
repo
stringclasses 856
values | pull_number
int64 3
127k
| instance_id
stringlengths 12
58
| issue_numbers
listlengths 1
5
| base_commit
stringlengths 40
40
| patch
stringlengths 67
1.54M
| test_patch
stringlengths 0
107M
| problem_statement
stringlengths 3
307k
| hints_text
stringlengths 0
908k
| created_at
timestamp[s] |
|---|---|---|---|---|---|---|---|---|---|
weni-ai/bothub-engine | 197 | weni-ai__bothub-engine-197 | [
"196"
]
| 497c30aaacf12a8c93502569dcd524dd12747659 | diff --git a/bothub/settings.py b/bothub/settings.py
--- a/bothub/settings.py
+++ b/bothub/settings.py
@@ -239,3 +239,8 @@
'SUPPORTED_LANGUAGES',
default='en|pt',
cast=cast_supported_languages)
+
+
+# SECURE PROXY SSL HEADER
+
+SECURE_PROXY_SSL_HEADER = ('HTTP_X_FORWARDED_PROTO', 'https')
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -3,7 +3,7 @@
setup(
name='bothub',
- version='1.15.0',
+ version='1.15.1',
description='bothub',
packages=find_packages(),
install_requires=[
| Rest API just generate HTTP urls
next links (List Views) and absolute urls are generated to HTTP protocol because the all requests are make in port 80.
| 2018-09-10T15:45:34 |
||
weni-ai/bothub-engine | 199 | weni-ai__bothub-engine-199 | [
"198"
]
| b0ed183455c7c77d565f457fa53b5ae4f37afa47 | diff --git a/bothub/common/models.py b/bothub/common/models.py
--- a/bothub/common/models.py
+++ b/bothub/common/models.py
@@ -190,7 +190,7 @@ def votes_sum(self):
@property
def intents(self):
return list(set(self.examples(
- exclude_deleted=False).exclude(
+ exclude_deleted=True).exclude(
intent='').values_list(
'intent',
flat=True)))
| diff --git a/bothub/common/tests.py b/bothub/common/tests.py
--- a/bothub/common/tests.py
+++ b/bothub/common/tests.py
@@ -292,7 +292,7 @@ def test_intents(self):
'greet',
self.repository.intents)
- RepositoryExample.objects.create(
+ example = RepositoryExample.objects.create(
repository_update=self.repository.current_update(
languages.LANGUAGE_PT),
text='tchau',
@@ -305,6 +305,12 @@ def test_intents(self):
'bye',
self.repository.intents)
+ example.delete()
+
+ self.assertNotIn(
+ 'bye',
+ self.repository.intents)
+
def test_entities(self):
example = RepositoryExample.objects.create(
repository_update=self.repository.current_update(
| Ghost Intent
Reported by @IlhasoftPeter in https://github.com/Ilhasoft/bothub/issues/26
| 2018-09-11T12:07:57 |
|
weni-ai/bothub-engine | 200 | weni-ai__bothub-engine-200 | [
"198"
]
| 756d2595a08669197d96a7ce7dbb8abf914c7bf7 | diff --git a/bothub/common/models.py b/bothub/common/models.py
--- a/bothub/common/models.py
+++ b/bothub/common/models.py
@@ -190,7 +190,7 @@ def votes_sum(self):
@property
def intents(self):
return list(set(self.examples(
- exclude_deleted=False).exclude(
+ exclude_deleted=True).exclude(
intent='').values_list(
'intent',
flat=True)))
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -3,7 +3,7 @@
setup(
name='bothub',
- version='1.15.1',
+ version='1.15.2',
description='bothub',
packages=find_packages(),
install_requires=[
| diff --git a/bothub/common/tests.py b/bothub/common/tests.py
--- a/bothub/common/tests.py
+++ b/bothub/common/tests.py
@@ -292,7 +292,7 @@ def test_intents(self):
'greet',
self.repository.intents)
- RepositoryExample.objects.create(
+ example = RepositoryExample.objects.create(
repository_update=self.repository.current_update(
languages.LANGUAGE_PT),
text='tchau',
@@ -305,6 +305,12 @@ def test_intents(self):
'bye',
self.repository.intents)
+ example.delete()
+
+ self.assertNotIn(
+ 'bye',
+ self.repository.intents)
+
def test_entities(self):
example = RepositoryExample.objects.create(
repository_update=self.repository.current_update(
| Ghost Intent
Reported by @IlhasoftPeter in https://github.com/Ilhasoft/bothub/issues/26
| 2018-09-11T18:26:01 |
|
weni-ai/bothub-engine | 212 | weni-ai__bothub-engine-212 | [
"209"
]
| 512276606e053e6b51ada114a9c28d91638d20ed | diff --git a/bothub/common/migrations/0021_auto_20180921_1259.py b/bothub/common/migrations/0021_auto_20180921_1259.py
--- a/bothub/common/migrations/0021_auto_20180921_1259.py
+++ b/bothub/common/migrations/0021_auto_20180921_1259.py
@@ -5,6 +5,11 @@
import re
+def populate_empty_intent(apps, *args):
+ RepositoryExample = apps.get_model('common', 'RepositoryExample')
+ RepositoryExample.objects.filter(intent='').update(intent='no_intent')
+
+
class Migration(migrations.Migration):
dependencies = [
@@ -17,4 +22,5 @@ class Migration(migrations.Migration):
name='intent',
field=models.CharField(default='no_intent', help_text='Example intent reference', max_length=64, validators=[django.core.validators.RegexValidator(re.compile('^[-a-z0-9_]+\\Z'), 'Enter a valid value consisting of lowercase letters, numbers, underscores or hyphens.', 'invalid')], verbose_name='intent'),
),
+ migrations.RunPython(populate_empty_intent),
]
| Fix intent default value to all examples, migration intent required
| 2018-10-04T13:00:08 |
||
weni-ai/bothub-engine | 226 | weni-ai__bothub-engine-226 | [
"225"
]
| c108169fa153cb511dc0d8296e2a06fc2aa4e161 | diff --git a/bothub/common/models.py b/bothub/common/models.py
--- a/bothub/common/models.py
+++ b/bothub/common/models.py
@@ -481,6 +481,9 @@ def ready_for_train(self):
not self.deleted.exists():
return False
+ if self.examples.count() == 0:
+ return False
+
return len(self.requirements_to_train) is 0
@property
| diff --git a/bothub/common/tests.py b/bothub/common/tests.py
--- a/bothub/common/tests.py
+++ b/bothub/common/tests.py
@@ -871,6 +871,15 @@ def test_entity_dont_have_min_examples(self):
entity='hi')
self.assertTrue(self.repository.current_update().ready_for_train)
+ def test_no_examples(self):
+ example = RepositoryExample.objects.create(
+ repository_update=self.repository.current_update(),
+ text='hi',
+ intent='greet')
+ self.repository.current_update().start_training(self.owner)
+ example.delete()
+ self.assertFalse(self.repository.current_update().ready_for_train)
+
class RequestRepositoryAuthorizationTestCase(TestCase):
def setUp(self):
| Training with no sentences
Reported by @johncordeiro in https://github.com/Ilhasoft/bothub/issues/36
| 2018-10-24T19:36:31 |
|
weni-ai/bothub-engine | 229 | weni-ai__bothub-engine-229 | [
"227"
]
| 7aa13760d4428a34ead94c6bf99d766d5f2bd42b | diff --git a/bothub/api/v2/repository/serializers.py b/bothub/api/v2/repository/serializers.py
--- a/bothub/api/v2/repository/serializers.py
+++ b/bothub/api/v2/repository/serializers.py
@@ -162,7 +162,7 @@ def get_intents(self, obj):
lambda intent: {
'value': intent,
'examples__count': obj.examples(
- exclude_deleted=False).filter(
+ exclude_deleted=True).filter(
intent=intent).count(),
},
obj.intents),
| diff --git a/bothub/api/v2/repository/tests.py b/bothub/api/v2/repository/tests.py
--- a/bothub/api/v2/repository/tests.py
+++ b/bothub/api/v2/repository/tests.py
@@ -8,11 +8,13 @@
from bothub.common.models import RepositoryCategory
from bothub.common.models import Repository
from bothub.common.models import RequestRepositoryAuthorization
+from bothub.common.models import RepositoryExample
from bothub.common import languages
from ..tests.utils import create_user_and_token
from .views import RepositoryViewSet
+from .serializers import RepositorySerializer
def get_valid_mockups(categories):
@@ -362,3 +364,36 @@ def test_false_when_request(self):
available_request_authorization = content_data.get(
'available_request_authorization')
self.assertFalse(available_request_authorization)
+
+
+class IntentsInRepositorySerializer(TestCase):
+ def setUp(self):
+ self.owner, self.owner_token = create_user_and_token('owner')
+
+ self.repository = Repository.objects.create(
+ owner=self.owner,
+ name='Testing',
+ slug='test',
+ language=languages.LANGUAGE_EN)
+ RepositoryExample.objects.create(
+ repository_update=self.repository.current_update(),
+ text='hi',
+ intent='greet')
+
+ def test_count_1(self):
+ repository_data = RepositorySerializer(self.repository).data
+ intent = repository_data.get('intents')[0]
+ self.assertEqual(intent.get('examples__count'), 1)
+
+ def test_example_deleted(self):
+ example = RepositoryExample.objects.create(
+ repository_update=self.repository.current_update(),
+ text='hi',
+ intent='greet')
+ repository_data = RepositorySerializer(self.repository).data
+ intent = repository_data.get('intents')[0]
+ self.assertEqual(intent.get('examples__count'), 2)
+ example.delete()
+ repository_data = RepositorySerializer(self.repository).data
+ intent = repository_data.get('intents')[0]
+ self.assertEqual(intent.get('examples__count'), 1)
| Wrong sentences counting in intents list
Reported by @johncordeiro in https://github.com/Ilhasoft/bothub/issues/43
| 2018-10-25T15:45:42 |
|
weni-ai/bothub-engine | 230 | weni-ai__bothub-engine-230 | [
"228"
]
| 65278d36ebad909166239914c081f0615a1623d7 | diff --git a/bothub/common/models.py b/bothub/common/models.py
--- a/bothub/common/models.py
+++ b/bothub/common/models.py
@@ -460,6 +460,9 @@ def ready_for_train(self):
if self.training_started_at:
return False
+ if len(self.requirements_to_train) > 0:
+ return False
+
previous_update = self.repository.updates.filter(
language=self.language,
by__isnull=False,
| diff --git a/bothub/common/tests.py b/bothub/common/tests.py
--- a/bothub/common/tests.py
+++ b/bothub/common/tests.py
@@ -767,7 +767,8 @@ def setUp(self):
owner=self.owner,
name='Test',
slug='test',
- language=languages.LANGUAGE_EN)
+ language=languages.LANGUAGE_EN,
+ use_language_model_featurizer=False)
def test_be_true(self):
RepositoryExample.objects.create(
@@ -871,6 +872,19 @@ def test_entity_dont_have_min_examples(self):
entity='hi')
self.assertTrue(self.repository.current_update().ready_for_train)
+ def test_settings_change_exists_requirements(self):
+ self.repository.current_update().start_training(self.owner)
+ self.repository.use_language_model_featurizer = True
+ self.repository.save()
+ RepositoryExample.objects.create(
+ repository_update=self.repository.current_update(),
+ text='hello',
+ intent='greet')
+ self.assertEqual(
+ len(self.repository.current_update().requirements_to_train),
+ 1)
+ self.assertFalse(self.repository.current_update().ready_for_train)
+
def test_no_examples(self):
example = RepositoryExample.objects.create(
repository_update=self.repository.current_update(),
| Updating settings and remove sentences, training keeps enabled
Reported by @johncordeiro in https://github.com/Ilhasoft/bothub/issues/44
| 2018-10-25T16:09:00 |
|
weni-ai/bothub-engine | 238 | weni-ai__bothub-engine-238 | [
"220"
]
| 8454f2a01da2677d8751f29a3a856ae17562013e | diff --git a/bothub/api/v1/views.py b/bothub/api/v1/views.py
--- a/bothub/api/v1/views.py
+++ b/bothub/api/v1/views.py
@@ -989,7 +989,7 @@ class RepositoryUpdatesViewSet(
mixins.ListModelMixin,
GenericViewSet):
queryset = RepositoryUpdate.objects.filter(
- training_started_at__isnull=False)
+ training_started_at__isnull=False).order_by('-trained_at')
serializer_class = RepositoryUpdateSerializer
filter_class = RepositoryUpdatesFilter
permission_classes = [
| Updates incorrect order
<img width="1060" alt="screen shot 2018-10-10 at 10 44 30 am" src="https://user-images.githubusercontent.com/8301135/46740768-fcd92b00-cc79-11e8-9d12-c19a2feb7768.png">
| 2018-12-17T20:43:21 |
||
pyg-team/pytorch_geometric | 2,691 | pyg-team__pytorch_geometric-2691 | [
"2684"
]
| 5bd5a8766116d8b346679aac56f1011bec5e2d3f | diff --git a/torch_geometric/nn/conv/x_conv.py b/torch_geometric/nn/conv/x_conv.py
--- a/torch_geometric/nn/conv/x_conv.py
+++ b/torch_geometric/nn/conv/x_conv.py
@@ -125,16 +125,11 @@ def forward(self, x: Tensor, pos: Tensor, batch: Optional[Tensor] = None):
edge_index = knn_graph(pos, K * self.dilation, batch, loop=True,
flow='target_to_source',
num_workers=self.num_workers)
- row, col = edge_index[0], edge_index[1]
if self.dilation > 1:
- dil = self.dilation
- index = torch.randint(K * dil, (N, K), dtype=torch.long,
- device=row.device)
- arange = torch.arange(N, dtype=torch.long, device=row.device)
- arange = arange * (K * dil)
- index = (index + arange.view(-1, 1)).view(-1)
- row, col = row[index], col[index]
+ edge_index = edge_index[:, ::K]
+
+ row, col = edge_index[0], edge_index[1]
pos = pos[col] - pos[row]
| PointCNN dilated KNN might select less than `K` neighbours
## 🐛 Bug
In the current X-Conv implementation, I can see the following:
https://github.com/rusty1s/pytorch_geometric/blob/e8e004439e3204a7b888a21e508c45d166c5817c/torch_geometric/nn/conv/x_conv.py#L130-L137
As, `torch.randint` would sample with replacement, there's a chance that the number of actual neighbours can be less than `K`. I am thinking we can fix this using something like:
```
indices = torch.randperm(K * dil)[:K]
```
| Yes, I think it makes sense to fix this, e.g., the official implementation just takes each `D`-th entry. Are you interested in fixing this?
Yup. PR on the way. | 2021-06-04T14:54:38 |
|
pyg-team/pytorch_geometric | 3,350 | pyg-team__pytorch_geometric-3350 | [
"3217"
]
| e8915ad1cb5831c33c77f0fa69ee8a2267074647 | diff --git a/examples/hetero/hetero_link_pred.py b/examples/hetero/hetero_link_pred.py
new file mode 100644
--- /dev/null
+++ b/examples/hetero/hetero_link_pred.py
@@ -0,0 +1,132 @@
+import os.path as osp
+import argparse
+
+import torch
+from torch.nn import Linear
+import torch.nn.functional as F
+
+import torch_geometric.transforms as T
+from torch_geometric.datasets import MovieLens
+from torch_geometric.nn import SAGEConv, to_hetero
+
+parser = argparse.ArgumentParser()
+parser.add_argument('--use_weighted_loss', action='store_true',
+ help='Whether to use weighted MSE loss.')
+args = parser.parse_args()
+
+device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
+
+path = osp.join(osp.dirname(osp.realpath(__file__)), '../../data/MovieLens')
+dataset = MovieLens(path, model_name='all-MiniLM-L6-v2')
+data = dataset[0].to(device)
+
+# Add user node features for message passing:
+data['user'].x = torch.eye(data['user'].num_nodes, device=device)
+del data['user'].num_nodes
+
+# Add a reverse ('movie', 'rev_rates', 'user') relation for message passing:
+data = T.ToUndirected()(data)
+del data['movie', 'rev_rates', 'user'].edge_label # Remove "reverse" label.
+
+# Perform a link-level split into training, validation, and test edges:
+train_data, val_data, test_data = T.RandomLinkSplit(
+ num_val=0.1,
+ num_test=0.1,
+ neg_sampling_ratio=0.0,
+ edge_types=[('user', 'rates', 'movie')],
+ rev_edge_types=[('movie', 'rev_rates', 'user')],
+)(data)
+
+# We have an unbalanced dataset with many labels for rating 3 and 4, and very
+# few for 0 and 1. Therefore we use a weighted MSE loss.
+if args.use_weighted_loss:
+ weight = torch.bincount(train_data['user', 'movie'].edge_label)
+ weight = weight.max() / weight
+else:
+ weight = None
+
+
+def weighted_mse_loss(pred, target, weight=None):
+ weight = 1. if weight is None else weight[target].to(pred.dtype)
+ return (weight * (pred - target.to(pred.dtype)).pow(2)).mean()
+
+
+class GNNEncoder(torch.nn.Module):
+ def __init__(self, hidden_channels, out_channels):
+ super().__init__()
+ self.conv1 = SAGEConv((-1, -1), hidden_channels)
+ self.conv2 = SAGEConv((-1, -1), out_channels)
+
+ def forward(self, x, edge_index):
+ x = self.conv1(x, edge_index).relu()
+ x = self.conv2(x, edge_index)
+ return x
+
+
+class EdgeDecoder(torch.nn.Module):
+ def __init__(self, hidden_channels):
+ super().__init__()
+ self.lin1 = Linear(2 * hidden_channels, hidden_channels)
+ self.lin2 = Linear(hidden_channels, 1)
+
+ def forward(self, z_dict, edge_label_index):
+ row, col = edge_label_index
+ z = torch.cat([z_dict['user'][row], z_dict['movie'][col]], dim=-1)
+
+ z = self.lin1(z).relu()
+ z = self.lin2(z)
+ return z.view(-1)
+
+
+class Model(torch.nn.Module):
+ def __init__(self, hidden_channels):
+ super().__init__()
+ self.encoder = GNNEncoder(hidden_channels, hidden_channels)
+ self.encoder = to_hetero(self.encoder, data.metadata(), aggr='sum')
+ self.decoder = EdgeDecoder(hidden_channels)
+
+ def forward(self, x_dict, edge_index_dict, edge_label_index):
+ z_dict = self.encoder(x_dict, edge_index_dict)
+ return self.decoder(z_dict, edge_label_index)
+
+
+model = Model(hidden_channels=32).to(device)
+
+# Due to lazy initialization, we need to run one model step so the number
+# of parameters can be inferred:
+with torch.no_grad():
+ model.encoder(train_data.x_dict, train_data.edge_index_dict)
+
+optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
+
+
+def train():
+ model.train()
+ optimizer.zero_grad()
+ pred = model(train_data.x_dict, train_data.edge_index_dict,
+ train_data['user', 'movie'].edge_label_index)
+ target = train_data['user', 'movie'].edge_label
+ loss = weighted_mse_loss(pred, target, weight)
+ loss.backward()
+ optimizer.step()
+ return float(loss)
+
+
[email protected]_grad()
+def test(data):
+ model.eval()
+ pred = model(data.x_dict, data.edge_index_dict,
+ data['user', 'movie'].edge_label_index)
+ pred = pred.clamp(min=0, max=5)
+ target = data['user', 'movie'].edge_label.float()
+ rmse = F.mse_loss(pred, target).sqrt()
+ return float(rmse)
+
+
+for epoch in range(1, 301):
+ loss = train()
+ train_rmse = test(train_data)
+ val_rmse = test(val_data)
+ test_rmse = test(test_data)
+ print(f'Epoch: {epoch:03d}, Loss: {loss:.4f}, Train: {train_rmse:.4f}, '
+ f'Val: {val_rmse:.4f}, Test: {test_rmse:.4f}')
diff --git a/torch_geometric/datasets/__init__.py b/torch_geometric/datasets/__init__.py
--- a/torch_geometric/datasets/__init__.py
+++ b/torch_geometric/datasets/__init__.py
@@ -50,6 +50,7 @@
from .actor import Actor
from .ogb_mag import OGB_MAG
from .dblp import DBLP
+from .movie_lens import MovieLens
from .imdb import IMDB
from .last_fm import LastFM
from .hgb_dataset import HGBDataset
@@ -126,6 +127,7 @@
'Actor',
'OGB_MAG',
'DBLP',
+ 'MovieLens',
'IMDB',
'LastFM',
'HGBDataset',
diff --git a/torch_geometric/datasets/movie_lens.py b/torch_geometric/datasets/movie_lens.py
new file mode 100644
--- /dev/null
+++ b/torch_geometric/datasets/movie_lens.py
@@ -0,0 +1,93 @@
+from typing import Optional, Callable, List
+
+import os
+import os.path as osp
+
+import torch
+
+from torch_geometric.data import (InMemoryDataset, HeteroData, download_url,
+ extract_zip)
+
+
+class MovieLens(InMemoryDataset):
+ r"""A heterogeneous rating dataset, assembled by GroupLens Research from
+ the `MovieLens web site <https://movielens.org>`_, consisting of nodes of
+ type :obj:`"movie"` and :obj:`"user"`.
+ User ratings for movies are available as ground truth labels for the edges
+ between the users and the movies :obj:`("user", "rates", "movie")`.
+
+ Args:
+ root (string): Root directory where the dataset should be saved.
+ transform (callable, optional): A function/transform that takes in an
+ :obj:`torch_geometric.data.HeteroData` object and returns a
+ transformed version. The data object will be transformed before
+ every access. (default: :obj:`None`)
+ pre_transform (callable, optional): A function/transform that takes in
+ an :obj:`torch_geometric.data.HeteroData` object and returns a
+ transformed version. The data object will be transformed before
+ being saved to disk. (default: :obj:`None`)
+ model_name (str): Name of model used to transform movie titles to node
+ features. The model comes from the`Huggingface SentenceTransformer
+ <https://huggingface.co/sentence-transformers>`_.
+ """
+
+ url = 'https://files.grouplens.org/datasets/movielens/ml-latest-small.zip'
+
+ def __init__(self, root, transform: Optional[Callable] = None,
+ pre_transform: Optional[Callable] = None,
+ model_name: Optional[str] = "all-MiniLM-L6-v2"):
+ self.model_name = model_name
+ super().__init__(root, transform, pre_transform)
+ self.data, self.slices = torch.load(self.processed_paths[0])
+
+ @property
+ def raw_file_names(self) -> List[str]:
+ return [
+ osp.join('ml-latest-small', 'movies.csv'),
+ osp.join('ml-latest-small', 'ratings.csv'),
+ ]
+
+ @property
+ def processed_file_names(self) -> str:
+ return f'data_{self.model_name}.pt'
+
+ def download(self):
+ path = download_url(self.url, self.raw_dir)
+ extract_zip(path, self.raw_dir)
+ os.remove(path)
+
+ def process(self):
+ import pandas as pd
+ from sentence_transformers import SentenceTransformer
+
+ data = HeteroData()
+
+ df = pd.read_csv(self.raw_paths[0], index_col='movieId')
+ movie_mapping = {idx: i for i, idx in enumerate(df.index)}
+
+ genres = df['genres'].str.get_dummies('|').values
+ genres = torch.from_numpy(genres).to(torch.float)
+
+ model = SentenceTransformer(self.model_name)
+ with torch.no_grad():
+ emb = model.encode(df['title'].values, show_progress_bar=True,
+ convert_to_tensor=True).cpu()
+
+ data['movie'].x = torch.cat([emb, genres], dim=-1)
+
+ df = pd.read_csv(self.raw_paths[1])
+ user_mapping = {idx: i for i, idx in enumerate(df['userId'].unique())}
+ data['user'].num_nodes = len(user_mapping)
+
+ src = [user_mapping[idx] for idx in df['userId']]
+ dst = [movie_mapping[idx] for idx in df['movieId']]
+ edge_index = torch.tensor([src, dst])
+
+ rating = torch.from_numpy(df['rating'].values).to(torch.long)
+ data['user', 'rates', 'movie'].edge_index = edge_index
+ data['user', 'rates', 'movie'].edge_label = rating
+
+ if self.pre_transform is not None:
+ data = self.pre_transform(data)
+
+ torch.save(self.collate([data]), self.processed_paths[0])
| An example of heterogeneous link prediction via `RandomLinkSplit`
| Hello! I'm thinking of picking this one up, if that's helpful. Did you have a specific dataset to use in mind already?
Cool :) I thought about extending the "Loading CSV" tutorial to showcase how one would apply a GNN on this one. I already started integrating the random link split behaviour, see [here](https://github.com/pyg-team/pytorch_geometric/blob/master/examples/hetero/load_csv.py#L109-L127). The next task would be to create a heterogeneous GNN model, and train it in a supervised fashion against ratings in the training set. WDYT?
Ah yes, that is indeed a nice start already! :)
This example feels a bit different from "typical" link prediction statements, in that I don't think you can really have a contrastive loss with negative edges, as a missing edge in this graph just means we want to predict what rating there should be for each edge of type `('user', 'rates', 'movie')`. So we don't want to train the algorithm to give good separation between "likely" and "unlikely" edges. I think that's fine though, I see this as an edge classification problem and it seems a relevant example, reminiscent of the problem statement of predicting how users would rate products on online stores.
Can you check that my plan for this fits your idea about what you would like?
- In the encoder step I perform heterogeneous message passing, maybe using a `GNN` with 2 layers
- In the decoder step I use a `DistMult` decoder to get scores for each edge label (from 0 to 5), so here I am - kind of - treating the edge labels as six different edge types. If `DistMult` doesn't do the trick, I could try a bilinear, `RESCAL` type decoder.
- Then I apply a `softmax` on the 6 scores I got from the decoder per training supervision edge to get something that "looks like" class probabilities, pick the class with the highest probability and use a loss suitable for a multiclass problem statement (such as `torch.nn.NLLLoss`)
- Then backpropagate etc...
I'm happy to try this approach, I just wanted to check if you already had some kind of plan that is quite different from mine, so we don't waste too much time. Thanks! :)
You are right, it's more of an edge classification problem in which no negative sampling is needed. Nonetheless, the model should be able to predict the ratings of unknown users/movies. Your approach sounds correct, and matches with the one I have in mind. Let me know how it goes :)
Alright, just a quick status update: I've put something together and it is learning but the performance is not amazing so I want to improve it a bit. The average test accuracy gets to about 40% after 400 epochs, which I guess is better than random for a 6 class problem but there are a few things I want to try to make it better before sharing it.
I'm afraid I only have time to do this in my evenings so progress is perhaps a bit slow. Hope that's ok.
Sure, please feel free to submit a PR early, so I can help with it :) | 2021-10-19T22:03:51 |
|
pyg-team/pytorch_geometric | 3,889 | pyg-team__pytorch_geometric-3889 | [
"3870"
]
| 0805d0597a9c5883969c1d216fc63b3b2e61d46b | diff --git a/torch_geometric/nn/glob/set2set.py b/torch_geometric/nn/glob/set2set.py
--- a/torch_geometric/nn/glob/set2set.py
+++ b/torch_geometric/nn/glob/set2set.py
@@ -1,5 +1,9 @@
+from typing import Optional
+
import torch
+from torch import Tensor
from torch_scatter import scatter_add
+
from torch_geometric.utils import softmax
@@ -27,8 +31,17 @@ class Set2Set(torch.nn.Module):
:obj:`num_layers=2` would mean stacking two LSTMs together to form
a stacked LSTM, with the second LSTM taking in outputs of the first
LSTM and computing the final results. (default: :obj:`1`)
+
+ Shapes:
+ - **input:**
+ node features :math:`(|\mathcal{V}|, F)`,
+ batch vector :math:`(|\mathcal{V}|)` *(optional)*
+ - **output:**
+ set features :math:`(|\mathcal{G}|, 2 * F)` where
+ :math:`|\mathcal{G}|` denotes the number of graphs in the batch
"""
- def __init__(self, in_channels, processing_steps, num_layers=1):
+ def __init__(self, in_channels: int, processing_steps: int,
+ num_layers: int = 1):
super().__init__()
self.in_channels = in_channels
@@ -44,8 +57,16 @@ def __init__(self, in_channels, processing_steps, num_layers=1):
def reset_parameters(self):
self.lstm.reset_parameters()
- def forward(self, x, batch):
- """"""
+ def forward(self, x: Tensor, batch: Optional[Tensor] = None) -> Tensor:
+ r"""
+ Args:
+ x (Tensor): The input node features.
+ batch (LongTensor, optional): A vector that maps each node to its
+ respective graph identifier. (default: :obj:`None`)
+ """
+ if batch is None:
+ batch = x.new_zeros(x.size(0), dtype=torch.int64)
+
batch_size = batch.max().item() + 1
h = (x.new_zeros((self.num_layers, batch_size, self.in_channels)),
| Improving documentation for Set2Set layer
### 📚 Describe the documentation issue
I am new to `pytorch_geometric` ecosystem and I was exploring it. At the first glance to the `Set2Set` layer in the [docs](https://pytorch-geometric.readthedocs.io/en/latest/modules/nn.html#torch_geometric.nn.glob.Set2Set), it is not clear what the inputs `x` and `batch` are to the forward pass.
If I am not wrong, `x` represents the node features of the graph and `batch` represents a mapping between the node features to their graph identifiers.
### Suggest a potential alternative/fix
I was wondering whether it will be good to include it to the docs or maybe also add typing.
Potential fix in `nn.glob.set2set.py`:
```
def forward(self, x: torch.Tensor, batch: torch.Tensor):
r"""
Args:
x: The input node features.
batch: A one dimension tensor representing a mapping between nodes and their graphs
"""
```
| @arunppsg I think its a good idea to add type hints. Please feel free to contribute this.
There is also some recent effort to bring shape information to all GNN operators, see [here](https://github.com/pyg-team/pytorch_geometric/blob/master/torch_geometric/nn/conv/gin_conv.py#L41-L48). We can likely also do this for any other PyG operator.
Putting up shape information will be super useful. I will put up a small PR regarding the suggestions later this week. Thanks! | 2022-01-19T14:30:07 |
|
pyg-team/pytorch_geometric | 3,930 | pyg-team__pytorch_geometric-3930 | [
"3925"
]
| 50b7bfc4a59b5b6f7ec547ff862985f3b2e22798 | diff --git a/examples/pna.py b/examples/pna.py
--- a/examples/pna.py
+++ b/examples/pna.py
@@ -19,8 +19,14 @@
val_loader = DataLoader(val_dataset, batch_size=128)
test_loader = DataLoader(test_dataset, batch_size=128)
-# Compute in-degree histogram over training data.
-deg = torch.zeros(5, dtype=torch.long)
+# Compute the maximum in-degree in the training data.
+max_degree = -1
+for data in train_dataset:
+ d = degree(data.edge_index[1], num_nodes=data.num_nodes, dtype=torch.long)
+ max_degree = max(max_degree, int(d.max()))
+
+# Compute the in-degree histogram tensor
+deg = torch.zeros(max_degree + 1, dtype=torch.long)
for data in train_dataset:
d = degree(data.edge_index[1], num_nodes=data.num_nodes, dtype=torch.long)
deg += torch.bincount(d, minlength=deg.numel())
| Computing the size of the in-degree histogram tensor dynamically in the PNA example
### 🛠 Proposed Refactor
The `deg` tensor in the PNA example is initialized with the size `5`.
https://github.com/pyg-team/pytorch_geometric/blob/50b7bfc4a59b5b6f7ec547ff862985f3b2e22798/examples/pna.py#L23
This value will obviously be different for different datasets. One can iterate over the training data and compute the maximum degree any node has. Then, the histogram tensor can be initialized with that value. Something like this:
```python
# compute the maximum in-degree in the training data
max_degree = 0
for data in train_dataset:
d = degree(data.edge_index[1], num_nodes=data.num_nodes, dtype=torch.long)
if d.max().item() > max_degree:
max_degree = d.max().item()
# create the in-degree histogram tensor
deg = torch.zeros(max_degree + 1, dtype=torch.long)
for data in train_dataset:
d = degree(data.edge_index[1], num_nodes=data.num_nodes, dtype=torch.long)
deg += torch.bincount(d, minlength=deg.numel())
```
### Suggest a potential alternative/fix
The results of the `degree` function can also be cached to avoid iterating two times. Further, for custom datasets where the split is made with indices or boolean masks e.g `Data(x=[10000, 100], edge_index=[2, 200000], edge_attr=[200000, 20], y=[10000], train_mask=[10000], val_mask=[10000], test_mask=[10000])`, the `subgraph` utility can be used.
```python
tr_subgraph = data.subgraph(data.train_mask)
# compute the in-degree of all the training nodes
d = degree(index=tr_subgraph.edge_index[1], num_nodes=tr_subgraph.num_nodes, dtype=torch.long)
# get the maximum in-degree, this will be the size of the histogram tensor
max_degree = d.max().item()
# create the in-degree histogram tensor
deg = torch.zeros(max_degree + 1, dtype=torch.long)
deg += torch.bincount(d, minlength=deg.numel())
```
| That is a good change, as it allows to apply `PNA` more easily to other datasets as well. Please go ahead and contribute this feature :) | 2022-01-24T12:37:44 |
|
pyg-team/pytorch_geometric | 4,299 | pyg-team__pytorch_geometric-4299 | [
"4298"
]
| 0833e05a5c8a46037c377aa42a12b4ff9de5015f | diff --git a/torch_geometric/nn/models/basic_gnn.py b/torch_geometric/nn/models/basic_gnn.py
--- a/torch_geometric/nn/models/basic_gnn.py
+++ b/torch_geometric/nn/models/basic_gnn.py
@@ -86,6 +86,7 @@ def __init__(
self.convs.append(
self.init_conv(hidden_channels, hidden_channels, **kwargs))
if out_channels is not None and jk is None:
+ self._is_conv_to_out = True
self.convs.append(
self.init_conv(hidden_channels, out_channels, **kwargs))
else:
@@ -282,14 +283,24 @@ class GAT(BasicGNN):
def init_conv(self, in_channels: int, out_channels: int,
**kwargs) -> MessagePassing:
- kwargs = copy.copy(kwargs)
- if 'heads' in kwargs and out_channels % kwargs['heads'] != 0:
- kwargs['heads'] = 1
- if 'concat' not in kwargs or kwargs['concat']:
- out_channels = out_channels // kwargs.get('heads', 1)
+ heads = kwargs.pop('heads', 1)
+ concat = kwargs.pop('concat', True)
- return GATConv(in_channels, out_channels, dropout=self.dropout,
- **kwargs)
+ # Do not use concatenation in case the layer `GATConv` layer maps to
+ # the desired output channels (out_channels != None and jk != None):
+ if getattr(self, '_is_conv_to_out', False):
+ concat = False
+
+ if concat and out_channels % heads != 0:
+ raise ValueError(f"Ensure that the number of output channels of "
+ f"'GATConv' (got '{out_channels}') is divisible "
+ f"by the number of heads (got '{heads}')")
+
+ if concat:
+ out_channels = out_channels // heads
+
+ return GATConv(in_channels, out_channels, heads=heads, concat=concat,
+ dropout=self.dropout, **kwargs)
class PNA(BasicGNN):
| GAT model - last layer incorrect?
### 🐛 Describe the bug
In GAT paper last layer averages attention heads instead of concatenation, which corresponds to `concat=False` in `GATConv` in PyTorchGeometric. This is also the case in all examples.
However, in `GAT` model the last layer is still concatenated, as only the convolution is passed to `BasicGNN`. This means that using `GAT`, we actually concatenate the attention heads in the last layer, which is incorrect, or at least an unexpected behavior.
If I'm correct, I see two ways of fixing this:
- leave as-is, but add a disclaimer to the docs, possibly with example how to go from the current output `(num_nodes, K * out_channels)` (for `K` attention heads) to `(num_nodes, out_channels)`, where attention heads are averaged
- override the `.forward()` method in `GAT` and add `concat_last_layer=False` option:
- if `True`, run as-is
- if `False`, override the `.forward()` method, use the parent's `.forward()` up to `N-1` layer, and run the last layer separately, using concat=False`
### Environment
* PyG version: 2.0.4
* PyTorch version: 1.10
* OS: Windows 10
* Python version: 3.9
* CUDA/cuDNN version: 11.3
* How you installed PyTorch and PyG (`conda`, `pip`, source): `pip`
* Any other relevant information (*e.g.*, version of `torch-scatter`):
| That is interesting, I think you are right that we need to fix the `concat` option in the last layer for `GAT`. In my understanding, we only need to fix this in case `GAT` makes use of the `out_channels` argument, i.e. the last `GATConv` layer actually maps to `out_channels`. In that case, it might be the easiest to just fix `concat=False`.
I think something like this would work:
```
class GAT(BasicGNN):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
kwargs = copy.copy(kwargs)
kwargs["concat"] = False
if out_channels is not None and jk is None:
self.convs[-1] = self.init_conv(hidden_channels, out_channels, **kwargs)
else:
self.convs[-1] = self.init_conv(hidden_channels, hidden_channels, **kwargs)
```
So we always make sure that the last `GATConv` layer uses `concat=False`. This fixes the parameter, but according to the paper this makes sense, and previous layers can still use either concatenation or summation.
If this seems correct, I can make a PR. | 2022-03-18T12:24:50 |
|
pyg-team/pytorch_geometric | 4,635 | pyg-team__pytorch_geometric-4635 | [
"4001"
]
| 90fa81de6b6e63781ca305ebc35a18878179fc39 | diff --git a/torch_geometric/data/hetero_data.py b/torch_geometric/data/hetero_data.py
--- a/torch_geometric/data/hetero_data.py
+++ b/torch_geometric/data/hetero_data.py
@@ -12,7 +12,7 @@
from torch_geometric.data.data import BaseData, Data, size_repr
from torch_geometric.data.storage import BaseStorage, EdgeStorage, NodeStorage
from torch_geometric.typing import EdgeType, NodeType, QueryType
-from torch_geometric.utils import is_undirected
+from torch_geometric.utils import bipartite_subgraph, is_undirected
NodeOrEdgeType = Union[NodeType, EdgeType]
NodeOrEdgeStorage = Union[NodeStorage, EdgeStorage]
@@ -445,6 +445,83 @@ def rename(self, name: NodeType, new_name: NodeType) -> 'HeteroData':
return self
+ def subgraph(self, subset_dict: Dict[NodeType, Tensor]) -> 'HeteroData':
+ r"""Returns the induced subgraph containing the node types and
+ corresponding nodes in :obj:`subset_dict`.
+
+ .. code-block:: python
+
+ data = HeteroData()
+ data['paper'].x = ...
+ data['author'].x = ...
+ data['conference'].x = ...
+ data['paper', 'cites', 'paper'].edge_index = ...
+ data['author', 'paper'].edge_index = ...
+ data['paper', 'conference'].edge_index = ...
+ print(data)
+ >>> HeteroData(
+ paper={ x=[10, 16] },
+ author={ x=[5, 32] },
+ conference={ x=[5, 8] },
+ (paper, cites, paper)={ edge_index=[2, 50] },
+ (author, to, paper)={ edge_index=[2, 30] },
+ (paper, to, conference)={ edge_index=[2, 25] }
+ )
+
+ subset_dict = {
+ 'paper': torch.tensor([3, 4, 5, 6]),
+ 'author': torch.tensor([0, 2]),
+ }
+
+ print(data.subgraph(subset_dict))
+ >>> HeteroData(
+ paper={ x=[4, 16] },
+ author={ x=[2, 32] },
+ (paper, cites, paper)={ edge_index=[2, 24] },
+ (author, to, paper)={ edge_index=[2, 5] }
+ )
+
+ Args:
+ subset_dict (Dict[str, LongTensor or BoolTensor]): A dictonary
+ holding the nodes to keep for each node type.
+ """
+ data = self.__class__(self._global_store)
+
+ for node_type, subset in subset_dict.items():
+ for key, value in self[node_type].items():
+ if key == 'num_nodes':
+ if subset.dtype == torch.bool:
+ data[node_type].num_nodes = int(subset.sum())
+ else:
+ data[node_type].num_nodes = subset.size(0)
+ elif self[node_type].is_node_attr(key):
+ data[node_type][key] = value[subset]
+ else:
+ data[node_type][key] = value
+
+ for edge_type in self.edge_types:
+ src, _, dst = edge_type
+ if src not in subset_dict or dst not in subset_dict:
+ continue
+
+ edge_index, _, edge_mask = bipartite_subgraph(
+ (subset_dict[src], subset_dict[dst]),
+ self[edge_type].edge_index,
+ relabel_nodes=True,
+ size=(self[src].num_nodes, self[dst].num_nodes),
+ return_edge_mask=True,
+ )
+
+ for key, value in self[edge_type].items():
+ if key == 'edge_index':
+ data[edge_type].edge_index = edge_index
+ elif self[edge_type].is_edge_attr(key):
+ data[edge_type][key] = value[edge_mask]
+ else:
+ data[edge_type][key] = value
+
+ return data
+
def to_homogeneous(self, node_attrs: Optional[List[str]] = None,
edge_attrs: Optional[List[str]] = None,
add_node_type: bool = True,
| diff --git a/test/data/test_hetero_data.py b/test/data/test_hetero_data.py
--- a/test/data/test_hetero_data.py
+++ b/test/data/test_hetero_data.py
@@ -6,15 +6,20 @@
x_paper = torch.randn(10, 16)
x_author = torch.randn(5, 32)
+x_conference = torch.randn(5, 8)
idx_paper = torch.randint(x_paper.size(0), (100, ), dtype=torch.long)
idx_author = torch.randint(x_author.size(0), (100, ), dtype=torch.long)
+idx_conference = torch.randint(x_conference.size(0), (100, ), dtype=torch.long)
edge_index_paper_paper = torch.stack([idx_paper[:50], idx_paper[:50]], dim=0)
edge_index_paper_author = torch.stack([idx_paper[:30], idx_author[:30]], dim=0)
-edge_index_author_paper = torch.stack([idx_paper[:30], idx_author[:30]], dim=0)
+edge_index_author_paper = torch.stack([idx_author[:30], idx_paper[:30]], dim=0)
+edge_index_paper_conference = torch.stack(
+ [idx_paper[:25], idx_conference[:25]], dim=0)
edge_attr_paper_paper = torch.randn(edge_index_paper_paper.size(1), 8)
+edge_attr_author_paper = torch.randn(edge_index_author_paper.size(1), 8)
def get_edge_index(num_src_nodes, num_dst_nodes, num_edges):
@@ -159,6 +164,57 @@ def test_hetero_data_rename():
assert edge_index.tolist() == edge_index_paper_paper.tolist()
+def test_hetero_data_subgraph():
+ data = HeteroData()
+ data.num_node_types = 3
+ data['paper'].x = x_paper
+ data['paper'].name = 'paper'
+ data['paper'].num_nodes = x_paper.size(0)
+ data['author'].x = x_author
+ data['author'].num_nodes = x_author.size(0)
+ data['conference'].x = x_conference
+ data['conference'].num_nodes = x_conference.size(0)
+ data['paper', 'paper'].edge_index = edge_index_paper_paper
+ data['paper', 'paper'].edge_attr = edge_attr_paper_paper
+ data['paper', 'paper'].name = 'cites'
+ data['author', 'paper'].edge_index = edge_index_author_paper
+ data['paper', 'author'].edge_index = edge_index_paper_author
+ data['paper', 'conference'].edge_index = edge_index_paper_conference
+
+ subset = {
+ 'paper': torch.randperm(x_paper.size(0))[:4],
+ 'author': torch.randperm(x_author.size(0))[:2]
+ }
+
+ out = data.subgraph(subset)
+
+ assert out.num_node_types == data.num_node_types
+ assert out.node_types == ['paper', 'author']
+
+ assert len(out['paper']) == 3
+ assert torch.allclose(out['paper'].x, data['paper'].x[subset['paper']])
+ assert out['paper'].name == 'paper'
+ assert out['paper'].num_nodes == 4
+ assert len(out['author']) == 2
+ assert torch.allclose(out['author'].x, data['author'].x[subset['author']])
+ assert out['author'].num_nodes == 2
+
+ assert out.edge_types == [
+ ('paper', 'to', 'paper'),
+ ('author', 'to', 'paper'),
+ ('paper', 'to', 'author'),
+ ]
+
+ assert len(out['paper', 'paper']) == 3
+ assert out['paper', 'paper'].edge_index is not None
+ assert out['paper', 'paper'].edge_attr is not None
+ assert out['paper', 'paper'].name == 'cites'
+ assert len(out['paper', 'author']) == 1
+ assert out['paper', 'author'].edge_index is not None
+ assert len(out['author', 'paper']) == 1
+ assert out['author', 'paper'].edge_index is not None
+
+
def test_copy_hetero_data():
data = HeteroData()
data['paper'].x = x_paper
| `HeteroData.subgraph()`
### 🚀 The feature, motivation and pitch
Similar to `Data.subgraph()`, there should exist a `HeteroData.subgraph()` method to compute subgraphs in a heterogeneous graph setting, *e.g.*, for obtaining inductive node splits. Here, `mask`/`index` should be of type `dict`, holding masks/indices for each/a subset of node types:
```python
hetero_data.subgraph({'paper': mask})
```
### Alternatives
_No response_
### Additional context
_No response_
| Hi @rusty1s , I was about to open a new discussion, and just realized you are already on this. Just commenting to share my interest in this feature. Cheers.
@michalisfrangos are you interested in contributing this feature?
Pinging @mananshah99 and @sdulloor here who shared interest in contributing this feature as well.
It might be useful to implement a `utils.subgraph_bipartite(subset:Tuple[torch.Tensor,torch.Tensor],...)` or add support to `utils.subgraph` for bipartite graphs. I prefer adding a new function over modifying the existing one to make the code more clean.
That way `HeteroData.subgraph()` would make multiple calls to `subgraph_bipartite`. Something like
```
subgraph(node_mask_dict):
....
for edge_type in self.edge_types:
if edge_type[0] in node_mask_dict and..:
new_edge, _ , _ = utils.subgraph_bipartite((node_mask_dict[edge_type[0], node_mask_dict[edge_type[-1]))
```
WDYT?
Yes, this looks good to me. Although we overload a lot of functionality with bipartite graph support already (by passing tuples instead of single tensors), I agree that adding this directly to `subgraph` might makes the code overly complex. `bipartite_subgraph` is a good alternative that we do not even have to expose.
how would this be different from just sampling a heterogeneous graph with large neighbourhoods to get different node types in the new sampled bipartite graph?
Not sure I understand. Can you clarify? The `subgraph()` method might be useful to gather subgraphs prior to any training or sampling, e.g. for obtaining inductive subgraphs based on a pre-defined split.
so I have a transductive problem (for now) and for heterognn classification I am planning to just use the `HGTLoader` to get smaller batches for a list of nodes to train my model. Does that set up seem correct? I'm not sure how/if i should be using something like the `subgraph()` method, (whenever its implemented).
It depends on which data you want to train on. If you want to shrink the data prior to training, then `HeteroData.subgraph` would be applicable to create a smaller subgraph from your original graph. If you just want to operate on smaller batches during training, then you may want to adjust the `batch_size` argument of a loader.
Let me know if that makes sense to you. | 2022-05-13T09:53:43 |
pyg-team/pytorch_geometric | 4,827 | pyg-team__pytorch_geometric-4827 | [
"4809"
]
| e3a52f9ac7b636289376a02f846376635c2a40d0 | diff --git a/torch_geometric/nn/glob/glob.py b/torch_geometric/nn/glob/glob.py
--- a/torch_geometric/nn/glob/glob.py
+++ b/torch_geometric/nn/glob/glob.py
@@ -24,9 +24,9 @@ def global_add_pool(x: Tensor, batch: Optional[Tensor],
Automatically calculated if not given. (default: :obj:`None`)
"""
if batch is None:
- return x.sum(dim=0, keepdim=True)
+ return x.sum(dim=-2, keepdim=x.dim() == 2)
size = int(batch.max().item() + 1) if size is None else size
- return scatter(x, batch, dim=0, dim_size=size, reduce='add')
+ return scatter(x, batch, dim=-2, dim_size=size, reduce='add')
def global_mean_pool(x: Tensor, batch: Optional[Tensor],
@@ -48,9 +48,9 @@ def global_mean_pool(x: Tensor, batch: Optional[Tensor],
Automatically calculated if not given. (default: :obj:`None`)
"""
if batch is None:
- return x.mean(dim=0, keepdim=True)
+ return x.mean(dim=-2, keepdim=x.dim() == 2)
size = int(batch.max().item() + 1) if size is None else size
- return scatter(x, batch, dim=0, dim_size=size, reduce='mean')
+ return scatter(x, batch, dim=-2, dim_size=size, reduce='mean')
def global_max_pool(x: Tensor, batch: Optional[Tensor],
@@ -72,9 +72,9 @@ def global_max_pool(x: Tensor, batch: Optional[Tensor],
Automatically calculated if not given. (default: :obj:`None`)
"""
if batch is None:
- return x.max(dim=0, keepdim=True)[0]
+ return x.max(dim=-2, keepdim=x.dim() == 2)[0]
size = int(batch.max().item() + 1) if size is None else size
- return scatter(x, batch, dim=0, dim_size=size, reduce='max')
+ return scatter(x, batch, dim=-2, dim_size=size, reduce='max')
class GlobalPooling(torch.nn.Module):
| diff --git a/test/nn/glob/test_glob.py b/test/nn/glob/test_glob.py
--- a/test/nn/glob/test_glob.py
+++ b/test/nn/glob/test_glob.py
@@ -65,3 +65,8 @@ def test_permuted_global_pool():
assert out.size() == (2, 4)
assert torch.allclose(out[0], px1.max(dim=0)[0])
assert torch.allclose(out[1], px2.max(dim=0)[0])
+
+
+def test_dense_global_pool():
+ x = torch.randn(3, 16, 32)
+ assert torch.allclose(global_add_pool(x, None), x.sum(dim=1))
| TypeError: global_add_pool() missing 1 required positional argument: 'batch'
### 🐛 Describe the bug
The documentation of `global_add_pool ` states that the batch parameter is optional, however I get this error ```TypeError: global_add_pool() missing 1 required positional argument: 'batch'``` when I don't pass a value for the batch.
Here is a snippet of code to reproduce the bug:
```Python
import torch
from torch_geometric.nn import global_add_pool
x = torch.zeros(4,5)
z = global_add_pool(x)
```
I think the origin of the issue is the absence of a default value for the batch parameter in the definition of `global_add_pool`.
And the same bug happens when using `global_mean_pool` or `global_max_pool`.
### Environment
* PyG version: 2.0.5
* PyTorch version: 1.11.0
* OS: Fedora release 35
* Python version: 3.9
* CUDA/cuDNN version: 11.3
* How you installed PyTorch and PyG (`conda`, `pip`, source): Poetry
| Yes, this is intended. I feel that `global_add_pool(x)` can lead to some serious bugs when not being careful, as such:
```python
def forward(x, edge_index, batch=None):
x = global_ad__pool(x, batch)
```
is a good and more robust workaround. WDYT?
I agree with being careful with the `global_add_pool` and the workaround looks good.
I have two additional remarks:
- The current documentation of `global_add_pool` doesn't reflect that `batch` is a mandatory parameter:
```global_add_pool(x: Tensor, batch: Optional[Tensor], size: Optional[int] = None) -> Tensor```
- When the batch is None it is likely because the node features matrix is a dense node feature tensor $X \in \mathbb{R}^{B \times N_{max} \times F}$. In this case the dimension to reduce is dim=1, however this is not the behavior of `global_add_pool`:
```python
if batch is None:
return x.sum(dim=0, keepdim=True)
```
I need to use `global_add_pool` after applying dense pooling layer such as diffpool. Although `torch.sum` can do the job, I prefer to have one function for global add pool to use with both sparse and dense batches. I think such function will help build modular pipelines such the one in GraphGym.
I think both suggestions are great. We could adjust the documentation to specify that batch is mendatory? And similarly for other global pooling functions too.
The ability to handle both sparse and dense batches sounds great too. As you said this seems to be easy with torch sum. Should we have a PR on this?
We should be able to do this by doing a dense aggregation in `dim=-2` instead of `dim=0`. Happy to accept a PR on this one. | 2022-06-20T12:12:37 |
pyg-team/pytorch_geometric | 5,051 | pyg-team__pytorch_geometric-5051 | [
"4848"
]
| 0e2d987d444c2884db94742a7e47117ac0496b6f | diff --git a/torch_geometric/loader/dataloader.py b/torch_geometric/loader/dataloader.py
--- a/torch_geometric/loader/dataloader.py
+++ b/torch_geometric/loader/dataloader.py
@@ -1,4 +1,5 @@
from collections.abc import Mapping, Sequence
+from inspect import signature
from typing import List, Optional, Union
import torch.utils.data
@@ -39,6 +40,28 @@ def collate(self, batch): # Deprecated...
return self(batch)
+# PyG 'Data' objects are subclasses of MutableMapping, which is an
+# instance of collections.abc.Mapping. Currently, PyTorch pin_memory
+# for DataLoaders treats the returned batches as Mapping objects and
+# calls `pin_memory` on each element in `Data.__dict__`, which is not
+# desired behavior if 'Data' has a `pin_memory` function. We patch
+# this behavior here by monkeypatching `pin_memory`, but can hopefully patch
+# this in PyTorch in the future:
+__torch_pin_memory = torch.utils.data._utils.pin_memory.pin_memory
+__torch_pin_memory_params = signature(__torch_pin_memory).parameters
+
+
+def pin_memory(data, device=None):
+ if hasattr(data, "pin_memory"):
+ return data.pin_memory()
+ if len(__torch_pin_memory_params) > 1:
+ return __torch_pin_memory(data, device)
+ return __torch_pin_memory(data)
+
+
+torch.utils.data._utils.pin_memory.pin_memory = pin_memory
+
+
class DataLoader(torch.utils.data.DataLoader):
r"""A data loader which merges data objects from a
:class:`torch_geometric.data.Dataset` to a mini-batch.
| Data Batch problem in PyG
### 🐛 Describe the bug
Hi. I am a computational physics researcher and was using PyG very well.
my pyg code was working well a few weeks ago, but now that I run my code, it is not working anymore without any changes.
the problem is like below.
I have many material structures and in my "custom_dataset" class, these are preprocessed and all graph informations (node features, edge features, edge index etc) are inserted into "Data" object in PyTorch geometric.
You can see that each preprocessed sample with index $i$ was printed normal "Data" object in pyg
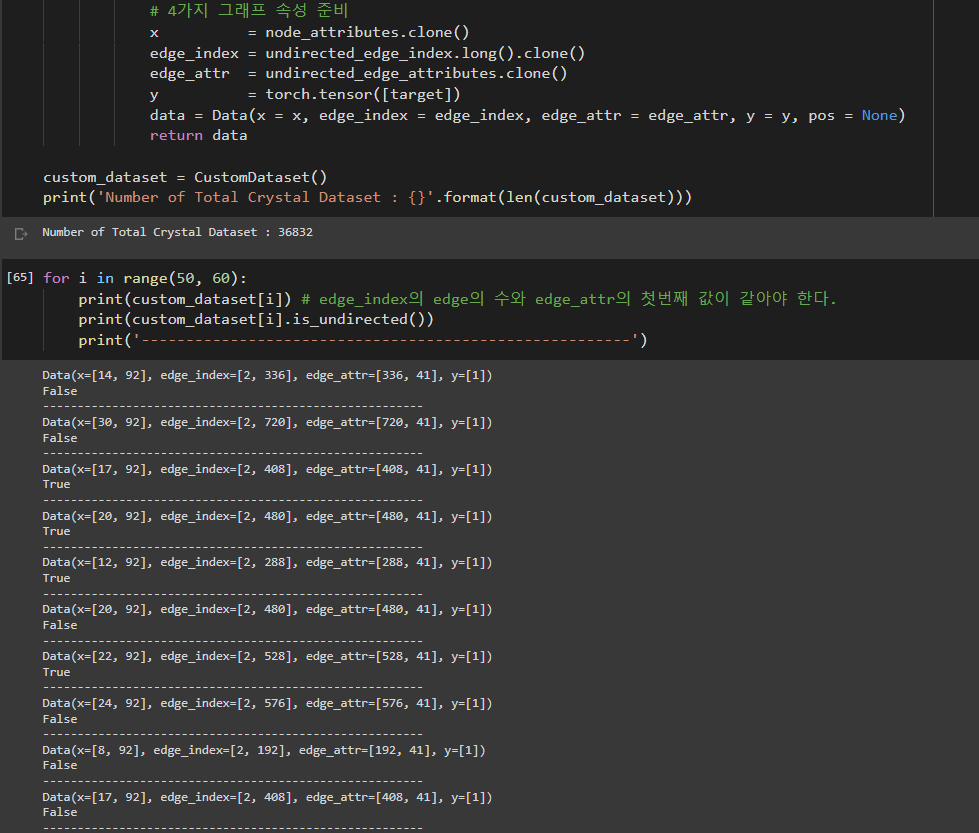
But When I insert my custom dataset class into pyg DataLoader and I did like below,
``` Python
sample = next(iter(train_loader)) # batch sample
```
batch sample is denoted by "DataDataBatch". I didn't see this kind of object name.
and i can't use "sample.x' or "sample.edge_index" command. Instead I need to do like this
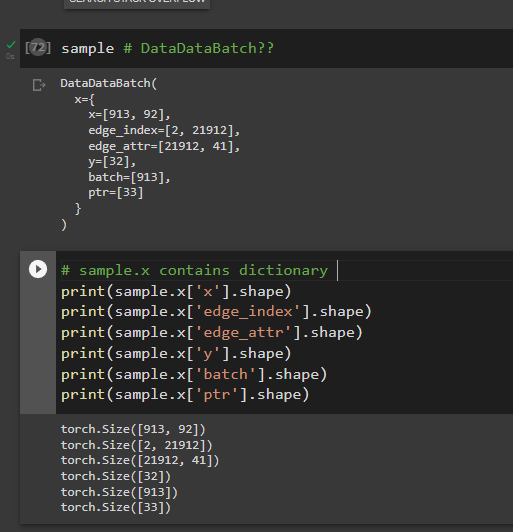
I want to use expressions like "sample.x", "sample.edge_index" or "sample.edge_attr" as like before.
I expect your kind explanations. Thank you.
### Environment
* PyG version: `2.0.5`
* PyTorch version: `1.11.0+cu113`
* OS: `GoogleColab Pro Plus`
* Python version: `Python 3.7.13 in colab`
* CUDA/cuDNN version:
* How you installed PyTorch and PyG (`conda`, `pip`, source):
``` python
# Install required packages.
import os
import torch
os.environ['TORCH'] = torch.__version__
print(torch.__version__)
!pip install -q torch-scatter -f https://data.pyg.org/whl/torch-${TORCH}.html
!pip install -q torch-sparse -f https://data.pyg.org/whl/torch-${TORCH}.html
!pip install -q git+https://github.com/pyg-team/pytorch_geometric.git
!pip install -q pymatgen==2020.11.11
```
* Any other relevant information (*e.g.*, version of `torch-scatter`):
| `DataDataBatch` indeed suggests that there is something weird going on. I am not able to reproduce this on any of our examples though. Do you have a minimal script to reproduce? This would help us out a lot!
cc @mananshah99 Related to recent changes to dynamic inheritance?
Acknowledged, will take a look shortly.
Here is an image captured in a few weeks ago.
And there was no changes in my code.
The object name is "DataBatch" clearly.

Maybe... Should I take down-grade pyg??
I have solved this problem! I just downgraded current version(2.0.5) of PyG to previous version (2.0.4).
In my opinion, "collate function" or any other components in PyG Dataloader could be the problem.
Until I put my custom dataset class into the dataloader, it was okay.
But after the step of dataloader, something changed.
Or maybe there's some dependency problem in googlecolab..
Anyway, I hope you guys should fix this problem soon.
Thanks for your effort.
The name `DataBatch` is correct. Is this for 2.0.4 or 2.0.5? Can you share an example that reproduces the issue?
I'm having the same problem.
## Example
``` python
from pprint import pprint
import networkx as nx
import torch as th
from torch_geometric.data import InMemoryDataset, LightningDataset
from torch_geometric.transforms import LocalDegreeProfile
from torch_geometric.utils import from_networkx
class PathGraph(InMemoryDataset):
def __init__(
self,
root="data",
transform=None,
pre_transform=None,
pre_filter=None,
):
super().__init__(root, transform, pre_transform, pre_filter)
self.data, self.slices = th.load(self.processed_paths[0])
@property
def raw_file_names(self):
return [f"path_graph_{i}.gml" for i in range(3, 6)]
@property
def processed_file_names(self):
return ["data.pt"]
def download(self):
graphs = (nx.path_graph(i) for i in range(3, 6))
for g, p in zip(graphs, self.raw_paths):
nx.write_gml(g, p)
def process(self):
graphs = map(nx.read_gml, self.raw_paths)
graphs = list(graphs)
data_list = [from_networkx(g) for g in graphs]
if self.pre_filter is not None:
data_list = [data for data in data_list if self.pre_filter(data)]
if self.pre_transform is not None:
data_list = [self.pre_transform(data) for data in data_list]
data, slices = self.collate(data_list)
th.save((data, slices), self.processed_paths[0])
def main():
data_module = LightningDataset(
train_dataset=PathGraph(transform=LocalDegreeProfile()),
batch_size=2,
)
batch = next(iter(data_module.train_dataloader()))
print("batch:")
pprint(batch)
print("batch.x:")
pprint(batch.x)
if __name__ == "__main__":
main()
```
The output is:
```
batch:
DataDataBatch(
x={
edge_index=[2, 10],
num_nodes=7,
x=[7, 5],
batch=[7],
ptr=[3]
}
)
batch.x:
{'batch': tensor([0, 0, 0, 0, 1, 1, 1]),
'edge_index': tensor([[0, 1, 1, 2, 2, 3, 4, 5, 5, 6],
[1, 0, 2, 1, 3, 2, 5, 4, 6, 5]]),
'num_nodes': 7,
'ptr': tensor([0, 4, 7]),
'x': tensor([[1.0000, 2.0000, 2.0000, 2.0000, 0.0000],
[2.0000, 1.0000, 2.0000, 1.5000, 0.7071],
[2.0000, 1.0000, 2.0000, 1.5000, 0.7071],
[1.0000, 2.0000, 2.0000, 2.0000, 0.0000],
[1.0000, 2.0000, 2.0000, 2.0000, 0.0000],
[2.0000, 1.0000, 1.0000, 1.0000, 0.0000],
[1.0000, 2.0000, 2.0000, 2.0000, 0.0000]])}
```
## Environment
- PyG version: pyg-nightly=2.0.5.dev20220706
- PyTorch version: 1.12.0
- OS: ArchLinux
- Python version: 3.10.5 (conda_forge)
- CUDA/cuDNN version: 11.6.0
- How you installed PyTorch and PyG (conda, pip, source):
```
mamba install pytorch pytorch-lightning scikit-learn networkx scipy
pip install torch-scatter -f https://data.pyg.org/whl/torch-1.12.0%2Bcu116.html
pip install torch-sparse -f https://data.pyg.org/whl/torch-1.12.0%2Bcu116.html
```
Thanks! I can indeed reproduce. Only happens with PyTorch Lightning and indeed related to the changes of `DynamicInheritance` in the `Batch` class (cc @mananshah99).
I'm glad that the problem will be resolved!! | 2022-07-25T23:16:21 |
|
pyg-team/pytorch_geometric | 5,089 | pyg-team__pytorch_geometric-5089 | [
"5053"
]
| 4240904a86a3f639cde84a5d8ffba3998ca63f2e | diff --git a/torch_geometric/data/storage.py b/torch_geometric/data/storage.py
--- a/torch_geometric/data/storage.py
+++ b/torch_geometric/data/storage.py
@@ -288,7 +288,7 @@ def num_nodes(self) -> Optional[int]:
@property
def num_node_features(self) -> int:
- if 'x' in self and isinstance(self.x, Tensor):
+ if 'x' in self and isinstance(self.x, (Tensor, SparseTensor)):
return 1 if self.x.dim() == 1 else self.x.size(-1)
return 0
| NELL dataset doesn't have num_features and num_node_features
### 🐛 Describe the bug
num_features and num_node_features are 0 for NELL dataset. I'm not familiar with PyG dataset internals, but I suspect it is due to node features in NELL is a `SparseTensor` instance instead of a normal `Tensor`.
```python
from torch_geometric.datasets import NELL
ds = NELL("data")
print(ds.num_node_features) # 0
print(ds.num_features) # 0
```
### Environment
* PyG version: 2.0.4
* PyTorch version: 1.11.0
* OS: macOS Monterey 12.4
* Python version: 3.10.5
* CUDA/cuDNN version: NA
* How you installed PyTorch and PyG (`conda`, `pip`, source): PyTorch through conda, PyG through pip
* Any other relevant information (*e.g.*, version of `torch-scatter`):
| Thanks for reporting. Let me take a look. | 2022-07-30T10:47:59 |
|
pyg-team/pytorch_geometric | 5,094 | pyg-team__pytorch_geometric-5094 | [
"5080"
]
| 75787eeefc85a1325ae62b8cea3e64f18bca4d13 | diff --git a/torch_geometric/nn/dense/linear.py b/torch_geometric/nn/dense/linear.py
--- a/torch_geometric/nn/dense/linear.py
+++ b/torch_geometric/nn/dense/linear.py
@@ -137,15 +137,16 @@ def _save_to_state_dict(self, destination, prefix, keep_vars):
def _lazy_load_hook(self, state_dict, prefix, local_metadata, strict,
missing_keys, unexpected_keys, error_msgs):
- weight = state_dict[prefix + 'weight']
- if is_uninitialized_parameter(weight):
+ weight = state_dict.get(prefix + 'weight', None)
+
+ if weight is not None and is_uninitialized_parameter(weight):
self.in_channels = -1
self.weight = nn.parameter.UninitializedParameter()
if not hasattr(self, '_hook'):
self._hook = self.register_forward_pre_hook(
self.initialize_parameters)
- elif is_uninitialized_parameter(self.weight):
+ elif weight is not None and is_uninitialized_parameter(self.weight):
self.in_channels = weight.size(-1)
self.weight.materialize((self.out_channels, self.in_channels))
if hasattr(self, '_hook'):
| diff --git a/test/nn/dense/test_linear.py b/test/nn/dense/test_linear.py
--- a/test/nn/dense/test_linear.py
+++ b/test/nn/dense/test_linear.py
@@ -47,6 +47,10 @@ def test_load_lazy_linear(dim1, dim2):
assert hasattr(lin1, '_hook')
assert hasattr(lin2, '_hook')
+ with pytest.raises(RuntimeError, match="in state_dict"):
+ lin1.load_state_dict({}, strict=True)
+ lin1.load_state_dict({}, strict=False)
+
@pytest.mark.parametrize('lazy', [True, False])
def test_identical_linear_default_initialization(lazy):
| New attribute `self._load_hook` in linear class since 2.03 will raise KeyError when executing `load_state_dict` fucntion
### 🐛 Describe the bug
In Pytorch, the function `load_state_dict(state_dict, strict)` allows empty dict `state_dict=={}` when `strict` is False.
However, from version 2.03 the linear class in `torch_geometric.nn.dense.linear.py` has a new attribute `self._load_hook`, and when we execute `Linear(xxxx).load_state_dict({}, strict=False)`, the linear class will execute the `self._lazy_load_hook` function as follows
```
def _lazy_load_hook(self, state_dict, prefix, local_metadata, strict,
missing_keys, unexpected_keys, error_msgs):
weight = state_dict[prefix + 'weight']
if is_uninitialized_parameter(weight):
self.in_channels = -1
self.weight = nn.parameter.UninitializedParameter()
if not hasattr(self, '_hook'):
self._hook = self.register_forward_pre_hook(
self.initialize_parameters)
elif is_uninitialized_parameter(self.weight):
self.in_channels = weight.size(-1)
self.weight.materialize((self.out_channels, self.in_channels))
if hasattr(self, '_hook'):
self._hook.remove()
delattr(self, '_hook')
```
Since the `state_dict` is empty, the line `weight = state_dict[prefix + 'weight']` will report KeyError.
### Environment
* PyG version:
* PyTorch version:
* OS:
* Python version:
* CUDA/cuDNN version:
* How you installed PyTorch and PyG (`conda`, `pip`, source):
* Any other relevant information (*e.g.*, version of `torch-scatter`):
| 2022-07-30T16:33:14 |
|
pyg-team/pytorch_geometric | 5,098 | pyg-team__pytorch_geometric-5098 | [
"5054"
]
| 9bf3731d13cd25927524b45c748003724cc90257 | diff --git a/torch_geometric/nn/aggr/__init__.py b/torch_geometric/nn/aggr/__init__.py
--- a/torch_geometric/nn/aggr/__init__.py
+++ b/torch_geometric/nn/aggr/__init__.py
@@ -11,6 +11,7 @@
SoftmaxAggregation,
PowerMeanAggregation,
)
+from .quantile import MedianAggregation, QuantileAggregation
from .lstm import LSTMAggregation
from .set2set import Set2Set
from .scaler import DegreeScalerAggregation
@@ -31,6 +32,8 @@
'StdAggregation',
'SoftmaxAggregation',
'PowerMeanAggregation',
+ 'MedianAggregation',
+ 'QuantileAggregation',
'LSTMAggregation',
'Set2Set',
'DegreeScalerAggregation',
diff --git a/torch_geometric/nn/aggr/quantile.py b/torch_geometric/nn/aggr/quantile.py
new file mode 100644
--- /dev/null
+++ b/torch_geometric/nn/aggr/quantile.py
@@ -0,0 +1,151 @@
+from typing import List, Optional, Union
+
+import torch
+from torch import Tensor
+
+from torch_geometric.nn.aggr import Aggregation
+
+
+class QuantileAggregation(Aggregation):
+ r"""An aggregation operator that returns the feature-wise :math:`q`-th
+ quantile of a set :math:`\mathcal{X}`. That is, for every feature
+ :math:`d`, it computes
+
+ .. math::
+ {\mathrm{Q}_q(\mathcal{X})}_d = \begin{cases}
+ x_{\pi_i,d} & i = q \cdot n, \\
+ f(x_{\pi_i,d}, x_{\pi_{i+1},d}) & i < q \cdot n < i + 1,\\
+ \end{cases}
+
+ where :math:`x_{\pi_1,d} \le \dots \le x_{\pi_i,d} \le \dots \le
+ x_{\pi_n,d}` and :math:`f(a, b)` is an interpolation
+ function defined by :obj:`interpolation`.
+
+ Args:
+ q (float or list): The quantile value(s) :math:`q`. Can be a scalar or
+ a list of scalars in the range :math:`[0, 1]`. If more than a
+ quantile is passed, the results are concatenated.
+ interpolation (str): Interpolation method applied if the quantile point
+ :math:`q\cdot n` lies between two values
+ :math:`a \le b`. Can be one of the following:
+
+ * :obj:`"lower"`: Returns the one with lowest value.
+
+ * :obj:`"higher"`: Returns the one with highest value.
+
+ * :obj:`"midpoint"`: Returns the average of the two values.
+
+ * :obj:`"nearest"`: Returns the one whose index is nearest to the
+ quantile point.
+
+ * :obj:`"linear"`: Returns a linear combination of the two
+ elements, defined as
+ :math:`f(a, b) = a + (b - a)\cdot(q\cdot n - i)`.
+
+ (default: :obj:`"linear"`)
+ fill_value (float, optional): The default value in the case no entry is
+ found for a given index (default: :obj:`0.0`).
+ """
+ interpolations = {'linear', 'lower', 'higher', 'nearest', 'midpoint'}
+
+ def __init__(self, q: Union[float, List[float]],
+ interpolation: str = 'linear', fill_value: float = 0.0):
+ super().__init__()
+
+ qs = [q] if not isinstance(q, (list, tuple)) else q
+ if len(qs) == 0:
+ raise ValueError("Provide at least one quantile value for `q`.")
+ if not all(0. <= quantile <= 1. for quantile in qs):
+ raise ValueError("`q` must be in the range [0, 1].")
+ if interpolation not in self.interpolations:
+ raise ValueError(f"Invalid interpolation method "
+ f"got ('{interpolation}')")
+
+ self._q = q
+ self.register_buffer('q', torch.Tensor(qs).view(-1, 1))
+ self.interpolation = interpolation
+ self.fill_value = fill_value
+
+ def forward(self, x: Tensor, index: Optional[Tensor] = None,
+ ptr: Optional[Tensor] = None, dim_size: Optional[int] = None,
+ dim: int = -2) -> Tensor:
+
+ dim = x.dim() + dim if dim < 0 else dim
+
+ self.assert_index_present(index)
+ assert index is not None # Required for TorchScript.
+
+ count = torch.bincount(index, minlength=dim_size or 0)
+ cumsum = torch.cumsum(count, dim=0) - count
+
+ q_point = self.q * (count - 1) + cumsum
+ q_point = q_point.t().reshape(-1)
+
+ shape = [1] * x.dim()
+ shape[dim] = -1
+ index = index.view(shape).expand_as(x)
+
+ # Two sorts: the first one on the value,
+ # the second (stable) on the indices:
+ x, x_perm = torch.sort(x, dim=dim)
+ index = index.take_along_dim(x_perm, dim=dim)
+ index, index_perm = torch.sort(index, dim=dim, stable=True)
+ x = x.take_along_dim(index_perm, dim=dim)
+
+ # Compute the quantile interpolations:
+ if self.interpolation == 'lower':
+ quantile = x.index_select(dim, q_point.floor().long())
+ elif self.interpolation == 'higher':
+ quantile = x.index_select(dim, q_point.ceil().long())
+ elif self.interpolation == 'nearest':
+ quantile = x.index_select(dim, q_point.round().long())
+ else:
+ l_quant = x.index_select(dim, q_point.floor().long())
+ r_quant = x.index_select(dim, q_point.ceil().long())
+
+ if self.interpolation == 'linear':
+ q_frac = q_point.frac().view(shape)
+ quantile = l_quant + (r_quant - l_quant) * q_frac
+ else: # 'midpoint'
+ quantile = 0.5 * l_quant + 0.5 * r_quant
+
+ # If the number of elements is zero, fill with pre-defined value:
+ mask = (count == 0).repeat_interleave(self.q.numel()).view(shape)
+ out = quantile.masked_fill(mask, self.fill_value)
+
+ if self.q.numel() > 1:
+ shape = list(out.shape)
+ shape = (shape[:dim] + [shape[dim] // self.q.numel(), -1] +
+ shape[dim + 2:])
+ out = out.view(shape)
+
+ return out
+
+ def __repr__(self) -> str:
+ return (f'{self.__class__.__name__}(q={self._q})')
+
+
+class MedianAggregation(QuantileAggregation):
+ r"""An aggregation operator that returns the feature-wise median of a set.
+ That is, for every feature :math:`d`, it computes
+
+ .. math::
+ {\mathrm{median}(\mathcal{X})}_d = x_{\pi_i,d}
+
+ where :math:`x_{\pi_1,d} \le x_{\pi_2,d} \le \dots \le
+ x_{\pi_n,d}` and :math:`i = \lfloor \frac{n}{2} \rfloor`.
+
+ .. note::
+ If the median lies between two values, the lowest one is returned.
+ To compute the midpoint (or other kind of interpolation) of the two
+ values, use :class:`QuantileAggregation` instead.
+
+ Args:
+ fill_value (float, optional): The default value in the case no entry is
+ found for a given index (default: :obj:`0.0`).
+ """
+ def __init__(self, fill_value: float = 0.0):
+ super().__init__(0.5, 'lower', fill_value)
+
+ def __repr__(self) -> str:
+ return f"{self.__class__.__name__}()"
| diff --git a/test/nn/aggr/test_quantile.py b/test/nn/aggr/test_quantile.py
new file mode 100644
--- /dev/null
+++ b/test/nn/aggr/test_quantile.py
@@ -0,0 +1,103 @@
+import pytest
+import torch
+
+from torch_geometric.nn import MedianAggregation, QuantileAggregation
+
+
[email protected]('q', [0., .1, .2, .3, .4, .5, .6, .7, .8, .9, 1.])
[email protected]('interpolation', QuantileAggregation.interpolations)
[email protected]('dim', [0, 1])
+def test_quantile_aggregation(q, interpolation, dim):
+ x = torch.tensor([
+ [0.0, 1.0, 2.0],
+ [3.0, 4.0, 5.0],
+ [6.0, 7.0, 8.0],
+ [9.0, 0.0, 1.0],
+ [2.0, 3.0, 4.0],
+ [5.0, 6.0, 7.0],
+ [8.0, 9.0, 0.0],
+ [1.0, 2.0, 3.0],
+ [4.0, 5.0, 6.0],
+ [7.0, 8.0, 9.0],
+ ])
+ index = torch.zeros(x.size(dim), dtype=torch.long)
+
+ aggr = QuantileAggregation(q=q, interpolation=interpolation)
+ assert str(aggr) == f"QuantileAggregation(q={q})"
+
+ out = aggr(x, index, dim=dim)
+ expected = x.quantile(q, dim, interpolation=interpolation, keepdim=True)
+ assert torch.allclose(out, expected)
+
+
+def test_median_aggregation():
+ x = torch.tensor([
+ [0.0, 1.0, 2.0],
+ [3.0, 4.0, 5.0],
+ [6.0, 7.0, 8.0],
+ [9.0, 0.0, 1.0],
+ [2.0, 3.0, 4.0],
+ [5.0, 6.0, 7.0],
+ [8.0, 9.0, 0.0],
+ [1.0, 2.0, 3.0],
+ [4.0, 5.0, 6.0],
+ [7.0, 8.0, 9.0],
+ ])
+
+ aggr = MedianAggregation()
+ assert str(aggr) == "MedianAggregation()"
+
+ index = torch.tensor([0, 0, 0, 0, 1, 1, 1, 2, 2, 2])
+ assert aggr(x, index).tolist() == [
+ [3.0, 1.0, 2.0],
+ [5.0, 6.0, 4.0],
+ [4.0, 5.0, 6.0],
+ ]
+
+ index = torch.tensor([0, 1, 0])
+ assert aggr(x, index, dim=1).tolist() == [
+ [0.0, 1.0],
+ [3.0, 4.0],
+ [6.0, 7.0],
+ [1.0, 0.0],
+ [2.0, 3.0],
+ [5.0, 6.0],
+ [0.0, 9.0],
+ [1.0, 2.0],
+ [4.0, 5.0],
+ [7.0, 8.0],
+ ]
+
+
+def test_quantile_aggregation_multi():
+ x = torch.tensor([
+ [0.0, 1.0, 2.0],
+ [3.0, 4.0, 5.0],
+ [6.0, 7.0, 8.0],
+ [9.0, 0.0, 1.0],
+ [2.0, 3.0, 4.0],
+ [5.0, 6.0, 7.0],
+ [8.0, 9.0, 0.0],
+ [1.0, 2.0, 3.0],
+ [4.0, 5.0, 6.0],
+ [7.0, 8.0, 9.0],
+ ])
+ index = torch.tensor([0, 0, 0, 0, 1, 1, 1, 2, 2, 2])
+
+ qs = [0.25, 0.5, 0.75]
+
+ assert torch.allclose(
+ QuantileAggregation(qs)(x, index),
+ torch.cat([QuantileAggregation(q)(x, index) for q in qs], dim=-1),
+ )
+
+
+def test_quantile_aggregation_validate():
+ with pytest.raises(ValueError, match="at least one quantile"):
+ QuantileAggregation(q=[])
+
+ with pytest.raises(ValueError, match="must be in the range"):
+ QuantileAggregation(q=-1)
+
+ with pytest.raises(ValueError, match="Invalid interpolation method"):
+ QuantileAggregation(q=0.5, interpolation=None)
| Median Aggregation Support
### 🚀 The feature, motivation and pitch
I'm working on a noise graph, some papers show that the interference of noise can be largely reduced using median aggregation.
Papers:
Robustness of Graph Neural Networks at Scale [NIPS'21]
Understanding Structural Vulnerability in Graph Convolutional Networks [IJCAI'21]
### Alternatives
Using torch.argsort like https://github.com/EdisonLeeeee/MedianGCN in the large-scale graph is time costing.
The CUDA-accelerated version of median aggregation is implemented here,https://github.com/sigeisler/robustness_of_gnns_at_scale. However, it requires a specific software version and seems to have some inexplicable errors, which makes debugging difficult for many people who do not know CUDA programming.
If Pyg could support this kind of aggregation, it would be a great joy for the community! Thanks in advance.
### Additional context
_No response_
| Yeah, I always thought this is super challenging to implement in an efficient way. Thanks for the pointers! We can try to look into it but it currently has lower priority.
Maybe I'm wrong, but I don't think we can break the $\log(n)$ depth complexity of parallel (arg)sort (that is basically the time complexity in a parallel setting). The (sequential) time complexity of the [selection algorithm](https://en.wikipedia.org/wiki/Selection_algorithm) for computing the median is $O(n)$, and even doing an approximation using median of medians we would obtain a log-depth complexity. So, I think we could use sorting with no hesitation (btw, I don't think the slow part in the [official `MedianGCN` implementation](https://github.com/EdisonLeeeee/MedianGCN) is really the argsort, but rather the fact that they compute a masking and a median [for every different node degree](https://github.com/EdisonLeeeee/MedianGCN/blob/b1f3db62bf378935624f3f23cc31e3ce83f8908d/median_pyg.py#L94), which could become very time expensive).
I tried implementing the `MedianAggregation` using indeed stable sorting, which is available in the newest versions of PyTorch (I used a similar trick in an [implementation](https://gist.github.com/flandolfi/6df01e8b04b4093c2dddf2fd3629ff1d) of the top-$k$ aggregation). Here is the code:
```python
from typing import Optional
import torch
from torch import Tensor
from torch_geometric.nn.aggr.base import Aggregation
class MedianAggregation(Aggregation):
def forward(self, x: Tensor, index: Optional[Tensor] = None,
ptr: Optional[Tensor] = None, dim_size: Optional[int] = None,
dim: int = -2) -> Tensor:
self.assert_index_present(index) # we could also expand `ptr` to an index
if dim_size is None:
dim_size = index.max() + 1
# compute the two median indices (they coincide if the number of elements is odd)
count = torch.bincount(index, minlength=dim_size)
cumsum = torch.cumsum(count, dim=0)
l_idx = cumsum - count.div(2, rounding_mode='trunc') - 1
r_idx = cumsum - (count + 1).div(2, rounding_mode='trunc')
# shape used for expansions
# (1, ..., 1, -1, 1, ..., 1)
shape = [1] * x.dim()
shape[dim] = -1
# two sorts: the first one on the value, the second (stable) on the indices
x, x_perm = torch.sort(x, dim=dim)
index = index.view(*shape).expand_as(x)
index = index.take_along_dim(x_perm, dim=dim)
index, index_perm = torch.sort(index, dim=dim, stable=True)
x = x.take_along_dim(index_perm, dim=dim)
# median as an average of the two central elements
l_med = x.index_select(dim, l_idx)
r_med = x.index_select(dim, r_idx)
# if the number of elements is 0, return 'nan'
out_mask = (count > 0).view(*shape)
return torch.where(out_mask, 0.5*l_med + 0.5*r_med, float('nan'))
```
I did not made a proper testing, only some examples on the terminal:
```python
In [10]: x = torch.randint(10, size=(10, 5))
...: idx, _ = torch.randint(4, size=(10,)).sort()
...: aggr = MedianAggregation()
...: x, idx, aggr(x, idx, dim=0)
Out[10]:
(tensor([[4, 6, 6, 3, 5],
[3, 8, 1, 8, 3],
[0, 4, 1, 6, 8],
[0, 1, 9, 2, 1],
[7, 3, 4, 9, 5],
[4, 2, 1, 0, 9],
[3, 6, 4, 3, 4],
[7, 3, 7, 2, 9],
[4, 9, 8, 7, 4],
[5, 9, 3, 4, 4]]),
tensor([0, 0, 0, 1, 1, 2, 2, 2, 3, 3]),
tensor([[3.0000, 6.0000, 1.0000, 6.0000, 5.0000],
[3.5000, 2.0000, 6.5000, 5.5000, 3.0000],
[4.0000, 3.0000, 4.0000, 2.0000, 9.0000],
[4.5000, 9.0000, 5.5000, 5.5000, 4.0000]]))
```
I think this is pretty cool! I haven't verified the correctness yet, but happy to do that if you are interested in contributing this implementation. Let me know!
Sure, I'll willingly self-assign. But I have a question: should I make a PR in PyG or in torch-scatter (as a "composite", maybe)? In the second case I'll have to wait to be public in pip/conda before putting an aggregation in PyG. Let me know!
Let's go with the first option and integrate it directly into PyG :)
Perfect, I'll do a PR as soon as possible! | 2022-07-30T22:27:32 |
pyg-team/pytorch_geometric | 5,187 | pyg-team__pytorch_geometric-5187 | [
"5163"
]
| 797e3d98faf2c341423cf354773945ac5347d341 | diff --git a/torch_geometric/nn/conv/rgat_conv.py b/torch_geometric/nn/conv/rgat_conv.py
--- a/torch_geometric/nn/conv/rgat_conv.py
+++ b/torch_geometric/nn/conv/rgat_conv.py
@@ -441,7 +441,7 @@ def message(self, x_i: Tensor, x_j: Tensor, edge_type: Tensor,
elif self.mod == "scaled":
if self.attention_mode == "additive-self-attention":
- ones = torch.ones(index.size())
+ ones = alpha.new_ones(index.size())
degree = scatter_add(ones, index,
dim_size=size_i)[index].unsqueeze(-1)
degree = torch.matmul(degree, self.l1) + self.b1
@@ -453,7 +453,7 @@ def message(self, x_i: Tensor, x_j: Tensor, edge_type: Tensor,
alpha.view(-1, self.heads, 1),
degree.view(-1, 1, self.out_channels))
elif self.attention_mode == "multiplicative-self-attention":
- ones = torch.ones(index.size())
+ ones = alpha.new_ones(index.size())
degree = scatter_add(ones, index,
dim_size=size_i)[index].unsqueeze(-1)
degree = torch.matmul(degree, self.l1) + self.b1
@@ -469,7 +469,7 @@ def message(self, x_i: Tensor, x_j: Tensor, edge_type: Tensor,
alpha = torch.where(alpha > 0, alpha + 1, alpha)
elif self.mod == "f-scaled":
- ones = torch.ones(index.size())
+ ones = alpha.new_ones(index.size())
degree = scatter_add(ones, index,
dim_size=size_i)[index].unsqueeze(-1)
alpha = alpha * degree
| If RGATConv uses f-scaled mod, there will be bugs of different tensors on different devices
### 🐛 Describe the bug
When using RGATConv, set mod = 'f-scaled', tensor in different devices error will appear .
`RGATConv(in_channels, out_channels, 14, num_bases=8,mod='f-scaled',concat =False,heads=8)`
`RGATConv(in_channels, out_channels, 14, num_bases=8,concat =False,heads=8,)`,
error:
> File "/home/mist/tianchi/RevRgcn.py", line 365, in forward
return self.conv(x, edge_index,edge_type)
File "/mistgpu/site-packages/torch/nn/modules/module.py", line 1130, in _call_impl
return forward_call(*input, **kwargs)
File "/mistgpu/site-packages/torch_geometric/nn/conv/rgat_conv.py", line 341, in forward
out = self.propagate(edge_index=edge_index, edge_type=edge_type, x=x,
File "/mistgpu/site-packages/torch_geometric/nn/conv/message_passing.py", line 374, in propagate
out = self.message(**msg_kwargs)
File "/mistgpu/site-packages/torch_geometric/nn/conv/rgat_conv.py", line 473, in message
degree = scatter_add(ones, index,
File "/mistgpu/site-packages/torch_scatter/scatter.py", line 29, in scatter_add
return scatter_sum(src, index, dim, out, dim_size)
File "/mistgpu/site-packages/torch_scatter/scatter.py", line 21, in scatter_sum
return out.scatter_add_(dim, index, src)
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cpu and cuda:0! (when checking argument for argument index in method wrapper_scatter_add_)
### Environment
* PyG version:`2.0.4`
* PyTorch version:`1.12.1`
* OS:`ubuntu 18.04.6 LTS`
* Python version:`3.9.12`
* CUDA/cuDNN version:`cu116`
* How you installed PyTorch and PyG (`conda`, `pip`, source): `pip install torch-scatter torch-sparse torch-cluster torch-spline-conv torch-geometric -f https://data.pyg.org/whl/torch-1.12.0+cu116.html`
* Any other relevant information (*e.g.*, version of `torch-scatter`):
| Thanks for reporting. Will take a look! | 2022-08-10T16:28:55 |
|
pyg-team/pytorch_geometric | 5,399 | pyg-team__pytorch_geometric-5399 | [
"5421"
]
| fe87db0d89fffad7223e70c9a7c649644c10009e | diff --git a/benchmark/inference/inference_benchmark.py b/benchmark/inference/inference_benchmark.py
--- a/benchmark/inference/inference_benchmark.py
+++ b/benchmark/inference/inference_benchmark.py
@@ -3,7 +3,6 @@
import torch
from utils import get_dataset, get_model
-from torch_geometric import set_experimental_mode
from torch_geometric.loader import NeighborLoader
from torch_geometric.nn import PNAConv
from torch_geometric.profile import rename_profile_file, timeit, torch_profile
@@ -99,13 +98,12 @@ def run(args: argparse.ArgumentParser) -> None:
model.eval()
with amp:
- with set_experimental_mode(args.experimental_mode):
- for _ in range(args.warmup):
- model.inference(subgraph_loader, device,
- progress_bar=True)
- with timeit():
- model.inference(subgraph_loader, device,
- progress_bar=True)
+ for _ in range(args.warmup):
+ model.inference(subgraph_loader, device,
+ progress_bar=True)
+ with timeit():
+ model.inference(subgraph_loader, device,
+ progress_bar=True)
if args.profile:
with torch_profile():
@@ -143,8 +141,6 @@ def run(args: argparse.ArgumentParser) -> None:
'--hetero-num-neighbors', default=10, type=int,
help='number of neighbors to sample per layer for hetero workloads')
argparser.add_argument('--num-workers', default=0, type=int)
- argparser.add_argument('--experimental-mode', action='store_true',
- help='use experimental mode')
argparser.add_argument('--warmup', default=1, type=int)
argparser.add_argument('--profile', action='store_true')
argparser.add_argument('--bf16', action='store_true')
diff --git a/torch_geometric/experimental.py b/torch_geometric/experimental.py
--- a/torch_geometric/experimental.py
+++ b/torch_geometric/experimental.py
@@ -1,6 +1,6 @@
from typing import List, Optional, Union
-__experimental_flag__ = {'scatter_reduce': False}
+__experimental_flag__ = {}
Options = Optional[Union[str, List[str]]]
@@ -36,11 +36,8 @@ class experimental_mode:
... out = model(data.x, data.edge_index)
Args:
- options (str or list, optional): Possible option(s):
-
- - :obj:`"torch_scatter"`: Enables the usage of
- :meth:`torch.scatter_reduce` instead of
- :meth:`torch_scatter.scatter`. Requires :obj:`torch>=1.12`.
+ options (str or list, optional): Currently there are no experimental
+ features.
"""
def __init__(self, options: Options = None):
self.options = get_options(options)
diff --git a/torch_geometric/utils/scatter.py b/torch_geometric/utils/scatter.py
--- a/torch_geometric/utils/scatter.py
+++ b/torch_geometric/utils/scatter.py
@@ -1,66 +1,94 @@
-import warnings
from typing import Optional
import torch
-import torch_scatter
from torch import Tensor
-import torch_geometric
-
major, minor, _ = torch.__version__.split('.', maxsplit=2)
major, minor = int(major), int(minor)
has_pytorch112 = major > 1 or (major == 1 and minor >= 12)
+if has_pytorch112: # pragma: no cover
-class ScatterImpl(torch.nn.Module):
- def forward(self, src: Tensor, index: Tensor, dim: int = -1,
+ class ScatterHelpers:
+ @staticmethod
+ def broadcast(src: Tensor, other: Tensor, dim: int) -> Tensor:
+ dim = other.dim() + dim if dim < 0 else dim
+ if src.dim() == 1:
+ for _ in range(0, dim):
+ src = src.unsqueeze(0)
+ for _ in range(src.dim(), other.dim()):
+ src = src.unsqueeze(-1)
+ src = src.expand(other.size())
+ return src
+
+ @staticmethod
+ def generate_out(src: Tensor, index: Tensor, dim: int,
+ dim_size: Optional[int]) -> Tensor:
+ size = list(src.size())
+ if dim_size is not None:
+ size[dim] = dim_size
+ elif index.numel() > 0:
+ size[dim] = int(index.max()) + 1
+ else:
+ size[dim] = 0
+ return src.new_zeros(size)
+
+ @staticmethod
+ def scatter_mean(src: Tensor, index: Tensor, dim: int, out: Tensor,
+ dim_size: Optional[int]) -> Tensor:
+ out.scatter_add_(dim, index, src)
+
+ index_dim = dim
+ if index_dim < 0:
+ # `index_dim` counts axes from the begining (0)
+ index_dim = index_dim + src.dim()
+ if index.dim() <= index_dim:
+ # in case `index` was broadcasted, `count` scatter should be
+ # performed over the last axis
+ index_dim = index.dim() - 1
+
+ ones = torch.ones(index.size(), dtype=src.dtype, device=src.device)
+ count = ScatterHelpers.generate_out(ones, index, index_dim,
+ dim_size)
+ count.scatter_add_(index_dim, index, ones)
+ count[count < 1] = 1
+ count = ScatterHelpers.broadcast(count, out, dim)
+ if out.is_floating_point():
+ out.true_divide_(count)
+ else:
+ out.div_(count, rounding_mode='floor')
+ return out
+
+ def scatter(src: Tensor, index: Tensor, dim: int = -1,
+ out: Optional[Tensor] = None, dim_size: Optional[int] = None,
+ reduce: str = 'sum') -> Tensor:
+ reduce = 'sum' if reduce == 'add' else reduce
+ reduce = 'prod' if reduce == 'mul' else reduce
+ reduce = 'amin' if reduce == 'min' else reduce
+ reduce = 'amax' if reduce == 'max' else reduce
+
+ index = ScatterHelpers.broadcast(index, src, dim)
+ include_self = out is not None
+
+ if out is None: # Generate `out` if not given:
+ out = ScatterHelpers.generate_out(src, index, dim, dim_size)
+
+ # explicit usage of `torch.scatter_add_` and switching to
+ # `torch_scatter` implementation of mean algorithm comes with
+ # significant performance boost.
+ # TODO: use only `torch.scatter_reduce_` after performance issue will
+ # be fixed on the PyTorch side.
+ if reduce == 'mean':
+ return ScatterHelpers.scatter_mean(src, index, dim, out, dim_size)
+ elif reduce == 'sum':
+ return out.scatter_add_(dim, index, src)
+ return out.scatter_reduce_(dim, index, src, reduce,
+ include_self=include_self)
+
+else:
+ import torch_scatter
+
+ def scatter(src: Tensor, index: Tensor, dim: int = -1,
out: Optional[Tensor] = None, dim_size: Optional[int] = None,
reduce: str = 'sum') -> Tensor:
- if torch_geometric.is_experimental_mode_enabled('scatter_reduce'):
- if not has_pytorch112:
- warnings.warn("Cannot use 'scatter_reduce' experimental mode "
- "on PyTorch < 1.12")
- return torch_scatter.scatter(src, index, dim, out, dim_size,
- reduce)
-
- warnings.filterwarnings('ignore', '.*scatter_reduce.*')
-
- reduce = 'sum' if reduce == 'add' else reduce
- reduce = 'prod' if reduce == 'mul' else reduce
- reduce = 'amin' if reduce == 'min' else reduce
- reduce = 'amax' if reduce == 'max' else reduce
-
- # Broadcast `index`:
- dim = src.dim() + dim if dim < 0 else dim
- if index.dim() == 1:
- for _ in range(0, dim):
- index = index.unsqueeze(0)
- for _ in range(index.dim(), src.dim()):
- index = index.unsqueeze(-1)
- index = index.expand(src.size())
-
- include_self = out is not None
-
- if out is None: # Generate `out` if not given:
- size = list(src.size())
- if dim_size is not None:
- size[dim] = dim_size
- elif index.numel() > 0:
- size[dim] = int(index.max()) + 1
- else:
- size[dim] = 0
- out = src.new_zeros(size)
-
- return out.scatter_reduce_(dim, index, src, reduce,
- include_self=include_self)
-
return torch_scatter.scatter(src, index, dim, out, dim_size, reduce)
-
-
-_scatter_impl = ScatterImpl()
-
-
-def scatter(src: Tensor, index: Tensor, dim: int = -1,
- out: Optional[Tensor] = None, dim_size: Optional[int] = None,
- reduce: str = 'sum') -> Tensor:
- return _scatter_impl(src, index, dim, out, dim_size, reduce)
| diff --git a/test/nn/pool/test_asap.py b/test/nn/pool/test_asap.py
--- a/test/nn/pool/test_asap.py
+++ b/test/nn/pool/test_asap.py
@@ -1,7 +1,10 @@
+import io
+
+import pytest
import torch
from torch_geometric.nn import ASAPooling, GCNConv, GraphConv
-from torch_geometric.testing import is_full_test
+from torch_geometric.testing import is_full_test, onlyFullTest
def test_asap():
@@ -33,3 +36,14 @@ def test_asap():
out = pool(x, edge_index)
assert out[0].size() == (2, in_channels)
assert out[1].size() == (2, 2)
+
+
+@onlyFullTest
+def test_asap_jit_save():
+ pool = ASAPooling(in_channels=16)
+ pool_jit = pool.jittable()
+ model = torch.jit.script(pool_jit)
+ try:
+ torch.jit.save(model, io.BytesIO())
+ except RuntimeError:
+ pytest.fail('ASAP model serialization failed.')
diff --git a/test/test_experimental.py b/test/test_experimental.py
--- a/test/test_experimental.py
+++ b/test/test_experimental.py
@@ -7,7 +7,8 @@
)
[email protected]('options', [None, 'scatter_reduce'])
[email protected](reason='No experimental options available right now.')
[email protected]('options', [None])
def test_experimental_mode(options):
assert is_experimental_mode_enabled(options) is False
with experimental_mode(options):
diff --git a/test/utils/test_scatter.py b/test/utils/test_scatter.py
--- a/test/utils/test_scatter.py
+++ b/test/utils/test_scatter.py
@@ -2,7 +2,6 @@
import torch
import torch_scatter
-import torch_geometric
from torch_geometric.testing import withPackage
from torch_geometric.utils import scatter
@@ -14,8 +13,7 @@ def test_scatter(reduce):
src = torch.randn(8, 100, 32)
index = torch.randint(0, 10, (100, ), dtype=torch.long)
- with torch_geometric.experimental_mode('scatter_reduce'):
- out1 = scatter(src, index, dim=1, reduce=reduce)
+ out1 = scatter(src, index, dim=1, reduce=reduce)
out2 = torch_scatter.scatter(src, index, dim=1, reduce=reduce)
assert torch.allclose(out1, out2, atol=1e-6)
@@ -27,8 +25,7 @@ def test_pytorch_scatter_backward(reduce):
src = torch.randn(8, 100, 32).requires_grad_(True)
index = torch.randint(0, 10, (100, ), dtype=torch.long)
- with torch_geometric.experimental_mode('scatter_reduce'):
- out = scatter(src, index, dim=1, reduce=reduce).relu()
+ out = scatter(src, index, dim=1, reduce=reduce).relu()
assert src.grad is None
out.mean().backward()
@@ -36,15 +33,14 @@ def test_pytorch_scatter_backward(reduce):
@withPackage('torch>=1.12.0')
[email protected]('reduce', ['sum', 'add', 'mean', 'min', 'max'])
[email protected]('reduce', ['min', 'max'])
def test_pytorch_scatter_inplace_backward(reduce):
torch.manual_seed(12345)
src = torch.randn(8, 100, 32).requires_grad_(True)
index = torch.randint(0, 10, (100, ), dtype=torch.long)
- with torch_geometric.experimental_mode('scatter_reduce'):
- out = scatter(src, index, dim=1, reduce=reduce).relu_()
+ out = scatter(src, index, dim=1, reduce=reduce).relu_()
with pytest.raises(RuntimeError, match="modified by an inplace operation"):
out.mean().backward()
@@ -58,8 +54,7 @@ def test_scatter_with_out(reduce):
index = torch.randint(0, 10, (100, ), dtype=torch.long)
out = torch.randn(8, 10, 32)
- with torch_geometric.experimental_mode('scatter_reduce'):
- out1 = scatter(src, index, dim=1, out=out.clone(), reduce=reduce)
+ out1 = scatter(src, index, dim=1, out=out.clone(), reduce=reduce)
out2 = torch_scatter.scatter(src, index, dim=1, out=out.clone(),
reduce=reduce)
assert torch.allclose(out1, out2, atol=1e-6)
| ASAPooling: jit.save function model export failed
### 🐛 Describe the bug
ASAPooling: jit.save function model export failed. I need your help, thank you very much!
```python
class ASAP(torch.nn.Module):
def __init__(self):
super().__init__()
self.asapooling = ASAPooling(128, ratio=0.25, dropout=0.0).jittable()
def forward(self, x, edge_index):
edge_weight = None
batch = torch.zeros((x.shape[0])).cuda().long()
x, edge_index, edge_weight, batch, _ = self.asapooling(
x=x, edge_index=edge_index, edge_weight=edge_weight,
batch=batch)
return x
model = ASAP()
mm = torch.jit.script(model)
torch.jit.save(mm,"asapooling.pt")
```
#error
Traceback (most recent call last):
File "D:\pycharm\PyCharm Community Edition 2020.3.5\plugins\python-ce\helpers\pydev\pydevd.py", line 1477, in _exec
pydev_imports.execfile(file, globals, locals) # execute the script
File "D:\pycharm\PyCharm Community Edition 2020.3.5\plugins\python-ce\helpers\pydev\_pydev_imps\_pydev_execfile.py", line 18, in execfile
exec(compile(contents+"\n", file, 'exec'), glob, loc)
File "E:/python_program/mesh_gcn/teeth_classfication/net/jit_model.py", line 210, in <module>
torch.jit.save(mm,"asapooling.pt")
File "D:\Anaconda3\envs\teeth_deploy\lib\site-packages\torch\jit\_serialization.py", line 81, in save
m.save(f, _extra_files=_extra_files)
File "D:\Anaconda3\envs\teeth_deploy\lib\site-packages\torch\jit\_script.py", line 693, in save
return self._c.save(str(f), **kwargs)
RuntimeError:
Could not export Python function call '<python_value>'. Remove calls to Python functions before export. Did you forget to add @script or @script_method annotation? If this is a nn.ModuleList, add it to __constants__:
File "E:\python_program\mesh_gcn\teeth_classfication\torch_geometric\utils\scatter.py", line 66
out: Optional[Tensor] = None, dim_size: Optional[int] = None,
reduce: str = 'sum') -> Tensor:
return _scatter_impl(src, index, dim, out, dim_size, reduce)
~~~~~~~~~~~~~ <--- HERE
Process finished with exit code -1
### Environment
PyG version:2.04
PyTorch version:1.11.0
OS: windows
Python version:3.7.0
CUDA/cuDNN version: cuda=11.3.1 cudnn not have
How you installed PyTorch and PyG (conda, pip, source): conda
Any other relevant information (e.g., version of torch-scatter):
pytorch-scatter==2.0.9
pytorch-sparse==0.6.13
pytorch-cluster==1.6.0
| 2022-09-09T13:47:07 |
|
pyg-team/pytorch_geometric | 5,441 | pyg-team__pytorch_geometric-5441 | [
"5411"
]
| 83d0f326ac2681bdf7fd552d412b0870b84e1b9f | diff --git a/torch_geometric/io/tu.py b/torch_geometric/io/tu.py
--- a/torch_geometric/io/tu.py
+++ b/torch_geometric/io/tu.py
@@ -27,6 +27,8 @@ def read_tu_data(folder, prefix):
node_attributes = torch.empty((batch.size(0), 0))
if 'node_attributes' in names:
node_attributes = read_file(folder, prefix, 'node_attributes')
+ if node_attributes.dim() == 1:
+ node_attributes = node_attributes.unsqueeze(-1)
node_labels = torch.empty((batch.size(0), 0))
if 'node_labels' in names:
@@ -41,6 +43,8 @@ def read_tu_data(folder, prefix):
edge_attributes = torch.empty((edge_index.size(1), 0))
if 'edge_attributes' in names:
edge_attributes = read_file(folder, prefix, 'edge_attributes')
+ if edge_attributes.dim() == 1:
+ edge_attributes = edge_attributes.unsqueeze(-1)
edge_labels = torch.empty((edge_index.size(1), 0))
if 'edge_labels' in names:
| The the feature dim of data.x is zero in Proteins dataset with the pyg version after 2.0.5
### 🐛 Describe the bug
The main reason is in line 136 of tu_dataset.py
it is strange that the value of num_edge_attributes is larger than the feature dimension of self.data.x in proteins, which leads to the resulting dimension of self.data.x is num_nodes*0
### Environment
* PyG version:
* PyTorch version:
* OS:
* Python version:
* CUDA/cuDNN version:
* How you installed PyTorch and PyG (`conda`, `pip`, source):
* Any other relevant information (*e.g.*, version of `torch-scatter`):
| Second this, I just noticed the 3 atom types in `PROTEINS` are only added when setting `use_node_attr=True` in the constructor (but then we get an additional feature which was not there before). However this is not consistent with the behavior of other datasets like `NCI1`, where atom type is always present. This change of behavior can seriously impact the reproducibility of libraries using this dataset. Please fix it asap. | 2022-09-14T10:43:53 |
|
pyg-team/pytorch_geometric | 5,476 | pyg-team__pytorch_geometric-5476 | [
"5475"
]
| 6c41aec9cbd4725c45502e2c402e6313739c218b | diff --git a/torch_geometric/utils/to_dense_adj.py b/torch_geometric/utils/to_dense_adj.py
--- a/torch_geometric/utils/to_dense_adj.py
+++ b/torch_geometric/utils/to_dense_adj.py
@@ -47,9 +47,10 @@ def to_dense_adj(edge_index, batch=None, edge_attr=None, max_num_nodes=None):
[5., 0.]]])
"""
if batch is None:
- batch = edge_index.new_zeros(edge_index.max().item() + 1)
+ num_nodes = int(edge_index.max()) + 1 if edge_index.numel() > 0 else 0
+ batch = edge_index.new_zeros(num_nodes)
- batch_size = batch.max().item() + 1
+ batch_size = int(batch.max()) + 1 if batch.numel() > 0 else 1
one = batch.new_ones(batch.size(0))
num_nodes = scatter(one, batch, dim=0, dim_size=batch_size, reduce='add')
cum_nodes = torch.cat([batch.new_zeros(1), num_nodes.cumsum(dim=0)])
@@ -61,7 +62,8 @@ def to_dense_adj(edge_index, batch=None, edge_attr=None, max_num_nodes=None):
if max_num_nodes is None:
max_num_nodes = num_nodes.max().item()
- elif idx1.max() >= max_num_nodes or idx2.max() >= max_num_nodes:
+ elif ((idx1.numel() > 0 and idx1.max() >= max_num_nodes)
+ or (idx2.numel() > 0 and idx2.max() >= max_num_nodes)):
mask = (idx1 < max_num_nodes) & (idx2 < max_num_nodes)
idx0 = idx0[mask]
idx1 = idx1[mask]
| diff --git a/test/utils/test_to_dense_adj.py b/test/utils/test_to_dense_adj.py
--- a/test/utils/test_to_dense_adj.py
+++ b/test/utils/test_to_dense_adj.py
@@ -48,6 +48,23 @@ def test_to_dense_adj():
assert adj[0].nonzero(as_tuple=False).t().tolist() == edge_index.tolist()
+def test_to_dense_adj_with_empty_edge_index():
+ edge_index = torch.tensor([[], []], dtype=torch.long)
+ batch = torch.tensor([0, 0, 1, 1, 1])
+
+ adj = to_dense_adj(edge_index)
+ assert adj.size() == (1, 0, 0)
+
+ adj = to_dense_adj(edge_index, max_num_nodes=10)
+ assert adj.size() == (1, 10, 10) and adj.sum() == 0
+
+ adj = to_dense_adj(edge_index, batch)
+ assert adj.size() == (2, 3, 3) and adj.sum() == 0
+
+ adj = to_dense_adj(edge_index, batch, max_num_nodes=10)
+ assert adj.size() == (2, 10, 10) and adj.sum() == 0
+
+
def test_to_dense_adj_with_duplicate_entries():
edge_index = torch.tensor([
[0, 0, 0, 1, 2, 3, 3, 4],
| The ERROR of to_dense_adj: ''RuntimeError: max(): Expected reduction dim to be specified for input.numel() == 0. Specify the reduction dim with the 'dim' argument.''
### 🐛 Describe the bug
my code is
```
dataset = MoleculeDataset("dataset/" + args.dataset, dataset=args.dataset)
smiles_list = pd.read_csv('dataset/' + args.dataset + '/processed/smiles.csv', header=None)[0].tolist()
train_dataset, valid_dataset, test_dataset = scaffold_split(dataset, smiles_list, null_value=0, frac_train=0.8,frac_valid=0.1, frac_test=0.1)
class_graphs, y_idxs = split_class_graphs(train_dataset)
```
the ```MoleculeDataset`` code
```
class MoleculeDataset(InMemoryDataset):
def __init__(self,
root,
#data = None,
#slices = None,
transform=None,
pre_transform=None,
pre_filter=None,
dataset='zinc250k',
empty=False):
"""
Adapted from qm9.py. Disabled the download functionality
:param root: directory of the dataset, containing a raw and processed
dir. The raw dir should contain the file containing the smiles, and the
processed dir can either empty or a previously processed file
:param dataset: name of the dataset. Currently only implemented for
zinc250k, chembl_with_labels, tox21, hiv, bace, bbbp, clintox, esol,
freesolv, lipophilicity, muv, pcba, sider, toxcast
:param empty: if True, then will not load any data obj. For
initializing empty dataset
"""
self.dataset = dataset
self.root = root
super(MoleculeDataset, self).__init__(root, transform, pre_transform,
pre_filter)
self.transform, self.pre_transform, self.pre_filter = transform, pre_transform, pre_filter
if not empty:
self.data, self.slices = torch.load(self.processed_paths[0])
def get(self, idx):
data = Data()
for key in self.data.keys:
item, slices = self.data[key], self.slices[key]
s = list(repeat(slice(None), item.dim()))
s[data.__cat_dim__(key, item)] = slice(slices[idx],
slices[idx + 1])
data[key] = item[s]
return data
@property
def raw_file_names(self):
file_name_list = os.listdir(self.raw_dir)
# assert len(file_name_list) == 1 # currently assume we have a
# # single raw file
return file_name_list
@property
def processed_file_names(self):
return 'geometric_data_processed.pt'
def download(self):
raise NotImplementedError('Must indicate valid location of raw data. '
'No download allowed')
def process(self):
data_smiles_list = []
data_list = []
if self.dataset == 'zinc_standard_agent':
input_path = self.raw_paths[0]
input_df = pd.read_csv(input_path, sep=',', compression='gzip',
dtype='str')
smiles_list = list(input_df['smiles'])
zinc_id_list = list(input_df['zinc_id'])
for i in range(len(smiles_list)):
s = smiles_list[i]
# each example contains a single species
try:
rdkit_mol = AllChem.MolFromSmiles(s)
if rdkit_mol != None: # ignore invalid mol objects
# # convert aromatic bonds to double bonds
# Chem.SanitizeMol(rdkit_mol,
# sanitizeOps=Chem.SanitizeFlags.SANITIZE_KEKULIZE)
data = mol_to_graph_data_obj_simple(rdkit_mol)
# manually add mol id
id = int(zinc_id_list[i].split('ZINC')[1].lstrip('0'))
data.id = torch.tensor(
[id]) # id here is zinc id value, stripped of
# leading zeros
data_list.append(data)
data_smiles_list.append(smiles_list[i])
except:
continue
elif self.dataset == "zinc_sample":
input_path = self.raw_paths[0]
with open(input_path, "r") as f:
data = f.readlines()
all_data = [x.strip() for x in data]
data_smiles_list = []
data_list = []
for i, item in enumerate(all_data):
s = item
try:
rdkit_mol = AllChem.MolFromSmiles(s)
if rdkit_mol != None:
data = mol_to_graph_data_obj_simple(rdkit_mol)
# manually add mol id
id = i
data.id = torch.tensor([id]) # id here is zinc id value, stripped of
# leading zeros
data_list.append(data)
data_smiles_list.append(s)
except:
continue
elif self.dataset == 'chembl_filtered':
### get downstream test molecules.
from splitters import scaffold_split
###
downstream_dir = [
'dataset/bace',
'dataset/bbbp',
'dataset/clintox',
'dataset/esol',
'dataset/freesolv',
'dataset/hiv',
'dataset/lipophilicity',
'dataset/muv',
# 'dataset/pcba/processed/smiles.csv',
'dataset/sider',
'dataset/tox21',
'dataset/toxcast'
]
downstream_inchi_set = set()
for d_path in downstream_dir:
print(d_path)
dataset_name = d_path.split('/')[1]
downstream_dataset = MoleculeDataset(d_path, dataset=dataset_name)
downstream_smiles = pd.read_csv(os.path.join(d_path,
'processed', 'smiles.csv'),
header=None)[0].tolist()
assert len(downstream_dataset) == len(downstream_smiles)
_, _, _, (train_smiles, valid_smiles, test_smiles) = scaffold_split(downstream_dataset, downstream_smiles, task_idx=None, null_value=0,
frac_train=0.8,frac_valid=0.1, frac_test=0.1,
return_smiles=True)
### remove both test and validation molecules
remove_smiles = test_smiles + valid_smiles
downstream_inchis = []
for smiles in remove_smiles:
species_list = smiles.split('.')
for s in species_list: # record inchi for all species, not just
# largest (by default in create_standardized_mol_id if input has
# multiple species)
inchi = create_standardized_mol_id(s)
downstream_inchis.append(inchi)
downstream_inchi_set.update(downstream_inchis)
smiles_list, rdkit_mol_objs, folds, labels = \
_load_chembl_with_labels_dataset(os.path.join(self.root, 'raw'))
print('processing')
for i in range(len(rdkit_mol_objs)):
rdkit_mol = rdkit_mol_objs[i]
if rdkit_mol != None:
# # convert aromatic bonds to double bonds
# Chem.SanitizeMol(rdkit_mol,
# sanitizeOps=Chem.SanitizeFlags.SANITIZE_KEKULIZE)
mw = Descriptors.MolWt(rdkit_mol)
if 50 <= mw <= 900:
inchi = create_standardized_mol_id(smiles_list[i])
if inchi != None and inchi not in downstream_inchi_set:
data = mol_to_graph_data_obj_simple(rdkit_mol)
# manually add mol id
data.id = torch.tensor(
[i]) # id here is the index of the mol in
# the dataset
data.y = torch.tensor(labels[i, :])
# fold information
if i in folds[0]:
data.fold = torch.tensor([0])
elif i in folds[1]:
data.fold = torch.tensor([1])
else:
data.fold = torch.tensor([2])
data_list.append(data)
data_smiles_list.append(smiles_list[i])
elif self.dataset == 'tox21':
smiles_list, rdkit_mol_objs, labels = \
_load_tox21_dataset(self.raw_paths[0])
for i in range(len(smiles_list)):
rdkit_mol = rdkit_mol_objs[i]
## convert aromatic bonds to double bonds
#Chem.SanitizeMol(rdkit_mol,
#sanitizeOps=Chem.SanitizeFlags.SANITIZE_KEKULIZE)
data = mol_to_graph_data_obj_simple(rdkit_mol)
# manually add mol id
data.id = torch.tensor(
[i]) # id here is the index of the mol in
# the dataset
data.y = torch.tensor(labels[i, :])
data_list.append(data)
data_smiles_list.append(smiles_list[i])
elif self.dataset == 'hiv':
smiles_list, rdkit_mol_objs, labels = \
_load_hiv_dataset(self.raw_paths[0])
for i in range(len(smiles_list)):
rdkit_mol = rdkit_mol_objs[i]
# # convert aromatic bonds to double bonds
# Chem.SanitizeMol(rdkit_mol,
# sanitizeOps=Chem.SanitizeFlags.SANITIZE_KEKULIZE)
data = mol_to_graph_data_obj_simple(rdkit_mol)
# manually add mol id
data.id = torch.tensor(
[i]) # id here is the index of the mol in
# the dataset
data.y = torch.tensor([labels[i]])
data_list.append(data)
data_smiles_list.append(smiles_list[i])
elif self.dataset == 'bace':
smiles_list, rdkit_mol_objs, folds, labels = \
_load_bace_dataset(self.raw_paths[0])
for i in range(len(smiles_list)):
rdkit_mol = rdkit_mol_objs[i]
# # convert aromatic bonds to double bonds
# Chem.SanitizeMol(rdkit_mol,
# sanitizeOps=Chem.SanitizeFlags.SANITIZE_KEKULIZE)
data = mol_to_graph_data_obj_simple(rdkit_mol)
# manually add mol id
data.id = torch.tensor(
[i]) # id here is the index of the mol in
# the dataset
data.y = torch.tensor([labels[i]])
data.fold = torch.tensor([folds[i]])
data_list.append(data)
data_smiles_list.append(smiles_list[i])
elif self.dataset == 'bbbp':
smiles_list, rdkit_mol_objs, labels = \
_load_bbbp_dataset(self.raw_paths[0])
for i in range(len(smiles_list)):
rdkit_mol = rdkit_mol_objs[i]
if rdkit_mol != None:
# # convert aromatic bonds to double bonds
# Chem.SanitizeMol(rdkit_mol,
# sanitizeOps=Chem.SanitizeFlags.SANITIZE_KEKULIZE)
data = mol_to_graph_data_obj_simple(rdkit_mol)
# manually add mol id
data.id = torch.tensor(
[i]) # id here is the index of the mol in
# the dataset
data.y = torch.tensor([labels[i]])
data_list.append(data)
data_smiles_list.append(smiles_list[i])
elif self.dataset == 'clintox':
smiles_list, rdkit_mol_objs, labels = \
_load_clintox_dataset(self.raw_paths[0])
for i in range(len(smiles_list)):
rdkit_mol = rdkit_mol_objs[i]
if rdkit_mol != None:
# # convert aromatic bonds to double bonds
# Chem.SanitizeMol(rdkit_mol,
# sanitizeOps=Chem.SanitizeFlags.SANITIZE_KEKULIZE)
data = mol_to_graph_data_obj_simple(rdkit_mol)
# manually add mol id
data.id = torch.tensor(
[i]) # id here is the index of the mol in
# the dataset
data.y = torch.tensor(labels[i, :])
data_list.append(data)
data_smiles_list.append(smiles_list[i])
elif self.dataset == 'esol':
smiles_list, rdkit_mol_objs, labels = \
_load_esol_dataset(self.raw_paths[0])
for i in range(len(smiles_list)):
rdkit_mol = rdkit_mol_objs[i]
# # convert aromatic bonds to double bonds
# Chem.SanitizeMol(rdkit_mol,
# sanitizeOps=Chem.SanitizeFlags.SANITIZE_KEKULIZE)
data = mol_to_graph_data_obj_simple(rdkit_mol)
# manually add mol id
data.id = torch.tensor(
[i]) # id here is the index of the mol in
# the dataset
data.y = torch.tensor([labels[i]])
data_list.append(data)
data_smiles_list.append(smiles_list[i])
elif self.dataset == 'freesolv':
smiles_list, rdkit_mol_objs, labels = \
_load_freesolv_dataset(self.raw_paths[0])
for i in range(len(smiles_list)):
rdkit_mol = rdkit_mol_objs[i]
# # convert aromatic bonds to double bonds
# Chem.SanitizeMol(rdkit_mol,
# sanitizeOps=Chem.SanitizeFlags.SANITIZE_KEKULIZE)
data = mol_to_graph_data_obj_simple(rdkit_mol)
# manually add mol id
data.id = torch.tensor(
[i]) # id here is the index of the mol in
# the dataset
data.y = torch.tensor([labels[i]])
data_list.append(data)
data_smiles_list.append(smiles_list[i])
elif self.dataset == 'lipophilicity':
smiles_list, rdkit_mol_objs, labels = \
_load_lipophilicity_dataset(self.raw_paths[0])
for i in range(len(smiles_list)):
rdkit_mol = rdkit_mol_objs[i]
# # convert aromatic bonds to double bonds
# Chem.SanitizeMol(rdkit_mol,
# sanitizeOps=Chem.SanitizeFlags.SANITIZE_KEKULIZE)
data = mol_to_graph_data_obj_simple(rdkit_mol)
# manually add mol id
data.id = torch.tensor(
[i]) # id here is the index of the mol in
# the dataset
data.y = torch.tensor([labels[i]])
data_list.append(data)
data_smiles_list.append(smiles_list[i])
elif self.dataset == 'muv':
smiles_list, rdkit_mol_objs, labels = \
_load_muv_dataset(self.raw_paths[0])
for i in range(len(smiles_list)):
rdkit_mol = rdkit_mol_objs[i]
# # convert aromatic bonds to double bonds
# Chem.SanitizeMol(rdkit_mol,
# sanitizeOps=Chem.SanitizeFlags.SANITIZE_KEKULIZE)
data = mol_to_graph_data_obj_simple(rdkit_mol)
# manually add mol id
data.id = torch.tensor(
[i]) # id here is the index of the mol in
# the dataset
data.y = torch.tensor(labels[i, :])
data_list.append(data)
data_smiles_list.append(smiles_list[i])
elif self.dataset == 'pcba':
smiles_list, rdkit_mol_objs, labels = \
_load_pcba_dataset(self.raw_paths[0])
for i in range(len(smiles_list)):
rdkit_mol = rdkit_mol_objs[i]
# # convert aromatic bonds to double bonds
# Chem.SanitizeMol(rdkit_mol,
# sanitizeOps=Chem.SanitizeFlags.SANITIZE_KEKULIZE)
data = mol_to_graph_data_obj_simple(rdkit_mol)
# manually add mol id
data.id = torch.tensor(
[i]) # id here is the index of the mol in
# the dataset
data.y = torch.tensor(labels[i, :])
data_list.append(data)
data_smiles_list.append(smiles_list[i])
elif self.dataset == 'pcba_pretrain':
smiles_list, rdkit_mol_objs, labels = \
_load_pcba_dataset(self.raw_paths[0])
downstream_inchi = set(pd.read_csv(os.path.join(self.root,
'downstream_mol_inchi_may_24_2019'),
sep=',', header=None)[0])
for i in range(len(smiles_list)):
if '.' not in smiles_list[i]: # remove examples with
# multiples species
rdkit_mol = rdkit_mol_objs[i]
mw = Descriptors.MolWt(rdkit_mol)
if 50 <= mw <= 900:
inchi = create_standardized_mol_id(smiles_list[i])
if inchi != None and inchi not in downstream_inchi:
# # convert aromatic bonds to double bonds
# Chem.SanitizeMol(rdkit_mol,
# sanitizeOps=Chem.SanitizeFlags.SANITIZE_KEKULIZE)
data = mol_to_graph_data_obj_simple(rdkit_mol)
# manually add mol id
data.id = torch.tensor(
[i]) # id here is the index of the mol in
# the dataset
data.y = torch.tensor(labels[i, :])
data_list.append(data)
data_smiles_list.append(smiles_list[i])
# elif self.dataset == ''
elif self.dataset == 'sider':
smiles_list, rdkit_mol_objs, labels = \
_load_sider_dataset(self.raw_paths[0])
for i in range(len(smiles_list)):
rdkit_mol = rdkit_mol_objs[i]
# # convert aromatic bonds to double bonds
# Chem.SanitizeMol(rdkit_mol,
# sanitizeOps=Chem.SanitizeFlags.SANITIZE_KEKULIZE)
data = mol_to_graph_data_obj_simple(rdkit_mol)
# manually add mol id
data.id = torch.tensor(
[i]) # id here is the index of the mol in
# the dataset
data.y = torch.tensor(labels[i, :])
data_list.append(data)
data_smiles_list.append(smiles_list[i])
elif self.dataset == 'toxcast':
smiles_list, rdkit_mol_objs, labels = \
_load_toxcast_dataset(self.raw_paths[0])
for i in range(len(smiles_list)):
rdkit_mol = rdkit_mol_objs[i]
if rdkit_mol != None:
# # convert aromatic bonds to double bonds
# Chem.SanitizeMol(rdkit_mol,
# sanitizeOps=Chem.SanitizeFlags.SANITIZE_KEKULIZE)
data = mol_to_graph_data_obj_simple(rdkit_mol)
# manually add mol id
data.id = torch.tensor(
[i]) # id here is the index of the mol in
# the dataset
data.y = torch.tensor(labels[i, :])
data_list.append(data)
data_smiles_list.append(smiles_list[i])
elif self.dataset == 'ptc_mr':
input_path = self.raw_paths[0]
input_df = pd.read_csv(input_path, sep=',', header=None, names=['id', 'label', 'smiles'])
smiles_list = input_df['smiles']
labels = input_df['label'].values
for i in range(len(smiles_list)):
s = smiles_list[i]
rdkit_mol = AllChem.MolFromSmiles(s)
if rdkit_mol != None: # ignore invalid mol objects
# # convert aromatic bonds to double bonds
# Chem.SanitizeMol(rdkit_mol,
# sanitizeOps=Chem.SanitizeFlags.SANITIZE_KEKULIZE)
data = mol_to_graph_data_obj_simple(rdkit_mol)
# manually add mol id
data.id = torch.tensor(
[i])
data.y = torch.tensor([labels[i]])
data_list.append(data)
data_smiles_list.append(smiles_list[i])
elif self.dataset == 'mutag':
smiles_path = os.path.join(self.root, 'raw', 'mutag_188_data.can')
# smiles_path = 'dataset/mutag/raw/mutag_188_data.can'
labels_path = os.path.join(self.root, 'raw', 'mutag_188_target.txt')
# labels_path = 'dataset/mutag/raw/mutag_188_target.txt'
smiles_list = pd.read_csv(smiles_path, sep=' ', header=None)[0]
labels = pd.read_csv(labels_path, header=None)[0].values
for i in range(len(smiles_list)):
s = smiles_list[i]
rdkit_mol = AllChem.MolFromSmiles(s)
if rdkit_mol != None: # ignore invalid mol objects
# # convert aromatic bonds to double bonds
# Chem.SanitizeMol(rdkit_mol,
# sanitizeOps=Chem.SanitizeFlags.SANITIZE_KEKULIZE)
data = mol_to_graph_data_obj_simple(rdkit_mol)
# manually add mol id
data.id = torch.tensor(
[i])
data.y = torch.tensor([labels[i]])
data_list.append(data)
data_smiles_list.append(smiles_list[i])
else:
raise ValueError('Invalid dataset name')
if self.pre_filter is not None:
data_list = [data for data in data_list if self.pre_filter(data)]
if self.pre_transform is not None:
data_list = [self.pre_transform(data) for data in data_list]
# write data_smiles_list in processed paths
data_smiles_series = pd.Series(data_smiles_list)
data_smiles_series.to_csv(os.path.join(self.processed_dir,
'smiles.csv'), index=False,
header=False)
data, slices = self.collate(data_list)
torch.save((data, slices), self.processed_paths[0])
```
the ```scaffold_split``` code is
```
def scaffold_split(dataset, smiles_list, task_idx=None, null_value=0,
frac_train=0.8, frac_valid=0.1, frac_test=0.1,
return_smiles=False):
"""
Adapted from https://github.com/deepchem/deepchem/blob/master/deepchem/splits/splitters.py
Split dataset by Bemis-Murcko scaffolds
This function can also ignore examples containing null values for a
selected task when splitting. Deterministic split
:param dataset: pytorch geometric dataset obj
:param smiles_list: list of smiles corresponding to the dataset obj
:param task_idx: column idx of the data.y tensor. Will filter out
examples with null value in specified task column of the data.y tensor
prior to splitting. If None, then no filtering
:param null_value: float that specifies null value in data.y to filter if
task_idx is provided
:param frac_train:
:param frac_valid:
:param frac_test:
:param return_smiles:
:return: train, valid, test slices of the input dataset obj. If
return_smiles = True, also returns ([train_smiles_list],
[valid_smiles_list], [test_smiles_list])
"""
np.testing.assert_almost_equal(frac_train + frac_valid + frac_test, 1.0)
if task_idx != None:
# filter based on null values in task_idx
# get task array
y_task = np.array([data.y[task_idx].item() for data in dataset])
# boolean array that correspond to non null values
non_null = y_task != null_value
smiles_list = list(compress(enumerate(smiles_list), non_null))
else:
non_null = np.ones(len(dataset)) == 1
smiles_list = list(compress(enumerate(smiles_list), non_null))
# create dict of the form {scaffold_i: [idx1, idx....]}
all_scaffolds = {}
for i, smiles in smiles_list:
scaffold = generate_scaffold(smiles, include_chirality=True)
if scaffold not in all_scaffolds:
all_scaffolds[scaffold] = [i]
else:
all_scaffolds[scaffold].append(i)
# sort from largest to smallest sets
all_scaffolds = {key: sorted(value) for key, value in all_scaffolds.items()}
all_scaffold_sets = [
scaffold_set for (scaffold, scaffold_set) in sorted(
all_scaffolds.items(), key=lambda x: (len(x[1]), x[1][0]), reverse=True)
]
# get train, valid test indices
train_cutoff = frac_train * len(smiles_list)
valid_cutoff = (frac_train + frac_valid) * len(smiles_list)
train_idx, valid_idx, test_idx = [], [], []
for scaffold_set in all_scaffold_sets:
if len(train_idx) + len(scaffold_set) > train_cutoff:
if len(train_idx) + len(valid_idx) + len(scaffold_set) > valid_cutoff:
test_idx.extend(scaffold_set)
else:
valid_idx.extend(scaffold_set)
else:
train_idx.extend(scaffold_set)
assert len(set(train_idx).intersection(set(valid_idx))) == 0
assert len(set(test_idx).intersection(set(valid_idx))) == 0
train_dataset = dataset[torch.tensor(train_idx)]
valid_dataset = dataset[torch.tensor(valid_idx)]
test_dataset = dataset[torch.tensor(test_idx)]
if not return_smiles:
return train_dataset, valid_dataset, test_dataset
else:
train_smiles = [smiles_list[i][1] for i in train_idx]
valid_smiles = [smiles_list[i][1] for i in valid_idx]
test_smiles = [smiles_list[i][1] for i in test_idx]
return train_dataset, valid_dataset, test_dataset, (train_smiles,
valid_smiles,
test_smiles)
def random_scaffold_split(dataset, smiles_list, task_idx=None, null_value=0,
frac_train=0.8, frac_valid=0.1, frac_test=0.1, seed=0):
"""
Adapted from https://github.com/pfnet-research/chainer-chemistry/blob/master/chainer_chemistry/dataset/splitters/scaffold_splitter.py
Split dataset by Bemis-Murcko scaffolds
This function can also ignore examples containing null values for a
selected task when splitting. Deterministic split
:param dataset: pytorch geometric dataset obj
:param smiles_list: list of smiles corresponding to the dataset obj
:param task_idx: column idx of the data.y tensor. Will filter out
examples with null value in specified task column of the data.y tensor
prior to splitting. If None, then no filtering
:param null_value: float that specifies null value in data.y to filter if
task_idx is provided
:param frac_train:
:param frac_valid:
:param frac_test:
:param seed;
:return: train, valid, test slices of the input dataset obj
"""
np.testing.assert_almost_equal(frac_train + frac_valid + frac_test, 1.0)
if task_idx != None:
# filter based on null values in task_idx
# get task array
y_task = np.array([data.y[task_idx].item() for data in dataset])
# boolean array that correspond to non null values
non_null = y_task != null_value
smiles_list = list(compress(enumerate(smiles_list), non_null))
else:
non_null = np.ones(len(dataset)) == 1
smiles_list = list(compress(enumerate(smiles_list), non_null))
rng = np.random.RandomState(seed)
scaffolds = defaultdict(list)
for ind, smiles in smiles_list:
scaffold = generate_scaffold(smiles, include_chirality=True)
scaffolds[scaffold].append(ind)
scaffold_sets = rng.permutation(list(scaffolds.values()))
n_total_valid = int(np.floor(frac_valid * len(dataset)))
n_total_test = int(np.floor(frac_test * len(dataset)))
train_idx = []
valid_idx = []
test_idx = []
for scaffold_set in scaffold_sets:
if len(valid_idx) + len(scaffold_set) <= n_total_valid:
valid_idx.extend(scaffold_set)
elif len(test_idx) + len(scaffold_set) <= n_total_test:
test_idx.extend(scaffold_set)
else:
train_idx.extend(scaffold_set)
train_dataset = dataset[torch.tensor(train_idx)]
valid_dataset = dataset[torch.tensor(valid_idx)]
test_dataset = dataset[torch.tensor(test_idx)]
return train_dataset, valid_dataset, test_dataset
```
the ```split_class_graphs``` code is:
```
def split_class_graphs(dataset):
y_list = []
for data in dataset:
y_list.append(tuple(data.y.tolist()))
num_classes = len(set(y_list))
y_cetos = set(y_list)
y_idxs = []
for y_ceto in y_cetos:
y_idxs.append([idx for idx, y in enumerate(y_list) if y == y_ceto])
# for i in y_idxs:
# print(len(i))
#print(y_list)
all_graphs_list = []
for graph in dataset:
adj = to_dense_adj(graph.edge_index)[0].numpy()
#print(adj)
all_graphs_list.append(adj)
class_graphs = []
for class_label in set(y_list):
c_graph_list = [all_graphs_list[i] for i in range(len(y_list)) if y_list[i] == class_label]
print(len(c_graph_list))
class_graphs.append( ( np.array(class_label), c_graph_list ) )
return class_graphs, y_idxs
```
and report the error:
```
[03:31:05] WARNING: not removing hydrogen atom without neighbors
[03:31:05] WARNING: not removing hydrogen atom without neighbors
[03:31:06] WARNING: not removing hydrogen atom without neighbors
[03:31:06] WARNING: not removing hydrogen atom without neighbors
[03:31:06] WARNING: not removing hydrogen atom without neighbors
[03:31:06] WARNING: not removing hydrogen atom without neighbors
[03:31:06] WARNING: not removing hydrogen atom without neighbors
[03:31:06] WARNING: not removing hydrogen atom without neighbors
[03:31:06] WARNING: not removing hydrogen atom without neighbors
[03:31:06] WARNING: not removing hydrogen atom without neighbors
[03:31:06] WARNING: not removing hydrogen atom without neighbors
[03:31:07] WARNING: not removing hydrogen atom without neighbors
[03:31:07] WARNING: not removing hydrogen atom without neighbors
Traceback (most recent call last):
File "graohon_get.py", line 208, in <module>
class_graphs, y_idxs = split_class_graphs(train_dataset)
File "graohon_get.py", line 64, in split_class_graphs
adj = to_dense_adj(graph.edge_index)[0].numpy()
File "/opt/conda/lib/python3.7/site-packages/torch_geometric/utils/to_dense_adj.py", line 22, in to_dense_adj
batch = edge_index.new_zeros(edge_index.max().item() + 1)
RuntimeError: max(): Expected reduction dim to be specified for input.numel() == 0. Specify the reduction dim with the 'dim' argument.
```
The dataset is contained in MoleculeNet, I download in ```http://snap.stanford.edu/gnn-pretrain/data/chem_dataset.zip```
if run with ``` Tox21 ToxCast SIDER ClinTox MUV``` datasets will report this error, but datasets ```BACE BBBP HIV``` will not reported.
Could you help me ?
thanks!
### Environment
* PyG version: 2.0.4
* PyTorch version:1.9.0
* OS:centos7
* Python version:3.7.4
* CUDA/cuDNN version:20.2
* How you installed PyTorch and PyG (`conda`, `pip`, source):pip
* Any other relevant information (*e.g.*, version of `torch-scatter`):
torch 1.9.0
torch-cluster 1.6.0
torch-geometric 2.0.4
torch-points-kernels 0.6.10
torch-scatter 2.0.9
torch-sparse 0.6.12
torch-spline-conv 1.2.1
| 2022-09-20T08:53:55 |
|
pyg-team/pytorch_geometric | 5,990 | pyg-team__pytorch_geometric-5990 | [
"4150"
]
| 2c5f2cd9a8c9a6fa38b2d3b9674cbf38760af8d5 | diff --git a/torch_geometric/data/hetero_data.py b/torch_geometric/data/hetero_data.py
--- a/torch_geometric/data/hetero_data.py
+++ b/torch_geometric/data/hetero_data.py
@@ -1,5 +1,6 @@
import copy
import re
+import warnings
from collections import defaultdict, namedtuple
from collections.abc import Mapping
from itertools import chain
@@ -477,6 +478,18 @@ def collect(self, key: str) -> Dict[NodeOrEdgeType, Any]:
mapping[subtype] = getattr(store, key)
return mapping
+ def _check_type_name(self, name: str):
+ if not name.isidentifier():
+ warnings.warn(f"The type '{name}' contains invalid characters "
+ f"which might lead to unexpected behavior down the "
+ f"line. To avoid any issues, ensure that your type "
+ f"only contains letters, numbers and underscores.")
+ elif '__' in name:
+ warnings.warn(f"The type '{name}' contains double underscores "
+ f"('__') which might lead to unexpected behavior "
+ f"down the line. To avoid any issues, ensure that "
+ f"your type only contains single underscores.")
+
def get_node_store(self, key: NodeType) -> NodeStorage:
r"""Gets the :class:`~torch_geometric.data.storage.NodeStorage` object
of a particular node type :attr:`key`.
@@ -491,6 +504,7 @@ def get_node_store(self, key: NodeType) -> NodeStorage:
"""
out = self._node_store_dict.get(key, None)
if out is None:
+ self._check_type_name(key)
out = NodeStorage(_parent=self, _key=key)
self._node_store_dict[key] = out
return out
@@ -510,6 +524,7 @@ def get_edge_store(self, src: str, rel: str, dst: str) -> EdgeStorage:
key = (src, rel, dst)
out = self._edge_store_dict.get(key, None)
if out is None:
+ self._check_type_name(rel)
out = EdgeStorage(_parent=self, _key=key)
self._edge_store_dict[key] = out
return out
| diff --git a/test/data/test_hetero_data.py b/test/data/test_hetero_data.py
--- a/test/data/test_hetero_data.py
+++ b/test/data/test_hetero_data.py
@@ -420,6 +420,16 @@ def test_hetero_data_to_canonical():
data['user', 'product']
+def test_hetero_data_invalid_names():
+ data = HeteroData()
+ with pytest.warns(UserWarning, match="letters, numbers and underscores"):
+ data['my test'].x = torch.randn(10, 16)
+ assert data.node_types == ['my test']
+ with pytest.warns(UserWarning, match="single underscores"):
+ data['my test', 'a__b', 'my test'].edge_attr = torch.randn(10, 16)
+ assert data.edge_types == [('my test', 'a__b', 'my test')]
+
+
# Feature Store ###############################################################
diff --git a/test/loader/test_dynamic_batch_sampler.py b/test/loader/test_dynamic_batch_sampler.py
--- a/test/loader/test_dynamic_batch_sampler.py
+++ b/test/loader/test_dynamic_batch_sampler.py
@@ -1,5 +1,6 @@
from typing import List
+import pytest
import torch
from torch_geometric.data import Data
@@ -37,7 +38,8 @@ def test_dataloader_with_dynamic_batches():
num_steps=2)
loader = DataLoader(data_list, batch_sampler=batch_sampler)
- num_nodes_total = 0
- for data in loader:
- num_nodes_total += data.num_nodes
- assert num_nodes_total == 601
+ with pytest.warns(UserWarning, match="is larger than 300 nodes"):
+ num_nodes_total = 0
+ for data in loader:
+ num_nodes_total += data.num_nodes
+ assert num_nodes_total == 601
diff --git a/test/nn/conv/test_message_passing.py b/test/nn/conv/test_message_passing.py
--- a/test/nn/conv/test_message_passing.py
+++ b/test/nn/conv/test_message_passing.py
@@ -80,7 +80,7 @@ def test_my_conv():
assert torch.allclose(conv((x1, x2), adj.t()), out1)
assert torch.allclose(conv((x1, x2), torch_adj.t()), out1)
assert torch.allclose(conv((x1, None), adj.t()), out2)
- assert torch.allclose(conv((x1, None), torch_adj.t()), out2)
+ assert torch.allclose(conv((x1, None), torch_adj.t()), out2, atol=1e-6)
conv.fuse = False
assert torch.allclose(conv((x1, x2), adj.t()), out1)
assert torch.allclose(conv((x1, x2), torch_adj.t()), out1)
diff --git a/test/transforms/test_random_link_split.py b/test/transforms/test_random_link_split.py
--- a/test/transforms/test_random_link_split.py
+++ b/test/transforms/test_random_link_split.py
@@ -1,3 +1,4 @@
+import pytest
import torch
from torch_geometric.data import Data, HeteroData
@@ -205,7 +206,9 @@ def test_random_link_split_insufficient_negative_edges():
transform = RandomLinkSplit(num_val=0.34, num_test=0.34,
is_undirected=False, neg_sampling_ratio=2,
split_labels=True)
- train_data, val_data, test_data = transform(data)
+
+ with pytest.warns(UserWarning, match="not enough negative edges"):
+ train_data, val_data, test_data = transform(data)
assert train_data.neg_edge_label_index.size() == (2, 2)
assert val_data.neg_edge_label_index.size() == (2, 2)
diff --git a/test/utils/test_dropout.py b/test/utils/test_dropout.py
--- a/test/utils/test_dropout.py
+++ b/test/utils/test_dropout.py
@@ -1,3 +1,4 @@
+import pytest
import torch
from torch_geometric.testing import withPackage
@@ -16,17 +17,20 @@ def test_dropout_adj():
])
edge_attr = torch.Tensor([1, 2, 3, 4, 5, 6])
- out = dropout_adj(edge_index, edge_attr, training=False)
+ with pytest.warns(UserWarning, match="'dropout_adj' is deprecated"):
+ out = dropout_adj(edge_index, edge_attr, training=False)
assert edge_index.tolist() == out[0].tolist()
assert edge_attr.tolist() == out[1].tolist()
torch.manual_seed(5)
- out = dropout_adj(edge_index, edge_attr)
+ with pytest.warns(UserWarning, match="'dropout_adj' is deprecated"):
+ out = dropout_adj(edge_index, edge_attr)
assert out[0].tolist() == [[0, 1, 2, 2], [1, 2, 1, 3]]
assert out[1].tolist() == [1, 3, 4, 5]
torch.manual_seed(6)
- out = dropout_adj(edge_index, edge_attr, force_undirected=True)
+ with pytest.warns(UserWarning, match="'dropout_adj' is deprecated"):
+ out = dropout_adj(edge_index, edge_attr, force_undirected=True)
assert out[0].tolist() == [[0, 1, 1, 2], [1, 2, 0, 1]]
assert out[1].tolist() == [1, 3, 1, 3]
| Inconsistent behaviour with `to_hetero()` and custom edge types
### 🐛 Describe the bug
Hi, I'm trying to implement a heterogeneous network with a custom dataset. I've run into some issues but seems like it boils down to the following: when running the below, the transformed network seems to have different behaviour depending on the order of the node types in the edge.
```python
import torch
from torch_geometric.nn import Linear, GATConv, to_hetero
class HeteroNet(torch.nn.Module):
def __init__(self):
super(HeteroNet, self).__init__()
self.fc_1_input = Linear(-1, 64)
self.hidden_gat = GATConv((-1,-1), 64, heads=4, add_self_loops=False)
self.fc_1_output = Linear(-1, 1)
def forward(self, x, edge_index):
x = self.fc_1_input(x)
x = self.hidden_gat(x, edge_index)
x = self.fc_1_output(x)
return x
model_1 = HeteroNet()
model_1 = to_hetero(model_1, (['not_node', '<=_node'],[('<=_node', 'to', 'not_node')]))
print("Printing model_1!")
print(model_1)
model_2 = HeteroNet()
model_2 = to_hetero(model_2, (['not_node', '<=_node'],[('not_node', 'to', '<=_node')]))
print("Printing model_2!")
print(model_2)
```
This outputs the following:
```
Printing model_1!
GraphModule(
(fc_1_input): ModuleDict(
(not_node): Linear(-1, 64, bias=True)
(<=_node): Linear(-1, 64, bias=True)
)
(hidden_gat): ModuleDict(
(<=_node__to__not_node): GATConv((-1, -1), 64, heads=4)
)
(fc_1_output): ModuleDict(
(not_node): Linear(-1, 1, bias=True)
(<=_node): Linear(-1, 1, bias=True)
)
)
def forward(self, x, edge_index):
x__not_node = x.get('not_node'); x = None
fc_1_input__not_node = self.fc_1_input.not_node(x__not_node); x__not_node = None
hidden_gat__not_node = getattr(self.hidden_gat, "<=_node__to__not_node")((None, fc_1_input__not_node), (None, None)); fc_1_input__not_node = None
fc_1_output__not_node = self.fc_1_output.not_node(hidden_gat__not_node); hidden_gat__not_node = None
return {'not_node': fc_1_output__not_node, '<=_node': None}
Printing model_2!
GraphModule(
(fc_1_input): ModuleDict(
(not_node): Linear(-1, 64, bias=True)
(<=_node): Linear(-1, 64, bias=True)
)
(hidden_gat): ModuleDict(
(not_node): GATConv((-1, -1), 64, heads=4)
(<=_node): GATConv((-1, -1), 64, heads=4)
)
(fc_1_output): ModuleDict(
(not_node): Linear(-1, 1, bias=True)
(<=_node): Linear(-1, 1, bias=True)
)
)
def forward(self, x, edge_index):
fc_1_output__not_node = self.fc_1_output.not_node(None)
return {'not_node': fc_1_output__not_node, '<=_node': None}
```
As you can see, for `model_1` the transformed model contains the correct edge type for the `hidden_gat` layer, but with the reversed node types `model_2` doesn't generate the same network with edge reversed.
### Environment
* PyG version: 2.0.3
* PyTorch version: 1.10.2
* OS: Ubuntu 20.04.3 LTSc
* Python version: 3.8.10
* CUDA/cuDNN version: 11.6
* How you installed PyTorch and PyG: pip
| Thanks for reporting. Both `<` and `=` are non-valid characters for defining a `to_hetero` model since they are not allowed as part of Python attribute names. Furthermore, adding reverse edges fixes remaining issues for me:
```python
model_1 = to_hetero(model_1, (['not_node', 'node'], [
('node', 'to', 'not_node'),
('not_node', 'to', 'node'),
]))
```
Without it, we already print the following warning in PyG master:
```
UserWarning: There exist node types ({'node'}) whose representations do not get updated during message passing as they do not occur as destination type in any edge type. This may lead to unexpected behaviour.
```
Hi ! I came across a similar situation on a custom dataset whose node type and edge type names contained strings like "__", "-", ":" and camelCase names. It took me a while to realize some of these conventions were forbidden (I ended up reading the generated function thanks the `debug=True` option and saw the weird behavior). I think it would be great to have a sanity check within `to_hetero` or at least to raise a warning !
That is a great suggestion, will work on it! | 2022-11-16T09:11:51 |
pyg-team/pytorch_geometric | 6,242 | pyg-team__pytorch_geometric-6242 | [
"6241"
]
| f30a18c5dff24806ab23e22907895febbd60ab54 | diff --git a/torch_geometric/transforms/gdc.py b/torch_geometric/transforms/gdc.py
--- a/torch_geometric/transforms/gdc.py
+++ b/torch_geometric/transforms/gdc.py
@@ -303,11 +303,11 @@ def diffusion_matrix_approx(
deg = scatter_add(edge_weight, col, dim=0, dim_size=num_nodes)
edge_index_np = edge_index.cpu().numpy()
- # Assumes coalesced edge_index.
- _, indptr, out_degree = np.unique(edge_index_np[0],
- return_index=True,
- return_counts=True)
- indptr = np.append(indptr, len(edge_index_np[0]))
+
+ # Assumes sorted and coalesced edge indices:
+ indptr = torch._convert_indices_from_coo_to_csr(
+ edge_index[0], num_nodes).cpu().numpy()
+ out_degree = indptr[1:] - indptr[:-1]
neighbors, neighbor_weights = self.__calc_ppr__(
indptr, edge_index_np[1], out_degree, kwargs['alpha'],
| Approximate PPR implementation in the GDC transform expects the graph to not have isolated nodes
### 🐛 Describe the bug
Hi, the approximate implementation of the PPR algorithm that is present in the GDC transform expects the graph to not have any isolated nodes and crashes if it has. This is not documented in the docs or in the code (where there is a mention of coalesced edge index, but I believe that is a slightly different thing).
Example:
```python
from copy import deepcopy
from torch_geometric.data.data import Data
from torch_geometric.datasets import KarateClub
from torch_geometric.transforms import GDC
gdc = GDC(
self_loop_weight = 0,
normalization_in = "sym",
normalization_out = "col",
diffusion_kwargs = dict(method = "ppr", alpha = 0.15, eps = 1e-2),
sparsification_kwargs = dict(method = "threshold", eps = 1e-4),
exact = False
)
data: Data = KarateClub()[0]
# Run GDC on a graph without isolated nodes, works fine
data2 = gdc(deepcopy(data))
# Remove all edges leading to/from node 3
data.edge_index = data.edge_index[:, data.edge_index[0, :] != 3]
data.edge_index = data.edge_index[:, data.edge_index[1, :] != 3]
# Run GDC on graph with an isolated node, doesn't work
data3 = gdc(deepcopy(data))
```
The last line is where the problem lies. It may not manifest right away (in fact, with this minimal example it does not for me) because some o the code is JITed with numba. However, if I comment out line
https://github.com/pyg-team/pytorch_geometric/blob/01482d424bd04be2ca58fb921467d6b3933cc08b/torch_geometric/transforms/gdc.py#L545
I get:
```python
❯ python example.py
Traceback (most recent call last):
File "/home/user/pytorch_geometric/example.py", line 25, in <module>
data3 = gdc(deepcopy(data))
File "/opt/miniconda3/envs/pytorch_geometric/lib/python3.9/site-packages/torch/autograd/grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
File "/home/user/pytorch_geometric/torch_geometric/transforms/gdc.py", line 125, in __call__
edge_index, edge_weight = self.diffusion_matrix_approx(
File "/home/user/pytorch_geometric/torch_geometric/transforms/gdc.py", line 312, in diffusion_matrix_approx
neighbors, neighbor_weights = self.__calc_ppr__(
File "/home/user/torch_geometric/transforms/gdc.py", line 596, in calc_ppr
if res_vnode >= alpha_eps * out_degree[vnode]:
IndexError: index 33 is out of bounds for axis 0 with size 33
```
If numba is enabled, the issue manifests as a total process freeze for more complicated examples.
### Environment
* PyG version: 01482d424bd04be2ca58fb921467d6b3933cc08b
* PyTorch version: 1.13.0
* OS: Debian testing
* Python version: 3.9
* CUDA/cuDNN version: CPU only
* How you installed PyTorch and PyG (`conda`, `pip`, source): PyG from source, everything else with conda
* Any other relevant information (*e.g.*, version of `torch-scatter`): torch-scatter 2.1.0, torch-sparse 0.6.15
| 2022-12-15T14:12:08 |
||
pyg-team/pytorch_geometric | 6,546 | pyg-team__pytorch_geometric-6546 | [
"6507"
]
| 2b9c633ecd5c758b4836083238694b19a20daa6b | diff --git a/torch_geometric/utils/sparse.py b/torch_geometric/utils/sparse.py
--- a/torch_geometric/utils/sparse.py
+++ b/torch_geometric/utils/sparse.py
@@ -11,7 +11,10 @@ def dense_to_sparse(adj: Tensor) -> Tuple[Tensor, Tensor]:
by edge indices and edge attributes.
Args:
- adj (Tensor): The dense adjacency matrix.
+ adj (Tensor): The dense adjacency matrix of shape
+ :obj:`[num_nodes, num_nodes]` or
+ :obj:`[batch_size, num_nodes, num_nodes]`.
+
:rtype: (:class:`LongTensor`, :class:`Tensor`)
Examples:
@@ -34,8 +37,9 @@ def dense_to_sparse(adj: Tensor) -> Tuple[Tensor, Tensor]:
[0, 1, 0, 3, 3]]),
tensor([3, 1, 2, 1, 2]))
"""
- assert adj.dim() >= 2 and adj.dim() <= 3
- assert adj.size(-1) == adj.size(-2)
+ if adj.dim() < 2 or adj.dim() > 3:
+ raise ValueError(f"Dense adjacency matrix 'adj' must be 2- or "
+ f"3-dimensional (got {adj.dim()} dimensions)")
edge_index = adj.nonzero().t()
@@ -44,9 +48,8 @@ def dense_to_sparse(adj: Tensor) -> Tuple[Tensor, Tensor]:
return edge_index, edge_attr
else:
edge_attr = adj[edge_index[0], edge_index[1], edge_index[2]]
- batch = edge_index[0] * adj.size(-1)
- row = batch + edge_index[1]
- col = batch + edge_index[2]
+ row = edge_index[1] + adj.size(-2) * edge_index[0]
+ col = edge_index[2] + adj.size(-1) * edge_index[0]
return torch.stack([row, col], dim=0), edge_attr
| diff --git a/test/utils/test_sparse.py b/test/utils/test_sparse.py
--- a/test/utils/test_sparse.py
+++ b/test/utils/test_sparse.py
@@ -43,6 +43,12 @@ def test_dense_to_sparse():
assert edge_attr.tolist() == [3, 1, 2, 1, 2]
+def test_dense_to_sparse_bipartite():
+ edge_index, edge_attr = dense_to_sparse(torch.rand(2, 10, 5))
+ assert edge_index[0].max() == 19
+ assert edge_index[1].max() == 9
+
+
def test_is_torch_sparse_tensor():
x = torch.randn(5, 5)
| Bipartite graph support for utils.dense_to_sparse
### 🚀 The feature, motivation and pitch
I have a nearly-dense bipartite graph (that is, most features in node set A are connected to most features in node set B), and so it is easiest for me to define the edge adjacency matrix as a dense, non-square matrix. However, the message passing class expects a sparse edge adjacency layout. The dense_to_sparse utility would seem to be ideal for this purpose, but it can only take square matrices (thus, is unhelpful for bipartite graphs).
### Alternatives
A way to implicitly request propagate to pass messages from every node in A to every node in B would be even better (storing fully connected graphs is very memory inefficient), but I know that pyg is meant for sparser graph constructions so this would likely be a feature that wasn't used very much by other people.
### Additional context
_No response_
| Thanks for this feature request, we should definitely work on this. Do you have interest in helping with this?
I'm not at all familiar with the back-end and code base for pyg yet, just using it and the documentation. I can try to help, though. | 2023-01-30T14:57:32 |
pyg-team/pytorch_geometric | 6,550 | pyg-team__pytorch_geometric-6550 | [
"6549"
]
| 0c8f35fa9458bc4eb8ce43c3694ba35481623dde | diff --git a/examples/hetero/bipartite_sage_unsup.py b/examples/hetero/bipartite_sage_unsup.py
--- a/examples/hetero/bipartite_sage_unsup.py
+++ b/examples/hetero/bipartite_sage_unsup.py
@@ -139,7 +139,7 @@ def forward(self, x_dict, edge_index_dict):
user_x = self.conv3(
(item_x, user_x),
- edge_index_dict[('item', 'to', 'user')],
+ edge_index_dict[('item', 'rev_to', 'user')],
).relu()
return self.lin(user_x)
@@ -231,11 +231,12 @@ def test(loader):
target = batch['user', 'item'].edge_label.long().cpu()
preds.append(pred)
- targets.append(pred)
+ targets.append(target)
pred = torch.cat(preds, dim=0).numpy()
- target = torch.cat(target, dim=0).numpy()
+ target = torch.cat(targets, dim=0).numpy()
+ pred = pred > 0.5
acc = accuracy_score(target, pred)
prec = precision_score(target, pred)
rec = recall_score(target, pred)
| Classification metrics can't handle a mix of binary and continuous targets
### 🐛 Describe the bug
I was trying to run the [pytorch_geometric](https://github.com/pyg-team/pytorch_geometric)/[examples](https://github.com/pyg-team/pytorch_geometric/tree/master/examples)/[hetero](https://github.com/pyg-team/pytorch_geometric/tree/master/examples/hetero)/bipartite_sage_unsup.py . I received the following error in the training loop. The error happened after the test() function was called
## Error
```
ValueError Traceback (most recent call last)
[<ipython-input-7-449d394a8262>](https://localhost:8080/#) in <module>
54 for epoch in range(1, 21):
55 loss = train()
---> 56 val_acc, val_prec, val_rec, val_f1 = test(val_loader)
57 test_acc, test_prec, test_rec, test_f1 = test(test_loader)
58
3 frames
[/usr/local/lib/python3.8/dist-packages/sklearn/metrics/_classification.py](https://localhost:8080/#) in _check_targets(y_true, y_pred)
91
92 if len(y_type) > 1:
---> 93 raise ValueError(
94 "Classification metrics can't handle a mix of {0} and {1} targets".format(
95 type_true, type_pred
ValueError: Classification metrics can't handle a mix of binary and continuous targets
```
## Code modifications
```
@torch.no_grad()
def test(loader):
model.eval()
preds, targets = [], []
for batch in tqdm.tqdm(loader):
batch = batch.to(device)
pred = model(
batch.x_dict,
batch.edge_index_dict,
batch['user', 'item'].edge_label_index,
).sigmoid().view(-1).cpu()
target = batch['user', 'item'].edge_label.long().cpu()
preds.append(pred)
targets.append(target) #I assumed it was a typo in the original example
pred = torch.cat(preds, dim=0).numpy()
target = torch.cat(targets, dim=0).numpy() #I assumed it was a typo in the original example
acc = accuracy_score(target, pred)
prec = precision_score(target, pred)
rec = recall_score(target, pred)
f1 = f1_score(target, pred)
return acc, prec, rec, f1
```
### Environment
* PyG version:
* PyTorch version: 1.13.0
* OS: Linux(Colab)
* Python version: 3.8.10
* CUDA/cuDNN version: 11.6
* How you installed PyTorch and PyG (`conda`, `pip`, source): pip
* Any other relevant information (*e.g.*, version of `torch-scatter`):
| 2023-01-31T04:40:38 |
||
pyg-team/pytorch_geometric | 6,562 | pyg-team__pytorch_geometric-6562 | [
"6561"
]
| af45d6271f509114df6c0af6f8aa1abd4566d30e | diff --git a/torch_geometric/nn/models/dimenet.py b/torch_geometric/nn/models/dimenet.py
--- a/torch_geometric/nn/models/dimenet.py
+++ b/torch_geometric/nn/models/dimenet.py
@@ -275,7 +275,7 @@ def reset_parameters(self):
res_layer.reset_parameters()
glorot_orthogonal(self.lin.weight, scale=2.0)
self.lin.bias.data.fill_(0)
- for res_layer in self.layers_before_skip:
+ for res_layer in self.layers_after_skip:
res_layer.reset_parameters()
def forward(self, x: Tensor, rbf: Tensor, sbf: Tensor, idx_kj: Tensor,
| Some layer parameters are not reset
### 🐛 Describe the bug
For the file: `torch_geometric/nn/models/dimenet.py`
In `reset_parameters()` of `InteractionPPBlock`, `self.layers_before_skip` is reset twice, and `self.layers_after_skip` is not reset at all.
This is the current version:
```python
for res_layer in self.layers_before_skip:
res_layer.reset_parameters()
...
for res_layer in self.layers_before_skip:
res_layer.reset_parameters()
```
But I think it should be:
```python
for res_layer in self.layers_before_skip:
res_layer.reset_parameters()
...
for res_layer in self.layers_after_skip:
res_layer.reset_parameters()
```
This second (fixed) version is consistent with the rest of the classes in this file.
### Environment
* PyG version:
* PyTorch version:
* OS:
* Python version:
* CUDA/cuDNN version:
* How you installed PyTorch and PyG (`conda`, `pip`, source):
* Any other relevant information (*e.g.*, version of `torch-scatter`):
| 2023-02-01T13:49:52 |
||
pyg-team/pytorch_geometric | 6,928 | pyg-team__pytorch_geometric-6928 | [
"1141"
]
| a6db0abee70bd61e3c9c6782e9b5856395307c94 | diff --git a/torch_geometric/nn/dense/__init__.py b/torch_geometric/nn/dense/__init__.py
--- a/torch_geometric/nn/dense/__init__.py
+++ b/torch_geometric/nn/dense/__init__.py
@@ -1,4 +1,5 @@
from .linear import Linear, HeteroLinear
+from .dense_gat_conv import DenseGATConv
from .dense_sage_conv import DenseSAGEConv
from .dense_gcn_conv import DenseGCNConv
from .dense_graph_conv import DenseGraphConv
@@ -14,11 +15,12 @@
'DenseGINConv',
'DenseGraphConv',
'DenseSAGEConv',
+ 'DenseGATConv',
'dense_diff_pool',
'dense_mincut_pool',
'DMoNPooling',
]
lin_classes = __all__[:2]
-conv_classes = __all__[2:6]
-pool_classes = __all__[6:]
+conv_classes = __all__[2:7]
+pool_classes = __all__[7:]
diff --git a/torch_geometric/nn/dense/dense_gat_conv.py b/torch_geometric/nn/dense/dense_gat_conv.py
new file mode 100644
--- /dev/null
+++ b/torch_geometric/nn/dense/dense_gat_conv.py
@@ -0,0 +1,118 @@
+from typing import Optional
+
+import torch
+import torch.nn.functional as F
+from torch import Tensor
+from torch.nn import Parameter
+
+from torch_geometric.nn.dense.linear import Linear
+
+from ..inits import glorot, zeros
+
+
+class DenseGATConv(torch.nn.Module):
+ r"""See :class:`torch_geometric.nn.conv.GATConv`."""
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ heads: int = 1,
+ concat: bool = True,
+ negative_slope: float = 0.2,
+ dropout: float = 0.0,
+ bias: bool = True,
+ ):
+ # TODO Add support for edge features.
+ super().__init__()
+
+ self.in_channels = in_channels
+ self.out_channels = out_channels
+ self.heads = heads
+ self.concat = concat
+ self.negative_slope = negative_slope
+ self.dropout = dropout
+
+ self.lin = Linear(in_channels, heads * out_channels, bias=False,
+ weight_initializer='glorot')
+
+ # The learnable parameters to compute attention coefficients:
+ self.att_src = Parameter(torch.Tensor(1, 1, heads, out_channels))
+ self.att_dst = Parameter(torch.Tensor(1, 1, heads, out_channels))
+
+ if bias and concat:
+ self.bias = Parameter(torch.Tensor(heads * out_channels))
+ elif bias and not concat:
+ self.bias = Parameter(torch.Tensor(out_channels))
+ else:
+ self.register_parameter('bias', None)
+
+ self.reset_parameters()
+
+ def reset_parameters(self):
+ self.lin.reset_parameters()
+ glorot(self.att_src)
+ glorot(self.att_dst)
+ zeros(self.bias)
+
+ def forward(self, x: Tensor, adj: Tensor, mask: Optional[Tensor] = None,
+ add_loop: bool = True):
+ r"""
+ Args:
+ x (torch.Tensor): Node feature tensor
+ :math:`\mathbf{X} \in \mathbb{R}^{B \times N \times F}`, with
+ batch-size :math:`B`, (maximum) number of nodes :math:`N` for
+ each graph, and feature dimension :math:`F`.
+ adj (torch.Tensor): Adjacency tensor
+ :math:`\mathbf{A} \in \mathbb{R}^{B \times N \times N}`.
+ The adjacency tensor is broadcastable in the batch dimension,
+ resulting in a shared adjacency matrix for the complete batch.
+ mask (torch.Tensor, optional): Mask matrix
+ :math:`\mathbf{M} \in {\{ 0, 1 \}}^{B \times N}` indicating
+ the valid nodes for each graph. (default: :obj:`None`)
+ add_loop (bool, optional): If set to :obj:`False`, the layer will
+ not automatically add self-loops to the adjacency matrices.
+ (default: :obj:`True`)
+ """
+ x = x.unsqueeze(0) if x.dim() == 2 else x # [B, N, F]
+ adj = adj.unsqueeze(0) if adj.dim() == 2 else adj # [B, N, N]
+
+ H, C = self.heads, self.out_channels
+ B, N, _ = x.size()
+
+ if add_loop:
+ adj = adj.clone()
+ idx = torch.arange(N, dtype=torch.long, device=adj.device)
+ adj[:, idx, idx] = 1.0
+
+ x = self.lin(x).view(B, N, H, C) # [B, N, H, C]
+
+ alpha_src = torch.sum(x * self.att_src, dim=-1) # [B, N, H]
+ alpha_dst = torch.sum(x * self.att_dst, dim=-1) # [B, N, H]
+
+ alpha = alpha_src.unsqueeze(1) + alpha_dst.unsqueeze(2) # [B, N, N, H]
+
+ # Weighted and masked softmax:
+ alpha = F.leaky_relu(alpha, self.negative_slope)
+ alpha = alpha.masked_fill(adj.unsqueeze(-1) == 0, float('-inf'))
+ alpha = alpha.softmax(dim=2)
+ alpha = F.dropout(alpha, p=self.dropout, training=self.training)
+
+ out = torch.matmul(alpha.movedim(3, 1), x.movedim(2, 1))
+ out = out.movedim(1, 2) # [B,N,H,C]
+
+ if self.concat:
+ out = out.reshape(B, N, H * C)
+ else:
+ out = out.mean(dim=2)
+
+ if self.bias is not None:
+ out = out + self.bias
+
+ if mask is not None:
+ out = out * mask.view(-1, N, 1).to(x.dtype)
+
+ return out
+
+ def __repr__(self) -> str:
+ return (f'{self.__class__.__name__}({self.in_channels}, '
+ f'{self.out_channels}, heads={self.heads})')
| diff --git a/test/nn/dense/test_dense_gat_conv.py b/test/nn/dense/test_dense_gat_conv.py
new file mode 100644
--- /dev/null
+++ b/test/nn/dense/test_dense_gat_conv.py
@@ -0,0 +1,66 @@
+import pytest
+import torch
+
+from torch_geometric.nn import DenseGATConv, GATConv
+from torch_geometric.testing import is_full_test
+
+
[email protected]('heads', [1, 4])
[email protected]('concat', [True, False])
+def test_dense_gat_conv(heads, concat):
+ channels = 16
+ sparse_conv = GATConv(channels, channels, heads=heads, concat=concat)
+ dense_conv = DenseGATConv(channels, channels, heads=heads, concat=concat)
+ assert str(dense_conv) == f'DenseGATConv(16, 16, heads={heads})'
+
+ # Ensure same weights and bias:
+ dense_conv.lin = sparse_conv.lin_src
+ dense_conv.att_src = sparse_conv.att_src
+ dense_conv.att_dst = sparse_conv.att_dst
+ dense_conv.bias = sparse_conv.bias
+
+ x = torch.randn((5, channels))
+ edge_index = torch.tensor([[0, 1, 1, 2, 3, 4], [1, 0, 2, 1, 4, 3]])
+
+ sparse_out = sparse_conv(x, edge_index)
+
+ x = torch.cat([x, x.new_zeros(1, channels)], dim=0).view(2, 3, channels)
+ adj = torch.Tensor([
+ [
+ [0, 1, 0],
+ [1, 0, 1],
+ [0, 1, 0],
+ ],
+ [
+ [0, 1, 0],
+ [1, 0, 0],
+ [0, 0, 0],
+ ],
+ ])
+ mask = torch.tensor([[1, 1, 1], [1, 1, 0]], dtype=torch.bool)
+
+ dense_out = dense_conv(x, adj, mask)
+
+ assert dense_out[1, 2].abs().sum() == 0
+ dense_out = dense_out.view(6, dense_out.size(-1))[:-1]
+ assert torch.allclose(sparse_out, dense_out, atol=1e-4)
+
+ if is_full_test():
+ jit = torch.jit.script(dense_conv)
+ assert torch.allclose(jit(x, adj, mask), dense_out)
+
+
+def test_dense_gat_conv_with_broadcasting():
+ batch_size, num_nodes, channels = 8, 3, 16
+ conv = DenseGATConv(channels, channels, heads=4)
+
+ x = torch.randn(batch_size, num_nodes, channels)
+ adj = torch.Tensor([
+ [0, 1, 1],
+ [1, 0, 1],
+ [1, 1, 0],
+ ])
+
+ assert conv(x, adj).size() == (batch_size, num_nodes, 64)
+ mask = torch.tensor([1, 1, 1], dtype=torch.bool)
+ assert conv(x, adj, mask).size() == (batch_size, num_nodes, 64)
diff --git a/test/nn/dense/test_dense_gcn_conv.py b/test/nn/dense/test_dense_gcn_conv.py
--- a/test/nn/dense/test_dense_gcn_conv.py
+++ b/test/nn/dense/test_dense_gcn_conv.py
@@ -10,7 +10,7 @@ def test_dense_gcn_conv():
dense_conv = DenseGCNConv(channels, channels)
assert str(dense_conv) == 'DenseGCNConv(16, 16)'
- # Ensure same weights and bias.
+ # Ensure same weights and bias:
dense_conv.lin.weight = sparse_conv.lin.weight
dense_conv.bias = sparse_conv.bias
@@ -39,14 +39,14 @@ def test_dense_gcn_conv():
dense_out = dense_conv(x, adj, mask)
assert dense_out.size() == (2, 3, channels)
+ assert dense_out[1, 2].abs().sum() == 0
+ dense_out = dense_out.view(6, channels)[:-1]
+ assert torch.allclose(sparse_out, dense_out, atol=1e-4)
+
if is_full_test():
jit = torch.jit.script(dense_conv)
assert torch.allclose(jit(x, adj, mask), dense_out)
- assert dense_out[1, 2].abs().sum().item() == 0
- dense_out = dense_out.view(6, channels)[:-1]
- assert torch.allclose(sparse_out, dense_out, atol=1e-04)
-
def test_dense_gcn_conv_with_broadcasting():
batch_size, num_nodes, channels = 8, 3, 16
| GATConv but for Dense Networks
## 🚀 Feature
Hi, I have a very simple request. I've seen that you've made dense formulations of a couple of the graph convolution types and graph pooling operators. Could you make the same thing for GATConv (and NNConv for that matter). If you don't have the bandwidth, just give me some pointers as to how to make this thing myself.
## Motivation
I'm basically using GATConv as a full self-attention network (all nodes connected).
| That is a reasonable request, and I would be happy to include it into PyG. It would be great if you could work on this. For implementing, I would mostly follow the [`DenseGraphConv`](https://github.com/rusty1s/pytorch_geometric/blob/master/torch_geometric/nn/dense/dense_graph_conv.py) implementation. For GAT, you need to calculate attention weights first (with a masked softmax) before applying the matrix multiplication.
Hi there, my project also involves GAT operators on dense adjacency matrices. If this wasn't followed by anyone for now, I'll try to work on this for a `DenseGATConv` operator.
Super :) | 2023-03-16T10:54:52 |
pyg-team/pytorch_geometric | 7,104 | pyg-team__pytorch_geometric-7104 | [
"7103"
]
| 85559709322b698c0575efe5043fa3c147375cf9 | diff --git a/torch_geometric/data/storage.py b/torch_geometric/data/storage.py
--- a/torch_geometric/data/storage.py
+++ b/torch_geometric/data/storage.py
@@ -26,6 +26,7 @@
from torch_geometric.utils import (
coalesce,
contains_isolated_nodes,
+ is_torch_sparse_tensor,
is_undirected,
)
@@ -418,6 +419,8 @@ def num_edges(self) -> int:
for value in self.values('adj', 'adj_t'):
if isinstance(value, SparseTensor):
return value.nnz()
+ elif is_torch_sparse_tensor(value):
+ return value._nnz()
return 0
@property
| `data.num_edges` is 0 when using native PyTorch sparse tensor
### 🐛 Describe the bug
When using the native PyTorch sparse tensor for representing the adjacency matrix, the number of edges reported by the `Data` object is always zero. The following code reproduces the issue:
```python
import torch_geometric.transforms as T
from torch_geometric.datasets import Planetoid
transform = T.ToSparseTensor(layout=torch.sparse_csr)
dataset = Planetoid("Planetoid", name="Cora", transform=transform)
data = dataset[0]
print(data.num_edges)
```
### Environment
* PyG version: 2.3.0
* PyTorch version: 2.0.0
* OS: Linux (Debian)
* Python version: 3.10.9
| 2023-04-02T14:06:44 |
||
pyg-team/pytorch_geometric | 7,107 | pyg-team__pytorch_geometric-7107 | [
"7099"
]
| 3c1501833b13cb87e110a89edef5aa6ee164c190 | diff --git a/torch_geometric/nn/models/dimenet.py b/torch_geometric/nn/models/dimenet.py
--- a/torch_geometric/nn/models/dimenet.py
+++ b/torch_geometric/nn/models/dimenet.py
@@ -631,6 +631,7 @@ def copy_(src, name, transpose=False):
# Use the same random seed as the official DimeNet` implementation.
random_state = np.random.RandomState(seed=42)
perm = torch.from_numpy(random_state.permutation(np.arange(130831)))
+ perm = perm.long()
train_idx = perm[:110000]
val_idx = perm[110000:120000]
test_idx = perm[120000:]
@@ -905,6 +906,7 @@ def copy_(src, name, transpose=False):
random_state = np.random.RandomState(seed=42)
perm = torch.from_numpy(random_state.permutation(np.arange(130831)))
+ perm = perm.long()
train_idx = perm[:110000]
val_idx = perm[110000:120000]
test_idx = perm[120000:]
| IndexError when using dimnet plus plus with pretrained on qm9 dataset (just running the example provided by PYG)
### 🐛 Describe the bug
I was trying to run the example provided by PYG using dimnet plus plus pretrained on qm9 dataset, the lik for the example: https://github.com/pyg-team/pytorch_geometric/blob/master/examples/qm9_pretrained_dimenet.py
I didn't change anything in the code, yet it gave me this error:
IndexError: Only slices (':'), list, tuples, torch.tensor and np.ndarray of dtype long or bool are valid indices (got 'Tensor')
### Environment
* PyG version: 2.3.0
* PyTorch version: 2.0.0+cpu
* OS: Windows-10-10.0.19045-SP0
* Python version: 3.10
* CUDA/cuDNN version: N/A
* How you installed PyTorch and PyG (`conda`, `pip`, source): pip
* Any other relevant information (*e.g.*, version of `torch-scatter`):
| Thanks for reporting. @wsad1 do you mind to take a look?
@rusty1s @AmgadAbdallah This is because `perm` is a `torch.int32` Tensor but only `torch.int64` is supported for `torch_geometric.data.Dataset`. A quick fix is to convert `perm` to `torch.int64` Tensor.
https://github.com/pyg-team/pytorch_geometric/blob/3c1501833b13cb87e110a89edef5aa6ee164c190/torch_geometric/nn/models/dimenet.py#L633-L638 | 2023-04-03T07:07:00 |
|
pyg-team/pytorch_geometric | 7,387 | pyg-team__pytorch_geometric-7387 | [
"7386"
]
| ce84dd9216738e772ecb0214daea2ec5d5a23105 | diff --git a/torch_geometric/typing.py b/torch_geometric/typing.py
--- a/torch_geometric/typing.py
+++ b/torch_geometric/typing.py
@@ -105,6 +105,11 @@ def from_edge_index(
) -> 'SparseTensor':
raise ImportError("'SparseTensor' requires 'torch-sparse'")
+ @classmethod
+ def from_dense(self, mat: Tensor,
+ has_value: bool = True) -> 'SparseTensor':
+ raise ImportError("'SparseTensor' requires 'torch-sparse'")
+
def size(self, dim: int) -> int:
raise ImportError("'SparseTensor' requires 'torch-sparse'")
| Fail to import Nell dataset
### 🐛 Describe the bug
I tried to import Nell data set using NELL class:
from torch_geometric.datasets import NELL
dataset = NELL(root='data/Nell')
data = dataset[0]
But I got the following error message:
Traceback (most recent call last):
File "c:\Users\13466\Desktop\USTLab\LabDoc\HPCA23\Nell.py", line 10, in <module>
dataset = NELL(root='data/Nell')
File "C:\Users\13466\anaconda3\lib\site-packages\torch_geometric\datasets\nell.py", line 62, in __init__
super().__init__(root, transform, pre_transform)
File "C:\Users\13466\anaconda3\lib\site-packages\torch_geometric\data\in_memory_dataset.py", line 57, in __init__
super().__init__(root, transform, pre_transform, pre_filter, log)
File "C:\Users\13466\anaconda3\lib\site-packages\torch_geometric\data\dataset.py", line 97, in __init__
self._process()
File "C:\Users\13466\anaconda3\lib\site-packages\torch_geometric\data\dataset.py", line 230, in _process
self.process()
File "C:\Users\13466\anaconda3\lib\site-packages\torch_geometric\datasets\nell.py", line 82, in process
data = read_planetoid_data(self.raw_dir, 'nell.0.001')
File "C:\Users\13466\anaconda3\lib\site-packages\torch_geometric\io\planetoid.py", line 53, in read_planetoid_data
row, col, value = SparseTensor.from_dense(x).coo()
AttributeError: type object 'SparseTensor' has no attribute 'from_dense'
### Environment
* PyG version:2.3.1
* PyTorch version:2.0.1
* OS:Windows 11
* Python version:3.10
* CUDA/cuDNN version:
* How you installed PyTorch and PyG (`conda`, `pip`, source):pip
* Any other relevant information (*e.g.*, version of `torch-scatter`):
| You need to install `torch_sparse` to fix it. | 2023-05-18T07:09:17 |
|
pyg-team/pytorch_geometric | 7,391 | pyg-team__pytorch_geometric-7391 | [
"7390"
]
| dfd32668aea953c8bb56f97364d8e028f267bde6 | diff --git a/torch_geometric/explain/algorithm/captum_explainer.py b/torch_geometric/explain/algorithm/captum_explainer.py
--- a/torch_geometric/explain/algorithm/captum_explainer.py
+++ b/torch_geometric/explain/algorithm/captum_explainer.py
@@ -150,7 +150,7 @@ def forward(
metadata = None
captum_model = CaptumModel(model, mask_type, index)
- self.attribution_method = self.attribution_method(captum_model)
+ attribution_method = self.attribution_method(captum_model)
# In captum, the target is the index for which
# the attribution is computed.
@@ -159,7 +159,7 @@ def forward(
else:
target = target[index]
- attributions = self.attribution_method.attribute(
+ attributions = attribution_method.attribute(
inputs=inputs,
target=target,
additional_forward_args=add_forward_args,
| `CaptumExplainer` cannot be called multiple times in a row without creating an error
### 🐛 Describe the bug
Trying to call an instance of `CaptumExplainer` twice raises an error.
To replicate, change https://github.com/pyg-team/pytorch_geometric/blob/dfd32668aea953c8bb56f97364d8e028f267bde6/examples/explain/captum_explainer.py#L60
to
```python
explanation = explainer(data.x, data.edge_index, index=node_index)
explanation_2 = explanation = explainer(data.x, data.edge_index, index=node_index+1)
```
which will raise
```
Traceback (most recent call last):
File ".../pytorch_geometric/examples/explain/captum_explainer.py", line 62, in <module>
explanation_2 = explainer(data.x, data.edge_index, index=11)
File ".../pytorch_geometric/torch_geometric/explain/explainer.py", line 198, in __call__
explanation = self.algorithm(
File ".../pytorch_geometric/env/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File ".../torch_geometric/explain/algorithm/captum_explainer.py", line 153, in forward
self.attribution_method = self.attribution_method(captum_model)
TypeError: 'IntegratedGradients' object is not callable
```
This is because on the second call, the `CaptumExplainer` tries to recreates an attribution method from `captum`:
https://github.com/pyg-team/pytorch_geometric/blob/dfd32668aea953c8bb56f97364d8e028f267bde6/torch_geometric/explain/algorithm/captum_explainer.py#L153
### Environment
* PyG version: (from source, latest commit to date on master)
* PyTorch version: 2.0.0
| 2023-05-18T13:33:50 |
||
pyg-team/pytorch_geometric | 7,536 | pyg-team__pytorch_geometric-7536 | [
"7532"
]
| 0f0e0da31d2f2848d7f0bb77e9ffcf1911d5482f | diff --git a/torch_geometric/io/planetoid.py b/torch_geometric/io/planetoid.py
--- a/torch_geometric/io/planetoid.py
+++ b/torch_geometric/io/planetoid.py
@@ -30,9 +30,9 @@ def read_planetoid_data(folder, prefix):
# as zero vectors to `tx` and `ty`.
len_test_indices = (test_index.max() - test_index.min()).item() + 1
- tx_ext = torch.zeros(len_test_indices, tx.size(1))
+ tx_ext = torch.zeros(len_test_indices, tx.size(1), dtype=tx.dtype)
tx_ext[sorted_test_index - test_index.min(), :] = tx
- ty_ext = torch.zeros(len_test_indices, ty.size(1))
+ ty_ext = torch.zeros(len_test_indices, ty.size(1), dtype=ty.dtype)
ty_ext[sorted_test_index - test_index.min(), :] = ty
tx, ty = tx_ext, ty_ext
| Planetoid dtype mismatch for CiteSeer
### 🐛 Describe the bug
I find that I can't load the CiteSeer dataset with double precision
```python
import torch_geometric as tg
tg.datasets.Planetoid(root="/tmp", name="CiteSeer")
```
I get this error
```
File /user/work/pc22286/mambaforge/envs/dkm/lib/python3.11/site-packages/torch_geometric/io/planetoid.py:34, in read_planetoid_data(folder, prefix)
31 len_test_indices = (test_index.max() - test_index.min()).item() + 1
33 tx_ext = torch.zeros(len_test_indices, tx.size(1))
---> 34 tx_ext[sorted_test_index - test_index.min(), :] = tx
35 ty_ext = torch.zeros(len_test_indices, ty.size(1))
36 ty_ext[sorted_test_index - test_index.min(), :] = ty
RuntimeError: Index put requires the source and destination dtypes match, got Double for the destination and Float for the source.
```
Fortunately, there is a workaround if I set the default precision to single precision
```python
import torch as t
t.set_default_dtype(t.float32)
tg.datasets.Planetoid(root="/tmp", name="CiteSeer") ## success, this time
```
and then I will convert to double precision manually later. Not a bit problem, but I expected to be able to use float64
### Environment
* PyG version: 2.3.1
* PyTorch version: 2.0.1
* OS: CentOS 7
* Python version: 3.11.3
* CUDA/cuDNN version: 12.0
* How you installed PyTorch and PyG (`conda`, `pip`, source): installed torch by conda (mamba), PyG by pip
* Any other relevant information (*e.g.*, version of `torch-scatter`):
| 2023-06-07T14:10:47 |
||
pyg-team/pytorch_geometric | 7,654 | pyg-team__pytorch_geometric-7654 | [
"7653"
]
| 2ec1c4bbd9247f054855abd77acd6d63ed97bab3 | diff --git a/torch_geometric/utils/__init__.py b/torch_geometric/utils/__init__.py
--- a/torch_geometric/utils/__init__.py
+++ b/torch_geometric/utils/__init__.py
@@ -6,7 +6,6 @@
from .degree import degree
from .softmax import softmax
from .dropout import dropout_adj, dropout_node, dropout_edge, dropout_path
-from .augmentation import shuffle_node, mask_feature, add_random_edge
from .sort_edge_index import sort_edge_index
from .coalesce import coalesce
from .undirected import is_undirected, to_undirected
@@ -47,6 +46,7 @@
from .negative_sampling import (negative_sampling, batched_negative_sampling,
structured_negative_sampling,
structured_negative_sampling_feasible)
+from .augmentation import shuffle_node, mask_feature, add_random_edge
from .tree_decomposition import tree_decomposition
from .embedding import get_embeddings
from .trim_to_layer import trim_to_layer
@@ -62,9 +62,6 @@
'dropout_edge',
'dropout_path',
'dropout_adj',
- 'shuffle_node',
- 'mask_feature',
- 'add_random_edge',
'sort_edge_index',
'coalesce',
'is_undirected',
@@ -130,6 +127,9 @@
'batched_negative_sampling',
'structured_negative_sampling',
'structured_negative_sampling_feasible',
+ 'shuffle_node',
+ 'mask_feature',
+ 'add_random_edge',
'tree_decomposition',
'get_embeddings',
'trim_to_layer',
diff --git a/torch_geometric/utils/augmentation.py b/torch_geometric/utils/augmentation.py
--- a/torch_geometric/utils/augmentation.py
+++ b/torch_geometric/utils/augmentation.py
@@ -3,12 +3,14 @@
import torch
from torch import Tensor
-from torch_geometric.utils import scatter
-from torch_geometric.utils.num_nodes import maybe_num_nodes
+from torch_geometric.utils import negative_sampling, scatter
-def shuffle_node(x: Tensor, batch: Optional[Tensor] = None,
- training: bool = True) -> Tuple[Tensor, Tensor]:
+def shuffle_node(
+ x: Tensor,
+ batch: Optional[Tensor] = None,
+ training: bool = True,
+) -> Tuple[Tensor, Tensor]:
r"""Randomly shuffle the feature matrix :obj:`x` along the
first dimmension.
@@ -67,9 +69,13 @@ def shuffle_node(x: Tensor, batch: Optional[Tensor] = None,
return x[perm], perm
-def mask_feature(x: Tensor, p: float = 0.5, mode: str = 'col',
- fill_value: float = 0.,
- training: bool = True) -> Tuple[Tensor, Tensor]:
+def mask_feature(
+ x: Tensor,
+ p: float = 0.5,
+ mode: str = 'col',
+ fill_value: float = 0.,
+ training: bool = True,
+) -> Tuple[Tensor, Tensor]:
r"""Randomly masks feature from the feature matrix
:obj:`x` with probability :obj:`p` using samples from
a Bernoulli distribution.
@@ -149,9 +155,13 @@ def mask_feature(x: Tensor, p: float = 0.5, mode: str = 'col',
return x, mask
-def add_random_edge(edge_index, p: float, force_undirected: bool = False,
- num_nodes: Optional[Union[Tuple[int], int]] = None,
- training: bool = True) -> Tuple[Tensor, Tensor]:
+def add_random_edge(
+ edge_index,
+ p: float = 0.5,
+ force_undirected: bool = False,
+ num_nodes: Optional[Union[int, Tuple[int, int]]] = None,
+ training: bool = True,
+) -> Tuple[Tensor, Tensor]:
r"""Randomly adds edges to :obj:`edge_index`.
The method returns (1) the retained :obj:`edge_index`, (2) the added
@@ -160,6 +170,7 @@ def add_random_edge(edge_index, p: float, force_undirected: bool = False,
Args:
edge_index (LongTensor): The edge indices.
p (float): Ratio of added edges to the existing edges.
+ (default: :obj:`0.5`)
force_undirected (bool, optional): If set to :obj:`True`,
added edges will be undirected.
(default: :obj:`False`)
@@ -208,30 +219,24 @@ def add_random_edge(edge_index, p: float, force_undirected: bool = False,
[1, 3, 2]])
"""
if p < 0. or p > 1.:
- raise ValueError(f'Ratio of added edges has to be between 0 and 1 '
- f'(got {p}')
+ raise ValueError(f"Ratio of added edges has to be between 0 and 1 "
+ f"(got '{p}')")
if force_undirected and isinstance(num_nodes, (tuple, list)):
- raise RuntimeError('`force_undirected` is not supported for'
- ' heterogeneous graphs')
+ raise RuntimeError("'force_undirected' is not supported for "
+ "bipartite graphs")
device = edge_index.device
if not training or p == 0.0:
edge_index_to_add = torch.tensor([[], []], device=device)
return edge_index, edge_index_to_add
- if not isinstance(num_nodes, (tuple, list)):
- num_nodes = (num_nodes, num_nodes)
- num_src_nodes = maybe_num_nodes(edge_index, num_nodes[0])
- num_dst_nodes = maybe_num_nodes(edge_index, num_nodes[1])
-
- num_edges_to_add = round(edge_index.size(1) * p)
- row = torch.randint(0, num_src_nodes, size=(num_edges_to_add, ))
- col = torch.randint(0, num_dst_nodes, size=(num_edges_to_add, ))
+ edge_index_to_add = negative_sampling(
+ edge_index=edge_index,
+ num_nodes=num_nodes,
+ num_neg_samples=round(edge_index.size(1) * p),
+ force_undirected=force_undirected,
+ )
- if force_undirected:
- mask = row < col
- row, col = row[mask], col[mask]
- row, col = torch.cat([row, col]), torch.cat([col, row])
- edge_index_to_add = torch.stack([row, col], dim=0).to(device)
edge_index = torch.cat([edge_index, edge_index_to_add], dim=1)
+
return edge_index, edge_index_to_add
diff --git a/torch_geometric/utils/negative_sampling.py b/torch_geometric/utils/negative_sampling.py
--- a/torch_geometric/utils/negative_sampling.py
+++ b/torch_geometric/utils/negative_sampling.py
@@ -9,11 +9,13 @@
from torch_geometric.utils.num_nodes import maybe_num_nodes
-def negative_sampling(edge_index: Tensor,
- num_nodes: Optional[Union[int, Tuple[int, int]]] = None,
- num_neg_samples: Optional[int] = None,
- method: str = "sparse",
- force_undirected: bool = False) -> Tensor:
+def negative_sampling(
+ edge_index: Tensor,
+ num_nodes: Optional[Union[int, Tuple[int, int]]] = None,
+ num_neg_samples: Optional[int] = None,
+ method: str = "sparse",
+ force_undirected: bool = False,
+) -> Tensor:
r"""Samples random negative edges of a graph given by :attr:`edge_index`.
Args:
| diff --git a/test/utils/test_augmentation.py b/test/utils/test_augmentation.py
--- a/test/utils/test_augmentation.py
+++ b/test/utils/test_augmentation.py
@@ -1,6 +1,7 @@
import pytest
import torch
+from torch_geometric import seed_everything
from torch_geometric.utils import (
add_random_edge,
is_undirected,
@@ -77,28 +78,26 @@ def test_add_random_edge():
assert out[0].tolist() == edge_index.tolist()
assert out[1].tolist() == [[], []]
- torch.manual_seed(5)
+ seed_everything(5)
out = add_random_edge(edge_index, p=0.5)
- assert out[0].tolist() == [[0, 1, 1, 2, 2, 3, 3, 2, 3],
- [1, 0, 2, 1, 3, 2, 1, 2, 2]]
-
- assert out[1].tolist() == [[3, 2, 3], [1, 2, 2]]
+ assert out[0].tolist() == [[0, 1, 1, 2, 2, 3, 3, 1, 2],
+ [1, 0, 2, 1, 3, 2, 0, 3, 0]]
+ assert out[1].tolist() == [[3, 1, 2], [0, 3, 0]]
- torch.manual_seed(6)
+ seed_everything(6)
out = add_random_edge(edge_index, p=0.5, force_undirected=True)
- assert out[0].tolist() == [[0, 1, 1, 2, 2, 3, 1, 2],
- [1, 0, 2, 1, 3, 2, 2, 1]]
- assert out[1].tolist() == [[1, 2], [2, 1]]
+ assert out[0].tolist() == [[0, 1, 1, 2, 2, 3, 1, 3],
+ [1, 0, 2, 1, 3, 2, 3, 1]]
+ assert out[1].tolist() == [[1, 3], [3, 1]]
assert is_undirected(out[0])
assert is_undirected(out[1])
- # test with bipartite graph
- torch.manual_seed(7)
+ # Test for bipartite graph:
+ seed_everything(7)
edge_index = torch.tensor([[0, 1, 2, 3, 4, 5], [2, 3, 1, 4, 2, 1]])
- with pytest.raises(RuntimeError,
- match="not supported for heterogeneous graphs"):
- out = add_random_edge(edge_index, p=0.5, force_undirected=True,
- num_nodes=(6, 5))
+ with pytest.raises(RuntimeError, match="not supported for bipartite"):
+ add_random_edge(edge_index, force_undirected=True, num_nodes=(6, 5))
out = add_random_edge(edge_index, p=0.5, num_nodes=(6, 5))
- out[0].tolist() == [[0, 1, 2, 3, 4, 5, 3, 4, 1],
- [2, 3, 1, 4, 2, 1, 1, 3, 2]]
+ assert out[0].tolist() == [[0, 1, 2, 3, 4, 5, 2, 0, 2],
+ [2, 3, 1, 4, 2, 1, 0, 4, 2]]
+ assert out[1].tolist() == [[2, 0, 2], [0, 4, 2]]
| add_random_edge does not check existing edges
### 🐛 Describe the bug
Calling add_random_edge may introduce duplicate edges that already existing in the graph. This may have unintended downstream consequences.
Minimal code to reproduce.
```python
edge_index = torch.IntTensor(([0, 1, 2, 0, 1, 2, 0, 1, 2], [0, 0, 0, 1, 1, 1, 2, 2, 2]))
torch_geometric.utils.add_random_edge(edge_index, 0.4, num_nodes=3)
```
| 2023-06-27T11:53:07 |
|
pyg-team/pytorch_geometric | 7,655 | pyg-team__pytorch_geometric-7655 | [
"7651"
]
| 10b737322cfb39376a3d535df0c1a11c91f5adaa | diff --git a/torch_geometric/datasets/utils/cheatsheet.py b/torch_geometric/datasets/utils/cheatsheet.py
--- a/torch_geometric/datasets/utils/cheatsheet.py
+++ b/torch_geometric/datasets/utils/cheatsheet.py
@@ -4,7 +4,7 @@
from typing import Any, List, Optional
-def paper_link(cls: str) -> str:
+def paper_link(cls: str) -> Optional[str]:
cls = importlib.import_module('torch_geometric.datasets').__dict__[cls]
match = re.search('<.+?>', inspect.getdoc(cls), flags=re.DOTALL)
return None if match is None else match.group().replace('\n', ' ')[1:-1]
diff --git a/torch_geometric/nn/conv/utils/cheatsheet.py b/torch_geometric/nn/conv/utils/cheatsheet.py
--- a/torch_geometric/nn/conv/utils/cheatsheet.py
+++ b/torch_geometric/nn/conv/utils/cheatsheet.py
@@ -1,15 +1,16 @@
import importlib
import inspect
import re
+from typing import Optional
-def paper_title(cls: str) -> str:
+def paper_title(cls: str) -> Optional[str]:
cls = importlib.import_module('torch_geometric.nn.conv').__dict__[cls]
match = re.search('`\".+?\"', inspect.getdoc(cls), flags=re.DOTALL)
return None if match is None else match.group().replace('\n', ' ')[2:-1]
-def paper_link(cls: str) -> str:
+def paper_link(cls: str) -> Optional[str]:
cls = importlib.import_module('torch_geometric.nn.conv').__dict__[cls]
match = re.search('<.+?>', inspect.getdoc(cls), flags=re.DOTALL)
return None if match is None else match.group().replace('\n', ' ')[1:-1]
| Broken link in the GNN Cheat sheet
### 📚 Describe the documentation issue
In the cheatsheet [https://pytorch-geometric.readthedocs.io/en/latest/cheatsheet/gnn_cheatsheet.html](https://pytorch-geometric.readthedocs.io/en/latest/cheatsheet/gnn_cheatsheet.html). The paper link for SimpleConv points to a non-existant page. There should not be invalid links on the page.
[SimpleConv](https://pytorch-geometric.readthedocs.io/en/latest/generated/torch_geometric.nn.conv.SimpleConv.html#torch_geometric.nn.conv.SimpleConv) ([Paper](https://pytorch-geometric.readthedocs.io/en/latest/cheatsheet/None))
### Suggest a potential alternative/fix
I see the code does
```
not torch_geometric.nn.conv.utils.processes_point_clouds(cls) %}
* - :class:`~torch_geometric.nn.conv.{{ cls }}` (`Paper <{{ torch_geometric.nn.conv.utils.paper_link(cls) }}>`__)
- {% if torch_geometric.nn.conv.utils.supports_sparse_tensor(cls) %}✓{% endif %}
- {% if
```
If there is a valid appropriate paper - then we should point to that; if not then I suggest having a new document in this repository as the target for this link. The document should describe what SimpleConv does and why there is not paper for it; I assume because it is a very simple example.
| 2023-06-27T13:35:28 |
||
pyg-team/pytorch_geometric | 7,772 | pyg-team__pytorch_geometric-7772 | [
"7745"
]
| 67c0acc95dacfc5071efd8651c7478e69924565f | diff --git a/torch_geometric/nn/fx.py b/torch_geometric/nn/fx.py
--- a/torch_geometric/nn/fx.py
+++ b/torch_geometric/nn/fx.py
@@ -1,4 +1,5 @@
import copy
+import warnings
from typing import Any, Dict, Optional
import torch
@@ -127,6 +128,13 @@ def transform(self) -> GraphModule:
# We iterate over each node and determine its output level
# (node-level, edge-level) by filling `self._state`:
for node in list(self.graph.nodes):
+ if node.op == 'call_function' and 'training' in node.kwargs:
+ warnings.warn(f"Found function '{node.name}' with keyword "
+ f"argument 'training'. During FX tracing, this "
+ f"will likely be baked in as a constant value. "
+ f"Consider replacing this function by a module "
+ f"to properly encapsulate its training flag.")
+
if node.op == 'placeholder':
if node.name not in self._state:
if 'edge' in node.name or 'adj' in node.name:
diff --git a/torch_geometric/nn/models/basic_gnn.py b/torch_geometric/nn/models/basic_gnn.py
--- a/torch_geometric/nn/models/basic_gnn.py
+++ b/torch_geometric/nn/models/basic_gnn.py
@@ -2,7 +2,6 @@
from typing import Any, Callable, Dict, List, Optional, Tuple, Union
import torch
-import torch.nn.functional as F
from torch import Tensor
from torch.nn import Linear, ModuleList
from tqdm import tqdm
@@ -83,7 +82,7 @@ def __init__(
self.hidden_channels = hidden_channels
self.num_layers = num_layers
- self.dropout = dropout
+ self.dropout = torch.nn.Dropout(p=dropout)
self.act = activation_resolver(act, **(act_kwargs or {}))
self.jk_mode = jk
self.act_first = act_first
@@ -232,7 +231,7 @@ def forward(
x = self.norms[i](x)
if self.act is not None and not self.act_first:
x = self.act(x)
- x = F.dropout(x, p=self.dropout, training=self.training)
+ x = self.dropout(x)
if hasattr(self, 'jk'):
xs.append(x)
@@ -537,7 +536,7 @@ def init_conv(self, in_channels: Union[int, Tuple[int, int]],
Conv = GATConv if not v2 else GATv2Conv
return Conv(in_channels, out_channels, heads=heads, concat=concat,
- dropout=self.dropout, **kwargs)
+ dropout=self.dropout.p, **kwargs)
class PNA(BasicGNN):
| diff --git a/test/nn/test_fx.py b/test/nn/test_fx.py
new file mode 100644
--- /dev/null
+++ b/test/nn/test_fx.py
@@ -0,0 +1,22 @@
+import torch
+import torch.nn.functional as F
+from torch import Tensor
+
+
+def test_dropout():
+ class MyModule(torch.nn.Module):
+ def forward(self, x: Tensor) -> Tensor:
+ return F.dropout(x, p=1.0, training=self.training)
+
+ module = MyModule()
+ graph_module = torch.fx.symbolic_trace(module)
+ graph_module.recompile()
+
+ x = torch.randn(4)
+
+ graph_module.train()
+ assert torch.allclose(graph_module(x), torch.zeros_like(x))
+
+ # This is certainly undesired behavior due to tracing :(
+ graph_module.eval()
+ assert torch.allclose(graph_module(x), torch.zeros_like(x))
diff --git a/test/nn/test_model_summary.py b/test/nn/test_model_summary.py
--- a/test/nn/test_model_summary.py
+++ b/test/nn/test_model_summary.py
@@ -59,6 +59,7 @@ def test_summary_basic(gcn):
| Layer | Input Shape | Output Shape | #Param |
|---------------------+--------------------+----------------+----------|
| GCN | [100, 32], [2, 20] | [100, 32] | 1,072 |
+| ├─(dropout)Dropout | [100, 16] | [100, 16] | -- |
| ├─(act)ReLU | [100, 16] | [100, 16] | -- |
| ├─(convs)ModuleList | -- | -- | 1,072 |
| │ └─(0)GCNConv | [100, 32], [2, 20] | [100, 16] | 528 |
@@ -75,6 +76,7 @@ def test_summary_with_sparse_tensor(gcn):
| Layer | Input Shape | Output Shape | #Param |
|---------------------+-----------------------+----------------+----------|
| GCN | [100, 32], [100, 100] | [100, 32] | 1,072 |
+| ├─(dropout)Dropout | [100, 16] | [100, 16] | -- |
| ├─(act)ReLU | [100, 16] | [100, 16] | -- |
| ├─(convs)ModuleList | -- | -- | 1,072 |
| │ └─(0)GCNConv | [100, 32], [100, 100] | [100, 16] | 528 |
@@ -91,6 +93,7 @@ def test_summary_with_max_depth(gcn):
| Layer | Input Shape | Output Shape | #Param |
|---------------------+--------------------+----------------+----------|
| GCN | [100, 32], [2, 20] | [100, 32] | 1,072 |
+| ├─(dropout)Dropout | [100, 16] | [100, 16] | -- |
| ├─(act)ReLU | [100, 16] | [100, 16] | -- |
| ├─(convs)ModuleList | -- | -- | 1,072 |
+---------------------+--------------------+----------------+----------+
@@ -106,6 +109,7 @@ def test_summary_with_leaf_module(gcn):
| Layer | Input Shape | Output Shape | #Param |
|-----------------------------------------+--------------------+----------------+----------|
| GCN | [100, 32], [2, 20] | [100, 32] | 1,072 |
+| ├─(dropout)Dropout | [100, 16] | [100, 16] | -- |
| ├─(act)ReLU | [100, 16] | [100, 16] | -- |
| ├─(convs)ModuleList | -- | -- | 1,072 |
| │ └─(0)GCNConv | [100, 32], [2, 20] | [100, 16] | 528 |
diff --git a/test/nn/test_to_hetero_transformer.py b/test/nn/test_to_hetero_transformer.py
--- a/test/nn/test_to_hetero_transformer.py
+++ b/test/nn/test_to_hetero_transformer.py
@@ -277,7 +277,8 @@ def test_to_hetero_basic():
assert out['author'].size() == (8, 16)
model = Net10()
- model = to_hetero(model, metadata, debug=False)
+ with pytest.warns(UserWarning, match="with keyword argument 'training'"):
+ model = to_hetero(model, metadata, debug=False)
out = model(x_dict, edge_index_dict)
assert isinstance(out, dict) and len(out) == 2
assert out['paper'].size() == (100, 32)
| `self.training` is not passed to dropout layer after `to_hetero()` converts model
### 🐛 Describe the bug
Even when a user runs `model.eval()`, the model runs the dropout layer still with `training=True` if the model is converted with `to_hetero(model)`.
```python
import torch
import torch.nn.functional as F
from torch_geometric.nn import SAGEConv, to_hetero
from torch_geometric.data import HeteroData
class GNN(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv = SAGEConv((-1, -1), 1)
def forward(self, x, edge_index):
x = self.conv(x, edge_index)
return F.dropout(x, p=0.5, training=self.training)
def main():
data = HeteroData()
data["paper"].x = torch.randn(100, 3)
data["author"].x = torch.randn(100, 5)
data["author", "writes", "paper"].edge_index = torch.randint(0, 100, (2, 100))
data["paper", "written", "author"].edge_index = torch.randint(0, 100, (2, 100))
model = GNN()
model = to_hetero(model, data.metadata(), aggr="sum")
model.graph.print_tabular()
model.eval()
out1 = model(data.x_dict, data.edge_index_dict)
out2 = model(data.x_dict, data.edge_index_dict)
assert all(torch.allclose(o1, o2) for o1, o2 in zip(out1.values(), out2.values()))
if __name__ == "__main__":
main()
```
```
opcode name target args kwargs
------------- ---------------------------------- ------------------------------------- ----------------------------------------------------------- ----------------------------------------------
placeholder x x () {}
call_function x_dict <function get_dict at 0x7f1a4ab8dea0> (x,) {}
call_method x__paper get (x_dict, 'paper', None) {}
call_method x__author get (x_dict, 'author', None) {}
placeholder edge_index edge_index () {}
call_function edge_index_dict <function get_dict at 0x7f1a4ab8dea0> (edge_index,) {}
call_method edge_index__author__writes__paper get (edge_index_dict, ('author', 'writes', 'paper'), None) {}
call_method edge_index__paper__written__author get (edge_index_dict, ('paper', 'written', 'author'), None) {}
call_module conv__paper conv.author__writes__paper ((x__author, x__paper), edge_index__author__writes__paper) {}
call_module conv__author conv.paper__written__author ((x__paper, x__author), edge_index__paper__written__author) {}
call_function dropout__paper <function dropout at 0x7f1a61582170> (conv__paper,) {'p': 0.5, 'training': True, 'inplace': False}
call_function dropout__author <function dropout at 0x7f1a61582170> (conv__author,) {'p': 0.5, 'training': True, 'inplace': False}
output output output ({'paper': dropout__paper, 'author': dropout__author},) {}
Traceback (most recent call last):
File "/workspaces/pytorch_geometric/test.py", line 34, in <module>
main()
File "/workspaces/pytorch_geometric/test.py", line 30, in main
assert all(torch.allclose(o1, o2) for o1, o2 in zip(out1.values(), out2.values()))
AssertionError
```
### Environment
* PyG version: 9bc701731
* PyTorch version: 2.0.1
* OS: Linux codespaces-dc5000 5.15.0-1041-azure #48-Ubuntu SMP Tue Jun 20 20:34:08 UTC 2023 x86_64 x86_64 x86_64 GNU/Linux
* Python version: 3.10.8
* CUDA/cuDNN version: n/a
* How you installed PyTorch and PyG (`conda`, `pip`, source):
* Any other relevant information (*e.g.*, version of `torch-scatter`):
| This issue arises only when a user has `F.dropout(..., training=self.training)` in their model directly because `to_hetero` doesn't touch submodules of the user's model at all:
https://github.com/pyg-team/pytorch_geometric/blob/165b68eebdc4d5bf44e56ca12f081aa55020a883/torch_geometric/nn/fx.py#L274-L276
This issue stems from `torch.fx.symbolic_trace` being unable to preserve the reference to `self.training`. During symbolic tracing, it sets a bool constant as the argument of `torch.nn.functional.dropout(..., training=True|False)`.
### Workaround
One way to avoid this issue is to replace the functional form `torch.nn.functional.dropout(...)` with its class form `torch.nn.Dropout(...)`
```diff
class GNN(torch.nn.Module):
def __init__(self):
super().__init__()
...
+ self.dropout = torch.nn.Dropout(p=0.5)
def forward(self, x, edge_index):
...
- return F.dropout(x, p=0.5, training=self.training)
+ return self.dropout(x)
```
However, I cannot think of a way to fix this issue on PyG side so that all existing user code is automatically fixed in a newer PyG release.
References:
- https://pytorch.org/docs/2.0/fx.html#miscellanea
- https://pytorch.org/docs/2.0/fx.html#dynamic-control-flow
Thank you for this great catch. Shall we add a warning for this in `to_hetero`? Furthermore, is there any other workaround for this from PyTorch side (except using the module instance)? | 2023-07-19T10:57:01 |
pyg-team/pytorch_geometric | 7,775 | pyg-team__pytorch_geometric-7775 | [
"7743"
]
| 7a395bf935bc2032f8a8fc87e8121faa60535798 | diff --git a/torch_geometric/sampler/utils.py b/torch_geometric/sampler/utils.py
--- a/torch_geometric/sampler/utils.py
+++ b/torch_geometric/sampler/utils.py
@@ -1,13 +1,12 @@
from typing import Any, Dict, List, Optional, Tuple, TypeVar, Union
-import numpy as np
import torch
from torch import Tensor
from torch_geometric.data import Data, HeteroData
from torch_geometric.data.storage import EdgeStorage
from torch_geometric.typing import NodeType, OptTensor
-from torch_geometric.utils import coalesce, index_sort
+from torch_geometric.utils import coalesce, index_sort, lexsort
from torch_geometric.utils.sparse import index2ptr
# Edge Layout Conversion ######################################################
@@ -22,14 +21,7 @@ def sort_csc(
col, perm = index_sort(col)
return row[perm], col, perm
else:
- # We use `np.lexsort` to sort based on multiple keys.
- # TODO There does not seem to exist a PyTorch equivalent yet :(
- perm = np.lexsort([
- src_node_time[row].detach().cpu().numpy(),
- col.detach().cpu().numpy()
- ])
- perm = torch.from_numpy(perm).to(col.device)
-
+ perm = lexsort([src_node_time[row], col])
return row[perm], col[perm], perm
diff --git a/torch_geometric/utils/__init__.py b/torch_geometric/utils/__init__.py
--- a/torch_geometric/utils/__init__.py
+++ b/torch_geometric/utils/__init__.py
@@ -7,6 +7,7 @@
from .softmax import softmax
from .dropout import dropout_adj, dropout_node, dropout_edge, dropout_path
from .sort_edge_index import sort_edge_index
+from .lexsort import lexsort
from .coalesce import coalesce
from .undirected import is_undirected, to_undirected
from .loop import (contains_self_loops, remove_self_loops,
@@ -63,6 +64,7 @@
'dropout_path',
'dropout_adj',
'sort_edge_index',
+ 'lexsort',
'coalesce',
'is_undirected',
'to_undirected',
diff --git a/torch_geometric/utils/lexsort.py b/torch_geometric/utils/lexsort.py
new file mode 100644
--- /dev/null
+++ b/torch_geometric/utils/lexsort.py
@@ -0,0 +1,41 @@
+from typing import List
+
+import numpy as np
+import torch
+from torch import Tensor
+
+import torch_geometric.typing
+
+
+def lexsort(
+ keys: List[Tensor],
+ dim: int = -1,
+ descending: bool = False,
+) -> Tensor:
+ r"""Performs an indirect stable sort using a sequence of keys.
+
+ Given multiple sorting keys, returns an array of integer indices that
+ describe their sort order.
+ The last key in the sequence is used for the primary sort order, the
+ second-to-last key for the secondary sort order, and so on.
+
+ Args:
+ keys ([torch.Tensor]): The :math:`k` different columns to be sorted.
+ The last key is the primary sort key.
+ dim (int, optional): The dimension to sort along. (default: :obj:`-1`)
+ descending (bool, optional): Controls the sorting order (ascending or
+ descending). (default: :obj:`False`)
+ """
+ assert len(keys) >= 1
+
+ if not torch_geometric.typing.WITH_PT113:
+ keys = [k.neg() for k in keys] if descending else keys
+ out = np.lexsort([k.detach().cpu().numpy() for k in keys], axis=dim)
+ return torch.from_numpy(out).to(keys[0].device)
+
+ kwargs = dict(dim=dim, descending=descending, stable=True)
+ out = keys[0].argsort(**kwargs)
+ for k in keys[1:]:
+ out = out.gather(dim, k.gather(dim, out).argsort(**kwargs))
+
+ return out
| diff --git a/test/utils/test_lexsort.py b/test/utils/test_lexsort.py
new file mode 100644
--- /dev/null
+++ b/test/utils/test_lexsort.py
@@ -0,0 +1,11 @@
+import numpy as np
+import torch
+
+from torch_geometric.utils import lexsort
+
+
+def test_lexsort():
+ keys = [torch.randn(100) for _ in range(3)]
+
+ expected = np.lexsort([key.numpy() for key in keys])
+ assert torch.equal(lexsort(keys), torch.from_numpy(expected))
| PyTorch implementation of np.lexsort() in `sort_csc` util fucnction
### 🛠 Proposed Refactor
Hi,
I came upon this lexsort implementation in the `sort_csc` function in the following line:
https://github.com/pyg-team/pytorch_geometric/blob/9c79ce8570df194c15e4e6857c8b86d757dbbcb7/torch_geometric/sampler/utils.py#L27
And looks like an unofficial PyTorch implementation is proposed here:
https://discuss.pytorch.org/t/numpy-lexsort-equivalent-in-pytorch/47850/5?u=ebrahim.pichka
As below (with minor changes):
```py
def torch_lexsort(keys, dim=-1):
if len(keys) < 2:
raise ValueError(f"keys must be at least 2 sequences, but {len(keys)=}.")
idx = keys[0].argsort(dim=dim, stable=True)
for k in keys[1:]:
idx = idx.gather(dim, k.gather(dim, idx).argsort(dim=dim, stable=True))
return idx
```
I also ran some tests on the proposed implementation as follows:
```py
In [1]: import torch; import numpy as np
In [2]: N = 1000000
In [3]: a = np.random.rand(N); b = np.random.randint(N // 4, size=N)
In [4]: a_t = torch.tensor(a); b_t = torch.tensor(b)
In [5]: a_t_cu, b_t_cu = a_t.to(torch.device("cuda")), b_t.to(torch.device("cuda"))
In [6]: def torch_lexsort(keys, dim=-1):
...: # defined as above
In [7]: %timeit -n 2 -r 20 np.lexsort([a, b])
302 ms ± 31.2 ms per loop (mean ± std. dev. of 20 runs, 2 loops each)
In [8]: %timeit -n 2 -r 20 torch_lexsort([a_t, b_t])
293 ms ± 35.1 ms per loop (mean ± std. dev. of 20 runs, 2 loops each)
In [9]: %timeit -n 20 -r 100 torch_lexsort([a_t_cu, b_t_cu])
The slowest run took 5.27 times longer than the fastest. This could mean that an intermediate result is being cached.
3.97 ms ± 334 µs per loop (mean ± std. dev. of 100 runs, 20 loops each)
In [10]: idx_np = np.lexsort([a, b]); idx_pt = torch_lexsort([a_t, b_t])
In [11]: (idx_np == idx_pt.numpy()).all()
Out[11]: True
```
Seems it helps with GPU support as well.
Thought it could replace the current implementation which detaches and recasts the tensor.
### Suggest a potential alternative/fix
Mentioned Above
| Amazing. Do you wanna send a PR for this? Otherwise, I can go ahead and make the corresponding change as well.
@rusty1s I'd like to make a PR.
Super :) | 2023-07-19T12:43:40 |
pyg-team/pytorch_geometric | 7,819 | pyg-team__pytorch_geometric-7819 | [
"7777"
]
| 9fbb906283038b66f1502f0218f8485bbe78d832 | diff --git a/torch_geometric/data/batch.py b/torch_geometric/data/batch.py
--- a/torch_geometric/data/batch.py
+++ b/torch_geometric/data/batch.py
@@ -60,6 +60,23 @@ class Batch(metaclass=DynamicInheritance):
:class:`torch_geometric.data.HeteroData`.
In addition, single graphs can be identified via the assignment vector
:obj:`batch`, which maps each node to its respective graph identifier.
+
+ :pyg:`PyG` allows modification to the underlying batching procedure by
+ overwriting the :meth:`~Data.__inc__` and :meth:`~Data.__cat_dim__`
+ functionalities.
+ The :meth:`~Data.__inc__` method defines the incremental count between two
+ consecutive graph attributes.
+ By default, :pyg:`PyG` increments attributes by the number of nodes
+ whenever their attribute names contain the substring :obj:`index`
+ (for historical reasons), which comes in handy for attributes such as
+ :obj:`edge_index` or :obj:`node_index`.
+ However, note that this may lead to unexpected behavior for attributes
+ whose names contain the substring :obj:`index` but should not be
+ incremented.
+ To make sure, it is best practice to always double-check the output of
+ batching.
+ Furthermore, :meth:`~Data.__cat_dim__` defines in which dimension graph
+ tensors of the same attribute should be concatenated together.
"""
@classmethod
def from_data_list(cls, data_list: List[BaseData],
| Batch.from_data_list seems to give different batch results depending on attribute name
### 🐛 Describe the bug
Hi, when using the `torch_geometric.data.Batch` and `torch_geometric.data.Data` class to organize my graph information, I realized the following feature:
```python
import torch
import torch_geometric
from torch_geometric.data import Data, Batch
data_list = []
for i in range(3):
data = Data(x=torch.randn(5, 3))
data.image_index = torch.ones(5)
data_list.append(data)
batch = Batch.from_data_list(data_list)
print(batch.image_index)
# Gives tensor([ 1., 1., 1., 1., 1., 6., 6., 6., 6., 6., 11., 11., 11., 11., 11.])
data_list = []
for i in range(3):
data = Data(x=torch.randn(5, 3))
data.foo = torch.ones(5)
data_list.append(data)
batch = Batch.from_data_list(data_list)
print(batch.foo)
# Gives tensor([1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.])
```
So it seems that one can get different "batched" results depending on the name of the attribute to which one stores the information. In fact, it seems one gets the former behavior when the string `index` is contained in the attribute name. Was this feature put in place by intention? FYI, I'm using verion `2.2.0`
### Environment
* PyG version: `2.2.0`
* PyTorch version: `1.13.1+cu116`
* OS: Linux
* Python version: `3.8.10`
* CUDA/cuDNN version: `cu116`
* How you installed PyTorch and PyG (`conda`, `pip`, source): `pip`
* Any other relevant information (*e.g.*, version of `torch-scatter`):
| Yes, this is intended and is controlled by `Data.__cat_dim__`:
```python
>>> Data().__cat_dim__('image_index', torch.ones(5,3))
-1
>>> Data().__cat_dim__('foo', torch.ones(5,3))
0
```
Yes, you can either rename your attribute or override `__inc__`.
I see, thanks for the clarification--but should this be standard practice? I tend to think of this as "unexpected behavior", especially given that it does not flag any warnings or messages when setting attributes names containing the string "index". I think either it should flag a warning or block users from setting attribute names containing the string "index"--instead of changing the contents silently.
Yeah, this is a design decision we made pretty early on, and it is hard to change now. I definitely agree that this can feel like "magic". How would you like us to add a warning? There should at least exist a convenient way to turn this off it the behavior is indeed desired.
I see, in that case I agree that there's no ideal solution. Maybe a disclaimer on the documentation for `Batch` and `Data` would suffice?
Let me do this :) | 2023-07-31T12:44:35 |
|
pyg-team/pytorch_geometric | 7,902 | pyg-team__pytorch_geometric-7902 | [
"7899"
]
| c0c060c192e68f4088757bc12b6e551736bda87b | diff --git a/torch_geometric/nn/aggr/set_transformer.py b/torch_geometric/nn/aggr/set_transformer.py
--- a/torch_geometric/nn/aggr/set_transformer.py
+++ b/torch_geometric/nn/aggr/set_transformer.py
@@ -105,6 +105,8 @@ def forward(
for decoder in self.decoders:
x = decoder(x)
+ x = x.nan_to_num()
+
return x.flatten(1, 2) if self.concat else x.mean(dim=1)
def __repr__(self) -> str:
| diff --git a/test/nn/aggr/test_set_transformer.py b/test/nn/aggr/test_set_transformer.py
--- a/test/nn/aggr/test_set_transformer.py
+++ b/test/nn/aggr/test_set_transformer.py
@@ -6,7 +6,7 @@
def test_set_transformer_aggregation():
x = torch.randn(6, 16)
- index = torch.tensor([0, 0, 1, 1, 1, 2])
+ index = torch.tensor([0, 0, 1, 1, 1, 3])
aggr = SetTransformerAggregation(16, num_seed_points=2, heads=2)
aggr.reset_parameters()
@@ -14,7 +14,9 @@ def test_set_transformer_aggregation():
'heads=2, layer_norm=False, dropout=0.0)')
out = aggr(x, index)
- assert out.size() == (3, 2 * 16)
+ assert out.size() == (4, 2 * 16)
+ assert out.isnan().sum() == 0
+ assert out[2].abs().sum() == 0
if is_full_test():
jit = torch.jit.script(aggr)
| SetTransformerAggregation returns `nan` for an unconnected node.
### 🐛 Describe the bug
When you use message passing with a `SetTransformerAggregation` and the input graph includes any number of nodes that are disconnected from the rest of the graph, the `SetTransformerAggregation` returns `nan` for those nodes. This is in contrast to the `SumAggregation` which returns plain `0`.
```python
from torch import Tensor
import torch
from torch_geometric.nn import MessagePassing, SetTransformerAggregation
from torch_geometric.data import Data, Batch
from torch_geometric.utils import sort_edge_index
class MPNN4Set(MessagePassing):
def __init__(self, dim, n_heads):
super(MPNN4Set, self).__init__()
self.dim = dim
self.aggregator = SetTransformerAggregation(dim, heads=n_heads)
def forward(self, h, edge_index, batch):
edge_index = sort_edge_index(edge_index, sort_by_row=False)
h = self.propagate(edge_index, x=h, num_nodes=h.size(0), batch=batch)
return h
def message(self, x_i, x_j, edge_index, num_nodes, batch):
return x_j
def aggregate(self, inputs: Tensor, index: Tensor, ptr: Tensor | None = None, dim_size: int | None = None) -> Tensor:
h = self.aggregator(inputs, index, ptr, dim_size)
return h
def update(self, aggr_out, batch):
return aggr_out
m = MPNN4Set(10, 2)
graphs = [Data(x=torch.randn((3, 10)), edge_index=torch.tensor([[0, 1], [1, 0]], dtype=torch.long)), Data(x=torch.randn((3, 10)), edge_index=torch.tensor([[0, 1, 2], [2, 1, 0]], dtype=torch.long))]
batched_graphs = Batch.from_data_list(graphs)
res = m(batched_graphs.x, batched_graphs.edge_index, batched_graphs.batch)
assert res[2].isnan().any().item() is True
```
I managed to debug this a little bit and it seems like this stems from the fact that in PyTorch's `MultiHeadAttention` implementation you shouldn't mask a row completely:
```python
import torch
from torch.nn import functional as F
from torch import nn
m = nn.MultiheadAttention(10, 2)
t1 = torch.randn((3, 3, 10))
mask = torch.tensor([[True, True, True], [False, False, False], [False, False, False]])
m(t1, t1, t1, mask) # Includes nan
```
This happens because the `unbatch` function will mask the row corresponding to that node because it is not connected to any other node.
### Environment
* PyG version: 2.3.1
* PyTorch version: 2.1.0a0+b5021ba
* OS: Ubuntu 22.04
* Python version: 3.10.6
* CUDA/cuDNN version: 12.2
* How you installed PyTorch and PyG (`conda`, `pip`, source): pip
| 2023-08-18T11:29:13 |
|
pyg-team/pytorch_geometric | 7,990 | pyg-team__pytorch_geometric-7990 | [
"7979"
]
| c37899806dbcfdc1a8979bc4042128c66bfd6bd4 | diff --git a/torch_geometric/nn/aggr/base.py b/torch_geometric/nn/aggr/base.py
--- a/torch_geometric/nn/aggr/base.py
+++ b/torch_geometric/nn/aggr/base.py
@@ -93,9 +93,15 @@ def reset_parameters(self):
pass
@disable_dynamic_shapes(required_args=['dim_size'])
- def __call__(self, x: Tensor, index: Optional[Tensor] = None,
- ptr: Optional[Tensor] = None, dim_size: Optional[int] = None,
- dim: int = -2, **kwargs) -> Tensor:
+ def __call__(
+ self,
+ x: Tensor,
+ index: Optional[Tensor] = None,
+ ptr: Optional[Tensor] = None,
+ dim_size: Optional[int] = None,
+ dim: int = -2,
+ **kwargs,
+ ) -> Tensor:
if dim >= x.dim() or dim < -x.dim():
raise ValueError(f"Encountered invalid dimension '{dim}' of "
@@ -116,7 +122,8 @@ def __call__(self, x: Tensor, index: Optional[Tensor] = None,
dim_size = int(index.max()) + 1 if index.numel() > 0 else 0
try:
- return super().__call__(x, index, ptr, dim_size, dim, **kwargs)
+ return super().__call__(x, index=index, ptr=ptr, dim_size=dim_size,
+ dim=dim, **kwargs)
except (IndexError, RuntimeError) as e:
if index is not None:
if index.numel() > 0 and dim_size <= int(index.max()):
diff --git a/torch_geometric/sampler/neighbor_sampler.py b/torch_geometric/sampler/neighbor_sampler.py
--- a/torch_geometric/sampler/neighbor_sampler.py
+++ b/torch_geometric/sampler/neighbor_sampler.py
@@ -217,13 +217,12 @@ def _sample(
# TODO Support induced subgraph sampling in `pyg-lib`.
if (torch_geometric.typing.WITH_PYG_LIB
and self.subgraph_type != SubgraphType.induced):
- # TODO (matthias) `return_edge_id` if edge features present
# TODO (matthias) Ideally, `seed` inherits dtype from `colptr`
colptrs = list(self.colptr_dict.values())
dtype = colptrs[0].dtype if len(colptrs) > 0 else torch.int64
seed = {k: v.to(dtype) for k, v in seed.items()}
- out = torch.ops.pyg.hetero_neighbor_sample(
+ args = (
self.node_types,
self.edge_types,
self.colptr_dict,
@@ -232,13 +231,20 @@ def _sample(
self.num_neighbors.get_mapped_values(self.edge_types),
self.node_time,
seed_time,
+ )
+ if torch_geometric.typing.WITH_WEIGHTED_NEIGHBOR_SAMPLE:
+ args += (None, )
+ args += (
True, # csc
self.replace,
self.subgraph_type != SubgraphType.induced,
self.disjoint,
self.temporal_strategy,
+ # TODO (matthias) `return_edge_id` if edge features present
True, # return_edge_id
)
+
+ out = torch.ops.pyg.hetero_neighbor_sample(*args)
row, col, node, edge, batch = out[:4] + (None, )
# `pyg-lib>0.1.0` returns sampled number of nodes/edges:
diff --git a/torch_geometric/transforms/random_link_split.py b/torch_geometric/transforms/random_link_split.py
--- a/torch_geometric/transforms/random_link_split.py
+++ b/torch_geometric/transforms/random_link_split.py
@@ -41,10 +41,10 @@ class RandomLinkSplit(BaseTransform):
(default: :obj:`0.2`)
is_undirected (bool): If set to :obj:`True`, the graph is assumed to be
undirected, and positive and negative samples will not leak
- (reverse) edge connectivity across different splits. Note that this
- only affects the graph split, label data will not be returned
- undirected.
- (default: :obj:`False`)
+ (reverse) edge connectivity across different splits. This only
+ affects the graph split, label data will not be returned
+ undirected. This option is ignored for bipartite edge types or
+ whenever :obj:`edge_type != rev_edge_type`. (default: :obj:`False`)
key (str, optional): The name of the attribute holding
ground-truth labels.
If :obj:`data[key]` does not exist, it will be automatically
| diff --git a/test/loader/test_neighbor_loader.py b/test/loader/test_neighbor_loader.py
--- a/test/loader/test_neighbor_loader.py
+++ b/test/loader/test_neighbor_loader.py
@@ -564,8 +564,8 @@ def test_pyg_lib_and_torch_sparse_hetero_equality():
sample = torch.ops.pyg.hetero_neighbor_sample
out1 = sample(node_types, edge_types, colptr_dict, row_dict, seed_dict,
- num_neighbors_dict, None, None, True, False, True, False,
- "uniform", True)
+ num_neighbors_dict, None, None, None, True, False, True,
+ False, "uniform", True)
sample = torch.ops.torch_sparse.hetero_neighbor_sample
out2 = sample(node_types, edge_types, colptr_dict, row_dict, seed_dict,
num_neighbors_dict, 2, False, True)
diff --git a/test/nn/test_model_summary.py b/test/nn/test_model_summary.py
--- a/test/nn/test_model_summary.py
+++ b/test/nn/test_model_summary.py
@@ -148,10 +148,10 @@ def test_summary_with_leaf_module(gcn):
| ├─(act)ReLU | [100, 16] | [100, 16] | -- |
| ├─(convs)ModuleList | -- | -- | 1,072 |
| │ └─(0)GCNConv | [100, 32], [2, 20] | [100, 16] | 528 |
-| │ │ └─(aggr_module)SumAggregation | [120, 16], [120] | [100, 16] | -- |
+| │ │ └─(aggr_module)SumAggregation | [120, 16] | [100, 16] | -- |
| │ │ └─(lin)Linear | [100, 32] | [100, 16] | 512 |
| │ └─(1)GCNConv | [100, 16], [2, 20] | [100, 32] | 544 |
-| │ │ └─(aggr_module)SumAggregation | [120, 32], [120] | [100, 32] | -- |
+| │ │ └─(aggr_module)SumAggregation | [120, 32] | [100, 32] | -- |
| │ │ └─(lin)Linear | [100, 16] | [100, 32] | 512 |
| ├─(norms)ModuleList | -- | -- | -- |
| │ └─(0)Identity | [100, 16] | [100, 16] | -- |
| Aggregation.__call__ calls nn.Module.__call__ using (x, index, ptr, dim_size, dim, **kwargs) instead of (x=x, index=index, ptr=ptr, dim_size=dim_size, dim=dim, **kwargs)
### 🛠 Proposed Refactor
if somebody wants to inheric Aggregation base class, AND wants to add some conditional data used in aggregation, he must re-define forward as (x: Tensor, index: Tensor=None, ptr=None, dim_size: int=None, dim: int = -2, **condition: Tensor=None**), since the internal call of Aggregation to nn.Module uses fixed positional args. I think it is more elegant to define forward as (x, condition, index=None, ptr=None, dim_size=None, dim=None)
### Suggest a potential alternative/fix
As suggested
| 2023-09-06T11:42:07 |
|
pyg-team/pytorch_geometric | 8,016 | pyg-team__pytorch_geometric-8016 | [
"7998"
]
| c2cf68d3a1fbc49b64204ef5482e893a6bf1cfa7 | diff --git a/torch_geometric/utils/to_dense_adj.py b/torch_geometric/utils/to_dense_adj.py
--- a/torch_geometric/utils/to_dense_adj.py
+++ b/torch_geometric/utils/to_dense_adj.py
@@ -23,7 +23,10 @@ def to_dense_adj(
:math:`\mathbf{b} \in {\{ 0, \ldots, B-1\}}^N`, which assigns each
node to a specific example. (default: :obj:`None`)
edge_attr (Tensor, optional): Edge weights or multi-dimensional edge
- features. (default: :obj:`None`)
+ features.
+ If :obj:`edge_index` contains duplicated edges, the dense adjacency
+ matrix output holds the summed up entries of :obj:`edge_attr` for
+ duplicated edges. (default: :obj:`None`)
max_num_nodes (int, optional): The size of the output node dimension.
(default: :obj:`None`)
batch_size (int, optional) The batch size. (default: :obj:`None`)
| Strange behaviour with the to_dense_adj function
### 🐛 Describe the bug
While using to_dense_adj with edge attributes, I observed that the `idx` values generated are not unique ((line 94 in to_dense_adj.py). As such, the scatter_add function sums up overlapping values and generating an output greater than the original range of edge_attr values.

The required tensors can be downloaded from [here](https://filesender.switch.ch/filesender2/download.php?token=d4b1599a-6eee-4b06-8640-be16fb784ab5&files_ids=490595)
Any help or insights are highly appreciated.
Thanks,
Chinmay
### Environment
* PyG version:2.3.1
* PyTorch version: 2.0.1+cu117
* OS: Ubuntu 20.04
* Python version:3.8.10
* CUDA/cuDNN version:11.7
* How you installed PyTorch and PyG (`conda`, `pip`, source):pip
* Any other relevant information (*e.g.*, version of `torch-scatter`):
| 2023-09-11T06:14:40 |
||
pyg-team/pytorch_geometric | 8,143 | pyg-team__pytorch_geometric-8143 | [
"8131"
]
| ab271aa102142b751cc8b326d7fbe7b10dd3bc01 | diff --git a/torch_geometric/transforms/add_positional_encoding.py b/torch_geometric/transforms/add_positional_encoding.py
--- a/torch_geometric/transforms/add_positional_encoding.py
+++ b/torch_geometric/transforms/add_positional_encoding.py
@@ -52,6 +52,9 @@ class AddLaplacianEigenvectorPE(BaseTransform):
:obj:`False`) or :meth:`scipy.sparse.linalg.eigsh` (when
:attr:`is_undirected` is :obj:`True`).
"""
+ # Number of nodes from which to use sparse eigenvector computation:
+ SPARSE_THRESHOLD: int = 100
+
def __init__(
self,
k: int,
@@ -65,9 +68,6 @@ def __init__(
self.kwargs = kwargs
def forward(self, data: Data) -> Data:
- from scipy.sparse.linalg import eigs, eigsh
- eig_fn = eigs if not self.is_undirected else eigsh
-
num_nodes = data.num_nodes
edge_index, edge_weight = get_laplacian(
data.edge_index,
@@ -77,15 +77,23 @@ def forward(self, data: Data) -> Data:
)
L = to_scipy_sparse_matrix(edge_index, edge_weight, num_nodes)
- L = L.tocsr()
-
- eig_vals, eig_vecs = eig_fn(
- L,
- k=self.k + 1,
- which='SR' if not self.is_undirected else 'SA',
- return_eigenvectors=True,
- **self.kwargs,
- )
+
+ if num_nodes < self.SPARSE_THRESHOLD:
+ from numpy.linalg import eig, eigh
+ eig_fn = eig if not self.is_undirected else eigh
+
+ eig_vals, eig_vecs = eig_fn(L.todense())
+ else:
+ from scipy.sparse.linalg import eigs, eigsh
+ eig_fn = eigs if not self.is_undirected else eigsh
+
+ eig_vals, eig_vecs = eig_fn(
+ L,
+ k=self.k + 1,
+ which='SR' if not self.is_undirected else 'SA',
+ return_eigenvectors=True,
+ **self.kwargs,
+ )
eig_vecs = np.real(eig_vecs[:, eig_vals.argsort()])
pe = torch.from_numpy(eig_vecs[:, 1:self.k + 1])
| diff --git a/test/transforms/test_add_positional_encoding.py b/test/transforms/test_add_positional_encoding.py
--- a/test/transforms/test_add_positional_encoding.py
+++ b/test/transforms/test_add_positional_encoding.py
@@ -56,24 +56,22 @@ def test_eigenvector_permutation_invariance():
[1, 0, 4, 0, 4, 1, 3, 2, 5, 3]])
data = Data(edge_index=edge_index, num_nodes=6)
- perm = torch.tensor([5, 4, 3, 2, 1, 0])
+ perm = torch.randperm(data.num_nodes)
transform = AddLaplacianEigenvectorPE(
- k=1,
+ k=2,
is_undirected=True,
attr_name='x',
- v0=torch.arange(data.num_nodes),
)
out1 = transform(data)
transform = AddLaplacianEigenvectorPE(
- k=1,
+ k=2,
is_undirected=True,
attr_name='x',
- v0=perm,
)
out2 = transform(data.subgraph(perm))
- assert torch.allclose(out1.x[perm].abs(), out2.x.abs(), atol=1e-1)
+ assert torch.allclose(out1.x[perm].abs(), out2.x.abs(), atol=1e-6)
@onlyLinux # TODO (matthias) Investigate CSR @ CSR support on Windows.
| `test/transforms/test_add_positional_encoding.py::test_eigenvector_permutation_invariance` fails with AMD CPU
### 🐛 Describe the bug
The unit test added in #8087 fails with the error bellow on AMD CPU based systems.
```
NVIDIA_TF32_OVERRIDE=0 pytest -s --cov --cov-report=xml test/transforms/test_add_positional_encoding.py::test_eigenvector_permutation_invariance
```
Traceback:
```
======================================================================== FAILURES ========================================================================$
_________________________________________________________ test_eigenvector_permutation_invariance ________________________________________________________$
def test_eigenvector_permutation_invariance():
edge_index = torch.tensor([[0, 1, 0, 4, 1, 4, 2, 3, 3, 5],
[1, 0, 4, 0, 4, 1, 3, 2, 5, 3]])
data = Data(edge_index=edge_index, num_nodes=6)
perm = torch.tensor([5, 4, 3, 2, 1, 0])
transform = AddLaplacianEigenvectorPE(
k=1,
is_undirected=True,
attr_name='x',
v0=torch.arange(data.num_nodes),
)
out1 = transform(data)
transform = AddLaplacianEigenvectorPE(
k=1,
is_undirected=True,
attr_name='x',
v0=perm,
)
out2 = transform(data.subgraph(perm))
print(out1.x[perm].abs())
print(out2.x.abs())
> assert torch.allclose(out1.x[perm].abs(), out2.x.abs(), atol=1e-1)
E assert False
E + where False = <built-in method allclose of type object at 0x7f2f94b318a0>(tensor([[0.1360],\n [0.5556],\n [0.1924],\n [0.1
360],\n [0.5556],\n [0.5556]]), tensor([[0.2091],\n [0.5245],\n [0.2957],\n [0.2091],\n [0.5245],\n [0.524
5]]), atol=0.1)
E + where <built-in method allclose of type object at 0x7f2f94b318a0> = torch.allclose
E + and tensor([[0.1360],\n [0.5556],\n [0.1924],\n [0.1360],\n [0.5556],\n [0.5556]]) = <built-in method ab
s of Tensor object at 0x7f2bc6e1e160>()
E + where <built-in method abs of Tensor object at 0x7f2bc6e1e160> = tensor([[ 0.1360],\n [-0.5556],\n [ 0.1924],\n [ 0.13
60],\n [-0.5556],\n [-0.5556]]).abs
E + and tensor([[0.2091],\n [0.5245],\n [0.2957],\n [0.2091],\n [0.5245],\n [0.5245]]) = <built-in method ab
s of Tensor object at 0x7f2bc89d3470>()
E + where <built-in method abs of Tensor object at 0x7f2bc89d3470> = tensor([[ 0.2091],\n [-0.5245],\n [ 0.2957],\n [ 0.20
91],\n [-0.5245],\n [-0.5245]]).abs
E + where tensor([[ 0.2091],\n [-0.5245],\n [ 0.2957],\n [ 0.2091],\n [-0.5245],\n [-0.5245]]) = Data(edge
_index=[2, 10], num_nodes=6, x=[6, 1]).x
```
### Environment
* PyG version: 2.4.0 (built from source)
* PyTorch version: 2.1.0
* OS: Ubuntu 22.04.3 LTS
* Python version: 3.10.12
* CUDA/cuDNN version: 12.2
* How you installed PyTorch and PyG (`conda`, `pip`, source): source
| Is it just flaky or does it always fail? I don't see the test case use GPU so I wondered why this happens on an A100 particularly.
> Is it just flaky or does it always fail? I don't see the test case use GPU so I wondered why this happens on an A100 particularly.
You are right, it's a CPU only test, it was passing on our V100 machines and failing on A100 ones so I wrongly assumed it has something to do with the GPU.
So it always fails on certain machines but always pass on others.
After more runs across more machines it seems that it's a Intel vs AMD issue.
PASS on:
```
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 46 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 80
On-line CPU(s) list: 0-79
Vendor ID: GenuineIntel
Model name: Intel(R) Xeon(R) CPU E5-2698 v4 @ 2.20GHz
CPU family: 6
Model: 79
Thread(s) per core: 2
Core(s) per socket: 20
Socket(s): 2
```
FAIL on:
```
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 43 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 256
On-line CPU(s) list: 0-255
Vendor ID: AuthenticAMD
Model name: AMD EPYC 7742 64-Core Processor
CPU family: 23
Model: 49
Thread(s) per core: 2
Core(s) per socket: 64
Socket(s): 2
```
Changing the title and description accordingly. | 2023-10-06T14:22:17 |
pyg-team/pytorch_geometric | 8,164 | pyg-team__pytorch_geometric-8164 | [
"8160"
]
| 98ffec48676b6d433670dffa78f04d75635a7824 | diff --git a/torch_geometric/nn/models/dimenet_utils.py b/torch_geometric/nn/models/dimenet_utils.py
--- a/torch_geometric/nn/models/dimenet_utils.py
+++ b/torch_geometric/nn/models/dimenet_utils.py
@@ -71,6 +71,7 @@ def sph_harm_prefactor(k, m):
def associated_legendre_polynomials(k, zero_m_only=True):
+ r"""Helper function to calculate Y_l^m."""
z = sym.symbols('z')
P_l_m = [[0] * (j + 1) for j in range(k)]
@@ -79,15 +80,22 @@ def associated_legendre_polynomials(k, zero_m_only=True):
P_l_m[1][0] = z
for j in range(2, k):
+ # Use the property of Eq (7) in
+ # https://mathworld.wolfram.com/AssociatedLegendrePolynomial.html:
P_l_m[j][0] = sym.simplify(((2 * j - 1) * z * P_l_m[j - 1][0] -
(j - 1) * P_l_m[j - 2][0]) / j)
if not zero_m_only:
for i in range(1, k):
- P_l_m[i][i] = sym.simplify((1 - 2 * i) * P_l_m[i - 1][i - 1])
+ P_l_m[i][i] = sym.simplify(
+ (1 - 2 * i) * P_l_m[i - 1][i - 1] * (1 - z**2)**0.5)
if i + 1 < k:
+ # Use the property of Eq (11) in
+ # https://mathworld.wolfram.com/AssociatedLegendrePolynomial.html:
P_l_m[i + 1][i] = sym.simplify(
(2 * i + 1) * z * P_l_m[i][i])
for j in range(i + 2, k):
+ # Use the property of Eq (7) in
+ # https://mathworld.wolfram.com/AssociatedLegendrePolynomial.html:
P_l_m[j][i] = sym.simplify(
((2 * j - 1) * z * P_l_m[j - 1][i] -
(i + j - 1) * P_l_m[j - 2][i]) / (j - i))
| math term missed in dimenet_utils.associated_legendre_polynomials
### 🛠 Proposed Refactor
In order to get the function of 'spherical harmonics' basis used in DimeNet, we need to calc 'Associated Legendre Polynomial' in math. But I just found a term missed in torch_geometric.nn.models.dimenet_utils.associated_legendre_polynomials().
The author of DimeNet use `zero_m_only=True` by default, so there will be no error when running the code by default.
But just a warning for those who also read or use this code, the author of the code (version of pyg: 2.3.1) missed a term when calculating $P_l^l$ which make all results except $P_l^0$ wrong. [original code here](https://github.com/pyg-team/pytorch_geometric/blob/f71ead8ade8a67be23982114cfff649b7d074cfb/torch_geometric/nn/models/dimenet_utils.py#L86)
Take the result of $P_1^1$ as an example:
original code will output -1, but according to eq.14 at https://mathworld.wolfram.com/AssociatedLegendrePolynomial.html, the ground truth result is $-(1-x^2)^{0.5}$.
### Suggest a potential alternative/fix
Beyond adding the missed term, I also add some comment to help understanding.
```python
def associated_legendre_polynomials(k, zero_m_only=True):
'''
helper function to calc Y_l^m
'''
z = sym.symbols('z')
P_l_m = [[0] * (j + 1) for j in range(k)]
P_l_m[0][0] = 1
if k > 0:
P_l_m[1][0] = z
for j in range(2, k):
P_l_m[j][0] = sym.simplify(((2 * j - 1) * z * P_l_m[j - 1][0] -
(j - 1) * P_l_m[j - 2][0]) / j) # use the property of eq.7: https://mathworld.wolfram.com/AssociatedLegendrePolynomial.html
if not zero_m_only:
for i in range(1, k):
P_l_m[i][i] = sym.simplify((1 - 2 * i) * P_l_m[i - 1][i - 1]*(1-z**2)**0.5) # add missed term (*(1-z**2)**0.5) here
if i + 1 < k:
P_l_m[i + 1][i] = sym.simplify(
(2 * i + 1) * z * P_l_m[i][i]) # use the property of eq.11: https://mathworld.wolfram.com/AssociatedLegendrePolynomial.html
for j in range(i + 2, k):
P_l_m[j][i] = sym.simplify(
((2 * j - 1) * z * P_l_m[j - 1][i] -
(i + j - 1) * P_l_m[j - 2][i]) / (j - i)) # use the property of eq.7: https://mathworld.wolfram.com/AssociatedLegendrePolynomial.html
return P_l_m
```
After fixing this tiny bug, all the results are the right
| 2023-10-09T21:09:43 |
||
pyg-team/pytorch_geometric | 8,179 | pyg-team__pytorch_geometric-8179 | [
"8171"
]
| e9f62c0ee7146d0370760f7655e896f757b5144d | diff --git a/torch_geometric/datasets/citation_full.py b/torch_geometric/datasets/citation_full.py
--- a/torch_geometric/datasets/citation_full.py
+++ b/torch_geometric/datasets/citation_full.py
@@ -98,7 +98,8 @@ def raw_file_names(self) -> str:
@property
def processed_file_names(self) -> str:
- return 'data.pt'
+ suffix = 'undirected' if self.to_undirected else 'directed'
+ return f'data_{suffix}.pt'
def download(self):
download_url(self.url.format(self.name), self.raw_dir)
| Dataset is not undirected
### 🐛 Describe the bug
Dataset is not undirected, despite passing ``to_undirected=True`` flag.
```python
# !pip install pyg-nightly
from torch_geometric.datasets import CitationFull
from torch_geometric.utils import is_undirected
edge_index = CitationFull(root=".", name="Cora_ML", to_undirected=True).edge_index
is_undirected(edge_index)
```
The above outputs: *False*
### Environment
* PyG version: 2.4.0.dev20231010
* PyTorch version: 2.0.1+cu118
* OS: Colab
* Python version: 3.10.12
* CUDA/cuDNN version: 11.8
* How you installed PyTorch and PyG (`conda`, `pip`, source): pip
* Any other relevant information (*e.g.*, version of `torch-scatter`):
| Hey ! I ran it on colab and it ran. `is_undirected(edge_index)` is outputing `True`
@emalgorithm I don't see any issue running your code on my side as well. Would you mind trying it again and letting us know how to reproduce it?
You may have the old version stored on disk, so you can try to remove the `processed_dir` and re-process again. | 2023-10-11T12:56:16 |
|
pyg-team/pytorch_geometric | 8,207 | pyg-team__pytorch_geometric-8207 | [
"8185"
]
| bce92aa86a526066877ed5e0f92161c93d02418c | diff --git a/torch_geometric/nn/conv/hgt_conv.py b/torch_geometric/nn/conv/hgt_conv.py
--- a/torch_geometric/nn/conv/hgt_conv.py
+++ b/torch_geometric/nn/conv/hgt_conv.py
@@ -37,10 +37,6 @@ class HGTConv(MessagePassing):
information.
heads (int, optional): Number of multi-head-attentions.
(default: :obj:`1`)
- group (str, optional): The aggregation scheme to use for grouping node
- embeddings generated by different relations
- (:obj:`"sum"`, :obj:`"mean"`, :obj:`"min"`, :obj:`"max"`).
- (default: :obj:`"sum"`)
**kwargs (optional): Additional arguments of
:class:`torch_geometric.nn.conv.MessagePassing`.
"""
| unused `group` parameter in `HGTConv` still documented
### 📚 Describe the documentation issue
#7117 replaces `HGTConv` with the implementation done for the faster `FastHGTConv`. In the process of doing so, the `group` parameter has been removed falling back to the default `sum` operation. (@puririshi98: this was intentional, right?). The docs, however, haven't been updated accordingly.
https://github.com/pyg-team/pytorch_geometric/blob/737707c37fc2bd712a2289b683ec14549926ff49/torch_geometric/nn/conv/hgt_conv.py#L40-L43
### Suggest a potential alternative/fix
Remove the unused parameter from the docs.
| Hi, I want to work on this. Assign me. | 2023-10-17T11:31:40 |
|
pyg-team/pytorch_geometric | 8,248 | pyg-team__pytorch_geometric-8248 | [
"8246"
]
| b17555e5b91e00259a904b902d1774184f1e09f2 | diff --git a/torch_geometric/nn/models/metapath2vec.py b/torch_geometric/nn/models/metapath2vec.py
--- a/torch_geometric/nn/models/metapath2vec.py
+++ b/torch_geometric/nn/models/metapath2vec.py
@@ -248,10 +248,14 @@ def __repr__(self) -> str:
def sample(rowptr: Tensor, col: Tensor, rowcount: Tensor, subset: Tensor,
num_neighbors: int, dummy_idx: int) -> Tensor:
+ mask = subset >= dummy_idx
+ subset = subset.clamp(min=0, max=rowptr.numel() - 2)
+ count = rowcount[subset]
+
rand = torch.rand((subset.size(0), num_neighbors), device=subset.device)
- rand *= rowcount[subset].to(rand.dtype).view(-1, 1)
+ rand *= count.to(rand.dtype).view(-1, 1)
rand = rand.to(torch.long) + rowptr[subset].view(-1, 1)
- col = col[rand]
- col[(subset >= dummy_idx) | (rowcount[subset] == 0)] = dummy_idx
+ col = col[rand] if col.numel() > 0 else rand
+ col[mask | (count == 0)] = dummy_idx
return col
| diff --git a/test/nn/models/test_metapath2vec.py b/test/nn/models/test_metapath2vec.py
--- a/test/nn/models/test_metapath2vec.py
+++ b/test/nn/models/test_metapath2vec.py
@@ -39,3 +39,25 @@ def test_metapath2vec(device):
acc = model.test(torch.ones(20, 16), torch.randint(10, (20, )),
torch.ones(20, 16), torch.randint(10, (20, )))
assert 0 <= acc and acc <= 1
+
+
+def test_metapath2vec_empty_edges():
+ num_nodes_dict = {'a': 3, 'b': 4}
+ edge_index_dict = {
+ ('a', 'to', 'b'): torch.empty((2, 0), dtype=torch.long),
+ ('b', 'to', 'a'): torch.empty((2, 0), dtype=torch.long),
+ }
+ metapath = [('a', 'to', 'b'), ('b', 'to', 'a')]
+
+ model = MetaPath2Vec(
+ edge_index_dict,
+ embedding_dim=16,
+ metapath=metapath,
+ walk_length=10,
+ context_size=7,
+ walks_per_node=5,
+ num_negative_samples=5,
+ num_nodes_dict=num_nodes_dict,
+ )
+ loader = model.loader(batch_size=16, shuffle=True)
+ next(iter(loader))
| `MetaPath2Vec` fails in a heterogeneous graph with zero-degree nodes
### 🐛 Describe the bug
Just found that `MetaPath2Vec` does not work well on a heterogeneous graph with zero-degree nodes.
Here is the example to reproduce the bug:
```python
import torch
from torch_geometric.data import HeteroData
from torch_geometric.nn.models import MetaPath2Vec
data = HeteroData()
data['a'].x = torch.ones(3, 2)
data['b'].x = torch.ones(4, 2)
data[('a', 'to', 'b')].edge_index = torch.tensor([[0, 2], [0, 2]])
data[('b', 'to', 'a')].edge_index = torch.tensor([[0, 2], [0, 2]])
metapath = [('a', 'to', 'b'), ('b', 'to', 'a')]
model = MetaPath2Vec(data.edge_index_dict, embedding_dim=16,
metapath=metapath, walk_length=10, context_size=7,
walks_per_node=5, num_negative_samples=5,
num_nodes_dict=data.num_nodes_dict,
sparse=True)
loader = model.loader(batch_size=16, shuffle=True)
next(iter(loader))
```
It throws
```
248 def sample(rowptr: Tensor, col: Tensor, rowcount: Tensor, subset: Tensor,
249 num_neighbors: int, dummy_idx: int) -> Tensor:
251 rand = torch.rand((subset.size(0), num_neighbors), device=subset.device)
--> 252 rand *= rowcount[subset].to(rand.dtype).view(-1, 1)
253 rand = rand.to(torch.long) + rowptr[subset].view(-1, 1)
255 col = col[rand]
IndexError: index 7 is out of bounds for dimension 0 with size 4
```
That's because `MetaPath2Vec` assigns invalid sampled nodes with a `dummy_idx` (here `7`) during each sampling step. However, the `dummy_idx` is out-of-index for each (sub)graph, leading to the `IndexError` at the next sampleing step.
https://github.com/pyg-team/pytorch_geometric/blob/114ddcac8dc8a46b96734f55416750474b290666/torch_geometric/nn/models/metapath2vec.py#L256
### Environment
* PyG version: master
* PyTorch version: 2.0.0
* OS: macos
* Python version: 3.10
* CUDA/cuDNN version: N/A
* How you installed PyTorch and PyG (`conda`, `pip`, source): pip
* Any other relevant information (*e.g.*, version of `torch-scatter`): N/A
| 2023-10-23T21:07:24 |
|
pyg-team/pytorch_geometric | 8,343 | pyg-team__pytorch_geometric-8343 | [
"8341"
]
| 1725f14366039147a022f78becd21e4ccf7a65a7 | diff --git a/torch_geometric/warnings.py b/torch_geometric/warnings.py
--- a/torch_geometric/warnings.py
+++ b/torch_geometric/warnings.py
@@ -1,13 +1,14 @@
import warnings
+import torch
+
import torch_geometric
-if torch_geometric.typing.WITH_PT20: # pragma: no cover
- from torch._dynamo import is_compiling as _is_compiling
-else:
- def _is_compiling() -> bool: # pragma: no cover
- return False
+def _is_compiling() -> bool: # pragma: no cover
+ if torch_geometric.typing.WITH_PT21:
+ return torch._dynamo.is_compiling()
+ return False
def warn(message: str):
| Problem with torch_geometric.transforms
### 🐛 Describe the bug
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
[<ipython-input-20-2b41d296395c>](https://localhost:8080/#) in <cell line: 7>()
5 import torch.nn as nn
6 import torch.nn.functional as F
----> 7 import torch_geometric.transforms as T
8 from tqdm.auto import tqdm
9
3 frames
[/usr/local/lib/python3.10/dist-packages/torch_geometric/__init__.py](https://localhost:8080/#) in <module>
----> 1 import torch_geometric.utils
2 import torch_geometric.data
3 import torch_geometric.sampler
4 import torch_geometric.loader
5 import torch_geometric.transforms
[/usr/local/lib/python3.10/dist-packages/torch_geometric/utils/__init__.py](https://localhost:8080/#) in <module>
1 import copy
2
----> 3 from .scatter import scatter, group_argsort
4 from .segment import segment
5 from .sort import index_sort
[/usr/local/lib/python3.10/dist-packages/torch_geometric/utils/scatter.py](https://localhost:8080/#) in <module>
5
6 import torch_geometric.typing
----> 7 from torch_geometric import warnings
8 from torch_geometric.typing import torch_scatter
9 from torch_geometric.utils.functions import cumsum
[/usr/local/lib/python3.10/dist-packages/torch_geometric/warnings.py](https://localhost:8080/#) in <module>
3 import torch_geometric
4
----> 5 if torch_geometric.typing.WITH_PT20: # pragma: no cover
6 from torch._dynamo import is_compiling as _is_compiling
7 else:
AttributeError: partially initialized module 'torch_geometric' has no attribute 'typing' (most likely due to a circular import)
### Environment
* PyG version: 2.4.0
* PyTorch version: 2.1.0+cu118
* OS: Windows
* Python version: 3.10.12
* CUDA/cuDNN version:
Cuda compilation tools, release 11.8, V11.8.89
Build cuda_11.8.r11.8/compiler.31833905_0
cuDNN version: 8900
* How you installed PyTorch and PyG (`conda`, `pip`, source): pip
* Any other relevant information (*e.g.*, version of `torch-scatter`):
| 2023-11-08T15:37:55 |
||
pyg-team/pytorch_geometric | 8,356 | pyg-team__pytorch_geometric-8356 | [
"8355"
]
| 999af2312efcdd7bd35e40c9b21c4a6a45464ac5 | diff --git a/torch_geometric/data/hetero_data.py b/torch_geometric/data/hetero_data.py
--- a/torch_geometric/data/hetero_data.py
+++ b/torch_geometric/data/hetero_data.py
@@ -28,6 +28,7 @@
from torch_geometric.utils import (
bipartite_subgraph,
contains_isolated_nodes,
+ is_sparse,
is_undirected,
mask_select,
)
@@ -332,7 +333,7 @@ def update(self, data: 'HeteroData') -> 'HeteroData':
def __cat_dim__(self, key: str, value: Any,
store: Optional[NodeOrEdgeStorage] = None, *args,
**kwargs) -> Any:
- if isinstance(value, SparseTensor) and 'adj' in key:
+ if is_sparse(value) and 'adj' in key:
return (0, 1)
elif isinstance(store, EdgeStorage) and 'index' in key:
return -1
| Incorrect batching with graphs converted by `ToSparseTensor()`
### 🐛 Describe the bug
I've been debugging my code and have run into an issue with my custom dataset - at present, I have it return a `HeteroData` object that has been converted with the `ToSparseTensor()` transform to construct the sparse form (`adj_t`). I then feed this dataset into the torch_geometric custom dataloader (`torch_geometric.loader.DataLoader`).
However, when I get batches from this dataloader, the `adj_t` of the batched graph seems wildly incorrect (that is, it appears to properly extend the sparse adjacency matrix along just one dimension, but not both, leading to incorrect indices).
Minimally reproducible code snippet:
```
import torch
import torch_geometric
rng = torch.Generator().manual_seed(9)
bsize = 2
h_dataset = torch_geometric.datasets.FakeHeteroDataset(num_graphs=128,
num_node_types=4,
num_edge_types=16,
avg_num_nodes=1024,
num_classes=2,
transform=torch_geometric.transforms.ToSparseTensor())
train_ds, test_ds = torch.utils.data.random_split(h_dataset, [64, 64], rng)
for i in range(bsize):
print(train_ds[i])
train_dl = torch_geometric.loader.DataLoader(train_ds, shuffle=False, batch_size=2, drop_last=False)
batched_data = next(iter(train_dl))
print(batched_data)
```
Specifically, you'll see that the printing of the first two graphs in the train_ds (before batching) produces values around 1000 for the number of each node type and the adjacency matrices match appropriately.
For example, from my environment, the edge data contains: `(v2, e0, v2)={ adj_t=[1237, 1237] }` and `(v2, e0, v2)={ adj_t=[1005, 1005] }` for the two graphs.
After batching, the edge data contains: `(v2, e0, v2)={ adj_t=[2242, 1237] }` - which appears as if the batching worked along the first dimension but not the second.
### Environment
* PyG version: 2.4.0
* PyTorch version: 2.1.0
* OS: Mac OSX
* Python version: 3.10.13
* CUDA/cuDNN version: N/A
* How you installed PyTorch and PyG (`conda`, `pip`, source): pip
* Any other relevant information (*e.g.*, version of `torch-scatter`): N/A
| ~~While trying to figure out what was happening here, I think it has to do somehow with the collate function within the dataloader - specifically in the Collater class here (https://pytorch-geometric.readthedocs.io/en/latest/_modules/torch_geometric/loader/dataloader.html#DataLoader) which just calls https://github.com/pytorch/pytorch/blob/main/torch/utils/data/_utils/collate.py - but this doesn't seem to behave appropriately with the sparse tensor/adjacency format that is used here.~~
Never mind - I misread the code fundamentally. `Collater` (https://pytorch-geometric.readthedocs.io/en/latest/_modules/torch_geometric/loader/dataloader.html#Collater) calls
`Batch.from_data_list()` (https://pytorch-geometric.readthedocs.io/en/latest/_modules/torch_geometric/data/batch.html#Batch.from_data_list) which then calls
`torch_geometric.data.collate()` here (https://github.com/pyg-team/pytorch_geometric/blob/master/torch_geometric/data/collate.py).
I haven't dug deeply enough into `collate` to figure out where things are going wrong, but I am trying to write my own custom `collate` function to pass into a vanilla `DataLoader` to try to workaround this for now. I will report back if I find the specific issue.
I think I've localized the issue - `__cat_dim__` in HeteroData is defined to return (0,1) if the data is sparse and is the adjacency matrix; however, this check does not work if torch_sparse is not installed as it specifically checks for a `SparseTensor` from torch_sparse rather than any instance of a sparse tensor:
https://github.com/pyg-team/pytorch_geometric/blob/999af2312efcdd7bd35e40c9b21c4a6a45464ac5/torch_geometric/data/hetero_data.py#L335C17-L335C17 | 2023-11-09T21:23:17 |
|
pyg-team/pytorch_geometric | 8,388 | pyg-team__pytorch_geometric-8388 | [
"8374"
]
| 4aee57c22cc1a943d74727e0c40d57725ba5e18f | diff --git a/docs/source/conf.py b/docs/source/conf.py
--- a/docs/source/conf.py
+++ b/docs/source/conf.py
@@ -66,10 +66,12 @@
}
-def setup(app):
- def rst_jinja_render(app, _, source):
+def rst_jinja_render(app, _, source):
+ if hasattr(app.builder, 'templates'):
rst_context = {'torch_geometric': torch_geometric}
source[0] = app.builder.templates.render_string(source[0], rst_context)
+
+def setup(app):
app.connect('source-read', rst_jinja_render)
app.add_js_file('js/version_alert.js')
| LatexBuilder for docs fails
### 📚 Describe the documentation issue
The following line makes the docs building crash when using a LatexBuilder
https://github.com/pyg-team/pytorch_geometric/blob/88d7986b6d0a6de5895872270d2ff4fc95fae3b7/docs/source/conf.py#L69C1-L75C43
To reproduce build the docs with the latex builder
```bash
python -m sphinx -T -E -b latex -d _build/doctrees -D language=en . ./build
```
```bash
Extension error:
Handler <function setup.<locals>.rst_jinja_render at 0x1230b4dc0> for event 'source-read' threw an exception (exception: 'LaTeXBuilder' object has no attribute 'templates')
```
### Suggest a potential alternative/fix
_No response_
| 2023-11-16T14:50:43 |
||
pyg-team/pytorch_geometric | 8,406 | pyg-team__pytorch_geometric-8406 | [
"8398"
]
| ea2ab705716f02396b074cb1c6175b9224a3bf79 | diff --git a/torch_geometric/nn/aggr/attention.py b/torch_geometric/nn/aggr/attention.py
--- a/torch_geometric/nn/aggr/attention.py
+++ b/torch_geometric/nn/aggr/attention.py
@@ -3,7 +3,6 @@
import torch
from torch import Tensor
-import torch_geometric
from torch_geometric.nn.aggr import Aggregation
from torch_geometric.nn.inits import reset
from torch_geometric.utils import softmax
@@ -35,16 +34,32 @@ class AttentionalAggregation(Aggregation):
before combining them with the attention scores, *e.g.*, defined by
:class:`torch.nn.Sequential`. (default: :obj:`None`)
"""
- def __init__(self, gate_nn: torch.nn.Module,
- nn: Optional[torch.nn.Module] = None):
+ def __init__(
+ self,
+ gate_nn: torch.nn.Module,
+ nn: Optional[torch.nn.Module] = None,
+ ):
super().__init__()
- self.gate_nn = gate_nn
- self.nn = nn
- self.reset_parameters()
+
+ from torch_geometric.nn import MLP
+
+ self.gate_nn = self.gate_mlp = None
+ if isinstance(gate_nn, MLP):
+ self.gate_mlp = gate_nn
+ else:
+ self.gate_nn = gate_nn
+
+ self.nn = self.mlp = None
+ if isinstance(nn, MLP):
+ self.mlp = nn
+ else:
+ self.nn = nn
def reset_parameters(self):
reset(self.gate_nn)
+ reset(self.gate_mlp)
reset(self.nn)
+ reset(self.mlp)
def forward(self, x: Tensor, index: Optional[Tensor] = None,
ptr: Optional[Tensor] = None, dim_size: Optional[int] = None,
@@ -52,13 +67,13 @@ def forward(self, x: Tensor, index: Optional[Tensor] = None,
self.assert_two_dimensional_input(x, dim)
- if isinstance(self.gate_nn, torch_geometric.nn.MLP):
- gate = self.gate_nn(x, index, dim_size)
+ if self.gate_mlp is not None:
+ gate = self.gate_mlp(x, batch=index, batch_size=dim_size)
else:
gate = self.gate_nn(x)
- if isinstance(self.nn, torch_geometric.nn.MLP):
- x = self.nn(x, index, dim_size)
+ if self.mlp is not None:
+ x = self.mlp(x, batch=index, batch_size=dim_size)
elif self.nn is not None:
x = self.nn(x)
@@ -66,5 +81,6 @@ def forward(self, x: Tensor, index: Optional[Tensor] = None,
return self.reduce(gate * x, index, ptr, dim_size, dim)
def __repr__(self) -> str:
- return (f'{self.__class__.__name__}(gate_nn={self.gate_nn}, '
- f'nn={self.nn})')
+ return (f'{self.__class__.__name__}('
+ f'gate_nn={self.gate_mlp or self.gate_nn}, '
+ f'nn={self.mlp or self.nn})')
diff --git a/torch_geometric/nn/aggr/deep_sets.py b/torch_geometric/nn/aggr/deep_sets.py
--- a/torch_geometric/nn/aggr/deep_sets.py
+++ b/torch_geometric/nn/aggr/deep_sets.py
@@ -30,25 +30,46 @@ def __init__(
global_nn: Optional[torch.nn.Module] = None,
):
super().__init__()
- self.local_nn = local_nn
- self.global_nn = global_nn
+
+ from torch_geometric.nn import MLP
+
+ self.local_nn = self.local_mlp = None
+ if isinstance(local_nn, MLP):
+ self.local_mlp = local_nn
+ else:
+ self.local_nn = local_nn
+
+ self.global_nn = self.global_mlp = None
+ if isinstance(global_nn, MLP):
+ self.global_mlp = global_nn
+ else:
+ self.global_nn = global_nn
def reset_parameters(self):
- if self.local_nn is not None:
- reset(self.local_nn)
- if self.global_nn is not None:
- reset(self.global_nn)
+ reset(self.local_nn)
+ reset(self.local_mlp)
+ reset(self.global_nn)
+ reset(self.global_mlp)
def forward(self, x: Tensor, index: Optional[Tensor] = None,
ptr: Optional[Tensor] = None, dim_size: Optional[int] = None,
dim: int = -2) -> Tensor:
+
+ if self.local_mlp is not None:
+ x = self.local_mlp(x, batch=index, batch_size=dim_size)
if self.local_nn is not None:
x = self.local_nn(x)
+
x = self.reduce(x, index, ptr, dim_size, dim, reduce='sum')
- if self.global_nn is not None:
+
+ if self.global_mlp is not None:
+ x = self.global_mlp(x, batch=index, batch_size=dim_size)
+ elif self.global_nn is not None:
x = self.global_nn(x)
+
return x
def __repr__(self) -> str:
- return (f'{self.__class__.__name__}(local_nn={self.local_nn}, '
- f'global_nn={self.global_nn})')
+ return (f'{self.__class__.__name__}('
+ f'local_nn={self.local_mlp or self.local_nn}, '
+ f'global_nn={self.global_mlp or self.global_nn})')
diff --git a/torch_geometric/nn/aggr/mlp.py b/torch_geometric/nn/aggr/mlp.py
--- a/torch_geometric/nn/aggr/mlp.py
+++ b/torch_geometric/nn/aggr/mlp.py
@@ -32,8 +32,13 @@ class MLPAggregation(Aggregation):
**kwargs (optional): Additional arguments of
:class:`torch_geometric.nn.models.MLP`.
"""
- def __init__(self, in_channels: int, out_channels: int,
- max_num_elements: int, **kwargs):
+ def __init__(
+ self,
+ in_channels: int,
+ out_channels: int,
+ max_num_elements: int,
+ **kwargs,
+ ):
super().__init__()
self.in_channels = in_channels
@@ -41,8 +46,11 @@ def __init__(self, in_channels: int, out_channels: int,
self.max_num_elements = max_num_elements
from torch_geometric.nn import MLP
- self.mlp = MLP(in_channels=in_channels * max_num_elements,
- out_channels=out_channels, **kwargs)
+ self.mlp = MLP(
+ in_channels=in_channels * max_num_elements,
+ out_channels=out_channels,
+ **kwargs,
+ )
self.reset_parameters()
@@ -52,8 +60,10 @@ def reset_parameters(self):
def forward(self, x: Tensor, index: Optional[Tensor] = None,
ptr: Optional[Tensor] = None, dim_size: Optional[int] = None,
dim: int = -2) -> Tensor:
+
x, _ = self.to_dense_batch(x, index, ptr, dim_size, dim,
max_num_elements=self.max_num_elements)
+
return self.mlp(x.view(-1, x.size(1) * x.size(2)), index, dim_size)
def __repr__(self) -> str:
| diff --git a/test/nn/aggr/test_attention.py b/test/nn/aggr/test_attention.py
--- a/test/nn/aggr/test_attention.py
+++ b/test/nn/aggr/test_attention.py
@@ -15,6 +15,7 @@ def test_attentional_aggregation():
gate_nn = MLP([channels, 1], act='relu')
nn = MLP([channels, channels], act='relu')
aggr = AttentionalAggregation(gate_nn, nn)
+ aggr.reset_parameters()
assert str(aggr) == (f'AttentionalAggregation(gate_nn=MLP({channels}, 1), '
f'nn=MLP({channels}, {channels}))')
| TorchScript attentional aggregation error
I'm trying to compile gnn model with torch script and get following error:
```bash
RuntimeError:
Unknown type name 'torch_geometric.nn.MLP':
File "/usr/local/lib/python3.10/dist-packages/torch_geometric/nn/aggr/attention.py", line 55
self.assert_two_dimensional_input(x, dim)
if isinstance(self.gate_nn, torch_geometric.nn.MLP):
~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
gate = self.gate_nn(x, index, dim_size)
else:
```
Here is example to reproduce this error:
```python
import torch
from torch import nn
from torch_geometric.nn import aggr, TransformerConv
from torch_geometric.nn.norm import GraphNorm
class GNN(nn.Module):
def __init__(self):
super(GNN, self).__init__()
self.gnn = TransformerConv(10, 10, 1, dropout=0.1).jittable()
self.normalization = GraphNorm(in_channels=10)
self.act = nn.GELU()
self.aggr = aggr.AttentionalAggregation(gate_nn=nn.Linear(10, 1), nn=nn.Linear(10, 10)) #doesn't compile
def forward(self, x, edge_index, batch_ptr):
hidden = x
hidden = self.gnn(hidden, edge_index)
hidden = self.normalization(hidden)
hidden = self.act(hidden)
graph_rep = self.aggr(hidden, ptr=batch_ptr)
return graph_rep
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model = GNN().to(device)
x = torch.randn(100, 10).to(device)
edge_index = torch.randint(100, size=(2, 20)).to(device)
batch_ptr = torch.tensor([0, 100]).to(device)
res = model(x, edge_index, batch_ptr)
print(res)
model = torch.jit.script(model)
```
### Environment
* PyG version: 2.4.0
* PyTorch version: 2.1.0
* OS: ubuntu 22
* Python version: 3.10
* CUDA/cuDNN version: 12.3
* How you installed PyTorch and PyG (`conda`, `pip`, source): pip/source
| also need this | 2023-11-20T07:42:17 |
pyg-team/pytorch_geometric | 8,440 | pyg-team__pytorch_geometric-8440 | [
"8214"
]
| 9adb8d082cd1ea45394e137085404a9aacf4e261 | diff --git a/torch_geometric/explain/algorithm/captum.py b/torch_geometric/explain/algorithm/captum.py
--- a/torch_geometric/explain/algorithm/captum.py
+++ b/torch_geometric/explain/algorithm/captum.py
@@ -236,7 +236,9 @@ def to_captum_input(
raise ValueError(
"'x' and 'edge_index' need to be either"
f"'Dict' or 'Tensor' got({type(x)}, {type(edge_index)})")
+
additional_forward_args.extend(args)
+
return tuple(inputs), tuple(additional_forward_args)
diff --git a/torch_geometric/explain/algorithm/captum_explainer.py b/torch_geometric/explain/algorithm/captum_explainer.py
--- a/torch_geometric/explain/algorithm/captum_explainer.py
+++ b/torch_geometric/explain/algorithm/captum_explainer.py
@@ -138,7 +138,7 @@ def forward(
*kwargs.values(),
)
- if isinstance(x, dict):
+ if isinstance(x, dict): # Heterogeneous GNN:
metadata = (list(x.keys()), list(edge_index.keys()))
captum_model = CaptumHeteroModel(
model,
@@ -147,21 +147,24 @@ def forward(
metadata,
self.model_config,
)
- else:
+ else: # Homogeneous GNN:
metadata = None
- captum_model = CaptumModel(model, mask_type, index,
- self.model_config)
+ captum_model = CaptumModel(
+ model,
+ mask_type,
+ index,
+ self.model_config,
+ )
self.attribution_method_instance = self.attribution_method_class(
captum_model)
- # In captum, the target is the class index for which
- # the attribution is computed. With CaptumModel, we transform
- # the binary classification into a multi-class. This way we can
- # explain both classes and need to pass a target here as well.
+ # In Captum, the target is the class index for which the attribution is
+ # computed. Within CaptumModel, we transform the binary classification
+ # into a multi-class classification task.
if self.model_config.mode == ModelMode.regression:
target = None
- else:
+ elif index is not None:
target = target[index]
attributions = self.attribution_method_instance.attribute(
| CaptumExplainer binary graph classification
### 🐛 Describe the bug
Hello,
A while ago, I commented in #7702 about the impossibility of using CaptumExplainer with binary classification, which was corrected in PR #7787. However, I only use the fixed implementation now due to the release update.
However, a function converts binary classification to multi-class classification in `torch_geometric.explain.algorithm.captum.py` postprocess function (line 88).
Here is a code to reproduce the error:
```python
import torch
from tqdm import tqdm
import os.path as osp
import torch.nn as nn
from torch_geometric.loader import DataLoader
from torch_geometric.datasets import MoleculeNet
from torch_geometric.nn import GAT, global_mean_pool
from torch_geometric.explain import Explainer, CaptumExplainer
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
dataset = "hiv"
path = osp.join(osp.dirname(osp.realpath(__file__)), "MoleculeNet")
dataset = MoleculeNet(path, dataset)
loader = DataLoader(dataset, batch_size=32, shuffle=True)
model = GAT(in_channels=dataset.num_node_features,
hidden_channels=64,
out_channels=1,
num_layers=1,
dropout=0.2,
edge_dim=dataset.num_edge_features,
v2=True,
heads=2)
model = model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
loss_fn = nn.BCEWithLogitsLoss()
model.train()
for epoch in tqdm(range(1, 2), ncols=120):
for batch in loader:
batch.to(device)
optimizer.zero_grad()
out = model(x=batch.x.float(), edge_index=batch.edge_index,
edge_attr=batch.edge_attr.float())
out = global_mean_pool(out, batch.batch)
pred = torch.sigmoid(out)
loss = loss_fn(pred, batch.y)
loss.backward()
optimizer.step()
explainer = Explainer(model=model,
algorithm=CaptumExplainer("IntegratedGradients"),
explanation_type="model",
node_mask_type="attributes",
edge_mask_type="object",
model_config=dict(mode="binary_classification",
task_level="graph",
return_type="probs"))
data = dataset[0].to(device)
dummy = torch.zeros(data.x.shape[0], dtype=int, device=device)
explanation = explainer(x=data.x.float(), edge_index=data.edge_index,
edge_attr=data.edge_attr.float())
print(explanation.available_explanations)
```
This is the Traceback I received.
``` bash
Traceback (most recent call last):
File "/home/takaogahara/takaogahara/experiments/explain/issue.py", line 60, in <module>
explanation = explainer(x=data.x.float(), edge_index=data.edge_index,
File "/home/takaogahara/virtualenvs/graphchem/lib/python3.10/site-packages/torch_geometric/explain/explainer.py", line 204, in __call__
explanation = self.algorithm(
File "/home/takaogahara/virtualenvs/graphchem/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/takaogahara/virtualenvs/graphchem/lib/python3.10/site-packages/torch_geometric/explain/algorithm/captum_explainer.py", line 167, in forward
attributions = self.attribution_method_instance.attribute(
File "/home/takaogahara/virtualenvs/graphchem/lib/python3.10/site-packages/captum/log/__init__.py", line 42, in wrapper
return func(*args, **kwargs)
File "/home/takaogahara/virtualenvs/graphchem/lib/python3.10/site-packages/captum/attr/_core/integrated_gradients.py", line 274, in attribute
attributions = _batch_attribution(
File "/home/takaogahara/virtualenvs/graphchem/lib/python3.10/site-packages/captum/attr/_utils/batching.py", line 78, in _batch_attribution
current_attr = attr_method._attribute(
File "/home/takaogahara/virtualenvs/graphchem/lib/python3.10/site-packages/captum/attr/_core/integrated_gradients.py", line 351, in _attribute
grads = self.gradient_func(
File "/home/takaogahara/virtualenvs/graphchem/lib/python3.10/site-packages/captum/_utils/gradient.py", line 112, in compute_gradients
outputs = _run_forward(forward_fn, inputs, target_ind, additional_forward_args)
File "/home/takaogahara/virtualenvs/graphchem/lib/python3.10/site-packages/captum/_utils/common.py", line 487, in _run_forward
return _select_targets(output, target)
File "/home/takaogahara/virtualenvs/graphchem/lib/python3.10/site-packages/captum/_utils/common.py", line 506, in _select_targets
raise AssertionError(
AssertionError: Tensor target dimension torch.Size([1, 19]) is not valid. torch.Size([19, 2])
```
I believe the postprocess function in the `captum.py` file needs to be updated to keep the binary classification data, am I right?
### Environment
* PyG version: 2.4.0
* PyTorch version: 2.0.1+cu118
* OS: Ubuntu 22.04
* Python version: 3.10
* CUDA/cuDNN version: cu118
* How you installed PyTorch and PyG (`conda`, `pip`, source): pip
| I believe I am having the same issue, though I'm not entirely certain what the expected output of the model should be for binary classification (or for any of the options, actually) to confirm that it's not an issue with my code as opposed to the model itself. My setup is nearly identical to the minimally reproducible example by @Takaogahara above with the exception of the graph and model in question being heterogenous.
The issue with the code above is that the global pooling is performed outside of the loop, thus making configuration and model not align anymore. This fixes it for me:
```python
import os.path as osp
import torch
import torch.nn as nn
from torch_geometric.datasets import MoleculeNet
from torch_geometric.explain import CaptumExplainer, Explainer
from torch_geometric.loader import DataLoader
from torch_geometric.nn import GAT, global_mean_pool
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
dataset = "hiv"
path = osp.join(osp.dirname(osp.realpath(__file__)), "MoleculeNet")
dataset = MoleculeNet(path, dataset)
loader = DataLoader(dataset, batch_size=32, shuffle=True)
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.model = GAT(
in_channels=dataset.num_node_features,
hidden_channels=64,
out_channels=1,
num_layers=1,
dropout=0.2,
edge_dim=dataset.num_edge_features,
v2=True,
heads=2,
)
def forward(self, x, edge_index, edge_attr, batch):
x = self.model(x, edge_index, edge_attr=edge_attr)
return global_mean_pool(x, batch)
model = Model().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
loss_fn = nn.BCEWithLogitsLoss()
explainer = Explainer(
model=model,
algorithm=CaptumExplainer("IntegratedGradients"),
explanation_type="model",
node_mask_type="attributes",
edge_mask_type="object",
model_config=dict(mode="binary_classification", task_level="graph",
return_type="probs"),
)
data = dataset[0].to(device)
explanation = explainer(
x=data.x.float(),
edge_index=data.edge_index,
edge_attr=data.edge_attr.float(),
batch=torch.zeros(data.num_nodes, dtype=torch.long, device=device),
)
print(explanation.available_explanations) | 2023-11-26T11:11:57 |
|
pyg-team/pytorch_geometric | 8,519 | pyg-team__pytorch_geometric-8519 | [
"8509"
]
| bd4c99abce57257cbbbc50c2b4a1854b19ec2346 | diff --git a/torch_geometric/datasets/explainer_dataset.py b/torch_geometric/datasets/explainer_dataset.py
--- a/torch_geometric/datasets/explainer_dataset.py
+++ b/torch_geometric/datasets/explainer_dataset.py
@@ -119,12 +119,14 @@ def get_graph(self) -> Explanation:
if 'y' in motif:
ys.append(motif.y + 1 if motif.y.min() == 0 else motif.y)
+ else:
+ ys.append(torch.ones(motif.num_nodes, dtype=torch.long))
num_nodes += motif.num_nodes
return Explanation(
edge_index=torch.cat(edge_indices, dim=1),
- y=torch.cat(ys, dim=0) if len(ys) > 1 else None,
+ y=torch.cat(ys, dim=0),
edge_mask=torch.cat(edge_masks, dim=0),
node_mask=torch.cat(node_masks, dim=0),
)
| CycleMotif lack of label, therefore do not support GNNExplainer.
### 🐛 Describe the bug
when running ./examples/explain/gnn_explainer_ba_shapes.py, when I replace the dataset:
```
dataset = ExplainerDataset(
graph_generator=BAGraph(num_nodes=300, num_edges=5),
motif_generator='house',
num_motifs=80,
transform=T.Constant(),
)
```
with
```
dataset = ExplainerDataset(
graph_generator=BAGraph(num_nodes=300, num_edges=5),
motif_generator=CycleMotif(num_nodes=6),
num_motifs=80,
transform=T.Constant(),
)
```
There is an error:
```
Traceback (most recent call last):
File "/home/stt/py_github_repo_read/pytorch_geometric/examples/explain/gnn_explainer_ba_shapes.py", line 46, in <module>
out_channels=dataset.num_classes).to(device)
File "/home/stt/py_github_repo_read/pytorch_geometric/torch_geometric/data/in_memory_dataset.py", line 90, in num_classes
return super().num_classes
File "/home/stt/py_github_repo_read/pytorch_geometric/torch_geometric/data/dataset.py", line 173, in num_classes
y = torch.cat([data.y for data in data_list if 'y' in data], dim=0)
RuntimeError: torch.cat(): expected a non-empty list of Tensors
```
The reason behind locate at line 23 in `./torch_geometric/datasets/motif_generator/cycle.py`
```
structure = Data(
num_nodes=num_nodes,
edge_index=torch.stack([row, col], dim=0),
# TODO: lack of y label
)
```
lack of y label as in `./torch_geometric/datasets/motif_generator/house.py`
```
structure = Data(
num_nodes=5,
edge_index=torch.tensor([
[0, 0, 0, 1, 1, 1, 2, 2, 3, 3, 4, 4],
[1, 3, 4, 4, 2, 0, 1, 3, 2, 0, 0, 1],
]),
y=torch.tensor([0, 0, 1, 1, 2]),
)
```
According to GNNExplainer original repository, for the cycle motif, the node labels are the same. Therefore, we only need to add `y=torch.tensor([0]*num_nodes)`
### Versions
PyTorch version: 2.1.0+cu121
Is debug build: False
CUDA used to build PyTorch: 12.1
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.3 LTS (x86_64)
GCC version: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.9.18 | packaged by conda-forge | (main, Aug 30 2023, 03:49:32) [GCC 12.3.0] (64-bit runtime)
Python platform: Linux-6.2.0-34-generic-x86_64-with-glibc2.35
Is CUDA available: True
CUDA runtime version: 11.8.89
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3090
GPU 1: NVIDIA GeForce RTX 3090
Nvidia driver version: 535.113.01
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
架构: x86_64
CPU 运行模式: 32-bit, 64-bit
Address sizes: 39 bits physical, 48 bits virtual
字节序: Little Endian
CPU: 24
在线 CPU 列表: 0-23
厂商 ID: GenuineIntel
型号名称: 13th Gen Intel(R) Core(TM) i7-13700KF
CPU 系列: 6
型号: 183
每个核的线程数: 2
每个座的核数: 16
座: 1
步进: 1
CPU 最大 MHz: 5400.0000
CPU 最小 MHz: 800.0000
BogoMIPS: 6835.20
标记: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 sdbg fma cx16 xtpr pdcm sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb ssbd ibrs ibpb stibp ibrs_enhanced tpr_shadow vnmi flexpriority ept vpid ept_ad fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid rdseed adx smap clflushopt clwb intel_pt sha_ni xsaveopt xsavec xgetbv1 xsaves split_lock_detect avx_vnni dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp hwp_pkg_req hfi umip pku ospke waitpkg gfni vaes vpclmulqdq rdpid movdiri movdir64b fsrm md_clear serialize arch_lbr ibt flush_l1d arch_capabilities
虚拟化: VT-x
L1d 缓存: 640 KiB (16 instances)
L1i 缓存: 768 KiB (16 instances)
L2 缓存: 24 MiB (10 instances)
L3 缓存: 30 MiB (1 instance)
NUMA 节点: 1
NUMA 节点0 CPU: 0-23
Vulnerability Gather data sampling: Not affected
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Not affected
Vulnerability Spec rstack overflow: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] numpy==1.26.0
[pip3] torch==2.1.0
[pip3] torchvision==0.16.0
[pip3] triton==2.1.0
[conda] numpy 1.26.0 pypi_0 pypi
[conda] torch 2.1.0 pypi_0 pypi
[conda] torchvision 0.16.0 pypi_0 pypi
[conda] triton 2.1.0 pypi_0 pypi
| Additionally, the **grid motif** in GNNExplainer is absent from PYG. I'm interested in contributing to this project, especially as a beginner. If possible, this "good first issue" seems fitting for me, and it aligns with requirement for one of my course being studied. | 2023-12-04T06:37:30 |
|
pyg-team/pytorch_geometric | 8,550 | pyg-team__pytorch_geometric-8550 | [
"8543"
]
| dd1a5be993e902593a10767fb124168a4bc9c5b5 | diff --git a/torch_geometric/data/dataset.py b/torch_geometric/data/dataset.py
--- a/torch_geometric/data/dataset.py
+++ b/torch_geometric/data/dataset.py
@@ -158,7 +158,13 @@ def _infer_num_classes(self, y: Optional[Tensor]) -> int:
elif y.numel() == y.size(0) and not torch.is_floating_point(y):
return int(y.max()) + 1
elif y.numel() == y.size(0) and torch.is_floating_point(y):
- return torch.unique(y).numel()
+ num_classes = torch.unique(y).numel()
+ if num_classes > 2:
+ warnings.warn("Found floating-point labels while calling "
+ "`dataset.num_classes`. Returning the number of "
+ "unique elements. Please make sure that this "
+ "is expected before proceeding.")
+ return num_classes
else:
return y.size(-1)
@@ -170,7 +176,7 @@ def num_classes(self) -> int:
# may produce a tuple of data objects (e.g., when used in combination
# with `RandomLinkSplit`, so we take care of this case here as well:
data_list = _get_flattened_data_list([data for data in self])
- y = torch.cat([data.y for data in data_list if 'y' in data], dim=0)
+ y = torch.as_tensor([data.y for data in data_list if 'y' in data])
# Do not fill cache for `InMemoryDataset`:
if hasattr(self, '_data_list') and self._data_list is not None:
| `PCQnm4v2` dataset is regression and `data.y` gives ugly error message, could use a nicer error message
### 🐛 Describe the bug
```
Traceback (most recent call last):
File "/opt/pyg/pytorch_geometric/x.py", line 195, in <module>
main()
File "/opt/pyg/pytorch_geometric/x.py", line 136, in main
model = GCN(-1, args.emb_dim, args.num_layers, out_channels=train_dataset.num_classes, dropout=args.drop_ratio ).to(device)
File "/opt/pyg/pytorch_geometric/torch_geometric/data/dataset.py", line 173, in num_classes
y = torch.cat([data.y for data in data_list if 'y' in data], dim=0)
TypeError: expected Tensor as element 0 in argument 0, but got float
```
code used to repro:
[ondiskdrugdisc.py.zip](https://github.com/pyg-team/pytorch_geometric/files/13573430/ondiskdrugdisc.py.zip)
### Versions
latest stack
| This is a regression dataset, so `dataset.num_classes` is expected to fail. We can still print out a better error message though.
oh shoot thanks for lmk, that solves my issue lol, hand't looked too closely into the dataset yet. ill leave this issue about the error message in case this is something you want to change | 2023-12-06T13:32:09 |
|
pyg-team/pytorch_geometric | 8,564 | pyg-team__pytorch_geometric-8564 | [
"8541"
]
| d71bab228be20f04b67ecb67b15bfd3b45931608 | diff --git a/torch_geometric/edge_index.py b/torch_geometric/edge_index.py
--- a/torch_geometric/edge_index.py
+++ b/torch_geometric/edge_index.py
@@ -199,7 +199,7 @@ class EdgeIndex(Tensor):
_T_index: Tuple[Optional[Tensor], Optional[Tensor]] = (None, None)
_T_indptr: Optional[Tensor] = None
- # A cached "1"-vector for `torch.sparse` matrix multiplication:
+ # A cached "1"-value vector for `torch.sparse` matrix multiplication:
_value: Optional[Tensor] = None
def __new__(
@@ -502,13 +502,10 @@ def _get_value(self, dtype: Optional[torch.dtype] = None) -> Tensor:
if (dtype or torch.get_default_dtype()) == self._value.dtype:
return self._value
- if torch_geometric.typing.WITH_PT20 and not self.is_cuda:
- value = torch.ones(1, dtype=dtype, device=self.device)
- value = value.expand(self.size(1))
- else: # pragma: no cover
- value = torch.ones(self.size(1), dtype=dtype, device=self.device)
-
- self._value = value
+ # Expanded tensors are not yet supported in all PyTorch code paths :(
+ # value = torch.ones(1, dtype=dtype, device=self.device)
+ # value = value.expand(self.size(1))
+ self._value = torch.ones(self.size(1), dtype=dtype, device=self.device)
return self._value
diff --git a/torch_geometric/utils/sparse.py b/torch_geometric/utils/sparse.py
--- a/torch_geometric/utils/sparse.py
+++ b/torch_geometric/utils/sparse.py
@@ -184,14 +184,10 @@ def to_torch_coo_tensor(
edge_index, edge_attr = coalesce(edge_index, edge_attr, max(size))
if edge_attr is None:
- if torch_geometric.typing.WITH_PT20 and not edge_index.is_cuda:
- edge_attr = torch.ones(1, device=edge_index.device)
- edge_attr = edge_attr.expand(edge_index.size(1))
- else:
- edge_attr = torch.ones(
- edge_index.size(1),
- device=edge_index.device,
- )
+ # Expanded tensors are not yet supported in all PyTorch code paths :(
+ # edge_attr = torch.ones(1, device=edge_index.device)
+ # edge_attr = edge_attr.expand(edge_index.size(1))
+ edge_attr = torch.ones(edge_index.size(1), device=edge_index.device)
adj = torch.sparse_coo_tensor(
indices=edge_index,
@@ -248,14 +244,10 @@ def to_torch_csr_tensor(
edge_index, edge_attr = coalesce(edge_index, edge_attr, max(size))
if edge_attr is None:
- if torch_geometric.typing.WITH_PT20 and not edge_index.is_cuda:
- edge_attr = torch.ones(1, device=edge_index.device)
- edge_attr = edge_attr.expand(edge_index.size(1))
- else:
- edge_attr = torch.ones(
- edge_index.size(1),
- device=edge_index.device,
- )
+ # Expanded tensors are not yet supported in all PyTorch code paths :(
+ # edge_attr = torch.ones(1, device=edge_index.device)
+ # edge_attr = edge_attr.expand(edge_index.size(1))
+ edge_attr = torch.ones(edge_index.size(1), device=edge_index.device)
adj = torch.sparse_csr_tensor(
crow_indices=index2ptr(edge_index[0], size[0]),
@@ -319,14 +311,10 @@ def to_torch_csc_tensor(
sort_by_row=False)
if edge_attr is None:
- if torch_geometric.typing.WITH_PT20 and not edge_index.is_cuda:
- edge_attr = torch.ones(1, device=edge_index.device)
- edge_attr = edge_attr.expand(edge_index.size(1))
- else:
- edge_attr = torch.ones(
- edge_index.size(1),
- device=edge_index.device,
- )
+ # Expanded tensors are not yet supported in all PyTorch code paths :(
+ # edge_attr = torch.ones(1, device=edge_index.device)
+ # edge_attr = edge_attr.expand(edge_index.size(1))
+ edge_attr = torch.ones(edge_index.size(1), device=edge_index.device)
adj = torch.sparse_csc_tensor(
ccol_indices=index2ptr(edge_index[1], size[1]),
| many CI failures due to `RuntimeError: eigen accepts only contiguous tensors`
### 🐛 Describe the bug
```
FAILED test/data/test_edge_index.py::test_spspmm[directed--sum-cpu] - RuntimeError: eigen accepts only contiguous tensors
FAILED test/data/test_edge_index.py::test_spspmm[directed--add-cpu] - RuntimeError: eigen accepts only contiguous tensors
FAILED test/data/test_edge_index.py::test_spspmm[undirected--sum-cpu] - RuntimeError: eigen accepts only contiguous tensors
FAILED test/data/test_edge_index.py::test_spspmm[undirected--add-cpu] - RuntimeError: eigen accepts only contiguous tensors
FAILED test/data/test_edge_index.py::test_spspmm[undirected-transpose-sum-cpu] - RuntimeError: eigen accepts only contiguous tensors
FAILED test/data/test_edge_index.py::test_spspmm[undirected-transpose-add-cpu] - RuntimeError: eigen accepts only contiguous tensors
FAILED test/nn/pool/test_asap.py::test_asap - RuntimeError: eigen accepts only contiguous tensors
FAILED test/transforms/test_two_hop.py::test_two_hop - RuntimeError: eigen accepts only contiguous tensors
```
### Versions
latest stack as of this morning
| Can you post the full stack trace? I am not sure which tensors are not contiguous here, so this might help me track down the issue.
```
________________________ test_spspmm[directed--sum-cpu] ________________________
device = device(type='cpu'), reduce = 'sum', transpose = False
is_undirected = False
@withCUDA
@pytest.mark.parametrize('reduce', ReduceType.__args__)
@pytest.mark.parametrize('transpose', TRANSPOSE)
@pytest.mark.parametrize('is_undirected', IS_UNDIRECTED)
def test_spspmm(device, reduce, transpose, is_undirected):
if is_undirected:
kwargs = dict(device=device, sort_order='row', is_undirected=True)
adj1 = EdgeIndex([[0, 1, 1, 2], [1, 0, 2, 1]], **kwargs)
else:
kwargs = dict(device=device, sort_order='row')
adj1 = EdgeIndex([[0, 1, 1, 2], [2, 0, 1, 2]], **kwargs)
adj1_dense = adj1.to_dense().t() if transpose else adj1.to_dense()
adj2 = EdgeIndex([[1, 0, 2, 1], [0, 1, 1, 2]], sort_order='col',
device=device)
adj2_dense = adj2.to_dense()
if reduce in ['sum', 'add']:
> out, value = adj1.matmul(adj2, reduce=reduce, transpose=transpose)
test/data/test_edge_index.py:791:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
/usr/local/lib/python3.10/dist-packages/torch_geometric/data/edge_index.py:765: in matmul
return matmul(self, other, input_value, other_value, reduce, transpose)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
input = tensor(crow_indices=tensor([0, 1, 3, 4]),
col_indices=tensor([2, 0, 1, 2]),
values=tensor([1., 1., 1., 1.]), size=(3, 3), nnz=4,
layout=torch.sparse_csr)
other = tensor(ccol_indices=tensor([0, 1, 3, 4]),
row_indices=tensor([1, 0, 2, 1]),
values=tensor([1., 1., 1., 1.]), size=(3, 3), nnz=4,
layout=torch.sparse_csc)
input_value = None, other_value = None, reduce = 'sum', transpose = False
def matmul(
input: EdgeIndex,
other: Union[Tensor, EdgeIndex],
input_value: Optional[Tensor] = None,
other_value: Optional[Tensor] = None,
reduce: ReduceType = 'sum',
transpose: bool = False,
) -> Union[Tensor, Tuple[EdgeIndex, Tensor]]:
if reduce not in ReduceType.__args__:
raise NotImplementedError(f"`reduce='{reduce}'` not yet supported")
if not isinstance(other, EdgeIndex):
if other_value is not None:
raise ValueError("'other_value' not supported for sparse-dense "
"matrix multiplication")
return _spmm(input, other, input_value, reduce, transpose)
if reduce not in ['sum', 'add']:
raise NotImplementedError(f"`reduce='{reduce}'` not yet supported for "
f"sparse-sparse matrix multiplication")
transpose &= not input.is_undirected or input_value is not None
if torch_geometric.typing.WITH_WINDOWS: # pragma: no cover
input = input.to_sparse_coo(input_value)
elif input.is_sorted_by_col:
input = input.to_sparse_csc(input_value)
else:
input = input.to_sparse_csr(input_value)
if transpose:
input = input.t()
if torch_geometric.typing.WITH_WINDOWS: # pragma: no cover
other = other.to_sparse_coo(input_value)
elif other.is_sorted_by_col:
other = other.to_sparse_csc(other_value)
else:
other = other.to_sparse_csr(other_value)
> out = torch.matmul(input, other)
E RuntimeError: eigen accepts only contiguous tensors
/usr/local/lib/python3.10/dist-packages/torch_geometric/data/edge_index.py:1273: RuntimeError
________________________ test_spspmm[directed--add-cpu] ________________________
device = device(type='cpu'), reduce = 'add', transpose = False
is_undirected = False
@withCUDA
@pytest.mark.parametrize('reduce', ReduceType.__args__)
@pytest.mark.parametrize('transpose', TRANSPOSE)
@pytest.mark.parametrize('is_undirected', IS_UNDIRECTED)
def test_spspmm(device, reduce, transpose, is_undirected):
if is_undirected:
kwargs = dict(device=device, sort_order='row', is_undirected=True)
adj1 = EdgeIndex([[0, 1, 1, 2], [1, 0, 2, 1]], **kwargs)
else:
kwargs = dict(device=device, sort_order='row')
adj1 = EdgeIndex([[0, 1, 1, 2], [2, 0, 1, 2]], **kwargs)
adj1_dense = adj1.to_dense().t() if transpose else adj1.to_dense()
adj2 = EdgeIndex([[1, 0, 2, 1], [0, 1, 1, 2]], sort_order='col',
device=device)
adj2_dense = adj2.to_dense()
if reduce in ['sum', 'add']:
> out, value = adj1.matmul(adj2, reduce=reduce, transpose=transpose)
test/data/test_edge_index.py:791:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
/usr/local/lib/python3.10/dist-packages/torch_geometric/data/edge_index.py:765: in matmul
return matmul(self, other, input_value, other_value, reduce, transpose)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
input = tensor(crow_indices=tensor([0, 1, 3, 4]),
col_indices=tensor([2, 0, 1, 2]),
values=tensor([1., 1., 1., 1.]), size=(3, 3), nnz=4,
layout=torch.sparse_csr)
other = tensor(ccol_indices=tensor([0, 1, 3, 4]),
row_indices=tensor([1, 0, 2, 1]),
values=tensor([1., 1., 1., 1.]), size=(3, 3), nnz=4,
layout=torch.sparse_csc)
input_value = None, other_value = None, reduce = 'add', transpose = False
def matmul(
input: EdgeIndex,
other: Union[Tensor, EdgeIndex],
input_value: Optional[Tensor] = None,
other_value: Optional[Tensor] = None,
reduce: ReduceType = 'sum',
transpose: bool = False,
) -> Union[Tensor, Tuple[EdgeIndex, Tensor]]:
if reduce not in ReduceType.__args__:
raise NotImplementedError(f"`reduce='{reduce}'` not yet supported")
if not isinstance(other, EdgeIndex):
if other_value is not None:
raise ValueError("'other_value' not supported for sparse-dense "
"matrix multiplication")
return _spmm(input, other, input_value, reduce, transpose)
if reduce not in ['sum', 'add']:
raise NotImplementedError(f"`reduce='{reduce}'` not yet supported for "
f"sparse-sparse matrix multiplication")
transpose &= not input.is_undirected or input_value is not None
if torch_geometric.typing.WITH_WINDOWS: # pragma: no cover
input = input.to_sparse_coo(input_value)
elif input.is_sorted_by_col:
input = input.to_sparse_csc(input_value)
else:
input = input.to_sparse_csr(input_value)
if transpose:
input = input.t()
if torch_geometric.typing.WITH_WINDOWS: # pragma: no cover
other = other.to_sparse_coo(input_value)
elif other.is_sorted_by_col:
other = other.to_sparse_csc(other_value)
else:
other = other.to_sparse_csr(other_value)
> out = torch.matmul(input, other)
E RuntimeError: eigen accepts only contiguous tensors
/usr/local/lib/python3.10/dist-packages/torch_geometric/data/edge_index.py:1273: RuntimeError
_______________________ test_spspmm[undirected--sum-cpu] _______________________
device = device(type='cpu'), reduce = 'sum', transpose = False
is_undirected = True
@withCUDA
@pytest.mark.parametrize('reduce', ReduceType.__args__)
@pytest.mark.parametrize('transpose', TRANSPOSE)
@pytest.mark.parametrize('is_undirected', IS_UNDIRECTED)
def test_spspmm(device, reduce, transpose, is_undirected):
if is_undirected:
kwargs = dict(device=device, sort_order='row', is_undirected=True)
adj1 = EdgeIndex([[0, 1, 1, 2], [1, 0, 2, 1]], **kwargs)
else:
kwargs = dict(device=device, sort_order='row')
adj1 = EdgeIndex([[0, 1, 1, 2], [2, 0, 1, 2]], **kwargs)
adj1_dense = adj1.to_dense().t() if transpose else adj1.to_dense()
adj2 = EdgeIndex([[1, 0, 2, 1], [0, 1, 1, 2]], sort_order='col',
device=device)
adj2_dense = adj2.to_dense()
if reduce in ['sum', 'add']:
> out, value = adj1.matmul(adj2, reduce=reduce, transpose=transpose)
test/data/test_edge_index.py:791:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
/usr/local/lib/python3.10/dist-packages/torch_geometric/data/edge_index.py:765: in matmul
return matmul(self, other, input_value, other_value, reduce, transpose)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
input = tensor(crow_indices=tensor([0, 1, 3, 4]),
col_indices=tensor([1, 0, 2, 1]),
values=tensor([1., 1., 1., 1.]), size=(3, 3), nnz=4,
layout=torch.sparse_csr)
other = tensor(ccol_indices=tensor([0, 1, 3, 4]),
row_indices=tensor([1, 0, 2, 1]),
values=tensor([1., 1., 1., 1.]), size=(3, 3), nnz=4,
layout=torch.sparse_csc)
input_value = None, other_value = None, reduce = 'sum', transpose = False
def matmul(
input: EdgeIndex,
other: Union[Tensor, EdgeIndex],
input_value: Optional[Tensor] = None,
other_value: Optional[Tensor] = None,
reduce: ReduceType = 'sum',
transpose: bool = False,
) -> Union[Tensor, Tuple[EdgeIndex, Tensor]]:
if reduce not in ReduceType.__args__:
raise NotImplementedError(f"`reduce='{reduce}'` not yet supported")
if not isinstance(other, EdgeIndex):
if other_value is not None:
raise ValueError("'other_value' not supported for sparse-dense "
"matrix multiplication")
return _spmm(input, other, input_value, reduce, transpose)
if reduce not in ['sum', 'add']:
raise NotImplementedError(f"`reduce='{reduce}'` not yet supported for "
f"sparse-sparse matrix multiplication")
transpose &= not input.is_undirected or input_value is not None
if torch_geometric.typing.WITH_WINDOWS: # pragma: no cover
input = input.to_sparse_coo(input_value)
elif input.is_sorted_by_col:
input = input.to_sparse_csc(input_value)
else:
input = input.to_sparse_csr(input_value)
if transpose:
input = input.t()
if torch_geometric.typing.WITH_WINDOWS: # pragma: no cover
other = other.to_sparse_coo(input_value)
elif other.is_sorted_by_col:
other = other.to_sparse_csc(other_value)
else:
other = other.to_sparse_csr(other_value)
> out = torch.matmul(input, other)
E RuntimeError: eigen accepts only contiguous tensors
/usr/local/lib/python3.10/dist-packages/torch_geometric/data/edge_index.py:1273: RuntimeError
_______________________ test_spspmm[undirected--add-cpu] _______________________
device = device(type='cpu'), reduce = 'add', transpose = False
is_undirected = True
@withCUDA
@pytest.mark.parametrize('reduce', ReduceType.__args__)
@pytest.mark.parametrize('transpose', TRANSPOSE)
@pytest.mark.parametrize('is_undirected', IS_UNDIRECTED)
def test_spspmm(device, reduce, transpose, is_undirected):
if is_undirected:
kwargs = dict(device=device, sort_order='row', is_undirected=True)
adj1 = EdgeIndex([[0, 1, 1, 2], [1, 0, 2, 1]], **kwargs)
else:
kwargs = dict(device=device, sort_order='row')
adj1 = EdgeIndex([[0, 1, 1, 2], [2, 0, 1, 2]], **kwargs)
adj1_dense = adj1.to_dense().t() if transpose else adj1.to_dense()
adj2 = EdgeIndex([[1, 0, 2, 1], [0, 1, 1, 2]], sort_order='col',
device=device)
adj2_dense = adj2.to_dense()
if reduce in ['sum', 'add']:
> out, value = adj1.matmul(adj2, reduce=reduce, transpose=transpose)
test/data/test_edge_index.py:791:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
/usr/local/lib/python3.10/dist-packages/torch_geometric/data/edge_index.py:765: in matmul
return matmul(self, other, input_value, other_value, reduce, transpose)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
input = tensor(crow_indices=tensor([0, 1, 3, 4]),
col_indices=tensor([1, 0, 2, 1]),
values=tensor([1., 1., 1., 1.]), size=(3, 3), nnz=4,
layout=torch.sparse_csr)
other = tensor(ccol_indices=tensor([0, 1, 3, 4]),
row_indices=tensor([1, 0, 2, 1]),
values=tensor([1., 1., 1., 1.]), size=(3, 3), nnz=4,
layout=torch.sparse_csc)
input_value = None, other_value = None, reduce = 'add', transpose = False
def matmul(
input: EdgeIndex,
other: Union[Tensor, EdgeIndex],
input_value: Optional[Tensor] = None,
other_value: Optional[Tensor] = None,
reduce: ReduceType = 'sum',
transpose: bool = False,
) -> Union[Tensor, Tuple[EdgeIndex, Tensor]]:
if reduce not in ReduceType.__args__:
raise NotImplementedError(f"`reduce='{reduce}'` not yet supported")
if not isinstance(other, EdgeIndex):
if other_value is not None:
raise ValueError("'other_value' not supported for sparse-dense "
"matrix multiplication")
return _spmm(input, other, input_value, reduce, transpose)
if reduce not in ['sum', 'add']:
raise NotImplementedError(f"`reduce='{reduce}'` not yet supported for "
f"sparse-sparse matrix multiplication")
transpose &= not input.is_undirected or input_value is not None
if torch_geometric.typing.WITH_WINDOWS: # pragma: no cover
input = input.to_sparse_coo(input_value)
elif input.is_sorted_by_col:
input = input.to_sparse_csc(input_value)
else:
input = input.to_sparse_csr(input_value)
if transpose:
input = input.t()
if torch_geometric.typing.WITH_WINDOWS: # pragma: no cover
other = other.to_sparse_coo(input_value)
elif other.is_sorted_by_col:
other = other.to_sparse_csc(other_value)
else:
other = other.to_sparse_csr(other_value)
> out = torch.matmul(input, other)
E RuntimeError: eigen accepts only contiguous tensors
/usr/local/lib/python3.10/dist-packages/torch_geometric/data/edge_index.py:1273: RuntimeError
__________________ test_spspmm[undirected-transpose-sum-cpu] ___________________
device = device(type='cpu'), reduce = 'sum', transpose = True
is_undirected = True
@withCUDA
@pytest.mark.parametrize('reduce', ReduceType.__args__)
@pytest.mark.parametrize('transpose', TRANSPOSE)
@pytest.mark.parametrize('is_undirected', IS_UNDIRECTED)
def test_spspmm(device, reduce, transpose, is_undirected):
if is_undirected:
kwargs = dict(device=device, sort_order='row', is_undirected=True)
adj1 = EdgeIndex([[0, 1, 1, 2], [1, 0, 2, 1]], **kwargs)
else:
kwargs = dict(device=device, sort_order='row')
adj1 = EdgeIndex([[0, 1, 1, 2], [2, 0, 1, 2]], **kwargs)
adj1_dense = adj1.to_dense().t() if transpose else adj1.to_dense()
adj2 = EdgeIndex([[1, 0, 2, 1], [0, 1, 1, 2]], sort_order='col',
device=device)
adj2_dense = adj2.to_dense()
if reduce in ['sum', 'add']:
> out, value = adj1.matmul(adj2, reduce=reduce, transpose=transpose)
test/data/test_edge_index.py:791:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
/usr/local/lib/python3.10/dist-packages/torch_geometric/data/edge_index.py:765: in matmul
return matmul(self, other, input_value, other_value, reduce, transpose)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
input = tensor(crow_indices=tensor([0, 1, 3, 4]),
col_indices=tensor([1, 0, 2, 1]),
values=tensor([1., 1., 1., 1.]), size=(3, 3), nnz=4,
layout=torch.sparse_csr)
other = tensor(ccol_indices=tensor([0, 1, 3, 4]),
row_indices=tensor([1, 0, 2, 1]),
values=tensor([1., 1., 1., 1.]), size=(3, 3), nnz=4,
layout=torch.sparse_csc)
input_value = None, other_value = None, reduce = 'sum', transpose = False
def matmul(
input: EdgeIndex,
other: Union[Tensor, EdgeIndex],
input_value: Optional[Tensor] = None,
other_value: Optional[Tensor] = None,
reduce: ReduceType = 'sum',
transpose: bool = False,
) -> Union[Tensor, Tuple[EdgeIndex, Tensor]]:
if reduce not in ReduceType.__args__:
raise NotImplementedError(f"`reduce='{reduce}'` not yet supported")
if not isinstance(other, EdgeIndex):
if other_value is not None:
raise ValueError("'other_value' not supported for sparse-dense "
"matrix multiplication")
return _spmm(input, other, input_value, reduce, transpose)
if reduce not in ['sum', 'add']:
raise NotImplementedError(f"`reduce='{reduce}'` not yet supported for "
f"sparse-sparse matrix multiplication")
transpose &= not input.is_undirected or input_value is not None
if torch_geometric.typing.WITH_WINDOWS: # pragma: no cover
input = input.to_sparse_coo(input_value)
elif input.is_sorted_by_col:
input = input.to_sparse_csc(input_value)
else:
input = input.to_sparse_csr(input_value)
if transpose:
input = input.t()
if torch_geometric.typing.WITH_WINDOWS: # pragma: no cover
other = other.to_sparse_coo(input_value)
elif other.is_sorted_by_col:
other = other.to_sparse_csc(other_value)
else:
other = other.to_sparse_csr(other_value)
> out = torch.matmul(input, other)
E RuntimeError: eigen accepts only contiguous tensors
/usr/local/lib/python3.10/dist-packages/torch_geometric/data/edge_index.py:1273: RuntimeError
__________________ test_spspmm[undirected-transpose-add-cpu] ___________________
device = device(type='cpu'), reduce = 'add', transpose = True
is_undirected = True
@withCUDA
@pytest.mark.parametrize('reduce', ReduceType.__args__)
@pytest.mark.parametrize('transpose', TRANSPOSE)
@pytest.mark.parametrize('is_undirected', IS_UNDIRECTED)
def test_spspmm(device, reduce, transpose, is_undirected):
if is_undirected:
kwargs = dict(device=device, sort_order='row', is_undirected=True)
adj1 = EdgeIndex([[0, 1, 1, 2], [1, 0, 2, 1]], **kwargs)
else:
kwargs = dict(device=device, sort_order='row')
adj1 = EdgeIndex([[0, 1, 1, 2], [2, 0, 1, 2]], **kwargs)
adj1_dense = adj1.to_dense().t() if transpose else adj1.to_dense()
adj2 = EdgeIndex([[1, 0, 2, 1], [0, 1, 1, 2]], sort_order='col',
device=device)
adj2_dense = adj2.to_dense()
if reduce in ['sum', 'add']:
> out, value = adj1.matmul(adj2, reduce=reduce, transpose=transpose)
test/data/test_edge_index.py:791:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
/usr/local/lib/python3.10/dist-packages/torch_geometric/data/edge_index.py:765: in matmul
return matmul(self, other, input_value, other_value, reduce, transpose)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
input = tensor(crow_indices=tensor([0, 1, 3, 4]),
col_indices=tensor([1, 0, 2, 1]),
values=tensor([1., 1., 1., 1.]), size=(3, 3), nnz=4,
layout=torch.sparse_csr)
other = tensor(ccol_indices=tensor([0, 1, 3, 4]),
row_indices=tensor([1, 0, 2, 1]),
values=tensor([1., 1., 1., 1.]), size=(3, 3), nnz=4,
layout=torch.sparse_csc)
input_value = None, other_value = None, reduce = 'add', transpose = False
def matmul(
input: EdgeIndex,
other: Union[Tensor, EdgeIndex],
input_value: Optional[Tensor] = None,
other_value: Optional[Tensor] = None,
reduce: ReduceType = 'sum',
transpose: bool = False,
) -> Union[Tensor, Tuple[EdgeIndex, Tensor]]:
if reduce not in ReduceType.__args__:
raise NotImplementedError(f"`reduce='{reduce}'` not yet supported")
if not isinstance(other, EdgeIndex):
if other_value is not None:
raise ValueError("'other_value' not supported for sparse-dense "
"matrix multiplication")
return _spmm(input, other, input_value, reduce, transpose)
if reduce not in ['sum', 'add']:
raise NotImplementedError(f"`reduce='{reduce}'` not yet supported for "
f"sparse-sparse matrix multiplication")
transpose &= not input.is_undirected or input_value is not None
if torch_geometric.typing.WITH_WINDOWS: # pragma: no cover
input = input.to_sparse_coo(input_value)
elif input.is_sorted_by_col:
input = input.to_sparse_csc(input_value)
else:
input = input.to_sparse_csr(input_value)
if transpose:
input = input.t()
if torch_geometric.typing.WITH_WINDOWS: # pragma: no cover
other = other.to_sparse_coo(input_value)
elif other.is_sorted_by_col:
other = other.to_sparse_csc(other_value)
else:
other = other.to_sparse_csr(other_value)
> out = torch.matmul(input, other)
E RuntimeError: eigen accepts only contiguous tensors
/usr/local/lib/python3.10/dist-packages/torch_geometric/data/edge_index.py:1273: RuntimeError
__________________________________ test_asap ___________________________________
@onlyLinux # TODO (matthias) Investigate CSR @ CSR support on Windows.
def test_asap():
in_channels = 16
edge_index = torch.tensor([[0, 0, 0, 1, 1, 1, 2, 2, 2, 3, 3, 3],
[1, 2, 3, 0, 2, 3, 0, 1, 3, 0, 1, 2]])
num_nodes = edge_index.max().item() + 1
x = torch.randn((num_nodes, in_channels))
for GNN in [GraphConv, GCNConv]:
pool = ASAPooling(in_channels, ratio=0.5, GNN=GNN,
add_self_loops=False)
assert str(pool) == ('ASAPooling(16, ratio=0.5)')
> out = pool(x, edge_index)
test/nn/pool/test_asap.py:28:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py:1510: in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py:1519: in _call_impl
return forward_call(*args, **kwargs)
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = ASAPooling(16, ratio=0.5)
x = tensor([[-0.0009, -0.0015, -0.0009, 0.0011, 0.0041, 0.0013, -0.0012, -0.0023,
0.0003, -0.0016, -0.0004, ...0023,
0.0003, -0.0016, -0.0004, 0.0030, -0.0005, -0.0011, -0.0053, 0.0015]],
grad_fn=<MulBackward0>)
edge_index = tensor([[0, 0, 0, 1, 1, 1, 2, 2, 2, 3, 3, 3, 0, 1, 2, 3],
[1, 2, 3, 0, 2, 3, 0, 1, 3, 0, 1, 2, 0, 1, 2, 3]])
edge_weight = None, batch = tensor([0, 0])
def forward(
self,
x: Tensor,
edge_index: Tensor,
edge_weight: Optional[Tensor] = None,
batch: Optional[Tensor] = None,
) -> Tuple[Tensor, Tensor, Optional[Tensor], Tensor, Tensor]:
r"""Forward pass.
Args:
x (torch.Tensor): The node feature matrix.
edge_index (torch.Tensor): The edge indices.
edge_weight (torch.Tensor, optional): The edge weights.
(default: :obj:`None`)
batch (torch.Tensor, optional): The batch vector
:math:`\mathbf{b} \in {\{ 0, \ldots, B-1\}}^N`, which assigns
each node to a specific example. (default: :obj:`None`)
Return types:
* **x** (*torch.Tensor*): The pooled node embeddings.
* **edge_index** (*torch.Tensor*): The coarsened edge indices.
* **edge_weight** (*torch.Tensor, optional*): The coarsened edge
weights.
* **batch** (*torch.Tensor*): The coarsened batch vector.
* **index** (*torch.Tensor*): The top-:math:`k` node indices of
nodes which are kept after pooling.
"""
N = x.size(0)
edge_index, edge_weight = add_remaining_self_loops(
edge_index, edge_weight, fill_value=1., num_nodes=N)
if batch is None:
batch = edge_index.new_zeros(x.size(0))
x = x.unsqueeze(-1) if x.dim() == 1 else x
x_pool = x
if self.gnn_intra_cluster is not None:
x_pool = self.gnn_intra_cluster(x=x, edge_index=edge_index,
edge_weight=edge_weight)
x_pool_j = x_pool[edge_index[0]]
x_q = scatter(x_pool_j, edge_index[1], dim=0, reduce='max')
x_q = self.lin(x_q)[edge_index[1]]
score = self.att(torch.cat([x_q, x_pool_j], dim=-1)).view(-1)
score = F.leaky_relu(score, self.negative_slope)
score = softmax(score, edge_index[1], num_nodes=N)
# Sample attention coefficients stochastically.
score = F.dropout(score, p=self.dropout, training=self.training)
v_j = x[edge_index[0]] * score.view(-1, 1)
x = scatter(v_j, edge_index[1], dim=0, reduce='sum')
# Cluster selection.
fitness = self.gnn_score(x, edge_index).sigmoid().view(-1)
perm = self.select(fitness, batch).node_index
x = x[perm] * fitness[perm].view(-1, 1)
batch = batch[perm]
# Graph coarsening.
A = to_torch_csr_tensor(edge_index, edge_weight, size=(N, N))
S = to_torch_coo_tensor(edge_index, score, size=(N, N))
S = S.index_select(1, perm).to_sparse_csr()
> A = S.t().to_sparse_csr() @ (A @ S)
E RuntimeError: eigen accepts only contiguous tensors
/usr/local/lib/python3.10/dist-packages/torch_geometric/nn/pool/asap.py:151: RuntimeError
_________________________________ test_two_hop _________________________________
def test_two_hop():
transform = TwoHop()
assert str(transform) == 'TwoHop()'
edge_index = torch.tensor([[0, 0, 0, 1, 2, 3], [1, 2, 3, 0, 0, 0]])
edge_attr = torch.tensor([1, 2, 3, 1, 2, 3], dtype=torch.float)
data = Data(edge_index=edge_index, edge_attr=edge_attr, num_nodes=4)
> data = transform(data)
test/transforms/test_two_hop.py:15:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
/usr/local/lib/python3.10/dist-packages/torch_geometric/transforms/base_transform.py:32: in __call__
return self.forward(copy.copy(data))
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = TwoHop(), data = Data(edge_index=[2, 6], edge_attr=[6], num_nodes=4)
def forward(self, data: Data) -> Data:
edge_index, edge_attr = data.edge_index, data.edge_attr
N = data.num_nodes
if torch_geometric.typing.WITH_WINDOWS:
adj = to_torch_coo_tensor(edge_index, size=(N, N))
else:
adj = to_torch_csr_tensor(edge_index, size=(N, N))
> adj = adj @ adj
E RuntimeError: eigen accepts only contiguous tensors
/usr/local/lib/python3.10/dist-packages/torch_geometric/transforms/two_hop.py:30: RuntimeError
=============================== warnings summary ===============================
../../../usr/local/lib/python3.10/dist-packages/torch_geometric/graphgym/config.py:19
/usr/local/lib/python3.10/dist-packages/torch_geometric/graphgym/config.py:19: UserWarning: Could not define global config object. Please install 'yacs' via 'pip install yacs' in order to use GraphGym
warnings.warn("Could not define global config object. Please install "
../../../usr/local/lib/python3.10/dist-packages/torch_geometric/graphgym/imports.py:14
/usr/local/lib/python3.10/dist-packages/torch_geometric/graphgym/imports.py:14: UserWarning: Please install 'pytorch_lightning' via 'pip install pytorch_lightning' in order to use GraphGym
warnings.warn("Please install 'pytorch_lightning' via "
test/data/test_edge_index.py::test_spmm[directed--amin-enable_extensions-cuda:0]
test/data/test_edge_index.py::test_spmm[directed-transpose-amin-enable_extensions-cuda:0]
test/data/test_edge_index.py::test_spmm[undirected--amin-enable_extensions-cuda:0]
test/data/test_edge_index.py::test_spmm[undirected-transpose-amin-enable_extensions-cuda:0]
/usr/local/lib/python3.10/dist-packages/torch_geometric/warnings.py:19: UserWarning: The usage of `scatter(reduce='amin')` can be accelerated via the 'torch-scatter' package, but it was not found
warnings.warn(message)
test/data/test_edge_index.py::test_spmm[directed--amax-enable_extensions-cuda:0]
test/data/test_edge_index.py::test_spmm[directed-transpose-amax-enable_extensions-cuda:0]
test/data/test_edge_index.py::test_spmm[undirected--amax-enable_extensions-cuda:0]
test/data/test_edge_index.py::test_spmm[undirected-transpose-amax-enable_extensions-cuda:0]
/usr/local/lib/python3.10/dist-packages/torch_geometric/warnings.py:19: UserWarning: The usage of `scatter(reduce='amax')` can be accelerated via the 'torch-scatter' package, but it was not found
warnings.warn(message)
test/data/test_edge_index.py::test_spmm[directed--min-enable_extensions-cuda:0]
test/data/test_edge_index.py::test_spmm[directed-transpose-min-enable_extensions-cuda:0]
test/data/test_edge_index.py::test_spmm[undirected--min-enable_extensions-cuda:0]
test/data/test_edge_index.py::test_spmm[undirected-transpose-min-enable_extensions-cuda:0]
test/utils/test_scatter.py::test_scatter_backward[min-cuda:0]
/usr/local/lib/python3.10/dist-packages/torch_geometric/warnings.py:19: UserWarning: The usage of `scatter(reduce='min')` can be accelerated via the 'torch-scatter' package, but it was not found
warnings.warn(message)
test/data/test_edge_index.py::test_spmm[directed--max-enable_extensions-cuda:0]
test/data/test_edge_index.py::test_spmm[directed-transpose-max-enable_extensions-cuda:0]
test/data/test_edge_index.py::test_spmm[undirected--max-enable_extensions-cuda:0]
test/data/test_edge_index.py::test_spmm[undirected-transpose-max-enable_extensions-cuda:0]
test/utils/test_scatter.py::test_scatter_backward[max-cuda:0]
/usr/local/lib/python3.10/dist-packages/torch_geometric/warnings.py:19: UserWarning: The usage of `scatter(reduce='max')` can be accelerated via the 'torch-scatter' package, but it was not found
warnings.warn(message)
test/nn/conv/cugraph/test_cugraph_gat_conv.py: 24 warnings
test/nn/conv/cugraph/test_cugraph_rgcn_conv.py: 72 warnings
test/nn/conv/cugraph/test_cugraph_sage_conv.py: 64 warnings
/usr/local/lib/python3.10/dist-packages/pylibcugraphops/pytorch/graph.py:57: UserWarning: dst_max_in_degree currently has no effect
warnings.warn("dst_max_in_degree currently has no effect")
test/nn/conv/cugraph/test_cugraph_gat_conv.py: 24 warnings
test/nn/conv/cugraph/test_cugraph_sage_conv.py: 64 warnings
/usr/local/lib/python3.10/dist-packages/pylibcugraphops/pytorch/graph.py:250: DeprecationWarning: SampledCSC is deprecated with the 23.08 release and will be removed in 23.10, use CSC instead.
warnings.warn(
test/nn/conv/cugraph/test_cugraph_gat_conv.py: 24 warnings
test/nn/conv/cugraph/test_cugraph_sage_conv.py: 64 warnings
/usr/local/lib/python3.10/dist-packages/pylibcugraphops/pytorch/graph.py:275: DeprecationWarning: StaticCSC is deprecated with the 23.08 release and will be removed in 23.10, use CSC instead.
warnings.warn(
test/nn/conv/cugraph/test_cugraph_rgcn_conv.py: 72 warnings
/usr/local/lib/python3.10/dist-packages/pylibcugraphops/pytorch/graph.py:302: DeprecationWarning: SampledHeteroCSC is deprecated with the 23.08 release and will be removed in 23.10, use HeteroCSC instead.
warnings.warn(
test/nn/conv/cugraph/test_cugraph_rgcn_conv.py: 72 warnings
/usr/local/lib/python3.10/dist-packages/pylibcugraphops/pytorch/graph.py:330: DeprecationWarning: StaticHeteroCSC is deprecated with the 23.08 release and will be removed in 23.10, use HeteroCSC instead.
warnings.warn(
test/nn/dense/test_linear.py::test_hetero_linear[cpu]
test/nn/dense/test_linear.py::test_hetero_linear[cuda:0]
/usr/local/lib/python3.10/dist-packages/torch/jit/_check.py:178: UserWarning: The TorchScript type system doesn't support instance-level annotations on empty non-base types in `__init__`. Instead, either 1) use a type annotation in the class body, or 2) wrap the type in `torch.jit.Attribute`.
warnings.warn(
test/transforms/test_generate_mesh_normals.py::test_generate_mesh_normals
/usr/local/lib/python3.10/dist-packages/torch_geometric/transforms/generate_mesh_normals.py:20: UserWarning: Using torch.cross without specifying the dim arg is deprecated.
Please either pass the dim explicitly or simply use torch.linalg.cross.
The default value of dim will change to agree with that of linalg.cross in a future release. (Triggered internally at /opt/pytorch/pytorch/aten/src/ATen/native/Cross.cpp:63.)
face_norm = F.normalize(vec1.cross(vec2), p=2, dim=-1) # [F, 3]
-- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html
---------- coverage: platform linux, python 3.10.12-final-0 ----------
Coverage XML written to file coverage.xml
=========================== short test summary info ============================
FAILED test/data/test_edge_index.py::test_spspmm[directed--sum-cpu] - RuntimeError: eigen accepts only contiguous tensors
FAILED test/data/test_edge_index.py::test_spspmm[directed--add-cpu] - RuntimeError: eigen accepts only contiguous tensors
FAILED test/data/test_edge_index.py::test_spspmm[undirected--sum-cpu] - RuntimeError: eigen accepts only contiguous tensors
FAILED test/data/test_edge_index.py::test_spspmm[undirected--add-cpu] - RuntimeError: eigen accepts only contiguous tensors
FAILED test/data/test_edge_index.py::test_spspmm[undirected-transpose-sum-cpu] - RuntimeError: eigen accepts only contiguous tensors
FAILED test/data/test_edge_index.py::test_spspmm[undirected-transpose-add-cpu] - RuntimeError: eigen accepts only contiguous tensors
FAILED test/nn/pool/test_asap.py::test_asap - RuntimeError: eigen accepts only contiguous tensors
FAILED test/transforms/test_two_hop.py::test_two_hop - RuntimeError: eigen accepts only contiguous tensors
= 8 failed, 5775 passed, 570 skipped, 2 deselected, 503 warnings in 200.98s (0:03:20) =
``` | 2023-12-07T13:57:43 |
|
pyg-team/pytorch_geometric | 8,566 | pyg-team__pytorch_geometric-8566 | [
"8452"
]
| 26bd53887340c6e9eb7554dd3e2acf3b92f62dec | diff --git a/torch_geometric/nn/metrics.py b/torch_geometric/nn/metrics.py
--- a/torch_geometric/nn/metrics.py
+++ b/torch_geometric/nn/metrics.py
@@ -19,12 +19,11 @@ class LinkPredMetric(BaseMetric, ABC):
r"""An abstract class for computing link prediction retrieval metrics.
Args:
- k (int): The number of top-:math:`k` predictions to evaluate
- against.
+ k (int): The number of top-:math:`k` predictions to evaluate against.
"""
- is_differentiable: Optional[bool] = None
+ is_differentiable: bool = False
+ full_state_update: bool = False
higher_is_better: Optional[bool] = None
- full_state_update: Optional[bool] = None
def __init__(self, k: int):
super().__init__()
@@ -132,35 +131,44 @@ def _compute(self, pred_isin_mat: Tensor, y_count: Tensor) -> Tensor:
raise NotImplementedError
def __repr__(self) -> str:
- return f'{self.__class__.__name__}({self.k})'
+ return f'{self.__class__.__name__}(k={self.k})'
class LinkPredPrecision(LinkPredMetric):
r"""A link prediction metric to compute Precision@:math`k`.
Args:
- k (int): The number of top-:math:`k` predictions to evaluate
- against.
+ k (int): The number of top-:math:`k` predictions to evaluate against.
"""
- is_differentiable: bool = False
higher_is_better: bool = True
- full_state_update: bool = False
def _compute(self, pred_isin_mat: Tensor, y_count: Tensor) -> Tensor:
return pred_isin_mat.sum(dim=-1) / self.k
+class LinkPredRecall(LinkPredMetric):
+ r"""A link prediction metric to compute Recall@:math:`k`.
+
+ Args:
+ k (int): The number of top-:math:`k` predictions to evaluate against.
+ """
+ higher_is_better: bool = True
+
+ def __init__(self, k: int):
+ super().__init__(k)
+
+ def _compute(self, pred_isin_mat: Tensor, y_count: Tensor) -> Tensor:
+ return pred_isin_mat.sum(dim=1) / y_count.clamp(min=1e-7)
+
+
class LinkPredNDCG(LinkPredMetric):
r"""A link prediction metric to compute the Normalized Discounted
Cumulative Gain (NDCG).
Args:
- k (int): The number of top-:math:`k` predictions to evaluate
- against.
+ k (int): The number of top-:math:`k` predictions to evaluate against.
"""
- is_differentiable: bool = False
higher_is_better: bool = True
- full_state_update: bool = False
def __init__(self, k: int):
super().__init__(k=k)
| diff --git a/test/nn/test_metrics.py b/test/nn/test_metrics.py
--- a/test/nn/test_metrics.py
+++ b/test/nn/test_metrics.py
@@ -3,7 +3,11 @@
import pytest
import torch
-from torch_geometric.nn.metrics import LinkPredNDCG, LinkPredPrecision
+from torch_geometric.nn.metrics import (
+ LinkPredNDCG,
+ LinkPredPrecision,
+ LinkPredRecall,
+)
@pytest.mark.parametrize('num_src_nodes', [100])
@@ -21,7 +25,7 @@ def test_precision(num_src_nodes, num_dst_nodes, num_edges, batch_size, k):
top_k_pred_mat = pred.topk(k, dim=1)[1]
metric = LinkPredPrecision(k)
- assert str(metric) == f'LinkPredPrecision({k})'
+ assert str(metric) == f'LinkPredPrecision(k={k})'
for node_id in torch.split(torch.randperm(num_src_nodes), batch_size):
mask = torch.isin(edge_label_index[0], node_id)
@@ -48,11 +52,24 @@ def test_precision(num_src_nodes, num_dst_nodes, num_edges, batch_size, k):
assert torch.allclose(out, expected)
+def test_recall():
+ pred_mat = torch.tensor([[1, 0], [1, 2], [0, 2]])
+ edge_label_index = torch.tensor([[0, 0, 0, 2, 2], [0, 1, 2, 2, 1]])
+
+ metric = LinkPredRecall(k=2)
+ assert str(metric) == f'LinkPredRecall(k={2})'
+ metric.update(pred_mat, edge_label_index)
+ result = metric.compute()
+
+ assert float(result) == pytest.approx(0.5 * (2 / 3 + 0.5))
+
+
def test_ndcg():
pred_mat = torch.tensor([[1, 0], [1, 2], [0, 2]])
edge_label_index = torch.tensor([[0, 0, 2, 2], [0, 1, 2, 1]])
metric = LinkPredNDCG(k=2)
+ assert str(metric) == f'LinkPredNDCG(k={2})'
metric.update(pred_mat, edge_label_index)
result = metric.compute()
| [Roadmap] PyG for Recommendation 🚀
### 🚀 The feature, motivation and pitch
**This roadmap aims to bring better support for recommendation tasks to PyG.**
Currently, all/most of our link prediction models are trained and evaluated using binary classification metrics. However, this usually requires that we have a set of candidates in advance, from which we can then infer the existence of links. This is not necessarily practical, since in most cases, we want to find the top-k most likely links from the full set of `O(N^2)` pairs.
While training can still be done via negative sampling and binary classification, this roadmap resolves around bringing better support for link prediction evaluation into PyG, with the following end-to-end pipeline:
1. Embed all source and destination nodes
1. Use "Maximum Inner Product Search" (MIPS) to find the top-k most likely links (via [`MIPSKNNIndex`](https://pytorch-geometric.readthedocs.io/en/latest/generated/torch_geometric.nn.pool.MIPSKNNIndex.html#torch_geometric.nn.pool.MIPSKNNIndex))
1. Evaluate using common metrics for recommendation, e.g., `map@k`, `precision@k`, `recall@k`, `f1@k`, `ndcg@k`.
### Metrics
We need to support recommendation metrics, which can be updated and computed in a mini-batch fashion. A related issue can be found [here](https://github.com/pyg-team/pytorch_geometric/issues/8271). Its interface can/should follow the `torchmetrics.Metric` interface, *e.g.*:
```python
class LinkPredMetric(torchmetrics.Metric):
def __init__(self, k: int):
pass
def update(self, top_k_pred_mat: Tensor, edge_label_index: Tensor):
pass
def compute(self):
pass
```
where `top_k_pred_mat` holds the top-k indices for each left-hand-side (LHS) entity, and `edge_label_index` holds the ground-truth information as a `[2, num_targets]` matrix.
* [x] Implement `LinkPredMetric` interface
* [x] Implement `map@k`
* [x] Implement `precision@k`
* [x] Implement `recall@k`
* [x] Implement `f1@k`
* [x] Implement `ndcg@k` (#8326)
### Examples
With this, we can build one or more clear and descriptive examples of how to leverage PyG for recommendation.
* [x] Select and implement one or two datasets commonly used for recommendation
* [x] Add exclusion logic to `MIPSKNNIndex`
* [x] Build an example that implements this pipeline
* [ ] Write a tutorial about recommendation in PyG
* [ ] Advanced: Combine PyG's recommendation capabilities with its temporal GNN support (see #3230)
| @rusty1s I have done some similar work in the past extending PyG for better recommendation support (at a company where I couldn't contribute it to open source). Would love to contribute to this! | 2023-12-07T17:23:45 |
pyg-team/pytorch_geometric | 8,609 | pyg-team__pytorch_geometric-8609 | [
"8607"
]
| cd188588ac956d42345d16ad9d2d8ac8bc11b4b2 | diff --git a/torch_geometric/profile/profile.py b/torch_geometric/profile/profile.py
--- a/torch_geometric/profile/profile.py
+++ b/torch_geometric/profile/profile.py
@@ -213,9 +213,7 @@ def get_stats_summary(
max_reserved_gpu=max([s.max_reserved_gpu for s in stats_list]),
max_active_gpu=max([s.max_active_gpu for s in stats_list]))
- if all(isinstance(s, GPUStats) for s in stats_list):
- return GPUStatsSummary(**kwargs)
- else:
+ if all(isinstance(s, CUDAStats) for s in stats_list):
return CUDAStatsSummary(
**kwargs,
min_nvidia_smi_free_cuda=min(
@@ -223,6 +221,8 @@ def get_stats_summary(
max_nvidia_smi_used_cuda=max(
[s.nvidia_smi_used_cuda for s in stats_list]),
)
+ else:
+ return GPUStatsSummary(**kwargs)
###############################################################################
| test-profil-it-cuda fails w/ latest
### 🐛 Describe the bug
```
_____________________________ test_profileit_cuda ______________________________
get_dataset = functools.partial(<function load_dataset at 0xffff974227a0>, '/tmp/pyg_test_datasets')
@onlyCUDA
@onlyOnline
@withPackage('pytorch_memlab')
def test_profileit_cuda(get_dataset):
warnings.filterwarnings('ignore', '.*arguments of DataFrame.drop.*')
dataset = get_dataset(name='Cora')
data = dataset[0].cuda()
model = GraphSAGE(dataset.num_features, hidden_channels=64, num_layers=3,
out_channels=dataset.num_classes).cuda()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
@profileit('cuda')
def train(model, x, edge_index, y):
model.train()
optimizer.zero_grad()
out = model(x, edge_index)
loss = F.cross_entropy(out, y)
loss.backward()
return float(loss)
stats_list = []
for epoch in range(5):
_, stats = train(model, data.x, data.edge_index, data.y)
assert stats.time > 0
assert stats.max_allocated_gpu > 0
assert stats.max_reserved_gpu > 0
assert stats.max_active_gpu > 0
assert stats.nvidia_smi_free_cuda > 0
assert stats.nvidia_smi_used_cuda > 0
if epoch >= 2: # Warm-up
stats_list.append(stats)
stats_summary = get_stats_summary(stats_list)
assert stats_summary.time_mean > 0
assert stats_summary.time_std > 0
assert stats_summary.max_allocated_gpu > 0
assert stats_summary.max_reserved_gpu > 0
assert stats_summary.max_active_gpu > 0
> assert stats_summary.min_nvidia_smi_free_cuda > 0
E AttributeError: 'GPUStatsSummary' object has no attribute 'min_nvidia_smi_free_cuda'
test/profile/test_profile.py:86: AttributeError
```
### Versions
latest stack as of 12 hours ago
| https://github.com/pyg-team/pytorch_geometric/blob/master/torch_geometric/profile/profile.py#L34-L39
https://github.com/pyg-team/pytorch_geometric/commit/0e7458d21433f0191f50951dd2ff56e6aefa492d
it seems the profiler definition was updated but the tests weren't.
@DamianSzwichtenberg @rusty1s | 2023-12-13T06:25:55 |
|
pyg-team/pytorch_geometric | 8,663 | pyg-team__pytorch_geometric-8663 | [
"8662"
]
| c3c193818c4fc165244d710f7bb64a79d481a287 | diff --git a/torch_geometric/data/on_disk_dataset.py b/torch_geometric/data/on_disk_dataset.py
--- a/torch_geometric/data/on_disk_dataset.py
+++ b/torch_geometric/data/on_disk_dataset.py
@@ -152,7 +152,10 @@ def multi_get(
else:
data_list = self.db.multi_get(indices, batch_size)
- return [self.deserialize(data) for data in data_list]
+ data_list = [self.deserialize(data) for data in data_list]
+ if self.transform is not None:
+ data_list = [self.transform(data) for data in data_list]
+ return data_list
def __getitems__(self, indices: List[int]) -> List[BaseData]:
return self.multi_get(indices)
| `OnDiskDataset` doesn't apply transforms when used with `DataLoader`
### 🐛 Describe the bug
Transforms don't get applied when batching `OnDiskDataset` with `DataLoader`, however they DO get applied if I just used `__getitem__` to get a single data point.
```python
from torch_geometric.datasets import PCQM4Mv2
import torch_geometric.transforms as T
from torch_geometric.loader import DataLoader
ds = PCQM4Mv2(root="data/pcqm4m_small", transform=T.AddRandomWalkPE(5, "pe"))
dl = DataLoader(ds, batch_size=4, num_workers=0)
batch = next(iter(dl))
print("Through DataLoader:", batch)
print("Through indexing:", ds[0])
```
The output of this is:
```
Through DataLoader: DataBatch(x=[67, 9], edge_index=[2, 138], edge_attr=[138, 3], y=[4], smiles=[4], batch=[67], ptr=[5])
Through indexing: Data(x=[18, 9], edge_index=[2, 40], edge_attr=[40, 3], y=3.0476751256, smiles='O=C1[N]c2ccncc2[CH][C@@H]1c1ccc(cc1)C', pe=[18, 5])
```
`pe` attribute is not present in the first case, but is present in the second one
### Versions
```
Collecting environment information...
PyTorch version: 2.1.2
Is debug build: False
CUDA used to build PyTorch: 12.1
ROCM used to build PyTorch: N/A
OS: Manjaro Linux (x86_64)
GCC version: (GCC) 13.2.1 20230801
Clang version: 16.0.6
CMake version: Could not collect
Libc version: glibc-2.38
Python version: 3.11.7 | packaged by conda-forge | (main, Dec 15 2023, 08:38:37) [GCC 12.3.0] (64-bit runtime)
Python platform: Linux-5.10.203-1-MANJARO-x86_64-with-glibc2.38
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 2080 SUPER
Nvidia driver version: 545.29.06
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 48 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 16
On-line CPU(s) list: 0-15
Vendor ID: AuthenticAMD
Model name: AMD Ryzen 7 5800X 8-Core Processor
CPU family: 25
Model: 33
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 1
Stepping: 0
Frequency boost: enabled
CPU(s) scaling MHz: 71%
CPU max MHz: 6328.7100
CPU min MHz: 2200.0000
BogoMIPS: 8404.84
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_good nopl nonstop_tsc cpuid extd_apicid aperfmperf pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw ibs skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb cat_l3 cdp_l3 hw_pstate ssbd mba ibrs ibpb stibp vmmcall fsgsbase bmi1 avx2 smep bmi2 erms invpcid cqm rdt_a rdseed adx smap clflushopt clwb sha_ni xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local clzero irperf xsaveerptr rdpru wbnoinvd arat npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif umip pku ospke vaes vpclmulqdq rdpid overflow_recov succor smca fsrm
Virtualization: AMD-V
L1d cache: 256 KiB (8 instances)
L1i cache: 256 KiB (8 instances)
L2 cache: 4 MiB (8 instances)
L3 cache: 32 MiB (1 instance)
NUMA node(s): 1
NUMA node0 CPU(s): 0-15
Vulnerability Gather data sampling: Not affected
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Not affected
Vulnerability Spec rstack overflow: Mitigation; safe RET, no microcode
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, IBRS_FW, STIBP always-on, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] numpy==1.26.2
[pip3] pytorch-lightning==2.1.3
[pip3] torch==2.1.2
[pip3] torch-cluster==1.6.3
[pip3] torch_geometric==2.4.0
[pip3] torchaudio==2.1.2
[pip3] torchmetrics==1.2.1
[pip3] torchvision==0.16.2
[pip3] triton==2.1.0
[conda] blas 1.0 mkl
[conda] ffmpeg 4.3 hf484d3e_0 pytorch
[conda] libjpeg-turbo 2.0.0 h9bf148f_0 pytorch
[conda] mkl 2023.1.0 h213fc3f_46344
[conda] mkl-service 2.4.0 py311h5eee18b_1
[conda] mkl_fft 1.3.8 py311h5eee18b_0
[conda] mkl_random 1.2.4 py311hdb19cb5_0
[conda] numpy 1.26.2 py311h08b1b3b_0
[conda] numpy-base 1.26.2 py311hf175353_0
[conda] pyg 2.4.0 py311_torch_2.1.0_cu121 pyg
[conda] pytorch 2.1.2 py3.11_cuda12.1_cudnn8.9.2_0 pytorch
[conda] pytorch-cluster 1.6.3 py311_torch_2.1.0_cu121 pyg
[conda] pytorch-cuda 12.1 ha16c6d3_5 pytorch
[conda] pytorch-lightning 2.1.3 pypi_0 pypi
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] torchaudio 2.1.2 py311_cu121 pytorch
[conda] torchmetrics 1.2.1 pypi_0 pypi
[conda] torchtriton 2.1.0 py311 pytorch
[conda] torchvision 0.16.2 py311_cu121 pytorch
```
| 2023-12-22T11:13:04 |
||
pyg-team/pytorch_geometric | 8,670 | pyg-team__pytorch_geometric-8670 | [
"8664"
]
| 0317b0ce49b4bdd12fbaca5d6dd3dbb5a1282fa3 | diff --git a/torch_geometric/utils/sparse.py b/torch_geometric/utils/sparse.py
--- a/torch_geometric/utils/sparse.py
+++ b/torch_geometric/utils/sparse.py
@@ -493,37 +493,195 @@ def index2ptr(index: Tensor, size: int) -> Tensor:
index, size, out_int32=index.dtype == torch.int32)
-def cat(tensors: List[Tensor], dim: Union[int, Tuple[int, int]]) -> Tensor:
- # TODO (matthias) We can make this more efficient by directly operating on
- # the individual sparse tensor layouts.
+def cat_coo(tensors: List[Tensor], dim: Union[int, Tuple[int, int]]) -> Tensor:
assert dim in {0, 1, (0, 1)}
+ assert tensors[0].layout == torch.sparse_coo
+
+ indices, values = [], []
+ num_rows = num_cols = 0
+
+ if dim == 0:
+ for i, tensor in enumerate(tensors):
+ if i == 0:
+ indices.append(tensor.indices())
+ else:
+ offset = torch.tensor([[num_rows], [0]], device=tensor.device)
+ indices.append(tensor.indices() + offset)
+ values.append(tensor.values())
+ num_rows += tensor.size(0)
+ num_cols = max(num_cols, tensor.size(1))
+
+ elif dim == 1:
+ for i, tensor in enumerate(tensors):
+ if i == 0:
+ indices.append(tensor.indices())
+ else:
+ offset = torch.tensor([[0], [num_cols]], device=tensor.device)
+ indices.append(tensor.indices() + offset)
+ values.append(tensor.values())
+ num_rows = max(num_rows, tensor.size(0))
+ num_cols += tensor.size(1)
- size = (0, 0)
- edge_indices = []
- edge_attrs = []
- for tensor in tensors:
- assert is_torch_sparse_tensor(tensor)
- edge_index, edge_attr = to_edge_index(tensor)
- edge_index = edge_index.clone()
-
- if dim == 0:
- edge_index[0] += size[0]
- size = (size[0] + tensor.size(0), max(size[1], tensor.size(1)))
- elif dim == 1:
- edge_index[1] += size[1]
- size = (max(size[0], tensor.size(0)), size[1] + tensor.size(1))
- else:
- edge_index[0] += size[0]
- edge_index[1] += size[1]
- size = (size[0] + tensor.size(0), size[1] + tensor.size(1))
-
- edge_indices.append(edge_index)
- edge_attrs.append(edge_attr)
-
- return to_torch_sparse_tensor(
- edge_index=torch.cat(edge_indices, dim=1),
- edge_attr=torch.cat(edge_attrs, dim=0),
- size=size,
- is_coalesced=dim == (0, 1),
- layout=tensors[0].layout,
+ else:
+ for i, tensor in enumerate(tensors):
+ if i == 0:
+ indices.append(tensor.indices())
+ else:
+ offset = torch.tensor([[num_rows], [num_cols]],
+ device=tensor.device)
+ indices.append(tensor.indices() + offset)
+ values.append(tensor.values())
+ num_rows += tensor.size(0)
+ num_cols += tensor.size(1)
+
+ return torch.sparse_coo_tensor(
+ indices=torch.cat(indices, dim=-1),
+ values=torch.cat(values),
+ size=(num_rows, num_cols) + values[-1].size()[1:],
+ device=tensor.device,
)
+
+
+def cat_csr(tensors: List[Tensor], dim: Union[int, Tuple[int, int]]) -> Tensor:
+ assert dim in {0, 1, (0, 1)}
+ assert tensors[0].layout == torch.sparse_csr
+
+ rows, cols, values = [], [], []
+ num_rows = num_cols = nnz = 0
+
+ if dim == 0:
+ for i, tensor in enumerate(tensors):
+ if i == 0:
+ rows.append(tensor.crow_indices())
+ else:
+ rows.append(tensor.crow_indices()[1:] + nnz)
+ cols.append(tensor.col_indices())
+ values.append(tensor.values())
+ num_rows += tensor.size(0)
+ num_cols = max(num_cols, tensor.size(1))
+ nnz += cols[-1].numel()
+
+ return torch.sparse_csr_tensor(
+ crow_indices=torch.cat(rows),
+ col_indices=torch.cat(cols),
+ values=torch.cat(values),
+ size=(num_rows, num_cols) + values[-1].size()[1:],
+ device=tensor.device,
+ )
+
+ elif dim == 1:
+ for i, tensor in enumerate(tensors):
+ rows.append(ptr2index(tensor.crow_indices()))
+ if i == 0:
+ cols.append(tensor.col_indices())
+ else:
+ cols.append(tensor.col_indices() + num_cols)
+ values.append(tensor.values())
+ num_rows = max(num_rows, tensor.size(0))
+ num_cols += tensor.size(1)
+
+ return torch.sparse_coo_tensor(
+ indices=torch.stack((torch.cat(rows), torch.cat(cols)), 0),
+ values=torch.cat(values),
+ size=(num_rows, num_cols) + values[-1].size()[1:],
+ device=tensor.device,
+ )
+
+ else:
+ for i, tensor in enumerate(tensors):
+ if i == 0:
+ rows.append(tensor.crow_indices())
+ cols.append(tensor.col_indices())
+ else:
+ rows.append(tensor.crow_indices()[1:] + nnz)
+ cols.append(tensor.col_indices() + num_cols)
+ values.append(tensor.values())
+ num_rows += tensor.size(0)
+ num_cols += tensor.size(1)
+ nnz += cols[-1].numel()
+
+ return torch.sparse_csr_tensor(
+ crow_indices=torch.cat(rows),
+ col_indices=torch.cat(cols),
+ values=torch.cat(values),
+ size=(num_rows, num_cols) + values[-1].size()[1:],
+ device=tensor.device,
+ )
+
+
+def cat_csc(tensors: List[Tensor], dim: Union[int, Tuple[int, int]]) -> Tensor:
+ assert dim in {0, 1, (0, 1)}
+ assert tensors[0].layout == torch.sparse_csc
+
+ rows, cols, values = [], [], []
+ num_rows = num_cols = nnz = 0
+
+ if dim == 0:
+ for i, tensor in enumerate(tensors):
+ cols.append(ptr2index(tensor.ccol_indices()))
+ if i == 0:
+ rows.append(tensor.row_indices())
+ else:
+ rows.append(tensor.row_indices() + num_rows)
+ values.append(tensor.values())
+ num_rows += tensor.size(0)
+ num_cols = max(num_cols, tensor.size(1))
+
+ return torch.sparse_coo_tensor(
+ indices=torch.stack((torch.cat(rows), torch.cat(cols)), 0),
+ values=torch.cat(values),
+ size=(num_rows, num_cols) + values[-1].size()[1:],
+ device=tensor.device,
+ )
+
+ elif dim == 1:
+ for i, tensor in enumerate(tensors):
+ if i == 0:
+ cols.append(tensor.ccol_indices())
+ else:
+ cols.append(tensor.ccol_indices()[1:] + nnz)
+ rows.append(tensor.row_indices())
+ values.append(tensor.values())
+ num_rows = max(num_rows, tensor.size(0))
+ num_cols += tensor.size(1)
+ nnz += rows[-1].numel()
+
+ return torch.sparse_csc_tensor(
+ row_indices=torch.cat(rows),
+ ccol_indices=torch.cat(cols),
+ values=torch.cat(values),
+ size=(num_rows, num_cols) + values[-1].size()[1:],
+ device=tensor.device,
+ )
+
+ else:
+ for i, tensor in enumerate(tensors):
+ if i == 0:
+ rows.append(tensor.row_indices())
+ cols.append(tensor.ccol_indices())
+ else:
+ rows.append(tensor.row_indices() + num_rows)
+ cols.append(tensor.ccol_indices()[1:] + nnz)
+ values.append(tensor.values())
+ num_rows += tensor.size(0)
+ num_cols += tensor.size(1)
+ nnz += rows[-1].numel()
+
+ return torch.sparse_csc_tensor(
+ row_indices=torch.cat(rows),
+ ccol_indices=torch.cat(cols),
+ values=torch.cat(values),
+ size=(num_rows, num_cols) + values[-1].size()[1:],
+ device=tensor.device,
+ )
+
+
+def cat(tensors: List[Tensor], dim: Union[int, Tuple[int, int]]) -> Tensor:
+ assert is_torch_sparse_tensor(tensors[0])
+
+ if tensors[0].layout == torch.sparse_coo:
+ return cat_coo(tensors, dim)
+ elif tensors[0].layout == torch.sparse_csr:
+ return cat_csr(tensors, dim)
+ else:
+ return cat_csc(tensors, dim)
| diff --git a/test/data/test_batch.py b/test/data/test_batch.py
--- a/test/data/test_batch.py
+++ b/test/data/test_batch.py
@@ -509,7 +509,7 @@ def test_torch_sparse_batch(layout):
batch = Batch.from_data_list([data, data])
assert batch.x.size() == (6, 4)
- assert batch.x.layout == layout
+ assert batch.x.layout in {torch.sparse_coo, torch.sparse_csr}
assert torch.equal(batch.x.to_dense(), torch.cat([x_dense, x_dense], 0))
assert batch.adj.size() == (6, 6)
diff --git a/test/utils/test_sparse.py b/test/utils/test_sparse.py
--- a/test/utils/test_sparse.py
+++ b/test/utils/test_sparse.py
@@ -1,10 +1,11 @@
import os.path as osp
+import pytest
import torch
import torch_geometric.typing
from torch_geometric.profile import benchmark
-from torch_geometric.testing import is_full_test, withPackage
+from torch_geometric.testing import is_full_test, withCUDA, withPackage
from torch_geometric.typing import SparseTensor
from torch_geometric.utils import (
dense_to_sparse,
@@ -14,7 +15,9 @@
to_torch_coo_tensor,
to_torch_csc_tensor,
to_torch_csr_tensor,
+ to_torch_sparse_tensor,
)
+from torch_geometric.utils.sparse import cat
def test_dense_to_sparse():
@@ -246,6 +249,47 @@ def test_to_edge_index():
assert edge_attr.tolist() == [1., 1., 1., 1., 1., 1.]
+@withCUDA
[email protected](
+ 'layout',
+ [torch.sparse_coo, torch.sparse_csr, torch.sparse_csc],
+)
[email protected]('dim', [0, 1, (0, 1)])
+def test_cat(layout, dim, device):
+ edge_index = torch.tensor([[0, 1, 1, 2], [1, 0, 2, 1]], device=device)
+ if torch_geometric.typing.WITH_PT20:
+ edge_weight = torch.rand(4, 2, device=device)
+ else:
+ edge_weight = torch.rand(4, device=device)
+
+ adj = to_torch_sparse_tensor(edge_index, edge_weight, layout=layout)
+
+ out = cat([adj, adj], dim=dim)
+ edge_index, edge_weight = to_edge_index(out.to_sparse_csr())
+
+ if dim == 0:
+ if torch_geometric.typing.WITH_PT20:
+ assert out.size() == (6, 3, 2)
+ else:
+ assert out.size() == (6, 3)
+ assert edge_index[0].tolist() == [0, 1, 1, 2, 3, 4, 4, 5]
+ assert edge_index[1].tolist() == [1, 0, 2, 1, 1, 0, 2, 1]
+ elif dim == 1:
+ if torch_geometric.typing.WITH_PT20:
+ assert out.size() == (3, 6, 2)
+ else:
+ assert out.size() == (3, 6)
+ assert edge_index[0].tolist() == [0, 0, 1, 1, 1, 1, 2, 2]
+ assert edge_index[1].tolist() == [1, 4, 0, 2, 3, 5, 1, 4]
+ else:
+ if torch_geometric.typing.WITH_PT20:
+ assert out.size() == (6, 6, 2)
+ else:
+ assert out.size() == (6, 6)
+ assert edge_index[0].tolist() == [0, 1, 1, 2, 3, 4, 4, 5]
+ assert edge_index[1].tolist() == [1, 0, 2, 1, 4, 3, 5, 4]
+
+
if __name__ == '__main__':
import argparse
| Batching sparse tensors is very slow
### 🐛 Describe the bug
Hi,
I've been storing some sparse matrices(different dtypes - float32, int64, complex64) in my Data object which I batch block-diagonally. I've noticed that my training times have increased ~3x since then. I've narrowed it down to the batching of these sparse matrices.
I've made a simplified example that reprodouces the behaviour (I've left out the different dtypes and the block diagonal batching).
```python
from typing import Tuple
import numpy as np
import scipy
import torch
from scipy.sparse import csr_matrix
from torch_geometric.data import Data
from torch_geometric.loader import DataLoader
from tqdm import tqdm
def csr_to_sparse_tensor(csr: csr_matrix, size: Tuple[int, ...]):
"""
Convert a scipy csr matrix to a torch csr tensor.
:param csr: csr matrix
:param size: Size.
:return: csr tensor.
"""
return torch.sparse_csr_tensor(crow_indices=torch.LongTensor(csr.indptr),
col_indices=torch.LongTensor(csr.indices),
values=torch.tensor(csr.data),
size=size)
def main():
num_rows, num_columns = 42, 123
sparse = True
data_list = []
for i in range(1000):
random_csr_tensor = csr_to_sparse_tensor(csr=scipy.sparse.random(num_rows, num_columns, format='csr', dtype=np.float32),
size=(num_rows, num_columns))
data_list.append(
Data(
sparse_or_dense_matrix=random_csr_tensor if sparse else random_csr_tensor.to_dense()
)
)
loader = DataLoader(data_list, batch_size=128, shuffle=True)
for epoch in tqdm(range(500), ncols=75, ascii=True, desc="Execution time"):
for batch in loader:
pass
if __name__ == "__main__":
main()
```
The output of the script with `sparse = False` is: `Execution time: 100%|###################| 500/500 [00:01<00:00, 254.06it/s]`,
with `sparse = True`: `Execution time: 100%|####################| 500/500 [00:51<00:00, 9.74it/s]`
### Versions
I'm on Windows so I couldn't run the above command, but my pip freeze is:
```
pip freeze
antlr4-python3-runtime==4.9.3
appdirs==1.4.4
certifi==2023.7.22
charset-normalizer==3.3.0
click==8.1.7
colorama==0.4.6
contourpy==1.1.1
cycler==0.12.1
deepdiff==6.6.0
docker-pycreds==0.4.0
filelock==3.12.4
fonttools==4.43.1
fsspec==2023.9.2
gitdb==4.0.10
GitPython==3.1.37
hydra-core==1.3.2
idna==3.4
importlib-resources==6.1.0
Jinja2==3.1.2
joblib==1.3.2
kiwisolver==1.4.5
lightning-utilities==0.10.0
MarkupSafe==2.1.3
matplotlib==3.7.1
mpmath==1.3.0
networkx==3.1
numpy==1.24.3
omegaconf==2.3.0
ordered-set==4.1.0
packaging==23.2
pandapower==2.12.1
pandas==1.4.4
pathtools==0.1.2
Pillow==10.0.1
protobuf==4.24.4
psutil==5.9.5
pyg-nightly==2.4.0.dev20231028
pyparsing==3.1.1
PYPOWER==5.1.16
python-dateutil==2.8.2
pytz==2023.3.post1
PyYAML==6.0.1
requests==2.31.0
scikit-learn==1.2.2
scipy==1.10.1
sentry-sdk==1.32.0
setproctitle==1.3.3
six==1.16.0
smmap==5.0.1
sympy==1.12
threadpoolctl==3.2.0
torch==2.1.0+cu121
torch-cluster==1.6.3+pt21cu121
torch-scatter==2.1.2+pt21cu121
torch-sparse==0.6.18+pt21cu121
torch-spline-conv==1.2.2+pt21cu121
torch_geometric==2.4.0
torchaudio==2.1.0+cu121
torchmetrics==1.2.1
torchvision==0.16.0+cu121
tqdm==4.65.0
typing_extensions==4.8.0
urllib3==2.0.6
wandb==0.15.12
zipp==3.17.0
```
| 2023-12-24T10:36:15 |
|
pyg-team/pytorch_geometric | 8,723 | pyg-team__pytorch_geometric-8723 | [
"8711"
]
| 09733b493493083ab7cb09faf60716308e270093 | diff --git a/torch_geometric/utils/_subgraph.py b/torch_geometric/utils/_subgraph.py
--- a/torch_geometric/utils/_subgraph.py
+++ b/torch_geometric/utils/_subgraph.py
@@ -14,6 +14,14 @@ def get_num_hops(model: torch.nn.Module) -> int:
r"""Returns the number of hops the model is aggregating information
from.
+ .. note::
+
+ This function counts the number of message passing layers as an
+ approximation of the total number of hops covered by the model.
+ Its output may not necessarily correct in case message passing layers
+ perform multi-hop aggregation, *e.g.*, as in
+ :class:`~torch_geometric.nn.conv.ChebConv`.
+
Example:
>>> class GNN(torch.nn.Module):
... def __init__(self):
| `get_num_hops` incorrectly counts "multi-hop" layers
### 🐛 Describe the bug
Hello, this is very minor and maybe not a bug per se. The `torch_geometric.util.get_num_hops` counts the number of MessagePassing layers as a sort of proxy for the number of hops covered by a model.
However, there's at least one MessagePassing layer (`ChebConv`) that aggregates info from multiple hops. There may be a couple others, it looks like MixHopConv will also aggregate multiple hops if `p > 1`.
TL;DR, in my opinion, `get_num_hops` returns a slightly misleading number for layers like ChebConv. Even if it's hard and/or impossible to accurately get the hops for arbitrary models, I would expect this function to be "correct" for individual layers :shrug:
Maybe a suitable fix is just to update the docstring to explain it's counting the MessagePassing layers, not doing something super fancy?
```python
import torch
import torch_geometric
from torch_geometric.utils import get_num_hops, to_undirected
# define a graph that has 5 edges
# 0 <-> 1 <-> 2 <-> 3 <-> 4 <-> 5
# only node 0 has a non-zero feature.
x = torch.Tensor([1, 0, 0, 0, 0, 0]).unsqueeze(1)
edge_index = to_undirected(torch.Tensor([
[0, 1, 2, 3, 4],
[1, 2, 3, 4, 5]
])).to(torch.int64)
edge_weight = torch.ones(edge_index.size(1))
# make a model with 1 layer with filter size of K=3
model = torch_geometric.nn.conv.ChebConv(1, 1, K=3)
x = model(x, edge_index, edge_weight)
# the number of nonzero nodes now matches K - 1
print('get_num_hops: ', get_num_hops(model))
print('actual hops: ', torch.count_nonzero(x).item() - 1)
```
```
get_num_hops: 1
actual hops: 2
```
### Versions
```
PyTorch version: 2.0.1
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: Rocky Linux release 8.8 (Green Obsidian) (x86_64)
GCC version: (GCC) 8.5.0 20210514 (Red Hat 8.5.0-18)
Clang version: Could not collect
CMake version: version 3.27.5
Libc version: glibc-2.28
Python version: 3.9.18 (main, Sep 11 2023, 13:41:44) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-4.18.0-477.15.1.el8_8.x86_64-x86_64-with-glibc2.28
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 40
On-line CPU(s) list: 0-39
Thread(s) per core: 1
Core(s) per socket: 20
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Gold 6148 CPU @ 2.40GHz
Stepping: 4
CPU MHz: 2400.000
BogoMIPS: 4800.00
L1d cache: 32K
L1i cache: 32K
L2 cache: 1024K
L3 cache: 28160K
NUMA node0 CPU(s): 0-19
NUMA node1 CPU(s): 20-39
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf pni pclmulqdq dtes64 monitor ds_cpl smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb cat_l3 cdp_l3 invpcid_single pti intel_ppin ssbd mba ibrs ibpb stibp fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm mpx rdt_a avx512f avx512dq rdseed adx smap clflushopt clwb intel_pt avx512cd avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm ida arat pln pts pku ospke md_clear flush_l1d
Versions of relevant libraries:
[pip3] configmypy==0.1.0
[pip3] numpy==1.25.2
[pip3] tensorly-torch==0.4.0
[pip3] torch==1.13.1
[pip3] torch-cluster==1.6.1
[pip3] torch-geometric==2.3.1
[pip3] torch-scatter==2.1.1
[pip3] torch-sparse==0.6.18
[pip3] torchdeq==0.1.0
[pip3] torchvision==0.15.2
[pip3] triton==2.0.0
[conda] blas 1.0 mkl
[conda] mkl 2023.2.0 pypi_0 pypi
[conda] mkl-service 2.4.0 py39h5eee18b_1
[conda] mkl_fft 1.3.8 py39h5eee18b_0
[conda] mkl_random 1.2.4 py39hdb19cb5_0
[conda] numpy 1.25.2 py39h5f9d8c6_0
[conda] numpy-base 1.25.2 py39hb5e798b_0
[conda] pyg 2.3.1 py39_torch_2.0.0_cu117 pyg
[conda] pytorch 2.0.1 py3.9_cuda11.7_cudnn8.5.0_0 pytorch
[conda] pytorch-cluster 1.6.1 py39_torch_2.0.0_cu117 pyg
[conda] pytorch-cuda 11.7 h778d358_5 pytorch
[conda] pytorch-mutex 1.0 cuda pytorch
[conda] pytorch-scatter 2.1.1 py39_torch_2.0.0_cu117 pyg
[conda] pytorch-sparse 0.6.18 py39_torch_2.0.0_cu117 pyg
[conda] tensorly-torch 0.4.0 pypi_0 pypi
[conda] torchdeq 0.1.0 pypi_0 pypi
[conda] torchtriton 2.0.0 py39 pytorch
[conda] torchvision 0.15.2 py39_cu117 pytorch
```
| Since I assume `get_num_hops` is not called every batch iteration in most cases, we could possibly do something fancy without any performance concerns, but I'm not sure if there's a robust way to count the number of hops.
As a quick fix, we can update the docs as you suggest :) | 2024-01-05T14:36:02 |
|
pyg-team/pytorch_geometric | 8,831 | pyg-team__pytorch_geometric-8831 | [
"8817"
]
| 787598715c4f0f89d82ab310372c58ed0cc61308 | diff --git a/torch_geometric/transforms/largest_connected_components.py b/torch_geometric/transforms/largest_connected_components.py
--- a/torch_geometric/transforms/largest_connected_components.py
+++ b/torch_geometric/transforms/largest_connected_components.py
@@ -47,9 +47,11 @@ def forward(self, data: Data) -> Data:
return data
_, count = np.unique(component, return_counts=True)
- subset = np.in1d(component, count.argsort()[-self.num_components:])
+ subset_np = np.in1d(component, count.argsort()[-self.num_components:])
+ subset = torch.from_numpy(subset_np)
+ subset = subset.to(data.edge_index.device, torch.bool)
- return data.subgraph(torch.from_numpy(subset).to(torch.bool))
+ return data.subgraph(subset)
def __repr__(self) -> str:
return f'{self.__class__.__name__}({self.num_components})'
| in utils.subgraph.py RuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu)
### 🐛 Describe the bug
in utils.subgraph.py
edge_mask = node_mask[edge_index[0]] & node_mask[edge_index[1]]
RuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu)
because edge_index on 'cuda:0' and node_mask on 'cpu'
being solved with: node_mask=node_mask.to(device=device)
### Versions
last version
| Is this a bug? `subset` and `edge_index` needs to be on the same device. If that's not the case, the code is expected to crash.
Thank you for your prompt reply.
You must be right, I'm new to Python and the error can be on my side
Subset and edge_index were not on the same device, this causes the error
subset was generated by transform RadiusGraph<https://pytorch-geometric.readthedocs.io/en/latest/generated/torch_geometric.transforms.RadiusGraph.html#torch_geometric.transforms.RadiusGraph> or transform.largest_connected_components from a data on cuda:0
and ended up on the cpu whereas edge_index was cuda:0
I propose you to write the small piece of code that reproduce this error ?
Best,
Cedric
________________________________
De : Matthias Fey ***@***.***>
Envoyé : jeudi 25 janvier 2024 03:23
À : pyg-team/pytorch_geometric ***@***.***>
Cc : Allier, Cedric ***@***.***>; Author ***@***.***>
Objet : Re: [pyg-team/pytorch_geometric] in utils.subgraph.py RuntimeError: indices should be either on cpu or on the same device as the indexed tensor (cpu) (Issue #8817)
External Email: Use Caution
Is this a bug? subset and edge_index needs to be on the same device. If that's not the case, the code is expected to crash.
—
Reply to this email directly, view it on GitHub<https://urldefense.com/v3/__https://github.com/pyg-team/pytorch_geometric/issues/8817*issuecomment-1909639728__;Iw!!Eh6p8Q!AwlkJ5C8KHDsP_TlBDgeHSSSTijW5i_wsu400q9JUe3lh4jdubuJmsnSois5mvT3NWaFV5x9Gy4h0T2s_CfwsqTJj28$>, or unsubscribe<https://urldefense.com/v3/__https://github.com/notifications/unsubscribe-auth/A5KWXEF7NTA3QQNPRYHXVGDYQII7PAVCNFSM6AAAAABCJAS44WVHI2DSMVQWIX3LMV43OSLTON2WKQ3PNVWWK3TUHMYTSMBZGYZTSNZSHA__;!!Eh6p8Q!AwlkJ5C8KHDsP_TlBDgeHSSSTijW5i_wsu400q9JUe3lh4jdubuJmsnSois5mvT3NWaFV5x9Gy4h0T2s_CfwWIF0u5c$>.
You are receiving this because you authored the thread.Message ID: ***@***.***>
| 2024-01-29T07:38:31 |
|
pyg-team/pytorch_geometric | 8,870 | pyg-team__pytorch_geometric-8870 | [
"8867"
]
| 1f93077bbe8770c1c819568e1f484b91b0cc5060 | diff --git a/torch_geometric/nn/conv/gen_conv.py b/torch_geometric/nn/conv/gen_conv.py
--- a/torch_geometric/nn/conv/gen_conv.py
+++ b/torch_geometric/nn/conv/gen_conv.py
@@ -15,14 +15,7 @@
from torch_geometric.nn.dense.linear import Linear
from torch_geometric.nn.inits import reset
from torch_geometric.nn.norm import MessageNorm
-from torch_geometric.typing import (
- Adj,
- OptPairTensor,
- OptTensor,
- Size,
- SparseTensor,
-)
-from torch_geometric.utils import is_torch_sparse_tensor, to_edge_index
+from torch_geometric.typing import Adj, OptPairTensor, OptTensor, Size
class MLP(Sequential):
@@ -216,20 +209,6 @@ def forward(self, x: Union[Tensor, OptPairTensor], edge_index: Adj,
if hasattr(self, 'lin_src'):
x = (self.lin_src(x[0]), x[1])
- if isinstance(edge_index, SparseTensor):
- edge_attr = edge_index.storage.value()
- elif is_torch_sparse_tensor(edge_index):
- _, value = to_edge_index(edge_index)
- if value.dim() > 1 or not value.all():
- edge_attr = value
-
- if edge_attr is not None and hasattr(self, 'lin_edge'):
- edge_attr = self.lin_edge(edge_attr)
-
- # Node and edge feature dimensionalites need to match.
- if edge_attr is not None:
- assert x[0].size(-1) == edge_attr.size(-1)
-
# propagate_type: (x: OptPairTensor, edge_attr: OptTensor)
out = self.propagate(edge_index, x=x, edge_attr=edge_attr, size=size)
@@ -250,6 +229,12 @@ def forward(self, x: Union[Tensor, OptPairTensor], edge_index: Adj,
return self.mlp(out)
def message(self, x_j: Tensor, edge_attr: OptTensor) -> Tensor:
+ if edge_attr is not None and hasattr(self, 'lin_edge'):
+ edge_attr = self.lin_edge(edge_attr)
+
+ if edge_attr is not None:
+ assert x_j.size(-1) == edge_attr.size(-1)
+
msg = x_j if edge_attr is None else x_j + edge_attr
return msg.relu() + self.eps
| diff --git a/test/nn/conv/test_message_passing.py b/test/nn/conv/test_message_passing.py
--- a/test/nn/conv/test_message_passing.py
+++ b/test/nn/conv/test_message_passing.py
@@ -1,4 +1,5 @@
import copy
+import os.path as osp
from typing import Tuple, Union
import pytest
@@ -184,6 +185,15 @@ def test_my_conv_jit():
jit.fuse = True
+def test_my_conv_jit_save(tmp_path):
+ path = osp.join(tmp_path, 'model.pt')
+
+ conv = MyConv(8, 32)
+ conv = torch.jit.script(conv)
+ torch.jit.save(conv, path)
+ conv = torch.jit.load(path)
+
+
@pytest.mark.parametrize('aggr', ['add', 'sum', 'mean', 'min', 'max', 'mul'])
def test_my_conv_aggr(aggr):
x = torch.randn(4, 8)
| TorchScript instance from torch.jit.script() runs successfully but throws type mismatch when loading from file
### 🐛 Describe the bug
In my example below, I can compile a Torchscript model of GENConv and compute the result Y1, however when I load the model from the saved file and try to calculate Y2 it throws a Type mismatch error. This is related to the input validation of Union[Tensor, OptPairTensor] in the Message Passing class. Torchscript requires the type to be the same for the true/false branches.
I'm not sure how to resolve this and am happy to contribute if someone can point me in the right direction.
I'm using the latest nightly build of pyg.
```
import torch
from torch import nn, Tensor
from torch_geometric.typing import Adj, OptTensor, Union, OptPairTensor
from torch_geometric.nn.conv import GENConv, GraphConv
class MyConv(nn.Module):
def __init__(self):
super(MyConv, self).__init__()
self.conv = GENConv(64,
64,
learn_p=True,
num_layers=1)
def forward(self, x: Union[Tensor, OptPairTensor], edge_index: Adj,
edge_attr: OptTensor = None):
y = self.conv(x, edge_index, edge_attr)
return y
if __name__ == "__main__":
device = 'cpu'
save_path = "example.pt"
model = MyConv()
scripted_model = torch.jit.script(model)
scripted_model.save(save_path)
n_nodes = 200
n_edges = 100
x = torch.rand((n_nodes, 64), dtype=torch.float32, device=device)
edge_index = torch.randint(2, (2, n_edges), dtype=torch.int64, device=device)
edge_attr = torch.rand((n_edges, 64), dtype=torch.float32, device=device)
y1 = scripted_model(x=x,
edge_index=edge_index,
edge_attr=edge_attr)
model_from_file = torch.jit.load(save_path)
y2 = model_from_file(x=x,
edge_index=edge_index,
edge_attr=edge_attr)
```
**Error:**
```
/miniforge3/envs/pyg/bin/python ...../Example.py
Traceback (most recent call last):
File "......../Example.py", line 38, in <module>
model_from_file = torch.jit.load(save_path)
File "......../lib/python3.10/site-packages/torch/jit/_serialization.py", line 162, in load
cpp_module = torch._C.import_ir_module(cu, str(f), map_location, _extra_files, _restore_shapes) # type: ignore[call-arg]
RuntimeError:
Type mismatch: edge_index0 is set to type __torch__.torch_geometric.typing.SparseTensor (of Python compilation unit at: 0x561bb9716290) in the true branch and type Tensor in the false branch:
File "code/__torch__/torch_geometric/nn/conv/gen_conv.py", line 52
x0 = x2
_7 = isinstance(edge_index, __torch__.torch_geometric.typing.SparseTensor)
if _7:
~~~~~~
edge_index1 = unchecked_cast(__torch__.torch_geometric.typing.SparseTensor, edge_index)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
edge_attr1 = ((edge_index1).__storage_getter()).value()
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
edge_attr0, edge_index0 = edge_attr1, edge_index1
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
else:
~~~~~
edge_index2 = unchecked_cast(Tensor, edge_index)
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
if _4(edge_index2, ):
~~~~~~~~~~~~~~~~~~~~~
_8, value, = _5(edge_index2, )
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
if torch.gt(torch.dim(value), 1):
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
_9 = True
~~~~~~~~~
else:
~~~~~
_10 = torch.__not__(bool(torch.all(value)))
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
_9 = _10
~~~~~~~~
if _9:
~~~~~~
edge_attr3 : Optional[Tensor] = value
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
else:
~~~~~
edge_attr3 = edge_attr
~~~~~~~~~~~~~~~~~~~~~~
edge_attr2 : Optional[Tensor] = edge_attr3
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
else:
~~~~~
edge_attr2 = edge_attr
~~~~~~~~~~~~~~~~~~~~~~
edge_attr0, edge_index0 = edge_attr2, edge_index2
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ <--- HERE
if torch.__isnot__(edge_attr0, None):
edge_attr5 = unchecked_cast(Tensor, edge_attr0)
and was used here:
File "code/__torch__/torch_geometric/nn/conv/gen_conv.py", line 88
else:
edge_attr6 = edge_attr4
out = (self).propagate(edge_index0, x0, edge_attr6, size, )
~~~~~~~~~~~ <--- HERE
x_dst = (x0)[1]
if torch.__isnot__(x_dst, None):
Process finished with exit code 1
```
### Versions
pyg-nightly 2.4.0.dev20240205
pytorch 2.1.2 py3.10_cuda12.1_cudnn8.9.2_0 pytorch
pytorch-cluster 1.6.3 py310_torch_2.1.0_cu121 pyg
pytorch-cuda 12.1 ha16c6d3_5 pytorch
pytorch-lightning 2.1.3 pyhd8ed1ab_0 conda-forge
pytorch-mutex 1.0 cuda pytorch
pytorch-scatter 2.1.2 py310_torch_2.1.0_cu121 pyg
onnx 1.15.0 py310heee6c8b_1 conda-forge
onnxruntime 1.16.3 py310hd4b7fbc_4_cpu conda-forge
cuda-opencl 12.3.101 0 nvidia
cuda-runtime 12.1.0 0 nvidia
| 2024-02-06T09:38:13 |
|
pyg-team/pytorch_geometric | 8,914 | pyg-team__pytorch_geometric-8914 | [
"8910"
]
| 3a56d4bfd50f16515138be73b748fa586747c3ef | diff --git a/torch_geometric/nn/pool/knn.py b/torch_geometric/nn/pool/knn.py
--- a/torch_geometric/nn/pool/knn.py
+++ b/torch_geometric/nn/pool/knn.py
@@ -111,10 +111,15 @@ def search(
query_k = min(query_k, self.numel)
- if query_k > 2048: # `faiss` supports up-to `k=2048`:
+ if k > 2048: # `faiss` supports up-to `k=2048`:
warnings.warn(f"Capping 'k' to faiss' upper limit of 2048 "
f"(got {k}). This may cause some relevant items to "
f"not be retrieved.")
+ elif query_k > 2048:
+ warnings.warn(f"Capping 'k' to faiss' upper limit of 2048 "
+ f"(got {k} which got extended to {query_k} due to "
+ f"the exclusion of existing links). This may cause "
+ f"some relevant items to not be retrieved.")
query_k = 2048
score, index = self.index.search(emb.detach(), query_k)
diff --git a/torch_geometric/utils/_negative_sampling.py b/torch_geometric/utils/_negative_sampling.py
--- a/torch_geometric/utils/_negative_sampling.py
+++ b/torch_geometric/utils/_negative_sampling.py
@@ -86,11 +86,12 @@ def negative_sampling(
# invalid samples.
mask = idx.new_ones(population, dtype=torch.bool)
mask[idx] = False
- for _ in range(3): # Number of tries to sample negative indices.
+ for _ in range(100): # Number of tries to sample negative indices.
rnd = sample(population, sample_size, idx.device)
rnd = rnd[mask[rnd]] # Filter true negatives.
neg_idx = rnd if neg_idx is None else torch.cat([neg_idx, rnd])
if neg_idx.numel() >= num_neg_samples:
+ print("BREAK")
neg_idx = neg_idx[:num_neg_samples]
break
mask[neg_idx] = False
@@ -197,10 +198,14 @@ def batched_negative_sampling(
neg_edge_indices = []
for i, edge_index in enumerate(edge_indices):
edge_index = edge_index - ptr[i]
+ print(i, edge_index.shape, num_nodes[i])
+ print(num_neg_samples)
neg_edge_index = negative_sampling(edge_index, num_nodes[i],
num_neg_samples, method,
force_undirected)
neg_edge_index += ptr[i]
+ print(neg_edge_index)
+ print('out', neg_edge_index.shape)
neg_edge_indices.append(neg_edge_index)
return torch.cat(neg_edge_indices, dim=1)
| Confusing UserWarning for `recommender_system.py` example
### 🐛 Describe the bug
```
/usr/local/lib/python3.10/dist-packages/torch_geometric/nn/pool/knn.py:115: UserWarning: Capping 'k' to faiss' upper limit of 2048 (got 1000). This may cause some relevant items to not be retrieved.
warnings.warn(f"Capping 'k' to faiss' upper limit of 2048 "
self.numel= 9742
```
this happens because even though the user inputted k is <2048, query_k=min(query_l, self.numel)=9472. this then triggers the warning but the warning tells the user that we are capping at 2048 because they passed 1000. This is very unintuitive for a user unless they read through the code themselves.
Problem Warning Code:
```
query_k = k
if exclude_links is not None:
deg = degree(exclude_links[0], num_nodes=emb.size(0)).max()
query_k = k + int(deg.max() if deg.numel() > 0 else 0)
print("self.numel=",self.numel)
query_k = min(query_k, self.numel)
if query_k > 2048: # `faiss` supports up-to `k=2048`:
warnings.warn(f"Capping 'k' to faiss' upper limit of 2048 "
f"(got {k}). This may cause some relevant items to "
f"not be retrieved.")
query_k = 2048
score, index = self.index.search(emb.detach(), query_k)
```
### Versions
latest
| 2024-02-15T10:39:23 |
||
pyg-team/pytorch_geometric | 9,001 | pyg-team__pytorch_geometric-9001 | [
"8994"
]
| 8d625c4d65ed76e95990d57547c51f62fa2daf2b | diff --git a/torch_geometric/nn/conv/message_passing.py b/torch_geometric/nn/conv/message_passing.py
--- a/torch_geometric/nn/conv/message_passing.py
+++ b/torch_geometric/nn/conv/message_passing.py
@@ -185,7 +185,6 @@ def __init__(
fuse=self.fuse,
)
- # Cache to potentially disable later on:
self.__class__._orig_propagate = self.__class__.propagate
self.__class__._jinja_propagate = module.propagate
@@ -197,22 +196,30 @@ def __init__(
# Optimize `edge_updater()` via `*.jinja` templates (if implemented):
if (self.inspector.implements('edge_update')
- and not self.edge_updater.__module__.startswith(jinja_prefix)
- and self.inspector.can_read_source):
- module = module_from_template(
- module_name=f'{jinja_prefix}_edge_updater',
- template_path=osp.join(root_dir, 'edge_updater.jinja'),
- tmp_dirname='message_passing',
- # Keyword arguments:
- modules=self.inspector._modules,
- collect_name='edge_collect',
- signature=self._get_edge_updater_signature(),
- collect_param_dict=self.inspector.get_param_dict(
- 'edge_update'),
- )
+ and not self.edge_updater.__module__.startswith(jinja_prefix)):
+ if self.inspector.can_read_source:
+
+ module = module_from_template(
+ module_name=f'{jinja_prefix}_edge_updater',
+ template_path=osp.join(root_dir, 'edge_updater.jinja'),
+ tmp_dirname='message_passing',
+ # Keyword arguments:
+ modules=self.inspector._modules,
+ collect_name='edge_collect',
+ signature=self._get_edge_updater_signature(),
+ collect_param_dict=self.inspector.get_param_dict(
+ 'edge_update'),
+ )
- self.__class__.edge_updater = module.edge_updater
- self.__class__.edge_collect = module.edge_collect
+ self.__class__._orig_edge_updater = self.__class__.edge_updater
+ self.__class__._jinja_edge_updater = module.edge_updater
+
+ self.__class__.edge_updater = module.edge_updater
+ self.__class__.edge_collect = module.edge_collect
+ else:
+ self.__class__._orig_edge_updater = self.__class__.edge_updater
+ self.__class__._jinja_edge_updater = (
+ self.__class__.edge_updater)
# Explainability:
self._explain: Optional[bool] = None
diff --git a/torch_geometric/template.py b/torch_geometric/template.py
--- a/torch_geometric/template.py
+++ b/torch_geometric/template.py
@@ -1,13 +1,11 @@
import importlib
-import os
import os.path as osp
import sys
+import tempfile
from typing import Any
from jinja2 import Environment, FileSystemLoader
-from torch_geometric import get_home_dir
-
def module_from_template(
module_name: str,
@@ -23,13 +21,15 @@ def module_from_template(
template = env.get_template(osp.basename(template_path))
module_repr = template.render(**kwargs)
- instance_dir = osp.join(get_home_dir(), tmp_dirname)
- os.makedirs(instance_dir, exist_ok=True)
- instance_path = osp.join(instance_dir, f'{module_name}.py')
- with open(instance_path, 'w') as f:
- f.write(module_repr)
+ with tempfile.NamedTemporaryFile(
+ mode='w',
+ prefix=f'{module_name}_',
+ suffix='.py',
+ delete=False,
+ ) as tmp:
+ tmp.write(module_repr)
- spec = importlib.util.spec_from_file_location(module_name, instance_path)
+ spec = importlib.util.spec_from_file_location(module_name, tmp.name)
assert spec is not None
module = importlib.util.module_from_spec(spec)
sys.modules[module_name] = module
| Possible overwriting scenario with Jinja
### 🐛 Describe the bug
I am getting the following error, not always but from time to time:
```
File "/usr/local/lib/python3.8/dist-packages/torch_geometric/nn/conv/cg_conv.py", line 57, in __init__
super().__init__(aggr=aggr, **kwargs)
File "/usr/local/lib/python3.8/dist-packages/torch_geometric/nn/conv/message_passing.py", line 193, in __init__
self.__class__._jinja_propagate = module.propagate
AttributeError: module 'torch_geometric.nn.conv.cg_conv_CGConv_propagate' has no attribute 'propagate'
```
I am using pyg in a parallel setting with mpi. I think there is possibility of overwriting when pyg uses jina template here:
https://github.com/pyg-team/pytorch_geometric/blob/9b660ac6ca882604d1ae521912d20ded1d180ecf/torch_geometric/nn/conv/message_passing.py#L170
I put some following debug message around line 186:
```
print ("module:", module)
print ("dir(module):", dir(module))
```
Here is what I got from one process:
```
module: <module 'torch_geometric.nn.conv.pna_conv_PNAConv_propagate' from '/root/.cache/pyg/message_passing/torch_geometric.nn.conv.pna_conv_PNAConv_propagate.py'>
dir(module): ['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__']
```
And this is the output from the other process:
```
module: <module 'torch_geometric.nn.conv.pna_conv_PNAConv_propagate' from '/root/.cache/pyg/message_passing/torch_geometric.nn.conv.pna_conv_PNAConv_propagate.py'>
dir(module): ['Adj', 'Any', 'Callable', 'CollectArgs', 'DataLoader', 'DegreeScalerAggregation', 'Dict', 'Linear', 'List', 'MessagePassing', 'ModuleList', 'NamedTuple', 'OptTensor', 'Optional', 'PNAConv', 'Sequential', 'Size', 'SparseTensor', 'Tensor', 'Union', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'activation_resolver', 'collect', 'degree', 'is_compiling', 'is_sparse', 'is_torch_sparse_tensor', 'propagate', 'ptr2index', 'reset', 'torch', 'torch_geometric', 'typing']
```
It looks to me this can happen when two processes in the same node generate the same template file. One process read the python script in the middle, while the other process overwrites it.
This is just my thought. Anyhow, I am getting such error when using with MPI. Any help will be appreciated.
### Versions
```
PyTorch version: 2.0.1+cpu
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: Ubuntu 20.04.6 LTS (x86_64)
GCC version: (Ubuntu 9.4.0-1ubuntu1~20.04.2) 9.4.0
Clang version: Could not collect
CMake version: Could not collect
Libc version: glibc-2.31
Python version: 3.8.10 (default, Nov 22 2023, 10:22:35) [GCC 9.4.0] (64-bit runtime)
Python platform: Linux-6.6.12-linuxkit-x86_64-with-glibc2.29
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.24.4
[pip3] torch==2.0.1+cpu
[pip3] torch-cluster==1.6.3+pt20cpu
[pip3] torch_geometric==2.5.0
[pip3] torch-scatter==2.1.2+pt20cpu
[pip3] torch-sparse==0.6.18+pt20cpu
[pip3] torch-spline-conv==1.2.2+pt20cpu
[pip3] torchaudio==2.0.2+cpu
[pip3] torchvision==0.15.2+cpu
[conda] Could not collect
```
| Thanks for the issue. I will take a look :) | 2024-03-01T16:58:25 |
|
pyg-team/pytorch_geometric | 9,057 | pyg-team__pytorch_geometric-9057 | [
"9056"
]
| 12f6dcb786f5de9c5cc9a85f32df34a7958b0a04 | diff --git a/torch_geometric/nn/aggr/base.py b/torch_geometric/nn/aggr/base.py
--- a/torch_geometric/nn/aggr/base.py
+++ b/torch_geometric/nn/aggr/base.py
@@ -47,7 +47,7 @@ class Aggregation(torch.nn.Module):
# Define the boundary indices for three sets:
ptr = torch.tensor([0, 4, 7, 10])
- output = aggr(x, ptr=ptr) # Output shape: [4, 64]
+ output = aggr(x, ptr=ptr) # Output shape: [3, 64]
Note that at least one of :obj:`index` or :obj:`ptr` must be defined.
| Typo (?) in Aggr.Aggregation's description
### 📚 Describe the documentation issue
First of all, I would like to thank everyone who has helped me in the last weeks to get going with Pytorch-Geometric. I really appreciate it.
There might be a minor typo in the documentation regarding the abstract class `aggr.Aggregation`.
https://pytorch-geometric.readthedocs.io/en/latest/generated/torch_geometric.nn.aggr.Aggregation.html#torch_geometric.nn.aggr.Aggregation
See second code box:
```python
# Feature matrix holding 10 elements with 64 features each:
x = torch.randn(10, 64)
# Define the boundary indices for three sets:
ptr = torch.tensor([0, 4, 7, 10])
output = aggr(x, ptr=ptr) # Output shape: [4, 64]
```
### Suggest a potential alternative/fix
I believe it should be `# Output shape: [3, 64]` in the last line. It says *three sets* just above. The previous example on indices also has output shape `[3, 64]`.
| 2024-03-15T14:19:26 |
||
pyg-team/pytorch_geometric | 9,099 | pyg-team__pytorch_geometric-9099 | [
"9089"
]
| 37b76162e4deda8753abffbd9d6a8b5ec18484ce | diff --git a/torch_geometric/utils/sparse.py b/torch_geometric/utils/sparse.py
--- a/torch_geometric/utils/sparse.py
+++ b/torch_geometric/utils/sparse.py
@@ -502,48 +502,59 @@ def cat_coo(tensors: List[Tensor], dim: Union[int, Tuple[int, int]]) -> Tensor:
indices, values = [], []
num_rows = num_cols = 0
+ is_coalesced = True
if dim == 0:
for i, tensor in enumerate(tensors):
if i == 0:
- indices.append(tensor.indices())
+ indices.append(tensor._indices())
else:
offset = torch.tensor([[num_rows], [0]], device=tensor.device)
- indices.append(tensor.indices() + offset)
- values.append(tensor.values())
+ indices.append(tensor._indices() + offset)
+ values.append(tensor._values())
num_rows += tensor.size(0)
num_cols = max(num_cols, tensor.size(1))
+ if not tensor.is_coalesced():
+ is_coalesced = False
elif dim == 1:
for i, tensor in enumerate(tensors):
if i == 0:
- indices.append(tensor.indices())
+ indices.append(tensor._indices())
else:
offset = torch.tensor([[0], [num_cols]], device=tensor.device)
indices.append(tensor.indices() + offset)
- values.append(tensor.values())
+ values.append(tensor._values())
num_rows = max(num_rows, tensor.size(0))
num_cols += tensor.size(1)
+ is_coalesced = False
else:
for i, tensor in enumerate(tensors):
if i == 0:
- indices.append(tensor.indices())
+ indices.append(tensor._indices())
else:
offset = torch.tensor([[num_rows], [num_cols]],
device=tensor.device)
- indices.append(tensor.indices() + offset)
- values.append(tensor.values())
+ indices.append(tensor._indices() + offset)
+ values.append(tensor._values())
num_rows += tensor.size(0)
num_cols += tensor.size(1)
+ if not tensor.is_coalesced():
+ is_coalesced = False
- return torch.sparse_coo_tensor(
+ out = torch.sparse_coo_tensor(
indices=torch.cat(indices, dim=-1),
values=torch.cat(values),
size=(num_rows, num_cols) + values[-1].size()[1:],
device=tensor.device,
)
+ if is_coalesced:
+ out = out._coalesced_(True)
+
+ return out
+
def cat_csr(tensors: List[Tensor], dim: Union[int, Tuple[int, int]]) -> Tensor:
assert dim in {0, 1, (0, 1)}
| diff --git a/test/loader/test_dataloader.py b/test/loader/test_dataloader.py
--- a/test/loader/test_dataloader.py
+++ b/test/loader/test_dataloader.py
@@ -240,6 +240,19 @@ def test_dataloader_tensor_frame():
assert batch.edge_index.max() >= 10
+def test_dataloader_sparse():
+ adj_t = torch.sparse_coo_tensor(
+ indices=torch.tensor([[0, 1, 1, 2], [1, 0, 2, 1]]),
+ values=torch.randn(4),
+ size=(3, 3),
+ )
+ data = Data(adj_t=adj_t)
+
+ loader = DataLoader([data, data], batch_size=2)
+ for batch in loader:
+ assert batch.adj_t.size() == (6, 6)
+
+
if __name__ == '__main__':
import argparse
import time
| Cat uncoallesced sparse_coo tensor.
### 🐛 Describe the bug
I have a sparse_coo tensor in my dataset. When I want to load this tensor I get an error like this:
```
File "/home/amir/.pyenv/versions/3.9.13/lib/python3.9/site-packages/torch_geometric/data/batch.py", line 97, in from_data_list
batch, slice_dict, inc_dict = collate(
File "/home/amir/.pyenv/versions/3.9.13/lib/python3.9/site-packages/torch_geometric/data/collate.py", line 109, in collate
value, slices, incs = _collate(attr, values, data_list, stores,
File "/home/amir/.pyenv/versions/3.9.13/lib/python3.9/site-packages/torch_geometric/data/collate.py", line 232, in _collate
value = cat(values, dim=cat_dim)
File "/home/amir/.pyenv/versions/3.9.13/lib/python3.9/site-packages/torch_geometric/utils/sparse.py", line 686, in cat
return cat_coo(tensors, dim)
File "/home/amir/.pyenv/versions/3.9.13/lib/python3.9/site-packages/torch_geometric/utils/sparse.py", line 509, in cat_coo
indices.append(tensor.indices())
RuntimeError: Cannot get indices on an uncoalesced tensor, please call .coalesce() first
```
I do not want to coalesce my tensors because I will have some problems with my tensor dimensions.
I think the root cause of this issue is in the cat_coo method of torch_geometric.utils.sparse which calls tensor.indices(). I think it should be tensor._indices().
Can anyone help me with this issue?
### Versions
PyTorch version: N/A
Is debug build: N/A
CUDA used to build PyTorch: N/A
ROCM used to build PyTorch: N/A
OS: Ubuntu 22.04.1 LTS (x86_64)
GCC version: (Ubuntu 11.4.0-1ubuntu1~22.04) 11.4.0
Clang version: Could not collect
CMake version: version 3.22.1
Libc version: glibc-2.35
Python version: 3.9.18 (main, Sep 11 2023, 13:41:44) [GCC 11.2.0] (64-bit runtime)
Python platform: Linux-5.15.0-92-generic-x86_64-with-glibc2.35
Is CUDA available: N/A
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration:
GPU 0: NVIDIA GeForce RTX 3080
GPU 1: NVIDIA GeForce RTX 3080
Nvidia driver version: 525.147.05
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: N/A
CPU:
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 39 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 16
On-line CPU(s) list: 0-15
Vendor ID: GenuineIntel
Model name: 11th Gen Intel(R) Core(TM) i9-11900K @ 3.50GHz
CPU family: 6
Model: 167
Thread(s) per core: 2
Core(s) per socket: 8
Socket(s): 1
Stepping: 1
CPU max MHz: 5300.0000
CPU min MHz: 800.0000
BogoMIPS: 7008.00
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb invpcid_single ssbd ibrs ibpb stibp ibrs_enhanced fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid mpx avx512f avx512dq rdseed adx smap avx512ifma clflushopt intel_pt avx512cd sha_ni avx512bw avx512vl xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp hwp_pkg_req avx512vbmi umip pku ospke avx512_vbmi2 gfni vaes vpclmulqdq avx512_vnni avx512_bitalg avx512_vpopcntdq rdpid fsrm md_clear flush_l1d arch_capabilities
L1d cache: 384 KiB (8 instances)
L1i cache: 256 KiB (8 instances)
L2 cache: 4 MiB (8 instances)
L3 cache: 16 MiB (1 instance)
NUMA node(s): 1
NUMA node0 CPU(s): 0-15
Vulnerability Gather data sampling: Mitigation; Microcode
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Mitigation; Clear CPU buffers; SMT vulnerable
Vulnerability Retbleed: Mitigation; Enhanced IBRS
Vulnerability Spec rstack overflow: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Enhanced IBRS, IBPB conditional, RSB filling, PBRSB-eIBRS SW sequence
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
Versions of relevant libraries:
[pip3] No relevant packages
[conda] No relevant packages
| 2024-03-25T13:29:08 |
|
pyg-team/pytorch_geometric | 9,145 | pyg-team__pytorch_geometric-9145 | [
"9138"
]
| cbfd1dbcc8460085fa6efb0cd9163883dda90611 | diff --git a/torch_geometric/datasets/pascal.py b/torch_geometric/datasets/pascal.py
--- a/torch_geometric/datasets/pascal.py
+++ b/torch_geometric/datasets/pascal.py
@@ -192,19 +192,19 @@ def hook(module: torch.nn.Module, x: Tensor, y: Tensor) -> None:
child = obj.getElementsByTagName('xmin')[0].firstChild
assert child is not None
- xmin: float = float(child.data) # type: ignore
+ xmin = int(child.data) # type: ignore
child = obj.getElementsByTagName('xmax')[0].firstChild
assert child is not None
- xmax = float(child.data) # type: ignore
+ xmax = int(child.data) # type: ignore
child = obj.getElementsByTagName('ymin')[0].firstChild
assert child is not None
- ymin = float(child.data) # type: ignore
+ ymin = int(child.data) # type: ignore
child = obj.getElementsByTagName('ymax')[0].firstChild
assert child is not None
- ymax = float(child.data) # type: ignore
+ ymax = int(child.data) # type: ignore
box = (xmin, ymin, xmax, ymax)
diff --git a/torch_geometric/nn/models/metapath2vec.py b/torch_geometric/nn/models/metapath2vec.py
--- a/torch_geometric/nn/models/metapath2vec.py
+++ b/torch_geometric/nn/models/metapath2vec.py
@@ -256,6 +256,7 @@ def sample(rowptr: Tensor, col: Tensor, rowcount: Tensor, subset: Tensor,
rand = torch.rand((subset.size(0), num_neighbors), device=subset.device)
rand *= count.to(rand.dtype).view(-1, 1)
rand = rand.to(torch.long) + rowptr[subset].view(-1, 1)
+ rand = rand.clamp(max=col.numel() - 1) # If last node is isolated.
col = col[rand] if col.numel() > 0 else rand
col[mask | (count == 0)] = dummy_idx
| Metapath2vec index out of bounds error
### 🐛 Describe the bug
Hi, I got IndexError: index 1 is out of bounds for dimension 0 with size 1, when running the code below
```
num_nodes_dict = {'a': 2, 'b': 2}
edge_index_dict = {
('a', 'to', 'b'): torch.tensor([[0], [0]]),
('b', 'to', 'a'): torch.tensor([[0], [0]]),
}
metapath = [('a', 'to', 'b'), ('b', 'to', 'a')]
model = MetaPath2Vec(
edge_index_dict,
embedding_dim=16,
metapath=metapath,
walk_length=2,
context_size=2,
walks_per_node=1,
num_negative_samples=1,
num_nodes_dict=num_nodes_dict,
)
loader = model.loader(batch_size=16, shuffle=True)
next(iter(loader))
```
### Versions
Versions of relevant libraries:
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.5
[pip3] torch==2.1.2+cu121
[pip3] torch_geometric==2.5.2
[pip3] torcheval==0.0.7
[pip3] torchvision==0.16.2+cu121
[pip3] triton==2.1.0
| 2024-04-03T15:43:24 |
||
pyg-team/pytorch_geometric | 9,188 | pyg-team__pytorch_geometric-9188 | [
"9171"
]
| e213c297bb2aeb9ac50db258f5ab01ea11aea349 | diff --git a/torch_geometric/utils/convert.py b/torch_geometric/utils/convert.py
--- a/torch_geometric/utils/convert.py
+++ b/torch_geometric/utils/convert.py
@@ -527,10 +527,14 @@ def to_dgl(
if isinstance(data, Data):
if data.edge_index is not None:
row, col = data.edge_index
- else:
+ elif 'adj' in data:
+ row, col, _ = data.adj.coo()
+ elif 'adj_t' in data:
row, col, _ = data.adj_t.t().coo()
+ else:
+ row, col = [], []
- g = dgl.graph((row, col))
+ g = dgl.graph((row, col), num_nodes=data.num_nodes)
for attr in data.node_attrs():
g.ndata[attr] = data[attr]
| to_dgl does not convert graph with isolated nodes or zero edges graph
### 🐛 Describe the bug
```
import torch
from torch_geometric.data import Data
from torch_geometric.utils.convert import to_dgl
# 1nd example zero edge
data = Data()
data['x'] = torch.tensor([[0, 1, 2], [2,3,4]])
data.validate()
to_dgl(data)
# AttributeError: 'GlobalStorage' object has no attribute 'adj_t'
# 2nd example, isolated nodes
data = Data()
data['x'] = torch.tensor([[0, 1, 2], [2,3,4]])
data['edge_index'] = torch.tensor([[0],[0]])
data.validate()
to_dgl(data)`
# DGLError: Expect number of features to match number of nodes (len(u)). Got 2 and 1 instead.
```
The function initialized the dgl graph using data from the edges first. Hence any isolated nodes afterwards will cause node number mismatch.
### Versions
Collecting environment information...
PyTorch version: 2.2.2+cpu
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: Microsoft Windows 10 Enterprise
GCC version: Could not collect
Clang version: Could not collect
CMake version: Could not collect
Libc version: N/A
Python version: 3.9.19 | packaged by conda-forge | (main, Mar 20 2024, 12:38:46) [MSC v.1929 64 bit (AMD64)] (64-bit runtime)
Python platform: Windows-10-10.0.19045-SP0
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Revision=
Versions of relevant libraries:
[pip3] mypy-extensions==1.0.0
[pip3] numpy==1.26.4
[pip3] numpydoc==1.7.0
[pip3] torch==2.2.2
[pip3] torch_geometric==2.5.2
[pip3] torchdata==0.7.1
[conda] libblas 3.9.0 22_win64_mkl conda-forge
[conda] libcblas 3.9.0 22_win64_mkl conda-forge
[conda] liblapack 3.9.0 22_win64_mkl conda-forge
[conda] mkl 2024.1.0 h66d3029_692 conda-forge
[conda] numpy 1.26.4 py39hddb5d58_0 conda-forge
[conda] numpydoc 1.7.0 pypi_0 pypi
[conda] torch 2.2.2 pypi_0 pypi
[conda] torch-geometric 2.5.2 pypi_0 pypi
[conda] torchdata 0.7.1 pypi_0 pypi
| 2024-04-11T12:44:06 |
||
pyg-team/pytorch_geometric | 9,195 | pyg-team__pytorch_geometric-9195 | [
"9176"
]
| bbf0e1d6e8c5fda23ec174061690acdc33f43091 | diff --git a/torch_geometric/datasets/snap_dataset.py b/torch_geometric/datasets/snap_dataset.py
--- a/torch_geometric/datasets/snap_dataset.py
+++ b/torch_geometric/datasets/snap_dataset.py
@@ -22,6 +22,9 @@ def __inc__(self, key: str, value: Any, *args: Any, **kwargs: Any) -> Any:
def read_ego(files: List[str], name: str) -> List[EgoData]:
import pandas as pd
+ import tqdm
+
+ files = sorted(files)
all_featnames = []
files = [
@@ -38,7 +41,7 @@ def read_ego(files: List[str], name: str) -> List[EgoData]:
all_featnames_dict = {key: i for i, key in enumerate(all_featnames)}
data_list = []
- for i in range(0, len(files), 5):
+ for i in tqdm.tqdm(range(0, len(files), 5)):
circles_file = files[i]
edges_file = files[i + 1]
egofeat_file = files[i + 2]
@@ -65,6 +68,9 @@ def read_ego(files: List[str], name: str) -> List[EgoData]:
x_all[:, torch.tensor(indices)] = x
x = x_all
+ if x.size(1) > 100_000:
+ x = x.to_sparse_csr()
+
idx = pd.read_csv(feat_file, sep=' ', header=None, dtype=str,
usecols=[0]).squeeze()
| SNAPDataset ram usage
### 🐛 Describe the bug
Ran the following code on python 3.10/3.11 and the process got killed by the os(tried on windows/wsl/mac)
for using too much RAM (tried to run both on a laptop with 16gb of memory and a desktop pc with 64gb of memory).
```python
from torch_geometric.datasets import SNAPDataset
dataset = SNAPDataset("./datasets/snap/twitter", "ego-twitter")
```
### Versions
PyTorch version: 2.0.1
Is debug build: False
CUDA used to build PyTorch: None
ROCM used to build PyTorch: N/A
OS: macOS 14.0 (x86_64)
GCC version: Could not collect
Clang version: 15.0.0 (clang-1500.3.9.4)
CMake version: Could not collect
Libc version: N/A
Python version: 3.11.1 (main, Jan 26 2023, 14:19:45) [Clang 13.0.0 (clang-1300.0.29.30)] (64-bit runtime)
Python platform: macOS-14.0-x86_64-i386-64bit
Is CUDA available: False
CUDA runtime version: No CUDA
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Intel(R) Core(TM) i5-1038NG7 CPU @ 2.00GHz
Versions of relevant libraries:
[pip3] mypy==0.991
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.24.1
[pip3] torch==2.0.1
[pip3] torch_geometric==2.4.0
[pip3] torchaudio==2.0.2
[pip3] torchvision==0.15.2
[conda] Could not collect
| Info from windows machine:
PyTorch version: 2.0.1+cu117
Is debug build: False
CUDA used to build PyTorch: 11.7
ROCM used to build PyTorch: N/A
OS: ??Microsoft Windows 11 Pro
GCC version: Could not collect
Clang version: Could not collect
CMake version: Could not collect
Libc version: N/A
Python version: 3.11.5 (tags/v3.11.5:cce6ba9, Aug 24 2023, 14:38:34) [MSC v.1936 64 bit (AMD64)] (64-bit runtime)
Python platform: Windows-10-10.0.22631-SP0
Is CUDA available: True
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: LAZY
GPU models and configuration: GPU 0: NVIDIA GeForce RTX 3090
Nvidia driver version: 536.99
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
CPU:
Architecture=9
CurrentClockSpeed=3401
DeviceID=CPU0
Family=107
L2CacheSize=8192
L2CacheSpeed=
Manufacturer=AuthenticAMD
MaxClockSpeed=3401
Name=AMD Ryzen 9 5950X 16-Core Processor
ProcessorType=3
Revision=8448
Versions of relevant libraries:
[pip3] numpy==1.24.1
[pip3] torch==2.0.1+cu117
[pip3] torch_geometric==2.5.2
[pip3] torchaudio==2.0.2+cu117
[pip3] torchvision==0.15.2+cu117
[conda] Could not collect | 2024-04-12T12:39:59 |
|
pyg-team/pytorch_geometric | 9,335 | pyg-team__pytorch_geometric-9335 | [
"9333"
]
| 1bb7fc0c395c181cf7623767168159601a41e782 | diff --git a/torch_geometric/data/data.py b/torch_geometric/data/data.py
--- a/torch_geometric/data/data.py
+++ b/torch_geometric/data/data.py
@@ -291,13 +291,14 @@ def snapshot(
self,
start_time: Union[float, int],
end_time: Union[float, int],
+ attr: str = 'time',
) -> Self:
r"""Returns a snapshot of :obj:`data` to only hold events that occurred
in period :obj:`[start_time, end_time]`.
"""
out = copy.copy(self)
for store in out.stores:
- store.snapshot(start_time, end_time)
+ store.snapshot(start_time, end_time, attr)
return out
def up_to(self, end_time: Union[float, int]) -> Self:
diff --git a/torch_geometric/data/storage.py b/torch_geometric/data/storage.py
--- a/torch_geometric/data/storage.py
+++ b/torch_geometric/data/storage.py
@@ -370,18 +370,20 @@ def snapshot(
self,
start_time: Union[float, int],
end_time: Union[float, int],
+ attr: str = 'time',
) -> Self:
- if 'time' in self:
- mask = (self.time >= start_time) & (self.time <= end_time)
+ if attr in self:
+ time = self[attr]
+ mask = (time >= start_time) & (time <= end_time)
- if self.is_node_attr('time'):
+ if self.is_node_attr(attr):
keys = self.node_attrs()
- elif self.is_edge_attr('time'):
+ elif self.is_edge_attr(attr):
keys = self.edge_attrs()
self._select(keys, mask)
- if self.is_node_attr('time') and 'num_nodes' in self:
+ if self.is_node_attr(attr) and 'num_nodes' in self:
self.num_nodes: Optional[int] = int(mask.sum())
return self
| Add optional `attr` argument to `BaseData.snapshot` method
### 🛠 Proposed Refactor
The `snapshot` method of a PyG `dataset` currently requires that the temporal attribute data is stored as `dataset.time`.
The [method](https://pytorch-geometric.readthedocs.io/en/latest/generated/torch_geometric.data.Data.html#torch_geometric.data.Data.snapshot) supports both node- and edge-level temporal attributes. However, some datasets may include both node- and edge-level temporal data under distinct keys (e.g., `time` and `edge_time`), and there is currently no way to specify it.
Moreover, the result of `snapshot` when passing a node-level or edge-level data is different; the first returns a `dataset` object with filtered node data only, while the latter returns filtered edge data only, therefore fulfilling different use cases.
In order to avoid having to modify the `dataset.time` object on e.g. datasets with both attributes, PyG should IMHO ideally support receiving an `attr` argument that allows to specify the name of the attribute key in which the data is stored.
### Suggest a potential alternative/fix
See PR #9335.
| 2024-05-19T23:11:28 |
||
rpm-software-management/dnf | 1,907 | rpm-software-management__dnf-1907 | [
"1905"
]
| 53deb90a2caac2f44e48a7d6f89b5bf7e74ca5c1 | diff --git a/dnf/automatic/emitter.py b/dnf/automatic/emitter.py
--- a/dnf/automatic/emitter.py
+++ b/dnf/automatic/emitter.py
@@ -106,7 +106,7 @@ def commit(self):
smtp = smtplib.SMTP(self._conf.email_host, timeout=300)
smtp.sendmail(email_from, email_to, message.as_string())
smtp.close()
- except smtplib.SMTPException as exc:
+ except OSError as exc:
msg = _("Failed to send an email via '%s': %s") % (
self._conf.email_host, exc)
logger.error(msg)
| Bug on almalinux 9
Hi,
I have these messages on almalinux 9/ Rocky Linux 9
[mickael@srvalmalinux ~]$ sudo /usr/bin/dnf-automatic /etc/dnf/automatic.conf --timer
Last metadata expiration check: 2:45:52 ago on Fri Mar 10 14:38:38 2023.
Running transaction check
Transaction check succeeded.
Running transaction test
Transaction test succeeded.
Running transaction
Traceback (most recent call last):
File "/usr/bin/dnf-automatic", line 36, in <module>
sys.exit(dnf.automatic.main.main(sys.argv[1:]))
File "/usr/lib/python3.9/site-packages/dnf/automatic/main.py", line 342, in main
emitters.commit()
File "/usr/lib/python3.9/site-packages/dnf/util.py", line 526, in fn
return list(map(call_what, self))
File "/usr/lib/python3.9/site-packages/dnf/util.py", line 525, in call_what
return method(*args, **kwargs)
File "/usr/lib/python3.9/site-packages/dnf/automatic/emitter.py", line 106, in commit
smtp = smtplib.SMTP(self._conf.email_host, timeout=300)
File "/usr/lib64/python3.9/smtplib.py", line 255, in __init__
(code, msg) = self.connect(host, port)
File "/usr/lib64/python3.9/smtplib.py", line 341, in connect
self.sock = self._get_socket(host, port, self.timeout)
File "/usr/lib64/python3.9/smtplib.py", line 312, in _get_socket
return socket.create_connection((host, port), timeout,
File "/usr/lib64/python3.9/socket.py", line 844, in create_connection
raise err
File "/usr/lib64/python3.9/socket.py", line 832, in create_connection
sock.connect(sa)
ConnectionRefusedError: [Errno 111] Connection refused
| 2023-03-13T19:00:33 |
||
rpm-software-management/dnf | 1,956 | rpm-software-management__dnf-1956 | [
"1955"
]
| 96b5df9cdec68ab383624c09f9479ce3c274aac0 | diff --git a/dnf/automatic/emitter.py b/dnf/automatic/emitter.py
--- a/dnf/automatic/emitter.py
+++ b/dnf/automatic/emitter.py
@@ -95,6 +95,7 @@ def commit(self):
message.set_charset('utf-8')
email_from = self._conf.email_from
email_to = self._conf.email_to
+ email_port = self._conf.email_port
message['Date'] = email.utils.formatdate()
message['From'] = email_from
message['Subject'] = subj
@@ -103,7 +104,7 @@ def commit(self):
# Send the email
try:
- smtp = smtplib.SMTP(self._conf.email_host, timeout=300)
+ smtp = smtplib.SMTP(self._conf.email_host, self._conf.email_port, timeout=300)
smtp.sendmail(email_from, email_to, message.as_string())
smtp.close()
except OSError as exc:
| `email_port` option supported but not used
It looks like the `email_port` option, while parsed in [dnf/automatic/main.py:200](https://github.com/rpm-software-management/dnf/blob/master/dnf/automatic/main.py#L200), is not actually used anywhere.
| 2023-06-28T09:48:05 |
||
OpenCTI-Platform/connectors | 51 | OpenCTI-Platform__connectors-51 | [
"50"
]
| 9d47ffdad1c2a7fbdd709565d5c3f670693b148f | diff --git a/cve/src/cve.py b/cve/src/cve.py
--- a/cve/src/cve.py
+++ b/cve/src/cve.py
@@ -29,6 +29,9 @@ def __init__(self):
self.cve_nvd_data_feed = get_config_variable(
"CVE_NVD_DATA_FEED", ["cve", "nvd_data_feed"], config
)
+ self.cve_history_data_feed = get_config_variable(
+ "CVE_HISTORY_DATA_FEED", ["cve", "history_data_feed"], config
+ )
self.cve_interval = get_config_variable(
"CVE_INTERVAL", ["cve", "interval"], config, True
)
@@ -97,12 +100,10 @@ def run(self):
# If import history and never run
if last_run is None and self.cve_import_history:
now = datetime.now()
- years = list(range(2002, now.year))
+ years = list(range(2002, now.year+1))
for year in years:
self.convert_and_send(
- "https://nvd.nist.gov/feeds/json/cve/1.1/nvdcve-1.1-"
- + str(year)
- + ".json.gz"
+ f"{self.cve_history_data_feed}nvdcve-1.1-{year}.json.gz"
)
# Store the current timestamp as a last run
| [CVE] Download link to variable
## Description
Set the download CVE link to variable, because otherwise the tool can hardly be used offline. Offline we can host the CVEs on a link that is not : "https://nvd.nist.gov/feeds/json/cve/1.1/nvdcve-1.1-"
## Reproducible Steps
https://github.com/OpenCTI-Platform/connectors/blame/9d47ffdad1c2a7fbdd709565d5c3f670693b148f/cve/src/cve.py#L103
## Expected Output
Url as a variable in the .yml
## Actual Output
Permanent link : "https://nvd.nist.gov/feeds/json/cve/1.1/nvdcve-1.1-"
| 2020-03-01T22:11:32 |
||
OpenCTI-Platform/connectors | 214 | OpenCTI-Platform__connectors-214 | [
"213"
]
| d95edd27bd3f6ef826eaeb2d629f57885d4957ba | diff --git a/cybercrime-tracker/src/cybercrime-tracker.py b/cybercrime-tracker/src/cybercrime-tracker.py
--- a/cybercrime-tracker/src/cybercrime-tracker.py
+++ b/cybercrime-tracker/src/cybercrime-tracker.py
@@ -56,7 +56,7 @@ def __init__(self):
config,
)
self.interval = get_config_variable(
- "CYBERCRIMETRACKER_INTERVAL",
+ "CYBERCRIME_TRACKER_INTERVAL",
["cybercrime-tracker", "interval"],
config,
isNumber=True,
| [cybercrime-tracker] connector fails due to unchecked None
## Description
Cybercrime tracker connector fails while determining if the last run interval has been exceeded.
## Environment
1. OS (where OpenCTI server runs): Debian Buster 10.7
2. OpenCTI version: 4.0.x
3. OpenCTI client: pycti
4. Other environment details:
## Reproducible Steps
Steps to create the smallest reproducible scenario:
1. Setup the connector in accordance its the README (docker)
2. `docker-compose up`
3. See "ERROR" logs
```
Attaching to cybercrime-tracker_connector-cybercrimetracker_1
connector-cybercrimetracker_1 | INFO:root:Listing Threat-Actors with filters null.
connector-cybercrimetracker_1 | INFO:root:Connector registered with ID:cybercrime
connector-cybercrimetracker_1 | INFO:root:Starting ping alive thread
connector-cybercrimetracker_1 | INFO:root:Fetching data CYBERCRIME-TRACKER.NET...
connector-cybercrimetracker_1 | INFO:root:Listing Marking-Definitions with filters [{"key": "definition", "values": "TLP:WHITE"}].
connector-cybercrimetracker_1 | INFO:root:Connector last run: 2020-12-21 05:57:36
connector-cybercrimetracker_1 | ERROR:root:'>' not supported between instances of 'int' and 'NoneType'
```
This error seems to occur when [determining if it's time to run](https://github.com/OpenCTI-Platform/connectors/blob/master/cybercrime-tracker/src/cybercrime-tracker.py#L163).
## Expected Output
I expected the Data page to display the number of messages queued from this source.
## Actual Output
0 messages queued
| 2020-12-21T20:23:27 |
||
OpenCTI-Platform/connectors | 292 | OpenCTI-Platform__connectors-292 | [
"291"
]
| 082938dc268138555acb6b5b4e9d56527b968687 | diff --git a/misp/src/misp.py b/misp/src/misp.py
--- a/misp/src/misp.py
+++ b/misp/src/misp.py
@@ -206,6 +206,7 @@ def run(self):
self.helper.log_info(
"Fetching MISP events with args: " + json.dumps(kwargs)
)
+ kwargs = json.loads(json.dumps(kwargs))
events = []
try:
events = self.misp.search("events", **kwargs)
| [MISP] ERROR:root:search() keywords must be strings
## Description
I want to integrate MISP with OpenCTI. The connector errors and doesn't import events.
How do I debug this?
## Environment
1. OS (where OpenCTI server runs): https://github.com/OpenCTI-Platform/docker host: Debian 10
2. OpenCTI version: 4.3.0
3. OpenCTI client: 4.3.0? not sure and think it's irrelevant
4. Other environment details:
MISP: Latest commit on git, commit id 4474dcc, so probably version 2.4.140
misp-connector: 4.3.0
## Reproducible Steps
Steps to create the smallest reproducible scenario:
1. Setup OpenCTI using docker
2. Setup MISP connector in docker-compose.yml with correct MISP URL, MISP API KEY and following settings
```
- OPENCTI_URL=${OPENCTI_URL} # I confirm this is correct
- OPENCTI_TOKEN=${OPENCTI_ADMIN_TOKEN} # I confirm this is correct
- CONNECTOR_ID=${CONNECTOR_MISP_ID} # 1d67ffcf-5741-467f-844f-96f436440775
- CONNECTOR_TYPE=EXTERNAL_IMPORT
- CONNECTOR_NAME=MISP
- CONNECTOR_SCOPE=misp
- CONNECTOR_CONFIDENCE_LEVEL=3
- CONNECTOR_UPDATE_EXISTING_DATA=false
- CONNECTOR_LOG_LEVEL=info
- MISP_URL=${CONNECTOR_MISP_URL} # I confirm this is correct
- MISP_KEY=${CONNECTOR_MISP_API} # I confirm this is correct
- MISP_SSL_VERIFY=False
- MISP_CREATE_REPORTS=True
- MISP_REPORT_CLASS=MISP Event
- MISP_IMPORT_FROM_DATE=2000-01-01
- MISP_IMPORT_TAGS=opencti:import,type:osint
- MISP_INTERVAL=1
```
3. Create event in MISP with opencti:import or type:osint tag, won't get imported
## Expected Output
`INFO:root:MISP returned 1 events.`
## Actual Output
```
INFO:root:Fetching MISP events with args: {"tags": {"OR": ["opencti:import", "type:osint"]}, "null": 1616075539, "limit": 50, "page": 1}
ERROR:root:search() keywords must be strings
ERROR:root:search() keywords must be strings
INFO:root:MISP returned 0 events.
INFO:root:Connector successfully run (0 events have been processed), storing last_run as 1616075599
INFO:root:Reporting work update_received opencti-work--c1bc4bd2-4101-4430-95f4-da9e33c134b8
INFO:root:Initiate work for 1d67ffcf-5741-467f-844f-96f436440775
INFO:root:Connector last run: 2021-03-18 13:53:19
```
## Additional information
https://github.com/OpenCTI-Platform/connectors/blob/master/misp/src/misp.py#L215
I'm positive the error is from here, referencing the PyMISP api here:
https://github.com/MISP/PyMISP/blob/main/pymisp/api.py#L2207
the function gets called as
`events = self.misp.search("events", **kwargs)`
where json.dumps(kwargs) is:
```json
{"tags": {"OR": ["opencti:import", "type:osint"]}, "null": 1616075539, "limit": 50, "page": 1}
```
but when trying the following script inside the connector-misp container:
```python
import json
from pymisp import ExpandedPyMISP
misp = ExpandedPyMISP(url="MISP_URL", key="MISP_API_KEY", ssl=False, debug=False)
kwargs = json.loads('{"tags": {"OR": ["opencti:import", "type:osint"]}, "null": 1616075539, "limit": 50, "page": 1}')
events = misp.search("events", **kwargs)
print(events)
```
everything works correctly
This is is my temporary fix:
https://github.com/OpenCTI-Platform/connectors/blob/master/misp/src/misp.py#L215
will be
```python
self.helper.log_info(
"Fetching MISP events with args: " + json.dumps(kwargs)
)
kwargs = json.loads(json.dumps(kwargs))
events = []
try:
events = self.misp.search("events", **kwargs)
except Exception as e:
self.helper.log_error(str(e))
try:
events = self.misp.search("events", **kwargs)
except Exception as e:
self.helper.log_error(str(e))
```
| 2021-03-18T15:35:33 |
||
OpenCTI-Platform/connectors | 325 | OpenCTI-Platform__connectors-325 | [
"310"
]
| aa31c9c6417ae8d38acf8806a6c7280fb8d84237 | diff --git a/misp/src/misp.py b/misp/src/misp.py
--- a/misp/src/misp.py
+++ b/misp/src/misp.py
@@ -4,7 +4,6 @@
import json
from datetime import datetime
-from dateutil.parser import parse
from pymisp import ExpandedPyMISP
from stix2 import (
Bundle,
@@ -42,6 +41,7 @@
"transform": {"operation": "remove_string", "value": "AS"},
},
"mac-addr": {"type": "mac-addr", "path": ["value"]},
+ "hostname": {"type": "x-opencti-hostname", "path": ["value"]},
"domain": {"type": "domain-name", "path": ["value"]},
"ipv4-addr": {"type": "ipv4-addr", "path": ["value"]},
"ipv6-addr": {"type": "ipv6-addr", "path": ["value"]},
@@ -488,12 +488,14 @@ def process_events(self, work_id, events):
bundle_objects.append(object_relationship)
# Create the report if needed
- if self.misp_create_report and len(object_refs) > 0:
+ if self.misp_create_report:
report = Report(
id="report--" + event["Event"]["uuid"],
name=event["Event"]["info"],
description=event["Event"]["info"],
- published=parse(event["Event"]["date"]),
+ published=datetime.utcfromtimestamp(
+ int(event["Event"]["timestamp"])
+ ),
report_types=[self.misp_report_type],
created_by_ref=author,
object_marking_refs=event_markings,
| MISP only imports if there is galaxy tag from mitre-attack is added
## Description
I would like OpenCTI to also import events that do not have galaxy tags from the mitre-attack galaxy
## Environment
1. OS (where OpenCTI server runs): Debian 10
2. OpenCTI version: 4.3.4
3. OpenCTI client: docker
4. Other environment details: OpenCTI + MISP with default env
misp connector:
- MISP_CREATE_REPORTS=True # Required, create report for MISP event
- MISP_IMPORT_TAGS=opencti:import
## Reproducible Steps
1. Create MISP event with title, opencti:import tag, observables
2. Either don't add a galaxy tag, or one that isn't from mitre-attack
3. Publish
The event will not goto OpenCTI
If you reproduce the same steps but add e.g. attack patterns from mitre-attack it will get imported.
Is this the intended behaviour?
## Expected Output
OpenCTI imports all events
| 2021-04-14T10:18:18 |
||
OpenCTI-Platform/connectors | 401 | OpenCTI-Platform__connectors-401 | [
"365"
]
| 03901a1e41a2e6b11529e43f7c5323cae09aa19c | diff --git a/abuseipdb/src/abuseipdb.py b/abuseipdb/src/abuseipdb.py
--- a/abuseipdb/src/abuseipdb.py
+++ b/abuseipdb/src/abuseipdb.py
@@ -100,16 +100,27 @@ def _process_message(self, data):
return "IP found in AbuseIPDB WHITELIST."
if len(data["reports"]) > 0:
for report in data["reports"]:
- country = self.helper.api.stix_domain_object.get_by_stix_id_or_name(
- name=report["reporterCountryName"]
- )
- self.helper.api.stix_sighting_relationship.create(
- fromId=observable_id,
- toId=country["id"],
- count=1,
- first_seen=report["reportedAt"],
- last_seen=report["reportedAt"],
+ country = self.helper.api.location.read(
+ filters=[
+ {
+ "key": "x_opencti_aliases",
+ "values": [report["reporterCountryCode"]],
+ }
+ ],
+ getAll=True,
)
+ if country is None:
+ self.helper.log_warning(
+ f"No country found with Alpha 2 code {report['reporterCountryCode']}"
+ )
+ else:
+ self.helper.api.stix_sighting_relationship.create(
+ fromId=observable_id,
+ toId=country["id"],
+ count=1,
+ first_seen=report["reportedAt"],
+ last_seen=report["reportedAt"],
+ )
for category in report["categories"]:
category_text = self.extract_abuse_ipdb_category(category)
label = self.helper.api.label.create(value=category_text)
| [AbuseIPdb] Crash on listing "Korea (Republic of)" entity
## Description
The AbuseIPDB enrichment connector stops gathering data as soon as there is an entity of "Korea (Republic of)" is found.
## Actual Output
Example listing:
```
connector-abuseipdb_1 | 2021-05-20T13:07:59.843767030Z INFO:root:Listing Stix-Domain-Objects with filters [{"key": "name", "values": ["Korea (Republic of)"]}].
connector-abuseipdb_1 | 2021-05-20T13:07:59.859596474Z INFO:root:Listing Stix-Domain-Objects with filters [{"key": "aliases", "values": ["Korea (Republic of)"]}].
connector-abuseipdb_1 | 2021-05-20T13:07:59.959406389Z ERROR:root:Error in message processing, reporting error to API
connector-abuseipdb_1 | 2021-05-20T13:07:59.959533538Z Traceback (most recent call last):
connector-abuseipdb_1 | 2021-05-20T13:07:59.959542290Z File "/usr/local/lib/python3.9/site-packages/pycti/connector/opencti_connector_helper.py", line 145, in _data_handler
connector-abuseipdb_1 | 2021-05-20T13:07:59.959548366Z message = self.callback(json_data["event"])
connector-abuseipdb_1 | 2021-05-20T13:07:59.959553788Z File "/opt/opencti-connector-abuseipdb/abuseipdb.py", line 108, in _process_message
connector-abuseipdb_1 | 2021-05-20T13:07:59.959559549Z toId=country["id"],
connector-abuseipdb_1 | 2021-05-20T13:07:59.959564881Z TypeError: 'NoneType' object is not subscriptable
```
## Additional information
The error above has been using IP address 143.198.132.45
| The reason behind this crash is that the "Republic of Korea" has following names in the opencti geography dataset (https://github.com/OpenCTI-Platform/datasets/blob/master/data/geography.json#L4051-L4058):
* Republic of Korea (name)
* KOR (alias, ISO 3166-1 alpha-3 code)
* KO (alias, ISO 3166-1 alpha-2 code)
Due to those names there's no match with AbuseIPs naming scheme "Korea (Republic of)".
@SamuelHassine According to ISO [1] the official naming scheme should be "Korea (Republic of)". In cases like Iran the OpenCTI dataset seems to be correct, but for Korea it isn't. I think the easiest proper fix would be a change in the geography dataset from "Republic of Korea" to "Korea (Republic of)". Should I submit a PR for that change?
[1] https://www.iso.org/obp/ui/#search | 2021-06-23T10:45:38 |
|
OpenCTI-Platform/connectors | 448 | OpenCTI-Platform__connectors-448 | [
"413"
]
| 5a73816b0627aad9814db115b04edd5df1ef4238 | diff --git a/virustotal/src/virustotal.py b/virustotal/src/virustotal.py
--- a/virustotal/src/virustotal.py
+++ b/virustotal/src/virustotal.py
@@ -1,10 +1,9 @@
-from time import sleep
-import yaml
+import json
import os
import requests
-import json
-
+import yaml
from pycti import OpenCTIConnectorHelper, get_config_variable
+from time import sleep
class VirusTotalConnector:
@@ -68,17 +67,20 @@ def _process_file(self, observable):
key="size",
value=str(attributes["size"]),
)
- if observable["name"] is None and len(attributes["names"]) > 0:
- self.helper.api.stix_cyber_observable.update_field(
- id=final_observable["id"], key="name", value=attributes["names"][0]
- )
- del attributes["names"][0]
- if len(attributes["names"]) > 0:
+ if observable["name"] is None and len(attributes["names"]) > 0:
self.helper.api.stix_cyber_observable.update_field(
id=final_observable["id"],
- key="x_opencti_additional_names",
- value=attributes["names"],
+ key="name",
+ value=attributes["names"][0],
)
+ del attributes["names"][0]
+
+ if len(attributes["names"]) > 0:
+ self.helper.api.stix_cyber_observable.update_field(
+ id=final_observable["id"],
+ key="x_opencti_additional_names",
+ value=attributes["names"],
+ )
# Create external reference
external_reference = self.helper.api.external_reference.create(
| VirusTotal Connector error
Please replace every line in curly brackets { like this } with an appropriate answer, and remove this line.
## Description
When trying to enrich a artefact, VirusTotal report the following error every time
<img width="1022" alt="Screenshot 2021-07-05 at 6 55 12 PM" src="https://user-images.githubusercontent.com/79446411/124463810-fc880300-ddc5-11eb-9564-2a8bded488cc.png">
When I access to the log, it shows the following error
`ERROR:root:Error in message processing, reporting error to API
Traceback (most recent call last):
File "/usr/local/lib/python3.9/site-packages/pycti/connector/opencti_connector_helper.py", line 152, in _data_handler
message = self.callback(json_data["event"])
File "/opt/opencti-connector-virustotal/virustotal.py", line 116, in _process_message
return self._process_file(observable)
File "/opt/opencti-connector-virustotal/virustotal.py", line 71, in _process_file
if observable["name"] is None and len(attributes["names"]) > 0:
KeyError: 'name'
INFO:root:Reporting work update_received opencti-work--c2b1ef93-8b44-4915-b418-f759ee262f53
INFO:root:Message (delivery_tag=1) processed, thread terminated`
## Environment
1. AWS ubuntu-bionic-18.04-amd64-server
2. OpenCTI Version 4.5.5
3. OpenCTI client: frontend
4. Other environment details: VirusTotal connector version : opencti/connector-virustotal:latest
## Reproducible Steps
Steps to create the smallest reproducible scenario:
## Expected Output
Successfully extract information from VirusTotal
## Actual Output
Error occurred as mentioned above.
## Additional information
{ Any additional information, including logs or screenshots if you have any. }
| Hey @realzacharycheng
Thanks for the creating this issue! Could you please share the observable you were trying to enrich with virus total?
Thanks
> Hey @realzacharycheng
>
> Thanks for the creating this issue! Could you please share the observable you were trying to enrich with virus total?
>
> Thanks
I was testing using the latest version of mimikatz.exe from github
<img width="887" alt="Screenshot 2021-07-06 at 12 29 02 PM" src="https://user-images.githubusercontent.com/79446411/124542315-c2664200-de55-11eb-8b0a-267dc83cd276.png">
Thanks for the info. I'll have a look at it
Could you please share the SDO/SCO as a STIX2 file? That would help me when trying to reproduce the error. Thanks!
Hi @nor3th I exported the file, please help checking if this is correct and able to help you reproducing the error. Thank you so much.
[mimikatz.txt](https://github.com/OpenCTI-Platform/connectors/files/6974324/mimikatz.txt)
| 2021-08-13T20:31:35 |
|
OpenCTI-Platform/connectors | 463 | OpenCTI-Platform__connectors-463 | [
"462"
]
| ac34737376a91049a496cb30842aaa5266856d14 | diff --git a/internal-import-file/import-report/src/reportimporter/report_parser.py b/internal-import-file/import-report/src/reportimporter/report_parser.py
--- a/internal-import-file/import-report/src/reportimporter/report_parser.py
+++ b/internal-import-file/import-report/src/reportimporter/report_parser.py
@@ -181,9 +181,24 @@ def _extract_observable(self, observable: Observable, data: str) -> Dict:
matches = lookup_function(data)
for match in matches:
- start = data.index(str(match))
+ match_str = str(match)
+ if match_str in data:
+ start = data.index(match_str)
+ elif match_str in data.lower():
+ self.helper.log_debug(
+ f"External library manipulated the extracted value '{match_str}' from the "
+ f"original text '{data}' to lower case"
+ )
+ start = data.lower().index(match_str)
+ else:
+ self.helper.log_error(
+ f"The extracted text '{match_str}' is not part of the original text '{data}'. "
+ f"Please open a GitHub issue to report this problem!"
+ )
+ continue
+
ind_match = self._post_parse_observables(
- match, observable, (start, len(str(match)) + start)
+ match, observable, (start, len(match_str) + start)
)
if ind_match:
list_matches[match] = ind_match
| [import-report] Trouble parsing domains / URLs with capital letters
## Description
import-report appears to fail when parsing domains with capital letters. I've attached the txt file of domains I was trying to import below. The import fails with the error "'list' object has no attribute 'values'". I played with the input file by removing domains that appeared to be causing issues, and the problematic domains were:
- kAty197.chickenkiller[.]com
- Soure7788.chickenkiller[.]com
- Engaction[.]com
## Environment
1. OS (where OpenCTI server runs): Ubuntu 18
2. OpenCTI version: OpenCTI 4.5.5
3. OpenCTI client: frontend
4. Other environment details: import-connector: rolling
## Reproducible Steps
Steps to create the smallest reproducible scenario:
1. Import txt file with domains/URLs with capital letters
## Expected Output
Domains / URLs are parsed as observables
## Actual Output
Import-report connector crashes, no observables are parsed unless the capital letters become lowercase or the offending domains are removed
## Additional information
I've attached 3 files:
- **AA21-200A_domains_failed.txt** : The original txt file, with domains including capital letters
- **AA21-200A_domains_success.txt** : The revised txt file, with no capital letters
- **errorlog.txt** : The error log, from one of the times when I tried to import a version of the original file (this was an iteration of troubleshooting, so the error log shows what happens when I input the txt file having removed the first two offending domains)
[AA21-200A_domains_success.txt](https://github.com/OpenCTI-Platform/connectors/files/7101092/AA21-200A_domains_success.txt)
[errorlog.txt](https://github.com/OpenCTI-Platform/connectors/files/7101093/errorlog.txt)
[AA21-200A_domains_failed.txt](https://github.com/OpenCTI-Platform/connectors/files/7101094/AA21-200A_domains_failed.txt)
| 2021-09-03T13:52:38 |
||
OpenCTI-Platform/connectors | 561 | OpenCTI-Platform__connectors-561 | [
"535"
]
| d9fab504e2330689344aed8fa6e28aea0f0a9228 | diff --git a/stream/elastic/elastic/__init__.py b/stream/elastic/elastic/__init__.py
--- a/stream/elastic/elastic/__init__.py
+++ b/stream/elastic/elastic/__init__.py
@@ -1,6 +1,6 @@
import os
-__version__ = "1.0.0"
+__version__ = "5.1.1"
LOGGER_NAME = "elastic"
RE_DATEMATH = (
r"\{(?P<modulo>.*now[^{]*)(?:\{(?P<format>[^|]*)(?:\|(?P<offset>[^}]+))?\})?\}"
diff --git a/stream/elastic/elastic/console.py b/stream/elastic/elastic/console.py
--- a/stream/elastic/elastic/console.py
+++ b/stream/elastic/elastic/console.py
@@ -26,7 +26,7 @@
import yaml
from docopt import docopt
-from . import LOGGER_NAME, __version__, __DATA_DIR__
+from . import __DATA_DIR__, LOGGER_NAME, __version__
from .conf import defaults
from .elastic import ElasticConnector
from .utils import add_branch, dict_merge, remove_nones, setup_logger
diff --git a/stream/elastic/elastic/sightings_manager.py b/stream/elastic/elastic/sightings_manager.py
--- a/stream/elastic/elastic/sightings_manager.py
+++ b/stream/elastic/elastic/sightings_manager.py
@@ -74,12 +74,12 @@ def __init__(
logger.info("Signals manager thread initialized")
def _get_elastic_entity(self) -> str:
- """Get or create a Elastic Threatintel Connector entity if not exists"""
+ """Get or create a Elastic Connector entity if not exists"""
if self.author_id is not None:
return self.author_id
_entity_name = self.config.get(
- "connector.entity_name", "Elastic ThreatIntel Connector"
+ "connector.entity_name", "Elastic Detection Cluster"
)
_entity_desc = self.config.get("connector.entity_description", "")
@@ -89,8 +89,7 @@ def _get_elastic_entity(self) -> str:
if not elastic_entity:
logger.info(f"Creating {_entity_name} STIX identity")
self.author_id = self.helper.api.identity.create(
- # NOTE: This should maybe be `system` See https://github.com/OpenCTI-Platform/opencti/issues/1322
- type="Organization",
+ type="System",
name=_entity_name,
description=_entity_desc,
)["id"]
@@ -117,7 +116,8 @@ def run(self) -> None:
# Parse the results
for hit in results["hits"]["hits"]:
- for indicator in hit["_source"]["threat"]["indicator"]:
+ # This depends on ECS mappings >= 1.11
+ for indicator in hit["_source"]["threat"]["enrichments"]:
# Get original threatintel document
try:
_doc = self.es_client.get(
@@ -142,11 +142,33 @@ def run(self) -> None:
"internal_id"
]
else:
- logger.warn(
- "Signal for threatintel document doesn't have opencti reference. Skipping"
+ logger.info(
+ "Signal for threatintel document doesn't have opencti reference. Searching for matched indicator"
)
- # XXX Optionally, could look up via OpenCTI API for an indicator that matches
- continue
+ # This probably isn't perfect, but should get us close-ish
+ _filters = [
+ {
+ "key": "pattern_type",
+ "operator": "match",
+ "values": ["STIX"],
+ },
+ {
+ "key": "pattern",
+ "operator": "match",
+ "values": [indicator["matched"]["atomic"]],
+ },
+ ]
+
+ _cti_indicator = self.helper.api.indicator.read(
+ filters=_filters
+ )
+ if _cti_indicator:
+ _opencti_id = _cti_indicator["id"]
+ else:
+ logger.warn(
+ f"Unable to find matching indicator in OpenCTI for: {indicator['matched']['atomic']}"
+ )
+ continue
_timestamp = hit["_source"]["signal"]["original_time"]
if _opencti_id not in ids_dict:
| diff --git a/stream/elastic/tests/test_elastic_threatintel.py b/stream/elastic/tests/test_elastic_threatintel.py
--- a/stream/elastic/tests/test_elastic_threatintel.py
+++ b/stream/elastic/tests/test_elastic_threatintel.py
@@ -1,5 +1,9 @@
+from importlib.metadata import version
+
from elastic import __version__
def test_version():
- assert __version__ == "0.4.0"
+ """Ensure Connector version matches pycti version. If this fails, check __version__ in __init__.py and pycti version in pyproject.toml"""
+ pycti_ver: str = version("pycti")
+ assert __version__ == pycti_ver
| [Elastic Security] Incorrect field reference for sighting
# Description
Using an indictor match rule in elastic, the ["threat"]["indicator"] object will never be in the alerts, the outputs are stored in ["threat"]["enrichments"]["indicator"] as an array of objects.
https://github.com/OpenCTI-Platform/connectors/blob/1771fd54dc53b2f54afeaf254f9a80694363320a/stream/elastic/elastic/sightings_manager.py#L120
# Enviroment
elastic - 1.0.0
pyopencti - 5.0.3
elasticsearch - 7.15.0
# Reproducible Steps
1. Produce an indictor match alert
2. Connector pulls alerts
3. fails to parse alert
| The effect of this bug is that the connector runs and the stream works fine, but the connector is unable to create sightings to push back to opencti as it throws a KeyError when trying to access the indicators to create the sightings.
@dcode Are you able to take a look to this one? | 2021-11-30T19:32:57 |
OpenCTI-Platform/connectors | 608 | OpenCTI-Platform__connectors-608 | [
"606"
]
| a024c7f9f17f4f0f99e76687431fb45001a5abb3 | diff --git a/external-import/riskiq/src/riskiq/article_importer.py b/external-import/riskiq/src/riskiq/article_importer.py
--- a/external-import/riskiq/src/riskiq/article_importer.py
+++ b/external-import/riskiq/src/riskiq/article_importer.py
@@ -222,8 +222,14 @@ def _process_indicator(self, indicator: Indicator) -> list[_Observable]:
def run(self, work_id: str, state: Mapping[str, Any]) -> Mapping[str, Any]:
"""Run the importation of the article."""
self.work_id = work_id
- published = parser.parse(self.article["publishedDate"])
created = parser.parse(self.article["createdDate"])
+ # RisIQ API does not always provide the `publishedDate`.
+ # If it does not exist, take the value of the `createdDate` instead.
+ published = (
+ parser.parse(self.article["publishedDate"])
+ if self.article["publishedDate"] is not None
+ else created
+ )
indicators = itertools.chain(
*[
| Riskiq Connector throwing errors
## Description
RiskIQ connector is not working as expected with the correct credentials defined.
## Environment
1. OS - Ubuntu
2. OpenCTI version: 5.1.3
## Riskiq Connector Logs:
INFO:root:Listing Threat-Actors with filters null.,
INFO:root:Connector registered with ID: c455a3a4-cc8f-4133-9f8d-4098fa984de8,
INFO:root:Starting ping alive thread,
INFO:riskiq.client:URL: https://api.riskiq.net/pt/v2,
INFO:root:Starting RiskIQ connector...,
INFO:root:Running RiskIQ connector...,
INFO:root:Connector interval sec: 60,
INFO:root:[RiskIQ] loaded state: {},
INFO:root:RiskIQ connector clean run,
INFO:root:Initiate work for c455a3a4-cc8f-4133-9f8d-4098fa984de8,
INFO:root:[RiskIQ] workid opencti-work--2c314a8c-484e-4a68-9b31-bb782b3b22ed initiated,
INFO:root:[RiskIQ] last run: None,
**ERROR:root:Parser must be a string or character stream, not NoneType **

++Config File++
connector-riskiq:
image: opencti/connector-riskiq:5.1.3
environment:
- OPENCTI_URL=http://opencti:8080
- OPENCTI_TOKEN=c9dc7053-6bdf-44ca-9dfd-c0e3ff249eb8
- CONNECTOR_ID=c455a3a4-cc8f-4133-9f8d-4098fa984de8
- CONNECTOR_TYPE=EXTERNAL_IMPORT
- CONNECTOR_NAME=RISKIQ
- CONNECTOR_SCOPE=riskiq
- CONNECTOR_CONFIDENCE_LEVEL=15 # From 0 (Unknown) to 100 (Fully trusted)
- CONNECTOR_LOG_LEVEL=info
- RISKIQ_BASE_URL=https://api.riskiq.net/pt/v2
- [email protected]
- RISKIQ_PASSWORD=xxxxxxx
- RISKIQ_INTERVAL_SEC=86400
restart: always
It was working before, after a reboot the riskiq connector started logging the above error as "ERROR:root:Parser must be a string or character stream, not NoneType".
Please help to fix the same.
Thanks
| @axelfahy : Any idea where that error could come from?
I can reproduce, it seems the API is not providing the `publishedDate` anymore. I'll fix it. | 2022-01-31T08:34:44 |
|
OpenCTI-Platform/connectors | 672 | OpenCTI-Platform__connectors-672 | [
"669"
]
| 1e14ba49f23fca3dfbd02438c67ffc4dffe5ce36 | diff --git a/internal-import-file/import-document/src/reportimporter/constants.py b/internal-import-file/import-document/src/reportimporter/constants.py
--- a/internal-import-file/import-document/src/reportimporter/constants.py
+++ b/internal-import-file/import-document/src/reportimporter/constants.py
@@ -2,6 +2,7 @@
MIME_TXT = "text/plain"
MIME_HTML = "text/html"
MIME_CSV = "text/csv"
+MIME_MD = "text/markdown"
RESULT_FORMAT_TYPE = "type"
RESULT_FORMAT_CATEGORY = "category"
diff --git a/internal-import-file/import-document/src/reportimporter/report_parser.py b/internal-import-file/import-document/src/reportimporter/report_parser.py
--- a/internal-import-file/import-document/src/reportimporter/report_parser.py
+++ b/internal-import-file/import-document/src/reportimporter/report_parser.py
@@ -19,6 +19,7 @@
MIME_TXT,
MIME_HTML,
MIME_CSV,
+ MIME_MD,
OBSERVABLE_DETECTION_CUSTOM_REGEX,
OBSERVABLE_DETECTION_LIBRARY,
)
@@ -51,6 +52,7 @@ def __init__(
MIME_TXT: self._parse_text,
MIME_HTML: self._parse_html,
MIME_CSV: self._parse_text,
+ MIME_MD: self._parse_text,
}
self.library_lookup = library_mapping()
| [Import Document] Connector does not process MD files
## Description
The Import Document connector currently supports plain/text media type, however files with the `.md` file extension are not recognized as a valid document.
## Environment
1. OS (where OpenCTI server runs): AWS ECS Fargate
2. OpenCTI version: 5.1.4
3. OpenCTI client: python
4. Other environment details:
## Reproducible Steps
Steps to create the smallest reproducible scenario:
1. Run the Import External Reference connector to get a .md file OR just upload a .md file to the platform
2. Try to run an enrichment on the .md file
## Expected Output
I would expect that the Import connector would or could import a file, regardless of the file name.
## Actual Output
There is no Output as the connector/platform doesn't recognize the .md file. Only work around is to download the file, rename to a .txt file extension, and upload to the platform.
## Screenshots (optional)
<img width="1483" alt="Screen Shot 2022-04-28 at 9 24 53 AM" src="https://user-images.githubusercontent.com/30411037/165775435-87f694cf-ada9-439f-9cf7-246228283d80.png">
<img width="753" alt="Screen Shot 2022-04-28 at 9 24 20 AM" src="https://user-images.githubusercontent.com/30411037/165775444-fa1ade88-51f8-45a1-9fd8-f1d14002d903.png">
| Hey @TechBurn0ut
Could you please run the connector in debug mode and post the logs? It is just a bit odd, since .md files are also of exiftype 'text/plain' and should be parsed like .txt files.
Regards
Hey @TechBurn0ut
I had a look at it again, it is not a connector issue, rather than something platform related, since the import connector button is grayed out and it is not the connector which doesn't allow the file to parse.
I'll move this to the platform issues, but I don't know why this issue arises. Normally files are allowed to be parsed if a connector registers the file's exif type. The exif type should be extension independent, but this is not the case in the screenshots you showed.
I'll need a further look at this...
EDIT: Maybe first try adding `text/markdown` to the defined scopes?
Regards
@nor3th Yeah I wasn’t sure if it was on the connector side or platform. Thanks for looking into it! | 2022-05-04T06:25:54 |
|
OpenCTI-Platform/connectors | 861 | OpenCTI-Platform__connectors-861 | [
"738"
]
| 5115488e280183c8fccbed39e1d96004f5444fa6 | diff --git a/internal-enrichment/intezer-sandbox/src/intezer_api.py b/internal-enrichment/intezer-sandbox/src/intezer_api.py
--- a/internal-enrichment/intezer-sandbox/src/intezer_api.py
+++ b/internal-enrichment/intezer-sandbox/src/intezer_api.py
@@ -36,8 +36,7 @@ def upload_file(self, file_name, file_contents):
file_obj = io.BytesIO(file_contents)
files = {"file": ("file_name", file_obj)}
response = self._session.post(f"{self.base_url}/analyze", files=files)
- assert response.status_code == 201
-
+ response.raise_for_status()
return response.json()["result_url"]
def get_analysis_report(self, result_url):
diff --git a/internal-export-file/export-report-pdf/src/export-report-pdf.py b/internal-export-file/export-report-pdf/src/export-report-pdf.py
--- a/internal-export-file/export-report-pdf/src/export-report-pdf.py
+++ b/internal-export-file/export-report-pdf/src/export-report-pdf.py
@@ -4,7 +4,6 @@
import os
import sys
import time
-
import cairosvg
import yaml
from jinja2 import Environment, FileSystemLoader
@@ -92,11 +91,9 @@ def _get_readable_date_time(self, str_date_time):
def _process_message(self, data):
file_name = data["file_name"]
- # TODO this can be implemented to filter every entity and observable
- # max_marking = data["max_marking"]
if "entity_type" not in data or "entity_id" not in data:
raise ValueError(
- 'This Connector currently only handles direct export (single entity and no list) of the following entity types: "Report" and "Intrusion-Set'
+ 'This Connector currently only handles direct export (single entity and no list) of the following entity types: "Report", "Intrusion-Set", and "Threat-Actor"'
)
entity_type = data["entity_type"]
entity_id = data["entity_id"]
@@ -105,9 +102,11 @@ def _process_message(self, data):
self._process_report(entity_id, file_name)
elif entity_type == "Intrusion-Set":
self._process_intrusion_set(entity_id, file_name)
+ elif entity_type == "Threat-Actor":
+ self._process_threat_actor(entity_id, file_name)
else:
raise ValueError(
- f'This Connector currently only handles the entity types: "Report" and "Intrusion-Set", not "{entity_type}".'
+ f'This connector currently only handles the entity types: "Report", "Intrusion-Set", "Threat-Actor", not "{entity_type}".'
)
return "Export done"
@@ -269,18 +268,18 @@ def _process_intrusion_set(self, entity_id, file_name):
targeted_countries = []
for relationship in context["entities"]["relationship"]:
if (
- relationship["relationship_type"] != "targets"
- and relationship["to"]["entity_type"] != "Country"
+ relationship["entity_type"] == "targets"
+ and relationship["relationship_type"] == "targets"
+ and relationship["to"]["entity_type"] == "Country"
):
- continue
-
- country_name = relationship["to"]["name"]
- country_code = self._get_country_code(country_name)
- if not country_code:
- self.helper.log_error(f"{country_name} is not a supported country")
- continue
+ country_code = relationship["to"]["name"].lower()
+ if not self._validate_country_code(country_code):
+ self.helper.log_warning(
+ f"{country_code} is not a supported country code, skipping..."
+ )
+ continue
- targeted_countries.append(country_code)
+ targeted_countries.append(country_code)
# Build targeted countries image
if targeted_countries:
@@ -310,6 +309,100 @@ def _process_intrusion_set(self, entity_id, file_name):
entity_id, file_name, pdf_contents, "application/pdf"
)
+ def _process_threat_actor(self, entity_id, file_name):
+ """
+ Process a Threat Actor entity and upload as pdf.
+ """
+
+ now_date = datetime.datetime.now().strftime("%b %d %Y")
+
+ # Store context for usage in html template
+ context = {
+ "entities": {},
+ "target_map_country": None,
+ "report_date": now_date,
+ "company_address_line_1": self.company_address_line_1,
+ "company_address_line_2": self.company_address_line_2,
+ "company_address_line_3": self.company_address_line_3,
+ "company_phone_number": self.company_phone_number,
+ "company_email": self.company_email,
+ "company_website": self.company_website,
+ }
+
+ # Get a bundle of all objects affiliated with the threat actor
+ bundle = self.helper.api.stix2.export_entity("Threat-Actor", entity_id, "full")
+
+ for bundle_obj in bundle["objects"]:
+ obj_id = bundle_obj["id"]
+ obj_entity_type = bundle_obj["type"]
+
+ reader_func = self._get_reader(obj_entity_type)
+ if reader_func is None:
+ self.helper.log_error(
+ f'Could not find a function to read entity with type "{obj_entity_type}"'
+ )
+ continue
+
+ time.sleep(0.3)
+ entity_dict = reader_func(id=obj_id)
+
+ # Key names cannot have - in them for jinja2 templating
+ obj_entity_type = obj_entity_type.replace("-", "_")
+ if obj_entity_type not in context["entities"]:
+ context["entities"][obj_entity_type] = []
+
+ context["entities"][obj_entity_type].append(entity_dict)
+
+ # Generate the svg img contents for the targets map
+ if "relationship" in context["entities"]:
+
+ # Create world map
+ world_map = World()
+ world_map.title = "Targeted Countries"
+ targeted_countries = []
+ for relationship in context["entities"]["relationship"]:
+ if (
+ relationship["entity_type"] == "targets"
+ and relationship["relationship_type"] == "targets"
+ and relationship["to"]["entity_type"] == "Country"
+ ):
+ country_code = relationship["to"]["name"].lower()
+ if not self._validate_country_code(country_code):
+ self.helper.log_warning(
+ f"{country_code} is not a supported country code, skipping..."
+ )
+ continue
+
+ targeted_countries.append(country_code)
+
+ # Build targeted countries image
+ if targeted_countries:
+ world_map.add("Targeted Countries", targeted_countries)
+ # Convert the svg to base64 png
+ svg_bytes = world_map.render()
+ png_bytes = io.BytesIO()
+ cairosvg.svg2png(bytestring=svg_bytes, write_to=png_bytes)
+ base64_png = base64.b64encode(png_bytes.getvalue()).decode()
+ context["target_map_country"] = f"data:image/png;base64, {base64_png}"
+
+ # Render html with input variables
+ env = Environment(
+ loader=FileSystemLoader(self.current_dir), finalize=self._finalize
+ )
+ template = env.get_template("resources/threat-actor.html")
+ html_string = template.render(context)
+
+ # Generate pdf from html string
+ pdf_contents = HTML(
+ string=html_string, base_url=f"{self.current_dir}/resources"
+ ).write_pdf()
+
+ # Upload the output pdf
+ self.helper.log_info(f"Uploading: {file_name}")
+ self.helper.api.stix_domain_object.push_entity_export(
+ entity_id, file_name, pdf_contents, "application/pdf"
+ )
+
def _set_colors(self):
for root, dirs, files in os.walk(self.current_dir):
for file_name in files:
@@ -325,10 +418,13 @@ def _set_colors(self):
with open(os.path.join(root, file_name), "w") as f:
f.write(new_css)
- def _get_country_code(self, country_name):
- for code, name in COUNTRIES.items():
- if country_name.lower() in name.lower():
- return code
+ def _validate_country_code(self, country_code):
+ """
+ Returns a boolean indicating whether or not the country code is valid.
+ """
+ if country_code in COUNTRIES:
+ return True
+ return False
def _finalize(self, data):
"""
| [Intezer Connector] Error in message processing
## Description
The bug is present when using the Intezer connector. There is an error raised - see log:
`Traceback (most recent call last):
File "/usr/local/lib/python3.10/site-packages/pycti/connector/opencti_connector_helper.py", line 178, in _data_handler
message = self.callback(json_data["event"])
File "/opt/opencti-connector-intezer-sandbox/intezer_sandbox.py", line 183, in _process_message
return self._process_observable(observable)
File "/opt/opencti-connector-intezer-sandbox/intezer_sandbox.py", line 160, in _process_observable
return self._process_file(observable)
File "/opt/opencti-connector-intezer-sandbox/intezer_sandbox.py", line 118, in _process_file
raise ValueError(f"No files found for {observable['observable_value']}")
ValueError: No files found for 475835b6703aade008c297f726c4cbe8fe29ac4d67bcf28d3761aeab59d3e929
INFO:root:Reporting work update_received opencti-work--5fb6c917-1b18-4870-9f9b-a8961f1661d2
INFO:root:Message (delivery_tag=43) processed, thread terminated
INFO:root:Reporting work update_received opencti-work--ec7a2988-8df2-4f3a-8d7c-1802b18fdf01
INFO:root:Reading StixCyberObservable {8d79573b-0720-40b8-b92b-89b58fb64a6f}.
INFO:root:Processing the observable d486d807f4e11918a935df4673c32731fb292a8fa77158741aee2a16fb5b298f
ERROR:root:Error in message processing, reporting error to API
Traceback (most recent call last):
File "/usr/local/lib/python3.10/site-packages/pycti/connector/opencti_connector_helper.py", line 178, in _data_handler
message = self.callback(json_data["event"])
File "/opt/opencti-connector-intezer-sandbox/intezer_sandbox.py", line 183, in _process_message
return self._process_observable(observable)
File "/opt/opencti-connector-intezer-sandbox/intezer_sandbox.py", line 160, in _process_observable
return self._process_file(observable)
File "/opt/opencti-connector-intezer-sandbox/intezer_sandbox.py", line 127, in _process_file
result_url = self.intezer_client.upload_file(
File "/opt/opencti-connector-intezer-sandbox/intezer_api.py", line 39, in upload_file
assert response.status_code == 201
AssertionError
INFO:root:Reporting work update_received opencti-work--ec7a2988-8df2-4f3a-8d7c-1802b18fdf01
INFO:root:Message (delivery_tag=44) processed, thread terminated
INFO:root:Reporting work update_received opencti-work--0acea19e-6b8b-4602-a713-92476294c4d5
INFO:root:Reading StixCyberObservable {0e37c49b-6ae5-49b8-b984-26284e308604}.
INFO:root:Processing the observable 2a42f058cb8189ad5133b20a42dc23de418e6107926243132264a8d44d3f32f2
ERROR:root:Error in message processing, reporting error to API
Traceback (most recent call last):
File "/usr/local/lib/python3.10/site-packages/pycti/connector/opencti_connector_helper.py", line 178, in _data_handler
message = self.callback(json_data["event"])
File "/opt/opencti-connector-intezer-sandbox/intezer_sandbox.py", line 183, in _process_message
return self._process_observable(observable)
File "/opt/opencti-connector-intezer-sandbox/intezer_sandbox.py", line 160, in _process_observable
return self._process_file(observable)
File "/opt/opencti-connector-intezer-sandbox/intezer_sandbox.py", line 118, in _process_file
raise ValueError(f"No files found for {observable['observable_value']}")
ValueError: No files found for 2a42f058cb8189ad5133b20a42dc23de418e6107926243132264a8d44d3f32f2
INFO:root:Reporting work update_received opencti-work--0acea19e-6b8b-4602-a713-92476294c4d5
INFO:root:Message (delivery_tag=45) processed, thread terminated
INFO:root:Reporting work update_received opencti-work--04f265d8-a9f0-4750-b2a7-319d0b97fea6
INFO:root:Reading StixCyberObservable {6e44f30d-dab5-41af-86cc-dc4cf45616b6}.
INFO:root:Processing the observable d1a998486349214703d5aa3c13fe200e1098e5d0c8cf73561275e8211026a15c
ERROR:root:Error in message processing, reporting error to API
Traceback (most recent call last):
File "/usr/local/lib/python3.10/site-packages/pycti/connector/opencti_connector_helper.py", line 178, in _data_handler
message = self.callback(json_data["event"])
File "/opt/opencti-connector-intezer-sandbox/intezer_sandbox.py", line 183, in _process_message
return self._process_observable(observable)
File "/opt/opencti-connector-intezer-sandbox/intezer_sandbox.py", line 160, in _process_observable
return self._process_file(observable)
File "/opt/opencti-connector-intezer-sandbox/intezer_sandbox.py", line 127, in _process_file
result_url = self.intezer_client.upload_file(
File "/opt/opencti-connector-intezer-sandbox/intezer_api.py", line 39, in upload_file
assert response.status_code == 201
AssertionError
INFO:root:Reporting work update_received opencti-work--04f265d8-a9f0-4750-b2a7-319d0b97fea6
INFO:root:Message (delivery_tag=46) processed, thread terminated
INFO:root:Reporting work update_received opencti-work--6dbfdccc-597a-45d8-827d-4e571ec1ac0b
INFO:root:Reading StixCyberObservable {668236c5-7957-485a-9b9a-24354812be89}.
INFO:root:Processing the observable 09681462d42abbc451fc6d3b27d68a67dec8f999a17da7cc422b5240a4ee487a
ERROR:root:Error in message processing, reporting error to API
Traceback (most recent call last):
File "/usr/local/lib/python3.10/site-packages/pycti/connector/opencti_connector_helper.py", line 178, in _data_handler
message = self.callback(json_data["event"])
File "/opt/opencti-connector-intezer-sandbox/intezer_sandbox.py", line 183, in _process_message
return self._process_observable(observable)
File "/opt/opencti-connector-intezer-sandbox/intezer_sandbox.py", line 160, in _process_observable
return self._process_file(observable)
File "/opt/opencti-connector-intezer-sandbox/intezer_sandbox.py", line 127, in _process_file
result_url = self.intezer_client.upload_file(
File "/opt/opencti-connector-intezer-sandbox/intezer_api.py", line 39, in upload_file
assert response.status_code == 201
AssertionError
INFO:root:Reporting work update_received opencti-work--6dbfdccc-597a-45d8-827d-4e571ec1ac0b
INFO:root:Message (delivery_tag=47) processed, thread terminated
INFO:root:Reporting work update_received opencti-work--229fa15e-909a-4b82-a38e-937ae9de5a73
INFO:root:Reading StixCyberObservable {49e5ef94-ae0b-49f9-bf64-03c184d2ee43}.
INFO:root:Processing the observable 8cb5d6867d8460fbba1b3cf83e5ab95d22b9302f399b5094d20cb66565c240dd
ERROR:root:Error in message processing, reporting error to API
Traceback (most recent call last):
File "/usr/local/lib/python3.10/site-packages/pycti/connector/opencti_connector_helper.py", line 178, in _data_handler
message = self.callback(json_data["event"])
File "/opt/opencti-connector-intezer-sandbox/intezer_sandbox.py", line 183, in _process_message
return self._process_observable(observable)
File "/opt/opencti-connector-intezer-sandbox/intezer_sandbox.py", line 160, in _process_observable
return self._process_file(observable)
File "/opt/opencti-connector-intezer-sandbox/intezer_sandbox.py", line 127, in _process_file
result_url = self.intezer_client.upload_file(
File "/opt/opencti-connector-intezer-sandbox/intezer_api.py", line 39, in upload_file
assert response.status_code == 201
AssertionError
INFO:root:Reporting work update_received opencti-work--229fa15e-909a-4b82-a38e-937ae9de5a73`
## Environment
1. Ubuntu 20.04
2. OpenCTI version: 5.3.7
## Reproducible Steps
Install openCTI
Add Intezer connectorr
## Expected Output
Data enrichment.
| @YungBinary Any idea about this one? Thanks a lot!
@SamuelHassine It looks like the assertion is failing and the response status code is not 201. This may have changed in the API. See https://github.com/OpenCTI-Platform/connectors/blob/14c9e0670c170dd1da912e11974b2401cd8db2b5/internal-enrichment/intezer-sandbox/src/intezer_api.py#L39
I'll play around with it when I get a chance to see what's going on.
@fugitive101 Do you have an API key setup? According to the documentation, 201 response is returned upon success (https://analyze.intezer.com/api-docs.html#/paths/analyze/post). You may be getting a 403 response which indicates you don't have authorization to call the API. | 2022-10-03T20:11:28 |
|
OpenCTI-Platform/connectors | 975 | OpenCTI-Platform__connectors-975 | [
"973"
]
| a7c0f815873edb73e3fb6f34086c4591395fa243 | diff --git a/external-import/vxvault/src/vxvault.py b/external-import/vxvault/src/vxvault.py
--- a/external-import/vxvault/src/vxvault.py
+++ b/external-import/vxvault/src/vxvault.py
@@ -1,4 +1,5 @@
import os
+import re
import ssl
import sys
import time
@@ -7,6 +8,7 @@
import certifi
import yaml
+
from pycti import OpenCTIConnectorHelper, get_config_variable
from stix2 import TLP_WHITE, URL, Bundle, ExternalReference
@@ -101,6 +103,13 @@ def run(self):
count += 1
if count <= 3:
continue
+ line=line.strip()
+ matchHtmlTag = re.search(r'^<\/?\w+>', line)
+ if matchHtmlTag:
+ continue
+ matchBlankLine = re.search(r'^\s*$', line)
+ if matchBlankLine:
+ continue
external_reference = ExternalReference(
source_name="VX Vault",
url="http://vxvault.net",
| [VXVault] Connector imports garbage data (HTML tags and blank events)
## Description
The VXVault connector is importing garbage data as indicators and observables, including events like `<pre>`, </pre>` and blank entities.
## Environment
1. OS (where OpenCTI server runs): Docker on Ubuntu 20
2. OpenCTI version: 5.5.2
3. OpenCTI client: connectors/python
## Expected Output
Connector should download the URLs from the VXVault threat feed here: http://vxvault.net/URL_List.php and import them into OpenCTI as Observables and Indicators.
## Actual Output
The connector does import the URLs, but it fails to parse the page correctly and imports some of the HTML tags as well by accident, leading to garbage data like Indicators with names and values as just `<pre>`
## Additional information
I discussed this and a couple of other related issues with the VXVault connector + data with Samuel Hassine in the slack channel: https://filigran-community.slack.com/archives/CHZC2D38C/p1673599524232109
There are three related issues - I will raise a GH issue for two of them and then submit a proposed PR to fix both:
1 - Connector imports garbage data (HTML tags)
2 - Connector leaves trailing white-space at the end of Indicator/Observable name and value (Raised as #974)
3 - VXVault entities do not show up in bulk search, which is caused by issue 2, as bulk-search only does an exact match currently and can't match on the trailing `\n` characters. The developers are aware of this, so I will not raise an issue for it.
| 2023-01-16T13:01:43 |
||
OpenCTI-Platform/connectors | 1,121 | OpenCTI-Platform__connectors-1121 | [
"1109"
]
| 0828d6e186ea3821855728af8ad7687c7342b371 | diff --git a/internal-enrichment/shodan-internetdb/src/shodan_internetdb/connector.py b/internal-enrichment/shodan-internetdb/src/shodan_internetdb/connector.py
--- a/internal-enrichment/shodan-internetdb/src/shodan_internetdb/connector.py
+++ b/internal-enrichment/shodan-internetdb/src/shodan_internetdb/connector.py
@@ -100,7 +100,7 @@ def _process_message(self, data: Dict[str, Any]) -> str:
return "Skipping observable (TLP)"
# Process the observable value
- value = observable["value"]
+ value = observable["observable_value"]
if not validators.ipv4(value):
log.error("Observable value is not an IPv4 address")
return "Skipping observable (ipv4 validation)"
@@ -140,7 +140,7 @@ def format_list(alist: List[Union[str, int]]) -> str:
"""Format a list of primitives into a Markdown list"""
return "".join(f"\n- {name}" for name in alist) or "n/a"
- value = observable["value"]
+ value = observable["observable_value"]
abstract = f"Shodan InternetDB enrichment of {value}"
content = f"""```
Shodan InternetDB:
| Error KeyError: 'value' in Shodan-InternetDB connector
## Description
We get the following error in Shodan-InternetDB connector for every IP we try to process:
INFO:root:Reading StixCyberObservable {f14b0557-269b-478c-822d-dd206ce88060}.
ERROR:root:Error in message processing, reporting error to API
Traceback (most recent call last):
File "/usr/local/lib/python3.10/dist-packages/pycti/connector/opencti_connector_helper.py", line 181, in _data_handler
message = self.callback(json_data["event"])
File "/opt/opencti/connectors/internal-enrichment/shodan-internetdb/src/shodan_internetdb/connector.py", line 103, in _process_message
value = observable["value"]
KeyError: 'value'
INFO:root:Reporting work update_received work_6cbd1a73-9cfb-4825-9554-929cc42df702_2023-04-21T11:35:40.994Z
INFO:root:Message (delivery_tag=1) processed, thread terminated
## Environment
1. OS (where OpenCTI server runs): Ubuntu 22
2. OpenCTI version: 5.7.2
3. OpenCTI client: python
| 2023-05-02T17:07:10 |
||
OpenCTI-Platform/connectors | 1,415 | OpenCTI-Platform__connectors-1415 | [
"842"
]
| 2a5c0891e695aa5b5b4a08204918fe8d1d883be8 | diff --git a/external-import/restore-files/src/restore-files.py b/external-import/restore-files/src/restore-files.py
--- a/external-import/restore-files/src/restore-files.py
+++ b/external-import/restore-files/src/restore-files.py
@@ -77,8 +77,9 @@ def resolve_missing(self, dir_date, element_ids, data, acc=[]):
not_in = next((x for x in acc if x["id"] == ref), None)
if not_in is None:
missing_element = self.find_element(dir_date, ref)
- acc.insert(0, missing_element)
- self.resolve_missing(dir_date, element_ids, missing_element, acc)
+ if missing_element is not None:
+ acc.insert(0, missing_element)
+ self.resolve_missing(dir_date, element_ids, missing_element, acc)
def restore_files(self):
stix2_splitter = OpenCTIStix2Splitter()
| restore-files.py crashes when missing find_element returns None
## Description
When using restore-files to incrementally update a second instance of OpenCTI the process crashes whenever a referenced element is not in the data being restored (normally because it's already in the system). The return from find_element in the resolve_missing function (line 79 currently) is not checked for "None" (as is done in the restore_files function at line 121).
## Environment
1. OS (where OpenCTI server runs): Ubuntu 20.4
2. OpenCTI version: 5.3.11
3. OpenCTI client: python
4. Other environment details:
## Reproducible Steps
Steps to create the smallest reproducible scenario:
1. Run backup-files on system 1
2. copy output to system 2
3. Run restore-files on system 2
## Expected Output
Ingest of all elements.
## Actual Output
INFO:root:Restore run directory @ 20220314T200100Z
Traceback (most recent call last):
File "/opt/opencti-highside-sync/connectors-master/external-import/restore-files/src/restore-files.py", line 188, in <module>
RestoreFilesInstance.start()
File "/opt/opencti-highside-sync/connectors-master/external-import/restore-files/src/restore-files.py", line 181, in start
self.restore_files()
File "/opt/opencti-highside-sync/connectors-master/external-import/restore-files/src/restore-files.py", line 133, in restore_files
self.resolve_missing(dir_date, ids, missing_element, acc)
File "/opt/opencti-highside-sync/connectors-master/external-import/restore-files/src/restore-files.py", line 87, in resolve_missing
self.resolve_missing(dir_date, element_ids, missing_element, acc)
File "/opt/opencti-highside-sync/connectors-master/external-import/restore-files/src/restore-files.py", line 80, in resolve_missing
refs = ref_extractors([data])
File "/opt/opencti-highside-sync/connectors-master/external-import/restore-files/src/restore-files.py", line 17, in ref_extractors
for key in data.keys():
AttributeError: 'NoneType' object has no attribute 'keys'
Killed
| Backup restore is not designed to do incremental synchronization.
To do that you can use the builtin synchronizer.
Ok, now I'm using restore-files.py for just restoring a full backup. And I got this same error again. Note: it was after a restart of restore-files, but all of the input data was in place. It just needs: "if missing_element is not None:" after line 79 in resolve_missing (just like in restore_files).
Any chance to send me your backup directory to reproduce locally?
(We can of course sign an NDA or anything required) | 2023-09-19T15:41:31 |
|
OpenCTI-Platform/connectors | 2,071 | OpenCTI-Platform__connectors-2071 | [
"1834"
]
| bd6f2c36139226fb8568c08353c94008b9437175 | diff --git a/external-import/eset/src/eset.py b/external-import/eset/src/eset.py
--- a/external-import/eset/src/eset.py
+++ b/external-import/eset/src/eset.py
@@ -11,7 +11,13 @@
import stix2
import yaml
from dateutil.parser import parse
-from pycti import OpenCTIConnectorHelper, Report, get_config_variable
+from pycti import (
+ Indicator,
+ Malware,
+ OpenCTIConnectorHelper,
+ Report,
+ get_config_variable,
+)
TMP_DIR = "TMP"
@@ -195,12 +201,55 @@ def _import_collection(self, collection, work_id, start_epoch):
continue
parsed_content = json.loads(item.content)
objects = []
+ id_remaps = {}
+ removed_ids = set()
for object in parsed_content["objects"]:
if "confidence" in object_types_with_confidence:
if "confidence" not in object:
object["confidence"] = int(
self.helper.connect_confidence_level
)
+ # Don't consume identity entities w/ "customer" as the name.
+ # ESET uses this to indicate country targeting, and consuming
+ # these causes problems due to dedupe.
+ # TODO: Convert these & relevant relationship refs to country
+ # locations.
+ if (
+ object["type"] == "identity"
+ and "name" in object
+ and object["name"] == "customer"
+ ) or object["type"] == "observed-data":
+ removed_ids.add(object["id"])
+ continue
+
+ # Malware STIX IDs need to be manually recomputed so they're
+ # deterministic by malware name
+ if object["type"] == "malware" and "name" in object:
+ new_id = Malware.generate_id(object["name"])
+ if object["id"] in id_remaps:
+ new_id = id_remaps[object["id"]]
+ else:
+ id_remaps[object["id"]] = new_id
+ object["id"] = new_id
+
+ # If we remapped a STIX id earlier to a pycti one, we need to
+ # reflect that properly in any relevant relationship too
+ if object["type"] == "relationship":
+ if "source_ref" in object:
+ if object["source_ref"] in removed_ids:
+ continue # skip relationship if either ref is in removed_ids
+ if object["source_ref"] in id_remaps:
+ object["source_ref"] = id_remaps[
+ object["source_ref"]
+ ]
+ if "target_ref" in object:
+ if object["target_ref"] in removed_ids:
+ continue # skip relationship if either ref is in removed_ids
+ if object["target_ref"] in id_remaps:
+ object["target_ref"] = id_remaps[
+ object["target_ref"]
+ ]
+
if object["type"] == "indicator":
object["name"] = object["pattern"]
object["pattern_type"] = "stix"
@@ -209,6 +258,12 @@ def _import_collection(self, collection, work_id, start_epoch):
.replace("SHA1", "'SHA-1'")
.replace("SHA256", "'SHA-256'")
)
+ new_id = Indicator.generate_id(object["pattern"])
+ if object["id"] in id_remaps:
+ new_id = id_remaps[object["id"]]
+ else:
+ id_remaps[object["id"]] = new_id
+ object["id"] = new_id
if self.eset_create_observables:
object["x_opencti_create_observables"] = (
self.eset_create_observables
| ESET connector causing runaway Redis memory consumption despite REDIS__TRIMMING=1000000
## Description
When enabling the `external-import/eset` connector with defaults (from `external-import/eset/docker-compose.yml`), it causes redis to rapidly run away with consuming all memory. I have `REDIS__TRIMMING=1000000` set in my `docker-compose.yml` and it doesn't seem to make a difference for this particular connector, but seems to be working for everything else.
The `connector-eset` section of my `docker-compose.yml` is lifted almost verbatim from the example provided in the connector's directory:
```yaml
connector-eset:
image: opencti/connector-eset:5.12.32
environment:
- OPENCTI_URL=http://opencti-url
- OPENCTI_TOKEN=${OPENCTI_ADMIN_TOKEN}
- CONNECTOR_ID=${ESET_CONNECTOR_ID}
- "CONNECTOR_NAME=ESET Cyber Threat Intelligence"
- CONNECTOR_SCOPE=eset
- CONNECTOR_CONFIDENCE_LEVEL=30 # From 0 (Unknown) to 100 (Fully trusted)
- CONNECTOR_LOG_LEVEL=error
- ESET_API_URL=eti.eset.com
- ESET_USERNAME=${ESET_CONNECTOR_USER}
- ESET_PASSWORD=${ESET_CONNECTOR_PASSWORD}
- ESET_COLLECTIONS=ei.misp,ei.cc,ei.urls
- ESET_IMPORT_APT_REPORTS=true
- ESET_IMPORT_START_DATE=2022-04-01
- ESET_CREATE_OBSERVABLES=true
- ESET_INTERVAL=60 # Required, in minutes
restart: always
```
## Environment
1. OS (where OpenCTI server runs): Amazon Linux 2023
2. OpenCTI version: 5.12.32
3. OpenCTI client: connector
4. Other environment details: Using Docker CE and `docker-compose`
## Reproducible Steps
Steps to create the smallest reproducible scenario:
1. Add `connector-eset` in my `docker-compose.yml`
2. Update `.env` with proper credentials for access
3. `docker-compose up -d`
4. Wait for awhile and eventually redis grows to consume all RAM (in my case, it got to around 12GB in usage)
## Expected Output
Redis shouldn't consume all memory and `REDIS__TRIMMING=....` should be able to keep it within a reasonably predictable ceiling. In this particular case, `redis` resident memory size seems to stay under 2GB when trimming is set to `1000000`.
## Actual Output
`redis` memory consumption grows without restraint until the system runs out of memory and the OOM reaper has to kill something.
## Additional information
Here is a `docker-compose.yml` that seems to be working well for me with `REDIS__TRIMMING=2000000`: https://github.com/ckane/opencti-docker/blob/tf-main/docker-compose.yml
In the deployment I am trying to use it in, I reduced this to `1000000` to see if it would fix the problem, but it doesn't seem to have any impact at all.
In this case, `redis` memory consumption stays under control, but if I add `connector-eset` to it, then when the `eset` connector starts ingesting intel from their feed, `redis` consumption will grow rapidly until it exhausts all RAM in the system.
| @Megafredo & @helene-nguyen could you maybe have a look at this?
Hi @ckane, can you give me more details when using this connector, error logs or simply if you have works in progress or completed in your queues?
Have you tested in the config to change the import start date? example import_start_date: '2024-01-01'?
Thanks, when it occurs there doesn't seem to be any errors registering in the platform - I just see the ESET connector working normally, and the redis usage keeps climbing to consume all available RAM, which is a behavior I don't encounter from use of any of the other connectors, with the trimming config set.
I haven't tested recently since 6.0.0 was released...I'll update our dev to 6.0.3 and re-enable the eset connector and see if any recent changes cause it to behave differently, or if I can get more data points for you.
I will also try setting a more recent cut-off date to see how that changes things, but that solution isn't ideal: I don't need to do that for any other connectors, and I would like to be able to populate our database with more historical data from the vendor.
So from what you have observed, it may not be an error but maybe we can get more information in "debug" mode on what is happening with the connector, can you change the configuration and set this for this variable and can you provide me with the logs ? :
CONNECTOR_LOG_LEVEL=debug
So, I am able to reproduce the issue on **6.0.5** and was able to catch the system in the middle of the run-away memory usage. It looks like the ESET connector has finished collecting a large number of bundles from upstream, as its logging is now reporting the `Iterating with collection=...`/`Poll_Request`/`Poll_Response` to the logs. The bundles are all being processed by the workers, and it seems like while being processed by the workers the memory consumption of `redis-server` is increasing at a rate of about 100MB every 5 minutes or so, and it appears that the workers are doing all the work at this point.
In the worker logs I am seeing the following error happen a lot, but I don't know if it is related to the root cause or coincidental:
```
Traceback (most recent call last):
File "/opt/opencti-worker/worker.py", line 268, in data_handler
self.api.stix2.import_bundle_from_json(
File "/usr/local/lib/python3.12/site-packages/pycti/utils/opencti_stix2.py", line 215, in import_bundle_from_json
return self.import_bundle(
^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/pycti/utils/opencti_stix2.py", line 2357, in import_bundle
self.import_relationship(item, update, types)
File "/usr/local/lib/python3.12/site-packages/pycti/utils/opencti_stix2.py", line 1223, in import_relationship
stix_relation_result = self.opencti.stix_core_relationship.import_from_stix2(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/pycti/entities/opencti_stix_core_relationship.py", line 1132, in import_from_stix2
return self.create(
^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/pycti/entities/opencti_stix_core_relationship.py", line 611, in create
result = self.opencti.query(
^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/pycti/api/opencti_api_client.py", line 351, in query
raise ValueError(
ValueError: {'name': 'MISSING_REFERENCE_ERROR', 'message': 'Element(s) not found'}
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/opt/opencti-worker/worker.py", line 268, in data_handler
self.api.stix2.import_bundle_from_json(
File "/usr/local/lib/python3.12/site-packages/pycti/utils/opencti_stix2.py", line 215, in import_bundle_from_json
return self.import_bundle(
^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/pycti/utils/opencti_stix2.py", line 2357, in import_bundle
self.import_relationship(item, update, types)
File "/usr/local/lib/python3.12/site-packages/pycti/utils/opencti_stix2.py", line 1223, in import_relationship
stix_relation_result = self.opencti.stix_core_relationship.import_from_stix2(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/pycti/entities/opencti_stix_core_relationship.py", line 1132, in import_from_stix2
return self.create(
^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/pycti/entities/opencti_stix_core_relationship.py", line 611, in create
result = self.opencti.query(
^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/pycti/api/opencti_api_client.py", line 351, in query
raise ValueError(
ValueError: {'name': 'MISSING_REFERENCE_ERROR', 'message': 'Element(s) not found'}
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/opt/opencti-worker/worker.py", line 268, in data_handler
self.api.stix2.import_bundle_from_json(
File "/usr/local/lib/python3.12/site-packages/pycti/utils/opencti_stix2.py", line 215, in import_bundle_from_json
return self.import_bundle(
^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/pycti/utils/opencti_stix2.py", line 2357, in import_bundle
self.import_relationship(item, update, types)
File "/usr/local/lib/python3.12/site-packages/pycti/utils/opencti_stix2.py", line 1223, in import_relationship
stix_relation_result = self.opencti.stix_core_relationship.import_from_stix2(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/pycti/entities/opencti_stix_core_relationship.py", line 1132, in import_from_stix2
return self.create(
^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/pycti/entities/opencti_stix_core_relationship.py", line 611, in create
result = self.opencti.query(
^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/pycti/api/opencti_api_client.py", line 351, in query
raise ValueError(
ValueError: {'name': 'MISSING_REFERENCE_ERROR', 'message': 'Element(s) not found'}
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/opt/opencti-worker/worker.py", line 268, in data_handler
self.api.stix2.import_bundle_from_json(
File "/usr/local/lib/python3.12/site-packages/pycti/utils/opencti_stix2.py", line 215, in import_bundle_from_json
return self.import_bundle(
^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/pycti/utils/opencti_stix2.py", line 2357, in import_bundle
self.import_relationship(item, update, types)
File "/usr/local/lib/python3.12/site-packages/pycti/utils/opencti_stix2.py", line 1223, in import_relationship
stix_relation_result = self.opencti.stix_core_relationship.import_from_stix2(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/pycti/entities/opencti_stix_core_relationship.py", line 1132, in import_from_stix2
return self.create(
^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/pycti/entities/opencti_stix_core_relationship.py", line 611, in create
result = self.opencti.query(
^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/site-packages/pycti/api/opencti_api_client.py", line 351, in query
raise ValueError(
ValueError: {'name': 'MISSING_REFERENCE_ERROR', 'message': 'Element(s) not found'}
```
these seem to occur after the worker says it is forging a new `stix_core_relationship` - at least in this section, it is trying to create new `related-to` between an **Identity** and **Indicator**
I was also able to verify that the memory consumption in redis continues to increase even after I have stopped the `connector-eset` container. Clearing the works using the UI doesn't seem to change anything and the connector still says it is active with 330k+ bundles pending.
After I've waited for the connector to turn "red" after I stopped it, I was able to click the "clear connector" button, which did halt the growth in memory consumption (thus confirming my suspicion about the culprit), but clicking that button to clear the connector doesn't appear to clear out whatever has accumulated in redis.
I also see the `Message reprocess` message in the logs too, ahead of the aforementioned error, suggesting this block of code around line `355` in `worker.py` from the worker code is being hit a lot:
```python
elif (
"MISSING_REFERENCE_ERROR" in error_msg
and self.processing_count < PROCESSING_COUNT
):
bundles_missing_reference_error_counter.add(1)
# In case of missing reference, wait & retry
sleep_jitter = round(random.uniform(1, 3), 2)
time.sleep(sleep_jitter)
self.worker_logger.info(
"Message reprocess",
{"tag": delivery_tag, "count": self.processing_count},
)
self.data_handler(connection, channel, delivery_tag, data)
elif "MISSING_REFERENCE_ERROR" in error_msg:
```
I did save the logs, so I should be able to do some text parsing to determine how many retries are being attempted on each entity pair in the relationship, and how long these missing references are outstanding for.
Curious if these exceptions occurring may be causing OpenCTI to skip the trimming step on the redis database or something like that
Also came across the following error showing up in the `connector-eset` logs:
```
raceback (most recent call last):
File "/opt/opencti-connector-eset/eset.py", line 221, in _import_collection
self.helper.send_stix2_bundle(
File "/usr/local/lib/python3.11/site-packages/pycti/connector/opencti_connector_helper.py", line 1140, in send_stix2_bundle
bundles = stix2_splitter.split_bundle(bundle, True, event_version)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/pycti/utils/opencti_stix2_splitter.py", line 90, in split_bundle
self.enlist_element(item["id"], raw_data)
File "/usr/local/lib/python3.11/site-packages/pycti/utils/opencti_stix2_splitter.py", line 40, in enlist_element
nb_deps += self.enlist_element(element_ref, raw_data)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/pycti/utils/opencti_stix2_splitter.py", line 54, in enlist_element
nb_deps += self.enlist_element(value, raw_data)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/pycti/utils/opencti_stix2_splitter.py", line 40, in enlist_element
nb_deps += self.enlist_element(element_ref, raw_data)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/pycti/utils/opencti_stix2_splitter.py", line 54, in enlist_element
nb_deps += self.enlist_element(value, raw_data)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
```
..... the errors at line 40 & 54 repeat a whole lot .....
```
File "/usr/local/lib/python3.11/site-packages/pycti/utils/opencti_stix2_splitter.py", line 54, in enlist_element
nb_deps += self.enlist_element(value, raw_data)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/pycti/utils/opencti_stix2_splitter.py", line 40, in enlist_element
nb_deps += self.enlist_element(element_ref, raw_data)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/pycti/utils/opencti_stix2_splitter.py", line 43, in enlist_element
elif key.endswith("_ref") and self.is_ref_key_supported(key):
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.11/site-packages/pycti/utils/opencti_stix2_splitter.py", line 21, in is_ref_key_supported
if pattern.match(key):
^^^^^^^^^^^^^^^^^^
RecursionError: maximum recursion depth exceeded while calling a Python object
```
It looks like this happens exactly once. Otherwise, there are only 4 more errors in my connector's log, and all of them have to do with connectivity issues (likely just temporary network or service interruption).
@Megafredo I am now running into the redis memory consumption behavior on another instance using entirely OSINT connectors, where I am able to collect the data more easily to help determine root causes, etc...
Memory usage for `stream.opencti` seems like it stays around 5-6GB:
```
redis-cli memory usage stream.opencti
(integer) 5319923328
```
And, it does look like trimming is working correctly on it (keeping it at `2000000` entries)
```
Sampled 464565 keys in the keyspace!
Total key length in bytes is 29935559 (avg len 64.44)Biggest hash found '"work_Hatching_Triage_Sandbox_Auto_2024-02-15T05:56:56.212Z"' has 3 fieldsBiggest string found '"sess:XP5B5ZvQhttlL7ox8X2OD52Gwxa6If5e"' has 33259 bytesBiggest stream found '"stream.opencti"' has 2000000 entriesBiggest zset found '"platform_sessions"' has 343 members
```
Dumping all keys says that there are `464567` keys in my redis instance:
```
redis-cli keys \* | wc -l
464567
```
I am currently iterating through them 1 by 1 to get each individual size, and I'll try to get a summary of this data over to you later
So, I did some experiments where I used the `MEMORY USAGE <key>` on each of the keys in my redis instance to produce a table such as the following, with the size (in bytes) followed by the key name (we will call this table `redis_keys.txt`):
```
...
216 work_Hatching_Triage_Sandbox_Auto_2024-02-15T02:40:02.830Z
216 work_Hatching_Triage_Sandbox_Auto_2024-02-15T02:26:07.294Z
232 work_843bded1-b064-4269-99fb-b48b8e61c4bf_2024-02-17T12:53:21.313Z
232 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-28T07:35:53.427Z
232 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-03-05T01:03:52.765Z
232 work_b0d88b1a-9b5e-4400-83a0-239cc2cc6dbd_2024-02-28T01:32:43.860Z
232 work_b0d88b1a-9b5e-4400-83a0-239cc2cc6dbd_2024-02-24T21:21:33.871Z
232 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-15T03:10:28.923Z
232 work_b0d88b1a-9b5e-4400-83a0-239cc2cc6dbd_2024-02-17T21:43:33.292Z
232 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-21T23:10:41.025Z
...
```
This yielded the following when I pipe it to `sort -n` (showing just the tail of it here):
```
24664 sess:wxhlVhWmR3gsoXhriLsAuUjRvdcOaIyS
24664 sess:xCvrBGj76182cBrpwrVMB21g2SO9wxe8
24664 sess:xkZdJzPOWeQUp21V67Fy2ccfxLknJc9w
24664 sess:xqcan--juh6j5vZ1WzL_fvt1J2triAma
24664 sess:xtBqtgMJU44mriU8ggAIskgeDwCmOmt5
24664 sess:yDKxZVJ_je4hrNRRhZR0Km_qumGhg4Ws
24664 sess:yGSjcIZe6QMVbMz9nqEUMJ4g0HU9Ej--
24664 sess:yO-1xBSZaW7eCOeCoDjgzkOZ_5XoTJX4
24664 sess:yVqd7YeS_GrolN3juJRNhRkMR1w7eNoD
24664 sess:yZij54dVUrCBRWdCIjUbA9ZAI9KY18MJ
24664 sess:yb4uQtSvYApZ4du5cWZbx_ko8Wm_ywG_
24664 sess:yy01MNbLh1hmbkGQTAKo8i9DNH7GuKhN
24664 sess:z2Jh1iJ4sxoKzj8yCWaPekJFfe_vTtIG
24664 sess:zEy_vH3q706GC3sMSxNyfYiYejeoyRov
24664 sess:zHB2yYgk-L6G_60QtLBEDDF1n8zQiUvh
24664 sess:zkcIOp_J_N6yl0C5sxyq7IkkVGwPYpAX
41048 sess:XP5B5ZvQhttlL7ox8X2OD52Gwxa6If5e
44417 platform_sessions
20222660 stream.activity
5747354268 stream.opencti
```
In the above you can see that there are a bunch of sessions of ~24KB in size, but the biggest individual consumers are `stream.activity` at ~20MB of usage, and `stream.opencti` at ~5.7GB of usage.
However, if I do a `MEMORY STATS` in `redis-cli`, it gives the following usage report:
```
...
25) "keys.count"
26) (integer) 464903
27) "keys.bytes-per-key"
28) (integer) 29048
29) "dataset.bytes"
30) (integer) 13481932644
...
```
The above indicates that 464903 keys are consuming ~13.5GB of memory.
Curious, I dumped the `redis_keys.txt` table through `wc -l` to get the count of keys I had generated earlier (note the slight discrepancy is largely due to some time passing between running commands):
```
wc -l < redis_keys.txt
464589
```
Also wanting to measure the sum of data in each of the keys, I did `cat output.txt | cut -d' ' -f 1 | awk '{s+=$1} END {printf "%.0f\n", s }'`:
```
5882285305
```
Which indicates that the total data being contained within the keys is roughly 5.9GB. I definitely anticipate there would be some amount of per-key overhead, but this would suggest like a ~16KB average per-key overhead, to me.
To get the summary counts of all of the keys in each of the `work*` keys (disregarding the timestamps and counting them), I run `cut -d' ' -f 2 redis_keys.txt | grep work | sed 's/_[^_]*$//' | sort -n | uniq -c | sort -n`, which produces the following:
```
1 work:027aa3b2-7329-45bc-b61d-c2fd7040a805
1 work:25fedf57-2a77-4e14-b9de-bc3775e4ac7c
1 work:33002c41-4b4b-4642-b8f7-2006f2ac2979
1 work:37a2a506-17ca-47dc-96f0-33764f4754db
1 work:3e1112af-06ec-4d9d-87c3-8e5664df55b8
1 work:4cff7afc-90ba-420f-b8ee-8c4baffeae7e
1 work:6133a1fd-bd5c-4726-85bb-b17e7007d093
1 work:6feff0e9-86de-45cc-a0a3-082c3ef23cc1
1 work:72327164-0b35-482b-b5d6-a5a3f76b845f
1 work:746a3cfd-e891-4fe6-9b6f-6d4a94c3620f
1 work:843bded1-b064-4269-99fb-b48b8e61c4bf
1 work:8623972e-459d-47e3-84c7-ef269ed89d75
1 work:883fbe6c-4040-48c0-bc3c-398092dbf6b5
1 work:8ada702d-a621-4da4-905a-2f5f7f62f907
1 work:Hatching
1 work:acef2b25-306a-4bc5-b79d-a1e845e47b95
1 work:b0d88b1a-9b5e-4400-83a0-239cc2cc6dbd
1 work:cfcec2c7-7ea6-427c-b4a3-281683e9fb10
1 work:d246bd1e-8d1b-4739-9187-8e05fa36e79c
1 work:ed49e47d-a06a-4d4d-aa94-06dcf584f071
1 work:f7052268-95f0-49f2-9e70-42c8a87f2fd2
1 work:fc0eb101-1eef-4348-8953-a6bcda869c95
1 work:fe54a9c7-749e-499f-9298-3f977a7d3327
1 work_37a2a506-17ca-47dc-96f0-33764f4754db
1 work_6feff0e9-86de-45cc-a0a3-082c3ef23cc1
1 work_d246bd1e-8d1b-4739-9187-8e05fa36e79c
1 work_ed49e47d-a06a-4d4d-aa94-06dcf584f071
2 work_027aa3b2-7329-45bc-b61d-c2fd7040a805
3 work_6133a1fd-bd5c-4726-85bb-b17e7007d093
3 work_8623972e-459d-47e3-84c7-ef269ed89d75
4 work_4cff7afc-90ba-420f-b8ee-8c4baffeae7e
7 work_cfcec2c7-7ea6-427c-b4a3-281683e9fb10
8 work_883fbe6c-4040-48c0-bc3c-398092dbf6b5
10 work_72327164-0b35-482b-b5d6-a5a3f76b845f
58 work_fc0eb101-1eef-4348-8953-a6bcda869c95
807 work_acef2b25-306a-4bc5-b79d-a1e845e47b95
3059 work_f7052268-95f0-49f2-9e70-42c8a87f2fd2
4053 work_843bded1-b064-4269-99fb-b48b8e61c4bf
18500 work_25fedf57-2a77-4e14-b9de-bc3775e4ac7c
89189 work_Hatching_Triage_Sandbox_Auto
90471 work_b0d88b1a-9b5e-4400-83a0-239cc2cc6dbd
257942 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f
```
The `257942 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f` represents the "Google DNS" connector, which I have auto-enriching in this instance, but looking at the "Connectors" view it shows a `0` for the "MESSAGES" column of that particular connector. This instance did just recent pull in a whole bunch of `misp-feed` data from DIGITALSIDE.IT.
In the other instance that's consuming from ESET, I do not have any of these auto-enrichments turned on.
I decided to narrow-in to the work listed above with the `257942` keys, and do a summary count table that includes the date from the timestamp, but not the time:
```
cat output.txt | grep work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f | cut -d' ' -f 2 | sort | cut -dT -f 1 | uniq -c | sort -n
...
130 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2023-11-02
133 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2023-12-11
136 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2023-09-28
139 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-01-18
148 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-01-27
154 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2023-11-21
160 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2023-05-11
161 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2023-05-08
162 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2023-11-10
166 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-01-17
167 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-01-31
168 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2023-12-12
170 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-10
176 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2023-11-07
180 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-01-26
186 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-01-29
187 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2023-10-26
189 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2023-09-11
189 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-01-21
205 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-01-16
207 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-03-04
226 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-09
228 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2023-11-23
235 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2023-12-08
239 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-03-03
251 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2023-05-09
265 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2023-12-21
272 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2023-05-10
300 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2023-12-20
304 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2023-11-16
341 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-01
381 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-07
389 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2023-12-01
392 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-03
415 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2023-12-16
430 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-01-22
460 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-05
502 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-13
537 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-03-06
545 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2023-07-25
573 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2023-05-07
585 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-01-25
630 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-06
684 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2023-12-05
703 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-08
731 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2023-07-26
732 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-03-07
791 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-01-23
880 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-03-05
948 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-03-01
1219 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-04
1437 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-03-02
1538 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-03-08
1587 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-01-30
1608 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2023-05-06
2017 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-14
2489 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-26
3334 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-02
3719 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2023-11-12
4334 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-01-19
4997 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-20
5108 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-23
5112 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-22
6251 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-21
6428 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-25
6572 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2023-11-11
8399 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-29
10062 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-27
12296 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-16
15521 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-19
16708 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-24
22944 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-15
25492 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-17
33717 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-18
34154 work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2024-02-28
```
Many of these are fairly recent, but there also appear to be a considerable number that go back many months, with the earliest example I have in my system being `work_746a3cfd-e891-4fe6-9b6f-6d4a94c3620f_2023-05-06`. I'm wondering if certain failure states are maybe leaving these keys abandoned in `redis` never to get cleaned up.
Since this is merely a testing instance, I'm going to snapshot and try clearing out some older ones, and see if that changes the redis memory utilization.
@Megafredo Have you enough information to troubleshoot? You may reach out to platform team for some help regarding redis?
First of all, I wanted to thank you @ckane for your research! Since the connector is in the support: partners category, I don't really have all the necessary access to reproduce it on my end, so any feedback is welcome!
Yes, one of the best methods for a "clean" deletion of the connector is to stop it and wait for it to turn red, then delete it, this should clean everything in RabbitMQ that is associated with that connector (you can find all the information about what is waiting for the connector in RabbitMQ Management and in the "Queues and Streams" section).
"but clicking this button to clear the connector doesn't seem to clear whatever has accumulated in redis", is this still the case?
---
'MISSING_REFERENCE_ERROR', 'message': 'Item(s) not found'
For this error, it occurs when it cannot establish the relationship between an entity A and an entity B, and this can come from the fact that either entity A or entity B are incorrect or do not exist. just not. In our case, I don't think there is any effect on memory.
---
Do you have this error? "REDIS: Failed to extend resource
Example:

If this is the case, then the logic behind the "failed to extend resource" is that the loop of the process node of the ingest or backend is too slow (certainly overloaded by a process of its event loop) to reclaim a lock on say again.
The opencti and resource managers use locks in redis (the lock has a TTL of 30s), if the process node holding the lock does not reclaim it during the 30 seconds of its lifespan and it makes another request after that, then the failed to extend resource error will appear because the lock is no longer valid.
If the problem comes from this, we could test increasing the necessary pause time in the connector between each ingestion, or creating more workers to increase the ingestion speed (less recommended), or the test I showed you with today's date in the config to see if the memory increases even if the data is smaller.
---
"RecursionError: maximum recursion depth exceeded when calling a Python object"
For this error you have raised may indeed come from the connector, it will have to be reworked to remove the recursion through simple loops, but it will be necessary to investigate further in this direction.
> First of all, I wanted to thank you @ckane for your research! Since the connector is in the support: partners category, I don't really have all the necessary access to reproduce it on my end, so any feedback is welcome!
>
> Yes, one of the best methods for a "clean" deletion of the connector is to stop it and wait for it to turn red, then delete it, this should clean everything in RabbitMQ that is associated with that connector (you can find all the information about what is waiting for the connector in RabbitMQ Management and in the "Queues and Streams" section).
>
> "but clicking this button to clear the connector doesn't seem to clear whatever has accumulated in redis", is this still the case?
>
Yes, after the connector was cleared, it seems like `redis` still keeps all of the memory allocated and doesn't release it. It seems like this allocation gets committed to disk in the `dump.rdb` as well, as stopping and restarting redis doesn't seem to fix it.
Since the "redis grows uncontrollably" problem has been raised a few times by others that I've talked to (particularly in Slack), I'm curious if there's any interest in looking into any alternatives to it.
There is one project [Dragonfly DB](https://www.dragonflydb.io/) that offers a Redis-compatible interface (though it lacks some newer features in Redis 6/7), and it isn't compatible with newer `dump.rdb` for storage-migration.
While researching, I have been able to successfully stand up a new OpenCTI instance replacing the `redis` section with the following (and adjusting `opencti` configuration appropriately):
```yaml
dragonfly:
image: docker.dragonflydb.io/dragonflydb/dragonfly:v1.15.0
restart: always
command: --dbfilename dump --port 6379 --logtostderr --keys_output_limit 1000000
ulimits:
memlock: -1
volumes:
- dfdata:/data
```
Largely it seems to be working for me on this new test instance. DragonflyDB claims to be higher-performance and have a lower memory footprint as well as do a better job returning memory to the OS and managing its memory.
Challenge is that any migration from `redis` to `dragonfly` has to be done manually as a "live" migration using some specialized tools. I have a Python script that I cloned from someone else's repository and then modified which successfully migrated everything except for `stream.*` keys, which I think really just need the stream entries migrated in chunks rather than supporting the binary migration the rest of the key types support.
Would be interested in, if you happen to have some automated testing & data population that you could test with replacing the `redis` service with the `dragonfly` service above, and see if it results in any improvements or regressions.
FWIW I am still running regular `redis` 7.2.4 on my system that was pulling from ESET, for now. Next week, I may consider trying to re-deploy with this change as well, after trying to rewrite my migration script to support migrating streams by chunking them into smaller pieces, and then enable ESET again and see how that works out.
This is outside my area of expertise, I will invite the platform team for the rest. @pierremahot, @sbocahu !
Ty for all the help @Megafredo!
Here is another project that is backed by Snap Inc., is open source, is a drop-in replacement for Redis, and offers an eviction policy that can evict to disk rather than purging it from the database entirely: https://docs.keydb.dev/docs/flash
(The disk-backed eviction feature seems to have another dependency, and is advertised as "BETA" right now, but seems worth looking into since we're trying to solve a "redis must be persistent" problem here)
I'll try migrating one of my instances to this sometime over the next week or so and report back with my experience - it might help solve the limitation that prevents us from using `maxmemory` on redis today.
Seems like DragonflyDB is a decent compromise, along with setting `REDIS__TRIMMING=500000`. DragonflyDB seems to return RAM back to the OS more readily, while it seems like once it gets allocated in `dump.rdb`, redis then seems to hold onto all the RAM necessary for both the snapshot to disk as well as the run-time overhead.
Hello @ckane,
Just to explain a little bit and try to get the issue down.
- The connector is creating stix bunddle into the rabbitmq
- Then the worker consumer the queue of the connector and ask mutation to the opencti ingest/plaform
- The opencti ingest/platform then create the entry onto elasticsearch and publish the stix_bundle to the opencti Redis stream to inform other process for exporting data or playbooks or other process.
The REDIS_TRIMMING define the number of message into the stream. The more message you allow the more history you have but the more ram you consume. ESET connector may create big stix bundle that are with the stream consuming a lot of memory from REDIS.
The stream history may be needed for other process to react to creation deletion are update and the size of the history help to get recover from a big load but if you don't want to have redis memory going to infinit you can reduce the `REDIS__TRIMMING` to `100000`.
Thanks @pierremahot - I am also suspecting that the issue is a small number of large-size bundles that are ending up in the redis history cache, and stick around for a long time (until being pushed out by newer items). Also noticed that it occurred on some `misp-feed` connector instances as well, later on, so I don't think it is a problem specific to this connector, but rather an issue resulting from how Redis is employed for this purpose.
I suspect a more resilient alternative for higher availability would be using AWS ElastiCache w/ serverless or auto-scaling deployments.
Hi @pierremahot - I did some more digging on this tonight, and it appears that what is happening is that it keeps adding new entries to the `stream.opencti` stream key with increasingly long lists of STIX malware entities. I wrote a simple `bash` loop to extract every entry in `stream.opencti` and store it into a file named with its id. The data in the directory added up to 13GB which matches closely to the `redis` memory usage.
I am curious if the newer one should be overwriting the older one, rather than adding a brand new entry that's slightly longer, because it seems like the newer items contain a superset of the modification that the older ones do.
Here are some examples of what I am seeing when I get the `message` field from each really big item from the stream:
```
jq '.[7]' 1713040918333-0.json
"\"adds `malware--9d11ad68-46aa-4bc7-bf41-c80f9c078b9e, malware--a19dc0a8-1446-4d65-8b4e-b83f39f66113, malware--33495792-40e1-42a4-8b90-b1b58afe2bc7` in `STIX IDs` and 17767 more items\""
```
```
jq '.[7]' 1713040945081-0.json
"\"adds `malware--9d11ad68-46aa-4bc7-bf41-c80f9c078b9e, malware--a19dc0a8-1446-4d65-8b4e-b83f39f66113, malware--33495792-40e1-42a4-8b90-b1b58afe2bc7` in `STIX IDs` and 17779 more items | replaces `Detected malware tried to contact the URL.` in `Description`\""
```
```
jq '.[7]' 1713040946388-0.json
"\"adds `malware--9d11ad68-46aa-4bc7-bf41-c80f9c078b9e, malware--a19dc0a8-1446-4d65-8b4e-b83f39f66113, malware--33495792-40e1-42a4-8b90-b1b58afe2bc7` in `STIX IDs` and 17781 more items | replaces `Detected malware tried to contact the URL.` in `Description`\""
```
When the system goes out of memory, there are thousands of these in the queue, gradually going in size from oldest (smaller) to newest (largest). Whatever is generating this repeating pattern of making a copy of the prior stream entry with additional malware in the list - that's what is causing the memory consumption to go out of control.
Bash script I used to iterate across all entries in the `stream.opencti` in `redis` and write them to individual files on disk for analysis:
```bash
export h="0-0"
while true; do
docker compose exec redis redis-cli --json xread count 1 streams stream.opencti "$h" > cur.json
export h=$(jq -r '.["stream.opencti"][][0]' cur.json)
jq -r '.["stream.opencti"][][1]' < cur.json > "$h".json
done
```
Many of these entries are 100's of kB each, with the largest being 871kB (before the process crashed due to out of memory), and all contain largely redundant information that basically just extends a list with additional entities, which then is also included in its entirety in the `data` field - this is what causes the exploding memory consumption.
I extracted the `data` field from one of the entries with the really long list (over 17,000 entries) - here is its reformatted json, note that I have removed most of the stix ids from the list for brevity, but they are all in the original stream entry
```json
{
"id": "malware--4d6fe57a-e362-55f1-a812-e7aced9ec899",
"spec_version": "2.1",
"type": "malware",
"extensions": {
"extension-definition--ea279b3e-5c71-4632-ac08-831c66a786ba": {
"extension_type": "property-extension",
"id": "8d6de12a-de56-4739-ad05-2d6c9ad72c5b",
"type": "Malware",
"created_at": "2024-04-13T10:24:37.006Z",
"updated_at": "2024-04-13T20:42:25.403Z",
"stix_ids": [
"malware--9d11ad68-46aa-4bc7-bf41-c80f9c078b9e",
"malware--a19dc0a8-1446-4d65-8b4e-b83f39f66113",
"malware--33495792-40e1-42a4-8b90-b1b58afe2bc7",
// .... over 17,000 ids in this list ...
"malware--641886c5-1137-4c96-bf28-878734c0f310"
],
"is_inferred": false,
"creator_ids": [
"88ec0c6a-13ce-5e39-b486-354fe4a7084f"
],
"labels_ids": [
"d134d29e-814b-4fa5-9b76-5780aa73034b"
]
}
},
"created": "2024-03-29T01:05:15.000Z",
"modified": "2024-04-13T20:42:25.403Z",
"revoked": false,
"confidence": 100,
"lang": "en",
"labels": [
"trojan"
],
"name": "PDF/Phishing.D.Gen trojan",
"description": "Detected malware tried to contact the URL.",
"is_family": false
}
```
Looking at this, it seems like it might be an effect of merging `malware` entities? They're coming in as unique STIX ids from the source (maybe? or maybe auto-created in the connector?) and then the de-duplication feature is identifying that all of these entities match malware names, so folding them into a single malware sample, while adding the `stix_ids` to the logged event. I'm testing commenting out the `malware` type in the connector to see if/how that changes behavior, but these may be a result of malware relationships in other entities in the platform.
Might be worth stripping the `stix_ids` from what's sent to `redis` and seeing if that breaks anything.
Ok I think I have a better handle on what's going on here, I suspect it has to do with random STIX uuid's being autogenerated for each occurence of malware given, for instance, the name `"PDF/Phishing.D.Gen trojan"`, showing up in the ESET TAXII feed....likely because this is MISP-backed data where these would be handled as tags/galaxies/labels or something like that. Anyhow, the behavior populates a long sequence of increasingly growing lists as more random STIX ids for malware (not artifacts, but malware) get added (as aliases?) to a particular malware entity.
I'm messing with some mitigations that limit the length of the `stix_ids` list where they show up in the `property-extension` type above. I'll submit a separate PR for that after I get something working well, and continue the discussion there. | 2024-04-23T00:45:08 |
|
oobabooga/text-generation-webui | 235 | oobabooga__text-generation-webui-235 | [
"191"
]
| 026d60bd3424b5426c5ef80632aa6b71fe12d4c5 | diff --git a/modules/chat.py b/modules/chat.py
--- a/modules/chat.py
+++ b/modules/chat.py
@@ -120,6 +120,9 @@ def chatbot_wrapper(text, max_new_tokens, do_sample, temperature, top_p, typical
else:
prompt = custom_generate_chat_prompt(text, max_new_tokens, name1, name2, context, chat_prompt_size)
+ # Display user input and "*is typing...*" imediately
+ yield shared.history['visible']+[[visible_text, '*Is typing...*']]
+
# Generate
reply = ''
for i in range(chat_generation_attempts):
@@ -158,6 +161,9 @@ def impersonate_wrapper(text, max_new_tokens, do_sample, temperature, top_p, typ
prompt = generate_chat_prompt(text, max_new_tokens, name1, name2, context, chat_prompt_size, impersonate=True)
+ # Display "*is typing...*" imediately
+ yield '*Is typing...*'
+
reply = ''
for i in range(chat_generation_attempts):
for reply in generate_reply(prompt+reply, max_new_tokens, do_sample, temperature, top_p, typical_p, repetition_penalty, top_k, min_length, no_repeat_ngram_size, num_beams, penalty_alpha, length_penalty, early_stopping, eos_token=eos_token, stopping_string=f"\n{name2}:"):
diff --git a/modules/shared.py b/modules/shared.py
--- a/modules/shared.py
+++ b/modules/shared.py
@@ -90,4 +90,5 @@ def str2bool(v):
parser.add_argument('--listen-port', type=int, help='The listening port that the server will use.')
parser.add_argument('--share', action='store_true', help='Create a public URL. This is useful for running the web UI on Google Colab or similar.')
parser.add_argument('--verbose', action='store_true', help='Print the prompts to the terminal.')
+parser.add_argument('--auto-launch', action='store_true', default=False, help='Open the web UI in the default browser upon launch')
args = parser.parse_args()
diff --git a/server.py b/server.py
--- a/server.py
+++ b/server.py
@@ -272,10 +272,10 @@ def create_settings_menus(default_preset):
function_call = 'chat.cai_chatbot_wrapper' if shared.args.cai_chat else 'chat.chatbot_wrapper'
- gen_events.append(shared.gradio['Generate'].click(eval(function_call), shared.input_params, shared.gradio['display'], show_progress=shared.args.no_stream, api_name='textgen'))
- gen_events.append(shared.gradio['textbox'].submit(eval(function_call), shared.input_params, shared.gradio['display'], show_progress=shared.args.no_stream))
- gen_events.append(shared.gradio['Regenerate'].click(chat.regenerate_wrapper, shared.input_params, shared.gradio['display'], show_progress=shared.args.no_stream))
- gen_events.append(shared.gradio['Impersonate'].click(chat.impersonate_wrapper, shared.input_params, shared.gradio['textbox'], show_progress=shared.args.no_stream))
+ gen_events.append(shared.gradio['Generate'].click(eval(function_call), shared.input_params, shared.gradio['display'], show_progress=False, api_name='textgen'))
+ gen_events.append(shared.gradio['textbox'].submit(eval(function_call), shared.input_params, shared.gradio['display'], show_progress=False))
+ gen_events.append(shared.gradio['Regenerate'].click(chat.regenerate_wrapper, shared.input_params, shared.gradio['display'], show_progress=False))
+ gen_events.append(shared.gradio['Impersonate'].click(chat.impersonate_wrapper, shared.input_params, shared.gradio['textbox'], show_progress=False))
shared.gradio['Stop'].click(chat.stop_everything_event, [], [], cancels=gen_events)
shared.gradio['Copy last reply'].click(chat.send_last_reply_to_input, [], shared.gradio['textbox'], show_progress=shared.args.no_stream)
@@ -309,6 +309,7 @@ def create_settings_menus(default_preset):
reload_inputs = [shared.gradio['name1'], shared.gradio['name2']] if shared.args.cai_chat else []
shared.gradio['upload_chat_history'].upload(reload_func, reload_inputs, [shared.gradio['display']])
shared.gradio['upload_img_me'].upload(reload_func, reload_inputs, [shared.gradio['display']])
+ shared.gradio['Stop'].click(reload_func, reload_inputs, [shared.gradio['display']])
shared.gradio['interface'].load(lambda : chat.load_default_history(shared.settings[f'name1{suffix}'], shared.settings[f'name2{suffix}']), None, None)
shared.gradio['interface'].load(reload_func, reload_inputs, [shared.gradio['display']], show_progress=True)
@@ -372,9 +373,9 @@ def create_settings_menus(default_preset):
shared.gradio['interface'].queue()
if shared.args.listen:
- shared.gradio['interface'].launch(prevent_thread_lock=True, share=shared.args.share, server_name='0.0.0.0', server_port=shared.args.listen_port)
+ shared.gradio['interface'].launch(prevent_thread_lock=True, share=shared.args.share, server_name='0.0.0.0', server_port=shared.args.listen_port, inbrowser=shared.args.auto_launch)
else:
- shared.gradio['interface'].launch(prevent_thread_lock=True, share=shared.args.share, server_port=shared.args.listen_port)
+ shared.gradio['interface'].launch(prevent_thread_lock=True, share=shared.args.share, server_port=shared.args.listen_port, inbrowser=shared.args.auto_launch)
# I think that I will need this later
while True:
| Chat log no longer dims when generating
The chat log area no longer dims when responses are being generated.

Not sure if this is intended as part of one of the new upgrades. If so, is there any way yo make this a toggle-able feature, as it provides more of a visual feedback to let me know that the server is doing its thing.
| > This was done in a commit. If you are scrolling down and looking at stuff you can miss when your reply is finished.
Not sure, are you trying to say that this was done on purpose?
Yep, I changed this because I was annoyed by the chat blinking all the time. I felt like that broke immersion.
There is still a gradio progress indicator at the top of the chat box. | 2023-03-11T11:58:47 |
|
oobabooga/text-generation-webui | 628 | oobabooga__text-generation-webui-628 | [
"516"
]
| 1c413ed593b8024b1965ff7306bf9ebd076a870e | diff --git a/extensions/silero_tts/script.py b/extensions/silero_tts/script.py
--- a/extensions/silero_tts/script.py
+++ b/extensions/silero_tts/script.py
@@ -21,6 +21,7 @@
'autoplay': True,
'voice_pitch': 'medium',
'voice_speed': 'medium',
+ 'local_cache_path': '' # User can override the default cache path to something other via settings.json
}
current_params = params.copy()
@@ -44,14 +45,18 @@ def xmlesc(txt):
def load_model():
- model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_tts', language=params['language'], speaker=params['model_id'])
+ torch_cache_path = torch.hub.get_dir() if params['local_cache_path'] == '' else params['local_cache_path']
+ model_path = torch_cache_path + "/snakers4_silero-models_master/src/silero/model/" + params['model_id'] + ".pt"
+ if Path(model_path).is_file():
+ print(f'\nUsing Silero TTS cached checkpoint found at {torch_cache_path}')
+ model, example_text = torch.hub.load(repo_or_dir=torch_cache_path + '/snakers4_silero-models_master/', model='silero_tts', language=params['language'], speaker=params['model_id'], source='local', path=model_path, force_reload=True)
+ else:
+ print(f'\nSilero TTS cache not found at {torch_cache_path}. Attempting to download...')
+ model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_tts', language=params['language'], speaker=params['model_id'])
model.to(params['device'])
return model
-model = load_model()
-
-
def remove_tts_from_history(name1, name2, mode):
for i, entry in enumerate(shared.history['internal']):
shared.history['visible'][i] = [shared.history['visible'][i][0], entry[1]]
@@ -132,6 +137,11 @@ def bot_prefix_modifier(string):
return string
+def setup():
+ global model
+ model = load_model()
+
+
def ui():
# Gradio elements
with gr.Accordion("Silero TTS"):
| silero_tts will not load if I am not connected to the internet
### Describe the bug
I used to be able to use this extension offline, but now I can't load the extension if I am not online. If I am online the extension loads just fine. The actual language models is saved on my machine via the .cache file: C:\Users\myself\.cache\torch\hub\snakers4_silero-models_master\src\silero\model
The model name is called v3_en.pt, it's being cached on my machine and when I load the extension with an internet connection the miniconda console says that it's using the cached model, so I don't know why I NEED to be connected to the internet for it to work.
### Is there an existing issue for this?
- [x] I have searched the existing issues
### Reproduction
Run this (change your install location as necessary) with and without an internet connection.
cd F:\OoBaboogaMarch17\text-generation-webui
conda activate textgen
python .\server.py --auto-devices --gptq-bits 4 --cai-chat --gptq-model-type LLaMa --extension silero_tts
### Screenshot
I'm including two screenshots, one when I am connected to the internet, and one when I am not connected to the internet.


### Logs
```shell
See screenshots
```
### System Info
```shell
Window 10, 4090, i9 13900, windows mode not wsl
```
| This ain't a bug, it's just raising an exception because it can't connect to the torch hub. It tries to either way, regardless of local cache.
However, it is possible to check if the cached `.pt` exists and substitute the loader
Thank you Bralwence, this kind soul on Reddit has solved my issue and provided code: update there are two versions of the change. Mine is the first one and the original og Reddit change is below that. I couldn't get it to work without the comma they get it to work without the comman so 🤷♂️ try theirs first and if it doesn't work try mine I guess.
https://old.reddit.com/r/Oobabooga/comments/11zsw5s/anyone_know_how_to_load_the_silero_tts_extension/jdmvocy/
def load_model(): needs to be changed like this:
def load_model():
cache_path='C:/Users/Myself/.cache/torch/hub/snakers4_silero-models_master/'
model_path = cache_path + "src/silero/model/" + params['model_id'] + ".pt"
if Path(model_path).is_file():
model, example_text = torch.hub.load(repo_or_dir=cache_path, model='silero_tts', language=params['language'], speaker=params['model_id'], source='local', path = model_path, force_reload = True)
else: model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_tts', language=params['language'], speaker=params['model_id']), model.to(params['device'])
return model
def load_model():
cache_path='C:/Users/USER/.cache/torch/hub/snakers4_silero-models_master/'
model_path = cache_path + "src/silero/model/" + params['model_id'] + ".pt"
if Path(model_path).is_file():
model, example_text = torch.hub.load(repo_or_dir=cache_path, model='silero_tts', language=params['language'], speaker=params['model_id'], source='local', path = model_path, force_reload = True)
else:
model, example_text = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_tts', language=params['language'], speaker=params['model_id'])
model.to(params['device'])
return model | 2023-03-29T06:49:03 |
|
oobabooga/text-generation-webui | 1,082 | oobabooga__text-generation-webui-1082 | [
"920"
]
| 4f7e88c0431b2929f542fc3f2d4cf33eb7de6ce0 | diff --git a/extensions/sd_api_pictures/script.py b/extensions/sd_api_pictures/script.py
--- a/extensions/sd_api_pictures/script.py
+++ b/extensions/sd_api_pictures/script.py
@@ -138,14 +138,19 @@ def get_SD_pictures(description):
visible_result = ""
for img_str in r['images']:
- image = Image.open(io.BytesIO(base64.b64decode(img_str.split(",", 1)[0])))
if params['save_img']:
+ img_data = base64.b64decode(img_str)
+
variadic = f'{date.today().strftime("%Y_%m_%d")}/{shared.character}_{int(time.time())}'
output_file = Path(f'extensions/sd_api_pictures/outputs/{variadic}.png')
output_file.parent.mkdir(parents=True, exist_ok=True)
- image.save(output_file.as_posix())
+
+ with open(output_file.as_posix(), 'wb') as f:
+ f.write(img_data)
+
visible_result = visible_result + f'<img src="/file/extensions/sd_api_pictures/outputs/{variadic}.png" alt="{description}" style="max-width: unset; max-height: unset;">\n'
else:
+ image = Image.open(io.BytesIO(base64.b64decode(img_str.split(",", 1)[0])))
# lower the resolution of received images for the chat, otherwise the log size gets out of control quickly with all the base64 values in visible history
image.thumbnail((300, 300))
buffered = io.BytesIO()
| sd_api_pictures Should include SD metadata in generated images
I have the sd_api_pictures extension running and it seems like it is working as intended-
-The bot types something
-SD uses that as a prompt to generate an image
-The image appears in the chat, and also in the **/sd_api_pictures/outputs** directory.
**However, the output .PNG images do not have any Stable Diffusion metadata.**, which is very unfortunate.
_Originally posted by @altoiddealer in https://github.com/oobabooga/text-generation-webui/issues/309#issuecomment-1499245072_
<img width="945" alt="Screenshot 2023-04-08 092926" src="https://user-images.githubusercontent.com/1613484/230723811-8911a373-79a9-4655-9d96-877ef224193b.png">
| This is how the generated images should include metadata (example from a typical SD output)
<img width="1258" alt="Screenshot 2023-04-08 093148" src="https://user-images.githubusercontent.com/1613484/230723931-3ecfb28c-5793-4738-a8d7-17d53ab67bc1.png">
I have modify the API, and it's work, the image has now metadata
ln14 : `from PIL import Image, PngImagePlugin`
ln 147 :
`png_payload = {
"image": "data:image/png;base64," + img_str
}
response2 = requests.post(url=f'{params["address"]}/sdapi/v1/png-info', json=png_payload)
pnginfo = PngImagePlugin.PngInfo()
pnginfo.add_text("parameters", response2.json().get("info"))`
corrected API
[api.py.txt](https://github.com/oobabooga/text-generation-webui/files/11202380/api.py.txt)
| 2023-04-12T12:30:44 |
|
oobabooga/text-generation-webui | 1,261 | oobabooga__text-generation-webui-1261 | [
"1054"
]
| a2127239debf37432489fefa41ed36bd2b6083f6 | diff --git a/modules/text_generation.py b/modules/text_generation.py
--- a/modules/text_generation.py
+++ b/modules/text_generation.py
@@ -209,7 +209,7 @@ def generate_reply(question, state, eos_token=None, stopping_strings=[]):
else:
for k in ['max_new_tokens', 'do_sample', 'temperature']:
generate_params[k] = state[k]
- generate_params['stop'] = state['eos_token_ids'][-1]
+ generate_params['stop'] = eos_token_ids[-1]
if not shared.args.no_stream:
generate_params['max_new_tokens'] = 8
| Flexgen error with opt-13b-erebus
### Describe the bug
When I try to talk I get this error
### Is there an existing issue for this?
- [x] I have searched the existing issues
### Reproduction
python server.py --model opt-13b-erebus --chat --flexgen --compress-weight --verbose
### Screenshot
_No response_
### Logs
```shell
===================================BUG REPORT===================================
Welcome to bitsandbytes. For bug reports, please submit your error trace to: https://github.com/TimDettmers/bitsandbytes/issues
================================================================================
CUDA SETUP: CUDA runtime path found: /home/avolk/miniconda3/envs/textgen/lib/libcudart.so
CUDA SETUP: Highest compute capability among GPUs detected: 8.6
CUDA SETUP: Detected CUDA version 117
CUDA SETUP: Loading binary /home/avolk/miniconda3/envs/textgen/lib/python3.10/site-packages/bitsandbytes/libbitsandbytes_cuda117.so...
Loading opt-13b-erebus...
Loaded the model in 129.12 seconds.
Loading the extension "gallery"... Ok.
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
This is a conversation with your Assistant. The Assistant is very helpful and is eager to chat with you and answer your questions.
Assistant: Hello there!
You: hello
Assistant:
--------------------
Traceback (most recent call last):
File "/home/avolk/miniconda3/envs/textgen/lib/python3.10/site-packages/gradio/routes.py", line 393, in run_predict
output = await app.get_blocks().process_api(
File "/home/avolk/miniconda3/envs/textgen/lib/python3.10/site-packages/gradio/blocks.py", line 1108, in process_api
result = await self.call_function(
File "/home/avolk/miniconda3/envs/textgen/lib/python3.10/site-packages/gradio/blocks.py", line 929, in call_function
prediction = await anyio.to_thread.run_sync(
File "/home/avolk/miniconda3/envs/textgen/lib/python3.10/site-packages/anyio/to_thread.py", line 31, in run_sync
return await get_asynclib().run_sync_in_worker_thread(
File "/home/avolk/miniconda3/envs/textgen/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 937, in run_sync_in_worker_thread
return await future
File "/home/avolk/miniconda3/envs/textgen/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 867, in run
result = context.run(func, *args)
File "/home/avolk/miniconda3/envs/textgen/lib/python3.10/site-packages/gradio/utils.py", line 490, in async_iteration
return next(iterator)
File "/home/avolk/text-generation-webui/modules/chat.py", line 218, in cai_chatbot_wrapper
for history in chatbot_wrapper(text, state):
File "/home/avolk/text-generation-webui/modules/chat.py", line 152, in chatbot_wrapper
for reply in generate_reply(f"{prompt}{' ' if len(cumulative_reply) > 0 else ''}{cumulative_reply}", state, eos_token=eos_token, stopping_strings=stopping_strings):
File "/home/avolk/text-generation-webui/modules/text_generation.py", line 190, in generate_reply
generate_params['stop'] = state['eos_token_ids'][-1]
KeyError: 'eos_token_ids'
```
### System Info
```shell
OS: Ubuntu 22.04.2 LTS x86_64
CPU: AMD Ryzen 7 4800H
GPU: NVIDIA GeForce RTX 3050 Mobile
```
| I can confirm this bug.
Ok, does that mean I just have to wait for the update and then this bug will be fixed? | 2023-04-16T04:45:28 |
|
oobabooga/text-generation-webui | 1,547 | oobabooga__text-generation-webui-1547 | [
"1520"
]
| da812600f49309cd7090464d7ffcfa1246d3a309 | diff --git a/extensions/llava/script.py b/extensions/llava/script.py
--- a/extensions/llava/script.py
+++ b/extensions/llava/script.py
@@ -245,7 +245,9 @@ def tokenizer_modifier(state, prompt, input_ids, input_embeds):
prompt, input_ids, input_embeds, total_embedded = llava_embedder.forward(prompt, images, state)
print(f'LLaVA - Embedded {total_embedded} image(s) in {time.time()-start_ts:.2f}s')
- return prompt, input_ids.unsqueeze(0).to(shared.model.device), input_embeds.unsqueeze(0).to(shared.model.device)
+ return (prompt,
+ input_ids.unsqueeze(0).to(shared.model.device, dtype=torch.int64),
+ input_embeds.unsqueeze(0).to(shared.model.device, dtype=shared.model.dtype))
def ui():
| Error with images using LLaVA
### Describe the bug
RuntimeError when LLaVA tries to answer to an image.
Different errors depending on the settings(clip+projector), but always related to "Half", 16bit.
Only working combinations are:
* clip+projector 16bit on gpu
* clip 32bit cpu/gpu, projector 16bit gpu
I think the projector only works with 16 bit when using sdp attention.
The weird thing is that this worked witrhout any hassle before LLaVA was merged(using the pr branch).
If these are not directly fixable, maybe some settings should be overridden if sdp attention is used(if that is the cause) and warned about conflicting settings. And for me at least 16 bit does not work on cpu at all.
### Is there an existing issue for this?
- [X] I have searched the existing issues
### Reproduction
1. LLaVA settings anything with projector in 32 bit
2. Start webui with LLaVA and sdp attention
3. In chat add an image to your message
4. Image gets embedded, but when trying to give it to the model it'll error
### Screenshot
_No response_
### Logs
```shell
Traceback (most recent call last):
File "/home/laaza/ooba/text-generation-webui/modules/callbacks.py", line 66, in gentask
ret = self.mfunc(callback=_callback, **self.kwargs)
File "/home/laaza/ooba/text-generation-webui/modules/text_generation.py", line 257, in generate_with_callback
shared.model.generate(**kwargs)
File "/home/laaza/ooba/installer_files/env/lib/python3.10/site-packages/torch/utils/_contextlib.py", line 115, in decorate_context
return func(*args, **kwargs)
File "/home/laaza/ooba/installer_files/env/lib/python3.10/site-packages/transformers/generation/utils.py", line 1559, in generate
return self.sample(
File "/home/laaza/ooba/installer_files/env/lib/python3.10/site-packages/transformers/generation/utils.py", line 2598, in sample
outputs = self(
File "/home/laaza/ooba/installer_files/env/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/laaza/ooba/installer_files/env/lib/python3.10/site-packages/transformers/models/llama/modeling_llama.py", line 688, in forward
outputs = self.model(
File "/home/laaza/ooba/installer_files/env/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/laaza/ooba/installer_files/env/lib/python3.10/site-packages/transformers/models/llama/modeling_llama.py", line 578, in forward
layer_outputs = decoder_layer(
File "/home/laaza/ooba/installer_files/env/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/laaza/ooba/installer_files/env/lib/python3.10/site-packages/transformers/models/llama/modeling_llama.py", line 293, in forward
hidden_states, self_attn_weights, present_key_value = self.self_attn(
File "/home/laaza/ooba/installer_files/env/lib/python3.10/site-packages/torch/nn/modules/module.py", line 1501, in _call_impl
return forward_call(*args, **kwargs)
File "/home/laaza/ooba/text-generation-webui/modules/llama_attn_hijack.py", line 142, in sdp_attention_forward
attn_output = torch.nn.functional.scaled_dot_product_attention(query_states, key_states, value_states, attn_mask=attention_mask, is_causal=False)
RuntimeError: Expected attn_mask dtype to be bool or to match query dtype, but got attn_mask.dtype: float and query.dtype: c10::Half instead.
```
### System Info
```shell
WSL2 Ubuntu-22.04
GPTQ-for-LLaMA triton
RTX 3080 10 GB
Ryzen 5800X
24 GB RAM
webui 2f4f124
model: wojtab/llava-13b-v0-4bit-128g (fully on gpu)
run with LLaVA and sdp attention
```
| ok, can confirm, I'll fix it | 2023-04-25T20:55:16 |
|
oobabooga/text-generation-webui | 1,929 | oobabooga__text-generation-webui-1929 | [
"1909"
]
| 68dcbc7ebda3f0d9700dde43d0d29324f5c244b1 | diff --git a/extensions/superbooga/script.py b/extensions/superbooga/script.py
--- a/extensions/superbooga/script.py
+++ b/extensions/superbooga/script.py
@@ -52,10 +52,12 @@ def add(self, texts: list[str]):
self.collection.add(documents=texts, ids=self.ids)
def get(self, search_strings: list[str], n_results: int) -> list[str]:
+ n_results = min(len(self.ids), n_results)
result = self.collection.query(query_texts=search_strings, n_results=n_results, include=['documents'])['documents'][0]
return result
def get_ids(self, search_strings: list[str], n_results: int) -> list[str]:
+ n_results = min(len(self.ids), n_results)
result = self.collection.query(query_texts=search_strings, n_results=n_results, include=['documents'])['ids'][0]
return list(map(lambda x : int(x[2:]), result))
| Superbooga: Cannot return the results in a contigious 2D array. Probably ef or M is too small
### Describe the bug
Superbooga: When using any data input, "Cannot return the results in a contigious 2D array. Probably ef or M is too small."
MetaIX_GPT4-X-Alpasta30b-4bit
Instruct mode
Alpaca prompt
Input chunks loaded: 10
Chunk length: 500
Chunk count: 10
Max tokens: 1-2000
Found relevant report for langchain to provide more descriptive error: https://github.com/hwchase17/langchain/pull/1149
### Is there an existing issue for this?
- [X] I have searched the existing issues
### Reproduction
Set chunk length, chunk count, or max tokens outside of unspecified range from any data input source in Superbooga.
### Screenshot
_No response_
### Logs
```shell
Traceback (most recent call last):
File "/home/quietday/miniconda3/envs/textgen/lib/python3.10/site-packages/gradio/routes.py", line 395, in run_predict
output = await app.get_blocks().process_api(
File "/home/quietday/miniconda3/envs/textgen/lib/python3.10/site-packages/gradio/blocks.py", line 1193, in process_api
result = await self.call_function(
File "/home/quietday/miniconda3/envs/textgen/lib/python3.10/site-packages/gradio/blocks.py", line 930, in call_function
prediction = await anyio.to_thread.run_sync(
File "/home/quietday/miniconda3/envs/textgen/lib/python3.10/site-packages/anyio/to_thread.py", line 31, in run_sync
return await get_asynclib().run_sync_in_worker_thread(
File "/home/quietday/miniconda3/envs/textgen/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 937, in run_sync_in_worker_thread
return await future
File "/home/quietday/miniconda3/envs/textgen/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 867, in run
result = context.run(func, *args)
File "/home/quietday/miniconda3/envs/textgen/lib/python3.10/site-packages/gradio/utils.py", line 491, in async_iteration
return next(iterator)
File "/mnt/tank/AGI/text-generation-webui/modules/text_generation.py", line 164, in generate_reply
question = apply_extensions('input', question)
File "/mnt/tank/AGI/text-generation-webui/modules/extensions.py", line 132, in apply_extensions
return EXTENSION_MAP[typ](*args, **kwargs)
File "/mnt/tank/AGI/text-generation-webui/modules/extensions.py", line 58, in _apply_string_extensions
text = getattr(extension, function_name)(text)
File "/mnt/tank/AGI/text-generation-webui/extensions/superbooga/script.py", line 150, in input_modifier
results = collector.get(user_input, n_results=chunk_count)
File "/mnt/tank/AGI/text-generation-webui/extensions/superbooga/script.py", line 55, in get
result = self.collection.query(query_texts=search_strings, n_results=n_results, include=['documents'])['documents'][0]
File "/home/quietday/miniconda3/envs/textgen/lib/python3.10/site-packages/chromadb/api/models/Collection.py", line 203, in query
return self._client._query(
File "/home/quietday/miniconda3/envs/textgen/lib/python3.10/site-packages/chromadb/api/local.py", line 247, in _query
uuids, distances = self._db.get_nearest_neighbors(
File "/home/quietday/miniconda3/envs/textgen/lib/python3.10/site-packages/chromadb/db/clickhouse.py", line 521, in get_nearest_neighbors
uuids, distances = index.get_nearest_neighbors(embeddings, n_results, ids)
File "/home/quietday/miniconda3/envs/textgen/lib/python3.10/site-packages/chromadb/db/index/hnswlib.py", line 248, in get_nearest_neighbors
database_labels, distances = self._index.knn_query(query, k=k, filter=filter_function)
RuntimeError: Cannot return the results in a contigious 2D array. Probably ef or M is too small
```
### System Info
```shell
Ubuntu 22.04, Linux 6.2.6-76060206-generic
Latest 7 May 2023 pulls
text-generation-ui(main)
9754d6a8119a4c48226d40f69fe83d9f03079016
GPTQ-for-LLaMa(triton)
dfbf9a94b7426ea36051fd4146a7602ca461d235
```
| 2023-05-08T21:25:33 |
||
oobabooga/text-generation-webui | 1,935 | oobabooga__text-generation-webui-1935 | [
"1791"
]
| 943b5e5f804c34821b2598b47d754a0834869636 | diff --git a/extensions/openai/cache_embedding_model.py b/extensions/openai/cache_embedding_model.py
new file mode 100755
--- /dev/null
+++ b/extensions/openai/cache_embedding_model.py
@@ -0,0 +1,8 @@
+#!/usr/bin/env python3
+# preload the embedding model, useful for Docker images to prevent re-download on config change
+# Dockerfile:
+# ENV OPENEDAI_EMBEDDING_MODEL=all-mpnet-base-v2 # Optional
+# RUN python3 cache_embedded_model.py
+import os, sentence_transformers
+st_model = os.environ["OPENEDAI_EMBEDDING_MODEL"] if "OPENEDAI_EMBEDDING_MODEL" in os.environ else "all-mpnet-base-v2"
+model = sentence_transformers.SentenceTransformer(st_model)
diff --git a/extensions/openai/script.py b/extensions/openai/script.py
--- a/extensions/openai/script.py
+++ b/extensions/openai/script.py
@@ -2,6 +2,8 @@
import json
import os
import time
+import requests
+import yaml
from http.server import BaseHTTPRequestHandler, ThreadingHTTPServer
from threading import Thread
@@ -48,6 +50,31 @@ def clamp(value, minvalue, maxvalue):
return max(minvalue, min(value, maxvalue))
+def deduce_template():
+ # Alpaca is verbose so a good default prompt
+ default_template = (
+ "Below is an instruction that describes a task, paired with an input that provides further context. "
+ "Write a response that appropriately completes the request.\n\n"
+ "### Instruction:\n{instruction}\n\n### Input:\n{input}\n\n### Response:\n"
+ )
+
+ # Use the special instruction/input/response template for anything trained like Alpaca
+ if shared.settings['instruction_template'] in ['Alpaca', 'Alpaca-Input']:
+ return default_template
+
+ try:
+ instruct = yaml.safe_load(open(f"characters/instruction-following/{shared.settings['instruction_template']}.yaml", 'r'))
+
+ template = instruct['turn_template']
+ template = template\
+ .replace('<|user|>', instruct.get('user', ''))\
+ .replace('<|bot|>', instruct.get('bot', ''))\
+ .replace('<|user-message|>', '{instruction}\n{input}')
+ return instruct.get('context', '') + template[:template.find('<|bot-message|>')]
+ except:
+ return default_template
+
+
def float_list_to_base64(float_list):
# Convert the list to a float32 array that the OpenAPI client expects
float_array = np.array(float_list, dtype="float32")
@@ -120,11 +147,20 @@ def do_GET(self):
self.send_error(404)
def do_POST(self):
- content_length = int(self.headers['Content-Length'])
- body = json.loads(self.rfile.read(content_length).decode('utf-8'))
+ # ... haaack.
+ is_chat = shared.args.chat
+ try:
+ shared.args.chat = True
+ self.do_POST_wrap()
+ finally:
+ shared.args.chat = is_chat
+ def do_POST_wrap(self):
if debug:
print(self.headers) # did you know... python-openai sends your linux kernel & python version?
+ content_length = int(self.headers['Content-Length'])
+ body = json.loads(self.rfile.read(content_length).decode('utf-8'))
+
if debug:
print(body)
@@ -150,7 +186,7 @@ def do_POST(self):
truncation_length = default(shared.settings, 'truncation_length', 2048)
truncation_length = clamp(default(body, 'truncation_length', truncation_length), 1, truncation_length)
- default_max_tokens = truncation_length if is_chat else 16 # completions default, chat default is 'inf' so we need to cap it., the default for chat is "inf"
+ default_max_tokens = truncation_length if is_chat else 16 # completions default, chat default is 'inf' so we need to cap it.
max_tokens_str = 'length' if is_legacy else 'max_tokens'
max_tokens = default(body, max_tokens_str, default(shared.settings, 'max_new_tokens', default_max_tokens))
@@ -440,6 +476,129 @@ def do_POST(self):
else:
resp[resp_list][0]["text"] = answer
+ response = json.dumps(resp)
+ self.wfile.write(response.encode('utf-8'))
+ elif '/edits' in self.path:
+ self.send_response(200)
+ self.send_header('Content-Type', 'application/json')
+ self.end_headers()
+
+ created_time = int(time.time())
+
+ # Using Alpaca format, this may work with other models too.
+ instruction = body['instruction']
+ input = body.get('input', '')
+
+ instruction_template = deduce_template()
+ edit_task = instruction_template.format(instruction=instruction, input=input)
+
+ truncation_length = default(shared.settings, 'truncation_length', 2048)
+ token_count = len(encode(edit_task)[0])
+ max_tokens = truncation_length - token_count
+
+ req_params = {
+ 'max_new_tokens': max_tokens,
+ 'temperature': clamp(default(body, 'temperature', 1.0), 0.001, 1.999),
+ 'top_p': clamp(default(body, 'top_p', 1.0), 0.001, 1.0),
+ 'top_k': 1,
+ 'repetition_penalty': 1.18,
+ 'encoder_repetition_penalty': 1.0,
+ 'suffix': None,
+ 'stream': False,
+ 'echo': False,
+ 'seed': shared.settings.get('seed', -1),
+ # 'n' : default(body, 'n', 1), # 'n' doesn't have a direct map
+ 'truncation_length': truncation_length,
+ 'add_bos_token': shared.settings.get('add_bos_token', True),
+ 'do_sample': True,
+ 'typical_p': 1.0,
+ 'min_length': 0,
+ 'no_repeat_ngram_size': 0,
+ 'num_beams': 1,
+ 'penalty_alpha': 0.0,
+ 'length_penalty': 1,
+ 'early_stopping': False,
+ 'ban_eos_token': False,
+ 'skip_special_tokens': True,
+ 'custom_stopping_strings': [],
+ }
+
+ if debug:
+ print({'edit_template': edit_task, 'req_params': req_params, 'token_count': token_count})
+
+ generator = generate_reply(edit_task, req_params, stopping_strings=standard_stopping_strings)
+
+ answer = ''
+ for a in generator:
+ if isinstance(a, str):
+ answer = a
+ else:
+ answer = a[0]
+
+ completion_token_count = len(encode(answer)[0])
+
+ resp = {
+ "object": "edit",
+ "created": created_time,
+ "choices": [{
+ "text": answer,
+ "index": 0,
+ }],
+ "usage": {
+ "prompt_tokens": token_count,
+ "completion_tokens": completion_token_count,
+ "total_tokens": token_count + completion_token_count
+ }
+ }
+
+ if debug:
+ print({'answer': answer, 'completion_token_count': completion_token_count})
+
+ response = json.dumps(resp)
+ self.wfile.write(response.encode('utf-8'))
+ elif '/images/generations' in self.path and 'SD_WEBUI_URL' in os.environ:
+ # Stable Diffusion callout wrapper for txt2img
+ # Low effort implementation for compatibility. With only "prompt" being passed and assuming DALL-E
+ # the results will be limited and likely poor. SD has hundreds of models and dozens of settings.
+ # If you want high quality tailored results you should just use the Stable Diffusion API directly.
+ # it's too general an API to try and shape the result with specific tags like "masterpiece", etc,
+ # Will probably work best with the stock SD models.
+ # SD configuration is beyond the scope of this API.
+ # At this point I will not add the edits and variations endpoints (ie. img2img) because they
+ # require changing the form data handling to accept multipart form data, also to properly support
+ # url return types will require file management and a web serving files... Perhaps later!
+
+ self.send_response(200)
+ self.send_header('Content-Type', 'application/json')
+ self.end_headers()
+
+ width, height = [ int(x) for x in default(body, 'size', '1024x1024').split('x') ] # ignore the restrictions on size
+ response_format = default(body, 'response_format', 'url') # or b64_json
+
+ payload = {
+ 'prompt': body['prompt'], # ignore prompt limit of 1000 characters
+ 'width': width,
+ 'height': height,
+ 'batch_size': default(body, 'n', 1) # ignore the batch limits of max 10
+ }
+
+ resp = {
+ 'created': int(time.time()),
+ 'data': []
+ }
+
+ # TODO: support SD_WEBUI_AUTH username:password pair.
+ sd_url = f"{os.environ['SD_WEBUI_URL']}/sdapi/v1/txt2img"
+
+ response = requests.post(url=sd_url, json=payload)
+ r = response.json()
+ # r['parameters']...
+ for b64_json in r['images']:
+ if response_format == 'b64_json':
+ resp['data'].extend([{'b64_json': b64_json}])
+ else:
+ resp['data'].extend([{'url': f'data:image/png;base64,{b64_json}'}]) # yeah it's lazy. requests.get() will not work with this
+
response = json.dumps(resp)
self.wfile.write(response.encode('utf-8'))
elif '/embeddings' in self.path and embedding_model is not None:
@@ -540,11 +699,12 @@ def run_server():
try:
from flask_cloudflared import _run_cloudflared
public_url = _run_cloudflared(params['port'], params['port'] + 1)
- print(f'Starting OpenAI compatible api at {public_url}/')
+ print(f'Starting OpenAI compatible api at\nOPENAI_API_BASE={public_url}/v1')
except ImportError:
print('You should install flask_cloudflared manually')
else:
- print(f'Starting OpenAI compatible api at http://{server_addr[0]}:{server_addr[1]}/')
+ print(f'Starting OpenAI compatible api:\nOPENAI_API_BASE=http://{server_addr[0]}:{server_addr[1]}/v1')
+
server.serve_forever()
| Extra space at the beginning of generation
### Describe the bug
An extra space is generated at the beginning of text,
It is done here: https://github.com/oobabooga/text-generation-webui/commit/15940e762e9f9a257fb8ce4f711b5e1ca7740616
This breaks a lot of use cases, like python code formatting and sequence completions.
Why is this done?
### Is there an existing issue for this?
- [X] I have searched the existing issues
### Reproduction
In default mode, with max_tokens set to 2 try the following input (the next number should be 13):
0,1,1,2,3,5,8,
Instead it produces
0,1,1,2,3,5,8, 1
It should be:
0,1,1,2,3,5,8,13
### Screenshot
_No response_
### Logs
```shell
N/A
```
### System Info
```shell
Ubuntu
```
| 2023-05-09T05:36:33 |
||
oobabooga/text-generation-webui | 2,382 | oobabooga__text-generation-webui-2382 | [
"2326"
]
| 2cf711f35ec8453d8af818be631cb60447e759e2 | diff --git a/extensions/openai/script.py b/extensions/openai/script.py
--- a/extensions/openai/script.py
+++ b/extensions/openai/script.py
@@ -259,7 +259,7 @@ def do_POST(self):
role_formats = {
'user': 'user: {message}\n',
- 'bot': 'assistant: {message}\n',
+ 'assistant': 'assistant: {message}\n',
'system': '{message}',
'context': 'You are a helpful assistant. Answer as concisely as possible.',
'prompt': 'assistant:',
| extensions/openai KeyError: 'assistant'
### Describe the bug
Starting after [https://github.com/oobabooga/text-generation-webui/pull/2291]
Which I think it's a great improvement.
### Is there an existing issue for this?
- [X] I have searched the existing issues
### Reproduction
Start server with extension --openai --model openaccess-ai-collective_manticore-13b.
Starting [DGdev91 Auto-GPT](https://github.com/DGdev91/Auto-GPT), runs 1 cycle, give 'y' for the second, the error appears.
### Screenshot
_No response_
### Logs
```shell
openaccess-ai-collectiveException occurred during processing of request from ('127.0.0.1', 42032)
Traceback (most recent call last):
File "/home/mihai/miniconda3/envs/textgen/lib/python3.10/socketserver.py", line 683, in process_request_thread
self.finish_request(request, client_address)
File "/home/mihai/miniconda3/envs/textgen/lib/python3.10/socketserver.py", line 360, in finish_request
self.RequestHandlerClass(request, client_address, self)
File "/home/mihai/miniconda3/envs/textgen/lib/python3.10/socketserver.py", line 747, in __init__
self.handle()
File "/home/mihai/miniconda3/envs/textgen/lib/python3.10/http/server.py", line 433, in handle
self.handle_one_request()
File "/home/mihai/miniconda3/envs/textgen/lib/python3.10/http/server.py", line 421, in handle_one_request
method()
File "/home/mihai/text-generation-webui/extensions/openai/script.py", line 310, in do_POST
msg = role_formats[role].format(message=content)
KeyError: 'assistant'
----------------------------------------
```
### System Info
```shell
Win11 WSL2 Ubuntu 20.04
Python 3.10
```
| This looks like 2 problems:
1) you need to update your models/config.yaml (to include manticore) and/or your characters/instruction-following/Manticore Chat.yaml is missing.
2) There is a bug in the default template (says 'bot') should be 'assistant'
I will fix 2), for better results you should also fix 1). | 2023-05-27T18:41:12 |
|
oobabooga/text-generation-webui | 2,383 | oobabooga__text-generation-webui-2383 | [
"2331"
]
| 2cf711f35ec8453d8af818be631cb60447e759e2 | diff --git a/extensions/openai/script.py b/extensions/openai/script.py
--- a/extensions/openai/script.py
+++ b/extensions/openai/script.py
@@ -315,7 +315,7 @@ def do_POST(self):
# can't really truncate the system messages
system_msg = '\n'.join(system_msgs)
- if system_msg[-1] != '\n':
+ if system_msg and system_msg[-1] != '\n':
system_msg = system_msg + '\n'
system_token_count = len(encode(system_msg)[0])
| extension/openai chat/completion endpoint IndexError: string index out of range
### Describe the bug
openai extension /completion endpoint works correctly whilst /chat/completion returns IndexError: string index out of range in the logs and obviously no result in the API.
The issue seems at line 318 when checking if the string end with newline:
`if system_msg[-1] != '\n':`
### Is there an existing issue for this?
- [X] I have searched the existing issues
### Reproduction
```
curl http://192.168.178.35:5001/v1/chat/completions -H "Content-Type: application/json" -d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "Say this is a test!"}],
"temperature": 0.7
}'
```
### Screenshot
_No response_
### Logs
```shell
25/May/2023 14:03:09] "POST /v1/chat/completions HTTP/1.1" 200 -
----------------------------------------
Exception occurred during processing of request from ('192.168.196.154', 54388)
Traceback (most recent call last):
File "D:\Apps\oobabooga-windows\installer_files\env\lib\socketserver.py", line 683, in process_request_thread
self.finish_request(request, client_address)
File "D:\Apps\oobabooga-windows\installer_files\env\lib\socketserver.py", line 360, in finish_request
self.RequestHandlerClass(request, client_address, self)
File "D:\Apps\oobabooga-windows\installer_files\env\lib\socketserver.py", line 747, in init
self.handle()
File "D:\Apps\oobabooga-windows\installer_files\env\lib\http\server.py", line 433, in handle
self.handle_one_request()
File "D:\Apps\oobabooga-windows\installer_files\env\lib\http\server.py", line 421, in handle_one_request
method()
File "D:\Apps\oobabooga-windows\text-generation-webui\extensions\openai\script.py", line 318, in do_POST
if system_msg[-1] != '\n':
IndexError: string index out of range
```
### System Info
```shell
Windows 11
Nvidia Geforce 3060Ti
Python 3.10.11
```
| 2023-05-27T18:52:36 |
||
oobabooga/text-generation-webui | 2,443 | oobabooga__text-generation-webui-2443 | [
"2435"
]
| 9ab90d8b608170fe57d893c2150eda3bc11a8b06 | diff --git a/extensions/openai/script.py b/extensions/openai/script.py
--- a/extensions/openai/script.py
+++ b/extensions/openai/script.py
@@ -18,6 +18,41 @@
debug = True if 'OPENEDAI_DEBUG' in os.environ else False
+# Slightly different defaults for OpenAI's API
+default_req_params = {
+ 'max_new_tokens': 200,
+ 'temperature': 1.0,
+ 'top_p': 1.0,
+ 'top_k': 1,
+ 'repetition_penalty': 1.18,
+ 'encoder_repetition_penalty': 1.0,
+ 'suffix': None,
+ 'stream': False,
+ 'echo': False,
+ 'seed': -1,
+ # 'n' : default(body, 'n', 1), # 'n' doesn't have a direct map
+ 'truncation_length': 2048,
+ 'add_bos_token': True,
+ 'do_sample': True,
+ 'typical_p': 1.0,
+ 'epsilon_cutoff': 0, # In units of 1e-4
+ 'eta_cutoff': 0, # In units of 1e-4
+ 'tfs': 1.0,
+ 'top_a': 0.0,
+ 'min_length': 0,
+ 'no_repeat_ngram_size': 0,
+ 'num_beams': 1,
+ 'penalty_alpha': 0.0,
+ 'length_penalty': 1,
+ 'early_stopping': False,
+ 'mirostat_mode': 0,
+ 'mirostat_tau': 5,
+ 'mirostat_eta': 0.1,
+ 'ban_eos_token': False,
+ 'skip_special_tokens': True,
+ 'custom_stopping_strings': [],
+}
+
# Optional, install the module and download the model to enable
# v1/embeddings
try:
@@ -194,46 +229,18 @@ def do_POST(self):
max_tokens = default(body, max_tokens_str, default(shared.settings, 'max_new_tokens', default_max_tokens))
# if the user assumes OpenAI, the max_tokens is way too large - try to ignore it unless it's small enough
- req_params = {
- 'max_new_tokens': max_tokens,
- 'temperature': default(body, 'temperature', 1.0),
- 'top_p': default(body, 'top_p', 1.0),
- 'top_k': default(body, 'best_of', 1),
- # XXX not sure about this one, seems to be the right mapping, but the range is different (-2..2.0) vs 0..2
- # 0 is default in openai, but 1.0 is default in other places. Maybe it's scaled? scale it.
- 'repetition_penalty': 1.18, # (default(body, 'presence_penalty', 0) + 2.0 ) / 2.0, # 0 the real default, 1.2 is the model default, but 1.18 works better.
- # XXX not sure about this one either, same questions. (-2..2.0), 0 is default not 1.0, scale it.
- 'encoder_repetition_penalty': 1.0, # (default(body, 'frequency_penalty', 0) + 2.0) / 2.0,
- 'suffix': body.get('suffix', None),
- 'stream': default(body, 'stream', False),
- 'echo': default(body, 'echo', False),
- #####################################################
- 'seed': shared.settings.get('seed', -1),
- # int(body.get('n', 1)) # perhaps this should be num_beams or chat_generation_attempts? 'n' doesn't have a direct map
- # unofficial, but it needs to get set anyways.
- 'truncation_length': truncation_length,
- # no more args.
- 'add_bos_token': shared.settings.get('add_bos_token', True),
- 'do_sample': True,
- 'typical_p': 1.0,
- 'epsilon_cutoff': 0, # In units of 1e-4
- 'eta_cutoff': 0, # In units of 1e-4
- 'min_length': 0,
- 'no_repeat_ngram_size': 0,
- 'num_beams': 1,
- 'penalty_alpha': 0.0,
- 'length_penalty': 1,
- 'early_stopping': False,
- 'mirostat_mode': 0,
- 'mirostat_tau': 5,
- 'mirostat_eta': 0.1,
- 'ban_eos_token': False,
- 'skip_special_tokens': True,
- }
+ req_params = default_req_params.copy()
- # fixup absolute 0.0's
- for par in ['temperature', 'repetition_penalty', 'encoder_repetition_penalty']:
- req_params[par] = clamp(req_params[par], 0.001, 1.999)
+ req_params['max_new_tokens'] = max_tokens
+ req_params['truncation_length'] = truncation_length
+ req_params['temperature'] = clamp(default(body, 'temperature', default_req_params['temperature']), 0.001, 1.999) # fixup absolute 0.0
+ req_params['top_p'] = clamp(default(body, 'top_p', default_req_params['top_p']), 0.001, 1.0)
+ req_params['top_k'] = default(body, 'best_of', default_req_params['top_k'])
+ req_params['suffix'] = default(body, 'suffix', default_req_params['suffix'])
+ req_params['stream'] = default(body, 'stream', default_req_params['stream'])
+ req_params['echo'] = default(body, 'echo', default_req_params['echo'])
+ req_params['seed'] = shared.settings.get('seed', default_req_params['seed'])
+ req_params['add_bos_token'] = shared.settings.get('add_bos_token', default_req_params['add_bos_token'])
self.send_response(200)
if req_params['stream']:
@@ -550,37 +557,14 @@ def do_POST(self):
token_count = len(encode(edit_task)[0])
max_tokens = truncation_length - token_count
- req_params = {
- 'max_new_tokens': max_tokens,
- 'temperature': clamp(default(body, 'temperature', 1.0), 0.001, 1.999),
- 'top_p': clamp(default(body, 'top_p', 1.0), 0.001, 1.0),
- 'top_k': 1,
- 'repetition_penalty': 1.18,
- 'encoder_repetition_penalty': 1.0,
- 'suffix': None,
- 'stream': False,
- 'echo': False,
- 'seed': shared.settings.get('seed', -1),
- # 'n' : default(body, 'n', 1), # 'n' doesn't have a direct map
- 'truncation_length': truncation_length,
- 'add_bos_token': shared.settings.get('add_bos_token', True),
- 'do_sample': True,
- 'typical_p': 1.0,
- 'epsilon_cutoff': 0, # In units of 1e-4
- 'eta_cutoff': 0, # In units of 1e-4
- 'min_length': 0,
- 'no_repeat_ngram_size': 0,
- 'num_beams': 1,
- 'penalty_alpha': 0.0,
- 'length_penalty': 1,
- 'early_stopping': False,
- 'mirostat_mode': 0,
- 'mirostat_tau': 5,
- 'mirostat_eta': 0.1,
- 'ban_eos_token': False,
- 'skip_special_tokens': True,
- 'custom_stopping_strings': [],
- }
+ req_params = default_req_params.copy()
+
+ req_params['max_new_tokens'] = max_tokens
+ req_params['truncation_length'] = truncation_length
+ req_params['temperature'] = clamp(default(body, 'temperature', default_req_params['temperature']), 0.001, 1.999) # fixup absolute 0.0
+ req_params['top_p'] = clamp(default(body, 'top_p', default_req_params['top_p']), 0.001, 1.0)
+ req_params['seed'] = shared.settings.get('seed', default_req_params['seed'])
+ req_params['add_bos_token'] = shared.settings.get('add_bos_token', default_req_params['add_bos_token'])
if debug:
print({'edit_template': edit_task, 'req_params': req_params, 'token_count': token_count})
| Failed to load embedding model: all-mpnet-base-v2 While Running Textgen in Colab Notebook
### Describe the bug
I have used this command instead of using old Cuda in my ipynb
`!git clone https://github.com/qwopqwop200/GPTQ-for-LLaMa`
Now, I ran the server using following code -
`!python server.py --extensions openai --model guanaco-7B-GPTQ --model_type LLaMa --api --public-api --share --wbits 4 --groupsize 128`
I am getting below error -
```
WARNING:The gradio "share link" feature uses a proprietary executable to create a reverse tunnel. Use it with care.
2023-05-30 11:21:05.243240: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
bin /usr/local/lib/python3.10/dist-packages/bitsandbytes/libbitsandbytes_cuda118.so
INFO:Loading guanaco-7B-GPTQ...
INFO:Found the following quantized model: models/guanaco-7B-GPTQ/Guanaco-7B-GPTQ-4bit-128g.no-act-order.safetensors
INFO:Loaded the model in 14.96 seconds.
INFO:Loading the extension "openai"...
Failed to load embedding model: all-mpnet-base-v2
```
### Is there an existing issue for this?
- [X] I have searched the existing issues
### Reproduction
Run Colab.
Use this notebook. [Colab](https://colab.research.google.com/drive/1wURKtZgM_SWhjy-NlHNVjHl-SKT5AwtF?usp=sharing)
Openai Extension not working as intended
### Screenshot
_No response_
### Logs
```shell
WARNING:The gradio "share link" feature uses a proprietary executable to create a reverse tunnel. Use it with care.
2023-05-30 11:21:05.243240: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
bin /usr/local/lib/python3.10/dist-packages/bitsandbytes/libbitsandbytes_cuda118.so
INFO:Loading guanaco-7B-GPTQ...
INFO:Found the following quantized model: models/guanaco-7B-GPTQ/Guanaco-7B-GPTQ-4bit-128g.no-act-order.safetensors
INFO:Loaded the model in 14.96 seconds.
INFO:Loading the extension "openai"...
Failed to load embedding model: all-mpnet-base-v2
```
### System Info
```shell
Google COlab Notebook with T4 GPU
```
| I believe I know what went wrong. I installed the sentence-transformers package. That Error is resolved now. But still can not hit the openai api
Edit : added this command now - `!pip install git+https://github.com/mnt4/flask-cloudflared`
from
[https://github.com/oobabooga/text-generation-webui/issues/1524]
This is the error stack Trace now -
```
WARNING:The gradio "share link" feature uses a proprietary executable to create a reverse tunnel. Use it with care.
2023-05-30 12:20:26.338655: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
bin /usr/local/lib/python3.10/dist-packages/bitsandbytes/libbitsandbytes_cuda118.so
INFO:Loading guanaco-7B-GPTQ...
INFO:Found the following quantized model: models/guanaco-7B-GPTQ/Guanaco-7B-GPTQ-4bit-128g.no-act-order.safetensors
INFO:Loaded the model in 18.88 seconds.
INFO:Loading the extension "openai"...
Running on local URL: http://127.0.0.1:7860/
Loaded embedding model: all-mpnet-base-v2, max sequence length: 384
Running on public URL: https://6d95be3cd607be0555.gradio.live/
This share link expires in 72 hours. For free permanent hosting and GPU upgrades (NEW!), check out Spaces: https://huggingface.co/spaces
Starting OpenAI compatible api at
OPENAI_API_BASE=https://relative-flex-nose-useful.trycloudflare.com/v1
127.0.0.1 - - [30/May/2023 12:20:55] code 404, message Not Found
127.0.0.1 - - [30/May/2023 12:20:55] "GET /metrics HTTP/1.1" 404 -
Starting streaming server at public url wss://current-supported-lonely-walt.trycloudflare.com/api/v1/stream
127.0.0.1 - - [30/May/2023 12:20:58] code 404, message Not Found
127.0.0.1 - - [30/May/2023 12:20:58] "GET /metrics HTTP/1.1" 404 -
127.0.0.1 - - [30/May/2023 12:21:01] code 404, message Not Found
127.0.0.1 - - [30/May/2023 12:21:01] "GET /metrics HTTP/1.1" 404 -
127.0.0.1 - - [30/May/2023 12:21:04] code 404, message Not Found
127.0.0.1 - - [30/May/2023 12:21:04] "GET /metrics HTTP/1.1" 404 -
127.0.0.1 - - [30/May/2023 12:21:07] code 404, message Not Found
127.0.0.1 - - [30/May/2023 12:21:07] "GET /metrics HTTP/1.1" 404 -
127.0.0.1 - - [30/May/2023 12:21:10] code 404, message Not Found
127.0.0.1 - - [30/May/2023 12:21:10] "GET /metrics HTTP/1.1" 404 -
127.0.0.1 - - [30/May/2023 12:21:13] code 404, message Not Found
127.0.0.1 - - [30/May/2023 12:21:13] "GET /metrics HTTP/1.1" 404 -
127.0.0.1 - - [30/May/2023 12:21:16] code 404, message Not Found
127.0.0.1 - - [30/May/2023 12:21:16] "GET /metrics HTTP/1.1" 404 -
127.0.0.1 - - [30/May/2023 12:21:19] code 404, message Not Found
127.0.0.1 - - [30/May/2023 12:21:19] "GET /metrics HTTP/1.1" 404 -
Closing server running on port: 7860
INFO:Loading the extension "openai"...
Running on local URL: http://127.0.0.1:7860/
Running on public URL: https://0f095eaedadd0d8f1e.gradio.live/
This share link expires in 72 hours. For free permanent hosting and GPU upgrades (NEW!), check out Spaces: https://huggingface.co/spaces
127.0.0.1 - - [30/May/2023 12:21:55] code 404, message Not Found
127.0.0.1 - - [30/May/2023 12:21:55] "GET /v1 HTTP/1.1" 404 -
127.0.0.1 - - [30/May/2023 12:22:07] "POST /v1/completions HTTP/1.1" 200 -
----------------------------------------
Exception occurred during processing of request from ('127.0.0.1', 60196)
Traceback (most recent call last):
File "/usr/lib/python3.10/socketserver.py", line 683, in process_request_thread
self.finish_request(request, client_address)
File "/usr/lib/python3.10/socketserver.py", line 360, in finish_request
self.RequestHandlerClass(request, client_address, self)
File "/usr/lib/python3.10/socketserver.py", line 747, in __init__
self.handle()
File "/usr/lib/python3.10/http/server.py", line 433, in handle
self.handle_one_request()
File "/usr/lib/python3.10/http/server.py", line 421, in handle_one_request
method()
File "/content/text-generation-webui/extensions/openai/script.py", line 404, in do_POST
for a in generator:
File "/content/text-generation-webui/modules/text_generation.py", line 24, in generate_reply
for result in _generate_reply(*args, **kwargs):
File "/content/text-generation-webui/modules/text_generation.py", line 191, in _generate_reply
for reply in generate_func(question, original_question, seed, state, eos_token, stopping_strings, is_chat=is_chat):
File "/content/text-generation-webui/modules/text_generation.py", line 198, in generate_reply_HF
generate_params[k] = state[k]
KeyError: 'tfs'
```
I am using below code to hit the api -
```
OPENAI_API_KEY = "dummy"
os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
OPENAI_API_BASE = 'https://relative-flex-nose-useful.trycloudflare.com/v1'
os.environ['OPENAI_API_BASE'] = OPENAI_API_BASE
import os
import openai
openai.api_key = os.getenv("OPENAI_API_KEY")
openai.api_base = os.getenv("OPENAI_API_BASE")
response = openai.Completion.create(
model="dummy",
prompt="I am a highly intelligent question answering bot. If you ask me a question that is rooted in truth, I will give you the answer. If you ask me a question that is nonsense, trickery, or has no clear answer, I will respond with \"Unknown\".\n\nQ: What is human life expectancy in the United States?\nA: Human life expectancy in the United States is 78 years.\n\nQ: Who was president of the United States in 1955?\nA: Dwight D. Eisenhower was president of the United States in 1955.\n\nQ: Which party did he belong to?\nA: He belonged to the Republican Party.\n\nQ: What is the square root of banana?\nA: Unknown\n\nQ: How does a telescope work?\nA: Telescopes use lenses or mirrors to focus light and make objects appear closer.\n\nQ: Where were the 1992 Olympics held?\nA: The 1992 Olympics were held in Barcelona, Spain.\n\nQ: How many squigs are in a bonk?\nA: Unknown\n\nQ: Tell me something about vcovid\nA:",
temperature=0,
max_tokens=100,
top_p=1,
frequency_penalty=0.0,
presence_penalty=0.0,
stop=["\n"]
)
print(response)
```
I'm fixing the tfs error now, it's a new required parameter.
| 2023-05-30T16:35:43 |
|
oobabooga/text-generation-webui | 2,533 | oobabooga__text-generation-webui-2533 | [
"2505"
]
| 97f3fa843fea65fc3b89f56c47e34bf52e3a4d40 | diff --git a/extensions/openai/script.py b/extensions/openai/script.py
--- a/extensions/openai/script.py
+++ b/extensions/openai/script.py
@@ -20,6 +20,7 @@
debug = True if 'OPENEDAI_DEBUG' in os.environ else False
# Slightly different defaults for OpenAI's API
+# Data type is important, Ex. use 0.0 for a float 0
default_req_params = {
'max_new_tokens': 200,
'temperature': 1.0,
@@ -44,14 +45,14 @@
'no_repeat_ngram_size': 0,
'num_beams': 1,
'penalty_alpha': 0.0,
- 'length_penalty': 1,
+ 'length_penalty': 1.0,
'early_stopping': False,
'mirostat_mode': 0,
- 'mirostat_tau': 5,
+ 'mirostat_tau': 5.0,
'mirostat_eta': 0.1,
'ban_eos_token': False,
'skip_special_tokens': True,
- 'custom_stopping_strings': [],
+ 'custom_stopping_strings': ['\n###'],
}
# Optional, install the module and download the model to enable
@@ -64,8 +65,6 @@
st_model = os.environ["OPENEDAI_EMBEDDING_MODEL"] if "OPENEDAI_EMBEDDING_MODEL" in os.environ else "all-mpnet-base-v2"
embedding_model = None
-standard_stopping_strings = ['\nsystem:', '\nuser:', '\nhuman:', '\nassistant:', '\n###', ]
-
# little helper to get defaults if arg is present but None and should be the same type as default.
def default(dic, key, default):
val = dic.get(key, default)
@@ -86,31 +85,6 @@ def clamp(value, minvalue, maxvalue):
return max(minvalue, min(value, maxvalue))
-def deduce_template():
- # Alpaca is verbose so a good default prompt
- default_template = (
- "Below is an instruction that describes a task, paired with an input that provides further context. "
- "Write a response that appropriately completes the request.\n\n"
- "### Instruction:\n{instruction}\n\n### Input:\n{input}\n\n### Response:\n"
- )
-
- # Use the special instruction/input/response template for anything trained like Alpaca
- if shared.settings['instruction_template'] in ['Alpaca', 'Alpaca-Input']:
- return default_template
-
- try:
- instruct = yaml.safe_load(open(f"characters/instruction-following/{shared.settings['instruction_template']}.yaml", 'r'))
-
- template = instruct['turn_template']
- template = template\
- .replace('<|user|>', instruct.get('user', ''))\
- .replace('<|bot|>', instruct.get('bot', ''))\
- .replace('<|user-message|>', '{instruction}\n{input}')
- return instruct.get('context', '') + template[:template.find('<|bot-message|>')].rstrip(' ')
- except:
- return default_template
-
-
def float_list_to_base64(float_list):
# Convert the list to a float32 array that the OpenAPI client expects
float_array = np.array(float_list, dtype="float32")
@@ -139,8 +113,27 @@ def send_access_control_headers(self):
"Origin, Accept, X-Requested-With, Content-Type, "
"Access-Control-Request-Method, Access-Control-Request-Headers, "
"Authorization"
- )
-
+ )
+
+ def openai_error(self, message, code = 500, error_type = 'APIError', param = '', internal_message = ''):
+ self.send_response(code)
+ self.send_access_control_headers()
+ self.send_header('Content-Type', 'application/json')
+ self.end_headers()
+ error_resp = {
+ 'error': {
+ 'message': message,
+ 'code': code,
+ 'type': error_type,
+ 'param': param,
+ }
+ }
+ if internal_message:
+ error_resp['internal_message'] = internal_message
+
+ response = json.dumps(error_resp)
+ self.wfile.write(response.encode('utf-8'))
+
def do_OPTIONS(self):
self.send_response(200)
self.send_access_control_headers()
@@ -150,42 +143,24 @@ def do_OPTIONS(self):
def do_GET(self):
if self.path.startswith('/v1/models'):
-
self.send_response(200)
self.send_access_control_headers()
self.send_header('Content-Type', 'application/json')
self.end_headers()
- # TODO: list all models and allow model changes via API? Lora's?
+ # TODO: Lora's?
# This API should list capabilities, limits and pricing...
- models = [{
- "id": shared.model_name, # The real chat/completions model
- "object": "model",
- "owned_by": "user",
- "permission": []
- }, {
- "id": st_model, # The real sentence transformer embeddings model
- "object": "model",
- "owned_by": "user",
- "permission": []
- }, { # these are expected by so much, so include some here as a dummy
- "id": "gpt-3.5-turbo", # /v1/chat/completions
- "object": "model",
- "owned_by": "user",
- "permission": []
- }, {
- "id": "text-curie-001", # /v1/completions, 2k context
- "object": "model",
- "owned_by": "user",
- "permission": []
- }, {
- "id": "text-davinci-002", # /v1/embeddings text-embedding-ada-002:1536, text-davinci-002:768
- "object": "model",
- "owned_by": "user",
- "permission": []
- }]
-
- models.extend([{ "id": id, "object": "model", "owned_by": "user", "permission": [] } for id in get_available_models() ])
+ current_model_list = [ shared.model_name ] # The real chat/completions model
+ embeddings_model_list = [ st_model ] if embedding_model else [] # The real sentence transformer embeddings model
+ pseudo_model_list = [ # these are expected by so much, so include some here as a dummy
+ 'gpt-3.5-turbo', # /v1/chat/completions
+ 'text-curie-001', # /v1/completions, 2k context
+ 'text-davinci-002' # /v1/embeddings text-embedding-ada-002:1536, text-davinci-002:768
+ ]
+ available_model_list = get_available_models()
+ all_model_list = current_model_list + embeddings_model_list + pseudo_model_list + available_model_list
+
+ models = [{ "id": id, "object": "model", "owned_by": "user", "permission": [] } for id in all_model_list ]
response = ''
if self.path == '/v1/models':
@@ -203,6 +178,7 @@ def do_GET(self):
})
self.wfile.write(response.encode('utf-8'))
+
elif '/billing/usage' in self.path:
# Ex. /v1/dashboard/billing/usage?start_date=2023-05-01&end_date=2023-05-31
self.send_response(200)
@@ -214,6 +190,7 @@ def do_GET(self):
"total_usage": 0,
})
self.wfile.write(response.encode('utf-8'))
+
else:
self.send_error(404)
@@ -227,6 +204,11 @@ def do_POST(self):
print(body)
if '/completions' in self.path or '/generate' in self.path:
+
+ if not shared.model:
+ self.openai_error("No model loaded.")
+ return
+
is_legacy = '/generate' in self.path
is_chat = 'chat' in self.path
resp_list = 'data' if is_legacy else 'choices'
@@ -238,13 +220,16 @@ def do_POST(self):
cmpl_id = "chatcmpl-%d" % (created_time) if is_chat else "conv-%d" % (created_time)
+ # Request Parameters
# Try to use openai defaults or map them to something with the same intent
- stopping_strings = default(shared.settings, 'custom_stopping_strings', [])
+ req_params = default_req_params.copy()
+ req_params['custom_stopping_strings'] = default_req_params['custom_stopping_strings'].copy()
+
if 'stop' in body:
if isinstance(body['stop'], str):
- stopping_strings = [body['stop']]
+ req_params['custom_stopping_strings'].extend([body['stop']])
elif isinstance(body['stop'], list):
- stopping_strings = body['stop']
+ req_params['custom_stopping_strings'].extend(body['stop'])
truncation_length = default(shared.settings, 'truncation_length', 2048)
truncation_length = clamp(default(body, 'truncation_length', truncation_length), 1, truncation_length)
@@ -255,8 +240,6 @@ def do_POST(self):
max_tokens = default(body, max_tokens_str, default(shared.settings, 'max_new_tokens', default_max_tokens))
# if the user assumes OpenAI, the max_tokens is way too large - try to ignore it unless it's small enough
- req_params = default_req_params.copy()
-
req_params['max_new_tokens'] = max_tokens
req_params['truncation_length'] = truncation_length
req_params['temperature'] = clamp(default(body, 'temperature', default_req_params['temperature']), 0.001, 1.999) # fixup absolute 0.0
@@ -319,9 +302,14 @@ def do_POST(self):
'prompt': bot_prompt,
}
+ if instruct['user']: # WizardLM and some others have no user prompt.
+ req_params['custom_stopping_strings'].extend(['\n' + instruct['user'], instruct['user']])
+
if debug:
print(f"Loaded instruction role format: {shared.settings['instruction_template']}")
except:
+ req_params['custom_stopping_strings'].extend(['\nuser:'])
+
if debug:
print("Loaded default role format.")
@@ -396,11 +384,6 @@ def do_POST(self):
print(f"Warning: Ignoring max_new_tokens ({req_params['max_new_tokens']}), too large for the remaining context. Remaining tokens: {req_params['truncation_length'] - token_count}")
req_params['max_new_tokens'] = req_params['truncation_length'] - token_count
print(f"Warning: Set max_new_tokens = {req_params['max_new_tokens']}")
-
- # pass with some expected stop strings.
- # some strange cases of "##| Instruction: " sneaking through.
- stopping_strings += standard_stopping_strings
- req_params['custom_stopping_strings'] = stopping_strings
if req_params['stream']:
shared.args.chat = True
@@ -423,19 +406,17 @@ def do_POST(self):
chunk[resp_list][0]["message"] = {'role': 'assistant', 'content': ''}
chunk[resp_list][0]["delta"] = {'role': 'assistant', 'content': ''}
- data_chunk = 'data: ' + json.dumps(chunk) + '\r\n\r\n'
- chunk_size = hex(len(data_chunk))[2:] + '\r\n'
- response = chunk_size + data_chunk
+ response = 'data: ' + json.dumps(chunk) + '\r\n\r\n'
self.wfile.write(response.encode('utf-8'))
# generate reply #######################################
if debug:
- print({'prompt': prompt, 'req_params': req_params, 'stopping_strings': stopping_strings})
- generator = generate_reply(prompt, req_params, stopping_strings=stopping_strings, is_chat=False)
+ print({'prompt': prompt, 'req_params': req_params})
+ generator = generate_reply(prompt, req_params, is_chat=False)
answer = ''
seen_content = ''
- longest_stop_len = max([len(x) for x in stopping_strings])
+ longest_stop_len = max([len(x) for x in req_params['custom_stopping_strings']] + [0])
for a in generator:
answer = a
@@ -444,7 +425,7 @@ def do_POST(self):
len_seen = len(seen_content)
search_start = max(len_seen - longest_stop_len, 0)
- for string in stopping_strings:
+ for string in req_params['custom_stopping_strings']:
idx = answer.find(string, search_start)
if idx != -1:
answer = answer[:idx] # clip it.
@@ -457,7 +438,7 @@ def do_POST(self):
# is completed, buffer and generate more, don't send it
buffer_and_continue = False
- for string in stopping_strings:
+ for string in req_params['custom_stopping_strings']:
for j in range(len(string) - 1, 0, -1):
if answer[-j:] == string[:j]:
buffer_and_continue = True
@@ -498,9 +479,7 @@ def do_POST(self):
# So yeah... do both methods? delta and messages.
chunk[resp_list][0]['message'] = {'content': new_content}
chunk[resp_list][0]['delta'] = {'content': new_content}
- data_chunk = 'data: ' + json.dumps(chunk) + '\r\n\r\n'
- chunk_size = hex(len(data_chunk))[2:] + '\r\n'
- response = chunk_size + data_chunk
+ response = 'data: ' + json.dumps(chunk) + '\r\n\r\n'
self.wfile.write(response.encode('utf-8'))
completion_token_count += len(encode(new_content)[0])
@@ -527,10 +506,7 @@ def do_POST(self):
chunk[resp_list][0]['message'] = {'content': ''}
chunk[resp_list][0]['delta'] = {'content': ''}
- data_chunk = 'data: ' + json.dumps(chunk) + '\r\n\r\n'
- chunk_size = hex(len(data_chunk))[2:] + '\r\n'
- done = 'data: [DONE]\r\n\r\n'
- response = chunk_size + data_chunk + done
+ response = 'data: ' + json.dumps(chunk) + '\r\n\r\ndata: [DONE]\r\n\r\n'
self.wfile.write(response.encode('utf-8'))
# Finished if streaming.
if debug:
@@ -574,7 +550,12 @@ def do_POST(self):
response = json.dumps(resp)
self.wfile.write(response.encode('utf-8'))
+
elif '/edits' in self.path:
+ if not shared.model:
+ self.openai_error("No model loaded.")
+ return
+
self.send_response(200)
self.send_access_control_headers()
self.send_header('Content-Type', 'application/json')
@@ -586,15 +567,42 @@ def do_POST(self):
instruction = body['instruction']
input = body.get('input', '')
- instruction_template = deduce_template()
+ # Request parameters
+ req_params = default_req_params.copy()
+
+ # Alpaca is verbose so a good default prompt
+ default_template = (
+ "Below is an instruction that describes a task, paired with an input that provides further context. "
+ "Write a response that appropriately completes the request.\n\n"
+ "### Instruction:\n{instruction}\n\n### Input:\n{input}\n\n### Response:\n"
+ )
+
+ instruction_template = default_template
+ req_params['custom_stopping_strings'] = [ '\n###' ]
+
+ # Use the special instruction/input/response template for anything trained like Alpaca
+ if not (shared.settings['instruction_template'] in ['Alpaca', 'Alpaca-Input']):
+ try:
+ instruct = yaml.safe_load(open(f"characters/instruction-following/{shared.settings['instruction_template']}.yaml", 'r'))
+
+ template = instruct['turn_template']
+ template = template\
+ .replace('<|user|>', instruct.get('user', ''))\
+ .replace('<|bot|>', instruct.get('bot', ''))\
+ .replace('<|user-message|>', '{instruction}\n{input}')
+
+ instruction_template = instruct.get('context', '') + template[:template.find('<|bot-message|>')].rstrip(' ')
+ if instruct['user']:
+ req_params['custom_stopping_strings'] = [ '\n' + instruct['user'], instruct['user'] ]
+ except:
+ pass
+
edit_task = instruction_template.format(instruction=instruction, input=input)
truncation_length = default(shared.settings, 'truncation_length', 2048)
token_count = len(encode(edit_task)[0])
max_tokens = truncation_length - token_count
- req_params = default_req_params.copy()
-
req_params['max_new_tokens'] = max_tokens
req_params['truncation_length'] = truncation_length
req_params['temperature'] = clamp(default(body, 'temperature', default_req_params['temperature']), 0.001, 1.999) # fixup absolute 0.0
@@ -605,7 +613,7 @@ def do_POST(self):
if debug:
print({'edit_template': edit_task, 'req_params': req_params, 'token_count': token_count})
- generator = generate_reply(edit_task, req_params, stopping_strings=standard_stopping_strings, is_chat=False)
+ generator = generate_reply(edit_task, req_params, is_chat=False)
answer = ''
for a in generator:
@@ -636,6 +644,7 @@ def do_POST(self):
response = json.dumps(resp)
self.wfile.write(response.encode('utf-8'))
+
elif '/images/generations' in self.path and 'SD_WEBUI_URL' in os.environ:
# Stable Diffusion callout wrapper for txt2img
# Low effort implementation for compatibility. With only "prompt" being passed and assuming DALL-E
@@ -682,6 +691,7 @@ def do_POST(self):
response = json.dumps(resp)
self.wfile.write(response.encode('utf-8'))
+
elif '/embeddings' in self.path and embedding_model is not None:
self.send_response(200)
self.send_access_control_headers()
@@ -715,6 +725,7 @@ def enc_emb(emb):
if debug:
print(f"Embeddings return size: {len(embeddings[0])}, number: {len(embeddings)}")
self.wfile.write(response.encode('utf-8'))
+
elif '/moderations' in self.path:
# for now do nothing, just don't error.
self.send_response(200)
@@ -763,6 +774,7 @@ def enc_emb(emb):
}]
})
self.wfile.write(response.encode('utf-8'))
+
else:
print(self.path, self.headers)
self.send_error(404)
| [extensions/openai] Improve error handling with no model loaded
### Describe the bug
I was using a few days old version of webui (githash `6627f7f`) and openAI extension worked great.
After updating to latest ([19f7868](https://github.com/oobabooga/text-generation-webui/commit/19f78684e6d32d43cd5ce3ae82d6f2216421b9ae)), openAI extension throws an error on the `/completions` endpoint.
### Is there an existing issue for this?
- [X] I have searched the existing issues
### Reproduction
* enable openai extension
* run the completions api (via any openai supporting tool)
### Screenshot
_No response_
### Logs
```python
127.0.0.1 - - [03/Jun/2023 08:52:27] "POST /v1/chat/completions HTTP/1.1" 200 -
----------------------------------------
Exception occurred during processing of request from ('127.0.0.1', 41928)
Traceback (most recent call last):
File "/home/user/apps/anaconda3/envs/textgen/lib/python3.10/socketserver.py", line 683, in process_request_thread
self.finish_request(request, client_address)
File "/home/user/apps/anaconda3/envs/textgen/lib/python3.10/socketserver.py", line 360, in finish_request
self.RequestHandlerClass(request, client_address, self)
File "/home/user/apps/anaconda3/envs/textgen/lib/python3.10/socketserver.py", line 747, in __init__
self.handle()
File "/home/user/apps/anaconda3/envs/textgen/lib/python3.10/http/server.py", line 433, in handle
self.handle_one_request()
File "/home/user/apps/anaconda3/envs/textgen/lib/python3.10/http/server.py", line 421, in handle_one_request
method()
File "/mnt/nvbig/ai/text-generation-webui/extensions/openai/script.py", line 355, in do_POST
system_token_count = len(encode(system_msg)[0])
File "/mnt/ai/text-generation-webui/modules/text_generation.py", line 44, in encode
input_ids = shared.tokenizer.encode(str(prompt), return_tensors='pt', add_special_tokens=add_special_tokens)
AttributeError: 'NoneType' object has no attribute 'encode'
----------------------------------------
```
### System Info
```shell
linux
```
| This was a derp on my part.
This error was thrown because I didn't have a model loaded.
It would be nice to catch this error and output a clean error message to console or via the return on the completions api though (http 500 maybe?).
Leaving open in case someone wants to catch this no-model-loaded error case. Otherwise feel free to close.
Yes, you're right, that's a terrible error message. Error handling improvements planned, you can leave this open but can you change the bug to enhancement and subject "[extensions/openai] Improve error handling with no model loaded"?
Much appreciated, thanks.
Thanks for taking a look @matatonic . Great job on the extension by the way.
Tried it with both the official node.js Openai client as well as an unofficial [node.js openai NPM package](https://github.com/fern-openai/openai-node) (that has streaming support) and they both worked with this extension.
Only tricky part is matching the parameter settings from text-generation-ui to openai's parameters.. | 2023-06-05T16:44:36 |
|
oobabooga/text-generation-webui | 2,643 | oobabooga__text-generation-webui-2643 | [
"2482"
]
| 5d2a8b31be17a2992308d58b674274375a3f360c | diff --git a/modules/chat.py b/modules/chat.py
--- a/modules/chat.py
+++ b/modules/chat.py
@@ -513,11 +513,16 @@ def load_character(character, name1, name2, instruct=False):
if character != 'None':
folder = 'characters' if not instruct else 'characters/instruction-following'
picture = generate_pfp_cache(character)
+ filepath = None
for extension in ["yml", "yaml", "json"]:
filepath = Path(f'{folder}/{character}.{extension}')
if filepath.exists():
break
+ if filepath is None:
+ logger.error(f"Could not find character file for {character} in {folder} folder. Please check your spelling.")
+ return name1, name2, picture, greeting, context, turn_template.replace("\n", r"\n")
+
file_contents = open(filepath, 'r', encoding='utf-8').read()
data = json.loads(file_contents) if extension == "json" else yaml.safe_load(file_contents)
| Small bug, when arbitrary loading character.json that doesn't exist
### Describe the bug
Things will blow if character json doesn't exist (that webui loads arbitrary after model load)
text-generation-webui\modules\chat.py", line 513, in load_character
file_contents = open(filepath, 'r', encoding='utf-8').read()
FileNotFoundError: [Errno 2] No such file or directory:
Probably wrap it in
try:
....
except FileNotFoundError:
### Is there an existing issue for this?
- [X] I have searched the existing issues
### Reproduction
if json is missing
### Screenshot
_No response_
### Logs
```shell
File "H:\oobabooga_windows\installer_files\env\lib\site-packages\anyio\_backends\_asyncio.py", line 867, in run
result = context.run(func, *args)
File "H:\oobabooga_windows\text-generation-webui\modules\chat.py", line 513, in load_character
file_contents = open(filepath, 'r', encoding='utf-8').read()
```
### System Info
```shell
windows
```
| 2023-06-12T06:25:29 |
||
oobabooga/text-generation-webui | 2,849 | oobabooga__text-generation-webui-2849 | [
"2852",
"2852"
]
| cec5fb0ef6a2d74901f70824e15089b17670f2c8 | diff --git a/extensions/openai/script.py b/extensions/openai/script.py
--- a/extensions/openai/script.py
+++ b/extensions/openai/script.py
@@ -54,7 +54,7 @@
'mirostat_eta': 0.1,
'ban_eos_token': False,
'skip_special_tokens': True,
- 'custom_stopping_strings': ['\n###'],
+ 'custom_stopping_strings': '',
}
# Optional, install the module and download the model to enable
@@ -254,7 +254,7 @@ def do_POST(self):
return
is_legacy = '/generate' in self.path
- is_chat = 'chat' in self.path
+ is_chat_request = 'chat' in self.path
resp_list = 'data' if is_legacy else 'choices'
# XXX model is ignored for now
@@ -262,23 +262,23 @@ def do_POST(self):
model = shared.model_name
created_time = int(time.time())
- cmpl_id = "chatcmpl-%d" % (created_time) if is_chat else "conv-%d" % (created_time)
+ cmpl_id = "chatcmpl-%d" % (created_time) if is_chat_request else "conv-%d" % (created_time)
# Request Parameters
# Try to use openai defaults or map them to something with the same intent
req_params = default_req_params.copy()
- req_params['custom_stopping_strings'] = default_req_params['custom_stopping_strings'].copy()
+ stopping_strings = []
if 'stop' in body:
if isinstance(body['stop'], str):
- req_params['custom_stopping_strings'].extend([body['stop']])
+ stopping_strings.extend([body['stop']])
elif isinstance(body['stop'], list):
- req_params['custom_stopping_strings'].extend(body['stop'])
+ stopping_strings.extend(body['stop'])
truncation_length = default(shared.settings, 'truncation_length', 2048)
truncation_length = clamp(default(body, 'truncation_length', truncation_length), 1, truncation_length)
- default_max_tokens = truncation_length if is_chat else 16 # completions default, chat default is 'inf' so we need to cap it.
+ default_max_tokens = truncation_length if is_chat_request else 16 # completions default, chat default is 'inf' so we need to cap it.
max_tokens_str = 'length' if is_legacy else 'max_tokens'
max_tokens = default(body, max_tokens_str, default(shared.settings, 'max_new_tokens', default_max_tokens))
@@ -295,9 +295,11 @@ def do_POST(self):
req_params['seed'] = shared.settings.get('seed', default_req_params['seed'])
req_params['add_bos_token'] = shared.settings.get('add_bos_token', default_req_params['add_bos_token'])
+ is_streaming = req_params['stream']
+
self.send_response(200)
self.send_access_control_headers()
- if req_params['stream']:
+ if is_streaming:
self.send_header('Content-Type', 'text/event-stream')
self.send_header('Cache-Control', 'no-cache')
# self.send_header('Connection', 'keep-alive')
@@ -311,7 +313,7 @@ def do_POST(self):
stream_object_type = ''
object_type = ''
- if is_chat:
+ if is_chat_request:
# Chat Completions
stream_object_type = 'chat.completions.chunk'
object_type = 'chat.completions'
@@ -347,20 +349,22 @@ def do_POST(self):
'prompt': bot_prompt,
}
- if instruct['user']: # WizardLM and some others have no user prompt.
- req_params['custom_stopping_strings'].extend(['\n' + instruct['user'], instruct['user']])
+ if 'Alpaca' in shared.settings['instruction_template']:
+ stopping_strings.extend(['\n###'])
+ elif instruct['user']: # WizardLM and some others have no user prompt.
+ stopping_strings.extend(['\n' + instruct['user'], instruct['user']])
if debug:
print(f"Loaded instruction role format: {shared.settings['instruction_template']}")
except Exception as e:
- req_params['custom_stopping_strings'].extend(['\nuser:'])
+ stopping_strings.extend(['\nuser:'])
print(f"Exception: When loading characters/instruction-following/{shared.settings['instruction_template']}.yaml: {repr(e)}")
print("Warning: Loaded default instruction-following template for model.")
else:
- req_params['custom_stopping_strings'].extend(['\nuser:'])
+ stopping_strings.extend(['\nuser:'])
print("Warning: Loaded default instruction-following template for model.")
system_msgs = []
@@ -391,7 +395,7 @@ def do_POST(self):
system_msg = system_msg + '\n'
system_token_count = len(encode(system_msg)[0])
- remaining_tokens = req_params['truncation_length'] - system_token_count
+ remaining_tokens = truncation_length - system_token_count
chat_msg = ''
while chat_msgs:
@@ -424,20 +428,19 @@ def do_POST(self):
return
token_count = len(encode(prompt)[0])
- if token_count >= req_params['truncation_length']:
+ if token_count >= truncation_length:
new_len = int(len(prompt) * shared.settings['truncation_length'] / token_count)
prompt = prompt[-new_len:]
new_token_count = len(encode(prompt)[0])
print(f"Warning: truncating prompt to {new_len} characters, was {token_count} tokens. Now: {new_token_count} tokens.")
token_count = new_token_count
- if req_params['truncation_length'] - token_count < req_params['max_new_tokens']:
- print(f"Warning: Ignoring max_new_tokens ({req_params['max_new_tokens']}), too large for the remaining context. Remaining tokens: {req_params['truncation_length'] - token_count}")
- req_params['max_new_tokens'] = req_params['truncation_length'] - token_count
+ if truncation_length - token_count < req_params['max_new_tokens']:
+ print(f"Warning: Ignoring max_new_tokens ({req_params['max_new_tokens']}), too large for the remaining context. Remaining tokens: {truncation_length - token_count}")
+ req_params['max_new_tokens'] = truncation_length - token_count
print(f"Warning: Set max_new_tokens = {req_params['max_new_tokens']}")
- if req_params['stream']:
- shared.args.chat = True
+ if is_streaming:
# begin streaming
chunk = {
"id": cmpl_id,
@@ -463,11 +466,11 @@ def do_POST(self):
# generate reply #######################################
if debug:
print({'prompt': prompt, 'req_params': req_params})
- generator = generate_reply(prompt, req_params, stopping_strings=req_params['custom_stopping_strings'], is_chat=False)
+ generator = generate_reply(prompt, req_params, stopping_strings=stopping_strings, is_chat=False)
answer = ''
seen_content = ''
- longest_stop_len = max([len(x) for x in req_params['custom_stopping_strings']] + [0])
+ longest_stop_len = max([len(x) for x in stopping_strings] + [0])
for a in generator:
answer = a
@@ -476,7 +479,7 @@ def do_POST(self):
len_seen = len(seen_content)
search_start = max(len_seen - longest_stop_len, 0)
- for string in req_params['custom_stopping_strings']:
+ for string in stopping_strings:
idx = answer.find(string, search_start)
if idx != -1:
answer = answer[:idx] # clip it.
@@ -489,7 +492,7 @@ def do_POST(self):
# is completed, buffer and generate more, don't send it
buffer_and_continue = False
- for string in req_params['custom_stopping_strings']:
+ for string in stopping_strings:
for j in range(len(string) - 1, 0, -1):
if answer[-j:] == string[:j]:
buffer_and_continue = True
@@ -501,7 +504,7 @@ def do_POST(self):
if buffer_and_continue:
continue
- if req_params['stream']:
+ if is_streaming:
# Streaming
new_content = answer[len_seen:]
@@ -534,7 +537,7 @@ def do_POST(self):
self.wfile.write(response.encode('utf-8'))
completion_token_count += len(encode(new_content)[0])
- if req_params['stream']:
+ if is_streaming:
chunk = {
"id": cmpl_id,
"object": stream_object_type,
@@ -575,7 +578,7 @@ def do_POST(self):
completion_token_count = len(encode(answer)[0])
stop_reason = "stop"
- if token_count + completion_token_count >= req_params['truncation_length']:
+ if token_count + completion_token_count >= truncation_length:
stop_reason = "length"
resp = {
@@ -594,7 +597,7 @@ def do_POST(self):
}
}
- if is_chat:
+ if is_chat_request:
resp[resp_list][0]["message"] = {"role": "assistant", "content": answer}
else:
resp[resp_list][0]["text"] = answer
@@ -620,7 +623,7 @@ def do_POST(self):
# Request parameters
req_params = default_req_params.copy()
- req_params['custom_stopping_strings'] = default_req_params['custom_stopping_strings'].copy()
+ stopping_strings = []
# Alpaca is verbose so a good default prompt
default_template = (
@@ -632,26 +635,29 @@ def do_POST(self):
instruction_template = default_template
# Use the special instruction/input/response template for anything trained like Alpaca
- if shared.settings['instruction_template'] and not (shared.settings['instruction_template'] in ['Alpaca', 'Alpaca-Input']):
- try:
- instruct = yaml.safe_load(open(f"characters/instruction-following/{shared.settings['instruction_template']}.yaml", 'r'))
-
- template = instruct['turn_template']
- template = template\
- .replace('<|user|>', instruct.get('user', ''))\
- .replace('<|bot|>', instruct.get('bot', ''))\
- .replace('<|user-message|>', '{instruction}\n{input}')
+ if shared.settings['instruction_template']:
+ if 'Alpaca' in shared.settings['instruction_template']:
+ stopping_strings.extend(['\n###'])
+ else:
+ try:
+ instruct = yaml.safe_load(open(f"characters/instruction-following/{shared.settings['instruction_template']}.yaml", 'r'))
- instruction_template = instruct.get('context', '') + template[:template.find('<|bot-message|>')].rstrip(' ')
- if instruct['user']:
- req_params['custom_stopping_strings'].extend(['\n' + instruct['user'], instruct['user'] ])
+ template = instruct['turn_template']
+ template = template\
+ .replace('<|user|>', instruct.get('user', ''))\
+ .replace('<|bot|>', instruct.get('bot', ''))\
+ .replace('<|user-message|>', '{instruction}\n{input}')
- except Exception as e:
- instruction_template = default_template
- print(f"Exception: When loading characters/instruction-following/{shared.settings['instruction_template']}.yaml: {repr(e)}")
- print("Warning: Loaded default instruction-following template (Alpaca) for model.")
+ instruction_template = instruct.get('context', '') + template[:template.find('<|bot-message|>')].rstrip(' ')
+ if instruct['user']:
+ stopping_strings.extend(['\n' + instruct['user'], instruct['user'] ])
+ except Exception as e:
+ instruction_template = default_template
+ print(f"Exception: When loading characters/instruction-following/{shared.settings['instruction_template']}.yaml: {repr(e)}")
+ print("Warning: Loaded default instruction-following template (Alpaca) for model.")
else:
+ stopping_strings.extend(['\n###'])
print("Warning: Loaded default instruction-following template (Alpaca) for model.")
@@ -671,9 +677,9 @@ def do_POST(self):
if debug:
print({'edit_template': edit_task, 'req_params': req_params, 'token_count': token_count})
- generator = generate_reply(edit_task, req_params, stopping_strings=req_params['custom_stopping_strings'], is_chat=False)
+ generator = generate_reply(edit_task, req_params, stopping_strings=stopping_strings, is_chat=False)
- longest_stop_len = max([len(x) for x in req_params['custom_stopping_strings']] + [0])
+ longest_stop_len = max([len(x) for x in stopping_strings] + [0])
answer = ''
seen_content = ''
for a in generator:
@@ -683,7 +689,7 @@ def do_POST(self):
len_seen = len(seen_content)
search_start = max(len_seen - longest_stop_len, 0)
- for string in req_params['custom_stopping_strings']:
+ for string in stopping_strings:
idx = answer.find(string, search_start)
if idx != -1:
answer = answer[:idx] # clip it.
| OpenAI API reply TypeError
### Describe the bug
ERROR encountered while replying other front ends (e.g. langflow):
TypeError: must be str, not list
Seems to be something wrong with stream-reply
Full log:
2023-06-25 03:20:37 INFO:Loaded the model in 14.14 seconds.
2023-06-25 03:20:37 INFO:Loading the extension "openai"...
2023-06-25 03:20:38 INFO:Loading the extension "gallery"...
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
Loaded embedding model: all-mpnet-base-v2, max sequence length: 384
Starting OpenAI compatible api:
OPENAI_API_BASE=http://127.0.0.1:5001/v1
127.0.0.1 - - [25/Jun/2023 03:21:11] "POST /v1/chat/completions HTTP/1.1" 200 -
Host: 127.0.0.1:5001
X-OpenAI-Client-User-Agent: {"bindings_version": "0.27.8", "httplib": "requests", "lang": "python", "lang_version": "3.10.8", "platform": "Windows-10-10.0.22621-SP0", "publisher": "openai", "uname": "Windows 10 10.0.22621 AMD64"}
User-Agent: OpenAI/v1 PythonBindings/0.27.8
Authorization: Bearer sk-12345
Content-Type: application/json
Accept: */*
Accept-Encoding: gzip, deflate
Content-Length: 413
{'messages': [{'role': 'user', 'content': 'The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.\n\nCurrent conversation:\n\nHuman: Hello\nAI:'}], 'model': 'gpt-3.5-turbo', 'max_tokens': None, 'stream': True, 'n': 1, 'temperature': 0.7}
Loaded instruction role format: Vicuna-v0
{'prompt': "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n### Human: The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.\n\nCurrent conversation:\n\nHuman: Hello\nAI:\n### Assistant:", 'req_params': {'max_new_tokens': 1024, 'temperature': 0.7, 'top_p': 1.0, 'top_k': 1, 'repetition_penalty': 1.18, 'encoder_repetition_penalty': 1.0, 'suffix': None, 'stream': True, 'echo': False, 'seed': -1, 'truncation_length': 2048, 'add_bos_token': True, 'do_sample': True, 'typical_p': 1.0, 'epsilon_cutoff': 0.0, 'eta_cutoff': 0.0, 'tfs': 1.0, 'top_a': 0.0, 'min_length': 0, 'no_repeat_ngram_size': 0, 'num_beams': 1, 'penalty_alpha': 0.0, 'length_penalty': 1.0, 'early_stopping': False, 'mirostat_mode': 0, 'mirostat_tau': 5.0, 'mirostat_eta': 0.1, 'ban_eos_token': False, 'skip_special_tokens': True, 'custom_stopping_strings': ['\n###', '\n### Human:', '### Human:']}}
Exception ignored in: <generator object generate_reply_custom at 0x000001D4CFDD4F90>
Traceback (most recent call last):
File "D:\PyCharm Community Edition 2022.2.3\Projects\text-generation-webui\modules\text_generation.py", line 327, in generate_reply_custom
print(f'Output generated in {(t1-t0):.2f} seconds ({new_tokens/(t1-t0):.2f} tokens/s, {new_tokens} tokens, context {original_tokens}, seed {seed})')
ZeroDivisionError: float division by zero
----------------------------------------
Exception occurred during processing of request from ('127.0.0.1', 52167)
Traceback (most recent call last):
File "D:\AnaConda\envs\NLP\lib\socketserver.py", line 683, in process_request_thread
self.finish_request(request, client_address)
File "D:\AnaConda\envs\NLP\lib\socketserver.py", line 360, in finish_request
self.RequestHandlerClass(request, client_address, self)
File "D:\AnaConda\envs\NLP\lib\socketserver.py", line 747, in __init__
self.handle()
File "D:\AnaConda\envs\NLP\lib\http\server.py", line 432, in handle
self.handle_one_request()
File "D:\AnaConda\envs\NLP\lib\http\server.py", line 420, in handle_one_request
method()
File "D:\PyCharm Community Edition 2022.2.3\Projects\text-generation-webui\extensions\openai\script.py", line 472, in do_POST
for a in generator:
File "D:\PyCharm Community Edition 2022.2.3\Projects\text-generation-webui\modules\text_generation.py", line 23, in generate_reply
for result in _generate_reply(*args, **kwargs):
File "D:\PyCharm Community Edition 2022.2.3\Projects\text-generation-webui\modules\text_generation.py", line 210, in _generate_reply
reply, stop_found = apply_stopping_strings(reply, all_stop_strings)
File "D:\PyCharm Community Edition 2022.2.3\Projects\text-generation-webui\modules\text_generation.py", line 148, in apply_stopping_strings
idx = reply.find(string)
TypeError: must be str, not list
### Is there an existing issue for this?
- [X] I have searched the existing issues
### Reproduction
flags:
--chat --gpu-memory 22 --model Vicuna-33B-GPTQ-4bit --trust-remote-code --loader exllama --extensions openai
webui was working well.
### Screenshot
_No response_
### Logs
```shell
2023-06-25 03:20:37 INFO:Loaded the model in 14.14 seconds.
2023-06-25 03:20:37 INFO:Loading the extension "openai"...
2023-06-25 03:20:38 INFO:Loading the extension "gallery"...
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
Loaded embedding model: all-mpnet-base-v2, max sequence length: 384
Starting OpenAI compatible api:
OPENAI_API_BASE=http://127.0.0.1:5001/v1
Output generated in 2.19 seconds (12.33 tokens/s, 27 tokens, context 43, seed 951727781)
127.0.0.1 - - [25/Jun/2023 03:21:11] "POST /v1/chat/completions HTTP/1.1" 200 -
Host: 127.0.0.1:5001
X-OpenAI-Client-User-Agent: {"bindings_version": "0.27.8", "httplib": "requests", "lang": "python", "lang_version": "3.10.8", "platform": "Windows-10-10.0.22621-SP0", "publisher": "openai", "uname": "Windows 10 10.0.22621 AMD64"}
User-Agent: OpenAI/v1 PythonBindings/0.27.8
Authorization: Bearer sk-12345
Content-Type: application/json
Accept: */*
Accept-Encoding: gzip, deflate
Content-Length: 413
{'messages': [{'role': 'user', 'content': 'The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.\n\nCurrent conversation:\n\nHuman: Hello\nAI:'}], 'model': 'gpt-3.5-turbo', 'max_tokens': None, 'stream': True, 'n': 1, 'temperature': 0.7}
Loaded instruction role format: Vicuna-v0
{'prompt': "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n### Human: The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.\n\nCurrent conversation:\n\nHuman: Hello\nAI:\n### Assistant:", 'req_params': {'max_new_tokens': 1024, 'temperature': 0.7, 'top_p': 1.0, 'top_k': 1, 'repetition_penalty': 1.18, 'encoder_repetition_penalty': 1.0, 'suffix': None, 'stream': True, 'echo': False, 'seed': -1, 'truncation_length': 2048, 'add_bos_token': True, 'do_sample': True, 'typical_p': 1.0, 'epsilon_cutoff': 0.0, 'eta_cutoff': 0.0, 'tfs': 1.0, 'top_a': 0.0, 'min_length': 0, 'no_repeat_ngram_size': 0, 'num_beams': 1, 'penalty_alpha': 0.0, 'length_penalty': 1.0, 'early_stopping': False, 'mirostat_mode': 0, 'mirostat_tau': 5.0, 'mirostat_eta': 0.1, 'ban_eos_token': False, 'skip_special_tokens': True, 'custom_stopping_strings': ['\n###', '\n### Human:', '### Human:']}}
Exception ignored in: <generator object generate_reply_custom at 0x000001D4CFDD4F90>
Traceback (most recent call last):
File "D:\PyCharm Community Edition 2022.2.3\Projects\text-generation-webui\modules\text_generation.py", line 327, in generate_reply_custom
print(f'Output generated in {(t1-t0):.2f} seconds ({new_tokens/(t1-t0):.2f} tokens/s, {new_tokens} tokens, context {original_tokens}, seed {seed})')
ZeroDivisionError: float division by zero
----------------------------------------
Exception occurred during processing of request from ('127.0.0.1', 52167)
Traceback (most recent call last):
File "D:\AnaConda\envs\NLP\lib\socketserver.py", line 683, in process_request_thread
self.finish_request(request, client_address)
File "D:\AnaConda\envs\NLP\lib\socketserver.py", line 360, in finish_request
self.RequestHandlerClass(request, client_address, self)
File "D:\AnaConda\envs\NLP\lib\socketserver.py", line 747, in __init__
self.handle()
File "D:\AnaConda\envs\NLP\lib\http\server.py", line 432, in handle
self.handle_one_request()
File "D:\AnaConda\envs\NLP\lib\http\server.py", line 420, in handle_one_request
method()
File "D:\PyCharm Community Edition 2022.2.3\Projects\text-generation-webui\extensions\openai\script.py", line 472, in do_POST
for a in generator:
File "D:\PyCharm Community Edition 2022.2.3\Projects\text-generation-webui\modules\text_generation.py", line 23, in generate_reply
for result in _generate_reply(*args, **kwargs):
File "D:\PyCharm Community Edition 2022.2.3\Projects\text-generation-webui\modules\text_generation.py", line 210, in _generate_reply
reply, stop_found = apply_stopping_strings(reply, all_stop_strings)
File "D:\PyCharm Community Edition 2022.2.3\Projects\text-generation-webui\modules\text_generation.py", line 148, in apply_stopping_strings
idx = reply.find(string)
TypeError: must be str, not list
```
### System Info
```shell
OS: Windows 11
GPU: Nvidia Geforce RTX 4090 24G * 1
```
OpenAI API reply TypeError
### Describe the bug
ERROR encountered while replying other front ends (e.g. langflow):
TypeError: must be str, not list
Seems to be something wrong with stream-reply
Full log:
2023-06-25 03:20:37 INFO:Loaded the model in 14.14 seconds.
2023-06-25 03:20:37 INFO:Loading the extension "openai"...
2023-06-25 03:20:38 INFO:Loading the extension "gallery"...
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
Loaded embedding model: all-mpnet-base-v2, max sequence length: 384
Starting OpenAI compatible api:
OPENAI_API_BASE=http://127.0.0.1:5001/v1
127.0.0.1 - - [25/Jun/2023 03:21:11] "POST /v1/chat/completions HTTP/1.1" 200 -
Host: 127.0.0.1:5001
X-OpenAI-Client-User-Agent: {"bindings_version": "0.27.8", "httplib": "requests", "lang": "python", "lang_version": "3.10.8", "platform": "Windows-10-10.0.22621-SP0", "publisher": "openai", "uname": "Windows 10 10.0.22621 AMD64"}
User-Agent: OpenAI/v1 PythonBindings/0.27.8
Authorization: Bearer sk-12345
Content-Type: application/json
Accept: */*
Accept-Encoding: gzip, deflate
Content-Length: 413
{'messages': [{'role': 'user', 'content': 'The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.\n\nCurrent conversation:\n\nHuman: Hello\nAI:'}], 'model': 'gpt-3.5-turbo', 'max_tokens': None, 'stream': True, 'n': 1, 'temperature': 0.7}
Loaded instruction role format: Vicuna-v0
{'prompt': "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n### Human: The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.\n\nCurrent conversation:\n\nHuman: Hello\nAI:\n### Assistant:", 'req_params': {'max_new_tokens': 1024, 'temperature': 0.7, 'top_p': 1.0, 'top_k': 1, 'repetition_penalty': 1.18, 'encoder_repetition_penalty': 1.0, 'suffix': None, 'stream': True, 'echo': False, 'seed': -1, 'truncation_length': 2048, 'add_bos_token': True, 'do_sample': True, 'typical_p': 1.0, 'epsilon_cutoff': 0.0, 'eta_cutoff': 0.0, 'tfs': 1.0, 'top_a': 0.0, 'min_length': 0, 'no_repeat_ngram_size': 0, 'num_beams': 1, 'penalty_alpha': 0.0, 'length_penalty': 1.0, 'early_stopping': False, 'mirostat_mode': 0, 'mirostat_tau': 5.0, 'mirostat_eta': 0.1, 'ban_eos_token': False, 'skip_special_tokens': True, 'custom_stopping_strings': ['\n###', '\n### Human:', '### Human:']}}
Exception ignored in: <generator object generate_reply_custom at 0x000001D4CFDD4F90>
Traceback (most recent call last):
File "D:\PyCharm Community Edition 2022.2.3\Projects\text-generation-webui\modules\text_generation.py", line 327, in generate_reply_custom
print(f'Output generated in {(t1-t0):.2f} seconds ({new_tokens/(t1-t0):.2f} tokens/s, {new_tokens} tokens, context {original_tokens}, seed {seed})')
ZeroDivisionError: float division by zero
----------------------------------------
Exception occurred during processing of request from ('127.0.0.1', 52167)
Traceback (most recent call last):
File "D:\AnaConda\envs\NLP\lib\socketserver.py", line 683, in process_request_thread
self.finish_request(request, client_address)
File "D:\AnaConda\envs\NLP\lib\socketserver.py", line 360, in finish_request
self.RequestHandlerClass(request, client_address, self)
File "D:\AnaConda\envs\NLP\lib\socketserver.py", line 747, in __init__
self.handle()
File "D:\AnaConda\envs\NLP\lib\http\server.py", line 432, in handle
self.handle_one_request()
File "D:\AnaConda\envs\NLP\lib\http\server.py", line 420, in handle_one_request
method()
File "D:\PyCharm Community Edition 2022.2.3\Projects\text-generation-webui\extensions\openai\script.py", line 472, in do_POST
for a in generator:
File "D:\PyCharm Community Edition 2022.2.3\Projects\text-generation-webui\modules\text_generation.py", line 23, in generate_reply
for result in _generate_reply(*args, **kwargs):
File "D:\PyCharm Community Edition 2022.2.3\Projects\text-generation-webui\modules\text_generation.py", line 210, in _generate_reply
reply, stop_found = apply_stopping_strings(reply, all_stop_strings)
File "D:\PyCharm Community Edition 2022.2.3\Projects\text-generation-webui\modules\text_generation.py", line 148, in apply_stopping_strings
idx = reply.find(string)
TypeError: must be str, not list
### Is there an existing issue for this?
- [X] I have searched the existing issues
### Reproduction
flags:
--chat --gpu-memory 22 --model Vicuna-33B-GPTQ-4bit --trust-remote-code --loader exllama --extensions openai
webui was working well.
### Screenshot
_No response_
### Logs
```shell
2023-06-25 03:20:37 INFO:Loaded the model in 14.14 seconds.
2023-06-25 03:20:37 INFO:Loading the extension "openai"...
2023-06-25 03:20:38 INFO:Loading the extension "gallery"...
Running on local URL: http://127.0.0.1:7860
To create a public link, set `share=True` in `launch()`.
Loaded embedding model: all-mpnet-base-v2, max sequence length: 384
Starting OpenAI compatible api:
OPENAI_API_BASE=http://127.0.0.1:5001/v1
Output generated in 2.19 seconds (12.33 tokens/s, 27 tokens, context 43, seed 951727781)
127.0.0.1 - - [25/Jun/2023 03:21:11] "POST /v1/chat/completions HTTP/1.1" 200 -
Host: 127.0.0.1:5001
X-OpenAI-Client-User-Agent: {"bindings_version": "0.27.8", "httplib": "requests", "lang": "python", "lang_version": "3.10.8", "platform": "Windows-10-10.0.22621-SP0", "publisher": "openai", "uname": "Windows 10 10.0.22621 AMD64"}
User-Agent: OpenAI/v1 PythonBindings/0.27.8
Authorization: Bearer sk-12345
Content-Type: application/json
Accept: */*
Accept-Encoding: gzip, deflate
Content-Length: 413
{'messages': [{'role': 'user', 'content': 'The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.\n\nCurrent conversation:\n\nHuman: Hello\nAI:'}], 'model': 'gpt-3.5-turbo', 'max_tokens': None, 'stream': True, 'n': 1, 'temperature': 0.7}
Loaded instruction role format: Vicuna-v0
{'prompt': "A chat between a curious human and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the human's questions.\n\n### Human: The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.\n\nCurrent conversation:\n\nHuman: Hello\nAI:\n### Assistant:", 'req_params': {'max_new_tokens': 1024, 'temperature': 0.7, 'top_p': 1.0, 'top_k': 1, 'repetition_penalty': 1.18, 'encoder_repetition_penalty': 1.0, 'suffix': None, 'stream': True, 'echo': False, 'seed': -1, 'truncation_length': 2048, 'add_bos_token': True, 'do_sample': True, 'typical_p': 1.0, 'epsilon_cutoff': 0.0, 'eta_cutoff': 0.0, 'tfs': 1.0, 'top_a': 0.0, 'min_length': 0, 'no_repeat_ngram_size': 0, 'num_beams': 1, 'penalty_alpha': 0.0, 'length_penalty': 1.0, 'early_stopping': False, 'mirostat_mode': 0, 'mirostat_tau': 5.0, 'mirostat_eta': 0.1, 'ban_eos_token': False, 'skip_special_tokens': True, 'custom_stopping_strings': ['\n###', '\n### Human:', '### Human:']}}
Exception ignored in: <generator object generate_reply_custom at 0x000001D4CFDD4F90>
Traceback (most recent call last):
File "D:\PyCharm Community Edition 2022.2.3\Projects\text-generation-webui\modules\text_generation.py", line 327, in generate_reply_custom
print(f'Output generated in {(t1-t0):.2f} seconds ({new_tokens/(t1-t0):.2f} tokens/s, {new_tokens} tokens, context {original_tokens}, seed {seed})')
ZeroDivisionError: float division by zero
----------------------------------------
Exception occurred during processing of request from ('127.0.0.1', 52167)
Traceback (most recent call last):
File "D:\AnaConda\envs\NLP\lib\socketserver.py", line 683, in process_request_thread
self.finish_request(request, client_address)
File "D:\AnaConda\envs\NLP\lib\socketserver.py", line 360, in finish_request
self.RequestHandlerClass(request, client_address, self)
File "D:\AnaConda\envs\NLP\lib\socketserver.py", line 747, in __init__
self.handle()
File "D:\AnaConda\envs\NLP\lib\http\server.py", line 432, in handle
self.handle_one_request()
File "D:\AnaConda\envs\NLP\lib\http\server.py", line 420, in handle_one_request
method()
File "D:\PyCharm Community Edition 2022.2.3\Projects\text-generation-webui\extensions\openai\script.py", line 472, in do_POST
for a in generator:
File "D:\PyCharm Community Edition 2022.2.3\Projects\text-generation-webui\modules\text_generation.py", line 23, in generate_reply
for result in _generate_reply(*args, **kwargs):
File "D:\PyCharm Community Edition 2022.2.3\Projects\text-generation-webui\modules\text_generation.py", line 210, in _generate_reply
reply, stop_found = apply_stopping_strings(reply, all_stop_strings)
File "D:\PyCharm Community Edition 2022.2.3\Projects\text-generation-webui\modules\text_generation.py", line 148, in apply_stopping_strings
idx = reply.find(string)
TypeError: must be str, not list
```
### System Info
```shell
OS: Windows 11
GPU: Nvidia Geforce RTX 4090 24G * 1
```
| 2023-06-24T17:11:55 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.