
title
stringlengths 2
169
| diff
stringlengths 235
19.5k
| body
stringlengths 0
30.5k
| url
stringlengths 48
84
| created_at
stringlengths 20
20
| closed_at
stringlengths 20
20
| merged_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| diff_len
float64 101
3.99k
| repo_name
stringclasses 83
values | __index_level_0__
int64 15
52.7k
|
|---|---|---|---|---|---|---|---|---|---|---|
Add TryHackMe
|
diff --git a/sherlock/resources/data.json b/sherlock/resources/data.json
index fea689746..aa7591193 100644
--- a/sherlock/resources/data.json
+++ b/sherlock/resources/data.json
@@ -1652,6 +1652,13 @@
"username_claimed": "blue",
"username_unclaimed": "noonewouldeverusethis7"
},
+ "TryHackMe": {
+ "errorType": "status_code",
+ "url": "https://tryhackme.com/p/{}",
+ "urlMain": "https://tryhackme.com/",
+ "username_claimed": "ashu",
+ "username_unclaimed": "noonewouldeverusethis7"
+ },
"Twitch": {
"errorType": "status_code",
"url": "https://www.twitch.tv/{}",
|
Add new site:
- https://tryhackme.com
|
https://api.github.com/repos/sherlock-project/sherlock/pulls/732
|
2020-08-20T02:08:22Z
|
2020-08-20T04:18:33Z
|
2020-08-20T04:18:33Z
|
2020-08-20T18:07:54Z
| 199
|
sherlock-project/sherlock
| 36,216
|
[ie/crunchyroll] Extract `vo_adaptive_hls` formats by default
|
diff --git a/yt_dlp/extractor/crunchyroll.py b/yt_dlp/extractor/crunchyroll.py
index 8d997debf9b..d35e9995abc 100644
--- a/yt_dlp/extractor/crunchyroll.py
+++ b/yt_dlp/extractor/crunchyroll.py
@@ -136,7 +136,7 @@ def _call_api(self, path, internal_id, lang, note='api', query={}):
return result
def _extract_formats(self, stream_response, display_id=None):
- requested_formats = self._configuration_arg('format') or ['adaptive_hls']
+ requested_formats = self._configuration_arg('format') or ['vo_adaptive_hls']
available_formats = {}
for stream_type, streams in traverse_obj(
stream_response, (('streams', ('data', 0)), {dict.items}, ...)):
|
Closes #9439
<details open><summary>Template</summary> <!-- OPEN is intentional -->
### Before submitting a *pull request* make sure you have:
- [x] At least skimmed through [contributing guidelines](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#developer-instructions) including [yt-dlp coding conventions](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#yt-dlp-coding-conventions)
- [x] [Searched](https://github.com/yt-dlp/yt-dlp/search?q=is%3Apr&type=Issues) the bugtracker for similar pull requests
- [x] Checked the code with [flake8](https://pypi.python.org/pypi/flake8) and [ran relevant tests](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#developer-instructions)
### In order to be accepted and merged into yt-dlp each piece of code must be in public domain or released under [Unlicense](http://unlicense.org/). Check all of the following options that apply:
- [x] I am the original author of this code and I am willing to release it under [Unlicense](http://unlicense.org/)
### What is the purpose of your *pull request*?
- [x] Fix or improvement to an extractor (Make sure to add/update tests)
</details>
|
https://api.github.com/repos/yt-dlp/yt-dlp/pulls/9447
|
2024-03-14T16:37:06Z
|
2024-03-14T21:42:36Z
|
2024-03-14T21:42:35Z
|
2024-03-14T21:42:36Z
| 205
|
yt-dlp/yt-dlp
| 8,124
|
ui: accept 'q' as quit character
|
diff --git a/tests/test_ui.py b/tests/test_ui.py
index 5ac78cbc4..90efbac25 100644
--- a/tests/test_ui.py
+++ b/tests/test_ui.py
@@ -25,15 +25,16 @@ def test_read_actions(patch_get_key):
# Ignored:
'x', 'y',
# Up:
- const.KEY_UP,
+ const.KEY_UP, 'k',
# Down:
- const.KEY_DOWN,
+ const.KEY_DOWN, 'j',
# Ctrl+C:
- const.KEY_CTRL_C])
- assert list(islice(ui.read_actions(), 5)) \
+ const.KEY_CTRL_C, 'q'])
+ assert list(islice(ui.read_actions(), 8)) \
== [const.ACTION_SELECT, const.ACTION_SELECT,
- const.ACTION_PREVIOUS, const.ACTION_NEXT,
- const.ACTION_ABORT]
+ const.ACTION_PREVIOUS, const.ACTION_PREVIOUS,
+ const.ACTION_NEXT, const.ACTION_NEXT,
+ const.ACTION_ABORT, const.ACTION_ABORT]
def test_command_selector():
diff --git a/thefuck/ui.py b/thefuck/ui.py
index 417058da8..2a2f84ba7 100644
--- a/thefuck/ui.py
+++ b/thefuck/ui.py
@@ -16,7 +16,7 @@ def read_actions():
yield const.ACTION_PREVIOUS
elif key in (const.KEY_DOWN, 'j'):
yield const.ACTION_NEXT
- elif key == const.KEY_CTRL_C:
+ elif key in (const.KEY_CTRL_C, 'q'):
yield const.ACTION_ABORT
elif key in ('\n', '\r'):
yield const.ACTION_SELECT
|
'q' is a standard character used in traditional UNIX environment used for 'quit', so it makes sense to support it, in my opinion
Added tests and ammended the previous commit, added missing tests for 'j' and 'k'
|
https://api.github.com/repos/nvbn/thefuck/pulls/521
|
2016-06-25T10:12:13Z
|
2016-06-27T20:14:16Z
|
2016-06-27T20:14:16Z
|
2016-06-27T20:14:20Z
| 364
|
nvbn/thefuck
| 30,565
|
[`Pix2Struct`] Fix pix2struct cross attention
|
diff --git a/src/transformers/models/pix2struct/modeling_pix2struct.py b/src/transformers/models/pix2struct/modeling_pix2struct.py
index b9cfff26a26ac..015007a9679b9 100644
--- a/src/transformers/models/pix2struct/modeling_pix2struct.py
+++ b/src/transformers/models/pix2struct/modeling_pix2struct.py
@@ -1547,8 +1547,9 @@ def custom_forward(*inputs):
present_key_value_states = present_key_value_states + (present_key_value_state,)
if output_attentions:
- all_attentions = all_attentions + (layer_outputs[2],)
- all_cross_attentions = all_cross_attentions + (layer_outputs[3],)
+ all_attentions = all_attentions + (layer_outputs[3],)
+ if encoder_hidden_states is not None:
+ all_cross_attentions = all_cross_attentions + (layer_outputs[5],)
hidden_states = self.final_layer_norm(hidden_states)
hidden_states = self.dropout(hidden_states)
|
# What does this PR do?
Fixes https://github.com/huggingface/transformers/issues/25175
As pointed out by @leitro on the issue, I can confirm the cross-attention should be in `layer_outputs[5]`. Also fixes the attention output index that should be in index `3` as the index `2` is the `position_bias` (they have the same shape so we didn't noticed the silent bug on the CI tests.)
to repro:
```python
import requests
import torch
from PIL import Image
from transformers import Pix2StructForConditionalGeneration, Pix2StructProcessor
url = "https://www.ilankelman.org/stopsigns/australia.jpg"
image = Image.open(requests.get(url, stream=True).raw)
model = Pix2StructForConditionalGeneration.from_pretrained("google/pix2struct-textcaps-base")
processor = Pix2StructProcessor.from_pretrained("google/pix2struct-textcaps-base")
input_ids = torch.LongTensor([[0, 2, 3, 4]])
# image only
inputs = processor(images=image, return_tensors="pt")
outputs = model.forward(**inputs, decoder_input_ids=input_ids, output_attentions=True)
print(outputs.cross_attentions[0].shape)
>>> should be torch.Size([1, 12, 4, 2048])
```
cc @amyeroberts
|
https://api.github.com/repos/huggingface/transformers/pulls/25200
|
2023-07-31T08:48:55Z
|
2023-08-01T08:56:37Z
|
2023-08-01T08:56:37Z
|
2023-08-01T08:57:08Z
| 239
|
huggingface/transformers
| 12,690
|
[youtube_live_chat] use clickTrackingParams
|
diff --git a/yt_dlp/downloader/youtube_live_chat.py b/yt_dlp/downloader/youtube_live_chat.py
index 5303efd0d42..35e88e36706 100644
--- a/yt_dlp/downloader/youtube_live_chat.py
+++ b/yt_dlp/downloader/youtube_live_chat.py
@@ -44,7 +44,7 @@ def dl_fragment(url, data=None, headers=None):
return self._download_fragment(ctx, url, info_dict, http_headers, data)
def parse_actions_replay(live_chat_continuation):
- offset = continuation_id = None
+ offset = continuation_id = click_tracking_params = None
processed_fragment = bytearray()
for action in live_chat_continuation.get('actions', []):
if 'replayChatItemAction' in action:
@@ -53,28 +53,34 @@ def parse_actions_replay(live_chat_continuation):
processed_fragment.extend(
json.dumps(action, ensure_ascii=False).encode('utf-8') + b'\n')
if offset is not None:
- continuation_id = try_get(
+ continuation = try_get(
live_chat_continuation,
- lambda x: x['continuations'][0]['liveChatReplayContinuationData']['continuation'])
+ lambda x: x['continuations'][0]['liveChatReplayContinuationData'], dict)
+ if continuation:
+ continuation_id = continuation.get('continuation')
+ click_tracking_params = continuation.get('clickTrackingParams')
self._append_fragment(ctx, processed_fragment)
- return continuation_id, offset
+ return continuation_id, offset, click_tracking_params
def try_refresh_replay_beginning(live_chat_continuation):
# choose the second option that contains the unfiltered live chat replay
- refresh_continuation_id = try_get(
+ refresh_continuation = try_get(
live_chat_continuation,
- lambda x: x['header']['liveChatHeaderRenderer']['viewSelector']['sortFilterSubMenuRenderer']['subMenuItems'][1]['continuation']['reloadContinuationData']['continuation'], str)
- if refresh_continuation_id:
+ lambda x: x['header']['liveChatHeaderRenderer']['viewSelector']['sortFilterSubMenuRenderer']['subMenuItems'][1]['continuation']['reloadContinuationData'], dict)
+ if refresh_continuation:
# no data yet but required to call _append_fragment
self._append_fragment(ctx, b'')
- return refresh_continuation_id, 0
+ refresh_continuation_id = refresh_continuation.get('continuation')
+ offset = 0
+ click_tracking_params = refresh_continuation.get('trackingParams')
+ return refresh_continuation_id, offset, click_tracking_params
return parse_actions_replay(live_chat_continuation)
live_offset = 0
def parse_actions_live(live_chat_continuation):
nonlocal live_offset
- continuation_id = None
+ continuation_id = click_tracking_params = None
processed_fragment = bytearray()
for action in live_chat_continuation.get('actions', []):
timestamp = self.parse_live_timestamp(action)
@@ -95,11 +101,12 @@ def parse_actions_live(live_chat_continuation):
continuation_data = try_get(live_chat_continuation, continuation_data_getters, dict)
if continuation_data:
continuation_id = continuation_data.get('continuation')
+ click_tracking_params = continuation_data.get('clickTrackingParams')
timeout_ms = int_or_none(continuation_data.get('timeoutMs'))
if timeout_ms is not None:
time.sleep(timeout_ms / 1000)
self._append_fragment(ctx, processed_fragment)
- return continuation_id, live_offset
+ return continuation_id, live_offset, click_tracking_params
def download_and_parse_fragment(url, frag_index, request_data=None, headers=None):
count = 0
@@ -107,7 +114,7 @@ def download_and_parse_fragment(url, frag_index, request_data=None, headers=None
try:
success, raw_fragment = dl_fragment(url, request_data, headers)
if not success:
- return False, None, None
+ return False, None, None, None
try:
data = ie._extract_yt_initial_data(video_id, raw_fragment.decode('utf-8', 'replace'))
except RegexNotFoundError:
@@ -119,19 +126,19 @@ def download_and_parse_fragment(url, frag_index, request_data=None, headers=None
lambda x: x['continuationContents']['liveChatContinuation'], dict) or {}
if info_dict['protocol'] == 'youtube_live_chat_replay':
if frag_index == 1:
- continuation_id, offset = try_refresh_replay_beginning(live_chat_continuation)
+ continuation_id, offset, click_tracking_params = try_refresh_replay_beginning(live_chat_continuation)
else:
- continuation_id, offset = parse_actions_replay(live_chat_continuation)
+ continuation_id, offset, click_tracking_params = parse_actions_replay(live_chat_continuation)
elif info_dict['protocol'] == 'youtube_live_chat':
- continuation_id, offset = parse_actions_live(live_chat_continuation)
- return True, continuation_id, offset
+ continuation_id, offset, click_tracking_params = parse_actions_live(live_chat_continuation)
+ return True, continuation_id, offset, click_tracking_params
except compat_urllib_error.HTTPError as err:
count += 1
if count <= fragment_retries:
self.report_retry_fragment(err, frag_index, count, fragment_retries)
if count > fragment_retries:
self.report_error('giving up after %s fragment retries' % fragment_retries)
- return False, None, None
+ return False, None, None, None
self._prepare_and_start_frag_download(ctx)
@@ -165,6 +172,7 @@ def download_and_parse_fragment(url, frag_index, request_data=None, headers=None
chat_page_url = 'https://www.youtube.com/live_chat?continuation=' + continuation_id
frag_index = offset = 0
+ click_tracking_params = None
while continuation_id is not None:
frag_index += 1
request_data = {
@@ -173,13 +181,16 @@ def download_and_parse_fragment(url, frag_index, request_data=None, headers=None
}
if frag_index > 1:
request_data['currentPlayerState'] = {'playerOffsetMs': str(max(offset - 5000, 0))}
+ if click_tracking_params:
+ request_data['context']['clickTracking'] = {'clickTrackingParams': click_tracking_params}
headers = ie._generate_api_headers(ytcfg, visitor_data=visitor_data)
headers.update({'content-type': 'application/json'})
fragment_request_data = json.dumps(request_data, ensure_ascii=False).encode('utf-8') + b'\n'
- success, continuation_id, offset = download_and_parse_fragment(
+ success, continuation_id, offset, click_tracking_params = download_and_parse_fragment(
url, frag_index, fragment_request_data, headers)
else:
- success, continuation_id, offset = download_and_parse_fragment(chat_page_url, frag_index)
+ success, continuation_id, offset, click_tracking_params = download_and_parse_fragment(
+ chat_page_url, frag_index)
if not success:
return False
if test:
|
## Please follow the guide below
- You will be asked some questions, please read them **carefully** and answer honestly
- Put an `x` into all the boxes [ ] relevant to your *pull request* (like that [x])
- Use *Preview* tab to see how your *pull request* will actually look like
---
### Before submitting a *pull request* make sure you have:
- [x] At least skimmed through [adding new extractor tutorial](https://github.com/ytdl-org/youtube-dl#adding-support-for-a-new-site) and [youtube-dl coding conventions](https://github.com/ytdl-org/youtube-dl#youtube-dl-coding-conventions) sections
- [x] [Searched](https://github.com/yt-dlp/yt-dlp/search?q=is%3Apr&type=Issues) the bugtracker for similar pull requests
- [x] Checked the code with [flake8](https://pypi.python.org/pypi/flake8)
### In order to be accepted and merged into youtube-dl each piece of code must be in public domain or released under [Unlicense](http://unlicense.org/). Check one of the following options:
- [x] I am the original author of this code and I am willing to release it under [Unlicense](http://unlicense.org/)
- [ ] I am not the original author of this code but it is in public domain or released under [Unlicense](http://unlicense.org/) (provide reliable evidence)
### What is the purpose of your *pull request*?
- [x] Bug fix
- [ ] Improvement
- [ ] New extractor
- [ ] New feature
---
### Description of your *pull request* and other information
Fixes https://github.com/yt-dlp/yt-dlp/issues/433
I looked at my captures of members only live chat, and noticed that some of the API request payloads contained `clickTracking` but others didn't. It was always contained in the previous response when it was used. I still haven't been able to test this with an actual live members chat, but I tested that this doesn't break members replays or non-members chat, live or replay.
I'm hoping that @Lytexx could test this with cookies on a members live chat, but I might also be able to do that at some point.
|
https://api.github.com/repos/yt-dlp/yt-dlp/pulls/449
|
2021-06-26T15:54:10Z
|
2021-06-26T23:22:32Z
|
2021-06-26T23:22:32Z
|
2021-06-26T23:22:32Z
| 1,596
|
yt-dlp/yt-dlp
| 7,528
|
Bump black from 21.12b0 to 22.1.0
|
diff --git a/poetry.lock b/poetry.lock
index fcfe395fc..38171bea9 100644
--- a/poetry.lock
+++ b/poetry.lock
@@ -79,30 +79,26 @@ python-versions = "*"
[[package]]
name = "black"
-version = "21.12b0"
+version = "22.1.0"
description = "The uncompromising code formatter."
category = "dev"
optional = false
python-versions = ">=3.6.2"
[package.dependencies]
-click = ">=7.1.2"
+click = ">=8.0.0"
dataclasses = {version = ">=0.6", markers = "python_version < \"3.7\""}
mypy-extensions = ">=0.4.3"
-pathspec = ">=0.9.0,<1"
+pathspec = ">=0.9.0"
platformdirs = ">=2"
-tomli = ">=0.2.6,<2.0.0"
+tomli = ">=1.1.0"
typed-ast = {version = ">=1.4.2", markers = "python_version < \"3.8\" and implementation_name == \"cpython\""}
-typing-extensions = [
- {version = ">=3.10.0.0", markers = "python_version < \"3.10\""},
- {version = "!=3.10.0.1", markers = "python_version >= \"3.10\""},
-]
+typing-extensions = {version = ">=3.10.0.0", markers = "python_version < \"3.10\""}
[package.extras]
colorama = ["colorama (>=0.4.3)"]
d = ["aiohttp (>=3.7.4)"]
jupyter = ["ipython (>=7.8.0)", "tokenize-rt (>=3.2.0)"]
-python2 = ["typed-ast (>=1.4.3)"]
uvloop = ["uvloop (>=0.15.2)"]
[[package]]
@@ -1053,7 +1049,7 @@ jupyter = ["ipywidgets"]
[metadata]
lock-version = "1.1"
python-versions = "^3.6.2"
-content-hash = "74159f2d5dbb53418204e0fd27ef544256648663c41d0a2841c11c34589c52f6"
+content-hash = "656a91a327289529d8bb9135fef6c66486a192e7a7e8ed682d7c3e7bf5f7b239"
[metadata.files]
appnope = [
@@ -1104,8 +1100,29 @@ backcall = [
{file = "backcall-0.2.0.tar.gz", hash = "sha256:5cbdbf27be5e7cfadb448baf0aa95508f91f2bbc6c6437cd9cd06e2a4c215e1e"},
]
black = [
- {file = "black-21.12b0-py3-none-any.whl", hash = "sha256:a615e69ae185e08fdd73e4715e260e2479c861b5740057fde6e8b4e3b7dd589f"},
- {file = "black-21.12b0.tar.gz", hash = "sha256:77b80f693a569e2e527958459634f18df9b0ba2625ba4e0c2d5da5be42e6f2b3"},
+ {file = "black-22.1.0-cp310-cp310-macosx_10_9_universal2.whl", hash = "sha256:1297c63b9e1b96a3d0da2d85d11cd9bf8664251fd69ddac068b98dc4f34f73b6"},
+ {file = "black-22.1.0-cp310-cp310-macosx_10_9_x86_64.whl", hash = "sha256:2ff96450d3ad9ea499fc4c60e425a1439c2120cbbc1ab959ff20f7c76ec7e866"},
+ {file = "black-22.1.0-cp310-cp310-macosx_11_0_arm64.whl", hash = "sha256:0e21e1f1efa65a50e3960edd068b6ae6d64ad6235bd8bfea116a03b21836af71"},
+ {file = "black-22.1.0-cp310-cp310-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:e2f69158a7d120fd641d1fa9a921d898e20d52e44a74a6fbbcc570a62a6bc8ab"},
+ {file = "black-22.1.0-cp310-cp310-win_amd64.whl", hash = "sha256:228b5ae2c8e3d6227e4bde5920d2fc66cc3400fde7bcc74f480cb07ef0b570d5"},
+ {file = "black-22.1.0-cp36-cp36m-macosx_10_9_x86_64.whl", hash = "sha256:b1a5ed73ab4c482208d20434f700d514f66ffe2840f63a6252ecc43a9bc77e8a"},
+ {file = "black-22.1.0-cp36-cp36m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:35944b7100af4a985abfcaa860b06af15590deb1f392f06c8683b4381e8eeaf0"},
+ {file = "black-22.1.0-cp36-cp36m-win_amd64.whl", hash = "sha256:7835fee5238fc0a0baf6c9268fb816b5f5cd9b8793423a75e8cd663c48d073ba"},
+ {file = "black-22.1.0-cp37-cp37m-macosx_10_9_x86_64.whl", hash = "sha256:dae63f2dbf82882fa3b2a3c49c32bffe144970a573cd68d247af6560fc493ae1"},
+ {file = "black-22.1.0-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:5fa1db02410b1924b6749c245ab38d30621564e658297484952f3d8a39fce7e8"},
+ {file = "black-22.1.0-cp37-cp37m-win_amd64.whl", hash = "sha256:c8226f50b8c34a14608b848dc23a46e5d08397d009446353dad45e04af0c8e28"},
+ {file = "black-22.1.0-cp38-cp38-macosx_10_9_universal2.whl", hash = "sha256:2d6f331c02f0f40aa51a22e479c8209d37fcd520c77721c034517d44eecf5912"},
+ {file = "black-22.1.0-cp38-cp38-macosx_10_9_x86_64.whl", hash = "sha256:742ce9af3086e5bd07e58c8feb09dbb2b047b7f566eb5f5bc63fd455814979f3"},
+ {file = "black-22.1.0-cp38-cp38-macosx_11_0_arm64.whl", hash = "sha256:fdb8754b453fb15fad3f72cd9cad3e16776f0964d67cf30ebcbf10327a3777a3"},
+ {file = "black-22.1.0-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:f5660feab44c2e3cb24b2419b998846cbb01c23c7fe645fee45087efa3da2d61"},
+ {file = "black-22.1.0-cp38-cp38-win_amd64.whl", hash = "sha256:6f2f01381f91c1efb1451998bd65a129b3ed6f64f79663a55fe0e9b74a5f81fd"},
+ {file = "black-22.1.0-cp39-cp39-macosx_10_9_universal2.whl", hash = "sha256:efbadd9b52c060a8fc3b9658744091cb33c31f830b3f074422ed27bad2b18e8f"},
+ {file = "black-22.1.0-cp39-cp39-macosx_10_9_x86_64.whl", hash = "sha256:8871fcb4b447206904932b54b567923e5be802b9b19b744fdff092bd2f3118d0"},
+ {file = "black-22.1.0-cp39-cp39-macosx_11_0_arm64.whl", hash = "sha256:ccad888050f5393f0d6029deea2a33e5ae371fd182a697313bdbd835d3edaf9c"},
+ {file = "black-22.1.0-cp39-cp39-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:07e5c049442d7ca1a2fc273c79d1aecbbf1bc858f62e8184abe1ad175c4f7cc2"},
+ {file = "black-22.1.0-cp39-cp39-win_amd64.whl", hash = "sha256:373922fc66676133ddc3e754e4509196a8c392fec3f5ca4486673e685a421321"},
+ {file = "black-22.1.0-py3-none-any.whl", hash = "sha256:3524739d76b6b3ed1132422bf9d82123cd1705086723bc3e235ca39fd21c667d"},
+ {file = "black-22.1.0.tar.gz", hash = "sha256:a7c0192d35635f6fc1174be575cb7915e92e5dd629ee79fdaf0dcfa41a80afb5"},
]
bleach = [
{file = "bleach-4.1.0-py2.py3-none-any.whl", hash = "sha256:4d2651ab93271d1129ac9cbc679f524565cc8a1b791909c4a51eac4446a15994"},
diff --git a/pyproject.toml b/pyproject.toml
index d110cf38c..4f7d8dd26 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -40,7 +40,7 @@ jupyter = ["ipywidgets"]
[tool.poetry.dev-dependencies]
pytest = "^7.0.0"
-black = "^21.11b1"
+black = "^22.1"
mypy = "^0.930"
pytest-cov = "^3.0.0"
attrs = "^21.4.0"
|
Bumps [black](https://github.com/psf/black) from 21.12b0 to 22.1.0.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/psf/black/releases">black's releases</a>.</em></p>
<blockquote>
<h2>22.1.0</h2>
<p>At long last, Black is no longer a beta product! This is the first non-beta release and the first release covered by our new stability policy.</p>
<h3>Highlights</h3>
<ul>
<li>Remove Python 2 support (<a href="https://github-redirect.dependabot.com/psf/black/issues/2740">#2740</a>)</li>
<li>Introduce the <code>--preview</code> flag (<a href="https://github-redirect.dependabot.com/psf/black/issues/2752">#2752</a>)</li>
</ul>
<h3>Style</h3>
<ul>
<li>Deprecate <code>--experimental-string-processing</code> and move the functionality under <code>--preview</code> (<a href="https://github-redirect.dependabot.com/psf/black/issues/2789">#2789</a>)</li>
<li>For stubs, one blank line between class attributes and methods is now kept if there's at least one pre-existing blank line (<a href="https://github-redirect.dependabot.com/psf/black/issues/2736">#2736</a>)</li>
<li>Black now normalizes string prefix order (<a href="https://github-redirect.dependabot.com/psf/black/issues/2297">#2297</a>)</li>
<li>Remove spaces around power operators if both operands are simple (<a href="https://github-redirect.dependabot.com/psf/black/issues/2726">#2726</a>)</li>
<li>Work around bug that causes unstable formatting in some cases in the presence of the magic trailing comma (<a href="https://github-redirect.dependabot.com/psf/black/issues/2807">#2807</a>)</li>
<li>Use parentheses for attribute access on decimal float and int literals (<a href="https://github-redirect.dependabot.com/psf/black/issues/2799">#2799</a>)</li>
<li>Don't add whitespace for attribute access on hexadecimal, binary, octal, and complex literals (<a href="https://github-redirect.dependabot.com/psf/black/issues/2799">#2799</a>)</li>
<li>Treat blank lines in stubs the same inside top-level if statements (<a href="https://github-redirect.dependabot.com/psf/black/issues/2820">#2820</a>)</li>
<li>Fix unstable formatting with semicolons and arithmetic expressions (<a href="https://github-redirect.dependabot.com/psf/black/issues/2817">#2817</a>)</li>
<li>Fix unstable formatting around magic trailing comma (<a href="https://github-redirect.dependabot.com/psf/black/issues/2572">#2572</a>)</li>
</ul>
<h3>Parser</h3>
<ul>
<li>Fix mapping cases that contain as-expressions, like <code>case {"key": 1 | 2 as password}</code> (<a href="https://github-redirect.dependabot.com/psf/black/issues/2686">#2686</a>)</li>
<li>Fix cases that contain multiple top-level as-expressions, like <code>case 1 as a, 2 as b</code> (<a href="https://github-redirect.dependabot.com/psf/black/issues/2716">#2716</a>)</li>
<li>Fix call patterns that contain as-expressions with keyword arguments, like <code>case Foo(bar=baz as quux)</code> (<a href="https://github-redirect.dependabot.com/psf/black/issues/2749">#2749</a>)</li>
<li>Tuple unpacking on <code>return</code> and <code>yield</code> constructs now implies 3.8+ (<a href="https://github-redirect.dependabot.com/psf/black/issues/2700">#2700</a>)</li>
<li>Unparenthesized tuples on annotated assignments (e.g <code>values: Tuple[int, ...] = 1, 2, 3</code>) now implies 3.8+ (<a href="https://github-redirect.dependabot.com/psf/black/issues/2708">#2708</a>)</li>
<li>Fix handling of standalone <code>match()</code> or <code>case()</code> when there is a trailing newline or a comment inside of the parentheses. (<a href="https://github-redirect.dependabot.com/psf/black/issues/2760">#2760</a>)</li>
<li><code>from __future__ import annotations</code> statement now implies Python 3.7+ (<a href="https://github-redirect.dependabot.com/psf/black/issues/2690">#2690</a>)</li>
</ul>
<h3>Performance</h3>
<ul>
<li>Speed-up the new backtracking parser about 4X in general (enabled when <code>--target-version</code> is set to 3.10 and higher). (<a href="https://github-redirect.dependabot.com/psf/black/issues/2728">#2728</a>)</li>
<li>Black is now compiled with mypyc for an overall 2x speed-up. 64-bit Windows, MacOS, and Linux (not including musl) are supported. (<a href="https://github-redirect.dependabot.com/psf/black/issues/1009">#1009</a>, <a href="https://github-redirect.dependabot.com/psf/black/issues/2431">#2431</a>)</li>
</ul>
<h3>Configuration</h3>
<ul>
<li>Do not accept bare carriage return line endings in pyproject.toml (<a href="https://github-redirect.dependabot.com/psf/black/issues/2408">#2408</a>)</li>
<li>Add configuration option (<code>python-cell-magics</code>) to format cells with custom magics in Jupyter Notebooks (<a href="https://github-redirect.dependabot.com/psf/black/issues/2744">#2744</a>)</li>
<li>Allow setting custom cache directory on all platforms with environment variable <code>BLACK_CACHE_DIR</code> (<a href="https://github-redirect.dependabot.com/psf/black/issues/2739">#2739</a>).</li>
<li>Enable Python 3.10+ by default, without any extra need to specify -<code>-target-version=py310</code>. (<a href="https://github-redirect.dependabot.com/psf/black/issues/2758">#2758</a>)</li>
<li>Make passing <code>SRC</code> or <code>--code</code> mandatory and mutually exclusive (<a href="https://github-redirect.dependabot.com/psf/black/issues/2804">#2804</a>)</li>
</ul>
<h3>Output</h3>
<ul>
<li>Improve error message for invalid regular expression (<a href="https://github-redirect.dependabot.com/psf/black/issues/2678">#2678</a>)</li>
<li>Improve error message when parsing fails during AST safety check by embedding the underlying SyntaxError (<a href="https://github-redirect.dependabot.com/psf/black/issues/2693">#2693</a>)</li>
<li>No longer color diff headers white as it's unreadable in light themed terminals (<a href="https://github-redirect.dependabot.com/psf/black/issues/2691">#2691</a>)</li>
<li>Text coloring added in the final statistics (<a href="https://github-redirect.dependabot.com/psf/black/issues/2712">#2712</a>)</li>
<li>Verbose mode also now describes how a project root was discovered and which paths will be formatted. (<a href="https://github-redirect.dependabot.com/psf/black/issues/2526">#2526</a>)</li>
</ul>
<h3>Packaging</h3>
<ul>
<li>All upper version bounds on dependencies have been removed (<a href="https://github-redirect.dependabot.com/psf/black/issues/2718">#2718</a>)</li>
<li><code>typing-extensions</code> is no longer a required dependency in Python 3.10+ (<a href="https://github-redirect.dependabot.com/psf/black/issues/2772">#2772</a>)</li>
<li>Set <code>click</code> lower bound to <code>8.0.0</code> as <em>Black</em> crashes on <code>7.1.2</code> (<a href="https://github-redirect.dependabot.com/psf/black/issues/2791">#2791</a>)</li>
</ul>
<!-- raw HTML omitted -->
</blockquote>
<p>... (truncated)</p>
</details>
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a href="https://github.com/psf/black/blob/main/CHANGES.md">black's changelog</a>.</em></p>
<blockquote>
<h2>22.1.0</h2>
<p>At long last, <em>Black</em> is no longer a beta product! This is the first non-beta release
and the first release covered by our new stability policy.</p>
<h3>Highlights</h3>
<ul>
<li><strong>Remove Python 2 support</strong> (<a href="https://github-redirect.dependabot.com/psf/black/issues/2740">#2740</a>)</li>
<li>Introduce the <code>--preview</code> flag (<a href="https://github-redirect.dependabot.com/psf/black/issues/2752">#2752</a>)</li>
</ul>
<h3>Style</h3>
<ul>
<li>Deprecate <code>--experimental-string-processing</code> and move the functionality under
<code>--preview</code> (<a href="https://github-redirect.dependabot.com/psf/black/issues/2789">#2789</a>)</li>
<li>For stubs, one blank line between class attributes and methods is now kept if there's
at least one pre-existing blank line (<a href="https://github-redirect.dependabot.com/psf/black/issues/2736">#2736</a>)</li>
<li>Black now normalizes string prefix order (<a href="https://github-redirect.dependabot.com/psf/black/issues/2297">#2297</a>)</li>
<li>Remove spaces around power operators if both operands are simple (<a href="https://github-redirect.dependabot.com/psf/black/issues/2726">#2726</a>)</li>
<li>Work around bug that causes unstable formatting in some cases in the presence of the
magic trailing comma (<a href="https://github-redirect.dependabot.com/psf/black/issues/2807">#2807</a>)</li>
<li>Use parentheses for attribute access on decimal float and int literals (<a href="https://github-redirect.dependabot.com/psf/black/issues/2799">#2799</a>)</li>
<li>Don't add whitespace for attribute access on hexadecimal, binary, octal, and complex
literals (<a href="https://github-redirect.dependabot.com/psf/black/issues/2799">#2799</a>)</li>
<li>Treat blank lines in stubs the same inside top-level <code>if</code> statements (<a href="https://github-redirect.dependabot.com/psf/black/issues/2820">#2820</a>)</li>
<li>Fix unstable formatting with semicolons and arithmetic expressions (<a href="https://github-redirect.dependabot.com/psf/black/issues/2817">#2817</a>)</li>
<li>Fix unstable formatting around magic trailing comma (<a href="https://github-redirect.dependabot.com/psf/black/issues/2572">#2572</a>)</li>
</ul>
<h3>Parser</h3>
<ul>
<li>Fix mapping cases that contain as-expressions, like <code>case {"key": 1 | 2 as password}</code>
(<a href="https://github-redirect.dependabot.com/psf/black/issues/2686">#2686</a>)</li>
<li>Fix cases that contain multiple top-level as-expressions, like <code>case 1 as a, 2 as b</code>
(<a href="https://github-redirect.dependabot.com/psf/black/issues/2716">#2716</a>)</li>
<li>Fix call patterns that contain as-expressions with keyword arguments, like
<code>case Foo(bar=baz as quux)</code> (<a href="https://github-redirect.dependabot.com/psf/black/issues/2749">#2749</a>)</li>
<li>Tuple unpacking on <code>return</code> and <code>yield</code> constructs now implies 3.8+ (<a href="https://github-redirect.dependabot.com/psf/black/issues/2700">#2700</a>)</li>
<li>Unparenthesized tuples on annotated assignments (e.g
<code>values: Tuple[int, ...] = 1, 2, 3</code>) now implies 3.8+ (<a href="https://github-redirect.dependabot.com/psf/black/issues/2708">#2708</a>)</li>
<li>Fix handling of standalone <code>match()</code> or <code>case()</code> when there is a trailing newline or a
comment inside of the parentheses. (<a href="https://github-redirect.dependabot.com/psf/black/issues/2760">#2760</a>)</li>
<li><code>from __future__ import annotations</code> statement now implies Python 3.7+ (<a href="https://github-redirect.dependabot.com/psf/black/issues/2690">#2690</a>)</li>
</ul>
<h3>Performance</h3>
<ul>
<li>Speed-up the new backtracking parser about 4X in general (enabled when
<code>--target-version</code> is set to 3.10 and higher). (<a href="https://github-redirect.dependabot.com/psf/black/issues/2728">#2728</a>)</li>
<li><em>Black</em> is now compiled with <a href="https://github.com/mypyc/mypyc">mypyc</a> for an overall 2x
speed-up. 64-bit Windows, MacOS, and Linux (not including musl) are supported. (<a href="https://github-redirect.dependabot.com/psf/black/issues/1009">#1009</a>,
<a href="https://github-redirect.dependabot.com/psf/black/issues/2431">#2431</a>)</li>
</ul>
<!-- raw HTML omitted -->
</blockquote>
<p>... (truncated)</p>
</details>
<details>
<summary>Commits</summary>
<ul>
<li>See full diff in <a href="https://github.com/psf/black/commits/22.1.0">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- `@dependabot ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
</details>
|
https://api.github.com/repos/Textualize/rich/pulls/1892
|
2022-01-31T13:34:24Z
|
2022-02-11T11:09:31Z
|
2022-02-11T11:09:31Z
|
2022-02-11T11:09:32Z
| 2,750
|
Textualize/rich
| 48,213
|
Add xonsh shell is a Python-powered, Unix-gazing shell language and command prompt
|
diff --git a/README.md b/README.md
index baabcb127..d49717f32 100644
--- a/README.md
+++ b/README.md
@@ -77,6 +77,7 @@ Inspired by [awesome-php](https://github.com/ziadoz/awesome-php).
- [Search](#search)
- [Serialization](#serialization)
- [Serverless Frameworks](#serverless-frameworks)
+ - [Shell](#shell)
- [Specific Formats Processing](#specific-formats-processing)
- [Static Site Generator](#static-site-generator)
- [Tagging](#tagging)
@@ -1062,6 +1063,12 @@ Inspired by [awesome-php](https://github.com/ziadoz/awesome-php).
* [python-lambda](https://github.com/nficano/python-lambda) - A toolkit for developing and deploying Python code in AWS Lambda.
* [Zappa](https://github.com/Miserlou/Zappa) - A tool for deploying WSGI applications on AWS Lambda and API Gateway.
+## Shell
+
+*Shells based on Python.*
+
+* [xonsh](https://github.com/xonsh/xonsh/) - A Python-powered, cross-platform, Unix-gazing shell language and command prompt.
+
## Specific Formats Processing
*Libraries for parsing and manipulating specific text formats.*
|
## What is this Python project?
xonsh is a Python-powered, cross-platform, Unix-gazing shell language and command prompt. The language is a superset of Python 3.5+ with additional shell primitives. It is time-tested and very well documented project.
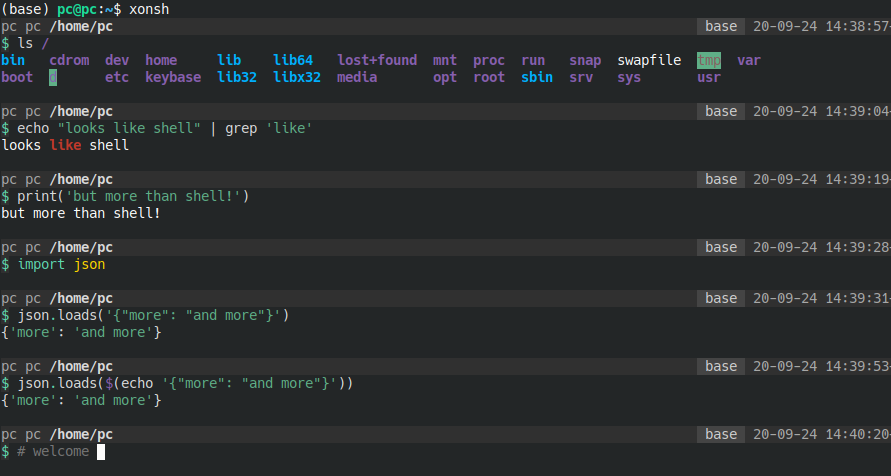
## What's the difference between this Python project and similar ones?
Xonsh is significantly different from most other shells or shell tools. The following table lists features and capabilities that various tools may or may not share.
<table class="colwidths-given docutils align-default">
<colgroup>
<col style="width: 33%">
<col style="width: 11%">
<col style="width: 11%">
<col style="width: 11%">
<col style="width: 11%">
<col style="width: 11%">
<col style="width: 11%">
</colgroup>
<thead>
<tr class="row-odd"><th class="head stub"></th>
<th class="head"><p>Bash</p></th>
<th class="head"><p>zsh</p></th>
<th class="head"><p>plumbum</p></th>
<th class="head"><p>fish</p></th>
<th class="head"><p>IPython</p></th>
<th class="head"><p>xonsh</p></th>
</tr>
</thead>
<tbody>
<tr class="row-even"><th class="stub"><p>Sane language</p></th>
<td></td>
<td></td>
<td><p>✓</p></td>
<td><p>✓</p></td>
<td><p>✓</p></td>
<td><p>✓</p></td>
</tr>
<tr class="row-odd"><th class="stub"><p>Easily scriptable</p></th>
<td><p>✓</p></td>
<td><p>✓</p></td>
<td><p>✓</p></td>
<td><p>✓</p></td>
<td></td>
<td><p>✓</p></td>
</tr>
<tr class="row-even"><th class="stub"><p>Native cross-platform support</p></th>
<td></td>
<td></td>
<td><p>✓</p></td>
<td><p>✓</p></td>
<td><p>✓</p></td>
<td><p>✓</p></td>
</tr>
<tr class="row-odd"><th class="stub"><p>Meant as a shell</p></th>
<td><p>✓</p></td>
<td><p>✓</p></td>
<td></td>
<td><p>✓</p></td>
<td></td>
<td><p>✓</p></td>
</tr>
<tr class="row-even"><th class="stub"><p>Tab completion</p></th>
<td><p>✓</p></td>
<td><p>✓</p></td>
<td></td>
<td><p>✓</p></td>
<td><p>✓</p></td>
<td><p>✓</p></td>
</tr>
<tr class="row-odd"><th class="stub"><p>Completion from man-page parsing</p></th>
<td></td>
<td></td>
<td></td>
<td><p>✓</p></td>
<td></td>
<td><p>✓</p></td>
</tr>
<tr class="row-even"><th class="stub"><p>Large standard library</p></th>
<td></td>
<td><p>✓</p></td>
<td></td>
<td></td>
<td><p>✓</p></td>
<td><p>✓</p></td>
</tr>
<tr class="row-odd"><th class="stub"><p>Typed variables</p></th>
<td></td>
<td></td>
<td><p>✓</p></td>
<td><p>✓</p></td>
<td><p>✓</p></td>
<td><p>✓</p></td>
</tr>
<tr class="row-even"><th class="stub"><p>Syntax highlighting</p></th>
<td></td>
<td></td>
<td></td>
<td><p>✓</p></td>
<td><p>in notebook</p></td>
<td><p>w/ prompt-toolkit</p></td>
</tr>
<tr class="row-odd"><th class="stub"><p>Pun in name</p></th>
<td><p>✓</p></td>
<td></td>
<td><p>✓</p></td>
<td></td>
<td></td>
<td><p>✓</p></td>
</tr>
<tr class="row-even"><th class="stub"><p>Rich history</p></th>
<td></td>
<td></td>
<td></td>
<td></td>
<td></td>
<td><p>✓</p></td>
</tr>
</tbody>
</table>
|
https://api.github.com/repos/vinta/awesome-python/pulls/1623
|
2020-09-24T11:35:18Z
|
2020-10-27T17:33:21Z
|
2020-10-27T17:33:21Z
|
2020-10-27T17:33:21Z
| 299
|
vinta/awesome-python
| 27,080
|
Fix dnsimple typo
|
diff --git a/certbot-dns-dnsimple/certbot_dns_dnsimple/_internal/dns_dnsimple.py b/certbot-dns-dnsimple/certbot_dns_dnsimple/_internal/dns_dnsimple.py
index 3d1017f0be9..c9ef1cdd186 100644
--- a/certbot-dns-dnsimple/certbot_dns_dnsimple/_internal/dns_dnsimple.py
+++ b/certbot-dns-dnsimple/certbot_dns_dnsimple/_internal/dns_dnsimple.py
@@ -39,7 +39,7 @@ def more_info(self) -> str:
@property
def _provider_name(self) -> str:
- return 'dnssimple'
+ return 'dnsimple'
def _handle_http_error(self, e: HTTPError, domain_name: str) -> errors.PluginError:
hint = None
diff --git a/certbot/CHANGELOG.md b/certbot/CHANGELOG.md
index 1026380217f..4506cb9ca4c 100644
--- a/certbot/CHANGELOG.md
+++ b/certbot/CHANGELOG.md
@@ -14,7 +14,8 @@ Certbot adheres to [Semantic Versioning](https://semver.org/).
### Fixed
-*
+* Fixed a bug that broke the DNS plugin for DNSimple that was introduced in
+ version 2.7.0 of the plugin.
More details about these changes can be found on our GitHub repo.
|
Fixes https://github.com/certbot/certbot/issues/9786.
|
https://api.github.com/repos/certbot/certbot/pulls/9787
|
2023-10-05T17:46:08Z
|
2023-10-05T20:15:30Z
|
2023-10-05T20:15:30Z
|
2023-10-05T20:15:32Z
| 334
|
certbot/certbot
| 3,594
|
Using CRLF as line marker according to http 1.1 definition
|
diff --git a/scrapy/core/downloader/handlers/http11.py b/scrapy/core/downloader/handlers/http11.py
index 52eb35eba7e..617a68ea4cd 100644
--- a/scrapy/core/downloader/handlers/http11.py
+++ b/scrapy/core/downloader/handlers/http11.py
@@ -66,12 +66,11 @@ def __init__(self, reactor, host, port, proxyConf, contextFactory,
def requestTunnel(self, protocol):
"""Asks the proxy to open a tunnel."""
- tunnelReq = 'CONNECT %s:%s HTTP/1.1\n' % (self._tunneledHost,
+ tunnelReq = 'CONNECT %s:%s HTTP/1.1\r\n' % (self._tunneledHost,
self._tunneledPort)
if self._proxyAuthHeader:
- tunnelReq += 'Proxy-Authorization: %s \n\n' % self._proxyAuthHeader
- else:
- tunnelReq += '\n'
+ tunnelReq += 'Proxy-Authorization: %s\r\n' % self._proxyAuthHeader
+ tunnelReq += '\r\n'
protocol.transport.write(tunnelReq)
self._protocolDataReceived = protocol.dataReceived
protocol.dataReceived = self.processProxyResponse
|
According to http 1.1 definition http://www.w3.org/Protocols/rfc2616/rfc2616-sec2.html we should using CRLF as end-of-line marker. In my case some of my proxies will return 407 if it's not ended with '\r\n'. And we can see it clearly in twisted's [http client](https://github.com/twisted/twisted/blob/trunk/twisted/web/http.py#L410) implementation.
|
https://api.github.com/repos/scrapy/scrapy/pulls/787
|
2014-07-08T07:03:20Z
|
2014-07-08T22:37:02Z
|
2014-07-08T22:37:02Z
|
2014-07-09T00:00:19Z
| 296
|
scrapy/scrapy
| 34,990
|
Adds options for grid margins to XYZ Plot and Prompt Matrix
|
diff --git a/modules/images.py b/modules/images.py
index f4b20b2817f..c2ca8849de8 100644
--- a/modules/images.py
+++ b/modules/images.py
@@ -199,7 +199,7 @@ def draw_texts(drawing, draw_x, draw_y, lines, initial_fnt, initial_fontsize):
pad_top = 0 if sum(hor_text_heights) == 0 else max(hor_text_heights) + line_spacing * 2
- result = Image.new("RGB", (im.width + pad_left + margin * (rows-1), im.height + pad_top + margin * (cols-1)), "white")
+ result = Image.new("RGB", (im.width + pad_left + margin * (cols-1), im.height + pad_top + margin * (rows-1)), "white")
for row in range(rows):
for col in range(cols):
@@ -223,7 +223,7 @@ def draw_texts(drawing, draw_x, draw_y, lines, initial_fnt, initial_fontsize):
return result
-def draw_prompt_matrix(im, width, height, all_prompts):
+def draw_prompt_matrix(im, width, height, all_prompts, margin=0):
prompts = all_prompts[1:]
boundary = math.ceil(len(prompts) / 2)
@@ -233,7 +233,7 @@ def draw_prompt_matrix(im, width, height, all_prompts):
hor_texts = [[GridAnnotation(x, is_active=pos & (1 << i) != 0) for i, x in enumerate(prompts_horiz)] for pos in range(1 << len(prompts_horiz))]
ver_texts = [[GridAnnotation(x, is_active=pos & (1 << i) != 0) for i, x in enumerate(prompts_vert)] for pos in range(1 << len(prompts_vert))]
- return draw_grid_annotations(im, width, height, hor_texts, ver_texts)
+ return draw_grid_annotations(im, width, height, hor_texts, ver_texts, margin)
def resize_image(resize_mode, im, width, height, upscaler_name=None):
diff --git a/scripts/prompt_matrix.py b/scripts/prompt_matrix.py
index de921ea84a5..3ee3cbe4c17 100644
--- a/scripts/prompt_matrix.py
+++ b/scripts/prompt_matrix.py
@@ -48,23 +48,17 @@ def ui(self, is_img2img):
gr.HTML('<br />')
with gr.Row():
with gr.Column():
- put_at_start = gr.Checkbox(label='Put variable parts at start of prompt',
- value=False, elem_id=self.elem_id("put_at_start"))
+ put_at_start = gr.Checkbox(label='Put variable parts at start of prompt', value=False, elem_id=self.elem_id("put_at_start"))
+ different_seeds = gr.Checkbox(label='Use different seed for each picture', value=False, elem_id=self.elem_id("different_seeds"))
with gr.Column():
- # Radio buttons for selecting the prompt between positive and negative
- prompt_type = gr.Radio(["positive", "negative"], label="Select prompt",
- elem_id=self.elem_id("prompt_type"), value="positive")
- with gr.Row():
- with gr.Column():
- different_seeds = gr.Checkbox(
- label='Use different seed for each picture', value=False, elem_id=self.elem_id("different_seeds"))
+ prompt_type = gr.Radio(["positive", "negative"], label="Select prompt", elem_id=self.elem_id("prompt_type"), value="positive")
+ variations_delimiter = gr.Radio(["comma", "space"], label="Select joining char", elem_id=self.elem_id("variations_delimiter"), value="comma")
with gr.Column():
- # Radio buttons for selecting the delimiter to use in the resulting prompt
- variations_delimiter = gr.Radio(["comma", "space"], label="Select delimiter", elem_id=self.elem_id(
- "variations_delimiter"), value="comma")
- return [put_at_start, different_seeds, prompt_type, variations_delimiter]
+ margin_size = gr.Slider(label="Grid margins (px)", min=0, max=500, value=0, step=2, elem_id=self.elem_id("margin_size"))
+
+ return [put_at_start, different_seeds, prompt_type, variations_delimiter, margin_size]
- def run(self, p, put_at_start, different_seeds, prompt_type, variations_delimiter):
+ def run(self, p, put_at_start, different_seeds, prompt_type, variations_delimiter, margin_size):
modules.processing.fix_seed(p)
# Raise error if promp type is not positive or negative
if prompt_type not in ["positive", "negative"]:
@@ -106,7 +100,7 @@ def run(self, p, put_at_start, different_seeds, prompt_type, variations_delimite
processed = process_images(p)
grid = images.image_grid(processed.images, p.batch_size, rows=1 << ((len(prompt_matrix_parts) - 1) // 2))
- grid = images.draw_prompt_matrix(grid, p.width, p.height, prompt_matrix_parts)
+ grid = images.draw_prompt_matrix(grid, p.width, p.height, prompt_matrix_parts, margin_size)
processed.images.insert(0, grid)
processed.index_of_first_image = 1
processed.infotexts.insert(0, processed.infotexts[0])
diff --git a/scripts/xyz_grid.py b/scripts/xyz_grid.py
index 3122f6f66db..5982cfbaa7a 100644
--- a/scripts/xyz_grid.py
+++ b/scripts/xyz_grid.py
@@ -205,7 +205,7 @@ def __init__(self, *args, **kwargs):
]
-def draw_xyz_grid(p, xs, ys, zs, x_labels, y_labels, z_labels, cell, draw_legend, include_lone_images, include_sub_grids, first_axes_processed, second_axes_processed):
+def draw_xyz_grid(p, xs, ys, zs, x_labels, y_labels, z_labels, cell, draw_legend, include_lone_images, include_sub_grids, first_axes_processed, second_axes_processed, margin_size):
hor_texts = [[images.GridAnnotation(x)] for x in x_labels]
ver_texts = [[images.GridAnnotation(y)] for y in y_labels]
title_texts = [[images.GridAnnotation(z)] for z in z_labels]
@@ -292,7 +292,7 @@ def index(ix, iy, iz):
end_index = start_index + len(xs) * len(ys)
grid = images.image_grid(image_cache[start_index:end_index], rows=len(ys))
if draw_legend:
- grid = images.draw_grid_annotations(grid, cell_size[0], cell_size[1], hor_texts, ver_texts)
+ grid = images.draw_grid_annotations(grid, cell_size[0], cell_size[1], hor_texts, ver_texts, margin_size)
sub_grids[i] = grid
if include_sub_grids and len(zs) > 1:
processed_result.images.insert(i+1, grid)
@@ -351,10 +351,16 @@ def ui(self, is_img2img):
fill_z_button = ToolButton(value=fill_values_symbol, elem_id="xyz_grid_fill_z_tool_button", visible=False)
with gr.Row(variant="compact", elem_id="axis_options"):
- draw_legend = gr.Checkbox(label='Draw legend', value=True, elem_id=self.elem_id("draw_legend"))
- include_lone_images = gr.Checkbox(label='Include Sub Images', value=False, elem_id=self.elem_id("include_lone_images"))
- include_sub_grids = gr.Checkbox(label='Include Sub Grids', value=False, elem_id=self.elem_id("include_sub_grids"))
- no_fixed_seeds = gr.Checkbox(label='Keep -1 for seeds', value=False, elem_id=self.elem_id("no_fixed_seeds"))
+ with gr.Column():
+ draw_legend = gr.Checkbox(label='Draw legend', value=True, elem_id=self.elem_id("draw_legend"))
+ no_fixed_seeds = gr.Checkbox(label='Keep -1 for seeds', value=False, elem_id=self.elem_id("no_fixed_seeds"))
+ with gr.Column():
+ include_lone_images = gr.Checkbox(label='Include Sub Images', value=False, elem_id=self.elem_id("include_lone_images"))
+ include_sub_grids = gr.Checkbox(label='Include Sub Grids', value=False, elem_id=self.elem_id("include_sub_grids"))
+ with gr.Column():
+ margin_size = gr.Slider(label="Grid margins (px)", min=0, max=500, value=0, step=2, elem_id=self.elem_id("margin_size"))
+
+ with gr.Row(variant="compact", elem_id="swap_axes"):
swap_xy_axes_button = gr.Button(value="Swap X/Y axes", elem_id="xy_grid_swap_axes_button")
swap_yz_axes_button = gr.Button(value="Swap Y/Z axes", elem_id="yz_grid_swap_axes_button")
swap_xz_axes_button = gr.Button(value="Swap X/Z axes", elem_id="xz_grid_swap_axes_button")
@@ -393,9 +399,9 @@ def select_axis(x_type):
(z_values, "Z Values"),
)
- return [x_type, x_values, y_type, y_values, z_type, z_values, draw_legend, include_lone_images, include_sub_grids, no_fixed_seeds]
+ return [x_type, x_values, y_type, y_values, z_type, z_values, draw_legend, include_lone_images, include_sub_grids, no_fixed_seeds, margin_size]
- def run(self, p, x_type, x_values, y_type, y_values, z_type, z_values, draw_legend, include_lone_images, include_sub_grids, no_fixed_seeds):
+ def run(self, p, x_type, x_values, y_type, y_values, z_type, z_values, draw_legend, include_lone_images, include_sub_grids, no_fixed_seeds, margin_size):
if not no_fixed_seeds:
modules.processing.fix_seed(p)
@@ -590,7 +596,8 @@ def cell(x, y, z):
include_lone_images=include_lone_images,
include_sub_grids=include_sub_grids,
first_axes_processed=first_axes_processed,
- second_axes_processed=second_axes_processed
+ second_axes_processed=second_axes_processed,
+ margin_size=margin_size
)
if opts.grid_save and len(sub_grids) > 1:
|
Adds slider options for grid margins in the XYZ Plot and Prompt Matrix. Works with or without legends/text, and 0 margin leaves it as before.
Closes #4779
## Changes
- Modifies `draw_prompt_matrix` to also take in margin size
- Fixes slight miscalculation with margin in `draw_grid_annotations`
- Adds `margin_size` slider to XYZ Plot and Prompt Matrix, slightly rearranged UI to allow for it. (Default `margin_size` is 0)
## Screenshots
### XYZ Plot (Note it only affects the X/Y Grids, Z Grids are separated already by column labels)


### Prompt Matrix


## Environment this was tested in
- OS: Windows
- Browser: Firefox
- Graphics card: NVIDIA GTX 1080
|
https://api.github.com/repos/AUTOMATIC1111/stable-diffusion-webui/pulls/7556
|
2023-02-05T08:47:56Z
|
2023-02-05T10:34:36Z
|
2023-02-05T10:34:36Z
|
2023-02-05T10:34:37Z
| 2,330
|
AUTOMATIC1111/stable-diffusion-webui
| 40,067
|
Fixed #24812 -- Fixed app registry RuntimeWarnings in schema and migrations tests.
|
diff --git a/tests/mail/tests.py b/tests/mail/tests.py
index 75d5dd619b089..03dfae7903b6e 100644
--- a/tests/mail/tests.py
+++ b/tests/mail/tests.py
@@ -868,6 +868,9 @@ class FakeSMTPServer(smtpd.SMTPServer, threading.Thread):
def __init__(self, *args, **kwargs):
threading.Thread.__init__(self)
+ # New kwarg added in Python 3.5; default switching to False in 3.6.
+ if sys.version_info >= (3, 5):
+ kwargs['decode_data'] = True
smtpd.SMTPServer.__init__(self, *args, **kwargs)
self._sink = []
self.active = False
diff --git a/tests/migrations/test_state.py b/tests/migrations/test_state.py
index 58bf18921a238..3c6abe3a913ee 100644
--- a/tests/migrations/test_state.py
+++ b/tests/migrations/test_state.py
@@ -396,17 +396,22 @@ def test_add_relations(self):
#24573 - Adding relations to existing models should reload the
referenced models too.
"""
+ new_apps = Apps()
+
class A(models.Model):
class Meta:
app_label = 'something'
+ apps = new_apps
class B(A):
class Meta:
app_label = 'something'
+ apps = new_apps
class C(models.Model):
class Meta:
app_label = 'something'
+ apps = new_apps
project_state = ProjectState()
project_state.add_model(ModelState.from_model(A))
@@ -447,15 +452,19 @@ def test_remove_relations(self):
#24225 - Tests that relations between models are updated while
remaining the relations and references for models of an old state.
"""
+ new_apps = Apps()
+
class A(models.Model):
class Meta:
app_label = "something"
+ apps = new_apps
class B(models.Model):
to_a = models.ForeignKey(A)
class Meta:
app_label = "something"
+ apps = new_apps
def get_model_a(state):
return [mod for mod in state.apps.get_models() if mod._meta.model_name == 'a'][0]
diff --git a/tests/schema/tests.py b/tests/schema/tests.py
index de38f6db9494f..ba20a8a9acb6f 100644
--- a/tests/schema/tests.py
+++ b/tests/schema/tests.py
@@ -765,8 +765,10 @@ class Meta:
app_label = 'schema'
apps = new_apps
- self.local_models = [LocalBookWithM2M]
-
+ self.local_models = [
+ LocalBookWithM2M,
+ LocalBookWithM2M._meta.get_field('tags').remote_field.through,
+ ]
# Create the tables
with connection.schema_editor() as editor:
editor.create_model(Author)
@@ -845,6 +847,7 @@ class Meta:
# Create an M2M field
new_field = M2MFieldClass("schema.TagM2MTest", related_name="authors")
new_field.contribute_to_class(LocalAuthorWithM2M, "tags")
+ self.local_models += [new_field.remote_field.through]
# Ensure there's no m2m table there
self.assertRaises(DatabaseError, self.column_classes, new_field.remote_field.through)
# Add the field
@@ -934,7 +937,10 @@ class Meta:
app_label = 'schema'
apps = new_apps
- self.local_models = [LocalBookWithM2M]
+ self.local_models = [
+ LocalBookWithM2M,
+ LocalBookWithM2M._meta.get_field('tags').remote_field.through,
+ ]
# Create the tables
with connection.schema_editor() as editor:
@@ -955,6 +961,7 @@ class Meta:
old_field = LocalBookWithM2M._meta.get_field("tags")
new_field = M2MFieldClass(UniqueTest)
new_field.contribute_to_class(LocalBookWithM2M, "uniques")
+ self.local_models += [new_field.remote_field.through]
with connection.schema_editor() as editor:
editor.alter_field(LocalBookWithM2M, old_field, new_field)
# Ensure old M2M is gone
|
https://code.djangoproject.com/ticket/24812
|
https://api.github.com/repos/django/django/pulls/4672
|
2015-05-18T13:13:57Z
|
2015-05-18T14:03:15Z
|
2015-05-18T14:03:15Z
|
2015-05-18T14:17:47Z
| 975
|
django/django
| 51,487
|
Fixed doc about domain whitelisting
|
diff --git a/docs/src/content/howto-ignoredomains.md b/docs/src/content/howto-ignoredomains.md
index b1b1483106..902a17bec6 100644
--- a/docs/src/content/howto-ignoredomains.md
+++ b/docs/src/content/howto-ignoredomains.md
@@ -72,8 +72,7 @@ method to do so:
>>> mitmproxy --ignore-hosts ^example\.com:443$
{{< /highlight >}}
-Here are some other examples for ignore
-patterns:
+Here are some other examples for ignore patterns:
{{< highlight none >}}
# Exempt traffic from the iOS App Store (the regex is lax, but usually just works):
@@ -84,15 +83,22 @@ patterns:
# Ignore example.com, but not its subdomains:
--ignore-hosts '^example.com:'
-# Ignore everything but example.com and mitmproxy.org:
---ignore-hosts '^(?!example\.com)(?!mitmproxy\.org)'
-
# Transparent mode:
--ignore-hosts 17\.178\.96\.59:443
# IP address range:
--ignore-hosts 17\.178\.\d+\.\d+:443
{{< / highlight >}}
+This option can also be used to whitelist some domains through negative lookahead expressions. However, ignore patterns are always matched against the IP address of the target before being matched against its domain name. Thus, the pattern must allow any IP addresses using an expression like `^(?![0-9\.]+:)` in order for domains whitelisting to work. Here are examples of such patterns:
+
+{{< highlight none >}}
+# Ignore everything but example.com and mitmproxy.org (not subdomains):
+--ignore-hosts '^(?![0-9\.]+:)(?!example\.com:)(?!mitmproxy\.org:)'
+
+# Ignore everything but example.com and its subdomains:
+--ignore-hosts '^(?![0-9\.]+:)(?!([^\.:]+\.)*example\.com:)'
+{{< / highlight >}}
+
**Footnotes**
1. This stems from an limitation of explicit HTTP proxying: A single connection
|
This PR fixes the documentation about domains whitelisting. Previous pattern did not work, and solution was given by @mhils in #2994.
I don't think this should close this ticket as there should be a clear way to specify if the pattern should match the IP address and/or the domain, but at least, this PR prevents confusion and gives a workaround.
|
https://api.github.com/repos/mitmproxy/mitmproxy/pulls/3344
|
2018-10-05T02:08:47Z
|
2018-10-10T15:07:17Z
|
2018-10-10T15:07:17Z
|
2018-10-10T15:07:17Z
| 474
|
mitmproxy/mitmproxy
| 28,340
|
[training] SAVE_STATE_WARNING was removed in pytorch
|
diff --git a/src/transformers/trainer_pt_utils.py b/src/transformers/trainer_pt_utils.py
index cb3d4a5bfe5b7..5cb45eb7bd366 100644
--- a/src/transformers/trainer_pt_utils.py
+++ b/src/transformers/trainer_pt_utils.py
@@ -23,7 +23,6 @@
import numpy as np
import torch
-from packaging import version
from torch.utils.data.distributed import DistributedSampler
from torch.utils.data.sampler import RandomSampler, Sampler
@@ -34,10 +33,11 @@
if is_torch_tpu_available():
import torch_xla.core.xla_model as xm
-if version.parse(torch.__version__) <= version.parse("1.4.1"):
- SAVE_STATE_WARNING = ""
-else:
+# this is used to supress an undesired warning emitted by pytorch versions 1.4.2-1.7.0
+try:
from torch.optim.lr_scheduler import SAVE_STATE_WARNING
+except ImportError:
+ SAVE_STATE_WARNING = ""
logger = logging.get_logger(__name__)
|
`SAVE_STATE_WARNING` has been removed from pytorch 3 days ago: pytorch/pytorch#46813
I had to add redundant ()'s to avoid a terrible auto-formatter outcome.
Fixes: #8232
@sgugger, @LysandreJik
|
https://api.github.com/repos/huggingface/transformers/pulls/8979
|
2020-12-08T02:42:29Z
|
2020-12-08T05:59:56Z
|
2020-12-08T05:59:56Z
|
2021-06-08T18:11:11Z
| 240
|
huggingface/transformers
| 12,741
|
Backport PR #36316 on branch 1.1.x (BUG: Don't overflow with large int scalar)
|
diff --git a/doc/source/whatsnew/v1.1.3.rst b/doc/source/whatsnew/v1.1.3.rst
index 25d223418fc92..5cbd160f29d66 100644
--- a/doc/source/whatsnew/v1.1.3.rst
+++ b/doc/source/whatsnew/v1.1.3.rst
@@ -25,6 +25,7 @@ Fixed regressions
Bug fixes
~~~~~~~~~
- Bug in :meth:`Series.str.startswith` and :meth:`Series.str.endswith` with ``category`` dtype not propagating ``na`` parameter (:issue:`36241`)
+- Bug in :class:`Series` constructor where integer overflow would occur for sufficiently large scalar inputs when an index was provided (:issue:`36291`)
.. ---------------------------------------------------------------------------
diff --git a/pandas/core/dtypes/cast.py b/pandas/core/dtypes/cast.py
index e6b4cb598989b..a87bddef481b5 100644
--- a/pandas/core/dtypes/cast.py
+++ b/pandas/core/dtypes/cast.py
@@ -697,6 +697,11 @@ def infer_dtype_from_scalar(val, pandas_dtype: bool = False) -> Tuple[DtypeObj,
else:
dtype = np.dtype(np.int64)
+ try:
+ np.array(val, dtype=dtype)
+ except OverflowError:
+ dtype = np.array(val).dtype
+
elif is_float(val):
if isinstance(val, np.floating):
dtype = np.dtype(type(val))
diff --git a/pandas/tests/series/test_constructors.py b/pandas/tests/series/test_constructors.py
index ce078059479b4..f811806a897ee 100644
--- a/pandas/tests/series/test_constructors.py
+++ b/pandas/tests/series/test_constructors.py
@@ -1474,3 +1474,10 @@ def test_construction_from_ordered_collection(self):
result = Series({"a": 1, "b": 2}.values())
expected = Series([1, 2])
tm.assert_series_equal(result, expected)
+
+ def test_construction_from_large_int_scalar_no_overflow(self):
+ # https://github.com/pandas-dev/pandas/issues/36291
+ n = 1_000_000_000_000_000_000_000
+ result = Series(n, index=[0])
+ expected = Series(n)
+ tm.assert_series_equal(result, expected)
|
Backport PR #36316: BUG: Don't overflow with large int scalar
|
https://api.github.com/repos/pandas-dev/pandas/pulls/36334
|
2020-09-13T13:29:10Z
|
2020-09-13T15:52:02Z
|
2020-09-13T15:52:02Z
|
2020-09-13T15:52:02Z
| 546
|
pandas-dev/pandas
| 44,803
|
Fix incorrect namespace in sitemap's template.
|
diff --git a/docs/ref/contrib/sitemaps.txt b/docs/ref/contrib/sitemaps.txt
index b89a9a13b02ca..fb3871e58e547 100644
--- a/docs/ref/contrib/sitemaps.txt
+++ b/docs/ref/contrib/sitemaps.txt
@@ -456,7 +456,7 @@ generate a Google News compatible sitemap:
<?xml version="1.0" encoding="UTF-8"?>
<urlset
xmlns="http://www.sitemaps.org/schemas/sitemap/0.9"
- xmlns:news="https://www.google.com/schemas/sitemap-news/0.9">
+ xmlns:news="http://www.google.com/schemas/sitemap-news/0.9">
{% spaceless %}
{% for url in urlset %}
<url>
|
According Google's webmaster tools namespace for news are invalid.
|
https://api.github.com/repos/django/django/pulls/7980
|
2017-01-28T19:12:11Z
|
2017-01-30T17:07:15Z
|
2017-01-30T17:07:15Z
|
2017-01-30T17:07:15Z
| 183
|
django/django
| 51,183
|
🔧 Update sponsors, add Jina back as bronze sponsor
|
diff --git a/docs/en/data/sponsors.yml b/docs/en/data/sponsors.yml
index 53cdb9bad1588..6cfd5b5564ba4 100644
--- a/docs/en/data/sponsors.yml
+++ b/docs/en/data/sponsors.yml
@@ -37,3 +37,6 @@ bronze:
- url: https://www.flint.sh
title: IT expertise, consulting and development by passionate people
img: https://fastapi.tiangolo.com/img/sponsors/flint.png
+ - url: https://bit.ly/3JJ7y5C
+ title: Build cross-modal and multimodal applications on the cloud
+ img: https://fastapi.tiangolo.com/img/sponsors/jina2.svg
|
🔧 Update sponsors, add Jina back as bronze sponsor
|
https://api.github.com/repos/tiangolo/fastapi/pulls/10050
|
2023-08-09T13:20:58Z
|
2023-08-09T13:26:33Z
|
2023-08-09T13:26:33Z
|
2023-08-09T13:26:35Z
| 165
|
tiangolo/fastapi
| 22,789
|
remove additional tags in Phind
|
diff --git a/g4f/Provider/Phind.py b/g4f/Provider/Phind.py
index dbf1e7ae36..e71568427d 100644
--- a/g4f/Provider/Phind.py
+++ b/g4f/Provider/Phind.py
@@ -69,6 +69,8 @@ async def create_async_generator(
pass
elif chunk.startswith(b"<PHIND_METADATA>") or chunk.startswith(b"<PHIND_INDICATOR>"):
pass
+ elif chunk.startswith(b"<PHIND_SPAN_BEGIN>") or chunk.startswith(b"<PHIND_SPAN_END>"):
+ pass
elif chunk:
yield chunk.decode()
elif new_line:
|
Phind added new additional tags to their reply and this commit removed them.
Example additional tags:
```
<PHIND_SPAN_BEGIN>{"id": "g30s0idmy56038rjky0i", "indicator": "Using GPT4", "parent": "qolbkr9srwccc7ir3m5f", "start": 1706418122.9927964, "end": null, "indent": 2, "children": []}</PHIND_SPAN_BEGIN><PHIND_SPAN_END>{"id": "g30s0idmy56038rjky0i", "indicator": "Using GPT4", "end": 1706418122.994516}</PHIND_SPAN_END>
```
|
https://api.github.com/repos/xtekky/gpt4free/pulls/1522
|
2024-01-28T13:13:19Z
|
2024-01-28T22:57:57Z
|
2024-01-28T22:57:57Z
|
2024-01-28T22:57:57Z
| 154
|
xtekky/gpt4free
| 38,101
|
Add version switch to flask cli
|
diff --git a/flask/cli.py b/flask/cli.py
index cf2c5c0c9c..90eb0353cf 100644
--- a/flask/cli.py
+++ b/flask/cli.py
@@ -18,7 +18,7 @@
from ._compat import iteritems, reraise
from .helpers import get_debug_flag
-
+from . import __version__
class NoAppException(click.UsageError):
"""Raised if an application cannot be found or loaded."""
@@ -108,6 +108,22 @@ def find_default_import_path():
return app
+def get_version(ctx, param, value):
+ if not value or ctx.resilient_parsing:
+ return
+ message = 'Flask %(version)s\nPython %(python_version)s'
+ click.echo(message % {
+ 'version': __version__,
+ 'python_version': sys.version,
+ }, color=ctx.color)
+ ctx.exit()
+
+version_option = click.Option(['--version'],
+ help='Show the flask version',
+ expose_value=False,
+ callback=get_version,
+ is_flag=True, is_eager=True)
+
class DispatchingApp(object):
"""Special application that dispatches to a flask application which
is imported by name in a background thread. If an error happens
@@ -270,12 +286,19 @@ class FlaskGroup(AppGroup):
:param add_default_commands: if this is True then the default run and
shell commands wil be added.
+ :param add_version_option: adds the :option:`--version` option.
:param create_app: an optional callback that is passed the script info
and returns the loaded app.
"""
- def __init__(self, add_default_commands=True, create_app=None, **extra):
- AppGroup.__init__(self, **extra)
+ def __init__(self, add_default_commands=True, create_app=None,
+ add_version_option=True, **extra):
+ params = list(extra.pop('params', None) or ())
+
+ if add_version_option:
+ params.append(version_option)
+
+ AppGroup.__init__(self, params=params, **extra)
self.create_app = create_app
if add_default_commands:
|
re #1828
|
https://api.github.com/repos/pallets/flask/pulls/1848
|
2016-06-02T10:59:01Z
|
2016-06-02T11:53:13Z
|
2016-06-02T11:53:13Z
|
2020-11-14T04:52:48Z
| 492
|
pallets/flask
| 20,568
|
Fix parameter typing for generateCode
|
diff --git a/frontend/src/App.tsx b/frontend/src/App.tsx
index f1301e04..3ae08a91 100644
--- a/frontend/src/App.tsx
+++ b/frontend/src/App.tsx
@@ -2,7 +2,7 @@ import { useEffect, useRef, useState } from "react";
import ImageUpload from "./components/ImageUpload";
import CodePreview from "./components/CodePreview";
import Preview from "./components/Preview";
-import { CodeGenerationParams, generateCode } from "./generateCode";
+import { generateCode } from "./generateCode";
import Spinner from "./components/Spinner";
import classNames from "classnames";
import {
@@ -18,7 +18,13 @@ import { Button } from "@/components/ui/button";
import { Textarea } from "@/components/ui/textarea";
import { Tabs, TabsContent, TabsList, TabsTrigger } from "./components/ui/tabs";
import SettingsDialog from "./components/SettingsDialog";
-import { Settings, EditorTheme, AppState, GeneratedCodeConfig } from "./types";
+import {
+ AppState,
+ CodeGenerationParams,
+ EditorTheme,
+ GeneratedCodeConfig,
+ Settings,
+} from "./types";
import { IS_RUNNING_ON_CLOUD } from "./config";
import { PicoBadge } from "./components/PicoBadge";
import { OnboardingNote } from "./components/OnboardingNote";
diff --git a/frontend/src/generateCode.ts b/frontend/src/generateCode.ts
index 8a05fe73..96fbdc1c 100644
--- a/frontend/src/generateCode.ts
+++ b/frontend/src/generateCode.ts
@@ -1,23 +1,16 @@
import toast from "react-hot-toast";
import { WS_BACKEND_URL } from "./config";
import { USER_CLOSE_WEB_SOCKET_CODE } from "./constants";
+import { FullGenerationSettings } from "./types";
const ERROR_MESSAGE =
"Error generating code. Check the Developer Console AND the backend logs for details. Feel free to open a Github issue.";
const STOP_MESSAGE = "Code generation stopped";
-export interface CodeGenerationParams {
- generationType: "create" | "update";
- image: string;
- resultImage?: string;
- history?: string[];
- // isImageGenerationEnabled: boolean; // TODO: Merge with Settings type in types.ts
-}
-
export function generateCode(
wsRef: React.MutableRefObject<WebSocket | null>,
- params: CodeGenerationParams,
+ params: FullGenerationSettings,
onChange: (chunk: string) => void,
onSetCode: (code: string) => void,
onStatusUpdate: (status: string) => void,
diff --git a/frontend/src/types.ts b/frontend/src/types.ts
index deb370a2..92027456 100644
--- a/frontend/src/types.ts
+++ b/frontend/src/types.ts
@@ -28,3 +28,12 @@ export enum AppState {
CODING = "CODING",
CODE_READY = "CODE_READY",
}
+
+export interface CodeGenerationParams {
+ generationType: "create" | "update";
+ image: string;
+ resultImage?: string;
+ history?: string[];
+}
+
+export type FullGenerationSettings = CodeGenerationParams & Settings;
|
The parameter type was not complete as `Settings` are also included and expected by the backend
|
https://api.github.com/repos/abi/screenshot-to-code/pulls/170
|
2023-12-08T00:19:23Z
|
2023-12-11T23:23:18Z
|
2023-12-11T23:23:18Z
|
2023-12-11T23:23:48Z
| 695
|
abi/screenshot-to-code
| 46,907
|
Fast path for disabled template load explain.
|
diff --git a/flask/templating.py b/flask/templating.py
index 8c95a6a706..2da4926d25 100644
--- a/flask/templating.py
+++ b/flask/templating.py
@@ -52,27 +52,36 @@ def __init__(self, app):
self.app = app
def get_source(self, environment, template):
- explain = self.app.config['EXPLAIN_TEMPLATE_LOADING']
+ if self.app.config['EXPLAIN_TEMPLATE_LOADING']:
+ return self._get_source_explained(environment, template)
+ return self._get_source_fast(environment, template)
+
+ def _get_source_explained(self, environment, template):
attempts = []
- tmplrv = None
+ trv = None
for srcobj, loader in self._iter_loaders(template):
try:
rv = loader.get_source(environment, template)
- if tmplrv is None:
- tmplrv = rv
- if not explain:
- break
+ if trv is None:
+ trv = rv
except TemplateNotFound:
rv = None
attempts.append((loader, srcobj, rv))
- if explain:
- from .debughelpers import explain_template_loading_attempts
- explain_template_loading_attempts(self.app, template, attempts)
+ from .debughelpers import explain_template_loading_attempts
+ explain_template_loading_attempts(self.app, template, attempts)
+
+ if trv is not None:
+ return trv
+ raise TemplateNotFound(template)
- if tmplrv is not None:
- return tmplrv
+ def _get_source_fast(self, environment, template):
+ for srcobj, loader in self._iter_loaders(template):
+ try:
+ return loader.get_source(environment, template)
+ except TemplateNotFound:
+ continue
raise TemplateNotFound(template)
def _iter_loaders(self, template):
|
Refs #1792
|
https://api.github.com/repos/pallets/flask/pulls/1814
|
2016-05-22T09:36:57Z
|
2016-05-26T19:34:56Z
|
2016-05-26T19:34:56Z
|
2020-11-14T04:42:50Z
| 428
|
pallets/flask
| 20,741
|
boardd: SPI bulk read + write
|
diff --git a/selfdrive/boardd/panda_comms.h b/selfdrive/boardd/panda_comms.h
index aef7b41d070f7e..f42eadc5b23b64 100644
--- a/selfdrive/boardd/panda_comms.h
+++ b/selfdrive/boardd/panda_comms.h
@@ -34,7 +34,7 @@ class PandaCommsHandle {
virtual int bulk_read(unsigned char endpoint, unsigned char* data, int length, unsigned int timeout=TIMEOUT) = 0;
protected:
- std::mutex hw_lock;
+ std::recursive_mutex hw_lock;
};
class PandaUsbHandle : public PandaCommsHandle {
@@ -74,6 +74,7 @@ class PandaSpiHandle : public PandaCommsHandle {
uint8_t rx_buf[SPI_BUF_SIZE];
int wait_for_ack(spi_ioc_transfer &transfer, uint8_t ack);
+ int bulk_transfer(uint8_t endpoint, uint8_t *tx_data, uint16_t tx_len, uint8_t *rx_data, uint16_t rx_len);
int spi_transfer(uint8_t endpoint, uint8_t *tx_data, uint16_t tx_len, uint8_t *rx_data, uint16_t max_rx_len);
int spi_transfer_retry(uint8_t endpoint, uint8_t *tx_data, uint16_t tx_len, uint8_t *rx_data, uint16_t max_rx_len);
};
diff --git a/selfdrive/boardd/spi.cc b/selfdrive/boardd/spi.cc
index 3969b313f0f14c..2803f58db009f2 100644
--- a/selfdrive/boardd/spi.cc
+++ b/selfdrive/boardd/spi.cc
@@ -2,6 +2,7 @@
#include <linux/spi/spidev.h>
#include <cassert>
+#include <cmath>
#include <cstring>
#include "common/util.h"
@@ -99,13 +100,45 @@ int PandaSpiHandle::control_read(uint8_t request, uint16_t param1, uint16_t para
}
int PandaSpiHandle::bulk_write(unsigned char endpoint, unsigned char* data, int length, unsigned int timeout) {
- return 0;
+ return bulk_transfer(endpoint, data, length, NULL, 0);
}
-
int PandaSpiHandle::bulk_read(unsigned char endpoint, unsigned char* data, int length, unsigned int timeout) {
- return 0;
+ return bulk_transfer(endpoint, NULL, 0, data, length);
+}
+
+int PandaSpiHandle::bulk_transfer(uint8_t endpoint, uint8_t *tx_data, uint16_t tx_len, uint8_t *rx_data, uint16_t rx_len) {
+ std::lock_guard lk(hw_lock);
+
+ const int xfer_size = 0x40;
+
+ int ret = 0;
+ uint16_t length = (tx_data != NULL) ? tx_len : rx_len;
+ for (int i = 0; i < (int)std::ceil((float)length / xfer_size); i++) {
+ int d;
+ if (tx_data != NULL) {
+ int len = std::min(xfer_size, tx_len - (xfer_size * i));
+ d = spi_transfer_retry(endpoint, tx_data + (xfer_size * i), len, NULL, 0);
+ } else {
+ d = spi_transfer_retry(endpoint, NULL, 0, rx_data + (xfer_size * i), xfer_size);
+ }
+
+ if (d < 0) {
+ LOGE("SPI: bulk transfer failed with %d", d);
+ comms_healthy = false;
+ return -1;
+ }
+
+ ret += d;
+ if ((rx_data != NULL) && d < xfer_size) {
+ break;
+ }
+ }
+
+ return ret;
}
+
+
std::vector<std::string> PandaSpiHandle::list() {
// TODO: list all pandas available over SPI
return {};
@@ -130,15 +163,15 @@ bool check_checksum(uint8_t *data, int data_len) {
int PandaSpiHandle::spi_transfer_retry(uint8_t endpoint, uint8_t *tx_data, uint16_t tx_len, uint8_t *rx_data, uint16_t max_rx_len) {
- int err;
+ int ret;
std::lock_guard lk(hw_lock);
do {
// TODO: handle error
- err = spi_transfer(endpoint, tx_data, tx_len, rx_data, max_rx_len);
- } while (err < 0 && connected && !PANDA_NO_RETRY);
+ ret = spi_transfer(endpoint, tx_data, tx_len, rx_data, max_rx_len);
+ } while (ret < 0 && connected && !PANDA_NO_RETRY);
- return err;
+ return ret;
}
int PandaSpiHandle::wait_for_ack(spi_ioc_transfer &transfer, uint8_t ack) {
@@ -153,7 +186,7 @@ int PandaSpiHandle::wait_for_ack(spi_ioc_transfer &transfer, uint8_t ack) {
if (rx_buf[0] == ack) {
break;
} else if (rx_buf[0] == SPI_NACK) {
- LOGW("SPI: got header NACK");
+ LOGW("SPI: got NACK");
return -1;
}
}
|
https://api.github.com/repos/commaai/openpilot/pulls/26462
|
2022-11-11T06:02:40Z
|
2022-11-11T20:51:15Z
|
2022-11-11T20:51:15Z
|
2022-11-11T20:51:16Z
| 1,199
|
commaai/openpilot
| 9,578
|
|
Fix two sections not showing links in the readme
|
diff --git a/README.md b/README.md
index 8f51254407..3376991534 100644
--- a/README.md
+++ b/README.md
@@ -143,7 +143,7 @@ For information on contributing to this project, please see the [contributing gu
### Documents & Productivity
-| API | Description | OAuth |Link |
+| API | Description | Auth | HTTPS |Link |
|---|---|---|---|---|
| File.io | Files | No | Yes | [Go!](https://file.io) |
| pdflayer API | HTML/URL to PDF | No | Yes | [Go!](https://pdflayer.com) |
@@ -176,7 +176,7 @@ For information on contributing to this project, please see the [contributing gu
### Data Validation
-| API | Description | OAuth |Link |
+| API | Description | OAuth | HTTPS | Link |
|---|---|---|---|---|
| languagelayer | Language detection | No | Yes | [Go!](https://languagelayer.com) |
| mailboxlayer | Email address validation | No | Yes | [Go!](https://mailboxlayer.com) |
|
[Documents & Productivity](https://github.com/toddmotto/public-apis#documents--productivity) and [Data Validation](https://github.com/toddmotto/public-apis#data-validation) were both missing the `HTTPS` column, so the links weren't rendering in the readme. Docs+Prod also said `OAuth` instead of `Auth` in the header.
|
https://api.github.com/repos/public-apis/public-apis/pulls/276
|
2017-02-04T09:50:44Z
|
2017-02-04T16:09:36Z
|
2017-02-04T16:09:36Z
|
2017-02-06T10:31:03Z
| 265
|
public-apis/public-apis
| 35,936
|
[NPU] Fix npu offload bug
|
diff --git a/csrc/includes/cpu_adagrad.h b/csrc/includes/cpu_adagrad.h
index 59888adf17c3..e60984d64b76 100644
--- a/csrc/includes/cpu_adagrad.h
+++ b/csrc/includes/cpu_adagrad.h
@@ -194,7 +194,7 @@ void Adagrad_Optimizer::Step_AVX(size_t* rounded_size,
#elif defined(__ENABLE_CANN__)
if (dev_params) {
size_t memcpy_size = copy_size * sizeof(_doubled_buffer[_buf_index][0]);
- if (half_precision) memoryCopySize /= 2;
+ if (half_precision) memcpy_size /= 2;
aclrtMemcpy(dev_params + t,
memcpy_size,
_doubled_buffer[_buf_index],
@@ -202,6 +202,7 @@ void Adagrad_Optimizer::Step_AVX(size_t* rounded_size,
aclrtMemcpyKind::ACL_MEMCPY_HOST_TO_DEVICE);
_buf_index = !_buf_index;
+ }
#endif
}
*rounded_size = new_rounded_size;
diff --git a/csrc/includes/cpu_adam.h b/csrc/includes/cpu_adam.h
index 44d3ed3cac61..b1a104b2571d 100644
--- a/csrc/includes/cpu_adam.h
+++ b/csrc/includes/cpu_adam.h
@@ -215,8 +215,7 @@ void Adam_Optimizer::Step_AVX(size_t* rounded_size,
#if defined(__ENABLE_CUDA__)
if ((t / TILE) >= 2) { cudaStreamSynchronize(_streams[_buf_index]); }
#elif defined(__ENABLE_CANN__)
- if ((t / TILE) >= 2) { aclrtSynchronizeStream((_streams[_buf_index].stream());
- }
+ if ((t / TILE) >= 2) { aclrtSynchronizeStream(_streams[_buf_index].stream()); }
#endif
#pragma omp parallel for
for (size_t i = t; i < offset; i += SIMD_WIDTH * span) {
@@ -274,7 +273,7 @@ void Adam_Optimizer::Step_AVX(size_t* rounded_size,
#elif defined(__ENABLE_CANN__)
if (dev_params) {
size_t memcpy_size = copy_size * sizeof(_doubled_buffer[_buf_index][0]);
- if (half_precision) memoryCopySize /= 2;
+ if (half_precision) memcpy_size /= 2;
aclrtMemcpy(dev_params + t,
memcpy_size,
_doubled_buffer[_buf_index],
@@ -282,6 +281,7 @@ void Adam_Optimizer::Step_AVX(size_t* rounded_size,
aclrtMemcpyKind::ACL_MEMCPY_HOST_TO_DEVICE);
_buf_index = !_buf_index;
+ }
#endif
}
*rounded_size = new_rounded_size;
diff --git a/csrc/includes/cpu_lion.h b/csrc/includes/cpu_lion.h
index d83fe9473332..34c29eec47db 100644
--- a/csrc/includes/cpu_lion.h
+++ b/csrc/includes/cpu_lion.h
@@ -223,7 +223,7 @@ void Lion_Optimizer::Step_AVX(size_t* rounded_size,
#elif defined(__ENABLE_CANN__)
if (dev_params) {
size_t memcpy_size = copy_size * sizeof(_doubled_buffer[_buf_index][0]);
- if (half_precision) memoryCopySize /= 2;
+ if (half_precision) memcpy_size /= 2;
aclrtMemcpy(dev_params + t,
memcpy_size,
_doubled_buffer[_buf_index],
@@ -231,6 +231,7 @@ void Lion_Optimizer::Step_AVX(size_t* rounded_size,
aclrtMemcpyKind::ACL_MEMCPY_HOST_TO_DEVICE);
_buf_index = !_buf_index;
+ }
#endif
}
*rounded_size = new_rounded_size;
|
There are some syntax errors in the NPU offload.
There may be no AVX instruction set on our server due to environment variables, as a result, this problem is not verified in our tests.
Sorry for the inconvenience and we will be more cautious in the next PRs.
|
https://api.github.com/repos/microsoft/DeepSpeed/pulls/4883
|
2023-12-29T01:28:42Z
|
2024-01-02T22:33:30Z
|
2024-01-02T22:33:30Z
|
2024-01-02T22:33:30Z
| 872
|
microsoft/DeepSpeed
| 10,096
|
Fix missed parameter from AUC config
|
diff --git a/keras/metrics/confusion_matrix_test.py b/keras/metrics/confusion_matrix_test.py
index 773323fe094..631e36596c1 100644
--- a/keras/metrics/confusion_matrix_test.py
+++ b/keras/metrics/confusion_matrix_test.py
@@ -1299,9 +1299,11 @@ class AUCTest(tf.test.TestCase, parameterized.TestCase):
def setup(self):
self.num_thresholds = 3
self.y_pred = tf.constant([0, 0.5, 0.3, 0.9], dtype=tf.float32)
+ self.y_pred_multi_label = tf.constant([[0., 0.4], [0.5, 0.7], [0.3, 0.2], [0.9, 0.3]], dtype=tf.float32)
epsilon = 1e-12
self.y_pred_logits = -tf.math.log(1.0 / (self.y_pred + epsilon) - 1.0)
self.y_true = tf.constant([0, 0, 1, 1])
+ self.y_true_multi_label = tf.constant([[0, 0], [1, 1], [1, 1], [1, 0]])
self.sample_weight = [1, 2, 3, 4]
# threshold values are [0 - 1e-7, 0.5, 1 + 1e-7]
@@ -1332,22 +1334,30 @@ def test_config(self):
curve="PR",
summation_method="majoring",
name="auc_1",
+ dtype=tf.float64,
+ multi_label=True,
+ num_labels=2,
+ from_logits=True
)
- auc_obj.update_state(self.y_true, self.y_pred)
+ auc_obj.update_state(self.y_true_multi_label, self.y_pred_multi_label)
self.assertEqual(auc_obj.name, "auc_1")
+ self.assertEqual(auc_obj._dtype, tf.float64)
self.assertLen(auc_obj.variables, 4)
self.assertEqual(auc_obj.num_thresholds, 100)
self.assertEqual(auc_obj.curve, metrics_utils.AUCCurve.PR)
self.assertEqual(
auc_obj.summation_method, metrics_utils.AUCSummationMethod.MAJORING
)
+ self.assertTrue(auc_obj.multi_label)
+ self.assertEqual(auc_obj.num_labels, 2)
+ self.assertTrue(auc_obj._from_logits)
old_config = auc_obj.get_config()
self.assertNotIn("thresholds", old_config)
self.assertDictEqual(old_config, json.loads(json.dumps(old_config)))
# Check save and restore config.
auc_obj2 = metrics.AUC.from_config(auc_obj.get_config())
- auc_obj2.update_state(self.y_true, self.y_pred)
+ auc_obj2.update_state(self.y_true_multi_label, self.y_pred_multi_label)
self.assertEqual(auc_obj2.name, "auc_1")
self.assertLen(auc_obj2.variables, 4)
self.assertEqual(auc_obj2.num_thresholds, 100)
@@ -1355,6 +1365,9 @@ def test_config(self):
self.assertEqual(
auc_obj2.summation_method, metrics_utils.AUCSummationMethod.MAJORING
)
+ self.assertTrue(auc_obj2.multi_label)
+ self.assertEqual(auc_obj2.num_labels, 2)
+ self.assertTrue(auc_obj2._from_logits)
new_config = auc_obj2.get_config()
self.assertNotIn("thresholds", new_config)
self.assertDictEqual(old_config, new_config)
@@ -2067,5 +2080,5 @@ def test_even_thresholds_correctness_2(self, metric_cls):
self.assertAllClose(v1, v2)
-if __name__ == "__main__":
- tf.test.main()
+if __name__ == '__main__':
+ tf.test.main()
diff --git a/keras/metrics/metrics.py b/keras/metrics/metrics.py
index f68dfd2f9ef..61eb231d5f4 100644
--- a/keras/metrics/metrics.py
+++ b/keras/metrics/metrics.py
@@ -1782,6 +1782,7 @@ def __init__(
# Handle multilabel arguments.
self.multi_label = multi_label
+ self.num_labels = num_labels
if label_weights is not None:
label_weights = tf.constant(label_weights, dtype=self.dtype)
tf.debugging.assert_non_negative(
@@ -2107,7 +2108,9 @@ def get_config(self):
"curve": self.curve.value,
"summation_method": self.summation_method.value,
"multi_label": self.multi_label,
+ 'num_labels': self.num_labels,
"label_weights": label_weights,
+ 'from_logits': self._from_logits,
}
# optimization to avoid serializing a large number of generated thresholds
if self._init_from_thresholds:
diff --git a/keras/utils/metrics_utils.py b/keras/utils/metrics_utils.py
index ee1de7668f5..50abd9e6e64 100644
--- a/keras/utils/metrics_utils.py
+++ b/keras/utils/metrics_utils.py
@@ -394,7 +394,7 @@ def _update_confusion_matrix_variables_optimized(
)
if not multi_label:
label_weights = tf.reshape(label_weights, [-1])
- weights = tf.multiply(sample_weights, label_weights)
+ weights = tf.cast(tf.multiply(sample_weights, label_weights), y_true.dtype)
# We shouldn't need this, but in case there are predict value that is out of
# the range of [0.0, 1.0]
|
AUC metrics missed `from_logits` parameter in `get_config` method, which will cause a error when load from a saved model and `from_logits` is True.
|
https://api.github.com/repos/keras-team/keras/pulls/16499
|
2022-05-05T15:25:51Z
|
2022-06-16T19:03:29Z
|
2022-06-16T19:03:29Z
|
2022-06-16T19:03:29Z
| 1,273
|
keras-team/keras
| 46,959
|
[autoscaler] rsync cluster
|
diff --git a/python/ray/autoscaler/commands.py b/python/ray/autoscaler/commands.py
index 9a89261be7dee..faaef8c6a1538 100644
--- a/python/ray/autoscaler/commands.py
+++ b/python/ray/autoscaler/commands.py
@@ -423,6 +423,8 @@ def rsync(config_file, source, target, override_cluster_name, down):
override_cluster_name: set the name of the cluster
down: whether we're syncing remote -> local
"""
+ assert bool(source) == bool(target), (
+ "Must either provide both or neither source and target.")
config = yaml.load(open(config_file).read())
if override_cluster_name is not None:
@@ -448,7 +450,12 @@ def rsync(config_file, source, target, override_cluster_name, down):
rsync = updater.rsync_down
else:
rsync = updater.rsync_up
- rsync(source, target, check_error=False)
+
+ if source and target:
+ rsync(source, target, check_error=False)
+ else:
+ updater.sync_file_mounts(rsync)
+
finally:
provider.cleanup()
diff --git a/python/ray/autoscaler/updater.py b/python/ray/autoscaler/updater.py
index 9fff0c7674679..c86750fe399d9 100644
--- a/python/ray/autoscaler/updater.py
+++ b/python/ray/autoscaler/updater.py
@@ -183,25 +183,9 @@ def wait_for_ssh(self, deadline):
return False
- def do_update(self):
- self.provider.set_node_tags(self.node_id,
- {TAG_RAY_NODE_STATUS: "waiting-for-ssh"})
-
- deadline = time.time() + NODE_START_WAIT_S
- self.set_ssh_ip_if_required()
-
- # Wait for SSH access
- with LogTimer("NodeUpdater: " "{}: Got SSH".format(self.node_id)):
- ssh_ok = self.wait_for_ssh(deadline)
- assert ssh_ok, "Unable to SSH to node"
-
+ def sync_file_mounts(self, sync_cmd):
# Rsync file mounts
- self.provider.set_node_tags(self.node_id,
- {TAG_RAY_NODE_STATUS: "syncing-files"})
for remote_path, local_path in self.file_mounts.items():
- logger.info("NodeUpdater: "
- "{}: Syncing {} to {}...".format(
- self.node_id, local_path, remote_path))
assert os.path.exists(local_path), local_path
if os.path.isdir(local_path):
if not local_path.endswith("/"):
@@ -217,7 +201,23 @@ def do_update(self):
"mkdir -p {}".format(os.path.dirname(remote_path)),
redirect=redirect,
)
- self.rsync_up(local_path, remote_path, redirect=redirect)
+ sync_cmd(local_path, remote_path, redirect=redirect)
+
+ def do_update(self):
+ self.provider.set_node_tags(self.node_id,
+ {TAG_RAY_NODE_STATUS: "waiting-for-ssh"})
+
+ deadline = time.time() + NODE_START_WAIT_S
+ self.set_ssh_ip_if_required()
+
+ # Wait for SSH access
+ with LogTimer("NodeUpdater: " "{}: Got SSH".format(self.node_id)):
+ ssh_ok = self.wait_for_ssh(deadline)
+ assert ssh_ok, "Unable to SSH to node"
+
+ self.provider.set_node_tags(self.node_id,
+ {TAG_RAY_NODE_STATUS: "syncing-files"})
+ self.sync_file_mounts(self.rsync_up)
# Run init commands
self.provider.set_node_tags(self.node_id,
@@ -236,6 +236,9 @@ def do_update(self):
self.ssh_cmd(cmd, redirect=redirect)
def rsync_up(self, source, target, redirect=None, check_error=True):
+ logger.info("NodeUpdater: "
+ "{}: Syncing {} to {}...".format(self.node_id, source,
+ target))
self.set_ssh_ip_if_required()
self.get_caller(check_error)(
[
@@ -247,6 +250,9 @@ def rsync_up(self, source, target, redirect=None, check_error=True):
stderr=redirect or sys.stderr)
def rsync_down(self, source, target, redirect=None, check_error=True):
+ logger.info("NodeUpdater: "
+ "{}: Syncing {} from {}...".format(self.node_id, source,
+ target))
self.set_ssh_ip_if_required()
self.get_caller(check_error)(
[
diff --git a/python/ray/scripts/scripts.py b/python/ray/scripts/scripts.py
index 1951af208573c..e993478c1011a 100644
--- a/python/ray/scripts/scripts.py
+++ b/python/ray/scripts/scripts.py
@@ -529,8 +529,8 @@ def attach(cluster_config_file, start, tmux, cluster_name, new):
@cli.command()
@click.argument("cluster_config_file", required=True, type=str)
[email protected]("source", required=True, type=str)
[email protected]("target", required=True, type=str)
[email protected]("source", required=False, type=str)
[email protected]("target", required=False, type=str)
@click.option(
"--cluster-name",
"-n",
@@ -543,8 +543,8 @@ def rsync_down(cluster_config_file, source, target, cluster_name):
@cli.command()
@click.argument("cluster_config_file", required=True, type=str)
[email protected]("source", required=True, type=str)
[email protected]("target", required=True, type=str)
[email protected]("source", required=False, type=str)
[email protected]("target", required=False, type=str)
@click.option(
"--cluster-name",
"-n",
diff --git a/python/ray/tune/examples/mnist_pytorch_trainable.py b/python/ray/tune/examples/mnist_pytorch_trainable.py
index ac26d0353a981..7163dcfd6a01c 100644
--- a/python/ray/tune/examples/mnist_pytorch_trainable.py
+++ b/python/ray/tune/examples/mnist_pytorch_trainable.py
@@ -49,6 +49,11 @@
action="store_true",
default=False,
help="disables CUDA training")
+parser.add_argument(
+ "--redis-address",
+ default=None,
+ type=str,
+ help="The Redis address of the cluster.")
parser.add_argument(
"--seed",
type=int,
@@ -173,7 +178,7 @@ def _restore(self, checkpoint_path):
from ray import tune
from ray.tune.schedulers import HyperBandScheduler
- ray.init()
+ ray.init(redis_address=args.redis_address)
sched = HyperBandScheduler(
time_attr="training_iteration", reward_attr="neg_mean_loss")
tune.run(
|
<!-- Thank you for your contribution! Please review https://github.com/ray-project/ray/blob/master/CONTRIBUTING.rst before opening a pull request. -->
## What do these changes do?
If `source` and `target` are not provided for `rsync`, `ray rsync-up/rsync-down`
will automatically upload all file_mounts listed in the cluster yaml.
This PR is based off #4782.
## Related issue number
## Linter
- [x] I've run `scripts/format.sh` to lint the changes in this PR.
|
https://api.github.com/repos/ray-project/ray/pulls/4785
|
2019-05-15T00:13:35Z
|
2019-05-17T06:11:06Z
|
2019-05-17T06:11:06Z
|
2019-05-17T06:11:11Z
| 1,527
|
ray-project/ray
| 19,252
|
Fixed #30967 -- Fixed TrigramTest failures on PostgreSQL 12+.
|
diff --git a/tests/postgres_tests/test_trigram.py b/tests/postgres_tests/test_trigram.py
index b340b41869ddd..2a123faa5e545 100644
--- a/tests/postgres_tests/test_trigram.py
+++ b/tests/postgres_tests/test_trigram.py
@@ -26,22 +26,26 @@ def test_trigram_search(self):
def test_trigram_similarity(self):
search = 'Bat sat on cat.'
+ # Round result of similarity because PostgreSQL 12+ uses greater
+ # precision.
self.assertQuerysetEqual(
self.Model.objects.filter(
field__trigram_similar=search,
).annotate(similarity=TrigramSimilarity('field', search)).order_by('-similarity'),
[('Cat sat on mat.', 0.625), ('Dog sat on rug.', 0.333333)],
- transform=lambda instance: (instance.field, instance.similarity),
+ transform=lambda instance: (instance.field, round(instance.similarity, 6)),
ordered=True,
)
def test_trigram_similarity_alternate(self):
+ # Round result of distance because PostgreSQL 12+ uses greater
+ # precision.
self.assertQuerysetEqual(
self.Model.objects.annotate(
distance=TrigramDistance('field', 'Bat sat on cat.'),
).filter(distance__lte=0.7).order_by('distance'),
[('Cat sat on mat.', 0.375), ('Dog sat on rug.', 0.666667)],
- transform=lambda instance: (instance.field, instance.distance),
+ transform=lambda instance: (instance.field, round(instance.distance, 6)),
ordered=True,
)
|
Ticket: https://code.djangoproject.com/ticket/30967
|
https://api.github.com/repos/django/django/pulls/12048
|
2019-11-08T20:22:26Z
|
2019-11-11T12:30:32Z
|
2019-11-11T12:30:32Z
|
2019-11-11T12:30:32Z
| 361
|
django/django
| 51,460
|
chore: add GitHub metadata
|
diff --git a/CITATION.cff b/CITATION.cff
new file mode 100644
index 000000000..73a213df7
--- /dev/null
+++ b/CITATION.cff
@@ -0,0 +1,25 @@
+# This CITATION.cff file was generated with cffinit.
+# Visit https://bit.ly/cffinit to generate yours today!
+
+cff-version: 1.2.0
+title: PrivateGPT
+message: >-
+ If you use this software, please cite it using the
+ metadata from this file.
+type: software
+authors:
+ - given-names: Iván
+ family-names: Martínez Toro
+ email: [email protected]
+ orcid: 'https://orcid.org/0009-0004-5065-2311'
+ - family-names: Gallego Vico
+ given-names: Daniel
+ email: [email protected]
+ orcid: 'https://orcid.org/0009-0006-8582-4384'
+ - given-names: Pablo
+ family-names: Orgaz
+ email: [email protected]
+ orcid: 'https://orcid.org/0009-0008-0080-1437'
+repository-code: 'https://github.com/imartinez/privateGPT'
+license: Apache-2.0
+date-released: '2023-05-02'
diff --git a/LICENSE b/LICENSE
new file mode 100644
index 000000000..261eeb9e9
--- /dev/null
+++ b/LICENSE
@@ -0,0 +1,201 @@
+ Apache License
+ Version 2.0, January 2004
+ http://www.apache.org/licenses/
+
+ TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
+
+ 1. Definitions.
+
+ "License" shall mean the terms and conditions for use, reproduction,
+ and distribution as defined by Sections 1 through 9 of this document.
+
+ "Licensor" shall mean the copyright owner or entity authorized by
+ the copyright owner that is granting the License.
+
+ "Legal Entity" shall mean the union of the acting entity and all
+ other entities that control, are controlled by, or are under common
+ control with that entity. For the purposes of this definition,
+ "control" means (i) the power, direct or indirect, to cause the
+ direction or management of such entity, whether by contract or
+ otherwise, or (ii) ownership of fifty percent (50%) or more of the
+ outstanding shares, or (iii) beneficial ownership of such entity.
+
+ "You" (or "Your") shall mean an individual or Legal Entity
+ exercising permissions granted by this License.
+
+ "Source" form shall mean the preferred form for making modifications,
+ including but not limited to software source code, documentation
+ source, and configuration files.
+
+ "Object" form shall mean any form resulting from mechanical
+ transformation or translation of a Source form, including but
+ not limited to compiled object code, generated documentation,
+ and conversions to other media types.
+
+ "Work" shall mean the work of authorship, whether in Source or
+ Object form, made available under the License, as indicated by a
+ copyright notice that is included in or attached to the work
+ (an example is provided in the Appendix below).
+
+ "Derivative Works" shall mean any work, whether in Source or Object
+ form, that is based on (or derived from) the Work and for which the
+ editorial revisions, annotations, elaborations, or other modifications
+ represent, as a whole, an original work of authorship. For the purposes
+ of this License, Derivative Works shall not include works that remain
+ separable from, or merely link (or bind by name) to the interfaces of,
+ the Work and Derivative Works thereof.
+
+ "Contribution" shall mean any work of authorship, including
+ the original version of the Work and any modifications or additions
+ to that Work or Derivative Works thereof, that is intentionally
+ submitted to Licensor for inclusion in the Work by the copyright owner
+ or by an individual or Legal Entity authorized to submit on behalf of
+ the copyright owner. For the purposes of this definition, "submitted"
+ means any form of electronic, verbal, or written communication sent
+ to the Licensor or its representatives, including but not limited to
+ communication on electronic mailing lists, source code control systems,
+ and issue tracking systems that are managed by, or on behalf of, the
+ Licensor for the purpose of discussing and improving the Work, but
+ excluding communication that is conspicuously marked or otherwise
+ designated in writing by the copyright owner as "Not a Contribution."
+
+ "Contributor" shall mean Licensor and any individual or Legal Entity
+ on behalf of whom a Contribution has been received by Licensor and
+ subsequently incorporated within the Work.
+
+ 2. Grant of Copyright License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ copyright license to reproduce, prepare Derivative Works of,
+ publicly display, publicly perform, sublicense, and distribute the
+ Work and such Derivative Works in Source or Object form.
+
+ 3. Grant of Patent License. Subject to the terms and conditions of
+ this License, each Contributor hereby grants to You a perpetual,
+ worldwide, non-exclusive, no-charge, royalty-free, irrevocable
+ (except as stated in this section) patent license to make, have made,
+ use, offer to sell, sell, import, and otherwise transfer the Work,
+ where such license applies only to those patent claims licensable
+ by such Contributor that are necessarily infringed by their
+ Contribution(s) alone or by combination of their Contribution(s)
+ with the Work to which such Contribution(s) was submitted. If You
+ institute patent litigation against any entity (including a
+ cross-claim or counterclaim in a lawsuit) alleging that the Work
+ or a Contribution incorporated within the Work constitutes direct
+ or contributory patent infringement, then any patent licenses
+ granted to You under this License for that Work shall terminate
+ as of the date such litigation is filed.
+
+ 4. Redistribution. You may reproduce and distribute copies of the
+ Work or Derivative Works thereof in any medium, with or without
+ modifications, and in Source or Object form, provided that You
+ meet the following conditions:
+
+ (a) You must give any other recipients of the Work or
+ Derivative Works a copy of this License; and
+
+ (b) You must cause any modified files to carry prominent notices
+ stating that You changed the files; and
+
+ (c) You must retain, in the Source form of any Derivative Works
+ that You distribute, all copyright, patent, trademark, and
+ attribution notices from the Source form of the Work,
+ excluding those notices that do not pertain to any part of
+ the Derivative Works; and
+
+ (d) If the Work includes a "NOTICE" text file as part of its
+ distribution, then any Derivative Works that You distribute must
+ include a readable copy of the attribution notices contained
+ within such NOTICE file, excluding those notices that do not
+ pertain to any part of the Derivative Works, in at least one
+ of the following places: within a NOTICE text file distributed
+ as part of the Derivative Works; within the Source form or
+ documentation, if provided along with the Derivative Works; or,
+ within a display generated by the Derivative Works, if and
+ wherever such third-party notices normally appear. The contents
+ of the NOTICE file are for informational purposes only and
+ do not modify the License. You may add Your own attribution
+ notices within Derivative Works that You distribute, alongside
+ or as an addendum to the NOTICE text from the Work, provided
+ that such additional attribution notices cannot be construed
+ as modifying the License.
+
+ You may add Your own copyright statement to Your modifications and
+ may provide additional or different license terms and conditions
+ for use, reproduction, or distribution of Your modifications, or
+ for any such Derivative Works as a whole, provided Your use,
+ reproduction, and distribution of the Work otherwise complies with
+ the conditions stated in this License.
+
+ 5. Submission of Contributions. Unless You explicitly state otherwise,
+ any Contribution intentionally submitted for inclusion in the Work
+ by You to the Licensor shall be under the terms and conditions of
+ this License, without any additional terms or conditions.
+ Notwithstanding the above, nothing herein shall supersede or modify
+ the terms of any separate license agreement you may have executed
+ with Licensor regarding such Contributions.
+
+ 6. Trademarks. This License does not grant permission to use the trade
+ names, trademarks, service marks, or product names of the Licensor,
+ except as required for reasonable and customary use in describing the
+ origin of the Work and reproducing the content of the NOTICE file.
+
+ 7. Disclaimer of Warranty. Unless required by applicable law or
+ agreed to in writing, Licensor provides the Work (and each
+ Contributor provides its Contributions) on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
+ implied, including, without limitation, any warranties or conditions
+ of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
+ PARTICULAR PURPOSE. You are solely responsible for determining the
+ appropriateness of using or redistributing the Work and assume any
+ risks associated with Your exercise of permissions under this License.
+
+ 8. Limitation of Liability. In no event and under no legal theory,
+ whether in tort (including negligence), contract, or otherwise,
+ unless required by applicable law (such as deliberate and grossly
+ negligent acts) or agreed to in writing, shall any Contributor be
+ liable to You for damages, including any direct, indirect, special,
+ incidental, or consequential damages of any character arising as a
+ result of this License or out of the use or inability to use the
+ Work (including but not limited to damages for loss of goodwill,
+ work stoppage, computer failure or malfunction, or any and all
+ other commercial damages or losses), even if such Contributor
+ has been advised of the possibility of such damages.
+
+ 9. Accepting Warranty or Additional Liability. While redistributing
+ the Work or Derivative Works thereof, You may choose to offer,
+ and charge a fee for, acceptance of support, warranty, indemnity,
+ or other liability obligations and/or rights consistent with this
+ License. However, in accepting such obligations, You may act only
+ on Your own behalf and on Your sole responsibility, not on behalf
+ of any other Contributor, and only if You agree to indemnify,
+ defend, and hold each Contributor harmless for any liability
+ incurred by, or claims asserted against, such Contributor by reason
+ of your accepting any such warranty or additional liability.
+
+ END OF TERMS AND CONDITIONS
+
+ APPENDIX: How to apply the Apache License to your work.
+
+ To apply the Apache License to your work, attach the following
+ boilerplate notice, with the fields enclosed by brackets "[]"
+ replaced with your own identifying information. (Don't include
+ the brackets!) The text should be enclosed in the appropriate
+ comment syntax for the file format. We also recommend that a
+ file or class name and description of purpose be included on the
+ same "printed page" as the copyright notice for easier
+ identification within third-party archives.
+
+ Copyright [yyyy] [name of copyright owner]
+
+ Licensed under the Apache License, Version 2.0 (the "License");
+ you may not use this file except in compliance with the License.
+ You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing, software
+ distributed under the License is distributed on an "AS IS" BASIS,
+ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+ See the License for the specific language governing permissions and
+ limitations under the License.
diff --git a/README.md b/README.md
index 00f6e399a..5ed6168a2 100644
--- a/README.md
+++ b/README.md
@@ -149,14 +149,24 @@ Join the conversation around PrivateGPT on our:
- [Discord](https://discord.gg/bK6mRVpErU)
## 📖 Citation
-Reference to cite if you use PrivateGPT in a paper:
-
-```
-@software{PrivateGPT_2023,
-authors = {Martinez, I., Gallego, D. Orgaz, P.},
-month = {5},
-title = {PrivateGPT},
+If you use PrivateGPT in a paper, check out the [Citation file](CITATION.cff) for the correct citation.
+You can also use the "Cite this repository" button in this repo to get the citation in different formats.
+
+Here are a couple of examples:
+
+#### BibTeX
+```bibtex
+@software{Martinez_Toro_PrivateGPT_2023,
+author = {Martínez Toro, Iván and Gallego Vico, Daniel and Orgaz, Pablo},
+license = {Apache-2.0},
+month = may,
+title = {{PrivateGPT}},
url = {https://github.com/imartinez/privateGPT},
year = {2023}
}
```
+
+#### APA
+```
+Martínez Toro, I., Gallego Vico, D., & Orgaz, P. (2023). PrivateGPT [Computer software]. https://github.com/imartinez/privateGPT
+```
|
This PR adds a citation file and a license to the repository.
While this info was already available in one form or another, adding it using the standard files not only makes it more accessible, but also allows GitHub to display it more promptly.
I created the citation file with the info I could find, so it's not really complete. You can also add your ORCIDs!
Closes #1006
|
https://api.github.com/repos/zylon-ai/private-gpt/pulls/1085
|
2023-10-20T09:31:25Z
|
2023-10-23T08:49:03Z
|
2023-10-23T08:49:03Z
|
2023-10-24T10:17:58Z
| 3,224
|
zylon-ai/private-gpt
| 38,467
|
[CPAC] Add extractor for Canadian Parliament
|
diff --git a/youtube_dl/extractor/cpac.py b/youtube_dl/extractor/cpac.py
new file mode 100644
index 00000000000..22741152c64
--- /dev/null
+++ b/youtube_dl/extractor/cpac.py
@@ -0,0 +1,148 @@
+# coding: utf-8
+from __future__ import unicode_literals
+
+from .common import InfoExtractor
+from ..compat import compat_str
+from ..utils import (
+ int_or_none,
+ str_or_none,
+ try_get,
+ unified_timestamp,
+ update_url_query,
+ urljoin,
+)
+
+# compat_range
+try:
+ if callable(xrange):
+ range = xrange
+except (NameError, TypeError):
+ pass
+
+
+class CPACIE(InfoExtractor):
+ IE_NAME = 'cpac'
+ _VALID_URL = r'https?://(?:www\.)?cpac\.ca/(?P<fr>l-)?episode\?id=(?P<id>[\da-f]{8}(?:-[\da-f]{4}){3}-[\da-f]{12})'
+ _TEST = {
+ # 'url': 'http://www.cpac.ca/en/programs/primetime-politics/episodes/65490909',
+ 'url': 'https://www.cpac.ca/episode?id=fc7edcae-4660-47e1-ba61-5b7f29a9db0f',
+ 'md5': 'e46ad699caafd7aa6024279f2614e8fa',
+ 'info_dict': {
+ 'id': 'fc7edcae-4660-47e1-ba61-5b7f29a9db0f',
+ 'ext': 'mp4',
+ 'upload_date': '20220215',
+ 'title': 'News Conference to Celebrate National Kindness Week – February 15, 2022',
+ 'description': 'md5:466a206abd21f3a6f776cdef290c23fb',
+ 'timestamp': 1644901200,
+ },
+ 'params': {
+ 'format': 'bestvideo',
+ 'hls_prefer_native': True,
+ },
+ }
+
+ def _real_extract(self, url):
+ video_id = self._match_id(url)
+ url_lang = 'fr' if '/l-episode?' in url else 'en'
+
+ content = self._download_json(
+ 'https://www.cpac.ca/api/1/services/contentModel.json?url=/site/website/episode/index.xml&crafterSite=cpacca&id=' + video_id,
+ video_id)
+ video_url = try_get(content, lambda x: x['page']['details']['videoUrl'], compat_str)
+ formats = []
+ if video_url:
+ content = content['page']
+ title = str_or_none(content['details']['title_%s_t' % (url_lang, )])
+ formats = self._extract_m3u8_formats(video_url, video_id, m3u8_id='hls', ext='mp4')
+ for fmt in formats:
+ # prefer language to match URL
+ fmt_lang = fmt.get('language')
+ if fmt_lang == url_lang:
+ fmt['language_preference'] = 10
+ elif not fmt_lang:
+ fmt['language_preference'] = -1
+ else:
+ fmt['language_preference'] = -10
+
+ self._sort_formats(formats)
+
+ category = str_or_none(content['details']['category_%s_t' % (url_lang, )])
+
+ def is_live(v_type):
+ return (v_type == 'live') if v_type is not None else None
+
+ return {
+ 'id': video_id,
+ 'formats': formats,
+ 'title': title,
+ 'description': str_or_none(content['details'].get('description_%s_t' % (url_lang, ))),
+ 'timestamp': unified_timestamp(content['details'].get('liveDateTime')),
+ 'category': [category] if category else None,
+ 'thumbnail': urljoin(url, str_or_none(content['details'].get('image_%s_s' % (url_lang, )))),
+ 'is_live': is_live(content['details'].get('type')),
+ }
+
+
+class CPACPlaylistIE(InfoExtractor):
+ IE_NAME = 'cpac:playlist'
+ _VALID_URL = r'(?i)https?://(?:www\.)?cpac\.ca/(?:program|search|(?P<fr>emission|rechercher))\?(?:[^&]+&)*?(?P<id>(?:id=\d+|programId=\d+|key=[^&]+))'
+
+ _TESTS = [{
+ 'url': 'https://www.cpac.ca/program?id=6',
+ 'info_dict': {
+ 'id': 'id=6',
+ 'title': 'Headline Politics',
+ 'description': 'Watch CPAC’s signature long-form coverage of the day’s pressing political events as they unfold.',
+ },
+ 'playlist_count': 10,
+ }, {
+ 'url': 'https://www.cpac.ca/search?key=hudson&type=all&order=desc',
+ 'info_dict': {
+ 'id': 'key=hudson',
+ 'title': 'hudson',
+ },
+ 'playlist_count': 22,
+ }, {
+ 'url': 'https://www.cpac.ca/search?programId=50',
+ 'info_dict': {
+ 'id': 'programId=50',
+ 'title': '50',
+ },
+ 'playlist_count': 9,
+ }, {
+ 'url': 'https://www.cpac.ca/emission?id=6',
+ 'only_matching': True,
+ }, {
+ 'url': 'https://www.cpac.ca/rechercher?key=hudson&type=all&order=desc',
+ 'only_matching': True,
+ }]
+
+ def _real_extract(self, url):
+ video_id = self._match_id(url)
+ url_lang = 'fr' if any(x in url for x in ('/emission?', '/rechercher?')) else 'en'
+ pl_type, list_type = ('program', 'itemList') if any(x in url for x in ('/program?', '/emission?')) else ('search', 'searchResult')
+ api_url = (
+ 'https://www.cpac.ca/api/1/services/contentModel.json?url=/site/website/%s/index.xml&crafterSite=cpacca&%s'
+ % (pl_type, video_id, ))
+ content = self._download_json(api_url, video_id)
+ entries = []
+ total_pages = int_or_none(try_get(content, lambda x: x['page'][list_type]['totalPages']), default=1)
+ for page in range(1, total_pages + 1):
+ if page > 1:
+ api_url = update_url_query(api_url, {'page': '%d' % (page, ), })
+ content = self._download_json(
+ api_url, video_id,
+ note='Downloading continuation - %d' % (page, ),
+ fatal=False)
+
+ for item in try_get(content, lambda x: x['page'][list_type]['item'], list) or []:
+ episode_url = urljoin(url, try_get(item, lambda x: x['url_%s_s' % (url_lang, )]))
+ if episode_url:
+ entries.append(episode_url)
+
+ return self.playlist_result(
+ (self.url_result(entry) for entry in entries),
+ playlist_id=video_id,
+ playlist_title=try_get(content, lambda x: x['page']['program']['title_%s_t' % (url_lang, )]) or video_id.split('=')[-1],
+ playlist_description=try_get(content, lambda x: x['page']['program']['description_%s_t' % (url_lang, )]),
+ )
diff --git a/youtube_dl/extractor/extractors.py b/youtube_dl/extractor/extractors.py
index 50b7cb4a04f..9474c85193e 100644
--- a/youtube_dl/extractor/extractors.py
+++ b/youtube_dl/extractor/extractors.py
@@ -254,6 +254,10 @@
from .condenast import CondeNastIE
from .contv import CONtvIE
from .corus import CorusIE
+from .cpac import (
+ CPACIE,
+ CPACPlaylistIE,
+)
from .cracked import CrackedIE
from .crackle import CrackleIE
from .crooksandliars import CrooksAndLiarsIE
|
## Please follow the guide below
---
### Before submitting a *pull request* make sure you have:
- [x] [Searched](https://github.com/ytdl-org/youtube-dl/search?q=is%3Apr&type=Issues) the bugtracker for similar pull requests
- [x] Read [adding new extractor tutorial](https://github.com/ytdl-org/youtube-dl#adding-support-for-a-new-site)
- [x] Read [youtube-dl coding conventions](https://github.com/ytdl-org/youtube-dl#youtube-dl-coding-conventions) and adjusted the code to meet them
- [x] Covered the code with tests (note that PRs without tests will be REJECTED)
- [x] Checked the code with [flake8](https://pypi.python.org/pypi/flake8)
### In order to be accepted and merged into youtube-dl each piece of code must be in public domain or released under [Unlicense](http://unlicense.org/). Check one of the following options:
- [x] I am the original author of this code and I am willing to release it under [Unlicense](http://unlicense.org/)
- [ ] I am not the original author of this code but it is in public domain or released under [Unlicense](http://unlicense.org/) (provide reliable evidence)
### What is the purpose of your *pull request*?
- [ ] Bug fix
- [ ] Improvement
- [x] New extractor
- [ ] New feature
---
### Description of your *pull request* and other information
Adds support for CPAC (Canadian Parliament) through new extractors:
* CPACIE: single episode
* CPACPlaylistIE: playlists and searches.
Resolves #18148
Resolves #30668
Closes #18265 (superseded)
|
https://api.github.com/repos/ytdl-org/youtube-dl/pulls/30675
|
2022-02-24T12:18:08Z
|
2022-02-24T18:27:58Z
|
2022-02-24T18:27:57Z
|
2022-02-24T18:27:58Z
| 1,987
|
ytdl-org/youtube-dl
| 49,822
|
Fixed #27216 -- Corrected import location in admin deprecation messages.
|
diff --git a/django/contrib/admin/helpers.py b/django/contrib/admin/helpers.py
index f808d8a8996cd..157c90af47cdc 100644
--- a/django/contrib/admin/helpers.py
+++ b/django/contrib/admin/helpers.py
@@ -213,8 +213,8 @@ def contents(self):
if getattr(attr, "allow_tags", False):
warnings.warn(
"Deprecated allow_tags attribute used on %s. "
- "Use django.utils.safestring.format_html(), "
- "format_html_join(), or mark_safe() instead." % attr,
+ "Use django.utils.html.format_html(), format_html_join(), "
+ "or django.utils.safestring.mark_safe() instead." % attr,
RemovedInDjango20Warning
)
result_repr = mark_safe(value)
diff --git a/django/contrib/admin/templatetags/admin_list.py b/django/contrib/admin/templatetags/admin_list.py
index 63b428ec68988..ce2a80cbc2585 100644
--- a/django/contrib/admin/templatetags/admin_list.py
+++ b/django/contrib/admin/templatetags/admin_list.py
@@ -229,8 +229,8 @@ def link_in_col(is_first, field_name, cl):
if allow_tags:
warnings.warn(
"Deprecated allow_tags attribute used on field {}. "
- "Use django.utils.safestring.format_html(), "
- "format_html_join(), or mark_safe() instead.".format(field_name),
+ "Use django.utils.html.format_html(), format_html_join(), "
+ "or django.utils.safestring.mark_safe() instead.".format(field_name),
RemovedInDjango20Warning
)
result_repr = mark_safe(result_repr)
|
Fixed the referenced deprecation messages
|
https://api.github.com/repos/django/django/pulls/7242
|
2016-09-13T14:51:01Z
|
2016-09-13T17:45:24Z
|
2016-09-13T17:45:24Z
|
2016-09-13T17:45:24Z
| 389
|
django/django
| 51,537
|
[requires.io] dependency update on main branch
|
diff --git a/setup.py b/setup.py
index dfebe40fb4..e920b2415f 100644
--- a/setup.py
+++ b/setup.py
@@ -97,7 +97,7 @@
"pydivert>=2.0.3,<2.2",
],
'dev': [
- "hypothesis>=5.8,<6.9",
+ "hypothesis>=5.8,<6.10",
"parver>=0.1,<2.0",
"pdoc>=4.0.0",
"pytest-asyncio>=0.10.0,<0.14,!=0.14",
|
https://api.github.com/repos/mitmproxy/mitmproxy/pulls/4559
|
2021-04-11T04:39:37Z
|
2021-04-13T22:34:46Z
|
2021-04-13T22:34:46Z
|
2021-04-13T22:34:49Z
| 148
|
mitmproxy/mitmproxy
| 28,371
|
|
Fix some typos in the concurrency section
|
diff --git a/CppCoreGuidelines.md b/CppCoreGuidelines.md
index 082bbf524..e7ac12d45 100644
--- a/CppCoreGuidelines.md
+++ b/CppCoreGuidelines.md
@@ -10253,7 +10253,7 @@ the same memory. Concurrent programming is tricky for many reasons, most
importantly that it is undefined behavior to read data in one thread after it
was written by another thread, if there is no proper synchronization between
those threads. Making existing single-threaded code execute concurrently can be
-as trivial as adding `std::async` or `std::thread` strategically, or it can be
+as trivial as adding `std::async` or `std::thread` strategically, or it can
necessitate a full rewrite, depending on whether the original code was written
in a thread-friendly way.
@@ -10432,7 +10432,7 @@ Help the tools:
##### Reason
If you don't share writable data, you can't have a data race.
-The less sharing you do, the less chance you have to forget to synchanize access (and get data races).
+The less sharing you do, the less chance you have to forget to synchronize access (and get data races).
The less sharing you do, the less chance you have to wait on a lock (so performance can improve).
##### Example
@@ -10458,7 +10458,7 @@ The less sharing you do, the less chance you have to wait on a lock (so performa
// ...
}
-Without those `const`s, we would have to review every asynchroneously invoked function for potential data races on `surface_readings`.
+Without those `const`s, we would have to review every asynchronously invoked function for potential data races on `surface_readings`.
##### Note
@@ -10474,7 +10474,7 @@ No locking is needed: You can't have a data race on a constant.
##### Reason
-A `thread` is a implementation concept, a way of thinking about the machine.
+A `thread` is an implementation concept, a way of thinking about the machine.
A task is an application notion, something you'd like to do, preferably concurrently with other tasks.
Application concepts are easier to reason about.
@@ -10565,7 +10565,7 @@ Concurrency rule summary:
* [CP.27: Use plain `std::thread` for `thread`s that detach based on a run-time condition (only)](#Rconc-thread)
* [CP.28: Remember to join scoped `thread`s that are not `detach()`ed](#Rconc-join)
* [CP.30: Do not pass pointers to local variables to non-`raii_thread's](#Rconc-pass)
-* [CP.31: Pass small amounts of data between threads by value, reather by reference or pointer](#Rconc-data)
+* [CP.31: Pass small amounts of data between threads by value, rather than by reference or pointer](#Rconc-data)
* [CP.32: To share ownership beween unrelated `thread`s use `shared_ptr`](#Rconc-shared)
* [CP.40: Minimize context switching](#Rconc-switch)
* [CP.41: Minimize thread creation and destruction](#Rconc-create)
@@ -10708,7 +10708,7 @@ If, as it is likely, `f()` invokes operations on `*this`, we must make sure that
##### Reason
-To maintain pointer safety and avoid leaks, we need to consider what pointers a used by a `thread`.
+To maintain pointer safety and avoid leaks, we need to consider what pointers are used by a `thread`.
If a `thread` joins, we can safely pass pointers to objects in the scope of the `thread` and its enclosing scopes.
##### Example
@@ -10747,7 +10747,7 @@ After that, the usual lifetime and ownership (for local objects) enforcement app
##### Reason
-To maintain pointer safety and avoid leaks, we need to consider what pointers a used by a `thread`.
+To maintain pointer safety and avoid leaks, we need to consider what pointers are used by a `thread`.
If a `thread` is detached, we can safely pass pointers to static and free store objects (only).
##### Example
@@ -10907,7 +10907,7 @@ A `thread` that has not been `detach()`ed when it is destroyed terminates the pr
###### Reason
-In general, you cannot know whether a non-`raii_thread` will outlife your thread (so that those pointers will become invalid.
+In general, you cannot know whether a non-`raii_thread` will outlive the scope of the variables, so that those pointers will become invalid.
##### Example, bad
@@ -10919,7 +10919,7 @@ In general, you cannot know whether a non-`raii_thread` will outlife your thread
t0.detach();
}
-The detach` may not be so easy to spot.
+The `detach` may not be so easy to spot.
Use a `raii_thread` or don't pass the pointer.
##### Example, bad
@@ -10928,10 +10928,10 @@ Use a `raii_thread` or don't pass the pointer.
##### Enforcement
-Flage pointers to locals passed in the constructor of a plain `thread`.
+Flag pointers to locals passed in the constructor of a plain `thread`.
-### <a name="Rconc-switch"></a>CP.31: Pass small amounts of data between threads by value, reather by reference or pointer
+### <a name="Rconc-switch"></a>CP.31: Pass small amounts of data between threads by value, rather by reference or pointer
##### Reason
@@ -10940,7 +10940,7 @@ Copying naturally gives unique ownership (simplifies code) and eliminates the po
##### Note
-Defining "small amount" precisely and is impossible.
+Defining "small amount" precisely is impossible.
##### Example
@@ -10955,7 +10955,7 @@ Defining "small amount" precisely and is impossible.
The call of `modify1` involves copying two `string` values; the call of `modify2` does not.
On the other hand, the implementation of `modify1` is exactly as we would have written in for single-threaded code,
-wheread the implementation of `modify2` will need some form of locking to avoid data races.
+whereas the implementation of `modify2` will need some form of locking to avoid data races.
If the string is short (say 10 characters), the call of `modify1` can be surprisingly fast;
essentially all the cost is in the `thread` switch. If the string is long (say 1,000,000 characters), copying it twice
is probably not a good idea.
@@ -10972,7 +10972,7 @@ message passing or shared memory.
##### Reason
-If treads are unrelated (that is, not known to be in the same scope or one within the lifetime of the other)
+If threads are unrelated (that is, not known to be in the same scope or one within the lifetime of the other)
and they need to share free store memory that needs to be deleted, a `shared_ptr` (or equivalent) is the only
safe way to ensure proper deletion.
@@ -10982,7 +10982,7 @@ safe way to ensure proper deletion.
##### Note
-* A static object (e.g. a global) can be shard because it is not owned in the sense that some thread is responsible for it's deletion.
+* A static object (e.g. a global) can be shared because it is not owned in the sense that some thread is responsible for it's deletion.
* An object on free store that is never to be deleted can be shared.
* An object owned by one thread can be safely shared with another as long as that second thread doesn't outlive the owner.
@@ -10995,7 +10995,7 @@ safe way to ensure proper deletion.
##### Reason
-Context swtiches are expesive.
+Context swtiches are expensive.
##### Example
@@ -11054,7 +11054,7 @@ Instead, we could have a set of pre-created worker threads processing the messag
###### Note
-If you system has a good thread pool, use it.
+If your system has a good thread pool, use it.
If your system has a good message queue, use it.
##### Enforcement
@@ -11129,7 +11129,7 @@ it will immediately go back to sleep, waiting.
##### Enforcement
-Flag all `waits` without conditions.
+Flag all `wait`s without conditions.
### <a name="Rconc-time"></a>CP.43: Minimize time spent in a critical section
|
https://api.github.com/repos/isocpp/CppCoreGuidelines/pulls/605
|
2016-05-09T12:55:10Z
|
2016-08-15T18:45:02Z
|
2016-08-15T18:45:02Z
|
2016-08-15T18:45:02Z
| 1,912
|
isocpp/CppCoreGuidelines
| 15,387
|
|
Fix typo in ephemeris parsing
|
diff --git a/selfdrive/locationd/ublox_msg.cc b/selfdrive/locationd/ublox_msg.cc
index 154200c08857e6..e0463d8e175f50 100644
--- a/selfdrive/locationd/ublox_msg.cc
+++ b/selfdrive/locationd/ublox_msg.cc
@@ -59,7 +59,7 @@ class EphemerisData {
int i_0 = (GET_FIELD_S(subframes[3][2+2], 8, 6) << 24) | GET_FIELD_U(
subframes[3][2+3], 24, 6);
int c_rc = GET_FIELD_S(subframes[3][2+4], 16, 14);
- int w = (GET_FIELD_S(subframes[3][2+4], 8, 6) << 24) | GET_FIELD_U(subframes[3][5], 24, 6);
+ int w = (GET_FIELD_S(subframes[3][2+4], 8, 6) << 24) | GET_FIELD_U(subframes[3][2+5], 24, 6);
int omega_dot = GET_FIELD_S(subframes[3][2+6], 24, 6);
int idot = GET_FIELD_S(subframes[3][2+7], 14, 8);
diff --git a/selfdrive/test/process_replay/ref_commit b/selfdrive/test/process_replay/ref_commit
index 89312f384f0690..f5c80e086ea2d2 100644
--- a/selfdrive/test/process_replay/ref_commit
+++ b/selfdrive/test/process_replay/ref_commit
@@ -1 +1 @@
-1a3391dcabbcef563062010bda7ac89793528004
\ No newline at end of file
+abdaa764cc8aec4e30522e951667c5473970cfe1
\ No newline at end of file
|
<!-- Please copy and paste the relevant template -->
<!--- ***** Template: Car bug fix *****
**Description** [](A description of the bug and the fix. Also link any relevant issues.)
**Verification** [](Explain how you tested this bug fix.)
**Route**
Route: [a route with the bug fix]
-->
<!--- ***** Template: Bug fix *****
**Description** [](A description of the bug and the fix. Also link any relevant issues.)
**Verification** [](Explain how you tested this bug fix.)
-->
<!--- ***** Template: Car port *****
**Checklist**
- [ ] added to README
- [ ] test route added to [test_routes.py](../../selfdrive/test/test_routes.py)
- [ ] route with openpilot:
- [ ] route with stock system:
-->
<!--- ***** Template: Refactor *****
**Description** [](A description of the refactor, including the goals it accomplishes.)
**Verification** [](Explain how you tested the refactor for regressions.)
-->
|
https://api.github.com/repos/commaai/openpilot/pulls/20677
|
2021-04-13T16:00:15Z
|
2021-04-14T09:25:43Z
|
2021-04-14T09:25:43Z
|
2021-04-14T09:25:44Z
| 433
|
commaai/openpilot
| 9,636
|
Use ==/!= to compare str, bytes, and int literals
|
diff --git a/irrelevant/generate_contributions.py b/irrelevant/generate_contributions.py
index 136f653..f396f32 100644
--- a/irrelevant/generate_contributions.py
+++ b/irrelevant/generate_contributions.py
@@ -39,7 +39,7 @@
issue_string = ', '.join([issue_format.format(i, i) for i in issues])
resp = requests.get(github_rest_api.format(handle))
name = handle
- if resp.status_code is 200:
+ if resp.status_code == 200:
pprint.pprint(resp.json()['name'])
else:
print(handle, resp.content)
@@ -48,4 +48,4 @@
handle,
issue_string))
-print(table_header + "\n".join(rows_so_far))
\ No newline at end of file
+print(table_header + "\n".join(rows_so_far))
|
Identity is not the same thing as equality in Python.
$ __[flake8](http://flake8.pycqa.org) . --count --select=E9,F63,F7,F82 --show-source --statistics__
```
if resp.status_code is 200:
^
1 F632 use ==/!= to compare str, bytes, and int literals
1
```
|
https://api.github.com/repos/satwikkansal/wtfpython/pulls/126
|
2019-07-02T13:36:31Z
|
2019-07-06T08:04:29Z
|
2019-07-06T08:04:29Z
|
2019-07-06T08:08:35Z
| 196
|
satwikkansal/wtfpython
| 25,881
|
Spelling fix in CONTRIBUTING.md
|
diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 525cb9c183d..0687aaeee52 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -45,7 +45,7 @@ $ black-primer [-k -w /tmp/black_test_repos]
## black-primer
`black-primer` is used by CI to pull down well-known _Black_ formatted projects and see
-if we get soure code changes. It will error on formatting changes or errors. Please run
+if we get source code changes. It will error on formatting changes or errors. Please run
before pushing your PR to see if you get the actions you would expect from _Black_ with
your PR. You may need to change
[primer.json](https://github.com/psf/black/blob/master/src/black_primer/primer.json)
|
https://api.github.com/repos/psf/black/pulls/1547
|
2020-07-13T22:13:55Z
|
2020-07-13T22:27:05Z
|
2020-07-13T22:27:05Z
|
2020-07-13T22:27:06Z
| 198
|
psf/black
| 24,284
|
|
[utils] Support Python 3.10
|
diff --git a/.github/workflows/core.yml b/.github/workflows/core.yml
index be932275a28..8111d17899a 100644
--- a/.github/workflows/core.yml
+++ b/.github/workflows/core.yml
@@ -10,7 +10,7 @@ jobs:
matrix:
os: [ubuntu-18.04]
# py3.9 is in quick-test
- python-version: [3.7, 3.8, pypy-3.6, pypy-3.7]
+ python-version: [3.7, 3.8, 3.10-dev, pypy-3.6, pypy-3.7]
run-tests-ext: [sh]
include:
# atleast one of the tests must be in windows
diff --git a/.github/workflows/download.yml b/.github/workflows/download.yml
index 9e650d2dc48..f27cf2142a7 100644
--- a/.github/workflows/download.yml
+++ b/.github/workflows/download.yml
@@ -9,7 +9,7 @@ jobs:
fail-fast: true
matrix:
os: [ubuntu-18.04]
- python-version: [3.7, 3.8, 3.9, pypy-3.6, pypy-3.7]
+ python-version: [3.7, 3.8, 3.9, 3.10-dev, pypy-3.6, pypy-3.7]
run-tests-ext: [sh]
include:
- os: windows-latest
diff --git a/yt_dlp/utils.py b/yt_dlp/utils.py
index 4d12c0a8e2d..4ff53573f1f 100644
--- a/yt_dlp/utils.py
+++ b/yt_dlp/utils.py
@@ -3964,7 +3964,7 @@ def detect_exe_version(output, version_re=None, unrecognized='present'):
return unrecognized
-class LazyList(collections.Sequence):
+class LazyList(collections.abc.Sequence):
''' Lazy immutable list from an iterable
Note that slices of a LazyList are lists and not LazyList'''
@@ -6313,4 +6313,4 @@ def traverse_dict(dictn, keys, casesense=True):
def variadic(x, allowed_types=(str, bytes)):
- return x if isinstance(x, collections.Iterable) and not isinstance(x, allowed_types) else (x,)
+ return x if isinstance(x, collections.abc.Iterable) and not isinstance(x, allowed_types) else (x,)
|
## Please follow the guide below
- You will be asked some questions, please read them **carefully** and answer honestly
- Put an `x` into all the boxes [ ] relevant to your *pull request* (like that [x])
- Use *Preview* tab to see how your *pull request* will actually look like
---
### Before submitting a *pull request* make sure you have:
- [x] At least skimmed through [adding new extractor tutorial](https://github.com/ytdl-org/youtube-dl#adding-support-for-a-new-site) and [youtube-dl coding conventions](https://github.com/ytdl-org/youtube-dl#youtube-dl-coding-conventions) sections
- [x] [Searched](https://github.com/yt-dlp/yt-dlp/search?q=is%3Apr&type=Issues) the bugtracker for similar pull requests
- [x] Checked the code with [flake8](https://pypi.python.org/pypi/flake8)
### In order to be accepted and merged into youtube-dl each piece of code must be in public domain or released under [Unlicense](http://unlicense.org/). Check one of the following options:
- [x] I am the original author of this code and I am willing to release it under [Unlicense](http://unlicense.org/)
- [ ] I am not the original author of this code but it is in public domain or released under [Unlicense](http://unlicense.org/) (provide reliable evidence)
### What is the purpose of your *pull request*?
- [x] Bug fix
- [ ] Improvement
- [ ] New extractor
- [ ] New feature
---
### Description of your *pull request* and other information
Use `collections.abc.Sequence` instead of `collections.Sequence`
Note that this change is incompatible with Python 3.4.x or earlier.
|
https://api.github.com/repos/yt-dlp/yt-dlp/pulls/480
|
2021-07-10T07:11:47Z
|
2021-07-23T15:02:48Z
|
2021-07-23T15:02:48Z
|
2021-07-25T18:32:38Z
| 578
|
yt-dlp/yt-dlp
| 7,664
|
Remove wrongly placed double qoutes
|
diff --git a/ciphers/baconian_cipher.py b/ciphers/baconian_cipher.py
index 027fbc50e89d..f146ba91b78f 100644
--- a/ciphers/baconian_cipher.py
+++ b/ciphers/baconian_cipher.py
@@ -83,7 +83,7 @@ def decode(coded: str) -> str:
return decoded.strip()
-if "__name__" == "__main__":
+if __name__ == "__main__":
from doctest import testmod
testmod()
diff --git a/strings/join.py b/strings/join.py
index 0cb88b76065d..c17ddd144597 100644
--- a/strings/join.py
+++ b/strings/join.py
@@ -3,7 +3,7 @@
"""
-def join(separator: str, separated: list) -> str:
+def join(separator: str, separated: list[str]) -> str:
"""
>>> join("", ["a", "b", "c", "d"])
'abcd'
@@ -26,7 +26,7 @@ def join(separator: str, separated: list) -> str:
return joined.strip(separator)
-if "__name__" == "__main__":
+if __name__ == "__main__":
from doctest import testmod
testmod()
|
### **Describe your change:**
* [ ] Add an algorithm?
* [x] Fix a bug or typo in an existing algorithm?
* [ ] Documentation change?
### **Checklist:**
* [x] I have read [CONTRIBUTING.md](https://github.com/TheAlgorithms/Python/blob/master/CONTRIBUTING.md).
* [x] This pull request is all my own work -- I have not plagiarized.
* [x] I know that pull requests will not be merged if they fail the automated tests.
* [x] This PR only changes one algorithm file. To ease review, please open separate PRs for separate algorithms.
* [x] All new Python files are placed inside an existing directory.
* [x] All filenames are in all lowercase characters with no spaces or dashes.
* [x] All functions and variable names follow Python naming conventions.
* [x] All function parameters and return values are annotated with Python [type hints](https://docs.python.org/3/library/typing.html).
* [x] All functions have [doctests](https://docs.python.org/3/library/doctest.html) that pass the automated testing.
* [x] All new algorithms have a URL in its comments that points to Wikipedia or other similar explanation.
* [x] If this pull request resolves one or more open issues then the commit message contains `Fixes: #{$ISSUE_NO}`.
|
https://api.github.com/repos/TheAlgorithms/Python/pulls/5530
|
2021-10-22T16:00:11Z
|
2021-10-22T17:14:08Z
|
2021-10-22T17:14:08Z
|
2021-10-22T20:19:33Z
| 291
|
TheAlgorithms/Python
| 29,871
|
Generalized fragmented media file downloader
|
diff --git a/youtube_dl/downloader/f4m.py b/youtube_dl/downloader/f4m.py
index b1a858c4526..275564b5976 100644
--- a/youtube_dl/downloader/f4m.py
+++ b/youtube_dl/downloader/f4m.py
@@ -7,8 +7,7 @@
import time
import xml.etree.ElementTree as etree
-from .common import FileDownloader
-from .http import HttpFD
+from .fragment import FragmentFD
from ..compat import (
compat_urlparse,
compat_urllib_error,
@@ -16,8 +15,6 @@
from ..utils import (
struct_pack,
struct_unpack,
- encodeFilename,
- sanitize_open,
xpath_text,
)
@@ -226,16 +223,13 @@ def _add_ns(prop):
return '{http://ns.adobe.com/f4m/1.0}%s' % prop
-class HttpQuietDownloader(HttpFD):
- def to_screen(self, *args, **kargs):
- pass
-
-
-class F4mFD(FileDownloader):
+class F4mFD(FragmentFD):
"""
A downloader for f4m manifests or AdobeHDS.
"""
+ FD_NAME = 'f4m'
+
def _get_unencrypted_media(self, doc):
media = doc.findall(_add_ns('media'))
if not media:
@@ -288,7 +282,7 @@ def _parse_bootstrap_node(self, node, base_url):
def real_download(self, filename, info_dict):
man_url = info_dict['url']
requested_bitrate = info_dict.get('tbr')
- self.to_screen('[download] Downloading f4m manifest')
+ self.to_screen('[%s] Downloading f4m manifest' % self.FD_NAME)
manifest = self.ydl.urlopen(man_url).read()
doc = etree.fromstring(manifest)
@@ -320,67 +314,20 @@ def real_download(self, filename, info_dict):
# For some akamai manifests we'll need to add a query to the fragment url
akamai_pv = xpath_text(doc, _add_ns('pv-2.0'))
- self.report_destination(filename)
- http_dl = HttpQuietDownloader(
- self.ydl,
- {
- 'continuedl': True,
- 'quiet': True,
- 'noprogress': True,
- 'ratelimit': self.params.get('ratelimit', None),
- 'test': self.params.get('test', False),
- }
- )
- tmpfilename = self.temp_name(filename)
- (dest_stream, tmpfilename) = sanitize_open(tmpfilename, 'wb')
+ ctx = {
+ 'filename': filename,
+ 'total_frags': total_frags,
+ }
+
+ self._prepare_frag_download(ctx)
+
+ dest_stream = ctx['dest_stream']
write_flv_header(dest_stream)
if not live:
write_metadata_tag(dest_stream, metadata)
- # This dict stores the download progress, it's updated by the progress
- # hook
- state = {
- 'status': 'downloading',
- 'downloaded_bytes': 0,
- 'frag_index': 0,
- 'frag_count': total_frags,
- 'filename': filename,
- 'tmpfilename': tmpfilename,
- }
- start = time.time()
-
- def frag_progress_hook(s):
- if s['status'] not in ('downloading', 'finished'):
- return
-
- frag_total_bytes = s.get('total_bytes', 0)
- if s['status'] == 'finished':
- state['downloaded_bytes'] += frag_total_bytes
- state['frag_index'] += 1
-
- estimated_size = (
- (state['downloaded_bytes'] + frag_total_bytes) /
- (state['frag_index'] + 1) * total_frags)
- time_now = time.time()
- state['total_bytes_estimate'] = estimated_size
- state['elapsed'] = time_now - start
-
- if s['status'] == 'finished':
- progress = self.calc_percent(state['frag_index'], total_frags)
- else:
- frag_downloaded_bytes = s['downloaded_bytes']
- frag_progress = self.calc_percent(frag_downloaded_bytes,
- frag_total_bytes)
- progress = self.calc_percent(state['frag_index'], total_frags)
- progress += frag_progress / float(total_frags)
-
- state['eta'] = self.calc_eta(
- start, time_now, estimated_size, state['downloaded_bytes'] + frag_downloaded_bytes)
- state['speed'] = s.get('speed')
- self._hook_progress(state)
-
- http_dl.add_progress_hook(frag_progress_hook)
+ self._start_frag_download(ctx)
frags_filenames = []
while fragments_list:
@@ -391,9 +338,9 @@ def frag_progress_hook(s):
url += '?' + akamai_pv.strip(';')
if info_dict.get('extra_param_to_segment_url'):
url += info_dict.get('extra_param_to_segment_url')
- frag_filename = '%s-%s' % (tmpfilename, name)
+ frag_filename = '%s-%s' % (ctx['tmpfilename'], name)
try:
- success = http_dl.download(frag_filename, {'url': url})
+ success = ctx['dl'].download(frag_filename, {'url': url})
if not success:
return False
with open(frag_filename, 'rb') as down:
@@ -425,20 +372,9 @@ def frag_progress_hook(s):
msg = 'Missed %d fragments' % (fragments_list[0][1] - (frag_i + 1))
self.report_warning(msg)
- dest_stream.close()
+ self._finish_frag_download(ctx)
- elapsed = time.time() - start
- self.try_rename(tmpfilename, filename)
for frag_file in frags_filenames:
os.remove(frag_file)
- fsize = os.path.getsize(encodeFilename(filename))
- self._hook_progress({
- 'downloaded_bytes': fsize,
- 'total_bytes': fsize,
- 'filename': filename,
- 'status': 'finished',
- 'elapsed': elapsed,
- })
-
return True
diff --git a/youtube_dl/downloader/fragment.py b/youtube_dl/downloader/fragment.py
new file mode 100644
index 00000000000..5f9d6796dc8
--- /dev/null
+++ b/youtube_dl/downloader/fragment.py
@@ -0,0 +1,110 @@
+from __future__ import division, unicode_literals
+
+import os
+import time
+
+from .common import FileDownloader
+from .http import HttpFD
+from ..utils import (
+ encodeFilename,
+ sanitize_open,
+)
+
+
+class HttpQuietDownloader(HttpFD):
+ def to_screen(self, *args, **kargs):
+ pass
+
+
+class FragmentFD(FileDownloader):
+ """
+ A base file downloader class for fragmented media (e.g. f4m/m3u8 manifests).
+ """
+
+ def _prepare_and_start_frag_download(self, ctx):
+ self._prepare_frag_download(ctx)
+ self._start_frag_download(ctx)
+
+ def _prepare_frag_download(self, ctx):
+ self.to_screen('[%s] Total fragments: %d' % (self.FD_NAME, ctx['total_frags']))
+ self.report_destination(ctx['filename'])
+ dl = HttpQuietDownloader(
+ self.ydl,
+ {
+ 'continuedl': True,
+ 'quiet': True,
+ 'noprogress': True,
+ 'ratelimit': self.params.get('ratelimit', None),
+ 'test': self.params.get('test', False),
+ }
+ )
+ tmpfilename = self.temp_name(ctx['filename'])
+ dest_stream, tmpfilename = sanitize_open(tmpfilename, 'wb')
+ ctx.update({
+ 'dl': dl,
+ 'dest_stream': dest_stream,
+ 'tmpfilename': tmpfilename,
+ })
+
+ def _start_frag_download(self, ctx):
+ total_frags = ctx['total_frags']
+ # This dict stores the download progress, it's updated by the progress
+ # hook
+ state = {
+ 'status': 'downloading',
+ 'downloaded_bytes': 0,
+ 'frag_index': 0,
+ 'frag_count': total_frags,
+ 'filename': ctx['filename'],
+ 'tmpfilename': ctx['tmpfilename'],
+ }
+ start = time.time()
+ ctx['started'] = start
+
+ def frag_progress_hook(s):
+ if s['status'] not in ('downloading', 'finished'):
+ return
+
+ frag_total_bytes = s.get('total_bytes', 0)
+ if s['status'] == 'finished':
+ state['downloaded_bytes'] += frag_total_bytes
+ state['frag_index'] += 1
+
+ estimated_size = (
+ (state['downloaded_bytes'] + frag_total_bytes) /
+ (state['frag_index'] + 1) * total_frags)
+ time_now = time.time()
+ state['total_bytes_estimate'] = estimated_size
+ state['elapsed'] = time_now - start
+
+ if s['status'] == 'finished':
+ progress = self.calc_percent(state['frag_index'], total_frags)
+ else:
+ frag_downloaded_bytes = s['downloaded_bytes']
+ frag_progress = self.calc_percent(frag_downloaded_bytes,
+ frag_total_bytes)
+ progress = self.calc_percent(state['frag_index'], total_frags)
+ progress += frag_progress / float(total_frags)
+
+ state['eta'] = self.calc_eta(
+ start, time_now, estimated_size, state['downloaded_bytes'] + frag_downloaded_bytes)
+ state['speed'] = s.get('speed')
+ self._hook_progress(state)
+
+ ctx['dl'].add_progress_hook(frag_progress_hook)
+
+ return start
+
+ def _finish_frag_download(self, ctx):
+ ctx['dest_stream'].close()
+ elapsed = time.time() - ctx['started']
+ self.try_rename(ctx['tmpfilename'], ctx['filename'])
+ fsize = os.path.getsize(encodeFilename(ctx['filename']))
+
+ self._hook_progress({
+ 'downloaded_bytes': fsize,
+ 'total_bytes': fsize,
+ 'filename': ctx['filename'],
+ 'status': 'finished',
+ 'elapsed': elapsed,
+ })
diff --git a/youtube_dl/downloader/hls.py b/youtube_dl/downloader/hls.py
index 8be4f424907..60dca0ab1fe 100644
--- a/youtube_dl/downloader/hls.py
+++ b/youtube_dl/downloader/hls.py
@@ -4,12 +4,11 @@
import re
import subprocess
-from ..postprocessor.ffmpeg import FFmpegPostProcessor
from .common import FileDownloader
-from ..compat import (
- compat_urlparse,
- compat_urllib_request,
-)
+from .fragment import FragmentFD
+
+from ..compat import compat_urlparse
+from ..postprocessor.ffmpeg import FFmpegPostProcessor
from ..utils import (
encodeArgument,
encodeFilename,
@@ -51,54 +50,50 @@ def real_download(self, filename, info_dict):
return False
-class NativeHlsFD(FileDownloader):
+class NativeHlsFD(FragmentFD):
""" A more limited implementation that does not require ffmpeg """
+ FD_NAME = 'hlsnative'
+
def real_download(self, filename, info_dict):
- url = info_dict['url']
- self.report_destination(filename)
- tmpfilename = self.temp_name(filename)
+ man_url = info_dict['url']
+ self.to_screen('[%s] Downloading m3u8 manifest' % self.FD_NAME)
+ manifest = self.ydl.urlopen(man_url).read()
- self.to_screen(
- '[hlsnative] %s: Downloading m3u8 manifest' % info_dict['id'])
- data = self.ydl.urlopen(url).read()
- s = data.decode('utf-8', 'ignore')
- segment_urls = []
+ s = manifest.decode('utf-8', 'ignore')
+ fragment_urls = []
for line in s.splitlines():
line = line.strip()
if line and not line.startswith('#'):
segment_url = (
line
if re.match(r'^https?://', line)
- else compat_urlparse.urljoin(url, line))
- segment_urls.append(segment_url)
-
- is_test = self.params.get('test', False)
- remaining_bytes = self._TEST_FILE_SIZE if is_test else None
- byte_counter = 0
- with open(tmpfilename, 'wb') as outf:
- for i, segurl in enumerate(segment_urls):
- self.to_screen(
- '[hlsnative] %s: Downloading segment %d / %d' %
- (info_dict['id'], i + 1, len(segment_urls)))
- seg_req = compat_urllib_request.Request(segurl)
- if remaining_bytes is not None:
- seg_req.add_header('Range', 'bytes=0-%d' % (remaining_bytes - 1))
-
- segment = self.ydl.urlopen(seg_req).read()
- if remaining_bytes is not None:
- segment = segment[:remaining_bytes]
- remaining_bytes -= len(segment)
- outf.write(segment)
- byte_counter += len(segment)
- if remaining_bytes is not None and remaining_bytes <= 0:
+ else compat_urlparse.urljoin(man_url, line))
+ fragment_urls.append(segment_url)
+ # We only download the first fragment during the test
+ if self.params.get('test', False):
break
- self._hook_progress({
- 'downloaded_bytes': byte_counter,
- 'total_bytes': byte_counter,
+ ctx = {
'filename': filename,
- 'status': 'finished',
- })
- self.try_rename(tmpfilename, filename)
+ 'total_frags': len(fragment_urls),
+ }
+
+ self._prepare_and_start_frag_download(ctx)
+
+ frags_filenames = []
+ for i, frag_url in enumerate(fragment_urls):
+ frag_filename = '%s-Frag%d' % (ctx['tmpfilename'], i)
+ success = ctx['dl'].download(frag_filename, {'url': frag_url})
+ if not success:
+ return False
+ with open(frag_filename, 'rb') as down:
+ ctx['dest_stream'].write(down.read())
+ frags_filenames.append(frag_filename)
+
+ self._finish_frag_download(ctx)
+
+ for frag_file in frags_filenames:
+ os.remove(frag_file)
+
return True
|
- Adds a base file downloader class to be used by fragmented media file downloaders (e.g. f4m/m3u8 manifests).
- Rewrites `F4mFD` and `NativeHlsFD` in terms of `FragmentFD`.
- Adds generic progress output and resume for `NativeHlsFD`.
|
https://api.github.com/repos/ytdl-org/youtube-dl/pulls/6392
|
2015-07-28T20:41:23Z
|
2015-08-01T14:22:49Z
|
2015-08-01T14:22:49Z
|
2015-08-01T14:22:49Z
| 3,330
|
ytdl-org/youtube-dl
| 50,547
|
langchain[patch]: Release 0.1.2
|
diff --git a/libs/langchain/_test_minimum_requirements.txt b/libs/langchain/_test_minimum_requirements.txt
index a370010215cb0b..464405b7ec9ffb 100644
--- a/libs/langchain/_test_minimum_requirements.txt
+++ b/libs/langchain/_test_minimum_requirements.txt
@@ -1,2 +1,2 @@
-langchain-core==0.1.9
-langchain-community==0.0.13
+langchain-core==0.1.14
+langchain-community==0.0.14
diff --git a/libs/langchain/poetry.lock b/libs/langchain/poetry.lock
index 294271e414d944..9bf50ce8bf98c2 100644
--- a/libs/langchain/poetry.lock
+++ b/libs/langchain/poetry.lock
@@ -3049,6 +3049,7 @@ files = [
{file = "jq-1.6.0-cp37-cp37m-musllinux_1_1_i686.whl", hash = "sha256:227b178b22a7f91ae88525810441791b1ca1fc71c86f03190911793be15cec3d"},
{file = "jq-1.6.0-cp37-cp37m-musllinux_1_1_x86_64.whl", hash = "sha256:780eb6383fbae12afa819ef676fc93e1548ae4b076c004a393af26a04b460742"},
{file = "jq-1.6.0-cp38-cp38-macosx_10_9_x86_64.whl", hash = "sha256:08ded6467f4ef89fec35b2bf310f210f8cd13fbd9d80e521500889edf8d22441"},
+ {file = "jq-1.6.0-cp38-cp38-macosx_11_0_arm64.whl", hash = "sha256:49e44ed677713f4115bd5bf2dbae23baa4cd503be350e12a1c1f506b0687848f"},
{file = "jq-1.6.0-cp38-cp38-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:984f33862af285ad3e41e23179ac4795f1701822473e1a26bf87ff023e5a89ea"},
{file = "jq-1.6.0-cp38-cp38-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:f42264fafc6166efb5611b5d4cb01058887d050a6c19334f6a3f8a13bb369df5"},
{file = "jq-1.6.0-cp38-cp38-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:a67154f150aaf76cc1294032ed588436eb002097dd4fd1e283824bf753a05080"},
@@ -3446,7 +3447,7 @@ files = [
[[package]]
name = "langchain-community"
-version = "0.0.13"
+version = "0.0.14"
description = "Community contributed LangChain integrations."
optional = false
python-versions = ">=3.8.1,<4.0"
@@ -3456,7 +3457,7 @@ develop = true
[package.dependencies]
aiohttp = "^3.8.3"
dataclasses-json = ">= 0.5.7, < 0.7"
-langchain-core = ">=0.1.9,<0.2"
+langchain-core = ">=0.1.14,<0.2"
langsmith = "~0.0.63"
numpy = "^1"
PyYAML = ">=5.3"
@@ -3474,7 +3475,7 @@ url = "../community"
[[package]]
name = "langchain-core"
-version = "0.1.11"
+version = "0.1.14"
description = "Building applications with LLMs through composability"
optional = false
python-versions = ">=3.8.1,<4.0"
@@ -3484,7 +3485,7 @@ develop = true
[package.dependencies]
anyio = ">=3,<5"
jsonpatch = "^1.33"
-langsmith = "~0.0.63"
+langsmith = "^0.0.83"
packaging = "^23.2"
pydantic = ">=1,<3"
PyYAML = ">=5.3"
@@ -3743,6 +3744,16 @@ files = [
{file = "MarkupSafe-2.1.3-cp311-cp311-musllinux_1_1_x86_64.whl", hash = "sha256:5bbe06f8eeafd38e5d0a4894ffec89378b6c6a625ff57e3028921f8ff59318ac"},
{file = "MarkupSafe-2.1.3-cp311-cp311-win32.whl", hash = "sha256:dd15ff04ffd7e05ffcb7fe79f1b98041b8ea30ae9234aed2a9168b5797c3effb"},
{file = "MarkupSafe-2.1.3-cp311-cp311-win_amd64.whl", hash = "sha256:134da1eca9ec0ae528110ccc9e48041e0828d79f24121a1a146161103c76e686"},
+ {file = "MarkupSafe-2.1.3-cp312-cp312-macosx_10_9_universal2.whl", hash = "sha256:f698de3fd0c4e6972b92290a45bd9b1536bffe8c6759c62471efaa8acb4c37bc"},
+ {file = "MarkupSafe-2.1.3-cp312-cp312-macosx_10_9_x86_64.whl", hash = "sha256:aa57bd9cf8ae831a362185ee444e15a93ecb2e344c8e52e4d721ea3ab6ef1823"},
+ {file = "MarkupSafe-2.1.3-cp312-cp312-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:ffcc3f7c66b5f5b7931a5aa68fc9cecc51e685ef90282f4a82f0f5e9b704ad11"},
+ {file = "MarkupSafe-2.1.3-cp312-cp312-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:47d4f1c5f80fc62fdd7777d0d40a2e9dda0a05883ab11374334f6c4de38adffd"},
+ {file = "MarkupSafe-2.1.3-cp312-cp312-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:1f67c7038d560d92149c060157d623c542173016c4babc0c1913cca0564b9939"},
+ {file = "MarkupSafe-2.1.3-cp312-cp312-musllinux_1_1_aarch64.whl", hash = "sha256:9aad3c1755095ce347e26488214ef77e0485a3c34a50c5a5e2471dff60b9dd9c"},
+ {file = "MarkupSafe-2.1.3-cp312-cp312-musllinux_1_1_i686.whl", hash = "sha256:14ff806850827afd6b07a5f32bd917fb7f45b046ba40c57abdb636674a8b559c"},
+ {file = "MarkupSafe-2.1.3-cp312-cp312-musllinux_1_1_x86_64.whl", hash = "sha256:8f9293864fe09b8149f0cc42ce56e3f0e54de883a9de90cd427f191c346eb2e1"},
+ {file = "MarkupSafe-2.1.3-cp312-cp312-win32.whl", hash = "sha256:715d3562f79d540f251b99ebd6d8baa547118974341db04f5ad06d5ea3eb8007"},
+ {file = "MarkupSafe-2.1.3-cp312-cp312-win_amd64.whl", hash = "sha256:1b8dd8c3fd14349433c79fa8abeb573a55fc0fdd769133baac1f5e07abf54aeb"},
{file = "MarkupSafe-2.1.3-cp37-cp37m-macosx_10_9_x86_64.whl", hash = "sha256:8e254ae696c88d98da6555f5ace2279cf7cd5b3f52be2b5cf97feafe883b58d2"},
{file = "MarkupSafe-2.1.3-cp37-cp37m-manylinux_2_17_aarch64.manylinux2014_aarch64.whl", hash = "sha256:cb0932dc158471523c9637e807d9bfb93e06a95cbf010f1a38b98623b929ef2b"},
{file = "MarkupSafe-2.1.3-cp37-cp37m-manylinux_2_17_x86_64.manylinux2014_x86_64.whl", hash = "sha256:9402b03f1a1b4dc4c19845e5c749e3ab82d5078d16a2a4c2cd2df62d57bb0707"},
@@ -5796,7 +5807,6 @@ files = [
{file = "pymongo-4.5.0-cp312-cp312-manylinux_2_5_i686.manylinux1_i686.manylinux_2_17_i686.manylinux2014_i686.whl", hash = "sha256:6422b6763b016f2ef2beedded0e546d6aa6ba87910f9244d86e0ac7690f75c96"},
{file = "pymongo-4.5.0-cp312-cp312-win32.whl", hash = "sha256:77cfff95c1fafd09e940b3fdcb7b65f11442662fad611d0e69b4dd5d17a81c60"},
{file = "pymongo-4.5.0-cp312-cp312-win_amd64.whl", hash = "sha256:e57d859b972c75ee44ea2ef4758f12821243e99de814030f69a3decb2aa86807"},
- {file = "pymongo-4.5.0-cp37-cp37m-macosx_10_9_x86_64.whl", hash = "sha256:8443f3a8ab2d929efa761c6ebce39a6c1dca1c9ac186ebf11b62c8fe1aef53f4"},
{file = "pymongo-4.5.0-cp37-cp37m-manylinux1_i686.whl", hash = "sha256:2b0176f9233a5927084c79ff80b51bd70bfd57e4f3d564f50f80238e797f0c8a"},
{file = "pymongo-4.5.0-cp37-cp37m-manylinux1_x86_64.whl", hash = "sha256:89b3f2da57a27913d15d2a07d58482f33d0a5b28abd20b8e643ab4d625e36257"},
{file = "pymongo-4.5.0-cp37-cp37m-manylinux2014_aarch64.whl", hash = "sha256:5caee7bd08c3d36ec54617832b44985bd70c4cbd77c5b313de6f7fce0bb34f93"},
@@ -9118,4 +9128,4 @@ text-helpers = ["chardet"]
[metadata]
lock-version = "2.0"
python-versions = ">=3.8.1,<4.0"
-content-hash = "395f3b3b3c486be29ab663cdb12ce577c231027b32671c4f48848944883db9f8"
+content-hash = "9eb6114c56ea7772809c5cddd72986099861c63903eaed1649b205dbb662fa09"
diff --git a/libs/langchain/pyproject.toml b/libs/langchain/pyproject.toml
index 1547b98c5ea46f..455b0fbbfc4c9a 100644
--- a/libs/langchain/pyproject.toml
+++ b/libs/langchain/pyproject.toml
@@ -1,6 +1,6 @@
[tool.poetry]
name = "langchain"
-version = "0.1.1"
+version = "0.1.2"
description = "Building applications with LLMs through composability"
authors = []
license = "MIT"
@@ -12,8 +12,8 @@ langchain-server = "langchain.server:main"
[tool.poetry.dependencies]
python = ">=3.8.1,<4.0"
-langchain-core = ">=0.1.9,<0.2"
-langchain-community = ">=0.0.13,<0.1"
+langchain-core = ">=0.1.14,<0.2"
+langchain-community = ">=0.0.14,<0.1"
pydantic = ">=1,<3"
SQLAlchemy = ">=1.4,<3"
requests = "^2"
|
https://api.github.com/repos/langchain-ai/langchain/pulls/16388
|
2024-01-22T16:59:11Z
|
2024-01-22T17:32:25Z
|
2024-01-22T17:32:24Z
|
2024-01-22T17:32:25Z
| 3,313
|
langchain-ai/langchain
| 43,069
|
|
Remove `is_authorized_cluster_activity` from auth manager
|
diff --git a/airflow/auth/managers/base_auth_manager.py b/airflow/auth/managers/base_auth_manager.py
index f50e40082b901..fb57c984d5b29 100644
--- a/airflow/auth/managers/base_auth_manager.py
+++ b/airflow/auth/managers/base_auth_manager.py
@@ -134,20 +134,6 @@ def is_authorized_configuration(
:param user: the user to perform the action on. If not provided (or None), it uses the current user
"""
- @abstractmethod
- def is_authorized_cluster_activity(
- self,
- *,
- method: ResourceMethod,
- user: BaseUser | None = None,
- ) -> bool:
- """
- Return whether the user is authorized to perform a given action on the cluster activity.
-
- :param method: the method to perform
- :param user: the user to perform the action on. If not provided (or None), it uses the current user
- """
-
@abstractmethod
def is_authorized_connection(
self,
diff --git a/airflow/providers/amazon/aws/auth_manager/aws_auth_manager.py b/airflow/providers/amazon/aws/auth_manager/aws_auth_manager.py
index 99b6d4f70c560..20234f5f2b027 100644
--- a/airflow/providers/amazon/aws/auth_manager/aws_auth_manager.py
+++ b/airflow/providers/amazon/aws/auth_manager/aws_auth_manager.py
@@ -99,9 +99,6 @@ def is_authorized_configuration(
entity_id=config_section,
)
- def is_authorized_cluster_activity(self, *, method: ResourceMethod, user: BaseUser | None = None) -> bool:
- return self.is_logged_in()
-
def is_authorized_connection(
self,
*,
diff --git a/airflow/providers/fab/auth_manager/fab_auth_manager.py b/airflow/providers/fab/auth_manager/fab_auth_manager.py
index cc9c590db45c4..3f160da49708e 100644
--- a/airflow/providers/fab/auth_manager/fab_auth_manager.py
+++ b/airflow/providers/fab/auth_manager/fab_auth_manager.py
@@ -193,9 +193,6 @@ def is_authorized_configuration(
) -> bool:
return self._is_authorized(method=method, resource_type=RESOURCE_CONFIG, user=user)
- def is_authorized_cluster_activity(self, *, method: ResourceMethod, user: BaseUser | None = None) -> bool:
- return self._is_authorized(method=method, resource_type=RESOURCE_CLUSTER_ACTIVITY, user=user)
-
def is_authorized_connection(
self,
*,
diff --git a/airflow/www/auth.py b/airflow/www/auth.py
index 8519fc8153d74..5aaf5913dba65 100644
--- a/airflow/www/auth.py
+++ b/airflow/www/auth.py
@@ -182,10 +182,6 @@ def _has_access(*, is_authorized: bool, func: Callable, args, kwargs):
return redirect(get_auth_manager().get_url_login(next=request.url))
-def has_access_cluster_activity(method: ResourceMethod) -> Callable[[T], T]:
- return _has_access_no_details(lambda: get_auth_manager().is_authorized_cluster_activity(method=method))
-
-
def has_access_configuration(method: ResourceMethod) -> Callable[[T], T]:
return _has_access_no_details(lambda: get_auth_manager().is_authorized_configuration(method=method))
diff --git a/airflow/www/views.py b/airflow/www/views.py
index f51fbb9e79c93..8fef6aea588a1 100644
--- a/airflow/www/views.py
+++ b/airflow/www/views.py
@@ -1055,7 +1055,7 @@ def datasets(self):
)
@expose("/cluster_activity")
- @auth.has_access_cluster_activity("GET")
+ @auth.has_access_view(AccessView.CLUSTER_ACTIVITY)
def cluster_activity(self):
"""Cluster Activity view."""
state_color_mapping = State.state_color.copy()
@@ -3556,7 +3556,7 @@ def grid_data(self):
)
@expose("/object/historical_metrics_data")
- @auth.has_access_cluster_activity("GET")
+ @auth.has_access_view(AccessView.CLUSTER_ACTIVITY)
def historical_metrics_data(self):
"""Return cluster activity historical metrics."""
start_date = _safe_parse_datetime(request.args.get("start_date"))
diff --git a/tests/auth/managers/test_base_auth_manager.py b/tests/auth/managers/test_base_auth_manager.py
index 832ae50d2ad94..6655c0113285e 100644
--- a/tests/auth/managers/test_base_auth_manager.py
+++ b/tests/auth/managers/test_base_auth_manager.py
@@ -57,9 +57,6 @@ def is_authorized_configuration(
) -> bool:
raise NotImplementedError()
- def is_authorized_cluster_activity(self, *, method: ResourceMethod, user: BaseUser | None = None) -> bool:
- raise NotImplementedError()
-
def is_authorized_connection(
self,
*,
diff --git a/tests/providers/fab/auth_manager/test_fab_auth_manager.py b/tests/providers/fab/auth_manager/test_fab_auth_manager.py
index 12aaeb0488d3c..e4c574553656b 100644
--- a/tests/providers/fab/auth_manager/test_fab_auth_manager.py
+++ b/tests/providers/fab/auth_manager/test_fab_auth_manager.py
@@ -34,7 +34,6 @@
ACTION_CAN_DELETE,
ACTION_CAN_EDIT,
ACTION_CAN_READ,
- RESOURCE_CLUSTER_ACTIVITY,
RESOURCE_CONFIG,
RESOURCE_CONNECTION,
RESOURCE_DAG,
@@ -52,7 +51,6 @@
IS_AUTHORIZED_METHODS_SIMPLE = {
"is_authorized_configuration": RESOURCE_CONFIG,
- "is_authorized_cluster_activity": RESOURCE_CLUSTER_ACTIVITY,
"is_authorized_connection": RESOURCE_CONNECTION,
"is_authorized_dataset": RESOURCE_DATASET,
"is_authorized_variable": RESOURCE_VARIABLE,
diff --git a/tests/www/test_auth.py b/tests/www/test_auth.py
index a85fa9803dad6..bd2e963f86ebe 100644
--- a/tests/www/test_auth.py
+++ b/tests/www/test_auth.py
@@ -45,7 +45,6 @@ def test_function():
@pytest.mark.parametrize(
"decorator_name, is_authorized_method_name",
[
- ("has_access_cluster_activity", "is_authorized_cluster_activity"),
("has_access_configuration", "is_authorized_configuration"),
("has_access_dataset", "is_authorized_dataset"),
("has_access_view", "is_authorized_view"),
|
There is a duplicate way to check permissions access for cluster activity page, `is_authorized_view` is the correct one.
<!--
Licensed to the Apache Software Foundation (ASF) under one
or more contributor license agreements. See the NOTICE file
distributed with this work for additional information
regarding copyright ownership. The ASF licenses this file
to you under the Apache License, Version 2.0 (the
"License"); you may not use this file except in compliance
with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing,
software distributed under the License is distributed on an
"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
KIND, either express or implied. See the License for the
specific language governing permissions and limitations
under the License.
-->
<!--
Thank you for contributing! Please make sure that your code changes
are covered with tests. And in case of new features or big changes
remember to adjust the documentation.
Feel free to ping committers for the review!
In case of an existing issue, reference it using one of the following:
closes: #ISSUE
related: #ISSUE
How to write a good git commit message:
http://chris.beams.io/posts/git-commit/
-->
<!-- Please keep an empty line above the dashes. -->
---
**^ Add meaningful description above**
Read the **[Pull Request Guidelines](https://github.com/apache/airflow/blob/main/CONTRIBUTING.rst#pull-request-guidelines)** for more information.
In case of fundamental code changes, an Airflow Improvement Proposal ([AIP](https://cwiki.apache.org/confluence/display/AIRFLOW/Airflow+Improvement+Proposals)) is needed.
In case of a new dependency, check compliance with the [ASF 3rd Party License Policy](https://www.apache.org/legal/resolved.html#category-x).
In case of backwards incompatible changes please leave a note in a newsfragment file, named `{pr_number}.significant.rst` or `{issue_number}.significant.rst`, in [newsfragments](https://github.com/apache/airflow/tree/main/newsfragments).
|
https://api.github.com/repos/apache/airflow/pulls/36175
|
2023-12-11T19:14:55Z
|
2023-12-11T21:41:49Z
|
2023-12-11T21:41:49Z
|
2024-01-10T11:03:08Z
| 1,470
|
apache/airflow
| 14,330
|
Made a bulk_create test work without Pillow.
|
diff --git a/tests/bulk_create/models.py b/tests/bulk_create/models.py
index 75d4a3cbdc79e..b98ce4a1527fb 100644
--- a/tests/bulk_create/models.py
+++ b/tests/bulk_create/models.py
@@ -5,6 +5,11 @@
from django.db import models
from django.utils import timezone
+try:
+ from PIL import Image
+except ImportError:
+ Image = None
+
class Country(models.Model):
name = models.CharField(max_length=255)
@@ -76,11 +81,11 @@ class NullableFields(models.Model):
# Fields not required in BulkInsertMapper
char_field = models.CharField(null=True, max_length=4, default='char')
email_field = models.EmailField(null=True, default='[email protected]')
- duration_field = models.DurationField(null=True, default=datetime.timedelta(1))
file_field = models.FileField(null=True, default='file.txt')
file_path_field = models.FilePathField(path='/tmp', null=True, default='file.txt')
generic_ip_address_field = models.GenericIPAddressField(null=True, default='127.0.0.1')
- image_field = models.ImageField(null=True, default='image.jpg')
+ if Image:
+ image_field = models.ImageField(null=True, default='image.jpg')
slug_field = models.SlugField(null=True, default='slug')
text_field = models.TextField(null=True, default='text')
url_field = models.URLField(null=True, default='/')
|
Test didn't work since c4e2fc5d9872c9a0c9c052a2e124f8a9b87de9b4.
|
https://api.github.com/repos/django/django/pulls/8054
|
2017-02-12T11:12:55Z
|
2017-02-13T13:58:11Z
|
2017-02-13T13:58:11Z
|
2017-02-13T18:37:39Z
| 332
|
django/django
| 51,198
|
Remove experimental TDD step configs
|
diff --git a/gpt_engineer/preprompts/fix_code b/gpt_engineer/preprompts/fix_code
deleted file mode 100644
index 54efcb243d..0000000000
--- a/gpt_engineer/preprompts/fix_code
+++ /dev/null
@@ -1,5 +0,0 @@
-You are a super smart developer.
-You have been tasked with fixing a program and making it work according to the best of your knowledge.
-There might be placeholders in the code you have to fill in.
-You provide fully functioning, well formatted code with few comments, that works and has no bugs.
-Please return the full new code in the same format.
diff --git a/gpt_engineer/preprompts/spec b/gpt_engineer/preprompts/spec
deleted file mode 100644
index 7be78bd564..0000000000
--- a/gpt_engineer/preprompts/spec
+++ /dev/null
@@ -1,10 +0,0 @@
-You are a super smart developer. You have been asked to make a specification for a program.
-
-Think step by step to make sure we get a high quality specification and we don't miss anything.
-First, be super explicit about what the program should do, which features it should have
-and give details about anything that might be unclear. **Don't leave anything unclear or undefined.**
-
-Second, lay out the names of the core classes, functions, methods that will be necessary,
-as well as a quick comment on their purpose.
-
-This specification will be used later as the basis for the implementation.
diff --git a/gpt_engineer/preprompts/unit_tests b/gpt_engineer/preprompts/unit_tests
deleted file mode 100644
index 4c9534b4aa..0000000000
--- a/gpt_engineer/preprompts/unit_tests
+++ /dev/null
@@ -1,3 +0,0 @@
-You are a super smart developer using Test Driven Development to write tests according to a specification.
-
-Please generate tests based on the above specification. The tests should be as simple as possible, but still cover all the functionality.
diff --git a/gpt_engineer/steps.py b/gpt_engineer/steps.py
index 11b1b0d7dc..606c71dbf9 100644
--- a/gpt_engineer/steps.py
+++ b/gpt_engineer/steps.py
@@ -57,9 +57,6 @@ def curr_fn() -> str:
return inspect.stack()[1].function
-# All steps below have the Step signature
-
-
def lite_gen(ai: AI, dbs: DBs) -> List[Message]:
"""Run the AI on only the main prompt and save the results"""
messages = ai.start(
@@ -118,41 +115,6 @@ def clarify(ai: AI, dbs: DBs) -> List[Message]:
return messages
-def gen_spec(ai: AI, dbs: DBs) -> List[Message]:
- """
- Generate a spec from the main prompt + clarifications and save the results to
- the workspace
- """
- messages = [
- ai.fsystem(setup_sys_prompt(dbs)),
- ai.fsystem(f"Instructions: {dbs.input['prompt']}"),
- ]
-
- messages = ai.next(messages, dbs.preprompts["spec"], step_name=curr_fn())
-
- dbs.memory["specification"] = messages[-1].content.strip()
-
- return messages
-
-
-def gen_unit_tests(ai: AI, dbs: DBs) -> List[Message]:
- """
- Generate unit tests based on the specification, that should work.
- """
- messages = [
- ai.fsystem(setup_sys_prompt(dbs)),
- ai.fuser(f"Instructions: {dbs.input['prompt']}"),
- ai.fuser(f"Specification:\n\n{dbs.memory['specification']}"),
- ]
-
- messages = ai.next(messages, dbs.preprompts["unit_tests"], step_name=curr_fn())
-
- dbs.memory["unit_tests"] = messages[-1].content.strip()
- to_files(dbs.memory["unit_tests"], dbs.workspace)
-
- return messages
-
-
def gen_clarified_code(ai: AI, dbs: DBs) -> List[dict]:
"""Takes clarification and generates code"""
messages = AI.deserialize_messages(dbs.logs[clarify.__name__])
@@ -172,23 +134,6 @@ def gen_clarified_code(ai: AI, dbs: DBs) -> List[dict]:
return messages
-def gen_code_after_unit_tests(ai: AI, dbs: DBs) -> List[dict]:
- """Generates project code after unit tests have been produced"""
- messages = [
- ai.fsystem(setup_sys_prompt(dbs)),
- ai.fuser(f"Instructions: {dbs.input['prompt']}"),
- ai.fuser(f"Specification:\n\n{dbs.memory['specification']}"),
- ai.fuser(f"Unit tests:\n\n{dbs.memory['unit_tests']}"),
- ]
- messages = ai.next(
- messages,
- dbs.preprompts["generate"].replace("FILE_FORMAT", dbs.preprompts["file_format"]),
- step_name=curr_fn(),
- )
- to_files(messages[-1].content.strip(), dbs.workspace)
- return messages
-
-
def execute_entrypoint(ai: AI, dbs: DBs) -> List[dict]:
command = dbs.workspace["run.sh"]
@@ -351,22 +296,6 @@ def improve_existing_code(ai: AI, dbs: DBs):
return messages
-def fix_code(ai: AI, dbs: DBs):
- messages = AI.deserialize_messages(dbs.logs[gen_code_after_unit_tests.__name__])
- code_output = messages[-1].content.strip()
- messages = [
- ai.fsystem(setup_sys_prompt(dbs)),
- ai.fuser(f"Instructions: {dbs.input['prompt']}"),
- ai.fuser(code_output),
- ai.fsystem(dbs.preprompts["fix_code"]),
- ]
- messages = ai.next(
- messages, "Please fix any errors in the code above.", step_name=curr_fn()
- )
- to_files(messages[-1].content.strip(), dbs.workspace)
- return messages
-
-
def human_review(ai: AI, dbs: DBs):
"""Collects and stores human review of the code"""
review = human_review_input()
@@ -380,8 +309,6 @@ class Config(str, Enum):
BENCHMARK = "benchmark"
SIMPLE = "simple"
LITE = "lite"
- TDD = "tdd"
- TDD_PLUS = "tdd+"
CLARIFY = "clarify"
RESPEC = "respec"
EXECUTE_ONLY = "execute_only"
@@ -392,7 +319,6 @@ class Config(str, Enum):
EVAL_NEW_CODE = "eval_new_code"
-# Define the steps to run for different configs
STEPS = {
Config.DEFAULT: [
simple_gen,
@@ -419,23 +345,6 @@ class Config(str, Enum):
gen_entrypoint,
execute_entrypoint,
],
- Config.TDD: [
- gen_spec,
- gen_unit_tests,
- gen_code_after_unit_tests,
- gen_entrypoint,
- execute_entrypoint,
- human_review,
- ],
- Config.TDD_PLUS: [
- gen_spec,
- gen_unit_tests,
- gen_code_after_unit_tests,
- fix_code,
- gen_entrypoint,
- execute_entrypoint,
- human_review,
- ],
Config.USE_FEEDBACK: [use_feedback, gen_entrypoint, execute_entrypoint, human_review],
Config.EXECUTE_ONLY: [execute_entrypoint],
Config.EVALUATE: [execute_entrypoint, human_review],
@@ -448,6 +357,7 @@ class Config(str, Enum):
Config.EVAL_NEW_CODE: [simple_gen],
}
+
# Future steps that can be added:
# run_tests_and_fix_files
# execute_entrypoint_and_fix_files_if_it_results_in_error
diff --git a/tests/test_collect.py b/tests/test_collect.py
index b375e2a139..9859142412 100644
--- a/tests/test_collect.py
+++ b/tests/test_collect.py
@@ -8,8 +8,8 @@
from gpt_engineer.collect import collect_learnings, steps_file_hash
from gpt_engineer.db import DB, DBs
-from gpt_engineer.learning import extract_learning
-from gpt_engineer.steps import gen_code_after_unit_tests
+from gpt_engineer.learning import collect_consent, extract_learning
+from gpt_engineer.steps import simple_gen
def test_collect_learnings(monkeypatch):
@@ -18,7 +18,7 @@ def test_collect_learnings(monkeypatch):
model = "test_model"
temperature = 0.5
- steps = [gen_code_after_unit_tests]
+ steps = [simple_gen]
dbs = DBs(
DB("/tmp"), DB("/tmp"), DB("/tmp"), DB("/tmp"), DB("/tmp"), DB("/tmp"), DB("/tmp")
)
@@ -27,11 +27,7 @@ def test_collect_learnings(monkeypatch):
"feedback": "test feedback",
}
code = "this is output\n\nit contains code"
- dbs.logs = {
- gen_code_after_unit_tests.__name__: json.dumps(
- [{"role": "system", "content": code}]
- )
- }
+ dbs.logs = {steps[0].__name__: json.dumps([{"role": "system", "content": code}])}
dbs.workspace = {"all_output.txt": "test workspace\n" + code}
collect_learnings(model, temperature, steps, dbs)
|
Solves #656
Kept them on the experimental branch
|
https://api.github.com/repos/gpt-engineer-org/gpt-engineer/pulls/737
|
2023-09-23T09:21:35Z
|
2023-09-24T08:24:44Z
|
2023-09-24T08:24:44Z
|
2023-12-04T12:54:35Z
| 2,156
|
gpt-engineer-org/gpt-engineer
| 33,228
|
Change raw strings to strings in docstrings
|
diff --git a/rich/console.py b/rich/console.py
index de5c2ab85..5525fd3ac 100644
--- a/rich/console.py
+++ b/rich/console.py
@@ -733,7 +733,7 @@ def _collect_renderables(
Args:
renderables (Iterable[Union[str, ConsoleRenderable]]): Anyting that Rich can render.
sep (str, optional): String to write between print data. Defaults to " ".
- end (str, optional): String to write at end of print data. Defaults to "\n".
+ end (str, optional): String to write at end of print data. Defaults to "\\n".
justify (str, optional): One of "left", "right", "center", or "full". Defaults to ``None``.
emoji (Optional[bool], optional): Enable emoji code, or ``None`` to use console default.
markup (Optional[bool], optional): Enable markup, or ``None`` to use console default.
@@ -833,12 +833,12 @@ def print(
highlight: bool = None,
width: int = None,
) -> None:
- r"""Print to the console.
+ """Print to the console.
Args:
objects (positional args): Objects to log to the terminal.
sep (str, optional): String to write between print data. Defaults to " ".
- end (str, optional): String to write at end of print data. Defaults to "\n".
+ end (str, optional): String to write at end of print data. Defaults to "\\n".
style (Union[str, Style], optional): A style to apply to output. Defaults to None.
justify (str, optional): Justify method: "default", "left", "right", "center", or "full". Defaults to ``None``.
overflow (str, optional): Overflow method: "crop", "fold", or "ellipsis". Defaults to None.
@@ -915,12 +915,12 @@ def log(
log_locals: bool = False,
_stack_offset=1,
) -> None:
- r"""Log rich content to the terminal.
+ """Log rich content to the terminal.
Args:
objects (positional args): Objects to log to the terminal.
sep (str, optional): String to write between print data. Defaults to " ".
- end (str, optional): String to write at end of print data. Defaults to "\n".
+ end (str, optional): String to write at end of print data. Defaults to "\\n".
justify (str, optional): One of "left", "right", "center", or "full". Defaults to ``None``.
emoji (Optional[bool], optional): Enable emoji code, or ``None`` to use console default. Defaults to None.
markup (Optional[bool], optional): Enable markup, or ``None`` to use console default. Defaults to None.
diff --git a/rich/rule.py b/rich/rule.py
index 5c8918ca5..ddf167ac3 100644
--- a/rich/rule.py
+++ b/rich/rule.py
@@ -8,7 +8,7 @@
class Rule(JupyterMixin):
- r"""A console renderable to draw a horizontal rule (line).
+ """A console renderable to draw a horizontal rule (line).
Args:
title (Union[str, Text], optional): Text to render in the rule. Defaults to "".
diff --git a/rich/segment.py b/rich/segment.py
index 6e69ac1a9..31840b78f 100644
--- a/rich/segment.py
+++ b/rich/segment.py
@@ -216,10 +216,10 @@ def adjust_line_length(
@classmethod
def get_line_length(cls, line: List["Segment"]) -> int:
- r"""Get the length of list of segments.
+ """Get the length of list of segments.
Args:
- line (List[Segment]): A line encoded as a list of Segments (assumes no '\n' characters),
+ line (List[Segment]): A line encoded as a list of Segments (assumes no '\\n' characters),
Returns:
int: The length of the line.
@@ -228,10 +228,10 @@ def get_line_length(cls, line: List["Segment"]) -> int:
@classmethod
def get_shape(cls, lines: List[List["Segment"]]) -> Tuple[int, int]:
- r"""Get the shape (enclosing rectangle) of a list of lines.
+ """Get the shape (enclosing rectangle) of a list of lines.
Args:
- lines (List[List[Segment]]): A list of lines (no '\n' characters).
+ lines (List[List[Segment]]): A list of lines (no '\\n' characters).
Returns:
Tuple[int, int]: Width and height in characters.
diff --git a/rich/text.py b/rich/text.py
index 625f78f62..69cbc0048 100644
--- a/rich/text.py
+++ b/rich/text.py
@@ -102,7 +102,7 @@ def right_crop(self, offset: int) -> "Span":
class Text(JupyterMixin):
- r"""Text with color / style.
+ """Text with color / style.
Args:
text (str, optional): Default unstyled text. Defaults to "".
@@ -110,7 +110,7 @@ class Text(JupyterMixin):
justify (str, optional): Justify method: "left", "center", "full", "right". Defaults to None.
overflow (str, optional): Overflow method: "crop", "fold", "ellipsis". Defaults to None.
no_wrap (bool, optional): Disable text wrapping, or None for default. Defaults to None.
- end (str, optional): Character to end text with. Defaults to "\n".
+ end (str, optional): Character to end text with. Defaults to "\\n".
tab_size (int): Number of spaces per tab, or ``None`` to use ``console.tab_size``. Defaults to 8.
spans (List[Span], optional). A list of predefined style spans. Defaults to None.
"""
@@ -243,7 +243,7 @@ def assemble(
end: str = "\n",
tab_size: int = 8,
) -> "Text":
- r"""Construct a text instance by combining a sequence of strings with optional styles.
+ """Construct a text instance by combining a sequence of strings with optional styles.
The positional arguments should be either strings, or a tuple of string + style.
Args:
@@ -765,10 +765,10 @@ def split(
include_separator: bool = False,
allow_blank: bool = False,
) -> Lines:
- r"""Split rich text in to lines, preserving styles.
+ """Split rich text in to lines, preserving styles.
Args:
- separator (str, optional): String to split on. Defaults to "\n".
+ separator (str, optional): String to split on. Defaults to "\\n".
include_separator (bool, optional): Include the separator in the lines. Defaults to False.
allow_blank (bool, optional): Return a blank line if the text ends with a separator. Defaults to False.
|
## Type of changes
- [ ] Bug fix
- [ ] New feature
- [X] Documentation / docstrings
- [ ] Tests
- [ ] Other
## Checklist
- [X] I've run the latest [black](https://github.com/ambv/black) with default args on new code.
- [ ] I've updated CHANGELOG.md and CONTRIBUTORS.md where appropriate.
- [ ] I've added tests for new code.
- [X] I accept that @willmcgugan may be pedantic in the code review.
## Description
Change raw strings to strings in docstrings.
|
https://api.github.com/repos/Textualize/rich/pulls/219
|
2020-08-08T11:55:22Z
|
2020-08-08T20:13:02Z
|
2020-08-08T20:13:02Z
|
2020-08-08T20:13:02Z
| 1,618
|
Textualize/rich
| 48,181
|
Fix the width of riemann rectangles
|
diff --git a/manimlib/mobject/coordinate_systems.py b/manimlib/mobject/coordinate_systems.py
index 3ad0108622..dbfadb618d 100644
--- a/manimlib/mobject/coordinate_systems.py
+++ b/manimlib/mobject/coordinate_systems.py
@@ -235,6 +235,7 @@ def get_riemann_rectangles(self,
stroke_color=BLACK,
fill_opacity=1,
colors=(BLUE, GREEN),
+ stroke_background=True,
show_signed_area=True):
if x_range is None:
x_range = self.x_range[:2]
@@ -257,7 +258,8 @@ def get_riemann_rectangles(self,
height = get_norm(
self.i2gp(sample, graph) - self.c2p(sample, 0)
)
- rect = Rectangle(width=x1 - x0, height=height)
+ rect = Rectangle(width=self.x_axis.n2p(x1)[0] - self.x_axis.n2p(x0)[0],
+ height=height)
rect.move_to(self.c2p(x0, 0), DL)
rects.append(rect)
result = VGroup(*rects)
@@ -266,6 +268,7 @@ def get_riemann_rectangles(self,
stroke_width=stroke_width,
stroke_color=stroke_color,
fill_opacity=fill_opacity,
+ stroke_background=stroke_background
)
return result
|
<!-- Thanks for contributing to manim!
Please ensure that your pull request works with the latest version of manim.
-->
## Motivation
Fix the width of riemann rectangles
## Proposed changes
Change the width from `x1 - x0` to `width=self.x_axis.n2p(x1)[0] - self.x_axis.n2p(x0)[0]`.
The former means the global coord width while the latter means custom coord width.
## Test
<!-- How do you test your changes -->

|
https://api.github.com/repos/3b1b/manim/pulls/1762
|
2022-03-17T06:16:07Z
|
2022-03-17T16:06:42Z
|
2022-03-17T16:06:42Z
|
2022-03-17T16:06:43Z
| 319
|
3b1b/manim
| 18,442
|
MRG Use scores, not p-values, for feature selection
|
diff --git a/doc/modules/feature_selection.rst b/doc/modules/feature_selection.rst
index 0c7bb54b77ec6..574a7b8ad745f 100644
--- a/doc/modules/feature_selection.rst
+++ b/doc/modules/feature_selection.rst
@@ -17,12 +17,13 @@ Univariate feature selection
Univariate feature selection works by selecting the best features based on
univariate statistical tests. It can seen as a preprocessing step
-to an estimator. Scikit-Learn exposes feature selection routines
-a objects that implement the `transform` method:
+to an estimator. Scikit-learn exposes feature selection routines
+as objects that implement the `transform` method:
- * selecting the k-best features :class:`SelectKBest`
+ * :class:`SelectKBest` removes all but the `k` highest scoring features
- * setting a percentile of features to keep :class:`SelectPercentile`
+ * :class:`SelectPercentile` removes all but a user-specified highest scoring
+ percentile of features
* using common univariate statistical tests for each feature:
false positive rate :class:`SelectFpr`, false discovery rate
diff --git a/doc/whats_new.rst b/doc/whats_new.rst
index 14ce0966c5cfc..2e2f2a5948d77 100644
--- a/doc/whats_new.rst
+++ b/doc/whats_new.rst
@@ -14,6 +14,12 @@ Changelog
- :class:`feature_selection.SelectPercentile` now breaks ties
deterministically instead of returning all equally ranked features.
+ - :class:`feature_selection.SelectKBest` and
+ :class:`feature_selection.SelectPercentile` are more numerically stable
+ since they use scores, rather than p-values, to rank results. This means
+ that they might sometimes select different features than they did
+ previously.
+
- Ridge regression and ridge classification fitting with ``sparse_cg`` solver
no longer has quadratic memory complexity, by `Lars Buitinck`_ and
`Fabian Pedregosa`_.
diff --git a/sklearn/feature_selection/tests/test_feature_select.py b/sklearn/feature_selection/tests/test_feature_select.py
index 7c66cbe5b3082..3b5707bbd4954 100644
--- a/sklearn/feature_selection/tests/test_feature_select.py
+++ b/sklearn/feature_selection/tests/test_feature_select.py
@@ -2,12 +2,14 @@
Todo: cross-check the F-value with stats model
"""
+import itertools
import numpy as np
+from scipy import stats, sparse
import warnings
from nose.tools import assert_equal, assert_raises, assert_true
from numpy.testing import assert_array_equal, assert_array_almost_equal
-from scipy import stats, sparse
+from sklearn.utils.testing import assert_not_in
from sklearn.datasets.samples_generator import (make_classification,
make_regression)
@@ -402,7 +404,7 @@ def test_selectkbest_tiebreaking():
def test_selectpercentile_tiebreaking():
- """Test if SelectPercentile actually selects k features in case of ties.
+ """Test if SelectPercentile selects the right n_features in case of ties.
"""
X = [[1, 0, 0], [0, 1, 1]]
y = [0, 1]
@@ -413,3 +415,21 @@ def test_selectpercentile_tiebreaking():
X2 = SelectPercentile(chi2, percentile=67).fit_transform(X, y)
assert_equal(X2.shape[1], 2)
+
+
+def test_tied_pvalues():
+ """Test whether k-best and percentiles work with tied pvalues from chi2."""
+ # chi2 will return the same p-values for the following features, but it
+ # will return different scores.
+ X0 = np.array([[10000, 9999, 9998], [1, 1, 1]])
+ y = [0, 1]
+
+ for perm in itertools.permutations((0, 1, 2)):
+ X = X0[:, perm]
+ Xt = SelectKBest(chi2, k=2).fit_transform(X, y)
+ assert_equal(Xt.shape, (2, 2))
+ assert_not_in(9998, Xt)
+
+ Xt = SelectPercentile(chi2, percentile=67).fit_transform(X, y)
+ assert_equal(Xt.shape, (2, 2))
+ assert_not_in(9998, Xt)
diff --git a/sklearn/feature_selection/univariate_selection.py b/sklearn/feature_selection/univariate_selection.py
index 1c9fa19a35ae6..e5e08c1eb24dc 100644
--- a/sklearn/feature_selection/univariate_selection.py
+++ b/sklearn/feature_selection/univariate_selection.py
@@ -293,7 +293,7 @@ def inverse_transform(self, X):
######################################################################
class SelectPercentile(_AbstractUnivariateFilter):
- """Filter: Select the best percentile of the p-values.
+ """Select features according to a percentile of the highest scores.
Parameters
----------
@@ -331,24 +331,24 @@ def _get_support_mask(self):
if percentile > 100:
raise ValueError("percentile should be between 0 and 100"
" (%f given)" % (percentile))
- # Cater for Nans
+ # Cater for NaNs
if percentile == 100:
- return np.ones(len(self.pvalues_), dtype=np.bool)
+ return np.ones(len(self.scores_), dtype=np.bool)
elif percentile == 0:
- return np.zeros(len(self.pvalues_), dtype=np.bool)
- alpha = stats.scoreatpercentile(self.pvalues_, percentile)
+ return np.zeros(len(self.scores_), dtype=np.bool)
+ alpha = stats.scoreatpercentile(self.scores_, 100 - percentile)
# XXX refactor the indices -> mask -> indices -> mask thing
- inds = np.where(self.pvalues_ <= alpha)[0]
- # if we selected to many because of equal p-values,
+ inds = np.where(self.scores_ >= alpha)[0]
+ # if we selected too many features because of equal scores,
# we throw them away now
- inds = inds[:len(self.pvalues_) * percentile // 100]
- mask = np.zeros(self.pvalues_.shape, dtype=np.bool)
+ inds = inds[:len(self.scores_) * percentile // 100]
+ mask = np.zeros(self.scores_.shape, dtype=np.bool)
mask[inds] = True
return mask
class SelectKBest(_AbstractUnivariateFilter):
- """Filter: Select the k lowest p-values.
+ """Select features according to the k highest scores.
Parameters
----------
@@ -369,7 +369,7 @@ class SelectKBest(_AbstractUnivariateFilter):
Notes
-----
- Ties between features with equal p-values will be broken in an unspecified
+ Ties between features with equal scores will be broken in an unspecified
way.
"""
@@ -380,15 +380,15 @@ def __init__(self, score_func=f_classif, k=10):
def _get_support_mask(self):
k = self.k
- if k > len(self.pvalues_):
+ if k > len(self.scores_):
raise ValueError("cannot select %d features among %d"
- % (k, len(self.pvalues_)))
+ % (k, len(self.scores_)))
# XXX This should be refactored; we're getting an array of indices
# from argsort, which we transform to a mask, which we probably
# transform back to indices later.
- mask = np.zeros(self.pvalues_.shape, dtype=bool)
- mask[np.argsort(self.pvalues_)[:k]] = 1
+ mask = np.zeros(self.scores_.shape, dtype=bool)
+ mask[np.argsort(self.scores_)[-k:]] = 1
return mask
@@ -527,9 +527,13 @@ class GenericUnivariateSelect(_AbstractUnivariateFilter):
}
def __init__(self, score_func=f_classif, mode='percentile', param=1e-5):
+ if not callable(score_func):
+ raise TypeError(
+ "The score function should be a callable, %r (type %s) "
+ "was passed." % (score_func, type(score_func)))
if mode not in self._selection_modes:
raise ValueError(
- "The mode passed should be one of %s, %r "
+ "The mode passed should be one of %s, %r, (type %s) "
"was passed." % (
self._selection_modes.keys(),
mode, type(mode)))
|
This solves the numerical stability issue that @amueller encountered some time ago: p-values, at least those returned by `chi2`, may contain ties even when the scores don't.
This also paves the way for score functions that are not based on significance tests, such as mutual information and infogain (whence the name of this branch, but I won't be pushing those in this PR).
|
https://api.github.com/repos/scikit-learn/scikit-learn/pulls/1204
|
2012-10-04T09:37:52Z
|
2012-10-11T15:24:58Z
|
2012-10-11T15:24:58Z
|
2015-10-02T14:21:33Z
| 1,972
|
scikit-learn/scikit-learn
| 46,181
|
ref: remove patching of pickle dumping
|
diff --git a/src/sentry/monkey/pickle.py b/src/sentry/monkey/pickle.py
index 7f5619183190b..97d4ab84c2cb9 100644
--- a/src/sentry/monkey/pickle.py
+++ b/src/sentry/monkey/pickle.py
@@ -45,53 +45,14 @@
# contains a datetime object, or non-ASCII str data, it will fail with a
# UnicodeDecodeError, in which case we will decode strings as latin-1.
#
-# - At the moment we DO NOT patch `pickle.load`, since it may or may not be
-# the case that we can seek to the start of the passed file-like object. If
-# we do have usages of it, we'll have to patch them specifically based on
-# how the file is passed.
-#
# [0]: https://rebeccabilbro.github.io/convert-py2-pickles-to-py3/#python-2-objects-vs-python-3-objects
def patch_pickle_loaders():
import pickle
- # TODO(python3): We use the pickles `2` protocol as it is supported in 2 and 3.
- #
- # - python3 defaults to a protocol > 2 (depending on the version, see [0]).
- # - python2 defaults to protocol 2.
- #
- # This is ONLY required for the transition of Python 2 -> 3. There will be
- # a brief period where data may be pickled in python3 (during deploy, or if
- # we rollback), where if we did not declare the version, would be in format
- # that python 2's pickle COULD NOT decode.
- #
- # Once the python3 transition is complete we can use a higher version
- #
- # NOTE: from the documentation:
- # > The protocol version of the pickle is detected automatically
- #
- # [0]: https://docs.python.org/3/library/pickle.html#pickle-protocols
- #
- # XXX(epurkhiser): Unfortunately changing this module property is NOT
- # enough. Python 3 will use _pickle (aka new cpickle) if it is available
- # (which it usually will be). In this case it will NOT read from
- # DEFAULT_PROTOCOL, as the module functions passthrough to the C
- # implementation, which does not have a mutable DEFAULT_PROTOCOL module
- # property.
- #
- # I'm primarily leaving this here for consistency and documentation
- #
- # XXX(epurkhiser): BIG IMPORTANT NOTE! When changing this, we will have to
- # make some updates to our data pipeline, which currently uses 'pickle.js'
- # to depickle some data using javascript.
- pickle.DEFAULT_PROTOCOL = 2
-
original_pickle_load = pickle.load
- original_pickle_dump = pickle.dump
original_pickle_loads = pickle.loads
- original_pickle_dumps = pickle.dumps
- original_pickle_Pickler = pickle.Pickler
original_pickle_Unpickler = pickle.Unpickler
# Patched Picker and Unpickler
@@ -100,25 +61,6 @@ def patch_pickle_loaders():
# C module we can't subclass, so instead we just delegate with __getattr__.
# It's very possible we missed some more subtle uses of the classes here.
- class CompatPickler:
- def __init__(self, *args, **kwargs):
- # If we don't explicitly pass in a protocol, use DEFAULT_PROTOCOL
- # Enforce protocol kwarg as DEFAULT_PROTOCOL. See the comment above
- # DEFAULT_PROTOCOL above to understand why we must pass the kwarg due
- # to _pickle.
- if len(args) == 1:
- if not kwargs.get("protocol"):
- kwargs["protocol"] = pickle.DEFAULT_PROTOCOL
- else:
- largs = list(args)
- largs[1] = pickle.DEFAULT_PROTOCOL
- args = tuple(largs)
-
- self.__pickler = original_pickle_Pickler(*args, **kwargs)
-
- def __getattr__(self, key):
- return getattr(self.__pickler, key)
-
class CompatUnpickler:
def __init__(self, *args, **kwargs):
self.__orig_args = args
@@ -151,38 +93,6 @@ def load(self):
self.__make_unpickler()
return self.__unpickler.load()
- # Patched dump and dumps
-
- def py3_compat_pickle_dump(*args, **kwargs):
- # If we don't explicitly pass in a protocol, use DEFAULT_PROTOCOL
- # Enforce protocol kwarg as DEFAULT_PROTOCOL. See the comment above
- # DEFAULT_PROTOCOL above to understand why we must pass the kwarg due
- # to _pickle.
- if len(args) == 1:
- if not kwargs.get("protocol"):
- kwargs["protocol"] = pickle.DEFAULT_PROTOCOL
- else:
- largs = list(args)
- largs[1] = pickle.DEFAULT_PROTOCOL
- args = tuple(largs)
-
- return original_pickle_dump(*args, **kwargs)
-
- def py3_compat_pickle_dumps(*args, **kwargs):
- # If we don't explicitly pass in a protocol, use DEFAULT_PROTOCOL
- # Enforce protocol kwarg as DEFAULT_PROTOCOL. See the comment above
- # DEFAULT_PROTOCOL above to understand why we must pass the kwarg due
- # to _pickle.
- if len(args) == 1:
- if not kwargs.get("protocol"):
- kwargs["protocol"] = pickle.DEFAULT_PROTOCOL
- else:
- largs = list(args)
- largs[1] = pickle.DEFAULT_PROTOCOL
- args = tuple(largs)
-
- return original_pickle_dumps(*args, **kwargs)
-
# Patched load and loads
def py3_compat_pickle_load(*args, **kwargs):
@@ -208,8 +118,5 @@ def py3_compat_pickle_loads(*args, **kwargs):
return original_pickle_loads(*args, **kwargs)
pickle.load = py3_compat_pickle_load
- pickle.dump = py3_compat_pickle_dump
pickle.loads = py3_compat_pickle_loads
- pickle.dumps = py3_compat_pickle_dumps
- pickle.Pickler = CompatPickler
pickle.Unpickler = CompatUnpickler
diff --git a/tests/sentry/utils/test_pickle_protocol.py b/tests/sentry/utils/test_pickle_protocol.py
deleted file mode 100644
index cb4e2c4b87e10..0000000000000
--- a/tests/sentry/utils/test_pickle_protocol.py
+++ /dev/null
@@ -1,29 +0,0 @@
-import pickle
-from pickle import PickleBuffer, PickleError
-
-import pytest
-
-from sentry.testutils.cases import TestCase
-
-
-class PickleProtocolTestCase(TestCase):
- """
- At the time of adding this test we still monkey patch `pickle` and hardcode the protocol to be 2.
- For legacy reasons see `src/sentry/monkey/pickle.py`.
-
- This test is for a change that's being made to allow explicitly passing a newer protocol to
- pickle. If we remove the monkey patching to pickle there is no longer a need for this test.
-
- """
-
- def test_pickle_protocol(self):
- data = b"iamsomedata"
-
- pickled_data = PickleBuffer(data)
- with pytest.raises(PickleError) as excinfo:
- result = pickle.dumps(pickled_data)
-
- assert "PickleBuffer can only pickled with protocol >= 5" == str(excinfo.value)
-
- result = pickle.dumps(pickled_data, protocol=5)
- assert result
|
python 2 is long in the past and we are no longer using pickle in the data pipeline after changing all postgres data to json
<!-- Describe your PR here. -->
|
https://api.github.com/repos/getsentry/sentry/pulls/67241
|
2024-03-19T16:43:26Z
|
2024-03-19T17:10:26Z
|
2024-03-19T17:10:26Z
|
2024-04-04T00:23:58Z
| 1,749
|
getsentry/sentry
| 43,987
|
TST Avoid raising a spurious warning in test_kernel_approximation.py
|
diff --git a/sklearn/tests/test_kernel_approximation.py b/sklearn/tests/test_kernel_approximation.py
index 42e82e4dd36ff..f864214e49504 100644
--- a/sklearn/tests/test_kernel_approximation.py
+++ b/sklearn/tests/test_kernel_approximation.py
@@ -303,11 +303,11 @@ def logging_histogram_kernel(x, y, log):
).fit(X)
assert len(kernel_log) == n_samples * (n_samples - 1) / 2
- # if degree, gamma or coef0 is passed, we raise a warning
+ # if degree, gamma or coef0 is passed, we raise a ValueError
msg = "Don't pass gamma, coef0 or degree to Nystroem"
params = ({"gamma": 1}, {"coef0": 1}, {"degree": 2})
for param in params:
- ny = Nystroem(kernel=_linear_kernel, **param)
+ ny = Nystroem(kernel=_linear_kernel, n_components=(n_samples - 1), **param)
with pytest.raises(ValueError, match=msg):
ny.fit(X)
|
Remove a spurious warning related to the size of `n_components` compared to `n_samples` in `test_nystroem_callable`.
|
https://api.github.com/repos/scikit-learn/scikit-learn/pulls/20513
|
2021-07-12T16:53:13Z
|
2021-07-13T08:53:42Z
|
2021-07-13T08:53:42Z
|
2021-07-13T08:54:30Z
| 256
|
scikit-learn/scikit-learn
| 46,759
|
Use cached states for neato when possible
|
diff --git a/homeassistant/components/switch/neato.py b/homeassistant/components/switch/neato.py
index dca5d63b43dd30..34dad9bb5818ad 100644
--- a/homeassistant/components/switch/neato.py
+++ b/homeassistant/components/switch/neato.py
@@ -67,7 +67,7 @@ def update(self):
_LOGGER.debug('self._state=%s', self._state)
if self.type == SWITCH_TYPE_SCHEDULE:
_LOGGER.debug("State: %s", self._state)
- if self.robot.schedule_enabled:
+ if self._state['details']['isScheduleEnabled']:
self._schedule_state = STATE_ON
else:
self._schedule_state = STATE_OFF
diff --git a/homeassistant/components/vacuum/neato.py b/homeassistant/components/vacuum/neato.py
index 1b32fff9e5b8f7..6289fed265d065 100644
--- a/homeassistant/components/vacuum/neato.py
+++ b/homeassistant/components/vacuum/neato.py
@@ -96,14 +96,14 @@ def update(self):
elif self._state['state'] == 4:
self._status_state = ERRORS.get(self._state['error'])
- if (self.robot.state['action'] == 1 or
- self.robot.state['action'] == 2 or
- self.robot.state['action'] == 3 and
- self.robot.state['state'] == 2):
+ if (self._state['action'] == 1 or
+ self._state['action'] == 2 or
+ self._state['action'] == 3 and
+ self._state['state'] == 2):
self._clean_state = STATE_ON
- elif (self.robot.state['action'] == 11 or
- self.robot.state['action'] == 12 and
- self.robot.state['state'] == 2):
+ elif (self._state['action'] == 11 or
+ self._state['action'] == 12 and
+ self._state['state'] == 2):
self._clean_state = STATE_ON
else:
self._clean_state = STATE_OFF
|
## Description:
The neato `vacuum` and `switch` components were not making correct use of cached states. This PR makes sure to use the cached states when possible. Thanks to @MartinHjelmare for pointing this out in #15161 !
**Related issue (if applicable):** fixes #<home-assistant issue number goes here>
**Pull request in [home-assistant.github.io](https://github.com/home-assistant/home-assistant.github.io) with documentation (if applicable):** home-assistant/home-assistant.github.io#<home-assistant.github.io PR number goes here>
## Example entry for `configuration.yaml` (if applicable):
```yaml
neato:
username: username
password: password
```
## Checklist:
- [ ] The code change is tested and works locally.
- [ ] Local tests pass with `tox`. **Your PR cannot be merged unless tests pass**
If user exposed functionality or configuration variables are added/changed:
- [ ] Documentation added/updated in [home-assistant.github.io](https://github.com/home-assistant/home-assistant.github.io)
If the code communicates with devices, web services, or third-party tools:
- [ ] New dependencies have been added to the `REQUIREMENTS` variable ([example][ex-requir]).
- [ ] New dependencies are only imported inside functions that use them ([example][ex-import]).
- [ ] New or updated dependencies have been added to `requirements_all.txt` by running `script/gen_requirements_all.py`.
- [ ] New files were added to `.coveragerc`.
If the code does not interact with devices:
- [ ] Tests have been added to verify that the new code works.
[ex-requir]: https://github.com/home-assistant/home-assistant/blob/dev/homeassistant/components/keyboard.py#L14
[ex-import]: https://github.com/home-assistant/home-assistant/blob/dev/homeassistant/components/keyboard.py#L54
|
https://api.github.com/repos/home-assistant/core/pulls/15218
|
2018-06-29T19:55:29Z
|
2018-06-29T21:27:19Z
|
2018-06-29T21:27:19Z
|
2019-03-21T04:19:09Z
| 491
|
home-assistant/core
| 39,449
|
Fix typos in section CP: Concurrency
|
diff --git a/CppCoreGuidelines.md b/CppCoreGuidelines.md
index 2e26d74dd..2f874803e 100644
--- a/CppCoreGuidelines.md
+++ b/CppCoreGuidelines.md
@@ -11501,7 +11501,7 @@ Concurrency and parallelism rule summary:
* [CP.2: Avoid data races](#Rconc-races)
* [CP.3: Minimize explicit sharing of writable data](#Rconc-data)
* [CP.4: Think in terms of tasks, rather than threads](#Rconc-task)
-* [CP.8 Don't try to use `volatile` for synchronization](#Rconc-volatile)
+* [CP.8: Don't try to use `volatile` for synchronization](#Rconc-volatile)
See also:
@@ -11711,7 +11711,7 @@ This is a potent argument for using higher level, more applications-oriented lib
???
-### <a name="Rconc-volatile"></a>CP.8 Don't try to use `volatile` for synchronization
+### <a name="Rconc-volatile"></a>CP.8: Don't try to use `volatile` for synchronization
##### Reason
@@ -11783,7 +11783,7 @@ Concurrency rule summary:
* [CP.26: Prefer `gsl::detached_thread` over `std::thread` if you plan to `detach()`](#Rconc-detached_thread)
* [CP.27: Use plain `std::thread` for `thread`s that detach based on a run-time condition (only)](#Rconc-thread)
* [CP.28: Remember to join scoped `thread`s that are not `detach()`ed](#Rconc-join-undetached)
-* [CP.30: Do not pass pointers to local variables to non-`raii_thread's](#Rconc-pass)
+* [CP.30: Do not pass pointers to local variables to non-`raii_thread`s](#Rconc-pass)
* [CP.31: Pass small amounts of data between threads by value, rather than by reference or pointer](#Rconc-data-by-value)
* [CP.32: To share ownership between unrelated `thread`s use `shared_ptr`](#Rconc-shared)
* [CP.40: Minimize context switching](#Rconc-switch)
@@ -12122,7 +12122,7 @@ A `thread` that has not been `detach()`ed when it is destroyed terminates the pr
* Flag `detach`s for `detached_thread`s
-### <a name="RRconc-pass"></a>CP.30: Do not pass pointers to local variables to non-`raii_thread's
+### <a name="RRconc-pass"></a>CP.30: Do not pass pointers to local variables to non-`raii_thread`s
##### Reason
@@ -12592,7 +12592,7 @@ If you are doing lock-free programming for performance, you need to check for re
Instruction reordering (static and dynamic) makes it hard for us to think effectively at this level (especially if you use relaxed memory models).
Experience, (semi)formal models and model checking can be useful.
Testing - often to an extreme extent - is essential.
-"Don't fly too close to the wind."
+"Don't fly too close to the sun."
##### Enforcement
|
CP.8: Add missing colon to title
CP.30: In title, close inline code block with backtick
CP.101: Correct saying, Icarus flew to close to the sun, not the wind
|
https://api.github.com/repos/isocpp/CppCoreGuidelines/pulls/800
|
2016-11-22T13:04:52Z
|
2016-11-22T15:53:52Z
|
2016-11-22T15:53:52Z
|
2016-11-22T16:43:47Z
| 731
|
isocpp/CppCoreGuidelines
| 16,121
|
Fix a typo in gym/utils/play.py
|
diff --git a/gym/utils/play.py b/gym/utils/play.py
index 592ae67d066..694089ec129 100644
--- a/gym/utils/play.py
+++ b/gym/utils/play.py
@@ -65,7 +65,7 @@ def callback(obs_t, obs_tp1, rew, done, info):
obs_tp1: observation after performing action
action: action that was executed
rew: reward that was received
- done: whether the environemnt is done or not
+ done: whether the environment is done or not
info: debug info
keys_to_action: dict: tuple(int) -> int or None
Mapping from keys pressed to action performed.
|
https://api.github.com/repos/openai/gym/pulls/1187
|
2018-10-05T10:39:30Z
|
2018-10-23T21:20:15Z
|
2018-10-23T21:20:15Z
|
2018-10-23T21:20:15Z
| 156
|
openai/gym
| 5,587
|
|
feat(discover): Add SnQL support for error.unhandled
|
diff --git a/src/sentry/search/events/base.py b/src/sentry/search/events/base.py
index 5e92baf8b81d3..868ebaa149d14 100644
--- a/src/sentry/search/events/base.py
+++ b/src/sentry/search/events/base.py
@@ -7,6 +7,7 @@
from sentry.models import Project
from sentry.search.events.constants import (
+ ERROR_HANDLED_ALIAS,
ERROR_UNHANDLED_ALIAS,
ISSUE_ALIAS,
ISSUE_ID_ALIAS,
@@ -53,8 +54,9 @@ def __init__(self, dataset: Dataset, params: ParamsType):
TIMESTAMP_TO_DAY_ALIAS: self._resolve_timestamp_to_day_alias,
USER_DISPLAY_ALIAS: self._resolve_user_display_alias,
TRANSACTION_STATUS_ALIAS: self._resolve_transaction_status,
+ ERROR_UNHANDLED_ALIAS: self._resolve_error_unhandled_alias,
+ ERROR_HANDLED_ALIAS: self._resolve_error_handled_alias,
# TODO: implement these
- ERROR_UNHANDLED_ALIAS: self._resolve_unimplemented_alias,
KEY_TRANSACTION_ALIAS: self._resolve_unimplemented_alias,
TEAM_KEY_TRANSACTION_ALIAS: self._resolve_unimplemented_alias,
PROJECT_THRESHOLD_CONFIG_ALIAS: self._resolve_unimplemented_alias,
@@ -131,6 +133,16 @@ def _resolve_transaction_status(self, _: str) -> SelectType:
"toUInt8", [self.column(TRANSACTION_STATUS_ALIAS)], TRANSACTION_STATUS_ALIAS
)
+ def _resolve_error_unhandled_alias(self, _: str) -> SelectType:
+ return Function("notHandled", [], ERROR_UNHANDLED_ALIAS)
+
+ def _resolve_error_handled_alias(self, _: str) -> SelectType:
+ # Columns in snuba doesn't support aliasing right now like Function does.
+ # Adding a no-op here to get the alias.
+ return Function(
+ "cast", [self.column("error.handled"), "Array(Nullable(UInt8))"], ERROR_HANDLED_ALIAS
+ )
+
def _resolve_unimplemented_alias(self, alias: str) -> SelectType:
"""Used in the interim as a stub for ones that have not be implemented in SnQL yet.
Can be deleted once all field aliases have been implemented.
diff --git a/src/sentry/search/events/constants.py b/src/sentry/search/events/constants.py
index 1e703b3f515b2..4c1b53e4bfcbc 100644
--- a/src/sentry/search/events/constants.py
+++ b/src/sentry/search/events/constants.py
@@ -9,6 +9,7 @@
PROJECT_THRESHOLD_CONFIG_ALIAS = "project_threshold_config"
TEAM_KEY_TRANSACTION_ALIAS = "team_key_transaction"
ERROR_UNHANDLED_ALIAS = "error.unhandled"
+ERROR_HANDLED_ALIAS = "error.handled"
USER_DISPLAY_ALIAS = "user.display"
PROJECT_ALIAS = "project"
PROJECT_NAME_ALIAS = "project.name"
@@ -97,6 +98,7 @@
TIMESTAMP_TO_HOUR_ALIAS,
TIMESTAMP_TO_DAY_ALIAS,
TRANSACTION_STATUS_ALIAS,
+ ERROR_UNHANDLED_ALIAS,
}
OPERATOR_NEGATION_MAP = {
diff --git a/src/sentry/search/events/filter.py b/src/sentry/search/events/filter.py
index 60dc8388f859c..13df565402dc4 100644
--- a/src/sentry/search/events/filter.py
+++ b/src/sentry/search/events/filter.py
@@ -25,6 +25,7 @@
from sentry.search.events.constants import (
ARRAY_FIELDS,
EQUALITY_OPERATORS,
+ ERROR_HANDLED_ALIAS,
ERROR_UNHANDLED_ALIAS,
ISSUE_ALIAS,
ISSUE_ID_ALIAS,
@@ -1021,6 +1022,8 @@ def __init__(self, dataset: Dataset, params: ParamsType):
ISSUE_ALIAS: self._issue_filter_converter,
TRANSACTION_STATUS_ALIAS: self._transaction_status_filter_converter,
ISSUE_ID_ALIAS: self._issue_id_filter_converter,
+ ERROR_HANDLED_ALIAS: self._error_handled_filter_converter,
+ ERROR_UNHANDLED_ALIAS: self._error_unhandled_filter_converter,
}
def resolve_where(self, query: Optional[str]) -> List[WhereType]:
@@ -1270,3 +1273,37 @@ def _issue_id_filter_converter(self, search_filter: SearchFilter) -> Optional[Wh
# Skip isNull check on group_id value as we want to
# allow snuba's prewhere optimizer to find this condition.
return Condition(lhs, Op(search_filter.operator), rhs)
+
+ def _error_unhandled_filter_converter(
+ self,
+ search_filter: SearchFilter,
+ ) -> Optional[WhereType]:
+ value = search_filter.value.value
+ # Treat has filter as equivalent to handled
+ if search_filter.value.raw_value == "":
+ output = 0 if search_filter.operator == "!=" else 1
+ return Condition(Function("isHandled", []), Op.EQ, output)
+ if value in ("1", 1):
+ return Condition(Function("notHandled", []), Op.EQ, 1)
+ if value in ("0", 0):
+ return Condition(Function("isHandled", []), Op.EQ, 1)
+ raise InvalidSearchQuery(
+ "Invalid value for error.unhandled condition. Accepted values are 1, 0"
+ )
+
+ def _error_handled_filter_converter(
+ self,
+ search_filter: SearchFilter,
+ ) -> Optional[WhereType]:
+ value = search_filter.value.value
+ # Treat has filter as equivalent to handled
+ if search_filter.value.raw_value == "":
+ output = 1 if search_filter.operator == "!=" else 0
+ return Condition(Function("isHandled", []), Op.EQ, output)
+ if value in ("1", 1):
+ return Condition(Function("isHandled", []), Op.EQ, 1)
+ if value in ("0", 0):
+ return Condition(Function("notHandled", []), Op.EQ, 1)
+ raise InvalidSearchQuery(
+ "Invalid value for error.handled condition. Accepted values are 1, 0"
+ )
diff --git a/tests/sentry/snuba/test_discover.py b/tests/sentry/snuba/test_discover.py
index 7afba21a75bb7..4f47d96fc17a2 100644
--- a/tests/sentry/snuba/test_discover.py
+++ b/tests/sentry/snuba/test_discover.py
@@ -497,6 +497,92 @@ def run_query(query, expected_statuses, message):
)
run_query("!has:transaction.status", [], "status nonexistant")
+ def test_error_handled_alias(self):
+ data = load_data("android-ndk", timestamp=before_now(minutes=10))
+ events = (
+ ("a" * 32, "not handled", False),
+ ("b" * 32, "is handled", True),
+ ("c" * 32, "undefined", None),
+ )
+ for event in events:
+ data["event_id"] = event[0]
+ data["message"] = event[1]
+ data["exception"]["values"][0]["value"] = event[1]
+ data["exception"]["values"][0]["mechanism"]["handled"] = event[2]
+ self.store_event(data=data, project_id=self.project.id)
+
+ queries = [
+ ("", [[0], [1], [None]]),
+ ("error.handled:true", [[1], [None]]),
+ ("!error.handled:true", [[0]]),
+ ("has:error.handled", [[1], [None]]),
+ ("has:error.handled error.handled:true", [[1], [None]]),
+ ("error.handled:false", [[0]]),
+ ("has:error.handled error.handled:false", []),
+ ]
+
+ for query, expected_data in queries:
+ for query_fn in [discover.query, discover.wip_snql_query]:
+ result = query_fn(
+ selected_columns=["error.handled"],
+ query=query,
+ params={
+ "organization_id": self.organization.id,
+ "project_id": [self.project.id],
+ "start": before_now(minutes=12),
+ "end": before_now(minutes=8),
+ },
+ )
+
+ data = result["data"]
+ data = sorted(
+ data, key=lambda k: (k["error.handled"][0] is None, k["error.handled"][0])
+ )
+
+ assert len(data) == len(expected_data), query_fn
+ assert [item["error.handled"] for item in data] == expected_data
+
+ def test_error_unhandled_alias(self):
+ data = load_data("android-ndk", timestamp=before_now(minutes=10))
+ events = (
+ ("a" * 32, "not handled", False),
+ ("b" * 32, "is handled", True),
+ ("c" * 32, "undefined", None),
+ )
+ for event in events:
+ data["event_id"] = event[0]
+ data["message"] = event[1]
+ data["exception"]["values"][0]["value"] = event[1]
+ data["exception"]["values"][0]["mechanism"]["handled"] = event[2]
+ self.store_event(data=data, project_id=self.project.id)
+
+ queries = [
+ ("error.unhandled:true", ["a" * 32], [1]),
+ ("!error.unhandled:true", ["b" * 32, "c" * 32], [0, 0]),
+ ("has:error.unhandled", ["a" * 32], [1]),
+ ("!has:error.unhandled", ["b" * 32, "c" * 32], [0, 0]),
+ ("has:error.unhandled error.unhandled:true", ["a" * 32], [1]),
+ ("error.unhandled:false", ["b" * 32, "c" * 32], [0, 0]),
+ ("has:error.unhandled error.unhandled:false", [], []),
+ ]
+
+ for query, expected_events, error_handled in queries:
+ for query_fn in [discover.query, discover.wip_snql_query]:
+ result = query_fn(
+ selected_columns=["error.unhandled"],
+ query=query,
+ params={
+ "organization_id": self.organization.id,
+ "project_id": [self.project.id],
+ "start": before_now(minutes=12),
+ "end": before_now(minutes=8),
+ },
+ )
+ data = result["data"]
+
+ assert len(data) == len(expected_events), query_fn
+ assert [item["error.unhandled"] for item in data] == error_handled
+
def test_field_aliasing_in_selected_columns(self):
result = discover.query(
selected_columns=["project.id", "user", "release", "timestamp.to_hour"],
diff --git a/tests/snuba/api/endpoints/test_organization_events_stats.py b/tests/snuba/api/endpoints/test_organization_events_stats.py
index a3b0c7fc68a81..74cb0816f4824 100644
--- a/tests/snuba/api/endpoints/test_organization_events_stats.py
+++ b/tests/snuba/api/endpoints/test_organization_events_stats.py
@@ -1494,6 +1494,7 @@ def test_top_events_with_error_handled(self):
assert response.status_code == 200, response.content
data = response.data
+
assert len(data) == 3
results = data[""]
|
Add support for error.unhandled
in SnQL. Fields and Filter.
|
https://api.github.com/repos/getsentry/sentry/pulls/27330
|
2021-07-12T19:29:37Z
|
2021-07-15T21:40:42Z
|
2021-07-15T21:40:42Z
|
2021-07-31T00:01:09Z
| 2,546
|
getsentry/sentry
| 44,625
|
Fixes 2 typos in the chat prompt
|
diff --git a/llama_index/prompts/chat_prompts.py b/llama_index/prompts/chat_prompts.py
index 97d673294144b..d6d41afc7ec41 100644
--- a/llama_index/prompts/chat_prompts.py
+++ b/llama_index/prompts/chat_prompts.py
@@ -64,7 +64,7 @@
CHAT_REFINE_PROMPT_TMPL_MSGS = [
ChatMessage(
content=(
- "You are an expert Q&A system that stricly operates in two modes"
+ "You are an expert Q&A system that strictly operates in two modes "
"when refining existing answers:\n"
"1. **Rewrite** an original answer using the new context.\n"
"2. **Repeat** the original answer if the new context isn't useful.\n"
|
# Description
While debugging I noticed the CHAT_REFINE_PROMPT_TMPL_MSGS prompt template had two obvious typos: a missing "t" and a missing space at the end of a line, that caused two words to run together.
## Type of Change
- [x] Bug fix (non-breaking change which fixes an issue)
- [ ] New feature (non-breaking change which adds functionality)
- [ ] Breaking change (fix or feature that would cause existing functionality to not work as expected)
- [ ] This change requires a documentation update
# How Has This Been Tested?
Please describe the tests that you ran to verify your changes. Provide instructions so we can reproduce. Please also list any relevant details for your test configuration
- [ ] Added new unit/integration tests
- [ ] Added new notebook (that tests end-to-end)
- [x] I stared at the code and made sure it makes sense
# Suggested Checklist:
- [x] I have performed a self-review of my own code
- [ ] I have commented my code, particularly in hard-to-understand areas
- [ ] I have made corresponding changes to the documentation
- [ ] My changes generate no new warnings
- [ ] I have added tests that prove my fix is effective or that my feature works
- [ ] New and existing unit tests pass locally with my changes
|
https://api.github.com/repos/run-llama/llama_index/pulls/7798
|
2023-09-23T22:32:51Z
|
2023-09-23T22:56:42Z
|
2023-09-23T22:56:42Z
|
2023-09-23T22:56:43Z
| 186
|
run-llama/llama_index
| 6,197
|
Fixed #26933 -- Fixed an update_or_create test sometimes failing.
|
diff --git a/tests/get_or_create/tests.py b/tests/get_or_create/tests.py
index 0a774eff772cf..108c8e3b4f6cb 100644
--- a/tests/get_or_create/tests.py
+++ b/tests/get_or_create/tests.py
@@ -5,7 +5,7 @@
from datetime import date, datetime, timedelta
from threading import Thread
-from django.db import DatabaseError, IntegrityError
+from django.db import DatabaseError, IntegrityError, connection
from django.test import (
TestCase, TransactionTestCase, ignore_warnings, skipUnlessDBFeature,
)
@@ -441,14 +441,27 @@ def test_updates_in_transaction(self):
while it holds the lock. The updated field isn't a field in 'defaults',
so update_or_create() shouldn't have an effect on it.
"""
+ lock_status = {'has_grabbed_lock': False}
+
def birthday_sleep():
- time.sleep(0.3)
+ lock_status['has_grabbed_lock'] = True
+ time.sleep(0.5)
return date(1940, 10, 10)
def update_birthday_slowly():
Person.objects.update_or_create(
first_name='John', defaults={'birthday': birthday_sleep}
)
+ # Avoid leaking connection for Oracle
+ connection.close()
+
+ def lock_wait():
+ # timeout after ~0.5 seconds
+ for i in range(20):
+ time.sleep(0.025)
+ if lock_status['has_grabbed_lock']:
+ return True
+ return False
Person.objects.create(first_name='John', last_name='Lennon', birthday=date(1940, 10, 9))
@@ -457,8 +470,8 @@ def update_birthday_slowly():
before_start = datetime.now()
t.start()
- # Wait for lock to begin
- time.sleep(0.05)
+ if not lock_wait():
+ self.skipTest('Database took too long to lock the row')
# Update during lock
Person.objects.filter(first_name='John').update(last_name='NotLennon')
@@ -469,5 +482,5 @@ def update_birthday_slowly():
# The update remains and it blocked.
updated_person = Person.objects.get(first_name='John')
- self.assertGreater(after_update - before_start, timedelta(seconds=0.3))
+ self.assertGreater(after_update - before_start, timedelta(seconds=0.5))
self.assertEqual(updated_person.last_name, 'NotLennon')
|
https://api.github.com/repos/django/django/pulls/6985
|
2016-07-27T20:37:03Z
|
2016-07-29T01:45:35Z
|
2016-07-29T01:45:35Z
|
2016-07-29T01:45:35Z
| 555
|
django/django
| 50,961
|
|
Fix global_state not disconnected after ray.shutdown
|
diff --git a/python/ray/experimental/state.py b/python/ray/experimental/state.py
index eea005874bd1d..68d48a6df5ccb 100644
--- a/python/ray/experimental/state.py
+++ b/python/ray/experimental/state.py
@@ -120,6 +120,11 @@ def _check_connected(self):
raise Exception("The ray.global_state API cannot be used before "
"ray.init has been called.")
+ def disconnect(self):
+ """Disconnect global state from GCS."""
+ self.redis_client = None
+ self.redis_clients = None
+
def _initialize_global_state(self,
redis_ip_address,
redis_port,
diff --git a/python/ray/tests/test_basic.py b/python/ray/tests/test_basic.py
index 88c64d3e3f115..4c05e7466ae3f 100644
--- a/python/ray/tests/test_basic.py
+++ b/python/ray/tests/test_basic.py
@@ -2887,3 +2887,12 @@ def test_load_code_from_local(shutdown_only):
base_actor_class = ray.remote(num_cpus=1)(BaseClass)
base_actor = base_actor_class.remote(message)
assert ray.get(base_actor.get_data.remote()) == message
+
+
+def test_shutdown_disconnect_global_state():
+ ray.init(num_cpus=0)
+ ray.shutdown()
+
+ with pytest.raises(Exception) as e:
+ ray.global_state.object_table()
+ assert str(e.value).endswith("ray.init has been called.")
diff --git a/python/ray/worker.py b/python/ray/worker.py
index 3938d9256d864..2e358302996b4 100644
--- a/python/ray/worker.py
+++ b/python/ray/worker.py
@@ -1566,6 +1566,9 @@ def shutdown(exiting_interpreter=False):
disconnect()
+ # Disconnect global state from GCS.
+ global_state.disconnect()
+
# Shut down the Ray processes.
global _global_node
if _global_node is not None:
@@ -2054,7 +2057,7 @@ def connect(info,
def disconnect():
- """Disconnect this worker from the scheduler and object store."""
+ """Disconnect this worker from the raylet and object store."""
# Reset the list of cached remote functions and actors so that if more
# remote functions or actors are defined and then connect is called again,
# the remote functions will be exported. This is mostly relevant for the
|
## What do these changes do?
Considering this script:
```python
import ray
ray.init()
ray.shutdown()
ray.global_state.object_table()
```
It throws a `ConnectionRefusedError` error. Worse, `_check_connected ()` will pass.
|
https://api.github.com/repos/ray-project/ray/pulls/4354
|
2019-03-13T07:33:05Z
|
2019-03-18T23:44:50Z
|
2019-03-18T23:44:50Z
|
2019-03-27T10:14:36Z
| 551
|
ray-project/ray
| 19,687
|
DOC: update the Index.shift docstring
|
diff --git a/pandas/core/indexes/base.py b/pandas/core/indexes/base.py
index 52283e4e223b4..3c357788c9d6b 100644
--- a/pandas/core/indexes/base.py
+++ b/pandas/core/indexes/base.py
@@ -2256,18 +2256,19 @@ def sortlevel(self, level=None, ascending=True, sort_remaining=None):
return self.sort_values(return_indexer=True, ascending=ascending)
def shift(self, periods=1, freq=None):
- """Shift index by desired number of time frequency increments.
+ """
+ Shift index by desired number of time frequency increments.
This method is for shifting the values of datetime-like indexes
by a specified time increment a given number of times.
Parameters
----------
- periods : int
+ periods : int, default 1
Number of periods (or increments) to shift by,
- can be positive or negative (default is 1).
- freq : pandas.DateOffset, pandas.Timedelta or string
- Frequency increment to shift by (default is None).
+ can be positive or negative.
+ freq : pandas.DateOffset, pandas.Timedelta or string, optional
+ Frequency increment to shift by.
If None, the index is shifted by its own `freq` attribute.
Offset aliases are valid strings, e.g., 'D', 'W', 'M' etc.
@@ -2276,6 +2277,10 @@ def shift(self, periods=1, freq=None):
pandas.Index
shifted index
+ See Also
+ --------
+ Series.shift : Shift values of Series.
+
Examples
--------
Put the first 5 month starts of 2011 into an index.
|
Checklist for the pandas documentation sprint (ignore this if you are doing
an unrelated PR):
- [x] PR title is "DOC: update the <your-function-or-method> docstring"
- [ ] The validation script passes: `scripts/validate_docstrings.py <your-function-or-method>`
- [x] The PEP8 style check passes: `git diff upstream/master -u -- "*.py" | flake8 --diff`
- [x] The html version looks good: `python doc/make.py --single <your-function-or-method>`
- [x] It has been proofread on language by another sprint participant
Please include the output of the validation script below between the "```" ticks:
```
################################################################################
######################## Docstring (pandas.Index.shift) ########################
################################################################################
Shift index by desired number of time frequency increments.
This method is for shifting the values of datetime-like indexes
by a specified time increment a given number of times.
Parameters
----------
periods : int, default 1
Number of periods (or increments) to shift by,
can be positive or negative.
freq : pandas.DateOffset, pandas.Timedelta or string, optional
Frequency increment to shift by.
If None, the index is shifted by its own `freq` attribute.
Offset aliases are valid strings, e.g., 'D', 'W', 'M' etc.
Returns
-------
pandas.Index
shifted index
Examples
--------
Put the first 5 month starts of 2011 into an index.
>>> month_starts = pd.date_range('1/1/2011', periods=5, freq='MS')
>>> month_starts
DatetimeIndex(['2011-01-01', '2011-02-01', '2011-03-01', '2011-04-01',
'2011-05-01'],
dtype='datetime64[ns]', freq='MS')
Shift the index by 10 days.
>>> month_starts.shift(10, freq='D')
DatetimeIndex(['2011-01-11', '2011-02-11', '2011-03-11', '2011-04-11',
'2011-05-11'],
dtype='datetime64[ns]', freq=None)
The default value of `freq` is the `freq` attribute of the index,
which is 'MS' (month start) in this example.
>>> month_starts.shift(10)
DatetimeIndex(['2011-11-01', '2011-12-01', '2012-01-01', '2012-02-01',
'2012-03-01'],
dtype='datetime64[ns]', freq='MS')
Notes
-----
This method is only implemented for datetime-like index classes,
i.e., DatetimeIndex, PeriodIndex and TimedeltaIndex.
################################################################################
################################## Validation ##################################
################################################################################
Errors found:
See Also section not found
```
If the validation script still gives errors, but you think there is a good reason
to deviate in this case (and there are certainly such cases), please state this
explicitly.
-- We haven't included a See Also section because there are no functions in pandas that are related to this.
Checklist for other PRs (remove this part if you are doing a PR for the pandas documentation sprint):
- [ ] closes #xxxx
- [ ] tests added / passed
- [ ] passes `git diff upstream/master -u -- "*.py" | flake8 --diff`
- [ ] whatsnew entry
|
https://api.github.com/repos/pandas-dev/pandas/pulls/20192
|
2018-03-10T16:04:36Z
|
2018-03-10T19:15:48Z
|
2018-03-10T19:15:48Z
|
2018-03-10T19:15:51Z
| 389
|
pandas-dev/pandas
| 45,337
|
DEPR: Deprecate tupleize_cols in to_csv
|
diff --git a/doc/source/whatsnew/v0.21.0.txt b/doc/source/whatsnew/v0.21.0.txt
index 5577089c776ed..b0d1169b6bcd6 100644
--- a/doc/source/whatsnew/v0.21.0.txt
+++ b/doc/source/whatsnew/v0.21.0.txt
@@ -803,6 +803,7 @@ Deprecations
- :func:`read_excel()` has deprecated ``sheetname`` in favor of ``sheet_name`` for consistency with ``.to_excel()`` (:issue:`10559`).
- :func:`read_excel()` has deprecated ``parse_cols`` in favor of ``usecols`` for consistency with :func:`read_csv` (:issue:`4988`)
- :func:`read_csv()` has deprecated the ``tupleize_cols`` argument. Column tuples will always be converted to a ``MultiIndex`` (:issue:`17060`)
+- :meth:`DataFrame.to_csv` has deprecated the ``tupleize_cols`` argument. Multi-index columns will be always written as rows in the CSV file (:issue:`17060`)
- The ``convert`` parameter has been deprecated in the ``.take()`` method, as it was not being respected (:issue:`16948`)
- ``pd.options.html.border`` has been deprecated in favor of ``pd.options.display.html.border`` (:issue:`15793`).
- :func:`SeriesGroupBy.nth` has deprecated ``True`` in favor of ``'all'`` for its kwarg ``dropna`` (:issue:`11038`).
diff --git a/pandas/core/frame.py b/pandas/core/frame.py
index 97943f153319b..8d6786d7bb838 100644
--- a/pandas/core/frame.py
+++ b/pandas/core/frame.py
@@ -1432,7 +1432,7 @@ def to_csv(self, path_or_buf=None, sep=",", na_rep='', float_format=None,
columns=None, header=True, index=True, index_label=None,
mode='w', encoding=None, compression=None, quoting=None,
quotechar='"', line_terminator='\n', chunksize=None,
- tupleize_cols=False, date_format=None, doublequote=True,
+ tupleize_cols=None, date_format=None, doublequote=True,
escapechar=None, decimal='.'):
r"""Write DataFrame to a comma-separated values (csv) file
@@ -1485,8 +1485,13 @@ def to_csv(self, path_or_buf=None, sep=",", na_rep='', float_format=None,
chunksize : int or None
rows to write at a time
tupleize_cols : boolean, default False
- write multi_index columns as a list of tuples (if True)
- or new (expanded format) if False)
+ .. deprecated:: 0.21.0
+ This argument will be removed and will always write each row
+ of the multi-index as a separate row in the CSV file.
+
+ Write MultiIndex columns as a list of tuples (if True) or in
+ the new, expanded format, where each MultiIndex column is a row
+ in the CSV (if False).
date_format : string, default None
Format string for datetime objects
decimal: string, default '.'
@@ -1494,6 +1499,14 @@ def to_csv(self, path_or_buf=None, sep=",", na_rep='', float_format=None,
European data
"""
+
+ if tupleize_cols is not None:
+ warnings.warn("The 'tupleize_cols' parameter is deprecated and "
+ "will be removed in a future version",
+ FutureWarning, stacklevel=2)
+ else:
+ tupleize_cols = False
+
formatter = fmt.CSVFormatter(self, path_or_buf,
line_terminator=line_terminator, sep=sep,
encoding=encoding,
diff --git a/pandas/tests/frame/test_to_csv.py b/pandas/tests/frame/test_to_csv.py
index b0cc414861818..4162a586f8063 100644
--- a/pandas/tests/frame/test_to_csv.py
+++ b/pandas/tests/frame/test_to_csv.py
@@ -577,7 +577,8 @@ def _make_frame(names=None):
# tupleize_cols=True and index=False
df = _make_frame(True)
- df.to_csv(path, tupleize_cols=True, index=False)
+ with tm.assert_produces_warning(FutureWarning):
+ df.to_csv(path, tupleize_cols=True, index=False)
with tm.assert_produces_warning(FutureWarning,
check_stacklevel=False):
@@ -602,7 +603,8 @@ def _make_frame(names=None):
# column & index are multi-index (compatibility)
df = mkdf(5, 3, r_idx_nlevels=2, c_idx_nlevels=4)
- df.to_csv(path, tupleize_cols=True)
+ with tm.assert_produces_warning(FutureWarning):
+ df.to_csv(path, tupleize_cols=True)
with tm.assert_produces_warning(FutureWarning,
check_stacklevel=False):
|
Title is self-explanatory.
xref #17060
|
https://api.github.com/repos/pandas-dev/pandas/pulls/17877
|
2017-10-15T00:31:46Z
|
2017-10-16T10:28:35Z
|
2017-10-16T10:28:35Z
|
2017-10-16T14:54:57Z
| 1,118
|
pandas-dev/pandas
| 45,460
|
Switch to use or not einsum op. Needed for ORT
|
diff --git a/deepspeed/moe/sharded_moe.py b/deepspeed/moe/sharded_moe.py
index af1cafbe3bfd..08cbc4074f8f 100644
--- a/deepspeed/moe/sharded_moe.py
+++ b/deepspeed/moe/sharded_moe.py
@@ -96,6 +96,41 @@ def backward(ctx: Any, *grad_output: Tensor) -> Tuple[None, Tensor]:
import math
+# einsum rewrites are on par or more performant
+# switch can be bubbled up in future
+USE_EINSUM = True
+
+
+def einsum(rule, a, b):
+ if USE_EINSUM:
+ return torch.einsum(rule, a, b)
+ elif rule == 's,se->se':
+ return a.reshape(a.shape[0], -1) * b
+ elif rule == 'se,sc->sec':
+ return a.unsqueeze(2) * b.unsqueeze(1)
+ elif rule == 'se,se->s':
+ return torch.bmm(a.unsqueeze(1), b.unsqueeze(2)).reshape(-1)
+ elif rule == 'sec,sm->ecm':
+ s = a.shape[0]
+ e = a.shape[1]
+ c = a.shape[2]
+ m = b.shape[1]
+ return torch.matmul(a.reshape(s, -1).t(), b).reshape(e, c, m)
+ elif rule == 'sec,ecm->sm':
+ return torch.matmul(a.reshape(a.shape[0], -1), b.reshape(-1, b.shape[-1]))
+ elif rule == 'ks,ksm->sm':
+ k = b.shape[0]
+ s = b.shape[1]
+ m = b.shape[2]
+ # [k, s] -> [s, k] -> [s, 1, k]
+ a = a.t().unsqueeze(1)
+ # [k,s,m] -> [k, sm] -> [sm, k] -> [s, m, k]
+ b = b.reshape(k, -1).t().reshape(s, m, k)
+ # bmm([s, 1, k], [s, m, k]^t) -> [s, m, 1]
+ return torch.bmm(a, b.transpose(1, 2)).squeeze(2)
+ else:
+ return torch.einsum(rule, a, b)
+
def top1gating(logits: torch.Tensor,
capacity_factor: float,
@@ -127,7 +162,7 @@ def top1gating(logits: torch.Tensor,
# mask only used tokens
if used_token is not None:
- mask1 = torch.einsum("s,se->se", used_token, mask1)
+ mask1 = einsum("s,se->se", used_token, mask1)
# gating decisions
exp_counts = torch.sum(mask1, dim=0).detach().to('cpu')
@@ -165,7 +200,8 @@ def top1gating(logits: torch.Tensor,
gates = gates * mask1_float
locations1_sc = F.one_hot(locations1_s, num_classes=capacity).float()
- combine_weights = torch.einsum("se,sc->sec", gates, locations1_sc)
+ combine_weights = einsum("se,sc->sec", gates, locations1_sc)
+
dispatch_mask = combine_weights.bool()
return l_aux, combine_weights, dispatch_mask, exp_counts
@@ -224,8 +260,8 @@ def top2gating(logits: torch.Tensor,
# Normalize gate probabilities
mask1_float = mask1.float()
mask2_float = mask2.float()
- gates1_s = torch.einsum("se,se->s", gates, mask1_float)
- gates2_s = torch.einsum("se,se->s", gates, mask2_float)
+ gates1_s = einsum("se,se->s", gates, mask1_float)
+ gates2_s = einsum("se,se->s", gates, mask2_float)
denom_s = gates1_s + gates2_s
# Avoid divide-by-zero
denom_s = torch.clamp(denom_s, min=torch.finfo(denom_s.dtype).eps)
@@ -233,12 +269,12 @@ def top2gating(logits: torch.Tensor,
gates2_s /= denom_s
# Calculate combine_weights and dispatch_mask
- gates1 = torch.einsum("s,se->se", gates1_s, mask1_float)
- gates2 = torch.einsum("s,se->se", gates2_s, mask2_float)
+ gates1 = einsum("s,se->se", gates1_s, mask1_float)
+ gates2 = einsum("s,se->se", gates2_s, mask2_float)
locations1_sc = F.one_hot(locations1_s, num_classes=capacity).float()
locations2_sc = F.one_hot(locations2_s, num_classes=capacity).float()
- combine1_sec = torch.einsum("se,sc->sec", gates1, locations1_sc)
- combine2_sec = torch.einsum("se,sc->sec", gates2, locations2_sc)
+ combine1_sec = einsum("se,sc->sec", gates1, locations1_sc)
+ combine2_sec = einsum("se,sc->sec", gates2, locations2_sc)
combine_weights = combine1_sec + combine2_sec
dispatch_mask = combine_weights.bool()
@@ -374,9 +410,9 @@ def forward(self, *input: Tensor, **kwargs: Any) -> Tensor:
self.l_aux, combine_weights, dispatch_mask, self.exp_counts = self.gate(reshaped_input, input[1])
- dispatched_input = torch.einsum("sec,sm->ecm",
- dispatch_mask.type_as(input[0]),
- reshaped_input)
+ dispatched_input = einsum("sec,sm->ecm",
+ dispatch_mask.type_as(input[0]),
+ reshaped_input)
if self.wall_clock_breakdown:
self.timers('falltoall').start()
@@ -409,9 +445,9 @@ def forward(self, *input: Tensor, **kwargs: Any) -> Tensor:
-1,
d_model)
- combined_output = torch.einsum("sec,ecm->sm",
- combine_weights.type_as(input[0]),
- expert_output)
+ combined_output = einsum("sec,ecm->sm",
+ combine_weights.type_as(input[0]),
+ expert_output)
a = combined_output.reshape(input[0].shape)
|
Replace einsum op as its not supported by onnxruntime.
Branch by USE_EINSUM flag.
Example:
...
deepspeed.moe.sharded_moe.USE_EINSUM = False
...
self.fc3 = deepspeed.moe.layer.MoE(..)
...
|
https://api.github.com/repos/microsoft/DeepSpeed/pulls/1456
|
2021-10-14T21:21:18Z
|
2021-10-21T20:08:53Z
|
2021-10-21T20:08:53Z
|
2021-10-21T20:08:53Z
| 1,498
|
microsoft/DeepSpeed
| 10,580
|
Add git_branch_delete rule
|
diff --git a/tests/rules/test_git_branch_delete.py b/tests/rules/test_git_branch_delete.py
new file mode 100644
index 000000000..44a8f4490
--- /dev/null
+++ b/tests/rules/test_git_branch_delete.py
@@ -0,0 +1,22 @@
+import pytest
+from thefuck.rules.git_branch_delete import match, get_new_command
+from tests.utils import Command
+
+
[email protected]
+def stderr():
+ return '''error: The branch 'branch' is not fully merged.
+If you are sure you want to delete it, run 'git branch -D branch'.
+
+'''
+
+
+def test_match(stderr):
+ assert match(Command('git branch -d branch', stderr=stderr), None)
+ assert not match(Command('git branch -d branch'), None)
+ assert not match(Command('ls', stderr=stderr), None)
+
+
+def test_get_new_command(stderr):
+ assert get_new_command(Command('git branch -d branch', stderr=stderr), None)\
+ == "git branch -D branch"
diff --git a/thefuck/rules/git_branch_delete.py b/thefuck/rules/git_branch_delete.py
new file mode 100644
index 000000000..ad465af6a
--- /dev/null
+++ b/thefuck/rules/git_branch_delete.py
@@ -0,0 +1,7 @@
+def match(command, settings):
+ return ('git branch -d' in command.script
+ and 'If you are sure you want to delete it' in command.stderr)
+
+
+def get_new_command(command, settings):
+ return command.script.replace('-d', '-D')
|
I have never written python before, so this is just copy-pasting and slashing. So if I missed some convention, or wrote the test in some wrong way, please tell me :smile:
This is to be able to give a fuck in this situation:

|
https://api.github.com/repos/nvbn/thefuck/pulls/292
|
2015-07-19T11:47:22Z
|
2015-07-19T18:26:39Z
|
2015-07-19T18:26:39Z
|
2015-07-19T19:03:52Z
| 365
|
nvbn/thefuck
| 30,618
|
Refs #27795 -- Replaced force_bytes() usage in django.core.signing
|
diff --git a/django/core/signing.py b/django/core/signing.py
index 5daad4d8efaa7..1a55bcda03c90 100644
--- a/django/core/signing.py
+++ b/django/core/signing.py
@@ -74,7 +74,7 @@ def base64_hmac(salt, value, key):
def get_cookie_signer(salt='django.core.signing.get_cookie_signer'):
Signer = import_string(settings.SIGNING_BACKEND)
- key = force_bytes(settings.SECRET_KEY)
+ key = force_bytes(settings.SECRET_KEY) # SECRET_KEY may be str or bytes.
return Signer(b'django.http.cookies' + key, salt=salt)
@@ -131,7 +131,7 @@ def loads(s, key=None, salt='django.core.signing', serializer=JSONSerializer, ma
"""
# TimestampSigner.unsign() returns str but base64 and zlib compression
# operate on bytes.
- base64d = force_bytes(TimestampSigner(key, salt=salt).unsign(s, max_age=max_age))
+ base64d = TimestampSigner(key, salt=salt).unsign(s, max_age=max_age).encode()
decompress = base64d[:1] == b'.'
if decompress:
# It's compressed; uncompress it first
|
https://api.github.com/repos/django/django/pulls/9654
|
2018-02-02T08:55:38Z
|
2018-02-07T17:47:34Z
|
2018-02-07T17:47:34Z
|
2019-03-03T08:04:07Z
| 304
|
django/django
| 51,332
|
|
chore(github-comments): fix flaky test
|
diff --git a/tests/sentry/tasks/integrations/github/test_pr_comment.py b/tests/sentry/tasks/integrations/github/test_pr_comment.py
index 992ac5ef5db0c..d1fa67b0522f8 100644
--- a/tests/sentry/tasks/integrations/github/test_pr_comment.py
+++ b/tests/sentry/tasks/integrations/github/test_pr_comment.py
@@ -348,6 +348,8 @@ def setUp(self):
@responses.activate
def test_comment_workflow(self, mock_metrics, mock_issues):
groups = [g.id for g in Group.objects.all()]
+ titles = [g.title for g in Group.objects.all()]
+ culprits = [g.culprit for g in Group.objects.all()]
mock_issues.return_value = [{"group_id": id, "event_count": 10} for id in groups]
responses.add(
@@ -361,7 +363,7 @@ def test_comment_workflow(self, mock_metrics, mock_issues):
assert (
responses.calls[0].request.body
- == f'{{"body": "## Suspect Issues\\nThis pull request was deployed and Sentry observed the following issues:\\n\\n- \\u203c\\ufe0f **issue 1** `issue1` [View Issue](http://testserver/organizations/foo/issues/{groups[0]}/?referrer=github-pr-bot)\\n- \\u203c\\ufe0f **issue 2** `issue2` [View Issue](http://testserver/organizations/foobar/issues/{groups[1]}/?referrer=github-pr-bot)\\n\\n<sub>Did you find this useful? React with a \\ud83d\\udc4d or \\ud83d\\udc4e</sub>"}}'.encode()
+ == f'{{"body": "## Suspect Issues\\nThis pull request was deployed and Sentry observed the following issues:\\n\\n- \\u203c\\ufe0f **{titles[0]}** `{culprits[0]}` [View Issue](http://testserver/organizations/foo/issues/{groups[0]}/?referrer=github-pr-bot)\\n- \\u203c\\ufe0f **{titles[1]}** `{culprits[1]}` [View Issue](http://testserver/organizations/foobar/issues/{groups[1]}/?referrer=github-pr-bot)\\n\\n<sub>Did you find this useful? React with a \\ud83d\\udc4d or \\ud83d\\udc4e</sub>"}}'.encode()
)
pull_request_comment_query = PullRequestComment.objects.all()
assert len(pull_request_comment_query) == 1
|
Fixes SENTRY-TESTS-QRW ([link](https://sentry.sentry.io/issues/4740260799/))
|
https://api.github.com/repos/getsentry/sentry/pulls/63032
|
2024-01-11T19:41:52Z
|
2024-01-11T21:02:33Z
|
2024-01-11T21:02:33Z
|
2024-01-27T00:02:16Z
| 589
|
getsentry/sentry
| 43,940
|
Fixed #12756: Improved error message when yaml module is missing.
|
diff --git a/AUTHORS b/AUTHORS
index c343eeb67bd86..75db3005130d3 100644
--- a/AUTHORS
+++ b/AUTHORS
@@ -58,6 +58,7 @@ answer newbie questions, and generally made Django that much better:
Gisle Aas <[email protected]>
Chris Adams
Mathieu Agopian <[email protected]>
+ Roberto Aguilar <[email protected]>
ajs <[email protected]>
[email protected]
A S Alam <[email protected]>
diff --git a/django/core/management/commands/dumpdata.py b/django/core/management/commands/dumpdata.py
index c74eede846403..ed58ec79a1909 100644
--- a/django/core/management/commands/dumpdata.py
+++ b/django/core/management/commands/dumpdata.py
@@ -106,11 +106,11 @@ def handle(self, *app_labels, **options):
# Check that the serialization format exists; this is a shortcut to
# avoid collating all the objects and _then_ failing.
if format not in serializers.get_public_serializer_formats():
- raise CommandError("Unknown serialization format: %s" % format)
+ try:
+ serializers.get_serializer(format)
+ except serializers.SerializerDoesNotExist:
+ pass
- try:
- serializers.get_serializer(format)
- except KeyError:
raise CommandError("Unknown serialization format: %s" % format)
def get_objects():
diff --git a/django/core/serializers/__init__.py b/django/core/serializers/__init__.py
index dc3d139d3b6d6..89d9877ebf910 100644
--- a/django/core/serializers/__init__.py
+++ b/django/core/serializers/__init__.py
@@ -27,17 +27,29 @@
"xml" : "django.core.serializers.xml_serializer",
"python" : "django.core.serializers.python",
"json" : "django.core.serializers.json",
+ "yaml" : "django.core.serializers.pyyaml",
}
-# Check for PyYaml and register the serializer if it's available.
-try:
- import yaml
- BUILTIN_SERIALIZERS["yaml"] = "django.core.serializers.pyyaml"
-except ImportError:
- pass
-
_serializers = {}
+
+class BadSerializer(object):
+ """
+ Stub serializer to hold exception raised during registration
+
+ This allows the serializer registration to cache serializers and if there
+ is an error raised in the process of creating a serializer it will be
+ raised and passed along to the caller when the serializer is used.
+ """
+ internal_use_only = False
+
+ def __init__(self, exception):
+ self.exception = exception
+
+ def __call__(self, *args, **kwargs):
+ raise self.exception
+
+
def register_serializer(format, serializer_module, serializers=None):
"""Register a new serializer.
@@ -53,12 +65,23 @@ def register_serializer(format, serializer_module, serializers=None):
"""
if serializers is None and not _serializers:
_load_serializers()
- module = importlib.import_module(serializer_module)
+
+ try:
+ module = importlib.import_module(serializer_module)
+ except ImportError, exc:
+ bad_serializer = BadSerializer(exc)
+
+ module = type('BadSerializerModule', (object,), {
+ 'Deserializer': bad_serializer,
+ 'Serializer': bad_serializer,
+ })
+
if serializers is None:
_serializers[format] = module
else:
serializers[format] = module
+
def unregister_serializer(format):
"Unregister a given serializer. This is not a thread-safe operation."
if not _serializers:
diff --git a/tests/serializers/tests.py b/tests/serializers/tests.py
index 381cc5ed87b3a..9af8165314c64 100644
--- a/tests/serializers/tests.py
+++ b/tests/serializers/tests.py
@@ -1,6 +1,7 @@
# -*- coding: utf-8 -*-
from __future__ import unicode_literals
+import importlib
import json
from datetime import datetime
import re
@@ -14,7 +15,7 @@
from django.conf import settings
-from django.core import serializers
+from django.core import management, serializers
from django.db import transaction, connection
from django.test import TestCase, TransactionTestCase, Approximate
from django.utils import six
@@ -440,6 +441,69 @@ class JsonSerializerTransactionTestCase(SerializersTransactionTestBase, Transact
}]"""
+YAML_IMPORT_ERROR_MESSAGE = r'No module named yaml'
+class YamlImportModuleMock(object):
+ """Provides a wrapped import_module function to simulate yaml ImportError
+
+ In order to run tests that verify the behavior of the YAML serializer
+ when run on a system that has yaml installed (like the django CI server),
+ mock import_module, so that it raises an ImportError when the yaml
+ serializer is being imported. The importlib.import_module() call is
+ being made in the serializers.register_serializer().
+
+ Refs: #12756
+ """
+ def __init__(self):
+ self._import_module = importlib.import_module
+
+ def import_module(self, module_path):
+ if module_path == serializers.BUILTIN_SERIALIZERS['yaml']:
+ raise ImportError(YAML_IMPORT_ERROR_MESSAGE)
+
+ return self._import_module(module_path)
+
+
+class NoYamlSerializerTestCase(TestCase):
+ """Not having pyyaml installed provides a misleading error
+
+ Refs: #12756
+ """
+ @classmethod
+ def setUpClass(cls):
+ """Removes imported yaml and stubs importlib.import_module"""
+ super(NoYamlSerializerTestCase, cls).setUpClass()
+
+ cls._import_module_mock = YamlImportModuleMock()
+ importlib.import_module = cls._import_module_mock.import_module
+
+ # clear out cached serializers to emulate yaml missing
+ serializers._serializers = {}
+
+ @classmethod
+ def tearDownClass(cls):
+ """Puts yaml back if necessary"""
+ super(NoYamlSerializerTestCase, cls).tearDownClass()
+
+ importlib.import_module = cls._import_module_mock._import_module
+
+ # clear out cached serializers to clean out BadSerializer instances
+ serializers._serializers = {}
+
+ def test_serializer_pyyaml_error_message(self):
+ """Using yaml serializer without pyyaml raises ImportError"""
+ jane = Author(name="Jane")
+ self.assertRaises(ImportError, serializers.serialize, "yaml", [jane])
+
+ def test_deserializer_pyyaml_error_message(self):
+ """Using yaml deserializer without pyyaml raises ImportError"""
+ self.assertRaises(ImportError, serializers.deserialize, "yaml", "")
+
+ def test_dumpdata_pyyaml_error_message(self):
+ """Calling dumpdata produces an error when yaml package missing"""
+ self.assertRaisesRegexp(management.CommandError, YAML_IMPORT_ERROR_MESSAGE,
+ management.call_command, 'dumpdata', format='yaml')
+
+
@unittest.skipUnless(HAS_YAML, "No yaml library detected")
class YamlSerializerTestCase(SerializersTestBase, TestCase):
serializer_name = "yaml"
diff --git a/tests/serializers_regress/tests.py b/tests/serializers_regress/tests.py
index 3173f73985af0..bd71d4da6add0 100644
--- a/tests/serializers_regress/tests.py
+++ b/tests/serializers_regress/tests.py
@@ -523,7 +523,10 @@ def streamTest(format, self):
else:
self.assertEqual(string_data, stream.content.decode('utf-8'))
-for format in serializers.get_serializer_formats():
+for format in [
+ f for f in serializers.get_serializer_formats()
+ if not isinstance(serializers.get_serializer(f), serializers.BadSerializer)
+ ]:
setattr(SerializerTests, 'test_' + format + '_serializer', curry(serializerTest, format))
setattr(SerializerTests, 'test_' + format + '_natural_key_serializer', curry(naturalKeySerializerTest, format))
setattr(SerializerTests, 'test_' + format + '_serializer_fields', curry(fieldsTest, format))
diff --git a/tests/timezones/tests.py b/tests/timezones/tests.py
index 49169f90f2ed8..9390eb93dfd90 100644
--- a/tests/timezones/tests.py
+++ b/tests/timezones/tests.py
@@ -599,7 +599,7 @@ def test_naive_datetime(self):
obj = next(serializers.deserialize('xml', data)).object
self.assertEqual(obj.dt, dt)
- if 'yaml' in serializers.get_serializer_formats():
+ if not isinstance(serializers.get_serializer('yaml'), serializers.BadSerializer):
data = serializers.serialize('yaml', [Event(dt=dt)])
self.assert_yaml_contains_datetime(data, "2011-09-01 13:20:30")
obj = next(serializers.deserialize('yaml', data)).object
@@ -623,7 +623,7 @@ def test_naive_datetime_with_microsecond(self):
obj = next(serializers.deserialize('xml', data)).object
self.assertEqual(obj.dt, dt)
- if 'yaml' in serializers.get_serializer_formats():
+ if not isinstance(serializers.get_serializer('yaml'), serializers.BadSerializer):
data = serializers.serialize('yaml', [Event(dt=dt)])
self.assert_yaml_contains_datetime(data, "2011-09-01 13:20:30.405060")
obj = next(serializers.deserialize('yaml', data)).object
@@ -647,7 +647,7 @@ def test_aware_datetime_with_microsecond(self):
obj = next(serializers.deserialize('xml', data)).object
self.assertEqual(obj.dt, dt)
- if 'yaml' in serializers.get_serializer_formats():
+ if not isinstance(serializers.get_serializer('yaml'), serializers.BadSerializer):
data = serializers.serialize('yaml', [Event(dt=dt)])
self.assert_yaml_contains_datetime(data, "2011-09-01 17:20:30.405060+07:00")
obj = next(serializers.deserialize('yaml', data)).object
@@ -671,7 +671,7 @@ def test_aware_datetime_in_utc(self):
obj = next(serializers.deserialize('xml', data)).object
self.assertEqual(obj.dt, dt)
- if 'yaml' in serializers.get_serializer_formats():
+ if not isinstance(serializers.get_serializer('yaml'), serializers.BadSerializer):
data = serializers.serialize('yaml', [Event(dt=dt)])
self.assert_yaml_contains_datetime(data, "2011-09-01 10:20:30+00:00")
obj = next(serializers.deserialize('yaml', data)).object
@@ -695,7 +695,7 @@ def test_aware_datetime_in_local_timezone(self):
obj = next(serializers.deserialize('xml', data)).object
self.assertEqual(obj.dt, dt)
- if 'yaml' in serializers.get_serializer_formats():
+ if not isinstance(serializers.get_serializer('yaml'), serializers.BadSerializer):
data = serializers.serialize('yaml', [Event(dt=dt)])
self.assert_yaml_contains_datetime(data, "2011-09-01 13:20:30+03:00")
obj = next(serializers.deserialize('yaml', data)).object
@@ -719,7 +719,7 @@ def test_aware_datetime_in_other_timezone(self):
obj = next(serializers.deserialize('xml', data)).object
self.assertEqual(obj.dt, dt)
- if 'yaml' in serializers.get_serializer_formats():
+ if not isinstance(serializers.get_serializer('yaml'), serializers.BadSerializer):
data = serializers.serialize('yaml', [Event(dt=dt)])
self.assert_yaml_contains_datetime(data, "2011-09-01 17:20:30+07:00")
obj = next(serializers.deserialize('yaml', data)).object
|
Running dumpdata without `pyyaml` installed will now produce a useful error message:
```
[berto@scratch]$ python manage.py dumpdata --format=yaml
CommandError: Unable to serialize database: No module named yaml
```
|
https://api.github.com/repos/django/django/pulls/1582
|
2013-09-06T22:35:17Z
|
2013-09-06T23:05:05Z
|
2013-09-06T23:05:05Z
|
2014-06-26T05:37:58Z
| 2,635
|
django/django
| 51,563
|
Change string to enum in SomfyThermostat
|
diff --git a/homeassistant/components/overkiz/climate_entities/somfy_thermostat.py b/homeassistant/components/overkiz/climate_entities/somfy_thermostat.py
index 8242fdc85768be..aaae64e0454cf8 100644
--- a/homeassistant/components/overkiz/climate_entities/somfy_thermostat.py
+++ b/homeassistant/components/overkiz/climate_entities/somfy_thermostat.py
@@ -22,13 +22,10 @@
PRESET_FREEZE = "freeze"
PRESET_NIGHT = "night"
-STATE_DEROGATION_ACTIVE = "active"
-STATE_DEROGATION_INACTIVE = "inactive"
-
OVERKIZ_TO_HVAC_MODES: dict[str, HVACMode] = {
- STATE_DEROGATION_ACTIVE: HVACMode.HEAT,
- STATE_DEROGATION_INACTIVE: HVACMode.AUTO,
+ OverkizCommandParam.ACTIVE: HVACMode.HEAT,
+ OverkizCommandParam.INACTIVE: HVACMode.AUTO,
}
HVAC_MODES_TO_OVERKIZ = {v: k for k, v in OVERKIZ_TO_HVAC_MODES.items()}
|
## Proposed change
While working on another PR
(needs https://github.com/home-assistant/core/pull/88808)
## Type of change
<!--
What type of change does your PR introduce to Home Assistant?
NOTE: Please, check only 1! box!
If your PR requires multiple boxes to be checked, you'll most likely need to
split it into multiple PRs. This makes things easier and faster to code review.
-->
- [ ] Dependency upgrade
- [ ] Bugfix (non-breaking change which fixes an issue)
- [ ] New integration (thank you!)
- [ ] New feature (which adds functionality to an existing integration)
- [ ] Deprecation (breaking change to happen in the future)
- [ ] Breaking change (fix/feature causing existing functionality to break)
- [x] Code quality improvements to existing code or addition of tests
## Additional information
<!--
Details are important, and help maintainers processing your PR.
Please be sure to fill out additional details, if applicable.
-->
- This PR fixes or closes issue: fixes #
- This PR is related to issue:
- Link to documentation pull request:
## Checklist
<!--
Put an `x` in the boxes that apply. You can also fill these out after
creating the PR. If you're unsure about any of them, don't hesitate to ask.
We're here to help! This is simply a reminder of what we are going to look
for before merging your code.
-->
- [x] The code change is tested and works locally.
- [x] Local tests pass. **Your PR cannot be merged unless tests pass**
- [x] There is no commented out code in this PR.
- [x] I have followed the [development checklist][dev-checklist]
- [x] The code has been formatted using Black (`black --fast homeassistant tests`)
- [ ] Tests have been added to verify that the new code works.
If user exposed functionality or configuration variables are added/changed:
- [ ] Documentation added/updated for [www.home-assistant.io][docs-repository]
If the code communicates with devices, web services, or third-party tools:
- [ ] The [manifest file][manifest-docs] has all fields filled out correctly.
Updated and included derived files by running: `python3 -m script.hassfest`.
- [ ] New or updated dependencies have been added to `requirements_all.txt`.
Updated by running `python3 -m script.gen_requirements_all`.
- [ ] For the updated dependencies - a link to the changelog, or at minimum a diff between library versions is added to the PR description.
- [ ] Untested files have been added to `.coveragerc`.
<!--
This project is very active and we have a high turnover of pull requests.
Unfortunately, the number of incoming pull requests is higher than what our
reviewers can review and merge so there is a long backlog of pull requests
waiting for review. You can help here!
By reviewing another pull request, you will help raise the code quality of
that pull request and the final review will be faster. This way the general
pace of pull request reviews will go up and your wait time will go down.
When picking a pull request to review, try to choose one that hasn't yet
been reviewed.
Thanks for helping out!
-->
To help with the load of incoming pull requests:
- [ ] I have reviewed two other [open pull requests][prs] in this repository.
[prs]: https://github.com/home-assistant/core/pulls?q=is%3Aopen+is%3Apr+-author%3A%40me+-draft%3Atrue+-label%3Awaiting-for-upstream+sort%3Acreated-desc+review%3Anone+-status%3Afailure
<!--
Thank you for contributing <3
Below, some useful links you could explore:
-->
[dev-checklist]: https://developers.home-assistant.io/docs/en/development_checklist.html
[manifest-docs]: https://developers.home-assistant.io/docs/en/creating_integration_manifest.html
[quality-scale]: https://developers.home-assistant.io/docs/en/next/integration_quality_scale_index.html
[docs-repository]: https://github.com/home-assistant/home-assistant.io
|
https://api.github.com/repos/home-assistant/core/pulls/88813
|
2023-02-26T22:18:49Z
|
2023-02-27T16:24:02Z
|
2023-02-27T16:24:02Z
|
2023-02-28T18:02:14Z
| 255
|
home-assistant/core
| 38,693
|
[ie/tiktok] Restore `carrier_region` API param
|
diff --git a/yt_dlp/extractor/tiktok.py b/yt_dlp/extractor/tiktok.py
index 295e14932a8..3f5261ad968 100644
--- a/yt_dlp/extractor/tiktok.py
+++ b/yt_dlp/extractor/tiktok.py
@@ -155,6 +155,7 @@ def _build_api_query(self, query):
'locale': 'en',
'ac2': 'wifi5g',
'uoo': '1',
+ 'carrier_region': 'US',
'op_region': 'US',
'build_number': self._APP_INFO['app_version'],
'region': 'US',
|
Avoids some geo-blocks, see https://github.com/yt-dlp/yt-dlp/issues/9506#issuecomment-2041044419
Thanks @oifj34f34f
<details open><summary>Template</summary> <!-- OPEN is intentional -->
### Before submitting a *pull request* make sure you have:
- [x] At least skimmed through [contributing guidelines](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#developer-instructions) including [yt-dlp coding conventions](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#yt-dlp-coding-conventions)
- [x] [Searched](https://github.com/yt-dlp/yt-dlp/search?q=is%3Apr&type=Issues) the bugtracker for similar pull requests
- [x] Checked the code with [flake8](https://pypi.python.org/pypi/flake8) and [ran relevant tests](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#developer-instructions)
### In order to be accepted and merged into yt-dlp each piece of code must be in public domain or released under [Unlicense](http://unlicense.org/). Check all of the following options that apply:
- [x] I am the original author of this code and I am willing to release it under [Unlicense](http://unlicense.org/)
### What is the purpose of your *pull request*?
- [x] Fix or improvement to an extractor (Make sure to add/update tests)
</details>
|
https://api.github.com/repos/yt-dlp/yt-dlp/pulls/9637
|
2024-04-06T23:34:13Z
|
2024-04-07T15:32:11Z
|
2024-04-07T15:32:11Z
|
2024-04-07T15:32:11Z
| 157
|
yt-dlp/yt-dlp
| 8,052
|
[3.11] GH-92678: Document that you shouldn't be doing your own dictionary offset calculations. (GH-95598)
|
diff --git a/Doc/c-api/object.rst b/Doc/c-api/object.rst
index 07a625bac02fc4..fb03366056b0d2 100644
--- a/Doc/c-api/object.rst
+++ b/Doc/c-api/object.rst
@@ -126,6 +126,14 @@ Object Protocol
A generic implementation for the getter of a ``__dict__`` descriptor. It
creates the dictionary if necessary.
+ This function may also be called to get the :py:attr:`~object.__dict__`
+ of the object *o*. Pass ``NULL`` for *context* when calling it.
+ Since this function may need to allocate memory for the
+ dictionary, it may be more efficient to call :c:func:`PyObject_GetAttr`
+ when accessing an attribute on the object.
+
+ On failure, returns ``NULL`` with an exception set.
+
.. versionadded:: 3.3
@@ -137,6 +145,16 @@ Object Protocol
.. versionadded:: 3.3
+.. c:function:: PyObject** _PyObject_GetDictPtr(PyObject *obj)
+
+ Return a pointer to :py:attr:`~object.__dict__` of the object *obj*.
+ If there is no ``__dict__``, return ``NULL`` without setting an exception.
+
+ This function may need to allocate memory for the
+ dictionary, so it may be more efficient to call :c:func:`PyObject_GetAttr`
+ when accessing an attribute on the object.
+
+
.. c:function:: PyObject* PyObject_RichCompare(PyObject *o1, PyObject *o2, int opid)
Compare the values of *o1* and *o2* using the operation specified by *opid*,
diff --git a/Doc/c-api/typeobj.rst b/Doc/c-api/typeobj.rst
index e6df34e7db9551..47e1c8602197f7 100644
--- a/Doc/c-api/typeobj.rst
+++ b/Doc/c-api/typeobj.rst
@@ -1709,18 +1709,11 @@ and :c:type:`PyType_Type` effectively act as defaults.)
:c:member:`~PyTypeObject.tp_dictoffset` should be set to ``-4`` to indicate that the dictionary is
at the very end of the structure.
- The real dictionary offset in an instance can be computed from a negative
- :c:member:`~PyTypeObject.tp_dictoffset` as follows::
-
- dictoffset = tp_basicsize + abs(ob_size)*tp_itemsize + tp_dictoffset
- if dictoffset is not aligned on sizeof(void*):
- round up to sizeof(void*)
-
- where :c:member:`~PyTypeObject.tp_basicsize`, :c:member:`~PyTypeObject.tp_itemsize` and :c:member:`~PyTypeObject.tp_dictoffset` are
- taken from the type object, and :attr:`ob_size` is taken from the instance. The
- absolute value is taken because ints use the sign of :attr:`ob_size` to
- store the sign of the number. (There's never a need to do this calculation
- yourself; it is done for you by :c:func:`_PyObject_GetDictPtr`.)
+ The :c:member:`~PyTypeObject.tp_dictoffset` should be regarded as write-only.
+ To get the pointer to the dictionary call :c:func:`PyObject_GenericGetDict`.
+ Calling :c:func:`PyObject_GenericGetDict` may need to allocate memory for the
+ dictionary, so it is may be more efficient to call :c:func:`PyObject_GetAttr`
+ when accessing an attribute on the object.
**Inheritance:**
diff --git a/Doc/whatsnew/3.11.rst b/Doc/whatsnew/3.11.rst
index 3ea3fa63d408d6..a36564a8ab1905 100644
--- a/Doc/whatsnew/3.11.rst
+++ b/Doc/whatsnew/3.11.rst
@@ -1549,6 +1549,10 @@ Changes in the Python API
:func:`compile` and other related functions. If invalid positions are detected,
a :exc:`ValueError` will be raised. (Contributed by Pablo Galindo in :gh:`93351`)
+* :c:member:`~PyTypeObject.tp_dictoffset` should be treated as write-only.
+ It can be set to describe C extension clases to the VM, but should be regarded
+ as meaningless when read. To get the pointer to the object's dictionary call
+ :c:func:`PyObject_GenericGetDict` instead.
Build Changes
=============
diff --git a/Objects/object.c b/Objects/object.c
index d9fa779462a916..cb7853ca8cfd99 100644
--- a/Objects/object.c
+++ b/Objects/object.c
@@ -1086,7 +1086,11 @@ _PyObject_DictPointer(PyObject *obj)
/* Helper to get a pointer to an object's __dict__ slot, if any.
* Creates the dict from inline attributes if necessary.
- * Does not set an exception. */
+ * Does not set an exception.
+ *
+ * Note that the tp_dictoffset docs used to recommend this function,
+ * so it should be treated as part of the public API.
+ */
PyObject **
_PyObject_GetDictPtr(PyObject *obj)
{
|
Co-authored-by: Petr Viktorin <[email protected]>
Co-authored-by: Stanley <[email protected]>
(cherry picked from commit 8d37c62c2a2579ae7839ecaf8351e862f2ecc9bb)
Co-authored-by: Mark Shannon <[email protected]>
<!-- gh-issue-number: gh-92678 -->
* Issue: gh-92678
<!-- /gh-issue-number -->
|
https://api.github.com/repos/python/cpython/pulls/95821
|
2022-08-09T13:26:48Z
|
2022-08-09T15:22:54Z
|
2022-08-09T15:22:54Z
|
2022-08-09T15:23:03Z
| 1,222
|
python/cpython
| 4,380
|
remove resnet name
|
diff --git a/ppocr/modeling/backbones/det_resnet_vd.py b/ppocr/modeling/backbones/det_resnet_vd.py
index 3bb4a0d505..a29cf1b5e1 100644
--- a/ppocr/modeling/backbones/det_resnet_vd.py
+++ b/ppocr/modeling/backbones/det_resnet_vd.py
@@ -25,16 +25,14 @@
class ConvBNLayer(nn.Layer):
- def __init__(
- self,
- in_channels,
- out_channels,
- kernel_size,
- stride=1,
- groups=1,
- is_vd_mode=False,
- act=None,
- name=None, ):
+ def __init__(self,
+ in_channels,
+ out_channels,
+ kernel_size,
+ stride=1,
+ groups=1,
+ is_vd_mode=False,
+ act=None):
super(ConvBNLayer, self).__init__()
self.is_vd_mode = is_vd_mode
@@ -47,19 +45,8 @@ def __init__(
stride=stride,
padding=(kernel_size - 1) // 2,
groups=groups,
- weight_attr=ParamAttr(name=name + "_weights"),
bias_attr=False)
- if name == "conv1":
- bn_name = "bn_" + name
- else:
- bn_name = "bn" + name[3:]
- self._batch_norm = nn.BatchNorm(
- out_channels,
- act=act,
- param_attr=ParamAttr(name=bn_name + '_scale'),
- bias_attr=ParamAttr(bn_name + '_offset'),
- moving_mean_name=bn_name + '_mean',
- moving_variance_name=bn_name + '_variance')
+ self._batch_norm = nn.BatchNorm(out_channels, act=act)
def forward(self, inputs):
if self.is_vd_mode:
@@ -75,29 +62,25 @@ def __init__(self,
out_channels,
stride,
shortcut=True,
- if_first=False,
- name=None):
+ if_first=False):
super(BottleneckBlock, self).__init__()
self.conv0 = ConvBNLayer(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=1,
- act='relu',
- name=name + "_branch2a")
+ act='relu')
self.conv1 = ConvBNLayer(
in_channels=out_channels,
out_channels=out_channels,
kernel_size=3,
stride=stride,
- act='relu',
- name=name + "_branch2b")
+ act='relu')
self.conv2 = ConvBNLayer(
in_channels=out_channels,
out_channels=out_channels * 4,
kernel_size=1,
- act=None,
- name=name + "_branch2c")
+ act=None)
if not shortcut:
self.short = ConvBNLayer(
@@ -105,8 +88,7 @@ def __init__(self,
out_channels=out_channels * 4,
kernel_size=1,
stride=1,
- is_vd_mode=False if if_first else True,
- name=name + "_branch1")
+ is_vd_mode=False if if_first else True)
self.shortcut = shortcut
@@ -125,13 +107,13 @@ def forward(self, inputs):
class BasicBlock(nn.Layer):
- def __init__(self,
- in_channels,
- out_channels,
- stride,
- shortcut=True,
- if_first=False,
- name=None):
+ def __init__(
+ self,
+ in_channels,
+ out_channels,
+ stride,
+ shortcut=True,
+ if_first=False, ):
super(BasicBlock, self).__init__()
self.stride = stride
self.conv0 = ConvBNLayer(
@@ -139,14 +121,12 @@ def __init__(self,
out_channels=out_channels,
kernel_size=3,
stride=stride,
- act='relu',
- name=name + "_branch2a")
+ act='relu')
self.conv1 = ConvBNLayer(
in_channels=out_channels,
out_channels=out_channels,
kernel_size=3,
- act=None,
- name=name + "_branch2b")
+ act=None)
if not shortcut:
self.short = ConvBNLayer(
@@ -154,8 +134,7 @@ def __init__(self,
out_channels=out_channels,
kernel_size=1,
stride=1,
- is_vd_mode=False if if_first else True,
- name=name + "_branch1")
+ is_vd_mode=False if if_first else True)
self.shortcut = shortcut
@@ -201,22 +180,19 @@ def __init__(self, in_channels=3, layers=50, **kwargs):
out_channels=32,
kernel_size=3,
stride=2,
- act='relu',
- name="conv1_1")
+ act='relu')
self.conv1_2 = ConvBNLayer(
in_channels=32,
out_channels=32,
kernel_size=3,
stride=1,
- act='relu',
- name="conv1_2")
+ act='relu')
self.conv1_3 = ConvBNLayer(
in_channels=32,
out_channels=64,
kernel_size=3,
stride=1,
- act='relu',
- name="conv1_3")
+ act='relu')
self.pool2d_max = nn.MaxPool2D(kernel_size=3, stride=2, padding=1)
self.stages = []
@@ -226,13 +202,6 @@ def __init__(self, in_channels=3, layers=50, **kwargs):
block_list = []
shortcut = False
for i in range(depth[block]):
- if layers in [101, 152] and block == 2:
- if i == 0:
- conv_name = "res" + str(block + 2) + "a"
- else:
- conv_name = "res" + str(block + 2) + "b" + str(i)
- else:
- conv_name = "res" + str(block + 2) + chr(97 + i)
bottleneck_block = self.add_sublayer(
'bb_%d_%d' % (block, i),
BottleneckBlock(
@@ -241,8 +210,7 @@ def __init__(self, in_channels=3, layers=50, **kwargs):
out_channels=num_filters[block],
stride=2 if i == 0 and block != 0 else 1,
shortcut=shortcut,
- if_first=block == i == 0,
- name=conv_name))
+ if_first=block == i == 0))
shortcut = True
block_list.append(bottleneck_block)
self.out_channels.append(num_filters[block] * 4)
@@ -252,7 +220,6 @@ def __init__(self, in_channels=3, layers=50, **kwargs):
block_list = []
shortcut = False
for i in range(depth[block]):
- conv_name = "res" + str(block + 2) + chr(97 + i)
basic_block = self.add_sublayer(
'bb_%d_%d' % (block, i),
BasicBlock(
@@ -261,8 +228,7 @@ def __init__(self, in_channels=3, layers=50, **kwargs):
out_channels=num_filters[block],
stride=2 if i == 0 and block != 0 else 1,
shortcut=shortcut,
- if_first=block == i == 0,
- name=conv_name))
+ if_first=block == i == 0))
shortcut = True
block_list.append(basic_block)
self.out_channels.append(num_filters[block])
|
https://api.github.com/repos/PaddlePaddle/PaddleOCR/pulls/4870
|
2021-12-08T09:53:16Z
|
2021-12-08T14:53:49Z
|
2021-12-08T14:53:49Z
|
2021-12-08T14:53:49Z
| 1,748
|
PaddlePaddle/PaddleOCR
| 41,941
|
|
fix(search): Correct a few types on the frontend grammar parser
|
diff --git a/static/app/components/searchSyntax/parser.tsx b/static/app/components/searchSyntax/parser.tsx
index ab6839cae4344..edfb011cc7229 100644
--- a/static/app/components/searchSyntax/parser.tsx
+++ b/static/app/components/searchSyntax/parser.tsx
@@ -310,8 +310,8 @@ class TokenConverter {
tokenKeyAggregate = (
name: ReturnType<TokenConverter['tokenKeySimple']>,
args: ReturnType<TokenConverter['tokenKeyAggregateArgs']> | null,
- argsSpaceBefore: string,
- argsSpaceAfter: string
+ argsSpaceBefore: ReturnType<TokenConverter['tokenSpaces']>,
+ argsSpaceAfter: ReturnType<TokenConverter['tokenSpaces']>
) =>
this.makeToken({
type: Token.KeyAggregate as const,
@@ -321,7 +321,10 @@ class TokenConverter {
argsSpaceAfter,
});
- tokenKeyAggregateArgs = (arg1: string, args: ListItem<string>[]) =>
+ tokenKeyAggregateArgs = (
+ arg1: ReturnType<TokenConverter['tokenKeySimple']>,
+ args: ListItem<ReturnType<TokenConverter['tokenKeySimple']>>[]
+ ) =>
this.makeToken({
type: Token.KeyAggregateArgs as const,
args: [{separator: '', value: arg1}, ...args.map(listJoiner)],
|
https://api.github.com/repos/getsentry/sentry/pulls/26554
|
2021-06-11T05:34:44Z
|
2021-06-11T06:54:48Z
|
2021-06-11T06:54:48Z
|
2021-06-26T12:00:54Z
| 289
|
getsentry/sentry
| 44,381
|
|
undo noise
|
diff --git a/deepspeed/runtime/zero/stage3.py b/deepspeed/runtime/zero/stage3.py
index 5d47edaa44ac..5350b06e654e 100755
--- a/deepspeed/runtime/zero/stage3.py
+++ b/deepspeed/runtime/zero/stage3.py
@@ -35,7 +35,7 @@
from deepspeed.utils.debug import debug_module2name_id, debug_param2name_id_numel, debug_param2name_id_shape_device, debug_module2name_class, printflock, log_rank_file
-def print_rank_0(message, debug=False, force=True):
+def print_rank_0(message, debug=False, force=False):
rank = torch.distributed.get_rank()
if rank == 0 and (debug or force):
print(message)
diff --git a/deepspeed/utils/debug.py b/deepspeed/utils/debug.py
index 06f966dfa7a5..bb2b5f7ef75b 100644
--- a/deepspeed/utils/debug.py
+++ b/deepspeed/utils/debug.py
@@ -68,7 +68,7 @@ def printflock(*msgs):
1. Enable the force debug in say partitioning and zero3 files
2. Override the usual versions with ::
- def print_rank_0(message, debug=False, force=True):
+ def print_rank_0(message, debug=False, force=False):
rank = torch.distributed.get_rank()
printflock(f"[{rank}] {message}")
3. run the program and you get both logs non-interleaved
@@ -99,7 +99,7 @@ def log_rank_file(rank, *msgs):
1. Enable the force debug in say partitioning and zero3 files
2. Override the usual versions of print_rank_0 in those files with ::
- def print_rank_0(message, debug=False, force=True):
+ def print_rank_0(message, debug=False, force=False):
rank = torch.distributed.get_rank()
log_rank_file(rank, message)
|
This PR:
- fixes an omission in my PR that left low-level debug on :( sorry about that. https://github.com/microsoft/DeepSpeed/pull/1136
Let's merge this asap, so that those using master don't suffer!
Thank you!
|
https://api.github.com/repos/microsoft/DeepSpeed/pulls/1191
|
2021-06-26T02:40:22Z
|
2021-06-26T02:50:38Z
|
2021-06-26T02:50:38Z
|
2021-06-26T02:51:32Z
| 451
|
microsoft/DeepSpeed
| 10,406
|
[README.md] correct the test command
|
diff --git a/README.md b/README.md
index 9ae838b589e..897603e3e68 100644
--- a/README.md
+++ b/README.md
@@ -357,7 +357,7 @@ If you want to create a build of youtube-dl yourself, you'll need
### Adding support for a new site
-If you want to add support for a new site, copy *any* [recently modified](https://github.com/rg3/youtube-dl/commits/master/youtube_dl/extractor) file in `youtube_dl/extractor`, add an import in [`youtube_dl/extractor/__init__.py`](https://github.com/rg3/youtube-dl/blob/master/youtube_dl/extractor/__init__.py). Have a look at [`youtube_dl/common/extractor/common.py`](https://github.com/rg3/youtube-dl/blob/master/youtube_dl/extractor/common.py) for possible helper methods and a [detailed description of what your extractor should return](https://github.com/rg3/youtube-dl/blob/master/youtube_dl/extractor/common.py#L38). Don't forget to run the tests with `python test/test_download.py Test_Download.test_YourExtractor`! For a detailed tutorial, refer to [this blog post](http://filippo.io/add-support-for-a-new-video-site-to-youtube-dl/).
+If you want to add support for a new site, copy *any* [recently modified](https://github.com/rg3/youtube-dl/commits/master/youtube_dl/extractor) file in `youtube_dl/extractor`, add an import in [`youtube_dl/extractor/__init__.py`](https://github.com/rg3/youtube-dl/blob/master/youtube_dl/extractor/__init__.py). Have a look at [`youtube_dl/common/extractor/common.py`](https://github.com/rg3/youtube-dl/blob/master/youtube_dl/extractor/common.py) for possible helper methods and a [detailed description of what your extractor should return](https://github.com/rg3/youtube-dl/blob/master/youtube_dl/extractor/common.py#L38). Don't forget to run the tests with `python test/test_download.py TestDownload.test_YourExtractor`! For a detailed tutorial, refer to [this blog post](http://filippo.io/add-support-for-a-new-video-site-to-youtube-dl/).
# BUGS
|
replaced `Test_Download.test_YourExtractor` for `TestDownload.test_YourExtractor`
|
https://api.github.com/repos/ytdl-org/youtube-dl/pulls/2408
|
2014-02-19T15:16:01Z
|
2014-02-19T15:45:14Z
|
2014-02-19T15:45:14Z
|
2014-06-12T05:18:29Z
| 529
|
ytdl-org/youtube-dl
| 49,741
|
Update quickstart.md
|
diff --git a/doc/doc_ch/quickstart.md b/doc/doc_ch/quickstart.md
index cac7664c2f..cdae287f7f 100644
--- a/doc/doc_ch/quickstart.md
+++ b/doc/doc_ch/quickstart.md
@@ -176,13 +176,14 @@ for idx in range(len(result)):
print(line)
# 显示结果
+# 如果本地没有simfang.ttf,可以在doc/fonts目录下下载
from PIL import Image
result = result[0]
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
-im_show = draw_ocr(image, boxes, txts, scores, font_path='./fonts/simfang.ttf')
+im_show = draw_ocr(image, boxes, txts, scores, font_path='doc/fonts/simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('result.jpg')
```
|
https://api.github.com/repos/PaddlePaddle/PaddleOCR/pulls/8622
|
2022-12-14T06:58:22Z
|
2022-12-26T02:50:36Z
|
2022-12-26T02:50:36Z
|
2022-12-26T02:50:37Z
| 232
|
PaddlePaddle/PaddleOCR
| 42,330
|
|
Fix python3 and nonascii handling in inventory plugins
|
diff --git a/lib/ansible/plugins/inventory/__init__.py b/lib/ansible/plugins/inventory/__init__.py
index 5f6a818d7fe089..72c33006ca73c4 100644
--- a/lib/ansible/plugins/inventory/__init__.py
+++ b/lib/ansible/plugins/inventory/__init__.py
@@ -60,18 +60,18 @@ def parse(self, inventory, loader, path, cache=True):
def verify_file(self, path):
''' Verify if file is usable by this plugin, base does minimal accessability check '''
- b_path = to_bytes(path)
+ b_path = to_bytes(path, errors='surrogate_or_strict')
return (os.path.exists(b_path) and os.access(b_path, os.R_OK))
def get_cache_prefix(self, path):
''' create predictable unique prefix for plugin/inventory '''
m = hashlib.sha1()
- m.update(to_bytes(self.NAME))
+ m.update(to_bytes(self.NAME, errors='surrogate_or_strict'))
d1 = m.hexdigest()
n = hashlib.sha1()
- n.update(to_bytes(path))
+ n.update(to_bytes(path, errors='surrogate_or_strict'))
d2 = n.hexdigest()
return 's_'.join([d1[:5], d2[:5]])
diff --git a/lib/ansible/plugins/inventory/advanced_host_list.py b/lib/ansible/plugins/inventory/advanced_host_list.py
index 1783efa961598c..5e4711f9b9f0de 100644
--- a/lib/ansible/plugins/inventory/advanced_host_list.py
+++ b/lib/ansible/plugins/inventory/advanced_host_list.py
@@ -36,9 +36,9 @@ class InventoryModule(BaseInventoryPlugin):
def verify_file(self, host_list):
valid = False
- b_path = to_bytes(host_list)
+ b_path = to_bytes(host_list, errors='surrogate_or_strict')
if not os.path.exists(b_path) and ',' in host_list:
- valid = True
+ valid = True
return valid
def parse(self, inventory, loader, host_list, cache=True):
@@ -61,7 +61,7 @@ def parse(self, inventory, loader, host_list, cache=True):
if host not in self.inventory.hosts:
self.inventory.add_host(host, group='ungrouped', port=port)
except Exception as e:
- raise AnsibleParserError("Invalid data from string, could not parse: %s" % str(e))
+ raise AnsibleParserError("Invalid data from string, could not parse: %s" % to_native(e))
def _expand_hostpattern(self, hostpattern):
'''
diff --git a/lib/ansible/plugins/inventory/host_list.py b/lib/ansible/plugins/inventory/host_list.py
index b9bfa9dbd5c46b..6c166349167330 100644
--- a/lib/ansible/plugins/inventory/host_list.py
+++ b/lib/ansible/plugins/inventory/host_list.py
@@ -27,8 +27,7 @@
import os
from ansible.errors import AnsibleError, AnsibleParserError
-from ansible.module_utils.six import string_types
-from ansible.module_utils._text import to_bytes, to_text, to_native
+from ansible.module_utils._text import to_bytes, to_native
from ansible.parsing.utils.addresses import parse_address
from ansible.plugins.inventory import BaseInventoryPlugin
@@ -40,9 +39,9 @@ class InventoryModule(BaseInventoryPlugin):
def verify_file(self, host_list):
valid = False
- b_path = to_bytes(host_list)
+ b_path = to_bytes(host_list, errors='surrogate_or_strict')
if not os.path.exists(b_path) and ',' in host_list:
- valid = True
+ valid = True
return valid
def parse(self, inventory, loader, host_list, cache=True):
@@ -64,4 +63,4 @@ def parse(self, inventory, loader, host_list, cache=True):
if host not in self.inventory.hosts:
self.inventory.add_host(host, group='ungrouped', port=port)
except Exception as e:
- raise AnsibleParserError("Invalid data from string, could not parse: %s" % str(e))
+ raise AnsibleParserError("Invalid data from string, could not parse: %s" % to_native(e))
diff --git a/lib/ansible/plugins/inventory/ini.py b/lib/ansible/plugins/inventory/ini.py
index 8033ccf3151d30..68d0380b2d9eb1 100644
--- a/lib/ansible/plugins/inventory/ini.py
+++ b/lib/ansible/plugins/inventory/ini.py
@@ -105,7 +105,7 @@ def parse(self, inventory, loader, path, cache=True):
if self.loader:
(b_data, private) = self.loader._get_file_contents(path)
else:
- b_path = to_bytes(path)
+ b_path = to_bytes(path, errors='surrogate_or_strict')
with open(b_path, 'rb') as fh:
b_data = fh.read()
@@ -366,14 +366,14 @@ def _compile_patterns(self):
# [naughty:children] # only get coal in their stockings
self.patterns['section'] = re.compile(
- r'''^\[
+ to_text(r'''^\[
([^:\]\s]+) # group name (see groupname below)
(?::(\w+))? # optional : and tag name
\]
\s* # ignore trailing whitespace
(?:\#.*)? # and/or a comment till the
$ # end of the line
- ''', re.X
+ ''', errors='surrogate_or_strict'), re.X
)
# FIXME: What are the real restrictions on group names, or rather, what
@@ -382,10 +382,10 @@ def _compile_patterns(self):
# precise rules in order to support better diagnostics.
self.patterns['groupname'] = re.compile(
- r'''^
+ to_text(r'''^
([^:\]\s]+)
\s* # ignore trailing whitespace
(?:\#.*)? # and/or a comment till the
$ # end of the line
- ''', re.X
+ ''', errors='surrogate_or_strict'), re.X
)
diff --git a/lib/ansible/plugins/inventory/virtualbox.py b/lib/ansible/plugins/inventory/virtualbox.py
index 9efb74da7776cf..1b80945b91362d 100644
--- a/lib/ansible/plugins/inventory/virtualbox.py
+++ b/lib/ansible/plugins/inventory/virtualbox.py
@@ -49,10 +49,11 @@
import os
+from collections import MutableMapping
from subprocess import Popen, PIPE
from ansible.errors import AnsibleParserError
-from ansible.module_utils._text import to_bytes, to_text
+from ansible.module_utils._text import to_bytes, to_native, to_text
from ansible.plugins.inventory import BaseInventoryPlugin
@@ -60,14 +61,14 @@ class InventoryModule(BaseInventoryPlugin):
''' Host inventory parser for ansible using local virtualbox. '''
NAME = 'virtualbox'
- VBOX = "VBoxManage"
+ VBOX = b"VBoxManage"
def _query_vbox_data(self, host, property_path):
ret = None
try:
- cmd = [self.VBOX, 'guestproperty', 'get', host, property_path]
+ cmd = [self.VBOX, b'guestproperty', b'get', to_bytes(host, errors='surrogate_or_strict'), to_bytes(property_path, errors='surrogate_or_strict')]
x = Popen(cmd, stdout=PIPE)
- ipinfo = x.stdout.read()
+ ipinfo = to_text(x.stdout.read(), errors='surrogate_or_strict')
if 'Value' in ipinfo:
a, ip = ipinfo.split(':', 1)
ret = ip.strip()
@@ -81,7 +82,7 @@ def _set_variables(self, hostvars, data):
for host in hostvars:
# create vars from vbox properties
- if data.get('query') and isinstance(data['query'], dict):
+ if data.get('query') and isinstance(data['query'], MutableMapping):
for varname in data['query']:
hostvars[host][varname] = self._query_vbox_data(host, data['query'][varname])
@@ -168,7 +169,7 @@ def parse(self, inventory, loader, path, cache=True):
try:
config_data = self.loader.load_from_file(path)
except Exception as e:
- raise AnsibleParserError(e)
+ raise AnsibleParserError(to_native(e))
if not config_data or config_data.get('plugin') != self.NAME:
# this is not my config file
@@ -182,26 +183,26 @@ def parse(self, inventory, loader, path, cache=True):
pass
if not source_data:
- pwfile = to_bytes(config_data.get('settings_password_file'))
+ b_pwfile = to_bytes(config_data.get('settings_password_file'), errors='surrogate_or_strict')
running = config_data.get('running_only', False)
# start getting data
- cmd = [self.VBOX, 'list', '-l']
+ cmd = [self.VBOX, b'list', b'-l']
if running:
- cmd.append('runningvms')
+ cmd.append(b'runningvms')
else:
- cmd.append('vms')
+ cmd.append(b'vms')
- if pwfile and os.path.exists(pwfile):
- cmd.append('--settingspwfile')
- cmd.append(pwfile)
+ if b_pwfile and os.path.exists(b_pwfile):
+ cmd.append(b'--settingspwfile')
+ cmd.append(b_pwfile)
try:
p = Popen(cmd, stdout=PIPE)
except Exception as e:
- AnsibleParserError(e)
+ AnsibleParserError(to_native(e))
- source_data = p.stdout.readlines()
- inventory.cache[cache_key] = to_text(source_data)
+ source_data = p.stdout.read()
+ inventory.cache[cache_key] = to_text(source_data, errors='surrogate_or_strict')
- self._populate_from_source(source_data, config_data)
+ self._populate_from_source(source_data.splitlines(), config_data)
diff --git a/lib/ansible/plugins/inventory/yaml.py b/lib/ansible/plugins/inventory/yaml.py
index 560d25d96bcbc3..8d5c457341c63d 100644
--- a/lib/ansible/plugins/inventory/yaml.py
+++ b/lib/ansible/plugins/inventory/yaml.py
@@ -51,11 +51,12 @@
import re
import os
+from collections import MutableMapping
from ansible import constants as C
from ansible.errors import AnsibleParserError
from ansible.module_utils.six import string_types
-from ansible.module_utils._text import to_bytes, to_text
+from ansible.module_utils._text import to_native
from ansible.parsing.utils.addresses import parse_address
from ansible.plugins.inventory import BaseFileInventoryPlugin, detect_range, expand_hostname_range
@@ -74,9 +75,8 @@ def __init__(self):
def verify_file(self, path):
valid = False
- b_path = to_bytes(path)
- if super(InventoryModule, self).verify_file(b_path):
- file_name, ext = os.path.splitext(b_path)
+ if super(InventoryModule, self).verify_file(path):
+ file_name, ext = os.path.splitext(path)
if ext and ext in C.YAML_FILENAME_EXTENSIONS:
valid = True
return valid
@@ -96,11 +96,11 @@ def parse(self, inventory, loader, path, cache=True):
# We expect top level keys to correspond to groups, iterate over them
# to get host, vars and subgroups (which we iterate over recursivelly)
- if isinstance(data, dict):
+ if isinstance(data, MutableMapping):
for group_name in data:
self._parse_group(group_name, data[group_name])
else:
- raise AnsibleParserError("Invalid data from file, expected dictionary and got:\n\n%s" % data)
+ raise AnsibleParserError("Invalid data from file, expected dictionary and got:\n\n%s" % to_native(data))
def _parse_group(self, group, group_data):
@@ -108,7 +108,7 @@ def _parse_group(self, group, group_data):
self.inventory.add_group(group)
- if isinstance(group_data, dict):
+ if isinstance(group_data, MutableMapping):
# make sure they are dicts
for section in ['vars', 'children', 'hosts']:
if section in group_data and isinstance(group_data[section], string_types):
@@ -167,4 +167,4 @@ def _compile_patterns(self):
'''
Compiles the regular expressions required to parse the inventory and stores them in self.patterns.
'''
- self.patterns['groupname'] = re.compile(r'''^[A-Za-z_][A-Za-z0-9_]*$''')
+ self.patterns['groupname'] = re.compile(u'''^[A-Za-z_][A-Za-z0-9_]*$''')
|
Fixes #30663
##### SUMMARY
* Fixes one known problem fixed where we compared a byte string with text strings (which is always false on python3).
* Also fixes places that would likely fail on python2 with nonascii strings
* Fixes some unreported problems comparing byte strings with text strings.
* Fixes loading the virtualbox cache with a mangled entry.
##### ISSUE TYPE
- Bugfix Pull Request
##### COMPONENT NAME
<!--- Name of the module/plugin/module/task -->
various inventory plugins
##### ANSIBLE VERSION
<!--- Paste verbatim output from "ansible --version" between quotes below -->
```
devel 2.4
```
|
https://api.github.com/repos/ansible/ansible/pulls/30666
|
2017-09-21T00:08:18Z
|
2017-09-21T02:39:16Z
|
2017-09-21T02:39:16Z
|
2019-04-26T22:41:55Z
| 2,976
|
ansible/ansible
| 49,624
|
Remove comment about extensions being reviewed by the core team
|
diff --git a/docs/foreword.rst b/docs/foreword.rst
index f0dfaee253..37b4d109b1 100644
--- a/docs/foreword.rst
+++ b/docs/foreword.rst
@@ -38,9 +38,7 @@ Growing with Flask
------------------
Once you have Flask up and running, you'll find a variety of extensions
-available in the community to integrate your project for production. The Flask
-core team reviews extensions and ensures approved extensions do not break with
-future releases.
+available in the community to integrate your project for production.
As your codebase grows, you are free to make the design decisions appropriate
for your project. Flask will continue to provide a very simple glue layer to
|
This PR removes the comment in the foreword that tells Flask extensions are reviewed by Flask maintainers
|
https://api.github.com/repos/pallets/flask/pulls/3462
|
2020-01-04T14:59:18Z
|
2020-02-11T01:29:10Z
|
2020-02-11T01:29:10Z
|
2020-11-14T01:42:45Z
| 165
|
pallets/flask
| 20,375
|
CI Disable pytest-xdist in pylatest_pip_openblas_pandas build
|
diff --git a/azure-pipelines.yml b/azure-pipelines.yml
index af25f0e09862f..66e00ee54b07d 100644
--- a/azure-pipelines.yml
+++ b/azure-pipelines.yml
@@ -199,6 +199,10 @@ jobs:
CHECK_PYTEST_SOFT_DEPENDENCY: 'true'
CHECK_WARNINGS: 'true'
SKLEARN_TESTS_GLOBAL_RANDOM_SEED: '3' # non-default seed
+ # disable pytest-xdist to have 1 job where OpenMP and BLAS are not single
+ # threaded because by default the tests configuration (sklearn/conftest.py)
+ # makes sure that they are single threaded in each xdist subprocess.
+ PYTEST_XDIST_VERSION: 'none'
- template: build_tools/azure/posix-docker.yml
parameters:
|
to make sure that OpenMP and OpenBLAS are not single threaded in at least 1 job
follow-up of https://github.com/scikit-learn/scikit-learn/pull/25918
|
https://api.github.com/repos/scikit-learn/scikit-learn/pulls/25943
|
2023-03-22T15:28:35Z
|
2023-03-23T10:10:00Z
|
2023-03-23T10:10:00Z
|
2023-03-23T10:10:21Z
| 188
|
scikit-learn/scikit-learn
| 46,698
|
deepbooru tags for textual inversion preproccessing
|
diff --git a/modules/deepbooru.py b/modules/deepbooru.py
index 7e3c0618298..29529949067 100644
--- a/modules/deepbooru.py
+++ b/modules/deepbooru.py
@@ -1,21 +1,75 @@
import os.path
from concurrent.futures import ProcessPoolExecutor
-from multiprocessing import get_context
+import multiprocessing
+import time
+def get_deepbooru_tags(pil_image):
+ """
+ This method is for running only one image at a time for simple use. Used to the img2img interrogate.
+ """
+ from modules import shared # prevents circular reference
+ create_deepbooru_process(shared.opts.interrogate_deepbooru_score_threshold, shared.opts.deepbooru_sort_alpha)
+ shared.deepbooru_process_return["value"] = -1
+ shared.deepbooru_process_queue.put(pil_image)
+ while shared.deepbooru_process_return["value"] == -1:
+ time.sleep(0.2)
+ tags = shared.deepbooru_process_return["value"]
+ release_process()
+ return tags
-def _load_tf_and_return_tags(pil_image, threshold):
+
+def deepbooru_process(queue, deepbooru_process_return, threshold, alpha_sort):
+ model, tags = get_deepbooru_tags_model()
+ while True: # while process is running, keep monitoring queue for new image
+ pil_image = queue.get()
+ if pil_image == "QUIT":
+ break
+ else:
+ deepbooru_process_return["value"] = get_deepbooru_tags_from_model(model, tags, pil_image, threshold, alpha_sort)
+
+
+def create_deepbooru_process(threshold, alpha_sort):
+ """
+ Creates deepbooru process. A queue is created to send images into the process. This enables multiple images
+ to be processed in a row without reloading the model or creating a new process. To return the data, a shared
+ dictionary is created to hold the tags created. To wait for tags to be returned, a value of -1 is assigned
+ to the dictionary and the method adding the image to the queue should wait for this value to be updated with
+ the tags.
+ """
+ from modules import shared # prevents circular reference
+ shared.deepbooru_process_manager = multiprocessing.Manager()
+ shared.deepbooru_process_queue = shared.deepbooru_process_manager.Queue()
+ shared.deepbooru_process_return = shared.deepbooru_process_manager.dict()
+ shared.deepbooru_process_return["value"] = -1
+ shared.deepbooru_process = multiprocessing.Process(target=deepbooru_process, args=(shared.deepbooru_process_queue, shared.deepbooru_process_return, threshold, alpha_sort))
+ shared.deepbooru_process.start()
+
+
+def release_process():
+ """
+ Stops the deepbooru process to return used memory
+ """
+ from modules import shared # prevents circular reference
+ shared.deepbooru_process_queue.put("QUIT")
+ shared.deepbooru_process.join()
+ shared.deepbooru_process_queue = None
+ shared.deepbooru_process = None
+ shared.deepbooru_process_return = None
+ shared.deepbooru_process_manager = None
+
+def get_deepbooru_tags_model():
import deepdanbooru as dd
import tensorflow as tf
import numpy as np
-
this_folder = os.path.dirname(__file__)
model_path = os.path.abspath(os.path.join(this_folder, '..', 'models', 'deepbooru'))
if not os.path.exists(os.path.join(model_path, 'project.json')):
# there is no point importing these every time
import zipfile
from basicsr.utils.download_util import load_file_from_url
- load_file_from_url(r"https://github.com/KichangKim/DeepDanbooru/releases/download/v3-20211112-sgd-e28/deepdanbooru-v3-20211112-sgd-e28.zip",
- model_path)
+ load_file_from_url(
+ r"https://github.com/KichangKim/DeepDanbooru/releases/download/v3-20211112-sgd-e28/deepdanbooru-v3-20211112-sgd-e28.zip",
+ model_path)
with zipfile.ZipFile(os.path.join(model_path, "deepdanbooru-v3-20211112-sgd-e28.zip"), "r") as zip_ref:
zip_ref.extractall(model_path)
os.remove(os.path.join(model_path, "deepdanbooru-v3-20211112-sgd-e28.zip"))
@@ -24,7 +78,13 @@ def _load_tf_and_return_tags(pil_image, threshold):
model = dd.project.load_model_from_project(
model_path, compile_model=True
)
+ return model, tags
+
+def get_deepbooru_tags_from_model(model, tags, pil_image, threshold, alpha_sort):
+ import deepdanbooru as dd
+ import tensorflow as tf
+ import numpy as np
width = model.input_shape[2]
height = model.input_shape[1]
image = np.array(pil_image)
@@ -46,28 +106,27 @@ def _load_tf_and_return_tags(pil_image, threshold):
for i, tag in enumerate(tags):
result_dict[tag] = y[i]
- result_tags_out = []
+
+ unsorted_tags_in_theshold = []
result_tags_print = []
for tag in tags:
if result_dict[tag] >= threshold:
if tag.startswith("rating:"):
continue
- result_tags_out.append(tag)
+ unsorted_tags_in_theshold.append((result_dict[tag], tag))
result_tags_print.append(f'{result_dict[tag]} {tag}')
- print('\n'.join(sorted(result_tags_print, reverse=True)))
-
- return ', '.join(result_tags_out).replace('_', ' ').replace(':', ' ')
-
+ # sort tags
+ result_tags_out = []
+ sort_ndx = 0
+ if alpha_sort:
+ sort_ndx = 1
-def subprocess_init_no_cuda():
- import os
- os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
+ # sort by reverse by likelihood and normal for alpha
+ unsorted_tags_in_theshold.sort(key=lambda y: y[sort_ndx], reverse=(not alpha_sort))
+ for weight, tag in unsorted_tags_in_theshold:
+ result_tags_out.append(tag)
+ print('\n'.join(sorted(result_tags_print, reverse=True)))
-def get_deepbooru_tags(pil_image, threshold=0.5):
- context = get_context('spawn')
- with ProcessPoolExecutor(initializer=subprocess_init_no_cuda, mp_context=context) as executor:
- f = executor.submit(_load_tf_and_return_tags, pil_image, threshold, )
- ret = f.result() # will rethrow any exceptions
- return ret
\ No newline at end of file
+ return ', '.join(result_tags_out).replace('_', ' ').replace(':', ' ')
diff --git a/modules/shared.py b/modules/shared.py
index c1092ff7928..5456c4778aa 100644
--- a/modules/shared.py
+++ b/modules/shared.py
@@ -248,15 +248,20 @@ def options_section(section_identifier, options_dict):
"random_artist_categories": OptionInfo([], "Allowed categories for random artists selection when using the Roll button", gr.CheckboxGroup, {"choices": artist_db.categories()}),
}))
-options_templates.update(options_section(('interrogate', "Interrogate Options"), {
+interrogate_option_dictionary = {
"interrogate_keep_models_in_memory": OptionInfo(False, "Interrogate: keep models in VRAM"),
"interrogate_use_builtin_artists": OptionInfo(True, "Interrogate: use artists from artists.csv"),
"interrogate_clip_num_beams": OptionInfo(1, "Interrogate: num_beams for BLIP", gr.Slider, {"minimum": 1, "maximum": 16, "step": 1}),
"interrogate_clip_min_length": OptionInfo(24, "Interrogate: minimum description length (excluding artists, etc..)", gr.Slider, {"minimum": 1, "maximum": 128, "step": 1}),
"interrogate_clip_max_length": OptionInfo(48, "Interrogate: maximum description length", gr.Slider, {"minimum": 1, "maximum": 256, "step": 1}),
- "interrogate_clip_dict_limit": OptionInfo(1500, "Interrogate: maximum number of lines in text file (0 = No limit)"),
- "interrogate_deepbooru_score_threshold": OptionInfo(0.5, "Interrogate: deepbooru score threshold", gr.Slider, {"minimum": 0, "maximum": 1, "step": 0.01}),
-}))
+ "interrogate_clip_dict_limit": OptionInfo(1500, "Interrogate: maximum number of lines in text file (0 = No limit)")
+}
+
+if cmd_opts.deepdanbooru:
+ interrogate_option_dictionary["interrogate_deepbooru_score_threshold"] = OptionInfo(0.5, "Interrogate: deepbooru score threshold", gr.Slider, {"minimum": 0, "maximum": 1, "step": 0.01})
+ interrogate_option_dictionary["deepbooru_sort_alpha"] = OptionInfo(True, "Interrogate: deepbooru sort alphabetically", gr.Checkbox)
+
+options_templates.update(options_section(('interrogate', "Interrogate Options"), interrogate_option_dictionary))
options_templates.update(options_section(('ui', "User interface"), {
"show_progressbar": OptionInfo(True, "Show progressbar"),
diff --git a/modules/textual_inversion/preprocess.py b/modules/textual_inversion/preprocess.py
index 1a672725526..113cecf1d9a 100644
--- a/modules/textual_inversion/preprocess.py
+++ b/modules/textual_inversion/preprocess.py
@@ -3,11 +3,14 @@
import platform
import sys
import tqdm
+import time
from modules import shared, images
+from modules.shared import opts, cmd_opts
+if cmd_opts.deepdanbooru:
+ import modules.deepbooru as deepbooru
-
-def preprocess(process_src, process_dst, process_width, process_height, process_flip, process_split, process_caption):
+def preprocess(process_src, process_dst, process_width, process_height, process_flip, process_split, process_caption, process_caption_deepbooru=False):
width = process_width
height = process_height
src = os.path.abspath(process_src)
@@ -25,10 +28,21 @@ def preprocess(process_src, process_dst, process_width, process_height, process_
if process_caption:
shared.interrogator.load()
+ if process_caption_deepbooru:
+ deepbooru.create_deepbooru_process(opts.interrogate_deepbooru_score_threshold, opts.deepbooru_sort_alpha)
+
def save_pic_with_caption(image, index):
if process_caption:
caption = "-" + shared.interrogator.generate_caption(image)
caption = sanitize_caption(os.path.join(dst, f"{index:05}-{subindex[0]}"), caption, ".png")
+ elif process_caption_deepbooru:
+ shared.deepbooru_process_return["value"] = -1
+ shared.deepbooru_process_queue.put(image)
+ while shared.deepbooru_process_return["value"] == -1:
+ time.sleep(0.2)
+ caption = "-" + shared.deepbooru_process_return["value"]
+ caption = sanitize_caption(os.path.join(dst, f"{index:05}-{subindex[0]}"), caption, ".png")
+ shared.deepbooru_process_return["value"] = -1
else:
caption = filename
caption = os.path.splitext(caption)[0]
@@ -83,6 +97,10 @@ def save_pic(image, index):
if process_caption:
shared.interrogator.send_blip_to_ram()
+ if process_caption_deepbooru:
+ deepbooru.release_process()
+
+
def sanitize_caption(base_path, original_caption, suffix):
operating_system = platform.system().lower()
if (operating_system == "windows"):
diff --git a/modules/ui.py b/modules/ui.py
index 1204eef7b34..fa45edca7a8 100644
--- a/modules/ui.py
+++ b/modules/ui.py
@@ -317,7 +317,7 @@ def interrogate(image):
def interrogate_deepbooru(image):
- prompt = get_deepbooru_tags(image, opts.interrogate_deepbooru_score_threshold)
+ prompt = get_deepbooru_tags(image)
return gr_show(True) if prompt is None else prompt
@@ -1058,6 +1058,10 @@ def create_ui(wrap_gradio_gpu_call):
process_flip = gr.Checkbox(label='Create flipped copies')
process_split = gr.Checkbox(label='Split oversized images into two')
process_caption = gr.Checkbox(label='Use BLIP caption as filename')
+ if cmd_opts.deepdanbooru:
+ process_caption_deepbooru = gr.Checkbox(label='Use deepbooru caption as filename')
+ else:
+ process_caption_deepbooru = gr.Checkbox(label='Use deepbooru caption as filename', visible=False)
with gr.Row():
with gr.Column(scale=3):
@@ -1135,6 +1139,7 @@ def create_ui(wrap_gradio_gpu_call):
process_flip,
process_split,
process_caption,
+ process_caption_deepbooru
],
outputs=[
ti_output,
|
Added the option of using deepbooru tags for textual inversion preprocessing file names. This resulted in the need to restructure the deepbooru module file to allow for running images through the model multiple times without needing to reload the module. This resulting in signification speed up for using deepbooru for generating tags on multiple images for textual inversion preprocessing.
The addition of deepbooru to textual inversion as an option for tags follows the guidance of not loading ui elements unless the --deepdanbooru option is enabled.
https://github.com/AUTOMATIC1111/stable-diffusion-webui/pull/1752#issuecomment-1272483756
|
https://api.github.com/repos/AUTOMATIC1111/stable-diffusion-webui/pulls/2143
|
2022-10-10T05:10:57Z
|
2022-10-12T05:35:27Z
|
2022-10-12T05:35:27Z
|
2022-10-12T05:35:28Z
| 2,996
|
AUTOMATIC1111/stable-diffusion-webui
| 40,232
|
Strip comments from hires fix prompt
|
diff --git a/modules/processing_scripts/comments.py b/modules/processing_scripts/comments.py
index 638e39f2989..cf81dfd8b49 100644
--- a/modules/processing_scripts/comments.py
+++ b/modules/processing_scripts/comments.py
@@ -26,6 +26,13 @@ def process(self, p, *args):
p.main_prompt = strip_comments(p.main_prompt)
p.main_negative_prompt = strip_comments(p.main_negative_prompt)
+ if getattr(p, 'enable_hr', False):
+ p.all_hr_prompts = [strip_comments(x) for x in p.all_hr_prompts]
+ p.all_hr_negative_prompts = [strip_comments(x) for x in p.all_hr_negative_prompts]
+
+ p.hr_prompt = strip_comments(p.hr_prompt)
+ p.hr_negative_prompt = strip_comments(p.hr_negative_prompt)
+
def before_token_counter(params: script_callbacks.BeforeTokenCounterParams):
if not shared.opts.enable_prompt_comments:
|
## Description
Fixes #15258
## Checklist:
- [x] I have read [contributing wiki page](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Contributing)
- [x] I have performed a self-review of my own code
- [x] My code follows the [style guidelines](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Contributing#code-style)
- [x] My code passes [tests](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Tests)
|
https://api.github.com/repos/AUTOMATIC1111/stable-diffusion-webui/pulls/15263
|
2024-03-15T04:27:42Z
|
2024-03-16T05:30:16Z
|
2024-03-16T05:30:16Z
|
2024-03-16T05:30:18Z
| 211
|
AUTOMATIC1111/stable-diffusion-webui
| 40,503
|
correct the reST rendering of the R() note
|
diff --git a/docs/docsite/rst/dev_guide/developing_modules_documenting.rst b/docs/docsite/rst/dev_guide/developing_modules_documenting.rst
index 6be4fcd0e7ef8c..c56cd718232130 100644
--- a/docs/docsite/rst/dev_guide/developing_modules_documenting.rst
+++ b/docs/docsite/rst/dev_guide/developing_modules_documenting.rst
@@ -253,8 +253,8 @@ content in a uniform way:
.. note::
- To refer to a group of modules in a collection, use ``R()``. When a collection is not the right granularity, use ``C(..)``:
- -``Refer to the R(community.kubernetes collection, plugins_in_community.kubernetes) for information on managing kubernetes clusters.``
- -``The C(win_*) modules (spread across several collections) allow you to manage various aspects of windows hosts.``
+ - ``Refer to the R(community.kubernetes collection, plugins_in_community.kubernetes) for information on managing kubernetes clusters.``
+ - ``The C(win_*) modules (spread across several collections) allow you to manage various aspects of windows hosts.``
.. note::
|
##### SUMMARY
without the space, it's not rendered as a list
##### ISSUE TYPE
- Docs Pull Request
+label: docsite_pr
##### COMPONENT NAME
<!--- Write the short name of the module, plugin, task or feature below -->
##### ADDITIONAL INFORMATION
<!--- Include additional information to help people understand the change here -->
<!--- A step-by-step reproduction of the problem is helpful if there is no related issue -->
<!--- Paste verbatim command output below, e.g. before and after your change -->
```paste below
```
|
https://api.github.com/repos/ansible/ansible/pulls/72896
|
2020-12-08T07:22:32Z
|
2020-12-08T15:46:10Z
|
2020-12-08T15:46:10Z
|
2021-01-15T14:01:06Z
| 269
|
ansible/ansible
| 49,324
|
Dev2
|
diff --git a/fooocus_version.py b/fooocus_version.py
index e1578ebba..70a5e92a9 100644
--- a/fooocus_version.py
+++ b/fooocus_version.py
@@ -1 +1 @@
-version = '2.1.849'
+version = '2.1.850'
diff --git a/modules/patch_clip.py b/modules/patch_clip.py
index 0ef22e8b9..5a3e85dfb 100644
--- a/modules/patch_clip.py
+++ b/modules/patch_clip.py
@@ -23,7 +23,7 @@
from transformers import CLIPTextModel, CLIPTextConfig, modeling_utils, CLIPVisionConfig, CLIPVisionModelWithProjection
-def encode_token_weights_fooocus(self, token_weight_pairs):
+def patched_encode_token_weights(self, token_weight_pairs):
to_encode = list()
max_token_len = 0
has_weights = False
@@ -153,38 +153,59 @@ def patched_SDClipModel_forward(self, tokens):
return z.float(), pooled_output
-class ClipVisionModelFooocus:
- def __init__(self, json_config):
- config = CLIPVisionConfig.from_json_file(json_config)
+def patched_ClipVisionModel__init__(self, json_config):
+ config = CLIPVisionConfig.from_json_file(json_config)
- self.load_device = ldm_patched.modules.model_management.text_encoder_device()
- self.offload_device = ldm_patched.modules.model_management.text_encoder_offload_device()
+ self.load_device = ldm_patched.modules.model_management.text_encoder_device()
+ self.offload_device = ldm_patched.modules.model_management.text_encoder_offload_device()
- if ldm_patched.modules.model_management.should_use_fp16(self.load_device, prioritize_performance=False):
- self.dtype = torch.float16
- else:
- self.dtype = torch.float32
+ if ldm_patched.modules.model_management.should_use_fp16(self.load_device, prioritize_performance=False):
+ self.dtype = torch.float16
+ else:
+ self.dtype = torch.float32
+
+ if 'cuda' not in self.load_device.type:
+ self.dtype = torch.float32
+
+ with modeling_utils.no_init_weights():
+ self.model = CLIPVisionModelWithProjection(config)
- if 'cuda' not in self.load_device.type:
- self.dtype = torch.float32
+ self.model.to(self.dtype)
+ self.patcher = ldm_patched.modules.model_patcher.ModelPatcher(
+ self.model,
+ load_device=self.load_device,
+ offload_device=self.offload_device
+ )
+
+
+def patched_ClipVisionModel_encode_image(self, image):
+ ldm_patched.modules.model_management.load_model_gpu(self.patcher)
+ pixel_values = ldm_patched.modules.clip_vision.clip_preprocess(image.to(self.load_device))
+
+ if self.dtype != torch.float32:
+ precision_scope = torch.autocast
+ else:
+ precision_scope = lambda a, b: contextlib.nullcontext(a)
- with modeling_utils.no_init_weights():
- self.model = CLIPVisionModelWithProjection(config)
+ with precision_scope(ldm_patched.modules.model_management.get_autocast_device(self.load_device), torch.float32):
+ outputs = self.model(pixel_values=pixel_values, output_hidden_states=True)
- self.model.to(self.dtype)
- self.patcher = ldm_patched.modules.model_patcher.ModelPatcher(
- self.model,
- load_device=self.load_device,
- offload_device=self.offload_device
- )
+ for k in outputs:
+ t = outputs[k]
+ if t is not None:
+ if k == 'hidden_states':
+ outputs["penultimate_hidden_states"] = t[-2].to(ldm_patched.modules.model_management.intermediate_device())
+ outputs["hidden_states"] = None
+ else:
+ outputs[k] = t.to(ldm_patched.modules.model_management.intermediate_device())
- def load_sd(self, sd):
- return self.model.load_state_dict(sd, strict=False)
+ return outputs
def patch_all_clip():
- ldm_patched.modules.sd1_clip.ClipTokenWeightEncoder.encode_token_weights = encode_token_weights_fooocus
+ ldm_patched.modules.sd1_clip.ClipTokenWeightEncoder.encode_token_weights = patched_encode_token_weights
ldm_patched.modules.sd1_clip.SDClipModel.__init__ = patched_SDClipModel__init__
ldm_patched.modules.sd1_clip.SDClipModel.forward = patched_SDClipModel_forward
- ldm_patched.modules.clip_vision.ClipVisionModel = ClipVisionModelFooocus
+ ldm_patched.modules.clip_vision.ClipVisionModel.__init__ = patched_ClipVisionModel__init__
+ ldm_patched.modules.clip_vision.ClipVisionModel.encode_image = patched_ClipVisionModel_encode_image
return
|
https://api.github.com/repos/lllyasviel/Fooocus/pulls/1463
|
2023-12-17T08:12:52Z
|
2023-12-17T08:13:51Z
|
2023-12-17T08:13:51Z
|
2023-12-17T08:13:54Z
| 1,090
|
lllyasviel/Fooocus
| 7,235
|
|
[CI] Add HF transformers tests
|
diff --git a/.github/workflows/main.yml b/.github/workflows/main.yml
index ec6df08793c7..69e3da34e05f 100644
--- a/.github/workflows/main.yml
+++ b/.github/workflows/main.yml
@@ -53,6 +53,7 @@ jobs:
python --version
which nvcc
nvcc --version
+ pip install torch==1.8.2+cu111 torchvision==0.9.2+cu111 -f https://download.pytorch.org/whl/lts/1.8/torch_lts.html
python -c "import torch; print('torch:', torch.__version__, torch)"
python -c "import torch; print('CUDA available:', torch.cuda.is_available())"
- name: Install deepspeed
@@ -65,3 +66,34 @@ jobs:
if [[ -d ./torch-extensions ]]; then rm -rf ./torch-extensions; fi
cd tests
TORCH_EXTENSIONS_DIR=./torch-extensions pytest --durations=0 --forked --verbose unit/
+
+ nv-transformers-v100:
+ runs-on: [self-hosted, nvidia, torch18, v100]
+
+ steps:
+ - uses: actions/checkout@v2
+
+ - name: environment
+ run: |
+ nvidia-smi
+ which python
+ python --version
+ which nvcc
+ nvcc --version
+ pip install torch==1.8.2+cu111 torchvision==0.9.2+cu111 -f https://download.pytorch.org/whl/lts/1.8/torch_lts.html
+ python -c "import torch; print('torch:', torch.__version__, torch)"
+ python -c "import torch; print('CUDA available:', torch.cuda.is_available())"
+ - name: Install deepspeed
+ run: |
+ pip install .[dev]
+ ds_report
+ - name: HF transformers tests
+ run: |
+ if [[ -d ./torch-extensions ]]; then rm -rf ./torch-extensions; fi
+ git clone https://github.com/huggingface/transformers
+ git rev-parse --short HEAD
+ cd transformers
+ pip install .[testing]
+ # find reqs used in ds integration tests
+ find examples/pytorch -regextype posix-egrep -regex '.*(language-modeling|question-answering|summarization|text-classification|translation).*/requirements.txt' -exec pip install -r {} \;
+ TORCH_EXTENSIONS_DIR=./torch-extensions RUN_SLOW=1 pytest --durations=0 --verbose tests/deepspeed
diff --git a/.github/workflows/torch16.yml b/.github/workflows/torch16.yml
deleted file mode 100755
index 0b23144cec0b..000000000000
--- a/.github/workflows/torch16.yml
+++ /dev/null
@@ -1,46 +0,0 @@
-# Unit test config for manual use on torch1.6 runners
-
-name: Torch16
-
-# Controls when the action will run.
-on:
- # Allows you to run this workflow manually from the Actions tab
- workflow_dispatch:
-
-# A workflow run is made up of one or more jobs that can run sequentially or in parallel
-jobs:
- # This workflow contains a single job called "build"
- build:
- # The type of runner that the job will run on
- runs-on: [self-hosted, torch1.6]
-
- # Steps represent a sequence of tasks that will be executed as part of the job
- steps:
- # Checks-out your repository under $GITHUB_WORKSPACE, so your job can access it
- - uses: actions/checkout@v2
-
- # Runs a single command using the runners shell
- - name: environment
- run: |
- nvidia-smi
- which python
- python --version
- which nvcc
- nvcc --version
- python -c "import torch; print('torch:', torch.__version__, torch)"
- python -c "import torch; print('CUDA available:', torch.cuda.is_available())"
- # Runs a set of commands using the runners shell
- - name: Install deepspeed
- run: |
- pip install .[dev]
- ds_report
-
- - name: Formatting checks
- run: |
- pre-commit run --all-files
-
- # Runs a set of commands using the runners shell
- - name: Unit tests
- run: |
- if [[ -d ./torch-extensions ]]; then rm -rf ./torch-extensions; fi
- TORCH_EXTENSIONS_DIR=./torch-extensions pytest --durations=0 --forked --verbose -x tests/unit/
|
Adding the tests from here: https://github.com/microsoft/DeepSpeed/issues/937
|
https://api.github.com/repos/microsoft/DeepSpeed/pulls/958
|
2021-04-14T18:01:11Z
|
2021-09-24T22:47:01Z
|
2021-09-24T22:47:01Z
|
2021-09-24T22:47:05Z
| 1,088
|
microsoft/DeepSpeed
| 10,493
|
CLN: misc tslibs, annotations, unused imports
|
diff --git a/pandas/_libs/tslibs/resolution.pyx b/pandas/_libs/tslibs/resolution.pyx
index c0b20c14e9920..1e0eb7f97ec54 100644
--- a/pandas/_libs/tslibs/resolution.pyx
+++ b/pandas/_libs/tslibs/resolution.pyx
@@ -27,7 +27,7 @@ cdef:
# ----------------------------------------------------------------------
-cpdef resolution(int64_t[:] stamps, tz=None):
+cpdef resolution(const int64_t[:] stamps, tz=None):
cdef:
Py_ssize_t i, n = len(stamps)
npy_datetimestruct dts
@@ -38,7 +38,7 @@ cpdef resolution(int64_t[:] stamps, tz=None):
return _reso_local(stamps, tz)
-cdef _reso_local(int64_t[:] stamps, object tz):
+cdef _reso_local(const int64_t[:] stamps, object tz):
cdef:
Py_ssize_t i, n = len(stamps)
int reso = RESO_DAY, curr_reso
@@ -106,7 +106,7 @@ cdef inline int _reso_stamp(npy_datetimestruct *dts):
return RESO_DAY
-def get_freq_group(freq):
+def get_freq_group(freq) -> int:
"""
Return frequency code group of given frequency str or offset.
@@ -189,7 +189,7 @@ class Resolution:
_freq_reso_map = {v: k for k, v in _reso_freq_map.items()}
@classmethod
- def get_str(cls, reso):
+ def get_str(cls, reso: int) -> str:
"""
Return resolution str against resolution code.
@@ -201,7 +201,7 @@ class Resolution:
return cls._reso_str_map.get(reso, 'day')
@classmethod
- def get_reso(cls, resostr):
+ def get_reso(cls, resostr: str) -> int:
"""
Return resolution str against resolution code.
@@ -216,7 +216,7 @@ class Resolution:
return cls._str_reso_map.get(resostr, cls.RESO_DAY)
@classmethod
- def get_freq_group(cls, resostr):
+ def get_freq_group(cls, resostr: str) -> int:
"""
Return frequency str against resolution str.
@@ -228,7 +228,7 @@ class Resolution:
return get_freq_group(cls.get_freq(resostr))
@classmethod
- def get_freq(cls, resostr):
+ def get_freq(cls, resostr: str) -> str:
"""
Return frequency str against resolution str.
@@ -240,7 +240,7 @@ class Resolution:
return cls._reso_freq_map[resostr]
@classmethod
- def get_str_from_freq(cls, freq):
+ def get_str_from_freq(cls, freq: str) -> str:
"""
Return resolution str against frequency str.
@@ -252,7 +252,7 @@ class Resolution:
return cls._freq_reso_map.get(freq, 'day')
@classmethod
- def get_reso_from_freq(cls, freq):
+ def get_reso_from_freq(cls, freq: str) -> int:
"""
Return resolution code against frequency str.
diff --git a/pandas/_libs/tslibs/timedeltas.pyx b/pandas/_libs/tslibs/timedeltas.pyx
index ad7cf6ae9307d..3742506a7f8af 100644
--- a/pandas/_libs/tslibs/timedeltas.pyx
+++ b/pandas/_libs/tslibs/timedeltas.pyx
@@ -1,5 +1,4 @@
import collections
-import textwrap
import cython
diff --git a/pandas/_libs/tslibs/timestamps.pyx b/pandas/_libs/tslibs/timestamps.pyx
index 4915671aa6512..b8c462abe35f1 100644
--- a/pandas/_libs/tslibs/timestamps.pyx
+++ b/pandas/_libs/tslibs/timestamps.pyx
@@ -1,4 +1,3 @@
-import sys
import warnings
import numpy as np
|
https://api.github.com/repos/pandas-dev/pandas/pulls/31673
|
2020-02-04T23:09:40Z
|
2020-02-05T00:46:52Z
|
2020-02-05T00:46:52Z
|
2020-02-05T00:48:50Z
| 935
|
pandas-dev/pandas
| 45,327
|
|
Upgrade aladdin_connect to 0.3 and provide Unique ID
|
diff --git a/homeassistant/components/cover/aladdin_connect.py b/homeassistant/components/cover/aladdin_connect.py
index efaea39bb864..ef1f94d1bcd3 100644
--- a/homeassistant/components/cover/aladdin_connect.py
+++ b/homeassistant/components/cover/aladdin_connect.py
@@ -14,7 +14,7 @@
STATE_OPENING, STATE_CLOSING, STATE_OPEN)
import homeassistant.helpers.config_validation as cv
-REQUIREMENTS = ['aladdin_connect==0.1']
+REQUIREMENTS = ['aladdin_connect==0.3']
_LOGGER = logging.getLogger(__name__)
@@ -79,6 +79,11 @@ def supported_features(self):
"""Flag supported features."""
return SUPPORTED_FEATURES
+ @property
+ def unique_id(self):
+ """Return a unique ID."""
+ return '{}-{}'.format(self._device_id, self._number)
+
@property
def name(self):
"""Return the name of the garage door."""
diff --git a/requirements_all.txt b/requirements_all.txt
index 4736e4e4c6d1..cb42709a47fc 100644
--- a/requirements_all.txt
+++ b/requirements_all.txt
@@ -111,7 +111,7 @@ aiolifx_effects==0.1.2
aiopvapi==1.5.4
# homeassistant.components.cover.aladdin_connect
-aladdin_connect==0.1
+aladdin_connect==0.3
# homeassistant.components.alarmdecoder
alarmdecoder==1.13.2
|
## Description:
Update dependency for a few bug fixes and provide unique id to allow renaming.
## Checklist:
- [x] The code change is tested and works locally.
- [x] Local tests pass with `tox`. **Your PR cannot be merged unless tests pass**
If the code communicates with devices, web services, or third-party tools:
- [x] New dependencies have been added to the `REQUIREMENTS` variable ([example][ex-requir]).
- [x] New or updated dependencies have been added to `requirements_all.txt` by running `script/gen_requirements_all.py`.
[ex-requir]: https://github.com/home-assistant/home-assistant/blob/dev/homeassistant/components/keyboard.py#L14
[ex-import]: https://github.com/home-assistant/home-assistant/blob/dev/homeassistant/components/keyboard.py#L54
|
https://api.github.com/repos/home-assistant/core/pulls/15986
|
2018-08-15T00:28:26Z
|
2018-08-16T05:18:30Z
|
2018-08-16T05:18:30Z
|
2019-03-21T04:15:30Z
| 350
|
home-assistant/core
| 39,324
|
Fix allreduce for BF16 and ZeRO0
|
diff --git a/deepspeed/runtime/engine.py b/deepspeed/runtime/engine.py
index e15cc49339ff..5c1202ba06ae 100644
--- a/deepspeed/runtime/engine.py
+++ b/deepspeed/runtime/engine.py
@@ -1911,9 +1911,6 @@ def print_forward_breakdown(self, fwd_time):
@instrument_w_nvtx
def allreduce_gradients(self, bucket_size=MEMORY_OPT_ALLREDUCE_SIZE):
- assert not (self.bfloat16_enabled() and self.pipeline_parallelism), \
- f'allreduce_gradients() is not valid when bfloat+pipeline_parallelism is enabled'
-
# Pass (PP) gas boundary flag to optimizer (required for zero)
self.optimizer.is_gradient_accumulation_boundary = self.is_gradient_accumulation_boundary()
# ZeRO stage >= 2 communicates during non gradient accumulation boundaries as well
@@ -1926,7 +1923,11 @@ def allreduce_gradients(self, bucket_size=MEMORY_OPT_ALLREDUCE_SIZE):
self.optimizer, 'reduce_gradients'):
self.optimizer.reduce_gradients(pipeline_parallel=self.pipeline_parallelism)
else:
- self.buffered_allreduce_fallback(elements_per_buffer=bucket_size)
+ grads = None
+ if hasattr(self.optimizer, "get_grads_for_reduction"):
+ # This is currently for BF16 optimizer
+ grads = self.optimizer.get_grads_for_reduction()
+ self.buffered_allreduce_fallback(grads=grads, elements_per_buffer=bucket_size)
@instrument_w_nvtx
def backward(self, loss, allreduce_gradients=True, release_loss=False, retain_graph=False, scale_wrt_gas=True):
|
This PR fixes an issue with allreducing for ZeRO0 + BF16. (This replaces #5154)
DeepSpeed uses `BF16_Optimizer` when ZeRO0 and BF16 are enabled. The optimizer accumulates gradients on FP32 buffer soon after a backward pass completes. However, DeepSpeed engine performs allreduce on BF16 gradients.
This PR fixes the issue by performing allreduce on the FP32 buffer. It also eliminates an assertion that prohibits BF16+PP+Z1, which is actually runnable.
This shows loss curves of the following conditions:
- BF16/Z0,Z1,Z2,Z3/NoPP
- BF16/Z0,Z1/PP(2 stages)
(all used 8GPUs, gradient accumulation step: 4)

|
https://api.github.com/repos/microsoft/DeepSpeed/pulls/5170
|
2024-02-21T16:56:39Z
|
2024-02-21T20:08:02Z
|
2024-02-21T20:08:02Z
|
2024-04-11T03:15:08Z
| 358
|
microsoft/DeepSpeed
| 10,077
|
Fix moe cpu offload
|
diff --git a/deepspeed/runtime/zero/stage_1_and_2.py b/deepspeed/runtime/zero/stage_1_and_2.py
index e4009f6ac883..71a01b2391f8 100755
--- a/deepspeed/runtime/zero/stage_1_and_2.py
+++ b/deepspeed/runtime/zero/stage_1_and_2.py
@@ -1946,8 +1946,10 @@ def _average_expert_grad_norms(self, norm_groups):
for i, norm in enumerate(norm_groups):
if self.is_moe_param_group[i]:
scaled_norm_tensor = norm * 1.0 / dist.get_world_size(group=self.real_dp_process_group[i])
+ if self.device == 'cpu':
+ scaled_norm_tensor = scaled_norm_tensor.to(get_accelerator().current_device_name())
dist.all_reduce(scaled_norm_tensor, group=self.real_dp_process_group[i])
- norm_groups[i] = scaled_norm_tensor
+ norm_groups[i] = scaled_norm_tensor.to(self.device)
def unscale_and_clip_grads(self, grad_groups_flat, total_norm):
# compute combined scale factor for this group
|
The MoE- param gradients norms don't need to be averaged when created on CPU only when using 1-DP training. However, I just moved the tensor back to GPU to get average when having data-parallel on the MoE parameters and using CPU-offload.
This PR addresses https://github.com/microsoft/DeepSpeed/issues/5203
|
https://api.github.com/repos/microsoft/DeepSpeed/pulls/5220
|
2024-03-02T00:42:22Z
|
2024-03-04T19:34:17Z
|
2024-03-04T19:34:16Z
|
2024-03-04T19:34:17Z
| 256
|
microsoft/DeepSpeed
| 10,251
|
Add async support for mistral embeddings
|
diff --git a/llama_index/embeddings/mistralai.py b/llama_index/embeddings/mistralai.py
index 995ad17166924..2bd444859f280 100644
--- a/llama_index/embeddings/mistralai.py
+++ b/llama_index/embeddings/mistralai.py
@@ -5,6 +5,7 @@
from llama_index.bridge.pydantic import PrivateAttr
from llama_index.callbacks.base import CallbackManager
from llama_index.embeddings.base import DEFAULT_EMBED_BATCH_SIZE, BaseEmbedding
+from llama_index.llms.generic_utils import get_from_param_or_env
class MistralAIEmbedding(BaseEmbedding):
@@ -19,6 +20,7 @@ class MistralAIEmbedding(BaseEmbedding):
# Instance variables initialized via Pydantic's mechanism
_mistralai_client: Any = PrivateAttr()
+ _mistralai_async_client: Any = PrivateAttr()
def __init__(
self,
@@ -29,12 +31,21 @@ def __init__(
**kwargs: Any,
):
try:
+ from mistralai.async_client import MistralAsyncClient
from mistralai.client import MistralClient
except ImportError:
raise ImportError(
"mistralai package not found, install with" "'pip install mistralai'"
)
+ api_key = get_from_param_or_env("api_key", api_key, "MISTRAL_API_KEY", "")
+
+ if not api_key:
+ raise ValueError(
+ "You must provide an API key to use mistralai. "
+ "You can either pass it in as an argument or set it `MISTRAL_API_KEY`."
+ )
self._mistralai_client = MistralClient(api_key=api_key)
+ self._mistralai_async_client = MistralAsyncClient(api_key=api_key)
super().__init__(
model_name=model_name,
embed_batch_size=embed_batch_size,
@@ -56,7 +67,15 @@ def _get_query_embedding(self, query: str) -> List[float]:
async def _aget_query_embedding(self, query: str) -> List[float]:
"""The asynchronous version of _get_query_embedding."""
- return self._get_query_embedding(query)
+ return (
+ (
+ await self._mistralai_async_client.embeddings(
+ model=self.model_name, input=[query]
+ )
+ )
+ .data[0]
+ .embedding
+ )
def _get_text_embedding(self, text: str) -> List[float]:
"""Get text embedding."""
@@ -68,7 +87,15 @@ def _get_text_embedding(self, text: str) -> List[float]:
async def _aget_text_embedding(self, text: str) -> List[float]:
"""Asynchronously get text embedding."""
- return self._get_text_embedding(text)
+ return (
+ (
+ await self._mistralai_async_client.embeddings(
+ model=self.model_name, input=[text]
+ )
+ )
+ .data[0]
+ .embedding
+ )
def _get_text_embeddings(self, texts: List[str]) -> List[List[float]]:
"""Get text embeddings."""
@@ -79,4 +106,7 @@ def _get_text_embeddings(self, texts: List[str]) -> List[List[float]]:
async def _aget_text_embeddings(self, texts: List[str]) -> List[List[float]]:
"""Asynchronously get text embeddings."""
- return self._get_text_embeddings(texts)
+ embedding_response = await self._mistralai_async_client.embeddings(
+ model=self.model_name, input=texts
+ )
+ return [embed.embedding for embed in embedding_response.data]
diff --git a/llama_index/llms/mistral.py b/llama_index/llms/mistral.py
index 8a47b862980a1..e72f22fc488a0 100644
--- a/llama_index/llms/mistral.py
+++ b/llama_index/llms/mistral.py
@@ -104,9 +104,7 @@ def __init__(
additional_kwargs = additional_kwargs or {}
callback_manager = callback_manager or CallbackManager([])
- api_key = api_key = get_from_param_or_env(
- "api_key", api_key, "MISTRAL_API_KEY", ""
- )
+ api_key = get_from_param_or_env("api_key", api_key, "MISTRAL_API_KEY", "")
if not api_key:
raise ValueError(
|
# Description
PR to add async support for mistral embeddings and syntax fix for mistral llm.
Fixes # (issue)
## Type of Change
Please delete options that are not relevant.
- [x] Bug fix (non-breaking change which fixes an issue)
# How Has This Been Tested?
Please describe the tests that you ran to verify your changes. Provide instructions so we can reproduce. Please also list any relevant details for your test configuration
- [ ] Added new unit/integration tests
- [ ] Added new notebook (that tests end-to-end)
- [x] I stared at the code and made sure it makes sense
# Suggested Checklist:
- [x] I have performed a self-review of my own code
- [x] I have commented my code, particularly in hard-to-understand areas
- [ ] I have made corresponding changes to the documentation
- [ ] I have added Google Colab support for the newly added notebooks.
- [x] My changes generate no new warnings
- [ ] I have added tests that prove my fix is effective or that my feature works
- [ ] New and existing unit tests pass locally with my changes
- [x] I ran `make format; make lint` to appease the lint gods
|
https://api.github.com/repos/run-llama/llama_index/pulls/9466
|
2023-12-12T17:19:23Z
|
2023-12-12T18:16:43Z
|
2023-12-12T18:16:43Z
|
2023-12-12T18:16:43Z
| 1,000
|
run-llama/llama_index
| 6,715
|
[runtime env] [1.11.0 release cherry-pick] fix bug where pip options don't work in `requirements.txt`
|
diff --git a/python/ray/_private/runtime_env/pip.py b/python/ray/_private/runtime_env/pip.py
index 1ce0ed2de0481..d0fc43d33b49e 100644
--- a/python/ray/_private/runtime_env/pip.py
+++ b/python/ray/_private/runtime_env/pip.py
@@ -29,11 +29,25 @@ def _install_pip_list_to_dir(
target_dir: str,
logger: Optional[logging.Logger] = default_logger):
try_to_create_directory(target_dir)
- exit_code, output = exec_cmd_stream_to_logger(
- ["pip", "install", f"--target={target_dir}"] + pip_list, logger)
- if exit_code != 0:
- shutil.rmtree(target_dir)
- raise RuntimeError(f"Failed to install pip requirements:\n{output}")
+ try:
+ pip_requirements_file = os.path.join(target_dir, "requirements.txt")
+ with open(pip_requirements_file, "w") as file:
+ for line in pip_list:
+ file.write(line + "\n")
+ exit_code, output = exec_cmd_stream_to_logger(
+ [
+ "pip", "install", f"--target={target_dir}", "-r",
+ pip_requirements_file
+ ],
+ logger,
+ )
+ if exit_code != 0:
+ shutil.rmtree(target_dir)
+ raise RuntimeError(
+ f"Failed to install pip requirements:\n{output}")
+ finally:
+ if os.path.exists(pip_requirements_file):
+ os.remove(pip_requirements_file)
def get_uri(runtime_env: Dict) -> Optional[str]:
diff --git a/python/ray/_private/runtime_env/validation.py b/python/ray/_private/runtime_env/validation.py
index 8e06ba726f7b3..c515cbdcbe39a 100644
--- a/python/ray/_private/runtime_env/validation.py
+++ b/python/ray/_private/runtime_env/validation.py
@@ -110,9 +110,34 @@ def parse_and_validate_conda(conda: Union[str, dict]) -> Union[str, dict]:
def _rewrite_pip_list_ray_libraries(pip_list: List[str]) -> List[str]:
+ """Remove Ray and replace Ray libraries with their dependencies.
+
+ The `pip` field of runtime_env installs packages into the current
+ environment, inheriting the existing environment. If users want to
+ use Ray libraries like `ray[serve]` in their job, they must include
+ `ray[serve]` in their `runtime_env` `pip` field. However, without this
+ function, the Ray installed at runtime would take precedence over the
+ Ray that exists in the cluster, which would lead to version mismatch
+ issues.
+
+ To work around this, this function deletes Ray from the input `pip_list`
+ if it's specified without any libraries (e.g. "ray" or "ray>1.4"). If
+ a Ray library is specified (e.g. "ray[serve]"), it is replaced by
+ its dependencies (e.g. "uvicorn", ...).
+
+ """
result = []
for specifier in pip_list:
- requirement = Requirement.parse(specifier)
+ try:
+ requirement = Requirement.parse(specifier)
+ except Exception:
+ # Some lines in a pip_list might not be requirements but
+ # rather options for `pip`; e.g. `--extra-index-url MY_INDEX`.
+ # Requirement.parse would raise an InvalidRequirement in this
+ # case. Since we are only interested in lines specifying Ray
+ # or its libraries, we should just skip this line.
+ result.append(specifier)
+ continue
package_name = requirement.name
if package_name == "ray":
libraries = requirement.extras # e.g. ("serve", "tune")
diff --git a/python/ray/tests/test_runtime_env_conda_and_pip.py b/python/ray/tests/test_runtime_env_conda_and_pip.py
index 30fe8ebeee7e9..70dbbac3bf8cb 100644
--- a/python/ray/tests/test_runtime_env_conda_and_pip.py
+++ b/python/ray/tests/test_runtime_env_conda_and_pip.py
@@ -8,7 +8,10 @@
check_local_files_gced,
generate_runtime_env_dict)
from ray._private.runtime_env.conda import _get_conda_dict_with_ray_inserted
-from ray._private.runtime_env.validation import ParsedRuntimeEnv
+from ray._private.runtime_env.validation import (
+ ParsedRuntimeEnv,
+ _rewrite_pip_list_ray_libraries,
+)
import yaml
import tempfile
@@ -22,6 +25,15 @@
os.environ["RAY_RUNTIME_ENV_LOCAL_DEV_MODE"] = "1"
+def test_rewrite_pip_list_ray_libraries():
+ input = ["--extra-index-url my.url", "ray==1.4", "requests", "ray[serve]"]
+ output = _rewrite_pip_list_ray_libraries(input)
+ assert "ray" not in output
+ assert "ray==1.4" not in output
+ assert "ray[serve]" not in output
+ assert output[:2] == ["--extra-index-url my.url", "requests"]
+
+
def test_get_conda_dict_with_ray_inserted_m1_wheel(monkeypatch):
# Disable dev mode to prevent Ray dependencies being automatically inserted
# into the conda dict.
@@ -58,11 +70,15 @@ def test_get_conda_dict_with_ray_inserted_m1_wheel(monkeypatch):
os.environ.get("CI") and sys.platform != "linux",
reason="Requires PR wheels built in CI, so only run on linux CI machines.")
@pytest.mark.parametrize("field", ["conda", "pip"])
-def test_files_remote_cluster(start_cluster, field):
- """Test that requirements files are parsed on the driver, not the cluster.
+def test_requirements_files(start_cluster, field):
+ """Test the use of requirements.txt and environment.yaml.
+ Tests that requirements files are parsed on the driver, not the cluster.
This is the desired behavior because the file paths only make sense on the
driver machine. The files do not exist on the remote cluster.
+
+ Also tests the common use case of specifying the option --extra-index-url
+ in a pip requirements.txt file.
"""
cluster, address = start_cluster
@@ -72,18 +88,17 @@ def test_files_remote_cluster(start_cluster, field):
# temporary directory. So if the nodes try to read the requirements file,
# this test should fail because the relative path won't make sense.
with tempfile.TemporaryDirectory() as tmpdir, chdir(tmpdir):
+ pip_list = [
+ "--extra-index-url https://pypi.org/simple",
+ "pip-install-test==0.5",
+ ]
if field == "conda":
- conda_dict = {
- "dependencies": ["pip", {
- "pip": ["pip-install-test==0.5"]
- }]
- }
+ conda_dict = {"dependencies": ["pip", {"pip": pip_list}]}
relative_filepath = "environment.yml"
conda_file = Path(relative_filepath)
conda_file.write_text(yaml.dump(conda_dict))
runtime_env = {"conda": relative_filepath}
elif field == "pip":
- pip_list = ["pip-install-test==0.5"]
relative_filepath = "requirements.txt"
pip_file = Path(relative_filepath)
pip_file.write_text("\n".join(pip_list))
|
<!-- Thank you for your contribution! Please review https://github.com/ray-project/ray/blob/master/CONTRIBUTING.rst before opening a pull request. -->
<!-- Please add a reviewer to the assignee section when you create a PR. If you don't have the access to it, we will shortly find a reviewer and assign them to your PR. -->
## Why are these changes needed?
This PR cherry-picks the fix https://github.com/ray-project/ray/pull/22065 to the 1.11.0 release branch.
Merging this PR requires two approvals: -- one committer and the TL owning the component (@edoakes).
<!-- Please give a short summary of the change and the problem this solves. -->
## Related issue number
<!-- For example: "Closes #1234" -->
## Checks
- [ ] I've run `scripts/format.sh` to lint the changes in this PR.
- [ ] I've included any doc changes needed for https://docs.ray.io/en/master/.
- [ ] I've made sure the tests are passing. Note that there might be a few flaky tests, see the recent failures at https://flakey-tests.ray.io/
- Testing Strategy
- [ ] Unit tests
- [ ] Release tests
- [ ] This PR is not tested :(
|
https://api.github.com/repos/ray-project/ray/pulls/22127
|
2022-02-04T21:52:08Z
|
2022-02-14T15:13:37Z
|
2022-02-14T15:13:37Z
|
2022-02-14T15:13:38Z
| 1,667
|
ray-project/ray
| 19,881
|
[tune] Improve BOHB/ConfigSpace dependency check
|
diff --git a/python/ray/tune/suggest/bohb.py b/python/ray/tune/suggest/bohb.py
index 995c0f86f23ff..bef5b9ed3defa 100644
--- a/python/ray/tune/suggest/bohb.py
+++ b/python/ray/tune/suggest/bohb.py
@@ -5,7 +5,6 @@
import math
from typing import Dict, List, Optional, Union
-import ConfigSpace
from ray.tune.result import DEFAULT_METRIC
from ray.tune.sample import Categorical, Domain, Float, Integer, LogUniform, \
Normal, \
@@ -17,6 +16,12 @@
from ray.tune.suggest.variant_generator import parse_spec_vars
from ray.tune.utils.util import flatten_dict, unflatten_list_dict
+try:
+ import ConfigSpace
+ from hpbandster.optimizers.config_generators.bohb import BOHB
+except ImportError:
+ BOHB = ConfigSpace = None
+
logger = logging.getLogger(__name__)
@@ -105,15 +110,14 @@ class TuneBOHB(Searcher):
"""
def __init__(self,
- space: Optional[Union[Dict,
- ConfigSpace.ConfigurationSpace]] = None,
+ space: Optional[Union[
+ Dict, "ConfigSpace.ConfigurationSpace"]] = None,
bohb_config: Optional[Dict] = None,
max_concurrent: int = 10,
metric: Optional[str] = None,
mode: Optional[str] = None,
points_to_evaluate: Optional[List[Dict]] = None,
seed: Optional[int] = None):
- from hpbandster.optimizers.config_generators.bohb import BOHB
assert BOHB is not None, """HpBandSter must be installed!
You can install HpBandSter with the command:
`pip install hpbandster ConfigSpace`."""
@@ -236,7 +240,7 @@ def on_unpause(self, trial_id: str):
self.running.add(trial_id)
@staticmethod
- def convert_search_space(spec: Dict) -> ConfigSpace.ConfigurationSpace:
+ def convert_search_space(spec: Dict) -> "ConfigSpace.ConfigurationSpace":
resolved_vars, domain_vars, grid_vars = parse_spec_vars(spec)
if grid_vars:
|
<!-- Thank you for your contribution! Please review https://github.com/ray-project/ray/blob/master/CONTRIBUTING.rst before opening a pull request. -->
<!-- Please add a reviewer to the assignee section when you create a PR. If you don't have the access to it, we will shortly find a reviewer and assign them to your PR. -->
## Why are these changes needed?
Remove hard dependency for ConfigSpace on BOHB import
## Related issue number
https://github.com/ray-project/tune-sklearn/pull/198
## Checks
- [ ] I've run `scripts/format.sh` to lint the changes in this PR.
- [ ] I've included any doc changes needed for https://docs.ray.io/en/master/.
- [ ] I've made sure the tests are passing. Note that there might be a few flaky tests, see the recent failures at https://flakey-tests.ray.io/
- Testing Strategy
- [ ] Unit tests
- [ ] Release tests
- [ ] This PR is not tested :(
|
https://api.github.com/repos/ray-project/ray/pulls/15064
|
2021-04-01T15:03:08Z
|
2021-04-02T08:19:49Z
|
2021-04-02T08:19:49Z
|
2021-04-02T08:19:52Z
| 502
|
ray-project/ray
| 19,574
|
[docker] Check for GPUs before setting runtime-nvidia
|
diff --git a/python/ray/autoscaler/_private/command_runner.py b/python/ray/autoscaler/_private/command_runner.py
index 5f38ecee03eda..e708bfbac366d 100644
--- a/python/ray/autoscaler/_private/command_runner.py
+++ b/python/ray/autoscaler/_private/command_runner.py
@@ -667,14 +667,14 @@ def run_init(self, *, as_head, file_mounts):
for mnt in BOOTSTRAP_MOUNTS:
cleaned_bind_mounts.pop(mnt, None)
- start_command = docker_start_cmds(
- self.ssh_command_runner.ssh_user, image, cleaned_bind_mounts,
- self.container_name,
- self.docker_config.get("run_options", []) + self.docker_config.get(
- f"{'head' if as_head else 'worker'}_run_options",
- []) + self._configure_runtime())
-
if not self._check_container_status():
+ start_command = docker_start_cmds(
+ self.ssh_command_runner.ssh_user, image, cleaned_bind_mounts,
+ self.container_name,
+ self.docker_config.get(
+ "run_options", []) + self.docker_config.get(
+ f"{'head' if as_head else 'worker'}_run_options",
+ []) + self._configure_runtime())
self.run(start_command, run_env="host")
else:
running_image = self.run(
@@ -724,5 +724,13 @@ def _configure_runtime(self):
"docker info -f '{{.Runtimes}}' ",
with_output=True).decode().strip()
if "nvidia-container-runtime" in runtime_output:
- return ["--runtime=nvidia"]
+ try:
+ self.ssh_command_runner.run("nvidia-smi", with_output=False)
+ return ["--runtime=nvidia"]
+ except Exception as e:
+ logger.warning(
+ "Nvidia Container Runtime is present, but no GPUs found.")
+ logger.debug(f"nvidia-smi error: {e}")
+ return []
+
return []
|
<!-- Thank you for your contribution! Please review https://github.com/ray-project/ray/blob/master/CONTRIBUTING.rst before opening a pull request. -->
<!-- Please add a reviewer to the assignee section when you create a PR. If you don't have the access to it, we will shortly find a reviewer and assign them to your PR. -->
## Why are these changes needed?
Ray up fails under the following conditions:
* `nvidia-container-runtime` is installed on the host
* **No** GPUs are present on the hsot
* A CUDA based image is being used for running
The output is
```
docker: Error response from daemon: OCI runtime create failed: container_linux.go:349: starting container process caused "process_linux.go:449: container init caused \"process_linux.go:432: running prestart hook 0 caused \\\"error running hook: exit status 1, stdout: , stderr: nvidia-container-cli: initialization error: nvml error: driver not loaded\\\\n\\\"\"": unknown.
```
<!-- Please give a short summary of the change and the problem this solves. -->
## Related issue number
<!-- For example: "Closes #1234" -->
## Checks
- [ ] I've run `scripts/format.sh` to lint the changes in this PR.
- [ ] I've included any doc changes needed for https://docs.ray.io/en/master/.
- [ ] I've made sure the tests are passing. Note that there might be a few flaky tests, see the recent failures at https://flakey-tests.ray.io/
- Testing Strategy
- [ ] Unit tests
- [ ] Release tests
- [ ] This PR is not tested :(
|
https://api.github.com/repos/ray-project/ray/pulls/11418
|
2020-10-15T17:45:23Z
|
2020-10-15T22:43:10Z
|
2020-10-15T22:43:10Z
|
2020-10-15T22:43:10Z
| 453
|
ray-project/ray
| 19,922
|
fix(bybit): error mapping (InvalidOrder -> BadRequest)
|
diff --git a/ts/src/bybit.ts b/ts/src/bybit.ts
index 58dd8e7823e9..472235c8452e 100644
--- a/ts/src/bybit.ts
+++ b/ts/src/bybit.ts
@@ -728,7 +728,7 @@ export default class bybit extends Exchange {
'110023': InvalidOrder, // This contract only supports position reduction operation, please contact customer service for details
'110024': InvalidOrder, // You have an existing position, so position mode cannot be switched
'110025': InvalidOrder, // Position mode is not modified
- '110026': InvalidOrder, // Cross/isolated margin mode is not modified
+ '110026': BadRequest, // Cross/isolated margin mode is not modified
'110027': InvalidOrder, // Margin is not modified
'110028': InvalidOrder, // Open orders exist, so you cannot change position mode
'110029': InvalidOrder, // Hedge mode is not available for this symbol
|
- relates to https://github.com/ccxt/ccxt/issues/19311
DEMO
```
n bybit setMarginMode "isolated" "BTC/USDT:USDT" '{"leverage": 3}' --sandbox
2023-09-19T10:54:30.792Z
Node.js: v18.14.0
CCXT v4.0.100
bybit.setMarginMode (isolated, BTC/USDT:USDT, [object Object])
BadRequest bybit {"retCode":110026,"retMsg":"Cross/isolated margin mode is not modified","result":{},"retExtInfo":{},"time":1695120874155}
---------------------------------------------------
[BadRequest] bybit {"retCode":110026,"retMsg":"Cross/isolated margin mode is not modified","result":{},"retExtInfo":{},"time":1695120874155}
at throwExactlyMatchedException Users/cjg/Git/ccxt10/ccxt/js/src/base/Exchange.js:3114
at handleErrors Users/cjg/Git/ccxt10/ccxt/js/src/bybit.js:7387
at Users/cjg/Git/ccxt10/ccxt/js/src/base/Exchange.js:764
at processTicksAndRejections node:internal/process/task_queues:95
at fetch2 Users/cjg/Git/ccxt10/ccxt/js/src/base/Exchange.js:2693
at request Users/cjg/Git/ccxt10/ccxt/js/src/base/Exchange.js:2696
at setMarginMode Users/cjg/Git/ccxt10/ccxt/js/src/bybit.js:6056
at async run Users/cjg/Git/ccxt10/ccxt/examples/js/cli.js:298
bybit {"retCode":110026,"retMsg":"Cross/isolated margin mode is not modified","result":{},"retExtInfo":{},"time":1695120874155}
```
|
https://api.github.com/repos/ccxt/ccxt/pulls/19327
|
2023-09-19T10:54:52Z
|
2023-09-19T11:08:16Z
|
2023-09-19T11:08:16Z
|
2023-09-19T11:08:16Z
| 222
|
ccxt/ccxt
| 13,877
|
MNT minor clean-up of sklearn/conftests.py
|
diff --git a/sklearn/conftest.py b/sklearn/conftest.py
index 27ac720cbfe2e..90b30506e8cae 100644
--- a/sklearn/conftest.py
+++ b/sklearn/conftest.py
@@ -132,8 +132,6 @@ def pytest_collection_modifyitems(config, items):
)
item.add_marker(marker)
- # numpy changed the str/repr formatting of numpy arrays in 1.14. We want to
- # run doctests only for numpy >= 1.14.
skip_doctests = False
try:
import matplotlib # noqa
@@ -141,18 +139,15 @@ def pytest_collection_modifyitems(config, items):
skip_doctests = True
reason = "matplotlib is required to run the doctests"
- try:
- if _IS_32BIT:
- reason = "doctest are only run when the default numpy int is 64 bits."
- skip_doctests = True
- elif sys.platform.startswith("win32"):
- reason = (
- "doctests are not run for Windows because numpy arrays "
- "repr is inconsistent across platforms."
- )
- skip_doctests = True
- except ImportError:
- pass
+ if _IS_32BIT:
+ reason = "doctest are only run when the default numpy int is 64 bits."
+ skip_doctests = True
+ elif sys.platform.startswith("win32"):
+ reason = (
+ "doctests are not run for Windows because numpy arrays "
+ "repr is inconsistent across platforms."
+ )
+ skip_doctests = True
# Normally doctest has the entire module's scope. Here we set globs to an empty dict
# to remove the module's scope:
|
Noticed an old comment about numpy >= 14, which is not relevant any more. Also there is a `try/except` which I don't think is needed.
|
https://api.github.com/repos/scikit-learn/scikit-learn/pulls/25358
|
2023-01-11T14:11:15Z
|
2023-01-11T16:05:27Z
|
2023-01-11T16:05:27Z
|
2023-03-31T06:31:19Z
| 411
|
scikit-learn/scikit-learn
| 46,330
|
CLN: avoid getattr(obj, "values", obj)
|
diff --git a/pandas/_libs/hashtable_func_helper.pxi.in b/pandas/_libs/hashtable_func_helper.pxi.in
index 6e5509a5570e8..c63f368dfae43 100644
--- a/pandas/_libs/hashtable_func_helper.pxi.in
+++ b/pandas/_libs/hashtable_func_helper.pxi.in
@@ -125,7 +125,7 @@ cpdef value_count_{{dtype}}({{c_type}}[:] values, bint dropna):
{{if dtype == 'object'}}
def duplicated_{{dtype}}(ndarray[{{dtype}}] values, object keep='first'):
{{else}}
-def duplicated_{{dtype}}({{c_type}}[:] values, object keep='first'):
+def duplicated_{{dtype}}(const {{c_type}}[:] values, object keep='first'):
{{endif}}
cdef:
int ret = 0
diff --git a/pandas/core/algorithms.py b/pandas/core/algorithms.py
index e6967630b97ac..eca1733b61a52 100644
--- a/pandas/core/algorithms.py
+++ b/pandas/core/algorithms.py
@@ -49,6 +49,7 @@
ABCExtensionArray,
ABCIndex,
ABCIndexClass,
+ ABCMultiIndex,
ABCSeries,
)
from pandas.core.dtypes.missing import isna, na_value_for_dtype
@@ -89,6 +90,10 @@ def _ensure_data(values, dtype=None):
values : ndarray
pandas_dtype : str or dtype
"""
+ if not isinstance(values, ABCMultiIndex):
+ # extract_array would raise
+ values = extract_array(values, extract_numpy=True)
+
# we check some simple dtypes first
if is_object_dtype(dtype):
return ensure_object(np.asarray(values)), "object"
@@ -151,7 +156,6 @@ def _ensure_data(values, dtype=None):
elif is_categorical_dtype(values) and (
is_categorical_dtype(dtype) or dtype is None
):
- values = getattr(values, "values", values)
values = values.codes
dtype = "category"
diff --git a/pandas/core/arrays/interval.py b/pandas/core/arrays/interval.py
index 220b70ff71b28..66faca29670cb 100644
--- a/pandas/core/arrays/interval.py
+++ b/pandas/core/arrays/interval.py
@@ -648,7 +648,6 @@ def fillna(self, value=None, method=None, limit=None):
)
raise TypeError(msg)
- value = getattr(value, "_values", value)
self._check_closed_matches(value, name="value")
left = self.left.fillna(value=value.left)
diff --git a/pandas/core/computation/expressions.py b/pandas/core/computation/expressions.py
index 7f93472c766d7..d9cd2c7be0093 100644
--- a/pandas/core/computation/expressions.py
+++ b/pandas/core/computation/expressions.py
@@ -102,8 +102,8 @@ def _evaluate_numexpr(op, op_str, a, b):
# we were originally called by a reversed op method
a, b = b, a
- a_value = getattr(a, "values", a)
- b_value = getattr(b, "values", b)
+ a_value = a
+ b_value = b
result = ne.evaluate(
f"a_value {op_str} b_value",
diff --git a/pandas/core/window/rolling.py b/pandas/core/window/rolling.py
index 3b14921528890..05400f63db972 100644
--- a/pandas/core/window/rolling.py
+++ b/pandas/core/window/rolling.py
@@ -37,6 +37,7 @@
from pandas.core.base import DataError, PandasObject, SelectionMixin, ShallowMixin
import pandas.core.common as com
+from pandas.core.construction import extract_array
from pandas.core.indexes.api import Index, ensure_index
from pandas.core.util.numba_ import NUMBA_FUNC_CACHE
from pandas.core.window.common import (
@@ -252,7 +253,7 @@ def __iter__(self):
def _prep_values(self, values: Optional[np.ndarray] = None) -> np.ndarray:
"""Convert input to numpy arrays for Cython routines"""
if values is None:
- values = getattr(self._selected_obj, "values", self._selected_obj)
+ values = extract_array(self._selected_obj, extract_numpy=True)
# GH #12373 : rolling functions error on float32 data
# make sure the data is coerced to float64
|
xref #27167
@mroeschke can you pls double-check me on the change in window.rolling
|
https://api.github.com/repos/pandas-dev/pandas/pulls/33776
|
2020-04-24T18:45:06Z
|
2020-04-25T20:48:05Z
|
2020-04-25T20:48:05Z
|
2020-04-25T21:03:58Z
| 1,027
|
pandas-dev/pandas
| 45,406
|
rm model type check
|
diff --git a/paddleocr.py b/paddleocr.py
index a530d78685..f19d1defee 100644
--- a/paddleocr.py
+++ b/paddleocr.py
@@ -47,7 +47,9 @@
BASE_DIR = os.path.expanduser("~/.paddleocr/")
DEFAULT_OCR_MODEL_VERSION = 'PP-OCR'
+SUPPORT_OCR_MODEL_VERSION = ['PP-OCR', 'PP-OCRv2']
DEFAULT_STRUCTURE_MODEL_VERSION = 'STRUCTURE'
+SUPPORT_STRUCTURE_MODEL_VERSION = ['STRUCTURE']
MODEL_URLS = {
'OCR': {
'PP-OCRv2': {
@@ -190,6 +192,7 @@ def parse_args(mMain=True):
parser.add_argument(
"--ocr_version",
type=str,
+ choices=SUPPORT_OCR_MODEL_VERSION,
default='PP-OCRv2',
help='OCR Model version, the current model support list is as follows: '
'1. PP-OCRv2 Support Chinese detection and recognition model. '
@@ -198,6 +201,7 @@ def parse_args(mMain=True):
parser.add_argument(
"--structure_version",
type=str,
+ choices=SUPPORT_STRUCTURE_MODEL_VERSION,
default='STRUCTURE',
help='Model version, the current model support list is as follows:'
' 1. STRUCTURE Support en table structure model.')
@@ -257,26 +261,20 @@ def get_model_config(type, version, model_type, lang):
DEFAULT_MODEL_VERSION = DEFAULT_STRUCTURE_MODEL_VERSION
else:
raise NotImplementedError
+
model_urls = MODEL_URLS[type]
if version not in model_urls:
- logger.warning('version {} not in {}, auto switch to version {}'.format(
- version, model_urls.keys(), DEFAULT_MODEL_VERSION))
version = DEFAULT_MODEL_VERSION
if model_type not in model_urls[version]:
if model_type in model_urls[DEFAULT_MODEL_VERSION]:
- logger.warning(
- 'version {} not support {} models, auto switch to version {}'.
- format(version, model_type, DEFAULT_MODEL_VERSION))
version = DEFAULT_MODEL_VERSION
else:
logger.error('{} models is not support, we only support {}'.format(
model_type, model_urls[DEFAULT_MODEL_VERSION].keys()))
sys.exit(-1)
+
if lang not in model_urls[version][model_type]:
if lang in model_urls[DEFAULT_MODEL_VERSION][model_type]:
- logger.warning(
- 'lang {} is not support in {}, auto switch to version {}'.
- format(lang, version, DEFAULT_MODEL_VERSION))
version = DEFAULT_MODEL_VERSION
else:
logger.error(
@@ -296,6 +294,8 @@ def __init__(self, **kwargs):
"""
params = parse_args(mMain=False)
params.__dict__.update(**kwargs)
+ assert params.ocr_version in SUPPORT_OCR_MODEL_VERSION, "ocr_version must in {}, but get {}".format(
+ SUPPORT_OCR_MODEL_VERSION, params.ocr_version)
params.use_gpu = check_gpu(params.use_gpu)
if not params.show_log:
@@ -398,6 +398,8 @@ class PPStructure(OCRSystem):
def __init__(self, **kwargs):
params = parse_args(mMain=False)
params.__dict__.update(**kwargs)
+ assert params.structure_version in SUPPORT_STRUCTURE_MODEL_VERSION, "structure_version must in {}, but get {}".format(
+ SUPPORT_STRUCTURE_MODEL_VERSION, params.structure_version)
params.use_gpu = check_gpu(params.use_gpu)
if not params.show_log:
|
https://api.github.com/repos/PaddlePaddle/PaddleOCR/pulls/5222
|
2022-01-10T03:36:29Z
|
2022-01-10T07:10:26Z
|
2022-01-10T07:10:26Z
|
2022-01-10T07:10:27Z
| 758
|
PaddlePaddle/PaddleOCR
| 41,839
|
|
YoutubeIE: Detect new Vevo style videos
|
diff --git a/youtube_dl/InfoExtractors.py b/youtube_dl/InfoExtractors.py
index 8d228d40dc9..af11333d1a6 100755
--- a/youtube_dl/InfoExtractors.py
+++ b/youtube_dl/InfoExtractors.py
@@ -379,6 +379,17 @@ def report_rtmp_download(self):
"""Indicate the download will use the RTMP protocol."""
self.to_screen(u'RTMP download detected')
+ @staticmethod
+ def _decrypt_signature(s):
+ """Decrypt the key the two subkeys must have a length of 43"""
+ (a,b) = s.split('.')
+ if len(a) != 43 or len(b) != 43:
+ raise ExtractorError(u'Unable to decrypt signature, subkeys lengths not valid')
+ b = ''.join([b[:8],a[0],b[9:18],b[-4],b[19:39], b[18]])[0:40]
+ a = a[-40:]
+ s_dec = '.'.join((a,b))[::-1]
+ return s_dec
+
def _get_available_subtitles(self, video_id):
self.report_video_subtitles_download(video_id)
request = compat_urllib_request.Request('http://video.google.com/timedtext?hl=en&type=list&v=%s' % video_id)
@@ -724,6 +735,17 @@ def _real_extract(self, url):
# Decide which formats to download
req_format = self._downloader.params.get('format', None)
+ try:
+ mobj = re.search(r';ytplayer.config = ({.*?});', video_webpage)
+ info = json.loads(mobj.group(1))
+ args = info['args']
+ if args.get('ptk','') == 'vevo' or 'dashmpd':
+ # Vevo videos with encrypted signatures
+ self.to_screen(u'Vevo video detected.')
+ video_info['url_encoded_fmt_stream_map'] = [args['url_encoded_fmt_stream_map']]
+ except ValueError:
+ pass
+
if 'conn' in video_info and video_info['conn'][0].startswith('rtmp'):
self.report_rtmp_download()
video_url_list = [(None, video_info['conn'][0])]
@@ -735,6 +757,9 @@ def _real_extract(self, url):
url = url_data['url'][0]
if 'sig' in url_data:
url += '&signature=' + url_data['sig'][0]
+ if 's' in url_data:
+ signature = self._decrypt_signature(url_data['s'][0])
+ url += '&signature=' + signature
if 'ratebypass' not in url:
url += '&ratebypass=yes'
url_map[url_data['itag'][0]] = url
|
The url_encoded_fmt_stream_map can be found in the video page, but the signature must be decrypted, we get it from the webpage instead of the `get_video_info` pages because we have only discover the algorithm for keys with both sub keys of size 43.
This should fix #897, I've tested with a few videos and it has worked.
Thanks to all the people that has contributed test videos and specially to @speedyapocalypse for getting all the example keys and @FiloSottile for solving the algorithm.
Some things that should be improved:
- [x] The function for decripting the key should be in a better place, maybe as a staticmethod of the extractor.
- [ ] The algorithm should be documented, probably with a good example.
- [ ] Add tests?, we have ready at least three keys and it's easy to get them now, just by printing to screen when downlodaning a video.
|
https://api.github.com/repos/ytdl-org/youtube-dl/pulls/900
|
2013-06-21T19:59:39Z
|
2013-06-23T17:45:52Z
|
2013-06-23T17:45:52Z
|
2014-06-17T21:48:59Z
| 632
|
ytdl-org/youtube-dl
| 50,242
|
build extras together
|
diff --git a/SConstruct b/SConstruct
index e015218f2ab81a..23ab37dc1eb7a0 100644
--- a/SConstruct
+++ b/SConstruct
@@ -431,11 +431,12 @@ SConscript(['selfdrive/sensord/SConscript'])
SConscript(['selfdrive/ui/SConscript'])
SConscript(['selfdrive/navd/SConscript'])
-SConscript(['tools/replay/SConscript'])
+if arch in ['x86_64', 'Darwin'] or GetOption('extras'):
+ SConscript(['tools/replay/SConscript'])
-opendbc = abspath([File('opendbc/can/libdbc.so')])
-Export('opendbc')
-SConscript(['tools/cabana/SConscript'])
+ opendbc = abspath([File('opendbc/can/libdbc.so')])
+ Export('opendbc')
+ SConscript(['tools/cabana/SConscript'])
if GetOption('test'):
SConscript('panda/tests/safety/SConscript')
diff --git a/tools/cabana/SConscript b/tools/cabana/SConscript
index b94741ea9c74d2..8dbd4f1d1ce79a 100644
--- a/tools/cabana/SConscript
+++ b/tools/cabana/SConscript
@@ -11,7 +11,6 @@ else:
base_libs.append('OpenCL')
qt_libs = ['qt_util', 'Qt5Charts'] + base_libs
-if arch in ['x86_64', 'Darwin'] and GetOption('extras'):
- cabana_libs = [widgets, cereal, messaging, visionipc, replay_lib, opendbc,'avutil', 'avcodec', 'avformat', 'bz2', 'curl', 'yuv'] + qt_libs
- qt_env.Program('_cabana', ['cabana.cc', 'mainwin.cc', 'chartswidget.cc', 'historylog.cc', 'videowidget.cc', 'signaledit.cc', 'dbcmanager.cc',
- 'canmessages.cc', 'messageswidget.cc', 'detailwidget.cc'], LIBS=cabana_libs, FRAMEWORKS=base_frameworks)
+cabana_libs = [widgets, cereal, messaging, visionipc, replay_lib, opendbc,'avutil', 'avcodec', 'avformat', 'bz2', 'curl', 'yuv'] + qt_libs
+qt_env.Program('_cabana', ['cabana.cc', 'mainwin.cc', 'chartswidget.cc', 'historylog.cc', 'videowidget.cc', 'signaledit.cc', 'dbcmanager.cc',
+ 'canmessages.cc', 'messageswidget.cc', 'detailwidget.cc'], LIBS=cabana_libs, FRAMEWORKS=base_frameworks)
diff --git a/tools/replay/SConscript b/tools/replay/SConscript
index 9985375688f52b..4ddeb662e0175c 100644
--- a/tools/replay/SConscript
+++ b/tools/replay/SConscript
@@ -12,15 +12,14 @@ else:
base_libs.append('OpenCL')
qt_libs = ['qt_util'] + base_libs
-if arch in ['x86_64', 'Darwin'] or GetOption('extras'):
- qt_env['CXXFLAGS'] += ["-Wno-deprecated-declarations"]
+qt_env['CXXFLAGS'] += ["-Wno-deprecated-declarations"]
- replay_lib_src = ["replay.cc", "consoleui.cc", "camera.cc", "filereader.cc", "logreader.cc", "framereader.cc", "route.cc", "util.cc"]
+replay_lib_src = ["replay.cc", "consoleui.cc", "camera.cc", "filereader.cc", "logreader.cc", "framereader.cc", "route.cc", "util.cc"]
- replay_lib = qt_env.Library("qt_replay", replay_lib_src, LIBS=qt_libs, FRAMEWORKS=base_frameworks)
- Export('replay_lib')
- replay_libs = [replay_lib, 'avutil', 'avcodec', 'avformat', 'bz2', 'curl', 'yuv', 'ncurses'] + qt_libs
- qt_env.Program("replay", ["main.cc"], LIBS=replay_libs, FRAMEWORKS=base_frameworks)
+replay_lib = qt_env.Library("qt_replay", replay_lib_src, LIBS=qt_libs, FRAMEWORKS=base_frameworks)
+Export('replay_lib')
+replay_libs = [replay_lib, 'avutil', 'avcodec', 'avformat', 'bz2', 'curl', 'yuv', 'ncurses'] + qt_libs
+qt_env.Program("replay", ["main.cc"], LIBS=replay_libs, FRAMEWORKS=base_frameworks)
- if GetOption('test'):
- qt_env.Program('tests/test_replay', ['tests/test_runner.cc', 'tests/test_replay.cc'], LIBS=[replay_libs])
+if GetOption('test'):
+ qt_env.Program('tests/test_replay', ['tests/test_runner.cc', 'tests/test_replay.cc'], LIBS=[replay_libs])
|
I think https://github.com/commaai/openpilot/pull/26004 broke builds as `replay_lib` is not always exported, but the cabana build imports it
|
https://api.github.com/repos/commaai/openpilot/pulls/26051
|
2022-10-12T21:50:35Z
|
2022-10-12T22:14:02Z
|
2022-10-12T22:14:02Z
|
2022-10-12T22:14:03Z
| 1,162
|
commaai/openpilot
| 9,141
|
Simplify GraphQL Tool Initialization documentation by Removing 'llm' Argument
|
diff --git a/docs/extras/modules/agents/tools/integrations/graphql.ipynb b/docs/extras/modules/agents/tools/integrations/graphql.ipynb
index d80341725891fa..ecc0de58430b1c 100644
--- a/docs/extras/modules/agents/tools/integrations/graphql.ipynb
+++ b/docs/extras/modules/agents/tools/integrations/graphql.ipynb
@@ -52,7 +52,6 @@
"tools = load_tools(\n",
" [\"graphql\"],\n",
" graphql_endpoint=\"https://swapi-graphql.netlify.app/.netlify/functions/index\",\n",
- " llm=llm,\n",
")\n",
"\n",
"agent = initialize_agent(\n",
|
This PR is aimed at enhancing the clarity of the documentation in the langchain project.
**Description**:
In the graphql.ipynb file, I have removed the unnecessary 'llm' argument from the initialization process of the GraphQL tool (of type _EXTRA_OPTIONAL_TOOLS). The 'llm' argument is not required for this process. Its presence could potentially confuse users. This modification simplifies the understanding of tool initialization and minimizes potential confusion.
**Issue**: Not applicable, as this is a documentation improvement.
**Dependencies**: None.
**I kindly request a review from the following maintainer**: @hinthornw, who is responsible for Agents / Tools / Toolkits.
No new integration is being added in this PR, hence no need for a test or an example notebook.
Please see the changes for more detail and let me know if any further modification is necessary.
|
https://api.github.com/repos/langchain-ai/langchain/pulls/7651
|
2023-07-13T11:36:00Z
|
2023-07-13T18:52:07Z
|
2023-07-13T18:52:07Z
|
2023-07-13T18:52:07Z
| 172
|
langchain-ai/langchain
| 43,652
|
Fixed #33543 -- Deprecated passing nulls_first/nulls_last=False to OrderBy and Expression.asc()/desc().
|
diff --git a/django/db/models/expressions.py b/django/db/models/expressions.py
index 4bc55a1c893ad..2057dbd2721c2 100644
--- a/django/db/models/expressions.py
+++ b/django/db/models/expressions.py
@@ -2,6 +2,7 @@
import datetime
import functools
import inspect
+import warnings
from collections import defaultdict
from decimal import Decimal
from uuid import UUID
@@ -12,6 +13,7 @@
from django.db.models.constants import LOOKUP_SEP
from django.db.models.query_utils import Q
from django.utils.deconstruct import deconstructible
+from django.utils.deprecation import RemovedInDjango50Warning
from django.utils.functional import cached_property
from django.utils.hashable import make_hashable
@@ -1501,11 +1503,20 @@ class OrderBy(Expression):
template = "%(expression)s %(ordering)s"
conditional = False
- def __init__(
- self, expression, descending=False, nulls_first=False, nulls_last=False
- ):
+ def __init__(self, expression, descending=False, nulls_first=None, nulls_last=None):
if nulls_first and nulls_last:
raise ValueError("nulls_first and nulls_last are mutually exclusive")
+ if nulls_first is False or nulls_last is False:
+ # When the deprecation ends, replace with:
+ # raise ValueError(
+ # "nulls_first and nulls_last values must be True or None."
+ # )
+ warnings.warn(
+ "Passing nulls_first=False or nulls_last=False is deprecated, use None "
+ "instead.",
+ RemovedInDjango50Warning,
+ stacklevel=2,
+ )
self.nulls_first = nulls_first
self.nulls_last = nulls_last
self.descending = descending
@@ -1572,9 +1583,12 @@ def get_group_by_cols(self, alias=None):
def reverse_ordering(self):
self.descending = not self.descending
- if self.nulls_first or self.nulls_last:
- self.nulls_first = not self.nulls_first
- self.nulls_last = not self.nulls_last
+ if self.nulls_first:
+ self.nulls_last = True
+ self.nulls_first = None
+ elif self.nulls_last:
+ self.nulls_first = True
+ self.nulls_last = None
return self
def asc(self):
diff --git a/docs/internals/deprecation.txt b/docs/internals/deprecation.txt
index 39007eb3e9fb3..bb6b889f912ec 100644
--- a/docs/internals/deprecation.txt
+++ b/docs/internals/deprecation.txt
@@ -105,6 +105,10 @@ details on these changes.
* The ``django.contrib.auth.hashers.CryptPasswordHasher`` will be removed.
+* The ability to pass ``nulls_first=False`` or ``nulls_last=False`` to
+ ``Expression.asc()`` and ``Expression.desc()`` methods, and the ``OrderBy``
+ expression will be removed.
+
.. _deprecation-removed-in-4.1:
4.1
diff --git a/docs/ref/models/expressions.txt b/docs/ref/models/expressions.txt
index b3702116d7777..da533ba5c352a 100644
--- a/docs/ref/models/expressions.txt
+++ b/docs/ref/models/expressions.txt
@@ -1033,20 +1033,40 @@ calling the appropriate methods on the wrapped expression.
to a column. The ``alias`` parameter will be ``None`` unless the
expression has been annotated and is used for grouping.
- .. method:: asc(nulls_first=False, nulls_last=False)
+ .. method:: asc(nulls_first=None, nulls_last=None)
Returns the expression ready to be sorted in ascending order.
``nulls_first`` and ``nulls_last`` define how null values are sorted.
See :ref:`using-f-to-sort-null-values` for example usage.
- .. method:: desc(nulls_first=False, nulls_last=False)
+ .. versionchanged:: 4.1
+
+ In older versions, ``nulls_first`` and ``nulls_last`` defaulted to
+ ``False``.
+
+ .. deprecated:: 4.1
+
+ Passing ``nulls_first=False`` or ``nulls_last=False`` to ``asc()``
+ is deprecated. Use ``None`` instead.
+
+ .. method:: desc(nulls_first=None, nulls_last=None)
Returns the expression ready to be sorted in descending order.
``nulls_first`` and ``nulls_last`` define how null values are sorted.
See :ref:`using-f-to-sort-null-values` for example usage.
+ .. versionchanged:: 4.1
+
+ In older versions, ``nulls_first`` and ``nulls_last`` defaulted to
+ ``False``.
+
+ .. deprecated:: 4.1
+
+ Passing ``nulls_first=False`` or ``nulls_last=False`` to ``desc()``
+ is deprecated. Use ``None`` instead.
+
.. method:: reverse_ordering()
Returns ``self`` with any modifications required to reverse the sort
diff --git a/docs/releases/4.1.txt b/docs/releases/4.1.txt
index af129a149e427..84eca035639f1 100644
--- a/docs/releases/4.1.txt
+++ b/docs/releases/4.1.txt
@@ -685,6 +685,10 @@ Miscellaneous
* ``django.contrib.auth.hashers.CryptPasswordHasher`` is deprecated.
+* The ability to pass ``nulls_first=False`` or ``nulls_last=False`` to
+ ``Expression.asc()`` and ``Expression.desc()`` methods, and the ``OrderBy``
+ expression is deprecated. Use ``None`` instead.
+
Features removed in 4.1
=======================
diff --git a/tests/expressions/tests.py b/tests/expressions/tests.py
index 72e6020fa0cd1..39e6c18b1a126 100644
--- a/tests/expressions/tests.py
+++ b/tests/expressions/tests.py
@@ -69,6 +69,7 @@
isolate_apps,
register_lookup,
)
+from django.utils.deprecation import RemovedInDjango50Warning
from django.utils.functional import SimpleLazyObject
from .models import (
@@ -2537,7 +2538,7 @@ def test_equal(self):
)
self.assertNotEqual(
OrderBy(F("field"), nulls_last=True),
- OrderBy(F("field"), nulls_last=False),
+ OrderBy(F("field")),
)
def test_hash(self):
@@ -2547,5 +2548,22 @@ def test_hash(self):
)
self.assertNotEqual(
hash(OrderBy(F("field"), nulls_last=True)),
- hash(OrderBy(F("field"), nulls_last=False)),
+ hash(OrderBy(F("field"))),
)
+
+ def test_nulls_false(self):
+ # These tests will catch ValueError in Django 5.0 when passing False to
+ # nulls_first and nulls_last becomes forbidden.
+ # msg = "nulls_first and nulls_last values must be True or None."
+ msg = (
+ "Passing nulls_first=False or nulls_last=False is deprecated, use None "
+ "instead."
+ )
+ with self.assertRaisesMessage(RemovedInDjango50Warning, msg):
+ OrderBy(F("field"), nulls_first=False)
+ with self.assertRaisesMessage(RemovedInDjango50Warning, msg):
+ OrderBy(F("field"), nulls_last=False)
+ with self.assertRaisesMessage(RemovedInDjango50Warning, msg):
+ F("field").asc(nulls_first=False)
+ with self.assertRaisesMessage(RemovedInDjango50Warning, msg):
+ F("field").desc(nulls_last=False)
|
ticket-33543
Thanks Allen Jonathan David for the initial patch.
|
https://api.github.com/repos/django/django/pulls/15682
|
2022-05-11T08:18:15Z
|
2022-05-12T09:30:03Z
|
2022-05-12T09:30:03Z
|
2022-05-12T09:30:22Z
| 1,783
|
django/django
| 51,542
|
[WIP] Mention of pairwise_distances in Guide on Metrics
|
diff --git a/doc/modules/metrics.rst b/doc/modules/metrics.rst
index 0c3d255d3b134..e1bb6931fb95d 100644
--- a/doc/modules/metrics.rst
+++ b/doc/modules/metrics.rst
@@ -33,6 +33,34 @@ the kernel:
2. ``S = 1. / (D / np.max(D))``
+.. currentmodule:: sklearn.metrics
+
+The distances between the row vectors of ``X`` and the row vectors of ``Y``
+can be evaluated using :func:`pairwise_distances`. If ``Y`` is omitted the
+pairwise distances of the row vectors of ``X`` are calculated. Similarly,
+:func:`pairwise.pairwise_kernels` can be used to calculate the kernel between `X`
+and `Y` using different kernel functions. See the API reference for more
+details.
+
+ >>> import numpy as np
+ >>> from sklearn.metrics import pairwise_distances
+ >>> from sklearn.metrics.pairwise import pairwise_kernels
+ >>> X = np.array([[2, 3], [3, 5], [5, 8]])
+ >>> Y = np.array([[1, 0], [2, 1]])
+ >>> pairwise_distances(X, Y, metric='manhattan')
+ array([[ 4., 2.],
+ [ 7., 5.],
+ [12., 10.]])
+ >>> pairwise_distances(X, metric='manhattan')
+ array([[0., 3., 8.],
+ [3., 0., 5.],
+ [8., 5., 0.]])
+ >>> pairwise_kernels(X, Y, metric='linear')
+ array([[ 2., 7.],
+ [ 3., 11.],
+ [ 5., 18.]])
+
+
.. currentmodule:: sklearn.metrics.pairwise
.. _cosine_similarity:
|
#### Reference Issues/PRs
Fixes #9428.
#### What does this implement/fix? Explain your changes.
Section [4.8. Pairwise metrics, Affinities and Kernels](http://scikit-learn.org/stable/modules/metrics.html) of the guide talks about "evaluate pairwise distances" but does not mention the functions `pairwise_distances` or `pairwise_kernels`.
This hint with some example code has been added.
|
https://api.github.com/repos/scikit-learn/scikit-learn/pulls/12416
|
2018-10-18T20:43:30Z
|
2018-10-30T01:47:51Z
|
2018-10-30T01:47:50Z
|
2018-10-30T01:47:51Z
| 434
|
scikit-learn/scikit-learn
| 46,096
|
adds minutes + seconds to examples
|
diff --git a/doc/sphinxext/gen_rst.py b/doc/sphinxext/gen_rst.py
index 56e0638c10e76..6615b8d74798b 100644
--- a/doc/sphinxext/gen_rst.py
+++ b/doc/sphinxext/gen_rst.py
@@ -332,7 +332,8 @@ def resolve(self, cobj, this_url):
.. literalinclude:: %(fname)s
:lines: %(end_row)s-
-**Total running time of the example:** %(time_elapsed) .2f seconds
+**Total running time of the example:** %(time_elapsed) .2f seconds
+(%(time_m) .0f minutes %(time_s) .2f seconds)
"""
# The following strings are used when we have several pictures: we use
@@ -772,6 +773,8 @@ def generate_file_rst(fname, target_dir, src_dir, root_dir, plot_gallery):
'time_%s.txt' % base_image_name)
thumb_file = os.path.join(thumb_dir, fname[:-3] + '.png')
time_elapsed = 0
+ time_m = 0
+ time_s = 0
if plot_gallery and fname.startswith('plot'):
# generate the plot as png image if file name
# starts with plot and if it is more recent than an
@@ -963,6 +966,7 @@ def generate_file_rst(fname, target_dir, src_dir, root_dir, plot_gallery):
for figure_name in figure_list:
image_list += HLIST_IMAGE_TEMPLATE % figure_name.lstrip('/')
+ time_m, time_s = divmod(time_elapsed, 60)
f = open(os.path.join(target_dir, fname[:-2] + 'rst'), 'w')
f.write(this_template % locals())
f.flush()
|
This adds the amount of minutes and seconds in addition to the usual time in seconds to examples

|
https://api.github.com/repos/scikit-learn/scikit-learn/pulls/2515
|
2013-10-14T06:53:18Z
|
2013-10-14T15:16:19Z
|
2013-10-14T15:16:19Z
|
2014-06-13T11:37:47Z
| 398
|
scikit-learn/scikit-learn
| 46,331
|
fix side menu regression
|
diff --git a/website/src/components/SideMenu.tsx b/website/src/components/SideMenu.tsx
index 25dabf30f3..ee7dba4db8 100644
--- a/website/src/components/SideMenu.tsx
+++ b/website/src/components/SideMenu.tsx
@@ -21,8 +21,9 @@ export function SideMenu(props: SideMenuProps) {
return (
<main className="sticky top-0 sm:h-full">
<Card
+ display={{ base: "grid", sm: "flex" }}
width={["100%", "100%", "100px", "280px"]}
- className="grid grid-cols-4 gap-2 sm:flex sm:flex-col sm:justify-between p-4 h-full"
+ className="grid-cols-4 gap-2 sm:flex-col sm:justify-between p-4 h-full"
>
<nav className="grid grid-cols-3 col-span-3 sm:flex sm:flex-col gap-2">
{props.buttonOptions.map((item, itemIndex) => (
|
fix regression introduced in #1049. just notice this bug when visiting our dev website with a mobile.
|
https://api.github.com/repos/LAION-AI/Open-Assistant/pulls/1067
|
2023-02-02T09:12:38Z
|
2023-02-02T10:36:12Z
|
2023-02-02T10:36:11Z
|
2023-02-08T06:23:24Z
| 232
|
LAION-AI/Open-Assistant
| 37,600
|
Set the cloned directory as PYTHONPATH in appveyor.yml
|
diff --git a/appveyor.yml b/appveyor.yml
index 93cfd469e55..7fd63686499 100644
--- a/appveyor.yml
+++ b/appveyor.yml
@@ -12,7 +12,8 @@ branches:
install:
- "SET PATH=%PYTHON%;%PYTHON%\\Scripts;%PATH%"
- - "SET TOX_TESTENV_PASSENV=HOME USERPROFILE HOMEPATH HOMEDRIVE"
+ - "SET PYTHONPATH=%APPVEYOR_BUILD_FOLDER%"
+ - "SET TOX_TESTENV_PASSENV=HOME HOMEDRIVE HOMEPATH PYTHONPATH USERPROFILE"
- "pip install -U tox"
build: false
|
Fixes #3809
I’m unsure how it broke, I suspect it was a change in the AppVeyor side.
|
https://api.github.com/repos/scrapy/scrapy/pulls/3827
|
2019-06-11T13:51:11Z
|
2019-06-12T20:40:09Z
|
2019-06-12T20:40:09Z
|
2019-06-25T20:29:28Z
| 159
|
scrapy/scrapy
| 34,962
|
removing lsr from libraries and moving it to books
|
diff --git a/README.md b/README.md
index b1df067f..6ef0244c 100644
--- a/README.md
+++ b/README.md
@@ -865,7 +865,6 @@ on MNIST digits[DEEP LEARNING]
<a name="r-data-analysis" />
#### Data Analysis / Data Visualization
-* [Learning Statistics Using R](http://health.adelaide.edu.au/psychology/ccs/teaching/lsr/)
* [ggplot2](http://ggplot2.org/) - A data visualization package based on the grammar of graphics.
<a name="scala" />
|
https://api.github.com/repos/josephmisiti/awesome-machine-learning/pulls/160
|
2015-06-08T21:58:22Z
|
2015-06-08T22:24:20Z
|
2015-06-08T22:24:20Z
|
2015-06-08T22:24:24Z
| 136
|
josephmisiti/awesome-machine-learning
| 51,902
|
|
Add Tesla to organizations list
|
diff --git a/README.md b/README.md
index 7bf0ed8d16..f9061c3386 100644
--- a/README.md
+++ b/README.md
@@ -138,7 +138,7 @@ Twisted, LocalStack, every Datadog Agent Integration, Home Assistant, Zulip, Ked
many more.
The following organizations use _Black_: Facebook, Dropbox, Mozilla, Quora, Duolingo,
-QuantumBlack.
+QuantumBlack, Tesla.
Are we missing anyone? Let us know.
|
<!-- Hello! Thanks for submitting a PR. To help make things go a bit more
smoothly we would appreciate that you go through this template. -->
### Description
<!-- Good things to put here include: reasoning for the change (please link
any relevant issues!), any noteworthy (or hacky) choices to be aware of,
or what the problem resolved here looked like ... we won't mind a ranty
story :) -->
### Checklist - did you ...
<!-- If any of the following items aren't relevant for your contribution
please still tick them so we know you've gone through the checklist.
All user-facing changes should get an entry. Otherwise, signal to us
this should get the magical label to silence the CHANGELOG entry check.
Tests are required for bugfixes and new features. Documentation changes
are necessary for formatting and most enhancement changes. -->
- [x] Add a CHANGELOG entry if necessary?
- [x] Add / update tests if necessary?
- [x] Add new / update outdated documentation?
<!-- Just as a reminder, everyone in all psf/black spaces including PRs
must follow the PSF Code of Conduct (link below).
Finally, once again thanks for your time and effort. If you have any
feedback in regards to your experience contributing here, please
let us know!
Helpful links:
PSF COC: https://www.python.org/psf/conduct/
Contributing docs: https://black.readthedocs.io/en/latest/contributing/index.html
Chat on Python Discord: https://discord.gg/RtVdv86PrH -->
|
https://api.github.com/repos/psf/black/pulls/2577
|
2021-10-30T03:19:28Z
|
2021-10-30T18:45:09Z
|
2021-10-30T18:45:09Z
|
2021-10-30T18:45:09Z
| 125
|
psf/black
| 24,449
|
Smoother practice experience for random_question.py
|
diff --git a/scripts/random_question.py b/scripts/random_question.py
index a0e2b7eb6..7bf743891 100644
--- a/scripts/random_question.py
+++ b/scripts/random_question.py
@@ -1,6 +1,6 @@
import random
import optparse
-
+import os
def main():
"""Reads through README.md for question/answer pairs and adds them to a
@@ -39,9 +39,13 @@ def main():
if options.skip and not answer.strip():
continue
-
- if input(f'Q: {question} ...Show answer? "y" for yes: ').lower() == 'y':
- print('A: ', answer)
+ os.system("clear")
+ print(question)
+ print("...Press Enter to show answer...")
+ input()
+ print('A: ', answer)
+ print("... Press Enter to continue, Ctrl-C to exit")
+ input()
except KeyboardInterrupt:
break
|
1. Clear the screen when viewing new questions
2. " y + enter" is too complex, "enter" is enough.
|
https://api.github.com/repos/bregman-arie/devops-exercises/pulls/306
|
2022-11-01T09:39:31Z
|
2022-11-06T07:58:04Z
|
2022-11-06T07:58:04Z
|
2022-11-06T07:58:04Z
| 217
|
bregman-arie/devops-exercises
| 17,462
|
Do not list the field name twice
|
diff --git a/acme/acme/messages.py b/acme/acme/messages.py
index c824c43cfbe..1d907e5fc06 100644
--- a/acme/acme/messages.py
+++ b/acme/acme/messages.py
@@ -245,7 +245,7 @@ def __getattr__(self, name):
try:
return self[name.replace('_', '-')]
except KeyError as error:
- raise AttributeError(str(error) + ': ' + name)
+ raise AttributeError(str(error))
def __getitem__(self, name):
try:
|
https://github.com/certbot/certbot/pull/7687 improved our `acme` module by adding the name of the missing field to the error message raised from `messages.Directory.__getitem__`.
One slight downside is `messages.Directory.__getattr__` uses `__getitem__` and was previously adding the missing field to the error message so now it is listed twice in this case. This PR fixes that problem.
|
https://api.github.com/repos/certbot/certbot/pulls/7689
|
2020-01-16T19:38:57Z
|
2020-01-16T21:44:09Z
|
2020-01-16T21:44:09Z
|
2020-01-16T21:44:09Z
| 124
|
certbot/certbot
| 3,063
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.