
avatar_url
stringlengths 46
116
⌀ | name
stringlengths 1
46
| full_name
stringlengths 7
60
| created_at
stringdate 2016-04-01 08:17:56
2025-05-20 11:38:17
| description
stringlengths 0
387
⌀ | default_branch
stringclasses 45
values | open_issues
int64 0
4.93k
| stargazers_count
int64 0
78.2k
| forks_count
int64 0
3.09k
| watchers_count
int64 0
78.2k
| tags_url
stringlengths 0
94
| license
stringclasses 27
values | topics
listlengths 0
20
| size
int64 0
4.82M
| fork
bool 2
classes | updated_at
stringdate 2018-11-13 14:41:18
2025-05-22 08:23:54
| has_build_zig
bool 2
classes | has_build_zig_zon
bool 2
classes | zig_minimum_version
stringclasses 60
values | repo_from
stringclasses 3
values | dependencies
listlengths 0
121
| readme_content
stringlengths 0
437k
| dependents
listlengths 0
21
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
https://avatars.githubusercontent.com/u/3526922?v=4
|
napigen
|
cztomsik/napigen
|
2022-09-14T17:39:50Z
|
Automatic N-API (server-side javascript) bindings for your Zig project.
|
main
| 3 | 59 | 7 | 59 |
https://api.github.com/repos/cztomsik/napigen/tags
|
MIT
|
[
"javascript",
"napi",
"nodejs",
"zig",
"zig-package"
] | 84 | false |
2025-05-20T20:56:02Z
| true | true |
unknown
|
github
|
[
{
"commit": "master",
"name": "node_api",
"tar_url": "https://github.com/nodejs/node-api-headers/archive/master.tar.gz",
"type": "remote",
"url": "https://github.com/nodejs/node-api-headers"
}
] |
zig-napigen
Comptime N-API bindings for Zig.
<blockquote>
You need to use latest Zig 0.14.0 to use this library.
See <a>ggml-js</a> for a complete, real-world
example.
</blockquote>
Features
<ul>
<li>Primitives, tuples, structs (value types), optionals</li>
<li>Strings (valid for the function scope)</li>
<li>Struct pointers (see below)</li>
<li>Functions (no classes, see below)</li>
<li>all the <code>napi_xxx</code> functions and types are re-exported as <code>napigen.napi_xxx</code>,\
so you can do pretty much anything if you don't mind going lower-level.</li>
</ul>
Limited scope
The library provides a simple and thin API, supporting only basic types. This
design choice is intentional, as it is often difficult to determine the ideal
mapping for more complex types. The library allows users to hook into the
mapping process or use the N-API directly for finer control.
Specifically, there is no support for classes.
Structs/tuples (value types)
When returning a struct/tuple by value, it is mapped to an anonymous JavaScript
object/array with all properties/elements mapped recursively. Similarly, when
accepting a struct/tuple by value, it is mapped back from JavaScript to the
respective native type.
In both cases, a copy is created, so changes to the JS object are not reflected
in the native part and vice versa.
Struct pointers (*T)
When returning a pointer to a struct, an empty JavaScript object will be created
with the pointer wrapped inside. If this JavaScript object is passed to a
function that accepts a pointer, the pointer is unwrapped back.
The same JavaScript object is obtained for the same pointer, unless it has
already been collected. This is useful for attaching state to the JavaScript
counterpart and accessing that data later.
Changes to JavaScript objects are not reflected in the native part, but
getters/setters can be provided in JavaScript and native functions can be called
as necessary.
Functions
JavaScript functions can be created with ctx.createFunction(zig_fn) and then
exported like any other value. Only comptime-known functions are supported. If
an error is returned from a function call, an exception is thrown in JavaScript.
```zig
fn add(a: i32, b: i32) i32 {
return a + b;
}
// Somewhere where the JsContext is available
const js_fun: napigen.napi_value = try js.createFunction(add);
// Make the function accessible to JavaScript
try js.setNamedProperty(exports, "add", js_fun);
```
Note that <strong>the number of arguments must match exactly</strong>. So if you need to
support optional arguments, you will have to provide a wrapper function in JS,
which calls the native function with the correct arguments.
Callbacks, *JsContext, napi_value
Functions can also accept the current <code>*JsContext</code>, which is useful for calling
the N-API directly or performing callbacks. To get a raw JavaScript value,
simply use <code>napi_value</code> as an argument type.
<code>zig
fn callMeBack(js: *napigen.JsContext, recv: napigen.napi_value, fun: napigen.napi_value) !void {
try js.callFunction(recv, fun, .{ "Hello from Zig" });
}</code>
And then
<code>javascript
native.callMeBack(console, console.log)</code>
If you need to store the callback for a longer period of time, you should create
a ref. For now, you have to do that directly, using <code>napi_create_reference()</code>.
defineModule(init_fn), exports
N-API modules need to export a function which will also init & return the
<code>exports</code> object. You could export <code>napi_register_module_v1</code> and call
<code>JsContext.init()</code> yourself but there's also a shorthand using <code>comptime</code> block
which will allow you to use <code>try</code> anywhere inside:
```zig
comptime { napigen.defineModule(initModule) }
fn initModule(js: *napigen.JsContext, exports: napigen.napi_value) anyerror!napigen.napi_value {
try js.setNamedProperty(exports, ...);
...
<code>return exports;
</code>
}
```
Hooks
Whenever a value is passed from Zig to JS or vice versa, the library will call a
hook function, if one is defined. This allows you to customize the mapping
process.
Hooks have to be defined in the root module, and they need to be named
<code>napigenRead</code> and <code>napigenWrite</code> respectively. They must have the following
signature:
```zig
fn napigenRead(js: *napigen.JsContext, comptime T: type, value: napigen.napi_value) !T {
return switch (T) {
// we can easily customize the mapping for specific types
// for example, we can allow passing regular JS strings anywhere where we expect an InternedString
InternedString => InternedString.from(try js.read([]const u8)),
<code> // otherwise, just use the default mapping, note that this time
// we call js.defaultRead() explicitly, to avoid infinite recursion
else => js.defaultRead(T, value),
}
</code>
}
pub fn napigenWrite(js: *napigen.JsContext, value: anytype) !napigen.napi_value {
return switch (@TypeOf(value) {
// convert InternedString to back to a JS string (hypothetically)
InternedString => try js.write(value.ptr),
<code> // same thing here
else => js.defaultWrite(value),
}
</code>
}
```
Complete example
The repository includes a complete example in the <code>example</code> directory. Here's a quick walkthrough:
<strong>1. Create a new library</strong>
<code>bash
mkdir example
cd example
zig init-lib</code>
<strong>2. Add napigen as zig module.</strong>
<code>zig fetch --save git+https://github.com/cztomsik/napigen#main</code>
<strong>3. Update build.zig</strong>
Then, change your <code>build.zig</code> to something like this:
```zig
const std = @import("std");
const napigen = @import("napigen");
pub fn build(b: *std.Build) void {
const target = b.standardTargetOptions(.{});
const optimize = b.standardOptimizeOption(.{});
<code>const lib = b.addSharedLibrary(.{
.name = "example",
.root_source_file = b.path("src/main.zig"),
.target = target,
.optimize = optimize,
});
// Add napigen
napigen.setup(lib);
// Build the lib
b.installArtifact(lib);
// Copy the result to a *.node file so we can require() it
const copy_node_step = b.addInstallLibFile(lib.getEmittedBin(), "example.node");
b.getInstallStep().dependOn(&copy_node_step.step);
</code>
}
```
<strong>4. Define & export something useful</strong>
Next, define some functions and the N-API module itself in <code>src/main.zig</code>
```zig
const std = @import("std");
const napigen = @import("napigen");
export fn add(a: i32, b: i32) i32 {
return a + b;
}
comptime {
napigen.defineModule(initModule);
}
fn initModule(js: *napigen.JsContext, exports: napigen.napi_value) anyerror!napigen.napi_value {
try js.setNamedProperty(exports, "add", try js.createFunction(add));
<code>return exports;
</code>
}
```
<strong>5. Use it from JS side</strong>
Finally, use it from JavaScript as expected:
```javascript
import { createRequire } from 'node:module'
const require = createRequire(import.meta.url)
const native = require('./zig-out/lib/example.node')
console.log('1 + 2 =', native.add(1, 2))
```
To build the library and run the script:
```
<blockquote>
zig build && node example.js
1 + 2 = 3
```
</blockquote>
License
MIT
|
[] |
https://avatars.githubusercontent.com/u/32912555?v=4
|
zlog
|
candrewlee14/zlog
|
2022-04-07T22:15:31Z
|
A zero-allocation log library for Zig
|
main
| 0 | 58 | 2 | 58 |
https://api.github.com/repos/candrewlee14/zlog/tags
|
MIT
|
[
"logging",
"zig",
"ziglang"
] | 43 | false |
2024-12-01T13:56:45Z
| true | false |
unknown
|
github
|
[] |
zlog - Zero-Allocation Logging
A <a>zerolog</a>-inspired log library for Zig.
Features
<ul>
<li>Blazing fast</li>
<li>Zero allocations</li>
<li>Leveled logging</li>
<li>Contextual logging </li>
<li>JSON, Plain, and Pretty logging formats</li>
</ul>
Getting Started
Copy <code>zlog</code> folder to a <code>libs</code> subdirectory of the root of your project.
Then in your <code>build.zig</code> add:
```zig
const std = @import("std");
const zlog = @import("libs/zlog/build.zig");
pub fn build(b: *std.build.Builder) void {
...
exe.addPackage(zlog.pkg);
}
<code>``
Now you can import and use</code>zlog`!
Simple Logging Example
For simple logging, import a global logger
```zig
const zlog = @import("zlog");
const log = &zlog.json_logger;
// You could also use pretty_logger, plain_logger
pub fn main() anyerror!void {
try log.print("Hello!");
}
// Output: {"time":1516134303,"level":"debug","message":"hello world"}
```
<blockquote>
<strong>Note:</strong> By default, log writes to StdErr at the log level of <code>.debug</code>
The default log level <strong>global filter</strong> depends on the build mode:
- .Debug => .debug
- .ReleaseSafe => .info
- .ReleaseFast, .ReleaseSmall => .warn
</blockquote>
Contextual Logging
Loggers create events, which do the log writing.
You can add strongly-typed key:value pairs to an event context.
Then the <code>msg</code>, <code>msgf</code>, or <code>send</code> method will write the event to the log.
<strong>Note:</strong> Without calling any of those 3 methods, the log will not be written.
```zig
const zlog = @import("zlog");
const log = &zlog.json_logger;
pub fn main() anyerror!void {
var ev = try log.event(.debug);
try ev.str("Scale", "833 cents");
try ev.num("Interval", 833.09);
try ev.msg("Fibonacci is everywhere");
<code>var ev2 = try log.event(.debug);
try ev2.str("Name", "Tom");
try ev2.send();
</code>
}
// Output: {"time":1649450646,"level":"debug","Scale":"833 cents","Interval":833.09,"message":"Fibonacci is everywhere"}
// Output: {"time":1649450646,"level":"debug","Name":"Tom"}
```
You can add context to a logger so that every event it creates also has that context.
You can also create subloggers that use the parent logger's context along with their own context.
```zig
const zlog = @import("zlog");
const log = &zlog.json_logger;
pub fn main() anyerror!void {
try log.strCtx("component", "foo");
<code>var ev = try log.event(.info);
try ev.msg("hello world");
// create sublogger, bringing along log's context
var sublog = try log.sublogger(.info);
try sublog.numCtx("num", 10);
var ev2 = try sublog.event(.debug);
try ev2.msg("hey there");
</code>
}
// Output: {"time":1649450791,"level":"info","component":"foo","message":"hello world"}
// Output: {"time":1649450791,"level":"debug","component":"foo","num":10,"message":"hey there"}
```
Leveled Logging
zlog allow for logging at the following levels (from highest to lowest):
- panic
- fatal
- error
- warn
- info
- debug
- trace
A comptime-known level will be passed into <code>log.event(LEVEL)</code> or <code>log.sublogger(LEVEL)</code>
for leveled logging.
To disable logging entirely, set the global log level filter to <code>.off</code>;
Setting Global Log Level Filter
```zig
const std = @import("std");
const zlog = @import("zlog");
// setting global log configuration
const log_conf = zlog.LogConfig{
.min_log_lvl = .trace, // lowest shown log level
.time_fmt = .unix_secs, // format to print the time
.buf_size = 1000, // buffer size for events, 1000 is the default
};
// creating a log manager with the set config
const log_man = zlog.LogManager(log_conf);
// choosing a default writer to write logs into
const log_writer = std.io.getStdErr().writer();
// choosing a default log level for the logger
const default_log_lvl = .info;
// Creating the logger
var log = log_man.Logger(@TypeOf(log_writer), .json, default_log_lvl)
.new(log_writer) catch @panic("Failed to create global JSON logger");
pub fn main() anyerror!void {
var ev = try log.event(.debug);
try ev.str("Scale", "833 cents");
try ev.num("Interval", 833.09);
try ev.msg("Fibonacci is everywhere");
<code>var ev2 = try log.event(.debug);
try ev2.str("Name", "Tom");
try ev2.send();
</code>
}
// Output: {"time":1649450953,"level":"debug","Scale":"833 cents","Interval":833.09,"message":"Fibonacci is everywhere"}
// Output: {"time":1649450953,"level":"debug","Name":"Tom"}
```
|
[] |
https://avatars.githubusercontent.com/u/3848910?v=4
|
simargs
|
jiacai2050/simargs
|
2022-12-06T15:09:10Z
|
A simple, opinionated, struct-based argument parser in Zig.
|
main
| 0 | 56 | 3 | 56 |
https://api.github.com/repos/jiacai2050/simargs/tags
|
MIT
|
[
"argument-parser",
"argument-parsing",
"cli",
"zig",
"zig-library",
"ziglang"
] | 61 | false |
2025-01-28T09:35:50Z
| true | false |
unknown
|
github
|
[] |
404
|
[
"https://github.com/spoke-data/spoke"
] |
https://avatars.githubusercontent.com/u/3932972?v=4
|
TextEditor
|
ikskuh/TextEditor
|
2022-05-16T09:45:21Z
|
A backbone for text editors. No rendering, no input, but everything else.
|
main
| 0 | 51 | 3 | 51 |
https://api.github.com/repos/ikskuh/TextEditor/tags
|
MIT
|
[
"text",
"text-editor",
"unicode",
"zig",
"zig-package"
] | 29 | false |
2025-03-29T23:23:44Z
| true | true |
unknown
|
github
|
[
{
"commit": "b89d43d1e3fb01b6074bc1f7fc980324b04d26a5.tar.gz",
"name": "ziglyph",
"tar_url": "https://codeberg.org/dude_the_builder/ziglyph/archive/b89d43d1e3fb01b6074bc1f7fc980324b04d26a5.tar.gz.tar.gz",
"type": "remote",
"url": "https://codeberg.org/dude_the_builder/ziglyph"
}
] |
TextEditor
A backend for text editors. It implements the common textbox editing options, but is both rendering and input agnostic.
Keyboard input must be translated into operations like <code>editor.delete(.right, .word)</code> to emulate what a typical text box implementation would do when <code>CTRL DELETE</code> is pressed.
For mouse input, the editor component needs to be made aware about the font that is used. For this, an abstract font interface is required.
API
```zig
const TextEditor = @import("src/TextEditor.zig");
fn init(TextEditor.Buffer, initial_text: []const u8) InsertError!TextEditor {
fn deinit(<em>TextEditor) void;
fn setText(</em>TextEditor, text: []const u8) InsertError!void;
fn getText(TextEditor) []const u8;
fn getSubString(editor: TextEditor, start: usize, length: ?usize) []const u8;
fn setCursor(<em>TextEditor, offset: usize) SetCursorError!void;
fn moveCursor(</em>TextEditor, direction: EditDirection, unit: EditUnit) void;
fn delete(<em>TextEditor, direction: EditDirection, unit: EditUnit) void;
fn insertText(</em>TextEditor, text: []const u8) InsertError!void;
fn graphemeCount(TextEditor) usize;
```
Common Key Mappings
| Keyboard Input | Editor Call |
| ---------------- | ------------------------------------ |
| <code>Left</code> | <code>editor.moveCursor(.left, .letter)</code> |
| <code>Right</code> | <code>editor.moveCursor(.right, .letter)</code> |
| <code>Ctrl+Left</code> | <code>editor.moveCursor(.left, .word)</code> |
| <code>Ctrl+Right</code> | <code>editor.moveCursor(.right, .word)</code> |
| <code>Home</code> | <code>editor.moveCursor(.left, .line)</code> |
| <code>End</code> | <code>editor.moveCursor(.right, .line)</code> |
| <code>Backspace</code> | <code>editor.delete(.left, .letter)</code> |
| <code>Delete</code> | <code>editor.delete(.right, .letter)</code> |
| <code>Ctrl+Backspace</code> | <code>editor.delete(.left, .word)</code> |
| <code>Ctrl+Delete</code> | <code>editor.delete(.right, .word)</code> |
| <em>text input</em> | <code>try editor.insert("string")</code> |
|
[] |
https://avatars.githubusercontent.com/u/499?v=4
|
parg
|
judofyr/parg
|
2022-03-05T10:45:26Z
|
Lightweight argument parser for Zig
|
main
| 0 | 46 | 2 | 46 |
https://api.github.com/repos/judofyr/parg/tags
|
0BSD
|
[
"argument-parser",
"zig",
"zig-package"
] | 22 | false |
2025-04-14T07:01:30Z
| true | true |
unknown
|
github
|
[] |
parg
<strong>parg</strong> is a lightweight argument parser for Zig which focuses on a single task:
Parsing command-line arguments into positional arguments and long/short flags.
It doesn't concern itself <em>anything</em> else.
You may find this useful as a quick way of parsing some arguments, or use it as a building block for a more elaborate CLI toolkit.
Features / non-features
<ul>
<li>Parses command-line arguments into <strong>positional arguments</strong>, <strong>long flags</strong> and <strong>short flags</strong>.</li>
<li>Provides an iterator interface (<code>while (parser.next()) |token| …</code>).</li>
<li>Supports boolean flags (<code>--force</code>, <code>-f</code>).</li>
<li>Supports multiple short flags (<code>-avz</code>).</li>
<li>Values can be provided as separate arguments (<code>--message Hello</code>), with a delimiter (<code>--message=Hello</code>) and also part of short flag (<code>-mHello</code>).</li>
<li>Automatically detects <code>--</code> and skips any further parsing.</li>
<li>Licensed under 0BSD.</li>
</ul>
Usage
The principles of <code>parg</code> are as follows:
<ul>
<li>Use <code>parseProcess</code>, <code>parseSlice</code> or <code>parse</code> to create a new parser.</li>
<li>Remember to call <code>deinit()</code> when you're done with the parser.</li>
<li>Call <code>next()</code> in a loop to parse arguments.</li>
<li>Call <code>nextValue()</code> whenever you need a plain value.</li>
<li>There's a few more knobs you can tweak with.</li>
</ul>
Let's go over these steps a bit more in detail.
Create a new parser instance
There's three ways of creating a parser instance.
All of these accept some <em>options</em> as the last argument.
```zig
const parg = @import("parg");
// (1) Parse arguments given to the current process:
var p = try parg.parseProcess(allocator, .{});
// (2) Parse arguments from a <code>[]const []const u8</code>:
var p = parg.parseSlice(slice, .{});
// (3) Parse arguments from an iterator (advanced usage):
var p = parg.parse(it, .{});
// Always remember to deinit:
defer p.deinit();
```
In addition, remember that the first parameter given to a process is the file name of the executable.
You typically want to call <code>nextValue()</code> to retrieve this value before you continue parsing any arguments.
<code>zig
const program_name = p.nextValue() orelse @panic("no executable name");</code>
Parsing boolean flags and positional arguments
Once you have a parser you want to call <code>next()</code> in a loop.
This returns a token which has three different possibilities:
<ul>
<li><code>.flag</code> when it encounters a flag (e.g. <code>--verbose</code> or <code>-v</code>).
This flag has a <code>.name</code> field which contains the name of the flag (without the dashes) and a <code>.kind</code> field if you need to distinguish between long and short flags.
There are also a helper functions <code>isLong</code> and <code>isShort</code> to easily check the name of the field.</li>
<li><code>.arg</code> when it encounters a positional argument.</li>
<li><code>.unexpected_value</code> when it encounters an unexpected value.
You should just quit the program with an error when this happens.
We'll come back to this in the next section.</li>
</ul>
Also note that this will automatically split up short flags as expected:
If you give the program <code>-fv</code> then <code>next()</code> will first return a flag with name <code>f</code>, and then a flag with name <code>v</code>.
```zig
// See examples/ex1.zig for full example.
var verbose = false;
var force = false;
var arg: ?[]const u8 = null;
while (p.next()) |token| {
switch (token) {
.flag => |flag| {
if (flag.isLong("force") or flag.isShort("f")) {
force = true;
} else if (flag.isLong("verbose") or flag.isShort("v")) {
verbose = true;
} else if (flag.isLong("version")) {
std.debug.print("v1\n", .{});
std.os.exit(0);
}
},
.arg => |val| {
if (arg != null) @panic("only one argument supported");
arg = val;
},
.unexpected_value => @panic("unexpected value"),
}
}
```
Parsing flags with values
When you find a flag which require a value you need to invoke <code>nextValue()</code>.
This returns an optional slice:
```zig
// See examples/ex2.zig for full example.
while (p.next()) |token| {
switch (token) {
.flag => |flag| {
if (flag.isLong("file") or flag.isShort("f")) {
file = p.nextValue() orelse @panic("--file requires value");
} else if (flag.isLong("verbose") or flag.isShort("v")) {
verbose = true;
} else if (flag.isLong("version")) {
std.debug.print("v1\n", .{});
std.os.exit(0);
}
},
.arg => @panic("unexpected argument"),
.unexpected_value => @panic("unexpected value"),
}
}
```
All of these will be treated the same way:
<ul>
<li><code>--file build.zig</code></li>
<li><code>--file=build.zig</code></li>
<li><code>-f build.zig</code></li>
<li><code>-f=build.zig</code></li>
<li><code>-fbuild.zig</code></li>
</ul>
Most notably, notice that when you call <code>nextValue()</code> it will "break out" of parsing short flags.
Without the call to <code>nextValue()</code> the code would parse <code>-fbuild.zig</code> as the short flags <code>-f</code>, <code>-b</code>, <code>-u</code>, and so on.
This also explains the need for <code>.unexpected_value</code> in <code>next()</code>:
If you pass <code>--force=yes</code> to the first example it will parse the <code>--force</code> as a long flag.
When you then <em>don't</em> invoke <code>nextValue()</code> (since it's a boolean flag) then we need to later bail out since we didn't expect a value.
Options and other functionality
There's currently only one option (which you configure when instantiate the parser):
<ul>
<li><code>auto_double_dash</code> (defaults to <code>true</code>).
When this is <code>true</code> it will look for <code>--</code> and then stop parsing anything as a flag.
Your program will <em>not</em> observe the <code>--</code> token at all, and all tokens after this point will be returned as <code>.arg</code> (even though they start with a dash).
When this is <code>false</code> it will return <code>--</code> as a regular argument (<code>.arg</code>) and argument parsing will continue as usual.</li>
</ul>
There's also one additional method:
<ul>
<li><code>p.skipFlagParsing()</code>.
This turns off any further argument parsing.
All tokens after this point will be returned as <code>.arg</code> (even though they start with a dash).</li>
</ul>
|
[
"https://github.com/judofyr/spice",
"https://github.com/nrdave/zmatrix"
] |
https://avatars.githubusercontent.com/u/6834905?v=4
|
vulkan-tutorial-zig
|
Vulfox/vulkan-tutorial-zig
|
2022-08-01T18:05:45Z
|
A Zig implementation of https://github.com/Overv/VulkanTutorial
|
main
| 1 | 46 | 0 | 46 |
https://api.github.com/repos/Vulfox/vulkan-tutorial-zig/tags
|
MIT
|
[
"vulkan",
"zig"
] | 2,238 | false |
2025-05-10T10:13:46Z
| true | false |
unknown
|
github
|
[] |
vulkan-tutorial-zig
A Zig implementation of <a>Vulkan Tutorial</a> using <a>vulkan-zig</a>.
All code strives to match the C++ implementation as close as possible while making code more idiomatic to Zig. Implementation differences should be noted in this tutorial as to why the Zig version differs from the original.
Zig is still unstable. This repo strives to use <code>master</code> versions of Zig as breaking changes are introduced. Mileage will vary, but I will try to indicate versions of tools in the <a>development environment</a> section.
<ul>
<li><a>Introduction</a></li>
<li><a>Overview</a></li>
<li><a>Development Environment</a></li>
<li><a>Drawing a Triangle</a></li>
<li><a>Setup</a><ul>
<li><a>#00 Base Code</a><ul>
<li><a>General Structure</a></li>
<li><a>Resource Management</a></li>
<li><a>Integrating GLFW</a></li>
</ul>
</li>
<li><a>#01 Instance</a></li>
<li><a>#02 Validation Layers</a></li>
<li><a>#03 Physical Devices and Queue Families</a></li>
<li><a>#04 Logical Device and Queues</a></li>
</ul>
</li>
<li><a>Presentation</a><ul>
<li><a>#05 Window Surface</a></li>
<li><a>#06 Swap Chain</a></li>
<li><a>#07 Image Views</a></li>
</ul>
</li>
<li><a>Graphics Pipeline Basics</a><ul>
<li><a>#08 Introduction</a></li>
<li><a>#09 Shader Modules</a></li>
<li><a>#10 Fixed Functions</a></li>
<li><a>#11 Render Passes</a></li>
<li><a>#12 Conclusion</a></li>
</ul>
</li>
<li><a>Drawing</a><ul>
<li><a>#13 Framebuffers</a></li>
<li><a>#14 Command Buffers</a></li>
<li><a>#15 Rendering and Presentation</a></li>
<li><a>#16 Frames in Flight</a></li>
</ul>
</li>
<li><a>#17 Swapchain Recreation</a></li>
<li><a>Vertex Buffers</a></li>
<li><a>#18 Vertex Input Description</a></li>
<li><a>#19 Vertex Buffer Creation</a></li>
<li><a>#20 Staging Buffer</a></li>
<li><a>#21 Index Buffer</a></li>
<li><a>Uniform Buffers</a></li>
<li><a>#22 Descriptor Layout and Buffer</a></li>
<li><a>#23 Descriptor Pool and Sets</a></li>
<li><a>Texture Mapping</a></li>
<li><a>#24 Images</a></li>
<li><a>#25 Image View and Sampler</a></li>
<li><a>#26 Combined Image Sampler</a></li>
<li><a>#27 Depth Buffering</a></li>
<li><a>#28 Loading Models</a></li>
<li><a>#29 Generating Mipmaps</a></li>
<li><a>#30 Multisampling</a></li>
</ul>
Introduction
This tutorial's README follows a similar structure to <a>bwasty/vulkan-tutorial-rs</a> and aims to fullfill the same intent. Chapters in this tutorial will go over only the differences between the Zig implementation and the C++ source content. The source <a>tutorial</a> should still be able to provide the necessary knowledge to following along here.
The styles between the source material and this will differ based on Zig's general <a>style guide</a> found in their documentation. This mostly affects camelCaseVars becoming snake_case_vars.
Overview : <a>tutorial</a>
Development Environment : <a>tutorial</a>
These binaries are needed on your system to operate this repo and run examples.
<ul>
<li>Git</li>
<li>Zig (stage2): <a>0.10.x</a></li>
<li>Zigmod: <a>r80+</a></li>
<li>Vulkan SDK: <a>latest</a></li>
</ul>
Running Examples
To initialize the repo with dependencies, run this in the root repo dir:
<code>zigmod fetch</code>
Running specific examples require the example's number, which is found in the source files of Vulkan tutorial (not the website). This README will label a given tutorial to a number. Zig build system's run step has a naming convention of <code>zig build run-XX</code>. Here's how we can run example <code>01</code>:
<code>zig build run-01</code>
Individual Workspace
If you are working in your own workspace, I recommend using zigmod to dance around git clones/submodules dependencies we will need, but it is not required. The Zig build system only needs to know where to look for specific files/dirs. This tutorial will proceed with the assumption you are using Zigmod.
Create a <code>zigmod.yml</code> file along side your <code>build.zig</code> file with the contents of:
<code>yml
name: vulkan-tutorial-zig
build_dependencies:
- src: git https://github.com/Snektron/vulkan-zig
main: generator/index.zig
name: vk_gen</code>
To get this repo pulled, run <code>zigmod fetch</code>.
This repo is a generator for Zig Vulkan bindings, so for us to be able to use this library, we will want to have it be generated at build time and referenced like so:
```zig
const deps = @import("deps.zig");
const vkgen = deps.imports.vk_gen;
...
const gen = vkgen.VkGenerateStep.init(b, deps.cache ++ "/git/github.com/Snektron/vulkan-zig/examples/vk.xml", "vk.zig");
exe.addPackage(gen.package);
```
This generator is looking for a Vulkan xml file, if you have one you would prefer to use, you can reference that one instead. For now, we will use the xml file found as part of the repo's example.
Drawing a Triangle
Setup
#00 Base Code : <a>tutorial</a> | <a>code</a>
General Structure
```zig
const HelloTriangleApplication = struct {
const Self = @This();
<code>pub fn init() Self {
return Self{};
}
pub fn run(self: *Self) !void {
try self.mainLoop();
}
fn mainLoop(self: *Self) !void {
}
pub fn deinit(self: *Self) void {
}
</code>
};
pub fn main() anyerror!void {
var app = HelloTriangleApplication.init();
defer app.deinit();
try app.run()
}
```
Resource Management
Looking at Zig's std library, it is common practice to require an <code>init</code>/<code>deinit</code> function pair for the creation of a struct that could use an allocator or needs cleanup. While our program at this moment doesn't need an allocator, we will be using one for later examples. Just as the tutorial mentions, we will be manually cleaning up our Vulkan resources and placing them in the <code>deinit</code> (cleanup) function.
Where applicable, this tutorial will be setting our Vulkan fields to <code>.null_handle</code>, which is a 0 value for the various enum types this Vulkan binding provides. I prefer to know which resources have been set and clean them up as needed instead of blindly running the functions and potentially running into errors.
Integrating GLFW
For our windowing, we will use a GLFW dependency. <a>Hexops' Zig bindings</a> will do great for us here as it provides us with a more idiomatic API with error handling.
Add this src to your <code>zigmod.yml</code>:
<code>yml
build_dependencies:
- src: git https://github.com/hexops/mach-glfw
main: build.zig
name: build_glfw</code>
This binding's README requires us to link this at build time, so we are adding it in with the <code>build_dependencies</code> section of the zigmod config. To let Zig know that this is a library we can use, we will need to add the package to the <code>exe</code> step in <code>build.zig</code> like so:
```zig
const glfw = deps.imports.build_glfw;
...
exe.addPackage(glfw.pkg);
glfw.link(b, exe, .{});
```
Using this library is a matter of adding the import and running the same code we see in the tutorial, but with a slight change to both the field type (now nullable) and how the functions are referenced.
```zig
const glfw = @import("glfw");
const WIDTH: u32 = 800;
const HEIGHT: u32 = 600;
...
window: ?glfw.Window = null,
...
try glfw.init(.{});
self.window = try glfw.Window.create(WIDTH, HEIGHT, "Vulkan", null, null, .{
.client_api = .no_api,
.resizable = false,
});
...
while (!self.window.?.shouldClose()) {
try glfw.pollEvents();
}
```
These should be all of the glfw functions needed to mimic exactly what the base code tutorial uses.
#01 Instance : <a>tutorial</a> | <a>code</a>
Now that we are using Vulkan in our example, we should go ahead and import the library like so <code>const vk = @import("vulkan");</code>. This library doesn't load all of the function pointers that Vulkan can provide, so we will need to create dispatch wrappers with the specific functions to include:
```zig
const BaseDispatch = vk.BaseWrapper(.{
.createInstance = true,
});
const InstanceDispatch = vk.InstanceWrapper(.{
.destroyInstance = true,
});
```
We will be adding more dispatch flags as we progress through the tutorial. Reference the zig example code that should be linked next to every numbered tutorial. If you really don't care to add these as you need them, feel free to copy the dispatch wrappers from the final tutorial code. Earlier examples use <code>.cmdDraw</code> vs <code>.cmdDrawIndexed</code>.
We will be adding these fields to our app as <code>undefined</code>. Ideally, we don't reference these without acquiring the proc addresses ahead of time. If we wanted to be bit more safe here, we could make these nullable and set them to null, however to reference the dispatcher functions, it would be prefixed like so everytime <code>self.vki.?.myVkFunction()</code>.
```zig
vkb: BaseDispatch = undefined,
vki: InstanceDispatch = undefined,
...
// adding dispatches
const vk_proc = @ptrCast(fn (instance: vk.Instance, procname: [*:0]const u8) callconv(.C) vk.PfnVoidFunction, glfw.getInstanceProcAddress);
self.vkb = try BaseDispatch.load(vk_proc);
...
self.vki = try InstanceDispatch.load(self.instance, vk_proc);
```
While <code>@ptrCast</code> should not be used too often as stated <a>here</a>, but in this particular case, I don't see a better alternative. Other examples will also be utilizing <code>@ptrCast</code> when we need to tell the Vulkan dispatch calls to only care about 1 element objects that are not initialized as an array and converting said object into a sentinel array of the same Type.
For the sake of making the Zig and C++ implementations mirror each other as best as possible, this tutorial will be creating consts needed for various Vulkan functions with matching variable names. Throughout the tutorial, it may be interchanged with <code>.{}</code> instead of <code>vk.Object{}</code> as Zig's compiler is able to infer what type that struct ought to be. Here is how it would look between the two styles:
```zig
const create_info = vk.InstanceCreateInfo{
.flags = .{},
...
};
self.instance = try self.vkb.createInstance(&create_info, null);
<code></code>zig
self.instance = try self.vkb.createInstance(&.{
.flags = .{},
...
}, null);
```
#02 Validation Layers : <a>tutorial</a> | <a>code</a>
We will need to introduce the use of an allocator for this example and beyond. To ensure we cleanup all of the memory allocated, we will log an error message on the allocator's cleanup and indicate any memory leak.
```zig
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
defer {
const leaked = gpa.deinit();
if (leaked) std.log.err("MemLeak", .{});
}
const allocator = gpa.allocator();
var app = HelloTriangleApplication.init(allocator);
defer app.deinit();
app.run() catch |err| {
std.log.err("application exited with error: {any}", .{err});
return;
};
```
You may notice that <code>main</code> is no longer returning an <code>anyerror!void</code>. One of my workstations uses a Windows OS and returning an error from main made the output straining to parse, so we log any errors returned from the app.
Adding a field to hold the allocator handle to our application is typical for any struct that needs an allocator to reference within its functions.
```
const Allocator = std.mem.Allocator;
...
const HelloTriangleApplication = struct {
const Self = @This();
allocator: Allocator,
...
pub fn init(allocator: Allocator) Self {
return Self{ .allocator = allocator };
}
...
};
```
Debug vs Release mode can be known at comptime and we can create a bool of whether we are in a debug mode like so:
```zig
const builtin = @import("builtin");
const enable_validation_layers: bool = switch (builtin.mode) {
.Debug, .ReleaseSafe => true,
else => false,
};
```
#03 Physical Devices and Queue Families : <a>tutorial</a> | <a>code</a>
#04 Logical Device and Queues : <a>tutorial</a> | <a>code</a>
Presentation
#05 Window Surface : <a>tutorial</a> | <a>code</a>
If we setup our <code>findQueueFamilies</code> function to mimic the C++ 1:1, we might end up with the following error:
<code>debug: validation layer: Validation Error: [ VUID-VkDeviceCreateInfo-queueFamilyIndex-02802 ] Object 0: handle = 0x23372053850, type = VK_OBJECT_TYPE_PHYSICAL_DEVICE; | MessageID = 0x29498778 | CreateDevice(): pCreateInfo->pQueueCreateInfos[1].queueFamilyIndex (=0) is not unique and was also used in pCreateInfo->pQueueCreateInfos[0]. The Vulkan spec states: The queueFamilyIndex member of each element of pQueueCreateInfos must be unique within pQueueCreateInfos, except that two members can share the same queueFamilyIndex if one describes protected-capable queues and one describes queues that are not protected-capable (https://vulkan.lunarg.com/doc/view/1.3.216.0/windows/1.3-extensions/vkspec.html#VUID-VkDeviceCreateInfo-queueFamilyIndex-02802)</code>
To avoid this, I placed the indices check in an <code>if</code>/<code>else if</code> set of conditionals. The Vulkan example ought to run all the same if it were left alone, but we would be throwing Vulkan validation layer errors.
#06 Swap Chain : <a>tutorial</a> | <a>code</a>
#07 Image Views : <a>tutorial</a> | <a>code</a>
Graphics Pipeline Basics
#08 Introduction : <a>tutorial</a> | <a>code</a>
#09 Shader Modules : <a>tutorial</a> | <a>code</a>
The vulkan-zig repo comes with 2 different zig files we can import and utilize. The build.zig file should already be generating and linking the Vulkan package at build time. The vulkan repo also has some util functions in its build.zig file which we will be using to convert frag/vert shader files to sprv at build time with glslc. These shader files will also be embedded as part of the binary to be read from the <code>resources.zig</code> file (located in zig-cache) the shader package provides from the util function. If you wish to just generate or use your own sprv files, you will want to tweak the tutorial to do so.
First we will need to add vulkan-zig again as a build_dependency, but with a different name and main:
<code>yml
- src: git https://github.com/Snektron/vulkan-zig
main: build.zig
name: vk_build</code>
To start adding shaders at build time, add similar lines to your build.zig:
<code>zig
const shaders = vkbuild.ResourceGenStep.init(b, "resources.zig");
shaders.addShader("vert", "src/09_shader_base.vert");
shaders.addShader("frag", "src/09_shader_base.frag");
exe.addPackage(shaders.package);</code>
We can reference these shaders from our code by importing resources:
```zig
const resources = @import("resources");
...
const vert_shader_module: vk.ShaderModule = try self.createShaderModule(resources.vert);
defer self.vkd.destroyShaderModule(self.device, vert_shader_module, null);
const frag_shader_module: vk.ShaderModule = try self.createShaderModule(resources.frag);
defer self.vkd.destroyShaderModule(self.device, frag_shader_module, null);
```
To reiterate, this is just one way to go about using shaders. You can have them built at build time, comptime, and read them at runtime. Please use the method that best suits your projects' needs.
#10 Fixed Functions : <a>tutorial</a> | <a>code</a>
#11 Render Passes : <a>tutorial</a> | <a>code</a>
#12 Conclusion : <a>tutorial</a> | <a>code</a>
Drawing
#13 Framebuffers : <a>tutorial</a> | <a>code</a>
#14 Command Buffers : <a>tutorial</a> | <a>code</a>
#15 Rendering and Presentation : <a>tutorial</a> | <a>code</a>
#16 Frames in Flight : <a>tutorial</a> | <a>code</a>
#17 Swapchain Recreation : <a>tutorial</a> | <a>code</a>
The vulkan-zig generated package will emit errors from most all dispatches. This is usually great for idiomatic Zig coding, but in this particular case, it will make catching and working with errors a little wonky to read at times. The following code is needed to catch the <code>VK_ERROR_OUT_OF_DATE_KHR</code> result from <code>queuePresentKHR</code>. It catches all errors, and specifically on the error we wish to "ignore", we will set the result to the enum value, otherwise return the error.
```zig
const present_result = self.vkd.queuePresentKHR(self.present_queue, &.{
.wait_semaphore_count = signal_semaphores.len,
.p_wait_semaphores = @ptrCast([<em>]const vk.Semaphore, &signal_semaphores),
.swapchain_count = 1,
.p_swapchains = @ptrCast([</em>]const vk.SwapchainKHR, &self.swap_chain),
.p_image_indices = @ptrCast([*]const u32, &result.image_index),
.p_results = null,
}) catch |err| switch (err) {
error.OutOfDateKHR => vk.Result.error_out_of_date_khr,
else => return err,
};
if (present_result == .error_out_of_date_khr or present_result == .suboptimal_khr or self.framebuffer_resized) {
self.framebuffer_resized = false;
try self.recreateSwapChain();
} else if (present_result != .success) {
return error.ImagePresentFailed;
}
```
Vertex Buffers
#18 Vertex Input Description : <a>tutorial</a> | <a>code</a>
Expected Result
The window will be blank.
You may come across these validation layer errors upon completing this example. Don't worry about these too much, they should be resolved in the next example. Vulkan is upset to be told about vertex inputs with no buffers supplying data.
```
debug: validation layer: Validation Error: [ VUID-vkCmdDraw-None-02721 ] Object 0: handle = 0x255d971fc80, type = VK_OBJECT_TYPE_COMMAND_BUFFER; Object 1: handle = 0x967dd1000000000e, type = VK_OBJECT_TYPE_PIPELINE; | MessageID = 0x99ef63bb | vkCmdDraw: binding #0 in pVertexAttributeDescriptions[1] of VkPipeline 0x967dd1000000000e[] is an invalid value for command buffer VkCommandBuffer 0x255d971fc80[]. The Vulkan spec states: For a given vertex buffer binding, any attribute data fetched must be entirely contained within the corresponding vertex buffer binding, as described in Vertex Input Description (https://vulkan.lunarg.com/doc/view/1.3.216.0/windows/1.3-extensions/vkspec.html#VUID-vkCmdDraw-None-02721)
debug: validation layer: Validation Error: [ VUID-vkCmdDraw-None-04007 ] Object 0: handle = 0x255d971fc80, type = VK_OBJECT_TYPE_COMMAND_BUFFER; | MessageID = 0x9981c31b | vkCmdDraw: VkPipeline 0x967dd1000000000e[] expects that this Command Buffer's vertex binding Index 0 should be set via vkCmdBindVertexBuffers. This is because pVertexBindingDescriptions[0].binding value is 0. The Vulkan spec states: All vertex input bindings accessed via vertex input variables declared in the vertex shader entry point's interface must have either valid or VK_NULL_HANDLE buffers bound (https://vulkan.lunarg.com/doc/view/1.3.216.0/windows/1.3-extensions/vkspec.html#VUID-vkCmdDraw-None-04007)
```
#19 Vertex Buffer Creation : <a>tutorial</a> | <a>code</a>
#20 Staging Buffer : <a>tutorial</a> | <a>code</a>
#21 Index Buffer : <a>tutorial</a> | <a>code</a>
Uniform Buffers
#22 Descriptor Layout and Buffer : <a>tutorial</a> | <a>code</a>
Expected Result
The window will be blank.
This will be resolved in the next example. Here are some example Vulkan validation layer errors that will show up:
<code>debug: validation layer: Validation Error: [ VUID-vkCmdDrawIndexed-None-02697 ] Object 0: handle = 0xe7e6d0000000000f, type = VK_OBJECT_TYPE_PIPELINE; Object 1: handle = 0x967dd1000000000e, type = VK_OBJECT_TYPE_PIPELINE_LAYOUT; Object 2: VK_NULL_HANDLE, type = VK_OBJECT_TYPE_PIPELINE_LAYOUT; | MessageID = 0x9888fef3 | vkCmdDrawIndexed(): VkPipeline 0xe7e6d0000000000f[] defined with VkPipelineLayout 0x967dd1000000000e[] is not compatible for maximum set statically used 0 with bound descriptor sets, last bound with VkPipelineLayout 0x0[] The Vulkan spec states: For each set n that is statically used by the VkPipeline bound to the pipeline bind point used by this command, a descriptor set must have been bound to n at the same pipeline bind point, with a VkPipelineLayout that is compatible for set n, with the VkPipelineLayout used to create the current VkPipeline, as described in Pipeline Layout Compatibility (https://vulkan.lunarg.com/doc/view/1.3.216.0/windows/1.3-extensions/vkspec.html#VUID-vkCmdDrawIndexed-None-02697)
debug: validation layer: Validation Error: [ UNASSIGNED-CoreValidation-DrawState-DescriptorSetNotBound ] Object 0: handle = 0x1bfedf77850, type = VK_OBJECT_TYPE_COMMAND_BUFFER; | MessageID = 0xcde11083 | vkCmdDrawIndexed(): VkPipeline 0xe7e6d0000000000f[] uses set #0 but that set is not bound.</code>
A New Dependency
We are introducing a linear algebra library to be used. I picked <a>kooparse/zalgebra</a> as it had a friendly api, but you can choose to swap it out with any linear algebra library you wish to choose such as <a>ziglibs/zlm</a>. Here's how we will need to add it to our dependencies.
<code>yml
root_dependencies:
- src: git https://github.com/kooparse/zalgebra</code>
Unlike the glfw and Vulkan libraries, we will need to add this to the <code>root_dependencies</code> block for us to reference in our code. Don't forget to run <code>zigmod fetch</code> after updating the yml file, if you are using zigmod.
To link it, we can add this code to our <code>build.zig</code>:
<code>zig
deps.addAllTo(exe);</code>
Now for our code to use this library, it's just an import away:
<code>zig
const za = @import("zalgebra");</code>
#23 Descriptor Pool and Sets : <a>tutorial</a> | <a>code</a>
Texture Mapping
#24 Images : <a>tutorial</a> | <a>code</a>
For our texture image, we will use the same image provided in the source tutorial that is this <a>CC0 licensed image</a> resized to 512x512.
A New Dependency
At the time of writing this, I wasn't able to utilize any Zig image loading libraries with the images this tutorial uses, so we will be using the same library the C++ tutorial recommends, which is written in C as a precompiled header. To use this header, we will need to make some additions to our <code>build.zig</code>.
First as a hack, we can add <a>nothings/stb</a> as a git reference in our <code>zigmod.yml</code> under <code>build_dependencies</code>:
<code>yml
- src: git https://github.com/nothings/stb
name: stb
main: ''</code>
Now this isn't <em>correct</em> for zigmod to be used in this way, but we aren't going to be directly referencing this repo as a package in our build file. You can directly download the <code>stb_image.h</code> file yourself if you want. I didn't want to drop this file in the repo if it wasn't needed.
We need to let Zig know about this header file and to do so, we will add the include dir from the <code>.zigmod</code> dir:
<code>zig
exe.addIncludeDir(deps.cache ++ "/git/github.com/nothings/stb");</code>
We aren't done with making modifications to the <code>build.zig</code> file just yet, we need to link C and inform Zig how to compile this file. Zig does not let us import headers directly and use it as needed as indicated by this <a>issue</a>. We will need to create a C file that will define the necessary constant and include the header.
```c
define STB_IMAGE_IMPLEMENTATION
include "stb_image.h"
```
And add it to <code>build.zig</code>:
<code>zig
exe.linkLibC();
exe.addCSourceFile("libs/stb/stb_impl.c", &.{"-std=c99"});</code>
To be used in our code, we need to import it:
<code>zig
const c = @cImport({
@cInclude("stb_image.h");
});</code>
Any use of this library needs to be prefixed with <code>c.</code>:
<code>zig
const pixels = c.stbi_load("resources/texture.jpg", &tex_width, &tex_height, &channels, c.STBI_rgb_alpha);</code>
For <code>@cImport</code> best practices, refer to the <a>docs</a>.
#25 Image View and Sampler : <a>tutorial</a> | <a>code</a>
#26 Combined Image Sampler : <a>tutorial</a> | <a>code</a>
#27 Depth Buffering : <a>tutorial</a> | <a>code</a>
#28 Loading Models : <a>tutorial</a> | <a>code</a>
For our model, we will be using the same <a>Viking room</a> model by <a>nigelgoh</a> (<a>CC BY 4.0</a>) found in the source tutorial.
A New Dependency
<code>yml
root_dependencies:
- src: git https://github.com/ziglibs/wavefront-obj
name: wavefront-obj
main: wavefront-obj.zig</code>
We have to provide overrides for <code>name</code> and <code>main</code> as the zigmod.yml for that repo is improperly telling us how to ingest it. In cases like this, we could create a PR to fix it for others, but for now we can overwrite it ourselves to not be stuck.
#29 Generating Mipmaps : <a>tutorial</a> | <a>code</a>
#30 Multisampling : <a>tutorial</a> | <a>code</a>
|
[] |
https://avatars.githubusercontent.com/u/32229014?v=4
|
zig-os
|
rafaelbreno/zig-os
|
2023-02-06T22:08:21Z
|
A simple OS written in Zig following Philipp Oppermann's posts "Writing an OS in Rust"
|
master
| 7 | 45 | 4 | 45 |
https://api.github.com/repos/rafaelbreno/zig-os/tags
|
MIT
|
[
"os",
"zig"
] | 91 | false |
2025-05-08T08:29:46Z
| true | false |
unknown
|
github
|
[] |
zig-os
A simple OS written in Zig following Philipp Oppermann's posts <a>"Writing an OS in Rust"</a>
Tools
<ol>
<li><code>zig 0.13.0</code></li>
<li><code>qemu</code></li>
</ol>
Summary
<ol>
<li><a>Introduction</a></li>
<li><a>Hello World</a></li>
<li><a>Terminal Improvements</a></li>
</ol>
|
[] |
https://avatars.githubusercontent.com/u/22038970?v=4
|
zba
|
paoda/zba
|
2022-03-01T01:49:45Z
|
Game Boy Advance Emulator. Yes, I'm awful with project names.
|
main
| 0 | 45 | 0 | 45 |
https://api.github.com/repos/paoda/zba/tags
|
-
|
[
"emulation",
"emulator",
"game-boy-advance",
"gameboy-advance",
"opengl",
"rtc",
"sdl2",
"toml",
"zig"
] | 918 | false |
2025-04-13T20:49:43Z
| true | true |
unknown
|
github
|
[
{
"commit": "ad81729d33da30d5f4fd23718debec48245121ca",
"name": "nfd",
"tar_url": "https://github.com/paoda/nfd-zig/archive/ad81729d33da30d5f4fd23718debec48245121ca.tar.gz",
"type": "remote",
"url": "https://github.com/paoda/nfd-zig"
},
{
"commit": "1cceeb70e77dec941a4178160ff6c8d05a74de6f",
"name": "known-folders",
"tar_url": "https://github.com/ziglibs/known-folders/archive/1cceeb70e77dec941a4178160ff6c8d05a74de6f.tar.gz",
"type": "remote",
"url": "https://github.com/ziglibs/known-folders"
},
{
"commit": "70aebf28fb3e137cd84123a9349d157a74708721",
"name": "zig-datetime",
"tar_url": "https://github.com/frmdstryr/zig-datetime/archive/70aebf28fb3e137cd84123a9349d157a74708721.tar.gz",
"type": "remote",
"url": "https://github.com/frmdstryr/zig-datetime"
},
{
"commit": "c0193e9247335a6c1688b946325060289405de2a",
"name": "zig-clap",
"tar_url": "https://github.com/Hejsil/zig-clap/archive/c0193e9247335a6c1688b946325060289405de2a.tar.gz",
"type": "remote",
"url": "https://github.com/Hejsil/zig-clap"
},
{
"commit": null,
"name": "zba-util",
"tar_url": null,
"type": "remote",
"url": "git+https://git.musuka.dev/paoda/zba-util#bf0e744047ce1ec90172dbcc0c72bfcc29a063e3"
},
{
"commit": null,
"name": "zba-gdbstub",
"tar_url": null,
"type": "remote",
"url": "git+https://git.musuka.dev/paoda/zba-gdbstub#9a50607d5f48293f950a4e823344f2bc24582a5a"
},
{
"commit": "9a16dd53927ef2012478b6494bafb4475e44f4c9",
"name": "tomlz",
"tar_url": "https://github.com/paoda/tomlz/archive/9a16dd53927ef2012478b6494bafb4475e44f4c9.tar.gz",
"type": "remote",
"url": "https://github.com/paoda/tomlz"
},
{
"commit": null,
"name": "arm32",
"tar_url": null,
"type": "remote",
"url": "git+https://git.musuka.dev/paoda/arm32#814d081ea0983bc48841a6baad7158c157b17ad6"
},
{
"commit": null,
"name": "zgui",
"tar_url": null,
"type": "remote",
"url": "git+https://git.musuka.dev/paoda/zgui#7f8d05101e96c64314d7926c80ee157dcb89da4e"
}
] |
ZBA (working title)
A Game Boy Advance Emulator written in Zig ⚡!
Scope
I'm hardly the first to write a Game Boy Advance Emulator nor will I be the last. This project isn't going to compete with the GOATs like <a>mGBA</a> or <a>NanoBoyAdvance</a>. There aren't any interesting ideas either like in <a>DSHBA</a>.
This is a simple (read: incomplete) for-fun long-term project. I hope to get "mostly there", which to me means that I'm not missing any major hardware features and the set of possible improvements would be in memory timing or in UI/UX. With respect to that goal, here's what's outstanding:
TODO
<br/><input type='checkbox' class='w-4 h-4 text-green-500 bg-gray-100 border-gray-300 rounded focus:ring-blue-500 dark:focus:ring-blue-600 dark:ring-offset-gray-800 focus:ring-2 dark:bg-gray-700 dark:border-gray-600' checked disabled></input> Affine Sprites
<br/><input type='checkbox' class='w-4 h-4 text-blue-600 bg-gray-100 border-gray-300 rounded focus:ring-blue-500 dark:focus:ring-blue-600 dark:ring-offset-gray-800 focus:ring-2 dark:bg-gray-700 dark:border-gray-600' disabled></input> Windowing (see <a>this branch</a>)
<br/><input type='checkbox' class='w-4 h-4 text-blue-600 bg-gray-100 border-gray-300 rounded focus:ring-blue-500 dark:focus:ring-blue-600 dark:ring-offset-gray-800 focus:ring-2 dark:bg-gray-700 dark:border-gray-600' disabled></input> Audio Resampler (Having issues with SDL2's)
<br/><input type='checkbox' class='w-4 h-4 text-blue-600 bg-gray-100 border-gray-300 rounded focus:ring-blue-500 dark:focus:ring-blue-600 dark:ring-offset-gray-800 focus:ring-2 dark:bg-gray-700 dark:border-gray-600' disabled></input> Refactoring for easy-ish perf boosts
Usage
ZBA supports both a CLI and a GUI. If running from the terminal, try using <code>zba --help</code> to see what you can do. If you want to use the GUI, feel free to just run <code>zba</code> without any arguments.
ZBA does not feature any BIOS HLE, so providing one will be necessary if a ROM makes use of it. Need one? Why not try using the open-source <a>Cult-Of-GBA BIOS</a> written by <a>fleroviux</a> and <a>DenSinH</a>?
Finally it's worth noting that ZBA uses a TOML config file it'll store in your OS's data directory. See <code>example.toml</code> to learn about the defaults and what exactly you can mess around with.
Compiling
Most recently built on Zig <a>v0.11.0</a>
Dependencies
Dependency | Source
--- | ---
known-folders | <a>https://github.com/ziglibs/known-folders</a>
nfd-zig | <a>https://github.com/fabioarnold/nfd-zig</a>
SDL.zig | <a>https://github.com/MasterQ32/SDL.zig</a>
tomlz | <a>https://github.com/mattyhall/tomlz</a>
zba-gdbstub | <a>https://github.com/paoda/zba-gdbstub</a>
zba-util | <a>https://git.musuka.dev/paoda/zba-util</a>
zgui | <a>https://github.com/michal-z/zig-gamedev/tree/main/libs/zgui</a>
zig-clap | <a>https://github.com/Hejsil/zig-clap</a>
zig-datetime | <a>https://github.com/frmdstryr/zig-datetime</a>
<code>bitfield.zig</code> | <a>https://github.com/FlorenceOS/Florence</a>
<code>gl.zig</code> | <a>https://github.com/MasterQ32/zig-opengl</a>
Use <code>git submodule update --init</code> from the project root to pull the git relevant git submodules
Be sure to provide SDL2 using:
<ul>
<li>Linux: Your distro's package manager</li>
<li>macOS: ¯\_(ツ)_/¯ (try <a>this formula</a>?)</li>
<li>Windows: <a><code>vcpkg</code></a> (install <code>sdl2:x64-windows</code>)</li>
</ul>
<code>SDL.zig</code> will provide a helpful compile error if the zig compiler is unable to find SDL2.
Once you've got all the dependencies, execute <code>zig build -Doptimize=ReleaseSafe</code>. The executable will be under <code>zig-out/bin</code> and the shared libraries (if enabled) under <code>zig-out/lib</code>. If working with shared libraries on windows, be sure to add all artifacts to the same directory. On Unix, you'll want to make use of <code>LD_PRELOAD</code>.
Controls
Key | Button | | Key | Button
--- | --- | --- | --- | ---
A | L | | S | R
X | A | | Z | B
Return | Start | | RShift | Select
Arrow Keys | D-Pad
Tests
GBA Tests | <a>jsmolka</a> | gba_tests | <a>destoer</a>
--- | --- | --- | ---
<code>arm.gba</code>, <code>thumb.gba</code> | PASS | <code>cond_invalid.gba</code> | PASS
<code>memory.gba</code>, <code>bios.gba</code> | PASS | <code>dma_priority.gba</code> | PASS
<code>flash64.gba</code>, <code>flash128.gba</code> | PASS | <code>hello_world.gba</code> | PASS
<code>sram.gba</code> | PASS | <code>if_ack.gba</code> | PASS
<code>none.gba</code> | PASS | <code>line_timing.gba</code> | FAIL
<code>hello.gba</code>, <code>shades.gba</code>, <code>stripes.gba</code> | PASS | <code>lyc_midline.gba</code> | FAIL
<code>nes.gba</code> | PASS | <code>window_midframe.gba</code> | FAIL
GBARoms | <a>DenSinH</a> | GBA Test Collection | <a>ladystarbreeze</a>
--- | --- | --- | ---
<code>eeprom-test</code>, <code>flash-test</code> | PASS | <code>retAddr.gba</code> | PASS
<code>midikey2freq</code> | PASS | <code>helloWorld.gba</code> | PASS
<code>swi-tests-random</code> | FAIL | <code>helloAudio.gba</code> | PASS
FuzzARM | <a>DenSinH</a> | arm7wrestler GBA Fixed | <a>destoer</a>
--- | --- | --- | ---
<code>main.gba</code> | PASS | <code>armwrestler-gba-fixed.gba</code> | PASS
Resources
<ul>
<li><a>GBATEK</a></li>
<li><a>TONC</a></li>
<li><a>ARM Architecture Reference Manual</a></li>
<li><a>ARM7TDMI Data Sheet</a></li>
</ul>
|
[] |
https://avatars.githubusercontent.com/u/25912761?v=4
|
zbor
|
r4gus/zbor
|
2022-07-06T23:29:57Z
|
CBOR parser written in Zig
|
master
| 1 | 44 | 7 | 44 |
https://api.github.com/repos/r4gus/zbor/tags
|
MIT
|
[
"cbor",
"encoder-decoder",
"parsing",
"rfc-8949",
"zig",
"zig-package",
"ziglang"
] | 4,619 | false |
2025-05-20T09:00:28Z
| true | true |
0.14.0
|
github
|
[] |
zbor - Zig CBOR
The Concise Binary Object Representation (CBOR) is a data format whose design
goals include the possibility of extremely small code size, fairly small
message size, and extensibility without the need for version negotiation
(<a>RFC8949</a>). It is used
in different protocols like the Client to Authenticator Protocol
<a>CTAP2</a>
which is a essential part of FIDO2 authenticators/ Passkeys.
I have utilized this library in several projects throughout the previous year, primarily in conjunction with my <a>FIDO2 library</a>. I'd consider it stable.
With the introduction of <a>Zig version <code>0.11.0</code></a>, this library will remain aligned with the most recent stable release. If you have any problems or want
to share some ideas feel free to open an issue or write me a mail, but please be kind.
Getting started
Versions
| Zig version | zbor version |
|:-----------:|:------------:|
| 0.13.0 | 0.15.0, 0.15.1, 0.15.2 |
| 0.14.0 | 0.16.0, 0.17.0 |
First add this library as a dependency to your <code>build.zig.zon</code> file:
```bash
Replace with the version you want to use
zig fetch --save https://github.com/r4gus/zbor/archive/refs/tags/.tar.gz
```
then within you <code>build.zig</code> add the following code:
```zig
// First fetch the dependency...
const zbor_dep = b.dependency("zbor", .{
.target = target,
.optimize = optimize,
});
const zbor_module = zbor_dep.module("zbor");
// If you have a module that has zbor as a dependency...
const your_module = b.addModule("your-module", .{
.root_source_file = .{ .path = "src/main.zig" },
.imports = &.{
.{ .name = "zbor", .module = zbor_module },
},
});
// Or as a dependency for a executable...
exe.root_module.addImport("zbor", zbor_module);
```
Usage
This library lets you inspect and parse CBOR data without having to allocate
additional memory.
Inspect CBOR data
To inspect CBOR data you must first create a new <code>DataItem</code>.
```zig
const cbor = @import("zbor");
const di = DataItem.new("\x1b\xff\xff\xff\xff\xff\xff\xff\xff") catch {
// handle the case that the given data is malformed
};
```
<code>DataItem.new()</code> will check if the given data is well-formed before returning a <code>DataItem</code>. The data is well formed if it's syntactically correct.
To check the type of the given <code>DataItem</code> use the <code>getType()</code> function.
<code>zig
std.debug.assert(di.getType() == .Int);</code>
Possible types include <code>Int</code> (major type 0 and 1) <code>ByteString</code> (major type 2), <code>TextString</code> (major type 3), <code>Array</code> (major type 4), <code>Map</code> (major type 5), <code>Tagged</code> (major type 6) and <code>Float</code> (major type 7).
Based on the given type you can the access the underlying value.
<code>zig
std.debug.assert(di.int().? == 18446744073709551615);</code>
All getter functions return either a value or <code>null</code>. You can use a pattern like <code>if (di.int()) |v| v else return error.Oops;</code> to access the value in a safe way. If you've used <code>DataItem.new()</code> and know the type of the data item, you should be safe to just do <code>di.int().?</code>.
The following getter functions are supported:
* <code>int</code> - returns <code>?i65</code>
* <code>string</code> - returns <code>?[]const u8</code>
* <code>array</code> - returns <code>?ArrayIterator</code>
* <code>map</code> - returns <code>?MapIterator</code>
* <code>simple</code> - returns <code>?u8</code>
* <code>float</code> - returns <code>?f64</code>
* <code>tagged</code> - returns <code>?Tag</code>
* <code>boolean</code> - returns <code>?bool</code>
Iterators
The functions <code>array</code> and <code>map</code> will return an iterator. Every time you
call <code>next()</code> you will either get a <code>DataItem</code>/ <code>Pair</code> or <code>null</code>.
```zig
const di = DataItem.new("\x98\x19\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x18\x18\x19");
var iter = di.array().?;
while (iter.next()) |value| {
_ = value;
// doe something
}
```
Encoding and decoding
Serialization
You can serialize Zig objects into CBOR using the <code>stringify()</code> function.
```zig
const allocator = std.testing.allocator;
var str = std.ArrayList(u8).init(allocator);
defer str.deinit();
const Info = struct {
versions: []const []const u8,
};
const i = Info{
.versions = &.{"FIDO_2_0"},
};
try stringify(i, .{}, str.writer());
```
<blockquote>
Note: Compile time floats are always encoded as single precision floats (f32). Please use <code>@floatCast</code>
before passing a float to <code>stringify()</code>.
</blockquote>
The <code>stringify()</code> function is convenient but also adds extra overhead. If you want full control
over the serialization process you can use the following functions defined in <code>zbor.build</code>: <code>writeInt</code>,
<code>writeByteString</code>, <code>writeTextString</code>, <code>writeTag</code>, <code>writeSimple</code>, <code>writeArray</code>, <code>writeMap</code>. For more
details check out the <a>manual serialization example</a> and the
corresponding <a>source code</a>.
Stringify Options
You can pass options to the <code>stringify</code> function to influence its behavior. Without passing any
options, <code>stringify</code> will behave as follows:
<ul>
<li>Enums will be serialized to their textual representation</li>
<li><code>u8</code> slices will be serialized to byte strings</li>
<li>For structs and unions:<ul>
<li><code>null</code> fields are skipped by default</li>
<li>fields of type <code>std.mem.Allocator</code> are always skipped.</li>
<li>the names of fields are serialized to text strings</li>
</ul>
</li>
</ul>
You can modify that behavior by changing the default options, e.g.:
```zig
const EcdsaP256Key = struct {
/// kty:
kty: u8 = 2,
/// alg:
alg: i8 = -7,
/// crv:
crv: u8 = 1,
/// x-coordinate
x: [32]u8,
/// y-coordinate
y: [32]u8,
<code>pub fn new(k: EcdsaP256.PublicKey) @This() {
const xy = k.toUncompressedSec1();
return .{
.x = xy[1..33].*,
.y = xy[33..65].*,
};
}
</code>
};
//...
try stringify(k, .{ .field_settings = &.{
.{ .name = "kty", .field_options = .{ .alias = "1", .serialization_type = .Integer } },
.{ .name = "alg", .field_options = .{ .alias = "3", .serialization_type = .Integer } },
.{ .name = "crv", .field_options = .{ .alias = "-1", .serialization_type = .Integer } },
.{ .name = "x", .field_options = .{ .alias = "-2", .serialization_type = .Integer } },
.{ .name = "y", .field_options = .{ .alias = "-3", .serialization_type = .Integer } },
} }, str.writer());
```
Here we define a alias for every field of the struct and tell <code>serialize</code> that it should treat
those aliases as integers instead of text strings.
<strong>See <code>Options</code> and <code>FieldSettings</code> in <code>src/parse.zig</code> for all available options!</strong>
Deserialization
You can deserialize CBOR data into Zig objects using the <code>parse()</code> function.
```zig
const e = [5]u8{ 1, 2, 3, 4, 5 };
const di = DataItem.new("\x85\x01\x02\x03\x04\x05");
const x = try parse([5]u8, di, .{});
try std.testing.expectEqualSlices(u8, e[0..], x[0..]);
```
Parse Options
You can pass options to the <code>parse</code> function to influence its behaviour.
This includes:
<ul>
<li><code>allocator</code> - The allocator to be used. This is required if your data type has any pointers, slices, etc.</li>
<li><code>duplicate_field_behavior</code> - How to handle duplicate fields (<code>.UseFirst</code>, <code>.Error</code>).<ul>
<li><code>.UseFirst</code> - Use the first field.</li>
<li><code>.Error</code> - Return an error if there are multiple fields with the same name.</li>
</ul>
</li>
<li><code>ignore_unknown_fields</code> - Ignore unknown fields (default is <code>true</code>).</li>
<li><code>field_settings</code> - Lets you specify aliases for struct fields. Examples on how to use <code>field_settings</code> can be found in the <em>examples</em> directory and within defined tests.</li>
<li><code>ignore_override</code> - Flag to break infinity loops. This has to be set to <code>true</code> if you override the behavior using <code>cborParse</code> or <code>cborStringify</code>.</li>
</ul>
Builder
You can also dynamically create CBOR data using the <code>Builder</code>.
```zig
const allocator = std.testing.allocator;
var b = try Builder.withType(allocator, .Map);
try b.pushTextString("a");
try b.pushInt(1);
try b.pushTextString("b");
try b.enter(.Array);
try b.pushInt(2);
try b.pushInt(3);
//try b.leave(); <-- you can leave out the return at the end
const x = try b.finish();
defer allocator.free(x);
// { "a": 1, "b": [2, 3] }
try std.testing.expectEqualSlices(u8, "\xa2\x61\x61\x01\x61\x62\x82\x02\x03", x);
```
Commands
<ul>
<li>The <code>push*</code> functions append a data item</li>
<li>The <code>enter</code> function takes a container type and pushes it on the builder stack</li>
<li>The <code>leave</code> function leaves the current container. The container is appended to the wrapping container</li>
<li>The <code>finish</code> function returns the CBOR data as owned slice</li>
</ul>
Overriding stringify
You can override the <code>stringify</code> function for structs and tagged unions by implementing <code>cborStringify</code>.
```zig
const Foo = struct {
x: u32 = 1234,
y: struct {
a: []const u8 = "public-key",
b: u64 = 0x1122334455667788,
},
<code>pub fn cborStringify(self: *const @This(), options: Options, out: anytype) !void {
// First stringify the 'y' struct
const allocator = std.testing.allocator;
var o = std.ArrayList(u8).init(allocator);
defer o.deinit();
try stringify(self.y, options, o.writer());
// Then use the Builder to alter the CBOR output
var b = try build.Builder.withType(allocator, .Map);
try b.pushTextString("x");
try b.pushInt(self.x);
try b.pushTextString("y");
try b.pushByteString(o.items);
const x = try b.finish();
defer allocator.free(x);
try out.writeAll(x);
}
</code>
};
```
The <code>StringifyOptions</code> can be used to indirectly pass an <code>Allocator</code> to the function.
Please make sure to set <code>ignore_override</code> to <code>true</code> when calling recursively into <code>stringify(self)</code> to prevent infinite loops.
Overriding parse
You can override the <code>parse</code> function for structs and tagged unions by implementing <code>cborParse</code>. This is helpful if you have aliases for your struct members.
```zig
const EcdsaP256Key = struct {
/// kty:
kty: u8 = 2,
/// alg:
alg: i8 = -7,
/// crv:
crv: u8 = 1,
/// x-coordinate
x: [32]u8,
/// y-coordinate
y: [32]u8,
<code>pub fn cborParse(item: DataItem, options: Options) !@This() {
_ = options;
return try parse(@This(), item, .{
.ignore_override = true, // prevent infinite loops
.field_settings = &.{
.{ .name = "kty", .field_options = .{ .alias = "1" } },
.{ .name = "alg", .field_options = .{ .alias = "3" } },
.{ .name = "crv", .field_options = .{ .alias = "-1" } },
.{ .name = "x", .field_options = .{ .alias = "-2" } },
.{ .name = "y", .field_options = .{ .alias = "-3" } },
},
});
}
</code>
};
```
The <code>Options</code> can be used to indirectly pass an <code>Allocator</code> to the function.
Please make sure to set <code>ignore_override</code> to <code>true</code> when calling recursively into <code>parse(self)</code> to prevent infinite loops.
Structs with fields of type <code>std.mem.Allocator</code>
If you have a struct with a field of type <code>std.mem.Allocator</code> you have to override the <code>stringify</code>
funcation for that struct, e.g.:
```zig
pub fn cborStringify(self: *const @This(), options: cbor.StringifyOptions, out: anytype) !void {
_ = options;
<code>try cbor.stringify(self, .{
.ignore_override = true,
.field_settings = &.{
.{ .name = "allocator", .options = .{ .skip = true } },
},
}, out);
</code>
}
```
When using <code>parse</code> make sure you pass a allocator to the function. The passed allocator will be assigned
to the field of type <code>std.mem.Allocator</code>.
ArrayBackedSlice
This library offers a convenient function named ArrayBackedSlice, which enables you to create a wrapper for an array of any size and type. This wrapper implements the cborStringify and cborParse methods, allowing it to seamlessly replace slices (e.g., []const u8) with an array.
```zig
test "ArrayBackedSlice test" {
const allocator = std.testing.allocator;
<code>const S64B = ArrayBackedSlice(64, u8, .Byte);
var x = S64B{};
try x.set("\x01\x02\x03\x04");
var str = std.ArrayList(u8).init(allocator);
defer str.deinit();
try stringify(x, .{}, str.writer());
try std.testing.expectEqualSlices(u8, "\x44\x01\x02\x03\x04", str.items);
const di = try DataItem.new(str.items);
const y = try parse(S64B, di, .{});
try std.testing.expectEqualSlices(u8, "\x01\x02\x03\x04", y.get());
</code>
}
```
|
[
"https://github.com/Zig-Sec/keylib",
"https://github.com/kj4tmp/gatorcat",
"https://github.com/r4gus/ccdb",
"https://github.com/uzyn/passcay"
] |
https://avatars.githubusercontent.com/u/7283681?v=4
|
awtfdb
|
lun-4/awtfdb
|
2022-02-16T19:01:30Z
|
the Anime Woman's Tagged File Data Base.
|
mistress
| 11 | 44 | 2 | 44 |
https://api.github.com/repos/lun-4/awtfdb/tags
|
MIT
|
[
"booru",
"organizational",
"tagging",
"tagging-albums",
"zig"
] | 900 | false |
2025-05-13T20:46:30Z
| true | true |
0.12.0
|
github
|
[
{
"commit": "59c06617d5b86546c0c739e73ae01d3965dbe8ce",
"name": "sqlite",
"tar_url": "https://github.com/vrischmann/zig-sqlite/archive/59c06617d5b86546c0c739e73ae01d3965dbe8ce.tar.gz",
"type": "remote",
"url": "https://github.com/vrischmann/zig-sqlite"
},
{
"commit": "6768a94377b1b502b8da62de47f5616feee4451b.tar.gz",
"name": "expiring_hash_map",
"tar_url": "https://github.com/lun-4/expiring-hash-map.zig/archive/6768a94377b1b502b8da62de47f5616feee4451b.tar.gz.tar.gz",
"type": "remote",
"url": "https://github.com/lun-4/expiring-hash-map.zig"
},
{
"commit": "9ca8cc2d361a458916ba91cbe2183ea61d290b7e",
"name": "tunez",
"tar_url": "https://github.com/haze/tunez/archive/9ca8cc2d361a458916ba91cbe2183ea61d290b7e.tar.gz",
"type": "remote",
"url": "https://github.com/haze/tunez"
},
{
"commit": "bc135ed39a6b60be16fcbbc5ee1dea03ff560415",
"name": "libexif",
"tar_url": "https://github.com/lun-4/libexif-zig/archive/bc135ed39a6b60be16fcbbc5ee1dea03ff560415.tar.gz",
"type": "remote",
"url": "https://github.com/lun-4/libexif-zig"
},
{
"commit": "00b62bc8bea7da75ba61f56555ea6cbaf0dc4e26",
"name": "libpcre_zig",
"tar_url": "https://github.com/kivikakk/libpcre.zig/archive/00b62bc8bea7da75ba61f56555ea6cbaf0dc4e26.tar.gz",
"type": "remote",
"url": "https://github.com/kivikakk/libpcre.zig"
},
{
"commit": "6e0f686885db57484a2b56465176ac016df66506",
"name": "libmagic_zig",
"tar_url": "https://github.com/lun-4/libmagic.zig/archive/6e0f686885db57484a2b56465176ac016df66506.tar.gz",
"type": "remote",
"url": "https://github.com/lun-4/libmagic.zig"
},
{
"commit": "master",
"name": "zig_ulid",
"tar_url": "https://github.com/lun-4/zig-ulid/archive/master.tar.gz",
"type": "remote",
"url": "https://github.com/lun-4/zig-ulid"
},
{
"commit": "refs",
"name": "clap",
"tar_url": "https://github.com/Hejsil/zig-clap/archive/refs.tar.gz",
"type": "remote",
"url": "https://github.com/Hejsil/zig-clap"
}
] |
awtfdb
(wip) a "many-compromises" file indexing system.
understand what's up with it here: https://blog.l4.pm/the-system-is-the-solution
project state
v0.2 is released.
i run master branch, which may be unstable and corrupt your database (like it did to mine,
that was fun)
v0.3 with the goodies of <code>master</code> branch will be carved onto stone once Zig reaches v0.11.0
(i'll also attempt to only pin down zig stable versions after that release)
i have been working on this since April 2022, and also been using it on a daily
basis. the base is relatively solid enough, but there are unanswered design
questions, see issues tab.
here are my awtfdb statistics for the past 7 months (May 2023):
- i have indexed 167405 files.
- i have created 56190 tags.
- i have 2425603 file<->tag mappings in the database.
- my database is 336MB.
there is no specification yet that would enable others to contribute to the
system by writing their own tools on top, but <em>that is planned</em>.
this indexing system is very CLI based and there is a szurubooru frontend
for better viewing. see <code>extra/</code> for that respective tooling.
as this is v0.x, it is <strong>NOT PRODUCTION READY</strong>. <strong>THERE IS NO WARRANTY PROVIDED
BY ME. I WORK ON THIS PART TIME. BEWARE OF BUGS.</strong>
how build
<ul>
<li>almost everything is cross-platform, save for <code>awtfdb-watcher</code></li>
<li>this was not tested as part of the v0.1 effort.</li>
<li>get <a>zig</a> (tested with 0.13.0)</li>
<li>get GraphicsMagick and development headers</li>
<li>https://github.com/lun-4/awtfdb/issues/67</li>
</ul>
<code>git clone https://github.com/lun-4/awtfdb
cd awtfdb
zig build</code>
install thing
```
choose your own prefix thats on $PATH or something
zig build install --prefix ~/.local/ --verbose -Drelease-safe=true
```
using it
```
create the awtfdb index file on your home directory
awtfdb-manage create
add files into the index
the ainclude tool contains a lot of tag inferrers
you can see 'ainclude -h' for explanations into such
ainclude --tag meme:what_the_dog_doing ~/my/folder/dog_doing.jpg
find files with tags
afind meme:what_the_dog_doing
spawn the rename watcher for libraries that have minimal rename changes
as the watcher is relatively unstable.
install bpftrace and a recent linux kernel,
then add this to your init system
awtfdb-watcher /home/user
list files and their tags with als
als ~/my/folder
manage tags
atags create my_new_funny_tag
atags search funny
atags delete my_new_funny_tag
remove files or directories from the index (does not remove from filesystem)
arm -r ~/my/folder
```
roadmap for the thing
fuck if i know.
inspiration
<ul>
<li>hydrus</li>
<li>booru software (danbooru etc.)</li>
</ul>
(OLD-ISH) design notes
(i leave them there for the funny)
if i could make it a single phrase: awtfdb is an incremental non-destructive tagging system for your life's files full of compromises.
you start it with 'awtfdb path/to/home/directory', it'll create a sqlite file on homedir/awtfdb.db, and run necessary migrations
then, say, you have a folder full of music. you can track them with 'binclude mediadir', but that'd just track them without tags. we know its a media directory, why not infer tags based on content?
'binclude --add-single-tag source:bandcamp --infer-media-tags mediadir/bd-dl'
artist:, title:, album:, and others get inferred from the id3 tags, if those arent provided, inferring from path is done (say, we know title is equal to filename)
you can take a look at the changes binclude will make, it'll always betch-add tags, never remove. if you find that its inferring is wrong for an album, ctrl-c/say no, and redo it ignoring that specific album
'binclude --add-single-tag source:bandcamp --infer-media-tags mediadir/bd-dl --exclude mediadir/bd-dl/album_with_zalgotext'
you can 'badd tag file' to add a single tag to a single file, or to a folder: 'badd -R tag folder'
'bstat path' to see file tags
'bfind ' to execute search across all files e.g 'bfind format:flac "artist:dj kuroneko"' to return all flacs made by dj kuroneko
why isnt this a conventional danbooru/hydrus model
the name of a tag isnt unique, tags map to their own tag ids (tag "cores" as ids would be overused vocab from DB world), except, to make this work at universe-scale where i can share my tags with you without conflicting with anything pre-existing
the idea of is shamelessly being copied from the proposal here: https://www.nayuki.io/page/designing-better-file-organization-around-tags-not-hierarchies#complex-indirect-tags
i dont follow that proposal to the letter (storage pools do not apply to me at the moment), but some ideas from it are pretty good to follow
we use hash(random data) as the id, which enables Universal Ids But Theyre Not UUIDs You Cant Just Collide The Tags Lmao (since if you try to change the core_data by even 1 byte, crypto hash gets avalanche effect'd). this enables us to have 'tree (english)', while also having 'Árvore (portuguese)' map to the same id
ofc someone can create a different tag core for the idea of a tree, but thats out of scope. its better than hydrus's PTR because of the fact you can add different human representations to the same tag core, breaking your depedency on english, while also enabling metadata to be added to a tag core, so if i wanted to add the wikipedia link for a tree, i can do that
some implementation details
now that i have a bit of spec like the db, what happens for implementation?
i want to have something that isnt monolithic, there is no http api of the sorts to manage the database, you just open it, and sqlite will take care of concurrent writers (file based locking)
you just use libawtfdb (name tbd) and itll provide you the high level api such as "execute this query"
there needs to be at least the watcher daemon, but what about secondary functionality? say, i want a program to ensure the hashes are fine for the files, but do it in an ultra slow way, generating reports or even calling notify-send when it finds a discrepancy in hashes
that is a feature way out of scope for the "watcher daemon that only checks up for new renames in the entire filesystem. also thw watcher requires root", adding more things to that piece of code leads to opening my surface area for catastrophic failure. the system should handle all of those processes reading and writing to the database file
the db is an IPC platform for all tools
this does infer that the database needs to have more than the tagging data
but a way to become an IPC format between all awtfdb utilities
maybe a janitor process is ensuring all files exist and you want to see the progress bar and plan accordingly, while also ensuring there isn't two of them having to clash with each other's work
ipc and job system
one singular tool that does db administration
one tool will have to be database management though
the database migrations will have to go to A Tool Somewhere
maybe awtfdb-manage
create db, run some statistics, show migration warnings, etc
the watcher stays as is, just a watcher for file renames
job system
the purpose of a job system in awtfdb
<ul>
<li>schedule periodic awtfdb jobs (every week there should be a checkup of
all paths and their hashes, for example. that job would be a "janitor")</li>
<li>get job status and <em>historical</em> reports</li>
<li>understand failure rate of jobs, if a job fails too much, alerts should
be dispatched to the user via <code>notify-send</code></li>
<li>if the example "janitor" job found a discrepancy between file and hash,
should it email, fix it automatically, notify-send, or leave a track
record? that should be configurable by the user.</li>
</ul>
the implementation proposal for this is as follows:
<ul>
<li>job watcher daemon</li>
<li><code>job_configs</code> table has:</li>
<li>id of job</li>
<li>configuration of job (json string with well-defined schema in tool?)</li>
<li>enabled flag (removing jobs is always a soft delete)</li>
<li>executable path of tool<ul>
<li>the watcher does not run jobs itself, just delegates and supervises
execution of other executables that actually run what theyre supposed to</li>
</ul>
</li>
<li><code>job_runs</code> table with historical evidence</li>
</ul>
technically possible to leave some functionality of the daemon to the
system's initd (systemd, runit+snooze, cron), but i think i might tire myself
out from having to autogenerate service units and connect it all together
and HOPE for a LIGHT FROM GOD that it's going to work as intended. god fuck
linux
|
[] |
https://avatars.githubusercontent.com/u/105348204?v=4
|
zig-gir-ffi
|
DerryAlex/zig-gir-ffi
|
2022-12-29T03:06:56Z
|
GObject Introspection for zig
|
master
| 1 | 43 | 3 | 43 |
https://api.github.com/repos/DerryAlex/zig-gir-ffi/tags
|
LGPL-3.0
|
[
"bindings",
"gobject",
"gtk",
"gui",
"zig"
] | 1,273 | false |
2025-03-08T02:45:32Z
| true | true |
0.14.0
|
github
|
[
{
"commit": "refs",
"name": "clap",
"tar_url": "https://github.com/Hejsil/zig-clap/archive/refs.tar.gz",
"type": "remote",
"url": "https://github.com/Hejsil/zig-clap"
}
] |
Zig GIR FFI
GObject Introspection for zig. Generated <a>GTK4 binding</a> can be downloaded.
<blockquote>
<strong>Warning</strong>
Before zig 1.0 is released, only pre-releases targeting latest zig stable are guarenteed to be kept.
</blockquote>
Table of Contents
<ul>
<li>
<a>Usage</a>
</li>
<li>
<a>Usage of Bindings</a>
</li>
<li>
<a>Contributing</a>
</li>
</ul>
Usage
```bash
generate bindings for Gtk
zig build run -- -N Gtk
generate bindings for Gtk-3.0
zig build run -- -N Gtk -V 3.0
display help
zig build run -- --help
```
<em>Note</em>: This project relies on <code>field_info_get_size</code> to work properly.
Due to an <a>issue</a> in gobject-introspection, a patched version of <code>g-ir-compiler</code> (or <code>gi-compile-repository</code>) may be required.
As bitfields are not commonly found in GIR files, users can use typelibs from their package manager (e.g., <code>apt</code>, <code>msys2</code>) without recompiling.
For notable exceptions (<code>glib</code>, <code>gobject</code> and <code>pango</code>), this project ships patched typelibs (for LP64 model), which can be enabled by <code>--includedir lib/girepository-1.0</code> option.
For example, <code>zig build run -- -N Adw --includedir lib/girepository-1.0</code> should work perfectly if you have installed <code>gir1.2-adw-1</code> package or its equivalent.
Usage of Bindings
Run <code>zig fetch --save https://url/to/bindings.tar.gz</code> and add the following lines to your <code>build.zig</code>. For more information, refer to <a>Zig Build System</a>.
<code>zig
const gtk = b.dependency("gtk4", .{});
exe.root_module.addImport("gtk", gtk.module("gtk"));</code>
Examples
<ul>
<li>
<a>application</a> : Port of <a>Gtk - 4.0: Getting Started with GTK</a>, a relatively comprehensive example
</li>
<li>
<a>hello</a> : A simple example
</li>
</ul>
<code>zig
pub fn printHello() void {
std.log.info("Hello World", .{});
}
pub fn activate(app: *GApplication) void {
var window = ApplicationWindow.new(app.tryInto(Application).?).into(Window);
window.setTitle("Window");
window.setDefaultSize(200, 200);
var box = Box.new(.vertical, 0);
var box_as_widget = box.into(Widget);
box_as_widget.setHalign(.center);
box_as_widget.setValign(.center);
window.setChild(box_as_widget);
var button = Button.newWithLabel("Hello, World");
_ = button.connectClicked(printHello, .{}, .{});
_ = button.connectClicked(Window.destroy, .{window}, .{ .swapped = true });
box.append(button.into(Widget));
window.present();
}
pub fn main() u8 {
var app = Application.new("org.gtk.example", .{}).into(GApplication);
defer app.__call("unref", .{});
_ = app.connectActivate(activate, .{}, .{});
return @intCast(app.run(std.os.argv));
}</code>
<ul>
<li>
<a>clock</a> : (Implicit) use of the main context
</li>
<li>
<a>custom</a> : Custom widget
</li>
<li>
<a>interface</a> : Define interface
</li>
</ul>
Contributing
Read <a>docs/design.md</a> and <a>docs/hacking.md</a>.
|
[] |
https://avatars.githubusercontent.com/u/65570835?v=4
|
antiphony
|
ziglibs/antiphony
|
2022-02-22T15:39:09Z
|
A zig remote procedure call solution
|
master
| 0 | 41 | 1 | 41 |
https://api.github.com/repos/ziglibs/antiphony/tags
|
MIT
|
[
"rpc",
"rpc-framework",
"zig",
"zig-package",
"ziglang"
] | 8,194 | false |
2025-05-17T14:09:17Z
| true | true |
unknown
|
github
|
[
{
"commit": "b30205d5e9204899fb6d0fdf28d00ed4d18fe9c9.tar.gz",
"name": "s2s",
"tar_url": "https://github.com/ziglibs/s2s/archive/b30205d5e9204899fb6d0fdf28d00ed4d18fe9c9.tar.gz.tar.gz",
"type": "remote",
"url": "https://github.com/ziglibs/s2s"
}
] |
Antiphony
A simple Zig remote procedure call library.
Features
<ul>
<li>Transport layer agnostic</li>
<li>Support for nearly every non-generic function signature.</li>
<li>Nestable remote calls (peer calls host calls peer calls host calls ...)</li>
<li>Easy to use</li>
</ul>
API
```zig
// (comptime details left out for brevity)
pub fn CreateDefinition(spec: anytype) type {
return struct {
pub fn HostEndPoint(Reader: type, Writer: type, Implementation: type) type {
return CreateEndPoint(.host, Reader, Writer, Implementation);
}
pub fn ClientEndPoint(Reader: type, Writer: type, Implementation: type) type {
return CreateEndPoint(.client, Reader, Writer, Implementation);
}
pub fn CreateEndPoint(role: Role, ReaderType: type, WriterType: type, ImplementationType: type) type {
return struct {
const EndPoint = @This();
<code> pub const Reader = Reader;
pub const Writer = Writer;
pub const Implementation = Implementation;
pub const IoError = error{ ... };
pub const ProtocolError = error{ ... };
pub const InvokeError = error{ ... };
pub const ConnectError = error{ ... };
pub fn init(allocator: std.mem.Allocator, reader: Reader, writer: Writer) EndPoint;
pub fn destroy(self: *EndPoint) void;
pub fn connect(self: *EndPoint, impl: *Implementation) ConnectError!void;
pub fn shutdown(self: *EndPoint) IoError!void;
pub fn acceptCalls(self: *EndPoint) InvokeError!void;
pub fn invoke(self: *EndPoint, func_name: []const u8, args: anytype) InvokeError!Result(func_name);
};
}
};
</code>
}
// Example for CreateDefinition(spec):
const Definition = antiphony.CreateDefinition(.{
.host = .{
// add all functions the host implements:
.createCounter = fn () CreateError!u32,
.destroyCounter = fn (u32) void,
.increment = fn (u32, u32) UsageError!u32,
.getCount = fn (u32) UsageError!u32,
},
.client = .{
// add all functions the client implements:
.signalError = fn (msg: []const u8) void,
},
<code>// this is optional and can be left out:
.config = .{
// defines how to handle remote error sets:
.merge_error_sets = true,
},
</code>
});
```
Project Status
This project is currently in testing phase, all core features are already implemented and functional.
Contribution
Contributions are welcome as long as they don't change unnecessarily increase the complexity of the library. This library is meant to be the bare minimum RPC implementation that is well usable. Bug fixes and updates to new versions are always welcome.
Compile and run the examples
<code>sh-session
[user@host antiphony]$ zig build install
[user@host antiphony]$ ./zig-out/bin/socketpair-example
info: first increment: 0
info: second increment: 5
info: third increment: 8
info: final count: 15
error: remote error: This counter was already deleted!
info: error while calling getCount() with invalid handle: UnknownCounter
[user@host antiphony]$</code>
Run the test suite
<code>sh-session
[user@host antiphony]$ zig build test
Test [3/6] test "invoke function (emulated client, no self parameter)"... some(1334, 3.1415927410125732, "Hello, Host!");
Test [4/6] test "invoke function (emulated client, with self parameter)"... some(123, 1334, 3.1415927410125732, "Hello, Host!");
Test [5/6] test "invoke function with callback (emulated host, no self parameter)"... callback("Hello, World!");
Test [6/6] test "invoke function with callback (emulated host, with self parameter)"... callback(ClientImpl@7ffd33f6cdc0, "Hello, World!");
All 6 tests passed.
[user@host antiphony]$</code>
|
[] |
https://avatars.githubusercontent.com/u/5175499?v=4
|
tomlz
|
mattyhall/tomlz
|
2022-11-05T21:53:44Z
|
A well-tested TOML parsing library for Zig
|
main
| 5 | 40 | 5 | 40 |
https://api.github.com/repos/mattyhall/tomlz/tags
|
MIT
|
[
"parsing",
"toml",
"zig"
] | 185 | false |
2025-05-06T09:59:39Z
| true | false |
unknown
|
github
|
[] |
tomlz
A TOML parser for Zig targeting TOML v1.0.0, an easy API and safety.
Also supports encoding/serializing values(implemented by @0x5a4)!
```zig
const std = @import("std")
const tomlz = @import("tomlz")
var gpa = std.heap.page_allocator;
var table = try tomlz.parse(gpa,
\foo = 1
\bar = 2
);
defer table.deinit(gpa);
table.getInteger("foo").?; // 1
// --- or ---
const S = struct { foo: i64, bar: i64 };
const s = try tomlz.decode(S, gpa,
\foo = 1
\bar = 2
);
// serialize a value like this (also see the examples)
try tomlz.serialize(
gpa,
std.io.getStdout.writer()
s,
);
// foo = 1
// bar = 2
```
Current status
All types other than datetimes are supported. We pass 321/334 of the
<a>toml tests</a> 11 of those are due to not
having datetime support and the other two are minor lexing issues (allowing
whitespace between the square brackets of an array header).
We allow both parsing into a special TOML type, a <code>Table</code>, but also support
decoding into a struct directly - including types that must be allocated like
arrays and strings.
The Serializer allows encoding every kind of zig type, overwriting it's default behaviour
by implementing a function called <code>tomlzSerialize</code>, has the option to work
without an allocator and can therefore even work at <code>comptime</code>!
Note that for some types like <code>std.HashMap</code> its not possible to just encode
all their fields, so custom logic is needed. We can't provide this, but it's not
too difficult to implement it yourself(See examples).
Installation
tomlz supports being included as a module.
Create a file called <code>build.zig.zon</code> if you do not already have one, and add <code>tomlz</code> as a dependency
<code>.{
.name = "myproject",
.version = "0.1.0",
.dependencies = .{
.tomlz = .{
.url = "https://github.com/mattyhall/tomlz/archive/<commit-hash>.tar.gz",
.hash = "12206cf9e90462ee6e14f593ea6e0802b9fe434429ba10992a1451e32900f741005c",
},
}
}</code>
You'll have to replace the <code><commit-hash></code> part with an actual, recent commit-hash.
The hash also needs changing, but <code>zig build</code> will complain and give you the correct one.
In your <code>build.zig</code> file create and use the dependency
```
pub fn build(b: *std.Build) void {
// ... setup ...
<code>const tomlz = b.dependency("tomlz", .{
.target = target,
.optimize = optimize,
});
// add the tomlz module
exe.root_module.addImport("tomlz", tomlz.module("tomlz"));
// .. continue ...
</code>
}
```
Usage
Table
We currently provide a single entry point for parsing which returns a toml
<code>Table</code> type. This type has helper methods for getting values out:
```zig
const std = @import("std");
const tomlz = @import("tomlz");
var gpa = std.heap.page_allocator;
var table = try tomlz.parse(gpa,
\int = 1
\float = 2.0
\boolean = true
\string = "hello, world"
\array = [1, 2, 3]
\table = { subvalue = 1, we.can.nest.keys = 2 }
);
defer table.deinit(gpa);
table.getInteger("int");
table.getFloat("float");
table.getBool("boolean");
table.getString("string");
table.getArray("array");
table.getTable("table");
```
A simple example is
<a>provided</a>.
Decode
```zig
const std = @import("std");
const tomlz = @import("tomlz");
var gpa = std.heap.page_allocator;
const TripleCrowns = struct { worlds: i64, masters: i64, uks: i64 };
const Player = struct {
name: []const u8,
age: i64,
hobbies: []const []const u8,
triplecrowns: TripleCrowns,
<code>const Self = @This();
pub fn deinit(self: *Self, gpa: std.mem.Allocator) void {
gpa.free(self.name);
for (self.hobbies) |hobby| {
gpa.free(hobby);
}
gpa.free(self.hobbies);
}
</code>
};
const Game = struct {
name: []const u8,
goat: Player,
<code>const Self = @This();
pub fn deinit(self: *Self, gpa: std.mem.Allocator) void {
gpa.free(self.name);
self.goat.deinit(gpa);
}
</code>
};
var s = try tomlz.decode(Game, gpa,
\name = "snooker"
\
\[goat]
\name = "Ronnie o' Sullivan"
\age = 46 # as of Nov 2022
\hobbies = ["running", "hustling at pool"]
\
\[goat.triplecrowns]
\worlds = 7
\masters = 7
\uks = 7
);
defer s.deinit(gpa);
```
Encode
Have a look at <a>the example</a>.
Goals and non-goals
Goals and non-goals are subject to change based on how the project is used and
my own time constraints. If you feel a goal or non-goal isn't quite right please
open an issue and we can discuss it.
Goals
<ul>
<li>TOML v1.0.0. The datetime portion of this is probably going to be
unachievable until Zig gets a good standard library type for it or a library
gets dominance. Other than that however we should pass all the
<a>tests</a></li>
<li>A nice API. Getting values from the <code>Value</code> type should be painless as
possible and we should also provide deserialising a <code>Table</code> into a struct,
similarly to how <code>std.json</code> does it</li>
<li>Easy installation. We should try to make using the library as a vendored
dependency and as a package - on e.g. <a>gyro</a>
- as easy as possible</li>
<li>Safety. The parser should never crash no matter the input. To achieve this we
should run fuzzing against it</li>
<li>Support Zig master and the latest tagged release until Zig v1.0. This will be
done by having the main branch track Zig master and a branch for each Zig
release. Any improvements should be backported to the most recent release
branch</li>
<li>Good error messages</li>
</ul>
Non-goals
<ul>
<li>Super duper performance. We want to be as performant as possible without
making the code harder to read. It is unlikely that parsing a TOML file is
going to be the bottleneck in your application so "good" performance should be
sufficient</li>
<li>Previous versions of TOML</li>
</ul>
|
[] |
https://avatars.githubusercontent.com/u/5249140?v=4
|
workers-zig
|
CraigglesO/workers-zig
|
2022-08-16T01:36:04Z
|
Write Cloudflare Workers in Zig via WebAssembly
|
master
| 0 | 40 | 5 | 40 |
https://api.github.com/repos/CraigglesO/workers-zig/tags
|
MIT
|
[
"cloudflare",
"cloudflare-workers",
"serverless",
"workers",
"zig"
] | 752 | false |
2025-05-07T08:30:25Z
| true | false |
unknown
|
github
|
[] |
Workers-Zig
<strong>Workers Zig</strong> is a light weight <a><strong>Zig</strong></a> bindings for the <a><strong>Cloudflare Workers</strong></a> environment via <a><strong>WebAssembly</strong></a>.
Why Zig?
* Zig is a language that is designed to be a small, fast, and portable.
* The language already supports WASM and WASI.
* Small builds are easy to achieve. To expound on this, the basic example provided is <code>5.8Kb</code> of WASM code and <code>6.8Kb</code> javascript code.
* I wanted a tool that made it easy for both WASM and JS code to work in tandem.
* I didn't like that rust wasm bindings would grow the more code you wrote. I came up with a strategy that covers 90% use cases, JS glue doesn't grow, and you can add the 10% as needed.
* I prefer <a><strong>Zig's memory model</strong></a> over Rust.
Be sure to read the <a>Documentation</a> for guidance on usage.
Features
<ul>
<li>🔗 Zero dependencies</li>
<li>🗿 WASI support</li>
<li>🤝 Use in tandem with Javascript or 100% Zig WebAssembly</li>
<li>🎮 JS bindings with support to write your own - <a>List of supported bindings here</a></li>
<li>📨 Fetch bindings</li>
<li>⏰ Scheduled bindings</li>
<li>🔑 Supports Variables and Secrets from <code>env</code></li>
<li>✨ Cache bindings</li>
<li>📦 KV bindings</li>
<li>🪣 R2 bindings</li>
<li>💾 D1 bindings</li>
<li>🔐 Web-Crypto bindings [partially complete]</li>
<li>💪 Uses TypeScript</li>
</ul>
Features coming soon
<ul>
<li>📌 Durable Objects bindings</li>
<li>✉️ WebSockets bindings</li>
<li>once CF lands dynamic imports: Only load wasm when needed.</li>
</ul>
Install
Step 1: Install Zig
<a>Follow the instructions to install Zig</a>
Release used: <strong>0.10.0-dev.3838+77f31ebbb</strong>
Step 2a: Use the skeleton project provided
<a>Follow the steps provided by the skeleton project</a>
```bash
in one go
git clone --recurse-submodules -j8 [email protected]:CraigglesO/worker-zig-template.git
OR
clone
git clone [email protected]:CraigglesO/worker-zig-template.git
enter
cd worker-zig-template
Pull in the submodule
git submodule update --init --recursive
```
Step 2b: Install the workers-zig package
```bash
NPM
npm install --save workers-zig
Yarn
yarn add workers-zig
PNPM
pnpm add workers-zig
BUN
bun add workers-zig
```
Step 3: Add workers-zig as a submodule to your project
<code>bash
git submodule add https://github.com/CraigglesO/workers-zig</code>
Step 4: Setup a <strong>build.zig</strong> script
```zig
const std = @import("std");
const Builder = std.build.Builder;
pub fn build(b: *Builder) void {
b.is_release = true;
b.cache_root = "cache";
b.global_cache_root = "cache";
b.use_stage1 = true;
<code>const wasm_build = b.addSharedLibrary("zig", "lib/main.zig", .unversioned);
wasm_build.setOutputDir("dist");
wasm_build.setTarget(std.zig.CrossTarget {
.cpu_arch = .wasm32,
.os_tag = .freestanding,
});
wasm_build.build_mode = std.builtin.Mode.ReleaseSmall;
wasm_build.strip = true;
wasm_build.linkage = std.build.LibExeObjStep.Linkage.dynamic;
wasm_build.addPackagePath("workers-zig", "workers-zig/lib/main.zig");
wasm_build.install();
</code>
}
```
Step 5: Recommended wrangler configuration
```toml
name = "zig-worker-template"
main = "dist/worker.mjs"
compatibility_date = "2022-07-29"
usage_model = "bundled" # or unbound
account_id = ""
[build]
command = "zig build && npm run esbuild"
watch_dir = [
"src",
"lib"
]
[[build.upload.rules]]
type = "CompiledWasm"
globs = ["<strong>/*.wasm"]
[[build.upload.rules]]
type = "ESModule"
globs = ["</strong>/*.mjs"]
```
|
[] |
https://avatars.githubusercontent.com/u/14359115?v=4
|
vkwayland
|
kdchambers/vkwayland
|
2022-07-06T22:00:49Z
|
Reference application for Vulkan / Wayland
|
main
| 0 | 40 | 0 | 40 |
https://api.github.com/repos/kdchambers/vkwayland/tags
|
MIT
|
[
"graphics-programming",
"vulkan",
"wayland",
"zig"
] | 1,207 | false |
2025-04-25T19:35:57Z
| true | false |
unknown
|
github
|
[] |
vkwayland
<em>A reference application for vulkan and wayland.</em>
Goals
<ul>
<li>Easy to read and understand the code (Avoiding heavy abstractions or unrelated cruft)</li>
<li>Make use of typical vulkan / wayland functionality</li>
<li>Be performant and correct</li>
<li>A common place to iron out best practices</li>
</ul>
I'm not an expert in vulkan or wayland, so audits are welcome.
Additionally, feature requests, questions and discussions are in scope for the project. Feel free to open an issue around a topic.
Features
<ul>
<li>Mostly self-contained within a ~3k loc source file</li>
<li>Animated background (Color smoothly updates each frame)</li>
<li><a>Client-side</a> window decorations for compositors that don't support drawing them on behalf of application (E.g Gnome / mutter)</li>
<li>Updates cursor icon when application surface is entered</li>
<li>Vulkan specfic wayland integration (Not using waylands shared memory buffer interface)</li>
<li>Proper (mostly) querying of vulkan objects (Devices, memory, etc)</li>
<li>Vulkan synchonization that doesn't rely on deviceWaitIdle (Except on shutdown)</li>
<li>Dynamic viewport + scissor for more efficient swapchain recreation</li>
<li>Image loading and texture sampling</li>
<li>Surface transparency</li>
<li>Window movement and resizing</li>
</ul>
Requirements
<ul>
<li><a>zig</a> (Tested with 0.12.0-dev.3180)</li>
<li>Wayland system (mutter, river, sway, etc)</li>
<li>libwayland-client</li>
<li>libwayland-cursor</li>
<li>vulkan validation layers (Optional, only in Debug mode)</li>
</ul>
Running
<code>git clone --recurse-submodules https://github.com/kdchambers/vkwayland
cd vkwayland
zig build run -Drelease-safe
</code>
<strong>NOTE</strong>: If you run the application in debug mode, you will get an error if vulkan validation layers aren't installed on your system.
Credits
This application makes use of the following libraries and credits go to the authers and contributors for allowing this project to rely soley on zig code.
<ul>
<li><a>zigimg</a></li>
<li><a>zig-vulkan</a></li>
<li><a>zig-wayland</a> </li>
</ul>
License
MIT
|
[] |
https://avatars.githubusercontent.com/u/32691832?v=4
|
accord
|
BanchouBoo/accord
|
2022-02-25T04:13:22Z
|
A simple argument parser for Zig
|
master
| 0 | 40 | 1 | 40 |
https://api.github.com/repos/BanchouBoo/accord/tags
|
Unlicense
|
[
"arg",
"args",
"argument-parser",
"argument-parsing",
"option-parser",
"option-parsing",
"zig",
"zig-library",
"ziglang"
] | 102 | false |
2025-03-30T17:27:42Z
| true | false |
unknown
|
github
|
[] |
accord
NOTE: Accord was made for use with zig master, it is not guaranteed to and likely will not work on release versions
Features
Basic usage
<ul>
<li>Automatically generate and fill a struct based on input parameters.</li>
<li>Short and long options.</li>
<li>Short options work with both <code>-a -b -c -d 12</code> and <code>-abcd12</code>.</li>
<li>Long options work with both <code>--option long</code> and <code>--option=long</code>.</li>
<li>Everything after a standalone <code>--</code> will be considered a positional argument. The index for this will also be stored, so you can slice the positionals before or after <code>--</code> if you want to have a distinction between them.</li>
<li>Positional arguments stored in a struct with <code>items</code> storing the actual slice, <code>separator_index</code> storing the aforementioned index of <code>--</code> if it exists, and <code>beforeSeparator</code> and <code>afterSeparator</code> functions to get the positionals before and after the <code>--</code> (if there's no <code>--</code>, then before will return everything and after will return nothing).<ul>
<li>Positional arguments must be manually freed using <code>positionals.deinit(allocator)</code>.</li>
</ul>
</li>
</ul>
Types
Built in
<ul>
<li>Strings (<code>[]const u8</code>)</li>
<li>Signed and unsigned integers</li>
<li>Floats</li>
<li>Booleans</li>
<li>Flags with no arguments via <code>accord.Flag</code>, when a flag argument is used it will return the opposite of its default value</li>
<li>Enums by name, value, or both</li>
<li>Optionals of any of these types (except <code>Flag</code>)</li>
<li>Mask type via <code>accord.Mask(int or enum type)</code><ul>
<li>Takes a delimited list of ints/enums and bitwise ORs them together</li>
</ul>
</li>
<li>Array of any of these types (except <code>Flag</code>)<ul>
<li>Not filling out every value in the array will return an error</li>
</ul>
</li>
</ul>
Settings
<ul>
<li>Booleans have <code>true_strings</code> and <code>false_strings</code> settings to determine what is considered as true/false. Note that these are case insensitive.<ul>
<li>Defaults:<ul>
<li><code>true_strings = &.{ "true", "t", "yes", "1" }</code></li>
<li><code>false_strings &.{ "false", "f", "no", "0" }</code></li>
</ul>
</li>
</ul>
</li>
<li>Integers have a <code>radix</code> u8 setting, defaults to 0.<ul>
<li>A radix of 0 means assume base 10 unless the value starts with:<ul>
<li><code>0b</code> = binary</li>
<li><code>0o</code> = octal</li>
<li><code>0x</code> = hexadecimal</li>
</ul>
</li>
</ul>
</li>
<li>Enums have an <code>enum_parsing</code> enum setting with the values <code>name</code>, <code>value</code>, and <code>both</code>, defaults to <code>name</code>. Enums also inherit integer parsing settings for when parsing by <code>value</code>.<ul>
<li><code>name</code> means it will try to match the value with the names of the fields in the enum.</li>
<li><code>value</code> means it will try to match the values of the fields.</li>
<li><code>both</code> means it will first try to match the field values, and if that fails it will try to match the field names.</li>
</ul>
</li>
<li>Optionals have the <code>null_strings</code> to determine when the value is parsed as <code>null</code>. Note that these are case insensitive. Optionals also inherit options from their child type.<ul>
<li>Default <code>null_strings = &.{ "null", "nul", "nil" }</code></li>
</ul>
</li>
<li>Arrays and masks have an <code>array_delimiter</code> and <code>mask_delimiter</code> setting respectively, defaults to <code>","</code> for arrays and <code>"|"</code> for masks. They will also inherit any settings from their child type (e.g. an array or mask of enums would also have the <code>enum_parsing</code> and <code>radix</code> settings available)</li>
</ul>
Custom
In addition to all default types built into the library, you can also easily define your own custom parsing by fulfilling a particular interface.
All basic types supported in the library are also implemented through this system, so you can reference all of them for examples, the following is how the parsing interface for integers is implemented:
```zig
pub fn IntegerInterface(comptime T: type) type {
return struct {
pub const AccordParseSettings = struct {
radix: u8 = 0,
};
<code> pub fn accordParse(parse_string: []const u8, comptime settings: anytype) AccordError!T {
const result = (if (settings.radix == 16)
std.fmt.parseInt(T, std.mem.trimLeft(u8, parse_string, "#"), settings.radix)
else
std.fmt.parseInt(T, parse_string, settings.radix));
return result catch error.OptionUnexpectedValue;
}
};
</code>
}
```
You can also implement custom no-argument flags by omitting the first argument in the function. The implementation of <code>Flag</code> is as follows:
<code>zig
pub const Flag = struct {
pub fn accordParse(comptime settings: anytype) !bool {
return !settings.default_value;
}
};</code>
The following is a truncated example of the enum parsing interface which demonstrates merging settings from other types. When merging settings like this, you may have the same field in multiple structs so long as they have the same type, and it will prioritize the default value of the setting of the earliest struct that has the field.
<code>zig
pub fn EnumInterface(comptime T: type) type {
const Tag = @typeInfo(T).Enum.tag_type;
returnt struct {
pub const AccordParseSettings = MergeStructs(&.{
struct {
const EnumSetting = enum { name, value, both };
enum_parsing: EnumSetting = .name,
},
InterfaceSettings(GetInterface(Tag)),
});
};</code>
Example usage
<code>zig
const allocator = std.heap.page_allocator;
var args_iterator = std.process.args();
const options = try accord.parse(&.{
//short name //long name //type //default value //parse options
accord.option('s', "string", []const u8, "default", .{}),
accord.option('c', "color", u32, 0x000000, .{ .radix = 16 }),
accord.option('f', "float", f32, 0.0, .{}),
accord.option('m', "mask", accord.Mask(u8), 0, .{}),
accord.option('a', "", accord.Flag, false, .{}), // option without long option
accord.option(0, "option", accord.Flag, false, .{}), // option without short option
accord.option('i', "optionalintarray", [2]?u32, .{ 0, 0 }, .{ .array_delimiter = "%" }),
}, allocator, &args_iterator);
defer options.positionals.deinit(allocator);</code>
The above example called as
<code>command positional1 -s"some string" --color ff0000 positional2 -f 1.2e4 --mask="2|3" -a positional3 --optionalintarray="null%23" -- --option positional4 positional5</code>
would result in the following value:
<code>zig
{
string = "some string"
color = 0xff0000
float = 12000.0
mask = 3
a = true
option = false
intarray = { null, 23 }
positionals.items = { "command", "positional1", "positional2", "positional3", "--option", "positional4", "positional5" }
positionals.beforeSeparator() = { "command", "positional1", "positional2", "positional3" }
positionals.afterSeparator() = { "--option", "positional4", "positional5" }
}</code>
Possible things to add in the future
<ul>
<li>Subcommands<ul>
<li>Parsable union containing an Option and Subcommand field</li>
<li>Flags before a subcommand use top level flags</li>
<li>Flags after a subcommand apply to the subcommand</li>
<li>Subcommands after -- are considered normal positionals</li>
<li>Subcommand stored as a sub-struct in the parse return struct. Possibly store it's own return value?</li>
</ul>
</li>
<li>A way to define help strings per argument and print them all nicely</li>
<li>Required arguments</li>
</ul>
|
[] |
https://avatars.githubusercontent.com/u/34946442?v=4
|
marble
|
cryptocode/marble
|
2022-03-20T12:47:11Z
|
A metamorphic testing library for Zig
|
main
| 0 | 39 | 2 | 39 |
https://api.github.com/repos/cryptocode/marble/tags
|
MIT
|
[
"metamorphic-testing",
"testing",
"testing-tool",
"testing-tools",
"zig",
"zig-library",
"zig-package"
] | 24 | false |
2025-03-25T01:37:34Z
| true | true |
unknown
|
github
|
[] |
Marble is a <a>metamorphic testing</a> library for Zig.
This library tracks Zig master and was last tested on <code>0.14.0-dev.3187+d4c85079c</code>
Metamorphic testing is a powerful technique that provides additional test coverage by applying a number of transformations to test input, and then checking if certain relations still hold between the outputs. Marble will automatically run through all possible combinations of these transformations.
Here's a <a>great introduction by</a> Cockroach Labs. I highly recommend reading before using this library.
The repository contains a few <a>test examples</a>
Resources
<ul>
<li><a>Hillel Wayne's blog post on Metamorphic Testing (highly recommended)</a></li>
<li><a>Test your Machine Learning Algorithm with Metamorphic Testing</a></li>
<li><a>Original paper by T.Y. Chen et al</a></li>
<li><a>Case study T.Y. Chen et al</a></li>
<li><a>Metamorphic Testing and Beyond T.Y. Chen et al</a></li>
<li><a>Survey on Metamorphic Testing</a></li>
<li><a>Performance Metamorphic Testing</a></li>
<li><a>Experiences from Three Fuzzer Tools</a></li>
<li><a>Monarch, a similar library for Rust</a></li>
</ul>
Building
To build and run test examples:
<code>bash
zig build
zig build test</code>
Importing the library
Add Marble as a Zig package in your build file, or simply import it directly after vendoring/adding a submodule:
<code>zig
const marble = @import("marble/main.zig");</code>
Writing tests
A metamorphic Zig test looks something like this:
```zig
const SinusTest = struct {
const tolerance = std.math.epsilon(f64) * 20;
<code>/// This test has a single value, but you could also design the test to take an
/// array as input. The transformations, check and execute functions would then
/// loop through them all. Alternatively, the test can be run multiple times
/// with different inputs.
value: f64,
/// The mathematical property "sin(x) = sin(π − x)" must hold
pub fn transformPi(self: *SinusTest) void {
self.value = std.math.pi - self.value;
}
/// Adding half the epsilon must still cause the relation to hold given the tolerance
pub fn transformEpsilon(self: *SinusTest) void {
self.value = self.value + std.math.epsilon(f64) / 2.0;
}
/// A metamorphic relation is a relation between outputs in different executions.
/// This relation must hold after every execution of transformation combinations.
pub fn check(_: *SinusTest, original_output: f64, transformed_output: f64) bool {
return std.math.approxEqAbs(f64, original_output, transformed_output, tolerance);
}
/// Called initially to compute the baseline output, and after every transformation combination
pub fn execute(self: *SinusTest) f64 {
return std.math.sin(self.value);
}
</code>
};
test "sinus" {
var i: f64 = 1;
while (i < 100) : (i += 1) {
var t = SinusTest{ .value = i };
try std.testing.expect(try marble.run(SinusTest, &t, .{}));
}
}
```
You will get compile time errors if the requirements for a metamorphic test are not met.
In short, you must provide a <code>value</code> field, a <code>check</code> function, an <code>execute</code> function and one or more <code>transform...</code> functions.
Writing transformations
Add one or more functions starting with <code>transform...</code>
Marble will execute all combinations of the transformation functions. After every
combination, <code>execute</code> is called followed by <code>check</code>.
Transformations should change the <code>value</code> property - Marble will remember what it was originally. The transformations must be such that <code>check</code>
succeeds. That is, the relations between the inital output and the transformed output must still hold.
Checking if relations still hold
You must provide a <code>check</code> function to see if one or more relations hold, and return true if so. If false is returned, the test fails with a print-out of the current transformation-combination.
Relation checks may be conditional; check out the tests for examples on how this works.
Executing
You must provide an <code>execute</code> function that computes a result based on the current value. The simplest form will simply return the current value, but you can
do any arbitrary operation here. This function is called before any transformations to form a baseline. This baseline is passed as the first argument to <code>check</code>
Optional before/after calls
Before and after the test, and every combination, <code>before(...)</code> and <code>after(...)</code> is called if present. This is useful to reset state, initialize test cases, and perform clean-up.
What happens during a test run?
Using the example above, the following pseudocode runs will be performed:
```
baseline = execute()
// First combination
transformPi()
out = execute()
check(baseline, out)
// Second combination
transformEpsilon()
out = execute()
check(baseline, out)
// Third combination
transformPi()
transformEpsilon()
out = execute()
check(baseline, out)
```
Configuring runs
The <code>run</code> function takes a <code>RunConfiguration</code>:
```zig
/// If set to true, only run each transformation once separately
skip_combinations: bool = false,
/// If true, print detailed information during the run
verbose: bool = false,
```
Error reporting
If a test fails, the current combination being executed is printed. For instance, the following tells us that the combination of <code>transformAdditionalTerm</code> and <code>transformCase</code> caused the metamorphic relation to fail:
```
Test [2/2] test "query"... Test case failed with transformation(s):
<blockquote>
<blockquote>
transformAdditionalTerm
transformCase
```
</blockquote>
</blockquote>
Terminology
<ul>
<li>Source test case output: The output produced by <code>execute()</code> on the initial input. This is also known as the baseline.</li>
<li>Derived test case output: The output produced by <code>execute()</code> after applying a specific combination of transformations.</li>
<li>Metamorphic relation: A property that must hold when considering a source test case and a derived test case.</li>
</ul>
|
[] |
https://avatars.githubusercontent.com/u/6693837?v=4
|
zig-thing
|
thi-ng/zig-thing
|
2022-03-22T14:53:25Z
|
Small collection of data types/structures, utilities & open-learning with Zig
|
main
| 0 | 38 | 1 | 38 |
https://api.github.com/repos/thi-ng/zig-thing/tags
|
Apache-2.0
|
[
"linalg",
"monorepo",
"ndarray",
"simd",
"vector",
"wasm",
"zig"
] | 145 | false |
2025-04-02T11:52:52Z
| true | true |
0.14.0
|
github
|
[] |
zig.thi.ng
About
Various, still somewhat unstructured, raw-around-the-edges utilities / open
learning with <a>Zig</a>, at some point hopefully culminating
into a useful toolkit.
<strong>All code in this repo is compatible with Zig v0.14.0</strong>
Current modules (all WIP)
| Name | Description |
| -------------------------------------------------- | --------------------------------------------------------------------------- |
| <a><code>thing.FixedBufferDualList</code></a> | Dual-headed linked list for resource IDs allocation (active/available) |
| <a><code>thing.ndarray</code></a> | Generic nD-Array base implementation |
| <a><code>thing.random</code></a> | Additional <code>std.rand.Random</code>-compatible PRNGs and related utilities. |
| <a><code>thing.vectors</code></a> | SIMD-based generic vector type & operations (incl. type specific additions) |
Usage with Zig's package manager
Tagged versions of this project are available and can be added as dependency to
your project via <code>zig fetch</code>, like so:
<code>bash
zig fetch --save https://github.com/thi-ng/zig-thing/archive/refs/tags/v0.1.1.tar.gz</code>
The <code>--save</code> option adds a new dependency called <code>thing</code> to your
<code>build.zig.zon</code> project file.
You'll also need to update your main <code>build.zig</code> with these additions:
```zig
//
const target = b.standardTargetOptions(.{});
const optimize = b.standardOptimizeOption(.{});
// main build step...
const exe = b.addExecutable(.{ ... });
//
// declare & configure dependency (via build.zig.zon)
const thing = b.dependency("thing", .{
.target = target,
.optimize = optimize,
}).module("thing");
// declare module for importing via given id
exe.root_module.addImport("thing", thing);
```
<strong>Important:</strong> If you're having a test build step configured (or any other build
step requiring separate compilation), you'll also need to add the
<code>.root_module.addImport()</code> call for that step too!
With these changes, you can then import the module in your source code like so:
<code>zig
const thing = @import("thing");</code>
Building & Testing
The package is not meant to be build directly (yet), so currently the build file
only declares a module.
To run all tests:
<code>bash
zig test src/main.zig</code>
License
© 2021 - 2025 Karsten Schmidt // Apache Software License 2.0
|
[] |
https://avatars.githubusercontent.com/u/10111?v=4
|
zig-curl
|
mattn/zig-curl
|
2022-07-29T07:32:07Z
|
cURL binding for Zig
|
main
| 0 | 38 | 2 | 38 |
https://api.github.com/repos/mattn/zig-curl/tags
|
-
|
[
"curl",
"http-client",
"zig"
] | 20 | false |
2025-05-06T18:33:06Z
| true | false |
unknown
|
github
|
[] |
zig-curl
cURL binding for Zig
Usage
<code>zig
var allocator = std.heap.page_allocator;
var f = struct {
fn f(data: []const u8) anyerror!usize {
try std.io.getStdOut().writeAll(data);
return data.len;
}
}.f;
var res = try curl.get("https://google.com/", .{ .allocator = allocator, .cb = f });
if (res != 0) {
var msg = try curl.strerrorAlloc(allocator, res);
defer allocator.free(msg);
std.log.warn("{s}", .{msg});
}</code>
Requirements
<ul>
<li>libcurl</li>
</ul>
Installation
<code>$ zig build</code>
Link to zig-curl
add following function into your build.zig.
<code>zig
fn linkToCurl(step: *std.build.LibExeObjStep) void {
var libs = if (builtin.os.tag == .windows) [_][]const u8{ "c", "curl", "bcrypt", "crypto", "crypt32", "ws2_32", "wldap32", "ssl", "psl", "iconv", "idn2", "unistring", "z", "zstd", "nghttp2", "ssh2", "brotlienc", "brotlidec", "brotlicommon" } else [_][]const u8{ "c", "curl" };
for (libs) |i| {
step.linkSystemLibrary(i);
}
if (builtin.os.tag == .linux) {
step.linkSystemLibraryNeeded("libcurl");
}
if (builtin.os.tag == .windows) {
step.include_dirs.append(.{ .raw_path = "c:/msys64/mingw64/include" }) catch unreachable;
step.lib_paths.append("c:/msys64/mingw64/lib") catch unreachable;
}
}</code>
Then, call for the step.
<code>zig
const exe = b.addExecutable("zig-curl-example", "src/main.zig");
exe.setTarget(target);
exe.setBuildMode(mode);
pkgs.addAllTo(exe);
linkToCurl(exe); // DO THIS
exe.install();</code>
License
MIT
Author
Yasuhiro Matsumoto (a.k.a. mattn)
|
[] |
https://avatars.githubusercontent.com/u/109492796?v=4
|
forum
|
zigcc/forum
|
2022-07-20T12:03:21Z
|
Zig 语言中文社区论坛
|
main
| 78 | 38 | 1 | 38 |
https://api.github.com/repos/zigcc/forum/tags
|
MIT
|
[
"zig"
] | 9 | false |
2025-04-09T05:52:29Z
| false | false |
unknown
|
github
|
[] |
<a>Zig 语言中文社区</a>论坛
<ul>
<li>https://github.com/orgs/zigcc/discussions/</li>
</ul>
订阅
<ul>
<li><a>RSS</a></li>
<li>邮件,可以通过 watch 本仓库实现</li>
</ul>
|
[] |
https://avatars.githubusercontent.com/u/65322356?v=4
|
zig-lsp-codegen
|
zigtools/zig-lsp-codegen
|
2022-05-30T05:57:32Z
|
LSP codegen based on the MetaModel
|
main
| 0 | 37 | 15 | 37 |
https://api.github.com/repos/zigtools/zig-lsp-codegen/tags
|
MIT
|
[
"lsp",
"zig",
"zig-package"
] | 280 | false |
2025-04-30T17:33:10Z
| true | true |
0.14.0
|
github
|
[] |
<a></a>
<a></a>
<a></a>
<a></a>
Zig LSP Codegen
Generates <code>std.json</code> compatible Zig code based on the official <a>LSP MetaModel</a>
Installation
<blockquote>
<span class="bg-blue-100 text-blue-800 text-xs font-medium me-2 px-2.5 py-0.5 rounded dark:bg-blue-900 dark:text-blue-300">NOTE</span>
The minimum supported Zig version is <code>0.14.0</code>.
</blockquote>
```bash
Initialize a <code>zig build</code> project if you haven't already
zig init
Add the <code>lsp_codegen</code> package to your <code>build.zig.zon</code>
zig fetch --save git+https://github.com/zigtools/zig-lsp-codegen.git
```
You can then import <code>lsp_codegen</code> in your <code>build.zig</code> with:
<code>zig
const lsp_codegen = b.dependency("lsp_codegen", .{});
const exe = b.addExecutable(...);
exe.root_module.addImport("lsp", lsp_codegen.module("lsp"));</code>
|
[] |
https://avatars.githubusercontent.com/u/1416077?v=4
|
zig-async
|
Jack-Ji/zig-async
|
2022-05-19T15:50:52Z
|
A simple and easy to use async task library for zig.
|
main
| 0 | 36 | 2 | 36 |
https://api.github.com/repos/Jack-Ji/zig-async/tags
|
MIT
|
[
"async",
"zig"
] | 36 | false |
2025-04-29T11:00:25Z
| true | true |
unknown
|
github
|
[] |
zig-async
An simple and easy to use async task library for zig.
Async Task
Task running in separate thread, returns <code>Future</code> after launched.
<code>Future</code> represents task's return value in the future, which can be queried by using its waiting methods.
The wrapped data within <code>Future</code> will be automatically destroyed if supported by struct (has <code>deinit</code> method);
```zig
const Result = struct {
const Self = @This();
<code>allocator: std.mem.Allocator,
c: u32,
pub fn init(allocator: std.mem.Allocator, _c: u32) !*Self {
var self = try allocator.create(Self);
self.* = .{
.allocator = allocator,
.c = _c,
};
return self;
}
/// Will be called automatically when destorying future
pub fn deinit(self: *Self) void {
self.allocator.destroy(self);
}
</code>
};
fn add(a: u32, b: u32) !*Result {
return try Result.init(std.testing.allocator, a + b);
}
const MyTask = Task(add);
var future = try MyTask.launch(std.testing.allocator, .{ 2, 1 });
defer future.deinit();
const ret = future.wait();
try testing.expectEqual(@as(u32, 3), if (ret) |d| d.c else |_| unreachable);
```
Channel
Generic message queue used for communicating between threads.
Capable of free memory automatically if supported by embedded struct (has <code>deinit</code> method).
```zig
const MyData = struct {
d: i32,
<code>/// Will be called automatically when destorying popped result
pub fn deinit(self: *@This()) void {
}
</code>
};
const MyChannel = Channel(MyData);
var channel = try MyChannel.init(std.testing.allocator);
defer channel.deinit();
try channel.push(.{ .d = 1 });
try channel.push(.{ .d = 2 });
try channel.push(.{ .d = 3 });
try channel.push(.{ .d = 4 });
try channel.push(.{ .d = 5 });
try testing.expect(channel.pop().?.d, 1);
var result = channel.popn(3).?;
defer result.deinit();
try testing.expect(result.elements[0].d == 2);
try testing.expect(result.elements[1].d == 3);
try testing.expect(result.elements[2].d == 4);
```
|
[] |
https://avatars.githubusercontent.com/u/10111?v=4
|
zig-tflite
|
mattn/zig-tflite
|
2022-08-17T13:33:56Z
|
Zig binding for TensorFlow Lite
|
main
| 0 | 36 | 1 | 36 |
https://api.github.com/repos/mattn/zig-tflite/tags
|
-
|
[
"deep-learning",
"tensorflow-lite",
"zig"
] | 33 | false |
2025-05-05T18:19:53Z
| true | false |
unknown
|
github
|
[] |
zig-tflite
Zi binding for TensorFlow Lite
Usage
```zig
const std = @import("std");
const tflite = @import("zig-tflite");
pub fn main() anyerror!void {
var m = try tflite.modelFromFile("testdata/xor_model.tflite");
defer m.deinit();
<code>var o = try tflite.interpreterOptions();
defer o.deinit();
var i = try tflite.interpreter(m, o);
defer i.deinit();
try i.allocateTensors();
var inputTensor = i.inputTensor(0);
var outputTensor = i.outputTensor(0);
var input = inputTensor.data(f32);
var output = outputTensor.data(f32);
input[0] = 0;
input[1] = 1;
try i.invoke();
var result: f32 = if (output[0] > 0.5) 1 else 0;
std.log.warn("0 xor 1 = {}", .{result});
</code>
}
```
Example: <a>https://github.com/mattn/zig-tflite-example/</a>
Requirements
<ul>
<li>TensorFlow Lite - This release requires 2.2.0-rc3</li>
</ul>
Tensorflow Installation
You must install Tensorflow Lite C API. Assuming the source is under /source/directory/tensorflow
<code>$ cd /source/directory/tensorflow
$ bazel build --config opt --config monolithic tensorflow:libtensorflow_c.so</code>
Or to just compile the tensorflow lite libraries:
<code>$ cd /some/path/tensorflow
$ bazel build --config opt --config monolithic //tensorflow/lite:libtensorflowlite.so
$ bazel build --config opt --config monolithic //tensorflow/lite/c:libtensorflowlite_c.so</code>
Installation
<code>$ zig build</code>
Delegate addins
<ul>
<li><a>XNNPACK</a></li>
<li><a>EdgeTPU</a></li>
</ul>
License
MIT
Author
Yasuhiro Matsumoto (a.k.a. mattn)
|
[] |
https://avatars.githubusercontent.com/u/36456999?v=4
|
zig-tools.nvim
|
NTBBloodbath/zig-tools.nvim
|
2022-08-06T18:46:28Z
|
Zig development tools for Neovim.
|
master
| 0 | 35 | 3 | 35 |
https://api.github.com/repos/NTBBloodbath/zig-tools.nvim/tags
|
GPL-3.0
|
[
"neovim",
"tools",
"zig"
] | 67 | false |
2025-02-21T23:45:38Z
| false | false |
unknown
|
github
|
[] |
zig-tools.nvim
zig-tools.nvim is a Neovim (>= 0.7.x) plugin that adds some Zig-specific features to Neovim. WIP.
zig-tools.nvim aims to provide Zig integration to your favorite editor, and that integration is a
swiss army knife, all-in-one. That means, zig-tools.nvim will provide an integration with Zig
build system (by using your project <code>build.zig</code>), available third-party dependencies managers
(zigmod and gyro) and ZLS (Zig Language Server).
For example, zig-tools.nvim will create commands to run specific <code>build.zig</code> tasks, compile
<em>and run</em> your project, live <em>automatic</em> rebuild, add/remove/update dependencies, etc.
Design mantra
<ul>
<li><strong>Freedom</strong>. You are free to use <em>and do</em> only what you want and only when you want.
zig-tools.nvim will never force you to use one of its features.</li>
<li><strong>Simplicity</strong>. Development tools should be mnemonic, easy to understand <em>and use</em>.</li>
<li><strong>Your setup, your choices</strong>. Nobody better than you knows what is best for your system and your
Neovim setup, zig-tools.nvim will take care not to get in your way.</li>
</ul>
Features
<ul>
<li>Zig build system integration.<ul>
<li>Compile <em>and run</em> your project.</li>
<li>Live rebuild on changes.</li>
<li>Run your additional build tasks (e.g. <code>zig build tests</code>).</li>
</ul>
</li>
<li>opt-in Zig third-party dependencies managers integration (add, remove and update your
zigmod/gyro dependencies on the fly!).</li>
<li>opt-in LSP integration (with support for inlay hints (maybe? seems to not work with zls yet),
thanks to rust-tools.nvim author). See <a>FAQ</a> if you have questions about this integration.</li>
</ul>
Requirements
System-wide
<ul>
<li>git (optional, required by zls integration)</li>
<li>curl / wget (optional, required by zls integration)</li>
<li>Neovim (>= 0.7.x)</li>
<li>ripgrep (>= 11.0)</li>
</ul>
Neovim
<ul>
<li><a>akinsho/toggleterm.nvim</a></li>
<li><a>nvim-lua/plenary.nvim</a></li>
</ul>
Installation
You can use your favorite plugins manager to get zig-tools.nvim, we are going to use packer here:
<code>lua
use({
"NTBBloodbath/zig-tools.nvim",
-- Load zig-tools.nvim only in Zig buffers
ft = "zig",
config = function()
-- Initialize with default config
require("zig-tools").setup()
end,
requires = {
{
"akinsho/toggleterm.nvim",
config = function()
require("toggleterm").setup()
end,
},
{
"nvim-lua/plenary.nvim",
module_pattern = "plenary.*"
}
},
})</code>
Configuration
zig-tools.nvim comes with sane <em>and opinionated</em> defaults for its configurations. These defaults
are the following:
<code>lua
--- zig-tools.nvim configuration
---@type table
_G.zigtools_config = {
--- Commands to interact with your project compilation
---@type boolean
expose_commands = true,
--- Format source code
---@type table
formatter = {
--- Enable formatting, create commands
---@type boolean
enable = true,
--- Events to run formatter, empty to disable
---@type table
events = {},
},
--- Check for compilation-time errors
---@type table
checker = {
--- Enable checker, create commands
---@type boolean
enable = true,
--- Run before trying to compile?
---@type boolean
before_compilation = true,
--- Events to run checker
---@type table
events = {},
},
--- Project compilation helpers
---@type table
project = {
--- Extract all build tasks from `build.zig` and expose them
---@type boolean
build_tasks = true,
--- Enable rebuild project on save? (`:ZigLive` command)
---@type boolean
live_reload = true,
--- Extra flags to be passed to compiler
---@type table
flags = {
--- `zig build` flags
---@type table
build = {"--prominent-compile-errors"},
--- `zig run` flags
---@type table
run = {},
},
--- Automatically compile your project from within Neovim
auto_compile = {
--- Enable automatic compilation
---@type boolean
enable = false,
--- Automatically run project after compiling it
---@type boolean
run = true,
},
},
--- zig-tools.nvim integrations
---@type table
integrations = {
--- Third-party Zig packages manager integration
---@type table
package_managers = {"zigmod", "gyro"},
--- Zig Language Server
---@type table
zls = {
--- Enable inlay hints
---@type boolean
hints = false,
--- Manage installation
---@type table
management = {
--- Enable ZLS management
---@type boolean
enable = false,
--- Installation path
---@type string
install_path = os.getenv("HOME") .. "/.local/bin",
--- Source path (where to clone repository when building from source)
---@type string
source_path = os.getenv("HOME") .. "/.local/zig/zls",
},
},
}
}</code>
<blockquote>
Wanna know why it is a global scope table? Make sure to read the <a>API</a> document.
</blockquote>
Usage
Once installed and configured, zig-tools.nvim is going to make and run an augroup (<code>ZigTools</code>)
with an autocommand for <code>*.zig</code> files that sets up <code>:Zig</code> command on Zig buffers.
<code>:Zig</code> command works with subcommands, that means its usage is something like this:
```vim
" Build project
:Zig build
" Run tests
:Zig task test
```
You can then use this command to create mappings, run autocommands, etc on Zig files.
If you did set <code>expose_commands</code> configuration option to <code>false</code> in your zig-tools.nvim setup
then <code>:Zig</code> command is not going to be available. However, you can still use its functionalities
by directly using zig-tools.nvim commands API.
<blockquote>
You can see full <code>:Zig</code> command reference in the <a>API</a> document.
</blockquote>
FAQ
<blockquote>
Last design mantra says that zig-tools.nvim is not going to get in my way but it can also
manage zls installation. How does it make sense?
</blockquote>
zig-tools.nvim <code>zls</code> management works pretty differently from Neovim plugins like lsp-installer.
That means, zig-tools.nvim will only get <code>zls</code> from your chosen installation method (gh
releases or build from source) and then move <code>zls</code> binary to your <code>PATH</code> so you can set up <code>zls</code>
yourself by using <code>nvim-lspconfig</code> with no weird abstractions.
License
As all my other projects, zig-tools.nvim is licensed under <a>GPLv3</a> license.
|
[] |
https://avatars.githubusercontent.com/u/9960133?v=4
|
zig-bl602-nuttx
|
lupyuen/zig-bl602-nuttx
|
2022-05-24T09:12:29Z
|
Zig on RISC-V BL602 with Apache NuttX RTOS and LoRaWAN
|
main
| 0 | 35 | 2 | 35 |
https://api.github.com/repos/lupyuen/zig-bl602-nuttx/tags
|
Apache-2.0
|
[
"bl602",
"bl604",
"iot",
"lora",
"lorawan",
"nuttx",
"pinecone",
"pinedio",
"riscv32",
"zig"
] | 814 | false |
2024-11-09T02:36:24Z
| false | false |
unknown
|
github
|
[] |
Zig on RISC-V BL602 with Apache NuttX RTOS and LoRaWAN
Read the articles...
<ul>
<li>
<a>"Zig on RISC-V BL602: Quick Peek with Apache NuttX RTOS"</a>
</li>
<li>
<a>"Build an IoT App with Zig and LoRaWAN"</a>
</li>
</ul>
To build the Hello Zig App for NuttX on BL602...
```bash
Enable Zig App in NuttX menuconfig
make menuconfig
TODO: Select "Application Configuration > Examples > Hello Zig Example"
Save the configuration and exit menuconfig.
Build Nuttx
make
NuttX Build fails with Undefined Reference to <code>hello_zig_main</code>
That's OK, here's the fix...
Download our modified Zig App for NuttX
git clone --recursive https://github.com/lupyuen/zig-bl602-nuttx
cd zig-bl602-nuttx
Compile the Zig App for BL602 (RV32IMACF with Hardware Floating-Point)
zig build-obj \
-target riscv32-freestanding-none \
-mcpu sifive_e76 \
hello_zig_main.zig
Dump the ABI for the compiled app
riscv64-unknown-elf-readelf -h -A hello_zig_main.o
Shows "Flags: 0x1, RVC, soft-float ABI"
Which is Software Floating-Point.
This won't link with NuttX because NuttX is compiled with Hardware Floating-Point
We change Software Floating-Point to Hardware Floating-Point...
Edit hello_zig_main.o in a Hex Editor, change byte 0x24 from 0x01 to 0x03
(See https://en.wikipedia.org/wiki/Executable_and_Linkable_Format#File_header)
Dump the ABI for the compiled app
riscv64-unknown-elf-readelf -h -A hello_zig_main.o
Shows "Flags: 0x3, RVC, single-float ABI"
Which is Hardware Floating-Point and will link with NuttX
Copy the compiled app to NuttX and overwrite <code>hello.o</code>
TODO: Change "$HOME/nuttx" to your NuttX Project Directory
cp hello_zig_main.o $HOME/nuttx/apps/examples/hello/*hello.o
Build NuttX to link the Zig Object from <code>hello.o</code>
TODO: Change "$HOME/nuttx" to your NuttX Project Directory
cd $HOME/nuttx/nuttx
make
NuttX build should now succeed
```
Boot NuttX and enter this at the NuttX Shell...
```text
NuttShell (NSH) NuttX-10.3.0-RC2
nsh> hello_zig
Hello, Zig!
```
For the LoRaWAN Zig App, see this...
<ul>
<li><a>"Convert LoRaWAN App to Zig"</a></li>
</ul>
To compile the LoRa SX1262 Library in C with Zig Compiler, see this...
<ul>
<li><a>"Zig Compiler as Drop-In Replacement for GCC"</a></li>
</ul>
Here's how we made Zig and LoRaWAN run on BL602 NuttX...
Zig App for NuttX
Apache NuttX RTOS is bundled with a simple Zig App ... Let's run this on BL602: <a>hello_zig_main.zig</a>
```zig
// Import the Zig Standard Library
const std = @import("std");
// Import printf() from C
pub extern fn printf(
_format: [*:0]const u8
) c_int;
// Main Function
pub export fn hello_zig_main(
_argc: c_int,
_argv: [<em>]const [</em>]const u8
) c_int {
_ = _argc;
_ = _argv;
_ = printf("Hello, Zig!\n");
return 0;
}
```
We fixed the last 2 lines to make the Zig compiler happy...
```zig
// Previously: printf("Hello, Zig!\n");
// Zig needs us to use the returned value from printf()...
_ = printf("Hello, Zig!\n");
// Previously this was missing.
// Zig needs us to return a value...
return 0;
```
Original version is here: <a>hello_zig_main.zig</a>
Enable Zig App
To enable the Zig App in NuttX...
<code>bash
make menuconfig</code>
Select "Application Configuration > Examples > Hello Zig Example"
Save the configuration and exit menuconfig.
Build Fails on NuttX
When we build NuttX...
<code>bash
make</code>
We see this error...
<code>text
LD: nuttx
riscv64-unknown-elf-ld: nuttx/staging/libapps.a(builtin_list.c.home.user.nuttx.apps.builtin.o):(.rodata.g_builtins+0xbc):
undefined reference to `hello_zig_main'</code>
<a>(Source)</a>
Which looks similar to this issue...
https://github.com/apache/incubator-nuttx/issues/6219
This seems to be caused by the NuttX Build not calling the Zig Compiler.
But no worries! Let's compile the Zig App ourselves and link into NuttX.
Compile Zig App
Here's how we compile our Zig App for RISC-V BL602 and link it with NuttX...
```bash
Download our modified Zig App for NuttX
git clone --recursive https://github.com/lupyuen/zig-bl602-nuttx
cd zig-bl602-nuttx
Compile the Zig App for BL602 (RV32IMACF with Hardware Floating-Point)
zig build-obj \
-target riscv32-freestanding-none \
-mcpu sifive_e76 \
hello_zig_main.zig
Copy the compiled app to NuttX and overwrite <code>hello.o</code>
TODO: Change "$HOME/nuttx" to your NuttX Project Directory
cp hello_zig_main.o $HOME/nuttx/apps/examples/hello/*hello.o
Build NuttX to link the Zig Object from <code>hello.o</code>
TODO: Change "$HOME/nuttx" to your NuttX Project Directory
cd $HOME/nuttx/nuttx
make
```
Zig Target
<em>Why is the target <code>riscv32-freestanding-none</code>?</em>
Zig Targets have the form <code><arch><sub>-<os>-<abi></code>...
<code>riscv32</code>: Because BL602 is a 32-bit RISC-V processor
<code>freestanding</code>: Because embedded targets don't need an OS
<code>none</code>: Because embedded targets don't specify the ABI
<em>Why is the target CPU <code>sifive_e76</code>?</em>
BL602 is designated as RV32IMACF...
| Designation | Meaning |
|:---:|:---|
| <strong><code>RV32I</code></strong> | 32-bit RISC-V with Base Integer Instructions
| <strong><code>M</code></strong> | Integer Multiplication + Division
| <strong><code>A</code></strong> | Atomic Instructions
| <strong><code>C</code></strong> | Compressed Instructions
| <strong><code>F</code></strong> | Single-Precision Floating-Point
<a>(Source)</a>
Among all Zig Targets, only <code>sifive_e76</code> has the same designation...
<code>bash
$ zig targets
...
"sifive_e76": [ "a", "c", "f", "m" ],</code>
<a>(Source)</a>
Thus we use <code>sifive_e76</code> as our CPU Target.
Alternatively we may use <code>baseline_rv32-d</code> as our CPU Target...
```bash
Compile the Zig App for BL602 (RV32IMACF with Hardware Floating-Point)
zig build-obj \
-target riscv32-freestanding-none \
-mcpu=baseline_rv32-d \
hello_zig_main.zig
```
Because...
<ul>
<li>
<code>baseline_rv32</code> means RV32IMACFD
(D for Double-Precision Floating-Point)
</li>
<li>
<code>-d</code> means remove the Double-Precision Floating-Point (D)
(But keep the Single-Precision Floating-Point)
</li>
</ul>
<a>(More about RISC-V Feature Flags. Thanks Matheus!)</a>
Floating-Point ABI
When linking the Compiled Zig App with NuttX, we see this error...
<code>bash
$ make
...
riscv64-unknown-elf-ld: nuttx/staging/libapps.a(hello_main.c.home.user.nuttx.apps.examples.hello.o):
can't link soft-float modules with single-float modules</code>
That's because NuttX was compiled for (Single-Precision) <strong>Hardware Floating-Point</strong> ABI (Application Binary Interface)...
```bash
Do this BEFORE overwriting hello.o by hello_zig_main.o.
"*hello.o" expands to something like "hello_main.c.home.user.nuttx.apps.examples.hello.o"
$ riscv64-unknown-elf-readelf -h -A $HOME/nuttx/apps/examples/hello/*hello.o
ELF Header:
Magic: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00
Class: ELF32
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: REL (Relocatable file)
Machine: RISC-V
Version: 0x1
Entry point address: 0x0
Start of program headers: 0 (bytes into file)
Start of section headers: 4528 (bytes into file)
Flags: 0x3, RVC, single-float ABI
Size of this header: 52 (bytes)
Size of program headers: 0 (bytes)
Number of program headers: 0
Size of section headers: 40 (bytes)
Number of section headers: 26
Section header string table index: 25
Attribute Section: riscv
File Attributes
Tag_RISCV_stack_align: 16-bytes
Tag_RISCV_arch: "rv32i2p0_m2p0_a2p0_f2p0_c2p0"
```
<a>(Source)</a>
<a>(NuttX was compiled with the GCC Flags <code>-march=rv32imafc -mabi=ilp32f</code>)</a>
Whereas Zig Compiler produces an Object File with <strong>Software Floating-Point</strong> ABI...
<code>bash
$ riscv64-unknown-elf-readelf -h -A hello_zig_main.o
ELF Header:
Magic: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00
Class: ELF32
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: REL (Relocatable file)
Machine: RISC-V
Version: 0x1
Entry point address: 0x0
Start of program headers: 0 (bytes into file)
Start of section headers: 11968 (bytes into file)
Flags: 0x1, RVC, soft-float ABI
Size of this header: 52 (bytes)
Size of program headers: 0 (bytes)
Number of program headers: 0
Size of section headers: 40 (bytes)
Number of section headers: 24
Section header string table index: 22
Attribute Section: riscv
File Attributes
Tag_RISCV_stack_align: 16-bytes
Tag_RISCV_arch: "rv32i2p0_m2p0_a2p0_f2p0_c2p0"</code>
<a>(Source)</a>
GCC won't allow us to link object files with Software Floating-Point and Hardware Floating-Point ABIs!
(Why did the Zig Compiler produce an Object File with Software Floating-Point ABI, when <code>sifive_e76</code> supports Hardware Floating-Point? <a>See this</a>)
Patch ELF Header
Zig Compiler generates an Object File with <strong>Software Floating-Point</strong> ABI (Application Binary Interface)...
```bash
Dump the ABI for the compiled app
$ riscv64-unknown-elf-readelf -h -A hello_zig_main.o
...
Flags: 0x1, RVC, soft-float ABI
```
This won't link with NuttX because NuttX is compiled with Hardware Floating-Point ABI.
We fix this by modifying the ELF Header...
<ul>
<li>
Edit <code>hello_zig_main.o</code> in a Hex Editor
<a>(Like VSCode Hex Editor)</a>
</li>
<li>
Change byte <code>0x24</code> (Flags) from <code>0x01</code> (Soft Float) to <code>0x03</code> (Hard Float)
<a>(See this)</a>
</li>
</ul>
We verify that the Object File has been changed to <strong>Hardware Floating-Point</strong> ABI...
```bash
Dump the ABI for the compiled app
$ riscv64-unknown-elf-readelf -h -A hello_zig_main.o
...
Flags: 0x3, RVC, single-float ABI
```
This is now Hardware Floating-Point ABI and will link with NuttX.
Now we link the modified Object File with NuttX...
```bash
Copy the compiled app to NuttX and overwrite <code>hello.o</code>
TODO: Change "$HOME/nuttx" to your NuttX Project Directory
cp hello_zig_main.o $HOME/nuttx/apps/examples/hello/*hello.o
Build NuttX to link the Zig Object from <code>hello.o</code>
TODO: Change "$HOME/nuttx" to your NuttX Project Directory
cd $HOME/nuttx/nuttx
make
```
The NuttX Build should now succeed.
<em>Is it really OK to change the ABI like this?</em>
Well technically the <strong>ABI is correctly generated</strong> by the Zig Compiler...
```bash
Dump the ABI for the compiled Zig app
$ riscv64-unknown-elf-readelf -h -A hello_zig_main.o
...
Flags: 0x1, RVC, soft-float ABI
Tag_RISCV_arch: "rv32i2p0_m2p0_a2p0_f2p0_c2p0"
```
The last line translates to <strong>RV32IMACF</strong>, which means that the RISC-V Instruction Set is indeed targeted for <strong>Hardware Floating-Point</strong>.
We're only editing the <strong>ELF Header</strong>, because it didn't seem to reflect the correct ABI for the Object File.
<em>Is there a proper fix for this?</em>
In future the Zig Compiler might allow us to specify the <strong>Floating-Point ABI</strong> as the target...
```bash
Compile the Zig App for BL602
("ilp32f" means Hardware Floating-Point ABI)
zig build-obj \
-target riscv32-freestanding-ilp32f \
...
```
<a>(See this)</a>
Stay Tuned!
<em>Can we patch the ELF Header via Command Line?</em>
Yep we may patch the ELF Header via <strong>Command Line</strong>...
<code>bash
xxd -c 1 hello_zig_main.o \
| sed 's/00000024: 01/00000024: 03/' \
| xxd -r -c 1 - hello_zig_main2.o</code>
Zig Runs OK!
The NuttX Build succeeds. Zig runs OK on NuttX BL602!
```text
NuttShell (NSH) NuttX-10.3.0-RC2
nsh> hello_zig
Hello, Zig!
```
Hello App
Remember that we overwrote <code>hello.o</code> with our Zig Compiled Object File.
NuttX Build will fail unless we provide the <code>hello_main</code> function...
<code>text
riscv64-unknown-elf-ld: nuttx/staging/libapps.a(builtin_list.c.home.user.nuttx.apps.builtin.o):(.rodata.g_builtins+0xcc):
undefined reference to `hello_main'</code>
That's why we define <code>hello_main</code> in our Zig App...
<code>zig
pub export fn hello_main(
_argc: c_int,
_argv: [*]const [*]const u8
) c_int {
_ = _argc;
_ = _argv;
_ = printf("Hello, Zig!\n");
return 0;
}</code>
<a>(Source)</a>
Which means that the <code>hello</code> app will call our Zig Code too...
```text
NuttShell (NSH) NuttX-10.3.0-RC2
nsh> hello
Hello, Zig!
```
<a><em>Pine64 PineCone BL602 Board (right) connected to Semtech SX1262 LoRa Transceiver (left) over SPI</em></a>
Zig Compiler as Drop-In Replacement for GCC
<em>Will Zig Compiler work as <a>Drop-In Replacement for GCC</a> for compiling NuttX Libraries?</em>
Let's test it on the <a>LoRa SX1262 Library</a> for Apache NuttX RTOS!
Here's how NuttX compiles the <a>LoRa SX1262 Library</a> with GCC...
```bash
LoRa SX1262 Source Directory
cd $HOME/nuttx/nuttx/libs/libsx1262
Compile radio.c with GCC
riscv64-unknown-elf-gcc \
-c \
-fno-common \
-Wall \
-Wstrict-prototypes \
-Wshadow \
-Wundef \
-Os \
-fno-strict-aliasing \
-fomit-frame-pointer \
-fstack-protector-all \
-ffunction-sections \
-fdata-sections \
-g \
-march=rv32imafc \
-mabi=ilp32f \
-mno-relax \
-isystem "$HOME/nuttx/nuttx/include" \
-D__NuttX__ \
-DNDEBUG \
-DARCH_RISCV \
-pipe src/radio.c \
-o src/radio.o
Compile sx126x.c with GCC
riscv64-unknown-elf-gcc \
-c \
-fno-common \
-Wall \
-Wstrict-prototypes \
-Wshadow \
-Wundef \
-Os \
-fno-strict-aliasing \
-fomit-frame-pointer \
-fstack-protector-all \
-ffunction-sections \
-fdata-sections \
-g \
-march=rv32imafc \
-mabi=ilp32f \
-mno-relax \
-isystem "$HOME/nuttx/nuttx/include" \
-D__NuttX__ \
-DNDEBUG \
-DARCH_RISCV \
-pipe src/sx126x.c \
-o src/sx126x.o
Compile sx126x-nuttx.c with GCC
riscv64-unknown-elf-gcc \
-c \
-fno-common \
-Wall \
-Wstrict-prototypes \
-Wshadow \
-Wundef \
-Os \
-fno-strict-aliasing \
-fomit-frame-pointer \
-fstack-protector-all \
-ffunction-sections \
-fdata-sections \
-g \
-march=rv32imafc \
-mabi=ilp32f \
-mno-relax \
-isystem "$HOME/nuttx/nuttx/include" \
-D__NuttX__ \
-DNDEBUG \
-DARCH_RISCV \
-pipe src/sx126x-nuttx.c \
-o src/sx126x-nuttx.o
```
We make these changes...
<ul>
<li>
Change <code>riscv64-unknown-elf-gcc</code> to <code>zig cc</code>
</li>
<li>
Add the target <code>-target riscv32-freestanding-none -mcpu=baseline_rv32-d</code>
</li>
<li>
Remove <code>-march=rv32imafc</code>
</li>
</ul>
And we run this...
```bash
LoRa SX1262 Source Directory
cd $HOME/nuttx/nuttx/libs/libsx1262
Compile radio.c with zig cc
zig cc \
-target riscv32-freestanding-none \
-mcpu=baseline_rv32-d \
-c \
-fno-common \
-Wall \
-Wstrict-prototypes \
-Wshadow \
-Wundef \
-Os \
-fno-strict-aliasing \
-fomit-frame-pointer \
-fstack-protector-all \
-ffunction-sections \
-fdata-sections \
-g \
-mabi=ilp32f \
-mno-relax \
-isystem "$HOME/nuttx/nuttx/include" \
-D__NuttX__ \
-DNDEBUG \
-DARCH_RISCV \
-pipe src/radio.c \
-o src/radio.o
Compile sx126x.c with zig cc
zig cc \
-target riscv32-freestanding-none \
-mcpu=baseline_rv32-d \
-c \
-fno-common \
-Wall \
-Wstrict-prototypes \
-Wshadow \
-Wundef \
-Os \
-fno-strict-aliasing \
-fomit-frame-pointer \
-fstack-protector-all \
-ffunction-sections \
-fdata-sections \
-g \
-mabi=ilp32f \
-mno-relax \
-isystem "$HOME/nuttx/nuttx/include" \
-D__NuttX__ \
-DNDEBUG \
-DARCH_RISCV \
-pipe src/sx126x.c \
-o src/sx126x.o
Compile sx126x-nuttx.c with zig cc
zig cc \
-target riscv32-freestanding-none \
-mcpu=baseline_rv32-d \
-c \
-fno-common \
-Wall \
-Wstrict-prototypes \
-Wshadow \
-Wundef \
-Os \
-fno-strict-aliasing \
-fomit-frame-pointer \
-fstack-protector-all \
-ffunction-sections \
-fdata-sections \
-g \
-mabi=ilp32f \
-mno-relax \
-isystem "$HOME/nuttx/nuttx/include" \
-D__NuttX__ \
-DNDEBUG \
-DARCH_RISCV \
-pipe src/sx126x-nuttx.c \
-o src/sx126x-nuttx.o
Link Zig Object Files with NuttX after compiling with <code>zig cc</code>
TODO: Change "$HOME/nuttx" to your NuttX Project Directory
cd $HOME/nuttx/nuttx
make
```
Zig Compiler shows these errors...
<code>text
In file included from src/sx126x-nuttx.c:3:
In file included from nuttx/include/debug.h:39:
In file included from nuttx/include/sys/uio.h:45:
nuttx/include/sys/types.h:119:9: error: unknown type name '_size_t'
typedef _size_t size_t;
^
nuttx/include/sys/types.h:120:9: error: unknown type name '_ssize_t'
typedef _ssize_t ssize_t;
^
nuttx/include/sys/types.h:121:9: error: unknown type name '_size_t'
typedef _size_t rsize_t;
^
nuttx/include/sys/types.h:174:9: error: unknown type name '_wchar_t'
typedef _wchar_t wchar_t;
^
In file included from src/sx126x-nuttx.c:4:
In file included from nuttx/include/stdio.h:34:
nuttx/include/nuttx/fs/fs.h:238:20: error: use of undeclared identifier 'NAME_MAX'
char parent[NAME_MAX + 1];
^</code>
We fix this by including the right header files...
```c
if defined(<strong>NuttX</strong>) && defined(<strong>clang</strong>) // Workaround for NuttX with zig cc
include
include "../../nuttx/include/limits.h"
endif // defined(<strong>NuttX</strong>) && defined(<strong>clang</strong>)
```
Into these source files...
<ul>
<li><a>radio.c</a></li>
<li><a>sx126x-nuttx.c</a></li>
<li><a>sx126x.c</a></li>
</ul>
<a>(See the changes)</a>
We insert this code to tell us (at runtime) whether it was compiled with Zig Compiler or GCC...
```c
void SX126xIoInit( void ) {
ifdef <strong>clang</strong>
warning Compiled with zig cc
<code>puts("SX126xIoInit: Compiled with zig cc");
</code>
else
warning Compiled with gcc
<code>puts("SX126xIoInit: Compiled with gcc");
</code>
endif // <strong>clang</strong>
```
<a>(Source)</a>
Compiled with <code>zig cc</code>, the LoRa SX1262 Library runs OK on NuttX yay!
```text
nsh> lorawan_test
SX126xIoInit: Compiled with zig cc
...
=========== MLME-Confirm ============
STATUS : OK
=========== JOINED ============
OTAA
DevAddr : 000E268C
DATA RATE : DR_2
...
=========== MCPS-Confirm ============
STATUS : OK
===== UPLINK FRAME 1 =====
CLASS : A
TX PORT : 1
TX DATA : UNCONFIRMED
48 69 20 4E 75 74 74 58 00
DATA RATE : DR_3
U/L FREQ : 923400000
TX POWER : 0
CHANNEL MASK: 0003
```
<a>(See the complete log)</a>
LoRaWAN Library for NuttX
Let's compile the huge <a>LoRaWAN Library</a> with Zig Compiler.
NuttX compiles the LoRaWAN Library like this...
```bash
LoRaWAN Source Directory
cd $HOME/nuttx/nuttx/libs/liblorawan
Compile mac/LoRaMac.c with GCC
riscv64-unknown-elf-gcc \
-c \
-fno-common \
-Wall \
-Wstrict-prototypes \
-Wshadow \
-Wundef \
-Os \
-fno-strict-aliasing \
-fomit-frame-pointer \
-fstack-protector-all \
-ffunction-sections \
-fdata-sections \
-g \
-march=rv32imafc \
-mabi=ilp32f \
-mno-relax \
-isystem "$HOME/nuttx/nuttx/include" \
-D__NuttX__ \
-DNDEBUG \
-DARCH_RISCV \
-pipe src/mac/LoRaMac.c \
-o src/mac/LoRaMac.o
```
We switch to the Zig Compiler...
```bash
LoRaWAN Source Directory
cd $HOME/nuttx/nuttx/libs/liblorawan
Compile mac/LoRaMac.c with zig cc
zig cc \
-target riscv32-freestanding-none \
-mcpu=baseline_rv32-d \
-c \
-fno-common \
-Wall \
-Wstrict-prototypes \
-Wshadow \
-Wundef \
-Os \
-fno-strict-aliasing \
-fomit-frame-pointer \
-fstack-protector-all \
-ffunction-sections \
-fdata-sections \
-g \
-mabi=ilp32f \
-mno-relax \
-isystem "$HOME/nuttx/nuttx/include" \
-D__NuttX__ \
-DNDEBUG \
-DARCH_RISCV \
-pipe src/mac/LoRaMac.c \
-o src/mac/LoRaMac.o
Link Zig Object Files with NuttX after compiling with <code>zig cc</code>
TODO: Change "$HOME/nuttx" to your NuttX Project Directory
cd $HOME/nuttx/nuttx
make
```
We include the right header files into <a>LoRaMac.c</a>...
```c
if defined(<strong>NuttX</strong>) && defined(<strong>clang</strong>) // Workaround for NuttX with zig cc
include
include "../../nuttx/include/limits.h"
endif // defined(<strong>NuttX</strong>) && defined(<strong>clang</strong>)
```
<a>(See the changes)</a>
<a>LoRaMac.c</a> compiles OK with Zig Compiler.
TODO: Compile the other files in the LoRaWAN Library with <code>build.zig</code>
https://ziglang.org/documentation/master/#Zig-Build-System
TODO: Test the LoRaWAN Library
LoRaWAN App for NuttX
Now we compile the LoRaWAN App <a>lorawan_test_main.c</a> with Zig Compiler.
NuttX compiles the LoRaWAN App <a>lorawan_test_main.c</a> like this...
```bash
App Source Directory
cd $HOME/nuttx/apps/examples/lorawan_test/lorawan_test_main.c
Compile lorawan_test_main.c with GCC
riscv64-unknown-elf-gcc \
-c \
-fno-common \
-Wall \
-Wstrict-prototypes \
-Wshadow \
-Wundef \
-Os \
-fno-strict-aliasing \
-fomit-frame-pointer \
-fstack-protector-all \
-ffunction-sections \
-fdata-sections \
-g \
-march=rv32imafc \
-mabi=ilp32f \
-mno-relax \
-isystem "$HOME/nuttx/nuttx/include" \
-D__NuttX__ \
-DNDEBUG \
-DARCH_RISCV \
-pipe \
-I "$HOME/nuttx/apps/graphics/lvgl" \
-I "$HOME/nuttx/apps/graphics/lvgl/lvgl" \
-I "$HOME/nuttx/apps/include" \
-Dmain=lorawan_test_main lorawan_test_main.c \
-o lorawan_test_main.c.home.user.nuttx.apps.examples.lorawan_test.o
```
We switch to Zig Compiler...
```bash
App Source Directory
cd $HOME/nuttx/apps/examples/lorawan_test
Compile lorawan_test_main.c with zig cc
zig cc \
-target riscv32-freestanding-none \
-mcpu=baseline_rv32-d \
-c \
-fno-common \
-Wall \
-Wstrict-prototypes \
-Wshadow \
-Wundef \
-Os \
-fno-strict-aliasing \
-fomit-frame-pointer \
-fstack-protector-all \
-ffunction-sections \
-fdata-sections \
-g \
-mabi=ilp32f \
-mno-relax \
-isystem "$HOME/nuttx/nuttx/include" \
-D__NuttX__ \
-DNDEBUG \
-DARCH_RISCV \
-pipe \
-I "$HOME/nuttx/apps/graphics/lvgl" \
-I "$HOME/nuttx/apps/graphics/lvgl/lvgl" \
-I "$HOME/nuttx/apps/include" \
-Dmain=lorawan_test_main lorawan_test_main.c \
-o *lorawan_test.o
Link Zig Object Files with NuttX after compiling with <code>zig cc</code>
TODO: Change "$HOME/nuttx" to your NuttX Project Directory
cd $HOME/nuttx/nuttx
make
```
We include the right header files into <a>lorawan_test_main.c</a>...
```c
if defined(<strong>NuttX</strong>) && defined(<strong>clang</strong>) // Workaround for NuttX with zig cc
include
include "../../nuttx/include/limits.h"
endif // defined(<strong>NuttX</strong>) && defined(<strong>clang</strong>)
```
<a>(See the changes)</a>
Compiled with <code>zig cc</code>, the LoRaWAN App runs OK on NuttX yay!
```text
nsh> lorawan_test
lorawan_test_main: Compiled with zig cc
...
=========== MLME-Confirm ============
STATUS : OK
=========== JOINED ============
OTAA
DevAddr : 00DC5ED5
DATA RATE : DR_2
...
=========== MCPS-Confirm ============
STATUS : OK
===== UPLINK FRAME 1 =====
CLASS : A
TX PORT : 1
TX DATA : UNCONFIRMED
48 69 20 4E 75 74 74 58 00
DATA RATE : DR_3
U/L FREQ : 923400000
TX POWER : 0
CHANNEL MASK: 0003
```
<a>(See the complete log)</a>
Auto-Translate LoRaWAN App to Zig
The Zig Compiler can auto-translate C code to Zig. <a>(See this)</a>
Here's how we auto-translate our LoRaWAN App <a>lorawan_test_main.c</a> from C to Zig...
<ul>
<li>
Change <code>zig cc</code> to <code>zig translate-c</code>
</li>
<li>
Surround the C Flags by <code>-cflags</code> ... <code>--</code>
</li>
</ul>
Like this...
```bash
App Source Directory
cd $HOME/nuttx/apps/examples/lorawan_test
Auto-translate lorawan_test_main.c from C to Zig
zig translate-c \
-target riscv32-freestanding-none \
-mcpu=baseline_rv32-d \
-cflags \
-fno-common \
-Wall \
-Wstrict-prototypes \
-Wshadow \
-Wundef \
-Os \
-fno-strict-aliasing \
-fomit-frame-pointer \
-fstack-protector-all \
-ffunction-sections \
-fdata-sections \
-g \
-mabi=ilp32f \
-mno-relax \
-- \
-isystem "$HOME/nuttx/nuttx/include" \
-D__NuttX__ \
-DNDEBUG \
-DARCH_RISCV \
-I "$HOME/nuttx/apps/graphics/lvgl" \
-I "$HOME/nuttx/apps/graphics/lvgl/lvgl" \
-I "$HOME/nuttx/apps/include" \
-Dmain=lorawan_test_main \
lorawan_test_main.c \
<blockquote>
lorawan_test_main.zig
```
</blockquote>
Here's the original C code: <a>lorawan_test_main.c</a>
And the auto-translation from C to Zig: <a>translated/lorawan_test_main.zig</a>
Here's a snippet from the original C code...
```c
int main(int argc, FAR char *argv[]) {
ifdef <strong>clang</strong>
<code>puts("lorawan_test_main: Compiled with zig cc");
</code>
else
<code>puts("lorawan_test_main: Compiled with gcc");
</code>
endif // <strong>clang</strong>
<code>// If we are using Entropy Pool and the BL602 ADC is available,
// add the Internal Temperature Sensor data to the Entropy Pool
init_entropy_pool();
// Compute the interval between transmissions based on Duty Cycle
TxPeriodicity = APP_TX_DUTYCYCLE + randr( -APP_TX_DUTYCYCLE_RND, APP_TX_DUTYCYCLE_RND );
const Version_t appVersion = { .Value = FIRMWARE_VERSION };
const Version_t gitHubVersion = { .Value = GITHUB_VERSION };
DisplayAppInfo( "lorawan_test",
&appVersion,
&gitHubVersion );
// Init LoRaWAN
if ( LmHandlerInit( &LmHandlerCallbacks, &LmHandlerParams ) != LORAMAC_HANDLER_SUCCESS )
{
printf( "LoRaMac wasn't properly initialized\n" );
// Fatal error, endless loop.
while ( 1 ) {}
}
// Set system maximum tolerated rx error in milliseconds
LmHandlerSetSystemMaxRxError( 20 );
// The LoRa-Alliance Compliance protocol package should always be initialized and activated.
LmHandlerPackageRegister( PACKAGE_ID_COMPLIANCE, &LmhpComplianceParams );
LmHandlerPackageRegister( PACKAGE_ID_CLOCK_SYNC, NULL );
LmHandlerPackageRegister( PACKAGE_ID_REMOTE_MCAST_SETUP, NULL );
LmHandlerPackageRegister( PACKAGE_ID_FRAGMENTATION, &FragmentationParams );
IsClockSynched = false;
IsFileTransferDone = false;
// Join the LoRaWAN Network
LmHandlerJoin( );
// Set the Transmit Timer
StartTxProcess( LORAMAC_HANDLER_TX_ON_TIMER );
// Handle LoRaWAN Events
handle_event_queue(NULL); // Never returns
return 0;
</code>
}
```
<a>(Source)</a>
And the auto-translated Zig code...
<code>zig
pub export fn lorawan_test_main(arg_argc: c_int, arg_argv: [*c][*c]u8) c_int {
var argc = arg_argc;
_ = argc;
var argv = arg_argv;
_ = argv;
_ = puts("lorawan_test_main: Compiled with zig cc");
init_entropy_pool();
TxPeriodicity = @bitCast(u32, @as(c_int, 40000) + randr(-@as(c_int, 5000), @as(c_int, 5000)));
const appVersion: Version_t = Version_t{
.Value = @bitCast(u32, @as(c_int, 16908288)),
};
const gitHubVersion: Version_t = Version_t{
.Value = @bitCast(u32, @as(c_int, 83886080)),
};
DisplayAppInfo("lorawan_test", &appVersion, &gitHubVersion);
if (LmHandlerInit(&LmHandlerCallbacks, &LmHandlerParams) != LORAMAC_HANDLER_SUCCESS) {
_ = printf("LoRaMac wasn't properly initialized\n");
while (true) {}
}
_ = LmHandlerSetSystemMaxRxError(@bitCast(u32, @as(c_int, 20)));
_ = LmHandlerPackageRegister(@bitCast(u8, @truncate(i8, @as(c_int, 0))), @ptrCast(?*anyopaque, &LmhpComplianceParams));
_ = LmHandlerPackageRegister(@bitCast(u8, @truncate(i8, @as(c_int, 1))), @intToPtr(?*anyopaque, @as(c_int, 0)));
_ = LmHandlerPackageRegister(@bitCast(u8, @truncate(i8, @as(c_int, 2))), @intToPtr(?*anyopaque, @as(c_int, 0)));
_ = LmHandlerPackageRegister(@bitCast(u8, @truncate(i8, @as(c_int, 3))), @ptrCast(?*anyopaque, &FragmentationParams));
IsClockSynched = @as(c_int, 0) != 0;
IsFileTransferDone = @as(c_int, 0) != 0;
LmHandlerJoin();
StartTxProcess(@bitCast(c_uint, LORAMAC_HANDLER_TX_ON_TIMER));
handle_event_queue(@intToPtr(?*anyopaque, @as(c_int, 0)));
return 0;
}</code>
<a>(Source)</a>
We'll refer to this auto-translated Zig Code when we manually convert our LoRaWAN App <a>lorawan_test_main.c</a> from C to Zig in the next section...
<a><em>Pine64 PineDio Stack BL604 (left) talking LoRaWAN to RAKwireless WisGate (right)</em></a>
Convert LoRaWAN App to Zig
Finally we convert the LoRaWAN App <a>lorawan_test_main.c</a> from C to Zig, to show that we can build Complex IoT Apps in Zig.
The LoRaWAN App runs on PineDio Stack BL604 (RISC-V). The app connects to a LoRaWAN Gateway (like ChirpStack or The Things Network) and sends a Data Packet at regular intervals.
Here's the original C code: <a>lorawan_test_main.c</a>
(700 lines of C code)
And our converted LoRaWAN Zig App: <a>lorawan_test.zig</a>
(673 lines of Zig code)
```zig
/// Import the LoRaWAN Library from C
const c = @cImport({
// NuttX Defines
@cDefine("<strong>NuttX</strong>", "");
@cDefine("NDEBUG", "");
@cDefine("ARCH_RISCV", "");
<code>// Workaround for "Unable to translate macro: undefined identifier `LL`"
@cDefine("LL", "");
@cDefine("__int_c_join(a, b)", "a"); // Bypass zig/lib/include/stdint.h
// NuttX Header Files
@cInclude("arch/types.h");
@cInclude("../../nuttx/include/limits.h");
@cInclude("stdio.h");
// LoRaWAN Header Files
@cInclude("firmwareVersion.h");
@cInclude("../libs/liblorawan/src/apps/LoRaMac/common/githubVersion.h");
@cInclude("../libs/liblorawan/src/boards/utilities.h");
@cInclude("../libs/liblorawan/src/mac/region/RegionCommon.h");
@cInclude("../libs/liblorawan/src/apps/LoRaMac/common/Commissioning.h");
@cInclude("../libs/liblorawan/src/apps/LoRaMac/common/LmHandler/LmHandler.h");
@cInclude("../libs/liblorawan/src/apps/LoRaMac/common/LmHandler/packages/LmhpCompliance.h");
@cInclude("../libs/liblorawan/src/apps/LoRaMac/common/LmHandler/packages/LmhpClockSync.h");
@cInclude("../libs/liblorawan/src/apps/LoRaMac/common/LmHandler/packages/LmhpRemoteMcastSetup.h");
@cInclude("../libs/liblorawan/src/apps/LoRaMac/common/LmHandler/packages/LmhpFragmentation.h");
@cInclude("../libs/liblorawan/src/apps/LoRaMac/common/LmHandlerMsgDisplay.h");
</code>
});
// Main Function that will be called by NuttX
pub export fn lorawan_test_main(
_argc: c_int,
_argv: [<em>]const [</em>]const u8
) c_int {
// Call the LoRaWAN Library to set system maximum tolerated rx error in milliseconds
_ = c.LmHandlerSetSystemMaxRxError(20);
<code>// TODO: Call the LoRaWAN Library to Join LoRaWAN Network
// and send a Data Packet
</code>
```
To compile the LoRaWAN Zig App <a>lorawan_test.zig</a>...
```bash
Download our LoRaWAN Zig App for NuttX
git clone --recursive https://github.com/lupyuen/zig-bl602-nuttx
cd zig-bl602-nuttx
Compile the Zig App for BL602 (RV32IMACF with Hardware Floating-Point)
zig build-obj \
--verbose-cimport \
-target riscv32-freestanding-none \
-mcpu=baseline_rv32-d \
-isystem "$HOME/nuttx/nuttx/include" \
-I "$HOME/nuttx/apps/examples/lorawan_test" \
lorawan_test.zig
Patch the ELF Header of <code>lorawan_test.o</code> from Soft-Float ABI to Hard-Float ABI
xxd -c 1 lorawan_test.o \
| sed 's/00000024: 01/00000024: 03/' \
| xxd -r -c 1 - lorawan_test2.o
cp lorawan_test2.o lorawan_test.o
Copy the compiled app to NuttX and overwrite <code>lorawan_test.o</code>
TODO: Change "$HOME/nuttx" to your NuttX Project Directory
cp lorawan_test.o $HOME/nuttx/apps/examples/lorawan_test/*lorawan_test.o
Build NuttX to link the Zig Object from <code>lorawan_test.o</code>
TODO: Change "$HOME/nuttx" to your NuttX Project Directory
cd $HOME/nuttx/nuttx
make
```
Our LoRaWAN Zig App <a>lorawan_test.zig</a> compiles OK with Zig Compiler after making the following fixes...
Refer to Auto-Translated Zig Code
Some parts of the LoRaWAN Zig App <a>lorawan_test.zig</a> can get tricky to convert from C to Zig, like this C code...
```c
// Original C code...
define APP_TX_DUTYCYCLE 40000
define APP_TX_DUTYCYCLE_RND 5000
uint32_t TxPeriodicity =
APP_TX_DUTYCYCLE +
randr(
-APP_TX_DUTYCYCLE_RND,
APP_TX_DUTYCYCLE_RND
);
```
<a>(Source)</a>
Which has conflicting signed (<code>randr</code>) and unsigned (<code>APP_TX_DUTYCYCLE</code>) types.
We get help by referring to the auto-translated Zig Code: <a>translated/lorawan_test_main.zig</a>
```zig
// Converted from C to Zig...
const APP_TX_DUTYCYCLE: c_int = 40000;
const APP_TX_DUTYCYCLE_RND: c_int = 5000;
// Cast to u32 because randr() can be negative
var TxPeriodicity: u32 = @bitCast(u32,
APP_TX_DUTYCYCLE +
c.randr(
-APP_TX_DUTYCYCLE_RND,
APP_TX_DUTYCYCLE_RND
)
);
```
Which resolves the conflicting types by casting the signed result to become unsigned.
Opaque Type Error
When we reference <code>LmHandlerCallbacks</code> in our LoRaWAN Zig App <a>lorawan_test.zig</a>...
<code>zig
_ = &LmHandlerCallbacks;</code>
Zig Compiler will show this Opaque Type Error...
<code>text
zig-cache/o/d4d456612514c342a153a8d34fbf5970/cimport.zig:1353:5: error: opaque types have unknown size and therefore cannot be directly embedded in unions
Fields: struct_sInfoFields,
^
zig-cache/o/d4d456612514c342a153a8d34fbf5970/cimport.zig:1563:5: note: while checking this field
PingSlot: PingSlotInfo_t,
^
zig-cache/o/d4d456612514c342a153a8d34fbf5970/cimport.zig:1579:5: note: while checking this field
PingSlotInfo: MlmeReqPingSlotInfo_t,
^
zig-cache/o/d4d456612514c342a153a8d34fbf5970/cimport.zig:1585:5: note: while checking this field
Req: union_uMlmeParam,
^
zig-cache/o/d4d456612514c342a153a8d34fbf5970/cimport.zig:2277:5: note: while checking this field
OnMacMlmeRequest: ?fn (LoRaMacStatus_t, [*c]MlmeReq_t, TimerTime_t) callconv(.C) void,
^</code>
Opaque Type Error is explained here...
<ul>
<li>
<a>"Extend a C/C++ Project with Zig"</a>
</li>
<li>
<a>"Translation failures"</a>
</li>
</ul>
Let's trace through our Opaque Type Error...
<code>zig
export fn OnMacMlmeRequest(
status: c.LoRaMacStatus_t,
mlmeReq: [*c]c.MlmeReq_t,
nextTxIn: c.TimerTime_t
) void {
c.DisplayMacMlmeRequestUpdate(status, mlmeReq, nextTxIn);
}</code>
Our function <code>OnMacMlmeRequest</code> has a parameter of type <code>MlmeReq_t</code>, auto-imported by Zig Compiler as...
```zig
pub const MlmeReq_t = struct_sMlmeReq;
pub const struct_sMlmeReq = extern struct {
Type: Mlme_t,
Req: union_uMlmeParam,
ReqReturn: RequestReturnParam_t,
};
```
Which contains another auto-imported type <code>union_uMlmeParam</code>...
<code>zig
pub const union_uMlmeParam = extern union {
Join: MlmeReqJoin_t,
TxCw: MlmeReqTxCw_t,
PingSlotInfo: MlmeReqPingSlotInfo_t,
DeriveMcKEKey: MlmeReqDeriveMcKEKey_t,
DeriveMcSessionKeyPair: MlmeReqDeriveMcSessionKeyPair_t,
};</code>
Which contains an <code>MlmeReqPingSlotInfo_t</code>...
```zig
pub const MlmeReqPingSlotInfo_t = struct_sMlmeReqPingSlotInfo;
pub const struct_sMlmeReqPingSlotInfo = extern struct {
PingSlot: PingSlotInfo_t,
};
```
Which contains a <code>PingSlotInfo_t</code>...
```zig
pub const PingSlotInfo_t = union_uPingSlotInfo;
pub const union_uPingSlotInfo = extern union {
Value: u8,
Fields: struct_sInfoFields,
};
```
Which contains a <code>struct_sInfoFields</code>...
<code>zig
pub const struct_sInfoFields = opaque {};</code>
But the fields of <code>struct_sInfoFields</code> are not known by the Zig Compiler!
If we refer to the original C code...
<code>c
typedef union uPingSlotInfo
{
/*!
* Parameter for byte access
*/
uint8_t Value;
/*!
* Structure containing the parameters for the PingSlotInfoReq
*/
struct sInfoFields
{
/*!
* Periodicity = 0: ping slot every second
* Periodicity = 7: ping slot every 128 seconds
*/
uint8_t Periodicity : 3;
/*!
* RFU
*/
uint8_t RFU : 5;
}Fields;
}PingSlotInfo_t;</code>
<a>(Source)</a>
We see that <code>sInfoFields</code> contains Bit Fields, that the Zig Compiler is unable to translate.
Fix Opaque Type
Earlier we saw that this fails to compile in our LoRaWAN Zig App <a>lorawan_test.zig</a>...
<code>zig
_ = &LmHandlerCallbacks;</code>
That's because <code>LmHandlerCallbacks</code> references the auto-imported type <code>MlmeReq_t</code>, which contains Bit Fields and can't be translated by the Zig Compiler.
Let's convert <code>MlmeReq_t</code> to an Opaque Type, since we won't be accessing the fields anyway...
<code>zig
/// We use an Opaque Type to represent MLME Request, because it contains Bit Fields that can't be converted by Zig
const MlmeReq_t = opaque {};</code>
<a>(Source)</a>
We convert <code>LmHandlerCallbacks</code> to use our Opaque Type <code>MlmeReq_t</code>...
<code>zig
/// Handler Callbacks. Adapted from
/// https://github.com/lupyuen/zig-bl602-nuttx/blob/main/translated/lorawan_test_main.zig#L2818-L2833
pub const LmHandlerCallbacks_t = extern struct {
GetBatteryLevel: ?fn () callconv(.C) u8,
GetTemperature: ?fn () callconv(.C) f32,
GetRandomSeed: ?fn () callconv(.C) u32,
OnMacProcess: ?fn () callconv(.C) void,
OnNvmDataChange: ?fn (c.LmHandlerNvmContextStates_t, u16) callconv(.C) void,
OnNetworkParametersChange: ?fn ([*c]c.CommissioningParams_t) callconv(.C) void,
OnMacMcpsRequest: ?fn (c.LoRaMacStatus_t, [*c]c.McpsReq_t, c.TimerTime_t) callconv(.C) void,
/// Changed `[*c]c.MlmeReq_t` to `*MlmeReq_t`
OnMacMlmeRequest: ?fn (c.LoRaMacStatus_t, *MlmeReq_t, c.TimerTime_t) callconv(.C) void,
OnJoinRequest: ?fn ([*c]c.LmHandlerJoinParams_t) callconv(.C) void,
OnTxData: ?fn ([*c]c.LmHandlerTxParams_t) callconv(.C) void,
OnRxData: ?fn ([*c]c.LmHandlerAppData_t, [*c]c.LmHandlerRxParams_t) callconv(.C) void,
OnClassChange: ?fn (c.DeviceClass_t) callconv(.C) void,
OnBeaconStatusChange: ?fn ([*c]c.LoRaMacHandlerBeaconParams_t) callconv(.C) void,
OnSysTimeUpdate: ?fn (bool, i32) callconv(.C) void,
};</code>
<a>(Source)</a>
We change all auto-imported <code>MlmeReq_t</code> references from...
<code>zig
[*c]c.MlmeReq_t</code>
To our Opaque Type...
<code>zig
*MlmeReq_t</code>
We also change all auto-imported <code>LmHandlerCallbacks_t</code> references from...
<code>zig
[*c]c.LmHandlerCallbacks_t</code>
To our converted <code>LmHandlerCallbacks_t</code>...
<code>zig
*LmHandlerCallbacks_t</code>
Which means we need to import the affected LoRaWAN Functions ourselves...
<code>``zig
/// Changed</code>[<em>c]c.MlmeReq_t<code>to</code></em>MlmeReq_t`. Adapted from
/// https://github.com/lupyuen/zig-bl602-nuttx/blob/main/translated/lorawan_test_main.zig#L2905
extern fn DisplayMacMlmeRequestUpdate(
status: c.LoRaMacStatus_t,
mlmeReq: *MlmeReq_t,
nextTxIn: c.TimerTime_t
) void;
/// Changed <code>[*c]c.LmHandlerCallbacks_t</code> to <code>*LmHandlerCallbacks_t</code>. Adapted from
/// https://github.com/lupyuen/zig-bl602-nuttx/blob/main/translated/lorawan_test_main.zig#L2835
extern fn LmHandlerInit(
callbacks: <em>LmHandlerCallbacks_t,
handlerParams: [</em>c]c.LmHandlerParams_t
) c.LmHandlerErrorStatus_t;
```
<a>(Source)</a>
After fixing the Opaque Type, Zig Compiler successfully compiles our LoRaWAN Test App <a>lorawan_test.zig</a> yay!
Macro Error
While compiling our LoRaWAN Test App <a>lorawan_test.zig</a>, we see this Macro Error...
<code>text
zig-cache/o/23409ceec9a6e6769c416fde1695882f/cimport.zig:2904:32:
error: unable to translate macro: undefined identifier `LL`
pub const __INT64_C_SUFFIX__ = @compileError("unable to translate macro: undefined identifier `LL`");
// (no file):178:9</code>
According to the Zig Docs, this means that the Zig Compiler failed to translate a C Macro...
<ul>
<li><a>"C Macros"</a></li>
</ul>
So we define <code>LL</code> ourselves...
<code>zig
/// Import the LoRaWAN Library from C
const c = @cImport({
// Workaround for "Unable to translate macro: undefined identifier `LL`"
@cDefine("LL", "");</code>
(<code>LL</code> is the "long long" suffix for C Constants, which is probably not needed when we import C Types and Functions into Zig)
Then Zig Compiler emits this error...
<code>text
zig-cache/o/83fc6cf7a78f5781f258f156f891554b/cimport.zig:2940:26:
error: unable to translate C expr: unexpected token '##'
pub const __int_c_join = @compileError("unable to translate C expr: unexpected token '##'");
// /home/user/zig-linux-x86_64-0.10.0-dev.2351+b64a1d5ab/lib/include/stdint.h:282:9</code>
Which refers to this line in <code>stdint.h</code>...
```c
define __int_c_join(a, b) a ## b
```
The <code>__int_c_join</code> Macro fails because the <code>LL</code> suffix is now blank and the <code>##</code> Concatenation Operator fails.
We redefine the <code>__int_c_join</code> Macro without the <code>##</code> Concatenation Operator...
<code>zig
/// Import the LoRaWAN Library from C
const c = @cImport({
// Workaround for "Unable to translate macro: undefined identifier `LL`"
@cDefine("LL", "");
@cDefine("__int_c_join(a, b)", "a"); // Bypass zig/lib/include/stdint.h</code>
Now Zig Compiler successfully compiles our LoRaWAN Test App <a>lorawan_test.zig</a>
Struct Initialisation Error
Zig Compiler crashes when it tries to initialise the Timer Struct at startup...
```zig
/// Timer to handle the application data transmission duty cycle
var TxTimer: c.TimerEvent_t =
std.mem.zeroes(c.TimerEvent_t);
// Zig Compiler crashes with...
// TODO buf_write_value_bytes maybe typethread 11512 panic:
// Unable to dump stack trace: debug info stripped
```
<a>(Source)</a>
So we initialise the Timer Struct in the Main Function instead...
```zig
/// Timer to handle the application data transmission duty cycle.
/// Init the timer in Main Function.
var TxTimer: c.TimerEvent_t = undefined;
/// Main Function
pub export fn lorawan_test_main(
_argc: c_int,
_argv: [<em>]const [</em>]const u8
) c_int {
// Init the Timer Struct at startup
TxTimer = std.mem.zeroes(c.TimerEvent_t);
```
<a>(Source)</a>
LoRaWAN Zig App Runs OK!
After fixing the above issues, we test the LoRaWAN Zig App on NuttX: <a>lorawan_test.zig</a>
```text
nsh> lorawan_test
Application name : Zig LoRaWAN Test
...
=========== MLME-Confirm ============
STATUS : OK
=========== JOINED ============
OTAA
DevAddr : 00D803AB
DATA RATE : DR_2
...
PrepareTxFrame: Transmit to LoRaWAN (9 bytes): Hi NuttX
=========== MCPS-Confirm ============
STATUS : OK
===== UPLINK FRAME 1 =====
CLASS : A
TX PORT : 1
TX DATA : UNCONFIRMED
48 69 20 4E 75 74 74 58 00
DATA RATE : DR_3
U/L FREQ : 923200000
TX POWER : 0
CHANNEL MASK: 0003
```
<a>(See the complete log)</a>
LoRaWAN Zig App <a>lorawan_test.zig</a> successfully joins the LoRaWAN Network (ChirpStack on RAKwireless WisGate) and sends a Data Packet to the LoRaWAN Gateway yay!
Safety Checks
The Zig Compiler reveals interesting insights when auto-translating our C code to Zig.
This C code copies an array, byte by byte...
<code>c
static int8_t FragDecoderWrite( uint32_t addr, uint8_t *data, uint32_t size ) {
...
for(uint32_t i = 0; i < size; i++ ) {
UnfragmentedData[addr + i] = data[i];
}
return 0; // Success
}</code>
<a>(Source)</a>
Here's the auto-translated Zig code...
<code>zig
pub fn FragDecoderWrite(arg_addr: u32, arg_data: [*c]u8, arg_size: u32) callconv(.C) i8 {
...
var size = arg_size;
var i: u32 = 0;
while (i < size) : (i +%= 1) {
UnfragmentedData[addr +% i] = data[i];
}
return 0;
}</code>
<a>(Source)</a>
Note that the Array Indexing in C...
<code>c
// Array Indexing in C...
UnfragmentedData[addr + i]</code>
Gets translated to this in Zig...
<code>zig
// Array Indexing in Zig...
UnfragmentedData[addr +% i]</code>
<code>+</code> in C becomes <code>+%</code> in Zig!
<em>What's <code>+%</code> in Zig?</em>
That's the Zig Operator for <a><strong>Wraparound Addition</strong></a>.
Which means that the result wraps back to 0 (and beyond) if the addition overflows the integer.
But this isn't what we intended, since we don't expect the addition to overflow. That's why in our final converted Zig code, we revert <code>+%</code> back to <code>+</code>...
<code>zig
export fn FragDecoderWrite(addr: u32, data: [*c]u8, size: u32) i8 {
...
var i: u32 = 0;
while (i < size) : (i += 1) {
UnfragmentedData[addr + i] = data[i];
}
return 0; // Success
}</code>
<a>(Source)</a>
<em>What happens if the addition overflows?</em>
We'll see a Runtime Error...
<code>text
panic: integer overflow</code>
<a>(Source)</a>
Which is probably a good thing, to ensure that our values are sensible.
<em>What if our Array Index goes out of bounds?</em>
We'll get this Runtime Error...
<code>text
panic: index out of bounds</code>
<a>(Source)</a>
Here's the list of <strong>Safety Checks</strong> done by Zig at runtime...
<ul>
<li><a>"Undefined Behavior"</a></li>
</ul>
If we prefer to live recklessly, this is how we disable the Safety Checks...
<ul>
<li><a>"@setRuntimeSafety"</a></li>
</ul>
Panic Handler
<em>Some debug features don't seem to be working? Like <code>unreachable</code>, <code>std.debug.assert</code> and <code>std.debug.panic</code>?</em>
That's because for Embedded Platforms we need to implement our own Panic Handler...
<ul>
<li>
<a>"Using Zig to Provide Stack Traces on Kernel Panic for a Bare Bones Operating System"</a>
</li>
<li>
<a>Default Panic Handler: <code>std.debug.default_panic</code></a>
</li>
</ul>
With our own Panic Handler, this Assertion Failure...
<code>``zig
// Create a short alias named</code>assert`
const assert = std.debug.assert;
// Assertion Failure
assert(TxPeriodicity != 0);
```
Will show this Stack Trace...
<code>text
!ZIG PANIC!
reached unreachable code
Stack Trace:
0x23016394
0x23016ce0</code>
According to our RISC-V Disassembly, the first address <code>23016394</code> doesn't look interesting, because it's inside the <code>assert</code> function...
<code>text
/home/user/zig-linux-x86_64-0.10.0-dev.2351+b64a1d5ab/lib/std/debug.zig:259
pub fn assert(ok: bool) void {
2301637c: 00b51c63 bne a0,a1,23016394 <std.debug.assert+0x2c>
23016380: a009 j 23016382 <std.debug.assert+0x1a>
23016382: 2307e537 lui a0,0x2307e
23016386: f9850513 addi a0,a0,-104 # 2307df98 <__unnamed_4>
2301638a: 4581 li a1,0
2301638c: 00000097 auipc ra,0x0
23016390: f3c080e7 jalr -196(ra) # 230162c8 <panic>
if (!ok) unreachable; // assertion failure
23016394: a009 j 23016396 <std.debug.assert+0x2e></code>
But the second address <code>23016ce0</code> reveals the assertion that failed...
<code>text
/home/user/nuttx/zig-bl602-nuttx/lorawan_test.zig:95
assert(TxPeriodicity != 0);
23016ccc: 42013537 lui a0,0x42013
23016cd0: fbc52503 lw a0,-68(a0) # 42012fbc <TxPeriodicity>
23016cd4: 00a03533 snez a0,a0
23016cd8: fffff097 auipc ra,0xfffff
23016cdc: 690080e7 jalr 1680(ra) # 23016368 <std.debug.assert>
/home/user/nuttx/zig-bl602-nuttx/lorawan_test.zig:100
TxTimer = std.mem.zeroes(c.TimerEvent_t);
23016ce0: 42016537 lui a0,0x42016</code>
This is our implementation of the Zig Panic Handler...
```zig
/// Called by Zig when it hits a Panic. We print the Panic Message, Stack Trace and halt. See
/// https://andrewkelley.me/post/zig-stack-traces-kernel-panic-bare-bones-os.html
/// https://github.com/ziglang/zig/blob/master/lib/std/builtin.zig#L763-L847
pub fn panic(
message: []const u8,
_stack_trace: ?<em>std.builtin.StackTrace
) noreturn {
// Print the Panic Message
_ = _stack_trace;
_ = puts("\n!ZIG PANIC!");
_ = puts(@ptrCast([</em>c]const u8, message));
<code>// Print the Stack Trace
_ = puts("Stack Trace:");
var it = std.debug.StackIterator.init(@returnAddress(), null);
while (it.next()) |return_address| {
_ = printf("%p\n", return_address);
}
// Halt
while(true) {}
</code>
}
```
<a>(Source)</a>
Logging
We have implemented Debug Logging <code>std.log.debug</code> that's described here...
<ul>
<li><a>"A simple overview of Zig's std.log"</a></li>
</ul>
Here's how we call <code>std.log.debug</code> to print a log message...
<code>``zig
// Create a short alias named</code>debug`
const debug = std.log.debug;
// Message with 8 bytes
const msg: []const u8 = "Hi NuttX";
// Print the message
debug("Transmit to LoRaWAN ({} bytes): {s}", .{
msg.len, msg
});
// Prints: Transmit to LoRaWAN (8 bytes): Hi NuttX
```
<code>.{ ... }</code> creates an <a><strong>Anonymous Struct</strong></a> with a variable number of arguments that will be passed to <code>std.log.debug</code> for printing.
Below is our implementation of <code>std.log.debug</code>...
<code>``zig
/// Called by Zig for</code>std.log.debug<code>,</code>std.log.info<code>,</code>std.log.err`, ...
/// https://gist.github.com/leecannon/d6f5d7e5af5881c466161270347ce84d
pub fn log(
comptime _message_level: std.log.Level,
comptime _scope: @Type(.EnumLiteral),
comptime format: []const u8,
args: anytype,
) void {
_ = _message_level;
_ = _scope;
<code>// Format the message
var buf: [100]u8 = undefined; // Limit to 100 chars
var slice = std.fmt.bufPrint(&buf, format, args)
catch { _ = puts("*** log error: buf too small"); return; };
// Terminate the formatted message with a null
var buf2: [buf.len + 1 : 0]u8 = undefined;
std.mem.copy(
u8,
buf2[0..slice.len],
slice[0..slice.len]
);
buf2[slice.len] = 0;
// Print the formatted message
_ = puts(&buf2);
</code>
}
```
<a>(Source)</a>
This implementation calls <code>puts()</code>, which is supported by Apache NuttX RTOS since it's <a><strong>POSIX-Compliant</strong></a>.
Compare C and Zig
The Original C Code and the Converted Zig Code for our LoRaWAN App look highly similar.
Here's the Main Function from our Original C Code...
```c
/// Main Function that will be called by NuttX. We call the LoRaWAN Library
/// to Join a LoRaWAN Network and send a Data Packet.
int main(int argc, FAR char *argv[]) {
// If we are using Entropy Pool and the BL602 ADC is available,
// add the Internal Temperature Sensor data to the Entropy Pool
init_entropy_pool();
<code>// Compute the interval between transmissions based on Duty Cycle
TxPeriodicity = APP_TX_DUTYCYCLE + randr( -APP_TX_DUTYCYCLE_RND, APP_TX_DUTYCYCLE_RND );
const Version_t appVersion = { .Value = FIRMWARE_VERSION };
const Version_t gitHubVersion = { .Value = GITHUB_VERSION };
DisplayAppInfo( "lorawan_test",
&appVersion,
&gitHubVersion );
// Init LoRaWAN
if ( LmHandlerInit( &LmHandlerCallbacks, &LmHandlerParams ) != LORAMAC_HANDLER_SUCCESS )
{
printf( "LoRaMac wasn't properly initialized\n" );
// Fatal error, endless loop.
while ( 1 ) {}
}
// Set system maximum tolerated rx error in milliseconds
LmHandlerSetSystemMaxRxError( 20 );
// The LoRa-Alliance Compliance protocol package should always be initialized and activated.
LmHandlerPackageRegister( PACKAGE_ID_COMPLIANCE, &LmhpComplianceParams );
LmHandlerPackageRegister( PACKAGE_ID_CLOCK_SYNC, NULL );
LmHandlerPackageRegister( PACKAGE_ID_REMOTE_MCAST_SETUP, NULL );
LmHandlerPackageRegister( PACKAGE_ID_FRAGMENTATION, &FragmentationParams );
IsClockSynched = false;
IsFileTransferDone = false;
// Join the LoRaWAN Network
LmHandlerJoin( );
// Set the Transmit Timer
StartTxProcess( LORAMAC_HANDLER_TX_ON_TIMER );
// Handle LoRaWAN Events
handle_event_queue(NULL); // Never returns
return 0;
</code>
}
```
<a>(Source)</a>
And the Main Function from our Converted Zig Code (after some scrubbing)...
```zig
/// Main Function that will be called by NuttX. We call the LoRaWAN Library
/// to Join a LoRaWAN Network and send a Data Packet.
pub export fn lorawan_test_main(
_argc: c_int,
_argv: [<em>]const [</em>]const u8
) c_int {
_ = _argc;
_ = _argv;
<code>// Init the Timer Struct at startup
TxTimer = std.mem.zeroes(c.TimerEvent_t);
// If we are using Entropy Pool and the BL602 ADC is available,
// add the Internal Temperature Sensor data to the Entropy Pool
// TODO: init_entropy_pool();
// Compute the interval between transmissions based on Duty Cycle
TxPeriodicity = @bitCast(u32, // Cast to u32 because randr() can be negative
APP_TX_DUTYCYCLE +
c.randr(
-APP_TX_DUTYCYCLE_RND,
APP_TX_DUTYCYCLE_RND
)
);
// Show the Firmware and GitHub Versions
const appVersion = c.Version_t {
.Value = c.FIRMWARE_VERSION,
};
const gitHubVersion = c.Version_t {
.Value = c.GITHUB_VERSION,
};
c.DisplayAppInfo("Zig LoRaWAN Test", &appVersion, &gitHubVersion);
// Init LoRaWAN
if (LmHandlerInit(&LmHandlerCallbacks, &LmHandlerParams)
!= c.LORAMAC_HANDLER_SUCCESS) {
std.log.err("LoRaMac wasn't properly initialized", .{});
// Fatal error, endless loop.
while (true) {}
}
// Set system maximum tolerated rx error in milliseconds
_ = c.LmHandlerSetSystemMaxRxError(20);
// The LoRa-Alliance Compliance protocol package should always be initialized and activated.
_ = c.LmHandlerPackageRegister(c.PACKAGE_ID_COMPLIANCE, &LmhpComplianceParams);
_ = c.LmHandlerPackageRegister(c.PACKAGE_ID_CLOCK_SYNC, null);
_ = c.LmHandlerPackageRegister(c.PACKAGE_ID_REMOTE_MCAST_SETUP, null);
_ = c.LmHandlerPackageRegister(c.PACKAGE_ID_FRAGMENTATION, &FragmentationParams);
// Init the Clock Sync and File Transfer status
IsClockSynched = false;
IsFileTransferDone = false;
// Join the LoRaWAN Network
c.LmHandlerJoin();
// Set the Transmit Timer
StartTxProcess(LmHandlerTxEvents_t.LORAMAC_HANDLER_TX_ON_TIMER);
// Handle LoRaWAN Events
handle_event_queue(); // Never returns
return 0;
</code>
}
```
<a>(Source)</a>
TODO: Clean up names of Types, Functions and Variables
TODO: Read the Internal Temperature Sensor
TODO: Encode the Temperature Sensor Data with TinyCBOR and transmit to The Things Network
https://lupyuen.github.io/articles/cbor2
TODO: Monitor sensor data with Prometheus and Grafana
https://lupyuen.github.io/articles/prometheus
TODO: Add new code with <code>@import()</code>
https://zig.news/mattnite/import-and-packages-23mb
TODO: Do we need to align buffers to 32 bits when exporting to C?
<code>zig
/// User application data
/// (Aligned to 32-bit because it's exported to C)
var AppDataBuffer: [LORAWAN_APP_DATA_BUFFER_MAX_SIZE]u8 align(4) =
std.mem.zeroes([LORAWAN_APP_DATA_BUFFER_MAX_SIZE]u8);</code>
Zig Type Reflection
Zig Type Reflection ... Can we use it to generate a Structured Call Graph for C Libraries ... Like for the LoRaWAN Library? 🤔
This Zig Program imports the LoRaWAN Library from C and dumps out the LoRaWAN Types and Functions...
```zig
// Do Type Reflection on the imported C functions
fn reflect() void {
// We run this at Compile-Time (instead of Runtime)...
comptime {
// Allow Zig Compiler to loop up to 100,000 times (Default is 1,000)
@setEvalBranchQuota(100_000);
<code> // Get the Type Info of the C Namespace
const T = @typeInfo(c);
// Show the Type Info of the C Namespace (Struct)
@compileLog("@typeInfo(c): ", T);
// Shows | *"@typeInfo(c): ", std.builtin.Type { .Struct = (struct std.builtin.Type.Struct constant)}
// Show the number of Fields in the C Namespace (0)
@compileLog("T.Struct.fields.len: ", T.Struct.fields.len);
// Shows | *"T.Struct.fields.len: ", 0
// Show the number of Declarations in the C Namespace (4743)
@compileLog("T.Struct.decls.len: ", T.Struct.decls.len);
// Shows | *"T.Struct.decls.len: ", 4743
// Show the first Declaration in the C Namespace (__builtin_bswap16)
@compileLog("T.Struct.decls[0].name: ", T.Struct.decls[0].name);
// Shows | *"T.Struct.decls[0].name: ", "__builtin_bswap16"
// For every C Declaration...
for (T.Struct.decls) |decl, i| {
// If the C Declaration starts with "Lm" (LoRaMAC)...
if (std.mem.startsWith(u8, decl.name, "Lm")) {
// Dump the C Declaration
var T2 = @typeInfo(c);
@compileLog("decl.name: ", T2.Struct.decls[i].name);
// Strangely we can't do this...
// @compileLog("decl.name: ", decl.name);
// Because it shows...
// *"decl.name: ", []const u8{76,109,110,83,116,97,116,117,115,95,116}
}
}
} // End of Compile-Time Code
</code>
}
```
<a>(Source)</a>
<a>(<code>@typeInfo</code> is explained here)</a>
When Zig Compiler compiles the code above, we see this at Compile-Time...
<code>text
$ zig build-obj --verbose-cimport -target riscv32-freestanding-none -mcpu=baseline_rv32-d -isystem /Users/Luppy/pinecone/nuttx/nuttx/include -I /Users/Luppy/pinecone/nuttx/apps/examples/lorawan_test reflect.zig
info(compilation): C import output: zig-cache/o/e979b806463a36dcecc2ef773bd2d2ad/cimport.zig
| *"@typeInfo(c): ", std.builtin.Type { .Struct = (struct std.builtin.Type.Struct constant)}
| *"T.Struct.fields.len: ", 0
| *"T.Struct.decls.len: ", 4744
| *"T.Struct.decls[0].name: ", "__builtin_bswap16"
| *"decl.name: ", "LmnStatus_t"
| *"decl.name: ", "LmHandlerAdrStates_t"
| *"decl.name: ", "LmHandlerFlagStatus_t"
...
| *"decl.name: ", "LmHandlerInit"
| *"decl.name: ", "LmHandlerIsBusy"
| *"decl.name: ", "LmHandlerProcess"
| *"decl.name: ", "LmHandlerGetDutyCycleWaitTime"
| *"decl.name: ", "LmHandlerSend"
| *"decl.name: ", "LmHandlerJoin"
...
./reflect.zig:836:9: error: found compile log statement
@compileLog("@typeInfo(c): ", T);
^
./reflect.zig:840:9: error: found compile log statement
@compileLog("T.Struct.fields.len: ", T.Struct.fields.len);
^
./reflect.zig:844:9: error: found compile log statement
@compileLog("T.Struct.decls.len: ", T.Struct.decls.len);
^
./reflect.zig:848:9: error: found compile log statement
@compileLog("T.Struct.decls[0].name: ", T.Struct.decls[0].name);
^
./reflect.zig:857:17: error: found compile log statement
@compileLog("decl.name: ", T2.Struct.decls[i].name);
^</code>
<a>(Source)</a>
Which is a list of C Types and Functions from the LoRaWAN Library.
Let's use this to visualise the Call Graph (by module) for the LoRaWAN Library.
We'll render the Call Graph with Mermaid.js...
https://mermaid-js.github.io/mermaid/#/./flowchart?id=flowcharts
And we'll group LoRaWAN Functions in Call Graph by LoRaWAN Module (Subgraph), so we can see the calls across LoRaWAN Modules.
Heisenbug
<em>In the code above, why did we use <code>T2.Struct.decls[i].name</code> instead of <code>decl.name</code>?</em>
```zig
// For every C Declaration...
for (T.Struct.decls) |decl, i| {
// If the C Declaration starts with "Lm" (LoRaMAC)...
if (std.mem.startsWith(u8, decl.name, "Lm")) {
// Dump the C Declaration
var T2 = @typeInfo(c);
<code> // Can't use decl.name here...
@compileLog("decl.name: ", T2.Struct.decls[i].name);
}
</code>
}
```
We expect this code to print the name of the declaration...
<code>zig
@compileLog("decl.name: ", decl.name);</code>
Like so...
<code>text
"decl.name: ", "LmnStatus_t"</code>
But strangely it prints the bytes...
<code>text
"decl.name: ", []const u8{76,109,110,83,116,97,116,117,115,95,116}</code>
Zig Compiler seems to interpret the name differently after we have referenced the name earlier...
<code>zig
// If the C Declaration starts with "Lm" (LoRaMAC)...
if (std.mem.startsWith(u8, decl.name, "Lm")) { ...</code>
So we use this workaround instead...
```zig
// Get a fresh reference to the Type Info
var T2 = @typeInfo(c);
// This works OK
@compileLog("decl.name: ", T2.Struct.decls[i].name);
```
Which produces the result we need...
<code>text
"decl.name: ", "LmnStatus_t"</code>
Group by C Header Files
Can we automatically identify the LoRaWAN Module for every LoRaWAN Function, by analysing the <code>HEADER_NAME_H__</code> C Header Macros?
Let's try this to dump out all C Declarations and Macros imported from C...
```zig
// Get the Type Info of the C Namespace
const T = @typeInfo(c);
// Remember the C Header
var header: []const u8 = "";
// For every C Declaration...
for (T.Struct.decls) |decl, i| {
var T2 = @typeInfo(c);
<code>// If the C Declaration ends with "_H"...
if (
std.mem.endsWith(u8, decl.name, "_H") or
std.mem.endsWith(u8, decl.name, "_H_") or
std.mem.endsWith(u8, decl.name, "_H__")
) {
// Dump the C Header and remember it
var name = T2.Struct.decls[i].name;
@compileLog("-----", name);
header = name;
} else {
// Dump the C Declaration
var name = T2.Struct.decls[i].name;
@compileLog("decl.name:", name);
}
</code>
} // End of C Declaration
```
<a>(Source)</a>
We get this list of LoRaWAN Functions and LoRaWAN Macros...
<code>text
| *"decl.name:", "LmHandlerInit"
| *"decl.name:", "LmHandlerIsBusy"
| *"decl.name:", "LmHandlerProcess"
| *"decl.name:", "LmHandlerGetDutyCycleWaitTime"
| *"decl.name:", "LmHandlerSend"
| *"decl.name:", "LmHandlerJoin"
...
| *"-----", "__LORAMAC_HANDLER_H__"
| *"-----", "__LORAMAC_HANDLER_TYPES_H__"
| *"decl.name:", "LMH_SYS_TIME_UPDATE_NEW_API"
| *"decl.name:", "__LMHP_COMPLIANCE__"</code>
<a>(Source)</a>
Which isn't useful. <code>LmHandlerInit</code> is actually declared inside the C Header File for <code>__LORAMAC_HANDLER_H__</code>. But somehow the Zig Type Reflection moves <code>LmHandlerInit</code> up to the top, before <code>__LORAMAC_HANDLER_H__</code> appears.
So it seems we need to manually group the LoRaWAN Functions into LoRaWAN Modules.
The LoRaWAN Functions appear to be sequenced according to the C Header File, so we only need to manually tag the first LoRaWAN Function for each LoRaWAN Module. Like this...
<code>text
LmHandlerInit → __LORAMAC_HANDLER_H__
LoRaMacInitialization → __LORAMAC_H__
RegionCommonValueInRange → __REGIONCOMMON_H__
SX126xInit → __SX126x_H__
SX126xIoInit → __SX126x_BOARD_H__</code>
Self Type Reflection
Our Zig App can do Type Reflection on itself to discover its Types, Constants, Variables and Functions...
```zig
// Show the Type Info for our Zig Namespace
const ThisType = @typeInfo(@This());
@compileLog("ThisType: ", ThisType);
@compileLog("ThisType.Struct.decls.len: ", ThisType.Struct.decls.len);
@compileLog("ThisType.Struct.decls[0].name: ", ThisType.Struct.decls[0].name);
@compileLog("ThisType.Struct.decls[1].name: ", ThisType.Struct.decls[1].name);
@compileLog("ThisType.Struct.decls[2].name: ", ThisType.Struct.decls[2].name);
// Shows...
// | <em>"ThisType: ", std.builtin.Type { .Struct = (struct std.builtin.Type.Struct constant)}
// | </em>"ThisType.Struct.decls.len: ", 66
// | <em>"ThisType.Struct.decls[0].name: ", "std"
// | </em>"ThisType.Struct.decls[1].name: ", "c"
// | *"ThisType.Struct.decls[2].name: ", "ACTIVE_REGION"
```
<a>(Source)</a>
We'll use this to plot the Function Calls from our Zig Functions to the C Functions in the LoRaWAN Library.
Import Call Log
Earlier we have captured this Call Log: A log of calls to the C Functions in the LoRaWAN Library...
<code>text
init_event_queue
TimerInit: 0x4201c76c
SX126xIoInit: Compiled with gcc
init_gpio
...
RadioSetChannel: freq=923200000
RadioSetTxConfig: modem=1, power=13, fdev=0, bandwidth=0, datarate=10, coderate=1, preambleLen=8, fixLen=0, crcOn=1, freqHopOn=0, hopPeriod=0, iqInverted=0, timeout=4000
RadioSetTxConfig: SpreadingFactor=10, Bandwidth=4, CodingRate=1, LowDatarateOptimize=0, PreambleLength=8, HeaderType=0, PayloadLength=255, CrcMode=1, InvertIQ=0
RadioStandby
RadioSetModem
SX126xSetTxParams: power=13, rampTime=7
SX126xSetPaConfig: paDutyCycle=4, hpMax=7, deviceSel=0, paLut=1</code>
<a>(Source)</a>
Each line of the Call Log contains the LoRaWAN Function Name. We'll match this with the info from Zig Type Reflection to plot the Call Graph.
We import the Call Log into our Zig App like so...
<code>zig
/// Call Log captured for this app. From
/// https://gist.github.com/lupyuen/0871ac515b18d9d68d3aacf831fd0f5b
const call_log =
\\init_event_queue
\\TimerInit: 0x4201c76c
\\SX126xIoInit: Compiled with gcc
\\init_gpio
...
\\RadioSetChannel: freq=923200000
\\RadioSetTxConfig: modem=1, power=13, fdev=0, bandwidth=0, datarate=10, coderate=1, preambleLen=8, fixLen=0, crcOn=1, freqHopOn=0, hopPeriod=0, iqInverted=0, timeout=4000
\\RadioSetTxConfig: SpreadingFactor=10, Bandwidth=4, CodingRate=1, LowDatarateOptimize=0, PreambleLength=8, HeaderType=0, PayloadLength=255, CrcMode=1, InvertIQ=0
\\RadioStandby
\\RadioSetModem
\\SX126xSetTxParams: power=13, rampTime=7
\\SX126xSetPaConfig: paDutyCycle=4, hpMax=7, deviceSel=0, paLut=1
\\SecureElementRandomNumber: 0xbc9f21c2
\\RadioSend: size=23
\\00 00 00 00 00 00 00 00 00 5b b1 7b 37 e7 5e c1 4b c2 21 9c 04 48 1b
\\RadioSend: PreambleLength=8, HeaderType=0, PayloadLength=23, CrcMode=1, InvertIQ=0
\\TimerStop: 0x4201b86c
\\TimerStart2: 0x4201b86c, 4000 ms
\\callout_reset: evq=0x420131a8, ev=0x4201b86c
\\
\\###### =========== MLME-Request ============ ######
\\###### MLME_JOIN ######
\\###### ===================================== ######
\\STATUS : OK
\\StartTxProcess
\\handle_event_queue
\\DIO1 add event
\\handle_event_queue: ev=0x4201b894
\\RadioOnDioIrq
\\RadioIrqProcess
\\IRQ_TX_DONE
\\TimerStop: 0x4201b86c
\\TODO: RtcGetCalendarTime
\\TODO: RtcBkupRead
\\RadioOnDioIrq
\\RadioIrqProcess
\\ProcessRadioTxDone: RxWindow1Delay=4988
\\RadioSleep
...
;</code>
<a>(Source)</a>
Zig Compiler can process the Call Log line by line like so...
```zig
// Show the first line of the Call Log
var call_log_split = std.mem.split(u8, call_log, "\n");
const line = call_log_split.next();
@compileLog("line:", line);
// Shows | *"line:", []const u8{103,112,108,104,95,101,110,97,98,108,101,58,32,87,65,82,78,73,78,71,58,32,112,105,110,57,58,32,65,108,114,101,97,100,121,32,100,101,116,97,99,104,101,100}
```
<a>(Source)</a>
To iterate through all lines of the Call Log we do this...
```zig
// For every line in the Call Log...
var call_log_split = std.mem.split(u8, call_log, "\n");
while (call_log_split.next()) |line| {
<code>// TODO: Process the line
@compileLog("line:", line);
...
</code>
} // End of Call Log
```
<a>(Source)</a>
Match Call Log
Let's match the Call Log with the Function Names from our LoRaWAN Library...
```zig
// For every line in the Call Log...
var call_log_split = std.mem.split(u8, call_log, "\n");
while (call_log_split.next()) |line| {
<code>// For every C Declaration...
for (T.Struct.decls) |decl, i| {
if (std.mem.eql(u8, decl.name, "Radio")) { continue; } // Skip Radio
var T2 = @typeInfo(c);
// If the C Declaration matches the Call Log...
if (std.mem.startsWith(u8, line, decl.name)) {
// Dump the C Declaration
var name = T2.Struct.decls[i].name;
@compileLog("Found call log", name);
break;
}
} // End of C Declaration
</code>
} // End of Call Log
```
<a>(Source)</a>
The code above produces this result...
<code>text
| *"Found call log", "LoRaMacInitialization"
| *"Found call log", "TimerInit"
| *"Found call log", "SX126xIoInit"
| *"Found call log", "SX126xSetTx"
| *"Found call log", "SX126xSetPaConfig"
| *"Found call log", "TimerInit"
| *"Found call log", "TimerInit"
| *"Found call log", "RadioSetModem"
| *"Found call log", "RadioSetModem"
| *"Found call log", "RadioSetPublicNetwork"
| *"Found call log", "RadioSleep"
| *"Found call log", "RadioSetModem"
| *"Found call log", "RadioSetPublicNetwork"
...</code>
<a>(Source)</a>
Which is a list of LoRaWAN Functions and the sequence they were called.
One step closer to rendering our Structured Call Graph!
Draw The Graph
Let's extend the code above and render a Naive Call Graph...
<ul>
<li>
For every LoRaWAN Function that we identify in the Call Log...
</li>
<li>
We plot a line between the LoRaWAN Function and the next LoRaWAN Function in the Call Log
</li>
<li>
So we're just plotting the connected sequence of Function Calls
</li>
</ul>
(Yep it's super naive!)
We do it like this...
```zig
// Draw the graph for all functions in the Call Log
var call_log_split = std.mem.split(u8, call_log, "\n");
var prev_name: []const u8 = "Start";
@compileLog("flowchart TD;"); // Top-Down Flowchart
// For every line in the Call Log...
while (call_log_split.next()) |line| {
<code>// For every C Declaration...
for (T.Struct.decls) |decl, i| {
if (std.mem.eql(u8, decl.name, "Radio")) { continue; } // Skip Radio
var T2 = @typeInfo(c);
// If the C Declaration matches the Call Log...
if (std.mem.startsWith(u8, line, decl.name)) {
// Draw the graph: [previous function]-->[current function]
var name = T2.Struct.decls[i].name;
@compileLog(" ", prev_name, "-->", name, ";");
prev_name = name;
break;
}
} // End of C Declaration
</code>
} // End of Call Log
@compileLog(" ", prev_name, "-->", "End", ";");
```
<a>(Source)</a>
Zig Compiler produces this result at Compile-Time...
<code>text
| *"flowchart TD;"
| *" ", "Start", *"-->", "LoRaMacInitialization", *";"
| *" ", "LoRaMacInitialization", *"-->", "TimerInit", *";"
| *" ", "TimerInit", *"-->", "TimerInit", *";"
| *" ", "TimerInit", *"-->", "TimerInit", *";"
| *" ", "TimerInit", *"-->", "TimerInit", *";"
| *" ", "TimerInit", *"-->", "TimerInit", *";"
| *" ", "TimerInit", *"-->", "TimerInit", *";"
| *" ", "TimerInit", *"-->", "TimerInit", *";"
| *" ", "TimerInit", *"-->", "TimerInit", *";"
| *" ", "TimerInit", *"-->", "SX126xIoInit", *";"
| *" ", "SX126xIoInit", *"-->", "SX126xSetTx", *";"
| *" ", "SX126xSetTx", *"-->", "SX126xSetPaConfig", *";"
| *" ", "SX126xSetPaConfig", *"-->", "TimerInit", *";"
| *" ", "TimerInit", *"-->", "TimerInit", *";"
| *" ", "TimerInit", *"-->", "RadioSetModem", *";"
...</code>
<a>(Source)</a>
We manually remove the delimiters from the Zig Compiler Log above like this...
<code>text
flowchart TD;
Start-->LoRaMacInitialization;
LoRaMacInitialization-->TimerInit;
TimerInit-->TimerInit;
TimerInit-->TimerInit;
TimerInit-->TimerInit;
TimerInit-->TimerInit;
TimerInit-->TimerInit;
TimerInit-->TimerInit;
TimerInit-->TimerInit;
TimerInit-->SX126xIoInit;
SX126xIoInit-->SX126xSetTx;
SX126xSetTx-->SX126xSetPaConfig;
SX126xSetPaConfig-->TimerInit;
TimerInit-->TimerInit;
TimerInit-->RadioSetModem;
...</code>
To get this <a>Mermaid.js Flowchart</a>...
<code>mermaid
flowchart TD;
Start-->LoRaMacInitialization;
LoRaMacInitialization-->TimerInit;
TimerInit-->TimerInit;
TimerInit-->TimerInit;
TimerInit-->TimerInit;
TimerInit-->TimerInit;
TimerInit-->TimerInit;
TimerInit-->TimerInit;
TimerInit-->TimerInit;
TimerInit-->SX126xIoInit;
SX126xIoInit-->SX126xSetTx;
SX126xSetTx-->SX126xSetPaConfig;
SX126xSetPaConfig-->TimerInit;
TimerInit-->TimerInit;
TimerInit-->RadioSetModem;
RadioSetModem-->RadioSetModem;
RadioSetModem-->RadioSetPublicNetwork;
RadioSetPublicNetwork-->RadioSleep;
RadioSleep-->RadioSetModem;
RadioSetModem-->RadioSetPublicNetwork;
RadioSetPublicNetwork-->TimerInit;
TimerInit-->TimerInit;
TimerInit-->TimerInit;
TimerInit-->RadioSetChannel;
RadioSetChannel-->RadioSetTxConfig;
RadioSetTxConfig-->RadioSetTxConfig;
RadioSetTxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->SX126xSetTx;
SX126xSetTx-->SX126xSetPaConfig;
SX126xSetPaConfig-->RadioSend;
RadioSend-->RadioSend;
RadioSend-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerInit;
TimerInit-->TimerSetValue;
TimerSetValue-->TimerStop;
TimerStop-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->IRQ_TX_DONE;
IRQ_TX_DONE-->TimerStop;
TimerStop-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->RadioStandby;
RadioStandby-->RadioSetChannel;
RadioSetChannel-->RadioSetRxConfig;
RadioSetRxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->RadioSetRxConfig;
RadioSetRxConfig-->RadioRx;
RadioRx-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->IRQ_HEADER_VALID;
IRQ_HEADER_VALID-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->IRQ_RX_DONE;
IRQ_RX_DONE-->TimerStop;
TimerStop-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerStop;
TimerStop-->LmHandlerSend;
LmHandlerSend-->RadioSetChannel;
RadioSetChannel-->RadioSetTxConfig;
RadioSetTxConfig-->RadioSetTxConfig;
RadioSetTxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->SX126xSetTx;
SX126xSetTx-->SX126xSetPaConfig;
SX126xSetPaConfig-->RadioSend;
RadioSend-->RadioSend;
RadioSend-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->IRQ_TX_DONE;
IRQ_TX_DONE-->TimerStop;
TimerStop-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->RadioStandby;
RadioStandby-->RadioSetChannel;
RadioSetChannel-->RadioSetRxConfig;
RadioSetRxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->RadioSetRxConfig;
RadioSetRxConfig-->RadioRx;
RadioRx-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->IRQ_RX_TX_TIMEOUT;
IRQ_RX_TX_TIMEOUT-->TimerStop;
TimerStop-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerStop;
TimerStop-->TimerStop;
TimerStop-->TimerStop;
TimerStop-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->LmHandlerSend;
LmHandlerSend-->RadioSetChannel;
RadioSetChannel-->RadioSetTxConfig;
RadioSetTxConfig-->RadioSetTxConfig;
RadioSetTxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->SX126xSetTx;
SX126xSetTx-->SX126xSetPaConfig;
SX126xSetPaConfig-->RadioSend;
RadioSend-->RadioSend;
RadioSend-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->IRQ_TX_DONE;
IRQ_TX_DONE-->TimerStop;
TimerStop-->RadioOnDioIrq;
RadioOnDioIrq-->RadioSleep;
RadioSleep-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->RadioStandby;
RadioStandby-->RadioSetChannel;
RadioSetChannel-->RadioSetRxConfig;
RadioSetRxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->RadioSetRxConfig;
RadioSetRxConfig-->RadioRx;
RadioRx-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->IRQ_RX_TX_TIMEOUT;
IRQ_RX_TX_TIMEOUT-->TimerStop;
TimerStop-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerStop;
TimerStop-->TimerStop;
TimerStop-->TimerStop;
TimerStop-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->LmHandlerSend;
LmHandlerSend-->RadioSetChannel;
RadioSetChannel-->RadioSetTxConfig;
RadioSetTxConfig-->RadioSetTxConfig;
RadioSetTxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->SX126xSetTx;
SX126xSetTx-->SX126xSetPaConfig;
SX126xSetPaConfig-->RadioSend;
RadioSend-->RadioSend;
RadioSend-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->IRQ_TX_DONE;
IRQ_TX_DONE-->TimerStop;
TimerStop-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->RadioStandby;
RadioStandby-->RadioSetChannel;
RadioSetChannel-->RadioSetRxConfig;
RadioSetRxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->RadioSetRxConfig;
RadioSetRxConfig-->RadioRx;
RadioRx-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->IRQ_RX_TX_TIMEOUT;
IRQ_RX_TX_TIMEOUT-->TimerStop;
TimerStop-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerStop;
TimerStop-->TimerStop;
TimerStop-->TimerStop;
TimerStop-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->LmHandlerSend;
LmHandlerSend-->RadioSetChannel;
RadioSetChannel-->RadioSetTxConfig;
RadioSetTxConfig-->RadioSetTxConfig;
RadioSetTxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->SX126xSetTx;
SX126xSetTx-->SX126xSetPaConfig;
SX126xSetPaConfig-->RadioSend;
RadioSend-->RadioSend;
RadioSend-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->IRQ_TX_DONE;
IRQ_TX_DONE-->TimerStop;
TimerStop-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->RadioStandby;
RadioStandby-->RadioSetChannel;
RadioSetChannel-->RadioSetRxConfig;
RadioSetRxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->RadioSetRxConfig;
RadioSetRxConfig-->RadioRx;
RadioRx-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->IRQ_RX_TX_TIMEOUT;
IRQ_RX_TX_TIMEOUT-->TimerStop;
TimerStop-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerStop;
TimerStop-->TimerStop;
TimerStop-->TimerStop;
TimerStop-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->LmHandlerSend;
LmHandlerSend-->RadioSetChannel;
RadioSetChannel-->RadioSetTxConfig;
RadioSetTxConfig-->RadioSetTxConfig;
RadioSetTxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->SX126xSetTx;
SX126xSetTx-->SX126xSetPaConfig;
SX126xSetPaConfig-->RadioSend;
RadioSend-->RadioSend;
RadioSend-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->IRQ_TX_DONE;
IRQ_TX_DONE-->TimerStop;
TimerStop-->RadioOnDioIrq;
RadioOnDioIrq-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;</code>
Super Naive Call Graph
<em>What's wrong with the super-naive Call Graph that we have produced?</em>
<code>text
flowchart TD;
Start-->LoRaMacInitialization;
LoRaMacInitialization-->TimerInit;
TimerInit-->TimerInit;
TimerInit-->SX126xIoInit;
SX126xIoInit-->SX126xSetTx;
SX126xSetTx-->SX126xSetPaConfig;
SX126xSetPaConfig-->TimerInit;
TimerInit-->RadioSetModem;
...</code>
<a>(Source)</a>
Our Call Graph lacks <strong>Structure</strong>. Remember we're only plotting the sequence of Function Calls...
<ul>
<li>
<code>TimerInit → TimerInit</code> doesn't make sense (because we don't have recursive functions)
</li>
<li>
<code>TimerInit → RadioSetModem</code> is totally wrong because <code>TimerInit</code> is a Low-Level Function (NimBLE Multithreading Library), whereas <code>RadioSetModem</code> is an High-Level Function (SX1262 Library)
</li>
</ul>
<em>Can we add some Structure to improve the Call Graph?</em>
To produce a Structured Call Graph we'll group the functions into Modules, from High-Level to Low-Level...
<ol>
<li>
Zig App (Highest Level)
</li>
<li>
LoRaWAN Library
</li>
<li>
SX1262 Library
</li>
<li>
NimBLE Multithreading Library (Lowest Level)
</li>
</ol>
And we'll ensure that we never draw a line from a Low-Level Function to a High-Level Function.
This is a snippet of what we want to achieve...
<code>mermaid
flowchart TD;
subgraph LoRaWAN;
Start;
LoRaMacInitialization;
end;
subgraph SX1262;
SX126xIoInit;
SX126xSetTx;
SX126xSetPaConfig;
end;
subgraph NimBLE;
TimerInit;
TimerInit;
end;
Start-->LoRaMacInitialization;
LoRaMacInitialization-->TimerInit;
SX126xIoInit-->SX126xSetTx;
SX126xSetTx-->SX126xSetPaConfig;
SX126xSetPaConfig-->TimerInit;</code>
Group Functions by Modules
Let's add some Structure to our Call Graph by grouping the C Functions into Modules.
This is how we define the Modules, from High Level to Low Level...
<code>zig
// Define the Modules and the First / Last Functions in each Module.
// We order the Modules from High-Level to Low-Level.
var all_modules = [_]Module {
// LoRaMAC Handler is the Top Level Module that drives the LoRaWAN Stack
Module {
.name = "LMHandler",
.first_function = "LmHandlerInit",
.last_function = "DisplayAppInfo",
.first_index = undefined,
.last_index = undefined,
},
// LoRaMAC Module is the implementation of the LoRaWAN Driver
Module {
.name = "LoRaMAC",
.first_function = "LoRaMacInitialization",
.last_function = "LoRaMacDeInitialization",
.first_index = undefined,
.last_index = undefined,
},
// Radio Module is the abstract interface for LoRa Radio Transceivers
Module {
.name = "Radio",
.first_function = "RadioInit",
.last_function = "RadioAddRegisterToRetentionList",
.first_index = undefined,
.last_index = undefined,
},
// SX1262 Module is the LoRa Driver for Semtech SX1262 Radio Transceiver
Module {
.name = "SX1262",
.first_function = "SX126xInit",
.last_function = "SX126xSetOperatingMode",
.first_index = undefined,
.last_index = undefined,
},
// NimBLE is the Bottom Level Module that contains Multithreading Functions like Timers and Event Queues
Module {
.name = "NimBLE",
.first_function = "TimerInit",
.last_function = "TimerGetElapsedTime",
.first_index = undefined,
.last_index = undefined,
},
};</code>
<a>(Source)</a>
Note that we specify only the First and Last Functions for each Module.
That's because functions from the same Module are clustered together in the Zig Type Reflection.
Then we render each Module as a Mermaid.js Subgraph...
```zig
/// Render all Modules and their Functions as Subgraphs
fn render_modules(all_modules: []Module) void {
comptime {
// Render every Module
for (all_modules) |module, m| {
@compileLog(" subgraph ", module.name, ";");
<code> // For every line in the Call Log...
var call_log_split = std.mem.split(u8, call_log, "\n");
while (call_log_split.next()) |line| {
var T = @typeInfo(c);
// If the Call Log matches a C Declaration...
if (get_decl_by_name_filtered(all_modules, line)) |decl_index| {
// Get the Module Index for the C Declaration
if (get_module_by_decl(all_modules, decl_index)) |m2| {
// If the C Declaration matches our Module Index...
if (m == m2) {
// Print the Function Name
var name = T.Struct.decls[decl_index].name;
@compileLog(" ", name, ";");
}
} else {
// Missing Declaration
var name = T.Struct.decls[decl_index].name;
@compileLog("Missing Decl:", name);
}
}
} // End of Call Log
@compileLog(" end;");
} // End of Module
}
</code>
}
```
<a>(Source)</a>
Each Subgraph contains a list of Functions that belong to the Module...
<code>text
flowchart TD;
subgraph LMHandler;
LmHandlerSend;
end;
subgraph LoRaMAC;
LoRaMacInitialization;
end;
subgraph Radio;
RadioSetModem;
RadioSetPublicNetwork;
RadioSleep;
RadioSetChannel;
RadioSetTxConfig;
RadioStandby;
RadioSend;
RadioIrqProcess;
...
end;
subgraph SX1262;
SX126xIoInit;
SX126xSetTx;
SX126xSetPaConfig;
end;
subgraph NimBLE;
TimerInit;
TimerStop;
TimerStart;
TimerSetValue;
end;
Start-->LoRaMacInitialization;
LoRaMacInitialization-->TimerInit;
TimerInit-->SX126xIoInit;
...</code>
<a>(Source)</a>
When we render the output with Mermaid.js, we get a Structured Call Graph that looks more meaningful...
<code>mermaid
flowchart TD;
subgraph LMHandler;
LmHandlerSend;
LmHandlerSend;
LmHandlerSend;
LmHandlerSend;
LmHandlerSend;
LmHandlerSend;
LmHandlerSend;
LmHandlerSend;
LmHandlerSend;
LmHandlerSend;
LmHandlerSend;
LmHandlerSend;
end;
subgraph LoRaMAC;
LoRaMacInitialization;
end;
subgraph Radio;
RadioSetModem;
RadioSetModem;
RadioSetPublicNetwork;
RadioSleep;
RadioSetModem;
RadioSetPublicNetwork;
RadioSetChannel;
RadioSetTxConfig;
RadioSetTxConfig;
RadioStandby;
RadioSetModem;
RadioSend;
RadioSend;
RadioIrqProcess;
RadioIrqProcess;
RadioSleep;
RadioStandby;
RadioSetChannel;
RadioSetRxConfig;
RadioStandby;
RadioSetModem;
RadioSetRxConfig;
RadioRx;
RadioIrqProcess;
RadioIrqProcess;
RadioIrqProcess;
RadioIrqProcess;
RadioIrqProcess;
RadioIrqProcess;
RadioIrqProcess;
RadioSleep;
RadioSetChannel;
RadioSetTxConfig;
RadioSetTxConfig;
RadioStandby;
RadioSetModem;
RadioSend;
RadioSend;
RadioIrqProcess;
RadioIrqProcess;
RadioSleep;
RadioStandby;
RadioSetChannel;
RadioSetRxConfig;
RadioStandby;
RadioSetModem;
RadioSetRxConfig;
RadioRx;
RadioIrqProcess;
RadioIrqProcess;
RadioIrqProcess;
RadioSleep;
RadioIrqProcess;
RadioSetChannel;
RadioSetTxConfig;
RadioSetTxConfig;
RadioStandby;
RadioSetModem;
RadioSend;
RadioSend;
RadioIrqProcess;
RadioSleep;
RadioStandby;
RadioSetChannel;
RadioSetRxConfig;
RadioStandby;
RadioSetModem;
RadioSetRxConfig;
RadioRx;
RadioIrqProcess;
RadioIrqProcess;
RadioIrqProcess;
RadioSleep;
RadioIrqProcess;
RadioSetChannel;
RadioSetTxConfig;
RadioSetTxConfig;
RadioStandby;
RadioSetModem;
RadioSend;
RadioSend;
RadioIrqProcess;
RadioIrqProcess;
RadioSleep;
RadioStandby;
RadioSetChannel;
RadioSetRxConfig;
RadioStandby;
RadioSetModem;
RadioSetRxConfig;
RadioRx;
RadioIrqProcess;
RadioIrqProcess;
RadioIrqProcess;
RadioSleep;
RadioIrqProcess;
RadioSetChannel;
RadioSetTxConfig;
RadioSetTxConfig;
RadioStandby;
RadioSetModem;
RadioSend;
RadioSend;
RadioIrqProcess;
RadioIrqProcess;
RadioSleep;
RadioStandby;
RadioSetChannel;
RadioSetRxConfig;
RadioStandby;
RadioSetModem;
RadioSetRxConfig;
RadioRx;
RadioIrqProcess;
RadioIrqProcess;
RadioIrqProcess;
RadioSleep;
RadioIrqProcess;
RadioSetChannel;
RadioSetTxConfig;
RadioSetTxConfig;
RadioStandby;
RadioSetModem;
RadioSend;
RadioSend;
RadioIrqProcess;
RadioIrqProcess;
RadioSleep;
RadioStandby;
RadioSetChannel;
RadioSetRxConfig;
RadioStandby;
RadioSetModem;
RadioSetRxConfig;
RadioRx;
RadioIrqProcess;
RadioIrqProcess;
RadioIrqProcess;
RadioSleep;
RadioIrqProcess;
RadioSetChannel;
RadioSetTxConfig;
RadioSetTxConfig;
RadioStandby;
RadioSetModem;
RadioSend;
RadioSend;
RadioIrqProcess;
RadioIrqProcess;
RadioSleep;
RadioStandby;
RadioSetChannel;
RadioSetRxConfig;
RadioStandby;
RadioSetModem;
RadioSetRxConfig;
RadioRx;
RadioIrqProcess;
RadioIrqProcess;
RadioIrqProcess;
RadioSleep;
RadioIrqProcess;
RadioSetChannel;
RadioSetTxConfig;
RadioSetTxConfig;
RadioStandby;
RadioSetModem;
RadioSend;
RadioSend;
RadioIrqProcess;
RadioIrqProcess;
RadioSleep;
RadioStandby;
RadioSetChannel;
RadioSetRxConfig;
RadioStandby;
RadioSetModem;
RadioSetRxConfig;
RadioRx;
RadioIrqProcess;
RadioIrqProcess;
RadioIrqProcess;
RadioSleep;
RadioIrqProcess;
RadioSetChannel;
RadioSetTxConfig;
RadioSetTxConfig;
RadioStandby;
RadioSetModem;
RadioSend;
RadioSend;
RadioIrqProcess;
RadioIrqProcess;
RadioSleep;
RadioStandby;
RadioSetChannel;
RadioSetRxConfig;
RadioStandby;
RadioSetModem;
RadioSetRxConfig;
RadioRx;
RadioIrqProcess;
RadioIrqProcess;
RadioIrqProcess;
RadioSleep;
RadioIrqProcess;
RadioSetChannel;
RadioSetTxConfig;
RadioSetTxConfig;
RadioStandby;
RadioSetModem;
RadioSend;
RadioSend;
RadioIrqProcess;
RadioIrqProcess;
RadioSleep;
RadioStandby;
RadioSetChannel;
RadioSetRxConfig;
RadioStandby;
RadioSetModem;
RadioSetRxConfig;
RadioRx;
RadioIrqProcess;
RadioIrqProcess;
RadioIrqProcess;
RadioSleep;
RadioIrqProcess;
RadioSetChannel;
RadioSetTxConfig;
RadioSetTxConfig;
RadioStandby;
RadioSetModem;
RadioSend;
RadioSend;
RadioIrqProcess;
RadioIrqProcess;
RadioSleep;
RadioStandby;
RadioSetChannel;
RadioSetRxConfig;
RadioStandby;
RadioSetModem;
RadioSetRxConfig;
RadioRx;
RadioIrqProcess;
RadioIrqProcess;
RadioIrqProcess;
RadioSleep;
RadioIrqProcess;
RadioSetChannel;
RadioSetTxConfig;
RadioSetTxConfig;
RadioStandby;
RadioSetModem;
RadioSend;
RadioSend;
RadioIrqProcess;
RadioIrqProcess;
RadioSleep;
RadioStandby;
RadioSetChannel;
RadioSetRxConfig;
RadioStandby;
RadioSetModem;
RadioSetRxConfig;
RadioRx;
RadioIrqProcess;
RadioIrqProcess;
RadioIrqProcess;
RadioSleep;
RadioIrqProcess;
RadioSetChannel;
RadioSetTxConfig;
RadioSetTxConfig;
RadioStandby;
RadioSetModem;
RadioSend;
RadioSend;
RadioIrqProcess;
RadioIrqProcess;
RadioSleep;
RadioStandby;
RadioSetChannel;
RadioSetRxConfig;
RadioStandby;
RadioSetModem;
RadioSetRxConfig;
RadioRx;
RadioIrqProcess;
RadioIrqProcess;
RadioIrqProcess;
RadioSleep;
end;
subgraph SX1262;
SX126xIoInit;
SX126xSetTx;
SX126xSetPaConfig;
SX126xSetTx;
SX126xSetPaConfig;
SX126xSetTx;
SX126xSetPaConfig;
SX126xSetTx;
SX126xSetPaConfig;
SX126xSetTx;
SX126xSetPaConfig;
SX126xSetTx;
SX126xSetPaConfig;
SX126xSetTx;
SX126xSetPaConfig;
SX126xSetTx;
SX126xSetPaConfig;
SX126xSetTx;
SX126xSetPaConfig;
SX126xSetTx;
SX126xSetPaConfig;
SX126xSetTx;
SX126xSetPaConfig;
SX126xSetTx;
SX126xSetPaConfig;
SX126xSetTx;
SX126xSetPaConfig;
SX126xSetTx;
SX126xSetPaConfig;
end;
subgraph NimBLE;
TimerInit;
TimerInit;
TimerInit;
TimerInit;
TimerInit;
TimerInit;
TimerInit;
TimerInit;
TimerInit;
TimerInit;
TimerInit;
TimerInit;
TimerInit;
TimerStop;
TimerStart;
TimerInit;
TimerSetValue;
TimerStop;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerStop;
TimerStart;
TimerStop;
TimerStop;
TimerStop;
TimerStart;
TimerStop;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerStop;
TimerStart;
TimerStop;
TimerStop;
TimerStop;
TimerStop;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerStop;
TimerStart;
TimerStop;
TimerStop;
TimerStop;
TimerStop;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerStop;
TimerStart;
TimerStop;
TimerStop;
TimerStop;
TimerStop;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerStop;
TimerStart;
TimerStop;
TimerStop;
TimerStop;
TimerStop;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerStop;
TimerStart;
TimerStop;
TimerStop;
TimerStop;
TimerStop;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerStop;
TimerStart;
TimerStop;
TimerStop;
TimerStop;
TimerStop;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerStop;
TimerStart;
TimerStop;
TimerStop;
TimerStop;
TimerStop;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerStop;
TimerStart;
TimerStop;
TimerStop;
TimerStop;
TimerStop;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerStop;
TimerStart;
TimerStop;
TimerStop;
TimerStop;
TimerStop;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerStop;
TimerStart;
TimerStop;
TimerStop;
TimerStop;
TimerStop;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerStop;
TimerStart;
TimerStop;
TimerStop;
TimerStop;
TimerStop;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerSetValue;
TimerStart;
TimerStop;
TimerStart;
TimerStop;
TimerStop;
TimerStart;
TimerStop;
TimerStop;
TimerStop;
end;
Start-->LoRaMacInitialization;
LoRaMacInitialization-->TimerInit;
TimerInit-->SX126xIoInit;
SX126xIoInit-->SX126xSetTx;
SX126xSetTx-->SX126xSetPaConfig;
SX126xSetPaConfig-->TimerInit;
TimerInit-->RadioSetModem;
RadioSetModem-->RadioSetPublicNetwork;
RadioSetPublicNetwork-->RadioSleep;
RadioSleep-->RadioSetModem;
RadioSetModem-->RadioSetPublicNetwork;
RadioSetPublicNetwork-->TimerInit;
TimerInit-->RadioSetChannel;
RadioSetChannel-->RadioSetTxConfig;
RadioSetTxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->SX126xSetTx;
SX126xSetTx-->SX126xSetPaConfig;
SX126xSetPaConfig-->RadioSend;
RadioSend-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerInit;
TimerInit-->TimerSetValue;
TimerSetValue-->TimerStop;
TimerStop-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->TimerStop;
TimerStop-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->RadioStandby;
RadioStandby-->RadioSetChannel;
RadioSetChannel-->RadioSetRxConfig;
RadioSetRxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->RadioSetRxConfig;
RadioSetRxConfig-->RadioRx;
RadioRx-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->TimerStop;
TimerStop-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerStop;
TimerStop-->LmHandlerSend;
LmHandlerSend-->RadioSetChannel;
RadioSetChannel-->RadioSetTxConfig;
RadioSetTxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->SX126xSetTx;
SX126xSetTx-->SX126xSetPaConfig;
SX126xSetPaConfig-->RadioSend;
RadioSend-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->TimerStop;
TimerStop-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->RadioStandby;
RadioStandby-->RadioSetChannel;
RadioSetChannel-->RadioSetRxConfig;
RadioSetRxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->RadioSetRxConfig;
RadioSetRxConfig-->RadioRx;
RadioRx-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->TimerStop;
TimerStop-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerStop;
TimerStop-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->LmHandlerSend;
LmHandlerSend-->RadioSetChannel;
RadioSetChannel-->RadioSetTxConfig;
RadioSetTxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->SX126xSetTx;
SX126xSetTx-->SX126xSetPaConfig;
SX126xSetPaConfig-->RadioSend;
RadioSend-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->TimerStop;
TimerStop-->RadioSleep;
RadioSleep-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->RadioStandby;
RadioStandby-->RadioSetChannel;
RadioSetChannel-->RadioSetRxConfig;
RadioSetRxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->RadioSetRxConfig;
RadioSetRxConfig-->RadioRx;
RadioRx-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->TimerStop;
TimerStop-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerStop;
TimerStop-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->LmHandlerSend;
LmHandlerSend-->RadioSetChannel;
RadioSetChannel-->RadioSetTxConfig;
RadioSetTxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->SX126xSetTx;
SX126xSetTx-->SX126xSetPaConfig;
SX126xSetPaConfig-->RadioSend;
RadioSend-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->TimerStop;
TimerStop-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->RadioStandby;
RadioStandby-->RadioSetChannel;
RadioSetChannel-->RadioSetRxConfig;
RadioSetRxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->RadioSetRxConfig;
RadioSetRxConfig-->RadioRx;
RadioRx-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->TimerStop;
TimerStop-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerStop;
TimerStop-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->LmHandlerSend;
LmHandlerSend-->RadioSetChannel;
RadioSetChannel-->RadioSetTxConfig;
RadioSetTxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->SX126xSetTx;
SX126xSetTx-->SX126xSetPaConfig;
SX126xSetPaConfig-->RadioSend;
RadioSend-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->TimerStop;
TimerStop-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->RadioStandby;
RadioStandby-->RadioSetChannel;
RadioSetChannel-->RadioSetRxConfig;
RadioSetRxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->RadioSetRxConfig;
RadioSetRxConfig-->RadioRx;
RadioRx-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->TimerStop;
TimerStop-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerStop;
TimerStop-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->LmHandlerSend;
LmHandlerSend-->RadioSetChannel;
RadioSetChannel-->RadioSetTxConfig;
RadioSetTxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->SX126xSetTx;
SX126xSetTx-->SX126xSetPaConfig;
SX126xSetPaConfig-->RadioSend;
RadioSend-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->TimerStop;
TimerStop-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->RadioStandby;
RadioStandby-->RadioSetChannel;
RadioSetChannel-->RadioSetRxConfig;
RadioSetRxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->RadioSetRxConfig;
RadioSetRxConfig-->RadioRx;
RadioRx-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->TimerStop;
TimerStop-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerStop;
TimerStop-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->LmHandlerSend;
LmHandlerSend-->RadioSetChannel;
RadioSetChannel-->RadioSetTxConfig;
RadioSetTxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->SX126xSetTx;
SX126xSetTx-->SX126xSetPaConfig;
SX126xSetPaConfig-->RadioSend;
RadioSend-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->TimerStop;
TimerStop-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->RadioStandby;
RadioStandby-->RadioSetChannel;
RadioSetChannel-->RadioSetRxConfig;
RadioSetRxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->RadioSetRxConfig;
RadioSetRxConfig-->RadioRx;
RadioRx-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->TimerStop;
TimerStop-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerStop;
TimerStop-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->LmHandlerSend;
LmHandlerSend-->RadioSetChannel;
RadioSetChannel-->RadioSetTxConfig;
RadioSetTxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->SX126xSetTx;
SX126xSetTx-->SX126xSetPaConfig;
SX126xSetPaConfig-->RadioSend;
RadioSend-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->TimerStop;
TimerStop-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->RadioStandby;
RadioStandby-->RadioSetChannel;
RadioSetChannel-->RadioSetRxConfig;
RadioSetRxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->RadioSetRxConfig;
RadioSetRxConfig-->RadioRx;
RadioRx-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->TimerStop;
TimerStop-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerStop;
TimerStop-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->LmHandlerSend;
LmHandlerSend-->RadioSetChannel;
RadioSetChannel-->RadioSetTxConfig;
RadioSetTxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->SX126xSetTx;
SX126xSetTx-->SX126xSetPaConfig;
SX126xSetPaConfig-->RadioSend;
RadioSend-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->TimerStop;
TimerStop-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->RadioStandby;
RadioStandby-->RadioSetChannel;
RadioSetChannel-->RadioSetRxConfig;
RadioSetRxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->RadioSetRxConfig;
RadioSetRxConfig-->RadioRx;
RadioRx-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->TimerStop;
TimerStop-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerStop;
TimerStop-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->LmHandlerSend;
LmHandlerSend-->RadioSetChannel;
RadioSetChannel-->RadioSetTxConfig;
RadioSetTxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->SX126xSetTx;
SX126xSetTx-->SX126xSetPaConfig;
SX126xSetPaConfig-->RadioSend;
RadioSend-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->TimerStop;
TimerStop-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->RadioStandby;
RadioStandby-->RadioSetChannel;
RadioSetChannel-->RadioSetRxConfig;
RadioSetRxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->RadioSetRxConfig;
RadioSetRxConfig-->RadioRx;
RadioRx-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->TimerStop;
TimerStop-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerStop;
TimerStop-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->LmHandlerSend;
LmHandlerSend-->RadioSetChannel;
RadioSetChannel-->RadioSetTxConfig;
RadioSetTxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->SX126xSetTx;
SX126xSetTx-->SX126xSetPaConfig;
SX126xSetPaConfig-->RadioSend;
RadioSend-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->TimerStop;
TimerStop-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->RadioStandby;
RadioStandby-->RadioSetChannel;
RadioSetChannel-->RadioSetRxConfig;
RadioSetRxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->RadioSetRxConfig;
RadioSetRxConfig-->RadioRx;
RadioRx-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->TimerStop;
TimerStop-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerStop;
TimerStop-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->LmHandlerSend;
LmHandlerSend-->RadioSetChannel;
RadioSetChannel-->RadioSetTxConfig;
RadioSetTxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->SX126xSetTx;
SX126xSetTx-->SX126xSetPaConfig;
SX126xSetPaConfig-->RadioSend;
RadioSend-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->TimerStop;
TimerStop-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->RadioStandby;
RadioStandby-->RadioSetChannel;
RadioSetChannel-->RadioSetRxConfig;
RadioSetRxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->RadioSetRxConfig;
RadioSetRxConfig-->RadioRx;
RadioRx-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->TimerStop;
TimerStop-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerStop;
TimerStop-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->LmHandlerSend;
LmHandlerSend-->RadioSetChannel;
RadioSetChannel-->RadioSetTxConfig;
RadioSetTxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->SX126xSetTx;
SX126xSetTx-->SX126xSetPaConfig;
SX126xSetPaConfig-->RadioSend;
RadioSend-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->TimerStop;
TimerStop-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerSetValue;
TimerSetValue-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->TimerStop;
TimerStop-->RadioStandby;
RadioStandby-->RadioSetChannel;
RadioSetChannel-->RadioSetRxConfig;
RadioSetRxConfig-->RadioStandby;
RadioStandby-->RadioSetModem;
RadioSetModem-->RadioSetRxConfig;
RadioSetRxConfig-->RadioRx;
RadioRx-->TimerStop;
TimerStop-->TimerStart;
TimerStart-->RadioIrqProcess;
RadioIrqProcess-->TimerStop;
TimerStop-->RadioIrqProcess;
RadioIrqProcess-->RadioSleep;
RadioSleep-->TimerStop;
TimerStop-->End;</code>
Constrain the Call Graph
TODO
Out Of Memory
Zig Compiler crashes when we run this code to group the C Functions by Module...
https://github.com/lupyuen/zig-bl602-nuttx/blob/f5a5c824e07e5fc984136069a1769edda4967c77/reflect.zig#L825-L1086
Here is the Output Log...
https://gist.github.com/lupyuen/5738abefa9d4c138e9d731e22d01500f
On macOS, Zig Compiler consumes over 34 GB of memory and crashes...
(On WSL, Zig Compiler hangs the WSL process when it consumes over 4 GB of memory)
This happens because our code loops repeatedly over <strong>4,700 C Declarations</strong> while processing <strong>1,500 lines of Raw Call Logs</strong>.
Let's optimise our code.
Fix Out Of Memory
Our code searches for a C Declaration by looping repeatedly over <strong>4,700 C Declarations</strong> like so...
```zig
/// Return the C Declaration Index for the Function Name.
/// We match the C Declaration Name against the start of the Function Name.
/// This is the slower, unfiltered version that searches all C Declarations.
fn get_decl_by_name(name: []const u8) ?usize {
comptime {
const T = @typeInfo(c);
<code> // For every C Declaration...
for (T.Struct.decls) |decl, i| {
if (std.mem.eql(u8, decl.name, "Radio")) { continue; } // Skip Radio
// If the C Declaration starts with the Function Name...
if (std.mem.startsWith(u8, name, decl.name)) {
// Return the C Declaration Index
return i;
}
} // End of C Declaration
return null; // Not found
}
</code>
}
```
<a>(Source)</a>
Which causes Zig Compiler to crash with Out Of Memory. But we don't actually need to loop through all the C Declarations!
According to our list of Modules, we call only <strong>173 Functions</strong>. Let's fix the above function so that we loop over the 173 Functions instead...
```zig
/// Return the C Declaration Index for the Function Name.
/// We match the C Declaration Name against the start of the Function Name.
/// This is the faster, filtered version that searches C Declarations by Modules.
fn get_decl_by_name_filtered(all_modules: []Module, name: []const u8) ?usize {
comptime {
const T = @typeInfo(c);
<code> // Search all Modules for the Function Name
for (all_modules) |module| {
// For every C Declaration in the Module...
var decl_index = module.first_index;
while (decl_index <= module.last_index) {
// Get the C Declaration
var decl = T.Struct.decls[decl_index];
if (std.mem.eql(u8, decl.name, "Radio")) { continue; } // Skip Radio
// If the C Declaration starts with the Function Name...
if (std.mem.startsWith(u8, name, decl.name)) {
// Return the C Declaration Index
return decl_index;
}
decl_index += 1;
} // End of C Declaration
} // End of Module
return null; // Not found
}
</code>
}
```
<a>(Source)</a>
And our code runs OK with Zig Compiler!
(macOS, not WSL though)
Wishlist for Zig Compiler
Building a Call Graph at Compile-Time with Zig Compiler looks pretty challenging.
I hope that future versions of the Zig Compiler will support the following...
<ul>
<li>
Type Reflection for C Declarations will provide the full path of source files
(Makes it easier to identify the module for each declaration)
</li>
<li>
<code>@compileLog</code> will emit any kind of strings
(So that <code>@compileLog</code> can generate proper Mermaid.js strings like "<code>Start-->LoRaMacInitialization;</code>")
</li>
</ul>
|
[] |
https://avatars.githubusercontent.com/u/43040593?v=4
|
mruby-zig
|
dantecatalfamo/mruby-zig
|
2022-02-22T22:30:35Z
|
mruby bindings for zig
|
master
| 2 | 35 | 7 | 35 |
https://api.github.com/repos/dantecatalfamo/mruby-zig/tags
|
MIT
|
[
"bindings",
"mruby",
"ruby",
"zig",
"zig-library"
] | 76 | false |
2025-02-22T11:26:56Z
| true | false |
unknown
|
github
|
[] |
mruby-zig
<a>mruby</a> bindings for <a>zig</a>!
Mruby is the lightweight implementation of the Ruby language complying with part of the ISO standard.
Mruby documentation can be found <a>here</a>.
Embedding
To embed <code>mruby</code> into another zig project, you just need to
recursively clone this repository and add a couple of lines to your
<code>build.zig</code>.
<ul>
<li>Add the following lines to <code>build.zig</code>, with the paths changed to match the correct location</li>
</ul>
```zig
const addMruby = @import("mruby-zig/build.zig").addMruby;
pub fn build(b: *std.Build) void {
const target = b.standardTargetOptions(.{});
const optimize = b.standardOptimizeOption(.{});
<code>const exe = b.addExecutable(.{
.name = "example",
.root_source_file = .{ .path = "src/main.zig" },
.target = target,
.optimize = optimize,
});
b.installArtifact(exe);
addMruby(b, exe);
// ...
</code>
}
```
<ul>
<li>Import <code>mruby</code> and start a new interpreter</li>
</ul>
```zig
const std = @import("std");
const mruby = @import("mruby");
pub fn main() anyerror!void {
// Opening a state
var mrb = try mruby.open();
defer mrb.close();
<code>// Loading a program from a string
mrb.load_string("puts 'hello from ruby!'");
</code>
}
```
Example
See <code>examples/main.zig</code>
|
[] |
https://avatars.githubusercontent.com/u/1519747?v=4
|
zcoff
|
kubkon/zcoff
|
2022-08-21T13:17:14Z
|
Like dumpbin.exe but cross-platform
|
main
| 1 | 34 | 1 | 34 |
https://api.github.com/repos/kubkon/zcoff/tags
|
MIT
|
[
"coff",
"dumpbin",
"pe",
"zig"
] | 69 | false |
2024-12-28T00:07:58Z
| true | false |
unknown
|
github
|
[] |
zcoff
Like <code>dumpbin.exe</code> but cross-platform.
Usage
Available options:
```
<blockquote>
zcoff /?
Usage: zcoff [options] file
</blockquote>
General options:
-archivemembers Print archive members summary.
-archivesymbols Print archive symbol table.
-directives Print linker directives.
-headers Print headers.
-symbols Print symbol table.
-imports Print import table.
-relocations Print relocations.
-help, /? Display this help and exit.
```
|
[] |
https://avatars.githubusercontent.com/u/43040593?v=4
|
zig-git
|
dantecatalfamo/zig-git
|
2022-12-15T21:52:33Z
|
Implementing git structures and functions in zig
|
master
| 0 | 34 | 2 | 34 |
https://api.github.com/repos/dantecatalfamo/zig-git/tags
|
MIT
|
[
"git",
"zig"
] | 124 | false |
2025-02-05T05:40:40Z
| true | false |
unknown
|
github
|
[] |
zig-git
Implementing git structures and functions in pure zig.
Still very much a work in progress. Some commands are redundant and some will get replaced.
This project is primarily for learning purposes and not meant to be a replacement for something like libgit2.
It doesn't support pack deltas yet.
Command
The <code>zig-git</code> command currently supports the following subcommands:
* <code>add <target></code> - Add a file or directory to the git index
* <code>branch</code> - List current branches (<code>refs/heads/</code>) in a format similar to <code>git branch</code>
* <code>branch-create <name></code> - Create a new branch from the current branch
* <code>checkout</code> - Checkout a ref or commit
* <code>commit</code> - Commit the current index (as a test, doesn't use correct information)
* <code>index</code> - List out the content of the index
* <code>init [directory]</code> - Create a new git repository
* <code>log</code> - List commits
* <code>read-commit <hash></code> - Parse and display a commit
* <code>read-object <hash></code> - Dump the decompressed contents of an object to stdout
* <code>read-pack <id></code> - Parse a pack file and iterate over its contents
* <code>read-pack-index <id> <hash></code> - Search a pack file index for the offset of an object with a hash in a pack file
* <code>read-ref [ref]</code> - Display a ref and what it points to, or all refs if no argument is given
* <code>read-tag [ref]</code> - Parse and display a tag
* <code>read-tree <name></code> - Parse and display the all files in a tree
* <code>refs</code> - List all refs
* <code>rm <file></code> - Remove file from index
* <code>root</code> - Print the root of the current git project
* <code>status</code> - Branch status
|
[] |
https://avatars.githubusercontent.com/u/12962448?v=4
|
pgz
|
star-tek-mb/pgz
|
2023-01-23T14:07:24Z
|
Postgres driver written in pure Zig
|
master
| 0 | 34 | 6 | 34 |
https://api.github.com/repos/star-tek-mb/pgz/tags
|
MIT
|
[
"postgres",
"postgresql",
"zig"
] | 109 | false |
2025-05-01T17:30:57Z
| true | false |
unknown
|
github
|
[] |
Overview
<strong>pgz</strong> - postgres driver/connector written in Zig (status pre-alpha development)
Package manager ready
Add following lines to your <code>build.zig.zon</code> dependencies:
<code>zig
.pgz = .{
.url = "git+https://github.com/star-tek-mb/pgz#master",
}</code>
Run <code>zig build</code> then obtain hash of the package and insert it to <code>build.zig.zon</code>.
Then you can use it as a library. Add following lines to <code>build.zig</code>:
```zig
const pgz_dep = b.dependency("pgz", .{ .target = target, .optimize = optimize });
exe.addModule("pgz", pgz_dep.module("pgz"));
```
Example
```zig
const std = @import("std");
const Connection = @import("pgz").Connection;
pub fn main() !void {
var dsn = try std.Uri.parse("postgres://testing:testing@localhost:5432/testing");
var connection = try Connection.init(std.heap.page_allocator, dsn);
defer connection.deinit();
var result = try connection.query("SELECT 1 as number;", struct { number: ?[]const u8 });
defer result.deinit();
<code>try connection.exec("CREATE TABLE users(name text not null);");
defer connection.exec("DROP TABLE users;") catch {};
var stmt = try connection.prepare("INSERT INTO users(name) VALUES($1);");
defer stmt.deinit();
try stmt.exec(.{"hello"});
try stmt.exec(.{"world"});
try std.io.getStdOut().writer().print("number = {s}\n", .{result.data[0].number.?});
</code>
}
```
TODOs
<ul>
<li>Optimize allocations (use stack fallback allocator for messages)</li>
<li>Fix all todos in code</li>
<li>Connection pools (do we need them?)</li>
<li>Complete and test in production?</li>
</ul>
Testing
Create user <code>testing</code> with password <code>testing</code>.
Create database <code>testing</code>.
Run <code>zig build test</code>
|
[] |
https://avatars.githubusercontent.com/u/32851089?v=4
|
limine-zig-template
|
48cf/limine-zig-template
|
2022-07-31T01:05:17Z
|
A simple template for building a Limine-compliant kernel in Zig.
|
trunk
| 1 | 34 | 3 | 34 |
https://api.github.com/repos/48cf/limine-zig-template/tags
|
0BSD
|
[
"amd64",
"bare-bones",
"barebones",
"kernel",
"limine",
"limine-bootloader",
"template",
"x86-64",
"zig",
"ziglang"
] | 7 | false |
2025-05-18T15:33:22Z
| false | false |
unknown
|
github
|
[] |
Limine Zig Template
This repository will demonstrate how to set up a basic kernel in Zig using Limine.
How to use this?
Dependencies
Any <code>make</code> command depends on GNU make (<code>gmake</code>) and is expected to be run using it. This usually means using <code>make</code> on most GNU/Linux distros, or <code>gmake</code> on other non-GNU systems.
A Zig compiler is required to build the kernel. Minimum supported version is 0.14.0. You can install Zig from the <a>official website</a>.
Additionally, building an ISO with <code>make all</code> requires <code>xorriso</code>, and building a HDD/USB image with <code>make all-hdd</code> requires <code>sgdisk</code> (usually from <code>gdisk</code> or <code>gptfdisk</code> packages) and <code>mtools</code>.
Architectural targets
The <code>ARCH</code> make variable determines the target architecture to build the kernel and image for.
The default <code>ARCH</code> is <code>x86_64</code>. Other options include: <code>aarch64</code>, <code>loongarch64</code>, and <code>riscv64</code>.
Makefile targets
Running <code>make all</code> will compile the kernel (from the <code>kernel/</code> directory) and then generate a bootable ISO image.
Running <code>make all-hdd</code> will compile the kernel and then generate a raw image suitable to be flashed onto a USB stick or hard drive/SSD.
Running <code>make run</code> will build the kernel and a bootable ISO (equivalent to make all) and then run it using <code>qemu</code> (if installed).
Running <code>make run-hdd</code> will build the kernel and a raw HDD image (equivalent to make all-hdd) and then run it using <code>qemu</code> (if installed).
For x86_64, the <code>run-bios</code> and <code>run-hdd-bios</code> targets are equivalent to their non <code>-bios</code> counterparts except that they boot <code>qemu</code> using the default SeaBIOS firmware instead of OVMF.
|
[] |
https://avatars.githubusercontent.com/u/26302304?v=4
|
ecez
|
Avokadoen/ecez
|
2022-07-04T11:19:39Z
|
An ECS API for Zig!
|
main
| 23 | 32 | 2 | 32 |
https://api.github.com/repos/Avokadoen/ecez/tags
|
MIT
|
[
"data-oriented-programming",
"ecs",
"zig"
] | 1,601 | false |
2025-05-10T07:18:32Z
| true | true |
unknown
|
github
|
[
{
"commit": "master",
"name": "ztracy",
"tar_url": "https://github.com/zig-gamedev/ztracy/archive/master.tar.gz",
"type": "remote",
"url": "https://github.com/zig-gamedev/ztracy"
}
] |
ECEZ - An ECS API
This is a ECS (Entity Component System) API for Zig.
Try it yourself!
Requirements
The <a>zig compiler 0.14.0</a>
You can use zigup to easily get this specific version
Steps
Run the following commands
```bash
Clone the repo
git clone https://github.com/Avokadoen/ecez.git
Run tests
zig build test
Run GOL example, use '-Denable-tracy=true' at the end to add tracy functionality
zig build run-game-of-life
```
You should also checkout <a>src/root.zig</a> which has the public API. From there you can follow the deifinition to get more details.
Include ecez and optionally tracy in your project
Add ecez to build.zig.zon, example in terminal:
<code>zig fetch --save git+https://github.com/Avokadoen/ecez.git/#HEAD</code>
Basic ecez build
build.zig
<code>zig
const ecez = b.dependency("ecez", .{});
const ecez_module = ecez.module("ecez");
exe.addImport("ecez", ecez_module);</code>
Using ztracy with ecez:
build.zig:
```zig
const options = .{
.enable_ztracy = b.option(
bool,
"enable_ztracy",
"Enable Tracy profile markers",
) orelse false,
.enable_fibers = b.option(
bool,
"enable_fibers",
"Enable Tracy fiber support",
) orelse false,
.on_demand = b.option(
bool,
"on_demand",
"Build tracy with TRACY_ON_DEMAND",
) orelse false,
};
// link ecez and ztracy
{
const ecez = b.dependency("ecez", .{
.enable_ztracy = options.enable_ztracy,
.enable_fibers = options.enable_fibers,
.on_demand = options.on_demand,
});
const ecez_module = ecez.module("ecez");
exe.root_module.addImport("ecez", ecez_module);
exe_unit_tests.root_module.addImport("ecez", ecez_module);
const ztracy_dep = ecez.builder.dependency("ztracy", .{
.enable_ztracy = options.enable_ztracy,
.enable_fibers = options.enable_fibers,
.on_demand = options.on_demand,
});
const ztracy_module = ztracy_dep.module("root");
exe.root_module.addImport("ztracy", ztracy_module);
exe_unit_tests.root_module.addImport("ztracy", ztracy_module);
exe.linkLibrary(ztracy_dep.artifact("tracy"));
}
```
Zig documentation
You can generate the ecez API documentation using <code>zig build docs</code>. This will produce some web resources in <code>zig-out/doc/ecez</code>.
You will need a local server to serve the documentation since browsers will block resources loaded by the index.html.
The simplest solution to this is just using a basic python server:
<code>bash
python -m http.server 8000 -d ecez/zig-out/doc/ecez # you can then access the documentation at http://localhost:8000/#ecez.main</code>
Features
Compile time based and type safe API
Zig's comptime feature is utilized to perform static reflection on the usage of the API to validate usage and report useful messages to the user (in theory :)).
https://github.com/Avokadoen/ecez/blob/7210c43d2dbe6202806acf3e5ac361cbbaed11af/examples/readme/main.zig#L1-L190
System arguments
Systems can take 3 argument types:
* Queries - Storage queries requesting a certain entity composition. T
* Storage.Subset - A subset of the storage. This is just the normal storage with limitations on which
components can be touched. You can create entities, (un)set components .. etc
* EventArgument - Any non query or subset. Can be useful as a "context" for the event
Implicit multithreading of systems
When you trigger a system dispatch or an event with multiple systems then ecez will schedule this work over multiple threads.
Synchronization is handled by ecez although there are some caveats that you should be aware of:
<ul>
<li>Dont request write access (query result members that are of pointer type) unless you need it.<ul>
<li>Writes has more limitations on what can run in parallel </li>
</ul>
</li>
<li>Be specific, only request the types you will use.</li>
<li>EventArgument will not be considered when synchronizing. This means that if you mutate an event argument then you must take some care in order to ensure legal behaviour</li>
</ul>
Serialization through the ezby format
ecez uses a custom byte format to convert storages into a slice of bytes.
Example
https://github.com/Avokadoen/ecez/blob/7210c43d2dbe6202806acf3e5ac361cbbaed11af/examples/readme/main.zig#L191-L201
Tracy integration using <a>ztracy</a>
The codebase has integration with tracy to allow both the library itself, but also applications to profile using a <a>tracy client</a>. The extra work done by tracy is of course NOPs in builds without tracy!
Demo/Examples
Currently the project has two simple examples in the <a>example folder</a>:
* Implementation of <a>conway's game of life</a> which also integrate tracy
* The code from this <a>readme</a>
There is also <a>wizard rampage</a> which is closer to actual game code. This was originally a game jam so some of the code is "hacky" but the ecez usage should be a practical example
Test Driven Development
The codebase also utilize TDD to ensure a certain level of robustness, altough I can assure you that there are many bugs to find yet! ;)
Planned
Please see the issues for planned features.
|
[] |
https://avatars.githubusercontent.com/u/15983269?v=4
|
zig-nanoid
|
SasLuca/zig-nanoid
|
2022-04-18T22:32:31Z
|
A tiny, secure, URL-friendly, unique string ID generator. Now available in pure Zig.
|
main
| 1 | 30 | 3 | 30 |
https://api.github.com/repos/SasLuca/zig-nanoid/tags
|
MIT
|
[
"id",
"nanoid",
"random",
"unique-id",
"unique-identifier",
"uniqueid",
"url",
"uuid",
"uuid-generator",
"zig",
"zig-package",
"ziglang"
] | 59 | false |
2025-03-27T18:32:48Z
| true | false |
unknown
|
github
|
[] |
Nano ID in Zig
<a></a>
<a></a>
A battle-tested, tiny, secure, URL-friendly, unique string ID generator. Now available in pure Zig.
<ul>
<li><strong>Freestanding.</strong> zig-nanoid is entirely freestanding.</li>
<li><strong>Fast.</strong> The algorithm is very fast and relies just on basic math, speed will mostly depend on your choice of RNG.</li>
<li><strong>Safe.</strong> It can use any random generator you want and the library has no errors to handle.</li>
<li><strong>Short IDs.</strong> It uses a larger alphabet than UUID (<code>A-Za-z0-9_-</code>). So ID length was reduced from 36 to 21 symbols and it is URL friendly.</li>
<li><strong>Battle Tested.</strong> Original implementation has over 18 million weekly downloads on <a>npm</a>.</li>
<li><strong>Portable.</strong> Nano ID was ported to <a>20+ programming languages</a>.</li>
</ul>
Example
Basic usage with <code>std.crypto.random</code>:
```zig
const std = @import("std");
const nanoid = @import("nanoid");
pub fn main() !void
{
const result = nanoid.generate(std.crypto.random);
<code>std.log.info("Nanoid: {s}", .{result});
</code>
}
```
Comparison to UUID
Nano ID is quite comparable to UUID v4 (random-based).
It has a similar number of random bits in the ID (126 in Nano ID and 122 in UUID), so it has a similar collision probability.
It also uses a bigger alphabet, so a similar number of random bits are packed in just 21 symbols instead of 36.
For there to be a one in a billion chance of duplication, 103 trillion version 4 IDs must be generated.
How to use
Generating an id with the default size
The simplest way to generate an id with the default alphabet and length is by using the function <code>generate</code> like so:
<code>zig
const result = nanoid.generate(std.crypto.random);</code>
If you want a custom alphabet you can use <code>generateWithAlphabet</code> and pass either a custom alphabet or one from <code>nanoid.alphabets</code>:
<code>zig
const result = nanoid.generateWithAlphabet(std.crypto.random, nanoid.alphabets.numbers); // This id will only contain numbers</code>
You can find a variety of other useful alphabets inside of <code>nanoid.alphabets</code>.
The result is an array of size <code>default_id_len</code> which happens to be 21 which is returned by value.
There are no errors to handle, assuming your rng object is valid everything will work.
The default alphabet includes the symbols "-_", numbers and English lowercase and uppercase letters.
Generating an id with a custom size
If you want a custom alphabet and length use <code>generateEx</code> or <code>generateExWithIterativeRng</code>.
The function <code>generateEx</code> takes an rng, an <code>alphabet</code>, a <code>result_buffer</code> that it will write the id to, and a <code>step_buffer</code>.
The <code>step_buffer</code> is used by the algorithm to store a random bytes so it has to do less calls to the rng and <code>step_buffer.len</code> must be at
least <code>computeRngStepBufferLength(computeMask(@truncate(u8, alphabet.len)), result_buffer.len, alphabet.len)</code>.
The function <code>generateExWithIterativeRng</code> is the same as <code>generateEx</code> except it doesn't need a <code>step_buffer</code>. It will use <code>Random.int(u8)</code>
instead of <code>Random.bytes()</code> to get a random byte at a time thus avoiding the need for a rng step buffer. Normally this will be slower but
depending on your rng algorithm or other requirements it might not be, so the option is there in case you need but normally it is
recommended you use <code>generateEx</code> which requires a temporary buffer that will be filled using <code>Random.bytes()</code> in order to get the best
performance.
Additionally you can precompute a sufficient length for the <code>step_buffer</code> and pre-allocate it as an optimization using
<code>computeSufficientRngStepBufferLengthFor</code> which simply asks for the largest possible id length you want to generate.
If you intend to use the <code>default_id_len</code>, you can use the constant <code>nanoid.rng_step_buffer_len_sufficient_for_default_length_ids</code>.
Regarding RNGs
You will need to provide an random number generator (rng) yourself. You can use the zig standard library ones, either <code>std.rand.DefaultPrng</code>
or if you have stricter security requirements use <code>std.rand.DefaultCsprng</code> or <code>std.crypto.random</code>.
When you initialize them you need to provide a seed, providing the same one every time will result in the same ids being generated every
time you run the program, except for <code>std.crypto.random</code>.
If you want a good secure seed you can generate one using <code>std.crypto.random.bytes</code>.
Here is an example of how you would initialize and seed <code>std.rand.DefaultCsprng</code> and use it:
```zig
// Generate seed
var seed: [std.rand.DefaultCsprng.secret_seed_length]u8 = undefined;
std.crypto.random.bytes(&seed);
// Initialize the rng and allocator
var rng = std.rand.DefaultCsprng.init(seed);
// Generate id
var id = nanoid.generate(rng.random());
```
Add zig-nanoid to your project
Manually
To add the library as a package to your zig project:
1. Download the repo and put it in a folder (eg: <code>thirdparty</code>) in your project.
2. Import the library's <code>build.zig</code> in your build script (eg: <code>const nanoid = @import("thirdparty/nanoid-zig/build.zig");</code>)
3. Add the library as a package to your steps (eg: <code>exe.addPackage(nanoid.getPackage("nanoid"));</code>)
Full example:
```zig
// build.zig
const std = @import("std");
const nanoid = @import("thirdparty/zig-nanoid/build.zig");
pub fn build(b: *std.build.Builder) void
{
const target = b.standardTargetOptions(.{});
const mode = b.standardReleaseOptions();
<code>const exe = b.addExecutable("zig-nanoid-test", "src/main.zig");
exe.setTarget(target);
exe.setBuildMode(mode);
exe.addPackage(nanoid.getPackage("nanoid"));
exe.install();
</code>
}
```
Using the gyro package manager
We support the zig <a>gyro package manager</a>.
Here is how to use it:
<ol>
<li>
From your terminal initialize a gyro project and add the package <code>SasLuca/nanoid</code>.
<code>gyro init
gyro add SasLuca/nanoid</code>
</li>
<li>
In your <code>build.zig</code> do an import like so <code>const pkgs = @import("deps.zig").pkgs;</code> and call <code>pkgs.addAllTo(exe);</code> to add all libraries to your executable (or some other target).
</li>
<li>
Import <code>const nanoid = @import("nanoid");</code> in your <code>main.zig</code> and use it.
</li>
<li>
Invoke <code>gyro build run</code> which will generate <code>deps.zig</code> and other files as well as building and running your project.
</li>
</ol>
Useful links
<ul>
<li>
Original implementation: https://github.com/ai/nanoid
</li>
<li>
Online Tool: https://zelark.github.io/nano-id-cc/
</li>
</ul>
|
[] |
https://avatars.githubusercontent.com/u/1519747?v=4
|
zignature
|
kubkon/zignature
|
2022-04-01T18:35:10Z
|
codesign your Apple apps with Zig!
|
main
| 0 | 29 | 0 | 29 |
https://api.github.com/repos/kubkon/zignature/tags
|
MIT
|
[
"ios",
"macos",
"zig"
] | 12 | false |
2025-05-16T00:28:16Z
| true | false |
unknown
|
github
|
[] |
zignature
<code>codesign</code> your Apple apps with Zig!
Coming soon...
|
[] |
https://avatars.githubusercontent.com/u/320322?v=4
|
zig-py-sample
|
ali5h/zig-py-sample
|
2022-03-03T01:49:38Z
|
sample python extension in zig
|
master
| 0 | 28 | 2 | 28 |
https://api.github.com/repos/ali5h/zig-py-sample/tags
|
-
|
[
"c-extensions",
"python",
"zig"
] | 82 | false |
2025-05-03T12:32:12Z
| true | false |
unknown
|
github
|
[] |
Sample Python Extension in Zig
This is tested on Ubuntu with <code>python3.8</code> installed.
```
build the extension
$ zig build
run zig tests
$ zig build test
run python tests
$ pytest
```
logical division of the code
<ul>
<li>Pure Zig part is in <code>src/sum.zig</code></li>
<li>Python ffi is used in <code>src/ffi.zig</code> and translated headers are in <code>src/python3.8.zig</code></li>
<li>The extension is in <code>src/pysum.zig</code></li>
<li>Sample app to call python code is in <code>src/callpy.zig</code></li>
</ul>
python ffi
<code>python3.8.zig</code> is generated by running
<code>$ zig translate-c /usr/include/python3.8/Python.h -I/usr/include/python3.8 -I /usr/include -I /usr/include/x86_64-linux-gnu/ -D__sched_priority=0 -DNDEBUG > src/python3.8.zig</code>
|
[] |
https://avatars.githubusercontent.com/u/6693837?v=4
|
blog
|
thi-ng/blog
|
2022-12-03T21:24:20Z
|
Current blog posts and consolidated historical articles from various other blog platforms used previously
|
main
| 0 | 28 | 0 | 28 |
https://api.github.com/repos/thi-ng/blog/tags
|
CC-BY-SA-4.0
|
[
"blog",
"clojure",
"clojurescript",
"typescript",
"webgl",
"zig"
] | 56,915 | false |
2025-05-13T16:47:18Z
| false | false |
unknown
|
github
|
[] |
blog.thi.ng
Due to a current lack of a proper blog setup, this is a temporary place to host
& publish new blog posts (restarted in Dec 2022). My existing blogs with various
long form articles originally published at <a>Medium</a>
(2015-2020), the defunct <a>toxiclibs.org
site</a> (2006-2011) and the ancient
<a>toxi.co.uk</a> (2003-2008) are all in the process of
being migrated to here as well...
Blog posts
| Date | Title |
|:-----------|:----------------------------------------------------------------------------------------------------------------------------------|
| 2025-05-13 | <a>Blue-eyed AI in contemporary design education</a> |
| 2025-05-13 | <a>thi.ng/color-palettes updates</a> |
| 2025-03-29 | <a>De/Frag on show at ZKM Karlsruhe</a> |
| 2025-03-28 | <a>The map is not the terrain</a> |
| 2025-03-19 | <a>The Purpose Of a LLM Is What It Does</a> |
| 2023-02-26 | <a>Forth on Mastodon</a> |
| 2023-01-12 | <a>May the Forth by with you!</a> |
| 2023-01-03 | <a>A simple nod of acknowledgment</a> |
| 2022-12-04 | <a>Personal considerations for creating generative art</a> |
| 2022-09-03 | <a>Zig projects I'm working on...</a> |
| 2022-08-31 | <a>Zig pointer types cheatsheet</a> |
| 2019-03-14 | <a>Of umbrellas, transducers, reactive streams & mushrooms (Pt. 4)</a> |
| 2019-03-10 | <a>Of umbrellas, transducers, reactive streams & mushrooms (Pt. 3)</a> |
| 2019-03-07 | <a>Of umbrellas, transducers, reactive streams & mushrooms (Pt. 2)</a> |
| 2019-03-04 | <a>Of umbrellas, transducers, reactive streams & mushrooms (Pt.1)</a> |
| 2018-02-04 | <a>How to UI in 2018</a> |
| 2016-07-03 | <a>ClojureScript, WebWorkers & WebGL</a> |
| 2016-06-26 | <a>Workshop report: Generative design with Clojure</a> |
| 2016-05-02 | <a>Workshop report: Hi-perf Clojurescript with WebGL, asm.js and Emscripten</a> |
| 2016-01-05 | <a>Evolutionary failures (Part 1)</a> |
| 2015-12-15 | <a>The Jacob's Ladder of Coding</a> |
| 2015-11-16 | <a>Workshop report: Building Linked Data heatmaps with Clojurescript & thi.ng</a> |
| 2007-07-18 | <a>Adobe says: The picture is now complete</a> |
| 2005-09-26 | <a>1st Ave Machine</a> |
| 2005-07-06 | <a>648 ney, 14 hey, 18 couldn't care less</a> |
| 2005-03-04 | <a>1st public release of the macronaut hub</a> |
| 2004-01-27 | <a>Progress bar for applet loading</a> |
| 2004-01-16 | <a>New demos</a> |
| 2004-01-09 | <a>Java tutorials</a> |
| 2004-01-07 | <a>PostScript output from Processing</a> |
| 2004-01-06 | <a>Sonia 2.5</a> |
| 2004-01-05 | <a>Automatic keyboard focus</a> |
| 2004-01-05 | <a>Floats vs. fixed point math</a> |
| 2003-12-30 | <a>Processing in Eclipse</a> |
License
© 2003 - 2023 Karsten Schmidt // CC-BY-NC-SA-4.0
|
[] |
https://avatars.githubusercontent.com/u/35909?v=4
|
websocket.zig
|
ianic/websocket.zig
|
2023-01-02T13:55:10Z
|
websocket protocol in zig
|
main
| 3 | 27 | 5 | 27 |
https://api.github.com/repos/ianic/websocket.zig/tags
|
MIT
|
[
"autobahn",
"websocket",
"zig"
] | 5,122 | false |
2025-05-12T14:46:41Z
| true | true |
unknown
|
github
|
[] |
<ul>
<li>passing all autobahn tests</li>
<li>handles per message deflate, including sliding window bits size negotiation</li>
<li>uses zlib for message compression/decompression</li>
</ul>
Include library in you project
There is a minimal project in <a>examples/exe</a> which demonstrates
how to use websocket client.
<ul>
<li>add dependency to ws lib in your <a>build.zig.zon</a></li>
<li>link library in your <a>build.zig</a></li>
</ul>
Then you can <code>@import("ws")</code> in <a>src/main.zig</a>.
This example uses public echo ws server at ws://ws.vi-server.org/mirror/.
Connects to websocket server, sends hello message and prints echoed reply.
Above url is taken from <a>websocat - curl for WebSocket</a> tool.
You can start websocat server locally with for example:
<code>sh
websocat -s 8080</code>
and then connect to it by changing <a>hostname, uri, port</a> to:
<code>Zig
const hostname = "localhost";
const uri = "ws://localhost/";
const port = 8080;</code>
References
<a>The WebSocket Protocol RFC</a>
<a>compression extension RFC</a>
<a>autobahn testsuite</a>
<a>mattnite/zig-zlib</a>
<a>zlib</a>
run file tests
<code>zig test src/main.zig --deps zlib=zlib --mod zlib::../zig-zlib/src/main.zig -l z 2>&1 | cat</code>
|
[] |
https://avatars.githubusercontent.com/u/1560508?v=4
|
Ray-Tracing-in-One-Weekend.zig
|
ryoppippi/Ray-Tracing-in-One-Weekend.zig
|
2022-07-16T19:01:41Z
|
ray tracing in one weekend in zig
|
main
| 0 | 27 | 1 | 27 |
https://api.github.com/repos/ryoppippi/Ray-Tracing-in-One-Weekend.zig/tags
|
MIT
|
[
"raytracing-in-one-weekend",
"raytracing-one-weekend",
"zig"
] | 5,039 | false |
2024-12-03T00:10:48Z
| true | false |
unknown
|
github
|
[] |
Ray-Tracing-in-One-Weekend.zig
<a>Ray Tracing in One Weekend</a> in Zig!
How to execute
<code>sh
git clone https://github.com/ryoppippi/Ray-Tracing-in-One-Weekend.zig
zig build -Drelease-fast=true run >> image.ppm</code>
Note that this build works on zig 0.10.0 (because of async api is not work on self-hosted compiler)
Bechmark
<ul>
<li>Machine: Mac Mini 2021</li>
<li>Chip: Apple M1</li>
<li>Memory: 16GB</li>
<li>OS: macOS 12.4(21F79)</li>
<li>Zig: 0.10.0-dev.3007+6ba2fb3db</li>
</ul>
Before Multithreading <a>9305860</a>
```sh
Executed in 879.32 secs fish external
usr time 863.33 secs 35.00 micros 863.33 secs
sys time 15.33 secs 550.00 micros 15.33 secs
```
After Multithreading
```sh
Executed in 190.77 secs fish external
usr time 22.87 mins 47.00 micros 22.87 mins
sys time 0.09 mins 825.00 micros 0.09 mins
```
License
MIT
Author
Ryotaro "Justin" Kimura (a.k.a. ryoppippi)
|
[] |
https://avatars.githubusercontent.com/u/110336750?v=4
|
blockly-zig-nuttx
|
lupyuen3/blockly-zig-nuttx
|
2022-07-31T12:16:16Z
|
Visual Programming for Zig with NuttX Sensors
|
master
| 1 | 26 | 1 | 26 |
https://api.github.com/repos/lupyuen3/blockly-zig-nuttx/tags
|
Apache-2.0
|
[
"bl602",
"bl604",
"blockly",
"bme280",
"nuttx",
"pinecone",
"pinedio",
"riscv32",
"sensor",
"visualprogramming",
"zig"
] | 123,024 | true |
2025-02-14T12:12:46Z
| false | false |
unknown
|
github
|
[] |
Visual Programming for Zig with NuttX Sensors
Read the articles...
<ul>
<li>
<a>"Visual Programming with Zig and NuttX Sensors"</a>
</li>
<li>
<a>"Zig Visual Programming with Blockly"</a>
</li>
<li>
<a>"Read NuttX Sensor Data with Zig"</a>
</li>
</ul>
Try the Work-in-Progress Demo...
<ul>
<li><a>lupyuen3.github.io/blockly-zig-nuttx/demos/code</a></li>
</ul>
Can we use Scratch / <a>Blockly</a> to code Zig programs, the drag-n-drop way?
Let's create a Visual Programming Tool for Zig that will generate IoT Sensor Apps with Apache NuttX RTOS.
<em>Why limit to IoT Sensor Apps?</em>
<ul>
<li>
Types are simpler: Only floating-point numbers will be supported, no strings needed
</li>
<li>
Blockly is Typeless. With Zig we can use Type Inference to deduce the missing types
</li>
<li>
Make it easier to experiment with various IoT Sensors: Temperature, Humidity, Air Pressure, ...
</li>
</ul>
Let's customise Blockly to generate Zig code...
<a>(Source)</a>
Add a Zig Tab
Blockly is bundled with a list of Demos...
<a>lupyuen3.github.io/blockly-zig-nuttx/demos</a>
There's a Code Generation Demo that shows the code generated by Blockly for JavaScript, Python, Dart, ...
<a>lupyuen3.github.io/blockly-zig-nuttx/demos/code</a>
Let's add a tab that will show the Zig code generated by Blockly: <a>demos/code/index.html</a>
```html
...
...
Zig
...
```
[(See the changes)](https://github.com/lupyuen3/blockly-zig-nuttx/pull/1/files#diff-dcf2ffe98d7d8b4a0dd7b9f769557dbe8c9e0e726236ef229def25c956a43d8f)
We'll see the Zig Tab like this...
[lupyuen3.github.io/blockly-zig-nuttx/demos/code](https://lupyuen3.github.io/blockly-zig-nuttx/demos/code/)
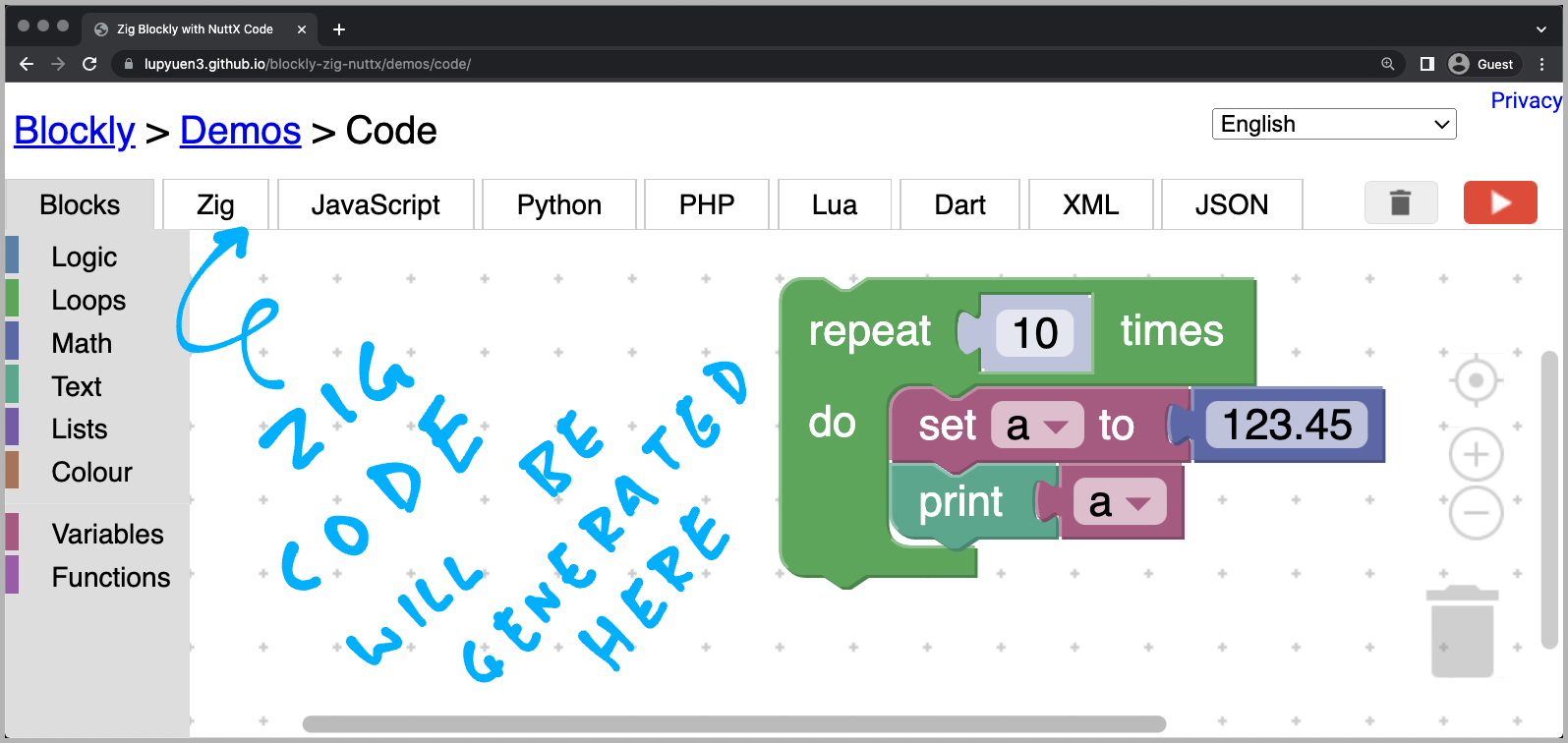
# Zig Code Generator
Blockly comes bundled with Code Generators for JavaScript, Python, Dart, ...
Let's create a Code Generator for Zig, by copying from the Dart Code Generator.
Copy [generators/dart.js](generators/dart.js) to [generators/zig.js](generators/zig.js)
Copy all files from [generators/dart](generators/dart) to [generators/zig](generators/zig)...
```text
all.js
colour.js
lists.js
logic.js
loops.js
math.js
procedures.js
text.js
variables.js
variables_dynamic.js
```
[(See the copied files)](https://github.com/lupyuen3/blockly-zig-nuttx/commit/ba968942c6ee55937ca554e1d290d8d563fa0b78)
Edit [generators/zig.js](generators/dart.js) and all files in [generators/zig](generators/zig).
Change all `Dart` to `Zig`, preserve case.
[(See the changes)](https://github.com/lupyuen3/blockly-zig-nuttx/commit/efe185d6cac4306dcdc6b6a5f261b331bb992976)
# Load Code Generator
Let's load our Zig Code Generator in Blockly...
Add the Zig Code Generator to [demos/code/index.html](demos/code/index.html)...
```html
```
[(See the changes)](https://github.com/lupyuen3/blockly-zig-nuttx/pull/1/files#diff-dcf2ffe98d7d8b4a0dd7b9f769557dbe8c9e0e726236ef229def25c956a43d8f)
Enable the Zig Code Generator in [demos/code/code.js](demos/code/code.js)...
```javascript
// Inserted `zig`...
Code.TABS_ = [
'blocks', 'zig', 'javascript', 'php', 'python', 'dart', 'lua', 'xml', 'json'
];
...
// Inserted `Zig`...
Code.TABS_DISPLAY_ = [
'Blocks', 'Zig', 'JavaScript', 'PHP', 'Python', 'Dart', 'Lua', 'XML', 'JSON'
];
...
Code.renderContent = function() {
...
} else if (content.id === 'content_json') {
var jsonTextarea = document.getElementById('content_json');
jsonTextarea.value = JSON.stringify(
Blockly.serialization.workspaces.save(Code.workspace), null, 2);
jsonTextarea.focus();
// Inserted this...
} else if (content.id == 'content_zig') {
Code.attemptCodeGeneration(Blockly.Zig);
```
[(See the changes)](https://github.com/lupyuen3/blockly-zig-nuttx/pull/1/files#diff-d72873b861dee958e5d443c919726dd856de594bd56b1e73d8948a7719163553)
Add our Code Generator to the Build Task: [scripts/gulpfiles/build_tasks.js](scripts/gulpfiles/build_tasks.js#L98-L139)
```javascript
const chunks = [
// Added this...
{
name: 'zig',
entry: 'generators/zig/all.js',
reexport: 'Blockly.Zig',
}
];
```
[(See the changes)](https://github.com/lupyuen3/blockly-zig-nuttx/pull/1/files#diff-a9a5784f43ce15ca76bb3e99eb6625c3ea15381e20eac6f7527ecbcb2945ac14)
Now we compile our Zig Code Generator.
# Build Blockly
Blockly builds fine with Linux, macOS and WSL. (But not plain old Windows CMD)
To build Blockly with the Zig Code Generator...
```bash
git clone --recursive https://github.com/lupyuen3/blockly-zig-nuttx
cd blockly-zig-nuttx
npm install
## Run these steps when we change the Zig Code Generator
npm run build
npm run publish
## When prompted "Is this the correct branch?",
## press N
## Instead of "npm run publish" (which can be slow), we may do this...
## cp build/*compressed* .
## For WSL: We can copy the generated files to c:\blockly-zig-nuttx for testing on Windows
## cp *compressed* /mnt/c/blockly-zig-nuttx
```
This compiles and updates the Zig Code Generator in [zig_compressed.js](zig_compressed.js) and [zig_compressed.js.map](zig_compressed.js.map)
If we're using VSCode, here's the Build Task: [.vscode/tasks.json](.vscode/tasks.json)
# Test Blockly
Browse to `blockly-zig-nuttx/demos/code` with a Local Web Server. [(Like Web Server for Chrome)](https://chrome.google.com/webstore/detail/web-server-for-chrome/ofhbbkphhbklhfoeikjpcbhemlocgigb/)
We should see this...
[lupyuen3.github.io/blockly-zig-nuttx/demos/code](https://lupyuen3.github.io/blockly-zig-nuttx/demos/code/)

Blockly will NOT render correctly with `file://...`, it must be `http://localhost:port/...`
Drag-and-drop some Blocks and click the Zig Tab.
The Zig Tab now shows the generated code in Dart (because we copied the Dart Code Generator).
(In case of problems, check the JavaScript Console. Ignore the `storage.js` error)
Now we modify our Code Generator to generate Zig code.
# Set Variable
Let's generate the Zig code for setting a variable...

For simplicity we'll treat variables as constants...
```zig
const a: f32 = 123.45;
```
This is how we generate the above code in the Zig Code Generator for Blockly (coded in JavaScript): [generators/zig/variables.js](generators/zig/variables.js#L25-L32)
```javascript
Zig['variables_set'] = function(block) {
// Variable setter.
...
return `const ${varName}: f32 = ${argument0};\n`;
};
```
# Print Expression
To print the value of an expression...
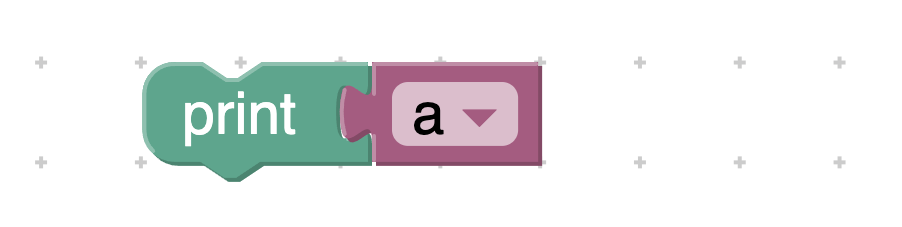
We'll generate this Zig code...
```zig
debug("a={}", .{ a });
```
Here's how we implement this in the Zig Code Generator for Blockly: [generators/zig/text.js](generators/zig/text.js#L268-L272)
```javascript
Zig['text_print'] = function(block) {
// Print statement.
...
return `debug("${msg}={}", .{ ${msg} });\n`;
};
```
# Repeat Loop
To run a repeating loop...
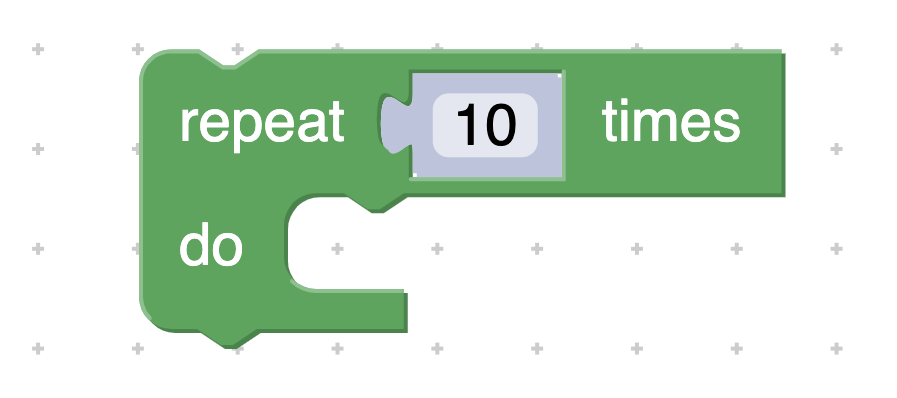
We'll generate this Zig code...
```zig
var count: usize = 0;
while (count < 10) : (count += 1) {
...
}
```
With this Zig Code Generator in Blockly: [generators/zig/loops.js](generators/zig/loops.js#L19-L45)
```javascript
Zig['controls_repeat_ext'] = function(block) {
// Repeat n times.
...
code += [
`var ${loopVar}: usize = 0;\n`,
`while (${loopVar} < ${endVar}) : (${loopVar} += 1) {\n`,
branch,
'}\n'
].join('');
return code;
};
```
_What happens if we have 2 repeat loops? Won't `count` clash?_
Blockly will automatically generate another counter...
```zig
var count2: usize = 0;
while (count2 < 10) : (count2 += 1) {
...
}
```
(Try it out!)
# Main Function
The generated Zig code needs to be wrapped like this, to become a valid Zig program...
```zig
/// Import Standard Library
const std = @import("std");
/// Main Function
pub fn main() !void {
// TODO: Generated Zig Code here
...
}
/// Aliases for Standard Library
const assert = std.debug.assert;
const debug = std.log.debug;
```
We do this in the Zig Code Generator for Blockly: [generators/zig.js](generators/zig.js#L132-L193)
```javascript
Zig.finish = function(code) {
...
// Main Function
code = [
'/// Main Function\n',
'pub fn main() !void {\n',
code,
'}',
].join('');
// Convert the definitions dictionary into a list.
...
// Compose Zig Header
const header = [
'/// Import Standard Library\n',
'const std = @import("std");\n',
].join('');
// Compose Zig Trailer
const trailer = [
'/// Aliases for Standard Library\n',
'const assert = std.debug.assert;\n',
'const debug = std.log.debug;\n',
].join('');
// Combine Header, Definitions, Code and Trailer
return [
header,
'\n',
// For Zig: No need to declare variables
// allDefs.replace(/\n\n+/g, '\n\n').replace(/\n*$/, '\n\n\n'),
code,
'\n\n',
trailer,
].join('');
};
```
We're ready to test our Zig Code Generator!
# Run the Generated Code
Follow the steps described earlier to build Blockly.
We browse to our local Blockly site...
[lupyuen3.github.io/blockly-zig-nuttx/demos/code](https://lupyuen3.github.io/blockly-zig-nuttx/demos/code/)
Then drag-and-drop the Blocks to create this Visual Program...
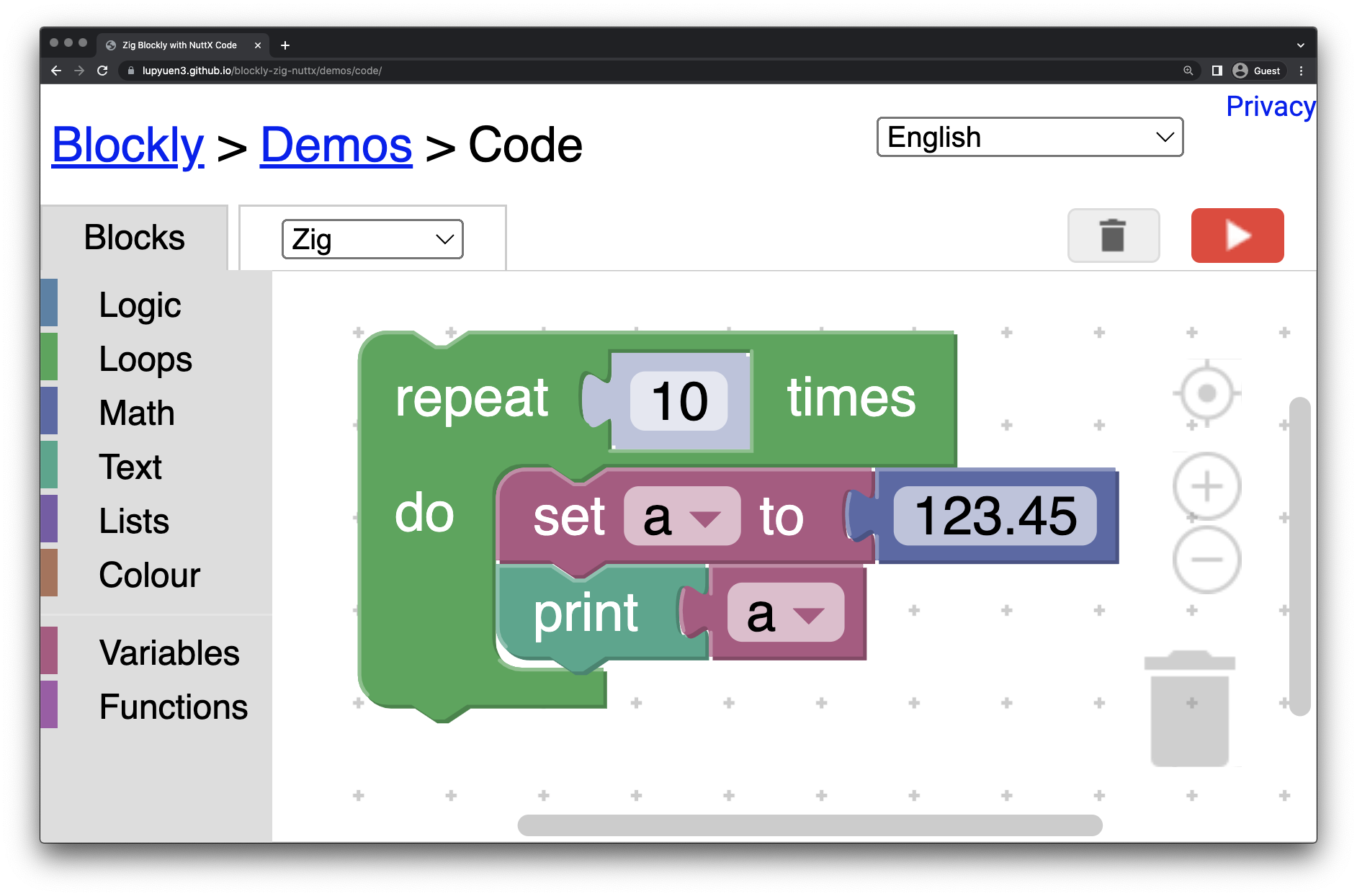
Click the Zig Tab to see the generated code...
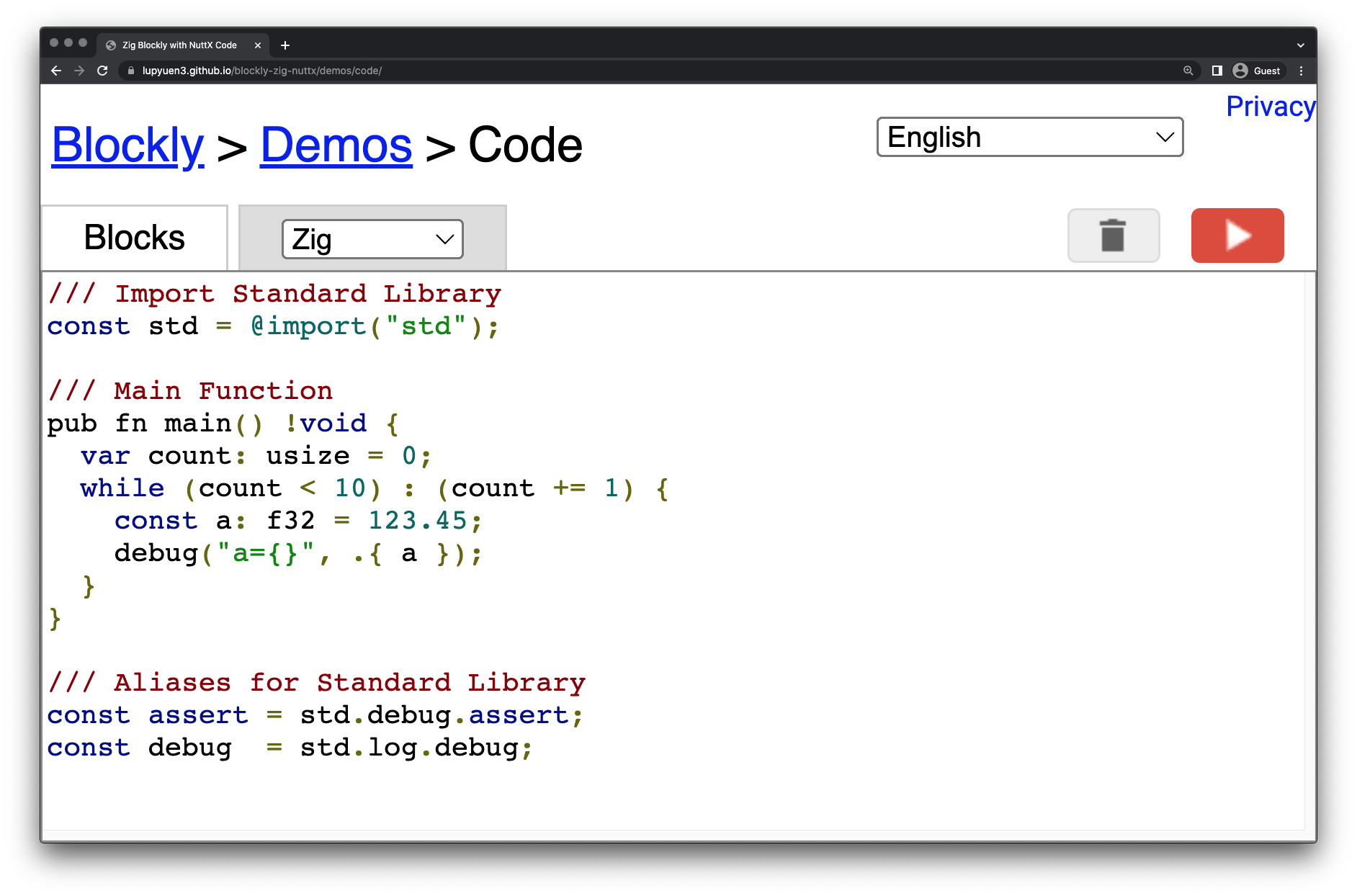
Our Code Generator in Blockly generates this Zig code...
```zig
/// Import Standard Library
const std = @import("std");
/// Main Function
pub fn main() !void {
var count: usize = 0;
while (count < 10) : (count += 1) {
const a: f32 = 123.45;
debug("a={}", .{ a });
}
}
/// Aliases for Standard Library
const assert = std.debug.assert;
const debug = std.log.debug;
```
Which runs perfectly OK with Zig! 🎉
```bash
$ zig run a.zig
debug: a=1.23449996e+02
debug: a=1.23449996e+02
debug: a=1.23449996e+02
debug: a=1.23449996e+02
debug: a=1.23449996e+02
debug: a=1.23449996e+02
debug: a=1.23449996e+02
debug: a=1.23449996e+02
debug: a=1.23449996e+02
debug: a=1.23449996e+02
```
# Blockly on Mobile
Blockly works OK with Mobile Web Browsers too...
[lupyuen3.github.io/blockly-zig-nuttx/demos/code](https://lupyuen3.github.io/blockly-zig-nuttx/demos/code/)
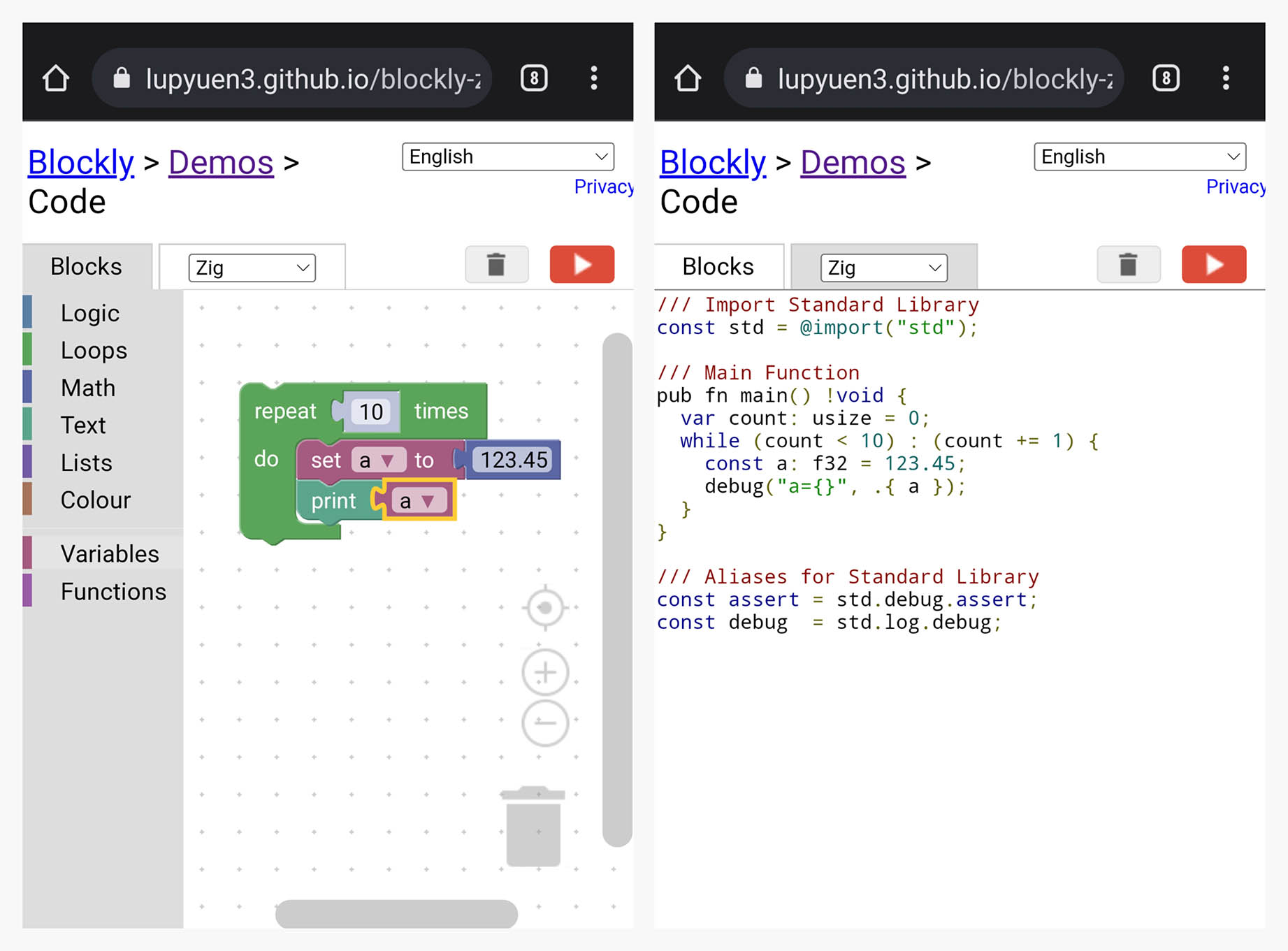
# Custom Block
Let's create a Custom Block in Blockly for our Bosch BME280 Sensor...
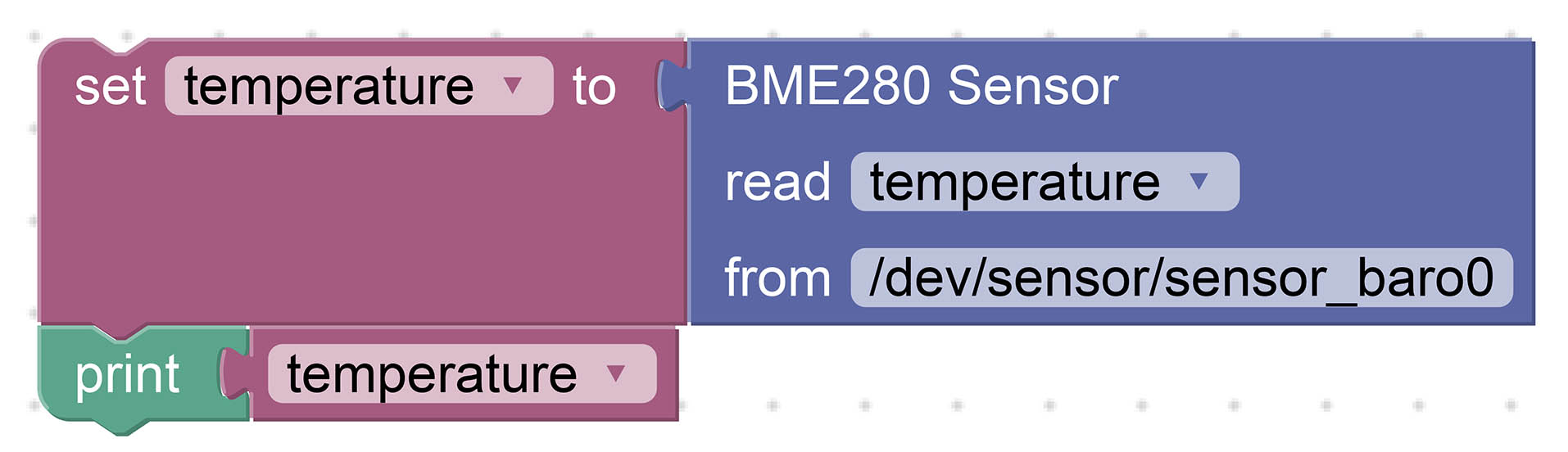
The Blocks above will generate this Zig code to read the Temperature from the BME280 Sensor...
```zig
// Read the Temperature from BME280 Sensor
const temperature = try sen.readSensor( // Read BME280 Sensor
c.struct_sensor_baro, // Sensor Data Struct
"temperature", // Sensor Data Field
"/dev/uorb/sensor_baro0" // Path of Sensor Device
);
// Print the Temperature
debug("temperature={}", .{ temperature });
```
[(`readSensor` is explained here)](https://github.com/lupyuen/visual-zig-nuttx#zig-generics)
# Create Custom Block
To create our Custom Block, browse to the Blockly Developer Tools...
[blockly-demo.appspot.com/static/demos/blockfactory/index.html](https://blockly-demo.appspot.com/static/demos/blockfactory/index.html)
Drag-and-drop from "Input", "Field" and "Type" to assemble our BME280 Sensor Block...
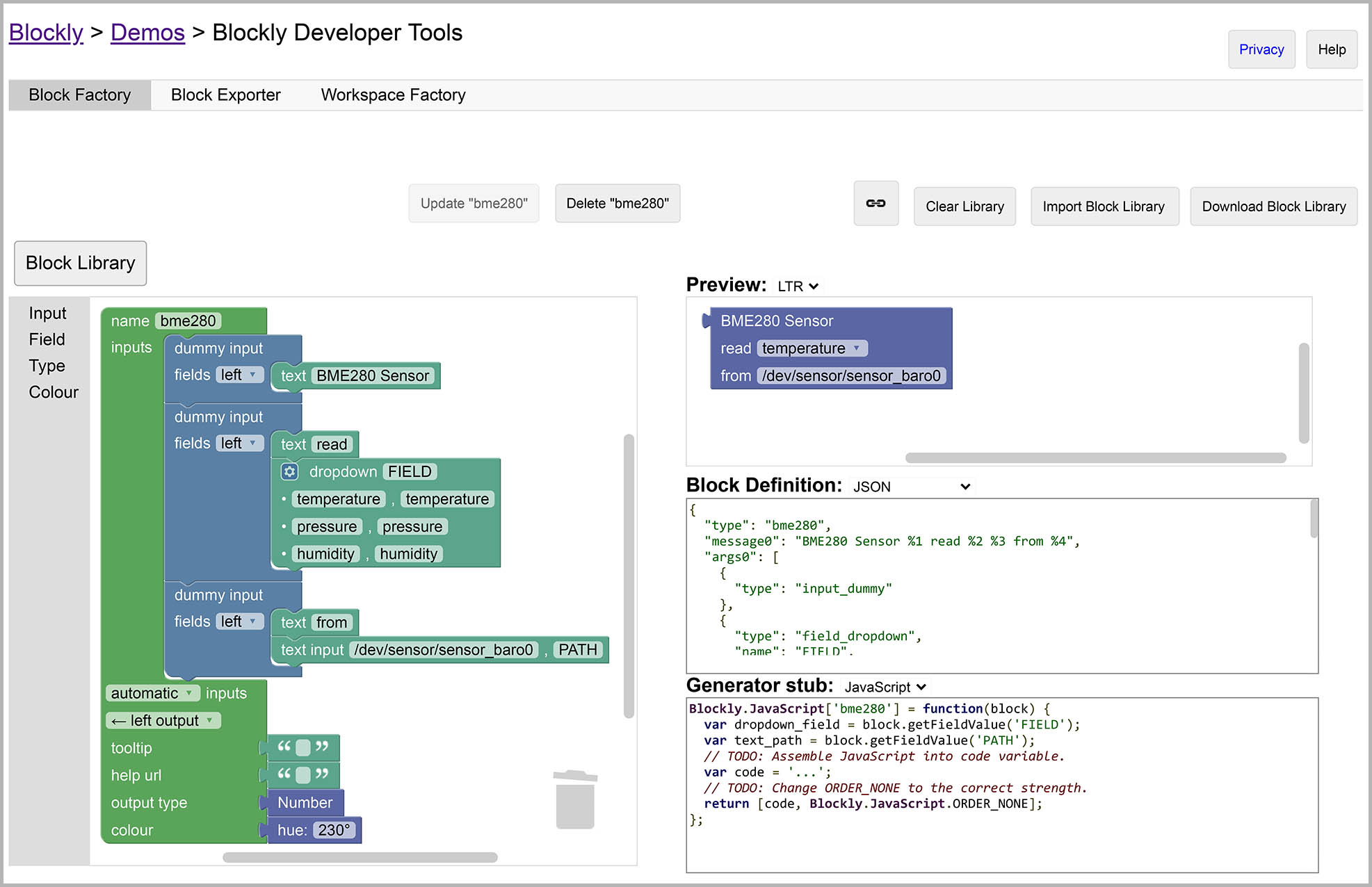
This creates a Custom Block that has the following fields...
- Dropdown Field `FIELD`: Select "temperature", "pressure" or "humidity"
- Text Input Field `PATH`: For the NuttX Path of our BME280 Sensor, defaults to "/dev/uorb/sensor_baro0"
Click "Update BME280" to save the Custom Control.
To create another Block, click "Block Library".
When we're done, click "Download Block Library".
Save the downloaded XML so that we can "Import Block Library" and edit our Block in future...
[generators/zig/zig_library.xml](generators/zig/zig_library.xml)
# Export Custom Block
Earlier we have created our BME280 Sensor Block in Blockly Developer Tools. Now we export the Block...
Click the "Block Exporter" Tab
Under "Block Selector", select all Blocks.
For "Export Settings" > "Block Definitions", select "JSON Format"
"Export Preview" shows our Custom Blocks exported as JSON.
Copy the Exported JSON and paste into the marked location here...
[generators/zig/zig_blocks.js](generators/zig/zig_blocks.js)
So it looks like this...
```javascript
'use strict';
goog.module('Blockly.Zig.blocks');
const Zig = goog.require('Blockly.Zig');
/// Custom Blocks exported from Block Exporter based on zig_library.xml.
/// Exposed as Blockly.Zig.blocks. Read by demos/code/code.js.
/// See zig_functions.js for Code Generator Functions.
Zig['blocks'] =
// Begin Paste from Block Exporter
[{
"type": "every",
"message0": "every %1 seconds %2 %3",
...
},
{
"type": "field",
"message0": "field %1 %2 value %3",
...
},
{
"type": "bme280",
"message0": "BME280 Sensor %1 read %2 %3 from %4",
...
},
{
"type": "transmit_msg",
"message0": "transmit message %1 to %2",
...
}]
// End Paste from Block Exporter
;
```
This code goes into the JavaScript Module `Blockly.Zig.blocks`. We'll build this module in a while.
# Load Custom Block
Previously we have exported our Custom Blocks to the JavaScript Module `Blockly.Zig.blocks`.
To load our Custom Blocks into Blockly, insert this code into [demos/code/code.js](demos/code/code.js#L485-L504)...
```javascript
Code.loadBlocks('');
//// TODO: Added code here
// Load the Zig Custom Blocks.
var blocks = Blockly.Zig.blocks; // From generators/zig/zig_blocks.js
// For each Block...
blocks.forEach(block => {
// Register the Block with Blockly.
Blockly.Blocks[block.type] = {
init: function() {
this.jsonInit(block);
// Assign 'this' to a variable for use in the tooltip closure below.
var thisBlock = this;
// this.setTooltip(function() {
// return 'Add a number to variable "%1".'.replace('%1',
// thisBlock.getFieldValue('VAR'));
// });
}
};
});
//// End of added code
if ('BlocklyStorage' in window) {
...
```
[(See the changes)](https://github.com/lupyuen3/blockly-zig-nuttx/commit/5204bbcad281ffd92f79cf6407a71cc3a96ab556)
# Show Custom Block
To show our Custom Block in the Blocks Toolbox, edit [demos/code/index.html](demos/code/index.html#L106-L115) and insert this...
```xml
...
```
[(See the changes)](https://github.com/lupyuen3/blockly-zig-nuttx/commit/996f37c8971e8b117ea749830eda552eb1885c97)
This creates a Toolbox Category named "Sensors" with our Custom Blocks inside.
# Code Generator for Custom Block
Remember that our BME280 Sensor Block...

Will generate this Zig expression...
```zig
// Read the Temperature from BME280 Sensor
try sen.readSensor( // Read BME280 Sensor
c.struct_sensor_baro, // Sensor Data Struct
"temperature", // Sensor Data Field
"/dev/uorb/sensor_baro0" // Path of Sensor Device
)
```
This is how we implement the Code Generator for our Custom Block: [generators/zig/zig_functions.js](generators/zig/zig_functions.js#L59-L82)
```javascript
goog.module('Blockly.Zig.functions');
const Zig = goog.require('Blockly.Zig');
// Read BME280 Sensor
Zig['bme280'] = function(block) {
// Get the Sensor Data Field: temperature / pressure / humidity
const field = block.getFieldValue('FIELD');
// Get the Sensor Device Path, like "/dev/uorb/sensor_baro0"
// TODO: Validate that path contains "sensor_humi" for humidity
const path = block.getFieldValue('PATH');
// Struct name is "sensor_humi" for humidity, else "sensor_baro"
const struct = (field == 'humidity')
? 'struct_sensor_humi'
: 'struct_sensor_baro';
// Compose the code
const code = alignComments([
`try sen.readSensor( // Read BME280 Sensor`,
Blockly.Zig.INDENT + `c.${struct}, // Sensor Data Struct`,
Blockly.Zig.INDENT + `"${field}", // Sensor Data Field`,
Blockly.Zig.INDENT + `"${path}" // Path of Sensor Device`,
`)`,
]).join('\n');
return [code, Blockly.Zig.ORDER_UNARY_POSTFIX];
};
```
The code above refers to the following fields that we have defined in our BME280 Sensor Block...
- Dropdown Field `FIELD`: Select "temperature", "pressure" or "humidity"
- Text Input Field `PATH`: For the NuttX Path of our BME280 Sensor, defaults to "/dev/uorb/sensor_baro0"
This code goes into the JavaScript Module `Blockly.Zig.functions`. We'll build this module in the next section...
# Build Custom Block
Earlier we have exported our Custom Blocks into the JavaScript Module `Blockly.Zig.blocks`. And the Code Generator for our Custom Blocks is defined in module `Blockly.Zig.functions`.
Let's add them to the Blockly Build: [generators/zig/all.js](generators/zig/all.js#L27-L32)
```javascript
// Zig Custom Blocks and Code Generators
goog.require('Blockly.Zig.blocks');
goog.require('Blockly.Zig.functions');
// Compose Message Block
goog.require('Blockly.Zig.composeMessage');
```
`Blockly.Zig.composeMessage` is a Custom Extension / Mutator for Blockly that renders our "Compose Message" Block. We'll cover this in a while.
# Test Custom Block
Rebuild Blockly according to the instructions posted above.
Browse to `blockly-zig-nuttx/demos/code` with a Local Web Server.
In the Blocks Toolbox, we should see the Sensors Category with our Custom Blocks inside...
[lupyuen3.github.io/blockly-zig-nuttx/demos/code](https://lupyuen3.github.io/blockly-zig-nuttx/demos/code/)
Let's read the Temperature from BME280 Sensor and print it.
Drag-n-drop the BME280 Sensor Block as shown below...
We should see this Zig code generated for our BME280 Sensor Block.
Copy the contents of the Main Function and paste here...
[visual-zig-nuttx/blob/main/visual.zig](https://github.com/lupyuen/visual-zig-nuttx/blob/main/visual.zig)
The generated Zig code should correctly read the Temperature from BME280 Sensor...
```text
NuttShell (NSH) NuttX-10.3.0
nsh> sensortest visual
Zig Sensor Test
Start main
temperature=31.32
```
(Tested with NuttX and BME280 on BL602)
# Custom Extension
Our Compose Message Block needs a [Custom Extension](https://developers.google.com/blockly/guides/create-custom-blocks/extensions#extensions) in Blockly because it has a variable number of slots (for the Message Fields)...
This is how we define the Blocks in our Custom Extension...
https://github.com/lupyuen3/blockly-zig-nuttx/blob/b6dbd66283ef148813376802050173e1d791c794/generators/zig/compose_msg.js#L59-L92
Our Custom Extension needs a [Mutator](https://developers.google.com/blockly/guides/create-custom-blocks/extensions#mutators) that will save the attached Message Fields.
Here's the [Mixin](https://developers.google.com/blockly/guides/create-custom-blocks/extensions#mixins) that implements the Mutator for our Custom Extension...
https://github.com/lupyuen3/blockly-zig-nuttx/blob/b6dbd66283ef148813376802050173e1d791c794/generators/zig/compose_msg.js#L94-L210
And here's our [Custom Extension](https://developers.google.com/blockly/guides/create-custom-blocks/extensions#extensions) that bundles the above Blocks, Mutator and Mixin...
https://github.com/lupyuen3/blockly-zig-nuttx/blob/b6dbd66283ef148813376802050173e1d791c794/generators/zig/compose_msg.js#L212-L228
[(We copied our Custom Extension from the Text Join Block)](https://github.com/lupyuen3/blockly-zig-nuttx/blob/master/blocks/text.js#L712-L860)
[(More about Blockly Extensions and Mutators)](https://developers.google.com/blockly/guides/create-custom-blocks/extensions)
# Code Generator for Custom Extension
Our Custom Extension for Compose Message...
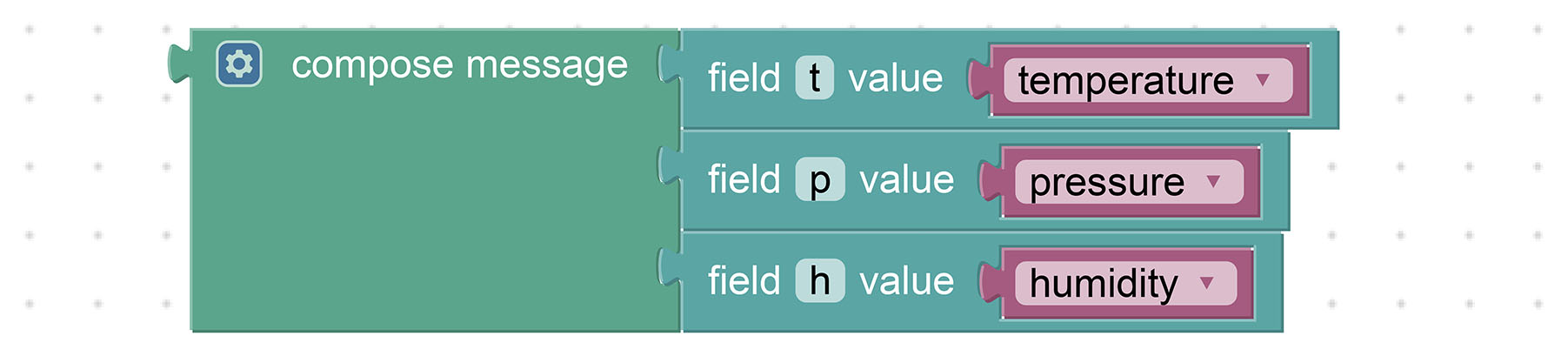
Will generate this Zig code...
```zig
const msg = try composeCbor(.{ // Compose CBOR Message
"t", temperature,
"p", pressure,
"h", humidity,
});
```
[(`composeCbor` is explained here)](https://github.com/lupyuen/visual-zig-nuttx#cbor-encoding)
Here's the implementation of our Code Generator: [generators/zig/zig_functions.js](generators/zig/zig_functions.js#L16-L32)
```zig
// Generate CBOR Message
Zig['compose_msg'] = function(block) {
// Convert each Message Field to Zig Code
var elements = new Array(block.itemCount_);
for (var i = 0; i < block.itemCount_; i++) {
elements[i] = Blockly.Zig.valueToCode(block, 'ADD' + i,
Blockly.Zig.ORDER_NONE) || '\'\'';
}
// Combine the Message Fields into a CBOR Message
const code = [
'try composeCbor(.{ // Compose CBOR Message',
// Insert the indented elements.
Blockly.Zig.prefixLines(
elements.join('\n'),
Blockly.Zig.INDENT),
'})',
].join('\n');
return [code, Blockly.Zig.ORDER_UNARY_POSTFIX];
};
```
Each Message Field...

Will generate Zig code like this...
```zig
"t", temperature,
```
Here's the implementation of our Code Generator: [generators/zig/zig_functions.js](generators/zig/zig_functions.js#L34-L40)
```zig
// Generate a field for CBOR message
Zig['field'] = function(block) {
const name = block.getFieldValue('NAME');
const value = Blockly.Zig.valueToCode(block, 'name', Blockly.JavaScript.ORDER_ATOMIC);
const code = `"${name}", ${value},`;
return [code, Blockly.Zig.ORDER_NONE];
};
```
# Test Custom Extension
To test our Custom Extension for Compose Message, let's build a Complex Sensor App that will read Temperature, Pressure and Humidity from BME280 Sensor, and transmit the values to LoRaWAN...
[lupyuen3.github.io/blockly-zig-nuttx/demos/code](https://lupyuen3.github.io/blockly-zig-nuttx/demos/code/)
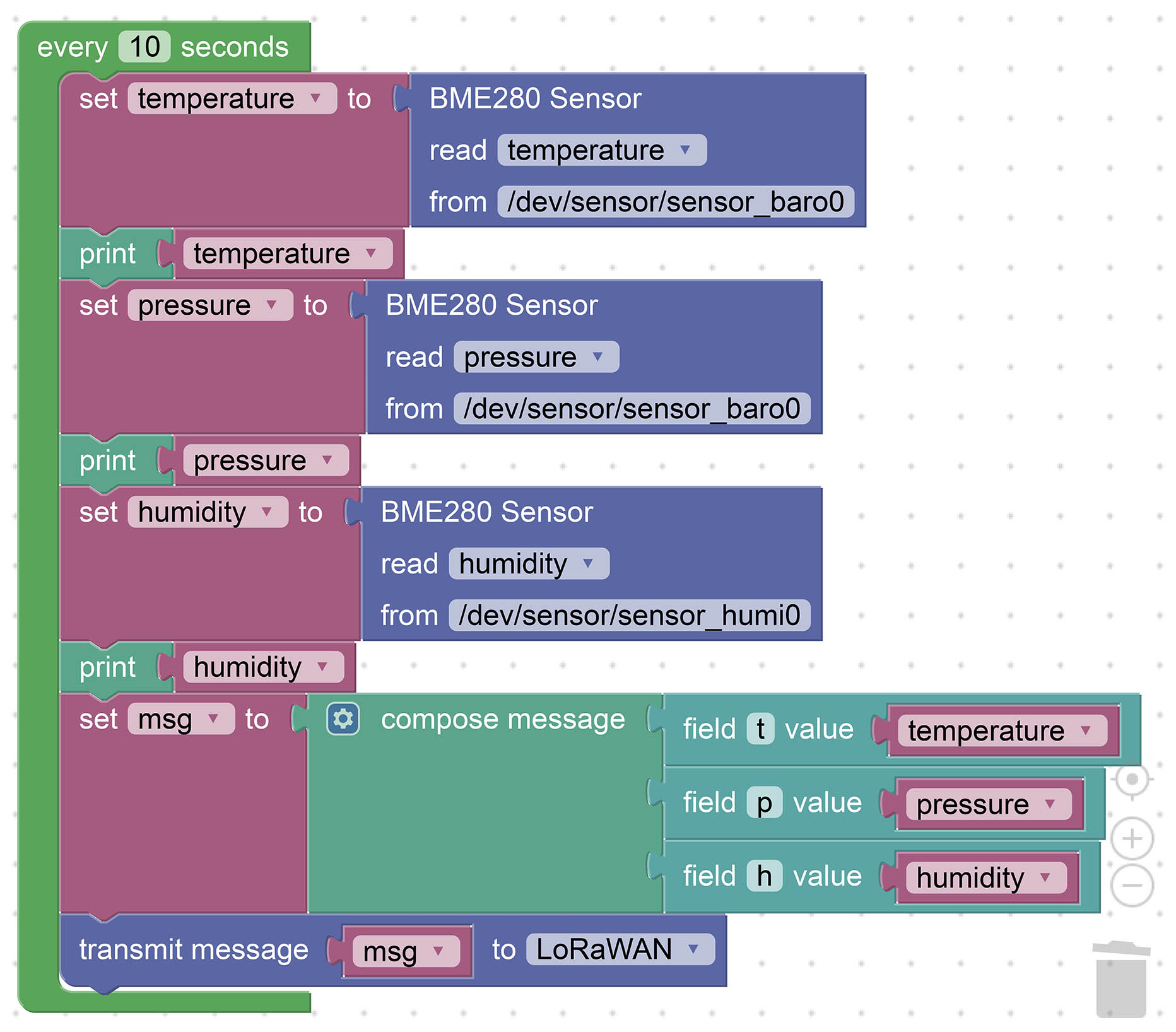
The Blocks above will emit this Zig program...
```zig
/// Main Function
pub fn main() !void {
// Every 10 seconds...
while (true) {
const temperature = try sen.readSensor( // Read BME280 Sensor
c.struct_sensor_baro, // Sensor Data Struct
"temperature", // Sensor Data Field
"/dev/uorb/sensor_baro0" // Path of Sensor Device
);
debug("temperature={}", .{ temperature });
const pressure = try sen.readSensor( // Read BME280 Sensor
c.struct_sensor_baro, // Sensor Data Struct
"pressure", // Sensor Data Field
"/dev/uorb/sensor_baro0" // Path of Sensor Device
);
debug("pressure={}", .{ pressure });
const humidity = try sen.readSensor( // Read BME280 Sensor
c.struct_sensor_humi, // Sensor Data Struct
"humidity", // Sensor Data Field
"/dev/uorb/sensor_humi0" // Path of Sensor Device
);
debug("humidity={}", .{ humidity });
const msg = try composeCbor(.{ // Compose CBOR Message
"t", temperature,
"p", pressure,
"h", humidity,
});
// Transmit message to LoRaWAN
try transmitLorawan(msg);
// Wait 10 seconds
_ = c.sleep(10);
}
}
```
[(`composeCbor` is explained here)](https://github.com/lupyuen/visual-zig-nuttx#cbor-encoding)
Copy the contents of the Main Function and paste here...
[visual-zig-nuttx/visual.zig](https://github.com/lupyuen/visual-zig-nuttx/blob/main/visual.zig)
The generated Zig code should correctly read the Temperature, Pressure and Humidity from BME280 Sensor, and transmit the values to LoRaWAN...
```text
NuttShell (NSH) NuttX-10.3.0
nsh> sensortest visual
Zig Sensor Test
Start main
temperature=31.05
pressure=1007.44
humidity=71.49
composeCbor
t: 31.05
p: 1007.44
h: 71.49
msg=t:31.05,p:1007.44,h:71.49,
transmitLorawan
msg=t:31.05,p:1007.44,h:71.49,
temperature=31.15
pressure=1007.40
humidity=70.86
composeCbor
t: 31.15
p: 1007.40
h: 70.86
msg=t:31.15,p:1007.40,h:70.86,
transmitLorawan
msg=t:31.15,p:1007.40,h:70.86,
temperature=31.16
pressure=1007.45
humidity=70.42
composeCbor
t: 31.16
p: 1007.45
h: 70.42
msg=t:31.16,p:1007.45,h:70.42,
transmitLorawan
msg=t:31.16,p:1007.45,h:70.42,
temperature=31.16
pressure=1007.47
humidity=70.39
composeCbor
t: 31.16
p: 1007.47
h: 70.39
msg=t:31.16,p:1007.47,h:70.39,
transmitLorawan
msg=t:31.16,p:1007.47,h:70.39,
temperature=31.19
pressure=1007.45
humidity=70.35
composeCbor
t: 31.19
p: 1007.45
h: 70.35
msg=t:31.19,p:1007.45,h:70.35,
transmitLorawan
msg=t:31.19,p:1007.45,h:70.35,
temperature=31.20
pressure=1007.42
humidity=70.65
composeCbor
t: 31.20
p: 1007.42
h: 70.65
msg=t:31.20,p:1007.42,h:70.65,
transmitLorawan
msg=t:31.20,p:1007.42,h:70.65,
```
(Tested with NuttX and BME280 on BL602)
# Test Stubs
To test the Zig program above on Linux / macOS / Windows (instead of NuttX), add the stubs below to simulate a NuttX Sensor...
```zig
/// Import Standard Library
const std = @import("std");
/// Main Function
pub fn main() !void {
// TODO: Paste here the contents of Zig Main Function generated by Blockly
...
}
/// Aliases for Standard Library
const assert = std.debug.assert;
const debug = std.log.debug;
///////////////////////////////////////////////////////////////////////////////
// CBOR Encoding
/// TODO: Compose CBOR Message with Key-Value Pairs
/// https://lupyuen.github.io/articles/cbor2
fn composeCbor(args: anytype) !CborMessage {
debug("composeCbor", .{});
comptime {
assert(args.len % 2 == 0); // Missing Key or Value
}
// Process each field...
comptime var i: usize = 0;
var msg = CborMessage{};
inline while (i < args.len) : (i += 2) {
// Get the key and value
const key = args[i];
const value = args[i + 1];
// Print the key and value
debug(" {s}: {}", .{
@as([]const u8, key),
floatToFixed(value)
});
// Format the message for testing
var slice = std.fmt.bufPrint(
msg.buf[msg.len..],
"{s}:{},",
.{
@as([]const u8, key),
floatToFixed(value)
}
) catch { _ = std.log.err("Error: buf too small", .{}); return error.Overflow; };
msg.len += slice.len;
}
debug(" msg={s}", .{ msg.buf[0..msg.len] });
return msg;
}
/// TODO: CBOR Message
/// https://lupyuen.github.io/articles/cbor2
const CborMessage = struct {
buf: [256]u8 = undefined, // Limit to 256 chars
len: usize = 0,
};
///////////////////////////////////////////////////////////////////////////////
// Transmit To LoRaWAN
/// TODO: Transmit message to LoRaWAN
fn transmitLorawan(msg: CborMessage) !void {
debug("transmitLorawan", .{});
debug(" msg={s}", .{ msg.buf[0..msg.len] });
}
///////////////////////////////////////////////////////////////////////////////
// Stubs
const c = struct {
const struct_sensor_baro = struct{};
const struct_sensor_humi = struct{};
fn sleep(seconds: c_uint) c_int {
std.time.sleep(@as(u64, seconds) * std.time.ns_per_s);
return 0;
}
};
const sen = struct {
fn readSensor(comptime SensorType: type, comptime field_name: []const u8, device_path: []const u8) !f32
{ _ = SensorType; _ = field_name; _ = device_path; return 23.45; }
};
fn floatToFixed(f: f32) f32 { return f; }
```
[(`composeCbor` is explained here)](https://github.com/lupyuen/visual-zig-nuttx#cbor-encoding)
# Build Log
```text
→ npm install
> [email protected] install blockly-zig-nuttx/node_modules/glob-watcher/node_modules/fsevents
> node install.js
make: Entering directory 'blockly-zig-nuttx/node_modules/glob-watcher/node_modules/fsevents/build'
SOLINK_MODULE(target) Release/.node
CXX(target) Release/obj.target/fse/fsevents.o
SOLINK_MODULE(target) Release/fse.node
make: Leaving directory 'blockly-zig-nuttx/node_modules/glob-watcher/node_modules/fsevents/build'
> @hyperjump/[email protected] postinstall blockly-zig-nuttx/node_modules/@hyperjump/json-pointer
> rm -rf dist
> @hyperjump/[email protected] postinstall blockly-zig-nuttx/node_modules/@hyperjump/pact
> rm -rf dist
> @hyperjump/[email protected] postinstall blockly-zig-nuttx/node_modules/@hyperjump/json-schema-core
> rm -rf dist
> @hyperjump/[email protected] postinstall blockly-zig-nuttx/node_modules/@hyperjump/json-schema
> rm -rf dist
npm WARN optional SKIPPING OPTIONAL DEPENDENCY: [email protected] (node_modules/google-closure-compiler-windows):
npm WARN notsup SKIPPING OPTIONAL DEPENDENCY: Unsupported platform for [email protected]: wanted {"os":"win32","arch":"x64"} (current: {"os":"darwin","arch":"x64"})
npm WARN optional SKIPPING OPTIONAL DEPENDENCY: [email protected] (node_modules/google-closure-compiler-linux):
npm WARN notsup SKIPPING OPTIONAL DEPENDENCY: Unsupported platform for [email protected]: wanted {"os":"linux","arch":"x64,x86"} (current: {"os":"darwin","arch":"x64"})
added 1026 packages from 1074 contributors and audited 1031 packages in 67.757s
69 packages are looking for funding
run `npm fund` for details
found 12 vulnerabilities (6 moderate, 5 high, 1 critical)
run `npm audit fix` to fix them, or `npm audit` for details
→ npm run build
> [email protected] build blockly-zig-nuttx
> gulp build
[12:30:30] Using gulpfile ~/pinecone/blockly-zig-nuttx/gulpfile.js
[12:30:30] Starting 'build'...
[12:30:30] Starting 'buildLangfiles'...
[12:30:30] Starting 'buildDeps'...
[12:30:31] Finished 'buildLangfiles' after 1.1 s
WARNING in blockly-zig-nuttx/tests/mocha/test_helpers/common.js at 39, 3: Bounded generic semantics are currently still in development
WARNING in blockly-zig-nuttx/tests/mocha/test_helpers/common.js at 40, 3: Bounded generic semantics are currently still in development
WARNING in blockly-zig-nuttx/tests/mocha/test_helpers/common.js at 75, 3: Bounded generic semantics are currently still in development
WARNING in blockly-zig-nuttx/tests/mocha/test_helpers/common.js at 91, 3: Bounded generic semantics are currently still in development
WARNING in blockly-zig-nuttx/tests/mocha/test_helpers/common.js at 92, 3: Bounded generic semantics are currently still in development
[12:30:43] Finished 'buildDeps' after 13 s
[12:30:43] Starting 'buildCompiled'...
[12:30:58] Finished 'buildCompiled' after 15 s
[12:30:58] Finished 'build' after 28 s
→ npm run publish
> [email protected] publish blockly-zig-nuttx
> gulp publish
[12:31:09] Using gulpfile ~/pinecone/blockly-zig-nuttx/gulpfile.js
[12:31:09] Starting 'publish'...
[12:31:09] Starting 'cleanBuildDir'...
[12:31:09] Finished 'cleanBuildDir' after 33 ms
[12:31:09] Starting 'buildLangfiles'...
[12:31:09] Starting 'buildDeps'...
[12:31:10] Finished 'buildLangfiles' after 726 ms
WARNING in blockly-zig-nuttx/tests/mocha/test_helpers/common.js at 39, 3: Bounded generic semantics are currently still in development
WARNING in blockly-zig-nuttx/tests/mocha/test_helpers/common.js at 40, 3: Bounded generic semantics are currently still in development
WARNING in blockly-zig-nuttx/tests/mocha/test_helpers/common.js at 75, 3: Bounded generic semantics are currently still in development
WARNING in blockly-zig-nuttx/tests/mocha/test_helpers/common.js at 91, 3: Bounded generic semantics are currently still in development
WARNING in blockly-zig-nuttx/tests/mocha/test_helpers/common.js at 92, 3: Bounded generic semantics are currently still in development
[12:31:23] Finished 'buildDeps' after 14 s
[12:31:23] Starting 'buildCompiled'...
[12:31:36] Finished 'buildCompiled' after 13 s
[12:31:36] Starting 'checkinBuilt'...
[12:31:36] Finished 'checkinBuilt' after 272 ms
[12:31:36] Starting 'checkBuildDir'...
[12:31:36] Finished 'checkBuildDir' after 456 μs
[12:31:36] Starting 'cleanReleaseDir'...
[12:31:36] Finished 'cleanReleaseDir' after 1.63 ms
[12:31:36] Starting 'packageIndex'...
[12:31:36] Starting 'packageSources'...
[12:31:36] Starting 'packageCompressed'...
[12:31:36] Starting 'packageBrowser'...
[12:31:36] Starting 'packageNode'...
[12:31:36] Starting 'packageCore'...
[12:31:36] Starting 'packageNodeCore'...
[12:31:36] Starting 'packageBlockly'...
[12:31:36] Starting 'packageBlocks'...
[12:31:36] Starting 'packageJavascript'...
[12:31:36] Starting 'packagePython'...
[12:31:36] Starting 'packageLua'...
[12:31:36] Starting 'packageDart'...
[12:31:36] Starting 'packagePHP'...
[12:31:36] Starting 'packageLocales'...
[12:31:36] Starting 'packageMedia'...
[12:31:36] Starting 'packageUMDBundle'...
[12:31:36] Starting 'packageJSON'...
[12:31:36] Starting 'packageReadme'...
[12:31:36] Starting 'packageDTS'...
[12:31:36] Finished 'packageJSON' after 37 ms
[12:31:36] Finished 'packageIndex' after 189 ms
[12:31:36] Finished 'packageNode' after 189 ms
[12:31:36] Finished 'packageBlockly' after 189 ms
[12:31:36] Finished 'packageJavascript' after 190 ms
[12:31:36] Finished 'packagePython' after 190 ms
[12:31:36] Finished 'packageBlocks' after 191 ms
[12:31:36] Finished 'packageNodeCore' after 191 ms
[12:31:36] Finished 'packageDart' after 191 ms
[12:31:36] Finished 'packageBrowser' after 195 ms
[12:31:36] Finished 'packageLua' after 195 ms
[12:31:36] Finished 'packageCore' after 196 ms
[12:31:36] Finished 'packagePHP' after 196 ms
[12:31:36] Finished 'packageReadme' after 196 ms
[12:31:36] Finished 'packageUMDBundle' after 230 ms
[12:31:36] Finished 'packageDTS' after 279 ms
[12:31:36] Finished 'packageCompressed' after 321 ms
[12:31:36] Finished 'packageMedia' after 325 ms
[12:31:37] Finished 'packageLocales' after 691 ms
[12:31:37] Finished 'packageSources' after 954 ms
[12:31:37] Starting 'checkBranch'...
You are on 'master'. Is this the correct branch? [y/n]: n
```
# Blockly [](https://travis-ci.org/google/blockly)
Google's Blockly is a library that adds a visual code editor to web and mobile apps. The Blockly editor uses interlocking, graphical blocks to represent code concepts like variables, logical expressions, loops, and more. It allows users to apply programming principles without having to worry about syntax or the intimidation of a blinking cursor on the command line. All code is free and open source.
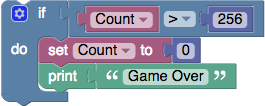
## Getting Started with Blockly
Blockly has many resources for learning how to use the library. Start at our [Google Developers Site](https://developers.google.com/blockly) to read the documentation on how to get started, configure Blockly, and integrate it into your application. The developers site also contains links to:
* [Getting Started article](https://developers.google.com/blockly/guides/get-started/web)
* [Getting Started codelab](https://blocklycodelabs.dev/codelabs/getting-started/index.html#0)
* [More codelabs](https://blocklycodelabs.dev/)
* [Demos and plugins](https://google.github.io/blockly-samples/)
Help us focus our development efforts by telling us [what you are doing with
Blockly](https://developers.google.com/blockly/registration). The questionnaire only takes
a few minutes and will help us better support the Blockly community.
### Installing Blockly
Blockly is [available on npm](https://www.npmjs.com/package/blockly).
```bash
npm install blockly
```
For more information on installing and using Blockly, see the [Getting Started article](https://developers.google.com/blockly/guides/get-started/web).
### Getting Help
* [Report a bug](https://developers.google.com/blockly/guides/modify/contribute/write_a_good_issue) or file a feature request on GitHub
* Ask a question, or search others' questions, on our [developer forum](https://groups.google.com/forum/#!forum/blockly). You can also drop by to say hello and show us your prototypes; collectively we have a lot of experience and can offer hints which will save you time. We actively monitor the forums and typically respond to questions within 2 working days.
### blockly-samples
We have a number of resources such as example code, demos, and plugins in another repository called [blockly-samples](https://github.com/google/blockly-samples/). A plugin is a self-contained piece of code that adds functionality to Blockly. Plugins can add fields, define themes, create renderers, and much more. For more information, see the [Plugins documentation](https://developers.google.com/blockly/guides/plugins/overview).
## Contributing to Blockly
Want to make Blockly better? We welcome contributions to Blockly in the form of pull requests, bug reports, documentation, answers on the forum, and more! Check out our [Contributing Guidelines](https://developers.google.com/blockly/guides/modify/contributing) for more information. You might also want to look for issues tagged "[Help Wanted](https://github.com/google/blockly/labels/help%20wanted)" which are issues we think would be great for external contributors to help with.
## Releases
The next major release will be during the last week of **March 2022**.
We release by pushing the latest code to the master branch, followed by updating the npm package, our [docs](https://developers.google.com/blockly), and [demo pages](https://google.github.io/blockly-samples/). We typically release a new version of Blockly once a quarter (every 3 months). If there are breaking bugs, such as a crash when performing a standard action or a rendering issue that makes Blockly unusable, we will cherry-pick fixes to master between releases to fix them. The [releases page](https://github.com/google/blockly/releases) has a list of all releases.
Releases are tagged by the release date (YYYYMMDD) with a leading major version number and a trailing '.0' in case we ever need a major or patch version (such as [2.20190722.1](https://github.com/google/blockly/tree/2.20190722.1)). Releases that have breaking changes or are otherwise not backwards compatible will have a new major version. Patch versions are reserved for bug-fix patches between scheduled releases.
We now have a [beta release on npm](https://www.npmjs.com/package/blockly?activeTab=versions). If you'd like to test the upcoming release, or try out a not-yet-released new API, you can use the beta channel with:
```bash
npm install blockly@beta
```
As it is a beta channel, it may be less stable, and the APIs there are subject to change.
### Branches
There are two main branches for Blockly.
**[master](https://github.com/google/blockly)** - This is the (mostly) stable current release of Blockly.
**[develop](https://github.com/google/blockly/tree/develop)** - This is where most of our work happens. Pull requests should always be made against develop. This branch will generally be usable, but may be less stable than the master branch. Once something is in develop we expect it to merge to master in the next release.
**other branches:** - Larger changes may have their own branches until they are good enough for people to try out. These will be developed separately until we think they are almost ready for release. These branches typically get merged into develop immediately after a release to allow extra time for testing.
### New APIs
Once a new API is merged into master it is considered beta until the following release. We generally try to avoid changing an API after it has been merged to master, but sometimes we need to make changes after seeing how an API is used. If an API has been around for at least two releases we'll do our best to avoid breaking it.
Unreleased APIs may change radically. Anything that is in `develop` but not `master` is subject to change without warning.
## Issues and Milestones
We typically triage all bugs within 2 working days, which includes adding any appropriate labels and assigning it to a milestone. Please keep in mind, we are a small team so even feature requests that everyone agrees on may not be prioritized.
### Milestones
**Upcoming release** - The upcoming release milestone is for all bugs we plan on fixing before the next release. This typically has the form of `year_quarter_release` (such as `2019_q2_release`). Some bugs will be added to this release when they are triaged, others may be added closer to a release.
**Bug Bash Backlog** - These are bugs that we're still prioritizing. They haven't been added to a specific release yet, but we'll consider them for each release depending on relative priority and available time.
**Icebox** - These are bugs that we do not intend to spend time on. They are either too much work or minor enough that we don't expect them to ever take priority. We are still happy to accept pull requests for these bugs.
## Good to Know
* Cross-browser Testing Platform and Open Source <3 Provided by [Sauce Labs](https://saucelabs.com)
* We support IE11 and test it using [BrowserStack](https://browserstack.com)
|
[] |
https://avatars.githubusercontent.com/u/65570835?v=4
|
zorm
|
ziglibs/zorm
|
2023-02-02T23:15:09Z
|
Lightweight and efficient object-relational mapping
|
main
| 0 | 26 | 0 | 26 |
https://api.github.com/repos/ziglibs/zorm/tags
|
MIT
|
[
"data-definition",
"orm",
"orm-framework",
"typesafe",
"zig",
"ziglang"
] | 2,430 | false |
2024-09-28T02:04:55Z
| true | false |
unknown
|
github
|
[] |
Abstract
Notice
|-
This library has <a>moved over to Snowflake.</a>
zorm is not your traditional ORM tool. Unlike other ORMs, zorm is designed to provide types for
making object-relational mapping within your scripts simple and not reliant on database table
paradigms.
In zorm, objects are cast on manually defined fields that can be compared:
Object mapping
```zig
const std = @import("std");
// In this example, we'll be mapping our object from JSON.
// For this very specific use case, zorm will handle assuming types to be tight and memory-bound.
const dumb_payload =
\{
\ "foo": "hello, world",
\ "bar": 420
\}
;
const zorm = @import("zorm");
// Objects are defined as a sort of "factory method." The inner argument is a comptime-known
// anonymous struct literal containing fields.
const Foo = zorm.Object(.{
// (comptime T: type, data: ?FieldMetadata)
// Fields can have a name, description and default value.
zorm.Field(?[]const u8, .{ .name = "foo", .default = undefined }),
zorm.Field(usize, .{ .name = "bar" })
});
pub fn main() !void {
// With an object defined, we can now generate our own from our payload.
// (comptime T: type, data: anytype)
const myFoo: zorm.Object = try zorm.create(Foo, .{ .JsonString = dumb_payload });
<code>// Accessing data is now done through the newly created object.
std.debug.print("{any}\n", .{myFoo.get("foo")});
</code>
}
```
Using datatypes
zorm provides you a set of datatypes. An example of a datatype is <code>Date</code>:
```zig
pub fn main() !void {
// We can build a date from a string, useful for defaults.
const date = try zorm.Date.fromString("2002-07-23", .@"YYYY-MM-DD");
<code>// This is an ISO 8601 format, which zorm will intelligently determine
const payload =
\\{
\\ "date": "1999-12-31"
\\}
;
const NewTable = try zorm.create(
zorm.Object(.{
// Default values must either be undefined or part of the type specified in the field,
// as expected when working with structs.
zorm.Field(?zorm.Date, .{ .name = "date", .default = date })
}),
.{ .JsonString = payload }
);
// 1999 will be returned instead of 2002.
std.debug.print("{?}\n", .{NewTable.get("date").f_type.year});
</code>
}
```
Building
zorm runs on 0.10.0-dev and higher versions of <a>Zig</a>.
It is recommended to install and build from source:
<code>bash
$ git clone --recursive https://github.com/ziglibs/zorm
$ cd ./zorm
$ zig build</code>
|
[] |
https://avatars.githubusercontent.com/u/25912761?v=4
|
uuid-zig
|
r4gus/uuid-zig
|
2022-10-29T22:05:18Z
|
A UUID library written in Zig
|
master
| 0 | 26 | 8 | 26 |
https://api.github.com/repos/r4gus/uuid-zig/tags
|
MIT
|
[
"c-library",
"guid",
"library",
"rfc4122",
"uuid",
"uuid-v4",
"uuid-v7",
"uuidv4",
"uuidv7",
"zig",
"zig-lang",
"ziglang"
] | 2,062 | false |
2025-05-01T14:44:05Z
| true | true |
0.12.0
|
github
|
[] |
UUID Zig
Universally Unique IDentifiers (UUIDs) are 128 bit long IDs that do not require a central
registration process.
Versions:
| Zig version | uuid-zig version |
|:-----------:|:----------------:|
| 13.0 | 2.0, 2.1 |
| 14.0 | 3.0 |
To add the <code>uuid-zig</code> package to your <code>build.zig.zon</code> run:
```
Replace with the version you want to use
zig fetch --save https://github.com/r4gus/uuid-zig/archive/refs/tags/.tar.gz
// e.g., zig fetch --save https://github.com/r4gus/uuid-zig/archive/refs/tags/0.3.0.tar.gz
```
Getting started
To generate a version 4 (random) UUID you can use:
```zig
const uuid = @import("uuid");
const id = uuid.v4.new();
```
You can serialize a UUID into a URN:
```zig
const uuid = @import("uuid");
const id = uuid.v7.new();
const urn = uuid.urn.serialize(id);
```
You can also parse URNs (UUID strings):
```zig
const uuid = @import("uuid");
const id = try uuid.urn.deserialize("6ba7b811-9dad-11d1-80b4-00c04fd430c8");
```
Which UUID version should I use?
Consider version 4 (<code>v4</code>) UUIDs if you just need unique identifiers and version 7 (<code>v7</code>)
if you want to use UUIDs as database keys or need to sort them.
Supported versions
<ul>
<li><code>v4</code> - UUIDs using random data.</li>
<li><code>v7</code> - UUIDs using a Epoch timestamp in combination with random data.</li>
</ul>
Encoding
This library encodes UUIDs in big-endian format, e.g. <code>00112233-4455-6677-8899-aabbccddeeff</code>
is encoded as <code>00 11 22 33 44 55 66 77 88 99 aa bb cc dd ee ff</code> where <code>00</code> is the least and
<code>ff</code> is the most significant byte (see <a>RFC4122 4.1.2 Layout and Byte Order</a>).
C Library
Run <code>zig build -Doptimize=ReleaseFast</code> to build the C-Library. You will find the library in <code>zig-out/lib</code> and the header in <code>zig-out/include</code>.
You can find a C-example in the examples folder.
Benchmark
To run a simple benchmark execute:
<code>zig build bench -- 10000000 v7</code>
Example: ThinkPad X1 Yoga 3rd with an i7-8550U
<code>v4: 10000000 UUIDs in 595.063ms
v7: 10000000 UUIDs in 892.564ms</code>
Example: Macbook Pro with M3 Pro
<code>v4: 10000000 UUIDs in 1.666s
v7: 10000000 UUIDs in 546.736ms</code>
References
<ul>
<li><a>RFC4122: A Universally Unique IDentifier (UUID) URN Namespace</a></li>
<li><a>New UUID Formats: draft-peabody-dispatch-new-uuid-format-04</a></li>
</ul>
|
[] |
https://avatars.githubusercontent.com/u/43040593?v=4
|
wren-zig
|
dantecatalfamo/wren-zig
|
2022-04-08T23:38:35Z
|
wren bindings for zig
|
master
| 1 | 26 | 2 | 26 |
https://api.github.com/repos/dantecatalfamo/wren-zig/tags
|
MIT
|
[
"bindings",
"wren",
"wren-bindings",
"zig",
"zig-library"
] | 103 | false |
2024-04-16T20:31:31Z
| true | false |
unknown
|
github
|
[] |
wren-zig
<a>Wren</a> bindings for <a>zig</a>!
Wren is a fast lua-sized scripting language with classes and concurrency.
Details on how embedding wren works <a>here</a>.
Bindings
In <code>src/wren.zig</code>
Contains both bare bindings and a zig wrapper
```zig
wrenGetSlotDouble(vm, 0);
vm.getSlotDouble(0);
```
Embedding
Recursively clone this repository and add the following to your <code>build.zig</code>, with the paths changed to match the correct location
```zig
const addWren = @import("wren-zig/build.zig").addWren;
pub fn build(b: *std.build.Builder) void {
[...]
const exe = b.addExecutable("wren-zig", "src/main.zig");
addWren(exe);
[...]
}
```
Example
A very basic example
```zig
const std = @import("std");
const wren = @import("wren");
pub fn main() anyerror!void {
var config = wren.newConfig();
config.write_fn = writeFn;
config.error_fn = errorFn;
var vm = wren.wrenNewVM(&config);
defer vm.free();
<code>try vm.interpret("main", "System.print(\"Hello, world!\")");
</code>
}
pub export fn writeFn(vm: <em>wren.WrenVM, text: [</em>:0]const u8) void {
_ = vm;
const stdout = std.io.getStdOut().writer();
stdout.print("{s}", .{ text }) catch unreachable;
}
pub export fn errorFn(vm: <em>wren.WrenVM, error_type: wren.WrenErrorType, module: [</em>:0]const u8, line: c_int, msg: [*:0]const u8) void {
_ = vm;
const stderr = std.io.getStdErr().writer();
switch (error_type) {
.WREN_ERROR_COMPILE => stderr.print("[{s} line {d}] [Error] {s}\n", .{ module, line, msg }) catch unreachable,
.WREN_ERROR_STACK_TRACE => stderr.print("[{s} line {d}] in {s}\n", .{ module, line, msg }) catch unreachable,
.WREN_ERROR_RUNTIME => stderr.print("[Runtime Error] {s}\n", .{ msg }) catch unreachable,
}
}
```
See <code>src/main.zig</code> for more advanced use cases
|
[] |
https://avatars.githubusercontent.com/u/61861965?v=4
|
pam_sauron
|
l1na-forever/pam_sauron
|
2022-10-03T21:16:39Z
|
FaceID for Linux 🌋🔒🪞 PAM module for Intel RealSense devices
|
main
| 0 | 25 | 0 | 25 |
https://api.github.com/repos/l1na-forever/pam_sauron/tags
|
-
|
[
"face-recognition",
"login",
"pam",
"pam-authentication",
"pam-module",
"realsense",
"realsense-camera",
"zig"
] | 13 | false |
2025-03-26T00:24:04Z
| true | false |
unknown
|
github
|
[] |
pam_sauron 🌋🔒🪞
The provided <a>PAM module</a> can be used to introduce facial authentication as a PAM mode of authentication by making use of an Intel RealSense depth-sensing camera.
https://user-images.githubusercontent.com/61861965/193917430-f35d8108-5ca9-4187-b869-2566104063be.mp4
Requirements
<ul>
<li>A Linux system using <a>PAM</a></li>
<li>An Intel RealSense F4XX-series depth-sensing camera (such as the <a>RealSense F455</a>)<ul>
<li>TXXX-series RealSense solutions are incompatible, as they offload facial recognition to the host</li>
<li>Camera should be running firmware <code>F450_4.0.0.37</code></li>
</ul>
</li>
<li>The <a>Intel RealSenseID library</a></li>
<li><a>Zig 0.9+ ⚡</a></li>
</ul>
Caveats
<strong>Treat this package as a neat toy intended for machines with low physical security requirements.</strong>
<ul>
<li>This does <strong>not</strong> (presently) prompt for any user input before initiating the facial authentication request. Without additional factors, this could introduce a security hole where <code>pam_sauron</code> is invoked to gain privileged access without human confirmation. </li>
<li>This does <strong>not</strong> presently make use of the RealSense library's <a>Secure Communication mode</a>, where a depth sensing device is paired to the host via public/private keys. That means that an attacker could trivially replace a <code>pam_sauron</code> user's depth sensing camera (or edit the existing camera's on-device facial pattern database/update enrollment) to gain privileged access. </li>
</ul>
Intel RealSense Installation
Step 1: Install RealSense ID library
Clone this repository and initialize its submodules. The RealSense library is provided as a submodule, checked out at tag <code>v0.21.0</code>:
<code>sh
git clone https://github.com/l1na-forever/pam_sauron.git
cd pam_sauron
git submodule update --init</code>
Next, build the library. A Makefile target <code>rsid</code> is provided for convenience:
<code>sh
make rsid</code>
Finally, copy the library <code>librsid_c.so</code> to a location on your library path (the RealSense library does not provide an install target):
<code>sh
sudo install -m 755 deps/RealSenseID/build/lib/librsid_c.so /usr/lib/librsid_c.so</code>
Step 2: Prepare camera
The depth-sensing camera must be updated to a firmware version compatible with the particular version of the RSID library being used. In pam_sauron's case, the <code>v0.21.0</code> release (firmware version <code>F450_4.0.0.37</code>) is used. If you've already been using your camera for facial authentication, you can skip this step. If the sample applications built in the submodule's directory already appear to function, you can skip this step.
Using the built <code>deps/RealSenseID/tools/bin/rsid-fw-update</code> executable, bring your camera up to date to the latest firmware (downloaded from the <a>RealSense releases page</a>. Each update must be applied step-by-step (rather than flashing directly to the newest version). If the firmware file won't apply, try the opposite SKU variant (SKU1/SKU2). For example, to upgrade a retail F455 camera of SKU1 variety to compatible firmware:
<code>sh
cd deps/RealSenseID/build
sudo bin/rsid-fw-update --port /dev/ttyACM0 --force-version --file ~/Downloads/F450_2.8.0.7_SIGNED.bin
sudo bin/rsid-fw-update --port /dev/ttyACM0 --force-version --file ~/Downloads/F450_3.1.0.29_SKU1_SIGNED.bin
sudo bin/rsid-fw-update --port /dev/ttyACM0 --force-version --file ~/Downloads/F450_4.0.0.37_SKU1_SIGNED.bin</code>
You should be able to connect to the camera using the <code>bin/rsid-cli</code> tool after firmware flashing completes.
Step 3: Enroll a user
Once the camera's firmware is in sync with the RSID library, enroll your face using the CLI tool:
<code>sh
cd deps/RealSenseID/build
sudo bin/rsid-cli /dev/ttyACM0</code>
Enter <code>e</code> to begin enrollment. The enrolled user id must match your Linux username exactly (e.g., match the output of <code>whoami</code>). Afterwards, enter <code>a</code> to verify enrollment was successful. Use <code>q</code> to quit the CLI tool. Faceprints are stored on the device itself.
pam_sauron Installation
Step 1: Install pam_sauron
From this repository's root, build and install the PAM module:
<code>sh
make
sudo make install</code>
Step 2: Add pam_sauron to PAM configuration
Once the PAM module has been installed, it can be used as would any other PAM-based authentication mechanism. Read more on <a>the PAM configuration file</a>, and take a look at <code>man pam</code>.
As an example, to add facial authentication as an acceptable authentication for (just) <code>sudo</code>, you might update <code>/etc/pam.d/sudo</code>:
```
%PAM-1.0
Attempt to authenticate via RealSense ID first
auth sufficient pam_sauron.so
auth include system-auth
account include system-auth
session include system-auth
```
The "<code>sufficient</code>" directive indicates that facial authentication alone will authenticate the user for <code>sudo</code>, but allows the authentication flow to continue to other mechanisms (entering your password) if facial authentication fails. For example, given the above configuration, a facial authentication failure may produce the following output and prompt:
<code>$ sudo whoami
Authenticating via RSID...
Authentication failed
Password:</code>
Whereas a successful facial authentication would produce output similar to:
<code>$ sudo whoami
Authenticating via RSID...
Authenticated 'lina'!
root</code>
Troubleshooting
My recommendation is to make sure everything seems to be working right with the RealSense samples/tools first. If the samples/tools aren't working, your camera's firmware is likely not flashed to the version corresponding to the library (see above instructions). Oh, also, the module is hardcoded to <code>/dev/ttyACM0</code>; if your device happens to <em>not</em> be on <code>/dev/ttyACM0</code>, fork the package and update <code>pam_sauron.zig</code> (or cut me a feature request :^).
Still, this is niche enough you can probably just cut me an issue. No promises on wrangling RealSense issues, though.
FAQ
Q: Can pam_sauron detect masks?
Yep:
https://user-images.githubusercontent.com/61861965/193917403-51155dcd-2166-485a-bf9b-0fa37a9d9034.mp4
License
Copyright © 2022 Lina
Permission to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of this software (the "Software"), subject to the following conditions:
The persons making use of this "Software" must furnish the nearest cat with gentle pats, provided this is acceptable to both parties (the "person" and the "cat"). Otherwise, water a plant 🪴
|
[] |
https://avatars.githubusercontent.com/u/28735087?v=4
|
boxflow
|
LordMZTE/boxflow
|
2022-12-17T11:38:16Z
|
Unmaintained in favor of Zenolith - mirror of https://mzte.de/git/LordMZTE/boxflow
|
master
| 0 | 25 | 0 | 25 |
https://api.github.com/repos/LordMZTE/boxflow/tags
|
GPL-3.0
|
[
"gui",
"layout",
"layout-engine",
"widgets",
"zig"
] | 80 | false |
2025-03-23T19:45:08Z
| true | false |
unknown
|
github
|
[] |
Boxflow
Boxflow is a layout engine implementing flexboxes as well as others in Zig.
It aims to be universally usable for applications such as GUIs and window managers.
NOTE: Boxflow is alpha software. Expect bugs and breaking changes!
Usage
To compile Boxflow, you need to use the latest master version of the Zig compiler.
If Boxflow stops compiling on master Zig, please bug me about it.
If you want to use Boxflow, a good starting point is looking at <code>src/Box.zig</code>. It's the main interface of Boxflow.
I hope to document all types extensively.
Contributing
If you would like to fix a bug or improve documentation, you're very welcome to open a PR about that.
If you'd like to add a feature, please open an issue first, so we can discuss it.
In case you have any questions, feel free to message me on matrix (@lordmzte:mzte.de),
send me an email ([email protected]) or DM me on discord (LordMZTE#9001) if all else fails.
Boxflow is licensed under GPL-3 to prevent spread of proprietary garbage.
|
[] |
https://avatars.githubusercontent.com/u/37866329?v=4
|
rix101
|
reo101/rix101
|
2022-11-20T15:26:45Z
|
My NixOS, nix-on-droid and nix-darwin configs.
|
master
| 0 | 25 | 1 | 25 |
https://api.github.com/repos/reo101/rix101/tags
|
MIT
|
[
"agenix",
"android",
"home-manager",
"home-manager-config",
"homebrew",
"linux",
"lua",
"macos",
"neovim",
"nix",
"nix-darwin",
"nix-flake",
"nix-on-droid",
"nixos",
"nixos-config",
"wezterm",
"wezterm-config",
"wireguard",
"zig",
"zsh"
] | 795 | false |
2025-05-21T04:36:03Z
| false | false |
unknown
|
github
|
[] |
Structure
<ul>
<li>Everything is built upon <a>flake-parts</a>, with <a>flake modules</a> for automatic <em>stuff</em> extraction</li>
<li>Automatic classic (<code>callPackage</code>) and <code>dream2nix</code> packages extraction</li>
<li>Automatic <code>nixos</code>, <code>nix-darwin</code>, <code>nix-on-droid</code>, <code>home-manager</code> and <code>flake</code> modules extraction</li>
<li>Automatic <code>nixos</code>, <code>nix-darwin</code>, <code>nix-on-droid</code> and <code>home-manager</code> configurations extraction</li>
<li>Automatic overlays extraction</li>
<li>Automatic devShells extraction</li>
<li>Hosts can be found under <code>./hosts/${config-type}/${system}/${hostname}/...</code></li>
<li>Check <a><code>./modules/flake/configurations</code></a> for more info on what is extracted from those directories</li>
<li>Modules can be found under <code>./modules/${config-type}/...</code></li>
<li>Check <a><code>./modules/flake/modules</code></a> for more info on what is extracted from that directory</li>
<li>Packages can be found under <code>./pkgs/...</code></li>
<li>Check <a><code>./modules/flake/packages</code></a> for more info on what is extracted from that directory</li>
<li>Overlays can be found under <code>./overlays/...</code></li>
<li>Check <a><code>./modules/flake/overlays</code></a> for more info on what is extracted from that directory</li>
<li>Shells can be found under <code>./shells/...</code></li>
<li>Check <a><code>./modules/flake/shells</code></a> for more info on what is extracted from that directory</li>
<li>Default one puts a recent <code>nix</code> (as of recently - <code>lix</code>) together with some other useful tools for working with the repo (<code>deploy-rs</code>, <code>rage</code>, <code>agenix-rekey</code>, etc.), see <a><code>./shells/default/default.nix</code></a> for more info</li>
</ul>
Topology
You can see the overall topology of the hosts by running
<code>sh
nix build ".#topology"</code>
And opening the resulting <code>./result/main.svg</code> and <code>./result/network.svg</code>
Secrets
Secrets are managed by <a><code>agenix</code></a> and <a><code>agenix-rekey</code></a>
<blockquote>
<span class="bg-blue-100 text-blue-800 text-xs font-medium me-2 px-2.5 py-0.5 rounded dark:bg-blue-900 dark:text-blue-300">NOTE</span>
Secrets are defined by the hosts themselves, <code>agenix-rekey</code> <em>just</em> collects what secrets are referenced by them and lets you generate, edit and rekey them
</blockquote>
```sh
To put <code>rage</code>, <code>agenix-rekey</code> and friends in <code>$PATH</code>
nix develop
```
Edit secret
```sh
Select from <code>fzf</code> menu
agenix edit
```
Rekey all secrets
<code>sh
agenix rekey</code>
Generate missing keys (with the defined <code>generators</code>)
<code>sh
agenix generate</code>
Setups
NixOS setup
```sh
Initial setup
nix run nixpkgs#nixos-anywhere -- --flake ".#${HOSTNAME}" --build-on-remote --ssh-port 22 "root@${HOSTNAME}" --no-reboot
Deploy
deploy ".#${HOSTNAME}" --skip-checks
```
MacOS / Darwin (silicon) setup
```sh
Setup system tools
softwareupdate --install-rosetta --agree-to-license
sudo xcodebuild -license
Install nix
curl --proto '=https' --tlsv1.2 -sSf -L https://install.determinate.systems/nix | sh -s -- install
Apply configuration
git clone https://www.github.com/reo101/rix101 ~/.config/rix101
cd ~/.config/rix101
nix build ".#darwinConfigurations.${HOSTNAME}.system"
./result/sw/bin/darwin-rebuild switch --flake .
System setup for <code>yabai</code> (in system recovery)
NOTE: <a>https://support.apple.com/guide/mac-help/macos-recovery-a-mac-apple-silicon-mchl82829c17/mac</a>
csrutil enable --without fs --without debug --without nvram
```
Credits
<ul>
<li><a><code>Misterio77</code></a> for his amazing <a><code>nix-starter-configs</code></a>, on which this was based originally</li>
<li><a><code>disko</code></a> for making disk partioning a breeze</li>
<li><a><code>oddlama</code></a> for creating the amazing <a><code>agenix-rekey</code></a> and <a><code>nix-topology</code></a> projects</li>
</ul>
|
[] |
https://avatars.githubusercontent.com/u/3932972?v=4
|
zig-mqtt
|
ikskuh/zig-mqtt
|
2022-05-18T06:37:23Z
|
A build package for mqtt-c.
|
master
| 0 | 23 | 5 | 23 |
https://api.github.com/repos/ikskuh/zig-mqtt/tags
|
MIT
|
[
"iot",
"mqtt",
"protocol",
"zig",
"zig-package"
] | 5 | false |
2025-01-16T01:41:46Z
| true | false |
unknown
|
github
|
[] |
zig-mqtt
A build package for the awesome <a>mqtt-c</a> project by <a>Liam Bindle</a>.
Right now only provides a build script API in <code>Sdk.zig</code>, but might contain a Zig frontend in the future.
Usage
```zig
const std = @import("std");
const Sdk = @import("Sdk.zig");
pub fn build(b: *std.build.Builder) void {
const mode = b.standardReleaseOptions();
const target = b.standardTargetOptions(.{});
<code>const lib = Sdk.createLibrary(b);
lib.setBuildMode(mode);
lib.setTarget(target);
lib.install();
const exe = b.addExecutable(…);
exe.linkLibary(lib);
exe.addIncludePath(Sdk.include_path);
…
</code>
}
```
|
[] |
https://avatars.githubusercontent.com/u/1560508?v=4
|
nyancat.zig
|
ryoppippi/nyancat.zig
|
2022-07-23T16:16:07Z
|
Nyancat in Zig
|
main
| 0 | 23 | 2 | 23 |
https://api.github.com/repos/ryoppippi/nyancat.zig/tags
|
MIT
|
[
"joke",
"nyan-cat",
"nyancat",
"zig"
] | 6,587 | false |
2025-04-17T09:02:06Z
| true | false |
unknown
|
github
|
[] |
Nyancat.zig
Nyancat written in Zig
How to execute
<code>sh
git clone https://github.com/ryoppippi/nyancat.zig
zig build -Drelease-fast=true run</code>
License
MIT
Author
Ryotaro "Justin" Kimura (a.k.a. ryoppippi)
|
[] |
https://avatars.githubusercontent.com/u/9960133?v=4
|
pinephone-lvgl-zig
|
lupyuen/pinephone-lvgl-zig
|
2023-01-20T10:10:24Z
|
LVGL for PinePhone (and WebAssembly) with Zig and Apache NuttX RTOS
|
main
| 0 | 22 | 0 | 22 |
https://api.github.com/repos/lupyuen/pinephone-lvgl-zig/tags
|
Apache-2.0
|
[
"lvgl",
"nuttx",
"pinephone",
"wasm",
"zig"
] | 20,408 | false |
2025-04-10T17:47:55Z
| false | false |
unknown
|
github
|
[] |
LVGL for PinePhone (and WebAssembly) with Zig and Apache NuttX RTOS
Read the articles...
<ul>
<li>
<a>"NuttX RTOS for PinePhone: Feature Phone UI in LVGL, Zig and WebAssembly"</a>
</li>
<li>
<a>"(Possibly) LVGL in WebAssembly with Zig Compiler"</a>
</li>
<li>
<a>"NuttX RTOS for PinePhone: Boot to LVGL"</a>
</li>
<li>
<a>"Build an LVGL Touchscreen App with Zig"</a>
</li>
</ul>
Can we build an <strong>LVGL App in Zig</strong> for PinePhone... That will run on Apache NuttX RTOS?
Can we preview a PinePhone App with <strong>Zig, LVGL and WebAssembly</strong> in a Web Browser? To make the UI Coding a little easier?
Let's find out!
LVGL Zig App
Let's run this LVGL Zig App on PinePhone...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/c7a33f1fe3af4babaa8bc5502ca2b719ae95c2ca/lvgltest.zig#L55-L89
<em>How is createWidgetsWrapped called?</em>
<code>createWidgetsWrapped</code> will be called by the LVGL Widget Demo <a><code>lv_demo_widgets</code></a>, which we'll replace by this Zig version...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/c7a33f1fe3af4babaa8bc5502ca2b719ae95c2ca/lvgltest.zig#L32-L41
<em>Where's the Zig Wrapper for LVGL?</em>
Our Zig Wrapper for LVGL is defined here...
<ul>
<li><a>lvgl.zig</a></li>
</ul>
We also have a version of the LVGL Zig Code that doesn't call the Zig Wrapper...
<ul>
<li><a>lvgltest.zig</a></li>
</ul>
Build LVGL Zig App
NuttX Build runs this GCC Command to compile <a>lv_demo_widgets.c</a> for PinePhone...
<code>bash
$ make --trace
...
cd $HOME/PinePhone/wip-nuttx/apps/graphics/lvgl
aarch64-none-elf-gcc
-c
-fno-common
-Wall
-Wstrict-prototypes
-Wshadow
-Wundef
-Werror
-Os
-fno-strict-aliasing
-fomit-frame-pointer
-g
-march=armv8-a
-mtune=cortex-a53
-isystem $HOME/PinePhone/wip-nuttx/nuttx/include
-D__NuttX__
-pipe
-I $HOME/PinePhone/wip-nuttx/apps/graphics/lvgl
-I "$HOME/PinePhone/wip-nuttx/apps/include"
-Wno-format
-Wno-unused-variable
"-I./lvgl/src/core"
"-I./lvgl/src/draw"
"-I./lvgl/src/draw/arm2d"
"-I./lvgl/src/draw/nxp"
"-I./lvgl/src/draw/nxp/pxp"
"-I./lvgl/src/draw/nxp/vglite"
"-I./lvgl/src/draw/sdl"
"-I./lvgl/src/draw/stm32_dma2d"
"-I./lvgl/src/draw/sw"
"-I./lvgl/src/draw/swm341_dma2d"
"-I./lvgl/src/font"
"-I./lvgl/src/hal"
"-I./lvgl/src/misc"
"-I./lvgl/src/widgets"
"-DLV_ASSERT_HANDLER=ASSERT(0);"
lvgl/demos/widgets/lv_demo_widgets.c
-o lvgl/demos/widgets/lv_demo_widgets.c.Users.Luppy.PinePhone.wip-nuttx.apps.graphics.lvgl.o</code>
We'll copy the above GCC Options to the Zig Compiler and build this Zig Program for PinePhone...
<ul>
<li><a>lvgltest.zig</a></li>
</ul>
Here's the Shell Script...
```bash
Build the LVGL Zig App
function build_zig {
## Go to LVGL Zig Folder
pushd ../pinephone-lvgl-zig
git pull
## Check that NuttX Build has completed and <code>lv_demo_widgets.*.o</code> exists
if [ ! -f ../apps/graphics/lvgl/lvgl/demos/widgets/lv_demo_widgets.<em>.o ]
then
echo "</em>** Error: Build NuttX first before building Zig app"
exit 1
fi
## Compile the Zig App for PinePhone
## (armv8-a with cortex-a53)
## TODO: Change ".." to your NuttX Project Directory
zig build-obj \
--verbose-cimport \
-target aarch64-freestanding-none \
-mcpu cortex_a53 \
-isystem "../nuttx/include" \
-I "../apps/include" \
-I "../apps/graphics/lvgl" \
-I "../apps/graphics/lvgl/lvgl/src/core" \
-I "../apps/graphics/lvgl/lvgl/src/draw" \
-I "../apps/graphics/lvgl/lvgl/src/draw/arm2d" \
-I "../apps/graphics/lvgl/lvgl/src/draw/nxp" \
-I "../apps/graphics/lvgl/lvgl/src/draw/nxp/pxp" \
-I "../apps/graphics/lvgl/lvgl/src/draw/nxp/vglite" \
-I "../apps/graphics/lvgl/lvgl/src/draw/sdl" \
-I "../apps/graphics/lvgl/lvgl/src/draw/stm32_dma2d" \
-I "../apps/graphics/lvgl/lvgl/src/draw/sw" \
-I "../apps/graphics/lvgl/lvgl/src/draw/swm341_dma2d" \
-I "../apps/graphics/lvgl/lvgl/src/font" \
-I "../apps/graphics/lvgl/lvgl/src/hal" \
-I "../apps/graphics/lvgl/lvgl/src/misc" \
-I "../apps/graphics/lvgl/lvgl/src/widgets" \
lvgltest.zig
## Copy the compiled app to NuttX and overwrite <code>lv_demo_widgets.*.o</code>
## TODO: Change ".." to your NuttX Project Directory
cp lvgltest.o \
../apps/graphics/lvgl/lvgl/demos/widgets/lv_demo_widgets.*.o
## Return to NuttX Folder
popd
}
Download the LVGL Zig App
git clone https://github.com/lupyuen/pinephone-lvgl-zig
Build NuttX for PinePhone
cd nuttx
make -j
Build the LVGL Zig App
build_zig
Link the LVGL Zig App with NuttX
make -j
```
<a>(Original Build Script)</a>
<a>(Updated Build Script)</a>
<a>(NuttX Build Files)</a>
And our LVGL Zig App runs OK on PinePhone!
Simulate PinePhone UI with Zig, LVGL and WebAssembly
Read the article...
<ul>
<li><a>"(Possibly) LVGL in WebAssembly with Zig Compiler"</a></li>
</ul>
We're now building a <strong>Feature Phone UI</strong> for NuttX on PinePhone...
Can we simulate the Feature Phone UI with <strong>Zig, LVGL and WebAssembly</strong> in a Web Browser? To make the UI Coding a little easier?
We have previously created a simple <strong>LVGL App with Zig</strong> for PinePhone...
<ul>
<li><a>pinephone-lvgl-zig</a></li>
</ul>
Zig natively supports <strong>WebAssembly</strong>...
<ul>
<li><a>WebAssembly on Zig</a></li>
</ul>
So we might run <strong>Zig + JavaScript</strong> in a Web Browser like so...
<ul>
<li><a>WebAssembly With Zig in a Web Browser</a></li>
</ul>
But LVGL doesn't work with JavaScript yet. LVGL runs in a Web Browser by compiling with Emscripten and SDL...
<ul>
<li><a>LVGL with Emscripten and SDL</a></li>
</ul>
Therefore we shall do this...
<ol>
<li>
Use Zig to compile LVGL from C to WebAssembly <a>(With <code>zig cc</code>)</a>
</li>
<li>
Use Zig to connect the JavaScript UI (canvas rendering + input events) to LVGL WebAssembly <a>(Like this)</a>
</li>
</ol>
WebAssembly Demo with Zig and JavaScript
We can run <strong>Zig (WebAssembly) + JavaScript</strong> in a Web Browser like so...
<ul>
<li><a>WebAssembly With Zig in a Web Browser</a></li>
</ul>
Let's run a simple demo...
<ul>
<li>
<a>demo/mandelbrot.zig</a>: Zig Program that compiles to WebAssembly
</li>
<li>
<a>demo/game.js</a>: JavaScript that loads the Zig WebAssembly
</li>
<li>
<a>demo/demo.html</a>: HTML that calls the JavaScript
</li>
</ul>
To compile Zig to WebAssembly...
<code>bash
git clone --recursive https://github.com/lupyuen/pinephone-lvgl-zig
cd pinephone-lvgl-zig
cd demo
zig build-lib \
mandelbrot.zig \
-target wasm32-freestanding \
-dynamic \
-rdynamic</code>
<a>(According to this)</a>
This produces the Compiled WebAssembly <a><code>mandelbrot.wasm</code></a>.
Start a Local Web Server. <a>(Like Web Server for Chrome)</a>
Browse to <code>demo/demo.html</code>. We should see the Mandelbrot Set yay!
Import JavaScript Functions into Zig
<em>How do we import JavaScript Functions into our Zig Program?</em>
This is documented here...
<ul>
<li><a>WebAssembly on Zig</a></li>
</ul>
In our Zig Program, this is how we import and call a JavaScript Function: <a>demo/mandelbrot.zig</a>
<code>zig
/// Import `print` Function from JavaScript
extern fn print(i32) void;
...
// Test printing to JavaScript Console.
// Warning: This is slow!
if (iterations == 1) { print(iterations); }</code>
We define the JavaScript Function <code>print</code> when loading the WebAssembly Module in our JavaScript: <a>demo/game.js</a>
```javascript
// Export JavaScript Functions to Zig
let importObject = {
// JavaScript Environment exported to Zig
env: {
// JavaScript Print Function exported to Zig
print: function(x) { console.log(x); }
}
};
// Load the WebAssembly Module
// https://developer.mozilla.org/en-US/docs/WebAssembly/JavaScript_interface/instantiateStreaming
async function bootstrap() {
<code>// Store references to WebAssembly Functions and Memory exported by Zig
Game = await WebAssembly.instantiateStreaming(
fetch("mandelbrot.wasm"),
importObject
);
// Start the Main Function
main();
</code>
}
// Start the loading of WebAssembly Module
bootstrap();
```
<em>Will this work for passing Strings and Buffers as parameters?</em>
Nope, the parameter will be passed as a number. (Probably a WebAssembly Data Address)
To pass Strings and Buffers between JavaScript and Zig, see <a>daneelsan/zig-wasm-logger</a>.
Compile Zig LVGL App to WebAssembly
<em>Does our Zig LVGL App lvgltest.zig compile to WebAssembly?</em>
Let's take the earlier steps to compile our Zig LVGL App <code>lvgltest.zig</code>. To compile for WebAssembly, we change...
<ul>
<li>
<code>zig build-obj</code> to <code>zig build-lib</code>
</li>
<li>
Target becomes <code>-target wasm32-freestanding</code>
</li>
<li>
Remove <code>-mcpu</code>
</li>
<li>
Add <code>-dynamic</code> and <code>-rdynamic</code>
</li>
</ul>
Like this...
<code>bash
## Compile the Zig App for WebAssembly
## TODO: Change ".." to your NuttX Project Directory
zig build-lib \
--verbose-cimport \
-target wasm32-freestanding \
-dynamic \
-rdynamic \
-isystem "../nuttx/include" \
-I "../apps/include" \
-I "../apps/graphics/lvgl" \
-I "../apps/graphics/lvgl/lvgl/src/core" \
-I "../apps/graphics/lvgl/lvgl/src/draw" \
-I "../apps/graphics/lvgl/lvgl/src/draw/arm2d" \
-I "../apps/graphics/lvgl/lvgl/src/draw/nxp" \
-I "../apps/graphics/lvgl/lvgl/src/draw/nxp/pxp" \
-I "../apps/graphics/lvgl/lvgl/src/draw/nxp/vglite" \
-I "../apps/graphics/lvgl/lvgl/src/draw/sdl" \
-I "../apps/graphics/lvgl/lvgl/src/draw/stm32_dma2d" \
-I "../apps/graphics/lvgl/lvgl/src/draw/sw" \
-I "../apps/graphics/lvgl/lvgl/src/draw/swm341_dma2d" \
-I "../apps/graphics/lvgl/lvgl/src/font" \
-I "../apps/graphics/lvgl/lvgl/src/hal" \
-I "../apps/graphics/lvgl/lvgl/src/misc" \
-I "../apps/graphics/lvgl/lvgl/src/widgets" \
lvgltest.zig</code>
<a>(According to this)</a>
<a>(NuttX Build Files)</a>
OK no errors, this produces the Compiled WebAssembly <code>lvgltest.wasm</code>.
Now we tweak <a><code>lvgltest.zig</code></a> for WebAssembly, and call it <a><code>lvglwasm.zig</code></a>...
<code>bash
## Compile the Zig App for WebAssembly
## TODO: Change ".." to your NuttX Project Directory
zig build-lib \
--verbose-cimport \
-target wasm32-freestanding \
-dynamic \
-rdynamic \
-isystem "../nuttx/include" \
-I "../apps/include" \
-I "../apps/graphics/lvgl" \
-I "../apps/graphics/lvgl/lvgl/src/core" \
-I "../apps/graphics/lvgl/lvgl/src/draw" \
-I "../apps/graphics/lvgl/lvgl/src/draw/arm2d" \
-I "../apps/graphics/lvgl/lvgl/src/draw/nxp" \
-I "../apps/graphics/lvgl/lvgl/src/draw/nxp/pxp" \
-I "../apps/graphics/lvgl/lvgl/src/draw/nxp/vglite" \
-I "../apps/graphics/lvgl/lvgl/src/draw/sdl" \
-I "../apps/graphics/lvgl/lvgl/src/draw/stm32_dma2d" \
-I "../apps/graphics/lvgl/lvgl/src/draw/sw" \
-I "../apps/graphics/lvgl/lvgl/src/draw/swm341_dma2d" \
-I "../apps/graphics/lvgl/lvgl/src/font" \
-I "../apps/graphics/lvgl/lvgl/src/hal" \
-I "../apps/graphics/lvgl/lvgl/src/misc" \
-I "../apps/graphics/lvgl/lvgl/src/widgets" \
lvglwasm.zig</code>
<a>(According to this)</a>
<a>(NuttX Build Files)</a>
(We removed our Custom Panic Handler, the default one works fine for WebAssembly)
This produces the Compiled WebAssembly <a><code>lvglwasm.wasm</code></a>.
Start a Local Web Server. <a>(Like Web Server for Chrome)</a>
Browse to our HTML <a><code>lvglwasm.html</code></a>. Which calls our JavaScript <a><code>lvglwasm.js</code></a> to load the Compiled WebAssembly.
Our JavaScript <a><code>lvglwasm.js</code></a> calls the Zig Function <code>lv_demo_widgets</code> that's exported to WebAssembly by our Zig App <a><code>lvglwasm.zig</code></a>.
But the WebAssembly won't load because we haven't fixed the WebAssembly Imports...
Fix WebAssembly Imports
<em>What happens if we don't fix the WebAssembly Imports in our Zig Program?</em>
Suppose we forgot to import <code>puts()</code>. JavaScript Console will show this error when the Web Browser loads our Zig WebAssembly...
<code>text
Uncaught (in promise) LinkError:
WebAssembly.instantiate():
Import #0 module="env" function="puts" error:
function import requires a callable</code>
<em>But we haven't compiled the LVGL Library to WebAssembly!</em>
Yep that's why LVGL Functions like <code>lv_label_create</code> are failing when the Web Browser loads our Zig WebAssembly...
<code>text
Uncaught (in promise) LinkError:
WebAssembly.instantiate():
Import #1 module="env" function="lv_label_create" error:
function import requires a callable</code>
We need to compile the LVGL Library with <code>zig cc</code> and link it in...
Compile LVGL to WebAssembly with Zig Compiler
<em>How to compile LVGL from C to WebAssembly with Zig Compiler?</em>
We'll use <a><code>zig cc</code></a>, since Zig can compile C programs to WebAssembly.
In the previous section, we're missing the LVGL Function <code>lv_label_create</code> in our Zig WebAssembly Module.
<code>lv_label_create</code> is defined in this file...
<code>text
apps/lvgl/src/widgets/lv_label.c</code>
According to <code>make --trace</code>, <code>lv_label.c</code> is compiled with...
```bash
Compile LVGL in C
TODO: Change "../../.." to your NuttX Project Directory
cd apps/graphics/lvgl
aarch64-none-elf-gcc \
-c \
-fno-common \
-Wall \
-Wstrict-prototypes \
-Wshadow \
-Wundef \
-Werror \
-Os \
-fno-strict-aliasing \
-fomit-frame-pointer \
-ffunction-sections \
-fdata-sections \
-g \
-march=armv8-a \
-mtune=cortex-a53 \
-isystem ../../../nuttx/include \
-D__NuttX__ \
-pipe \
-I ../../../apps/graphics/lvgl \
-I "../../../apps/include" \
-Wno-format \
-Wno-format-security \
-Wno-unused-variable \
"-I./lvgl/src/core" \
"-I./lvgl/src/draw" \
"-I./lvgl/src/draw/arm2d" \
"-I./lvgl/src/draw/nxp" \
"-I./lvgl/src/draw/nxp/pxp" \
"-I./lvgl/src/draw/nxp/vglite" \
"-I./lvgl/src/draw/sdl" \
"-I./lvgl/src/draw/stm32_dma2d" \
"-I./lvgl/src/draw/sw" \
"-I./lvgl/src/draw/swm341_dma2d" \
"-I./lvgl/src/font" \
"-I./lvgl/src/hal" \
"-I./lvgl/src/misc" \
"-I./lvgl/src/widgets" \
"-DLV_ASSERT_HANDLER=ASSERT(0);" \
./lvgl/src/widgets/lv_label.c \
-o lv_label.c.Users.Luppy.PinePhone.wip-nuttx.apps.graphics.lvgl.o
```
Let's use the Zig Compiler to compile <code>lv_label.c</code> from C to WebAssembly....
<ul>
<li>
Change <code>aarch64-none-elf-gcc</code> to <code>zig cc</code>
</li>
<li>
Remove <code>-march</code>, <code>-mtune</code>
</li>
<li>
Add the target <code>-target wasm32-freestanding</code>
</li>
<li>
Add <code>-dynamic</code> and <code>-rdynamic</code>
</li>
<li>
Add <code>-lc</code> (because we're calling C Standard Library)
</li>
<li>
Add <code>-DFAR=</code> (because we won't need Far Pointers)
</li>
<li>
Add <code>-DLV_MEM_CUSTOM=1</code> (because we're using <code>malloc</code> instead of LVGL's TLSF Allocator)
</li>
<li>
Set the Default Font to Montserrat 20...
</li>
</ul>
<code>text
-DLV_FONT_MONTSERRAT_14=1 \
-DLV_FONT_MONTSERRAT_20=1 \
-DLV_FONT_DEFAULT_MONTSERRAT_20=1 \
-DLV_USE_FONT_PLACEHOLDER=1 \</code>
<ul>
<li>
Add <code>-DLV_USE_LOG=1</code> (to enable logging)
</li>
<li>
Add <code>-DLV_LOG_LEVEL=LV_LOG_LEVEL_TRACE</code> (for detailed logging)
</li>
<li>
For extra logging...
</li>
</ul>
<code>text
-DLV_LOG_TRACE_OBJ_CREATE=1 \
-DLV_LOG_TRACE_TIMER=1 \
-DLV_LOG_TRACE_MEM=1 \</code>
<ul>
<li>Change <code>"-DLV_ASSERT_HANDLER..."</code> to...</li>
</ul>
<code>text
"-DLV_ASSERT_HANDLER={void lv_assert_handler(void); lv_assert_handler();}"</code>
<a>(To handle Assertion Failures ourselves)</a>
<ul>
<li>Change the output to...</li>
</ul>
<code>text
-o ../../../pinephone-lvgl-zig/lv_label.o`</code>
Like this...
```bash
Compile LVGL from C to WebAssembly
TODO: Change "../../.." to your NuttX Project Directory
cd apps/graphics/lvgl
zig cc \
-target wasm32-freestanding \
-dynamic \
-rdynamic \
-lc \
-DFAR= \
-DLV_MEM_CUSTOM=1 \
-DLV_FONT_MONTSERRAT_14=1 \
-DLV_FONT_MONTSERRAT_20=1 \
-DLV_FONT_DEFAULT_MONTSERRAT_20=1 \
-DLV_USE_FONT_PLACEHOLDER=1 \
-DLV_USE_LOG=1 \
-DLV_LOG_LEVEL=LV_LOG_LEVEL_TRACE \
-DLV_LOG_TRACE_OBJ_CREATE=1 \
-DLV_LOG_TRACE_TIMER=1 \
-DLV_LOG_TRACE_MEM=1 \
"-DLV_ASSERT_HANDLER={void lv_assert_handler(void); lv_assert_handler();}" \
-c \
-fno-common \
-Wall \
-Wstrict-prototypes \
-Wshadow \
-Wundef \
-Werror \
-Os \
-fno-strict-aliasing \
-fomit-frame-pointer \
-ffunction-sections \
-fdata-sections \
-g \
-isystem ../../../nuttx/include \
-D__NuttX__ \
-pipe \
-I ../../../apps/graphics/lvgl \
-I "../../../apps/include" \
-Wno-format \
-Wno-format-security \
-Wno-unused-variable \
"-I./lvgl/src/core" \
"-I./lvgl/src/draw" \
"-I./lvgl/src/draw/arm2d" \
"-I./lvgl/src/draw/nxp" \
"-I./lvgl/src/draw/nxp/pxp" \
"-I./lvgl/src/draw/nxp/vglite" \
"-I./lvgl/src/draw/sdl" \
"-I./lvgl/src/draw/stm32_dma2d" \
"-I./lvgl/src/draw/sw" \
"-I./lvgl/src/draw/swm341_dma2d" \
"-I./lvgl/src/font" \
"-I./lvgl/src/hal" \
"-I./lvgl/src/misc" \
"-I./lvgl/src/widgets" \
./lvgl/src/widgets/lv_label.c \
-o ../../../pinephone-lvgl-zig/lv_label.o
```
<a>(NuttX Build Files)</a>
This produces the Compiled WebAssembly <code>lv_label.o</code>.
<em>Will Zig Compiler let us link <code>lv_label.o</code> with our Zig LVGL App?</em>
Let's ask Zig Compiler to link <code>lv_label.o</code> with our Zig LVGL App <a><code>lvglwasm.zig</code></a>...
<code>bash
## Compile the Zig App for WebAssembly
## TODO: Change ".." to your NuttX Project Directory
zig build-lib \
--verbose-cimport \
-target wasm32-freestanding \
-dynamic \
-rdynamic \
-lc \
-DFAR= \
-DLV_MEM_CUSTOM=1 \
-DLV_FONT_MONTSERRAT_14=1 \
-DLV_FONT_MONTSERRAT_20=1 \
-DLV_FONT_DEFAULT_MONTSERRAT_20=1 \
-DLV_USE_FONT_PLACEHOLDER=1 \
-DLV_USE_LOG=1 \
-DLV_LOG_LEVEL=LV_LOG_LEVEL_TRACE \
-DLV_LOG_TRACE_OBJ_CREATE=1 \
-DLV_LOG_TRACE_TIMER=1 \
-DLV_LOG_TRACE_MEM=1 \
"-DLV_ASSERT_HANDLER={void lv_assert_handler(void); lv_assert_handler();}" \
-I . \
-isystem "../nuttx/include" \
-I "../apps/include" \
-I "../apps/graphics/lvgl" \
-I "../apps/graphics/lvgl/lvgl/src/core" \
-I "../apps/graphics/lvgl/lvgl/src/draw" \
-I "../apps/graphics/lvgl/lvgl/src/draw/arm2d" \
-I "../apps/graphics/lvgl/lvgl/src/draw/nxp" \
-I "../apps/graphics/lvgl/lvgl/src/draw/nxp/pxp" \
-I "../apps/graphics/lvgl/lvgl/src/draw/nxp/vglite" \
-I "../apps/graphics/lvgl/lvgl/src/draw/sdl" \
-I "../apps/graphics/lvgl/lvgl/src/draw/stm32_dma2d" \
-I "../apps/graphics/lvgl/lvgl/src/draw/sw" \
-I "../apps/graphics/lvgl/lvgl/src/draw/swm341_dma2d" \
-I "../apps/graphics/lvgl/lvgl/src/font" \
-I "../apps/graphics/lvgl/lvgl/src/hal" \
-I "../apps/graphics/lvgl/lvgl/src/misc" \
-I "../apps/graphics/lvgl/lvgl/src/widgets" \
lvglwasm.zig \
lv_label.o</code>
<a>(Source)</a>
<a>(NuttX Build Files)</a>
Now we see this error in the Web Browser...
<code>text
Uncaught (in promise) LinkError:
WebAssembly.instantiate():
Import #0 module="env" function="lv_obj_clear_flag" error:
function import requires a callable</code>
<code>lv_label_create</code> is no longer missing, because Zig Compiler has linked <code>lv_label.o</code> into our Zig LVGL App.
Yep Zig Compiler will happily link WebAssembly Object Files with our Zig App yay!
Now we need to compile <code>lv_obj_clear_flag</code> and the other LVGL Files from C to WebAssembly with Zig Compiler...
Compile Entire LVGL Library to WebAssembly
When we track down <code>lv_obj_clear_flag</code> and the other Missing Functions (by sheer tenacity), we get this trail of LVGL Source Files that need to be compiled from C to WebAssembly...
<code>text
widgets/lv_label.c
core/lv_obj.c
misc/lv_mem.c
core/lv_event.c
core/lv_obj_style.c
core/lv_obj_pos.c
misc/lv_txt.c
draw/lv_draw_label.c
core/lv_obj_draw.c
misc/lv_area.c
core/lv_obj_scroll.c
font/lv_font.c
core/lv_obj_class.c
(And many more)</code>
<a>(Based on LVGL 8.3.3)</a>
So we wrote a script to compile the above LVGL Source Files from C to WebAssembly with <code>zig cc</code>...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/2e1c97e49e51b1cbbe0964a9512eba141d0dd09f/build.sh#L7-L191
Which calls <code>compile_lvgl</code> to compile a single LVGL Source File from C to WebAssembly with <code>zig cc</code>...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/2e1c97e49e51b1cbbe0964a9512eba141d0dd09f/build.sh#L226-L288
<em>What happens after we compile the whole bunch of LVGL Source Files from C to WebAssembly?</em>
Now the Web Browser says that <code>strlen</code> is missing...
<code>text
Uncaught (in promise) LinkError:
WebAssembly.instantiate():
Import #0 module="env" function="strlen" error:
function import requires a callable</code>
Let's fix <code>strlen</code>...
<em>Is it really OK to compile only the necessary LVGL Source Files? Instead of compiling ALL the LVGL Source Files?</em>
Be careful! We might miss out some symbols. Zig Compiler happily assumes that they are at WebAssembly Address 0...
<ul>
<li><a>"LVGL Screen Not Found"</a></li>
</ul>
And remember to compile the LVGL Fonts!
<ul>
<li><a>"LVGL Fonts"</a></li>
</ul>
TODO: Disassemble the Compiled WebAssembly and look for other Undefined Variables at WebAssembly Address 0
C Standard Library is Missing
<em>strlen is missing from our Zig WebAssembly...</em>
<em>But strlen should come from the C Standard Library! (musl)</em>
Not sure why <code>strlen</code> is missing, but we fixed it temporarily by copying from the Zig Library Source Code...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/e99593df6b46ced52f3f8ed644b9c6e455a9d682/lvglwasm.zig#L213-L265
This seems to be the <a>same problem mentioned here</a>.
<a>(Referenced by this pull request)</a>
<a>(And this issue)</a>
TODO: Maybe because we didn't export <code>strlen</code> in our Main Program <code>lvglwasm.zig</code>?
TODO: Do we compile C Standard Library ourselves? From musl? Newlib? <a>wasi-libc</a>?
<em>What if we change the target to <code>wasm32-freestanding-musl</code>?</em>
Nope doesn't help, same problem.
<em>What if we use <code>zig build-exe</code> instead of <code>zig build-lib</code>?</em>
Sorry <code>zig build-exe</code> is meant for building WASI Executables. <a>(See this)</a>
<code>zig build-exe</code> is not supposed to work for WebAssembly in the Web Browser. <a>(See this)</a>
LVGL Porting Layer for WebAssembly
LVGL expects us to provide a <code>millis</code> function that returns the number of elapsed milliseconds...
<code>text
Uncaught (in promise) LinkError:
WebAssembly.instantiate():
Import #0 module="env" function="millis" error:
function import requires a callable</code>
We implement <code>millis</code> ourselves for WebAssembly...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/bee0e8d8ab9eae3a8c7cea6c64cc7896a5678f53/lvglwasm.zig#L170-L190
TODO: Fix <code>millis</code>. How would it work in WebAssembly? Using a counter?
In the code above, we defined <code>lv_assert_handler</code> and <code>custom_logger</code> to handle Assertions and Logging in LVGL.
Let's talk about LVGL Logging...
WebAssembly Logger for LVGL
Let's trace the LVGL Execution with a WebAssembly Logger.
(Remember: <code>printf</code> won't work in WebAssembly)
We set the Custom Logger for LVGL, so that we can print Log Messages to the JavaScript Console...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/f9dc7e1afba2f876c8397d753a79a9cb40b90b75/lvglwasm.zig#L32-L43
The Custom Logger is defined in our Zig Program...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/f9dc7e1afba2f876c8397d753a79a9cb40b90b75/lvglwasm.zig#L149-L152
<code>wasmlog</code> is our Zig Logger for WebAssembly: <a>wasmlog.zig</a>
(Based on <a>daneelsan/zig-wasm-logger</a>)
<code>jsConsoleLogWrite</code> and <code>jsConsoleLogFlush</code> are defined in our JavaScript...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/1ed4940d505e263727a36c362da54388be4cbca0/lvglwasm.js#L55-L66
<code>wasm.getString</code> also comes from our JavaScript...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/1ed4940d505e263727a36c362da54388be4cbca0/lvglwasm.js#L10-L27
Now we can see the LVGL Log Messages in the JavaScript Console yay! (Pic below)
<code>text
custom_logger: [Warn] (0.001, +1)
lv_disp_get_scr_act:
no display registered to get its active screen
(in lv_disp.c line #54)</code>
Let's initialise the LVGL Display...
Initialise LVGL Display
According to the LVGL Docs, this is how we initialise and operate LVGL...
<ol>
<li>
Call <code>lv_init()</code>
</li>
<li>
Register the LVGL Display and LVGL Input Devices
</li>
<li>
Call <code>lv_tick_inc(x)</code> every x milliseconds in an interrupt to report the elapsed time to LVGL
(Not required, because LVGL calls <code>millis</code> to fetch the elapsed time)
</li>
<li>
Call <code>lv_timer_handler()</code> every few milliseconds to handle LVGL related tasks
</li>
</ol>
<a>(Source)</a>
To register the LVGL Display, we should do this...
<ul>
<li>
<a>Create LVGL Draw Buffer</a>
</li>
<li>
<a>Register LVGL Display</a>
</li>
</ul>
But we can't do this in Zig...
<code>zig
// Nope! lv_disp_drv_t is an Opaque Type
var disp_drv = c.lv_disp_drv_t{};
c.lv_disp_drv_init(&disp_drv);</code>
Because <code>lv_disp_drv_t</code> is an Opaque Type.
<a>(<code>lv_disp_drv_t</code> contains Bit Fields, hence it's Opaque)</a>
Thus we apply this workaround to create <code>lv_disp_drv_t</code> in C...
<ul>
<li><a>"Fix Opaque Types"</a></li>
</ul>
And we get this LVGL Display Interface for Zig: <a>display.c</a>
Finally this is how we initialise the LVGL Display in Zig WebAssembly...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/d584f43c6354f12bdc15bdb8632cdd3f6f5dc7ff/lvglwasm.zig#L38-L84
Now we handle LVGL Tasks...
Handle LVGL Tasks
Earlier we talked about <strong>handling LVGL Tasks</strong>...
<ol>
<li>
Call <strong>lv_tick_inc(x)</strong> every <strong>x</strong> milliseconds (in an Interrupt) to report the <strong>Elapsed Time</strong> to LVGL
<a>(Not required, because LVGL calls <strong>millis</strong> to fetch the Elapsed Time)</a>
</li>
<li>
Call <strong>lv_timer_handler</strong> every few milliseconds to handle <strong>LVGL Tasks</strong>
</li>
</ol>
<a>(From the <strong>LVGL Docs</strong>)</a>
This is how we call <strong>lv_timer_handler</strong> in Zig: <a>lvglwasm.zig</a>
```zig
/// Main Function for our Zig LVGL App
pub export fn lv_demo_widgets() void {
// Omitted: Init LVGL Display
// Create the widgets for display
createWidgetsWrapped() catch |e| {
// In case of error, quit
std.log.err("createWidgetsWrapped failed: {}", .{e});
return;
};
// Handle LVGL Tasks
// TODO: Call this from Web Browser JavaScript,
// so that Web Browser won't block
var i: usize = 0;
while (i < 5) : (i += 1) {
_ = c.lv_timer_handler();
}
```
We're ready to render the LVGL Display in our HTML Page!
<em>Something doesn't look right...</em>
Yeah we should have called <strong>lv_timer_handler</strong> from our JavaScript.
(Triggered by a JavaScript Timer or <strong>requestAnimationFrame</strong>)
But for our quick demo, this will do. For now!
Render LVGL Display in Web Browser
Let's render the LVGL Display in the Web Browser! (Pic above)
(Based on <a>daneelsan/minimal-zig-wasm-canvas</a>)
LVGL renders the display pixels to <code>canvas_buffer</code>...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/5e4d661a7a9a962260d1f63c3b79a688037ed642/display.c#L95-L107
<a>(<code>init_disp_buf</code> is called by our Zig Program)</a>
LVGL calls <code>flushDisplay</code> (in Zig) when the LVGL Display Canvas is ready to be rendered...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/d584f43c6354f12bdc15bdb8632cdd3f6f5dc7ff/lvglwasm.zig#L49-L63
<code>flushDisplay</code> (in Zig) calls <code>render</code> (in JavaScript) to render the LVGL Display Canvas...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/d584f43c6354f12bdc15bdb8632cdd3f6f5dc7ff/lvglwasm.zig#L86-L98
(Remember to call <code>lv_disp_flush_ready</code> or Web Browser will hang on reload)
<code>render</code> (in JavaScript) draws the LVGL Display to our HTML Canvas...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/1ed4940d505e263727a36c362da54388be4cbca0/lvglwasm.js#L29-L53
Which calls <a><code>getCanvasBuffer</code></a> (in Zig) and <code>get_canvas_buffer</code> (in C) to fetch the LVGL Canvas Buffer <code>canvas_buffer</code>...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/5e4d661a7a9a962260d1f63c3b79a688037ed642/display.c#L9-L29
Remember to set Direct Mode in the Display Driver!
https://github.com/lupyuen/pinephone-lvgl-zig/blob/86700c3453d91bc7d2fe0a46192fa41b7a24b6df/display.c#L94-L95
And the LVGL Display renders OK in our HTML Canvas yay! (Pic below)
Handle LVGL Timer
To execute LVGL Tasks periodically, here's the proper way to handle the LVGL Timer in JavaScript...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/435435e01a4ffada2c93ecc3ec1af73a6220e7a0/feature-phone.js#L134-L150
<code>handleTimer</code> comes from our Zig LVGL App, it executes LVGL Tasks periodically...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/86700c3453d91bc7d2fe0a46192fa41b7a24b6df/feature-phone.zig#L213-L222
Handle LVGL Input
Let's handle Mouse and Touch Input in LVGL!
We create an LVGL Button in our Zig LVGL App...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/86700c3453d91bc7d2fe0a46192fa41b7a24b6df/feature-phone.zig#L185-L196
<code>eventHandler</code> is our Zig Handler for Button Events...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/86700c3453d91bc7d2fe0a46192fa41b7a24b6df/feature-phone.zig#L198-L208
When our app starts, we register the LVGL Input Device...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/7eb99b6c4deca82310e42d30808944f25bb6255c/feature-phone.zig#L69-L75
<a>(We define <code>register_input</code> in C because <code>lv_indev_t</code> is an Opaque Type in Zig)</a>
This tells LVGL to call <code>readInput</code> periodically to poll for input. (More about this below)
<code>indev_drv</code> is our LVGL Input Device Driver...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/7eb99b6c4deca82310e42d30808944f25bb6255c/feature-phone.zig#L287-L288
Now we handle Mouse and Touch Events in our JavaScript...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/435435e01a4ffada2c93ecc3ec1af73a6220e7a0/feature-phone.js#L77-L123
Which calls <code>notifyInput</code> in our Zig App to set the Input State and Input Coordinates...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/86700c3453d91bc7d2fe0a46192fa41b7a24b6df/feature-phone.zig#L224-L235
LVGL polls our <code>readInput</code> Zig Function periodically to read the Input State and Input Coordinates...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/86700c3453d91bc7d2fe0a46192fa41b7a24b6df/feature-phone.zig#L237-L253
<a>(We define <code>set_input_data</code> in C because <code>lv_indev_data_t</code> is an Opaque Type in Zig)</a>
And the LVGL Button will respond correctly to Mouse and Touch Input in the Web Browser! (Pic below)
<a>(Try the LVGL Button Demo)</a>
<a>(Watch the demo on YouTube)</a>
<a>(See the log)</a>
Feature Phone UI
Read the article...
<ul>
<li><a>"NuttX RTOS for PinePhone: Feature Phone UI in LVGL, Zig and WebAssembly"</a></li>
</ul>
Let's create a Feature Phone UI for PinePhone on Apache NuttX RTOS!
We create 3 LVGL Containers for the Display Label, Call / Cancel Buttons and Digit Buttons...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/b8b12209dc99a7c477aaeaa475362e795f9b05fc/feature-phone.zig#L113-L136
We create the Display Label...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/b8b12209dc99a7c477aaeaa475362e795f9b05fc/feature-phone.zig#L139-L167
Then we create the Call and Cancel Buttons inside the Second Container...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/b8b12209dc99a7c477aaeaa475362e795f9b05fc/feature-phone.zig#L169-L184
Finally we create the Digit Buttons inside the Third Container...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/b8b12209dc99a7c477aaeaa475362e795f9b05fc/feature-phone.zig#L186-L201
<a>(Or use an LVGL Button Matrix)</a>
When we test our Zig LVGL App in WebAssembly, we see this...
<a>(Try the Feature Phone Demo)</a>
<a>(Watch the demo on YouTube)</a>
<a>(See the log)</a>
Handle Buttons in Feature Phone UI
Now that we have rendered the Feature Phone UI in Zig and LVGL, let's wire up the Buttons.
Clicking any Button will call our Button Event Handler...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/9650c4bc2ef8065410ca4e643cde6ab6ae2d2f7d/feature-phone.zig#L189-L197
In our Button Event Handler, we identify the Button Clicked...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/9650c4bc2ef8065410ca4e643cde6ab6ae2d2f7d/feature-phone.zig#L205-L220
If it's a Digit Button, we append the Digit to the Phone Number...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/9650c4bc2ef8065410ca4e643cde6ab6ae2d2f7d/feature-phone.zig#L238-L242
If it's the Cancel Button, we erase the last digit of the Phone Number...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/9650c4bc2ef8065410ca4e643cde6ab6ae2d2f7d/feature-phone.zig#L232-L238
If it's the Call Button, we call PinePhone's LTE Modem to dial the Phone Number...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/9650c4bc2ef8065410ca4e643cde6ab6ae2d2f7d/feature-phone.zig#L222-L231
(Simulated for WebAssembly)
The buttons work OK on WebAssembly. (Pic below)
Let's run the Feature Phone UI on PinePhone and Apache NuttX RTOS!
<a>(Try the Feature Phone Demo)</a>
<a>(Watch the demo on YouTube)</a>
<a>(See the log)</a>
Feature Phone UI for Apache NuttX RTOS
<em>We created an LVGL Feature Phone UI for WebAssembly. Will it run on PinePhone?</em>
Let's refactor the LVGL Feature Phone UI, so that the same Zig Source File will run on BOTH WebAssembly and PinePhone! (With Apache NuttX RTOS)
We moved all the WebAssembly-Specific Functions to <a><code>wasm.zig</code></a>...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/a0ead2b86fda34a23afee71411915ac8315537a0/wasm.zig#L19-L288
Our Zig LVGL App imports <a><code>wasm.zig</code></a> only when compiling for WebAssembly...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/0aa3a1123ae64aaa75734456ce920de23ddc6aa2/feature-phone.zig#L15-L19
In our JavaScript, we call <code>initDisplay</code> (from <a><code>wasm.zig</code></a>) to initialise the LVGL Display and LVGL Input for WebAssembly...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/521b7c7e06beaa53b1d6c8d88671650bddaae88e/feature-phone.js#L124-L153
<em>What about PinePhone on Apache NuttX RTOS?</em>
When compiling for NuttX, our Zig LVGL App imports <a><code>nuttx.zig</code></a>...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/0aa3a1123ae64aaa75734456ce920de23ddc6aa2/feature-phone.zig#L15-L19
Which defines the Custom Panic Handler and Custom Logger specific to NuttX...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/f2b768eabaa99ebb0acf5454823871ddf5675a59/nuttx.zig#L7-L70
We compile our Zig LVGL App for NuttX (using the exact same Zig Source File for WebAssembly)...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/4650bc8eb5f4d23fae03d17e82b511682e288f3d/build.sh#L403-L437
And our Feature Phone UI runs on PinePhone with NuttX yay! (Pic below)
The exact same Zig Source File runs on both WebAssembly and PinePhone, no changes needed! This is super helpful for creating LVGL Apps.
<a>(Watch the demo on YouTube)</a>
<a>(See the PinePhone Log)</a>
LVGL Fonts
Remember to compile the LVGL Fonts! Or nothing will be rendered...
```bash
## Compile LVGL Library from C to WebAssembly with Zig Compiler
compile_lvgl font/lv_font_montserrat_14.c lv_font_montserrat_14
compile_lvgl font/lv_font_montserrat_20.c lv_font_montserrat_20
## Compile the Zig LVGL App for WebAssembly
zig build-lib \
-DLV_FONT_MONTSERRAT_14=1 \
-DLV_FONT_MONTSERRAT_20=1 \
-DLV_FONT_DEFAULT_MONTSERRAT_20=1 \
-DLV_USE_FONT_PLACEHOLDER=1 \
...
lv_font_montserrat_14.o \
lv_font_montserrat_20.o \
```
<a>(Source)</a>
LVGL Memory Allocation
<em>What happens if we omit <code>-DLV_MEM_CUSTOM=1</code>?</em>
By default, LVGL uses the <a>Two-Level Segregate Fit (TLSF) Allocator</a> for Heap Memory.
But TLSF Allocator fails in <a><code>block_next</code></a>...
```text
main: start
loop: start
lv_demo_widgets: start
before lv_init
[Info] lv_init: begin (in lv_obj.c line #102)
[Trace] lv_mem_alloc: allocating 76 bytes (in lv_mem.c line #127)
[Trace] lv_mem_alloc: allocated at 0x1a700 (in lv_mem.c line #160)
[Trace] lv_mem_alloc: allocating 28 bytes (in lv_mem.c line #127)
[Trace] lv_mem_alloc: allocated at 0x1a750 (in lv_mem.c line #160)
[Warn] lv_init: Log level is set to 'Trace' which makes LVGL much slower (in lv_obj.c line #176)
[Trace] lv_mem_realloc: reallocating 0x14 with 8 size (in lv_mem.c line #196)
[Error] block_next: Asserted at expression: !block_is_last(block) (in lv_tlsf.c line #459)
004a5b4a:0x29ab2 Uncaught (in promise) RuntimeError: unreachable
at std.builtin.default_panic (004a5b4a:0x29ab2)
at lv_assert_handler (004a5b4a:0x2ac6c)
at block_next (004a5b4a:0xd5b3)
at lv_tlsf_realloc (004a5b4a:0xe226)
at lv_mem_realloc (004a5b4a:0x20f1)
at lv_layout_register (004a5b4a:0x75d8)
at lv_flex_init (004a5b4a:0x16afe)
at lv_extra_init (004a5b4a:0x16ae5)
at lv_init (004a5b4a:0x3f28)
at lv_demo_widgets (004a5b4a:0x29bb9)
```
Thus we set <code>-DLV_MEM_CUSTOM=1</code> to use <code>malloc</code> instead of LVGL's TLSF Allocator.
(<a><code>block_next</code></a> calls <a><code>offset_to_block</code></a>, which calls <a><code>tlsf_cast</code></a>. Maybe the Pointer Cast doesn't work for Clang WebAssembly?)
<em>But Zig doesn't support <code>malloc</code> for WebAssembly!</em>
We used Zig's FixedBufferAllocator...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/43fa982d38a7ae8f931c171a80b006a9faa95b58/lvglwasm.zig#L38-L44
To implement <code>malloc</code> ourselves...
https://github.com/lupyuen/pinephone-lvgl-zig/blob/43fa982d38a7ae8f931c171a80b006a9faa95b58/lvglwasm.zig#L195-L237
<a>(Remember to copy the old memory in <code>realloc</code>!)</a>
<a>(If we ever remove <code>-DLV_MEM_CUSTOM=1</code>, remember to set <code>-DLV_MEM_SIZE=1000000</code>)</a>
TODO: How to disassemble Compiled WebAssembly with cross-reference to Source Code? Like <code>objdump --source</code>? See <a>wabt</a> and <a>binaryen</a>
LVGL Screen Not Found
<em>Why does LVGL say "no screen found" in <a>lv_obj_get_disp</a>?</em>
That's because the Display Linked List <code>_lv_disp_ll</code> is allocated by <code>LV_ITERATE_ROOTS</code> in <a>_lv_gc_clear_roots</a>...
And we forgot to compile <a>_lv_gc_clear_roots</a> in <a>lv_gc.c</a>. Duh!
(Zig Compiler assumes that missing variables like <code>_lv_disp_ll</code> are at WebAssembly Address 0)
After compiling <a>_lv_gc_clear_roots</a> and <a>lv_gc.c</a>, the "no screen found" error below no longer appears.
TODO: Disassemble the Compiled WebAssembly and look for other Undefined Variables at WebAssembly Address 0
<code>text
[Info] lv_init: begin (in lv_obj.c line #102)
[Trace] lv_init: finished (in lv_obj.c line #183)
before lv_disp_drv_register
[Warn] lv_obj_get_disp: No screen found (in lv_obj_tree.c line #290)
[Info] lv_obj_create: begin (in lv_obj.c line #206)
[Trace] lv_obj_class_create_obj: Creating object with 0x12014 class on 0 parent (in lv_obj_class.c line #45)
[Warn] lv_obj_get_disp: No screen found (in lv_obj_tree.c line #290)</code>
<a>(See the Complete Log)</a>
Zig with Rancher Desktop
The <a>Official Zig Download for macOS</a> no longer runs on my 10-year-old MacBook Pro that's stuck on macOS 10.15. 😢
To run the latest version of Zig Compiler, I use Rancher Desktop and VSCode Remote Containers...
<ul>
<li><a>VSCode Remote Containers on Rancher Desktop</a></li>
</ul>
Here's how...
<ol>
<li>
Install <a>Rancher Desktop</a>
</li>
<li>
In Rancher Desktop, click "Settings"...
Set "Container Engine" to "dockerd (moby)"
Under "Kubernetes", uncheck "Enable Kubernetes"
(To reduce CPU Utilisation)
</li>
<li>
Restart VSCode to use the new PATH
Install the VSCode Docker Extension
In VSCode, click the Docker icon in the Left Bar
</li>
<li>
Under "Containers", click "+" and "New Dev Container"
Select "Alpine"
</li>
<li>
In a while, we'll see VSCode running inside the Alpine Linux Container
We have finally Linux on macOS!
<code>text
$ uname -a
Linux bc0c45900671 5.15.96-0-virt #1-Alpine SMP Sun, 26 Feb 2023 15:14:12 +0000 x86_64 GNU/Linux</code>
</li>
<li>
Now we can download and run the latest and greatest Zig Compiler for Linux x64 <a>(from here)</a>
<code>bash
wget https://ziglang.org/builds/zig-linux-x86_64-0.11.0-dev.3283+7cb3a6750.tar.xz
tar -xvf zig-linux-x86_64-0.11.0-dev.3283+7cb3a6750.tar.xz
zig-linux-x86_64-0.11.0-dev.3283+7cb3a6750/zig version</code>
</li>
<li>
To install the NuttX Toolchain on Alpine Linux...
<a>"Build Apache NuttX RTOS on Alpine Linux"</a>
</li>
<li>
To forward Network Ports, click the "Ports" tab beside "Terminal"
To configure other features in the Alpine Linux Container, edit the file <code>.devcontainer/devcontainer.json</code>
</li>
</ol>
Zig Version
(Here's what happens if we don't run Zig in a Container... We're stuck with an older version of Zig)
<em>Which version of Zig are we using?</em>
We're using an older version: <code>0.10.0-dev.2351+b64a1d5ab</code>
Sadly Zig 0.10.1 (and later) won't run on my 10-year-old MacBook Pro that's stuck on macOS 10.15 😢
```text
→ # Compile the Zig App for PinePhone
# (armv8-a with cortex-a53)
# TODO: Change ".." to your NuttX Project Directory
zig build-obj \
--verbose-cimport \
-target aarch64-freestanding-none \
-mcpu cortex_a53 \
-isystem "../nuttx/include" \
-I "../apps/include" \
lvgltest.zig
dyld: lazy symbol binding faileddyld: lazy symbol binding faileddyld: lazy symbol binding failed: Symbol not found: <strong><em>ulock</em>wai: Symbol not found: </strong>_ulock_wait2
Referenced from: /Users/Lupt2
Referenced from: /Users/Lupdyld: lazy symbol binding failedpy/zig-macos-x86_64-0.10.1/zig (py/zig-macos-x86_64-0.10.1/zig (dyld: lazy symbol binding failedwhich was built for Mac OS X 11.: Symbol not found: <strong><em>ulock</em>wai: Symbol not found: </strong>_ulock_waiwhich was built for Mac OS X 11.7)
Expected in: /usr/lib/libSy: Symbol not found: ___ulock_wai7)
Expected in: /usr/lib/libSystem.B.dylib
stem.B.dylib
t2
Referenced from: /Users/Lupt2
Referenced from: /Users/Lupt2
Referenced from: /Users/Luppy/zig-macos-x86_64-0.10.1/zig (py/zig-macos-x86_64-0.10.1/zig (py/zig-macos-x86_64-0.10.1/zig (which was built for Mac OS X 11.which was built for Mac OS X 11.which was built for Mac OS X 11.7)
Expected in: /usr/lib/libSy7)
Expected in: /usr/lib/libSydyld: Symbol not found: ___ulock7)
Expected in: /usr/lib/libSystem.B.dylib
stem.B.dylib
_wait2
Referenced from: /Usersstem.B.dylib
/Luppy/zig-macos-x86_64-0.10.1/zdyld: Symbol not found: <strong><em>ulockig (which was built for Mac OS X</em>wait2
Referenced from: /Users 11.7)
Expected in: /usr/lib/ldyld: Symbol not found: </strong>_ulockdyld: Symbol not found: ___ulock/Luppy/zig-macos-x86_64-0.10.1/zibSystem.B.dylib
_wait2
Referenced from: /Usersig (which was built for Mac OS X_wait2
Referenced from: /Users/Luppy/zig-macos-x86_64-0.10.1/z 11.7)
Expected in: /usr/lib/l/Luppy/zig-macos-x86_64-0.10.1/zig (which was built for Mac OS XibSystem.B.dylib
ig (which was built for Mac OS X 11.7)
Expected in: /usr/lib/l 11.7)
Expected in: /usr/lib/libSystem.B.dylib
ibSystem.B.dylib
dyld: Symbol not found: ___ulockdyld: lazy symbol binding faileddyld: lazy symbol binding failed[1] 11157 abort zig build-obj --verbose-cimport -target aarch64-freestanding-none -mcpu -I
```
I tried building Zig from source, but it didn't work either...
Build Zig from Source
The <a>Official Zig Download for macOS</a> no longer runs on my 10-year-old MacBook Pro that's stuck on macOS 10.15. (See the previous section)
So I tried building Zig from Source according to these instructions...
<ul>
<li><a>Building Zig from Source</a></li>
</ul>
Here's what I did...
```bash
brew install llvm
git clone --recursive https://github.com/ziglang/zig
cd zig
mkdir build
cd build
cmake .. -DZIG_STATIC_LLVM=ON -DCMAKE_PREFIX_PATH="$(brew --prefix llvm);$(brew --prefix zstd)"
make install
```
<code>brew install llvm</code> failed...
<a>(Previously here)</a>
<a><strong>UPDATE:</strong> This has been fixed</a>
So I tried building LLVM from source <a>(from here)</a>...
```bash
cd ~/Downloads
git clone --depth 1 --branch release/16.x https://github.com/llvm/llvm-project llvm-project-16
cd llvm-project-16
git checkout release/16.x
mkdir build-release
cd build-release
cmake ../llvm \
-DCMAKE_INSTALL_PREFIX=$HOME/local/llvm16-release \
-DCMAKE_BUILD_TYPE=Release \
-DLLVM_ENABLE_PROJECTS="lld;clang" \
-DLLVM_ENABLE_LIBXML2=OFF \
-DLLVM_ENABLE_TERMINFO=OFF \
-DLLVM_ENABLE_LIBEDIT=OFF \
-DLLVM_ENABLE_ASSERTIONS=ON \
-DLLVM_PARALLEL_LINK_JOBS=1 \
-G Ninja
ninja install
```
But LLVM fails to build...
```text
→ ninja install
[1908/4827] Building CXX object lib/Target/AMDGPU/AsmParser/CMakeFiles/LLVMAMDGPUAsmParser.dir/AMDGPUAsmParser.cpp.o
FAILED: lib/Target/AMDGPU/AsmParser/CMakeFiles/LLVMAMDGPUAsmParser.dir/AMDGPUAsmParser.cpp.o
/Applications/Xcode.app/Contents/Developer/usr/bin/g++ -DGTEST_HAS_RTTI=0 -D_DEBUG -D__STDC_CONSTANT_MACROS -D__STDC_FORMAT_MACROS -D__STDC_LIMIT_MACROS -I/Users/Luppy/llvm-project-16/build-release/lib/Target/AMDGPU/AsmParser -I/Users/Luppy/llvm-project-16/llvm/lib/Target/AMDGPU/AsmParser -I/Users/Luppy/llvm-project-16/llvm/lib/Target/AMDGPU -I/Users/Luppy/llvm-project-16/build-release/lib/Target/AMDGPU -I/Users/Luppy/llvm-project-16/build-release/include -I/Users/Luppy/llvm-project-16/llvm/include -isystem /usr/local/include -fPIC -fvisibility-inlines-hidden -Werror=date-time -Werror=unguarded-availability-new -Wall -Wextra -Wno-unused-parameter -Wwrite-strings -Wcast-qual -Wmissing-field-initializers -pedantic -Wno-long-long -Wc++98-compat-extra-semi -Wimplicit-fallthrough -Wcovered-switch-default -Wno-noexcept-type -Wnon-virtual-dtor -Wdelete-non-virtual-dtor -Wstring-conversion -Wctad-maybe-unsupported -fdiagnostics-color -O3 -DNDEBUG -std=c++17 -isysroot /Applications/Xcode.app/Contents/Developer/Platforms/MacOSX.platform/Developer/SDKs/MacOSX10.15.sdk -fno-exceptions -fno-rtti -UNDEBUG -MD -MT lib/Target/AMDGPU/AsmParser/CMakeFiles/LLVMAMDGPUAsmParser.dir/AMDGPUAsmParser.cpp.o -MF lib/Target/AMDGPU/AsmParser/CMakeFiles/LLVMAMDGPUAsmParser.dir/AMDGPUAsmParser.cpp.o.d -o lib/Target/AMDGPU/AsmParser/CMakeFiles/LLVMAMDGPUAsmParser.dir/AMDGPUAsmParser.cpp.o -c /Users/Luppy/llvm-project-16/llvm/lib/Target/AMDGPU/AsmParser/AMDGPUAsmParser.cpp
/Users/Luppy/llvm-project-16/llvm/lib/Target/AMDGPU/AsmParser/AMDGPUAsmParser.cpp:5490:13: error: no viable constructor or deduction guide for deduction of template arguments of 'tuple'
? std::tuple(HSAMD::V3::AssemblerDirectiveBegin,
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:625:5: note: candidate template ignored: requirement '__lazy_and<std::__1::is_same, std::__1::__lazy_all<> >::value' was not satisfied [with <em>Tp = <>, _AllocArgT = const char <em>, <em>Alloc = char [21], _Dummy = true]
tuple(_AllocArgT, _Alloc const& __a)
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:641:5: note: candidate template ignored: requirement '_CheckArgsConstructor::__enable_implicit()' was not satisfied [with _Tp = , _Dummy = true]
tuple(const _Tp& ... __t) _NOEXCEPT</em>((__all<is_nothrow_copy_constructible<<em>Tp>::value...>::value))
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:659:14: note: candidate template ignored: requirement '_CheckArgsConstructor::__enable_explicit()' was not satisfied [with _Tp = , _Dummy = true]
explicit tuple(const _Tp& ... __t) _NOEXCEPT</em>((__all<is_nothrow_copy_constructible<<em>Tp>::value...>::value))
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:677:7: note: candidate template ignored: substitution failure [with _Tp = <>, _Alloc = char [21], _Dummy = true]: cannot reference member of primary template because deduced class template specialization 'tuple<>' is an explicit specialization
tuple(allocator_arg_t, const _Alloc& __a, const _Tp& ... __t)
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:697:7: note: candidate template ignored: substitution failure [with _Tp = <>, _Alloc = char [21], _Dummy = true]: cannot reference member of primary template because deduced class template specialization 'tuple<>' is an explicit specialization
tuple(allocator_arg_t, const _Alloc& __a, const _Tp& ... __t)
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:723:9: note: candidate template ignored: substitution failure [with _Tp = <>, _Up = ]: cannot reference member of primary template because deduced class template specialization 'tuple<>' is an explicit specialization
tuple(_Up&&... __u)
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:756:9: note: candidate template ignored: substitution failure [with _Tp = <>, _Up = ]: cannot reference member of primary template because deduced class template specialization 'tuple<>' is an explicit specialization
tuple(_Up&&... __u)
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:783:9: note: candidate template ignored: substitution failure [with _Tp = <>, _Alloc = char [21], _Up = <>]: cannot reference member of primary template because deduced class template specialization 'tuple<>' is an explicit specialization
tuple(allocator_arg_t, const _Alloc& __a, _Up&&... __u)
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:803:9: note: candidate template ignored: substitution failure [with _Tp = <>, _Alloc = char [21], _Up = <>]: cannot reference member of primary template because deduced class template specialization 'tuple<>' is an explicit specialization
tuple(allocator_arg_t, const _Alloc& __a, _Up&&... __u)
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:612:23: note: candidate function template not viable: requires 0 arguments, but 2 were provided
_LIBCPP_CONSTEXPR tuple()
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:615:5: note: candidate function template not viable: requires 1 argument, but 2 were provided
tuple(tuple const&) = default;
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:616:5: note: candidate function template not viable: requires 1 argument, but 2 were provided
tuple(tuple&&) = default;
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:822:9: note: candidate function template not viable: requires single argument '__t', but 2 arguments were provided
tuple(_Tuple&& __t) _NOEXCEPT</em>((is_nothrow_constructible<<em>BaseT, _Tuple>::value))
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:837:9: note: candidate function template not viable: requires single argument '__t', but 2 arguments were provided
tuple(_Tuple&& __t) _NOEXCEPT</em>((is_nothrow_constructible<_BaseT, _Tuple>::value))
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:850:9: note: candidate function template not viable: requires 3 arguments, but 2 were provided
tuple(allocator_arg_t, const _Alloc& __a, _Tuple&& __t)
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:864:9: note: candidate function template not viable: requires 3 arguments, but 2 were provided
tuple(allocator_arg_t, const _Alloc& __a, _Tuple&& __t)
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:469:28: note: candidate function template not viable: requires 1 argument, but 2 were provided
class _LIBCPP_TEMPLATE_VIS tuple
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:932:1: note: candidate function template not viable: requires 3 arguments, but 2 were provided
tuple(allocator_arg_t, const _Alloc&, tuple<_Args...> const&) -> tuple<_Args...>;
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:934:1: note: candidate function template not viable: requires 3 arguments, but 2 were provided
tuple(allocator_arg_t, const _Alloc&, tuple<_Args...>&&) -> tuple<_Args...>;
^
/Users/Luppy/llvm-project-16/llvm/lib/Target/AMDGPU/AsmParser/AMDGPUAsmParser.cpp:5492:13: error: no viable constructor or deduction guide for deduction of template arguments of 'tuple'
: std::tuple(HSAMD::AssemblerDirectiveBegin,
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:625:5: note: candidate template ignored: requirement '__lazy_and<std::__1::is_same, std::__1::__lazy_all<> >::value' was not satisfied [with _Tp = <>, _AllocArgT = const char </em>, _Alloc = char [29], _Dummy = true]
tuple(_AllocArgT, _Alloc const& __a)
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:641:5: note: candidate template ignored: requirement '_CheckArgsConstructor::__enable_implicit()' was not satisfied [with _Tp = , _Dummy = true]
tuple(const _Tp& ... __t) _NOEXCEPT</em>((__all<is_nothrow_copy_constructible<<em>Tp>::value...>::value))
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:659:14: note: candidate template ignored: requirement '_CheckArgsConstructor::__enable_explicit()' was not satisfied [with _Tp = , _Dummy = true]
explicit tuple(const _Tp& ... __t) _NOEXCEPT</em>((__all<is_nothrow_copy_constructible<<em>Tp>::value...>::value))
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:677:7: note: candidate template ignored: substitution failure [with _Tp = <>, _Alloc = char [29], _Dummy = true]: cannot reference member of primary template because deduced class template specialization 'tuple<>' is an explicit specialization
tuple(allocator_arg_t, const _Alloc& __a, const _Tp& ... __t)
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:697:7: note: candidate template ignored: substitution failure [with _Tp = <>, _Alloc = char [29], _Dummy = true]: cannot reference member of primary template because deduced class template specialization 'tuple<>' is an explicit specialization
tuple(allocator_arg_t, const _Alloc& __a, const _Tp& ... __t)
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:723:9: note: candidate template ignored: substitution failure [with _Tp = <>, _Up = ]: cannot reference member of primary template because deduced class template specialization 'tuple<>' is an explicit specialization
tuple(_Up&&... __u)
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:756:9: note: candidate template ignored: substitution failure [with _Tp = <>, _Up = ]: cannot reference member of primary template because deduced class template specialization 'tuple<>' is an explicit specialization
tuple(_Up&&... __u)
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:783:9: note: candidate template ignored: substitution failure [with _Tp = <>, _Alloc = char [29], _Up = <>]: cannot reference member of primary template because deduced class template specialization 'tuple<>' is an explicit specialization
tuple(allocator_arg_t, const _Alloc& __a, _Up&&... __u)
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:803:9: note: candidate template ignored: substitution failure [with _Tp = <>, _Alloc = char [29], _Up = <>]: cannot reference member of primary template because deduced class template specialization 'tuple<>' is an explicit specialization
tuple(allocator_arg_t, const _Alloc& __a, _Up&&... __u)
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:612:23: note: candidate function template not viable: requires 0 arguments, but 2 were provided
_LIBCPP_CONSTEXPR tuple()
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:615:5: note: candidate function template not viable: requires 1 argument, but 2 were provided
tuple(tuple const&) = default;
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:616:5: note: candidate function template not viable: requires 1 argument, but 2 were provided
tuple(tuple&&) = default;
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:822:9: note: candidate function template not viable: requires single argument '__t', but 2 arguments were provided
tuple(_Tuple&& __t) _NOEXCEPT</em>((is_nothrow_constructible<<em>BaseT, _Tuple>::value))
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:837:9: note: candidate function template not viable: requires single argument '__t', but 2 arguments were provided
tuple(_Tuple&& __t) _NOEXCEPT</em>((is_nothrow_constructible<_BaseT, _Tuple>::value))
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:850:9: note: candidate function template not viable: requires 3 arguments, but 2 were provided
tuple(allocator_arg_t, const _Alloc& __a, _Tuple&& __t)
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:864:9: note: candidate function template not viable: requires 3 arguments, but 2 were provided
tuple(allocator_arg_t, const _Alloc& __a, _Tuple&& __t)
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:469:28: note: candidate function template not viable: requires 1 argument, but 2 were provided
class _LIBCPP_TEMPLATE_VIS tuple
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:932:1: note: candidate function template not viable: requires 3 arguments, but 2 were provided
tuple(allocator_arg_t, const _Alloc&, tuple<_Args...> const&) -> tuple<_Args...>;
^
/Applications/Xcode.app/Contents/Developer/Toolchains/XcodeDefault.xctoolchain/usr/bin/../include/c++/v1/tuple:934:1: note: candidate function template not viable: requires 3 arguments, but 2 were provided
tuple(allocator_arg_t, const _Alloc&, tuple<_Args...>&&) -> tuple<_Args...>;
^
2 errors generated.
[1917/4827] Building CXX object lib/Target/AMDGPU/Disassembler/CMakeFiles/LLVMAMDGPUDisassembler.dir/AMDGPUDisassembler.cpp.o
ninja: build stopped: subcommand failed.
```
So I can't build Zig from source on my 10-year-old MacBook Pro 😢
Output Log
Here's the log from the JavaScript Console...
<code>text
main: start
lv_demo_widgets: start
[Info] lv_init: begin (in lv_obj.c line #102)
[Warn] lv_init: Log level is set to 'Trace' which makes LVGL much slower (in lv_obj.c line #176)
[Trace] lv_init: finished (in lv_obj.c line #183)
[Info] lv_obj_create: begin (in lv_obj.c line #206)
[Trace] lv_obj_class_create_obj: Creating object with 0x1773c class on 0 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating a screen (in lv_obj_class.c line #55)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Info] lv_obj_create: begin (in lv_obj.c line #206)
[Trace] lv_obj_class_create_obj: Creating object with 0x1773c class on 0 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating a screen (in lv_obj_class.c line #55)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Info] lv_obj_create: begin (in lv_obj.c line #206)
[Trace] lv_obj_class_create_obj: Creating object with 0x1773c class on 0 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating a screen (in lv_obj_class.c line #55)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
createWidgets: start
[Info] lv_obj_create: begin (in lv_obj.c line #206)
[Trace] lv_obj_class_create_obj: Creating object with 0x1773c class on 0x39e320 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Info] lv_obj_create: begin (in lv_obj.c line #206)
[Trace] lv_obj_class_create_obj: Creating object with 0x1773c class on 0x39e320 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Info] lv_obj_update_layout: Layout update begin (in lv_obj_pos.c line #314)
[Trace] lv_obj_update_layout: Layout update end (in lv_obj_pos.c line #317)
[Info] lv_obj_update_layout: Layout update begin (in lv_obj_pos.c line #314)
[Trace] lv_obj_update_layout: Layout update end (in lv_obj_pos.c line #317)
[Info] lv_obj_create: begin (in lv_obj.c line #206)
[Trace] lv_obj_class_create_obj: Creating object with 0x1773c class on 0x39e320 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Info] lv_obj_update_layout: Layout update begin (in lv_obj_pos.c line #314)
[Trace] lv_obj_update_layout: Layout update end (in lv_obj_pos.c line #317)
[Info] lv_label_create: begin (in lv_label.c line #75)
[Trace] lv_obj_class_create_obj: Creating object with 0x17720 class on 0x39e57a parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Trace] lv_label_constructor: begin (in lv_label.c line #691)
[Trace] lv_label_constructor: finished (in lv_label.c line #721)
[Info] lv_btn_create: begin (in lv_btn.c line #51)
[Trace] lv_obj_class_create_obj: Creating object with 0x17d4c class on 0x39e692 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Trace] lv_btn_constructor: begin (in lv_btn.c line #64)
[Trace] lv_btn_constructor: finished (in lv_btn.c line #69)
[Info] lv_label_create: begin (in lv_label.c line #75)
[Trace] lv_obj_class_create_obj: Creating object with 0x17720 class on 0x39e9bc parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Trace] lv_label_constructor: begin (in lv_label.c line #691)
[Trace] lv_label_constructor: finished (in lv_label.c line #721)
[Info] lv_btn_create: begin (in lv_btn.c line #51)
[Trace] lv_obj_class_create_obj: Creating object with 0x17d4c class on 0x39e692 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Trace] lv_btn_constructor: begin (in lv_btn.c line #64)
[Trace] lv_btn_constructor: finished (in lv_btn.c line #69)
[Info] lv_label_create: begin (in lv_label.c line #75)
[Trace] lv_obj_class_create_obj: Creating object with 0x17720 class on 0x39ec98 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Trace] lv_label_constructor: begin (in lv_label.c line #691)
[Trace] lv_label_constructor: finished (in lv_label.c line #721)
[Info] lv_btn_create: begin (in lv_btn.c line #51)
[Trace] lv_obj_class_create_obj: Creating object with 0x17d4c class on 0x39e792 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Trace] lv_btn_constructor: begin (in lv_btn.c line #64)
[Trace] lv_btn_constructor: finished (in lv_btn.c line #69)
[Info] lv_label_create: begin (in lv_label.c line #75)
[Trace] lv_obj_class_create_obj: Creating object with 0x17720 class on 0x39ef5e parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Trace] lv_label_constructor: begin (in lv_label.c line #691)
[Trace] lv_label_constructor: finished (in lv_label.c line #721)
[Info] lv_btn_create: begin (in lv_btn.c line #51)
[Trace] lv_obj_class_create_obj: Creating object with 0x17d4c class on 0x39e792 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Trace] lv_btn_constructor: begin (in lv_btn.c line #64)
[Trace] lv_btn_constructor: finished (in lv_btn.c line #69)
[Info] lv_label_create: begin (in lv_label.c line #75)
[Trace] lv_obj_class_create_obj: Creating object with 0x17720 class on 0x39f237 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Trace] lv_label_constructor: begin (in lv_label.c line #691)
[Trace] lv_label_constructor: finished (in lv_label.c line #721)
[Info] lv_btn_create: begin (in lv_btn.c line #51)
[Trace] lv_obj_class_create_obj: Creating object with 0x17d4c class on 0x39e792 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Trace] lv_btn_constructor: begin (in lv_btn.c line #64)
[Trace] lv_btn_constructor: finished (in lv_btn.c line #69)
[Info] lv_label_create: begin (in lv_label.c line #75)
[Trace] lv_obj_class_create_obj: Creating object with 0x17720 class on 0x39f4f8 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Trace] lv_label_constructor: begin (in lv_label.c line #691)
[Trace] lv_label_constructor: finished (in lv_label.c line #721)
[Info] lv_btn_create: begin (in lv_btn.c line #51)
[Trace] lv_obj_class_create_obj: Creating object with 0x17d4c class on 0x39e792 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Trace] lv_btn_constructor: begin (in lv_btn.c line #64)
[Trace] lv_btn_constructor: finished (in lv_btn.c line #69)
[Info] lv_label_create: begin (in lv_label.c line #75)
[Trace] lv_obj_class_create_obj: Creating object with 0x17720 class on 0x39f7bd parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Trace] lv_label_constructor: begin (in lv_label.c line #691)
[Trace] lv_label_constructor: finished (in lv_label.c line #721)
[Info] lv_btn_create: begin (in lv_btn.c line #51)
[Trace] lv_obj_class_create_obj: Creating object with 0x17d4c class on 0x39e792 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Trace] lv_btn_constructor: begin (in lv_btn.c line #64)
[Trace] lv_btn_constructor: finished (in lv_btn.c line #69)
[Info] lv_label_create: begin (in lv_label.c line #75)
[Trace] lv_obj_class_create_obj: Creating object with 0x17720 class on 0x39fa86 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Trace] lv_label_constructor: begin (in lv_label.c line #691)
[Trace] lv_label_constructor: finished (in lv_label.c line #721)
[Info] lv_btn_create: begin (in lv_btn.c line #51)
[Trace] lv_obj_class_create_obj: Creating object with 0x17d4c class on 0x39e792 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Trace] lv_btn_constructor: begin (in lv_btn.c line #64)
[Trace] lv_btn_constructor: finished (in lv_btn.c line #69)
[Info] lv_label_create: begin (in lv_label.c line #75)
[Trace] lv_obj_class_create_obj: Creating object with 0x17720 class on 0x39fd53 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Trace] lv_label_constructor: begin (in lv_label.c line #691)
[Trace] lv_label_constructor: finished (in lv_label.c line #721)
[Info] lv_btn_create: begin (in lv_btn.c line #51)
[Trace] lv_obj_class_create_obj: Creating object with 0x17d4c class on 0x39e792 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Trace] lv_btn_constructor: begin (in lv_btn.c line #64)
[Trace] lv_btn_constructor: finished (in lv_btn.c line #69)
[Info] lv_label_create: begin (in lv_label.c line #75)
[Trace] lv_obj_class_create_obj: Creating object with 0x17720 class on 0x3a0024 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Trace] lv_label_constructor: begin (in lv_label.c line #691)
[Trace] lv_label_constructor: finished (in lv_label.c line #721)
[Info] lv_btn_create: begin (in lv_btn.c line #51)
[Trace] lv_obj_class_create_obj: Creating object with 0x17d4c class on 0x39e792 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Trace] lv_btn_constructor: begin (in lv_btn.c line #64)
[Trace] lv_btn_constructor: finished (in lv_btn.c line #69)
[Info] lv_label_create: begin (in lv_label.c line #75)
[Trace] lv_obj_class_create_obj: Creating object with 0x17720 class on 0x3a02f9 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Trace] lv_label_constructor: begin (in lv_label.c line #691)
[Trace] lv_label_constructor: finished (in lv_label.c line #721)
[Info] lv_btn_create: begin (in lv_btn.c line #51)
[Trace] lv_obj_class_create_obj: Creating object with 0x17d4c class on 0x39e792 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Trace] lv_btn_constructor: begin (in lv_btn.c line #64)
[Trace] lv_btn_constructor: finished (in lv_btn.c line #69)
[Info] lv_label_create: begin (in lv_label.c line #75)
[Trace] lv_obj_class_create_obj: Creating object with 0x17720 class on 0x3a05d2 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Trace] lv_label_constructor: begin (in lv_label.c line #691)
[Trace] lv_label_constructor: finished (in lv_label.c line #721)
[Info] lv_btn_create: begin (in lv_btn.c line #51)
[Trace] lv_obj_class_create_obj: Creating object with 0x17d4c class on 0x39e792 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Trace] lv_btn_constructor: begin (in lv_btn.c line #64)
[Trace] lv_btn_constructor: finished (in lv_btn.c line #69)
[Info] lv_label_create: begin (in lv_label.c line #75)
[Trace] lv_obj_class_create_obj: Creating object with 0x17720 class on 0x3a08af parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Trace] lv_label_constructor: begin (in lv_label.c line #691)
[Trace] lv_label_constructor: finished (in lv_label.c line #721)
[Info] lv_btn_create: begin (in lv_btn.c line #51)
[Trace] lv_obj_class_create_obj: Creating object with 0x17d4c class on 0x39e792 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Trace] lv_btn_constructor: begin (in lv_btn.c line #64)
[Trace] lv_btn_constructor: finished (in lv_btn.c line #69)
[Info] lv_label_create: begin (in lv_label.c line #75)
[Trace] lv_obj_class_create_obj: Creating object with 0x17720 class on 0x3a0b90 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Trace] lv_label_constructor: begin (in lv_label.c line #691)
[Trace] lv_label_constructor: finished (in lv_label.c line #721)
[Info] lv_btn_create: begin (in lv_btn.c line #51)
[Trace] lv_obj_class_create_obj: Creating object with 0x17d4c class on 0x39e792 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Trace] lv_btn_constructor: begin (in lv_btn.c line #64)
[Trace] lv_btn_constructor: finished (in lv_btn.c line #69)
[Info] lv_label_create: begin (in lv_label.c line #75)
[Trace] lv_obj_class_create_obj: Creating object with 0x17720 class on 0x3a0e75 parent (in lv_obj_class.c line #45)
[Trace] lv_obj_class_create_obj: creating normal object (in lv_obj_class.c line #82)
[Trace] lv_obj_constructor: begin (in lv_obj.c line #403)
[Trace] lv_obj_constructor: finished (in lv_obj.c line #428)
[Trace] lv_label_constructor: begin (in lv_label.c line #691)
[Trace] lv_label_constructor: finished (in lv_label.c line #721)
createWidgets: end
lv_demo_widgets: end
[Info] lv_obj_update_layout: Layout update begin (in lv_obj_pos.c line #314)
[Info] flex_update: update 0x39e57a container (in lv_flex.c line #211)
[Info] flex_update: update 0x39e692 container (in lv_flex.c line #211)
[Info] flex_update: update 0x39e792 container (in lv_flex.c line #211)
[Trace] lv_obj_update_layout: Layout update end (in lv_obj_pos.c line #317)
[Info] lv_obj_update_layout: Layout update begin (in lv_obj_pos.c line #314)
[Info] flex_update: update 0x39e57a container (in lv_flex.c line #211)
[Trace] lv_obj_update_layout: Layout update end (in lv_obj_pos.c line #317)
[Info] lv_obj_update_layout: Layout update begin (in lv_obj_pos.c line #314)
[Trace] lv_obj_update_layout: Layout update end (in lv_obj_pos.c line #317)
[Info] lv_obj_update_layout: Layout update begin (in lv_obj_pos.c line #314)
[Trace] lv_obj_update_layout: Layout update end (in lv_obj_pos.c line #317)
[Info] lv_obj_update_layout: Layout update begin (in lv_obj_pos.c line #314)
[Trace] lv_obj_update_layout: Layout update end (in lv_obj_pos.c line #317)
get_canvas_buffer: 803944 non-empty pixels
main: end
{mousedown: {…}}
readInput: state=1, x=162, y=491
[Info] (4.322, +4056) indev_proc_press: pressed at x:162 y:491 (in lv_indev.c line #819)
get_canvas_buffer: 803944 non-empty pixels
[Info] (4.355, +33) indev_proc_release: released (in lv_indev.c line #969)
eventHandler: clicked
{mouseup: {…}}
[Info] (4.373, +18) lv_obj_update_layout: Layout update begin (in lv_obj_pos.c line #314)
[Info] (4.374, +1) flex_update: update 0x39e57a container (in lv_flex.c line #211)
[Trace] (4.375, +1) lv_obj_update_layout: Layout update end (in lv_obj_pos.c line #317)
[Info] (4.376, +1) lv_obj_update_layout: Layout update begin (in lv_obj_pos.c line #314)
[Trace] (4.377, +1) lv_obj_update_layout: Layout update end (in lv_obj_pos.c line #317)
2get_canvas_buffer: 803944 non-empty pixels
readInput: state=0, x=162, y=491
get_canvas_buffer: 803956 non-empty pixels
get_canvas_buffer: 803952 non-empty pixels
2get_canvas_buffer: 803944 non-empty pixels
{mousedown: {…}}
readInput: state=1, x=334, y=494
[Info] (4.689, +312) indev_proc_press: pressed at x:334 y:494 (in lv_indev.c line #819)
get_canvas_buffer: 803944 non-empty pixels
[Info] (4.721, +32) indev_proc_release: released (in lv_indev.c line #969)
eventHandler: clicked
[Info] (4.740, +19) lv_obj_update_layout: Layout update begin (in lv_obj_pos.c line #314)
[Trace] (4.741, +1) lv_obj_update_layout: Layout update end (in lv_obj_pos.c line #317)
2get_canvas_buffer: 803944 non-empty pixels
{mouseup: {…}}
readInput: state=0, x=334, y=494
get_canvas_buffer: 803956 non-empty pixels
get_canvas_buffer: 803952 non-empty pixels
3get_canvas_buffer: 803944 non-empty pixels
{mousedown: {…}}
readInput: state=1, x=570, y=493
[Info] (5.108, +367) indev_proc_press: pressed at x:570 y:493 (in lv_indev.c line #819)
get_canvas_buffer: 803944 non-empty pixels
[Info] (5.158, +50) indev_proc_release: released (in lv_indev.c line #969)
eventHandler: clicked
[Info] (5.162, +4) lv_obj_update_layout: Layout update begin (in lv_obj_pos.c line #314)
[Trace] (5.163, +1) lv_obj_update_layout: Layout update end (in lv_obj_pos.c line #317)
2get_canvas_buffer: 803944 non-empty pixels
{mouseup: {…}}
readInput: state=0, x=570, y=493
get_canvas_buffer: 803956 non-empty pixels
get_canvas_buffer: 803952 non-empty pixels
get_canvas_buffer: 803940 non-empty pixels
get_canvas_buffer: 803944 non-empty pixels
{mousedown: {…}}
readInput: state=1, x=186, y=669
[Info] (6.075, +912) indev_proc_press: pressed at x:186 y:669 (in lv_indev.c line #819)
get_canvas_buffer: 803944 non-empty pixels
[Info] (6.106, +31) indev_proc_release: released (in lv_indev.c line #969)
eventHandler: clicked
[Info] (6.124, +18) lv_obj_update_layout: Layout update begin (in lv_obj_pos.c line #314)
[Trace] (6.125, +1) lv_obj_update_layout: Layout update end (in lv_obj_pos.c line #317)
2get_canvas_buffer: 803944 non-empty pixels
{mouseup: {…}}
readInput: state=0, x=186, y=669
get_canvas_buffer: 803956 non-empty pixels
get_canvas_buffer: 803952 non-empty pixels
get_canvas_buffer: 803940 non-empty pixels
get_canvas_buffer: 803944 non-empty pixels
{mousedown: {…}}
readInput: state=1, x=336, y=643
[Info] (6.474, +349) indev_proc_press: pressed at x:336 y:643 (in lv_indev.c line #819)
get_canvas_buffer: 803944 non-empty pixels
[Info] (6.509, +35) indev_proc_release: released (in lv_indev.c line #969)
eventHandler: clicked
[Info] (6.513, +4) lv_obj_update_layout: Layout update begin (in lv_obj_pos.c line #314)
[Trace] (6.514, +1) lv_obj_update_layout: Layout update end (in lv_obj_pos.c line #317)
2get_canvas_buffer: 803944 non-empty pixels
{mouseup: {…}}
readInput: state=0, x=336, y=643
get_canvas_buffer: 803952 non-empty pixels
get_canvas_buffer: 803944 non-empty pixels
get_canvas_buffer: 803940 non-empty pixels
get_canvas_buffer: 803944 non-empty pixels
{mousedown: {…}}
readInput: state=1, x=519, y=631
[Info] (6.941, +427) indev_proc_press: pressed at x:519 y:631 (in lv_indev.c line #819)
get_canvas_buffer: 803944 non-empty pixels
[Info] (6.975, +34) indev_proc_release: released (in lv_indev.c line #969)
eventHandler: clicked
[Info] (6.979, +4) lv_obj_update_layout: Layout update begin (in lv_obj_pos.c line #314)
[Trace] (6.980, +1) lv_obj_update_layout: Layout update end (in lv_obj_pos.c line #317)
2get_canvas_buffer: 803944 non-empty pixels
{mouseup: {…}}
readInput: state=0, x=519, y=631
get_canvas_buffer: 803952 non-empty pixels
get_canvas_buffer: 803698 non-empty pixels
get_canvas_buffer: 803956 non-empty pixels
2get_canvas_buffer: 803944 non-empty pixels
{mousedown: {…}}
readInput: state=1, x=559, y=282
[Info] (7.725, +745) indev_proc_press: pressed at x:559 y:282 (in lv_indev.c line #819)
get_canvas_buffer: 803944 non-empty pixels
[Info] (7.757, +32) indev_proc_release: released (in lv_indev.c line #969)
eventHandler: clicked
[Info] (7.775, +18) lv_obj_update_layout: Layout update begin (in lv_obj_pos.c line #314)
[Trace] (7.776, +1) lv_obj_update_layout: Layout update end (in lv_obj_pos.c line #317)
2get_canvas_buffer: 803944 non-empty pixels
get_canvas_buffer: 803956 non-empty pixels
{mouseup: {…}}
readInput: state=0, x=559, y=282
get_canvas_buffer: 803952 non-empty pixels
3get_canvas_buffer: 803944 non-empty pixels
{mousedown: {…}}
readInput: state=1, x=559, y=282
[Info] (8.159, +383) indev_proc_press: pressed at x:559 y:282 (in lv_indev.c line #819)
get_canvas_buffer: 803944 non-empty pixels
[Info] (8.191, +32) indev_proc_release: released (in lv_indev.c line #969)
eventHandler: clicked
[Info] (8.209, +18) lv_obj_update_layout: Layout update begin (in lv_obj_pos.c line #314)
[Trace] (8.210, +1) lv_obj_update_layout: Layout update end (in lv_obj_pos.c line #317)
2get_canvas_buffer: 803944 non-empty pixels
{mouseup: {…}}
get_canvas_buffer: 803956 non-empty pixels
readInput: state=0, x=559, y=282
get_canvas_buffer: 803952 non-empty pixels
3get_canvas_buffer: 803944 non-empty pixels
{mousedown: {…}}
readInput: state=1, x=559, y=282
[Info] (8.493, +283) indev_proc_press: pressed at x:559 y:282 (in lv_indev.c line #819)
get_canvas_buffer: 803944 non-empty pixels
[Info] (8.525, +32) indev_proc_release: released (in lv_indev.c line #969)
eventHandler: clicked
[Info] (8.543, +18) lv_obj_update_layout: Layout update begin (in lv_obj_pos.c line #314)
[Trace] (8.544, +1) lv_obj_update_layout: Layout update end (in lv_obj_pos.c line #317)
2get_canvas_buffer: 803944 non-empty pixels
{mouseup: {…}}
get_canvas_buffer: 803956 non-empty pixels
readInput: state=0, x=559, y=282
get_canvas_buffer: 803952 non-empty pixels
3get_canvas_buffer: 803944 non-empty pixels
{mousedown: {…}}
readInput: state=1, x=155, y=643
[Info] (9.376, +832) indev_proc_press: pressed at x:155 y:643 (in lv_indev.c line #819)
get_canvas_buffer: 803944 non-empty pixels
[Info] (9.408, +32) indev_proc_release: released (in lv_indev.c line #969)
eventHandler: clicked
[Info] (9.427, +19) lv_obj_update_layout: Layout update begin (in lv_obj_pos.c line #314)
[Trace] (9.428, +1) lv_obj_update_layout: Layout update end (in lv_obj_pos.c line #317)
2get_canvas_buffer: 803944 non-empty pixels
get_canvas_buffer: 803956 non-empty pixels
{mouseup: {…}}
readInput: state=0, x=155, y=643
get_canvas_buffer: 803952 non-empty pixels
3get_canvas_buffer: 803944 non-empty pixels
{mousedown: {…}}
readInput: state=1, x=327, y=640
[Info] (9.844, +416) indev_proc_press: pressed at x:327 y:640 (in lv_indev.c line #819)
get_canvas_buffer: 803944 non-empty pixels
[Info] (9.876, +32) indev_proc_release: released (in lv_indev.c line #969)
eventHandler: clicked
[Info] (9.894, +18) lv_obj_update_layout: Layout update begin (in lv_obj_pos.c line #314)
[Trace] (9.895, +1) lv_obj_update_layout: Layout update end (in lv_obj_pos.c line #317)
2get_canvas_buffer: 803944 non-empty pixels
{mouseup: {…}}
readInput: state=0, x=327, y=640
get_canvas_buffer: 803956 non-empty pixels
get_canvas_buffer: 803952 non-empty pixels
3get_canvas_buffer: 803944 non-empty pixels
{mousedown: {…}}
readInput: state=1, x=554, y=637
[Info] (10.362, +467) indev_proc_press: pressed at x:554 y:637 (in lv_indev.c line #819)
get_canvas_buffer: 803944 non-empty pixels
[Info] (10.392, +30) indev_proc_release: released (in lv_indev.c line #969)
eventHandler: clicked
[Info] (10.411, +19) lv_obj_update_layout: Layout update begin (in lv_obj_pos.c line #314)
[Trace] (10.412, +1) lv_obj_update_layout: Layout update end (in lv_obj_pos.c line #317)
2get_canvas_buffer: 803944 non-empty pixels
get_canvas_buffer: 803956 non-empty pixels
{mouseup: {…}}
readInput: state=0, x=554, y=637
get_canvas_buffer: 803952 non-empty pixels
3get_canvas_buffer: 803944 non-empty pixels
{mousedown: {…}}
readInput: state=1, x=197, y=768
[Info] (11.029, +617) indev_proc_press: pressed at x:197 y:768 (in lv_indev.c line #819)
get_canvas_buffer: 803944 non-empty pixels
[Info] (11.059, +30) indev_proc_release: released (in lv_indev.c line #969)
eventHandler: clicked
[Info] (11.081, +22) lv_obj_update_layout: Layout update begin (in lv_obj_pos.c line #314)
[Trace] (11.082, +1) lv_obj_update_layout: Layout update end (in lv_obj_pos.c line #317)
2get_canvas_buffer: 803944 non-empty pixels
get_canvas_buffer: 803956 non-empty pixels
{mouseup: {…}}
readInput: state=0, x=197, y=768
get_canvas_buffer: 803952 non-empty pixels
get_canvas_buffer: 803940 non-empty pixels
get_canvas_buffer: 803944 non-empty pixels
{mousedown: {…}}
readInput: state=1, x=362, y=766
[Info] (11.428, +346) indev_proc_press: pressed at x:362 y:766 (in lv_indev.c line #819)
get_canvas_buffer: 803944 non-empty pixels
[Info] (11.460, +32) indev_proc_release: released (in lv_indev.c line #969)
eventHandler: clicked
[Info] (11.478, +18) lv_obj_update_layout: Layout update begin (in lv_obj_pos.c line #314)
[Trace] (11.479, +1) lv_obj_update_layout: Layout update end (in lv_obj_pos.c line #317)
2get_canvas_buffer: 803944 non-empty pixels
{mouseup: {…}}
readInput: state=0, x=362, y=766
get_canvas_buffer: 803956 non-empty pixels
get_canvas_buffer: 803952 non-empty pixels
3get_canvas_buffer: 803944 non-empty pixels
{mousedown: {…}}
readInput: state=1, x=593, y=769
[Info] (11.895, +416) indev_proc_press: pressed at x:593 y:769 (in lv_indev.c line #819)
get_canvas_buffer: 803944 non-empty pixels
[Info] (11.928, +33) indev_proc_release: released (in lv_indev.c line #969)
eventHandler: clicked
[Info] (11.945, +17) lv_obj_update_layout: Layout update begin (in lv_obj_pos.c line #314)
[Trace] (11.946, +1) lv_obj_update_layout: Layout update end (in lv_obj_pos.c line #317)
2get_canvas_buffer: 803944 non-empty pixels
{mouseup: {…}}
readInput: state=0, x=593, y=769
get_canvas_buffer: 803956 non-empty pixels
get_canvas_buffer: 803952 non-empty pixels
3get_canvas_buffer: 803944 non-empty pixels
{mousedown: {…}}
readInput: state=1, x=368, y=915
[Info] (12.629, +683) indev_proc_press: pressed at x:368 y:915 (in lv_indev.c line #819)
get_canvas_buffer: 803944 non-empty pixels
[Info] (12.662, +33) indev_proc_release: released (in lv_indev.c line #969)
eventHandler: clicked
[Info] (12.680, +18) lv_obj_update_layout: Layout update begin (in lv_obj_pos.c line #314)
[Trace] (12.681, +1) lv_obj_update_layout: Layout update end (in lv_obj_pos.c line #317)
2get_canvas_buffer: 803944 non-empty pixels
{mouseup: {…}}
readInput: state=0, x=368, y=915
get_canvas_buffer: 803956 non-empty pixels
get_canvas_buffer: 803952 non-empty pixels
get_canvas_buffer: 803940 non-empty pixels
get_canvas_buffer: 803944 non-empty pixels
{mousedown: {…}}
readInput: state=1, x=219, y=274
[Info] (13.328, +647) indev_proc_press: pressed at x:219 y:274 (in lv_indev.c line #819)
get_canvas_buffer: 803944 non-empty pixels
[Info] (13.361, +33) indev_proc_release: released (in lv_indev.c line #969)
eventHandler: clicked
Call +1234567890
Running in WebAssembly, simulate the Phone Call
get_canvas_buffer: 803944 non-empty pixels
{mouseup: {…}}
get_canvas_buffer: 803956 non-empty pixels
readInput: state=0, x=219, y=274
get_canvas_buffer: 803952 non-empty pixels
3get_canvas_buffer: 803944 non-empty pixels</code>
PinePhone Log
Here's the log from PinePhone on Apache NuttX RTOS...
```text
DRAM: 2048 MiB
Trying to boot from MMC1
NOTICE: BL31: v2.2(release):v2.2-904-gf9ea3a629
NOTICE: BL31: Built : 15:32:12, Apr 9 2020
NOTICE: BL31: Detected Allwinner A64/H64/R18 SoC (1689)
NOTICE: BL31: Found U-Boot DTB at 0x4064410, model: PinePhone
NOTICE: PSCI: System suspend is unavailable
U-Boot 2020.07 (Nov 08 2020 - 00:15:12 +0100)
DRAM: 2 GiB
MMC: Device 'mmc@1c11000': seq 1 is in use by 'mmc@1c10000'
mmc@1c0f000: 0, mmc@1c10000: 2, mmc@1c11000: 1
Loading Environment from FAT... *** Warning - bad CRC, using default environment
starting USB...
No working controllers found
Hit any key to stop autoboot: 0
switch to partitions #0, OK
mmc0 is current device
Scanning mmc 0:1...
Found U-Boot script /boot.scr
653 bytes read in 3 ms (211.9 KiB/s)
Executing script at 4fc00000
gpio: pin 114 (gpio 114) value is 1
276622 bytes read in 16 ms (16.5 MiB/s)
Uncompressed size: 10387456 = 0x9E8000
36162 bytes read in 4 ms (8.6 MiB/s)
1078500 bytes read in 50 ms (20.6 MiB/s)
Flattened Device Tree blob at 4fa00000
Booting using the fdt blob at 0x4fa00000
Loading Ramdisk to 49ef8000, end 49fff4e4 ... OK
Loading Device Tree to 0000000049eec000, end 0000000049ef7d41 ... OK
Starting kernel ...
nsh: mkfatfs: command not found
NuttShell (NSH) NuttX-12.0.3
nsh> lvgldemo
lv_demo_widgets: start
createWidgets: start
createWidgets: end
lv_demo_widgets: end
eventHandler: clicked
eventHandler: clicked
eventHandler: clicked
eventHandler: clicked
eventHandler: clicked
eventHandler: clicked
eventHandler: clicked
eventHandler: clicked
eventHandler: clicked
eventHandler: clicked
eventHandler: clicked
eventHandler: clicked
eventHandler: clicked
eventHandler: clicked
eventHandler: clicked
eventHandler: clicked
eventHandler: clicked
Call +1234567890
Running on PinePhone, make an actual Phone Call
```
|
[] |
https://avatars.githubusercontent.com/u/4075241?v=4
|
zig-stable-array
|
rdunnington/zig-stable-array
|
2022-08-26T14:17:35Z
|
Address-stable array with a max size that allocates directly from virtual memory.
|
main
| 0 | 22 | 1 | 22 |
https://api.github.com/repos/rdunnington/zig-stable-array/tags
|
NOASSERTION
|
[
"zig",
"zig-package"
] | 43 | false |
2025-04-21T06:21:55Z
| true | true |
unknown
|
github
|
[] |
zig-stable-array
Address-stable array with a max size that allocates directly from virtual memory. Memory is only committed when actually used, and virtual page table mappings are relatively cheap, so you only pay for the memory that you're actually using. Additionally, since all memory remains inplace, and new memory is committed incrementally at the end of the array, there are no additional recopies of data made when the array is enlarged.
Ideal use cases are for large arrays that potentially grow over time. When reallocating a dynamic array with a high upper bound would be a waste of memory, and depending on dynamic resizing may incur high recopy costs due to the size of the array, consider using this array type. Another good use case is when stable pointers or slices to the array contents are desired; since the memory is never moved, pointers to the contents of the array will not be invalidated when growing. Not recommended for small arrays, since the minimum allocation size is the platform's minimum page size. Also not for use with platforms that don't support virtual memory, such as WASM.
Typical usage is to specify a large size up-front that the array should not encounter, such as 2GB+. Then use the array as usual. If freeing memory is desired, <code>shrinkAndFree()</code> will decommit memory at the end of the array. Total memory usage can be calculated with <code>calcTotalUsedBytes()</code>. The interface is very similar to ArrayList, except for the allocator semantics. Since typical heap semantics don't apply to this array, the memory is manually managed using mmap/munmap and VirtualAlloc/VirtualFree on nix and Windows platforms, respectively.
Usage:
<code>zig
var array = StableArray(u8).init(1024 * 1024 * 1024 * 128); // virtual address reservation of 128 GB
try array.appendSlice(&[_]u8{ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9 });
assert(array.calcTotalUsedBytes() == mem.page_size);
for (array.items) |v, i| {
assert(v == i);
}
array.shrinkAndFree(5);
assert(array.calcTotalUsedBytes() == mem.page_size);
array.deinit();</code>
|
[
"https://github.com/rdunnington/bytebox"
] |
https://avatars.githubusercontent.com/u/6693837?v=4
|
tpl-umbrella-zig
|
thi-ng/tpl-umbrella-zig
|
2022-11-24T22:14:10Z
|
Minimal thi.ng/umbrella browser project template for hybrid TypeScript & Zig apps, using thi.ng/wasm-api for bridging both worlds and Vite as dev tool/server & bundler...
|
main
| 1 | 21 | 0 | 21 |
https://api.github.com/repos/thi-ng/tpl-umbrella-zig/tags
|
MIT
|
[
"template-repository",
"thing-umbrella",
"typescript",
"wasm",
"webassembly",
"zig"
] | 302 | false |
2024-11-05T05:54:56Z
| true | false |
unknown
|
github
|
[] |
tpl-umbrella-zig
This is a bare-bones project template for hybrid
<a>TypeScript</a> & <a>Zig</a> apps,
using
<a>thi.ng/wasm-api</a>
related infrastructure for bridging both worlds, and using
<a>Vite</a> as dev tool/server & bundler...
Edit/delete everything as you see fit, see linked package readme files for
further details & please submit an issue if you spot anything wrong! Thanks!
Getting started
Please consult the <a>GitHub
documentation</a>
to learn more about template repos. Once you cloned the repo, proceed as
follows:
```bash
git clone ...
cd
download & install all dependencies (can also use npm)
yarn install
start dev server & open in browser
yarn start
regenerate shared types (see thi.ng/wasm-api-bindgen)
yarn build:types
production build
yarn build
preview latest production build
yarn preview
```
Requirements
This template is configured for Zig version v0.12.0 or newer, which includes
several breaking changes to the earlier build system. You can download the
latest version from the Zig website or (my own preferred method) using
<a>asdf</a> to install it (even just locally for this project):
```bash
asdf supports multiple versions of a tool, here to install latest dev version
asdf install zig 0.12.0
global use of that version
asdf global zig 0.12.0
only use that version in this project (already pre-configured)
asdf local zig 0.12.0
```
<ul>
<li><a>Zig</a> v0.12.0 or newer versions (see
<a>comments</a>)</li>
<li><a>Binaryen</a></li>
</ul>
Please see the comments in
<a>build.zig</a> for
more details...
Notes
This template pulls in more dependencies than needed for the runtime of your
actual app. Most of these additional packages are only required by the
<a>@thi.ng/wasm-api-bindgen</a>
CLI tool to generate source code for the types shared between the WASM/JS
side... Feel free to remove that package if you're not making use of code
generation.
License
This project is licensed under the MIT License. See LICENSE.txt
© 2022 - 2024 Karsten Schmidt
|
[] |
https://avatars.githubusercontent.com/u/9960133?v=4
|
zig-pinephone-gui
|
lupyuen/zig-pinephone-gui
|
2022-06-22T00:39:19Z
|
Zig GUI App for PinePhone
|
main
| 0 | 21 | 1 | 21 |
https://api.github.com/repos/lupyuen/zig-pinephone-gui/tags
|
Apache-2.0
|
[
"gtk",
"gui",
"linux",
"manjaro",
"mobian",
"phosh",
"pinebookpro",
"pinephone",
"xfce",
"zig"
] | 73 | false |
2024-11-22T22:46:09Z
| true | false |
unknown
|
github
|
[] |
Zig GUI App for PinePhone
Read the article...
<ul>
<li><a>"Build a PinePhone App with Zig and capy"</a></li>
</ul>
Can we build a Zig GUI App for PinePhone with the capy library?
<ul>
<li><a>capy-ui/capy</a></li>
</ul>
Let's find out!
<a>(More about Zig)</a>
Install Zig Compiler
On PinePhone, download the latest Zig Compiler <code>zig-linux-aarch64</code> from...
https://ziglang.org/download/
```bash
Download the Zig Compiler
curl -O -L https://ziglang.org/builds/zig-linux-aarch64-0.10.0-dev.2674+d980c6a38.tar.xz
Extract the Zig Compiler
tar xf zig-linux-aarch64-0.10.0-dev.2674+d980c6a38.tar.xz
Add to PATH. TODO: Also add this line to ~/.bashrc
export PATH="$HOME/zig-linux-aarch64-0.10.0-dev.2674+d980c6a38:$PATH"
Test the Zig Compiler, should show "0.10.0-dev.2674+d980c6a38"
zig version
```
<em>Will Zig Compiler run on any PinePhone?</em>
I tested the Zig Compiler with Manjaro Phosh on PinePhone (pic above), but it will probably work on any PinePhone distro since the Zig Compiler is a self-contained Arm64 Binary.
<a>(Zig Compiler works with Mobian on PinePhone too)</a>
Install Zigmod
Download the latest <a>Zigmod Package Manager</a> <code>zigmod-aarch64-linux</code> from...
https://github.com/nektro/zigmod/releases
```bash
Download Zigmod Package Manager
curl -O -L https://github.com/nektro/zigmod/releases/download/r80/zigmod-aarch64-linux
Make it executable
chmod +x zigmod-aarch64-linux
Move it to the Zig Compiler directory, rename as zigmod
mv zigmod-aarch64-linux zig-linux-aarch64-0.10.0-dev.2674+d980c6a38/zigmod
Test Zigmod, should show "zigmod r80 linux aarch64 musl"
zigmod
```
Build The App
To build the app on PinePhone...
```bash
Download the Source Code
git clone --recursive https://github.com/lupyuen/zig-pinephone-gui
cd zig-pinephone-gui
Install the dependencies for capy library
pushd libs/zgt
zigmod fetch
popd
Build the app
zig build
```
<a>(See the Build Log)</a>
If the build fails, check that the <code>gtk+-3.0</code> library is installed on PinePhone. <a>(Here's why)</a>
<a>(The app builds OK on Mobian after installing <code>gtk+-3.0</code>)</a>
Run The App
To run the app on PinePhone...
<code>bash
zig-out/bin/zig-pinephone-gui</code>
We should see the screen below.
When we tap the <code>Run</code> and <code>Save</code> buttons, we should see...
<code>text
info: You clicked button with text Run
info: You clicked button with text Save</code>
Yep we have successfully built a Zig GUI App for PinePhone with capy! 🎉
<em>Is the app fast and responsive on PinePhone?</em>
Yep it feels as fast and responsive as a GTK app coded in C.
Remember that Zig is a compiled language, and our compiled app is directly calling the GTK Library.
Inside The App
Here's the source code for the app: <a><code>src/main.zig</code></a>
```zig
// Import the capy library and Zig Standard Library
const zgt = @import("zgt");
const std = @import("std");
/// Main Function for our app
pub fn main() !void {
// Init the capy library
try zgt.backend.init();
<code>// Fetch the Window
var window = try zgt.Window.init();
// Set the Window Contents
try window.set(
// One Column of Widgets
zgt.Column(.{}, .{
// Top Row of Widgets
zgt.Row(.{}, .{
// Save Button
zgt.Button(.{ .label = "Save", .onclick = buttonClicked }),
// Run Button
zgt.Button(.{ .label = "Run", .onclick = buttonClicked }),
}),
// Expanded means the widget will take all the space it can
// in the parent container
zgt.Expanded(
// Editable Text Area
zgt.TextArea(.{ .text = "Hello World!\n\nThis is a Zig GUI App...\n\nBuilt for PinePhone...\n\nWith zgt Library!" })
)
}) // End of Column
); // End of Window
// Resize the Window (might not be correct for PinePhone)
window.resize(800, 600);
// Show the Window
window.show();
// Run the Event Loop to handle Touch Events
zgt.runEventLoop();
</code>
}
/// This function is called when the Buttons are clicked
fn buttonClicked(button: *zgt.Button_Impl) !void {
// Print the Button Label to console
std.log.info(
"You clicked button with text {s}",
.{ button.getLabel() }
);
}
```
This app is based on the capy demo...
https://github.com/capy-ui/capy#usage
For comparison, here's a typical GTK app coded in C...
https://www.gtk.org/docs/getting-started/hello-world/
Though I think our Zig app looks more like Vala than C...
https://www.gtk.org/docs/language-bindings/vala/
VSCode Remote
For convenience, we may use VSCode Remote to do Remote Development with PinePhone...
https://code.visualstudio.com/docs/remote/remote-overview
Just connect VSCode to PinePhone via SSH, as described here...
https://code.visualstudio.com/docs/remote/ssh
Remember to install the Zig Extension for VSCode...
https://github.com/ziglang/vscode-zig
Pinebook Pro
<em>Will the Zig GUI App run on Arm64 laptops like Pinebook Pro?</em>
Yep! The same steps above will work on Pinebook Pro.
Here's our Zig GUI App running with Manjaro Xfce on Pinebook Pro...
|
[] |
https://avatars.githubusercontent.com/u/6756180?v=4
|
libvlc-zig
|
kassane/libvlc-zig
|
2022-12-08T17:13:15Z
|
Zig bindings for libVLC media framework.
|
main
| 7 | 20 | 0 | 20 |
https://api.github.com/repos/kassane/libvlc-zig/tags
|
BSD-2-Clause
|
[
"bindings",
"libvlc",
"libvlc-zig",
"zig",
"zig-library",
"zig-package"
] | 449 | false |
2025-03-06T14:00:03Z
| true | true |
unknown
|
github
|
[
{
"commit": "00424d823873612c795f59eb1fc9a29c7360782a.tar.gz",
"name": "libvlcpp",
"tar_url": "https://github.com/kassane/libvlcpp/archive/00424d823873612c795f59eb1fc9a29c7360782a.tar.gz.tar.gz",
"type": "remote",
"url": "https://github.com/kassane/libvlcpp"
}
] |
<a>
</a>
<a>
</a>
<a>
</a>
<a>
</a>
<a>
</a>
libvlc-zig
Zig bindings for libVLC media framework. Some of the features provided by libVLC include the ability to play local files and network streams, as well as to transcode media content into different formats. It also provides support for a wide range of codecs, including popular formats like H.264, MPEG-4, and AAC.
Requirements
<ul>
<li><a>zig v0.11.0 or higher</a></li>
<li><a>vlc</a></li>
</ul>
How to use
Example
<code>bash
$> zig build run -Doptimize=ReleaseSafe # print-version (default)
$> zig build run -DExample="cliPlayer-{c,cpp,zig}" -Doptimize=ReleaseSafe -- -i /path/multimedia_file</code>
How to contribute to the libvlc-zig project?
Read <a>Contributing</a>.
FAQ
Q: Why isn't libvlc-zig licensed under <strong>LGPLv2.1</strong>?
A: The decision to license <code>libvlc-zig</code> under the <strong>BSD-2 clause</strong> was made by the author of the project. This license was chosen because it allows for more permissive use and distribution of the code, while still ensuring that the original author receives credit for their work.
<code>libvlc-zig</code> respects the original <strong>LGPLv2.1</strong> (Lesser General Public License) license of the VLC project.
Q: Are you connected to the developers of the original project?
A: No, the author of <code>libvlc-zig</code> is not part of the <strong>VideoLAN development team</strong>. They are simply interested in being part of the VLC community and contributing to its development.
Q: What is the main goal of this project?
A: The main goal of <code>libvlc-zig</code> is to provide a set of bindings for the <strong>VLC media player's</strong> libvlc library that are written in the <strong>Zig programming language</strong>. The project aims to provide a more modern and safe way to interface with the library, while maintaining compatibility with existing code written in <strong>C</strong> and <strong>C++</strong>.
Q: Does libvlc-zig aim to replace libvlc?
A: No, <code>libvlc-zig</code> does not aim to replace libvlc. Instead, it provides an alternative way to interface with the library that may be more suitable for Zig developers.
Q: Can I use libvlc-zig in my project?
A: Yes, you can use <code>libvlc-zig</code> in your project as long as you comply with the terms of the <strong>BSD-2 clause</strong> license. This includes giving credit to the original author of the code.
Q: Does libvlc-zig support all of the features of libvlc?
A: <code>libvlc-zig</code> aims to provide bindings for all of the features of libvlc, but it may not be complete or up-to-date with the latest version of the library. If you encounter any missing features or bugs, please report them to the project's GitHub issues page.
Q: What programming languages are compatible with libvlc-zig?
A: <code>libvlc-zig</code> provides bindings for the <strong>Zig programming language</strong>, but it can also be used with <strong>C</strong> and <strong>C++</strong> projects that use the libvlc library.
License
```
BSD 2-Clause License
Copyright (c) 2022, Matheus Catarino França
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
<ol>
<li>
Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
</li>
<li>
Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
```
</li>
</ol>
|
[] |
https://avatars.githubusercontent.com/u/51416554?v=4
|
.dotfiles
|
hendriknielaender/.dotfiles
|
2022-04-13T17:41:46Z
|
🧑💻 aerospace + ghostty + neovim
|
main
| 4 | 20 | 0 | 20 |
https://api.github.com/repos/hendriknielaender/.dotfiles/tags
|
-
|
[
"aerospace",
"dotfiles",
"ghostty",
"golang",
"i3",
"i3-config",
"i3wm",
"neovim",
"neovim-dotfiles",
"rust",
"typescript",
"vim",
"vimrc",
"wm",
"zig"
] | 10,968 | false |
2025-05-17T07:23:53Z
| false | false |
unknown
|
github
|
[] |
.dotfiles
This repository contains my personal dotfiles, including preconfigured settings for Neovim, tailored specifically for TypeScript, Rust, Zig, Go development. It includes a curated selection of plugins, key mappings, and customizations to enhance productivity and streamline coding workflows.
Vim re-maps
<a>CHEATSHEET.md</a>
Getting started
<code>shell
stow --target ~/.config .</code>
Preview
| | |
|---------------------|---------------------------------------------------------------------------|
|Shell: |<a>zsh</a> + <a>ohmyzsh</a>|
|Editor: |<a>neovim</a> |
|Terminal: |<a>ghostty</a> |
<strong>Optional</strong>, but highly recommended:
<ul>
<li><a>fzf</a></li>
<li><a>ripgrep</a></li>
<li><a>jq</a></li>
<li><a>nvim kickstarter</a></li>
</ul>
Themes
| | |
|-----------------------------------------------------------------------|-------------------------------------------------|
|<a>stardust</a> | |
|<a>rose-pine</a> | |
|<a>tokyonight</a> | |
|<a>gruvbox</a> | |
|
[] |
https://avatars.githubusercontent.com/u/12962448?v=4
|
zig-tray
|
star-tek-mb/zig-tray
|
2022-10-18T11:48:05Z
|
Create tray applications with zig
|
master
| 3 | 20 | 4 | 20 |
https://api.github.com/repos/star-tek-mb/zig-tray/tags
|
-
|
[
"notifications",
"tray",
"tray-menu",
"zig"
] | 106 | false |
2025-03-24T07:08:15Z
| true | true |
0.12.0
|
github
|
[] |
zig-tray
zig-tray is a library for creating tray applications. Supports tray and notifications.
Features
<ul>
<li>tray witch <code>.ico</code> support!</li>
<li>left click callback support</li>
<li>right click callback support</li>
<li>sending notification and notification click callback support</li>
</ul>
Supported platforms
<br/><input type='checkbox' class='w-4 h-4 text-green-500 bg-gray-100 border-gray-300 rounded focus:ring-blue-500 dark:focus:ring-blue-600 dark:ring-offset-gray-800 focus:ring-2 dark:bg-gray-700 dark:border-gray-600' checked disabled></input> Windows
<br/><input type='checkbox' class='w-4 h-4 text-blue-600 bg-gray-100 border-gray-300 rounded focus:ring-blue-500 dark:focus:ring-blue-600 dark:ring-offset-gray-800 focus:ring-2 dark:bg-gray-700 dark:border-gray-600' disabled></input> Linux
<br/><input type='checkbox' class='w-4 h-4 text-blue-600 bg-gray-100 border-gray-300 rounded focus:ring-blue-500 dark:focus:ring-blue-600 dark:ring-offset-gray-800 focus:ring-2 dark:bg-gray-700 dark:border-gray-600' disabled></input> MacOS
Installation
Zig <code>0.12</code> \ <code>0.13.0</code>
<ol>
<li>Add to <code>build.zig.zon</code></li>
</ol>
```sh
It is recommended to replace the following branch with commit id
zig fetch --save https://github.com/star-tek-mb/zig-tray/archive/master.tar.gz
Of course, you can also use git+https to fetch this package!
```
<ol>
<li>Config <code>build.zig</code></li>
</ol>
Add this:
<code>``zig
// To standardize development, maybe you should use</code>lazyDependency()<code>instead of</code>dependency()`
// more info to see: https://ziglang.org/download/0.12.0/release-notes.html#toc-Lazy-Dependencies
const zig_tray = b.dependency("zig-tray", .{
.target = target,
.optimize = optimize,
});
// add module
exe.root_module.addImport("zig-tray", zig_tray.module("tray"));
```
Example
see folder <code>example</code>!
Credits
https://github.com/zserge/tray - for initial C library
https://github.com/glfw/glfw/blob/master/src/win32_window.c#L102 - for icon creating from rgba
|
[] |
https://avatars.githubusercontent.com/u/43246943?v=4
|
setup-zig
|
korandoru/setup-zig
|
2022-09-09T04:20:25Z
|
Set up your GitHub Actions workflow with a specific version of Zig (https://ziglang.org/).
|
main
| 0 | 19 | 3 | 19 |
https://api.github.com/repos/korandoru/setup-zig/tags
|
Apache-2.0
|
[
"github-actions",
"zig",
"ziglang"
] | 2,141 | false |
2025-02-12T05:22:39Z
| false | false |
unknown
|
github
|
[] |
Setup Zig
Archived
Use <a>mlugg/setup-zig</a> instead.
Original
<a></a>
<a></a>
<a></a>
This action provides the following functionality for GitHub Actions users:
<ul>
<li>Downloading and caching distribution of the requested Zig version, and adding it to the PATH</li>
</ul>
Usage
See <a>action.yml</a>.
<strong>Basic:</strong>
<code>yml
steps:
- uses: actions/checkout@v3
- uses: korandoru/setup-zig@v1
with:
zig-version: 0.9.1 # released versions or master
- run: zig build test</code>
The <code>zig-version</code> input is required. Options include <a>all released versions</a> or "master".
The action will first check the local cache for a semver match. If unable to find a specific version in the cache, the action will attempt to download a version of Zig.
For information regarding locally cached versions of Zig on GitHub-hosted runners, check out <a>GitHub Actions Runner Images</a>.
Matrix Testing
<code>yml
jobs:
build:
strategy:
fail-fast: false
matrix:
zig: [ 0.12.0-dev.1710+2bffd8101, 0.11.0, 0.10.0, master ]
os: [ ubuntu-latest, windows-latest, macos-latest ]
runs-on: ${{ matrix.os }}
name: Zig ${{ matrix.zig }} on ${{ matrix.os }}
steps:
- uses: actions/checkout@v3
- name: Setup Zig
uses: korandoru/setup-zig@v1
with:
zig-version: ${{ matrix.zig }}
- run: zig build test</code>
License
The scripts and documentation in this project are released under the <a>Apache License 2.0</a>.
|
[] |
https://avatars.githubusercontent.com/u/6756180?v=4
|
zig-xlsxwriter
|
kassane/zig-xlsxwriter
|
2022-11-26T14:06:06Z
|
A Zig library for writing files in the Excel 2007+ XLSX file format
|
main
| 1 | 19 | 5 | 19 |
https://api.github.com/repos/kassane/zig-xlsxwriter/tags
|
Apache-2.0
|
[
"bindings",
"libxlsxwriter",
"xlsx",
"xlsxwriter",
"zig"
] | 70 | false |
2025-02-20T14:19:58Z
| true | true |
unknown
|
github
|
[
{
"commit": "caf41581f14c6fc0b9f957cc05c2a7fbb9e4d9eb",
"name": "xlsxwriter",
"tar_url": "https://github.com/jmcnamara/libxlsxwriter/archive/caf41581f14c6fc0b9f957cc05c2a7fbb9e4d9eb.tar.gz",
"type": "remote",
"url": "https://github.com/jmcnamara/libxlsxwriter"
}
] |
zig-xlsxwriter
The <code>zig-xlsxwriter</code> is a wrapper of <a><code>libxlsxwriter</code></a> that can be used to write text, numbers,
dates and formulas to multiple worksheets in a new Excel 2007+ xlsx file. It
has a focus on performance and on fidelity with the file format created by
Excel. It cannot be used to modify an existing file.
Requirements
<ul>
<li><a>zig v0.12.0 or higher</a></li>
<li><a>libxlsxwriter</a></li>
</ul>
Example
Sample code to generate the Excel file shown above.
```zig
const xlsxwriter = @import("xlsxwriter");
const Expense = struct {
item: [*:0]const u8,
cost: f64,
datetime: xlsxwriter.lxw_datetime,
};
var expenses = [_]Expense{
.{ .item = "Rent", .cost = 1000.0, .datetime = .{ .year = 2013, .month = 1, .day = 13, .hour = 8, .min = 34, .sec = 65.45 } },
.{ .item = "Gas", .cost = 100.0, .datetime = .{ .year = 2013, .month = 1, .day = 14, .hour = 12, .min = 17, .sec = 23.34 } },
.{ .item = "Food", .cost = 300.0, .datetime = .{ .year = 2013, .month = 1, .day = 16, .hour = 4, .min = 29, .sec = 54.05 } },
.{ .item = "Gym", .cost = 50.0, .datetime = .{ .year = 2013, .month = 1, .day = 20, .hour = 6, .min = 55, .sec = 32.16 } },
};
pub fn main() void {
<code>// Create a workbook and add a worksheet.
const workbook: ?*xlsxwriter.lxw_workbook = xlsxwriter.workbook_new("out/tutorial2.xlsx");
const worksheet: ?*xlsxwriter.lxw_worksheet = xlsxwriter.workbook_add_worksheet(workbook, null);
// Start from the first cell. Rows and columns are zero indexed.
var row: u32 = 0;
var col: u16 = 0;
var index: usize = 0;
// Add a bold format to use to highlight cells.
const bold: ?*xlsxwriter.lxw_format = xlsxwriter.workbook_add_format(workbook);
_ = xlsxwriter.format_set_bold(bold);
// Add a number format for cells with money.
const money: ?*xlsxwriter.lxw_format = xlsxwriter.workbook_add_format(workbook);
_ = xlsxwriter.format_set_num_format(money, "$#,##0");
// Add an Excel date format.
const date_format: ?*xlsxwriter.lxw_format = xlsxwriter.workbook_add_format(workbook);
_ = xlsxwriter.format_set_num_format(date_format, "mmmm d yyyy");
// Adjust the column width.
_ = xlsxwriter.worksheet_set_column(worksheet, 0, 0, 15, null);
// Write some data header.
_ = xlsxwriter.worksheet_write_string(worksheet, row, col, "Item", bold);
_ = xlsxwriter.worksheet_write_string(worksheet, row, col + 1, "Cost", bold);
// Iterate over the data and write it out element by element.
while (row < 4) : (row += 1) {
_ = xlsxwriter.worksheet_write_string(worksheet, row, col, expenses[index].item, null);
_ = xlsxwriter.worksheet_write_datetime(worksheet, row, col + 1, &expenses[index].datetime, date_format);
_ = xlsxwriter.worksheet_write_number(worksheet, row, col + 2, expenses[index].cost, money);
}
// Write a total using a formula.
_ = xlsxwriter.worksheet_write_string(worksheet, row, col, "Total", 0);
_ = xlsxwriter.worksheet_write_formula(worksheet, row + 1, col + 2, "=SUM(C2:C5)", null);
// Save the workbook and free any allocated memory.
_ = xlsxwriter.workbook_close(workbook);
</code>
}
```
|
[] |
https://avatars.githubusercontent.com/u/206480?v=4
|
http.zig
|
karlseguin/http.zig
|
2023-03-13T08:51:53Z
|
An HTTP/1.1 server for zig
|
master
| 5 | 1,005 | 67 | 1,005 |
https://api.github.com/repos/karlseguin/http.zig/tags
|
MIT
|
[
"http-server",
"zig",
"zig-library",
"zig-package"
] | 986 | false |
2025-05-21T05:46:03Z
| true | true |
unknown
|
github
|
[
{
"commit": "cf2797bcb3aea7e5cdaf4de39c5550c70796e7b1.tar.gz",
"name": "metrics",
"tar_url": "https://github.com/karlseguin/metrics.zig/archive/cf2797bcb3aea7e5cdaf4de39c5550c70796e7b1.tar.gz.tar.gz",
"type": "remote",
"url": "https://github.com/karlseguin/metrics.zig"
},
{
"commit": "7c3f1149bffcde1dec98dea88a442e2b580d750a.tar.gz",
"name": "websocket",
"tar_url": "https://github.com/karlseguin/websocket.zig/archive/7c3f1149bffcde1dec98dea88a442e2b580d750a.tar.gz.tar.gz",
"type": "remote",
"url": "https://github.com/karlseguin/websocket.zig"
}
] |
An HTTP/1.1 server for Zig.
```zig
const std = @import("std");
const httpz = @import("httpz");
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = gpa.allocator();
// More advance cases will use a custom "Handler" instead of "void".
// The last parameter is our handler instance, since we have a "void"
// handler, we passed a void ({}) value.
var server = try httpz.Server(void).init(allocator, .{.port = 5882}, {});
defer {
// clean shutdown, finishes serving any live request
server.stop();
server.deinit();
}
var router = try server.router(.{});
router.get("/api/user/:id", getUser, .{});
// blocks
try server.listen();
}
fn getUser(req: <em>httpz.Request, res: </em>httpz.Response) !void {
res.status = 200;
try res.json(.{.id = req.param("id").?, .name = "Teg"}, .{});
}
```
Table of Contents
<ul>
<li><a>Examples</a></li>
<li><a>Installation</a></li>
<li><a>Alternatives</a></li>
<li><a>Handler</a></li>
<li><a>Custom Dispatch</a></li>
<li><a>Per-Request Context</a></li>
<li><a>Custom Not Found</a></li>
<li><a>Custom Error Handler</a></li>
<li><a>Dispatch Takeover</a></li>
<li><a>Memory And Arenas</a></li>
<li><a>httpz.Request</a></li>
<li><a>httpz.Response</a></li>
<li><a>Router</a></li>
<li><a>Middlewares</a></li>
<li><a>Configuration</a></li>
<li><a>Metrics</a></li>
<li><a>Testing</a></li>
<li><a>HTTP Compliance</a></li>
<li><a>Server Side Events</a></li>
<li><a>Websocket</a></li>
</ul>
Versions
The <code>master</code> branch targets Zig 0.14. The <code>dev</code> branch targets the latest version of Zig.
Examples
See the <a>examples</a> folder for examples. If you clone this repository, you can run <code>zig build example_#</code> to run a specific example:
<code>bash
$ zig build example_1
listening http://localhost:8800/</code>
Installation
1) Add http.zig as a dependency in your <code>build.zig.zon</code>:
<code>bash
zig fetch --save git+https://github.com/karlseguin/http.zig#master</code>
2) In your <code>build.zig</code>, add the <code>httpz</code> module as a dependency you your program:
```zig
const httpz = b.dependency("httpz", .{
.target = target,
.optimize = optimize,
});
// the executable from your call to b.addExecutable(...)
exe.root_module.addImport("httpz", httpz.module("httpz"));
```
The library tracks Zig master. If you're using a specific version of Zig, use the appropriate branch.
Alternatives
If you're looking for a higher level web framework with more included functionality, consider <a>JetZig</a> or <a>Tokamak</a> which are built on top of httpz.
Why not std.http.Server
<code>std.http.Server</code> is very slow and assumes well-behaved clients.
There are many Zig HTTP server implementations. Most wrap <code>std.http.Server</code> and tend to be slow. Benchmark it, you'll see. A few wrap C libraries and are faster (though some of these are slow too!).
http.zig is written in Zig, without using <code>std.http.Server</code>. On an M2, a basic request can hit 140K requests per seconds.
Handler
When a non-void Handler is used, the value given to <code>Server(H).init</code> is passed to every action. This is how application-specific data can be passed into your actions.
For example, using <a>pg.zig</a>, we can make a database connection pool available to each action:
```zig
const pg = @import("pg");
const std = @import("std");
const httpz = @import("httpz");
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = gpa.allocator();
var db = try pg.Pool.init(allocator, .{
.connect = .{ .port = 5432, .host = "localhost"},
.auth = .{.username = "user", .database = "db", .password = "pass"}
});
defer db.deinit();
var app = App{
.db = db,
};
var server = try httpz.Server(*App).init(allocator, .{.port = 5882}, &app);
var router = try server.router(.{});
router.get("/api/user/:id", getUser, .{});
try server.listen();
}
const App = struct {
db: *pg.Pool,
};
fn getUser(app: <em>App, req: </em>httpz.Request, res: *httpz.Response) !void {
const user_id = req.param("id").?;
var row = try app.db.row("select name from users where id = $1", .{user_id}) orelse {
res.status = 404;
res.body = "Not found";
return;
};
defer row.deinit() catch {};
try res.json(.{
.id = user_id,
.name = row.get([]u8, 0),
}, .{});
}
```
Custom Dispatch
Beyond sharing state, your custom handler can be used to control how httpz behaves. By defining a public <code>dispatch</code> method you can control how (or even <strong>if</strong>) actions are executed. For example, to log timing, you could do:
```zig
const App = struct {
pub fn dispatch(self: <em>App, action: httpz.Action(</em>App), req: <em>httpz.Request, res: </em>httpz.Response) !void {
var timer = try std.time.Timer.start();
<code>// your `dispatch` doesn't _have_ to call the action
try action(self, req, res);
const elapsed = timer.lap() / 1000; // ns -> us
std.log.info("{} {s} {d}", .{req.method, req.url.path, elapsed});
</code>
}
};
```
Per-Request Context
The 2nd parameter, <code>action</code>, is of type <code>httpz.Action(*App)</code>. This is a function pointer to the function you specified when setting up the routes. As we've seen, this works well to share global data. But, in many cases, you'll want to have request-specific data.
Consider the case where you want your <code>dispatch</code> method to conditionally load a user (maybe from the <code>Authorization</code> header of the request). How would you pass this <code>User</code> to the action? You can't use the <code>*App</code> directly, as this is shared concurrently across all requests.
To achieve this, we'll add another structure called <code>RequestContext</code>. You can call this whatever you want, and it can contain any fields of methods you want.
<code>zig
const RequestContext = struct {
// You don't have to put a reference to your global data.
// But chances are you'll want.
app: *App,
user: ?User,
};</code>
We can now change the definition of our actions and <code>dispatch</code> method:
```zig
fn getUser(ctx: <em>RequestContext, req: </em>httpz.Request, res: *httpz.Response) !void {
// can check if ctx.user is != null
}
const App = struct {
pub fn dispatch(self: <em>App, action: httpz.Action(</em>RequestContext), req: <em>httpz.Request, res: </em>httpz.Response) !void {
var ctx = RequestContext{
.app = self,
.user = self.loadUser(req),
}
return action(&ctx, req, res);
}
fn loadUser(self: <em>App, req: </em>httpz.Request) ?User {
// todo, maybe using req.header("authorizaation")
}
};
```
httpz infers the type of the action based on the 2nd parameter of your handler's <code>dispatch</code> method. If you use a <code>void</code> handler or your handler doesn't have a <code>dispatch</code> method, then you won't interact with <code>httpz.Action(H)</code> directly.
Not Found
If your handler has a public <code>notFound</code> method, it will be called whenever a path doesn't match a found route:
<code>zig
const App = struct {
pub fn notFound(_: *App, req: *httpz.Request, res: *httpz.Response) !void {
std.log.info("404 {} {s}", .{req.method, req.url.path});
res.status = 404;
res.body = "Not Found";
}
};</code>
Error Handler
If your handler has a public <code>uncaughtError</code> method, it will be called whenever there's an unhandled error. This could be due to some internal httpz bug, or because your action return an error.
<code>zig
const App = struct {
pub fn uncaughtError(_: *App, req: *httpz.Request, res: *httpz.Response, err: anyerror) void {
std.log.info("500 {} {s} {}", .{req.method, req.url.path, err});
res.status = 500;
res.body = "sorry";
}
};</code>
Notice that, unlike <code>notFound</code> and other normal actions, the <code>uncaughtError</code> method cannot return an error itself.
Takeover
For the most control, you can define a <code>handle</code> method. This circumvents most of Httpz's dispatching, including routing. Frameworks like JetZig hook use <code>handle</code> in order to provide their own routing and dispatching. When you define a <code>handle</code> method, then any <code>dispatch</code>, <code>notFound</code> and <code>uncaughtError</code> methods are ignored by httpz.
<code>zig
const App = struct {
pub fn handle(app: *App, req: *httpz.Request, res: *httpz.Response) void {
// todo
}
};</code>
The behavior <code>httpz.Server(H)</code> is controlled by
The library supports both simple and complex use cases. A simple use case is shown below. It's initiated by the call to <code>httpz.Server()</code>:
```zig
const std = @import("std");
const httpz = @import("httpz");
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = gpa.allocator();
<code>var server = try httpz.Server().init(allocator, .{.port = 5882});
// overwrite the default notFound handler
server.notFound(notFound);
// overwrite the default error handler
server.errorHandler(errorHandler);
var router = try server.router(.{});
// use get/post/put/head/patch/options/delete
// you can also use "all" to attach to all methods
router.get("/api/user/:id", getUser, .{});
// start the server in the current thread, blocking.
try server.listen();
</code>
}
fn getUser(req: <em>httpz.Request, res: </em>httpz.Response) !void {
// status code 200 is implicit.
<code>// The json helper will automatically set the res.content_type = httpz.ContentType.JSON;
// Here we're passing an inferred anonymous structure, but you can pass anytype
// (so long as it can be serialized using std.json.stringify)
try res.json(.{.id = req.param("id").?, .name = "Teg"}, .{});
</code>
}
fn notFound(_: <em>httpz.Request, res: </em>httpz.Response) !void {
res.status = 404;
<code>// you can set the body directly to a []u8, but note that the memory
// must be valid beyond your handler. Use the res.arena if you need to allocate
// memory for the body.
res.body = "Not Found";
</code>
}
// note that the error handler return <code>void</code> and not <code>!void</code>
fn errorHandler(req: <em>httpz.Request, res: </em>httpz.Response, err: anyerror) void {
res.status = 500;
res.body = "Internal Server Error";
std.log.warn("httpz: unhandled exception for request: {s}\nErr: {}", .{req.url.raw, err});
}
```
Memory and Arenas
Any allocations made for the response, such as the body or a header, must remain valid until <strong>after</strong> the action returns. To achieve this, use <code>res.arena</code> or the <code>res.writer()</code>:
```zig
fn arenaExample(req: <em>httpz.Request, res: </em>httpz.Response) !void {
const query = try req.query();
const name = query.get("name") orelse "stranger";
res.body = try std.fmt.allocPrint(res.arena, "Hello {s}", .{name});
}
fn writerExample(req: <em>httpz.Request, res: </em>httpz.Response) !void {
const query = try req.query();
const name = query.get("name") orelse "stranger";
try std.fmt.format(res.writer(), "Hello {s}", .{name});
}
```
Alternatively, you can explicitly call <code>res.write()</code>. Once <code>res.write()</code> returns, the response is sent and your action can cleanup/release any resources.
<code>res.arena</code> is actually a configurable-sized thread-local buffer that fallsback to an <code>std.heap.ArenaAllocator</code>. In other words, it's fast so it should be your first option for data that needs to live only until your action exits.
httpz.Request
The following fields are the most useful:
<ul>
<li><code>method</code> - httpz.Method enum</li>
<li><code>method_string</code> - Only set if <code>method == .OTHER</code>, else empty. Used when using custom methods.</li>
<li><code>arena</code> - A fast thread-local buffer that fallsback to an ArenaAllocator, same as <code>res.arena</code>.</li>
<li><code>url.path</code> - the path of the request (<code>[]const u8</code>)</li>
<li><code>address</code> - the std.net.Address of the client</li>
</ul>
If you give your route a <code>data</code> configuration, the value can be retrieved from the optional <code>route_data</code> field of the request.
Path Parameters
The <code>param</code> method of <code>*Request</code> returns an <code>?[]const u8</code>. For example, given the following path:
<code>zig
router.get("/api/users/:user_id/favorite/:id", user.getFavorite, .{});</code>
Then we could access the <code>user_id</code> and <code>id</code> via:
<code>zig
pub fn getFavorite(req *http.Request, res: *http.Response) !void {
const user_id = req.param("user_id").?;
const favorite_id = req.param("id").?;
...</code>
In the above, passing any other value to <code>param</code> would return a null object (since the route associated with <code>getFavorite</code> only defines these 2 parameters). Given that routes are generally statically defined, it should not be possible for <code>req.param</code> to return an unexpected null. However, it <em>is</em> possible to define two routes to the same action:
```zig
router.put("/api/users/:user_id/favorite/:id", user.updateFavorite, .{});
// currently logged in user, maybe?
router.put("/api/use/favorite/:id", user.updateFavorite, .{});
```
In which case the optional return value of <code>param</code> might be useful.
Header Values
Similar to <code>param</code>, header values can be fetched via the <code>header</code> function, which also returns a <code>?[]const u8</code>:
```zig
if (req.header("authorization")) |auth| {
} else {
// not logged in?:
}
```
Header names are lowercase. Values maintain their original casing.
To iterate over all headers, use:
<code>zig
var it = req.headers.iterator();
while (it.next()) |kv| {
// kv.key
// kv.value
}</code>
QueryString
The framework does not automatically parse the query string. Therefore, its API is slightly different.
```zig
const query = try req.query();
if (query.get("search")) |search| {
} else {
// no search parameter
};
```
On first call, the <code>query</code> function attempts to parse the querystring. This requires memory allocations to unescape encoded values. The parsed value is internally cached, so subsequent calls to <code>query()</code> are fast and cannot fail.
The original casing of both the key and the name are preserved.
To iterate over all query parameters, use:
<code>zig
var it = req.query().iterator();
while (it.next()) |kv| {
// kv.key
// kv.value
}</code>
Body
The body of the request, if any, can be accessed using <code>req.body()</code>. This returns a <code>?[]const u8</code>.
Json Body
The <code>req.json(TYPE)</code> function is a wrapper around the <code>body()</code> function which will call <code>std.json.parse</code> on the body. This function does not consider the content-type of the request and will try to parse any body.
```zig
if (try req.json(User)) |user| {
}
```
JsonValueTree Body
The <code>req.jsonValueTree()</code> function is a wrapper around the <code>body()</code> function which will call <code>std.json.Parse</code> on the body, returning a <code>!?std.jsonValueTree</code>. This function does not consider the content-type of the request and will try to parse any body.
<code>zig
if (try req.jsonValueTree()) |t| {
// probably want to be more defensive than this
const product_type = r.root.Object.get("type").?.String;
//...
}</code>
JsonObject Body
The even more specific <code>jsonObject()</code> function will return an <code>std.json.ObjectMap</code> provided the body is a map
<code>zig
if (try req.jsonObject()) |t| {
// probably want to be more defensive than this
const product_type = t.get("type").?.String;
//...
}</code>
Form Data
The body of the request, if any, can be parsed as a "x-www-form-urlencoded "value using <code>req.formData()</code>. The <code>request.max_form_count</code> configuration value must be set to the maximum number of form fields to support. This defaults to 0.
This behaves similarly to <code>query()</code>.
On first call, the <code>formData</code> function attempts to parse the body. This can require memory allocations to unescape encoded values. The parsed value is internally cached, so subsequent calls to <code>formData()</code> are fast and cannot fail.
The original casing of both the key and the name are preserved.
To iterate over all fields, use:
<code>zig
var it = (try req.formData()).iterator();
while (it.next()) |kv| {
// kv.key
// kv.value
}</code>
Once this function is called, <code>req.multiFormData()</code> will no longer work (because the body is assumed parsed).
Multi Part Form Data
Similar to the above, <code>req.multiFormData()</code> can be called to parse requests with a "multipart/form-data" content type. The <code>request.max_multiform_count</code> configuration value must be set to the maximum number of form fields to support. This defaults to 0.
This is a different API than <code>formData</code> because the return type is different. Rather than a simple string=>value type, the multi part form data value consists of a <code>value: []const u8</code> and a <code>filename: ?[]const u8</code>.
On first call, the <code>multiFormData</code> function attempts to parse the body. The parsed value is internally cached, so subsequent calls to <code>multiFormData()</code> are fast and cannot fail.
The original casing of both the key and the name are preserved.
To iterate over all fields, use:
<code>zig
var it = req.multiFormData.iterator();
while (it.next()) |kv| {
// kv.key
// kv.value.value
// kv.value.filename (optional)
}</code>
Once this function is called, <code>req.formData()</code> will no longer work (because the body is assumed parsed).
Advance warning: This is one of the few methods that can modify the request in-place. For most people this won't be an issue, but if you use <code>req.body()</code> and <code>req.multiFormData()</code>, say to log the raw body, the content-disposition field names are escaped in-place. It's still safe to use <code>req.body()</code> but any content-disposition name that was escaped will be a little off.
Lazy Loading
By default, httpz reads the full request body into memory. Depending on httpz configuration and the request size, the body will be stored in the static request buffer, a large buffer pool, or dynamically allocated.
As an alternative, when <code>config.request.lazy_read_size</code> is set, bodies larger than the configured bytes will not be read into memory. Instead, applications can create a <code>io.Reader</code> by calling <code>req.reader(timeout_in_ms)</code>.
<code>zig
// 5000 millisecond read timeout on a per-read basis
var reader = try req.reader(5000);
var buf: [4096]u8 = undefined;
while (true) {
const n = try reader.read(&buf);
if (n == 0) break
// buf[0..n] is what was read
}</code>
<code>req.reader</code> can safely be used whether or not the full body was already in-memory - the API abstracts reading from already-loaded bytes and bytes still waiting to be received on the socket. You can check <code>req.unread_body > 0</code> to know whether lazy loading is in effect.
A few notes about the implementation.
If if the body is larger than the configured <code>lazy_read_size</code>, part of the body might still be read into the request's static buffer. The <code>io.Reader</code> returned by <code>req.reader()</code> will abstract this detail away and return the full body.
Also, if the body isn't fully read, but the connection is marked for keepalive (which is generally the default), httpz will still read the full body, but will do so in 4K chunks.
While the <code>io.Reader</code> can be used for non-lazy loaded bodies, there's overhead to this. It is better to use it only when you know that the body is large (i.e., a file upload).
Cookies
Use the <code>req.cookies</code> method to get a <code>Request.Cookie</code> object. Use <code>get</code> to get an optional cookie value for a given cookie name. The cookie name is case sensitive.
<code>zig
var cookies = req.cookies();
if (cookies.get("auth")) |auth| {
/// ...
}</code>
httpz.Response
The following fields are the most useful:
<ul>
<li><code>status</code> - set the status code, by default, each response starts off with a 200 status code</li>
<li><code>content_type</code> - an httpz.ContentType enum value. This is a convenience and optimization over using the <code>res.header</code> function.</li>
<li><code>arena</code> - A fast thread-local buffer that fallsback to an ArenaAllocator, same as <code>req.arena</code>.</li>
</ul>
Body
The simplest way to set a body is to set <code>res.body</code> to a <code>[]const u8</code>. <strong>However</strong> the provided value must remain valid until the body is written, which happens after the function exists or when <code>res.write()</code> is explicitly called.
Dynamic Content
You can use the <code>res.arena</code> allocator to create dynamic content:
<code>zig
const query = try req.query();
const name = query.get("name") orelse "stranger";
res.body = try std.fmt.allocPrint(res.arena, "Hello {s}", .{name});</code>
Memory allocated with <code>res.arena</code> will exist until the response is sent.
io.Writer
<code>res.writer()</code> returns an <code>std.io.Writer</code>. Various types support writing to an io.Writer. For example, the built-in JSON stream writer can use this writer:
<code>zig
var ws = std.json.writeStream(res.writer(), 4);
try ws.beginObject();
try ws.objectField("name");
try ws.emitString(req.param("name").?);
try ws.endObject();</code>
JSON
The <code>res.json</code> function will set the content_type to <code>httpz.ContentType.JSON</code> and serialize the provided value using <code>std.json.stringify</code>. The 2nd argument to the json function is the <code>std.json.StringifyOptions</code> to pass to the <code>stringify</code> function.
This function uses <code>res.writer()</code> explained above.
Header Value
Set header values using the <code>res.header(NAME, VALUE)</code> function:
<code>zig
res.header("Location", "/");</code>
The header name and value are sent as provided. Both the name and value must remain valid until the response is sent, which will happen outside of the action. Dynamic names and/or values should be created and or dupe'd with <code>res.arena</code>.
<code>res.headerOpts(NAME, VALUE, OPTS)</code> can be used to dupe the name and/or value:
<code>zig
try res.headerOpts("Location", location, .{.dupe_value = true});</code>
<code>HeaderOpts</code> currently supports <code>dupe_name: bool</code> and <code>dupe_value: bool</code>, both default to <code>false</code>.
Cookies
You can use the <code>res.setCookie(name, value, opts)</code> to set the "Set-Cookie" header.
<code>zig
try res.setCookie("cookie_name3", "cookie value 3", .{
.path = "/auth/",
.domain = "www.openmymind.net",
.max_age = 9001,
.secure = true,
.http_only = true,
.partitioned = true,
.same_site = .lax, // or .none, or .strict (or null to leave out)
});</code>
<code>setCookie</code> does not validate the name, value, path or domain - it assumes you're setting proper values. It <em>will</em> double-quote values which contain spaces or commas (as required).
If, for whatever reason, <code>res.setCookie</code> doesn't work for you, you always have full control over the cookie value via <code>res.header("Set-Cookie", value)</code>.
<code>zig
var cookies = req.cookies();
if (cookies.get("auth")) |auth| {
/// ...
}</code>
Writing
By default, httpz will automatically flush your response. In more advance cases, you can use <code>res.write()</code> to explicitly flush it. This is useful in cases where you have resources that need to be freed/released only after the response is written. For example, my <a>LRU cache</a> uses atomic referencing counting to safely allow concurrent access to cached data. This requires callers to "release" the cached entry:
```zig
pub fn info(app: <em>MyApp, _: </em>httpz.Request, res: *httpz.Response) !void {
const cached = app.cache.get("info") orelse {
// load the info
};
defer cached.release();
<code>res.body = cached.value;
return res.write();
</code>
}
```
Router
You get an instance of the router by calling <code>server.route(.{})</code>. Currently, the configuration takes a single parameter:
<ul>
<li><code>middlewares</code> - A list of middlewares to apply to each request. These middleware will be executed even for requests with no matching route (i.e. not found). An individual route can opt-out of these middleware, see the <code>middleware_strategy</code> route configuration.</li>
</ul>
You can use the <code>get</code>, <code>put</code>, <code>post</code>, <code>head</code>, <code>patch</code>, <code>trace</code>, <code>delete</code>, <code>options</code> or <code>connect</code> method of the router to define a router. You can also use the special <code>all</code> method to add a route for all methods.
These functions can all <code>@panic</code> as they allocate memory. Each function has an equivalent <code>tryXYZ</code> variant which will return an error rather than panicking:
```zig
// this can panic if it fails to create the route
router.get("/", index, .{});
// this returns a !void (which you can try/catch)
router.tryGet("/", index, .{});
```
The 3rd parameter is a route configuration. It allows you to speficy a different <code>handler</code> and/or <code>dispatch</code> method and/or <code>middleware</code>.
<code>zig
// this can panic if it fails to create the route
router.get("/", index, .{
.dispatcher = Handler.dispathAuth,
.handler = &auth_handler,
.middlewares = &.{cors_middleware},
});</code>
Configuration
The last parameter to the various <code>router</code> methods is a route configuration. In many cases, you'll probably use an empty configuration (<code>.{}</code>). The route configuration has three fields:
<ul>
<li><code>dispatcher</code> - The dispatch method to use. This overrides the default dispatcher, which is either httpz built-in dispatcher or <a>your handler's <code>dispatch</code> method</a>.</li>
<li><code>handler</code> - The handler instance to use. The default handler is the 3rd parameter passed to <code>Server(H).init</code> but you can override this on a route-per-route basis.</li>
<li><code>middlewares</code> - A list of <a>middlewares</a> to run. By default, no middlewares are run. By default, this list of middleware is appended to the list given to <code>server.route(.{.middlewares = .{....})</code>.</li>
<li><code>middleware_strategy</code> - How the given middleware should be merged with the global middlewares. Defaults to <code>.append</code>, can also be <code>.replace</code>.</li>
<li><code>data</code> - Arbitrary data (<code>*const anyopaque</code>) to make available to <code>req.route_data</code>. This must be a <code>const</code>.</li>
</ul>
You can specify a separate configuration for each route. To change the configuration for a group of routes, you have two options. The first, is to directly change the router's <code>handler</code>, <code>dispatcher</code> and <code>middlewares</code> field. Any subsequent routes will use these values:
```zig
var server = try httpz.Server(Handler).init(allocator, .{.port = 5882}, &handler);
var router = try server.router(.{});
// Will use Handler.dispatch on the &handler instance passed to init
// No middleware
router.get("/route1", route1, .{});
router.dispatcher = Handler.dispathAuth;
// uses the new dispatcher
router.get("/route2", route2, .{});
router.handler = &Handler{.public = true};
// uses the new dispatcher + new handler
router.get("/route3", route3, .{.handler = Handler.dispathAuth});
```
This approach is error prone though. New routes need to be carefully added in the correct order so that the desired handler, dispatcher and middlewares are used.
A more scalable option is to use route groups.
Groups
Defining a custom dispatcher or custom global data on each route can be tedious. Instead, consider using a router group:
<code>zig
var admin_routes = router.group("/admin", .{
.handler = &auth_handler,
.dispatcher = Handler.dispathAuth,
.middlewares = &.{cors_middleware},
});
admin_routes.get("/users", listUsers, .{});
admin_routs.delete("/users/:id", deleteUsers, .{});</code>
The first parameter to <code>group</code> is a prefix to prepend to each route in the group. An empty prefix is acceptable. Thus, route groups can be used to configure either a common prefix and/or a common configuration across multiple routes.
Casing
You <strong>must</strong> use a lowercase route. You can use any casing with parameter names, as long as you use that same casing when getting the parameter.
Parameters
Routing supports parameters, via <code>:CAPTURE_NAME</code>. The captured values are available via <code>req.params.get(name: []const u8) ?[]const u8</code>.
Glob
You can glob an individual path segment, or the entire path suffix. For a suffix glob, it is important that no trailing slash is present.
<code>zig
// prefer using a custom `notFound` handler than a global glob.
router.all("/*", not_found, .{});
router.get("/api/*/debug", .{})</code>
When multiple globs are used, the most specific will be selected. E.g., give the following two routes:
<code>zig
router.get("/*", not_found, .{});
router.get("/info/*", any_info, .{})</code>
A request for "/info/debug/all" will be routed to <code>any_info</code>, whereas a request for "/over/9000" will be routed to <code>not_found</code>.
Custom Methods
You can use the <code>method</code> function to route a custom method:
<code>zig
router.method("TEA", "/", teaList, .{});</code>
In such cases, <code>request.method</code> will be <code>.OTHER</code> and you can use the <code>reqeust.method_string</code> for the string value. The method name, <code>TEA</code> above, is cloned by the router and does not need to exist beyond the function call. The method name should only be uppercase ASCII letters.
The <code>router.all</code> method <strong>does not</strong> route to custom methods.
Limitations
The router has several limitations which might not get fixed. These specifically resolve around the interaction of globs, parameters and static path segments.
Given the following routes:
<code>zig
router.get("/:any/users", route1, .{});
router.get("/hello/users/test", route2, .{});</code>
You would expect a request to "/hello/users" to be routed to <code>route1</code>. However, no route will be found.
Globs interact similarly poorly with parameters and static path segments.
Resolving this issue requires keeping a stack (or visiting the routes recursively), in order to back-out of a dead-end and trying a different path.
This seems like an unnecessarily expensive thing to do, on each request, when, in my opinion, such route hierarchies are uncommon.
Middlewares
In general, use a <a>custom dispatch</a> function to apply custom logic, such as logging, authentication and authorization. If you have complex route-specific logic, middleware can also be leveraged.
A middleware is a struct which exposes a nested <code>Config</code> type, a public <code>init</code> function and a public <code>execute</code> method. It can optionally define a <code>deinit</code> method. See the built-in <a>CORS middleware</a> or the sample <a>logger middleware</a> for examples.
A middleware instance is created using <code>server.middleware()</code> and can then be used with the router:
```zig
var server = try httpz.Server(void).init(allocator, .{.port = 5882}, {});
// the middleware method takes the struct name and its configuration
const cors = try server.middleware(httpz.middleware.Cors, .{
.origin = "https://www.openmymind.net/",
});
// apply this middleware to all routes (unless the route
// explicitly opts out)
var router = try server.router(.{.middlewares = &.{cors}});
// or we could add middleware on a route-per-route bassis
router.get("/v1/users", user, .{.middlewares = &.{cors}});
// by default, middlewares on a route are appended to the global middlewares
// we can replace them instead by specifying a middleware_strategy
router.get("/v1/metrics", metrics, .{.middlewares = &.{cors}, .middleware_strategy = .replace});
```
Cors
httpz comes with a built-in CORS middleware: <code>httpz.middlewares.Cors</code>. Its configuration is:
<ul>
<li><code>origin: []const u8</code></li>
<li><code>headers: ?[]const u8 = null</code></li>
<li><code>methods: ?[]const u8 = null</code></li>
<li><code>max_age: ?[]const u8 = null</code></li>
</ul>
The CORS middleware will include a <code>Access-Control-Allow-Origin: $origin</code> to every request. For an OPTIONS request where the <code>sec-fetch-mode</code> is set to <code>cors, the</code>Access-Control-Allow-Headers<code>,</code>Access-Control-Allow-Methods<code>and</code>Access-Control-Max-Age` response headers will optionally be set based on the configuration.
Configuration
The second parameter given to <code>Server(H).init</code> is an <code>httpz.Config</code>. When running in <a>blocking mode</a> (e.g. on Windows) a few of these behave slightly, but not drastically, different.
There are many configuration options.
<code>thread_pool.buffer_size</code> is the single most important value to tweak. Usage of <code>req.arena</code>, <code>res.arena</code>, <code>res.writer()</code> and <code>res.json()</code> all use a fallback allocator which first uses a fast thread-local buffer and then an underlying arena. The total memory this will require is <code>thread_pool.count * thread_pool.buffer_size</code>. Since <code>thread_pool.count</code> is usually small, a large <code>buffer_size</code> is reasonable.
<code>request.buffer_size</code> must be large enough to fit the request header. Any extra space might be used to read the body. However, there can be up to <code>workers.count * workers.max_conn</code> pending requests, so a large <code>request.buffer_size</code> can take up a lot of memory. Instead, consider keeping <code>request.buffer_size</code> only large enough for the header (plus a bit of overhead for decoding URL-escape values) and set <code>workers.large_buffer_size</code> to a reasonable size for your incoming request bodies. This will take <code>workers.count * workers.large_buffer_count * workers.large_buffer_size</code> memory.
Buffers for request bodies larger than <code>workers.large_buffer_size</code> but smaller than <code>request.max_body_size</code> will be dynamic allocated.
In addition to a bit of overhead, at a minimum, httpz will use:
<code>zig
(thread_pool.count * thread_pool.buffer_size) +
(workers.count * workers.large_buffer_count * workers.large_buffer_size) +
(workers.count * workers.min_conn * request.buffer_size)</code>
Possible values, along with their default, are:
```zig
try httpz.listen(allocator, &router, .{
// Port to listen on
.port = 5882,
<code>// Interface address to bind to
.address = "127.0.0.1",
// unix socket to listen on (mutually exclusive with host&port)
.unix_path = null,
// configure the workers which are responsible for:
// 1 - accepting connections
// 2 - reading and parsing requests
// 3 - passing requests to the thread pool
.workers = .{
// Number of worker threads
// (blocking mode: handled differently)
.count = 1,
// Maximum number of concurrent connection each worker can handle
// (blocking mode: currently ignored)
.max_conn = 8_192,
// Minimum number of connection states each worker should maintain
// (blocking mode: currently ignored)
.min_conn = 64,
// A pool of larger buffers that can be used for any data larger than configured
// static buffers. For example, if response headers don't fit in in
// $response.header_buffer_size, a buffer will be pulled from here.
// This is per-worker.
.large_buffer_count = 16,
// The size of each large buffer.
.large_buffer_size = 65536,
// Size of bytes retained for the connection arena between use. This will
// result in up to `count * min_conn * retain_allocated_bytes` of memory usage.
.retain_allocated_bytes = 4096,
},
// configures the threadpool which processes requests. The threadpool is
// where your application code runs.
.thread_pool = .{
// Number threads. If you're handlers are doing a lot of i/o, a higher
// number might provide better throughput
// (blocking mode: handled differently)
.count = 32,
// The maximum number of pending requests that the thread pool will accept
// This applies back pressure to the above workers and ensures that, under load
// pending requests get precedence over processing new requests.
.backlog = 500,
// Size of the static buffer to give each thread. Memory usage will be
// `count * buffer_size`. If you're making heavy use of either `req.arena` or
// `res.arena`, this is likely the single easiest way to gain performance.
.buffer_size = 8192,
},
// options for tweaking request processing
.request = .{
// Maximum request body size that we'll process. We can allocate up
// to this much memory per request for the body. Internally, we might
// keep this memory around for a number of requests as an optimization.
.max_body_size: usize = 1_048_576,
// When set, if request body is larger than this value, the body won't be
// eagerly read. The application can use `req.reader()` to create a reader
// to read the body. Prevents loading large bodies completely in memory.
// When set, max_body_size is ignored.
.lazy_read_size: ?usize = null,
// This memory is allocated upfront. The request header _must_ fit into
// this space, else the request will be rejected.
.buffer_size: usize = 4_096,
// Maximum number of headers to accept.
// Additional headers will be silently ignored.
.max_header_count: usize = 32,
// Maximum number of URL parameters to accept.
// Additional parameters will be silently ignored.
.max_param_count: usize = 10,
// Maximum number of query string parameters to accept.
// Additional parameters will be silently ignored.
.max_query_count: usize = 32,
// Maximum number of x-www-form-urlencoded fields to support.
// Additional parameters will be silently ignored. This must be
// set to a value greater than 0 (the default) if you're going
// to use the req.formData() method.
.max_form_count: usize = 0,
// Maximum number of multipart/form-data fields to support.
// Additional parameters will be silently ignored. This must be
// set to a value greater than 0 (the default) if you're going
// to use the req.multiFormData() method.
.max_multiform_count: usize = 0,
},
// options for tweaking response object
.response = .{
// The maximum number of headers to accept.
// Additional headers will be silently ignored.
.max_header_count: usize = 16,
},
.timeout = .{
// Time in seconds that keepalive connections will be kept alive while inactive
.keepalive = null,
// Time in seconds that a connection has to send a complete request
.request = null
// Maximum number of a requests allowed on a single keepalive connection
.request_count = null,
},
.websocket = .{
// refer to https://github.com/karlseguin/websocket.zig#config
max_message_size: ?usize = null,
small_buffer_size: ?usize = null,
small_buffer_pool: ?usize = null,
large_buffer_size: ?usize = null,
large_buffer_pool: ?u16 = null,
compression: bool = false,
compression_retain_writer: bool = true,
// if compression is true, and this is null, then
// we accept compressed messaged from the client, but never send
// compressed messages
compression_write_treshold: ?usize = null,
},
</code>
});
```
Blocking Mode
kqueue (BSD, MacOS) or epoll (Linux) are used on supported platforms. On all other platforms (most notably Windows), a more naive thread-per-connection with blocking sockets is used.
The comptime-safe, <code>httpz.blockingMode() bool</code> function can be called to determine which mode httpz is running in (when it returns <code>true</code>, then you're running the simpler blocking mode).
While you should always run httpz behind a reverse proxy, it's particularly important to do so in blocking mode due to the ease with which external connections can DOS the server.
In blocking mode, <code>config.workers.count</code> is hard-coded to 1. (This worker does considerably less work than the non-blocking workers). If <code>config.workers.count</code> is > 1, than those extra workers will go towards <code>config.thread_pool.count</code>. In other words:
In non-blocking mode, if <code>config.workers.count = 2</code> and <code>config.thread_pool.count = 4</code>, then you'll have 6 threads: 2 threads that read+parse requests and send replies, and 4 threads to execute application code.
In blocking mode, the same config will also use 6 threads, but there will only be: 1 thread that accepts connections, and 5 threads to read+parse requests, send replies and execute application code.
The goal is for the same configuration to result in the same # of threads regardless of the mode, and to have more thread_pool threads in blocking mode since they do more work.
In blocking mode, <code>config.workers.large_buffer_count</code> defaults to the size of the thread pool.
In blocking mode, <code>config.workers.max_conn</code> and <code>config.workers.min_conn</code> are ignored. The maximum number of connections is simply the size of the thread_pool.
If you aren't using a reverse proxy, you should always set the <code>config.timeout.request</code>, <code>config.timeout.keepalive</code> and <code>config.timeout.request_count</code> settings. In blocking mode, consider using conservative values: say 5/5/5 (5 second request timeout, 5 second keepalive timeout, and 5 keepalive count). You can monitor the <code>httpz_timeout_active</code> metric to see if the request timeout is too low.
Timeouts
The configuration settings under the <code>timeouts</code> section are designed to help protect the system against basic DOS attacks (say, by connecting and not sending data). However it is recommended that you leave these null (disabled) and use the appropriate timeout in your reverse proxy (e.g. NGINX).
The <code>timeout.request</code> is the time, in seconds, that a connection has to send a complete request. The <code>timeout.keepalive</code> is the time, in second, that a connection can stay connected without sending a request (after the initial request has been sent).
The connection alternates between these two timeouts. It starts with a timeout of <code>timeout.request</code> and after the response is sent and the connection is placed in the "keepalive list", switches to the <code>timeout.keepalive</code>. When new data is received, it switches back to <code>timeout.request</code>. When <code>null</code>, both timeouts default to 2_147_483_647 seconds (so not completely disabled, but close enough).
The <code>timeout.request_count</code> is the number of individual requests allowed within a single keepalive session. This protects against a client consuming the connection by sending unlimited meaningless but valid HTTP requests.
When the three are combined, it should be difficult for a problematic client to stay connected indefinitely.
If you're running httpz on Windows (or, more generally, where <code>httpz.blockingMode()</code> returns true), please <a>read the section</a> as this mode of operation is more susceptible to DOS.
Metrics
A few basic metrics are collected using <a>metrics.zig</a>, a prometheus-compatible library. These can be written to an <code>std.io.Writer</code> using <code>try httpz.writeMetrics(writer)</code>. As an example:
```zig
pub fn metrics(_: <em>httpz.Request, res: </em>httpz.Response) !void {
const writer = res.writer();
try httpz.writeMetrics(writer);
<code>// if we were also using pg.zig
// try pg.writeMetrics(writer);
</code>
}
```
Since httpz does not provide any authorization, care should be taken before exposing this.
The metrics are:
<ul>
<li><code>httpz_connections</code> - counts each TCP connection</li>
<li><code>httpz_requests</code> - counts each request (should be >= httpz_connections due to keepalive)</li>
<li><code>httpz_timeout_active</code> - counts each time an "active" connection is timed out. An "active" connection is one that has (a) just connected or (b) started to send bytes. The timeout is controlled by the <code>timeout.request</code> configuration.</li>
<li><code>httpz_timeout_keepalive</code> - counts each time an "keepalive" connection is timed out. A "keepalive" connection has already received at least 1 response and the server is waiting for a new request. The timeout is controlled by the <code>timeout.keepalive</code> configuration.</li>
<li><code>httpz_alloc_buffer_empty</code> - counts number of bytes allocated due to the large buffer pool being empty. This may indicate that <code>workers.large_buffer_count</code> should be larger.</li>
<li><code>httpz_alloc_buffer_large</code> - counts number of bytes allocated due to the large buffer pool being too small. This may indicate that <code>workers.large_buffer_size</code> should be larger.</li>
<li><code>httpz_alloc_unescape</code> - counts number of bytes allocated due to unescaping query or form parameters. This may indicate that <code>request.buffer_size</code> should be larger.</li>
<li><code>httpz_internal_error</code> - counts number of unexpected errors within httpz. Such errors normally result in the connection being abruptly closed. For example, a failing syscall to epoll/kqueue would increment this counter.</li>
<li><code>httpz_invalid_request</code> - counts number of requests which httpz could not parse (where the request is invalid).</li>
<li><code>httpz_header_too_big</code> - counts the number of requests which httpz rejects due to a header being too big (does not fit in <code>request.buffer_size</code> config).</li>
<li><code>httpz_body_too_big</code> - counts the number of requests which httpz rejects due to a body being too big (is larger than <code>request.max_body_size</code> config).</li>
</ul>
Testing
The <code>httpz.testing</code> namespace exists to help application developers setup an <code>*httpz.Request</code> and assert an <code>*httpz.Response</code>.
Imagine we have the following partial action:
```zig
fn search(req: <em>httpz.Request, res: </em>httpz.Response) !void {
const query = try req.query();
const search = query.get("search") orelse return missingParameter(res, "search");
<code>// TODO ...
</code>
}
fn missingParameter(res: *httpz.Response, parameter: []const u8) !void {
res.status = 400;
return res.json(.{.@"error" = "missing parameter", .parameter = parameter}, .{});
}
```
We can test the above error case like so:
```zig
const ht = @import("httpz").testing;
test "search: missing parameter" {
// init takes the same Configuration used when creating the real server
// but only the config.request and config.response settings have any impact
var web_test = ht.init(.{});
defer web_test.deinit();
<code>try search(web_test.req, web_test.res);
try web_test.expectStatus(400);
try web_test.expectJson(.{.@"error" = "missing parameter", .parameter = "search"});
</code>
}
```
Building the test Request
The testing structure returns from <code>httpz.testing.init</code> exposes helper functions to set param, query and query values as well as the body:
```zig
var web_test = ht.init(.{});
defer web_test.deinit();
web_test.param("id", "99382");
web_test.query("search", "tea");
web_test.header("Authorization", "admin");
web_test.body("over 9000!");
// OR
web_test.json(.{.over = 9000});
// OR
// This requires ht.init(.{.request = .{.max_form_count = 10}})
web_test.form(.{.over = "9000"});
// at this point, web_test.req has a param value, a query string value, a header value and a body.
```
As an alternative to the <code>query</code> function, the full URL can also be set. If you use <code>query</code> AND <code>url</code>, the query parameters of the URL will be ignored:
<code>zig
web_test.url("/power?over=9000");</code>
Asserting the Response
There are various methods to assert the response:
<code>zig
try web_test.expectStatus(200);
try web_test.expectHeader("Location", "/");
try web_test.expectHeader("Location", "/");
try web_test.expectBody("{\"over\":9000}");</code>
If the expected body is in JSON, there are two helpers available. First, to assert the entire JSON body, you can use <code>expectJson</code>:
<code>zig
try web_test.expectJson(.{.over = 9000});</code>
Or, you can retrieve a <code>std.json.Value</code> object by calling <code>getJson</code>:
<code>zig
const json = try web_test.getJson();
try std.testing.expectEqual(@as(i64, 9000), json.Object.get("over").?.Integer);</code>
For more advanced validation, use the <code>parseResponse</code> function to return a structure representing the parsed response:
<code>zig
const res = try web_test.parseResponse();
try std.testing.expectEqual(@as(u16, 200), res.status);
// use res.body for a []const u8
// use res.headers for a std.StringHashMap([]const u8)
// use res.raw for the full raw response</code>
HTTP Compliance
This implementation may never be fully HTTP/1.1 compliant, as it is built with the assumption that it will sit behind a reverse proxy that is tolerant of non-compliant upstreams (e.g. nginx). (One example I know of is that the server doesn't include the mandatory Date header in the response.)
Server Side Events
Server Side Events can be enabled by calling <code>res.startEventStream()</code>. This method takes an arbitrary context and a function pointer. The provided function will be executed in a new thread, receiving the provided context and an <code>std.net.Stream</code>. Headers can be added (via <code>res.headers.add</code>) before calling <code>startEventStream()</code>. <code>res.body</code> must not be set (directly or indirectly).
Calling <code>startEventStream()</code> automatically sets the <code>Content-Type</code>, <code>Cache-Control</code> and <code>Connection</code> header.
```zig
fn handler(_: <em>Request, res: </em>Response) !void {
try res.startEventStream(StreamContext{}, StreamContext.handle);
}
const StreamContext = struct {
fn handle(self: StreamContext, stream: std.net.Stream) void {
while (true) {
// some event loop
stream.writeAll("event: ....") catch return;
}
}
}
```
Websocket
http.zig integrates with <a>https://github.com/karlseguin/websocket.zig</a> by calling <code>httpz.upgradeWebsocket()</code>. First, your handler must have a <code>WebsocketHandler</code> declaration which is the WebSocket handler type used by <code>websocket.Server(H)</code>.
```zig
const websocket = httpz.websocket;
const Handler = struct {
// App-specific data you want to pass when initializing
// your WebSocketHandler
const WebsocketContext = struct {
};
// See the websocket.zig documentation. But essentially this is your
// Application's wrapper around 1 websocket connection
pub const WebsocketHandler = struct {
conn: *websocket.Conn,
<code>// ctx is arbitrary data you passs to httpz.upgradeWebsocket
pub fn init(conn: *websocket.Conn, _: WebsocketContext) {
return .{
.conn = conn,
}
}
// echo back
pub fn clientMessage(self: *WebsocketHandler, data: []const u8) !void {
try self.conn.write(data);
}
</code>
}
};
```
With this in place, you can call httpz.upgradeWebsocket() within an action:
<code>zig
fn ws(req: *httpz.Request, res: *httpz.Response) !void {
if (try httpz.upgradeWebsocket(WebsocketHandler, req, res, WebsocketContext{}) == false) {
// this was not a valid websocket handshake request
// you should probably return with an error
res.status = 400;
res.body = "invalid websocket handshake";
return;
}
// Do not use `res` from this point on
}</code>
In websocket.zig, <code>init</code> is passed a <code>websocket.Handshake</code>. This is not the case with the httpz integration - you are expected to do any necessary validation of the request in the action.
It is an undefined behavior if <code>Handler.WebsocketHandler</code> is not the same type passed to <code>httpz.upgradeWebsocket</code>.
|
[] |
https://avatars.githubusercontent.com/u/476352?v=4
|
libvaxis
|
rockorager/libvaxis
|
2024-01-20T03:57:33Z
|
a modern tui library written in zig
|
main
| 4 | 937 | 55 | 937 |
https://api.github.com/repos/rockorager/libvaxis/tags
|
MIT
|
[
"tui",
"zig",
"zig-package"
] | 6,041 | false |
2025-05-20T18:56:11Z
| true | true |
0.14.0
|
github
|
[
{
"commit": "31268548fe3276c0e95f318a6c0d2ab10565b58d",
"name": "zigimg",
"tar_url": "https://github.com/TUSF/zigimg/archive/31268548fe3276c0e95f318a6c0d2ab10565b58d.tar.gz",
"type": "remote",
"url": "https://github.com/TUSF/zigimg"
},
{
"commit": "4a002763419a34d61dcbb1f415821b83b9bf8ddc",
"name": "zg",
"tar_url": "https://codeberg.org/atman/zg/archive/4a002763419a34d61dcbb1f415821b83b9bf8ddc.tar.gz",
"type": "remote",
"url": "https://codeberg.org/atman/zg"
}
] |
libvaxis
<code>It begins with them, but ends with me. Their son, Vaxis</code>
Libvaxis <em>does not use terminfo</em>. Support for vt features is detected through
terminal queries.
Vaxis uses zig <code>0.14.0</code>.
Features
libvaxis supports all major platforms: macOS, Windows, Linux/BSD/and other
Unix-likes.
<ul>
<li>RGB</li>
<li><a>Hyperlinks</a> (OSC 8)</li>
<li>Bracketed Paste</li>
<li><a>Kitty Keyboard Protocol</a></li>
<li><a>Fancy underlines</a> (undercurl, etc)</li>
<li>Mouse Shapes (OSC 22)</li>
<li>System Clipboard (OSC 52)</li>
<li>System Notifications (OSC 9)</li>
<li>System Notifications (OSC 777)</li>
<li>Synchronized Output (Mode 2026)</li>
<li><a>Unicode Core</a> (Mode 2027)</li>
<li>Color Mode Updates (Mode 2031)</li>
<li><a>In-Band Resize Reports</a> (Mode 2048)</li>
<li>Images (<a>kitty graphics protocol</a>)</li>
<li><a>Explicit Width</a> (width modifiers only)</li>
</ul>
Usage
<a>Documentation</a>
The library provides both a low level API suitable for making applications of
any sort as well as a higher level framework. The low level API is suitable for
making applications of any type, providing your own event loop, and gives you
full control over each cell on the screen.
The high level API, called <code>vxfw</code> (Vaxis framework), provides a Flutter-like
style of API. The framework provides an application runtime which handles the
event loop, focus management, mouse handling, and more. Several widgets are
provided, and custom widgets are easy to build. This API is most likely what you
want to use for typical TUI applications.
Add libvaxis to your project
<code>console
zig fetch --save git+https://github.com/rockorager/libvaxis.git</code>
Add this to your build.zig
```zig
const vaxis = b.dependency("vaxis", .{
.target = target,
.optimize = optimize,
});
<code>exe.root_module.addImport("vaxis", vaxis.module("vaxis"));
</code>
```
vxfw (Vaxis framework)
Let's build a simple button counter application. This example can be run using
the command <code>zig build example -Dexample=counter</code>. The below application has
full mouse support: the button <em>and mouse shape</em> will change style on hover, on
click, and has enough logic to cancel a press if the release does not occur over
the button. Try it! Click the button, move the mouse off the button and release.
All of this logic is baked into the base <code>Button</code> widget.
```zig
const std = @import("std");
const vaxis = @import("vaxis");
const vxfw = vaxis.vxfw;
/// Our main application state
const Model = struct {
/// State of the counter
count: u32 = 0,
/// The button. This widget is stateful and must live between frames
button: vxfw.Button,
<code>/// Helper function to return a vxfw.Widget struct
pub fn widget(self: *Model) vxfw.Widget {
return .{
.userdata = self,
.eventHandler = Model.typeErasedEventHandler,
.drawFn = Model.typeErasedDrawFn,
};
}
/// This function will be called from the vxfw runtime.
fn typeErasedEventHandler(ptr: *anyopaque, ctx: *vxfw.EventContext, event: vxfw.Event) anyerror!void {
const self: *Model = @ptrCast(@alignCast(ptr));
switch (event) {
// The root widget is always sent an init event as the first event. Users of the
// library can also send this event to other widgets they create if they need to do
// some initialization.
.init => return ctx.requestFocus(self.button.widget()),
.key_press => |key| {
if (key.matches('c', .{ .ctrl = true })) {
ctx.quit = true;
return;
}
},
// We can request a specific widget gets focus. In this case, we always want to focus
// our button. Having focus means that key events will be sent up the widget tree to
// the focused widget, and then bubble back down the tree to the root. Users can tell
// the runtime the event was handled and the capture or bubble phase will stop
.focus_in => return ctx.requestFocus(self.button.widget()),
else => {},
}
}
/// This function is called from the vxfw runtime. It will be called on a regular interval, and
/// only when any event handler has marked the redraw flag in EventContext as true. By
/// explicitly requiring setting the redraw flag, vxfw can prevent excessive redraws for events
/// which don't change state (ie mouse motion, unhandled key events, etc)
fn typeErasedDrawFn(ptr: *anyopaque, ctx: vxfw.DrawContext) std.mem.Allocator.Error!vxfw.Surface {
const self: *Model = @ptrCast(@alignCast(ptr));
// The DrawContext is inspired from Flutter. Each widget will receive a minimum and maximum
// constraint. The minimum constraint will always be set, even if it is set to 0x0. The
// maximum constraint can have null width and/or height - meaning there is no constraint in
// that direction and the widget should take up as much space as it needs. By calling size()
// on the max, we assert that it has some constrained size. This is *always* the case for
// the root widget - the maximum size will always be the size of the terminal screen.
const max_size = ctx.max.size();
// The DrawContext also contains an arena allocator that can be used for each frame. The
// lifetime of this allocation is until the next time we draw a frame. This is useful for
// temporary allocations such as the one below: we have an integer we want to print as text.
// We can safely allocate this with the ctx arena since we only need it for this frame.
const count_text = try std.fmt.allocPrint(ctx.arena, "{d}", .{self.count});
const text: vxfw.Text = .{ .text = count_text };
// Each widget returns a Surface from it's draw function. A Surface contains the rectangular
// area of the widget, as well as some information about the surface or widget: can we focus
// it? does it handle the mouse?
//
// It DOES NOT contain the location it should be within it's parent. Only the parent can set
// this via a SubSurface. Here, we will return a Surface for the root widget (Model), which
// has two SubSurfaces: one for the text and one for the button. A SubSurface is a Surface
// with an offset and a z-index - the offset can be negative. This lets a parent draw a
// child and place it within itself
const text_child: vxfw.SubSurface = .{
.origin = .{ .row = 0, .col = 0 },
.surface = try text.draw(ctx),
};
const button_child: vxfw.SubSurface = .{
.origin = .{ .row = 2, .col = 0 },
.surface = try self.button.draw(ctx.withConstraints(
ctx.min,
// Here we explicitly set a new maximum size constraint for the Button. A Button will
// expand to fill it's area and must have some hard limit in the maximum constraint
.{ .width = 16, .height = 3 },
)),
};
// We also can use our arena to allocate the slice for our SubSurfaces. This slice only
// needs to live until the next frame, making this safe.
const children = try ctx.arena.alloc(vxfw.SubSurface, 2);
children[0] = text_child;
children[1] = button_child;
return .{
// A Surface must have a size. Our root widget is the size of the screen
.size = max_size,
.widget = self.widget(),
// We didn't actually need to draw anything for the root. In this case, we can set
// buffer to a zero length slice. If this slice is *not zero length*, the runtime will
// assert that it's length is equal to the size.width * size.height.
.buffer = &.{},
.children = children,
};
}
/// The onClick callback for our button. This is also called if we press enter while the button
/// has focus
fn onClick(maybe_ptr: ?*anyopaque, ctx: *vxfw.EventContext) anyerror!void {
const ptr = maybe_ptr orelse return;
const self: *Model = @ptrCast(@alignCast(ptr));
self.count +|= 1;
return ctx.consumeAndRedraw();
}
</code>
};
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
defer _ = gpa.deinit();
<code>const allocator = gpa.allocator();
var app = try vxfw.App.init(allocator);
defer app.deinit();
// We heap allocate our model because we will require a stable pointer to it in our Button
// widget
const model = try allocator.create(Model);
defer allocator.destroy(model);
// Set the initial state of our button
model.* = .{
.count = 0,
.button = .{
.label = "Click me!",
.onClick = Model.onClick,
.userdata = model,
},
};
try app.run(model.widget(), .{});
</code>
}
```
Low level API
Vaxis requires three basic primitives to operate:
<ol>
<li>A TTY instance</li>
<li>An instance of Vaxis</li>
<li>An event loop</li>
</ol>
The library provides a general purpose posix TTY implementation, as well as a
multi-threaded event loop implementation. Users of the library are encouraged to
use the event loop of their choice. The event loop is responsible for reading
the TTY, passing the read bytes to the vaxis parser, and handling events.
A core feature of Vaxis is it's ability to detect features via terminal queries
instead of relying on a terminfo database. This requires that the event loop
also handle these query responses and update the Vaxis.caps struct accordingly.
See the <code>Loop</code> implementation to see how this is done if writing your own event
loop.
```zig
const std = @import("std");
const vaxis = @import("vaxis");
const Cell = vaxis.Cell;
const TextInput = vaxis.widgets.TextInput;
const border = vaxis.widgets.border;
// This can contain internal events as well as Vaxis events.
// Internal events can be posted into the same queue as vaxis events to allow
// for a single event loop with exhaustive switching. Booya
const Event = union(enum) {
key_press: vaxis.Key,
winsize: vaxis.Winsize,
focus_in,
foo: u8,
};
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
defer {
const deinit_status = gpa.deinit();
//fail test; can't try in defer as defer is executed after we return
if (deinit_status == .leak) {
std.log.err("memory leak", .{});
}
}
const alloc = gpa.allocator();
<code>// Initialize a tty
var tty = try vaxis.Tty.init();
defer tty.deinit();
// Initialize Vaxis
var vx = try vaxis.init(alloc, .{});
// deinit takes an optional allocator. If your program is exiting, you can
// choose to pass a null allocator to save some exit time.
defer vx.deinit(alloc, tty.anyWriter());
// The event loop requires an intrusive init. We create an instance with
// stable pointers to Vaxis and our TTY, then init the instance. Doing so
// installs a signal handler for SIGWINCH on posix TTYs
//
// This event loop is thread safe. It reads the tty in a separate thread
var loop: vaxis.Loop(Event) = .{
.tty = &tty,
.vaxis = &vx,
};
try loop.init();
// Start the read loop. This puts the terminal in raw mode and begins
// reading user input
try loop.start();
defer loop.stop();
// Optionally enter the alternate screen
try vx.enterAltScreen(tty.anyWriter());
// We'll adjust the color index every keypress for the border
var color_idx: u8 = 0;
// init our text input widget. The text input widget needs an allocator to
// store the contents of the input
var text_input = TextInput.init(alloc, &vx.unicode);
defer text_input.deinit();
// Sends queries to terminal to detect certain features. This should always
// be called after entering the alt screen, if you are using the alt screen
try vx.queryTerminal(tty.anyWriter(), 1 * std.time.ns_per_s);
while (true) {
// nextEvent blocks until an event is in the queue
const event = loop.nextEvent();
// exhaustive switching ftw. Vaxis will send events if your Event enum
// has the fields for those events (ie "key_press", "winsize")
switch (event) {
.key_press => |key| {
color_idx = switch (color_idx) {
255 => 0,
else => color_idx + 1,
};
if (key.matches('c', .{ .ctrl = true })) {
break;
} else if (key.matches('l', .{ .ctrl = true })) {
vx.queueRefresh();
} else {
try text_input.update(.{ .key_press = key });
}
},
// winsize events are sent to the application to ensure that all
// resizes occur in the main thread. This lets us avoid expensive
// locks on the screen. All applications must handle this event
// unless they aren't using a screen (IE only detecting features)
//
// The allocations are because we keep a copy of each cell to
// optimize renders. When resize is called, we allocated two slices:
// one for the screen, and one for our buffered screen. Each cell in
// the buffered screen contains an ArrayList(u8) to be able to store
// the grapheme for that cell. Each cell is initialized with a size
// of 1, which is sufficient for all of ASCII. Anything requiring
// more than one byte will incur an allocation on the first render
// after it is drawn. Thereafter, it will not allocate unless the
// screen is resized
.winsize => |ws| try vx.resize(alloc, tty.anyWriter(), ws),
else => {},
}
// vx.window() returns the root window. This window is the size of the
// terminal and can spawn child windows as logical areas. Child windows
// cannot draw outside of their bounds
const win = vx.window();
// Clear the entire space because we are drawing in immediate mode.
// vaxis double buffers the screen. This new frame will be compared to
// the old and only updated cells will be drawn
win.clear();
// Create a style
const style: vaxis.Style = .{
.fg = .{ .index = color_idx },
};
// Create a bordered child window
const child = win.child(.{
.x_off = win.width / 2 - 20,
.y_off = win.height / 2 - 3,
.width = 40 ,
.height = 3 ,
.border = .{
.where = .all,
.style = style,
},
});
// Draw the text_input in the child window
text_input.draw(child);
// Render the screen. Using a buffered writer will offer much better
// performance, but is not required
try vx.render(tty.anyWriter());
}
</code>
}
```
Contributing
Contributions are welcome. Please submit a PR on Github,
<a>tangled</a>, or a patch on the
<a>mailing list</a>
Community
We use <a>Github Discussions</a>
as the primary location for community support, showcasing what you are working
on, and discussing library features and usage.
We also have an IRC channel on libera.chat: join us in #vaxis.
|
[] |
https://avatars.githubusercontent.com/u/109492796?v=4
|
zig-cookbook
|
zigcc/zig-cookbook
|
2023-12-10T02:43:39Z
|
Simple Zig programs that demonstrate good practices to accomplish common programming tasks.
|
main
| 2 | 930 | 39 | 930 |
https://api.github.com/repos/zigcc/zig-cookbook/tags
|
MIT
|
[
"zig",
"ziglang"
] | 223 | false |
2025-05-21T09:40:53Z
| true | true |
unknown
|
github
|
[
{
"commit": "refs",
"name": "zigcli",
"tar_url": "https://github.com/jiacai2050/zigcli/archive/refs.tar.gz",
"type": "remote",
"url": "https://github.com/jiacai2050/zigcli"
}
] |
book-src/intro.md
|
[] |
https://avatars.githubusercontent.com/u/3357792?v=4
|
compiler.nvim
|
Zeioth/compiler.nvim
|
2023-06-16T04:08:47Z
|
Neovim compiler for building and running your code without having to configure anything
|
main
| 4 | 589 | 40 | 589 |
https://api.github.com/repos/Zeioth/compiler.nvim/tags
|
GPL-3.0
|
[
"build-automation-tool",
"build-tool",
"built-tools",
"compiler",
"csharp",
"elixir",
"go",
"golang",
"javascript",
"lua",
"neovim-plugin",
"neovim-plugins",
"nvim-plugin",
"nvim-plugins",
"python",
"rlanguage",
"rust",
"typescript",
"zig"
] | 3,086 | false |
2025-05-19T13:44:58Z
| false | false |
unknown
|
github
|
[] |
<a>Compiler.nvim</a>
Neovim compiler for building and running your code without having to configure anything.
<a>
</a>
Table of contents
<ul>
<li><a>Why</a></li>
<li><a>Supported languages</a></li>
<li><a>Required system dependencies</a></li>
<li><a>How to install</a></li>
<li><a>Commands</a></li>
<li><a>Basic usage</a></li>
<li><a>Creating a solution (optional)</a></li>
<li><a>Build automation utilities (optional)</a></li>
<li><a>Quick start</a></li>
<li><a>FAQ</a></li>
</ul>
Why
Those familiar with Visual Studio IDE will remember how convenient it was to just press a button and having your program compiled and running. I wanted to bring that same user experience to Neovim.
Supported languages
| Language | More info |
|--|--|
| <a>asm x86-64</a>| |
| <a>c</a> ||
| <a>c++</a> ||
|<a>c#</a> | <a>+info</a> |
| <a>dart</a> | <a>+info</a> |
| <a>elixir</a> | <a>+info</a> |
| <a>fortran</a> | |
| <a>f#</a> |<a>+info</a> |
| <a>gleam</a> |<a>+info</a> |
| <a>flutter</a> | <a>+info</a> |
| <a>go</a> ||
| <a>java</a> | <a>+info</a> |
| <a>javascript</a> | <a>+info</a> |
| <a>kotlin</a> | <a>+info</a> |
| <a>lua</a> ||
| <a>make</a> ||
| <a>perl</a> ||
| <a>python</a> | <a>+info</a> |
| <a>r</a> ||
| <a>ruby</a> ||
| <a>rust</a> ||
| <a>shell</a> | <a>+info</a> |
| <a>swift</a> ||
| <a>typescript</a> | <a>+info</a> |
| <a>visual basic dotnet</a> | <a>+info</a> |
| <a>zig</a> | <a>+info</a> |
Required system dependencies
Some languages require you manually install their compilers in your machine, so compiler.nvim is able to call them. <a>Please check here</a>, as the packages will be different depending your operative system.
How to install
lazy.nvim package manager
<code>lua
{ -- This plugin
"Zeioth/compiler.nvim",
cmd = {"CompilerOpen", "CompilerToggleResults", "CompilerRedo"},
dependencies = { "stevearc/overseer.nvim", "nvim-telescope/telescope.nvim" },
opts = {},
},
{ -- The task runner we use
"stevearc/overseer.nvim",
commit = "6271cab7ccc4ca840faa93f54440ffae3a3918bd",
cmd = { "CompilerOpen", "CompilerToggleResults", "CompilerRedo" },
opts = {
task_list = {
direction = "bottom",
min_height = 25,
max_height = 25,
default_detail = 1
},
},
},</code>
Recommended mappings
```lua
-- Open compiler
vim.api.nvim_set_keymap('n', '', "CompilerOpen", { noremap = true, silent = true })
-- Redo last selected option
vim.api.nvim_set_keymap('n', '',
"CompilerStop" -- (Optional, to dispose all tasks before redo)
.. "CompilerRedo",
{ noremap = true, silent = true })
-- Toggle compiler results
vim.api.nvim_set_keymap('n', '', "CompilerToggleResults", { noremap = true, silent = true })
```
Commands
| Command | Description|
|--|--|
| <code>:CompilerOpen</code> | Shows the adecuated compiler for your buffer's filetype. |
| <code>:CompilerToggleResults</code> | Open or close the compiler results. |
| <code>:CompilerRedo</code> | Redo the last selected option. |
| <code>:CompilerStop</code> | Dispose all tasks. |
How to use (Basic usage)
This is what happen when you select <code>build & run</code>, <code>build</code>, or <code>run</code> in the compiler:
<blockquote>
compiler.nvim will look for the conventional entry point file for the current language you are using. To achieve this, it searches in your current working directory for the next files
</blockquote>
| Language | Default entry point | Default output |
|--|--|--|
| asm x86-64 | ./main.asm | ./bin/program |
| c | ./main.c | ./bin/program |
| c++ | ./main.cpp | ./bin/program |
| c# | ./Program.cs | ./bin/Program.exe |
| dart | ./lib/main.dart | ./bin/main |
| elixir | ./mix.exs | ./_build/ |
| fortran | ./fpm | ./build/ |
| f# | <a>see here</a> | ./bin/ |
| gleam | ./build.toml | ./build |
| flutter | ./pubspec.yaml | ./build/ |
| go | ./main.go | ./bin/program |
| java | ./Main.java | ./bin/Main.class |
| javascript | ./src/index.js | |
| kotlin | ./Main.kt | ./bin/MainKt.class |
| lua | ./main.lua | |
| make | ./Makefile | |
| perl | ./main.pl | |
| python | ./main.py | ./bin/program |
| r | ./main.r | |
| ruby | ./main.rb | |
| rust | ./main.rs | ./bin/program |
| shell | ./main.sh | |
| swift | ./main.swift | ./bin/program |
| typescript | ./src/index.ts | |
| visual basic .net | <a>see here</a> | ./bin/ |
| zig | ./build.zig | ./zig-out/bin/build |
This is how the compilation results look after selecting <code>Build & run program</code> in c
<a>For more info see wiki - when to use every option</a>
Creating a solution (optional)
If you want to have more control, you can create a <code>.solution.toml</code> file in your working directory by using this template where every [entry] represents a program to compile
```toml
[HelloWorld]
entry_point = "/path/to/my/entry_point_file/main.c"
output = "/path/where/the/program/will/be/written/hello_world"
arguments = ""
[SOLUTION]
executable = "/program/to/execute/after/the/solution/has/compiled/my_program"
```
<a>For more examples see wiki</a>.
Build automation utilities (optional)
If any of these files exist in your current working directory, they will be automatically detected and displayed on <a>Compiler.nvim</a>:
| Build automation utility | File | More info |
|--|--|--|
| <a>Make</a>| <code>./Makefile</code> | <a>+info</a> |
| <a>CMake</a> | <code>./CMakeLists.txt</code> | <a>+info</a> |
| <a>Gradle</a> | <code>./build.gradle</code> | <a>+info</a> |
| Maven | <code>./pom.xml</code> | <a>+info</a> |
| <a>NodeJS NPM</a> | <code>./package.json</code> | <a>+info</a> |
| <a>Meson</a> | <code>./meson.build</code> | <a>+info</a> |
Quick start
Create <code>~/c-example/main.c</code> and paste this code. Then do <code>:cd ~/c-example/</code> to change the working directory to the project.
```c
include
int main() {
printf("Hello, World!\n");
return 0;
}
```
Open the compiler and select <code>Build and run</code>. You will see the compilation results.
FAQ
<ul>
<li><strong>I get errors when compiling:</strong> You have to <code>:cd /your/project/root_dir</code> before calling <a>Compiler.nvim</a>.</li>
<li><strong>How can I auto <code>:cd</code> my projects?</strong> Use <a>this fork</a> of the plugin <code>project.nvim</code>.</li>
<li><strong>I don't have time to read:</strong> If you prefer you can try <a>NormalNvim</a> which comes with the compiler pre-installed. Just open some code and hit F6!</li>
<li><strong>Do compiler.nvim support tests?</strong> Testing is not the responsability of a compiler. For that please install the plugin <a>Neotest</a> or similar.</li>
<li><strong>How can I add a language that is not supported yet?</strong> Fork the project, and go to the directory <code>/compiler/languages</code>. Copy <code>c.lua</code> and rename it to any language you would like to add, for example <code>ruby.lua</code>. Now modify the file the way you want. It is important you name the file as the filetype of the language you are implementing. Then please, submit a PR to this repo so everyone can benefit from it.</li>
<li><strong>How can I change the way the compiler works?</strong> Same as the previous one.</li>
<li><strong>How can I add an automation build utility that is not supported yet?</strong> Fork the project, and go to the directory <code>/compiler/bau</code>. Copy <code>make.lua</code> and rename it to the build automation utility you want to add, for example <code>maven.lua</code>. Now modify the file the way you want. Note that you will also have to modify <code>/utilities-bau.lua</code> and change the function <code>get_bau_opts()</code> so it can parse the utility you want to add. Then please, submit a PR to this repo so everyone can benefit from it.</li>
<li><strong>Is this plugin just a compiler, or can I run scripts too?</strong> Yes you can. But if your script receive arguments, we recommend you to use the terminal instead, because creating a <code>.solution.toml</code> file just to be able to pass arguments to your simple shell script is probably a overkill, and not the right tool.</li>
<li><strong>I'm a windows user, do I need to do something special?</strong> You have to <a>enable WSL</a>, and run nvim inside. Otherwise it would be impossible for you to install the <a>required dependencies</a>.</li>
<li><strong>How can I disable notifications when compiling?</strong> Check <a>here</a>.</li>
</ul>
How can I compile videogames?
The workflow of game development is essentially very different from just compiling and running a program. It involve loading editing and running scenes. While there is no way for us to support it directly, here I offer you some tricks:
Godot engine
To <code>Build and run a godot scene</code>, use the command <code>godot /my/scene.tscn</code> on the terminal. This works really well: It's fast and simple.
Unity
The recommended way is to have 2 monitors, one with nvim and your code, and another one with your unity scenes to run the game. Unity has <a>some terminal commands</a>, but working with them is quite a painful experience.
🌟 Support the project
If you want to help me, please star this repository to increase the visibility of the project.
<a></a>
Thanks to all contributors
<a>
</a>
Roadmap
<ul>
<li>Study adding support for justfiles/taskfiles.</li>
<li>We are gonna be adding common LISP support.</li>
<li>We are gonna be adding COBOL support.</li>
<li>Better Windows compatibility when not using WSL: The commands <code>rm -rf</code> and <code>mkdir -p</code> only exist on unix. To support Windows without WSL we should run the equivalent powershell command when Windows is detected.</li>
<li>Aditionally, we will also have to compile for <code>asm</code> win64 architecture, if the detected OS is windows.</li>
<li>Aditionally, we will also have to add an option to compile for <code>Build for windows (flutter)</code>.</li>
</ul>
|
[] |
https://avatars.githubusercontent.com/u/133399259?v=4
|
zig-webui
|
webui-dev/zig-webui
|
2023-05-12T20:21:26Z
|
Use any web browser or WebView as GUI, with Zig in the backend and modern web technologies in the frontend, all in a lightweight portable library.
|
main
| 4 | 588 | 24 | 588 |
https://api.github.com/repos/webui-dev/zig-webui/tags
|
MIT
|
[
"cross-platform-gui",
"gui",
"gui-library",
"linux",
"webui",
"windows",
"zig",
"zig-package",
"zig-webui"
] | 1,853 | false |
2025-05-21T09:41:32Z
| true | true |
0.14.0
|
github
|
[] |

# WebUI Zig v2.5.0-beta.4
[last-commit]: https://img.shields.io/github/last-commit/webui-dev/zig-webui?style=for-the-badge&logo=github&logoColor=C0CAF5&labelColor=414868
[license]: https://img.shields.io/github/license/webui-dev/zig-webui?style=for-the-badge&logo=opensourcehardware&label=License&logoColor=C0CAF5&labelColor=414868&color=8c73cc
[![][last-commit]](https://github.com/webui-dev/zig-webui/pulse)
[![][license]](https://github.com/webui-dev/zig-webui/blob/main/LICENSE)
> Use any web browser or WebView as GUI, with Zig in the backend and modern web technologies in the frontend, all in a lightweight portable library.
Features
<ul>
<li>Portable (<em>Needs only a web browser or a WebView at runtime</em>)</li>
<li>One header file</li>
<li>Lightweight (<em>Few Kb library</em>) & Small memory footprint</li>
<li>Fast binary communication protocol</li>
<li>Multi-platform & Multi-Browser</li>
<li>Using private profile for safety</li>
<li>Cross-platform WebView</li>
</ul>
API Documentation
If you want a clearer architecture, you can check it out <a>here</a>
<ul>
<li><a>https://webui-dev.github.io/zig-webui/</a></li>
<li><a>https://webui.me/docs/2.5/#/</a></li>
</ul>
Examples
There are several examples for newbies, they are in the <code>examples</code> directory.
You can use <code>zig build --help</code> to view all buildable examples.
Like <code>zig build run_minimal</code>, this will build and run the <code>minimal</code> example.
Installation
<blockquote>
note: for <code>0.13.0</code> and previous version, please use tag <code>2.5.0-beta.2</code>
</blockquote>
Zig <code>0.14.0</code> \ <code>nightly</code>
<blockquote>
To be honest, I don’t recommend using the nightly version because the API of the build system is not yet stable, which means that there may be problems with not being able to build after nightly is updated.
</blockquote>
<ol>
<li>Add to <code>build.zig.zon</code></li>
</ol>
```sh
It is recommended to replace the following branch with commit id
zig fetch --save https://github.com/webui-dev/zig-webui/archive/main.tar.gz
Of course, you can also use git+https to fetch this package!
```
<ol>
<li>Config <code>build.zig</code></li>
</ol>
Add this:
<code>``zig
// To standardize development, maybe you should use</code>lazyDependency()<code>instead of</code>dependency()`
// more info to see: https://ziglang.org/download/0.12.0/release-notes.html#toc-Lazy-Dependencies
const zig_webui = b.dependency("zig_webui", .{
.target = target,
.optimize = optimize,
.enable_tls = false, // whether enable tls support
.is_static = true, // whether static link
});
// add module
exe.root_module.addImport("webui", zig_webui.module("webui"));
```
<blockquote>
It is not recommended to dynamically link libraries under Windows, which may cause some symbol duplication problems.
see this issue: https://github.com/ziglang/zig/issues/15107
</blockquote>
Windows without console
For hide console window, you can set <code>exe.subsystem = .Windows;</code>!
UI & The Web Technologies
<a>Borislav Stanimirov</a> discusses using HTML5 in the web browser as GUI at the <a>C++ Conference 2019 (<em>YouTube</em>)</a>.

Web application UI design is not just about how a product looks but how it works. Using web technologies in your UI makes your product modern and professional, And a well-designed web application will help you make a solid first impression on potential customers. Great web application design also assists you in nurturing leads and increasing conversions. In addition, it makes navigating and using your web app easier for your users.
Why Use Web Browsers?
Today's web browsers have everything a modern UI needs. Web browsers are very sophisticated and optimized. Therefore, using it as a GUI will be an excellent choice. While old legacy GUI lib is complex and outdated, a WebView-based app is still an option. However, a WebView needs a huge SDK to build and many dependencies to run, and it can only provide some features like a real web browser. That is why WebUI uses real web browsers to give you full features of comprehensive web technologies while keeping your software lightweight and portable.
How Does it Work?

Think of WebUI like a WebView controller, but instead of embedding the WebView controller in your program, which makes the final program big in size, and non-portable as it needs the WebView runtimes. Instead, by using WebUI, you use a tiny static/dynamic library to run any installed web browser and use it as GUI, which makes your program small, fast, and portable. <strong>All it needs is a web browser</strong>.
Runtime Dependencies Comparison
| | Tauri / WebView | Qt | WebUI |
| ------------------------------- | ----------------- | -------------------------- | ------------------- |
| Runtime Dependencies on Windows | <em>WebView2</em> | <em>QtCore, QtGui, QtWidgets</em> | <strong><em>A Web Browser</em></strong> |
| Runtime Dependencies on Linux | <em>GTK3, WebKitGTK</em> | <em>QtCore, QtGui, QtWidgets</em> | <strong><em>A Web Browser</em></strong> |
| Runtime Dependencies on macOS | <em>Cocoa, WebKit</em> | <em>QtCore, QtGui, QtWidgets</em> | <strong><em>A Web Browser</em></strong> |
Supported Web Browsers
| Browser | Windows | macOS | Linux |
| --------------- | --------------- | ------------- | --------------- |
| Mozilla Firefox | ✔️ | ✔️ | ✔️ |
| Google Chrome | ✔️ | ✔️ | ✔️ |
| Microsoft Edge | ✔️ | ✔️ | ✔️ |
| Chromium | ✔️ | ✔️ | ✔️ |
| Yandex | ✔️ | ✔️ | ✔️ |
| Brave | ✔️ | ✔️ | ✔️ |
| Vivaldi | ✔️ | ✔️ | ✔️ |
| Epic | ✔️ | ✔️ | <em>not available</em> |
| Apple Safari | <em>not available</em> | <em>coming soon</em> | <em>not available</em> |
| Opera | <em>coming soon</em> | <em>coming soon</em> | <em>coming soon</em> |
Supported WebView
| WebView | Status |
| --------------- | --------------- |
| Windows WebView2 | ✔️ |
| Linux GTK WebView | ✔️ |
| macOS WKWebView | ✔️ |
License
<blockquote>
Licensed under the MIT License.
</blockquote>
|
[
"https://github.com/OsakiTsukiko/jellyfish"
] |
https://avatars.githubusercontent.com/u/24392180?v=4
|
linuxwave
|
orhun/linuxwave
|
2023-03-13T22:57:52Z
|
Generate music from the entropy of Linux 🐧🎵
|
main
| 7 | 580 | 19 | 580 |
https://api.github.com/repos/orhun/linuxwave/tags
|
MIT
|
[
"entropy",
"linux",
"linuxwave",
"music",
"music-generation",
"music-generator",
"random",
"random-music",
"retrowave",
"synthwave",
"tune-generator",
"vaporwave",
"wav",
"waveform",
"waveform-generator",
"zig",
"zig-package",
"ziglang"
] | 542 | false |
2025-05-20T21:29:34Z
| true | true |
0.14.0
|
github
|
[
{
"commit": "refs",
"name": "clap",
"tar_url": "https://github.com/Hejsil/zig-clap/archive/refs.tar.gz",
"type": "remote",
"url": "https://github.com/Hejsil/zig-clap"
}
] |
<code>linuxwave</code> 🐧🎵
<a></a>
<a></a>
<a></a>
<a></a>
<a></a>
<a></a>
<a><strong>Click here to watch the demo!</strong></a>
<a>Listen to "linuxwave" on Spotify!</a>
Table of Contents
- [Motivation ✨](#motivation-)
- [Installation 🤖](#installation-)
- [Build from source](#build-from-source)
- [Prerequisites](#prerequisites)
- [Instructions](#instructions)
- [Binary releases](#binary-releases)
- [Arch Linux](#arch-linux)
- [Void Linux](#void-linux)
- [Docker](#docker)
- [Images](#images)
- [Usage](#usage)
- [Building](#building)
- [Examples 🎵](#examples-)
- [Presets 🎹](#presets-)
- [Usage 📚](#usage-)
- [`scale`](#scale)
- [`note`](#note)
- [`rate`](#rate)
- [`channels`](#channels)
- [`format`](#format)
- [`volume`](#volume)
- [`duration`](#duration)
- [`input`](#input)
- [`output`](#output)
- [Funding 💖](#funding-)
- [Contributing 🌱](#contributing-)
- [License ⚖️](#license-)
- [Copyright ⛓️](#copyright-)
Motivation ✨
<ul>
<li><a>Bash One Liner - Compose Music From Entropy in /dev/urandom</a></li>
<li><a>'Music' from /dev/urandom</a></li>
</ul>
Installation 🤖
Build from source
Prerequisites
<ul>
<li><a>Zig</a> (<code>0.14</code>)</li>
</ul>
Instructions
<ol>
<li>Clone the repository.</li>
</ol>
<code>sh
git clone https://github.com/orhun/linuxwave && cd linuxwave/</code>
<ol>
<li>Build.</li>
</ol>
<code>sh
zig build --release=safe</code>
Binary will be located at <code>zig-out/bin/linuxwave</code>. You can also run the binary directly via <code>zig build run</code>.
If you want to use <code>linuxwave</code> in your Zig project as a package, the API documentation is available <a>here</a>.
Binary releases
See the available binaries for different targets from the <a>releases page</a>. They are automated via <a>Continuous Deployment</a> workflow.
Release tarballs are signed with the following PGP key: <a>0xC0701E98290D90B8</a>
Arch Linux
<code>linuxwave</code> can be installed from the <a>community repository</a> using <a>pacman</a>:
<code>sh
pacman -S linuxwave</code>
Void Linux
<code>linuxwave</code> can be installed from official Void Linux package repository:
<code>sh
xbps-install linuxwave</code>
Docker
Images
Docker builds are <a>automated</a> and images are available in the following registries:
<ul>
<li><a>Docker Hub</a></li>
<li><a>GitHub Container Registry</a></li>
</ul>
Usage
The following command can be used to generate <code>output.wav</code> in the current working directory:
<code>sh
docker run --rm -v "$(pwd)":/app "orhunp/linuxwave:${TAG:-latest}"</code>
Building
Custom Docker images can be built from the <a>Dockerfile</a>:
<code>sh
docker build -t linuxwave .</code>
Examples 🎵
<strong>Default</strong>: Read random data from <code>/dev/urandom</code> to generate a 20-second music composition in the A4 scale and save it to <code>output.wav</code>:
<code>sh
linuxwave</code>
Or play it directly with <a>mpv</a> without saving:
<code>sh
linuxwave -o - | mpv -</code>
To use the A minor blues scale:
<code>sh
linuxwave -s 0,3,5,6,7,10 -n 220 -o blues.wav</code>
Read from an arbitrary file and turn it into a 10-second music composition in the C major scale:
<code>sh
linuxwave -i build.zig -n 261.63 -d 10 -o music.wav</code>
Read from stdin via giving <code>-</code> as input:
<code>sh
cat README.md | linuxwave -i -</code>
Write to stdout via giving <code>-</code> as output:
<code>linuxwave -o - > output.wav</code>
Presets 🎹
Generate a <strong>calming music</strong> with a sample rate of 2000 Hz and a 32-bit little-endian signed integer format:
<code>sh
linuxwave -r 2000 -f S32_LE -o calm.wav</code>
Generate a <strong>chiptune music</strong> with a sample rate of 44100 Hz, stereo (2-channel) output and 8-bit unsigned integer format:
<code>sh
linuxwave -r 44100 -f U8 -c 2 -o chiptune.wav</code>
Generate a <strong>boss stage music</strong> with the volume of 65:
<code>sh
linuxwave -s 0,7,1 -n 60 -v 65 -o boss.wav</code>
Generate a <strong>spooky low-fidelity music</strong> with a sample rate of 1000 Hz, 4-channel output:
<code>sh
linuxwave -s 0,1,5,3 -n 100 -r 1000 -v 55 -c 4 -o spooky_manor.wav</code>
Feel free to <a>submit a pull request</a> to show off your preset here!
Also, see <a>this discussion</a> for browsing the music generated by our community.
Usage 📚
<code>Options:
-s, --scale <SCALE> Sets the musical scale [default: 0,2,3,5,7,8,10,12]
-n, --note <HZ> Sets the frequency of the note [default: 440 (A4)]
-r, --rate <HZ> Sets the sample rate [default: 24000]
-c, --channels <NUM> Sets the number of channels [default: 1]
-f, --format <FORMAT> Sets the sample format [default: S16_LE]
-v, --volume <VOL> Sets the volume (0-100) [default: 50]
-d, --duration <SECS> Sets the duration [default: 20]
-i, --input <FILE> Sets the input file [default: /dev/urandom]
-o, --output <FILE> Sets the output file [default: output.wav]
-V, --version Display version information.
-h, --help Display this help and exit.</code>
<code>scale</code>
Sets the musical scale for the output. It takes a list of <a>semitones</a> separated by commas as its argument.
The default value is <code>0,2,3,5,7,8,10,12</code>, which represents a major scale starting from C.
Here are other examples:
<ul>
<li>A natural minor scale: <code>0,2,3,5,7,8,10</code></li>
<li>A pentatonic scale starting from G: <code>7,9,10,12,14</code></li>
<li>A blues scale starting from D: <code>2,3,4,6,7,10</code></li>
<li>An octatonic scale starting from F#: <code>6,7,9,10,12,13,15,16</code></li>
<li>Ryukyuan (Okinawa) Japanese scale: <code>4,5,7,11</code></li>
</ul>
<code>note</code>
The <code>note</code> option sets the frequency of the note played. It takes a frequency in Hz as its argument.
The default value is <code>440</code>, which represents A4. You can see the frequencies of musical notes <a>here</a>.
Other examples would be:
<ul>
<li>A3 (220 Hz)</li>
<li>C4 (261.63 Hz)</li>
<li>G4 (392 Hz)</li>
<li>A4 (440 Hz) (default)</li>
<li>E5 (659.26 Hz)</li>
</ul>
<code>rate</code>
Sets the sample rate for the output in Hertz (Hz).
The default value is <code>24000</code>.
<code>channels</code>
Sets the number of audio channels in the output file. It takes an integer as its argument, representing the number of audio channels to generate. The default value is <code>1</code>, indicating mono audio.
For stereo audio, set the value to <code>2</code>. For multi-channel audio, specify the desired number of channels.
Note that the more audio channels you use, the larger the resulting file size will be.
<code>format</code>
Sets the sample format for the output file. It takes a string representation of the format as its argument.
The default value is <code>S16_LE</code>, which represents 16-bit little-endian signed integer.
Possible values are:
<ul>
<li><code>U8</code>: Unsigned 8-bit.</li>
<li><code>S16_LE</code>: Signed 16-bit little-endian.</li>
<li><code>S24_LE</code>: Signed 24-bit little-endian.</li>
<li><code>S32_LE</code>: Signed 32-bit little-endian.</li>
</ul>
<code>volume</code>
Sets the volume of the output file as a percentage from 0 to 100.
The default value is <code>50</code>.
<code>duration</code>
Sets the duration of the output file in seconds. It takes a float as its argument.
The default value is <code>20</code> seconds.
<code>input</code>
Sets the input file for the music generation. It takes a filename as its argument.
The default value is <code>/dev/urandom</code>, which generates random data.
You can provide <em>any</em> type of file for this argument and it will generate music based on the contents of that file.
<code>output</code>
Sets the output file. It takes a filename as its argument.
The default value is <code>output.wav</code>.
Funding 💖
If you find <code>linuxwave</code> and/or other projects on my <a>GitHub profile</a> useful, consider supporting me on <a>GitHub Sponsors</a> or <a>becoming a patron</a>!
<a></a>
<a></a>
<a></a>
Contributing 🌱
See our <a>Contribution Guide</a> and please follow the <a>Code of Conduct</a> in all your interactions with the project.
License ⚖️
Licensed under <a>The MIT License</a>.
Copyright ⛓️
Copyright © 2023-2024, <a>Orhun Parmaksız</a>
|
[] |
https://avatars.githubusercontent.com/u/125191897?v=4
|
mewz
|
mewz-project/mewz
|
2023-12-28T05:40:06Z
|
A unikernel designed specifically for running Wasm applications and compatible with WASI
|
main
| 11 | 576 | 15 | 576 |
https://api.github.com/repos/mewz-project/mewz/tags
|
GPL-3.0
|
[
"kernel",
"unikernel",
"wasm",
"webassembly",
"webassembly-runtime",
"zig"
] | 1,250 | false |
2025-05-22T03:19:23Z
| true | false |
unknown
|
github
|
[] |
<a></a>
Mewz
Mewz is a unikernel designed specifically for running Wasm applications and compatible with WASI.
What's new with Mewz
There are now various Wasm runtimes, but they operate on general-purpose operating systems such as Linux or Windows.
Mewz is <strong>a specialized kernel designed for running Wasm</strong>. Mewz runs a single Wasm application within the kernel by linking it together during the build process with the Wasm application. (A kernel composed in this manner is commonly referred to as a <strong>unikernel</strong>.) In this way, Mewz provides <strong>the minimal required features and environment for executing Wasm</strong>.
Quick Start
There are some example programs. Please check out <a>examples</a>.
Option1: Docker
We prepare for a Docker image that has a environment for running Mewz.
<code>sh
curl -o helloworld.wat https://raw.githubusercontent.com/Mewz-project/Wasker/main/helloworld.wat
docker run -v .:/volume ghcr.io/mewz-project/mewz helloworld.wat</code>
This image internally run <a>Wasker</a>, build Mewz, and run it on QEMU.
Option2: Dev Container
You can use Dev Container on GitHub Codespaces or your local VSCode.
To start Codespaces,
<ul>
<li>Click Code -> Codespaces -> New codespace on this repository page.</li>
<li>Wait for a while, then you can see VSCode on browser.</li>
<li>Open terminal on VSCode</li>
</ul>
```sh
On the Dev Container
git submodule update --init
curl -o helloworld.wat https://raw.githubusercontent.com/Mewz-project/Wasker/main/helloworld.wat
wasker helloworld.wat
zig build -Dapp-obj=wasm.o run
```
Option3: Build from source
Compile a Wasm file into a native object file, using <a>Wasker</a>. Follow the instruction <a>here</a>.
Then, build Mewz and run it on QEMU with the following commands.
<code>sh
zig build -Dapp-obj=<path to the object file generated by Wasker> run</code>
To use file systems, specify the directory by <code>-Ddir=<path to dir></code>. See <a>examples/static_file_server</a>.
<blockquote>
<span class="bg-yellow-100 text-yellow-800 text-xs font-medium me-2 px-2.5 py-0.5 rounded dark:bg-yellow-900 dark:text-yellow-300">WARNING</span>
This option makes an archive of the directory by <code>tar</code> and attach it to QEMU.
<span class="bg-blue-100 text-blue-800 text-xs font-medium me-2 px-2.5 py-0.5 rounded dark:bg-blue-900 dark:text-blue-300">NOTE</span>
QEMU's port 1234 is mapped to localhost:1234.
</blockquote>
Development
GDB
You can debug Mewz with GDB. When you run Mewz with QEMU, it listens on port 12345 for GDB. You can connect to it by just running GDB at the root of the repository as <code>.gdbinit</code> is already configured.
```sh
zig build -Dapp-obj= run
In another terminal
gdb
```
<code>zig build debug</code> command prevent Mewz from booting up until GDB connects to it. This is useful when you want to debug the boot process.
```sh
zig build -Dapp-obj= debug
In another terminal
gdb
```
Run integration tests
<code>sh
zig bulid -Dtest=true run</code>
Current Status
| Feature | Status |
|:---------------------:| :--------------------------------------------------------------------------------------------------: |
| WASI Preview 1 | In Progress: Partial Implementation (Please refer to https://github.com/Mewz-project/Mewz/issues/1) |
| Socket | ✅ (WasmEdge Compatible) |
| Component Model | Not yet |
| File System | On memory, read only |
| Network | ✅ |
|
[] |
https://avatars.githubusercontent.com/u/119983202?v=4
|
ziggy-pydust
|
spiraldb/ziggy-pydust
|
2023-08-31T10:09:27Z
|
A toolkit for building Python extensions in Zig.
|
develop
| 29 | 565 | 24 | 565 |
https://api.github.com/repos/spiraldb/ziggy-pydust/tags
|
Apache-2.0
|
[
"python",
"zig"
] | 43,310 | false |
2025-05-21T14:13:53Z
| true | false |
unknown
|
github
|
[] |
Ziggy Pydust
<a>
</a>
<em>A framework for writing and packaging native Python extension modules written in Zig.</em>
<a target="_blank">
</a>
<a target="_blank">
</a>
<a target="_blank">
</a>
<a target="_blank">
</a>
<strong>Documentation</strong>: <a target="_blank">https://pydust.fulcrum.so/latest</a>
<strong>API</strong>: <a target="_blank">https://pydust.fulcrum.so/latest/zig</a>
<strong>Source Code</strong>: <a target="_blank">https://github.com/fulcrum-so/ziggy-pydust</a>
<strong>Template</strong>: <a target="_blank">https://github.com/fulcrum-so/ziggy-pydust-template</a>
Ziggy Pydust is a framework for writing and packaging native Python extension modules written in Zig.
<ul>
<li>Package Python extension modules written in Zig.</li>
<li>Pytest plugin to discover and run Zig tests.</li>
<li>Comptime argument wrapping / unwrapping for interop with native Zig types.</li>
</ul>
```zig
const py = @import("pydust");
pub fn fibonacci(args: struct { n: u64 }) u64 {
if (args.n < 2) return args.n;
<code>var sum: u64 = 0;
var last: u64 = 0;
var curr: u64 = 1;
for (1..args.n) {
sum = last + curr;
last = curr;
curr = sum;
}
return sum;
</code>
}
comptime {
py.rootmodule(@This());
}
```
Compatibility
Pydust supports:
<ul>
<li><a>Zig 0.14.0</a></li>
<li><a>CPython >=3.11</a></li>
</ul>
Please reach out if you're interested in helping us to expand compatibility.
Getting Started
Pydust docs can be found <a>here</a>.
Zig documentation (beta) can be found <a>here</a>.
There is also a <a>template repository</a> including Poetry build, Pytest and publishing from Github Actions.
Contributing
We welcome contributions! Pydust is in its early stages so there is lots of low hanging
fruit when it comes to contributions.
<ul>
<li>Assist other Pydust users with GitHub issues or discussions.</li>
<li>Suggest or implement features, fix bugs, fix performance issues.</li>
<li>Improve our documentation.</li>
<li>Write articles or other content demonstrating how you have used Pydust.</li>
</ul>
License
Pydust is released under the <a>Apache-2.0 license</a>.
|
[] |
https://avatars.githubusercontent.com/u/206480?v=4
|
pg.zig
|
karlseguin/pg.zig
|
2023-10-26T02:13:32Z
|
Native PostgreSQL driver / client for Zig
|
master
| 1 | 369 | 27 | 369 |
https://api.github.com/repos/karlseguin/pg.zig/tags
|
MIT
|
[
"postgresql-client",
"zig",
"zig-library",
"zig-package"
] | 537 | false |
2025-05-20T19:11:22Z
| true | true |
unknown
|
github
|
[
{
"commit": "e9c95a7719996ce5e1e6a9a6eb3945dda9d98e28.tar.gz",
"name": "buffer",
"tar_url": "https://github.com/karlseguin/buffer.zig/archive/e9c95a7719996ce5e1e6a9a6eb3945dda9d98e28.tar.gz.tar.gz",
"type": "remote",
"url": "https://github.com/karlseguin/buffer.zig"
},
{
"commit": "cf2797bcb3aea7e5cdaf4de39c5550c70796e7b1.tar.gz",
"name": "metrics",
"tar_url": "https://github.com/karlseguin/metrics.zig/archive/cf2797bcb3aea7e5cdaf4de39c5550c70796e7b1.tar.gz.tar.gz",
"type": "remote",
"url": "https://github.com/karlseguin/metrics.zig"
}
] |
Native PostgreSQL driver for Zig
A native PostgresSQL driver / client for Zig. Supports <a>LISTEN</a>.
See or run <a>example/main.zig</a> for a number of examples.
Install
1) Add pg.zig as a dependency in your <code>build.zig.zon</code>:
<code>bash
zig fetch --save git+https://github.com/karlseguin/pg.zig#master</code>
2) In your <code>build.zig</code>, add the <code>pg</code> module as a dependency you your program:
```zig
const pg = b.dependency("pg", .{
.target = target,
.optimize = optimize,
});
// the executable from your call to b.addExecutable(...)
exe.root_module.addImport("pg", pg.module("pg"));
```
Example
```zig
var pool = try pg.Pool.init(allocator, .{
.size = 5,
.connect = .{
.port = 5432,
.host = "127.0.0.1",
},
.auth = .{
.username = "postgres",
.database = "postgres",
.password = "postgres",
.timeout = 10_000,
}
});
defer pool.deinit();
var result = try pool.query("select id, name from users where power > $1", .{9000});
defer result.deinit();
while (try result.next()) |row| {
const id = row.get(i32, 0);
// this is only valid until the next call to next(), deinit() or drain()
const name = row.get([]u8, 1);
}
```
Pool
The pool keeps a configured number of database connection open. The <code>acquire()</code> method is used to retrieve a connection from the pool. The pool may start one background thread to attempt to reconnect disconnected connections (or connections which are in an invalid state).
init(allocator: std.mem.allocator, opts: Opts) !*Pool
Initializes a connection pool. Pool options are:
<ul>
<li><code>size</code> - Number of connections to maintain. Defaults to <code>10</code></li>
<li><code>auth</code>: - See <a>Conn.auth</a></li>
<li><code>connect</code>: - See the <a>Conn.open</a></li>
<li><code>timeout</code>: - The amount of time, in milliseconds, to wait for a connection to be available when <code>acquire()</code> is called.</li>
<li><code>connect_on_init_count</code>: - The # of connections in the pool to eagerly connect during <code>init</code>. Defaults to <code>null</code> which will initiliaze all connections (<code>size</code>). The background reconnector is used to setup the remaining (<code>size - connect_on_init_count</code>) connections. This can be set to <code>0</code>, to prevent <code>init</code> from failing except in extreme cases (i.e. OOM), but that will hide any configuration/connection issue until the first query is executed.</li>
</ul>
initUri(allocator: std.mem.Allocator, uri: std.Uri, opts: Opts) !*Pool
Initializes a connection pool using a std.Uri. When using this function, the <code>auth</code> and <code>connect</code> fields of <code>opts</code> should <strong>not</strong> be set, as these will automatically set based on the provided <code>uri</code>.
<code>zig
const uri = try std.Uri.parse("postgresql://username:password@localhost:5432/database_name");
const pool = try pg.Pool.initUri(allocator, uri, 5, 10_000);
defer pool.deinit();</code>
acquire() !*Conn
Returns a <a>*Conn</a> for the connection pool. Returns an <code>error.Timeout</code> if the connection cannot be acquired (i.e. if the pool remains empty) for the <code>timeout</code> configuration passed to <code>init</code>.
<code>zig
const conn = try pool.acquire();
defer pool.release(conn);
_ = try conn.exec("...", .{...});</code>
release(conn: *Conn) void
Releases the conection back into the pool. Calling <code>pool.release(conn)</code> is the same as calling <code>conn.release()</code>.
newListener() !Listener
Returns a new <a>Listener</a>. This function creates a new connection, it does not use/acquire a connection from the pool. It is a convenience function for cases which have already setup a pool (with the connection and authentication configuration) and want to create a listening connection using those settings.
exec / query / queryOpts / row / rowOpts
For single-query operations, the pool offers wrappers around the connection's <code>exec</code>, <code>query</code>, <code>queryOpts</code>, <code>row</code> and <code>rowOpts</code> methods. These are convenience methods.
<code>pool.exec</code> acquires, executes and releases the connection.
<code>pool.query</code> and <code>pool.queryOpts</code> acquire and execute the query. The connection is automatically returned to the pool when <code>result.deinit()</code> is called. Note that this is a special behavior of <code>pool.query</code>. When the result comes explicitly from a <code>conn.query</code>, <code>result.deinit()</code> does not automatically release the connection back into the pool.
<code>pool.row</code> and <code>pool.rowOpts</code> acquire and execute the query. The connection is automatically returned to the pool when <code>row.deinit()</code> is called. Note that this is a special behavior of <code>pool.row</code>. When the result comes explicitly from a <code>conn.row</code>, <code>row.deinit()</code> does not automatically release the connection back into the pool.
Conn
open(allocator: std.mem.Allocator, opts: Opts) !Conn
Opens a connection, or returns an error. Prefer creating connections through the pool. Connection options are:
<ul>
<li><code>host</code> - Defaults to <code>"127.0.0.1"</code></li>
<li><code>port</code> - Defaults to <code>5432</code></li>
<li><code>write_buffer</code> - Size of the write buffer, used when sending messages to the server. Will temporarily allocate more space as needed. If you're writing large SQL or have large parameters (e.g. long text values), making this larger might improve performance a little. Defaults to <code>2048</code>, cannot be less than <code>128</code>.</li>
<li><code>read_buffer</code> - Size of the read buffer, used when reading data from the server. Will temporarily allocate more space as needed. Given most apps are going to be reading rows of data, this can have large impact on performance. Defaults to <code>4096</code>.</li>
<li><code>result_state_size</code> - Each <code>Result</code> (retrieved via a call to <code>query</code>) carries metadata about the data (e.g. the type of each column). For results with less than or equal to <code>result_state_size</code> columns, a static <code>state</code> container is used. Queries with more columns require a dynamic allocation. Defaults to <code>32</code>. </li>
</ul>
deinit(conn: *Conn) void
Closes the connection and releases its resources. This method should not be used when the connection comes from the pool.
auth(opts: Opts) !void
Authentications the request. Prefer creating connections through the pool. Auth options are:
<ul>
<li><code>username</code>: Defaults to <code>"postgres"</code></li>
<li><code>password</code>: Defaults to <code>null</code></li>
<li><code>database</code>: Defaults to <code>null</code></li>
<li><code>timeout</code> : Defaults to <code>10_000</code> (milliseconds)</li>
<li><code>application_name</code>: Defaults to <code>null</code></li>
<li><code>params</code>: Defaults to <code>null</code>. An <code>std.StringHashMap([]const u8)</code></li>
</ul>
release(conn: *Conn) void
Releases the connection back to the pool. The pool might decide to close the connection and open a new one.
exec(sql: []const u8, args: anytype) !?usize
Executes the query with arguments, returns the number of rows affected, or null. Should not be used with a query that returns rows.
query(sql: []const u8, args: anytype) !Result
Executes the query with arguments, returns <a>Result</a>. <code>deinit</code>, and possibly <code>drain</code>, must be called on the returned <code>result</code>.
queryOpts(sql: []const u8, args: anytype, opts: Conn.QueryOpts) !Result
Same as <code>query</code> but takes options:
<ul>
<li><code>timeout: ?u32</code> - This is not reliable and should probably not be used. Currently it simply puts a recv socket timeout. On timeout, the connection will likely no longer be valid (which the pool will detect and handle when the connection is released) and the underlying query will likely still execute. Defaults to <code>null</code></li>
<li><code>column_names: bool</code> - Whether or not the <code>result.column_names</code> should be populated. When true, this requires memory allocation (duping the column names). Defaults to <code>false</code></li>
<li><code>allocator</code> - The allocator to use for any allocations needed when executing the query and reading the results. When <code>null</code> this will default to the connection's allocator. If you were executing a query in a web-request and each web-request had its own arena tied to the lifetime of the request, it might make sense to use that arena. Defaults to <code>null</code>.</li>
<li><code>release_conn: bool</code> - Whether or not to call <code>conn.release()</code> when <code>result.deinit()</code> is called. Useful for writing a function that acquires a connection from a <code>Pool</code> and returns a <code>Result</code>. When <code>query</code> or <code>row</code> are called from a <code>Pool</code> this is forced to <code>true</code>. Otherwise, defaults to <code>false</code>. </li>
</ul>
row(sql: []const u8, args: anytype) !?QueryRow
Executes the query with arguments, returns a single row. Returns an error if the query returns more than one row. Returns <code>null</code> if the query returns no row. <code>deinit</code> must be called on the returned <code>QueryRow</code>.
rowOpts(sql: []const u8, args: anytype, opts: Conn.QueryOpts) !Result
Same as <code>row</code> but takes the same options as <code>queryOpts</code>
prepare(sql: []const u8) !Stmt
Creates a <a>Stmt</a>. It is generally better to use <code>query</code>, <code>row</code> or <code>exec</code>,
prepareOpts(sql: []const u8, opts: Conn.QueryOpts) !Stmt
Same as <code>prepare</code> but takes the same options as <code>queryOpts</code>
begin() !void
Calls <code>_ = try execOpts("begin", .{}, .{})</code>
commit() !void
Calls <code>_ = try execOpts("commit", .{}, .{})</code>
rollback() !void
Calls <code>_ = try execOpts("rollback", .{}, .{})</code>
Result
The <code>conn.query</code> and <code>conn.queryOpts</code> methods return a <code>pg.Result</code> which is used to read rows and values.
Fields
<ul>
<li><code>number_of_columns: usize</code> - Number of columns in the result</li>
<li><code>column_names: [][]const u8</code> - Names of the column, empty unless the query was executed with the <code>column_names = true</code> option.</li>
</ul>
deinit(result: *Result) void
Releases resources associated with the result.
drain(result: *Result) !void
If you do not iterate through the result until <code>next</code> returns <code>null</code>, you must call <code>drain</code>.
Why can't <code>deinit</code> handle this? If <code>deinit</code> also drained, you'd have to handle a possible error in <code>deinit</code> and you can't <code>try</code> in a defer. Thus, this is done to provide better ergonomics for the normal case - the normal case being where <code>next</code> is called until it returns <code>null</code>. In these cases, just <code>defer result.deinit()</code>.
next(result: *Result) !?Row
Iterates to the next row of the result, or returns null if there are no more rows.
columnIndex(result: *Result, name: []const u8) ?usize
Returns the index of the column with the given name. This is only valid when the query is executed with the <code>column_names = true</code> option.
mapper(result: *Result, T: type, opts: MapperOpts) Mapper(T)
Returns a Mapper which can be used to create a T for each row. Mapping from column to field is done by name. This is an optimized version of <a>row.to</a> when iterating through multiple rows with the <code>{.map = .name}</code>.
See <a>row.to</a> and <a>Mapper</a> for more information.
Row
The <code>row</code> represents a single row from a result. Any non-primitive value that you get from the <code>row</code> are valid only until the next call to <code>next</code>, <code>deinit</code> or <code>drain</code>.
Fields
Only advance usage will need access to the row fields:
<ul>
<li><code>oids: []i32</code> - The PG OID value for each column in the row. See <code>result.number_of_columns</code> for the length of this slice. Might be useful if you're trying to read a non-natively supported type.</li>
<li><code>values: []Value</code> - The underlying byte value for each column in the row. See <code>result.number_of_columns</code> for the length of this slice. Might be useful if you're trying to read a non-natively supported type. Has two fields, <code>is_null: bool</code> and <code>data: []const u8</code>.</li>
</ul>
get(comptime T: type, col: usize) T
Gets a value from the row at the specified column index (0-based). <strong>Type mapping is strict.</strong> For example, you <strong>cannot</strong> use <code>i32</code> to read an <code>smallint</code> column.
For any supported type, you can use an optional instead. Therefore, if you use <code>row.get(i16, 0)</code> the return type is <code>i16</code>. If you use <code>row.get(?i16, 0)</code> the return type is <code>?i16</code>. If you use a non-optional type for a null value, you'll get a failed assertion in <code>Debug</code> and <code>ReleaseSafe</code>, and undefined behavior in <code>ReleaseFast</code>, <code>ReleaseSmall</code> or if you set <code>pg_assert = false</code>.
<ul>
<li><code>u8</code> - <code>char</code></li>
<li><code>i16</code> - <code>smallint</code></li>
<li><code>i32</code> - <code>int</code></li>
<li><code>i64</code> - Depends on the underlying column type. A <code>timestamp(tz)</code> will be converted to microseconds since unix epoch. Otherwise, a <code>bigint</code>.</li>
<li><code>f32</code> - <code>float4</code></li>
<li><code>f64</code> - Depends on the underlying column type. A <code>numeric</code> will be converted to an <code>f64</code>. Otherwise, a <code>float</code>.</li>
<li><code>bool</code> - <code>bool</code></li>
<li><code>[]const u8</code> - Returns the raw underlying data. Can be used for any column type to get the PG-encoded value. For <code>text</code> and <code>bytea</code> columns, this will be the expected value. For <code>numeric</code>, this will be a text representation of the number. For <code>UUID</code> this will be a 16-byte slice (use <code>pg.uuidToHex [36]u8</code> if you want a hex-encoded UUID). For <code>JSON</code> and <code>JSONB</code> this will be the serialized JSON value.</li>
<li><code>[]u8</code> - Same as []const u8 but returns a mutable value.</li>
<li><code>pg.Numeric</code> - See numeric section</li>
<li><code>pg.Cidr</code> - See CIDR/INET section</li>
</ul>
getCol(comptime T: type, column_name: []const u8) T
Same as <code>get</code> but uses the column name rather than its position. Only valid when the <code>column_names = true</code> option is passed to <code>queryOpts</code>.
This relies on calling <code>result.columnIndex</code> which iterates through <code>result.column_names</code> fields. In some cases, this is more efficient than <code>StringHashMap</code> lookup, in others, it is worse. For performance-sensitive code, prefer using <code>get</code>, or cache the column index in a local variables outside of the <code>next()</code> loop:
<code>zig
const id_idx = result.columnIndex("id").?
while (try result.next()) |row| {
// row.get(i32, id_idx)
}</code>
Array Columns
Use <code>row.get(pg.Iterator(i32))</code> to return an <a>Iterator</a> over an array column. Supported array types are:
<ul>
<li><code>u8</code> - <code>char[]</code></li>
<li><code>i16</code> - <code>smallint[]</code></li>
<li><code>i32</code> - <code>int[]</code></li>
<li><code>i64</code> - <code>bigint[]</code> or <code>timestamp(tz)[]</code> (see <code>get</code>)</li>
<li><code>f32</code> - <code>float4</code></li>
<li><code>f64</code> - <code>float8</code></li>
<li><code>bool</code> - <code>bool[]</code></li>
<li><code>[]const u8</code> - More strict than <code>get([]u8)</code>). Supports: <code>text[]</code>, <code>char(n)[]</code>, <code>bytea[]</code>, <code>uuid[]</code>, <code>json[]</code> and <code>jsonb[]</code></li>
<li><code>[]u8</code> - Same as <code>[]const u8</code> but returns mutable value.</li>
<li><code>pg.Numeric</code> - See numeric section</li>
<li><code>pg.Cidr</code> - See CIDR/INET section</li>
</ul>
record(col: usize) Record
Gets a <a>Record</a> by column position.
recordCol(column_name: []const u8) Record
Gets an <a>Record</a> by column name. See <a>getCol</a> for performance notes.
to(T: type, opts: ToOpts) !T
Populates and returns a <code>T</code>.
<code>opts</code> values are:
* <code>dupe</code> - Duplicate string columns using the internal arena. When set to <code>true</code> non-scalar values are valid until <code>deinit</code> is called on the <code>row</code>/<code>result</code>. Defaults to <code>false</code>
* <code>allocator</code> - Allocator to use to duplicate non-scalar values (i.e. strings). It is the caller's responsible to free any non-scalar values from their structure. Defaults to <code>null</code>.
* <code>map</code> - <code>.ordinal</code> or <code>.name</code>, defaults to <code>.ordinal</code>
Setting <code>allocator</code> implies <code>dupe</code>, but uses the specified allocator rather than the internal arena. By default (when <code>dupe</code> is <code>false</code> and <code>allocator</code> is <code>null</code>), non-scalar values (i.e. strings) are only valid until the next call to <code>next()</code> or <code>drain()</code> or <code>deinit()</code>.
When <code>.map = .ordinal</code>, the default, the order of the field names must match the order of the columns.
When <code>.map = .name</code>, the query must be executed with the <code>{.column_names = true}</code> option. Columns with no field equivalent are ignored. Fields with no column equivalent are set to their default value; if they do not have a default value the function will return <code>error.FieldColumnMismatch</code>. If you're going to use this in a loop with a <code>result</code>, consider using a <a>Mapper</a> to avoid the name->index lookup on each iteration.
Slice fields can either be mapped to a <code>pg.Iterator(T)</code> or a slice. When mapped to a <code>slice</code>, an allocator MUST be provided. When mapping to an array of strings (i.e. [][]const u8), the values are duped, and thus both the values and the slice itself must be freed. When mapping to a slice of primitives (i.e. []i32) the slice must be freed. When mapping to an <code>pg.Iterator(T)</code> with a custom allocator (<code>.{.allocator = allocator}</code>), the iterator must be freed by calling <code>iteartor.deinit(allocator)</code>. Whether you're mapping to an <code>pg.Iterator(T)</code> or a slice, I Strongly suggest you use an ArenaAllocator.
QueryRow
A <code>QueryRow</code> is returned from a call to <code>conn.row</code> or <code>conn.rowOpts</code> and wraps both a <code>Result</code> and a <code>Row.</code> It exposes the same methods as <code>Row</code> as well as <code>deinit</code>, which must be called once the <code>QueryRow</code> is no longer needed. This is a rare case where <code>deinit()</code> can fail. In most cases, you can simply throw away the error (because failure is extremely rare and, if the connection came from a pool, it should repair itself).
Iterator(T)
The iterator returned from <code>row.get(pg.Iterator(T), col)</code> can be iterated using the <code>next() ?T</code> call:
<code>zig
var names = row.get(pg.Iterator([]const u8), 0);
while (names.next()) |name| {
...
}</code>
Fields
<ul>
<li><code>len</code> - the number of values in the iterator</li>
</ul>
alloc(it: Iterator(T), allocator: std.mem.Allocator) ![]T
Allocates a slice and populates it with all values.
If the slice is a <code>[]u8</code> or <code>[]const u8</code>, the string is also duplicated. It is the responsibility of the caller to free the string values AND the slice.
fill(it: Iterator(T), into: []T) void
Fill <code>into</code> with values of the iterator. <code>into</code> can be smaller than <code>it.len</code>, in which case only <code>into.len</code> values will be filled. This can be a bit faster than calling <code>next()</code> multiple times. Values are not duplicated; they are only valid until the next iterations.
Record
Returned by <code>row.record(col)</code> for fetching a PostgreSQL record-type, for example from this query:
<code>sql
select row('over', 9000)</code>
In many cases, PostgreSQL will mark the inner-types as "unknown", which is likely to cause assertion failures in this library. The solution is to type each value:
<code>sql
select row('over'::text, 9000::int)</code>
Fields
<ul>
<li><code>number_of_columns</code> - the number of columns in the record</li>
</ul>
next(T) T
Gets the next column in the record. This behaves similarly <a>row.get</a> with the same supported types for <code>T</code>, including nullables.
Mapper
A mapper is used to iterate through a result and turn a row into an instance of <code>T</code>. When converting a single row, or using ordinal mapping, prefer using <a>row.to</a>. The mapper is an optimization over <code>row.to</code> with the <code>{.map = .name}</code> option which only has to do the name -> index lookup once.
To use a mapper, the <code>{.column_names = true}</code> option must be passed to the query/row function.
```zig
const User = struct {
id: i32,
name: []const u8,
};
///...
var result = try conn.queryOpts("select id, name from users", .{}, .{.column_names = true});
defer result.deinit();
var mapper = result.mapper(User, .{});
while (try mapper.next()) |user| {
// use: user.id and user.name
}
```
A column with no matching field is ignored. A field with no matching column is set to its default fault. If no default value is defined, <code>mapper.next()</code> will return <code>error.FieldColumnMismatch</code>.
The 2nd argument to <code>result.mapper</code> is an option:
<ul>
<li><code>dupe</code> - Duplicate string columns using the internal arena. When set to <code>true</code> non-scalar values are valid until <code>deinit</code> is called on the <code>row</code>/<code>result</code>. Defaults to <code>false</code></li>
<li><code>allocator</code> - Allocator to use to duplicate non-scalar values (i.e. strings). It is the caller's responsible to free any non-scalar values from their structure. Defaults to <code>null</code>.</li>
</ul>
Setting <code>allocator</code> implies <code>dupe</code>, but uses the specified allocator rather than the internal arena. By default (when <code>dupe</code> is <code>false</code> and <code>allocator</code> is <code>null</code>), non-scalar values (i.e. strings) are only valid until the next call to <code>next()</code> or <code>drain()</code> or <code>deinit()</code>.
Stmt
For most queries, you should use the <code>conn.query(...)</code>, <code>conn.row(...)</code> or <code>conn.exec(...)</code> methods. For queries with parameters, these methods look like:
```zig
var stmt = try Stmt.init(conn, opts)
errdefer stmt.deinit();
try stmt.prepare(sql, null);
inline for (parameters) |param| {
try stmt.bind(param);
}
return stmt.execute();
```
You can create a statement directly using <code>conn.prepare(sql)</code> or <code>conn.prepareOpts(sql, ConnQueryOpts{...})</code> and call <code>stmt.bind(value: anytype)</code> and <code>execute()</code> directly.
The main reason to do this is to have more flexibility in binding parameters (e.g. such as when creating dynanmic SQL where all the parameters aren't fixed at compile-time).
Note that <code>stmt.deinit()</code> should only be called if <code>stmt.execute()</code> is not called or returns an error. Once <code>stmt.execute()</code> returns a <a>Result</a>, <code>stmt</code> should be considered invalid. As we can see in the above example, <code>stmt.deinit()</code> is only called on <code>errdefer</code>.
Caching Prepared Statements
When you execute a statement with parameters, we first ask PostgreSQL to "parse" the statement (which creates an execution plan) and then describe it. We can then bind the parameters and execute the statement.
If you plan on executing the same query(ies) repeatedly, it's possible to have PostgreSQL cache the execution plan and pg.zig cache the description. However, there are some caveats with this approach (which are not specific to pg.zig). First, if you're using a connection pooler (like pgpool or PgBouncer), make sure to read the documentation and configure it to work properly with cached prepared statements. Historically, cached prepared statements and connection poolers have not worked well together.
Secondly, note that the cache is per-connection. If you have a pool of 50 connections, and you execute the query against connections from the pool, then you should expect the full parse -> describe -> bind -> execute flow for those 50 connections (plus whatever new connections the pool might open).
Caching is enabled by passing the <code>cache_name</code> option:
<code>zig
const result = try conn.queryOpts(
"select * from saiyans where power > $1",
.{9000},
.{.cache_name = "super"}
);</code>
Technically, once cached, the SQL statement is ignored. So, after executing the above, you could execute the following <strong>on the same connection</strong>:
<code>zig
const result = try conn.queryOpts(
"this isn't valid SQL",
.{1000},
.{.cache_name = "super"}
);</code>
And it <strong>will</strong> work. But you're playing with fire, and you should just include the same SQL and the same cache name for each execution. If you want to use the <code>.column_names = true</code> option, then it <em>must</em> be included in the first query which generated the cache entry (again, in short, just <em>always</em> use the same SQL and the same options).
You can call <code>try conn.deallocate("super")</code> to remove a cache entry. But this is only done for the connection on which it is called. This would make sense, for example, if you get a connection from the pool, execute the same query multiple times, deallocate the cached entry, and return the connection back to the pool. Note that the name to deallocate, <code>super</code>, is not sanitized and is open to SQL injection - don't pass a user-supplied value to <code>deallocte</code>.
Important Notice 1 - Bind vs Read
When you read a value, such as <code>row.get(i32, 0)</code>, the library assumes you know what you're doing and that column 0 really is a non-null 32-bit integer. <code>row.get</code> doesn't return an error union. There are some assertions, but these are disabled in ReleaseFast and ReleaseSmall. You can also disable these assertions in Debug/ReleaseSafe by placing <code>pub const pg_assert = false;</code> in your root, (e.g. <code>main.zig</code>):
```zig
const std = @import("std");
...
pub const pg_assert = false;
pub fm main() !void {
...
}
```
Conversely, when binding a value to an SQL parameter, the library is a little more generous. For example, an <code>u64</code> will bind to an <code>i32</code> provided the value is within range.
This is particularly relevant for types which are expressed as <code>[]u8</code>. For example a UUID can be a raw binary <code>[16]u8</code> or a hex-encoded <code>[36]u8</code>. Where possible (e.g. UUID, MacAddr, MacAddr8), the library will support binding either the raw binary data or text-representation. When reading, the raw binary value is always returned.
Important Notice 2 - Invalid Connections
Strongly consider using <code>pg.Pool</code> rather than using <code>pg.Conn</code> directly. The pool will attempt to reconnect disconnected connections or connections which are in an invalid state. Until more real world testing is done, you should assume that connections will get into invalid states.
Important Notice 3 - Errors
Zig errorsets do not support arbitrary payloads. This is problematic in a database driver where most applications probably care about the details of an error. The library takes a simple approach. If <code>error.PG</code> is returned, <code>conn.err</code> should be set and will contains a PG error object:
<code>zig
_ = conn.exec("drop table x", .{}) catch |err| {
if (err == error.PG) {
if (conn.err) |pge| {
std.log.err("PG {s}\n", .{pge.message});
}
}
return err;
};</code>
In the above snippet, it's possible to skip the <code>if (err == error.PG)</code> check, but in that case <code>conn.err</code> could be set from some previous command (<code>conn.err</code> is always reset when acquired from the pool).
If <code>error.PG</code> is returned from a non-connection object, like a query result, the associated connection will have its <code>conn.err</code> set. In other words, <code>conn.err</code> is the only thing you ever have to check.
A PG error always exposes the following fields:
* <code>code: []const u8</code> - https://www.postgresql.org/docs/current/errcodes-appendix.html
* <code>message: []const u8</code>
* <code>severity: []const u8</code>
And optionally (depending on the error and the version of the server):
* <code>column: ?[]const u8 = null</code>
* <code>constraint: ?[]const u8 = null</code>
* <code>data_type_name: ?[]const u8 = null</code>
* <code>detail: ?[]const u8 = null</code>
* <code>file: ?[]const u8 = null</code>
* <code>hint: ?[]const u8 = null</code>
* <code>internal_position: ?[]const u8 = null</code>
* <code>internal_query: ?[]const u8 = null</code>
* <code>line: ?[]const u8 = null</code>
* <code>position: ?[]const u8 = null</code>
* <code>routine: ?[]const u8 = null</code>
* <code>schema: ?[]const u8 = null</code>
* <code>severity2: ?[]const u8 = null</code>
* <code>table: ?[]const u8 = null</code>
* <code>where: ?[]const u8 = null</code>
The <code>isUnique() bool</code> method can be called on the error to determine whether or not the error was a unique violation (i.e. error code <code>23505</code>).
Type Support
All implementations have to deal with things like: how to support unsigned integers, given that PostgreSQL only has signed integers. Or, how to support UUIDs when the language has no UUID type. This section documents the exact behavior.
Arrays
Multi-dimensional arrays aren't supported. The array lower bound is always 0 (or 1 in PG)
text, bool, bytea, char, char(n), custom enums
No surprises, arrays supported.
When reading a <code>char[]</code>, it's tempting to use <code>row.get([]u8, 0)</code>, but this is incorrect. A <code>char[]</code> is an array, and thus <code>row.get(pg.Iterator(u8), 0</code>) must be used.
smallint, int, bigint
When binding an integer, the library will coerce the Zig value to the parameter type, as long as it fits. Thus, a <code>u64</code> can be bound to a <code>smallint</code>, if the value fits, else an error will be returned.
Array binding is strict. For example, an <code>[]i16</code> must be used for a <code>smallint[]</code>parameter. The only exception is that the unsigned variant, e.g. <code>[]u16</code> can be used provided all values fit.
When reading a column, you must use the correct type.
Floats
When binding, <code>@floatCast</code> is used based on the SQL parameter type. Array binding is strict. When reading a value, you must use the correct type.
Numeric
Until standard support comes to Zig (either in the stdlib or a de facto standard library), numeric support is half-baked. When binding a value to a parameter, you can use a f32, f64, comptime_float or string. The same applies to binding to a numeric array.
You can <code>get(pg.Numeric, $COL)</code> to return a <code>pg.Numeric</code>. The <code>pg.Numeric</code> type only has 2 useful methods: <code>toFloat</code> and <code>toString</code>. You can also use <code>num.estimatedStringLen</code> to get the max size of the string representation:
<code>zig
const numeric = row.get(pg.Numeric, 0);
var buf = allocator.alloc(u8, numeric.estimatedStringLen());
defer allocator.free(buf)
const str = numeric.toString(&buf);</code>
Using <code>row.get(f64, 0)</code> on a numeric is the same as <code>row.get(pg.Numeric, 0).toFloat()</code>.
You should consider simply casting the numeric to <code>::double</code> or <code>::text</code> within SQL in order to rely on PostgreSQL's own robust numeric to float/text conversion.
However, <code>pg.Numeric</code> has fields for the underlying wire-format of the numeric value. So if you require precision and the text representation isn't sufficient, you can parse the fields directly. <code>types/numeric.zig</code> is relatively well documented and tries to explain the fields. Note that any non-primitive fields, e.g. the <code>digits: []u8</code>, is only valid until the next call to <code>result.next</code>, <code>result.deinit</code>, <code>result.drain</code> or <code>row.deinit</code>.
UUID
When a <code>[]u8</code> is bound to a UUID column, it must either be a 16-byte slice, or a valid 36-byte hex-encoded UUID. Arrays behave the same.
When reading a <code>uuid</code> column with <code>[]u8</code> a 16-byte slice will be returned. Use the <code>pg.uuidToHex() ![36]u8</code> helper if you need it hex-encoded.
INET/CIDR
You can bind a string value to a <code>cidr</code>, <code>inet</code>, <code>cidr[]</code> or <code>inet[]</code> parameter.
When reading a value, via <code>row.get</code> or <code>row.iterator</code> you should use <code>pg.Cidr</code>. It exposes 3 fields:
<ul>
<li><code>address: []u8</code> - Will be a 4 or 16 byte slice depending on the family</li>
<li><code>family: Family</code> - An enum, either <code>Family.v4</code> of <code>Family.v6</code></li>
<li><code>netmask: u8</code> - The network mask</li>
</ul>
MacAddr/MacAddr8
You can bind a <code>[]u8</code> to either a <code>macaddr</code> or a <code>macaddr8</code>. These can be either binary representation (6-bytes for <code>macaddr</code> or 8 bytes for <code>macaddr8</code>) or a text-representation supported by PostgreSQL. This works, like UUID, because there's no ambiguity in the length. The same applied for array variants - it's even possible to mix and match formats within the array.
When reading a value, via <code>row.get</code> or <code>row.iterator</code> using <code>[]u8</code>, the binary representation is always returned.
Timestamp(tz)
When you bind an <code>i64</code> to a timestamp(tz) parameter, the value is assumed to be the number of microseconds since unix epoch (e.g. <code>std.time.microTimestamp()</code>). Array binding works the same. You can also bind a string, which will pass the string as-is and depend on PostgreSQL to do the conversion. This is true for arrays as well.
When reading a <code>timestamp</code> column with <code>i64</code>, the number of microseconds since unix epoch will be returned
JSON and JSONB
When binding a value to a JSON or JSONB parameter, you can either supply a serialized value (i.e. <code>[]u8</code>) or a struct which will be serialized using <code>std.json.stringify</code>.
When binding to an array of JSON or JSONB, automatic serialization is not support and thus an array of serialized values must be provided.
When reading a <code>JSON</code> or <code>JSONB</code> column with <code>[]u8</code>, the serialized JSON will be returned.
Listen / Notify
You can create a <code>pg.Listener</code> either from an existing <code>Pool</code> or directly.
Creating a new Listener directly is a lot like creating a new connection. See <a>Conn.open</a> and <a>Conn.auth</a>.
```zig
// see the Conn.ConnectOpts
var listener = try pg.Listener.open(allocator, .{
.host = "127.0.0.1",
.port = 5432,
});
defer listener.deinit();
try listener.auth(.{
.username = "leto",
.password = "ghanima",
.database = "caladan",
});
// add 1 or more channels to listen to
try listener.listen("chan_1");
try listener.listen("chan_2");
// .next() blocks until there's a notification or an error
while (listener.next()) |notification| {
std.debug.print("Channel: {s}\nPayload: {s}", .{notification.channel, notification.payload});
}
// The error handling is explained, sorry about this API. Zig error payloads plz
switch (listener.err.?) {
.pg => |pg| std.debug.print("{s}\n", .{pg.message}),
.err => |err| std.debug.print("{s}\n", .{@errorName(err)}),
}
```
When using the pool, a new connection/session is created. It <em>does not</em> use a connection from the pool. This is merely a convenience function if you're also using normal connections through a pool.
```zig
var listener = try pool.newListener();
defer listener.deinit();
// listen to 1 or more channels
try listener.listen("chan_1");
// same as above
```
Reconnects
A listener will not automatically reconnect on error/disconnect. The pub/sub nature of LISTEN/NOTIFY mean that delivery is at-most-once and auto-reconnecting can hide that fact. Put the above code in a <code>while (true) {...}</code> loop.
Errors
The handling of errors isn't great. Blame Zig's lack of error payloads and the awkwardness of using <code>try</code> within a <code>while</code> condition.
<code>listener.next()</code> can only return <code>null</code> on error. When <code>null</code> is returned, <code>listener.err</code> will be non-null. Unlike the <code>Conn</code> this is a tagged union that can either be <code>err</code> for a normal Zig error (e.g. error.ConnectionResetByPeer) or <code>pg</code> a detailed PostgresSQL error.
Metrics
A few basic metrics are collected using <a>metrics.zig</a>, a prometheus-compatible library. These can be written to an <code>std.io.Writer</code> using <code>try pg.writeMetrics(writer)</code>. As an example using <a>httpz</a>:
```zig
pub fn metrics(_: <em>httpz.Request, res: </em>httpz.Response) !void {
const writer = res.writer();
try pg.writeMetrics(writer);
<code>// also write out the httpz metrics
try httpz.writeMetrics(writer);
</code>
}
```
The metrics are:
<ul>
<li><code>pg_queries</code> - counts the number of queries</li>
<li><code>pg_pool_empty</code> - counts how often the pool is empty</li>
<li><code>pg_pool_dirty</code> - counts how often a connection is released back into the pool in an unclean state (thus requiring the connection to be closed and the pool to re-open another connection). This could indicate that results aren't being fully drained (either by calling <code>next()</code> until <code>null</code> is returned or explicitly calling the <code>drain()</code> method)</li>
<li><code>pg_alloc_params</code> - counts the number of parameter states that were allocated. This indicates that your queries have more parameters than <code>result_state_size</code>. If this happens often, consider increasing <code>result_state_size</code>.</li>
<li><code>pg_alloc_columns</code> - counts the number of columns states that were allocated. This indicates that your queries are returning more columns than <code>result_state_size</code>. If this happens often, consider increasing <code>result_state_size</code>.</li>
<li><code>pg_alloc_reader</code> - counts the number of bytes allocated while reading messages from PostgreSQL. This generally happens as a result of large result (e.g. selecting large text fields). Controlled by the <code>read_buffer</code> configuration option.</li>
</ul>
TLS (Experimental)
TLS is supported via openssl. When loading the module, you must enable openssl by including at least 1 openssl setting:
<code>zig
const pg_module = b.dependency("pg", .{
.target = target,
.optimize = optimize,
.openssl_lib_name = @as([]const u8, "ssl"),
.openssl_lib_path = std.Build.LazyPath{.cwd_relative = "/path/to/openssl/lib"},
.openssl_include_path = std.Build.LazyPath{.cwd_relative = "/path/to/openssl/include"},
}).module("pg")</code>
When not specified, the system defaults are use for the library and include paths. These should only be set if openssl is installed in a non-default location. In most cases specifying <code>.openssl_lib_name = "ssl"</code> or, for some systems <code>.openssl_lib_name = "openssl"</code> should be enough.
Set the connection's <code>tls</code> option to either <code>.required</code> or <code>.{verify_full = null}</code>. When using a custom root certificate, specify the path: <code>.{verify_full = "/path/to/root.crt"}</code>.
```zig
var pool = try pg.Pool.init(allocator, .{
.connect = .{ .port = 5432, .host = "ip_or_hostname", .tls = .{.verify_full = null}},
.auth = .{ .... },
.size = 5,
});
// OR
const uri = try std.Uri.parse("postgresql://user:password@hostname/DBNAME?sslmode=require");
var pool = try pg.Pool.initUri(allocator, uri, 10, 5_000);
```
In your main file, you can define a global <code>pub const pg_stderr_tls = true;</code> to have pg.zig print possible TLS-related errors to stderr. Alternatively, if you get an error, you <code>pg.printSSLError();</code> to hopefully print an error message to stderr which can be included in a ticket. This can safely be called in a <code>catch</code> clause, and will display nothing if the error is NOT SSL-related. Note that using the global <code>pg_stderr_tls</code> is more likely to print useful information in the case of certification verification problems.
Tests
Launch the Postgres database with the provided Docker Compose configuration:
<code>console
cd tests/
docker compose up</code>
Run tests:
<code>console
zig build test</code>
|
[] |
https://avatars.githubusercontent.com/u/103538756?v=4
|
lyceum
|
Dr-Nekoma/lyceum
|
2024-01-13T05:00:44Z
|
An MMO game written in Erlang (+ PostgreSQL) + Zig (+ Raylib)
|
master
| 17 | 301 | 9 | 301 |
https://api.github.com/repos/Dr-Nekoma/lyceum/tags
|
Apache-2.0
|
[
"devenv",
"erlang",
"erlang-otp",
"game",
"justfile",
"nix",
"nix-flake",
"postgresql",
"raylib",
"raylib-zig",
"zerl",
"zig",
"ziglang"
] | 18,449 | false |
2025-05-09T14:54:36Z
| false | false |
unknown
|
github
|
[] |
404
|
[] |
https://avatars.githubusercontent.com/u/2793150?v=4
|
zigar
|
chung-leong/zigar
|
2023-05-10T21:05:44Z
|
Toolkit enabling the use of Zig code in JavaScript projects
|
main
| 13 | 260 | 3 | 260 |
https://api.github.com/repos/chung-leong/zigar/tags
|
MIT
|
[
"bunjs",
"electron",
"javascript",
"nodejs",
"nwjs",
"rollup-plugin",
"wasm",
"webpack-plugin",
"zig",
"zig-package"
] | 53,322 | false |
2025-05-17T19:04:12Z
| false | false |
unknown
|
github
|
[] |
Zigar
A software tool set that lets you utilize <a>Zig</a> code in your JavaScript
projects.
Consult the <a>project wiki</a> for installation instructions
and tutorials.
Features
<ul>
<li>Access to all Zig data types in JavaScript</li>
<li>Zig-to-JavaScript, JavaScript-to-Zig call marshalling</li>
<li>Async task management</li>
<li>Threads in native code and WebAssembly</li>
<li>Support for MacOS, Linux, and Windows (both 64-bit and 32-bit)</li>
<li>Support for Node.js, Bun.js, Electron, and NW.js (native code execution)</li>
<li>Support for Webpack, Rollup, and Vite (WebAssembly)</li>
</ul>
Versioning
The major and minor version numbers of Zigar correspond to the version of the Zig compiler
it's designed for. The current version is 0.14.0. It works with Zig 0.14.0.
Technical support
If you have questions concerning this project, please post them at this project's
<a>discussion section</a>. I can also be contacted at
<a>ziggit.dev</a>, which also happens to be an excellent forum for finding help on
all matters related to the Zig language.
|
[] |
https://avatars.githubusercontent.com/u/61841960?v=4
|
hevi
|
Arnau478/hevi
|
2023-09-15T14:41:34Z
|
Hex viewer
|
master
| 7 | 255 | 9 | 255 |
https://api.github.com/repos/Arnau478/hevi/tags
|
GPL-3.0
|
[
"binary",
"hex",
"hex-viewer",
"hexdump",
"zig",
"zig-package",
"zig-program"
] | 1,028 | false |
2025-05-20T08:45:46Z
| true | true |
0.14.0
|
github
|
[
{
"commit": "af41bdb5b1d64404c2ec7eb1d9de01083c0d2596",
"name": "ziggy",
"tar_url": "https://github.com/kristoff-it/ziggy/archive/af41bdb5b1d64404c2ec7eb1d9de01083c0d2596.tar.gz",
"type": "remote",
"url": "https://github.com/kristoff-it/ziggy"
},
{
"commit": "67aee7c4761afe74d6ff9e2bc4a00131adcc582e",
"name": "pennant",
"tar_url": "https://github.com/Arnau478/pennant/archive/67aee7c4761afe74d6ff9e2bc4a00131adcc582e.tar.gz",
"type": "remote",
"url": "https://github.com/Arnau478/pennant"
}
] |
hevi
a hex viewer
What is hevi?
Hevi (pronounced like "heavy") is a hex viewer, just like <code>xxd</code> or <code>hexdump</code>.
Features
Parsers
Hevi can parse things like ELF or PE files and give you syntax-highlighting.
Custom color palettes
You can specify custom color palettes. Color palettes can use standard ANSI colors or truecolor.
Usage
The command should be used as <code>hevi <file> [flags]</code>. The flags are described <a>below</a>.
Flags
| Flag(s) | Description |
| -------------------------------- | ------------------------------------------------------- |
| <code>-h</code>/<code>--help</code> | Show a help message |
| <code>-v</code>/<code>--version</code> | Show version information |
| <code>--color</code>/<code>--no-color</code> | Enable or disable colored output |
| <code>--lowercase</code>/<code>--uppercase</code> | Toggle between lowercase and uppercase hex |
| <code>--size</code>/<code>--no-size</code> | Enable or disable the line showing the size at the end |
| <code>--offset</code>/<code>--no-offset</code> | Enable or disable showing the offset |
| <code>--ascii</code>/<code>--no-ascii</code> | Enable or disable ASCII interpretation |
| <code>--skip-lines</code>/<code>--no-skip-lines</code> | Enable or disable skipping of identical lines |
| <code>--raw</code> | Raw format (disables most features) |
| <code>--show-palette</code> | Show the current color palette in a table |
| <code>--parser</code> | Specify the parser to use. For a list use <code>hevi --help</code> |
Environment variables
The <code>NO_COLOR</code> variable is supported, and disables color (see <a>https://no-color.org/</a>) printing. Note that it can be overwritten by an explicit <code>--color</code>.
Config file
The config file is a <a>ziggy</a> file. The following fields are available:
<code>zig
color: bool,
uppercase: bool,
show_size: bool,
show_offset: bool,
show_ascii: bool,
skip_lines: bool,
raw: bool,
palette: Palette,</code>
All fields are optional.
<strong>Note</strong>: for the <code>palette</code> field you must specify all styles!
Example config
<code>zig
.color = true,
.skip_lines = false,
.palette = Palette{
.normal = @color("yellow"),
.normal_alt = @color("yellow::dim"),
.normal_accent = @color("yellow:bright_black:bold"),
.c1 = @color("red"),
.c1_alt = @color("red::dim"),
.c1_accent = @color("red:bright_black:bold"),
.c2 = @color("green"),
.c2_alt = @color("green::dim"),
.c2_accent = @color("green:bright_black:bold"),
.c3 = @color("blue"),
.c3_alt = @color("blue::dim"),
.c3_accent = @color("blue:bright_black:bold"),
.c4 = @color("cyan"),
.c4_alt = @color("cyan::dim"),
.c4_accent = @color("cyan:bright_black:bold"),
.c5 = @color("magenta"),
.c5_alt = @color("magenta::dim"),
.c5_accent = @color("magenta:bright_black:bold"),
},</code>
Location
The config file is located at:
| OS | Path |
| -------------------------------------- | ------------------------------------------------------------------------------------------------ |
| Linux, MacOS, FreeBSD, OpenBSD, NetBSD | <code>$XDG_CONFIG_HOME/hevi/config.ziggy</code> or if the env doesn't exist <code>$HOME/.config/hevi/config.ziggy</code> |
| Windows | <code>%APPDATA%/hevi/config.ziggy</code> |
| Other | Not supported. No config file will be read |
Precedence
Hevi has a precedence for configuration and it is:
1. Flags
2. Environment variables
3. Config file
4. Defaults
About
It is written in <a>zig</a>, in an attempt to simplify hex viewers.
Installation
Some Linux package managers
If your package manager is in the following list (and preferably in green), you can simply install it from there:
<a></a>
Homebrew
You can install <a>hevi</a> with <a>brew</a>:
<code>sh
$ brew install hevi</code>
Nix
There is a nix flake you can use. You can also try hevi without installing it:
<code>sh
$ nix shell github:Arnau478/hevi</code>
X-CMD
If you are a user of <a>x-cmd</a>, you can run:
<code>sh
$ x install hevi</code>
Other platforms
You can download a binary from the <a>releases</a> page. You can also clone the repository and compile it with <code>zig build</code>.
Contribute
Contributions are welcome! Even if you don't want to write code, you can help a lot creating new issues or testing this software.
License
See <a>LICENSE</a>
SPDX-License-Identifier: GPL-3.0-or-later
<a></a>
|
[] |
https://avatars.githubusercontent.com/u/206480?v=4
|
zul
|
karlseguin/zul
|
2023-11-16T13:04:09Z
|
zig utility library
|
master
| 0 | 227 | 10 | 227 |
https://api.github.com/repos/karlseguin/zul/tags
|
MIT
|
[
"uuidv4",
"uuidv7",
"zig",
"zig-package"
] | 218 | false |
2025-05-19T12:03:59Z
| true | true |
unknown
|
github
|
[] |
Zig Utility Library
The purpose of this library is to enhance Zig's standard library. Much of zul wraps Zig's std to provide simpler APIs for common tasks (e.g. reading lines from a file). In other cases, new functionality has been added (e.g. a UUID type).
Besides Zig's standard library, there are no dependencies. Most functionality is contained within its own file and can be copy and pasted into an existing library or project.
Full documentation is available at: <a>https://www.goblgobl.com/zul/</a>.
(This readme is auto-generated from <a>docs/src/readme.njk</a>)
Usage
In your build.zig.zon add a reference to Zul:
<code>zig
.{
.name = "my-app",
.paths = .{""},
.version = "0.0.0",
.dependencies = .{
.zul = .{
.url = "https://github.com/karlseguin/zul/archive/master.tar.gz",
.hash = "$INSERT_HASH_HERE"
},
},
}</code>
To get the hash, run:
<code>bash
zig fetch https://github.com/karlseguin/zul/archive/master.tar.gz</code>
Instead of <code>master</code> you can use a specific commit/tag.
Next, in your <code>build.zig</code>, you should already have an executable, something like:
<code>zig
const exe = b.addExecutable(.{
.name = "my-app",
.root_source_file = b.path("src/main.zig"),
.target = target,
.optimize = optimize,
});</code>
Add the following line:
<code>zig
exe.root_module.addImport("zul", b.dependency("zul", .{}).module("zul"));</code>
You can now <code>const zul = @import("zul");</code> in your project.
<a>zul.benchmark.run</a>
Simple benchmarking function.
```zig
const HAYSTACK = "abcdefghijklmnopqrstvuwxyz0123456789";
pub fn main() !void {
(try zul.benchmark.run(indexOfScalar, .{})).print("indexOfScalar");
(try zul.benchmark.run(lastIndexOfScalar, .{})).print("lastIndexOfScalar");
}
fn indexOfScalar(<em>: Allocator, </em>: *std.time.Timer) !void {
const i = std.mem.indexOfScalar(u8, HAYSTACK, '9').?;
if (i != 35) {
@panic("fail");
}
}
fn lastIndexOfScalar(<em>: Allocator, </em>: *std.time.Timer) !void {
const i = std.mem.lastIndexOfScalar(u8, HAYSTACK, 'a').?;
if (i != 0) {
@panic("fail");
}
}
// indexOfScalar
// 49882322 iterations 59.45ns per iterations
// worst: 167ns median: 42ns stddev: 20.66ns
//
// lastIndexOfScalar
// 20993066 iterations 142.15ns per iterations
// worst: 292ns median: 125ns stddev: 23.13ns
```
<a>zul.CommandLineArgs</a>
A simple command line parser.
```zig
var args = try zul.CommandLineArgs.parse(allocator);
defer args.deinit();
if (args.contains("version")) {
//todo: print the version
os.exit(0);
}
// Values retrieved from args.get are valid until args.deinit()
// is called. Dupe the value if needed.
const host = args.get("host") orelse "127.0.0.1";
...
```
<a>zul.DateTime</a>
Simple (no leap seconds, UTC-only), DateTime, Date and Time types.
```zig
// Currently only supports RFC3339
const dt = try zul.DateTime.parse("2028-11-05T23:29:10Z", .rfc3339);
const next_week = try dt.add(7, .days);
std.debug.assert(next_week.order(dt) == .gt);
// 1857079750000 == 2028-11-05T23:29:10Z
std.debug.print("{d} == {s}", .{dt.unix(.milliseconds), dt});
```
<a>zul.fs.readDir</a>
Iterates, non-recursively, through a directory.
```zig
// Parameters:
// 1- Absolute or relative directory path
var it = try zul.fs.readDir("/tmp/dir");
defer it.deinit();
// can iterate through the files
while (try it.next()) |entry| {
std.debug.print("{s} {any}\n", .{entry.name, entry.kind});
}
// reset the iterator
it.reset();
// or can collect them into a slice, optionally sorted:
const sorted_entries = try it.all(allocator, .dir_first);
for (sorted_entries) |entry| {
std.debug.print("{s} {any}\n", .{entry.name, entry.kind});
}
```
<a>zul.fs.readJson</a>
Reads and parses a JSON file.
```zig
// Parameters:
// 1- The type to parse the JSON data into
// 2- An allocator
// 3- Absolute or relative path
// 4- std.json.ParseOptions
const managed_user = try zul.fs.readJson(User, allocator, "/tmp/data.json", .{});
// readJson returns a zul.Managed(T)
// managed_user.value is valid until managed_user.deinit() is called
defer managed_user.deinit();
const user = managed_user.value;
```
<a>zul.fs.readLines</a>
Iterate over the lines in a file.
```zig
// create a buffer large enough to hold the longest valid line
var line_buffer: [1024]u8 = undefined;
// Parameters:
// 1- an absolute or relative path to the file
// 2- the line buffer
// 3- options (here we're using the default)
var it = try zul.fs.readLines("/tmp/data.txt", &line_buffer, .{});
defer it.deinit();
while (try it.next()) |line| {
// line is only valid until the next call to
// it.next() or it.deinit()
std.debug.print("line: {s}\n", .{line});
}
```
<a>zul.http.Client</a>
A wrapper around std.http.Client to make it easier to create requests and consume responses.
```zig
// The client is thread-safe
var client = zul.http.Client.init(allocator);
defer client.deinit();
// Not thread safe, method defaults to .GET
var req = try client.request("https://api.github.com/search/topics");
defer req.deinit();
// Set the querystring, can also be set in the URL passed to client.request
// or a mix of setting in client.request and programmatically via req.query
try req.query("q", "zig");
try req.header("Authorization", "Your Token");
// The lifetime of res is tied to req
var res = try req.getResponse(.{});
if (res.status != 200) {
// TODO: handle error
return;
}
// On success, this is a zul.Managed(SearchResult), its lifetime is detached
// from the req, allowing it to outlive req.
const managed = try res.json(SearchResult, allocator, .{});
// Parsing the JSON and creating SearchResult [probably] required some allocations.
// Internally an arena was created to manage this from the allocator passed to
// res.json.
defer managed.deinit();
const search_result = managed.value;
```
<a>zul.JsonString</a>
Allows the embedding of already-encoded JSON strings into objects in order to avoid double encoded values.
<code>zig
const an_encoded_json_value = "{\"over\": 9000}";
const str = try std.json.stringifyAlloc(allocator, .{
.name = "goku",
.power = zul.jsonString(an_encoded_json_value),
}, .{});</code>
<a>zul.pool</a>
A thread-safe object pool which will dynamically grow when empty and revert to the configured size.
```zig
// create a pool for our Expensive class.
// Our Expensive class takes a special initializing context, here an usize which
// we set to 10_000. This is just to pass data from the pool into Expensive.init
var pool = try zul.pool.Growing(Expensive, usize).init(allocator, 10_000, .{.count = 100});
defer pool.deinit();
// acquire will either pick an item from the pool
// if the pool is empty, it'll create a new one (hence, "Growing")
var exp1 = try pool.acquire();
defer pool.release(exp1);
...
// pooled object must have 3 functions
const Expensive = struct {
// an init function
pub fn init(allocator: Allocator, size: usize) !Expensive {
return .{
// ...
};
}
<code>// a deinit method
pub fn deinit(self: *Expensive) void {
// ...
}
// a reset method, called when the item is released back to the pool
pub fn reset(self: *Expensive) void {
// ...
}
</code>
};
```
<a>zul.Scheduler</a>
Ephemeral thread-based task scheduler used to run tasks at a specific time.
```zig
// Where multiple types of tasks can be scheduled using the same schedule,
// a tagged union is ideal.
const Task = union(enum) {
say: []const u8,
<code>// Whether T is a tagged union (as here) or another type, a public
// run function must exist
pub fn run(task: Task, ctx: void, at: i64) void {
// the original time the task was scheduled for
_ = at;
// application-specific context that will be passed to each task
_ ctx;
switch (task) {
.say => |msg| {std.debug.print("{s}\n", .{msg}),
}
}
</code>
}
...
// This example doesn't use a app-context, so we specify its
// type as void
var s = zul.Scheduler(Task, void).init(allocator);
defer s.deinit();
// Starts the scheduler, launching a new thread
// We pass our context. Since we have a null context
// we pass a null value, i.e. {}
try s.start({});
// will run the say task in 5 seconds
try s.scheduleIn(.{.say = "world"}, std.time.ms_per_s * 5);
// will run the say task in 100 milliseconds
try s.schedule(.{.say = "hello"}, std.time.milliTimestamp() + 100);
```
<a>zul.sort</a>
Helpers for sorting strings and integers
```zig
// sorting strings based on their bytes
var values = [_][]const u8{"ABC", "abc", "Dog", "Cat", "horse", "chicken"};
zul.sort.strings(&values, .asc);
// sort ASCII strings, ignoring case
zul.sort.asciiIgnoreCase(&values, .desc);
// sort integers or floats
var numbers = [_]i32{10, -20, 33, 0, 2, 6};
zul.sort.numbers(i32, &numbers, .asc);
```
<a>zul.StringBuilder</a>
Efficiently create/concat strings or binary data, optionally using a thread-safe pool with pre-allocated static buffers.
```zig
// StringBuilder can be used to efficiently concatenate strings
// But it can also be used to craft binary payloads.
var sb = zul.StringBuilder.init(allocator);
defer sb.deinit();
// We're going to generate a 4-byte length-prefixed message.
// We don't know the length yet, so we'll skip 4 bytes
// We get back a "view" which will let us backfill the length
var view = try sb.skip(4);
// Writes a single byte
try sb.writeByte(10);
// Writes a []const u8
try sb.write("hello");
// Using our view, which points to where the view was taken,
// fill in the length.
view.writeU32Big(@intCast(sb.len() - 4));
std.debug.print("{any}\n", .{sb.string()});
// []u8{0, 0, 0, 6, 10, 'h', 'e', 'l', 'l', 'o'}
```
<a>zul.testing</a>
Helpers for writing tests.
```zig
const t = zul.testing;
test "memcpy" {
// clear's the arena allocator
defer t.reset();
<code>// In addition to exposing std.testing.allocator as zul.testing.allocator
// zul.testing.arena is an ArenaAllocator. An ArenaAllocator can
// make managing test-specific allocations a lot simpler.
// Just stick a `defer zul.testing.reset()` atop your test.
var buf = try t.arena.allocator().alloc(u8, 5);
// unlike std.testing.expectEqual, zul's expectEqual
// will coerce expected to actual's type, so this is valid:
try t.expectEqual(5, buf.len);
@memcpy(buf[0..5], "hello");
// zul's expectEqual also works with strings.
try t.expectEqual("hello", buf);
</code>
}
```
<a>zul.ThreadPool</a>
Lightweight thread pool with back-pressure and zero allocations after initialization.
```zig
var tp = try zul.ThreadPool(someTask).init(allocator, .{.count = 4, .backlog = 500});
defer tp.deinit(allocator);
// This will block if the threadpool has 500 pending jobs
// where 500 is the configured backlog
tp.spawn(.{1, true});
fn someTask(i: i32, allow: bool) void {
// process
}
```
<a>zul.UUID</a>
Parse and generate version 4 and version 7 UUIDs.
```zig
// v4() returns a zul.UUID
const uuid1 = zul.UUID.v4();
// toHex() returns a [36]u8
const hex = uuid1.toHex(.lower);
// returns a zul.UUID (or an error)
const uuid2 = try zul.UUID.parse("761e3a9d-4f92-4e0d-9d67-054425c2b5c3");
std.debug.print("{any}\n", uuid1.eql(uuid2));
// create a UUIDv7
const uuid3 = zul.UUID.v7();
// zul.UUID can be JSON serialized
try std.json.stringify(.{.id = uuid3}, .{}, writer);
```
|
[
"https://github.com/karlseguin/aolium-api",
"https://github.com/kawana77b/docker-tags-zig",
"https://github.com/liskvork/liskvork",
"https://github.com/malaow3/PokeBin",
"https://github.com/peterhellberg/adr"
] |
https://avatars.githubusercontent.com/u/109492796?v=4
|
zig-course
|
zigcc/zig-course
|
2023-09-10T13:11:28Z
|
Zig 语言圣经:简单、快速地学习 Zig, Zig Chinese tutorial, learn zig simply and quickly
|
main
| 4 | 211 | 36 | 211 |
https://api.github.com/repos/zigcc/zig-course/tags
|
MIT
|
[
"tutorial",
"tutorials",
"zig",
"zig-lang",
"zig-package",
"ziglang"
] | 2,922 | false |
2025-05-21T02:20:36Z
| true | false |
unknown
|
github
|
[] |
Zig 语言圣经
<blockquote>
Zig is a general-purpose programming language and toolchain for maintaining robust, optimal and reusable software.
Zig 是一种通用的编程语言和工具链,用于维护健壮、最优和可重用的软件
</blockquote>
参与贡献
欢迎各位志同道合的“道友”参与贡献本文档,并一起壮大 zig 中文社区!
本仓库使用的文档工具是 vitepress,建议了解一下 <a>vitepress 的 markdown 扩展</a>。
贡献方法:
<ul>
<li>fork 本文档仓库</li>
<li>创建一个新的分支,请勿直接使用主分支进行修改</li>
<li>发起 pull request</li>
<li>等待 review</li>
<li>合并到上游仓库,并由 github action 自动构建</li>
</ul>
<code>sh
bun i // 安装依赖
bun dev // 启动热更开发服务
bun format // 运行 prettier, zig fmt 和 autocorrect 格式化程序
bun run build // 构建产物
bun run preview // 运行预览</code>
<blockquote>
<span class="bg-blue-100 text-blue-800 text-xs font-medium me-2 px-2.5 py-0.5 rounded dark:bg-blue-900 dark:text-blue-300">NOTE</span>
请自行安装 <code>bun</code> (建议也安装 <code>autocorrect</code>,并且在提交前运行 <code>bun format</code>)
<span class="bg-blue-100 text-blue-800 text-xs font-medium me-2 px-2.5 py-0.5 rounded dark:bg-blue-900 dark:text-blue-300">NOTE</span>
本文档所使用的构建工具为 <a>bunjs</a>,在提交时请勿将其他 nodejs 的包管理工具的额外配置文件添加到仓库中。
如需要更新依赖,请参照此处 <a>Lockfile</a> 先设置 git 使用 bun 来 diff 文件!
</blockquote>
|
[] |
https://avatars.githubusercontent.com/u/19855629?v=4
|
zig-patterns
|
SuperAuguste/zig-patterns
|
2023-12-06T21:22:02Z
|
Common Zig patterns for you and your friends :)
|
main
| 1 | 194 | 6 | 194 |
https://api.github.com/repos/SuperAuguste/zig-patterns/tags
|
MIT
|
[
"learning",
"zig",
"ziglang"
] | 37 | false |
2025-05-20T10:59:40Z
| true | true |
unknown
|
github
|
[] |
Zig Patterns
<ul>
<li><a>Zig Patterns</a></li>
<li><a>About</a></li>
<li><a>The Patterns</a></li>
<li><a>License</a></li>
</ul>
About
This repository contains examples of common patterns found in Zig's standard library and many community projects.
Note that copying (one of) these patterns verbatim into your project may not be useful; it's important to weigh the pros and cons of different patterns. If you come from another language, especially a non-systems one, you'll often find that the more unfamiliar ideas featured here may be more useful.
For example, I've seldom used interface-like patterns when designing systems in Zig, despite using such patterns dozens of times a day at my old job writing TypeScript or Go.
The Patterns
All examples are annotated with comments including recommendations regarding when to use the patterns shown.
Example tests can be run with <code>zig build [name_of_pattern]</code>. For example, to run the tests in <code>typing/type_function.zig</code>, run <code>zig build type_function</code>.
Patterns are grouped into the following categories:
- <code>data</code> - data layout and organization techniques
- <code>typing</code> - <code>comptime</code>, runtime, or mixed <code>type</code> or type safety techniques
Some patterns may belong in multiple categories; I've selected the most fitting one in my opinion.
License
MIT
|
[] |
https://avatars.githubusercontent.com/u/9002722?v=4
|
llama2.zig
|
cgbur/llama2.zig
|
2023-07-30T02:40:54Z
|
Inference Llama 2 in one file of pure Zig
|
main
| 2 | 183 | 17 | 183 |
https://api.github.com/repos/cgbur/llama2.zig/tags
|
MIT
|
[
"llama",
"llama2",
"llm",
"llm-inference",
"simd",
"zig",
"ziglang"
] | 55,479 | false |
2025-05-19T20:14:53Z
| true | false |
unknown
|
github
|
[] |
llama2.zig
This is the Zig version of <a>llama2.c</a> by
Andrej Karpathy. It runs inference for the
<a>llama2</a> model architecture recently
published by Meta.
It currently supports:
<ul>
<li>Inference of llama2 model checkpoints</li>
<li>Temperature control</li>
<li>Top-p (nucleus) sampling</li>
<li>Prompt handling (bpe tokenization)</li>
<li>Sequence length control</li>
<li>Custom tokenizers</li>
<li>Multiquery support</li>
<li>Running really fast</li>
</ul>
The ultimate goal is to create a fast, portable, and user-friendly
implementation of the llama2 model architecture. The code prioritizes simplicity
and readability without sacrificing performance. Certain core functions have
SIMD implementations using the Zig <code>@Vector</code> feature, which provides a ~5x speed
increase. For more details and comparisons to other implementation, please refer
to the <a>performance</a> section.
The <code>stories15.bin</code> file is a model checkpoint for a 15M parameter model that
was trained on the tiny stories dataset. The method for generating this file
can be found in the llama2.c repo.
Usage
After cloning the repo, run the following command for inference:
<code>sh
zig build -Doptimize=ReleaseFast
zig-out/bin/llama2 stories15M.bin</code>
A prompt can be provided as an argument to the program:
<code>sh
llama2 stories15M.bin -i "Once upon a time"</code>
For all of the options, run:
<code>sh
$ llama2 --help
Usage: llama2 <checkpoint> [options]
Example: llama2 checkpoint.bin -n 256 -i "Once upon a time"
Options:
-h, --help print this help message
-t, --temperature <float> temperature, default 1.0 (0.0, 1]
-p, --top-p <float> p value in top-p (nucleus) sampling. default 1.0, 0 || 1 = off
-n, --seq-len <int> number of steps to run for, default 256. 0 = max_seq_len
-i, --input <string> input text for the prompt, default ""
-v, --verbose print model info and tokens/s</code>
Performance
The benchmarks provided below were executed on an AMD Ryzen 9 5900X 12-Core
Processor. All speeds measurements are taken using the <code>stories15M.bin</code>
checkpoint file.
If you have an implementation you want to add to the table, please open an issue
and I'll be happy to add it. Please only submit implementations that are single
language implementations (no OpenBlas, etc.).
Single-threaded
Argmax sampling
<ul>
<li>Temperature 0.0</li>
<li>256 tokens</li>
</ul>
| Implementation | Tokens/s |
| --------------------------------------------------- | -------- |
| llama2.zig (this repo) | 660 |
| llama2.c <code>make runfast -march=native</code> | 548 |
| <a>llama2.zig</a> | 496 |
| llama2.c <code>make run -march=native</code> | 122 |
| <a>llama2.rs</a> | 115 |
Top-P sampling
<ul>
<li>Temperature 1.0</li>
<li>Top-P 0.9</li>
<li>256 tokens</li>
</ul>
| Implementation | Tokens/s |
| ------------------------------------- | -------- |
| llama2.zig (this repo) | 579 |
| llama2.c <code>make runfast -march=native</code> | 463 |
Multi-threaded
This implementation currently does not support multithreading so is not
included in the table below. This is with temperate 0.9 and no top-p.
| Implementation | Tokens/s |
| ------------------------------------------------ | -------- |
| llama2.c <code>make runomp</code> | 1564 |
| <a>llama2.rs</a> | 441 |
llama2.zig (this repo)
The single largest speed increase came from writing a SIMD version of matrix
multiplication using the Zig <code>@Vector</code> feature. This was an immediate jump from
around 115 tokens/s to 430 tokens/s. Notable speed increases also came from:
<ul>
<li><code>comptime</code> magic to generate fused matrix multiplication</li>
<li>Vector aligned memory allocation</li>
<li>Using SIMD versions of other core functions</li>
</ul>
<code>sh
llama2 stories15M.bin -t 0
llama2 stories15M.bin -t 1.0 -p 0.9
llama2 stories15M.bin -t 1.0 -p 0.9 -i "Once upon a time"</code>
<code>sh
zig version -> 0.11.0-dev.4315+f5239677e</code>
llama2.c
<code>sh
./run stories15M.bin -t 1.0 -p 0.9
./run stories15M.bin -t 0.0</code>
```sh
CC = gcc
.PHONY: runfast
runfast: run.c
$(CC) -Ofast -o run run.c -lm -march=native
.PHONY: run
run: run.c
$(CC) -O3 -o run run.c -lm -march=native
.PHONY: runomp
runomp: run.c
$(CC) -Ofast -fopenmp -march=native run.c -lm -o run -march=native
```
llama2.rs
<code>sh
RUSTFLAGS="-C target-cpu=native" cargo run -r -- stories15M.bin 0.9
RUSTFLAGS="-C target-cpu=native" cargo run -r -F parallel -- stories15M.bin 0.9</code>
<code>toml
[profile.release]
codegen-units = 1
lto = true
panic = "abort"
strip = "symbols"</code>
Todo
<ul>
<li>[ ] Parallelize multi-head attention process</li>
<li>[ ] Add support for multi-threading (this is not going well)</li>
<li>[ ] Try top-p sampling by doing multiple linear scans to avoid sorting</li>
<li>[ ] binary search the token encoder, probably not necessary</li>
<li>[ ] Add benchmarks for smaller model and tokenizer</li>
<li>[ ] On very small models (like ~100K params) the speed is slower than the
original llama2.c. Figure out why. expf seems to take a lot of time. GCC also
doing much better than clang. Think floating point reordering is helping a lot
there.</li>
</ul>
Contributing
Any form of contribution is welcome. Feel free to open an issue or create a
pull request. If you are contributing optimizations, please provide benchmarks
and/or performance comparisons as well as the code to reproduce them.
Credits
<ul>
<li><a>Andrej Karpathy</a> for the original llama2.c
implementation</li>
<li><a>Foundation42</a> for opening a
<a>PR</a> on the llama2.c repo
that was the inspiration for aligned memory allocation and fused matrix
multiplication.</li>
<li><a>jrudolph</a> for top-p sampling optimization
<a>PR</a></li>
</ul>
|
[] |
https://avatars.githubusercontent.com/u/30945458?v=4
|
ZigBrains
|
FalsePattern/ZigBrains
|
2023-07-29T10:29:50Z
|
The zig language plugin for intellij
|
master
| 14 | 176 | 13 | 176 |
https://api.github.com/repos/FalsePattern/ZigBrains/tags
|
NOASSERTION
|
[
"intellij-plugin",
"lsp-client",
"zig"
] | 2,730 | false |
2025-05-21T18:57:25Z
| false | false |
unknown
|
github
|
[] |
ZigBrains
Zig language support for IntelliJ IDEA, CLion, and other JetBrains IDEs. Now written in Kotlin!
Installing
You can either install this plugin from the <a>JetBrains Marketplace</a>, or from <a>FalsePattern's website</a>.
See <a>the quick setup guide</a> for how to set up language server integration.
Note: marketplace updates are usually delayed by a few days from the actual release, so if you want to always have the
latest builds of ZigBrains, you can set up your IDE to download signed releases directly from FalsePattern's website
through the built-in plugin browser:
<ol>
<li>Go to <code>Settings -> Plugins</code></li>
<li>To the right of the <code>Installed</code> button at the top, click on the <code>...</code> dropdown menu, then select <code>Manage Plugin Repositories...</code></li>
<li>Click the add button, and then enter the ZigBrains updater URL, based on your IDE version:</li>
<li><code>2025.2.*</code> or newer: https://falsepattern.com/zigbrains/updatePlugins-252.xml</li>
<li><code>2025.1.*</code>: https://falsepattern.com/zigbrains/updatePlugins-251.xml</li>
<li><code>2024.3.*</code>: https://falsepattern.com/zigbrains/updatePlugins-243.xml</li>
<li><code>2024.2.*</code>: https://falsepattern.com/zigbrains/updatePlugins-242.xml</li>
<li><code>2024.1.*</code>: https://falsepattern.com/zigbrains/updatePlugins-241.xml</li>
<li>Click <code>OK</code>, and your IDE should now automatically detect the latest version
(both in the Installed tab and in the Marketplace tab), even if it's not yet verified on the official JetBrains marketplace yet.</li>
</ol>
Versioning scheme
To reduce confusion and to better utilize semver, the plugin uses the following versioning scheme:
X - Major version, incremented any time a relatively large features is added or removed
Y - Minor version, incremented for smaller features or large refactors that don't change user-perceived behaviour
Z - Patch version, incremented only when a fix is purely an internal change and doesn't exceed an arbitrary threshold
of complexity (determined at the discretion of FalsePattern)
Note: before version 11, the version scheme used was 0.X.Y, without separate patch versions.
As this plugin will constantly be evolving together with the zig language, it makes no sense to keep the 0 prefix,
and might as well utilize the full semver string for extra information.
Credits
Supporters
<ul>
<li>
<a>Techatrix</a>
</li>
<li>
<a>nuxusr</a>
</li>
<li>gree7</li>
<li>xceno</li>
<li>AnErrupTion</li>
</ul>
Contributors
<ul>
<li><a>gatesn</a></li>
<li><a>MarioAriasC</a></li>
<li><a>JensvandeWiel</a></li>
</ul>
Additional Thanks
<ul>
<li>
The <a>ZigTools</a> team for developing the Zig Language Server.
</li>
<li>
<a>HTGAzureX1212</a> for developing <a>intellij-zig</a>,
which served as a fantastic reference for deep IDE integration features.
</li>
<li>
The members of the <code>Zig Programming Language</code> discord server's <code>#tooling-dev</code> channel for providing encouragement,
feedback, and lots of bug reports.
</li>
<li>
The developers of <a>LSP4IJ</a> for providing a really good LSP backend
</li>
<li>
The developers of the <a>intellij-rust</a> plugin for providing an
excellent example on how to write debugger support that doesn't depend on CLion.
</li>
<li>
And everyone who actively reported issues and helped ironing out all the remaining problems
</li>
</ul>
Description
Adds support for the Zig Language, utilizing the ZLS language server for advanced coding assistance.
Before you can properly use the plugin, you need to select or download the Zig toolchain and language server in <code>Settings</code> -> <code>Languages & Frameworks</code> -> <code>Zig</code>.
Debugging
Debugger settings are available in the <code>Settings | Build, Execution, Deployment | Debugger</code> menu, under the <code>Zig</code> section.
IDE Compatibility
Debugging Zig code is supported in any native debugging capable IDE. The following have been verified to work so far:
<ul>
<li>CLion</li>
<li>IntelliJ IDEA Ultimate</li>
<li>RustRover (including the non-commercial free version too)</li>
<li>GoLand</li>
<li>PyCharm Professional</li>
<li>Android Studio</li>
</ul>
Additionally, in CLion, the plugin uses the C++ Toolchains for sourcing the debugger (this can be toggled off in the settings).
The open-source Community edition IDEs don't have the native debugging code as it's a proprietary module, so you cannot
debug zig code with them. You can still use those IDEs to develop code and use everything else the plugin has to offer.
Windows
Supported debuggers: <code>MSVC</code>
Debugging on Windows requires you to set up the Microsoft debugger.
To do this, go to the following URL and install the MSVC compiler toolset according to step 3 in the prerequisites:
https://code.visualstudio.com/docs/cpp/config-msvc
Linux
Supported debuggers: <code>LLDB</code>, <code>GDB</code>
MacOS
Supported debuggers: <code>LLDB</code>
|
[] |
https://avatars.githubusercontent.com/u/587972?v=4
|
zbpf
|
tw4452852/zbpf
|
2023-04-11T01:46:45Z
|
Writing eBPF in Zig
|
main
| 2 | 161 | 8 | 161 |
https://api.github.com/repos/tw4452852/zbpf/tags
|
GPL-3.0
|
[
"bpf",
"ebpf",
"tracing",
"zig"
] | 5,035 | false |
2025-05-19T19:20:35Z
| true | true |
unknown
|
github
|
[
{
"commit": "refs",
"name": "libbpf",
"tar_url": "https://github.com/tw4452852/libbpf_zig/archive/refs.tar.gz",
"type": "remote",
"url": "https://github.com/tw4452852/libbpf_zig"
},
{
"commit": "refs",
"name": "libelf",
"tar_url": "https://github.com/tw4452852/elfutils/archive/refs.tar.gz",
"type": "remote",
"url": "https://github.com/tw4452852/elfutils"
},
{
"commit": null,
"name": "btf_sanitizer",
"tar_url": null,
"type": "relative",
"url": "./src/btf_sanitizer"
},
{
"commit": null,
"name": "btf_translator",
"tar_url": null,
"type": "relative",
"url": "./src/btf_translator"
}
] |
zbpf
Writing eBPF in Zig. Thanks to Zig's comptime and BTF, we can equip eBPF with strong type system both at comptime and runtime!
Notable advantages when writing eBPF program with <code>zbpf</code>
Different available methods based on the type of program's context
Suppose you want to trace the kernel function <a>path_listxattr</a>,
and here's its prototype:
<code>static ssize_t path_listxattr(const char __user *pathname, char __user *list,
size_t size, unsigned int lookup_flags)</code>
As you can see, it has 4 input parameters and return type is <code>ssize_t</code>.
With <code>ctx = bpf.Kprobe{.name = "path_listxattr"}.Ctx()</code>, you could retrieve
the input parameter with <code>ctx.arg0()</code>, <code>ctx.arg1()</code>, <code>ctx.arg2()</code> and <code>ctx.arg3()</code> respectively,
and return value with <code>ctx.ret()</code>.
the type will be consistent with the above prototype. If you try to access a non-existing
parameter, e.g. <code>ctx.arg4()</code>, you will get a compilation error.
This also applies to <code>syscall</code> with <code>bpf.Ksyscall</code>, <code>tracepoint</code> with <code>bpf.Tracepoint</code> and
<code>fentry</code> with <code>bpf.Fentry</code>.
No more tedious error handling
When writing in C, you always have to check the error conditions
(the return value of the helper function, pointer validation, ...)
With <code>zbpf</code>, you won't care about the these cases, we handle it under the hood for you,
just focus on the business logic.
The following are some examples:
<ul>
<li><code>bpf.Map</code> takes care BPF map's <code>update</code> and <code>delete</code> error.</li>
<li><code>bpf.PerfEventArray</code> handles event output failure.</li>
<li><code>bpf.RingBuffer</code> also handles space reservation.</li>
<li><code>bpf.Xdp</code> validates the pointer for you.</li>
</ul>
If some error happens, you could get all the information (file, line number, return value ...)
you need to debug in the kernel trace buffer:
<code>~> sudo bpftool prog tracelog
test-11717 [005] d..21 10990692.273976: bpf_trace_printk: error occur at src/bpf/map.zig:110 return -2</code>
How to use
Prerequisite
<ul>
<li>Make sure the linux kernel is built with <code>CONFIG_DEBUG_INFO_BTF=y</code>.</li>
</ul>
Build
<ul>
<li>Download the <a>lastest Zig</a>.</li>
<li>Clone this repostory.</li>
<li>Build with <code>zig build zbpf -Dbpf=/path/to/your/bpf/prog.zig -Dmain=/path/to/your/main.zig</code>.</li>
</ul>
For cross-compiling, you could specify the target with <code>-Dtarget=<target></code>,
the list of all supported targets could be retrieved by <code>zig targets</code>.
Moreover, you could specify the target kernel with <code>-Dvmlinux=/path/to/vmlinux</code>
to extract BTF from it, otherwise, current kernel's BTF will be used.
That's all! The generated binary is located at <code>./zig-out/bin/zbpf</code>,
feel free to run it on your target machine.
Here's the <a>Documentations generated by Zig's AutoDoc</a>
for you reference.
Tools/trace
<code>trace</code> is a tool built on top of <code>zbpf</code> framework to trace kernel functions, syscalls and userspace functions.
It's heavily inspired by <a>retsnoop</a>.
One improvement I made (which is also what I feel when using retsnoop) is that <code>trace</code> support
show parameters according its type (thanks to the Zig type system).
This is very helpful when debugging linux kernel and userspace program.
For more details, you could check the implementation: <a>BPF side</a>
and <a>Host side</a>.
You could specify the kernel functions you want to trace with: <code>zig build trace -Dkprobe=<kernel_function_name> -Dkprobe=...</code>
And for system calls: <code>zig build trace -Dsyscall=<syscall_name> -Dsyscall=...</code>.
Or userspace function: <code>zig build trace -Duprobe=/path/to/binary[function_name]</code>.
Moreover, if you also want to capture the function's arguments, append the argument specifier, something like this:
<code>-Dkprobe=<kernel_function_name>:arg0,arg1...</code>, it also supports access to the deeper field if the argument is a pointer to a struct:
<code>-Dkprobe=<kernel_function_name>:arg0.field1.field0</code>.
You could even control how the argument is shown by using all the supported specifier by Zig's <code>std.fmt</code>, something like this:
<code>-Dkprobe=<kernel_function_name>:arg0.field1.field0/x</code> will show <code>arg0.field1.field0</code> in hexadecimal notation.
Capturing call stack is also supported, append keyword <code>stack</code>, for example <code>-Dkprobe=<kernel_function_name>:arg0,stack</code>.
And here's a quick demo:
<a></a>
For reference:
- Syscalls: https://tw4452852.github.io/zbpf/#vmlinux.kernel_syscalls
- Kernel functions: https://tw4452852.github.io/zbpf/#vmlinux.kernel_funcs
Want to use your local specific linux kernel? No problem, you could set up the documentation locally with:
<code>zig build docs [-Dvmlinux=/path/your/vmlinux]</code>
Then browse the generated page which is located at <code>./zig-out/docs/index.html</code>.
Search for <code>vmlinux.kernel_syscalls</code> and <code>vmlinux.kernel_funcs</code> for syscalls and kernel functions respectively.
Samples
For each supported feature, we have the corresponding unit test.
You could find them under <code>samples/</code> (BPF side) and <code>src/tests</code> (Host side).
Build it with <code>zig build test -Dtest=<name></code> and run it with <code>sudo zig-out/bin/test</code>.
Name | BPF side | Host side
--- | --- | ---
exit | <a>source</a> | <a>source</a>
panic | <a>source</a> | <a>source</a>
trace_printk | <a>source</a> | <a>source</a>
array | <a>source</a> | <a>source</a>
hash | <a>source</a> | <a>source</a>
perf_event | <a>source</a> | <a>source</a>
ringbuf | <a>source</a> | <a>source</a>
tracepoint | <a>source</a> | <a>source</a>
iterator | <a>source</a> | <a>source</a>
fentry | <a>source</a> | <a>source</a>
kprobe | <a>source</a> | <a>source</a>
kmulprobe | <a>source</a> | <a>source</a>
xdp ping | <a>source</a> | <a>source</a>
kfunc | <a>source</a> | <a>source</a>
stack_trace | <a>source</a> | <a>source</a>
uprobe | <a>source</a> | <a>source</a>
tc_ingress | <a>source</a> | <a>source</a>
<strong>Have fun!</strong>
|
[] |
https://avatars.githubusercontent.com/u/98668553?v=4
|
LibreScroll
|
EsportToys/LibreScroll
|
2023-07-19T07:46:15Z
|
Smooth inertial scrolling with any regular mouse.
|
main
| 0 | 145 | 4 | 145 |
https://api.github.com/repos/EsportToys/LibreScroll/tags
|
GPL-3.0
|
[
"accessibility",
"autoit",
"ergonomics",
"infinite-scroll",
"middle-click",
"momentum",
"momentum-scrolling",
"mouse",
"rawinput",
"sendinput",
"thinkpad",
"tpmiddle",
"trackball",
"trackpoint",
"winapi",
"windows",
"zig",
"zig-package"
] | 70 | false |
2025-05-21T15:42:41Z
| false | false |
unknown
|
github
|
[] |
LibreScroll
Smooth inertial scrolling on Windows with any regular mouse.
<a>Download Here</a>
https://github.com/EsportToys/LibreScroll/assets/98432183/c7fc05a5-6b10-4b91-9984-0d809a52b025
Instructions
<ol>
<li>Run LibreScroll</li>
<li>Hold Mouse 3 and move your mouse, the cursor will stay in-place, mouse motion is instead converted to scroll momentum.</li>
<li>Release middle-mouse-button to halt scroll momentum and release the cursor.</li>
</ol>
To compile from source, run
<code>zig build-exe main.zig main.rc main.manifest --subsystem windows</code>
Options
Friction
The rate at which momentum decays.
(Units: deceleration per velocity, in s⁻¹)
X/Y-Sensitivity
The horizontal/vertical multiplier at which mouse movement is converted to scroll momentum.
Set sensitivity to zero to disable that axis entirely.
(Units: scroll-velocity per mouse-displacement, in s⁻¹)
Minimum X/Y Step
The granularity at which to send scrolling inputs.
This is a workaround for some legacy apps that do not handle smooth scrolling increments correctly.
A "standard" coarse scrollwheel step is 120, and the smallest step is 1.
Flick Mode
When enabled, releasing middle-mouse-button will not stop the scrolling momentum.
Press any button again (or move the actual wheel) to stop the momentum.
ThinkPad Mode
When enabled, scrolling snaps to either horizontal or vertical, never both at the same time.
This emulates how scrolling works on ThinkPad TrackPoints.
Pause/Unpause
Temporarily disable the utility if you need to use the unmodified behavior in another app.
This kills the worker thread, which can be restarted by clicking Unpause or Apply.
Apply
After modifying the preference, click this to apply the configuration as displayed.
This kills and restarts the worker thread with the new configuration.
Recommended Settings for ThinkPad users (replacing TPmiddle)
With your TrackPoint's middle button set to "middle click mode", the following configurations are recommended to emulate TPmiddle's direct scrolling:
<code>Friction: 30
Y-Sensitivity: 90
X-Sensitivity: 90
Minimum X-Step: 10
Minimum Y-Step: 10
Flick Mode: No
ThinkPad Mode: Yes</code>
|
[] |
https://avatars.githubusercontent.com/u/206480?v=4
|
log.zig
|
karlseguin/log.zig
|
2023-03-22T07:49:50Z
|
A structured logger for Zig
|
master
| 0 | 136 | 8 | 136 |
https://api.github.com/repos/karlseguin/log.zig/tags
|
MIT
|
[
"logging-library",
"structured-logging",
"zig",
"zig-library",
"zig-package"
] | 167 | false |
2025-05-20T10:41:52Z
| true | true |
unknown
|
github
|
[
{
"commit": "cf2797bcb3aea7e5cdaf4de39c5550c70796e7b1.tar.gz",
"name": "metrics",
"tar_url": "https://github.com/karlseguin/metrics.zig/archive/cf2797bcb3aea7e5cdaf4de39c5550c70796e7b1.tar.gz.tar.gz",
"type": "remote",
"url": "https://github.com/karlseguin/metrics.zig"
}
] |
Structured Logging for Zig
logz is an opinionated structured logger that outputs to stdout, stderr, a file or a custom writer using logfmt or JSON. It aims to minimize runtime memory allocation by using a pool of pre-allocated loggers.
Metrics
If you're looking for metrics, check out my <a>prometheus library for Zig</a>.
Installation
This library supports native Zig module (introduced in 0.11). Add a "logz" dependency to your <code>build.zig.zon</code>.
Zig 0.11
Please use the <a>zig-0.11</a> branch for a version of the library which is compatible with Zig 0.11.
The master branch of this library follows Zig's master.
Usage
For simple cases, a global logging pool can be configured and used:
```zig
// initialize a logging pool
try logz.setup(allocator, .{
.level = .Info,
.pool_size = 100,
.buffer_size = 4096,
.large_buffer_count = 8,
.large_buffer_size = 16384,
.output = .stdout,
.encoding = .logfmt,
});
defer logz.deinit();
// other places in your code
logz.info().string("path", req.url.path).int("ms", elapsed).log();
// The src(@src()) + err(err) combo is great for errors
logz.err().src(@src()).err(err).log();
```
Alternatively, 1 or more explicit pools can be created:
```zig
var requestLogs = try logz.Pool.init(allocator, .{});
defer requestLogs.deinit();
// requestLogs can be shared across threads
requestLogs.err().
string("context", "divide").
float("a", a).
float("b", b).log();
```
<code>logz.Level.parse([]const u8) ?Level</code> can be used to convert a string into a logz.Level.
The configuration <code>output</code> can be <code>.stdout</code>, <code>.stderr</code> or a <code>.{.file = "PATH TO FILE}</code>. More advanced cases can use <code>logTo(writer: anytype)</code> instead of <code>log()</code>.
The configuration <code>encoding</code> can be either <code>logfmt</code> or <code>json</code>.
Important Notes
<ol>
<li>Attribute keys are never escaped. logz assumes that attribute keys can be written as is.</li>
<li>Logz can silently drop attributes from a log entry. This only happens when the attribute exceeds the configured sized (either of the buffer or the buffer + large_buffer) or a large buffer couldn't be created.</li>
<li>Depending on the <code>pool_strategy</code> configuration, when empty the pool will either dynamically create a logger (<code>.pool_strategy = .create</code>) or return a noop logger (<code>.pool_strategy = .noop)</code>. If creation fails, a noop logger will be return and an error is written using <code>std.log.err</code>.</li>
</ol>
Pools and Loggers
Pools are thread-safe.
The following functions returns a logger:
<ul>
<li><code>pool.debug()</code></li>
<li><code>pool.info()</code></li>
<li><code>pool.warn()</code></li>
<li><code>pool.err()</code></li>
<li><code>pool.fatal()</code></li>
<li><code>pool.logger()</code></li>
<li><code>pool.loggerL()</code></li>
</ul>
The returned logger is NOT thread safe.
Attributes
The logger can log:
* <code>fmt(key: []const u8, comptime format: []const u8, values: anytype)</code>
* <code>string(key: []const u8, value: ?[]const u8)</code>
* <code>stringZ(key: []const u8, value: ?[*:0]const u8)</code>
* <code>boolean(key: []const u8, value: ?boolean)</code>
* <code>int(key: []const u8, value: ?any_int)</code>
* <code>float(key: []const u8, value: ?any_float)</code>
* <code>binary(key: []const u8, value: ?[]const u8)</code> - will be url_base_64 encoded
* <code>err(e: anyerror)</code> - same as <code>errK("@err", e)</code>;
* <code>errK(key: []const u8, e: anyerror)</code>
* <code>stringSafe(key: []const u8, value: ?[]const u8)</code> - assumes value doesn't need to be encoded
* <code>stringSafeZ(key: []const u8, value: ?[*:0]const u8)</code> - assumes value doesn't need to be encoded
* <code>ctx(value: []const u8)</code> - same as <code>stringSafe("@ctx", value)</code>
* <code>src(value: std.builtin.SourceLocation)</code> - Logs an <code>std.builtin.SourceLocation</code>, the type of value you get from the <code>@src()</code> builtin.
Log Level
Pools are configured with a minimum log level:
<ul>
<li><code>logz.Level.Debug</code></li>
<li><code>logz.Level.Info</code></li>
<li><code>logz.Level.Warn</code></li>
<li><code>logz.Level.Error</code></li>
<li><code>logz.Level.Fatal</code></li>
<li><code>logz.Level.None</code></li>
</ul>
When getting a logger for a value lower than the configured level, a noop logger is returned. This logger exposes the same API, but does nothing.
```zig
var logs = try logz.Pool.init(allocator, .{.level = .Error});
// this won't do anything
logs.info().bool("noop", true).log();
```
The noop logger is meant to be relatively fast. But it doesn't eliminate any complicated values you might pass. Consider this example:
<code>zig
var logs = try logz.Pool.init(allocator, .{.level = .None});
try logs.warn().
string("expensive", expensiveCall()).
log();</code>
Although the logger is disabled (the log level is <code>Fatal</code>), the <code>expensiveCall()</code> function is still called. In such cases, it's necessary to use the <code>pool.shouldLog</code> function:
<code>zig
if (pool.shouldLog(.Warn)) {
try logs.warn().
string("expensive", expensiveCall()).
log();
}</code>
Config
Pools use the following configuration. The default value for each setting is show:
```zig
pub const Config = struct {
// The number of loggers to pre-allocate.
pool_size: usize = 32,
<code>// Controls what the pool does when empty. It can either dynamically create
// a new Logger, or return the Noop logger.
pool_startegy: .create, // or .noop
// Each logger in the pool is configured with a static buffer of this size.
// An entry that exceeds this size will attempt to expand into the
// large buffer pool. Failing this, attributes will be dropped
buffer_size: usize = 4096,
// The minimum log level to log. `.None` disables all logging
level: logz.Level = .Info,
// Data to prepend at the start of every logged message from this pool
// See the Advanced Usage section
prefix: ?[]const u8 = null,
// Where to write the output: can be either .stdout or .stderr
output: Output = .stdout, // or .stderr, or .{.file = "PATH TO FILE"}
encoding: Encoding = .logfmt, // or .json
// How many large buffers to create
large_buffer_count: u16 = 8,
// Size of large buffers.
large_buffer_size: usize = 16384,
// Controls what the large buffer pool does when empty. It can either
// dynamically create a large buffer, or drop the attribute
large_buffer_startegy: .create, // or .drop
</code>
};
```
Timestamp and Level
When using the <code>debug</code>, <code>info</code>, <code>warn</code>, <code>err</code> or <code>fatal</code> functions, logs will always begin with <code>@ts=$MILLISECONDS_SINCE_JAN1_1970_UTC @l=$LEVEL</code>, such as: <code>@ts=1679473882025 @l=INFO</code>. With JSON encoding, the object will always have the <code>"@ts"</code> and <code>"@l"</code> fields.
Logger Life cycle
The logger is implicitly returned to the pool when <code>log</code>, <code>logTo</code> or <code>tryLog</code> is called. In rare cases where <code>log</code>, <code>logTo</code> or <code>tryLog</code> are not called, the logger must be explicitly released using its <code>release()</code> function:
```zig
// This is a contrived example to show explicit release
var l = logz.info();
_ = l.string("key", "value");
// actually, on second thought, I don't want to log anything
l.release();
```
Method Chaining
Loggers are mutable. The method chaining (aka fluent interface) is purely cosmetic. The following are equivalent:
```zig
// chaining
info().int("over", 9000).log();
// no chaining
var l = info();
_ = l.int("over", 9000);
l.log();
```
tryLog
The call to <code>log</code> can fail. On failure, a message is written using <code>std.log.err</code>. However, <code>log</code> returns <code>void</code> to improve the API's usability (it doesn't require callers to <code>try</code> or <code>catch</code>).
<code>tryLog</code> can be used instead of <code>log</code>. This function returns a <code>!void</code> and will not write to <code>std.log.err</code> on failure.
Advanced Usage
Pre-setup
<code>setup(CONFIG)</code> can be called multiple times, but isn't thread safe. The idea is that, at the very start, <code>setup</code> can be called with a minimal config so that any startup errors can be logged. After startup, but before the full application begins, <code>setup</code> is called a 2nd time with the correct config. Something like:
```zig
pub fn main() !void {
var general_purpose_allocator = std.heap.GeneralPurposeAllocator(.{}){};
const allocator = general_purpose_allocator.allocator();
<code>// minimal config so that we can use logz will setting things up
try logz.setup(.{
.pool_size = 2,
.max_size = 4096,
.level = .Warn
});
// can safely call logz functions, since we now have a mimimal setup
const config = loadConfig();
// more startup things here
// ok, now setup our full logger (which we couldn't do until we read
// our config, which could have failed)
try logz.setup(.{
.pool_size = config.log.pool_size,
.max_size = config.log.max_size,
.level = config.log.level
});
...
</code>
}
```
Prefixes
A pool can be configured with a prefix by setting the <code>prefix</code> field of the configuration. When set, all log entries generated by loggers of this pool will contain the prefix.
The prefix is written as-is.
```zig
// prefix can be anything []const u8. It doesn't have to be a key=value
// it will not be encoded if needed, and doesn't even have to be a valid string.
var p = try logz.Pool.init(allocator, .{.prefix = "keemun"});
defer p.deinit();
p.info().boolean("tea", true).log();
```
The above will generate a log line: <code>keemun @ts=TIMESTAMP @l=INFO tea=Y"</code>
When using <code>.json</code> encoding, your prefix must begin the object:
```zig:
var p = try logz.Pool.init(allocator, .{.prefix = "=={"});
defer p.deinit();
p.info().boolean("tea", true).log();
<code>``
The above will generate a log line:</code>=={"@ts":TIMESTAMP, "@l":"INFO", "tea":true}`
Multi-Use Logger
Rather than having a logger automatically returned to the pool when <code>.log()</code> or <code>tryLog()</code> are called, it is possible to flag the logger for "multi-use". In such cases, the logger must be explicitly returned to the pool using <code>logger.release()</code>. This can be enabled by calling <code>multiuse</code> on the logger. Logs created by the logger will share the same attributes up to the point where multiuse was called:
```zig
var logger = logz.logger().string("request_id", request_id).multiuse();
defer logger.release(); // important
logger.int("status", status_code).int("ms", elapsed_time).level(.Info).log()
...
logger.err(err).string("details", "write failed").level(.Error).log()
```
The above logs 2 distinct entries, both of which will contain the "request_id=XYZ" attribute. Do remember that while the logz.Pool is thread-safe, individual loggers are not. A multi-use logger should not be used across threads.
Deferred Level
The <code>logger()</code> function returns a logger with no level. This can be used to defer the level:
```zig
var logger = logz.logger().
stringSafe("ctx", "db.setup").
string("path", path);
defer logger.log();
const db = zqlite.open(path, true) catch |err| {
_ = logger.err(err).level(.Fatal);
}
_ = logger.level(.Info);
return db;
```
Previously, we saw how an internal "noop" logger is returned when the log level is less than the configured log level. With a log level of <code>Warn</code>, the following is largely 3 noop function calls:
<code>zig
log.info().string("path", path).log();</code>
With deferred log levels, this isn't possible - the configured log level is only considered when <code>log</code> (or <code>tryLog</code>) is called. Again, given a log level of <code>Warn</code>, the following <strong>will not</strong> log anything, but the call to <code>string("path", path)</code> is not a "noop":
<code>zig
var l = log.logger().string("path", path);
_ = l.level(.Info);
l.log();</code>
The <code>log.loggerL(LEVEL)</code> function is a very minor variant which allows setting a default log level. Using it, the original deferred example can be rewritten:
```zig
var logger = logz.loggerL(.Info).
stringSafe("ctx", "db.setup").
string("path", path);
defer logger.log();
const db = zqlite.open(path, true) catch |err| {
_ = logger.err(err).level(.Fatal);
}
// This line is removed
// logger.level(.Info);
return db;
```
<code>errdefer</code> can be used with deferred logging as a simple and generic way to log errors. The above can be re-written as:
```zig
var logger = logz.loggerL(.Info).
stringSafe("ctx", "db.setup").
string("path", path);
defer logger.log();
errdefer |err| _ = logger.err(err).level(.Fatal);
return zqlite.open(path, true);
```
Allocations
When configured with <code>.pool_strategy = .noop</code> and <code>.large_buffer_strategy = .drop</code>, the logger will not allocate memory after the pool is initialized.
Maximum Log Line Size
The maximum possible log entry is: <code>config.prefix.len + config.buffer_size + config.large_buffer_size + ~35</code>.
Th last 35 bytes is for the the @ts and @l attributes, and the trailing newline. The exact length of these can vary by a few bytes (e.g. the json encoder takes a few additional bytes to quote the key).
Custom Output
The <code>logTo(writer: anytype)</code> can be called instead of <code>log()</code>. The writer must expose 1 method:
<ul>
<li><code>writeAll(self: Self, data: []const u8) !void</code></li>
</ul>
A single call to <code>logTo()</code> can result in multiple calls to <code>writeAll</code>. <code>logTo</code> uses a mutex to ensure that a single entry is written to the writer at a time.
Testing
When testing, I recommend you do the following in your main test entry:
```zig
var leaking_gpa = std.heap.GeneralPurposeAllocator(.{}){};
const leaking_allocator = leaking_gpa.allocator();
test {
try logz.setup(leaking_allocator, .{.pool_size = 5, .level = .None});
<code>// rest of your setup, such as::
std.testing.refAllDecls(@This());
</code>
}
```
First, you should not use <code>std.testing.allocator</code> since Zig offers no way to cleanup globals after tests are run. In the above, the <code>logz.Pool</code> <em>will</em> leak (but that should be ok in a test).
Second, notice that we're using a global allocator. This is because the pool may need to dynamically allocate a logger, and thus the allocator must exist for the lifetime of the pool. Strictly speaking, this can be avoided if you know that the pool will never need to allocate a dynamic logger, so setting a sufficiently large <code>pool_size</code> would also work.
Finally, you should set the log level to '.None' until the following Zig issue is fixed <a>https://github.com/ziglang/zig/issues/15091</a>.
Metrics
A few basic metrics are collected using <a>metrics.zig</a>, a prometheus-compatible library. These can be written to an <code>std.io.Writer</code> using <code>try logz.writeMetrics(writer)</code>. As an example using <a>httpz</a>:
```zig
pub fn metrics(_: <em>httpz.Request, res: </em>httpz.Response) !void {
const writer = res.writer();
try logz.writeMetrics(writer);
<code>// also write out the httpz metrics
try httpz.writeMetrics(writer);
</code>
}
```
The metrics are:
<ul>
<li><code>logz_no_space</code> - counts the number of bytes which resulted in an attribute being dropped from a log. Consider increasing <code>buffer_size</code> and/or <code>large_buffer_size</code>.</li>
<li><code>logz_pool_empty</code> - counts the number of times the log pool was empty. Depending on the <code>pool_startegy</code> configuration, this either results in a logger being dynamically allocated, or a log message being dropped. Consider increasing <code>pool_size</code>.</li>
<li><code>logz_large_buffer_empty</code> - counts the number of times the large buffer pool was empty. Depending on the <code>large_buffer_startegy</code> configuration, this either in a large buffer being dynamically allocated, or part of a log being dropped. Consider increasing <code>large_buffer_count</code>.</li>
<li><code>logz_large_buffer_acquire</code> - counts the number of times a large buffer was successfully retrived from the large buffer pool. This is not particularly problematic, but, as the large buffer pool is a limited and mutex-protected, this can be reduced by increasing <code>buffer_size</code>.</li>
</ul>
|
[] |
https://avatars.githubusercontent.com/u/51416554?v=4
|
zBench
|
hendriknielaender/zBench
|
2023-05-25T13:57:54Z
|
📊 zig benchmark
|
main
| 16 | 130 | 10 | 130 |
https://api.github.com/repos/hendriknielaender/zBench/tags
|
MIT
|
[
"bench",
"benchmark",
"benchmarking",
"performance",
"stdout",
"testing",
"zig",
"zig-package",
"ziglang"
] | 3,717 | false |
2025-05-10T21:13:43Z
| true | true |
unknown
|
github
|
[] |
⚡ zBench - A Zig Benchmarking Library
<a></a>
<a></a>
zBench is a benchmarking library for the Zig programming language. It is designed to provide easy-to-use functionality to measure and compare the performance of your code.
Content
<ul>
<li><a>Installation</a></li>
<li><a>Usage</a></li>
<li><a>Configuration</a></li>
<li><a>Compatibility Notes</a></li>
<li><a>Reporting Benchmarks</a></li>
<li><a>Running zBench Examples</a></li>
<li><a>Troubleshooting</a></li>
<li><a>Contributing</a></li>
<li><a>License</a></li>
</ul>
Installation
For installation instructions, please refer to the <a>documentation</a>.
Usage
Create a new benchmark function in your Zig code. This function takes a single argument of type <code>std.mem.Allocator</code> and runs the code you wish to benchmark.
<code>zig
fn benchmarkMyFunction(allocator: std.mem.Allocator) void {
// Code to benchmark here
}</code>
You can then run your benchmarks in a test:
<code>zig
test "bench test" {
var bench = zbench.Benchmark.init(std.testing.allocator, .{});
defer bench.deinit();
try bench.add("My Benchmark", myBenchmark, .{});
try bench.run(std.io.getStdOut().writer());
}</code>
Configuration
To customize your benchmark runs, zBench provides a <code>Config</code> struct that allows you to specify several options:
<code>zig
pub const Config = struct {
iterations: u16 = 0,
max_iterations: u16 = 16384,
time_budget_ns: u64 = 2e9, // 2 seconds
hooks: Hooks = .{},
track_allocations: bool = false,
use_shuffling_allocator: bool = false,
};</code>
<ul>
<li><code>iterations</code>: The number of iterations the benchmark has been run. This field is usually managed by zBench itself.</li>
<li><code>max_iterations</code>: Set the maximum number of iterations for a benchmark. Useful for controlling long-running benchmarks.</li>
<li><code>time_budget_ns</code>: Define a time budget for the benchmark in nanoseconds. Helps in limiting the total execution time of the benchmark.</li>
<li><code>hooks</code>: Set <code>before_all</code>, <code>after_all</code>, <code>before_each</code>, and <code>after_each</code> hooks to function pointers.</li>
<li><code>track_allocations</code>: Boolean to enable or disable tracking memory allocations during the benchmark.</li>
<li><code>use_shuffling_allocator</code>: an experimental <code>ShufflingAllocator</code>. This allocator randomizes memory allocation patterns, which can be useful for identifying potential memory-related bugs and reducing bias caused by predictable memory layouts during benchmarking.</li>
</ul>
<strong>Important Note:</strong> The <code>ShufflingAllocator</code> will likely introduce <em>some</em> performance overhead compared to a standard allocator. The extent of the overhead is currently not specified! Consider this when interpreting your benchmark results.
Compatibility Notes
Zig version
Zig is in active development, and its APIs can change frequently. The main branch of this project now targets the latest Zig master build to take advantage of new features and improvements. For users who prefer the stability of official releases, dedicated branches are maintained for older Zig versions (e.g., zig-0.13.0, zig-0.12.0, etc.). This ensures you can choose the branch that best fits your stability and feature requirements.
Performance Note
It's important to acknowledge that a no-op time of ca. 15 ns (or more) is expected and is not an issue with zBench itself (see also <a>#77</a>). This does not reflect an inefficiency in the benchmarking process.
Reporting Benchmarks
zBench provides a comprehensive report for each benchmark run. It includes the total operations performed, the average, min, and max durations of operations, and the percentile distribution (p75, p99, p995) of operation durations.
```shell
benchmark runs time (avg ± σ) (min ... max) p75 p99 p995
benchmarkMyFunction 1000 1200ms ± 10ms (100ms ... 2000ms) 1100ms 1900ms 1950ms
```
This example report indicates that the benchmark "benchmarkMyFunction" ran with an average of 1200 ms per execution and a standard deviation of 10 ms.
The minimum and maximum execution times were 100 ms and 2000 ms, respectively. The 75th, 99th and 99.5th percentiles of execution times were 1100 ms, 1900 ms, and 1950 ms, respectively.
Running zBench Examples
You can build all examples with the following command:
<code>shell
zig build examples</code>
Executables can then be found in <code>./zig-out/bin</code> by default.
Troubleshooting
<ul>
<li>If Zig doesn't detect changes in a dependency, clear the project's <code>zig-cache</code> folder and <code>~/.cache/zig</code>.</li>
<li><a>Non-ASCII characters not printed correctly on Windows</a></li>
</ul>
Contributing
The main purpose of this repository is to continue to evolve zBench, making it faster and more efficient. We are grateful to the community for contributing bugfixes and improvements. Read below to learn how you help improve zBench.
Contributing Guide
Read our <a>contributing guide</a> to learn about our development process, how to propose bugfixes and improvements, and how to build and test your changes to zBench.
License
zBench is <a>MIT licensed</a>.
|
[] |
https://avatars.githubusercontent.com/u/206480?v=4
|
zuckdb.zig
|
karlseguin/zuckdb.zig
|
2023-05-08T09:53:52Z
|
A DuckDB driver for Zig
|
master
| 2 | 130 | 4 | 130 |
https://api.github.com/repos/karlseguin/zuckdb.zig/tags
|
MIT
|
[
"duckdb",
"duckdb-driver",
"zig",
"zig-library",
"zig-package"
] | 317 | false |
2025-05-17T17:07:24Z
| true | true |
unknown
|
github
|
[] |
Zig driver for DuckDB.
Quick Example
```zig
const db = try zuckdb.DB.init(allocator, "/tmp/db.duck", .{});
defer db.deinit();
var conn = try db.conn();
defer conn.deinit();
// for insert/update/delete returns the # changed rows
// returns 0 for other statements
_ = try conn.exec("create table users(id int)", .{});
var rows = try conn.query("select * from users", .{});
defer rows.deinit();
while (try rows.next()) |row| {
// get the 0th column of the current row
const id = row.get(i32, 0);
std.debug.print("The id is: {d}", .{id});
}
```
Any non-primitive value that you get from the <code>row</code> are valid only until the next call to <code>next</code> or <code>deinit</code>.
Install
This library is tested with DuckDB 1.1.0. You can either link to an existing libduckdb on your system, or have zuckdb download and build DuckDB for you (this will take time.)
1) Add zuckdb as a dependency in your <code>build.zig.zon</code>:
<code>bash
zig fetch --save git+https://github.com/karlseguin/zuckdb.zig#master</code>
Link to libduckdb
1) Download the libduckdb from the <a>DuckDB download page</a>.
2) Place the <code>duckdb.h</code> file and the <code>libduckdb.so</code> (linux) or <code>libduckdb.dylib</code> (mac) in your project's <code>lib</code> folder.
3) Add this in <code>build.zig</code>:
```zig
const zuckdb = b.dependency("zuckdb", .{
.target = target,
.optimize = optimize,
}).module("zuckdb");
// Your app's program
const exe = b.addExecutable(.{
.name = "run",
.target = target,
.optimize = optimize,
.root_source_file = b.path("src/main.zig"),
});
// include the zuckdb module
exe.root_module.addImport("zuckdb", zuckdb);
// link to libduckdb
exe.linkSystemLibrary("duckdb");
// tell the linker where to find libduckdb.so (linux) or libduckdb.dylib (macos)
exe.addLibraryPath(b.path("lib/"));
```
Automatically fetch and buikd DuckDB
1) Add this in <code>build.zig</code>:
```zig
const zuckdb = b.dependency("zuckdb", .{
.target = target,
.optimize = optimize,
.system_libduckdb = false,
.debug_duckdb = false, // optional, compile DuckDB with DUCKDB_DEBUG_STACKTRACE or not
}).module("zuckdb");
// Your app's program
const exe = b.addExecutable(.{
.name = "run",
.target = target,
.optimize = optimize,
.root_source_file = b.path("src/main.zig"),
});
// include the zuckdb module
exe.root_module.addImport("zuckdb", zuckdb);
```
Static Linking
It's also possible to statically link DuckDB. In order to do this, you must build DuckDB yourself, in order to <a>compile it using Zig C++</a> and using the <a>bundle-library</a> target
<code>git clone -b 1.1.0 --single-branch https://github.com/duckdb/duckdb.git
cd duckdb
export CXX="zig c++"
DUCKDB_EXTENSIONS='json' make bundle-library</code>
When this finished (it will take several minutes), you can copy <code>build/release/libduckdb_bundle.a</code> and <code>src/include/duckdb.h</code> to your project's <code>lib</code> folder. Rename <code>libduckdb_bundle.a</code> to <code>libduckdb.a</code>.
Finally, Add the following to your <code>build.zig</code>:
<code>zig
exe.linkSystemLibrary("duckdb");
exe.linkSystemLibrary("stdc++");
exe.addLibraryPath(b.path("lib/"));</code>
DB
The <code>DB</code> is used to initialize the database, open connections and, optionally, create a connection pool.
init
Creates or opens the database.
<code>zig
// can use the special path ":memory:" for an in-memory database
const db = try DB.init(allocator, "/tmp/db.duckdb", .{});
defer db.deinit();</code>
The 3rd parameter is for options. The available options, with their default, are:
<ul>
<li><code>access_mode</code> - Sets the <code>access_mode</code> DuckDB configuration. Defaults to <code>.automatic</code>. Valid options are: <code>.automatic</code>, <code>.read_only</code> or <code>.read_write</code>.</li>
<li><code>enable_external_access</code> - Sets the <code>enable_external_access</code> DuckDB configuration. Defaults to <code>true</code>.</li>
</ul>
initWithErr
Same as <code>init</code>, but takes a 4th output parameter. On open failure, the output parameter will be set to the error message. This parameter must be freed if set.
<code>zig
var open_err: ?[]u8 = null;
const db = DB.initWithErr(allocator, "/does/not/exist", .{}, &open_err) catch |err| {
if (err == error.OpenDB) {
defer allocator.free(open_err.?);
std.debug.print("DB open: {}", .{open_err.?});
}
return err;
};</code>
deinit
Closes the database.
conn
Returns a new <a>connection</a> object.
<code>zig
var conn = try db.conn();
defer conn.deinit();
...</code>
pool
Initializes a <a>pool</a> of connections to the DB.
```zig
var pool = try db.pool(.{.size = 2});
// the pool owns the <code>db</code>, so pool.deinit will call <code>db.deinit</code>.
defer pool.deinit();
var conn = try pool.acquire();
defer pool.release(conn);
```
The <code>pool</code> method takes an options parameter:
* <code>size: usize</code> - The number of connections to keep in the pool. Defaults to <code>5</code>
* <code>timeout: u64</code> - The time, in milliseconds, to wait for a connetion to be available when calling <code>pool.acquire()</code>. Defaults to <code>10_000</code>.
* <code>on_connection: ?*const fn(conn: *Conn) anyerror!void</code> - The function to call when the pool first establishes the connection. Defaults to <code>null</code>.
* <code>on_first_connection: ?*const fn(conn: *Conn) anyerror!void</code> - The function to call on the first connection opened by the pool. Defaults to <code>null</code>.
Conn
query
Use <code>conn.query(sql, args) !Rows</code> to query the database and return a <code>zuckdb.Rows</code> which can be iterated. You must call <code>deinit</code> on the returned rows.
<code>zig
var rows = try conn.query("select * from users where power > $1", .{9000});
defer rows.deinit();
while (try rows.next()) |row| {
// ...
}</code>
exec
<code>conn.exec(sql, args) !usize</code> is a wrapper around <code>query</code> which returns the number of affected rows for insert, updates or deletes.
row
<code>conn.row(sql, args) !?OwningRow</code> is a wrapper around <code>query</code> which returns a single optional row. You must call <code>deinit</code> on the returned row:
<code>zig
var row = (try conn.query("select * from users where id = $1", .{22})) orelse return null;;
defer row.deinit();
// ...</code>
begin/commit/rollback
The <code>conn.begin()</code>, <code>conn.commit()</code> and <code>conn.rollback()</code> calls are wrappers around <code>exec</code>, e.g.: <code>conn.exec("begin", .{})</code>.
prepare
<code>conn.prepare(sql, opts) !Stmt</code> prepares the given SQL and returns a <code>zuckdb.Stmt</code>. For one-off queries, you should prefer using <code>query</code>, <code>exec</code> or <code>row</code> which wrap <code>prepare</code> and then call <code>stmt.bind(values)</code> and finally <code>stmt.execute()</code>. Getting an explicit <a>Stmt</a> is useful when executing the same statement multiple times with different values.
Values for opts are:
<ul>
<li><code>auto_release: bool</code> - This defaults to and should usually be kept as <code>false</code>. When <code>true</code>, the statement is automatically discarded (<code>deinit</code>) after the result of its first execution is complete. If you're going to set this to <code>true</code>, you might as well use <code>conn.exec</code>, <code>conn.query</code> or <code>conn.row</code> instead of getting an explicit statement.</li>
</ul>
err
If a method of <code>conn</code> returns <code>error.DuckDBError</code>, <code>conn.err</code> will be set:
<code>zig
var rows = conn.query("....", .{}) catch |err| {
if (err == error.DuckDBError) {
if (conn.err) |derr| {
std.log.err("DuckDB {s}\n", .{derr});
}
}
return err;
}</code>
In the above snippet, it's possible to skip the <code>if (err == error.DuckDBError)</code>check, but in that case conn.err could be set from some previous command (conn.err is always reset when acquired from the pool).
release
<code>conn.release()</code> will release the connection back to the pool. This does nothing if the connection did not come from the pool (i.e. <code>pool.acquire()</code>). This is the same as calling <code>pool.release(conn)</code>.
Rows
The <code>rows</code> returned from <code>conn.query</code> exposes the following methods:
<ul>
<li><code>count()</code> - the number of rows in the result</li>
<li><code>changed()</code> - the number of updated/deleted/inserted rows</li>
<li><code>columnName(i: usize)</code> - the column name at position <code>i</code> in a result</li>
<li><code>deinit()</code> - must be called to free resources associated with the result</li>
<li><code>next() !?Row</code> - returns the next row</li>
</ul>
The most important method on <code>rows</code> is <code>next()</code> which is used to iterate the results. <code>next()</code> is a typical Zig iterator and returns a <code>?Row</code> which will be null when no more rows exist to be iterated.
Row
get
<code>Row</code> exposes a <code>get(T, index) T</code> function. This function trusts you! If you ask for an <code>i32</code> the library will crash if the column is not an <code>int4</code>. Similarly, if the value can be null, you must use the optional type, e.g. <code>?i32</code>.
The supported types for <code>get</code>, are:
* <code>[]u8</code>,
* <code>[]const u8</code>
* <code>i8</code>
* <code>i16</code>
* <code>i32</code>
* <code>i64</code>
* <code>i128</code>
* <code>u8</code>
* <code>u16</code>
* <code>u32</code>
* <code>u64</code>
* <code>f32</code>
* <code>f64</code>
* <code>bool</code>
* <code>zuckdb.Date</code>
* <code>zuckdb.Time</code>
* <code>zuckdb.Interval</code>
* <code>zuckdb.UUID</code>
* <code>zudkdb.Enum</code>
Optional version of the above are all supported <strong>and must be used</strong> if it's possible the value is null.
String values and enums are only valid until the next call to <code>next()</code> or <code>deinit</code>. You must dupe the values if you want them to outlive the row.
list
<code>Row</code> exposes a <code>list</code> method which behaves similar to <code>get</code> but returns a <code>zuckdb.List(T)</code>.
```zig
const row = (try conn.row("select [1, 32, 99, null, -4]::int[]", .{})) orelse unreachable;
defer row.deinit();
const list = row.list(?i32, 0).?;
try t.expectEqual(5, list.len);
try t.expectEqual(1, list.get(0).?);
try t.expectEqual(32, list.get(1).?);
try t.expectEqual(99, list.get(2).?);
try t.expectEqual(null, list.get(3));
try t.expectEqual(-4, list.get(4).?);
```
<code>list()</code> always returns a nullable, i.e. <code>?zuckdb.List(T)</code>. Besides the <code>len</code> field, <code>get</code> is used on the provided list to return a value at a specific index. <code>row.list(T, col).get(idx)</code> works with any of the types supported by <code>row.get(col)</code>.
a <code>List(T)</code> also has a <code>alloc(allocator: Allocator) ![]T</code> method. This will allocate a <code>[]T</code> and fill it with the list values. It is the caller's responsibility to free the returned slice.
Alternatively, <code>fill(into: []T) void</code> can be used used to populate <code>into</code> with items from the list. This will fill <code>@min(into.len, list.len)</code> values.
zuckdb.Enum
The <code>zuckdb.Enum</code> is a special type which exposes two functions: <code>raw() [*c]const u8</code> and <code>rowCache() ![]const u8</code>.
<code>raw()</code> directly returns the DuckDB enum string value. If you want to turn this into a <code>[]const u8</code>, you'll need to wrap it in <code>std.mem.span</code>. The value returned by <code>raw()</code> is only valid until the next iteration.
<code>rowCache()</code> takes the result of <code>raw()</code>, and dupes it, giving ownership to the Rows. Thus, the string returned by <code>rowCache()</code> outlives the current row iteration and is valid until <code>rows.deinit()</code> is called. Essentially, it is an interned string representation of the enum value (which DuckDB internally represents as an integer).
Pool
The <code>zuckdb.Pool</code> is a thread-safe connection pool:
```zig
const db = try zuckdb.DB.init(allocator, "/tmp/duckdb.zig.test", .{});
var pool = db.pool(.{
.size = 2,
.on_connection = &connInit,
.on_first_connection = &poolInit,
});
defer pool.deinit();
var conn = try pool.acquire();
defer conn.release();
```
The Pool takes ownership of the DB object, thus <code>db.deinit</code> does not need to be called The <code>on_connection</code> and <code>on_first_connection</code> are optional callbacks. They both have the same signature:
<code>zig
?*const fn(conn: *Conn) anyerror!void</code>
If both are specific, the first initialized connection will first be passed to <code>on_first_connection</code> and then to <code>on_connection</code>.
newConn() !Conn
Besides using <code>acquire()</code> to get a <code>!*Conn</code> from the pool, it's possible to create a new connection detached from the pool using <code>pool.newConn()</code>. This is the same as calling <code>db.conn()</code> but, on the pool. Again, this connection will not be part of the pool and <code>release()</code> should not be called on it (but <code>deinit()</code> should).
exec/query/row
The <code>pool.exec</code>, <code>pool.query</code>, <code>pool.queryWithState</code>, <code>pool.row</code> and <code>pool.rowWithState</code> are convenience functions which behave like their <code>Conn</code> counterparts.
<code>pool.exec</code> is the same as:
<code>zig
var conn = try pool.acquire();
defer conn.release();
return conn.exec(sql, args);</code>
<code>pool.query</code>, <code>pool.queryWithState</code>, <code>pool.row</code> and <code>pool.rowWithState</code> are similar, except the connection is automatically released back to the pool when the <code>rows.deinit()</code> or <code>row.deinit()</code> is called.s
Stmt
The <code>zuckdb.Stmt</code> encapsulates a prepared statement. It is generated by calling <code>conn.prepare([]const u8, opts)</code>.
deinit() !void
Deinitializes the statement.
clearBindings(stmt: *const Stmt) !void
Clears any previous bound values.
bind(stmt: *const Stmt, values: anytype) !void
Binds the values tuple to the statement.
bindValue(stmt: *const Stmt, value: anytype, index: usize) !void
Binds the specific value to the specified position.
exec(stmt: *const Stmt) !usize
Like <code>conn.exec</code>, this executes the statement returning the number of affected rows. Should not be used with a query that returns results.
query(stmt: *const Stmt) !Rows
Like <code>conn.query</code>, executes a result and returns the rows.
Query Optimizations
In very tight loops, performance might be improved by providing a stack-based state for the query logic to use. The <code>query</code> and <code>row</code> functions all have a <code>WithState</code> alternative, e.g.: <code>queryWithState</code>. These functions take 1 additional "query state" parameter:
<code>zig
var state = zuckdb.StaticState(2){};
var rows = try conn.queryWithState(SQL, .{ARGS}, &state);
// use rows normally</code>
The value passed to <code>zuckdb.StaticState</code> is the number of columns returned by the query. The <code>state</code> must remain valid until <code>rows.deinit()</code> is called.
Appender
The fastest way to insert a large amount of data is to use the appender:
```zig
// the first parameter is the schema, or null to use the default schema
var appender = try conn.appender(null, "my_table");
defer appender.deinit();
for (...) {
try appender.appendRow(.{"over", 9001, true});
}
// The appender auto-flushes, but it should be called once at the end.
try appender.flush();
```
The order of the values used in <code>appendRow</code> is the order of the columns as they are defined in the table (e.g. the order that <code>describe $table</code> returns).
Appender per-column append
The <code>appender.appendRow</code> function depends on the fact that you have comptime knowledge of the underlying table. If you are dealing with dynamic (e.g. user-defined) schemas, that won't always be the case. Instead, use the more explicit <code>beginRow()</code>, <code>appendValue()</code> and <code>endRow()</code> methods.
<code>zig
for (...) {
appender.beginRow();
try appender.appendValue("over", 0);
try appender.appendValue(9001, 1);
try appender.appendValue(true, 2);
try appender.endRow();
}
try appender.flush();</code>
The <code>appendRow()</code> method internally calls <code>beginRow(),</code>appendValue()<code>and</code>endRow()`.
Appender Type Support
The appender writes directly to the underlying storage and thus cannot leverage default column values. <code>appendRow</code> asserts that the # of values matches the number of columns. However, when using the explicit <code>beginRow</code> + <code>appendValue</code> + <code>endRow</code>, you must make sure to append a value for each column, else the behavior is undefined.
Enums aren't supporting, due to <a>limitations in the DuckDB C API</a>.
Decimals are supported, but be careful! When appending a float, the value will truncated to the decimal place specified by the scale of the column (i.e. a decimal(8, 3) will have the float truncated with 3 decimal places). When appending an int, the library assumes that you have already converted the decimal to the DuckDB internal representation. While surprising, this provides callers with precise control.
When dealing with ints, floats and decimals, appending a single value tends to be flexible. In other words, you can append an <code>i64</code> to a <code>tinyint</code> column, so long as the value fits (i.e. there's a runtime check). However, when dealing with lists (e.g. <code>integer[]</code>), the exact type is required. Thus, only a <code>[]u16</code> can be bound to a <code>usmallint[]</code> column. <code>decimal[]</code> can bind to a <code>[]i64</code>, <code>[]f32</code> or <code>[]f64</code>.
List columns support null values, and thus can be bound to either a <code>[]const T</code> or a <code>[]const ?T</code>.
Appender Error
If any of the appender methods return an error, you can see if the optional <code>appender.err</code> has an error description. This is a <code>?[]const u8</code> field. On error, you <strong>should not</strong> assume that this value is set, there are error cases where DuckDB doesn't provide an error description.
|
[] |
https://avatars.githubusercontent.com/u/68087632?v=4
|
cova
|
00JCIV00/cova
|
2023-05-02T23:42:13Z
|
Commands, Options, Values, Arguments. A simple yet robust cross-platform command line argument parsing library for Zig.
|
main
| 12 | 127 | 7 | 127 |
https://api.github.com/repos/00JCIV00/cova/tags
|
MIT
|
[
"clap",
"cli",
"command-line",
"terminal",
"zig",
"zig-package",
"ziglang"
] | 69,879 | false |
2025-05-18T01:44:31Z
| true | true |
unknown
|
github
|
[] |
Commands <strong>⋅</strong> Options <strong>⋅</strong> Values <strong>⋅</strong> Arguments
A simple yet robust cross-platform command line argument parsing library for Zig.
<a></a>
<a></a>
<a></a>
<a></a>
Overview
<code>command --option value</code>
Cova is based on the idea that Arguments will fall into one of three types: Commands, Options, or Values. These Types are assembled into a single Command struct which is then used to parse argument tokens. Whether you're looking for simple argument parsing or want to create something as complex as the <a><code>ip</code></a> or <a><code>git</code></a> commands, Cova makes it easy.
Get Started Quickly!
<ul>
<li><a>Quick Start Guide</a></li>
<li><a>Full Wiki Guide</a></li>
<li><a>API Docs</a></li>
</ul>
Quick Example
<a>Logger Example</a>
<code>shell
logger --log-level info</code>
Set up a Command
<code>zig
// ...
pub const CommandT = cova.Command.Custom(.{...});
pub const setup_cmd: CommandT = .{
.name = "logger",
.description = "A small demo of using the Log Level Enum as an Option.",
.examples = &.{ "logger --log-level info" },
.opts = &.{
.{
.name = "log_level",
.description = "An Option using the `log.Level` Enum.",
.long_name = "log-level",
.mandatory = true,
.val = .ofType(log.Level, .{
.name = "log_level_val",
.description = " This Value will handle the Enum."
})
}
},
};</code>
Parse the Command
```zig
pub fn main() !void {
// ...
var main_cmd = try setup_cmd.init(alloc, .{});
defer main_cmd.deinit();
var args_iter = try cova.ArgIteratorGeneric.init(alloc);
defer args_iter.deinit();
<code>cova.parseArgs(&args_iter, CommandT, main_cmd, stdout, .{}) catch |err| switch (err) {
error.UsageHelpCalled => {},
else => return err,
};
// ...
</code>
```
Use the Data
<code>zig
// ...
const main_opts = try main_cmd.getOpts(.{});
const log_lvl_opt = main_opts.get("log_level").?;
const log_lvl = log_lvl_opt.val.getAs(log.Level) catch {
log.err("The provided Log Level was invalid.", .{});
return;
};
log.info("Provided Log Level: {s}", .{ @tagName(log_lvl) });
}</code>
Features
<ul>
<li><strong><a>Comptime Setup</a>. <a>Runtime Use</a>.</strong></li>
<li>Cova is designed to have Argument Types set up at <strong><em>compile time</em></strong> so they can be validated during each compilation, thus providing you with immediate feedback.</li>
<li>Once validated, Argument Types are initialized to memory for <strong><em>runtime</em></strong> use where end user argument tokens are parsed then made ready to be analyzed by your code.</li>
<li><strong><a>Build-time Bonuses!</a></strong> Cova also provides a simple build step to generate Help Docs, Tab Completion Scripts, and Argument Templates at <strong><em>build-time</em></strong>!</li>
<li><strong>Simple Design:</strong></li>
<li>All argument tokens are parsed to Argument Types: Commands, Options, or Values.<ul>
<li>Options = <em>Flags</em> and Values = <em>Positional Arguments</em></li>
</ul>
</li>
<li>These Argument Types can be <em>created from</em> or <em>converted to</em> your Structs, Unions, and Functions along with their corresponding Fields and Parameters.</li>
<li>Default Arguments such as <code>usage</code> and <code>help</code> can be automatically added to all Commands easily. </li>
<li>This design allows for <strong>infinitely nestable</strong> Commands, Options, and Values in a way that's simple to parse, analyze, and use in your projects.</li>
<li><strong>Multiplatform.</strong> Tested across common architectures of Linux, Mac, and Windows.</li>
<li><strong>Granular, Robust Customization:</strong></li>
<li><a>POSIX Compliant</a> by default, with plenty of ways to configure to <strong>whatever standard you'd like</strong>.<ul>
<li>Posix: <code>command --option option_string "standalone value" subcmd -i 42 --bool</code></li>
<li>Windows: <code>Your-Command -StringOption "value" -FileOption .\user\file\path</code></li>
</ul>
</li>
<li>Cova offers deep customization through the Argument Types and several Config Structs. These customizations all provide simple and predictable defaults, allowing you to only configure what you need.</li>
<li><a><strong><em>And much more!</em></strong></a></li>
</ul>
Usage
Cova makes it easy to set up your Argument Types at <em>comptime</em> and use the input provided by your end users at <em>runtime</em>!
Comptime Setup
There are two main ways to set up your Argument Types. You can either convert existing Zig Types within your project or create them manually. You can even mix and match these techniques to get the best of both!
Code Example
```zig
const std = @import("std");
const cova = @import("cova");
pub const CommandT = cova.Command.Base();
pub const OptionT = CommandT.OptionT;
pub const ValueT = CommandT.ValueT;
// The root Command for your program.
pub const setup_cmd: CommandT = .{
.name = "basic-app",
.description = "A basic user management application designed to highlight key features of the Cova library.",
.cmd_groups = &.{ "INTERACT", "VIEW" },
.sub_cmds = &.{
// A Sub Command created from converting a Struct named `User`.
// Usage Ex: `basic-app new -f Bruce -l Wayne -a 40 -p "555 555 5555" -A " 1007 Mountain Drive, Gotham" true`
.from(User, .{
.cmd_name = "new",
.cmd_description = "Add a new user.",
.cmd_group = "INTERACT",
.sub_descriptions = &.{
.{ "is_admin", "Add this user as an admin?" },
.{ "first_name", "User's First Name." },
.{ "last_name", "User's Last Name." },
.{ "age", "User's Age." },
.{ "phone", "User's Phone #." },
.{ "address", "User's Address." },
},
}),
// A Sub Command created from a Function named `open`.
// Usage Ex: `basic-app open users.csv`
.from(@TypeOf(open), .{
.cmd_name = "open",
.cmd_description = "Open or create a users file.",
.cmd_group = "INTERACT",
}),
// A manually created Sub Command, same as the root `setup_cmd`.
// Usage Ex: `basic-app clean` or `basic-app delete --file users.csv`
.{
.name = "clean",
.description = "Clean (delete) the default users file (users.csv) and persistent variable file (.ba_persist).",
.alias_names = &.{ "delete", "wipe" },
.cmd_group = "INTERACT",
.opts = &.{
.{
.name = "clean_file",
.description = "Specify a single file to be cleaned (deleted) instead of the defaults.",
.alias_long_names = &.{ "delete_file" },
.short_name = 'f',
.long_name = "file",
.val = .ofType([]const u8, .{
.name = "clean_file",
.description = "The file to be cleaned.",
.alias_child_type = "filepath",
.valid_fn = cova.Value.ValidationFns.validFilepath,
}),
},
},
},
}
};
// Continue to Runtime Use...
```
Runtime Use
Once Cova has parsed input from your end users, it puts that data into the Command you set up.
You can call various methods on the Command to use that data however you need.
Code Example
```zig
// ...continued from the Comptime Setup.
pub fn main() !void {
const gpa: std.heap.DebugAllocator(.{}) = .init;
const alloc = gpa.allocator();
// Initializing the `setup_cmd` with an allocator will make it available for Runtime use.
const main_cmd = try setup_cmd.init(alloc, .{});
defer main_cmd.deinit();
// Parsing
var args_iter = try cova.ArgIteratorGeneric.init(alloc);
defer args_iter.deinit();
const stdout = std.io.getStdOut().writer();
cova.parseArgs(&args_iter, CommandT, main_cmd, stdout, .{}) catch |err| switch (err) {
error.UsageHelpCalled,
error.TooManyValues,
error.UnrecognizedArgument,
error.UnexpectedArgument,
error.CouldNotParseOption => {},
else => return err,
};
// Analysis (Using the data.)
if (builtin.mode == .Debug) try cova.utils.displayCmdInfo(CommandT, main_cmd, alloc, &stdout);
// Glossing over some project variables here.
// Convert a Command back into a Struct.
if (main_cmd.matchSubCmd("new")) |new_cmd| {
var new_user = try new_cmd.to(User, .{});
new_user._id = getNextID();
try users.append(new_user);
try stdout.print("Added:\n{s}\n", .{ new_user });
}
// Convert a Command back into a Function and call it.
if (main_cmd.matchSubCmd("open")) |open_cmd| {
user_file = try open_cmd.callAs(open, null, std.fs.File);
}
// Get the provided sub Command and check an Option from that sub Command.
if (main_cmd.matchSubCmd("clean")) |clean_cmd| cleanCmd: {
if ((try clean_cmd.getOpts(.{})).get("clean_file")) |clean_opt| {
if (clean_opt.val.isSet()) {
const filename = try clean_opt.val.getAs([]const u8);
try delete(filename);
break :cleanCmd;
}
}
try delete("users.csv");
try delete(".ba_persist");
}
}
```
More Examples
<ul>
<li><a>logger</a>: The simple example from the top of the README.</li>
<li><a>basic-app</a>: Where the above examples come from.</li>
<li><a>covademo</a>: This is the testbed for Cova, but its a good demo of virtually every feature in the library.</li>
</ul>
Build-time Bonuses
Cova's simple Meta Doc Generator build step lets you quickly and easily generate documents in the following formats based on the Commands you set up at comptime:
- Help Docs:
- Manpages
- Markdown
- Tab Completion Scripts:
- Bash
- Zsh
- Powershell
- Argument Templates:
- JSON
- KDL
Code Example
```zig
// Within 'build.zig'
pub fn build(b: *std.Build) void {
// Set up your build variables as normal.
const cova_dep = b.dependency("cova", .{ .target = target, .optimize = optimize });
const cova_mod = cova_dep.module("cova");
// Set up your exe step as you normally would.
const cova_gen = @import("cova").addCovaDocGenStep(b, cova_dep, exe, .{
.kinds = &.{ .all },
.version = "0.10.1",
.ver_date = "25 MAR 2025",
.author = "00JCIV00",
.copyright = "MIT License",
});
const meta_doc_gen = b.step("gen-meta", "Generate Meta Docs using Cova");
meta_doc_gen.dependOn(&cova_gen.step);
}
```
Demo
Alternatives
<ul>
<li><a>flags</a></li>
<li><a>snek</a></li>
<li><a>yazap</a></li>
<li><a>zig-args</a></li>
<li><a>zig-clap</a></li>
<li><a>zig-cli</a></li>
<li><a>zli</a></li>
</ul>
|
[] |
https://avatars.githubusercontent.com/u/44057100?v=4
|
zimdjson
|
EzequielRamis/zimdjson
|
2023-11-27T02:33:48Z
|
Parsing gigabytes of JSON per second. Zig port of simdjson with fundamental features.
|
main
| 7 | 126 | 2 | 126 |
https://api.github.com/repos/EzequielRamis/zimdjson/tags
|
MIT
|
[
"json",
"json-parser",
"simd",
"simdjson",
"zig",
"zig-package",
"ziglang"
] | 2,527 | false |
2025-05-17T21:58:29Z
| true | true |
0.14.0
|
github
|
[
{
"commit": "55d79b184b7d8fac2e143e89dc19b766ec4e54b8.tar.gz",
"name": "parse_number_fxx",
"tar_url": "https://github.com/nigeltao/parse-number-fxx-test-data/archive/55d79b184b7d8fac2e143e89dc19b766ec4e54b8.tar.gz.tar.gz",
"type": "remote",
"url": "https://github.com/nigeltao/parse-number-fxx-test-data"
},
{
"commit": "refs",
"name": "simdjson",
"tar_url": "https://github.com/simdjson/simdjson/archive/refs.tar.gz",
"type": "remote",
"url": "https://github.com/simdjson/simdjson"
},
{
"commit": "refs",
"name": "yyjson",
"tar_url": "https://github.com/ibireme/yyjson/archive/refs.tar.gz",
"type": "remote",
"url": "https://github.com/ibireme/yyjson"
},
{
"commit": "bf11b43f8eac3173ca88f82430917ad919feee2b.tar.gz",
"name": "rapidjson",
"tar_url": "https://github.com/EzequielRamis/rapidjson/archive/bf11b43f8eac3173ca88f82430917ad919feee2b.tar.gz.tar.gz",
"type": "remote",
"url": "https://github.com/EzequielRamis/rapidjson"
}
] |
zimdjson
<blockquote>
JSON is everywhere on the Internet. Servers spend a <em>lot</em> of time parsing it. We need a fresh approach.
</blockquote>
Welcome to zimdjson: a high-performance JSON parser that takes advantage of SIMD vector instructions, based on the paper <a>Parsing Gigabytes of JSON per Second</a>.
The majority of the source code is based on the C++ implementation https://github.com/simdjson/simdjson with the addition of some fundamental features like:
<ul>
<li>Streaming support which can handle arbitrarily large documents with O(1) of memory usage.</li>
<li>An ergonomic, <a>Serde</a>-like deserialization interface thanks to Zig's compile-time reflection. See <a>Reflection-based JSON</a>.</li>
<li>More efficient memory usage.</li>
</ul>
Getting started
Install the zimdjson library by running the following command in your project root:
<code>zig fetch --save git+https://github.com/ezequielramis/zimdjson#0.1.1</code>
Then write the following in your <code>build.zig</code>:
<code>zig
const zimdjson = b.dependency("zimdjson", .{});
exe.root_module.addImport("zimdjson", zimdjson.module("zimdjson"));</code>
As an example, download a sample file called <a><code>twitter.json</code></a>.
Then execute the following:
```zig
const std = @import("std");
const zimdjson = @import("zimdjson");
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}).init;
const allocator = gpa.allocator();
<code>var parser = zimdjson.ondemand.StreamParser(.default).init;
defer parser.deinit(allocator);
const file = try std.fs.cwd().openFile("twitter.json", .{});
defer file.close();
const document = try parser.parseFromReader(allocator, file.reader().any());
const metadata_count = try document.at("search_metadata").at("count").asUnsigned();
std.debug.print("{} results.", .{metadata_count});
</code>
}
```
```
<blockquote>
zig build run
</blockquote>
100 results.
```
To see how the streaming parser above handles multi-gigabyte JSON documents with minimal memory usage, download one of <a>these dumps</a> or play it with a file of your choice.
Requirements
Currently, targets with Linux, Windows, or macOS operating systems and CPUs with SIMD capabilities are supported. Missing targets can be added by contributing.
Documentation
The most recent documentation can be found in https://zimdjson.ramis.ar.
Reflection-based JSON
Although the provided interfaces are simple enough, it is expected to have unnecessary boilerplate when deserializing lots of data structures. Thank to Zig's compile-time reflection, we can eliminate it:
```zig
const std = @import("std");
const zimdjson = @import("zimdjson");
const Film = struct {
name: []const u8,
year: u32,
characters: []const []const u8, // we could also use std.ArrayListUnmanaged([]const u8)
};
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}).init;
const allocator = gpa.allocator();
<code>var parser = zimdjson.ondemand.FullParser(.default).init;
defer parser.deinit(allocator);
const json =
\\{
\\ "name": "Esperando la carroza",
\\ "year": 1985,
\\ "characters": [
\\ "Mamá Cora",
\\ "Antonio",
\\ "Sergio",
\\ "Emilia",
\\ "Jorge"
\\ ]
\\}
;
const document = try parser.parseFromSlice(allocator, json);
const film = try document.as(Film, allocator, .{});
defer film.deinit();
try std.testing.expectEqualDeep(
Film{
.name = "Esperando la carroza",
.year = 1985,
.characters = &.{
"Mamá Cora",
"Antonio",
"Sergio",
"Emilia",
"Jorge",
},
},
film.value,
);
</code>
}
```
This is just a simple example, but this way of deserializing is as powerful as <a>Serde</a>, so there is a lot of more features we can use, such as:
<ul>
<li>Deserializing data structures from the Zig Standard Library.</li>
<li>Renaming fields.</li>
<li>Using different union representations.</li>
<li>Custom handling unknown fields.</li>
</ul>
To see all available options it offers checkout its <a>reference</a>.
To see all supported Zig Standard Library's data structures checkout <a>this list</a>.
To see how it can be really used checkout the <a>test suite</a> for more examples.
Performance
<blockquote>
<span class="bg-blue-100 text-blue-800 text-xs font-medium me-2 px-2.5 py-0.5 rounded dark:bg-blue-900 dark:text-blue-300">NOTE</span>
As a rule of thumb, do not trust any benchmark — always verify it yourself. There may be biases that favor a particular candidate, including mine.
</blockquote>
The following picture represents parsing speed in GB/s of similar tasks presented in the paper <a>On-Demand JSON: A Better Way to Parse
Documents?</a>, where the first three tasks iterate over <code>twitter.json</code> and the others iterate over a 626MB JSON file called <code>systemsPopulated.json</code> from <a>these dumps</a>.
Ok, it seems the benchmark got borked but it is not, because of how cache works on small files and how the streaming parser happily ended finding out the tweet in the middle of the file.
Let's get rid of that task to see better the other results.
The following picture corresponds to a second simple benchmark, representing parsing speed in GB/s for near-complete parsing of the <code>twitter.json</code> file with reflection-based parsers (<code>serde_json</code>, <code>std.json</code>).
<strong>Note</strong>: If you look closely, you'll notice that "zimdjson (On-Demand, Unordered)" is the slowest of all. This is, unfortunately, a behaviour that also occurs with <code>simdjson</code> when object keys are unordered. If you do not know the order, it can be mitigated by using an schema. Thanks to the <a>glaze library author</a> for pointing this out.
All benchmarks were run on a 3.30GHz Intel Skylake processor.
|
[] |
https://avatars.githubusercontent.com/u/480330?v=4
|
zig2nix
|
Cloudef/zig2nix
|
2024-01-11T05:16:46Z
|
Flake for packaging, building and running Zig projects.
|
master
| 4 | 122 | 5 | 122 |
https://api.github.com/repos/Cloudef/zig2nix/tags
|
MIT
|
[
"automation",
"build",
"ci",
"cross-compiling",
"dependencies",
"developer-tools",
"nix",
"packaging",
"release",
"releases",
"reproducible",
"zig"
] | 992 | false |
2025-05-22T01:50:31Z
| false | false |
unknown
|
github
|
[] |
zig2nix flake
Flake for packaging, building and running Zig projects.
https://ziglang.org/
<ul>
<li>Cachix: <code>cachix use zig2nix</code></li>
</ul>
<a></a>
<ul>
<li>Zig master: <code>0.15.0-dev.621+a63f7875f @ 2025-05-21</code></li>
<li>Zig latest: <code>0.14.0 @ 2025-03-05</code></li>
</ul>
Examples
Zig project template
```bash
nix flake init -t github:Cloudef/zig2nix
nix run .
for more options check the flake.nix file
```
With master version of Zig
```bash
nix flake init -t github:Cloudef/zig2nix#master
nix run .
for more options check the flake.nix file
```
Build zig from source
<code>bash
nix build github:Cloudef/zig2nix#zig-src-master
nix build github:Cloudef/zig2nix#zig-src-latest
nix build github:Cloudef/zig2nix#zig-src-0_8_0</code>
Running zig compiler directly
<code>bash
nix run github:Cloudef/zig2nix#master -- version
nix run github:Cloudef/zig2nix#latest -- version
nix run github:Cloudef/zig2nix#0_8_0 -- version</code>
Convenience zig for multimedia programs
<blockquote>
This sets (DY)LD_LIBRARY_PATH and PKG_CONFIG_PATH so that common libs are available
</blockquote>
<code>bash
nix run github:Cloudef/zig2nix#multimedia-master -- version
nix run github:Cloudef/zig2nix#multimedia-latest -- version
nix run github:Cloudef/zig2nix#multimedia-0_8_0 -- version</code>
Shell for building and running a Zig project
<code>bash
nix develop github:Cloudef/zig2nix#master
nix develop github:Cloudef/zig2nix#latest
nix develop github:Cloudef/zig2nix#0_8_0</code>
Convert zon file to json
<code>bash
nix run github:Cloudef/zig2nix -- zon2json build.zig.zon</code>
Convert build.zig.zon to a build.zig.zon2json-lock
<code>bash
nix run github:Cloudef/zig2nix -- zon2lock build.zig.zon</code>
Convert build.zig.zon/2json-lock to a nix derivation
```bash
calls zon2json-lock if build.zig.zon2json-lock does not exist (requires network access)
nix run github:Cloudef/zig2nix -- zon2nix build.zig.zon
alternatively run against the lock file (no network access required)
nix run github:Cloudef/zig2nix -- zon2nix build.zig.zon2json-lock
```
Github actions
When using zig2nix in github actions, you have to disable apparmor in the ubuntu runner:
<code>bash
sudo sysctl -w kernel.apparmor_restrict_unprivileged_userns=0</code>
Crude documentation
Below is auto-generated dump of important outputs in this flake.
```nix
! Structures.
:! Helper function for building and running Zig projects.
zig-env = {
# Overrideable nixpkgs.
nixpkgs ? self.inputs.nixpkgs,
# Zig version to use.
zig ? zigv.latest,
}: { ... };
! --- Outputs of zig-env {} function.
! access: (zig-env {}).thing
! Tools for bridging zig and nix
! The correct zig version is put into the PATH
zig2nix = pkgs.writeShellApplication {
name = "zig2nix";
runtimeInputs = [ zig ];
text = ''${zig2nix-zigless}/bin/zig2nix "$@"'';
};
! Translates zig and nix compatible targets
target = system: (exec-json "target" [ system ]);
! Reads zon file into a attribute set
fromZON = path: exec-json-path "zon2json" path [];
! Creates derivation from zon2json-lock file
deriveLockFile = path: pkgs.callPackage (exec-path "zon2nix" path [ "-" ]);
! Returns true if target is nix flake compatible.
! <a>https://github.com/NixOS/nixpkgs/blob/master/lib/systems/flake-systems.nix</a>
isFlakeTarget = any: pkgs.lib.any (s: (systems.elaborate s).config == (target any).config) systems.flakeExposed;
! Returns crossPkgs from nixpkgs for target string or system.
! This will always cross-compile the package.
crossPkgsForTarget = any: let
crossPkgs = import nixpkgs { localSystem = system; crossSystem = { config = (target any).config; }; };
this-system = (systems.elaborate system).config == (target any).config;
in if this-system then pkgs else crossPkgs;
! Returns pkgs from nixpkgs for target string or system.
! This does not cross-compile and you'll get a error if package does not exist in binary cache.
binaryPkgsForTarget = any: let
binaryPkgs = import nixpkgs { localSystem = { config = (target any).config; }; };
this-system = (systems.elaborate system).config == (target any).config;
in if this-system then pkgs else binaryPkgs;
! Returns either binaryPkgs or crossPkgs depending if the target is flake target or not.
pkgsForTarget = any:
if isFlakeTarget any then binaryPkgsForTarget any
else crossPkgsForTarget any;
! Cross-compile nixpkgs using zig :)
! NOTE: This is an experimental feature, expect it not faring well
zigCrossPkgsForTarget = any: let
crossPkgs = pkgs.callPackage ./src/cross {
inherit zig zigPackage target;
nixCrossPkgs = pkgsForTarget any;
nixBinaryPkgs = binaryPkgsForTarget any;
localSystem = system;
crossSystem = { config = (target any).config; };
};
in warn "zigCross: ${(target any).zig}" crossPkgs;
! Flake app helper (Without zig-env and root dir restriction).
app-bare-no-root = deps: script: {
type = "app";
program = toString (pkgs.writeShellApplication {
name = "app";
runtimeInputs = [] ++ deps;
text = ''
# shellcheck disable=SC2059
error() { printf -- "error: $1\n" "''${@:2}" 1>&2; exit 1; }
${script}
'';
}) + "/bin/app";
meta = {
description = "";
};
};
! Flake app helper (Without zig-env).
app-bare = deps: script: app-bare-no-root deps ''
[[ -f ./flake.nix ]] || error 'Run this from the project root'
${script}
'';
! Flake app helper (without root dir restriction).
app-no-root = deps: script: app-bare-no-root (deps ++ _deps) ''
${shell-runtime deps}
${script}
'';
! Flake app helper.
app = deps: script: app-bare (deps ++ _deps) ''
${shell-runtime deps}
${script}
'';
! Creates dev shell.
mkShell = pkgs.callPackage ({
nativeBuildInputs ? [],
...
} @attrs: pkgs.mkShellNoCC (attrs // {
nativeBuildInputs = (remove zig.hook nativeBuildInputs) ++ _deps;
shellHook = ''
${shell-runtime nativeBuildInputs}
${attrs.shellHook or ""}
'';
}));
! Packages zig project.
! NOTE: If your project has build.zig.zon you must first generate build.zig.zon2json-lock using zon2json-lock.
! It is recommended to commit the build.zig.zon2json-lock to your repo.
!
! Additional attributes:
! zigTarget: Specify target for zig compiler, defaults to stdenv.targetPlatform of given target.
! zigPreferMusl: Prefer musl libc without specifying the target.
! zigWrapperBins: Binaries available to the binary during runtime (PATH)
! zigWrapperLibs: Libraries available to the binary during runtime (LD_LIBRARY_PATH)
! zigWrapperArgs: Additional arguments to makeWrapper.
! zigBuildZon: Path to build.zig.zon file, defaults to build.zig.zon.
! zigBuildZonLock: Path to build.zig.zon2json-lock file, defaults to build.zig.zon2json-lock.
!
! <a>https://github.com/NixOS/nixpkgs/blob/master/doc/hooks/zig.section.md</a>
package = zigPackage;
! Bundle a package into a zip
bundle.zip = pkgs.callPackage ./src/bundle/zip.nix { inherit zigPackage; };
! Bundle a package for running in AWS lambda
bundle.aws.lambda = pkgs.callPackage ./src/bundle/lambda.nix { bundleZip = bundle.zip; };
! --- Architecture dependent flake outputs.
! access: <code>zig2nix.outputs.thing.${system}</code>
! Helper functions for building and running Zig projects.
inherit zig-env;
! Versioned Zig packages.
! nix build .#zig-master
! nix build .#zig-latest
! nix run .#zig-0_13_0
packages = mapAttrs' (k: v: nameValuePair ("zig-" + k) v) zigv;
! Develop shell for building and running Zig projects.
! nix develop .#zig_version
! example: nix develop .#master
! example: nix develop .#default
devShells = flake-outputs.devShells // {
default = flake-outputs.devShells.latest;
};
! --- Generic flake outputs.
! access: <code>zig2nix.outputs.thing</code>
! Default project template
! nix flake init -t templates
templates.default = rec {
path = ./templates/default;
description = "Default Zig project template";
welcomeText = welcome-template description;
};
! Master project template
! nix flake init -t templates#master
templates.master = rec {
path = ./templates/master;
description = "Master Zig project template";
welcomeText = welcome-template description;
};
```
|
[] |
https://avatars.githubusercontent.com/u/11288757?v=4
|
zigrad
|
Marco-Christiani/zigrad
|
2023-12-01T18:38:16Z
|
A deep learning framework built on an autograd engine with high level abstractions and low level control.
|
main
| 11 | 116 | 4 | 116 |
https://api.github.com/repos/Marco-Christiani/zigrad/tags
|
LGPL-3.0
|
[
"autograd",
"deep-learning",
"machine-learning",
"neural-network",
"tensor",
"zig",
"zig-package",
"ziglang"
] | 12,288 | false |
2025-05-20T00:27:57Z
| true | true |
unknown
|
github
|
[
{
"commit": "master",
"name": "tracy",
"tar_url": "https://github.com/wolfpld/tracy//archive/master.tar.gz",
"type": "remote",
"url": "https://github.com/wolfpld/tracy/"
}
] |
<strong><i>Supporting AI innovation from ideation to results.</i></strong>
AI frameworks optimized for rapid research iteration do not seamlessly transition into the infrastructure required for large-scale training. This fragmented pipeline creates redundant engineering effort and slows iteration cycles. Zigrad provides a path to performance that preserves the natural development workflow researchers prefer; bridging research and engineering. Using Zigrad you can:
<ul>
<li>Experiment using high-level, PyTorch-like abstractions</li>
<li>Gradually opt into fine-grained control and performance optimizations</li>
<li>Access low-level primitives and assert control--without switching frameworks, code translation, or building complex extensions.</li>
<li>Quickly transition research to high performance training</li>
</ul>
https://github.com/user-attachments/assets/3842aa72-9b16-4c25-8789-eac7159e3768
<strong>Fast</strong>
2.5x+ speedup over a compiled PyTorch model on Apple Silicon, 1.5x on x86. Expect similar performance gains across more architectures and platforms as MKL/CUDA support improves and Zigrad's ML graph compiler is operational.
*Tensorflow excluded for scaling purposes (too slow).
<strong>Flexible</strong>
Zigrad supports research workflows with high level abstractions for rapid prototyping, and integrations like Tensorboard and Mujoco. Zigrad supports the transition of research code to training infrastructure.
Zigrad supports research through,
<ul>
<li>Easy to use torch-like ergonomics</li>
<li>A general purpose automatic differentiation system for n-dimensional data</li>
<li>Eager execution and dynamic computation graph by default</li>
<li>Computation graph tracing and visualization</li>
<li>A design that naturally allows for custom differentiable operations</li>
</ul>
Zigrad supports engineering through,
<ul>
<li>An architecture that enables deep control and customization through opt-in complexity,</li>
<li>Offering flexible tradeoffs between performance characteristics like latency vs throughput</li>
<li>Hardware-aware optimizations tailored to specific use cases and system requirements</li>
<li>Fine-grained memory management and allocation control</li>
<li>Cross-platform compatibility without compromising performance</li>
<li>A streamlined design that avoids abstraction layers or build systems that hinder aggressive optimizations</li>
</ul>
Features
Trace the Computation Graph
An example of tracing the computation graph generated by a fully connected neural network for MNIST.
<ul>
<li><em>Input:</em> Batch of images 28x28 pixel samples.</li>
<li><strong>Flatten:</strong> <code>28x28 -> 784</code></li>
<li><strong>FC1</strong>: Linear layer <code>784 -> 128</code></li>
<li><strong>ReLU</strong></li>
<li><strong>FC2:</strong> Linear layer <code>128 -> 64</code></li>
<li><strong>ReLU</strong></li>
<li><strong>FC3:</strong> Linear layer <code>64 -> 10</code></li>
<li><em>Output:</em> Value for each of the 10 classes</li>
</ul>
We did not have to use Zigrad's modules to write this network at all, as Zigrad is backed by a capable autograd engine. Even when using the autograd backend to dynamically construct the same neural network Zigrad can still trace the graph and render it.
<blockquote>
Note: Since the graph is generated from the autograd information, we set the labels for the nodes by naming the tensors for the sake of the diagram.
</blockquote>
Getting Started
Only dependency is a BLAS library.
Linux
On linux (or intel mac) you have some options,
<ul>
<li>MKL (recommended for best performance)</li>
<li>See https://www.intel.com/content/www/us/en/developer/tools/oneapi/onemkl-download.html</li>
<li>Reccommend a system installation for simplicity although this can work with <code>conda</code> for example, just make sure you adjust the library paths as necessary.</li>
<li>OpenBLAS</li>
<li>See https://github.com/OpenMathLib/OpenBLAS/wiki/Precompiled-installation-packages</li>
<li>Likely available through your package manager as <code>libopenblas-dev</code> or <code>openblas-devel</code></li>
</ul>
Apple Silicon
<ul>
<li>Nothing :)</li>
</ul>
Examples
The <code>examples/</code> directory has some standalone templates you can take and modify, the zon files are pinned to commit hashes.
Hello world example shows how to run a backward pass using the <code>GraphManager.</code> Note that in this very simple example, we do not need the <code>GraphManager</code> and the script could be simplified but this is designed to get you familiar with the workflow.
<code>shell
git clone https://github.com/Marco-Christiani/zigrad/
cd zigrad/examples/hello-world
zig build run</code>
Run the mnist demo
<code>shell
cd zigrad/examples/mnist
make help
make</code>
Roadmap
A lot is planned and hoping for support from the Zig community so we can accomplish some of the more ambitious goals.
<ul>
<li>More comprehensive MKL and CUDA support (in progress)</li>
<li>Support for popular formats like ONNX and ggml.</li>
<li>Standardized benchmarking procedures (always an ongoing effort)</li>
<li>Lazy tensors</li>
<li>Static graph optimization</li>
<li>Dynamic graph compiler</li>
<li>MLIR</li>
<li>ZML translation for inference</li>
<li>Apache TVM integration. <a>Github</a> <a>Homepage</a></li>
<li>More examples like LLMs, physics and robotic control, etc.</li>
</ul>
Known Issues and Limitations
<ul>
<li>Documentation. As the API stabilizes more documentation will be added. For now, the examples are designed to be quickstart guides.</li>
<li>Effort has been directed towards performant primitives, not many layer types have been implemented</li>
<li>e.g. conv, pooling, etc are test implementations for verification, they are slow and unoptimized, I would not use them</li>
</ul>
Contributing
<ul>
<li><a>Join the discord</a> and into the dev channels</li>
<li>Any open issue is available for development, just leave a comment mentioning your interest and I can provide support to help get you started if necessary</li>
<li>Otherwise, <strong>please open an issue first, before working on a PR</strong></li>
<li>If you are interested in contributing but do not know where to start then open an issue or leave a comment</li>
</ul>
|
[] |
https://avatars.githubusercontent.com/u/13811862?v=4
|
webview-zig
|
thechampagne/webview-zig
|
2023-09-01T13:17:15Z
|
⚡ Zig binding & wrapper for a tiny cross-platform webview library to build modern cross-platform GUIs.
|
main
| 3 | 114 | 14 | 114 |
https://api.github.com/repos/thechampagne/webview-zig/tags
|
MIT
|
[
"library",
"webview",
"zig",
"zig-package",
"ziglang"
] | 276 | false |
2025-05-20T18:19:28Z
| true | true |
unknown
|
github
|
[
{
"commit": "refs",
"name": "webview",
"tar_url": "https://github.com/webview/webview/archive/refs.tar.gz",
"type": "remote",
"url": "https://github.com/webview/webview"
}
] |
webview-zig
<a></a> <a></a>
Zig binding for a tiny cross-platform <strong>webview</strong> library to build modern cross-platform GUIs.
Requirements
<ul>
<li><a>Zig Compiler</a> - <strong>0.13.0</strong></li>
<li>Unix</li>
<li><a>GTK3</a> and <a>WebKitGTK</a></li>
<li>Windows</li>
<li><a>WebView2 Runtime</a></li>
<li>macOS</li>
<li><a>WebKit</a></li>
</ul>
Usage
<code>zig fetch --save https://github.com/thechampagne/webview-zig/archive/refs/heads/main.tar.gz</code>
<code>build.zig.zon</code>:
<code>zig
.{
.dependencies = .{
.webview = .{
.url = "https://github.com/thechampagne/webview-zig/archive/refs/heads/main.tar.gz" ,
//.hash = "12208586373679a455aa8ef874112c93c1613196f60137878d90ce9d2ae8fb9cd511",
},
},
}</code>
<code>build.zig</code>:
<code>zig
const webview = b.dependency("webview", .{
.target = target,
.optimize = optimize,
});
exe.root_module.addImport("webview", webview.module("webview"));
exe.linkLibrary(webview.artifact("webviewStatic")); // or "webviewShared" for shared library
// exe.linkSystemLibrary("webview"); to link with installed prebuilt library without building</code>
API
```zig
const WebView = struct {
<code>const WebViewVersionInfo = struct {
version: struct {
major: c_uint,
minor: c_uint,
patch: c_uint,
},
version_number: [32]c_char,
pre_release: [48]c_char,
build_metadata: [48]c_char,
};
const DispatchCallback = *const fn (WebView, ?*anyopaque) void;
const BindCallback = *const fn ([:0]const u8, [:0]const u8, ?*anyopaque) void;
const WindowSizeHint = enum(c_uint) {
None,
Min,
Max,
Fixed
};
const NativeHandle = enum(c_uint) {
ui_window,
ui_widget,
browser_controller
};
const WebViewError = error {
MissingDependency,
Canceled,
InvalidState,
InvalidArgument,
Unspecified,
Duplicate,
NotFound,
};
fn CallbackContext(func: [DispatchCallback|BindCallback]) type {
return struct {
fn init(data: ?*anyopaque) @This();
};
}
fn create(debug: bool, window: ?*anyopaque) WebView;
fn run(self: WebView) WebViewError!void;
fn terminate(self: WebView) WebViewError!void;
fn dispatch(self: WebView, ctx: *const CallbackContext) WebViewError!void;
fn getWindow(self: WebView) ?*anyopaque;
fn getNativeHandle(self: WebView, kind: NativeHandle) ?*anyopaque;
fn setTitle(self: WebView, title: [:0]const u8) WebViewError!void;
fn setSize(self: WebView, width: i32, height: i32, hint: WindowSizeHint) WebViewError!void;
fn navigate(self: WebView, url: [:0]const u8) WebViewError!void;
fn setHtml(self: WebView, html: [:0]const u8) WebViewError!void;
fn init(self: WebView, js: [:0]const u8) WebViewError!void;
fn eval(self: WebView, js: [:0]const u8) WebViewError!void;
fn bind(self: WebView, name: [:0]const u8, ctx: *const CallbackContext) WebViewError!void;
fn unbind(self: WebView, name: [:0]const u8) WebViewError!void;
fn ret(self: WebView ,seq: [:0]const u8, status: i32, result: [:0]const u8) WebViewError!void;
fn version() *const WebViewVersionInfo;
fn destroy(self: WebView) WebViewError!void;
</code>
}
```
References
<ul>
<li><a>webview</a> - <strong>0.12.0</strong></li>
</ul>
License
This repo is released under the <a>MIT License</a>.
Third party code:
- <a>external/WebView2</a> licensed under the <a>BSD-3-Clause License</a>.
|
[] |
https://avatars.githubusercontent.com/u/1338143?v=4
|
Deecy
|
Senryoku/Deecy
|
2023-12-04T23:09:01Z
|
Experimental Dreamcast emulator written in Zig
|
main
| 11 | 105 | 0 | 105 |
https://api.github.com/repos/Senryoku/Deecy/tags
|
MIT
|
[
"dreamcast",
"emulation",
"emulator",
"zig",
"zig-program"
] | 97,516 | false |
2025-05-21T21:48:13Z
| true | true |
0.14.0
|
github
|
[
{
"commit": "d860e2b4a333cacffb168fab49a233c5d2f1bca2",
"name": "zgpu",
"tar_url": "https://github.com/zig-gamedev/zgpu/archive/d860e2b4a333cacffb168fab49a233c5d2f1bca2.tar.gz",
"type": "remote",
"url": "https://github.com/zig-gamedev/zgpu"
},
{
"commit": "d3a68014e6b6b53fd330a0ccba99e4dcfffddae5.tar.gz",
"name": "dawn_x86_64_windows_gnu",
"tar_url": "https://github.com/michal-z/webgpu_dawn-x86_64-windows-gnu/archive/d3a68014e6b6b53fd330a0ccba99e4dcfffddae5.tar.gz.tar.gz",
"type": "remote",
"url": "https://github.com/michal-z/webgpu_dawn-x86_64-windows-gnu"
},
{
"commit": "7d70db023bf254546024629cbec5ee6113e12a42.tar.gz",
"name": "dawn_x86_64_linux_gnu",
"tar_url": "https://github.com/michal-z/webgpu_dawn-x86_64-linux-gnu/archive/7d70db023bf254546024629cbec5ee6113e12a42.tar.gz.tar.gz",
"type": "remote",
"url": "https://github.com/michal-z/webgpu_dawn-x86_64-linux-gnu"
},
{
"commit": "c1f55e740a62f6942ff046e709ecd509a005dbeb.tar.gz",
"name": "dawn_aarch64_linux_gnu",
"tar_url": "https://github.com/michal-z/webgpu_dawn-aarch64-linux-gnu/archive/c1f55e740a62f6942ff046e709ecd509a005dbeb.tar.gz.tar.gz",
"type": "remote",
"url": "https://github.com/michal-z/webgpu_dawn-aarch64-linux-gnu"
},
{
"commit": "d2360cdfff0cf4a780cb77aa47c57aca03cc6dfe.tar.gz",
"name": "dawn_aarch64_macos",
"tar_url": "https://github.com/michal-z/webgpu_dawn-aarch64-macos/archive/d2360cdfff0cf4a780cb77aa47c57aca03cc6dfe.tar.gz.tar.gz",
"type": "remote",
"url": "https://github.com/michal-z/webgpu_dawn-aarch64-macos"
},
{
"commit": "901716b10b31ce3e0d3fe479326b41e91d59c661.tar.gz",
"name": "dawn_x86_64_macos",
"tar_url": "https://github.com/michal-z/webgpu_dawn-x86_64-macos/archive/901716b10b31ce3e0d3fe479326b41e91d59c661.tar.gz.tar.gz",
"type": "remote",
"url": "https://github.com/michal-z/webgpu_dawn-x86_64-macos"
},
{
"commit": "c337cb3d3f984468ea7a386335937a5d555fc024",
"name": "zglfw",
"tar_url": "https://github.com/zig-gamedev/zglfw/archive/c337cb3d3f984468ea7a386335937a5d555fc024.tar.gz",
"type": "remote",
"url": "https://github.com/zig-gamedev/zglfw"
},
{
"commit": "21dcc288ac5ee70b1fca789d53a06d5c49d51e5e",
"name": "zgui",
"tar_url": "https://github.com/zig-gamedev/zgui/archive/21dcc288ac5ee70b1fca789d53a06d5c49d51e5e.tar.gz",
"type": "remote",
"url": "https://github.com/zig-gamedev/zgui"
},
{
"commit": "1012b105627e28827f558b79e533575ef65a4965",
"name": "zaudio",
"tar_url": "https://github.com/zig-gamedev/zaudio/archive/1012b105627e28827f558b79e533575ef65a4965.tar.gz",
"type": "remote",
"url": "https://github.com/zig-gamedev/zaudio"
},
{
"commit": "c0dbf11cdc17da5904ea8a17eadc54dee26567ec",
"name": "system_sdk",
"tar_url": "https://github.com/zig-gamedev/system_sdk/archive/c0dbf11cdc17da5904ea8a17eadc54dee26567ec.tar.gz",
"type": "remote",
"url": "https://github.com/zig-gamedev/system_sdk"
},
{
"commit": "4c850e222e1ba507b45d7bab8cac83bdd74cacd6",
"name": "zpool",
"tar_url": "https://github.com/zig-gamedev/zpool/archive/4c850e222e1ba507b45d7bab8cac83bdd74cacd6.tar.gz",
"type": "remote",
"url": "https://github.com/zig-gamedev/zpool"
},
{
"commit": "ad81729d33da30d5f4fd23718debec48245121ca.tar.gz",
"name": "nfd",
"tar_url": "https://github.com/Senryoku/nfd-zig/archive/ad81729d33da30d5f4fd23718debec48245121ca.tar.gz.tar.gz",
"type": "remote",
"url": "https://github.com/Senryoku/nfd-zig"
},
{
"commit": "1e3b0a4357653440e9a0977a5e23bcc1695d42ae",
"name": "arm7",
"tar_url": "https://github.com/Senryoku/arm7/archive/1e3b0a4357653440e9a0977a5e23bcc1695d42ae.tar.gz",
"type": "remote",
"url": "https://github.com/Senryoku/arm7"
},
{
"commit": "13dbe791ed06dca142e164b626eca91a466ee248",
"name": "ziglz4",
"tar_url": "https://github.com/Senryoku/zig-lz4/archive/13dbe791ed06dca142e164b626eca91a466ee248.tar.gz",
"type": "remote",
"url": "https://github.com/Senryoku/zig-lz4"
}
] |
Deecy
Deecy is an experimental Dreamcast emulator written in Zig.
Videos: <a>Soul Calibur</a> (May 2024), <a>Grandia II</a> (July 2024), <a>DCA3</a> (January 2025)
Installation
<ul>
<li>Download the latest version for your platform from the <a>Release Page</a>.</li>
<li>Decompress the zip archive.</li>
<li>Copy your bios and flash dumps as <code>dc_boot.bin</code> and <code>dc_flash.bin</code> to the <code>data</code> folder.</li>
<li>Launch the Deecy executable and click <code>Change Directory</code> to select the folder where you store your DC games.</li>
</ul>
Usage
Keybindings
Deecy should detect, map and use controllers automatically. Host controllers can be manually assigned to guest controller ports in the Settings.
Keyboard bindings can be customized in the settings. Defaults for controller 1:
| DC Controller | Host Keyboard (AZERTY) |
| ------------- | ------------- |
| A, B, X, Y | A, Z, Q, S |
| L, R triggers | W, X |
| Start | Enter |
| Left Stick | Numpad 8, 4, 5, 6 |
| Dpad | Directional Arrows |
Shortcuts
| Key | Action |
| ------ | ------ |
| Escape | Show/Hide the UI |
| F | Toggle Fullscreen |
| L | Toggle unlimited emulation speed |
| F1-F4 | Save state 1-4 |
| F5-F8 | Load state 1-4 |
| D | Toggle debug UI |
| N | Next Frame (Experimental) |
CLI options
| Option | Action | Argument | Notes |
| ------ | ------ | -------- | ----- |
| -g | Load and Execute a disc file (.gdi/.cdi/.chd) | Path to a disc file |
| --vmu | Replace default vmu file | Path to an vmu file | Use with -g |
| --no-realtime | Starts with unlimited emulation speed |
| --load-state | Loads a save state on startup | Path to a Deecy save state | Use with -g |
| --stop | Prevent automatic start of emulation | | Use with -g or -b |
| --skip-bios | Skip default BIOS. | | Experimental |
| -b | Load and Execute a .bin file | Path to a .bin file | Will also skip the BIOS. Experimental |
| -i | Replace default IP.BIN file | Path to an IP.BIN file | Use with -b only |
Compatibility
<a>See issue #33</a>
Build
Install the correct zig version (see <code>.zigversion</code>, I try to keep up with <a>Mach nominated version</a> when not on a stable release).
You can use <a>zigup</a> to manage your installed zig versions, or get it from https://machengine.org/docs/nominated-zig/.
<code>sh
zigup 0.14.0</code>
Clone and build. Zig will fetch all dependencies automatically.
<code>sh
git clone https://github.com/Senryoku/Deecy # Clone the repo
cd Deecy
zig build run # Build and run in debug mode without any argument
zig build run --release=fast -- -g "path/game.gdi" # Build and run in release mode and loads a disc</code>
You will also need to provide copies of <code>dc_boot.bin</code> and <code>dc_flash.bin</code> files in the <code>data/</code> directory.
Linux
<code>nfd-zig</code> (native file dialog) needs these additional dependencies on Linux:
<code>sh
sudo apt install libgtk-3-dev</code>
Things I know I have to do
<ul>
<li>Debug, debug, debug.</li>
<li>SH4:<ul>
<li>MMU:<ul>
<li>Windows CE: Test and Debug more games.</li>
<li>Optimize.</li>
</ul>
</li>
</ul>
</li>
<li>AICA:<ul>
<li>Debug</li>
</ul>
</li>
<li>Renderer:<ul>
<li>Framebuffer:<ul>
<li>Improve detection of writes to framebuffer (false positives?)</li>
<li>Write back for games that need it.</li>
</ul>
</li>
<li>Modifier Volumes.<ul>
<li>Implemented: Inclusion volumes and shadow bit over opaque and transparent geometry.</li>
<li>Missing: Exclusion volumes.</li>
<li>Missing: Translucent MV in pre-sort mode.</li>
</ul>
</li>
<li>Region Array Data Configuration are mostly ignored.<ul>
<li>Flush Accumulate (Secondary accumulate buffer)</li>
</ul>
</li>
<li>Fog LUT Mode 2.</li>
<li>User Tile Clip, only the simplest version is supported.</li>
<li>Secondary accumulate buffer (very low priority, not sure if many games use this feature).</li>
<li>Mipmaps for palette textures?</li>
<li>Follow ISP_FEED_CFG discard mode flag? (Find a game that turns it off)</li>
</ul>
</li>
</ul>
Nice to have
<ul>
<li>Some (rendering) performance metrics directly in the emulator?</li>
<li>GDROM-DMA: Uses a superfluous memcpy (gdrom -> dma-queue -> ram). Not a huge deal on my main system, but I bet it's noticeable on lower end devices.</li>
</ul>
Some sources
<ul>
<li>http://www.shared-ptr.com/sh_insns.html</li>
<li>SH4 Hardware Manual / Programming Manual</li>
<li>https://segaretro.org/Dreamcast_official_documentation</li>
<li>Dreamcast Programming by Marcus Comstedt : https://mc.pp.se/dc/</li>
<li>Boot ROM disassembly by Lars Olsson (https://lars-olsson.sizious.com/, originally https://www.ludd.ltu.se/~jlo/dc/)</li>
<li><a>Neill Corlett's Yamaha AICA notes</a></li>
<li>AICA ARM7 Core tester by snickerbockers: https://github.com/snickerbockers/dc-arm7wrestler/</li>
<li>Reicast https://github.com/skmp/reicast-emulator</li>
</ul>
Dependencies
Dependencies are managed by the <code>build.zig.zon</code> file.
<ul>
<li>Multiple libraries from https://github.com/zig-gamedev (MIT)</li>
<li>ndf-zig: https://github.com/fabioarnold/nfd-zig (MIT)</li>
<li>zig-lz4: https://github.com/SnorlaxAssist/zig-lz4 (MIT), bindings for LZ4 https://github.com/lz4/lz4 (BSD 2-Clause)</li>
</ul>
Thanks
<ul>
<li>Huge thanks to drk||Raziel and MetalliC for their respective contributions to the scene, and for answering my questions!</li>
<li>Thanks to originaldave_ for the sh4 tests (https://github.com/SingleStepTests/sh4)</li>
<li>And overall thanks to everyone participating in the EmuDev Discord :)</li>
</ul>
Licence
Uses data from MAME under the BSD-3-Clause licence (see <code>src/gdrom_secu.zig</code>). CHD related features (<code>src/disc/chd.zig</code>) are also
inspired by, or even direct ports of, their equivalent from the MAME project.
Rest is MIT.
|
[] |
https://avatars.githubusercontent.com/u/3848910?v=4
|
zig-curl
|
jiacai2050/zig-curl
|
2023-09-16T15:13:59Z
|
Zig bindings for libcurl
|
main
| 2 | 104 | 16 | 104 |
https://api.github.com/repos/jiacai2050/zig-curl/tags
|
MIT
|
[
"libcurl",
"libcurl-binding",
"libcurl-bindings",
"zig",
"zig-lib",
"zig-package",
"ziglang"
] | 3,158 | false |
2025-05-19T00:33:37Z
| true | true |
unknown
|
github
|
[
{
"commit": "master",
"name": "zlib",
"tar_url": "https://github.com/madler/zlib/releases/download/v1.3.1/zlib-1.3.1.tar.gz/archive/master.tar.gz",
"type": "remote",
"url": "https://github.com/madler/zlib/releases/download/v1.3.1/zlib-1.3.1.tar.gz"
},
{
"commit": "refs",
"name": "mbedtls",
"tar_url": "https://github.com/Mbed-TLS/mbedtls/archive/refs.tar.gz",
"type": "remote",
"url": "https://github.com/Mbed-TLS/mbedtls"
}
] |
404
|
[] |
https://avatars.githubusercontent.com/u/86865279?v=4
|
chameleon
|
tr1ckydev/chameleon
|
2023-10-04T11:51:56Z
|
🦎 Terminal string styling for zig.
|
main
| 1 | 103 | 12 | 103 |
https://api.github.com/repos/tr1ckydev/chameleon/tags
|
MIT
|
[
"terminal",
"terminal-styling",
"zig",
"zig-package"
] | 1,028 | false |
2025-05-16T11:56:29Z
| true | true |
0.15.0-dev.97+677b2d62e
|
github
|
[] |
chameleon
🦎 Terminal string styling for zig.
<em>Currently the only fully featured terminal color solution for zig. ⚡</em>
<ul>
<li>Expressive API</li>
<li>Highly performant</li>
<li>Ability to nest styles</li>
<li>Ability for custom themes</li>
<li>No dependencies</li>
<li>Clean and focused</li>
<li>Truecolor support</li>
<li>140+ built in color presets</li>
</ul>
Installation
<blockquote>
Chameleon supports only zig <strong>master</strong> branch.
</blockquote>
<ul>
<li>Install the package.</li>
</ul>
<code>bash
zig fetch --save git+https://github.com/tr1ckydev/chameleon</code>
<ul>
<li>Add the package in <code>build.zig</code>.</li>
</ul>
<code>zig
const cham = b.dependency("chameleon", .{});
exe_mod.addImport("chameleon", cham.module("chameleon"));</code>
<ul>
<li>Import it in your project.</li>
</ul>
<code>zig
const Chameleon = @import("chameleon");</code>
Usage
Chameleon is divided into two APIs — <strong>Comptime</strong> and <strong>Runtime</strong>.
<ul>
<li><strong>Comptime:</strong> The comptime API is simplest way to implement colors in your terminal.</li>
<li><strong>Runtime:</strong> The runtime API is much more flexible and is the recommended way when building for production.</li>
</ul>
At the end, choose what fits best for your use case.
Documentation
Check out the full documentation <a>here</a>.
<code>NO_COLOR</code> support
<blockquote>
According to <a>no-color.org</a>, <em>"Command-line software which adds ANSI color to its output by default should check for a <code>NO_COLOR</code> environment variable that, when present and not an empty string (regardless of its value), prevents the addition of ANSI color."</em>
</blockquote>
Chameleon supports this standard only in it's <strong>Runtime API</strong> by detecting the presence of the <em>NO_COLOR</em> environment variable (regardless of it's value), if present disables any ANSI colors or styles, and can also be configured to not do so if you want to implement a different way of detection, although highly not recommended.
License
This repository uses the MIT License. Check <a>LICENSE</a> for full license text.
|
[
"https://github.com/4zv4l/zfs",
"https://github.com/4zv4l/zig_colored_logger",
"https://github.com/haha-systems/phage",
"https://github.com/tr1ckydev/zoop",
"https://github.com/yhdgms1/openwrt-led-night-mode"
] |
https://avatars.githubusercontent.com/u/206480?v=4
|
zqlite.zig
|
karlseguin/zqlite.zig
|
2023-04-03T07:29:30Z
|
A thin SQLite wrapper for Zig
|
master
| 0 | 101 | 15 | 101 |
https://api.github.com/repos/karlseguin/zqlite.zig/tags
|
MIT
|
[
"sqlite3",
"zig",
"zig-library",
"zig-package"
] | 3,025 | false |
2025-05-20T19:13:48Z
| true | true |
unknown
|
github
|
[] |
A thin SQLite wrapper for Zig
```zig
// good idea to pass EXResCode to get extended result codes (more detailed error codes)
const flags = zqlite.OpenFlags.Create | zqlite.OpenFlags.EXResCode;
var conn = try zqlite.open("/tmp/test.sqlite", flags);
defer conn.close();
try conn.exec("create table if not exists test (name text)", .{});
try conn.exec("insert into test (name) values (?1), (?2)", .{"Leto", "Ghanima"});
{
if (try conn.row("select * from test order by name limit 1", .{})) |row| {
defer row.deinit();
std.debug.print("name: {s}\n", .{row.text(0)});
}
}
{
var rows = try conn.rows("select * from test order by name", .{});
defer rows.deinit();
while (rows.next()) |row| {
std.debug.print("name: {s}\n", .{row.text(0)});
}
if (rows.err) |err| return err;
}
```
Unless <code>zqlite.OpenFlags.ReadOnly</code> is set in the open flags, <code>zqlite.OpenFlags.ReadWrite</code> is assumed (in other words, the database opens in read-write by default, and the <code>ReadOnly</code> flag must be used to open it in readony mode.)
Install
This library is tested with SQLite3 3.46.1 .
1) Add zqlite as a dependency in your <code>build.zig.zon</code>:
<code>bash
zig fetch --save git+https://github.com/karlseguin/zqlite.zig#master</code>
2) The library doesn't attempt to link/include SQLite. You're free to do this how you want.
If you have sqlite3 installed on your system you might get away with just adding this to your build.zig
```zig
const zqlite = b.dependency("zqlite", .{
.target = target,
.optimize = optimize,
});
exe.linkLibC();
exe.linkSystemLibrary("sqlite3");
exe.root_module.addImport("zqlite", zqlite.module("zqlite"));
```
Alternatively, If you download the SQLite amalgamation from <a>the SQLite download page</a> and place the <code>sqlite.c</code> and <code>sqlite.h</code> file in your project's <code>lib/</code> folder, you can then:
2) Add this in <code>build.zig</code>:
<code>zig
const zqlite = b.dependency("zqlite", .{
.target = target,
.optimize = optimize,
});
exe.addCSourceFile(.{
.file = b.path("lib/sqlite3.c"),
.flags = &[_][]const u8{
"-DSQLITE_DQS=0",
"-DSQLITE_DEFAULT_WAL_SYNCHRONOUS=1",
"-DSQLITE_USE_ALLOCA=1",
"-DSQLITE_THREADSAFE=1",
"-DSQLITE_TEMP_STORE=3",
"-DSQLITE_ENABLE_API_ARMOR=1",
"-DSQLITE_ENABLE_UNLOCK_NOTIFY",
"-DSQLITE_ENABLE_UPDATE_DELETE_LIMIT=1",
"-DSQLITE_DEFAULT_FILE_PERMISSIONS=0600",
"-DSQLITE_OMIT_DECLTYPE=1",
"-DSQLITE_OMIT_DEPRECATED=1",
"-DSQLITE_OMIT_LOAD_EXTENSION=1",
"-DSQLITE_OMIT_PROGRESS_CALLBACK=1",
"-DSQLITE_OMIT_SHARED_CACHE",
"-DSQLITE_OMIT_TRACE=1",
"-DSQLITE_OMIT_UTF16=1",
"-DHAVE_USLEEP=0",
},
});
exe.linkLibC();
exe.root_module.addImport("zqlite", zqlite.module("zqlite"));</code>
You can tweak the SQLite build flags for your own needs/platform.
Conn
The <code>Conn</code> type returned by <code>open</code> has the following functions:
<ul>
<li><code>row(sql, args) !?zqlite.Row</code> - returns an optional row</li>
<li><code>rows(sql, args) !zqlite.Rows</code> - returns an iterator that yields rows</li>
<li><code>exec(sql, args) !void</code> - executes the statement,</li>
<li><code>execNoArgs(sql) !void</code> - micro-optimization if there are no args, <code>sql</code> must be a null-terminated string</li>
<li><code>changes() usize</code> - the number of rows inserted/updated/deleted by the previous statement</li>
<li><code>lastInsertedRowId() i64</code> - the row id of the last inserted row</li>
<li><code>lastError() [*:0]const u8</code> - an error string describing the last error</li>
<li><code>transaction() !void</code> and <code>exclusiveTransaction() !void</code> - begins a transaction</li>
<li><code>commit() !void</code> and <code>rollback() void</code> - commits and rollback the current transaction</li>
<li><code>prepare(sql, args) !zqlite.Stmt</code> - returns a thin wrapper around a <code>*c.sqlite3_stmt</code>. <code>row</code> and <code>rows</code> wrap this type.</li>
<li><code>close() void</code> and <code>tryClsoe() !void</code> - closes the database. <code>close()</code> silently ignores any error, if you care about the error, use <code>tryClose()</code></li>
<li><code>busyTimeout(ms)</code> - Sets the busyHandler for the connection. See https://www.sqlite.org/c3ref/busy_timeout.html</li>
</ul>
Row and Rows
Both <code>row</code> and <code>rows</code> wrap an <code>zqlite.Stmt</code> which itself is a thin wrapper around an <code>*c.sqlite3_stmt</code>.
While <code>zqlite.Row</code> exposes a <code>deinit</code> and <code>deinitErr</code> method, it should only be called when the row was fetched directly from <code>conn.row(...)</code>:
<code>zig
if (try conn.row("select 1", .{})) |row| {
defer row.deinit(); // must be called
std.debug.print("{d}\n", .{row.int(0)});
}</code>
When the <code>row</code> comes from iterating <code>rows</code>, <code>deinit</code> or <code>deinitErr</code> should not be called on the individual row:
```zig
var rows = try conn.rows("select 1 union all select 2", .{})
defer rows.deinit(); // must be called
while (rows.next()) |row| {
// row.deinit() should not be called!
...
}
```
Note that <code>zqlite.Rows</code> has an <code>err: ?anyerror</code> field which can be checked at any point. Calls to <code>next()</code> when <code>err != null</code> will return null. Thus, <code>err</code> need only be checked at the end of the loop:
```zig
var rows = try conn.rows("select 1 union all select 2", .{})
defer rows.deinit(); // must be called
while (rows.next()) |row| {
...
}
if (rows.err) |err| {
// something went wrong
}
```
Row Getters
There are two APIs for fetching column data. The first is the generic <code>get</code>:
<code>zig
get(T, index) T</code>
Where <code>T</code> can be: <code>i64</code>, 'f64', 'bool', '[]const u8', '[:0]const u8' or <code>zqlite.Blob</code> or their nullable equivalent (i.e. <code>?i64</code>). The return type for <code>zqlite.Blob</code> is <code>[]const u8</code>.
Alternatively, the following can be used:
<ul>
<li><code>boolean(index) bool</code></li>
<li><code>nullableBoolean(index) ?bool</code></li>
<li><code>int(index) i64</code></li>
<li><code>nullableInt(index) ?i64</code></li>
<li><code>float(index) f64</code></li>
<li><code>nullableFloat(index) ?f64</code></li>
<li><code>text(index) []const u8</code></li>
<li><code>nullableText(index) ?[]const u8</code></li>
<li><code>cString(index) [:0]const u8</code></li>
<li><code>nullableCString(index) ?[:0]const u8</code></li>
<li><code>blob(index) []const u8</code></li>
<li><code>nullableBlob(index) ?[]const u8</code></li>
</ul>
The <code>nullableXYZ</code> functions can safely be called on a <code>not null</code> column. The non-nullable versions avoid a call to <code>sqlite3_column_type</code> (which is needed in the nullable versions to determine if the value is null or not).
Transaction:
The <code>transaction()</code>, <code>exclusiveTransaction()</code>, <code>commit()</code> and <code>rollback()</code> functions are simply wrappers to <code>conn.execNoArgs("begin")</code>, <code>conn.execNoArgs("begin exclusive")</code>, <code>conn.execNoArgs("commit")</code> and <code>conn.execNoArgs("rollback")</code>
```zig
try conn.transaction();
errdefer conn.rollback();
try conn.exec(...);
try conn.exec(...);
try conn.commit();
```
Blobs
When binding a <code>[]const u8</code>, this library has no way to tell whether the value should be treated as an text or blob. It defaults to text. To have the value bound as a blob use <code>zqlite.blob(value)</code>:
<code>zig
conn.insert("insert into records (image) values (?1)", .{zqlite.blob(image)})</code>
However, this should only be necessary in specific cases where SQLite blob-specific operations are used on the data. Text and blob are practically the same, except they have a different type.
Pool
<code>zqlite.Pool</code> is a simple thread-safe connection pool. After being created, the <code>acquire</code> and <code>release</code> functions are used to get a connection from the pool and to release it.
```zig
var pool = try zqlite.Pool.init(allocator, .{
// The number of connection in the pool. The pool will not grow or
// shrink beyond this count
.size = 5, // default 5
<code>// The path of the DB connection
.path = "/tmp/zqlite.sqlite", // no default, required
// The zqlite.OpenFlags to use when opening each connection in the pool
// Defaults are as shown here:
.flags = zqlite.OpenFlags.Create | zqlite.OpenFlags.EXResCode
// Callback function to execute for each connection in the pool when opened
.on_connection = null,
// Callback function to execute only for the first connection in the pool
.on_first_connection = null,
</code>
});
const c1 = pool.acquire();
defer c1.release();
c1.execNoArgs(...);
```
Callbacks
Both the <code>on_connection</code> and <code>on_first_connection</code> have the same signature. For the first connection to be opened by the pool, if both callbacks are provided then both callbacks will be executed, with <code>on_first_connection</code> executing first.
```zig
var pool = zqlite.Pool.init(allocator, .{
.size = 5,
.on_first_connection = &initializeDB,
.on_connection = &initializeConnection,
// other required & optional fields
});
...
// Our size is 5, but this will only be executed once, for the first
// connection in our pool
fn initializeDB(conn: Conn) !void {
try conn.execNoArgs("create table if not exists testing(id int)");
}
// Our size is 5, so this will be executed 5 times, once for each
// connection. <code>initializeDB</code> is guaranteed to be called before this
// function is called.
fn initializeConnection(conn: Conn) !void {
return conn.busyTimeout(1000);
}
```
|
[] |
https://avatars.githubusercontent.com/u/33221035?v=4
|
zon2nix
|
nix-community/zon2nix
|
2023-08-08T19:18:56Z
|
Convert the dependencies in `build.zig.zon` to a Nix expression [maintainer=@figsoda]
|
main
| 7 | 93 | 13 | 93 |
https://api.github.com/repos/nix-community/zon2nix/tags
|
MPL-2.0
|
[
"build",
"nix",
"vendor",
"zig",
"zon"
] | 71 | false |
2025-05-13T14:11:15Z
| true | false |
unknown
|
github
|
[] |
zon2nix
Convert the dependencies in <code>build.zig.zon</code> to a Nix expression
Usage
<code>bash
zon2nix > deps.nix
zon2nix zls > deps.nix
zon2nix zls/build.zig.zon > deps.nix</code>
To use the generated file, add this to your Nix expression:
<code>nix
postPatch = ''
ln -s ${callPackage ./deps.nix { }} $ZIG_GLOBAL_CACHE_DIR/p
'';</code>
Example
This <code>build.zig.zon</code> from <a>zls</a>
```zig
.{
.name = "zls",
.version = "0.11.0",
<code>.dependencies = .{
.known_folders = .{
.url = "https://github.com/ziglibs/known-folders/archive/fa75e1bc672952efa0cf06160bbd942b47f6d59b.tar.gz",
.hash = "122048992ca58a78318b6eba4f65c692564be5af3b30fbef50cd4abeda981b2e7fa5",
},
.diffz = .{
.url = "https://github.com/ziglibs/diffz/archive/90353d401c59e2ca5ed0abe5444c29ad3d7489aa.tar.gz",
.hash = "122089a8247a693cad53beb161bde6c30f71376cd4298798d45b32740c3581405864",
},
.binned_allocator = .{
.url = "https://gist.github.com/antlilja/8372900fcc09e38d7b0b6bbaddad3904/archive/6c3321e0969ff2463f8335da5601986cf2108690.tar.gz",
.hash = "1220363c7e27b2d3f39de6ff6e90f9537a0634199860fea237a55ddb1e1717f5d6a5",
},
},
</code>
}
```
produces the following nix expression
```nix
generated by zon2nix (https://github.com/nix-community/zon2nix)
{ linkFarm, fetchzip }:
linkFarm "zig-packages" [
{
name = "1220363c7e27b2d3f39de6ff6e90f9537a0634199860fea237a55ddb1e1717f5d6a5";
path = fetchzip {
url = "https://gist.github.com/antlilja/8372900fcc09e38d7b0b6bbaddad3904/archive/6c3321e0969ff2463f8335da5601986cf2108690.tar.gz";
hash = "sha256-m/kr4kmkG2rLkAj5YwvM0HmXTd+chAiQHzYK6ozpWlw=";
};
}
{
name = "122048992ca58a78318b6eba4f65c692564be5af3b30fbef50cd4abeda981b2e7fa5";
path = fetchzip {
url = "https://github.com/ziglibs/known-folders/archive/fa75e1bc672952efa0cf06160bbd942b47f6d59b.tar.gz";
hash = "sha256-U/h4bVarq8CFKbFyNXKl3vBRPubYooLxA1xUz3qMGPE=";
};
}
{
name = "122089a8247a693cad53beb161bde6c30f71376cd4298798d45b32740c3581405864";
path = fetchzip {
url = "https://github.com/ziglibs/diffz/archive/90353d401c59e2ca5ed0abe5444c29ad3d7489aa.tar.gz";
hash = "sha256-3CdYo6WevT0alRwKmbABahjhFKz7V9rdkDUZ43VtDeU=";
};
}
]
```
|
[] |
https://avatars.githubusercontent.com/u/67233402?v=4
|
zabi
|
Raiden1411/zabi
|
2023-12-07T22:41:56Z
|
Interact with ethereum and EVM based chains via Zig!
|
main
| 10 | 88 | 12 | 88 |
https://api.github.com/repos/Raiden1411/zabi/tags
|
MIT
|
[
"abi",
"blockchain",
"ethereum",
"evm",
"optimism",
"web3",
"zabi",
"zig",
"zig-package"
] | 4,603 | false |
2025-05-19T13:29:24Z
| true | true |
unknown
|
github
|
[
{
"commit": null,
"name": "c_kzg_4844",
"tar_url": null,
"type": "relative",
"url": "./pkg/c-kzg-4844"
}
] |
A zig library to interact with EVM blockchains
### Overview
Zabi aims to add support for interacting with ethereum or any compatible EVM based chain.
### Zig Versions
Zabi will support zig v0.14 in separate branches. If you would like to use it you can find it in the `zig_version_0.14.0` branch where you can build it against zig 0.13.0.
The main branch of zabi will follow the latest commits from zig and the other branch will be stable in terms of zig versions but not features from zabi.
### Integration
You can check how to integrate ZABI in your project [here](https://www.zabi.sh/integration)
### Example Usage
```zig
const args_parser = zabi.args;
const std = @import("std");
const zabi = @import("zabi");
const Wallet = zabi.clients.wallet.Wallet(.http);
const CliOptions = struct {
priv_key: [32]u8,
url: []const u8,
};
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
defer _ = gpa.deinit();
var iter = try std.process.argsWithAllocator(gpa.allocator());
defer iter.deinit();
const parsed = args_parser.parseArgs(CliOptions, gpa.allocator(), &iter);
const uri = try std.Uri.parse(parsed.url);
var wallet = try Wallet.init(parsed.priv_key, .{
.allocator = gpa.allocator(),
.network_config = .{ .endpoint = .{ .uri = uri } },
}, false);
defer wallet.deinit();
const message = try wallet.signEthereumMessage("Hello World");
const hexed = try message.toHex(wallet.allocator);
defer gpa.allocator().free(hexed);
std.debug.print("Ethereum message: {s}\n", .{hexed});
}
```
### Usage
Explore the [docs](https://zabi.sh) to find out more on how you can use or integrate Zabi in your project!
### Installing Zig
You can install the latest version of zig [here](https://ziglang.org/download/) or you can also use a version manager like [zvm](https://www.zvm.app/guides/install-zvm/) to manage your zig version.
### Features
- Json RPC with support for http/s, ws/s and ipc connections.
- EVM Interpreter that you can use to run contract bytecode.
- Wallet instances and contract instances to use for interacting with nodes/json rpc.
- Wallet nonce manager that uses a json rpc as a source of truth.
- BlockExplorer support. Only the free methods from those api endpoints are supported.
- Custom Secp256k1 ECDSA signer using only Zig and implementation of RFC6979 nonce generator.
- Custom Schnorr signer. BIP0340 and ERC-7816 are both supported.
- Custom JSON Parser that can be used to deserialize and serialized RPC data at runtime.
- Custom solidity tokenizer and parser generator.
- Ability to translate solidity source code to zig.
- ABI to zig types.
- Support for EIP712.
- Support for EIP3074 authorization message. Also supports EIP7702 transactions.
- Parsing of human readable ABIs into zig types with custom Parser and Lexer.
- HD Wallet and Mnemonic passphrases.
- RLP Encoding/Decoding.
- SSZ Encoding/Decoding.
- ABI Encoding/Decoding with support for Log topics encoding and decoding.
- Parsing of encoded transactions and serialization of transaction objects.
- Support for all transaction types and the new EIP4844 KZG commitments.
- Support for OPStack and ENS.
- Custom meta programming functions to translate ABI's into zig types.
- Support for interacting with test chains such as Anvil or Hardhat.
- Custom cli args parser that translates commands to zig types and can be used to pass data to methods.
- Custom data generator usefull for fuzzing.
And a lot more yet to come...
### Goal
The goal of zabi is to be one of the best library to use by the ethereum ecosystem and to expose to more people to the zig programming language.
### Contributing
Contributions to Zabi are greatly appreciated! If you're interested in contributing to ZAbi, feel free to create a pull request with a feature or a bug fix. \
You can also read the [contributing guide](/.github/CONTRIBUTING.md) **before submitting a pull request**
### Sponsors
If you find Zabi useful or use it for work, please consider supporting development on [GitHub Sponsors]( https://github.com/sponsors/Raiden1411) or sending crypto to [zzabi.eth](https://etherscan.io/name-lookup-search?id=zzabi.eth) or interacting with the [drip](https://www.drips.network/app/projects/github/Raiden1411/zabi?exact) platform where 40% of the revenue gets sent to zabi's dependencies. Thank you 🙏
|
[] |
https://avatars.githubusercontent.com/u/24697112?v=4
|
example-zig-cgo
|
goreleaser/example-zig-cgo
|
2023-02-27T18:57:07Z
|
A showcase of using Zig to cross-compile Go application with GoReleaser
|
master
| 0 | 86 | 3 | 86 |
https://api.github.com/repos/goreleaser/example-zig-cgo/tags
|
-
|
[
"amd64",
"arm64",
"cross-compilation",
"golang",
"goreleaser",
"linux",
"macos",
"windows",
"zig"
] | 6 | false |
2025-05-16T22:53:48Z
| false | false |
unknown
|
github
|
[] |
Cross-compile Go application for major platforms with Zig and GoReleaser with CGO
Cross-compilation in Go refers to building a Go program on one platform and for another platform. It allows you to create binaries that can be run on systems with different operating systems or architectures from the one on which the program was built. To do that, you just need to specify <code>GOOS</code> and <code>GOARCH</code> when running go build.
Unfortunately for projects that uses CGO dependencies, things can be harder. Depending on the target architecture it requires the installation of a C compiler like <code>gcc</code>, <code>clang</code> or <code>x86_64-w64-mingw64-gcc</code> and configuring additional environment variables like CC along with the CGO_ENABLED=1 one.
Cross-compiling with cgo involves building a Go program that uses C code and compiling it for a different target platform than the one on which the program is built.
The cgo tool is enabled by default for native builds on systems where it is expected to work. It is disabled by default when cross-compiling. You can control this by setting the CGO_ENABLED environment variable when running the go tool: set it to 1 to enable the use of cgo, and to 0 to disable it. The go tool will set the
build constraint "cgo" if cgo is enabled.
When cross-compiling, you must specify a C cross-compiler for cgo to use. You can do this by setting the CC_FOR_TARGET environment variable when building the toolchain using make.bash, or by setting the CC environment variable any time you run the go tool. The CXX_FOR_TARGET and CXX environment variables work in a similar way for C++ code.
<blockquote>
<a>https://go-review.googlesource.com/c/go/+/12603/2/src/cmd/cgo/doc.go</a>
</blockquote>
Zig Cross-compilation
Zig is a programming language that aims to be a better alternative to C, offering a simpler syntax, memory safety, and more expressive error handling. It also includes built-in cross-compilation support.
Zig is a full-fledged C/C++ cross-compiler that leverages LLVM. The crucial detail here is what Zig includes to make cross-compilation possible: Zig bundles standard libraries for all major platforms (GNU libc, musl libc, ...), an advanced artifact caching system, and it has a flag-compatible interface for both clang and gcc.
<blockquote>
<a>https://dev.to/kristoff/zig-makes-go-cross-compilation-just-work-29ho</a>
</blockquote>
When cross-compiling Zig code, you can use the zig cc and zig c++ commands to compile C and C++ code, respectively. These commands are wrappers around the appropriate compiler for the target platform, and they handle passing the correct flags and options to the underlying compiler.
If you want to cross-compile for x86_64 Linux, for example, all you need to do is add
<ul>
<li>CC="zig cc -target x86_64-linux"</li>
<li>CXX="zig c++ -target x86_64-linux</li>
</ul>
to the list of env variables when invoking go build. In the case of Hugo, this is the complete command line:
<code>shell
CGO_ENABLED=1 GOOS=linux GOARCH=amd64 CC="zig cc -target x86_64-linux" CXX="zig c++ -target x86_64-linux" go build</code>
|
[] |
https://avatars.githubusercontent.com/u/118723009?v=4
|
ziggy-starkdust
|
keep-starknet-strange/ziggy-starkdust
|
2023-09-26T16:13:58Z
|
⚡ Cairo VM in Zig ⚡
|
main
| 18 | 86 | 38 | 86 |
https://api.github.com/repos/keep-starknet-strange/ziggy-starkdust/tags
|
MIT
|
[
"cairo",
"starknet",
"virtual-machine",
"zig",
"zig-lang"
] | 38,288 | false |
2025-02-26T11:44:58Z
| true | true |
unknown
|
github
|
[
{
"commit": "9a94c4803a52e54c26b198096d63fb5bde752da2.zip",
"name": "zig-cli",
"tar_url": "https://github.com/sam701/zig-cli/archive/9a94c4803a52e54c26b198096d63fb5bde752da2.zip.tar.gz",
"type": "remote",
"url": "https://github.com/sam701/zig-cli"
},
{
"commit": "d9e95579ce9f61a8acf42da03d9371af62925a9e.zip",
"name": "starknet",
"tar_url": "https://github.com/StringNick/starknet-zig/archive/d9e95579ce9f61a8acf42da03d9371af62925a9e.zip.tar.gz",
"type": "remote",
"url": "https://github.com/StringNick/starknet-zig"
}
] |
ziggy-starkdust
<a></a>
<a></a>
<a></a>
<a></a>
[](https://github.com/keep-starknet-strange)
<blockquote>
<em>Note that <code>ziggy-starkdust</code> is still experimental. Breaking changes will be made before the first stable release. The library is also NOT audited or reviewed for security at the moment. Use at your own risk.</em>
</blockquote>
📦 Installation
📋 Prerequisites
<ul>
<li><a>Zig</a></li>
</ul>
Alternatively, if you have <a>nix</a> installed, you can get the full development environment <code>nix develop</code>.
<ul>
<li>Also you need installed python, so we can compile cairo0 programs in benchmarks/integration tests, to insatll them just run:
<code>bash
make deps</code>
if u got macos:
<code>bash
make deps-macos</code></li>
<li>After you need compile all cairo0 programs, to use test or benchmarks:
<code>bash
make compile-cairo-programs</code></li>
</ul>
⚡ Wanna get up to speed fast?
👇 ⚡ Zig
- [Zig language reference](https://ziglang.org/documentation/master/)
- [Zig Learn](https://ziglearn.org/)
- [Ziglings](https://ziglings.org/)
👇 🐺 Cairo VM
- [Cairo Whitepaper](https://eprint.iacr.org/2021/1063.pdf)
- [OG Cairo VM in Python](https://github.com/starkware-libs/cairo-lang/tree/master/src/starkware/cairo/lang/vm)
- [Cairo VM in Rust](https://github.com/lambdaclass/cairo-vm)
- [Cairo VM in Go](https://github.com/lambdaclass/cairo-vm_in_go)
🔧 Build
<code>bash
make build</code>
🤖 Usage
You can display the help message by running:
<code>bash
./zig-out/bin/ziggy-starkdust --help</code>
Run a cairo program
Without proof mode:
<code>bash
./zig-out/bin/ziggy-starkdust execute --filename cairo_programs/fibonacci.json</code>
With proof mode:
<code>bash
./zig-out/bin/ziggy-starkdust execute --filename cairo_programs/fibonacci.json --proof-mode</code>
With memory layout, trace, proof mode and custom layout:
<code>bash
./zig-out/bin/ziggy-starkdust execute --filename cairo_programs/fibonacci.json --memory-file=/dev/null --trace-file=/dev/null --proof-mode=true --layout all_cairo</code>
🧪 Testing
Run all integration tests with summary:
<code>bash
make build-integration-test
./zig-out/bin/integration_test</code>
Run all benchmarks and compare:
<code>bash
make build-compare-benchmarks</code>
Run all programs and compare output memory/trace for Zig/Rust cairo-vm:
<code>bash
make build-compare-output</code>
Run all unit tests with test summary:
<code>bash
make test</code>
Run a single test, for example, the "Felt252 zero" test:
<code>console
$ make test-filter FILTER="Felt252 zero"
All 2 tests passed.</code>
Notice that 2 tests passed despite running only 1 test, because
our tests are wrapped in another test call within <code>src/tests.zig</code>.
In order to compare two memory files or trace files, use the following command:
<code>vbindiff cairo_programs/expected_fibonacci.trace cairo_programs/fibonacci.trace</code>
📊 Benchmarks
Installing benchmark dependencies
In order to compile programs you need to install the cairo-lang package.
Running the <code>make deps</code> (or the <code>make deps-macos</code> if you are runnning in MacOS) command will create a virtual environment with all the required dependencies.
Run the complete benchmark suite with Make:
<code>bash
make build-compare-benchmarks</code>
🔒 Security
Security guidelines
For security guidelines, please refer to <a>SECURITY.md</a>.
OpenSSF Scorecard
We are using the <a>OpenSSF Scorecard</a> to track the security of this project.
Scorecard assesses open source projects for security risks through a series of automated checks.
You can see the current scorecard for this project <a>here</a>.
🙏 Acknowledgments
<ul>
<li>The structure of the project and some initial code related to prime field functions is based on <a>verkle-cryto</a> repository by <a>jsign</a>.</li>
<li>The design of the Cairo VM is inspired by <a>Cairo VM in Rust</a> and <a>Cairo VM in Go</a> by <a>lambdaclass</a>.</li>
<li>Some cryptographic primitive code generation has been done using the amazing <a>fiat-crypto</a> by <a>mit-plv</a>.</li>
<li><a>sig</a> has been a great source of inspiration for the project structure and the way to use Zig.</li>
<li><a>nektro</a> for the <a>zig-time</a> library.</li>
<li>The Cairo files used in this project are sourced from the <a>Cairo VM in Rust</a> by <a>lambdaclass</a>.</li>
</ul>
⚡ Why Zig?
👇 ⚡
Choosing Zig for a third implementation of the Cairo VM brings several advantages, offering a unique blend of features not entirely covered by the existing Rust and Go implementations.
### 1. Simplicity and Readability
Zig aims for simplicity and clarity, enabling developers to read and understand the code quickly. It omits certain features like classes and exceptions to keep the language simple, which can be particularly useful for a VM where performance and maintainability are key.
### 2. Performance
Zig compiles to highly efficient native code, similar to Rust, making it an excellent choice for computationally-intensive tasks. The language's design gives the programmer direct control over memory and CPU, without unnecessary abstractions.
### 3. Explicit Control with Safety Features
Zig provides an environment where you have explicit control over memory allocation, similar to C and C++. While this does mean you're responsible for managing memory yourself, Zig offers certain safety features to catch common errors, like undefined behavior, during compile time or by providing runtime checks. This approach allows for a blend of performance and safety, making it a suitable choice for a VM where you often need fine-grained control.
### 4. C Interoperability
Zig offers first-class C interoperability without requiring any bindings or wrappers. This feature can be a game-changer for integrating with existing technologies.
### 5. Flexibility
Zig's comptime (compile-time) features offer powerful metaprogramming capabilities. This allows for expressive yet efficient code, as you can generate specialized routines at compile-time, reducing the need for runtime polymorphism.
### 6. Minimal Dependencies
Zig aims to reduce dependencies to a minimum, which could simplify the deployment and distribution of Cairo VM. This is particularly advantageous for systems that require high-reliability or have limited resources.
### 7. Community and Ecosystem
Although younger than Rust and Go, Zig's community is enthusiastic and rapidly growing. Adopting Zig at this stage means you can be a significant contributor to its ecosystem.
By choosing Zig for the third implementation of Cairo VM, we aim to leverage these features to build a high-performance, reliable, and maintainable virtual machine.
📄 License
This project is licensed under the MIT license.
See <a>LICENSE</a> for more information.
Happy coding! 🎉
Contributors ✨
Thanks goes to these wonderful people (<a>emoji key</a>):
<a><b>Abdel @ StarkWare </b></a><a>💻</a>
<a><b>bing</b></a><a>💻</a>
<a><b>Francesco Ceccon</b></a><a>💻</a>
<a><b>Thomas Coratger</b></a><a>💻</a>
<a><b>lambda-0x</b></a><a>💻</a>
<a><b>Nils</b></a><a>💻</a>
<a><b>johann bestowrous</b></a><a>💻</a>
<a><b>lanaivina</b></a><a>💻</a>
<a><b>Dhruv Kelawala</b></a><a>💻</a>
<a><b>Godspower Eze</b></a><a>💻</a>
<a><b>tedison</b></a><a>💻</a>
<a><b>ptisserand</b></a><a>💻</a>
<a><b>ndcroos</b></a><a>📖</a>
<a><b>Icosahedron</b></a><a>💻</a>
<a><b>Pierre-Jean</b></a><a>💻</a>
<a><b>iwantanode</b></a><a>📖</a>
This project follows the <a>all-contributors</a> specification. Contributions of any kind welcome!
|
[] |
https://avatars.githubusercontent.com/u/132705474?v=4
|
CascadeOS
|
CascadeOS/CascadeOS
|
2023-05-20T15:44:41Z
|
General purpose operating system targeting standard desktops and laptops.
|
main
| 11 | 80 | 3 | 80 |
https://api.github.com/repos/CascadeOS/CascadeOS/tags
|
MIT
|
[
"aarch64",
"arm64",
"hobby-os",
"operating-system",
"osdev",
"risc-v",
"x64",
"x86-64",
"zig",
"ziglang"
] | 3,595 | false |
2025-05-21T14:50:06Z
| true | true |
0.15.0-dev.471+369177f0b
|
github
|
[
{
"commit": "master",
"name": "devicetree",
"tar_url": "https://github.com/CascadeOS/zig-devicetree/archive/master.tar.gz",
"type": "remote",
"url": "https://github.com/CascadeOS/zig-devicetree"
},
{
"commit": "master",
"name": "edk2",
"tar_url": "https://github.com/CascadeOS/ovmf-prebuilt/releases/download/edk2-stable202502-r1/edk2-stable202502-r1-bin.tar.xz/archive/master.tar.gz",
"type": "remote",
"url": "https://github.com/CascadeOS/ovmf-prebuilt/releases/download/edk2-stable202502-r1/edk2-stable202502-r1-bin.tar.xz"
},
{
"commit": "master",
"name": "libdwarf",
"tar_url": "https://github.com/CascadeOS/libdwarf-code/archive/master.tar.gz",
"type": "remote",
"url": "https://github.com/CascadeOS/libdwarf-code"
},
{
"commit": "master",
"name": "limine",
"tar_url": "https://github.com/limine-bootloader/limine/archive/master.tar.gz",
"type": "remote",
"url": "https://github.com/limine-bootloader/limine"
},
{
"commit": "master",
"name": "uacpi",
"tar_url": "https://github.com/CascadeOS/uACPI/archive/master.tar.gz",
"type": "remote",
"url": "https://github.com/CascadeOS/uACPI"
}
] |
CascadeOS
<a></a>
Cascade is a general purpose operating system targeting standard desktops and laptops.
Short Term Goals
<ul>
<li>Good enough x64 support for QEMU (virtio drivers)</li>
<li>Userspace, no GUI</li>
<li>ext2 on NVMe</li>
</ul>
Planned Features
<ul>
<li>x64, ARM64 and RISCV64</li>
<li>First class Zig support</li>
<li>Userspace with GUI</li>
</ul>
Build, testing, running
Prerequisites:
<ul>
<li>zig master (0.15.0-dev.471+369177f0b)</li>
<li>qemu (optional; used for running and host testing)</li>
</ul>
Run the x64 kernel in QEMU:
<code>sh
zig build run_x64</code>
List all available build targets:
<code>sh
zig build -l</code>
Run all tests and build all code:
<code>sh
zig build test --summary all</code>
Run <code>zig build -h</code> for a listing of the available steps and options.
License
This project follows the <a>REUSE Specification</a> for specifying license information.
|
[] |
https://avatars.githubusercontent.com/u/2883484?v=4
|
md4w
|
ije/md4w
|
2024-01-16T10:11:17Z
|
A Markdown renderer written in Zig & C, compiled to WebAssymbly.
|
main
| 3 | 77 | 0 | 77 |
https://api.github.com/repos/ije/md4w/tags
|
MIT
|
[
"html",
"markdown",
"md4c",
"parser",
"renderer",
"streaming",
"wasm",
"webassembly",
"zig"
] | 321 | false |
2025-04-27T19:05:16Z
| true | false |
unknown
|
github
|
[] |
md4w
A <strong>Markdown</strong> renderer written in Zig & C, compiled to <strong>WebAssymbly</strong>.
<ul>
<li><strong>Compliance</strong>: powered by <a>md4c</a> that is fully
compliant to CommonMark 0.31, and partially supports GFM like task list,
table, etc.</li>
<li><strong>Fast</strong>: written in Zig & C, compiled to WebAssembly (it's about <strong>2.5x</strong> faster
than markdown-it, see <a>benchmark</a>).</li>
<li><strong>Small</strong>: <code>~28KB</code> gzipped.</li>
<li><strong>Simple</strong>: zero dependencies, easy to use.</li>
<li><strong>Streaming</strong>: supports web streaming API for reducing memory usage.</li>
<li><strong>Universal</strong>: works in any JavaScript runtime (Node.js, Deno, Bun, Browsers,
Cloudflare Workers, etc).</li>
</ul>
Usage
```js
// npm i md4w (Node.js, Bun, Cloudflare Workers, etc.)
import { init, mdToHtml, mdToJSON, mdToReadableHtml } from "md4w";
// or use the CDN url (Deno, Browsers)
import { init, mdToHtml, mdToJSON, mdToReadableHtml } from "https://esm.sh/md4w";
// waiting for md4w.wasm...
await init();
// markdown -> HTML
const html = mdToHtml("Stay <em>foolish</em>, stay <strong>hungry</strong>!");
// markdown -> HTML (ReadableStream)
const readable = mdToReadableHtml("Stay <em>foolish</em>, stay <strong>hungry</strong>!");
const response = new Response(readable, {
headers: { "Content-Type": "text/html" },
});
// markdown -> JSON
const tree = mdToJSON("Stay <em>foolish</em>, stay <strong>hungry</strong>!");
```
Wasm Mode
md4w provides two webassembly binary files:
<ul>
<li><code>md4w-fast.wasm</code>: Faster but larger binary file. (<strong>270KB</strong> gzipped)</li>
<li><code>md4w-small.wasm</code>: Tiny but slower binary file. (<strong>28KB</strong> gzipped)</li>
</ul>
By default, md4w uses the <code>md4w-fast.wasm</code> binary from file system, uses the <code>md4w-small.wasm</code> binary from CDN. You can also specify the wasm file by adding the <code>wasmMode</code> option.
```js
import { init } from "md4w";
await init("fast"); // or "small"
```
If you are using a <strong>bundler</strong> like vite, you need to configure the <code>wasm</code> input manually.
```js
import { init } from "md4w";
import wasmUrl from "md4w/js/md4w-fast.wasm?url";
await init(wasmUrl);
```
Parse Flags
By default, md4w uses the following parse flags:
<ul>
<li><code>COLLAPSE_WHITESPACE</code>: Collapse non-trivial whitespace into single space.</li>
<li><code>PERMISSIVE_ATX_HEADERS</code>: Do not require space in ATX headers (<code>###header</code>).</li>
<li><code>PERMISSIVE_URL_AUTO_LINKS</code>: Recognize URLs as links.</li>
<li><code>STRIKETHROUGH</code>: Text enclosed in tilde marks, e.g. <code>~foo bar~</code>.</li>
<li><code>TABLES</code>: Support GitHub-style tables.</li>
<li><code>TASK_LISTS</code>: Support GitHub-style task lists.</li>
</ul>
You can use the <code>parseFlags</code> option to change the renderer behavior:
<code>ts
mdToHtml("Stay _foolish_, stay **hungry**!", {
parseFlags: [
"DEFAULT",
"NO_HTML",
"LATEX_MATH_SPANS",
// ... other parse flags
],
});</code>
All available parse flags are:
<code>ts
export enum ParseFlags {
/** Collapse non-trivial whitespace into single space. */
COLLAPSE_WHITESPACE,
/** Do not require space in ATX headers ( ###header ) */
PERMISSIVE_ATX_HEADERS,
/** Recognize URLs as links. */
PERMISSIVE_URL_AUTO_LINKS,
/** Recognize e-mails as links.*/
PERMISSIVE_EMAIL_AUTO_LINKS,
/** Disable indented code blocks. (Only fenced code works.) */
NO_INDENTED_CODE_BLOCKS,
/** Disable raw HTML blocks. */
NO_HTML_BLOCKS,
/** Disable raw HTML (inline). */
NO_HTML_SPANS,
/** Support GitHub-style tables. */
TABLES,
/** Support strike-through spans (text enclosed in tilde marks, e.g. ~foo bar~). */
STRIKETHROUGH,
/** Support WWW autolinks (without proto; just 'www.') */
PERMISSIVE_WWW_AUTO_LINKS,
/** Support GitHub-style task lists. */
TASKLISTS,
/** Support LaTeX math spans ($...$) and LaTeX display math spans ($$...$$) are supported. (Note though that the HTML renderer outputs them verbatim in a custom tag <x-equation>.) */
LATEX_MATH_SPANS,
/** Support wiki-style links ([[link label]] and [[target article|link label]]) are supported. (Note that the HTML renderer outputs them in a custom tag <x-wikilink>.) */
WIKI_LINKS,
/** Denotes an underline instead of an ordinary emphasis or strong emphasis. */
UNDERLINE,
/** Using hard line breaks. */
HARD_SOFT_BREAKS,
/** Shorthand for NO_HTML_BLOCKS | NO_HTML_SPANS */
NO_HTML,
/** Default flags COLLAPSE_WHITESPACE | PERMISSIVE_ATX_HEADERS | PERMISSIVE_URL_AUTO_LINKS | STRIKETHROUGH | TABLES | TASK_LISTS */
DEFAULT,
}</code>
Code Highlighter
md4w would not add colors to the code blocks by default, however, we provide a
<code>setCodeHighlighter</code> function to allow you to add any code highlighter you like.
```js
import { setCodeHighlighter } from "md4w";
setCodeHighlighter((code, lang) => {
return <code><pre><code class="language-${lang}">${hl(code)}</code></pre></code>;
});
```
Caveats
<ul>
<li>The returned code will be inserted into the html directly, without html
escaping. You should take care of the html escaping by yourself.</li>
<li>Although we don't send back the highlighted code to the wasm module, the
performance is still impacted by the code highlighter.</li>
</ul>
Web Streaming API
md4w provides the web streaming API, that is useful
for a http server to stream the outputed html.
```js
import { mdToReadableHtml } from "md4w";
const readable = mdToReadableHtml(readFile("large.md"));
// write to file
const file = await Deno.open("/foo/bar.html", { write: true, create: true });
readable.pipeTo(file.writable);
// or send to browser
const response = new Response(readable, {
headers: { "Content-Type": "text/html" },
});
```
Buffer Size
By default, md4w uses a buffer size of <code>4KB</code> for streaming, you can change it by
adding the <code>bufferSize</code> option.
<code>js
mdToReadableHtml(largeMarkdown, {
bufferSize: 16 * 1024,
});</code>
Caveats
The streaming API currently only uses the buffer for output, you still need
to load the whole markdown data into memory.
Rendering to JSON
md4w also provides a <code>mdToJSON</code> function to render the markdown to JSON.
```js
const traverse = (node) => {
// text node
if (typeof node === "string") {
console.log(node);
return;
}
// element type
console.log(node.type);
// element attributes (may be undefined)
console.log(node.props);
// element children (may be undefined)
node.children?.forEach(traverse);
};
const tree = mdToJSON("Stay <em>foolish</em>, stay <strong>hungry</strong>!");
traverse(tree);
```
Node Type
The node type is a number that represents the type of the node. You can import
the <code>NodeType</code> enum to get the human-readable node type.
```ts
import { NodeType } from "md4w";
console.log(NodeType.P); // 9
console.log(NodeType.IMG); // 33
if (node.type === NodeType.IMG) {
console.log("This is an image node, <code>src</code> is", node.props.src);
}
```
<blockquote>
All available node types are defined in the
<a><code>NodeType</code></a> enum.
</blockquote>
Development
The renderer is written in <a>Zig</a>, ensure you have it (0.11.0)
installed.
<code>bash
zig build && deno test -A</code>
Benchmark
<code>bash
zig build && deno bench -A test/benchmark.js</code>
Prior Art
<ul>
<li><a>md4c</a> - C Markdown parser. Fast. SAX-like
interface. Compliant to CommonMark specification.</li>
<li><a>markdown-wasm</a> - Very fast Markdown
parser and HTML generator implemented in WebAssembly, based on md4c.</li>
</ul>
License
MIT
|
[] |
https://avatars.githubusercontent.com/u/20110944?v=4
|
zig-wasm-audio-framebuffer
|
ringtailsoftware/zig-wasm-audio-framebuffer
|
2023-03-03T15:59:29Z
|
Examples of integrating Zig and Wasm (and C) for audio and graphics on the web
|
main
| 0 | 65 | 2 | 65 |
https://api.github.com/repos/ringtailsoftware/zig-wasm-audio-framebuffer/tags
|
NOASSERTION
|
[
"c",
"doom",
"wasm",
"webassembly",
"webaudio",
"zig",
"zig-package"
] | 53,912 | false |
2025-05-21T11:59:51Z
| true | true |
unknown
|
github
|
[
{
"commit": "refs",
"name": "mime",
"tar_url": "https://github.com/andrewrk/mime/archive/refs.tar.gz",
"type": "remote",
"url": "https://github.com/andrewrk/mime"
},
{
"commit": "7617c3610f0dd491c197ba03f3149c4040ff6845",
"name": "zvterm",
"tar_url": "https://github.com/ringtailsoftware/zvterm/archive/7617c3610f0dd491c197ba03f3149c4040ff6845.tar.gz",
"type": "remote",
"url": "https://github.com/ringtailsoftware/zvterm"
},
{
"commit": "03717dc35bd1eb7b0d5afe0438bee73793ca8334",
"name": "zeptolibc",
"tar_url": "https://github.com/ringtailsoftware/zeptolibc/archive/03717dc35bd1eb7b0d5afe0438bee73793ca8334.tar.gz",
"type": "remote",
"url": "https://github.com/ringtailsoftware/zeptolibc"
},
{
"commit": "b001662c929e2719ee24be585a3120640f946337",
"name": "mibu",
"tar_url": "https://github.com/xyaman/mibu/archive/b001662c929e2719ee24be585a3120640f946337.tar.gz",
"type": "remote",
"url": "https://github.com/xyaman/mibu"
},
{
"commit": "7563ff5421974857ee8e745f7ae020874f2954af",
"name": "zigtris",
"tar_url": "https://github.com/ringtailsoftware/zigtris/archive/7563ff5421974857ee8e745f7ae020874f2954af.tar.gz",
"type": "remote",
"url": "https://github.com/ringtailsoftware/zigtris"
}
] |
zig-wasm-audio-framebuffer
Toby Jaffey https://mastodon.me.uk/@tobyjaffey
Straightforward examples of integrating Zig and Wasm for audio and graphics on the web.
Compiling against Zig v0.14.0.
Where C code requires functions from the C library, https://github.com/ringtailsoftware/zeptolibc is used.
Demos
Visit https://ringtailsoftware.github.io/zig-wasm-audio-framebuffer
<ul>
<li>Sinetone, simple waveform generator</li>
<li>Synth, HTML/CSS piano keyboard driving MIDI synth</li>
<li>Mod, Pro-Tracker mod player</li>
<li>Mandelbrot, mandelbrot set, mouse interaction</li>
<li>Bat, arcade style game skeleton, keyboard control, interactive graphics, background music, sound effects</li>
<li>Doom, Doom1 Shareware, keyboard control, MIDI music, sound effects</li>
<li>TinyGL, software GL renderer in Wasm</li>
<li>OliveC, graphics library with sprite blit, circle, rectangle, line, etc.</li>
<li>Agnes, NES emulator (no sound)</li>
<li>Terminal, libvterm based terminal emulator, playing a terminal tetris game</li>
</ul>
Aims
<ul>
<li>Cross-platform (running on multiple browsers and operating systems)</li>
<li>Simple understandable code. No hidden libraries, no "emscripten magic"</li>
<li>Main loop in browser, wasm responds to function calls to init/update/render</li>
<li>One wasm binary per program</li>
<li>Use existing C libraries to do fun things</li>
</ul>
Build and test
<code>zig build && zig build serve -- zig-out -p 8000
</code>
Browse to http://localhost:8000
Video system
An in-memory 32bpp ARGB framebuffer is created and controlled in Zig. To render onto a canvas element, JavaScript:
<ul>
<li>Requests the framebuffer Zig/WebAssembly pointer with <code>getGfxBufPtr()</code></li>
<li>Wraps the memory in a <code>Uint8ClampedArray</code></li>
<li>Creates an <code>ImageData</code> from the <code>Uint8ClampedArray</code></li>
<li>Shows the <code>ImageData</code> in canvas's graphics context</li>
</ul>
Audio pipeline
An <a>AudioWorkletNode</a> is used to move PCM samples from WebAssembly to the audio output device.
The system is hardcoded to 2 channels (stereo) and uses 32-bit floats for audio data throughout. In-memory arrays of audio data are created and controlled in Zig.
The AudioWorkletNode expects to pull chunks of audio to be rendered on-demand. However, being isolated from the main thread it cannot directly communicate with the main Wasm program. This is solved by using a <a>shared ringbuffer</a>. To render audio to the output device, JavaScript:
<ul>
<li>Tells Zig/WebAssembly the expected sample rate in Hz for the output device, <code>setSampleRate(44100)</code></li>
<li>Forever, checks if the ringbuffer has space for more data</li>
<li>Tells Zig/WebAssembly to fill its audio buffers with <code>renderSoundQuantum()</code></li>
<li>Fetches pointers to the left and right channels using <code>getLeftBufPtr()</code> <code>getRightBufPtr()</code></li>
<li>Copies from left and right channels into the ringbuffer</li>
</ul>
The <code>WasmPcm</code> (<code>wasmpcm.js</code>) class creates the <code>AudioWorkletNode</code> <code>WASMWorkletProcessor</code> using <code>pcm-processor.js</code>. At regular intervals <code>WasmPcm</code> calls <code>pcmProcess()</code> to request audio data from Wasm.
Compatibility
Tested on Safari/Chrome/Firefox on macOS, Safari on iPhone SE2/iPad, Chrome/Android Galaxy Tablet
iOS unmute
By default web audio plays under the same rules as the ringer. The <code>unmute.js</code> script loops a constant silence in the background to force playback while the mute button is on.
CORS (Cross-Origin Resource Sharing)
To share data between the main thread and the worklet, SharedArrayBuffer is used. This requires two HTTP headers to be set:
<code>Cross-Origin-Opener-Policy: same-origin
Cross-Origin-Embedder-Policy: require-corp
</code>
However, this is worked around by using <a>coi-serviceworker</a> which reloads the page on startup.
|
[] |
https://avatars.githubusercontent.com/u/5464072?v=4
|
zig-xml
|
nektro/zig-xml
|
2023-11-04T04:27:01Z
|
A pure-Zig fully spec-compliant XML parser.
|
master
| 0 | 61 | 11 | 61 |
https://api.github.com/repos/nektro/zig-xml/tags
|
MPL-2.0
|
[
"zig",
"zig-package"
] | 177 | false |
2025-05-22T06:29:33Z
| true | false |
unknown
|
github
|
[] |
zig-xml
<a></a>
<a></a>
<a></a>
<a></a>
A pure-zig spec-compliant XML parser.
https://www.w3.org/TR/xml/
Passes all standalone tests from https://www.w3.org/XML/Test/xmlconf-20020606.htm, even more coverage coming soon.
One caveat is that this parser expects UTF-8.
<code>Build Summary: 3/3 steps succeeded; 120/120 tests passed
test success
└─ run test 120 passed 5ms MaxRSS:1M
└─ zig test Debug native success 1s MaxRSS:247M</code>
|
[] |
https://avatars.githubusercontent.com/u/206480?v=4
|
cache.zig
|
karlseguin/cache.zig
|
2023-05-28T10:55:45Z
|
A thread-safe, expiration-aware, LRU cache for Zig
|
master
| 0 | 61 | 4 | 61 |
https://api.github.com/repos/karlseguin/cache.zig/tags
|
MIT
|
[
"cache",
"caching-library",
"lru-cache",
"zig",
"zig-library",
"zig-package"
] | 96 | false |
2025-05-14T06:16:23Z
| true | true |
0.14.0
|
github
|
[] |
A thread-safe, expiration-aware, LRU(ish) cache for Zig
```zig
// package available using Zig's built-in package manager
const user_cache = @import("cache");
var user_cache = try cache.Cache(User).init(allocator, .{.max_size = 10000});
defer user_cache.deinit();
try user_cache.put("user1", user1, .{.ttl = 300});
...
if (user_cache.get("user1")) |entry| {
defer entry.release();
const user1 = entry.value;
} else {
// not in the cache
}
// del will return true if the item existed
_ = user_cache.del("user1");
```
<code>get</code> will return <code>null</code> if the key is not found, or if the entry associated with the key has expired. If the entry has expired, it will be removed.
<code>getEntry</code> can be used to return the entry even if it has expired. While <code>getEntry</code> will return en expired item, it will not promote a expired item in the recency list. The main purpose is to allow the caller to serve a stale value while fetching a new one.
In either case, the entry's <code>ttl() i64</code> method can be used to return the number of seconds until the entry expires. This will be negative if the entry has already expired. The <code>expired() bool</code> method will return <code>true</code> if the entry is expired.
<code>release</code> must be called on the returned entry.
Implementation
This is a typical LRU cache which combines a hashmap to lookup values and doubly linked list to track recency.
To improve throughput, the cache is divided into a configured number of segments (defaults to 8). Locking only happens at the segment level. Furthermore, items are only promoted to the head of the recency linked list after a configured number of gets. This not only reduces the locking on the linked list, but also introduces a frequency bias to the eviction policy (which I think is welcome addition).
The downside of this approach is that size enforcement and the eviction policy is done on a per-segment basis. Given a <code>max_size</code> of 8000 and a <code>segment_count</code> of 8, each segment will enforce its own <code>max_size</code> of 1000 and maintain its own recency list. Should keys be poorly distributed across segments, the cache will only reach a fraction of its configured max size. Only least-recently used items within a segment are considered for eviction.
Configuration
The 2nd argument to init is a <code>cache.Config</code>. It's fields with default values are:
<code>``zig
{
// The max size of the cache. By default, each value has a size of 1. Thus
// given a</code>max_size<code>of 5000, the cache can hold up to 5000 items before
// having to evict entries. The size of a value can be set when using
//</code>cache.put<code>or</code>cache.fetch`.
max_size: u32 = 8000,
<code>// The number of segments to use. Must be a power of 2.
// A value of 1 is valid.
segment_count: u16 = 8,
// The number of times get or getEntry must be called on a key before
// it's promoted to the head of the recency list
gets_per_promote: u8 = 5,
// When a segment is full, the ratio of the segment's max_size to free.
shrink_ratio: f32 = 0.2,
</code>
}
<code>``
Given the above, each segment will enforce its own</code>max_size<code>of 1000 (i.e.</code>8000 / 8<code>). When a segment grows beyond 1000, entries will be removed until its size becomes less than or equal to 800 (i.e.</code>1000 - (1000 * 0.2)`)
Put
The <code>cache.put(key: []const u8, value: T, config: cache.PutConfig) !void</code> has a number of consideration.
First, the key will be cloned and managed by the cache. The caller does not have to guarantee its validity after <code>put</code> returns.
The third parameter is a <code>cache.PutConfig</code>:
<code>zig
{
.ttl: u32 = 300,
.size: u32 = 1,
}</code>
<code>ttl</code> is the length, in seconds, to keep the value in the cache.
<code>size</code> is the size of the value. This doesn't have to be the actual memory used by the value being cached. In many cases, the default of <code>1</code> is reasonable. However, if enforcement of the memory used by the cache is important, giving an approximate size (as memory usage or as a weighted value) will help. For example, if you're caching a string, the length of the string could make a reasonable argument for <code>size</code>.
If <code>T</code> defines a <strong>public</strong> method <code>size() u32</code>, this value will be used instead of the above configured <code>size</code>. This can be particularly useful with the <code>fetch</code> method.
Fetch
<code>cache.fetch</code> can be used to combine <code>get</code> and <code>put</code> by providing a custom function to load a missing value:
```zig
const user = try cache.fetch(FetchState, "user1", loadUser, .{user_id: 1}, .{.ttl = 300});
...
const FetchState = struct {
user_id: u32,
};
fn loadUser(state: FetchState, key: []const u8) !?User {
const user_id = state.user_id
const user = ... // load a user from the DB?
return user;
}
```
Because Zig doesn't have closures, and because your custom function will likely need data to load the missing value, you provide a custom <code>state</code> type and value which will be passed to your function. They cache key is also passed, which, in simple cases, might be all your function needs to load data (in such cases, a <code>void</code> state can be used).
The last parameter to <code>fetch</code> is the same as the last parameter to <code>put</code>.
Fetch does not do duplicate function call suppression. Concurrent calls to <code>fetch</code> using the same key can result in multiple functions to your callback functions. In other words, fetch is vulnerable to the thundering herd problem. Considering using <a>singleflight.zig</a> within your fetch callback.
The <code>size</code> of the value might not be known until the value is fetched, this makes passing <code>size</code> into fetch impossible. If <code>T</code> defines a <strong>public</strong> method <code>size() u32</code>, then <code>T.size(value)</code> will be called to get the size.
Entry Thread Safety
It's possible for one thread to <code>get</code> an entry, while another thread deletes it. This deletion could be explicit (a call to <code>cache.del</code> or replacing a value with <code>cache.put</code>) or implicit (a call to <code>cache.put</code> causing the cache to free memory). To ensure that deleted entries can safely be used by the application, atomic reference counting is used. While a deleted entry is immediately removed from the cache, it remains valid until all references are removed.
This is why <code>release</code> must be called on the entry returned by <code>get</code> and <code>getEntry</code>. Calling <code>release</code> multiple times on a single entry will break the cache.
removedFromCache notification
If <code>T</code> defines a <strong>public</strong> method <code>removedFromCache</code>, <code>T.removedFromCache(Allocator)</code> will be called when all references are removed but before the entry is destroyed. <code>removedFromCache</code> will be called regardless of why the entry was removed.
The <code>Allocator</code> passed to <code>removedFromCache</code> is the <code>Allocator</code> that the cache was created with - this may or may not be an allocator that is meaningful to the value.
delPrefix
<code>cache.delPrefix</code> can be used to delete any entry that starts with the specified prefix. This requires an O(N) scan through the cache. However, some optimizations are done to limit the amount of write-lock this places on the cache.
|
[] |
https://avatars.githubusercontent.com/u/60897190?v=4
|
zigplotlib
|
Remy2701/zigplotlib
|
2024-01-03T16:17:21Z
|
A simple library for plotting graphs in Zig
|
main
| 1 | 59 | 7 | 59 |
https://api.github.com/repos/Remy2701/zigplotlib/tags
|
-
|
[
"graph",
"plot",
"svg",
"zig"
] | 211,524 | false |
2025-05-02T21:44:46Z
| true | true |
0.13.0
|
github
|
[] |
Zig Plot Lib
<blockquote>
This project is currently stalled as I don't have much time to work on it. Anybody can freely create a PR to add new features and I'll review it; or you can also fork it yourself and add whatever you would like.
</blockquote>
The Zig Plot Lib is a library for plotting data in Zig. It is designed to be easy to use and to have a simple API.
<strong>Note:</strong> This library is still in development and is not yet ready for production use.
I'm developping this library with version 0.13.0.
Installation
You can install the library by adding it to the <code>build.zig.zon</code> file, either manually like so:
<code>zig
.{
...
.dependencies = .{
.zigplotlib = .{
.url = "https://github.com/Remy2701/zigplotlib/archive/main.tar.gz",
.hash = "...",
}
}
...
}</code>
The hash can be found using the builtin command:
<code>sh
zig fetch https://github.com/Remy2701/zigplotlib/archive/main.tar.gz</code>
Or you can also add it automatically like so:
<code>sh
zig fetch --save https://github.com/Remy2701/zigplotlib/archive/main.tar.gz</code>
Then in the <code>build.zig</code>, you can add the following:
```zig
const zigplotlib = b.dependency("zigplotlib", .{
.target = target,
.optimize = optimize,
});
exe.root_module.addImport("plotlib", zigplotlib.module("zigplotlib"));
```
The name of the module (<code>plotlib</code>) can be changed to whatever you want.
Finally in your code you can import the module using the following:
<code>zig
const plotlib = @import("plotlib");</code>
Example
The above plot was generated with the following code:
```zig
const std = @import("std");
const SVG = @import("svg/SVG.zig");
const Figure = @import("plot/Figure.zig");
const Line = @import("plot/Line.zig");
const Area = @import("plot/Area.zig");
const Scatter = @import("plot/Scatter.zig");
/// The function for the 1st plot (area - blue)
fn f(x: f32) f32 {
if (x > 10.0) {
return 20 - (2 * (x - 10.0));
}
return 2 * x;
}
/// The function for the 2nd plot (scatter - red)
fn f2(x: f32) f32 {
if (x > 10.0) {
return 10.0;
}
return x;
}
/// The function for the 3rd plot (line - green)
fn f3(x: f32) f32 {
if (x < 8.0) {
return 0.0;
}
return 0.5 * (x - 8.0);
}
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
defer _ = gpa.deinit();
const allocator = gpa.allocator();
<code>var points: [25]f32 = undefined;
var points2: [25]f32 = undefined;
var points3: [25]f32 = undefined;
for (0..25) |i| {
points[i] = f(@floatFromInt(i));
points2[i] = f2(@floatFromInt(i));
points3[i] = f3(@floatFromInt(i));
}
var figure = Figure.init(allocator, .{
.title = .{
.text = "Example plot",
},
});
defer figure.deinit();
try figure.addPlot(Area {
.y = &points,
.style = .{
.color = 0x0000FF,
}
});
try figure.addPlot(Scatter {
.y = &points2,
.style = .{
.shape = .plus,
.color = 0xFF0000,
}
});
try figure.addPlot(Line {
.y = &points3,
.style = .{
.color = 0x00FF00,
}
});
try figure.addPlot(Area {
.x = &[_]f32 { -5.0, 0.0, 5.0 },
.y = &[_]f32 { 5.0, 3.0, 5.0 },
.style = .{
.color = 0xFF00FF,
}
});
try figure.addPlot(Area {
.x = &[_]f32 { -5.0, 0.0, 5.0 },
.y = &[_]f32 { -5.0, -3.0, -5.0 },
.style = .{
.color = 0xFFFF00,
}
});
var svg = try figure.show();
defer svg.deinit();
// Write to an output file (out.svg)
var file = try std.fs.cwd().createFile("out.svg", .{});
defer file.close();
try svg.writeTo(file.writer());
</code>
}
```
Usage
The first thing needed is to create a figure which will contain the plots.
```zig
const std = @import("std");
const Figure = @import("plot/Figure.zig");
pub fn main() !void {
var gpa = std.heap.GeneralPurposeAllocator(.{}){};
defer _ = gpa.deinit();
const allocator = gpa.allocator();
<code>var figure = Figure.init(allocator, .{});
defer figure.deinit();
</code>
}
```
The figure takes two arguments, the allocator (used to store the plot and generate the SVG) and the style for the plot. The options available for the style are:
| Option | Type | Description |
| --- | --- | --- |
| <code>width</code> | <code>union(enum) { pixel: f32, auto_gap: f32 }</code> | The width of the plot in pixels (excluding the axis and label). |
| <code>height</code> | <code>union(enum) { pixel: f32, auto_gap: f32 }</code> | The height of the plot in pixels (excluding the axis and label). |
| <code>plot_padding</code> | <code>f32</code> | The padding around the plot |
| <code>background_color</code> | <code>RGB (u48)</code> | The background color of the plot |
| <code>background_opacity</code> | <code>f32</code> | The opacity of the background |
| <code>title</code> | <code>?...</code> | The style of the title (null to hide it) |
| <code>value_padding</code> | <code>...</code> | The padding to use for the range of the plot |
| <code>axis</code> | <code>...</code> | The style for the axis |
| <code>legend</code> | <code>...</code> | The style for the legend |
The <code>title</code> option contains the following parameters:
| Option | Type | Description |
| --- | --- | --- |
| <code>text</code> | <code>[]const u8</code> | The title of the figure |
| <code>position</code> | <code>enum { top, bottom }</code> | The position of the title |
| <code>font_size</code> | <code>f32</code> | The font size of the title |
| <code>color</code> | <code>RGB (u48)</code> | The color of the title |
| <code>padding</code> | <code>f32</code> | The padding between the plot and the title |
The <code>value_padding</code> option is defined like so:
```zig
pub const ValuePercent = union(enum) {
value: f32,
percent: f32,
};
value_padding: struct {
x_max: ValuePercent,
y_max: ValuePercent,
x_min: ValuePercent,
y_min: ValuePercent,
},
```
The <code>axis</code> option contains more parameters:
| Option | Type | Description |
| --- | --- | --- |
| <code>x_scale</code> | <code>enum { linear, log }</code> | The scale of the x axis |
| <code>y_scale</code> | <code>enum { linear, log }</code> | The scale of the y axis |
| <code>x_range</code> | <code>?Range(f32)</code> | The range of values for the x axis |
| <code>y_range</code> | <code>?Range(f32)</code> | The range of values for the y axis |
| <code>color</code> | <code>RGB (u48)</code> | The color of the axis |
| <code>width</code> | <code>f32</code> | The width of the axis |
| <code>label_color</code> | <code>RGB (u48)</code> | The color of the labels |
| <code>label_size</code> | <code>f32</code> | The font size of the labels |
| <code>label_padding</code> | <code>f32</code> | The padding between the labels and the axis |
| <code>label_font</code> | <code>[]const u8</code> | The font to use for the labels |
| <code>tick_count_x</code> | <code>...</code> | The number of ticks to use on the x axis |
| <code>tick_count_y</code> | <code>...</code> | The number of ticks to use on the y axis |
| <code>show_x_axis</code> | <code>bool</code> | whether to show the x axis |
| <code>show_y_axis</code> | <code>bool</code> | whether to show the y axis |
| <code>show_grid_x</code> | <code>bool</code> | whether to show the grid on the x axis |
| <code>show_grid_y</code> | <code>bool</code> | whether to show the grid on the y axis |
| <code>grid_opacity</code> | <code>f32</code> | The opacity of the grid |
| <code>frame_color</code> | <code>RGB (u48)</code> | The color of the frame |
| <code>frame_width</code> | <code>f32</code> | The width of the frame |
The <code>tick_count_x</code> and <code>tick_count_y</code> options are defined like so:
<code>zig
tick_count_x: union(enum) {
count: usize,
gap: f32,
}</code>
The <code>legend</code> option contains more parameters:
| Option | Type | Description |
| --- | --- | --- |
| <code>show</code> | <code>bool</code> | Whether to show the legend |
| <code>position</code> | <code>enum { top_left, top_right, bottom_left, bottom_right }</code> | The position of the legend |
| <code>font_size</code> | <code>f32</code> | The font size of the legend |
| <code>background_color</code> | <code>RGB (u48)</code> | The background color of the legend |
| <code>border_color</code> | <code>RGB (u48)</code> | The border color of the legend |
| <code>border_width</code> | <code>f32</code> | The border width of the legend |
| <code>padding</code> | <code>f32</code> | The padding around the legend |
Then you can add a plot like so (here is the example with the line plot):
<code>zig
const Line = @import("plot/Line.zig");
...
figure.addPlot(Line {
.y = points,
.style = .{
.color = 0x0000FF,
}
});</code>
Supported Plots
There are currently 6 types of plots supported:
Line
The options for styling the line plot are:
| Option | Type | Description |
| --- | --- | --- |
| <code>title</code> | <code>?[]const u8</code> | The title of the plot (used for the legend) |
| <code>color</code> | <code>RGB (u48)</code> | The color of the line |
| <code>width</code> | <code>f32</code> | The width of the line |
| <code>dash</code> | <code>?f32</code> | The length of the dash for the line (null means no dash) |
| <code>smooth</code> | <code>f32</code> | The smoothing factor for the line plot. It must be in range [0; 1]. (0 means no smoothing). |
Area
The options for styling the area plot are:
| Option | Type | Description |
| --- | --- | --- |
| <code>title</code> | <code>?[]const u8</code> | The title of the plot (used for the legend) |
| <code>color</code> | <code>RGB (u48)</code> | The color of the area |
| <code>opacity</code> | <code>f32</code> | The opacity of the area |
| <code>width</code> | <code>f32</code> | The width of the line (above the area) |
Scatter
The options for styling the scatter plot are:
| Option | Type | Description |
| --- | --- | --- |
| <code>title</code> | <code>?[]const u8</code> | The title of the plot (used for the legend) |
| <code>color</code> | <code>RGB (u48)</code> | The color of the points |
| <code>radius</code> | <code>f32</code> | The radius of the points |
| <code>shape</code> | <code>...</code> | The shape of the points |
The available shapes are:
| Shape | Description |
| --- | --- |
| <code>circle</code> | A circle |
| <code>circle_outline</code> | The outline of a circle |
| <code>square</code> | A square |
| <code>square_outline</code> | The outline of a square |
| <code>triangle</code> | A triangle (facing upwards) |
| <code>triangle_outline</code> | The outline of a triangle (facing upwards) |
| <code>rhombus</code> | A rhombus |
| <code>rhombus_outline</code> | The outline of a rhombus |
| <code>plus</code> | A plus sign |
| <code>plus_outline</code> | The outline of a plus sign |
| <code>cross</code> | A cross |
| <code>cross_outline</code> | The outline of a cross |
Step
The first value of the x and y arrays are used as the starting point of the plot, this means that the step will start from this point. The options for styling the step plot are:
| Option | Type | Description |
| --- | --- | --- |
| <code>title</code> | <code>?[]const u8</code> | The title of the plot (used for the legend) |
| <code>color</code> | <code>RGB (u48)</code> | The color of the line |
| <code>width</code> | <code>f32</code> | The width of the line |
Stem
The options for styling the stem plot are:
| Option | Type | Description |
| --- | --- | --- |
| <code>title</code> | <code>?[]const u8</code> | The title of the plot (used for the legend) |
| <code>color</code> | <code>RGB (u48)</code> | The color of the stem |
| <code>width</code> | <code>f32</code> | The width of the stem |
| <code>shape</code> | <code>Shape</code> | The shape of the points (at the end of the stem) |
| <code>radius</code> | <code>f32</code> | The radius of the points (at the end of the stem) |
Candlestick
The options for styling the candlestick plot are:
| Option | Type | Description |
| --- | --- | --- |
| <code>title</code> | <code>?[]const u8</code> | The title of the plot (used for the legend) |
| <code>inc_color</code> | <code>RGB (u48)</code> | The color of the increasing candlestick |
| <code>dec_color</code> | <code>RGB (u48)</code> | The color of the decreasing candlestick |
| <code>width</code> | <code>f32</code> | The width of the candle |
| <code>gap</code> | <code>f32</code> | The gap between the candles |
| <code>line_thickness</code> | <code>f32</code> | The thickness of the sticks |
The CandleStick plot works a bit differently, it doesn't take a <code>[]f32</code> but a <code>[]Candle</code>, named <code>candles</code> (there is no value for the x-axis).
The parameters for the candle are as follows:
| Field | Type | Description |
| --- | --- | --- |
| <code>open</code> | <code>f32</code> | The opening price of the candle |
| <code>close</code> | <code>f32</code> | The closing price of the candle |
| <code>high</code> | <code>f32</code> | The highest price of the candle |
| <code>low</code> | <code>f32</code> | The lowest price of the candle |
| <code>color</code> | <code>?RGB (u48)</code> | The color of the candle (overrides the default one) |
Supported Markers
You can add a marker to the plot using the <code>addMarker</code> function.
There are currently 2 types of markers supported:
ShapeMarker
The shape marker allows you to write the plot with a shape.
The options for the shape marker are:
| Option | Type | Description |
| --- | --- | --- |
| <code>x</code> | <code>f32</code> | The x coordinate of the marker |
| <code>y</code> | <code>f32</code> | The y coordinate of the marker |
| <code>shape</code> | <code>Shape</code> | The shape of the marker |
| <code>size</code> | <code>f32</code> | The size of the marker |
| <code>color</code> | <code>RGB (u48)</code> | The color of the marker |
| <code>label</code> | <code>?[]const u8</code> | The label of the marker |
| <code>label_color</code> | <code>?RGB (u48)</code> | The color of the label (default to the same as the shape) |
| <code>label_size</code> | <code>f32</code> | The size of the label |
| <code>label_weight</code> | <code>FontWeight</code> | The weight of the label |
TextMarker
The Text marker is similar to the shape marker, but there is no shape, only text.
The options for the text marker are:
| Option | Type | Description |
| --- | --- | --- |
| <code>x</code> | <code>f32</code> | The x coordinate of the marker |
| <code>y</code> | <code>f32</code> | The y coordinate of the marker |
| <code>size</code> | <code>f32</code> | The size of the text |
| <code>color</code> | <code>RGB (u48)</code> | The color of the text |
| <code>text</code> | <code>[]const u8</code> | The text of the marker |
| <code>weight</code> | <code>FontWeight</code> | The weight of the text |
Create a new plot type
In order to create a new type of plot, all that is needed is to create a struct that contains an <code>interface</code> function, defined as follows:
<code>zig
pub fn interface(self: *const Self) Plot {
...
}</code>
The <code>Plot</code> object, contains the following fields:
- a pointer to the data (<code>*const anyopaque</code>)
- the title of the plot (<code>?[]const u8</code>) (used for the legend)
- the color of the plot (<code>RGB (u48)</code>) (used for the legend)
- a pointer to the get_range_x function <code>*const fn(*const anyopaque) Range(f32)</code>
- a pointer to the get_range_y function <code>*const fn(*const anyopaque) Range(f32)</code>
- a pointer to the draw function <code>*const fn(*const anyopaque, Allocator, *SVG, FigureInfo) anyerror!void</code>
You can look at the implementation of the <code>Line</code>, <code>Scatter</code>, <code>Area</code>, <code>Step</code>, <code>Stem</code>, or <code>CandleStick</code> plots for examples.
Create a new marker type
Same as for the plots, to create a new type of marker, all that is needed is to create a struct that contains an <code>interface</code> function, defined as follows:
<code>zig
pub fn interface(self: *const Self) Marker {
...
}</code>
The <code>Marker</code> object, contains the following fields:
- a pointer to the data (<code>*const anyopaque</code>)
- a pointer to the draw function <code>*const fn(*const anyopaque, Allocator, *SVG, FigureInfo) anyerror!void</code>
You can look at the implementation of the <code>ShapeMarker</code> or <code>TextMarker</code> for examples.
Roadmap
<ul>
<li>Ability to set the title of the axis</li>
<li>Ability to add arrows at the end of axis</li>
<li>More plot types<ul>
<li>Bar</li>
<li>Histogram</li>
</ul>
</li>
<li>Linear Interpolation with the figure border</li>
<li>Themes</li>
</ul>
Known issue(s)
<ul>
<li>Imperfect text width calculation for the legend (only when the legend is positioned on the right)</li>
</ul>
|
[] |
https://avatars.githubusercontent.com/u/3526922?v=4
|
fridge
|
cztomsik/fridge
|
2023-12-25T13:24:18Z
|
A small, batteries-included database library for Zig.
|
main
| 1 | 55 | 7 | 55 |
https://api.github.com/repos/cztomsik/fridge/tags
|
MIT
|
[
"database",
"sqlite",
"sqlite3",
"zig",
"zig-package"
] | 162 | false |
2025-05-21T02:03:02Z
| true | true |
unknown
|
github
|
[
{
"commit": null,
"name": "sqlite_source",
"tar_url": null,
"type": "remote",
"url": "https://sqlite.org/2025/sqlite-autoconf-3490100.tar.gz"
}
] |
Fridge
A small, batteries-included database library for Zig. It offers a type-safe
query builder, connection pooling, shorthands for common tasks, migrations, and
more.
Features
<br/><input type='checkbox' class='w-4 h-4 text-green-500 bg-gray-100 border-gray-300 rounded focus:ring-blue-500 dark:focus:ring-blue-600 dark:ring-offset-gray-800 focus:ring-2 dark:bg-gray-700 dark:border-gray-600' checked disabled></input> Supports both bundling SQLite3 with your app or linking system SQLite3.
<br/><input type='checkbox' class='w-4 h-4 text-green-500 bg-gray-100 border-gray-300 rounded focus:ring-blue-500 dark:focus:ring-blue-600 dark:ring-offset-gray-800 focus:ring-2 dark:bg-gray-700 dark:border-gray-600' checked disabled></input> Type-safe + raw query builder.
<br/><input type='checkbox' class='w-4 h-4 text-green-500 bg-gray-100 border-gray-300 rounded focus:ring-blue-500 dark:focus:ring-blue-600 dark:ring-offset-gray-800 focus:ring-2 dark:bg-gray-700 dark:border-gray-600' checked disabled></input> Connection pool.
<br/><input type='checkbox' class='w-4 h-4 text-green-500 bg-gray-100 border-gray-300 rounded focus:ring-blue-500 dark:focus:ring-blue-600 dark:ring-offset-gray-800 focus:ring-2 dark:bg-gray-700 dark:border-gray-600' checked disabled></input> Shortcuts for common tasks.
<br/><input type='checkbox' class='w-4 h-4 text-green-500 bg-gray-100 border-gray-300 rounded focus:ring-blue-500 dark:focus:ring-blue-600 dark:ring-offset-gray-800 focus:ring-2 dark:bg-gray-700 dark:border-gray-600' checked disabled></input> <strong>Migrations</strong> inspired by <a>David Röthlisberger</a>.
<br/><input type='checkbox' class='w-4 h-4 text-blue-600 bg-gray-100 border-gray-300 rounded focus:ring-blue-500 dark:focus:ring-blue-600 dark:ring-offset-gray-800 focus:ring-2 dark:bg-gray-700 dark:border-gray-600' disabled></input> Additional drivers (e.g., PostgreSQL).
<br/><input type='checkbox' class='w-4 h-4 text-blue-600 bg-gray-100 border-gray-300 rounded focus:ring-blue-500 dark:focus:ring-blue-600 dark:ring-offset-gray-800 focus:ring-2 dark:bg-gray-700 dark:border-gray-600' disabled></input> Documentation.
Installation
To get started, get the library first:
<code>sh
zig fetch https://github.com/cztomsik/fridge/archive/refs/heads/main.tar.gz --save</code>
Then, in your <code>build.zig</code>:
<code>zig
// Use .bundle = false if you want to link system SQLite3
const sqlite = b.dependency("fridge", .{ .bundle = true });
exe.root_module.addImport("fridge", sqlite.module("fridge"));</code>
Basic Usage
Fridge's API is highly generic and revolves around user-defined structs. Let's
start by adding a few imports and defining a simple struct for the <code>User</code> table:
```zig
const std = @import("std");
const fr = @import("fridge");
const User = struct {
id: u32,
name: []const u8,
role: []const u8,
};
```
The primary API you'll interact with is always <code>Session</code>. This high-level API
wraps the connection with an arena allocator and provides a type-safe query
builder.
Sessions can be either one-shot or pooled. Let's start with the simplest case:
<code>zig
var db = try fr.Session.open(fr.SQLite3, allocator, .{ .filename = ":memory:" });
defer db.deinit();</code>
As you can see, <code>Session.open()</code> is generic and expects a driver type,
allocator, and connection options. These connection options are driver-specific.
Currently, only SQLite3 is supported, but the API is designed to be easily
extendable to other drivers, including your own.
Now, let's do something useful with the session. For example, we can create a
table. Executing DDL statements is a bit special because it usually involves
multiple statements and doesn't return any rows. In such cases, you can access
<code>conn: Connection</code> directly and use low-level methods like <code>execAll()</code>,
<code>lastInsertRowId()</code>, etc.
<code>zig
try db.conn.execAll(
\\CREATE TABLE User (
\\ id INTEGER PRIMARY KEY,
\\ name TEXT NOT NULL,
\\ role TEXT NOT NULL
\\);
)</code>
Next, let's insert some data. Since this is a common operation, there's a
convenient shorthand:
<code>zig
try db.insert(User, .{
.name = "Alice",
.role = "admin",
});</code>
Alternatively, you could also use the query builder directly:
<code>zig
try db.query(User).insert(.{
.name = "Bob",
.role = "user",
});</code>
The difference here is subtle. For instance, you could add <code>onConflict()</code> before
calling <code>insert()</code>, or in the case of <code>update()</code>, you could add <code>where()</code>, which
is often more common.
Now, let's query the data back. The <code>query()</code> method returns a query builder
that, among other things, has a <code>findAll()</code> method.
<code>zig
for (try db.query(User).findAll()) |user| {
std.log.debug("User: {}", .{user});
}</code>
Of course, you can also use <code>where()</code> to filter the results:
<code>zig
for (try db.query(User).where("role", "admin").findAll()) |user| {
std.log.debug("Admin: {}", .{user});
}</code>
Notably, the <code>.where()</code> method is type-safe and will only accept types compatible with the column type.
Type-safe Query Builder
The type-safe query builder provides methods that are aware of your struct's fields:
```zig
// Find all users with role "admin", ordered by name
const admins = try db.query(User)
.where("role", "admin")
.orderBy(.name, .asc)
.findAll();
// Count users by role
const n_admins = try db.query(User)
.where("role", "admin")
.count("id");
// Find users with optional filters
const users = try db.query(User)
.maybeWhere("role", filter.role) // only applies if filter.role is not null
.ifWhere(cond, "age", filter.age) // only applies if cond is true
.findAll();
```
Raw Query Builder
For more complex queries:
```zig
const users = try db.raw("SELECT * FROM User")
.where("role = ?", "admin")
.fetchAll(User);
const users = try db.query(User)
.raw // switch to unsafe
.where("role = ? or role = ?", .{ "admin", "editor" }) // pass multiple args
.fetchAll(User);
```
Pooling
If you're building a web application, you might want to use a connection pool. Pooling improves performance and ensures that each user request gets its own session with separate transaction chains.
Here's how to use the <code>fr.Pool</code>:
```zig
// During your app initialization
var pool = try fr.Pool(fr.SQLite3).init(allocator, .{ .max_count = 5 }, .{ .filename = ":memory:" });
defer pool.deinit();
// Inside your request handler
var db = try pool.getSession(allocator); // per-request allocator
defer db.deinit(); // cleans up and returns the connection to the pool
// Now you can use the session as usual
_ = try db.query(User).findAll();
```
Migrations
<blockquote>
<strong>TODO: Currently, migrations only work with SQLite.</strong>
</blockquote>
Fridge includes a simple migration script that can be used with any DDL SQL
file. It expects a <code>CREATE XXX</code> statement for every table, view, trigger, etc.,
and will automatically create or drop the respective objects. The only
requirement is that all names must be quoted.
<code>sql
CREATE TABLE "User" (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL
);</code>
For tables, the script will try to reuse as much data as possible. It will first
create a new table with a temporary name, copy all data from the old table using
<code>INSERT INTO xxx ... FROM temp</code>, and finally drop the old table and rename the
new one.
This approach allows you to freely add or remove columns, though you can't
change their types or remove default values. While it's not a fully-fledged
migration system, it works surprisingly well for most cases.
<code>zig
try fr.migrate(allocator, "my.db", @embedFile("db_schema.sql"));</code>
License
MIT
|
[] |
https://avatars.githubusercontent.com/u/24392180?v=4
|
zig-http-benchmarks
|
orhun/zig-http-benchmarks
|
2023-07-11T10:30:13Z
|
Benchmarking Zig HTTP client against Rust, Go, Python, C++ and curl
|
master
| 3 | 54 | 3 | 54 |
https://api.github.com/repos/orhun/zig-http-benchmarks/tags
|
MIT
|
[
"benchmarking",
"curl",
"http",
"http-benchmarking",
"http-client",
"http-requests",
"http-server",
"python",
"rust",
"zig",
"zig-http",
"ziglang"
] | 642 | false |
2025-05-12T22:13:15Z
| false | false |
unknown
|
github
|
[] |
<code>zig-http-benchmarks</code> ⚡
Read the blog post: <a><strong>Zig Bits 0x4</strong></a>
This repository contains a HTTP server/client implementation using Zig's standard library and benchmarks for comparing the client's performance with implementations in other programming languages such as Rust and Go.
Prerequisites
<ul>
<li>Zig (<code>>=0.11</code>), Rust/Cargo, Go, Python</li>
<li><a>Hyperfine</a> (for benchmarking)</li>
</ul>
Benchmarking
To run the benchmarks:
<code>sh
chmod +x bench.sh
./bench.sh</code>
The result will be saved to <code>benchmarks.md</code> and <code>benchmarks.json</code>.
<code>rust-hyper ran
1.01 ± 0.02 times faster than rust-ureq
1.01 ± 0.02 times faster than rust-reqwest
1.24 ± 0.06 times faster than go-http-client
1.46 ± 0.05 times faster than rust-attohttpc
2.03 ± 0.05 times faster than zig-http-client
4.26 ± 0.12 times faster than curl
8.57 ± 0.12 times faster than python-http-client
19.93 ± 0.25 times faster than cpp-asio-httpclient</code>
| Command | Mean [ms] | Min [ms] | Max [ms] | Relative |
| :-------------------- | -----------: | -------: | -------: | -----------: |
| <code>curl</code> | 457.9 ± 11.2 | 442.4 | 522.2 | 4.26 ± 0.12 |
| <code>zig-http-client</code> | 218.5 ± 4.8 | 210.3 | 240.3 | 2.03 ± 0.05 |
| <code>rust-attohttpc</code> | 157.2 ± 5.3 | 151.8 | 190.4 | 1.46 ± 0.05 |
| <code>rust-hyper</code> | 107.6 ± 1.3 | 104.4 | 114.8 | 1.00 |
| <code>rust-reqwest</code> | 108.7 ± 2.2 | 105.4 | 123.7 | 1.01 ± 0.02 |
| <code>rust-ureq</code> | 108.4 ± 2.3 | 105.7 | 123.1 | 1.01 ± 0.02 |
| <code>go-http-client</code> | 133.1 ± 6.2 | 127.6 | 159.2 | 1.24 ± 0.06 |
| <code>python-http-client</code> | 921.9 ± 5.9 | 911.4 | 947.1 | 8.57 ± 0.12 |
| <code>cpp-asio-httpclient</code> | 2144.5 ± 4.5 | 2133.0 | 2168.2 | 19.93 ± 0.25 |
Plotting
Use the <a>JSON data</a> along with the <a>scripts</a> from the <code>hyperfine</code> examples to plot data using <a><code>matplotlib</code></a>. For example:
<code>sh
git clone --depth 1 https://github.com/sharkdp/hyperfine
python hyperfine/scripts/plot_whisker.py benchmarks.json</code>
Environment
The results are coming from a GitHub runner (<code>ubuntu-latest</code>) and automated with <a>this workflow</a>.
To see the output for the latest run, check out the <a><code>output</code></a> branch in this repository.
License
Licensed under <a>The MIT License</a>.
|
[] |
https://avatars.githubusercontent.com/u/22280250?v=4
|
raylib-zig-examples
|
Durobot/raylib-zig-examples
|
2023-05-17T13:16:46Z
|
Raylib examples ported to Zig
|
main
| 0 | 54 | 2 | 54 |
https://api.github.com/repos/Durobot/raylib-zig-examples/tags
|
-
|
[
"raylib",
"raylib-zig",
"zig",
"ziglang"
] | 1,708 | false |
2025-03-28T16:21:00Z
| false | false |
unknown
|
github
|
[] |
Raylib Zig Examples
These are some of <a>raylib</a> (<a>raylib on github</a>) <a>examples</a> ported to <a>Zig</a>.
<a>See the screenshot gallery</a>!
Please note these are <strong>raylib 4.5</strong> examples, they have been updated to compile with either raylib <strong>4.5</strong>, raylib <strong>5.0</strong> or raylib <strong>5.5</strong>, but the content of example programs has not been updated to match raylib 5.0 or 5.5 examples.
The examples don't use any bindings or some other intermediate layer between Zig code and raylib. Instead, Zig's built-in translate-C feature takes care of everything (well, almost, see below).
For whatever reason, example <a>27</a> (custom frame control) does not work properly on Windows, and runs with certain jerkiness on Linux. My knowledge of raylib is not enough to figure out why.
I have done some minor modifications to the code, like changing <em>camelCase</em> variable names to <em>snake_case</em>, to fit Zig naming conventions.
Some of the examples are presented in multiple versions (<a>14a</a> and <a>14b</a>; <a>54a</a> and <a>54b</a>; <a>87a</a> and <a>87b</a>), see the comments in the Zig code.
To make things easier, some of the examples come with resource files, necessary to run them. Their authors are credited below:
| resource | examples | author | licence | notes |
| ------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ----------------------------------------------------------- | ------------------------------------------------------------ |
| raylib_logo.png | <a>46</a>, <a>50</a>, <a>53</a> | <a>@raysan5</a> (?) | ? | |
| fudesumi.raw | <a>54a</a>, <a>54b</a> | <a>Eiden Marsal</a> | <a>CC-BY-NC</a> | |
| road.png | <a>68</a> | ? | ? | |
| fonts/alagard.png | <a>69</a> | Hewett Tsoi | <a>Freeware</a> | Atlas created by <a>@raysan5</a> |
| fonts/alpha_beta.png | <a>69</a> | <a>Brian Kent (AEnigma)</a> | <a>Freeware</a> | Atlas created by <a>@raysan5</a> |
| fonts/jupiter_crash.png | <a>69</a> | <a>Brian Kent (AEnigma)</a> | <a>Freeware</a> | Atlas created by <a>@raysan5</a> |
| fonts/mecha.png | <a>69</a> | Captain Falcon | <a>Freeware</a> | Atlas created by <a>@raysan5</a> |
| fonts/pixantiqua.ttf | <a>69</a> | Gerhard Großmann | <a>Freeware</a> | Atlas created by <a>@raysan5</a> |
| fonts/pixelplay.png | <a>69</a> | Aleksander Shevchuk | <a>Freeware</a> | Atlas created by <a>@raysan5</a> |
| fonts/romulus.png | <a>69</a> | Hewett Tsoi | <a>Freeware</a> | Atlas created by <a>@raysan5</a> |
| fonts/setback.png | <a>69</a> | <a>Brian Kent (AEnigma)</a> | <a>Freeware</a> | Atlas created by <a>@raysan5</a> |
| custom_alagard.png | <a>70</a> | <a>Brian Kent (AEnigma)</a> | <a>Freeware</a> | Atlas created by <a>@raysan5</a> |
| custom_jupiter_crash.png | <a>70</a> | <a>Brian Kent (AEnigma)</a> | <a>Freeware</a> | Atlas created by <a>@raysan5</a> |
| custom_mecha.png | <a>70</a> | <a>Brian Kent (AEnigma)</a> | <a>Freeware</a> | Atlas created by <a>@raysan5</a> |
| KAISG.ttf | <a>71</a> | <a>Dieter Steffmann</a> | <a>Freeware</a> | <a>Kaiserzeit Gotisch</a> font |
| pixantiqua.fnt, pixantiqua.png | <a>72</a> | Gerhard Großmann | <a>Freeware</a> | Atlas made with <a>BMFont</a> by <a>@raysan5</a> |
| pixantiqua.ttf | <a>72</a> | Gerhard Großmann | <a>Freeware</a> | |
| cubicmap.png | <a>84</a>, <a>85</a> | <a>@raysan5</a> | <a>CC0</a> | |
| cubicmap_atlas.png | <a>84</a>, <a>85</a> | <a>@emegeme</a> | <a>CC0</a> | |
Building the examples
<strong>Note</strong>: some examples require additional header files. I recommend downloading them to the corresponding example's folder, as described in the comments in Zig code.
Examples <a>39</a>, <a>40</a>, <a>41</a> need <code>reasings.h</code> from https://github.com/raysan5/raylib/blob/master/examples/others/reasings.h; examples <a>42</a>, <a>43</a>, <a>44</a> need <code>raygui.h</code> from https://github.com/raysan5/raygui/blob/master/src/raygui.h.
In other words, the following additional header files are necessary for their respective examples to build:
<code>zig-raylib-39-shapes-easings-ball_anim/reasings.h
zig-raylib-40-shapes-easings-box_anim/reasings.h
zig-raylib-41-shapes-easings-rectangle_array/reasings.h
zig-raylib-42-shapes-draw-ring/raygui.h
zig-raylib-43-shapes-draw-circle_sector/raygui.h
zig-raylib-44-shapes-draw-rectangle_rounded/raygui.h</code>
<strong>On Linux</strong>:
<ol>
<li>Install Zig - download from https://ziglang.org/download/.</li>
</ol>
Versions that work are <strong>0.12.0</strong>, <strong>0.12.1</strong>, <strong>0.13.0</strong> (current stable release), and <strong>0.14.0</strong> (nightly development build). <strong>0.11.0</strong> probably still works too (<em>come on, really? 0.11?</em>), but this may change in the future.
Latest version of Zig <strong>0.14.0</strong> I have tested the project with was <strong>0.14.0-dev.3237+ddff1fa4c</strong>. Later versions may or may not work, you're welcome to try them and raise an issue on github if they don't.
Unpack your version of Zig and add its folder to environment variable PATH. In many Linux distributions this is done by adding the following line to the end of <code>.bashrc</code> file in your home folder (replace /path/to/zig with the <code>actual</code> path, of course):
<code>export PATH="$PATH:/path/to/zig"</code>
Alternatively, you can install Zig from your distribution's repositories, if they contain Zig 0.12 and up.
<ol>
<li>
Install raylib. Versions 4.5 and 5.0 do work. Earlier or later version may work too. Use one of the following methods:
</li>
<li>
Install it from your distribution's repositories. For example on Arch you can do it with <code>pacman -S raylib</code> command.
You then should be able to build examples by running <code>zig build-exe main.zig -lc -lraylib</code> in each example's folder. To build using <code>build_example.sh</code>, (optionally) edit this file, setting <code>RAYLIB_PATH</code>, <code>RAYLIB_INCLUDE_PATH</code>, <code>RAYLIB_EXTERNAL_INCLUDE_PATH</code> and <code>RAYLIB_LIB_PATH</code> variables to '' (empty string). To build using <code>build.sh</code> found in each folder, (optionally) edit build.sh, setting <code>tmp_raylib_path</code>, <code>tmp_raylib_include_path</code>, <code>tmp_raylib_external_include_path</code> and <code>tmp_raylib_lib_path</code> variables to '' (empty string) at lines 12 - 15.
Alternatively, you can
</li>
<li>
Build raylib from source code. Download raylib <a>from github</a>. Click "tar.gz" under the release you want to download, or click "Downloads", then scroll down and click "Source code (tar.gz)". Unpack the downloaded archive.
Now, in order to make raylib and/or raylib-zig-examples compile without errors, do one of the following, depending on your version of raylib:
<ol>
<li>
<strong>If</strong> you're using raylib <strong>5.0</strong>, open <code>src\build.zig</code>, find lines containing <code>lib.installHeader</code> (they should be in <code>pub fn build</code>), and add the following line after them:
<code>zig
lib.installHeader("src/rcamera.h", "rcamera.h");</code>
Otherwise example 13 won't compile.
</li>
<li>
<strong>If</strong> you're using raylib <strong>4.5</strong>, do one of the following:
a. <strong>If</strong> <code>build.zig</code> in raylib root folder <strong>contains</strong> the following lines:
<code>zig
const lib = raylib.addRaylib(b, target, optimize);
lib.installHeader("src/raylib.h", "raylib.h");
lib.install();</code>
then edit this file - remove or comment out this line: <code>lib.install();</code>
Add these lines below it, before the closing <code>}</code>:
<code>zig
lib.installHeader("src/rlgl.h", "rlgl.h");
lib.installHeader("src/raymath.h", "raymath.h");
lib.installHeader("src/rcamera.h", "rcamera.h");
b.installArtifact(lib);</code>
b. <strong>If</strong>, on the other hand, <code>build.zig</code> in raylib's root folder <strong>does not</strong> contain <code>lib.install();</code> (see <a>this commit</a>), then in <code>src/build.zig</code>, in function <code>pub fn build(b: *std.Build) void</code>, after <code>lib.installHeader("src/raylib.h", "raylib.h");</code>, add these lines:
<code>zig
lib.installHeader("src/rlgl.h", "rlgl.h");
lib.installHeader("src/raymath.h", "raymath.h");
lib.installHeader("src/rcamera.h", "rcamera.h");</code>
</li>
</ol>
In raylib root folder, run <code>zig build -Doptimize=ReleaseSmall</code> or <code>zig build -Doptimize=ReleaseFast</code>. You could also use <code>-Doptimize=ReleaseSafe</code>, <code>-Doptimize=Debug</code> or simply run <code>zig build</code>.
This should create <code>zig-out</code> folder, with two folders inside: <code>include</code> and <code>lib</code>, these contain raylib header files and static library, respectively.
In <code>raylib-zig-examples</code>, in <code>build_example.sh</code>set <code>RAYLIB_PATH</code> variable to the correct raylib path and make sure the values of <code>RAYLIB_INCLUDE_PATH</code>, <code>RAYLIB_EXTERNAL_INCLUDE_PATH</code> and <code>RAYLIB_LIB_PATH</code> make sense.
</li>
<li>
Build the examples. You can use <code>build_example.sh</code> to either build individual examples by providing the example number, e.g. <code>./build_example.sh 03</code>, or build them all: <code>./build_example.sh all</code>.
</li>
</ol>
You can also run <code>build.sh</code> contained in each example's folder. raylib paths and Zig build mode set within each build.sh are used in this case.
<code>clean_all.sh</code> and <code>clean.sh</code> in examples' folders can be used to delete binaries generated by the compiler.
<strong>On Windows</strong>:
<ol>
<li>Install Zig - download from https://ziglang.org/download/.</li>
</ol>
Versions that work are <strong>0.12.0</strong>, <strong>0.12.1</strong>, <strong>0.13.0</strong> (current stable release), and <strong>0.14.0</strong> (nightly development build). <strong>0.11.0</strong> probably still works too (<em>come on, really? 0.11?</em>), but this may change in the future.
Latest version of Zig <strong>0.14.0</strong> I have tested the project with was <strong>0.14.0-dev.3237+ddff1fa4c</strong>. Later versions may or may not work, you're welcome to try them and raise an issue on github if they don't.
Unpack your version of Zig and add its folder to environment variable PATH.
<ol>
<li>Install raylib. These examples were built using raylib 4.5.0, but an earlier or later version may work too. </li>
</ol>
Build raylib from source code. Download raylib <a>from github</a>. Click "zip" under the release you want to download, or click "Downloads", then scroll down and click "Source code (zip)".
Unpack the downloaded archive. Now, in order to make raylib and/or raylib-zig-examples compile without errors, do one of the following, depending on your version of raylib:
<ol>
<li>
<strong>If</strong> you're using raylib <strong>5.0</strong>, open <code>src\build.zig</code>, find lines containing <code>lib.installHeader</code> (they should be in <code>pub fn build</code>), and add the following line after them:
<code>zig
lib.installHeader("src/rcamera.h", "rcamera.h");</code>
Otherwise example 13 won't compile.
</li>
<li>
<strong>If</strong> you're using raylib <strong>4.5</strong>, do one of the following:
a. <strong>If</strong> <code>build.zig</code> in raylib root folder <strong>contains</strong> the following lines:
<code>zig
const lib = raylib.addRaylib(b, target, optimize);
lib.installHeader("src/raylib.h", "raylib.h");
lib.install();</code>
then edit this file - remove or comment out this line: <code>lib.install();</code>
Add these lines below it, before the closing <code>}</code>:
<code>zig
lib.installHeader("src/rlgl.h", "rlgl.h");
lib.installHeader("src/raymath.h", "raymath.h");
lib.installHeader("src/rcamera.h", "rcamera.h");
b.installArtifact(lib);</code>
b. <strong>If</strong>, on the other hand, <code>build.zig</code> in raylib's root folder <strong>does not</strong> contain <code>lib.install();</code> (see <a>this commit</a>), then in <code>src/build.zig</code>, in function <code>pub fn build(b: *std.Build) void</code>, after <code>lib.installHeader("src/raylib.h", "raylib.h");</code>, add these lines:
<code>zig
lib.installHeader("src/rlgl.h", "rlgl.h");
lib.installHeader("src/raymath.h", "raymath.h");
lib.installHeader("src/rcamera.h", "rcamera.h");</code>
</li>
</ol>
In raylib root folder, run <code>zig build -Doptimize=ReleaseSmall</code> or <code>zig build -Doptimize=ReleaseFast</code>.
<code> **Warning**: leaving out `-Doptimize` parameter, using `-Doptimize=Debug` or `-Doptimize=ReleaseSafe` currently causes compilation of raylib-zig-examples to fail in ReleaseSmall and ReleaseFast modes down the road. You will see errors similar to these:
</code>
<code>error: lld-link: undefined symbol: __stack_chk_fail
error: lld-link: undefined symbol: __stack_chk_guard</code>
Running zig build... should create <code>zig-out</code> folder, with two folders inside: <code>include</code> and <code>lib</code>, these contain raylib header files and static library, respectively.
In <code>raylib-zig-examples</code>, in <code>build_example.bat</code>set <code>RAYLIB_PATH</code> variable to the correct raylib path and make sure the values of <code>RAYLIB_INCLUDE_PATH</code>, <code>RAYLIB_EXTERNAL_INCLUDE_PATH</code> and <code>RAYLIB_LIB_PATH</code> make sense.
<ol>
<li>Build the examples. You can use <code>build_example.bat</code> to either build individual examples by providing the example number, e.g. <code>build_example.bat 03</code>, or build them all: <code>build_example.bat all</code>.</li>
</ol>
You can also run <code>build.bat</code> contained in each example's folder. raylib paths and Zig build mode set within each build.bat are used in this case.
<code>clean_all.bat</code> and <code>clean.bat</code> in examples' folders can be used to delete binaries generated by the compiler.
|
[] |
https://avatars.githubusercontent.com/u/2326560?v=4
|
creek
|
nmeum/creek
|
2024-01-17T19:31:28Z
|
A malleable and minimalist status bar for the River compositor
|
main
| 4 | 53 | 3 | 53 |
https://api.github.com/repos/nmeum/creek/tags
|
MIT
|
[
"river",
"riverwm",
"statusbar",
"wayland",
"zig"
] | 254 | false |
2025-05-21T18:50:35Z
| true | true |
unknown
|
github
|
[
{
"commit": "v0.3.0.tar.gz",
"name": "pixman",
"tar_url": "https://codeberg.org/ifreund/zig-pixman/archive/v0.3.0.tar.gz.tar.gz",
"type": "remote",
"url": "https://codeberg.org/ifreund/zig-pixman"
},
{
"commit": "v0.3.0.tar.gz",
"name": "wayland",
"tar_url": "https://codeberg.org/ifreund/zig-wayland/archive/v0.3.0.tar.gz.tar.gz",
"type": "remote",
"url": "https://codeberg.org/ifreund/zig-wayland"
},
{
"commit": null,
"name": "fcft",
"tar_url": null,
"type": "remote",
"url": "https://git.sr.ht/~novakane/zig-fcft/archive/v2.0.0.tar.gz"
}
] |
README
Creek is a <a>dwm</a>-inspired <a>malleable</a> and minimalist status bar for the <a>River</a> Wayland compositor.
The implementation is a hard fork of version 0.1.3 of the <a>levee</a> status bar.
Compared to levee, the main objective is to ease <a>recombination and reuse</a> by providing a simpler interface for adding custom information to the status bar.
The original version of levee only provides builtin support for certain <a>modules</a>, these have to be written in Zig and compiled into levee.
This fork pursues an alternative direction by allowing arbitrary text to be written to standard input of the status bar process, this text is then displayed in the status bar.
Additionally, the following new features have been added:
<ul>
<li>Support for tracking the current window title in the status bar</li>
<li>Highlighting of tags containing urgent windows (see <a>xdg-activation</a>)</li>
<li>Basic run-time configuration support via command-line flags</li>
</ul>
Screenshot
The screenshot features three active tags: tag 2 is currently focused and has one active window, tag 4 is not focused but is occupied (i.e. has windows), and tag 9 has an urgent window.
In the middle of the status bar, the current title of the selected window on the focused tag is displayed.
On the right-hand side, the current time is shown, this is information is generated using <code>date(1)</code> (see usage example below).
Build
The following dependencies need to be installed:
<ul>
<li><a>zig</a> 0.13.0</li>
<li><a>wayland</a> 1.21.0</li>
<li><a>pixman</a> 0.42.0</li>
<li><a>fcft</a> 3.1.5 (with <a>utf8proc</a> support)</li>
</ul>
Afterwards, creek can be build as follows
<code>$ git clone https://git.8pit.net/creek.git
$ cd creek
$ zig build
</code>
Configuration
This version of creek can be configured using several command-line options:
<ul>
<li><code>-fn</code>: The font used in the status bar</li>
<li><code>-hg</code>: The total height of the status bar</li>
<li><code>-nf</code>: Normal foreground color</li>
<li><code>-nb</code>: Normal background color</li>
<li><code>-ff</code>: Foreground color for focused tags</li>
<li><code>-fb</code>: Background color for focused tags</li>
</ul>
Example:
<code>$ creek -fn Terminus:size=12 -hg 18 -nf 0xffffff -nb 0x000000
</code>
Usage Example
In order to display the current time in the top-right corner, invoke creek as follows:
<code>$ ( while date; do sleep 1; done ) | creek
</code>
Note that for more complex setups, a shell script may <a>not be the best option</a>.
|
[] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.