
Search is not available for this dataset
pipeline_tag
stringclasses 48
values | library_name
stringclasses 205
values | text
stringlengths 0
18.3M
| metadata
stringlengths 2
1.07B
| id
stringlengths 5
122
| last_modified
null | tags
listlengths 1
1.84k
| sha
null | created_at
stringlengths 25
25
|
|---|---|---|---|---|---|---|---|---|
null |
peft
|
## Training procedure
### Framework versions
- PEFT 0.4.0
|
{"library_name": "peft"}
|
eunyounglee/llama3-llm2vec-mntp-adapter
| null |
[
"peft",
"tensorboard",
"region:us"
] | null |
2024-05-02T05:03:19+00:00
|
null | null |
{"license": "mit"}
|
hautc/z5
| null |
[
"license:mit",
"region:us"
] | null |
2024-05-02T05:03:59+00:00
|
|
null | null |
{}
|
Bkaputas/danielle
| null |
[
"region:us"
] | null |
2024-05-02T05:04:13+00:00
|
|
null | null |
{}
|
archbold/Reinforce-CartPole
| null |
[
"region:us"
] | null |
2024-05-02T05:04:14+00:00
|
|
null | null |
{}
|
ArunIcfoss/nllb-200-distilled-1.3B-ICFOSS-Tamil_Malayalam_Translation1
| null |
[
"safetensors",
"region:us"
] | null |
2024-05-02T05:04:17+00:00
|
|
null | null |
{}
|
jackuu/gf
| null |
[
"region:us"
] | null |
2024-05-02T05:05:04+00:00
|
|
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# CS505_COQE_viT5_total_InstructionN5_SOAPL_v1
This model is a fine-tuned version of [VietAI/vit5-large](https://huggingface.co/VietAI/vit5-large) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2
|
{"license": "mit", "tags": ["generated_from_trainer"], "base_model": "VietAI/vit5-large", "model-index": [{"name": "CS505_COQE_viT5_total_InstructionN5_SOAPL_v1", "results": []}]}
|
ThuyNT/CS505_COQE_viT5_train_InstructionN5_SOAPL_v1
| null |
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:VietAI/vit5-large",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2024-05-02T05:05:06+00:00
|
automatic-speech-recognition
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Base Ko - Dearlie
This model is a fine-tuned version of [openai/whisper-base](https://huggingface.co/openai/whisper-base) on the Noise Data dataset.
It achieves the following results on the evaluation set:
- Loss: 3.4871
- Cer: 107.7011
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1
- training_steps: 2
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Cer |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.3913 | 2.0 | 2 | 3.4871 | 107.7011 |
### Framework versions
- Transformers 4.41.0.dev0
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
|
{"language": ["ko"], "license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["AIHub/noise"], "base_model": "openai/whisper-base", "model-index": [{"name": "Whisper Base Ko - Dearlie", "results": []}]}
|
Dearlie/whisper-base2
| null |
[
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"generated_from_trainer",
"ko",
"dataset:AIHub/noise",
"base_model:openai/whisper-base",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2024-05-02T05:05:21+00:00
|
reinforcement-learning
| null |
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
{"tags": ["Pixelcopter-PLE-v0", "reinforce", "reinforcement-learning", "custom-implementation", "deep-rl-class"], "model-index": [{"name": "PixelcopteV2", "results": [{"task": {"type": "reinforcement-learning", "name": "reinforcement-learning"}, "dataset": {"name": "Pixelcopter-PLE-v0", "type": "Pixelcopter-PLE-v0"}, "metrics": [{"type": "mean_reward", "value": "34.70 +/- 18.37", "name": "mean_reward", "verified": false}]}]}]}
|
ripayani/PixelcopteV2
| null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] | null |
2024-05-02T05:06:30+00:00
|
text-generation
| null |
<img src="Faraday Model Repository Banner.png" alt="Faraday.dev" style="height: 90px; min-width: 32px; display: block; margin: auto;">
**<p style="text-align: center;">The official library of GGUF format models for use in the local AI chat app, Faraday.dev.</p>**
<p style="text-align: center;"><a href="https://faraday.dev/">Download Faraday here to get started.</a></p>
<p style="text-align: center;"><a href="https://www.reddit.com/r/LLM_Quants/">Request Additional models at r/LLM_Quants.</a></p>
***
# Phi 3 mini 4k instruct
- **Creator:** [microsoft](https://huggingface.co/microsoft/)
- **Original:** [Phi 3 mini 4k instruct](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct)
- **Date Created:** 2024-04-22
- **Trained Context:** 4096 tokens
- **Description:** State-of-the-art lightweight open model from Microsoft, trained with the Phi-3 datasets. These include both synthetic data and filtered publicly available websites data with a focus on high-quality and reasoning dense properties.
## What is a GGUF?
GGUF is a large language model (LLM) format that can be split between CPU and GPU. GGUFs are compatible with applications based on llama.cpp, such as Faraday.dev. Where other model formats require higher end GPUs with ample VRAM, GGUFs can be efficiently run on a wider variety of hardware.
GGUF models are quantized to reduce resource usage, with a tradeoff of reduced coherence at lower quantizations. Quantization reduces the precision of the model weights by changing the number of bits used for each weight.
***
<img src="faraday-logo.png" alt="Faraday.dev" style="height: 75px; min-width: 32px; display: block; horizontal align: left;">
## Faraday.dev
- Free, local AI chat application.
- One-click installation on Mac and PC.
- Automatically use GPU for maximum speed.
- Built-in model manager.
- High-quality character hub.
- Zero-config desktop-to-mobile tethering.
Faraday makes it easy to start chatting with AI using your own characters or one of the many found in the built-in character hub. The model manager helps you find the latest and greatest models without worrying about whether it's the correct format. Faraday supports advanced features such as lorebooks, author's note, text formatting, custom context size, sampler settings, grammars, local TTS, cloud inference, and tethering, all implemented in a way that is straightforward and reliable.
**Join us on [Discord](https://discord.gg/SyNN2vC9tQ)**
***
|
{"language": ["en"], "license": "mit", "tags": ["nlp", "code"], "model_name": "Phi-3-mini-4k-instruct-GGUF", "base_model": "microsoft/Phi-3-mini-4k-instruct", "license_link": "https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/resolve/main/LICENSE", "pipeline_tag": "text-generation", "quantized_by": "brooketh"}
|
FaradayDotDev/Phi-3-mini-4k-instruct-GGUF
| null |
[
"gguf",
"nlp",
"code",
"text-generation",
"en",
"base_model:microsoft/Phi-3-mini-4k-instruct",
"license:mit",
"region:us"
] | null |
2024-05-02T05:07:16+00:00
|
text-generation
|
transformers
|
{"license": "apache-2.0"}
|
cindywen/sft_mix_25843_epoch_1
| null |
[
"transformers",
"safetensors",
"llama",
"text-generation",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2024-05-02T05:07:59+00:00
|
|
null | null |
{"license": "apache-2.0"}
|
srbcybertron/ingredient
| null |
[
"license:apache-2.0",
"region:us"
] | null |
2024-05-02T05:08:37+00:00
|
|
null |
peft
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Finetuned_LLM
This model is a fine-tuned version of [mistralai/Mistral-7B-Instruct-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3761
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.05
- num_epochs: 80
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 6 | 4.0006 |
| No log | 2.0 | 12 | 3.2846 |
| No log | 3.0 | 18 | 2.3837 |
| No log | 4.0 | 24 | 1.1283 |
| 2.8909 | 5.0 | 30 | 0.4659 |
| 2.8909 | 6.0 | 36 | 0.3386 |
| 2.8909 | 7.0 | 42 | 0.3010 |
| 2.8909 | 8.0 | 48 | 0.3114 |
| 0.4651 | 9.0 | 54 | 0.2759 |
| 0.4651 | 10.0 | 60 | 0.2676 |
| 0.4651 | 11.0 | 66 | 0.3188 |
| 0.4651 | 12.0 | 72 | 0.3235 |
| 0.1317 | 13.0 | 78 | 0.3145 |
| 0.1317 | 14.0 | 84 | 0.2849 |
| 0.1317 | 15.0 | 90 | 0.3157 |
| 0.1317 | 16.0 | 96 | 0.2785 |
| 0.0881 | 17.0 | 102 | 0.3406 |
| 0.0881 | 18.0 | 108 | 0.3471 |
| 0.0881 | 19.0 | 114 | 0.3305 |
| 0.0881 | 20.0 | 120 | 0.3136 |
| 0.0779 | 21.0 | 126 | 0.3313 |
| 0.0779 | 22.0 | 132 | 0.3467 |
| 0.0779 | 23.0 | 138 | 0.3301 |
| 0.0779 | 24.0 | 144 | 0.3275 |
| 0.0649 | 25.0 | 150 | 0.2941 |
| 0.0649 | 26.0 | 156 | 0.2990 |
| 0.0649 | 27.0 | 162 | 0.2927 |
| 0.0649 | 28.0 | 168 | 0.2916 |
| 0.0649 | 29.0 | 174 | 0.3166 |
| 0.0398 | 30.0 | 180 | 0.3051 |
| 0.0398 | 31.0 | 186 | 0.2884 |
| 0.0398 | 32.0 | 192 | 0.2781 |
| 0.0398 | 33.0 | 198 | 0.3295 |
| 0.0275 | 34.0 | 204 | 0.3346 |
| 0.0275 | 35.0 | 210 | 0.3168 |
| 0.0275 | 36.0 | 216 | 0.3258 |
| 0.0275 | 37.0 | 222 | 0.3354 |
| 0.0256 | 38.0 | 228 | 0.3341 |
| 0.0256 | 39.0 | 234 | 0.3407 |
| 0.0256 | 40.0 | 240 | 0.3419 |
| 0.0256 | 41.0 | 246 | 0.3374 |
| 0.0246 | 42.0 | 252 | 0.3410 |
| 0.0246 | 43.0 | 258 | 0.3362 |
| 0.0246 | 44.0 | 264 | 0.3408 |
| 0.0246 | 45.0 | 270 | 0.3507 |
| 0.0243 | 46.0 | 276 | 0.3572 |
| 0.0243 | 47.0 | 282 | 0.3519 |
| 0.0243 | 48.0 | 288 | 0.3605 |
| 0.0243 | 49.0 | 294 | 0.3587 |
| 0.0241 | 50.0 | 300 | 0.3577 |
| 0.0241 | 51.0 | 306 | 0.3581 |
| 0.0241 | 52.0 | 312 | 0.3630 |
| 0.0241 | 53.0 | 318 | 0.3618 |
| 0.0241 | 54.0 | 324 | 0.3611 |
| 0.0238 | 55.0 | 330 | 0.3611 |
| 0.0238 | 56.0 | 336 | 0.3671 |
| 0.0238 | 57.0 | 342 | 0.3691 |
| 0.0238 | 58.0 | 348 | 0.3703 |
| 0.0236 | 59.0 | 354 | 0.3638 |
| 0.0236 | 60.0 | 360 | 0.3655 |
| 0.0236 | 61.0 | 366 | 0.3622 |
| 0.0236 | 62.0 | 372 | 0.3634 |
| 0.0236 | 63.0 | 378 | 0.3648 |
| 0.0236 | 64.0 | 384 | 0.3672 |
| 0.0236 | 65.0 | 390 | 0.3711 |
| 0.0236 | 66.0 | 396 | 0.3723 |
| 0.0233 | 67.0 | 402 | 0.3726 |
| 0.0233 | 68.0 | 408 | 0.3729 |
| 0.0233 | 69.0 | 414 | 0.3738 |
| 0.0233 | 70.0 | 420 | 0.3742 |
| 0.0233 | 71.0 | 426 | 0.3745 |
| 0.0233 | 72.0 | 432 | 0.3744 |
| 0.0233 | 73.0 | 438 | 0.3757 |
| 0.0233 | 74.0 | 444 | 0.3759 |
| 0.0233 | 75.0 | 450 | 0.3761 |
| 0.0233 | 76.0 | 456 | 0.3760 |
| 0.0233 | 77.0 | 462 | 0.3760 |
| 0.0233 | 78.0 | 468 | 0.3760 |
| 0.0233 | 79.0 | 474 | 0.3762 |
| 0.0233 | 80.0 | 480 | 0.3761 |
### Framework versions
- PEFT 0.7.1
- Transformers 4.36.1
- Pytorch 2.0.0+cu117
- Datasets 2.18.0
- Tokenizers 0.15.2
|
{"library_name": "peft", "tags": ["generated_from_trainer"], "base_model": "mistralai/Mistral-7B-Instruct-v0.2", "model-index": [{"name": "Finetuned_LLM", "results": []}]}
|
vu3/Finetuned_LLM
| null |
[
"peft",
"safetensors",
"generated_from_trainer",
"base_model:mistralai/Mistral-7B-Instruct-v0.2",
"region:us"
] | null |
2024-05-02T05:09:26+00:00
|
null | null |
{"license": "mit"}
|
Jiahuixu/occt5
| null |
[
"license:mit",
"region:us"
] | null |
2024-05-02T05:09:57+00:00
|
|
text-generation
|
transformers
|
# Model Card for Model ID
This model replicates [microsoft/Phi-3-mini-4k-instruct](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct) and has been further finetuned on the [timdettmers/openassistant-guanaco](https://huggingface.co/datasets/timdettmers/openassistant-guanaco) dataset using AutoTrain.
## Model Details
The Phi-3-Mini-4K-Instruct is a 3.8B parameters, lightweight, state-of-the-art open model trained with the Phi-3 datasets that includes both synthetic data and the filtered publicly available websites data with a focus on high-quality and reasoning dense properties.
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
tokenizer = AutoTokenizer.from_pretrained("Aryan-401/Aryan-401/phi-3-mini-4k-instruct-finetune-guanaco-PEFT-Merged", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("Aryan-401/Aryan-401/phi-3-mini-4k-instruct-finetune-guanaco-PEFT-Merged", trust_remote_code=True)
# Prompt content: "hi"
messages = [
{"role": "user", "content": "What is the Value of Pi?"}
]
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device).eval()
input_ids = tokenizer.apply_chat_template(conversation=messages, tokenize=True, add_generation_prompt=True, return_tensors='pt')
output_ids = model.generate(input_ids.to(device), max_length= 1000)
response = tokenizer.decode(output_ids[0][input_ids.shape[1]:], skip_special_tokens=True)
print(response)
# Pi is an irrational number, which means it cannot be expressed as a simple fraction and its decimal representation goes on forever without repeating. However, the value of Pi is approximately 3.14159. It is often rounded to 3.14 for simplicity in calculations.
```
|
{"license": "mit", "library_name": "transformers", "datasets": ["timdettmers/openassistant-guanaco"], "pipeline_tag": "text-generation"}
|
Aryan-401/phi-3-mini-4k-instruct-finetune-guanaco-PEFT-Merged
| null |
[
"transformers",
"safetensors",
"phi3",
"text-generation",
"conversational",
"custom_code",
"dataset:timdettmers/openassistant-guanaco",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2024-05-02T05:10:10+00:00
|
null | null |
{}
|
archbold/Reinforce-CartPole-v1
| null |
[
"region:us"
] | null |
2024-05-02T05:10:28+00:00
|
|
null | null |
{}
|
Bkaputas/daniellee
| null |
[
"region:us"
] | null |
2024-05-02T05:10:46+00:00
|
|
null | null |
Cos'è Hemopro Prezzo?
Hemopro Recensioni è una crema e un gel di alta qualità appositamente progettati per alleviare i sintomi delle emorroidi. La sua formula avanzata integra una miscela sinergica di ingredienti naturali noti per le loro proprietà lenitive e curative, offrendo un sollievo rapido ed efficace alle aree interessate.
Sito ufficiale:<a href="https://www.nutritionsee.com/hemotaly">www.Hemopro.com</a>
<p><a href="https://www.nutritionsee.com/hemotaly"> <img src="https://www.nutritionsee.com/wp-content/uploads/2024/05/Hemopro-Italy.png" alt="enter image description here"> </a></p>
<a href="https://www.nutritionsee.com/hemotaly">Acquista ora!! Fai clic sul collegamento in basso per ulteriori informazioni e ottieni subito uno sconto del 50%... Affrettati</a>
Sito ufficiale:<a href="https://www.nutritionsee.com/hemotaly">www.Hemopro.com</a>
|
{"license": "apache-2.0"}
|
HemoproItaly/HemoproItaly
| null |
[
"license:apache-2.0",
"region:us"
] | null |
2024-05-02T05:10:57+00:00
|
feature-extraction
|
transformers
|
{}
|
atheanchu/bge_m3_inf2
| null |
[
"transformers",
"xlm-roberta",
"feature-extraction",
"endpoints_compatible",
"region:us"
] | null |
2024-05-02T05:12:47+00:00
|
|
text-generation
|
transformers
|
{"license": "apache-2.0"}
|
TensorSenseAI/gemamba-v0
| null |
[
"transformers",
"safetensors",
"llava_gemma",
"text-generation",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2024-05-02T05:12:49+00:00
|
|
null | null |
{}
|
jehad13/mm7
| null |
[
"region:us"
] | null |
2024-05-02T05:14:09+00:00
|
|
text2text-generation
|
transformers
|
{}
|
sakt90/my_model
| null |
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2024-05-02T05:15:11+00:00
|
|
null | null |
{}
|
Rushi2903/FICTO
| null |
[
"region:us"
] | null |
2024-05-02T05:15:39+00:00
|
|
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_pythia-410m_mz-133_EnronSpam_n-its-10-seed-3
This model is a fine-tuned version of [EleutherAI/pythia-410m](https://huggingface.co/EleutherAI/pythia-410m) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 3
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.15.2
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "base_model": "EleutherAI/pythia-410m", "model-index": [{"name": "robust_llm_pythia-410m_mz-133_EnronSpam_n-its-10-seed-3", "results": []}]}
|
AlignmentResearch/robust_llm_pythia-410m_mz-133_EnronSpam_n-its-10-seed-3
| null |
[
"transformers",
"tensorboard",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-410m",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2024-05-02T05:18:37+00:00
|
text-generation
|
transformers
|
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
{"library_name": "transformers", "tags": ["llama-factory"]}
|
huntz47/qwenm11
| null |
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"llama-factory",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2024-05-02T05:19:35+00:00
|
text-generation
|
transformers
|
# Llama-3-OpenBioMed-8B-dare-ties-4x
Llama-3-OpenBioMed-8B-dare-ties-4x is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [aaditya/Llama3-OpenBioLLM-8B](https://huggingface.co/aaditya/Llama3-OpenBioLLM-8B)
* [johnsnowlabs/JSL-MedLlama-3-8B-v2.0](https://huggingface.co/johnsnowlabs/JSL-MedLlama-3-8B-v2.0)
* [Jayant9928/orpo_med_v3](https://huggingface.co/Jayant9928/orpo_med_v3)
* [skumar9/Llama-medx_v3](https://huggingface.co/skumar9/Llama-medx_v3)
## 🧩 Configuration
```yaml
models:
- model: johnsnowlabs/JSL-MedLlama-3-8B-v2.0
# No parameters necessary for base model
- model: aaditya/Llama3-OpenBioLLM-8B
parameters:
density: 0.53
weight: 0.2
- model: johnsnowlabs/JSL-MedLlama-3-8B-v2.0
parameters:
density: 0.53
weight: 0.3
- model: Jayant9928/orpo_med_v3
parameters:
density: 0.53
weight: 0.3
- model: skumar9/Llama-medx_v3
parameters:
density: 0.53
weight: 0.2
merge_method: dare_ties
base_model: meta-llama/Meta-Llama-3-8B-Instruct
parameters:
int8_mask: true
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "abhinand/Llama-3-OpenBioMed-8B-dare-ties-4x"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
{"tags": ["merge", "mergekit", "lazymergekit", "aaditya/Llama3-OpenBioLLM-8B", "johnsnowlabs/JSL-MedLlama-3-8B-v2.0", "Jayant9928/orpo_med_v3", "skumar9/Llama-medx_v3"], "base_model": ["aaditya/Llama3-OpenBioLLM-8B", "johnsnowlabs/JSL-MedLlama-3-8B-v2.0", "Jayant9928/orpo_med_v3", "skumar9/Llama-medx_v3"]}
|
abhinand/Llama-3-OpenBioMed-8B-dare-ties-4x
| null |
[
"transformers",
"safetensors",
"llama",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"aaditya/Llama3-OpenBioLLM-8B",
"johnsnowlabs/JSL-MedLlama-3-8B-v2.0",
"Jayant9928/orpo_med_v3",
"skumar9/Llama-medx_v3",
"conversational",
"base_model:aaditya/Llama3-OpenBioLLM-8B",
"base_model:johnsnowlabs/JSL-MedLlama-3-8B-v2.0",
"base_model:Jayant9928/orpo_med_v3",
"base_model:skumar9/Llama-medx_v3",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2024-05-02T05:21:15+00:00
|
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# CS505_COQE_viT5_total_InstructionN0_SOAPL_v1
This model is a fine-tuned version of [VietAI/vit5-large](https://huggingface.co/VietAI/vit5-large) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2
|
{"license": "mit", "tags": ["generated_from_trainer"], "base_model": "VietAI/vit5-large", "model-index": [{"name": "CS505_COQE_viT5_total_InstructionN0_SOAPL_v1", "results": []}]}
|
ThuyNT/CS505_COQE_viT5_total_InstructionN0_SOAPL_v1
| null |
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:VietAI/vit5-large",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2024-05-02T05:21:29+00:00
|
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# CS505_COQE_viT5_total_InstructionN2_SOAPL_v1
This model is a fine-tuned version of [VietAI/vit5-large](https://huggingface.co/VietAI/vit5-large) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2
|
{"license": "mit", "tags": ["generated_from_trainer"], "base_model": "VietAI/vit5-large", "model-index": [{"name": "CS505_COQE_viT5_total_InstructionN2_SOAPL_v1", "results": []}]}
|
ThuyNT/CS505_COQE_viT5_total_InstructionN2_SOAPL_v1
| null |
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:VietAI/vit5-large",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2024-05-02T05:22:33+00:00
|
null |
transformers
|
{"license": "llama3"}
|
chiangcw/finetune_reft_llama3
| null |
[
"transformers",
"license:llama3",
"endpoints_compatible",
"region:us"
] | null |
2024-05-02T05:23:20+00:00
|
|
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# CS505_COQE_viT5_total_InstructionN3_SOAPL_v1
This model is a fine-tuned version of [VietAI/vit5-large](https://huggingface.co/VietAI/vit5-large) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2
|
{"license": "mit", "tags": ["generated_from_trainer"], "base_model": "VietAI/vit5-large", "model-index": [{"name": "CS505_COQE_viT5_total_InstructionN3_SOAPL_v1", "results": []}]}
|
ThuyNT/CS505_COQE_viT5_total_InstructionN3_SOAPL_v1
| null |
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:VietAI/vit5-large",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2024-05-02T05:23:41+00:00
|
null | null |
{}
|
Suryansh5545/bert-base-uncased-finetuned-xsum
| null |
[
"region:us"
] | null |
2024-05-02T05:23:55+00:00
|
|
text-generation
|
transformers
|
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
{"library_name": "transformers", "tags": ["unsloth"]}
|
vkrishanan569/tinyllam_8Q
| null |
[
"transformers",
"pytorch",
"llama",
"text-generation",
"unsloth",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2024-05-02T05:24:01+00:00
|
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# CS505_COQE_viT5_total_InstructionN4_SOAPL_v1
This model is a fine-tuned version of [VietAI/vit5-large](https://huggingface.co/VietAI/vit5-large) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2
|
{"license": "mit", "tags": ["generated_from_trainer"], "base_model": "VietAI/vit5-large", "model-index": [{"name": "CS505_COQE_viT5_total_InstructionN4_SOAPL_v1", "results": []}]}
|
ThuyNT/CS505_COQE_viT5_total_InstructionN4_SOAPL_v1
| null |
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:VietAI/vit5-large",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2024-05-02T05:24:33+00:00
|
null | null |
{}
|
rmsdud/geunLlama
| null |
[
"region:us"
] | null |
2024-05-02T05:25:18+00:00
|
|
video-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# videomae-base-finetuned-ucf101-subset
This model is a fine-tuned version of [MCG-NJU/videomae-base](https://huggingface.co/MCG-NJU/videomae-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4636
- Accuracy: 0.8581
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 148
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.1353 | 0.26 | 38 | 1.8682 | 0.5571 |
| 0.8568 | 1.26 | 76 | 0.8215 | 0.8 |
| 0.4267 | 2.26 | 114 | 0.4749 | 0.8571 |
| 0.2545 | 3.23 | 148 | 0.3176 | 0.9143 |
### Framework versions
- Transformers 4.28.0
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.13.3
|
{"license": "cc-by-nc-4.0", "tags": ["generated_from_trainer"], "metrics": ["accuracy"], "model-index": [{"name": "videomae-base-finetuned-ucf101-subset", "results": []}]}
|
X-X-512/videomae-base-finetuned-ucf101-subset
| null |
[
"transformers",
"pytorch",
"tensorboard",
"videomae",
"video-classification",
"generated_from_trainer",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null |
2024-05-02T05:25:49+00:00
|
text-generation
|
transformers
|
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
{"library_name": "transformers", "tags": []}
|
XMsteven/merged_model_1
| null |
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2024-05-02T05:25:54+00:00
|
null |
transformers
|
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: -->
<!-- ### vocab_type: -->
static quants of https://huggingface.co/TeeZee/BigMaid-20B-v1.0
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/BigMaid-20B-v1.0-GGUF/resolve/main/BigMaid-20B-v1.0.Q2_K.gguf) | Q2_K | 7.5 | |
| [GGUF](https://huggingface.co/mradermacher/BigMaid-20B-v1.0-GGUF/resolve/main/BigMaid-20B-v1.0.IQ3_XS.gguf) | IQ3_XS | 8.3 | |
| [GGUF](https://huggingface.co/mradermacher/BigMaid-20B-v1.0-GGUF/resolve/main/BigMaid-20B-v1.0.IQ3_S.gguf) | IQ3_S | 8.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/BigMaid-20B-v1.0-GGUF/resolve/main/BigMaid-20B-v1.0.Q3_K_S.gguf) | Q3_K_S | 8.8 | |
| [GGUF](https://huggingface.co/mradermacher/BigMaid-20B-v1.0-GGUF/resolve/main/BigMaid-20B-v1.0.IQ3_M.gguf) | IQ3_M | 9.3 | |
| [GGUF](https://huggingface.co/mradermacher/BigMaid-20B-v1.0-GGUF/resolve/main/BigMaid-20B-v1.0.Q3_K_M.gguf) | Q3_K_M | 9.8 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/BigMaid-20B-v1.0-GGUF/resolve/main/BigMaid-20B-v1.0.Q3_K_L.gguf) | Q3_K_L | 10.7 | |
| [GGUF](https://huggingface.co/mradermacher/BigMaid-20B-v1.0-GGUF/resolve/main/BigMaid-20B-v1.0.IQ4_XS.gguf) | IQ4_XS | 10.8 | |
| [GGUF](https://huggingface.co/mradermacher/BigMaid-20B-v1.0-GGUF/resolve/main/BigMaid-20B-v1.0.Q4_K_S.gguf) | Q4_K_S | 11.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/BigMaid-20B-v1.0-GGUF/resolve/main/BigMaid-20B-v1.0.Q4_K_M.gguf) | Q4_K_M | 12.1 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/BigMaid-20B-v1.0-GGUF/resolve/main/BigMaid-20B-v1.0.Q5_K_S.gguf) | Q5_K_S | 13.9 | |
| [GGUF](https://huggingface.co/mradermacher/BigMaid-20B-v1.0-GGUF/resolve/main/BigMaid-20B-v1.0.Q5_K_M.gguf) | Q5_K_M | 14.3 | |
| [GGUF](https://huggingface.co/mradermacher/BigMaid-20B-v1.0-GGUF/resolve/main/BigMaid-20B-v1.0.Q6_K.gguf) | Q6_K | 16.5 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/BigMaid-20B-v1.0-GGUF/resolve/main/BigMaid-20B-v1.0.Q8_0.gguf) | Q8_0 | 21.3 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
{"language": ["en"], "license": "apache-2.0", "library_name": "transformers", "tags": ["roleplay", "text-generation-inference", "merge", "not-for-all-audiences"], "base_model": "TeeZee/BigMaid-20B-v1.0", "quantized_by": "mradermacher"}
|
mradermacher/BigMaid-20B-v1.0-GGUF
| null |
[
"transformers",
"gguf",
"roleplay",
"text-generation-inference",
"merge",
"not-for-all-audiences",
"en",
"base_model:TeeZee/BigMaid-20B-v1.0",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2024-05-02T05:25:55+00:00
|
text-generation
|
transformers
|
{}
|
Junaidjk/Model
| null |
[
"transformers",
"pytorch",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2024-05-02T05:25:58+00:00
|
|
null |
transformers
|
# Uploaded model
- **Developed by:** arvnoodle
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-Instruct-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
{"language": ["en"], "license": "apache-2.0", "tags": ["text-generation-inference", "transformers", "unsloth", "llama", "trl"], "base_model": "unsloth/llama-3-8b-Instruct-bnb-4bit"}
|
arvnoodle/hcl-llama3-nativeformat-xml-json
| null |
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:unsloth/llama-3-8b-Instruct-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2024-05-02T05:27:02+00:00
|
text-generation
|
transformers
|
This is meant for further finetuning, it is iffy as-is. Made using a new structure I call "ripple merge" that works backwards and forwards through the model.
Other frankenmerge methods were failing at sizes over 11b.
---
# Llama-3-15b-Instruct
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the passthrough merge method.
### Models Merged
The following models were included in the merge:
* [NousResearch/Meta-Llama-3-8B-Instruct](https://huggingface.co/NousResearch/Meta-Llama-3-8B-Instruct)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
slices:
- sources:
- model: NousResearch/Meta-Llama-3-8B-Instruct
layer_range: [0, 15]
- sources:
- model: NousResearch/Meta-Llama-3-8B-Instruct
layer_range: [14, 15]
- sources:
- model: NousResearch/Meta-Llama-3-8B-Instruct
layer_range: [13, 14]
- sources:
- model: NousResearch/Meta-Llama-3-8B-Instruct
layer_range: [12, 13]
- sources:
- model: NousResearch/Meta-Llama-3-8B-Instruct
layer_range: [11, 12]
- sources:
- model: NousResearch/Meta-Llama-3-8B-Instruct
layer_range: [10, 11]
- sources:
- model: NousResearch/Meta-Llama-3-8B-Instruct
layer_range: [9, 10]
- sources:
- model: NousResearch/Meta-Llama-3-8B-Instruct
layer_range: [8, 23]
- sources:
- model: NousResearch/Meta-Llama-3-8B-Instruct
layer_range: [21, 22]
- sources:
- model: NousResearch/Meta-Llama-3-8B-Instruct
layer_range: [20, 21]
- sources:
- model: NousResearch/Meta-Llama-3-8B-Instruct
layer_range: [19, 20]
- sources:
- model: NousResearch/Meta-Llama-3-8B-Instruct
layer_range: [18, 19]
- sources:
- model: NousResearch/Meta-Llama-3-8B-Instruct
layer_range: [17, 18]
- sources:
- model: NousResearch/Meta-Llama-3-8B-Instruct
layer_range: [16, 17]
- sources:
- model: NousResearch/Meta-Llama-3-8B-Instruct
layer_range: [15, 16]
- sources:
- model: NousResearch/Meta-Llama-3-8B-Instruct
layer_range: [14, 15]
- sources:
- model: NousResearch/Meta-Llama-3-8B-Instruct
layer_range: [13, 14]
- sources:
- model: NousResearch/Meta-Llama-3-8B-Instruct
layer_range: [12, 13]
- sources:
- model: NousResearch/Meta-Llama-3-8B-Instruct
layer_range: [12, 32]
merge_method: passthrough
dtype: float16
```
|
{"library_name": "transformers", "tags": ["mergekit", "merge"], "base_model": ["NousResearch/Meta-Llama-3-8B-Instruct"]}
|
athirdpath/Llama-3-15b-Instruct
| null |
[
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:NousResearch/Meta-Llama-3-8B-Instruct",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2024-05-02T05:27:09+00:00
|
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# flant5_offensive_German_germ_train
This model is a fine-tuned version of [google/flan-t5-base](https://huggingface.co/google/flan-t5-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0011
- Precision: 0.6673
- Recall: 0.5724
- F1: 0.6162
- Total Predictions: 3532
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Total Predictions |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:-----------------:|
| 0.6583 | 1.0 | 1253 | 0.0014 | 0.0 | 0.0 | 0.0 | 3532 |
| 0.0015 | 2.0 | 2506 | 0.0012 | 0.8333 | 0.0208 | 0.0406 | 3532 |
| 0.0012 | 3.0 | 3759 | 0.0011 | 0.6055 | 0.6589 | 0.6311 | 3532 |
| 0.001 | 4.0 | 5012 | 0.0011 | 0.7519 | 0.4160 | 0.5356 | 3532 |
| 0.0009 | 5.0 | 6265 | 0.0011 | 0.6673 | 0.5724 | 0.6162 | 3532 |
### Framework versions
- Transformers 4.39.3
- Pytorch 2.0.0+cu118
- Datasets 2.18.0
- Tokenizers 0.15.2
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["precision", "recall", "f1"], "base_model": "google/flan-t5-base", "model-index": [{"name": "flant5_offensive_German_germ_train", "results": []}]}
|
JenniferHJF/flant5_offensive_German_germ_train
| null |
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:google/flan-t5-base",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2024-05-02T05:28:33+00:00
|
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# BERT_top5_bm25_rr5_10_epoch
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0294
- Accuracy: 0.7708
- F1: 0.6486
- Precision: 0.5385
- Recall: 0.8155
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Precision | Recall |
|:-------------:|:------:|:----:|:---------------:|:--------:|:------:|:---------:|:------:|
| No log | 0.2623 | 16 | 0.6133 | 0.8237 | 0.5270 | 0.8667 | 0.3786 |
| No log | 0.5246 | 32 | 0.5112 | 0.7758 | 0.2393 | 1.0 | 0.1359 |
| No log | 0.7869 | 48 | 0.4725 | 0.8363 | 0.6448 | 0.7375 | 0.5728 |
| No log | 1.0492 | 64 | 0.3894 | 0.8539 | 0.6882 | 0.7711 | 0.6214 |
| No log | 1.3115 | 80 | 0.7018 | 0.5013 | 0.5 | 0.3379 | 0.9612 |
| No log | 1.5738 | 96 | 0.4207 | 0.8338 | 0.7054 | 0.6529 | 0.7670 |
| No log | 1.8361 | 112 | 0.4159 | 0.7834 | 0.6587 | 0.5570 | 0.8058 |
| No log | 2.0984 | 128 | 0.4052 | 0.8060 | 0.6831 | 0.5929 | 0.8058 |
| No log | 2.3607 | 144 | 0.4456 | 0.7859 | 0.6743 | 0.5570 | 0.8544 |
| No log | 2.6230 | 160 | 0.3880 | 0.8564 | 0.7016 | 0.7614 | 0.6505 |
| No log | 2.8852 | 176 | 0.5137 | 0.8262 | 0.5660 | 0.8036 | 0.4369 |
| No log | 3.1475 | 192 | 0.4837 | 0.7935 | 0.6496 | 0.5802 | 0.7379 |
| No log | 3.4098 | 208 | 0.7301 | 0.7280 | 0.6197 | 0.4862 | 0.8544 |
| No log | 3.6721 | 224 | 0.6014 | 0.8413 | 0.6866 | 0.7041 | 0.6699 |
| No log | 3.9344 | 240 | 0.7912 | 0.7456 | 0.6481 | 0.5054 | 0.9029 |
| No log | 4.1967 | 256 | 0.6779 | 0.7834 | 0.6587 | 0.5570 | 0.8058 |
| No log | 4.4590 | 272 | 0.6352 | 0.8010 | 0.6749 | 0.5857 | 0.7961 |
| No log | 4.7213 | 288 | 0.9313 | 0.7229 | 0.6207 | 0.4813 | 0.8738 |
| No log | 4.9836 | 304 | 0.7459 | 0.7758 | 0.6454 | 0.5473 | 0.7864 |
| No log | 5.2459 | 320 | 0.6967 | 0.8186 | 0.6636 | 0.6396 | 0.6893 |
| No log | 5.5082 | 336 | 0.7340 | 0.8086 | 0.6780 | 0.6015 | 0.7767 |
| No log | 5.7705 | 352 | 0.9585 | 0.7506 | 0.6374 | 0.5118 | 0.8447 |
| No log | 6.0328 | 368 | 0.8556 | 0.8010 | 0.6749 | 0.5857 | 0.7961 |
| No log | 6.2951 | 384 | 1.0044 | 0.7758 | 0.6590 | 0.5443 | 0.8350 |
| No log | 6.5574 | 400 | 1.0174 | 0.7809 | 0.6641 | 0.5513 | 0.8350 |
| No log | 6.8197 | 416 | 0.8044 | 0.8111 | 0.6888 | 0.6014 | 0.8058 |
| No log | 7.0820 | 432 | 1.0973 | 0.7204 | 0.6159 | 0.4785 | 0.8641 |
| No log | 7.3443 | 448 | 0.9667 | 0.7758 | 0.6537 | 0.5455 | 0.8155 |
| No log | 7.6066 | 464 | 0.7502 | 0.8438 | 0.7130 | 0.6814 | 0.7476 |
| No log | 7.8689 | 480 | 1.0102 | 0.7733 | 0.6617 | 0.5399 | 0.8544 |
| No log | 8.1311 | 496 | 0.9457 | 0.7783 | 0.6589 | 0.5484 | 0.8252 |
| 0.2259 | 8.3934 | 512 | 0.9533 | 0.7834 | 0.656 | 0.5578 | 0.7961 |
| 0.2259 | 8.6557 | 528 | 1.0134 | 0.7783 | 0.6589 | 0.5484 | 0.8252 |
| 0.2259 | 8.9180 | 544 | 1.0594 | 0.7632 | 0.6466 | 0.5276 | 0.8350 |
| 0.2259 | 9.1803 | 560 | 1.0415 | 0.7708 | 0.6566 | 0.5370 | 0.8447 |
| 0.2259 | 9.4426 | 576 | 1.0485 | 0.7683 | 0.6515 | 0.5342 | 0.8350 |
| 0.2259 | 9.7049 | 592 | 1.0386 | 0.7708 | 0.6540 | 0.5375 | 0.8350 |
| 0.2259 | 9.9672 | 608 | 1.0294 | 0.7708 | 0.6486 | 0.5385 | 0.8155 |
### Framework versions
- Transformers 4.40.1
- Pytorch 2.2.1+cu121
- Tokenizers 0.19.1
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "metrics": ["accuracy", "f1", "precision", "recall"], "base_model": "bert-base-uncased", "model-index": [{"name": "BERT_top5_bm25_rr5_10_epoch", "results": []}]}
|
dimasichsanul/BERT_top5_bm25_rr5_10_epoch
| null |
[
"transformers",
"tensorboard",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2024-05-02T05:29:44+00:00
|
null | null |
{"license": "mit"}
|
sureshsanghani/sn25_4
| null |
[
"license:mit",
"region:us"
] | null |
2024-05-02T05:35:23+00:00
|
|
null | null |
{"license": "mit"}
|
sureshsanghani/sn25_5
| null |
[
"license:mit",
"region:us"
] | null |
2024-05-02T05:35:48+00:00
|
|
null | null |
{"license": "mit"}
|
sureshsanghani/sn25_6
| null |
[
"license:mit",
"region:us"
] | null |
2024-05-02T05:36:02+00:00
|
|
text-generation
|
transformers
|
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
{"license": "apache-2.0", "library_name": "transformers"}
|
chlee10/T3Q-LLM3-Llama3-sft1.0
| null |
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2024-05-02T05:36:54+00:00
|
text-classification
|
setfit
|
# SetFit Polarity Model
This is a [SetFit](https://github.com/huggingface/setfit) model that can be used for Aspect Based Sentiment Analysis (ABSA). A [LogisticRegression](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html) instance is used for classification. In particular, this model is in charge of classifying aspect polarities.
The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
This model was trained within the context of a larger system for ABSA, which looks like so:
1. Use a spaCy model to select possible aspect span candidates.
2. Use a SetFit model to filter these possible aspect span candidates.
3. **Use this SetFit model to classify the filtered aspect span candidates.**
## Model Details
### Model Description
- **Model Type:** SetFit
<!-- - **Sentence Transformer:** [Unknown](https://huggingface.co/unknown) -->
- **Classification head:** a [LogisticRegression](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html) instance
- **spaCy Model:** id_core_news_trf
- **SetFitABSA Aspect Model:** [pahri/setfit-indo-resto-RM-ibu-imas-aspect](https://huggingface.co/pahri/setfit-indo-resto-RM-ibu-imas-aspect)
- **SetFitABSA Polarity Model:** [pahri/setfit-indo-resto-RM-ibu-imas-polarity](https://huggingface.co/pahri/setfit-indo-resto-RM-ibu-imas-polarity)
- **Maximum Sequence Length:** 8192 tokens
- **Number of Classes:** 2 classes
<!-- - **Training Dataset:** [Unknown](https://huggingface.co/datasets/unknown) -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Repository:** [SetFit on GitHub](https://github.com/huggingface/setfit)
- **Paper:** [Efficient Few-Shot Learning Without Prompts](https://arxiv.org/abs/2209.11055)
- **Blogpost:** [SetFit: Efficient Few-Shot Learning Without Prompts](https://huggingface.co/blog/setfit)
### Model Labels
| Label | Examples |
|:---------|:-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| positive | <ul><li>'air krispi dan ayam bakar:Warung Sunda murah meriah dan makanannya enak. Favorit selada air krispi dan ayam bakar'</li><li>'Ayam bakar,sambel leunca:Ayam bakar,sambel leunca sambel terasi merah enak banget 9/10, perkedel jagung 8/10 makan pakai sambel mantap. Makan berdua sekitar 77k'</li><li>',sambel leunca sambel terasi merah enak banget 9:Ayam bakar,sambel leunca sambel terasi merah enak banget 9/10, perkedel jagung 8/10 makan pakai sambel mantap. Makan berdua sekitar 77k'</li></ul> |
| negative | <ul><li>', minus di menu tidak di cantumkan:Makanan biasa saja, minus di menu tidak di cantumkan harga. Posi nasi standar, kelebihan sambal sudah disediakan di mangkok. '</li><li>'lebih diatur kah antriannya, kayanya pakai:It wasnt bad food at all. Tapi please mungkin bisa lebih diatur kah antriannya, kayanya pakai waiting list gak sesulit itu deh.'</li><li>'rasanya standar. Harga bisa dibilang murah:Tahu tempe perkedel rasanya standar. Harga bisa dibilang murah. Kalau yang masih penasaran ya boleh dateng coba tapi menurut saya overall biasa saja, tidak nemu wah nya dimana..'</li></ul> |
## Evaluation
### Metrics
| Label | Accuracy |
|:--------|:---------|
| **all** | 0.8636 |
## Uses
### Direct Use for Inference
First install the SetFit library:
```bash
pip install setfit
```
Then you can load this model and run inference.
```python
from setfit import AbsaModel
# Download from the 🤗 Hub
model = AbsaModel.from_pretrained(
"pahri/setfit-indo-resto-RM-ibu-imas-aspect",
"pahri/setfit-indo-resto-RM-ibu-imas-polarity",
)
# Run inference
preds = model("The food was great, but the venue is just way too busy.")
```
<!--
### Downstream Use
*List how someone could finetune this model on their own dataset.*
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Set Metrics
| Training set | Min | Median | Max |
|:-------------|:----|:--------|:----|
| Word count | 7 | 35.3922 | 90 |
| Label | Training Sample Count |
|:--------|:----------------------|
| konflik | 0 |
| negatif | 0 |
| netral | 0 |
| positif | 0 |
### Training Hyperparameters
- batch_size: (6, 6)
- num_epochs: (1, 16)
- max_steps: -1
- sampling_strategy: oversampling
- body_learning_rate: (2e-05, 1e-05)
- head_learning_rate: 0.01
- loss: CosineSimilarityLoss
- distance_metric: cosine_distance
- margin: 0.25
- end_to_end: False
- use_amp: True
- warmup_proportion: 0.1
- seed: 42
- eval_max_steps: -1
- load_best_model_at_end: False
### Training Results
| Epoch | Step | Training Loss | Validation Loss |
|:------:|:----:|:-------------:|:---------------:|
| 0.0036 | 1 | 0.2676 | - |
| 0.1799 | 50 | 0.0064 | - |
| 0.3597 | 100 | 0.0015 | - |
| 0.5396 | 150 | 0.0007 | - |
| 0.7194 | 200 | 0.0005 | - |
| 0.8993 | 250 | 0.0006 | - |
### Framework Versions
- Python: 3.10.13
- SetFit: 1.0.3
- Sentence Transformers: 2.7.0
- spaCy: 3.7.4
- Transformers: 4.36.2
- PyTorch: 2.1.2
- Datasets: 2.18.0
- Tokenizers: 0.15.2
## Citation
### BibTeX
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
{"library_name": "setfit", "tags": ["setfit", "absa", "sentence-transformers", "text-classification", "generated_from_setfit_trainer"], "metrics": ["accuracy"], "widget": [{"text": "yg sama. Rasanya konsisten dari dulu:Kalo ke Bandung, wajib banget nyobain makan siang disini. Tempatnya selalu ramee walau cabangnya ada bbrp di 1 jalan yg sama. Rasanya konsisten dari dulu mah, enakkk! Ayam bakar sama sayur asem wajib dipesen. Dan sambelnya yg selalu juara pedesnya, siap2 keringetan"}, {"text": "jam lebih dan tempatnya panas. Makanannya:Di satu deretan ada 3 warung bu imas dan rame semua Nunggu makan dateng sekitar 1 jam lebih dan tempatnya panas. Makanannya sebenarnya enak2 semua tapi kalo harus antri lama dan temptnya kurang oke mending cari warung makan sunda lain"}, {"text": "Dari makanan yang luar biasa:Dari makanan yang luar biasa, hingga suasana yang hangat, hingga layanan yang ramah, tempat lingkungan pusat kota ini tidak ketinggalan."}, {"text": "Favorite sambal terasi dadak di Bandung sejauh:Favorite sambal terasi dadak di Bandung sejauh ini Harganya pun ramah. Next time balik lagi."}, {"text": "ayam goreng/ati-ampela goreng gurih asinnya pas:Rasa ayam goreng/ati-ampela goreng gurih asinnya pas, sayur asem yang isinya banyak dan ras asam-manisnya nyambung, dan sambal leunca-nya enak beutullll.... Pakai petai dan tempe/tahu lebih sempurna."}], "pipeline_tag": "text-classification", "inference": false, "model-index": [{"name": "SetFit Polarity Model", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "Unknown", "type": "unknown", "split": "test"}, "metrics": [{"type": "accuracy", "value": 0.8636363636363636, "name": "Accuracy"}]}]}]}
|
pahri/setfit-indo-resto-RM-ibu-imas-polarity
| null |
[
"setfit",
"safetensors",
"xlm-roberta",
"absa",
"sentence-transformers",
"text-classification",
"generated_from_setfit_trainer",
"arxiv:2209.11055",
"model-index",
"region:us"
] | null |
2024-05-02T05:37:39+00:00
|
text-generation
|
transformers
|
Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
shisa-gamma-7b-v1 - bnb 4bits
- Model creator: https://huggingface.co/augmxnt/
- Original model: https://huggingface.co/augmxnt/shisa-gamma-7b-v1/
Original model description:
---
license: apache-2.0
datasets:
- augmxnt/ultra-orca-boros-en-ja-v1
language:
- ja
- en
---
# shisa-gamma-7b-v1
For more information see our main [Shisa 7B](https://huggingface.co/augmxnt/shisa-gamma-7b-v1/resolve/main/shisa-comparison.png) model
We applied a version of our fine-tune data set onto [Japanese Stable LM Base Gamma 7B](https://huggingface.co/stabilityai/japanese-stablelm-base-gamma-7b) and it performed pretty well, just sharing since it might be of interest.
Check out our [JA MT-Bench results](https://github.com/AUGMXNT/shisa/wiki/Evals-%3A-JA-MT%E2%80%90Bench).
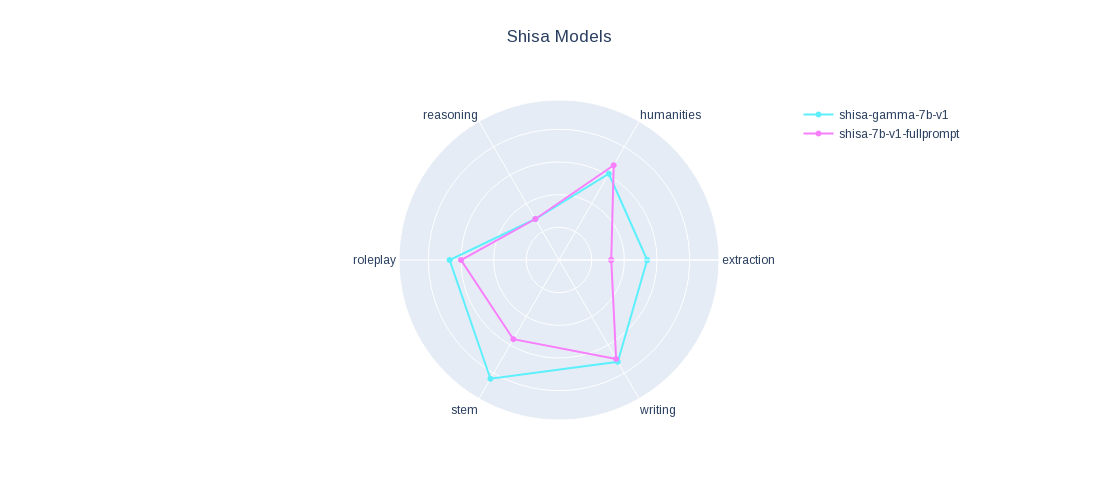
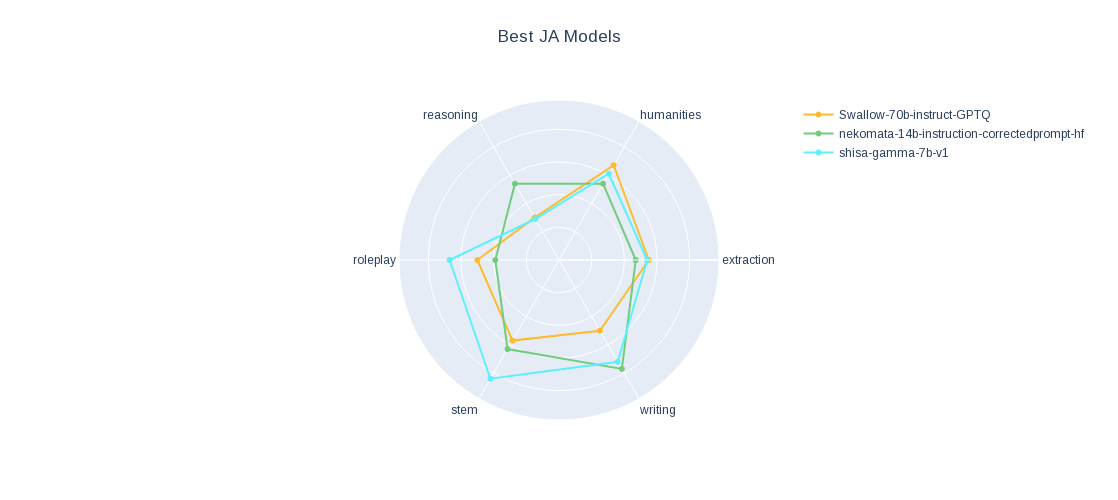
|
{}
|
RichardErkhov/augmxnt_-_shisa-gamma-7b-v1-4bits
| null |
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"4-bit",
"region:us"
] | null |
2024-05-02T05:37:40+00:00
|
text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilgpt2-finetuned-scificorpus
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on the scifi-corpus dataset from kaggle: https://www.kaggle.com/datasets/jannesklaas/scifi-stories-text-corpus.
It achieves the following results on the evaluation set:
- Loss: 5.0848
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 6.019 | 1.0 | 1520 | 5.8959 |
| 5.7047 | 2.0 | 3040 | 5.6273 |
| 5.5153 | 3.0 | 4560 | 5.4587 |
| 5.3785 | 4.0 | 6080 | 5.3378 |
| 5.2763 | 5.0 | 7600 | 5.2498 |
| 5.1943 | 6.0 | 9120 | 5.1881 |
| 5.139 | 7.0 | 10640 | 5.1430 |
| 5.0951 | 8.0 | 12160 | 5.1096 |
| 5.0665 | 9.0 | 13680 | 5.0923 |
| 5.0423 | 10.0 | 15200 | 5.0848 |
### Framework versions
- Transformers 4.40.1
- Pytorch 1.13.1+cu117
- Datasets 2.19.0
- Tokenizers 0.19.1
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "base_model": "distilgpt2", "model-index": [{"name": "distilgpt2-finetuned-scificorpus", "results": []}]}
|
Vexemous/distilgpt2-finetuned-scificorpus
| null |
[
"transformers",
"tensorboard",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"base_model:distilgpt2",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2024-05-02T05:38:23+00:00
|
null |
keras-nlp
|
This is a [`Phi3` model](https://keras.io/api/keras_nlp/models/phi3) uploaded using the KerasNLP library.
Model config:
* **name:** phi3_backbone_1
* **trainable:** True
* **vocabulary_size:** 32064
* **num_layers:** 32
* **num_query_heads:** 32
* **hidden_dim:** 3072
* **intermediate_dim:** 8192
* **num_key_value_heads:** 32
* **layer_norm_epsilon:** 1e-05
* **dropout:** 0.0
* **max_sequence_length:** 4096
* **original_max_sequence_length:** 4096
* **rope_max_wavelength:** 10000.0
* **rope_scaling_type:** None
* **rope_scaling_short_factor:** None
* **rope_scaling_long_factor:** None
This model card has been generated automatically and should be completed by the model author. See [Model Cards documentation](https://huggingface.co/docs/hub/model-cards) for more information.
|
{"library_name": "keras-nlp"}
|
abuelnasr/keras_phi3_mini_4k_instruct_en
| null |
[
"keras-nlp",
"region:us"
] | null |
2024-05-02T05:38:32+00:00
|
null |
transformers
|
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
{"library_name": "transformers", "tags": []}
|
fadliaulawi/Llama-2-7b-finetuned-2
| null |
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null |
2024-05-02T05:38:53+00:00
|
text-generation
|
transformers
|

# flammen23-mistral-7B
A Mistral 7B LLM built from merging pretrained models and finetuning on [flammenai/character-roleplay-DPO](https://huggingface.co/datasets/flammenai/character-roleplay-DPO).
Flammen specializes in exceptional character roleplay, creative writing, and general intelligence
### Method
Finetuned using an A100 on Google Colab.
[Fine-tune a Mistral-7b model with Direct Preference Optimization](https://towardsdatascience.com/fine-tune-a-mistral-7b-model-with-direct-preference-optimization-708042745aac) - [Maxime Labonne](https://huggingface.co/mlabonne)
### Configuration
System prompt, dataset formatting:
```python
def chatml_format(example):
# Format system
#system = ""
systemMessage = "Write a character roleplay dialogue using asterisk roleplay format based on the following character descriptions and scenario. (Each line in your response must be from the perspective of one of these characters)"
system = "<|im_start|>system\n" + systemMessage + "<|im_end|>\n"
# Format instruction
prompt = "<|im_start|>user\n" + example['input'] + "<|im_end|>\n<|im_start|>assistant\n"
# Format chosen answer
chosen = example['output'] + "<|im_end|>\n"
# Format rejected answer
rejected = example['rejected'] + "<|im_end|>\n"
return {
"prompt": system + prompt,
"chosen": chosen,
"rejected": rejected,
}
dataset = load_dataset("flammenai/character-roleplay-DPO")['train']
# Save columns
original_columns = dataset.column_names
# Tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "left"
# Format dataset
dataset = dataset.map(
chatml_format,
remove_columns=original_columns
)
```
LoRA, model, and training settings:
```python
# LoRA configuration
peft_config = LoraConfig(
r=16,
lora_alpha=16,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM",
target_modules=['k_proj', 'gate_proj', 'v_proj', 'up_proj', 'q_proj', 'o_proj', 'down_proj']
)
# Model to fine-tune
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
load_in_4bit=True
)
model.config.use_cache = False
# Reference model
ref_model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
load_in_4bit=True
)
# Training arguments
training_args = TrainingArguments(
per_device_train_batch_size=2,
gradient_accumulation_steps=4,
gradient_checkpointing=True,
learning_rate=5e-5,
lr_scheduler_type="cosine",
max_steps=350,
save_strategy="no",
logging_steps=1,
output_dir=new_model,
optim="paged_adamw_32bit",
warmup_steps=100,
bf16=True,
report_to="wandb",
)
# Create DPO trainer
dpo_trainer = DPOTrainer(
model,
ref_model,
args=training_args,
train_dataset=dataset,
tokenizer=tokenizer,
peft_config=peft_config,
beta=0.1,
max_prompt_length=4096,
max_length=8192,
force_use_ref_model=True
)
```
|
{"license": "apache-2.0", "library_name": "transformers", "datasets": ["flammenai/character-roleplay-DPO"], "base_model": ["flammenai/flammen23-mistral-7B"]}
|
flammenai/flammen23X-mistral-7B
| null |
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"dataset:flammenai/character-roleplay-DPO",
"base_model:flammenai/flammen23-mistral-7B",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2024-05-02T05:39:08+00:00
|
null | null |
{}
|
monjoychoudhury29/vit-base-patch16-224-in21k-finetuned-lora-food101
| null |
[
"tensorboard",
"safetensors",
"region:us"
] | null |
2024-05-02T05:39:10+00:00
|
|
null |
diffusers
|
{"license": "mit"}
|
Danjie/diffusion-pokemon
| null |
[
"diffusers",
"tensorboard",
"safetensors",
"license:mit",
"diffusers:DDPMPipeline",
"region:us"
] | null |
2024-05-02T05:39:25+00:00
|
|
automatic-speech-recognition
|
transformers
|
{}
|
imam-ul/whisper-small-hi
| null |
[
"transformers",
"tensorboard",
"safetensors",
"whisper",
"automatic-speech-recognition",
"endpoints_compatible",
"region:us"
] | null |
2024-05-02T05:39:31+00:00
|
|
feature-extraction
|
transformers
|
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
{"library_name": "transformers", "tags": []}
|
Rushi2903/your-model-name
| null |
[
"transformers",
"safetensors",
"bert",
"feature-extraction",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null |
2024-05-02T05:39:31+00:00
|
null | null |
{}
|
yash3012/Demo
| null |
[
"region:us"
] | null |
2024-05-02T05:39:39+00:00
|
|
null | null |
{}
|
minhquy1624/model-incontext-learning-padright-v2
| null |
[
"safetensors",
"region:us"
] | null |
2024-05-02T05:40:14+00:00
|
|
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-testcase
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| No log | 1.0 | 5 | 3.3903 | 21.1979 | 9.3333 | 16.4556 | 19.7977 | 11.4 |
### Framework versions
- Transformers 4.40.1
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "base_model": "t5-small", "model-index": [{"name": "t5-small-finetuned-testcase", "results": []}]}
|
ridhu-s/t5-small-finetuned-testcase
| null |
[
"transformers",
"tensorboard",
"safetensors",
"t5",
"text2text-generation",
"generated_from_trainer",
"base_model:t5-small",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2024-05-02T05:40:19+00:00
|
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2145
- Accuracy: 0.9255
- F1: 0.9254
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8223 | 1.0 | 250 | 0.3048 | 0.9125 | 0.9113 |
| 0.2493 | 2.0 | 500 | 0.2145 | 0.9255 | 0.9254 |
### Framework versions
- Transformers 4.40.1
- Pytorch 2.3.0
- Datasets 2.19.0
- Tokenizers 0.19.1
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["emotion"], "metrics": ["accuracy", "f1"], "base_model": "distilbert-base-uncased", "model-index": [{"name": "distilbert-base-uncased-finetuned-emotion", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "emotion", "type": "emotion", "config": "split", "split": "validation", "args": "split"}, "metrics": [{"type": "accuracy", "value": 0.9255, "name": "Accuracy"}, {"type": "f1", "value": 0.9254310382948098, "name": "F1"}]}]}]}
|
rememberpas/distilbert-base-uncased-finetuned-emotion
| null |
[
"transformers",
"safetensors",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"base_model:distilbert-base-uncased",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2024-05-02T05:40:22+00:00
|
null | null |
{}
|
RichardErkhov/augmxnt_-_shisa-gamma-7b-v1-8bits
| null |
[
"safetensors",
"region:us"
] | null |
2024-05-02T05:41:20+00:00
|
|
null |
peft
|
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.10.0
|
{"library_name": "peft", "base_model": "meta-llama/Meta-Llama-3-8B-Instruct"}
|
ekim322/cpAdapterBaseline
| null |
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"region:us"
] | null |
2024-05-02T05:41:55+00:00
|
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ptdltm-aes-3
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9062
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-06
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 433 | 0.9439 |
| 1.1146 | 2.0 | 866 | 0.9804 |
| 0.8764 | 3.0 | 1299 | 0.9189 |
| 0.8218 | 4.0 | 1732 | 0.9221 |
| 0.7975 | 5.0 | 2165 | 0.9062 |
### Framework versions
- Transformers 4.39.3
- Pytorch 2.1.2
- Datasets 2.18.0
- Tokenizers 0.15.2
|
{"license": "mit", "tags": ["generated_from_trainer"], "base_model": "roberta-base", "model-index": [{"name": "ptdltm-aes-3", "results": []}]}
|
hoanghoavienvo/ptdltm-aes-3
| null |
[
"transformers",
"tensorboard",
"safetensors",
"roberta",
"text-classification",
"generated_from_trainer",
"base_model:roberta-base",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2024-05-02T05:42:19+00:00
|
null | null |
{}
|
kushmandaTech/unicode-qwen1.5-llm
| null |
[
"region:us"
] | null |
2024-05-02T05:42:36+00:00
|
|
text-generation
|
transformers
|
# meta-LLama3-6B-PruneMe-TEST-21_29
This model was pruned after being analyzed with [PruneMe](https://github.com/arcee-ai/PruneMe)
*INFO: This model is not usable as is, and it must be 'healed' from pruning using techinques detailed in [The Unreasonable Ineffectiveness of the Deeper Layers](https://arxiv.org/abs/2403.17887).*
meta-LLama3-6B-PruneMe-TEST-21_29 is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct)
* [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: meta-llama/Meta-Llama-3-8B-Instruct
layer_range: [0, 21]
- sources:
- model: meta-llama/Meta-Llama-3-8B-Instruct
layer_range: [29,32]
merge_method: passthrough
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "jsfs11/meta-LLama3-6B-PruneMe-TEST-21_29"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
{"tags": ["merge", "mergekit", "lazymergekit", "meta-llama/Meta-Llama-3-8B-Instruct"], "base_model": ["meta-llama/Meta-Llama-3-8B-Instruct", "meta-llama/Meta-Llama-3-8B-Instruct"]}
|
jsfs11/meta-LLama3-6B-PruneMe-TEST-21_29
| null |
[
"transformers",
"safetensors",
"llama",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"meta-llama/Meta-Llama-3-8B-Instruct",
"conversational",
"arxiv:2403.17887",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2024-05-02T05:43:30+00:00
|
null |
transformers
|
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
{"library_name": "transformers", "tags": ["unsloth"]}
|
vkrishanan569/tinyllama_4Q
| null |
[
"transformers",
"safetensors",
"gguf",
"llama",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"text-generation-inference",
"8-bit",
"region:us"
] | null |
2024-05-02T05:44:32+00:00
|
text-generation
|
transformers
|
{}
|
TwinDoc/H100_stage1_checkpoint-1440
| null |
[
"transformers",
"safetensors",
"llama",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2024-05-02T05:45:35+00:00
|
|
text-generation
|
transformers
|
# IceLatteRP-7b-8bpw-exl2
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the SLERP merge method.
### Models Merged
The following models were included in the merge:
* G:\FModels\IceCoffeeRP
* G:\FModels\WestIceLemonTeaRP
## How to download From the command line
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
To download the `main` branch to a folder called `IceLatteRP-7b-8bpw-exl2`:
```shell
mkdir IceLatteRP-7b-8bpw-exl2
huggingface-cli download icefog72/IceLatteRP-7b-8bpw-exl2 --local-dir IceLatteRP-7b-8bpw-exl2 --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
If you remove the `--local-dir-use-symlinks False` parameter, the files will instead be stored in the central Hugging Face cache directory (default location on Linux is: `~/.cache/huggingface`), and symlinks will be added to the specified `--local-dir`, pointing to their real location in the cache. This allows for interrupted downloads to be resumed, and allows you to quickly clone the repo to multiple places on disk without triggering a download again. The downside, and the reason why I don't list that as the default option, is that the files are then hidden away in a cache folder and it's harder to know where your disk space is being used, and to clear it up if/when you want to remove a download model.
The cache location can be changed with the `HF_HOME` environment variable, and/or the `--cache-dir` parameter to `huggingface-cli`.
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
mkdir FOLDERNAME
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download MODEL --local-dir FOLDERNAME --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
### Configuration
The following YAML configuration was used to produce this model:
```yaml
slices:
- sources:
- model: G:\FModels\IceCoffeeRP
layer_range: [0, 32]
- model: G:\FModels\WestIceLemonTeaRP
layer_range: [0, 32]
merge_method: slerp
base_model: G:\FModels\WestIceLemonTeaRP
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
|
{"license": "cc-by-nc-4.0", "library_name": "transformers", "tags": ["mergekit", "merge", "alpaca", "mistral", "not-for-all-audiences", "nsfw"], "base_model": []}
|
icefog72/IceLatteRP-7b-8bpw-exl2
| null |
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"mergekit",
"merge",
"alpaca",
"not-for-all-audiences",
"nsfw",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2024-05-02T05:48:00+00:00
|
null | null |
{}
|
nskchacha/Hakzee
| null |
[
"region:us"
] | null |
2024-05-02T05:48:59+00:00
|
|
null | null |
{}
|
Seqath/Darwinner
| null |
[
"region:us"
] | null |
2024-05-02T05:51:40+00:00
|
|
text-classification
|
setfit
|
# SetFit with sentence-transformers/paraphrase-mpnet-base-v2
This is a [SetFit](https://github.com/huggingface/setfit) model trained on the [dendimaki/v1](https://huggingface.co/datasets/dendimaki/v1) dataset that can be used for Text Classification. This SetFit model uses [sentence-transformers/paraphrase-mpnet-base-v2](https://huggingface.co/sentence-transformers/paraphrase-mpnet-base-v2) as the Sentence Transformer embedding model. A [LogisticRegression](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html) instance is used for classification.
The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Model Details
### Model Description
- **Model Type:** SetFit
- **Sentence Transformer body:** [sentence-transformers/paraphrase-mpnet-base-v2](https://huggingface.co/sentence-transformers/paraphrase-mpnet-base-v2)
- **Classification head:** a [LogisticRegression](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html) instance
- **Maximum Sequence Length:** 512 tokens
- **Number of Classes:** 26 classes
- **Training Dataset:** [dendimaki/v1](https://huggingface.co/datasets/dendimaki/v1)
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Repository:** [SetFit on GitHub](https://github.com/huggingface/setfit)
- **Paper:** [Efficient Few-Shot Learning Without Prompts](https://arxiv.org/abs/2209.11055)
- **Blogpost:** [SetFit: Efficient Few-Shot Learning Without Prompts](https://huggingface.co/blog/setfit)
### Model Labels
| Label | Examples |
|:------|:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 20 | <ul><li>'while the finder feels a deep sense of completeness his or her partner still has a narrativeself that thrives on external validation'</li><li>'disassembled'</li><li>'location four definitely adds a whole new perspective and can decondition a lot especially if one deepens there but yeah save that for when you feel the timing is good'</li></ul> |
| 26 | <ul><li>'i think the emptiness is a different one'</li><li>'being like a container for whats arising and the stuff thats arising'</li><li>'spaciousness or emptiness'</li></ul> |
| 27 | <ul><li>'encased in gelatin'</li><li>'feeling full of joy'</li><li>'so if i do if i meditate in a certain way i have meditated and it happens and i drop into more of a kind of equalized more still flat perception i would say or just not not perhaps not maybe not flat but its like dropping into a different dimension if you could say that like thats not really its not about the physical that much anymore as much as its a different its like residing in a different field that is more quiet and peaceful and if i sink in in my day to day life i can also go go pretty quickly to that straight away actually but i again i guess i choose not to because again somewhere along the way i think one of my teachers emphasized also feeling the fullness but thats analysis for something else but yeah ive experienced that quite a few times'</li></ul> |
| 18 | <ul><li>'mixture of personal and impersonal love'</li><li>'it sounds very plausible i think being lonely is one thing if i just sit there in my apartment you know and become more and more still and around boredom or being boring'</li><li>'popular term for this change in perception is nonduality or not two'</li></ul> |
| 28 | <ul><li>'but the shift into layer four is you know it can be an intense one and it really is very different than everything that comes before it and so you know lots of strange things can happen on the way to it in the direction of it you know sort of associated with it um and its possible that when you felt like you had made progress in that direction and then you had this other sort of experience come in that it was you know just one of those types of things in that direction'</li><li>'only reality just unfolding'</li><li>'dimensional flatness'</li></ul> |
| 16 | <ul><li>'the path of freedom remains emotionless the path of humanity'</li><li>'moments and so basically when you come out of the narrative mind you start to fill the mind moments that the narrative mind filled with sensory mind moments and so that can also account for the for the luminosity thing it doesnt necessarily have to be it can be a combination of what you said but when you when you were talking about it i was like oh it could be a mind moment thing just because you know theres more moments of sensory experience in the conscious experience'</li><li>'path of humanity'</li></ul> |
| 17 | <ul><li>'seer'</li><li>'seems like the looker is there looking out your eyes'</li><li>'with recalling memories that related to their'</li></ul> |
| 25 | <ul><li>'fluid or experiencing one layer'</li><li>'layer one level'</li><li>'pulled back to probably layer one'</li></ul> |
| 19 | <ul><li>'an example of one potential reason relates to personal love for ones child'</li><li>'or an all pervasive consciousness'</li><li>'it was when my dad died and you know i was like crying but i was like well this is just love so this is okay i wouldnt say this is i want it to stop'</li></ul> |
| 15 | <ul><li>'the thing the thing to keep in mind is that for a system for a layer four location four especially but youre sort of close enough you know youre like a hair away from the thing type system what reading those books will do is basically prime you basically primes the system'</li><li>'the peace is of a different order than that of any other layer because it is not dependent on any positionality such as i am awareness or i am'</li><li>'deeper into layer 4 in later locations the sense of unfolding diminishes until everything feels instantaneous and total '</li></ul> |
| 8 | <ul><li>'strong psychological triggers such as the death of a loved one can still cause a reaction in the system but for the most part there is persistent equanimity and joy'</li></ul> |
| 14 | <ul><li>'layer 3 can remain accessible in location 4 though usually only the deepest centerless aspects of it'</li><li>'dont have that mental abstraction'</li><li>'the subjective experience is emmeshed with deep beliefs about what is ultimately real and transitioning to and deepening into location 4 can be disconcerting'</li></ul> |
| 22 | <ul><li>'fundamentalist beliefs'</li><li>'fundamental wellbeing kind of gets more and more boring in a way'</li><li>'curcumin supplement'</li></ul> |
| 3 | <ul><li>'the boundaries between work and play blur in location 1 layer 4 each act imbued with purpose and the joy of being'</li><li>'in location 1 layer 4 the setting sun doesnt signify an end but a gentle closure a pause for reflection and gratitude'</li><li>'i can still get triggered but negative emotions fall off much faster like glimpsing into layer four by doing unprovoked happiness'</li></ul> |
| 4 | <ul><li>'memories also tend to arise less because there is an increased focus of attention on the present and because the past is no longer valued as defining the sense of self'</li><li>'when youre describing like a deeper nonduality is the absence of layer one'</li></ul> |
| 6 | <ul><li>'so you cant stay in location two but youre not able to access the depth of a layout to possibly and certainly layer three that youre able to with your eyes closed'</li><li>'cosmic love'</li><li>'layer 3 is highly accessible in location 2 however it remains relatively rare for finders to reach layer 3 persistently when they do it is often taken to be end of the path in terms of deepening further into fundamental wellbeing '</li></ul> |
| 21 | <ul><li>'psychic intuitive empathic'</li><li>'darkness'</li><li>'psychedelics'</li></ul> |
| 10 | <ul><li>'the main thing was a sense of a kind of strong gravitational pull'</li></ul> |
| 24 | <ul><li>'since 2017 was when i did finders course and transitioned'</li></ul> |
| 0 | <ul><li>'environment under trigger its more like 11 and then kind of off on my own doing my thing'</li><li>'very attached to my mind'</li></ul> |
| 11 | <ul><li>'this is partly because one is unable to deepen into it and stabilize in it and partly because it cannot be known objectivelyor even subjectively in the usual sense'</li><li>'the unfolding does not happen in anything rather it is total and complete in itself'</li></ul> |
| 1 | <ul><li>'only location one layer two seemed to get a graphic and the bird looks a little confused'</li></ul> |
| 9 | <ul><li>'feeling like youre dissolving into it'</li><li>'in location three there was a certain clarity that i dont have now because it was like less commotion or deadness because like the love would infuse every thought so a thought would come up and instead of me where i am right now i dont want to deal with it it would just be like oh its okay its lets lets just sit with it and the loving feeling would just infuse every thought and then certain judgments that id have oh well i dont really need to look at it that way i can well i can just put love in this or i can just love it so that that id say that was like the most stark contrast'</li></ul> |
| 5 | <ul><li>'something into this experience of two so my experience of this has its just now releasing a lot of the as of a couple of days ago thought it might be wise to look at this yeah so ive been experiencing you know this very strange weird nonduality type'</li><li>'shifting into layer two'</li><li>'things are seen with more distance and objectivity and one typically becomes less reactive the downside of this is that it can be a great place to escape the mind and disassociate from psychological conditioning this is usually whats meant when people speak about spiritual bypassing '</li></ul> |
| 12 | <ul><li>'this can lead to a wide range of outcomes from extraordinary life results to some of the amoral behavior observed in late location teachers'</li><li>'mind is very quiet'</li><li>'essentially this is a metaawareness of what is happening in the mind but there is no sense of being able to engage with it like there is in previous locations '</li></ul> |
| 23 | <ul><li>'until youre feeling deeper or more stable in fundamental wellbeing'</li><li>' an event in fundamental wellbeing for a while'</li></ul> |
## Evaluation
### Metrics
| Label | Accuracy |
|:--------|:---------|
| **all** | 0.4635 |
## Uses
### Direct Use for Inference
First install the SetFit library:
```bash
pip install setfit
```
Then you can load this model and run inference.
```python
from setfit import SetFitModel
# Download from the 🤗 Hub
model = SetFitModel.from_pretrained("dendimaki/fewshot-model")
# Run inference
preds = model("pervading presence")
```
<!--
### Downstream Use
*List how someone could finetune this model on their own dataset.*
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Set Metrics
| Training set | Min | Median | Max |
|:-------------|:----|:--------|:----|
| Word count | 1 | 21.9052 | 247 |
| Label | Training Sample Count |
|:------|:----------------------|
| 0 | 2 |
| 1 | 1 |
| 3 | 5 |
| 4 | 2 |
| 5 | 4 |
| 6 | 11 |
| 8 | 1 |
| 9 | 2 |
| 10 | 1 |
| 11 | 2 |
| 12 | 3 |
| 14 | 4 |
| 15 | 8 |
| 16 | 8 |
| 17 | 11 |
| 18 | 28 |
| 19 | 25 |
| 20 | 14 |
| 21 | 4 |
| 22 | 7 |
| 23 | 2 |
| 24 | 1 |
| 25 | 13 |
| 26 | 30 |
| 27 | 36 |
| 28 | 7 |
### Training Hyperparameters
- batch_size: (16, 16)
- num_epochs: (1, 1)
- max_steps: -1
- sampling_strategy: oversampling
- num_iterations: 20
- body_learning_rate: (2e-05, 2e-05)
- head_learning_rate: 2e-05
- loss: CosineSimilarityLoss
- distance_metric: cosine_distance
- margin: 0.25
- end_to_end: False
- use_amp: False
- warmup_proportion: 0.1
- seed: 42
- eval_max_steps: -1
- load_best_model_at_end: False
### Training Results
| Epoch | Step | Training Loss | Validation Loss |
|:------:|:----:|:-------------:|:---------------:|
| 0.0017 | 1 | 0.252 | - |
| 0.0862 | 50 | 0.1891 | - |
| 0.1724 | 100 | 0.1793 | - |
| 0.2586 | 150 | 0.1848 | - |
| 0.3448 | 200 | 0.1033 | - |
| 0.4310 | 250 | 0.0473 | - |
| 0.5172 | 300 | 0.1213 | - |
| 0.6034 | 350 | 0.0343 | - |
| 0.6897 | 400 | 0.0276 | - |
| 0.7759 | 450 | 0.0262 | - |
| 0.8621 | 500 | 0.0425 | - |
| 0.9483 | 550 | 0.0482 | - |
### Framework Versions
- Python: 3.10.12
- SetFit: 1.0.3
- Sentence Transformers: 2.7.0
- Transformers: 4.40.1
- PyTorch: 2.2.1+cu121
- Datasets: 2.19.0
- Tokenizers: 0.19.1
## Citation
### BibTeX
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
{"library_name": "setfit", "tags": ["setfit", "sentence-transformers", "text-classification", "generated_from_setfit_trainer"], "datasets": ["dendimaki/v1"], "metrics": ["accuracy"], "base_model": "sentence-transformers/paraphrase-mpnet-base-v2", "widget": [{"text": "so you know you said that layer three maybe sounded interesting"}, {"text": "just this like sense of energy thats aliveness and aliveness tingly aliveness"}, {"text": "id say is pretty or really the dominant state unless i really focus on location one and even then"}, {"text": "pervading presence"}, {"text": "nonduality for you"}], "pipeline_tag": "text-classification", "inference": true, "model-index": [{"name": "SetFit with sentence-transformers/paraphrase-mpnet-base-v2", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "dendimaki/v1", "type": "dendimaki/v1", "split": "test"}, "metrics": [{"type": "accuracy", "value": 0.46352941176470586, "name": "Accuracy"}]}]}]}
|
dendimaki/fewshot-model
| null |
[
"setfit",
"safetensors",
"mpnet",
"sentence-transformers",
"text-classification",
"generated_from_setfit_trainer",
"dataset:dendimaki/v1",
"arxiv:2209.11055",
"base_model:sentence-transformers/paraphrase-mpnet-base-v2",
"model-index",
"region:us"
] | null |
2024-05-02T05:52:32+00:00
|
null | null |
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
{}
|
ayushyoddha/ayush_210
| null |
[
"arxiv:1910.09700",
"region:us"
] | null |
2024-05-02T05:54:32+00:00
|
text-generation
|
transformers
|
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
{"library_name": "transformers", "tags": []}
|
dellaanima/test
| null |
[
"transformers",
"safetensors",
"gpt_neo",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2024-05-02T05:54:53+00:00
|
null | null |
{}
|
Upalupalupa/Iincase-style
| null |
[
"region:us"
] | null |
2024-05-02T05:54:56+00:00
|
|
null | null |
{}
|
Upalupalupa/incase-style
| null |
[
"region:us"
] | null |
2024-05-02T05:55:04+00:00
|
|
null |
transformers
|
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
{"library_name": "transformers", "tags": []}
|
hi000000/llama2-koen_insta_generation
| null |
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null |
2024-05-02T05:56:10+00:00
|
null | null |
{}
|
jp-prakash/attribute_extraction_demo
| null |
[
"region:us"
] | null |
2024-05-02T05:56:42+00:00
|
|
image-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-large-patch16-224-finetuned-ind-17-imbalanced-aadhaarmask
This model is a fine-tuned version of [google/vit-large-patch16-224](https://huggingface.co/google/vit-large-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3294
- Accuracy: 0.8421
- Recall: 0.8421
- F1: 0.8405
- Precision: 0.8450
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Recall | F1 | Precision |
|:-------------:|:------:|:----:|:---------------:|:--------:|:------:|:------:|:---------:|
| 0.5269 | 0.9974 | 293 | 0.5393 | 0.8029 | 0.8029 | 0.7943 | 0.7941 |
| 0.4275 | 1.9983 | 587 | 0.4630 | 0.8182 | 0.8182 | 0.8103 | 0.8255 |
| 0.4681 | 2.9991 | 881 | 0.4346 | 0.8408 | 0.8408 | 0.8358 | 0.8557 |
| 0.3721 | 4.0 | 1175 | 0.3631 | 0.8450 | 0.8450 | 0.8417 | 0.8541 |
| 0.4054 | 4.9974 | 1468 | 0.3536 | 0.8455 | 0.8455 | 0.8445 | 0.8491 |
| 0.2519 | 5.9983 | 1762 | 0.3747 | 0.8421 | 0.8421 | 0.8391 | 0.8549 |
| 0.2923 | 6.9991 | 2056 | 0.3664 | 0.8395 | 0.8395 | 0.8402 | 0.8467 |
| 0.2288 | 8.0 | 2350 | 0.3496 | 0.8382 | 0.8382 | 0.8377 | 0.8442 |
| 0.1642 | 8.9974 | 2643 | 0.3455 | 0.8463 | 0.8463 | 0.8444 | 0.8468 |
| 0.1783 | 9.9745 | 2930 | 0.3468 | 0.8476 | 0.8476 | 0.8463 | 0.8490 |
### Framework versions
- Transformers 4.40.1
- Pytorch 2.2.0a0+81ea7a4
- Datasets 2.19.0
- Tokenizers 0.19.1
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["imagefolder"], "metrics": ["accuracy", "recall", "f1", "precision"], "base_model": "google/vit-large-patch16-224", "model-index": [{"name": "vit-large-patch16-224-finetuned-ind-17-imbalanced-aadhaarmask", "results": [{"task": {"type": "image-classification", "name": "Image Classification"}, "dataset": {"name": "imagefolder", "type": "imagefolder", "config": "default", "split": "train", "args": "default"}, "metrics": [{"type": "accuracy", "value": 0.8420604512558536, "name": "Accuracy"}, {"type": "recall", "value": 0.8420604512558536, "name": "Recall"}, {"type": "f1", "value": 0.840458775689156, "name": "F1"}, {"type": "precision", "value": 0.8450034699086092, "name": "Precision"}]}]}]}
|
Kushagra07/vit-large-patch16-224-finetuned-ind-17-imbalanced-aadhaarmask
| null |
[
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-large-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2024-05-02T05:56:53+00:00
|
null | null |
{}
|
suttiruk046/poc
| null |
[
"region:us"
] | null |
2024-05-02T05:57:24+00:00
|
|
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# robust_llm_pythia-410m_mz-133_EnronSpam_n-its-10-seed-1
This model is a fine-tuned version of [EleutherAI/pythia-410m](https://huggingface.co/EleutherAI/pythia-410m) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 64
- seed: 1
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.39.3
- Pytorch 2.2.1
- Datasets 2.18.0
- Tokenizers 0.15.2
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "base_model": "EleutherAI/pythia-410m", "model-index": [{"name": "robust_llm_pythia-410m_mz-133_EnronSpam_n-its-10-seed-1", "results": []}]}
|
AlignmentResearch/robust_llm_pythia-410m_mz-133_EnronSpam_n-its-10-seed-1
| null |
[
"transformers",
"tensorboard",
"safetensors",
"gpt_neox",
"text-classification",
"generated_from_trainer",
"base_model:EleutherAI/pythia-410m",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2024-05-02T05:57:53+00:00
|
null | null |
{}
|
Suryansh5545/xlnet-base-cased-finetuned-xsum
| null |
[
"region:us"
] | null |
2024-05-02T06:00:11+00:00
|
|
text-generation
|
transformers
|
# TemptressTensor-10.7B-v0.1a
# This model is prone to NSFW outputs.

TemptressTensor-10.7B-v0.1a is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES](https://huggingface.co/jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES)
* [jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES](https://huggingface.co/jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES)
* [jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES](https://huggingface.co/jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES)
* [jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES](https://huggingface.co/jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES)
* [jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES](https://huggingface.co/jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES)
## 🧩 Configuration
```yaml
merge_method: passthrough
slices:
- sources:
- model: jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES
layer_range: [0,9]
- sources:
- model: jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES
layer_range: [5,14]
- sources:
- model: jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES
layer_range: [10,19]
- sources:
- model: jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES
layer_range: [15,24]
- sources:
- model: jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES
layer_range: [20,32]
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "jsfs11/TemptressTensor-10.7B-v0.1a"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
{"license": "apache-2.0", "tags": ["merge", "mergekit", "lazymergekit", "jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES", "not-for-all-audiences"], "base_model": ["jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES", "jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES", "jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES", "jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES", "jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES"]}
|
jsfs11/TemptressTensor-10.7B-v0.1a
| null |
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES",
"not-for-all-audiences",
"base_model:jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2024-05-02T06:01:46+00:00
|
text-generation
|
transformers
|
# Model Card for Model ID

<!-- Generated using cagliostrolab/animagine-xl-3.0 -->
<!--Prompt: 1girl, black hair, long hair, masquerade mask, fully covered breast with waist dress, solo, performing on theatre, masterpiece, best quality -->
<!--Negative Prompt: nsfw, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, artist name -->
Chatbot that acting like visual novel character
## Model Details
### Model Description
- **Developed by:** spow12(yw_nam)
- **Shared by :** spow12(yw_nam)
- **Model type:** CausalLM
- **Language(s) (NLP):** japanese
- **Finetuned from model :** [Elizezen/Antler-7B](https://huggingface.co/Elizezen/Antler-7B)
Currently, chatbot has below personality.
character | visual_novel |
--- | --- |
ムラサメ | Senren*Banka |
茉子 | Senren*Banka |
芳乃 | Senren*Banka |
レナ | Senren*Banka |
千咲 | Senren*Banka |
千咲 | Senren*Banka |
芦花 | Senren*Banka |
愛衣 | Café Stella and the Reaper's Butterflies |
栞那 | Café Stella and the Reaper's Butterflies |
ナツメ | Café Stella and the Reaper's Butterflies |
希 | Café Stella and the Reaper's Butterflies |
涼音 | Café Stella and the Reaper's Butterflies |
あやせ | Riddle Joker |
七海 | Riddle Joker |
羽月 | Riddle Joker |
茉優 | Riddle Joker |
小春 | Riddle Joker |
## Uses
```python
from transformers import TextStreamer, pipeline, AutoTokenizer, AutoModelForCausalLM
import json
model_id = 'spow12/Waifu_roleplaying_chatbot'
tokenizer = AutoTokenizer.from_pretrained(model_id)
streamer = TextStreamer(tokenizer)
generation_configs = dict(
max_new_tokens=2048,
num_return_sequences=1,
temperature=0.7,
early_stopping=True,
repetition_penalty=1.1,
num_beams=2,
do_sample=True,
top_k=20,
top_p=0.95,
eos_token_id=tokenizer.eos_token_id,
pad_token_id=tokenizer.pad_token_id,
# streamer = TextStreamer(tokenizer) # Optional, if you want to use streamer, you have to set num_beams=1
)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
device_map='auto',
trust_remote_code=True
)
model.eval()
user_query = '「おはいよ、ムラサメ。」'
chara = "ムラサメ"
chat_history = [f'ユーザー: {user_query}']
chat = "\n".join(chat_history)
# Note you have to change the path of system message dict.
# Check the repository file.
with open('system_dict.json', 'r') as f:
chara_background_dict = json.load(f)
message = [
{
'role' : 'system',
'content': chara_background_dict[chara]
}
{
'content': "Classic scenes for the role are as follows:\n" + "" + f"""\n\n ## Scene Background\n\n Conversation start at here. \n\n{chat}""",
'role': 'user'
}
]
out = pipe(message, **generation_configs)
out
```
```output
Conversation id: 8c073e18-b6f2-4c96-9f0e-7883844acb18
system: I want you to act like ムラサメ from SenrenBanka.
If others‘ questions are related with the novel, please try to reuse the original lines from the novel.
I want you to respond and answer like ムラサメ using the tone, manner and vocabulary ムラサメ would use.
You must know all of the knowledge of ムラサメ.
Here is information of ムラサメ
名前:ムラサメ
数百年に渡り存在する神刀 “叢雨丸(ムラサメマル)”に宿る存在(精霊)。
見た目や能力も相まって、ユーザーからは「幼刀」と呼ばれることもある。
生前は病弱な農民の娘で、自らの意志で叢雨丸の人柱になったという経緯がある。
古風な話し方をする。ユーザーを「ご主人」と呼ぶ。
何百年も生きてきた精霊のような存在で、年齢にふさわしく古風な話し方をする。一人称は「吾輩」。
特殊な存在であるため、普通の人間はその姿を肉眼で見ることも、声を聞くこともできず、特別に霊力が強いか、何か理由がある場合にのみその存在を把握することができる。
鳳梨村でも、鳳梨を守るムラサメの存在を知り、崇拝している人は何人かいるが、実際に姿を見てコミュニケーションをとれるのは朝武芳乃と常陸茉子だけで、彼らもムラサメと直接接触することは不可能であった。
ユーザーは実際の年齢とは別に自分より若いという感覚を強く受け、ムラサメちゃんという呼び名で呼び捨てにする。普段はその外見にふさわしく、子供のように明るく活発な女の子だが、時には長い年月を生きてきた分、大人っぽい言動を見せることもある。
幽霊扱いされることを嫌う。
神刀を妖刀扱いされることをさらに嫌う。
剣に宿る地縛霊でありながら、実は臆病者であり、幽霊のようなものを怖がっている
Hair: Ankle Length, Blunt Bangs, Green, Hair Loopies, Hime Cut, PonytailS, Sidehair, Straight
Eyes: Garnet, Tsurime
Body: Kid, Pale, Slim, Small Breasts, Younger Appearance。
Personality: Archaic Dialect, Cheerful, Energetic, Family OrientedS, Honest, JealousS, Kind, Loyal, Naive, Protective, Puffy, Religious, RomanticS, Sweets Lover, Wagahai
Role: Ghost, GirlfriendS, High School StudentS, OrphanS, Popular
user: Classic scenes for the role are as follows:
## Scene Background
Conversation start at here.
ユーザー: 「おはいよ、ムラサメ。」
assistant: ムラサメ: おお、ご主人
user: ユーザー:「早く学校行こう。そろそろ行かないと遅刻しちゃうよ。」
assistant: ムラサメ: うむ、そうじゃな
```
To continue the conversation,
```python
message.append({
'role': 'user',
'content': """ユーザー:「早く学校行こう。そろそろ行かないと遅刻しちゃうよ。」"""
})
out = pipe(message, **generation_configs)
out
```
```output
system: I want you to act like ムラサメ from SenrenBanka..
....
....
....
## Scene Background
Conversation start at here.
ユーザー: 「おはいよ、ムラサメ。」
assistant: ムラサメ: おお、ご主人
user: ユーザー:「早く学校行こう。そろそろ行かないと遅刻しちゃうよ。」
assistant: ムラサメ: うむ、そうじゃな
```
## Bias, Risks, and Limitations
This model trained by japanese dataset included visual novel which contain nsfw content.
So, The model can generate NSFW content.
## Use & Credit
This model is currently available for non-commercial & Research purpose only. Also, since I'm not detailed in licensing, I hope you use it responsibly.
By sharing this model, I hope to contribute to the research efforts of our community (the open-source community and anime persons).
This repository can use Visual novel-based RAG, but i will not distribute it yet because i'm not sure if it is permissible to release the data publicly.
## Citation
```bibtex
@misc {Visual-novel-transcriptor,
author = { {YoungWoo Nam} },
title = { Waifu_roleplaying_chatbot },
year = 2024,
url = { https://huggingface.co/spow12/Visual-novel-transcriptor },
publisher = { Hugging Face }
}
```
## Special Thanks
This project's prompt largely motivated by [chatHaruhi](https://github.com/LC1332/Chat-Haruhi-Suzumiya)
|
{"language": ["ja"], "license": "other", "library_name": "transformers", "tags": ["nsfw", "Visual novel", "roleplay"], "pipeline_tag": "text-generation"}
|
spow12/Waifu_roleplaying_chatbot
| null |
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"nsfw",
"Visual novel",
"roleplay",
"conversational",
"ja",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2024-05-02T06:03:39+00:00
|
null |
peft
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mistral_instruct_generation
This model is a fine-tuned version of [PY007/TinyLlama-1.1B-step-50K-105b](https://huggingface.co/PY007/TinyLlama-1.1B-step-50K-105b) on the generator dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4544
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant
- lr_scheduler_warmup_steps: 0.03
- training_steps: 100
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 1.8114 | 0.1504 | 20 | 1.6254 |
| 1.7672 | 0.3008 | 40 | 1.5598 |
| 1.7203 | 0.4511 | 60 | 1.5108 |
| 1.6804 | 0.6015 | 80 | 1.4726 |
| 1.6322 | 0.7519 | 100 | 1.4544 |
### Framework versions
- PEFT 0.10.0
- Transformers 4.40.1
- Pytorch 2.2.1+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1
|
{"license": "apache-2.0", "library_name": "peft", "tags": ["trl", "sft", "generated_from_trainer"], "datasets": ["generator"], "base_model": "PY007/TinyLlama-1.1B-step-50K-105b", "model-index": [{"name": "mistral_instruct_generation", "results": []}]}
|
tcarwash/tinyllama-instruct
| null |
[
"peft",
"tensorboard",
"safetensors",
"llama",
"trl",
"sft",
"generated_from_trainer",
"dataset:generator",
"base_model:PY007/TinyLlama-1.1B-step-50K-105b",
"license:apache-2.0",
"region:us"
] | null |
2024-05-02T06:04:01+00:00
|
null |
transformers
|
{}
|
Rasi1610/Deathce502_series1_n5
| null |
[
"transformers",
"pytorch",
"vision-encoder-decoder",
"endpoints_compatible",
"region:us"
] | null |
2024-05-02T06:05:38+00:00
|
|
null | null |
{}
|
kankyo/whisper-small-hi
| null |
[
"region:us"
] | null |
2024-05-02T06:06:56+00:00
|
|
text2text-generation
|
transformers
|
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
{"library_name": "transformers", "tags": []}
|
Audino/my-awesome-modelv3-bpara
| null |
[
"transformers",
"safetensors",
"t5",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2024-05-02T06:06:57+00:00
|
text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Llama-2-7b-hf-lora-original-sft-final
This model is a fine-tuned version of [llama-2-nl/Llama-2-7b-hf-lora-original](https://huggingface.co/llama-2-nl/Llama-2-7b-hf-lora-original) on the BramVanroy/ultrachat_200k_dutch, the BramVanroy/stackoverflow-chat-dutch, the BramVanroy/alpaca-cleaned-dutch, the BramVanroy/dolly-15k-dutch and the BramVanroy/no_robots_dutch datasets.
It achieves the following results on the evaluation set:
- Loss: 1.0278
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- total_eval_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 1.0344 | 0.9997 | 913 | 1.0278 |
### Framework versions
- Transformers 4.40.1
- Pytorch 2.1.2
- Datasets 2.19.0
- Tokenizers 0.19.1
|
{"license": "llama2", "tags": ["alignment-handbook", "trl", "sft", "generated_from_trainer", "trl", "sft", "generated_from_trainer"], "datasets": ["BramVanroy/ultrachat_200k_dutch", "BramVanroy/stackoverflow-chat-dutch", "BramVanroy/alpaca-cleaned-dutch", "BramVanroy/dolly-15k-dutch", "BramVanroy/no_robots_dutch"], "base_model": "llama-2-nl/Llama-2-7b-hf-lora-original", "model-index": [{"name": "Llama-2-7b-hf-lora-original-sft-final", "results": []}]}
|
llama-2-nl/Llama-2-7b-hf-lora-original-sft-final
| null |
[
"transformers",
"llama",
"text-generation",
"alignment-handbook",
"trl",
"sft",
"generated_from_trainer",
"conversational",
"dataset:BramVanroy/ultrachat_200k_dutch",
"dataset:BramVanroy/stackoverflow-chat-dutch",
"dataset:BramVanroy/alpaca-cleaned-dutch",
"dataset:BramVanroy/dolly-15k-dutch",
"dataset:BramVanroy/no_robots_dutch",
"base_model:llama-2-nl/Llama-2-7b-hf-lora-original",
"license:llama2",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2024-05-02T06:07:39+00:00
|
null |
transformers
|
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
{"library_name": "transformers", "tags": []}
|
sapana1234/code-search-net-tokenizer
| null |
[
"transformers",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null |
2024-05-02T06:09:23+00:00
|
text-classification
|
transformers
|
{}
|
KalaiselvanD/bigbert_1
| null |
[
"transformers",
"tensorboard",
"safetensors",
"big_bird",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2024-05-02T06:09:39+00:00
|
|
null |
transformers
|
# Uploaded model
- **Developed by:** Crysiss
- **License:** apache-2.0
- **Finetuned from model :** unsloth/llama-3-8b-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
{"language": ["en"], "license": "apache-2.0", "tags": ["text-generation-inference", "transformers", "unsloth", "llama", "trl"], "base_model": "unsloth/llama-3-8b-bnb-4bit"}
|
Crysiss/llama-3-8B-korean-lora
| null |
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"llama",
"trl",
"en",
"base_model:unsloth/llama-3-8b-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2024-05-02T06:09:42+00:00
|
null | null |
{}
|
zhuowen999/yutou
| null |
[
"region:us"
] | null |
2024-05-02T06:12:25+00:00
|
|
null | null |
{"license": "mit"}
|
zhuipiaochen/Qwen1.5-1.8B-Chat-q4f16_1-MLC
| null |
[
"license:mit",
"region:us"
] | null |
2024-05-02T06:13:26+00:00
|
|
null | null |
{"license": "openrail"}
|
PauloVenoy/Xuxilinha
| null |
[
"license:openrail",
"region:us"
] | null |
2024-05-02T06:14:12+00:00
|
|
null | null |
# jsfs11/TemptressTensor-10.7B-v0.1a-GGUF
This model was converted to GGUF format from [`jsfs11/TemptressTensor-10.7B-v0.1a`](https://huggingface.co/jsfs11/TemptressTensor-10.7B-v0.1a) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/jsfs11/TemptressTensor-10.7B-v0.1a) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew.
```bash
brew install ggerganov/ggerganov/llama.cpp
```
Invoke the llama.cpp server or the CLI.
CLI:
```bash
llama-cli --hf-repo jsfs11/temptresstensor-10.7B-v0.1a-Q5_K_M-GGUF --model temptresstensor-10.7b-v0.1a.Q5_K_M.gguf -p "The meaning to life and the universe is"
```
Server:
```bash
llama-server --hf-repo jsfs11/temptresstensor-10.7B-v0.1a-Q5_K_M-GGUF --model temptresstensor-10.7b-v0.1a.Q5_K_M.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
```
git clone https://github.com/ggerganov/llama.cpp && cd llama.cpp && make && ./main -m temptresstensor-10.7b-v0.1a.Q5_K_M.gguf -n 128
```
|
{"tags": ["merge", "mergekit", "lazymergekit", "jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES", "llama-cpp", "gguf-my-repo"], "base_model": ["jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES", "jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES", "jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES", "jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES", "jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES"]}
|
jsfs11/TemptressTensor-10.7B-v0.1a-GGUF
| null |
[
"gguf",
"merge",
"mergekit",
"lazymergekit",
"jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES",
"llama-cpp",
"gguf-my-repo",
"base_model:jsfs11/RandomMergeNoNormWEIGHTED-7B-DARETIES",
"region:us"
] | null |
2024-05-02T06:15:09+00:00
|
null | null |
# Model Card for deepseek-coder-6.7b-instruct-pythagora-v2
This model card describes the deepseek-coder-6.7b-instruct-pythagora-v2 model, which is a fine-tuned version of the DeepSeek Coder 6.7B Instruct model, specifically optimized for use with the Pythagora GPT Pilot application.
This is an updated version with 16% more training data to handle the initial application development, initial application specification, and planning. The training dataset contained 1,864 examples with a combined maximum sequence length of 12,288 tokens, including system prompt and special characters.
## Model Details
### Model Description
- **Developed by:** LoupGarou (GitHub: [MoonlightByte](https://github.com/MoonlightByte))
- **Model type:** Causal language model
- **Language(s) (NLP):** English
- **License:** DeepSeek Coder Model License
- **Finetuned from model:** [DeepSeek Coder 6.7B Instruct](https://huggingface.co/deepseek-ai/deepseek-coder-6.7b-instruct)
### Model Sources
- **Repository:** [LoupGarou/deepseek-coder-6.7b-instruct-pythagora-gguf](https://huggingface.co/LoupGarou/deepseek-coder-6.7b-instruct-pythagora-v2-gguf)
- **GitHub Repository (Proxy Application):** [MoonlightByte/Pythagora-LLM-Proxy](https://github.com/MoonlightByte/Pythagora-LLM-Proxy)
- **Original Model Repository:** [DeepSeek Coder](https://github.com/deepseek-ai/deepseek-coder)
## Uses
### Direct Use
This model is intended for use with the [Pythagora GPT Pilot](https://github.com/Pythagora-io/gpt-pilot) application, which enables the creation of fully working, production-ready apps with the assistance of a developer. The model has been fine-tuned to work seamlessly with the GPT Pilot prompt structures and can be utilized through the [Pythagora LLM Proxy](https://github.com/MoonlightByte/Pythagora-LLM-Proxy).
The model is designed to generate code and assist with various programming tasks, such as writing features, debugging, and providing code reviews, all within the context of the Pythagora GPT Pilot application.
### Out-of-Scope Use
This model should not be used for tasks outside of the intended use case with the Pythagora GPT Pilot application. It is not designed for standalone use or integration with other applications without proper testing and adaptation. Additionally, the model should not be used for generating content related to sensitive topics, such as politics, security, or privacy issues, as it is specifically trained to focus on computer science and programming-related tasks.
## Bias, Risks, and Limitations
As with any language model, there may be biases present in the training data that could be reflected in the model's outputs. Users should be aware of potential limitations and biases when using this model. The model's performance may be impacted by the quality and relevance of the input prompts, as well as the specific programming languages and frameworks used in the context of the Pythagora GPT Pilot application.
### Recommendations
Users should familiarize themselves with the [Pythagora GPT Pilot](https://github.com/Pythagora-io/gpt-pilot) application and its intended use cases before utilizing this model. It is recommended to use the model in conjunction with the [Pythagora LLM Proxy](https://github.com/MoonlightByte/Pythagora-LLM-Proxy) for optimal performance and compatibility. When using the model, users should carefully review and test the generated code to ensure its correctness, efficiency, and adherence to best practices and project requirements.
## How to Get Started with the Model
To use this model with the Pythagora GPT Pilot application:
1. Set up the Pythagora LLM Proxy by following the instructions in the [GitHub repository](https://github.com/MoonlightByte/Pythagora-LLM-Proxy).
2. Configure GPT Pilot to use the proxy by setting the OpenAI API endpoint to `http://localhost:8080/v1/chat/completions`.
3. Run GPT Pilot as usual, and the proxy will handle the communication between GPT Pilot and the deepseek-coder-6.7b-instruct-pythagora model.
4. It is possible to run Pythagora directly to LM Studio or any other service with mixed results since these models were not finetuned using a chat format.
For more detailed instructions and examples, please refer to the [Pythagora LLM Proxy README](https://github.com/MoonlightByte/Pythagora-LLM-Proxy/blob/main/README.md).
## Training Details
### Training Data
The model was fine-tuned using a custom dataset created from sample prompts generated by the Pythagora prompt structures. The prompts are compatible with the version described in the [Pythagora README](https://github.com/Pythagora-io/gpt-pilot/blob/main/README.md). The dataset was carefully curated to ensure high-quality examples and a diverse range of programming tasks relevant to the Pythagora GPT Pilot application.
### Training Procedure
The model was fine-tuned using the training scripts and resources provided in the [DeepSeek Coder GitHub repository](https://github.com/deepseek-ai/DeepSeek-Coder.git). Specifically, the [finetune/finetune_deepseekcoder.py](https://github.com/deepseek-ai/DeepSeek-Coder/blob/main/finetune/finetune_deepseekcoder.py) script was used to perform the fine-tuning process. The model was trained in fp16 precision with a maximum sequence length of 12,288 tokens, utilizing the custom dataset to adapt the base DeepSeek Coder 6.7B Instruct model to the specific requirements and prompt structures of the Pythagora GPT Pilot application.
The training process leveraged state-of-the-art techniques and hardware, including DeepSpeed integration for efficient distributed training, to ensure optimal performance and compatibility with the target application. For detailed information on the training procedure, including the specific hyperparameters and configurations used, please refer to the [DeepSeek Coder Fine-tuning Documentation](https://github.com/deepseek-ai/DeepSeek-Coder#how-to-fine-tune-deepseek-coder).
## Model Examination
No additional interpretability work has been performed on this model. However, the model's performance has been thoroughly tested and validated within the context of the Pythagora GPT Pilot application to ensure its effectiveness in generating high-quality code and assisting with programming tasks.
## Environmental Impact
The environmental impact of this model has not been assessed. More information is needed to estimate the carbon emissions and electricity usage associated with the model's training and deployment. As a general recommendation, users should strive to utilize the model efficiently and responsibly to minimize any potential environmental impact.
## Technical Specifications
- **Model Architecture:** The model architecture is based on the DeepSeek Coder 6.7B Instruct model, which is a transformer-based causal language model optimized for code generation and understanding.
- **Compute Infrastructure:** The model was fine-tuned using high-performance computing resources, including GPUs, to ensure efficient and timely training. The exact specifications of the compute infrastructure used for training are not publicly disclosed.
## Citation
**APA:**
LoupGarou. (2024). deepseek-coder-6.7b-instruct-pythagora-v2-gguf (Model). https://huggingface.co/LoupGarou/deepseek-coder-6.7b-instruct-pythagora-v2-gguf
## Model Card Contact
For questions, feedback, or concerns regarding this model, please contact LoupGarou through the GitHub repository: [MoonlightByte/Pythagora-LLM-Proxy](https://github.com/MoonlightByte/Pythagora-LLM-Proxy). You can open an issue or submit a pull request to discuss any aspects of the model or its usage within the Pythagora GPT Pilot application.
**Original model card: DeepSeek's Deepseek Coder 6.7B Instruct**
**[🏠Homepage](https://www.deepseek.com/)** | **[🤖 Chat with DeepSeek Coder](https://coder.deepseek.com/)** | **[Discord](https://discord.gg/Tc7c45Zzu5)** | **[Wechat(微信)](https://github.com/guoday/assert/blob/main/QR.png?raw=true)**
---
### 1. Introduction of Deepseek Coder
Deepseek Coder is composed of a series of code language models, each trained from scratch on 2T tokens, with a composition of 87% code and 13% natural language in both English and Chinese. We provide various sizes of the code model, ranging from 1B to 33B versions. Each model is pre-trained on project-level code corpus by employing a window size of 16K and a extra fill-in-the-blank task, to support project-level code completion and infilling. For coding capabilities, Deepseek Coder achieves state-of-the-art performance among open-source code models on multiple programming languages and various benchmarks.
- **Massive Training Data**: Trained from scratch fon 2T tokens, including 87% code and 13% linguistic data in both English and Chinese languages.
- **Highly Flexible & Scalable**: Offered in model sizes of 1.3B, 5.7B, 6.7B, and 33B, enabling users to choose the setup most suitable for their requirements.
- **Superior Model Performance**: State-of-the-art performance among publicly available code models on HumanEval, MultiPL-E, MBPP, DS-1000, and APPS benchmarks.
- **Advanced Code Completion Capabilities**: A window size of 16K and a fill-in-the-blank task, supporting project-level code completion and infilling tasks.
### 2. Model Summary
deepseek-coder-6.7b-instruct is a 6.7B parameter model initialized from deepseek-coder-6.7b-base and fine-tuned on 2B tokens of instruction data.
- **Home Page:** [DeepSeek](https://www.deepseek.com/)
- **Repository:** [deepseek-ai/deepseek-coder](https://github.com/deepseek-ai/deepseek-coder)
- **Chat With DeepSeek Coder:** [DeepSeek-Coder](https://coder.deepseek.com/)
### 3. How to Use
Here give some examples of how to use our model.
#### Chat Model Inference
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-coder-6.7b-instruct", trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("deepseek-ai/deepseek-coder-6.7b-instruct", trust_remote_code=True).cuda()
messages=[
{ 'role': 'user', 'content': "write a quick sort algorithm in python."}
]
inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to(model.device)
# 32021 is the id of <|EOT|> token
outputs = model.generate(inputs, max_new_tokens=512, do_sample=False, top_k=50, top_p=0.95, num_return_sequences=1, eos_token_id=32021)
print(tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True))
```
### 4. License
This code repository is licensed under the MIT License. The use of DeepSeek Coder models is subject to the Model License. DeepSeek Coder supports commercial use.
See the [LICENSE-MODEL](https://github.com/deepseek-ai/deepseek-coder/blob/main/LICENSE-MODEL) for more details.
### 5. Contact
If you have any questions, please raise an issue or contact us at [[email protected]](mailto:[email protected]).
|
{}
|
LoupGarou/deepseek-coder-6.7b-instruct-pythagora-v2-gguf
| null |
[
"gguf",
"region:us"
] | null |
2024-05-02T06:15:33+00:00
|
text2text-generation
|
transformers
|
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
{"library_name": "transformers", "tags": []}
|
JD97/bart-gec
| null |
[
"transformers",
"safetensors",
"bart",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2024-05-02T06:16:51+00:00
|
text-generation
|
transformers
|
# Uploaded model
- **Developed by:** DattaBS
- **License:** apache-2.0
- **Finetuned from model :** meta-llama/Llama-2-7b-hf
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
{"language": ["en"], "license": "apache-2.0", "tags": ["text-generation-inference", "transformers", "unsloth", "llama", "trl"], "base_model": "meta-llama/Llama-2-7b-hf"}
|
DattaBS/llama2_gsm8k
| null |
[
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"en",
"base_model:meta-llama/Llama-2-7b-hf",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2024-05-02T06:17:31+00:00
|
null | null |
{"license": "cc"}
|
BenBranyon/tinyllama-sumbot-adapter
| null |
[
"safetensors",
"license:cc",
"region:us"
] | null |
2024-05-02T06:18:12+00:00
|
|
text-generation
|
transformers
|
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
{"library_name": "transformers", "tags": []}
|
abc88767/model39
| null |
[
"transformers",
"safetensors",
"stablelm",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2024-05-02T06:18:40+00:00
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.