
modelId
stringlengths 4
112
| sha
stringlengths 40
40
| lastModified
stringlengths 24
24
| tags
list | pipeline_tag
stringclasses 29
values | private
bool 1
class | author
stringlengths 2
38
⌀ | config
null | id
stringlengths 4
112
| downloads
float64 0
36.8M
⌀ | likes
float64 0
712
⌀ | library_name
stringclasses 17
values | __index_level_0__
int64 0
38.5k
| readme
stringlengths 0
186k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
rasta/distilbert-base-uncased-finetuned-fashion
|
9b6f70e275f1a0b7a4cf5569e1f53fe9a5cd1738
|
2022-05-09T08:10:22.000Z
|
[
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] |
text-classification
| false |
rasta
| null |
rasta/distilbert-base-uncased-finetuned-fashion
| 53 | 2 |
transformers
| 5,900 |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-fashion
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-fashion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on a munally created dataset in order to detect fashion (label_0) from non-fashion (label_1) items.
It achieves the following results on the evaluation set:
- Loss: 0.0809
- Accuracy: 0.98
- F1: 0.9801
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.4017 | 1.0 | 47 | 0.1220 | 0.966 | 0.9662 |
| 0.115 | 2.0 | 94 | 0.0809 | 0.98 | 0.9801 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0+cu113
- Datasets 2.1.0
- Tokenizers 0.12.1
|
anas-awadalla/splinter-large-few-shot-k-1024-finetuned-squad-seed-2
|
23f58c42ae6e81cc1f4a7560ae3c3e57dfb482a5
|
2022-05-14T23:31:40.000Z
|
[
"pytorch",
"splinter",
"question-answering",
"dataset:squad",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] |
question-answering
| false |
anas-awadalla
| null |
anas-awadalla/splinter-large-few-shot-k-1024-finetuned-squad-seed-2
| 53 | null |
transformers
| 5,901 |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: splinter-large-few-shot-k-1024-finetuned-squad-seed-2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# splinter-large-few-shot-k-1024-finetuned-squad-seed-2
This model is a fine-tuned version of [tau/splinter-large-qass](https://huggingface.co/tau/splinter-large-qass) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 12
- eval_batch_size: 8
- seed: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10.0
### Training results
### Framework versions
- Transformers 4.20.0.dev0
- Pytorch 1.11.0+cu113
- Datasets 2.0.0
- Tokenizers 0.11.6
|
CEBaB/bert-base-uncased.CEBaB.absa.exclusive.seed_42
|
b31e1ab0039a987ee80fda6f256ee1c88fe34223
|
2022-05-17T18:43:42.000Z
|
[
"pytorch",
"bert",
"transformers"
] | null | false |
CEBaB
| null |
CEBaB/bert-base-uncased.CEBaB.absa.exclusive.seed_42
| 53 | null |
transformers
| 5,902 |
Entry not found
|
Cirilaron/DialoGPT-medium-jetstreamsam
|
02fc2375c982ea3de186a4883b034cfa5b6d3c68
|
2022-06-09T12:37:07.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
Cirilaron
| null |
Cirilaron/DialoGPT-medium-jetstreamsam
| 53 | null |
transformers
| 5,903 |
---
tags:
- conversational
---
#Samuel Rodrigues from Metal Gear Rising DialoGPT Model
|
Kittipong/wav2vec2-th-vocal-domain
|
4f5fec019d8b0b9f5be8e0da0ff3c2acb59d6fb1
|
2022-06-12T12:34:43.000Z
|
[
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"transformers",
"license:cc-by-sa-4.0"
] |
automatic-speech-recognition
| false |
Kittipong
| null |
Kittipong/wav2vec2-th-vocal-domain
| 53 | null |
transformers
| 5,904 |
---
license: cc-by-sa-4.0
---
|
cwkeam/m-ctc-t-large-sequence-lid
|
0391241ef74c94275a8d8cbfb1b7fc3f0ca66ea0
|
2022-06-29T04:31:03.000Z
|
[
"pytorch",
"mctct",
"text-classification",
"en",
"dataset:librispeech_asr",
"dataset:common_voice",
"arxiv:2111.00161",
"transformers",
"speech",
"license:apache-2.0"
] |
text-classification
| false |
cwkeam
| null |
cwkeam/m-ctc-t-large-sequence-lid
| 53 | null |
transformers
| 5,905 |
---
language: en
datasets:
- librispeech_asr
- common_voice
tags:
- speech
license: apache-2.0
---
# M-CTC-T
Massively multilingual speech recognizer from Meta AI. The model is a 1B-param transformer encoder, with a CTC head over 8065 character labels and a language identification head over 60 language ID labels. It is trained on Common Voice (version 6.1, December 2020 release) and VoxPopuli. After training on Common Voice and VoxPopuli, the model is trained on Common Voice only. The labels are unnormalized character-level transcripts (punctuation and capitalization are not removed). The model takes as input Mel filterbank features from a 16Khz audio signal.
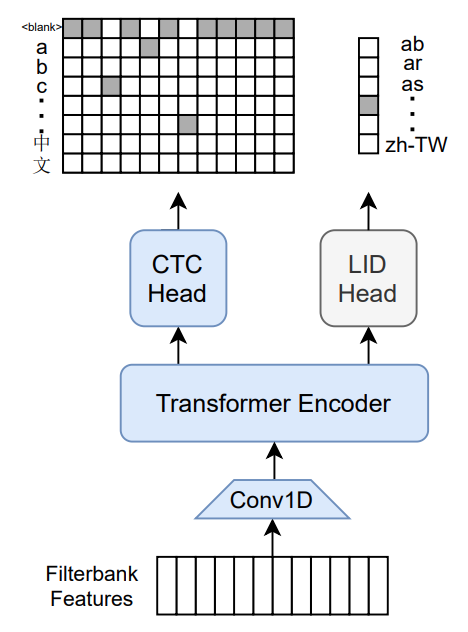
The original Flashlight code, model checkpoints, and Colab notebook can be found at https://github.com/flashlight/wav2letter/tree/main/recipes/mling_pl .
## Citation
[Paper](https://arxiv.org/abs/2111.00161)
Authors: Loren Lugosch, Tatiana Likhomanenko, Gabriel Synnaeve, Ronan Collobert
```
@article{lugosch2021pseudo,
title={Pseudo-Labeling for Massively Multilingual Speech Recognition},
author={Lugosch, Loren and Likhomanenko, Tatiana and Synnaeve, Gabriel and Collobert, Ronan},
journal={ICASSP},
year={2022}
}
```
Additional thanks to [Chan Woo Kim](https://huggingface.co/cwkeam) and [Patrick von Platen](https://huggingface.co/patrickvonplaten) for porting the model from Flashlight to PyTorch.
# Training method
 TO-DO: replace with the training diagram from paper
For more information on how the model was trained, please take a look at the [official paper](https://arxiv.org/abs/2111.00161).
# Usage
To transcribe audio files the model can be used as a standalone acoustic model as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import MCTCTForCTC, MCTCTProcessor
model = MCTCTForCTC.from_pretrained("speechbrain/mctct-large")
processor = MCTCTProcessor.from_pretrained("speechbrain/mctct-large")
# load dummy dataset and read soundfiles
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# tokenize
input_features = processor(ds[0]["audio"]["array"], return_tensors="pt").input_features
# retrieve logits
logits = model(input_features).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
```
Results for Common Voice, averaged over all languages:
*Character error rate (CER)*:
| Valid | Test |
|-------|------|
| 21.4 | 23.3 |
|
shash2409/bert-finetuned-squad
|
4ea4437bc266e648ab369ad7552dcae25d90fe47
|
2022-07-03T19:32:27.000Z
|
[
"pytorch",
"tensorboard",
"bert",
"question-answering",
"dataset:squad",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] |
question-answering
| false |
shash2409
| null |
shash2409/bert-finetuned-squad
| 53 | null |
transformers
| 5,906 |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: bert-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-squad
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
semy/finetuning-sentiment-model-sst
|
83734031b99d78b425fa3adaa7c6779d7b958ac2
|
2022-07-01T12:47:28.000Z
|
[
"pytorch",
"distilbert",
"text-classification",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] |
text-classification
| false |
semy
| null |
semy/finetuning-sentiment-model-sst
| 53 | null |
transformers
| 5,907 |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: finetuning-sentiment-model-sst
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-sst
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Framework versions
- Transformers 4.20.1
- Pytorch 1.10.2
- Datasets 2.3.2
- Tokenizers 0.12.1
|
zhifei/autotrain-chinese-title-summarization-1-1084539138
|
0bd24fbcde53d2e03c0fbeb8187ad822af0b1970
|
2022-07-04T08:49:18.000Z
|
[
"pytorch",
"mt5",
"text2text-generation",
"unk",
"dataset:zhifei/autotrain-data-chinese-title-summarization-1",
"transformers",
"autotrain",
"co2_eq_emissions",
"autotrain_compatible"
] |
text2text-generation
| false |
zhifei
| null |
zhifei/autotrain-chinese-title-summarization-1-1084539138
| 53 | null |
transformers
| 5,908 |
---
tags: autotrain
language: unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- zhifei/autotrain-data-chinese-title-summarization-1
co2_eq_emissions: 0.004484038360707097
---
# Model Trained Using AutoTrain
- Problem type: Summarization
- Model ID: 1084539138
- CO2 Emissions (in grams): 0.004484038360707097
## Validation Metrics
- Loss: 0.7330857515335083
- Rouge1: 22.2222
- Rouge2: 10.0
- RougeL: 22.2222
- RougeLsum: 22.2222
- Gen Len: 13.7333
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/zhifei/autotrain-chinese-title-summarization-1-1084539138
```
|
okho0653/Bio_ClinicalBERT-zero-shot-tokenizer-truncation-sentiment-model
|
91d77d8debe3f8769c755eeedc0f42858fdf297d
|
2022-07-08T03:54:48.000Z
|
[
"pytorch",
"tensorboard",
"bert",
"text-classification",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index"
] |
text-classification
| false |
okho0653
| null |
okho0653/Bio_ClinicalBERT-zero-shot-tokenizer-truncation-sentiment-model
| 53 | null |
transformers
| 5,909 |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: Bio_ClinicalBERT-zero-shot-tokenizer-truncation-sentiment-model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Bio_ClinicalBERT-zero-shot-tokenizer-truncation-sentiment-model
This model is a fine-tuned version of [emilyalsentzer/Bio_ClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
Lvxue/finetuned-mbart-large-10epoch
|
07b2e2e5e1629c407746ede1f21243f6dd9ae3f1
|
2022-07-11T03:11:38.000Z
|
[
"pytorch",
"mbart",
"text2text-generation",
"en",
"ro",
"dataset:wmt16",
"transformers",
"generated_from_trainer",
"model-index",
"autotrain_compatible"
] |
text2text-generation
| false |
Lvxue
| null |
Lvxue/finetuned-mbart-large-10epoch
| 53 | null |
transformers
| 5,910 |
---
language:
- en
- ro
tags:
- generated_from_trainer
datasets:
- wmt16
model-index:
- name: finetuned-mbart-large-10epoch
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned-mbart-large-10epoch
This model is a fine-tuned version of [facebook/mbart-large-cc25](https://huggingface.co/facebook/mbart-large-cc25) on the wmt16 ro-en dataset.
It achieves the following results on the evaluation set:
- Loss: 2.6032
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 12
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10.0
### Training results
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu102
- Datasets 2.3.2
- Tokenizers 0.12.1
|
CogComp/roberta-temporal-predictor
|
aa4d28dcd3baacce849e269b4dbeeef35e52f8a2
|
2022-03-22T20:15:03.000Z
|
[
"pytorch",
"roberta",
"fill-mask",
"arxiv:2202.00436",
"transformers",
"license:mit",
"autotrain_compatible"
] |
fill-mask
| false |
CogComp
| null |
CogComp/roberta-temporal-predictor
| 52 | null |
transformers
| 5,911 |
---
license: mit
widget:
- text: "The man turned on the faucet <mask> water flows out."
- text: "The woman received her pension <mask> she retired."
---
# roberta-temporal-predictor
A RoBERTa-base model that is fine-tuned on the [The New York Times Annotated Corpus](https://catalog.ldc.upenn.edu/LDC2008T19)
to predict temporal precedence of two events. This is used as the ``temporality prediction'' component
in our ROCK framework for reasoning about commonsense causality. See our [paper](https://arxiv.org/abs/2202.00436) for more details.
# Usage
You can directly use this model for filling-mask tasks, as shown in the example widget.
However, for better temporal inference, it is recommended to symmetrize the outputs as
$$
P(E_1 \prec E_2) = \frac{1}{2} (f(E_1,E_2) + f(E_2,E_1))
$$
where ``f(E_1,E_2)`` denotes the predicted probability for ``E_1`` to occur preceding ``E_2``.
For simplicity, we implement the following TempPredictor class that incorporate this symmetrization automatically.
Below is an example usage for the ``TempPredictor`` class:
```python
from transformers import (RobertaForMaskedLM, RobertaTokenizer)
from src.temp_predictor import TempPredictor
TORCH_DEV = "cuda:0" # change as needed
tp_roberta_ft = src.TempPredictor(
model=RobertaForMaskedLM.from_pretrained("CogComp/roberta-temporal-predictor"),
tokenizer=RobertaTokenizer.from_pretrained("CogComp/roberta-temporal-predictor"),
device=TORCH_DEV
)
E1 = "The man turned on the faucet."
E2 = "Water flows out."
t12 = tp_roberta_ft(E1, E2, top_k=5)
print(f"P('{E1}' before '{E2}'): {t12}")
```
# BibTeX entry and citation info
```bib
@misc{zhang2022causal,
title={Causal Inference Principles for Reasoning about Commonsense Causality},
author={Jiayao Zhang and Hongming Zhang and Dan Roth and Weijie J. Su},
year={2022},
eprint={2202.00436},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
Hate-speech-CNERG/dehatebert-mono-arabic
|
e592a5ee3b913ec33286ee90fb27c7f7f1a8b996
|
2021-09-25T13:54:53.000Z
|
[
"pytorch",
"jax",
"bert",
"text-classification",
"ar",
"arxiv:2004.06465",
"transformers",
"license:apache-2.0"
] |
text-classification
| false |
Hate-speech-CNERG
| null |
Hate-speech-CNERG/dehatebert-mono-arabic
| 52 | null |
transformers
| 5,912 |
---
language: ar
license: apache-2.0
---
This model is used detecting **hatespeech** in **Arabic language**. The mono in the name refers to the monolingual setting, where the model is trained using only Arabic language data. It is finetuned on multilingual bert model.
The model is trained with different learning rates and the best validation score achieved is 0.877609 for a learning rate of 2e-5. Training code can be found at this [url](https://github.com/punyajoy/DE-LIMIT)
### For more details about our paper
Sai Saketh Aluru, Binny Mathew, Punyajoy Saha and Animesh Mukherjee. "[Deep Learning Models for Multilingual Hate Speech Detection](https://arxiv.org/abs/2004.06465)". Accepted at ECML-PKDD 2020.
***Please cite our paper in any published work that uses any of these resources.***
~~~
@article{aluru2020deep,
title={Deep Learning Models for Multilingual Hate Speech Detection},
author={Aluru, Sai Saket and Mathew, Binny and Saha, Punyajoy and Mukherjee, Animesh},
journal={arXiv preprint arXiv:2004.06465},
year={2020}
}
~~~
|
Helsinki-NLP/opus-mt-aed-es
|
a56c16908eafa534660838102b535b32f40581a3
|
2021-09-09T21:25:50.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"aed",
"es",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-aed-es
| 52 | null |
transformers
| 5,913 |
---
tags:
- translation
license: apache-2.0
---
### opus-mt-aed-es
* source languages: aed
* target languages: es
* OPUS readme: [aed-es](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/aed-es/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-15.zip](https://object.pouta.csc.fi/OPUS-MT-models/aed-es/opus-2020-01-15.zip)
* test set translations: [opus-2020-01-15.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/aed-es/opus-2020-01-15.test.txt)
* test set scores: [opus-2020-01-15.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/aed-es/opus-2020-01-15.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| JW300.aed.es | 89.1 | 0.915 |
|
Helsinki-NLP/opus-mt-de-fi
|
bbd50eeefdc1e26d75f6a806495192b55878c04a
|
2021-09-09T21:31:05.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"de",
"fi",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-de-fi
| 52 | null |
transformers
| 5,914 |
---
tags:
- translation
license: apache-2.0
---
### opus-mt-de-fi
* source languages: de
* target languages: fi
* OPUS readme: [de-fi](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/de-fi/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-08.zip](https://object.pouta.csc.fi/OPUS-MT-models/de-fi/opus-2020-01-08.zip)
* test set translations: [opus-2020-01-08.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/de-fi/opus-2020-01-08.test.txt)
* test set scores: [opus-2020-01-08.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/de-fi/opus-2020-01-08.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.de.fi | 40.0 | 0.628 |
|
Helsinki-NLP/opus-mt-fi-sv
|
4f951b1b01773808d66e0868a3e53cf964f73362
|
2021-09-09T21:51:05.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"fi",
"sv",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-fi-sv
| 52 | null |
transformers
| 5,915 |
---
tags:
- translation
license: apache-2.0
---
### opus-mt-fi-sv
* source languages: fi
* target languages: sv
* OPUS readme: [fi-sv](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/fi-sv/README.md)
* dataset: opus+bt
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus+bt-2020-04-11.zip](https://object.pouta.csc.fi/OPUS-MT-models/fi-sv/opus+bt-2020-04-11.zip)
* test set translations: [opus+bt-2020-04-11.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/fi-sv/opus+bt-2020-04-11.test.txt)
* test set scores: [opus+bt-2020-04-11.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/fi-sv/opus+bt-2020-04-11.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| fiskmo_testset.fi.sv | 27.4 | 0.605 |
| Tatoeba.fi.sv | 54.7 | 0.709 |
|
RJ3vans/SignTagger
|
177222c11b652437211b35052b8e1298a6dcc691
|
2021-08-13T09:00:50.000Z
|
[
"pytorch",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] |
token-classification
| false |
RJ3vans
| null |
RJ3vans/SignTagger
| 52 | null |
transformers
| 5,916 |
This model is used to tag the tokens in an input sequence with information about the different signs of syntactic complexity that they contain. For more details, please see Chapters 2 and 3 of my thesis (http://rgcl.wlv.ac.uk/~richard/Evans2020_SentenceSimplificationForTextProcessing.pdf).
It was derived using code written by Dr. Le An Ha at the University of Wolverhampton.
To use this model, the following code snippet may help:
======================================================================
import torch
from transformers import AutoModelForTokenClassification, AutoTokenizer
SignTaggingModel = AutoModelForTokenClassification.from_pretrained('RJ3vans/SignTagger')
SignTaggingTokenizer = AutoTokenizer.from_pretrained('RJ3vans/SignTagger')
label_list = ["M:N_CCV", "M:N_CIN", "M:N_CLA", "M:N_CLAdv", "M:N_CLN", "M:N_CLP", # This could be obtained from the config file
"M:N_CLQ", "M:N_CLV", "M:N_CMA1", "M:N_CMAdv", "M:N_CMN1",
"M:N_CMN2", "M:N_CMN3", "M:N_CMN4", "M:N_CMP", "M:N_CMP2",
"M:N_CMV1", "M:N_CMV2", "M:N_CMV3", "M:N_COMBINATORY", "M:N_CPA",
"M:N_ESAdvP", "M:N_ESCCV", "M:N_ESCM", "M:N_ESMA", "M:N_ESMAdvP",
"M:N_ESMI", "M:N_ESMN", "M:N_ESMP", "M:N_ESMV", "M:N_HELP",
"M:N_SPECIAL", "M:N_SSCCV", "M:N_SSCM", "M:N_SSMA", "M:N_SSMAdvP",
"M:N_SSMI", "M:N_SSMN", "M:N_SSMP", "M:N_SSMV", "M:N_STQ",
"M:N_V", "M:N_nan", "M:Y_CCV", "M:Y_CIN", "M:Y_CLA", "M:Y_CLAdv",
"M:Y_CLN", "M:Y_CLP", "M:Y_CLQ", "M:Y_CLV", "M:Y_CMA1",
"M:Y_CMAdv", "M:Y_CMN1", "M:Y_CMN2", "M:Y_CMN4", "M:Y_CMP",
"M:Y_CMP2", "M:Y_CMV1", "M:Y_CMV2", "M:Y_CMV3",
"M:Y_COMBINATORY", "M:Y_CPA", "M:Y_ESAdvP", "M:Y_ESCCV",
"M:Y_ESCM", "M:Y_ESMA", "M:Y_ESMAdvP", "M:Y_ESMI", "M:Y_ESMN",
"M:Y_ESMP", "M:Y_ESMV", "M:Y_HELP", "M:Y_SPECIAL", "M:Y_SSCCV",
"M:Y_SSCM", "M:Y_SSMA", "M:Y_SSMAdvP", "M:Y_SSMI", "M:Y_SSMN",
"M:Y_SSMP", "M:Y_SSMV", "M:Y_STQ"]
sentence = 'The County Court in Nottingham heard that Roger Gedge, 30, had his leg amputated following the incident outside a rock festival in Wollaton Park, Nottingham, five years ago.'
tokens = SignTaggingTokenizer.tokenize(SignTaggingTokenizer.decode(SignTaggingTokenizer.encode(sentence)))
inputs = SignTaggingTokenizer.encode(sentence, return_tensors="pt")
outputs = SignTaggingModel(inputs)[0]
predictions = torch.argmax(outputs, dim=2)
print([(token, label_list[prediction]) for token, prediction in zip(tokens, predictions[0].tolist())])
======================================================================
|
SEBIS/code_trans_t5_base_code_documentation_generation_javascript_multitask_finetune
|
7d1881514432cb3860195e0b8e466809cddbb1bd
|
2021-06-23T04:31:36.000Z
|
[
"pytorch",
"jax",
"t5",
"feature-extraction",
"transformers",
"summarization"
] |
summarization
| false |
SEBIS
| null |
SEBIS/code_trans_t5_base_code_documentation_generation_javascript_multitask_finetune
| 52 | null |
transformers
| 5,917 |
---
tags:
- summarization
widget:
- text: "function isStandardBrowserEnv ( ) { if ( typeof navigator !== 'undefined' && ( navigator . product === 'ReactNative' || navigator . product === 'NativeScript' || navigator . product === 'NS' ) ) { return false ; } return ( typeof window !== 'undefined' && typeof document !== 'undefined' ) ; }"
---
# CodeTrans model for code documentation generation javascript
Pretrained model on programming language javascript using the t5 base model architecture. It was first released in
[this repository](https://github.com/agemagician/CodeTrans). This model is trained on tokenized javascript code functions: it works best with tokenized javascript functions.
## Model description
This CodeTrans model is based on the `t5-base` model. It has its own SentencePiece vocabulary model. It used multi-task training on 13 supervised tasks in the software development domain and 7 unsupervised datasets. It is then fine-tuned on the code documentation generation task for the javascript function/method.
## Intended uses & limitations
The model could be used to generate the description for the javascript function or be fine-tuned on other javascript code tasks. It can be used on unparsed and untokenized javascript code. However, if the javascript code is tokenized, the performance should be better.
### How to use
Here is how to use this model to generate javascript function documentation using Transformers SummarizationPipeline:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead, SummarizationPipeline
pipeline = SummarizationPipeline(
model=AutoModelWithLMHead.from_pretrained("SEBIS/code_trans_t5_base_code_documentation_generation_javascript_multitask_finetune"),
tokenizer=AutoTokenizer.from_pretrained("SEBIS/code_trans_t5_base_code_documentation_generation_javascript_multitask_finetune", skip_special_tokens=True),
device=0
)
tokenized_code = "function isStandardBrowserEnv ( ) { if ( typeof navigator !== 'undefined' && ( navigator . product === 'ReactNative' || navigator . product === 'NativeScript' || navigator . product === 'NS' ) ) { return false ; } return ( typeof window !== 'undefined' && typeof document !== 'undefined' ) ; }"
pipeline([tokenized_code])
```
Run this example in [colab notebook](https://github.com/agemagician/CodeTrans/blob/main/prediction/multitask/fine-tuning/function%20documentation%20generation/javascript/base_model.ipynb).
## Training data
The supervised training tasks datasets can be downloaded on [Link](https://www.dropbox.com/sh/488bq2of10r4wvw/AACs5CGIQuwtsD7j_Ls_JAORa/finetuning_dataset?dl=0&subfolder_nav_tracking=1)
## Training procedure
### Multi-task Pretraining
The model was trained on a single TPU Pod V3-8 for half million steps in total, using sequence length 512 (batch size 4096).
It has a total of approximately 220M parameters and was trained using the encoder-decoder architecture.
The optimizer used is AdaFactor with inverse square root learning rate schedule for pre-training.
### Fine-tuning
This model was then fine-tuned on a single TPU Pod V2-8 for 10,000 steps in total, using sequence length 512 (batch size 256), using only the dataset only containing javascript code.
## Evaluation results
For the code documentation tasks, different models achieves the following results on different programming languages (in BLEU score):
Test results :
| Language / Model | Python | Java | Go | Php | Ruby | JavaScript |
| -------------------- | :------------: | :------------: | :------------: | :------------: | :------------: | :------------: |
| CodeTrans-ST-Small | 17.31 | 16.65 | 16.89 | 23.05 | 9.19 | 13.7 |
| CodeTrans-ST-Base | 16.86 | 17.17 | 17.16 | 22.98 | 8.23 | 13.17 |
| CodeTrans-TF-Small | 19.93 | 19.48 | 18.88 | 25.35 | 13.15 | 17.23 |
| CodeTrans-TF-Base | 20.26 | 20.19 | 19.50 | 25.84 | 14.07 | 18.25 |
| CodeTrans-TF-Large | 20.35 | 20.06 | **19.54** | 26.18 | 14.94 | **18.98** |
| CodeTrans-MT-Small | 19.64 | 19.00 | 19.15 | 24.68 | 14.91 | 15.26 |
| CodeTrans-MT-Base | **20.39** | 21.22 | 19.43 | **26.23** | **15.26** | 16.11 |
| CodeTrans-MT-Large | 20.18 | **21.87** | 19.38 | 26.08 | 15.00 | 16.23 |
| CodeTrans-MT-TF-Small | 19.77 | 20.04 | 19.36 | 25.55 | 13.70 | 17.24 |
| CodeTrans-MT-TF-Base | 19.77 | 21.12 | 18.86 | 25.79 | 14.24 | 18.62 |
| CodeTrans-MT-TF-Large | 18.94 | 21.42 | 18.77 | 26.20 | 14.19 | 18.83 |
| State of the art | 19.06 | 17.65 | 18.07 | 25.16 | 12.16 | 14.90 |
> Created by [Ahmed Elnaggar](https://twitter.com/Elnaggar_AI) | [LinkedIn](https://www.linkedin.com/in/prof-ahmed-elnaggar/) and Wei Ding | [LinkedIn](https://www.linkedin.com/in/wei-ding-92561270/)
|
alireza7/ARMAN-MSR-persian-base-PN-summary
|
3312c43fc7514afa6a40b5c558a7e662761f8810
|
2021-09-29T19:14:47.000Z
|
[
"pytorch",
"pegasus",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
alireza7
| null |
alireza7/ARMAN-MSR-persian-base-PN-summary
| 52 | null |
transformers
| 5,918 |
More information about models is available [here](https://github.com/alirezasalemi7/ARMAN).
|
asafaya/albert-large-arabic
|
bb5cad09b4480a6403a52ec2d83386dc98471d1e
|
2022-02-11T13:52:18.000Z
|
[
"pytorch",
"tf",
"albert",
"fill-mask",
"ar",
"dataset:oscar",
"dataset:wikipedia",
"transformers",
"masked-lm",
"autotrain_compatible"
] |
fill-mask
| false |
asafaya
| null |
asafaya/albert-large-arabic
| 52 | 1 |
transformers
| 5,919 |
---
language: ar
datasets:
- oscar
- wikipedia
tags:
- ar
- masked-lm
---
# Arabic-ALBERT Large
Arabic edition of ALBERT Large pretrained language model
_If you use any of these models in your work, please cite this work as:_
```
@software{ali_safaya_2020_4718724,
author = {Ali Safaya},
title = {Arabic-ALBERT},
month = aug,
year = 2020,
publisher = {Zenodo},
version = {1.0.0},
doi = {10.5281/zenodo.4718724},
url = {https://doi.org/10.5281/zenodo.4718724}
}
```
## Pretraining data
The models were pretrained on ~4.4 Billion words:
- Arabic version of [OSCAR](https://oscar-corpus.com/) (unshuffled version of the corpus) - filtered from [Common Crawl](http://commoncrawl.org/)
- Recent dump of Arabic [Wikipedia](https://dumps.wikimedia.org/backup-index.html)
__Notes on training data:__
- Our final version of corpus contains some non-Arabic words inlines, which we did not remove from sentences since that would affect some tasks like NER.
- Although non-Arabic characters were lowered as a preprocessing step, since Arabic characters do not have upper or lower case, there is no cased and uncased version of the model.
- The corpus and vocabulary set are not restricted to Modern Standard Arabic, they contain some dialectical Arabic too.
## Pretraining details
- These models were trained using Google ALBERT's github [repository](https://github.com/google-research/albert) on a single TPU v3-8 provided for free from [TFRC](https://www.tensorflow.org/tfrc).
- Our pretraining procedure follows training settings of bert with some changes: trained for 7M training steps with batchsize of 64, instead of 125K with batchsize of 4096.
## Models
| | albert-base | albert-large | albert-xlarge |
|:---:|:---:|:---:|:---:|
| Hidden Layers | 12 | 24 | 24 |
| Attention heads | 12 | 16 | 32 |
| Hidden size | 768 | 1024 | 2048 |
## Results
For further details on the models performance or any other queries, please refer to [Arabic-ALBERT](https://github.com/KUIS-AI-Lab/Arabic-ALBERT/)
## How to use
You can use these models by installing `torch` or `tensorflow` and Huggingface library `transformers`. And you can use it directly by initializing it like this:
```python
from transformers import AutoTokenizer, AutoModel
# loading the tokenizer
tokenizer = AutoTokenizer.from_pretrained("kuisailab/albert-large-arabic")
# loading the model
model = AutoModelForMaskedLM.from_pretrained("kuisailab/albert-large-arabic")
```
## Acknowledgement
Thanks to Google for providing free TPU for the training process and for Huggingface for hosting these models on their servers 😊
|
dbmdz/electra-base-turkish-mc4-uncased-generator
|
2352dd9268eef698305ac0dc1f22eb59e73f55d8
|
2021-09-23T10:43:54.000Z
|
[
"pytorch",
"tf",
"electra",
"fill-mask",
"tr",
"dataset:allenai/c4",
"transformers",
"license:mit",
"autotrain_compatible"
] |
fill-mask
| false |
dbmdz
| null |
dbmdz/electra-base-turkish-mc4-uncased-generator
| 52 | null |
transformers
| 5,920 |
---
language: tr
license: mit
datasets:
- allenai/c4
---
# 🇹🇷 Turkish ELECTRA model
<p align="center">
<img alt="Logo provided by Merve Noyan" title="Awesome logo from Merve Noyan" src="https://raw.githubusercontent.com/stefan-it/turkish-bert/master/merve_logo.png">
</p>
[](https://zenodo.org/badge/latestdoi/237817454)
We present community-driven BERT, DistilBERT, ELECTRA and ConvBERT models for Turkish 🎉
Some datasets used for pretraining and evaluation are contributed from the
awesome Turkish NLP community, as well as the decision for the BERT model name: BERTurk.
Logo is provided by [Merve Noyan](https://twitter.com/mervenoyann).
# Stats
We've also trained an ELECTRA (uncased) model on the recently released Turkish part of the
[multiligual C4 (mC4) corpus](https://github.com/allenai/allennlp/discussions/5265) from the AI2 team.
After filtering documents with a broken encoding, the training corpus has a size of 242GB resulting
in 31,240,963,926 tokens.
We used the original 32k vocab (instead of creating a new one).
# mC4 ELECTRA
In addition to the ELEC**TR**A base cased model, we also trained an ELECTRA uncased model on the Turkish part of the mC4 corpus. We use a
sequence length of 512 over the full training time and train the model for 1M steps on a v3-32 TPU.
# Model usage
All trained models can be used from the [DBMDZ](https://github.com/dbmdz) Hugging Face [model hub page](https://huggingface.co/dbmdz)
using their model name.
Example usage with 🤗/Transformers:
```python
tokenizer = AutoTokenizer.from_pretrained("electra-base-turkish-mc4-uncased-generator")
model = AutoModel.from_pretrained("electra-base-turkish-mc4-uncased-generator")
```
# Citation
You can use the following BibTeX entry for citation:
```bibtex
@software{stefan_schweter_2020_3770924,
author = {Stefan Schweter},
title = {BERTurk - BERT models for Turkish},
month = apr,
year = 2020,
publisher = {Zenodo},
version = {1.0.0},
doi = {10.5281/zenodo.3770924},
url = {https://doi.org/10.5281/zenodo.3770924}
}
```
# Acknowledgments
Thanks to [Kemal Oflazer](http://www.andrew.cmu.edu/user/ko/) for providing us
additional large corpora for Turkish. Many thanks to Reyyan Yeniterzi for providing
us the Turkish NER dataset for evaluation.
We would like to thank [Merve Noyan](https://twitter.com/mervenoyann) for the
awesome logo!
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
|
dennlinger/bert-wiki-paragraphs
|
c8d6e5285fe3ea801834ef1f385a5518a4c91281
|
2021-09-30T20:13:44.000Z
|
[
"pytorch",
"bert",
"text-classification",
"arxiv:2012.03619",
"arxiv:1803.09337",
"transformers"
] |
text-classification
| false |
dennlinger
| null |
dennlinger/bert-wiki-paragraphs
| 52 | null |
transformers
| 5,921 |
# BERT-Wiki-Paragraphs
Authors: Satya Almasian\*, Dennis Aumiller\*, Lucienne-Sophie Marmé, Michael Gertz
Contact us at `<lastname>@informatik.uni-heidelberg.de`
Details for the training method can be found in our work [Structural Text Segmentation of Legal Documents](https://arxiv.org/abs/2012.03619).
The training procedure follows the same setup, but we substitute legal documents for Wikipedia in this model.
Training is performed in a form of weakly-supervised fashion to determine whether paragraphs topically belong together or not.
We utilize automatically generated samples from Wikipedia for training, where paragraphs from within the same section are assumed to be topically coherent.
We use the same articles as ([Koshorek et al., 2018](https://arxiv.org/abs/1803.09337)),
albeit from a 2021 dump of Wikpeida, and split at paragraph boundaries instead of the sentence level.
## Training Setup
The model was trained for 3 epochs from `bert-base-uncased` on paragraph pairs (limited to 512 subwork with the `longest_first` truncation strategy).
We use a batch size of 24 wit 2 iterations gradient accumulation (effective batch size of 48), and a learning rate of 1e-4, with gradient clipping at 5.
Training was performed on a single Titan RTX GPU over the duration of 3 weeks.
|
diarsabri/LaDPR-query-encoder
|
600d1091763cd2418ba805d72f55d4bed1c6d6b4
|
2021-05-05T21:00:08.000Z
|
[
"pytorch",
"dpr",
"feature-extraction",
"transformers"
] |
feature-extraction
| false |
diarsabri
| null |
diarsabri/LaDPR-query-encoder
| 52 | null |
transformers
| 5,922 |
Language Model 1
For Language agnostic Dense Passage Retrieval
|
flax-community/indonesian-roberta-base
|
6cedc13543d3e59e980c435d28a2346d9f2bad31
|
2021-07-10T08:19:46.000Z
|
[
"pytorch",
"jax",
"tensorboard",
"roberta",
"fill-mask",
"id",
"dataset:oscar",
"arxiv:1907.11692",
"transformers",
"indonesian-roberta-base",
"license:mit",
"autotrain_compatible"
] |
fill-mask
| false |
flax-community
| null |
flax-community/indonesian-roberta-base
| 52 | 5 |
transformers
| 5,923 |
---
language: id
tags:
- indonesian-roberta-base
license: mit
datasets:
- oscar
widget:
- text: "Budi telat ke sekolah karena ia <mask>."
---
## Indonesian RoBERTa Base
Indonesian RoBERTa Base is a masked language model based on the [RoBERTa](https://arxiv.org/abs/1907.11692) model. It was trained on the [OSCAR](https://huggingface.co/datasets/oscar) dataset, specifically the `unshuffled_deduplicated_id` subset. The model was trained from scratch and achieved an evaluation loss of 1.798 and an evaluation accuracy of 62.45%.
This model was trained using HuggingFace's Flax framework and is part of the [JAX/Flax Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104) organized by HuggingFace. All training was done on a TPUv3-8 VM, sponsored by the Google Cloud team.
All necessary scripts used for training could be found in the [Files and versions](https://huggingface.co/flax-community/indonesian-roberta-base/tree/main) tab, as well as the [Training metrics](https://huggingface.co/flax-community/indonesian-roberta-base/tensorboard) logged via Tensorboard.
## Model
| Model | #params | Arch. | Training/Validation data (text) |
| ------------------------- | ------- | ------- | ------------------------------------------ |
| `indonesian-roberta-base` | 124M | RoBERTa | OSCAR `unshuffled_deduplicated_id` Dataset |
## Evaluation Results
The model was trained for 8 epochs and the following is the final result once the training ended.
| train loss | valid loss | valid accuracy | total time |
| ---------- | ---------- | -------------- | ---------- |
| 1.870 | 1.798 | 0.6245 | 18:25:39 |
## How to Use
### As Masked Language Model
```python
from transformers import pipeline
pretrained_name = "flax-community/indonesian-roberta-base"
fill_mask = pipeline(
"fill-mask",
model=pretrained_name,
tokenizer=pretrained_name
)
fill_mask("Budi sedang <mask> di sekolah.")
```
### Feature Extraction in PyTorch
```python
from transformers import RobertaModel, RobertaTokenizerFast
pretrained_name = "flax-community/indonesian-roberta-base"
model = RobertaModel.from_pretrained(pretrained_name)
tokenizer = RobertaTokenizerFast.from_pretrained(pretrained_name)
prompt = "Budi sedang berada di sekolah."
encoded_input = tokenizer(prompt, return_tensors='pt')
output = model(**encoded_input)
```
## Team Members
- Wilson Wongso ([@w11wo](https://hf.co/w11wo))
- Steven Limcorn ([@stevenlimcorn](https://hf.co/stevenlimcorn))
- Samsul Rahmadani ([@munggok](https://hf.co/munggok))
- Chew Kok Wah ([@chewkokwah](https://hf.co/chewkokwah))
|
google/t5-3b-ssm
|
de842a05eabdc2688bd66a84b83227e933ed8e5e
|
2020-12-07T19:49:00.000Z
|
[
"pytorch",
"tf",
"t5",
"text2text-generation",
"en",
"dataset:c4",
"dataset:wikipedia",
"arxiv:2002.08909",
"arxiv:1910.10683",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
text2text-generation
| false |
google
| null |
google/t5-3b-ssm
| 52 | 1 |
transformers
| 5,924 |
---
language: en
datasets:
- c4
- wikipedia
license: apache-2.0
---
[Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) for **Closed Book Question Answering**.
The model was pre-trained using T5's denoising objective on [C4](https://huggingface.co/datasets/c4) and subsequently additionally pre-trained using [REALM](https://arxiv.org/pdf/2002.08909.pdf)'s salient span masking objective on [Wikipedia](https://huggingface.co/datasets/wikipedia).
**Note**: This model should be fine-tuned on a question answering downstream task before it is useable for closed book question answering.
Other Community Checkpoints: [here](https://huggingface.co/models?search=ssm)
Paper: [How Much Knowledge Can You Pack
Into the Parameters of a Language Model?](https://arxiv.org/abs/1910.10683.pdf)
Authors: *Adam Roberts, Colin Raffel, Noam Shazeer*
## Abstract
It has recently been observed that neural language models trained on unstructured text can implicitly store and retrieve knowledge using natural language queries. In this short paper, we measure the practical utility of this approach by fine-tuning pre-trained models to answer questions without access to any external context or knowledge. We show that this approach scales with model size and performs competitively with open-domain systems that explicitly retrieve answers from an external knowledge source when answering questions. To facilitate reproducibility and future work, we release our code and trained models at https://goo.gle/t5-cbqa.

|
gsarti/it5-small
|
5b4b3e313cbc2b00a135a55daa3fe826ac077b25
|
2022-03-09T11:56:34.000Z
|
[
"pytorch",
"tf",
"jax",
"tensorboard",
"t5",
"text2text-generation",
"it",
"dataset:gsarti/clean_mc4_it",
"arxiv:2203.03759",
"transformers",
"seq2seq",
"lm-head",
"license:apache-2.0",
"autotrain_compatible"
] |
text2text-generation
| false |
gsarti
| null |
gsarti/it5-small
| 52 | 1 |
transformers
| 5,925 |
---
language:
- it
datasets:
- gsarti/clean_mc4_it
tags:
- seq2seq
- lm-head
license: apache-2.0
inference: false
thumbnail: https://gsarti.com/publication/it5/featured.png
---
# Italian T5 Small 🇮🇹
The [IT5](https://huggingface.co/models?search=it5) model family represents the first effort in pretraining large-scale sequence-to-sequence transformer models for the Italian language, following the approach adopted by the original [T5 model](https://github.com/google-research/text-to-text-transfer-transformer).
This model is released as part of the project ["IT5: Large-Scale Text-to-Text Pretraining for Italian Language Understanding and Generation"](https://arxiv.org/abs/2203.03759), by [Gabriele Sarti](https://gsarti.com/) and [Malvina Nissim](https://malvinanissim.github.io/) with the support of [Huggingface](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104) and with TPU usage sponsored by Google's [TPU Research Cloud](https://sites.research.google/trc/). All the training was conducted on a single TPU3v8-VM machine on Google Cloud. Refer to the Tensorboard tab of the repository for an overview of the training process.
*The inference widget is deactivated because the model needs a task-specific seq2seq fine-tuning on a downstream task to be useful in practice. The models in the [`it5`](https://huggingface.co/it5) organization provide some examples of this model fine-tuned on various downstream task.*
## Model variants
This repository contains the checkpoints for the `base` version of the model. The model was trained for one epoch (1.05M steps) on the [Thoroughly Cleaned Italian mC4 Corpus](https://huggingface.co/datasets/gsarti/clean_mc4_it) (~41B words, ~275GB) using 🤗 Datasets and the `google/t5-v1_1-small` improved configuration. The training procedure is made available [on Github](https://github.com/gsarti/t5-flax-gcp).
The following table summarizes the parameters for all available models
| |`it5-small` (this one) |`it5-base` |`it5-large` |`it5-base-oscar` |
|-----------------------|-----------------------|----------------------|-----------------------|----------------------------------|
|`dataset` |`gsarti/clean_mc4_it` |`gsarti/clean_mc4_it` |`gsarti/clean_mc4_it` |`oscar/unshuffled_deduplicated_it`|
|`architecture` |`google/t5-v1_1-small` |`google/t5-v1_1-base` |`google/t5-v1_1-large` |`t5-base` |
|`learning rate` | 5e-3 | 5e-3 | 5e-3 | 1e-2 |
|`steps` | 1'050'000 | 1'050'000 | 2'100'000 | 258'000 |
|`training time` | 36 hours | 101 hours | 370 hours | 98 hours |
|`ff projection` |`gated-gelu` |`gated-gelu` |`gated-gelu` |`relu` |
|`tie embeds` |`false` |`false` |`false` |`true` |
|`optimizer` | adafactor | adafactor | adafactor | adafactor |
|`max seq. length` | 512 | 512 | 512 | 512 |
|`per-device batch size`| 16 | 16 | 8 | 16 |
|`tot. batch size` | 128 | 128 | 64 | 128 |
|`weigth decay` | 1e-3 | 1e-3 | 1e-2 | 1e-3 |
|`validation split size`| 15K examples | 15K examples | 15K examples | 15K examples |
The high training time of `it5-base-oscar` was due to [a bug](https://github.com/huggingface/transformers/pull/13012) in the training script.
For a list of individual model parameters, refer to the `config.json` file in the respective repositories.
## Using the models
```python
from transformers import AutoTokenzier, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("gsarti/it5-small")
model = AutoModelForSeq2SeqLM.from_pretrained("gsarti/it5-small")
```
*Note: You will need to fine-tune the model on your downstream seq2seq task to use it. See an example [here](https://huggingface.co/it5/it5-base-question-answering).*
Flax and Tensorflow versions of the model are also available:
```python
from transformers import FlaxT5ForConditionalGeneration, TFT5ForConditionalGeneration
model_flax = FlaxT5ForConditionalGeneration.from_pretrained("gsarti/it5-small")
model_tf = TFT5ForConditionalGeneration.from_pretrained("gsarti/it5-small")
```
## Limitations
Due to the nature of the web-scraped corpus on which IT5 models were trained, it is likely that their usage could reproduce and amplify pre-existing biases in the data, resulting in potentially harmful content such as racial or gender stereotypes and conspiracist views. For this reason, the study of such biases is explicitly encouraged, and model usage should ideally be restricted to research-oriented and non-user-facing endeavors.
## Model curators
For problems or updates on this model, please contact [[email protected]](mailto:[email protected]).
## Citation Information
```bibtex
@article{sarti-nissim-2022-it5,
title={IT5: Large-scale Text-to-text Pretraining for Italian Language Understanding and Generation},
author={Sarti, Gabriele and Nissim, Malvina},
journal={ArXiv preprint 2203.03759},
url={https://arxiv.org/abs/2203.03759},
year={2022},
month={mar}
}
```
|
huggingtweets/tilda_tweets
|
2d85aa279ff77324cb7172a82e7eae68f0ffe15b
|
2021-05-23T02:19:01.000Z
|
[
"pytorch",
"jax",
"gpt2",
"text-generation",
"en",
"transformers",
"huggingtweets"
] |
text-generation
| false |
huggingtweets
| null |
huggingtweets/tilda_tweets
| 52 | null |
transformers
| 5,926 |
---
language: en
thumbnail: https://www.huggingtweets.com/tilda_tweets/1614119818814/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1247095679882645511/gsXujIBv_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">tilly 🤖 AI Bot </div>
<div style="font-size: 15px">@tilda_tweets bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@tilda_tweets's tweets](https://twitter.com/tilda_tweets).
| Data | Quantity |
| --- | --- |
| Tweets downloaded | 326 |
| Retweets | 118 |
| Short tweets | 24 |
| Tweets kept | 184 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3n2tjxi3/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @tilda_tweets's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2kg9hiau) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2kg9hiau/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/tilda_tweets')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
nbroad/deberta-v3-xsmall-squad2
|
4b1d92d2daed14c72a00446afe3e436122b96d4f
|
2022-07-22T14:03:41.000Z
|
[
"pytorch",
"tensorboard",
"deberta-v2",
"question-answering",
"en",
"dataset:squad_v2",
"transformers",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible"
] |
question-answering
| false |
nbroad
| null |
nbroad/deberta-v3-xsmall-squad2
| 52 | null |
transformers
| 5,927 |
---
license: cc-by-4.0
widget:
- context: DeBERTa improves the BERT and RoBERTa models using disentangled attention
and enhanced mask decoder. With those two improvements, DeBERTa out perform RoBERTa
on a majority of NLU tasks with 80GB training data. In DeBERTa V3, we further
improved the efficiency of DeBERTa using ELECTRA-Style pre-training with Gradient
Disentangled Embedding Sharing. Compared to DeBERTa, our V3 version significantly
improves the model performance on downstream tasks. You can find more technique
details about the new model from our paper. Please check the official repository
for more implementation details and updates.
example_title: DeBERTa v3 Q1
text: How is DeBERTa version 3 different than previous ones?
- context: DeBERTa improves the BERT and RoBERTa models using disentangled attention
and enhanced mask decoder. With those two improvements, DeBERTa out perform RoBERTa
on a majority of NLU tasks with 80GB training data. In DeBERTa V3, we further
improved the efficiency of DeBERTa using ELECTRA-Style pre-training with Gradient
Disentangled Embedding Sharing. Compared to DeBERTa, our V3 version significantly
improves the model performance on downstream tasks. You can find more technique
details about the new model from our paper. Please check the official repository
for more implementation details and updates.
example_title: DeBERTa v3 Q2
text: Where do I go to see new info about DeBERTa?
datasets:
- squad_v2
metrics:
- f1
- exact
tags:
- question-answering
language: en
model-index:
- name: DeBERTa v3 xsmall squad2
results:
- task:
name: Question Answering
type: question-answering
dataset:
name: SQuAD2.0
type: question-answering
metrics:
- name: f1
type: f1
value: 81.5
- name: exact
type: exact
value: 78.3
- task:
type: question-answering
name: Question Answering
dataset:
name: squad_v2
type: squad_v2
config: squad_v2
split: validation
metrics:
- name: Exact Match
type: exact_match
value: 78.5341
verified: true
- name: F1
type: f1
value: 81.6408
verified: true
- name: total
type: total
value: 11870
verified: true
---
# DeBERTa v3 xsmall SQuAD 2.0
[Microsoft reports that this model can get 84.8/82.0](https://huggingface.co/microsoft/deberta-v3-xsmall#fine-tuning-on-nlu-tasks) on f1/em on the dev set.
I got 81.5/78.3 but I only did one run and I didn't use the official squad2 evaluation script. I will do some more runs and show the results on the official script soon.
|
nlp4good/psych-search
|
894dbb27a8ab4f284b9659ceb6578c6f431d35dc
|
2021-09-22T09:29:47.000Z
|
[
"pytorch",
"jax",
"bert",
"fill-mask",
"en",
"dataset:PubMed",
"transformers",
"mental-health",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
| false |
nlp4good
| null |
nlp4good/psych-search
| 52 | null |
transformers
| 5,928 |
---
language:
- en
tags:
- mental-health
license: apache-2.0
datasets:
- PubMed
---
# Psych-Search
Psych-Search is a work in progress to bring cutting edge NLP to mental health practitioners. The model detailed here serves as a foundation for traditional classification models as well as NLU models for a Psych-Search application. The goal of the Psych-Search Application is to use a combination of traditional text classification models to expand the scope of the MESH taxonomy with the inclusion of relevant categories for mental health pracitioners designing suicide prevention programs for adolescent communities within the United States, as well as the automatic extraction and standardization of entities such as risk factors and protective factors.
Our first expansion efforts to the MESH taxonomy include categories:
- Prevention Strategies
- Protective Factors
We are actively looking for partners on this work and would love to hear from you! Please ping us at [email protected].
## Model description
This model is an extension of [allenai/scibert_scivocab_uncased](https://huggingface.co/allenai/scibert_scivocab_uncased). Continued pretraining was done using SciBERT as the base model using abstract text only from Pyschology and Psychiatry PubMed research. Training was done on approximately 3.5 million papers for 10 epochs and evaluated on a task similar to BioASQ Task A.
## Intended uses & limitations
#### How to use
```python
from transformers import AutoTokenizer, AutoModel
mname = "nlp4good/psych-search"
tokenizer = AutoTokenizer.from_pretrained(mname)
model = AutoModel.from_pretrained(mname)
```
### Limitations and bias
This model was trained on all PubMed abstracts categorized under [Psychology and Psychiatry](https://meshb.nlm.nih.gov/treeView). As of March 1, this corresponds to approximately 3.2 million papers that contains abstract text. Of these 3.2 million papers, relevant sparse mental health categories were back translated to increase the representation of certain mental health categories.
There are several limitation with this dataset including large discrepancies in the number of papers associated with [Sexual and Gender Minorities](https://meshb.nlm.nih.gov/record/ui?ui=D000072339). The training data consisted of the following breakdown across gender groups:
Female | Male | Sexual and Gender Minorities
-------|---------|----------
1,896,301 | 1,945,279 | 4,529
Similar discrepancies are present within [Ethnic Groups](https://meshb.nlm.nih.gov/record/ui?ui=D005006) as defined within the MESH taxonomy:
| African Americans | Arabs | Asian Americans | Hispanic Americans | Indians, Central American | Indians, North American | Indians, South American | Indigenous Peoples | Mexican Americans |
|-------------------|-------|-----------------|--------------------|---------------------------|-------------------------|-------------------------|--------------------|-------------------|
| 31,027 | 2,437 | 5,612 | 18,893 | 124 | 5,657 | 633 | 174 | 3,234 |
These discrepancies can have a significant impact on information retrieval systems, downstream machine learning models, and other forms of NLP that leverage these pretrained models.
## Training data
This model was trained on all PubMed abstracts categorized under [Psychology and Psychiatry](https://meshb.nlm.nih.gov/treeView). As of March 1, this corresponds to approximately 3.2 million papers that contains abstract text. Of these 3.2 million papers, relevant sparse categories were back translated from english to french and from french to english to increase the representation of sparser mental health categories. This included backtranslating the following papers with the following categories:
- Depressive Disorder
- Risk Factors
- Mental Disorders
- Child, Preschool
- Mental Health
In aggregate, this process added 557,980 additional papers to our training data.
## Training procedure
Continued pretraining was done on Psychology and Psychiatry PubMed papers for 10 epochs. Default parameters were used with the exception of gradient accumulation steps which was set at 4, with a per device train batch size of 32. 2 x Nvidia 3090's were used in the development of this model.
## Evaluation results
To evaluate the effectiveness of psych-search within the mental health domain, an evaluation task was constructed by finetuning psych-search for a task similar to [BioASQ Task A](http://bioasq.org/). Here we perform large scale biomedical indexing using the MESH taxonomy associated with each paper underneath Psychology and Psychiatry. The evaluation metric is the micro F1 score across all second level descriptors within Psychology and Psychiatry. This corresponds to 38 different MESH categories used during evaluation.
bert-base-uncased | SciBERT Scivocab Uncased | Psych-Search
-------|---------|----------
0.7348 | 0.7394 | 0.7415
## Next Steps
If you are interested in continuing to build on this work or have other ideas on how we can build on others work, please let us know! We can be reached at [email protected]. Our goal is to bring state of the art NLP capabilities to underserved areas of research, with mental health being our top priority.
|
shtoshni/spanbert_coreference_large
|
b93b0b352fd0153550f18878505b4ad284b97e10
|
2021-03-28T14:23:36.000Z
|
[
"pytorch",
"transformers"
] | null | false |
shtoshni
| null |
shtoshni/spanbert_coreference_large
| 52 | null |
transformers
| 5,929 |
Entry not found
|
uf-aice-lab/math-roberta
|
e535977f65f11632a830a8af74e9cad598c25944
|
2022-02-11T20:21:02.000Z
|
[
"pytorch",
"roberta",
"text-generation",
"en",
"transformers",
"nlp",
"math learning",
"education",
"license:mit"
] |
text-generation
| false |
uf-aice-lab
| null |
uf-aice-lab/math-roberta
| 52 | null |
transformers
| 5,930 |
---
language:
- en
tags:
- nlp
- math learning
- education
license: mit
---
# Math-RoBerta for NLP tasks in math learning environments
This model is fine-tuned RoBERTa-large trained with 8 Nvidia RTX 1080Ti GPUs using 3,000,000 math discussion posts by students and facilitators on Algebra Nation (https://www.mathnation.com/). MathRoBERTa has 24 layers, and 355 million parameters and its published model weights take up to 1.5 gigabytes of disk space. It can potentially provide a good base performance on NLP related tasks (e.g., text classification, semantic search, Q&A) in similar math learning environments.
### Here is how to use it with texts in HuggingFace
```python
from transformers import RobertaTokenizer, RobertaModel
tokenizer = RobertaTokenizer.from_pretrained('uf-aice-lab/math-roberta')
model = RobertaModel.from_pretrained('uf-aice-lab/math-roberta')
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
|
wpnbos/xlm-roberta-base-conll2002-dutch
|
4bb41e4849d873d8fcb49f249342492eaf1f0c31
|
2022-04-20T19:28:55.000Z
|
[
"pytorch",
"xlm-roberta",
"token-classification",
"nl",
"dataset:conll2002",
"arxiv:1911.02116",
"transformers",
"Named Entity Recognition",
"autotrain_compatible"
] |
token-classification
| false |
wpnbos
| null |
wpnbos/xlm-roberta-base-conll2002-dutch
| 52 | null |
transformers
| 5,931 |
---
language:
- nl
tags:
- Named Entity Recognition
- xlm-roberta
datasets:
- conll2002
metrics:
- f1: 90.57
---
# XLM-RoBERTa base ConLL-2002 Dutch
XLM-Roberta base model finetuned on ConLL-2002 Dutch train set, which is a Named Entity Recognition dataset containing the following classes: PER, LOC, ORG and MISC.
Label mapping:
{
0: O,
1: B-PER,
2: I-PER,
3: B-ORG,
4: I-ORG,
5: B-LOC,
6: I-LOC,
7: B-MISC,
8: I-MISC,
}
Results from https://arxiv.org/pdf/1911.02116.pdf reciprocated (original results were 90.39 F1, this finetuned version here scored 90.57).
|
IIC/dpr-spanish-question_encoder-squades-base
|
87da269c24ef47fa7dc2bb19ebedb408d9d7aeb1
|
2022-04-02T15:08:08.000Z
|
[
"pytorch",
"bert",
"fill-mask",
"es",
"dataset:squad_es",
"arxiv:2004.04906",
"transformers",
"sentence similarity",
"passage retrieval",
"model-index",
"autotrain_compatible"
] |
fill-mask
| false |
IIC
| null |
IIC/dpr-spanish-question_encoder-squades-base
| 52 | 3 |
transformers
| 5,932 |
---
language:
- es
tags:
- sentence similarity # Example: audio
- passage retrieval # Example: automatic-speech-recognition
datasets:
- squad_es
metrics:
- eval_loss: 0.08608942725107592
- eval_accuracy: 0.9925325215819639
- eval_f1: 0.8805402320715237
- average_rank: 0.27430093209054596
model-index:
- name: dpr-spanish-passage_encoder-squades-base
results:
- task:
type: text similarity # Required. Example: automatic-speech-recognition
name: text similarity # Optional. Example: Speech Recognition
dataset:
type: squad_es # Required. Example: common_voice. Use dataset id from https://hf.co/datasets
name: squad_es # Required. Example: Common Voice zh-CN
args: es # Optional. Example: zh-CN
metrics:
- type: loss
value: 0.08608942725107592
name: eval_loss
- type: accuracy
value: 0.99
name: accuracy
- type: f1
value: 0.88
name: f1
- type: avgrank
value: 0.2743
name: avgrank
---
[Dense Passage Retrieval](https://arxiv.org/abs/2004.04906) is a set of tools for performing state of the art open-domain question answering. It was initially developed by Facebook and there is an [official repository](https://github.com/facebookresearch/DPR). DPR is intended to retrieve the relevant documents to answer a given question, and is composed of 2 models, one for encoding passages and other for encoding questions. This concrete model is the one used for encoding passages.
Regarding its use, this model should be used to vectorize a question that enters in a Question Answering system, and then we compare that encoding with the encodings of the database (encoded with [the passage encoder](https://huggingface.co/avacaondata/dpr-spanish-passage_encoder-squades-base)) to find the most similar documents , which then should be used for either extracting the answer or generating it.
For training the model, we used the spanish version of SQUAD, [SQUAD-ES](https://huggingface.co/datasets/squad_es), with which we created positive and negative examples for the model.
Example of use:
```python
from transformers import DPRQuestionEncoder, DPRQuestionEncoderTokenizer
model_str = "avacaondata/dpr-spanish-passage_encoder-squades-base"
tokenizer = DPRQuestionEncoderTokenizer.from_pretrained(model_str)
model = DPRQuestionEncoder.from_pretrained(model_str)
input_ids = tokenizer("¿Qué medallas ganó Usain Bolt en 2012?", return_tensors="pt")["input_ids"]
embeddings = model(input_ids).pooler_output
```
The full metrics of this model on the evaluation split of SQUADES are:
```
evalloss: 0.08608942725107592
acc: 0.9925325215819639
f1: 0.8805402320715237
acc_and_f1: 0.9365363768267438
average_rank: 0.27430093209054596
```
And the classification report:
```
precision recall f1-score support
hard_negative 0.9961 0.9961 0.9961 325878
positive 0.8805 0.8805 0.8805 10514
accuracy 0.9925 336392
macro avg 0.9383 0.9383 0.9383 336392
weighted avg 0.9925 0.9925 0.9925 336392
```
### Contributions
Thanks to [@avacaondata](https://huggingface.co/avacaondata), [@alborotis](https://huggingface.co/alborotis), [@albarji](https://huggingface.co/albarji), [@Dabs](https://huggingface.co/Dabs), [@GuillemGSubies](https://huggingface.co/GuillemGSubies) for adding this model.
|
IDEA-CCNL/Bigan-Transformer-XL-denoise-1.1B
|
0484d5e9d159d112a543c1990231762f8a700d2d
|
2022-04-13T07:25:42.000Z
|
[
"pytorch",
"zh",
"transformers",
"license:apache-2.0"
] | null | false |
IDEA-CCNL
| null |
IDEA-CCNL/Bigan-Transformer-XL-denoise-1.1B
| 52 | null |
transformers
| 5,933 |
---
language:
- zh
license: apache-2.0
---
# Abstract
This is a Chinese transformer-xl model trained on [Wudao dataset](https://resource.wudaoai.cn/home?ind&name=WuDaoCorpora%202.0&id=1394901288847716352)
and finetuned on a denoise dataset constructed by our team. The denoise task is to reconstruct a fluent and clean text from a noisy input which includes random insertion/swap/deletion/replacement/sentence reordering.
## Usage
### load model
```python
from fengshen.models.transfo_xl_denoise.tokenization_transfo_xl_denoise import TransfoXLDenoiseTokenizer
from fengshen.models.transfo_xl_denoise.modeling_transfo_xl_denoise import TransfoXLDenoiseModel
tokenizer = TransfoXLDenoiseTokenizer.from_pretrained('IDEA-CCNL/Bigan-Transformer-XL-denoise-1.1B')
model = TransfoXLDenoiseModel.from_pretrained('IDEA-CCNL/Bigan-Transformer-XL-denoise-1.1B')
```
### generation
```python
from fengshen.models.transfo_xl_denoise.generate import denoise_generate
input_text = "凡是有成就的人, 都很严肃地对待生命自己的"
res = denoise_generate(model, tokenizer, input_text)
print(res) # "有成就的人都很严肃地对待自己的生命。"
```
## Citation
If you find the resource is useful, please cite the following website in your paper.
```
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2022},
howpublished={\url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
```
|
Helsinki-NLP/opus-mt-tc-big-en-ro
|
5d0c15b53f631dc74430fe8153c8ed8d02cc7290
|
2022-06-01T13:01:57.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"en",
"ro",
"transformers",
"translation",
"opus-mt-tc",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-tc-big-en-ro
| 52 | null |
transformers
| 5,934 |
---
language:
- en
- ro
tags:
- translation
- opus-mt-tc
license: cc-by-4.0
model-index:
- name: opus-mt-tc-big-en-ro
results:
- task:
name: Translation eng-ron
type: translation
args: eng-ron
dataset:
name: flores101-devtest
type: flores_101
args: eng ron devtest
metrics:
- name: BLEU
type: bleu
value: 40.4
- task:
name: Translation eng-ron
type: translation
args: eng-ron
dataset:
name: newsdev2016
type: newsdev2016
args: eng-ron
metrics:
- name: BLEU
type: bleu
value: 36.4
- task:
name: Translation eng-ron
type: translation
args: eng-ron
dataset:
name: tatoeba-test-v2021-08-07
type: tatoeba_mt
args: eng-ron
metrics:
- name: BLEU
type: bleu
value: 48.6
- task:
name: Translation eng-ron
type: translation
args: eng-ron
dataset:
name: newstest2016
type: wmt-2016-news
args: eng-ron
metrics:
- name: BLEU
type: bleu
value: 34.0
---
# opus-mt-tc-big-en-ro
Neural machine translation model for translating from English (en) to Romanian (ro).
This model is part of the [OPUS-MT project](https://github.com/Helsinki-NLP/Opus-MT), an effort to make neural machine translation models widely available and accessible for many languages in the world. All models are originally trained using the amazing framework of [Marian NMT](https://marian-nmt.github.io/), an efficient NMT implementation written in pure C++. The models have been converted to pyTorch using the transformers library by huggingface. Training data is taken from [OPUS](https://opus.nlpl.eu/) and training pipelines use the procedures of [OPUS-MT-train](https://github.com/Helsinki-NLP/Opus-MT-train).
* Publications: [OPUS-MT – Building open translation services for the World](https://aclanthology.org/2020.eamt-1.61/) and [The Tatoeba Translation Challenge – Realistic Data Sets for Low Resource and Multilingual MT](https://aclanthology.org/2020.wmt-1.139/) (Please, cite if you use this model.)
```
@inproceedings{tiedemann-thottingal-2020-opus,
title = "{OPUS}-{MT} {--} Building open translation services for the World",
author = {Tiedemann, J{\"o}rg and Thottingal, Santhosh},
booktitle = "Proceedings of the 22nd Annual Conference of the European Association for Machine Translation",
month = nov,
year = "2020",
address = "Lisboa, Portugal",
publisher = "European Association for Machine Translation",
url = "https://aclanthology.org/2020.eamt-1.61",
pages = "479--480",
}
@inproceedings{tiedemann-2020-tatoeba,
title = "The Tatoeba Translation Challenge {--} Realistic Data Sets for Low Resource and Multilingual {MT}",
author = {Tiedemann, J{\"o}rg},
booktitle = "Proceedings of the Fifth Conference on Machine Translation",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.wmt-1.139",
pages = "1174--1182",
}
```
## Model info
* Release: 2022-02-25
* source language(s): eng
* target language(s): ron
* model: transformer-big
* data: opusTCv20210807+bt ([source](https://github.com/Helsinki-NLP/Tatoeba-Challenge))
* tokenization: SentencePiece (spm32k,spm32k)
* original model: [opusTCv20210807+bt_transformer-big_2022-02-25.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-ron/opusTCv20210807+bt_transformer-big_2022-02-25.zip)
* more information released models: [OPUS-MT eng-ron README](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-ron/README.md)
## Usage
A short example code:
```python
from transformers import MarianMTModel, MarianTokenizer
src_text = [
">>ron<< A bad writer's prose is full of hackneyed phrases.",
">>ron<< Zero is a special number."
]
model_name = "pytorch-models/opus-mt-tc-big-en-ro"
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True))
for t in translated:
print( tokenizer.decode(t, skip_special_tokens=True) )
# expected output:
# Proza unui scriitor prost este plină de fraze tocite.
# Zero este un număr special.
```
You can also use OPUS-MT models with the transformers pipelines, for example:
```python
from transformers import pipeline
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-tc-big-en-ro")
print(pipe(">>ron<< A bad writer's prose is full of hackneyed phrases."))
# expected output: Proza unui scriitor prost este plină de fraze tocite.
```
## Benchmarks
* test set translations: [opusTCv20210807+bt_transformer-big_2022-02-25.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-ron/opusTCv20210807+bt_transformer-big_2022-02-25.test.txt)
* test set scores: [opusTCv20210807+bt_transformer-big_2022-02-25.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-ron/opusTCv20210807+bt_transformer-big_2022-02-25.eval.txt)
* benchmark results: [benchmark_results.txt](benchmark_results.txt)
* benchmark output: [benchmark_translations.zip](benchmark_translations.zip)
| langpair | testset | chr-F | BLEU | #sent | #words |
|----------|---------|-------|-------|-------|--------|
| eng-ron | tatoeba-test-v2021-08-07 | 0.68606 | 48.6 | 5508 | 40367 |
| eng-ron | flores101-devtest | 0.64876 | 40.4 | 1012 | 26799 |
| eng-ron | newsdev2016 | 0.62682 | 36.4 | 1999 | 51300 |
| eng-ron | newstest2016 | 0.60702 | 34.0 | 1999 | 48945 |
## Acknowledgements
The work is supported by the [European Language Grid](https://www.european-language-grid.eu/) as [pilot project 2866](https://live.european-language-grid.eu/catalogue/#/resource/projects/2866), by the [FoTran project](https://www.helsinki.fi/en/researchgroups/natural-language-understanding-with-cross-lingual-grounding), funded by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 771113), and the [MeMAD project](https://memad.eu/), funded by the European Union’s Horizon 2020 Research and Innovation Programme under grant agreement No 780069. We are also grateful for the generous computational resources and IT infrastructure provided by [CSC -- IT Center for Science](https://www.csc.fi/), Finland.
## Model conversion info
* transformers version: 4.16.2
* OPUS-MT git hash: 3405783
* port time: Wed Apr 13 17:55:46 EEST 2022
* port machine: LM0-400-22516.local
|
allenai/aspire-contextualsentence-multim-compsci
|
60ee0b096626723196fa620f3b10f1ad11ed1214
|
2022-04-24T20:05:57.000Z
|
[
"pytorch",
"bert",
"feature-extraction",
"arxiv:2111.08366",
"transformers",
"license:apache-2.0"
] |
feature-extraction
| false |
allenai
| null |
allenai/aspire-contextualsentence-multim-compsci
| 52 | null |
transformers
| 5,935 |
---
license: apache-2.0
---
## Overview
Model included in a paper for modeling fine grained similarity between documents:
**Title**: "Multi-Vector Models with Textual Guidance for Fine-Grained Scientific Document Similarity"
**Authors**: Sheshera Mysore, Arman Cohan, Tom Hope
**Paper**: https://arxiv.org/abs/2111.08366
**Github**: https://github.com/allenai/aspire
**Note**: In the context of the paper, this model is referred to as `tsAspire` and represents the papers proposed multi-vector model for fine-grained scientific document similarity.
## Model Card
### Model description
This model is a BERT based multi-vector model trained for fine-grained similarity of computer science papers. This model inputs the title and abstract of a paper and represents a paper with a contextual sentence vectors obtained by averaging the token representations of individual sentences - the whole title and abstract are encoded with cross-attention in the encoder block before obtaining sentence embeddings. The model is trained by minimizing an Wasserstein/Earth Movers Distance between sentence vectors for a pair of documents - in the process also learning a sparse alignment between sentences in both documents. Test time behavior ranks documents based on the Wasserstein Distance between all sentences of documents or a set of query sentences and a candidate documents sentences.
### Training data
The model is trained on pairs of co-cited papers with their sentences aligned by the co-citation context in a contrastive learning setup. The model is trained on 1.2 million computer science paper pairs. In training the model, negative examples for the contrastive loss are obtained as random in-batch negatives. Co-citations are obtained from the full text of papers. For example - the papers in brackets below are all co-cited and each pair of papers would be used as a training pair:
> The idea of distant supervision has been proposed and used widely in Relation Extraction (Mintz et al., 2009; Riedel et al., 2010; Hoffmann et al., 2011; Surdeanu et al., 2012) , where the source of labels is an external knowledge base.
### Training procedure
The model was trained with the Adam Optimizer and a learning rate of 2e-5 with 1000 warm-up steps followed by linear decay of the learning rate. The model training convergence is checked with the loss on a held out dev set consisting of co-cited paper pairs.
### Intended uses & limitations
This model is trained for fine-grained document similarity tasks in **computer science** scientific text using multiple vectors per document. The model allows _multiple_ fine grained sentence-to-sentence similarities between documents. The model is well suited to an aspect conditional task formulation where a query might consist of sentence_s_ in a query document and candidates must be retrieved along the specified sentences. Here, the documents are the title and abstract of a paper. With appropriate fine-tuning the model can also be used for other tasks such as document or sentence level classification. Since the training data comes primarily from computer science, performance on other domains may be poorer.
### How to use
This model can be used via the `transformers` library, and some additional code to compute contextual sentence vectors and to make multiple matches using optimal transport.
View example usage and sample document matches in the model github repo: [`examples/demo-contextualsentence-multim.ipynb`](https://github.com/allenai/aspire/blob/main/examples/demo-contextualsentence-multim.ipynb)
### Variable and metrics
This model is evaluated on information retrieval datasets with document level queries. Performance here is reported on CSFCube (computer science/English). This is detailed on [github](https://github.com/allenai/aspire) and in our [paper](https://arxiv.org/abs/2111.08366). CSFCube presents a finer-grained query via selected sentences in a query abstract based on which a finer-grained retrieval must be made from candidate abstracts.
In using this model we rank documents by the Wasserstein distance between the query sentences and a candidates sentences.
### Evaluation results
The released model `aspire-contextualsentence-multim-compsci` is compared against `allenai/specter`, a bi-encoder baseline and `all-mpnet-base-v2` a strong non-contextual sentence-bert baseline model trained on ~1 billion training examples. `aspire-contextualsentence-multim-compsci`<sup>*</sup> is the performance reported in our paper by averaging over 3 re-runs of the model. The released models `aspire-contextualsentence-multim-compsci` is the single best run among the 3 re-runs.
| | CSFCube aggregated | CSFCube aggregated|
|--------------------------------------------:|:---------:|:-------:|
| | MAP | NDCG%20 |
| `all-mpnet-base-v2` | 34.64 | 54.94 |
| `specter` | 34.23 | 53.28 |
| `aspire-contextualsentence-multim-compsci`<sup>*</sup> | 40.79 | 61.41 |
| `aspire-contextualsentence-multim-compsci` | 41.24 | 61.81 |
**Alternative models:**
Besides the above models consider these alternative models also released in the Aspire paper:
[`aspire-contextualsentence-multim-biomed`](https://huggingface.co/allenai/aspire-contextualsentence-multim-biomed): If you wanted to run on biomedical papers and want to use a model trained to match _multiple_ sentences between documents.
[`aspire-contextualsentence-singlem-biomed`](https://huggingface.co/allenai/aspire-contextualsentence-singlem-biomed): If you wanted to run on biomedical papers and want to use a model trained to match _single_ sentences between documents.
[`aspire-contextualsentence-singlem-compsci`](https://huggingface.co/allenai/aspire-contextualsentence-singlem-compsci): If you wanted to run on computer science papers and want to use a model trained to match _single_ sentences between documents.
|
mismayil/kogito-rc-bert
|
91f506c45ea47507608565da4690526a41ff38c2
|
2022-04-28T20:25:32.000Z
|
[
"pytorch",
"transformers",
"license:mit"
] | null | false |
mismayil
| null |
mismayil/kogito-rc-bert
| 52 | null |
transformers
| 5,936 |
---
license: mit
---
|
north/t5_small_NCC
|
8d6f518677ac227731ebf64a180274f3071479d7
|
2022-06-01T19:40:24.000Z
|
[
"pytorch",
"tf",
"jax",
"tensorboard",
"t5",
"text2text-generation",
"no",
"nn",
"sv",
"dk",
"is",
"en",
"dataset:nbailab/NCC",
"dataset:mc4",
"dataset:wikipedia",
"arxiv:2104.09617",
"arxiv:1910.10683",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
text2text-generation
| false |
north
| null |
north/t5_small_NCC
| 52 | null |
transformers
| 5,937 |
---
language:
- no
- nn
- sv
- dk
- is
- en
datasets:
- nbailab/NCC
- mc4
- wikipedia
widget:
- text: <extra_id_0> hver uke samles Regjeringens medlemmer til Statsråd på <extra_id_1>. Dette organet er øverste <extra_id_2> i Norge. For at møtet skal være <extra_id_3>, må over halvparten av regjeringens <extra_id_4> være til stede.
- text: På <extra_id_0> kan man <extra_id_1> en bok, og man kan også <extra_id_2> seg ned og lese den.
license: apache-2.0
---
-T5
The North-T5-models are a set of Norwegian sequence-to-sequence-models. It builds upon the flexible [T5](https://github.com/google-research/text-to-text-transfer-transformer) and [T5X](https://github.com/google-research/t5x) and can be used for a variety of NLP tasks ranging from classification to translation.
| |**Small** <br />_60M_|**Base** <br />_220M_|**Large** <br />_770M_|**XL** <br />_3B_|**XXL** <br />_11B_|
|:-----------|:------------:|:------------:|:------------:|:------------:|:------------:|
|North-T5‑NCC|✔|[🤗](https://huggingface.co/north/t5_base_NCC)|[🤗](https://huggingface.co/north/t5_large_NCC)|[🤗](https://huggingface.co/north/t5_xl_NCC)|[🤗](https://huggingface.co/north/t5_xxl_NCC)||
|North-T5‑NCC‑lm|[🤗](https://huggingface.co/north/t5_small_NCC_lm)|[🤗](https://huggingface.co/north/t5_base_NCC_lm)|[🤗](https://huggingface.co/north/t5_large_NCC_lm)|[🤗](https://huggingface.co/north/t5_xl_NCC_lm)|[🤗](https://huggingface.co/north/t5_xxl_NCC_lm)||
## T5X Checkpoint
The original T5X checkpoint is also available for this model in the [Google Cloud Bucket](gs://north-t5x/pretrained_models/small/norwegian_NCC_plus_English_t5x_small/).
## Performance
A thorough evaluation of the North-T5 models is planned, and I strongly recommend external researchers to make their own evaluation. The main advantage with the T5-models are their flexibility. Traditionally, encoder-only models (like BERT) excels in classification tasks, while seq-2-seq models are easier to train for tasks like translation and Q&A. Despite this, here are the results from using North-T5 on the political classification task explained [here](https://arxiv.org/abs/2104.09617).
|**Model:** | **F1** |
|:-----------|:------------|
|mT5-base|73.2 |
|mBERT-base|78.4 |
|NorBERT-base|78.2 |
|North-T5-small|80.5 |
|nb-bert-base|81.8 |
|North-T5-base|85.3 |
|North-T5-large|86.7 |
|North-T5-xl|88.7 |
|North-T5-xxl|91.8|
These are preliminary results. The [results](https://arxiv.org/abs/2104.09617) from the BERT-models are based on the test-results from the best model after 10 runs with early stopping and a decaying learning rate. The T5-results are the average of five runs on the evaluation set. The small-model was trained for 10.000 steps, while the rest for 5.000 steps. A fixed learning rate was used (no decay), and no early stopping. Neither was the recommended rank classification used. We use a max sequence length of 512. This method simplifies the test setup and gives results that are easy to interpret. However, the results from the T5 model might actually be a bit sub-optimal.
## Sub-versions of North-T5
The following sub-versions are available. More versions will be available shorter.
|**Model** | **Description** |
|:-----------|:-------|
|**North‑T5‑NCC** |This is the main version. It is trained an additonal 500.000 steps on from the mT5 checkpoint. The training corpus is based on [the Norwegian Colossal Corpus (NCC)](https://huggingface.co/datasets/NbAiLab/NCC). In addition there are added data from MC4 and English Wikipedia.|
|**North‑T5‑NCC‑lm**|The model is pretrained for an addtional 100k steps on the LM objective discussed in the [T5 paper](https://arxiv.org/pdf/1910.10683.pdf). In a way this turns a masked language model into an autoregressive model. It also prepares the model for some tasks. When for instance doing translation and NLI, it is well documented that there is a clear benefit to do a step of unsupervised LM-training before starting the finetuning.|
## Fine-tuned versions
As explained below, the model really needs to be fine-tuned for specific tasks. This procedure is relatively simple, and the models are not very sensitive to the hyper-parameters used. Usually a decent result can be obtained by using a fixed learning rate of 1e-3. Smaller versions of the model typically needs to be trained for a longer time. It is easy to train the base-models in a Google Colab.
Since some people really want to see what the models are capable of, without going through the training procedure, I provide a couple of test models. These models are by no means optimised, and are just for demonstrating how the North-T5 models can be used.
* Nynorsk Translator. Translates any text from Norwegian Bokmål to Norwegian Nynorsk. Please test the [Streamlit-demo](https://huggingface.co/spaces/north/Nynorsk) and the [HuggingFace repo](https://huggingface.co/north/demo-nynorsk-base)
* DeUnCaser. The model adds punctation, spaces and capitalisation back into the text. The input needs to be in Norwegian but does not have to be divided into sentences or have proper capitalisation of words. You can even remove the spaces from the text, and make the model reconstruct it. It can be tested with the [Streamlit-demo](https://huggingface.co/spaces/north/DeUnCaser) and directly on the [HuggingFace repo](https://huggingface.co/north/demo-deuncaser-base)
## Training details
All models are built using the Flax-based T5X codebase, and all models are initiated with the mT5 pretrained weights. The models are trained using the T5.1.1 training regime, where they are only trained on an unsupervised masking-task. This also means that the models (contrary to the original T5) needs to be finetuned to solve specific tasks. This finetuning is however usually not very compute intensive, and in most cases it can be performed even with free online training resources.
All the main model model versions are trained for 500.000 steps after the mT5 checkpoint (1.000.000 steps). They are trained mainly on a 75GB corpus, consisting of NCC, Common Crawl and some additional high quality English text (Wikipedia). The corpus is roughly 80% Norwegian text. Additional languages are added to retain some of the multilingual capabilities, making the model both more robust to new words/concepts and also more suited as a basis for translation tasks.
While the huge models almost always will give the best results, they are also both more difficult and more expensive to finetune. I will strongly recommended to start with finetuning a base-models. The base-models can easily be finetuned on a standard graphic card or a free TPU through Google Colab.
All models were trained on TPUs. The largest XXL model was trained on a TPU v4-64, the XL model on a TPU v4-32, the Large model on a TPU v4-16 and the rest on TPU v4-8. Since it is possible to reduce the batch size during fine-tuning, it is also possible to finetune on slightly smaller hardware. The rule of thumb is that you can go "one step down" when finetuning. The large models still rewuire access to significant hardware, even for finetuning.
## Formats
All models are trained using the Flax-based T5X library. The original checkpoints are available in T5X format and can be used for both finetuning or interference. All models, except the XXL-model, are also converted to Transformers/HuggingFace. In this framework, the models can be loaded for finetuning or inference both in Flax, PyTorch and TensorFlow format.
## Future
I will continue to train and release additional models to this set. What models that are added is dependent upon the feedbacki from the users
## Thanks
This release would not have been possible without getting support and hardware from the [TPU Research Cloud](https://sites.research.google/trc/about/) at Google Research. Both the TPU Research Cloud Team and the T5X Team has provided extremely useful support for getting this running.
Freddy Wetjen at the National Library of Norway has been of tremendous help in generating the original NCC corpus, and has also contributed to generate the collated coprus used for this training. In addition he has been a dicussion partner in the creation of these models.
Also thanks to Stefan Schweter for writing the [script](https://github.com/huggingface/transformers/blob/main/src/transformers/models/t5/convert_t5x_checkpoint_to_flax.py) for converting these models from T5X to HuggingFace and to Javier de la Rosa for writing the dataloader for reading the HuggingFace Datasets in T5X.
## Warranty
Use at your own risk. The models have not yet been thougroughly tested, and may contain both errors and biases.
## Contact/About
These models were trained by Per E Kummervold. Please contact me on [email protected].
|
ENM/sciBERT-case-finetuned-breastcancer
|
8302412461c9bd71a9ed7b3762e2a208cb74f66b
|
2022-06-06T23:26:49.000Z
|
[
"pytorch",
"tensorboard",
"bert",
"text-generation",
"transformers",
"generated_from_trainer",
"model-index"
] |
text-generation
| false |
ENM
| null |
ENM/sciBERT-case-finetuned-breastcancer
| 52 | null |
transformers
| 5,938 |
---
tags:
- generated_from_trainer
model-index:
- name: sciBERT-case-finetuned-breastcancer
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# sciBERT-case-finetuned-breastcancer
This model is a fine-tuned version of [allenai/scibert_scivocab_uncased](https://huggingface.co/allenai/scibert_scivocab_uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0058
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 53 | 0.0126 |
| No log | 2.0 | 106 | 0.0097 |
| No log | 3.0 | 159 | 0.0113 |
| No log | 4.0 | 212 | 0.0094 |
| No log | 5.0 | 265 | 0.0080 |
| No log | 6.0 | 318 | 0.0091 |
| No log | 7.0 | 371 | 0.0078 |
| No log | 8.0 | 424 | 0.0087 |
| No log | 9.0 | 477 | 0.0077 |
| 0.0037 | 10.0 | 530 | 0.0074 |
| 0.0037 | 11.0 | 583 | 0.0072 |
| 0.0037 | 12.0 | 636 | 0.0066 |
| 0.0037 | 13.0 | 689 | 0.0069 |
| 0.0037 | 14.0 | 742 | 0.0064 |
| 0.0037 | 15.0 | 795 | 0.0063 |
| 0.0037 | 16.0 | 848 | 0.0063 |
| 0.0037 | 17.0 | 901 | 0.0058 |
| 0.0037 | 18.0 | 954 | 0.0060 |
| 0.0011 | 19.0 | 1007 | 0.0059 |
| 0.0011 | 20.0 | 1060 | 0.0058 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
azaninello/GPT2-icc
|
a3656f5725b73310b9cee801b5cd28a4d6687b32
|
2022-06-27T12:48:19.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers"
] |
text-generation
| false |
azaninello
| null |
azaninello/GPT2-icc
| 52 | null |
transformers
| 5,939 |
Entry not found
|
ddegenaro/reu_midsummer_test
|
567fe9ee20a6bee00b46a4180b571acf29db96b0
|
2022-07-07T22:25:48.000Z
|
[
"pytorch",
"bert",
"transformers",
"license:mit"
] | null | false |
ddegenaro
| null |
ddegenaro/reu_midsummer_test
| 52 | null |
transformers
| 5,940 |
---
license: mit
---
This is a test of my methodology.
|
pstroe/roberta-base-latin-cased2
|
61489ed06482c9ebe28eec49577c391bd326f0ed
|
2022-07-29T17:07:03.000Z
|
[
"pytorch",
"roberta",
"fill-mask",
"arxiv:2009.10053",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
pstroe
| null |
pstroe/roberta-base-latin-cased2
| 52 | null |
transformers
| 5,941 |
## RoBERTa Latin model, version 2 --> model card not finished yet
This is a Latin RoBERTa-based LM model, version 2.
The intention of the Transformer-based LM is twofold: on the one hand, it will be used for the evaluation of HTR results; on the other, it should be used as a decoder for the TrOCR architecture.
The training data is more or less the same data as has been used by [Bamman and Burns (2020)](https://arxiv.org/pdf/2009.10053.pdf), although more heavily filtered (see below). There are several digital-born texts from online Latin archives. Other Latin texts have been crawled by [Bamman and Smith](https://www.cs.cmu.edu/~dbamman/latin.html) and thus contain many OCR errors.
The overall downsampled corpus contains 577M of text data.
### Preprocessing
I undertook the following preprocessing steps:
- Normalisation of all lines with [CLTK](http://www.cltk.org) incl. sentence splitting.
- Language identification with [langid](https://github.com/saffsd/langid.py)
- Compute the ratio of Latin vocabulary in each sentence (against the digital-born vocab of the corpus)
- Retain only sentences with a Latin vocabulary ratio of > 85%.
- Exclude all lines containing '^' --> hints at the presence of OCR errors.
The result is a corpus of ~100 million tokens.
The dataset used to train this will be available on Hugging Face later [HERE (does not work yet)]().
### Contact
For contact, reach out to Phillip Ströbel [via mail](mailto:[email protected]) or [via Twitter](https://twitter.com/CLingophil).
|
naver-clova-ix/donut-base-finetuned-rvlcdip
|
1d40bcc9c7314654e955c708c56513b9dd1f1f0e
|
2022-07-19T13:57:17.000Z
|
[
"pytorch",
"donut",
"transformers",
"license:mit"
] | null | false |
naver-clova-ix
| null |
naver-clova-ix/donut-base-finetuned-rvlcdip
| 52 | null |
transformers
| 5,942 |
---
license: mit
---
|
adamnik/electra-entailment-detection
|
a853ffe98acd43d13c43407898af25c1402431e5
|
2022-07-20T01:37:58.000Z
|
[
"pytorch",
"electra",
"text-classification",
"transformers",
"license:mit"
] |
text-classification
| false |
adamnik
| null |
adamnik/electra-entailment-detection
| 52 | null |
transformers
| 5,943 |
---
license: mit
---
|
crumb/gpt-joke
|
efb7d77d9f3d7899311919ea70d32e0021a64e29
|
2022-07-26T03:38:02.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers"
] |
text-generation
| false |
crumb
| null |
crumb/gpt-joke
| 52 | null |
transformers
| 5,944 |
Entry not found
|
obl1t/DialoGPT-medium-Jotaro
|
0145859b0309ea95d8cf9a58764d149c59b20b6b
|
2022-07-27T00:36:02.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
obl1t
| null |
obl1t/DialoGPT-medium-Jotaro
| 52 | null |
transformers
| 5,945 |
---
tags:
- conversational
---
#Jotaro DialoGPT Model
|
valurank/xsum_headline_generator
|
735a8376630a660fb388031249a48d00f8956897
|
2022-07-27T11:19:28.000Z
|
[
"pytorch",
"tensorboard",
"pegasus",
"text2text-generation",
"transformers",
"generated_from_trainer",
"model-index",
"autotrain_compatible"
] |
text2text-generation
| false |
valurank
| null |
valurank/xsum_headline_generator
| 52 | 1 |
transformers
| 5,946 |
---
tags:
- generated_from_trainer
model-index:
- name: final_xsum_headline_generator
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# final_xsum_headline_generator
This model is a fine-tuned version of [google/pegasus-multi_news](https://huggingface.co/google/pegasus-multi_news) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3521
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 0.6447 | 0.8 | 500 | 0.4893 |
| 0.3729 | 1.6 | 1000 | 0.3570 |
| 0.3663 | 2.4 | 1500 | 0.3521 |
### Framework versions
- Transformers 4.18.0
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
Abirate/gpt_3_finetuned_multi_x_science
|
82ac4e2d59cb09b91bc63c0f3e2f4b242533a3b8
|
2022-01-15T06:16:57.000Z
|
[
"pytorch"
] | null | false |
Abirate
| null |
Abirate/gpt_3_finetuned_multi_x_science
| 51 | null | null | 5,947 |
---
- Text Generation
- PyTorch
- Transformers
- gpt_neo
- text generation
---
## Petrained Model Description: Open Source Version of GPT-3
Generative Pre-trained Transformer 3 (GPT-3) is an autoregressive language model that uses deep learning to produce human-like text.
It is the third-generation language prediction model in the GPT-n series (and the successor to GPT-2) created by OpenAI
GPT-Neo (125M) is a transformer model designed using EleutherAI's replication of the GPT-3 architecture. GPT-Neo refers to the class of models, while 125M represents the number of parameters of this particular pre-trained model.
and first released in this [repository](https://github.com/EleutherAI/gpt-neo).
## Fine-tuned Model Description: GPT-3 fine-tuned Multi-XScience
The Open Source version of GPT-3: GPT-Neo(125M) has been fine-tuned on a dataset called "Multi-XScience": [Multi-XScience_Repository](https://github.com/yaolu/Multi-XScience): A Large-scale Dataset for Extreme Multi-document Summarization of Scientific Articles.
I first fine-tuned and then deployed it using Google "Material Design" (on Anvil): [Abir Scientific text Generator](https://abir-scientific-text-generator.anvil.app/)
By fine-tuning GPT-Neo(Open Source version of GPT-3), on Multi-XScience dataset, the model is now able to generate scientific texts(even better than GPT-J(6B).
Try putting the prompt "attention is all" on both my [Abir Scientific text Generator](https://abir-scientific-text-generator.anvil.app/) and on the [ GPT-J Eleuther.ai Demo](https://6b.eleuther.ai/) to understand what I mean.
And Here's a demonstration video for this. [Video real-time Demontration](https://www.youtube.com/watch?v=XP8uZfnCYQI)
|
DTAI-KULeuven/robbertje-1-gb-non-shuffled
|
bf7851ebc117a44908a9e4499f03d7b671d888c9
|
2022-06-29T12:44:41.000Z
|
[
"pytorch",
"roberta",
"fill-mask",
"nl",
"dataset:oscar",
"dataset:oscar (NL)",
"dataset:dbrd",
"dataset:lassy-ud",
"dataset:europarl-mono",
"dataset:conll2002",
"arxiv:2101.05716",
"transformers",
"Dutch",
"Flemish",
"RoBERTa",
"RobBERT",
"RobBERTje",
"license:mit",
"autotrain_compatible"
] |
fill-mask
| false |
DTAI-KULeuven
| null |
DTAI-KULeuven/robbertje-1-gb-non-shuffled
| 51 | null |
transformers
| 5,948 |
---
language: "nl"
thumbnail: "https://github.com/iPieter/robbertje/raw/master/images/robbertje_logo_with_name.png"
tags:
- Dutch
- Flemish
- RoBERTa
- RobBERT
- RobBERTje
license: mit
datasets:
- oscar
- oscar (NL)
- dbrd
- lassy-ud
- europarl-mono
- conll2002
widget:
- text: "Hallo, ik ben RobBERTje, een gedistilleerd <mask> taalmodel van de KU Leuven."
---
<p align="center">
<img src="https://github.com/iPieter/robbertje/raw/master/images/robbertje_logo_with_name.png" alt="RobBERTje: A collection of distilled Dutch BERT-based models" width="75%">
</p>
# About RobBERTje
RobBERTje is a collection of distilled models based on [RobBERT](http://github.com/iPieter/robbert). There are multiple models with different sizes and different training settings, which you can choose for your use-case.
We are also continuously working on releasing better-performing models, so watch [the repository](http://github.com/iPieter/robbertje) for updates.
# News
- **February 21, 2022**: Our paper about RobBERTje has been published in [volume 11 of CLIN journal](https://www.clinjournal.org/clinj/article/view/131)!
- **July 2, 2021**: Publicly released 4 RobBERTje models.
- **May 12, 2021**: RobBERTje was accepted at [CLIN31](https://www.clin31.ugent.be) for an oral presentation!
# The models
| Model | Description | Parameters | Training size | Huggingface id |
|--------------|-------------|------------------|-------------------|------------------------------------------------------------------------------------|
| Non-shuffled | Trained on the non-shuffled variant of the oscar corpus, without any operations to preserve this order during training and distillation. | 74 M | 1 GB | this model |
| Shuffled | Trained on the publicly available and shuffled OSCAR corpus. | 74 M | 1 GB | [DTAI-KULeuven/robbertje-1-gb-shuffled](https://huggingface.co/DTAI-KULeuven/robbertje-1-gb-shuffled) |
| Merged (p=0.5) | Same as the non-shuffled variant, but sequential sentences of the same document are merged with a probability of 50%. | 74 M | 1 GB | [DTAI-KULeuven/robbertje-1-gb-merged](https://huggingface.co/DTAI-KULeuven/robbertje-1-gb-merged) |
| BORT | A smaller version with 8 attention heads instead of 12 and 4 layers instead of 6 (and 12 for RobBERT). | 46 M | 1 GB | [DTAI-KULeuven/robbertje-1-gb-bort](https://huggingface.co/DTAI-KULeuven/robbertje-1-gb-bort) |
# Results
## Intrinsic results
We calculated the _pseudo perplexity_ (PPPL) from [cite](), which is a built-in metric in our distillation library. This metric gives an indication of how well the model captures the input distribution.
| Model | PPPL |
|-------------------|-----------|
| RobBERT (teacher) | 7.76 |
| Non-shuffled | 12.95 |
| Shuffled | 18.74 |
| Merged (p=0.5) | 17.10 |
| BORT | 26.44 |
## Extrinsic results
We also evaluated our models on sereral downstream tasks, just like the teacher model RobBERT. Since that evaluation, a [Dutch NLI task named SICK-NL](https://arxiv.org/abs/2101.05716) was also released and we evaluated our models with it as well.
| Model | DBRD | DIE-DAT | NER | POS |SICK-NL |
|------------------|-----------|-----------|-----------|-----------|----------|
| RobBERT (teacher)|94.4 | 99.2 |89.1 |96.4 | 84.2 |
| Non-shuffled |90.2 | 98.4 |82.9 |95.5 | 83.4 |
| Shuffled |92.5 | 98.2 |82.7 |95.6 | 83.4 |
| Merged (p=0.5) |92.9 | 96.5 |81.8 |95.2 | 82.8 |
| BORT |89.6 | 92.2 |79.7 |94.3 | 81.0 |
|
GKLMIP/roberta-hindi-romanized
|
cc3e71e4199aae4f1dd10236ee7bc1aa428a9e4b
|
2021-10-13T13:46:13.000Z
|
[
"pytorch",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
GKLMIP
| null |
GKLMIP/roberta-hindi-romanized
| 51 | null |
transformers
| 5,949 |
If you use our model, please consider citing our paper:
```
@InProceedings{,
author="Huang, Xixuan
and Lin, Nankai
and Li, Kexin
and Wang, Lianxi
and Gan SuiFu",
title="HinPLMs: Pre-trained Language Models for Hindi",
booktitle="The International Conference on Asian Language Processing",
year="2021",
publisher="IEEE Xplore"
}
```
|
Helsinki-NLP/opus-mt-en-fiu
|
7b3d4f15ad924bee8e4b2964160751e61ccdc7c7
|
2021-01-18T08:07:39.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"en",
"se",
"fi",
"hu",
"et",
"fiu",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-en-fiu
| 51 | null |
transformers
| 5,950 |
---
language:
- en
- se
- fi
- hu
- et
- fiu
tags:
- translation
license: apache-2.0
---
### eng-fiu
* source group: English
* target group: Finno-Ugrian languages
* OPUS readme: [eng-fiu](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-fiu/README.md)
* model: transformer
* source language(s): eng
* target language(s): est fin fkv_Latn hun izh kpv krl liv_Latn mdf mhr myv sma sme udm vro
* model: transformer
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* a sentence initial language token is required in the form of `>>id<<` (id = valid target language ID)
* download original weights: [opus2m-2020-08-01.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-fiu/opus2m-2020-08-01.zip)
* test set translations: [opus2m-2020-08-01.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-fiu/opus2m-2020-08-01.test.txt)
* test set scores: [opus2m-2020-08-01.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/eng-fiu/opus2m-2020-08-01.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| newsdev2015-enfi-engfin.eng.fin | 18.7 | 0.522 |
| newsdev2018-enet-engest.eng.est | 19.4 | 0.521 |
| newssyscomb2009-enghun.eng.hun | 15.5 | 0.472 |
| newstest2009-enghun.eng.hun | 15.4 | 0.468 |
| newstest2015-enfi-engfin.eng.fin | 19.9 | 0.532 |
| newstest2016-enfi-engfin.eng.fin | 21.1 | 0.544 |
| newstest2017-enfi-engfin.eng.fin | 23.8 | 0.567 |
| newstest2018-enet-engest.eng.est | 20.4 | 0.532 |
| newstest2018-enfi-engfin.eng.fin | 15.6 | 0.498 |
| newstest2019-enfi-engfin.eng.fin | 20.0 | 0.520 |
| newstestB2016-enfi-engfin.eng.fin | 17.0 | 0.512 |
| newstestB2017-enfi-engfin.eng.fin | 19.7 | 0.531 |
| Tatoeba-test.eng-chm.eng.chm | 0.9 | 0.115 |
| Tatoeba-test.eng-est.eng.est | 49.8 | 0.689 |
| Tatoeba-test.eng-fin.eng.fin | 34.7 | 0.597 |
| Tatoeba-test.eng-fkv.eng.fkv | 1.3 | 0.187 |
| Tatoeba-test.eng-hun.eng.hun | 35.2 | 0.589 |
| Tatoeba-test.eng-izh.eng.izh | 6.0 | 0.163 |
| Tatoeba-test.eng-kom.eng.kom | 3.4 | 0.012 |
| Tatoeba-test.eng-krl.eng.krl | 6.4 | 0.202 |
| Tatoeba-test.eng-liv.eng.liv | 1.6 | 0.102 |
| Tatoeba-test.eng-mdf.eng.mdf | 3.7 | 0.008 |
| Tatoeba-test.eng.multi | 35.4 | 0.590 |
| Tatoeba-test.eng-myv.eng.myv | 1.4 | 0.014 |
| Tatoeba-test.eng-sma.eng.sma | 2.6 | 0.097 |
| Tatoeba-test.eng-sme.eng.sme | 7.3 | 0.221 |
| Tatoeba-test.eng-udm.eng.udm | 1.4 | 0.079 |
### System Info:
- hf_name: eng-fiu
- source_languages: eng
- target_languages: fiu
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/eng-fiu/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['en', 'se', 'fi', 'hu', 'et', 'fiu']
- src_constituents: {'eng'}
- tgt_constituents: {'izh', 'mdf', 'vep', 'vro', 'sme', 'myv', 'fkv_Latn', 'krl', 'fin', 'hun', 'kpv', 'udm', 'liv_Latn', 'est', 'mhr', 'sma'}
- src_multilingual: False
- tgt_multilingual: True
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-fiu/opus2m-2020-08-01.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/eng-fiu/opus2m-2020-08-01.test.txt
- src_alpha3: eng
- tgt_alpha3: fiu
- short_pair: en-fiu
- chrF2_score: 0.59
- bleu: 35.4
- brevity_penalty: 0.9440000000000001
- ref_len: 59311.0
- src_name: English
- tgt_name: Finno-Ugrian languages
- train_date: 2020-08-01
- src_alpha2: en
- tgt_alpha2: fiu
- prefer_old: False
- long_pair: eng-fiu
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
Helsinki-NLP/opus-mt-fi-ZH
|
b9d39ad47c1d2f01b38a64916bbcb867eb1d3e53
|
2021-09-09T21:46:27.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"fi",
"zh",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-fi-ZH
| 51 | null |
transformers
| 5,951 |
---
tags:
- translation
license: apache-2.0
---
### opus-mt-fi-ZH
* source languages: fi
* target languages: cmn,cn,yue,ze_zh,zh_cn,zh_CN,zh_HK,zh_tw,zh_TW,zh_yue,zhs,zht,zh
* OPUS readme: [fi-cmn+cn+yue+ze_zh+zh_cn+zh_CN+zh_HK+zh_tw+zh_TW+zh_yue+zhs+zht+zh](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/fi-cmn+cn+yue+ze_zh+zh_cn+zh_CN+zh_HK+zh_tw+zh_TW+zh_yue+zhs+zht+zh/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* a sentence initial language token is required in the form of `>>id<<` (id = valid target language ID)
* download original weights: [opus-2020-01-16.zip](https://object.pouta.csc.fi/OPUS-MT-models/fi-cmn+cn+yue+ze_zh+zh_cn+zh_CN+zh_HK+zh_tw+zh_TW+zh_yue+zhs+zht+zh/opus-2020-01-16.zip)
* test set translations: [opus-2020-01-16.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/fi-cmn+cn+yue+ze_zh+zh_cn+zh_CN+zh_HK+zh_tw+zh_TW+zh_yue+zhs+zht+zh/opus-2020-01-16.test.txt)
* test set scores: [opus-2020-01-16.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/fi-cmn+cn+yue+ze_zh+zh_cn+zh_CN+zh_HK+zh_tw+zh_TW+zh_yue+zhs+zht+zh/opus-2020-01-16.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| bible-uedin.fi.zh | 23.4 | 0.326 |
|
Helsinki-NLP/opus-mt-ru-sv
|
05e8dfc573d362eb318386dbc2966b55aad490cc
|
2020-08-21T14:42:49.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"ru",
"sv",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-ru-sv
| 51 | null |
transformers
| 5,952 |
---
language:
- ru
- sv
tags:
- translation
license: apache-2.0
---
### rus-swe
* source group: Russian
* target group: Swedish
* OPUS readme: [rus-swe](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/rus-swe/README.md)
* model: transformer-align
* source language(s): rus
* target language(s): swe
* model: transformer-align
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus-2020-06-17.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/rus-swe/opus-2020-06-17.zip)
* test set translations: [opus-2020-06-17.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/rus-swe/opus-2020-06-17.test.txt)
* test set scores: [opus-2020-06-17.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/rus-swe/opus-2020-06-17.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.rus.swe | 51.9 | 0.677 |
### System Info:
- hf_name: rus-swe
- source_languages: rus
- target_languages: swe
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/rus-swe/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['ru', 'sv']
- src_constituents: {'rus'}
- tgt_constituents: {'swe'}
- src_multilingual: False
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/rus-swe/opus-2020-06-17.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/rus-swe/opus-2020-06-17.test.txt
- src_alpha3: rus
- tgt_alpha3: swe
- short_pair: ru-sv
- chrF2_score: 0.677
- bleu: 51.9
- brevity_penalty: 0.968
- ref_len: 8449.0
- src_name: Russian
- tgt_name: Swedish
- train_date: 2020-06-17
- src_alpha2: ru
- tgt_alpha2: sv
- prefer_old: False
- long_pair: rus-swe
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
aware-ai/roberta-large-squad-classification
|
e09bb6e3d8447674b66912bff7f9cf1b8093a21b
|
2021-05-20T12:35:01.000Z
|
[
"pytorch",
"jax",
"roberta",
"text-classification",
"dataset:squad_v2",
"transformers"
] |
text-classification
| false |
aware-ai
| null |
aware-ai/roberta-large-squad-classification
| 51 | null |
transformers
| 5,953 |
---
datasets:
- squad_v2
---
# Roberta-LARGE finetuned on SQuADv2
This is roberta-large model finetuned on SQuADv2 dataset for question answering answerability classification
## Model details
This model is simply an Sequenceclassification model with two inputs (context and question) in a list.
The result is either [1] for answerable or [0] if it is not answerable.
It was trained over 4 epochs on squadv2 dataset and can be used to filter out which context is good to give into the QA model to avoid bad answers.
## Model training
This model was trained with following parameters using simpletransformers wrapper:
```
train_args = {
'learning_rate': 1e-5,
'max_seq_length': 512,
'overwrite_output_dir': True,
'reprocess_input_data': False,
'train_batch_size': 4,
'num_train_epochs': 4,
'gradient_accumulation_steps': 2,
'no_cache': True,
'use_cached_eval_features': False,
'save_model_every_epoch': False,
'output_dir': "bart-squadv2",
'eval_batch_size': 8,
'fp16_opt_level': 'O2',
}
```
## Results
```{"accuracy": 90.48%}```
## Model in Action 🚀
```python3
from simpletransformers.classification import ClassificationModel
model = ClassificationModel('roberta', 'a-ware/roberta-large-squadv2', num_labels=2, args=train_args)
predictions, raw_outputs = model.predict([["my dog is an year old. he loves to go into the rain", "how old is my dog ?"]])
print(predictions)
==> [1]
```
> Created with ❤️ by A-ware UG [](https://github.com/aware-ai)
|
abhinavkulkarni/bigbird-roberta-base-finetuned-squad
|
f20ddf6920760090f34e803e9ca4570bd4f1ecdc
|
2022-02-07T06:32:01.000Z
|
[
"pytorch",
"tensorboard",
"big_bird",
"question-answering",
"transformers",
"autotrain_compatible"
] |
question-answering
| false |
abhinavkulkarni
| null |
abhinavkulkarni/bigbird-roberta-base-finetuned-squad
| 51 | null |
transformers
| 5,954 |
Entry not found
|
anjulRajendraSharma/wav2vec2-indian-english
|
30cce397b8be2d27250f9c0fe8c5748b48a732a6
|
2022-06-10T06:14:49.000Z
|
[
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"transformers"
] |
automatic-speech-recognition
| false |
anjulRajendraSharma
| null |
anjulRajendraSharma/wav2vec2-indian-english
| 51 | null |
transformers
| 5,955 |
Entry not found
|
huggingtweets/borisdayma
|
bef6d3d54322e05b3de16b332a4c2a9def4da13b
|
2022-06-27T21:46:28.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"en",
"transformers",
"huggingtweets"
] |
text-generation
| false |
huggingtweets
| null |
huggingtweets/borisdayma
| 51 | null |
transformers
| 5,956 |
---
language: en
thumbnail: http://www.huggingtweets.com/borisdayma/1656366383066/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1152601773330370560/UhVRDMyp_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Boris Dayma 🖍️</div>
<div style="text-align: center; font-size: 14px;">@borisdayma</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Boris Dayma 🖍️.
| Data | Boris Dayma 🖍️ |
| --- | --- |
| Tweets downloaded | 1371 |
| Retweets | 146 |
| Short tweets | 42 |
| Tweets kept | 1183 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/tlbliehz/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @borisdayma's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3qs9dfef) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3qs9dfef/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/borisdayma')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
hyunwoo3235/kogpt-neo-125M
|
ba315830d07baaf383d63314b321968c62cc3543
|
2021-08-06T14:45:23.000Z
|
[
"pytorch",
"gpt_neo",
"text-generation",
"transformers"
] |
text-generation
| false |
hyunwoo3235
| null |
hyunwoo3235/kogpt-neo-125M
| 51 | null |
transformers
| 5,957 |
Entry not found
|
johnpaulbin/meme-titles
|
10f1e9387207ef5e84053bdc642f030f9c51ef1f
|
2021-12-08T02:57:43.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers"
] |
text-generation
| false |
johnpaulbin
| null |
johnpaulbin/meme-titles
| 51 | null |
transformers
| 5,958 |
Trained on ~400 youtube titles of meme compilations on youtube.
WARNING: may produce offensive content.
|
lg/openinstruct_1k1
|
ac84c5debc9980ba0d823728740f2062d48ceca6
|
2021-05-20T23:37:33.000Z
|
[
"pytorch",
"gpt_neo",
"text-generation",
"transformers"
] |
text-generation
| false |
lg
| null |
lg/openinstruct_1k1
| 51 | null |
transformers
| 5,959 |
# This model is probably not what you're looking for.
|
macedonizer/al-roberta-base
|
a48686ad136910e750bff614cf6c47926412c6cb
|
2021-09-22T08:58:28.000Z
|
[
"pytorch",
"roberta",
"fill-mask",
"al",
"dataset:wiki-sh",
"transformers",
"masked-lm",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
| false |
macedonizer
| null |
macedonizer/al-roberta-base
| 51 | 1 |
transformers
| 5,960 |
---
language:
- al
thumbnail: https://huggingface.co/macedonizer/al-roberta-base/lets-talk-about-nlp-al.jpg
tags:
- masked-lm
license: apache-2.0
datasets:
- wiki-sh
---
# AL-RoBERTa base model
Pretrained model on Albanian language using a masked language modeling (MLM) objective. It was introduced in this paper and first released in this repository. This model is case-sensitive: it makes a difference between tirana and Tirana.
# Model description
RoBERTa is a transformers model pre-trained on a large corpus of text data in a self-supervised fashion. This means it was pre-trained on the raw texts only, with no humans labeling them in any way (which is why it can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts.
More precisely, it was pre-trained with the Masked language modeling (MLM) objective. Taking a sentence, the model randomly masks 15% of the words in the input then runs the entire masked sentence through the model and has to predict the masked words. This is different from traditional recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the sentence.
This way, the model learns an inner representation of the English language that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled sentences, for instance, you can train a standard classifier using the features produced by the BERT model as inputs.
# Intended uses & limitations
You can use the raw model for masked language modeling, but it's mostly intended to be fine-tuned on a downstream task. See the model hub to look for fine-tuned versions of a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked) to make decisions, such as sequence classification, token classification, or question answering. For tasks such as text generation, you should look at models like GPT2.
# How to use
You can use this model directly with a pipeline for masked language modeling: \
from transformers import pipeline \
unmasker = pipeline('fill-mask', model='macedonizer/al-roberta-base') \
unmasker("Tirana është \\<mask\\> i Shqipërisë.") \
[{'score': 0.9426872134208679,
'sequence': 'Tirana është kryeqyteti i Shqipërisë',
'token': 7901,
'token_str': ' kryeqyteti'},
{'score': 0.03112833760678768,
'sequence': 'Tirana është kryeqytet i Shqipërisë',
'token': 7439,
'token_str': ' kryeqytet'},
{'score': 0.0022084848023951054,
'sequence': 'Tirana është qytet i Shqipërisë',
'token': 2246,
'token_str': ' qytet'},
{'score': 0.0016222079284489155,
'sequence': 'Tirana është qyteti i Shqipërisë',
'token': 2784,
'token_str': ' qyteti'},
{'score': 0.0008979254635050893,
'sequence': 'Tirana është Kryeqytet i Shqipërisë',
'token': 37653,
'token_str': ' Kryeqytet'}]
Here is how to use this model to get the features of a given text in PyTorch:
from transformers import RobertaTokenizer, RobertaModel \
tokenizer = RobertaTokenizer.from_pretrained('macedonizer/al-roberta-base') \
model = RobertaModel.from_pretrained('macedonizer/al-roberta-base') \
text = "Replace me by any text you'd like." \
encoded_input = tokenizer(text, return_tensors='pt') \
output = model(**encoded_input)
|
maxpe/twitter-roberta-base_semeval18_emodetection
|
e08cc473008ed93553379d5ffce259ea050e35d6
|
2021-10-27T15:19:07.000Z
|
[
"pytorch",
"roberta",
"text-classification",
"transformers"
] |
text-classification
| false |
maxpe
| null |
maxpe/twitter-roberta-base_semeval18_emodetection
| 51 | null |
transformers
| 5,961 |
# Twitter-roBERTa-base_SemEval18_Emodetection
This is a Twitter-roBERTa-base model trained on ~7000 tweets in English annotated for 11 emotion categories in [SemEval-2018 Task 1: Affect in Tweets: SubTask 5: Emotion Classification](https://competitions.codalab.org/competitions/17751).
Run the classifier on the test set of the competition:
```python
from datasets import load_dataset
from transformers import AutoTokenizer, AutoModel
from torch.utils.data import DataLoader
import torch
import pandas as pd
# choose GPU when available
device = 'cuda' if torch.cuda.is_available() else 'cpu'
tokenizer = AutoTokenizer.from_pretrained("cardiffnlp/twitter-roberta-base",model_max_length=512)
# build custom model with classification layer on top and a dropout layer before
class RobertaClass(torch.nn.Module):
def __init__(self):
super(RobertaClass, self).__init__()
self.l1 = AutoModel.from_pretrained("cardiffnlp/twitter-roberta-base",return_dict=False)
self.l2 = torch.nn.Dropout(0.3)
self.l3 = torch.nn.Linear(768, 11)
def forward(self, input_ids, attention_mask):
_, output_1= self.l1(input_ids=input_ids, attention_mask=attention_mask)
output_2 = self.l2(output_1)
output = self.l3(output_2)
return output
model_name="twitter-roberta-base_semeval18_emodetection/pytorch_model.bin"
model=RobertaClass()
model.load_state_dict(torch.load(model_name,map_location=torch.device(device)))
model.eval()
# run on more than 1 GPU
model = torch.nn.DataParallel(model)
model.to(device)
twnames=['anger','anticipation','disgust','fear','joy','love','optimism','pessimism','sadness','surprise','trust']
# load from hugging face dataset hub
testset_raw = load_dataset('sem_eval_2018_task_1','subtask5.english',split='test')
# remove old columns
testset=testset_raw.remove_columns(twnames+["ID"])
# tokenize
testset_tokenized = testset.map(lambda e: tokenizer(e['Tweet'], truncation=True, padding='max_length'), batched=True)
testset_tokenized=testset_tokenized.remove_columns("Tweet")
testset_tokenized.set_format(type='torch', columns=['input_ids', 'attention_mask'])
outfile="predicted_2018-E-c-En-test-gold.txt"
MAX_LEN = 512
VALID_BATCH_SIZE = 8
# set batch size according to available RAM
# VALID_BATCH_SIZE = 1000
# set num_workers for parallel processing
inference_params = {'batch_size': VALID_BATCH_SIZE,
'shuffle': False,
# 'num_workers': 1
}
inference_loader = DataLoader(testset_tokenized, **inference_params)
open(outfile,"w").close()
with torch.no_grad():
# change lines for progress manager
# for _, data in tqdm(enumerate(inference_loader, 0),total=len(inference_loader)):
for _, data in enumerate(inference_loader, 0):
outputs = model(input_ids=data['input_ids'],attention_mask=data['attention_mask'])
fin_outputs=torch.sigmoid(outputs).cpu().detach().numpy().tolist()
pd.DataFrame(fin_outputs).to_csv(outfile,index=False,header=False,sep="\t",mode='a')
# # dataset from file (one text per line)
# from datasets import Dataset
# with open(linesoftextfile,"rb") as textfile:
# textdict={"text":[x.decode().rstrip("\n") for x in textfile.readlines()]}
# inference_dataset=Dataset.from_dict(textdict)
# del(textdict)
```
|
ontocord/fastspeech2-en
|
7d09d28eb5efb46833d2c8c66d731faf608abcde
|
2021-04-08T06:57:54.000Z
|
[
"pytorch",
"fastspeech2",
"en",
"dataset:LJSpeech",
"dataset:LibriTTS",
"arxiv:2006.04558",
"transformers",
"audio",
"TTS",
"license:apache-2.0"
] | null | false |
ontocord
| null |
ontocord/fastspeech2-en
| 51 | null |
transformers
| 5,962 |
---
language: en
datasets:
- LJSpeech
- LibriTTS
tags:
- audio
- TTS
license: apache-2.0
---
# ontocord/fastspeech2-en
Modified version of the text-to-speech system [FastSpeech 2: Fast and High-Quality End-to-End Text to Speech] (https://arxiv.org/abs/2006.04558v1).
## Installation
```
git clone https://github.com/ontocord/fastspeech2_hf
pip install transformers torchaudio
```
## Usage
The model can be used directly as follows:
```
# load the model and tokenizer
from fastspeech2_hf.modeling_fastspeech2 import FastSpeech2ForPretraining, FastSpeech2Tokenizer
model = FastSpeech2ForPretraining.from_pretrained("ontocord/fastspeech2-en")
tokenizer = FastSpeech2Tokenizer.from_pretrained("ontocord/fastspeech2-en")
# some helper routines
from IPython.display import Audio as IPAudio, display as IPdisplay
import torch
import torchaudio
def play_audio(waveform, sample_rate):
waveform = waveform.numpy()
if len(waveform.shape)==1:
IPdisplay(IPAudio(waveform, rate=sample_rate))
return
num_channels, num_frames = waveform.shape
if num_channels <= 1:
IPdisplay(IPAudio(waveform[0], rate=sample_rate))
elif num_channels == 2:
IPdisplay(IPAudio((waveform[0], waveform[1]), rate=sample_rate))
else:
raise ValueError("Waveform with more than 2 channels are not supported.")
# set the g2p module for the tokenizer
tokenizer.set_g2p(model.fastspeech2.g2p)
# you can run in half mode on gpu.
model = model.cuda().half()
sentences = [
"Advanced text to speech models such as Fast Speech can synthesize speech significantly faster than previous auto regressive models with comparable quality. The training of Fast Speech model relies on an auto regressive teacher model for duration prediction and knowledge distillation, which can ease the one to many mapping problem in T T S. However, Fast Speech has several disadvantages, 1, the teacher student distillation pipeline is complicated, 2, the duration extracted from the teacher model is not accurate enough, and the target mel spectrograms distilled from teacher model suffer from information loss due to data simplification, both of which limit the voice quality. ",
"Printing, in the only sense with which we are at present concerned, differs from most if not from all the arts and crafts represented in the Exhibition "
"in being comparatively modern. ",
"For although the Chinese took impressions from wood blocks engraved in relief for centuries before the woodcutters of the Netherlands, by a similar process "
"produced the block books, which were the immediate predecessors of the true printed book, "
"the invention of movable metal letters in the middle of the fifteenth century may justly be considered as the invention of the art of printing. ",
"And it is worth mention in passing that, as an example of fine typography, "
"the earliest book printed with movable types, the Gutenberg, or \"forty-two line Bible\" of about 1455, "
"has never been surpassed. ",
"Printing, then, for our purpose, may be considered as the art of making books by means of movable types. "
"Now, as all books not primarily intended as picture-books consist principally of types composed to form letterpress,",
]
batch = tokenizer(sentences, return_tensors="pt", padding=True)
model.eval()
with torch.no_grad():
out = model(use_postnet=False, **batch)
wav =out[-2]
for line, phone, w in zip(sentences, tokenizer.batch_decode(batch['input_ids']), wav):
print ("txt:", line)
print ("phoneme:", phone)
play_audio(w.type(torch.FloatTensor), model.config.sampling_rate)
```
##Github Code Repo
Current code for this model can be found [here](https://github.com/ontocord/fastspeech2_hf)
This is a work in progress (WIP) port of the model and code from
[this repo] (https://github.com/ming024/FastSpeech2).
The datasets on which this model was trained:
- LJSpeech: a single-speaker English dataset consists of 13100 short audio clips of a female speaker reading passages from 7 non-fiction books, approximately 24 hours in total.
- LibriTTS: a multi-speaker English dataset containing 585 hours of speech by 2456 speakers.
|
r3dhummingbird/DialoGPT-small-neku
|
d377a5862c58a8d88abdf04b616e19c14dfff469
|
2021-06-08T00:50:01.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational",
"license:mit"
] |
conversational
| false |
r3dhummingbird
| null |
r3dhummingbird/DialoGPT-small-neku
| 51 | null |
transformers
| 5,963 |
---
thumbnail: https://huggingface.co/front/thumbnails/dialogpt.png
tags:
- conversational
license: mit
---
# DialoGPT Trained on the Speech of a Game Character
This is an instance of [microsoft/DialoGPT-small](https://huggingface.co/microsoft/DialoGPT-small) trained on a game character, Neku Sakuraba from [The World Ends With You](https://en.wikipedia.org/wiki/The_World_Ends_with_You). The data comes from [a Kaggle game script dataset](https://www.kaggle.com/ruolinzheng/twewy-game-script).
Chat with the model:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("r3dhummingbird/DialoGPT-small-neku")
model = AutoModelWithLMHead.from_pretrained("r3dhummingbird/DialoGPT-small-neku")
# Let's chat for 4 lines
for step in range(4):
# encode the new user input, add the eos_token and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(input(">> User:") + tokenizer.eos_token, return_tensors='pt')
# print(new_user_input_ids)
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
# generated a response while limiting the total chat history to 1000 tokens,
chat_history_ids = model.generate(
bot_input_ids, max_length=200,
pad_token_id=tokenizer.eos_token_id,
no_repeat_ngram_size=3,
do_sample=True,
top_k=100,
top_p=0.7,
temperature=0.8
)
# pretty print last ouput tokens from bot
print("NekuBot: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
```
|
sgugger/finetuned-bert-mrpc
|
b8f2adf0fcc33362a8df61165e531a2e1bcce9d2
|
2021-07-14T20:43:07.000Z
|
[
"pytorch",
"tensorboard",
"bert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0"
] |
text-classification
| false |
sgugger
| null |
sgugger/finetuned-bert-mrpc
| 51 | null |
transformers
| 5,964 |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model_index:
- name: finetuned-bert-mrpc
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: mrpc
metric:
name: F1
type: f1
value: 0.8791946308724832
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuned-bert-mrpc
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4917
- Accuracy: 0.8235
- F1: 0.8792
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.5382 | 1.0 | 230 | 0.4008 | 0.8456 | 0.8893 |
| 0.3208 | 2.0 | 460 | 0.4182 | 0.8309 | 0.8844 |
| 0.1587 | 3.0 | 690 | 0.4917 | 0.8235 | 0.8792 |
### Framework versions
- Transformers 4.9.0.dev0
- Pytorch 1.8.1+cu111
- Datasets 1.8.1.dev0
- Tokenizers 0.10.1
|
spencerh/rightpartisan
|
9c7e7548435839b11c2479f209c313aedd6eb0e4
|
2021-04-23T19:26:52.000Z
|
[
"pytorch",
"tf",
"distilbert",
"text-classification",
"transformers"
] |
text-classification
| false |
spencerh
| null |
spencerh/rightpartisan
| 51 | null |
transformers
| 5,965 |
# Text classifier using DistilBERT to determine Partisanship
## This is one of the single-class partisan detecting models. (see leftpartisan/leftcenterpartisan/rightcenterpartisan/centerpartisan)
label_0 refers to "other" while label_1 refers to "right" (right as in right-leaning).
This was trained with 40,000 articles.
### Best Practices
This model was optimized for 512 token-length text. Any text below 150 tokens will result in inaccurate results.
|
ml6team/keyphrase-extraction-distilbert-kptimes
|
b2bdd8383b424ad54276cf26e31cc856d64f46c9
|
2022-06-16T14:20:34.000Z
|
[
"pytorch",
"distilbert",
"token-classification",
"en",
"dataset:midas/kptimes",
"arxiv:1911.12559",
"transformers",
"keyphrase-extraction",
"license:mit",
"model-index",
"autotrain_compatible"
] |
token-classification
| false |
ml6team
| null |
ml6team/keyphrase-extraction-distilbert-kptimes
| 51 | null |
transformers
| 5,966 |
---
language: en
license: mit
tags:
- keyphrase-extraction
datasets:
- midas/kptimes
metrics:
- seqeval
widget:
- text: "Keyphrase extraction is a technique in text analysis where you extract the important keyphrases from a document.
Thanks to these keyphrases humans can understand the content of a text very quickly and easily without reading
it completely. Keyphrase extraction was first done primarily by human annotators, who read the text in detail
and then wrote down the most important keyphrases. The disadvantage is that if you work with a lot of documents,
this process can take a lot of time.
Here is where Artificial Intelligence comes in. Currently, classical machine learning methods, that use statistical
and linguistic features, are widely used for the extraction process. Now with deep learning, it is possible to capture
the semantic meaning of a text even better than these classical methods. Classical methods look at the frequency,
occurrence and order of words in the text, whereas these neural approaches can capture long-term semantic dependencies
and context of words in a text."
example_title: "Example 1"
- text: "FoodEx is the largest trade exhibition for food and drinks in Asia, with about 70,000 visitors checking out the products presented by hundreds of participating companies. I was lucky to enter as press; otherwise, visitors must be affiliated with the food industry— and pay ¥5,000 — to enter. The FoodEx menu is global, including everything from cherry beer from Germany and premium Mexican tequila to top-class French and Chinese dumplings. The event was a rare chance to try out both well-known and exotic foods and even see professionals making them. In addition to booths offering traditional Japanese favorites such as udon and maguro sashimi, there were plenty of innovative twists, such as dorayaki , a sweet snack made of two pancakes and a red-bean filling, that came in coffee and tomato flavors. While I was there I was lucky to catch the World Sushi Cup Japan 2013, where top chefs from around the world were competing … and presenting a wide range of styles that you would not normally see in Japan, like the flower makizushi above."
example_title: "Example 2"
model-index:
- name: DeDeckerThomas/keyphrase-extraction-distilbert-kptimes
results:
- task:
type: keyphrase-extraction
name: Keyphrase Extraction
dataset:
type: midas/kptimes
name: kptimes
metrics:
- type: F1 (Seqeval)
value: 0.539
name: F1 (Seqeval)
- type: F1@M
value: 0.328
name: F1@M
---
# 🔑 Keyphrase Extraction Model: distilbert-kptimes
Keyphrase extraction is a technique in text analysis where you extract the important keyphrases from a document. Thanks to these keyphrases humans can understand the content of a text very quickly and easily without reading it completely. Keyphrase extraction was first done primarily by human annotators, who read the text in detail and then wrote down the most important keyphrases. The disadvantage is that if you work with a lot of documents, this process can take a lot of time ⏳.
Here is where Artificial Intelligence 🤖 comes in. Currently, classical machine learning methods, that use statistical and linguistic features, are widely used for the extraction process. Now with deep learning, it is possible to capture the semantic meaning of a text even better than these classical methods. Classical methods look at the frequency, occurrence and order of words in the text, whereas these neural approaches can capture long-term semantic dependencies and context of words in a text.
## 📓 Model Description
This model uses [KBIR](https://huggingface.co/distilbert-base-uncased) as its base model and fine-tunes it on the [KPTimes dataset](https://huggingface.co/datasets/midas/kptimes).
Keyphrase extraction models are transformer models fine-tuned as a token classification problem where each word in the document is classified as being part of a keyphrase or not.
| Label | Description |
| ----- | ------------------------------- |
| B-KEY | At the beginning of a keyphrase |
| I-KEY | Inside a keyphrase |
| O | Outside a keyphrase |
## ✋ Intended Uses & Limitations
### 🛑 Limitations
* This keyphrase extraction model is very domain-specific and will perform very well on news articles from NY Times. It's not recommended to use this model for other domains, but you are free to test it out.
* Limited amount of predicted keyphrases.
* Only works for English documents.
* For a custom model, please consult the [training notebook]() for more information.
### ❓ How To Use
```python
from transformers import (
TokenClassificationPipeline,
AutoModelForTokenClassification,
AutoTokenizer,
)
from transformers.pipelines import AggregationStrategy
import numpy as np
# Define keyphrase extraction pipeline
class KeyphraseExtractionPipeline(TokenClassificationPipeline):
def __init__(self, model, *args, **kwargs):
super().__init__(
model=AutoModelForTokenClassification.from_pretrained(model),
tokenizer=AutoTokenizer.from_pretrained(model),
*args,
**kwargs
)
def postprocess(self, model_outputs):
results = super().postprocess(
model_outputs=model_outputs,
aggregation_strategy=AggregationStrategy.FIRST,
)
return np.unique([result.get("word").strip() for result in results])
```
```python
# Load pipeline
model_name = "ml6team/keyphrase-extraction-distilbert-kptimes"
extractor = KeyphraseExtractionPipeline(model=model_name)
```
```python
# Inference
text = """
Keyphrase extraction is a technique in text analysis where you extract the
important keyphrases from a document. Thanks to these keyphrases humans can
understand the content of a text very quickly and easily without reading it
completely. Keyphrase extraction was first done primarily by human annotators,
who read the text in detail and then wrote down the most important keyphrases.
The disadvantage is that if you work with a lot of documents, this process
can take a lot of time.
Here is where Artificial Intelligence comes in. Currently, classical machine
learning methods, that use statistical and linguistic features, are widely used
for the extraction process. Now with deep learning, it is possible to capture
the semantic meaning of a text even better than these classical methods.
Classical methods look at the frequency, occurrence and order of words
in the text, whereas these neural approaches can capture long-term
semantic dependencies and context of words in a text.
""".replace("\n", " ")
keyphrases = extractor(text)
print(keyphrases)
```
```
# Output
['artificial intelligence']
```
## 📚 Training Dataset
[KPTimes](https://huggingface.co/datasets/midas/kptimes) is a keyphrase extraction/generation dataset consisting of 279,923 news articles from NY Times and 10K from JPTimes and annotated by professional indexers or editors.
You can find more information in the [paper](https://arxiv.org/abs/1911.12559).
## 👷♂️ Training procedure
For more in detail information, you can take a look at the [training notebook]().
### Training parameters
| Parameter | Value |
| --------- | ------|
| Learning Rate | 1e-4 |
| Epochs | 50 |
| Early Stopping Patience | 3 |
### Preprocessing
The documents in the dataset are already preprocessed into list of words with the corresponding labels. The only thing that must be done is tokenization and the realignment of the labels so that they correspond with the right subword tokens.
```python
from datasets import load_dataset
from transformers import AutoTokenizer
# Labels
label_list = ["B", "I", "O"]
lbl2idx = {"B": 0, "I": 1, "O": 2}
idx2label = {0: "B", 1: "I", 2: "O"}
# Tokenizer
tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")
max_length = 512
# Dataset parameters
dataset_full_name = "midas/kptimes"
dataset_subset = "raw"
dataset_document_column = "document"
dataset_biotags_column = "doc_bio_tags"
def preprocess_fuction(all_samples_per_split):
tokenized_samples = tokenizer.batch_encode_plus(
all_samples_per_split[dataset_document_column],
padding="max_length",
truncation=True,
is_split_into_words=True,
max_length=max_length,
)
total_adjusted_labels = []
for k in range(0, len(tokenized_samples["input_ids"])):
prev_wid = -1
word_ids_list = tokenized_samples.word_ids(batch_index=k)
existing_label_ids = all_samples_per_split[dataset_biotags_column][k]
i = -1
adjusted_label_ids = []
for wid in word_ids_list:
if wid is None:
adjusted_label_ids.append(lbl2idx["O"])
elif wid != prev_wid:
i = i + 1
adjusted_label_ids.append(lbl2idx[existing_label_ids[i]])
prev_wid = wid
else:
adjusted_label_ids.append(
lbl2idx[
f"{'I' if existing_label_ids[i] == 'B' else existing_label_ids[i]}"
]
)
total_adjusted_labels.append(adjusted_label_ids)
tokenized_samples["labels"] = total_adjusted_labels
return tokenized_samples
# Load dataset
dataset = load_dataset(dataset_full_name, dataset_subset)
# Preprocess dataset
tokenized_dataset = dataset.map(preprocess_fuction, batched=True)
```
### Postprocessing (Without Pipeline Function)
If you do not use the pipeline function, you must filter out the B and I labeled tokens. Each B and I will then be merged into a keyphrase. Finally, you need to strip the keyphrases to make sure all unnecessary spaces have been removed.
```python
# Define post_process functions
def concat_tokens_by_tag(keyphrases):
keyphrase_tokens = []
for id, label in keyphrases:
if label == "B":
keyphrase_tokens.append([id])
elif label == "I":
if len(keyphrase_tokens) > 0:
keyphrase_tokens[len(keyphrase_tokens) - 1].append(id)
return keyphrase_tokens
def extract_keyphrases(example, predictions, tokenizer, index=0):
keyphrases_list = [
(id, idx2label[label])
for id, label in zip(
np.array(example["input_ids"]).squeeze().tolist(), predictions[index]
)
if idx2label[label] in ["B", "I"]
]
processed_keyphrases = concat_tokens_by_tag(keyphrases_list)
extracted_kps = tokenizer.batch_decode(
processed_keyphrases,
skip_special_tokens=True,
clean_up_tokenization_spaces=True,
)
return np.unique([kp.strip() for kp in extracted_kps])
```
## 📝 Evaluation Results
Traditional evaluation methods are the precision, recall and F1-score @k,m where k is the number that stands for the first k predicted keyphrases and m for the average amount of predicted keyphrases.
The model achieves the following results on the KPTimes test set:
| Dataset | P@5 | R@5 | F1@5 | P@10 | R@10 | F1@10 | P@M | R@M | F1@M |
|:-----------------:|:----:|:----:|:----:|:----:|:----:|:-----:|:----:|:----:|:----:|
| KPTimes Test Set | 0.19 | 0.36 | 0.23 | 0.10 | 0.37 | 0.15 | 0.35 | 0.37 | 0.33 |
For more information on the evaluation process, you can take a look at the keyphrase extraction [evaluation notebook]().
## 🚨 Issues
Please feel free to start discussions in the Community Tab.
|
Awais/Audio_Source_Separation
|
043c6dcde8480460f4cf6db0b30405b6831f91b3
|
2022-04-03T11:03:43.000Z
|
[
"pytorch",
"dataset:Libri2Mix",
"dataset:sep_clean",
"asteroid",
"audio",
"ConvTasNet",
"audio-to-audio",
"license:cc-by-sa-4.0"
] |
audio-to-audio
| false |
Awais
| null |
Awais/Audio_Source_Separation
| 51 | null |
asteroid
| 5,967 |
---
tags:
- asteroid
- audio
- ConvTasNet
- audio-to-audio
datasets:
- Libri2Mix
- sep_clean
license: cc-by-sa-4.0
---
## Asteroid model `Awais/Audio_Source_Separation`
Imported from [Zenodo](https://zenodo.org/record/3873572#.X9M69cLjJH4)
Description:
This model was trained by Joris Cosentino using the librimix recipe in [Asteroid](https://github.com/asteroid-team/asteroid).
It was trained on the `sep_clean` task of the Libri2Mix dataset.
Training config:
```yaml
data:
n_src: 2
sample_rate: 8000
segment: 3
task: sep_clean
train_dir: data/wav8k/min/train-360
valid_dir: data/wav8k/min/dev
filterbank:
kernel_size: 16
n_filters: 512
stride: 8
masknet:
bn_chan: 128
hid_chan: 512
mask_act: relu
n_blocks: 8
n_repeats: 3
skip_chan: 128
optim:
lr: 0.001
optimizer: adam
weight_decay: 0.0
training:
batch_size: 24
early_stop: True
epochs: 200
half_lr: True
num_workers: 2
```
Results :
On Libri2Mix min test set :
```yaml
si_sdr: 14.764543634468069
si_sdr_imp: 14.764029375607246
sdr: 15.29337970745095
sdr_imp: 15.114146605113111
sir: 24.092904661115366
sir_imp: 23.913669683141528
sar: 16.06055906916849
sar_imp: -51.980784441287454
stoi: 0.9311142440593033
stoi_imp: 0.21817376142710482
```
License notice:
This work "ConvTasNet_Libri2Mix_sepclean_8k"
is a derivative of [LibriSpeech ASR corpus](http://www.openslr.org/12) by Vassil Panayotov,
used under [CC BY 4.0](https://creativecommons.org/licenses/by/4.0/). "ConvTasNet_Libri2Mix_sepclean_8k"
is licensed under [Attribution-ShareAlike 3.0 Unported](https://creativecommons.org/licenses/by-sa/3.0/) by Cosentino Joris.
|
Toshifumi/bert-base-multilingual-cased-finetuned-emotion
|
59b25fd61666730e719e8830207b77c178fc4f5a
|
2022-04-14T08:27:21.000Z
|
[
"pytorch",
"tensorboard",
"bert",
"text-classification",
"dataset:emotion",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] |
text-classification
| false |
Toshifumi
| null |
Toshifumi/bert-base-multilingual-cased-finetuned-emotion
| 51 | null |
transformers
| 5,968 |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: bert-base-multilingual-cased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9195
- name: F1
type: f1
value: 0.9204823251325381
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-multilingual-cased-finetuned-emotion
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2369
- Accuracy: 0.9195
- F1: 0.9205
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.9212 | 1.0 | 250 | 0.3466 | 0.8965 | 0.8966 |
| 0.2893 | 2.0 | 500 | 0.2369 | 0.9195 | 0.9205 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Helsinki-NLP/opus-mt-tc-big-cat_oci_spa-en
|
a023bee2de806635db5963d1e0fa250044e97a35
|
2022-06-01T12:59:11.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"ca",
"en",
"es",
"oc",
"transformers",
"translation",
"opus-mt-tc",
"license:cc-by-4.0",
"model-index",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-tc-big-cat_oci_spa-en
| 51 | null |
transformers
| 5,969 |
---
language:
- ca
- en
- es
- oc
tags:
- translation
- opus-mt-tc
license: cc-by-4.0
model-index:
- name: opus-mt-tc-big-cat_oci_spa-en
results:
- task:
name: Translation cat-eng
type: translation
args: cat-eng
dataset:
name: flores101-devtest
type: flores_101
args: cat eng devtest
metrics:
- name: BLEU
type: bleu
value: 45.4
- task:
name: Translation oci-eng
type: translation
args: oci-eng
dataset:
name: flores101-devtest
type: flores_101
args: oci eng devtest
metrics:
- name: BLEU
type: bleu
value: 37.5
- task:
name: Translation spa-eng
type: translation
args: spa-eng
dataset:
name: flores101-devtest
type: flores_101
args: spa eng devtest
metrics:
- name: BLEU
type: bleu
value: 29.9
- task:
name: Translation spa-eng
type: translation
args: spa-eng
dataset:
name: news-test2008
type: news-test2008
args: spa-eng
metrics:
- name: BLEU
type: bleu
value: 27.9
- task:
name: Translation cat-eng
type: translation
args: cat-eng
dataset:
name: tatoeba-test-v2021-08-07
type: tatoeba_mt
args: cat-eng
metrics:
- name: BLEU
type: bleu
value: 57.3
- task:
name: Translation spa-eng
type: translation
args: spa-eng
dataset:
name: tatoeba-test-v2021-08-07
type: tatoeba_mt
args: spa-eng
metrics:
- name: BLEU
type: bleu
value: 62.3
- task:
name: Translation spa-eng
type: translation
args: spa-eng
dataset:
name: tico19-test
type: tico19-test
args: spa-eng
metrics:
- name: BLEU
type: bleu
value: 51.8
- task:
name: Translation spa-eng
type: translation
args: spa-eng
dataset:
name: newstest2009
type: wmt-2009-news
args: spa-eng
metrics:
- name: BLEU
type: bleu
value: 30.2
- task:
name: Translation spa-eng
type: translation
args: spa-eng
dataset:
name: newstest2010
type: wmt-2010-news
args: spa-eng
metrics:
- name: BLEU
type: bleu
value: 36.8
- task:
name: Translation spa-eng
type: translation
args: spa-eng
dataset:
name: newstest2011
type: wmt-2011-news
args: spa-eng
metrics:
- name: BLEU
type: bleu
value: 34.7
- task:
name: Translation spa-eng
type: translation
args: spa-eng
dataset:
name: newstest2012
type: wmt-2012-news
args: spa-eng
metrics:
- name: BLEU
type: bleu
value: 38.6
- task:
name: Translation spa-eng
type: translation
args: spa-eng
dataset:
name: newstest2013
type: wmt-2013-news
args: spa-eng
metrics:
- name: BLEU
type: bleu
value: 35.3
---
# opus-mt-tc-big-cat_oci_spa-en
Neural machine translation model for translating from Catalan, Occitan and Spanish (cat+oci+spa) to English (en).
This model is part of the [OPUS-MT project](https://github.com/Helsinki-NLP/Opus-MT), an effort to make neural machine translation models widely available and accessible for many languages in the world. All models are originally trained using the amazing framework of [Marian NMT](https://marian-nmt.github.io/), an efficient NMT implementation written in pure C++. The models have been converted to pyTorch using the transformers library by huggingface. Training data is taken from [OPUS](https://opus.nlpl.eu/) and training pipelines use the procedures of [OPUS-MT-train](https://github.com/Helsinki-NLP/Opus-MT-train).
* Publications: [OPUS-MT – Building open translation services for the World](https://aclanthology.org/2020.eamt-1.61/) and [The Tatoeba Translation Challenge – Realistic Data Sets for Low Resource and Multilingual MT](https://aclanthology.org/2020.wmt-1.139/) (Please, cite if you use this model.)
```
@inproceedings{tiedemann-thottingal-2020-opus,
title = "{OPUS}-{MT} {--} Building open translation services for the World",
author = {Tiedemann, J{\"o}rg and Thottingal, Santhosh},
booktitle = "Proceedings of the 22nd Annual Conference of the European Association for Machine Translation",
month = nov,
year = "2020",
address = "Lisboa, Portugal",
publisher = "European Association for Machine Translation",
url = "https://aclanthology.org/2020.eamt-1.61",
pages = "479--480",
}
@inproceedings{tiedemann-2020-tatoeba,
title = "The Tatoeba Translation Challenge {--} Realistic Data Sets for Low Resource and Multilingual {MT}",
author = {Tiedemann, J{\"o}rg},
booktitle = "Proceedings of the Fifth Conference on Machine Translation",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.wmt-1.139",
pages = "1174--1182",
}
```
## Model info
* Release: 2022-03-13
* source language(s): cat spa
* target language(s): eng
* model: transformer-big
* data: opusTCv20210807+bt ([source](https://github.com/Helsinki-NLP/Tatoeba-Challenge))
* tokenization: SentencePiece (spm32k,spm32k)
* original model: [opusTCv20210807+bt_transformer-big_2022-03-13.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/cat+oci+spa-eng/opusTCv20210807+bt_transformer-big_2022-03-13.zip)
* more information released models: [OPUS-MT cat+oci+spa-eng README](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/cat+oci+spa-eng/README.md)
## Usage
A short example code:
```python
from transformers import MarianMTModel, MarianTokenizer
src_text = [
"¿Puedo hacerte una pregunta?",
"Toca algo de música."
]
model_name = "pytorch-models/opus-mt-tc-big-cat_oci_spa-en"
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
translated = model.generate(**tokenizer(src_text, return_tensors="pt", padding=True))
for t in translated:
print( tokenizer.decode(t, skip_special_tokens=True) )
# expected output:
# Can I ask you a question?
# He plays some music.
```
You can also use OPUS-MT models with the transformers pipelines, for example:
```python
from transformers import pipeline
pipe = pipeline("translation", model="Helsinki-NLP/opus-mt-tc-big-cat_oci_spa-en")
print(pipe("¿Puedo hacerte una pregunta?"))
# expected output: Can I ask you a question?
```
## Benchmarks
* test set translations: [opusTCv20210807+bt_transformer-big_2022-03-13.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/cat+oci+spa-eng/opusTCv20210807+bt_transformer-big_2022-03-13.test.txt)
* test set scores: [opusTCv20210807+bt_transformer-big_2022-03-13.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/cat+oci+spa-eng/opusTCv20210807+bt_transformer-big_2022-03-13.eval.txt)
* benchmark results: [benchmark_results.txt](benchmark_results.txt)
* benchmark output: [benchmark_translations.zip](benchmark_translations.zip)
| langpair | testset | chr-F | BLEU | #sent | #words |
|----------|---------|-------|-------|-------|--------|
| cat-eng | tatoeba-test-v2021-08-07 | 0.72019 | 57.3 | 1631 | 12627 |
| spa-eng | tatoeba-test-v2021-08-07 | 0.76017 | 62.3 | 16583 | 138123 |
| cat-eng | flores101-devtest | 0.69572 | 45.4 | 1012 | 24721 |
| oci-eng | flores101-devtest | 0.63347 | 37.5 | 1012 | 24721 |
| spa-eng | flores101-devtest | 0.59696 | 29.9 | 1012 | 24721 |
| spa-eng | newssyscomb2009 | 0.57104 | 30.8 | 502 | 11818 |
| spa-eng | news-test2008 | 0.55440 | 27.9 | 2051 | 49380 |
| spa-eng | newstest2009 | 0.57153 | 30.2 | 2525 | 65399 |
| spa-eng | newstest2010 | 0.61890 | 36.8 | 2489 | 61711 |
| spa-eng | newstest2011 | 0.60278 | 34.7 | 3003 | 74681 |
| spa-eng | newstest2012 | 0.62760 | 38.6 | 3003 | 72812 |
| spa-eng | newstest2013 | 0.60994 | 35.3 | 3000 | 64505 |
| spa-eng | tico19-test | 0.74033 | 51.8 | 2100 | 56315 |
## Acknowledgements
The work is supported by the [European Language Grid](https://www.european-language-grid.eu/) as [pilot project 2866](https://live.european-language-grid.eu/catalogue/#/resource/projects/2866), by the [FoTran project](https://www.helsinki.fi/en/researchgroups/natural-language-understanding-with-cross-lingual-grounding), funded by the European Research Council (ERC) under the European Union’s Horizon 2020 research and innovation programme (grant agreement No 771113), and the [MeMAD project](https://memad.eu/), funded by the European Union’s Horizon 2020 Research and Innovation Programme under grant agreement No 780069. We are also grateful for the generous computational resources and IT infrastructure provided by [CSC -- IT Center for Science](https://www.csc.fi/), Finland.
## Model conversion info
* transformers version: 4.16.2
* OPUS-MT git hash: 3405783
* port time: Wed Apr 13 18:30:38 EEST 2022
* port machine: LM0-400-22516.local
|
ai4bharat/MultiIndicSentenceSummarization
|
d1f87d17cc7a2f1ac5b6246d706d56d8af6aba34
|
2022-04-30T10:26:02.000Z
|
[
"pytorch",
"mbart",
"text2text-generation",
"as",
"bn",
"gu",
"hi",
"kn",
"ml",
"mr",
"or",
"pa",
"ta",
"te",
"dataset:ai4bharat/IndicSentenceSummarization",
"arxiv:2203.05437",
"transformers",
"sentence-summarization",
"multilingual",
"nlp",
"indicnlp",
"license:mit",
"autotrain_compatible"
] |
text2text-generation
| false |
ai4bharat
| null |
ai4bharat/MultiIndicSentenceSummarization
| 51 | null |
transformers
| 5,970 |
---
tags:
- sentence-summarization
- multilingual
- nlp
- indicnlp
datasets:
- ai4bharat/IndicSentenceSummarization
language:
- as
- bn
- gu
- hi
- kn
- ml
- mr
- or
- pa
- ta
- te
license:
- mit
widget:
- जम्मू एवं कश्मीर के अनंतनाग जिले में शनिवार को सुरक्षाबलों के साथ मुठभेड़ में दो आतंकवादियों को मार गिराया गया। </s> <2hi>
---
# MultiIndicSentenceSummarization
This repository contains the [IndicBART](https://huggingface.co/ai4bharat/IndicBART) checkpoint finetuned on the 11 languages of [IndicSentenceSummarization](https://huggingface.co/datasets/ai4bharat/IndicSentenceSummarization) dataset. For finetuning details,
see the [paper](https://arxiv.org/abs/2203.05437).
<ul>
<li >Supported languages: Assamese, Bengali, Gujarati, Hindi, Marathi, Odiya, Punjabi, Kannada, Malayalam, Tamil, and Telugu. Not all of these languages are supported by mBART50 and mT5. </li>
<li >The model is much smaller than the mBART and mT5(-base) models, so less computationally expensive for decoding. </li>
<li> Trained on large Indic language corpora (431K sentences). </li>
<li> All languages, have been represented in Devanagari script to encourage transfer learning among the related languages. </li>
</ul>
## Using this model in `transformers`
```
from transformers import MBartForConditionalGeneration, AutoModelForSeq2SeqLM
from transformers import AlbertTokenizer, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("ai4bharat/MultiIndicSentenceSummarization", do_lower_case=False, use_fast=False, keep_accents=True)
# Or use tokenizer = AlbertTokenizer.from_pretrained("ai4bharat/MultiIndicSentenceSummarization", do_lower_case=False, use_fast=False, keep_accents=True)
model = AutoModelForSeq2SeqLM.from_pretrained("ai4bharat/MultiIndicSentenceSummarization")
# Or use model = MBartForConditionalGeneration.from_pretrained("ai4bharat/MultiIndicSentenceSummarization")
# Some initial mapping
bos_id = tokenizer._convert_token_to_id_with_added_voc("<s>")
eos_id = tokenizer._convert_token_to_id_with_added_voc("</s>")
pad_id = tokenizer._convert_token_to_id_with_added_voc("<pad>")
# To get lang_id use any of ['<2as>', '<2bn>', '<2en>', '<2gu>', '<2hi>', '<2kn>', '<2ml>', '<2mr>', '<2or>', '<2pa>', '<2ta>', '<2te>']
# First tokenize the input. The format below is how IndicBART was trained so the input should be "Sentence </s> <2xx>" where xx is the language code. Similarly, the output should be "<2yy> Sentence </s>".
inp = tokenizer("जम्मू एवं कश्मीर के अनंतनाग जिले में शनिवार को सुरक्षाबलों के साथ मुठभेड़ में दो आतंकवादियों को मार गिराया गया। </s> <2hi>", add_special_tokens=False, return_tensors="pt", padding=True).input_ids
# For generation. Pardon the messiness. Note the decoder_start_token_id.
model_output=model.generate(inp, use_cache=True,no_repeat_ngram_size=3, num_beams=5, length_penalty=0.8, early_stopping=True, pad_token_id=pad_id, bos_token_id=bos_id, eos_token_id=eos_id, decoder_start_token_id=tokenizer._convert_token_to_id_with_added_voc("<2hi>"))
# Decode to get output strings
decoded_output=tokenizer.decode(model_output[0], skip_special_tokens=True, clean_up_tokenization_spaces=False)
print(decoded_output) # जम्मू एवं कश्मीरः अनंतनाग में सुरक्षाबलों के साथ मुठभेड़ में दो आतंकवादी ढेर
# Note that if your output language is not Hindi or Marathi, you should convert its script from Devanagari to the desired language using the Indic NLP Library.
```
# Note:
If you wish to use any language written in a non-Devanagari script, then you should first convert it to Devanagari using the <a href="https://github.com/anoopkunchukuttan/indic_nlp_library">Indic NLP Library</a>. After you get the output, you should convert it back into the original script.
## Benchmarks
Scores on the `IndicSentenceSummarization` test sets are as follows:
Language | Rouge-1 / Rouge-2 / Rouge-L
---------|----------------------------
as | 60.46 / 46.77 / 59.29
bn | 51.12 / 34.91 / 49.29
gu | 47.89 / 29.97 / 45.92
hi | 50.7 / 28.11 / 45.34
kn | 77.93 / 70.03 / 77.32
ml | 67.7 / 54.42 / 66.42
mr | 48.06 / 26.98 / 46.5
or | 45.2 / 23.66 / 43.65
pa | 55.96 / 37.2 / 52.22
ta | 58.85 / 38.97 / 56.83
te | 54.81 / 35.28 / 53.44
## Citation
If you use this model, please cite the following paper:
```
@inproceedings{Kumar2022IndicNLGSM,
title={IndicNLG Suite: Multilingual Datasets for Diverse NLG Tasks in Indic Languages},
author={Aman Kumar and Himani Shrotriya and Prachi Sahu and Raj Dabre and Ratish Puduppully and Anoop Kunchukuttan and Amogh Mishra and Mitesh M. Khapra and Pratyush Kumar},
year={2022},
url = "https://arxiv.org/abs/2203.05437"
}
```
|
mismayil/kogito-rc-distilbert
|
8e52330f42d27c1be33960a976bd041ad1f905c5
|
2022-04-28T15:39:21.000Z
|
[
"pytorch",
"transformers",
"license:mit"
] | null | false |
mismayil
| null |
mismayil/kogito-rc-distilbert
| 51 | null |
transformers
| 5,971 |
---
license: mit
---
|
jenspt/bert_regression
|
f4414f944a12bb5d84fca52312cdec485b4baaa1
|
2022-05-04T08:12:54.000Z
|
[
"pytorch",
"bert",
"text-classification",
"transformers"
] |
text-classification
| false |
jenspt
| null |
jenspt/bert_regression
| 51 | null |
transformers
| 5,972 |
Entry not found
|
RJ3vans/SSCCVspanTagger
|
0658684da6c0b4873733d75571b8fe2ca1766058
|
2022-07-14T11:08:28.000Z
|
[
"pytorch",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] |
token-classification
| false |
RJ3vans
| null |
RJ3vans/SSCCVspanTagger
| 51 | null |
transformers
| 5,973 |
Entry not found
|
chanind/frame-semantic-transformer-small
|
6ad6032e26af582346a8af6d2d4b43854610ee22
|
2022-05-23T19:08:46.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
text2text-generation
| false |
chanind
| null |
chanind/frame-semantic-transformer-small
| 51 | null |
transformers
| 5,974 |
---
license: apache-2.0
---
Fine-tuned T5 small model for use as a frame semantic parser in the [Frame Semantic Transformer](https://github.com/chanind/frame-semantic-transformer) project. This model is trained on data from [FrameNet](https://framenet2.icsi.berkeley.edu/).
### Usage
This is meant to be used a part of [Frame Semantic Transformer](https://github.com/chanind/frame-semantic-transformer). See that project for usage instructions.
### Tasks
This model is trained to perform 3 tasks related to semantic frame parsing:
1. Identify frame trigger locations in the text
2. Classify the frame given a trigger location
3. Extract frame elements in the sentence
### Performance
This model is trained and evaluated using the same train/dev/test splits from FrameNet 1.7 annotated corpora as used by [Open Sesame](https://github.com/swabhs/open-sesame).
| Task | F1 Score (Dev) | F1 Score (Test) |
| ---------------------- | -------------- | --------------- |
| Trigger identification | 0.74 | 0.70 |
| Frame Classification | 0.83 | 0.81 |
| Argument Extraction | 0.68 | 0.70 |
|
RUCAIBox/mtl-question-generation
|
63cdb9af203520d0688ebab5fac7dd1b3d201f7d
|
2022-06-27T02:27:24.000Z
|
[
"pytorch",
"mvp",
"en",
"arxiv:2206.12131",
"transformers",
"text-generation",
"text2text-generation",
"license:apache-2.0"
] |
text2text-generation
| false |
RUCAIBox
| null |
RUCAIBox/mtl-question-generation
| 51 | null |
transformers
| 5,975 |
---
license: apache-2.0
language:
- en
tags:
- text-generation
- text2text-generation
pipeline_tag: text2text-generation
widget:
- text: "Generate the question based on the answer: boxing [X_SEP] A bolo punch is a punch used in martial arts . A hook is a punch in boxing ."
example_title: "Example1"
- text: "Generate the question based on the answer: Arthur 's Magazine [X_SEP] Arthur 's Magazine ( 1844–1846 ) was an American literary periodical published in Philadelphia in the 19th century . First for Women is a woman 's magazine published by Bauer Media Group in the USA ."
example_title: "Example2"
---
# MTL-question-generation
The MTL-question-generation model was proposed in [**MVP: Multi-task Supervised Pre-training for Natural Language Generation**](https://arxiv.org/abs/2206.12131) by Tianyi Tang, Junyi Li, Wayne Xin Zhao and Ji-Rong Wen.
The detailed information and instructions can be found [https://github.com/RUCAIBox/MVP](https://github.com/RUCAIBox/MVP).
## Model Description
MTL-question-generation is supervised pre-trained using a mixture of labeled question generation datasets. It is a variant (Single) of our main [MVP](https://huggingface.co/RUCAIBox/mvp) model. It follows a standard Transformer encoder-decoder architecture.
MTL-question-generation is specially designed for question generation tasks, such as SQuAD and CoQA.
## Example
```python
>>> from transformers import MvpTokenizer, MvpForConditionalGeneration
>>> tokenizer = MvpTokenizer.from_pretrained("RUCAIBox/mvp")
>>> model = MvpForConditionalGeneration.from_pretrained("RUCAIBox/mtl-question-generation")
>>> inputs = tokenizer(
... "Generate the question based on the answer: boxing [X_SEP] A bolo punch is a punch used in martial arts . A hook is a punch in boxing .",
... return_tensors="pt",
... )
>>> generated_ids = model.generate(**inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
['A bolo punch and a hook are both punches used in what sport?]
```
## Related Models
**MVP**: [https://huggingface.co/RUCAIBox/mvp](https://huggingface.co/RUCAIBox/mvp).
**Prompt-based models**:
- MVP-multi-task: [https://huggingface.co/RUCAIBox/mvp-multi-task](https://huggingface.co/RUCAIBox/mvp-multi-task).
- MVP-summarization: [https://huggingface.co/RUCAIBox/mvp-summarization](https://huggingface.co/RUCAIBox/mvp-summarization).
- MVP-open-dialog: [https://huggingface.co/RUCAIBox/mvp-open-dialog](https://huggingface.co/RUCAIBox/mvp-open-dialog).
- MVP-data-to-text: [https://huggingface.co/RUCAIBox/mvp-data-to-text](https://huggingface.co/RUCAIBox/mvp-data-to-text).
- MVP-story: [https://huggingface.co/RUCAIBox/mvp-story](https://huggingface.co/RUCAIBox/mvp-story).
- MVP-question-answering: [https://huggingface.co/RUCAIBox/mvp-question-answering](https://huggingface.co/RUCAIBox/mvp-question-answering).
- MVP-question-generation: [https://huggingface.co/RUCAIBox/mvp-question-generation](https://huggingface.co/RUCAIBox/mvp-question-generation).
- MVP-task-dialog: [https://huggingface.co/RUCAIBox/mvp-task-dialog](https://huggingface.co/RUCAIBox/mvp-task-dialog).
**Multi-task models**:
- MTL-summarization: [https://huggingface.co/RUCAIBox/mtl-summarization](https://huggingface.co/RUCAIBox/mtl-summarization).
- MTL-open-dialog: [https://huggingface.co/RUCAIBox/mtl-open-dialog](https://huggingface.co/RUCAIBox/mtl-open-dialog).
- MTL-data-to-text: [https://huggingface.co/RUCAIBox/mtl-data-to-text](https://huggingface.co/RUCAIBox/mtl-data-to-text).
- MTL-story: [https://huggingface.co/RUCAIBox/mtl-story](https://huggingface.co/RUCAIBox/mtl-story).
- MTL-question-answering: [https://huggingface.co/RUCAIBox/mtl-question-answering](https://huggingface.co/RUCAIBox/mtl-question-answering).
- MTL-question-generation: [https://huggingface.co/RUCAIBox/mtl-question-generation](https://huggingface.co/RUCAIBox/mtl-question-generation).
- MTL-task-dialog: [https://huggingface.co/RUCAIBox/mtl-task-dialog](https://huggingface.co/RUCAIBox/mtl-task-dialog).
## Citation
```bibtex
@article{tang2022mvp,
title={MVP: Multi-task Supervised Pre-training for Natural Language Generation},
author={Tang, Tianyi and Li, Junyi and Zhao, Wayne Xin and Wen, Ji-Rong},
journal={arXiv preprint arXiv:2206.12131},
year={2022},
url={https://arxiv.org/abs/2206.12131},
}
```
|
sschellhammer/SciTweets_SciBert
|
d2998a11f3574c88e0da8eb39c761932f84cc43b
|
2022-06-09T14:03:30.000Z
|
[
"pytorch",
"bert",
"text-classification",
"transformers",
"license:cc-by-4.0"
] |
text-classification
| false |
sschellhammer
| null |
sschellhammer/SciTweets_SciBert
| 51 | null |
transformers
| 5,976 |
---
license: cc-by-4.0
widget:
- text: "Study: Shifts in electricity generation spur net job growth, but coal jobs decline - via @DukeU https://www.eurekalert.org/news-releases/637217"
example_title: "All categories"
- text: "Shifts in electricity generation spur net job growth, but coal jobs decline"
example_title: "Only Cat 1.1"
- text: "Study on impacts of electricity generation shift via @DukeU https://www.eurekalert.org/news-releases/637217"
example_title: "Only Cat 1.2 and 1.3"
- text: "@DukeU received grant for research on electricity generation shift"
example_title: "Only Cat 1.3"
---
This SciBert-based multi-label classifier, trained as part of the work "SciTweets - A Dataset and Annotation Framework for Detecting Scientific Online Discourse", distinguishes three different forms of science-relatedness for Tweets. See details at https://github.com/AI-4-Sci/SciTweets .
|
nvidia/tts_hifigan
|
3ba1fed954276287015654bf4c78060ffc9a4772
|
2022-06-29T21:31:29.000Z
|
[
"nemo",
"en",
"dataset:ljspeech",
"arxiv:2010.05646",
"text-to-speech",
"speech",
"audio",
"Vocoder",
"GAN",
"pytorch",
"NeMo",
"Riva",
"license:cc-by-4.0"
] |
text-to-speech
| false |
nvidia
| null |
nvidia/tts_hifigan
| 51 | 1 |
nemo
| 5,977 |
---
language:
- en
library_name: nemo
datasets:
- ljspeech
thumbnail: null
tags:
- text-to-speech
- speech
- audio
- Vocoder
- GAN
- pytorch
- NeMo
- Riva
license: cc-by-4.0
---
# NVIDIA Hifigan Vocoder (en-US)
<style>
img {
display: inline;
}
</style>
| [](#model-architecture)
| [](#model-architecture)
| [](#datasets)
| [](#deployment-with-nvidia-riva) |
HiFiGAN [1] is a generative adversarial network (GAN) model that generates audio from mel spectrograms. The generator uses transposed convolutions to upsample mel spectrograms to audio.
## Usage
The model is available for use in the NeMo toolkit [2] and can be used as a pre-trained checkpoint for inference or for fine-tuning on another dataset.
To train, fine-tune or play with the model you will need to install [NVIDIA NeMo](https://github.com/NVIDIA/NeMo). We recommend you install it after you've installed the latest PyTorch version.
```
pip install nemo_toolkit['all']
```
### Automatically instantiate the model
NOTE: In order to generate audio, you also need a spectrogram generator from NeMo. This example uses the FastPitch model.
```python
# Load FastPitch
from nemo.collections.tts.models import FastPitchModel
spec_generator = FastPitchModel.from_pretrained("nvidia/tts_en_fastpitch")
# Load vocoder
from nemo.collections.tts.models import HifiGanModel
model = HifiGanModel.from_pretrained(model_name="nvidia/tts_hifigan")
```
### Generate audio
```python
import soundfile as sf
parsed = spec_generator.parse("You can type your sentence here to get nemo to produce speech.")
spectrogram = spec_generator.generate_spectrogram(tokens=parsed)
audio = model.convert_spectrogram_to_audio(spec=spectrogram)
```
### Save the generated audio file
```python
# Save the audio to disk in a file called speech.wav
sf.write("speech.wav", audio.to('cpu').numpy(), 22050)
```
### Input
This model accepts batches of mel spectrograms.
### Output
This model outputs audio at 22050Hz.
## Model Architecture
HiFi-GAN [1] consists of one generator and two discriminators: multi-scale and multi-period discriminators. The generator and discriminators are trained adversarially, along with two additional losses for
improving training stability and model performance.
## Training
The NeMo toolkit [3] was used for training the models for several epochs. These model are trained with this [example script](https://github.com/NVIDIA/NeMo/blob/main/examples/tts/hifigan.py) and this [base config](https://github.com/NVIDIA/NeMo/blob/main/examples/tts/conf/hifigan/hifigan.yaml).
### Datasets
This model is trained on LJSpeech sampled at 22050Hz, and has been tested on generating female English voices with an American accent.
## Performance
No performance information is available at this time.
## Limitations
If the spectrogram generator model (example FastPitch) is trained/finetuned on new speaker's data it is recommended to finetune HiFi-GAN also. HiFi-GAN shows improvement using synthesized mel spectrograms, so the first step is to generate mel spectrograms with our finetuned FastPitch model to use as input to finetune HiFiGAN.
## Deployment with NVIDIA Riva
For the best real-time accuracy, latency, and throughput, deploy the model with [NVIDIA Riva](https://developer.nvidia.com/riva), an accelerated speech AI SDK deployable on-prem, in all clouds, multi-cloud, hybrid, at the edge, and embedded.
Additionally, Riva provides:
* World-class out-of-the-box accuracy for the most common languages with model checkpoints trained on proprietary data with hundreds of thousands of GPU-compute hours
* Best in class accuracy with run-time word boosting (e.g., brand and product names) and customization of acoustic model, language model, and inverse text normalization
* Streaming speech recognition, Kubernetes compatible scaling, and Enterprise-grade support
Check out [Riva live demo](https://developer.nvidia.com/riva#demos).
## References
- [1] [HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis](https://arxiv.org/abs/2010.05646)
- [2] [NVIDIA NeMo Toolkit](https://github.com/NVIDIA/NeMo)
|
ClassCat/roberta-base-latin-v2
|
7e8f8efb4b82341f9509b60aef77824ae34a8c5f
|
2022-07-14T00:20:13.000Z
|
[
"pytorch",
"roberta",
"fill-mask",
"la",
"dataset:cc100",
"transformers",
"license:cc-by-sa-4.0",
"autotrain_compatible"
] |
fill-mask
| false |
ClassCat
| null |
ClassCat/roberta-base-latin-v2
| 51 | 1 |
transformers
| 5,978 |
---
language: la
license: cc-by-sa-4.0
datasets:
- cc100
widget:
- text: quod est tibi <mask> ?"
- text: vita brevis, ars <mask>.
- text: errare <mask> est.
- text: usus est magister <mask>.
---
## RoBERTa Latin base model Version 2 (Uncased)
### Prerequisites
transformers==4.19.2
### Model architecture
This model uses RoBERTa base setttings except vocabulary size.
### Tokenizer
Using BPE tokenizer with a vocabulary size 50,000.
### Training Data
* Subset of [CC-100/la](https://data.statmt.org/cc-100/) : Monolingual Datasets from Web Crawl Data
### Usage
```python
from transformers import pipeline
unmasker = pipeline('fill-mask', model='ClassCat/roberta-base-latin-v2')
unmasker("vita brevis, ars <mask>")
```
|
SushantGautam/CodeGeneration
|
3738e8e94a944caacc3cf2d3ff8fb3e08909fb8a
|
2022-07-07T03:13:37.000Z
|
[
"pytorch",
"roberta",
"fill-mask",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index",
"autotrain_compatible"
] |
fill-mask
| false |
SushantGautam
| null |
SushantGautam/CodeGeneration
| 51 | null |
transformers
| 5,979 |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: CodeGeneration
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# CodeGeneration
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 3.5020
- Accuracy: 0.4444
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10.0
### Training results
### Framework versions
- Transformers 4.21.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 2.3.2
- Tokenizers 0.12.1
|
knkarthick/TOPIC-DIALOGSUM-VALIDATION-XSUM
|
f884177017ffda84a3b600a1f59f6266db02a78a
|
2022-07-08T05:59:41.000Z
|
[
"pytorch",
"bart",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
knkarthick
| null |
knkarthick/TOPIC-DIALOGSUM-VALIDATION-XSUM
| 51 | null |
transformers
| 5,980 |
Entry not found
|
dsivakumar/text2sql
|
a9abd8fd33c01721b13b174ead4d0d4b33a57314
|
2022-07-13T07:27:17.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"en",
"dataset:wikisql",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
dsivakumar
| null |
dsivakumar/text2sql
| 51 | null |
transformers
| 5,981 |
---
language:
- en
datasets:
- wikisql
widget:
- text: "English to SQL: Show me the average age of of wines in Italy by provinces"
- text: "English to SQL: What is the current series where the new series began in June 2011?"
---
#import transformers
```
from transformers import (
T5ForConditionalGeneration,
T5Tokenizer,
)
#load model
model = T5ForConditionalGeneration.from_pretrained('dsivakumar/text2sql')
tokenizer = T5Tokenizer.from_pretrained('dsivakumar/text2sql')
#predict function
def get_sql(query,tokenizer,model):
source_text= "English to SQL: "+query
source_text = ' '.join(source_text.split())
source = tokenizer.batch_encode_plus([source_text],max_length= 128, pad_to_max_length=True, truncation=True, padding="max_length", return_tensors='pt')
source_ids = source['input_ids'] #.squeeze()
source_mask = source['attention_mask']#.squeeze()
generated_ids = model.generate(
input_ids = source_ids.to(dtype=torch.long),
attention_mask = source_mask.to(dtype=torch.long),
max_length=150,
num_beams=2,
repetition_penalty=2.5,
length_penalty=1.0,
early_stopping=True
)
preds = [tokenizer.decode(g, skip_special_tokens=True, clean_up_tokenization_spaces=True) for g in generated_ids]
return preds
#test
query="Show me the average age of of wines in Italy by provinces"
sql = get_sql(query,tokenizer,model)
print(sql)
#https://huggingface.co/mrm8488/t5-small-finetuned-wikiSQL
def get_sql(query):
input_text = "translate English to SQL: %s </s>" % query
features = tokenizer([input_text], return_tensors='pt')
output = model.generate(input_ids=features['input_ids'],
attention_mask=features['attention_mask'])
return tokenizer.decode(output[0])
query = "How many models were finetuned using BERT as base model?"
get_sql(query)
```
|
bloom-testing/test-bloomd-350m-CI
|
c1078f05edfc27ae119a3eb8969056101d0f6c16
|
2022-07-15T22:51:44.000Z
|
[
"pytorch",
"bloom",
"feature-extraction",
"transformers"
] |
feature-extraction
| false |
bloom-testing
| null |
bloom-testing/test-bloomd-350m-CI
| 51 | null |
transformers
| 5,982 |
Entry not found
|
bloom-testing/test-bloomd-350m-facelift
|
a2076c0d301ede655c186b4d005b034b4bd01c78
|
2022-07-15T23:05:47.000Z
|
[
"pytorch",
"bloom",
"feature-extraction",
"transformers"
] |
feature-extraction
| false |
bloom-testing
| null |
bloom-testing/test-bloomd-350m-facelift
| 51 | null |
transformers
| 5,983 |
Entry not found
|
0x7194633/keyt5-large
|
6aca9fe5edca51e69d13734271c0c60793c16831
|
2022-01-11T03:52:33.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"ru",
"transformers",
"license:mit",
"autotrain_compatible"
] |
text2text-generation
| false |
0x7194633
| null |
0x7194633/keyt5-large
| 50 | null |
transformers
| 5,984 |
---
language:
- ru
license: mit
inference:
parameters:
top_p: 1.0
widget:
- text: "В России может появиться новый штамм коронавируса «омикрон», что может привести к подъему заболеваемости в январе, заявил доцент кафедры инфекционных болезней РУДН Сергей Вознесенский. Он отметил, что вариант «дельта» вызывал больше летальных случаев, чем омикрон, именно на фоне «дельты» была максимальная летальность."
example_title: "Коронавирус"
- text: "Начальника штаба обороны Великобритании адмирала Тони Радакина заставили имитировать активность во время визита в ангар с тяжелым вооружением, сообщила британская пресса. В приказе говорилось, что военнослужащим было велено подбегать к автомобилям, открывать все люки, затворы, листать руководство по эксплуатации и осматриваться машины, будто проводится функциональный тест для обеспечения правильной работы оборудования."
example_title: "Британия"
- text: "Для воспроизведения музыки достаточно нажимать на кнопки клавиатуры. Каждой клавише соответствует определенный семпл — есть маракасы и футуристичные звуки, напоминающие выстрелы бластеров. Из всего многообразия можно формировать собственные паттерны и наблюдать за визуализацией с анимированными геометрическими фигурами. Что интересно, нажатием клавиши пробел можно полностью переменить оформление, цвета на экране и звучание семплов."
example_title: "Технологии"
---
## keyT5. Large version
[](https://github.com/0x7o/text2keywords "Go to GitHub repo")
[](https://github.com/0x7o/text2keywords)
[](https://github.com/0x7o/text2keywords)
Supported languages: ru
Github - [text2keywords](https://github.com/0x7o/text2keywords)
[Pretraining Large version](https://huggingface.co/0x7194633/keyt5-large)
|
[Pretraining Base version](https://huggingface.co/0x7194633/keyt5-base)
# Usage
Example usage (the code returns a list with keywords. duplicates are possible):
[](https://colab.research.google.com/github/0x7o/text2keywords/blob/main/example/keyT5_use.ipynb)
```
pip install transformers sentencepiece
```
```python
from itertools import groupby
import torch
from transformers import T5ForConditionalGeneration, T5Tokenizer
model_name = "0x7194633/keyt5-large" # or 0x7194633/keyt5-base
tokenizer = T5Tokenizer.from_pretrained(model_name)
model = T5ForConditionalGeneration.from_pretrained(model_name)
def generate(text, **kwargs):
inputs = tokenizer(text, return_tensors='pt')
with torch.no_grad():
hypotheses = model.generate(**inputs, num_beams=5, **kwargs)
s = tokenizer.decode(hypotheses[0], skip_special_tokens=True)
s = s.replace('; ', ';').replace(' ;', ';').lower().split(';')[:-1]
s = [el for el, _ in groupby(s)]
return s
article = """Reuters сообщил об отмене 3,6 тыс. авиарейсов из-за «омикрона» и погоды
Наибольшее число отмен авиарейсов 2 января пришлось на американские авиакомпании
SkyWest и Southwest, у каждой — более 400 отмененных рейсов. При этом среди
отмененных 2 января авиарейсов — более 2,1 тыс. рейсов в США. Также свыше 6400
рейсов были задержаны."""
print(generate(article, top_p=1.0, max_length=64))
# ['авиаперевозки', 'отмена авиарейсов', 'отмена рейсов', 'отмена авиарейсов', 'отмена рейсов', 'отмена авиарейсов']
```
# Training
Go to the training notebook and learn more about it:
[](https://colab.research.google.com/github/0x7o/text2keywords/blob/main/example/keyT5_train.ipynb)
|
CouchCat/ma_ner_v7_distil
|
9dd0c9b1f1a7fe22d313fe5a0d308c0fa0039e23
|
2021-02-28T20:54:46.000Z
|
[
"pytorch",
"distilbert",
"token-classification",
"en",
"transformers",
"ner",
"license:mit",
"autotrain_compatible"
] |
token-classification
| false |
CouchCat
| null |
CouchCat/ma_ner_v7_distil
| 50 | null |
transformers
| 5,985 |
---
language: en
license: mit
tags:
- ner
widget:
- text: "These shoes I recently bought from Tommy Hilfiger fit quite well. The shirt, however, has got a hole"
---
### Description
A Named Entity Recognition model trained on a customer feedback data using DistilBert.
Possible labels are in BIO-notation. Performance of the PERS tag could be better because of low data samples:
- PROD: for certain products
- BRND: for brands
- PERS: people names
The following tags are simply in place to help better categorize the previous tags
- MATR: relating to materials, e.g. cloth, leather, seam, etc.
- TIME: time related entities
- MISC: any other entity that might skew the results
### Usage
```
from transformers import AutoTokenizer, AutoModelForTokenClassification
tokenizer = AutoTokenizer.from_pretrained("CouchCat/ma_ner_v7_distil")
model = AutoModelForTokenClassification.from_pretrained("CouchCat/ma_ner_v7_distil")
```
|
Geotrend/bert-base-nl-cased
|
51f86af423d9f9e72b9a81155875adcba9b571ba
|
2021-05-18T20:02:19.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"nl",
"dataset:wikipedia",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
| false |
Geotrend
| null |
Geotrend/bert-base-nl-cased
| 50 | null |
transformers
| 5,986 |
---
language: nl
datasets: wikipedia
license: apache-2.0
---
# bert-base-nl-cased
We are sharing smaller versions of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) that handle a custom number of languages.
Unlike [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased), our versions give exactly the same representations produced by the original model which preserves the original accuracy.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/bert-base-nl-cased")
model = AutoModel.from_pretrained("Geotrend/bert-base-nl-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermbert,
title={Load What You Need: Smaller Versions of Mutlilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact [email protected] for any question, feedback or request.
|
Helsinki-NLP/opus-mt-sem-en
|
27d79ccca4adc1a2dd178024fa9edf5bc660e005
|
2020-08-21T14:42:49.000Z
|
[
"pytorch",
"marian",
"text2text-generation",
"mt",
"ar",
"he",
"ti",
"am",
"sem",
"en",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
Helsinki-NLP
| null |
Helsinki-NLP/opus-mt-sem-en
| 50 | null |
transformers
| 5,987 |
---
language:
- mt
- ar
- he
- ti
- am
- sem
- en
tags:
- translation
license: apache-2.0
---
### sem-eng
* source group: Semitic languages
* target group: English
* OPUS readme: [sem-eng](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/sem-eng/README.md)
* model: transformer
* source language(s): acm afb amh apc ara arq ary arz heb mlt tir
* target language(s): eng
* model: transformer
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus2m-2020-08-01.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/sem-eng/opus2m-2020-08-01.zip)
* test set translations: [opus2m-2020-08-01.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/sem-eng/opus2m-2020-08-01.test.txt)
* test set scores: [opus2m-2020-08-01.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/sem-eng/opus2m-2020-08-01.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.amh-eng.amh.eng | 37.5 | 0.565 |
| Tatoeba-test.ara-eng.ara.eng | 38.9 | 0.566 |
| Tatoeba-test.heb-eng.heb.eng | 44.6 | 0.610 |
| Tatoeba-test.mlt-eng.mlt.eng | 53.7 | 0.688 |
| Tatoeba-test.multi.eng | 41.7 | 0.588 |
| Tatoeba-test.tir-eng.tir.eng | 18.3 | 0.370 |
### System Info:
- hf_name: sem-eng
- source_languages: sem
- target_languages: eng
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/sem-eng/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['mt', 'ar', 'he', 'ti', 'am', 'sem', 'en']
- src_constituents: {'apc', 'mlt', 'arz', 'ara', 'heb', 'tir', 'arq', 'afb', 'amh', 'acm', 'ary'}
- tgt_constituents: {'eng'}
- src_multilingual: True
- tgt_multilingual: False
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/sem-eng/opus2m-2020-08-01.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/sem-eng/opus2m-2020-08-01.test.txt
- src_alpha3: sem
- tgt_alpha3: eng
- short_pair: sem-en
- chrF2_score: 0.588
- bleu: 41.7
- brevity_penalty: 0.987
- ref_len: 72950.0
- src_name: Semitic languages
- tgt_name: English
- train_date: 2020-08-01
- src_alpha2: sem
- tgt_alpha2: en
- prefer_old: False
- long_pair: sem-eng
- helsinki_git_sha: 480fcbe0ee1bf4774bcbe6226ad9f58e63f6c535
- transformers_git_sha: 2207e5d8cb224e954a7cba69fa4ac2309e9ff30b
- port_machine: brutasse
- port_time: 2020-08-21-14:41
|
HueyNemud/das22-10-camembert_pretrained
|
a54f5177528f2e319b97b1f3960d0a00fd9e3ef3
|
2022-05-19T12:05:12.000Z
|
[
"pytorch",
"camembert",
"fill-mask",
"transformers",
"generated_from_trainer",
"model-index",
"autotrain_compatible"
] |
fill-mask
| false |
HueyNemud
| null |
HueyNemud/das22-10-camembert_pretrained
| 50 | null |
transformers
| 5,988 |
---
tags:
- generated_from_trainer
model-index:
- name: CamemBERT pretrained on french trade directories from the XIXth century
results: []
---
# CamemBERT pretrained on french trade directories from the XIXth century
This mdoel is part of the material of the paper
> Abadie, N., Carlinet, E., Chazalon, J., Duménieu, B. (2022). A
> Benchmark of Named Entity Recognition Approaches in Historical
> Documents Application to 19𝑡ℎ Century French Directories. In: Uchida,
> S., Barney, E., Eglin, V. (eds) Document Analysis Systems. DAS 2022.
> Lecture Notes in Computer Science, vol 13237. Springer, Cham.
> https://doi.org/10.1007/978-3-031-06555-2_30
The source code to train this model is available on the [GitHub repository](https://github.com/soduco/paper-ner-bench-das22) of the paper as a Jupyter notebook in `src/ner/10-camembert_pretraining.ipynb`.
## Model description
This model pre-train the model [Jean-Baptiste/camembert-ner](https://huggingface.co/Jean-Baptiste/camembert-ner) on a set of ~845k entries from Paris trade directories from the XIXth century extracted with OCR.
Trade directory entries are short and strongly structured texts that giving the name, activity and location of a person or business, e.g:
```
Peynaud, R. de la Vieille Bouclerie, 18. Richard, Joullain et comp., (commission- —Phéâtre Français. naire, (entrepôt), au port de la Rapée-
```
## Intended uses & limitations
This model is intended for reproducibility of the NER evaluation published in the DAS2022 paper.
Several derived models trained for NER on trade directories are available on HuggingFace, each trained on a different dataset :
- [das22-10-camembert_pretrained_finetuned_ref](): trained for NER on ~6000 directory entries manually corrected.
- [das22-10-camembert_pretrained_finetuned_pero](): trained for NER on ~6000 directory entries extracted with PERO-OCR.
- [das22-10-camembert_pretrained_finetuned_tess](): trained for NER on ~6000 directory entries extracted with Tesseract.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:------:|:---------------:|
| 1.9603 | 1.0 | 100346 | 1.8005 |
| 1.7032 | 2.0 | 200692 | 1.6460 |
| 1.5879 | 3.0 | 301038 | 1.5570 |
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.1+cu102
- Datasets 1.17.0
- Tokenizers 0.10.3
|
RJ3vans/13.05.2022.SSCCVspanTagger
|
095f0d0797a201b9e90b4c95d30d2b09770e6608
|
2021-10-28T09:50:19.000Z
|
[
"pytorch",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] |
token-classification
| false |
RJ3vans
| null |
RJ3vans/13.05.2022.SSCCVspanTagger
| 50 | null |
transformers
| 5,989 |
Try the test sentences:
<i>My name is Sarah and I live in London[, which] is the largest city in the UK.</i>
<i>John thought that that was a strange idea.</i>
<i>It was on Tuesdays when Peter took Tess for a walk.</i>
<i>John was so large that he had to crouch to fit through the front door.</i>
The model should tag the tokens in the sentence with information about whether or not they are contained within particular types of syntactic constituents.
If you find the model useful, please cite my thesis which presents the dataset used for finetuning:
Evans, R. (2020) Sentence Simplification for Text Processing. Doctoral thesis. University of Wolverhampton. Wolverhampton, UK. (http://rgcl.wlv.ac.uk/~richard/Evans2020_SentenceSimplificationForTextProcessing.pdf)
There you will find more information about the tagging scheme.
|
apoorvumang/kgt5-wikikg90mv2
|
01c5197af858f32f62522665d2e040d325ea42ce
|
2022-03-22T17:02:33.000Z
|
[
"pytorch",
"tf",
"t5",
"text2text-generation",
"transformers",
"license:mit",
"autotrain_compatible"
] |
text2text-generation
| false |
apoorvumang
| null |
apoorvumang/kgt5-wikikg90mv2
| 50 | null |
transformers
| 5,990 |
---
license: mit
widget:
- text: "Apoorv Umang Saxena| family name"
example_title: "Family name prediction"
- text: "Apoorv Saxena| country"
example_title: "Country prediction"
- text: "World War 2| followed by"
example_title: "followed by"
---
This is a t5-small model trained from scratch on WikiKG90Mv2 dataset. Please see https://github.com/apoorvumang/kgt5/ for more details on the method.
This model was trained on the tail entity prediction task ie. given subject entity and relation, predict the object entity. Input should be provided in the form of "\<entity text\>| \<relation text\>".
We used the raw text title and descriptions to get entity and relation textual representations. These raw texts were obtained from ogb dataset itself (dataset/wikikg90m-v2/mapping/entity.csv and relation.csv). Entity representation was set to the title, and description was used to disambiguate if 2 entities had the same title. If still no disambiguation was possible, we used the wikidata ID (eg. Q123456).
We trained the model on WikiKG90Mv2 for approx 1.5 epochs on 4x1080Ti GPUs. The training time for 1 epoch was approx 5.5 days.
To evaluate the model, we sample 300 times from the decoder for each input (s,r) pair. We then remove predictions which do not map back to a valid entity, and then rank the predictions by their log probabilities. Filtering was performed subsequently. We achieve 0.22 validation MRR (the full leaderboard is here https://ogb.stanford.edu/docs/lsc/leaderboards/#wikikg90mv2)
You can try the following code in an ipython notebook to evaluate the pre-trained model. The full procedure of mapping entity to ids, filtering etc. is not included here for sake of simplicity but can be provided on request if needed. Please contact Apoorv ([email protected]) for clarifications/details.
---------
```
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("apoorvumang/kgt5-wikikg90mv2")
model = AutoModelForSeq2SeqLM.from_pretrained("apoorvumang/kgt5-wikikg90mv2")
```
```
import torch
def getScores(ids, scores, pad_token_id):
"""get sequence scores from model.generate output"""
scores = torch.stack(scores, dim=1)
log_probs = torch.log_softmax(scores, dim=2)
# remove start token
ids = ids[:,1:]
# gather needed probs
x = ids.unsqueeze(-1).expand(log_probs.shape)
needed_logits = torch.gather(log_probs, 2, x)
final_logits = needed_logits[:, :, 0]
padded_mask = (ids == pad_token_id)
final_logits[padded_mask] = 0
final_scores = final_logits.sum(dim=-1)
return final_scores.cpu().detach().numpy()
def topkSample(input, model, tokenizer,
num_samples=5,
num_beams=1,
max_output_length=30):
tokenized = tokenizer(input, return_tensors="pt")
out = model.generate(**tokenized,
do_sample=True,
num_return_sequences = num_samples,
num_beams = num_beams,
eos_token_id = tokenizer.eos_token_id,
pad_token_id = tokenizer.pad_token_id,
output_scores = True,
return_dict_in_generate=True,
max_length=max_output_length,)
out_tokens = out.sequences
out_str = tokenizer.batch_decode(out_tokens, skip_special_tokens=True)
out_scores = getScores(out_tokens, out.scores, tokenizer.pad_token_id)
pair_list = [(x[0], x[1]) for x in zip(out_str, out_scores)]
sorted_pair_list = sorted(pair_list, key=lambda x:x[1], reverse=True)
return sorted_pair_list
def greedyPredict(input, model, tokenizer):
input_ids = tokenizer([input], return_tensors="pt").input_ids
out_tokens = model.generate(input_ids)
out_str = tokenizer.batch_decode(out_tokens, skip_special_tokens=True)
return out_str[0]
```
```
# an example from validation set that the model predicts correctly
# you can try your own examples here. what's your noble title?
input = "Sophie Valdemarsdottir| noble title"
out = topkSample(input, model, tokenizer, num_samples=5)
out
```
You can further load the list of entity aliases, then filter only those predictions which are valid entities then create a reverse mapping from alias -> integer id to get final predictions in required format.
However, loading these aliases in memory as a dictionary requires a lot of RAM + you need to download the aliases file (made available here https://storage.googleapis.com/kgt5-wikikg90mv2/ent_alias_list.pickle) (relation file: https://storage.googleapis.com/kgt5-wikikg90mv2/rel_alias_list.pickle)
The submitted validation/test results for were obtained by sampling 300 times for each input, then applying above procedure, followed by filtering known entities. The final MRR can vary slightly due to this sampling nature (we found that although beam search gives deterministic output, the results are inferior to sampling large number of times).
```
# download valid.txt. you can also try same url with test.txt. however test does not contain the correct tails
!wget https://storage.googleapis.com/kgt5-wikikg90mv2/valid.txt
```
```
fname = 'valid.txt'
valid_lines = []
f = open(fname)
for line in f:
valid_lines.append(line.rstrip())
f.close()
print(valid_lines[0])
```
```
from tqdm.auto import tqdm
# try unfiltered hits@k. this is approximation since model can sample same seq multiple times
# you should run this on gpu if you want to evaluate on all points with 300 samples each
k = 1
count_at_k = 0
max_predictions = k
max_points = 1000
for line in tqdm(valid_lines[:max_points]):
input, target = line.split('\t')
model_output = topkSample(input, model, tokenizer, num_samples=max_predictions)
prediction_strings = [x[0] for x in model_output]
if target in prediction_strings:
count_at_k += 1
print('Hits at {0} unfiltered: {1}'.format(k, count_at_k/max_points))
```
|
asafaya/hubert-large-arabic-ft
|
76875c200def77031c77363973258f1b49925cb3
|
2022-03-26T15:25:10.000Z
|
[
"hubert",
"feature-extraction",
"ar",
"dataset:commonvoice",
"arxiv:2106.07447",
"speechbrain",
"CTC",
"Attention",
"pytorch",
"Transformer",
"hf-asr-leaderboard",
"license:cc-by-nc-4.0",
"automatic-speech-recognition",
"model-index"
] |
automatic-speech-recognition
| false |
asafaya
| null |
asafaya/hubert-large-arabic-ft
| 50 | 1 |
speechbrain
| 5,991 |
---
language: "ar"
pipeline_tag: automatic-speech-recognition
tags:
- CTC
- Attention
- pytorch
- speechbrain
- Transformer
- hf-asr-leaderboard
license: "cc-by-nc-4.0"
datasets:
- commonvoice
metrics:
- wer
- cer
model-index:
- name: asafaya/hubert-large-arabic-ft
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 8.0 ar
type: common_voice
args: ar
metrics:
- name: Test WER
type: wer
value: 17.68
- name: Test CER
type: cer
value: 5.49
- name: Validation WER
type: wer
value: 10.93
- name: Validation CER
type: cer
value: 3.13
---
# Arabic Hubert-Large - with CTC fine-tuned on Common Voice 8.0 (No LM)
This model is a fine-tuned version of [Arabic Hubert-Large](https://huggingface.co/asafaya/hubert-large-arabic). We finetuned this model on the Arabic CommonVoice dataset, acheiving a state of the art for commonvoice arabic test set WER of `17.68%` and CER of `5.49%`.
The original model was pre-trained on 2,000 hours of 16kHz sampled Arabic speech audio. When using the model make sure that your speech input is also sampled at 16Khz, see the original [paper](https://arxiv.org/abs/2106.07447) for more details on the model.
The performance of the model on CommonVoice Arabic 8.0 is the following:
| Valid WER | Valid CER | Test WER | Test CER |
|:---------:|:---------:|:--------:|:--------:|
| 10.93 | 3.13 | 17.68 | 5.49 |
This model is trained using [SpeechBrain](https://speechbrain.github.io).
# Usage
You can try the model using SpeechBrain as follows:
Install SpeechBrain and Transformers:
```
pip install speechbrain transformers
```
Then run the following code:
```python
from speechbrain.pretrained import EncoderASR
asr_model = EncoderASR.from_hparams(source="asafaya/hubert-large-arabic-ft", savedir="pretrained_models/asafaya/hubert-large-arabic-ft")
print(asr_model.transcribe_file("pretrained_models/asafaya/hubert-large-arabic-ft/example.wav"))
> وصلوا واحدا خلف الآخر
```
More about [SpeechBrain](https://speechbrain.github.io).
# License
This work is licensed under [CC BY-NC-4.0](https://creativecommons.org/licenses/by-nc/4.0/legalcode).
# Citation
# Acknowledgement
Model fine-tuning and data processing for in this work were performed at [KUACC](ai.ku.edu.tr/) Cluster.
|
blizrys/distilbert-base-uncased-finetuned-mnli
|
1722a09d8351d49906bf2fceaaee4eac2b7c0f0c
|
2021-09-11T19:31:42.000Z
|
[
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] |
text-classification
| false |
blizrys
| null |
blizrys/distilbert-base-uncased-finetuned-mnli
| 50 | null |
transformers
| 5,992 |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-mnli
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: mnli
metrics:
- name: Accuracy
type: accuracy
value: 0.8205807437595517
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-mnli
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6753
- Accuracy: 0.8206
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:------:|:---------------:|:--------:|
| 0.5146 | 1.0 | 24544 | 0.4925 | 0.8049 |
| 0.4093 | 2.0 | 49088 | 0.5090 | 0.8164 |
| 0.3122 | 3.0 | 73632 | 0.5299 | 0.8185 |
| 0.2286 | 4.0 | 98176 | 0.6753 | 0.8206 |
| 0.182 | 5.0 | 122720 | 0.8372 | 0.8195 |
### Framework versions
- Transformers 4.10.2
- Pytorch 1.9.0+cu102
- Datasets 1.11.0
- Tokenizers 0.10.3
|
csatapathy/interview-ratings-bert
|
6e138bfae1be2a716a8b5fa732714478ecaf3469
|
2021-05-19T14:33:34.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"text-classification",
"transformers"
] |
text-classification
| false |
csatapathy
| null |
csatapathy/interview-ratings-bert
| 50 | null |
transformers
| 5,993 |
Entry not found
|
flax-community/gpt2-small-indonesian
|
a635ebaa0dc3bfe76071a74e6e1581428378533e
|
2021-09-02T12:26:52.000Z
|
[
"pytorch",
"jax",
"tensorboard",
"gpt2",
"text-generation",
"id",
"transformers"
] |
text-generation
| false |
flax-community
| null |
flax-community/gpt2-small-indonesian
| 50 | 2 |
transformers
| 5,994 |
---
language: id
widget:
- text: "Sewindu sudah kita tak berjumpa, rinduku padamu sudah tak terkira."
---
# GPT2-small-indonesian
This is a pretrained model on Indonesian language using a causal language modeling (CLM) objective, which was first
introduced in [this paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)
and first released at [this page](https://openai.com/blog/better-language-models/).
This model was trained using HuggingFace's Flax framework and is part of the [JAX/Flax Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104)
organized by [HuggingFace](https://huggingface.co). All training was done on a TPUv3-8 VM sponsored by the Google Cloud team.
The demo can be found [here](https://huggingface.co/spaces/flax-community/gpt2-indonesian).
## How to use
You can use this model directly with a pipeline for text generation. Since the generation relies on some randomness,
we set a seed for reproducibility:
```python
>>> from transformers import pipeline, set_seed
>>> generator = pipeline('text-generation', model='flax-community/gpt2-small-indonesian')
>>> set_seed(42)
>>> generator("Sewindu sudah kita tak berjumpa,", max_length=30, num_return_sequences=5)
[{'generated_text': 'Sewindu sudah kita tak berjumpa, dua dekade lalu, saya hanya bertemu sekali. Entah mengapa, saya lebih nyaman berbicara dalam bahasa Indonesia, bahasa Indonesia'},
{'generated_text': 'Sewindu sudah kita tak berjumpa, tapi dalam dua hari ini, kita bisa saja bertemu.”\
“Kau tau, bagaimana dulu kita bertemu?” aku'},
{'generated_text': 'Sewindu sudah kita tak berjumpa, banyak kisah yang tersimpan. Tak mudah tuk kembali ke pelukan, di mana kini kita berada, sebuah tempat yang jauh'},
{'generated_text': 'Sewindu sudah kita tak berjumpa, sejak aku lulus kampus di Bandung, aku sempat mencari kabar tentangmu. Ah, masih ada tempat di hatiku,'},
{'generated_text': 'Sewindu sudah kita tak berjumpa, tapi Tuhan masih saja menyukarkan doa kita masing-masing.\
Tuhan akan memberi lebih dari apa yang kita'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import GPT2Tokenizer, GPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('flax-community/gpt2-small-indonesian')
model = GPT2Model.from_pretrained('flax-community/gpt2-small-indonesian')
text = "Ubah dengan teks apa saja."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
and in TensorFlow:
```python
from transformers import GPT2Tokenizer, TFGPT2Model
tokenizer = GPT2Tokenizer.from_pretrained('flax-community/gpt2-small-indonesian')
model = TFGPT2Model.from_pretrained('flax-community/gpt2-small-indonesian')
text = "Ubah dengan teks apa saja."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
## Limitations and bias
The training data used for this model are Indonesian websites of [OSCAR](https://oscar-corpus.com/),
[mc4](https://huggingface.co/datasets/mc4) and [Wikipedia](https://huggingface.co/datasets/wikipedia). The datasets
contain a lot of unfiltered content from the internet, which is far from neutral. While we have done some filtering on
the dataset (see the **Training data** section), the filtering is by no means a thorough mitigation of biased content
that is eventually used by the training data. These biases might also affect models that are fine-tuned using this model.
As the openAI team themselves point out in their [model card](https://github.com/openai/gpt-2/blob/master/model_card.md#out-of-scope-use-cases):
> Because large-scale language models like GPT-2 do not distinguish fact from fiction, we don’t support use-cases
> that require the generated text to be true.
> Additionally, language models like GPT-2 reflect the biases inherent to the systems they were trained on, so we
> do not recommend that they be deployed into systems that interact with humans > unless the deployers first carry
> out a study of biases relevant to the intended use-case. We found no statistically significant difference in gender,
> race, and religious bias probes between 774M and 1.5B, implying all versions of GPT-2 should be approached with
> similar levels of caution around use cases that are sensitive to biases around human attributes.
We have done a basic bias analysis that you can find in this [notebook](https://huggingface.co/flax-community/gpt2-small-indonesian/blob/main/bias_analysis/gpt2_medium_indonesian_bias_analysis.ipynb), performed on [Indonesian GPT2 medium](https://huggingface.co/flax-community/gpt2-medium-indonesian), based on the bias analysis for [Polish GPT2](https://huggingface.co/flax-community/papuGaPT2) with modifications.
### Gender bias
We generated 50 texts starting with prompts "She/He works as". After doing some preprocessing (lowercase and stopwords removal) we obtain texts that are used to generate word clouds of female/male professions. The most salient terms for male professions are: driver, sopir (driver), ojek, tukang, online.

The most salient terms for female professions are: pegawai (employee), konsultan (consultant), asisten (assistant).

### Ethnicity bias
We generated 1,200 texts to assess bias across ethnicity and gender vectors. We will create prompts with the following scheme:
* Person - we will assess 5 ethnicities: Sunda, Batak, Minahasa, Dayak, Asmat, Neutral (no ethnicity)
* Topic - we will use 5 different topics:
* random act: *entered home*
* said: *said*
* works as: *works as*
* intent: *let [person] ...*
* define: *is*
Sample of generated prompt: "seorang perempuan sunda masuk ke rumah..." (a Sundanese woman enters the house...)
We used a [model](https://huggingface.co/Hate-speech-CNERG/dehatebert-mono-indonesian) trained on Indonesian hate speech corpus ([dataset 1](https://github.com/okkyibrohim/id-multi-label-hate-speech-and-abusive-language-detection), [dataset 2](https://github.com/ialfina/id-hatespeech-detection)) to obtain the probability that each generated text contains hate speech. To avoid leakage, we removed the first word identifying the ethnicity and gender from the generated text before running the hate speech detector.
The following chart demonstrates the intensity of hate speech associated with the generated texts with outlier scores removed. Some ethnicities score higher than the neutral baseline.

### Religion bias
With the same methodology above, we generated 1,400 texts to assess bias across religion and gender vectors. We will assess 6 religions: Islam, Protestan (Protestant), Katolik (Catholic), Buddha (Buddhism), Hindu (Hinduism), and Khonghucu (Confucianism) with Neutral (no religion) as a baseline.
The following chart demonstrates the intensity of hate speech associated with the generated texts with outlier scores removed. Some religions score higher than the neutral baseline.

## Training data
The model was trained on a combined dataset of [OSCAR](https://oscar-corpus.com/), [mc4](https://huggingface.co/datasets/mc4)
and Wikipedia for the Indonesian language. We have filtered and reduced the mc4 dataset so that we end up with 29 GB
of data in total. The mc4 dataset was cleaned using [this filtering script](https://github.com/Wikidepia/indonesian_datasets/blob/master/dump/mc4/cleanup.py)
and we also only included links that have been cited by the Indonesian Wikipedia.
## Training procedure
The model was trained on a TPUv3-8 VM provided by the Google Cloud team. The training duration was `4d 14h 50m 47s`.
### Evaluation results
The model achieves the following results without any fine-tuning (zero-shot):
| dataset | train loss | eval loss | eval perplexity |
| ---------- | ---------- | -------------- | ---------- |
| ID OSCAR+mc4+wikipedia (29GB) | 3.046 | 2.926 | 18.66 |
### Tracking
The training process was tracked in [TensorBoard](https://huggingface.co/flax-community/gpt2-small-indonesian/tensorboard) and [Weights and Biases](https://wandb.ai/wandb/hf-flax-gpt2-indonesian?workspace=user-cahya).
## Team members
- Akmal ([@Wikidepia](https://huggingface.co/Wikidepia))
- alvinwatner ([@alvinwatner](https://huggingface.co/alvinwatner))
- Cahya Wirawan ([@cahya](https://huggingface.co/cahya))
- Galuh Sahid ([@Galuh](https://huggingface.co/Galuh))
- Muhammad Agung Hambali ([@AyameRushia](https://huggingface.co/AyameRushia))
- Muhammad Fhadli ([@muhammadfhadli](https://huggingface.co/muhammadfhadli))
- Samsul Rahmadani ([@munggok](https://huggingface.co/munggok))
## Future work
We would like to pre-train further the models with larger and cleaner datasets and fine-tune it to specific domains
if we can get the necessary hardware resources.
|
huggingartists/ariana-grande
|
9b31d93bb4ea82e4f0fdb1b553bb04ce58ec4624
|
2021-09-19T02:10:10.000Z
|
[
"pytorch",
"jax",
"gpt2",
"text-generation",
"en",
"dataset:huggingartists/ariana-grande",
"transformers",
"huggingartists",
"lyrics",
"lm-head",
"causal-lm"
] |
text-generation
| false |
huggingartists
| null |
huggingartists/ariana-grande
| 50 | null |
transformers
| 5,995 |
---
language: en
datasets:
- huggingartists/ariana-grande
tags:
- huggingartists
- lyrics
- lm-head
- causal-lm
widget:
- text: "I am"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:DISPLAY_1; margin-left: auto; margin-right: auto; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://images.genius.com/d36a47955ac0ddb12748c5e7c2bd4b4b.640x640x1.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 HuggingArtists Model 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Ariana Grande</div>
<a href="https://genius.com/artists/ariana-grande">
<div style="text-align: center; font-size: 14px;">@ariana-grande</div>
</a>
</div>
I was made with [huggingartists](https://github.com/AlekseyKorshuk/huggingartists).
Create your own bot based on your favorite artist with [the demo](https://colab.research.google.com/github/AlekseyKorshuk/huggingartists/blob/master/huggingartists-demo.ipynb)!
## How does it work?
To understand how the model was developed, check the [W&B report](https://wandb.ai/huggingartists/huggingartists/reportlist).
## Training data
The model was trained on lyrics from Ariana Grande.
Dataset is available [here](https://huggingface.co/datasets/huggingartists/ariana-grande).
And can be used with:
```python
from datasets import load_dataset
dataset = load_dataset("huggingartists/ariana-grande")
```
[Explore the data](https://wandb.ai/huggingartists/huggingartists/runs/2nfg7v7i/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on Ariana Grande's lyrics.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/huggingartists/huggingartists/runs/3u3sn1bx) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/huggingartists/huggingartists/runs/3u3sn1bx/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingartists/ariana-grande')
generator("I am", num_return_sequences=5)
```
Or with Transformers library:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("huggingartists/ariana-grande")
model = AutoModelWithLMHead.from_pretrained("huggingartists/ariana-grande")
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Aleksey Korshuk*
[](https://github.com/AlekseyKorshuk)
[](https://twitter.com/intent/follow?screen_name=alekseykorshuk)
[](https://t.me/joinchat/_CQ04KjcJ-4yZTky)
For more details, visit the project repository.
[](https://github.com/AlekseyKorshuk/huggingartists)
|
huggingtweets/emailoctopus
|
1b0f6f50bf9a4d272fe30663749d81519cf1b5ee
|
2021-05-22T03:00:30.000Z
|
[
"pytorch",
"jax",
"gpt2",
"text-generation",
"en",
"transformers",
"huggingtweets"
] |
text-generation
| false |
huggingtweets
| null |
huggingtweets/emailoctopus
| 50 | null |
transformers
| 5,996 |
---
language: en
thumbnail: https://github.com/borisdayma/huggingtweets/blob/master/img/logo.png?raw=true
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<link rel="stylesheet" href="https://unpkg.com/@tailwindcss/[email protected]/dist/typography.min.css">
<style>
@media (prefers-color-scheme: dark) {
.prose { color: #E2E8F0 !important; }
.prose h2, .prose h3, .prose a, .prose thead { color: #F7FAFC !important; }
}
</style>
<section class='prose'>
<div>
<div style="width: 132px; height:132px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1323402841596305408/KLR3mtk8_400x400.jpg')">
</div>
<div style="margin-top: 8px; font-size: 19px; font-weight: 800">EmailOctopus 🤖 AI Bot </div>
<div style="font-size: 15px; color: #657786">@emailoctopus bot</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://app.wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-model-to-generate-tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on [@emailoctopus's tweets](https://twitter.com/emailoctopus).
<table style='border-width:0'>
<thead style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #CBD5E0'>
<th style='border-width:0'>Data</th>
<th style='border-width:0'>Quantity</th>
</tr>
</thead>
<tbody style='border-width:0'>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Tweets downloaded</td>
<td style='border-width:0'>2238</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Retweets</td>
<td style='border-width:0'>415</td>
</tr>
<tr style='border-width:0 0 1px 0; border-color: #E2E8F0'>
<td style='border-width:0'>Short tweets</td>
<td style='border-width:0'>100</td>
</tr>
<tr style='border-width:0'>
<td style='border-width:0'>Tweets kept</td>
<td style='border-width:0'>1723</td>
</tr>
</tbody>
</table>
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3cty91ha/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @emailoctopus's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/3f0s4i3n) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/3f0s4i3n/artifacts) is logged and versioned.
## Intended uses & limitations
### How to use
You can use this model directly with a pipeline for text generation:
<pre><code><span style="color:#03A9F4">from</span> transformers <span style="color:#03A9F4">import</span> pipeline
generator = pipeline(<span style="color:#FF9800">'text-generation'</span>,
model=<span style="color:#FF9800">'huggingtweets/emailoctopus'</span>)
generator(<span style="color:#FF9800">"My dream is"</span>, num_return_sequences=<span style="color:#8BC34A">5</span>)</code></pre>
### Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
</section>
[](https://twitter.com/intent/follow?screen_name=borisdayma)
<section class='prose'>
For more details, visit the project repository.
</section>
[](https://github.com/borisdayma/huggingtweets)
|
iamalpharius/GPT-Small-BenderBot
|
6092a5fcd20be607f69bd65a4a9b00fcd85063e0
|
2021-10-14T12:47:24.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
iamalpharius
| null |
iamalpharius/GPT-Small-BenderBot
| 50 | null |
transformers
| 5,997 |
---
tags:
- conversational
---
# Bender DialoGPT model
|
julien-c/EsperBERTo-small
|
2439f60ef33a0d46d85da5001d52aeda5b00ce9f
|
2021-05-20T17:29:32.000Z
|
[
"pytorch",
"jax",
"roberta",
"fill-mask",
"eo",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
julien-c
| null |
julien-c/EsperBERTo-small
| 50 | 2 |
transformers
| 5,998 |
---
language: eo
thumbnail: https://huggingface.co/blog/assets/01_how-to-train/EsperBERTo-thumbnail-v2.png
widget:
- text: "Jen la komenco de bela <mask>."
- text: "Uno du <mask>"
- text: "Jen finiĝas bela <mask>."
---
# EsperBERTo: RoBERTa-like Language model trained on Esperanto
**Companion model to blog post https://huggingface.co/blog/how-to-train** 🔥
## Training Details
- current checkpoint: 566000
- machine name: `galinette`

## Example pipeline
```python
from transformers import pipeline
fill_mask = pipeline(
"fill-mask",
model="julien-c/EsperBERTo-small",
tokenizer="julien-c/EsperBERTo-small"
)
fill_mask("Jen la komenco de bela <mask>.")
# This is the beginning of a beautiful <mask>.
# =>
# {
# 'score':0.06502299010753632
# 'sequence':'<s> Jen la komenco de bela vivo.</s>'
# 'token':1099
# }
# {
# 'score':0.0421181358397007
# 'sequence':'<s> Jen la komenco de bela vespero.</s>'
# 'token':5100
# }
# {
# 'score':0.024884626269340515
# 'sequence':'<s> Jen la komenco de bela laboro.</s>'
# 'token':1570
# }
# {
# 'score':0.02324388362467289
# 'sequence':'<s> Jen la komenco de bela tago.</s>'
# 'token':1688
# }
# {
# 'score':0.020378097891807556
# 'sequence':'<s> Jen la komenco de bela festo.</s>'
# 'token':4580
# }
```
|
julien-c/distilbert-sagemaker-1609802168
|
574fad7897a3379b995bfe9b0a8791dd1a857e58
|
2022-07-18T20:05:27.000Z
|
[
"pytorch",
"distilbert",
"text-classification",
"dataset:imdb",
"transformers",
"sagemaker"
] |
text-classification
| false |
julien-c
| null |
julien-c/distilbert-sagemaker-1609802168
| 50 | null |
transformers
| 5,999 |
---
tags:
- sagemaker
datasets:
- imdb
---
## distilbert-sagemaker-1609802168
Trained from SageMaker HuggingFace extension.
Fine-tuned from [distilbert-base-uncased](/distilbert-base-uncased) on [imdb](/datasets/imdb) 🔥
#### Eval
| key | value |
| --- | ----- |
| eval_loss | 0.19187863171100616 |
| eval_accuracy | 0.9259 |
| eval_f1 | 0.9272173656811707 |
| eval_precision | 0.9147286821705426 |
| eval_recall | 0.9400517825134436 |
| epoch | 1.0 |
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.