
modelId
stringlengths 4
112
| sha
stringlengths 40
40
| lastModified
stringlengths 24
24
| tags
list | pipeline_tag
stringclasses 29
values | private
bool 1
class | author
stringlengths 2
38
⌀ | config
null | id
stringlengths 4
112
| downloads
float64 0
36.8M
⌀ | likes
float64 0
712
⌀ | library_name
stringclasses 17
values | __index_level_0__
int64 0
38.5k
| readme
stringlengths 0
186k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
aloxatel/AVG | 03327ae501855a31f95411020c419d12d86daddf | 2021-05-20T13:47:24.000Z | [
"pytorch",
"jax",
"roberta",
"text-classification",
"transformers"
]
| text-classification | false | aloxatel | null | aloxatel/AVG | 7 | null | transformers | 14,000 | Entry not found |
aloxatel/QHR | 1720186d8f621a1e109c2b03dffe094eb7aff2e4 | 2021-05-20T13:57:08.000Z | [
"pytorch",
"jax",
"roberta",
"text-classification",
"transformers"
]
| text-classification | false | aloxatel | null | aloxatel/QHR | 7 | null | transformers | 14,001 | Entry not found |
alvp/autonlp-alberti-stanza-names-34318169 | f3173e4593bb824bf042cd791c3e7ad8ebd3b8b2 | 2021-11-19T13:41:53.000Z | [
"pytorch",
"bert",
"text-classification",
"unk",
"dataset:alvp/autonlp-data-alberti-stanza-names",
"transformers",
"autonlp",
"co2_eq_emissions"
]
| text-classification | false | alvp | null | alvp/autonlp-alberti-stanza-names-34318169 | 7 | null | transformers | 14,002 | ---
tags: autonlp
language: unk
widget:
- text: "I love AutoNLP 🤗"
datasets:
- alvp/autonlp-data-alberti-stanza-names
co2_eq_emissions: 8.612473981829835
---
# Model Trained Using AutoNLP
- Problem type: Multi-class Classification
- Model ID: 34318169
- CO2 Emissions (in grams): 8.612473981829835
## Validation Metrics
- Loss: 1.3520570993423462
- Accuracy: 0.6083916083916084
- Macro F1: 0.5420169617715481
- Micro F1: 0.6083916083916084
- Weighted F1: 0.5963328136975058
- Macro Precision: 0.5864033493660455
- Micro Precision: 0.6083916083916084
- Weighted Precision: 0.6364793882921277
- Macro Recall: 0.5545405576555766
- Micro Recall: 0.6083916083916084
- Weighted Recall: 0.6083916083916084
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/alvp/autonlp-alberti-stanza-names-34318169
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("alvp/autonlp-alberti-stanza-names-34318169", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("alvp/autonlp-alberti-stanza-names-34318169", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` |
anantoj/wav2vec2-xls-r-300m-zh-CN | a91c8f050699ba920330eb28dec505805492c4e8 | 2022-03-23T18:27:08.000Z | [
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"zh-CN",
"dataset:common_voice",
"transformers",
"common_voice",
"generated_from_trainer",
"hf-asr-leaderboard",
"robust-speech-event",
"sv",
"license:apache-2.0",
"model-index"
]
| automatic-speech-recognition | false | anantoj | null | anantoj/wav2vec2-xls-r-300m-zh-CN | 7 | null | transformers | 14,003 | ---
language:
- zh-CN
license: apache-2.0
tags:
- automatic-speech-recognition
- common_voice
- generated_from_trainer
- hf-asr-leaderboard
- robust-speech-event
- sv
datasets:
- common_voice
model-index:
- name: ''
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Dev Data
type: speech-recognition-community-v2/dev_data
args: zh-CN
metrics:
- name: Test CER
type: cer
value: 66.22
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Test Data
type: speech-recognition-community-v2/eval_data
args: zh-CN
metrics:
- name: Test CER
type: cer
value: 37.51
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
#
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the COMMON_VOICE - ZH-CN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8122
- Wer: 0.8392
- Cer: 0.2059
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 100.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer | Cer |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|
| 69.215 | 0.74 | 500 | 74.9751 | 1.0 | 1.0 |
| 8.2109 | 1.48 | 1000 | 7.0617 | 1.0 | 1.0 |
| 6.4277 | 2.22 | 1500 | 6.3811 | 1.0 | 1.0 |
| 6.3513 | 2.95 | 2000 | 6.3061 | 1.0 | 1.0 |
| 6.2522 | 3.69 | 2500 | 6.2147 | 1.0 | 1.0 |
| 5.9757 | 4.43 | 3000 | 5.7906 | 1.1004 | 0.9924 |
| 5.0642 | 5.17 | 3500 | 4.2984 | 1.7729 | 0.8214 |
| 4.6346 | 5.91 | 4000 | 3.7129 | 1.8946 | 0.7728 |
| 4.267 | 6.65 | 4500 | 3.2177 | 1.7526 | 0.6922 |
| 3.9964 | 7.39 | 5000 | 2.8337 | 1.8055 | 0.6546 |
| 3.8035 | 8.12 | 5500 | 2.5726 | 2.1851 | 0.6992 |
| 3.6273 | 8.86 | 6000 | 2.3391 | 2.1029 | 0.6511 |
| 3.5248 | 9.6 | 6500 | 2.1944 | 2.3617 | 0.6859 |
| 3.3683 | 10.34 | 7000 | 1.9827 | 2.1014 | 0.6063 |
| 3.2411 | 11.08 | 7500 | 1.8610 | 1.6160 | 0.5135 |
| 3.1299 | 11.82 | 8000 | 1.7446 | 1.5948 | 0.4946 |
| 3.0574 | 12.56 | 8500 | 1.6454 | 1.1291 | 0.4051 |
| 2.985 | 13.29 | 9000 | 1.5919 | 1.0673 | 0.3893 |
| 2.9573 | 14.03 | 9500 | 1.4903 | 1.0604 | 0.3766 |
| 2.8897 | 14.77 | 10000 | 1.4614 | 1.0059 | 0.3653 |
| 2.8169 | 15.51 | 10500 | 1.3997 | 1.0030 | 0.3550 |
| 2.8155 | 16.25 | 11000 | 1.3444 | 0.9980 | 0.3441 |
| 2.7595 | 16.99 | 11500 | 1.2911 | 0.9703 | 0.3325 |
| 2.7107 | 17.72 | 12000 | 1.2462 | 0.9565 | 0.3227 |
| 2.6358 | 18.46 | 12500 | 1.2466 | 0.9955 | 0.3333 |
| 2.5801 | 19.2 | 13000 | 1.2059 | 1.0010 | 0.3226 |
| 2.5554 | 19.94 | 13500 | 1.1919 | 1.0094 | 0.3223 |
| 2.5314 | 20.68 | 14000 | 1.1703 | 0.9847 | 0.3156 |
| 2.509 | 21.42 | 14500 | 1.1733 | 0.9896 | 0.3177 |
| 2.4391 | 22.16 | 15000 | 1.1811 | 0.9723 | 0.3164 |
| 2.4631 | 22.89 | 15500 | 1.1382 | 0.9698 | 0.3059 |
| 2.4414 | 23.63 | 16000 | 1.0893 | 0.9644 | 0.2972 |
| 2.3771 | 24.37 | 16500 | 1.0930 | 0.9505 | 0.2954 |
| 2.3658 | 25.11 | 17000 | 1.0756 | 0.9609 | 0.2926 |
| 2.3215 | 25.85 | 17500 | 1.0512 | 0.9614 | 0.2890 |
| 2.3327 | 26.59 | 18000 | 1.0627 | 1.1984 | 0.3282 |
| 2.3055 | 27.33 | 18500 | 1.0582 | 0.9520 | 0.2841 |
| 2.299 | 28.06 | 19000 | 1.0356 | 0.9480 | 0.2817 |
| 2.2673 | 28.8 | 19500 | 1.0305 | 0.9367 | 0.2771 |
| 2.2166 | 29.54 | 20000 | 1.0139 | 0.9223 | 0.2702 |
| 2.2378 | 30.28 | 20500 | 1.0095 | 0.9268 | 0.2722 |
| 2.2168 | 31.02 | 21000 | 1.0001 | 0.9085 | 0.2691 |
| 2.1766 | 31.76 | 21500 | 0.9884 | 0.9050 | 0.2640 |
| 2.1715 | 32.5 | 22000 | 0.9730 | 0.9505 | 0.2719 |
| 2.1104 | 33.23 | 22500 | 0.9752 | 0.9362 | 0.2656 |
| 2.1158 | 33.97 | 23000 | 0.9720 | 0.9263 | 0.2624 |
| 2.0718 | 34.71 | 23500 | 0.9573 | 1.0005 | 0.2759 |
| 2.0824 | 35.45 | 24000 | 0.9609 | 0.9525 | 0.2643 |
| 2.0591 | 36.19 | 24500 | 0.9662 | 0.9570 | 0.2667 |
| 2.0768 | 36.93 | 25000 | 0.9528 | 0.9574 | 0.2646 |
| 2.0893 | 37.67 | 25500 | 0.9810 | 0.9169 | 0.2612 |
| 2.0282 | 38.4 | 26000 | 0.9556 | 0.8877 | 0.2528 |
| 1.997 | 39.14 | 26500 | 0.9523 | 0.8723 | 0.2501 |
| 2.0209 | 39.88 | 27000 | 0.9542 | 0.8773 | 0.2503 |
| 1.987 | 40.62 | 27500 | 0.9427 | 0.8867 | 0.2500 |
| 1.9663 | 41.36 | 28000 | 0.9546 | 0.9065 | 0.2546 |
| 1.9945 | 42.1 | 28500 | 0.9431 | 0.9119 | 0.2536 |
| 1.9604 | 42.84 | 29000 | 0.9367 | 0.9030 | 0.2490 |
| 1.933 | 43.57 | 29500 | 0.9071 | 0.8916 | 0.2432 |
| 1.9227 | 44.31 | 30000 | 0.9048 | 0.8882 | 0.2428 |
| 1.8784 | 45.05 | 30500 | 0.9106 | 0.8991 | 0.2437 |
| 1.8844 | 45.79 | 31000 | 0.8996 | 0.8758 | 0.2379 |
| 1.8776 | 46.53 | 31500 | 0.9028 | 0.8798 | 0.2395 |
| 1.8372 | 47.27 | 32000 | 0.9047 | 0.8778 | 0.2379 |
| 1.832 | 48.01 | 32500 | 0.9016 | 0.8941 | 0.2393 |
| 1.8154 | 48.74 | 33000 | 0.8915 | 0.8916 | 0.2372 |
| 1.8072 | 49.48 | 33500 | 0.8781 | 0.8872 | 0.2365 |
| 1.7489 | 50.22 | 34000 | 0.8738 | 0.8956 | 0.2340 |
| 1.7928 | 50.96 | 34500 | 0.8684 | 0.8872 | 0.2323 |
| 1.7748 | 51.7 | 35000 | 0.8723 | 0.8718 | 0.2321 |
| 1.7355 | 52.44 | 35500 | 0.8760 | 0.8842 | 0.2331 |
| 1.7167 | 53.18 | 36000 | 0.8746 | 0.8817 | 0.2324 |
| 1.7479 | 53.91 | 36500 | 0.8762 | 0.8753 | 0.2281 |
| 1.7428 | 54.65 | 37000 | 0.8733 | 0.8699 | 0.2277 |
| 1.7058 | 55.39 | 37500 | 0.8816 | 0.8649 | 0.2263 |
| 1.7045 | 56.13 | 38000 | 0.8733 | 0.8689 | 0.2297 |
| 1.709 | 56.87 | 38500 | 0.8648 | 0.8654 | 0.2232 |
| 1.6799 | 57.61 | 39000 | 0.8717 | 0.8580 | 0.2244 |
| 1.664 | 58.35 | 39500 | 0.8653 | 0.8723 | 0.2259 |
| 1.6488 | 59.08 | 40000 | 0.8637 | 0.8803 | 0.2271 |
| 1.6298 | 59.82 | 40500 | 0.8553 | 0.8768 | 0.2253 |
| 1.6185 | 60.56 | 41000 | 0.8512 | 0.8718 | 0.2240 |
| 1.574 | 61.3 | 41500 | 0.8579 | 0.8773 | 0.2251 |
| 1.6192 | 62.04 | 42000 | 0.8499 | 0.8743 | 0.2242 |
| 1.6275 | 62.78 | 42500 | 0.8419 | 0.8758 | 0.2216 |
| 1.5697 | 63.52 | 43000 | 0.8446 | 0.8699 | 0.2222 |
| 1.5384 | 64.25 | 43500 | 0.8462 | 0.8580 | 0.2200 |
| 1.5115 | 64.99 | 44000 | 0.8467 | 0.8674 | 0.2214 |
| 1.5547 | 65.73 | 44500 | 0.8505 | 0.8669 | 0.2204 |
| 1.5597 | 66.47 | 45000 | 0.8421 | 0.8684 | 0.2192 |
| 1.505 | 67.21 | 45500 | 0.8485 | 0.8619 | 0.2187 |
| 1.5101 | 67.95 | 46000 | 0.8489 | 0.8649 | 0.2204 |
| 1.5199 | 68.69 | 46500 | 0.8407 | 0.8619 | 0.2180 |
| 1.5207 | 69.42 | 47000 | 0.8379 | 0.8496 | 0.2163 |
| 1.478 | 70.16 | 47500 | 0.8357 | 0.8595 | 0.2163 |
| 1.4817 | 70.9 | 48000 | 0.8346 | 0.8496 | 0.2151 |
| 1.4827 | 71.64 | 48500 | 0.8362 | 0.8624 | 0.2169 |
| 1.4513 | 72.38 | 49000 | 0.8355 | 0.8451 | 0.2137 |
| 1.4988 | 73.12 | 49500 | 0.8325 | 0.8624 | 0.2161 |
| 1.4267 | 73.85 | 50000 | 0.8396 | 0.8481 | 0.2157 |
| 1.4421 | 74.59 | 50500 | 0.8355 | 0.8491 | 0.2122 |
| 1.4311 | 75.33 | 51000 | 0.8358 | 0.8476 | 0.2118 |
| 1.4174 | 76.07 | 51500 | 0.8289 | 0.8451 | 0.2101 |
| 1.4349 | 76.81 | 52000 | 0.8372 | 0.8580 | 0.2140 |
| 1.3959 | 77.55 | 52500 | 0.8325 | 0.8436 | 0.2116 |
| 1.4087 | 78.29 | 53000 | 0.8351 | 0.8446 | 0.2105 |
| 1.415 | 79.03 | 53500 | 0.8363 | 0.8476 | 0.2123 |
| 1.4122 | 79.76 | 54000 | 0.8310 | 0.8481 | 0.2112 |
| 1.3969 | 80.5 | 54500 | 0.8239 | 0.8446 | 0.2095 |
| 1.361 | 81.24 | 55000 | 0.8282 | 0.8427 | 0.2091 |
| 1.3611 | 81.98 | 55500 | 0.8282 | 0.8407 | 0.2092 |
| 1.3677 | 82.72 | 56000 | 0.8235 | 0.8436 | 0.2084 |
| 1.3361 | 83.46 | 56500 | 0.8231 | 0.8377 | 0.2069 |
| 1.3779 | 84.19 | 57000 | 0.8206 | 0.8436 | 0.2070 |
| 1.3727 | 84.93 | 57500 | 0.8204 | 0.8392 | 0.2065 |
| 1.3317 | 85.67 | 58000 | 0.8207 | 0.8436 | 0.2065 |
| 1.3332 | 86.41 | 58500 | 0.8186 | 0.8357 | 0.2055 |
| 1.3299 | 87.15 | 59000 | 0.8193 | 0.8417 | 0.2075 |
| 1.3129 | 87.89 | 59500 | 0.8183 | 0.8431 | 0.2065 |
| 1.3352 | 88.63 | 60000 | 0.8151 | 0.8471 | 0.2062 |
| 1.3026 | 89.36 | 60500 | 0.8125 | 0.8486 | 0.2067 |
| 1.3468 | 90.1 | 61000 | 0.8124 | 0.8407 | 0.2058 |
| 1.3028 | 90.84 | 61500 | 0.8122 | 0.8461 | 0.2051 |
| 1.2884 | 91.58 | 62000 | 0.8086 | 0.8427 | 0.2048 |
| 1.3005 | 92.32 | 62500 | 0.8110 | 0.8387 | 0.2055 |
| 1.2996 | 93.06 | 63000 | 0.8126 | 0.8328 | 0.2057 |
| 1.2707 | 93.8 | 63500 | 0.8098 | 0.8402 | 0.2047 |
| 1.3026 | 94.53 | 64000 | 0.8097 | 0.8402 | 0.2050 |
| 1.2546 | 95.27 | 64500 | 0.8111 | 0.8402 | 0.2055 |
| 1.2426 | 96.01 | 65000 | 0.8088 | 0.8372 | 0.2059 |
| 1.2869 | 96.75 | 65500 | 0.8093 | 0.8397 | 0.2048 |
| 1.2782 | 97.49 | 66000 | 0.8099 | 0.8412 | 0.2049 |
| 1.2457 | 98.23 | 66500 | 0.8134 | 0.8412 | 0.2062 |
| 1.2967 | 98.97 | 67000 | 0.8115 | 0.8382 | 0.2055 |
| 1.2817 | 99.7 | 67500 | 0.8128 | 0.8392 | 0.2063 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.3.dev0
- Tokenizers 0.11.0
|
andrejmiscic/simcls-scorer-billsum | 7859d52a26734d388cd5dec05fe6be63637f1e11 | 2021-10-16T19:31:32.000Z | [
"pytorch",
"roberta",
"feature-extraction",
"en",
"dataset:billsum",
"arxiv:2106.01890",
"arxiv:1910.00523",
"transformers",
"simcls"
]
| feature-extraction | false | andrejmiscic | null | andrejmiscic/simcls-scorer-billsum | 7 | null | transformers | 14,004 | ---
language:
- en
tags:
- simcls
datasets:
- billsum
---
# SimCLS
SimCLS is a framework for abstractive summarization presented in [SimCLS: A Simple Framework for Contrastive Learning of Abstractive Summarization](https://arxiv.org/abs/2106.01890).
It is a two-stage approach consisting of a *generator* and a *scorer*. In the first stage, a large pre-trained model for abstractive summarization (the *generator*) is used to generate candidate summaries, whereas, in the second stage, the *scorer* assigns a score to each candidate given the source document. The final summary is the highest-scoring candidate.
This model is the *scorer* trained for summarization of BillSum ([paper](https://arxiv.org/abs/1910.00523), [datasets](https://huggingface.co/datasets/billsum)). It should be used in conjunction with [google/pegasus-billsum](https://huggingface.co/google/pegasus-billsum). See [our Github repository](https://github.com/andrejmiscic/simcls-pytorch) for details on training, evaluation, and usage.
## Usage
```bash
git clone https://github.com/andrejmiscic/simcls-pytorch.git
cd simcls-pytorch
pip3 install torch torchvision torchaudio transformers sentencepiece
```
```python
from src.model import SimCLS, GeneratorType
summarizer = SimCLS(generator_type=GeneratorType.Pegasus,
generator_path="google/pegasus-billsum",
scorer_path="andrejmiscic/simcls-scorer-billsum")
document = "This is a legal document."
summary = summarizer(document)
print(summary)
```
### Results
All of our results are reported together with 95% confidence intervals computed using 10000 iterations of bootstrap. See [SimCLS paper](https://arxiv.org/abs/2106.01890) for a description of baselines.
We believe the discrepancies of Rouge-L scores between the original Pegasus work and our evaluation are due to the computation of the metric. Namely, we use a summary level Rouge-L score.
| System | Rouge-1 | Rouge-2 | Rouge-L\* |
|-----------------|----------------------:|----------------------:|----------------------:|
| Pegasus | 57.31 | 40.19 | 45.82 |
| **Our results** | --- | --- | --- |
| Origin | 56.24, [55.74, 56.74] | 37.46, [36.89, 38.03] | 50.71, [50.19, 51.22] |
| Min | 44.37, [43.85, 44.89] | 25.75, [25.30, 26.22] | 38.68, [38.18, 39.16] |
| Max | 62.88, [62.42, 63.33] | 43.96, [43.39, 44.54] | 57.50, [57.01, 58.00] |
| Random | 54.93, [54.43, 55.43] | 35.42, [34.85, 35.97] | 49.19, [48.68, 49.70] |
| **SimCLS** | 57.49, [57.01, 58.00] | 38.54, [37.98, 39.10] | 51.91, [51.39, 52.43] |
### Citation of the original work
```bibtex
@inproceedings{liu-liu-2021-simcls,
title = "{S}im{CLS}: A Simple Framework for Contrastive Learning of Abstractive Summarization",
author = "Liu, Yixin and
Liu, Pengfei",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 2: Short Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-short.135",
doi = "10.18653/v1/2021.acl-short.135",
pages = "1065--1072",
}
```
|
anirudh21/bert-base-uncased-finetuned-mrpc | 620f498599978dd494b057e027fd894824eed3fc | 2022-01-27T05:26:21.000Z | [
"pytorch",
"tensorboard",
"bert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| text-classification | false | anirudh21 | null | anirudh21/bert-base-uncased-finetuned-mrpc | 7 | 1 | transformers | 14,005 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: bert-base-uncased-finetuned-mrpc
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: mrpc
metrics:
- name: Accuracy
type: accuracy
value: 0.7916666666666666
- name: F1
type: f1
value: 0.8590381426202321
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-mrpc
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6645
- Accuracy: 0.7917
- F1: 0.8590
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 63 | 0.5387 | 0.7402 | 0.8349 |
| No log | 2.0 | 126 | 0.5770 | 0.7696 | 0.8513 |
| No log | 3.0 | 189 | 0.5357 | 0.7574 | 0.8223 |
| No log | 4.0 | 252 | 0.6645 | 0.7917 | 0.8590 |
| No log | 5.0 | 315 | 0.6977 | 0.7721 | 0.8426 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.18.1
- Tokenizers 0.10.3
|
anirudh21/distilbert-base-uncased-finetuned-mrpc | 3106d5b937946dc70297f2a57718127be3d2b768 | 2022-01-12T08:30:57.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| text-classification | false | anirudh21 | null | anirudh21/distilbert-base-uncased-finetuned-mrpc | 7 | null | transformers | 14,006 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-mrpc
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: mrpc
metrics:
- name: Accuracy
type: accuracy
value: 0.8455882352941176
- name: F1
type: f1
value: 0.8958677685950412
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-mrpc
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3830
- Accuracy: 0.8456
- F1: 0.8959
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 230 | 0.3826 | 0.8186 | 0.8683 |
| No log | 2.0 | 460 | 0.3830 | 0.8456 | 0.8959 |
| 0.4408 | 3.0 | 690 | 0.3835 | 0.8382 | 0.8866 |
| 0.4408 | 4.0 | 920 | 0.5036 | 0.8431 | 0.8919 |
| 0.1941 | 5.0 | 1150 | 0.5783 | 0.8431 | 0.8930 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
anirudh21/electra-base-discriminator-finetuned-rte | da687125f0dc8320cbc05ee98e6efba0a3dff348 | 2022-01-25T15:43:18.000Z | [
"pytorch",
"tensorboard",
"electra",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| text-classification | false | anirudh21 | null | anirudh21/electra-base-discriminator-finetuned-rte | 7 | null | transformers | 14,007 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: electra-base-discriminator-finetuned-rte
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: rte
metrics:
- name: Accuracy
type: accuracy
value: 0.8231046931407943
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# electra-base-discriminator-finetuned-rte
This model is a fine-tuned version of [google/electra-base-discriminator](https://huggingface.co/google/electra-base-discriminator) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4793
- Accuracy: 0.8231
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 156 | 0.6076 | 0.6570 |
| No log | 2.0 | 312 | 0.4824 | 0.7762 |
| No log | 3.0 | 468 | 0.4793 | 0.8231 |
| 0.4411 | 4.0 | 624 | 0.7056 | 0.7906 |
| 0.4411 | 5.0 | 780 | 0.6849 | 0.8159 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.18.0
- Tokenizers 0.10.3
|
anjulRajendraSharma/WavLm-base-en | 4d7d181e54789a88cc2af322aa58abdf26c4b12f | 2022-01-28T16:40:52.000Z | [
"pytorch",
"tensorboard",
"wavlm",
"automatic-speech-recognition",
"transformers",
"english_asr",
"generated_from_trainer",
"model-index"
]
| automatic-speech-recognition | false | anjulRajendraSharma | null | anjulRajendraSharma/WavLm-base-en | 7 | null | transformers | 14,008 | ---
tags:
- automatic-speech-recognition
- english_asr
- generated_from_trainer
model-index:
- name: wavlm-base-english
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wavlm-base-english
This model is a fine-tuned version of [microsoft/wavlm-base](https://huggingface.co/microsoft/wavlm-base) on the english_ASR - CLEAN dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0955
- Wer: 0.0773
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 1.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 2.8664 | 0.17 | 300 | 2.8439 | 1.0 |
| 0.5009 | 0.34 | 600 | 0.2709 | 0.2162 |
| 0.2056 | 0.5 | 900 | 0.1934 | 0.1602 |
| 0.1648 | 0.67 | 1200 | 0.1576 | 0.1306 |
| 0.1922 | 0.84 | 1500 | 0.1358 | 0.1114 |
| 0.093 | 1.01 | 1800 | 0.1277 | 0.1035 |
| 0.0652 | 1.18 | 2100 | 0.1251 | 0.1005 |
| 0.0848 | 1.35 | 2400 | 0.1188 | 0.0964 |
| 0.0706 | 1.51 | 2700 | 0.1091 | 0.0905 |
| 0.0846 | 1.68 | 3000 | 0.1018 | 0.0840 |
| 0.0684 | 1.85 | 3300 | 0.0978 | 0.0809 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.9.1
- Datasets 1.18.0
- Tokenizers 0.10.3
|
anshengli2/DialogGPT-small-Bot | 128b91bc1a5dd354e5de3a929a50918486e3a55b | 2021-09-13T05:39:55.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | false | anshengli2 | null | anshengli2/DialogGPT-small-Bot | 7 | null | transformers | 14,009 | ---
tags:
- conversational
---
|
anton-l/hubert-base-ft-keyword-spotting | 9bf54fa186c91561a6f72837b678cb6ecbf3ab1a | 2021-10-27T22:34:38.000Z | [
"pytorch",
"tensorboard",
"hubert",
"audio-classification",
"dataset:superb",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| audio-classification | false | anton-l | null | anton-l/hubert-base-ft-keyword-spotting | 7 | null | transformers | 14,010 | ---
license: apache-2.0
tags:
- audio-classification
- generated_from_trainer
datasets:
- superb
metrics:
- accuracy
model-index:
- name: hubert-base-ft-keyword-spotting
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hubert-base-ft-keyword-spotting
This model is a fine-tuned version of [facebook/hubert-base-ls960](https://huggingface.co/facebook/hubert-base-ls960) on the superb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0774
- Accuracy: 0.9819
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 0
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.0422 | 1.0 | 399 | 0.8999 | 0.6918 |
| 0.3296 | 2.0 | 798 | 0.1505 | 0.9778 |
| 0.2088 | 3.0 | 1197 | 0.0901 | 0.9816 |
| 0.202 | 4.0 | 1596 | 0.0848 | 0.9813 |
| 0.1535 | 5.0 | 1995 | 0.0774 | 0.9819 |
### Framework versions
- Transformers 4.12.0.dev0
- Pytorch 1.9.1+cu111
- Datasets 1.14.0
- Tokenizers 0.10.3
|
anuragshas/wav2vec2-xls-r-300m-sl-cv8-with-lm | 24e0664e4881b928bbae5aa119a43fcb918c29ee | 2022-03-23T18:29:27.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"sl",
"dataset:mozilla-foundation/common_voice_8_0",
"transformers",
"generated_from_trainer",
"hf-asr-leaderboard",
"mozilla-foundation/common_voice_8_0",
"robust-speech-event",
"license:apache-2.0",
"model-index"
]
| automatic-speech-recognition | false | anuragshas | null | anuragshas/wav2vec2-xls-r-300m-sl-cv8-with-lm | 7 | null | transformers | 14,011 | ---
language:
- sl
license: apache-2.0
tags:
- automatic-speech-recognition
- generated_from_trainer
- hf-asr-leaderboard
- mozilla-foundation/common_voice_8_0
- robust-speech-event
datasets:
- mozilla-foundation/common_voice_8_0
model-index:
- name: XLS-R-300M - Slovenian
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 8
type: mozilla-foundation/common_voice_8_0
args: sl
metrics:
- name: Test WER
type: wer
value: 12.736
- name: Test CER
type: cer
value: 3.605
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Dev Data
type: speech-recognition-community-v2/dev_data
args: sl
metrics:
- name: Test WER
type: wer
value: 45.587
- name: Test CER
type: cer
value: 20.886
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Test Data
type: speech-recognition-community-v2/eval_data
args: sl
metrics:
- name: Test WER
type: wer
value: 45.42
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# XLS-R-300M - Slovenian
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_8_0 - SL dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2578
- Wer: 0.2273
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.5e-05
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 60.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.1829 | 4.88 | 400 | 3.1228 | 1.0 |
| 2.8675 | 9.76 | 800 | 2.8616 | 0.9993 |
| 1.583 | 14.63 | 1200 | 0.6392 | 0.6239 |
| 1.1959 | 19.51 | 1600 | 0.3602 | 0.3651 |
| 1.0276 | 24.39 | 2000 | 0.3021 | 0.2981 |
| 0.9671 | 29.27 | 2400 | 0.2872 | 0.2739 |
| 0.873 | 34.15 | 2800 | 0.2593 | 0.2459 |
| 0.8513 | 39.02 | 3200 | 0.2617 | 0.2473 |
| 0.8132 | 43.9 | 3600 | 0.2548 | 0.2426 |
| 0.7935 | 48.78 | 4000 | 0.2637 | 0.2353 |
| 0.7565 | 53.66 | 4400 | 0.2629 | 0.2322 |
| 0.7359 | 58.54 | 4800 | 0.2579 | 0.2253 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.2.dev0
- Tokenizers 0.11.0
#### Evaluation Commands
1. To evaluate on `mozilla-foundation/common_voice_8_0` with split `test`
```bash
python eval.py --model_id anuragshas/wav2vec2-xls-r-300m-sl-cv8-with-lm --dataset mozilla-foundation/common_voice_8_0 --config sl --split test
```
2. To evaluate on `speech-recognition-community-v2/dev_data`
```bash
python eval.py --model_id anuragshas/wav2vec2-xls-r-300m-sl-cv8-with-lm --dataset speech-recognition-community-v2/dev_data --config sl --split validation --chunk_length_s 5.0 --stride_length_s 1.0
```
### Inference With LM
```python
import torch
from datasets import load_dataset
from transformers import AutoModelForCTC, AutoProcessor
import torchaudio.functional as F
model_id = "anuragshas/wav2vec2-xls-r-300m-sl-cv8-with-lm"
sample_iter = iter(load_dataset("mozilla-foundation/common_voice_8_0", "sl", split="test", streaming=True, use_auth_token=True))
sample = next(sample_iter)
resampled_audio = F.resample(torch.tensor(sample["audio"]["array"]), 48_000, 16_000).numpy()
model = AutoModelForCTC.from_pretrained(model_id)
processor = AutoProcessor.from_pretrained(model_id)
input_values = processor(resampled_audio, return_tensors="pt").input_values
with torch.no_grad():
logits = model(input_values).logits
transcription = processor.batch_decode(logits.numpy()).text
# => "zmago je divje od letel s helikopterjem visoko vzrak"
```
### Eval results on Common Voice 8 "test" (WER):
| Without LM | With LM (run `./eval.py`) |
|---|---|
| 19.938 | 12.736 | |
appleternity/bert-base-uncased-finetuned-coda19 | 25627d0283be4c4decfafaa8937d822cb977c507 | 2021-05-19T00:00:47.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
]
| text-classification | false | appleternity | null | appleternity/bert-base-uncased-finetuned-coda19 | 7 | null | transformers | 14,012 | Entry not found |
aristotletan/scim-distilroberta | 6c48e576f628b82fe36addd8f86144ded407a210 | 2021-05-20T14:14:24.000Z | [
"pytorch",
"jax",
"roberta",
"text-classification",
"transformers"
]
| text-classification | false | aristotletan | null | aristotletan/scim-distilroberta | 7 | null | transformers | 14,013 | Entry not found |
arjunth2001/priv_ftc | 74acbe22d2444a3257575c137af4f1cdb1363f71 | 2021-10-07T16:55:05.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
]
| text-classification | false | arjunth2001 | null | arjunth2001/priv_ftc | 7 | null | transformers | 14,014 | Entry not found |
asapp/sew-d-mid-400k-ft-ls100h | b2ff9fdb3bddc81657cf5f16bc0c510be0a39b3e | 2022-05-24T13:09:41.000Z | [
"pytorch",
"sew-d",
"automatic-speech-recognition",
"en",
"dataset:librispeech_asr",
"arxiv:2109.06870",
"transformers",
"audio",
"speech",
"hf-asr-leaderboard",
"license:apache-2.0",
"model-index"
]
| automatic-speech-recognition | false | asapp | null | asapp/sew-d-mid-400k-ft-ls100h | 7 | 1 | transformers | 14,015 | ---
language: en
datasets:
- librispeech_asr
tags:
- audio
- speech
- automatic-speech-recognition
- hf-asr-leaderboard
license: apache-2.0
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
model-index:
- name: sew-d-mid-400k-ft-ls100h
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: LibriSpeech (clean)
type: librispeech_asr
config: clean
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 4.94
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: LibriSpeech (other)
type: librispeech_asr
config: other
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 11.51
---
# SEW-D-mid
[SEW-D by ASAPP Research](https://github.com/asappresearch/sew)
The base model pretrained on 16kHz sampled speech audio. When using the model make sure that your speech input is also sampled at 16Khz. Note that this model should be fine-tuned on a downstream task, like Automatic Speech Recognition, Speaker Identification, Intent Classification, Emotion Recognition, etc...
Paper: [Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition](https://arxiv.org/abs/2109.06870)
Authors: Felix Wu, Kwangyoun Kim, Jing Pan, Kyu Han, Kilian Q. Weinberger, Yoav Artzi
**Abstract**
This paper is a study of performance-efficiency trade-offs in pre-trained models for automatic speech recognition (ASR). We focus on wav2vec 2.0, and formalize several architecture designs that influence both the model performance and its efficiency. Putting together all our observations, we introduce SEW (Squeezed and Efficient Wav2vec), a pre-trained model architecture with significant improvements along both performance and efficiency dimensions across a variety of training setups. For example, under the 100h-960h semi-supervised setup on LibriSpeech, SEW achieves a 1.9x inference speedup compared to wav2vec 2.0, with a 13.5% relative reduction in word error rate. With a similar inference time, SEW reduces word error rate by 25-50% across different model sizes.
The original model can be found under https://github.com/asappresearch/sew#model-checkpoints .
# Usage
To transcribe audio files the model can be used as a standalone acoustic model as follows:
```python
from transformers import Wav2Vec2Processor, SEWDForCTC
from datasets import load_dataset
import soundfile as sf
import torch
# load the model and preprocessor
processor = Wav2Vec2Processor.from_pretrained("asapp/sew-d-mid-400k-ft-ls100h")
model = SEWDForCTC.from_pretrained("asapp/sew-d-mid-400k-ft-ls100h")
# load the dummy dataset with speech samples
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# preprocess
input_values = processor(ds[0]["audio"]["array"], return_tensors="pt").input_values # Batch size 1
# retrieve logits
logits = model(input_values).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
```
## Evaluation
This code snippet shows how to evaluate **asapp/sew-d-mid-400k-ft-ls100hh** on LibriSpeech's "clean" and "other" test data.
```python
from datasets import load_dataset
from transformers import SEWDForCTC, Wav2Vec2Processor
import torch
from jiwer import wer
librispeech_eval = load_dataset("librispeech_asr", "clean", split="test")
model = SEWDForCTC.from_pretrained("asapp/sew-d-mid-400k-ft-ls100h").to("cuda")
processor = Wav2Vec2Processor.from_pretrained("asapp/sew-d-mid-400k-ft-ls100h")
def map_to_pred(batch):
input_values = processor(batch["audio"][0]["array"], sampling_rate=16000,
return_tensors="pt", padding="longest").input_values
with torch.no_grad():
logits = model(input_values.to("cuda")).logits
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
batch["transcription"] = transcription
return batch
result = librispeech_eval.map(map_to_pred, batched=True, batch_size=1, remove_columns=["audio"])
print("WER:", wer(result["text"], result["transcription"]))
```
*Result (WER)*:
| "clean" | "other" |
| --- | --- |
| 4.94 | 11.51 |
|
aseifert/byt5-base-jfleg-wi | d5c8b9ed4d137fd88cb203841fb9309db037ce0b | 2021-11-19T21:52:55.000Z | [
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | false | aseifert | null | aseifert/byt5-base-jfleg-wi | 7 | 1 | transformers | 14,016 | Entry not found |
austin/adr-ner | f004d373710b62fdbc74bebe8f79e5ceb9f1a642 | 2021-12-20T06:48:11.000Z | [
"pytorch",
"deberta",
"token-classification",
"transformers",
"generated_from_trainer",
"license:mit",
"model-index",
"autotrain_compatible"
]
| token-classification | false | austin | null | austin/adr-ner | 7 | null | transformers | 14,017 | ---
license: mit
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: adr-ner
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# adr-ner
This model is a fine-tuned version of [austin/Austin-MeDeBERTa](https://huggingface.co/austin/Austin-MeDeBERTa) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0434
- Precision: 0.7305
- Recall: 0.6934
- F1: 0.7115
- Accuracy: 0.9941
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 12
- eval_batch_size: 12
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 15
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 107 | 0.0630 | 0.0 | 0.0 | 0.0 | 0.9876 |
| No log | 2.0 | 214 | 0.0308 | 0.4282 | 0.3467 | 0.3832 | 0.9900 |
| No log | 3.0 | 321 | 0.0254 | 0.5544 | 0.5603 | 0.5573 | 0.9920 |
| No log | 4.0 | 428 | 0.0280 | 0.6430 | 0.5751 | 0.6071 | 0.9929 |
| 0.0465 | 5.0 | 535 | 0.0266 | 0.5348 | 0.7146 | 0.6118 | 0.9915 |
| 0.0465 | 6.0 | 642 | 0.0423 | 0.7632 | 0.5793 | 0.6587 | 0.9939 |
| 0.0465 | 7.0 | 749 | 0.0336 | 0.6957 | 0.6765 | 0.6860 | 0.9939 |
| 0.0465 | 8.0 | 856 | 0.0370 | 0.6876 | 0.6702 | 0.6788 | 0.9936 |
| 0.0465 | 9.0 | 963 | 0.0349 | 0.6555 | 0.7040 | 0.6789 | 0.9932 |
| 0.0044 | 10.0 | 1070 | 0.0403 | 0.6910 | 0.6808 | 0.6858 | 0.9938 |
| 0.0044 | 11.0 | 1177 | 0.0415 | 0.7140 | 0.6808 | 0.6970 | 0.9939 |
| 0.0044 | 12.0 | 1284 | 0.0440 | 0.7349 | 0.6681 | 0.6999 | 0.9941 |
| 0.0044 | 13.0 | 1391 | 0.0423 | 0.7097 | 0.6977 | 0.7036 | 0.9941 |
| 0.0044 | 14.0 | 1498 | 0.0435 | 0.7174 | 0.6977 | 0.7074 | 0.9941 |
| 0.0006 | 15.0 | 1605 | 0.0434 | 0.7305 | 0.6934 | 0.7115 | 0.9941 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.0+cu113
- Datasets 1.16.1
- Tokenizers 0.10.3
|
avorozhko/ruDialoGpt3-medium-finetuned-context | 083bbcac63050721598fc7470d50fb8ea234f733 | 2022-03-13T11:41:17.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | false | avorozhko | null | avorozhko/ruDialoGpt3-medium-finetuned-context | 7 | 1 | transformers | 14,018 | ## Описание модели
Этот чатбот - дипломная работа студента Андрея Ворожко в УИИ (Университет Искусственного Интеллекта).
Окончание обучения - март 2022 года.
Чатбот сделан на основе модели [Kirili4ik/ruDialoGpt3-medium-finetuned-telegram](https://huggingface.co/Kirili4ik/ruDialoGpt3-medium-finetuned-telegram)
Теперь модель дообучена на основе 27000 анекдотов (14 эпох, скорость обучения в колабе 2-6 часов на эпоху) и умеет понимать контекст разговора. Однако контекст приходится ограничивать несколькими последними сообщениями потому что чем больше контекста тем медленнее модель работает, а контекст растет как снежный ком в процессе разговора.
Инференс находится в [spaces](https://huggingface.co/spaces/avorozhko/funbot):
Там с ботом можно поговорить. Контекст ограничен 10 последними сообщениями.
Шутки бот выдает, но пока скорее случайно, чем намеренно. Однако разговор поддержать способен и даже немного развлечь.
Так как это генерация текста, то на одну и ту же фразу бот всегда будет выдавать разные ответы.
Также для определения качества данной модели использовалась кастомная метрика - угловое расстояния между эмбеддингами y_train и предикта.
То есть мы взяли первый слой эмбеддинга модели и прогоняли предикты и лейблы, получили вектора слов. Потом вектора слов суммировали и получили общие (суммарные) вектора лейблов и предиктов. Чем меньше угол между ними, тем лучше. При рассчетах ориентировались на косинус этого угла, так как cos 0 = 1, то это очень удобно - чем ближе показатель к 1, тем лучше.
Вот такое распределение этих значений получилось по эпохам на ПРОВЕРОЧНОЙ выборке (1406 анекдотов):
```
{1: tensor(0.9357, device='cuda:0', grad_fn=<DivBackward0>),
2: tensor(0.9390, device='cuda:0', grad_fn=<DivBackward0>),
3: tensor(0.9417, device='cuda:0', grad_fn=<DivBackward0>),
4: tensor(0.9439, device='cuda:0', grad_fn=<DivBackward0>),
5: tensor(0.9470, device='cuda:0', grad_fn=<DivBackward0>),
6: tensor(0.9537, device='cuda:0', grad_fn=<DivBackward0>),
7: tensor(0.9568, device='cuda:0', grad_fn=<DivBackward0>),
8: tensor(0.9592, device='cuda:0', grad_fn=<DivBackward0>),
9: tensor(0.9610, device='cuda:0', grad_fn=<DivBackward0>),
10: tensor(0.9622, device='cuda:0', grad_fn=<DivBackward0>),
11: tensor(0.9628, device='cuda:0', grad_fn=<DivBackward0>),
12: tensor(0.9632, device='cuda:0', grad_fn=<DivBackward0>),
13: tensor(0.9630, device='cuda:0', grad_fn=<DivBackward0>),
14: tensor(0.9634, device='cuda:0', grad_fn=<DivBackward0>),
15: tensor(0.9634, device='cuda:0', grad_fn=<DivBackward0>)}
```
Для инференса выбрана 14-я эпоха с точностью 0.9634. Далее, судя по всему идет уже переобучение. |
baykenney/bert-large-gpt2detector-topp92 | 5502f558a3d9dc0bcce996b13d449f807a48dd84 | 2021-05-19T12:23:59.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
]
| text-classification | false | baykenney | null | baykenney/bert-large-gpt2detector-topp92 | 7 | null | transformers | 14,019 | Entry not found |
benjaminbeilharz/bert-base-uncased-sentiment-classifier | 798958e8fdb8c94ed00951ec71620a010a7dc0c3 | 2022-02-03T22:43:30.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
]
| text-classification | false | benjaminbeilharz | null | benjaminbeilharz/bert-base-uncased-sentiment-classifier | 7 | null | transformers | 14,020 | Entry not found |
benjaminbeilharz/distilbert-base-uncased-empatheticdialogues-sentiment-classifier | bdbdc409ed8535041007c5085ecd08721e56174e | 2022-01-26T09:52:00.000Z | [
"pytorch",
"distilbert",
"text-classification",
"transformers"
]
| text-classification | false | benjaminbeilharz | null | benjaminbeilharz/distilbert-base-uncased-empatheticdialogues-sentiment-classifier | 7 | null | transformers | 14,021 | Entry not found |
beomi/beep-KR-Medium-hate | 10763e5670878d0e13ae6ee57a8f75c53acb465d | 2021-10-24T09:17:31.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
]
| text-classification | false | beomi | null | beomi/beep-KR-Medium-hate | 7 | null | transformers | 14,022 | Entry not found |
berkergurcay/1k-pretrained-bert-model | 09804bfebef63e98b026e357ad28b8381972c718 | 2021-05-23T12:03:10.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
]
| text-classification | false | berkergurcay | null | berkergurcay/1k-pretrained-bert-model | 7 | null | transformers | 14,023 | Entry not found |
bertin-project/bertin-base-paws-x-es | eb31f791bb745c33156911179c467e99a7b17b1b | 2021-09-23T13:41:52.000Z | [
"pytorch",
"roberta",
"text-classification",
"es",
"transformers",
"spanish",
"paws-x",
"license:cc-by-4.0"
]
| text-classification | false | bertin-project | null | bertin-project/bertin-base-paws-x-es | 7 | 1 | transformers | 14,024 | ---
language: es
license: cc-by-4.0
tags:
- spanish
- roberta
- paws-x
---
This checkpoint has been trained for the PAWS-X task using the CoNLL 2002-es dataset.
This checkpoint was created from **Bertin Gaussian 512**, which is a **RoBERTa-base** model trained from scratch in Spanish. Information on this base model may be found at [its own card](https://huggingface.co/bertin-project/bertin-base-gaussian-exp-512seqlen) and at deeper detail on [the main project card](https://huggingface.co/bertin-project/bertin-roberta-base-spanish).
The training dataset for the base model is [mc4](https://huggingface.co/datasets/bertin-project/mc4-es-sampled ) subsampling documents to a total of about 50 million examples. Sampling is biased towards average perplexity values (using a Gaussian function), discarding more often documents with very large values (poor quality) of very small values (short, repetitive texts).
This is part of the
[Flax/Jax Community Week](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104), organised by [HuggingFace](https://huggingface.co/) and TPU usage sponsored by Google.
## Team members
- Eduardo González ([edugp](https://huggingface.co/edugp))
- Javier de la Rosa ([versae](https://huggingface.co/versae))
- Manu Romero ([mrm8488](https://huggingface.co/))
- María Grandury ([mariagrandury](https://huggingface.co/))
- Pablo González de Prado ([Pablogps](https://huggingface.co/Pablogps))
- Paulo Villegas ([paulo](https://huggingface.co/paulo)) |
bettertextapp/m2m-418m-en-de-seed-words-v2 | 10cbafb2c0a522d5775bc16608117255767bf231 | 2022-02-05T22:01:35.000Z | [
"pytorch",
"tensorboard",
"m2m_100",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | false | bettertextapp | null | bettertextapp/m2m-418m-en-de-seed-words-v2 | 7 | null | transformers | 14,025 | Entry not found |
birgermoell/wav2vec2-common_voice-tr-demo | 865c8fa4c96bc0dd1dd1ca66d44a18ccaa007ef8 | 2022-01-24T18:52:26.000Z | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"sv-SE",
"dataset:common_voice",
"transformers",
"common_voice",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| automatic-speech-recognition | false | birgermoell | null | birgermoell/wav2vec2-common_voice-tr-demo | 7 | null | transformers | 14,026 | ---
language:
- sv-SE
license: apache-2.0
tags:
- automatic-speech-recognition
- common_voice
- generated_from_trainer
datasets:
- common_voice
model-index:
- name: wav2vec2-common_voice-tr-demo
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-common_voice-tr-demo
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the COMMON_VOICE - SV-SE dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5528
- Wer: 0.3811
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 15.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 0.74 | 100 | 3.4444 | 1.0 |
| No log | 1.47 | 200 | 2.9421 | 1.0 |
| No log | 2.21 | 300 | 2.2802 | 1.0137 |
| No log | 2.94 | 400 | 0.9683 | 0.7611 |
| 3.7264 | 3.68 | 500 | 0.7941 | 0.6594 |
| 3.7264 | 4.41 | 600 | 0.6695 | 0.5751 |
| 3.7264 | 5.15 | 700 | 0.6507 | 0.5314 |
| 3.7264 | 5.88 | 800 | 0.5731 | 0.4927 |
| 3.7264 | 6.62 | 900 | 0.5723 | 0.4580 |
| 0.4592 | 7.35 | 1000 | 0.5913 | 0.4479 |
| 0.4592 | 8.09 | 1100 | 0.5562 | 0.4423 |
| 0.4592 | 8.82 | 1200 | 0.5566 | 0.4292 |
| 0.4592 | 9.56 | 1300 | 0.5492 | 0.4303 |
| 0.4592 | 10.29 | 1400 | 0.5665 | 0.4331 |
| 0.2121 | 11.03 | 1500 | 0.5610 | 0.4084 |
| 0.2121 | 11.76 | 1600 | 0.5703 | 0.4014 |
| 0.2121 | 12.5 | 1700 | 0.5669 | 0.3898 |
| 0.2121 | 13.24 | 1800 | 0.5586 | 0.3962 |
| 0.2121 | 13.97 | 1900 | 0.5656 | 0.3897 |
| 0.1326 | 14.71 | 2000 | 0.5565 | 0.3813 |
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.1+cu113
- Datasets 1.18.0
- Tokenizers 0.10.3
|
birgermoell/wav2vec2-large-xlsr-hungarian | 2d18e8dadcf9fa4c04748fea59ea76a64e6f9c32 | 2021-07-05T23:16:31.000Z | [
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"hu",
"dataset:common_voice",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
]
| automatic-speech-recognition | false | birgermoell | null | birgermoell/wav2vec2-large-xlsr-hungarian | 7 | null | transformers | 14,027 | ---
language: hu
datasets:
- common_voice
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Hugarian by Birger Moell
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice hu
type: common_voice
args: hu
metrics:
- name: Test WER
type: wer
value: 46.97
---
# Wav2Vec2-Large-XLSR-53-Hungarian
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) in Hungarian using the [Common Voice](https://huggingface.co/datasets/common_voice)
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "hu", split="test[:2%]").
processor = Wav2Vec2Processor.from_pretrained("birgermoell/wav2vec2-large-xlsr-hungarian")
model = Wav2Vec2ForCTC.from_pretrained("birgermoell/wav2vec2-large-xlsr-hungarian")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
\tspeech_array, sampling_rate = torchaudio.load(batch["path"])
\tbatch["speech"] = resampler(speech_array).squeeze().numpy()
\treturn batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
\tlogits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Hungarian test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "hu", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("birgermoell/wav2vec2-large-xlsr-hungarian")
model = Wav2Vec2ForCTC.from_pretrained("birgermoell/wav2vec2-large-xlsr-hungarian")
model.to("cuda")
chars_to_ignore_regex = '[\\,\\?\\.\\!\\-\\;\\:\\"\\“]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
\tbatch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
\tspeech_array, sampling_rate = torchaudio.load(batch["path"])
\tbatch["speech"] = resampler(speech_array).squeeze().numpy()
\treturn batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
\tinputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
\twith torch.no_grad():
\t\tlogits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
\tbatch["pred_strings"] = processor.batch_decode(pred_ids)
\treturn batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 46.97 %
## Training
The Common Voice `train` and `validation` datasets were used for training.
The script used for training can be found [here](https://colab.research.google.com/drive/1c8LS-RP-RMukvXkpqJ9kLXRWmRKFjevs?usp=sharing)
|
biu-nlp/alephbert-base | 0643e83be2ca786f7ea675bd8e3b985e7eac72fc | 2021-10-12T10:58:33.000Z | [
"pytorch",
"bert",
"fill-mask",
"he",
"dataset:oscar",
"dataset:wikipedia",
"dataset:twitter",
"arxiv:1810.04805",
"transformers",
"language model",
"license:apache-2.0",
"autotrain_compatible"
]
| fill-mask | false | biu-nlp | null | biu-nlp/alephbert-base | 7 | null | transformers | 14,028 | ---
language:
- he
tags:
- language model
license: apache-2.0
datasets:
- oscar
- wikipedia
- twitter
---
# AlephBERT
## Hebrew Language Model
State-of-the-art language model for Hebrew.
Based on Google's BERT architecture [(Devlin et al. 2018)](https://arxiv.org/abs/1810.04805).
#### How to use
```python
from transformers import BertModel, BertTokenizerFast
alephbert_tokenizer = BertTokenizerFast.from_pretrained('onlplab/alephbert-base')
alephbert = BertModel.from_pretrained('onlplab/alephbert-base')
# if not finetuning - disable dropout
alephbert.eval()
```
## Training data
1. OSCAR [(Ortiz, 2019)](https://oscar-corpus.com/) Hebrew section (10 GB text, 20 million sentences).
2. Hebrew dump of [Wikipedia](https://dumps.wikimedia.org/hewiki/latest/) (650 MB text, 3 million sentences).
3. Hebrew Tweets collected from the Twitter sample stream (7 GB text, 70 million sentences).
## Training procedure
Trained on a DGX machine (8 V100 GPUs) using the standard huggingface training procedure.
Since the larger part of our training data is based on tweets we decided to start by optimizing using Masked Language Model loss only.
To optimize training time we split the data into 4 sections based on max number of tokens:
1. num tokens < 32 (70M sentences)
2. 32 <= num tokens < 64 (12M sentences)
3. 64 <= num tokens < 128 (10M sentences)
4. 128 <= num tokens < 512 (1.5M sentences)
Each section was first trained for 5 epochs with an initial learning rate set to 1e-4. Then each section was trained for another 5 epochs with an initial learning rate set to 1e-5, for a total of 10 epochs.
Total training time was 8 days.
|
bob1966/distilbert-base-uncased-finetuned-cola | 24ebf2e8d4eb2339526ee643eaab60b57153cbe7 | 2022-02-01T10:15:52.000Z | [
"pytorch",
"distilbert",
"text-classification",
"transformers"
]
| text-classification | false | bob1966 | null | bob1966/distilbert-base-uncased-finetuned-cola | 7 | null | transformers | 14,029 | Entry not found |
bochaowei/t5-small-finetuned-cnn-wei0 | aa2c5b0b85d419d3d2b6d12f5b30b493c533aaa6 | 2021-10-20T18:58:40.000Z | [
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"dataset:cnn_dailymail",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
]
| text2text-generation | false | bochaowei | null | bochaowei/t5-small-finetuned-cnn-wei0 | 7 | null | transformers | 14,030 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- cnn_dailymail
metrics:
- rouge
model-index:
- name: t5-small-finetuned-cnn-wei0
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: cnn_dailymail
type: cnn_dailymail
args: 3.0.0
metrics:
- name: Rouge1
type: rouge
value: 24.2324
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-cnn-wei0
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the cnn_dailymail dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7149
- Rouge1: 24.2324
- Rouge2: 11.7178
- Rougel: 20.0508
- Rougelsum: 22.8698
- Gen Len: 19.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 12
- eval_batch_size: 12
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:-------:|:-------:|:---------:|:-------:|
| 1.9068 | 1.0 | 4786 | 1.7149 | 24.2324 | 11.7178 | 20.0508 | 22.8698 | 19.0 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.9.0+cu111
- Datasets 1.14.0
- Tokenizers 0.10.3
|
boronbrown48/sentiment_neutral_from_other_v2 | 99f5b5f4be6246a8dde42c2a0db4ba1c54e2d44b | 2021-11-26T08:45:17.000Z | [
"pytorch",
"camembert",
"text-classification",
"transformers"
]
| text-classification | false | boronbrown48 | null | boronbrown48/sentiment_neutral_from_other_v2 | 7 | null | transformers | 14,031 | Entry not found |
boychaboy/MNLI_bert-base-cased_2 | c9505b8de7c74a8c639b89c972750bb15d900c5b | 2021-05-19T13:12:53.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
]
| text-classification | false | boychaboy | null | boychaboy/MNLI_bert-base-cased_2 | 7 | null | transformers | 14,032 | Entry not found |
boychaboy/MNLI_bert-large-cased | 2548854d69459ebbbd99e0b2ee22822297d58442 | 2021-05-19T13:19:32.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
]
| text-classification | false | boychaboy | null | boychaboy/MNLI_bert-large-cased | 7 | null | transformers | 14,033 | Entry not found |
boychaboy/SNLI_bert-base-uncased | cbc8a64a2f22b523dd39be600833b4a39ed6d8ce | 2021-05-19T13:24:51.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
]
| text-classification | false | boychaboy | null | boychaboy/SNLI_bert-base-uncased | 7 | null | transformers | 14,034 | Entry not found |
bs-modeling-metadata/website_metadata_exp_1_model_25k_checkpoint | f1f0249fe6a742005d19a24e476df6128a443ff9 | 2021-11-25T15:47:57.000Z | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | false | bs-modeling-metadata | null | bs-modeling-metadata/website_metadata_exp_1_model_25k_checkpoint | 7 | null | transformers | 14,035 | Entry not found |
bshlgrs/autonlp-classification-9522090 | 4791bdda04edf9b2c915b31a6855e5881e55e141 | 2021-09-04T20:47:49.000Z | [
"pytorch",
"bert",
"text-classification",
"en",
"dataset:bshlgrs/autonlp-data-classification",
"transformers",
"autonlp"
]
| text-classification | false | bshlgrs | null | bshlgrs/autonlp-classification-9522090 | 7 | null | transformers | 14,036 | ---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- bshlgrs/autonlp-data-classification
---
# Model Trained Using AutoNLP
- Problem type: Multi-class Classification
- Model ID: 9522090
## Validation Metrics
- Loss: 0.3541755676269531
- Accuracy: 0.8759671179883946
- Macro F1: 0.5330133182738012
- Micro F1: 0.8759671179883946
- Weighted F1: 0.8482773065757196
- Macro Precision: 0.537738108882869
- Micro Precision: 0.8759671179883946
- Weighted Precision: 0.8241048710814852
- Macro Recall: 0.5316621214820499
- Micro Recall: 0.8759671179883946
- Weighted Recall: 0.8759671179883946
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/bshlgrs/autonlp-classification-9522090
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("bshlgrs/autonlp-classification-9522090", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("bshlgrs/autonlp-classification-9522090", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` |
bshlgrs/autonlp-old-data-trained-10022181 | c30a691fb3793c962d7153d86c511d8a7a3b85b2 | 2021-09-09T21:46:53.000Z | [
"pytorch",
"bert",
"text-classification",
"en",
"dataset:bshlgrs/autonlp-data-old-data-trained",
"transformers",
"autonlp"
]
| text-classification | false | bshlgrs | null | bshlgrs/autonlp-old-data-trained-10022181 | 7 | null | transformers | 14,037 | ---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- bshlgrs/autonlp-data-old-data-trained
---
# Model Trained Using AutoNLP
- Problem type: Multi-class Classification
- Model ID: 10022181
## Validation Metrics
- Loss: 0.369505375623703
- Accuracy: 0.8706206896551724
- Macro F1: 0.5410226656476808
- Micro F1: 0.8706206896551724
- Weighted F1: 0.8515634683886795
- Macro Precision: 0.5159711665622992
- Micro Precision: 0.8706206896551724
- Weighted Precision: 0.8346991124101657
- Macro Recall: 0.5711653346601209
- Micro Recall: 0.8706206896551724
- Weighted Recall: 0.8706206896551724
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/bshlgrs/autonlp-old-data-trained-10022181
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("bshlgrs/autonlp-old-data-trained-10022181", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("bshlgrs/autonlp-old-data-trained-10022181", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` |
cactode/gpt2_urbandict_textgen | 2523ac594c246f1337a5836e41fcdeec64720f4c | 2021-10-21T06:43:28.000Z | [
"pytorch",
"tf",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | false | cactode | null | cactode/gpt2_urbandict_textgen | 7 | null | transformers | 14,038 | # GPT2 Fine Tuned on UrbanDictionary
Honestly a little horrifying, but still funny.
## Usage
Use with GPT2Tokenizer. Pad token should be set to the EOS token.
Inputs should be of the form "define <your word>: ".
## Training Data
All training data was obtained from [Urban Dictionary Words And Definitions on Kaggle](https://www.kaggle.com/therohk/urban-dictionary-words-dataset). Data was additionally filtered, normalized, and spell-checked.
## Bias
This model was trained on public internet data and will almost definitely produce offensive results. Some efforts were made to reduce this (i.e definitions with ethnic / gender-based slurs were removed), but the final model should not be trusted to produce non-offensive definitions. |
cahya/gpt2-small-indonesian-story | 69d41ac315c0d0b545fb827f31eae873c63b89e3 | 2021-09-03T17:48:26.000Z | [
"pytorch",
"jax",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | false | cahya | null | cahya/gpt2-small-indonesian-story | 7 | null | transformers | 14,039 | Entry not found |
candra/indo-headline-similarity | f1e9a526126f068144e99bf21522ecfd27208860 | 2022-02-10T05:48:51.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
]
| text-classification | false | candra | null | candra/indo-headline-similarity | 7 | null | transformers | 14,040 | Entry not found |
cardiffnlp/bertweet-base-stance-hillary | b3be4664ad1e2172ce877d0de6e19212d93643e0 | 2021-05-20T14:58:18.000Z | [
"pytorch",
"tf",
"jax",
"roberta",
"text-classification",
"transformers"
]
| text-classification | false | cardiffnlp | null | cardiffnlp/bertweet-base-stance-hillary | 7 | null | transformers | 14,041 | |
charlecheng/distilbert-base-uncased-finetuned-ner | e1b32616a8ebdf1e735f3c63a2389d863c673269 | 2021-09-08T03:51:22.000Z | [
"pytorch",
"tensorboard",
"distilbert",
"token-classification",
"dataset:conll2003",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
]
| token-classification | false | charlecheng | null | charlecheng/distilbert-base-uncased-finetuned-ner | 7 | null | transformers | 14,042 | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.9276454293628809
- name: Recall
type: recall
value: 0.9365700861393892
- name: F1
type: f1
value: 0.9320863950122468
- name: Accuracy
type: accuracy
value: 0.9840500738716699
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ner
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0607
- Precision: 0.9276
- Recall: 0.9366
- F1: 0.9321
- Accuracy: 0.9841
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.246 | 1.0 | 878 | 0.0696 | 0.9152 | 0.9215 | 0.9183 | 0.9812 |
| 0.0518 | 2.0 | 1756 | 0.0606 | 0.9196 | 0.9342 | 0.9269 | 0.9831 |
| 0.0309 | 3.0 | 2634 | 0.0607 | 0.9276 | 0.9366 | 0.9321 | 0.9841 |
### Framework versions
- Transformers 4.10.0
- Pytorch 1.9.0+cu102
- Datasets 1.11.0
- Tokenizers 0.10.3
|
chenqian/bert_finetuning_test | f4672372b9bf747692d2eb88fdd98aea79a705b0 | 2021-05-19T14:02:25.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
]
| text-classification | false | chenqian | null | chenqian/bert_finetuning_test | 7 | null | transformers | 14,043 | Entry not found |
chihao/bert_cn_finetuning | 61420b4a85731cdd501a8e525b12f04073a97334 | 2021-05-19T14:04:26.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
]
| text-classification | false | chihao | null | chihao/bert_cn_finetuning | 7 | null | transformers | 14,044 | Entry not found |
chinhon/bart-large-commentaries_hdwriter | 38b337e6a824150711dfba57f226ae78e4e6f942 | 2022-01-17T05:11:56.000Z | [
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
]
| text2text-generation | false | chinhon | null | chinhon/bart-large-commentaries_hdwriter | 7 | null | transformers | 14,045 | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: bart-large-commentaries_hdwriter
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-large-commentaries_hdwriter
This model is a fine-tuned version of [facebook/bart-large](https://huggingface.co/facebook/bart-large) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 3.1619
- Rouge1: 26.1101
- Rouge2: 9.928
- Rougel: 22.9007
- Rougelsum: 23.117
- Gen Len: 15.9536
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| 2.6237 | 1.0 | 5072 | 2.5309 | 26.4063 | 9.1795 | 22.6699 | 22.9125 | 17.3103 |
| 1.8808 | 2.0 | 10144 | 2.5049 | 25.3706 | 8.7568 | 21.8594 | 22.1233 | 15.8579 |
| 1.3084 | 3.0 | 15216 | 2.6680 | 26.6284 | 9.9914 | 23.1477 | 23.3625 | 16.8832 |
| 0.9247 | 4.0 | 20288 | 2.8923 | 26.3827 | 9.8217 | 22.9524 | 23.1651 | 15.4529 |
| 0.692 | 5.0 | 25360 | 3.1619 | 26.1101 | 9.928 | 22.9007 | 23.117 | 15.9536 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
clem/autonlp-test3-2101779 | 6633fbda0647b141a98f1df927ee404ff76ae859 | 2021-06-29T04:15:35.000Z | [
"pytorch",
"bert",
"text-classification",
"en",
"dataset:clem/autonlp-data-test3",
"transformers",
"autonlp"
]
| text-classification | false | clem | null | clem/autonlp-test3-2101779 | 7 | null | transformers | 14,046 | ---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- clem/autonlp-data-test3
---
# Model Trained Using AutoNLP
- Problem type: Binary Classification
- Model ID: 2101779
## Validation Metrics
- Loss: 0.282466858625412
- Accuracy: 1.0
- Precision: 1.0
- Recall: 1.0
- AUC: 1.0
- F1: 1.0
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/clem/autonlp-test3-2101779
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("clem/autonlp-test3-2101779", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("clem/autonlp-test3-2101779", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` |
climatebert/distilroberta-base-climate-s | 81225f2af7148ac7bfd55df37adfdfcdb6718a51 | 2021-10-26T08:19:19.000Z | [
"pytorch",
"roberta",
"fill-mask",
"en",
"arxiv:2110.12010",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
]
| fill-mask | false | climatebert | null | climatebert/distilroberta-base-climate-s | 7 | 3 | transformers | 14,047 | ---
language: en
license: apache-2.0
---
Using the [DistilRoBERTa](https://huggingface.co/distilroberta-base) model as starting point, the ClimateBERT Language Model is additionally pretrained on a text corpus comprising climate-related research paper abstracts, corporate and general news and reports from companies. The underlying methodology can be found in our [language model research paper](https://arxiv.org/abs/2110.12010).
### BibTeX entry and citation info
```bibtex
@article{wkbl2021,
title={ClimateBERT: A Pretrained Language Model for Climate-Related Text},
author={Webersinke, Nicolas and Kraus, Mathias and Bingler, Julia and Leippold, Markus},
journal={arXiv preprint arXiv:2110.12010},
year={2021}
}
``` |
comacrae/roberta-paraphrasev3 | 8a00cb53e7918521b2acc99008d4d30e7249e804 | 2022-02-22T22:14:11.000Z | [
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | false | comacrae | null | comacrae/roberta-paraphrasev3 | 7 | null | transformers | 14,048 | Entry not found |
conrizzo/dialogue_summarization_with_BART | 92a3b4f35dd0d2bb6a9dcb93dabe5fe5522c013e | 2022-02-11T18:21:20.000Z | [
"pytorch",
"bart",
"text2text-generation",
"transformers",
"license:mit",
"autotrain_compatible"
]
| text2text-generation | false | conrizzo | null | conrizzo/dialogue_summarization_with_BART | 7 | null | transformers | 14,049 | ---
license: mit
---
|
creat89/NER_FEDA_Ru | cdb7660503106b06d6e4d3c62a71feb041c36fc5 | 2022-04-13T09:32:54.000Z | [
"pytorch",
"bert",
"ru",
"transformers",
"rubert",
"ner",
"license:mit"
]
| null | false | creat89 | null | creat89/NER_FEDA_Ru | 7 | null | transformers | 14,050 | ---
license: mit
language:
- ru
tags:
- rubert
- ner
---
This is a Russian NER system trained using a Frustratingly Easy Domain Adaptation architecture. It is based on RuBERT and supports different tagsets all using IOBES formats:
1. Wikiann (LOC, PER, ORG)
2. SlavNER 19/21 (EVT, LOC, ORG, PER, PRO)
4. CNE5 (GEOPOLIT, LOC, MEDIA, PER, ORG)
5. FactRuEval (LOC, ORG, PER)
PER: person, LOC: location, ORG: organization, EVT: event, PRO: product, MISC: Miscellaneous, MEDIA: media, ART: Artifact, TIME: time, DATE: date, GEOPOLIT: Geopolitical,
You can select the tagset to use in the output by configuring the model. This models manages differently uppercase words.
More information about the model can be found in the paper (https://aclanthology.org/2021.bsnlp-1.12.pdf) and GitHub repository (https://github.com/EMBEDDIA/NER_FEDA). |
damien-ir/ko-rest-electra-discriminator | 23970724273b52fc56ee022148eba57ff1dbbe2e | 2020-07-27T18:57:52.000Z | [
"pytorch",
"electra",
"pretraining",
"transformers"
]
| null | false | damien-ir | null | damien-ir/ko-rest-electra-discriminator | 7 | null | transformers | 14,051 | Entry not found |
damien-ir/ko-rest-electra-generator | 690ff11497f8b23832b5f8cd3ba4c0be3b38d5cd | 2020-07-27T19:00:02.000Z | [
"pytorch",
"electra",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | false | damien-ir | null | damien-ir/ko-rest-electra-generator | 7 | null | transformers | 14,052 | Entry not found |
damien-ir/kosentelectra-discriminator-v2-small | d167e91ac75b548df01b7f44b4bba08e5cbde4d5 | 2020-10-16T10:23:45.000Z | [
"pytorch",
"electra",
"pretraining",
"transformers"
]
| null | false | damien-ir | null | damien-ir/kosentelectra-discriminator-v2-small | 7 | null | transformers | 14,053 | Entry not found |
danurahul/german_gpt_4g | a559310442c4003b680ff42f04f034aafa19a74e | 2021-05-21T15:22:52.000Z | [
"pytorch",
"jax",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | false | danurahul | null | danurahul/german_gpt_4g | 7 | null | transformers | 14,054 | Entry not found |
deeq/dbert-sentiment | c406cd94c4f99e7cee05ebb46b1599b62163b68b | 2021-07-01T08:39:23.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
]
| text-classification | false | deeq | null | deeq/dbert-sentiment | 7 | null | transformers | 14,055 | ```
from transformers import BertForSequenceClassification, BertTokenizer, TextClassificationPipeline
model = BertForSequenceClassification.from_pretrained("deeq/dbert-sentiment")
tokenizer = BertTokenizer.from_pretrained("deeq/dbert")
nlp = TextClassificationPipeline(model=model, tokenizer=tokenizer)
print(nlp("좋아요"))
print(nlp("글쎄요"))
```
|
defex/distilgpt2-finetuned-amazon-reviews | 6034d221dabc8d098ac4210840278801fce38885 | 2021-07-21T10:36:15.000Z | [
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"transformers",
"generated_from_trainer"
]
| text-generation | false | defex | null | defex/distilgpt2-finetuned-amazon-reviews | 7 | null | transformers | 14,056 | ---
tags:
- generated_from_trainer
datasets:
- null
model_index:
- name: distilgpt2-finetuned-amazon-reviews
results:
- task:
name: Causal Language Modeling
type: text-generation
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilgpt2-finetuned-amazon-reviews
This model was trained from scratch on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Framework versions
- Transformers 4.8.2
- Pytorch 1.9.0+cu102
- Datasets 1.9.0
- Tokenizers 0.10.3
|
dingkun/retrievalv2 | 44a27e6cf4ef07bc531bee29ed8de1491b49fe88 | 2022-06-13T03:19:02.000Z | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | false | dingkun | null | dingkun/retrievalv2 | 7 | null | transformers | 14,057 | Entry not found |
diwank/dyda-deberta-pair | dd61dd9a07072219f74170886a986623d67f84c3 | 2022-02-02T10:48:52.000Z | [
"pytorch",
"tf",
"deberta",
"text-classification",
"transformers",
"license:mit"
]
| text-classification | false | diwank | null | diwank/dyda-deberta-pair | 7 | null | transformers | 14,058 | ---
license: mit
---
# diwank/dyda-deberta-pair
Deberta-based Daily Dialog style dialog-act annotations classification model. It takes two sentences as inputs (one previous and one current of a dialog). The previous sentence can be an empty string if this is the first utterance of a speaker in a dialog. Outputs one of four labels (exactly as in the [daily-dialog dataset](https://huggingface.co/datasets/daily_dialog) ): *__dummy__ (0), inform (1), question (2), directive (3), commissive (4)*
## Usage
```python
from simpletransformers.classification import (
ClassificationModel, ClassificationArgs
)
model = ClassificationModel("deberta", "diwank/dyda-deberta-pair")
convert_to_label = lambda n: ["__dummy__ (0), inform (1), question (2), directive (3), commissive (4)".split(', ')[i] for i in n]
predictions, raw_outputs = model.predict([["Say what is the meaning of life?", "I dont know"]])
convert_to_label(predictions) # inform (1)
``` |
dkleczek/Polish_RoBERTa_large_OPI | 7ec9c7103520978489e5f02b68ddb81f5cf23fa6 | 2021-08-26T22:13:27.000Z | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
]
| feature-extraction | false | dkleczek | null | dkleczek/Polish_RoBERTa_large_OPI | 7 | null | transformers | 14,059 | Entry not found |
echarlaix/bert-base-dynamic-quant-test | 321d4a1190df93d5cb4b006502f692c12fc75b83 | 2021-10-27T09:49:27.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
]
| text-classification | false | echarlaix | null | echarlaix/bert-base-dynamic-quant-test | 7 | null | transformers | 14,060 | Entry not found |
echarlaix/distilbert-base-uncased-sst2-magnitude-pruning-test | 46a71aefd5ed5e54d8c7df8ccf4d60b8a879cf26 | 2022-01-13T08:55:40.000Z | [
"pytorch",
"distilbert",
"text-classification",
"transformers"
]
| text-classification | false | echarlaix | null | echarlaix/distilbert-base-uncased-sst2-magnitude-pruning-test | 7 | null | transformers | 14,061 | Entry not found |
edwardgowsmith/bert-base-cased-best | 305c966f7235ff9ec0de703d0746924c5c47f63a | 2021-05-19T16:19:42.000Z | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
]
| text-classification | false | edwardgowsmith | null | edwardgowsmith/bert-base-cased-best | 7 | null | transformers | 14,062 | Entry not found |
eli4s/Bert-L12-h240-A12 | 5ed85ef6ecc873f77e3f48df02e8eb9a1a741675 | 2021-07-30T10:39:52.000Z | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | false | eli4s | null | eli4s/Bert-L12-h240-A12 | 7 | 2 | transformers | 14,063 | This model was pretrained on the bookcorpus dataset using knowledge distillation.
The particularity of this model is that even though it shares the same architecture as BERT, it has a hidden size of 240. Since it has 12 attention heads, the head size (20) is different from the one of the BERT base model (64).
The knowledge distillation was performed using multiple loss functions.
The weights of the model were initialized from scratch.
PS : the tokenizer is the same as the one of the model bert-base-uncased.
To load the model \& tokenizer :
````python
from transformers import AutoModelForMaskedLM, BertTokenizer
model_name = "eli4s/Bert-L12-h240-A12"
model = AutoModelForMaskedLM.from_pretrained(model_name)
tokenizer = BertTokenizer.from_pretrained(model_name)
````
To use it as a masked language model :
````python
import torch
sentence = "Let's have a [MASK]."
model.eval()
inputs = tokenizer([sentence], padding='longest', return_tensors='pt')
output = model(inputs['input_ids'], attention_mask=inputs['attention_mask'])
mask_index = inputs['input_ids'].tolist()[0].index(103)
masked_token = output['logits'][0][mask_index].argmax(axis=-1)
predicted_token = tokenizer.decode(masked_token)
print(predicted_token)
````
Or we can also predict the n most relevant predictions :
````python
top_n = 5
vocab_size = model.config.vocab_size
logits = output['logits'][0][mask_index].tolist()
top_tokens = sorted(list(range(vocab_size)), key=lambda i:logits[i], reverse=True)[:top_n]
tokenizer.decode(top_tokens)
````
|
emekaboris/autonlp-txc-17923124 | b3e145b79a05954a80af29d6b34b6f2b0e18482d | 2021-10-14T07:56:17.000Z | [
"pytorch",
"roberta",
"text-classification",
"en",
"dataset:emekaboris/autonlp-data-txc",
"transformers",
"autonlp",
"co2_eq_emissions"
]
| text-classification | false | emekaboris | null | emekaboris/autonlp-txc-17923124 | 7 | null | transformers | 14,064 | ---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- emekaboris/autonlp-data-txc
co2_eq_emissions: 133.57087522185148
---
# Model Trained Using AutoNLP
- Problem type: Multi-class Classification
- Model ID: 17923124
- CO2 Emissions (in grams): 133.57087522185148
## Validation Metrics
- Loss: 0.2080804407596588
- Accuracy: 0.9325402190077058
- Macro F1: 0.7283811287183823
- Micro F1: 0.9325402190077058
- Weighted F1: 0.9315711955594153
- Macro Precision: 0.8106599661500661
- Micro Precision: 0.9325402190077058
- Weighted Precision: 0.9324644116921059
- Macro Recall: 0.7020515544343829
- Micro Recall: 0.9325402190077058
- Weighted Recall: 0.9325402190077058
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/emekaboris/autonlp-txc-17923124
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("emekaboris/autonlp-txc-17923124", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("emekaboris/autonlp-txc-17923124", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` |
emekaboris/autonlp-txc-17923129 | 86b6fc218cbfbafb542b52e35e746132198e33f4 | 2021-10-14T12:19:07.000Z | [
"pytorch",
"bert",
"text-classification",
"en",
"dataset:emekaboris/autonlp-data-txc",
"transformers",
"autonlp",
"co2_eq_emissions"
]
| text-classification | false | emekaboris | null | emekaboris/autonlp-txc-17923129 | 7 | null | transformers | 14,065 | ---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- emekaboris/autonlp-data-txc
co2_eq_emissions: 610.861733873082
---
# Model Trained Using AutoNLP
- Problem type: Multi-class Classification
- Model ID: 17923129
- CO2 Emissions (in grams): 610.861733873082
## Validation Metrics
- Loss: 0.2319454699754715
- Accuracy: 0.9264228741381642
- Macro F1: 0.6730537318152493
- Micro F1: 0.9264228741381642
- Weighted F1: 0.9251493598895151
- Macro Precision: 0.7767479491141245
- Micro Precision: 0.9264228741381642
- Weighted Precision: 0.9277971545757154
- Macro Recall: 0.6617262519071917
- Micro Recall: 0.9264228741381642
- Weighted Recall: 0.9264228741381642
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/emekaboris/autonlp-txc-17923129
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("emekaboris/autonlp-txc-17923129", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("emekaboris/autonlp-txc-17923129", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` |
emfa/danish-roberta-botxo-danish-finetuned-hatespeech | 6079fc4717eb5428b173ff7a3730639e8d0ec8b7 | 2021-12-06T11:14:17.000Z | [
"pytorch",
"tensorboard",
"roberta",
"text-classification",
"transformers",
"generated_from_trainer",
"license:cc-by-4.0",
"model-index"
]
| text-classification | false | emfa | null | emfa/danish-roberta-botxo-danish-finetuned-hatespeech | 7 | null | transformers | 14,066 | ---
license: cc-by-4.0
tags:
- generated_from_trainer
model-index:
- name: danish-roberta-botxo-danish-finetuned-hatespeech
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# danish-roberta-botxo-danish-finetuned-hatespeech
This model is for a university project and is uploaded for sharing between students. It is training on a danish hate speech labeled training set. Feel free to use it, but as of now, we don't promise any good results ;-)
This model is a fine-tuned version of [flax-community/roberta-base-danish](https://huggingface.co/flax-community/roberta-base-danish) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2849
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 315 | 0.3074 |
| 0.3016 | 2.0 | 630 | 0.3152 |
| 0.3016 | 3.0 | 945 | 0.2849 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
emre/wav2vec2-xls-r-300m-Russian-small | b3c7007a5dcb81403cfef5b192f5abe23424d69c | 2022-03-23T18:28:22.000Z | [
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"ru",
"dataset:common_voice",
"transformers",
"generated_from_trainer",
"hf-asr-leaderboard",
"robust-speech-event",
"license:apache-2.0",
"model-index"
]
| automatic-speech-recognition | false | emre | null | emre/wav2vec2-xls-r-300m-Russian-small | 7 | null | transformers | 14,067 | ---
license: apache-2.0
language:
- ru
tags:
- generated_from_trainer
- hf-asr-leaderboard
- robust-speech-event
datasets:
- common_voice
model-index:
- name: wav2vec2-xls-r-300m-Russian-small
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice ru
type: common_voice
args: ru
metrics:
- name: Test WER
type: wer
value: 48.38
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Dev Data
type: speech-recognition-community-v2/dev_data
args: ru
metrics:
- name: Test WER
type: wer
value: 58.25
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Test Data
type: speech-recognition-community-v2/eval_data
args: ru
metrics:
- name: Test WER
type: wer
value: 56.83
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-xls-r-300m-Russian-small
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3514
- Wer: 0.4838
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 5.512 | 1.32 | 400 | 3.2207 | 1.0 |
| 3.1562 | 2.65 | 800 | 3.0166 | 1.0 |
| 1.5211 | 3.97 | 1200 | 0.7134 | 0.8275 |
| 0.6724 | 5.3 | 1600 | 0.4713 | 0.6402 |
| 0.4693 | 6.62 | 2000 | 0.3904 | 0.5668 |
| 0.3693 | 7.95 | 2400 | 0.3609 | 0.5121 |
| 0.3004 | 9.27 | 2800 | 0.3514 | 0.4838 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.14.0
- Tokenizers 0.10.3
|
emre/wav2vec2-xls-r-300m-bas-CV8-v2 | 8005cdaa4dafb4ec51bce274b811b0553ec2ff15 | 2022-03-24T11:55:34.000Z | [
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"bas",
"dataset:mozilla-foundation/common_voice_8_0",
"transformers",
"common_voice",
"generated_from_trainer",
"robust-speech-event",
"hf-asr-leaderboard",
"license:apache-2.0",
"model-index"
]
| automatic-speech-recognition | false | emre | null | emre/wav2vec2-xls-r-300m-bas-CV8-v2 | 7 | null | transformers | 14,068 | ---
license: apache-2.0
language: bas
tags:
- automatic-speech-recognition
- common_voice
- generated_from_trainer
- bas
- robust-speech-event
- hf-asr-leaderboard
datasets:
- mozilla-foundation/common_voice_8_0
model-index:
- name: wav2vec2-xls-r-300m-bas-CV8-v2
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 8
type: mozilla-foundation/common_voice_8_0
args: bas
metrics:
- name: Test WER
type: wer
value: 56.97
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-xls-r-300m-bas-CV8-v2
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6121
- Wer: 0.5697
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 300
- num_epochs: 90
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 6.5211 | 16.13 | 500 | 1.2661 | 0.9153 |
| 0.7026 | 32.25 | 1000 | 0.6245 | 0.6516 |
| 0.3752 | 48.38 | 1500 | 0.6039 | 0.6148 |
| 0.2752 | 64.51 | 2000 | 0.6080 | 0.5808 |
| 0.2155 | 80.63 | 2500 | 0.6121 | 0.5697 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.10.3
|
enelpi/bert-question-answering-cased-squadv2_tr | f723dbd8467c585ec5a29cce626cc9e3af06e027 | 2021-05-19T16:27:24.000Z | [
"pytorch",
"jax",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | false | enelpi | null | enelpi/bert-question-answering-cased-squadv2_tr | 7 | 1 | transformers | 14,069 | Entry not found |
erst/xlm-roberta-base-finetuned-db07 | 6fffe93b2748bf710f012213832c35548118178e | 2021-01-28T11:30:10.000Z | [
"pytorch",
"xlm-roberta",
"text-classification",
"transformers"
]
| text-classification | false | erst | null | erst/xlm-roberta-base-finetuned-db07 | 7 | null | transformers | 14,070 | # Classifying Text into DB07 Codes
This model is [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) fine-tuned to classify Danish descriptions of activities into [Dansk Branchekode DB07](https://www.dst.dk/en/Statistik/dokumentation/nomenklaturer/dansk-branchekode-db07) codes.
## Data
Approximately 2.5 million business names and descriptions of activities from Norwegian and Danish businesses were used to fine-tune the model. The Norwegian descriptions were translated into Danish and the Norwegian SN 2007 codes were translated into Danish DB07 codes.
Activity descriptions and business names were concatenated but separated by the separator token `</s>`. Thus, the model was trained on input texts in the format `f"{description_of_activity}</s>{business_name}"`.
## Quick Start
```python
from transformers import pipeline, AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("erst/xlm-roberta-base-finetuned-db07")
model = AutoModelForSequenceClassification.from_pretrained("erst/xlm-roberta-base-finetuned-db07")
pl = pipeline(
"sentiment-analysis",
model=model,
tokenizer=tokenizer,
return_all_scores=False,
)
pl("Vi sælger sko")
pl("We sell clothes</s>Clothing ApS")
```
|
ewriji/heil-A.412C-negative | bc362f6b41205b1d304834a016d6346939cfb50c | 2021-12-17T01:18:37.000Z | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | false | ewriji | null | ewriji/heil-A.412C-negative | 7 | null | transformers | 14,071 | Entry not found |
ewriji/heil-A.412C-positive | b048e0c45015b14d065167d57ed1ba34bcbd1745 | 2021-12-17T01:25:41.000Z | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | false | ewriji | null | ewriji/heil-A.412C-positive | 7 | null | transformers | 14,072 | Entry not found |
facebook/s2t-small-covost2-es-en-st | eb516e712b7e1a603c95b834d7e06ccc512b0bab | 2022-02-07T15:23:32.000Z | [
"pytorch",
"tf",
"speech_to_text",
"automatic-speech-recognition",
"es",
"en",
"dataset:covost2",
"arxiv:2010.05171",
"arxiv:1912.06670",
"arxiv:1904.08779",
"transformers",
"audio",
"speech-translation",
"license:mit"
]
| automatic-speech-recognition | false | facebook | null | facebook/s2t-small-covost2-es-en-st | 7 | null | transformers | 14,073 | ---
language:
- es
- en
datasets:
- covost2
tags:
- audio
- speech-translation
- automatic-speech-recognition
license: mit
pipeline_tag: automatic-speech-recognition
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
---
# S2T-SMALL-COVOST2-ES-EN-ST
`s2t-small-covost2-es-en-st` is a Speech to Text Transformer (S2T) model trained for end-to-end Speech Translation (ST).
The S2T model was proposed in [this paper](https://arxiv.org/abs/2010.05171) and released in
[this repository](https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text)
## Model description
S2T is a transformer-based seq2seq (encoder-decoder) model designed for end-to-end Automatic Speech Recognition (ASR) and Speech
Translation (ST). It uses a convolutional downsampler to reduce the length of speech inputs by 3/4th before they are
fed into the encoder. The model is trained with standard autoregressive cross-entropy loss and generates the
transcripts/translations autoregressively.
## Intended uses & limitations
This model can be used for end-to-end Spanish speech to English text translation.
See the [model hub](https://huggingface.co/models?filter=speech_to_text) to look for other S2T checkpoints.
### How to use
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
*Note: The `Speech2TextProcessor` object uses [torchaudio](https://github.com/pytorch/audio) to extract the
filter bank features. Make sure to install the `torchaudio` package before running this example.*
You could either install those as extra speech dependancies with
`pip install transformers"[speech, sentencepiece]"` or install the packages seperatly
with `pip install torchaudio sentencepiece`.
```python
import torch
from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
from datasets import load_dataset
import soundfile as sf
model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-small-covost2-es-en-st")
processor = Speech2TextProcessor.from_pretrained("facebook/s2t-small-covost2-es-en-st")
def map_to_array(batch):
speech, _ = sf.read(batch["file"])
batch["speech"] = speech
return batch
ds = load_dataset(
"patrickvonplaten/librispeech_asr_dummy",
"clean",
split="validation"
)
ds = ds.map(map_to_array)
inputs = processor(
ds["speech"][0],
sampling_rate=48_000,
return_tensors="pt"
)
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"])
translation = processor.batch_decode(generated_ids, skip_special_tokens=True)
```
## Training data
The s2t-small-covost2-es-en-st is trained on Spanish-English subset of [CoVoST2](https://github.com/facebookresearch/covost).
CoVoST is a large-scale multilingual ST corpus based on [Common Voice](https://arxiv.org/abs/1912.06670), created to to foster
ST research with the largest ever open dataset
## Training procedure
### Preprocessing
The speech data is pre-processed by extracting Kaldi-compliant 80-channel log mel-filter bank features automatically from
WAV/FLAC audio files via PyKaldi or torchaudio. Further utterance-level CMVN (cepstral mean and variance normalization)
is applied to each example.
The texts are lowercased and tokenized using character based SentencePiece vocab.
### Training
The model is trained with standard autoregressive cross-entropy loss and using [SpecAugment](https://arxiv.org/abs/1904.08779).
The encoder receives speech features, and the decoder generates the transcripts autoregressively. To accelerate
model training and for better performance the encoder is pre-trained for English ASR.
## Evaluation results
CoVOST2 test results for es-en (BLEU score): 22.31
### BibTeX entry and citation info
```bibtex
@inproceedings{wang2020fairseqs2t,
title = {fairseq S2T: Fast Speech-to-Text Modeling with fairseq},
author = {Changhan Wang and Yun Tang and Xutai Ma and Anne Wu and Dmytro Okhonko and Juan Pino},
booktitle = {Proceedings of the 2020 Conference of the Asian Chapter of the Association for Computational Linguistics (AACL): System Demonstrations},
year = {2020},
}
```
|
facebook/s2t-small-mustc-en-nl-st | 642280abe21918c82d06527f975fa9f4ad68e857 | 2022-02-07T15:29:27.000Z | [
"pytorch",
"tf",
"speech_to_text",
"automatic-speech-recognition",
"en",
"nl",
"dataset:mustc",
"arxiv:2010.05171",
"arxiv:1904.08779",
"transformers",
"audio",
"speech-translation",
"license:mit"
]
| automatic-speech-recognition | false | facebook | null | facebook/s2t-small-mustc-en-nl-st | 7 | null | transformers | 14,074 | ---
language:
- en
- nl
datasets:
- mustc
tags:
- audio
- speech-translation
- automatic-speech-recognition
license: mit
pipeline_tag: automatic-speech-recognition
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
---
# S2T-SMALL-MUSTC-EN-NL-ST
`s2t-small-mustc-en-nl-st` is a Speech to Text Transformer (S2T) model trained for end-to-end Speech Translation (ST).
The S2T model was proposed in [this paper](https://arxiv.org/abs/2010.05171) and released in
[this repository](https://github.com/pytorch/fairseq/tree/master/examples/speech_to_text)
## Model description
S2T is a transformer-based seq2seq (encoder-decoder) model designed for end-to-end Automatic Speech Recognition (ASR) and Speech
Translation (ST). It uses a convolutional downsampler to reduce the length of speech inputs by 3/4th before they are
fed into the encoder. The model is trained with standard autoregressive cross-entropy loss and generates the
transcripts/translations autoregressively.
## Intended uses & limitations
This model can be used for end-to-end English speech to Dutch text translation.
See the [model hub](https://huggingface.co/models?filter=speech_to_text) to look for other S2T checkpoints.
### How to use
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
*Note: The `Speech2TextProcessor` object uses [torchaudio](https://github.com/pytorch/audio) to extract the
filter bank features. Make sure to install the `torchaudio` package before running this example.*
You could either install those as extra speech dependancies with
`pip install transformers"[speech, sentencepiece]"` or install the packages seperatly
with `pip install torchaudio sentencepiece`.
```python
import torch
from transformers import Speech2TextProcessor, Speech2TextForConditionalGeneration
from datasets import load_dataset
import soundfile as sf
model = Speech2TextForConditionalGeneration.from_pretrained("facebook/s2t-small-mustc-en-nl-st")
processor = Speech2TextProcessor.from_pretrained("facebook/s2t-small-mustc-en-nl-st")
def map_to_array(batch):
speech, _ = sf.read(batch["file"])
batch["speech"] = speech
return batch
ds = load_dataset(
"patrickvonplaten/librispeech_asr_dummy",
"clean",
split="validation"
)
ds = ds.map(map_to_array)
inputs = processor(
ds["speech"][0],
sampling_rate=16_000,
return_tensors="pt"
)
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"])
translation = processor.batch_decode(generated_ids, skip_special_tokens=True)
```
## Training data
The s2t-small-mustc-en-nl-st is trained on English-Dutch subset of [MuST-C](https://ict.fbk.eu/must-c/).
MuST-C is a multilingual speech translation corpus whose size and quality facilitates the training of end-to-end systems
for speech translation from English into several languages. For each target language, MuST-C comprises several hundred
hours of audio recordings from English TED Talks, which are automatically aligned at the sentence level with their manual
transcriptions and translations.
## Training procedure
### Preprocessing
The speech data is pre-processed by extracting Kaldi-compliant 80-channel log mel-filter bank features automatically from
WAV/FLAC audio files via PyKaldi or torchaudio. Further utterance-level CMVN (cepstral mean and variance normalization)
is applied to each example.
The texts are lowercased and tokenized using SentencePiece and a vocabulary size of 8,000.
### Training
The model is trained with standard autoregressive cross-entropy loss and using [SpecAugment](https://arxiv.org/abs/1904.08779).
The encoder receives speech features, and the decoder generates the transcripts autoregressively. To accelerate
model training and for better performance the encoder is pre-trained for English ASR.
## Evaluation results
MuST-C test results for en-nl (BLEU score): 27.3
### BibTeX entry and citation info
```bibtex
@inproceedings{wang2020fairseqs2t,
title = {fairseq S2T: Fast Speech-to-Text Modeling with fairseq},
author = {Changhan Wang and Yun Tang and Xutai Ma and Anne Wu and Dmytro Okhonko and Juan Pino},
booktitle = {Proceedings of the 2020 Conference of the Asian Chapter of the Association for Computational Linguistics (AACL): System Demonstrations},
year = {2020},
}
```
|
facebook/wav2vec2-base-10k-voxpopuli | daedd815b28863b4ab0018641ae8d4cc89b7a437 | 2021-07-06T01:53:26.000Z | [
"pytorch",
"wav2vec2",
"pretraining",
"multilingual",
"arxiv:2101.00390",
"transformers",
"audio",
"automatic-speech-recognition",
"voxpopuli",
"license:cc-by-nc-4.0"
]
| automatic-speech-recognition | false | facebook | null | facebook/wav2vec2-base-10k-voxpopuli | 7 | null | transformers | 14,075 | ---
language: multilingual
tags:
- audio
- automatic-speech-recognition
- voxpopuli
license: cc-by-nc-4.0
---
# Wav2Vec2-Base-VoxPopuli
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) base model pretrained on the 10k unlabeled subset of [VoxPopuli corpus](https://arxiv.org/abs/2101.00390).
**Paper**: *[VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation
Learning, Semi-Supervised Learning and Interpretation](https://arxiv.org/abs/2101.00390)*
**Authors**: *Changhan Wang, Morgane Riviere, Ann Lee, Anne Wu, Chaitanya Talnikar, Daniel Haziza, Mary Williamson, Juan Pino, Emmanuel Dupoux* from *Facebook AI*
See the official website for more information, [here](https://github.com/facebookresearch/voxpopuli/)
# Fine-Tuning
Please refer to [this blog](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) on how to fine-tune this model on a specific language. Note that you should replace `"facebook/wav2vec2-large-xlsr-53"` with this checkpoint for fine-tuning.
|
felixhusen/scientific | 60cb1db7330d72b74fce78165736b7c692c9be2c | 2021-05-21T16:02:25.000Z | [
"pytorch",
"jax",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | false | felixhusen | null | felixhusen/scientific | 7 | null | transformers | 14,076 | Entry not found |
figurative-nlp/t5-figurative-generation | 57892b4a929284db499b40329e77c1e1a964377a | 2022-02-17T09:23:23.000Z | [
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | false | figurative-nlp | null | figurative-nlp/t5-figurative-generation | 7 | 1 | transformers | 14,077 | This model can convert the literal expression to figurative/metaphorical expression. Below is the usage of our model:
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("figurative-nlp/t5-figurative-generation")
model = AutoModelForSeq2SeqLM.from_pretrained("figurative-nlp/t5-figurative-generation")
input_ids = tokenizer(
"research is <m> very difficult </m> for me.", return_tensors="pt"
).input_ids # Batch size 1
outputs = model.generate(input_ids,beam_search = 5)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
#result : research is a tough nut to crack for me.
For example (the <m> and </m> is the mark that inform the model which literal expression we want to convert it as figurative expression):
**Input**: as of a cloud that softly <m> covers </m> the sun.
**Output**: as of a cloud that softly drapes over the sun.
**Input**: that car coming around the corner <m> surprised me. </m>
**Output**: that car coming around the corner knocked my socks off.
Note: the figurative language here includes metaphor, idiom and simile. We don't guarantee that the results generated results are satisfactory to you. We are trying to improve the effect of the model. |
flair/ner-danish | 5cac0154c3577673ae591cde8098f15740b73ebf | 2021-02-26T15:33:02.000Z | [
"pytorch",
"da",
"dataset:DaNE",
"flair",
"token-classification",
"sequence-tagger-model"
]
| token-classification | false | flair | null | flair/ner-danish | 7 | null | flair | 14,078 | ---
tags:
- flair
- token-classification
- sequence-tagger-model
language: da
datasets:
- DaNE
widget:
- text: "Jens Peter Hansen kommer fra Danmark"
---
# Danish NER in Flair (default model)
This is the standard 4-class NER model for Danish that ships with [Flair](https://github.com/flairNLP/flair/).
F1-Score: **81.78** (DaNER)
Predicts 4 tags:
| **tag** | **meaning** |
|---------------------------------|-----------|
| PER | person name |
| LOC | location name |
| ORG | organization name |
| MISC | other name |
Based on Transformer embeddings and LSTM-CRF.
---
# Demo: How to use in Flair
Requires: **[Flair](https://github.com/flairNLP/flair/)** (`pip install flair`)
```python
from flair.data import Sentence
from flair.models import SequenceTagger
# load tagger
tagger = SequenceTagger.load("flair/ner-danish")
# make example sentence
sentence = Sentence("Jens Peter Hansen kommer fra Danmark")
# predict NER tags
tagger.predict(sentence)
# print sentence
print(sentence)
# print predicted NER spans
print('The following NER tags are found:')
# iterate over entities and print
for entity in sentence.get_spans('ner'):
print(entity)
```
This yields the following output:
```
Span [1,2,3]: "Jens Peter Hansen" [− Labels: PER (0.9961)]
Span [6]: "Danmark" [− Labels: LOC (0.9816)]
```
So, the entities "*Jens Peter Hansen*" (labeled as a **person**) and "*Danmark*" (labeled as a **location**) are found in the sentence "*Jens Peter Hansen kommer fra Danmark*".
---
### Training: Script to train this model
The model was trained by the [DaNLP project](https://github.com/alexandrainst/danlp) using the [DaNE corpus](https://github.com/alexandrainst/danlp/blob/master/docs/docs/datasets.md#danish-dependency-treebank-dane-dane). Check their repo for more information.
The following Flair script may be used to train such a model:
```python
from flair.data import Corpus
from flair.datasets import DANE
from flair.embeddings import WordEmbeddings, StackedEmbeddings, FlairEmbeddings
# 1. get the corpus
corpus: Corpus = DANE()
# 2. what tag do we want to predict?
tag_type = 'ner'
# 3. make the tag dictionary from the corpus
tag_dictionary = corpus.make_tag_dictionary(tag_type=tag_type)
# 4. initialize each embedding we use
embedding_types = [
# GloVe embeddings
WordEmbeddings('da'),
# contextual string embeddings, forward
FlairEmbeddings('da-forward'),
# contextual string embeddings, backward
FlairEmbeddings('da-backward'),
]
# embedding stack consists of Flair and GloVe embeddings
embeddings = StackedEmbeddings(embeddings=embedding_types)
# 5. initialize sequence tagger
from flair.models import SequenceTagger
tagger = SequenceTagger(hidden_size=256,
embeddings=embeddings,
tag_dictionary=tag_dictionary,
tag_type=tag_type)
# 6. initialize trainer
from flair.trainers import ModelTrainer
trainer = ModelTrainer(tagger, corpus)
# 7. run training
trainer.train('resources/taggers/ner-danish',
train_with_dev=True,
max_epochs=150)
```
---
### Cite
Please cite the following papers when using this model.
```
@inproceedings{akbik-etal-2019-flair,
title = "{FLAIR}: An Easy-to-Use Framework for State-of-the-Art {NLP}",
author = "Akbik, Alan and
Bergmann, Tanja and
Blythe, Duncan and
Rasul, Kashif and
Schweter, Stefan and
Vollgraf, Roland",
booktitle = "Proceedings of the 2019 Conference of the North {A}merican Chapter of the Association for Computational Linguistics (Demonstrations)",
year = "2019",
url = "https://www.aclweb.org/anthology/N19-4010",
pages = "54--59",
}
```
And check the [DaNLP project](https://github.com/alexandrainst/danlp) for more information.
---
### Issues?
The Flair issue tracker is available [here](https://github.com/flairNLP/flair/issues/).
|
flax-community/code-mt5-base | a424f3c2663be1d9f129206e49a749212b2518ab | 2021-07-19T05:27:02.000Z | [
"pytorch",
"jax",
"tensorboard",
"mt5",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | false | flax-community | null | flax-community/code-mt5-base | 7 | null | transformers | 14,079 | # Tokenizer
We trained our tokenizer using [sentencepiece](https://github.com/google/sentencepiece)'s unigram tokenizer. Then loaded the tokenizer as MT5TokenizerFast.
## Model
We used [MT5-base](https://huggingface.co/google/mt5-base) model.
## Datasets
We used [Code Search Net](https://huggingface.co/datasets/code_search_net)'s dataset and some scrapped data from internet to train the model. We maintained a list of datasets where each dataset had codes of same language.
## Plots
### Train loss

### Evaluation loss

### Evaluation accuracy

### Learning rate

## Fine tuning (WIP)
We fine tuned the model with [CodeXGLUE code-to-code-trans dataset](https://huggingface.co/datasets/code_x_glue_cc_code_to_code_trans), and scrapper data.
|
flax-community/gpt-neo-1.3B-apps | 709c738170ede6f2f33e0755190d6ff155665c69 | 2021-09-22T08:25:27.000Z | [
"pytorch",
"jax",
"gpt_neo",
"text-generation",
"en",
"python",
"dataset:apps",
"arxiv:2107.03374",
"transformers",
"code_synthesis",
"license:mit"
]
| text-generation | false | flax-community | null | flax-community/gpt-neo-1.3B-apps | 7 | 2 | transformers | 14,080 | ---
language:
- en
- python
license: mit
tags:
- gpt_neo
- code_synthesis
datasets:
- apps
---
# GPT-Neo-1.3B-APPS
> **Please refer to our new [GitHub Wiki](https://github.com/ncoop57/gpt-code-clippy/wiki) which documents our efforts in detail in creating the open source version of GitHub Copilot**
## Model Description
GPT-Neo-1.3B-APPS is a GPT-Neo-125M finetuned on APPS dataset. This model is specialized to solve programming tasks.
## Training data
The model is trained on the [Automated Programming Progress Standard (APPS) dataset](https://github.com/hendrycks/apps). The dataset consists of 10,000 coding problems in total, with 131,836 test cases for checking solutions and 232,444 ground-truth solutions written by humans. Problems can be complicated, as the average length of a problem is 293.2 words. The data are split evenly into training and test sets, with 5,000 problems each.
This model is fine-tuned using most of the APPS dataset including both train and test split to explore the impact of this training task on model performance on other code synthesis evaluation metrics. A model fine-tuned on train set only can be found [here](https://huggingface.co/flax-community/gpt-neo-125M-apps).
## Training procedure
The training script used to train this model can be found [here](https://github.com/ncoop57/gpt-code-clippy/blob/camera-ready/training/run_clm_apps.py).
Training is done for 5 epochs using AdamW optimizer and leaner decay learning rate schedule with 800 warmup steps. To reproduce the training one can use this command with the above script:
```bash
python run_clm_apps.py \
--output_dir $HOME/gpt-neo-1.3B-apps \
--model_name_or_path EleutherAI/gpt-neo-1.3B \
--dataset_name $HOME/gpt-code-clippy/data_processing/apps.py \
--dataset_config_name formatted \
--do_train --do_eval \
--block_size="1024" \
--per_device_train_batch_size="3" \
--per_device_eval_batch_size="3" \
--preprocessing_num_workers="16" \
--learning_rate="8e-5" \
--warmup_steps="800" \
--adam_beta1="0.9" \
--adam_beta2="0.98" \
--weight_decay="0.1" \
--overwrite_output_dir \
--num_train_epochs="5" \
--logging_steps="50" \
--eval_steps="2000" \
--report_to="wandb" \
--dtype="bfloat16" \
--save_strategy epoch \
--gradient_accumulation_steps 1 \
```
## Intended Use and Limitations
The model is finetuned to solve programming problems given a text description and optional starter code.
### How to use
You can use this model directly with a pipeline for text generation. This example generates a different sequence each time it's run:
```py
from transformers import AutoModelForCausalLM, AutoTokenizer, FlaxAutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("flax-community/gpt-code-clippy-1.3B-apps")
tokenizer = AutoTokenizer.from_pretrained("flax-community/gpt-code-clippy-1.3B-apps")
prompt = """
A function to greet user. Given a user name it should say hello
def greet(name):
ANSWER:
"""
input_ids = tokenizer(prompt, return_tensors='pt').input_ids.to(device)
start = input_ids.size(1)
out = model.generate(input_ids, do_sample=True, max_length=50, num_beams=2,
early_stopping=True, eos_token_id=tokenizer.eos_token_id, )
print(tokenizer.decode(out[0][start:]))
```
### Limitations and Biases
The model is intended to be used for research purposes and comes with no guarantees of quality of generated code.
The paper ["Evaluating Large Language Models Trained on Code"](https://arxiv.org/abs/2107.03374) from OpenAI has a good discussion on what the impact of a large language model trained on code could be. Therefore, some parts of their discuss are highlighted here as it pertains to this dataset and models that may be trained from it. **As well as some differences in views from the paper, particularly around legal implications**.
1. **Over-reliance:** This model may generate plausible solutions that may appear correct, but are not necessarily the correct solution. Not properly evaluating the generated code may cause have negative consequences such as the introduction of bugs, or the introduction of security vulnerabilities. Therefore, it is important that users are aware of the limitations and potential negative consequences of using this language model.
2. **Economic and labor market impacts:** Large language models trained on large code datasets such as this one that are capable of generating high-quality code have the potential to automate part of the software development process. This may negatively impact software developers. However, as discussed in the paper, as shown in the Summary Report of software developers from [O*NET OnLine](https://www.onetonline.org/link/summary/15-1252.00), developers don't just write software.
5. **Biases:** The model is trained on data containing prompt questions formatted in specific way. The performance of the model can be worse if the prompt
formatting is different from that used in APPS dataset.
GPT-CC is finetuned GPT-Neo and might have inhereted biases and limitations from it. See [GPT-Neo model card](https://huggingface.co/EleutherAI/gpt-neo-125M#limitations-and-biases) for details.
## Eval results
Coming soon...
|
foundkim/topic_classifier | 1af161c15cbdc0f4806045e6be5b6616dd2dc816 | 2021-09-14T14:51:33.000Z | [
"pytorch",
"bert",
"text-classification",
"transformers"
]
| text-classification | false | foundkim | null | foundkim/topic_classifier | 7 | null | transformers | 14,081 | Entry not found |
gagan3012/project-code-py | badb1a88f5a13f9514c7c929b3c89a833e1efa94 | 2021-05-21T16:08:09.000Z | [
"pytorch",
"jax",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | false | gagan3012 | null | gagan3012/project-code-py | 7 | null | transformers | 14,082 | # Leetcode using AI :robot:
GPT-2 Model for Leetcode Questions in python
**Note**: the Answers might not make sense in some cases because of the bias in GPT-2
**Contribtuions:** If you would like to make the model better contributions are welcome Check out [CONTRIBUTIONS.md](https://github.com/gagan3012/project-code-py/blob/master/CONTRIBUTIONS.md)
### 📢 Favour:
It would be highly motivating, if you can STAR⭐ this repo if you find it helpful.
## Model
Two models have been developed for different use cases and they can be found at https://huggingface.co/gagan3012
The model weights can be found here: [GPT-2](https://huggingface.co/gagan3012/project-code-py) and [DistilGPT-2](https://huggingface.co/gagan3012/project-code-py-small)
### Example usage:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("gagan3012/project-code-py")
model = AutoModelWithLMHead.from_pretrained("gagan3012/project-code-py")
```
## Demo
[](https://share.streamlit.io/gagan3012/project-code-py/app.py)
A streamlit webapp has been setup to use the model: https://share.streamlit.io/gagan3012/project-code-py/app.py
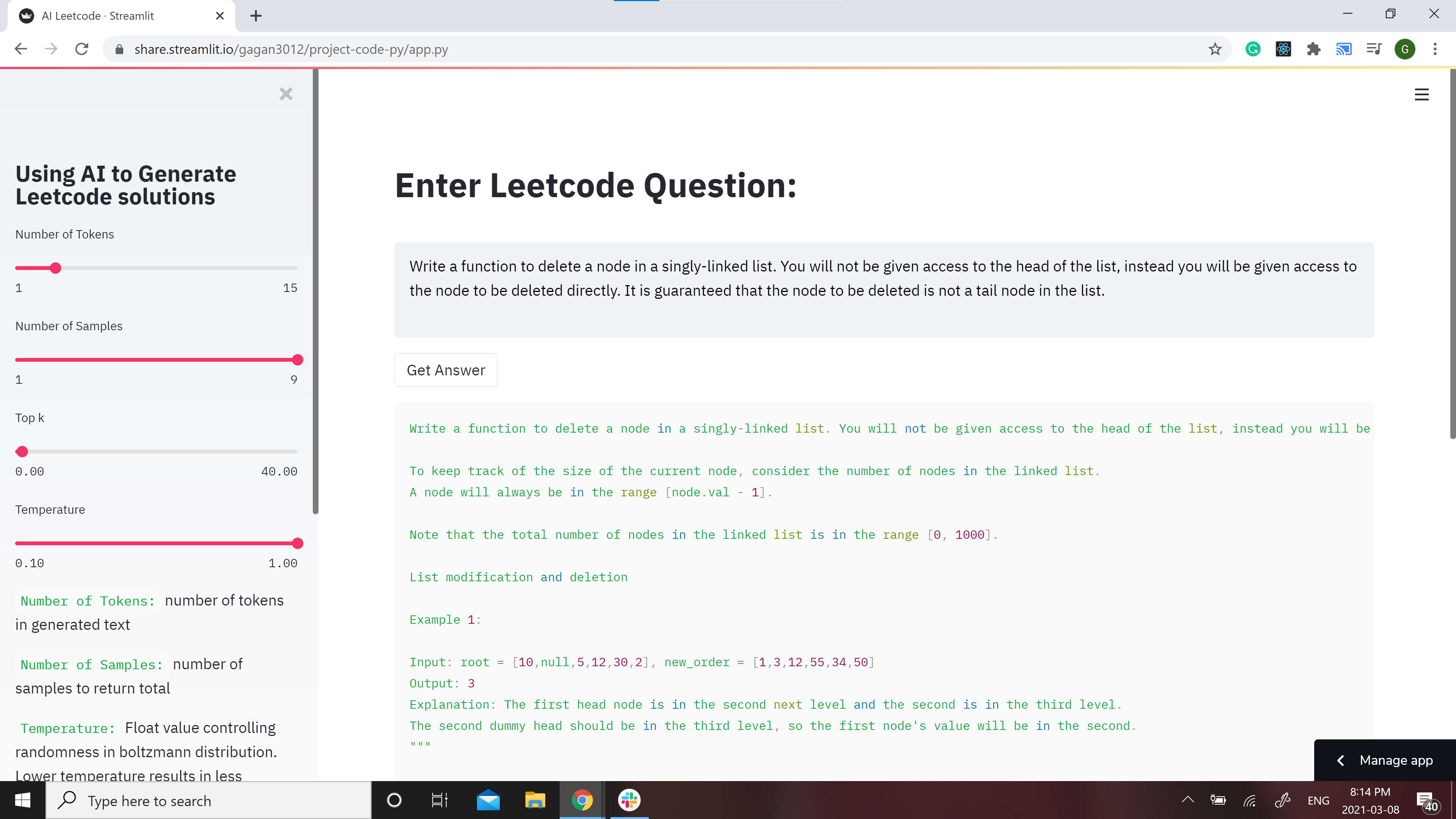
## Example results:
### Question:
```
Write a function to delete a node in a singly-linked list. You will not be given access to the head of the list, instead you will be given access to the node to be deleted directly. It is guaranteed that the node to be deleted is not a tail node in the list.
```
### Answer:
```python
""" Write a function to delete a node in a singly-linked list. You will not be given access to the head of the list, instead you will be given access to the node to be deleted directly. It is guaranteed that the node to be deleted is not a tail node in the list.
For example,
a = 1->2->3
b = 3->1->2
t = ListNode(-1, 1)
Note: The lexicographic ordering of the nodes in a tree matters. Do not assign values to nodes in a tree.
Example 1:
Input: [1,2,3]
Output: 1->2->5
Explanation: 1->2->3->3->4, then 1->2->5[2] and then 5->1->3->4.
Note:
The length of a linked list will be in the range [1, 1000].
Node.val must be a valid LinkedListNode type.
Both the length and the value of the nodes in a linked list will be in the range [-1000, 1000].
All nodes are distinct.
"""
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution:
def deleteNode(self, head: ListNode, val: int) -> None:
"""
BFS
Linked List
:param head: ListNode
:param val: int
:return: ListNode
"""
if head is not None:
return head
dummy = ListNode(-1, 1)
dummy.next = head
dummy.next.val = val
dummy.next.next = head
dummy.val = ""
s1 = Solution()
print(s1.deleteNode(head))
print(s1.deleteNode(-1))
print(s1.deleteNode(-1))
```
|
gagandeepkundi/latam-question-quality | fb6fe35c3bacb2751ab6fdb6ec3314a84fd28596 | 2021-10-16T16:32:19.000Z | [
"pytorch",
"roberta",
"text-classification",
"es",
"dataset:gagandeepkundi/autonlp-data-text-classification",
"transformers",
"autonlp",
"co2_eq_emissions"
]
| text-classification | false | gagandeepkundi | null | gagandeepkundi/latam-question-quality | 7 | null | transformers | 14,083 | ---
tags: autonlp
language: es
widget:
- text: "I love AutoNLP 🤗"
datasets:
- gagandeepkundi/autonlp-data-text-classification
co2_eq_emissions: 20.790169878009916
---
# Model Trained Using AutoNLP
- Problem type: Binary Classification
- Model ID: 19984005
- CO2 Emissions (in grams): 20.790169878009916
## Validation Metrics
- Loss: 0.06693269312381744
- Accuracy: 0.9789
- Precision: 0.9843244336569579
- Recall: 0.9733
- AUC: 0.99695552
- F1: 0.9787811745776348
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/gagandeepkundi/autonlp-text-classification-19984005
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("gagandeepkundi/autonlp-text-classification-19984005", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("gagandeepkundi/autonlp-text-classification-19984005", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` |
gchhablani/fnet-base-finetuned-qqp | 583d54294e01b5da20b1eb15aa93d1ef68ccc4b9 | 2021-09-20T09:08:34.000Z | [
"pytorch",
"tensorboard",
"fnet",
"text-classification",
"en",
"dataset:glue",
"arxiv:2105.03824",
"transformers",
"generated_from_trainer",
"fnet-bert-base-comparison",
"license:apache-2.0",
"model-index"
]
| text-classification | false | gchhablani | null | gchhablani/fnet-base-finetuned-qqp | 7 | null | transformers | 14,084 | ---
language:
- en
license: apache-2.0
tags:
- generated_from_trainer
- fnet-bert-base-comparison
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: fnet-base-finetuned-qqp
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE QQP
type: glue
args: qqp
metrics:
- name: Accuracy
type: accuracy
value: 0.8847390551570616
- name: F1
type: f1
value: 0.8466197090382463
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fnet-base-finetuned-qqp
This model is a fine-tuned version of [google/fnet-base](https://huggingface.co/google/fnet-base) on the GLUE QQP dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3686
- Accuracy: 0.8847
- F1: 0.8466
- Combined Score: 0.8657
The model was fine-tuned to compare [google/fnet-base](https://huggingface.co/google/fnet-base) as introduced in [this paper](https://arxiv.org/abs/2105.03824) against [bert-base-cased](https://huggingface.co/bert-base-cased).
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
This model is trained using the [run_glue](https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py) script. The following command was used:
```bash
#!/usr/bin/bash
#!/usr/bin/bash
python ../run_glue.py \\n --model_name_or_path google/fnet-base \\n --task_name qqp \\n --do_train \\n --do_eval \\n --max_seq_length 512 \\n --per_device_train_batch_size 16 \\n --learning_rate 2e-5 \\n --num_train_epochs 3 \\n --output_dir fnet-base-finetuned-qqp \\n --push_to_hub \\n --hub_strategy all_checkpoints \\n --logging_strategy epoch \\n --save_strategy epoch \\n --evaluation_strategy epoch \\n```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Combined Score |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|:--------------:|
| 0.3484 | 1.0 | 22741 | 0.3014 | 0.8676 | 0.8297 | 0.8487 |
| 0.2387 | 2.0 | 45482 | 0.3011 | 0.8801 | 0.8429 | 0.8615 |
| 0.1739 | 3.0 | 68223 | 0.3686 | 0.8847 | 0.8466 | 0.8657 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
gchhablani/fnet-base-finetuned-stsb | f1ebdea41f20cae0f57fc80ff81f55c3508a26eb | 2021-09-20T09:09:24.000Z | [
"pytorch",
"tensorboard",
"fnet",
"text-classification",
"en",
"dataset:glue",
"arxiv:2105.03824",
"transformers",
"generated_from_trainer",
"fnet-bert-base-comparison",
"license:apache-2.0",
"model-index"
]
| text-classification | false | gchhablani | null | gchhablani/fnet-base-finetuned-stsb | 7 | null | transformers | 14,085 | ---
language:
- en
license: apache-2.0
tags:
- generated_from_trainer
- fnet-bert-base-comparison
datasets:
- glue
metrics:
- spearmanr
model-index:
- name: fnet-base-finetuned-stsb
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE STSB
type: glue
args: stsb
metrics:
- name: Spearmanr
type: spearmanr
value: 0.8219397497728022
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fnet-base-finetuned-stsb
This model is a fine-tuned version of [google/fnet-base](https://huggingface.co/google/fnet-base) on the GLUE STSB dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7894
- Pearson: 0.8256
- Spearmanr: 0.8219
- Combined Score: 0.8238
The model was fine-tuned to compare [google/fnet-base](https://huggingface.co/google/fnet-base) as introduced in [this paper](https://arxiv.org/abs/2105.03824) against [bert-base-cased](https://huggingface.co/bert-base-cased).
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
This model is trained using the [run_glue](https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py) script. The following command was used:
```bash
#!/usr/bin/bash
python ../run_glue.py \\n --model_name_or_path google/fnet-base \\n --task_name stsb \\n --do_train \\n --do_eval \\n --max_seq_length 512 \\n --per_device_train_batch_size 16 \\n --learning_rate 2e-5 \\n --num_train_epochs 3 \\n --output_dir fnet-base-finetuned-stsb \\n --push_to_hub \\n --hub_strategy all_checkpoints \\n --logging_strategy epoch \\n --save_strategy epoch \\n --evaluation_strategy epoch \\n```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Combined Score | Validation Loss | Pearson | Spearmanr |
|:-------------:|:-----:|:----:|:--------------:|:---------------:|:-------:|:---------:|
| 1.5473 | 1.0 | 360 | 0.8120 | 0.7751 | 0.8115 | 0.8125 |
| 0.6954 | 2.0 | 720 | 0.8145 | 0.8717 | 0.8160 | 0.8130 |
| 0.4828 | 3.0 | 1080 | 0.8238 | 0.7894 | 0.8256 | 0.8219 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
ghadeermobasher/BC2GM-Gene-Modified_BioM-ELECTRA-Base-Discriminator | 5beca65f0fb46bb4df37131cad2a9e0896464685 | 2022-01-23T01:07:52.000Z | [
"pytorch",
"electra",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/BC2GM-Gene-Modified_BioM-ELECTRA-Base-Discriminator | 7 | null | transformers | 14,086 | Entry not found |
ghadeermobasher/BioNLP13CG-Modified-biobert-v1.1_latest | 481a6a960d0c52bc169f4f3bfd8863705221c6b1 | 2022-02-21T20:05:55.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/BioNLP13CG-Modified-biobert-v1.1_latest | 7 | null | transformers | 14,087 | Entry not found |
ghadeermobasher/BioNLP13CG-Modified-bluebert_pubmed_uncased_L-12_H-768_A-12_latest | c0ecc90d13cff2d1a284e2920f4c8593621315d2 | 2022-02-21T20:24:11.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/BioNLP13CG-Modified-bluebert_pubmed_uncased_L-12_H-768_A-12_latest | 7 | null | transformers | 14,088 | Entry not found |
ghadeermobasher/BioNLP13CG-Original-biobert-v1.1_latest | 178122bf74009d5103e8ae750e3913fc896b5e97 | 2022-02-21T20:14:39.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/BioNLP13CG-Original-biobert-v1.1_latest | 7 | null | transformers | 14,089 | Entry not found |
ghadeermobasher/BioNLP13CG-Original-scibert_latest | be5b2f2d33ed29451ac8a6cd54a0574183e8df1e | 2022-02-21T20:20:26.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/BioNLP13CG-Original-scibert_latest | 7 | null | transformers | 14,090 | Entry not found |
ghadeermobasher/CRAFT-Chem-Modified-BiomedNLP-PubMedBERT-base-uncased-abstract | 16e40123d56fed0e178e1a85f260595d9a2d4f10 | 2022-02-22T04:41:48.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/CRAFT-Chem-Modified-BiomedNLP-PubMedBERT-base-uncased-abstract | 7 | null | transformers | 14,091 | Entry not found |
ghadeermobasher/CRAFT-Chem-Modified-scibert_scivocab_uncased | fdb6ece1e0e816a634a0f8efcb3807068241acfe | 2022-02-22T04:39:39.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/CRAFT-Chem-Modified-scibert_scivocab_uncased | 7 | null | transformers | 14,092 | Entry not found |
ghadeermobasher/CRAFT-Chem_Original-biobert-v1.1 | c7e32c1e11da654b1bf3f46f065886ea28c3f963 | 2022-02-23T22:33:29.000Z | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | false | ghadeermobasher | null | ghadeermobasher/CRAFT-Chem_Original-biobert-v1.1 | 7 | null | transformers | 14,093 | Entry not found |
giacomomiolo/electramed_base_scivocab_1M | 8c25d516df3f7e62a92f3bb84409f41085698d8f | 2020-10-02T14:13:56.000Z | [
"pytorch",
"tf",
"electra",
"pretraining",
"transformers"
]
| null | false | giacomomiolo | null | giacomomiolo/electramed_base_scivocab_1M | 7 | null | transformers | 14,094 | Entry not found |
google/multiberts-seed_4-step_2000k | 43e01bb2e3efb5df21e332f6b84705831e125bfa | 2021-11-06T03:50:46.000Z | [
"pytorch",
"tf",
"bert",
"pretraining",
"en",
"arxiv:2106.16163",
"arxiv:1908.08962",
"transformers",
"multiberts",
"multiberts-seed_4",
"multiberts-seed_4-step_2000k",
"license:apache-2.0"
]
| null | false | google | null | google/multiberts-seed_4-step_2000k | 7 | null | transformers | 14,095 | ---
language: en
tags:
- multiberts
- multiberts-seed_4
- multiberts-seed_4-step_2000k
license: apache-2.0
---
# MultiBERTs, Intermediate Checkpoint - Seed 4, Step 2000k
MultiBERTs is a collection of checkpoints and a statistical library to support
robust research on BERT. We provide 25 BERT-base models trained with
similar hyper-parameters as
[the original BERT model](https://github.com/google-research/bert) but
with different random seeds, which causes variations in the initial weights and order of
training instances. The aim is to distinguish findings that apply to a specific
artifact (i.e., a particular instance of the model) from those that apply to the
more general procedure.
We also provide 140 intermediate checkpoints captured
during the course of pre-training (we saved 28 checkpoints for the first 5 runs).
The models were originally released through
[http://goo.gle/multiberts](http://goo.gle/multiberts). We describe them in our
paper
[The MultiBERTs: BERT Reproductions for Robustness Analysis](https://arxiv.org/abs/2106.16163).
This is model #4, captured at step 2000k (max: 2000k, i.e., 2M steps).
## Model Description
This model was captured during a reproduction of
[BERT-base uncased](https://github.com/google-research/bert), for English: it
is a Transformers model pretrained on a large corpus of English data, using the
Masked Language Modelling (MLM) and the Next Sentence Prediction (NSP)
objectives.
The intended uses, limitations, training data and training procedure for the fully trained model are similar
to [BERT-base uncased](https://github.com/google-research/bert). Two major
differences with the original model:
* We pre-trained the MultiBERTs models for 2 million steps using sequence
length 512 (instead of 1 million steps using sequence length 128 then 512).
* We used an alternative version of Wikipedia and Books Corpus, initially
collected for [Turc et al., 2019](https://arxiv.org/abs/1908.08962).
This is a best-effort reproduction, and so it is probable that differences with
the original model have gone unnoticed. The performance of MultiBERTs on GLUE after full training is oftentimes comparable to that of original
BERT, but we found significant differences on the dev set of SQuAD (MultiBERTs outperforms original BERT).
See our [technical report](https://arxiv.org/abs/2106.16163) for more details.
### How to use
Using code from
[BERT-base uncased](https://huggingface.co/bert-base-uncased), here is an example based on
Tensorflow:
```
from transformers import BertTokenizer, TFBertModel
tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_4-step_2000k')
model = TFBertModel.from_pretrained("google/multiberts-seed_4-step_2000k")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='tf')
output = model(encoded_input)
```
PyTorch version:
```
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('google/multiberts-seed_4-step_2000k')
model = BertModel.from_pretrained("google/multiberts-seed_4-step_2000k")
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
output = model(**encoded_input)
```
## Citation info
```bibtex
@article{sellam2021multiberts,
title={The MultiBERTs: BERT Reproductions for Robustness Analysis},
author={Thibault Sellam and Steve Yadlowsky and Jason Wei and Naomi Saphra and Alexander D'Amour and Tal Linzen and Jasmijn Bastings and Iulia Turc and Jacob Eisenstein and Dipanjan Das and Ian Tenney and Ellie Pavlick},
journal={arXiv preprint arXiv:2106.16163},
year={2021}
}
```
|
google/realm-cc-news-pretrained-openqa | 24f245432ffb94f52bc83338c72e1785374edfbf | 2022-01-05T17:28:49.000Z | [
"pytorch",
"realm",
"en",
"transformers",
"license:apache-2.0"
]
| null | false | google | null | google/realm-cc-news-pretrained-openqa | 7 | null | transformers | 14,096 | ---
language: en
license: apache-2.0
---
# realm-cc-news-pretrained-openqa
## Model description
The REALM checkpoint pretrained with CC-News as target corpus and Wikipedia as knowledge corpus, converted from the TF checkpoint provided by Google Language.
The original paper, code, and checkpoints can be found [here](https://github.com/google-research/language/tree/master/language/realm).
## Usage
```python
from transformers import RealmForOpenQA
openqa = RealmForOpenQA.from_pretrained("qqaatw/realm-cc-news-pretrained-openqa")
``` |
google/t5-11b-ssm-tqao | e0a0648fcef9f79f6ea6d569bac33378d6df7a7b | 2020-12-07T08:35:44.000Z | [
"pytorch",
"tf",
"t5",
"text2text-generation",
"en",
"dataset:c4",
"dataset:wikipedia",
"dataset:trivia_qa",
"arxiv:2002.08909",
"arxiv:1910.10683",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
]
| text2text-generation | false | google | null | google/t5-11b-ssm-tqao | 7 | null | transformers | 14,097 | ---
language: en
datasets:
- c4
- wikipedia
- trivia_qa
license: apache-2.0
---
[Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) for **Closed Book Question Answering**.
The model was pre-trained using T5's denoising objective on [C4](https://huggingface.co/datasets/c4), subsequently additionally pre-trained using [REALM](https://arxiv.org/pdf/2002.08909.pdf)'s salient span masking objective on [Wikipedia](https://huggingface.co/datasets/wikipedia), and finally fine-tuned on [Trivia QA (TQA)](https://huggingface.co/datasets/trivia_qa).
**Note**: The model was fine-tuned on 90% of the train splits of [Trivia QA (TQA)](https://huggingface.co/datasets/trivia_qa) for 20k steps and validated on the held-out 10% of the train split.
Other community Checkpoints: [here](https://huggingface.co/models?search=ssm)
Paper: [How Much Knowledge Can You Pack
Into the Parameters of a Language Model?](https://arxiv.org/abs/1910.10683.pdf)
Authors: *Adam Roberts, Colin Raffel, Noam Shazeer*
## Results on Trivia QA - Test Set
|Id | link | Exact Match |
|---|---|---|
|**T5-11b**|**https://huggingface.co/google/t5-large-ssm-tqao**|**51.0**|
|T5-xxl|https://huggingface.co/google/t5-xxl-ssm-tqao|51.9|
## Usage
The model can be used as follows for **closed book question answering**:
```python
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
t5_qa_model = AutoModelForSeq2SeqLM.from_pretrained("google/t5-11b-ssm-tqao")
t5_tok = AutoTokenizer.from_pretrained("google/t5-11b-ssm-tqao")
input_ids = t5_tok("When was Franklin D. Roosevelt born?", return_tensors="pt").input_ids
gen_output = t5_qa_model.generate(input_ids)[0]
print(t5_tok.decode(gen_output, skip_special_tokens=True))
```
## Abstract
It has recently been observed that neural language models trained on unstructured text can implicitly store and retrieve knowledge using natural language queries. In this short paper, we measure the practical utility of this approach by fine-tuning pre-trained models to answer questions without access to any external context or knowledge. We show that this approach scales with model size and performs competitively with open-domain systems that explicitly retrieve answers from an external knowledge source when answering questions. To facilitate reproducibility and future work, we release our code and trained models at https://goo.gle/t5-cbqa.
 |
google/t5-3b-ssm-nqo | ca5ea4d706797c3ee0333532bd0b142259744432 | 2020-12-07T08:43:29.000Z | [
"pytorch",
"tf",
"t5",
"text2text-generation",
"en",
"dataset:c4",
"dataset:wikipedia",
"dataset:natural_questions",
"arxiv:2002.08909",
"arxiv:1910.10683",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
]
| text2text-generation | false | google | null | google/t5-3b-ssm-nqo | 7 | null | transformers | 14,098 | ---
language: en
datasets:
- c4
- wikipedia
- natural_questions
license: apache-2.0
---
[Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) for **Closed Book Question Answering**.
The model was pre-trained using T5's denoising objective on [C4](https://huggingface.co/datasets/c4), subsequently additionally pre-trained using [REALM](https://arxiv.org/pdf/2002.08909.pdf)'s salient span masking objective on [Wikipedia](https://huggingface.co/datasets/wikipedia), and finally fine-tuned on [Natural Questions (NQ)](https://huggingface.co/datasets/natural_questions).
**Note**: The model was fine-tuned on 90% of the train splits of [Natural Questions (NQ)](https://huggingface.co/datasets/natural_questions) for 20k steps and validated on the held-out 10% of the train split.
Other community Checkpoints: [here](https://huggingface.co/models?search=ssm)
Paper: [How Much Knowledge Can You Pack
Into the Parameters of a Language Model?](https://arxiv.org/abs/1910.10683.pdf)
Authors: *Adam Roberts, Colin Raffel, Noam Shazeer*
## Results on Natural Questions - Test Set
|Id | link | Exact Match |
|---|---|---|
|T5-large|https://huggingface.co/google/t5-large-ssm-nqo|29.0|
|T5-xxl|https://huggingface.co/google/t5-xxl-ssm-nqo|35.2|
|**T5-3b**|**https://huggingface.co/google/t5-3b-ssm-nqo**|**31.7**|
|T5-11b|https://huggingface.co/google/t5-11b-ssm-nqo|34.8|
## Usage
The model can be used as follows for **closed book question answering**:
```python
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
t5_qa_model = AutoModelForSeq2SeqLM.from_pretrained("google/t5-3b-ssm-nqo")
t5_tok = AutoTokenizer.from_pretrained("google/t5-3b-ssm-nqo")
input_ids = t5_tok("When was Franklin D. Roosevelt born?", return_tensors="pt").input_ids
gen_output = t5_qa_model.generate(input_ids)[0]
print(t5_tok.decode(gen_output, skip_special_tokens=True))
```
## Abstract
It has recently been observed that neural language models trained on unstructured text can implicitly store and retrieve knowledge using natural language queries. In this short paper, we measure the practical utility of this approach by fine-tuning pre-trained models to answer questions without access to any external context or knowledge. We show that this approach scales with model size and performs competitively with open-domain systems that explicitly retrieve answers from an external knowledge source when answering questions. To facilitate reproducibility and future work, we release our code and trained models at https://goo.gle/t5-cbqa.
 |
google/t5-efficient-large-dm2000 | 794b04779085668b120fde68e4f43fcd5db3b811 | 2022-02-15T10:49:56.000Z | [
"pytorch",
"tf",
"jax",
"t5",
"text2text-generation",
"en",
"dataset:c4",
"arxiv:2109.10686",
"transformers",
"deep-narrow",
"license:apache-2.0",
"autotrain_compatible"
]
| text2text-generation | false | google | null | google/t5-efficient-large-dm2000 | 7 | null | transformers | 14,099 | ---
language:
- en
datasets:
- c4
tags:
- deep-narrow
inference: false
license: apache-2.0
---
# T5-Efficient-LARGE-DM2000 (Deep-Narrow version)
T5-Efficient-LARGE-DM2000 is a variation of [Google's original T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) following the [T5 model architecture](https://huggingface.co/docs/transformers/model_doc/t5).
It is a *pretrained-only* checkpoint and was released with the
paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)**
by *Yi Tay, Mostafa Dehghani, Jinfeng Rao, William Fedus, Samira Abnar, Hyung Won Chung, Sharan Narang, Dani Yogatama, Ashish Vaswani, Donald Metzler*.
In a nutshell, the paper indicates that a **Deep-Narrow** model architecture is favorable for **downstream** performance compared to other model architectures
of similar parameter count.
To quote the paper:
> We generally recommend a DeepNarrow strategy where the model’s depth is preferentially increased
> before considering any other forms of uniform scaling across other dimensions. This is largely due to
> how much depth influences the Pareto-frontier as shown in earlier sections of the paper. Specifically, a
> tall small (deep and narrow) model is generally more efficient compared to the base model. Likewise,
> a tall base model might also generally more efficient compared to a large model. We generally find
> that, regardless of size, even if absolute performance might increase as we continue to stack layers,
> the relative gain of Pareto-efficiency diminishes as we increase the layers, converging at 32 to 36
> layers. Finally, we note that our notion of efficiency here relates to any one compute dimension, i.e.,
> params, FLOPs or throughput (speed). We report all three key efficiency metrics (number of params,
> FLOPS and speed) and leave this decision to the practitioner to decide which compute dimension to
> consider.
To be more precise, *model depth* is defined as the number of transformer blocks that are stacked sequentially.
A sequence of word embeddings is therefore processed sequentially by each transformer block.
## Details model architecture
This model checkpoint - **t5-efficient-large-dm2000** - is of model type **Large** with the following variations:
- **dm** is **2000**
It has **1475.39** million parameters and thus requires *ca.* **5901.57 MB** of memory in full precision (*fp32*)
or **2950.78 MB** of memory in half precision (*fp16* or *bf16*).
A summary of the *original* T5 model architectures can be seen here:
| Model | nl (el/dl) | ff | dm | kv | nh | #Params|
| ----| ---- | ---- | ---- | ---- | ---- | ----|
| Tiny | 4/4 | 1024 | 256 | 32 | 4 | 16M|
| Mini | 4/4 | 1536 | 384 | 32 | 8 | 31M|
| Small | 6/6 | 2048 | 512 | 32 | 8 | 60M|
| Base | 12/12 | 3072 | 768 | 64 | 12 | 220M|
| Large | 24/24 | 4096 | 1024 | 64 | 16 | 738M|
| Xl | 24/24 | 16384 | 1024 | 128 | 32 | 3B|
| XXl | 24/24 | 65536 | 1024 | 128 | 128 | 11B|
whereas the following abbreviations are used:
| Abbreviation | Definition |
| ----| ---- |
| nl | Number of transformer blocks (depth) |
| dm | Dimension of embedding vector (output vector of transformers block) |
| kv | Dimension of key/value projection matrix |
| nh | Number of attention heads |
| ff | Dimension of intermediate vector within transformer block (size of feed-forward projection matrix) |
| el | Number of transformer blocks in the encoder (encoder depth) |
| dl | Number of transformer blocks in the decoder (decoder depth) |
| sh | Signifies that attention heads are shared |
| skv | Signifies that key-values projection matrices are tied |
If a model checkpoint has no specific, *el* or *dl* than both the number of encoder- and decoder layers correspond to *nl*.
## Pre-Training
The checkpoint was pretrained on the [Colossal, Cleaned version of Common Crawl (C4)](https://huggingface.co/datasets/c4) for 524288 steps using
the span-based masked language modeling (MLM) objective.
## Fine-Tuning
**Note**: This model is a **pretrained** checkpoint and has to be fine-tuned for practical usage.
The checkpoint was pretrained in English and is therefore only useful for English NLP tasks.
You can follow on of the following examples on how to fine-tune the model:
*PyTorch*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/pytorch/summarization)
- [Question Answering](https://github.com/huggingface/transformers/blob/master/examples/pytorch/question-answering/run_seq2seq_qa.py)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/pytorch/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*Tensorflow*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/tensorflow/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
*JAX/Flax*:
- [Summarization](https://github.com/huggingface/transformers/tree/master/examples/flax/summarization)
- [Text Classification](https://github.com/huggingface/transformers/tree/master/examples/flax/text-classification) - *Note*: You will have to slightly adapt the training example here to make it work with an encoder-decoder model.
## Downstream Performance
TODO: Add table if available
## Computational Complexity
TODO: Add table if available
## More information
We strongly recommend the reader to go carefully through the original paper **[Scale Efficiently: Insights from Pre-training and Fine-tuning Transformers](https://arxiv.org/abs/2109.10686)** to get a more nuanced understanding of this model checkpoint.
As explained in the following [issue](https://github.com/google-research/google-research/issues/986#issuecomment-1035051145), checkpoints including the *sh* or *skv*
model architecture variations have *not* been ported to Transformers as they are probably of limited practical usage and are lacking a more detailed description. Those checkpoints are kept [here](https://huggingface.co/NewT5SharedHeadsSharedKeyValues) as they might be ported potentially in the future. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.