type": "BINARY"},
+ "USER_METADATA": {"type_code": 11, "type": "BINARY"},
+ },
+ "REQUEST_FEATURE_VIEWS": {
+ "REQUEST_FEATURE_VIEW_NAME": {"type_code": 2, "type": "VARCHAR"},
+ "PROJECT_ID": {"type_code": 2, "type": "VARCHAR"},
+ "LAST_UPDATED_TIMESTAMP": {"type_code": 6, "type": "TIMESTAMP_LTZ"},
+ "REQUEST_FEATURE_VIEW_PROTO": {"type_code": 11, "type": "BINARY"},
+ "USER_METADATA": {"type_code": 11, "type": "BINARY"},
+ },
+ "SAVED_DATASETS": {
+ "SAVED_DATASET_NAME": {"type_code": 2, "type": "VARCHAR"},
+ "PROJECT_ID": {"type_code": 2, "type": "VARCHAR"},
+ "LAST_UPDATED_TIMESTAMP": {"type_code": 6, "type": "TIMESTAMP_LTZ"},
+ "SAVED_DATASET_PROTO": {"type_code": 11, "type": "BINARY"},
+ },
+ "STREAM_FEATURE_VIEWS": {
+ "STREAM_FEATURE_VIEW_NAME": {"type_code": 2, "type": "VARCHAR"},
+ "PROJECT_ID": {"type_code": 2, "type": "VARCHAR"},
+ "LAST_UPDATED_TIMESTAMP": {"type_code": 6, "type": "TIMESTAMP_LTZ"},
+ "STREAM_FEATURE_VIEW_PROTO": {"type_code": 11, "type": "BINARY"},
+ "USER_METADATA": {"type_code": 11, "type": "BINARY"},
+ },
+ "VALIDATION_REFERENCES": {
+ "VALIDATION_REFERENCE_NAME": {"type_code": 2, "type": "VARCHAR"},
+ "PROJECT_ID": {"type_code": 2, "type": "VARCHAR"},
+ "LAST_UPDATED_TIMESTAMP": {"type_code": 6, "type": "TIMESTAMP_LTZ"},
+ "VALIDATION_REFERENCE_PROTO": {"type_code": 11, "type": "BINARY"},
+ },
+}
diff --git a/sdk/python/feast/infra/utils/snowflake/snowflake_utils.py b/sdk/python/feast/infra/utils/snowflake/snowflake_utils.py
--- a/sdk/python/feast/infra/utils/snowflake/snowflake_utils.py
+++ b/sdk/python/feast/infra/utils/snowflake/snowflake_utils.py
@@ -49,19 +49,19 @@ def __init__(self, config: str, autocommit=True):
def __enter__(self):
- assert self.config.type in [
+ assert self.config.type in {
"snowflake.registry",
"snowflake.offline",
"snowflake.engine",
"snowflake.online",
- ]
+ }
if self.config.type not in _cache:
if self.config.type == "snowflake.registry":
config_header = "connections.feast_registry"
elif self.config.type == "snowflake.offline":
config_header = "connections.feast_offline_store"
- if self.config.type == "snowflake.engine":
+ elif self.config.type == "snowflake.engine":
config_header = "connections.feast_batch_engine"
elif self.config.type == "snowflake.online":
config_header = "connections.feast_online_store"
@@ -113,11 +113,11 @@ def __exit__(self, exc_type, exc_val, exc_tb):
def assert_snowflake_feature_names(feature_view: FeatureView) -> None:
for feature in feature_view.features:
- assert feature.name not in [
+ assert feature.name not in {
"entity_key",
"feature_name",
"feature_value",
- ], f"Feature Name: {feature.name} is a protected name to ensure query stability"
+ }, f"Feature Name: {feature.name} is a protected name to ensure query stability"
return None
| allow read-only feature while using snowflake as (sql) registry host.
**Is your feature request related to a problem? Please describe.**
Based on the community user's (Zvonimir Cikojevic) feedback, we want to create a read-only feature for snowflake user who only can do READ to the registry on snowflake.
Hi guys! I hope I’m in the right channel.
I have Feast deployed on Snowflake and I’d like to limit the write access to the feature store.
The idea was to have a Snowflake role that only has Read privileges to the feature store schema (where the feast registry and our batch sources are deployed).
However, when assuming this role and running
store = feast.FeatureStore()
I get unauthorized error since the first SQL query Feast runs is CREATE TABLE IF NOT EXISTS DB.SCHEMA.DATA_SOURCES…
Does this mean that anyone who wishes to query the feature store has to have RW access?
Can you help me understand the reasoning behind this or did I miss something?
Thanks!
Yes, Feast tries to create registry Snowflake tables if they don't exist. I've created the registry when I first ran feast apply. This block of code always executed https://github.com/feast-dev/feast/blob/9df2224283e04760116b61bed3c8bfa7f17cbf7e/sdk/python/feast/infra/registry/snowflake.py#L128
when I run store = FeatureStore() .
In my case, this is unnecessary since I've (as a feature store admin) already created the registry.
I'd like to enable users to just have the ability to query the feature store - and not give them the privileges to write to the feature store tables (if they're not developers/admins).
**Describe the solution you'd like**
(TBD)
**Describe alternatives you've considered**
(TBD)
**Additional context**
(TBD)
|
Zvonimir, please be aware that this PR only changes the behavior of the initialization of the class: SnowflakeRegistry().
The default design of FEAST Registry allows all users to have modification privileges for their own "project", which means they can insert or delete records (with specified project_id) from FEAST Registry tables. If I go back to your original usage scenario, maybe we can create a dedicated (non-critical) Registry database for those "READ-only" users, and let them play free (or crash it :p)
| 2023-12-01T04:05:30 |
|
feast-dev/feast | 3,857 | feast-dev__feast-3857 | [
"3856"
]
| 4e450ad3b1b6d2f66fd87e07805bb57772390142 | diff --git a/sdk/python/feast/infra/online_stores/redis.py b/sdk/python/feast/infra/online_stores/redis.py
--- a/sdk/python/feast/infra/online_stores/redis.py
+++ b/sdk/python/feast/infra/online_stores/redis.py
@@ -106,6 +106,39 @@ def delete_entity_values(self, config: RepoConfig, join_keys: List[str]):
logger.debug(f"Deleted {deleted_count} rows for entity {', '.join(join_keys)}")
+ def delete_table(self, config: RepoConfig, table: FeatureView):
+ """
+ Delete all rows in Redis for a specific feature view
+
+ Args:
+ config: Feast config
+ table: Feature view to delete
+ """
+ client = self._get_client(config.online_store)
+ deleted_count = 0
+ prefix = _redis_key_prefix(table.join_keys)
+
+ redis_hash_keys = [_mmh3(f"{table.name}:{f.name}") for f in table.features]
+ redis_hash_keys.append(bytes(f"_ts:{table.name}", "utf8"))
+
+ with client.pipeline(transaction=False) as pipe:
+ for _k in client.scan_iter(
+ b"".join([prefix, b"*", config.project.encode("utf8")])
+ ):
+ _tables = {
+ _hk[4:] for _hk in client.hgetall(_k) if _hk.startswith(b"_ts:")
+ }
+ if bytes(table.name, "utf8") not in _tables:
+ continue
+ if len(_tables) == 1:
+ pipe.delete(_k)
+ else:
+ pipe.hdel(_k, *redis_hash_keys)
+ deleted_count += 1
+ pipe.execute()
+
+ logger.debug(f"Deleted {deleted_count} rows for feature view {table.name}")
+
@log_exceptions_and_usage(online_store="redis")
def update(
self,
@@ -117,16 +150,19 @@ def update(
partial: bool,
):
"""
- Look for join_keys (list of entities) that are not in use anymore
- (usually this happens when the last feature view that was using specific compound key is deleted)
- and remove all features attached to this "join_keys".
+ Delete data from feature views that are no longer in use.
+
+ Args:
+ config: Feast config
+ tables_to_delete: Feature views to delete
+ tables_to_keep: Feature views to keep
+ entities_to_delete: Entities to delete
+ entities_to_keep: Entities to keep
+ partial: Whether to do a partial update
"""
- join_keys_to_keep = set(tuple(table.join_keys) for table in tables_to_keep)
- join_keys_to_delete = set(tuple(table.join_keys) for table in tables_to_delete)
-
- for join_keys in join_keys_to_delete - join_keys_to_keep:
- self.delete_entity_values(config, list(join_keys))
+ for table in tables_to_delete:
+ self.delete_table(config, table)
def teardown(
self,
| Add delete_table to redis online store
Even if the feature view is no longer used, the data is not deleted until there are no feature views left in the join key.
Memory in redis is a very expensive resource.
When deleting feature_view, a function is added so that the corresponding key can be found and deleted in the redis hash.
| 2023-12-05T11:12:49 |
||
feast-dev/feast | 3,861 | feast-dev__feast-3861 | [
"3860"
]
| 052182bcca046e35456674fc7d524825882f4b35 | diff --git a/sdk/python/feast/infra/offline_stores/bigquery.py b/sdk/python/feast/infra/offline_stores/bigquery.py
--- a/sdk/python/feast/infra/offline_stores/bigquery.py
+++ b/sdk/python/feast/infra/offline_stores/bigquery.py
@@ -356,7 +356,10 @@ def write_logged_features(
# In Pyarrow v13.0, the parquet version was upgraded to v2.6 from v2.4.
# Set the coerce_timestamps to "us"(microseconds) for backward compatibility.
pyarrow.parquet.write_table(
- table=data, where=parquet_temp_file, coerce_timestamps="us"
+ table=data,
+ where=parquet_temp_file,
+ coerce_timestamps="us",
+ allow_truncated_timestamps=True,
)
parquet_temp_file.seek(0)
@@ -407,7 +410,10 @@ def offline_write_batch(
# In Pyarrow v13.0, the parquet version was upgraded to v2.6 from v2.4.
# Set the coerce_timestamps to "us"(microseconds) for backward compatibility.
pyarrow.parquet.write_table(
- table=table, where=parquet_temp_file, coerce_timestamps="us"
+ table=table,
+ where=parquet_temp_file,
+ coerce_timestamps="us",
+ allow_truncated_timestamps=True,
)
parquet_temp_file.seek(0)
diff --git a/sdk/python/feast/infra/utils/aws_utils.py b/sdk/python/feast/infra/utils/aws_utils.py
--- a/sdk/python/feast/infra/utils/aws_utils.py
+++ b/sdk/python/feast/infra/utils/aws_utils.py
@@ -353,7 +353,12 @@ def upload_arrow_table_to_redshift(
with tempfile.TemporaryFile(suffix=".parquet") as parquet_temp_file:
# In Pyarrow v13.0, the parquet version was upgraded to v2.6 from v2.4.
# Set the coerce_timestamps to "us"(microseconds) for backward compatibility.
- pq.write_table(table, parquet_temp_file, coerce_timestamps="us")
+ pq.write_table(
+ table,
+ parquet_temp_file,
+ coerce_timestamps="us",
+ allow_truncated_timestamps=True,
+ )
parquet_temp_file.seek(0)
s3_resource.Object(bucket, key).put(Body=parquet_temp_file)
| An error occurs when pushing to bigquery with microseconds timestamp fields
## Expected Behavior
When you call the push API to add data with bigquery, you will receive a response of 200.
## Current Behavior
If timestamp_fields is entered in Microseconds, a 500 error occurs.
## Steps to reproduce
Call the API by inserting an Integer with microseconds precision into the timestamp field.
### Specifications
- Version: master branch
- Platform:
- Subsystem:
## Possible Solution
Allow truncation of numbers when coercing nano seconds in pyarrow write_table.
| 2023-12-08T04:26:56 |
||
feast-dev/feast | 3,874 | feast-dev__feast-3874 | [
"3884"
]
| e436f776ccf291809c802c469073adf7f1540d69 | diff --git a/sdk/python/feast/type_map.py b/sdk/python/feast/type_map.py
--- a/sdk/python/feast/type_map.py
+++ b/sdk/python/feast/type_map.py
@@ -12,6 +12,7 @@
# See the License for the specific language governing permissions and
# limitations under the License.
+import json
from collections import defaultdict
from datetime import datetime, timezone
from typing import (
@@ -297,7 +298,7 @@ def _type_err(item, dtype):
None,
),
ValueType.FLOAT: ("float_val", lambda x: float(x), None),
- ValueType.DOUBLE: ("double_val", lambda x: x, {float, np.float64}),
+ ValueType.DOUBLE: ("double_val", lambda x: x, {float, np.float64, int, np.int_}),
ValueType.STRING: ("string_val", lambda x: str(x), None),
ValueType.BYTES: ("bytes_val", lambda x: x, {bytes}),
ValueType.BOOL: ("bool_val", lambda x: x, {bool, np.bool_, int, np.int_}),
@@ -353,6 +354,19 @@ def _python_value_to_proto_value(
feast_value_type
]
+ # Bytes to array type conversion
+ if isinstance(sample, (bytes, bytearray)):
+ # Bytes of an array containing elements of bytes not supported
+ if feast_value_type == ValueType.BYTES_LIST:
+ raise _type_err(sample, ValueType.BYTES_LIST)
+
+ json_value = json.loads(sample)
+ if isinstance(json_value, list):
+ if feast_value_type == ValueType.BOOL_LIST:
+ json_value = [bool(item) for item in json_value]
+ return [ProtoValue(**{field_name: proto_type(val=json_value)})] # type: ignore
+ raise _type_err(sample, valid_types[0])
+
if sample is not None and not all(
type(item) in valid_types for item in sample
):
@@ -631,6 +645,7 @@ def redshift_to_feast_value_type(redshift_type_as_str: str) -> ValueType:
"varchar": ValueType.STRING,
"timestamp": ValueType.UNIX_TIMESTAMP,
"timestamptz": ValueType.UNIX_TIMESTAMP,
+ "super": ValueType.BYTES,
# skip date, geometry, hllsketch, time, timetz
}
| diff --git a/sdk/python/tests/unit/test_type_map.py b/sdk/python/tests/unit/test_type_map.py
--- a/sdk/python/tests/unit/test_type_map.py
+++ b/sdk/python/tests/unit/test_type_map.py
@@ -48,3 +48,35 @@ def test_python_values_to_proto_values_bool(values):
converted = feast_value_type_to_python_type(protos[0])
assert converted is bool(values[0])
+
+
[email protected](
+ "values, value_type, expected",
+ (
+ (np.array([b"[1,2,3]"]), ValueType.INT64_LIST, [1, 2, 3]),
+ (np.array([b"[1,2,3]"]), ValueType.INT32_LIST, [1, 2, 3]),
+ (np.array([b"[1.5,2.5,3.5]"]), ValueType.FLOAT_LIST, [1.5, 2.5, 3.5]),
+ (np.array([b"[1.5,2.5,3.5]"]), ValueType.DOUBLE_LIST, [1.5, 2.5, 3.5]),
+ (np.array([b'["a","b","c"]']), ValueType.STRING_LIST, ["a", "b", "c"]),
+ (np.array([b"[true,false]"]), ValueType.BOOL_LIST, [True, False]),
+ (np.array([b"[1,0]"]), ValueType.BOOL_LIST, [True, False]),
+ (np.array([None]), ValueType.STRING_LIST, None),
+ ([b"[1,2,3]"], ValueType.INT64_LIST, [1, 2, 3]),
+ ([b"[1,2,3]"], ValueType.INT32_LIST, [1, 2, 3]),
+ ([b"[1.5,2.5,3.5]"], ValueType.FLOAT_LIST, [1.5, 2.5, 3.5]),
+ ([b"[1.5,2.5,3.5]"], ValueType.DOUBLE_LIST, [1.5, 2.5, 3.5]),
+ ([b'["a","b","c"]'], ValueType.STRING_LIST, ["a", "b", "c"]),
+ ([b"[true,false]"], ValueType.BOOL_LIST, [True, False]),
+ ([b"[1,0]"], ValueType.BOOL_LIST, [True, False]),
+ ([None], ValueType.STRING_LIST, None),
+ ),
+)
+def test_python_values_to_proto_values_bytes_to_list(values, value_type, expected):
+ protos = python_values_to_proto_values(values, value_type)
+ converted = feast_value_type_to_python_type(protos[0])
+ assert converted == expected
+
+
+def test_python_values_to_proto_values_bytes_to_list_not_supported():
+ with pytest.raises(TypeError):
+ _ = python_values_to_proto_values([b"[]"], ValueType.BYTES_LIST)
| can't /push (inferred) integers to a float feature
## Expected Behavior
Attempts to `/push` the following data
```
{
"df": {
"feature_one": [123, 456]
}
}
```
to the online store where the feature view field is `Field("feature_one", dtype=types.Float64)` should succeed.
## Current Behavior
This fails with the following error.
<img width="780" alt="image" src="https://github.com/feast-dev/feast/assets/5652308/cd918be6-7791-4b9c-b8ee-4c1265a1331e">
## Possible Solution
The `PYTHON_SCALAR_VALUE_TYPE_TO_PROTO_VALUE` map defined [here](https://github.com/feast-dev/feast/blob/e436f776ccf291809c802c469073adf7f1540d69/sdk/python/feast/type_map.py#L299-L300) states that value types of `FLOAT` have to be inferred as either `np.float` or `float`. Add `int` and `np.int_` to the list and it works as expected.
| 2023-12-29T19:01:13 |
|
feast-dev/feast | 3,904 | feast-dev__feast-3904 | [
"3903"
]
| f494f02e1254b91b56b0b69f4a15edafe8d7291a | diff --git a/sdk/python/feast/infra/online_stores/contrib/postgres.py b/sdk/python/feast/infra/online_stores/contrib/postgres.py
--- a/sdk/python/feast/infra/online_stores/contrib/postgres.py
+++ b/sdk/python/feast/infra/online_stores/contrib/postgres.py
@@ -99,6 +99,7 @@ def online_write_batch(
cur_batch,
page_size=batch_size,
)
+ conn.commit()
if progress:
progress(len(cur_batch))
| Table in Postgres OnlineStore is not populated after calling `materialize`
## Expected Behavior
When calling the `materialize` functionality to materialize data from a `SnowflakeSource` offline store to a local `PostgreSQLOnlineStore`, the table is not populated with the data.
## Current Behavior
The feature table in the local Postgres instance is not populated, while no exception is raised, and from the logs it seems like the data should be pushed to Postgres.
## Steps to reproduce
1) Use this feature_store.yaml file:
```
project: my_project
provider: local
registry:
registry_type: sql
path: postgresql://postgres:[email protected]:5432/feature_store
cache_ttl_seconds: 60
online_store:
type: postgres
host: 0.0.0.0
port: 5432
database: feature_store
db_schema: public
user: postgres
password: test
offline_store:
<SNOWFLAKE_INFORMATION>
entity_key_serialization_version: 2
```
2) Spin up this docker-compose file:
```
---
version: "3"
services:
db:
restart: always
image: postgres:15-alpine
container_name: feast_db
ports:
- "5432:5432"
volumes:
- ~/feast_postgres_data:/var/lib/postgresql/data
environment:
- POSTGRES_DB=feature_store
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=test
volumes:
feast_postgres_data: null
```
3) Initialize the Entities, SnowflakeSource (or another source), FeatureView, and FeatureService, and apply these. All using the Python SDK.
```
from datetime import timedelta
from feast import (
Entity,
FeatureService,
FeatureView,
Field,
SnowflakeSource,
ValueType,
FeatureStore,
)
from feast.types import Float32
feature_store = FeatureStore()
entity = Entity(
name="entity",
join_keys=["entity_ID"],
value_type=ValueType.STRING,
)
source = SnowflakeSource(
name="snowflake_source_name",
timestamp_field="EVENT_TIMESTAMP",
schema="TEMP",
table="TABLE"
)
feature_view = FeatureView(
name="feature_view_name",
entities=[entity],
ttl=timedelta(days=0),
schema=[
Field(name="feature_1", dtype=Float32),
Field(name="feature_2", dtype=Float32),
],
online=True,
source=source,
tags={"team": "team"},
)
feature_service = FeatureService(
name="feature_service",
features=[feature_view],
)
feature_store.apply(
[
entity,
source,
feature_view,
feature_service,
]
)
```
4) Run materialize commands using the Python SDK
```
feature_store = FeatureStore()
feature_store.materialize(
start_date=datetime.utcnow() - timedelta(weeks=52),
end_date=datetime.utcnow(),
feature_views=["feature_view_name"],
)
```
### Specifications
- Version: 0.35.0
- Platform: Local MacBook M1
## Possible Solution
It seems like a `conn.commit()` statement is missing in the `online_write_batch` method of the `PostgreSQLOnlineStore`. Specifically, on [this line](https://github.com/feast-dev/feast/blob/master/sdk/python/feast/infra/online_stores/contrib/postgres.py#L102).
After adding this, the table is populated.
The PR implementing this proposed fix can be found [here](https://github.com/feast-dev/feast/pull/3904).
## Additional notes
When replacing the the postgres online store with the following sqlite online store in the config file, everything works without any code changes
```
online_store:
type: sqlite
path: data/online_store.db
```
| 2024-01-25T10:28:04 |
||
feast-dev/feast | 3,925 | feast-dev__feast-3925 | [
"3916"
]
| 8bce6dc143837b1dc88f59336994148894d5ccbe | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -116,7 +116,7 @@
"psycopg2-binary>=2.8.3,<3",
]
-MYSQL_REQUIRED = ["mysqlclient", "pymysql", "types-PyMySQL"]
+MYSQL_REQUIRED = ["pymysql", "types-PyMySQL"]
HBASE_REQUIRED = [
"happybase>=1.2.0,<3",
| diff --git a/sdk/python/tests/unit/test_sql_registry.py b/sdk/python/tests/unit/test_sql_registry.py
--- a/sdk/python/tests/unit/test_sql_registry.py
+++ b/sdk/python/tests/unit/test_sql_registry.py
@@ -103,7 +103,7 @@ def mysql_registry():
registry_config = RegistryConfig(
registry_type="sql",
- path=f"mysql+mysqldb://{POSTGRES_USER}:{POSTGRES_PASSWORD}@127.0.0.1:{container_port}/{POSTGRES_DB}",
+ path=f"mysql+pymysql://{POSTGRES_USER}:{POSTGRES_PASSWORD}@127.0.0.1:{container_port}/{POSTGRES_DB}",
)
yield SqlRegistry(registry_config, "project", None)
| Dev Environment Breaks with MySQL 8.3 During Installation
## Description
When setting up the development environment with MySQL version 8.3, `pip install -e ".[dev]"` fails.
## Expected Behavior
Running `pip install -e ".[dev]"` should successfully install all necessary development dependencies without errors, even with MySQL 8.3.
## Current Behavior
The installation process breaks when attempting `pip install -e ".[dev]"`. The following errors are encountered:
```
src/MySQLdb/_mysql.c:527:9: error: call to undeclared function 'mysql_ssl_set'; ISO C99 and later do not support implicit function declarations [-Wimplicit-function-declaration]
mysql_ssl_set(&(self->connection), key, cert, ca, capath, cipher);
^
src/MySQLdb/_mysql.c:527:9: note: did you mean 'mysql_close'?
/usr/local/Cellar/mysql/8.3.0/include/mysql/mysql.h:797:14: note: 'mysql_close' declared here
void STDCALL mysql_close(MYSQL *sock);
^
src/MySQLdb/_mysql.c:1795:9: error: call to undeclared function 'mysql_kill'; ISO C99 and later do not support implicit function declarations [-Wimplicit-function-declaration]
r = mysql_kill(&(self->connection), pid);
^
src/MySQLdb/_mysql.c:1795:9: note: did you mean 'mysql_ping'?
/usr/local/Cellar/mysql/8.3.0/include/mysql/mysql.h:525:13: note: 'mysql_ping' declared here
int STDCALL mysql_ping(MYSQL *mysql);
^
src/MySQLdb/_mysql.c:2011:9: error: call to undeclared function 'mysql_shutdown'; ISO C99 and later do not support implicit function declarations [-Wimplicit-function-declaration]
r = mysql_shutdown(&(self->connection), SHUTDOWN_DEFAULT);
^
3 errors generated.
error: command '/usr/bin/clang' failed with exit code 1
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
ERROR: Failed building wheel for mysqlclient
Successfully built feast
Failed to build mysqlclient
ERROR: Could not build wheels for mysqlclient, which is required to install pyproject.toml-based projects
```
## Steps to reproduce
1. Create and activate a new Conda environment for `feast`:
```
conda create --name feast python=3.9
conda activate feast
```
2. Install dependencies:
```
pip install pip-tools
brew install [email protected]
brew install xz protobuf openssl zlib
pip install cryptography -U
conda install protobuf
conda install pymssql
pip install -e ".[dev]"
```
| Note: **MySQL 8.3** release last month(14 Dec 2023) . @tsisodia10 you tried with older version <8.3 which is working fine right ?
> Note: **MySQL 8.3** release last month(14 Dec 2023) . @tsisodia10 you tried with older version <8.3 which is working fine right ?
@redhatHameed That's right, I tried with the older version(8.0 to be precise).
same for me. 8.3 just falls apart
I looked at how `mysqlclient` is used in the project and found that we are actually barely using it at all. mysql online store implementation uses `pymysql`, the only place `mysqlclient` is used right now is a single test for sql registry and even that's done through sqlalchemy, therefore it will be pretty straightforward to change that test to use `pymysql` as well. I'll open a PR to remove `mysqlclient` from feast requirements altogether. | 2024-02-02T06:07:41 |
feast-dev/feast | 3,943 | feast-dev__feast-3943 | [
"3940"
]
| 21931d59f8a2f8b69383de0dd371a780149ccda8 | diff --git a/sdk/python/feast/infra/registry/caching_registry.py b/sdk/python/feast/infra/registry/caching_registry.py
new file mode 100644
--- /dev/null
+++ b/sdk/python/feast/infra/registry/caching_registry.py
@@ -0,0 +1,342 @@
+import logging
+from abc import abstractmethod
+from datetime import datetime, timedelta
+from threading import Lock
+from typing import List, Optional
+
+from feast import usage
+from feast.data_source import DataSource
+from feast.entity import Entity
+from feast.feature_service import FeatureService
+from feast.feature_view import FeatureView
+from feast.infra.infra_object import Infra
+from feast.infra.registry import proto_registry_utils
+from feast.infra.registry.base_registry import BaseRegistry
+from feast.on_demand_feature_view import OnDemandFeatureView
+from feast.project_metadata import ProjectMetadata
+from feast.request_feature_view import RequestFeatureView
+from feast.saved_dataset import SavedDataset, ValidationReference
+from feast.stream_feature_view import StreamFeatureView
+
+logger = logging.getLogger(__name__)
+
+
+class CachingRegistry(BaseRegistry):
+ def __init__(
+ self,
+ project: str,
+ cache_ttl_seconds: int,
+ ):
+ self.cached_registry_proto = self.proto()
+ proto_registry_utils.init_project_metadata(self.cached_registry_proto, project)
+ self.cached_registry_proto_created = datetime.utcnow()
+ self._refresh_lock = Lock()
+ self.cached_registry_proto_ttl = timedelta(
+ seconds=cache_ttl_seconds if cache_ttl_seconds is not None else 0
+ )
+
+ @abstractmethod
+ def _get_data_source(self, name: str, project: str) -> DataSource:
+ pass
+
+ def get_data_source(
+ self, name: str, project: str, allow_cache: bool = False
+ ) -> DataSource:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.get_data_source(
+ self.cached_registry_proto, name, project
+ )
+ return self._get_data_source(name, project)
+
+ @abstractmethod
+ def _list_data_sources(self, project: str) -> List[DataSource]:
+ pass
+
+ def list_data_sources(
+ self, project: str, allow_cache: bool = False
+ ) -> List[DataSource]:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.list_data_sources(
+ self.cached_registry_proto, project
+ )
+ return self._list_data_sources(project)
+
+ @abstractmethod
+ def _get_entity(self, name: str, project: str) -> Entity:
+ pass
+
+ def get_entity(self, name: str, project: str, allow_cache: bool = False) -> Entity:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.get_entity(
+ self.cached_registry_proto, name, project
+ )
+ return self._get_entity(name, project)
+
+ @abstractmethod
+ def _list_entities(self, project: str) -> List[Entity]:
+ pass
+
+ def list_entities(self, project: str, allow_cache: bool = False) -> List[Entity]:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.list_entities(
+ self.cached_registry_proto, project
+ )
+ return self._list_entities(project)
+
+ @abstractmethod
+ def _get_feature_view(self, name: str, project: str) -> FeatureView:
+ pass
+
+ def get_feature_view(
+ self, name: str, project: str, allow_cache: bool = False
+ ) -> FeatureView:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.get_feature_view(
+ self.cached_registry_proto, name, project
+ )
+ return self._get_feature_view(name, project)
+
+ @abstractmethod
+ def _list_feature_views(self, project: str) -> List[FeatureView]:
+ pass
+
+ def list_feature_views(
+ self, project: str, allow_cache: bool = False
+ ) -> List[FeatureView]:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.list_feature_views(
+ self.cached_registry_proto, project
+ )
+ return self._list_feature_views(project)
+
+ @abstractmethod
+ def _get_on_demand_feature_view(
+ self, name: str, project: str
+ ) -> OnDemandFeatureView:
+ pass
+
+ def get_on_demand_feature_view(
+ self, name: str, project: str, allow_cache: bool = False
+ ) -> OnDemandFeatureView:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.get_on_demand_feature_view(
+ self.cached_registry_proto, name, project
+ )
+ return self._get_on_demand_feature_view(name, project)
+
+ @abstractmethod
+ def _list_on_demand_feature_views(self, project: str) -> List[OnDemandFeatureView]:
+ pass
+
+ def list_on_demand_feature_views(
+ self, project: str, allow_cache: bool = False
+ ) -> List[OnDemandFeatureView]:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.list_on_demand_feature_views(
+ self.cached_registry_proto, project
+ )
+ return self._list_on_demand_feature_views(project)
+
+ @abstractmethod
+ def _get_request_feature_view(self, name: str, project: str) -> RequestFeatureView:
+ pass
+
+ def get_request_feature_view(
+ self, name: str, project: str, allow_cache: bool = False
+ ) -> RequestFeatureView:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.get_request_feature_view(
+ self.cached_registry_proto, name, project
+ )
+ return self._get_request_feature_view(name, project)
+
+ @abstractmethod
+ def _list_request_feature_views(self, project: str) -> List[RequestFeatureView]:
+ pass
+
+ def list_request_feature_views(
+ self, project: str, allow_cache: bool = False
+ ) -> List[RequestFeatureView]:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.list_request_feature_views(
+ self.cached_registry_proto, project
+ )
+ return self._list_request_feature_views(project)
+
+ @abstractmethod
+ def _get_stream_feature_view(self, name: str, project: str) -> StreamFeatureView:
+ pass
+
+ def get_stream_feature_view(
+ self, name: str, project: str, allow_cache: bool = False
+ ) -> StreamFeatureView:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.get_stream_feature_view(
+ self.cached_registry_proto, name, project
+ )
+ return self._get_stream_feature_view(name, project)
+
+ @abstractmethod
+ def _list_stream_feature_views(self, project: str) -> List[StreamFeatureView]:
+ pass
+
+ def list_stream_feature_views(
+ self, project: str, allow_cache: bool = False
+ ) -> List[StreamFeatureView]:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.list_stream_feature_views(
+ self.cached_registry_proto, project
+ )
+ return self._list_stream_feature_views(project)
+
+ @abstractmethod
+ def _get_feature_service(self, name: str, project: str) -> FeatureService:
+ pass
+
+ def get_feature_service(
+ self, name: str, project: str, allow_cache: bool = False
+ ) -> FeatureService:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.get_feature_service(
+ self.cached_registry_proto, name, project
+ )
+ return self._get_feature_service(name, project)
+
+ @abstractmethod
+ def _list_feature_services(self, project: str) -> List[FeatureService]:
+ pass
+
+ def list_feature_services(
+ self, project: str, allow_cache: bool = False
+ ) -> List[FeatureService]:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.list_feature_services(
+ self.cached_registry_proto, project
+ )
+ return self._list_feature_services(project)
+
+ @abstractmethod
+ def _get_saved_dataset(self, name: str, project: str) -> SavedDataset:
+ pass
+
+ def get_saved_dataset(
+ self, name: str, project: str, allow_cache: bool = False
+ ) -> SavedDataset:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.get_saved_dataset(
+ self.cached_registry_proto, name, project
+ )
+ return self._get_saved_dataset(name, project)
+
+ @abstractmethod
+ def _list_saved_datasets(self, project: str) -> List[SavedDataset]:
+ pass
+
+ def list_saved_datasets(
+ self, project: str, allow_cache: bool = False
+ ) -> List[SavedDataset]:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.list_saved_datasets(
+ self.cached_registry_proto, project
+ )
+ return self._list_saved_datasets(project)
+
+ @abstractmethod
+ def _get_validation_reference(self, name: str, project: str) -> ValidationReference:
+ pass
+
+ def get_validation_reference(
+ self, name: str, project: str, allow_cache: bool = False
+ ) -> ValidationReference:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.get_validation_reference(
+ self.cached_registry_proto, name, project
+ )
+ return self._get_validation_reference(name, project)
+
+ @abstractmethod
+ def _list_validation_references(self, project: str) -> List[ValidationReference]:
+ pass
+
+ def list_validation_references(
+ self, project: str, allow_cache: bool = False
+ ) -> List[ValidationReference]:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.list_validation_references(
+ self.cached_registry_proto, project
+ )
+ return self._list_validation_references(project)
+
+ @abstractmethod
+ def _list_project_metadata(self, project: str) -> List[ProjectMetadata]:
+ pass
+
+ def list_project_metadata(
+ self, project: str, allow_cache: bool = False
+ ) -> List[ProjectMetadata]:
+ if allow_cache:
+ self._refresh_cached_registry_if_necessary()
+ return proto_registry_utils.list_project_metadata(
+ self.cached_registry_proto, project
+ )
+ return self._list_project_metadata(project)
+
+ @abstractmethod
+ def _get_infra(self, project: str) -> Infra:
+ pass
+
+ def get_infra(self, project: str, allow_cache: bool = False) -> Infra:
+ return self._get_infra(project)
+
+ def refresh(self, project: Optional[str] = None):
+ if project:
+ project_metadata = proto_registry_utils.get_project_metadata(
+ registry_proto=self.cached_registry_proto, project=project
+ )
+ if project_metadata:
+ usage.set_current_project_uuid(project_metadata.project_uuid)
+ else:
+ proto_registry_utils.init_project_metadata(
+ self.cached_registry_proto, project
+ )
+ self.cached_registry_proto = self.proto()
+ self.cached_registry_proto_created = datetime.utcnow()
+
+ def _refresh_cached_registry_if_necessary(self):
+ with self._refresh_lock:
+ expired = (
+ self.cached_registry_proto is None
+ or self.cached_registry_proto_created is None
+ ) or (
+ self.cached_registry_proto_ttl.total_seconds()
+ > 0 # 0 ttl means infinity
+ and (
+ datetime.utcnow()
+ > (
+ self.cached_registry_proto_created
+ + self.cached_registry_proto_ttl
+ )
+ )
+ )
+
+ if expired:
+ logger.info("Registry cache expired, so refreshing")
+ self.refresh()
diff --git a/sdk/python/feast/infra/registry/sql.py b/sdk/python/feast/infra/registry/sql.py
--- a/sdk/python/feast/infra/registry/sql.py
+++ b/sdk/python/feast/infra/registry/sql.py
@@ -1,9 +1,8 @@
import logging
import uuid
-from datetime import datetime, timedelta
+from datetime import datetime
from enum import Enum
from pathlib import Path
-from threading import Lock
from typing import Any, Callable, Dict, List, Optional, Set, Union
from pydantic import StrictStr
@@ -37,8 +36,7 @@
from feast.feature_service import FeatureService
from feast.feature_view import FeatureView
from feast.infra.infra_object import Infra
-from feast.infra.registry import proto_registry_utils
-from feast.infra.registry.base_registry import BaseRegistry
+from feast.infra.registry.caching_registry import CachingRegistry
from feast.on_demand_feature_view import OnDemandFeatureView
from feast.project_metadata import ProjectMetadata
from feast.protos.feast.core.DataSource_pb2 import DataSource as DataSourceProto
@@ -194,7 +192,7 @@ class SqlRegistryConfig(RegistryConfig):
""" Dict[str, Any]: Extra arguments to pass to SQLAlchemy.create_engine. """
-class SqlRegistry(BaseRegistry):
+class SqlRegistry(CachingRegistry):
def __init__(
self,
registry_config: Optional[Union[RegistryConfig, SqlRegistryConfig]],
@@ -202,20 +200,14 @@ def __init__(
repo_path: Optional[Path],
):
assert registry_config is not None, "SqlRegistry needs a valid registry_config"
+
self.engine: Engine = create_engine(
registry_config.path, **registry_config.sqlalchemy_config_kwargs
)
metadata.create_all(self.engine)
- self.cached_registry_proto = self.proto()
- proto_registry_utils.init_project_metadata(self.cached_registry_proto, project)
- self.cached_registry_proto_created = datetime.utcnow()
- self._refresh_lock = Lock()
- self.cached_registry_proto_ttl = timedelta(
- seconds=registry_config.cache_ttl_seconds
- if registry_config.cache_ttl_seconds is not None
- else 0
+ super().__init__(
+ project=project, cache_ttl_seconds=registry_config.cache_ttl_seconds
)
- self.project = project
def teardown(self):
for t in {
@@ -232,49 +224,7 @@ def teardown(self):
stmt = delete(t)
conn.execute(stmt)
- def refresh(self, project: Optional[str] = None):
- if project:
- project_metadata = proto_registry_utils.get_project_metadata(
- registry_proto=self.cached_registry_proto, project=project
- )
- if project_metadata:
- usage.set_current_project_uuid(project_metadata.project_uuid)
- else:
- proto_registry_utils.init_project_metadata(
- self.cached_registry_proto, project
- )
- self.cached_registry_proto = self.proto()
- self.cached_registry_proto_created = datetime.utcnow()
-
- def _refresh_cached_registry_if_necessary(self):
- with self._refresh_lock:
- expired = (
- self.cached_registry_proto is None
- or self.cached_registry_proto_created is None
- ) or (
- self.cached_registry_proto_ttl.total_seconds()
- > 0 # 0 ttl means infinity
- and (
- datetime.utcnow()
- > (
- self.cached_registry_proto_created
- + self.cached_registry_proto_ttl
- )
- )
- )
-
- if expired:
- logger.info("Registry cache expired, so refreshing")
- self.refresh()
-
- def get_stream_feature_view(
- self, name: str, project: str, allow_cache: bool = False
- ):
- if allow_cache:
- self._refresh_cached_registry_if_necessary()
- return proto_registry_utils.get_stream_feature_view(
- self.cached_registry_proto, name, project
- )
+ def _get_stream_feature_view(self, name: str, project: str):
return self._get_object(
table=stream_feature_views,
name=name,
@@ -286,14 +236,7 @@ def get_stream_feature_view(
not_found_exception=FeatureViewNotFoundException,
)
- def list_stream_feature_views(
- self, project: str, allow_cache: bool = False
- ) -> List[StreamFeatureView]:
- if allow_cache:
- self._refresh_cached_registry_if_necessary()
- return proto_registry_utils.list_stream_feature_views(
- self.cached_registry_proto, project
- )
+ def _list_stream_feature_views(self, project: str) -> List[StreamFeatureView]:
return self._list_objects(
stream_feature_views,
project,
@@ -311,12 +254,7 @@ def apply_entity(self, entity: Entity, project: str, commit: bool = True):
proto_field_name="entity_proto",
)
- def get_entity(self, name: str, project: str, allow_cache: bool = False) -> Entity:
- if allow_cache:
- self._refresh_cached_registry_if_necessary()
- return proto_registry_utils.get_entity(
- self.cached_registry_proto, name, project
- )
+ def _get_entity(self, name: str, project: str) -> Entity:
return self._get_object(
table=entities,
name=name,
@@ -328,14 +266,7 @@ def get_entity(self, name: str, project: str, allow_cache: bool = False) -> Enti
not_found_exception=EntityNotFoundException,
)
- def get_feature_view(
- self, name: str, project: str, allow_cache: bool = False
- ) -> FeatureView:
- if allow_cache:
- self._refresh_cached_registry_if_necessary()
- return proto_registry_utils.get_feature_view(
- self.cached_registry_proto, name, project
- )
+ def _get_feature_view(self, name: str, project: str) -> FeatureView:
return self._get_object(
table=feature_views,
name=name,
@@ -347,14 +278,9 @@ def get_feature_view(
not_found_exception=FeatureViewNotFoundException,
)
- def get_on_demand_feature_view(
- self, name: str, project: str, allow_cache: bool = False
+ def _get_on_demand_feature_view(
+ self, name: str, project: str
) -> OnDemandFeatureView:
- if allow_cache:
- self._refresh_cached_registry_if_necessary()
- return proto_registry_utils.get_on_demand_feature_view(
- self.cached_registry_proto, name, project
- )
return self._get_object(
table=on_demand_feature_views,
name=name,
@@ -366,14 +292,7 @@ def get_on_demand_feature_view(
not_found_exception=FeatureViewNotFoundException,
)
- def get_request_feature_view(
- self, name: str, project: str, allow_cache: bool = False
- ):
- if allow_cache:
- self._refresh_cached_registry_if_necessary()
- return proto_registry_utils.get_request_feature_view(
- self.cached_registry_proto, name, project
- )
+ def _get_request_feature_view(self, name: str, project: str):
return self._get_object(
table=request_feature_views,
name=name,
@@ -385,14 +304,7 @@ def get_request_feature_view(
not_found_exception=FeatureViewNotFoundException,
)
- def get_feature_service(
- self, name: str, project: str, allow_cache: bool = False
- ) -> FeatureService:
- if allow_cache:
- self._refresh_cached_registry_if_necessary()
- return proto_registry_utils.get_feature_service(
- self.cached_registry_proto, name, project
- )
+ def _get_feature_service(self, name: str, project: str) -> FeatureService:
return self._get_object(
table=feature_services,
name=name,
@@ -404,14 +316,7 @@ def get_feature_service(
not_found_exception=FeatureServiceNotFoundException,
)
- def get_saved_dataset(
- self, name: str, project: str, allow_cache: bool = False
- ) -> SavedDataset:
- if allow_cache:
- self._refresh_cached_registry_if_necessary()
- return proto_registry_utils.get_saved_dataset(
- self.cached_registry_proto, name, project
- )
+ def _get_saved_dataset(self, name: str, project: str) -> SavedDataset:
return self._get_object(
table=saved_datasets,
name=name,
@@ -423,14 +328,7 @@ def get_saved_dataset(
not_found_exception=SavedDatasetNotFound,
)
- def get_validation_reference(
- self, name: str, project: str, allow_cache: bool = False
- ) -> ValidationReference:
- if allow_cache:
- self._refresh_cached_registry_if_necessary()
- return proto_registry_utils.get_validation_reference(
- self.cached_registry_proto, name, project
- )
+ def _get_validation_reference(self, name: str, project: str) -> ValidationReference:
return self._get_object(
table=validation_references,
name=name,
@@ -442,14 +340,7 @@ def get_validation_reference(
not_found_exception=ValidationReferenceNotFound,
)
- def list_validation_references(
- self, project: str, allow_cache: bool = False
- ) -> List[ValidationReference]:
- if allow_cache:
- self._refresh_cached_registry_if_necessary()
- return proto_registry_utils.list_validation_references(
- self.cached_registry_proto, project
- )
+ def _list_validation_references(self, project: str) -> List[ValidationReference]:
return self._list_objects(
table=validation_references,
project=project,
@@ -458,12 +349,7 @@ def list_validation_references(
proto_field_name="validation_reference_proto",
)
- def list_entities(self, project: str, allow_cache: bool = False) -> List[Entity]:
- if allow_cache:
- self._refresh_cached_registry_if_necessary()
- return proto_registry_utils.list_entities(
- self.cached_registry_proto, project
- )
+ def _list_entities(self, project: str) -> List[Entity]:
return self._list_objects(
entities, project, EntityProto, Entity, "entity_proto"
)
@@ -496,14 +382,7 @@ def delete_feature_service(self, name: str, project: str, commit: bool = True):
FeatureServiceNotFoundException,
)
- def get_data_source(
- self, name: str, project: str, allow_cache: bool = False
- ) -> DataSource:
- if allow_cache:
- self._refresh_cached_registry_if_necessary()
- return proto_registry_utils.get_data_source(
- self.cached_registry_proto, name, project
- )
+ def _get_data_source(self, name: str, project: str) -> DataSource:
return self._get_object(
table=data_sources,
name=name,
@@ -515,14 +394,7 @@ def get_data_source(
not_found_exception=DataSourceObjectNotFoundException,
)
- def list_data_sources(
- self, project: str, allow_cache: bool = False
- ) -> List[DataSource]:
- if allow_cache:
- self._refresh_cached_registry_if_necessary()
- return proto_registry_utils.list_data_sources(
- self.cached_registry_proto, project
- )
+ def _list_data_sources(self, project: str) -> List[DataSource]:
return self._list_objects(
data_sources, project, DataSourceProto, DataSource, "data_source_proto"
)
@@ -564,14 +436,7 @@ def delete_data_source(self, name: str, project: str, commit: bool = True):
if rows.rowcount < 1:
raise DataSourceObjectNotFoundException(name, project)
- def list_feature_services(
- self, project: str, allow_cache: bool = False
- ) -> List[FeatureService]:
- if allow_cache:
- self._refresh_cached_registry_if_necessary()
- return proto_registry_utils.list_feature_services(
- self.cached_registry_proto, project
- )
+ def _list_feature_services(self, project: str) -> List[FeatureService]:
return self._list_objects(
feature_services,
project,
@@ -580,26 +445,12 @@ def list_feature_services(
"feature_service_proto",
)
- def list_feature_views(
- self, project: str, allow_cache: bool = False
- ) -> List[FeatureView]:
- if allow_cache:
- self._refresh_cached_registry_if_necessary()
- return proto_registry_utils.list_feature_views(
- self.cached_registry_proto, project
- )
+ def _list_feature_views(self, project: str) -> List[FeatureView]:
return self._list_objects(
feature_views, project, FeatureViewProto, FeatureView, "feature_view_proto"
)
- def list_saved_datasets(
- self, project: str, allow_cache: bool = False
- ) -> List[SavedDataset]:
- if allow_cache:
- self._refresh_cached_registry_if_necessary()
- return proto_registry_utils.list_saved_datasets(
- self.cached_registry_proto, project
- )
+ def _list_saved_datasets(self, project: str) -> List[SavedDataset]:
return self._list_objects(
saved_datasets,
project,
@@ -608,14 +459,7 @@ def list_saved_datasets(
"saved_dataset_proto",
)
- def list_request_feature_views(
- self, project: str, allow_cache: bool = False
- ) -> List[RequestFeatureView]:
- if allow_cache:
- self._refresh_cached_registry_if_necessary()
- return proto_registry_utils.list_request_feature_views(
- self.cached_registry_proto, project
- )
+ def _list_request_feature_views(self, project: str) -> List[RequestFeatureView]:
return self._list_objects(
request_feature_views,
project,
@@ -624,14 +468,7 @@ def list_request_feature_views(
"feature_view_proto",
)
- def list_on_demand_feature_views(
- self, project: str, allow_cache: bool = False
- ) -> List[OnDemandFeatureView]:
- if allow_cache:
- self._refresh_cached_registry_if_necessary()
- return proto_registry_utils.list_on_demand_feature_views(
- self.cached_registry_proto, project
- )
+ def _list_on_demand_feature_views(self, project: str) -> List[OnDemandFeatureView]:
return self._list_objects(
on_demand_feature_views,
project,
@@ -640,14 +477,7 @@ def list_on_demand_feature_views(
"feature_view_proto",
)
- def list_project_metadata(
- self, project: str, allow_cache: bool = False
- ) -> List[ProjectMetadata]:
- if allow_cache:
- self._refresh_cached_registry_if_necessary()
- return proto_registry_utils.list_project_metadata(
- self.cached_registry_proto, project
- )
+ def _list_project_metadata(self, project: str) -> List[ProjectMetadata]:
with self.engine.connect() as conn:
stmt = select(feast_metadata).where(
feast_metadata.c.project_id == project,
@@ -740,7 +570,7 @@ def update_infra(self, infra: Infra, project: str, commit: bool = True):
name="infra_obj",
)
- def get_infra(self, project: str, allow_cache: bool = False) -> Infra:
+ def _get_infra(self, project: str) -> Infra:
infra_object = self._get_object(
table=managed_infra,
name="infra_obj",
| Add abstract caching registry
**Is your feature request related to a problem? Please describe.**
Several registry implementations employ client-side caching of registry proto, for example `sql` and `snowflake`. The code for caching is virtually identical and repeated.
**Describe the solution you'd like**
Add an abstract layer on top of base registry that implements caching logic and lets subclasses handle the logic only for the cases when there's a cache miss.
| 2024-02-08T17:48:30 |
||
feast-dev/feast | 3,954 | feast-dev__feast-3954 | [
"3771"
]
| ec11a7cb8d56d8e2e5cda07e06b4c98dcc9d2ba3 | diff --git a/sdk/python/feast/cli.py b/sdk/python/feast/cli.py
--- a/sdk/python/feast/cli.py
+++ b/sdk/python/feast/cli.py
@@ -76,6 +76,7 @@ def format_options(self, ctx: click.Context, formatter: click.HelpFormatter):
)
@click.option(
"--feature-store-yaml",
+ "-f",
help="Override the directory where the CLI should look for the feature_store.yaml file.",
)
@click.pass_context
| No such option: -f for feast CLI
## Expected Behavior
According to documentation:
https://docs.feast.dev/how-to-guides/feast-snowflake-gcp-aws/structuring-repos
```
feast -f staging/feature_store.yaml apply
```
should work
## Current Behavior
```
Usage: feast [OPTIONS] COMMAND [ARGS]...
Try 'feast --help' for help.
Error: No such option: -f
```
## Steps to reproduce
### Specifications
- Version: 0.34.1
- Platform: Linux
- Subsystem:
| I think this is just a docs error. The [correct flag ](https://github.com/feast-dev/feast/blob/2192e6527fa10f1580e4dd8f350e05e45af981b7/sdk/python/feast/cli.py#L74)is `--feature-store-yaml` if you need this functionality, eg
```
feast --feature-store-yaml=staging/feature_store.yaml apply
```
I agree.
> I agree.
I'm happy to open a PR to update these docs.
go for it if you have time. :) | 2024-02-16T23:32:15 |
|
feast-dev/feast | 3,957 | feast-dev__feast-3957 | [
"3709"
]
| 591ba4e39842b5fbb49db32be4fce28e6d520d93 | diff --git a/sdk/python/feast/infra/offline_stores/file.py b/sdk/python/feast/infra/offline_stores/file.py
--- a/sdk/python/feast/infra/offline_stores/file.py
+++ b/sdk/python/feast/infra/offline_stores/file.py
@@ -4,6 +4,7 @@
from pathlib import Path
from typing import Any, Callable, List, Literal, Optional, Tuple, Union
+import dask
import dask.dataframe as dd
import pandas as pd
import pyarrow
@@ -42,6 +43,11 @@
_run_dask_field_mapping,
)
+# FileRetrievalJob will cast string objects to string[pyarrow] from dask version 2023.7.1
+# This is not the desired behavior for our use case, so we set the convert-string option to False
+# See (https://github.com/dask/dask/issues/10881#issuecomment-1923327936)
+dask.config.set({"dataframe.convert-string": False})
+
class FileOfflineStoreConfig(FeastConfigBaseModel):
"""Offline store config for local (file-based) store"""
@@ -366,8 +372,6 @@ def evaluate_offline_job():
source_df[DUMMY_ENTITY_ID] = DUMMY_ENTITY_VAL
columns_to_extract.add(DUMMY_ENTITY_ID)
- source_df = source_df.persist()
-
return source_df[list(columns_to_extract)].persist()
# When materializing a single feature view, we don't need full feature names. On demand transforms aren't materialized
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -44,7 +44,6 @@
"click>=7.0.0,<9.0.0",
"colorama>=0.3.9,<1",
"dill~=0.3.0",
- "fastavro>=1.1.0,<2",
"grpcio>=1.56.2,<2",
"grpcio-tools>=1.56.2,<2",
"grpcio-reflection>=1.56.2,<2",
@@ -54,9 +53,7 @@
"jsonschema",
"mmh3",
"numpy>=1.22,<1.25",
- "pandas>=1.4.3,<2",
- # For some reason pandavro higher than 1.5.* only support pandas less than 1.3.
- "pandavro~=1.5.0",
+ "pandas>=1.4.3,<3",
# Higher than 4.23.4 seems to cause a seg fault
"protobuf<4.23.4,>3.20",
"proto-plus>=1.20.0,<2",
@@ -190,6 +187,7 @@
"types-setuptools",
"types-tabulate",
"virtualenv<20.24.2",
+ "pandas>=1.4.3,<2; python_version < '3.9'",
]
+ GCP_REQUIRED
+ REDIS_REQUIRED
| diff --git a/sdk/python/tests/integration/e2e/test_validation.py b/sdk/python/tests/integration/e2e/test_validation.py
--- a/sdk/python/tests/integration/e2e/test_validation.py
+++ b/sdk/python/tests/integration/e2e/test_validation.py
@@ -167,7 +167,7 @@ def test_logged_features_validation(environment, universal_data_sources):
{
"customer_id": 2000 + i,
"driver_id": 6000 + i,
- "event_timestamp": datetime.datetime.now(),
+ "event_timestamp": make_tzaware(datetime.datetime.now()),
}
]
),
diff --git a/sdk/python/tests/integration/offline_store/test_universal_historical_retrieval.py b/sdk/python/tests/integration/offline_store/test_universal_historical_retrieval.py
--- a/sdk/python/tests/integration/offline_store/test_universal_historical_retrieval.py
+++ b/sdk/python/tests/integration/offline_store/test_universal_historical_retrieval.py
@@ -340,6 +340,11 @@ def test_historical_features_with_entities_from_query(
table_from_sql_entities = job_from_sql.to_arrow().to_pandas()
for col in table_from_sql_entities.columns:
+ # check if col dtype is timezone naive
+ if pd.api.types.is_datetime64_dtype(table_from_sql_entities[col]):
+ table_from_sql_entities[col] = table_from_sql_entities[col].dt.tz_localize(
+ "UTC"
+ )
expected_df_query[col] = expected_df_query[col].astype(
table_from_sql_entities[col].dtype
)
| Pandas 2.0 support
**Is your feature request related to a problem? Please describe.**
I'm trying to install feast with pandas 2.0.3, but feast is pinned to pandas `<2`: https://github.com/feast-dev/feast/blob/c75a01fce2d52cd18479ace748b8eb2e6c81c988/setup.py#L55
**Describe the solution you'd like**
Allow pandas >2. I'm not sure how much effort it will be, my experience upgrading has been simple, and provided there's a good test coverage of the pandas features being used by feast, it should be fine.
**Describe alternatives you've considered**
I could rollback my codebase to an older version of pandas but I'm using some of the new feature and rely on recent bug fixes.
**Additional context**
```
python3.9 -m venv --clear tmp
source tmp/bin/activate/
pip install pandas==2.0.3 feast==0.31.1
ERROR: Cannot install feast==0.31.1 and pandas==2.0.3 because these package versions have conflicting dependencies.
The conflict is caused by:
The user requested pandas==2.0.3
feast 0.31.1 depends on pandas<2 and >=1.4.3
```
| I reopened my PR here
#3664
java_pr failed somehow 😢
Is this considered a priority for Feast? We're attempting to use Feast but resolving the dependencies and downgrading Pandas so far to accommodate this library is problematic.
Hello,
The issue that blocked the PR https://github.com/feast-dev/feast/pull/3664 to extend Pandas version support has been solved. Could you please reconsider this request? Thanks.
Great to know, thanks @ddl-joyce-zhao
I'm going to handle this soon | 2024-02-18T13:03:38 |
feast-dev/feast | 3,961 | feast-dev__feast-3961 | [
"3960"
]
| b83a70227c6afe7258328ff5847a26b526d0b5df | diff --git a/sdk/python/feast/infra/materialization/snowflake_engine.py b/sdk/python/feast/infra/materialization/snowflake_engine.py
--- a/sdk/python/feast/infra/materialization/snowflake_engine.py
+++ b/sdk/python/feast/infra/materialization/snowflake_engine.py
@@ -14,7 +14,7 @@
import feast
from feast.batch_feature_view import BatchFeatureView
from feast.entity import Entity
-from feast.feature_view import FeatureView
+from feast.feature_view import DUMMY_ENTITY_ID, FeatureView
from feast.infra.materialization.batch_materialization_engine import (
BatchMaterializationEngine,
MaterializationJob,
@@ -274,7 +274,11 @@ def _materialize_one(
fv_latest_values_sql = offline_job.to_sql()
- if feature_view.entity_columns:
+ if (
+ feature_view.entity_columns[0].name == DUMMY_ENTITY_ID
+ ): # entityless Feature View's placeholder entity
+ entities_to_write = 1
+ else:
join_keys = [entity.name for entity in feature_view.entity_columns]
unique_entities = '"' + '", "'.join(join_keys) + '"'
@@ -287,10 +291,6 @@ def _materialize_one(
with GetSnowflakeConnection(self.repo_config.offline_store) as conn:
entities_to_write = conn.cursor().execute(query).fetchall()[0][0]
- else:
- entities_to_write = (
- 1 # entityless feature view has a placeholder entity
- )
if feature_view.batch_source.field_mapping is not None:
fv_latest_mapped_values_sql = _run_snowflake_field_mapping(
| diff --git a/sdk/python/tests/integration/materialization/test_snowflake.py b/sdk/python/tests/integration/materialization/test_snowflake.py
--- a/sdk/python/tests/integration/materialization/test_snowflake.py
+++ b/sdk/python/tests/integration/materialization/test_snowflake.py
@@ -185,3 +185,65 @@ def test_snowflake_materialization_consistency_internal_with_lists(
finally:
fs.teardown()
snowflake_environment.data_source_creator.teardown()
+
+
[email protected]
+def test_snowflake_materialization_entityless_fv():
+ snowflake_config = IntegrationTestRepoConfig(
+ online_store=SNOWFLAKE_ONLINE_CONFIG,
+ offline_store_creator=SnowflakeDataSourceCreator,
+ batch_engine=SNOWFLAKE_ENGINE_CONFIG,
+ )
+ snowflake_environment = construct_test_environment(snowflake_config, None)
+
+ df = create_basic_driver_dataset()
+ entityless_df = df.drop("driver_id", axis=1)
+ ds = snowflake_environment.data_source_creator.create_data_source(
+ entityless_df,
+ snowflake_environment.feature_store.project,
+ field_mapping={"ts_1": "ts"},
+ )
+
+ fs = snowflake_environment.feature_store
+
+ # We include the driver entity so we can provide an entity ID when fetching features
+ driver = Entity(
+ name="driver_id",
+ join_keys=["driver_id"],
+ )
+
+ overall_stats_fv = FeatureView(
+ name="overall_hourly_stats",
+ entities=[],
+ ttl=timedelta(weeks=52),
+ source=ds,
+ )
+
+ try:
+ fs.apply([overall_stats_fv, driver])
+
+ # materialization is run in two steps and
+ # we use timestamp from generated dataframe as a split point
+ split_dt = df["ts_1"][4].to_pydatetime() - timedelta(seconds=1)
+
+ print(f"Split datetime: {split_dt}")
+
+ now = datetime.utcnow()
+
+ start_date = (now - timedelta(hours=5)).replace(tzinfo=utc)
+ end_date = split_dt
+ fs.materialize(
+ feature_views=[overall_stats_fv.name],
+ start_date=start_date,
+ end_date=end_date,
+ )
+
+ response_dict = fs.get_online_features(
+ [f"{overall_stats_fv.name}:value"],
+ [{"driver_id": 1}], # Included because we need an entity
+ ).to_dict()
+ assert response_dict["value"] == [0.3]
+
+ finally:
+ fs.teardown()
+ snowflake_environment.data_source_creator.teardown()
| Entityless Feature Views don't work with Snowflake during materialization step
## Expected Behavior
We can successfully materialize an entityless feature view from Snowflake to Redis (or any other Online provider).
## Current Behavior
When running the materialization step from Snowflake to Redis I'm seeing an error when I add an entityless feature view.
## Steps to reproduce
### Specifications
- Version:
- Platform:
- Subsystem:
## Possible Solution
I'll have a PR up shortly. It looks like the check for an entityless feature view is incorrect, causing it to fail.
| 2024-02-21T20:24:23 |
|
feast-dev/feast | 3,964 | feast-dev__feast-3964 | [
"3963"
]
| b83a70227c6afe7258328ff5847a26b526d0b5df | diff --git a/sdk/python/feast/infra/offline_stores/snowflake.py b/sdk/python/feast/infra/offline_stores/snowflake.py
--- a/sdk/python/feast/infra/offline_stores/snowflake.py
+++ b/sdk/python/feast/infra/offline_stores/snowflake.py
@@ -463,7 +463,9 @@ def _to_df_internal(self, timeout: Optional[int] = None) -> pd.DataFrame:
Array(Float32),
Array(Bool),
]:
- df[feature.name] = [json.loads(x) for x in df[feature.name]]
+ df[feature.name] = [
+ json.loads(x) if x else None for x in df[feature.name]
+ ]
return df
| diff --git a/sdk/python/tests/unit/infra/offline_stores/test_snowflake.py b/sdk/python/tests/unit/infra/offline_stores/test_snowflake.py
--- a/sdk/python/tests/unit/infra/offline_stores/test_snowflake.py
+++ b/sdk/python/tests/unit/infra/offline_stores/test_snowflake.py
@@ -1,14 +1,18 @@
import re
from unittest.mock import ANY, MagicMock, patch
+import pandas as pd
import pytest
+from pytest_mock import MockFixture
+from feast import FeatureView, Field, FileSource
from feast.infra.offline_stores.snowflake import (
SnowflakeOfflineStoreConfig,
SnowflakeRetrievalJob,
)
from feast.infra.online_stores.sqlite import SqliteOnlineStoreConfig
from feast.repo_config import RepoConfig
+from feast.types import Array, String
@pytest.fixture(params=["s3", "s3gov"])
@@ -55,3 +59,25 @@ def test_to_remote_storage(retrieval_job):
mock_get_file_names_from_copy.assert_called_once_with(ANY, ANY)
native_path = mock_get_file_names_from_copy.call_args[0][1]
assert re.match("^s3://.*", native_path), "path should be s3://*"
+
+
+def test_snowflake_to_df_internal(
+ retrieval_job: SnowflakeRetrievalJob, mocker: MockFixture
+):
+ mock_execute = mocker.patch(
+ "feast.infra.offline_stores.snowflake.execute_snowflake_statement"
+ )
+ mock_execute.return_value.fetch_pandas_all.return_value = pd.DataFrame.from_dict(
+ {"feature1": ['["1", "2", "3"]', None, "[]"]} # For Valid, Null, and Empty
+ )
+
+ feature_view = FeatureView(
+ name="my-feature-view",
+ entities=[],
+ schema=[
+ Field(name="feature1", dtype=Array(String)),
+ ],
+ source=FileSource(path="dummy.path"), # Dummy value
+ )
+ retrieval_job._feature_views = [feature_view]
+ retrieval_job._to_df_internal()
| Error when fetching historical data from Snowflake with null array type fields
## Expected Behavior
When fetching data for an entity that has no record for a feature view with an array type column it should return `None` and not throw an exception.
## Current Behavior
When fetching historical data from a Snowflake offline store it'll throw an exception when an entity has no record in a FeatureView with an array-type field.
## Steps to reproduce
### Specifications
- Version:
- Platform:
- Subsystem:
## Possible Solution
I'll have a PR up shortly.
| 2024-02-21T22:30:41 |
|
feast-dev/feast | 3,966 | feast-dev__feast-3966 | [
"3950"
]
| 1cc94f2d23f88e0d9412b2fab8761abc81f5d35c | diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -148,7 +148,7 @@
[
"build",
"virtualenv==20.23.0",
- "cryptography>=35.0,<42",
+ "cryptography>=35.0,<43",
"flake8>=6.0.0,<6.1.0",
"black>=22.6.0,<23",
"isort>=5,<6",
| Bump the cryptography version to 42
**Is your feature request related to a problem? Please describe.**
`cryptography<42` package has some medium vulnerabilities. Example: https://scout.docker.com/vulnerabilities/id/CVE-2023-50782?s=github&n=cryptography&t=pypi&vr=%3C42.0.0&utm_source=desktop&utm_medium=ExternalLink
starlette and fastapi had some high vulnerabilities but that was recently bumped up and thanks to that, they are removed.
**Describe the solution you'd like**
Bump the cryptography package to>=42. Nice to have: bumping up of other compatible packages also.
| snowflake-connector-python is blocking the bump https://github.com/snowflakedb/snowflake-connector-python/blob/v3.7.0/setup.cfg#L48 | 2024-02-23T10:58:46 |
|
feast-dev/feast | 3,969 | feast-dev__feast-3969 | [
"3945"
]
| 0a9fae8fd42e7348365ef902038f3f71f977ef3e | diff --git a/sdk/python/feast/on_demand_feature_view.py b/sdk/python/feast/on_demand_feature_view.py
--- a/sdk/python/feast/on_demand_feature_view.py
+++ b/sdk/python/feast/on_demand_feature_view.py
@@ -1,5 +1,6 @@
import copy
import functools
+import inspect
import warnings
from datetime import datetime
from types import FunctionType
@@ -17,6 +18,7 @@
from feast.feature_view_projection import FeatureViewProjection
from feast.field import Field, from_value_type
from feast.on_demand_pandas_transformation import OnDemandPandasTransformation
+from feast.on_demand_substrait_transformation import OnDemandSubstraitTransformation
from feast.protos.feast.core.OnDemandFeatureView_pb2 import (
OnDemandFeatureView as OnDemandFeatureViewProto,
)
@@ -210,6 +212,9 @@ def to_proto(self) -> OnDemandFeatureViewProto:
user_defined_function=self.transformation.to_proto()
if type(self.transformation) == OnDemandPandasTransformation
else None,
+ on_demand_substrait_transformation=self.transformation.to_proto() # type: ignore
+ if type(self.transformation) == OnDemandSubstraitTransformation
+ else None,
description=self.description,
tags=self.tags,
owner=self.owner,
@@ -255,6 +260,13 @@ def from_proto(cls, on_demand_feature_view_proto: OnDemandFeatureViewProto):
transformation = OnDemandPandasTransformation.from_proto(
on_demand_feature_view_proto.spec.user_defined_function
)
+ elif (
+ on_demand_feature_view_proto.spec.WhichOneof("transformation")
+ == "on_demand_substrait_transformation"
+ ):
+ transformation = OnDemandSubstraitTransformation.from_proto(
+ on_demand_feature_view_proto.spec.on_demand_substrait_transformation
+ )
else:
raise Exception("At least one transformation type needs to be provided")
@@ -460,10 +472,47 @@ def mainify(obj) -> None:
obj.__module__ = "__main__"
def decorator(user_function):
- udf_string = dill.source.getsource(user_function)
- mainify(user_function)
+ return_annotation = inspect.signature(user_function).return_annotation
+ if (
+ return_annotation
+ and return_annotation.__module__ == "ibis.expr.types.relations"
+ and return_annotation.__name__ == "Table"
+ ):
+ import ibis
+ import ibis.expr.datatypes as dt
+ from ibis_substrait.compiler.core import SubstraitCompiler
+
+ compiler = SubstraitCompiler()
+
+ input_fields: Field = []
+
+ for s in sources:
+ if type(s) == FeatureView:
+ fields = s.projection.features
+ else:
+ fields = s.features
+
+ input_fields.extend(
+ [
+ (
+ f.name,
+ dt.dtype(
+ feast_value_type_to_pandas_type(f.dtype.to_value_type())
+ ),
+ )
+ for f in fields
+ ]
+ )
+
+ expr = user_function(ibis.table(input_fields, "t"))
- transformation = OnDemandPandasTransformation(user_function, udf_string)
+ transformation = OnDemandSubstraitTransformation(
+ substrait_plan=compiler.compile(expr).SerializeToString()
+ )
+ else:
+ udf_string = dill.source.getsource(user_function)
+ mainify(user_function)
+ transformation = OnDemandPandasTransformation(user_function, udf_string)
on_demand_feature_view_obj = OnDemandFeatureView(
name=user_function.__name__,
diff --git a/sdk/python/feast/on_demand_substrait_transformation.py b/sdk/python/feast/on_demand_substrait_transformation.py
new file mode 100644
--- /dev/null
+++ b/sdk/python/feast/on_demand_substrait_transformation.py
@@ -0,0 +1,50 @@
+import pandas as pd
+import pyarrow
+import pyarrow.substrait as substrait # type: ignore # noqa
+
+from feast.protos.feast.core.OnDemandFeatureView_pb2 import (
+ OnDemandSubstraitTransformation as OnDemandSubstraitTransformationProto,
+)
+
+
+class OnDemandSubstraitTransformation:
+ def __init__(self, substrait_plan: bytes):
+ """
+ Creates an OnDemandSubstraitTransformation object.
+
+ Args:
+ substrait_plan: The user-provided substrait plan.
+ """
+ self.substrait_plan = substrait_plan
+
+ def transform(self, df: pd.DataFrame) -> pd.DataFrame:
+ def table_provider(names, schema: pyarrow.Schema):
+ return pyarrow.Table.from_pandas(df[schema.names])
+
+ table: pyarrow.Table = pyarrow.substrait.run_query(
+ self.substrait_plan, table_provider=table_provider
+ ).read_all()
+ return table.to_pandas()
+
+ def __eq__(self, other):
+ if not isinstance(other, OnDemandSubstraitTransformation):
+ raise TypeError(
+ "Comparisons should only involve OnDemandSubstraitTransformation class objects."
+ )
+
+ if not super().__eq__(other):
+ return False
+
+ return self.substrait_plan == other.substrait_plan
+
+ def to_proto(self) -> OnDemandSubstraitTransformationProto:
+ return OnDemandSubstraitTransformationProto(substrait_plan=self.substrait_plan)
+
+ @classmethod
+ def from_proto(
+ cls,
+ on_demand_substrait_transformation_proto: OnDemandSubstraitTransformationProto,
+ ):
+ return OnDemandSubstraitTransformation(
+ substrait_plan=on_demand_substrait_transformation_proto.substrait_plan
+ )
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -100,7 +100,7 @@
AWS_REQUIRED = ["boto3>=1.17.0,<2", "docker>=5.0.2", "fsspec<=2024.1.0"]
-BYTEWAX_REQUIRED = ["bytewax==0.18.2", "docker>=5.0.2", "kubernetes<=20.13.0"]
+BYTEWAX_REQUIRED = ["bytewax==0.15.1", "docker>=5.0.2", "kubernetes<=20.13.0"]
SNOWFLAKE_REQUIRED = [
"snowflake-connector-python[pandas]>=3,<4",
@@ -144,6 +144,11 @@
"hazelcast-python-client>=5.1",
]
+IBIS_REQUIRED = [
+ "ibis-framework",
+ "ibis-substrait"
+]
+
CI_REQUIRED = (
[
"build",
@@ -201,6 +206,7 @@
+ AZURE_REQUIRED
+ ROCKSET_REQUIRED
+ HAZELCAST_REQUIRED
+ + IBIS_REQUIRED
)
@@ -368,6 +374,7 @@ def run(self):
"cassandra": CASSANDRA_REQUIRED,
"hazelcast": HAZELCAST_REQUIRED,
"rockset": ROCKSET_REQUIRED,
+ "ibis": IBIS_REQUIRED
},
include_package_data=True,
license="Apache",
| diff --git a/sdk/python/tests/unit/test_on_demand_substrait_transformation.py b/sdk/python/tests/unit/test_on_demand_substrait_transformation.py
new file mode 100644
--- /dev/null
+++ b/sdk/python/tests/unit/test_on_demand_substrait_transformation.py
@@ -0,0 +1,112 @@
+import os
+import tempfile
+from datetime import datetime, timedelta
+
+import pandas as pd
+
+from feast import Entity, FeatureStore, FeatureView, FileSource, RepoConfig
+from feast.driver_test_data import create_driver_hourly_stats_df
+from feast.field import Field
+from feast.infra.online_stores.sqlite import SqliteOnlineStoreConfig
+from feast.on_demand_feature_view import on_demand_feature_view
+from feast.types import Float32, Float64, Int64
+
+
+def test_ibis_pandas_parity():
+ with tempfile.TemporaryDirectory() as data_dir:
+ store = FeatureStore(
+ config=RepoConfig(
+ project="test_on_demand_substrait_transformation",
+ registry=os.path.join(data_dir, "registry.db"),
+ provider="local",
+ entity_key_serialization_version=2,
+ online_store=SqliteOnlineStoreConfig(
+ path=os.path.join(data_dir, "online.db")
+ ),
+ )
+ )
+
+ # Generate test data.
+ end_date = datetime.now().replace(microsecond=0, second=0, minute=0)
+ start_date = end_date - timedelta(days=15)
+
+ driver_entities = [1001, 1002, 1003, 1004, 1005]
+ driver_df = create_driver_hourly_stats_df(driver_entities, start_date, end_date)
+ driver_stats_path = os.path.join(data_dir, "driver_stats.parquet")
+ driver_df.to_parquet(path=driver_stats_path, allow_truncated_timestamps=True)
+
+ driver = Entity(name="driver", join_keys=["driver_id"])
+
+ driver_stats_source = FileSource(
+ name="driver_hourly_stats_source",
+ path=driver_stats_path,
+ timestamp_field="event_timestamp",
+ created_timestamp_column="created",
+ )
+
+ driver_stats_fv = FeatureView(
+ name="driver_hourly_stats",
+ entities=[driver],
+ ttl=timedelta(days=1),
+ schema=[
+ Field(name="conv_rate", dtype=Float32),
+ Field(name="acc_rate", dtype=Float32),
+ Field(name="avg_daily_trips", dtype=Int64),
+ ],
+ online=True,
+ source=driver_stats_source,
+ )
+
+ @on_demand_feature_view(
+ sources=[driver_stats_fv],
+ schema=[Field(name="conv_rate_plus_acc", dtype=Float64)],
+ )
+ def pandas_view(inputs: pd.DataFrame) -> pd.DataFrame:
+ df = pd.DataFrame()
+ df["conv_rate_plus_acc"] = inputs["conv_rate"] + inputs["acc_rate"]
+ return df
+
+ from ibis.expr.types import Table
+
+ @on_demand_feature_view(
+ sources=[driver_stats_fv[["conv_rate", "acc_rate"]]],
+ schema=[Field(name="conv_rate_plus_acc_substrait", dtype=Float64)],
+ )
+ def substrait_view(inputs: Table) -> Table:
+ return inputs.select(
+ (inputs["conv_rate"] + inputs["acc_rate"]).name(
+ "conv_rate_plus_acc_substrait"
+ )
+ )
+
+ store.apply(
+ [driver, driver_stats_source, driver_stats_fv, substrait_view, pandas_view]
+ )
+
+ entity_df = pd.DataFrame.from_dict(
+ {
+ # entity's join key -> entity values
+ "driver_id": [1001, 1002, 1003],
+ # "event_timestamp" (reserved key) -> timestamps
+ "event_timestamp": [
+ datetime(2021, 4, 12, 10, 59, 42),
+ datetime(2021, 4, 12, 8, 12, 10),
+ datetime(2021, 4, 12, 16, 40, 26),
+ ],
+ }
+ )
+
+ training_df = store.get_historical_features(
+ entity_df=entity_df,
+ features=[
+ "driver_hourly_stats:conv_rate",
+ "driver_hourly_stats:acc_rate",
+ "driver_hourly_stats:avg_daily_trips",
+ "substrait_view:conv_rate_plus_acc_substrait",
+ "pandas_view:conv_rate_plus_acc",
+ ],
+ ).to_df()
+
+ assert training_df["conv_rate_plus_acc"].equals(
+ training_df["conv_rate_plus_acc_substrait"]
+ )
| Substrait-based on demand feature views
**Is your feature request related to a problem? Please describe.**
On demand feature views as implemented right now are very limited. The only way to specify odfvs is through a python function that takes in pandas Dataframe as input and outputs another pandas Dataframe. This leads to problems for both offline and online interfaces:
- Even the most scalable offline stores are forced to collect the whole dataset as a single pandas Dataframe to apply odfv function. There's no way for offline stores to incorporate computation in their engines.
- udfs in odfvs are inherently bound to pandas and python runtime. Non-python feature servers are stuck with the problem of figuring out how to run this functions if necessary. Java feature server for example has a separate python transformation service only for this reason, but that's obviously a subpar solution as the whole point of a java feature server was to avoid python runtime in feature serving in the first place.
**Describe the solution you'd like**
Allow constructing odfvs as substrait plans. [Substrait](https://substrait.io/) is a protobuf-based serialization format for relational algebra operations. It is meant to be used as a cross-language and cross-engine format for sharing logical or physical execution plans. It has a number of producers (tools that can generate substrait) and consumers (engines that can run substrait) in different languages.
- Different offline stores will be able to inspect and incorporate substrait plans in their transformations. Even if that's impossible the default implementation inside feast to apply these functions will avoid pandas.
- Most importantly, non-python feature servers like a java feature server will be able to apply the functions without a separate python component. Apache Arrow java implementation comes with java bindings to Acero query engine that can consume substrait plans. (https://arrow.apache.org/docs/java/substrait.html#executing-queries-using-substrait-plans)
The example code in my PoC implementation looks something like this:
```
def generate_substrait():
import ibis
from ibis_substrait.compiler.core import SubstraitCompiler
compiler = SubstraitCompiler()
t = ibis.table([("conv_rate", "float"), ("acc_rate", "float")], "t")
expr = t.select((t['conv_rate'] + t['acc_rate']).name('conv_rate_plus_acc_substrait'))
return compiler.compile(expr).SerializeToString()
substrait_odfv = OnDemandFeatureView(
name='substrait_view',
sources=[driver_stats_fv],
schema=[
Field(name="conv_rate_plus_acc_substrait", dtype=Float64)
],
substrait_plan=generate_substrait()
)
```
Substait plan object that feast accepts is `bytes` and introduces no external dependency. I'm using `ibis` and `ibis-substrait` to generate the plan. Right now that's the most practical way to generate substrait plan in python with DataFrame-like API, but this could have been any other substrait producer.
**Describe alternatives you've considered**
An obvious alternative to substrait is sql-based odfvs, but using SQL has a number of important downsides:
1. The presence of different sql dialects means that, it will be especially hard to ensure that sql-based feature functions will behave the same way across different offline store and online store implementations.
2. The user is implicitly bound to their offline store and online store of choice, because the dialect used in sql strings has to match offline store engine.
Having said that, it probably makes sense to support both substrait-based and sql-based odfvs, because at the moment it might be easier for sql-based logic to be incorporated inside offline store engines.
| 2024-02-24T17:19:37 |
|
feast-dev/feast | 3,999 | feast-dev__feast-3999 | [
"3921"
]
| 42a7b8170d6dc994055c67989046d11c238af40f | diff --git a/sdk/python/feast/feature_store.py b/sdk/python/feast/feature_store.py
--- a/sdk/python/feast/feature_store.py
+++ b/sdk/python/feast/feature_store.py
@@ -82,6 +82,7 @@
from feast.infra.registry.sql import SqlRegistry
from feast.on_demand_feature_view import OnDemandFeatureView
from feast.online_response import OnlineResponse
+from feast.protos.feast.core.InfraObject_pb2 import Infra as InfraProto
from feast.protos.feast.serving.ServingService_pb2 import (
FieldStatus,
GetOnlineFeaturesResponse,
@@ -745,7 +746,8 @@ def plan(
# Compute the desired difference between the current infra, as stored in the registry,
# and the desired infra.
self._registry.refresh(project=self.project)
- current_infra_proto = self._registry.proto().infra.__deepcopy__()
+ current_infra_proto = InfraProto()
+ current_infra_proto.CopyFrom(self._registry.proto().infra)
desired_registry_proto = desired_repo_contents.to_registry_proto()
new_infra = self._provider.plan_infra(self.config, desired_registry_proto)
new_infra_proto = new_infra.to_proto()
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -51,7 +51,7 @@
"numpy>=1.22,<1.25",
"pandas>=1.4.3,<3",
# Higher than 4.23.4 seems to cause a seg fault
- "protobuf<4.23.4,>3.20",
+ "protobuf>=4.24.0,<5.0.0",
"proto-plus>=1.20.0,<2",
"pyarrow>=4",
"pydantic>=2.0.0",
| crash (segfault?) on protobuf>=4.24.0
## Expected Behavior
Feast should not crash.
## Current Behavior
As commented in 028cc20a28118bd31deca8965782d5ad25f74300, Feast crashes with protobuf>=4.24.0. The most recent version of protobuf that Feast can use is 4.23 which stopped being supported in August of 2023 <https://protobuf.dev/support/version-support/>
## Steps to reproduce
I see this on `feast apply`, the original report is unclear.
| this one seems an urgent bug.
working on this. I do see segmentation errors.
I find this related issue from protobuf's Github repo: https://github.com/protocolbuffers/protobuf/issues/13485 , especially, this comment: https://github.com/protocolbuffers/protobuf/issues/13485#issuecomment-1686758403 | 2024-03-08T18:57:55 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.