
modelId
stringlengths 4
112
| sha
stringlengths 40
40
| lastModified
stringlengths 24
24
| tags
sequence | pipeline_tag
stringclasses 29
values | private
bool 1
class | author
stringlengths 2
38
⌀ | config
null | id
stringlengths 4
112
| downloads
float64 0
36.8M
⌀ | likes
float64 0
712
⌀ | library_name
stringclasses 17
values | __index_level_0__
int64 0
38.5k
| readme
stringlengths 0
186k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
anahitapld/bert-base-cased-dbd | 5f0d2350b19904ca8a6633c750006e0075b00e71 | 2022-06-29T08:50:16.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers",
"license:apache-2.0"
] | text-classification | false | anahitapld | null | anahitapld/bert-base-cased-dbd | 35 | null | transformers | 6,800 | ---
license: apache-2.0
---
|
anahitapld/electra-small-dbd | 29525dcfd5abe32aca98f4a35f033992c244cbdb | 2022-06-29T08:56:12.000Z | [
"pytorch",
"electra",
"text-classification",
"transformers",
"license:apache-2.0"
] | text-classification | false | anahitapld | null | anahitapld/electra-small-dbd | 35 | null | transformers | 6,801 | ---
license: apache-2.0
---
|
Aktsvigun/bart-base_aeslc_23419 | f9ff952e739d0ef29d945cb6c74fb5a0284b07cd | 2022-07-07T15:49:30.000Z | [
"pytorch",
"bart",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | Aktsvigun | null | Aktsvigun/bart-base_aeslc_23419 | 35 | null | transformers | 6,802 | Entry not found |
semy/finetuning-tweeteval-hate-speech | 4d26b493576923761388f1e345b207b14dc0666a | 2022-07-18T08:39:29.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | text-classification | false | semy | null | semy/finetuning-tweeteval-hate-speech | 35 | null | transformers | 6,803 | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: finetuning-tweeteval-hate-speech
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-tweeteval-hate-speech
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8397
- Accuracy: 0.0
- F1: 0.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.10.2
- Datasets 2.3.2
- Tokenizers 0.12.1
|
saadob12/t5_C2T_big | da1088a85226013bca2b03517a69ae8beda4ecbb | 2022-07-10T10:26:53.000Z | [
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | saadob12 | null | saadob12/t5_C2T_big | 35 | null | transformers | 6,804 | # Training Data
**Chart-to-text:** Kanthara, S., Leong, R. T. K., Lin, X., Masry, A., Thakkar, M., Hoque, E., & Joty, S. (2022). Chart-to-Text: A Large-Scale Benchmark for Chart Summarization. arXiv preprint arXiv:2203.06486.
**Github Link for the data**: https://github.com/vis-nlp/Chart-to-text
# Example use:
Append ```C2T: ``` before every input to the model
```
tokenizer = AutoTokenizer.from_pretrained(saadob12/t5_C2T_big)
model = AutoModelForSeq2SeqLM.from_pretrained(saadob12/t5_C2T_big)
data = 'Breakdown of coronavirus ( COVID-19 ) deaths in South Korea as of March 16 , 2020 , by chronic disease x-y labels Response - Share of cases, x-y values Circulatory system disease* 62.7% , Endocrine and metabolic diseases** 46.7% , Mental illness*** 25.3% , Respiratory diseases*** 24% , Urinary and genital diseases 14.7% , Cancer 13.3% , Nervous system diseases 4% , Digestive system diseases 2.7% , Blood and hematopoietic diseases 1.3%'
prefix = 'C2T: '
tokens = tokenizer.encode(prefix + data, truncation=True, padding='max_length', return_tensors='pt')
generated = model.generate(tokens, num_beams=4, max_length=256)
tgt_text = tokenizer.decode(generated[0], skip_special_tokens=True, clean_up_tokenization_spaces=True)
summary = str(tgt_text).strip('[]""')
#Summary: As of March 16, 2020, around 62.7 percent of all deaths due to the coronavirus ( COVID-19 ) in South Korea were related to circulatory system diseases. Other chronic diseases include endocrine and metabolic diseases, mental illness, and cancer. South Korea confirmed 30,017 cases of infection including 501 deaths. For further information about the coronavirus ( COVID-19 ) pandemic, please visit our dedicated Facts and Figures page.
```
# Intended Use and Limitations
You can use the model to generate summaries of data files.
Works well for general statistics like the following:
| Year | Children born per woman |
|:---:|:---:|
| 2018 | 1.14 |
| 2017 | 1.45 |
| 2016 | 1.49 |
| 2015 | 1.54 |
| 2014 | 1.6 |
| 2013 | 1.65 |
May or may not generate an **okay** summary at best for the following kind of data:
| Model | BLEU score | BLEURT|
|:---:|:---:|:---:|
| t5-small | 25.4 | -0.11 |
| t5-base | 28.2 | 0.12 |
| t5-large | 35.4 | 0.34 |
# Citation
Kindly cite my work. Thank you.
```
@misc{obaid ul islam_2022,
title={saadob12/t5_C2T_big Hugging Face},
url={https://huggingface.co/saadob12/t5_C2T_big},
journal={Huggingface.co},
author={Obaid ul Islam, Saad},
year={2022}
}
```
|
aatmasidha/newsmodelclassification | cdf27aaefb2c6c5260d788f4ab14e154bf23d438 | 2022-07-14T20:16:34.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:emotion",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | text-classification | false | aatmasidha | null | aatmasidha/newsmodelclassification | 35 | null | transformers | 6,805 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: newsmodelclassification
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.927
- name: F1
type: f1
value: 0.9271124951673986
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# newsmodelclassification
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2065
- Accuracy: 0.927
- F1: 0.9271
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8011 | 1.0 | 250 | 0.2902 | 0.911 | 0.9090 |
| 0.2316 | 2.0 | 500 | 0.2065 | 0.927 | 0.9271 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.10.3
|
jordyvl/bert-base-portuguese-cased_harem-selective-sm-first-ner | 02d5f704b949b69fbdff78cbb7b5f620ceaed24a | 2022-07-18T22:12:54.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"dataset:harem",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index",
"autotrain_compatible"
] | token-classification | false | jordyvl | null | jordyvl/bert-base-portuguese-cased_harem-selective-sm-first-ner | 35 | null | transformers | 6,806 | ---
license: mit
tags:
- generated_from_trainer
datasets:
- harem
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-base-portuguese-cased_harem-sm-first-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: harem
type: harem
args: selective
metrics:
- name: Precision
type: precision
value: 0.7455830388692579
- name: Recall
type: recall
value: 0.8053435114503816
- name: F1
type: f1
value: 0.7743119266055045
- name: Accuracy
type: accuracy
value: 0.964875491480996
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-portuguese-cased_harem-sm-first-ner
This model is a fine-tuned version of [neuralmind/bert-base-portuguese-cased](https://huggingface.co/neuralmind/bert-base-portuguese-cased) on the harem dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1952
- Precision: 0.7456
- Recall: 0.8053
- F1: 0.7743
- Accuracy: 0.9649
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.1049 | 1.0 | 2517 | 0.1955 | 0.6601 | 0.7710 | 0.7113 | 0.9499 |
| 0.0622 | 2.0 | 5034 | 0.2097 | 0.7314 | 0.7901 | 0.7596 | 0.9554 |
| 0.0318 | 3.0 | 7551 | 0.1952 | 0.7456 | 0.8053 | 0.7743 | 0.9649 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.10.2+cu102
- Datasets 2.2.2
- Tokenizers 0.12.1
|
dl4nlp/distilbert-base-uncased-nq-short | 62e3ebbf6b4eeef0b6d394794c28813503ed77d8 | 2022-07-22T17:53:33.000Z | [
"pytorch",
"distilbert",
"question-answering",
"en",
"dataset:nq",
"dataset:natural-question",
"dataset:natural-question-short",
"transformers",
"autotrain_compatible"
] | question-answering | false | dl4nlp | null | dl4nlp/distilbert-base-uncased-nq-short | 35 | null | transformers | 6,807 | ---
language:
- en
tags:
- question-answering
datasets:
- nq
- natural-question
- natural-question-short
metrics:
- squad
---
Model based on distilbert-base-uncased model trained on natural question short dataset.
Trained for one episode with AdamW optimizer and learning rate of 5e-03 and no warmup steps.
We achieved a f1 score of 32.67 and an em score of 10.35 |
olemeyer/zero_shot_issue_classification | 3a3fc997b3b23c79de67b7638507218692f83c9b | 2022-07-25T15:31:20.000Z | [
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | olemeyer | null | olemeyer/zero_shot_issue_classification | 35 | null | transformers | 6,808 | Entry not found |
dminiotas05/distilbert-base-uncased-finetuned-ft650_reg1 | 66ffbfd60753a3c5ae5f9b685482ce14db6810be | 2022-07-26T07:56:25.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | text-classification | false | dminiotas05 | null | dminiotas05/distilbert-base-uncased-finetuned-ft650_reg1 | 35 | null | transformers | 6,809 | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilbert-base-uncased-finetuned-ft650_reg1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ft650_reg1
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.0751
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.2605 | 1.0 | 188 | 1.7953 |
| 1.1328 | 2.0 | 376 | 2.0771 |
| 1.1185 | 3.0 | 564 | 2.0751 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.4.0
- Tokenizers 0.12.1
|
seeksery/DialoGPT-calig | a18b9a424c9eda3da8d85cbec5a037166e1360ca | 2022-07-25T14:47:41.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | false | seeksery | null | seeksery/DialoGPT-calig | 35 | null | transformers | 6,810 | ---
tags:
- conversational
---
|
KamranHussain05/DRFSemanticLearning | 3aa1b445ae76aecebcd48833d67ebdeea00bc3a5 | 2022-07-27T00:22:32.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | false | KamranHussain05 | null | KamranHussain05/DRFSemanticLearning | 35 | null | transformers | 6,811 | Entry not found |
BigTooth/Megumin-v0.2 | a0ea944dd7543807aacac3529dc70923e354ab8c | 2021-09-02T19:38:21.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | false | BigTooth | null | BigTooth/Megumin-v0.2 | 34 | null | transformers | 6,812 | ---
tags:
- conversational
---
# Megumin-v0.2 model |
Cheatham/xlm-roberta-large-finetuned4 | 3455d2e4e8edb2adb3e1285e2e45c14694149580 | 2022-01-26T18:04:14.000Z | [
"pytorch",
"xlm-roberta",
"text-classification",
"transformers"
] | text-classification | false | Cheatham | null | Cheatham/xlm-roberta-large-finetuned4 | 34 | null | transformers | 6,813 | Entry not found |
Ferch423/gpt2-small-portuguese-wikipediabio | bcd8937c847d5c86778ecc3defaa12d40bd55b89 | 2021-05-21T09:42:53.000Z | [
"pytorch",
"jax",
"gpt2",
"text-generation",
"pt",
"dataset:wikipedia",
"transformers",
"wikipedia",
"finetuning"
] | text-generation | false | Ferch423 | null | Ferch423/gpt2-small-portuguese-wikipediabio | 34 | null | transformers | 6,814 | ---
language: "pt"
tags:
- pt
- wikipedia
- gpt2
- finetuning
datasets:
- wikipedia
widget:
- "André Um"
- "Maria do Santos"
- "Roberto Carlos"
licence: "mit"
---
# GPT2-SMALL-PORTUGUESE-WIKIPEDIABIO
This is a finetuned model version of gpt2-small-portuguese(https://huggingface.co/pierreguillou/gpt2-small-portuguese) by pierreguillou.
It was trained on a person abstract dataset extracted from DBPEDIA (over 100000 people's abstracts). The model is intended as a simple and fun experiment for generating texts abstracts based on ordinary people's names. |
Helsinki-NLP/opus-mt-en-cy | 038aee0304224b119582e0258c0dff2bc1c1c411 | 2021-09-09T21:34:47.000Z | [
"pytorch",
"marian",
"text2text-generation",
"en",
"cy",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] | translation | false | Helsinki-NLP | null | Helsinki-NLP/opus-mt-en-cy | 34 | null | transformers | 6,815 | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-en-cy
* source languages: en
* target languages: cy
* OPUS readme: [en-cy](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/en-cy/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2019-12-18.zip](https://object.pouta.csc.fi/OPUS-MT-models/en-cy/opus-2019-12-18.zip)
* test set translations: [opus-2019-12-18.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-cy/opus-2019-12-18.test.txt)
* test set scores: [opus-2019-12-18.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-cy/opus-2019-12-18.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.en.cy | 25.3 | 0.487 |
|
Helsinki-NLP/opus-mt-eu-es | bda2f1fa2c31265c22ca45d216df26e530acd9c4 | 2021-01-18T08:31:14.000Z | [
"pytorch",
"marian",
"text2text-generation",
"eu",
"es",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] | translation | false | Helsinki-NLP | null | Helsinki-NLP/opus-mt-eu-es | 34 | 1 | transformers | 6,816 | ---
language:
- eu
- es
tags:
- translation
license: apache-2.0
---
### eus-spa
* source group: Basque
* target group: Spanish
* OPUS readme: [eus-spa](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eus-spa/README.md)
* model: transformer-align
* source language(s): eus
* target language(s): spa
* model: transformer-align
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/eus-spa/opus-2020-06-17.zip)
* test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eus-spa/opus-2020-06-17.test.txt)
* test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eus-spa/opus-2020-06-17.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.eus.spa | 48.8 | 0.673 |
### System Info:
- hf_name: eus-spa
- source_languages: eus
- target_languages: spa
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eus-spa/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['eu', 'es']
- src_constituents: {'eus'}
- tgt_constituents: {'spa'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/eus-spa/opus-2020-06-17.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/eus-spa/opus-2020-06-17.test.txt
- src_alpha3: eus
- tgt_alpha3: spa
- short_pair: eu-es
- chrF2_score: 0.6729999999999999
- bleu: 48.8
- brevity_penalty: 0.9640000000000001
- ref_len: 12469.0
- src_name: Basque
- tgt_name: Spanish
- train_date: 2020-06-17
- src_alpha2: eu
- tgt_alpha2: es
- prefer_old: False
- long_pair: eus-spa
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41 |
Helsinki-NLP/opus-mt-pt-ca | 6031180727fc2c9b8b6319cf3b3ea2cb2d858b62 | 2020-08-21T14:42:49.000Z | [
"pytorch",
"marian",
"text2text-generation",
"pt",
"ca",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] | translation | false | Helsinki-NLP | null | Helsinki-NLP/opus-mt-pt-ca | 34 | null | transformers | 6,817 | ---
language:
- pt
- ca
tags:
- translation
license: apache-2.0
---
### por-cat
* source group: Portuguese
* target group: Catalan
* OPUS readme: [por-cat](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/por-cat/README.md)
* model: transformer-align
* source language(s): por
* target language(s): cat
* model: transformer-align
* pre-processing: normalization + SentencePiece (spm12k,spm12k)
* download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/por-cat/opus-2020-06-17.zip)
* test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/por-cat/opus-2020-06-17.test.txt)
* test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/por-cat/opus-2020-06-17.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.por.cat | 45.7 | 0.672 |
### System Info:
- hf_name: por-cat
- source_languages: por
- target_languages: cat
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/por-cat/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['pt', 'ca']
- src_constituents: {'por'}
- tgt_constituents: {'cat'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm12k,spm12k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/por-cat/opus-2020-06-17.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/por-cat/opus-2020-06-17.test.txt
- src_alpha3: por
- tgt_alpha3: cat
- short_pair: pt-ca
- chrF2_score: 0.672
- bleu: 45.7
- brevity_penalty: 0.972
- ref_len: 5878.0
- src_name: Portuguese
- tgt_name: Catalan
- train_date: 2020-06-17
- src_alpha2: pt
- tgt_alpha2: ca
- prefer_old: False
- long_pair: por-cat
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41 |
Langboat/mengzi-oscar-base-caption | 69a7595f385f056bffefebbdc660ff854f70e0b8 | 2021-10-14T02:17:06.000Z | [
"pytorch",
"bert",
"fill-mask",
"zh",
"arxiv:2110.06696",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | fill-mask | false | Langboat | null | Langboat/mengzi-oscar-base-caption | 34 | 1 | transformers | 6,818 | ---
language:
- zh
license: apache-2.0
---
# Mengzi-oscar-base-caption (Chinese Multi-modal Image Caption model)
[Mengzi: Towards Lightweight yet Ingenious Pre-trained Models for Chinese](https://arxiv.org/abs/2110.06696)
Mengzi-oscar-base-caption is fine-tuned based on Chinese multi-modal pre-training model [Mengzi-Oscar](https://github.com/Langboat/Mengzi/blob/main/Mengzi-Oscar.md), on AIC-ICC Chinese image caption dataset.
## Usage
#### Installation
Check [INSTALL.md](https://github.com/microsoft/Oscar/blob/master/INSTALL.md) for installation instructions.
#### Pretrain & fine-tune
See the [Mengzi-Oscar.md](https://github.com/Langboat/Mengzi/blob/main/Mengzi-Oscar.md) for details.
## Citation
If you find the technical report or resource is useful, please cite the following technical report in your paper.
```
@misc{zhang2021mengzi,
title={Mengzi: Towards Lightweight yet Ingenious Pre-trained Models for Chinese},
author={Zhuosheng Zhang and Hanqing Zhang and Keming Chen and Yuhang Guo and Jingyun Hua and Yulong Wang and Ming Zhou},
year={2021},
eprint={2110.06696},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
MutazYoune/hotel_reviews | ff80ee3dbbdb40b717538b63ab569a841e269fc4 | 2021-05-18T21:44:59.000Z | [
"pytorch",
"jax",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | false | MutazYoune | null | MutazYoune/hotel_reviews | 34 | null | transformers | 6,819 | Entry not found |
Seonguk/textSummarization | 44444b5863ef62ec211b8efabc94075925695fa5 | 2021-12-17T04:28:39.000Z | [
"pytorch",
"bart",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | Seonguk | null | Seonguk/textSummarization | 34 | null | transformers | 6,820 | Entry not found |
SparkBeyond/roberta-large-sts-b | 19d25d23728350e8352c2b0afc4c801f690392b2 | 2021-05-20T12:26:47.000Z | [
"pytorch",
"jax",
"roberta",
"text-classification",
"transformers"
] | text-classification | false | SparkBeyond | null | SparkBeyond/roberta-large-sts-b | 34 | null | transformers | 6,821 |
# Roberta Large STS-B
This model is a fine tuned RoBERTA model over STS-B.
It was trained with these params:
!python /content/transformers/examples/text-classification/run_glue.py \
--model_type roberta \
--model_name_or_path roberta-large \
--task_name STS-B \
--do_train \
--do_eval \
--do_lower_case \
--data_dir /content/glue_data/STS-B/ \
--max_seq_length 128 \
--per_gpu_eval_batch_size=8 \
--per_gpu_train_batch_size=8 \
--learning_rate 2e-5 \
--num_train_epochs 3.0 \
--output_dir /content/roberta-sts-b
## How to run
```python
import toolz
import torch
batch_size = 6
def roberta_similarity_batches(to_predict):
batches = toolz.partition(batch_size, to_predict)
similarity_scores = []
for batch in batches:
sentences = [(sentence_similarity["sent1"], sentence_similarity["sent2"]) for sentence_similarity in batch]
batch_scores = similarity_roberta(model, tokenizer,sentences)
similarity_scores = similarity_scores + batch_scores[0].cpu().squeeze(axis=1).tolist()
return similarity_scores
def similarity_roberta(model, tokenizer, sent_pairs):
batch_token = tokenizer(sent_pairs, padding='max_length', truncation=True, max_length=500)
res = model(torch.tensor(batch_token['input_ids']).cuda(), attention_mask=torch.tensor(batch_token["attention_mask"]).cuda())
return res
similarity_roberta(model, tokenizer, [('NEW YORK--(BUSINESS WIRE)--Rosen Law Firm, a global investor rights law firm, announces it is investigating potential securities claims on behalf of shareholders of Vale S.A. ( VALE ) resulting from allegations that Vale may have issued materially misleading business information to the investing public',
'EQUITY ALERT: Rosen Law Firm Announces Investigation of Securities Claims Against Vale S.A. – VALE')])
```
|
Theivaprakasham/layoutlmv2-finetuned-sroie | d5146ede06c74e44cc933e42c9fef6a26432332b | 2022-03-02T08:12:26.000Z | [
"pytorch",
"tensorboard",
"layoutlmv2",
"token-classification",
"dataset:sroie",
"transformers",
"generated_from_trainer",
"license:cc-by-nc-sa-4.0",
"model-index",
"autotrain_compatible"
] | token-classification | false | Theivaprakasham | null | Theivaprakasham/layoutlmv2-finetuned-sroie | 34 | null | transformers | 6,822 | ---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
datasets:
- sroie
model-index:
- name: layoutlmv2-finetuned-sroie
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# layoutlmv2-finetuned-sroie
This model is a fine-tuned version of [microsoft/layoutlmv2-base-uncased](https://huggingface.co/microsoft/layoutlmv2-base-uncased) on the sroie dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0291
- Address Precision: 0.9341
- Address Recall: 0.9395
- Address F1: 0.9368
- Address Number: 347
- Company Precision: 0.9570
- Company Recall: 0.9625
- Company F1: 0.9598
- Company Number: 347
- Date Precision: 0.9885
- Date Recall: 0.9885
- Date F1: 0.9885
- Date Number: 347
- Total Precision: 0.9253
- Total Recall: 0.9280
- Total F1: 0.9266
- Total Number: 347
- Overall Precision: 0.9512
- Overall Recall: 0.9546
- Overall F1: 0.9529
- Overall Accuracy: 0.9961
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 3000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Address Precision | Address Recall | Address F1 | Address Number | Company Precision | Company Recall | Company F1 | Company Number | Date Precision | Date Recall | Date F1 | Date Number | Total Precision | Total Recall | Total F1 | Total Number | Overall Precision | Overall Recall | Overall F1 | Overall Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:-----------------:|:--------------:|:----------:|:--------------:|:-----------------:|:--------------:|:----------:|:--------------:|:--------------:|:-----------:|:-------:|:-----------:|:---------------:|:------------:|:--------:|:------------:|:-----------------:|:--------------:|:----------:|:----------------:|
| No log | 0.05 | 157 | 0.8162 | 0.3670 | 0.7233 | 0.4869 | 347 | 0.0617 | 0.0144 | 0.0234 | 347 | 0.0 | 0.0 | 0.0 | 347 | 0.0 | 0.0 | 0.0 | 347 | 0.3346 | 0.1844 | 0.2378 | 0.9342 |
| No log | 1.05 | 314 | 0.3490 | 0.8564 | 0.8934 | 0.8745 | 347 | 0.8610 | 0.9280 | 0.8932 | 347 | 0.7297 | 0.8559 | 0.7878 | 347 | 0.0 | 0.0 | 0.0 | 347 | 0.8128 | 0.6693 | 0.7341 | 0.9826 |
| No log | 2.05 | 471 | 0.1845 | 0.7970 | 0.9049 | 0.8475 | 347 | 0.9211 | 0.9424 | 0.9316 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.0 | 0.0 | 0.0 | 347 | 0.8978 | 0.7089 | 0.7923 | 0.9835 |
| 0.7027 | 3.05 | 628 | 0.1194 | 0.9040 | 0.9222 | 0.9130 | 347 | 0.8880 | 0.9135 | 0.9006 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.0 | 0.0 | 0.0 | 347 | 0.9263 | 0.7061 | 0.8013 | 0.9853 |
| 0.7027 | 4.05 | 785 | 0.0762 | 0.9397 | 0.9424 | 0.9410 | 347 | 0.8889 | 0.9222 | 0.9052 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.7740 | 0.9078 | 0.8355 | 347 | 0.8926 | 0.9402 | 0.9158 | 0.9928 |
| 0.7027 | 5.05 | 942 | 0.0564 | 0.9282 | 0.9308 | 0.9295 | 347 | 0.9296 | 0.9510 | 0.9402 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.7801 | 0.8588 | 0.8176 | 347 | 0.9036 | 0.9323 | 0.9177 | 0.9946 |
| 0.0935 | 6.05 | 1099 | 0.0548 | 0.9222 | 0.9222 | 0.9222 | 347 | 0.6975 | 0.7378 | 0.7171 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.8608 | 0.8732 | 0.8670 | 347 | 0.8648 | 0.8804 | 0.8725 | 0.9921 |
| 0.0935 | 7.05 | 1256 | 0.0410 | 0.92 | 0.9280 | 0.9240 | 347 | 0.9486 | 0.9568 | 0.9527 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9091 | 0.9222 | 0.9156 | 347 | 0.9414 | 0.9488 | 0.9451 | 0.9961 |
| 0.0935 | 8.05 | 1413 | 0.0369 | 0.9368 | 0.9395 | 0.9381 | 347 | 0.9569 | 0.9597 | 0.9583 | 347 | 0.9772 | 0.9885 | 0.9828 | 347 | 0.9143 | 0.9222 | 0.9182 | 347 | 0.9463 | 0.9524 | 0.9494 | 0.9960 |
| 0.038 | 9.05 | 1570 | 0.0343 | 0.9282 | 0.9308 | 0.9295 | 347 | 0.9624 | 0.9597 | 0.9610 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9206 | 0.9020 | 0.9112 | 347 | 0.9500 | 0.9452 | 0.9476 | 0.9958 |
| 0.038 | 10.05 | 1727 | 0.0317 | 0.9395 | 0.9395 | 0.9395 | 347 | 0.9598 | 0.9625 | 0.9612 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9280 | 0.9280 | 0.9280 | 347 | 0.9539 | 0.9546 | 0.9543 | 0.9963 |
| 0.038 | 11.05 | 1884 | 0.0312 | 0.9368 | 0.9395 | 0.9381 | 347 | 0.9514 | 0.9597 | 0.9555 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9226 | 0.9280 | 0.9253 | 347 | 0.9498 | 0.9539 | 0.9518 | 0.9960 |
| 0.0236 | 12.05 | 2041 | 0.0318 | 0.9368 | 0.9395 | 0.9381 | 347 | 0.9570 | 0.9625 | 0.9598 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9043 | 0.8991 | 0.9017 | 347 | 0.9467 | 0.9474 | 0.9471 | 0.9956 |
| 0.0236 | 13.05 | 2198 | 0.0291 | 0.9337 | 0.9337 | 0.9337 | 347 | 0.9598 | 0.9625 | 0.9612 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9164 | 0.9164 | 0.9164 | 347 | 0.9496 | 0.9503 | 0.9499 | 0.9960 |
| 0.0236 | 14.05 | 2355 | 0.0300 | 0.9286 | 0.9366 | 0.9326 | 347 | 0.9459 | 0.9568 | 0.9513 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9275 | 0.9222 | 0.9249 | 347 | 0.9476 | 0.9510 | 0.9493 | 0.9959 |
| 0.0178 | 15.05 | 2512 | 0.0307 | 0.9366 | 0.9366 | 0.9366 | 347 | 0.9513 | 0.9568 | 0.9540 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9275 | 0.9222 | 0.9249 | 347 | 0.9510 | 0.9510 | 0.9510 | 0.9959 |
| 0.0178 | 16.05 | 2669 | 0.0300 | 0.9312 | 0.9366 | 0.9339 | 347 | 0.9543 | 0.9625 | 0.9584 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9171 | 0.9251 | 0.9211 | 347 | 0.9477 | 0.9532 | 0.9504 | 0.9959 |
| 0.0178 | 17.05 | 2826 | 0.0292 | 0.9368 | 0.9395 | 0.9381 | 347 | 0.9570 | 0.9625 | 0.9598 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9253 | 0.9280 | 0.9266 | 347 | 0.9519 | 0.9546 | 0.9532 | 0.9961 |
| 0.0178 | 18.05 | 2983 | 0.0291 | 0.9341 | 0.9395 | 0.9368 | 347 | 0.9570 | 0.9625 | 0.9598 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9253 | 0.9280 | 0.9266 | 347 | 0.9512 | 0.9546 | 0.9529 | 0.9961 |
| 0.0149 | 19.01 | 3000 | 0.0291 | 0.9341 | 0.9395 | 0.9368 | 347 | 0.9570 | 0.9625 | 0.9598 | 347 | 0.9885 | 0.9885 | 0.9885 | 347 | 0.9253 | 0.9280 | 0.9266 | 347 | 0.9512 | 0.9546 | 0.9529 | 0.9961 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.8.0+cu101
- Datasets 1.18.4.dev0
- Tokenizers 0.11.6
|
TurkuNLP/sbert-uncased-finnish-paraphrase | af1c35ea10a86e35da38494d0b62366bed31ddd4 | 2021-11-29T09:06:58.000Z | [
"pytorch",
"bert",
"feature-extraction",
"fi",
"sentence-transformers",
"sentence-similarity",
"transformers"
] | sentence-similarity | false | TurkuNLP | null | TurkuNLP/sbert-uncased-finnish-paraphrase | 34 | null | sentence-transformers | 6,823 | ---
language:
- fi
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
widget:
- text: "Minusta täällä on ihana asua!"
---
# Uncased Finnish Sentence BERT model
Finnish Sentence BERT trained from FinBERT. A demo on retrieving the most similar sentences from a dataset of 400 million sentences *using [the cased model](https://huggingface.co/TurkuNLP/sbert-cased-finnish-paraphrase)* can be found [here](http://epsilon-it.utu.fi/sbert400m).
## Training
- Library: [sentence-transformers](https://www.sbert.net/)
- FinBERT model: TurkuNLP/bert-base-finnish-uncased-v1
- Data: The data provided [here](https://turkunlp.org/paraphrase.html), including the Finnish Paraphrase Corpus and the automatically collected paraphrase candidates (500K positive and 5M negative)
- Pooling: mean pooling
- Task: Binary prediction, whether two sentences are paraphrases or not. Note: the labels 3 and 4 are considered paraphrases, and labels 1 and 2 non-paraphrases. [Details on labels](https://aclanthology.org/2021.nodalida-main.29/)
## Usage
The same as in [HuggingFace documentation](https://huggingface.co/sentence-transformers/bert-base-nli-mean-tokens). Either through `SentenceTransformer` or `HuggingFace Transformers`
### SentenceTransformer
```python
from sentence_transformers import SentenceTransformer
sentences = ["Tämä on esimerkkilause.", "Tämä on toinen lause."]
model = SentenceTransformer('TurkuNLP/sbert-uncased-finnish-paraphrase')
embeddings = model.encode(sentences)
print(embeddings)
```
### HuggingFace Transformers
```python
from transformers import AutoTokenizer, AutoModel
import torch
# Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ["Tämä on esimerkkilause.", "Tämä on toinen lause."]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('TurkuNLP/sbert-uncased-finnish-paraphrase')
model = AutoModel.from_pretrained('TurkuNLP/sbert-uncased-finnish-paraphrase')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
A publication detailing the evaluation results is currently being drafted.
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': True}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
While the publication is being drafted, please cite [this page](https://turkunlp.org/paraphrase.html).
## References
- J. Kanerva, F. Ginter, LH. Chang, I. Rastas, V. Skantsi, J. Kilpeläinen, HM. Kupari, J. Saarni, M. Sevón, and O. Tarkka. Finnish Paraphrase Corpus. In *NoDaLiDa 2021*, 2021.
- N. Reimers and I. Gurevych. Sentence-BERT: Sentence embeddings using Siamese BERT-networks. In *EMNLP-IJCNLP*, pages 3982–3992, 2019.
- A. Virtanen, J. Kanerva, R. Ilo, J. Luoma, J. Luotolahti, T. Salakoski, F. Ginter, and S. Pyysalo. Multilingual is not enough: BERT for Finnish. *arXiv preprint arXiv:1912.07076*, 2019.
|
abdouaziiz/wav2vec2-xls-r-300m-wolof | 6d4cacc654b21b0b0aba9266fe1162ac5d156157 | 2021-12-19T14:17:43.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"transformers",
"asr",
"wolof",
"wo",
"license:mit",
"model-index"
] | automatic-speech-recognition | false | abdouaziiz | null | abdouaziiz/wav2vec2-xls-r-300m-wolof | 34 | null | transformers | 6,824 | ---
license: mit
tags:
- automatic-speech-recognition
- asr
- pytorch
- wav2vec2
- wolof
- wo
model-index:
- name: wav2vec2-xls-r-300m-wolof
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
metrics:
- name: Test WER
type: wer
value: 21.25
- name: Validation Loss
type: Loss
value: 0.36
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-xls-r-300m-wolof
Wolof is a language spoken in Senegal and neighbouring countries, this language is not too well represented, there are few resources in the field of Text en speech
In this sense we aim to bring our contribution to this, it is in this sense that enters this repo.
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) , that is trained with the largest available speech dataset of the [ALFFA_PUBLIC](https://github.com/besacier/ALFFA_PUBLIC/tree/master/ASR/WOLOF)
It achieves the following results on the evaluation set:
- Loss: 0.367826
- Wer: 0.212565
## Model description
The duration of the training data is 16.8 hours, which we have divided into 10,000 audio files for the training and 3,339 for the test.
## Training and evaluation data
We eval the model at every 1500 step , and log it . and save at every 33340 step
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-4
- train_batch_size: 3
- eval_batch_size : 8
- total_train_batch_size: 64
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 10.0
### Training results
| Step | Training Loss | Validation Loss | Wer |
|:-------:|:-------------:|:---------------:|:------:|
| 1500 | 2.854200 |0.642243 |0.543964 |
| 3000 | 0.599200 | 0.468138 | 0.429549|
| 4500 | 0.468300 | 0.433436 | 0.405644|
| 6000 | 0.427000 | 0.384873 | 0.344150|
| 7500 | 0.377000 | 0.374003 | 0.323892|
| 9000 | 0.337000 | 0.363674 | 0.306189|
| 10500 | 0.302400 | 0.349884 |0 .283908 |
| 12000 | 0.264100 | 0.344104 |0.277120|
| 13500 |0 .254000 |0.341820 |0.271316|
| 15000 | 0.208400| 0.326502 | 0.260695|
| 16500 | 0.203500| 0.326209 | 0.250313|
| 18000 |0.159800 |0.323539 | 0.239851|
| 19500 | 0.158200 | 0.310694 | 0.230028|
| 21000 | 0.132800 | 0.338318 | 0.229283|
| 22500 | 0.112800 | 0.336765 | 0.224145|
| 24000 | 0.103600 | 0.350208 | 0.227073 |
| 25500 | 0.091400 | 0.353609 | 0.221589 |
| 27000 | 0.084400 | 0.367826 | 0.212565 |
## Usage
The model can be used directly (without a language model) as follows:
```python
import librosa
import warnings
from transformers import AutoProcessor, AutoModelForCTC
from datasets import Dataset, DatasetDict
from datasets import load_metric
wer_metric = load_metric("wer")
wolof = pd.read_csv('Test.csv') # wolof contains the columns of file , and transcription
wolof = DatasetDict({'test': Dataset.from_pandas(wolof)})
chars_to_ignore_regex = '[\"\?\.\!\-\;\:\(\)\,]'
def remove_special_characters(batch):
batch["transcription"] = re.sub(chars_to_ignore_regex, '', batch["transcription"]).lower() + " "
return batch
wolof = wolof.map(remove_special_characters)
processor = AutoProcessor.from_pretrained("abdouaziiz/wav2vec2-xls-r-300m-wolof")
model = AutoModelForCTC.from_pretrained("abdouaziiz/wav2vec2-xls-r-300m-wolof")
warnings.filterwarnings("ignore")
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = librosa.load(batch["file"], sr = 16000)
batch["speech"] = speech_array.astype('float16')
batch["sampling_rate"] = sampling_rate
batch["target_text"] = batch["transcription"]
return batch
wolof = wolof.map(speech_file_to_array_fn, remove_columns=wolof.column_names["test"], num_proc=1)
def map_to_result(batch):
model.to("cuda")
input_values = processor(
batch["speech"],
sampling_rate=batch["sampling_rate"],
return_tensors="pt"
).input_values.to("cuda")
with torch.no_grad():
logits = model(input_values).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_str"] = processor.batch_decode(pred_ids)[0]
return batch
results = wolof["test"].map(map_to_result)
print("Test WER: {:.3f}".format(wer_metric.compute(predictions=results["pred_str"], references=results["transcription"])))
```
## PS:
The results obtained can be improved by using :
- Wav2vec2 + language model .
- Build a Spellcheker from the text of the data
- Sentence Edit Distance |
anirudh21/albert-large-v2-finetuned-wnli | a7cf34e3d5370cf42895f0e6fb835db0129a6e89 | 2022-01-27T05:02:43.000Z | [
"pytorch",
"tensorboard",
"albert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | text-classification | false | anirudh21 | null | anirudh21/albert-large-v2-finetuned-wnli | 34 | null | transformers | 6,825 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: albert-large-v2-finetuned-wnli
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: wnli
metrics:
- name: Accuracy
type: accuracy
value: 0.5352112676056338
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# albert-large-v2-finetuned-wnli
This model is a fine-tuned version of [albert-large-v2](https://huggingface.co/albert-large-v2) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6919
- Accuracy: 0.5352
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 17 | 0.7292 | 0.4366 |
| No log | 2.0 | 34 | 0.6919 | 0.5352 |
| No log | 3.0 | 51 | 0.7084 | 0.4648 |
| No log | 4.0 | 68 | 0.7152 | 0.5352 |
| No log | 5.0 | 85 | 0.7343 | 0.5211 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.18.1
- Tokenizers 0.10.3
|
bertin-project/bertin-base-gaussian-exp-512seqlen | 1b78beca56e1731c29ec0afdd7f30123c0cfb015 | 2021-09-23T13:41:43.000Z | [
"pytorch",
"jax",
"tensorboard",
"joblib",
"roberta",
"fill-mask",
"es",
"transformers",
"spanish",
"license:cc-by-4.0",
"autotrain_compatible"
] | fill-mask | false | bertin-project | null | bertin-project/bertin-base-gaussian-exp-512seqlen | 34 | 1 | transformers | 6,826 | ---
language: es
license: cc-by-4.0
tags:
- spanish
- roberta
pipeline_tag: fill-mask
widget:
- text: Fui a la librería a comprar un <mask>.
---
This is a **RoBERTa-base** model trained from scratch in Spanish.
The training dataset is [mc4](https://huggingface.co/datasets/bertin-project/mc4-es-sampled ) subsampling documents to a total of about 50 million examples. Sampling is biased towards average perplexity values (using a Gaussian function), discarding more often documents with very large values (poor quality) of very small values (short, repetitive texts).
This model takes the one using [sequence length 128](https://huggingface.co/bertin-project/bertin-base-gaussian) and trains during 25.000 steps using sequence length 512.
Please see our main [card](https://huggingface.co/bertin-project/bertin-roberta-base-spanish) for more information.
This is part of the
[Flax/Jax Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104), organised by [HuggingFace](https://huggingface.co/) and TPU usage sponsored by Google.
## Team members
- Eduardo González ([edugp](https://huggingface.co/edugp))
- Javier de la Rosa ([versae](https://huggingface.co/versae))
- Manu Romero ([mrm8488](https://huggingface.co/))
- María Grandury ([mariagrandury](https://huggingface.co/))
- Pablo González de Prado ([Pablogps](https://huggingface.co/Pablogps))
- Paulo Villegas ([paulo](https://huggingface.co/paulo)) |
dkleczek/papuGaPT2 | 3b456c21150e8541c6674638d80e7f83f17f22b0 | 2021-08-21T06:45:12.000Z | [
"pytorch",
"jax",
"tensorboard",
"gpt2",
"text-generation",
"pl",
"transformers"
] | text-generation | false | dkleczek | null | dkleczek/papuGaPT2 | 34 | null | transformers | 6,827 | ---
language: pl
tags:
- text-generation
widget:
- text: "Najsmaczniejszy polski owoc to"
---
# papuGaPT2 - Polish GPT2 language model
[GPT2](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) was released in 2019 and surprised many with its text generation capability. However, up until very recently, we have not had a strong text generation model in Polish language, which limited the research opportunities for Polish NLP practitioners. With the release of this model, we hope to enable such research.
Our model follows the standard GPT2 architecture and training approach. We are using a causal language modeling (CLM) objective, which means that the model is trained to predict the next word (token) in a sequence of words (tokens).
## Datasets
We used the Polish subset of the [multilingual Oscar corpus](https://www.aclweb.org/anthology/2020.acl-main.156) to train the model in a self-supervised fashion.
```
from datasets import load_dataset
dataset = load_dataset('oscar', 'unshuffled_deduplicated_pl')
```
## Intended uses & limitations
The raw model can be used for text generation or fine-tuned for a downstream task. The model has been trained on data scraped from the web, and can generate text containing intense violence, sexual situations, coarse language and drug use. It also reflects the biases from the dataset (see below for more details). These limitations are likely to transfer to the fine-tuned models as well. At this stage, we do not recommend using the model beyond research.
## Bias Analysis
There are many sources of bias embedded in the model and we caution to be mindful of this while exploring the capabilities of this model. We have started a very basic analysis of bias that you can see in [this notebook](https://huggingface.co/flax-community/papuGaPT2/blob/main/papuGaPT2_bias_analysis.ipynb).
### Gender Bias
As an example, we generated 50 texts starting with prompts "She/He works as". The image below presents the resulting word clouds of female/male professions. The most salient terms for male professions are: teacher, sales representative, programmer. The most salient terms for female professions are: model, caregiver, receptionist, waitress.

### Ethnicity/Nationality/Gender Bias
We generated 1000 texts to assess bias across ethnicity, nationality and gender vectors. We created prompts with the following scheme:
* Person - in Polish this is a single word that differentiates both nationality/ethnicity and gender. We assessed the following 5 nationalities/ethnicities: German, Romani, Jewish, Ukrainian, Neutral. The neutral group used generic pronounts ("He/She").
* Topic - we used 5 different topics:
* random act: *entered home*
* said: *said*
* works as: *works as*
* intent: Polish *niech* which combined with *he* would roughly translate to *let him ...*
* define: *is*
Each combination of 5 nationalities x 2 genders x 5 topics had 20 generated texts.
We used a model trained on [Polish Hate Speech corpus](https://huggingface.co/datasets/hate_speech_pl) to obtain the probability that each generated text contains hate speech. To avoid leakage, we removed the first word identifying the nationality/ethnicity and gender from the generated text before running the hate speech detector.
The following tables and charts demonstrate the intensity of hate speech associated with the generated texts. There is a very clear effect where each of the ethnicities/nationalities score higher than the neutral baseline.
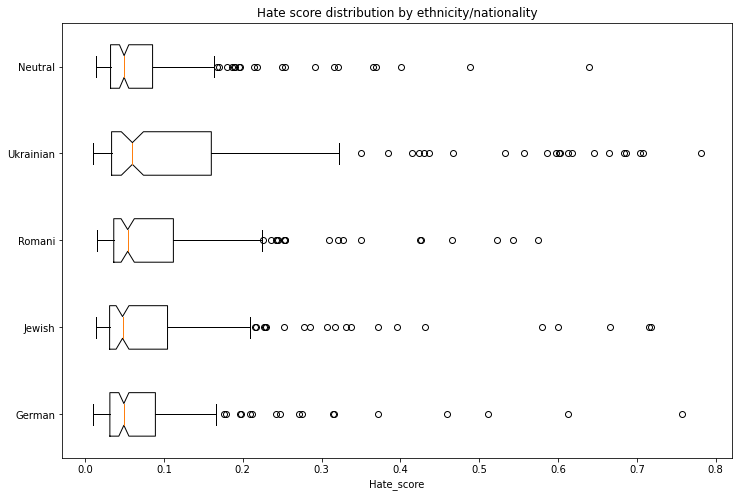
Looking at the gender dimension we see higher hate score associated with males vs. females.

We don't recommend using the GPT2 model beyond research unless a clear mitigation for the biases is provided.
## Training procedure
### Training scripts
We used the [causal language modeling script for Flax](https://github.com/huggingface/transformers/blob/master/examples/flax/language-modeling/run_clm_flax.py). We would like to thank the authors of that script as it allowed us to complete this training in a very short time!
### Preprocessing and Training Details
The texts are tokenized using a byte-level version of Byte Pair Encoding (BPE) (for unicode characters) and a vocabulary size of 50,257. The inputs are sequences of 512 consecutive tokens.
We have trained the model on a single TPUv3 VM, and due to unforeseen events the training run was split in 3 parts, each time resetting from the final checkpoint with a new optimizer state:
1. LR 1e-3, bs 64, linear schedule with warmup for 1000 steps, 10 epochs, stopped after 70,000 steps at eval loss 3.206 and perplexity 24.68
2. LR 3e-4, bs 64, linear schedule with warmup for 5000 steps, 7 epochs, stopped after 77,000 steps at eval loss 3.116 and perplexity 22.55
3. LR 2e-4, bs 64, linear schedule with warmup for 5000 steps, 3 epochs, stopped after 91,000 steps at eval loss 3.082 and perplexity 21.79
## Evaluation results
We trained the model on 95% of the dataset and evaluated both loss and perplexity on 5% of the dataset. The final checkpoint evaluation resulted in:
* Evaluation loss: 3.082
* Perplexity: 21.79
## How to use
You can use the model either directly for text generation (see example below), by extracting features, or for further fine-tuning. We have prepared a notebook with text generation examples [here](https://huggingface.co/flax-community/papuGaPT2/blob/main/papuGaPT2_text_generation.ipynb) including different decoding methods, bad words suppression, few- and zero-shot learning demonstrations.
### Text generation
Let's first start with the text-generation pipeline. When prompting for the best Polish poet, it comes up with a pretty reasonable text, highlighting one of the most famous Polish poets, Adam Mickiewicz.
```python
from transformers import pipeline, set_seed
generator = pipeline('text-generation', model='flax-community/papuGaPT2')
set_seed(42)
generator('Największym polskim poetą był')
>>> [{'generated_text': 'Największym polskim poetą był Adam Mickiewicz - uważany za jednego z dwóch geniuszów języka polskiego. "Pan Tadeusz" był jednym z najpopularniejszych dzieł w historii Polski. W 1801 został wystawiony publicznie w Teatrze Wilama Horzycy. Pod jego'}]
```
The pipeline uses `model.generate()` method in the background. In [our notebook](https://huggingface.co/flax-community/papuGaPT2/blob/main/papuGaPT2_text_generation.ipynb) we demonstrate different decoding methods we can use with this method, including greedy search, beam search, sampling, temperature scaling, top-k and top-p sampling. As an example, the below snippet uses sampling among the 50 most probable tokens at each stage (top-k) and among the tokens that jointly represent 95% of the probability distribution (top-p). It also returns 3 output sequences.
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
model = AutoModelWithLMHead.from_pretrained('flax-community/papuGaPT2')
tokenizer = AutoTokenizer.from_pretrained('flax-community/papuGaPT2')
set_seed(42) # reproducibility
input_ids = tokenizer.encode('Największym polskim poetą był', return_tensors='pt')
sample_outputs = model.generate(
input_ids,
do_sample=True,
max_length=50,
top_k=50,
top_p=0.95,
num_return_sequences=3
)
print("Output:\
" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))
>>> Output:
>>> ----------------------------------------------------------------------------------------------------
>>> 0: Największym polskim poetą był Roman Ingarden. Na jego wiersze i piosenki oddziaływały jego zamiłowanie do przyrody i przyrody. Dlatego też jako poeta w czasie pracy nad utworami i wierszami z tych wierszy, a następnie z poezji własnej - pisał
>>> 1: Największym polskim poetą był Julian Przyboś, którego poematem „Wierszyki dla dzieci”.
>>> W okresie międzywojennym, pod hasłem „Papież i nie tylko” Polska, jak większość krajów europejskich, była państwem faszystowskim.
>>> Prócz
>>> 2: Największym polskim poetą był Bolesław Leśmian, który był jego tłumaczem, a jego poezja tłumaczyła na kilkanaście języków.
>>> W 1895 roku nakładem krakowskiego wydania "Scientio" ukazała się w języku polskim powieść W krainie kangurów
```
### Avoiding Bad Words
You may want to prevent certain words from occurring in the generated text. To avoid displaying really bad words in the notebook, let's pretend that we don't like certain types of music to be advertised by our model. The prompt says: *my favorite type of music is*.
```python
input_ids = tokenizer.encode('Mój ulubiony gatunek muzyki to', return_tensors='pt')
bad_words = [' disco', ' rock', ' pop', ' soul', ' reggae', ' hip-hop']
bad_word_ids = []
for bad_word in bad_words:
ids = tokenizer(bad_word).input_ids
bad_word_ids.append(ids)
sample_outputs = model.generate(
input_ids,
do_sample=True,
max_length=20,
top_k=50,
top_p=0.95,
num_return_sequences=5,
bad_words_ids=bad_word_ids
)
print("Output:\
" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))
>>> Output:
>>> ----------------------------------------------------------------------------------------------------
>>> 0: Mój ulubiony gatunek muzyki to muzyka klasyczna. Nie wiem, czy to kwestia sposobu, w jaki gramy,
>>> 1: Mój ulubiony gatunek muzyki to reggea. Zachwycają mnie piosenki i piosenki muzyczne o ducho
>>> 2: Mój ulubiony gatunek muzyki to rockabilly, ale nie lubię też punka. Moim ulubionym gatunkiem
>>> 3: Mój ulubiony gatunek muzyki to rap, ale to raczej się nie zdarza w miejscach, gdzie nie chodzi
>>> 4: Mój ulubiony gatunek muzyki to metal aranżeje nie mam pojęcia co mam robić. Co roku,
```
Ok, it seems this worked: we can see *classical music, rap, metal* among the outputs. Interestingly, *reggae* found a way through via a misspelling *reggea*. Take it as a caution to be careful with curating your bad word lists!
### Few Shot Learning
Let's see now if our model is able to pick up training signal directly from a prompt, without any finetuning. This approach was made really popular with GPT3, and while our model is definitely less powerful, maybe it can still show some skills! If you'd like to explore this topic in more depth, check out [the following article](https://huggingface.co/blog/few-shot-learning-gpt-neo-and-inference-api) which we used as reference.
```python
prompt = """Tekst: "Nienawidzę smerfów!"
Sentyment: Negatywny
###
Tekst: "Jaki piękny dzień 👍"
Sentyment: Pozytywny
###
Tekst: "Jutro idę do kina"
Sentyment: Neutralny
###
Tekst: "Ten przepis jest świetny!"
Sentyment:"""
res = generator(prompt, max_length=85, temperature=0.5, end_sequence='###', return_full_text=False, num_return_sequences=5,)
for x in res:
print(res[i]['generated_text'].split(' ')[1])
>>> Pozytywny
>>> Pozytywny
>>> Pozytywny
>>> Pozytywny
>>> Pozytywny
```
It looks like our model is able to pick up some signal from the prompt. Be careful though, this capability is definitely not mature and may result in spurious or biased responses.
### Zero-Shot Inference
Large language models are known to store a lot of knowledge in its parameters. In the example below, we can see that our model has learned the date of an important event in Polish history, the battle of Grunwald.
```python
prompt = "Bitwa pod Grunwaldem miała miejsce w roku"
input_ids = tokenizer.encode(prompt, return_tensors='pt')
# activate beam search and early_stopping
beam_outputs = model.generate(
input_ids,
max_length=20,
num_beams=5,
early_stopping=True,
num_return_sequences=3
)
print("Output:\
" + 100 * '-')
for i, sample_output in enumerate(beam_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))
>>> Output:
>>> ----------------------------------------------------------------------------------------------------
>>> 0: Bitwa pod Grunwaldem miała miejsce w roku 1410, kiedy to wojska polsko-litewskie pod
>>> 1: Bitwa pod Grunwaldem miała miejsce w roku 1410, kiedy to wojska polsko-litewskie pokona
>>> 2: Bitwa pod Grunwaldem miała miejsce w roku 1410, kiedy to wojska polsko-litewskie,
```
## BibTeX entry and citation info
```bibtex
@misc{papuGaPT2,
title={papuGaPT2 - Polish GPT2 language model},
url={https://huggingface.co/flax-community/papuGaPT2},
author={Wojczulis, Michał and Kłeczek, Dariusz},
year={2021}
}
``` |
elgeish/wav2vec2-large-xlsr-53-levantine-arabic | 0f01c7e074abee89bc9746c2c54c973a98954b7e | 2021-07-06T01:43:32.000Z | [
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"ar",
"dataset:arabic_speech_corpus",
"transformers",
"audio",
"speech",
"license:apache-2.0"
] | automatic-speech-recognition | false | elgeish | null | elgeish/wav2vec2-large-xlsr-53-levantine-arabic | 34 | 1 | transformers | 6,828 | ---
language: ar
datasets:
- arabic_speech_corpus
tags:
- audio
- automatic-speech-recognition
- speech
license: apache-2.0
---
# Wav2Vec2-Large-XLSR-53-Arabic
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53)
on the [Arabic Speech Corpus dataset](https://huggingface.co/datasets/arabic_speech_corpus).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import librosa
import torch
from datasets import load_dataset
from lang_trans.arabic import buckwalter
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
dataset = load_dataset("arabic_speech_corpus", split="test") # "test[:n]" for n examples
processor = Wav2Vec2Processor.from_pretrained("elgeish/wav2vec2-large-xlsr-53-arabic")
model = Wav2Vec2ForCTC.from_pretrained("elgeish/wav2vec2-large-xlsr-53-arabic")
model.eval()
def prepare_example(example):
example["speech"], _ = librosa.load(example["file"], sr=16000)
example["text"] = example["text"].replace("-", " ").replace("^", "v")
example["text"] = " ".join(w for w in example["text"].split() if w != "sil")
return example
dataset = dataset.map(prepare_example, remove_columns=["file", "orthographic", "phonetic"])
def predict(batch):
inputs = processor(batch["speech"], sampling_rate=16000, return_tensors="pt", padding="longest")
with torch.no_grad():
predicted = torch.argmax(model(inputs.input_values).logits, dim=-1)
predicted[predicted == -100] = processor.tokenizer.pad_token_id # see fine-tuning script
batch["predicted"] = processor.tokenizer.batch_decode(predicted)
return batch
dataset = dataset.map(predict, batched=True, batch_size=1, remove_columns=["speech"])
for reference, predicted in zip(dataset["text"], dataset["predicted"]):
print("reference:", reference)
print("predicted:", predicted)
print("reference (untransliterated):", buckwalter.untrans(reference))
print("predicted (untransliterated):", buckwalter.untrans(predicted))
print("--")
```
Here's the output:
```
reference: >atAHat lilbA}iEi lmutajaw~ili >an yakuwna jA*iban lilmuwATini l>aqal~i daxlan
predicted: >ataAHato lilobaA}iEi Alomutajaw~ili >ano yakuwna jaA*ibAF lilomuwaATini Alo>aqal~i daxolAF
reference (untransliterated): أَتاحَت لِلبائِعِ لمُتَجَوِّلِ أَن يَكُونَ جاذِبَن لِلمُواطِنِ لأَقَلِّ دَخلَن
predicted (untransliterated): أَتَاحَتْ لِلْبَائِعِ الْمُتَجَوِّلِ أَنْ يَكُونَ جَاذِباً لِلْمُوَاطِنِ الْأَقَلِّ دَخْلاً
--
reference: >aHrazat muntaxabAtu lbarAziyli wa>lmAnyA waruwsyA fawzan fiy muqAbalAtihim l<iEdAdiy~api l~atiy >uqiymat istiEdAdan linihA}iy~Ati ka>si lEAlam >al~atiy satanTaliqu baEda >aqal~i min >usbuwE
predicted: >aHorazato munotaxabaAtu AlobaraAziyli wa>alomaAnoyaA waruwsoyaA fawozAF fiy muqaAbalaAtihimo >aliEodaAdiy~api Al~atiy >uqiymat AsotiEodaAdAF linahaA}iy~aAti ka>osi AloEaAlamo >al~atiy satanoTaliqu baEoda >aqal~i mino >usobuwEo
reference (untransliterated): أَحرَزَت مُنتَخَباتُ لبَرازِيلِ وَألمانيا وَرُوسيا فَوزَن فِي مُقابَلاتِهِم لإِعدادِيَّةِ لَّتِي أُقِيمَت ِستِعدادَن لِنِهائِيّاتِ كَأسِ لعالَم أَلَّتِي سَتَنطَلِقُ بَعدَ أَقَلِّ مِن أُسبُوع
predicted (untransliterated): أَحْرَزَتْ مُنْتَخَبَاتُ الْبَرَازِيلِ وَأَلْمَانْيَا وَرُوسْيَا فَوْزاً فِي مُقَابَلَاتِهِمْ أَلِعْدَادِيَّةِ الَّتِي أُقِيمَت اسْتِعْدَاداً لِنَهَائِيَّاتِ كَأْسِ الْعَالَمْ أَلَّتِي سَتَنْطَلِقُ بَعْدَ أَقَلِّ مِنْ أُسْبُوعْ
--
reference: >axfaqa majlisu ln~uw~Abi ll~ubnAniy~u fiy xtiyAri ra}iysin jadiydin lilbilAdi xalafan lilr~a}iysi lHAliy~i l~a*iy tantahiy wilAyatuhu fiy lxAmisi wAlEi$riyn min mAyuw >ayAra lmuqbil
predicted: >axofaqa majolisu Aln~uw~aAbi All~ubonaAniy~u fiy AxotiyaAri ra}iysK jadiydK lilobilaAdi xalafAF lilr~a}iysi AloHaAliy~i Al~a*iy tanotahiy wilaAyatuhu fiy AloxaAmisi waAloEi$oriyno mino maAyuw >ay~aAra Alomuqobilo
reference (untransliterated): أَخفَقَ مَجلِسُ لنُّوّابِ للُّبنانِيُّ فِي ختِيارِ رَئِيسِن جَدِيدِن لِلبِلادِ خَلَفَن لِلرَّئِيسِ لحالِيِّ لَّذِي تَنتَهِي وِلايَتُهُ فِي لخامِسِ والعِشرِين مِن مايُو أَيارَ لمُقبِل
predicted (untransliterated): أَخْفَقَ مَجْلِسُ النُّوَّابِ اللُّبْنَانِيُّ فِي اخْتِيَارِ رَئِيسٍ جَدِيدٍ لِلْبِلَادِ خَلَفاً لِلرَّئِيسِ الْحَالِيِّ الَّذِي تَنْتَهِي وِلَايَتُهُ فِي الْخَامِسِ وَالْعِشْرِينْ مِنْ مَايُو أَيَّارَ الْمُقْبِلْ
--
reference: <i* sayaHDuru liqA'a ha*A lEAmi xamsun wavalAvuwna minhum
predicted: <i*o sayaHoDuru riqaA'a ha*aA AloEaAmi xamosN wa valaAvuwna minohumo
reference (untransliterated): إِذ سَيَحضُرُ لِقاءَ هَذا لعامِ خَمسُن وَثَلاثُونَ مِنهُم
predicted (untransliterated): إِذْ سَيَحْضُرُ رِقَاءَ هَذَا الْعَامِ خَمْسٌ وَ ثَلَاثُونَ مِنْهُمْ
--
reference: >aElanati lHukuwmapu lmiSriy~apu Ean waqfi taqdiymi ld~aEmi ln~aqdiy~i limuzAriEiy lquTni <iEtibAran mina lmuwsimi lz~irAEiy~i lmuqbil
predicted: >aEolanati AloHukuwmapu AlomiSoriy~apu Eano waqofi taqodiymi Ald~aEomi Aln~aqodiy~i limuzaAriEiy AloquToni <iEotibaArAF mina Alomuwsimi Alz~iraAEiy~i Alomuqobilo
reference (untransliterated): أَعلَنَتِ لحُكُومَةُ لمِصرِيَّةُ عَن وَقفِ تَقدِيمِ لدَّعمِ لنَّقدِيِّ لِمُزارِعِي لقُطنِ إِعتِبارَن مِنَ لمُوسِمِ لزِّراعِيِّ لمُقبِل
predicted (untransliterated): أَعْلَنَتِ الْحُكُومَةُ الْمِصْرِيَّةُ عَنْ وَقْفِ تَقْدِيمِ الدَّعْمِ النَّقْدِيِّ لِمُزَارِعِي الْقُطْنِ إِعْتِبَاراً مِنَ الْمُوسِمِ الزِّرَاعِيِّ الْمُقْبِلْ
--
reference: >aElanat wizArapu lSi~Ha~pi lsa~Euwdiya~pu lyawma Ean wafAtayni jadiydatayni biAlfayruwsi lta~Ajiyi kuwruwnA nuwfil
predicted: >aEolanato wizaArapu AlS~iH~api Als~aEuwdiy~apu Aloyawoma Eano wafaAtayoni jadiydatayoni biAlofayoruwsi Alt~aAjiy kuwruwnaA nuwfiylo
reference (untransliterated): أَعلَنَت وِزارَةُ لصِّحَّةِ لسَّعُودِيَّةُ ليَومَ عَن وَفاتَينِ جَدِيدَتَينِ بِالفَيرُوسِ لتَّاجِيِ كُورُونا نُوفِل
predicted (untransliterated): أَعْلَنَتْ وِزَارَةُ الصِّحَّةِ السَّعُودِيَّةُ الْيَوْمَ عَنْ وَفَاتَيْنِ جَدِيدَتَيْنِ بِالْفَيْرُوسِ التَّاجِي كُورُونَا نُوفِيلْ
--
reference: <iftutiHati ljumuEapa faE~Aliy~Atu ld~awrapi lr~AbiEapa Ea$rapa mina lmihrajAni ld~awliy~i lilfiylmi bimur~Aki$
predicted: <ifotutiHapi AlojumuwEapa faEaAliyaAtu Ald~aworapi Alr~aAbiEapa Ea$orapa miyna AlomihorajaAni Ald~awoliy~i lilofiylomi bimur~Aki$
reference (untransliterated): إِفتُتِحَتِ لجُمُعَةَ فَعّالِيّاتُ لدَّورَةِ لرّابِعَةَ عَشرَةَ مِنَ لمِهرَجانِ لدَّولِيِّ لِلفِيلمِ بِمُرّاكِش
predicted (untransliterated): إِفْتُتِحَةِ الْجُمُوعَةَ فَعَالِيَاتُ الدَّوْرَةِ الرَّابِعَةَ عَشْرَةَ مِينَ الْمِهْرَجَانِ الدَّوْلِيِّ لِلْفِيلْمِ بِمُرّاكِش
--
reference: >ak~adat Ea$ru duwalin Earabiy~apin $Arakati lxamiysa lmADiya fiy jtimAEi jd~ap muwAfaqatahA EalY l<inDimAmi <ilY Hilfin maEa lwilAyAti lmut~aHidapi li$an~i Hamlapin Easkariy~apin munas~aqapin Did~a tanZiymi >ald~awlapi l<islAmiy~api
predicted: >ak~adato Ea$oru duwalK Earabiy~apK $aArakapiy Aloxamiysa AlomaADiya fiy AjotimaAEi jad~ap muwaAfaqatahaA EalaY Alo<inoDimaAmi <ilaY HilofK maEa AlowilaAyaAti Alomut~aHidapi li$an~i HamolapK Easokariy~apK munas~aqapK id~a tanoZiymi Ald~awolapi Alo<isolaAmiy~api
reference (untransliterated): أَكَّدَت عَشرُ دُوَلِن عَرَبِيَّةِن شارَكَتِ لخَمِيسَ لماضِيَ فِي جتِماعِ جدَّة مُوافَقَتَها عَلى لإِنضِمامِ إِلى حِلفِن مَعَ لوِلاياتِ لمُتَّحِدَةِ لِشَنِّ حَملَةِن عَسكَرِيَّةِن مُنَسَّقَةِن ضِدَّ تَنظِيمِ أَلدَّولَةِ لإِسلامِيَّةِ
predicted (untransliterated): أَكَّدَتْ عَشْرُ دُوَلٍ عَرَبِيَّةٍ شَارَكَةِي الْخَمِيسَ الْمَاضِيَ فِي اجْتِمَاعِ جَدَّة مُوَافَقَتَهَا عَلَى الْإِنْضِمَامِ إِلَى حِلْفٍ مَعَ الْوِلَايَاتِ الْمُتَّحِدَةِ لِشَنِّ حَمْلَةٍ عَسْكَرِيَّةٍ مُنَسَّقَةٍ ِدَّ تَنْظِيمِ الدَّوْلَةِ الْإِسْلَامِيَّةِ
--
reference: <iltaHaqa luwkA ziydAna <ibnu ln~ajmi ld~awliy~i lfaransiy~i ljazA}iriy~i l>Sli zayni ld~iyni ziydAn biAlfariyq
predicted: <ilotaHaqa luwkaA ziydaAna <ibonu Aln~ajomi Ald~awoliy~i Alofaranosiy~i AlojazaA}iriy~i Alo>aSoli zayoni Ald~iyni zayodaAno biAlofariyqo
reference (untransliterated): إِلتَحَقَ لُوكا زِيدانَ إِبنُ لنَّجمِ لدَّولِيِّ لفَرَنسِيِّ لجَزائِرِيِّ لأصلِ زَينِ لدِّينِ زِيدان بِالفَرِيق
predicted (untransliterated): إِلْتَحَقَ لُوكَا زِيدَانَ إِبْنُ النَّجْمِ الدَّوْلِيِّ الْفَرَنْسِيِّ الْجَزَائِرِيِّ الْأَصْلِ زَيْنِ الدِّينِ زَيْدَانْ بِالْفَرِيقْ
--
reference: >alma$Akilu l~atiy yatrukuhA xalfahu dA}iman
predicted: Aloma$aAkilu Al~atiy yatorukuhaA xalofahu daA}imAF
reference (untransliterated): أَلمَشاكِلُ لَّتِي يَترُكُها خَلفَهُ دائِمَن
predicted (untransliterated): الْمَشَاكِلُ الَّتِي يَتْرُكُهَا خَلْفَهُ دَائِماً
--
reference: >al~a*iy yataDam~anu mazAyA barmajiy~apan wabaSariy~apan Eadiydapan tahdifu limuwAkabapi lt~aTaw~uri lHASili fiy lfaDA'i l<ilktruwniy watashiyli stifAdapi lqur~A'i min xadamAti lmawqiE
predicted: >al~a*iy yataDam~anu mazaAyaA baromajiy~apF wabaSariy~apF EadiydapF tahodifu limuwaAkabapi Alt~aTaw~uri AloHaASili fiy AlofaDaA'i Alo<iloktoruwniy watasohiyli AsotifaAdapi Aloqur~aA'i mino xadaAmaAti AlomawoqiEo
reference (untransliterated): أَلَّذِي يَتَضَمَّنُ مَزايا بَرمَجِيَّةَن وَبَصَرِيَّةَن عَدِيدَةَن تَهدِفُ لِمُواكَبَةِ لتَّطَوُّرِ لحاصِلِ فِي لفَضاءِ لإِلكترُونِي وَتَسهِيلِ ستِفادَةِ لقُرّاءِ مِن خَدَماتِ لمَوقِع
predicted (untransliterated): أَلَّذِي يَتَضَمَّنُ مَزَايَا بَرْمَجِيَّةً وَبَصَرِيَّةً عَدِيدَةً تَهْدِفُ لِمُوَاكَبَةِ التَّطَوُّرِ الْحَاصِلِ فِي الْفَضَاءِ الْإِلْكتْرُونِي وَتَسْهِيلِ اسْتِفَادَةِ الْقُرَّاءِ مِنْ خَدَامَاتِ الْمَوْقِعْ
--
reference: >alfikrapu wa<in badat jadiydapan EalY mujtamaEin yaEiy$u wAqiEan sayi}aan lA tu$aj~iEu EalY lD~aHik
predicted: >alofikorapu wa<inobadato jadiydapF EalaY mujotamaEK yaEiy$u waAqi Eano say~i}AF laA tu$aj~iEu EalaY AlD~aHiko
reference (untransliterated): أَلفِكرَةُ وَإِن بَدَت جَدِيدَةَن عَلى مُجتَمَعِن يَعِيشُ واقِعَن سَيِئََن لا تُشَجِّعُ عَلى لضَّحِك
predicted (untransliterated): أَلْفِكْرَةُ وَإِنْبَدَتْ جَدِيدَةً عَلَى مُجْتَمَعٍ يَعِيشُ وَاقِ عَنْ سَيِّئاً لَا تُشَجِّعُ عَلَى الضَّحِكْ
--
reference: mu$iyraan <ilY xidmapi lqur>Ani lkariymi wataEziyzi EalAqapi lmuslimiyna bihi
predicted: mu$iyrAF <ilaY xidomapi Aloquro|ni Alokariymi wataEoziyzi EalaAqapi Alomusolimiyna bihi
reference (untransliterated): مُشِيرََن إِلى خِدمَةِ لقُرأانِ لكَرِيمِ وَتَعزِيزِ عَلاقَةِ لمُسلِمِينَ بِهِ
predicted (untransliterated): مُشِيراً إِلَى خِدْمَةِ الْقُرْآنِ الْكَرِيمِ وَتَعْزِيزِ عَلَاقَةِ الْمُسْلِمِينَ بِهِ
--
reference: <in~ahu EindamA yakuwnu >aHadu lz~awjayni yastaxdimu >aHada >a$kAli lt~iknuwluwjyA >akvara mina l>Axar
predicted: <in~ahu EinodamaA yakuwnu >aHadu Alz~awojayoni yasotaxodimu >aHada >a$okaAli Alt~iykonuwluwjoyaA >akovara mina Alo|xaro
reference (untransliterated): إِنَّهُ عِندَما يَكُونُ أَحَدُ لزَّوجَينِ يَستَخدِمُ أَحَدَ أَشكالِ لتِّكنُولُوجيا أَكثَرَ مِنَ لأاخَر
predicted (untransliterated): إِنَّهُ عِنْدَمَا يَكُونُ أَحَدُ الزَّوْجَيْنِ يَسْتَخْدِمُ أَحَدَ أَشْكَالِ التِّيكْنُولُوجْيَا أَكْثَرَ مِنَ الْآخَرْ
--
reference: wa*alika biHuDuwri ra}yisi lhay}api
predicted: wa*alika biHuDuwri ra}iysi Alohayo>api
reference (untransliterated): وَذَلِكَ بِحُضُورِ رَئيِسِ لهَيئَةِ
predicted (untransliterated): وَذَلِكَ بِحُضُورِ رَئِيسِ الْهَيْأَةِ
--
reference: wa*alika fiy buTuwlapa ka>si lEAlami lil>andiyapi baEda nusxapin tAriyxiy~apin >alEAma lmADiya <intahat bitatwiyji bAyrin miyuwniyxa l>almAniy~a EalY HisAbi lr~ajA'i lmagribiy~i fiy >aw~ali ta>ah~ulin lifariyqin Earabiy~in <ilY nihA}iy~i lmusAbaqapi
predicted: wa*alika fiy buTuwlapi ka>osiy AloEaAlami lilo>anodiyapi baEoda nusoxapK taAriyxiy~apK >aloEaAma AlomaADiya <inotahato bitatowiyji bAyorinmoyuwnixa Alo>alomaAniy~a EalaY HisaAbi Alr~ajaA'i Alomagoribiy~ifiy >aw~ali ta>ah~ulK lifariyqKEarabiy~K <ilaY nihaA}iy~i AlomusaAbaqapi
reference (untransliterated): وَذَلِكَ فِي بُطُولَةَ كَأسِ لعالَمِ لِلأَندِيَةِ بَعدَ نُسخَةِن تارِيخِيَّةِن أَلعامَ لماضِيَ إِنتَهَت بِتَتوِيجِ بايرِن مِيُونِيخَ لأَلمانِيَّ عَلى حِسابِ لرَّجاءِ لمَغرِبِيِّ فِي أَوَّلِ تَأَهُّلِن لِفَرِيقِن عَرَبِيِّن إِلى نِهائِيِّ لمُسابَقَةِ
predicted (untransliterated): وَذَلِكَ فِي بُطُولَةِ كَأْسِي الْعَالَمِ لِلْأَنْدِيَةِ بَعْدَ نُسْخَةٍ تَارِيخِيَّةٍ أَلْعَامَ الْمَاضِيَ إِنْتَهَتْ بِتَتْوِيجِ بايْرِنمْيُونِخَ الْأَلْمَانِيَّ عَلَى حِسَابِ الرَّجَاءِ الْمَغْرِبِيِّفِي أَوَّلِ تَأَهُّلٍ لِفَرِيقٍعَرَبِيٍّ إِلَى نِهَائِيِّ الْمُسَابَقَةِ
--
reference: bal yajibu lbaHvu fiymA tumav~iluhu min <iDAfapin Haqiyqiy~apin lil<iqtiSAdi lmaSriy~i fiy majAlAti lt~awZiyf biAEtibAri >an~a mu$kilapa lbiTAlapi mina lmu$kilAti lr~a}iysiy~api fiy miSr
predicted: balo yajibu AlobaHovu fiymaA tumav~iluhu mino <iDaAfapK Haqiyqiy~apK lilo<iqotiSaAdi AlomaSoriy~i fiy majaAlaAti Alt~awoZiyfo biAEotibaAri >an~a mu$okilapa AlobiTaAlapi mina Alomu$okilaAti Alr~a}iysiy~api fiy miSori
reference (untransliterated): بَل يَجِبُ لبَحثُ فِيما تُمَثِّلُهُ مِن إِضافَةِن حَقِيقِيَّةِن لِلإِقتِصادِ لمَصرِيِّ فِي مَجالاتِ لتَّوظِيف بِاعتِبارِ أَنَّ مُشكِلَةَ لبِطالَةِ مِنَ لمُشكِلاتِ لرَّئِيسِيَّةِ فِي مِصر
predicted (untransliterated): بَلْ يَجِبُ الْبَحْثُ فِيمَا تُمَثِّلُهُ مِنْ إِضَافَةٍ حَقِيقِيَّةٍ لِلْإِقْتِصَادِ الْمَصْرِيِّ فِي مَجَالَاتِ التَّوْظِيفْ بِاعْتِبَارِ أَنَّ مُشْكِلَةَ الْبِطَالَةِ مِنَ الْمُشْكِلَاتِ الرَّئِيسِيَّةِ فِي مِصْرِ
--
reference: taHtaDinu qAEapu *A fiynyuw wasaTa bayruwta maEriDa lfan~i l<istivnA}iy~i
predicted: taHotaDinu qaAEapu *aAfiynoyw wasaTa bayoruwta maEoriDa Alofan~i Alo<isotivonaA}iy~i
reference (untransliterated): تَحتَضِنُ قاعَةُ ذا فِينيُو وَسَطَ بَيرُوتَ مَعرِضَ لفَنِّ لإِستِثنائِيِّ
predicted (untransliterated): تَحْتَضِنُ قَاعَةُ ذَافِينْيو وَسَطَ بَيْرُوتَ مَعْرِضَ الْفَنِّ الْإِسْتِثْنَائِيِّ
--
reference: tarbiyapu lHamAmi hiwAyapun wamihnapun libaEDi ln~As
predicted: tarobiy~apu AloHamaAmi hiwaAyapN wamihonapN libaEoDi Aln~aAs
reference (untransliterated): تَربِيَةُ لحَمامِ هِوايَةُن وَمِهنَةُن لِبَعضِ لنّاس
predicted (untransliterated): تَرْبِيَّةُ الْحَمَامِ هِوَايَةٌ وَمِهْنَةٌ لِبَعْضِ النَّاس
--
reference: tasEY $abakapu lt~awASuli l<ijtimAEiy~i lS~AEidapu <iylw <ilY munAfasapi $abakapi fysbuwk Eabra lt~axal~iy Eani l<iElAnAti wAlHifAZi EalY lxuSuwSiy~api waHimAyapi lbayAnAt
predicted: tasoEap $abakapu Alt~awaASuli Alo<ijotimaAEiy~i AlS~aAEidapu <iylw <ilaY munaAfasapi $abakapi fysobuwko Eabora Alt~axal~iy Eani Alo<iEolaAnaAti waAloHifaAZi EalaY AloxuSuwSiy~api waHimaAyapi AlobayaAnaAt
reference (untransliterated): تَسعى شَبَكَةُ لتَّواصُلِ لإِجتِماعِيِّ لصّاعِدَةُ إِيلو إِلى مُنافَسَةِ شَبَكَةِ فيسبُوك عَبرَ لتَّخَلِّي عَنِ لإِعلاناتِ والحِفاظِ عَلى لخُصُوصِيَّةِ وَحِمايَةِ لبَيانات
predicted (untransliterated): تَسْعَة شَبَكَةُ التَّوَاصُلِ الْإِجْتِمَاعِيِّ الصَّاعِدَةُ إِيلو إِلَى مُنَافَسَةِ شَبَكَةِ فيسْبُوكْ عَبْرَ التَّخَلِّي عَنِ الْإِعْلَانَاتِ وَالْحِفَاظِ عَلَى الْخُصُوصِيَّةِ وَحِمَايَةِ الْبَيَانَات
--
reference: jamEu lmu&ana~vi lsa~Alimi mivla fAzat <iHdY lTa~AlibAti fiy musAbaqapi lqirA'Ati lqur>Aniya~pi
predicted: jamoEu Alomu&an~avi Als~aAlimi mivola faAzato <iHodaY AlT~aAlibaAti fiy musaAbaqapi AloqiraA'aAti Aloquro|niy~api
reference (untransliterated): جَمعُ لمُؤَنَّثِ لسَّالِمِ مِثلَ فازَت إِحدى لطَّالِباتِ فِي مُسابَقَةِ لقِراءاتِ لقُرأانِيَّةِ
predicted (untransliterated): جَمْعُ الْمُؤَنَّثِ السَّالِمِ مِثْلَ فَازَتْ إِحْدَى الطَّالِبَاتِ فِي مُسَابَقَةِ الْقِرَاءَاتِ الْقُرْآنِيَّةِ
--
reference: Hat~Y l>amsi lqariyb kAna lkaviyru mina l>uwkrAniy~iyn yu$ak~ikuwna fiy ntimA'i tatAri $ibhi jaziyrapi lqarm
predicted: Hat~aY Alo>amosi Aloqariybo kaAna Alokaviyru mina Alo>uwkoraAniy~iyno yu$ak~ikuwna fiy AnotimaA'i tataAri $ibohi jaziyrapi Aloqaromo
reference (untransliterated): حَتّى لأَمسِ لقَرِيب كانَ لكَثِيرُ مِنَ لأُوكرانِيِّين يُشَكِّكُونَ فِي نتِماءِ تَتارِ شِبهِ جَزِيرَةِ لقَرم
predicted (untransliterated): حَتَّى الْأَمْسِ الْقَرِيبْ كَانَ الْكَثِيرُ مِنَ الْأُوكْرَانِيِّينْ يُشَكِّكُونَ فِي انْتِمَاءِ تَتَارِ شِبْهِ جَزِيرَةِ الْقَرْمْ
--
reference: Ha*~arati l>umamu lmut~aHidapu min >an~a lEAlama sayuwAjihu xilAla lEuquwdi lmuqbilapi tafAquma >azmapin muzdawijapin fiy lmiyAh wAlkahrabA'
predicted: Ha*~arapi Alo>umamu Alomut~aHidapu mino >an~a AloEaAlama sayuwaAjihu xilaAla AloEuquwdi Alomuqobilapi tafaAq~uma >azomapK muzodawyijapK fiy AlomiyaA waAlokahorabaA'o
reference (untransliterated): حَذَّرَتِ لأُمَمُ لمُتَّحِدَةُ مِن أَنَّ لعالَمَ سَيُواجِهُ خِلالَ لعُقُودِ لمُقبِلَةِ تَفاقُمَ أَزمَةِن مُزدَوِجَةِن فِي لمِياه والكَهرَباء
predicted (untransliterated): حَذَّرَةِ الْأُمَمُ الْمُتَّحِدَةُ مِنْ أَنَّ الْعَالَمَ سَيُوَاجِهُ خِلَالَ الْعُقُودِ الْمُقْبِلَةِ تَفَاقُّمَ أَزْمَةٍ مُزْدَويِجَةٍ فِي الْمِيَا وَالْكَهْرَبَاءْ
--
reference: HuDuwru baEDi lz~uEamA'i fiy >almasiyrapi ljumhuwriy~api bibAriys
predicted: HuDuwru baEoDi Alz~aEamaA'ifiy >alomasiyrapi Alojumohuwriy~api bibaArys
reference (untransliterated): حُضُورُ بَعضِ لزُّعَماءِ فِي أَلمَسِيرَةِ لجُمهُورِيَّةِ بِبارِيس
predicted (untransliterated): حُضُورُ بَعْضِ الزَّعَمَاءِفِي أَلْمَسِيرَةِ الْجُمْهُورِيَّةِ بِبَاريس
--
reference: Hayvu kAna lEarabu >w~ala man Earafa qiymatahA lEilAjiy~apa fiy lqarni lEA$iri qabla lmiylAd fiy mamlakapi saba>
predicted: Hayovu kaAna AloEarabu >aw~ala mano Earafa qiymatahaA AloEilaAjiy~apa fiy Aloqaroni AloEaA$iri qabola AlomiylaAd fiy mamolakapi saba>o
reference (untransliterated): حَيثُ كانَ لعَرَبُ أوَّلَ مَن عَرَفَ قِيمَتَها لعِلاجِيَّةَ فِي لقَرنِ لعاشِرِ قَبلَ لمِيلاد فِي مَملَكَةِ سَبَأ
predicted (untransliterated): حَيْثُ كَانَ الْعَرَبُ أَوَّلَ مَنْ عَرَفَ قِيمَتَهَا الْعِلَاجِيَّةَ فِي الْقَرْنِ الْعَاشِرِ قَبْلَ الْمِيلَاد فِي مَمْلَكَةِ سَبَأْ
--
reference: daxalati lt~iknuwluwjyA fiy kul~i baytin wa>usrapin wa>aSbaHat tu$ak~ilu ljuz'a lkabiyra min HayAtinA
predicted: daxalati Alt~ikonuwluwjoyaA fiy kul~i bayotK wa>usorapK wa>aSobaHaAtlotu$ak~ilu Alojuzo'a Alokabiyra mino HayaAtina
reference (untransliterated): دَخَلَتِ لتِّكنُولُوجيا فِي كُلِّ بَيتِن وَأُسرَةِن وَأَصبَحَت تُشَكِّلُ لجُزءَ لكَبِيرَ مِن حَياتِنا
predicted (untransliterated): دَخَلَتِ التِّكْنُولُوجْيَا فِي كُلِّ بَيْتٍ وَأُسْرَةٍ وَأَصْبَحَاتلْتُشَكِّلُ الْجُزْءَ الْكَبِيرَ مِنْ حَيَاتِنَ
--
reference: duwna taHmiyli ljismi juhdan kabiyran fiy lbidAyapi qad yatasaba~bu fiy nufuwri l$a~xSi mina l<istimrAr
predicted: duwna taHomiyli Alojisomi juhodAF kabiyrAF fiy AlobidaAyapi qado yatasab~abu fiy nufuwri Al$~axoSi mina Al<isotimoraAro
reference (untransliterated): دُونَ تَحمِيلِ لجِسمِ جُهدَن كَبِيرَن فِي لبِدايَةِ قَد يَتَسَبَّبُ فِي نُفُورِ لشَّخصِ مِنَ لإِستِمرار
predicted (untransliterated): دُونَ تَحْمِيلِ الْجِسْمِ جُهْداً كَبِيراً فِي الْبِدَايَةِ قَدْ يَتَسَبَّبُ فِي نُفُورِ الشَّخْصِ مِنَ الإِسْتِمْرَارْ
--
reference: ragma ln~izAEi ld~Amiy >al~a*iy yaESifu biAlbilAd mun*u val>avi sanawAt
predicted: ragoma Aln~izaAEi Ald~aAmiy >al~a*iy yaEoSifu biAlobilAd muno*u valAvi sanawAt
reference (untransliterated): رَغمَ لنِّزاعِ لدّامِي أَلَّذِي يَعصِفُ بِالبِلاد مُنذُ ثَلأَثِ سَنَوات
predicted (untransliterated): رَغْمَ النِّزَاعِ الدَّامِي أَلَّذِي يَعْصِفُ بِالْبِلاد مُنْذُ ثَلاثِ سَنَوات
--
reference: rafaDa majlisu l>amni ld~awliy~u ma$ruwEa lqarAri lfilisTiyniy~i lr~Amiy <ilY <inhA'i l<iHtilAli l<isrA}iyliy~i fiy EAmayn
predicted: rafaDa majolisu Alo>amoni Ald~awoliy~u ma$oruwEa AloqaraAri AlofilisoTiyniy~i Alr~aAmi <ilaY <inohaA'i Alo<iHotilaAli Alo<isoraA}iyliy~i fiy EaAmayno
reference (untransliterated): رَفَضَ مَجلِسُ لأَمنِ لدَّولِيُّ مَشرُوعَ لقَرارِ لفِلِسطِينِيِّ لرّامِي إِلى إِنهاءِ لإِحتِلالِ لإِسرائِيلِيِّ فِي عامَين
predicted (untransliterated): رَفَضَ مَجْلِسُ الْأَمْنِ الدَّوْلِيُّ مَشْرُوعَ الْقَرَارِ الْفِلِسْطِينِيِّ الرَّامِ إِلَى إِنْهَاءِ الْإِحْتِلَالِ الْإِسْرَائِيلِيِّ فِي عَامَينْ
--
reference: ramzu ld~awlapi lt~urkiy~api lEilmAniy~api al~atiy ta>as~asat Eaqiba nhiyAri ld~awlapi lEuvmAniy~api
predicted: ramozu Ald~awolapi Alt~urokiy~api AloEilomaAniy~api Al~atiy ta>as~asato EaqibaAF hiyaAri Ald~awolapi AloEuvomaAniy~api
reference (untransliterated): رَمزُ لدَّولَةِ لتُّركِيَّةِ لعِلمانِيَّةِ َلَّتِي تَأَسَّسَت عَقِبَ نهِيارِ لدَّولَةِ لعُثمانِيَّةِ
predicted (untransliterated): رَمْزُ الدَّوْلَةِ التُّرْكِيَّةِ الْعِلْمَانِيَّةِ الَّتِي تَأَسَّسَتْ عَقِبَاً هِيَارِ الدَّوْلَةِ الْعُثْمَانِيَّةِ
--
reference: $Araka mawqiEu >aljaziyrapi litaEal~umi lEarabiy~api fiy lmu&tamari ld~awliy~i lv~Aniy lil~ugapi lEarabiy~api >al~a*iy naZ~amathu jAmiEapu mawlAnA mAlik <ibrAhiym >al<islAmiy~apu lHukuwmiyapu bimadiynapi mAlAnq biAlt~aEAwuni maEa jAmiEapi dAri ls~alAm bimadiynapi kuwntuwr fiy >anduwniysyA
predicted: $aAraka mawoqiEu >alojaziyrapi litaEal~umi AloEarabiy~api fiy Alomu&otamari Ald~awoliy~i Alv~aAniy lill~ugapi AloEarabiy~api >al~a*iy naZ~amatohu jaAmiEapu mawolaAnaA maAlik <iboraAhiymo >alo<isolaAmiy~apu AloHukuwmiy~apu bimadiynapi maA laAnoqo biAlt~aEaAwuni maEa jaAmiEapi daAri Als~alaAmo bimadiynapi kuwnotuwro fiy >anoduwniysoyaA
reference (untransliterated): شارَكَ مَوقِعُ أَلجَزِيرَةِ لِتَعَلُّمِ لعَرَبِيَّةِ فِي لمُؤتَمَرِ لدَّولِيِّ لثّانِي لِلُّغَةِ لعَرَبِيَّةِ أَلَّذِي نَظَّمَتهُ جامِعَةُ مَولانا مالِك إِبراهِيم أَلإِسلامِيَّةُ لحُكُومِيَةُ بِمَدِينَةِ مالانق بِالتَّعاوُنِ مَعَ جامِعَةِ دارِ لسَّلام بِمَدِينَةِ كُونتُور فِي أَندُونِيسيا
predicted (untransliterated): شَارَكَ مَوْقِعُ أَلْجَزِيرَةِ لِتَعَلُّمِ الْعَرَبِيَّةِ فِي الْمُؤْتَمَرِ الدَّوْلِيِّ الثَّانِي لِللُّغَةِ الْعَرَبِيَّةِ أَلَّذِي نَظَّمَتْهُ جَامِعَةُ مَوْلَانَا مَالِك إِبْرَاهِيمْ أَلْإِسْلَامِيَّةُ الْحُكُومِيَّةُ بِمَدِينَةِ مَا لَانْقْ بِالتَّعَاوُنِ مَعَ جَامِعَةِ دَارِ السَّلَامْ بِمَدِينَةِ كُونْتُورْ فِي أَنْدُونِيسْيَا
--
reference: $araEa l<it~iHAdu lt~uwnusiy~u lilfuruwsiy~api fiy tanfiy* xuT~apin tarnuw <ilY lmuDiy~i biha*ihi lr~iyADapi naHwa buluwgi lEAlamiy~api
predicted: $aAraEa Alo<it~iHaAdu Alt~uwnusiy~u lilofuruwsiy~api fiy tanofiy*o xuT~apK taronuwA <ilaY AlomuDiy~i biha*ihi Alr~iy~aADapi naHowa buluwgi AloEaAlamiy~api
reference (untransliterated): شَرَعَ لإِتِّحادُ لتُّونُسِيُّ لِلفُرُوسِيَّةِ فِي تَنفِيذ خُطَّةِن تَرنُو إِلى لمُضِيِّ بِهَذِهِ لرِّياضَةِ نَحوَ بُلُوغِ لعالَمِيَّةِ
predicted (untransliterated): شَارَعَ الْإِتِّحَادُ التُّونُسِيُّ لِلْفُرُوسِيَّةِ فِي تَنْفِيذْ خُطَّةٍ تَرْنُوا إِلَى الْمُضِيِّ بِهَذِهِ الرِّيَّاضَةِ نَحْوَ بُلُوغِ الْعَالَمِيَّةِ
--
reference: $ahida EAmu >alfayni wa>arbaEapa Ea$rapa Eid~apa <injAzAtin Tib~iy~apin
predicted: $ahida EaAmu >alfayni wa>arobaEapa Ea$orapa Eid~apa <inojaAzaAtK Tib~iy~apK
reference (untransliterated): شَهِدَ عامُ أَلفَينِ وَأَربَعَةَ عَشرَةَ عِدَّةَ إِنجازاتِن طِبِّيَّةِن
predicted (untransliterated): شَهِدَ عَامُ أَلفَينِ وَأَرْبَعَةَ عَشْرَةَ عِدَّةَ إِنْجَازَاتٍ طِبِّيَّةٍ
--
reference: EAda <irtifAEu >asEAri l>dwiyapi wa$uH~u lmunqi*i lilHayApi minhA liyuTil~a bira>sihi fiy ls~uwdAni min jadiydin
predicted: EaAda <irotifaAEu >asoEaAri Alo>adowiyapi wa$uH~u Alomunoqi*i liloHayaAti minohaA liyuTil~a bira>osihi fiy Als~uwdaAni mino jadiydK
reference (untransliterated): عادَ إِرتِفاعُ أَسعارِ لأدوِيَةِ وَشُحُّ لمُنقِذِ لِلحَياةِ مِنها لِيُطِلَّ بِرَأسِهِ فِي لسُّودانِ مِن جَدِيدِن
predicted (untransliterated): عَادَ إِرْتِفَاعُ أَسْعَارِ الْأَدْوِيَةِ وَشُحُّ الْمُنْقِذِ لِلْحَيَاتِ مِنْهَا لِيُطِلَّ بِرَأْسِهِ فِي السُّودَانِ مِنْ جَدِيدٍ
--
reference: EalY EtibArihA tusAEidu EalY tawsiyEi madAriki l>aTfAl watajEalu minhum >unAsan muvaq~afiyna mustaqbalan wamuwAkibiyna liEaSri tiknuwluwjyA lmaEluwmAt
predicted: EalaY AEotibaArihaA tusaAEidu EalaY tawosiyEi ma*ariki Alo>aTofaAl watajoEalu minohumo >unaAsAF muvaq~afiyna musotaqobalAF wamuwaAkibiyna liEaSori Alt~ikonuwluwjoyaA AlomaEoluwmaAt
reference (untransliterated): عَلى عتِبارِها تُساعِدُ عَلى تَوسِيعِ مَدارِكِ لأَطفال وَتَجعَلُ مِنهُم أُناسَن مُثَقَّفِينَ مُستَقبَلَن وَمُواكِبِينَ لِعَصرِ تِكنُولُوجيا لمَعلُومات
predicted (untransliterated): عَلَى اعْتِبَارِهَا تُسَاعِدُ عَلَى تَوْسِيعِ مَذَرِكِ الْأَطْفَال وَتَجْعَلُ مِنْهُمْ أُنَاساً مُثَقَّفِينَ مُسْتَقْبَلاً وَمُوَاكِبِينَ لِعَصْرِ التِّكْنُولُوجْيَا الْمَعْلُومَات
--
reference: wa*alika EalY xilAfi nuZarA}ihi ls~Abiqiyn
predicted: wa*alika EalaY xilaAfi nuZaraA}ihi Als~aAbiqiyno
reference (untransliterated): وَذَلِكَ عَلى خِلافِ نُظَرائِهِ لسّابِقِين
predicted (untransliterated): وَذَلِكَ عَلَى خِلَافِ نُظَرَائِهِ السَّابِقِينْ
--
reference: fataHat >akAdiymiy~apu lmuwsiyqY lEarabiy~api rasmiy~an yawma ls~abt >abwAbahA fiy bruwksil biHuDuwri majmuwEapin mina lwuzarA' warijAli lfan~i lbaljiykiy~iyna wAlEarab
predicted: fataHato >akaAdiymiy~apu AlomuwsiyqaY AloEarabiy~api rasomiy~AF yawoma Als~abot >abowaAbahaA fiy boruwkosil biHuDuwri majomuwEapK mina AlowuzaraYA warijaAli Alofan~i Alobalojiykiy~iyna waAloEarabo
reference (untransliterated): فَتَحَت أَكادِيمِيَّةُ لمُوسِيقى لعَرَبِيَّةِ رَسمِيَّن يَومَ لسَّبت أَبوابَها فِي برُوكسِل بِحُضُورِ مَجمُوعَةِن مِنَ لوُزَراء وَرِجالِ لفَنِّ لبَلجِيكِيِّينَ والعَرَب
predicted (untransliterated): فَتَحَتْ أَكَادِيمِيَّةُ الْمُوسِيقَى الْعَرَبِيَّةِ رَسْمِيّاً يَوْمَ السَّبْت أَبْوَابَهَا فِي بْرُوكْسِل بِحُضُورِ مَجْمُوعَةٍ مِنَ الْوُزَرَىا وَرِجَالِ الْفَنِّ الْبَلْجِيكِيِّينَ وَالْعَرَبْ
--
reference: fataHZY bitaEal~umin yamHuw >um~iy~atahA wayuDiy'u lahA Tariyqa lmaErifapi wAlt~iknuwluwjyA
predicted: fataHoZaY bitaEal~umK yamoHu >um~iy~atahaA wayuDiy'u lahaA Tariyqa AlomaEorifapi waAlt~iykonuwluwjoyaA
reference (untransliterated): فَتَحظى بِتَعَلُّمِن يَمحُو أُمِّيَّتَها وَيُضِيءُ لَها طَرِيقَ لمَعرِفَةِ والتِّكنُولُوجيا
predicted (untransliterated): فَتَحْظَى بِتَعَلُّمٍ يَمْحُ أُمِّيَّتَهَا وَيُضِيءُ لَهَا طَرِيقَ الْمَعْرِفَةِ وَالتِّيكْنُولُوجْيَا
--
reference: faha*A lmanzilu lmutawADiE >aSbaHa maHaj~aan liEadadin kabiyrin mina ln~isA'i lmariyDAti biAls~araTAn
predicted: faha*aA Alomanozilu AlomutawaADiEi >aSobaHa maHaj~AF liEadadK kabiyrK mina Aln~isaA'i AlomariyDaAti biAls~araTaAno
reference (untransliterated): فَهَذا لمَنزِلُ لمُتَواضِع أَصبَحَ مَحَجََّن لِعَدَدِن كَبِيرِن مِنَ لنِّساءِ لمَرِيضاتِ بِالسَّرَطان
predicted (untransliterated): فَهَذَا الْمَنْزِلُ الْمُتَوَاضِعِ أَصْبَحَ مَحَجّاً لِعَدَدٍ كَبِيرٍ مِنَ النِّسَاءِ الْمَرِيضَاتِ بِالسَّرَطَانْ
--
reference: Hadava *alika fiy Hay yaEquwba lmanSuwr l$~aEbiy~i
predicted: Hadava *alika fiy Hay yaEoquwba AlomanoSuwro >al$~aEobiy~i
reference (untransliterated): حَدَثَ ذَلِكَ فِي حَي يَعقُوبَ لمَنصُور لشَّعبِيِّ
predicted (untransliterated): حَدَثَ ذَلِكَ فِي حَي يَعْقُوبَ الْمَنْصُورْ أَلشَّعْبِيِّ
--
reference: fiy Hiyni kAna lmarkazu l>aw~alu fiy lwavbi lEAliy min naSiybi lkuruwAtiy~api >AnA siymiyt$
predicted: fiy Hiyni kaAna Alomarokazu Alo>aw~alu fiy Alowavobi AloEaAli mino naSiybi AlokuruwaAtiy~api |naA siymito$
reference (untransliterated): فِي حِينِ كانَ لمَركَزُ لأَوَّلُ فِي لوَثبِ لعالِي مِن نَصِيبِ لكُرُواتِيَّةِ أانا سِيمِيتش
predicted (untransliterated): فِي حِينِ كَانَ الْمَرْكَزُ الْأَوَّلُ فِي الْوَثْبِ الْعَالِ مِنْ نَصِيبِ الْكُرُوَاتِيَّةِ آنَا سِيمِتْش
--
reference: qAla bAHivuwna <in~a riyAHan >aqwY mina lmuEtAd xaf~afat min HarArapi saTHi lmuHiyTi lhAdiy hiya sababu lt~abATu}i lmu&aq~at fiy rtifAEi darajapi HarArapi l>arD mun*u bidAyapi lqarni lHAdiy wAlEi$riyn
predicted: qaAla baAHivuwna <in~a riyaAHAF >aqowaY mina AlomuEotaAd xaf~afato mino HaraArapi saToHi AlomuHiyTi AlohaAdiy hiya sababu Alt~abaATu&i Alomu&aq~aTi fiy ArotifaAEi darajapi HaraArapi Alo>aroD muno*u bidaAyapi Aloqaroni AloHaAdiy waAloEi$oriyno
reference (untransliterated): قالَ باحِثُونَ إِنَّ رِياحَن أَقوى مِنَ لمُعتاد خَفَّفَت مِن حَرارَةِ سَطحِ لمُحِيطِ لهادِي هِيَ سَبَبُ لتَّباطُئِ لمُؤَقَّت فِي رتِفاعِ دَرَجَةِ حَرارَةِ لأَرض مُنذُ بِدايَةِ لقَرنِ لحادِي والعِشرِين
predicted (untransliterated): قَالَ بَاحِثُونَ إِنَّ رِيَاحاً أَقْوَى مِنَ الْمُعْتَاد خَفَّفَتْ مِنْ حَرَارَةِ سَطْحِ الْمُحِيطِ الْهَادِي هِيَ سَبَبُ التَّبَاطُؤِ الْمُؤَقَّطِ فِي ارْتِفَاعِ دَرَجَةِ حَرَارَةِ الْأَرْض مُنْذُ بِدَايَةِ الْقَرْنِ الْحَادِي وَالْعِشْرِينْ
--
reference: qabla >an yuslima liyudAfiEa Ean diynih muHib~aan wamuHtariman li>aSlihi wamADiyh
predicted: qabola >ano yusolima liyudaAfiEa Eano diyni muHib~AF wamuHotarimAF li>aSolihi wamaADiyh
reference (untransliterated): قَبلَ أَن يُسلِمَ لِيُدافِعَ عَن دِينِه مُحِبََّن وَمُحتَرِمَن لِأَصلِهِ وَماضِيه
predicted (untransliterated): قَبْلَ أَنْ يُسْلِمَ لِيُدَافِعَ عَنْ دِينِ مُحِبّاً وَمُحْتَرِماً لِأَصْلِهِ وَمَاضِيه
--
reference: kamA tam~a taHsiynu wAjihAti lt~anaq~ul wAxtiyAri wasA}ili ln~aqli lmunAsibapi bi$aklin kabiyr
predicted: kamaA tam~a taHosiynu waAjihaAti Alt~anaq~ulo waAxotiyaAri wasaA}ili Aln~aqoli AlomunaAsibapi bi$akolK kabiyro
reference (untransliterated): كَما تَمَّ تَحسِينُ واجِهاتِ لتَّنَقُّل واختِيارِ وَسائِلِ لنَّقلِ لمُناسِبَةِ بِشَكلِن كَبِير
predicted (untransliterated): كَمَا تَمَّ تَحْسِينُ وَاجِهَاتِ التَّنَقُّلْ وَاخْتِيَارِ وَسَائِلِ النَّقْلِ الْمُنَاسِبَةِ بِشَكْلٍ كَبِيرْ
--
reference: kamA tuwuf~iyati lr~iwA}iy~apu lbArizapu wAl>ustA*apu ljAmiEiy~apu lmiSriy~apu raDwY EA$uwr Ean vamAniy wasit~iyna EAman
predicted: kamaA tuwuf~iyapi Alr~iwaA}iy~apu AlobaArizapu waAlo>usotaA*apu Alj~aAmiEiy~apu AlomiSoriy~apu raDowaY EaA$uwro Eano vamaAniy wasit~iyna EaAmAF
reference (untransliterated): كَما تُوُفِّيَتِ لرِّوائِيَّةُ لبارِزَةُ والأُستاذَةُ لجامِعِيَّةُ لمِصرِيَّةُ رَضوى عاشُور عَن ثَمانِي وَسِتِّينَ عامَن
predicted (untransliterated): كَمَا تُوُفِّيَةِ الرِّوَائِيَّةُ الْبَارِزَةُ وَالْأُسْتَاذَةُ الجَّامِعِيَّةُ الْمِصْرِيَّةُ رَضْوَى عَاشُورْ عَنْ ثَمَانِي وَسِتِّينَ عَاماً
--
reference: kamA $Arakat TAlibAtun min madArisa filasTiyniy~apin >alfan~Anapa lt~urkiy~apa fiy Eamali lawHAt
predicted: kamaA $aArakato TaAlibaAtN mino madaArisa fiylasoTiydiy~apK >alofan~aAnapa Alt~urokiy~apa fiy Eamali lawoHaAt
reference (untransliterated): كَما شارَكَت طالِباتُن مِن مَدارِسَ فِلَسطِينِيَّةِن أَلفَنّانَةَ لتُّركِيَّةَ فِي عَمَلِ لَوحات
predicted (untransliterated): كَمَا شَارَكَتْ طَالِبَاتٌ مِنْ مَدَارِسَ فِيلَسْطِيدِيَّةٍ أَلْفَنَّانَةَ التُّرْكِيَّةَ فِي عَمَلِ لَوْحَات
--
reference: lAmasa mu*an~abun yuTlaqu Ealayhi <ismu sAydiyng sbriyng kawkaba lmir~iyxi Einda muruwrihi bimuHA*Atih
predicted: laAmasa mu*an~abN yuTolaqu Ealayohi <isomu saAyodynosoboriynogo kawokaba Alomar~iyxi Einoda muruwrihi bimuHaA*aAti
reference (untransliterated): لامَسَ مُذَنَّبُن يُطلَقُ عَلَيهِ إِسمُ سايدِينغ سبرِينغ كَوكَبَ لمِرِّيخِ عِندَ مُرُورِهِ بِمُحاذاتِه
predicted (untransliterated): لَامَسَ مُذَنَّبٌ يُطْلَقُ عَلَيْهِ إِسْمُ سَايْدينْسْبْرِينْغْ كَوْكَبَ الْمَرِّيخِ عِنْدَ مُرُورِهِ بِمُحَاذَاتِ
--
reference: laqad sAhamati lt~iknuluwjyA fiy taqliyli ln~izAEAti l>usariy~api wa>aETat likul~i fardin nawEan mina l<istiqlAliy~api
predicted: laqado saAhamapi Alt~iykonuwluwjoyaA fiy taqoliyli Aln~izaAEaAti Alo>usariy~api wa>aEoTaTo likul~i farodK nawoEAF mina Alo<isotiqolaAliy~api
reference (untransliterated): لَقَد ساهَمَتِ لتِّكنُلُوجيا فِي تَقلِيلِ لنِّزاعاتِ لأُسَرِيَّةِ وَأَعطَت لِكُلِّ فَردِن نَوعَن مِنَ لإِستِقلالِيَّةِ
predicted (untransliterated): لَقَدْ سَاهَمَةِ التِّيكْنُولُوجْيَا فِي تَقْلِيلِ النِّزَاعَاتِ الْأُسَرِيَّةِ وَأَعْطَطْ لِكُلِّ فَرْدٍ نَوْعاً مِنَ الْإِسْتِقْلَالِيَّةِ
--
reference: lakin~a maSdaran fiy lwafdi qAl <in~a ls~iEra sayanxafiDu baEda nxifADi >asEAri ln~afTi fiy lEAlam
predicted: lakin~a maSodarAF fiy Alowafodi qaAl <in~a Als~iEoara sayanoxafiDu baEoda AnoxifaADi >asoEaAri Aln~afoTi fiy AloEaAlamo
reference (untransliterated): لَكِنَّ مَصدَرَن فِي لوَفدِ قال إِنَّ لسِّعرَ سَيَنخَفِضُ بَعدَ نخِفاضِ أَسعارِ لنَّفطِ فِي لعالَم
predicted (untransliterated): لَكِنَّ مَصْدَراً فِي الْوَفْدِ قَال إِنَّ السِّعَْرَ سَيَنْخَفِضُ بَعْدَ انْخِفَاضِ أَسْعَارِ النَّفْطِ فِي الْعَالَمْ
--
reference: lam yamnaE DaEfu mawAridi lt~amwiyl wArtifAEu kulfapi lmu$ArakAti ld~awliy~api riyADapa lfuruwsiy~api fiy tuwnusa min >an tastaqTiba lmi}At min Eu$~AqihA fiy baladin yakAdu l<ihtimAmu fiyhi yaqtaSir EalY riyADAtin $aEbiy~apin muEay~anapin
predicted: lamo yamonaEoDaEaofu mawaAridi Alt~amowiylo waArotifaAEu kulofapi Alomu$aArakaAti Ald~awoliy~api riyaADapa Alofuruwsiy~api fiy tuwnusa mino >ano tasotaqoTiba Almi}At mino Eu$~aAqihaA fiy baladK yakaAdu Al<ihotimaAmu fiy hiyaqotaSir EalaY riy~aADaAtK $aEobiy~apK muEay~inapK
reference (untransliterated): لَم يَمنَع ضَعفُ مَوارِدِ لتَّموِيل وارتِفاعُ كُلفَةِ لمُشارَكاتِ لدَّولِيَّةِ رِياضَةَ لفُرُوسِيَّةِ فِي تُونُسَ مِن أَن تَستَقطِبَ لمِئات مِن عُشّاقِها فِي بَلَدِن يَكادُ لإِهتِمامُ فِيهِ يَقتَصِر عَلى رِياضاتِن شَعبِيَّةِن مُعَيَّنَةِن
predicted (untransliterated): لَمْ يَمْنَعْضَعَْفُ مَوَارِدِ التَّمْوِيلْ وَارْتِفَاعُ كُلْفَةِ الْمُشَارَكَاتِ الدَّوْلِيَّةِ رِيَاضَةَ الْفُرُوسِيَّةِ فِي تُونُسَ مِنْ أَنْ تَسْتَقْطِبَ المِئات مِنْ عُشَّاقِهَا فِي بَلَدٍ يَكَادُ الإِهْتِمَامُ فِي هِيَقْتَصِر عَلَى رِيَّاضَاتٍ شَعْبِيَّةٍ مُعَيِّنَةٍ
--
reference: liyaDaEA bi*alika Hadaan lilEadiydi mina lt~aqAriyr >al~atiy >ak~adat <imkAniy~apa raHiyli ll~AEibi lmu$Agibi qariybaan
predicted: liyaDaEaAbi *alika Had~AF liloEadiydi mina Alt~aqaAriyro >al~atiy >ak~adat <imokaAniy~apa raHiyli All~aAEibi Alomu$aAgibi qariybAF
reference (untransliterated): لِيَضَعا بِذَلِكَ حَدََن لِلعَدِيدِ مِنَ لتَّقارِير أَلَّتِي أَكَّدَت إِمكانِيَّةَ رَحِيلِ للّاعِبِ لمُشاغِبِ قَرِيبََن
predicted (untransliterated): لِيَضَعَابِ ذَلِكَ حَدّاً لِلْعَدِيدِ مِنَ التَّقَارِيرْ أَلَّتِي أَكَّدَت إِمْكَانِيَّةَ رَحِيلِ اللَّاعِبِ الْمُشَاغِبِ قَرِيباً
--
reference: muDiyfan nuHAwilu xalqa furaSi Eamalin bi>aydiynA
predicted: muDiyfAF nuHaAwilu xaloqa furaSi EamalK bi>ayodiyna
reference (untransliterated): مُضِيفَن نُحاوِلُ خَلقَ فُرَصِ عَمَلِن بِأَيدِينا
predicted (untransliterated): مُضِيفاً نُحَاوِلُ خَلْقَ فُرَصِ عَمَلٍ بِأَيْدِينَ
--
reference: wa*alika muqAranapan maEa lmaHASiyli lz~irAEiy~api l>uxrY
predicted: wa*alika muqaAranapF maEa AlomaHaASiyli Alz~iraAEiy~api Alo>uxoraY
reference (untransliterated): وَذَلِكَ مُقارَنَةَن مَعَ لمَحاصِيلِ لزِّراعِيَّةِ لأُخرى
predicted (untransliterated): وَذَلِكَ مُقَارَنَةً مَعَ الْمَحَاصِيلِ الزِّرَاعِيَّةِ الْأُخْرَى
--
reference: mulqiyan lD~aw'a EalY qaDiy~api lfitnapi lT~A}ifiy~api fiy lmujtamaEi lmiSriy~i bi>usluwbin basiyTin min xilAli EalAqAti l>aTfAl fiy lmadrasapi bizamiylihimu lmasiyHiy~i
predicted: muloqiyani AlD~awo'a EalaY qadiy~api Alofitonapi AlT~aA}ifiy~api fiy AlomujotamaEi AlomiSoriy~i bi>usoluwbK basiyTK mino xilaAli EalaAqaAti Alo>aTofaAlo fiy Alomadorasapi bizamiylihimu AlomasiyHiy~i
reference (untransliterated): مُلقِيَن لضَّوءَ عَلى قَضِيَّةِ لفِتنَةِ لطّائِفِيَّةِ فِي لمُجتَمَعِ لمِصرِيِّ بِأُسلُوبِن بَسِيطِن مِن خِلالِ عَلاقاتِ لأَطفال فِي لمَدرَسَةِ بِزَمِيلِهِمُ لمَسِيحِيِّ
predicted (untransliterated): مُلْقِيَنِ الضَّوْءَ عَلَى قَدِيَّةِ الْفِتْنَةِ الطَّائِفِيَّةِ فِي الْمُجْتَمَعِ الْمِصْرِيِّ بِأُسْلُوبٍ بَسِيطٍ مِنْ خِلَالِ عَلَاقَاتِ الْأَطْفَالْ فِي الْمَدْرَسَةِ بِزَمِيلِهِمُ الْمَسِيحِيِّ
--
reference: mim~A yadEamu natA}ija dirAsAtin sAbiqapin tuHa*~iru min maxATiri l<ifrATi fiy stiEmAli ljaw~Al
predicted: mim~aA yadoEamu nataA}ija diraAsaAtK saAbiqapK tuHa*~iru mino maxaATiri Alo<iforaATi fiy AsotiEomaAli Alj~aw~aAl
reference (untransliterated): مِمّا يَدعَمُ نَتائِجَ دِراساتِن سابِقَةِن تُحَذِّرُ مِن مَخاطِرِ لإِفراطِ فِي ستِعمالِ لجَوّال
predicted (untransliterated): مِمَّا يَدْعَمُ نَتَائِجَ دِرَاسَاتٍ سَابِقَةٍ تُحَذِّرُ مِنْ مَخَاطِرِ الْإِفْرَاطِ فِي اسْتِعْمَالِ الجَّوَّال
--
reference: min baynihA >al<istiqrAru wanawEiy~apu lr~iEAyapi lS~iH~iy~api wAlv~aqAfapi wAlbiy}api wAlt~aEliymi wAlbinyapi lt~aHtiy~api
predicted: mino bayonihaA >alo<isotiqoraAru wanawoEiy~apu Alr~iEaAyapi AlS~iH~iy~api waAlv~aqaAfapi waAlobiy}api waAlt~aEoliymi waAlobinoyapi Alt~aHotiy~api
reference (untransliterated): مِن بَينِها أَلإِستِقرارُ وَنَوعِيَّةُ لرِّعايَةِ لصِّحِّيَّةِ والثَّقافَةِ والبِيئَةِ والتَّعلِيمِ والبِنيَةِ لتَّحتِيَّةِ
predicted (untransliterated): مِنْ بَيْنِهَا أَلْإِسْتِقْرَارُ وَنَوْعِيَّةُ الرِّعَايَةِ الصِّحِّيَّةِ وَالثَّقَافَةِ وَالْبِيئَةِ وَالتَّعْلِيمِ وَالْبِنْيَةِ التَّحْتِيَّةِ
--
reference: minhA >aqmi$apun wa>adawAtun maEdaniy~apun waxa$abiy~apun waqinAnun blAstiykiy~apun wazujAjiy~apun wa>awrAqu SuHuf
predicted: minohaA >aqomi$apN wa>adawaAtN maEodaniy~apN waxa$abiy~apN waqinAnN bolaAsotiykiy~apN wazujaAjiy~atN wa>aworaAqu SuHafo
reference (untransliterated): مِنها أَقمِشَةُن وَأَدَواتُن مَعدَنِيَّةُن وَخَشَبِيَّةُن وَقِنانُن بلاستِيكِيَّةُن وَزُجاجِيَّةُن وَأَوراقُ صُحُف
predicted (untransliterated): مِنْهَا أَقْمِشَةٌ وَأَدَوَاتٌ مَعْدَنِيَّةٌ وَخَشَبِيَّةٌ وَقِنانٌ بْلَاسْتِيكِيَّةٌ وَزُجَاجِيَّتٌ وَأَوْرَاقُ صُحَفْ
--
reference: hal lilS~iyAmi ta>viyrun EalY Eamali lmuslimiyna fiy l$~arikAti bi>uwruwb~A
predicted: hal~i AlS~iyaAmi ta>oviyrN EalaY Eamali Alomusolimiyna fiy Al$~arikaAti bi>uwruwb~aA
reference (untransliterated): هَل لِلصِّيامِ تَأثِيرُن عَلى عَمَلِ لمُسلِمِينَ فِي لشَّرِكاتِ بِأُورُوبّا
predicted (untransliterated): هَلِّ الصِّيَامِ تَأْثِيرٌ عَلَى عَمَلِ الْمُسْلِمِينَ فِي الشَّرِكَاتِ بِأُورُوبَّا
--
reference: hunAka fikrapun TuriHat bAdi}a l>amr biEaqdi qim~apin >uwruwbiy~apin fiy sarayiyfuw biha*ihi lmunAsabapi
predicted: hunaAka fikorapN TuriHato baAdi >alo>amor biEaqoDi qim~apK >uwruwbiy~apK fiy sarayiyfuw biha*ihi AlomunaAsabapi
reference (untransliterated): هُناكَ فِكرَةُن طُرِحَت بادِئَ لأَمر بِعَقدِ قِمَّةِن أُورُوبِيَّةِن فِي سَرَيِيفُو بِهَذِهِ لمُناسَبَةِ
predicted (untransliterated): هُنَاكَ فِكْرَةٌ طُرِحَتْ بَادِ أَلْأَمْر بِعَقْضِ قِمَّةٍ أُورُوبِيَّةٍ فِي سَرَيِيفُو بِهَذِهِ الْمُنَاسَبَةِ
--
reference: wa yumkinu >an tuHSada lv~imAr EalY madY fatrapin zamaniy~apin Tawiylapin
predicted: wayumokinu >ano tuHoSada Alv~imaAr EalaY madaY fatorapK zamaniy~apK TawiylapK
reference (untransliterated): وَ يُمكِنُ أَن تُحصَدَ لثِّمار عَلى مَدى فَترَةِن زَمَنِيَّةِن طَوِيلَةِن
predicted (untransliterated): وَيُمْكِنُ أَنْ تُحْصَدَ الثِّمَار عَلَى مَدَى فَتْرَةٍ زَمَنِيَّةٍ طَوِيلَةٍ
--
reference: wa>Hraza lmarkaza lv~Aliv >alr~iwA}iy~u ljazA}iriy~u >aHmadu TiybAwiy Ean riwAyatihi mawtun nAEim
predicted: wa>aHoraza Alomarokaza Alv~aAlivo >alr~iwaA}iy~u AlojazaA}iriy~u >aHomadu TiybaAwi Eano riwaAyatihi mawotunnaAEimo
reference (untransliterated): وَأحرَزَ لمَركَزَ لثّالِث أَلرِّوائِيُّ لجَزائِرِيُّ أَحمَدُ طِيباوِي عَن رِوايَتِهِ مَوتُن ناعِم
predicted (untransliterated): وَأَحْرَزَ الْمَرْكَزَ الثَّالِثْ أَلرِّوَائِيُّ الْجَزَائِرِيُّ أَحْمَدُ طِيبَاوِ عَنْ رِوَايَتِهِ مَوْتُننَاعِمْ
--
reference: wAxtatama lbarAziyliy~uwna mubArAyAtihimi l<iEdAdiy~apa biAlfawzi EalY SirbyA bihadafin waHiydin saj~alahu lmuhAjimu farydun fiy l$~awTi lv~Aniy mina lmubArApi >al~atiy >uqiymat fiy sAwbAwluw
predicted: waAxotatama AlobaraAziyliy~uwna mubaArayaAtihimi Alo<iEodaAdiy~api biAlofawozi EalaY Sirobiya bihadafK waHiydK saj~alahu AlomuhaAjimu fariydN fiy Al$~awoTi Alv~aAniy mina AlomubaAraApi >al~atiy >uqiymato fiy saAwobaAluw
reference (untransliterated): واختَتَمَ لبَرازِيلِيُّونَ مُباراياتِهِمِ لإِعدادِيَّةَ بِالفَوزِ عَلى صِربيا بِهَدَفِن وَحِيدِن سَجَّلَهُ لمُهاجِمُ فَريدُن فِي لشَّوطِ لثّانِي مِنَ لمُباراةِ أَلَّتِي أُقِيمَت فِي ساوباولُو
predicted (untransliterated): وَاخْتَتَمَ الْبَرَازِيلِيُّونَ مُبَارَيَاتِهِمِ الْإِعْدَادِيَّةِ بِالْفَوْزِ عَلَى صِرْبِيَ بِهَدَفٍ وَحِيدٍ سَجَّلَهُ الْمُهَاجِمُ فَرِيدٌ فِي الشَّوْطِ الثَّانِي مِنَ الْمُبَارَاةِ أَلَّتِي أُقِيمَتْ فِي سَاوْبَالُو
--
reference: wA$tahara lr~AHilu bimaqAlAtihi wakutubihi lr~aSiynapi >al~atiy taDam~anat qirA'Atin mustaqbaliy~apan lil>AfAqi ls~iyAsiy~api wAl<ijtimAEiy~api fiy lEAlami lEarabiy~i l<islAmiy~i
predicted: waA$otahara Alr~aAHilu bimaqaAlaAtihi wakutubihi Alr~aSiynapi >al~atiy taDam~anato qiraA'aAtK musotaqobaliy~apF lilo|faAqi Als~iyaAsiy~api waAlo<ijotimaAEiy~api fiy AloEaAlami AloEarabiy~i Alo<isolaAmiy~i
reference (untransliterated): واشتَهَرَ لرّاحِلُ بِمَقالاتِهِ وَكُتُبِهِ لرَّصِينَةِ أَلَّتِي تَضَمَّنَت قِراءاتِن مُستَقبَلِيَّةَن لِلأافاقِ لسِّياسِيَّةِ والإِجتِماعِيَّةِ فِي لعالَمِ لعَرَبِيِّ لإِسلامِيِّ
predicted (untransliterated): وَاشْتَهَرَ الرَّاحِلُ بِمَقَالَاتِهِ وَكُتُبِهِ الرَّصِينَةِ أَلَّتِي تَضَمَّنَتْ قِرَاءَاتٍ مُسْتَقْبَلِيَّةً لِلْآفَاقِ السِّيَاسِيَّةِ وَالْإِجْتِمَاعِيَّةِ فِي الْعَالَمِ الْعَرَبِيِّ الْإِسْلَامِيِّ
--
reference: wa>aSbaHa ha*A lS~arHu matHafan rasmiy~an
predicted: wa>aSobaHa ha*aA AlS~aroHu matoHafAF rasomiy~AF
reference (untransliterated): وَأَصبَحَ هَذا لصَّرحُ مَتحَفَن رَسمِيَّن
predicted (untransliterated): وَأَصْبَحَ هَذَا الصَّرْحُ مَتْحَفاً رَسْمِيّاً
--
reference: w>aDAfa lbayAnu an~a fariyqaan min l>aTib~A'i wAlmumar~iDAt w<ixtiSASiy~iyna >Axariyna fiy majAli lS~iH~api yaEtanuwna bimAndiyl~A EalY madAri ls~AEapi
predicted: wa>aDaAfa AlobayaAnu >an~a fariyqAF mina Alo>aTib~aA'i waAlomumar~iDaAt waAxotiSaASiy~iyna |xariyna fiy majaAli AlS~iH~api yaEotanuwna bimaAnodil~aA EalaY madaAri Als~aAEapi
reference (untransliterated): وأَضافَ لبَيانُ َنَّ فَرِيقََن مِن لأَطِبّاءِ والمُمَرِّضات وإِختِصاصِيِّينَ أاخَرِينَ فِي مَجالِ لصِّحَّةِ يَعتَنُونَ بِماندِيلّا عَلى مَدارِ لسّاعَةِ
predicted (untransliterated): وَأَضَافَ الْبَيَانُ أَنَّ فَرِيقاً مِنَ الْأَطِبَّاءِ وَالْمُمَرِّضَات وَاخْتِصَاصِيِّينَ آخَرِينَ فِي مَجَالِ الصِّحَّةِ يَعْتَنُونَ بِمَانْدِلَّا عَلَى مَدَارِ السَّاعَةِ
--
reference: wAEtabaruwhA falsafapan ruwHiy~apan mutakAmilapan litaHriyri ljismi wAlfikr
predicted: waAEotabaruwhaA falosafapF ruwHiy~apF mutakaAmilapF litaHoriyri Alojisomi waAlofikor
reference (untransliterated): واعتَبَرُوها فَلسَفَةَن رُوحِيَّةَن مُتَكامِلَةَن لِتَحرِيرِ لجِسمِ والفِكر
predicted (untransliterated): وَاعْتَبَرُوهَا فَلْسَفَةً رُوحِيَّةً مُتَكَامِلَةً لِتَحْرِيرِ الْجِسْمِ وَالْفِكْر
--
reference: >alt~awaH~udu huwa majmuwEapu DTirAbAtin EaSabiy~apin fiy lt~aTaw~ur ta$malu >aErADuhA wujuwda ma$Akila fiy ls~uluwki lAjtimAEiy~i lil$~axSi lmuSAb
predicted: >alt~awaH~udu huwa majomuwEapu AlT~iraAbaAtK EaSabiy~apK fiy Alt~aTaw~uro ta$omalu >aEoraADuhaA bujuwda ma$aAkila fiy Als~uluwki Alo<ijotimaAEiy~i lil$~axoSi AlomuSaAbo
reference (untransliterated): أَلتَّوَحُّدُ هُوَ مَجمُوعَةُ ضطِراباتِن عَصَبِيَّةِن فِي لتَّطَوُّر تَشمَلُ أَعراضُها وُجُودَ مَشاكِلَ فِي لسُّلُوكِ لاجتِماعِيِّ لِلشَّخصِ لمُصاب
predicted (untransliterated): أَلتَّوَحُّدُ هُوَ مَجْمُوعَةُ الطِّرَابَاتٍ عَصَبِيَّةٍ فِي التَّطَوُّرْ تَشْمَلُ أَعْرَاضُهَا بُجُودَ مَشَاكِلَ فِي السُّلُوكِ الْإِجْتِمَاعِيِّ لِلشَّخْصِ الْمُصَابْ
--
reference: wAlEamalu lr~a}iysiy~u lahu huwa riwAyatahu lmalHamiy~apu mA}apu EAmin mina lEuzlapi >al~atiy nAla EanhA jA}izapa nuwbila fiy l>adab EAma >alfin watisEimi}apin wa<ivnAni wavamAnuwn
predicted: waAloEamalu Alr~a}iysiy~u lahu huwa riwaAyatahu AlomaloHamiy~apu ma>apu EaAmK mina AloEuzolapi >al~atiy naAla EanohaA jaA}izapa nuwbila fiy Alo>adabo EaAma >alofK watisoEi ma}apK wa<ivnaAni wavamAnuwna
reference (untransliterated): والعَمَلُ لرَّئِيسِيُّ لَهُ هُوَ رِوايَتَهُ لمَلحَمِيَّةُ مائَةُ عامِن مِنَ لعُزلَةِ أَلَّتِي نالَ عَنها جائِزَةَ نُوبِلَ فِي لأَدَب عامَ أَلفِن وَتِسعِمِئَةِن وَإِثنانِ وَثَمانُون
predicted (untransliterated): وَالْعَمَلُ الرَّئِيسِيُّ لَهُ هُوَ رِوَايَتَهُ الْمَلْحَمِيَّةُ مَأَةُ عَامٍ مِنَ الْعُزْلَةِ أَلَّتِي نَالَ عَنْهَا جَائِزَةَ نُوبِلَ فِي الْأَدَبْ عَامَ أَلْفٍ وَتِسْعِ مَئَةٍ وَإِثنَانِ وَثَمانُونَ
--
reference: wAlmiykuwng was>aluwyn fiy januwbi $arqi >AsyA
predicted: waAlomiykuwnogo wasaAluwiyno fiy januwbi $aroqi |soyaA
reference (untransliterated): والمِيكُونغ وَسأَلُوين فِي جَنُوبِ شَرقِ أاسيا
predicted (untransliterated): وَالْمِيكُونْغْ وَسَالُوِينْ فِي جَنُوبِ شَرْقِ آسْيَا
--
reference: wa>n~a >aham~a muEaw~iqAti najAHihA takmunu fiy Eadami tafar~ugi >aSHAbihA li<idAratihA
predicted: wa>an~a >aham~a muEaw~iqaAti najaAHihaA takomunu fiy Eadami tafar~ugi >aSoHaAbihaA li<idaAratihaA
reference (untransliterated): وَأنَّ أَهَمَّ مُعَوِّقاتِ نَجاحِها تَكمُنُ فِي عَدَمِ تَفَرُّغِ أَصحابِها لِإِدارَتِها
predicted (untransliterated): وَأَنَّ أَهَمَّ مُعَوِّقَاتِ نَجَاحِهَا تَكْمُنُ فِي عَدَمِ تَفَرُّغِ أَصْحَابِهَا لِإِدَارَتِهَا
--
reference: wa>awDaHa lbAHivuwna >an~a suw'a lt~ag*iyapi huwa ls~ababu lr~a}iysiy~u litawaq~ufi ln~umuw Einda l>aTfAl
predicted: wa>awoDaHa AlobaAHivuwna >an~a suw'a Alt~ago*iyapi huwa Als~ababu Alr~a}iysiy~u litawaq~ufi Aln~umuw Einoda Alo>aTofaAlo
reference (untransliterated): وَأَوضَحَ لباحِثُونَ أَنَّ سُوءَ لتَّغذِيَةِ هُوَ لسَّبَبُ لرَّئِيسِيُّ لِتَوَقُّفِ لنُّمُو عِندَ لأَطفال
predicted (untransliterated): وَأَوْضَحَ الْبَاحِثُونَ أَنَّ سُوءَ التَّغْذِيَةِ هُوَ السَّبَبُ الرَّئِيسِيُّ لِتَوَقُّفِ النُّمُو عِنْدَ الْأَطْفَالْ
--
reference: wa>awDaHati lmajal~apu >an~a ls~ababa fiy *alika yarjiEu <ilY taDay~uqi l$~uEabi lhawA}iy~api wata$an~ujihA bifiEli lhawA'i lbArid
predicted: wa>awoDaHati Alomajal~apu >an~a Als~ababa fiy *alika yarojiEu <ilaY taDay~uqi Al$~uEabi AlohawaA}iy~api wata$an~ujihaA bifiEoli AlohawaA'i AlobaArid
reference (untransliterated): وَأَوضَحَتِ لمَجَلَّةُ أَنَّ لسَّبَبَ فِي ذَلِكَ يَرجِعُ إِلى تَضَيُّقِ لشُّعَبِ لهَوائِيَّةِ وَتَشَنُّجِها بِفِعلِ لهَواءِ لبارِد
predicted (untransliterated): وَأَوْضَحَتِ الْمَجَلَّةُ أَنَّ السَّبَبَ فِي ذَلِكَ يَرْجِعُ إِلَى تَضَيُّقِ الشُّعَبِ الْهَوَائِيَّةِ وَتَشَنُّجِهَا بِفِعْلِ الْهَوَاءِ الْبَارِد
--
reference: wabAta >atlitiykuw madriyd fiy SadArapi lt~artiybi lEAm~i bi>arbaEi niqAT
predicted: wabaAta >atolitiykuw madoriydo fiy SadaArapi Alt~arotiybi AloEaAm~i bi>arobaEi niqaAT
reference (untransliterated): وَباتَ أَتلِتِيكُو مَدرِيد فِي صَدارَةِ لتَّرتِيبِ لعامِّ بِأَربَعِ نِقاط
predicted (untransliterated): وَبَاتَ أَتْلِتِيكُو مَدْرِيدْ فِي صَدَارَةِ التَّرْتِيبِ الْعَامِّ بِأَرْبَعِ نِقَاط
--
reference: wabiAlt~Aliy tusAEidu EalY lwiqAyapi mina l<imsAk
predicted: wabiAt~aAliy tusaAEidu EalaY AlowiyqaAyapi mina Alo<imosaAko
reference (untransliterated): وَبِالتّالِي تُساعِدُ عَلى لوِقايَةِ مِنَ لإِمساك
predicted (untransliterated): وَبِاتَّالِي تُسَاعِدُ عَلَى الْوِيقَايَةِ مِنَ الْإِمْسَاكْ
--
reference: wa*alika biziyArapi jumhuwrin xAS~in jid~an sanawiy~an
predicted: wa*alika biziyaArapi jumohuwrK xaAS~K jid~AF sanawiy~AF
reference (untransliterated): وَذَلِكَ بِزِيارَةِ جُمهُورِن خاصِّن جِدَّن سَنَوِيَّن
predicted (untransliterated): وَذَلِكَ بِزِيَارَةِ جُمْهُورٍ خَاصٍّ جِدّاً سَنَوِيّاً
--
reference: wabisababi $ukuwkin bi>an~a lT~A}irapa kAnat tuqil~u idwArd snuwdun >al~a*iy tat~ahimuhu wA$inTun biAlt~ajas~us
predicted: wabisababi $ukuwkK bi>an~a AlT~aA}irapa kaAna Alt~uqil~u <idowaAbo snuwduno >al~a*iy tat~ahimuhu wa $inoTun biAlt~ajas~us
reference (untransliterated): وَبِسَبَبِ شُكُوكِن بِأَنَّ لطّائِرَةَ كانَت تُقِلُّ ِدوارد سنُودُن أَلَّذِي تَتَّهِمُهُ واشِنطُن بِالتَّجَسُّس
predicted (untransliterated): وَبِسَبَبِ شُكُوكٍ بِأَنَّ الطَّائِرَةَ كَانَ التُّقِلُّ إِدْوَابْ سنُودُنْ أَلَّذِي تَتَّهِمُهُ وَ شِنْطُن بِالتَّجَسُّس
--
reference: wabaEavuwA risAlapan <ilY lra~}iysi tataDama~nu maTAliba liEawdatihim
predicted: wabaEavuwA risaAlapF <ilaY Alr~a}iysi tataDam~anu maTaAliba liEawodatihimo
reference (untransliterated): وَبَعَثُوا رِسالَةَن إِلى لرَّئِيسِ تَتَضَمَّنُ مَطالِبَ لِعَودَتِهِم
predicted (untransliterated): وَبَعَثُوا رِسَالَةً إِلَى الرَّئِيسِ تَتَضَمَّنُ مَطَالِبَ لِعَوْدَتِهِمْ
--
reference: wabaEda $uhuwrin mina lHayrapi wAlqalaq taEara~fa kuwmAr EalY markazi Eabdi llhi bni zaydi lva~qAfiy~i lilta~Eriyfi biAl<islAm
predicted: wabaEoda $uhuwrK mina AloHayorapi waAloqalaqo taEar~afa kuwmaAra EalaY marokazi Eabodi All~aAhi bonizayodi Alv~aqaAfiy~i lilt~aEoriyfi biAlo<isolaAmo
reference (untransliterated): وَبَعدَ شُهُورِن مِنَ لحَيرَةِ والقَلَق تَعَرَّفَ كُومار عَلى مَركَزِ عَبدِ للهِ بنِ زَيدِ لثَّقافِيِّ لِلتَّعرِيفِ بِالإِسلام
predicted (untransliterated): وَبَعْدَ شُهُورٍ مِنَ الْحَيْرَةِ وَالْقَلَقْ تَعَرَّفَ كُومَارَ عَلَى مَرْكَزِ عَبْدِ اللَّاهِ بْنِزَيْدِ الثَّقَافِيِّ لِلتَّعْرِيفِ بِالْإِسْلَامْ
--
reference: wabiha*A yabqY mi}apun wasit~apun wav~l>avuwna muHtajazan fiy lmuEtaqali lmuviyri liljadal
predicted: wabiha*A yaboqaY mi}apN wasit~apN wavalaAvuwna muHotajazAF fiy AlomuEotaqali Alomuviyri lilojadaYlo
reference (untransliterated): وَبِهَذا يَبقى مِئَةُن وَسِتَّةُن وَثّلأَثُونَ مُحتَجَزَن فِي لمُعتَقَلِ لمُثِيرِ لِلجَدَل
predicted (untransliterated): وَبِهَذا يَبْقَى مِئَةٌ وَسِتَّةٌ وَثَلَاثُونَ مُحْتَجَزاً فِي الْمُعْتَقَلِ الْمُثِيرِ لِلْجَدَىلْ
--
reference: watustaxdamu fiy baEDi ld~uwal wasA}ilu EilAjin muxtalifapun
predicted: watusotaxodamu fiy baEoDi Ald~uwalo wasaA}ilu EilaAjK muxotalifapN
reference (untransliterated): وَتُستَخدَمُ فِي بَعضِ لدُّوَل وَسائِلُ عِلاجِن مُختَلِفَةُن
predicted (untransliterated): وَتُسْتَخْدَمُ فِي بَعْضِ الدُّوَلْ وَسَائِلُ عِلَاجٍ مُخْتَلِفَةٌ
--
reference: wataTaw~ara stixdAmu lT~A}irAti lEAmilapi biduwni Tay~Ar wabada>ati ls~AEAtu l*~akiy~apu al<inti$Ara waka*alika lT~ibAEapu lv~ulAviy~apu l>abEAd
predicted: wataTaw~ara AsotixodaAmu AlT~aA}iraAti AloEaAmilapi biduwni Tay~aAr wabada>ati Als~aAEaAtu Al*~akiy~apu Alo<inoti$aAra waka*alika AlT~ibaAEapu Alv~ulAviy~apu Al>aboEAd
reference (untransliterated): وَتَطَوَّرَ ستِخدامُ لطّائِراتِ لعامِلَةِ بِدُونِ طَيّار وَبَدَأَتِ لسّاعاتُ لذَّكِيَّةُ َلإِنتِشارَ وَكَذَلِكَ لطِّباعَةُ لثُّلاثِيَّةُ لأَبعاد
predicted (untransliterated): وَتَطَوَّرَ اسْتِخْدَامُ الطَّائِرَاتِ الْعَامِلَةِ بِدُونِ طَيَّار وَبَدَأَتِ السَّاعَاتُ الذَّكِيَّةُ الْإِنْتِشَارَ وَكَذَلِكَ الطِّبَاعَةُ الثُّلاثِيَّةُ الأَبْعاد
--
reference: wajA'a ha*A lqarAr baEda <iElAni lsa~Euwdiya~pi taxfiyDa >aEdAdi lHuja~Aji ha*A lEAm
predicted: wajaA'a ha*aA AloqaraAro baEoda <iEolaAni Als~uEuwdiy~api taxofiyDa >aEodaAdi AloHuj~aAji ha*aA AloEaAmo
reference (untransliterated): وَجاءَ هَذا لقَرار بَعدَ إِعلانِ لسَّعُودِيَّةِ تَخفِيضَ أَعدادِ لحُجَّاجِ هَذا لعام
predicted (untransliterated): وَجَاءَ هَذَا الْقَرَارْ بَعْدَ إِعْلَانِ السُّعُودِيَّةِ تَخْفِيضَ أَعْدَادِ الْحُجَّاجِ هَذَا الْعَامْ
--
reference: wajA'ati l>arqAmu SAdimapan fiy mA yaxuS~u l$~arqa l>awsaT
predicted: wajaA'api Alo>aroqaAmu SaAdimapF fiymaA yaxuS~u Al$~aroqa Alo>awoSaTo
reference (untransliterated): وَجاءَتِ لأَرقامُ صادِمَةَن فِي ما يَخُصُّ لشَّرقَ لأَوسَط
predicted (untransliterated): وَجَاءَةِ الْأَرْقَامُ صَادِمَةً فِيمَا يَخُصُّ الشَّرْقَ الْأَوْصَطْ
--
reference: waSadarati lr~asA}il bi<ismi mubdiEiy wafan~Aniy miSra
predicted: wasaDarati Alr~asaA'ilo bi<isomi mubodiEi wafan~aAniy miSora
reference (untransliterated): وَصَدَرَتِ لرَّسائِل بِإِسمِ مُبدِعِي وَفَنّانِي مِصرَ
predicted (untransliterated): وَسَضَرَتِ الرَّسَاءِلْ بِإِسْمِ مُبْدِعِ وَفَنَّانِي مِصْرَ
--
reference: wafiy ftitAHi lmu&tamari qAlati l$~AEirapu $ariyfapa ls~ay~id <in~a lEaq~Ada it~axa*a mina lqirA'api wAl<iT~ilAEi EalY kul~i lEuluwm wamuxtalafi lHaDArAt silAHan yuHaT~imu bihi lS~anamiy~apa wayaksiru lmuHar~amAt
predicted: wafiy AfotitaAHi Alomu&otamari qaAlati Al$~aAEirapu $ariyfapa Als~ay~ido <in~a AloEaq~aAda Alt~axa*a mina AloqiraA'api waliADoTilaAEi EalaY kul~i AloEuluwmo wamuxotalifi AloHaDaAraAt silaAHAF yuHaT~i mgubihi AlS~anamiy~apa wayakosiru AlomuHar~amaAt
reference (untransliterated): وَفِي فتِتاحِ لمُؤتَمَرِ قالَتِ لشّاعِرَةُ شَرِيفَةَ لسَّيِّد إِنَّ لعَقّادَ ِتَّخَذَ مِنَ لقِراءَةِ والإِطِّلاعِ عَلى كُلِّ لعُلُوم وَمُختَلَفِ لحَضارات سِلاحَن يُحَطِّمُ بِهِ لصَّنَمِيَّةَ وَيَكسِرُ لمُحَرَّمات
predicted (untransliterated): وَفِي افْتِتَاحِ الْمُؤْتَمَرِ قَالَتِ الشَّاعِرَةُ شَرِيفَةَ السَّيِّدْ إِنَّ الْعَقَّادَ التَّخَذَ مِنَ الْقِرَاءَةِ وَلِاضْطِلَاعِ عَلَى كُلِّ الْعُلُومْ وَمُخْتَلِفِ الْحَضَارَات سِلَاحاً يُحَطِّ مغُبِهِ الصَّنَمِيَّةَ وَيَكْسِرُ الْمُحَرَّمَات
--
reference: wafiy kuwryA ljanuwbiy~api taquwmu lHukuwmapu bitamwiyli musta$fayAtin liEilAji ha*A l<idmAni l~a*iy yuEtabaru mu$kilapan qawmiy~apan
predicted: wafiy kuwriyaA Alojanuwbiy~api taquwmu AloHukuwmapu bitamowiyli musota$ofayaAtK liEilaAji ha*aA Alo<idomaAni Al~a*iy yuEotabaru mu$okilapF qawomiy~apF
reference (untransliterated): وَفِي كُوريا لجَنُوبِيَّةِ تَقُومُ لحُكُومَةُ بِتَموِيلِ مُستَشفَياتِن لِعِلاجِ هَذا لإِدمانِ لَّذِي يُعتَبَرُ مُشكِلَةَن قَومِيَّةَن
predicted (untransliterated): وَفِي كُورِيَا الْجَنُوبِيَّةِ تَقُومُ الْحُكُومَةُ بِتَمْوِيلِ مُسْتَشْفَيَاتٍ لِعِلَاجِ هَذَا الْإِدْمَانِ الَّذِي يُعْتَبَرُ مُشْكِلَةً قَوْمِيَّةً
--
reference: wakAna l>amalu >an takuwna ha*ihi ld~iymuqrATiy~Atu maSHuwbapan bi>adA'in tanmawiy~in muxtalif
predicted: wakAna Alo>amalu >ano takuwna ha*ihi Ald~iymuwqoraATiy~aAtu maSoHuwbapF bi>adaA'K tF mawiy~K muxotalifo
reference (untransliterated): وَكانَ لأَمَلُ أَن تَكُونَ هَذِهِ لدِّيمُقراطِيّاتُ مَصحُوبَةَن بِأَداءِن تَنمَوِيِّن مُختَلِف
predicted (untransliterated): وَكانَ الْأَمَلُ أَنْ تَكُونَ هَذِهِ الدِّيمُوقْرَاطِيَّاتُ مَصْحُوبَةً بِأَدَاءٍ تً مَوِيٍّ مُخْتَلِفْ
--
reference: wakatabuwA fiy dawriy~api lkul~iy~api l>amiyrikiy~api li>amrADi lqalb >an~a ls~umnapa tartabiTu biHuduwvi tagayiyrAt fiy lqalbi ladY lbAligiyn
predicted: wakatabuwA fiy daworiy~api Alokul~iy~api Alo>amiyriykiy~api li>amoraADi Aloqalo >an~a Als~umonapa tarotabiTu biHuduwvi tagoyiyraAt fiy Aloqalobi ladaY AlobaAligiyno
reference (untransliterated): وَكَتَبُوا فِي دَورِيَّةِ لكُلِّيَّةِ لأَمِيرِكِيَّةِ لِأَمراضِ لقَلب أَنَّ لسُّمنَةَ تَرتَبِطُ بِحُدُوثِ تَغَيِيرات فِي لقَلبِ لَدى لبالِغِين
predicted (untransliterated): وَكَتَبُوا فِي دَوْرِيَّةِ الْكُلِّيَّةِ الْأَمِيرِيكِيَّةِ لِأَمْرَاضِ الْقَلْ أَنَّ السُّمْنَةَ تَرْتَبِطُ بِحُدُوثِ تَغْيِيرَات فِي الْقَلْبِ لَدَى الْبَالِغِينْ
--
reference: wakul~u *alika bimuHtawYan munxafiDin lilgAyapi mina ls~uErAti lHarAriy~api
predicted: wakul~u *alika bimuHotawAF munoxafiDK lilogaAyapi mina Als~uEoraAti AloHaraAriy~api
reference (untransliterated): وَكُلُّ ذَلِكَ بِمُحتَوىَن مُنخَفِضِن لِلغايَةِ مِنَ لسُّعراتِ لحَرارِيَّةِ
predicted (untransliterated): وَكُلُّ ذَلِكَ بِمُحْتَواً مُنْخَفِضٍ لِلْغَايَةِ مِنَ السُّعْرَاتِ الْحَرَارِيَّةِ
--
reference: wakul~amA zAdat kamiy~apu ls~uk~ari lmutanAwalapi maEa lt~amri taqil~u fA}idatuhu lgi*A}iy~apu
predicted: wakul~amaA zaAdato kam~ay~apu Als~uk~ari AlomutanaAwalapi maEa Alotamori taqil~u faA}idatuhu Alogi*aA}iy~apu
reference (untransliterated): وَكُلَّما زادَت كَمِيَّةُ لسُّكَّرِ لمُتَناوَلَةِ مَعَ لتَّمرِ تَقِلُّ فائِدَتُهُ لغِذائِيَّةُ
predicted (untransliterated): وَكُلَّمَا زَادَتْ كَمَّيَّةُ السُّكَّرِ الْمُتَنَاوَلَةِ مَعَ الْتَمْرِ تَقِلُّ فَائِدَتُهُ الْغِذَائِيَّةُ
--
reference: walA yazAlu ha*A lbaladu mutamas~ikan bitaqwiymi lkaniysapi lqibTiy~api >almaEruwfi maHal~iy~an biAlt~aqwiymi l<ivyuwbiy~i
predicted: walaA yazaAlu ha*aA Alobaladu mutamas~ikAF bitaqowiymi Alokaniysapi AloqiboTiy~api >alomaEoruwfi maHal~iy~AF biAlt~aqowiymi Alo<ivoyuwbiy~i
reference (untransliterated): وَلا يَزالُ هَذا لبَلَدُ مُتَمَسِّكَن بِتَقوِيمِ لكَنِيسَةِ لقِبطِيَّةِ أَلمَعرُوفِ مَحَلِّيَّن بِالتَّقوِيمِ لإِثيُوبِيِّ
predicted (untransliterated): وَلَا يَزَالُ هَذَا الْبَلَدُ مُتَمَسِّكاً بِتَقْوِيمِ الْكَنِيسَةِ الْقِبْطِيَّةِ أَلْمَعْرُوفِ مَحَلِّيّاً بِالتَّقْوِيمِ الْإِثْيُوبِيِّ
--
reference: walaEibati lxibrapu dawrahA fiy tatwiyji EA$uwra lxAmisi EAlamiy~an
predicted: walaEibapi Aloxiborapu daworahaA fiy tatowiyji EaA$uwra AloxaAmisi EaAlamiy~AF
reference (untransliterated): وَلَعِبَتِ لخِبرَةُ دَورَها فِي تَتوِيجِ عاشُورَ لخامِسِ عالَمِيَّن
predicted (untransliterated): وَلَعِبَةِ الْخِبْرَةُ دَوْرَهَا فِي تَتْوِيجِ عَاشُورَ الْخَامِسِ عَالَمِيّاً
--
reference: tatawAlY lEamalyAtu ls~ir~iyapa biAlHuduwv
predicted: tatawaAlaY AloEamaliy~aAtu Als~ir~iy~apu biAloHuduwv
reference (untransliterated): تَتَوالى لعَمَلياتُ لسِّرِّيَةَ بِالحُدُوث
predicted (untransliterated): تَتَوَالَى الْعَمَلِيَّاتُ السِّرِّيَّةُ بِالْحُدُوث
--
reference: wamin tilka ls~ilaE >al$~Ayu lS~iyniy~u wAlwaraqu wAlbAruwdu wAlbuwSilapu
predicted: wamino tiloka Als~ilaE >al$~aAyu AlS~iyniy~u waAlowaraqu waAlobaAruwdu waAlobuwSilapu
reference (untransliterated): وَمِن تِلكَ لسِّلَع أَلشّايُ لصِّينِيُّ والوَرَقُ والبارُودُ والبُوصِلَةُ
predicted (untransliterated): وَمِنْ تِلْكَ السِّلَع أَلشَّايُ الصِّينِيُّ وَالْوَرَقُ وَالْبَارُودُ وَالْبُوصِلَةُ
--
reference: wamanaHa >AbA}uhumu lqudrapa EalY lt~aHak~umi fiy kayfiy~api stixdAmi ha*ihi lxidmapi
predicted: wamanaHa |baA&uhumu Aloqudorapa EalaY Alt~aHak~umi fiy kayofiy~api AsotixodaAmi ha*ihi Aloxidomapi
reference (untransliterated): وَمَنَحَ أابائُهُمُ لقُدرَةَ عَلى لتَّحَكُّمِ فِي كَيفِيَّةِ ستِخدامِ هَذِهِ لخِدمَةِ
predicted (untransliterated): وَمَنَحَ آبَاؤُهُمُ الْقُدْرَةَ عَلَى التَّحَكُّمِ فِي كَيْفِيَّةِ اسْتِخْدَامِ هَذِهِ الْخِدْمَةِ
--
reference: waya>mulu lbAHivuwna taTwiyra Hubuwbin >aw nusxapin mina ld~awA' qAbilapan lilHaqni xilAla xamsi sanawAt
predicted: waya>omulu AlobaAHivuwna taTowiyra HuwuwbK >awo nusoxapK mina Ald~awaA qaAbilapF liloHaqoni xilaAla xamosi sanawaAt
reference (untransliterated): وَيَأمُلُ لباحِثُونَ تَطوِيرَ حُبُوبِن أَو نُسخَةِن مِنَ لدَّواء قابِلَةَن لِلحَقنِ خِلالَ خَمسِ سَنَوات
predicted (untransliterated): وَيَأْمُلُ الْبَاحِثُونَ تَطْوِيرَ حُوُوبٍ أَوْ نُسْخَةٍ مِنَ الدَّوَا قَابِلَةً لِلْحَقْنِ خِلَالَ خَمْسِ سَنَوَات
--
reference: wayastaxdimu lbarnAmaju niZAman saHAbiy~an lil*~akA'i lS~unEiy~i yasmaHu lahu bitaHliyli l<iymA'Ati wAlt~aEAbiyr
predicted: wayasotaxodimu AlobaronaAmaju niZaAmAF saHaAbiy~AF lil*~akaA'i AlS~unoEiy~i yasomaHu lahu bitaHoliyli Alo<iymaA'aAti waAlt~aEaAbiyro
reference (untransliterated): وَيَستَخدِمُ لبَرنامَجُ نِظامَن سَحابِيَّن لِلذَّكاءِ لصُّنعِيِّ يَسمَحُ لَهُ بِتَحلِيلِ لإِيماءاتِ والتَّعابِير
predicted (untransliterated): وَيَسْتَخْدِمُ الْبَرْنَامَجُ نِظَاماً سَحَابِيّاً لِلذَّكَاءِ الصُّنْعِيِّ يَسْمَحُ لَهُ بِتَحْلِيلِ الْإِيمَاءَاتِ وَالتَّعَابِيرْ
--
reference: wayuEtabaru mihrajAnu qarTAja ls~iynamA}iy~u min >aEraqi mihrajAnAti >afriyqyA
predicted: wayuEotabaru mihorajaAnu qaroTaAja Als~iynamaA}iy~u mino >aEoraqi mihorajaAnaAti >afriyqoyaA
reference (untransliterated): وَيُعتَبَرُ مِهرَجانُ قَرطاجَ لسِّينَمائِيُّ مِن أَعرَقِ مِهرَجاناتِ أَفرِيقيا
predicted (untransliterated): وَيُعْتَبَرُ مِهْرَجَانُ قَرْطَاجَ السِّينَمَائِيُّ مِنْ أَعْرَقِ مِهْرَجَانَاتِ أَفرِيقْيَا
--
reference: wayaquwlu lEulamA'u <in~ahu min gayri lmuraj~aHi >an tuTaw~ira lbaktiyryA lmuEdiyapu muqAwamapan Did~a lEilAji ljadiyd >al~a*iy >aSbaHa mutAHan biAlfiEl fiy $akli marhamin lil>amrADi ljildiy~api
predicted: wayaquwlu AloEulamaA'u <in~ahu mino gayori Alomuraj~aHi >ano tuTaw~ira AlobakotiyroyaA AlomuEodiyapu muqaAwamapF Did~a AloEilaAji lojadiyd >al~a*iy >aSobaHa mutaAHAF biAlofiEol fiy $akoli marohamK lilo>amoraADi Alojiylodiy~api
reference (untransliterated): وَيَقُولُ لعُلَماءُ إِنَّهُ مِن غَيرِ لمُرَجَّحِ أَن تُطَوِّرَ لبَكتِيريا لمُعدِيَةُ مُقاوَمَةَن ضِدَّ لعِلاجِ لجَدِيد أَلَّذِي أَصبَحَ مُتاحَن بِالفِعل فِي شَكلِ مَرهَمِن لِلأَمراضِ لجِلدِيَّةِ
predicted (untransliterated): وَيَقُولُ الْعُلَمَاءُ إِنَّهُ مِنْ غَيْرِ الْمُرَجَّحِ أَنْ تُطَوِّرَ الْبَكْتِيرْيَا الْمُعْدِيَةُ مُقَاوَمَةً ضِدَّ الْعِلَاجِ لْجَدِيد أَلَّذِي أَصْبَحَ مُتَاحاً بِالْفِعْل فِي شَكْلِ مَرْهَمٍ لِلْأَمْرَاضِ الْجِيلْدِيَّةِ
--
reference: wayumkinuka lHuSuwlu EalY taTbiyqAtin lilt~adriybAti l>asAsiy~api maj~Anan
predicted: wayumokinuka AloHuSuwlu EalaY taTobiyqaAtK liltadoriybaAti Alo>asaAsiy~api maj~aAnAF
reference (untransliterated): وَيُمكِنُكَ لحُصُولُ عَلى تَطبِيقاتِن لِلتَّدرِيباتِ لأَساسِيَّةِ مَجّانَن
predicted (untransliterated): وَيُمْكِنُكَ الْحُصُولُ عَلَى تَطْبِيقَاتٍ لِلتَدْرِيبَاتِ الْأَسَاسِيَّةِ مَجَّاناً
--
```
## Fine-Tuning Script
You can find the script used to produce this model
[here](https://github.com/elgeish/transformers/blob/cfc0bd01f2ac2ea3a5acc578ef2e204bf4304de7/examples/research_projects/wav2vec2/finetune_base_arabic_speech_corpus.sh).
|
facebook/data2vec-audio-base-10m | d3dc1a06286f03a78e0dd7dbfdae5c66e7fc3402 | 2022-04-18T16:18:38.000Z | [
"pytorch",
"data2vec-audio",
"automatic-speech-recognition",
"en",
"dataset:librispeech_asr",
"arxiv:2202.03555",
"transformers",
"speech",
"license:apache-2.0"
] | automatic-speech-recognition | false | facebook | null | facebook/data2vec-audio-base-10m | 34 | 1 | transformers | 6,829 | ---
language: en
datasets:
- librispeech_asr
tags:
- speech
license: apache-2.0
---
# Data2Vec-Audio-Base-10m
[Facebook's Data2Vec](https://ai.facebook.com/research/data2vec-a-general-framework-for-self-supervised-learning-in-speech-vision-and-language/)
The base model pretrained and fine-tuned on 10 minutes of Librispeech on 16kHz sampled speech audio. When using the model
make sure that your speech input is also sampled at 16Khz.
[Paper](https://arxiv.org/abs/2202.03555)
Authors: Alexei Baevski, Wei-Ning Hsu, Qiantong Xu, Arun Babu, Jiatao Gu, Michael Auli
**Abstract**
While the general idea of self-supervised learning is identical across modalities, the actual algorithms and objectives differ widely because they were developed with a single modality in mind. To get us closer to general self-supervised learning, we present data2vec, a framework that uses the same learning method for either speech, NLP or computer vision. The core idea is to predict latent representations of the full input data based on a masked view of the input in a self-distillation setup using a standard Transformer architecture. Instead of predicting modality-specific targets such as words, visual tokens or units of human speech which are local in nature, data2vec predicts contextualized latent representations that contain information from the entire input. Experiments on the major benchmarks of speech recognition, image classification, and natural language understanding demonstrate a new state of the art or competitive performance to predominant approaches.
The original model can be found under https://github.com/pytorch/fairseq/tree/main/examples/data2vec .
# Pre-Training method

For more information, please take a look at the [official paper](https://arxiv.org/abs/2202.03555).
# Usage
To transcribe audio files the model can be used as a standalone acoustic model as follows:
```python
from transformers import Wav2Vec2Processor, Data2VecForCTC
from datasets import load_dataset
import torch
# load model and processor
processor = Wav2Vec2Processor.from_pretrained("facebook/data2vec-audio-base-10m")
model = Data2VecForCTC.from_pretrained("facebook/data2vec-audio-base-10m")
# load dummy dataset and read soundfiles
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# tokenize
input_values = processor(ds[0]["audio"]["array"],, return_tensors="pt", padding="longest").input_values # Batch size 1
# retrieve logits
logits = model(input_values).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
```
|
flax-community/roberta-swahili | 095dc7fd54c3169c21283447e3e8ec37de2c1e81 | 2021-07-25T16:21:02.000Z | [
"pytorch",
"jax",
"tensorboard",
"roberta",
"fill-mask",
"sw",
"dataset:flax-community/swahili-safi",
"transformers",
"autotrain_compatible"
] | fill-mask | false | flax-community | null | flax-community/roberta-swahili | 34 | 1 | transformers | 6,830 | ---
language: sw
widget:
- text: "Si kila mwenye makucha <mask> simba."
datasets:
- flax-community/swahili-safi
---
## RoBERTa in Swahili
This model was trained using HuggingFace's Flax framework and is part of the [JAX/Flax Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104) organized by [HuggingFace](https://huggingface.co). All training was done on a TPUv3-8 VM sponsored by the Google Cloud team.
## How to use
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("flax-community/roberta-swahili")
model = AutoModelForMaskedLM.from_pretrained("flax-community/roberta-swahili")
print(round((model.num_parameters())/(1000*1000)),"Million Parameters")
105 Million Parameters
```
#### **Training Data**:
This model was trained on [Swahili Safi](https://huggingface.co/datasets/flax-community/swahili-safi)
#### **Results**:
[MasakhaNER](https://github.com/masakhane-io/masakhane-ner) [](https://colab.research.google.com/drive/1OIurb4J91X7461NQXLCCGzjeEGJq_Tyl?usp=sharing)
```
Eval metrics: {'f1': 86%}
```
This [model](https://huggingface.co/flax-community/roberta-swahili-news-classification) was fine-tuned based off this model for the
[Zindi News Classification Challenge](https://zindi.africa/hackathons/ai4d-swahili-news-classification-challenge)
#### **More Details**:
For more details and Demo please check [HF Swahili Space](https://huggingface.co/spaces/flax-community/Swahili)
|
gchhablani/fnet-base-finetuned-sst2 | eaf6272ede4ff626570817a6040ee5d4dac8ce74 | 2021-11-13T08:23:41.000Z | [
"pytorch",
"tensorboard",
"rust",
"fnet",
"text-classification",
"en",
"dataset:glue",
"arxiv:2105.03824",
"transformers",
"generated_from_trainer",
"fnet-bert-base-comparison",
"license:apache-2.0",
"model-index"
] | text-classification | false | gchhablani | null | gchhablani/fnet-base-finetuned-sst2 | 34 | null | transformers | 6,831 | ---
language:
- en
license: apache-2.0
tags:
- generated_from_trainer
- fnet-bert-base-comparison
datasets:
- glue
metrics:
- accuracy
model-index:
- name: fnet-base-finetuned-sst2
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE SST2
type: glue
args: sst2
metrics:
- name: Accuracy
type: accuracy
value: 0.8944954128440367
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fnet-base-finetuned-sst2
This model is a fine-tuned version of [google/fnet-base](https://huggingface.co/google/fnet-base) on the GLUE SST2 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4674
- Accuracy: 0.8945
The model was fine-tuned to compare [google/fnet-base](https://huggingface.co/google/fnet-base) as introduced in [this paper](https://arxiv.org/abs/2105.03824) against [bert-base-cased](https://huggingface.co/bert-base-cased).
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
This model is trained using the [run_glue](https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py) script. The following command was used:
```bash
#!/usr/bin/bash
python ../run_glue.py \\n --model_name_or_path google/fnet-base \\n --task_name sst2 \\n --do_train \\n --do_eval \\n --max_seq_length 512 \\n --per_device_train_batch_size 16 \\n --learning_rate 2e-5 \\n --num_train_epochs 3 \\n --output_dir fnet-base-finetuned-sst2 \\n --push_to_hub \\n --hub_strategy all_checkpoints \\n --logging_strategy epoch \\n --save_strategy epoch \\n --evaluation_strategy epoch \\n```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Accuracy | Validation Loss |
|:-------------:|:-----:|:-----:|:--------:|:---------------:|
| 0.2956 | 1.0 | 4210 | 0.8819 | 0.3128 |
| 0.1746 | 2.0 | 8420 | 0.8979 | 0.3850 |
| 0.1204 | 3.0 | 12630 | 0.8945 | 0.4674 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
harshit345/xlsr-53-wav2vec-hi | 9b30f03f4a8918ecf8ce17d5c9dde3c162ebb11f | 2021-12-12T11:52:01.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"hi",
"dataset:Interspeech 2021",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | false | harshit345 | null | harshit345/xlsr-53-wav2vec-hi | 34 | null | transformers | 6,832 | ---
language: hi
datasets:
- Interspeech 2021
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Hindi by Shyam Sunder Kumar
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice hi
type: common_voice
args: hi
metrics:
- name: Test WER
type: wer
value: 20.22
---
# Wav2Vec2-Large-XLSR-53-hindi
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) hindi using the [Multilingual and code-switching ASR challenges for low resource Indian languages](https://navana-tech.github.io/IS21SS-indicASRchallenge/data.html).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "hi", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("theainerd/Wav2Vec2-large-xlsr-hindi")
model = Wav2Vec2ForCTC.from_pretrained("theainerd/Wav2Vec2-large-xlsr-hindi")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the hindi test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "hi", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("theainerd/Wav2Vec2-large-xlsr-hindi")
model = Wav2Vec2ForCTC.from_pretrained("theainerd/Wav2Vec2-large-xlsr-hindi")
model.to("cuda")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“]'
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**:20.22 %
## Training
The script used for training can be found [Hindi ASR Fine Tuning Wav2Vec2](https://colab.research.google.com/drive/1nY5WMj1oNlexD_qDeNYL7ZM427A021CV?usp=sharing) |
huggingtweets/gadgetgreen | cc5c68e1942db459b6de3683c033a277aee16ee2 | 2021-05-22T04:55:42.000Z | [
"pytorch",
"jax",
"gpt2",
"text-generation",
"en",
"transformers",
"huggingtweets"
] | text-generation | false | huggingtweets | null | huggingtweets/gadgetgreen | 34 | null | transformers | 6,833 | ---
language: en
thumbnail: https://www.huggingtweets.com/gadgetgreen/1602201219260/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/[email protected]/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1312899140615979008/ulnJKPCT_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">ZOZANZI ♤☆♤ VIRAGO 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@gadgetgreen bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@gadgetgreen's tweets](https://twitter.com/gadgetgreen).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>3189</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>1537</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>215</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>1437</td>
</tr>
</tbody>
</table>
[Explore the data](https://app.wandb.ai/wandb/huggingtweets/runs/1f29q7ag/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @gadgetgreen's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://app.wandb.ai/wandb/huggingtweets/runs/1df6ql9u) for full transparency and reproducibility.
At the end of training, [the final model](https://app.wandb.ai/wandb/huggingtweets/runs/1df6ql9u/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/gadgetgreen'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
<!--- random size file --> |
huggingtweets/wwm_shakespeare | fb0b29a16e85277aaf6488b65d216f311538430b | 2021-05-23T04:45:54.000Z | [
"pytorch",
"jax",
"gpt2",
"text-generation",
"en",
"transformers",
"huggingtweets"
] | text-generation | false | huggingtweets | null | huggingtweets/wwm_shakespeare | 34 | null | transformers | 6,834 | ---
language: en
thumbnail: https://www.huggingtweets.com/wwm_shakespeare/1610567717562/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/[email protected]/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/68000547/1863715-big_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">William Shakespeare 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@wwm_shakespeare bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@wwm_shakespeare's tweets](https://twitter.com/wwm_shakespeare).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>3234</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>18</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>196</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>3020</td>
</tr>
</tbody>
</table>
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/27cac1ob/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @wwm_shakespeare's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/1qqhve6t) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/1qqhve6t/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/wwm_shakespeare'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
|
icelab/spacescibert | 093a74941b96a458d32a519241db9691682e5408 | 2021-10-21T08:39:47.000Z | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | icelab | null | icelab/spacescibert | 34 | null | transformers | 6,835 | ### SpaceSciBERT
This is one of the 3 further pre-trained models from the SpaceTransformers family presented in [SpaceTransformers: Language Modeling for Space Systems](https://ieeexplore.ieee.org/document/9548078). The original Git repo is [strath-ace/smart-nlp](https://github.com/strath-ace/smart-nlp).
The further pre-training corpus includes publications abstracts, books, and Wikipedia pages related to space systems. Corpus size is 14.3 GB. SpaceSciBERT was further pre-trained on this domain-specific corpus from [SciBERT-SciVocab (uncased)](https://huggingface.co/allenai/scibert_scivocab_uncased). In our paper, it is then fine-tuned for a Concept Recognition task.
### BibTeX entry and citation info
```
@ARTICLE{
9548078,
author={Berquand, Audrey and Darm, Paul and Riccardi, Annalisa},
journal={IEEE Access},
title={SpaceTransformers: Language Modeling for Space Systems},
year={2021},
volume={9},
number={},
pages={133111-133122},
doi={10.1109/ACCESS.2021.3115659}
}
``` |
jkeruotis/LitBERTa-uncased | 962fe3c5f9ceb5971866a3bd9a99fe5091f1744d | 2021-05-20T17:15:42.000Z | [
"pytorch",
"jax",
"roberta",
"fill-mask",
"lt",
"transformers",
"exbert",
"license:mit",
"autotrain_compatible"
] | fill-mask | false | jkeruotis | null | jkeruotis/LitBERTa-uncased | 34 | null | transformers | 6,836 | ---
language: lt
tags:
- exbert
license: mit
---
# LitBERTa uncased model
Not the best model because of limited resources (Trained on ~4.7 GB of data on RTX2070 8GB for ~10 days) but it covers special lithuanian symbols `ąčęėįšųūž`. 128K vocabulary chosen because language has a lot of word forms.
## How to use
```python
from transformers import pipeline
unmasker = pipeline('fill-mask', model='jkeruotis/LitBERTa-uncased')
unmasker('lietuvių kalba yra viena iš <mask> kalbų pasaulyje.')
[{'sequence': 'lietuvių kalba yra viena iš populiariausių kalbų pasaulyje.',
'score': 0.13887910544872284,
'token': 9404,
'token_str': ' populiariausių'},
{'sequence': 'lietuvių kalba yra viena iš pirmaujančių kalbų pasaulyje.',
'score': 0.13532795011997223,
'token': 27431,
'token_str': ' pirmaujančių'},
{'sequence': 'lietuvių kalba yra viena iš seniausių kalbų pasaulyje.',
'score': 0.1184583529829979,
'token': 14775,
'token_str': ' seniausių'},
{'sequence': 'lietuvių kalba yra viena iš geriausių kalbų pasaulyje.',
'score': 0.09306756407022476,
'token': 5617,
'token_str': ' geriausių'},
{'sequence': 'lietuvių kalba yra viena iš nedaugelio kalbų pasaulyje.',
'score': 0.08187634497880936,
'token': 28150,
'token_str': ' nedaugelio'}]```
|
ken11/mbart-ja-en | bd1ceff1c6ce1cc10640758dc598d2e48a4b93c7 | 2021-10-12T18:44:43.000Z | [
"pytorch",
"mbart",
"text2text-generation",
"ja",
"en",
"transformers",
"translation",
"japanese",
"license:mit",
"autotrain_compatible"
] | translation | false | ken11 | null | ken11/mbart-ja-en | 34 | null | transformers | 6,837 | ---
tags:
- translation
- japanese
language:
- ja
- en
license: mit
widget:
- text: "今日もご安全に"
---
## mbart-ja-en
このモデルは[facebook/mbart-large-cc25](https://huggingface.co/facebook/mbart-large-cc25)をベースに[JESC dataset](https://nlp.stanford.edu/projects/jesc/index_ja.html)でファインチューニングしたものです。
This model is based on [facebook/mbart-large-cc25](https://huggingface.co/facebook/mbart-large-cc25) and fine-tuned with [JESC dataset](https://nlp.stanford.edu/projects/jesc/index_ja.html).
## How to use
```py
from transformers import (
MBartForConditionalGeneration, MBartTokenizer
)
tokenizer = MBartTokenizer.from_pretrained("ken11/mbart-ja-en")
model = MBartForConditionalGeneration.from_pretrained("ken11/mbart-ja-en")
inputs = tokenizer("こんにちは", return_tensors="pt")
translated_tokens = model.generate(**inputs, decoder_start_token_id=tokenizer.lang_code_to_id["en_XX"], early_stopping=True, max_length=48)
pred = tokenizer.batch_decode(translated_tokens, skip_special_tokens=True)[0]
print(pred)
```
## Training Data
I used the [JESC dataset](https://nlp.stanford.edu/projects/jesc/index_ja.html) for training.
Thank you for publishing such a large dataset.
## Tokenizer
The tokenizer uses the [sentencepiece](https://github.com/google/sentencepiece) trained on the JESC dataset.
## Note
The result of evaluating the sacrebleu score for [JEC Basic Sentence Data of Kyoto University](https://nlp.ist.i.kyoto-u.ac.jp/EN/?JEC+Basic+Sentence+Data#i0163896) was `18.18` .
## Licenese
[The MIT license](https://opensource.org/licenses/MIT)
|
l3cube-pune/marathi-bert | 7c4601047db559c1098df0b466167f00013921a0 | 2022-06-26T15:15:17.000Z | [
"pytorch",
"bert",
"fill-mask",
"mr",
"dataset:L3Cube-MahaCorpus",
"arxiv:2202.01159",
"transformers",
"license:cc-by-4.0",
"autotrain_compatible"
] | fill-mask | false | l3cube-pune | null | l3cube-pune/marathi-bert | 34 | null | transformers | 6,838 | ---
license: cc-by-4.0
language: mr
datasets:
- L3Cube-MahaCorpus
---
## MahaBERT
MahaBERT is a Marathi BERT model. It is a multilingual BERT (bert-base-multilingual-cased) model fine-tuned on L3Cube-MahaCorpus and other publicly available Marathi monolingual datasets.
[dataset link] (https://github.com/l3cube-pune/MarathiNLP)
More details on the dataset, models, and baseline results can be found in our [paper] (https://arxiv.org/abs/2202.01159)
```
@InProceedings{joshi:2022:WILDRE6,
author = {Joshi, Raviraj},
title = {L3Cube-MahaCorpus and MahaBERT: Marathi Monolingual Corpus, Marathi BERT Language Models, and Resources},
booktitle = {Proceedings of The WILDRE-6 Workshop within the 13th Language Resources and Evaluation Conference},
month = {June},
year = {2022},
address = {Marseille, France},
publisher = {European Language Resources Association},
pages = {97--101}
}
``` |
lassl/roberta-ko-small | cdf55ffe4dc1fed77e2b0ebf46de93fe370281ce | 2022-02-19T09:49:04.000Z | [
"pytorch",
"roberta",
"fill-mask",
"ko",
"transformers",
"korean",
"lassl",
"license:apache-2.0",
"autotrain_compatible"
] | fill-mask | false | lassl | null | lassl/roberta-ko-small | 34 | 2 | transformers | 6,839 | ---
license: apache-2.0
language: ko
tags:
- korean
- lassl
mask_token: "<mask>"
widget:
- text: 대한민국의 수도는 <mask> 입니다.
---
# LASSL roberta-ko-small
## How to use
```python
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained("lassl/roberta-ko-small")
tokenizer = AutoTokenizer.from_pretrained("lassl/roberta-ko-small")
```
## Evaluation
Pretrained `roberta-ko-small` on korean language was trained by [LASSL](https://github.com/lassl/lassl) framework. Below performance was evaluated at 2021/12/15.
| nsmc | klue_nli | klue_sts | korquadv1 | klue_mrc | avg |
| ---- | -------- | -------- | --------- | ---- | -------- |
| 87.8846 | 66.3086 | 83.8353 | 83.1780 | 42.4585 | 72.7330 |
## Corpora
This model was trained from 6,860,062 examples (whose have 3,512,351,744 tokens). 6,860,062 examples are extracted from below corpora. If you want to get information for training, you should see `config.json`.
```bash
corpora/
├── [707M] kowiki_latest.txt
├── [ 26M] modu_dialogue_v1.2.txt
├── [1.3G] modu_news_v1.1.txt
├── [9.7G] modu_news_v2.0.txt
├── [ 15M] modu_np_v1.1.txt
├── [1008M] modu_spoken_v1.2.txt
├── [6.5G] modu_written_v1.0.txt
└── [413M] petition.txt
```
|
mrm8488/t5-base-finetuned-boolq | 2fccf65be575b5d2337094528b91801e8271d38b | 2021-06-23T12:42:18.000Z | [
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | false | mrm8488 | null | mrm8488/t5-base-finetuned-boolq | 34 | null | transformers | 6,840 | Entry not found |
patrickvonplaten/wav2vec2-2-bert | 57762a07f35e6ad39fecc24e8a860baf88e04486 | 2021-12-16T13:40:59.000Z | [
"pytorch",
"speech-encoder-decoder",
"automatic-speech-recognition",
"transformers"
] | automatic-speech-recognition | false | patrickvonplaten | null | patrickvonplaten/wav2vec2-2-bert | 34 | null | transformers | 6,841 | Entry not found |
persiannlp/mbert-base-parsinlu-multiple-choice | 5ab6fc43527b15868c27d3fa1141e64ef1047864 | 2021-09-23T16:19:49.000Z | [
"pytorch",
"jax",
"bert",
"multiple-choice",
"fa",
"multilingual",
"dataset:parsinlu",
"transformers",
"mbert",
"persian",
"farsi",
"license:cc-by-nc-sa-4.0",
"text-classification"
] | text-classification | false | persiannlp | null | persiannlp/mbert-base-parsinlu-multiple-choice | 34 | null | transformers | 6,842 | ---
language:
- fa
- multilingual
thumbnail: https://upload.wikimedia.org/wikipedia/commons/a/a2/Farsi.svg
tags:
- multiple-choice
- mbert
- persian
- farsi
pipeline_tag: text-classification
license: cc-by-nc-sa-4.0
datasets:
- parsinlu
metrics:
- accuracy
---
# Multiple-Choice Question Answering (مدل برای پاسخ به سوالات چهار جوابی)
This is a mbert-based model for multiple-choice question answering.
Here is an example of how you can run this model:
```python
from typing import List
import torch
from transformers import AutoConfig, AutoModelForMultipleChoice, AutoTokenizer
model_name = "persiannlp/mbert-base-parsinlu-multiple-choice"
tokenizer = AutoTokenizer.from_pretrained(model_name)
config = AutoConfig.from_pretrained(model_name)
model = AutoModelForMultipleChoice.from_pretrained(model_name, config=config)
def run_model(question: str, candicates: List[str]):
assert len(candicates) == 4, "you need four candidates"
choices_inputs = []
for c in candicates:
text_a = "" # empty context
text_b = question + " " + c
inputs = tokenizer(
text_a,
text_b,
add_special_tokens=True,
max_length=128,
padding="max_length",
truncation=True,
return_overflowing_tokens=True,
)
choices_inputs.append(inputs)
input_ids = torch.LongTensor([x["input_ids"] for x in choices_inputs])
output = model(input_ids=input_ids)
print(output)
return output
run_model(question="وسیع ترین کشور جهان کدام است؟", candicates=["آمریکا", "کانادا", "روسیه", "چین"])
run_model(question="طامع یعنی ؟", candicates=["آزمند", "خوش شانس", "محتاج", "مطمئن"])
run_model(
question="زمینی به ۳۱ قطعه متساوی مفروض شده است و هر روز مساحت آماده شده برای احداث، دو برابر مساحت روز قبل است.اگر پس از (۵ روز) تمام زمین آماده شده باشد، در چه روزی یک قطعه زمین آماده شده ",
candicates=["روز اول", "روز دوم", "روز سوم", "هیچکدام"])
```
For more details, visit this page: https://github.com/persiannlp/parsinlu/
|
persiannlp/mt5-small-parsinlu-squad-reading-comprehension | af6d49d8e70e2e4579739f6c4bf7831d7267f253 | 2021-09-23T16:20:45.000Z | [
"pytorch",
"mt5",
"text2text-generation",
"fa",
"multilingual",
"dataset:parsinlu",
"dataset:squad",
"transformers",
"reading-comprehension",
"persian",
"farsi",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible"
] | text2text-generation | false | persiannlp | null | persiannlp/mt5-small-parsinlu-squad-reading-comprehension | 34 | 2 | transformers | 6,843 | ---
language:
- fa
- multilingual
thumbnail: https://upload.wikimedia.org/wikipedia/commons/a/a2/Farsi.svg
tags:
- reading-comprehension
- mt5
- persian
- farsi
license: cc-by-nc-sa-4.0
datasets:
- parsinlu
- squad
metrics:
- f1
---
# Reading Comprehension (مدل برای پاسخ به درک مطلب)
This is a mT5-based model for reading comprehension.
Here is an example of how you can run this model:
```python
from transformers import MT5ForConditionalGeneration, MT5Tokenizer
model_size = "small"
model_name = f"persiannlp/mt5-{model_size}-parsinlu-squad-reading-comprehension"
tokenizer = MT5Tokenizer.from_pretrained(model_name)
model = MT5ForConditionalGeneration.from_pretrained(model_name)
def run_model(paragraph, question, **generator_args):
input_ids = tokenizer.encode(question + "\n" + paragraph, return_tensors="pt")
res = model.generate(input_ids, **generator_args)
output = tokenizer.batch_decode(res, skip_special_tokens=True)
print(output)
return output
run_model(
"یک شی را دارای تقارن مینامیم زمانی که ان شی را بتوان به دو یا چند قسمت تقسیم کرد که آنها قسمتی از یک طرح سازمان یافته باشند یعنی بر روی شکل تنها جابجایی و چرخش و بازتاب و تجانس انجام شود و در اصل شکل تغییری به وجود نیایید آنگاه ان را تقارن مینامیم مرکز تقارن:اگر در یک شکل نقطهای مانندA وجود داشته باشد که هر نقطهٔ روی شکل (محیط) نسبت به نقطه یAمتقارن یک نقطهٔ دیگر شکل (محیط) باشد، نقطهٔ Aمرکز تقارن است. یعنی هر نقطه روی شکل باید متقارنی داشته باشد شکلهای که منتظم هستند و زوج ضلع دارند دارای مرکز تقارند ولی شکلهای فرد ضلعی منتظم مرکز تقارن ندارند. متوازیالأضلاع و دایره یک مرکز تقارن دارند ممکن است یک شکل خط تقارن نداشته باشد ولی مرکز تقارن داشته باشد. (منبع:س. گ)",
"اشکالی که یک مرکز تقارن دارند"
)
run_model(
"شُتُر یا اُشتر را که در زبان پهلوی (ushtar)[نیازمند منبع] میگفتند حیوانی است نیرومند و تنومند با توش و توان بالا از خانواده شتران؛ شبه نشخوارکننده و با دست و گردنی دراز. بر پشت خود یک یا دو کوهان دارد که ساختارش از پیه و چربی است. در دین اسلام گوشت او حلال است. اما ذبح آن با دیگر جانوران حلال گوشت متفاوت است و آن را نحر (بریدن گلو) میکنند و اگر سر آن را مانند گوسفند پیش از نحر ببرند گوشت آن حلال نیست. شیرش نیز نوشیده میشود ولی بیشتر کاربرد بارکشی دارد. پشم و پوستش نیز برای ریسندگی و پارچهبافی و کفشدوزی کاربرد دارد. گونههای دیگری از شتران نیز در آمریکای جنوبی زندگی میکنند، به نامهای لاما، آلپاکا، گواناکو که دارای کوهان نیستند. شتر ویژگیهای خاصّی دارد که مهمترین آنها تحمّل شرایط سخت صحرا و دماهای گوناگون و بهویژه گرمای شدید تابستان و کمبود آب و علوفه است. ترکیب جسمانی شتر با دیگر جانوران اختلاف زیادی دارد، و این اختلاف انگیزه شده که شتر در درازا روزهای سال در بیابان زندگی کند و از بوتهها و درختچههای گوناگون صحرایی و کویری و حتی از بوتههای شور و خاردار تغذیه کند. عربها از زمانهای بسیار دور از شتر استفاده کرده و میکنند. آنها به این حیوان اهلی لقب کشتی صحرا (به عربی: سفینةالصحراء) دادهاند.",
"غذای شترچیست؟"
)
run_model(
"""حسین میرزایی میگوید مرحله اول پرداخت وام حمایتی کرونا به همگی خانوارهای یارانهبگیر متقاضی تکمیل شده است و حال چهار میلیون خانوار که به عنوان "اقشار خاص" و "آسیبپذیر" شناسایی شدند، میتوانند برای یک میلیون تومان وام دیگر درخواست بدهند. آقای میرزایی گفته خانوارهای "آسیبپذیر" که شرایط گرفتن وام یک میلیونی اضافی را دارند با پیامک از این امکان مطلع شدهاند. بنا به گزارشهای رسمی با شیوع کرونا در ایران یک میلیون نفر بیکار شدهاند و درآمد کارکنان مشاغل غیررسمی نیز ضربه قابل توجهی خورده است. ارزش ریال هم در هفتههای اخیر در برابر ارزهای خارجی سقوط کرده است. اقتصاد ایران پیش از شیوع کرونا نیز با مشکلات مزمن رکود، تورم، تحریم و فساد روبرو بود.""",
"وام یارانه به چه کسانی میدهند؟"
)
run_model(
"در ۲۲ ژوئن ۱۹۴۱ نیروهای محور در عملیات بارباروسا حمله سنگینی به اتحاد شوروی کرده و یکی از بزرگترین نبردهای زمینی تاریخ بشر را رقم زدند. همچنین جبهه شرقی باعث به دام افتادن نیروهای محور شد و بیش از همه ارتش آلمان نازی را درگیر جنگ فرسایشی کرد. در دسامبر ۱۹۴۱ ژاپن یک در عملیاتی ناگهانی با نام نبرد پرل هاربر به پایگاه دریایی ایالات متحده آمریکا حمله کرد. به دنبال این اتفاق آمریکا نیز بلافاصله علیه ژاپن اعلان جنگ کرد که با حمایت بریتانیا همراه شد. پس از آن متحدین (نیروهای محور در اروپا) نیز با اتحاد ژاپن علیه آمریکا اعلام جنگ کردند. دستآوردهای ژاپن در یورش به آمریکا باعث ایجاد این احساس در آسیا شد که آسیا از تسلط غرب خارج شدهاست از این رو بسیاری از ارتشهای شکست خورده با آنها همراهی کردند.",
"چرا امریکا وارد جنگ جهانی دوم شد؟"
)
```
For more details, visit this page: https://github.com/persiannlp/parsinlu/
|
pie/example-re-textclf-tacred | 0916b802558a4e52b14392943bf61cea5a26d813 | 2022-01-02T11:03:42.000Z | [
"pytorch",
"TransformerTextClassificationModel",
"transformers"
] | null | false | pie | null | pie/example-re-textclf-tacred | 34 | 1 | transformers | 6,844 | Entry not found |
qanastek/pos-french-camembert | a6ad37e00c42ba2cd02313fa59279d44a1422e90 | 2022-07-06T23:48:53.000Z | [
"pytorch",
"camembert",
"token-classification",
"fr",
"dataset:qanastek/ANTILLES",
"arxiv:1911.03894",
"transformers",
"Transformers",
"sequence-tagger-model",
"autotrain_compatible"
] | token-classification | false | qanastek | null | qanastek/pos-french-camembert | 34 | 1 | transformers | 6,845 | ---
tags:
- Transformers
- token-classification
- sequence-tagger-model
language: fr
datasets:
- qanastek/ANTILLES
widget:
- text: "George Washington est allé à Washington"
---
# POET: A French Extended Part-of-Speech Tagger
- Corpora: [ANTILLES](https://github.com/qanastek/ANTILLES)
- Embeddings & Sequence Labelling: [CamemBERT](https://arxiv.org/abs/1911.03894)
- Number of Epochs: 115
**People Involved**
* [LABRAK Yanis](https://www.linkedin.com/in/yanis-labrak-8a7412145/) (1)
* [DUFOUR Richard](https://cv.archives-ouvertes.fr/richard-dufour) (2)
**Affiliations**
1. [LIA, NLP team](https://lia.univ-avignon.fr/), Avignon University, Avignon, France.
2. [LS2N, TALN team](https://www.ls2n.fr/equipe/taln/), Nantes University, Nantes, France.
## Demo: How to use in HuggingFace Transformers
Requires [transformers](https://pypi.org/project/transformers/): ```pip install transformers```
```python
from transformers import CamembertTokenizer, CamembertForTokenClassification, TokenClassificationPipeline
tokenizer = CamembertTokenizer.from_pretrained('qanastek/pos-french-camembert')
model = CamembertForTokenClassification.from_pretrained('qanastek/pos-french-camembert')
pos = TokenClassificationPipeline(model=model, tokenizer=tokenizer)
def make_prediction(sentence):
labels = [l['entity'] for l in pos(sentence)]
return list(zip(sentence.split(" "), labels))
res = make_prediction("George Washington est allé à Washington")
```
Output:

## Training data
`ANTILLES` is a part-of-speech tagging corpora based on [UD_French-GSD](https://universaldependencies.org/treebanks/fr_gsd/index.html) which was originally created in 2015 and is based on the [universal dependency treebank v2.0](https://github.com/ryanmcd/uni-dep-tb).
Originally, the corpora consists of 400,399 words (16,341 sentences) and had 17 different classes. Now, after applying our tags augmentation we obtain 60 different classes which add linguistic and semantic information such as the gender, number, mood, person, tense or verb form given in the different CoNLL-03 fields from the original corpora.
We based our tags on the level of details given by the [LIA_TAGG](http://pageperso.lif.univ-mrs.fr/frederic.bechet/download.html) statistical POS tagger written by [Frédéric Béchet](http://pageperso.lif.univ-mrs.fr/frederic.bechet/index-english.html) in 2001.
The corpora used for this model is available on [Github](https://github.com/qanastek/ANTILLES) at the [CoNLL-U format](https://universaldependencies.org/format.html).
Training data are fed to the model as free language and doesn't pass a normalization phase. Thus, it's made the model case and punctuation sensitive.
## Original Tags
```plain
PRON VERB SCONJ ADP CCONJ DET NOUN ADJ AUX ADV PUNCT PROPN NUM SYM PART X INTJ
```
## New additional POS tags
| Abbreviation | Description | Examples |
|:--------:|:--------:|:--------:|
| PREP | Preposition | de |
| AUX | Auxiliary Verb | est |
| ADV | Adverb | toujours |
| COSUB | Subordinating conjunction | que |
| COCO | Coordinating Conjunction | et |
| PART | Demonstrative particle | -t |
| PRON | Pronoun | qui ce quoi |
| PDEMMS | Demonstrative Pronoun - Singular Masculine | ce |
| PDEMMP | Demonstrative Pronoun - Plural Masculine | ceux |
| PDEMFS | Demonstrative Pronoun - Singular Feminine | cette |
| PDEMFP | Demonstrative Pronoun - Plural Feminine | celles |
| PINDMS | Indefinite Pronoun - Singular Masculine | tout |
| PINDMP | Indefinite Pronoun - Plural Masculine | autres |
| PINDFS | Indefinite Pronoun - Singular Feminine | chacune |
| PINDFP | Indefinite Pronoun - Plural Feminine | certaines |
| PROPN | Proper noun | Houston |
| XFAMIL | Last name | Levy |
| NUM | Numerical Adjective | trentaine vingtaine |
| DINTMS | Masculine Numerical Adjective | un |
| DINTFS | Feminine Numerical Adjective | une |
| PPOBJMS | Pronoun complements of objects - Singular Masculine | le lui |
| PPOBJMP | Pronoun complements of objects - Plural Masculine | eux y |
| PPOBJFS | Pronoun complements of objects - Singular Feminine | moi la |
| PPOBJFP | Pronoun complements of objects - Plural Feminine | en y |
| PPER1S | Personal Pronoun First-Person - Singular | je |
| PPER2S | Personal Pronoun Second-Person - Singular | tu |
| PPER3MS | Personal Pronoun Third-Person - Singular Masculine | il |
| PPER3MP | Personal Pronoun Third-Person - Plural Masculine | ils |
| PPER3FS | Personal Pronoun Third-Person - Singular Feminine | elle |
| PPER3FP | Personal Pronoun Third-Person - Plural Feminine | elles |
| PREFS | Reflexive Pronoun First-Person - Singular | me m' |
| PREF | Reflexive Pronoun Third-Person - Singular | se s' |
| PREFP | Reflexive Pronoun First / Second-Person - Plural | nous vous |
| VERB | Verb | obtient |
| VPPMS | Past Participle - Singular Masculine | formulé |
| VPPMP | Past Participle - Plural Masculine | classés |
| VPPFS | Past Participle - Singular Feminine | appelée |
| VPPFP | Past Participle - Plural Feminine | sanctionnées |
| DET | Determinant | les l' |
| DETMS | Determinant - Singular Masculine | les |
| DETFS | Determinant - Singular Feminine | la |
| ADJ | Adjective | capable sérieux |
| ADJMS | Adjective - Singular Masculine | grand important |
| ADJMP | Adjective - Plural Masculine | grands petits |
| ADJFS | Adjective - Singular Feminine | française petite |
| ADJFP | Adjective - Plural Feminine | légères petites |
| NOUN | Noun | temps |
| NMS | Noun - Singular Masculine | drapeau |
| NMP | Noun - Plural Masculine | journalistes |
| NFS | Noun - Singular Feminine | tête |
| NFP | Noun - Plural Feminine | ondes |
| PREL | Relative Pronoun | qui dont |
| PRELMS | Relative Pronoun - Singular Masculine | lequel |
| PRELMP | Relative Pronoun - Plural Masculine | lesquels |
| PRELFS | Relative Pronoun - Singular Feminine | laquelle |
| PRELFP | Relative Pronoun - Plural Feminine | lesquelles |
| INTJ | Interjection | merci bref |
| CHIF | Numbers | 1979 10 |
| SYM | Symbol | € % |
| YPFOR | Endpoint | . |
| PUNCT | Ponctuation | : , |
| MOTINC | Unknown words | Technology Lady |
| X | Typos & others | sfeir 3D statu |
## Evaluation results
The test corpora used for this evaluation is available on [Github](https://github.com/qanastek/ANTILLES/blob/main/ANTILLES/test.conllu).
```plain
precision recall f1-score support
ADJ 0.9040 0.8828 0.8933 128
ADJFP 0.9811 0.9585 0.9697 434
ADJFS 0.9606 0.9826 0.9715 918
ADJMP 0.9613 0.9357 0.9483 451
ADJMS 0.9561 0.9611 0.9586 952
ADV 0.9870 0.9948 0.9908 1524
AUX 0.9956 0.9964 0.9960 1124
CHIF 0.9798 0.9774 0.9786 1239
COCO 1.0000 0.9989 0.9994 884
COSUB 0.9939 0.9939 0.9939 328
DET 0.9972 0.9972 0.9972 2897
DETFS 0.9990 1.0000 0.9995 1007
DETMS 1.0000 0.9993 0.9996 1426
DINTFS 0.9967 0.9902 0.9934 306
DINTMS 0.9923 0.9948 0.9935 387
INTJ 0.8000 0.8000 0.8000 5
MOTINC 0.5049 0.5827 0.5410 266
NFP 0.9807 0.9675 0.9740 892
NFS 0.9778 0.9699 0.9738 2588
NMP 0.9687 0.9495 0.9590 1367
NMS 0.9759 0.9560 0.9659 3181
NOUN 0.6164 0.8673 0.7206 113
NUM 0.6250 0.8333 0.7143 6
PART 1.0000 0.9375 0.9677 16
PDEMFP 1.0000 1.0000 1.0000 3
PDEMFS 1.0000 1.0000 1.0000 89
PDEMMP 1.0000 1.0000 1.0000 20
PDEMMS 1.0000 1.0000 1.0000 222
PINDFP 1.0000 1.0000 1.0000 3
PINDFS 0.8571 1.0000 0.9231 12
PINDMP 0.9000 1.0000 0.9474 9
PINDMS 0.9286 0.9701 0.9489 67
PINTFS 0.0000 0.0000 0.0000 2
PPER1S 1.0000 1.0000 1.0000 62
PPER2S 0.7500 1.0000 0.8571 3
PPER3FP 1.0000 1.0000 1.0000 9
PPER3FS 1.0000 1.0000 1.0000 96
PPER3MP 1.0000 1.0000 1.0000 31
PPER3MS 1.0000 1.0000 1.0000 377
PPOBJFP 1.0000 0.7500 0.8571 4
PPOBJFS 0.9167 0.8919 0.9041 37
PPOBJMP 0.7500 0.7500 0.7500 12
PPOBJMS 0.9371 0.9640 0.9504 139
PREF 1.0000 1.0000 1.0000 332
PREFP 1.0000 1.0000 1.0000 64
PREFS 1.0000 1.0000 1.0000 13
PREL 0.9964 0.9964 0.9964 277
PRELFP 1.0000 1.0000 1.0000 5
PRELFS 0.8000 1.0000 0.8889 4
PRELMP 1.0000 1.0000 1.0000 3
PRELMS 1.0000 1.0000 1.0000 11
PREP 0.9971 0.9977 0.9974 6161
PRON 0.9836 0.9836 0.9836 61
PROPN 0.9468 0.9503 0.9486 4310
PUNCT 1.0000 1.0000 1.0000 4019
SYM 0.9394 0.8158 0.8732 76
VERB 0.9956 0.9921 0.9938 2273
VPPFP 0.9145 0.9469 0.9304 113
VPPFS 0.9562 0.9597 0.9580 273
VPPMP 0.8827 0.9728 0.9256 147
VPPMS 0.9778 0.9794 0.9786 630
VPPRE 0.0000 0.0000 0.0000 1
X 0.9604 0.9935 0.9766 1073
XFAMIL 0.9386 0.9113 0.9248 1342
YPFOR 1.0000 1.0000 1.0000 2750
accuracy 0.9778 47574
macro avg 0.9151 0.9285 0.9202 47574
weighted avg 0.9785 0.9778 0.9780 47574
```
## BibTeX Citations
Please cite the following paper when using this model.
ANTILLES corpus and POET taggers:
```latex
@inproceedings{labrak:hal-03696042,
TITLE = {{ANTILLES: An Open French Linguistically Enriched Part-of-Speech Corpus}},
AUTHOR = {Labrak, Yanis and Dufour, Richard},
URL = {https://hal.archives-ouvertes.fr/hal-03696042},
BOOKTITLE = {{25th International Conference on Text, Speech and Dialogue (TSD)}},
ADDRESS = {Brno, Czech Republic},
PUBLISHER = {{Springer}},
YEAR = {2022},
MONTH = Sep,
KEYWORDS = {Part-of-speech corpus ; POS tagging ; Open tools ; Word embeddings ; Bi-LSTM ; CRF ; Transformers},
PDF = {https://hal.archives-ouvertes.fr/hal-03696042/file/ANTILLES_A_freNch_linguisTIcaLLy_Enriched_part_of_Speech_corpus.pdf},
HAL_ID = {hal-03696042},
HAL_VERSION = {v1},
}
```
UD_French-GSD corpora:
```latex
@misc{
universaldependencies,
title={UniversalDependencies/UD_French-GSD},
url={https://github.com/UniversalDependencies/UD_French-GSD}, journal={GitHub},
author={UniversalDependencies}
}
```
LIA TAGG:
```latex
@techreport{LIA_TAGG,
author = {Frédéric Béchet},
title = {LIA_TAGG: a statistical POS tagger + syntactic bracketer},
institution = {Aix-Marseille University & CNRS},
year = {2001}
}
```
Flair Embeddings:
```latex
@inproceedings{akbik2018coling,
title={Contextual String Embeddings for Sequence Labeling},
author={Akbik, Alan and Blythe, Duncan and Vollgraf, Roland},
booktitle = {{COLING} 2018, 27th International Conference on Computational Linguistics},
pages = {1638--1649},
year = {2018}
}
```
## Acknowledgment
This work was financially supported by [Zenidoc](https://zenidoc.fr/)
|
sagorsarker/codeswitch-spaeng-pos-lince | 649f073de9389e2992817590be1e25f09f2b8052 | 2021-05-19T01:19:43.000Z | [
"pytorch",
"jax",
"bert",
"token-classification",
"es",
"en",
"dataset:lince",
"transformers",
"codeswitching",
"spanish-english",
"pos",
"license:mit",
"autotrain_compatible"
] | token-classification | false | sagorsarker | null | sagorsarker/codeswitch-spaeng-pos-lince | 34 | null | transformers | 6,846 | ---
language:
- es
- en
datasets:
- lince
license: mit
tags:
- codeswitching
- spanish-english
- pos
---
# codeswitch-spaeng-pos-lince
This is a pretrained model for **Part of Speech Tagging** of `spanish-english` code-mixed data used from [LinCE](https://ritual.uh.edu/lince/home)
This model is trained for this below repository.
[https://github.com/sagorbrur/codeswitch](https://github.com/sagorbrur/codeswitch)
To install codeswitch:
```
pip install codeswitch
```
## Part-of-Speech Tagging of Spanish-English Mixed Data
* **Method-1**
```py
from transformers import AutoTokenizer, AutoModelForTokenClassification, pipeline
tokenizer = AutoTokenizer.from_pretrained("sagorsarker/codeswitch-spaeng-pos-lince")
model = AutoModelForTokenClassification.from_pretrained("sagorsarker/codeswitch-spaeng-pos-lince")
pos_model = pipeline('ner', model=model, tokenizer=tokenizer)
pos_model("put any spanish english code-mixed sentence")
```
* **Method-2**
```py
from codeswitch.codeswitch import POS
pos = POS('spa-eng')
text = "" # your mixed sentence
result = pos.tag(text)
print(result)
```
|
saibo/legal-longformer-base-4096 | 6f70f7b1b610097dfe1ebb9445a53e6ad980f748 | 2020-12-28T12:57:09.000Z | [
"pytorch",
"tf",
"longformer",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | saibo | null | saibo/legal-longformer-base-4096 | 34 | null | transformers | 6,847 | Entry not found |
sanchit-gandhi/wav2vec2-2-bert-grid-search | 34989806e7b5a2a2a590f8e2ed9e644a57474973 | 2022-02-26T14:08:06.000Z | [
"pytorch",
"tensorboard",
"speech-encoder-decoder",
"automatic-speech-recognition",
"dataset:librispeech_asr",
"transformers",
"generated_from_trainer",
"model-index"
] | automatic-speech-recognition | false | sanchit-gandhi | null | sanchit-gandhi/wav2vec2-2-bert-grid-search | 34 | null | transformers | 6,848 | ---
tags:
- generated_from_trainer
datasets:
- librispeech_asr
model-index:
- name: ''
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
#
This model was trained from scratch on the librispeech_asr dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.001
- train_batch_size: 12
- eval_batch_size: 12
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 96
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 1.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu113
- Datasets 1.18.3
- Tokenizers 0.11.0
|
sismetanin/xlm_roberta_large-financial_phrasebank | ebc93fc16c486afad1168fec4faeba349537e314 | 2021-03-08T09:57:38.000Z | [
"pytorch",
"xlm-roberta",
"text-classification",
"transformers"
] | text-classification | false | sismetanin | null | sismetanin/xlm_roberta_large-financial_phrasebank | 34 | null | transformers | 6,849 | Entry not found |
tuhailong/SimCSE-bert-base | a1bbd62582f091dbcc48d2c6b202b3a5fbf50cbe | 2022-04-11T07:50:07.000Z | [
"pytorch",
"zh",
"dataset:dialogue",
"arxiv:2104.08821",
"simcse"
] | null | false | tuhailong | null | tuhailong/SimCSE-bert-base | 34 | null | null | 6,850 | ---
language: zh
tags:
- simcse
datasets:
- dialogue
---
# Data
unsupervise train data is E-commerce dialogue.
## Model
model is [simcse](https://arxiv.org/abs/2104.08821).
### Usage
```python
>>> from transformers import AutoTokenizer, AutoModel
>>> model = AutoModel.from_pretrained("tuhailong/SimCSE-bert-base")
>>> tokenizer = AutoTokenizer.from_pretrained("tuhailong/SimCSE-bert-base")
>>> sentences_str_list = ["今天天气不错的","天气不错的"]
>>> inputs = tokenizer(sentences_str_list,return_tensors="pt", padding='max_length', truncation=True, max_length=32)
>>> outputs = model(**inputs)
``` |
uer/simcse-base-chinese | fcf546021ccde2bafbd2a563e82fddd7d67dedd2 | 2021-08-23T11:12:34.000Z | [
"pytorch",
"bert",
"feature-extraction",
"sentence-transformers",
"sentence-similarity",
"transformers",
"license:apache-2.0"
] | sentence-similarity | false | uer | null | uer/simcse-base-chinese | 34 | 2 | sentence-transformers | 6,851 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
license: apache-2.0
---
模型正在测试中 |
l3cube-pune/mahahate-multi-roberta | c4bf1cca0dc3f59e7b94d52129b33efccdd081d5 | 2022-06-26T14:43:38.000Z | [
"pytorch",
"xlm-roberta",
"text-classification",
"mr",
"dataset:L3Cube-MahaHate",
"arxiv:2203.13778",
"transformers",
"license:cc-by-4.0"
] | text-classification | false | l3cube-pune | null | l3cube-pune/mahahate-multi-roberta | 34 | null | transformers | 6,852 | ---
language: mr
tags:
license: cc-by-4.0
datasets:
- L3Cube-MahaHate
widget:
- text: "I like you. </s></s> I love you."
---
## MahaHate-multi-RoBERTa
MahaHate-multi-RoBERTa (Marathi Hate speech identification) is a MahaRoBERTa(l3cube-pune/marathi-roberta) model fine-tuned on L3Cube-MahaHate - a Marathi tweet-based hate speech detection dataset. This is a four-class model with labels as hate, offensive, profane, and not. The 2-class model can be found <a href='https://huggingface.co/l3cube-pune/mahahate-bert'> here </a>
[dataset link] (https://github.com/l3cube-pune/MarathiNLP)
More details on the dataset, models, and baseline results can be found in our [paper] (https://arxiv.org/abs/2203.13778)
|
giggio/FarBrBERT-base | a3e38d0c7551580c7ee4fb044e45c1728fc15c90 | 2022-03-23T17:51:10.000Z | [
"pytorch",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | false | giggio | null | giggio/FarBrBERT-base | 34 | null | transformers | 6,853 | Entry not found |
Voicelab/sbert-base-cased-pl | c3872b25e64b89e653eb1d2660852f1950f3a5a8 | 2022-04-13T13:25:20.000Z | [
"pytorch",
"bert",
"feature-extraction",
"pl",
"dataset:Wikipedia",
"arxiv:1908.10084",
"sentence-transformers",
"sentence-similarity",
"license:cc-by-4.0"
] | sentence-similarity | false | Voicelab | null | Voicelab/sbert-base-cased-pl | 34 | 5 | sentence-transformers | 6,854 | ---
license: cc-by-4.0
language:
- pl
datasets:
- Wikipedia
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
widget:
- source_sentence: "Uczenie maszynowe jest konsekwencją rozwoju idei sztucznej inteligencji i metod jej wdrażania praktycznego."
sentences:
- "Głębokie uczenie maszynowe jest sktukiem wdrażania praktycznego metod sztucznej inteligencji oraz jej rozwoju."
- "Kasparow zarzucił firmie IBM oszustwo, kiedy odmówiła mu dostępu do historii wcześniejszych gier Deep Blue. "
- "Samica o długości ciała 10–11 mm, szczoteczki na tylnych nogach służące do zbierania pyłku oraz włoski na końcu odwłoka jaskrawo pomarańczowoczerwone. "
example_title: "Uczenie maszynowe"
---
# SHerbert - Polish SentenceBERT
SentenceBERT is a modification of the pretrained BERT network that use siamese and triplet network structures to derive semantically meaningful sentence embeddings that can be compared using cosine-similarity. Training was based on the original paper [Siamese BERT models for the task of semantic textual similarity (STS)](https://arxiv.org/abs/1908.10084) with a slight modification of how the training data was used. The goal of the model is to generate different embeddings based on the semantic and topic similarity of the given text.
> Semantic textual similarity analyzes how similar two pieces of texts are.
Read more about how the model was prepared in our [blog post](https://voicelab.ai/blog/).
The base trained model is a Polish HerBERT. HerBERT is a BERT-based Language Model. For more details, please refer to: "HerBERT: Efficiently Pretrained Transformer-based Language Model for Polish".
# Corpus
Te model was trained solely on [Wikipedia](https://dumps.wikimedia.org/).
# Tokenizer
As in the original HerBERT implementation, the training dataset was tokenized into subwords using a character level byte-pair encoding (CharBPETokenizer) with a vocabulary size of 50k tokens. The tokenizer itself was trained with a tokenizers library.
We kindly encourage you to use the Fast version of the tokenizer, namely HerbertTokenizerFast.
# Usage
```python
from transformers import AutoTokenizer, AutoModel
from sklearn.metrics import pairwise
sbert = AutoModel.from_pretrained("Voicelab/sbert-base-cased-pl")
tokenizer = AutoTokenizer.from_pretrained("Voicelab/sbert-base-cased-pl")
s0 = "Uczenie maszynowe jest konsekwencją rozwoju idei sztucznej inteligencji i metod jej wdrażania praktycznego."
s1 = "Głębokie uczenie maszynowe jest sktukiem wdrażania praktycznego metod sztucznej inteligencji oraz jej rozwoju."
s2 = "Kasparow zarzucił firmie IBM oszustwo, kiedy odmówiła mu dostępu do historii wcześniejszych gier Deep Blue. "
tokens = tokenizer([s0, s1, s2],
padding=True,
truncation=True,
return_tensors='pt')
x = sbert(tokens["input_ids"],
tokens["attention_mask"]).pooler_output
# similarity between sentences s0 and s1
print(pairwise.cosine_similarity(x[0], x[1])) # Result: 0.7952354
# similarity between sentences s0 and s2
print(pairwise.cosine_similarity(x[0], x[2))) # Result: 0.42359722
```
# Results
| Model | Accuracy | Source |
|--------------------------|------------|---------------------------------------------------------|
| SBERT-WikiSec-base (EN) | 80.42% | https://arxiv.org/abs/1908.10084 |
| SBERT-WikiSec-large (EN) | 80.78% | https://arxiv.org/abs/1908.10084 |
| **sbert-base-cased-pl** | **82.31%** | **https://huggingface.co/Voicelab/sbert-base-cased-pl** |
| sbert-large-cased-pl | 84.42% | https://huggingface.co/Voicelab/sbert-large-cased-pl |
# License
CC BY 4.0
# Citation
If you use this model, please cite the following paper:
# Authors
The model was trained by NLP Research Team at Voicelab.ai.
You can contact us [here](https://voicelab.ai/contact/). |
dbb/gbert-large-jobad-classification-34 | 12214e065ef0b2e946b619717c8c36040becd44f | 2022-04-28T11:46:29.000Z | [
"pytorch",
"bert",
"text-classification",
"de",
"transformers",
"recruiting"
] | text-classification | false | dbb | null | dbb/gbert-large-jobad-classification-34 | 34 | null | transformers | 6,855 | ---
language: de
tags:
- bert
- recruiting
---
# G(erman)BERT Large Fine-Tuned for Job Ad Classification

|
pistachiocow/product_description_generator | 32886e46cbb5b8d90e5452d321c6485762f9b989 | 2022-04-27T12:53:37.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | false | pistachiocow | null | pistachiocow/product_description_generator | 34 | null | transformers | 6,856 | Entry not found |
eslamxm/mt5-base-finetuned-persian | 5bf8d3727069e390cb8c0ecf131a4973c1e36573 | 2022-05-08T08:49:19.000Z | [
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"dataset:xlsum",
"transformers",
"summarization",
"persian",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | summarization | false | eslamxm | null | eslamxm/mt5-base-finetuned-persian | 34 | null | transformers | 6,857 | ---
license: apache-2.0
tags:
- summarization
- persian
- generated_from_trainer
datasets:
- xlsum
model-index:
- name: mt5-base-finetuned-persian
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-base-finetuned-persian
This model is a fine-tuned version of [google/mt5-base](https://huggingface.co/google/mt5-base) on the xlsum dataset.
It achieves the following results on the evaluation set:
- Loss: 3.6086
- Rouge-1: 22.02
- Rouge-2: 7.41
- Rouge-l: 18.95
- Gen Len: 19.0
- Bertscore: 69.89
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- label_smoothing_factor: 0.1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge-1 | Rouge-2 | Rouge-l | Gen Len | Bertscore |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:-------:|:---------:|
| 7.2823 | 0.96 | 19 | 3.9800 | 19.78 | 5.57 | 16.24 | 19.0 | 68.19 |
| 4.7334 | 1.96 | 38 | 3.7620 | 20.92 | 7.49 | 18.27 | 18.91 | 68.72 |
| 4.3891 | 2.96 | 57 | 3.6349 | 21.07 | 7.66 | 18.53 | 18.96 | 69.73 |
| 4.2 | 3.96 | 76 | 3.6315 | 19.63 | 6.49 | 16.61 | 19.0 | 69.15 |
| 3.9202 | 4.96 | 95 | 3.6086 | 21.2 | 6.8 | 17.06 | 19.0 | 69.48 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
gary109/STAS_detr-resnet-50 | e3828fe47ddec61d869404c047ee86831799acd7 | 2022-05-14T14:03:14.000Z | [
"pytorch",
"detr",
"object-detection",
"transformers"
] | object-detection | false | gary109 | null | gary109/STAS_detr-resnet-50 | 34 | null | transformers | 6,858 | Entry not found |
vives/distilbert-base-uncased-finetuned-cvent-2019_2022 | f49666724fe27faa38d1a6903dfd8bc0c6f61fc7 | 2022-05-17T15:05:30.000Z | [
"pytorch",
"distilbert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | false | vives | null | vives/distilbert-base-uncased-finetuned-cvent-2019_2022 | 34 | null | transformers | 6,859 | Entry not found |
cointegrated/rubert-tiny2-sentence-compression | e8a4782b748898aa0017074a07ee1e6a64421aaf | 2022-05-19T10:04:33.000Z | [
"pytorch",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | false | cointegrated | null | cointegrated/rubert-tiny2-sentence-compression | 34 | null | transformers | 6,860 | This model can be used for sentence compression (aka extractive sentence summarization).
It predicts for each word, whether the word can be dropped from the sentence without severely affecting its meaning.
The resulting sentences are often ungrammatical, but they still can be useful.
The model is [rubert-tiny2]() fine-tuned on the dataset from the paper
[Sentence compression for Russian: dataset and baselines](https://www.dialog-21.ru/media/5106/kuvshinovat-050.pdf).
Example usage:
```python
import torch
from transformers import AutoModelForTokenClassification, AutoTokenizer
model_name = 'cointegrated/rubert-tiny2-sentence-compression'
model = AutoModelForTokenClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
def compress(text, threshold=0.5, keep_ratio=None):
""" Compress a sentence by removing the least important words.
Parameters:
threshold: cutoff for predicted probabilities of word removal
keep_ratio: proportion of words to preserve
By default, threshold of 0.5 is used.
"""
with torch.inference_mode():
tok = tokenizer(text, return_tensors='pt').to(model.device)
proba = torch.softmax(model(**tok).logits, -1).cpu().numpy()[0, :, 1]
if keep_ratio is not None:
threshold = sorted(proba)[int(len(proba) * keep_ratio)]
kept_toks = []
keep = False
prev_word_id = None
for word_id, score, token in zip(tok.word_ids(), proba, tok.input_ids[0]):
if word_id is None:
keep = True
elif word_id != prev_word_id:
keep = score < threshold
if keep:
kept_toks.append(token)
prev_word_id = word_id
return tokenizer.decode(kept_toks, skip_special_tokens=True)
text = 'Кроме того, можно взять идею, рожденную из сердца, и выразить ее в рамках одной '\
'из этих структур, без потери искренности идеи и смысла песни.'
print(compress(text))
print(compress(text, threshold=0.3))
print(compress(text, threshold=0.1))
# можно взять идею, рожденную из сердца, и выразить ее в рамках одной из этих структур.
# можно взять идею, рожденную из сердца выразить ее в рамках одной из этих структур.
# можно взять идею рожденную выразить структур.
print(compress(text, keep_ratio=0.5))
# можно взять идею, рожденную из сердца выразить ее в рамках структур.
``` |
north/t5_base_NCC_lm | 97f6be4d3a7c62b106c9f9c90087496604866768 | 2022-06-01T19:40:39.000Z | [
"pytorch",
"tf",
"jax",
"tensorboard",
"t5",
"text2text-generation",
"no",
"nn",
"sv",
"dk",
"is",
"en",
"dataset:nbailab/NCC",
"dataset:mc4",
"dataset:wikipedia",
"arxiv:2104.09617",
"arxiv:1910.10683",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | text2text-generation | false | north | null | north/t5_base_NCC_lm | 34 | null | transformers | 6,861 | ---
language:
- no
- nn
- sv
- dk
- is
- en
datasets:
- nbailab/NCC
- mc4
- wikipedia
widget:
- text: <extra_id_0> hver uke samles Regjeringens medlemmer til Statsråd på <extra_id_1>. Dette organet er øverste <extra_id_2> i Norge. For at møtet skal være <extra_id_3>, må over halvparten av regjeringens <extra_id_4> være til stede.
- text: På <extra_id_0> kan man <extra_id_1> en bok, og man kan også <extra_id_2> seg ned og lese den.
license: apache-2.0
---
-T5
The North-T5-models are a set of Norwegian sequence-to-sequence-models. It builds upon the flexible [T5](https://github.com/google-research/text-to-text-transfer-transformer) and [T5X](https://github.com/google-research/t5x) and can be used for a variety of NLP tasks ranging from classification to translation.
| |**Small** <br />_60M_|**Base** <br />_220M_|**Large** <br />_770M_|**XL** <br />_3B_|**XXL** <br />_11B_|
|:-----------|:------------:|:------------:|:------------:|:------------:|:------------:|
|North-T5‑NCC|[🤗](https://huggingface.co/north/t5_small_NCC)|[🤗](https://huggingface.co/north/t5_base_NCC)|[🤗](https://huggingface.co/north/t5_large_NCC)|[🤗](https://huggingface.co/north/t5_xl_NCC)|[🤗](https://huggingface.co/north/t5_xxl_NCC)||
|North-T5‑NCC‑lm|[🤗](https://huggingface.co/north/t5_small_NCC_lm)|✔|[🤗](https://huggingface.co/north/t5_large_NCC_lm)|[🤗](https://huggingface.co/north/t5_xl_NCC_lm)|[🤗](https://huggingface.co/north/t5_xxl_NCC_lm)||
## T5X Checkpoint
The original T5X checkpoint is also available for this model in the [Google Cloud Bucket](gs://north-t5x/pretrained_models/base/norwegian_NCC_plus_English_pluss100k_lm_t5x_base/).
## Performance
A thorough evaluation of the North-T5 models is planned, and I strongly recommend external researchers to make their own evaluation. The main advantage with the T5-models are their flexibility. Traditionally, encoder-only models (like BERT) excels in classification tasks, while seq-2-seq models are easier to train for tasks like translation and Q&A. Despite this, here are the results from using North-T5 on the political classification task explained [here](https://arxiv.org/abs/2104.09617).
|**Model:** | **F1** |
|:-----------|:------------|
|mT5-base|73.2 |
|mBERT-base|78.4 |
|NorBERT-base|78.2 |
|North-T5-small|80.5 |
|nb-bert-base|81.8 |
|North-T5-base|85.3 |
|North-T5-large|86.7 |
|North-T5-xl|88.7 |
|North-T5-xxl|91.8|
These are preliminary results. The [results](https://arxiv.org/abs/2104.09617) from the BERT-models are based on the test-results from the best model after 10 runs with early stopping and a decaying learning rate. The T5-results are the average of five runs on the evaluation set. The small-model was trained for 10.000 steps, while the rest for 5.000 steps. A fixed learning rate was used (no decay), and no early stopping. Neither was the recommended rank classification used. We use a max sequence length of 512. This method simplifies the test setup and gives results that are easy to interpret. However, the results from the T5 model might actually be a bit sub-optimal.
## Sub-versions of North-T5
The following sub-versions are available. More versions will be available shorter.
|**Model** | **Description** |
|:-----------|:-------|
|**North‑T5‑NCC** |This is the main version. It is trained an additonal 500.000 steps on from the mT5 checkpoint. The training corpus is based on [the Norwegian Colossal Corpus (NCC)](https://huggingface.co/datasets/NbAiLab/NCC). In addition there are added data from MC4 and English Wikipedia.|
|**North‑T5‑NCC‑lm**|The model is pretrained for an addtional 100k steps on the LM objective discussed in the [T5 paper](https://arxiv.org/pdf/1910.10683.pdf). In a way this turns a masked language model into an autoregressive model. It also prepares the model for some tasks. When for instance doing translation and NLI, it is well documented that there is a clear benefit to do a step of unsupervised LM-training before starting the finetuning.|
## Fine-tuned versions
As explained below, the model really needs to be fine-tuned for specific tasks. This procedure is relatively simple, and the models are not very sensitive to the hyper-parameters used. Usually a decent result can be obtained by using a fixed learning rate of 1e-3. Smaller versions of the model typically needs to be trained for a longer time. It is easy to train the base-models in a Google Colab.
Since some people really want to see what the models are capable of, without going through the training procedure, I provide a couple of test models. These models are by no means optimised, and are just for demonstrating how the North-T5 models can be used.
* Nynorsk Translator. Translates any text from Norwegian Bokmål to Norwegian Nynorsk. Please test the [Streamlit-demo](https://huggingface.co/spaces/north/Nynorsk) and the [HuggingFace repo](https://huggingface.co/north/demo-nynorsk-base)
* DeUnCaser. The model adds punctation, spaces and capitalisation back into the text. The input needs to be in Norwegian but does not have to be divided into sentences or have proper capitalisation of words. You can even remove the spaces from the text, and make the model reconstruct it. It can be tested with the [Streamlit-demo](https://huggingface.co/spaces/north/DeUnCaser) and directly on the [HuggingFace repo](https://huggingface.co/north/demo-deuncaser-base)
## Training details
All models are built using the Flax-based T5X codebase, and all models are initiated with the mT5 pretrained weights. The models are trained using the T5.1.1 training regime, where they are only trained on an unsupervised masking-task. This also means that the models (contrary to the original T5) needs to be finetuned to solve specific tasks. This finetuning is however usually not very compute intensive, and in most cases it can be performed even with free online training resources.
All the main model model versions are trained for 500.000 steps after the mT5 checkpoint (1.000.000 steps). They are trained mainly on a 75GB corpus, consisting of NCC, Common Crawl and some additional high quality English text (Wikipedia). The corpus is roughly 80% Norwegian text. Additional languages are added to retain some of the multilingual capabilities, making the model both more robust to new words/concepts and also more suited as a basis for translation tasks.
While the huge models almost always will give the best results, they are also both more difficult and more expensive to finetune. I will strongly recommended to start with finetuning a base-models. The base-models can easily be finetuned on a standard graphic card or a free TPU through Google Colab.
All models were trained on TPUs. The largest XXL model was trained on a TPU v4-64, the XL model on a TPU v4-32, the Large model on a TPU v4-16 and the rest on TPU v4-8. Since it is possible to reduce the batch size during fine-tuning, it is also possible to finetune on slightly smaller hardware. The rule of thumb is that you can go "one step down" when finetuning. The large models still rewuire access to significant hardware, even for finetuning.
## Formats
All models are trained using the Flax-based T5X library. The original checkpoints are available in T5X format and can be used for both finetuning or interference. All models, except the XXL-model, are also converted to Transformers/HuggingFace. In this framework, the models can be loaded for finetuning or inference both in Flax, PyTorch and TensorFlow format.
## Future
I will continue to train and release additional models to this set. What models that are added is dependent upon the feedbacki from the users
## Thanks
This release would not have been possible without getting support and hardware from the [TPU Research Cloud](https://sites.research.google/trc/about/) at Google Research. Both the TPU Research Cloud Team and the T5X Team has provided extremely useful support for getting this running.
Freddy Wetjen at the National Library of Norway has been of tremendous help in generating the original NCC corpus, and has also contributed to generate the collated coprus used for this training. In addition he has been a dicussion partner in the creation of these models.
Also thanks to Stefan Schweter for writing the [script](https://github.com/huggingface/transformers/blob/main/src/transformers/models/t5/convert_t5x_checkpoint_to_flax.py) for converting these models from T5X to HuggingFace and to Javier de la Rosa for writing the dataloader for reading the HuggingFace Datasets in T5X.
## Warranty
Use at your own risk. The models have not yet been thougroughly tested, and may contain both errors and biases.
## Contact/About
These models were trained by Per E Kummervold. Please contact me on [email protected].
|
RUCAIBox/mtl-summarization | a20b0dafab716209f5afbe81b6e36864cec13ec4 | 2022-06-27T02:27:34.000Z | [
"pytorch",
"mvp",
"en",
"arxiv:2206.12131",
"transformers",
"text-generation",
"text2text-generation",
"summarization",
"license:apache-2.0"
] | text2text-generation | false | RUCAIBox | null | RUCAIBox/mtl-summarization | 34 | null | transformers | 6,862 | ---
license: apache-2.0
language:
- en
tags:
- text-generation
- text2text-generation
- summarization
pipeline_tag: text2text-generation
widget:
- text: "Summarize: You may want to stick it to your boss and leave your job, but don't do it if these are your reasons."
example_title: "Example1"
- text: "Summarize: Jorge Alfaro drove in two runs, Aaron Nola pitched seven innings of two-hit ball and the Philadelphia Phillies beat the Los Angeles Dodgers 2-1 Thursday, spoiling Clayton Kershaw's first start in almost a month. Hitting out of the No. 8 spot in the ..."
example_title: "Example2"
---
# MTL-summarization
The MTL-summarization model was proposed in [**MVP: Multi-task Supervised Pre-training for Natural Language Generation**](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
The detailed information and instructions can be found [https://github.com/RUCAIBox/MVP](https://github.com/RUCAIBox/MVP).
## Model Description
MTL-summarization is supervised pre-trained using a mixture of labeled summarization datasets. It is a variant (Single) of our main [MVP](https://huggingface.co/RUCAIBox/mvp) model. It follows a standard Transformer encoder-decoder architecture.
MTL-summarization is specially designed for summarization tasks, such as new summarization (CNN/DailyMail, XSum) and dialog summarization (SAMSum).
## Example
```python
>>> from transformers import MvpTokenizer, MvpForConditionalGeneration
>>> tokenizer = MvpTokenizer.from_pretrained("RUCAIBox/mvp")
>>> model = MvpForConditionalGeneration.from_pretrained("RUCAIBox/mtl-summarization")
>>> inputs = tokenizer(
... "Summarize: You may want to stick it to your boss and leave your job, but don't do it if these are your reasons.",
... return_tensors="pt",
... )
>>> generated_ids = model.generate(**inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
["Don't do it if these are your reasons"]
```
## Related Models
**MVP**: [https://huggingface.co/RUCAIBox/mvp](https://huggingface.co/RUCAIBox/mvp).
**Prompt-based models**:
- MVP-multi-task: [https://huggingface.co/RUCAIBox/mvp-multi-task](https://huggingface.co/RUCAIBox/mvp-multi-task).
- MVP-summarization: [https://huggingface.co/RUCAIBox/mvp-summarization](https://huggingface.co/RUCAIBox/mvp-summarization).
- MVP-open-dialog: [https://huggingface.co/RUCAIBox/mvp-open-dialog](https://huggingface.co/RUCAIBox/mvp-open-dialog).
- MVP-data-to-text: [https://huggingface.co/RUCAIBox/mvp-data-to-text](https://huggingface.co/RUCAIBox/mvp-data-to-text).
- MVP-story: [https://huggingface.co/RUCAIBox/mvp-story](https://huggingface.co/RUCAIBox/mvp-story).
- MVP-question-answering: [https://huggingface.co/RUCAIBox/mvp-question-answering](https://huggingface.co/RUCAIBox/mvp-question-answering).
- MVP-question-generation: [https://huggingface.co/RUCAIBox/mvp-question-generation](https://huggingface.co/RUCAIBox/mvp-question-generation).
- MVP-task-dialog: [https://huggingface.co/RUCAIBox/mvp-task-dialog](https://huggingface.co/RUCAIBox/mvp-task-dialog).
**Multi-task models**:
- MTL-summarization: [https://huggingface.co/RUCAIBox/mtl-summarization](https://huggingface.co/RUCAIBox/mtl-summarization).
- MTL-open-dialog: [https://huggingface.co/RUCAIBox/mtl-open-dialog](https://huggingface.co/RUCAIBox/mtl-open-dialog).
- MTL-data-to-text: [https://huggingface.co/RUCAIBox/mtl-data-to-text](https://huggingface.co/RUCAIBox/mtl-data-to-text).
- MTL-story: [https://huggingface.co/RUCAIBox/mtl-story](https://huggingface.co/RUCAIBox/mtl-story).
- MTL-question-answering: [https://huggingface.co/RUCAIBox/mtl-question-answering](https://huggingface.co/RUCAIBox/mtl-question-answering).
- MTL-question-generation: [https://huggingface.co/RUCAIBox/mtl-question-generation](https://huggingface.co/RUCAIBox/mtl-question-generation).
- MTL-task-dialog: [https://huggingface.co/RUCAIBox/mtl-task-dialog](https://huggingface.co/RUCAIBox/mtl-task-dialog).
## Citation
```bibtex
@article{tang2022mvp,
title={MVP: Multi-task Supervised Pre-training for Natural Language Generation},
author={Tang, Tianyi and Li, Junyi and Zhao, Wayne Xin and Wen, Ji-Rong},
journal={arXiv preprint arXiv:2206.12131},
year={2022},
url={https://arxiv.org/abs/2206.12131},
}
```
|
yanekyuk/camembert-keyword-extractor | 99e635ce87c9b2b3a4abd3497a1993a5fcc6237a | 2022-06-04T10:28:45.000Z | [
"pytorch",
"camembert",
"token-classification",
"fr",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index",
"autotrain_compatible"
] | token-classification | false | yanekyuk | null | yanekyuk/camembert-keyword-extractor | 34 | null | transformers | 6,863 | ---
license: mit
tags:
- generated_from_trainer
metrics:
- precision
- recall
- accuracy
- f1
language:
- fr
widget:
- text: "Le président de la République appelle en outre les Français à faire le choix d'une \"majorité stable et sérieuse pour les protéger face aux crises et pour agir pour l'avenir\". \"Je vois dans le projet de Jean-Luc Mélenchon ou de Madame Le Pen un projet de désordre et de soumission. Ils expliquent qu'il faut sortir de nos alliances, de l'Europe, et bâtir des alliances stratégiques avec la Russie. C'est la soumission à la Russie\", assure-t-il."
- text: "Top départ à l’ouverture des bureaux de vote. La Polynésie et les Français résidant à l'étranger, dont certains ont déjà pu voter en ligne, sont invités aux urnes ce week-end pour le premier tour des législatives, samedi 4 juin pour le continent américain et les Caraïbes, et dimanche 5 juin pour le reste du monde. En France métropolitaine, les premier et second tours auront lieu les 12 et 19 juin."
- text: "Le ministère a aussi indiqué que des missiles russes ont frappé un centre d'entraînement d'artillerie dans la région de Soumy où travaillaient des instructeurs étrangers. Il a jouté qu'une autre frappe avait détruit une position de \"mercenaires étrangers\" dans la région d'Odessa."
- text: "Le malaise est profond et ressemble à une crise existentielle. Fait rarissime au Quai d’Orsay, six syndicats et un collectif de 500 jeunes diplomates du ministère des Affaires étrangères ont appelé à la grève, jeudi 2 juin, pour protester contre la réforme de la haute fonction publique qui, à terme, entraînera la disparition des deux corps historiques de la diplomatie française : celui de ministre plénipotentiaire (ambassadeur) et celui de conseiller des affaires étrangères."
- text: "Ils se font passer pour des recruteurs de Lockheed Martin ou du géant britannique de la défense et de l’aérospatial BAE Systems. Ces soi-disant chasseurs de tête font miroiter des perspectives lucratives de carrière et des postes à responsabilité. Mais ce n’est que du vent. En réalité, il s’agit de cyberespions nord-coréens cherchant à voler des secrets industriels de groupes de défense ou du secteur de l’aérospatial, révèle Eset, une société slovaque de sécurité informatique, dans un rapport publié mardi 31 mai."
model-index:
- name: camembert-keyword-extractor
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# camembert-keyword-extractor
This model is a fine-tuned version of [camembert-base](https://huggingface.co/camembert-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2199
- Precision: 0.6743
- Recall: 0.6979
- Accuracy: 0.9346
- F1: 0.6859
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | Accuracy | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:--------:|:------:|
| 0.1747 | 1.0 | 1875 | 0.1780 | 0.5935 | 0.7116 | 0.9258 | 0.6472 |
| 0.1375 | 2.0 | 3750 | 0.1588 | 0.6505 | 0.7032 | 0.9334 | 0.6759 |
| 0.1147 | 3.0 | 5625 | 0.1727 | 0.6825 | 0.6689 | 0.9355 | 0.6756 |
| 0.0969 | 4.0 | 7500 | 0.1759 | 0.6886 | 0.6621 | 0.9350 | 0.6751 |
| 0.0837 | 5.0 | 9375 | 0.1967 | 0.6688 | 0.7112 | 0.9348 | 0.6893 |
| 0.0746 | 6.0 | 11250 | 0.2088 | 0.6646 | 0.7114 | 0.9334 | 0.6872 |
| 0.0666 | 7.0 | 13125 | 0.2169 | 0.6713 | 0.7054 | 0.9347 | 0.6879 |
| 0.0634 | 8.0 | 15000 | 0.2199 | 0.6743 | 0.6979 | 0.9346 | 0.6859 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
StanfordAIMI/stanford-deidentifier-with-radiology-reports-and-i2b2 | 48e3ae66e5d4a94989be60e2137838372dfd90e9 | 2022-07-18T03:48:45.000Z | [
"pytorch",
"bert",
"en",
"dataset:radreports",
"transformers",
"token-classification",
"sequence-tagger-model",
"pubmedbert",
"uncased",
"radiology",
"biomedical",
"license:mit"
] | token-classification | false | StanfordAIMI | null | StanfordAIMI/stanford-deidentifier-with-radiology-reports-and-i2b2 | 34 | 1 | transformers | 6,864 | ---
widget:
- text: "PROCEDURE: Chest xray. COMPARISON: last seen on 1/1/2020 and also record dated of March 1st, 2019. FINDINGS: patchy airspace opacities. IMPRESSION: The results of the chest xray of January 1 2020 are the most concerning ones. The patient was transmitted to another service of UH Medical Center under the responsability of Dr. Perez. We used the system MedClinical data transmitter and sent the data on 2/1/2020, under the ID 5874233. We received the confirmation of Dr Perez. He is reachable at 567-493-1234."
- text: "Dr. Curt Langlotz chose to schedule a meeting on 06/23."
tags:
- token-classification
- sequence-tagger-model
- pytorch
- transformers
- pubmedbert
- uncased
- radiology
- biomedical
datasets:
- radreports
language:
- en
license: mit
---
Stanford de-identifier was trained on a variety of radiology and biomedical documents with the goal of automatising the de-identification process while reaching satisfactory accuracy for use in production. Manuscript in-proceedings. |
binay1999/text_classification_cybertexts | f85d9c89055978caa39fa18fb2ebc13e35820aeb | 2022-06-20T16:26:04.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | text-classification | false | binay1999 | null | binay1999/text_classification_cybertexts | 34 | null | transformers | 6,865 | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: text_classification_cybertexts
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# text_classification_cybertexts
This model is a fine-tuned version of [binay1999/distilbert-cybertexts-preprocessed](https://huggingface.co/binay1999/distilbert-cybertexts-preprocessed) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0330
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:------:|:---------------:|
| 0.0333 | 1.0 | 38750 | 0.0389 |
| 0.0271 | 2.0 | 77500 | 0.0284 |
| 0.0135 | 3.0 | 116250 | 0.0330 |
### Framework versions
- Transformers 4.20.0
- Pytorch 1.11.0+cu113
- Tokenizers 0.12.1
|
waboucay/camembert-large-finetuned-xnli_fr_3_classes-finetuned-repnum_wl_3_classes | 299c68dbf42609bedae304527585ec2f0850838c | 2022-06-20T09:26:13.000Z | [
"pytorch",
"camembert",
"text-classification",
"fr",
"transformers",
"nli"
] | text-classification | false | waboucay | null | waboucay/camembert-large-finetuned-xnli_fr_3_classes-finetuned-repnum_wl_3_classes | 34 | null | transformers | 6,866 | ---
language:
- fr
tags:
- nli
metrics:
- f1
---
## Eval results
We obtain the following results on ```validation``` and ```test``` sets:
| Set | F1<sub>micro</sub> | F1<sub>macro</sub> |
|------------|--------------------|--------------------|
| validation | 78.3 | 78.3 |
| test | 79.5 | 79.4 | |
enoriega/rule_learning_margin_1mm_spanpred_attention | da9fd6bafff59e9b48db15b7ffee9b8d8951af1d | 2022-06-24T03:51:00.000Z | [
"pytorch",
"tensorboard",
"bert",
"dataset:enoriega/odinsynth_dataset",
"transformers",
"generated_from_trainer",
"model-index"
] | null | false | enoriega | null | enoriega/rule_learning_margin_1mm_spanpred_attention | 34 | null | transformers | 6,867 | ---
tags:
- generated_from_trainer
datasets:
- enoriega/odinsynth_dataset
model-index:
- name: rule_learning_margin_1mm_spanpred_attention
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# rule_learning_margin_1mm_spanpred_attention
This model is a fine-tuned version of [enoriega/rule_softmatching](https://huggingface.co/enoriega/rule_softmatching) on the enoriega/odinsynth_dataset dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3237
- Margin Accuracy: 0.8518
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 2000
- total_train_batch_size: 8000
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Margin Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------------:|
| 0.5768 | 0.16 | 20 | 0.5693 | 0.7577 |
| 0.4593 | 0.32 | 40 | 0.4338 | 0.8105 |
| 0.4219 | 0.48 | 60 | 0.3958 | 0.8218 |
| 0.3953 | 0.64 | 80 | 0.3809 | 0.8308 |
| 0.383 | 0.8 | 100 | 0.3684 | 0.8355 |
| 0.3781 | 0.96 | 120 | 0.3591 | 0.8396 |
| 0.354 | 1.12 | 140 | 0.3535 | 0.8420 |
| 0.3521 | 1.28 | 160 | 0.3491 | 0.8430 |
| 0.3533 | 1.44 | 180 | 0.3423 | 0.8466 |
| 0.344 | 1.6 | 200 | 0.3372 | 0.8472 |
| 0.3352 | 1.76 | 220 | 0.3345 | 0.8478 |
| 0.3318 | 1.92 | 240 | 0.3320 | 0.8487 |
| 0.3478 | 2.08 | 260 | 0.3286 | 0.8494 |
| 0.3329 | 2.24 | 280 | 0.3286 | 0.8505 |
| 0.3424 | 2.4 | 300 | 0.3262 | 0.8506 |
| 0.3463 | 2.56 | 320 | 0.3264 | 0.8512 |
| 0.3416 | 2.72 | 340 | 0.3247 | 0.8518 |
| 0.329 | 2.88 | 360 | 0.3247 | 0.8516 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0
- Datasets 2.2.1
- Tokenizers 0.12.1
|
Jimchoo91/distilbert-base-uncased-finetuned-emotion | 526a2c94834b467583ea59f245405d4aaf54302e | 2022-07-03T08:46:40.000Z | [
"pytorch",
"distilbert",
"text-classification",
"dataset:emotion",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] | text-classification | false | Jimchoo91 | null | Jimchoo91/distilbert-base-uncased-finetuned-emotion | 34 | null | transformers | 6,868 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.923
- name: F1
type: f1
value: 0.9231998923975969
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2251
- Accuracy: 0.923
- F1: 0.9232
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8243 | 1.0 | 250 | 0.3183 | 0.906 | 0.9019 |
| 0.2543 | 2.0 | 500 | 0.2251 | 0.923 | 0.9232 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.7.1
- Datasets 2.2.2
- Tokenizers 0.12.1
|
dfazage/nps-autotagger | 6938154b555142eca5550f75ad2f8c3e263c0153 | 2022-07-04T15:31:37.000Z | [
"pytorch",
"bert",
"transformers"
] | null | false | dfazage | null | dfazage/nps-autotagger | 34 | null | transformers | 6,869 | Entry not found |
juridics/bertimbaulaw-base-portuguese-cased | ea6ae27c897f19e0649b5be6fa2ee765e638d346 | 2022-07-04T21:47:21.000Z | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index",
"autotrain_compatible"
] | fill-mask | false | juridics | null | juridics/bertimbaulaw-base-portuguese-cased | 34 | null | transformers | 6,870 | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: output
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# output
This model is a fine-tuned version of [neuralmind/bert-base-portuguese-cased](https://huggingface.co/neuralmind/bert-base-portuguese-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6440
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-06
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 10000
- num_epochs: 15.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:------:|:---------------:|
| 1.1985 | 0.22 | 2500 | 1.0940 |
| 1.0937 | 0.44 | 5000 | 1.0033 |
| 1.0675 | 0.66 | 7500 | 0.9753 |
| 1.0565 | 0.87 | 10000 | 0.9801 |
| 1.0244 | 1.09 | 12500 | 0.9526 |
| 0.9943 | 1.31 | 15000 | 0.9298 |
| 0.9799 | 1.53 | 17500 | 0.9035 |
| 0.95 | 1.75 | 20000 | 0.8835 |
| 0.933 | 1.97 | 22500 | 0.8636 |
| 0.9079 | 2.18 | 25000 | 0.8507 |
| 0.8938 | 2.4 | 27500 | 0.8397 |
| 0.8781 | 2.62 | 30000 | 0.8195 |
| 0.8647 | 2.84 | 32500 | 0.8088 |
| 0.8422 | 3.06 | 35000 | 0.7954 |
| 0.831 | 3.28 | 37500 | 0.7871 |
| 0.8173 | 3.5 | 40000 | 0.7721 |
| 0.8072 | 3.71 | 42500 | 0.7611 |
| 0.8011 | 3.93 | 45000 | 0.7532 |
| 0.7828 | 4.15 | 47500 | 0.7431 |
| 0.7691 | 4.37 | 50000 | 0.7367 |
| 0.7659 | 4.59 | 52500 | 0.7292 |
| 0.7606 | 4.81 | 55000 | 0.7245 |
| 0.8082 | 5.02 | 57500 | 0.7696 |
| 0.8114 | 5.24 | 60000 | 0.7695 |
| 0.8022 | 5.46 | 62500 | 0.7613 |
| 0.7986 | 5.68 | 65000 | 0.7558 |
| 0.8018 | 5.9 | 67500 | 0.7478 |
| 0.782 | 6.12 | 70000 | 0.7435 |
| 0.7743 | 6.34 | 72500 | 0.7367 |
| 0.774 | 6.55 | 75000 | 0.7313 |
| 0.7692 | 6.77 | 77500 | 0.7270 |
| 0.7604 | 6.99 | 80000 | 0.7200 |
| 0.7468 | 7.21 | 82500 | 0.7164 |
| 0.7486 | 7.43 | 85000 | 0.7117 |
| 0.7399 | 7.65 | 87500 | 0.7043 |
| 0.7306 | 7.86 | 90000 | 0.6956 |
| 0.7243 | 8.08 | 92500 | 0.6959 |
| 0.7132 | 8.3 | 95000 | 0.6916 |
| 0.71 | 8.52 | 97500 | 0.6853 |
| 0.7128 | 8.74 | 100000 | 0.6855 |
| 0.7088 | 8.96 | 102500 | 0.6809 |
| 0.7002 | 9.18 | 105000 | 0.6784 |
| 0.6953 | 9.39 | 107500 | 0.6737 |
| 0.695 | 9.61 | 110000 | 0.6714 |
| 0.6871 | 9.83 | 112500 | 0.6687 |
| 0.7161 | 10.05 | 115000 | 0.6961 |
| 0.7265 | 10.27 | 117500 | 0.7006 |
| 0.7284 | 10.49 | 120000 | 0.6941 |
| 0.724 | 10.7 | 122500 | 0.6887 |
| 0.7266 | 10.92 | 125000 | 0.6931 |
| 0.7051 | 11.14 | 127500 | 0.6846 |
| 0.7106 | 11.36 | 130000 | 0.6816 |
| 0.7011 | 11.58 | 132500 | 0.6830 |
| 0.6997 | 11.8 | 135000 | 0.6784 |
| 0.6969 | 12.02 | 137500 | 0.6734 |
| 0.6968 | 12.23 | 140000 | 0.6709 |
| 0.6867 | 12.45 | 142500 | 0.6656 |
| 0.6925 | 12.67 | 145000 | 0.6661 |
| 0.6795 | 12.89 | 147500 | 0.6606 |
| 0.6774 | 13.11 | 150000 | 0.6617 |
| 0.6756 | 13.33 | 152500 | 0.6563 |
| 0.6728 | 13.54 | 155000 | 0.6547 |
| 0.6732 | 13.76 | 157500 | 0.6520 |
| 0.6704 | 13.98 | 160000 | 0.6492 |
| 0.6666 | 14.2 | 162500 | 0.6446 |
| 0.6615 | 14.42 | 165000 | 0.6488 |
| 0.6638 | 14.64 | 167500 | 0.6523 |
| 0.6588 | 14.85 | 170000 | 0.6415 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.1+cu113
- Datasets 1.17.0
- Tokenizers 0.10.3
|
aiknowyou/aiky-sentence-bertino | d75c170b753aa805943293c2caf2261b2b837db2 | 2022-07-13T12:51:22.000Z | [
"pytorch",
"distilbert",
"feature-extraction",
"sentence-transformers",
"sentence-similarity",
"transformers"
] | sentence-similarity | false | aiknowyou | null | aiknowyou/aiky-sentence-bertino | 34 | 0 | sentence-transformers | 6,871 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# Model aiky-sentence-bertino
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('aiknowyou/aiky-sentence-bertino')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('aiknowyou/aiky-sentence-bertino')
model = AutoModel.from_pretrained('aiknowyou/aiky-sentence-bertino')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=aiknowyou/aiky-sentence-bertino)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 391 with parameters:
```
{'batch_size': 64, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.OnlineContrastiveLoss.OnlineContrastiveLoss`
Parameters of the fit()-Method:
```
{
"epochs": 20,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 1000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: DistilBertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
BigSalmon/InformalToFormalLincoln56 | d297badbe1050de0b8af98b38f95556dc8c681db | 2022-07-20T21:47:52.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | false | BigSalmon | null | BigSalmon/InformalToFormalLincoln56 | 34 | null | transformers | 6,872 | ```
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("BigSalmon/InformalToFormalLincoln56")
model = AutoModelForCausalLM.from_pretrained("BigSalmon/InformalToFormalLincoln56")
```
```
How To Make Prompt:
informal english: i am very ready to do that just that.
Translated into the Style of Abraham Lincoln: you can assure yourself of my readiness to work toward this end.
Translated into the Style of Abraham Lincoln: please be assured that i am most ready to undertake this laborious task.
***
informal english: space is huge and needs to be explored.
Translated into the Style of Abraham Lincoln: space awaits traversal, a new world whose boundaries are endless.
Translated into the Style of Abraham Lincoln: space is a ( limitless / boundless ) expanse, a vast virgin domain awaiting exploration.
***
informal english: corn fields are all across illinois, visible once you leave chicago.
Translated into the Style of Abraham Lincoln: corn fields ( permeate illinois / span the state of illinois / ( occupy / persist in ) all corners of illinois / line the horizon of illinois / envelop the landscape of illinois ), manifesting themselves visibly as one ventures beyond chicago.
informal english:
```
```
infill: chrome extensions [MASK] accomplish everyday tasks.
Translated into the Style of Abraham Lincoln: chrome extensions ( expedite the ability to / unlock the means to more readily ) accomplish everyday tasks.
infill: at a time when nintendo has become inflexible, [MASK] consoles that are tethered to a fixed iteration, sega diligently curates its legacy of classic video games on handheld devices.
Translated into the Style of Abraham Lincoln: at a time when nintendo has become inflexible, ( stubbornly [MASK] on / firmly set on / unyielding in its insistence on ) consoles that are tethered to a fixed iteration, sega diligently curates its legacy of classic video games on handheld devices.
infill:
```
```
Essay Intro (Warriors vs. Rockets in Game 7):
text: eagerly anticipated by fans, game 7's are the highlight of the post-season.
text: ever-building in suspense, game 7's have the crowd captivated.
***
Essay Intro (South Korean TV Is Becoming Popular):
text: maturing into a bona fide paragon of programming, south korean television ( has much to offer / entertains without fail / never disappoints ).
text: increasingly held in critical esteem, south korean television continues to impress.
text: at the forefront of quality content, south korea is quickly achieving celebrity status.
***
Essay Intro (
```
```
Search: What is the definition of Checks and Balances?
https://en.wikipedia.org/wiki/Checks_and_balances
Checks and Balances is the idea of having a system where each and every action in government should be subject to one or more checks that would not allow one branch or the other to overly dominate.
https://www.harvard.edu/glossary/Checks_and_Balances
Checks and Balances is a system that allows each branch of government to limit the powers of the other branches in order to prevent abuse of power
https://www.law.cornell.edu/library/constitution/Checks_and_Balances
Checks and Balances is a system of separation through which branches of government can control the other, thus preventing excess power.
***
Search: What is the definition of Separation of Powers?
https://en.wikipedia.org/wiki/Separation_of_powers
The separation of powers is a principle in government, whereby governmental powers are separated into different branches, each with their own set of powers, that are prevent one branch from aggregating too much power.
https://www.yale.edu/tcf/Separation_of_Powers.html
Separation of Powers is the division of governmental functions between the executive, legislative and judicial branches, clearly demarcating each branch's authority, in the interest of ensuring that individual liberty or security is not undermined.
***
Search: What is the definition of Connection of Powers?
https://en.wikipedia.org/wiki/Connection_of_powers
Connection of Powers is a feature of some parliamentary forms of government where different branches of government are intermingled, typically the executive and legislative branches.
https://simple.wikipedia.org/wiki/Connection_of_powers
The term Connection of Powers describes a system of government in which there is overlap between different parts of the government.
***
Search: What is the definition of
```
```
Search: What are phrase synonyms for "second-guess"?
https://www.powerthesaurus.org/second-guess/synonyms
Shortest to Longest:
- feel dubious about
- raise an eyebrow at
- wrinkle their noses at
- cast a jaundiced eye at
- teeter on the fence about
***
Search: What are phrase synonyms for "mean to newbies"?
https://www.powerthesaurus.org/mean_to_newbies/synonyms
Shortest to Longest:
- readiness to balk at rookies
- absence of tolerance for novices
- hostile attitude toward newcomers
***
Search: What are phrase synonyms for "make use of"?
https://www.powerthesaurus.org/make_use_of/synonyms
Shortest to Longest:
- call upon
- glean value from
- reap benefits from
- derive utility from
- seize on the merits of
- draw on the strength of
- tap into the potential of
***
Search: What are phrase synonyms for "hurting itself"?
https://www.powerthesaurus.org/hurting_itself/synonyms
Shortest to Longest:
- erring
- slighting itself
- forfeiting its integrity
- doing itself a disservice
- evincing a lack of backbone
***
Search: What are phrase synonyms for "
```
```
original: sports teams are profitable for owners. [MASK], their valuations experience a dramatic uptick.
infill: sports teams are profitable for owners. ( accumulating vast sums / stockpiling treasure / realizing benefits / cashing in / registering robust financials / scoring on balance sheets ), their valuations experience a dramatic uptick.
***
original:
```
```
wordy: classical music is becoming less popular more and more.
Translate into Concise Text: interest in classic music is fading.
***
wordy:
```
make longer
```
sweet: savvy voters ousted him.
longer: voters who were informed delivered his defeat.
***
sweet: embodies compassion.
longer: is the personification of compassion.
***
sweet:
```
```
1: commercial space company spacex plans to launch a whopping 52 flights in 2022.
2: spacex, a commercial space company, intends to undertake a total of 52 flights in 2022.
3: in 2022, commercial space company spacex has its sights set on undertaking 52 flights.
4: 52 flights are in the pipeline for 2022, according to spacex, a commercial space company.
5: a commercial space company, spacex aims to conduct 52 flights in 2022.
***
1:
```
```
ngos are characterized by:
□ voluntary citizens' group that is organized on a local, national or international level
□ encourage political participation
□ often serve humanitarian functions
□ work for social, economic, or environmental change
***
what are the drawbacks of living near an airbnb?
□ noise
□ parking
□ traffic
□ security
□ strangers
***
```
```
original: musicals generally use spoken dialogue as well as songs to convey the story. operas are usually fully sung.
adapted: musicals generally use spoken dialogue as well as songs to convey the story. ( in a stark departure / on the other hand / in contrast / by comparison / at odds with this practice / far from being alike / in defiance of this standard / running counter to this convention ), operas are usually fully sung.
***
original: akoya and tahitian are types of pearls. akoya pearls are mostly white, and tahitian pearls are naturally dark.
adapted: akoya and tahitian are types of pearls. ( a far cry from being indistinguishable / easily distinguished / on closer inspection / setting them apart / not to be mistaken for one another / hardly an instance of mere synonymy / differentiating the two ), akoya pearls are mostly white, and tahitian pearls are naturally dark.
***
original:
```
```
original: work in an office ).
translated into journalism speak: ( beaver away in windowless offices / toil in drab cubicles / clock in at faceless workstations / report for duty in cheerless quarters / log hours in colorless confines / clack away on keyboards in offices with cinderblock walls / stare at computer screens in bland partitions / shuffle through mounds of paperwork in humdrum offices ).
***
original: easy job ).
translated into journalism speak: ( cushy / hassle-free / uninvolved / vanilla / sedentary / straightforward / effortless / lax / plush / frictionless / painless ) ( gig / perch / post / trade / calling / paycheck ).
***
original:
```
```
input: not loyal
1800s english: ( two-faced / inimical / perfidious / duplicitous / mendacious / double-dealing / shifty ).
***
input:
```
```
original: big businesses ).
translated into journalism speak: corporate ( behemoths / heavyweights / titans / steamrollers / powerhouses / bigwigs / kahunas / brutes / honchos / barons / kingpins / rainmakers / headliners ).
***
original: environmental movement ).
translated into journalism speak: ( green lobby / conservationist camp / tree-huggers / ecology-obsessed / sustainability crusaders / preservation-crazed / ecological campaigners ).
***
original:
```
```
first: ( was complicit in / was involved in ).
antonym: ( was blameless / was not an accomplice to / had no hand in / was uninvolved in ).
***
first: ( have no qualms about / see no issue with ).
antonym: ( are deeply troubled by / harbor grave reservations about / have a visceral aversion to / take ( umbrage at / exception to ) / are wary of ).
***
first: ( do not see eye to eye / disagree often ).
antonym: ( are in sync / are united / have excellent rapport / are like-minded / are in step / are of one mind / are in lockstep / operate in perfect harmony / march in lockstep ).
***
first:
```
```
stiff with competition, law school {A} is the launching pad for countless careers, {B} is a crowded field, {C} ranks among the most sought-after professional degrees, {D} is a professional proving ground.
***
languishing in viewership, saturday night live {A} is due for a creative renaissance, {B} is no longer a ratings juggernaut, {C} has been eclipsed by its imitators, {C} can still find its mojo.
***
dubbed the "manhattan of the south," atlanta {A} is a bustling metropolis, {B} is known for its vibrant downtown, {C} is a city of rich history, {D} is the pride of georgia.
***
embattled by scandal, harvard {A} is feeling the heat, {B} cannot escape the media glare, {C} is facing its most intense scrutiny yet, {D} is in the spotlight for all the wrong reasons.
``` |
ai4bharat/IndicBERTv2-alpha-SentimentClassification | c5ef4cb7eac5f2c337d43ca62f9767d789f6e883 | 2022-07-27T11:22:06.000Z | [
"pytorch",
"roberta",
"text-classification",
"transformers"
] | text-classification | false | ai4bharat | null | ai4bharat/IndicBERTv2-alpha-SentimentClassification | 34 | null | transformers | 6,873 | # IndicXLMv2-alpha-SentimentClassification
|
Frikallo/vgdunkey | f9f38cdcd13957b23631eea22a3e15ee86f625b1 | 2022-07-23T06:50:19.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | false | Frikallo | null | Frikallo/vgdunkey | 34 | null | transformers | 6,874 | Entry not found |
nishita/results | b78eff1c23e1387025f9fa79276d7bc2be4b8bd5 | 2022-07-24T01:28:03.000Z | [
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index",
"autotrain_compatible"
] | text2text-generation | false | nishita | null | nishita/results | 34 | null | transformers | 6,875 | ---
license: mit
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: results
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# results
This model is a fine-tuned version of [gagan3012/k2t](https://huggingface.co/gagan3012/k2t) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5481
- Rouge1: 65.0534
- Rouge2: 45.7092
- Rougel: 55.8222
- Rougelsum: 57.1866
- Gen Len: 17.8061
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 0.5049 | 1.0 | 1101 | 0.5527 | 65.0475 | 45.6298 | 55.8323 | 57.2102 | 17.7929 |
| 0.4994 | 2.0 | 2202 | 0.5490 | 65.0567 | 45.7082 | 55.8808 | 57.2343 | 17.8005 |
| 0.4969 | 3.0 | 3303 | 0.5481 | 65.0534 | 45.7092 | 55.8222 | 57.1866 | 17.8061 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
KDHyun08/TAACO_STS | 552be503457842e7ca33d9eafd269069fa0f1e03 | 2022-07-28T07:06:00.000Z | [
"pytorch",
"bert",
"feature-extraction",
"ko",
"sentence-transformers",
"sentence-similarity",
"transformers",
"TAACO"
] | sentence-similarity | false | KDHyun08 | null | KDHyun08/TAACO_STS | 34 | null | sentence-transformers | 6,876 | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- sentence-similarity
- transformers
- TAACO
language: ko
---
# TAACO_Similarity
본 모델은 [Sentence-transformers](https://www.SBERT.net)를 기반으로 하며 KLUE의 STS(Sentence Textual Similarity) 데이터셋을 통해 훈련을 진행한 모델입니다.
필자가 제작하고 있는 한국어 문장간 결속성 측정 도구인 K-TAACO(가제)의 지표 중 하나인 문장 간 의미적 결속성을 측정하기 위해 본 모델을 제작하였습니다.
또한 모두의 말뭉치의 문장간 유사도 데이터 등 다양한 데이터를 구해 추가 훈련을 진행할 예정입니다.
## Usage (Sentence-Transformers)
본 모델을 사용하기 위해서는 [Sentence-transformers](https://www.SBERT.net)를 설치하여야 합니다.
```
pip install -U sentence-transformers
```
모델을 사용하기 위해서는 아래 코드를 참조하시길 바랍니다.
```python
from sentence_transformers import SentenceTransformer, models
sentences = ["This is an example sentence", "Each sentence is converted"]
embedding_model = models.Transformer(
model_name_or_path="KDHyun08/TAACO_STS",
max_seq_length=256,
do_lower_case=True
)
pooling_model = models.Pooling(
embedding_model.get_word_embedding_dimension(),
pooling_mode_mean_tokens=True,
pooling_mode_cls_token=False,
pooling_mode_max_tokens=False,
)
model = SentenceTransformer(modules=[embedding_model, pooling_model])
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (실제 문장 간 유사도 비교)
[Sentence-transformers](https://www.SBERT.net) 를 설치한 후 아래 내용과 같이 문장 간 유사도를 비교할 수 있습니다.
query 변수는 비교 기준이 되는 문장(Source Sentence)이고 비교를 진행할 문장은 docs에 list 형식으로 구성하시면 됩니다.
```python
from sentence_transformers import SentenceTransformer, models
embedding_model = models.Transformer(
model_name_or_path="KDHyun08/TAACO_STS",
max_seq_length=256,
do_lower_case=True
)
pooling_model = models.Pooling(
embedding_model.get_word_embedding_dimension(),
pooling_mode_mean_tokens=True,
pooling_mode_cls_token=False,
pooling_mode_max_tokens=False,
)
model = SentenceTransformer(modules=[embedding_model, pooling_model])
docs = ['어제는 아내의 생일이었다', '생일을 맞이하여 아침을 준비하겠다고 오전 8시 30분부터 음식을 준비하였다. 주된 메뉴는 스테이크와 낙지볶음, 미역국, 잡채, 소야 등이었다', '스테이크는 자주 하는 음식이어서 자신이 준비하려고 했다', '앞뒤도 1분씩 3번 뒤집고 래스팅을 잘 하면 육즙이 가득한 스테이크가 준비되다', '아내도 그런 스테이크를 좋아한다. 그런데 상상도 못한 일이 벌이지고 말았다', '보통 시즈닝이 되지 않은 원육을 사서 스테이크를 했는데, 이번에는 시즈닝이 된 부챗살을 구입해서 했다', '그런데 케이스 안에 방부제가 들어있는 것을 인지하지 못하고 방부제와 동시에 프라이팬에 올려놓을 것이다', '그것도 인지 못한 체... 앞면을 센 불에 1분을 굽고 뒤집는 순간 방부제가 함께 구어진 것을 알았다', '아내의 생일이라 맛있게 구워보고 싶었는데 어처구니없는 상황이 발생한 것이다', '방부제가 센 불에 녹아서 그런지 물처럼 흘러내렸다', ' 고민을 했다. 방부제가 묻은 부문만 제거하고 다시 구울까 했는데 방부제에 절대 먹지 말라는 문구가 있어서 아깝지만 버리는 방향을 했다', '너무나 안타까웠다', '아침 일찍 아내가 좋아하는 스테이크를 준비하고 그것을 맛있게 먹는 아내의 모습을 보고 싶었는데 전혀 생각지도 못한 상황이 발생해서... 하지만 정신을 추스르고 바로 다른 메뉴로 변경했다', '소야, 소시지 야채볶음..', '아내가 좋아하는지 모르겠지만 냉장고 안에 있는 후랑크소세지를 보니 바로 소야를 해야겠다는 생각이 들었다. 음식은 성공적으로 완성이 되었다', '40번째를 맞이하는 아내의 생일은 성공적으로 준비가 되었다', '맛있게 먹어 준 아내에게도 감사했다', '매년 아내의 생일에 맞이하면 아침마다 생일을 차려야겠다. 오늘도 즐거운 하루가 되었으면 좋겠다', '생일이니까~']
#각 문장의 vector값 encoding
document_embeddings = model.encode(docs)
query = '생일을 맞이하여 아침을 준비하겠다고 오전 8시 30분부터 음식을 준비하였다'
query_embedding = model.encode(query)
top_k = min(10, len(docs))
# 코사인 유사도 계산 후,
cos_scores = util.pytorch_cos_sim(query_embedding, document_embeddings)[0]
# 코사인 유사도 순으로 문장 추출
top_results = torch.topk(cos_scores, k=top_k)
print(f"입력 문장: {query}")
print(f"\n<입력 문장과 유사한 {top_k} 개의 문장>\n")
for i, (score, idx) in enumerate(zip(top_results[0], top_results[1])):
print(f"{i+1}: {docs[idx]} {'(유사도: {:.4f})'.format(score)}\n")
```
## Evaluation Results
위 예시(Usage)를 실행하게 되면 아래와 같은 결과가 도출됩니다. 1에 가까울수록 유사한 문장입니다.
```
입력 문장: 생일을 맞이하여 아침을 준비하겠다고 오전 8시 30분부터 음식을 준비하였다
<입력 문장과 유사한 10 개의 문장>
1: 생일을 맞이하여 아침을 준비하겠다고 오전 8시 30분부터 음식을 준비하였다. 주된 메뉴는 스테이크와 낙지볶음, 미역국, 잡채, 소야 등이었다 (유사도: 0.6687)
2: 매년 아내의 생일에 맞이하면 아침마다 생일을 차려야겠다. 오늘도 즐거운 하루가 되었으면 좋겠다 (유사도: 0.6468)
3: 40번째를 맞이하는 아내의 생일은 성공적으로 준비가 되었다 (유사도: 0.4647)
4: 아내의 생일이라 맛있게 구워보고 싶었는데 어처구니없는 상황이 발생한 것이다 (유사도: 0.4469)
5: 생일이니까~ (유사도: 0.4218)
6: 어제는 아내의 생일이었다 (유사도: 0.4192)
7: 아침 일찍 아내가 좋아하는 스테이크를 준비하고 그것을 맛있게 먹는 아내의 모습을 보고 싶었는데 전혀 생각지도 못한 상황이 발생해서... 하지만 정신을 추스르고 바로 다른 메뉴로 변경했다 (유사도: 0.4156)
8: 맛있게 먹어 준 아내에게도 감사했다 (유사도: 0.3093)
9: 아내가 좋아하는지 모르겠지만 냉장고 안에 있는 후랑크소세지를 보니 바로 소야를 해야겠다는 생각이 들었다. 음식은 성공적으로 완성이 되었다 (유사도: 0.2259)
10: 아내도 그런 스테이크를 좋아한다. 그런데 상상도 못한 일이 벌이지고 말았다 (유사도: 0.1967)
```
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 142 with parameters:
```
{'batch_size': 32, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 4,
"evaluation_steps": 1000,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
Cameron/BERT-jigsaw-severetoxic | 8f37a4b397c1d6a3ace016eb6b61f9e0715d6936 | 2021-05-18T17:28:58.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
] | text-classification | false | Cameron | null | Cameron/BERT-jigsaw-severetoxic | 33 | null | transformers | 6,877 | Entry not found |
Helsinki-NLP/opus-mt-chk-en | d9a7fad4fdc70b734457a5eee20835d8899e7415 | 2021-09-09T21:28:41.000Z | [
"pytorch",
"marian",
"text2text-generation",
"chk",
"en",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] | translation | false | Helsinki-NLP | null | Helsinki-NLP/opus-mt-chk-en | 33 | null | transformers | 6,878 | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-chk-en
* source languages: chk
* target languages: en
* OPUS readme: [chk-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/chk-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2019-12-18.zip](https://object.pouta.csc.fi/OPUS-MT-models/chk-en/opus-2019-12-18.zip)
* test set translations: [opus-2019-12-18.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/chk-en/opus-2019-12-18.test.txt)
* test set scores: [opus-2019-12-18.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/chk-en/opus-2019-12-18.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.chk.en | 31.2 | 0.465 |
|
Helsinki-NLP/opus-mt-en-mh | ab95e0811620e963dbea2ebc42f5f04e6159142f | 2021-09-09T21:37:35.000Z | [
"pytorch",
"marian",
"text2text-generation",
"en",
"mh",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] | translation | false | Helsinki-NLP | null | Helsinki-NLP/opus-mt-en-mh | 33 | null | transformers | 6,879 | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-en-mh
* source languages: en
* target languages: mh
* OPUS readme: [en-mh](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/en-mh/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-08.zip](https://object.pouta.csc.fi/OPUS-MT-models/en-mh/opus-2020-01-08.zip)
* test set translations: [opus-2020-01-08.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-mh/opus-2020-01-08.test.txt)
* test set scores: [opus-2020-01-08.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-mh/opus-2020-01-08.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.en.mh | 29.7 | 0.479 |
|
Helsinki-NLP/opus-mt-ln-en | bfa0650570083f575357b69387c2ad8f6bce3c9a | 2021-09-10T13:55:01.000Z | [
"pytorch",
"marian",
"text2text-generation",
"ln",
"en",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] | translation | false | Helsinki-NLP | null | Helsinki-NLP/opus-mt-ln-en | 33 | null | transformers | 6,880 | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-ln-en
* source languages: ln
* target languages: en
* OPUS readme: [ln-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/ln-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-09.zip](https://object.pouta.csc.fi/OPUS-MT-models/ln-en/opus-2020-01-09.zip)
* test set translations: [opus-2020-01-09.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/ln-en/opus-2020-01-09.test.txt)
* test set scores: [opus-2020-01-09.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/ln-en/opus-2020-01-09.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.ln.en | 35.9 | 0.516 |
|
Helsinki-NLP/opus-mt-niu-en | ec1b88bcb1d9bc7aa1ca9efc5c79546fe7751da5 | 2021-09-10T13:58:48.000Z | [
"pytorch",
"marian",
"text2text-generation",
"niu",
"en",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] | translation | false | Helsinki-NLP | null | Helsinki-NLP/opus-mt-niu-en | 33 | null | transformers | 6,881 | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-niu-en
* source languages: niu
* target languages: en
* OPUS readme: [niu-en](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/niu-en/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-21.zip](https://object.pouta.csc.fi/OPUS-MT-models/niu-en/opus-2020-01-21.zip)
* test set translations: [opus-2020-01-21.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/niu-en/opus-2020-01-21.test.txt)
* test set scores: [opus-2020-01-21.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/niu-en/opus-2020-01-21.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.niu.en | 46.1 | 0.604 |
|
KoichiYasuoka/bert-base-thai-upos | cf52e08cec79754a0e5b17913282857cc6c07ca3 | 2022-05-07T13:38:34.000Z | [
"pytorch",
"bert",
"token-classification",
"th",
"dataset:universal_dependencies",
"transformers",
"thai",
"pos",
"wikipedia",
"dependency-parsing",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | false | KoichiYasuoka | null | KoichiYasuoka/bert-base-thai-upos | 33 | null | transformers | 6,882 | ---
language:
- "th"
tags:
- "thai"
- "token-classification"
- "pos"
- "wikipedia"
- "dependency-parsing"
datasets:
- "universal_dependencies"
license: "apache-2.0"
pipeline_tag: "token-classification"
widget:
- text: "หลายหัวดีกว่าหัวเดียว"
---
# bert-base-thai-upos
## Model Description
This is a BERT model pre-trained on Thai Wikipedia texts for POS-tagging and dependency-parsing, derived from [bert-base-th-cased](https://huggingface.co/Geotrend/bert-base-th-cased). Every word is tagged by [UPOS](https://universaldependencies.org/u/pos/) (Universal Part-Of-Speech).
## How to Use
```py
from transformers import AutoTokenizer,AutoModelForTokenClassification
tokenizer=AutoTokenizer.from_pretrained("KoichiYasuoka/bert-base-thai-upos")
model=AutoModelForTokenClassification.from_pretrained("KoichiYasuoka/bert-base-thai-upos")
```
or
```py
import esupar
nlp=esupar.load("KoichiYasuoka/bert-base-thai-upos")
```
## See Also
[esupar](https://github.com/KoichiYasuoka/esupar): Tokenizer POS-tagger and Dependency-parser with BERT/RoBERTa models
|
Luyu/bert-base-mdoc-hdct | e5bb3df33ed844dc2db824f5ac6dad2f2df7e637 | 2021-09-22T08:11:58.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"en",
"dataset:MS MARCO document ranking",
"transformers",
"text reranking",
"license:apache-2.0"
] | text-classification | false | Luyu | null | Luyu/bert-base-mdoc-hdct | 33 | null | transformers | 6,883 | ---
language:
- en
tags:
- text reranking
license: apache-2.0
datasets:
- MS MARCO document ranking
---
# BERT Reranker for MS-MARCO Document Ranking
## Model description
A text reranker trained for HDCT retriever on MS MARCO document dataset.
## Intended uses & limitations
It is possible to work with other retrievers like BM25 but using aligned HDCT works the best.
#### How to use
See our [project repo page](https://github.com/luyug/Reranker).
## Eval results
MRR @10: 0.434 on Dev.
MRR @10: 0.382 on Eval.
### BibTeX entry and citation info
```bibtex
@inproceedings{gao2021lce,
title={Rethink Training of BERT Rerankers in Multi-Stage Retrieval Pipeline},
author={Luyu Gao and Zhuyun Dai and Jamie Callan},
year={2021},
booktitle={The 43rd European Conference On Information Retrieval (ECIR)},
}
``` |
NLPC-UOM/SinBERT-large | 900302260c2fc36f67e705f119bb888eba54bb99 | 2022-04-29T05:05:04.000Z | [
"pytorch",
"roberta",
"fill-mask",
"si",
"transformers",
"license:mit",
"autotrain_compatible"
] | fill-mask | false | NLPC-UOM | null | NLPC-UOM/SinBERT-large | 33 | 1 | transformers | 6,884 | ---
language:
- si
license:
- mit
---
This is SinBERT-large model. SinBERT models are pretrained on a large Sinhala monolingual corpus (sin-cc-15M) using RoBERTa. If you use this model, please cite *BERTifying Sinhala - A Comprehensive Analysis of Pre-trained Language Models for Sinhala Text Classification, LREC 2022* |
QianWeiTech/GPT2-Titles | af6d73c9cf4e77335194a3cf4e27924bddc43559 | 2021-05-21T11:05:09.000Z | [
"pytorch",
"jax",
"gpt2",
"text-generation",
"transformers"
] | text-generation | false | QianWeiTech | null | QianWeiTech/GPT2-Titles | 33 | 1 | transformers | 6,885 | Entry not found |
SEBIS/code_trans_t5_large_code_documentation_generation_java_transfer_learning_finetune | 28251592098a15926e0f7548397d5ce59c6154fb | 2021-06-23T06:50:46.000Z | [
"pytorch",
"jax",
"t5",
"feature-extraction",
"transformers",
"summarization"
] | summarization | false | SEBIS | null | SEBIS/code_trans_t5_large_code_documentation_generation_java_transfer_learning_finetune | 33 | null | transformers | 6,886 | ---
tags:
- summarization
widget:
- text: "public static < T , U > Function < T , U > castFunction ( Class < U > target ) { return new CastToClass < T , U > ( target ) ; }"
---
# CodeTrans model for code documentation generation java
Pretrained model on programming language java using the t5 large model architecture. It was first released in
[this repository](https://github.com/agemagician/CodeTrans). This model is trained on tokenized java code functions: it works best with tokenized java functions.
## Model description
This CodeTrans model is based on the `t5-large` model. It has its own SentencePiece vocabulary model. It used transfer-learning pre-training on 7 unsupervised datasets in the software development domain. It is then fine-tuned on the code documentation generation task for the java function/method.
## Intended uses & limitations
The model could be used to generate the description for the java function or be fine-tuned on other java code tasks. It can be used on unparsed and untokenized java code. However, if the java code is tokenized, the performance should be better.
### How to use
Here is how to use this model to generate java function documentation using Transformers SummarizationPipeline:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead, SummarizationPipeline
pipeline = SummarizationPipeline(
model=AutoModelWithLMHead.from_pretrained("SEBIS/code_trans_t5_large_code_documentation_generation_java_transfer_learning_finetune"),
tokenizer=AutoTokenizer.from_pretrained("SEBIS/code_trans_t5_large_code_documentation_generation_java_transfer_learning_finetune", skip_special_tokens=True),
device=0
)
tokenized_code = "public static < T , U > Function < T , U > castFunction ( Class < U > target ) { return new CastToClass < T , U > ( target ) ; }"
pipeline([tokenized_code])
```
Run this example in [colab notebook](https://github.com/agemagician/CodeTrans/blob/main/prediction/transfer%20learning%20fine-tuning/function%20documentation%20generation/java/large_model.ipynb).
## Training data
The supervised training tasks datasets can be downloaded on [Link](https://www.dropbox.com/sh/488bq2of10r4wvw/AACs5CGIQuwtsD7j_Ls_JAORa/finetuning_dataset?dl=0&subfolder_nav_tracking=1)
## Training procedure
### Transfer-learning Pretraining
The model was trained on a single TPU Pod V3-8 for 240,000 steps in total, using sequence length 512 (batch size 4096).
It has a total of approximately 220M parameters and was trained using the encoder-decoder architecture.
The optimizer used is AdaFactor with inverse square root learning rate schedule for pre-training.
### Fine-tuning
This model was then fine-tuned on a single TPU Pod V2-8 for 500 steps in total, using sequence length 512 (batch size 256), using only the dataset only containing java code.
## Evaluation results
For the code documentation tasks, different models achieves the following results on different programming languages (in BLEU score):
Test results :
| Language / Model | Python | Java | Go | Php | Ruby | JavaScript |
| -------------------- | :------------: | :------------: | :------------: | :------------: | :------------: | :------------: |
| CodeTrans-ST-Small | 17.31 | 16.65 | 16.89 | 23.05 | 9.19 | 13.7 |
| CodeTrans-ST-Base | 16.86 | 17.17 | 17.16 | 22.98 | 8.23 | 13.17 |
| CodeTrans-TF-Small | 19.93 | 19.48 | 18.88 | 25.35 | 13.15 | 17.23 |
| CodeTrans-TF-Base | 20.26 | 20.19 | 19.50 | 25.84 | 14.07 | 18.25 |
| CodeTrans-TF-Large | 20.35 | 20.06 | **19.54** | 26.18 | 14.94 | **18.98** |
| CodeTrans-MT-Small | 19.64 | 19.00 | 19.15 | 24.68 | 14.91 | 15.26 |
| CodeTrans-MT-Base | **20.39** | 21.22 | 19.43 | **26.23** | **15.26** | 16.11 |
| CodeTrans-MT-Large | 20.18 | **21.87** | 19.38 | 26.08 | 15.00 | 16.23 |
| CodeTrans-MT-TF-Small | 19.77 | 20.04 | 19.36 | 25.55 | 13.70 | 17.24 |
| CodeTrans-MT-TF-Base | 19.77 | 21.12 | 18.86 | 25.79 | 14.24 | 18.62 |
| CodeTrans-MT-TF-Large | 18.94 | 21.42 | 18.77 | 26.20 | 14.19 | 18.83 |
| State of the art | 19.06 | 17.65 | 18.07 | 25.16 | 12.16 | 14.90 |
> Created by [Ahmed Elnaggar](https://twitter.com/Elnaggar_AI) | [LinkedIn](https://www.linkedin.com/in/prof-ahmed-elnaggar/) and Wei Ding | [LinkedIn](https://www.linkedin.com/in/wei-ding-92561270/)
|
Saviour/ChandlerBot | ba2070c8891acc48a1c9f95d6ddf09fa8570a4c4 | 2021-06-24T20:55:24.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | false | Saviour | null | Saviour/ChandlerBot | 33 | null | transformers | 6,887 | ---
tags:
- conversational
---
# My Awesome Model |
ShannonAI/ChineseBERT-large | 2099e312792212f473c65c9cfb06d2e102df402c | 2022-06-19T12:07:31.000Z | [
"pytorch",
"arxiv:2106.16038"
] | null | false | ShannonAI | null | ShannonAI/ChineseBERT-large | 33 | 0 | null | 6,888 | # ChineseBERT-large
This repository contains code, model, dataset for **ChineseBERT** at ACL2021.
paper:
**[ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information](https://arxiv.org/abs/2106.16038)**
*Zijun Sun, Xiaoya Li, Xiaofei Sun, Yuxian Meng, Xiang Ao, Qing He, Fei Wu and Jiwei Li*
code:
[ChineseBERT github link](https://github.com/ShannonAI/ChineseBert)
## Model description
We propose ChineseBERT, which incorporates both the glyph and pinyin information of Chinese
characters into language model pretraining.
First, for each Chinese character, we get three kind of embedding.
- **Char Embedding:** the same as origin BERT token embedding.
- **Glyph Embedding:** capture visual features based on different fonts of a Chinese character.
- **Pinyin Embedding:** capture phonetic feature from the pinyin sequence ot a Chinese Character.
Then, char embedding, glyph embedding and pinyin embedding
are first concatenated, and mapped to a D-dimensional embedding through a fully
connected layer to form the fusion embedding.
Finally, the fusion embedding is added with the position embedding, which is fed as input to the BERT model.
The following image shows an overview architecture of ChineseBERT model.

ChineseBERT leverages the glyph and pinyin information of Chinese
characters to enhance the model's ability of capturing
context semantics from surface character forms and
disambiguating polyphonic characters in Chinese. |
StivenLancheros/mBERT-base-Biomedical-NER | 0b2d656362761162f46ee033df829a477e307dd4 | 2022-03-03T00:45:07.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] | token-classification | false | StivenLancheros | null | StivenLancheros/mBERT-base-Biomedical-NER | 33 | null | transformers | 6,889 | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-base-multilingual-cased-finetuned-ner-4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-multilingual-cased-finetuned-ner-4
#This model is part of a test for creating multilingual BioMedical NER systems. Not intended for proffesional use now.
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on the CRAFT+BC4CHEMD+BioNLP09 datasets concatenated.
It achieves the following results on the evaluation set:
- Loss: 0.1027
- Precision: 0.9830
- Recall: 0.9832
- F1: 0.9831
- Accuracy: 0.9799
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0658 | 1.0 | 6128 | 0.0751 | 0.9795 | 0.9795 | 0.9795 | 0.9758 |
| 0.0406 | 2.0 | 12256 | 0.0753 | 0.9827 | 0.9815 | 0.9821 | 0.9786 |
| 0.0182 | 3.0 | 18384 | 0.0934 | 0.9834 | 0.9825 | 0.9829 | 0.9796 |
| 0.011 | 4.0 | 24512 | 0.1027 | 0.9830 | 0.9832 | 0.9831 | 0.9799 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
|
TurkuNLP/wikibert-base-hy-cased | f5140e06536f70975e5e0ae99125695aecca2f14 | 2020-05-24T20:00:33.000Z | [
"pytorch",
"transformers"
] | null | false | TurkuNLP | null | TurkuNLP/wikibert-base-hy-cased | 33 | null | transformers | 6,890 | Entry not found |
anton-l/wav2vec2-large-xlsr-53-ukrainian | 31f26425f71dc936f6f9cfa341923eb4dbe0d4fb | 2021-07-05T20:45:55.000Z | [
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"uk",
"dataset:common_voice",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | false | anton-l | null | anton-l/wav2vec2-large-xlsr-53-ukrainian | 33 | null | transformers | 6,891 | ---
language: uk
datasets:
- common_voice
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: Ukrainian XLSR Wav2Vec2 Large 53 by Anton Lozhkov
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice uk
type: common_voice
args: uk
metrics:
- name: Test WER
type: wer
value: 32.29
---
# Wav2Vec2-Large-XLSR-53-Ukrainian
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Ukrainian using the [Common Voice](https://huggingface.co/datasets/common_voice) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "uk", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("anton-l/wav2vec2-large-xlsr-53-ukrainian")
model = Wav2Vec2ForCTC.from_pretrained("anton-l/wav2vec2-large-xlsr-53-ukrainian")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Ukrainian test data of Common Voice.
```python
import torch
import torchaudio
import urllib.request
import tarfile
import pandas as pd
from tqdm.auto import tqdm
from datasets import load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
# Download the raw data instead of using HF datasets to save disk space
data_url = "https://voice-prod-bundler-ee1969a6ce8178826482b88e843c335139bd3fb4.s3.amazonaws.com/cv-corpus-6.1-2020-12-11/uk.tar.gz"
filestream = urllib.request.urlopen(data_url)
data_file = tarfile.open(fileobj=filestream, mode="r|gz")
data_file.extractall()
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("anton-l/wav2vec2-large-xlsr-53-ukrainian")
model = Wav2Vec2ForCTC.from_pretrained("anton-l/wav2vec2-large-xlsr-53-ukrainian")
model.to("cuda")
cv_test = pd.read_csv("cv-corpus-6.1-2020-12-11/uk/test.tsv", sep='\t')
clips_path = "cv-corpus-6.1-2020-12-11/uk/clips/"
def clean_sentence(sent):
sent = sent.lower()
# normalize apostrophes
sent = sent.replace("’", "'")
# replace non-alpha characters with space
sent = "".join(ch if ch.isalpha() or ch == "'" else " " for ch in sent)
# remove repeated spaces
sent = " ".join(sent.split())
return sent
targets = []
preds = []
for i, row in tqdm(cv_test.iterrows(), total=cv_test.shape[0]):
row["sentence"] = clean_sentence(row["sentence"])
speech_array, sampling_rate = torchaudio.load(clips_path + row["path"])
resampler = torchaudio.transforms.Resample(sampling_rate, 16_000)
row["speech"] = resampler(speech_array).squeeze().numpy()
inputs = processor(row["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
targets.append(row["sentence"])
preds.append(processor.batch_decode(pred_ids)[0])
print("WER: {:2f}".format(100 * wer.compute(predictions=preds, references=targets)))
```
**Test Result**: 32.29 %
## Training
The Common Voice `train` and `validation` datasets were used for training.
|
bgoel4132/twitter-sentiment | 9a5136ecd7b558099ad6dcd3ff47870954d664db | 2021-11-24T19:39:02.000Z | [
"pytorch",
"bert",
"text-classification",
"en",
"dataset:bgoel4132/autonlp-data-twitter-sentiment",
"transformers",
"autonlp",
"co2_eq_emissions"
] | text-classification | false | bgoel4132 | null | bgoel4132/twitter-sentiment | 33 | null | transformers | 6,892 | ---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- bgoel4132/autonlp-data-twitter-sentiment
co2_eq_emissions: 186.8637425115097
---
# Model Trained Using AutoNLP
- Problem type: Multi-class Classification
- Model ID: 35868888
- CO2 Emissions (in grams): 186.8637425115097
## Validation Metrics
- Loss: 0.2020547091960907
- Accuracy: 0.9233253193796257
- Macro F1: 0.9240407542958707
- Micro F1: 0.9233253193796257
- Weighted F1: 0.921800586774046
- Macro Precision: 0.9432284179846658
- Micro Precision: 0.9233253193796257
- Weighted Precision: 0.9247263361914827
- Macro Recall: 0.9139437626409382
- Micro Recall: 0.9233253193796257
- Weighted Recall: 0.9233253193796257
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/bgoel4132/autonlp-twitter-sentiment-35868888
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("bgoel4132/autonlp-twitter-sentiment-35868888", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("bgoel4132/autonlp-twitter-sentiment-35868888", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` |
cardiffnlp/twitter-roberta-base-jun2021 | 1aae9cacfb27322cde081f284d839109a2e5b0e8 | 2022-02-09T11:16:07.000Z | [
"pytorch",
"roberta",
"fill-mask",
"arxiv:2202.03829",
"transformers",
"autotrain_compatible"
] | fill-mask | false | cardiffnlp | null | cardiffnlp/twitter-roberta-base-jun2021 | 33 | null | transformers | 6,893 | # Twitter June 2021 (RoBERTa-base, 115M)
This is a RoBERTa-base model trained on 115.46M tweets until the end of June 2021.
More details and performance scores are available in the [TimeLMs paper](https://arxiv.org/abs/2202.03829).
Below, we provide some usage examples using the standard Transformers interface. For another interface more suited to comparing predictions and perplexity scores between models trained at different temporal intervals, check the [TimeLMs repository](https://github.com/cardiffnlp/timelms).
For other models trained until different periods, check this [table](https://github.com/cardiffnlp/timelms#released-models).
## Preprocess Text
Replace usernames and links for placeholders: "@user" and "http".
If you're interested in retaining verified users which were also retained during training, you may keep the users listed [here](https://github.com/cardiffnlp/timelms/tree/main/data).
```python
def preprocess(text):
new_text = []
for t in text.split(" "):
t = '@user' if t.startswith('@') and len(t) > 1 else t
t = 'http' if t.startswith('http') else t
new_text.append(t)
return " ".join(new_text)
```
## Example Masked Language Model
```python
from transformers import pipeline, AutoTokenizer
MODEL = "cardiffnlp/twitter-roberta-base-jun2021"
fill_mask = pipeline("fill-mask", model=MODEL, tokenizer=MODEL)
tokenizer = AutoTokenizer.from_pretrained(MODEL)
def print_candidates():
for i in range(5):
token = tokenizer.decode(candidates[i]['token'])
score = candidates[i]['score']
print("%d) %.5f %s" % (i+1, score, token))
texts = [
"So glad I'm <mask> vaccinated.",
"I keep forgetting to bring a <mask>.",
"Looking forward to watching <mask> Game tonight!",
]
for text in texts:
t = preprocess(text)
print(f"{'-'*30}\n{t}")
candidates = fill_mask(t)
print_candidates()
```
Output:
```
------------------------------
So glad I'm <mask> vaccinated.
1) 0.45169 fully
2) 0.22353 getting
3) 0.18540 not
4) 0.02392 still
5) 0.02231 already
------------------------------
I keep forgetting to bring a <mask>.
1) 0.06331 mask
2) 0.05423 book
3) 0.04505 knife
4) 0.03742 laptop
5) 0.03456 bag
------------------------------
Looking forward to watching <mask> Game tonight!
1) 0.69811 the
2) 0.14435 The
3) 0.02396 this
4) 0.00932 Championship
5) 0.00785 End
```
## Example Tweet Embeddings
```python
from transformers import AutoTokenizer, AutoModel, TFAutoModel
import numpy as np
from scipy.spatial.distance import cosine
from collections import Counter
def get_embedding(text):
text = preprocess(text)
encoded_input = tokenizer(text, return_tensors='pt')
features = model(**encoded_input)
features = features[0].detach().cpu().numpy()
features_mean = np.mean(features[0], axis=0)
return features_mean
MODEL = "cardiffnlp/twitter-roberta-base-jun2021"
tokenizer = AutoTokenizer.from_pretrained(MODEL)
model = AutoModel.from_pretrained(MODEL)
query = "The book was awesome"
tweets = ["I just ordered fried chicken 🐣",
"The movie was great",
"What time is the next game?",
"Just finished reading 'Embeddings in NLP'"]
sims = Counter()
for tweet in tweets:
sim = 1 - cosine(get_embedding(query), get_embedding(tweet))
sims[tweet] = sim
print('Most similar to: ', query)
print(f"{'-'*30}")
for idx, (tweet, sim) in enumerate(sims.most_common()):
print("%d) %.5f %s" % (idx+1, sim, tweet))
```
Output:
```
Most similar to: The book was awesome
------------------------------
1) 0.99014 The movie was great
2) 0.96346 Just finished reading 'Embeddings in NLP'
3) 0.95836 I just ordered fried chicken 🐣
4) 0.95051 What time is the next game?
```
## Example Feature Extraction
```python
from transformers import AutoTokenizer, AutoModel, TFAutoModel
import numpy as np
MODEL = "cardiffnlp/twitter-roberta-base-jun2021"
tokenizer = AutoTokenizer.from_pretrained(MODEL)
text = "Good night 😊"
text = preprocess(text)
# Pytorch
model = AutoModel.from_pretrained(MODEL)
encoded_input = tokenizer(text, return_tensors='pt')
features = model(**encoded_input)
features = features[0].detach().cpu().numpy()
features_mean = np.mean(features[0], axis=0)
#features_max = np.max(features[0], axis=0)
# # Tensorflow
# model = TFAutoModel.from_pretrained(MODEL)
# encoded_input = tokenizer(text, return_tensors='tf')
# features = model(encoded_input)
# features = features[0].numpy()
# features_mean = np.mean(features[0], axis=0)
# #features_max = np.max(features[0], axis=0)
``` |
ccoreilly/wav2vec2-large-100k-voxpopuli-catala | cb9f95d104a518913c674c1c7173fabb574975f7 | 2022-02-08T00:59:52.000Z | [
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"ca",
"dataset:common_voice",
"dataset:parlament_parla",
"transformers",
"audio",
"speech",
"speech-to-text",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | false | ccoreilly | null | ccoreilly/wav2vec2-large-100k-voxpopuli-catala | 33 | 1 | transformers | 6,894 | ---
language: ca
datasets:
- common_voice
- parlament_parla
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- speech-to-text
license: apache-2.0
model-index:
- name: Catalan VoxPopuli Wav2Vec2 Large
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
datasets:
- name: Common Voice ca
type: common_voice
args: ca
- name: ParlamentParla
url: https://www.openslr.org/59/
metrics:
- name: Test WER
type: wer
value: 5.98
- name: Google Crowsourced Corpus WER
type: wer
value: 12.14
- name: Audiobook “La llegenda de Sant Jordi” WER
type: wer
value: 12.02
---
# Wav2Vec2-Large-100k-VoxPopuli-Català
**⚠️NOTICE⚠️: THIS MODEL HAS BEEN MOVED TO THE FOLLOWING URL:**
https://huggingface.co/softcatala/wav2vec2-large-100k-voxpopuli-catala
Fine-tuned [facebook/wav2vec2-large-100k-voxpopuli](https://huggingface.co/facebook/wav2vec2-large-100k-voxpopuli) on Catalan language using the [Common Voice](https://huggingface.co/datasets/common_voice) and [ParlamentParla](https://www.openslr.org/59/) datasets.
**Attention:** The split train/dev/test used does not fully map with the CommonVoice 6.1 dataset. A custom split was used combining both the CommonVoice and ParlamentParla dataset and can be found [here](https://github.com/ccoreilly/wav2vec2-catala). Evaluating on the CV test dataset will produce a biased WER as 1144 audio files of that dataset were used in training/evaluation of this model.
WER was calculated using this [test.csv](https://github.com/ccoreilly/wav2vec2-catala/blob/master/test-filtered.csv) which was not seen by the model during training/evaluation.
You can find training and evaluation scripts in the github repository [ccoreilly/wav2vec2-catala](https://github.com/ccoreilly/wav2vec2-catala)
When using this model, make sure that your speech input is sampled at 16kHz.
## Results
Word error rate was evaluated on the following datasets unseen by the model:
| Dataset | WER |
| ------- | --- |
| [Test split CV+ParlamentParla]((https://github.com/ccoreilly/wav2vec2-catala/blob/master/test-filtered.csv)) | 5.98% |
| [Google Crowsourced Corpus](https://www.openslr.org/69/) | 12.14% |
| Audiobook “La llegenda de Sant Jordi” | 12.02% |
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "ca", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("ccoreilly/wav2vec2-large-100k-voxpopuli-catala")
model = Wav2Vec2ForCTC.from_pretrained("ccoreilly/wav2vec2-large-100k-voxpopuli-catala")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
``` |
chrisjay/fonxlsr | e3f3e1398f34c6d5ff2549593ba138aa4a339fa9 | 2022-03-31T13:35:06.000Z | [
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"fon",
"dataset:fon_dataset",
"arxiv:2103.07762",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"hf-asr-leaderboard",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | false | chrisjay | null | chrisjay/fonxlsr | 33 | 2 | transformers | 6,895 | ---
language: fon
datasets:
- fon_dataset
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
- hf-asr-leaderboard
license: apache-2.0
model-index:
- name: Fon XLSR Wav2Vec2 Large 53
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: fon
type: fon_dataset
args: fon
metrics:
- name: Test WER
type: wer
value: 14.97
---
# Wav2Vec2-Large-XLSR-53-Fon
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on [Fon (or Fongbe)](https://en.wikipedia.org/wiki/Fon_language) using the [Fon Dataset](https://github.com/laleye/pyFongbe/tree/master/data).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import json
import random
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
#Load test_dataset from saved files in folder
from datasets import load_dataset, load_metric
#for test
for root, dirs, files in os.walk(test/):
test_dataset= load_dataset("json", data_files=[os.path.join(root,i) for i in files],split="train")
#Remove unnecessary chars
chars_to_ignore_regex = '[\\,\\?\\.\\!\\-\\;\\:\\"\\“\\%\\‘\\”]'
def remove_special_characters(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower() + " "
return batch
test_dataset = test_dataset.map(remove_special_characters)
processor = Wav2Vec2Processor.from_pretrained("chrisjay/wav2vec2-large-xlsr-53-fon")
model = Wav2Vec2ForCTC.from_pretrained("chrisjay/wav2vec2-large-xlsr-53-fon")
#No need for resampling because audio dataset already at 16kHz
#resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"]=speech_array.squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
tlogits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on our unique Fon test data.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
for root, dirs, files in os.walk(test/):
test_dataset = load_dataset("json", data_files=[os.path.join(root,i) for i in files],split="train")
chars_to_ignore_regex = '[\\,\\?\\.\\!\\-\\;\\:\\"\\“\\%\\‘\\”]'
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower() + " "
return batch
test_dataset = test_dataset.map(remove_special_characters)
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("chrisjay/wav2vec2-large-xlsr-53-fon")
model = Wav2Vec2ForCTC.from_pretrained("chrisjay/wav2vec2-large-xlsr-53-fon")
model.to("cuda")
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = speech_array[0].numpy()
batch["sampling_rate"] = sampling_rate
batch["target_text"] = batch["sentence"]
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
#Evaluation on test dataset
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 14.97 %
## Training
The [Fon dataset](https://github.com/laleye/pyFongbe/tree/master/data) was split into `train`(8235 samples), `validation`(1107 samples), and `test`(1061 samples).
The script used for training can be found [here](https://colab.research.google.com/drive/11l6qhJCYnPTG1TQZ8f3EvKB9z12TQi4g?usp=sharing)
# Collaborators on this project
- Chris C. Emezue ([Twitter](https://twitter.com/ChrisEmezue))|([email protected])
- Bonaventure F.P. Dossou (HuggingFace Username: [bonadossou](https://huggingface.co/bonadossou))|([Twitter](https://twitter.com/bonadossou))|([email protected])
## This is a joint project continuing our research on [OkwuGbé: End-to-End Speech Recognition for Fon and Igbo](https://arxiv.org/abs/2103.07762) |
clagator/biobert_v1.1_pubmed_nli_sts | 90ba576fd7d847f8b16329c3636be8cfbc130d6d | 2021-05-19T14:23:22.000Z | [
"pytorch",
"jax",
"bert",
"feature-extraction",
"transformers"
] | feature-extraction | false | clagator | null | clagator/biobert_v1.1_pubmed_nli_sts | 33 | null | transformers | 6,896 | Entry not found |
clue/roberta_chinese_pair_large | c3ffc20012c37e45d3d79d2da34adeac670aac93 | 2021-05-20T15:31:42.000Z | [
"pytorch",
"jax",
"roberta",
"transformers"
] | null | false | clue | null | clue/roberta_chinese_pair_large | 33 | 2 | transformers | 6,897 | Entry not found |
educhav/Sam-DialoGPT-small | 9f5ad59bd6d1fd06e37faa18d19463a40ada47ec | 2022-01-22T09:18:30.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | false | educhav | null | educhav/Sam-DialoGPT-small | 33 | null | transformers | 6,898 | ---
tags:
- conversational
---
# Samuel Adams |
fgaim/tielectra-small-sentiment | 9fee9a0e6341620fe92ababde81158e16c2e893c | 2022-05-14T06:49:29.000Z | [
"pytorch",
"electra",
"text-classification",
"ti",
"transformers",
"model-index"
] | text-classification | false | fgaim | null | fgaim/tielectra-small-sentiment | 33 | 1 | transformers | 6,899 | ---
language: ti
widget:
- text: "ድምጻዊ ኣብርሃም ኣፈወርቂ ንዘልኣለም ህያው ኮይኑ ኣብ ልብና ይነብር"
metrics:
- f1
- precision
- recall
- accuracy
model-index:
- name: tielectra-small-sentiment
results:
- task:
name: Text Classification
type: text-classification
metrics:
- name: F1
type: f1
value: 0.8228962818003914
- name: Precision
type: precision
value: 0.8055555555555556
- name: Recall
type: recall
value: 0.841
- name: Accuracy
type: accuracy
value: 0.819
---
# Sentiment Analysis for Tigrinya with TiELECTRA small
This model is a fine-tuned version of [TiELECTRA small](https://huggingface.co/fgaim/tielectra-small) on a YouTube comments Sentiment Analysis dataset for Tigrinya (Tela et al. 2020).
## Basic usage
```python
from transformers import pipeline
ti_sent = pipeline("sentiment-analysis", model="fgaim/tielectra-small-sentiment")
ti_sent("ድምጻዊ ኣብርሃም ኣፈወርቂ ንዘልኣለም ህያው ኮይኑ ኣብ ልብና ይነብር")
```
## Training
### Hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Results
The model achieves the following results on the evaluation set:
- F1: 0.8229
- Precision: 0.8056
- Recall: 0.841
- Accuracy: 0.819
- Loss: 0.4299
### Framework versions
- Transformers 4.10.3
- Pytorch 1.9.0+cu111
- Datasets 1.10.2
- Tokenizers 0.10.1
## Citation
If you use this model in your product or research, please cite as follows:
```
@article{Fitsum2021TiPLMs,
author={Fitsum Gaim and Wonsuk Yang and Jong C. Park},
title={Monolingual Pre-trained Language Models for Tigrinya},
year=2021,
publisher= {WiNLP 2021/EMNLP 2021}
}
```
## References
```
Tela, A., Woubie, A. and Hautamäki, V. 2020.
Transferring Monolingual Model to Low-Resource Language: The Case of Tigrinya.
ArXiv, abs/2006.07698.
```
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.