
modelId
stringlengths 4
112
| sha
stringlengths 40
40
| lastModified
stringlengths 24
24
| tags
list | pipeline_tag
stringclasses 29
values | private
bool 1
class | author
stringlengths 2
38
⌀ | config
null | id
stringlengths 4
112
| downloads
float64 0
36.8M
⌀ | likes
float64 0
712
⌀ | library_name
stringclasses 17
values | __index_level_0__
int64 0
38.5k
| readme
stringlengths 0
186k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Shushant/nepaliBERT
|
7756f55f1a3baf78954db166fc4a5f72d2dd223f
|
2021-12-30T10:50:41.000Z
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
Shushant
| null |
Shushant/nepaliBERT
| 220 | 1 |
transformers
| 3,500 |
# Masked Language Model for nepali language trained on nepali news scrapped from different nepali news website. The data set contained about 10 million of nepali sentences mainly related to nepali news.
Usage
```
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("Shushant/nepaliBERT")
model = AutoModelForMaskedLM.from_pretrained("Shushant/nepaliBERT")
from transformers import pipeline
fill_mask = pipeline( "fill-mask", model=model, tokenizer=tokenizer, )
from pprint import pprint pprint(fill_mask(f"तिमीलाई कस्तो {tokenizer.mask_token}."))
```
## Data Description
Trained on about 4.6 GB of Nepali text corpus collected from various sources
These data were collected from nepali news site, OSCAR nepali corpus
|
salti/xlm-roberta-large-arabic_qa
|
9b67103437243acee1496171e03c470b07003b44
|
2020-08-16T06:11:43.000Z
|
[
"pytorch",
"xlm-roberta",
"question-answering",
"transformers",
"autotrain_compatible"
] |
question-answering
| false |
salti
| null |
salti/xlm-roberta-large-arabic_qa
| 220 | 1 |
transformers
| 3,501 |
Entry not found
|
sentence-transformers/gtr-t5-base
|
967b0854e46f8d3a0d42429301397715821a682f
|
2022-02-09T12:27:26.000Z
|
[
"pytorch",
"t5",
"en",
"arxiv:2112.07899",
"sentence-transformers",
"feature-extraction",
"sentence-similarity",
"transformers",
"license:apache-2.0"
] |
sentence-similarity
| false |
sentence-transformers
| null |
sentence-transformers/gtr-t5-base
| 220 | null |
sentence-transformers
| 3,502 |
---
pipeline_tag: sentence-similarity
language: en
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# sentence-transformers/gtr-t5-base
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space. The model was specifically trained for the task of sematic search.
This model was converted from the Tensorflow model [gtr-base-1](https://tfhub.dev/google/gtr/gtr-base/1) to PyTorch. When using this model, have a look at the publication: [Large Dual Encoders Are Generalizable Retrievers](https://arxiv.org/abs/2112.07899). The tfhub model and this PyTorch model can produce slightly different embeddings, however, when run on the same benchmarks, they produce identical results.
The model uses only the encoder from a T5-base model. The weights are stored in FP16.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('sentence-transformers/gtr-t5-base')
embeddings = model.encode(sentences)
print(embeddings)
```
The model requires sentence-transformers version 2.2.0 or newer.
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=sentence-transformers/gtr-t5-base)
## Citing & Authors
If you find this model helpful, please cite the respective publication:
[Large Dual Encoders Are Generalizable Retrievers](https://arxiv.org/abs/2112.07899)
|
okwach/mawaidhaChatbot2
|
ec5c5a7df9a91cc0b3b3c3bc8d036bb1c6ccce21
|
2022-05-20T00:32:11.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
okwach
| null |
okwach/mawaidhaChatbot2
| 220 | null |
transformers
| 3,503 |
---
tags:
- conversational
---
# mawaidhaChatbot Model
|
romainlhardy/t5-small-booksum
|
6e3603147c20f9e14818b881b623b287bb13d1b4
|
2022-07-04T08:24:36.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] |
text2text-generation
| false |
romainlhardy
| null |
romainlhardy/t5-small-booksum
| 220 | null |
transformers
| 3,504 |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: t5-small-booksum
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-booksum
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.1700
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 3.3266 | 1.0 | 29228 | 3.1859 |
| 3.2947 | 2.0 | 58456 | 3.1700 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.2+cu113
- Datasets 1.18.4
- Tokenizers 0.12.1
|
CAMeL-Lab/bert-base-arabic-camelbert-msa-sentiment
|
d383f6d3a1fd2aa63c99186b0155ed4258eb512f
|
2021-10-17T12:08:30.000Z
|
[
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] |
text-classification
| false |
CAMeL-Lab
| null |
CAMeL-Lab/bert-base-arabic-camelbert-msa-sentiment
| 219 | 2 |
transformers
| 3,505 |
---
language:
- ar
license: apache-2.0
widget:
- text: "أنا بخير"
---
# CAMeLBERT MSA SA Model
## Model description
**CAMeLBERT MSA SA Model** is a Sentiment Analysis (SA) model that was built by fine-tuning the [CAMeLBERT Modern Standard Arabic (MSA)](https://huggingface.co/CAMeL-Lab/bert-base-arabic-camelbert-msa/) model.
For the fine-tuning, we used the [ASTD](https://aclanthology.org/D15-1299.pdf), [ArSAS](http://lrec-conf.org/workshops/lrec2018/W30/pdf/22_W30.pdf), and [SemEval](https://aclanthology.org/S17-2088.pdf) datasets.
Our fine-tuning procedure and the hyperparameters we used can be found in our paper *"[The Interplay of Variant, Size, and Task Type in Arabic Pre-trained Language Models](https://arxiv.org/abs/2103.06678)."* Our fine-tuning code can be found [here](https://github.com/CAMeL-Lab/CAMeLBERT).
## Intended uses
You can use the CAMeLBERT MSA SA model directly as part of our [CAMeL Tools](https://github.com/CAMeL-Lab/camel_tools) SA component (*recommended*) or as part of the transformers pipeline.
#### How to use
To use the model with the [CAMeL Tools](https://github.com/CAMeL-Lab/camel_tools) SA component:
```python
>>> from camel_tools.sentiment import SentimentAnalyzer
>>> sa = SentimentAnalyzer("CAMeL-Lab/bert-base-arabic-camelbert-msa-sentiment")
>>> sentences = ['أنا بخير', 'أنا لست بخير']
>>> sa.predict(sentences)
>>> ['positive', 'negative']
```
You can also use the SA model directly with a transformers pipeline:
```python
>>> from transformers import pipeline
>>> sa = pipeline('sentiment-analysis', model='CAMeL-Lab/bert-base-arabic-camelbert-msa-sentiment')
>>> sentences = ['أنا بخير', 'أنا لست بخير']
>>> sa(sentences)
[{'label': 'positive', 'score': 0.9616648554801941},
{'label': 'negative', 'score': 0.9779177904129028}]
```
*Note*: to download our models, you would need `transformers>=3.5.0`.
Otherwise, you could download the models manually.
## Citation
```bibtex
@inproceedings{inoue-etal-2021-interplay,
title = "The Interplay of Variant, Size, and Task Type in {A}rabic Pre-trained Language Models",
author = "Inoue, Go and
Alhafni, Bashar and
Baimukan, Nurpeiis and
Bouamor, Houda and
Habash, Nizar",
booktitle = "Proceedings of the Sixth Arabic Natural Language Processing Workshop",
month = apr,
year = "2021",
address = "Kyiv, Ukraine (Online)",
publisher = "Association for Computational Linguistics",
abstract = "In this paper, we explore the effects of language variants, data sizes, and fine-tuning task types in Arabic pre-trained language models. To do so, we build three pre-trained language models across three variants of Arabic: Modern Standard Arabic (MSA), dialectal Arabic, and classical Arabic, in addition to a fourth language model which is pre-trained on a mix of the three. We also examine the importance of pre-training data size by building additional models that are pre-trained on a scaled-down set of the MSA variant. We compare our different models to each other, as well as to eight publicly available models by fine-tuning them on five NLP tasks spanning 12 datasets. Our results suggest that the variant proximity of pre-training data to fine-tuning data is more important than the pre-training data size. We exploit this insight in defining an optimized system selection model for the studied tasks.",
}
```
|
Plencers/DialoGPT-small-homer
|
7b3aff837e30d8f7b917b81f08f25875f96b246f
|
2021-08-28T07:37:46.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
Plencers
| null |
Plencers/DialoGPT-small-homer
| 219 | null |
transformers
| 3,506 |
---
tags:
- conversational
---
#Homer DialoGPT Model
|
madhurjindal/autonlp-Gibberish-Detector-492513457
|
db6c021260b82f42ba81a4e48dc2906ca8ba25c8
|
2022-01-12T10:42:19.000Z
|
[
"pytorch",
"distilbert",
"text-classification",
"en",
"dataset:madhurjindal/autonlp-data-Gibberish-Detector",
"transformers",
"autonlp",
"co2_eq_emissions"
] |
text-classification
| false |
madhurjindal
| null |
madhurjindal/autonlp-Gibberish-Detector-492513457
| 219 | 1 |
transformers
| 3,507 |
---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- madhurjindal/autonlp-data-Gibberish-Detector
co2_eq_emissions: 5.527544460835904
---
# Model Trained Using AutoNLP
- Problem type: Multi-class Classification
- Model ID: 492513457
- CO2 Emissions (in grams): 5.527544460835904
## Validation Metrics
- Loss: 0.07609463483095169
- Accuracy: 0.9735624586913417
- Macro F1: 0.9736173135739408
- Micro F1: 0.9735624586913417
- Weighted F1: 0.9736173135739408
- Macro Precision: 0.9737771415197378
- Micro Precision: 0.9735624586913417
- Weighted Precision: 0.9737771415197378
- Macro Recall: 0.9735624586913417
- Micro Recall: 0.9735624586913417
- Weighted Recall: 0.9735624586913417
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/madhurjindal/autonlp-Gibberish-Detector-492513457
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("madhurjindal/autonlp-Gibberish-Detector-492513457", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("madhurjindal/autonlp-Gibberish-Detector-492513457", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
```
|
mikabeebee/Peterbot
|
c24f8b63211f7098bf9761d27bfacbb55783cba8
|
2022-02-26T16:56:05.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
mikabeebee
| null |
mikabeebee/Peterbot
| 219 | null |
transformers
| 3,508 |
---
tags:
- conversational
---
# Peter from Your Boyfriend Game.
|
ChrisUPM/BioBERT_Re_trained
|
8e39448c5a6a226656f3872407286051bcda1307
|
2022-06-15T11:10:39.000Z
|
[
"pytorch",
"bert",
"text-classification",
"transformers"
] |
text-classification
| false |
ChrisUPM
| null |
ChrisUPM/BioBERT_Re_trained
| 219 | null |
transformers
| 3,509 |
PyTorch trained model on GAD dataset for relation classification, using BioBert weights.
|
laituan245/molt5-small
|
f3c5e3abbb55561901cadb09f798b70c8eba102e
|
2022-05-03T18:07:24.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"arxiv:2204.11817",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
text2text-generation
| false |
laituan245
| null |
laituan245/molt5-small
| 219 | 1 |
transformers
| 3,510 |
---
license: apache-2.0
---
## Example Usage
```python
from transformers import AutoTokenizer, T5ForConditionalGeneration
tokenizer = AutoTokenizer.from_pretrained("laituan245/molt5-small", model_max_length=512)
model = T5ForConditionalGeneration.from_pretrained('laituan245/molt5-small')
```
## Paper
For more information, please take a look at our paper.
Paper: [Translation between Molecules and Natural Language](https://arxiv.org/abs/2204.11817)
Authors: *Carl Edwards\*, Tuan Lai\*, Kevin Ros, Garrett Honke, Heng Ji*
|
Browbon/DialoGPT-medium-LucaChangretta
|
5842d11f7a2b77521cc5867ad973c2a1d8f0b8d3
|
2022-06-15T07:51:32.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
Browbon
| null |
Browbon/DialoGPT-medium-LucaChangretta
| 219 | null |
transformers
| 3,511 |
---
tags:
- conversational
---
# LucaChangretta DialoGPT Model
|
crystallyzing/DialoGPT-small-kiryu
|
49f8a05c3be7578bdc4cf46456449c19cce81917
|
2022-06-20T23:53:27.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
crystallyzing
| null |
crystallyzing/DialoGPT-small-kiryu
| 219 | null |
transformers
| 3,512 |
---
tags:
- conversational
---
# Kiryu Chatbot Model
|
ZeyadAhmed/AraElectra-Arabic-SQuADv2-QA
|
039af903dd4c78cfe36b87fc4115d4dfdfcc971a
|
2022-07-04T15:34:40.000Z
|
[
"pytorch",
"electra",
"question-answering",
"ar",
"dataset:ZeyadAhmed/Arabic-SQuADv2.0",
"transformers",
"autotrain_compatible"
] |
question-answering
| false |
ZeyadAhmed
| null |
ZeyadAhmed/AraElectra-Arabic-SQuADv2-QA
| 219 | null |
transformers
| 3,513 |
---
datasets:
- ZeyadAhmed/Arabic-SQuADv2.0
language:
- ar
metrics:
-
name: exact_match
type: exact_match
value: 65.12
-
name: F1
type: f1
value: 71.49
---
# AraElectra for Question Answering on Arabic-SQuADv2
This is the [AraElectra](https://huggingface.co/aubmindlab/araelectra-base-discriminator) model, fine-tuned using the [Arabic-SQuADv2.0](https://huggingface.co/datasets/ZeyadAhmed/Arabic-SQuADv2.0) dataset. It's been trained on question-answer pairs, including unanswerable questions, for the task of Question Answering. with help of [AraElectra Classifier](https://huggingface.co/ZeyadAhmed/AraElectra-Arabic-SQuADv2-CLS) to predicted unanswerable question.
## Overview
**Language model:** AraElectra <br>
**Language:** Arabic <br>
**Downstream-task:** Extractive QA
**Training data:** Arabic-SQuADv2.0
**Eval data:** Arabic-SQuADv2.0 <br>
**Test data:** Arabic-SQuADv2.0 <br>
**Code:** [See More Info on Github](https://github.com/zeyadahmed10/Arabic-MRC)
**Infrastructure**: 1x Tesla K80
## Hyperparameters
```
batch_size = 8
n_epochs = 4
base_LM_model = "AraElectra"
learning_rate = 3e-5
optimizer = AdamW
padding = dynamic
```
## Online Demo on Arabic Wikipedia and User Provided Contexts
See model in action hosted on streamlit [](https://share.streamlit.io/wissamantoun/arabic-wikipedia-qa-streamlit/main)
## Usage
For best results use the AraBert [preprocessor](https://github.com/aub-mind/arabert/blob/master/preprocess.py) by aub-mind
```python
from transformers import ElectraForQuestionAnswering, ElectraForSequenceClassification, AutoTokenizer, pipeline
from preprocess import ArabertPreprocessor
prep_object = ArabertPreprocessor("araelectra-base-discriminator")
question = prep_object('ما هي جامعة الدول العربية ؟')
context = prep_object('''
جامعة الدول العربية هيمنظمة إقليمية تضم دولاً عربية في آسيا وأفريقيا.
ينص ميثاقها على التنسيق بين الدول الأعضاء في الشؤون الاقتصادية، ومن ضمنها العلاقات التجارية الاتصالات، العلاقات الثقافية، الجنسيات ووثائق وأذونات السفر والعلاقات الاجتماعية والصحة. المقر الدائم لجامعة الدول العربية يقع في القاهرة، عاصمة مصر (تونس من 1979 إلى 1990).
''')
# a) Get predictions
qa_modelname = 'ZeyadAhmed/AraElectra-Arabic-SQuADv2-QA'
cls_modelname = 'ZeyadAhmed/AraElectra-Arabic-SQuADv2-CLS'
qa_pipe = pipeline('question-answering', model=qa_modelname, tokenizer=qa_modelname)
QA_input = {
'question': question,
'context': context
}
CLS_input = {
'text': question,
'text_pair': context
}
qa_res = qa_pipe(QA_input)
cls_res = cls_pipe(CLS_iput)
threshold = 0.5 #hyperparameter can be tweaked
## note classification results label0 probability it can be answered label1 probability can't be answered
## if label1 probability > threshold then consider the output of qa_res is empty string else take the qa_res
# b) Load model & tokenizer
qa_model = ElectraForQuestionAnswering.from_pretrained(qa_modelname)
cls_model = ElectraForSequenceClassification.from_pretrained(cls_modelname)
tokenizer = AutoTokenizer.from_pretrained(qa_modelname)
```
## Performance
Evaluated on the Arabic-SQuAD 2.0 test set with the [official eval script](https://worksheets.codalab.org/rest/bundles/0x6b567e1cf2e041ec80d7098f031c5c9e/contents/blob/) except changing in the preprocessing a little to fit the arabic language [the modified eval script](https://github.com/zeyadahmed10/Arabic-MRC/blob/main/evaluatev2.py).
```
"exact": 65.11555277951281,
"f1": 71.49042547237256,,
"total": 9606,
"HasAns_exact": 56.14535768645358,
"HasAns_f1": 67.79623803036668,
"HasAns_total": 5256,
"NoAns_exact": 75.95402298850574,
"NoAns_f1": 75.95402298850574,
"NoAns_total": 4350
```
|
cardiffnlp/twitter-roberta-base-jun2022
|
93359ad9421cd11b46684cd5c72ef496613db1d5
|
2022-07-19T17:08:36.000Z
|
[
"pytorch",
"roberta",
"fill-mask",
"arxiv:2202.03829",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
cardiffnlp
| null |
cardiffnlp/twitter-roberta-base-jun2022
| 219 | 1 |
transformers
| 3,514 |
# Twitter June 2022 (RoBERTa-base, 132M)
This is a RoBERTa-base model trained on 132.26M tweets until the end of June 2022.
More details and performance scores are available in the [TimeLMs paper](https://arxiv.org/abs/2202.03829).
Below, we provide some usage examples using the standard Transformers interface. For another interface more suited to comparing predictions and perplexity scores between models trained at different temporal intervals, check the [TimeLMs repository](https://github.com/cardiffnlp/timelms).
For other models trained until different periods, check this [table](https://github.com/cardiffnlp/timelms#released-models).
## Preprocess Text
Replace usernames and links for placeholders: "@user" and "http".
If you're interested in retaining verified users which were also retained during training, you may keep the users listed [here](https://github.com/cardiffnlp/timelms/tree/main/data).
```python
def preprocess(text):
new_text = []
for t in text.split(" "):
t = '@user' if t.startswith('@') and len(t) > 1 else t
t = 'http' if t.startswith('http') else t
new_text.append(t)
return " ".join(new_text)
```
## Example Masked Language Model
```python
from transformers import pipeline, AutoTokenizer
MODEL = "cardiffnlp/twitter-roberta-base-jun2022"
fill_mask = pipeline("fill-mask", model=MODEL, tokenizer=MODEL)
tokenizer = AutoTokenizer.from_pretrained(MODEL)
def print_candidates():
for i in range(5):
token = tokenizer.decode(candidates[i]['token'])
score = candidates[i]['score']
print("%d) %.5f %s" % (i+1, score, token))
texts = [
"So glad I'm <mask> vaccinated.",
"I keep forgetting to bring a <mask>.",
"Looking forward to watching <mask> Game tonight!",
]
for text in texts:
t = preprocess(text)
print(f"{'-'*30}\n{t}")
candidates = fill_mask(t)
print_candidates()
```
Output:
```
------------------------------
So glad I'm <mask> vaccinated.
1) 0.36928 not
2) 0.29651 fully
3) 0.15332 getting
4) 0.04144 still
5) 0.01805 all
------------------------------
I keep forgetting to bring a <mask>.
1) 0.06048 book
2) 0.03458 backpack
3) 0.03362 lighter
4) 0.03162 charger
5) 0.02832 pen
------------------------------
Looking forward to watching <mask> Game tonight!
1) 0.65149 the
2) 0.14239 The
3) 0.02432 this
4) 0.00877 End
5) 0.00866 Big
```
## Example Tweet Embeddings
```python
from transformers import AutoTokenizer, AutoModel, TFAutoModel
import numpy as np
from scipy.spatial.distance import cosine
from collections import Counter
def get_embedding(text):
text = preprocess(text)
encoded_input = tokenizer(text, return_tensors='pt')
features = model(**encoded_input)
features = features[0].detach().cpu().numpy()
features_mean = np.mean(features[0], axis=0)
return features_mean
MODEL = "cardiffnlp/twitter-roberta-base-jun2022"
tokenizer = AutoTokenizer.from_pretrained(MODEL)
model = AutoModel.from_pretrained(MODEL)
query = "The book was awesome"
tweets = ["I just ordered fried chicken 🐣",
"The movie was great",
"What time is the next game?",
"Just finished reading 'Embeddings in NLP'"]
sims = Counter()
for tweet in tweets:
sim = 1 - cosine(get_embedding(query), get_embedding(tweet))
sims[tweet] = sim
print('Most similar to: ', query)
print(f"{'-'*30}")
for idx, (tweet, sim) in enumerate(sims.most_common()):
print("%d) %.5f %s" % (idx+1, sim, tweet))
```
Output:
```
Most similar to: The book was awesome
------------------------------
1) 0.98882 The movie was great
2) 0.96087 Just finished reading 'Embeddings in NLP'
3) 0.95450 I just ordered fried chicken 🐣
4) 0.95300 What time is the next game?
```
## Example Feature Extraction
```python
from transformers import AutoTokenizer, AutoModel, TFAutoModel
import numpy as np
MODEL = "cardiffnlp/twitter-roberta-base-jun2022"
tokenizer = AutoTokenizer.from_pretrained(MODEL)
text = "Good night 😊"
text = preprocess(text)
# Pytorch
model = AutoModel.from_pretrained(MODEL)
encoded_input = tokenizer(text, return_tensors='pt')
features = model(**encoded_input)
features = features[0].detach().cpu().numpy()
features_mean = np.mean(features[0], axis=0)
#features_max = np.max(features[0], axis=0)
# # Tensorflow
# model = TFAutoModel.from_pretrained(MODEL)
# encoded_input = tokenizer(text, return_tensors='tf')
# features = model(encoded_input)
# features = features[0].numpy()
# features_mean = np.mean(features[0], axis=0)
# #features_max = np.max(features[0], axis=0)
```
|
Kyleiwaniec/COS_TAPT_n_RoBERTa
|
1ea115a0af6be092bfc37aef97b0227d67089794
|
2022-07-20T05:48:38.000Z
|
[
"pytorch",
"roberta",
"fill-mask",
"transformers",
"license:cc",
"autotrain_compatible"
] |
fill-mask
| false |
Kyleiwaniec
| null |
Kyleiwaniec/COS_TAPT_n_RoBERTa
| 219 | null |
transformers
| 3,515 |
---
license: cc
---
|
Newtral/xlm-r-finetuned-toxic-political-tweets-es
|
dcb737a20afc37daf8aeef107ee902de1cc2c7ec
|
2022-05-09T07:47:22.000Z
|
[
"pytorch",
"xlm-roberta",
"text-classification",
"es",
"transformers",
"license:apache-2.0"
] |
text-classification
| false |
Newtral
| null |
Newtral/xlm-r-finetuned-toxic-political-tweets-es
| 218 | 3 |
transformers
| 3,516 |
---
language: es
license: apache-2.0
---
# xlm-r-finetuned-toxic-political-tweets-es
This model is based on the pre-trained model [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) and was fine-tuned on a dataset of tweets from members of the [Spanish Congress of the Deputies](https://www.congreso.es/) annotated regarding the level of political toxicity they generate.
### Inputs
The model has been trained on the text of Spanish tweets authored by politicians in 2021, so this is the input expected and its performance can degrade when applied to texts from other domains.
### Outputs
The model predicts 2 signals of political toxicity:
* Toxic: the tweet has at least some degree of toxicity.
* Very Toxic: the tweet has a strong degree of toxicity.
A value between 0 and 1 is predicted for each signal.
### Intended uses & limitations
The model was created to be used as a toxicity detector of spanish tweets from Spanish Congress Deputies. If the intended use is other one, for instance; toxicity detection on films reviews, the results won't be reliable and you might look for another model with this concrete purpose.
### How to use
The model can be used directly with a text-classification pipeline:
```python
>>> from transformers import pipeline
>>> text = "Es usted un auténtico impresentable, su señoría."
>>> pipe = pipeline("text-classification", model="Newtral/xlm-r-finetuned-toxic-political-tweets-es")
>>> pipe(text, return_all_scores=True)
[[{'label': 'toxic', 'score': 0.92560875415802},
{'label': 'very toxic', 'score': 0.8310967683792114}]]
```
### Training procedure
The pre-trained model was fine-tuned for sequence classification using the following hyperparameters, which were selected from a validation set:
* Batch size = 32
* Learning rate = 2e-5
* Epochs = 5
* Max length = 64
The optimizer used was AdamW and the loss optimized was binary cross-entropy with class weights proportional to the class imbalance.
|
fmmolina/bert-base-spanish-wwm-uncased-finetuned-NER-medical
|
1003bba70adfafd239b13f805f641532ce007108
|
2022-04-03T13:39:03.000Z
|
[
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"generated_from_trainer",
"model-index",
"autotrain_compatible"
] |
token-classification
| false |
fmmolina
| null |
fmmolina/bert-base-spanish-wwm-uncased-finetuned-NER-medical
| 218 | null |
transformers
| 3,517 |
---
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-base-spanish-wwm-uncased-finetuned-NER-medical
results: []
widget:
- text: "El útero o matriz es el lugar donde se desarrolla el bebé cuando una mujer está embarazada."
- text: "El síndrome de dolor regional complejo es un trastorno de dolor crónico."
---
# bert-base-spanish-wwm-uncased-finetuned-NER-medical
This model is a fine-tuned version of [dccuchile/bert-base-spanish-wwm-uncased](https://huggingface.co/dccuchile/bert-base-spanish-wwm-uncased) on an adaptation of [eHealth-KD Challenge 2020 dataset](https://knowledge-learning.github.io/ehealthkd-2020/), filtered only for the task of NER. The dataset annotations for NER are ['Concept', 'Action', 'Predicate', 'Reference'].
Before the training process, the dataset had processed to label it with the BIO annotation format. Some cleaning and adaptations were needed, for example, to work with overlapped entities.
It achieves the following results on the evaluation set:
- Loss: 0.6433
- Precision: 0.8297
- Recall: 0.8367
- F1: 0.8332
- Accuracy: 0.8876
## Model description
A BERT adaptation for Spanish medical NER. This type of models can be part of NLP pipelines created, for example, to analyse clinical documents, automatic labelling of clinical documents following standard classifications such as CIE-10 o SNOMED, etc.
## Training and evaluation data
The adapted dataset has this structure:
- Training: 800 labelled sentences
- Development: 199 labelled sentences
- Testing: 100 labelled sentences
## Training procedure
The chapter [“Token classification”]( https://huggingface.co/course/chapter7/2) in the Hugging Face online course was used as starting point for the training process. We made some adaptions because our dataset follows a slightly different structure. Moreover, a conversion between string labels and integers labels was needed.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 12
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.1139 | 1.0 | 50 | 0.3932 | 0.8671 | 0.8378 | 0.8522 | 0.9004 |
| 0.074 | 2.0 | 100 | 0.4334 | 0.8682 | 0.8367 | 0.8522 | 0.9004 |
| 0.0564 | 3.0 | 150 | 0.4498 | 0.8654 | 0.8353 | 0.8501 | 0.8993 |
| 0.0431 | 4.0 | 200 | 0.4683 | 0.8629 | 0.8425 | 0.8526 | 0.8985 |
| 0.0328 | 5.0 | 250 | 0.4850 | 0.8508 | 0.8454 | 0.8481 | 0.8964 |
| 0.027 | 6.0 | 300 | 0.4983 | 0.8608 | 0.8432 | 0.8519 | 0.8988 |
| 0.0253 | 7.0 | 350 | 0.5334 | 0.8618 | 0.8457 | 0.8537 | 0.9004 |
| 0.0242 | 8.0 | 400 | 0.5546 | 0.8636 | 0.8450 | 0.8542 | 0.9009 |
| 0.0233 | 9.0 | 450 | 0.5507 | 0.8543 | 0.8436 | 0.8489 | 0.8961 |
| 0.0203 | 10.0 | 500 | 0.5410 | 0.8605 | 0.8432 | 0.8518 | 0.9001 |
| 0.0179 | 11.0 | 550 | 0.5547 | 0.8603 | 0.8507 | 0.8555 | 0.9006 |
| 0.0149 | 12.0 | 600 | 0.5568 | 0.8616 | 0.8446 | 0.8531 | 0.9012 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.0+cu111
- Datasets 2.0.0
- Tokenizers 0.11.6
|
yanekyuk/berturk-uncased-keyword-discriminator
|
622dcea3aac29e86bc7f4b1e6b9b878667251306
|
2022-06-06T17:09:35.000Z
|
[
"pytorch",
"bert",
"token-classification",
"tr",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index",
"autotrain_compatible"
] |
token-classification
| false |
yanekyuk
| null |
yanekyuk/berturk-uncased-keyword-discriminator
| 218 | null |
transformers
| 3,518 |
---
license: mit
tags:
- generated_from_trainer
metrics:
- precision
- recall
- accuracy
- f1
language:
- tr
widget:
- text: "İngiltere'de düzenlenen Avrupa Tekvando ve Para Tekvando Şampiyonası’nda millî tekvandocular 5 altın, 2 gümüş ve 4 bronz olmak üzere 11, millî para tekvandocular ise 4 altın, 3 gümüş ve 1 bronz olmak üzere 8 madalya kazanarak takım halinde Avrupa şampiyonu oldu."
- text: "Füme somon dedik ama aslında lox salamuralanmış somon anlamına geliyor, füme etme opsiyonel. Lox bagel, 1930'larda Eggs Benedict furyasında New Yorklu Yahudi cemaati tarafından koşer bir alternatif olarak çıkan bir lezzet. Günümüzde benim hangover yüreğim dâhil dünyanın birçok yerinde enfes bir kahvaltı sandviçi."
- text: "Türkiye'de son aylarda sıklıkla tartışılan konut satışı karşılığında yabancılara vatandaşlık verilmesi konusunu beyin göçü kapsamında ele almak mümkün. Daha önce 250 bin dolar olan vatandaşlık bedeli yükselen tepkiler üzerine 400 bin dolara çıkarılmıştı. Türkiye'den göç eden iyi eğitimli kişilerin , gittikleri ülkelerde 250 bin dolar tutarında yabancı yatırıma denk olduğu göz önüne alındığında nitelikli insan gücünün yabancılara konut karşılığında satılan vatandaşlık bedelin eş olduğunu görüyoruz. Yurt dışına giden her bir vatandaşın yüksek teknolojili katma değer üreten sektörlere yapacağı katkılar göz önünde bulundurulduğunda bu açığın inşaat sektörüyle kapatıldığını da görüyoruz. Beyin göçü konusunda sadece ekonomik perspektiften bakıldığında bile kısa vadeli döviz kaynağı yaratmak için kullanılan vatandaşlık satışı yerine beyin göçünü önleyecek önlemler alınmasının ülkemize çok daha faydalı olacağı sonucunu çıkarıyoruz."
- text: "Türkiye’de resmî verilere göre, 15 ve daha yukarı yaştaki kişilerde mevsim etkisinden arındırılmış işsiz sayısı, bu yılın ilk çeyreğinde bir önceki çeyreğe göre 50 bin kişi artarak 3 milyon 845 bin kişi oldu. Mevsim etkisinden arındırılmış işsizlik oranı ise 0,1 puanlık artışla %11,4 seviyesinde gerçekleşti. İşsizlik oranı, ilk çeyrekte geçen yılın aynı çeyreğine göre 1,7 puan azaldı."
- text: "Boeing’in insansız uzay aracı Starliner, birtakım sorunlara rağmen Uluslararası Uzay İstasyonuna (ISS) ulaşarak ilk kez başarılı bir şekilde kenetlendi. Aracın ISS’te beş gün kalmasını takiben sorunsuz bir şekilde New Mexico’ya inmesi halinde Boeing, sonbaharda astronotları yörüngeye göndermek için Starliner’ı kullanabilir.\n\nNeden önemli? NASA’nın personal aracı üretmeyi durdurmasından kaynaklı olarak görevli astronotlar ve kozmonotlar, ISS’te Rusya’nın ürettiği uzay araçları ile taşınıyordu. Starliner’ın kendini kanıtlaması ise bu konuda Rusya’ya olan bağımlılığın potansiyel olarak ortadan kalkabileceği anlamına geliyor."
model-index:
- name: berturk-uncased-keyword-discriminator
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# berturk-uncased-keyword-discriminator
This model is a fine-tuned version of [dbmdz/bert-base-turkish-uncased](https://huggingface.co/dbmdz/bert-base-turkish-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3989
- Precision: 0.6234
- Recall: 0.6508
- Accuracy: 0.9145
- F1: 0.6368
- Ent/precision: 0.6435
- Ent/accuracy: 0.7120
- Ent/f1: 0.6761
- Con/precision: 0.5834
- Con/accuracy: 0.5475
- Con/f1: 0.5649
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | Accuracy | F1 | Ent/precision | Ent/accuracy | Ent/f1 | Con/precision | Con/accuracy | Con/f1 |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:--------:|:------:|:-------------:|:------------:|:------:|:-------------:|:------------:|:------:|
| 0.2005 | 1.0 | 1875 | 0.2104 | 0.5981 | 0.5978 | 0.9148 | 0.5979 | 0.6280 | 0.6665 | 0.6467 | 0.5383 | 0.4820 | 0.5086 |
| 0.1468 | 2.0 | 3750 | 0.2094 | 0.5996 | 0.6568 | 0.9164 | 0.6269 | 0.6285 | 0.7049 | 0.6645 | 0.5477 | 0.5757 | 0.5614 |
| 0.1124 | 3.0 | 5625 | 0.2372 | 0.6106 | 0.6679 | 0.9154 | 0.6380 | 0.6285 | 0.7270 | 0.6741 | 0.5753 | 0.5684 | 0.5718 |
| 0.0861 | 4.0 | 7500 | 0.2736 | 0.6133 | 0.6707 | 0.9145 | 0.6407 | 0.6281 | 0.7359 | 0.6777 | 0.5830 | 0.5606 | 0.5716 |
| 0.0644 | 5.0 | 9375 | 0.3081 | 0.6115 | 0.6683 | 0.9145 | 0.6386 | 0.6291 | 0.7293 | 0.6755 | 0.5764 | 0.5657 | 0.5710 |
| 0.0498 | 6.0 | 11250 | 0.3449 | 0.6245 | 0.6466 | 0.9149 | 0.6353 | 0.6380 | 0.7097 | 0.6720 | 0.5965 | 0.5401 | 0.5669 |
| 0.0401 | 7.0 | 13125 | 0.3838 | 0.6223 | 0.6545 | 0.9140 | 0.6380 | 0.6449 | 0.7100 | 0.6759 | 0.5790 | 0.5610 | 0.5699 |
| 0.0329 | 8.0 | 15000 | 0.3989 | 0.6234 | 0.6508 | 0.9145 | 0.6368 | 0.6435 | 0.7120 | 0.6761 | 0.5834 | 0.5475 | 0.5649 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
|
IDEA-CCNL/Randeng-T5-784M
|
19a36b40eef4631a89929885e6f8af12b5c882f5
|
2022-06-08T13:04:59.000Z
|
[
"pytorch",
"mt5",
"text2text-generation",
"zh",
"transformers",
"T5",
"chinese",
"sentencepiece",
"license:apache-2.0",
"autotrain_compatible"
] |
text2text-generation
| false |
IDEA-CCNL
| null |
IDEA-CCNL/Randeng-T5-784M
| 218 | null |
transformers
| 3,519 |
---
language:
- zh
license: apache-2.0
tags:
- T5
- chinese
- sentencepiece
inference: true
widget:
- text: "北京有悠久的 <extra_id_0>和 <extra_id_1>。"
- type: "text-generation"
---
# Randeng-T5-784M, one model of [Fengshenbang-LM](https://github.com/IDEA-CCNL/Fengshenbang-LM).
Based on mt5-large, Randeng-T5-784M only retains the vocabulary and embedding corresponding to Chinese and English, and continues to train on the basis of 180G Chinese general pre-training corpus. Because we continue pretraining on mt5-large, the tokenizer use T5tokenizer(sentencepiece). The pretrain target is span corruption. We pretrain the model based on our [fengshen framework](https://github.com/IDEA-CCNL/Fengshenbang-LM/tree/main/fengshen), use 16 * A100 for 98 hours.
## Usage
```python
from transformers import T5ForConditionalGeneration, AutoTokenizer
import torch
tokenizer=AutoTokenizer.from_pretrained('IDEA-CCNL/Randeng-T5-784M', use_fast=false)
model=T5ForConditionalGeneration.from_pretrained('IDEA-CCNL/Randeng-T5-784M')
```
## Citation
If you find the resource is useful, please cite the following website in your paper.
```
@misc{Fengshenbang-LM,
title={Fengshenbang-LM},
author={IDEA-CCNL},
year={2022},
howpublished={\url{https://github.com/IDEA-CCNL/Fengshenbang-LM}},
}
```
|
wvangils/BLOOM-350m-Beatles-Lyrics-finetuned-newlyrics
|
99fddd1509379bd6a5a2c93bfdb80273c32e991f
|
2022-07-05T09:01:30.000Z
|
[
"pytorch",
"tensorboard",
"bloom",
"text-generation",
"transformers",
"generated_from_trainer",
"license:bigscience-bloom-rail-1.0",
"model-index"
] |
text-generation
| false |
wvangils
| null |
wvangils/BLOOM-350m-Beatles-Lyrics-finetuned-newlyrics
| 218 | null |
transformers
| 3,520 |
---
license: bigscience-bloom-rail-1.0
tags:
- generated_from_trainer
model-index:
- name: BLOOM-350m-Beatles-Lyrics-finetuned-newlyrics
results: []
widget:
- text: "Last night I couldn't sleep"
example_title: "Sleep"
- text: "It hasn't rained in weeks"
example_title: "Rain"
---
# BLOOM-350m-Beatles-Lyrics-finetuned-newlyrics
This model is a fine-tuned version of [bigscience/bloom-350m](https://huggingface.co/bigscience/bloom-350m) on the [Cmotions - Beatles lyrics](https://huggingface.co/datasets/cmotions/Beatles_lyrics) dataset. It will complete an input prompt with Beatles-like text.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 3.1135 | 1.0 | 138 | 3.4852 |
| 2.0717 | 2.0 | 276 | 3.8820 |
| 1.3296 | 3.0 | 414 | 3.6281 |
| 0.8146 | 4.0 | 552 | 3.8985 |
| 0.477 | 5.0 | 690 | 4.0317 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0+cu113
- Datasets 2.3.2
- Tokenizers 0.12.1
|
thannarot/hug-clip-bid
|
6f6b2967f2956fdee5db9c6092ef975f03446fd3
|
2022-07-14T08:07:35.000Z
|
[
"pytorch",
"clip",
"feature-extraction",
"transformers",
"generated_from_trainer",
"model-index"
] |
feature-extraction
| false |
thannarot
| null |
thannarot/hug-clip-bid
| 218 | null |
transformers
| 3,521 |
---
tags:
- generated_from_trainer
model-index:
- name: hug-clip-bid
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hug-clip-bid
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8276
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.0263 | 0.15 | 100 | 1.3193 |
| 0.9187 | 0.29 | 200 | 1.0286 |
| 0.7005 | 0.44 | 300 | 0.9560 |
| 0.5851 | 0.58 | 400 | 0.9433 |
| 0.6122 | 0.73 | 500 | 0.8936 |
| 0.5916 | 0.88 | 600 | 0.8276 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.12.0
- Datasets 2.3.2
- Tokenizers 0.11.6
|
EMBEDDIA/finest-bert
|
c61edda13bbf7eed6207fb1955c78a49f2dbe4c3
|
2021-05-18T18:22:50.000Z
|
[
"pytorch",
"jax",
"bert",
"fill-mask",
"fi",
"et",
"en",
"multilingual",
"arxiv:2006.07890",
"transformers",
"license:cc-by-4.0",
"autotrain_compatible"
] |
fill-mask
| false |
EMBEDDIA
| null |
EMBEDDIA/finest-bert
| 217 | 2 |
transformers
| 3,522 |
---
language:
- fi
- et
- en
- multilingual
license: cc-by-4.0
---
# FinEst BERT
FinEst BERT is a trilingual model, using bert-base architecture, trained on Finnish, Estonian, and English corpora. Focusing on three languages, the model performs better than [multilingual BERT](https://huggingface.co/bert-base-multilingual-cased), while still offering an option for cross-lingual knowledge transfer, which a monolingual model wouldn't.
Evaluation is presented in our article:
```
@Inproceedings{ulcar-robnik2020finest,
author = "Ulčar, M. and Robnik-Šikonja, M.",
year = 2020,
title = "{FinEst BERT} and {CroSloEngual BERT}: less is more in multilingual models",
editor = "Sojka, P and Kopeček, I and Pala, K and Horák, A",
booktitle = "Text, Speech, and Dialogue {TSD 2020}",
series = "Lecture Notes in Computer Science",
volume = 12284,
publisher = "Springer",
url = "https://doi.org/10.1007/978-3-030-58323-1_11",
}
```
The preprint is available at [arxiv.org/abs/2006.07890](https://arxiv.org/abs/2006.07890).
|
SkolkovoInstitute/t5-paraphrase-paws-msrp-opinosis-paranmt
|
b57298e55f51f97a69e563bc6abfa183d80a5c92
|
2021-11-02T17:58:47.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"arxiv:1711.05732",
"arxiv:1911.00536",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
SkolkovoInstitute
| null |
SkolkovoInstitute/t5-paraphrase-paws-msrp-opinosis-paranmt
| 217 | null |
transformers
| 3,523 |
This is a paraphraser based on [ceshine/t5-paraphrase-paws-msrp-opinosis](https://huggingface.co/ceshine/t5-paraphrase-paws-msrp-opinosis)
and additionally fine-tuned on [ParaNMT](https://arxiv.org/abs/1711.05732).
The model was trained for the paper [Text Detoxification using Large Pre-trained Neural Models](https://arxiv.org/abs/1911.00536).
An example of its use is given in https://github.com/skoltech-nlp/detox
|
Tejas3/distillbert_base_uncased_80_equal
|
ee468b60927a3f86b74d0b696cc1d21e58d99ae7
|
2021-07-15T08:48:42.000Z
|
[
"pytorch",
"distilbert",
"text-classification",
"transformers"
] |
text-classification
| false |
Tejas3
| null |
Tejas3/distillbert_base_uncased_80_equal
| 217 | null |
transformers
| 3,524 |
Entry not found
|
tprincessazula/Dialog-GPT-small-SOKKA-AVATAR
|
afe1e4694d9eb7d16c0c8f3955d68d86ed1cc816
|
2021-12-12T08:03:47.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
tprincessazula
| null |
tprincessazula/Dialog-GPT-small-SOKKA-AVATAR
| 217 | 1 |
transformers
| 3,525 |
---
tags:
- conversational
---
#SOKKA DialoGPT Model
|
north/demo-deuncaser-base
|
568a9c61bdc3a74c9cb4d98e9a1152fe260a69c2
|
2022-05-29T21:33:28.000Z
|
[
"pytorch",
"jax",
"tensorboard",
"t5",
"text2text-generation",
"no",
"transformers",
"translation",
"license:cc-by-4.0",
"autotrain_compatible"
] |
translation
| false |
north
| null |
north/demo-deuncaser-base
| 217 | null |
transformers
| 3,526 |
---
language: no
tags:
- translation
widget:
- text: "tirsdag var travel for ukrainas president volodymyr zelenskyj på morgenen tok han imot polens statsminister mateusz morawiecki"
- text: "tirsdagvartravelforukrainaspresidentvolodymyrzelenskyjpåkveldentokhanimotpolensstatsministermateuszmorawiecki"
- text: "deterikkelettåholderedepåstoreogsmåbokstavermanmåforeksempelhuskestorforbokstavnårmanskriveromkrimhalvøyamenkunbrukelitenforbokstavnårmanhenvisertilenkrimroman"
- text: "detteerenlitendemosomerlagetavperegilkummervoldhanerenforskersomtidligerejobbetvednasjonalbiblioteketimoirana"
license: cc-by-4.0
---
# DeUnCaser
The purpose of the DeUnCaser is to fix text that lacks punctation. It is particulary targeted towards the output from Automated Speak Recognition software. In addition to the lack of casing and punctation, it also often lacks pauses between words. Try this demo, and you will understand.
The DeUnCaser is based on North-T5. It is a sequence-to-sequence mT5 model. It will make an attempt to add punctation, spaces and capitalisation to any text that is thrown at it. It is primarily trained to fix Norwegian text.
|
dbmdz/distilbert-base-german-europeana-cased
|
1eaca02960b72f719043fbd4a8b026d4543b4dad
|
2022-06-09T07:27:27.000Z
|
[
"pytorch",
"tf",
"distilbert",
"de",
"transformers",
"historic german",
"license:mit"
] | null | false |
dbmdz
| null |
dbmdz/distilbert-base-german-europeana-cased
| 216 | 2 |
transformers
| 3,527 |
---
language: de
license: mit
tags:
- "historic german"
---
# 🤗 + 📚 dbmdz DistilBERT model
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources a German Europeana DistilBERT model 🎉
# German Europeana DistilBERT
We use the open source [Europeana newspapers](http://www.europeana-newspapers.eu/)
that were provided by *The European Library*. The final
training corpus has a size of 51GB and consists of 8,035,986,369 tokens.
Detailed information about the data and pretraining steps can be found in
[this repository](https://github.com/stefan-it/europeana-bert).
## Results
For results on Historic NER, please refer to [this repository](https://github.com/stefan-it/europeana-bert).
## Usage
With Transformers >= 4.3 our German Europeana DistilBERT model can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/distilbert-base-german-europeana-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
```
# Huggingface model hub
All other German Europeana models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our Europeana BERT, ELECTRA and ConvBERT models just open a new discussion
[here](https://github.com/stefan-it/europeana-bert/discussions) 🤗
# Acknowledgments
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
sakares/wav2vec2-large-xlsr-thai-demo
|
ba9ae764735fbb69671c7c2befb88ef3501683eb
|
2021-03-22T07:15:18.000Z
|
[
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"th",
"dataset:common_voice",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
] |
automatic-speech-recognition
| false |
sakares
| null |
sakares/wav2vec2-large-xlsr-thai-demo
| 216 | 2 |
transformers
| 3,528 |
---
language: th
datasets:
- common_voice
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Large Thai by Sakares
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice th
type: common_voice
args: th
metrics:
- name: Test WER
type: wer
value: 44.46
---
# Wav2Vec2-Large-XLSR-53-Thai
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) in Thai using the [Common Voice](https://huggingface.co/datasets/common_voice)
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
from pythainlp.tokenize import word_tokenize
test_dataset = load_dataset("common_voice", "th", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("sakares/wav2vec2-large-xlsr-thai-demo")
model = Wav2Vec2ForCTC.from_pretrained("sakares/wav2vec2-large-xlsr-thai-demo")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
## For Thai NLP Library, please feel free to check https://pythainlp.github.io/docs/2.2/api/tokenize.html
def th_tokenize(batch):
batch["sentence"] = " ".join(word_tokenize(batch["sentence"], engine="newmm"))
return batch
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn).map(th_tokenize)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
Usage script [here](https://colab.research.google.com/drive/1w0VywsBtjrO2pHHPmiPugYI9yeF8nUKg?usp=sharing)
## Evaluation
The model can be evaluated as follows on the {language} test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
from pythainlp.tokenize import word_tokenize
import re
test_dataset = load_dataset("common_voice", "th", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("sakares/wav2vec2-large-xlsr-thai-demo")
model = Wav2Vec2ForCTC.from_pretrained("sakares/wav2vec2-large-xlsr-thai-demo")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
## For Thai NLP Library, please feel free to check https://pythainlp.github.io/docs/2.2/api/tokenize.html
def th_tokenize(batch):
batch["sentence"] = " ".join(word_tokenize(batch["sentence"], engine="newmm"))
return batch
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn).map(th_tokenize)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 44.46 %
Evaluate script [here](https://colab.research.google.com/drive/1WZGtHKWXBztRsuXHIdebf6uoAsp7rTnK?usp=sharing)
## Training
The Common Voice `train`, `validation` datasets were used for training.
The script used for training can be found [here](https://colab.research.google.com/drive/18oUbeZgBGSkz16zC_WOa154QZOdmvjyt?usp=sharing)
|
SEBIS/code_trans_t5_large_code_documentation_generation_java_multitask
|
df97ce5e290c1764e73041a13a65b8729f999d60
|
2021-06-23T06:39:28.000Z
|
[
"pytorch",
"jax",
"t5",
"feature-extraction",
"transformers",
"summarization"
] |
summarization
| false |
SEBIS
| null |
SEBIS/code_trans_t5_large_code_documentation_generation_java_multitask
| 215 | null |
transformers
| 3,529 |
---
tags:
- summarization
widget:
- text: "public static < T , U > Function < T , U > castFunction ( Class < U > target ) { return new CastToClass < T , U > ( target ) ; }"
---
# CodeTrans model for code documentation generation java
Pretrained model on programming language java using the t5 large model architecture. It was first released in
[this repository](https://github.com/agemagician/CodeTrans). This model is trained on tokenized java code functions: it works best with tokenized java functions.
## Model description
This CodeTrans model is based on the `t5-large` model. It has its own SentencePiece vocabulary model. It used multi-task training on 13 supervised tasks in the software development domain and 7 unsupervised datasets.
## Intended uses & limitations
The model could be used to generate the description for the java function or be fine-tuned on other java code tasks. It can be used on unparsed and untokenized java code. However, if the java code is tokenized, the performance should be better.
### How to use
Here is how to use this model to generate java function documentation using Transformers SummarizationPipeline:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead, SummarizationPipeline
pipeline = SummarizationPipeline(
model=AutoModelWithLMHead.from_pretrained("SEBIS/code_trans_t5_large_code_documentation_generation_java_multitask"),
tokenizer=AutoTokenizer.from_pretrained("SEBIS/code_trans_t5_large_code_documentation_generation_java_multitask", skip_special_tokens=True),
device=0
)
tokenized_code = "public static < T , U > Function < T , U > castFunction ( Class < U > target ) { return new CastToClass < T , U > ( target ) ; }"
pipeline([tokenized_code])
```
Run this example in [colab notebook](https://github.com/agemagician/CodeTrans/blob/main/prediction/multitask/pre-training/function%20documentation%20generation/java/large_model.ipynb).
## Training data
The supervised training tasks datasets can be downloaded on [Link](https://www.dropbox.com/sh/488bq2of10r4wvw/AACs5CGIQuwtsD7j_Ls_JAORa/finetuning_dataset?dl=0&subfolder_nav_tracking=1)
## Training procedure
### Multi-task Pretraining
The model was trained on a single TPU Pod V3-8 for 180,000 steps in total, using sequence length 512 (batch size 4096).
It has a total of approximately 220M parameters and was trained using the encoder-decoder architecture.
The optimizer used is AdaFactor with inverse square root learning rate schedule for pre-training.
## Evaluation results
For the code documentation tasks, different models achieves the following results on different programming languages (in BLEU score):
Test results :
| Language / Model | Python | Java | Go | Php | Ruby | JavaScript |
| -------------------- | :------------: | :------------: | :------------: | :------------: | :------------: | :------------: |
| CodeTrans-ST-Small | 17.31 | 16.65 | 16.89 | 23.05 | 9.19 | 13.7 |
| CodeTrans-ST-Base | 16.86 | 17.17 | 17.16 | 22.98 | 8.23 | 13.17 |
| CodeTrans-TF-Small | 19.93 | 19.48 | 18.88 | 25.35 | 13.15 | 17.23 |
| CodeTrans-TF-Base | 20.26 | 20.19 | 19.50 | 25.84 | 14.07 | 18.25 |
| CodeTrans-TF-Large | 20.35 | 20.06 | **19.54** | 26.18 | 14.94 | **18.98** |
| CodeTrans-MT-Small | 19.64 | 19.00 | 19.15 | 24.68 | 14.91 | 15.26 |
| CodeTrans-MT-Base | **20.39** | 21.22 | 19.43 | **26.23** | **15.26** | 16.11 |
| CodeTrans-MT-Large | 20.18 | **21.87** | 19.38 | 26.08 | 15.00 | 16.23 |
| CodeTrans-MT-TF-Small | 19.77 | 20.04 | 19.36 | 25.55 | 13.70 | 17.24 |
| CodeTrans-MT-TF-Base | 19.77 | 21.12 | 18.86 | 25.79 | 14.24 | 18.62 |
| CodeTrans-MT-TF-Large | 18.94 | 21.42 | 18.77 | 26.20 | 14.19 | 18.83 |
| State of the art | 19.06 | 17.65 | 18.07 | 25.16 | 12.16 | 14.90 |
> Created by [Ahmed Elnaggar](https://twitter.com/Elnaggar_AI) | [LinkedIn](https://www.linkedin.com/in/prof-ahmed-elnaggar/) and Wei Ding | [LinkedIn](https://www.linkedin.com/in/wei-ding-92561270/)
|
ionite/DialoGPT-medium-IoniteAI
|
2466d0a29b45187b76471501039beac68f4e6bd4
|
2021-11-19T04:10:33.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
ionite
| null |
ionite/DialoGPT-medium-IoniteAI
| 215 | null |
transformers
| 3,530 |
---
tags:
- conversational
---
# IoniteAI DialoGPT Model
|
lrakotoson/scitldr-catts-xsum-ao
|
44d53024dcfd315d3af7259838399042748e0aac
|
2021-07-20T07:51:18.000Z
|
[
"pytorch",
"tf",
"bart",
"text2text-generation",
"en",
"dataset:xsum",
"dataset:scitldr",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
text2text-generation
| false |
lrakotoson
| null |
lrakotoson/scitldr-catts-xsum-ao
| 215 | 7 |
transformers
| 3,531 |
---
language:
- en
datasets:
- xsum
- scitldr
widget:
- text: "We introduce TLDR generation, a new form of extreme summarization, for scientific papers. TLDR generation involves high source compression and requires expert background knowledge and understanding of complex domain-specific language. To facilitate study on this task, we introduce SciTLDR, a new multi-target dataset of 5.4K TLDRs over 3.2K papers. SciTLDR contains both author-written and expert-derived TLDRs, where the latter are collected using a novel annotation protocol that produces high-quality summaries while minimizing annotation burden. We propose CATTS, a simple yet effective learning strategy for generating TLDRs that exploits titles as an auxiliary training signal. CATTS improves upon strong baselines under both automated metrics and human evaluations."
license: "apache-2.0"
---
# AI2 SciTLDR
Fairseq checkpoints from CATTS XSUM to Transformers BART (Abtract Only)
Original repository: [https://github.com/allenai/scitldr](https://github.com/allenai/scitldr)
## Demo
A running demo of AI2 model can be found [here](https://scitldr.apps.allenai.org).
### Citing
If you use code, dataset, or model weights in your research, please cite "TLDR: Extreme Summarization of Scientific Documents."
```
@article{cachola2020tldr,
title={{TLDR}: Extreme Summarization of Scientific Documents},
author={Isabel Cachola and Kyle Lo and Arman Cohan and Daniel S. Weld},
journal={arXiv:2004.15011},
year={2020},
}
```
SciTLDR is an open-source project developed by the Allen Institute for Artificial Intelligence (AI2). AI2 is a non-profit institute with the mission to contribute to humanity through high-impact AI research and engineering.
|
sh110495/kor-pegasus
|
401672258ab4df7d9201c796f40a3bf7a0542ef2
|
2022-07-19T13:52:32.000Z
|
[
"pytorch",
"pegasus",
"feature-extraction",
"transformers"
] |
feature-extraction
| false |
sh110495
| null |
sh110495/kor-pegasus
| 215 | 1 |
transformers
| 3,532 |
Entry not found
|
felinecity/DioloGPT-small-KaeyaBot2
|
37a4f9ea84aed5b65548a4f4f02576500df2e589
|
2022-01-15T06:26:04.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
felinecity
| null |
felinecity/DioloGPT-small-KaeyaBot2
| 214 | null |
transformers
| 3,533 |
---
tags:
- conversational
---
# DioloGPT KaeyaBot model
|
flax-community/t5-base-cnn-dm
|
8ee9fb4705b4682c7643eae5c0e0204e5b017200
|
2022-06-29T20:37:14.000Z
|
[
"pytorch",
"jax",
"tensorboard",
"t5",
"text2text-generation",
"en",
"dataset:cnn_dailymail",
"transformers",
"summarization",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] |
summarization
| false |
flax-community
| null |
flax-community/t5-base-cnn-dm
| 214 | 1 |
transformers
| 3,534 |
---
language: en
tags:
- summarization
license: apache-2.0
datasets:
- cnn_dailymail
model-index:
- name: flax-community/t5-base-cnn-dm
results:
- task:
type: summarization
name: Summarization
dataset:
name: cnn_dailymail
type: cnn_dailymail
config: 3.0.0
split: test
metrics:
- name: ROUGE-1
type: rouge
value: 24.2906
verified: true
- name: ROUGE-2
type: rouge
value: 11.1405
verified: true
- name: ROUGE-L
type: rouge
value: 19.8442
verified: true
- name: ROUGE-LSUM
type: rouge
value: 22.7556
verified: true
- name: loss
type: loss
value: 2.1426470279693604
verified: true
- name: gen_len
type: gen_len
value: 18.9993
verified: true
---
# Model
This model is fine-tuned from https://huggingface.co/flax-community/t5-base-openwebtext, fine-tuned on cnn_dailymail.
|
lgris/bp500-base10k_voxpopuli
|
d3f6416e7d2edb18abd5a604cf5c847bc52595c2
|
2022-04-01T20:34:35.000Z
|
[
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"pt",
"dataset:common_voice",
"dataset:mls",
"dataset:cetuc",
"dataset:lapsbm",
"dataset:voxforge",
"dataset:tedx",
"dataset:sid",
"arxiv:2012.03411",
"transformers",
"audio",
"speech",
"portuguese-speech-corpus",
"PyTorch",
"hf-asr-leaderboard",
"license:apache-2.0",
"model-index"
] |
automatic-speech-recognition
| false |
lgris
| null |
lgris/bp500-base10k_voxpopuli
| 214 | null |
transformers
| 3,535 |
---
language: pt
datasets:
- common_voice
- mls
- cetuc
- lapsbm
- voxforge
- tedx
- sid
metrics:
- wer
tags:
- audio
- speech
- wav2vec2
- pt
- portuguese-speech-corpus
- automatic-speech-recognition
- speech
- PyTorch
- hf-asr-leaderboard
model-index:
- name: bp500-base10k_voxpopuli
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice
type: common_voice
args: pt
metrics:
- name: Test WER
type: wer
value: 24.9
license: apache-2.0
---
# bp500-base10k_voxpopuli: Wav2vec 2.0 with Brazilian Portuguese (BP) Dataset
This is a the demonstration of a fine-tuned Wav2vec model for Brazilian Portuguese using the following datasets:
- [CETUC](http://www02.smt.ufrj.br/~igor.quintanilha/alcaim.tar.gz): contains approximately 145 hours of Brazilian Portuguese speech distributed among 50 male and 50 female speakers, each pronouncing approximately 1,000 phonetically balanced sentences selected from the [CETEN-Folha](https://www.linguateca.pt/cetenfolha/) corpus.
- [Common Voice 7.0](https://commonvoice.mozilla.org/pt): is a project proposed by Mozilla Foundation with the goal to create a wide open dataset in different languages. In this project, volunteers donate and validate speech using the [oficial site](https://commonvoice.mozilla.org/pt).
- [Lapsbm](https://github.com/falabrasil/gitlab-resources): "Falabrasil - UFPA" is a dataset used by the Fala Brasil group to benchmark ASR systems in Brazilian Portuguese. Contains 35 speakers (10 females), each one pronouncing 20 unique sentences, totalling 700 utterances in Brazilian Portuguese. The audios were recorded in 22.05 kHz without environment control.
- [Multilingual Librispeech (MLS)](https://arxiv.org/abs/2012.03411): a massive dataset available in many languages. The MLS is based on audiobook recordings in public domain like [LibriVox](https://librivox.org/). The dataset contains a total of 6k hours of transcribed data in many languages. The set in Portuguese [used in this work](http://www.openslr.org/94/) (mostly Brazilian variant) has approximately 284 hours of speech, obtained from 55 audiobooks read by 62 speakers.
- [Multilingual TEDx](http://www.openslr.org/100): a collection of audio recordings from TEDx talks in 8 source languages. The Portuguese set (mostly Brazilian Portuguese variant) contains 164 hours of transcribed speech.
- [Sidney](https://igormq.github.io/datasets/) (SID): contains 5,777 utterances recorded by 72 speakers (20 women) from 17 to 59 years old with fields such as place of birth, age, gender, education, and occupation;
- [VoxForge](http://www.voxforge.org/): is a project with the goal to build open datasets for acoustic models. The corpus contains approximately 100 speakers and 4,130 utterances of Brazilian Portuguese, with sample rates varying from 16kHz to 44.1kHz.
These datasets were combined to build a larger Brazilian Portuguese dataset. All data was used for training except Common Voice dev/test sets, that were used for validation/test respectively. We also made test sets for all the gathered datasets.
| Dataset | Train | Valid | Test |
|--------------------------------|-------:|------:|------:|
| CETUC | 94.0h | -- | 5.4h |
| Common Voice | 37.8h | 8.9h | 9.5h |
| LaPS BM | 0.8h | -- | 0.1h |
| MLS | 161.0h | -- | 3.7h |
| Multilingual TEDx (Portuguese) | 148.9h | -- | 1.8h |
| SID | 7.2h | -- | 1.0h |
| VoxForge | 3.9h | -- | 0.1h |
| Total | 453.6h | 8.9h | 21.6h |
The original model was fine-tuned using [fairseq](https://github.com/pytorch/fairseq). This notebook uses a converted version of the original one. The link to the original fairseq model is available [here](https://drive.google.com/file/d/19kkENi8uvczmw9OLSdqnjvKqBE53cl_W/view?usp=sharing).
#### Summary
| | CETUC | CV | LaPS | MLS | SID | TEDx | VF | AVG |
|----------------------|---------------|----------------|----------------|----------------|----------------|----------------|----------------|----------------|
| bp\_500-base10k_voxpopuli (demonstration below) | 0.120 | 0.249 | 0.039 | 0.227 | 0.169 | 0.349 | 0.116 | 0.181 |
| bp\_500-base10k_voxpopuli + 4-gram (demonstration below) | 0.074 | 0.174 | 0.032 | 0.182 | 0.181 | 0.349 | 0.111 | 0.157 |
#### Transcription examples
| Text | Transcription |
|------------------------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------------------|
|suco de uva e água misturam bem|suco **deúva** e água **misturão** bem|
|culpa do dinheiro|**cupa** do dinheiro|
|eu amo shooters call of duty é o meu favorito|eu **omo** **shúters cofedete** é meu favorito|
|você pode explicar por que isso acontece|você pode explicar *por* que isso **ontece**|
|no futuro você desejará ter começado a investir hoje|no futuro você desejará **a** ter começado a investir hoje|
## Demonstration
```python
MODEL_NAME = "lgris/bp500-base10k_voxpopuli"
```
### Imports and dependencies
```python
%%capture
!pip install torch==1.8.2+cu111 torchvision==0.9.2+cu111 torchaudio===0.8.2 -f https://download.pytorch.org/whl/lts/1.8/torch_lts.html
!pip install datasets
!pip install jiwer
!pip install transformers
!pip install soundfile
!pip install pyctcdecode
!pip install https://github.com/kpu/kenlm/archive/master.zip
```
```python
import jiwer
import torchaudio
from datasets import load_dataset, load_metric
from transformers import (
Wav2Vec2ForCTC,
Wav2Vec2Processor,
)
from pyctcdecode import build_ctcdecoder
import torch
import re
import sys
```
### Helpers
```python
chars_to_ignore_regex = '[\,\?\.\!\;\:\"]' # noqa: W605
def map_to_array(batch):
speech, _ = torchaudio.load(batch["path"])
batch["speech"] = speech.squeeze(0).numpy()
batch["sampling_rate"] = 16_000
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower().replace("’", "'")
batch["target"] = batch["sentence"]
return batch
```
```python
def calc_metrics(truths, hypos):
wers = []
mers = []
wils = []
for t, h in zip(truths, hypos):
try:
wers.append(jiwer.wer(t, h))
mers.append(jiwer.mer(t, h))
wils.append(jiwer.wil(t, h))
except: # Empty string?
pass
wer = sum(wers)/len(wers)
mer = sum(mers)/len(mers)
wil = sum(wils)/len(wils)
return wer, mer, wil
```
```python
def load_data(dataset):
data_files = {'test': f'{dataset}/test.csv'}
dataset = load_dataset('csv', data_files=data_files)["test"]
return dataset.map(map_to_array)
```
### Model
```python
class STT:
def __init__(self,
model_name,
device='cuda' if torch.cuda.is_available() else 'cpu',
lm=None):
self.model_name = model_name
self.model = Wav2Vec2ForCTC.from_pretrained(model_name).to(device)
self.processor = Wav2Vec2Processor.from_pretrained(model_name)
self.vocab_dict = self.processor.tokenizer.get_vocab()
self.sorted_dict = {
k.lower(): v for k, v in sorted(self.vocab_dict.items(),
key=lambda item: item[1])
}
self.device = device
self.lm = lm
if self.lm:
self.lm_decoder = build_ctcdecoder(
list(self.sorted_dict.keys()),
self.lm
)
def batch_predict(self, batch):
features = self.processor(batch["speech"],
sampling_rate=batch["sampling_rate"][0],
padding=True,
return_tensors="pt")
input_values = features.input_values.to(self.device)
with torch.no_grad():
logits = self.model(input_values).logits
if self.lm:
logits = logits.cpu().numpy()
batch["predicted"] = []
for sample_logits in logits:
batch["predicted"].append(self.lm_decoder.decode(sample_logits))
else:
pred_ids = torch.argmax(logits, dim=-1)
batch["predicted"] = self.processor.batch_decode(pred_ids)
return batch
```
### Download datasets
```python
%%capture
!gdown --id 1HFECzIizf-bmkQRLiQD0QVqcGtOG5upI
!mkdir bp_dataset
!unzip bp_dataset -d bp_dataset/
```
```python
%cd bp_dataset
```
/content/bp_dataset
### Tests
```python
stt = STT(MODEL_NAME)
```
#### CETUC
```python
ds = load_data('cetuc_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("CETUC WER:", wer)
```
CETUC WER: 0.12096759949218888
#### Common Voice
```python
ds = load_data('commonvoice_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("CV WER:", wer)
```
CV WER: 0.24977003159495725
#### LaPS
```python
ds = load_data('lapsbm_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("Laps WER:", wer)
```
Laps WER: 0.039769570707070705
#### MLS
```python
ds = load_data('mls_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("MLS WER:", wer)
```
MLS WER: 0.2269637077788063
#### SID
```python
ds = load_data('sid_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("Sid WER:", wer)
```
Sid WER: 0.1691680138494731
#### TEDx
```python
ds = load_data('tedx_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("TEDx WER:", wer)
```
TEDx WER: 0.34908555859018014
#### VoxForge
```python
ds = load_data('voxforge_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("VoxForge WER:", wer)
```
VoxForge WER: 0.11649350649350651
### Tests with LM
```python
!rm -rf ~/.cache
!gdown --id 1GJIKseP5ZkTbllQVgOL98R4yYAcIySFP # trained with wikipedia
stt = STT(MODEL_NAME, lm='pt-BR-wiki.word.4-gram.arpa')
# !gdown --id 1dLFldy7eguPtyJj5OAlI4Emnx0BpFywg # trained with bp
# stt = STT(MODEL_NAME, lm='pt-BR.word.4-gram.arpa')
```
### Cetuc
```python
ds = load_data('cetuc_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("CETUC WER:", wer)
```
CETUC WER: 0.07499558425787961
#### Common Voice
```python
ds = load_data('commonvoice_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("CV WER:", wer)
```
CV WER: 0.17442648452610307
#### LaPS
```python
ds = load_data('lapsbm_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("Laps WER:", wer)
```
Laps WER: 0.032774621212121206
#### MLS
```python
ds = load_data('mls_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("MLS WER:", wer)
```
MLS WER: 0.18213620321569274
#### SID
```python
ds = load_data('sid_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("Sid WER:", wer)
```
Sid WER: 0.18102544972868206
#### TEDx
```python
ds = load_data('tedx_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("TEDx WER:", wer)
```
TEDx WER: 0.3491402028105601
#### VoxForge
```python
ds = load_data('voxforge_dataset')
result = ds.map(stt.batch_predict, batched=True, batch_size=8)
wer, mer, wil = calc_metrics(result["sentence"], result["predicted"])
print("VoxForge WER:", wer)
```
VoxForge WER: 0.11189529220779222
|
munezah/DialoGPT-small-aot
|
8f45548e2773ab5ec614e093b8f8792399b739e7
|
2021-09-12T15:59:00.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
munezah
| null |
munezah/DialoGPT-small-aot
| 214 | null |
transformers
| 3,536 |
---
tags:
- conversational
---
# aot DialoGPT Model
|
Intel/bert-large-uncased-squadv1.1-sparse-80-1x4-block-pruneofa
|
64efe51573e91a5882bd5404a64f681add1e03f9
|
2022-03-27T21:44:13.000Z
|
[
"pytorch",
"onnx",
"bert",
"question-answering",
"en",
"arxiv:2111.05754",
"transformers",
"autotrain_compatible"
] |
question-answering
| false |
Intel
| null |
Intel/bert-large-uncased-squadv1.1-sparse-80-1x4-block-pruneofa
| 214 | null |
transformers
| 3,537 |
---
language: en
---
# 80% 1x4 Block Sparse BERT-Large (uncased) Fine Tuned on SQuADv1.1
This model is a result of fine-tuning a Prune OFA 80% 1x4 block sparse pre-trained BERT-Large combined with knowledge distillation.
This model yields the following results on SQuADv1.1 development set:<br>
`{"exact_match": 84.673, "f1": 91.174}`
For further details see our paper, [Prune Once for All: Sparse Pre-Trained Language Models](https://arxiv.org/abs/2111.05754), and our open source implementation available [here](https://github.com/IntelLabs/Model-Compression-Research-Package/tree/main/research/prune-once-for-all).
|
dmis-lab/biosyn-biobert-bc2gn
|
c4e5e1f07dba9f564624a8dae134e3d3c6ea0187
|
2022-02-25T13:34:38.000Z
|
[
"pytorch",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
| false |
dmis-lab
| null |
dmis-lab/biosyn-biobert-bc2gn
| 213 | null |
transformers
| 3,538 |
hello
|
shahrukhx01/gbert-germeval-2021
|
a864e82a4abec0bdd00cfae57b44836e21b393f8
|
2022-03-23T18:21:01.000Z
|
[
"pytorch",
"bert",
"text-classification",
"de",
"transformers",
"hate-speech-classification"
] |
text-classification
| false |
shahrukhx01
| null |
shahrukhx01/gbert-germeval-2021
| 213 | null |
transformers
| 3,539 |
---
language: "de"
tags:
- hate-speech-classification
widget:
- text: "Als jemand, der im real existierenden Sozialismus aufgewachsen ist, kann ich über George Weineberg nur sagen, dass er ein Voll...t ist. Finde es schon gut, dass der eingeladen wurde. Hat gezeigt, dass er viel Meinung hat, aber offensichtlich wenig Ahnung. Er hat sich eben so gut wie er kann, für alle sichtbar, zum Trottel gemacht"
- text: "Sobald klar ist dass Trump die Wahl gewinnt liegen alle Deutschen Framing Journalisten im Sauerstoffzelt. Wegen extremer Schnappatmung. Das ist zwar hart, aber Fair!"
---
# Usage
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("shahrukhx01/gbert-germeval-2021")
model = AutoModelForSequenceClassification.from_pretrained("shahrukhx01/gbert-germeval-2021")
```
# Dataset
```bibtext
@proceedings{germeval-2021-germeval,
title = "Proceedings of the GermEval 2021 Shared Task on the Identification of Toxic, Engaging, and Fact-Claiming Comments",
editor = "Risch, Julian and
Stoll, Anke and
Wilms, Lena and
Wiegand, Michael",
month = sep,
year = "2021",
address = "Duesseldorf, Germany",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.germeval-1.0",
}
```
---
license: mit
---
|
csebuetnlp/banglabert_generator
|
06dd644b4167462e40bb0354ee62a530b2d2febd
|
2022-06-07T12:16:59.000Z
|
[
"pytorch",
"electra",
"fill-mask",
"bn",
"en",
"arxiv:2101.00204",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
csebuetnlp
| null |
csebuetnlp/banglabert_generator
| 213 | 1 |
transformers
| 3,540 |
---
language:
- bn
- en
licenses:
- cc-by-nc-sa-4.0
---
# BanglishBERT
This repository contains the pretrained generator checkpoint of the model [**BanglaBERT**](). This is an [ELECTRA](https://openreview.net/pdf?id=r1xMH1BtvB) generator model pretrained with the Masked Language Modeling (MLM) objective on large amounts of Bengali corpora.
**Note**: This model was pretrained using a specific normalization pipeline available [here](https://github.com/csebuetnlp/normalizer).
## Using this model for MLM in `transformers` (tested on 4.11.0.dev0)
```python
from normalizer import normalize # pip install git+https://github.com/csebuetnlp/normalizer
from transformers import pipeline
fill_mask = pipeline(
"fill-mask",
model="csebuetnlp/banglabert_generator",
tokenizer="csebuetnlp/banglabert_generator"
)
print(
fill_mask(
normalize(f"আমি বাংলায় {fill_mask.tokenizer.mask_token} গাই।")
)
)
```
If you use this model, please cite the following paper:
```
@inproceedings{bhattacharjee-etal-2022-banglabert,
title = {BanglaBERT: Lagnuage Model Pretraining and Benchmarks for Low-Resource Language Understanding Evaluation in Bangla},
author = "Bhattacharjee, Abhik and
Hasan, Tahmid and
Mubasshir, Kazi and
Islam, Md. Saiful and
Uddin, Wasi Ahmad and
Iqbal, Anindya and
Rahman, M. Sohel and
Shahriyar, Rifat",
booktitle = "Findings of the North American Chapter of the Association for Computational Linguistics: NAACL 2022",
month = july,
year = {2022},
url = {https://arxiv.org/abs/2101.00204},
eprinttype = {arXiv},
eprint = {2101.00204}
}
```
If you use the normalization module, please cite the following paper:
```
@inproceedings{hasan-etal-2020-low,
title = "Not Low-Resource Anymore: Aligner Ensembling, Batch Filtering, and New Datasets for {B}engali-{E}nglish Machine Translation",
author = "Hasan, Tahmid and
Bhattacharjee, Abhik and
Samin, Kazi and
Hasan, Masum and
Basak, Madhusudan and
Rahman, M. Sohel and
Shahriyar, Rifat",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP)",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.emnlp-main.207",
doi = "10.18653/v1/2020.emnlp-main.207",
pages = "2612--2623",
abstract = "Despite being the seventh most widely spoken language in the world, Bengali has received much less attention in machine translation literature due to being low in resources. Most publicly available parallel corpora for Bengali are not large enough; and have rather poor quality, mostly because of incorrect sentence alignments resulting from erroneous sentence segmentation, and also because of a high volume of noise present in them. In this work, we build a customized sentence segmenter for Bengali and propose two novel methods for parallel corpus creation on low-resource setups: aligner ensembling and batch filtering. With the segmenter and the two methods combined, we compile a high-quality Bengali-English parallel corpus comprising of 2.75 million sentence pairs, more than 2 million of which were not available before. Training on neural models, we achieve an improvement of more than 9 BLEU score over previous approaches to Bengali-English machine translation. We also evaluate on a new test set of 1000 pairs made with extensive quality control. We release the segmenter, parallel corpus, and the evaluation set, thus elevating Bengali from its low-resource status. To the best of our knowledge, this is the first ever large scale study on Bengali-English machine translation. We believe our study will pave the way for future research on Bengali-English machine translation as well as other low-resource languages. Our data and code are available at https://github.com/csebuetnlp/banglanmt.",
}
```
|
xlm-roberta-large-finetuned-conll02-dutch
|
c0a0c5196da660dc28bc80e9d94edd28b35fc4e5
|
2022-07-22T08:07:08.000Z
|
[
"pytorch",
"rust",
"xlm-roberta",
"fill-mask",
"multilingual",
"af",
"am",
"ar",
"as",
"az",
"be",
"bg",
"bn",
"br",
"bs",
"ca",
"cs",
"cy",
"da",
"de",
"el",
"en",
"eo",
"es",
"et",
"eu",
"fa",
"fi",
"fr",
"fy",
"ga",
"gd",
"gl",
"gu",
"ha",
"he",
"hi",
"hr",
"hu",
"hy",
"id",
"is",
"it",
"ja",
"jv",
"ka",
"kk",
"km",
"kn",
"ko",
"ku",
"ky",
"la",
"lo",
"lt",
"lv",
"mg",
"mk",
"ml",
"mn",
"mr",
"ms",
"my",
"ne",
"nl",
"no",
"om",
"or",
"pa",
"pl",
"ps",
"pt",
"ro",
"ru",
"sa",
"sd",
"si",
"sk",
"sl",
"so",
"sq",
"sr",
"su",
"sv",
"sw",
"ta",
"te",
"th",
"tl",
"tr",
"ug",
"uk",
"ur",
"uz",
"vi",
"xh",
"yi",
"zh",
"arxiv:1911.02116",
"arxiv:1910.09700",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false | null | null |
xlm-roberta-large-finetuned-conll02-dutch
| 212 | null |
transformers
| 3,541 |
---
language:
- multilingual
- af
- am
- ar
- as
- az
- be
- bg
- bn
- br
- bs
- ca
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- he
- hi
- hr
- hu
- hy
- id
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- no
- om
- or
- pa
- pl
- ps
- pt
- ro
- ru
- sa
- sd
- si
- sk
- sl
- so
- sq
- sr
- su
- sv
- sw
- ta
- te
- th
- tl
- tr
- ug
- uk
- ur
- uz
- vi
- xh
- yi
- zh
---
# xlm-roberta-large-finetuned-conll02-dutch
# Table of Contents
1. [Model Details](#model-details)
2. [Uses](#uses)
3. [Bias, Risks, and Limitations](#bias-risks-and-limitations)
4. [Training](#training)
5. [Evaluation](#evaluation)
6. [Environmental Impact](#environmental-impact)
7. [Technical Specifications](#technical-specifications)
8. [Citation](#citation)
9. [Model Card Authors](#model-card-authors)
10. [How To Get Started With the Model](#how-to-get-started-with-the-model)
# Model Details
## Model Description
The XLM-RoBERTa model was proposed in [Unsupervised Cross-lingual Representation Learning at Scale](https://arxiv.org/abs/1911.02116) by Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer and Veselin Stoyanov. It is based on Facebook's RoBERTa model released in 2019. It is a large multi-lingual language model, trained on 2.5TB of filtered CommonCrawl data. This model is [XLM-RoBERTa-large](https://huggingface.co/xlm-roberta-large) fine-tuned with the [CoNLL-2002](https://huggingface.co/datasets/conll2002) dataset in Dutch.
- **Developed by:** See [associated paper](https://arxiv.org/abs/1911.02116)
- **Model type:** Multi-lingual language model
- **Language(s) (NLP):** XLM-RoBERTa is a multilingual model trained on 100 different languages; see [GitHub Repo](https://github.com/facebookresearch/fairseq/tree/main/examples/xlmr) for full list; model is fine-tuned on a dataset in Dutch
- **License:** More information needed
- **Related Models:** [RoBERTa](https://huggingface.co/roberta-base), [XLM](https://huggingface.co/docs/transformers/model_doc/xlm)
- **Parent Model:** [XLM-RoBERTa-large](https://huggingface.co/xlm-roberta-large)
- **Resources for more information:**
-[GitHub Repo](https://github.com/facebookresearch/fairseq/tree/main/examples/xlmr)
-[Associated Paper](https://arxiv.org/abs/1911.02116)
-[CoNLL-2002 data card](https://huggingface.co/datasets/conll2002)
# Uses
## Direct Use
The model is a language model. The model can be used for token classification, a natural language understanding task in which a label is assigned to some tokens in a text.
## Downstream Use
Potential downstream use cases include Named Entity Recognition (NER) and Part-of-Speech (PoS) tagging. To learn more about token classification and other potential downstream use cases, see the Hugging Face [token classification docs](https://huggingface.co/tasks/token-classification).
## Out-of-Scope Use
The model should not be used to intentionally create hostile or alienating environments for people.
# Bias, Risks, and Limitations
**CONTENT WARNING: Readers should be made aware that language generated by this model may be disturbing or offensive to some and may propagate historical and current stereotypes.**
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)).
## Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model.
# Training
See the following resources for training data and training procedure details:
- [XLM-RoBERTa-large model card](https://huggingface.co/xlm-roberta-large)
- [CoNLL-2002 data card](https://huggingface.co/datasets/conll2002)
- [Associated paper](https://arxiv.org/pdf/1911.02116.pdf)
# Evaluation
See the [associated paper](https://arxiv.org/pdf/1911.02116.pdf) for evaluation details.
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** 500 32GB Nvidia V100 GPUs (from the [associated paper](https://arxiv.org/pdf/1911.02116.pdf))
- **Hours used:** More information needed
- **Cloud Provider:** More information needed
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Technical Specifications
See the [associated paper](https://arxiv.org/pdf/1911.02116.pdf) for further details.
# Citation
**BibTeX:**
```bibtex
@article{conneau2019unsupervised,
title={Unsupervised Cross-lingual Representation Learning at Scale},
author={Conneau, Alexis and Khandelwal, Kartikay and Goyal, Naman and Chaudhary, Vishrav and Wenzek, Guillaume and Guzm{\'a}n, Francisco and Grave, Edouard and Ott, Myle and Zettlemoyer, Luke and Stoyanov, Veselin},
journal={arXiv preprint arXiv:1911.02116},
year={2019}
}
```
**APA:**
- Conneau, A., Khandelwal, K., Goyal, N., Chaudhary, V., Wenzek, G., Guzmán, F., ... & Stoyanov, V. (2019). Unsupervised cross-lingual representation learning at scale. arXiv preprint arXiv:1911.02116.
# Model Card Authors
This model card was written by the team at Hugging Face.
# How to Get Started with the Model
Use the code below to get started with the model. You can use this model directly within a pipeline for NER.
<details>
<summary> Click to expand </summary>
```python
>>> from transformers import AutoTokenizer, AutoModelForTokenClassification
>>> from transformers import pipeline
>>> tokenizer = AutoTokenizer.from_pretrained("xlm-roberta-large-finetuned-conll02-dutch")
>>> model = AutoModelForTokenClassification.from_pretrained("xlm-roberta-large-finetuned-conll02-dutch")
>>> classifier = pipeline("ner", model=model, tokenizer=tokenizer)
>>> classifier("Mijn naam is Emma en ik woon in Londen.")
[{'end': 17,
'entity': 'B-PER',
'index': 4,
'score': 0.9999807,
'start': 13,
'word': '▁Emma'},
{'end': 36,
'entity': 'B-LOC',
'index': 9,
'score': 0.9999871,
'start': 32,
'word': '▁Lond'}]
```
</details>
|
howey/roberta-large-sst2
|
39794fcd4c738aeb975812ff1e03f397725f5ecb
|
2021-06-03T11:35:36.000Z
|
[
"pytorch",
"roberta",
"text-classification",
"transformers"
] |
text-classification
| false |
howey
| null |
howey/roberta-large-sst2
| 212 | null |
transformers
| 3,542 |
Entry not found
|
otto-camp/DialoGPT-small-RickBot
|
6003ba0aa0854666ba3aa8a5c3b5cacc692e3a73
|
2021-10-16T14:49:59.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
otto-camp
| null |
otto-camp/DialoGPT-small-RickBot
| 212 | null |
transformers
| 3,543 |
---
tags:
- conversational
---
# Rick DialoGPT Model
|
K024/mt5-zh-ja-en-trimmed
|
6da335241a1792378b455db3e60a86472e50b8e9
|
2022-03-24T14:57:22.000Z
|
[
"pytorch",
"mt5",
"text2text-generation",
"zh",
"ja",
"en",
"transformers",
"translation",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible"
] |
translation
| false |
K024
| null |
K024/mt5-zh-ja-en-trimmed
| 211 | 5 |
transformers
| 3,544 |
---
language:
- zh
- ja
- en
tags:
- translation
widget:
- text: "ja2zh: 吾輩は猫である。名前はまだ無い。"
license: cc-by-nc-sa-4.0
---
This model is finetuned from [mt5-base](https://huggingface.co/google/mt5-base).
The model vocabulary is trimmed to ~1/3 by selecting top 85000 tokens in the training data. The code to trim the vocabulary can be found [here](https://gist.github.com/K024/4a100a0f4f4b07208958e0f3244da6ad).
Usage:
```python
from transformers import (
T5Tokenizer,
MT5ForConditionalGeneration,
Text2TextGenerationPipeline,
)
path = "K024/mt5-zh-ja-en-trimmed"
pipe = Text2TextGenerationPipeline(
model=MT5ForConditionalGeneration.from_pretrained(path),
tokenizer=T5Tokenizer.from_pretrained(path),
)
sentence = "ja2zh: 吾輩は猫である。名前はまだ無い。"
res = pipe(sentence, max_length=100, num_beams=4)
res[0]['generated_text']
```
Training data:
```
wikimedia-en-ja
wikimedia-en-zh
wikimedia-ja-zh
wikititles-ja-en
wikititles-zh-en
wikimatrix-ja-zh
news-commentary-en-ja
news-commentary-en-zh
news-commentary-ja-zh
ted2020-en-ja
ted2020-en-zh
ted2020-ja-zh
```
License: [![CC BY-NC-SA 4.0][cc-by-nc-sa-image]][cc-by-nc-sa]
[cc-by-nc-sa]: http://creativecommons.org/licenses/by-nc-sa/4.0/
[cc-by-nc-sa-image]: https://licensebuttons.net/l/by-nc-sa/4.0/88x31.png
|
adamlin/comet-atomic_2020_BART
|
2123a1f6509dbdfc006a336e3ea0321b155f88a0
|
2021-07-18T12:46:13.000Z
|
[
"pytorch",
"bart",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
adamlin
| null |
adamlin/comet-atomic_2020_BART
| 211 | 2 |
transformers
| 3,545 |
Entry not found
|
deepmind/optical-flow-perceiver
|
dd4bf60748100842873f4c74660f409889989faf
|
2021-12-11T13:28:43.000Z
|
[
"pytorch",
"perceiver",
"dataset:autoflow",
"arxiv:2107.14795",
"transformers",
"license:apache-2.0"
] | null | false |
deepmind
| null |
deepmind/optical-flow-perceiver
| 211 | 2 |
transformers
| 3,546 |
---
license: apache-2.0
tags:
datasets:
- autoflow
---
# Perceiver IO for optical flow
Perceiver IO model trained on [AutoFlow](https://autoflow-google.github.io/). It was introduced in the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Jaegle et al. and first released in [this repository](https://github.com/deepmind/deepmind-research/tree/master/perceiver).
Optical flow is a decades-old open problem in computer vision. Given two images of the same scene (e.g. two consecutive frames of a video), the task is to estimate the 2D displacement for each pixel in the first image. This has many broader applications, such as navigation and visual odometry in robots, estimation of 3D geometry, and even to aid transfer of more complex, learned inference such as 3D human pose estimation from synthetic to real images.
Disclaimer: The team releasing Perceiver IO did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
Perceiver IO is a transformer encoder model that can be applied on any modality (text, images, audio, video, ...). The core idea is to employ the self-attention mechanism on a not-too-large set of latent vectors (e.g. 256 or 512), and only use the inputs to perform cross-attention with the latents. This allows for the time and memory requirements of the self-attention mechanism to not depend on the size of the inputs.
To decode, the authors employ so-called decoder queries, which allow to flexibly decode the final hidden states of the latents to produce outputs of arbitrary size and semantics. For optical flow, the output is a tensor containing the predicted flow of shape (batch_size, height, width, 2).
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/perceiver_architecture.jpg" alt="drawing" width="600"/>
<small> Perceiver IO architecture.</small>
As the time and memory requirements of the self-attention mechanism don't depend on the size of the inputs, the Perceiver IO authors can train the model on raw pixel values, by concatenating a pair of images and extracting a 3x3 patch around each pixel.
The model obtains state-of-the-art results on important optical flow benchmarks, including [Sintel](http://sintel.is.tue.mpg.de/) and [KITTI](http://www.cvlibs.net/datasets/kitti/eval_scene_flow.php?benchmark=flow).
## Intended uses & limitations
You can use the raw model for predicting optical flow between a pair of images. See the [model hub](https://huggingface.co/models?search=deepmind/perceiver) to look for other versions on a task that may interest you.
### How to use
We refer to the [tutorial notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Perceiver/Perceiver_for_Optical_Flow.ipynb) regarding using the Perceiver for optical flow.
## Training data
This model was trained on [AutoFlow](https://autoflow-google.github.io/), a synthetic dataset consisting of 400,000 annotated image pairs.
## Training procedure
### Preprocessing
Frames are resized to a resolution of 368x496. The authors concatenate the frames along the channel dimension and extract a 3x3 patch around each pixel (leading to 3x3x3x2 = 54 values for each pixel).
### Pretraining
Hyperparameter details can be found in Appendix E of the [paper](https://arxiv.org/abs/2107.14795).
## Evaluation results
The model achieves a average end-point error (EPE) of 1.81 on Sintel.clean, 2.42 on Sintel.final and 4.98 on KITTI. For evaluation results, we refer to table 4 of the [paper](https://arxiv.org/abs/2107.14795).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2107-14795,
author = {Andrew Jaegle and
Sebastian Borgeaud and
Jean{-}Baptiste Alayrac and
Carl Doersch and
Catalin Ionescu and
David Ding and
Skanda Koppula and
Daniel Zoran and
Andrew Brock and
Evan Shelhamer and
Olivier J. H{\'{e}}naff and
Matthew M. Botvinick and
Andrew Zisserman and
Oriol Vinyals and
Jo{\~{a}}o Carreira},
title = {Perceiver {IO:} {A} General Architecture for Structured Inputs {\&}
Outputs},
journal = {CoRR},
volume = {abs/2107.14795},
year = {2021},
url = {https://arxiv.org/abs/2107.14795},
eprinttype = {arXiv},
eprint = {2107.14795},
timestamp = {Tue, 03 Aug 2021 14:53:34 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2107-14795.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
icelab/spaceroberta
|
e66632e6c6ba4d4a60f142694f98a28c4f33a8df
|
2021-10-21T08:40:55.000Z
|
[
"pytorch",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
icelab
| null |
icelab/spaceroberta
| 211 | null |
transformers
| 3,547 |
### SpaceRoBERTa
This is one of the 3 further pre-trained models from the SpaceTransformers family presented in [SpaceTransformers: Language Modeling for Space Systems](https://ieeexplore.ieee.org/document/9548078). The original Git repo is [strath-ace/smart-nlp](https://github.com/strath-ace/smart-nlp).
The further pre-training corpus includes publications abstracts, books, and Wikipedia pages related to space systems. Corpus size is 14.3 GB. SpaceRoBERTa was further pre-trained on this domain-specific corpus from [RoBERTa-Base](https://huggingface.co/roberta-base). In our paper, it is then fine-tuned for a Concept Recognition task.
### BibTeX entry and citation info
```
@ARTICLE{
9548078,
author={Berquand, Audrey and Darm, Paul and Riccardi, Annalisa},
journal={IEEE Access},
title={SpaceTransformers: Language Modeling for Space Systems},
year={2021},
volume={9},
number={},
pages={133111-133122},
doi={10.1109/ACCESS.2021.3115659}
}
```
|
textattack/distilbert-base-cased-QQP
|
8e5453d3a4d843a638701f7918896fee4d12ec8b
|
2020-06-09T16:46:12.000Z
|
[
"pytorch",
"distilbert",
"text-classification",
"transformers"
] |
text-classification
| false |
textattack
| null |
textattack/distilbert-base-cased-QQP
| 211 | null |
transformers
| 3,548 |
Entry not found
|
tartuNLP/nmt-all-to-liv-base
|
16d92cfae3fc7f8083e03b17219ac94c014c1bba
|
2022-04-04T06:49:23.000Z
|
[
"pytorch",
"m2m_100",
"text2text-generation",
"en",
"lt",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
tartuNLP
| null |
tartuNLP/nmt-all-to-liv-base
| 211 | null |
transformers
| 3,549 |
---
language:
- en
- lt
widget:
- text: "Let us translate some text to Livonian!"
---
# Livonian NMT
This model translates English, Estonian and Latvian into Livonian. It is based on [m2m100_418M](https://huggingface.co/facebook/m2m100_418M), fine-tuned to all-to-Livonian data from the [liv4ever](https://huggingface.co/datasets/tartuNLP/liv4ever-data) dataset.
|
imxly/t5-copy-summary
|
f986a2f4b5ea47473e830df512c8a5f8f3e9d63c
|
2022-05-05T11:05:44.000Z
|
[
"pytorch",
"mt5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
imxly
| null |
imxly/t5-copy-summary
| 211 | null |
transformers
| 3,550 |
Entry not found
|
StanfordAIMI/stanford-deidentifier-only-radiology-reports-augmented
|
9b3bce8b1fef32bba2f32b6c8452396a5580bc3d
|
2022-07-18T03:49:15.000Z
|
[
"pytorch",
"bert",
"en",
"dataset:radreports",
"transformers",
"token-classification",
"sequence-tagger-model",
"pubmedbert",
"uncased",
"radiology",
"biomedical",
"license:mit"
] |
token-classification
| false |
StanfordAIMI
| null |
StanfordAIMI/stanford-deidentifier-only-radiology-reports-augmented
| 211 | 2 |
transformers
| 3,551 |
---
widget:
- text: "PROCEDURE: Chest xray. COMPARISON: last seen on 1/1/2020 and also record dated of March 1st, 2019. FINDINGS: patchy airspace opacities. IMPRESSION: The results of the chest xray of January 1 2020 are the most concerning ones. The patient was transmitted to another service of UH Medical Center under the responsability of Dr. Perez. We used the system MedClinical data transmitter and sent the data on 2/1/2020, under the ID 5874233. We received the confirmation of Dr Perez. He is reachable at 567-493-1234."
- text: "Dr. Curt Langlotz chose to schedule a meeting on 06/23."
tags:
- token-classification
- sequence-tagger-model
- pytorch
- transformers
- pubmedbert
- uncased
- radiology
- biomedical
datasets:
- radreports
language:
- en
license: mit
---
Stanford de-identifier was trained on a variety of radiology and biomedical documents with the goal of automatising the de-identification process while reaching satisfactory accuracy for use in production. Manuscript in-proceedings.
|
KBLab/wav2vec2-large-voxrex-swedish
|
9f474d0de2343f862a2d3ee4984402814d30b3ca
|
2022-05-16T09:43:37.000Z
|
[
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"sv",
"dataset:common_voice",
"dataset:NST Swedish ASR Database",
"dataset:P4",
"arxiv:2205.03026",
"transformers",
"audio",
"speech",
"hf-asr-leaderboard",
"license:cc0-1.0",
"model-index"
] |
automatic-speech-recognition
| false |
KBLab
| null |
KBLab/wav2vec2-large-voxrex-swedish
| 210 | 1 |
transformers
| 3,552 |
---
language: sv
datasets:
- common_voice
- NST Swedish ASR Database
- P4
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- hf-asr-leaderboard
license: cc0-1.0
model-index:
- name: Wav2vec 2.0 large VoxRex Swedish
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice
type: common_voice
args: sv-SE
metrics:
- name: Test WER
type: wer
value: 8.49
---
# Wav2vec 2.0 large VoxRex Swedish (C)
**Disclaimer:** This is a work in progress. See [VoxRex](https://huggingface.co/KBLab/wav2vec2-large-voxrex) for more details.
**Update 2022-01-10:** Updated to VoxRex-C version.
**Update 2022-05-16:** Paper is is [here](https://arxiv.org/abs/2205.03026).
Finetuned version of KBs [VoxRex large](https://huggingface.co/KBLab/wav2vec2-large-voxrex) model using Swedish radio broadcasts, NST and Common Voice data. Evalutation without a language model gives the following: WER for NST + Common Voice test set (2% of total sentences) is **2.5%**. WER for Common Voice test set is **8.49%** directly and **7.37%** with a 4-gram language model.
When using this model, make sure that your speech input is sampled at 16kHz.
# Performance\*

<center><del>*<i>Chart shows performance without the additional 20k steps of Common Voice fine-tuning</i></del></center>
## Training
This model has been fine-tuned for 120000 updates on NST + CommonVoice<del> and then for an additional 20000 updates on CommonVoice only. The additional fine-tuning on CommonVoice hurts performance on the NST+CommonVoice test set somewhat and, unsurprisingly, improves it on the CommonVoice test set. It seems to perform generally better though [citation needed]</del>.

## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "sv-SE", split="test[:2%]").
processor = Wav2Vec2Processor.from_pretrained("KBLab/wav2vec2-large-voxrex-swedish")
model = Wav2Vec2ForCTC.from_pretrained("KBLab/wav2vec2-large-voxrex-swedish")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
|
ccdv/lsg-bart-base-4096
|
b19ad1086f91c4013dc9f0c609d244cf473b51b8
|
2022-07-25T05:36:15.000Z
|
[
"pytorch",
"bart",
"text2text-generation",
"en",
"arxiv:1910.13461",
"transformers",
"summarization",
"long context",
"fill-mask",
"autotrain_compatible"
] |
fill-mask
| false |
ccdv
| null |
ccdv/lsg-bart-base-4096
| 210 | null |
transformers
| 3,553 |
---
tags:
- summarization
- bart
- long context
language:
- en
pipeline_tag: fill-mask
---
# LSG model
**Transformers >= 4.18.0**\
**This model relies on a custom modeling file, you need to add trust_remote_code=True**\
**See [\#13467](https://github.com/huggingface/transformers/pull/13467)**
* [Usage](#usage)
* [Parameters](#parameters)
* [Sparse selection type](#sparse-selection-type)
* [Tasks](#tasks)
This model is adapted from [BART-base](https://huggingface.co/facebook/bart-base) for encoder-decoder tasks without additional pretraining. It uses the same number of parameters/layers and the same tokenizer.
This model can handle long sequences but faster and more efficiently than Longformer (LED) or BigBird (Pegasus) from the hub and relies on Local + Sparse + Global attention (LSG).
The model requires sequences whose length is a multiple of the block size. The model is "adaptive" and automatically pads the sequences if needed (adaptive=True in config). It is however recommended, thanks to the tokenizer, to truncate the inputs (truncation=True) and optionally to pad with a multiple of the block size (pad_to_multiple_of=...). \
Implemented in PyTorch.

## Usage
The model relies on a custom modeling file, you need to add trust_remote_code=True to use it.
```python:
from transformers import AutoModel, AutoTokenizer
model = AutoModel.from_pretrained("ccdv/lsg-bart-base-4096", trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("ccdv/lsg-bart-base-4096")
```
## Parameters
You can change various parameters like :
* the number of global tokens (num_global_tokens=1)
* local block size (block_size=128)
* sparse block size (sparse_block_size=128)
* sparsity factor (sparsity_factor=2)
* mask_first_token (mask first token since it is redundant with the first global token)
* see config.json file
Default parameters work well in practice. If you are short on memory, reduce block sizes, increase sparsity factor and remove dropout in the attention score matrix.
```python:
from transformers import AutoModel
model = AutoModel.from_pretrained("ccdv/lsg-bart-base-4096",
trust_remote_code=True,
num_global_tokens=16,
block_size=64,
sparse_block_size=64,
attention_probs_dropout_prob=0.0
sparsity_factor=4,
sparsity_type="none",
mask_first_token=True
)
```
## Sparse selection type
There are 5 different sparse selection patterns. The best type is task dependent. \
Note that for sequences with length < 2*block_size, the type has no effect.
* sparsity_type="norm", select highest norm tokens
* Works best for a small sparsity_factor (2 to 4)
* Additional parameters:
* None
* sparsity_type="pooling", use average pooling to merge tokens
* Works best for a small sparsity_factor (2 to 4)
* Additional parameters:
* None
* sparsity_type="lsh", use the LSH algorithm to cluster similar tokens
* Works best for a large sparsity_factor (4+)
* LSH relies on random projections, thus inference may differ slightly with different seeds
* Additional parameters:
* lsg_num_pre_rounds=1, pre merge tokens n times before computing centroids
* sparsity_type="stride", use a striding mecanism per head
* Each head will use different tokens strided by sparsify_factor
* Not recommended if sparsify_factor > num_heads
* sparsity_type="block_stride", use a striding mecanism per head
* Each head will use block of tokens strided by sparsify_factor
* Not recommended if sparsify_factor > num_heads
## Tasks
Seq2Seq example for summarization:
```python:
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
model = AutoModelForSeq2SeqLM.from_pretrained("ccdv/lsg-bart-base-4096",
trust_remote_code=True,
pass_global_tokens_to_decoder=True, # Pass encoder global tokens to decoder
)
tokenizer = AutoTokenizer.from_pretrained("ccdv/lsg-bart-base-4096")
SENTENCE = "This is a test sequence to test the model. " * 300
token_ids = tokenizer(
SENTENCE,
return_tensors="pt",
padding="max_length", # Optional but recommended
truncation=True # Optional but recommended
)
output = model(**token_ids)
```
Classification example:
```python:
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("ccdv/lsg-bart-base-4096",
trust_remote_code=True,
pass_global_tokens_to_decoder=True, # Pass encoder global tokens to decoder
)
tokenizer = AutoTokenizer.from_pretrained("ccdv/lsg-bart-base-4096")
SENTENCE = "This is a test sequence to test the model. " * 300
token_ids = tokenizer(
SENTENCE,
return_tensors="pt",
#pad_to_multiple_of=... # Optional
truncation=True
)
output = model(**token_ids)
> SequenceClassifierOutput(loss=None, logits=tensor([[-0.3051, -0.1762]], grad_fn=<AddmmBackward>), hidden_states=None, attentions=None)
```
**BART**
```
@article{DBLP:journals/corr/abs-1910-13461,
author = {Mike Lewis and
Yinhan Liu and
Naman Goyal and
Marjan Ghazvininejad and
Abdelrahman Mohamed and
Omer Levy and
Veselin Stoyanov and
Luke Zettlemoyer},
title = {{BART:} Denoising Sequence-to-Sequence Pre-training for Natural Language
Generation, Translation, and Comprehension},
journal = {CoRR},
volume = {abs/1910.13461},
year = {2019},
url = {http://arxiv.org/abs/1910.13461},
eprinttype = {arXiv},
eprint = {1910.13461},
timestamp = {Thu, 31 Oct 2019 14:02:26 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1910-13461.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
mkhalifa/gpt2-biographies
|
b444af05322fe1159e3a4044cb55f30a4e24a6b2
|
2021-05-23T09:37:00.000Z
|
[
"pytorch",
"jax",
"gpt2",
"text-generation",
"transformers"
] |
text-generation
| false |
mkhalifa
| null |
mkhalifa/gpt2-biographies
| 210 | 1 |
transformers
| 3,554 |
Entry not found
|
mrm8488/distilgpt2-finetuned-wsb-tweets
|
915d44dda5da9513770ed91ae43be53492973ef5
|
2021-05-23T10:23:17.000Z
|
[
"pytorch",
"jax",
"gpt2",
"text-generation",
"en",
"transformers",
"wsb",
"tweets"
] |
text-generation
| false |
mrm8488
| null |
mrm8488/distilgpt2-finetuned-wsb-tweets
| 210 | 0 |
transformers
| 3,555 |
---
language: en
tags:
- wsb
- tweets
widget:
- text: "Come on guys this is"
---
# distilGPT-2 fine-tuned on Kaggle WSB Reddit posts dataset
|
w11wo/indonesian-roberta-base-sentiment-classifier
|
b359aedef1ff88b64a47b2378cb542ef037bfc49
|
2021-07-19T18:17:52.000Z
|
[
"pytorch",
"tf",
"roberta",
"text-classification",
"id",
"dataset:indonlu",
"arxiv:1907.11692",
"transformers",
"indonesian-roberta-base-sentiment-classifier",
"license:mit"
] |
text-classification
| false |
w11wo
| null |
w11wo/indonesian-roberta-base-sentiment-classifier
| 210 | 1 |
transformers
| 3,556 |
---
language: id
tags:
- indonesian-roberta-base-sentiment-classifier
license: mit
datasets:
- indonlu
widget:
- text: "Jangan sampai saya telpon bos saya ya!"
---
## Indonesian RoBERTa Base Sentiment Classifier
Indonesian RoBERTa Base Sentiment Classifier is a sentiment-text-classification model based on the [RoBERTa](https://arxiv.org/abs/1907.11692) model. The model was originally the pre-trained [Indonesian RoBERTa Base](https://hf.co/flax-community/indonesian-roberta-base) model, which is then fine-tuned on [`indonlu`](https://hf.co/datasets/indonlu)'s `SmSA` dataset consisting of Indonesian comments and reviews.
After training, the model achieved an evaluation accuracy of 94.36% and F1-macro of 92.42%. On the benchmark test set, the model achieved an accuracy of 93.2% and F1-macro of 91.02%.
Hugging Face's `Trainer` class from the [Transformers](https://huggingface.co/transformers) library was used to train the model. PyTorch was used as the backend framework during training, but the model remains compatible with other frameworks nonetheless.
## Model
| Model | #params | Arch. | Training/Validation data (text) |
| ---------------------------------------------- | ------- | ------------ | ------------------------------- |
| `indonesian-roberta-base-sentiment-classifier` | 124M | RoBERTa Base | `SmSA` |
## Evaluation Results
The model was trained for 5 epochs and the best model was loaded at the end.
| Epoch | Training Loss | Validation Loss | Accuracy | F1 | Precision | Recall |
| ----- | ------------- | --------------- | -------- | -------- | --------- | -------- |
| 1 | 0.342600 | 0.213551 | 0.928571 | 0.898539 | 0.909803 | 0.890694 |
| 2 | 0.190700 | 0.213466 | 0.934127 | 0.901135 | 0.925297 | 0.882757 |
| 3 | 0.125500 | 0.219539 | 0.942857 | 0.920901 | 0.927511 | 0.915193 |
| 4 | 0.083600 | 0.235232 | 0.943651 | 0.924227 | 0.926494 | 0.922048 |
| 5 | 0.059200 | 0.262473 | 0.942063 | 0.920583 | 0.924084 | 0.917351 |
## How to Use
### As Text Classifier
```python
from transformers import pipeline
pretrained_name = "w11wo/indonesian-roberta-base-sentiment-classifier"
nlp = pipeline(
"sentiment-analysis",
model=pretrained_name,
tokenizer=pretrained_name
)
nlp("Jangan sampai saya telpon bos saya ya!")
```
## Disclaimer
Do consider the biases which come from both the pre-trained RoBERTa model and the `SmSA` dataset that may be carried over into the results of this model.
## Author
Indonesian RoBERTa Base Sentiment Classifier was trained and evaluated by [Wilson Wongso](https://w11wo.github.io/). All computation and development are done on Google Colaboratory using their free GPU access.
|
xcjthu/Lawformer
|
860b4e23118d5884b44abb060bf2a498d02c5ffc
|
2021-05-05T11:57:20.000Z
|
[
"pytorch",
"longformer",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
xcjthu
| null |
xcjthu/Lawformer
| 210 | 1 |
transformers
| 3,557 |
## Lawformer
### Introduction
This repository provides the source code and checkpoints of the paper "Lawformer: A Pre-trained Language Model forChinese Legal Long Documents". You can download the checkpoint from the [huggingface model hub](https://huggingface.co/xcjthu/Lawformer) or from [here](https://data.thunlp.org/legal/Lawformer.zip).
### Easy Start
We have uploaded our model to the huggingface model hub. Make sure you have installed transformers.
```python
>>> from transformers import AutoModel, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("hfl/chinese-roberta-wwm-ext")
>>> model = AutoModel.from_pretrained("xcjthu/Lawformer")
>>> inputs = tokenizer("任某提起诉讼,请求判令解除婚姻关系并对夫妻共同财产进行分割。", return_tensors="pt")
>>> outputs = model(**inputs)
```
### Cite
If you use the pre-trained models, please cite this paper:
```
@article{xiao2021lawformer,
title={Lawformer: A Pre-trained Language Model forChinese Legal Long Documents},
author={Xiao, Chaojun and Hu, Xueyu and Liu, Zhiyuan and Tu, Cunchao and Sun, Maosong},
year={2021}
}
```
|
yoshitomo-matsubara/bert-base-uncased-rte
|
18e5ebac21791f2672657f0388d42375f21acc29
|
2021-05-29T21:55:13.000Z
|
[
"pytorch",
"bert",
"text-classification",
"en",
"dataset:rte",
"transformers",
"rte",
"glue",
"torchdistill",
"license:apache-2.0"
] |
text-classification
| false |
yoshitomo-matsubara
| null |
yoshitomo-matsubara/bert-base-uncased-rte
| 210 | null |
transformers
| 3,558 |
---
language: en
tags:
- bert
- rte
- glue
- torchdistill
license: apache-2.0
datasets:
- rte
metrics:
- accuracy
---
`bert-base-uncased` fine-tuned on RTE dataset, using [***torchdistill***](https://github.com/yoshitomo-matsubara/torchdistill) and [Google Colab](https://colab.research.google.com/github/yoshitomo-matsubara/torchdistill/blob/master/demo/glue_finetuning_and_submission.ipynb).
The hyperparameters are the same as those in Hugging Face's example and/or the paper of BERT, and the training configuration (including hyperparameters) is available [here](https://github.com/yoshitomo-matsubara/torchdistill/blob/main/configs/sample/glue/rte/ce/bert_base_uncased.yaml).
I submitted prediction files to [the GLUE leaderboard](https://gluebenchmark.com/leaderboard), and the overall GLUE score was **77.9**.
|
zemi/jakebot
|
d24f6a4f049e6c29f2c752a42c81cf9de0089b09
|
2021-09-12T10:17:03.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
zemi
| null |
zemi/jakebot
| 210 | null |
transformers
| 3,559 |
---
tags:
- conversational
---
# Jake Peralta
|
etmckinley/BOTHALTEROUT
|
8b6271a4385c8775de14947020f57cdbe8229b87
|
2022-06-04T18:26:24.000Z
|
[
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"transformers",
"license:mit",
"model-index"
] |
text-generation
| false |
etmckinley
| null |
etmckinley/BOTHALTEROUT
| 210 | 2 |
transformers
| 3,560 |
---
license: mit
tags:
model-index:
- name: BERFALTER
results: []
widget:
- text: "Gregg Berhalter"
- text: "The USMNT won't win the World Cup"
- text: "The Soccer Media in this country"
- text: "Ball don't"
- text: "This lineup"
---
# BOTHALTEROUT
This model is a fine-tuned version of [GPT-2](https://huggingface.co/gpt2) using 21,832 tweets from 12 twitter users with very strong opinions about the United States Men's National Team.
## Limitations and bias
The model has all [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
Additionally, BOTHALTEROUT can create some problematic results based upon the tweets used to generate the model.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001372
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu113
- Datasets 2.2.2
- Tokenizers 0.12.1
## About
*Built by [Eliot McKinley](https://twitter.com/etmckinley) based upon [HuggingTweets](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb) by Boris Dayama*
|
HooshvareLab/bert-base-parsbert-peymaner-uncased
|
984799b9ec0f4a959c9af22072e40e440853717a
|
2021-05-18T20:45:45.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"token-classification",
"fa",
"arxiv:2005.12515",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
token-classification
| false |
HooshvareLab
| null |
HooshvareLab/bert-base-parsbert-peymaner-uncased
| 209 | null |
transformers
| 3,561 |
---
language: fa
license: apache-2.0
---
## ParsBERT: Transformer-based Model for Persian Language Understanding
ParsBERT is a monolingual language model based on Google’s BERT architecture with the same configurations as BERT-Base.
Paper presenting ParsBERT: [arXiv:2005.12515](https://arxiv.org/abs/2005.12515)
All the models (downstream tasks) are uncased and trained with whole word masking. (coming soon stay tuned)
## Persian NER [ARMAN, PEYMA, ARMAN+PEYMA]
This task aims to extract named entities in the text, such as names and label with appropriate `NER` classes such as locations, organizations, etc. The datasets used for this task contain sentences that are marked with `IOB` format. In this format, tokens that are not part of an entity are tagged as `”O”` the `”B”`tag corresponds to the first word of an object, and the `”I”` tag corresponds to the rest of the terms of the same entity. Both `”B”` and `”I”` tags are followed by a hyphen (or underscore), followed by the entity category. Therefore, the NER task is a multi-class token classification problem that labels the tokens upon being fed a raw text. There are two primary datasets used in Persian NER, `ARMAN`, and `PEYMA`. In ParsBERT, we prepared ner for both datasets as well as a combination of both datasets.
### PEYMA
PEYMA dataset includes 7,145 sentences with a total of 302,530 tokens from which 41,148 tokens are tagged with seven different classes.
1. Organization
2. Money
3. Location
4. Date
5. Time
6. Person
7. Percent
| Label | # |
|:------------:|:-----:|
| Organization | 16964 |
| Money | 2037 |
| Location | 8782 |
| Date | 4259 |
| Time | 732 |
| Person | 7675 |
| Percent | 699 |
**Download**
You can download the dataset from [here](http://nsurl.org/tasks/task-7-named-entity-recognition-ner-for-farsi/)
## Results
The following table summarizes the F1 score obtained by ParsBERT as compared to other models and architectures.
| Dataset | ParsBERT | MorphoBERT | Beheshti-NER | LSTM-CRF | Rule-Based CRF | BiLSTM-CRF |
|---------|----------|------------|--------------|----------|----------------|------------|
| PEYMA | 98.79* | - | 90.59 | - | 84.00 | - |
## How to use :hugs:
| Notebook | Description | |
|:----------|:-------------|------:|
| [How to use Pipelines](https://github.com/hooshvare/parsbert-ner/blob/master/persian-ner-pipeline.ipynb) | Simple and efficient way to use State-of-the-Art models on downstream tasks through transformers | [](https://colab.research.google.com/github/hooshvare/parsbert-ner/blob/master/persian-ner-pipeline.ipynb) |
## Cite
Please cite the following paper in your publication if you are using [ParsBERT](https://arxiv.org/abs/2005.12515) in your research:
```markdown
@article{ParsBERT,
title={ParsBERT: Transformer-based Model for Persian Language Understanding},
author={Mehrdad Farahani, Mohammad Gharachorloo, Marzieh Farahani, Mohammad Manthouri},
journal={ArXiv},
year={2020},
volume={abs/2005.12515}
}
```
## Acknowledgments
We hereby, express our gratitude to the [Tensorflow Research Cloud (TFRC) program](https://tensorflow.org/tfrc) for providing us with the necessary computation resources. We also thank [Hooshvare](https://hooshvare.com) Research Group for facilitating dataset gathering and scraping online text resources.
## Contributors
- Mehrdad Farahani: [Linkedin](https://www.linkedin.com/in/m3hrdadfi/), [Twitter](https://twitter.com/m3hrdadfi), [Github](https://github.com/m3hrdadfi)
- Mohammad Gharachorloo: [Linkedin](https://www.linkedin.com/in/mohammad-gharachorloo/), [Twitter](https://twitter.com/MGharachorloo), [Github](https://github.com/baarsaam)
- Marzieh Farahani: [Linkedin](https://www.linkedin.com/in/marziehphi/), [Twitter](https://twitter.com/marziehphi), [Github](https://github.com/marziehphi)
- Mohammad Manthouri: [Linkedin](https://www.linkedin.com/in/mohammad-manthouri-aka-mansouri-07030766/), [Twitter](https://twitter.com/mmanthouri), [Github](https://github.com/mmanthouri)
- Hooshvare Team: [Official Website](https://hooshvare.com/), [Linkedin](https://www.linkedin.com/company/hooshvare), [Twitter](https://twitter.com/hooshvare), [Github](https://github.com/hooshvare), [Instagram](https://www.instagram.com/hooshvare/)
+ And a special thanks to Sara Tabrizi for her fantastic poster design. Follow her on: [Linkedin](https://www.linkedin.com/in/sara-tabrizi-64548b79/), [Behance](https://www.behance.net/saratabrizi), [Instagram](https://www.instagram.com/sara_b_tabrizi/)
## Releases
### Release v0.1 (May 29, 2019)
This is the first version of our ParsBERT NER!
|
erfan226/persian-t5-paraphraser
|
c175f241a097a9e4f175e393fc2d012dddf68c7c
|
2022-02-11T09:19:12.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"fa",
"dataset:tapaco",
"transformers",
"paraphrasing",
"autotrain_compatible"
] |
text2text-generation
| false |
erfan226
| null |
erfan226/persian-t5-paraphraser
| 209 | null |
transformers
| 3,562 |
---
language: fa
tags:
- paraphrasing
datasets:
- tapaco
widget:
- text: "این یک مقالهٔ خرد آلمان است. میتوانید با گسترش آن به ویکیپدیا کمک کنید."
- text: "برای خرید یک کتاب باید از فروشگاه اینترنتی استفاده کنید."
---
# Persian-t5-paraphraser
This is a paraphrasing model for the Persian language. It is based on [the monolingual T5 model for Persian.](https://huggingface.co/Ahmad/parsT5-base)
## Usage
```python
>>> pip install transformers
>>> from transformers import (T5ForConditionalGeneration, AutoTokenizer, pipeline)
>>> import torch
model_path = 'erfan226/persian-t5-paraphraser'
model = T5ForConditionalGeneration.from_pretrained(model_path)
tokenizer = AutoTokenizer.from_pretrained(model_path)
pipe = pipeline(task='text2text-generation', model=model, tokenizer=tokenizer)
def paraphrase(text):
for j in range(5):
out = pipe(text, encoder_no_repeat_ngram_size=5, do_sample=True, num_beams=5, max_length=128)[0]['generated_text']
print("Paraphrase:", out)
text = "این یک مقالهٔ خرد آلمان است. میتوانید با گسترش آن به ویکیپدیا کمک کنید."
print("Original:", text)
paraphrase(text)
# Original: این یک مقالهٔ خرد آلمان است. میتوانید با گسترش آن به ویکیپدیا کمک کنید.
# Paraphrase: این یک مقالهٔ کوچک است.
# Paraphrase: این یک مقالهٔ کوچک است.
# Paraphrase: شما می توانید با گسترش این مقاله، به کسب و کار خود کمک کنید.
# Paraphrase: می توانید با گسترش این مقالهٔ خرد آلمان کمک کنید.
# Paraphrase: شما می توانید با گسترش این مقالهٔ خرد، به گسترش آن کمک کنید.
```
## Training data
This model was trained on the Persian subset of the [Tapaco dataset](https://huggingface.co/datasets/tapaco). It should be noted that this model was trained on a very small dataset and therefore the performance might not be as expected, for now.
|
facebook/wav2vec2-xls-r-300m-21-to-en
|
4df5c4fb8b8fa521c0d84cf5ce8e7a681ff14e3d
|
2022-05-26T22:23:06.000Z
|
[
"pytorch",
"speech-encoder-decoder",
"automatic-speech-recognition",
"multilingual",
"fr",
"de",
"es",
"ca",
"it",
"ru",
"zh",
"pt",
"fa",
"et",
"mn",
"nl",
"tr",
"ar",
"sv",
"lv",
"sl",
"ta",
"ja",
"id",
"cy",
"en",
"dataset:common_voice",
"dataset:multilingual_librispeech",
"dataset:covost2",
"arxiv:2111.09296",
"transformers",
"speech",
"xls_r",
"xls_r_translation",
"license:apache-2.0"
] |
automatic-speech-recognition
| false |
facebook
| null |
facebook/wav2vec2-xls-r-300m-21-to-en
| 209 | 3 |
transformers
| 3,563 |
---
language:
- multilingual
- fr
- de
- es
- ca
- it
- ru
- zh
- pt
- fa
- et
- mn
- nl
- tr
- ar
- sv
- lv
- sl
- ta
- ja
- id
- cy
- en
datasets:
- common_voice
- multilingual_librispeech
- covost2
tags:
- speech
- xls_r
- automatic-speech-recognition
- xls_r_translation
pipeline_tag: automatic-speech-recognition
license: apache-2.0
widget:
- example_title: Swedish
src: https://cdn-media.huggingface.co/speech_samples/cv_swedish_1.mp3
- example_title: Arabic
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ar_19058308.mp3
- example_title: Russian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ru_18849022.mp3
- example_title: German
src: https://cdn-media.huggingface.co/speech_samples/common_voice_de_17284683.mp3
- example_title: French
src: https://cdn-media.huggingface.co/speech_samples/common_voice_fr_17299386.mp3
- example_title: Indonesian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_id_19051309.mp3
- example_title: Italian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_it_17415776.mp3
- example_title: Japanese
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ja_19482488.mp3
- example_title: Mongolian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_mn_18565396.mp3
- example_title: Dutch
src: https://cdn-media.huggingface.co/speech_samples/common_voice_nl_17691471.mp3
- example_title: Russian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ru_18849022.mp3
- example_title: Turkish
src: https://cdn-media.huggingface.co/speech_samples/common_voice_tr_17341280.mp3
- example_title: Catalan
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ca_17367522.mp3
- example_title: English
src: https://cdn-media.huggingface.co/speech_samples/common_voice_en_18301577.mp3
- example_title: Dutch
src: https://cdn-media.huggingface.co/speech_samples/common_voice_nl_17691471.mp3
---
# Wav2Vec2-XLS-R-300M-21-EN
Facebook's Wav2Vec2 XLS-R fine-tuned for **Speech Translation.**

This is a [SpeechEncoderDecoderModel](https://huggingface.co/transformers/model_doc/speechencoderdecoder.html) model.
The encoder was warm-started from the [**`facebook/wav2vec2-xls-r-300m`**](https://huggingface.co/facebook/wav2vec2-xls-r-300m) checkpoint and
the decoder from the [**`facebook/mbart-large-50`**](https://huggingface.co/facebook/mbart-large-50) checkpoint.
Consequently, the encoder-decoder model was fine-tuned on 21 `{lang}` -> `en` translation pairs of the [Covost2 dataset](https://huggingface.co/datasets/covost2).
The model can translate from the following spoken languages `{lang}` -> `en` (English):
{`fr`, `de`, `es`, `ca`, `it`, `ru`, `zh-CN`, `pt`, `fa`, `et`, `mn`, `nl`, `tr`, `ar`, `sv-SE`, `lv`, `sl`, `ta`, `ja`, `id`, `cy`} -> `en`
For more information, please refer to Section *5.1.2* of the [official XLS-R paper](https://arxiv.org/abs/2111.09296).
## Usage
### Demo
The model can be tested directly on the speech recognition widget on this model card!
Simple record some audio in one of the possible spoken languages or pick an example audio file to see how well the checkpoint can translate the input.
### Example
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
You can use the model directly via the ASR pipeline
```python
from datasets import load_dataset
from transformers import pipeline
# replace following lines to load an audio file of your choice
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
audio_file = librispeech_en[0]["file"]
asr = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-xls-r-300m-21-to-en", feature_extractor="facebook/wav2vec2-xls-r-300m-21-to-en")
translation = asr(audio_file)
```
or step-by-step as follows:
```python
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
from datasets import load_dataset
model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-300m-21-to-en")
processor = Speech2Text2Processor.from_pretrained("facebook/wav2vec2-xls-r-300m-21-to-en")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["array"]["sampling_rate"], return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"])
transcription = processor.batch_decode(generated_ids)
```
## Results `{lang}` -> `en`
See the row of **XLS-R (0.3B)** for the performance on [Covost2](https://huggingface.co/datasets/covost2) for this model.
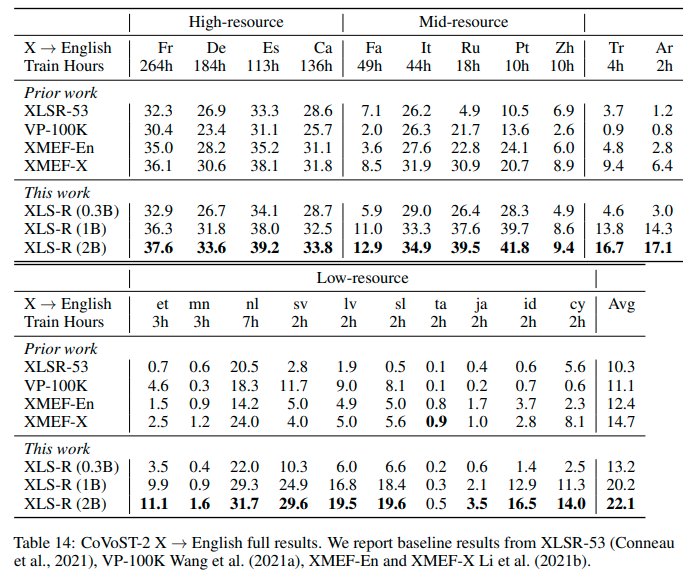
## More XLS-R models for `{lang}` -> `en` Speech Translation
- [Wav2Vec2-XLS-R-300M-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-300m-21-to-en)
- [Wav2Vec2-XLS-R-1B-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-1b-21-to-en)
- [Wav2Vec2-XLS-R-2B-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-2b-21-to-en)
- [Wav2Vec2-XLS-R-2B-22-16](https://huggingface.co/facebook/wav2vec2-xls-r-2b-22-to-16)
|
ken11/bert-japanese-ner
|
f5e3a9af91473242297737f91ce6b4ef4a83f032
|
2021-11-13T17:34:01.000Z
|
[
"pytorch",
"bert",
"token-classification",
"ja",
"transformers",
"ner",
"japanese",
"license:mit",
"autotrain_compatible"
] |
token-classification
| false |
ken11
| null |
ken11/bert-japanese-ner
| 209 | 1 |
transformers
| 3,564 |
---
tags:
- ner
- token-classification
- japanese
- bert
language:
- ja
license: mit
---
## bert-japanese-ner
このモデルは日本語の固有表現抽出タスクを目的として、[京都大学 黒橋・褚・村脇研究室が公開しているBERT日本語Pretrainedモデル](https://nlp.ist.i.kyoto-u.ac.jp/?ku_bert_japanese)をベースに[ストックマーク株式会社が公開しているner-wikipedia-dataset](https://github.com/stockmarkteam/ner-wikipedia-dataset)でファインチューニングしたものです。
## How to use
このモデルはTokenizerに上述の京都大学BERT日本語PretrainedモデルのTokenizerを利用します。
当リポジトリにTokenizerは含まれていません。
利用する際は別途ダウンロードしてご用意ください。
また、Tokenizerとは別に[Juman++](https://nlp.ist.i.kyoto-u.ac.jp/?JUMAN%2B%2B)と[pyknp](https://nlp.ist.i.kyoto-u.ac.jp/?PyKNP)を利用します。
予めインストールしておいてください。
```py
from transformers import (
BertForTokenClassification, BertTokenizer
)
from pyknp import Juman
jumanpp = Juman()
tokenizer = BertTokenizer.from_pretrained("ダウンロードした京都大学のTokenizerのファイルパス")
model = BertForTokenClassification.from_pretrained("ken11/bert-japanese-ner")
text = "なにか文章"
juman_result = jumanpp.analysis(text)
tokenized_text = [mrph.midasi for mrph in juman_result.mrph_list()]
inputs = tokenizer(tokenized_text, return_tensors="pt", padding='max_length', truncation=True, max_length=64, is_split_into_words=True)
pred = model(**inputs).logits[0]
pred = np.argmax(pred.detach().numpy(), axis=-1)
labels = []
for i, label in enumerate(pred):
if i + 1 > len(tokenized_text):
continue
labels.append(model.config.id2label[label])
print(f"{tokenized_text[i]}: {model.config.id2label[label]}")
print(tokenized_text)
print(labels)
```
## Training Data
学習には[ストックマーク株式会社が公開しているner-wikipedia-dataset](https://github.com/stockmarkteam/ner-wikipedia-dataset)を利用しました。
便利なデータセットを公開していただきありがとうございます。
## Note
固有表現抽出のラベルは学習データセットのものをBILUO形式に変換して使用しています。
ラベルの詳細については[ner-wikipedia-datasetの概要](https://github.com/stockmarkteam/ner-wikipedia-dataset#%E6%A6%82%E8%A6%81)をご確認ください。
## Licenese
[The MIT license](https://opensource.org/licenses/MIT)
|
microsoft/unispeech-sat-base-plus
|
74f559583458188867750f1b8cb6710b11f5be41
|
2021-11-05T12:40:37.000Z
|
[
"pytorch",
"unispeech-sat",
"pretraining",
"en",
"arxiv:1912.07875",
"arxiv:2106.06909",
"arxiv:2101.00390",
"arxiv:2110.05752",
"transformers",
"speech"
] | null | false |
microsoft
| null |
microsoft/unispeech-sat-base-plus
| 209 | null |
transformers
| 3,565 |
---
language:
- en
tags:
- speech
---
# UniSpeech-SAT-Base
[Microsoft's UniSpeech](https://www.microsoft.com/en-us/research/publication/unispeech-unified-speech-representation-learning-with-labeled-and-unlabeled-data/)
The base model pretrained on 16kHz sampled speech audio with utterance and speaker contrastive loss. When using the model, make sure that your speech input is also sampled at 16kHz.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data. Check out [this blog](https://huggingface.co/blog/fine-tune-wav2vec2-english) for more in-detail explanation of how to fine-tune the model.
The model was pre-trained on:
- 60,000 hours of [Libri-Light](https://arxiv.org/abs/1912.07875)
- 10,000 hours of [GigaSpeech](https://arxiv.org/abs/2106.06909)
- 24,000 hours of [VoxPopuli](https://arxiv.org/abs/2101.00390)
[Paper: UNISPEECH-SAT: UNIVERSAL SPEECH REPRESENTATION LEARNING WITH SPEAKER
AWARE PRE-TRAINING](https://arxiv.org/abs/2110.05752)
Authors: Sanyuan Chen, Yu Wu, Chengyi Wang, Zhengyang Chen, Zhuo Chen, Shujie Liu, Jian Wu, Yao Qian, Furu Wei, Jinyu Li, Xiangzhan Yu
**Abstract**
*Self-supervised learning (SSL) is a long-standing goal for speech processing, since it utilizes large-scale unlabeled data and avoids extensive human labeling. Recent years witness great successes in applying self-supervised learning in speech recognition, while limited exploration was attempted in applying SSL for modeling speaker characteristics. In this paper, we aim to improve the existing SSL framework for speaker representation learning. Two methods are introduced for enhancing the unsupervised speaker information extraction. First, we apply the multi-task learning to the current SSL framework, where we integrate the utterance-wise contrastive loss with the SSL objective function. Second, for better speaker discrimination, we propose an utterance mixing strategy for data augmentation, where additional overlapped utterances are created unsupervisely and incorporate during training. We integrate the proposed methods into the HuBERT framework. Experiment results on SUPERB benchmark show that the proposed system achieves state-of-the-art performance in universal representation learning, especially for speaker identification oriented tasks. An ablation study is performed verifying the efficacy of each proposed method. Finally, we scale up training dataset to 94 thousand hours public audio data and achieve further performance improvement in all SUPERB tasks..*
The original model can be found under https://github.com/microsoft/UniSpeech/tree/main/UniSpeech-SAT.
# Usage
This is an English pre-trained speech model that has to be fine-tuned on a downstream task like speech recognition or audio classification before it can be
used in inference. The model was pre-trained in English and should therefore perform well only in English. The model has been shown to work well on task such as speaker verification, speaker identification, and speaker diarization.
**Note**: The model was pre-trained on phonemes rather than characters. This means that one should make sure that the input text is converted to a sequence
of phonemes before fine-tuning.
## Speech Recognition
To fine-tune the model for speech recognition, see [the official speech recognition example](https://github.com/huggingface/transformers/tree/master/examples/pytorch/speech-recognition).
## Speech Classification
To fine-tune the model for speech classification, see [the official audio classification example](https://github.com/huggingface/transformers/tree/master/examples/pytorch/audio-classification).
## Speaker Verification
TODO
## Speaker Diarization
TODO
# Contribution
The model was contributed by [cywang](https://huggingface.co/cywang) and [patrickvonplaten](https://huggingface.co/patrickvonplaten).
# License
The official license can be found [here](https://github.com/microsoft/UniSpeech/blob/main/LICENSE)

|
mrm8488/deberta-v3-base-goemotions
|
0ae8ac01b571596b221dc06891d45f45ed112ffa
|
2021-12-28T20:55:50.000Z
|
[
"pytorch",
"tensorboard",
"deberta-v2",
"text-classification",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index"
] |
text-classification
| false |
mrm8488
| null |
mrm8488/deberta-v3-base-goemotions
| 209 | 1 |
transformers
| 3,566 |
---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
model-index:
- name: deberta-v3-base-goemotions
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# deberta-v3-base-goemotions
This model is a fine-tuned version of [microsoft/deberta-v3-base](https://huggingface.co/microsoft/deberta-v3-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7610
- F1: 0.4468
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:-----:|:---------------:|:------:|
| 1.5709 | 1.0 | 6164 | 1.5211 | 0.4039 |
| 1.3689 | 2.0 | 12328 | 1.5466 | 0.4198 |
| 1.1819 | 3.0 | 18492 | 1.5670 | 0.4520 |
| 1.0059 | 4.0 | 24656 | 1.6673 | 0.4479 |
| 0.8129 | 5.0 | 30820 | 1.7610 | 0.4468 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
tiedeman/opus-mt-he-en
|
d1f295aeecf3139b988f44cc2df27fb523dda9f9
|
2021-03-04T17:46:12.000Z
|
[
"pytorch",
"rust",
"marian",
"text2text-generation",
"he",
"en",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
| false |
tiedeman
| null |
tiedeman/opus-mt-he-en
| 209 | null |
transformers
| 3,567 |
---
language:
- he
- en
tags:
- translation
license: apache-2.0
---
### he-en
* source group: Hebrew
* target group: English
* OPUS readme: [heb-eng](https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/heb-eng/README.md)
* model: transformer
* source language(s): heb
* target language(s): eng
* model: transformer
* pre-processing: normalization + SentencePiece (spm32k,spm32k)
* download original weights: [opus-2020-10-04.zip](https://object.pouta.csc.fi/Tatoeba-MT-models/heb-eng/opus-2020-10-04.zip)
* test set translations: [opus-2020-10-04.test.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/heb-eng/opus-2020-10-04.test.txt)
* test set scores: [opus-2020-10-04.eval.txt](https://object.pouta.csc.fi/Tatoeba-MT-models/heb-eng/opus-2020-10-04.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba-test.heb.eng | 52.0 | 0.670 |
### System Info:
- hf_name: he-en
- source_languages: heb
- target_languages: eng
- opus_readme_url: https://github.com/Helsinki-NLP/Tatoeba-Challenge/tree/master/models/heb-eng/README.md
- original_repo: Tatoeba-Challenge
- tags: ['translation']
- languages: ['he', 'en']
- src_constituents: ('Hebrew', {'heb'})
- tgt_constituents: ('English', {'eng'})
- src_multilingual: False
- tgt_multilingual: False
- long_pair: heb-eng
- prepro: normalization + SentencePiece (spm32k,spm32k)
- url_model: https://object.pouta.csc.fi/Tatoeba-MT-models/heb-eng/opus-2020-10-04.zip
- url_test_set: https://object.pouta.csc.fi/Tatoeba-MT-models/heb-eng/opus-2020-10-04.test.txt
- src_alpha3: heb
- tgt_alpha3: eng
- chrF2_score: 0.67
- bleu: 52.0
- brevity_penalty: 0.9690000000000001
- ref_len: 73560.0
- src_name: Hebrew
- tgt_name: English
- train_date: 2020-10-04 00:00:00
- src_alpha2: he
- tgt_alpha2: en
- prefer_old: False
- short_pair: he-en
- helsinki_git_sha: 61fd6908b37d9a7b21cc3e27c1ae1fccedc97561
- transformers_git_sha: d99ed7ad618037ae878f0758157ed0764bd7f935
- port_machine: LM0-400-22516.local
- port_time: 2020-10-15-16:31
|
studio-ousia/luke-base-lite
|
97bed8f1d69c36c0e66d9fd79118d8053e91ab37
|
2022-04-13T10:28:03.000Z
|
[
"pytorch",
"luke",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
studio-ousia
| null |
studio-ousia/luke-base-lite
| 209 | null |
transformers
| 3,568 |
Entry not found
|
inywer/DialoGPT-medium-shouko01
|
df6d41a1a61e93f42d1cd300fd0fd8d685236b23
|
2022-07-10T05:50:04.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
inywer
| null |
inywer/DialoGPT-medium-shouko01
| 209 | null |
transformers
| 3,569 |
---
tags:
- conversational
---
# shouko01 DialoGPT Model
|
neulab/distilgpt2-finetuned-wikitext103
|
cc0607f13717bb7aadc98c4304f4d3b9a96a11ba
|
2022-07-14T15:38:33.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"arxiv:2201.12431",
"transformers"
] |
text-generation
| false |
neulab
| null |
neulab/distilgpt2-finetuned-wikitext103
| 209 | null |
transformers
| 3,570 |
This is a `distilgpt2` model, finetuned on the Wikitext-103 dataset.
It achieves a perplexity of **18.25** using a "sliding window" context, using the `run_clm.py` script at [https://github.com/neulab/knn-transformers](https://github.com/neulab/knn-transformers).
| Base LM: | `distilgpt2` | `gpt2` |
| :--- | ----: | ---: |
| base perplexity | 18.25 | 14.84 |
| + kNN-LM | 15.03 | 12.57 |
| + RetoMaton | **14.70** | **12.46** |
This model was released as part of the paper ["Neuro-Symbolic Language Modeling with Automaton-augmented Retrieval"](https://arxiv.org/pdf/2201.12431.pdf) (ICML'2022).
For more information, see: [https://github.com/neulab/knn-transformers](https://github.com/neulab/knn-transformers)
If you use this model, please cite:
```
@inproceedings{alon2022neuro,
title={Neuro-Symbolic Language Modeling with Automaton-augmented Retrieval},
author={Alon, Uri and Xu, Frank and He, Junxian and Sengupta, Sudipta and Roth, Dan and Neubig, Graham},
booktitle={International Conference on Machine Learning},
pages={468--485},
year={2022},
organization={PMLR}
}
```
|
log/DialoGPT-small-scott
|
4d876bab855ea75e8f0e7d043e33ca5f78fee4ed
|
2021-11-14T20:34:01.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
log
| null |
log/DialoGPT-small-scott
| 208 | null |
transformers
| 3,571 |
---
tags:
- conversational
---
# Game of thrones DialoGPT
|
monsoon-nlp/hindi-tpu-electra
|
62878f6bbd8fef1ecea9b7e2c5a8b8db7bff673c
|
2020-08-26T22:19:45.000Z
|
[
"pytorch",
"tf",
"electra",
"feature-extraction",
"hi",
"transformers"
] |
feature-extraction
| false |
monsoon-nlp
| null |
monsoon-nlp/hindi-tpu-electra
| 208 | 1 |
transformers
| 3,572 |
---
language: hi
---
# Hindi language model
## Trained with ELECTRA base size settings
<a href="https://colab.research.google.com/drive/1R8TciRSM7BONJRBc9CBZbzOmz39FTLl_">Tokenization and training CoLab</a>
## Example Notebooks
This model outperforms Multilingual BERT on <a href="https://colab.research.google.com/drive/1UYn5Th8u7xISnPUBf72at1IZIm3LEDWN">Hindi movie reviews / sentiment analysis</a> (using SimpleTransformers)
You can get higher accuracy using ktrain + TensorFlow, where you can adjust learning rate and
other hyperparameters: https://colab.research.google.com/drive/1mSeeSfVSOT7e-dVhPlmSsQRvpn6xC05w?usp=sharing
Question-answering on MLQA dataset: https://colab.research.google.com/drive/1i6fidh2tItf_-IDkljMuaIGmEU6HT2Ar#scrollTo=IcFoAHgKCUiQ
A smaller model (<a href="https://huggingface.co/monsoon-nlp/hindi-bert">Hindi-BERT</a>) performs better on a BBC news classification task.
## Corpus
The corpus is two files:
- Hindi CommonCrawl deduped by OSCAR https://traces1.inria.fr/oscar/
- latest Hindi Wikipedia ( https://dumps.wikimedia.org/hiwiki/ ) + WikiExtractor to txt
Bonus notes:
- Adding English wiki text or parallel corpus could help with cross-lingual tasks and training
## Vocabulary
https://drive.google.com/file/d/1-6tXrii3tVxjkbrpSJE9MOG_HhbvP66V/view?usp=sharing
Bonus notes:
- Created with HuggingFace Tokenizers; you can increase vocabulary size and re-train; remember to change ELECTRA vocab_size
## Training
Structure your files, with data-dir named "trainer" here
```
trainer
- vocab.txt
- pretrain_tfrecords
-- (all .tfrecord... files)
- models
-- modelname
--- checkpoint
--- graph.pbtxt
--- model.*
```
## Conversion
Use this process to convert an in-progress or completed ELECTRA checkpoint to a Transformers-ready model:
```
git clone https://github.com/huggingface/transformers
python ./transformers/src/transformers/convert_electra_original_tf_checkpoint_to_pytorch.py
--tf_checkpoint_path=./models/checkpointdir
--config_file=config.json
--pytorch_dump_path=pytorch_model.bin
--discriminator_or_generator=discriminator
python
```
```
from transformers import TFElectraForPreTraining
model = TFElectraForPreTraining.from_pretrained("./dir_with_pytorch", from_pt=True)
model.save_pretrained("tf")
```
Once you have formed one directory with config.json, pytorch_model.bin, tf_model.h5, special_tokens_map.json, tokenizer_config.json, and vocab.txt on the same level, run:
```
transformers-cli upload directory
```
|
mrm8488/deberta-v3-base-finetuned-squadv2
|
afe43d1ac6f4df735900f0d3ca06808e11c8f677
|
2021-12-09T19:15:29.000Z
|
[
"pytorch",
"deberta-v2",
"question-answering",
"transformers",
"autotrain_compatible"
] |
question-answering
| false |
mrm8488
| null |
mrm8488/deberta-v3-base-finetuned-squadv2
| 208 | 1 |
transformers
| 3,573 |
Entry not found
|
nvidia/segformer-b0-finetuned-cityscapes-512-1024
|
dd5010787e3453d0536d48de4c3c8bcf5bce2d6d
|
2022-07-20T09:54:11.000Z
|
[
"pytorch",
"tf",
"segformer",
"dataset:cityscapes",
"arxiv:2105.15203",
"transformers",
"vision",
"image-segmentation",
"license:apache-2.0"
] |
image-segmentation
| false |
nvidia
| null |
nvidia/segformer-b0-finetuned-cityscapes-512-1024
| 208 | null |
transformers
| 3,574 |
---
license: apache-2.0
tags:
- vision
- image-segmentation
datasets:
- cityscapes
widget:
- src: https://www.researchgate.net/profile/Anurag-Arnab/publication/315881952/figure/fig5/AS:667673876779033@1536197265755/Sample-results-on-the-Cityscapes-dataset-The-above-images-show-how-our-method-can-handle.jpg
example_title: road
---
# SegFormer (b4-sized) model fine-tuned on CityScapes
SegFormer model fine-tuned on CityScapes at resolution 512x1024. It was introduced in the paper [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Xie et al. and first released in [this repository](https://github.com/NVlabs/SegFormer).
Disclaimer: The team releasing SegFormer did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
SegFormer consists of a hierarchical Transformer encoder and a lightweight all-MLP decode head to achieve great results on semantic segmentation benchmarks such as ADE20K and Cityscapes. The hierarchical Transformer is first pre-trained on ImageNet-1k, after which a decode head is added and fine-tuned altogether on a downstream dataset.
## Intended uses & limitations
You can use the raw model for semantic segmentation. See the [model hub](https://huggingface.co/models?other=segformer) to look for fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import SegformerFeatureExtractor, SegformerForSemanticSegmentation
from PIL import Image
import requests
feature_extractor = SegformerFeatureExtractor.from_pretrained("nvidia/segformer-b0-finetuned-cityscapes-512-1024")
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-cityscapes-512-1024")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits # shape (batch_size, num_labels, height/4, width/4)
```
For more code examples, we refer to the [documentation](https://huggingface.co/transformers/model_doc/segformer.html#).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2105-15203,
author = {Enze Xie and
Wenhai Wang and
Zhiding Yu and
Anima Anandkumar and
Jose M. Alvarez and
Ping Luo},
title = {SegFormer: Simple and Efficient Design for Semantic Segmentation with
Transformers},
journal = {CoRR},
volume = {abs/2105.15203},
year = {2021},
url = {https://arxiv.org/abs/2105.15203},
eprinttype = {arXiv},
eprint = {2105.15203},
timestamp = {Wed, 02 Jun 2021 11:46:42 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2105-15203.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
spockinese/DialoGPT-small-sherlock
|
03cbdc6bb55a50e050ce84d97a903163148babc4
|
2021-09-25T10:40:24.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
spockinese
| null |
spockinese/DialoGPT-small-sherlock
| 208 | null |
transformers
| 3,575 |
---
tags:
- conversational
---
#Sherlock DialoGPT Model
|
luxxkat/Peterbot
|
d9b96c125da7616a1fb1b1efbc8a3fa2ff78cec5
|
2022-03-04T13:52:15.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
luxxkat
| null |
luxxkat/Peterbot
| 208 | null |
transformers
| 3,576 |
---
tags:
- conversational
---
# Peter from Your Boyfriend Game.
|
Willow/DialoGPT-large-willow
|
771c8262430ae6a051f58f29b59f6ab5c6b6066d
|
2022-05-07T21:40:52.000Z
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
| false |
Willow
| null |
Willow/DialoGPT-large-willow
| 208 | null |
transformers
| 3,577 |
---
tags:
- conversational
---
# Willow DialoGPT Model
|
T-Systems-onsite/mt5-small-sum-de-en-v2
|
30be2f4abcd905dd414fa378c48e3c273b188a36
|
2021-09-23T15:59:08.000Z
|
[
"pytorch",
"mt5",
"text2text-generation",
"de",
"en",
"dataset:cnn_dailymail",
"dataset:xsum",
"dataset:mlsum",
"dataset:swiss_text_2019",
"transformers",
"summarization",
"license:cc-by-nc-sa-4.0",
"autotrain_compatible"
] |
summarization
| false |
T-Systems-onsite
| null |
T-Systems-onsite/mt5-small-sum-de-en-v2
| 207 | 1 |
transformers
| 3,578 |
---
language:
- de
- en
license: cc-by-nc-sa-4.0
tags:
- summarization
datasets:
- cnn_dailymail
- xsum
- mlsum
- swiss_text_2019
---
# mT5-small-sum-de-en-v2
This is a bilingual summarization model for English and German. It is based on the multilingual T5 model [google/mt5-small](https://huggingface.co/google/mt5-small).
## Training
The training was conducted with the following hyperparameters:
- base model: [google/mt5-small](https://huggingface.co/google/mt5-small)
- source_prefix: `"summarize: "`
- batch size: 3
- max_source_length: 800
- max_target_length: 96
- warmup_ratio: 0.3
- number of train epochs: 10
- gradient accumulation steps: 2
- learning rate: 5e-5
## Datasets and Preprocessing
The datasets were preprocessed as follows:
The summary was tokenized with the [google/mt5-small](https://huggingface.co/google/mt5-small) tokenizer. Then only the records with no more than 94 summary tokens were selected.
The MLSUM dataset has a special characteristic. In the text, the summary is often included completely as one or more sentences. These have been removed from the texts. The reason is that we do not want to train a model that ultimately extracts only sentences as a summary.
This model is trained on the following datasets:
| Name | Language | License
|------|----------|--------
| [CNN Daily - Train](https://github.com/abisee/cnn-dailymail) | en | The license is unclear. The data comes from CNN and Daily Mail. We assume that it may only be used for research purposes and not commercially.
| [Extreme Summarization (XSum) - Train](https://github.com/EdinburghNLP/XSum) | en | The license is unclear. The data comes from BBC. We assume that it may only be used for research purposes and not commercially.
| [MLSUM German - Train](https://github.com/ThomasScialom/MLSUM) | de | Usage of dataset is restricted to non-commercial research purposes only. Copyright belongs to the original copyright holders (see [here](https://github.com/ThomasScialom/MLSUM#mlsum)).
| [SwissText 2019 - Train](https://www.swisstext.org/2019/shared-task/german-text-summarization-challenge.html) | de | The license is unclear. The data was published in the [German Text Summarization Challenge](https://www.swisstext.org/2019/shared-task/german-text-summarization-challenge.html). We assume that they may be used for research purposes and not commercially.
| Language | Size
|------|------
| German | 302,607
| English | 422,228
| Total | 724,835
## Evaluation on MLSUM German Test Set (no beams)
| Model | rouge1 | rouge2 | rougeL | rougeLsum
|-------|--------|--------|--------|----------
| [ml6team/mt5-small-german-finetune-mlsum](https://huggingface.co/ml6team/mt5-small-german-finetune-mlsum) | 18.3607 | 5.3604 | 14.5456 | 16.1946
| [deutsche-telekom/mT5-small-sum-de-en-01](https://huggingface.co/deutsche-telekom/mt5-small-sum-de-en-v1) | 21.7336 | 7.2614 | 17.1323 | 19.3977
| **T-Systems-onsite/mt5-small-sum-de-en-v2 (this)** | **21.7756** | **7.2662** | **17.1444** | **19.4242**
## Evaluation on CNN Daily English Test Set (no beams)
| Model | rouge1 | rouge2 | rougeL | rougeLsum
|-------|--------|--------|--------|----------
| [sshleifer/distilbart-xsum-12-6](https://huggingface.co/sshleifer/distilbart-xsum-12-6) | 26.7664 | 8.8243 | 18.3703 | 23.2614
| [facebook/bart-large-xsum](https://huggingface.co/facebook/bart-large-xsum) | 28.5374 | 9.8565 | 19.4829 | 24.7364
| [mrm8488/t5-base-finetuned-summarize-news](https://huggingface.co/mrm8488/t5-base-finetuned-summarize-news) | 37.576 | 14.7389 | 24.0254 | 34.4634
| [deutsche-telekom/mT5-small-sum-de-en-01](https://huggingface.co/deutsche-telekom/mt5-small-sum-de-en-v1) | 37.6339 | 16.5317 | 27.1418 | 34.9951
| **T-Systems-onsite/mt5-small-sum-de-en-v2 (this)** | **37.8096** | **16.6646** | **27.2239** | **35.1916**
## Evaluation on Extreme Summarization (XSum) English Test Set (no beams)
| Model | rouge1 | rouge2 | rougeL | rougeLsum
|-------|--------|--------|--------|----------
| [mrm8488/t5-base-finetuned-summarize-news](https://huggingface.co/mrm8488/t5-base-finetuned-summarize-news) | 18.6204 | 3.535 | 12.3997 | 15.2111
| [facebook/bart-large-xsum](https://huggingface.co/facebook/bart-large-xsum) | 28.5374 | 9.8565 | 19.4829 | 24.7364
| [deutsche-telekom/mT5-small-sum-de-en-01](https://huggingface.co/deutsche-telekom/mt5-small-sum-de-en-v1) | 32.3416 | 10.6191 | 25.3799 | 25.3908
| T-Systems-onsite/mt5-small-sum-de-en-v2 (this) | 32.4828 | 10.7004| 25.5238 | 25.5369
| [sshleifer/distilbart-xsum-12-6](https://huggingface.co/sshleifer/distilbart-xsum-12-6) | 44.2553 ♣ | 21.4289 ♣ | 36.2639 ♣ | 36.2696 ♣
♣: These values seem to be unusually high. It could be that the test set was used in the training data.
## License
Copyright (c) 2021 Philip May, T-Systems on site services GmbH
This work is licensed under the [Attribution-NonCommercial-ShareAlike 3.0 Unported (CC BY-NC-SA 3.0)](https://creativecommons.org/licenses/by-nc-sa/3.0/) license.
|
superb/wav2vec2-base-superb-er
|
441a7599c3b22107314dcbd9166621c5c83f2cc5
|
2021-11-04T16:03:36.000Z
|
[
"pytorch",
"wav2vec2",
"audio-classification",
"en",
"dataset:superb",
"arxiv:2105.01051",
"transformers",
"speech",
"audio",
"license:apache-2.0"
] |
audio-classification
| false |
superb
| null |
superb/wav2vec2-base-superb-er
| 207 | 1 |
transformers
| 3,579 |
---
language: en
datasets:
- superb
tags:
- speech
- audio
- wav2vec2
- audio-classification
license: apache-2.0
widget:
- example_title: IEMOCAP clip "happy"
src: https://cdn-media.huggingface.co/speech_samples/IEMOCAP_Ses01F_impro03_F013.wav
- example_title: IEMOCAP clip "neutral"
src: https://cdn-media.huggingface.co/speech_samples/IEMOCAP_Ses01F_impro04_F000.wav
---
# Wav2Vec2-Base for Emotion Recognition
## Model description
This is a ported version of
[S3PRL's Wav2Vec2 for the SUPERB Emotion Recognition task](https://github.com/s3prl/s3prl/tree/master/s3prl/downstream/emotion).
The base model is [wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base), which is pretrained on 16kHz
sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz.
For more information refer to [SUPERB: Speech processing Universal PERformance Benchmark](https://arxiv.org/abs/2105.01051)
## Task and dataset description
Emotion Recognition (ER) predicts an emotion class for each utterance. The most widely used ER dataset
[IEMOCAP](https://sail.usc.edu/iemocap/) is adopted, and we follow the conventional evaluation protocol:
we drop the unbalanced emotion classes to leave the final four classes with a similar amount of data points and
cross-validate on five folds of the standard splits.
For the original model's training and evaluation instructions refer to the
[S3PRL downstream task README](https://github.com/s3prl/s3prl/tree/master/s3prl/downstream#er-emotion-recognition).
## Usage examples
You can use the model via the Audio Classification pipeline:
```python
from datasets import load_dataset
from transformers import pipeline
dataset = load_dataset("anton-l/superb_demo", "er", split="session1")
classifier = pipeline("audio-classification", model="superb/wav2vec2-base-superb-er")
labels = classifier(dataset[0]["file"], top_k=5)
```
Or use the model directly:
```python
import torch
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForSequenceClassification, Wav2Vec2FeatureExtractor
def map_to_array(example):
speech, _ = librosa.load(example["file"], sr=16000, mono=True)
example["speech"] = speech
return example
# load a demo dataset and read audio files
dataset = load_dataset("anton-l/superb_demo", "er", split="session1")
dataset = dataset.map(map_to_array)
model = Wav2Vec2ForSequenceClassification.from_pretrained("superb/wav2vec2-base-superb-er")
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained("superb/wav2vec2-base-superb-er")
# compute attention masks and normalize the waveform if needed
inputs = feature_extractor(dataset[:4]["speech"], sampling_rate=16000, padding=True, return_tensors="pt")
logits = model(**inputs).logits
predicted_ids = torch.argmax(logits, dim=-1)
labels = [model.config.id2label[_id] for _id in predicted_ids.tolist()]
```
## Eval results
The evaluation metric is accuracy.
| | **s3prl** | **transformers** |
|--------|-----------|------------------|
|**session1**| `0.6343` | `0.6258` |
### BibTeX entry and citation info
```bibtex
@article{yang2021superb,
title={SUPERB: Speech processing Universal PERformance Benchmark},
author={Yang, Shu-wen and Chi, Po-Han and Chuang, Yung-Sung and Lai, Cheng-I Jeff and Lakhotia, Kushal and Lin, Yist Y and Liu, Andy T and Shi, Jiatong and Chang, Xuankai and Lin, Guan-Ting and others},
journal={arXiv preprint arXiv:2105.01051},
year={2021}
}
```
|
waboucay/french-camembert-postag-model-finetuned-perceo
|
f55ac8cabbad15f218b329a62230cf2f7cd37c2e
|
2022-03-11T09:37:32.000Z
|
[
"pytorch",
"camembert",
"token-classification",
"fr",
"transformers",
"pos-tagging",
"autotrain_compatible"
] |
token-classification
| false |
waboucay
| null |
waboucay/french-camembert-postag-model-finetuned-perceo
| 207 | null |
transformers
| 3,580 |
---
language:
- fr
tags:
- pos-tagging
---
## Eval results
We obtain the following results on ```validation``` and ```test``` sets:
| Set | F1<sub>micro</sub> | F1<sub>macro</sub> |
|------------|--------------------|--------------------|
| validation | 98.2 | 93.2 |
| test | 97.7 | 87.4 |
|
allenai/unifiedqa-v2-t5-11b-1251000
|
642be0a823e573a22ed41f6272e8f2ed3ce0c4b4
|
2022-02-22T17:41:50.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
allenai
| null |
allenai/unifiedqa-v2-t5-11b-1251000
| 206 | null |
transformers
| 3,581 |
# Further details: https://github.com/allenai/unifiedqa
|
anon-submission-mk/bert-base-macedonian-bulgarian-cased
|
f5bf50acb2c1c00fbf9939d14a406e236805b652
|
2021-05-18T23:39:42.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
| false |
anon-submission-mk
| null |
anon-submission-mk/bert-base-macedonian-bulgarian-cased
| 206 | null |
transformers
| 3,582 |
Entry not found
|
beomus/layoutxlm
|
749f96ed9384a170642be7d2c2e5675804198529
|
2022-02-02T08:21:14.000Z
|
[
"pytorch",
"layoutlmv2",
"token-classification",
"transformers",
"autotrain_compatible"
] |
token-classification
| false |
beomus
| null |
beomus/layoutxlm
| 206 | null |
transformers
| 3,583 |
# LayoutXLM finetuned on XFUN.ja
```python
import torch
import numpy as np
from PIL import Image, ImageDraw, ImageFont
from pathlib import Path
from itertools import chain
from tqdm.notebook import tqdm
from pdf2image import convert_from_path
from transformers import LayoutXLMProcessor, LayoutLMv2ForTokenClassification
import os
os.environ["TOKENIZERS_PARALLELISM"] = "false"
labels = [
'O',
'B-QUESTION',
'B-ANSWER',
'B-HEADER',
'I-ANSWER',
'I-QUESTION',
'I-HEADER'
]
id2label = {v: k for v, k in enumerate(labels)}
label2id = {k: v for v, k in enumerate(labels)}
def unnormalize_box(bbox, width, height):
return [
width * (bbox[0] / 1000),
height * (bbox[1] / 1000),
width * (bbox[2] / 1000),
height * (bbox[3] / 1000),
]
def iob_to_label(label):
label = label[2:]
if not label:
return 'other'
return label
label2color = {'question':'blue', 'answer':'green', 'header':'orange', 'other':'violet'}
def infer(image, processor, model, label2color):
# Use this if you're loading images
# image = Image.open(img_path).convert("RGB")
image = image.convert("RGB") # loading PDFs
encoding = processor(image, return_offsets_mapping=True, return_tensors="pt", truncation=True, max_length=514)
offset_mapping = encoding.pop('offset_mapping')
outputs = model(**encoding)
predictions = outputs.logits.argmax(-1).squeeze().tolist()
token_boxes = encoding.bbox.squeeze().tolist()
width, height = image.size
is_subword = np.array(offset_mapping.squeeze().tolist())[:,0] != 0
true_predictions = [id2label[pred] for idx, pred in enumerate(predictions) if not is_subword[idx]]
true_boxes = [unnormalize_box(box, width, height) for idx, box in enumerate(token_boxes) if not is_subword[idx]]
draw = ImageDraw.Draw(image)
font = ImageFont.load_default()
for prediction, box in zip(true_predictions, true_boxes):
predicted_label = iob_to_label(prediction).lower()
draw.rectangle(box, outline=label2color[predicted_label])
draw.text((box[0]+10, box[1]-10), text=predicted_label, fill=label2color[predicted_label], font=font)
return image
processor = LayoutXLMProcessor.from_pretrained('beomus/layoutxlm')
model = LayoutLMv2ForTokenClassification.from_pretrained("beomus/layoutxlm")
# imgs = [img_path for img_path in Path('/your/path/imgs/').glob('*.jpg')]
imgs = [convert_from_path(img_path) for img_path in Path('/your/path/pdfs/').glob('*.pdf')]
imgs = list(chain.from_iterable(imgs))
outputs = [infer(img_path, processor, model, label2color) for img_path in tqdm(imgs)]
# type(outputs[0]) -> PIL.Image.Image
```
|
noahjadallah/cause-effect-detection
|
b69d7b577bf92f74a2ceb77d916160be02af635b
|
2021-05-20T02:01:13.000Z
|
[
"pytorch",
"jax",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] |
token-classification
| false |
noahjadallah
| null |
noahjadallah/cause-effect-detection
| 206 | null |
transformers
| 3,584 |
---
widget:
- text: "If a user signs up, he will receive a confirmation email."
---
# Cause-Effect Detection for Software Requirements Based on Token Classification with BERT
This model uses BERT to detect cause and effect from a single sentence. The focus of this model is the domain of software requirements engineering, however, it can also be used for other domains.
The model outputs one of the following 5 labels for each token:
Other
B-Cause
I-Cause
B-Effect
I-Effect
The source code can be found here: https://colab.research.google.com/drive/14V9Ooy3aNPsRfTK88krwsereia8cfSPc?usp=sharing
|
smaranjitghose/big-cat-classifier
|
3148b97c10cb44e7a468cd1a8dc6af8badc969ae
|
2021-07-03T08:12:25.000Z
|
[
"pytorch",
"tensorboard",
"vit",
"image-classification",
"transformers",
"huggingpics",
"model-index"
] |
image-classification
| false |
smaranjitghose
| null |
smaranjitghose/big-cat-classifier
| 206 | null |
transformers
| 3,585 |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: big-cat-classifier
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.9107142686843872
---

An image classifier built using Vision Transformers that categories images of the big cats into the following classes:
| Class | Big Cat | Sample Image |
| :---: | :------ | -------------------------------- |
| 0 | Cheetah |  |
| 1 | Jaguar |  |
| 2 | Leopard |  |
| 3 | Lion |  |
| 4 | Tiger |  |
> **Note**:
>
> - Since jaguars and leopards have similar appearances, the model might confuse the two. These [[1](https://www.nationalgeographic.com/animals/article/animals-big-cats-jaguars-leopards)] [[2](https://safarisafricana.com/jaguar-v-leopard/)] two articles throw some light on the difference between the two species.
> - Theoretically the model should be able to accurately identify geographical population variants of each species. However, in practical scenarios this may not be true as during the training phases this was not kept in mind while collecting the dataset.
> - For example: images of Bengal Tigers, Siberian Tigers, Indochinese Tigers, and Malayan Tigers should be identified as Tigers
> - Lastly, the performance of the model in categorizing certain rare variants in the populations of big cats such as white tigers, snow leopards, or black panther has not been determined exclusively. Although some of the tests performed gave satisfactory results.
### Training and Inference
**Training**: [](https://colab.research.google.com/github/smaranjitghose/Big_Cat_Classifier/blob/master/notebooks/Big_Cat_Classifier.ipynb)
**Inference**: [](https://colab.research.google.com/github/smaranjitghose/Big_Cat_Classifier/blob/master/notebooks/Big_Cat_Classifier_Inference.ipynb)
## Usage
```python
from PIL import Image
import matplotlib.pyplot as plt
from transformers import ViTFeatureExtractor, ViTForImageClassification
def identify_big_cat(img_path:str)->str:
"""
Function that reads an image of a big cat (belonging to Panthera family) and returns the corresponding species
"""
img = Image.open(img_path)
model_panthera = ViTForImageClassification.from_pretrained("smaranjitghose/big-cat-classifier")
feature_extractor = ViTFeatureExtractor.from_pretrained('smaranjitghose/big-cat-classifier')
inputs = feature_extractor(images=img, return_tensors="pt")
outputs = model_panthera(**inputs)
logits = outputs.logits
predicted_class_idx = logits.argmax(-1).item()
return model_panthera.config.id2label[predicted_class_idx]
our_big_cat = identify_big_cat("path_of_the_image")
print(f"Predicted species: {our_big_cat}" )
```
## Hosted API:
Check it out [here](https://huggingface.co/smaranjitghose/big-cat-classifier)
## Library App Usage:
- Clone this repository
```
git clone https://github.com/smaranjitghose/Big_Cat_Classifier.git
```
- Move inside the cloned repository
```
cd Big_Cat_Classifier
```
- Now follow either of following two routes:
A) Without using Docker:
**Make sure you have installed the latest stable version [Python 3](https://www.python.org/downloads/) and added it to PATH**
- Install the python dependencies
```
pip install -r requirements.txt
```
- Start the streamlit app on local server
```
streamlit run app.py
```
B) Using Docker:
**Make sure you have installed [Docker](https://docs.docker.com/engine/install/)**
- Build the Docker Image
```
docker build -t smaranjitghose/big-cat-classifier:latest .
```
- Check if the image is available
```
docker images
```
- Create a Docker container from the image and Run it
```
docker run -t -i -p 8080:8080 --name "big-cat-classifier" smaranjitghose/big-cat-classifier
```
- Open your browser and visit `localhost:8080`

## Hosting
1. Heroku
- Remove the lines that exposed the particular port in the docker container
- Make sure the startup command is exposed with a variable Port Number
```
ENTRYPOINT ["streamlit", "run", "app.py", "--server.port=$PORT"]
```
- Login to Heroku
```
heroku login -i
```
- Create a new Heroku app
```
heroku create
```
- Login in to Container Registry
```
heroku container:login
```
- Build the Docker image and push it to Container Registry
```
heroku container:push web
```
- Release the app
```
heroku container:release web
```
- Check the hosted version and dashboard
```
heroku open
```
## Reference and Acknowledgement:
[Hugging Pics](https://github.com/nateraw/huggingpics)
|
Geotrend/bert-base-bg-cased
|
5189f67d1dfe16627a1e939cdc40699a7851958b
|
2021-05-18T18:48:47.000Z
|
[
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"bg",
"dataset:wikipedia",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
| false |
Geotrend
| null |
Geotrend/bert-base-bg-cased
| 205 | null |
transformers
| 3,586 |
---
language: bg
datasets: wikipedia
license: apache-2.0
---
# bert-base-bg-cased
We are sharing smaller versions of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) that handle a custom number of languages.
Unlike [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased), our versions give exactly the same representations produced by the original model which preserves the original accuracy.
For more information please visit our paper: [Load What You Need: Smaller Versions of Multilingual BERT](https://www.aclweb.org/anthology/2020.sustainlp-1.16.pdf).
## How to use
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("Geotrend/bert-base-bg-cased")
model = AutoModel.from_pretrained("Geotrend/bert-base-bg-cased")
```
To generate other smaller versions of multilingual transformers please visit [our Github repo](https://github.com/Geotrend-research/smaller-transformers).
### How to cite
```bibtex
@inproceedings{smallermbert,
title={Load What You Need: Smaller Versions of Mutlilingual BERT},
author={Abdaoui, Amine and Pradel, Camille and Sigel, Grégoire},
booktitle={SustaiNLP / EMNLP},
year={2020}
}
```
## Contact
Please contact [email protected] for any question, feedback or request.
|
akhooli/xlm-r-large-arabic-sent
|
009460bdbefcc7d4dd3d1475a7f78bbb4052578b
|
2020-12-11T21:32:16.000Z
|
[
"pytorch",
"xlm-roberta",
"text-classification",
"ar",
"en",
"transformers",
"license:mit"
] |
text-classification
| false |
akhooli
| null |
akhooli/xlm-r-large-arabic-sent
| 205 | 2 |
transformers
| 3,587 |
---
language:
- ar
- en
license: mit
---
### xlm-r-large-arabic-sent
Multilingual sentiment classification (Label_0: mixed, Label_1: negative, Label_2: positive) of Arabic reviews by fine-tuning XLM-Roberta-Large.
Zero shot classification of other languages (also works in mixed languages - ex. Arabic & English). Mixed category is not accurate and may confuse other
classes (was based on a rate of 3 out of 5 in reviews).
Usage: see last section in this [Colab notebook](https://lnkd.in/d3bCFyZ)
|
ayameRushia/bert-base-indonesian-1.5G-sentiment-analysis-smsa
|
8a508924465b34346a5ac40a33610219a316f0fe
|
2021-12-22T08:52:47.000Z
|
[
"pytorch",
"bert",
"text-classification",
"id",
"dataset:indonlu",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index"
] |
text-classification
| false |
ayameRushia
| null |
ayameRushia/bert-base-indonesian-1.5G-sentiment-analysis-smsa
| 205 | null |
transformers
| 3,588 |
---
license: mit
tags:
- generated_from_trainer
datasets:
- indonlu
metrics:
- accuracy
model-index:
- name: bert-base-indonesian-1.5G-finetuned-sentiment-analysis-smsa
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: indonlu
type: indonlu
args: smsa
metrics:
- name: Accuracy
type: accuracy
value: 0.9373015873015873
language: id
widget:
- text: "Saya mengapresiasi usaha anda"
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-indonesian-1.5G-finetuned-sentiment-analysis-smsa
This model is a fine-tuned version of [cahya/bert-base-indonesian-1.5G](https://huggingface.co/cahya/bert-base-indonesian-1.5G) on the indonlu dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3390
- Accuracy: 0.9373
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.2864 | 1.0 | 688 | 0.2154 | 0.9286 |
| 0.1648 | 2.0 | 1376 | 0.2238 | 0.9357 |
| 0.0759 | 3.0 | 2064 | 0.3351 | 0.9365 |
| 0.044 | 4.0 | 2752 | 0.3390 | 0.9373 |
| 0.0308 | 5.0 | 3440 | 0.4346 | 0.9365 |
| 0.0113 | 6.0 | 4128 | 0.4708 | 0.9365 |
| 0.006 | 7.0 | 4816 | 0.5533 | 0.9325 |
| 0.0047 | 8.0 | 5504 | 0.5888 | 0.9310 |
| 0.0001 | 9.0 | 6192 | 0.5961 | 0.9333 |
| 0.0 | 10.0 | 6880 | 0.5992 | 0.9357 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
castorini/tct_colbert-v2-msmarco-cqe
|
651951a336693452c5369eaf8c7d32fc690d393c
|
2021-10-18T23:34:32.000Z
|
[
"pytorch",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
| false |
castorini
| null |
castorini/tct_colbert-v2-msmarco-cqe
| 205 | 1 |
transformers
| 3,589 |
This model is to reproduce Contextualized Query Embeddings for Conversational Search described in the following paper:
> Sheng-Chieh Lin, Jheng-Hong Yang, and Jimmy Lin. [Contextualized Query Embeddings for Conversational Search.](https://cs.uwaterloo.ca/~jimmylin/publications/Lin_etal_EMNLP2021.pdf) EMNLP, Nov 2021.
This model is finetuend only on query ecoder with frezzed passage encoder. The starting point is the [tct_colbert-msmarco](https://huggingface.co/castorini/tct_colbert-msmarco/tree/main). The detailed usage of the model will be out soon on [Chatty Goose](https://github.com/castorini/chatty-goose). You can also check the fine-tuning and inference using tensorflow in our [CQE repo](https://github.com/castorini/CQE)
|
jackieliu930/bart-large-cnn-samsum
|
bc62810f58dd0360768236afb3b20b1828dc67dd
|
2022-06-28T03:46:12.000Z
|
[
"pytorch",
"bart",
"text2text-generation",
"en",
"dataset:samsum",
"transformers",
"sagemaker",
"summarization",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] |
summarization
| false |
jackieliu930
| null |
jackieliu930/bart-large-cnn-samsum
| 205 | 1 |
transformers
| 3,590 |
---
language: en
tags:
- sagemaker
- bart
- summarization
license: apache-2.0
datasets:
- samsum
model-index:
- name: bart-large-cnn-samsum
results:
- task:
name: Abstractive Text Summarization
type: abstractive-text-summarization
dataset:
name: 'SAMSum Corpus: A Human-annotated Dialogue Dataset for Abstractive Summarization'
type: samsum
metrics:
- name: Validation ROGUE-1
type: rogue-1
value: 42.621
- name: Validation ROGUE-2
type: rogue-2
value: 21.9825
- name: Validation ROGUE-L
type: rogue-l
value: 33.034
- name: Test ROGUE-1
type: rogue-1
value: 41.3174
- name: Test ROGUE-2
type: rogue-2
value: 20.8716
- name: Test ROGUE-L
type: rogue-l
value: 32.1337
- task:
type: summarization
name: Summarization
dataset:
name: samsum
type: samsum
config: samsum
split: test
metrics:
- name: ROUGE-1
type: rouge
value: 40.8911
verified: true
- name: ROUGE-2
type: rouge
value: 20.3551
verified: true
- name: ROUGE-L
type: rouge
value: 31.2696
verified: true
- name: ROUGE-LSUM
type: rouge
value: 37.9313
verified: true
- name: loss
type: loss
value: 1.4995627403259277
verified: true
- name: gen_len
type: gen_len
value: 60.2247
verified: true
widget:
- text: "Jeff: Can I train a \U0001F917 Transformers model on Amazon SageMaker? \n\
Philipp: Sure you can use the new Hugging Face Deep Learning Container. \nJeff:\
\ ok.\nJeff: and how can I get started? \nJeff: where can I find documentation?\
\ \nPhilipp: ok, ok you can find everything here. https://huggingface.co/blog/the-partnership-amazon-sagemaker-and-hugging-face "
---
## `bart-large-cnn-samsum`
This model was trained using Amazon SageMaker and the new Hugging Face Deep Learning container.
For more information look at:
- [🤗 Transformers Documentation: Amazon SageMaker](https://huggingface.co/transformers/sagemaker.html)
- [Example Notebooks](https://github.com/huggingface/notebooks/tree/master/sagemaker)
- [Amazon SageMaker documentation for Hugging Face](https://docs.aws.amazon.com/sagemaker/latest/dg/hugging-face.html)
- [Python SDK SageMaker documentation for Hugging Face](https://sagemaker.readthedocs.io/en/stable/frameworks/huggingface/index.html)
- [Deep Learning Container](https://github.com/aws/deep-learning-containers/blob/master/available_images.md#huggingface-training-containers)
## Hyperparameters
{
"dataset_name": "samsum",
"do_eval": true,
"do_predict": true,
"do_train": true,
"fp16": true,
"learning_rate": 5e-05,
"model_name_or_path": "facebook/bart-large-cnn",
"num_train_epochs": 3,
"output_dir": "/opt/ml/model",
"per_device_eval_batch_size": 4,
"per_device_train_batch_size": 4,
"predict_with_generate": true,
"sagemaker_container_log_level": 20,
"sagemaker_job_name": "huggingface-pytorch-training-2021-09-08-06-40-19-182",
"sagemaker_program": "run_summarization.py",
"sagemaker_region": "us-west-2",
"sagemaker_submit_directory": "s3://sagemaker-us-west-2-847380964353/huggingface-pytorch-training-2021-09-08-06-40-19-182/source/sourcedir.tar.gz",
"seed": 7
}
## Usage
from transformers import pipeline
summarizer = pipeline("summarization", model="philschmid/bart-large-cnn-samsum")
conversation = '''Jeff: Can I train a 🤗 Transformers model on Amazon SageMaker?
Philipp: Sure you can use the new Hugging Face Deep Learning Container.
Jeff: ok.
Jeff: and how can I get started?
Jeff: where can I find documentation?
Philipp: ok, ok you can find everything here. https://huggingface.co/blog/the-partnership-amazon-sagemaker-and-hugging-face
'''
nlp(conversation)
## Results
| key | value |
| --- | ----- |
| eval_rouge1 | 42.059 |
| eval_rouge2 | 21.5509 |
| eval_rougeL | 32.4083 |
| eval_rougeLsum | 39.0015 |
| test_rouge1 | 40.8656 |
| test_rouge2 | 20.3517 |
| test_rougeL | 31.2268 |
| test_rougeLsum | 37.9301 |
|
transformersbook/distilbert-base-uncased-finetuned-emotion
|
8e2ef1893047c2771f4c9bd895d18dccf4723d9a
|
2022-05-30T06:13:40.000Z
|
[
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:emotion",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] |
text-classification
| false |
transformersbook
| null |
transformersbook/distilbert-base-uncased-finetuned-emotion
| 205 | null |
transformers
| 3,591 |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.927
- name: F1
type: f1
value: 0.9271664736493986
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset. The model is trained in Chapter 2: Text Classification in the [NLP with Transformers book](https://learning.oreilly.com/library/view/natural-language-processing/9781098103231/). You can find the full code in the accompanying [Github repository](https://github.com/nlp-with-transformers/notebooks/blob/main/02_classification.ipynb).
It achieves the following results on the evaluation set:
- Loss: 0.2192
- Accuracy: 0.927
- F1: 0.9272
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8569 | 1.0 | 250 | 0.3386 | 0.894 | 0.8888 |
| 0.2639 | 2.0 | 500 | 0.2192 | 0.927 | 0.9272 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.9.1+cu102
- Datasets 1.13.0
- Tokenizers 0.10.3
|
facebook/levit-256
|
283f5f3d06de87c7a08f9852184bd86082a924a0
|
2022-06-01T13:21:14.000Z
|
[
"pytorch",
"levit",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2104.01136",
"transformers",
"vision",
"license:apache-2.0"
] |
image-classification
| false |
facebook
| null |
facebook/levit-256
| 205 | null |
transformers
| 3,592 |
---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-1k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# LeViT
LeViT-256 model pre-trained on ImageNet-1k at resolution 224x224. It was introduced in the paper [LeViT: a Vision Transformer in ConvNet's Clothing for Faster Inference
](https://arxiv.org/abs/2104.01136) by Graham et al. and first released in [this repository](https://github.com/facebookresearch/LeViT).
Disclaimer: The team releasing LeViT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Usage
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
from transformers import LevitFeatureExtractor, LevitForImageClassificationWithTeacher
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = LevitFeatureExtractor.from_pretrained('facebook/levit-256')
model = LevitForImageClassificationWithTeacher.from_pretrained('facebook/levit-256')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
logits = outputs.logits
# model predicts one of the 1000 ImageNet classes
predicted_class_idx = logits.argmax(-1).item()
print("Predicted class:", model.config.id2label[predicted_class_idx])
```
|
Salesforce/mixqg-base
|
387b4e5397cb5af4218208638c6ae168b42a20c8
|
2021-10-18T16:12:40.000Z
|
[
"pytorch",
"t5",
"text2text-generation",
"en",
"arxiv:2110.08175",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
Salesforce
| null |
Salesforce/mixqg-base
| 204 | 3 |
transformers
| 3,593 |
---
language: en
widget:
- text: Robert Boyle \\n In the late 17th century, Robert Boyle proved that air is necessary for combustion.
---
# MixQG (base-sized model)
MixQG is a new question generation model pre-trained on a collection of QA datasets with a mix of answer types. It was introduced in the paper [MixQG: Neural Question Generation with Mixed Answer Types](https://arxiv.org/abs/2110.08175) and the associated code is released in [this](https://github.com/salesforce/QGen) repository.
### How to use
Using Huggingface pipeline abstraction:
```
from transformers import pipeline
nlp = pipeline("text2text-generation", model='Salesforce/mixqg-base', tokenizer='Salesforce/mixqg-base')
CONTEXT = "In the late 17th century, Robert Boyle proved that air is necessary for combustion."
ANSWER = "Robert Boyle"
def format_inputs(context: str, answer: str):
return f"{answer} \\n {context}"
text = format_inputs(CONTEXT, ANSWER)
nlp(text)
# should output [{'generated_text': 'Who proved that air is necessary for combustion?'}]
```
Using the pre-trained model directly:
```
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained('Salesforce/mixqg-base')
model = AutoModelForSeq2SeqLM.from_pretrained('Salesforce/mixqg-base')
CONTEXT = "In the late 17th century, Robert Boyle proved that air is necessary for combustion."
ANSWER = "Robert Boyle"
def format_inputs(context: str, answer: str):
return f"{answer} \\n {context}"
text = format_inputs(CONTEXT, ANSWER)
input_ids = tokenizer(text, return_tensors="pt").input_ids
generated_ids = model.generate(input_ids, max_length=32, num_beams=4)
output = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
print(output)
# should output "Who proved that air is necessary for combustion?"
```
### Citation
```
@misc{murakhovska2021mixqg,
title={MixQG: Neural Question Generation with Mixed Answer Types},
author={Lidiya Murakhovs'ka and Chien-Sheng Wu and Tong Niu and Wenhao Liu and Caiming Xiong},
year={2021},
eprint={2110.08175},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
hf-internal-testing/tiny-random-deit
|
eb36ceed818f4098fe8c1308c9617d11f7c6e5c4
|
2021-09-17T19:22:55.000Z
|
[
"pytorch",
"deit",
"transformers"
] | null | false |
hf-internal-testing
| null |
hf-internal-testing/tiny-random-deit
| 204 | null |
transformers
| 3,594 |
Entry not found
|
jonatasgrosman/wav2vec2-large-english
|
81ac3bef3309f991c0a65b2d7a0719214d3a1b85
|
2022-07-27T23:34:18.000Z
|
[
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"en",
"dataset:common_voice",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
] |
automatic-speech-recognition
| false |
jonatasgrosman
| null |
jonatasgrosman/wav2vec2-large-english
| 204 | 1 |
transformers
| 3,595 |
---
language: en
datasets:
- common_voice
metrics:
- wer
- cer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: Wav2Vec2 English by Jonatas Grosman
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice en
type: common_voice
args: en
metrics:
- name: Test WER
type: wer
value: 21.53
- name: Test CER
type: cer
value: 9.66
---
# Fine-tuned wav2vec2 large model for speech recognition in English
Fine-tuned [facebook/wav2vec2-large](https://huggingface.co/facebook/wav2vec2-large) on English using the train and validation splits of [Common Voice 6.1](https://huggingface.co/datasets/common_voice).
When using this model, make sure that your speech input is sampled at 16kHz.
This model has been fine-tuned thanks to the GPU credits generously given by the [OVHcloud](https://www.ovhcloud.com/en/public-cloud/ai-training/) :)
The script used for training can be found here: https://github.com/jonatasgrosman/wav2vec2-sprint
## Usage
The model can be used directly (without a language model) as follows...
Using the [HuggingSound](https://github.com/jonatasgrosman/huggingsound) library:
```python
from huggingsound import SpeechRecognitionModel
model = SpeechRecognitionModel("jonatasgrosman/wav2vec2-large-english")
audio_paths = ["/path/to/file.mp3", "/path/to/another_file.wav"]
transcriptions = model.transcribe(audio_paths)
```
Writing your own inference script:
```python
import torch
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "en"
MODEL_ID = "jonatasgrosman/wav2vec2-large-english"
SAMPLES = 10
test_dataset = load_dataset("common_voice", LANG_ID, split=f"test[:{SAMPLES}]")
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = batch["sentence"].upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
predicted_sentences = processor.batch_decode(predicted_ids)
for i, predicted_sentence in enumerate(predicted_sentences):
print("-" * 100)
print("Reference:", test_dataset[i]["sentence"])
print("Prediction:", predicted_sentence)
```
| Reference | Prediction |
| ------------- | ------------- |
| "SHE'LL BE ALL RIGHT." | SHELL BE ALL RIGHT |
| SIX | SIX |
| "ALL'S WELL THAT ENDS WELL." | ALLAS WELL THAT ENDS WELL |
| DO YOU MEAN IT? | W MEAN IT |
| THE NEW PATCH IS LESS INVASIVE THAN THE OLD ONE, BUT STILL CAUSES REGRESSIONS. | THE NEW PATCH IS LESS INVASIVE THAN THE OLD ONE BUT STILL CAUSES REGRESTION |
| HOW IS MOZILLA GOING TO HANDLE AMBIGUITIES LIKE QUEUE AND CUE? | HOW IS MOSILLA GOING TO BANDL AND BE WHIT IS LIKE QU AND QU |
| "I GUESS YOU MUST THINK I'M KINDA BATTY." | RUSTION AS HAME AK AN THE POT |
| NO ONE NEAR THE REMOTE MACHINE YOU COULD RING? | NO ONE NEAR THE REMOTE MACHINE YOU COULD RING |
| SAUCE FOR THE GOOSE IS SAUCE FOR THE GANDER. | SAUCE FOR THE GUCE IS SAUCE FOR THE GONDER |
| GROVES STARTED WRITING SONGS WHEN SHE WAS FOUR YEARS OLD. | GRAFS STARTED WRITING SONGS WHEN SHE WAS FOUR YEARS OLD |
## Evaluation
The model can be evaluated as follows on the English (en) test data of Common Voice.
```python
import torch
import re
import librosa
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
LANG_ID = "en"
MODEL_ID = "jonatasgrosman/wav2vec2-large-english"
DEVICE = "cuda"
CHARS_TO_IGNORE = [",", "?", "¿", ".", "!", "¡", ";", ";", ":", '""', "%", '"', "�", "ʿ", "·", "჻", "~", "՞",
"؟", "،", "।", "॥", "«", "»", "„", "“", "”", "「", "」", "‘", "’", "《", "》", "(", ")", "[", "]",
"{", "}", "=", "`", "_", "+", "<", ">", "…", "–", "°", "´", "ʾ", "‹", "›", "©", "®", "—", "→", "。",
"、", "﹂", "﹁", "‧", "~", "﹏", ",", "{", "}", "(", ")", "[", "]", "【", "】", "‥", "〽",
"『", "』", "〝", "〟", "⟨", "⟩", "〜", ":", "!", "?", "♪", "؛", "/", "\\", "º", "−", "^", "ʻ", "ˆ"]
test_dataset = load_dataset("common_voice", LANG_ID, split="test")
wer = load_metric("wer.py") # https://github.com/jonatasgrosman/wav2vec2-sprint/blob/main/wer.py
cer = load_metric("cer.py") # https://github.com/jonatasgrosman/wav2vec2-sprint/blob/main/cer.py
chars_to_ignore_regex = f"[{re.escape(''.join(CHARS_TO_IGNORE))}]"
processor = Wav2Vec2Processor.from_pretrained(MODEL_ID)
model = Wav2Vec2ForCTC.from_pretrained(MODEL_ID)
model.to(DEVICE)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
with warnings.catch_warnings():
warnings.simplefilter("ignore")
speech_array, sampling_rate = librosa.load(batch["path"], sr=16_000)
batch["speech"] = speech_array
batch["sentence"] = re.sub(chars_to_ignore_regex, "", batch["sentence"]).upper()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to(DEVICE), attention_mask=inputs.attention_mask.to(DEVICE)).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
predictions = [x.upper() for x in result["pred_strings"]]
references = [x.upper() for x in result["sentence"]]
print(f"WER: {wer.compute(predictions=predictions, references=references, chunk_size=1000) * 100}")
print(f"CER: {cer.compute(predictions=predictions, references=references, chunk_size=1000) * 100}")
```
**Test Result**:
In the table below I report the Word Error Rate (WER) and the Character Error Rate (CER) of the model. I ran the evaluation script described above on other models as well (on 2021-06-17). Note that the table below may show different results from those already reported, this may have been caused due to some specificity of the other evaluation scripts used.
| Model | WER | CER |
| ------------- | ------------- | ------------- |
| jonatasgrosman/wav2vec2-large-xlsr-53-english | **18.98%** | **8.29%** |
| jonatasgrosman/wav2vec2-large-english | 21.53% | 9.66% |
| facebook/wav2vec2-large-960h-lv60-self | 22.03% | 10.39% |
| facebook/wav2vec2-large-960h-lv60 | 23.97% | 11.14% |
| boris/xlsr-en-punctuation | 29.10% | 10.75% |
| facebook/wav2vec2-large-960h | 32.79% | 16.03% |
| facebook/wav2vec2-base-960h | 39.86% | 19.89% |
| facebook/wav2vec2-base-100h | 51.06% | 25.06% |
| elgeish/wav2vec2-large-lv60-timit-asr | 59.96% | 34.28% |
| facebook/wav2vec2-base-10k-voxpopuli-ft-en | 66.41% | 36.76% |
| elgeish/wav2vec2-base-timit-asr | 68.78% | 36.81% |
## Citation
If you want to cite this model you can use this:
```bibtex
@misc{grosman2021wav2vec2-large-english,
title={Fine-tuned wav2vec2 large model for speech recognition in {E}nglish},
author={Grosman, Jonatas},
howpublished={\url{https://huggingface.co/jonatasgrosman/wav2vec2-large-english}},
year={2021}
}
```
|
lschneidpro/distilbert_uncased_imdb
|
8ba2d804414aee8d13fea68f193de309e5fff9e7
|
2020-09-07T16:11:36.000Z
|
[
"pytorch",
"tf",
"distilbert",
"text-classification",
"transformers"
] |
text-classification
| false |
lschneidpro
| null |
lschneidpro/distilbert_uncased_imdb
| 204 | null |
transformers
| 3,596 |
Entry not found
|
microsoft/unispeech-large-1500h-cv
|
4e1a2ace9d4d4ef4bafd208826ef02af0336ad7e
|
2021-11-05T12:41:56.000Z
|
[
"pytorch",
"unispeech",
"pretraining",
"en",
"dataset:common_voice",
"arxiv:2101.07597",
"transformers",
"speech"
] | null | false |
microsoft
| null |
microsoft/unispeech-large-1500h-cv
| 204 | null |
transformers
| 3,597 |
---
language:
- en
datasets:
- common_voice
tags:
- speech
---
# UniSpeech-Large
[Microsoft's UniSpeech](https://www.microsoft.com/en-us/research/publication/unispeech-unified-speech-representation-learning-with-labeled-and-unlabeled-data/)
The large model pretrained on 16kHz sampled speech audio and phonetic labels. When using the model make sure that your speech input is also sampled at 16kHz and your text in converted into a sequence of phonemes.
**Note**: This model does not have a tokenizer as it was pretrained on audio alone. In order to use this model **speech recognition**, a tokenizer should be created and the model should be fine-tuned on labeled text data. Check out [this blog](https://huggingface.co/blog/fine-tune-wav2vec2-english) for more in-detail explanation of how to fine-tune the model.
[Paper: UniSpeech: Unified Speech Representation Learning
with Labeled and Unlabeled Data](https://arxiv.org/abs/2101.07597)
Authors: Chengyi Wang, Yu Wu, Yao Qian, Kenichi Kumatani, Shujie Liu, Furu Wei, Michael Zeng, Xuedong Huang
**Abstract**
*In this paper, we propose a unified pre-training approach called UniSpeech to learn speech representations with both unlabeled and labeled data, in which supervised phonetic CTC learning and phonetically-aware contrastive self-supervised learning are conducted in a multi-task learning manner. The resultant representations can capture information more correlated with phonetic structures and improve the generalization across languages and domains. We evaluate the effectiveness of UniSpeech for cross-lingual representation learning on public CommonVoice corpus. The results show that UniSpeech outperforms self-supervised pretraining and supervised transfer learning for speech recognition by a maximum of 13.4% and 17.8% relative phone error rate reductions respectively (averaged over all testing languages). The transferability of UniSpeech is also demonstrated on a domain-shift speech recognition task, i.e., a relative word error rate reduction of 6% against the previous approach.*
The original model can be found under https://github.com/microsoft/UniSpeech/tree/main/UniSpeech.
# Usage
This is an English pre-trained speech model that has to be fine-tuned on a downstream task like speech recognition or audio classification before it can be
used in inference. The model was pre-trained in English and should therefore perform well only in English.
**Note**: The model was pre-trained on phonemes rather than characters. This means that one should make sure that the input text is converted to a sequence
of phonemes before fine-tuning.
## Speech Recognition
To fine-tune the model for speech recognition, see [the official speech recognition example](https://github.com/huggingface/transformers/tree/master/examples/pytorch/speech-recognition).
## Speech Classification
To fine-tune the model for speech classification, see [the official audio classification example](https://github.com/huggingface/transformers/tree/master/examples/pytorch/audio-classification).
# Contribution
The model was contributed by [cywang](https://huggingface.co/cywang) and [patrickvonplaten](https://huggingface.co/patrickvonplaten).
# License
The official license can be found [here](https://github.com/microsoft/UniSpeech/blob/main/LICENSE)
|
patrickvonplaten/bert2gpt2-cnn_dailymail-fp16
|
a30547834c8e029c92e00ece8402b210ec4aa2a9
|
2021-08-18T14:38:10.000Z
|
[
"pytorch",
"jax",
"encoder_decoder",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
| false |
patrickvonplaten
| null |
patrickvonplaten/bert2gpt2-cnn_dailymail-fp16
| 204 | 2 |
transformers
| 3,598 |
# Bert2GPT2 Summarization with 🤗 EncoderDecoder Framework
This model is a Bert2Bert model fine-tuned on summarization.
Bert2GPT2 is a `EncoderDecoderModel`, meaning that the encoder is a `bert-base-uncased`
BERT model and the decoder is a `gpt2` GPT2 model. Leveraging the [EncoderDecoderFramework](https://huggingface.co/transformers/model_doc/encoderdecoder.html#encoder-decoder-models), the
two pretrained models can simply be loaded into the framework via:
```python
bert2gpt2 = EncoderDecoderModel.from_encoder_decoder_pretrained("bert-base-uncased", "gpt2")
```
The decoder of an `EncoderDecoder` model needs cross-attention layers and usually makes use of causal
masking for auto-regressiv generation.
Thus, ``bert2gpt2`` is consequently fined-tuned on the `CNN/Daily Mail`dataset and the resulting model
`bert2gpt2-cnn_dailymail-fp16` is uploaded here.
## Example
The model is by no means a state-of-the-art model, but nevertheless
produces reasonable summarization results. It was mainly fine-tuned
as a proof-of-concept for the 🤗 EncoderDecoder Framework.
The model can be used as follows:
```python
from transformers import BertTokenizer, GPT2Tokenizer, EncoderDecoderModel
model = EncoderDecoderModel.from_pretrained("patrickvonplaten/bert2gpt2-cnn_dailymail-fp16")
# reuse tokenizer from bert2bert encoder-decoder model
bert_tokenizer = BertTokenizer.from_pretrained("patrickvonplaten/bert2bert-cnn_dailymail-fp16")
article = """(CNN)Sigma Alpha Epsilon is under fire for a video showing party-bound fraternity members singing a racist chant. SAE's national chapter suspended the students, but University of Oklahoma President David B
oren took it a step further, saying the university's affiliation with the fraternity is permanently done. The news is shocking, but it's not the first time SAE has faced controversy. SAE was founded March 9, 185
6, at the University of Alabama, five years before the American Civil War, according to the fraternity website. When the war began, the group had fewer than 400 members, of which "369 went to war for the Confede
rate States and seven for the Union Army," the website says. The fraternity now boasts more than 200,000 living alumni, along with about 15,000 undergraduates populating 219 chapters and 20 "colonies" seeking fu
ll membership at universities. SAE has had to work hard to change recently after a string of member deaths, many blamed on the hazing of new recruits, SAE national President Bradley Cohen wrote in a message on t
he fraternity's website. The fraternity's website lists more than 130 chapters cited or suspended for "health and safety incidents" since 2010. At least 30 of the incidents involved hazing, and dozens more invol
ved alcohol. However, the list is missing numerous incidents from recent months. Among them, according to various media outlets: Yale University banned the SAEs from campus activities last month after members al
legedly tried to interfere with a sexual misconduct investigation connected to an initiation rite. Stanford University in December suspended SAE housing privileges after finding sorority members attending a frat
ernity function were subjected to graphic sexual content. And Johns Hopkins University in November suspended the fraternity for underage drinking. "The media has labeled us as the 'nation's deadliest fraternity,
' " Cohen said. In 2011, for example, a student died while being coerced into excessive alcohol consumption, according to a lawsuit. SAE's previous insurer dumped the fraternity. "As a result, we are paying Lloy
d's of London the highest insurance rates in the Greek-letter world," Cohen said. Universities have turned down SAE's attempts to open new chapters, and the fraternity had to close 12 in 18 months over hazing in
cidents."""
input_ids = bert_tokenizer(article, return_tensors="pt").input_ids
output_ids = model.generate(input_ids)
# we need a gpt2 tokenizer for the output word embeddings
gpt2_tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
print(gpt2_tokenizer.decode(output_ids[0], skip_special_tokens=True))
# should produce
# SAE's national chapter suspended the students, but university president says it's permanent.
# The fraternity has had to deal with a string of incidents since 2010.
# SAE has more than 200,000 members, many of whom are students.
# A student died while being coerced into drinking alcohol.
```
## Training script:
**IMPORTANT**: In order for this code to work, make sure you checkout to the branch
[more_general_trainer_metric](https://github.com/huggingface/transformers/tree/more_general_trainer_metric), which slightly adapts
the `Trainer` for `EncoderDecoderModels` according to this PR: https://github.com/huggingface/transformers/pull/5840.
The following code shows the complete training script that was used to fine-tune `bert2gpt2-cnn_dailymail-fp16
` for reproducability. The training last ~11h on a standard GPU.
```python
#!/usr/bin/env python3
import nlp
import logging
from transformers import BertTokenizer, GPT2Tokenizer, EncoderDecoderModel, Trainer, TrainingArguments
logging.basicConfig(level=logging.INFO)
model = EncoderDecoderModel.from_encoder_decoder_pretrained("bert-base-cased", "gpt2")
# cache is currently not supported by EncoderDecoder framework
model.decoder.config.use_cache = False
bert_tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
# CLS token will work as BOS token
bert_tokenizer.bos_token = bert_tokenizer.cls_token
# SEP token will work as EOS token
bert_tokenizer.eos_token = bert_tokenizer.sep_token
# make sure GPT2 appends EOS in begin and end
def build_inputs_with_special_tokens(self, token_ids_0, token_ids_1=None):
outputs = [self.bos_token_id] + token_ids_0 + [self.eos_token_id]
return outputs
GPT2Tokenizer.build_inputs_with_special_tokens = build_inputs_with_special_tokens
gpt2_tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# set pad_token_id to unk_token_id -> be careful here as unk_token_id == eos_token_id == bos_token_id
gpt2_tokenizer.pad_token = gpt2_tokenizer.unk_token
# set decoding params
model.config.decoder_start_token_id = gpt2_tokenizer.bos_token_id
model.config.eos_token_id = gpt2_tokenizer.eos_token_id
model.config.max_length = 142
model.config.min_length = 56
model.config.no_repeat_ngram_size = 3
model.early_stopping = True
model.length_penalty = 2.0
model.num_beams = 4
# load train and validation data
train_dataset = nlp.load_dataset("cnn_dailymail", "3.0.0", split="train")
val_dataset = nlp.load_dataset("cnn_dailymail", "3.0.0", split="validation[:5%]")
# load rouge for validation
rouge = nlp.load_metric("rouge", experiment_id=1)
encoder_length = 512
decoder_length = 128
batch_size = 16
# map data correctly
def map_to_encoder_decoder_inputs(batch): # Tokenizer will automatically set [BOS] <text> [EOS]
# use bert tokenizer here for encoder
inputs = bert_tokenizer(batch["article"], padding="max_length", truncation=True, max_length=encoder_length)
# force summarization <= 128
outputs = gpt2_tokenizer(batch["highlights"], padding="max_length", truncation=True, max_length=decoder_length)
batch["input_ids"] = inputs.input_ids
batch["attention_mask"] = inputs.attention_mask
batch["decoder_input_ids"] = outputs.input_ids
batch["labels"] = outputs.input_ids.copy()
batch["decoder_attention_mask"] = outputs.attention_mask
# complicated list comprehension here because pad_token_id alone is not good enough to know whether label should be excluded or not
batch["labels"] = [
[-100 if mask == 0 else token for mask, token in mask_and_tokens] for mask_and_tokens in [zip(masks, labels) for masks, labels in zip(batch["decoder_attention_mask"], batch["labels"])]
]
assert all([len(x) == encoder_length for x in inputs.input_ids])
assert all([len(x) == decoder_length for x in outputs.input_ids])
return batch
def compute_metrics(pred):
labels_ids = pred.label_ids
pred_ids = pred.predictions
# all unnecessary tokens are removed
pred_str = gpt2_tokenizer.batch_decode(pred_ids, skip_special_tokens=True)
labels_ids[labels_ids == -100] = gpt2_tokenizer.eos_token_id
label_str = gpt2_tokenizer.batch_decode(labels_ids, skip_special_tokens=True)
rouge_output = rouge.compute(predictions=pred_str, references=label_str, rouge_types=["rouge2"])["rouge2"].mid
return {
"rouge2_precision": round(rouge_output.precision, 4),
"rouge2_recall": round(rouge_output.recall, 4),
"rouge2_fmeasure": round(rouge_output.fmeasure, 4),
}
# make train dataset ready
train_dataset = train_dataset.map(
map_to_encoder_decoder_inputs, batched=True, batch_size=batch_size, remove_columns=["article", "highlights"],
)
train_dataset.set_format(
type="torch", columns=["input_ids", "attention_mask", "decoder_input_ids", "decoder_attention_mask", "labels"],
)
# same for validation dataset
val_dataset = val_dataset.map(
map_to_encoder_decoder_inputs, batched=True, batch_size=batch_size, remove_columns=["article", "highlights"],
)
val_dataset.set_format(
type="torch", columns=["input_ids", "attention_mask", "decoder_input_ids", "decoder_attention_mask", "labels"],
)
# set training arguments - these params are not really tuned, feel free to change
training_args = TrainingArguments(
output_dir="./",
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
predict_from_generate=True,
evaluate_during_training=True,
do_train=True,
do_eval=True,
logging_steps=1000,
save_steps=1000,
eval_steps=1000,
overwrite_output_dir=True,
warmup_steps=2000,
save_total_limit=10,
fp16=True,
)
# instantiate trainer
trainer = Trainer(
model=model,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=train_dataset,
eval_dataset=val_dataset,
)
# start training
trainer.train()
```
## Evaluation
The following script evaluates the model on the test set of
CNN/Daily Mail.
```python
#!/usr/bin/env python3
import nlp
from transformers import BertTokenizer, GPT2Tokenizer, EncoderDecoderModel
model = EncoderDecoderModel.from_pretrained("patrickvonplaten/bert2gpt2-cnn_dailymail-fp16")
model.to("cuda")
bert_tokenizer = BertTokenizer.from_pretrained("bert-base-cased")
# CLS token will work as BOS token
bert_tokenizer.bos_token = bert_tokenizer.cls_token
# SEP token will work as EOS token
bert_tokenizer.eos_token = bert_tokenizer.sep_token
# make sure GPT2 appends EOS in begin and end
def build_inputs_with_special_tokens(self, token_ids_0, token_ids_1=None):
outputs = [self.bos_token_id] + token_ids_0 + [self.eos_token_id]
return outputs
GPT2Tokenizer.build_inputs_with_special_tokens = build_inputs_with_special_tokens
gpt2_tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# set pad_token_id to unk_token_id -> be careful here as unk_token_id == eos_token_id == bos_token_id
gpt2_tokenizer.pad_token = gpt2_tokenizer.unk_token
# set decoding params
model.config.decoder_start_token_id = gpt2_tokenizer.bos_token_id
model.config.eos_token_id = gpt2_tokenizer.eos_token_id
model.config.max_length = 142
model.config.min_length = 56
model.config.no_repeat_ngram_size = 3
model.early_stopping = True
model.length_penalty = 2.0
model.num_beams = 4
test_dataset = nlp.load_dataset("cnn_dailymail", "3.0.0", split="test")
batch_size = 64
# map data correctly
def generate_summary(batch):
# Tokenizer will automatically set [BOS] <text> [EOS]
# cut off at BERT max length 512
inputs = bert_tokenizer(batch["article"], padding="max_length", truncation=True, max_length=512, return_tensors="pt")
input_ids = inputs.input_ids.to("cuda")
attention_mask = inputs.attention_mask.to("cuda")
outputs = model.generate(input_ids, attention_mask=attention_mask)
# all special tokens including will be removed
output_str = gpt2_tokenizer.batch_decode(outputs, skip_special_tokens=True)
batch["pred"] = output_str
return batch
results = test_dataset.map(generate_summary, batched=True, batch_size=batch_size, remove_columns=["article"])
# load rouge for validation
rouge = nlp.load_metric("rouge")
pred_str = results["pred"]
label_str = results["highlights"]
rouge_output = rouge.compute(predictions=pred_str, references=label_str, rouge_types=["rouge2"])["rouge2"].mid
print(rouge_output)
```
The obtained results should be:
| - | Rouge2 - mid -precision | Rouge2 - mid - recall | Rouge2 - mid - fmeasure |
|----------|:-------------:|:------:|:------:|
| **CNN/Daily Mail** | 14.42 | 16.99 | **15.16** |
|
yangheng/deberta-v3-large-absa-v1.1
|
b63ac5f6e9e16438ec3b7daf8c59365085eafb8f
|
2022-03-19T00:42:23.000Z
|
[
"pytorch",
"deberta-v2",
"text-classification",
"en",
"dataset:laptop14",
"dataset:restaurant14",
"dataset:restaurant16",
"dataset:ACL-Twitter",
"dataset:MAMS",
"dataset:Television",
"dataset:TShirt",
"dataset:Yelp",
"arxiv:2110.08604",
"transformers",
"aspect-based-sentiment-analysis",
"PyABSA",
"license:mit"
] |
text-classification
| false |
yangheng
| null |
yangheng/deberta-v3-large-absa-v1.1
| 204 | 2 |
transformers
| 3,599 |
---
language:
- en
tags:
- aspect-based-sentiment-analysis
- PyABSA
license: mit
datasets:
- laptop14
- restaurant14
- restaurant16
- ACL-Twitter
- MAMS
- Television
- TShirt
- Yelp
metrics:
- accuracy
- macro-f1
widget:
- text: "[CLS] when tables opened up, the manager sat another party before us. [SEP] manager [SEP] "
---
# Note
This model is training with 30k+ ABSA samples, see [ABSADatasets](https://github.com/yangheng95/ABSADatasets). Yet the test sets are not included in pre-training, so you can use this model for training and benchmarking on common ABSA datasets, e.g., Laptop14, Rest14 datasets. (Except for the Rest15 dataset!)
# DeBERTa for aspect-based sentiment analysis
The `deberta-v3-large-absa` model for aspect-based sentiment analysis, trained with English datasets from [ABSADatasets](https://github.com/yangheng95/ABSADatasets).
## Training Model
This model is trained based on the FAST-LCF-BERT model with `microsoft/deberta-v3-large`, which comes from [PyABSA](https://github.com/yangheng95/PyABSA).
To track state-of-the-art models, please see [PyASBA](https://github.com/yangheng95/PyABSA).
## Usage
```python3
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("yangheng/deberta-v3-large-absa-v1.1")
model = AutoModelForSequenceClassification.from_pretrained("yangheng/deberta-v3-large-absa-v1.1")
```
## Example in PyASBA
An [example](https://github.com/yangheng95/PyABSA/blob/release/demos/aspect_polarity_classification/train_apc_multilingual.py) for using FAST-LCF-BERT in PyASBA datasets.
## Datasets
This model is fine-tuned with 180k examples for the ABSA dataset (including augmented data). Training dataset files:
```
loading: integrated_datasets/apc_datasets/SemEval/laptop14/Laptops_Train.xml.seg
loading: integrated_datasets/apc_datasets/SemEval/restaurant14/Restaurants_Train.xml.seg
loading: integrated_datasets/apc_datasets/SemEval/restaurant16/restaurant_train.raw
loading: integrated_datasets/apc_datasets/ACL_Twitter/acl-14-short-data/train.raw
loading: integrated_datasets/apc_datasets/MAMS/train.xml.dat
loading: integrated_datasets/apc_datasets/Television/Television_Train.xml.seg
loading: integrated_datasets/apc_datasets/TShirt/Menstshirt_Train.xml.seg
loading: integrated_datasets/apc_datasets/Yelp/yelp.train.txt
```
If you use this model in your research, please cite our paper:
```
@article{YangZMT21,
author = {Heng Yang and
Biqing Zeng and
Mayi Xu and
Tianxing Wang},
title = {Back to Reality: Leveraging Pattern-driven Modeling to Enable Affordable
Sentiment Dependency Learning},
journal = {CoRR},
volume = {abs/2110.08604},
year = {2021},
url = {https://arxiv.org/abs/2110.08604},
eprinttype = {arXiv},
eprint = {2110.08604},
timestamp = {Fri, 22 Oct 2021 13:33:09 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2110-08604.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.