
title
stringlengths 2
169
| diff
stringlengths 235
19.5k
| body
stringlengths 0
30.5k
| url
stringlengths 48
84
| created_at
stringlengths 20
20
| closed_at
stringlengths 20
20
| merged_at
stringlengths 20
20
| updated_at
stringlengths 20
20
| diff_len
float64 101
3.99k
| repo_name
stringclasses 83
values | __index_level_0__
int64 15
52.7k
|
|---|---|---|---|---|---|---|---|---|---|---|
Adding PHP library
|
diff --git a/README.md b/README.md
index d4b3c84..38cf5bf 100644
--- a/README.md
+++ b/README.md
@@ -34,6 +34,7 @@ Various implementations of the Big List of Naughty Strings have made it to vario
| Node | https://www.npmjs.com/package/blns |
| Node | https://www.npmjs.com/package/big-list-of-naughty-strings |
| .NET | https://github.com/SimonCropp/NaughtyStrings |
+| PHP | https://github.com/mattsparks/blns-php |
| C++ | https://github.com/eliabieri/blnscpp |
Please open a PR to list others.
|
https://api.github.com/repos/minimaxir/big-list-of-naughty-strings/pulls/206
|
2020-03-14T17:22:39Z
|
2020-04-19T16:13:25Z
|
2020-04-19T16:13:25Z
|
2020-04-19T16:13:25Z
| 160
|
minimaxir/big-list-of-naughty-strings
| 4,879
|
|
Added Arcade
|
diff --git a/README.md b/README.md
index 608e44350..0ccb3354a 100644
--- a/README.md
+++ b/README.md
@@ -679,6 +679,7 @@ Inspired by [awesome-php](https://github.com/ziadoz/awesome-php).
* [Harfang3D](http://www.harfang3d.com) - Python framework for 3D, VR and game development.
* [Panda3D](https://www.panda3d.org/) - 3D game engine developed by Disney.
* [Pygame](http://www.pygame.org/news.html) - Pygame is a set of Python modules designed for writing games.
+* [Arcade](https://arcade.academy/index.html) - Arcade is a modern Python framework for crafting games with compelling graphics and sound.
* [PyOgre](http://www.ogre3d.org/tikiwiki/PyOgre) - Python bindings for the Ogre 3D render engine, can be used for games, simulations, anything 3D.
* [PyOpenGL](http://pyopengl.sourceforge.net/) - Python ctypes bindings for OpenGL and it's related APIs.
* [PySDL2](https://pysdl2.readthedocs.io) - A ctypes based wrapper for the SDL2 library.
|
## What is Arcade?
The arcade library is a modern Python framework for crafting games with compelling graphics and sound. Object-oriented and built for Python 3.6 and up, arcade provides the programmer with a modern set of tools for crafting great Python game experiences.
## What's the difference between Arcade and Pygame?
Runs on top of OpenGL 3+ and Pyglet, rather than the old SDL1 library. (Currently PyGame is in the process of moving to SDL2.)
Has built-in physics engine for platformers.
Supports animated sprites.
Encourages separation of logic and display code. Pygame tends to put both into the same game loop.
With the use of sprite lists, uses the acceleration of the graphics card to improve performance.
Sound support: Pygame uses the old, unsupported Avbin library. Arcade uses SoLoud. Supports panning and volume.
Home Page of Arcade - https://arcade.academy/index.html
--
Anyone who agrees with this pull request could submit an *Approve* review to it.
|
https://api.github.com/repos/vinta/awesome-python/pulls/1575
|
2020-07-12T09:47:58Z
|
2020-07-12T16:51:01Z
|
2020-07-12T16:51:01Z
|
2020-07-12T16:51:01Z
| 285
|
vinta/awesome-python
| 27,259
|
use list instead of string, prevent injection attack.
|
diff --git a/utils/autoban.py b/utils/autoban.py
index c7af0a5f6..52aa16351 100755
--- a/utils/autoban.py
+++ b/utils/autoban.py
@@ -24,9 +24,17 @@
from __future__ import absolute_import, division, print_function, \
with_statement
-import os
import sys
+import socket
import argparse
+import subprocess
+
+
+def inet_pton(str_ip):
+ try:
+ return socket.inet_pton(socket.AF_INET, str_ip)
+ except socket.error:
+ return None
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='See README')
@@ -37,17 +45,22 @@
ips = {}
banned = set()
for line in sys.stdin:
- if 'can not parse header when' in line:
- ip = line.split()[-1].split(':')[-2]
- if ip not in ips:
- ips[ip] = 1
- print(ip)
- sys.stdout.flush()
- else:
- ips[ip] += 1
- if ip not in banned and ips[ip] >= config.count:
- banned.add(ip)
- cmd = 'iptables -A INPUT -s %s -j DROP' % ip
- print(cmd, file=sys.stderr)
- sys.stderr.flush()
- os.system(cmd)
+ if 'can not parse header when' not in line:
+ continue
+ ip_str = line.split()[-1].rsplit(':', 1)[0]
+ ip = inet_pton(ip_str)
+ if ip is None:
+ continue
+ if ip not in ips:
+ ips[ip] = 1
+ sys.stdout.flush()
+ else:
+ ips[ip] += 1
+ if ip not in banned and ips[ip] >= config.count:
+ banned.add(ip)
+ print('ban ip %s' % ip_str)
+ cmd = ['iptables', '-A', 'INPUT', '-s', ip_str, '-j', 'DROP',
+ '-m', 'comment', '--comment', 'autoban']
+ print(' '.join(cmd), file=sys.stderr)
+ sys.stderr.flush()
+ subprocess.call(cmd)
|
fix issue:
https://github.com/shadowsocks/shadowsocks/issues/995
Command Execution
|
https://api.github.com/repos/shadowsocks/shadowsocks/pulls/1009
|
2017-10-20T05:18:51Z
|
2018-02-19T02:42:32Z
|
2018-02-19T02:42:32Z
|
2018-02-19T02:42:44Z
| 509
|
shadowsocks/shadowsocks
| 24,716
|
bibox REVO -> Revo Network
|
diff --git a/js/bibox.js b/js/bibox.js
index db6ccadfb801..aaf21910d9ea 100644
--- a/js/bibox.js
+++ b/js/bibox.js
@@ -138,6 +138,7 @@ module.exports = class bibox extends Exchange {
'MTC': 'MTC Mesh Network', // conflict with MTC Docademic doc.com Token https://github.com/ccxt/ccxt/issues/6081 https://github.com/ccxt/ccxt/issues/3025
'NFT': 'NFT Protocol',
'PAI': 'PCHAIN',
+ 'REVO': 'Revo Network',
'TERN': 'Ternio-ERC20',
},
'options': {
|
https://coinmarketcap.com/currencies/revo-network/markets/
conflict with https://coinmarketcap.com/currencies/revomon/markets/
|
https://api.github.com/repos/ccxt/ccxt/pulls/9936
|
2021-09-05T20:44:05Z
|
2021-09-05T21:07:20Z
|
2021-09-05T21:07:20Z
|
2021-09-05T21:07:20Z
| 162
|
ccxt/ccxt
| 13,041
|
Added automated gui creation library for command line apps
|
diff --git a/README.md b/README.md
index b3f54a906..f7f05bfc8 100644
--- a/README.md
+++ b/README.md
@@ -259,6 +259,7 @@ A curated list of awesome Python frameworks, libraries and software. Inspired by
* [docopt](http://docopt.org/) - Pythonic command line arguments parser.
* [colorama](https://pypi.python.org/pypi/colorama) - Cross-platform colored terminal text.
* [pyCLI](https://pythonhosted.org/pyCLI/) - Command-line applications supporting standard command line parsing, logging, unit and functional testing.
+ * [Gooey](https://github.com/chriskiehl/Gooey) - Turn command line programs into a full GUI application with one line
* Productivity Tools
* [cookiecutter](https://github.com/audreyr/cookiecutter) - A command-line utility that creates projects from cookiecutters (project templates). E.g. Python package projects, jQuery plugin projects.
* [httpie](https://github.com/jakubroztocil/httpie) - A command line HTTP client, a user-friendly cURL replacement.
|
https://api.github.com/repos/vinta/awesome-python/pulls/207
|
2014-08-24T17:02:28Z
|
2014-08-26T15:08:46Z
|
2014-08-26T15:08:46Z
|
2014-08-26T15:08:46Z
| 266
|
vinta/awesome-python
| 27,124
|
|
replace utils.randombytes with os.urandom
|
diff --git a/requests/auth.py b/requests/auth.py
index e636b72402..cb851d2cde 100644
--- a/requests/auth.py
+++ b/requests/auth.py
@@ -7,13 +7,14 @@
This module contains the authentication handlers for Requests.
"""
+import os
import time
import hashlib
from base64 import b64encode
from .compat import urlparse, str
-from .utils import randombytes, parse_dict_header
+from .utils import parse_dict_header
try:
from oauthlib.oauth1.rfc5849 import (Client, SIGNATURE_HMAC, SIGNATURE_TYPE_AUTH_HEADER)
@@ -192,7 +193,7 @@ def sha_utf8(x):
s = str(nonce_count).encode('utf-8')
s += nonce.encode('utf-8')
s += time.ctime().encode('utf-8')
- s += randombytes(8)
+ s += os.urandom(8)
cnonce = (hashlib.sha1(s).hexdigest()[:16])
noncebit = "%s:%s:%s:%s:%s" % (nonce, ncvalue, cnonce, qop, hash_utf8(A2))
diff --git a/requests/sessions.py b/requests/sessions.py
index dd670dd33e..aa90ecc7cd 100644
--- a/requests/sessions.py
+++ b/requests/sessions.py
@@ -9,6 +9,7 @@
"""
+from copy import deepcopy
from .compat import cookielib
from .cookies import cookiejar_from_dict, remove_cookie_by_name
from .defaults import defaults
@@ -81,7 +82,7 @@ def __init__(self,
self.cert = cert
for (k, v) in list(defaults.items()):
- self.config.setdefault(k, v)
+ self.config.setdefault(k, deepcopy(v))
self.init_poolmanager()
diff --git a/requests/utils.py b/requests/utils.py
index 8365cc3699..e60b9c48e2 100644
--- a/requests/utils.py
+++ b/requests/utils.py
@@ -12,14 +12,12 @@
import cgi
import codecs
import os
-import random
import re
import zlib
from netrc import netrc, NetrcParseError
from .compat import parse_http_list as _parse_list_header
-from .compat import quote, is_py2, urlparse
-from .compat import basestring, bytes, str
+from .compat import quote, urlparse, basestring, bytes, str
from .cookies import RequestsCookieJar, cookiejar_from_dict
_hush_pyflakes = (RequestsCookieJar,)
@@ -248,15 +246,6 @@ def header_expand(headers):
return ''.join(collector)
-def randombytes(n):
- """Return n random bytes."""
- if is_py2:
- L = [chr(random.randrange(0, 256)) for i in range(n)]
- else:
- L = [chr(random.randrange(0, 256)).encode('utf-8') for i in range(n)]
- return b"".join(L)
-
-
def dict_from_cookiejar(cj):
"""Returns a key/value dictionary from a CookieJar.
|
My understanding is that Python's `random` module is not recommended for cryptographic use. `os.urandom` should provide random bytes on all major platforms: Linux, OS X, *nix, and Windows:
http://docs.python.org/library/os.html#os.urandom
http://docs.python.org/release/3.0.1/library/os.html#os.urandom
Since the function provides a `str` under 2.x and a `bytes` under 3.x, and the result is fed directly into SHA, there shouldn't be an issue with the encoding.
Thoughts? Thanks for your time.
|
https://api.github.com/repos/psf/requests/pulls/562
|
2012-04-24T09:06:04Z
|
2012-05-16T05:49:27Z
|
2012-05-16T05:49:27Z
|
2021-09-08T15:00:59Z
| 709
|
psf/requests
| 32,197
|
chore: Update setup
|
diff --git a/scripts/setup b/scripts/setup
index 3e02e6413..edba10498 100755
--- a/scripts/setup
+++ b/scripts/setup
@@ -10,7 +10,7 @@ from private_gpt.settings.settings import settings
resume_download = True
if __name__ == '__main__':
- parser = argparse.ArgumentParser(prog='Setup: Download models from huggingface')
+ parser = argparse.ArgumentParser(prog='Setup: Download models from Hugging Face')
parser.add_argument('--resume', default=True, action=argparse.BooleanOptionalAction, help='Enable/Disable resume_download options to restart the download progress interrupted')
args = parser.parse_args()
resume_download = args.resume
|
huggingface -> Hugging Face
|
https://api.github.com/repos/zylon-ai/private-gpt/pulls/1770
|
2024-03-20T14:01:10Z
|
2024-03-20T19:23:08Z
|
2024-03-20T19:23:08Z
|
2024-03-20T19:23:08Z
| 151
|
zylon-ai/private-gpt
| 38,539
|
[`HFQuantizer`] Remove `check_packages_compatibility` logic
|
diff --git a/src/transformers/quantizers/base.py b/src/transformers/quantizers/base.py
index c8eb8bacaa781..68adc3954df45 100644
--- a/src/transformers/quantizers/base.py
+++ b/src/transformers/quantizers/base.py
@@ -15,7 +15,6 @@
from typing import TYPE_CHECKING, Any, Dict, Optional, Union
from ..utils import is_torch_available
-from ..utils.import_utils import _is_package_available
from ..utils.quantization_config import QuantizationConfigMixin
@@ -64,8 +63,6 @@ def __init__(self, quantization_config: QuantizationConfigMixin, **kwargs):
f"pass `pre_quantized=True` while knowing what you are doing."
)
- self.check_packages_compatibility()
-
def update_torch_dtype(self, torch_dtype: "torch.dtype") -> "torch.dtype":
"""
Some quantization methods require to explicitly set the dtype of the model to a
@@ -152,25 +149,6 @@ def validate_environment(self, *args, **kwargs):
"""
return
- def check_packages_compatibility(self):
- """
- Check the compatibility of the quantizer with respect to the current environment. Loops over all packages
- name under `self.required_packages` and checks if that package is available.
- """
- if self.required_packages is not None:
- non_available_packages = []
- for package_name in self.required_packages:
- is_package_available = _is_package_available(package_name)
- if not is_package_available:
- non_available_packages.append(package_name)
-
- if len(non_available_packages) > 0:
- raise ValueError(
- f"The packages {self.required_packages} are required to use {self.__class__.__name__}"
- f" the following packages are missing in your environment: {non_available_packages}, please make sure"
- f" to install them in order to use the quantizer."
- )
-
def preprocess_model(self, model: "PreTrainedModel", **kwargs):
"""
Setting model attributes and/or converting model before weights loading. At this point
|
# What does this PR do?
Fixes the currently failing tests for AWQ: https://github.com/huggingface/transformers/actions/runs/7705429360/job/21003940543
I propose to remove the `check_package_compatiblity` logic in the `HfQuantizer` as:1
1- it is a duplicate of `validate_environment`
2- For some packages such as awq, `_is_package_available()` returns False because `importlib.util.find_spec(pkg_name) is not None` retruns correctly `True` but `importlib.metadata.version(pkg_name)` fails since autoawq is registered as `awq` module but the pypi package name is `autoawq`.
As I expect to face similar behaviour in future quantization packages I propose to simply remove that logic and handle everything in `validate_environment`
cc @ArthurZucker
|
https://api.github.com/repos/huggingface/transformers/pulls/28789
|
2024-01-31T02:05:21Z
|
2024-01-31T02:21:28Z
|
2024-01-31T02:21:28Z
|
2024-01-31T02:28:37Z
| 475
|
huggingface/transformers
| 12,153
|
Specify encoding when reading the user's script. Fixes #399
|
diff --git a/lib/streamlit/ScriptRunner.py b/lib/streamlit/ScriptRunner.py
index b16d3b689257..f1cb545558b7 100644
--- a/lib/streamlit/ScriptRunner.py
+++ b/lib/streamlit/ScriptRunner.py
@@ -22,6 +22,7 @@
from streamlit import config
from streamlit import magic
+from streamlit import source_util
from streamlit.ReportThread import ReportThread
from streamlit.ScriptRequestQueue import ScriptRequest
from streamlit.logger import get_logger
@@ -244,7 +245,7 @@ def _run_script(self, rerun_data):
# Python 3 got rid of the native execfile() command, so we read
# the file, compile it, and exec() it. This implementation is
# compatible with both 2 and 3.
- with open(self._report.script_path) as f:
+ with source_util.open_python_file(self._report.script_path) as f:
filebody = f.read()
if config.get_option("runner.magicEnabled"):
diff --git a/lib/streamlit/__init__.py b/lib/streamlit/__init__.py
index 5c16e986ba58..f29586e0562e 100644
--- a/lib/streamlit/__init__.py
+++ b/lib/streamlit/__init__.py
@@ -92,6 +92,7 @@
from streamlit import code_util as _code_util
from streamlit import util as _util
+from streamlit import source_util as _source_util
from streamlit.ReportThread import get_report_ctx, add_report_ctx
from streamlit.DeltaGenerator import DeltaGenerator as _DeltaGenerator
@@ -537,7 +538,7 @@ def echo():
else:
end_line = frame[1]
lines_to_display = []
- with open(filename) as source_file:
+ with source_util.open_python_file(filename) as source_file:
source_lines = source_file.readlines()
lines_to_display.extend(source_lines[start_line:end_line])
initial_spaces = _SPACES_RE.match(lines_to_display[0]).end()
diff --git a/lib/streamlit/caching.py b/lib/streamlit/caching.py
index 2c75c996ff11..60f0b0c1f693 100644
--- a/lib/streamlit/caching.py
+++ b/lib/streamlit/caching.py
@@ -611,8 +611,9 @@ def has_changes(self):
context_indent = len(code_context) - len(code_context.lstrip())
lines = []
- # TODO: Memoize open(filename, 'r') in a way that clears the memoized version with each
- # run of the user's script. Then use the memoized text here, in st.echo, and other places.
+ # TODO: Memoize open(filename, 'r') in a way that clears the memoized
+ # version with each run of the user's script. Then use the memoized
+ # text here, in st.echo, and other places.
with open(filename, "r") as f:
for line in f.readlines()[caller_lineno:]:
if line.strip() == "":
diff --git a/lib/streamlit/config.py b/lib/streamlit/config.py
index 65a059a89390..36a2bf07070c 100644
--- a/lib/streamlit/config.py
+++ b/lib/streamlit/config.py
@@ -814,7 +814,7 @@ def parse_config_file():
if not os.path.exists(filename):
continue
- with open(filename) as input:
+ with open(filename, "r") as input:
file_contents = input.read()
_update_config_with_toml(file_contents, filename)
diff --git a/lib/streamlit/elements/exception_proto.py b/lib/streamlit/elements/exception_proto.py
index 403f96aaeb61..4bc4a579bbca 100644
--- a/lib/streamlit/elements/exception_proto.py
+++ b/lib/streamlit/elements/exception_proto.py
@@ -39,20 +39,25 @@ def _format_syntax_error_message(exception):
str
"""
- return (
- 'File "%(filename)s", line %(lineno)d\n'
- " %(text)s\n"
- " %(caret_indent)s^\n"
- "%(errname)s: %(msg)s"
- % {
- "filename": exception.filename,
- "lineno": exception.lineno,
- "text": exception.text.rstrip(),
- "caret_indent": " " * max(exception.offset - 1, 0),
- "errname": type(exception).__name__,
- "msg": exception.msg,
- }
- )
+ if exception.text:
+ return (
+ 'File "%(filename)s", line %(lineno)d\n'
+ " %(text)s\n"
+ " %(caret_indent)s^\n"
+ "%(errname)s: %(msg)s"
+ % {
+ "filename": exception.filename,
+ "lineno": exception.lineno,
+ "text": exception.text.rstrip(),
+ "caret_indent": " " * max(exception.offset - 1, 0),
+ "errname": type(exception).__name__,
+ "msg": exception.msg,
+ }
+ )
+ # If a few edge cases, SyntaxErrors don't have all these nice fields. So we
+ # have a fall back here.
+ # Example edge case error message: encoding declaration in Unicode string
+ return str(exception)
def marshall(exception_proto, exception, exception_traceback=None):
diff --git a/lib/streamlit/source_util.py b/lib/streamlit/source_util.py
new file mode 100644
index 000000000000..7fd4adc1d3fa
--- /dev/null
+++ b/lib/streamlit/source_util.py
@@ -0,0 +1,31 @@
+# -*- coding: utf-8 -*-
+# Copyright 2018-2019 Streamlit Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+def open_python_file(filename):
+ """Open a read-only Python file taking proper care of its encoding.
+
+ In Python 3, we would like all files to be opened with utf-8 encoding.
+ However, some author like to specify PEP263 headers in their source files
+ with their own encodings. In that case, we should respect the author's
+ encoding.
+ """
+ import tokenize
+ if hasattr(tokenize, 'open'): # Added in Python 3.2
+ # Open file respecting PEP263 encoding. If no encoding header is
+ # found, opens as utf-8.
+ return tokenize.open(filename)
+ else:
+ return open(filename, 'r')
diff --git a/lib/tests/streamlit/scriptrunner/ScriptRunner_test.py b/lib/tests/streamlit/scriptrunner/ScriptRunner_test.py
index f47ae3805648..8f410528b1c9 100644
--- a/lib/tests/streamlit/scriptrunner/ScriptRunner_test.py
+++ b/lib/tests/streamlit/scriptrunner/ScriptRunner_test.py
@@ -20,6 +20,8 @@
import time
import unittest
+from parameterized import parameterized
+
from streamlit.DeltaGenerator import DeltaGenerator
from streamlit.Report import Report
from streamlit.ReportQueue import ReportQueue
@@ -43,6 +45,18 @@ def _create_widget(id, states):
return states.widgets[-1]
+import tokenize
+if hasattr(tokenize, 'open'):
+ text_utf = "complete! 👨🎤"
+ text_no_encoding = text_utf
+ text_latin = "complete! ð\x9f\x91¨â\x80\x8dð\x9f\x8e¤"
+else:
+ text_utf = u"complete! 👨🎤"
+ text_no_encoding = (
+ u"complete! \xf0\x9f\x91\xa8\xe2\x80\x8d\xf0\x9f\x8e\xa4")
+ text_latin = text_no_encoding
+
+
class ScriptRunnerTest(unittest.TestCase):
def test_startup_shutdown(self):
"""Test that we can create and shut down a ScriptRunner."""
@@ -54,9 +68,14 @@ def test_startup_shutdown(self):
self._assert_events(scriptrunner, [ScriptRunnerEvent.SHUTDOWN])
self._assert_text_deltas(scriptrunner, [])
- def test_run_script(self):
+ @parameterized.expand([
+ ("good_script.py", text_utf),
+ ("good_script_no_encoding.py", text_no_encoding),
+ ("good_script_latin_encoding.py", text_latin),
+ ])
+ def test_run_script(self, filename, text):
"""Tests that we can run a script to completion."""
- scriptrunner = TestScriptRunner("good_script.py")
+ scriptrunner = TestScriptRunner(filename)
scriptrunner.enqueue_rerun()
scriptrunner.start()
scriptrunner.join()
@@ -70,7 +89,7 @@ def test_run_script(self):
ScriptRunnerEvent.SHUTDOWN,
],
)
- self._assert_text_deltas(scriptrunner, ["complete!"])
+ self._assert_text_deltas(scriptrunner, [text])
# The following check is a requirement for the CodeHasher to
# work correctly. The CodeHasher is scoped to
# files contained in the directory of __main__.__file__, which we
@@ -244,7 +263,7 @@ def test_coalesce_rerun(self):
ScriptRunnerEvent.SHUTDOWN,
],
)
- self._assert_text_deltas(scriptrunner, ["complete!"])
+ self._assert_text_deltas(scriptrunner, [text_utf])
def test_multiple_scriptrunners(self):
"""Tests that multiple scriptrunners can run simultaneously."""
@@ -352,7 +371,8 @@ def _assert_text_deltas(self, scriptrunner, text_deltas):
[
delta.new_element.text.body
for delta in scriptrunner.deltas()
- if delta.HasField("new_element") and delta.new_element.HasField("text")
+ if delta.HasField("new_element")
+ and delta.new_element.HasField("text")
],
)
@@ -376,7 +396,8 @@ def enqueue_fn(msg):
)
self.script_request_queue = ScriptRequestQueue()
- script_path = os.path.join(os.path.dirname(__file__), "test_data", script_name)
+ script_path = os.path.join(
+ os.path.dirname(__file__), "test_data", script_name)
super(TestScriptRunner, self).__init__(
report=Report(script_path, "test command line"),
diff --git a/lib/tests/streamlit/scriptrunner/test_data/good_script.py b/lib/tests/streamlit/scriptrunner/test_data/good_script.py
index e675335e279d..ad5656358f34 100644
--- a/lib/tests/streamlit/scriptrunner/test_data/good_script.py
+++ b/lib/tests/streamlit/scriptrunner/test_data/good_script.py
@@ -17,4 +17,5 @@
import streamlit as st
-st.text("complete!")
+st.text(u"complete! 👨🎤")
+
diff --git a/lib/tests/streamlit/scriptrunner/test_data/good_script_latin_encoding.py b/lib/tests/streamlit/scriptrunner/test_data/good_script_latin_encoding.py
new file mode 100644
index 000000000000..9beda32f49a0
--- /dev/null
+++ b/lib/tests/streamlit/scriptrunner/test_data/good_script_latin_encoding.py
@@ -0,0 +1,20 @@
+# -*- coding: latin-1 -*-
+# Copyright 2018-2019 Streamlit Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""A test script for ScriptRunnerTest that enqueues a delta."""
+
+import streamlit as st
+
+st.text(u"complete! 👨🎤")
diff --git a/lib/tests/streamlit/scriptrunner/test_data/good_script_no_encoding.py b/lib/tests/streamlit/scriptrunner/test_data/good_script_no_encoding.py
new file mode 100644
index 000000000000..441713460acf
--- /dev/null
+++ b/lib/tests/streamlit/scriptrunner/test_data/good_script_no_encoding.py
@@ -0,0 +1,19 @@
+# Copyright 2018-2019 Streamlit Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+"""A test script for ScriptRunnerTest that enqueues a delta."""
+
+import streamlit as st
+
+st.text(u"complete! 👨🎤")
|
To solve #399 we need to specify the encoding as UTF8 when reading the user's script. So you'd think this is all we need to do:
```
open(the_file, encoding='utf-8')
```
But this doesn't always work because:
1) The `encoding` kwarg doesn't exist in Python 2
2) If we pass the `encoding` arg and it doesn't match whatever the user's script specifies (via [PEP263](https://www.python.org/dev/peps/pep-0263/) headers), Python raises a SyntaxError
For (2), we have to use the `tokenize` module's `open()` function, which respects PEP263 and defaults to UTF8.
But `tokenize.open()` doesn't exist in Python 2. So we need to provide a fallback in that case. The fallback is Streamlit's old behavior, where bug #399 exists.
---
In the process of writing this PR I noticed that some SyntaxErrors don't show up correctly in Streamlit — so I fixed that too.
|
https://api.github.com/repos/streamlit/streamlit/pulls/441
|
2019-10-17T06:45:05Z
|
2019-10-17T19:29:35Z
|
2019-10-17T19:29:34Z
|
2019-11-12T04:33:34Z
| 3,139
|
streamlit/streamlit
| 22,227
|
[test] fixed typo in test_format_note (test_YoutubeDL)
|
diff --git a/test/test_YoutubeDL.py b/test/test_YoutubeDL.py
index 8735013f727..e794cc97f0e 100644
--- a/test/test_YoutubeDL.py
+++ b/test/test_YoutubeDL.py
@@ -67,7 +67,7 @@ def test_prefer_free_formats(self):
downloaded = ydl.downloaded_info_dicts[0]
self.assertEqual(downloaded['ext'], 'mp4')
- # No prefer_free_formats => prefer mp4 and flv for greater compatibilty
+ # No prefer_free_formats => prefer mp4 and flv for greater compatibility
ydl = YDL()
ydl.params['prefer_free_formats'] = False
formats = [
@@ -279,7 +279,7 @@ def test_format_note(self):
self.assertEqual(ydl._format_note({}), '')
assertRegexpMatches(self, ydl._format_note({
'vbr': 10,
- }), '^x\s*10k$')
+ }), '^\s*10k$')
if __name__ == '__main__':
unittest.main()
|
This test was introduced in c57f7757101690681af2eb8c40c8bf81bbe6e64f.
For some reason, it tests if the format note begins with an `x` which is never the case?
|
https://api.github.com/repos/ytdl-org/youtube-dl/pulls/2960
|
2014-05-21T08:06:18Z
|
2014-05-24T22:36:03Z
|
2014-05-24T22:36:03Z
|
2014-05-25T01:20:38Z
| 243
|
ytdl-org/youtube-dl
| 50,336
|
Cache proxy bypass
|
diff --git a/AUTHORS.rst b/AUTHORS.rst
index 48cd155b49..e4a325bfe3 100644
--- a/AUTHORS.rst
+++ b/AUTHORS.rst
@@ -178,4 +178,5 @@ Patches and Suggestions
- Moinuddin Quadri <[email protected]> (`@moin18 <https://github.com/moin18>`_)
- Matt Kohl (`@mattkohl <https://github.com/mattkohl>`_)
- Jonathan Vanasco (`@jvanasco <https://github.com/jvanasco>`_)
+- David Fontenot (`@davidfontenot <https://github.com/davidfontenot>`_)
diff --git a/requests/structures.py b/requests/structures.py
index 05d2b3f57b..beb268e361 100644
--- a/requests/structures.py
+++ b/requests/structures.py
@@ -8,9 +8,12 @@
"""
import collections
+import time
from .compat import OrderedDict
+current_time = getattr(time, 'monotonic', time.time)
+
class CaseInsensitiveDict(collections.MutableMapping):
"""A case-insensitive ``dict``-like object.
@@ -103,3 +106,89 @@ def __getitem__(self, key):
def get(self, key, default=None):
return self.__dict__.get(key, default)
+
+
+class TimedCacheManaged(object):
+ """
+ Wrap a function call in a timed cache
+ """
+ def __init__(self, fnc):
+ self.fnc = fnc
+ self.cache = TimedCache()
+
+ def __call__(self, *args, **kwargs):
+ key = args[0]
+ found = None
+ try:
+ found = self.cache[key]
+ except KeyError:
+ found = self.fnc(key, **kwargs)
+ self.cache[key] = found
+
+ return found
+
+
+class TimedCache(collections.MutableMapping):
+ """
+ Evicts entries after expiration_secs. If none are expired and maxlen is hit,
+ will evict the oldest cached entry
+ """
+ def __init__(self, maxlen=32, expiration_secs=60):
+ """
+ :param maxlen: most number of entries to hold on to
+ :param expiration_secs: the number of seconds to hold on
+ to entries
+ """
+ self.maxlen = maxlen
+ self.expiration_secs = expiration_secs
+ self._dict = OrderedDict()
+
+ def __repr__(self):
+ return '<TimedCache maxlen:%d len:%d expiration_secs:%d>' % \
+ (self.maxlen, len(self._dict), self.expiration_secs)
+
+ def __iter__(self):
+ return map(lambda kv: (kv[0], kv[1][1]), self._dict.items()).__iter__()
+
+ def __delitem__(self, item):
+ return self._dict.__delitem__(item)
+
+ def __getitem__(self, key):
+ """
+ Look up an item in the cache. If the item
+ has already expired, it will be invalidated and not returned
+
+ :param key: which entry to look up
+ :return: the value in the cache, or None
+ """
+ occurred, value = self._dict[key]
+ now = int(current_time())
+
+ if now - occurred > self.expiration_secs:
+ del self._dict[key]
+ raise KeyError
+ else:
+ return value
+
+ def __setitem__(self, key, value):
+ """
+ Locates the value at lookup key, if cache is full, will evict the
+ oldest entry
+
+ :param key: the key to search the cache for
+ :param value: the value to be added to the cache
+ """
+ now = int(current_time())
+
+ while len(self._dict) >= self.maxlen:
+ self._dict.popitem(last=False)
+
+ return self._dict.__setitem__(key, (now, value))
+
+ def __len__(self):
+ """:return: the length of the cache"""
+ return len(self._dict)
+
+ def clear(self):
+ """Clears the cache"""
+ return self._dict.clear()
diff --git a/requests/utils.py b/requests/utils.py
index 6365034ca5..b6fcc5f56e 100644
--- a/requests/utils.py
+++ b/requests/utils.py
@@ -28,7 +28,7 @@
quote, urlparse, bytes, str, OrderedDict, unquote, getproxies,
proxy_bypass, urlunparse, basestring, integer_types)
from .cookies import RequestsCookieJar, cookiejar_from_dict
-from .structures import CaseInsensitiveDict
+from .structures import CaseInsensitiveDict, TimedCache, TimedCacheManaged
from .exceptions import (
InvalidURL, InvalidHeader, FileModeWarning, UnrewindableBodyError)
@@ -579,6 +579,16 @@ def set_environ(env_name, value):
os.environ[env_name] = old_value
+@TimedCacheManaged
+def _proxy_bypass_cached(netloc):
+ """
+ Looks for netloc in the cache, if not found, will call proxy_bypass
+ for the netloc and store its result in the cache
+
+ :rtype: bool
+ """
+ return proxy_bypass(netloc)
+
def should_bypass_proxies(url, no_proxy):
"""
Returns whether we should bypass proxies or not.
@@ -626,7 +636,7 @@ def should_bypass_proxies(url, no_proxy):
# legitimate problems.
with set_environ('no_proxy', no_proxy_arg):
try:
- bypass = proxy_bypass(netloc)
+ bypass = _proxy_bypass_cached(netloc)
except (TypeError, socket.gaierror):
bypass = False
diff --git a/tests/test_structures.py b/tests/test_structures.py
index e4d2459fe7..a28e041ee6 100644
--- a/tests/test_structures.py
+++ b/tests/test_structures.py
@@ -2,7 +2,7 @@
import pytest
-from requests.structures import CaseInsensitiveDict, LookupDict
+from requests.structures import CaseInsensitiveDict, LookupDict, TimedCache, TimedCacheManaged
class TestCaseInsensitiveDict:
@@ -74,3 +74,75 @@ def test_getitem(self, key, value):
@get_item_parameters
def test_get(self, key, value):
assert self.lookup_dict.get(key) == value
+
+
+class TestTimedCache(object):
+ @pytest.fixture(autouse=True)
+ def setup(self):
+ self.any_value = 'some value'
+ self.expiration_secs = 60
+ self.cache = TimedCache(expiration_secs=self.expiration_secs)
+ yield
+ self.cache.clear()
+
+ def test_get(self):
+ self.cache['a'] = self.any_value
+ assert self.cache['a'] is self.any_value
+
+ def test_repr(self):
+ repr = str(self.cache)
+ assert repr == '<TimedCache maxlen:32 len:0 expiration_secs:60>'
+
+ def test_get_expired_item(self, mocker):
+ self.cache = TimedCache(maxlen=1, expiration_secs=self.expiration_secs)
+
+ mocker.patch('requests.structures.current_time', lambda: 0)
+ self.cache['a'] = self.any_value
+ mocker.patch('requests.structures.current_time', lambda: self.expiration_secs + 1)
+ assert self.cache.get('a') is None
+
+ def test_evict_first_entry_when_full(self, mocker):
+ self.cache = TimedCache(maxlen=2, expiration_secs=2)
+ mocker.patch('requests.structures.current_time', lambda: 0)
+ self.cache['a'] = self.any_value
+ mocker.patch('requests.structures.current_time', lambda: 1)
+ self.cache['b'] = self.any_value
+ mocker.patch('requests.structures.current_time', lambda: 3)
+ self.cache['c'] = self.any_value
+ assert len(self.cache) is 2
+ with pytest.raises(KeyError, message='Expected key not found'):
+ self.cache['a']
+ assert self.cache['b'] is self.any_value
+ assert self.cache['c'] is self.any_value
+
+ def test_delete_item_removes_item(self):
+ self.cache['a'] = self.any_value
+ del self.cache['a']
+ with pytest.raises(KeyError, message='Expected key not found'):
+ self.cache['a']
+
+ def test_iterating_hides_timestamps(self):
+ self.cache['a'] = 1
+ self.cache['b'] = 2
+ expected = [('a', 1), ('b', 2)]
+ actual = [(key, val) for key, val in self.cache]
+ assert expected == actual
+
+
+class TestTimedCacheManagedDecorator(object):
+ def test_caches_repeated_calls(self, mocker):
+ mocker.patch('requests.structures.current_time', lambda: 0)
+
+ nonlocals = {'value': 0}
+
+ @TimedCacheManaged
+ def some_method(x):
+ nonlocals['value'] = nonlocals['value'] + x
+ return nonlocals['value']
+
+ first_result = some_method(1)
+ assert first_result is 1
+ second_result = some_method(1)
+ assert second_result is 1
+ third_result = some_method(2)
+ assert third_result is 3
|
Added simple cache over `urllib.proxy_bypass` to remedy #2988. Holds on to entries for a minute. Once it reaches its max size, will evict the first entry that is the oldest.
Added tests over the structure, did not add a test that `should_bypass_proxies` invokes the cache.
This is my first pull request; please let me know if I've overlooked something.
Additionally, when I check out master, run `make coverage` in pipenv, the test named 'TestRequests.test_proxy_error' fails. This is still the only failing test when I use my branch. The error is `ConnectionError: ('Connection aborted.', BadStatusLine("''",))`. Is there some additional setup I need to do to run the test suite?
|
https://api.github.com/repos/psf/requests/pulls/3885
|
2017-02-22T04:21:30Z
|
2017-02-27T08:56:44Z
|
2017-02-27T08:56:44Z
|
2021-09-07T00:06:29Z
| 2,186
|
psf/requests
| 32,534
|
More detailed error logging for nginx plugin
|
diff --git a/certbot-nginx/certbot_nginx/configurator.py b/certbot-nginx/certbot_nginx/configurator.py
index b80d95613cd..8d26fbe7b94 100644
--- a/certbot-nginx/certbot_nginx/configurator.py
+++ b/certbot-nginx/certbot_nginx/configurator.py
@@ -136,7 +136,9 @@ def prepare(self):
"""
# Verify Nginx is installed
if not util.exe_exists(self.conf('ctl')):
- raise errors.NoInstallationError
+ raise errors.NoInstallationError(
+ "Could not find a usable 'nginx' binary. Ensure nginx exists, "
+ "the binary is executable, and your PATH is set correctly.")
# Make sure configuration is valid
self.config_test()
diff --git a/certbot-nginx/certbot_nginx/parser.py b/certbot-nginx/certbot_nginx/parser.py
index 7d1da2e73a6..23ede8f71d1 100644
--- a/certbot-nginx/certbot_nginx/parser.py
+++ b/certbot-nginx/certbot_nginx/parser.py
@@ -222,7 +222,7 @@ def _find_config_root(self):
return os.path.join(self.root, name)
raise errors.NoInstallationError(
- "Could not find configuration root")
+ "Could not find Nginx root configuration file (nginx.conf)")
def filedump(self, ext='tmp', lazy=True):
"""Dumps parsed configurations into files.
|
This makes errors more useful when Nginx can't be found or when Nginx's
configuration can't be found. Previously, a generic `NoInstallationError` isn't descriptive enough to explain _what_ wasn't installed or what failed without going digging into the source code.
An error like:
```
The nginx plugin is not working; there may be problems with your existing configuration.
The error was: NoInstallationError()
```
seems to imply there's a problem with "configuration" which I've previously interpreted as Certbot config problem rather than the Nginx _installation_ or in other common cases the `PATH` isn't right when say run in `cron` (#5920).
This PR just makes the error messages more verbose, helping the user to know what to check:
```
Could not choose appropriate plugin for updaters: The nginx plugin is not working; there may be problems with your existing configuration.
The error was: NoInstallationError("Could not find a usable 'nginx' binary. Ensure nginx exists, the binary is executable, and your PATH is set correctly.",)
```
The error formatting isn't perfect, but that's beyond the scope of this PR; now the user knows what they need to go and check.
|
https://api.github.com/repos/certbot/certbot/pulls/6175
|
2018-07-03T02:20:54Z
|
2018-09-12T23:48:51Z
|
2018-09-12T23:48:51Z
|
2018-09-12T23:48:51Z
| 349
|
certbot/certbot
| 1,059
|
Subaru: log EPS torque
|
diff --git a/opendbc b/opendbc
index 3fcbe9db7211b2..e3704962060058 160000
--- a/opendbc
+++ b/opendbc
@@ -1 +1 @@
-Subproject commit 3fcbe9db7211b2f7524b80c351c7cf1f233c1e52
+Subproject commit e3704962060058c1ec1fb48a5aef767153d28fe7
diff --git a/selfdrive/car/subaru/carstate.py b/selfdrive/car/subaru/carstate.py
index b2611869775c8e..9246cbde182daf 100644
--- a/selfdrive/car/subaru/carstate.py
+++ b/selfdrive/car/subaru/carstate.py
@@ -47,6 +47,7 @@ def update(self, cp, cp_cam):
ret.steeringAngleDeg = cp.vl["Steering_Torque"]["Steering_Angle"]
ret.steeringTorque = cp.vl["Steering_Torque"]["Steer_Torque_Sensor"]
+ ret.steeringTorqueEps = cp.vl["Steering_Torque"]["Steer_Torque_Output"]
ret.steeringPressed = abs(ret.steeringTorque) > STEER_THRESHOLD[self.car_fingerprint]
ret.cruiseState.enabled = cp.vl["CruiseControl"]["Cruise_Activated"] != 0
@@ -80,6 +81,7 @@ def get_can_parser(CP):
signals = [
# sig_name, sig_address
("Steer_Torque_Sensor", "Steering_Torque"),
+ ("Steer_Torque_Output", "Steering_Torque"),
("Steering_Angle", "Steering_Torque"),
("Steer_Error_1", "Steering_Torque"),
("Cruise_On", "CruiseControl"),
diff --git a/selfdrive/test/process_replay/ref_commit b/selfdrive/test/process_replay/ref_commit
index 01e762d336f014..22cc2442b1886b 100644
--- a/selfdrive/test/process_replay/ref_commit
+++ b/selfdrive/test/process_replay/ref_commit
@@ -1 +1 @@
-66790e176b98244bb76ce19fb1aa943b36c87dec
\ No newline at end of file
+cfe79d760f161a46e48b60c1debe11b8f300e717
\ No newline at end of file
|
https://api.github.com/repos/commaai/openpilot/pulls/25304
|
2022-07-28T23:28:41Z
|
2022-07-28T23:42:42Z
|
2022-07-28T23:42:42Z
|
2022-07-28T23:42:43Z
| 549
|
commaai/openpilot
| 9,252
|
|
Send the original response url to `urlparse` rather than the `Response` object
|
diff --git a/requests/cookies.py b/requests/cookies.py
index 85726b0657..0415856160 100644
--- a/requests/cookies.py
+++ b/requests/cookies.py
@@ -39,7 +39,7 @@ def get_host(self):
def get_origin_req_host(self):
if self._r.response.history:
r = self._r.response.history[0]
- return urlparse(r).netloc
+ return urlparse(r.url).netloc
else:
return self.get_host()
|
`urlparse` cannot handle `Response` objects, so the way this is written this code always results in an exception.
|
https://api.github.com/repos/psf/requests/pulls/668
|
2012-06-08T13:01:54Z
|
2012-06-09T11:30:19Z
|
2012-06-09T11:30:19Z
|
2021-09-08T15:01:16Z
| 120
|
psf/requests
| 32,908
|
Backport PR #38715 on branch 1.2.x (CI: pin jedi version<0.18.0)
|
diff --git a/ci/deps/azure-38-locale.yaml b/ci/deps/azure-38-locale.yaml
index 90cd11037e472..15d503e8fd0a5 100644
--- a/ci/deps/azure-38-locale.yaml
+++ b/ci/deps/azure-38-locale.yaml
@@ -18,6 +18,7 @@ dependencies:
- html5lib
- ipython
- jinja2
+ - jedi<0.18.0
- lxml
- matplotlib <3.3.0
- moto
|
Backport PR #38715: CI: pin jedi version<0.18.0
|
https://api.github.com/repos/pandas-dev/pandas/pulls/38716
|
2020-12-27T10:53:32Z
|
2020-12-27T12:55:05Z
|
2020-12-27T12:55:05Z
|
2020-12-27T12:55:06Z
| 138
|
pandas-dev/pandas
| 45,353
|
Add support for passthrough arguments to NumpyArrayIterator
|
diff --git a/keras/preprocessing/image.py b/keras/preprocessing/image.py
index 35f14db1e7a..3e1de82d45a 100644
--- a/keras/preprocessing/image.py
+++ b/keras/preprocessing/image.py
@@ -672,9 +672,14 @@ def flow(self, x, y=None, batch_size=32, shuffle=True, seed=None,
augmented/normalized data.
# Arguments
- x: data. Should have rank 4.
- In case of grayscale data,
- the channels axis should have value 1, and in case
+ x: data. Numpy array of rank 4 or a tuple. If tuple, the first element
+ should contain the images and the second element another numpy array
+ or a list of numpy arrays of miscellaneous data that gets passed to the output
+ without any modifications. Can be used to feed the model miscellaneous data
+ along with the images.
+
+ In case of grayscale data, the channels axis of the image array
+ should have value 1, and in case
of RGB data, it should have value 3.
y: labels.
batch_size: int (default: 32).
@@ -691,8 +696,9 @@ def flow(self, x, y=None, batch_size=32, shuffle=True, seed=None,
`validation_split` is set in `ImageDataGenerator`.
# Returns
- An Iterator yielding tuples of `(x, y)` where `x` is a numpy array of image data and
- `y` is a numpy array of corresponding labels."""
+ An Iterator yielding tuples of `(x, y)` where `x` is a numpy array of image data
+ (in the case of a single image input) or a list of numpy arrays (in the case with
+ additional inputs) and `y` is a numpy array of corresponding labels."""
return NumpyArrayIterator(
x, y, self,
batch_size=batch_size,
@@ -1084,7 +1090,9 @@ class NumpyArrayIterator(Iterator):
"""Iterator yielding data from a Numpy array.
# Arguments
- x: Numpy array of input data.
+ x: Numpy array of input data or tuple. If tuple, the second elements is either
+ another numpy array or a list of numpy arrays, each of which gets passed
+ through as an output without any modifications.
y: Numpy array of targets data.
image_data_generator: Instance of `ImageDataGenerator`
to use for random transformations and normalization.
@@ -1109,6 +1117,20 @@ def __init__(self, x, y, image_data_generator,
data_format=None,
save_to_dir=None, save_prefix='', save_format='png',
subset=None):
+ if (type(x) is tuple) or (type(x) is list):
+ if type(x[1]) is not list:
+ x_misc = [np.asarray(x[1])]
+ else:
+ x_misc = [np.asarray(xx) for xx in x[1]]
+ x = x[0]
+ for xx in x_misc:
+ if len(x) != len(xx):
+ raise ValueError('All of the arrays in `x` should have the same length. '
+ 'Found a pair with: len(x[0]) = %s, len(x[?]) = %s' %
+ (len(x), len(xx)))
+ else:
+ x_misc = []
+
if y is not None and len(x) != len(y):
raise ValueError('`x` (images tensor) and `y` (labels) '
'should have the same length. '
@@ -1121,15 +1143,18 @@ def __init__(self, x, y, image_data_generator,
split_idx = int(len(x) * image_data_generator._validation_split)
if subset == 'validation':
x = x[:split_idx]
+ x_misc = [np.asarray(xx[:split_idx]) for xx in x_misc]
if y is not None:
y = y[:split_idx]
else:
x = x[split_idx:]
+ x_misc = [np.asarray(xx[split_idx:]) for xx in x_misc]
if y is not None:
y = y[split_idx:]
if data_format is None:
data_format = K.image_data_format()
self.x = np.asarray(x, dtype=K.floatx())
+ self.x_misc = x_misc
if self.x.ndim != 4:
raise ValueError('Input data in `NumpyArrayIterator` '
'should have rank 4. You passed an array '
@@ -1161,6 +1186,7 @@ def _get_batches_of_transformed_samples(self, index_array):
x = self.image_data_generator.random_transform(x.astype(K.floatx()))
x = self.image_data_generator.standardize(x)
batch_x[i] = x
+
if self.save_to_dir:
for i, j in enumerate(index_array):
img = array_to_img(batch_x[i], self.data_format, scale=True)
@@ -1169,10 +1195,12 @@ def _get_batches_of_transformed_samples(self, index_array):
hash=np.random.randint(1e4),
format=self.save_format)
img.save(os.path.join(self.save_to_dir, fname))
+ batch_x_miscs = [xx[index_array] for xx in self.x_misc]
+ output = (batch_x if batch_x_miscs == [] else [batch_x] + batch_x_miscs,)
if self.y is None:
- return batch_x
- batch_y = self.y[index_array]
- return batch_x, batch_y
+ return output[0]
+ output += (self.y[index_array],)
+ return output
def next(self):
"""For python 2.x.
diff --git a/tests/keras/preprocessing/image_test.py b/tests/keras/preprocessing/image_test.py
index 22c028182c7..7b0002959f9 100644
--- a/tests/keras/preprocessing/image_test.py
+++ b/tests/keras/preprocessing/image_test.py
@@ -71,6 +71,66 @@ def test_image_data_generator(self, tmpdir):
assert list(y) != [0, 1, 2]
break
+ # Test without y
+ for x in generator.flow(images, None,
+ shuffle=True, save_to_dir=str(tmpdir),
+ batch_size=3):
+ assert type(x) is np.ndarray
+ assert x.shape == images[:3].shape
+ # Check that the sequence is shuffled.
+ break
+
+ # Test with a single miscellaneous input data array
+ dsize = images.shape[0]
+ x_misc1 = np.random.random(dsize)
+
+ for i, (x, y) in enumerate(generator.flow((images, x_misc1),
+ np.arange(dsize),
+ shuffle=False, batch_size=2)):
+ assert x[0].shape == images[:2].shape
+ assert (x[1] == x_misc1[(i * 2):((i + 1) * 2)]).all()
+ if i == 2:
+ break
+
+ # Test with two miscellaneous inputs
+ x_misc2 = np.random.random((dsize, 3, 3))
+
+ for i, (x, y) in enumerate(generator.flow((images, [x_misc1, x_misc2]),
+ np.arange(dsize),
+ shuffle=False, batch_size=2)):
+ assert x[0].shape == images[:2].shape
+ assert (x[1] == x_misc1[(i * 2):((i + 1) * 2)]).all()
+ assert (x[2] == x_misc2[(i * 2):((i + 1) * 2)]).all()
+ if i == 2:
+ break
+
+ # Test cases with `y = None`
+ x = generator.flow(images, None, batch_size=3).next()
+ assert type(x) is np.ndarray
+ assert x.shape == images[:3].shape
+ x = generator.flow((images, x_misc1), None,
+ batch_size=3, shuffle=False).next()
+ assert type(x) is list
+ assert x[0].shape == images[:3].shape
+ assert (x[1] == x_misc1[:3]).all()
+ x = generator.flow((images, [x_misc1, x_misc2]), None,
+ batch_size=3, shuffle=False).next()
+ assert type(x) is list
+ assert x[0].shape == images[:3].shape
+ assert (x[1] == x_misc1[:3]).all()
+ assert (x[2] == x_misc2[:3]).all()
+
+ # Test some failure cases:
+ x_misc_err = np.random.random((dsize + 1, 3, 3))
+
+ with pytest.raises(ValueError) as e_info:
+ generator.flow((images, x_misc_err), np.arange(dsize), batch_size=3)
+ assert str(e_info.value).find('All of the arrays in') != -1
+
+ with pytest.raises(ValueError) as e_info:
+ generator.flow((images, x_misc1), np.arange(dsize + 1), batch_size=3)
+ assert str(e_info.value).find('`x` (images tensor) and `y` (labels) ') != -1
+
# Test `flow` behavior as Sequence
seq = generator.flow(images, np.arange(images.shape[0]),
shuffle=False, save_to_dir=str(tmpdir),
|
There have been some requests for more flexible behaviour for the ImageGenerator (see for example issue #9877). This pull request takes a step towards that direction (although it doesn't yet solve the problem in the issue I linked).
I add a support for multiple input arguments in NumpyArrayIterator (and thus, the flow() function). It now accepts following syntax: `flow((image_data, [other_data1, other_data2]), ...)`. The image_data part gets processed as before and the optional other_data arguments get passed through along with the image data without manipulations. This makes it possible to use flow() to feed a model multiple miscellaneous data arguments while still using the Keras image augmentations for the image data.
No old behaviour gets modified. All the modified functions can still be used as before by just leaving the additional arguments out.
|
https://api.github.com/repos/keras-team/keras/pulls/10035
|
2018-04-25T09:25:24Z
|
2018-04-26T16:13:59Z
|
2018-04-26T16:13:59Z
|
2018-04-26T16:13:59Z
| 2,158
|
keras-team/keras
| 47,456
|
Update folder produced by download-model
|
diff --git a/docs/Using-LoRAs.md b/docs/Using-LoRAs.md
index 0a679c0f24..fafd6cde2d 100644
--- a/docs/Using-LoRAs.md
+++ b/docs/Using-LoRAs.md
@@ -11,9 +11,9 @@ python download-model.py tloen/alpaca-lora-7b
2. Load the LoRA. 16-bit, 8-bit, and CPU modes work:
```
-python server.py --model llama-7b-hf --lora alpaca-lora-7b
-python server.py --model llama-7b-hf --lora alpaca-lora-7b --load-in-8bit
-python server.py --model llama-7b-hf --lora alpaca-lora-7b --cpu
+python server.py --model llama-7b-hf --lora tloen_alpaca-lora-7b
+python server.py --model llama-7b-hf --lora tloen_alpaca-lora-7b --load-in-8bit
+python server.py --model llama-7b-hf --lora tloen_alpaca-lora-7b --cpu
```
* For using LoRAs in 4-bit mode, follow [these special instructions](GPTQ-models-(4-bit-mode).md#using-loras-in-4-bit-mode).
|
See: https://github.com/oobabooga/text-generation-webui/blob/main/download-model.py#L160
|
https://api.github.com/repos/oobabooga/text-generation-webui/pulls/1601
|
2023-04-27T14:57:32Z
|
2023-04-27T15:03:02Z
|
2023-04-27T15:03:02Z
|
2023-04-27T15:44:51Z
| 322
|
oobabooga/text-generation-webui
| 26,003
|
Install `deepspeed-kernels` only on Linux
|
diff --git a/requirements/requirements-dev.txt b/requirements/requirements-dev.txt
index 105dd094f995..078386c457bd 100644
--- a/requirements/requirements-dev.txt
+++ b/requirements/requirements-dev.txt
@@ -1,7 +1,7 @@
accelerate
clang-format==16.0.2
coverage
-deepspeed-kernels
+deepspeed-kernels ; sys_platform == 'linux'
docutils<0.18
future
importlib-metadata>=4
|
The package[^1] does not have sdists, and the only wheels it has are for Linux. The package therefore fails to install on any other platform. The solution to install the dev requirements on macOS is to skip the installation on incompatible OS's.
[^1]: https://pypi.org/project/deepspeed-kernels/0.0.1.dev1698255861/#files
|
https://api.github.com/repos/microsoft/DeepSpeed/pulls/4739
|
2023-11-28T03:44:28Z
|
2023-11-28T21:45:30Z
|
2023-11-28T21:45:30Z
|
2023-11-28T21:45:31Z
| 111
|
microsoft/DeepSpeed
| 10,138
|
GitHub Workflows security hardening
|
diff --git a/.github/workflows/build.yml b/.github/workflows/build.yml
index ffe5ea193c9..8825bdf389f 100644
--- a/.github/workflows/build.yml
+++ b/.github/workflows/build.yml
@@ -1,6 +1,9 @@
name: build
on: [pull_request, push]
+permissions:
+ contents: read # to fetch code (actions/checkout)
+
jobs:
build:
runs-on: ubuntu-latest
diff --git a/.github/workflows/pre-commit.yml b/.github/workflows/pre-commit.yml
index b62f595ebb0..26cf2350d36 100644
--- a/.github/workflows/pre-commit.yml
+++ b/.github/workflows/pre-commit.yml
@@ -5,6 +5,8 @@ on:
pull_request:
push:
branches: [master]
+permissions:
+ contents: read # to fetch code (actions/checkout)
jobs:
pre-commit:
runs-on: ubuntu-latest
|
This PR adds explicit [permissions section](https://docs.github.com/en/actions/using-workflows/workflow-syntax-for-github-actions#permissions) to workflows. This is a security best practice because by default workflows run with [extended set of permissions](https://docs.github.com/en/actions/security-guides/automatic-token-authentication#permissions-for-the-github_token) (except from `on: pull_request` [from external forks](https://securitylab.github.com/research/github-actions-preventing-pwn-requests/)). By specifying any permission explicitly all others are set to none. By using the principle of least privilege the damage a compromised workflow can do (because of an [injection](https://securitylab.github.com/research/github-actions-untrusted-input/) or compromised third party tool or action) is restricted.
It is recommended to have [most strict permissions on the top level](https://github.com/ossf/scorecard/blob/main/docs/checks.md#token-permissions) and grant write permissions on [job level](https://docs.github.com/en/actions/using-jobs/assigning-permissions-to-jobs) case by case.
|
https://api.github.com/repos/openai/gym/pulls/3094
|
2022-09-24T19:54:54Z
|
2022-09-27T13:43:38Z
|
2022-09-27T13:43:38Z
|
2023-05-20T14:49:36Z
| 224
|
openai/gym
| 5,043
|
Data Coordinator to return unsub func
|
diff --git a/homeassistant/components/hue/hue_event.py b/homeassistant/components/hue/hue_event.py
index ed1bc1c8f7d9be..a588f68ea4e672 100644
--- a/homeassistant/components/hue/hue_event.py
+++ b/homeassistant/components/hue/hue_event.py
@@ -35,19 +35,13 @@ def __init__(self, sensor, name, bridge, primary_sensor=None):
self._last_updated = self.sensor.lastupdated
# Register callback in coordinator and add job to remove it on bridge reset.
- self.bridge.sensor_manager.coordinator.async_add_listener(
- self.async_update_callback
+ self.bridge.reset_jobs.append(
+ self.bridge.sensor_manager.coordinator.async_add_listener(
+ self.async_update_callback
+ )
)
- self.bridge.reset_jobs.append(self.async_will_remove_from_hass)
_LOGGER.debug("Hue event created: %s", self.event_id)
- @callback
- def async_will_remove_from_hass(self):
- """Remove listener on bridge reset."""
- self.bridge.sensor_manager.coordinator.async_remove_listener(
- self.async_update_callback
- )
-
@callback
def async_update_callback(self):
"""Fire the event if reason is that state is updated."""
diff --git a/homeassistant/components/hue/light.py b/homeassistant/components/hue/light.py
index e468c516676588..649be55e94e980 100644
--- a/homeassistant/components/hue/light.py
+++ b/homeassistant/components/hue/light.py
@@ -118,13 +118,9 @@ async def async_setup_entry(hass, config_entry, async_add_entities):
)
# We add a listener after fetching the data, so manually trigger listener
- light_coordinator.async_add_listener(update_lights)
+ bridge.reset_jobs.append(light_coordinator.async_add_listener(update_lights))
update_lights()
- bridge.reset_jobs.append(
- lambda: light_coordinator.async_remove_listener(update_lights)
- )
-
api_version = tuple(int(v) for v in bridge.api.config.apiversion.split("."))
allow_groups = bridge.allow_groups
@@ -155,13 +151,9 @@ async def async_setup_entry(hass, config_entry, async_add_entities):
partial(create_light, HueLight, group_coordinator, bridge, True),
)
- group_coordinator.async_add_listener(update_groups)
+ bridge.reset_jobs.append(group_coordinator.async_add_listener(update_groups))
await group_coordinator.async_refresh()
- bridge.reset_jobs.append(
- lambda: group_coordinator.async_remove_listener(update_groups)
- )
-
async def async_safe_fetch(bridge, fetch_method):
"""Safely fetch data."""
@@ -339,11 +331,9 @@ def device_info(self):
async def async_added_to_hass(self):
"""When entity is added to hass."""
- self.coordinator.async_add_listener(self.async_write_ha_state)
-
- async def async_will_remove_from_hass(self):
- """When entity will be removed from hass."""
- self.coordinator.async_remove_listener(self.async_write_ha_state)
+ self.async_on_remove(
+ self.coordinator.async_add_listener(self.async_write_ha_state)
+ )
async def async_turn_on(self, **kwargs):
"""Turn the specified or all lights on."""
diff --git a/homeassistant/components/hue/sensor_base.py b/homeassistant/components/hue/sensor_base.py
index 113957d140ef86..93b98a7c9ce8d3 100644
--- a/homeassistant/components/hue/sensor_base.py
+++ b/homeassistant/components/hue/sensor_base.py
@@ -76,9 +76,8 @@ async def async_register_component(self, platform, async_add_entities):
return
# We have all components available, start the updating.
- self.coordinator.async_add_listener(self.async_update_items)
self.bridge.reset_jobs.append(
- lambda: self.coordinator.async_remove_listener(self.async_update_items)
+ self.coordinator.async_add_listener(self.async_update_items)
)
await self.coordinator.async_refresh()
@@ -178,14 +177,10 @@ def available(self):
async def async_added_to_hass(self):
"""When entity is added to hass."""
- self.bridge.sensor_manager.coordinator.async_add_listener(
- self.async_write_ha_state
- )
-
- async def async_will_remove_from_hass(self):
- """When entity will be removed from hass."""
- self.bridge.sensor_manager.coordinator.async_remove_listener(
- self.async_write_ha_state
+ self.async_on_remove(
+ self.bridge.sensor_manager.coordinator.async_add_listener(
+ self.async_write_ha_state
+ )
)
async def async_update(self):
diff --git a/homeassistant/helpers/update_coordinator.py b/homeassistant/helpers/update_coordinator.py
index b2b048166168a3..d9a79d6555c1cf 100644
--- a/homeassistant/helpers/update_coordinator.py
+++ b/homeassistant/helpers/update_coordinator.py
@@ -62,7 +62,7 @@ def __init__(
self._debounced_refresh = request_refresh_debouncer
@callback
- def async_add_listener(self, update_callback: CALLBACK_TYPE) -> None:
+ def async_add_listener(self, update_callback: CALLBACK_TYPE) -> Callable[[], None]:
"""Listen for data updates."""
schedule_refresh = not self._listeners
@@ -72,6 +72,13 @@ def async_add_listener(self, update_callback: CALLBACK_TYPE) -> None:
if schedule_refresh:
self._schedule_refresh()
+ @callback
+ def remove_listener() -> None:
+ """Remove update listener."""
+ self.async_remove_listener(update_callback)
+
+ return remove_listener
+
@callback
def async_remove_listener(self, update_callback: CALLBACK_TYPE) -> None:
"""Remove data update."""
diff --git a/tests/helpers/test_update_coordinator.py b/tests/helpers/test_update_coordinator.py
index c17c79ccbc8acc..17caa1f747863f 100644
--- a/tests/helpers/test_update_coordinator.py
+++ b/tests/helpers/test_update_coordinator.py
@@ -18,11 +18,12 @@
@pytest.fixture
def crd(hass):
"""Coordinator mock."""
- calls = []
+ calls = 0
async def refresh():
- calls.append(None)
- return len(calls)
+ nonlocal calls
+ calls += 1
+ return calls
crd = update_coordinator.DataUpdateCoordinator(
hass,
@@ -46,16 +47,19 @@ async def test_async_refresh(crd):
def update_callback():
updates.append(crd.data)
- crd.async_add_listener(update_callback)
-
+ unsub = crd.async_add_listener(update_callback)
await crd.async_refresh()
+ assert updates == [2]
+ # Test unsubscribing through function
+ unsub()
+ await crd.async_refresh()
assert updates == [2]
+ # Test unsubscribing through method
+ crd.async_add_listener(update_callback)
crd.async_remove_listener(update_callback)
-
await crd.async_refresh()
-
assert updates == [2]
|
<!--
You are amazing! Thanks for contributing to our project!
Please, DO NOT DELETE ANY TEXT from this template! (unless instructed).
-->
## Breaking change
<!--
If your PR contains a breaking change for existing users, it is important
to tell them what breaks, how to make it work again and why we did this.
This piece of text is published with the release notes, so it helps if you
write it towards our users, not us.
Note: Remove this section if this PR is NOT a breaking change.
-->
## Proposed change
<!--
Describe the big picture of your changes here to communicate to the
maintainers why we should accept this pull request. If it fixes a bug
or resolves a feature request, be sure to link to that issue in the
additional information section.
-->
In #33510 I made sure that we use `Entity.async_on_remove` for cleaning up dispatcher connections. I realized that we don't support this for DataUpdateCoordinator so added this functionality and applied the clean up to the Hue integration.
## Type of change
<!--
What type of change does your PR introduce to Home Assistant?
NOTE: Please, check only 1! box!
If your PR requires multiple boxes to be checked, you'll most likely need to
split it into multiple PRs. This makes things easier and faster to code review.
-->
- [ ] Dependency upgrade
- [ ] Bugfix (non-breaking change which fixes an issue)
- [ ] New integration (thank you!)
- [ ] New feature (which adds functionality to an existing integration)
- [ ] Breaking change (fix/feature causing existing functionality to break)
- [x] Code quality improvements to existing code or addition of tests
## Example entry for `configuration.yaml`:
<!--
Supplying a configuration snippet, makes it easier for a maintainer to test
your PR. Furthermore, for new integrations, it gives an impression of how
the configuration would look like.
Note: Remove this section if this PR does not have an example entry.
-->
```yaml
# Example configuration.yaml
```
## Additional information
<!--
Details are important, and help maintainers processing your PR.
Please be sure to fill out additional details, if applicable.
-->
- This PR fixes or closes issue: fixes #
- This PR is related to issue:
- Link to documentation pull request:
## Checklist
<!--
Put an `x` in the boxes that apply. You can also fill these out after
creating the PR. If you're unsure about any of them, don't hesitate to ask.
We're here to help! This is simply a reminder of what we are going to look
for before merging your code.
-->
- [ ] The code change is tested and works locally.
- [ ] Local tests pass. **Your PR cannot be merged unless tests pass**
- [ ] There is no commented out code in this PR.
- [ ] I have followed the [development checklist][dev-checklist]
- [ ] The code has been formatted using Black (`black --fast homeassistant tests`)
- [ ] Tests have been added to verify that the new code works.
If user exposed functionality or configuration variables are added/changed:
- [ ] Documentation added/updated for [www.home-assistant.io][docs-repository]
If the code communicates with devices, web services, or third-party tools:
- [ ] The [manifest file][manifest-docs] has all fields filled out correctly.
Updated and included derived files by running: `python3 -m script.hassfest`.
- [ ] New or updated dependencies have been added to `requirements_all.txt`.
Updated by running `python3 -m script.gen_requirements_all`.
- [ ] Untested files have been added to `.coveragerc`.
The integration reached or maintains the following [Integration Quality Scale][quality-scale]:
<!--
The Integration Quality Scale scores an integration on the code quality
and user experience. Each level of the quality scale consists of a list
of requirements. We highly recommend getting your integration scored!
-->
- [ ] No score or internal
- [ ] 🥈 Silver
- [ ] 🥇 Gold
- [ ] 🏆 Platinum
<!--
Thank you for contributing <3
Below, some useful links you could explore:
-->
[dev-checklist]: https://developers.home-assistant.io/docs/en/development_checklist.html
[manifest-docs]: https://developers.home-assistant.io/docs/en/creating_integration_manifest.html
[quality-scale]: https://developers.home-assistant.io/docs/en/next/integration_quality_scale_index.html
[docs-repository]: https://github.com/home-assistant/home-assistant.io
|
https://api.github.com/repos/home-assistant/core/pulls/33588
|
2020-04-03T16:41:38Z
|
2020-04-03T18:15:43Z
|
2020-04-03T18:15:43Z
|
2020-04-04T19:38:26Z
| 1,593
|
home-assistant/core
| 39,459
|
[NRK] Improve extractor
|
diff --git a/yt_dlp/extractor/nrk.py b/yt_dlp/extractor/nrk.py
index 4d723e88688..0cf26d5981f 100644
--- a/yt_dlp/extractor/nrk.py
+++ b/yt_dlp/extractor/nrk.py
@@ -13,6 +13,7 @@
ExtractorError,
int_or_none,
parse_duration,
+ parse_iso8601,
str_or_none,
try_get,
urljoin,
@@ -247,6 +248,7 @@ def call_playback_api(item, query=None):
'age_limit': age_limit,
'formats': formats,
'subtitles': subtitles,
+ 'timestamp': parse_iso8601(try_get(manifest, lambda x: x['availability']['onDemand']['from'], str))
}
if is_series:
@@ -797,7 +799,7 @@ def _real_extract(self, url):
for video_id in re.findall(self._ITEM_RE, webpage)
]
- playlist_title = self. _extract_title(webpage)
+ playlist_title = self._extract_title(webpage)
playlist_description = self._extract_description(webpage)
return self.playlist_result(
|
## Please follow the guide below
- You will be asked some questions, please read them **carefully** and answer honestly
- Put an `x` into all the boxes [ ] relevant to your *pull request* (like that [x])
- Use *Preview* tab to see how your *pull request* will actually look like
---
### Before submitting a *pull request* make sure you have:
- [x] At least skimmed through [contributing guidelines](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#developer-instructions) including [yt-dlp coding conventions](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#yt-dlp-coding-conventions)
- [x] [Searched](https://github.com/yt-dlp/yt-dlp/search?q=is%3Apr&type=Issues) the bugtracker for similar pull requests
- [x] Checked the code with [flake8](https://pypi.python.org/pypi/flake8)
### In order to be accepted and merged into yt-dlp each piece of code must be in public domain or released under [Unlicense](http://unlicense.org/). Check one of the following options:
- [x] I am the original author of this code and I am willing to release it under [Unlicense](http://unlicense.org/)
- [ ] I am not the original author of this code but it is in public domain or released under [Unlicense](http://unlicense.org/) (provide reliable evidence)
### What is the purpose of your *pull request*?
- [x] Bug fix
- [x] Improvement
- [ ] New extractor
- [ ] New feature
---
### Description of your *pull request* and other information
Close #3211
|
https://api.github.com/repos/yt-dlp/yt-dlp/pulls/3231
|
2022-03-28T13:15:03Z
|
2022-04-07T15:52:28Z
|
2022-04-07T15:52:28Z
|
2022-04-07T15:52:28Z
| 273
|
yt-dlp/yt-dlp
| 7,625
|
🔧 Add new Translation tracking issues for German and Indonesian
|
diff --git a/.github/actions/notify-translations/app/translations.yml b/.github/actions/notify-translations/app/translations.yml
index 2ac9556738d64..3f53adb6580b3 100644
--- a/.github/actions/notify-translations/app/translations.yml
+++ b/.github/actions/notify-translations/app/translations.yml
@@ -10,3 +10,5 @@ fr: 1972
ko: 2017
sq: 2041
pl: 3169
+de: 3716
+id: 3717
|
🔧 Add new Translation tracking issues for German and Indonesian
|
https://api.github.com/repos/tiangolo/fastapi/pulls/3718
|
2021-08-18T13:42:15Z
|
2021-08-18T13:44:11Z
|
2021-08-18T13:44:11Z
|
2021-09-09T06:01:11Z
| 127
|
tiangolo/fastapi
| 23,147
|
Bump asgiref from 3.3.4 to 3.4.0
|
diff --git a/requirements/dev.txt b/requirements/dev.txt
index 4603468a49..a8908c6db1 100644
--- a/requirements/dev.txt
+++ b/requirements/dev.txt
@@ -8,7 +8,7 @@ alabaster==0.7.12
# via sphinx
appdirs==1.4.4
# via virtualenv
-asgiref==3.3.4
+asgiref==3.4.0
# via -r requirements/tests.in
attrs==21.2.0
# via pytest
diff --git a/requirements/tests.txt b/requirements/tests.txt
index deb93d62a2..600ad93aa2 100644
--- a/requirements/tests.txt
+++ b/requirements/tests.txt
@@ -4,7 +4,7 @@
#
# pip-compile requirements/tests.in
#
-asgiref==3.3.4
+asgiref==3.4.0
# via -r requirements/tests.in
attrs==21.2.0
# via pytest
|
[//]: # (dependabot-start)
⚠️ **Dependabot is rebasing this PR** ⚠️
Rebasing might not happen immediately, so don't worry if this takes some time.
Note: if you make any changes to this PR yourself, they will take precedence over the rebase.
---
[//]: # (dependabot-end)
Bumps [asgiref](https://github.com/django/asgiref) from 3.3.4 to 3.4.0.
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a href="https://github.com/django/asgiref/blob/main/CHANGELOG.txt">asgiref's changelog</a>.</em></p>
<blockquote>
<h2>3.4.0 (2021-06-27)</h2>
<ul>
<li>
<p>Calling sync_to_async directly from inside itself (which causes a deadlock
when in the default, thread-sensitive mode) now has deadlock detection.</p>
</li>
<li>
<p>asyncio usage has been updated to use the new versions of get_event_loop,
ensure_future, wait and gather, avoiding deprecation warnings in Python 3.10.
Python 3.6 installs continue to use the old versions; this is only for 3.7+</p>
</li>
<li>
<p>sync_to_async and async_to_sync now have improved type hints that pass
through the underlying function type correctly.</p>
</li>
<li>
<p>All Websocket* types are now spelled WebSocket, to match our specs and the
official spelling. The old names will work until release 3.5.0, but will
raise deprecation warnings.</p>
</li>
<li>
<p>The typing for WebSocketScope and HTTPScope's <code>extensions</code> key has been
fixed.</p>
</li>
</ul>
</blockquote>
</details>
<details>
<summary>Commits</summary>
<ul>
<li>See full diff in <a href="https://github.com/django/asgiref/commits">compare view</a></li>
</ul>
</details>
<br />
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- `@dependabot ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
</details>
|
https://api.github.com/repos/pallets/flask/pulls/4183
|
2021-07-01T08:03:15Z
|
2021-07-01T10:05:48Z
|
2021-07-01T10:05:48Z
|
2021-07-16T00:02:24Z
| 245
|
pallets/flask
| 20,764
|
[keras/layers/pooling] Standardise docstring usage of "Default to"
|
diff --git a/keras/layers/pooling/average_pooling2d.py b/keras/layers/pooling/average_pooling2d.py
index b818ed7e3a8..662ec99016e 100644
--- a/keras/layers/pooling/average_pooling2d.py
+++ b/keras/layers/pooling/average_pooling2d.py
@@ -108,9 +108,10 @@ class AveragePooling2D(Pooling2D):
`(batch, height, width, channels)` while `channels_first`
corresponds to inputs with shape
`(batch, channels, height, width)`.
- It defaults to the `image_data_format` value found in your
- Keras config file at `~/.keras/keras.json`.
- If you never set it, then it will be "channels_last".
+ When unspecified, uses
+ `image_data_format` value found in your Keras config file at
+ `~/.keras/keras.json` (if exists) else 'channels_last'.
+ Defaults to 'channels_last'.
Input shape:
- If `data_format='channels_last'`:
diff --git a/keras/layers/pooling/average_pooling3d.py b/keras/layers/pooling/average_pooling3d.py
index 41faa234aeb..9d1177e6c68 100644
--- a/keras/layers/pooling/average_pooling3d.py
+++ b/keras/layers/pooling/average_pooling3d.py
@@ -48,9 +48,10 @@ class AveragePooling3D(Pooling3D):
`(batch, spatial_dim1, spatial_dim2, spatial_dim3, channels)`
while `channels_first` corresponds to inputs with shape
`(batch, channels, spatial_dim1, spatial_dim2, spatial_dim3)`.
- It defaults to the `image_data_format` value found in your
- Keras config file at `~/.keras/keras.json`.
- If you never set it, then it will be "channels_last".
+ When unspecified, uses
+ `image_data_format` value found in your Keras config file at
+ `~/.keras/keras.json` (if exists) else 'channels_last'.
+ Defaults to 'channels_last'.
Input shape:
- If `data_format='channels_last'`:
diff --git a/keras/layers/pooling/global_average_pooling2d.py b/keras/layers/pooling/global_average_pooling2d.py
index beb7038122c..e219e241408 100644
--- a/keras/layers/pooling/global_average_pooling2d.py
+++ b/keras/layers/pooling/global_average_pooling2d.py
@@ -44,9 +44,9 @@ class GlobalAveragePooling2D(GlobalPooling2D):
`(batch, height, width, channels)` while `channels_first`
corresponds to inputs with shape
`(batch, channels, height, width)`.
- It defaults to the `image_data_format` value found in your
- Keras config file at `~/.keras/keras.json`.
- If you never set it, then it will be "channels_last".
+ When unspecified, uses `image_data_format` value found
+ in your Keras config file at `~/.keras/keras.json`
+ (if exists) else 'channels_last'. Defaults to 'channels_last'.
keepdims: A boolean, whether to keep the spatial dimensions or not.
If `keepdims` is `False` (default), the rank of the tensor is reduced
for spatial dimensions.
diff --git a/keras/layers/pooling/global_average_pooling3d.py b/keras/layers/pooling/global_average_pooling3d.py
index b2819c55164..04b95667ed8 100644
--- a/keras/layers/pooling/global_average_pooling3d.py
+++ b/keras/layers/pooling/global_average_pooling3d.py
@@ -36,9 +36,10 @@ class GlobalAveragePooling3D(GlobalPooling3D):
`(batch, spatial_dim1, spatial_dim2, spatial_dim3, channels)`
while `channels_first` corresponds to inputs with shape
`(batch, channels, spatial_dim1, spatial_dim2, spatial_dim3)`.
- It defaults to the `image_data_format` value found in your
- Keras config file at `~/.keras/keras.json`.
- If you never set it, then it will be "channels_last".
+ When unspecified, uses
+ `image_data_format` value found in your Keras config file at
+ `~/.keras/keras.json` (if exists) else 'channels_last'.
+ Defaults to 'channels_last'.
keepdims: A boolean, whether to keep the spatial dimensions or not.
If `keepdims` is `False` (default), the rank of the tensor is reduced
for spatial dimensions.
diff --git a/keras/layers/pooling/global_max_pooling2d.py b/keras/layers/pooling/global_max_pooling2d.py
index 3ef2ee74a54..77ef11b3abd 100644
--- a/keras/layers/pooling/global_max_pooling2d.py
+++ b/keras/layers/pooling/global_max_pooling2d.py
@@ -42,9 +42,10 @@ class GlobalMaxPooling2D(GlobalPooling2D):
`(batch, height, width, channels)` while `channels_first`
corresponds to inputs with shape
`(batch, channels, height, width)`.
- It defaults to the `image_data_format` value found in your
- Keras config file at `~/.keras/keras.json`.
- If you never set it, then it will be "channels_last".
+ When unspecified, uses
+ `image_data_format` value found in your Keras config file at
+ `~/.keras/keras.json` (if exists) else 'channels_last'.
+ Defaults to 'channels_last'.
keepdims: A boolean, whether to keep the spatial dimensions or not.
If `keepdims` is `False` (default), the rank of the tensor is reduced
for spatial dimensions.
diff --git a/keras/layers/pooling/global_max_pooling3d.py b/keras/layers/pooling/global_max_pooling3d.py
index ee153d9c3cd..f5385fc9b41 100644
--- a/keras/layers/pooling/global_max_pooling3d.py
+++ b/keras/layers/pooling/global_max_pooling3d.py
@@ -34,9 +34,10 @@ class GlobalMaxPooling3D(GlobalPooling3D):
`(batch, spatial_dim1, spatial_dim2, spatial_dim3, channels)`
while `channels_first` corresponds to inputs with shape
`(batch, channels, spatial_dim1, spatial_dim2, spatial_dim3)`.
- It defaults to the `image_data_format` value found in your
- Keras config file at `~/.keras/keras.json`.
- If you never set it, then it will be "channels_last".
+ When unspecified, uses
+ `image_data_format` value found in your Keras config file at
+ `~/.keras/keras.json` (if exists) else 'channels_last'.
+ Defaults to 'channels_last'.
keepdims: A boolean, whether to keep the spatial dimensions or not.
If `keepdims` is `False` (default), the rank of the tensor is reduced
for spatial dimensions.
diff --git a/keras/layers/pooling/max_pooling2d.py b/keras/layers/pooling/max_pooling2d.py
index 7378d3d91a9..f21ab07f214 100644
--- a/keras/layers/pooling/max_pooling2d.py
+++ b/keras/layers/pooling/max_pooling2d.py
@@ -127,9 +127,10 @@ class MaxPooling2D(Pooling2D):
`(batch, height, width, channels)` while `channels_first`
corresponds to inputs with shape
`(batch, channels, height, width)`.
- It defaults to the `image_data_format` value found in your
- Keras config file at `~/.keras/keras.json`.
- If you never set it, then it will be "channels_last".
+ When unspecified, uses
+ `image_data_format` value found in your Keras config file at
+ `~/.keras/keras.json` (if exists) else 'channels_last'.
+ Defaults to 'channels_last'.
Input shape:
- If `data_format='channels_last'`:
diff --git a/keras/layers/pooling/max_pooling3d.py b/keras/layers/pooling/max_pooling3d.py
index b0455dbf4d4..64b2575732e 100644
--- a/keras/layers/pooling/max_pooling3d.py
+++ b/keras/layers/pooling/max_pooling3d.py
@@ -48,9 +48,10 @@ class MaxPooling3D(Pooling3D):
`(batch, spatial_dim1, spatial_dim2, spatial_dim3, channels)`
while `channels_first` corresponds to inputs with shape
`(batch, channels, spatial_dim1, spatial_dim2, spatial_dim3)`.
- It defaults to the `image_data_format` value found in your
- Keras config file at `~/.keras/keras.json`.
- If you never set it, then it will be "channels_last".
+ When unspecified, uses
+ `image_data_format` value found in your Keras config file at
+ `~/.keras/keras.json` (if exists) else 'channels_last'.
+ Defaults to 'channels_last'.
Input shape:
- If `data_format='channels_last'`:
|
This is one of many PRs. Discussion + request to split into multiple PRs @ #17748
|
https://api.github.com/repos/keras-team/keras/pulls/17966
|
2023-04-13T01:03:19Z
|
2023-05-31T00:34:14Z
|
2023-05-31T00:34:14Z
|
2023-05-31T00:34:14Z
| 2,269
|
keras-team/keras
| 47,444
|
Add smugmug
|
diff --git a/sherlock/resources/data.json b/sherlock/resources/data.json
index 703b7ffda..917b82218 100644
--- a/sherlock/resources/data.json
+++ b/sherlock/resources/data.json
@@ -1640,6 +1640,12 @@
"urlMain": "https://slides.com/",
"username_claimed": "blue"
},
+ "SmugMug": {
+ "errorType": "status_code",
+ "url": "https://{}.smugmug.com",
+ "urlMain": "https://.smugmug.com",
+ "username_claimed": "winchester"
+ },
"Smule": {
"errorMsg": "Smule | Page Not Found (404)",
"errorType": "message",
diff --git a/sites.md b/sites.md
index 92885980f..c152b4c7a 100644
--- a/sites.md
+++ b/sites.md
@@ -1,4 +1,4 @@
-## List Of Supported Sites (381 Sites In Total!)
+## List Of Supported Sites (382 Sites In Total!)
1.  [2Dimensions](https://2Dimensions.com/)
1.  [3dnews](http://forum.3dnews.ru/)
1.  [7Cups](https://www.7cups.com/)
@@ -241,6 +241,7 @@
1.  [Slashdot](https://slashdot.org)
1.  [SlideShare](https://slideshare.net/)
1.  [Slides](https://slides.com/)
+1.  [SmugMug](https://.smugmug.com)
1.  [Smule](https://www.smule.com/)
1.  [Snapchat](https://www.snapchat.com)
1.  [SoundCloud](https://soundcloud.com/)
|
https://api.github.com/repos/sherlock-project/sherlock/pulls/1692
|
2023-02-16T20:08:13Z
|
2023-02-16T20:14:49Z
|
2023-02-16T20:14:49Z
|
2023-02-16T20:15:29Z
| 614
|
sherlock-project/sherlock
| 36,233
|
|
Add `gnupg` to Dockerfile-cpu
|
diff --git a/utils/docker/Dockerfile-cpu b/utils/docker/Dockerfile-cpu
index d6fac645dba..f3f81ec02c2 100644
--- a/utils/docker/Dockerfile-cpu
+++ b/utils/docker/Dockerfile-cpu
@@ -11,7 +11,7 @@ ADD https://ultralytics.com/assets/Arial.ttf https://ultralytics.com/assets/Aria
# Install linux packages
RUN apt update
RUN DEBIAN_FRONTEND=noninteractive TZ=Etc/UTC apt install -y tzdata
-RUN apt install --no-install-recommends -y python3-pip git zip curl htop libgl1-mesa-glx libglib2.0-0 libpython3-dev
+RUN apt install --no-install-recommends -y python3-pip git zip curl htop libgl1-mesa-glx libglib2.0-0 libpython3-dev gnupg
# RUN alias python=python3
# Install pip packages
|
Signed-off-by: Glenn Jocher <[email protected]>
<!--
Thank you for submitting a YOLOv5 🚀 Pull Request! We want to make contributing to YOLOv5 as easy and transparent as possible. A few tips to get you started:
- Search existing YOLOv5 [PRs](https://github.com/ultralytics/yolov5/pull) to see if a similar PR already exists.
- Link this PR to a YOLOv5 [issue](https://github.com/ultralytics/yolov5/issues) to help us understand what bug fix or feature is being implemented.
- Provide before and after profiling/inference/training results to help us quantify the improvement your PR provides (if applicable).
Please see our ✅ [Contributing Guide](https://github.com/ultralytics/yolov5/blob/master/CONTRIBUTING.md) for more details.
-->
## 🛠️ PR Summary
<sub>Made with ❤️ by [Ultralytics Actions](https://github.com/ultralytics/actions)<sub>
### 🌟 Summary
Update to YOLOv5's CPU Dockerfile to include `gnupg` package.
### 📊 Key Changes
- Addition of the `gnupg` package to the Dockerfile used for CPU-based installations.
### 🎯 Purpose & Impact
- **Purpose**: The `gnupg` package is used for encryption and signing data and communications. Its inclusion in the Dockerfile indicates a need for security features that can enforce authenticity or confidentiality in certain operations within the YOLOv5 environment.
- **Impact**: Users leveraging the Docker container for YOLOv5 on CPU systems will now have additional cryptographic capabilities, allowing for enhanced security measures when needed. This change might be in preparation for future features that require secure data transactions or verification of data integrity.
|
https://api.github.com/repos/ultralytics/yolov5/pulls/9932
|
2022-10-26T11:42:41Z
|
2022-10-26T11:42:52Z
|
2022-10-26T11:42:52Z
|
2024-01-19T04:48:06Z
| 219
|
ultralytics/yolov5
| 25,691
|
[MRG] Make modules private in feature_selection
|
diff --git a/.gitignore b/.gitignore
index e1c663693a43a..9b158da07a2ec 100644
--- a/.gitignore
+++ b/.gitignore
@@ -223,3 +223,10 @@ sklearn/semi_supervised/label_propagation.py
sklearn/preprocessing/data.py
sklearn/preprocessing/label.py
+
+sklearn/feature_selection/base.py
+sklearn/feature_selection/from_model.py
+sklearn/feature_selection/mutual_info.py
+sklearn/feature_selection/rfe.py
+sklearn/feature_selection/univariate_selection.py
+sklearn/feature_selection/variance_threshold.py
diff --git a/sklearn/_build_utils/deprecated_modules.py b/sklearn/_build_utils/deprecated_modules.py
index ccd18461a2008..e5963dcdf297a 100644
--- a/sklearn/_build_utils/deprecated_modules.py
+++ b/sklearn/_build_utils/deprecated_modules.py
@@ -248,6 +248,21 @@
('_label', 'sklearn.preprocessing.label', 'sklearn.preprocessing',
'LabelEncoder'),
+ ('_base', 'sklearn.feature_selection.base', 'sklearn.feature_selection',
+ 'SelectorMixin'),
+ ('_from_model', 'sklearn.feature_selection.from_model',
+ 'sklearn.feature_selection', 'SelectFromModel'),
+ ('_mutual_info', 'sklearn.feature_selection.mutual_info',
+ 'sklearn.feature_selection', 'mutual_info_regression'),
+ ('_rfe', 'sklearn.feature_selection.rfe',
+ 'sklearn.feature_selection.rfe', 'RFE'),
+ ('_univariate_selection',
+ 'sklearn.feature_selection.univariate_selection',
+ 'sklearn.feature_selection', 'chi2'),
+ ('_variance_threshold',
+ 'sklearn.feature_selection.variance_threshold',
+ 'sklearn.feature_selection', 'VarianceThreshold'),
+
('_testing', 'sklearn.utils.testing', 'sklearn.utils',
'all_estimators'),
]
diff --git a/sklearn/feature_selection/__init__.py b/sklearn/feature_selection/__init__.py
index ffa392b5b26db..f8bda21a5813d 100644
--- a/sklearn/feature_selection/__init__.py
+++ b/sklearn/feature_selection/__init__.py
@@ -4,25 +4,25 @@
recursive feature elimination algorithm.
"""
-from .univariate_selection import chi2
-from .univariate_selection import f_classif
-from .univariate_selection import f_oneway
-from .univariate_selection import f_regression
-from .univariate_selection import SelectPercentile
-from .univariate_selection import SelectKBest
-from .univariate_selection import SelectFpr
-from .univariate_selection import SelectFdr
-from .univariate_selection import SelectFwe
-from .univariate_selection import GenericUnivariateSelect
+from ._univariate_selection import chi2
+from ._univariate_selection import f_classif
+from ._univariate_selection import f_oneway
+from ._univariate_selection import f_regression
+from ._univariate_selection import SelectPercentile
+from ._univariate_selection import SelectKBest
+from ._univariate_selection import SelectFpr
+from ._univariate_selection import SelectFdr
+from ._univariate_selection import SelectFwe
+from ._univariate_selection import GenericUnivariateSelect
-from .variance_threshold import VarianceThreshold
+from ._variance_threshold import VarianceThreshold
-from .rfe import RFE
-from .rfe import RFECV
+from ._rfe import RFE
+from ._rfe import RFECV
-from .from_model import SelectFromModel
+from ._from_model import SelectFromModel
-from .mutual_info_ import mutual_info_regression, mutual_info_classif
+from ._mutual_info import mutual_info_regression, mutual_info_classif
__all__ = ['GenericUnivariateSelect',
diff --git a/sklearn/feature_selection/base.py b/sklearn/feature_selection/_base.py
similarity index 100%
rename from sklearn/feature_selection/base.py
rename to sklearn/feature_selection/_base.py
diff --git a/sklearn/feature_selection/from_model.py b/sklearn/feature_selection/_from_model.py
similarity index 99%
rename from sklearn/feature_selection/from_model.py
rename to sklearn/feature_selection/_from_model.py
index 2ab69184a3895..3e324fbec5535 100644
--- a/sklearn/feature_selection/from_model.py
+++ b/sklearn/feature_selection/_from_model.py
@@ -4,7 +4,7 @@
import numpy as np
import numbers
-from .base import SelectorMixin
+from ._base import SelectorMixin
from ..base import BaseEstimator, clone, MetaEstimatorMixin
from ..exceptions import NotFittedError
diff --git a/sklearn/feature_selection/mutual_info_.py b/sklearn/feature_selection/_mutual_info.py
similarity index 100%
rename from sklearn/feature_selection/mutual_info_.py
rename to sklearn/feature_selection/_mutual_info.py
diff --git a/sklearn/feature_selection/rfe.py b/sklearn/feature_selection/_rfe.py
similarity index 99%
rename from sklearn/feature_selection/rfe.py
rename to sklearn/feature_selection/_rfe.py
index 818af920f7616..86362f27ef181 100644
--- a/sklearn/feature_selection/rfe.py
+++ b/sklearn/feature_selection/_rfe.py
@@ -20,7 +20,7 @@
from ..model_selection import check_cv
from ..model_selection._validation import _score
from ..metrics import check_scoring
-from .base import SelectorMixin
+from ._base import SelectorMixin
def _rfe_single_fit(rfe, estimator, X, y, train, test, scorer):
diff --git a/sklearn/feature_selection/univariate_selection.py b/sklearn/feature_selection/_univariate_selection.py
similarity index 99%
rename from sklearn/feature_selection/univariate_selection.py
rename to sklearn/feature_selection/_univariate_selection.py
index 0be1dadbcafea..21990bb3a8167 100644
--- a/sklearn/feature_selection/univariate_selection.py
+++ b/sklearn/feature_selection/_univariate_selection.py
@@ -17,7 +17,7 @@
safe_mask)
from ..utils.extmath import safe_sparse_dot, row_norms
from ..utils.validation import check_is_fitted
-from .base import SelectorMixin
+from ._base import SelectorMixin
def _clean_nans(scores):
diff --git a/sklearn/feature_selection/variance_threshold.py b/sklearn/feature_selection/_variance_threshold.py
similarity index 98%
rename from sklearn/feature_selection/variance_threshold.py
rename to sklearn/feature_selection/_variance_threshold.py
index 62323f1ff2ec8..15576fe31025c 100644
--- a/sklearn/feature_selection/variance_threshold.py
+++ b/sklearn/feature_selection/_variance_threshold.py
@@ -3,7 +3,7 @@
import numpy as np
from ..base import BaseEstimator
-from .base import SelectorMixin
+from ._base import SelectorMixin
from ..utils import check_array
from ..utils.sparsefuncs import mean_variance_axis, min_max_axis
from ..utils.validation import check_is_fitted
diff --git a/sklearn/feature_selection/tests/test_base.py b/sklearn/feature_selection/tests/test_base.py
index 428528ad75b28..d1aaccde0efa3 100644
--- a/sklearn/feature_selection/tests/test_base.py
+++ b/sklearn/feature_selection/tests/test_base.py
@@ -5,7 +5,7 @@
from numpy.testing import assert_array_equal
from sklearn.base import BaseEstimator
-from sklearn.feature_selection.base import SelectorMixin
+from sklearn.feature_selection._base import SelectorMixin
from sklearn.utils import check_array
diff --git a/sklearn/feature_selection/tests/test_chi2.py b/sklearn/feature_selection/tests/test_chi2.py
index 232d31f81b76e..29a027bdb27a2 100644
--- a/sklearn/feature_selection/tests/test_chi2.py
+++ b/sklearn/feature_selection/tests/test_chi2.py
@@ -11,7 +11,7 @@
import scipy.stats
from sklearn.feature_selection import SelectKBest, chi2
-from sklearn.feature_selection.univariate_selection import _chisquare
+from sklearn.feature_selection._univariate_selection import _chisquare
from sklearn.utils._testing import assert_array_almost_equal
from sklearn.utils._testing import assert_array_equal
diff --git a/sklearn/feature_selection/tests/test_mutual_info.py b/sklearn/feature_selection/tests/test_mutual_info.py
index a431a64a4f17d..ca2459f365ba4 100644
--- a/sklearn/feature_selection/tests/test_mutual_info.py
+++ b/sklearn/feature_selection/tests/test_mutual_info.py
@@ -5,8 +5,9 @@
from sklearn.utils import check_random_state
from sklearn.utils._testing import assert_array_equal, assert_almost_equal
-from sklearn.feature_selection.mutual_info_ import (
- mutual_info_regression, mutual_info_classif, _compute_mi)
+from sklearn.feature_selection._mutual_info import _compute_mi
+from sklearn.feature_selection import (mutual_info_regression,
+ mutual_info_classif)
def test_compute_mi_dd():
diff --git a/sklearn/feature_selection/tests/test_rfe.py b/sklearn/feature_selection/tests/test_rfe.py
index 22720b7caa3a5..724c749ee636b 100644
--- a/sklearn/feature_selection/tests/test_rfe.py
+++ b/sklearn/feature_selection/tests/test_rfe.py
@@ -6,7 +6,7 @@
from numpy.testing import assert_array_almost_equal, assert_array_equal
from scipy import sparse
-from sklearn.feature_selection.rfe import RFE, RFECV
+from sklearn.feature_selection import RFE, RFECV
from sklearn.datasets import load_iris, make_friedman1
from sklearn.metrics import zero_one_loss
from sklearn.svm import SVC, SVR
|
<!--
Thanks for contributing a pull request! Please ensure you have taken a look at
the contribution guidelines: https://github.com/scikit-learn/scikit-learn/blob/master/CONTRIBUTING.md#pull-request-checklist
-->
#### Reference Issues/PRs
<!--
Example: Fixes #1234. See also #3456.
Please use keywords (e.g., Fixes) to create link to the issues or pull requests
you resolved, so that they will automatically be closed when your pull request
is merged. See https://github.com/blog/1506-closing-issues-via-pull-requests
-->
Partially addresses https://github.com/scikit-learn/scikit-learn/issues/9250
#### Any other comments?
CC @NicolasHug @adrinjalali
<!--
Please be aware that we are a loose team of volunteers so patience is
necessary; assistance handling other issues is very welcome. We value
all user contributions, no matter how minor they are. If we are slow to
review, either the pull request needs some benchmarking, tinkering,
convincing, etc. or more likely the reviewers are simply busy. In either
case, we ask for your understanding during the review process.
For more information, see our FAQ on this topic:
http://scikit-learn.org/dev/faq.html#why-is-my-pull-request-not-getting-any-attention.
Thanks for contributing!
-->
|
https://api.github.com/repos/scikit-learn/scikit-learn/pulls/15376
|
2019-10-28T14:38:52Z
|
2019-10-29T03:00:33Z
|
2019-10-29T03:00:33Z
|
2019-10-29T03:00:33Z
| 2,264
|
scikit-learn/scikit-learn
| 46,564
|
Several Training Enhancements
|
diff --git a/modules/training.py b/modules/training.py
index e629d86eb7..c98cfc3bbe 100644
--- a/modules/training.py
+++ b/modules/training.py
@@ -38,20 +38,21 @@
MODEL_CLASSES = {v: k for k, v in MODEL_FOR_CAUSAL_LM_MAPPING_NAMES}
except:
standard_modules = ["q_proj", "v_proj"]
- model_to_lora_modules = {"llama": standard_modules, "opt": standard_modules, "gptj": standard_modules, "gpt_neox": ["query_key_value"], "rw":["query_key_value"]}
+ model_to_lora_modules = {"llama": standard_modules, "opt": standard_modules, "gptj": standard_modules, "gpt_neox": ["query_key_value"], "rw": ["query_key_value"]}
MODEL_CLASSES = {
"LlamaForCausalLM": "llama",
"OPTForCausalLM": "opt",
"GPTJForCausalLM": "gptj",
"GPTNeoXForCausalLM": "gpt_neox",
"RWForCausalLM": "rw"
-
+
}
train_log = {}
+train_template = {}
WANT_INTERRUPT = False
-PARAMETERS = ["lora_name", "always_override", "save_steps", "micro_batch_size", "batch_size", "epochs", "learning_rate", "lr_scheduler_type", "lora_rank", "lora_alpha", "lora_dropout", "cutoff_len", "dataset", "eval_dataset", "format", "eval_steps", "raw_text_file", "overlap_len", "newline_favor_len", "higher_rank_limit", "warmup_steps", "optimizer", "hard_cut_string", "train_only_after"]
+PARAMETERS = ["lora_name", "always_override", "save_steps", "micro_batch_size", "batch_size", "epochs", "learning_rate", "lr_scheduler_type", "lora_rank", "lora_alpha", "lora_dropout", "cutoff_len", "dataset", "eval_dataset", "format", "eval_steps", "raw_text_file", "overlap_len", "newline_favor_len", "higher_rank_limit", "warmup_steps", "optimizer", "hard_cut_string", "train_only_after", "stop_at_loss"]
def create_train_interface():
@@ -109,6 +110,7 @@ def create_train_interface():
warmup_steps = gr.Number(label='Warmup Steps', value=100, info='For this many steps at the start, the learning rate will be lower than normal. This helps the trainer prepare the model and precompute statistics to improve the quality of training after the start.')
optimizer = gr.Dropdown(label='Optimizer', value='adamw_torch', choices=['adamw_hf', 'adamw_torch', 'adamw_torch_fused', 'adamw_torch_xla', 'adamw_apex_fused', 'adafactor', 'adamw_bnb_8bit', 'adamw_anyprecision', 'sgd', 'adagrad'], info='Different optimizer implementation options, for advanced users. Effects of different options are not well documented yet.')
train_only_after = gr.Textbox(label='Train Only After', value='', info='Only consider text *after* this string in any given chunk for training. For Alpaca datasets, use "### Response:" to only train the response and ignore the input.')
+ stop_at_loss = gr.Slider(label='Stop at loss', minimum=0.0, maximum=3.0, step=0.1, value=0.00, info='The process will automatically stop once the desired loss value is reached. (reasonable numbers are 1.5-1.8)')
with gr.Row():
higher_rank_limit = gr.Checkbox(label='Enable higher ranks', value=False, info='If checked, changes Rank/Alpha slider above to go much higher. This will not work without a datacenter-class GPU.')
@@ -142,7 +144,7 @@ def create_train_interface():
refresh_table = gr.Button('Refresh the table', elem_classes="small-button")
# Training events
- all_params = [lora_name, always_override, save_steps, micro_batch_size, batch_size, epochs, learning_rate, lr_scheduler_type, lora_rank, lora_alpha, lora_dropout, cutoff_len, dataset, eval_dataset, format, eval_steps, raw_text_file, overlap_len, newline_favor_len, higher_rank_limit, warmup_steps, optimizer, hard_cut_string, train_only_after]
+ all_params = [lora_name, always_override, save_steps, micro_batch_size, batch_size, epochs, learning_rate, lr_scheduler_type, lora_rank, lora_alpha, lora_dropout, cutoff_len, dataset, eval_dataset, format, eval_steps, raw_text_file, overlap_len, newline_favor_len, higher_rank_limit, warmup_steps, optimizer, hard_cut_string, train_only_after, stop_at_loss]
copy_from.change(do_copy_params, [copy_from] + all_params, all_params)
start_button.click(do_train, all_params, output)
stop_button.click(do_interrupt, None, None, queue=False)
@@ -206,7 +208,7 @@ def clean_path(base_path: str, path: str):
return f'{Path(base_path).absolute()}/{path}'
-def do_train(lora_name: str, always_override: bool, save_steps: int, micro_batch_size: int, batch_size: int, epochs: int, learning_rate: str, lr_scheduler_type: str, lora_rank: int, lora_alpha: int, lora_dropout: float, cutoff_len: int, dataset: str, eval_dataset: str, format: str, eval_steps: int, raw_text_file: str, overlap_len: int, newline_favor_len: int, higher_rank_limit: bool, warmup_steps: int, optimizer: str, hard_cut_string: str, train_only_after: str):
+def do_train(lora_name: str, always_override: bool, save_steps: int, micro_batch_size: int, batch_size: int, epochs: int, learning_rate: str, lr_scheduler_type: str, lora_rank: int, lora_alpha: int, lora_dropout: float, cutoff_len: int, dataset: str, eval_dataset: str, format: str, eval_steps: int, raw_text_file: str, overlap_len: int, newline_favor_len: int, higher_rank_limit: bool, warmup_steps: int, optimizer: str, hard_cut_string: str, train_only_after: str, stop_at_loss: float):
if shared.args.monkey_patch:
from monkeypatch.peft_tuners_lora_monkey_patch import (
@@ -296,9 +298,14 @@ def tokenize(prompt):
"attention_mask": input_ids.ne(shared.tokenizer.pad_token_id),
}
+ train_template.clear()
+
# == Prep the dataset, format, etc ==
if raw_text_file not in ['None', '']:
logger.info("Loading raw text file dataset...")
+
+ train_template["template_type"] = "raw_text"
+
with open(clean_path('training/datasets', f'{raw_text_file}.txt'), 'r', encoding='utf-8') as file:
raw_text = file.read().replace('\r', '')
@@ -330,7 +337,6 @@ def tokenize(prompt):
train_data = Dataset.from_list([tokenize(x) for x in text_chunks])
del text_chunks
eval_data = None
-
else:
if dataset in ['None', '']:
yield "**Missing dataset choice input, cannot continue.**"
@@ -340,9 +346,16 @@ def tokenize(prompt):
yield "**Missing format choice input, cannot continue.**"
return
- with open(clean_path('training/formats', f'{format}.json'), 'r', encoding='utf-8') as formatFile:
+ train_template["template_type"] = "dataset"
+
+ with open(clean_path('training/formats', f'{format}.json'), 'r', encoding='utf-8-sig') as formatFile:
format_data: dict[str, str] = json.load(formatFile)
+ # == store training prompt ==
+ for _, value in format_data.items():
+ prompt_key = f"template_{len(train_template)}"
+ train_template[prompt_key] = value
+
def generate_prompt(data_point: dict[str, str]):
for options, data in format_data.items():
if set(options.split(',')) == set(x[0] for x in data_point.items() if (x[1] is not None and len(x[1].strip()) > 0)):
@@ -369,7 +382,7 @@ def generate_and_tokenize_prompt(data_point):
# == Start prepping the model itself ==
if not hasattr(shared.model, 'lm_head') or hasattr(shared.model.lm_head, 'weight'):
logger.info("Getting model ready...")
- prepare_model_for_kbit_training(shared.model)
+ prepare_model_for_int8_training(shared.model)
logger.info("Prepping for training...")
config = LoraConfig(
@@ -418,19 +431,32 @@ def on_step_begin(self, args: transformers.TrainingArguments, state: transformer
control.should_training_stop = True
elif state.global_step > 0 and actual_save_steps > 0 and state.global_step % actual_save_steps == 0:
lora_model.save_pretrained(f"{lora_file_path}/checkpoint-{tracked.current_steps}/")
- # Save log
+ # Save log
with open(f"{lora_file_path}/checkpoint-{tracked.current_steps}/training_log.json", 'w', encoding='utf-8') as file:
- json.dump(train_log, file, indent=2)
-
+ json.dump(train_log, file, indent=2)
+ # == Save training prompt ==
+ with open(f"{lora_file_path}/checkpoint-{tracked.current_steps}/training_prompt.json", 'w', encoding='utf-8') as file:
+ json.dump(train_template, file, indent=2)
def on_substep_end(self, args: transformers.TrainingArguments, state: transformers.TrainerState, control: transformers.TrainerControl, **kwargs):
tracked.current_steps += 1
if WANT_INTERRUPT:
control.should_epoch_stop = True
control.should_training_stop = True
-
+
def on_log(self, args: transformers.TrainingArguments, state: transformers.TrainerState, control: transformers.TrainerControl, logs, **kwargs):
train_log.update(logs)
+ train_log.update({"current_steps": tracked.current_steps})
+ if WANT_INTERRUPT:
+ print("\033[1;31;1mInterrupted by user\033[0;37;0m")
+
+ print(f"\033[1;30;40mStep: {tracked.current_steps} \033[0;37;0m", end='')
+ if 'loss' in logs:
+ loss = float(logs['loss'])
+ if loss <= stop_at_loss:
+ control.should_epoch_stop = True
+ control.should_training_stop = True
+ print(f"\033[1;31;1mStop Loss {stop_at_loss} reached.\033[0;37;0m")
trainer = transformers.Trainer(
model=lora_model,
@@ -444,7 +470,7 @@ def on_log(self, args: transformers.TrainingArguments, state: transformers.Train
learning_rate=actual_lr,
fp16=False if shared.args.cpu else True,
optim=optimizer,
- logging_steps=5,
+ logging_steps=2 if stop_at_loss > 0 else 5,
evaluation_strategy="steps" if eval_data is not None else "no",
eval_steps=math.ceil(eval_steps / gradient_accumulation_steps) if eval_data is not None else None,
save_strategy="steps" if eval_data is not None else "no",
@@ -469,9 +495,22 @@ def on_log(self, args: transformers.TrainingArguments, state: transformers.Train
vars = locals()
json.dump({x: vars[x] for x in PARAMETERS}, file, indent=2)
+ # == Save training prompt ==
+ with open(f"{lora_file_path}/training_prompt.json", 'w', encoding='utf-8') as file:
+ json.dump(train_template, file, indent=2)
+
# == Main run and monitor loop ==
logger.info("Starting training...")
yield "Starting..."
+
+ train_log.update({"base_model_name": shared.model_name})
+ train_log.update({"base_model_class": shared.model.__class__.__name__})
+ train_log.update({"base_loaded_in_4bit": getattr(lora_model, "is_loaded_in_4bit", False)})
+ train_log.update({"base_loaded_in_8bit": getattr(lora_model, "is_loaded_in_8bit", False)})
+
+ if stop_at_loss > 0:
+ print(f"Monitoring loss \033[1;31;1m(Auto-Stop at: {stop_at_loss})\033[0;37;0m")
+
if WANT_INTERRUPT:
yield "Interrupted before start."
return
|
- more relevant data in training_log.json
- saves training_prompt.json to the LoRA folder with the prompt template used for LoRA training (in case of dataset)
- adds stop at loss slider to ui
- some minor cosmetics
all has been tested over several days
|
https://api.github.com/repos/oobabooga/text-generation-webui/pulls/2868
|
2023-06-25T18:21:40Z
|
2023-06-25T18:34:46Z
|
2023-06-25T18:34:46Z
|
2023-06-25T18:35:21Z
| 2,867
|
oobabooga/text-generation-webui
| 26,133
|
Removed Calendar Index (acquired by Calendarific)
|
diff --git a/README.md b/README.md
index e77ff0700b..1052e3d71c 100644
--- a/README.md
+++ b/README.md
@@ -294,7 +294,6 @@ API | Description | Auth | HTTPS | CORS |
API | Description | Auth | HTTPS | CORS |
|---|---|---|---|---|
| [Abstract Public Holidays](https://www.abstractapi.com/holidays-api) | Data on national, regional, and religious holidays via API | `apiKey` | Yes | Yes |
-| [Calendar Index](https://www.calendarindex.com/) | Worldwide Holidays and Working Days | `apiKey` | Yes | Yes |
| [Calendarific](https://calendarific.com/) | Worldwide Holidays | `apiKey` | Yes | Unknown |
| [Church Calendar](http://calapi.inadiutorium.cz/) | Catholic liturgical calendar | No | No | Unknown |
| [Czech Namedays Calendar](https://svatky.adresa.info) | Lookup for a name and returns nameday date | No | No | Unknown |
|
Removed Calendar Index to reflect acquisition by Calendarific (already listed).
<!-- Thank you for taking the time to work on a Pull Request for this project! -->
<!-- To ensure your PR is dealt with swiftly please check the following: -->
- [x] My submission is formatted according to the guidelines in the [contributing guide](/CONTRIBUTING.md)
- [x] My addition is ordered alphabetically
- [x] My submission has a useful description
- [x] The description does not have more than 100 characters
- [x] The description does not end with punctuation
- [x] Each table column is padded with one space on either side
- [x] I have searched the repository for any relevant issues or pull requests
- [x] Any category I am creating has the minimum requirement of 3 items
- [x] All changes have been [squashed][squash-link] into a single commit
[squash-link]: <https://github.com/todotxt/todo.txt-android/wiki/Squash-All-Commits-Related-to-a-Single-Issue-into-a-Single-Commit>
|
https://api.github.com/repos/public-apis/public-apis/pulls/2967
|
2021-12-21T22:22:21Z
|
2021-12-22T08:43:08Z
|
2021-12-22T08:43:08Z
|
2021-12-22T16:05:58Z
| 233
|
public-apis/public-apis
| 35,638
|
Double max_rounds in auth_handler
|
diff --git a/certbot/auth_handler.py b/certbot/auth_handler.py
index 9d7c75f5707..caf112c6196 100644
--- a/certbot/auth_handler.py
+++ b/certbot/auth_handler.py
@@ -189,7 +189,7 @@ def _send_responses(self, aauthzrs, resps, chall_update):
return active_achalls
def _poll_challenges(self, aauthzrs, chall_update,
- best_effort, min_sleep=3, max_rounds=15):
+ best_effort, min_sleep=3, max_rounds=30):
"""Wait for all challenge results to be determined."""
indices_to_check = set(chall_update.keys())
comp_indices = set()
|
Increase the maximum number of times we'll poll the authorization in Certbot. I increased `max_rounds` instead of `min_sleep` to keep sleep time low when the server is able to respond quickly.
|
https://api.github.com/repos/certbot/certbot/pulls/5842
|
2018-04-09T23:22:47Z
|
2018-04-09T23:58:59Z
|
2018-04-09T23:58:59Z
|
2018-04-09T23:59:02Z
| 169
|
certbot/certbot
| 3,506
|
add related project
|
diff --git a/README.md b/README.md
index ffc13bffe0..2db1f0231b 100644
--- a/README.md
+++ b/README.md
@@ -241,6 +241,13 @@ for token in chat_completion:
<td><a href="https://github.com/mishalhossin/Discord-Chatbot-Gpt4Free/issues"><img alt="Issues" src="https://img.shields.io/github/issues/mishalhossin/Discord-Chatbot-Gpt4Free?style=flat-square&labelColor=343b41"/></a></td>
<td><a href="https://github.com/mishalhossin/Coding-Chatbot-Gpt4Free/pulls"><img alt="Pull Requests" src="https://img.shields.io/github/issues-pr/mishalhossin/Discord-Chatbot-Gpt4Free?style=flat-square&labelColor=343b41"/></a></td>
</tr>
+ <tr>
+ <td><a href="https://github.com/MIDORIBIN/langchain-gpt4free"><b>LangChain gpt4free</b></a></td>
+ <td><a href="https://github.com/MIDORIBIN/langchain-gpt4free/stargazers"><img alt="Stars" src="https://img.shields.io/github/stars/MIDORIBIN/langchain-gpt4free?style=flat-square&labelColor=343b41"/></a></td>
+ <td><a href="https://github.com/MIDORIBIN/langchain-gpt4free/network/members"><img alt="Forks" src="https://img.shields.io/github/forks/MIDORIBIN/langchain-gpt4free?style=flat-square&labelColor=343b41"/></a></td>
+ <td><a href="https://github.com/MIDORIBIN/langchain-gpt4free/issues"><img alt="Issues" src="https://img.shields.io/github/issues/MIDORIBIN/langchain-gpt4free?style=flat-square&labelColor=343b41"/></a></td>
+ <td><a href="https://github.com/MIDORIBIN/langchain-gpt4free/pulls"><img alt="Pull Requests" src="https://img.shields.io/github/issues-pr/MIDORIBIN/langchain-gpt4free?style=flat-square&labelColor=343b41"/></a></td>
+ </tr>
</tbody>
</table>
|
I created a project that uses gpt4free from langchain.
The link has been added.
https://github.com/MIDORIBIN/langchain-gpt4free
|
https://api.github.com/repos/xtekky/gpt4free/pulls/736
|
2023-07-10T00:18:43Z
|
2023-07-11T18:24:36Z
|
2023-07-11T18:24:36Z
|
2023-08-13T17:13:51Z
| 559
|
xtekky/gpt4free
| 37,901
|
ref(sampling): Remove error rules code - backend - [TET-103]
|
diff --git a/src/sentry/api/endpoints/project_details.py b/src/sentry/api/endpoints/project_details.py
index daf5da497c282..ed9164dda5539 100644
--- a/src/sentry/api/endpoints/project_details.py
+++ b/src/sentry/api/endpoints/project_details.py
@@ -441,12 +441,6 @@ def put(self, request: Request, project) -> Response:
"organizations:filters-and-sampling", project.organization, actor=request.user
)
- allow_dynamic_sampling_error_rules = features.has(
- "organizations:filters-and-sampling-error-rules",
- project.organization,
- actor=request.user,
- )
-
if not allow_dynamic_sampling and result.get("dynamicSampling"):
# trying to set dynamic sampling with feature disabled
return Response(
@@ -616,19 +610,6 @@ def put(self, request: Request, project) -> Response:
if "dynamicSampling" in result:
raw_dynamic_sampling = result["dynamicSampling"]
- if (
- not allow_dynamic_sampling_error_rules
- and self._dynamic_sampling_contains_error_rule(raw_dynamic_sampling)
- ):
- return Response(
- {
- "detail": [
- "Dynamic Sampling only accepts rules of type transaction or trace"
- ]
- },
- status=400,
- )
-
fixed_rules = self._fix_rule_ids(project, raw_dynamic_sampling)
project.update_option("sentry:dynamic_sampling", fixed_rules)
diff --git a/src/sentry/conf/server.py b/src/sentry/conf/server.py
index fe27a36c06a3f..fd07bdc5bcef7 100644
--- a/src/sentry/conf/server.py
+++ b/src/sentry/conf/server.py
@@ -951,8 +951,6 @@ def create_partitioned_queues(name):
"organizations:event-attachments": True,
# Enable Filters & Sampling in the org settings
"organizations:filters-and-sampling": False,
- # Enable Dynamic Sampling errors in the org settings
- "organizations:filters-and-sampling-error-rules": False,
# Allow organizations to configure all symbol sources.
"organizations:symbol-sources": True,
# Allow organizations to configure custom external symbol sources.
diff --git a/src/sentry/features/__init__.py b/src/sentry/features/__init__.py
index cf748cfcbb4bd..d24d1d3fdfd2a 100644
--- a/src/sentry/features/__init__.py
+++ b/src/sentry/features/__init__.py
@@ -70,7 +70,6 @@
default_manager.add("organizations:duplicate-alert-rule", OrganizationFeature, True)
default_manager.add("organizations:enterprise-perf", OrganizationFeature)
default_manager.add("organizations:filters-and-sampling", OrganizationFeature, True)
-default_manager.add("organizations:filters-and-sampling-error-rules", OrganizationFeature, True)
default_manager.add("organizations:grouping-stacktrace-ui", OrganizationFeature, True)
default_manager.add("organizations:grouping-title-ui", OrganizationFeature, True)
default_manager.add("organizations:grouping-tree-ui", OrganizationFeature, True)
|
continuation of PR https://github.com/getsentry/sentry/pull/35003
|
https://api.github.com/repos/getsentry/sentry/pulls/35105
|
2022-05-30T11:01:26Z
|
2022-05-30T12:15:55Z
|
2022-05-30T12:15:55Z
|
2022-06-14T12:20:31Z
| 678
|
getsentry/sentry
| 43,970
|
add evostra for python
|
diff --git a/README.md b/README.md
index 14980838..8540498c 100644
--- a/README.md
+++ b/README.md
@@ -1102,6 +1102,7 @@ be
* [Lightwood](https://github.com/mindsdb/lightwood) - A Pytorch based framework that breaks down machine learning problems into smaller blocks that can be glued together seamlessly with objective to build predictive models with one line of code.
* [bayeso](https://github.com/jungtaekkim/bayeso) - A simple, but essential Bayesian optimization package, written in Python.
* [mljar-supervised](https://github.com/mljar/mljar-supervised) - An Automated Machine Learning (AutoML) python package for tabular data. It can handle: Binary Classification, MultiClass Classification and Regression. It provides explanations and markdown reports.
+* [evostra](https://github.com/alirezamika/evostra) - A fast Evolution Strategy implementation in Python.
<a name="python-data-analysis"></a>
#### Data Analysis / Data Visualization
|
https://api.github.com/repos/josephmisiti/awesome-machine-learning/pulls/714
|
2020-09-02T16:22:47Z
|
2020-09-11T14:52:33Z
|
2020-09-11T14:52:33Z
|
2020-09-11T14:52:33Z
| 233
|
josephmisiti/awesome-machine-learning
| 52,448
|
|
Revert "Remove minimum-scale on viewport"
|
diff --git a/index.html b/index.html
index 62ded9f8b..c6db98650 100644
--- a/index.html
+++ b/index.html
@@ -3,7 +3,7 @@
<head>
<meta charset="utf-8">
- <meta name="viewport" content="width=device-width, initial-scale=1" />
+ <meta name="viewport" content="width=device-width, initial-scale=1, minimum-scale=1" />
<title>Comprehensive Python Cheatsheet</title>
<meta name="description" content="Exhaustive, simple, beautiful and concise. A truly pythonic cheat sheet about Python programming language.">
<link rel="icon" href="web/favicon.png">
diff --git a/web/template.html b/web/template.html
index 5314d72d7..7be57e0bc 100644
--- a/web/template.html
+++ b/web/template.html
@@ -3,7 +3,7 @@
<head>
<meta charset="utf-8">
- <meta name="viewport" content="width=device-width, initial-scale=1" />
+ <meta name="viewport" content="width=device-width, initial-scale=1, minimum-scale=1" />
<title>Comprehensive Python Cheatsheet</title>
<meta name="description" content="Exhaustive, simple, beautiful and concise. A truly pythonic cheat sheet about Python programming language.">
<link rel="icon" href="web/favicon.png">
|
Reverts gto76/python-cheatsheet#36
|
https://api.github.com/repos/gto76/python-cheatsheet/pulls/37
|
2019-07-11T23:13:45Z
|
2019-07-11T23:14:24Z
|
2019-07-11T23:14:24Z
|
2021-05-13T13:43:15Z
| 332
|
gto76/python-cheatsheet
| 38,394
|
Fix IndexError when using bitbucket
|
diff --git a/tests/rules/test_git_push.py b/tests/rules/test_git_push.py
index cf45f4e70..b6aa7c604 100644
--- a/tests/rules/test_git_push.py
+++ b/tests/rules/test_git_push.py
@@ -15,6 +15,19 @@ def output(branch_name):
'''.format(branch_name, branch_name)
[email protected]
+def output_bitbucket():
+ return '''Total 0 (delta 0), reused 0 (delta 0)
+remote:
+remote: Create pull request for feature/set-upstream:
+remote: https://bitbucket.org/set-upstream
+remote:
+To [email protected]:test.git
+ e5e7fbb..700d998 feature/set-upstream -> feature/set-upstream
+Branch feature/set-upstream set up to track remote branch feature/set-upstream from origin.
+'''
+
+
@pytest.mark.parametrize('script, branch_name', [
('git push', 'master'),
('git push origin', 'master')])
@@ -22,6 +35,10 @@ def test_match(output, script, branch_name):
assert match(Command(script, output))
+def test_match_bitbucket(output_bitbucket):
+ assert not match(Command('git push origin', output_bitbucket))
+
+
@pytest.mark.parametrize('script, branch_name', [
('git push master', None),
('ls', 'master')])
diff --git a/thefuck/rules/git_push.py b/thefuck/rules/git_push.py
index 551b25dea..cccee67cc 100644
--- a/thefuck/rules/git_push.py
+++ b/thefuck/rules/git_push.py
@@ -6,7 +6,7 @@
@git_support
def match(command):
return ('push' in command.script_parts
- and 'set-upstream' in command.output)
+ and 'git push --set-upstream' in command.output)
def _get_upstream_option_index(command_parts):
|
This should fix #723.
|
https://api.github.com/repos/nvbn/thefuck/pulls/759
|
2018-01-02T22:35:18Z
|
2018-01-06T22:44:04Z
|
2018-01-06T22:44:03Z
|
2018-01-06T22:44:04Z
| 429
|
nvbn/thefuck
| 30,693
|
Deprecate Auto ML Library
|
diff --git a/README.md b/README.md
index f913fd40..7c35a477 100644
--- a/README.md
+++ b/README.md
@@ -604,7 +604,7 @@ Read the paper [here](https://arxiv.org/abs/1902.06714).
<a name="javascript-general-purpose-machine-learning"></a>
#### General-Purpose Machine Learning
-* [Auto ML](https://github.com/ClimbsRocks/auto_ml) - Automated machine learning, data formatting, ensembling, and hyperparameter optimization for competitions and exploration- just give it a .csv file!
+* [Auto ML](https://github.com/ClimbsRocks/auto_ml) - Automated machine learning, data formatting, ensembling, and hyperparameter optimization for competitions and exploration- just give it a .csv file! **[Deprecated]**
* [Convnet.js](https://cs.stanford.edu/people/karpathy/convnetjs/) - ConvNetJS is a Javascript library for training Deep Learning models[DEEP LEARNING] **[Deprecated]**
* [Clusterfck](https://harthur.github.io/clusterfck/) - Agglomerative hierarchical clustering implemented in Javascript for Node.js and the browser. **[Deprecated]**
* [Clustering.js](https://github.com/emilbayes/clustering.js) - Clustering algorithms implemented in Javascript for Node.js and the browser. **[Deprecated]**
|
Add a deprecation note for Auto ML. Auto ML library (https://github.com/ClimbsRocks/auto_ml) is unmaintained.
|
https://api.github.com/repos/josephmisiti/awesome-machine-learning/pulls/836
|
2021-12-21T18:18:15Z
|
2022-01-10T15:06:49Z
|
2022-01-10T15:06:49Z
|
2022-01-12T17:19:11Z
| 306
|
josephmisiti/awesome-machine-learning
| 52,007
|
Using slicing technique checking for palindrome
|
diff --git a/Palindrome_Checker.py b/Palindrome_Checker.py
index bdf13fe7a7..c5827b21e6 100644
--- a/Palindrome_Checker.py
+++ b/Palindrome_Checker.py
@@ -1,50 +1,12 @@
-# AUTHOR: ekbalba
-# DESCRIPTION: A simple script which checks if a given phrase is a Palindrome
-# PALINDROME: A word, phrase, or sequence that reads the same backward as forward
-
-samplePhrase = "A man, a plan, a cat, a ham, a yak, a yam, a hat, a canal-Panama!"
-# givenPhrase = ""
-# phrase = ""
-
-givenPhrase = input("\nPlease input a phrase:(Press ENTER to use the sample phrase) ") #takes a phrase for input
-
-#if nothing in given as input then the sample phrase is stored in the variable phrase otherwise the given phrase if stored
-if givenPhrase == "":
- print("\nThe sample phrase is: {0}".format(samplePhrase))
- phrase = samplePhrase
-else:
- phrase = givenPhrase
-
-phrase = ''.join([c for c in phrase.lower() if c.isalpha() or c.isdigit()]) #converting all the characters of the phrase to the lowercase
-
-length_ = len(phrase) #returns the length of string
-bol_ = True
-
-# check using two pointers, one at beginning
-# other at the end. Use only half of the list.
-for items in range(length_ // 2):
- if phrase[items] != phrase[length_ - 1 - items]:
- print("\nSorry, The given phrase is not a Palindrome.")
- bol_ = False
- break
-
-if bol_ == True:
- print("\nWow!, The phrase is a Palindrome!")
-
-
-
-
-
-
"""
-Method #2:
-A simple mmethod is , to reverse the string and and compare with original string.
+A simple method is , to reverse the string and and compare with original string.
If both are same that's means string is palindrome otherwise else.
"""
-if phrase==phrase[::-1]:#slicing technique
+phrase = input()
+if phrase == phrase[::-1]: # slicing technique
"""phrase[::-1] this code is for reverse a string very smartly """
-
- print("\nBy Method 2: Wow!, The phrase is a Palindrome!")
+
+ print("\n Wow!, The phrase is a Palindrome!")
else:
- print("\nBy Method 2: Sorry, The given phrase is not a Palindrome.")
+ print("\n Sorry, The given phrase is not a Palindrome.")
|
https://api.github.com/repos/geekcomputers/Python/pulls/1258
|
2020-12-26T09:31:35Z
|
2020-12-26T12:31:43Z
|
2020-12-26T12:31:43Z
|
2020-12-26T12:31:43Z
| 601
|
geekcomputers/Python
| 31,214
|
|
Add serverconnection scripthook
|
diff --git a/.travis.yml b/.travis.yml
index 5f4a36020a..c108431995 100644
--- a/.travis.yml
+++ b/.travis.yml
@@ -3,8 +3,13 @@ python:
- "2.7"
# command to install dependencies, e.g. pip install -r requirements.txt --use-mirrors
install:
+ - "pip install coveralls --use-mirrors"
+ - "pip install nose-cov --use-mirrors"
- "pip install -r requirements.txt --use-mirrors"
- "pip install --upgrade git+https://github.com/mitmproxy/netlib.git"
- "pip install --upgrade git+https://github.com/mitmproxy/pathod.git"
# command to run tests, e.g. python setup.py test
-script: nosetests
\ No newline at end of file
+script:
+ - "nosetests --with-cov --cov-report term-missing"
+after_success:
+ - coveralls
\ No newline at end of file
diff --git a/README.mkd b/README.mkd
index 8f564d7ff5..35b41413d4 100644
--- a/README.mkd
+++ b/README.mkd
@@ -1,3 +1,5 @@
+[](https://travis-ci.org/mitmproxy/mitmproxy) [](https://coveralls.io/r/mitmproxy/mitmproxy)
+
__mitmproxy__ is an interactive, SSL-capable man-in-the-middle proxy for HTTP
with a console interface.
diff --git a/libmproxy/flow.py b/libmproxy/flow.py
index 2404281263..40b7e535b5 100644
--- a/libmproxy/flow.py
+++ b/libmproxy/flow.py
@@ -1580,6 +1580,13 @@ def handle_clientdisconnect(self, r):
self.run_script_hook("clientdisconnect", r)
r.reply()
+ def handle_serverconnection(self, sc):
+ # To unify the mitmproxy script API, we call the script hook "serverconnect" rather than "serverconnection".
+ # As things are handled differently in libmproxy (ClientConnect + ClientDisconnect vs ServerConnection class),
+ # there is no "serverdisonnect" event at the moment.
+ self.run_script_hook("serverconnect", sc)
+ sc.reply()
+
def handle_error(self, r):
f = self.state.add_error(r)
if f:
diff --git a/libmproxy/proxy.py b/libmproxy/proxy.py
index 75a5419201..94f358bcb6 100644
--- a/libmproxy/proxy.py
+++ b/libmproxy/proxy.py
@@ -158,6 +158,7 @@ def get_server_connection(self, cc, scheme, host, port, sni):
if not self.server_conn:
try:
self.server_conn = ServerConnection(self.config, scheme, host, port, sni)
+ self.channel.ask(self.server_conn)
self.server_conn.connect()
except tcp.NetLibError, v:
raise ProxyError(502, v)
diff --git a/requirements.txt b/requirements.txt
new file mode 100644
index 0000000000..3ecd8ed4e4
--- /dev/null
+++ b/requirements.txt
@@ -0,0 +1,15 @@
+Flask>=0.9
+Jinja2>=2.7
+MarkupSafe>=0.18
+PIL>=1.1.7
+Werkzeug>=0.8.3
+lxml>=3.2.1
+netlib>=0.9.2
+nose>=1.3.0
+pathod>=0.9.2
+pyOpenSSL>=0.13
+pyasn1>=0.1.7
+requests>=1.2.2
+urwid>=1.1.1
+wsgiref>=0.1.2
+jsbeautifier>=1.4.0
\ No newline at end of file
|
Add server connect script hook as requested here: https://groups.google.com/forum/#!topic/mitmproxy/6FDkWfrh3HE
_Aldo_: We have ClientConnect and ClientDisconnect vs ServerConnection classes in mitmproxy. To provide an unified API, I opted for a serverconnect scripthook. Are there any planned internal refactorings? If there are no obligations from your side, leave a comment and I'll add docs and merge.
Cheers,
Max
PS: Branching with multiple remotes sucks, PR https://github.com/mitmproxy/mitmproxy/pull/168 is included here. I apologize! As there are no significant changes in it, I let it just as is...
|
https://api.github.com/repos/mitmproxy/mitmproxy/pulls/180
|
2013-11-18T16:31:41Z
|
2013-12-08T08:55:55Z
|
2013-12-08T08:55:55Z
|
2014-06-13T19:33:05Z
| 953
|
mitmproxy/mitmproxy
| 27,834
|
Added `PDFReader` to `readers.__init__` for convenience
|
diff --git a/llama_index/readers/__init__.py b/llama_index/readers/__init__.py
index 97ef5c9b3da69..97cf401ffa66c 100644
--- a/llama_index/readers/__init__.py
+++ b/llama_index/readers/__init__.py
@@ -20,6 +20,7 @@
# readers
from llama_index.readers.file.base import SimpleDirectoryReader
+from llama_index.readers.file.docs_reader import PDFReader
from llama_index.readers.file.html_reader import HTMLTagReader
from llama_index.readers.github_readers.github_repository_reader import (
GithubRepositoryReader,
@@ -88,4 +89,5 @@
"ChatGPTRetrievalPluginReader",
"BagelReader",
"HTMLTagReader",
+ "PDFReader",
]
|
# Description
See PR title
## Type of Change
- [x] New feature (non-breaking change which adds functionality)
# How Has This Been Tested?
- [ ] Added new unit/integration tests
- [ ] Added new notebook (that tests end-to-end)
- [x] I stared at the code and made sure it makes sense
|
https://api.github.com/repos/run-llama/llama_index/pulls/7990
|
2023-10-05T21:06:40Z
|
2023-10-06T15:45:51Z
|
2023-10-06T15:45:50Z
|
2023-10-06T16:07:27Z
| 185
|
run-llama/llama_index
| 6,380
|
register_tmp_file also for mtime
|
diff --git a/modules/ui_tempdir.py b/modules/ui_tempdir.py
index 621ed1ecab5..ecd6bdec355 100644
--- a/modules/ui_tempdir.py
+++ b/modules/ui_tempdir.py
@@ -35,7 +35,9 @@ def save_pil_to_file(self, pil_image, dir=None, format="png"):
already_saved_as = getattr(pil_image, 'already_saved_as', None)
if already_saved_as and os.path.isfile(already_saved_as):
register_tmp_file(shared.demo, already_saved_as)
- return f'{already_saved_as}?{os.path.getmtime(already_saved_as)}'
+ filename_with_mtime = f'{already_saved_as}?{os.path.getmtime(already_saved_as)}'
+ register_tmp_file(shared.demo, filename_with_mtime)
+ return filename_with_mtime
if shared.opts.temp_dir != "":
dir = shared.opts.temp_dir
|
## Description
I've found in my extension `OutputPanel`'s save button doesn't work, because of timestamp in filename. I doubled `register_tmp_file` function inside `save_pil_to_file` also for filename with timestamp
## Checklist:
- [x] I have read [contributing wiki page](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Contributing)
- [x] I have performed a self-review of my own code
- [x] My code follows the [style guidelines](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Contributing#code-style)
- [x] My code passes [tests](https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Tests)
|
https://api.github.com/repos/AUTOMATIC1111/stable-diffusion-webui/pulls/15012
|
2024-02-23T16:32:09Z
|
2024-02-26T09:53:21Z
|
2024-02-26T09:53:21Z
|
2024-02-26T09:53:52Z
| 201
|
AUTOMATIC1111/stable-diffusion-webui
| 40,344
|
Add more tests to nginx plugin
|
diff --git a/letsencrypt-nginx/letsencrypt_nginx/tests/configurator_test.py b/letsencrypt-nginx/letsencrypt_nginx/tests/configurator_test.py
index 56ad5110c22..3ad0b834f2b 100644
--- a/letsencrypt-nginx/letsencrypt_nginx/tests/configurator_test.py
+++ b/letsencrypt-nginx/letsencrypt_nginx/tests/configurator_test.py
@@ -40,6 +40,23 @@ def test_prepare(self):
self.assertEquals((1, 6, 2), self.config.version)
self.assertEquals(5, len(self.config.parser.parsed))
+ @mock.patch("letsencrypt_nginx.configurator.le_util.exe_exists")
+ @mock.patch("letsencrypt_nginx.configurator.subprocess.Popen")
+ def test_prepare_initializes_version(self, mock_popen, mock_exe_exists):
+ mock_popen().communicate.return_value = (
+ "", "\n".join(["nginx version: nginx/1.6.2",
+ "built by clang 6.0 (clang-600.0.56)"
+ " (based on LLVM 3.5svn)",
+ "TLS SNI support enabled",
+ "configure arguments: --prefix=/usr/local/Cellar/"
+ "nginx/1.6.2 --with-http_ssl_module"]))
+
+ mock_exe_exists.return_value = True
+
+ self.config.version = None
+ self.config.prepare()
+ self.assertEquals((1, 6, 2), self.config.version)
+
@mock.patch("letsencrypt_nginx.configurator.socket.gethostbyaddr")
def test_get_all_names(self, mock_gethostbyaddr):
mock_gethostbyaddr.return_value = ('155.225.50.69.nephoscale.net', [], [])
@@ -91,12 +108,26 @@ def test_choose_vhost(self):
'test.www.example.com': foo_conf,
'abc.www.foo.com': foo_conf,
'www.bar.co.uk': localhost_conf}
+
+ conf_path = {'localhost': "etc_nginx/nginx.conf",
+ 'alias': "etc_nginx/nginx.conf",
+ 'example.com': "etc_nginx/sites-enabled/example.com",
+ 'example.com.uk.test': "etc_nginx/sites-enabled/example.com",
+ 'www.example.com': "etc_nginx/sites-enabled/example.com",
+ 'test.www.example.com': "etc_nginx/foo.conf",
+ 'abc.www.foo.com': "etc_nginx/foo.conf",
+ 'www.bar.co.uk': "etc_nginx/nginx.conf"}
+
bad_results = ['www.foo.com', 'example', 't.www.bar.co',
'69.255.225.155']
for name in results:
- self.assertEqual(results[name],
- self.config.choose_vhost(name).names)
+ vhost = self.config.choose_vhost(name)
+ path = os.path.relpath(vhost.filep, self.temp_dir)
+
+ self.assertEqual(results[name], vhost.names)
+ self.assertEqual(conf_path[name], path)
+
for name in bad_results:
self.assertEqual(set([name]), self.config.choose_vhost(name).names)
@@ -330,6 +361,17 @@ def test_get_snakeoil_paths(self):
OpenSSL.crypto.load_privatekey(
OpenSSL.crypto.FILETYPE_PEM, key_file.read())
+ def test_redirect_enhance(self):
+ expected = [
+ ['if', '($scheme != "https")'],
+ [['return', '301 https://$host$request_uri']]
+ ]
+
+ example_conf = self.config.parser.abs_path('sites-enabled/example.com')
+ self.config.enhance("www.example.com", "redirect")
+
+ generated_conf = self.config.parser.parsed[example_conf]
+ self.assertTrue(util.contains_at_depth(generated_conf, expected, 2))
if __name__ == "__main__":
unittest.main() # pragma: no cover
|
Related to #960
|
https://api.github.com/repos/certbot/certbot/pulls/2095
|
2016-01-05T20:21:56Z
|
2016-01-06T15:53:25Z
|
2016-01-06T15:53:25Z
|
2016-05-06T19:21:22Z
| 859
|
certbot/certbot
| 2,635
|
Update Palindrome_Checker.py
|
diff --git a/Palindrome_Checker.py b/Palindrome_Checker.py
index 878873ff85..e5eade7607 100644
--- a/Palindrome_Checker.py
+++ b/Palindrome_Checker.py
@@ -28,5 +28,5 @@
bol_ = False
break
-if bol_:
- print("\nWow!, The phrase is a Palindrome!")
\ No newline at end of file
+if bol_==True:
+ print("\nWow!, The phrase is a Palindrome!")
|
https://api.github.com/repos/geekcomputers/Python/pulls/561
|
2019-10-03T07:18:22Z
|
2019-10-03T11:43:05Z
|
2019-10-03T11:43:05Z
|
2019-10-03T11:43:05Z
| 120
|
geekcomputers/Python
| 31,614
|
|
Update check_requirements.py
|
diff --git a/utils/general.py b/utils/general.py
index 053aeacd651..22119100575 100644
--- a/utils/general.py
+++ b/utils/general.py
@@ -388,10 +388,23 @@ def check_version(current='0.0.0', minimum='0.0.0', name='version ', pinned=Fals
@TryExcept()
-def check_requirements(requirements=ROOT / 'requirements.txt', exclude=(), install=True, cmds=''):
- # Check installed dependencies meet YOLOv5 requirements (pass *.txt file or list of packages or single package str)
+def check_requirements(requirements=ROOT.parent / 'requirements.txt', exclude=(), install=True, cmds=''):
+ """
+ Check if installed dependencies meet YOLOv5 requirements and attempt to auto-update if needed.
+
+ Args:
+ requirements (Union[Path, str, List[str]]): Path to a requirements.txt file, a single package requirement as a
+ string, or a list of package requirements as strings.
+ exclude (Tuple[str]): Tuple of package names to exclude from checking.
+ install (bool): If True, attempt to auto-update packages that don't meet requirements.
+ cmds (str): Additional commands to pass to the pip install command when auto-updating.
+
+ Returns:
+ None
+ """
prefix = colorstr('red', 'bold', 'requirements:')
check_python() # check python version
+ file = None
if isinstance(requirements, Path): # requirements.txt file
file = requirements.resolve()
assert file.exists(), f'{prefix} {file} not found, check failed.'
@@ -400,22 +413,25 @@ def check_requirements(requirements=ROOT / 'requirements.txt', exclude=(), insta
elif isinstance(requirements, str):
requirements = [requirements]
- s = ''
- n = 0
+ s = '' # console string
+ n = 0 # number of packages updates
for r in requirements:
try:
pkg.require(r)
except (pkg.VersionConflict, pkg.DistributionNotFound): # exception if requirements not met
- s += f'"{r}" '
- n += 1
+ try: # attempt to import (slower but more accurate)
+ import importlib
+ importlib.import_module(next(pkg.parse_requirements(r)).name)
+ except ImportError:
+ s += f'"{r}" '
+ n += 1
if s and install and AUTOINSTALL: # check environment variable
- LOGGER.info(f"{prefix} YOLOv5 requirement{'s' * (n > 1)} {s}not found, attempting AutoUpdate...")
+ LOGGER.info(f"{prefix} YOLOv8 requirement{'s' * (n > 1)} {s}not found, attempting AutoUpdate...")
try:
- # assert check_online(), "AutoUpdate skipped (offline)"
- LOGGER.info(check_output(f'pip install {s} {cmds}', shell=True).decode())
- source = file if 'file' in locals() else requirements
- s = f"{prefix} {n} package{'s' * (n > 1)} updated per {source}\n" \
+ assert check_online(), 'AutoUpdate skipped (offline)'
+ LOGGER.info(subprocess.check_output(f'pip install {s} {cmds}', shell=True).decode())
+ s = f"{prefix} {n} package{'s' * (n > 1)} updated per {file or requirements}\n" \
f"{prefix} ⚠️ {colorstr('bold', 'Restart runtime or rerun command for updates to take effect')}\n"
LOGGER.info(s)
except Exception as e:
|
<!--
Thank you for submitting a YOLOv5 🚀 Pull Request! We want to make contributing to YOLOv5 as easy and transparent as possible. A few tips to get you started:
- Search existing YOLOv5 [PRs](https://github.com/ultralytics/yolov5/pull) to see if a similar PR already exists.
- Link this PR to a YOLOv5 [issue](https://github.com/ultralytics/yolov5/issues) to help us understand what bug fix or feature is being implemented.
- Provide before and after profiling/inference/training results to help us quantify the improvement your PR provides (if applicable).
Please see our ✅ [Contributing Guide](https://github.com/ultralytics/yolov5/blob/master/CONTRIBUTING.md) for more details.
Note that Copilot will summarize this PR below, do not modify the 'copilot:all' line.
-->
<!--
copilot:all
-->
### <samp>🤖 Generated by Copilot at 95668f2</samp>
### Summary
🐛📈📝
<!--
1. 🐛 for fixing a bug
2. 📈 for improving the accuracy and reliability
3. 📝 for adding a docstring and making cosmetic changes
-->
Improved the `check_requirements` function in `utils/general.py` to check and install dependencies more accurately and reliably. Added documentation and code style improvements.
> _Oh we're the coders of the sea, and we work with skill and glee_
> _We fix the bugs and write the docs for `check_requirements`_
> _We heave and haul and push and pull, and we make the code more full_
> _Of accuracy and reliability for `check_requirements`_
### Walkthrough
* Fix bug and improve documentation of `check_requirements` function ([link](https://github.com/ultralytics/yolov5/pull/11358/files?diff=unified&w=0#diff-dd425673dc44b64697acc887bb7abefec7ca7d92cf434d7ac9a6d69a8268f47aL391-R407), [link](https://github.com/ultralytics/yolov5/pull/11358/files?diff=unified&w=0#diff-dd425673dc44b64697acc887bb7abefec7ca7d92cf434d7ac9a6d69a8268f47aL403-R434))
## 🛠️ PR Summary
<sub>Made with ❤️ by [Ultralytics Actions](https://github.com/ultralytics/actions)<sub>
### 🌟 Summary
Enhanced dependency checking and auto-update usability in YOLOv5.
### 📊 Key Changes
- Changed the default requirements file path to `ROOT.parent / 'requirements.txt'`.
- Extended the `check_requirements` function documentation for clarity.
- Improved exception handling to differentiate between importability and version compliance.
### 🎯 Purpose & Impact
- **Enhanced Clarity:** Updated function arguments and added detailed docstring to improve user understanding.
- **Better Dependency Handling:** The refined process accurately checks if a package is importable before attempting an update.
- **Intelligent Auto-Update:** The check now also determines if the user is offline before attempting any automatic package updates, saving time and reducing potential errors.
- **User Feedback:** Provides detailed console feedback about the packages updated, enhancing user awareness of changes to their environment.
|
https://api.github.com/repos/ultralytics/yolov5/pulls/11358
|
2023-04-14T12:23:35Z
|
2023-04-14T12:37:02Z
|
2023-04-14T12:37:02Z
|
2024-01-19T02:14:27Z
| 820
|
ultralytics/yolov5
| 24,764
|
Refs #27788 -- Removed unneeded Oracle 11 workarounds in GIS tests.
|
diff --git a/tests/gis_tests/distapp/tests.py b/tests/gis_tests/distapp/tests.py
index 9d67b7b013988..5f3dcb8f44f9f 100644
--- a/tests/gis_tests/distapp/tests.py
+++ b/tests/gis_tests/distapp/tests.py
@@ -104,20 +104,10 @@ def test_distance_lookups(self):
# Retrieving the cities within a 20km 'donut' w/a 7km radius 'hole'
# (thus, Houston and Southside place will be excluded as tested in
# the `test02_dwithin` above).
- qs1 = SouthTexasCity.objects.filter(point__distance_gte=(self.stx_pnt, D(km=7))).filter(
- point__distance_lte=(self.stx_pnt, D(km=20)),
- )
-
- # Oracle 11 incorrectly thinks it is not projected.
- if oracle:
- dist_qs = (qs1,)
- else:
- qs2 = SouthTexasCityFt.objects.filter(point__distance_gte=(self.stx_pnt, D(km=7))).filter(
+ for model in [SouthTexasCity, SouthTexasCityFt]:
+ qs = model.objects.filter(point__distance_gte=(self.stx_pnt, D(km=7))).filter(
point__distance_lte=(self.stx_pnt, D(km=20)),
)
- dist_qs = (qs1, qs2)
-
- for qs in dist_qs:
cities = self.get_names(qs)
self.assertEqual(cities, ['Bellaire', 'Pearland', 'West University Place'])
@@ -293,8 +283,6 @@ def test_distance_projected(self):
70870.188967, 165337.758878, 139196.085105]
# SELECT ST_Distance(point, ST_Transform(ST_GeomFromText('POINT(-96.876369 29.905320)', 4326), 2278))
# FROM distapp_southtexascityft;
- # Oracle 11 thinks this is not a projected coordinate system, so it's
- # not tested.
ft_distances = [482528.79154625, 458103.408123001, 462231.860397575,
455411.438904354, 519386.252102563, 696139.009211594,
232513.278304279, 542445.630586414, 456679.155883207]
@@ -302,11 +290,8 @@ def test_distance_projected(self):
# Testing using different variations of parameters and using models
# with different projected coordinate systems.
dist1 = SouthTexasCity.objects.annotate(distance=Distance('point', lagrange)).order_by('id')
- if oracle:
- dist_qs = [dist1]
- else:
- dist2 = SouthTexasCityFt.objects.annotate(distance=Distance('point', lagrange)).order_by('id')
- dist_qs = [dist1, dist2]
+ dist2 = SouthTexasCityFt.objects.annotate(distance=Distance('point', lagrange)).order_by('id')
+ dist_qs = [dist1, dist2]
# Original query done on PostGIS, have to adjust AlmostEqual tolerance
# for Oracle.
|
https://api.github.com/repos/django/django/pulls/8173
|
2017-03-13T19:24:06Z
|
2017-03-13T23:21:20Z
|
2017-03-13T23:21:20Z
|
2017-03-14T04:54:15Z
| 742
|
django/django
| 50,812
|
|
Use certificate instead of cert in DNS plugin descriptions
|
diff --git a/certbot-dns-cloudflare/certbot_dns_cloudflare/dns_cloudflare.py b/certbot-dns-cloudflare/certbot_dns_cloudflare/dns_cloudflare.py
index 6979581eeec..f1156642f30 100644
--- a/certbot-dns-cloudflare/certbot_dns_cloudflare/dns_cloudflare.py
+++ b/certbot-dns-cloudflare/certbot_dns_cloudflare/dns_cloudflare.py
@@ -21,7 +21,8 @@ class Authenticator(dns_common.DNSAuthenticator):
This Authenticator uses the Cloudflare API to fulfill a dns-01 challenge.
"""
- description = 'Obtain certs using a DNS TXT record (if you are using Cloudflare for DNS).'
+ description = ('Obtain certificates using a DNS TXT record (if you are using Cloudflare for '
+ 'DNS).')
ttl = 120
def __init__(self, *args, **kwargs):
diff --git a/certbot-dns-cloudxns/certbot_dns_cloudxns/dns_cloudxns.py b/certbot-dns-cloudxns/certbot_dns_cloudxns/dns_cloudxns.py
index 2e9d23a886d..674194fee68 100644
--- a/certbot-dns-cloudxns/certbot_dns_cloudxns/dns_cloudxns.py
+++ b/certbot-dns-cloudxns/certbot_dns_cloudxns/dns_cloudxns.py
@@ -22,7 +22,7 @@ class Authenticator(dns_common.DNSAuthenticator):
This Authenticator uses the CloudXNS DNS API to fulfill a dns-01 challenge.
"""
- description = 'Obtain certs using a DNS TXT record (if you are using CloudXNS for DNS).'
+ description = 'Obtain certificates using a DNS TXT record (if you are using CloudXNS for DNS).'
ttl = 60
def __init__(self, *args, **kwargs):
diff --git a/certbot-dns-dnsimple/certbot_dns_dnsimple/dns_dnsimple.py b/certbot-dns-dnsimple/certbot_dns_dnsimple/dns_dnsimple.py
index f489f889a35..f3a98567e5e 100644
--- a/certbot-dns-dnsimple/certbot_dns_dnsimple/dns_dnsimple.py
+++ b/certbot-dns-dnsimple/certbot_dns_dnsimple/dns_dnsimple.py
@@ -22,7 +22,7 @@ class Authenticator(dns_common.DNSAuthenticator):
This Authenticator uses the DNSimple v2 API to fulfill a dns-01 challenge.
"""
- description = 'Obtain certs using a DNS TXT record (if you are using DNSimple for DNS).'
+ description = 'Obtain certificates using a DNS TXT record (if you are using DNSimple for DNS).'
ttl = 60
def __init__(self, *args, **kwargs):
diff --git a/certbot-dns-google/certbot_dns_google/dns_google.py b/certbot-dns-google/certbot_dns_google/dns_google.py
index 908c020e133..39811782e59 100644
--- a/certbot-dns-google/certbot_dns_google/dns_google.py
+++ b/certbot-dns-google/certbot_dns_google/dns_google.py
@@ -25,7 +25,8 @@ class Authenticator(dns_common.DNSAuthenticator):
This Authenticator uses the Google Cloud DNS API to fulfill a dns-01 challenge.
"""
- description = 'Obtain certs using a DNS TXT record (if you are using Google Cloud DNS for DNS).'
+ description = ('Obtain certificates using a DNS TXT record (if you are using Google Cloud DNS '
+ 'for DNS).')
ttl = 60
def __init__(self, *args, **kwargs):
diff --git a/certbot-dns-nsone/certbot_dns_nsone/dns_nsone.py b/certbot-dns-nsone/certbot_dns_nsone/dns_nsone.py
index be60ff39dd7..28db126c141 100644
--- a/certbot-dns-nsone/certbot_dns_nsone/dns_nsone.py
+++ b/certbot-dns-nsone/certbot_dns_nsone/dns_nsone.py
@@ -22,7 +22,7 @@ class Authenticator(dns_common.DNSAuthenticator):
This Authenticator uses the NS1 API to fulfill a dns-01 challenge.
"""
- description = 'Obtain certs using a DNS TXT record (if you are using NS1 for DNS).'
+ description = 'Obtain certificates using a DNS TXT record (if you are using NS1 for DNS).'
ttl = 60
def __init__(self, *args, **kwargs):
diff --git a/certbot-route53/certbot_route53/authenticator.py b/certbot-route53/certbot_route53/authenticator.py
index 96b4d1abb74..b2a9821e94f 100644
--- a/certbot-route53/certbot_route53/authenticator.py
+++ b/certbot-route53/certbot_route53/authenticator.py
@@ -28,7 +28,7 @@ class Authenticator(common.Plugin):
This authenticator solves a DNS01 challenge by uploading the answer to AWS
Route53.
"""
- description = "Obtain certs using a DNS TXT record (if you are using AWS Route53 for DNS)."
+ description = "Obtain certificates using a DNS TXT record (if you are using AWS Route53 for DNS)."
def __init__(self, *args, **kwargs):
super(Authenticator, self).__init__(*args, **kwargs)
|
As #4783, but for descriptions.
|
https://api.github.com/repos/certbot/certbot/pulls/4784
|
2017-06-06T01:02:22Z
|
2017-06-06T02:06:35Z
|
2017-06-06T02:06:35Z
|
2017-06-07T16:43:55Z
| 1,279
|
certbot/certbot
| 1,541
|
Use `rng_seed` param when creating custom dataset sampler
|
diff --git a/model/model_training/trainer_rl.py b/model/model_training/trainer_rl.py
index 9821c481ec..f8756c3152 100644
--- a/model/model_training/trainer_rl.py
+++ b/model/model_training/trainer_rl.py
@@ -3,6 +3,7 @@
import os
import random
from argparse import Namespace
+from typing import Sequence
import numpy as np
import torch
@@ -21,7 +22,7 @@
from utils.utils_rl import prepare_tensor
-def argument_parsing(notebook=False, notebook_args=None, **kwargs):
+def argument_parsing(notebook: bool = False, notebook_args: Sequence[str] | None = None, **kwargs):
parser = argparse.ArgumentParser()
parser.add_argument("--configs", nargs="+", required=True)
parser.add_argument("--local_rank", type=int, default=-1)
diff --git a/model/model_training/trainer_rm.py b/model/model_training/trainer_rm.py
index 3f33ccb122..18c7e6b2e8 100644
--- a/model/model_training/trainer_rm.py
+++ b/model/model_training/trainer_rm.py
@@ -1,7 +1,7 @@
import argparse
import logging
import os
-from typing import Callable, Literal, Optional, Union
+from typing import Callable, Literal, Optional, Sequence, Union
import datasets
import torch
@@ -128,7 +128,7 @@ def get_train_dataloader(self):
return dataloader
-def argument_parsing(notebook=False, notebook_args=None):
+def argument_parsing(notebook: bool = False, notebook_args: Sequence[str] | None = None):
parser = argparse.ArgumentParser()
parser.add_argument("--configs", nargs="+", required=True)
parser.add_argument("--local_rank", type=int, default=-1)
diff --git a/model/model_training/trainer_sft.py b/model/model_training/trainer_sft.py
index 8788662081..4c4c820999 100755
--- a/model/model_training/trainer_sft.py
+++ b/model/model_training/trainer_sft.py
@@ -3,7 +3,7 @@
import logging
import os
from functools import partial
-from typing import Any, Callable, Dict, List, Optional, Tuple, Union
+from typing import Any, Callable, Dict, List, Optional, Sequence, Tuple, Union
import datasets
import torch
@@ -166,7 +166,7 @@ def get_train_dataloader(self):
return dataloader
-def argument_parsing(notebook=False, notebook_args=None):
+def argument_parsing(notebook: bool = False, notebook_args: Sequence[str] | None = None):
parser = argparse.ArgumentParser()
parser.add_argument(
"--configs",
diff --git a/model/model_training/utils/utils.py b/model/model_training/utils/utils.py
index 665732d9f6..e3c9098899 100644
--- a/model/model_training/utils/utils.py
+++ b/model/model_training/utils/utils.py
@@ -81,6 +81,7 @@ def __init__(
self.shuffle = shuffle
self.rank = rank
self.world_size = world_size
+ self.epoch = 0
if world_size == 1:
self.rank = 0
@@ -89,7 +90,7 @@ def __init__(
self.seed = seed
self.samples_length = samples_length
- def set_epoch(self, epoch) -> None:
+ def set_epoch(self, epoch: int) -> None:
self.epoch = epoch
def __len__(self) -> int:
@@ -126,11 +127,12 @@ def __iter__(self):
return iter(epoch_idx)
@classmethod
- def build_sampler_from_config(cls, training_conf, datasets: List[Dataset], verbose: bool = False, *args, **kwargs):
+ def build_sampler_from_config(cls, training_conf, datasets: List[Dataset], verbose: bool = False, **kwargs):
dataset_sizes = [len(x) for x in datasets]
fractions = get_dataset_fractions(training_conf.datasets, dataset_sizes, verbose)
dataset_size_per_epoch = [int(size * frac) for size, frac in zip(dataset_sizes, fractions)]
- return cls(dataset_sizes, dataset_size_per_epoch, *args, **kwargs)
+ seed = training_conf.rng_seed
+ return cls(dataset_sizes=dataset_sizes, dataset_size_per_epoch=dataset_size_per_epoch, seed=seed, **kwargs)
def get_dataset_fractions(conf, dataset_sizes: List[int], verbose: bool = False):
|
Use the `rng_seed` configuration parameter in class `PerDatasetSampler.build_sampler_from_config()` static factory class method. Until now always the fixed default value of 0 was used as seed for the dataset sampling (which I think was as a bug).
|
https://api.github.com/repos/LAION-AI/Open-Assistant/pulls/3592
|
2023-07-21T16:10:45Z
|
2023-07-21T17:38:48Z
|
2023-07-21T17:38:48Z
|
2023-07-21T17:38:49Z
| 986
|
LAION-AI/Open-Assistant
| 37,364
|
[live] Restore `sys.stderr` when an exception happens during a refresh
|
diff --git a/CHANGELOG.md b/CHANGELOG.md
index 52db0457b..bc33feab4 100644
--- a/CHANGELOG.md
+++ b/CHANGELOG.md
@@ -5,6 +5,12 @@ All notable changes to this project will be documented in this file.
The format is based on [Keep a Changelog](https://keepachangelog.com/en/1.0.0/),
and this project adheres to [Semantic Versioning](https://semver.org/spec/v2.0.0.html).
+## [Unreleased]
+
+### Fixed
+
+- Allow exceptions that are raised while a Live is rendered to be displayed and/or processed https://github.com/Textualize/rich/pull/2305
+
## [12.4.4] - 2022-05-24
### Changed
diff --git a/rich/live.py b/rich/live.py
index 6db5b605f..e635fe5c9 100644
--- a/rich/live.py
+++ b/rich/live.py
@@ -118,7 +118,15 @@ def start(self, refresh: bool = False) -> None:
self._enable_redirect_io()
self.console.push_render_hook(self)
if refresh:
- self.refresh()
+ try:
+ self.refresh()
+ except Exception:
+ # If refresh fails, we want to stop the redirection of sys.stderr,
+ # so the error stacktrace is properly displayed in the terminal.
+ # (or, if the code that calls Rich captures the exception and wants to display something,
+ # let this be displayed in the terminal).
+ self.stop()
+ raise
if self.auto_refresh:
self._refresh_thread = _RefreshThread(self, self.refresh_per_second)
self._refresh_thread.start()
|
Without this the user sees no error displayed in their terminal - and even capturing the exception and displayed their own error reporting is ineffective.
## Type of changes
- [x] Bug fix
- [ ] New feature
- [ ] Documentation / docstrings
- [ ] Tests
- [ ] Other
## Checklist
- [x] I've run the latest [black](https://github.com/psf/black) with default args on new code.
- [x] I've updated CHANGELOG.md and CONTRIBUTORS.md where appropriate.
- [ ] I've added tests for new code.
- [x] I accept that @willmcgugan may be pedantic in the code review.
## Description
fixes #2291
|
https://api.github.com/repos/Textualize/rich/pulls/2305
|
2022-05-27T11:03:19Z
|
2022-05-27T12:34:09Z
|
2022-05-27T12:34:08Z
|
2022-05-27T12:34:09Z
| 397
|
Textualize/rich
| 48,361
|
Fix Graphormer test suite
|
diff --git a/src/transformers/models/graphormer/configuration_graphormer.py b/src/transformers/models/graphormer/configuration_graphormer.py
index 17791bfb0cf1e..36a9262b079fa 100644
--- a/src/transformers/models/graphormer/configuration_graphormer.py
+++ b/src/transformers/models/graphormer/configuration_graphormer.py
@@ -39,8 +39,8 @@ class GraphormerConfig(PretrainedConfig):
Args:
- num_classes (`int`, *optional*, defaults to 2):
- Number of target classes or labels, set to 1 if the task is a regression task.
+ num_classes (`int`, *optional*, defaults to 1):
+ Number of target classes or labels, set to n for binary classification of n tasks.
num_atoms (`int`, *optional*, defaults to 512*9):
Number of node types in the graphs.
num_edges (`int`, *optional*, defaults to 512*3):
@@ -134,7 +134,7 @@ class GraphormerConfig(PretrainedConfig):
def __init__(
self,
- num_classes: int = 2,
+ num_classes: int = 1,
num_atoms: int = 512 * 9,
num_edges: int = 512 * 3,
num_in_degree: int = 512,
diff --git a/tests/models/graphormer/test_modeling_graphormer.py b/tests/models/graphormer/test_modeling_graphormer.py
index 90698d278175d..87bf4706557dc 100644
--- a/tests/models/graphormer/test_modeling_graphormer.py
+++ b/tests/models/graphormer/test_modeling_graphormer.py
@@ -40,7 +40,7 @@ class GraphormerModelTester:
def __init__(
self,
parent,
- num_classes=2,
+ num_classes=1,
num_atoms=512 * 9,
num_edges=512 * 3,
num_in_degree=512,
@@ -614,7 +614,7 @@ def test_inference_graph_classification(self):
[3, 3, 4, 3, 3, 3, 3, 4, 4, 3, 4, 2, 2, 0, 0, 0, 0],
]
),
- "x": tensor(
+ "input_nodes": tensor(
[
[[3], [3], [3], [3], [3], [3], [3], [3], [3], [3], [3], [3], [3], [3], [3], [3], [3]],
[[3], [3], [3], [3], [3], [3], [3], [3], [3], [3], [3], [3], [3], [0], [0], [0], [0]],
@@ -1279,15 +1279,11 @@ def test_inference_graph_classification(self):
output = model(**model_input)["logits"]
- print(output.shape)
- print(output)
-
- expected_shape = torch.Size(())
+ expected_shape = torch.Size((2, 1))
self.assertEqual(output.shape, expected_shape)
- # TODO Replace values below with what was printed above.
- expected_slice = torch.tensor(
- [[[-0.0483, 0.1188, -0.0313], [-0.0606, 0.1435, 0.0199], [-0.0235, 0.1519, 0.0175]]]
+ expected_logs = torch.tensor(
+ [[7.6060], [7.4126]]
)
- self.assertTrue(torch.allclose(output[:, :3, :3], expected_slice, atol=1e-4))
+ self.assertTrue(torch.allclose(output, expected_logs, atol=1e-4))
|
# What does this PR do?
Fixes comment in #21367, @ydshieh
Updated shape of model instantiation when calling pretrained in test suite, + updated values in the integration test.
|
https://api.github.com/repos/huggingface/transformers/pulls/21419
|
2023-02-02T11:03:15Z
|
2023-02-02T15:29:14Z
|
2023-02-02T15:29:14Z
|
2023-02-02T15:31:48Z
| 870
|
huggingface/transformers
| 12,253
|
Create RandomDice.py
|
diff --git a/RandomDice.py b/RandomDice.py
new file mode 100644
index 0000000000..a76e944ff9
--- /dev/null
+++ b/RandomDice.py
@@ -0,0 +1,13 @@
+#GGearing 01/10/19
+#Random Dice Game using Tkinter
+
+from tkinter import *
+from random import randint
+def roll():
+ text.delete(0.0,END)
+ text.insert(END,str(randint(1,100)))
+window=Tk()
+text=Text(window,width=3,height=1)
+buttonA=Button(window,text="Press to roll!", command=roll)
+text.pack()
+buttonA.pack()
|
https://api.github.com/repos/geekcomputers/Python/pulls/537
|
2019-10-01T09:16:53Z
|
2019-10-01T10:52:09Z
|
2019-10-01T10:52:09Z
|
2019-10-01T10:52:09Z
| 158
|
geekcomputers/Python
| 31,528
|
|
Refactor `get_output_location` method in AthenaHook
|
diff --git a/airflow/providers/amazon/aws/hooks/athena.py b/airflow/providers/amazon/aws/hooks/athena.py
index c8af86ee3a183..3715b4a1bc2c2 100644
--- a/airflow/providers/amazon/aws/hooks/athena.py
+++ b/airflow/providers/amazon/aws/hooks/athena.py
@@ -292,13 +292,12 @@ def get_output_location(self, query_execution_id: str) -> str:
:param query_execution_id: Id of submitted athena query
"""
- output_location = None
if query_execution_id:
response = self.get_query_info(query_execution_id=query_execution_id, use_cache=True)
if response:
try:
- output_location = response["QueryExecution"]["ResultConfiguration"]["OutputLocation"]
+ return response["QueryExecution"]["ResultConfiguration"]["OutputLocation"]
except KeyError:
self.log.error(
"Error retrieving OutputLocation. Query execution id: %s", query_execution_id
@@ -306,10 +305,7 @@ def get_output_location(self, query_execution_id: str) -> str:
raise
else:
raise
- else:
- raise ValueError("Invalid Query execution id. Query execution id: %s", query_execution_id)
-
- return output_location
+ raise ValueError("Invalid Query execution id. Query execution id: %s", query_execution_id)
def stop_query(self, query_execution_id: str) -> dict:
"""Cancel the submitted query.
|
https://api.github.com/repos/apache/airflow/pulls/35996
|
2023-12-01T09:50:39Z
|
2023-12-01T11:48:44Z
|
2023-12-01T11:48:44Z
|
2023-12-01T11:48:44Z
| 334
|
apache/airflow
| 14,813
|
|
Update webui.py
|
diff --git a/webui.py b/webui.py
index dd33442e3..6badcde73 100644
--- a/webui.py
+++ b/webui.py
@@ -165,7 +165,7 @@ def refresh_seed(r, s):
step=0.001, value=1.5, info='The scaler multiplied to positive ADM (use 1.0 to disable). ')
adm_scaler_negative = gr.Slider(label='Negative ADM Guidance Scaler', minimum=0.1, maximum=3.0,
step=0.001, value=0.8, info='The scaler multiplied to negative ADM (use 1.0 to disable). ')
- adaptive_cfg = gr.Slider(label='CFG Mimicking from TSNR', minimum=1.0, maximum=30.0, step=0.01, value=5.0,
+ adaptive_cfg = gr.Slider(label='CFG Mimicking from TSNR', minimum=1.0, maximum=30.0, step=0.01, value=7.0,
info='Enabling Fooocus\'s implementation of CFG mimicking for TSNR '
'(effective when real CFG > mimicked CFG).')
sampler_name = gr.Dropdown(label='Sampler', choices=flags.sampler_list, value=flags.default_sampler, info='Only effective in non-inpaint mode.')
|
https://api.github.com/repos/lllyasviel/Fooocus/pulls/523
|
2023-10-03T22:17:44Z
|
2023-10-03T22:17:49Z
|
2023-10-03T22:17:49Z
|
2023-10-03T22:17:51Z
| 298
|
lllyasviel/Fooocus
| 7,103
|
|
[generic] Support "data-video-url=" for YouTube embeds (Fixes #2862)
|
diff --git a/youtube_dl/extractor/generic.py b/youtube_dl/extractor/generic.py
index 0e5cf0efbd0..dfa8d615330 100644
--- a/youtube_dl/extractor/generic.py
+++ b/youtube_dl/extractor/generic.py
@@ -260,6 +260,20 @@ class GenericIE(InfoExtractor):
'uploader': 'Spi0n',
},
'add_ie': ['Dailymotion'],
+ },
+ # YouTube embed via <data-embed-url="">
+ {
+ 'url': 'https://play.google.com/store/apps/details?id=com.gameloft.android.ANMP.GloftA8HM',
+ 'md5': 'c267b1ab6d736057d64babaa37e07a66',
+ 'info_dict': {
+ 'id': 'Ybd-qmqYYpA',
+ 'ext': 'mp4',
+ 'title': 'Asphalt 8: Airborne - Chinese Great Wall - Android Game Trailer',
+ 'uploader': 'gameloftandroid',
+ 'uploader_id': 'gameloftandroid',
+ 'upload_date': '20140321',
+ 'description': 'md5:9c6dca5dd75b7131ce482ccf080749d6'
+ }
}
]
@@ -473,13 +487,21 @@ def _real_extract(self, url):
# Look for embedded YouTube player
matches = re.findall(r'''(?x)
- (?:<iframe[^>]+?src=|embedSWF\(\s*)
+ (?:<iframe[^>]+?src=|data-video-url=|embedSWF\(\s*)
(["\'])(?P<url>(?:https?:)?//(?:www\.)?youtube\.com/
(?:embed|v)/.+?)
\1''', webpage)
if matches:
urlrs = [self.url_result(unescapeHTML(tuppl[1]), 'Youtube')
for tuppl in matches]
+ # First, ensure we have a duplicate free list of entries
+ seen = set()
+ new_list = []
+ theurl = tuple(url.items())
+ if theurl not in seen:
+ seen.add(theurl)
+ new_list.append(url)
+ urlrs = new_list
return self.playlist_result(
urlrs, playlist_id=video_id, playlist_title=video_title)
@@ -489,6 +511,14 @@ def _real_extract(self, url):
if matches:
urlrs = [self.url_result(unescapeHTML(tuppl[1]))
for tuppl in matches]
+ # First, ensure we have a duplicate free list of entries
+ seen = set()
+ new_list = []
+ theurl = tuple(url.items())
+ if theurl not in seen:
+ seen.add(theurl)
+ new_list.append(url)
+ urlrs = new_list
return self.playlist_result(
urlrs, playlist_id=video_id, playlist_title=video_title)
@@ -601,6 +631,14 @@ def _real_extract(self, url):
if matches:
urlrs = [self.url_result(unescapeHTML(eurl), 'FunnyOrDie')
for eurl in matches]
+ # First, ensure we have a duplicate free list of entries
+ seen = set()
+ new_list = []
+ theurl = tuple(url.items())
+ if theurl not in seen:
+ seen.add(theurl)
+ new_list.append(url)
+ urlrs = new_list
return self.playlist_result(
urlrs, playlist_id=video_id, playlist_title=video_title)
|
This commit adds support for YouTube videos embedded using the "data-video-url" tag. It fixes/closes #2862.
|
https://api.github.com/repos/ytdl-org/youtube-dl/pulls/2948
|
2014-05-18T18:41:09Z
|
2014-08-22T16:20:52Z
|
2014-08-22T16:20:52Z
|
2014-08-22T16:20:52Z
| 827
|
ytdl-org/youtube-dl
| 50,069
|
[AIRFLOW-208] Add badge to show supported Python versions
|
diff --git a/README.md b/README.md
index e911225aeee2f..211d9844d1890 100644
--- a/README.md
+++ b/README.md
@@ -5,6 +5,7 @@
[](https://codecov.io/github/apache/incubator-airflow?branch=master)
[](https://airflow.readthedocs.io/en/latest/?badge=latest)
[](http://www.apache.org/licenses/LICENSE-2.0.txt)
+[](https://pypi.org/project/apache-airflow/)
[](https://gitter.im/apache/incubator-airflow?utm_source=badge&utm_medium=badge&utm_campaign=pr-badge&utm_content=badge)
_NOTE: The transition from 1.8.0 (or before) to 1.8.1 (or after) requires uninstalling Airflow before installing the new version. The package name was changed from `airflow` to `apache-airflow` as of version 1.8.1._
|
Make sure you have checked _all_ steps below.
### Jira
- [x] My PR addresses the following [Airflow Jira](https://issues.apache.org/jira/browse/AIRFLOW/) issues and references them in the PR title. For example, "\[AIRFLOW-XXX\] My Airflow PR"
- https://issues.apache.org/jira/browse/AIRFLOW-208
- In case you are fixing a typo in the documentation you can prepend your commit with \[AIRFLOW-XXX\], code changes always need a Jira issue.
### Description
- [x] Here are some details about my PR, including screenshots of any UI changes:
Add badge to show supported Python versions
### Tests
- [x] My PR adds the following unit tests __OR__ does not need testing for this extremely good reason:
### Commits
- [x] My commits all reference Jira issues in their subject lines, and I have squashed multiple commits if they address the same issue. In addition, my commits follow the guidelines from "[How to write a good git commit message](http://chris.beams.io/posts/git-commit/)":
1. Subject is separated from body by a blank line
1. Subject is limited to 50 characters (not including Jira issue reference)
1. Subject does not end with a period
1. Subject uses the imperative mood ("add", not "adding")
1. Body wraps at 72 characters
1. Body explains "what" and "why", not "how"
### Documentation
- [x] In case of new functionality, my PR adds documentation that describes how to use it.
- When adding new operators/hooks/sensors, the autoclass documentation generation needs to be added.
### Code Quality
- [x] Passes `git diff upstream/master -u -- "*.py" | flake8 --diff`
|
https://api.github.com/repos/apache/airflow/pulls/3839
|
2018-09-03T22:34:02Z
|
2018-09-04T07:34:21Z
|
2018-09-04T07:34:21Z
|
2018-09-04T08:24:24Z
| 333
|
apache/airflow
| 14,856
|
Samyamr/zero offload correctness
|
diff --git a/deepspeed/runtime/config.py b/deepspeed/runtime/config.py
index 206993dbe4c9..7637b091efe9 100755
--- a/deepspeed/runtime/config.py
+++ b/deepspeed/runtime/config.py
@@ -623,7 +623,7 @@ def _do_error_check(self):
assert self.zero_optimization_stage <= MAX_STAGE_ZERO_OPTIMIZATION, "DeepSpeedConfig: Maximum supported ZeRO stage is {}".format(MAX_STAGE_ZERO_OPTIMIZATION)
if self.zero_config.cpu_offload is True:
assert self.zero_optimization_stage == ZERO_OPTIMIZATION_GRADIENTS, "DeepSpeedConfig: cpu-offload supported ZeRO stage is {}".format(ZERO_OPTIMIZATION_GRADIENTS)
- assert self.gradient_accumulation_steps == 1, "DeepSpeedConfig: {}is not supported for {}".format(GRADIENT_ACCUMULATION_STEPS, ZERO_OPTIMIZATION_CPU_OFFLOAD)
+ #assert self.gradient_accumulation_steps == 1, "DeepSpeedConfig: {}is not supported for {}".format(GRADIENT_ACCUMULATION_STEPS, ZERO_OPTIMIZATION_CPU_OFFLOAD)
def _do_warning_check(self):
fp16_enabled = self.fp16_enabled or self.zero_enabled
diff --git a/deepspeed/runtime/zero/stage1.py b/deepspeed/runtime/zero/stage1.py
index 1acef4898e36..6f8953daa4cc 100755
--- a/deepspeed/runtime/zero/stage1.py
+++ b/deepspeed/runtime/zero/stage1.py
@@ -793,9 +793,12 @@ def _get_groups_without_padding(self, groups_with_padding):
def _get_state_without_padding(self, state_with_padding, padding):
lean_state = {}
for key, value in state_with_padding.items():
- lean_length = value.numel() - padding
- lean_state[key] = value[:lean_length]
-
+ if torch.is_tensor(value):
+ lean_length = value.numel() - padding
+ lean_state[key] = value[:lean_length]
+ else:
+ lean_state[key] = value
+
return lean_state
# Return base optimizer states.
diff --git a/deepspeed/runtime/zero/stage2.py b/deepspeed/runtime/zero/stage2.py
index 69cdcf34adf1..f10d16122320 100755
--- a/deepspeed/runtime/zero/stage2.py
+++ b/deepspeed/runtime/zero/stage2.py
@@ -477,9 +477,10 @@ def independent_gradient_partition_epilogue(self):
if self.overlap_comm:
torch.cuda.synchronize()
-
+
if self.cpu_offload is False:
for i, _ in enumerate(self.fp16_groups):
+
if not i in self.averaged_gradients or self.averaged_gradients[i] is None:
self.averaged_gradients[i] = self.get_flat_partition(
self.params_in_partition[i],
@@ -498,6 +499,8 @@ def independent_gradient_partition_epilogue(self):
for accumulated_grad, new_avg_grad in zip(self.averaged_gradients[i],avg_new):
accumulated_grad.add_(new_avg_grad)
+
+
self._release_ipg_buffers()
# No need to keep the gradients anymore.
@@ -867,6 +870,7 @@ def async_inplace_copy_grad_to_fp32_buffer_from_gpu(self, param):
src_tensor = param.grad.view(-1).narrow(0, source_offset, num_elements).float()
dest_tensor.copy_(src_tensor, non_blocking=True)
+ param.grad=None
def complete_grad_norm_calculation_for_cpu_offload(self, params):
total_norm = 0.0
@@ -899,25 +903,19 @@ def complete_grad_norm_calculation_for_cpu_offload(self, params):
def copy_grads_in_partition(self, param):
if self.cpu_offload:
- #print(f"GAS: {self.gradient_accumulation_steps}")
- #print(f"GAS: {self.is_gradient_accumulation_boundary}")
- #with torch.cuda.stream(torch.cuda.current_stream()):
-
- self.update_overflow_tracker_for_param_grad(param)
-
+
if self.gradient_accumulation_steps > 1:
self.async_accumulate_grad_in_cpu_via_gpu(param)
if self.is_gradient_accumulation_boundary:
self.set_norm_for_param_grad_in_gpu(param)
+
+ self.update_overflow_tracker_for_param_grad(param)
+
self.async_inplace_copy_grad_to_fp32_buffer_from_gpu(param)
- #new_grad_tensor = async_copy_to(param.grad.view(-1),
- # 'cpu',
- # self.cpu_computation_stream)
- #param.grad.data = new_grad_tensor.data.view_as(param.grad)
return
-
+ #print(f"ID {self.get_param_id(param)} grad norm {param.grad.norm()}")
if self.grads_in_partition is None:
self.grads_in_partition_offset = 0
total_size = 0
@@ -938,6 +936,7 @@ def copy_grads_in_partition(self, param):
param.numel())
new_grad_tensor.copy_(param.grad.view(-1))
param.grad.data = new_grad_tensor.data.view_as(param.grad)
+ #print(f"Grad norm after copy to contiguous_buffer {param.grad.data.norm()}")
self.grads_in_partition_offset += param.numel()
def reduce_ipg_grads(self):
@@ -1319,6 +1318,7 @@ def free_grad_in_param_list(self, param_list):
def reset_cpu_buffers(self):
self.norm_for_param_grads = {}
+ self.local_overflow = False
with torch.cuda.stream(self.migration_stream):
for key, value in self.accumulated_grads_in_cpu.items():
value.mul_(0.0)
@@ -1327,7 +1327,7 @@ def step(self, closure=None):
"""
Not supporting closure.
"""
- self.micro_step_id = 0
+ self.micro_step_id = -1
if self.cpu_offload:
torch.cuda.current_stream().wait_stream(self.migration_stream)
@@ -1346,6 +1346,8 @@ def step(self, closure=None):
self.zero_grad()
if self.cpu_offload:
self.reset_cpu_buffers()
+ else:
+ self.averaged_gradients = {}
see_memory_usage('After overflow after clearing gradients')
@@ -1557,6 +1559,7 @@ def backward(self, loss, retain_graph=False):
2. scaled_loss = fp32_loss*loss_scale
3. scaled_loss.backward(), which accumulates scaled gradients into the ``.grad`` attributes of the model's fp16 leaves
"""
+ self.micro_step_id += 1
if self.cpu_offload:
torch.cuda.current_stream().wait_stream(self.migration_stream)
@@ -1576,7 +1579,6 @@ def backward(self, loss, retain_graph=False):
self.ipg_index = 0
self.loss_scaler.backward(loss.float(), retain_graph=retain_graph)
- self.micro_step_id += 1
def check_overflow(self, partition_gradients=True):
self._check_overflow(partition_gradients)
|
Bug fixes and passing several correctness tests:
HD | AH | NL | GAS | MBZ | GPUs | MP | Steps | No ZeRO | ZeRO-2 | ZeRO+Offload | ZeRO-1
-- | -- | -- | -- | -- | -- | -- | -- | -- | -- | -- | --
512 | 16 | 4 | 2 | 12 | 1 | 1 | 200 | 7.658 | 7.66 | 7.66 | 7.66
1024 | 16 | 4 | 2 | 12 | 4 | 2 | 200 | 7.23 | 7.22 | 7.22 | 7.23
1024 | 16 | 4 | 5 | 12 | 16 | 4 | 400 | 7.314 | 7.27 | 7.268 | 7.284
|
https://api.github.com/repos/microsoft/DeepSpeed/pulls/359
|
2020-09-04T01:02:14Z
|
2020-09-04T03:39:32Z
|
2020-09-04T03:39:31Z
|
2021-09-24T04:42:33Z
| 1,574
|
microsoft/DeepSpeed
| 10,748
|
Fix cloudflare_dns proxied change detection
|
diff --git a/lib/ansible/modules/net_tools/cloudflare_dns.py b/lib/ansible/modules/net_tools/cloudflare_dns.py
index f3fcc1fffe1f88..97e22082267626 100644
--- a/lib/ansible/modules/net_tools/cloudflare_dns.py
+++ b/lib/ansible/modules/net_tools/cloudflare_dns.py
@@ -557,6 +557,8 @@ def ensure_dns_record(self, **kwargs):
do_update = True
if (params['priority'] is not None) and ('priority' in cur_record) and (cur_record['priority'] != params['priority']):
do_update = True
+ if ('proxied' in new_record) and ('proxied' in cur_record) and (cur_record['proxied'] != params['proxied']):
+ do_update = True
if ('data' in new_record) and ('data' in cur_record):
if (cur_record['data'] != new_record['data']):
do_update = True
diff --git a/test/legacy/roles/test_cloudflare_dns/tasks/a_record.yml b/test/legacy/roles/test_cloudflare_dns/tasks/a_record.yml
index 6f52bf9992b712..6ee621b9c2a6cb 100644
--- a/test/legacy/roles/test_cloudflare_dns/tasks/a_record.yml
+++ b/test/legacy/roles/test_cloudflare_dns/tasks/a_record.yml
@@ -178,3 +178,153 @@
that:
- cloudflare_dns is successful
- cloudflare_dns is not changed
+
+- name: "Test: proxiable A record creation"
+ cloudflare_dns:
+ account_email: "{{ cloudflare_email }}"
+ account_api_token: "{{ cloudflare_api_token }}"
+ zone: "{{ cloudflare_zone }}"
+ record: "{{ cloudflare_dns_record }}"
+ type: A
+ value: 192.0.2.47
+ ttl: 150
+ register: cloudflare_dns
+
+- name: "Validate: proxiable A record creation"
+ assert:
+ that:
+ - cloudflare_dns is successful
+ - cloudflare_dns is changed
+ - cloudflare_dns.result.record.content == '192.0.2.47'
+ - cloudflare_dns.result.record.proxiable == true
+ - cloudflare_dns.result.record.ttl == 150
+ - cloudflare_dns.result.record.type == 'A'
+ - cloudflare_dns.result.record.name == "{{ cloudflare_dns_record }}.{{ cloudflare_zone }}"
+ - cloudflare_dns.result.record.zone_name == "{{ cloudflare_zone }}"
+
+- name: "Test: proxiable A record creation succeeded"
+ cloudflare_dns:
+ account_email: "{{ cloudflare_email }}"
+ account_api_token: "{{ cloudflare_api_token }}"
+ zone: "{{ cloudflare_zone }}"
+ record: "{{ cloudflare_dns_record }}"
+ type: A
+ value: 192.0.2.47
+ ttl: 150
+ register: cloudflare_dns
+
+- name: "Validate: proxiable A record creation succeeded"
+ assert:
+ that:
+ - cloudflare_dns is successful
+ - cloudflare_dns is not changed
+
+- name: "Test: Enable A record proxied status"
+ cloudflare_dns:
+ account_email: "{{ cloudflare_email }}"
+ account_api_token: "{{ cloudflare_api_token }}"
+ zone: "{{ cloudflare_zone }}"
+ record: "{{ cloudflare_dns_record }}"
+ type: A
+ value: 192.0.2.47
+ proxied: yes
+ register: cloudflare_dns
+
+- name: "Validate: Enable A record proxied status"
+ assert:
+ that:
+ - cloudflare_dns is successful
+ - cloudflare_dns is changed
+ - cloudflare_dns.result.record.content == '192.0.2.47'
+ - cloudflare_dns.result.record.proxied == true
+ - cloudflare_dns.result.record.type == 'A'
+ - cloudflare_dns.result.record.name == "{{ cloudflare_dns_record }}.{{ cloudflare_zone }}"
+ - cloudflare_dns.result.record.zone_name == "{{ cloudflare_zone }}"
+
+- name: "Test: Enable A record proxied status succeeded"
+ cloudflare_dns:
+ account_email: "{{ cloudflare_email }}"
+ account_api_token: "{{ cloudflare_api_token }}"
+ zone: "{{ cloudflare_zone }}"
+ record: "{{ cloudflare_dns_record }}"
+ type: A
+ value: 192.0.2.47
+ proxied: yes
+ register: cloudflare_dns
+
+- name: "Validate: Enable A record proxied status succeeded"
+ assert:
+ that:
+ - cloudflare_dns is successful
+ - cloudflare_dns is not changed
+
+- name: "Test: Disable A record proxied status"
+ cloudflare_dns:
+ account_email: "{{ cloudflare_email }}"
+ account_api_token: "{{ cloudflare_api_token }}"
+ zone: "{{ cloudflare_zone }}"
+ record: "{{ cloudflare_dns_record }}"
+ type: A
+ value: 192.0.2.47
+ proxied: no
+ register: cloudflare_dns
+
+- name: "Validate: Enable A record proxied status"
+ assert:
+ that:
+ - cloudflare_dns is successful
+ - cloudflare_dns is changed
+ - cloudflare_dns.result.record.content == '192.0.2.47'
+ - cloudflare_dns.result.record.proxied == false
+ - cloudflare_dns.result.record.type == 'A'
+ - cloudflare_dns.result.record.name == "{{ cloudflare_dns_record }}.{{ cloudflare_zone }}"
+ - cloudflare_dns.result.record.zone_name == "{{ cloudflare_zone }}"
+
+- name: "Test: Disable A record proxied status succeeded"
+ cloudflare_dns:
+ account_email: "{{ cloudflare_email }}"
+ account_api_token: "{{ cloudflare_api_token }}"
+ zone: "{{ cloudflare_zone }}"
+ record: "{{ cloudflare_dns_record }}"
+ type: A
+ value: 192.0.2.47
+ proxied: no
+ register: cloudflare_dns
+
+- name: "Validate: Enable A record proxied status succeeded"
+ assert:
+ that:
+ - cloudflare_dns is successful
+ - cloudflare_dns is not changed
+
+- name: "Test: Full A record deletion"
+ cloudflare_dns:
+ account_email: "{{ cloudflare_email }}"
+ account_api_token: "{{ cloudflare_api_token }}"
+ zone: "{{ cloudflare_zone }}"
+ record: "{{ cloudflare_dns_record }}"
+ type: A
+ state: absent
+ register: cloudflare_dns
+
+- name: "Validate: Full A record deletion"
+ assert:
+ that:
+ - cloudflare_dns is successful
+ - cloudflare_dns is changed
+
+- name: "Test: Full A record deletion succeeded"
+ cloudflare_dns:
+ account_email: "{{ cloudflare_email }}"
+ account_api_token: "{{ cloudflare_api_token }}"
+ zone: "{{ cloudflare_zone }}"
+ record: "{{ cloudflare_dns_record }}"
+ type: A
+ state: absent
+ register: cloudflare_dns
+
+- name: "Validate: Full A record deletion succeeded"
+ assert:
+ that:
+ - cloudflare_dns is successful
+ - cloudflare_dns is not changed
diff --git a/test/legacy/roles/test_cloudflare_dns/tasks/aaaa_record.yml b/test/legacy/roles/test_cloudflare_dns/tasks/aaaa_record.yml
index eaa8a860991c8a..d4cae8d5b5db83 100644
--- a/test/legacy/roles/test_cloudflare_dns/tasks/aaaa_record.yml
+++ b/test/legacy/roles/test_cloudflare_dns/tasks/aaaa_record.yml
@@ -178,3 +178,153 @@
that:
- cloudflare_dns is successful
- cloudflare_dns is not changed
+
+- name: "Test: proxiable AAAA record creation"
+ cloudflare_dns:
+ account_email: "{{ cloudflare_email }}"
+ account_api_token: "{{ cloudflare_api_token }}"
+ zone: "{{ cloudflare_zone }}"
+ record: "{{ cloudflare_dns_record }}"
+ type: AAAA
+ value: 2001:db8::47
+ ttl: 150
+ register: cloudflare_dns
+
+- name: "Validate: proxiable AAAA record creation"
+ assert:
+ that:
+ - cloudflare_dns is successful
+ - cloudflare_dns is changed
+ - cloudflare_dns.result.record.content == '2001:db8::47'
+ - cloudflare_dns.result.record.proxiable == true
+ - cloudflare_dns.result.record.ttl == 150
+ - cloudflare_dns.result.record.type == 'AAAA'
+ - cloudflare_dns.result.record.name == "{{ cloudflare_dns_record }}.{{ cloudflare_zone }}"
+ - cloudflare_dns.result.record.zone_name == "{{ cloudflare_zone }}"
+
+- name: "Test: proxiable AAAA record creation succeeded"
+ cloudflare_dns:
+ account_email: "{{ cloudflare_email }}"
+ account_api_token: "{{ cloudflare_api_token }}"
+ zone: "{{ cloudflare_zone }}"
+ record: "{{ cloudflare_dns_record }}"
+ type: AAAA
+ value: 2001:db8::47
+ ttl: 150
+ register: cloudflare_dns
+
+- name: "Validate: proxiable AAAA record creation succeeded"
+ assert:
+ that:
+ - cloudflare_dns is successful
+ - cloudflare_dns is not changed
+
+- name: "Test: Enable AAAA record proxied status"
+ cloudflare_dns:
+ account_email: "{{ cloudflare_email }}"
+ account_api_token: "{{ cloudflare_api_token }}"
+ zone: "{{ cloudflare_zone }}"
+ record: "{{ cloudflare_dns_record }}"
+ type: AAAA
+ value: 2001:db8::47
+ proxied: yes
+ register: cloudflare_dns
+
+- name: "Validate: Enable AAAA record proxied status"
+ assert:
+ that:
+ - cloudflare_dns is successful
+ - cloudflare_dns is changed
+ - cloudflare_dns.result.record.content == '2001:db8::47'
+ - cloudflare_dns.result.record.proxied == true
+ - cloudflare_dns.result.record.type == 'AAAA'
+ - cloudflare_dns.result.record.name == "{{ cloudflare_dns_record }}.{{ cloudflare_zone }}"
+ - cloudflare_dns.result.record.zone_name == "{{ cloudflare_zone }}"
+
+- name: "Test: Enable AAAA record proxied status succeeded"
+ cloudflare_dns:
+ account_email: "{{ cloudflare_email }}"
+ account_api_token: "{{ cloudflare_api_token }}"
+ zone: "{{ cloudflare_zone }}"
+ record: "{{ cloudflare_dns_record }}"
+ type: AAAA
+ value: 2001:db8::47
+ proxied: yes
+ register: cloudflare_dns
+
+- name: "Validate: Enable AAAA record proxied status succeeded"
+ assert:
+ that:
+ - cloudflare_dns is successful
+ - cloudflare_dns is not changed
+
+- name: "Test: Disable AAAA record proxied status"
+ cloudflare_dns:
+ account_email: "{{ cloudflare_email }}"
+ account_api_token: "{{ cloudflare_api_token }}"
+ zone: "{{ cloudflare_zone }}"
+ record: "{{ cloudflare_dns_record }}"
+ type: AAAA
+ value: 2001:db8::47
+ proxied: no
+ register: cloudflare_dns
+
+- name: "Validate: Enable AAAA record proxied status"
+ assert:
+ that:
+ - cloudflare_dns is successful
+ - cloudflare_dns is changed
+ - cloudflare_dns.result.record.content == '2001:db8::47'
+ - cloudflare_dns.result.record.proxied == false
+ - cloudflare_dns.result.record.type == 'AAAA'
+ - cloudflare_dns.result.record.name == "{{ cloudflare_dns_record }}.{{ cloudflare_zone }}"
+ - cloudflare_dns.result.record.zone_name == "{{ cloudflare_zone }}"
+
+- name: "Test: Disable AAAA record proxied status succeeded"
+ cloudflare_dns:
+ account_email: "{{ cloudflare_email }}"
+ account_api_token: "{{ cloudflare_api_token }}"
+ zone: "{{ cloudflare_zone }}"
+ record: "{{ cloudflare_dns_record }}"
+ type: AAAA
+ value: 2001:db8::47
+ proxied: no
+ register: cloudflare_dns
+
+- name: "Validate: Enable AAAA record proxied status succeeded"
+ assert:
+ that:
+ - cloudflare_dns is successful
+ - cloudflare_dns is not changed
+
+- name: "Test: Full AAAA record deletion"
+ cloudflare_dns:
+ account_email: "{{ cloudflare_email }}"
+ account_api_token: "{{ cloudflare_api_token }}"
+ zone: "{{ cloudflare_zone }}"
+ record: "{{ cloudflare_dns_record }}"
+ type: AAAA
+ state: absent
+ register: cloudflare_dns
+
+- name: "Validate: Full AAAA record deletion"
+ assert:
+ that:
+ - cloudflare_dns is successful
+ - cloudflare_dns is changed
+
+- name: "Test: Full AAAA record deletion succeeded"
+ cloudflare_dns:
+ account_email: "{{ cloudflare_email }}"
+ account_api_token: "{{ cloudflare_api_token }}"
+ zone: "{{ cloudflare_zone }}"
+ record: "{{ cloudflare_dns_record }}"
+ type: AAAA
+ state: absent
+ register: cloudflare_dns
+
+- name: "Validate: Full AAAA record deletion succeeded"
+ assert:
+ that:
+ - cloudflare_dns is successful
+ - cloudflare_dns is not changed
|
##### SUMMARY
Resolves #35190
##### ISSUE TYPE
- Bugfix Pull Request
##### COMPONENT NAME
cloudflare_dns
##### ANSIBLE VERSION
```
ansible 2.7.0.dev0 (devel fdf51f2a43) last updated 2018/07/20 16:39:25 (GMT +200)
config file = /etc/ansible/ansible.cfg
configured module search path = [u'/home/andreas/.ansible/plugins/modules', u'/usr/share/ansible/plugins/modules']
ansible python module location = /home/andreas/labs/ansible/devel/lib/ansible
executable location = /home/andreas/labs/ansible/devel/bin/ansible
python version = 2.7.15rc1 (default, Apr 15 2018, 21:51:34) [GCC 7.3.0]
```
|
https://api.github.com/repos/ansible/ansible/pulls/43096
|
2018-07-20T14:42:21Z
|
2018-07-27T03:57:06Z
|
2018-07-27T03:57:06Z
|
2019-07-22T16:06:19Z
| 3,132
|
ansible/ansible
| 49,491
|
Updated Clearbit Logo auth
|
diff --git a/README.md b/README.md
index 620bb0d5e5..e4b632edd1 100644
--- a/README.md
+++ b/README.md
@@ -117,7 +117,7 @@ API | Description | Auth | HTTPS | CORS |
API | Description | Auth | HTTPS | CORS |
|---|---|---|---|---|
| [Charity Search](http://charityapi.orghunter.com/) | Non-profit charity data | `apiKey` | No | Unknown |
-| [Clearbit Logo](https://clearbit.com/docs#logo-api) | Search for company logos and embed them in your projects | No | Yes | Unknown |
+| [Clearbit Logo](https://clearbit.com/docs#logo-api) | Search for company logos and embed them in your projects | `apiKey` | Yes | Unknown |
| [Domainsdb.info](https://domainsdb.info/) | Registered Domain Names Search | No | Yes | Unknown |
| [Gmail](https://developers.google.com/gmail/api/) | Flexible, RESTful access to the user's inbox | `OAuth` | Yes | Unknown |
| [Google Analytics](https://developers.google.com/analytics/) | Collect, configure, and analyze your data to reach the right audience | `OAuth` | Yes | Unknown |
|
Updated 'Clearbit Logo' auth entry with 'apiKey'.
|
https://api.github.com/repos/public-apis/public-apis/pulls/779
|
2018-10-10T00:31:49Z
|
2018-10-10T07:12:15Z
|
2018-10-10T07:12:15Z
|
2018-10-10T07:12:15Z
| 281
|
public-apis/public-apis
| 35,333
|
Con.1 Issue #1905 Return local const
|
diff --git a/CppCoreGuidelines.md b/CppCoreGuidelines.md
index ec3200ed6..8b8bf0aef 100644
--- a/CppCoreGuidelines.md
+++ b/CppCoreGuidelines.md
@@ -16856,19 +16856,28 @@ Prevents accidental or hard-to-notice change of value.
for (int i : c) cout << i << '\n'; // BAD: just reading
-##### Exception
+##### Exceptions
+
+A local variable that is returned by value and is cheaper to move than copy should not be declared `const`
+because it can force an unnecessary copy.
+
+ std::vector<int> f(int i)
+ {
+ std::vector<int> v{ i, i, i }; // const not needed
+ return v;
+ }
Function parameters passed by value are rarely mutated, but also rarely declared `const`.
To avoid confusion and lots of false positives, don't enforce this rule for function parameters.
- void f(const char* const p); // pedantic
void g(const int i) { ... } // pedantic
Note that a function parameter is a local variable so changes to it are local.
##### Enforcement
-* Flag non-`const` variables that are not modified (except for parameters to avoid many false positives)
+* Flag non-`const` variables that are not modified (except for parameters to avoid many false positives
+and returned local variables)
### <a name="Rconst-fct"></a>Con.2: By default, make member functions `const`
|
Update for Issue #1905
|
https://api.github.com/repos/isocpp/CppCoreGuidelines/pulls/2114
|
2023-08-03T06:23:42Z
|
2023-10-12T20:02:28Z
|
2023-10-12T20:02:28Z
|
2023-10-12T20:02:29Z
| 349
|
isocpp/CppCoreGuidelines
| 15,356
|
Remove the --max-quality option
|
diff --git a/README.md b/README.md
index 7040be1ec99..948e0a4b946 100644
--- a/README.md
+++ b/README.md
@@ -188,7 +188,6 @@ which means you can modify it, redistribute it or use it however you like.
-f, --format FORMAT Video format code, see the "FORMAT SELECTION" for all the info
--all-formats Download all available video formats
--prefer-free-formats Prefer free video formats unless a specific one is requested
- --max-quality FORMAT Highest quality format to download
-F, --list-formats List all available formats
--youtube-skip-dash-manifest Do not download the DASH manifest on YouTube videos
--merge-output-format FORMAT If a merge is required (e.g. bestvideo+bestaudio), output to given container format. One of mkv, mp4, ogg, webm, flv.Ignored if no
@@ -324,9 +323,9 @@ YouTube changed their playlist format in March 2014 and later on, so you'll need
If you have installed youtube-dl with a package manager, pip, setup.py or a tarball, please use that to update. Note that Ubuntu packages do not seem to get updated anymore. Since we are not affiliated with Ubuntu, there is little we can do. Feel free to [report bugs](https://bugs.launchpad.net/ubuntu/+source/youtube-dl/+filebug) to the [Ubuntu packaging guys](mailto:[email protected]?subject=outdated%20version%20of%20youtube-dl) - all they have to do is update the package to a somewhat recent version. See above for a way to update.
-### Do I always have to pass in `--max-quality FORMAT`, or `-citw`?
+### Do I always have to pass `-citw`?
-By default, youtube-dl intends to have the best options (incidentally, if you have a convincing case that these should be different, [please file an issue where you explain that](https://yt-dl.org/bug)). Therefore, it is unnecessary and sometimes harmful to copy long option strings from webpages. In particular, `--max-quality` *limits* the video quality (so if you want the best quality, do NOT pass it in), and the only option out of `-citw` that is regularly useful is `-i`.
+By default, youtube-dl intends to have the best options (incidentally, if you have a convincing case that these should be different, [please file an issue where you explain that](https://yt-dl.org/bug)). Therefore, it is unnecessary and sometimes harmful to copy long option strings from webpages. In particular, the only option out of `-citw` that is regularly useful is `-i`.
### Can you please put the -b option back?
diff --git a/test/parameters.json b/test/parameters.json
index 48b5a062e52..7bf59c25fdf 100644
--- a/test/parameters.json
+++ b/test/parameters.json
@@ -8,7 +8,6 @@
"forcetitle": false,
"forceurl": false,
"format": "best",
- "format_limit": null,
"ignoreerrors": false,
"listformats": null,
"logtostderr": false,
diff --git a/test/test_YoutubeDL.py b/test/test_YoutubeDL.py
index 820e55ec2ae..bb4a65ee182 100644
--- a/test/test_YoutubeDL.py
+++ b/test/test_YoutubeDL.py
@@ -101,39 +101,6 @@ def test_prefer_free_formats(self):
downloaded = ydl.downloaded_info_dicts[0]
self.assertEqual(downloaded['ext'], 'flv')
- def test_format_limit(self):
- formats = [
- {'format_id': 'meh', 'url': 'http://example.com/meh', 'preference': 1},
- {'format_id': 'good', 'url': 'http://example.com/good', 'preference': 2},
- {'format_id': 'great', 'url': 'http://example.com/great', 'preference': 3},
- {'format_id': 'excellent', 'url': 'http://example.com/exc', 'preference': 4},
- ]
- info_dict = _make_result(formats)
-
- ydl = YDL()
- ydl.process_ie_result(info_dict)
- downloaded = ydl.downloaded_info_dicts[0]
- self.assertEqual(downloaded['format_id'], 'excellent')
-
- ydl = YDL({'format_limit': 'good'})
- assert ydl.params['format_limit'] == 'good'
- ydl.process_ie_result(info_dict.copy())
- downloaded = ydl.downloaded_info_dicts[0]
- self.assertEqual(downloaded['format_id'], 'good')
-
- ydl = YDL({'format_limit': 'great', 'format': 'all'})
- ydl.process_ie_result(info_dict.copy())
- self.assertEqual(ydl.downloaded_info_dicts[0]['format_id'], 'meh')
- self.assertEqual(ydl.downloaded_info_dicts[1]['format_id'], 'good')
- self.assertEqual(ydl.downloaded_info_dicts[2]['format_id'], 'great')
- self.assertTrue('3' in ydl.msgs[0])
-
- ydl = YDL()
- ydl.params['format_limit'] = 'excellent'
- ydl.process_ie_result(info_dict.copy())
- downloaded = ydl.downloaded_info_dicts[0]
- self.assertEqual(downloaded['format_id'], 'excellent')
-
def test_format_selection(self):
formats = [
{'format_id': '35', 'ext': 'mp4', 'preference': 1, 'url': TEST_URL},
diff --git a/youtube_dl/YoutubeDL.py b/youtube_dl/YoutubeDL.py
index 0fdcf1b0b72..977141881b0 100755
--- a/youtube_dl/YoutubeDL.py
+++ b/youtube_dl/YoutubeDL.py
@@ -64,7 +64,6 @@
sanitize_path,
std_headers,
subtitles_filename,
- takewhile_inclusive,
UnavailableVideoError,
url_basename,
version_tuple,
@@ -135,7 +134,6 @@ class YoutubeDL(object):
(or video) as a single JSON line.
simulate: Do not download the video files.
format: Video format code. See options.py for more information.
- format_limit: Highest quality format to try.
outtmpl: Template for output names.
restrictfilenames: Do not allow "&" and spaces in file names
ignoreerrors: Do not stop on download errors.
@@ -1068,12 +1066,6 @@ def process_video_result(self, info_dict, download=True):
full_format_info.update(format)
format['http_headers'] = self._calc_headers(full_format_info)
- format_limit = self.params.get('format_limit', None)
- if format_limit:
- formats = list(takewhile_inclusive(
- lambda f: f['format_id'] != format_limit, formats
- ))
-
# TODO Central sorting goes here
if formats[0] is not info_dict:
diff --git a/youtube_dl/__init__.py b/youtube_dl/__init__.py
index d7759db682d..c88489f2989 100644
--- a/youtube_dl/__init__.py
+++ b/youtube_dl/__init__.py
@@ -283,7 +283,6 @@ def _real_main(argv=None):
'simulate': opts.simulate or any_getting,
'skip_download': opts.skip_download,
'format': opts.format,
- 'format_limit': opts.format_limit,
'listformats': opts.listformats,
'outtmpl': outtmpl,
'autonumber_size': opts.autonumber_size,
diff --git a/youtube_dl/options.py b/youtube_dl/options.py
index 39c38c98088..4c9d39d9a47 100644
--- a/youtube_dl/options.py
+++ b/youtube_dl/options.py
@@ -331,10 +331,6 @@ def _hide_login_info(opts):
'--prefer-free-formats',
action='store_true', dest='prefer_free_formats', default=False,
help='Prefer free video formats unless a specific one is requested')
- video_format.add_option(
- '--max-quality',
- action='store', dest='format_limit', metavar='FORMAT',
- help='Highest quality format to download')
video_format.add_option(
'-F', '--list-formats',
action='store_true', dest='listformats',
diff --git a/youtube_dl/utils.py b/youtube_dl/utils.py
index edeee1853e3..c69d3e165fc 100644
--- a/youtube_dl/utils.py
+++ b/youtube_dl/utils.py
@@ -1109,15 +1109,6 @@ def shell_quote(args):
return ' '.join(quoted_args)
-def takewhile_inclusive(pred, seq):
- """ Like itertools.takewhile, but include the latest evaluated element
- (the first element so that Not pred(e)) """
- for e in seq:
- yield e
- if not pred(e):
- return
-
-
def smuggle_url(url, data):
""" Pass additional data in a URL for internal use. """
|
It doesn't work well with 'bestvideo' and 'bestaudio' because they are usually before the max quality.
Format filters should be used instead, they are more flexible and don't require the requested quality to exist for each video.
|
https://api.github.com/repos/ytdl-org/youtube-dl/pulls/5523
|
2015-04-25T10:07:30Z
|
2015-04-27T11:44:59Z
|
2015-04-27T11:44:59Z
|
2015-05-09T23:12:30Z
| 2,112
|
ytdl-org/youtube-dl
| 50,004
|
updated deprecated cgi.parse_qsl to use six's parse_qsl
|
diff --git a/scrapy/utils/url.py b/scrapy/utils/url.py
index ab4d75f874c..36490a39db5 100644
--- a/scrapy/utils/url.py
+++ b/scrapy/utils/url.py
@@ -6,9 +6,9 @@
to the w3lib.url module. Always import those from there instead.
"""
import posixpath
-from six.moves.urllib.parse import ParseResult, urlunparse, urldefrag, urlparse
+from six.moves.urllib.parse import (ParseResult, urlunparse, urldefrag,
+ urlparse, parse_qsl)
import urllib
-import cgi
# scrapy.utils.url was moved to w3lib.url and import * ensures this move doesn't break old code
from w3lib.url import *
@@ -54,7 +54,7 @@ def canonicalize_url(url, keep_blank_values=True, keep_fragments=False,
"""
scheme, netloc, path, params, query, fragment = parse_url(url)
- keyvals = cgi.parse_qsl(query, keep_blank_values)
+ keyvals = parse_qsl(query, keep_blank_values)
keyvals.sort()
query = urllib.urlencode(keyvals)
path = safe_url_string(_unquotepath(path)) or '/'
|
According to Python 2 documentation: https://docs.python.org/2/library/cgi.html#cgi.parse_qsl
> "This function is deprecated in this module. Use urlparse.parse_qsl() instead. It is maintained here only for backward compatiblity."
For future compatibility with Python 3, the `scrapy.utils.url` module is updated to use `six` library's `urllib.parse.parse_qsl` instead.
https://pythonhosted.org/six/#module-six.moves.urllib.parse
|
https://api.github.com/repos/scrapy/scrapy/pulls/909
|
2014-10-02T20:32:31Z
|
2014-10-03T10:30:39Z
|
2014-10-03T10:30:39Z
|
2014-10-03T10:30:39Z
| 271
|
scrapy/scrapy
| 34,512
|
Various docstring fixes, removing unused variables
|
diff --git a/rich/containers.py b/rich/containers.py
index e29cf3689..901ff8ba6 100644
--- a/rich/containers.py
+++ b/rich/containers.py
@@ -1,13 +1,13 @@
from itertools import zip_longest
from typing import (
- Iterator,
+ TYPE_CHECKING,
Iterable,
+ Iterator,
List,
Optional,
+ TypeVar,
Union,
overload,
- TypeVar,
- TYPE_CHECKING,
)
if TYPE_CHECKING:
@@ -119,7 +119,7 @@ def justify(
Args:
console (Console): Console instance.
- width (int): Number of characters per line.
+ width (int): Number of cells available per line.
justify (str, optional): Default justify method for text: "left", "center", "full" or "right". Defaults to "left".
overflow (str, optional): Default overflow for text: "crop", "fold", or "ellipsis". Defaults to "fold".
diff --git a/rich/markup.py b/rich/markup.py
index cb927edd1..bd9c05a71 100644
--- a/rich/markup.py
+++ b/rich/markup.py
@@ -113,7 +113,10 @@ def render(
Args:
markup (str): A string containing console markup.
+ style: (Union[str, Style]): The style to use.
emoji (bool, optional): Also render emoji code. Defaults to True.
+ emoji_variant (str, optional): Optional emoji variant, either "text" or "emoji". Defaults to None.
+
Raises:
MarkupError: If there is a syntax error in the markup.
diff --git a/rich/text.py b/rich/text.py
index 90b1cb14b..7091e4291 100644
--- a/rich/text.py
+++ b/rich/text.py
@@ -271,7 +271,9 @@ def from_markup(
Args:
text (str): A string containing console markup.
+ style (Union[str, Style], optional): Base style for text. Defaults to "".
emoji (bool, optional): Also render emoji code. Defaults to True.
+ emoji_variant (str, optional): Optional emoji variant, either "text" or "emoji". Defaults to None.
justify (str, optional): Justify method: "left", "center", "full", "right". Defaults to None.
overflow (str, optional): Overflow method: "crop", "fold", "ellipsis". Defaults to None.
end (str, optional): Character to end text with. Defaults to "\\\\n".
@@ -369,6 +371,7 @@ def assemble(
style (Union[str, Style], optional): Base style for text. Defaults to "".
justify (str, optional): Justify method: "left", "center", "full", "right". Defaults to None.
overflow (str, optional): Overflow method: "crop", "fold", "ellipsis". Defaults to None.
+ no_wrap (bool, optional): Disable text wrapping, or None for default. Defaults to None.
end (str, optional): Character to end text with. Defaults to "\\\\n".
tab_size (int): Number of spaces per tab, or ``None`` to use ``console.tab_size``. Defaults to None.
meta (Dict[str, Any], optional). Meta data to apply to text, or None for no meta data. Default to None
@@ -424,7 +427,7 @@ def spans(self, spans: List[Span]) -> None:
self._spans = spans[:]
def blank_copy(self, plain: str = "") -> "Text":
- """Return a new Text instance with copied meta data (but not the string or spans)."""
+ """Return a new Text instance with copied metadata (but not the string or spans)."""
copy_self = Text(
plain,
style=self.style,
@@ -505,7 +508,7 @@ def stylize_before(
def apply_meta(
self, meta: Dict[str, Any], start: int = 0, end: Optional[int] = None
) -> None:
- """Apply meta data to the text, or a portion of the text.
+ """Apply metadata to the text, or a portion of the text.
Args:
meta (Dict[str, Any]): A dict of meta information.
@@ -634,9 +637,9 @@ def highlight_words(
"""Highlight words with a style.
Args:
- words (Iterable[str]): Worlds to highlight.
+ words (Iterable[str]): Words to highlight.
style (Union[str, Style]): Style to apply.
- case_sensitive (bool, optional): Enable case sensitive matchings. Defaults to True.
+ case_sensitive (bool, optional): Enable case sensitive matching. Defaults to True.
Returns:
int: Number of words highlighted.
@@ -823,8 +826,6 @@ def expand_tabs(self, tab_size: Optional[int] = None) -> None:
if tab_size is None:
tab_size = 8
- result = self.blank_copy()
-
new_text: List[Text] = []
append = new_text.append
@@ -899,6 +900,7 @@ def pad(self, count: int, character: str = " ") -> None:
Args:
count (int): Width of padding.
+ character (str): The character to pad with. Must be a string of length 1.
"""
assert len(character) == 1, "Character must be a string of length 1"
if count:
@@ -1005,6 +1007,9 @@ def append_text(self, text: "Text") -> "Text":
"""Append another Text instance. This method is more performant that Text.append, but
only works for Text.
+ Args:
+ text (Text): The Text instance to append to this instance.
+
Returns:
Text: Returns self for chaining.
"""
@@ -1026,7 +1031,7 @@ def append_tokens(
"""Append iterable of str and style. Style may be a Style instance or a str style definition.
Args:
- pairs (Iterable[Tuple[str, Optional[StyleType]]]): An iterable of tuples containing str content and style.
+ tokens (Iterable[Tuple[str, Optional[StyleType]]]): An iterable of tuples containing str content and style.
Returns:
Text: Returns self for chaining.
@@ -1204,8 +1209,7 @@ def wrap(
Args:
console (Console): Console instance.
- width (int): Number of characters per line.
- emoji (bool, optional): Also render emoji code. Defaults to True.
+ width (int): Number of cells available per line.
justify (str, optional): Justify method: "default", "left", "center", "full", "right". Defaults to "default".
overflow (str, optional): Overflow method: "crop", "fold", or "ellipsis". Defaults to None.
tab_size (int, optional): Default tab size. Defaults to 8.
|
I found a bunch of issues with docstrings/unused variables during my time on #3180.
I gathered all of the diffs into this PR to keep #3180 focused.
|
https://api.github.com/repos/Textualize/rich/pulls/3191
|
2023-11-07T11:26:38Z
|
2023-11-07T16:22:13Z
|
2023-11-07T16:22:13Z
|
2023-11-07T16:22:14Z
| 1,561
|
Textualize/rich
| 48,644
|
R.20: 'represent ownership' clean up example and enforcement
|
diff --git a/CppCoreGuidelines.md b/CppCoreGuidelines.md
index 3bcf11222..3125b6f83 100644
--- a/CppCoreGuidelines.md
+++ b/CppCoreGuidelines.md
@@ -9785,19 +9785,17 @@ Consider:
void f()
{
- X x;
- X* p1 { new X }; // see also ???
- unique_ptr<X> p2 { new X }; // unique ownership; see also ???
- shared_ptr<X> p3 { new X }; // shared ownership; see also ???
- auto p4 = make_unique<X>(); // unique_ownership, preferable to the explicit use "new"
- auto p5 = make_shared<X>(); // shared ownership, preferable to the explicit use "new"
+ X* p1 { new X }; // bad, p1 will leak
+ auto p2 = make_unique<X>(); // good, unique ownership
+ auto p3 = make_shared<X>(); // good, shared ownership
}
This will leak the object used to initialize `p1` (only).
##### Enforcement
-(Simple) Warn if the return value of `new` or a function call with return value of pointer type is assigned to a raw pointer.
+* (Simple) Warn if the return value of `new` is assigned to a raw pointer.
+* (Simple) Warn if the result of a function returning a raw owning pointer is assigned to a raw pointer.
### <a name="Rr-unique"></a>R.21: Prefer `unique_ptr` over `shared_ptr` unless you need to share ownership
|
Simplified the example and clarified the enforcement to only apply for owning pointers.
|
https://api.github.com/repos/isocpp/CppCoreGuidelines/pulls/1992
|
2022-11-13T08:25:30Z
|
2022-12-01T22:27:29Z
|
2022-12-01T22:27:29Z
|
2022-12-01T22:27:39Z
| 368
|
isocpp/CppCoreGuidelines
| 15,297
|
fix link & test=document_fix
|
diff --git a/deploy/pdserving/README.md b/deploy/pdserving/README.md
index c461fd5e54..37b97589c4 100644
--- a/deploy/pdserving/README.md
+++ b/deploy/pdserving/README.md
@@ -19,10 +19,14 @@ The introduction and tutorial of Paddle Serving service deployment framework ref
## Contents
-- [Environmental preparation](#environmental-preparation)
-- [Model conversion](#model-conversion)
-- [Paddle Serving pipeline deployment](#paddle-serving-pipeline-deployment)
-- [FAQ](#faq)
+- [OCR Pipeline WebService](#ocr-pipeline-webservice)
+- [Service deployment based on PaddleServing](#service-deployment-based-on-paddleserving)
+ - [Contents](#contents)
+ - [Environmental preparation](#environmental-preparation)
+ - [Model conversion](#model-conversion)
+ - [Paddle Serving pipeline deployment](#paddle-serving-pipeline-deployment)
+ - [WINDOWS Users](#windows-users)
+ - [FAQ](#faq)
<a name="environmental-preparation"></a>
## Environmental preparation
@@ -201,7 +205,7 @@ The recognition model is the same.
## WINDOWS Users
-Windows does not support Pipeline Serving, if we want to lauch paddle serving on Windows, we should use Web Service, for more infomation please refer to [Paddle Serving for Windows Users](https://github.com/PaddlePaddle/Serving/blob/develop/doc/WINDOWS_TUTORIAL.md)
+Windows does not support Pipeline Serving, if we want to lauch paddle serving on Windows, we should use Web Service, for more infomation please refer to [Paddle Serving for Windows Users](https://github.com/PaddlePaddle/Serving/blob/develop/doc/Windows_Tutorial_EN.md)
**WINDOWS user can only use version 0.5.0 CPU Mode**
|
https://api.github.com/repos/PaddlePaddle/PaddleOCR/pulls/5437
|
2022-02-10T08:42:13Z
|
2022-02-10T08:53:53Z
|
2022-02-10T08:53:53Z
|
2022-02-10T08:53:53Z
| 424
|
PaddlePaddle/PaddleOCR
| 42,310
|
|
W&B: refactor W&B tables
|
diff --git a/train.py b/train.py
index 8d35f50afb1..9a5f402c350 100644
--- a/train.py
+++ b/train.py
@@ -475,7 +475,7 @@ def parse_opt(known=False):
# Weights & Biases arguments
parser.add_argument('--entity', default=None, help='W&B: Entity')
- parser.add_argument('--upload_dataset', action='store_true', help='W&B: Upload dataset as artifact table')
+ parser.add_argument('--upload_dataset', nargs='?', const=True, default=False, help='W&B: Upload data, "val" option')
parser.add_argument('--bbox_interval', type=int, default=-1, help='W&B: Set bounding-box image logging interval')
parser.add_argument('--artifact_alias', type=str, default='latest', help='W&B: Version of dataset artifact to use')
diff --git a/utils/loggers/wandb/README.md b/utils/loggers/wandb/README.md
index d787fb7a5a0..63d999859e6 100644
--- a/utils/loggers/wandb/README.md
+++ b/utils/loggers/wandb/README.md
@@ -2,6 +2,7 @@
* [About Weights & Biases](#about-weights-&-biases)
* [First-Time Setup](#first-time-setup)
* [Viewing runs](#viewing-runs)
+* [Disabling wandb](#disabling-wandb)
* [Advanced Usage: Dataset Versioning and Evaluation](#advanced-usage)
* [Reports: Share your work with the world!](#reports)
@@ -49,31 +50,36 @@ Run information streams from your environment to the W&B cloud console as you tr
* Environment: OS and Python types, Git repository and state, **training command**
<p align="center"><img width="900" alt="Weights & Biases dashboard" src="https://user-images.githubusercontent.com/26833433/135390767-c28b050f-8455-4004-adb0-3b730386e2b2.png"></p>
+</details>
+ ## Disabling wandb
+* training after running `wandb disabled` inside that directory creates no wandb run
+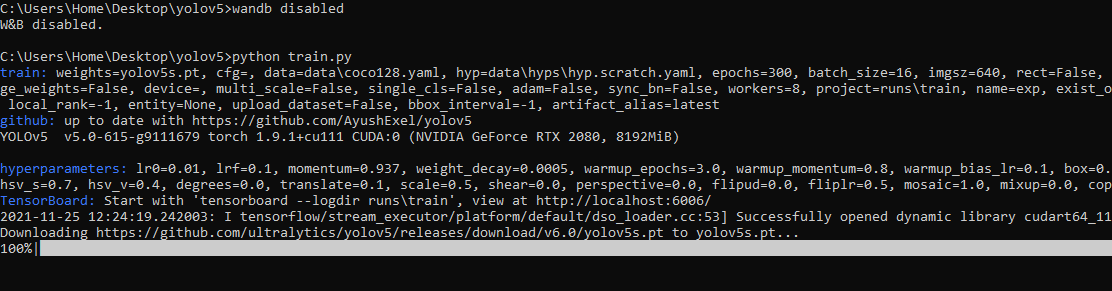
-</details>
+* To enable wandb again, run `wandb online`
+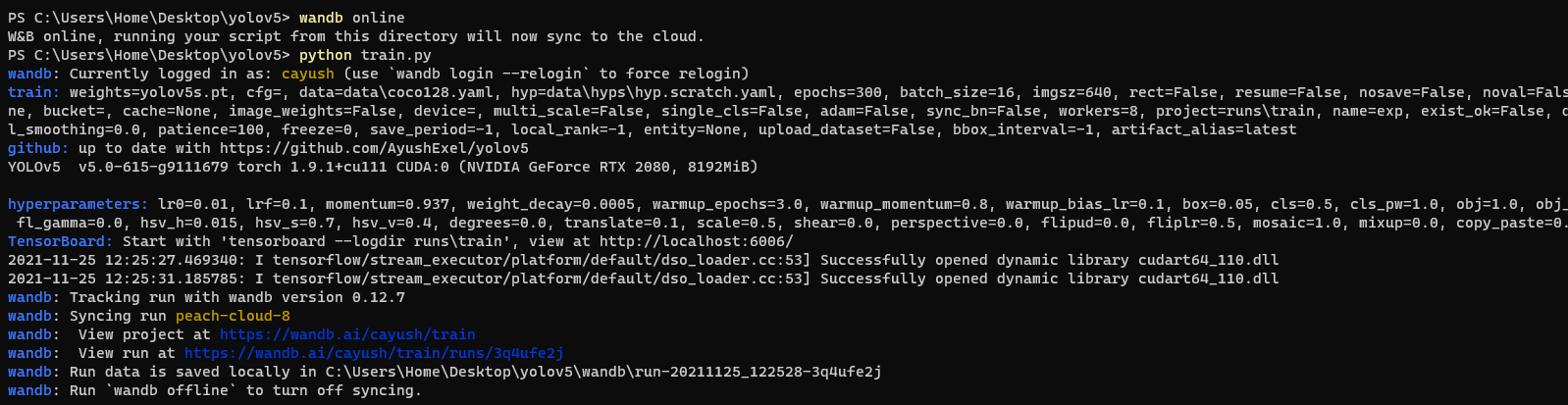
## Advanced Usage
You can leverage W&B artifacts and Tables integration to easily visualize and manage your datasets, models and training evaluations. Here are some quick examples to get you started.
<details open>
- <h3>1. Visualize and Version Datasets</h3>
- Log, visualize, dynamically query, and understand your data with <a href='https://docs.wandb.ai/guides/data-vis/tables'>W&B Tables</a>. You can use the following command to log your dataset as a W&B Table. This will generate a <code>{dataset}_wandb.yaml</code> file which can be used to train from dataset artifact.
- <details>
+ <h3> 1: Train and Log Evaluation simultaneousy </h3>
+ This is an extension of the previous section, but it'll also training after uploading the dataset. <b> This also evaluation Table</b>
+ Evaluation table compares your predictions and ground truths across the validation set for each epoch. It uses the references to the already uploaded datasets,
+ so no images will be uploaded from your system more than once.
+ <details open>
<summary> <b>Usage</b> </summary>
- <b>Code</b> <code> $ python utils/logger/wandb/log_dataset.py --project ... --name ... --data .. </code>
+ <b>Code</b> <code> $ python train.py --upload_data val</code>
- 
+
</details>
- <h3> 2: Train and Log Evaluation simultaneousy </h3>
- This is an extension of the previous section, but it'll also training after uploading the dataset. <b> This also evaluation Table</b>
- Evaluation table compares your predictions and ground truths across the validation set for each epoch. It uses the references to the already uploaded datasets,
- so no images will be uploaded from your system more than once.
+ <h3>2. Visualize and Version Datasets</h3>
+ Log, visualize, dynamically query, and understand your data with <a href='https://docs.wandb.ai/guides/data-vis/tables'>W&B Tables</a>. You can use the following command to log your dataset as a W&B Table. This will generate a <code>{dataset}_wandb.yaml</code> file which can be used to train from dataset artifact.
<details>
<summary> <b>Usage</b> </summary>
- <b>Code</b> <code> $ python utils/logger/wandb/log_dataset.py --data .. --upload_data </code>
+ <b>Code</b> <code> $ python utils/logger/wandb/log_dataset.py --project ... --name ... --data .. </code>
-
+ 
</details>
<h3> 3: Train using dataset artifact </h3>
@@ -81,7 +87,7 @@ You can leverage W&B artifacts and Tables integration to easily visualize and ma
can be used to train a model directly from the dataset artifact. <b> This also logs evaluation </b>
<details>
<summary> <b>Usage</b> </summary>
- <b>Code</b> <code> $ python utils/logger/wandb/log_dataset.py --data {data}_wandb.yaml </code>
+ <b>Code</b> <code> $ python train.py --data {data}_wandb.yaml </code>

</details>
@@ -123,7 +129,6 @@ Any run can be resumed using artifacts if the <code>--resume</code> argument sta
</details>
-
<h3> Reports </h3>
W&B Reports can be created from your saved runs for sharing online. Once a report is created you will receive a link you can use to publically share your results. Here is an example report created from the COCO128 tutorial trainings of all four YOLOv5 models ([link](https://wandb.ai/glenn-jocher/yolov5_tutorial/reports/YOLOv5-COCO128-Tutorial-Results--VmlldzozMDI5OTY)).
diff --git a/utils/loggers/wandb/wandb_utils.py b/utils/loggers/wandb/wandb_utils.py
index a4cbaee240d..2d6133ab94c 100644
--- a/utils/loggers/wandb/wandb_utils.py
+++ b/utils/loggers/wandb/wandb_utils.py
@@ -202,7 +202,6 @@ def check_and_upload_dataset(self, opt):
config_path = self.log_dataset_artifact(opt.data,
opt.single_cls,
'YOLOv5' if opt.project == 'runs/train' else Path(opt.project).stem)
- LOGGER.info(f"Created dataset config file {config_path}")
with open(config_path, errors='ignore') as f:
wandb_data_dict = yaml.safe_load(f)
return wandb_data_dict
@@ -244,7 +243,9 @@ def setup_training(self, opt):
if self.val_artifact is not None:
self.result_artifact = wandb.Artifact("run_" + wandb.run.id + "_progress", "evaluation")
- self.result_table = wandb.Table(["epoch", "id", "ground truth", "prediction", "avg_confidence"])
+ columns = ["epoch", "id", "ground truth", "prediction"]
+ columns.extend(self.data_dict['names'])
+ self.result_table = wandb.Table(columns)
self.val_table = self.val_artifact.get("val")
if self.val_table_path_map is None:
self.map_val_table_path()
@@ -331,28 +332,41 @@ def log_dataset_artifact(self, data_file, single_cls, project, overwrite_config=
returns:
the new .yaml file with artifact links. it can be used to start training directly from artifacts
"""
+ upload_dataset = self.wandb_run.config.upload_dataset
+ log_val_only = isinstance(upload_dataset, str) and upload_dataset == 'val'
self.data_dict = check_dataset(data_file) # parse and check
data = dict(self.data_dict)
nc, names = (1, ['item']) if single_cls else (int(data['nc']), data['names'])
names = {k: v for k, v in enumerate(names)} # to index dictionary
- self.train_artifact = self.create_dataset_table(LoadImagesAndLabels(
- data['train'], rect=True, batch_size=1), names, name='train') if data.get('train') else None
+
+ # log train set
+ if not log_val_only:
+ self.train_artifact = self.create_dataset_table(LoadImagesAndLabels(
+ data['train'], rect=True, batch_size=1), names, name='train') if data.get('train') else None
+ if data.get('train'):
+ data['train'] = WANDB_ARTIFACT_PREFIX + str(Path(project) / 'train')
+
self.val_artifact = self.create_dataset_table(LoadImagesAndLabels(
data['val'], rect=True, batch_size=1), names, name='val') if data.get('val') else None
- if data.get('train'):
- data['train'] = WANDB_ARTIFACT_PREFIX + str(Path(project) / 'train')
if data.get('val'):
data['val'] = WANDB_ARTIFACT_PREFIX + str(Path(project) / 'val')
- path = Path(data_file).stem
- path = (path if overwrite_config else path + '_wandb') + '.yaml' # updated data.yaml path
- data.pop('download', None)
- data.pop('path', None)
- with open(path, 'w') as f:
- yaml.safe_dump(data, f)
+
+ path = Path(data_file)
+ # create a _wandb.yaml file with artifacts links if both train and test set are logged
+ if not log_val_only:
+ path = (path.stem if overwrite_config else path.stem + '_wandb') + '.yaml' # updated data.yaml path
+ path = Path('data') / path
+ data.pop('download', None)
+ data.pop('path', None)
+ with open(path, 'w') as f:
+ yaml.safe_dump(data, f)
+ LOGGER.info(f"Created dataset config file {path}")
if self.job_type == 'Training': # builds correct artifact pipeline graph
+ if not log_val_only:
+ self.wandb_run.log_artifact(
+ self.train_artifact) # calling use_artifact downloads the dataset. NOT NEEDED!
self.wandb_run.use_artifact(self.val_artifact)
- self.wandb_run.use_artifact(self.train_artifact)
self.val_artifact.wait()
self.val_table = self.val_artifact.get('val')
self.map_val_table_path()
@@ -371,7 +385,7 @@ def map_val_table_path(self):
for i, data in enumerate(tqdm(self.val_table.data)):
self.val_table_path_map[data[3]] = data[0]
- def create_dataset_table(self, dataset: LoadImagesAndLabels, class_to_id: Dict[int,str], name: str = 'dataset'):
+ def create_dataset_table(self, dataset: LoadImagesAndLabels, class_to_id: Dict[int, str], name: str = 'dataset'):
"""
Create and return W&B artifact containing W&B Table of the dataset.
@@ -424,23 +438,34 @@ def log_training_progress(self, predn, path, names):
"""
class_set = wandb.Classes([{'id': id, 'name': name} for id, name in names.items()])
box_data = []
- total_conf = 0
+ avg_conf_per_class = [0] * len(self.data_dict['names'])
+ pred_class_count = {}
for *xyxy, conf, cls in predn.tolist():
if conf >= 0.25:
+ cls = int(cls)
box_data.append(
{"position": {"minX": xyxy[0], "minY": xyxy[1], "maxX": xyxy[2], "maxY": xyxy[3]},
- "class_id": int(cls),
+ "class_id": cls,
"box_caption": f"{names[cls]} {conf:.3f}",
"scores": {"class_score": conf},
"domain": "pixel"})
- total_conf += conf
+ avg_conf_per_class[cls] += conf
+
+ if cls in pred_class_count:
+ pred_class_count[cls] += 1
+ else:
+ pred_class_count[cls] = 1
+
+ for pred_class in pred_class_count.keys():
+ avg_conf_per_class[pred_class] = avg_conf_per_class[pred_class] / pred_class_count[pred_class]
+
boxes = {"predictions": {"box_data": box_data, "class_labels": names}} # inference-space
id = self.val_table_path_map[Path(path).name]
self.result_table.add_data(self.current_epoch,
id,
self.val_table.data[id][1],
wandb.Image(self.val_table.data[id][1], boxes=boxes, classes=class_set),
- total_conf / max(1, len(box_data))
+ *avg_conf_per_class
)
def val_one_image(self, pred, predn, path, names, im):
@@ -490,7 +515,8 @@ def end_epoch(self, best_result=False):
try:
wandb.log(self.log_dict)
except BaseException as e:
- LOGGER.info(f"An error occurred in wandb logger. The training will proceed without interruption. More info\n{e}")
+ LOGGER.info(
+ f"An error occurred in wandb logger. The training will proceed without interruption. More info\n{e}")
self.wandb_run.finish()
self.wandb_run = None
@@ -502,7 +528,9 @@ def end_epoch(self, best_result=False):
('best' if best_result else '')])
wandb.log({"evaluation": self.result_table})
- self.result_table = wandb.Table(["epoch", "id", "ground truth", "prediction", "avg_confidence"])
+ columns = ["epoch", "id", "ground truth", "prediction"]
+ columns.extend(self.data_dict['names'])
+ self.result_table = wandb.Table(columns)
self.result_artifact = wandb.Artifact("run_" + wandb.run.id + "_progress", "evaluation")
def finish_run(self):
|
This PR:
* refactors table integration to include avg. conf. of each class detected.
* Allows the user to upload only validation split of the dataset
* Improves W&B readme
### Before:

### After:
users can now sort/filter using any class, which enables inspecting on which classes models performs best/worst

TODO:
* Format using Pycharm
* Run additional tests
## 🛠️ PR Summary
<sub>Made with ❤️ by [Ultralytics Actions](https://github.com/ultralytics/actions)<sub>
### 🌟 Summary
Enhancements to Weights & Biases logging in YOLOv5 training script.
### 📊 Key Changes
- Updated the `--upload_dataset` argument to include an optional "val" value, allowing for more flexible dataset uploads.
- Added documentation on how to disable and enable Weights & Biases (wandb) logging.
- Introduced efficiency improvements by avoiding repeat image uploads when using evaluation tables.
- Adjusted the wandb logger to log average confidence per class during training rather than total confidence.
- Several internal code refinements within wandb_utils.py for better readability and maintainability.
### 🎯 Purpose & Impact
- The changes provide users with more control over dataset uploads to wandb and an option to disable logging if desired. 🎛️
- Enhanced evaluation tables now provide more detailed insights into model performance, potentially aiding in debugging and model improvement. 📈
- Streamlined usage and clarified documentation make it easier for both new and existing users to utilize wandb features with YOLOv5. 📚
- Overall, these updates aim to sharpen the development experience and provide richer datasets for those integrating YOLOv5 with wandb. 🔍
|
https://api.github.com/repos/ultralytics/yolov5/pulls/5737
|
2021-11-21T12:12:43Z
|
2021-11-25T16:19:22Z
|
2021-11-25T16:19:22Z
|
2024-01-19T14:17:39Z
| 3,603
|
ultralytics/yolov5
| 25,642
|
[API][Feature] Utils endpoints
|
diff --git a/modules/api/api.py b/modules/api/api.py
index 71c9c1601c4..a49f3755115 100644
--- a/modules/api/api.py
+++ b/modules/api/api.py
@@ -2,14 +2,17 @@
import io
import time
import uvicorn
-from gradio.processing_utils import decode_base64_to_file, decode_base64_to_image
-from fastapi import APIRouter, Depends, HTTPException
+from threading import Lock
+from gradio.processing_utils import encode_pil_to_base64, decode_base64_to_file, decode_base64_to_image
+from fastapi import APIRouter, Depends, FastAPI, HTTPException
import modules.shared as shared
from modules.api.models import *
from modules.processing import StableDiffusionProcessingTxt2Img, StableDiffusionProcessingImg2Img, process_images
-from modules.sd_samplers import all_samplers, sample_to_image, samples_to_image_grid
+from modules.sd_samplers import all_samplers
from modules.extras import run_extras, run_pnginfo
-
+from modules.sd_models import checkpoints_list
+from modules.realesrgan_model import get_realesrgan_models
+from typing import List
def upscaler_to_index(name: str):
try:
@@ -37,7 +40,7 @@ def encode_pil_to_base64(image):
class Api:
- def __init__(self, app, queue_lock):
+ def __init__(self, app: FastAPI, queue_lock: Lock):
self.router = APIRouter()
self.app = app
self.queue_lock = queue_lock
@@ -48,6 +51,18 @@ def __init__(self, app, queue_lock):
self.app.add_api_route("/sdapi/v1/png-info", self.pnginfoapi, methods=["POST"], response_model=PNGInfoResponse)
self.app.add_api_route("/sdapi/v1/progress", self.progressapi, methods=["GET"], response_model=ProgressResponse)
self.app.add_api_route("/sdapi/v1/interrupt", self.interruptapi, methods=["POST"])
+ self.app.add_api_route("/sdapi/v1/options", self.get_config, methods=["GET"], response_model=OptionsModel)
+ self.app.add_api_route("/sdapi/v1/options", self.set_config, methods=["POST"])
+ self.app.add_api_route("/sdapi/v1/cmd-flags", self.get_cmd_flags, methods=["GET"], response_model=FlagsModel)
+ self.app.add_api_route("/sdapi/v1/samplers", self.get_samplers, methods=["GET"], response_model=List[SamplerItem])
+ self.app.add_api_route("/sdapi/v1/upscalers", self.get_upscalers, methods=["GET"], response_model=List[UpscalerItem])
+ self.app.add_api_route("/sdapi/v1/sd-models", self.get_sd_models, methods=["GET"], response_model=List[SDModelItem])
+ self.app.add_api_route("/sdapi/v1/hypernetworks", self.get_hypernetworks, methods=["GET"], response_model=List[HypernetworkItem])
+ self.app.add_api_route("/sdapi/v1/face-restorers", self.get_face_restorers, methods=["GET"], response_model=List[FaceRestorerItem])
+ self.app.add_api_route("/sdapi/v1/realesrgan-models", self.get_realesrgan_models, methods=["GET"], response_model=List[RealesrganItem])
+ self.app.add_api_route("/sdapi/v1/prompt-styles", self.get_promp_styles, methods=["GET"], response_model=List[PromptStyleItem])
+ self.app.add_api_route("/sdapi/v1/artist-categories", self.get_artists_categories, methods=["GET"], response_model=List[str])
+ self.app.add_api_route("/sdapi/v1/artists", self.get_artists, methods=["GET"], response_model=List[ArtistItem])
def text2imgapi(self, txt2imgreq: StableDiffusionTxt2ImgProcessingAPI):
sampler_index = sampler_to_index(txt2imgreq.sampler_index)
@@ -190,6 +205,66 @@ def interruptapi(self):
shared.state.interrupt()
return {}
+
+ def get_config(self):
+ options = {}
+ for key in shared.opts.data.keys():
+ metadata = shared.opts.data_labels.get(key)
+ if(metadata is not None):
+ options.update({key: shared.opts.data.get(key, shared.opts.data_labels.get(key).default)})
+ else:
+ options.update({key: shared.opts.data.get(key, None)})
+
+ return options
+
+ def set_config(self, req: OptionsModel):
+ reqDict = vars(req)
+ for o in reqDict:
+ setattr(shared.opts, o, reqDict[o])
+
+ shared.opts.save(shared.config_filename)
+ return
+
+ def get_cmd_flags(self):
+ return vars(shared.cmd_opts)
+
+ def get_samplers(self):
+ return [{"name":sampler[0], "aliases":sampler[2], "options":sampler[3]} for sampler in all_samplers]
+
+ def get_upscalers(self):
+ upscalers = []
+
+ for upscaler in shared.sd_upscalers:
+ u = upscaler.scaler
+ upscalers.append({"name":u.name, "model_name":u.model_name, "model_path":u.model_path, "model_url":u.model_url})
+
+ return upscalers
+
+ def get_sd_models(self):
+ return [{"title":x.title, "model_name":x.model_name, "hash":x.hash, "filename": x.filename, "config": x.config} for x in checkpoints_list.values()]
+
+ def get_hypernetworks(self):
+ return [{"name": name, "path": shared.hypernetworks[name]} for name in shared.hypernetworks]
+
+ def get_face_restorers(self):
+ return [{"name":x.name(), "cmd_dir": getattr(x, "cmd_dir", None)} for x in shared.face_restorers]
+
+ def get_realesrgan_models(self):
+ return [{"name":x.name,"path":x.data_path, "scale":x.scale} for x in get_realesrgan_models(None)]
+
+ def get_promp_styles(self):
+ styleList = []
+ for k in shared.prompt_styles.styles:
+ style = shared.prompt_styles.styles[k]
+ styleList.append({"name":style[0], "prompt": style[1], "negative_prompr": style[2]})
+
+ return styleList
+
+ def get_artists_categories(self):
+ return shared.artist_db.cats
+
+ def get_artists(self):
+ return [{"name":x[0], "score":x[1], "category":x[2]} for x in shared.artist_db.artists]
def launch(self, server_name, port):
self.app.include_router(self.router)
diff --git a/modules/api/models.py b/modules/api/models.py
index 9ee42a17ad9..b54b188a620 100644
--- a/modules/api/models.py
+++ b/modules/api/models.py
@@ -1,11 +1,10 @@
import inspect
-from click import prompt
from pydantic import BaseModel, Field, create_model
-from typing import Any, Optional
+from typing import Any, Optional, Union
from typing_extensions import Literal
from inflection import underscore
from modules.processing import StableDiffusionProcessingTxt2Img, StableDiffusionProcessingImg2Img
-from modules.shared import sd_upscalers
+from modules.shared import sd_upscalers, opts, parser
API_NOT_ALLOWED = [
"self",
@@ -165,3 +164,68 @@ class ProgressResponse(BaseModel):
eta_relative: float = Field(title="ETA in secs")
state: dict = Field(title="State", description="The current state snapshot")
current_image: str = Field(default=None, title="Current image", description="The current image in base64 format. opts.show_progress_every_n_steps is required for this to work.")
+
+fields = {}
+for key, value in opts.data.items():
+ metadata = opts.data_labels.get(key)
+ optType = opts.typemap.get(type(value), type(value))
+
+ if (metadata is not None):
+ fields.update({key: (Optional[optType], Field(
+ default=metadata.default ,description=metadata.label))})
+ else:
+ fields.update({key: (Optional[optType], Field())})
+
+OptionsModel = create_model("Options", **fields)
+
+flags = {}
+_options = vars(parser)['_option_string_actions']
+for key in _options:
+ if(_options[key].dest != 'help'):
+ flag = _options[key]
+ _type = str
+ if(_options[key].default != None): _type = type(_options[key].default)
+ flags.update({flag.dest: (_type,Field(default=flag.default, description=flag.help))})
+
+FlagsModel = create_model("Flags", **flags)
+
+class SamplerItem(BaseModel):
+ name: str = Field(title="Name")
+ aliases: list[str] = Field(title="Aliases")
+ options: dict[str, str] = Field(title="Options")
+
+class UpscalerItem(BaseModel):
+ name: str = Field(title="Name")
+ model_name: str | None = Field(title="Model Name")
+ model_path: str | None = Field(title="Path")
+ model_url: str | None = Field(title="URL")
+
+class SDModelItem(BaseModel):
+ title: str = Field(title="Title")
+ model_name: str = Field(title="Model Name")
+ hash: str = Field(title="Hash")
+ filename: str = Field(title="Filename")
+ config: str = Field(title="Config file")
+
+class HypernetworkItem(BaseModel):
+ name: str = Field(title="Name")
+ path: str | None = Field(title="Path")
+
+class FaceRestorerItem(BaseModel):
+ name: str = Field(title="Name")
+ cmd_dir: str | None = Field(title="Path")
+
+class RealesrganItem(BaseModel):
+ name: str = Field(title="Name")
+ path: str | None = Field(title="Path")
+ scale: int | None = Field(title="Scale")
+
+class PromptStyleItem(BaseModel):
+ name: str = Field(title="Name")
+ prompt: str | None = Field(title="Prompt")
+ negative_prompt: str | None = Field(title="Negative Prompt")
+
+class ArtistItem(BaseModel):
+ name: str = Field(title="Name")
+ score: float = Field(title="Score")
+ category: str = Field(title="Category")
\ No newline at end of file
diff --git a/test/utils_test.py b/test/utils_test.py
new file mode 100644
index 00000000000..65d3d177d80
--- /dev/null
+++ b/test/utils_test.py
@@ -0,0 +1,63 @@
+import unittest
+import requests
+
+class UtilsTests(unittest.TestCase):
+ def setUp(self):
+ self.url_options = "http://localhost:7860/sdapi/v1/options"
+ self.url_cmd_flags = "http://localhost:7860/sdapi/v1/cmd-flags"
+ self.url_samplers = "http://localhost:7860/sdapi/v1/samplers"
+ self.url_upscalers = "http://localhost:7860/sdapi/v1/upscalers"
+ self.url_sd_models = "http://localhost:7860/sdapi/v1/sd-models"
+ self.url_hypernetworks = "http://localhost:7860/sdapi/v1/hypernetworks"
+ self.url_face_restorers = "http://localhost:7860/sdapi/v1/face-restorers"
+ self.url_realesrgan_models = "http://localhost:7860/sdapi/v1/realesrgan-models"
+ self.url_prompt_styles = "http://localhost:7860/sdapi/v1/prompt-styles"
+ self.url_artist_categories = "http://localhost:7860/sdapi/v1/artist-categories"
+ self.url_artists = "http://localhost:7860/sdapi/v1/artists"
+
+ def test_options_get(self):
+ self.assertEqual(requests.get(self.url_options).status_code, 200)
+
+ def test_options_write(self):
+ response = requests.get(self.url_options)
+ self.assertEqual(response.status_code, 200)
+
+ pre_value = response.json()["send_seed"]
+
+ self.assertEqual(requests.post(self.url_options, json={"send_seed":not pre_value}).status_code, 200)
+
+ response = requests.get(self.url_options)
+ self.assertEqual(response.status_code, 200)
+ self.assertEqual(response.json()["send_seed"], not pre_value)
+
+ requests.post(self.url_options, json={"send_seed": pre_value})
+
+ def test_cmd_flags(self):
+ self.assertEqual(requests.get(self.url_cmd_flags).status_code, 200)
+
+ def test_samplers(self):
+ self.assertEqual(requests.get(self.url_samplers).status_code, 200)
+
+ def test_upscalers(self):
+ self.assertEqual(requests.get(self.url_upscalers).status_code, 200)
+
+ def test_sd_models(self):
+ self.assertEqual(requests.get(self.url_sd_models).status_code, 200)
+
+ def test_hypernetworks(self):
+ self.assertEqual(requests.get(self.url_hypernetworks).status_code, 200)
+
+ def test_face_restorers(self):
+ self.assertEqual(requests.get(self.url_face_restorers).status_code, 200)
+
+ def test_realesrgan_models(self):
+ self.assertEqual(requests.get(self.url_realesrgan_models).status_code, 200)
+
+ def test_prompt_styles(self):
+ self.assertEqual(requests.get(self.url_prompt_styles).status_code, 200)
+
+ def test_artist_categories(self):
+ self.assertEqual(requests.get(self.url_artist_categories).status_code, 200)
+
+ def test_artists(self):
+ self.assertEqual(requests.get(self.url_artists).status_code, 200)
\ No newline at end of file
|
This PR adds a bunch of endpoints that clients can find useful:
- Get config
- Uses the current config to create a model automatically
- Update config
- Can't add new keys, they need to be created using `shared.opts.add_option(shared.OptionInfo(...))`
- Get cmd flags
- Get samplers list
- Gives names, aliases and options
- Get upscalers list
- Gives name, model name, model path and model URL
- Get SD models list
- Gives title, model name, hash, file path and config file path
- Get hypernetworks list
- Gives name and file path
- Get face restorers list
- Gives name and file path
- Get realesrgan models list
- Gives name, file path and scale
- Get promp styles list
- GIves name, prompt and negative prompt
- Get artist's categories list
- Just a list of names
- Get artists list
- Gives name, score and category
|
https://api.github.com/repos/AUTOMATIC1111/stable-diffusion-webui/pulls/4218
|
2022-11-03T13:24:12Z
|
2022-11-04T07:46:52Z
|
2022-11-04T07:46:52Z
|
2022-11-05T18:52:55Z
| 3,175
|
AUTOMATIC1111/stable-diffusion-webui
| 40,442
|
export.py replace `check_file` -> `check_yaml`
|
diff --git a/export.py b/export.py
index e3f6af93d1c..546087a4026 100644
--- a/export.py
+++ b/export.py
@@ -67,7 +67,7 @@
from models.experimental import attempt_load
from models.yolo import Detect
from utils.dataloaders import LoadImages
-from utils.general import (LOGGER, check_dataset, check_file, check_img_size, check_requirements, check_version,
+from utils.general import (LOGGER, check_dataset, check_img_size, check_requirements, check_version, check_yaml,
colorstr, file_size, print_args, url2file)
from utils.torch_utils import select_device
@@ -371,7 +371,7 @@ def export_tflite(keras_model, im, file, int8, data, nms, agnostic_nms, prefix=c
converter.optimizations = [tf.lite.Optimize.DEFAULT]
if int8:
from models.tf import representative_dataset_gen
- dataset = LoadImages(check_dataset(check_file(data))['train'], img_size=imgsz, auto=False)
+ dataset = LoadImages(check_dataset(check_yaml(data))['train'], img_size=imgsz, auto=False)
converter.representative_dataset = lambda: representative_dataset_gen(dataset, ncalib=100)
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
converter.target_spec.supported_types = []
|
## 🛠️ PR Summary
<sub>Made with ❤️ by [Ultralytics Actions](https://github.com/ultralytics/actions)<sub>
### 🌟 Summary
Enhancement of YAML dataset validation and reduction of dependencies in TensorFlow Lite export.
### 📊 Key Changes
- Removed `check_file` function and integrated `check_yaml` for dataset validation in TensorFlow Lite export process.
- Minor code cleanup in `export.py`, changing one line related to dataset loading.
### 🎯 Purpose & Impact
- 🎯 **Purpose**: The update ensures datasets are specifically validated as YAML files, improving reliability. Additionally, it contributes to cleaner and more maintainable code by using a more appropriate validation function.
- 🔍 **Impact**: Users exporting models to TensorFlow Lite may notice improved validation messages if there are issues with the dataset configuration. There should be no noticeable impact on the export functionality for users with correctly formatted datasets.
|
https://api.github.com/repos/ultralytics/yolov5/pulls/8852
|
2022-08-03T21:36:22Z
|
2022-08-03T21:38:36Z
|
2022-08-03T21:38:36Z
|
2024-01-19T07:46:43Z
| 311
|
ultralytics/yolov5
| 25,257
|
Fix MegatronLayerPolicy to have megatron_v2=True
|
diff --git a/deepspeed/module_inject/replace_policy.py b/deepspeed/module_inject/replace_policy.py
index 4dd9e5b0855e..dd80f9fc11d1 100755
--- a/deepspeed/module_inject/replace_policy.py
+++ b/deepspeed/module_inject/replace_policy.py
@@ -404,9 +404,10 @@ class MegatronLayerPolicy(TransformerPolicy):
_orig_layer_class = None
version = 0
moe_type = 'standard'
+ megatron_v2 = True
def __init__(self, client_module, inference=True):
- super().__init__(inference)
+ super().__init__(inference, megatron_v2=MegatronLayerPolicy.megatron_v2)
self.client_module = client_module
# we use megatron version to differentiate between the old and new
# megatron-lm source code
|
This PR updates the `MegatronLayerPolicy` to set `megatron_v2=True`, which is required in order to properly transpose in the `replace_with_policy()` function.
After the change in this PR, in conjunction with [PR #99](https://github.com/microsoft/Megatron-DeepSpeed/pull/99) in the Megatron-DeepSpeed fork, the Megatron text-generation example works with DS inference.
@RezaYazdaniAminabadi Any feedback is welcome!
|
https://api.github.com/repos/microsoft/DeepSpeed/pulls/2579
|
2022-12-07T00:57:37Z
|
2022-12-07T17:26:10Z
|
2022-12-07T17:26:10Z
|
2022-12-08T01:06:52Z
| 205
|
microsoft/DeepSpeed
| 9,956
|
Upgrade keyring to 13.1.0
|
diff --git a/homeassistant/scripts/keyring.py b/homeassistant/scripts/keyring.py
index 51d70d1f3b2cec..0ca60894f9b983 100644
--- a/homeassistant/scripts/keyring.py
+++ b/homeassistant/scripts/keyring.py
@@ -5,7 +5,7 @@
from homeassistant.util.yaml import _SECRET_NAMESPACE
-REQUIREMENTS = ['keyring==13.0.0', 'keyrings.alt==3.1']
+REQUIREMENTS = ['keyring==13.1.0', 'keyrings.alt==3.1']
def run(args):
diff --git a/requirements_all.txt b/requirements_all.txt
index 3f58fefb389d6f..4a88318a4c5c98 100644
--- a/requirements_all.txt
+++ b/requirements_all.txt
@@ -473,7 +473,7 @@ jsonrpc-async==0.6
jsonrpc-websocket==0.6
# homeassistant.scripts.keyring
-keyring==13.0.0
+keyring==13.1.0
# homeassistant.scripts.keyring
keyrings.alt==3.1
|
## Description:
Changelog: https://github.com/jaraco/keyring/blob/master/CHANGES.rst#1310
```bash
$ hass --script keyring --help
INFO:homeassistant.util.package:Attempting install of keyring==13.1.0
usage: hass [-h] [--script {keyring}] {get,set,del,info} [name]
Modify Home Assistant secrets in the default keyring. Use the secrets in
configuration files with: !secret <name>
positional arguments:
{get,set,del,info} Get, set or delete a secret
name Name of the secret
optional arguments:
-h, --help show this help message and exit
--script {keyring}
```
## Checklist:
- [x] The code change is tested and works locally.
- [x] Local tests pass with `tox`. **Your PR cannot be merged unless tests pass**
If the code communicates with devices, web services, or third-party tools:
- [x] New dependencies have been added to the `REQUIREMENTS` variable ([example][ex-requir]).
- [x] New dependencies have been added to `requirements_all.txt` by running `script/gen_requirements_all.py`.
|
https://api.github.com/repos/home-assistant/core/pulls/15268
|
2018-07-02T17:26:44Z
|
2018-07-02T21:03:57Z
|
2018-07-02T21:03:57Z
|
2018-12-10T16:01:40Z
| 264
|
home-assistant/core
| 39,586
|
Correct the joinus.png location
|
diff --git a/doc/doc_ch/joinus.PNG b/doc/doc_ch/joinus.PNG
deleted file mode 100644
index cd9de9c14b..0000000000
Binary files a/doc/doc_ch/joinus.PNG and /dev/null differ
diff --git a/doc/joinus.PNG b/doc/joinus.PNG
index b8724a9b0a..cd9de9c14b 100644
Binary files a/doc/joinus.PNG and b/doc/joinus.PNG differ
|
Correct the joinus.png location
|
https://api.github.com/repos/PaddlePaddle/PaddleOCR/pulls/4714
|
2021-11-20T14:19:46Z
|
2021-11-20T14:20:06Z
|
2021-11-20T14:20:06Z
|
2021-11-20T14:20:06Z
| 112
|
PaddlePaddle/PaddleOCR
| 42,726
|
Added Guanaco-QLoRA to Instruct character
|
diff --git a/api-examples/api-example-chat.py b/api-examples/api-example-chat.py
index 905fbca6e2..8ea6ed1e92 100644
--- a/api-examples/api-example-chat.py
+++ b/api-examples/api-example-chat.py
@@ -7,7 +7,7 @@
URI = f'http://{HOST}/api/v1/chat'
# For reverse-proxied streaming, the remote will likely host with ssl - https://
-# URI = 'https://your-uri-here.trycloudflare.com/api/v1/generate'
+# URI = 'https://your-uri-here.trycloudflare.com/api/v1/chat'
def run(user_input, history):
diff --git a/characters/instruction-following/Guanaco-QLoRA.yaml b/characters/instruction-following/Guanaco-QLoRA.yaml
new file mode 100644
index 0000000000..4c321cb82b
--- /dev/null
+++ b/characters/instruction-following/Guanaco-QLoRA.yaml
@@ -0,0 +1,4 @@
+user: "### Human:"
+bot: "### Assistant:"
+turn_template: "<|user|> <|user-message|>\n<|bot|> <|bot-message|></s>\n"
+context: ""
\ No newline at end of file
|
https://api.github.com/repos/oobabooga/text-generation-webui/pulls/2574
|
2023-06-08T05:36:50Z
|
2023-06-08T15:24:32Z
|
2023-06-08T15:24:32Z
|
2023-06-08T15:24:33Z
| 295
|
oobabooga/text-generation-webui
| 26,113
|
|
Add `exclude-patterns` option to `flask run` CLI
|
diff --git a/CHANGES.rst b/CHANGES.rst
index 3af9a70645..5f9c2e691e 100644
--- a/CHANGES.rst
+++ b/CHANGES.rst
@@ -39,6 +39,9 @@ Unreleased
load command entry points. :issue:`4419`
- Overriding ``FlaskClient.open`` will not cause an error on redirect.
:issue:`3396`
+- Add an ``--exclude-patterns`` option to the ``flask run`` CLI
+ command to specify patterns that will be ignored by the reloader.
+ :issue:`4188`
Version 2.0.3
diff --git a/docs/cli.rst b/docs/cli.rst
index e367c4b98c..4b40307e98 100644
--- a/docs/cli.rst
+++ b/docs/cli.rst
@@ -262,6 +262,15 @@ separated with ``:``, or ``;`` on Windows.
* Detected change in '/path/to/file1', reloading
+Ignore files with the Reloader
+~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+
+The reloader can also ignore files using :mod:`fnmatch` patterns with
+the ``--exclude-patterns`` option, or the ``FLASK_RUN_EXCLUDE_PATTERNS``
+environment variable. Multiple patterns are separated with ``:``, or
+``;`` on Windows.
+
+
Debug Mode
----------
diff --git a/src/flask/cli.py b/src/flask/cli.py
index 3a51535e33..d59942b86b 100644
--- a/src/flask/cli.py
+++ b/src/flask/cli.py
@@ -796,9 +796,28 @@ def convert(self, value, param, ctx):
f" are separated by {os.path.pathsep!r}."
),
)
[email protected](
+ "--exclude-patterns",
+ default=None,
+ type=SeparatedPathType(),
+ help=(
+ "Files matching these fnmatch patterns will not trigger a reload"
+ " on change. Multiple patterns are separated by"
+ f" {os.path.pathsep!r}."
+ ),
+)
@pass_script_info
def run_command(
- info, host, port, reload, debugger, eager_loading, with_threads, cert, extra_files
+ info,
+ host,
+ port,
+ reload,
+ debugger,
+ eager_loading,
+ with_threads,
+ cert,
+ extra_files,
+ exclude_patterns,
):
"""Run a local development server.
@@ -830,6 +849,7 @@ def run_command(
threaded=with_threads,
ssl_context=cert,
extra_files=extra_files,
+ exclude_patterns=exclude_patterns,
)
|
Pass `exclude_patterns` to Werkzeug's `run_simple` function.
This configures a list of patterns to ignore when running the reloader.
- fixes #4188
<!--
Before opening a PR, open a ticket describing the issue or feature the
PR will address. Follow the steps in CONTRIBUTING.rst.
Replace this comment with a description of the change. Describe how it
addresses the linked ticket.
-->
<!--
Link to relevant issues or previous PRs, one per line. Use "fixes" to
automatically close an issue.
-->
<!--
Ensure each step in CONTRIBUTING.rst is complete by adding an "x" to
each box below.
If only docs were changed, these aren't relevant and can be removed.
-->
Checklist:
- [ ] Add tests that demonstrate the correct behavior of the change. Tests should fail without the change.
- [x] Add or update relevant docs, in the docs folder and in code.
- [x] Add an entry in `CHANGES.rst` summarizing the change and linking to the issue.
- [ ] Add `.. versionchanged::` entries in any relevant code docs.
- [x] Run `pre-commit` hooks and fix any issues.
- [ ] Run `pytest` and `tox`, no tests failed.
|
https://api.github.com/repos/pallets/flask/pulls/4189
|
2021-07-06T18:48:10Z
|
2022-02-09T20:53:19Z
|
2022-02-09T20:53:19Z
|
2022-03-02T00:10:02Z
| 615
|
pallets/flask
| 20,911
|
Small how to uninstall certbot-auto
|
diff --git a/certbot/docs/install.rst b/certbot/docs/install.rst
index 42d46c33e03..d2124236761 100644
--- a/certbot/docs/install.rst
+++ b/certbot/docs/install.rst
@@ -70,11 +70,13 @@ The ``certbot-auto`` wrapper script installs Certbot, obtaining some dependencie
from your web server OS and putting others in a python virtual environment. You can
download and run it as follows::
- user@webserver:~$ wget https://dl.eff.org/certbot-auto
- user@webserver:~$ sudo mv certbot-auto /usr/local/bin/certbot-auto
- user@webserver:~$ sudo chown root /usr/local/bin/certbot-auto
- user@webserver:~$ chmod 0755 /usr/local/bin/certbot-auto
- user@webserver:~$ /usr/local/bin/certbot-auto --help
+ wget https://dl.eff.org/certbot-auto
+ sudo mv certbot-auto /usr/local/bin/certbot-auto
+ sudo chown root /usr/local/bin/certbot-auto
+ sudo chmod 0755 /usr/local/bin/certbot-auto
+ /usr/local/bin/certbot-auto --help
+
+To remove certbot-auto, just delete it and the files it places under /opt/eff.org, along with any cronjob or systemd timer you may have created.
To check the integrity of the ``certbot-auto`` script,
you can use these steps::
|
Also added missing sudo
feel free to edit it or discard it
|
https://api.github.com/repos/certbot/certbot/pulls/7648
|
2019-12-18T23:36:32Z
|
2019-12-19T21:30:13Z
|
2019-12-19T21:30:13Z
|
2019-12-19T21:30:14Z
| 351
|
certbot/certbot
| 3,074
|
[shardformer] fix base policy
|
diff --git a/colossalai/shardformer/policies/base_policy.py b/colossalai/shardformer/policies/base_policy.py
index 68fde0115de6..69493bfb6007 100644
--- a/colossalai/shardformer/policies/base_policy.py
+++ b/colossalai/shardformer/policies/base_policy.py
@@ -156,7 +156,10 @@ def append_or_create_submodule_replacement(
# append or create a new description
if target_key in policy:
- policy[target_key].sub_module_replacement.extend(description)
+ if policy[target_key].sub_module_replacement is None:
+ policy[target_key].sub_module_replacement = description
+ else:
+ policy[target_key].sub_module_replacement.extend(description)
else:
policy[target_key] = ModulePolicyDescription(sub_module_replacement=description)
@@ -174,7 +177,10 @@ def append_or_create_method_replacement(
target_key (Union[str, nn.Module]): the key of the policy to be updated
"""
if target_key in policy:
- policy[target_key].method_replacement.update(description)
+ if policy[target_key].method_replacement is None:
+ policy[target_key].method_replacement = description
+ else:
+ policy[target_key].method_replacement.update(description)
else:
policy[target_key] = ModulePolicyDescription(method_replacement=description)
|
## 📌 Checklist before creating the PR
- [ ] I have created an issue for this PR for traceability
- [ ] The title follows the standard format: `[doc/gemini/tensor/...]: A concise description`
- [ ] I have added relevant tags if possible for us to better distinguish different PRs
## 🚨 Issue number
> Link this PR to your issue with words like fixed to automatically close the linked issue upon merge
>
> e.g. `fixed #1234`, `closed #1234`, `resolved #1234`
## 📝 What does this PR do?
> Summarize your work here.
> if you have any plots/diagrams/screenshots/tables, please attach them here.
The default value of `sub_module_replacement` and `method_replacement` is None, current code may lead to error.
## 💥 Checklist before requesting a review
- [ ] I have linked my PR to an issue ([instruction](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue))
- [ ] My issue clearly describes the problem/feature/proposal, with diagrams/charts/table/code if possible
- [ ] I have performed a self-review of my code
- [ ] I have added thorough tests.
- [ ] I have added docstrings for all the functions/methods I implemented
## ⭐️ Do you enjoy contributing to Colossal-AI?
- [x] 🌝 Yes, I do.
- [ ] 🌚 No, I don't.
Tell us more if you don't enjoy contributing to Colossal-AI.
|
https://api.github.com/repos/hpcaitech/ColossalAI/pulls/4229
|
2023-07-13T08:02:55Z
|
2023-07-14T01:51:54Z
|
2023-07-14T01:51:54Z
|
2023-07-14T01:51:57Z
| 312
|
hpcaitech/ColossalAI
| 11,133
|
Update docstrings for st.form, st.toast, st.date_input
|
diff --git a/lib/streamlit/elements/form.py b/lib/streamlit/elements/form.py
index 00de2795eeca..80e8ebc22507 100644
--- a/lib/streamlit/elements/form.py
+++ b/lib/streamlit/elements/form.py
@@ -134,9 +134,8 @@ def form(self, key: str, clear_on_submit: bool = False) -> DeltaGenerator:
* ``st.button`` and ``st.download_button`` cannot be added to a form.
* Forms can appear anywhere in your app (sidebar, columns, etc),
but they cannot be embedded inside other forms.
-
- For more information about forms, check out our
- `blog post <https://blog.streamlit.io/introducing-submit-button-and-forms/>`_.
+ * Within a form, the only widget that can have a callback function is
+ ``st.form_submit_button``.
Parameters
----------
@@ -167,6 +166,10 @@ def form(self, key: str, clear_on_submit: bool = False) -> DeltaGenerator:
...
>>> st.write("Outside the form")
+ .. output::
+ https://doc-form1.streamlit.app/
+ height: 425px
+
Inserting elements out of order:
>>> import streamlit as st
@@ -178,6 +181,10 @@ def form(self, key: str, clear_on_submit: bool = False) -> DeltaGenerator:
>>> # Now add a submit button to the form:
>>> form.form_submit_button("Submit")
+ .. output::
+ https://doc-form2.streamlit.app/
+ height: 375px
+
"""
# Import this here to avoid circular imports.
from streamlit.elements.utils import check_session_state_rules
diff --git a/lib/streamlit/elements/time_widgets.py b/lib/streamlit/elements/time_widgets.py
index 6a14e845a1ce..75fe0f962ac1 100644
--- a/lib/streamlit/elements/time_widgets.py
+++ b/lib/streamlit/elements/time_widgets.py
@@ -488,19 +488,38 @@ def date_input(
datetime.date or a tuple with 0-2 dates
The current value of the date input widget.
- Example
- -------
+ Examples
+ --------
>>> import datetime
>>> import streamlit as st
>>>
- >>> d = st.date_input(
- ... "When\'s your birthday",
- ... datetime.date(2019, 7, 6))
+ >>> d = st.date_input("When's your birthday", datetime.date(2019, 7, 6))
>>> st.write('Your birthday is:', d)
.. output::
https://doc-date-input.streamlit.app/
- height: 260px
+ height: 380px
+
+ >>> import datetime
+ >>> import streamlit as st
+ >>>
+ >>> today = datetime.datetime.now()
+ >>> next_year = today.year + 1
+ >>> jan_1 = datetime.date(next_year, 1, 1)
+ >>> dec_31 = datetime.date(next_year, 12, 31)
+ >>>
+ >>> d = st.date_input(
+ ... "Select your vacation for next year",
+ ... (jan_1, datetime.date(next_year, 1, 7)),
+ ... jan_1,
+ ... dec_31,
+ ... format="MM.DD.YYYY",
+ ... )
+ >>> d
+
+ .. output::
+ https://doc-date-input1.streamlit.app/
+ height: 380px
"""
ctx = get_script_run_ctx()
diff --git a/lib/streamlit/elements/toast.py b/lib/streamlit/elements/toast.py
index e7aeb65d93f4..0582a47807e2 100644
--- a/lib/streamlit/elements/toast.py
+++ b/lib/streamlit/elements/toast.py
@@ -44,6 +44,11 @@ def toast(
"""Display a short message, known as a notification "toast".
The toast appears in the app's bottom-right corner and disappears after four seconds.
+ .. warning::
+ ``st.toast`` is not compatible with Streamlit's `caching \
+ <https://docs.streamlit.io/library/advanced-features/caching>`_ and
+ cannot be called within a cached function.
+
Parameters
----------
body : str
|
Update st.form docstring to include embedded apps and link to new forms guide. Update st.toast docstring to warn against use within cached functions. Update st.date_input docstring to add example and embedded app showing date format.
## Describe your changes
Docsting-only edit to st.form, st.toast, st.date_input
## Testing Plan
None. Documentation only.
**Contribution License Agreement**
By submitting this pull request you agree that all contributions to this project are made under the Apache 2.0 license.
|
https://api.github.com/repos/streamlit/streamlit/pulls/7043
|
2023-07-20T04:19:50Z
|
2023-07-21T11:05:53Z
|
2023-07-21T11:05:53Z
|
2023-07-21T11:06:01Z
| 997
|
streamlit/streamlit
| 21,979
|
DOC cleanup the roadmap
|
diff --git a/doc/roadmap.rst b/doc/roadmap.rst
index b46ed12de11b6..7cc2bf08ba115 100644
--- a/doc/roadmap.rst
+++ b/doc/roadmap.rst
@@ -1,5 +1,13 @@
.. _roadmap:
+.. |ss| raw:: html
+
+ <strike>
+
+.. |se| raw:: html
+
+ </strike>
+
Roadmap
=======
@@ -54,40 +62,44 @@ Architectural / general goals
-----------------------------
The list is numbered not as an indication of the order of priority, but to
make referring to specific points easier. Please add new entries only at the
-bottom.
-
-#. Everything in Scikit-learn should conform to our API contract
+bottom. Note that the crossed out entries are already done, and we try to keep
+the document up to date as we work on these issues.
- * `Pipeline <pipeline.Pipeline>` and `FeatureUnion` modify their input
- parameters in fit. Fixing this requires making sure we have a good
- grasp of their use cases to make sure all current functionality is
- maintained. :issue:`8157` :issue:`7382`
-#. Improved handling of Pandas DataFrames and SparseDataFrames
+#. Improved handling of Pandas DataFrames
* document current handling
* column reordering issue :issue:`7242`
* avoiding unnecessary conversion to ndarray :issue:`12147`
* returning DataFrames from transformers :issue:`5523`
- * getting DataFrames from dataset loaders :issue:`10733`, :issue:`13902`
+ * getting DataFrames from dataset loaders :issue:`10733`,
+ |ss| :issue:`13902` |se|
* Sparse currently not considered :issue:`12800`
#. Improved handling of categorical features
* Tree-based models should be able to handle both continuous and categorical
- features :issue:`4899`
- * In dataset loaders :issue:`13902`
+ features :issue:`12866` and :issue:`15550`.
+ * |ss| In dataset loaders :issue:`13902` |se|
* As generic transformers to be used with ColumnTransforms (e.g. ordinal
encoding supervised by correlation with target variable) :issue:`5853`,
:issue:`11805`
+ * Handling mixtures of categorical and continuous variables
#. Improved handling of missing data
- * Making sure meta-estimators are lenient towards missing data
- * Non-trivial imputers :issue:`11977`, :issue:`12852`
- * Learners directly handling missing data :issue:`13911`
+ * Making sure meta-estimators are lenient towards missing data,
+ :issue:`15319`
+ * Non-trivial imputers |ss| :issue:`11977`, :issue:`12852` |se|
+ * Learners directly handling missing data |ss| :issue:`13911` |se|
* An amputation sample generator to make parts of a dataset go missing
- * Handling mixtures of categorical and continuous variables
+ :issue:`6284`
+
+#. More didactic documentation
+
+ * More and more options have been added to scikit-learn. As a result, the
+ documentation is crowded which makes it hard for beginners to get the big
+ picture. Some work could be done in prioritizing the information.
#. Passing around information that is not (X, y): Sample properties
@@ -114,7 +126,7 @@ bottom.
* More flexible estimator checks that do not select by estimator name
:issue:`6599` :issue:`6715`
- * Example of how to develop a meta-estimator
+ * Example of how to develop an estimator or a meta-estimator, :issue:`14582`
* More self-sufficient running of scikit-learn-contrib or a similar resource
#. Support resampling and sample reduction
@@ -124,12 +136,13 @@ bottom.
#. Better interfaces for interactive development
- * __repr__ and HTML visualisations of estimators :issue:`6323`
+ * |ss| __repr__ |se| and HTML visualisations of estimators
+ |ss| :issue:`6323` |se| and :pr:`14180`.
* Include plotting tools, not just as examples. :issue:`9173`
#. Improved tools for model diagnostics and basic inference
- * alternative feature importances implementations, :issue:`13146`
+ * |ss| alternative feature importances implementations, :issue:`13146` |se|
* better ways to handle validation sets when fitting
* better ways to find thresholds / create decision rules :issue:`8614`
@@ -138,17 +151,22 @@ bottom.
* Grid search and cross validation are not applicable to most clustering
tasks. Stability-based selection is more relevant.
+#. Better support for manual and automatic pipeline building
+
+ * Easier way to construct complex pipelines and valid search spaces
+ :issue:`7608` :issue:`5082` :issue:`8243`
+ * provide search ranges for common estimators??
+ * cf. `searchgrid <https://searchgrid.readthedocs.io/en/latest/>`_
+
#. Improved tracking of fitting
* Verbose is not very friendly and should use a standard logging library
- :issue:`6929`
+ :issue:`6929`, :issue:`78`
* Callbacks or a similar system would facilitate logging and early stopping
#. Distributed parallelism
- * Joblib can now plug onto several backends, some of them can distribute the
- computation across computers
- * However, we want to stay high level in scikit-learn
+ * Accept data which complies with ``__array_function__``
#. A way forward for more out of core
@@ -157,13 +175,6 @@ bottom.
learning is on smaller data than ETL, hence we can maybe adapt to very
large scale while supporting only a fraction of the patterns.
-#. Better support for manual and automatic pipeline building
-
- * Easier way to construct complex pipelines and valid search spaces
- :issue:`7608` :issue:`5082` :issue:`8243`
- * provide search ranges for common estimators??
- * cf. `searchgrid <https://searchgrid.readthedocs.io/en/latest/>`_
-
#. Support for working with pre-trained models
* Estimator "freezing". In particular, right now it's impossible to clone a
@@ -198,6 +209,15 @@ bottom.
recover the previous predictive performance: if this is not the case
there is probably a bug in scikit-learn that needs to be reported.
+#. Everything in Scikit-learn should probably conform to our API contract.
+ We are still in the process of making decisions on some of these related
+ issues.
+
+ * `Pipeline <pipeline.Pipeline>` and `FeatureUnion` modify their input
+ parameters in fit. Fixing this requires making sure we have a good
+ grasp of their use cases to make sure all current functionality is
+ maintained. :issue:`8157` :issue:`7382`
+
#. (Optional) Improve scikit-learn common tests suite to make sure that (at
least for frequently used) models have stable predictions across-versions
(to be discussed);
@@ -210,30 +230,26 @@ bottom.
model and good practices for re-training on fresh data without causing
catastrophic predictive performance regressions.
-#. More didactic documentation
-
- * More and more options have been added to scikit-learn. As a result, the
- documentation is crowded which makes it hard for beginners to get the big
- picture. Some work could be done in prioritizing the information.
Subpackage-specific goals
-------------------------
+:mod:`sklearn.ensemble`
+
+* |ss| a stacking implementation, :issue:`11047` |se|
+
:mod:`sklearn.cluster`
* kmeans variants for non-Euclidean distances, if we can show these have
benefits beyond hierarchical clustering.
-:mod:`sklearn.ensemble`
-
-* a stacking implementation
-
:mod:`sklearn.model_selection`
-* multi-metric scoring is slow :issue:`9326`
+* |ss| multi-metric scoring is slow :issue:`9326` |se|
* perhaps we want to be able to get back more than multiple metrics
* the handling of random states in CV splitters is a poor design and
- contradicts the validation of similar parameters in estimators.
+ contradicts the validation of similar parameters in estimators,
+ :issue:`15177`
* exploit warm-starting and path algorithms so the benefits of `EstimatorCV`
objects can be accessed via `GridSearchCV` and used in Pipelines.
:issue:`1626`
@@ -245,9 +261,9 @@ Subpackage-specific goals
:mod:`sklearn.neighbors`
-* Ability to substitute a custom/approximate/precomputed nearest neighbors
+* |ss| Ability to substitute a custom/approximate/precomputed nearest neighbors
implementation for ours in all/most contexts that nearest neighbors are used
- for learning. :issue:`10463`
+ for learning. :issue:`10463` |se|
:mod:`sklearn.pipeline`
|
This cleans up the roadmap a bit. Removes the links to issues and PRs which are already solved, and is an effort to keep it up to date.
I'm happy to put things which are deleted in this PR back. I've mostly deleted them for us to talk about them if you still think they should be there.
ping @scikit-learn/core-devs
|
https://api.github.com/repos/scikit-learn/scikit-learn/pulls/15332
|
2019-10-22T14:17:32Z
|
2019-11-06T11:08:28Z
|
2019-11-06T11:08:28Z
|
2019-11-06T11:47:02Z
| 2,101
|
scikit-learn/scikit-learn
| 46,731
|
bpo-46752: Slight improvements to TaskGroup API
|
diff --git a/Lib/asyncio/taskgroups.py b/Lib/asyncio/taskgroups.py
index 718277892c51c9..57b0eafefc16fe 100644
--- a/Lib/asyncio/taskgroups.py
+++ b/Lib/asyncio/taskgroups.py
@@ -3,10 +3,6 @@
__all__ = ["TaskGroup"]
-import itertools
-import textwrap
-import traceback
-import types
import weakref
from . import events
@@ -15,12 +11,7 @@
class TaskGroup:
- def __init__(self, *, name=None):
- if name is None:
- self._name = f'tg-{_name_counter()}'
- else:
- self._name = str(name)
-
+ def __init__(self):
self._entered = False
self._exiting = False
self._aborting = False
@@ -33,11 +24,8 @@ def __init__(self, *, name=None):
self._base_error = None
self._on_completed_fut = None
- def get_name(self):
- return self._name
-
def __repr__(self):
- msg = f'<TaskGroup {self._name!r}'
+ msg = f'<TaskGroup'
if self._tasks:
msg += f' tasks:{len(self._tasks)}'
if self._unfinished_tasks:
@@ -152,12 +140,13 @@ async def __aexit__(self, et, exc, tb):
me = BaseExceptionGroup('unhandled errors in a TaskGroup', errors)
raise me from None
- def create_task(self, coro):
+ def create_task(self, coro, *, name=None):
if not self._entered:
raise RuntimeError(f"TaskGroup {self!r} has not been entered")
if self._exiting and self._unfinished_tasks == 0:
raise RuntimeError(f"TaskGroup {self!r} is finished")
task = self._loop.create_task(coro)
+ tasks._set_task_name(task, name)
task.add_done_callback(self._on_task_done)
self._unfinished_tasks += 1
self._tasks.add(task)
@@ -230,6 +219,3 @@ def _on_task_done(self, task):
# # after TaskGroup is finished.
self._parent_cancel_requested = True
self._parent_task.cancel()
-
-
-_name_counter = itertools.count(1).__next__
diff --git a/Lib/test/test_asyncio/test_taskgroups.py b/Lib/test/test_asyncio/test_taskgroups.py
index ea6ee2ed43d2f8..aab1fd1ebb38d8 100644
--- a/Lib/test/test_asyncio/test_taskgroups.py
+++ b/Lib/test/test_asyncio/test_taskgroups.py
@@ -368,10 +368,10 @@ async def crash_after(t):
raise ValueError(t)
async def runner():
- async with taskgroups.TaskGroup(name='g1') as g1:
+ async with taskgroups.TaskGroup() as g1:
g1.create_task(crash_after(0.1))
- async with taskgroups.TaskGroup(name='g2') as g2:
+ async with taskgroups.TaskGroup() as g2:
g2.create_task(crash_after(0.2))
r = asyncio.create_task(runner())
@@ -387,10 +387,10 @@ async def crash_after(t):
raise ValueError(t)
async def runner():
- async with taskgroups.TaskGroup(name='g1') as g1:
+ async with taskgroups.TaskGroup() as g1:
g1.create_task(crash_after(10))
- async with taskgroups.TaskGroup(name='g2') as g2:
+ async with taskgroups.TaskGroup() as g2:
g2.create_task(crash_after(0.1))
r = asyncio.create_task(runner())
@@ -407,7 +407,7 @@ async def crash_soon():
1 / 0
async def runner():
- async with taskgroups.TaskGroup(name='g1') as g1:
+ async with taskgroups.TaskGroup() as g1:
g1.create_task(crash_soon())
try:
await asyncio.sleep(10)
@@ -430,7 +430,7 @@ async def crash_soon():
1 / 0
async def nested_runner():
- async with taskgroups.TaskGroup(name='g1') as g1:
+ async with taskgroups.TaskGroup() as g1:
g1.create_task(crash_soon())
try:
await asyncio.sleep(10)
@@ -692,3 +692,10 @@ async def runner():
self.assertEqual(get_error_types(cm.exception), {ZeroDivisionError})
self.assertGreaterEqual(nhydras, 10)
+
+ async def test_taskgroup_task_name(self):
+ async def coro():
+ await asyncio.sleep(0)
+ async with taskgroups.TaskGroup() as g:
+ t = g.create_task(coro(), name="yolo")
+ self.assertEqual(t.get_name(), "yolo")
|
- Remove the optional name argument to the TaskGroup constructor
- Add an optional name argument to the create_task() method
- Some cleanup
Note that there's a big discussion on cancellation edge cases going on in [bpo-46771](https://bugs.python.org/issue46771), this is unrelated to that and uncontroversial.
I'll also update typeshed.
<!--
Thanks for your contribution!
Please read this comment in its entirety. It's quite important.
# Pull Request title
It should be in the following format:
```
bpo-NNNN: Summary of the changes made
```
Where: bpo-NNNN refers to the issue number in the https://bugs.python.org.
Most PRs will require an issue number. Trivial changes, like fixing a typo, do not need an issue.
# Backport Pull Request title
If this is a backport PR (PR made against branches other than `main`),
please ensure that the PR title is in the following format:
```
[X.Y] <title from the original PR> (GH-NNNN)
```
Where: [X.Y] is the branch name, e.g. [3.6].
GH-NNNN refers to the PR number from `main`.
-->
<!-- issue-number: [bpo-46752](https://bugs.python.org/issue46752) -->
https://bugs.python.org/issue46752
<!-- /issue-number -->
|
https://api.github.com/repos/python/cpython/pulls/31398
|
2022-02-17T23:58:32Z
|
2022-02-18T05:30:45Z
|
2022-02-18T05:30:45Z
|
2022-02-18T05:30:49Z
| 1,133
|
python/cpython
| 3,908
|
move chat to top of sidebar
|
diff --git a/website/src/components/Layout.tsx b/website/src/components/Layout.tsx
index b31e069868..13de07a4f3 100644
--- a/website/src/components/Layout.tsx
+++ b/website/src/components/Layout.tsx
@@ -37,6 +37,15 @@ export const getDashboardLayout = (page: React.ReactElement) => (
<ToSWrapper>
<SideMenuLayout
items={[
+ ...(getEnv().ENABLE_CHAT
+ ? [
+ {
+ labelID: "chat",
+ pathname: "/chat",
+ icon: MessageCircle,
+ },
+ ]
+ : []),
{
labelID: "dashboard",
pathname: "/dashboard",
@@ -57,15 +66,6 @@ export const getDashboardLayout = (page: React.ReactElement) => (
pathname: "/stats",
icon: TrendingUp,
},
- ...(getEnv().ENABLE_CHAT
- ? [
- {
- labelID: "chat",
- pathname: "/chat",
- icon: MessageCircle,
- },
- ]
- : []),
{
labelID: "guidelines",
pathname: "https://projects.laion.ai/Open-Assistant/docs/guides/guidelines",
|
attempt to move chat to top of sidebar
https://github.com/LAION-AI/Open-Assistant/issues/2428
not sure if is really this simple or not - will test more on my end to see.
|
https://api.github.com/repos/LAION-AI/Open-Assistant/pulls/2429
|
2023-04-09T14:43:40Z
|
2023-04-10T08:39:33Z
|
2023-04-10T08:39:33Z
|
2023-04-10T10:10:32Z
| 282
|
LAION-AI/Open-Assistant
| 37,583
|
dns-rfc2136: use certbot's own is_ipaddress func
|
diff --git a/certbot-dns-rfc2136/certbot_dns_rfc2136/_internal/dns_rfc2136.py b/certbot-dns-rfc2136/certbot_dns_rfc2136/_internal/dns_rfc2136.py
index 9fa68c9d984..98687e6abc6 100644
--- a/certbot-dns-rfc2136/certbot_dns_rfc2136/_internal/dns_rfc2136.py
+++ b/certbot-dns-rfc2136/certbot_dns_rfc2136/_internal/dns_rfc2136.py
@@ -3,7 +3,6 @@
from typing import Optional
import dns.flags
-from dns.inet import is_address
import dns.message
import dns.name
import dns.query
@@ -16,6 +15,7 @@
from certbot import errors
from certbot.plugins import dns_common
from certbot.plugins.dns_common import CredentialsConfiguration
+from certbot.util import is_ipaddress
logger = logging.getLogger(__name__)
@@ -57,7 +57,7 @@ def more_info(self): # pylint: disable=missing-function-docstring
def _validate_credentials(self, credentials):
server = credentials.conf('server')
- if not is_address(server):
+ if not is_ipaddress(server):
raise errors.PluginError("The configured target DNS server ({0}) is not a valid IPv4 "
"or IPv6 address. A hostname is not allowed.".format(server))
algorithm = credentials.conf('algorithm')
diff --git a/certbot-dns-rfc2136/setup.py b/certbot-dns-rfc2136/setup.py
index 8ae2e255753..151ffad31f4 100644
--- a/certbot-dns-rfc2136/setup.py
+++ b/certbot-dns-rfc2136/setup.py
@@ -7,7 +7,7 @@
version = '1.20.0.dev0'
install_requires = [
- 'dnspython',
+ 'dnspython>=1.15.0',
'setuptools>=39.0.1',
]
diff --git a/certbot/CHANGELOG.md b/certbot/CHANGELOG.md
index ff40b3f1a2d..19cc1a60438 100644
--- a/certbot/CHANGELOG.md
+++ b/certbot/CHANGELOG.md
@@ -15,7 +15,8 @@ Certbot adheres to [Semantic Versioning](https://semver.org/).
### Fixed
-*
+* The certbot-dns-rfc2136 plugin in Certbot 1.19.0 inadvertently had an implicit
+ dependency on `dnspython>=2.0`. This has been relaxed to `dnspython>=1.15.0`.
More details about these changes can be found on our GitHub repo.
diff --git a/pytest.ini b/pytest.ini
index a3ec1ce174d..5091f28362a 100644
--- a/pytest.ini
+++ b/pytest.ini
@@ -20,9 +20,12 @@
# the certbot.interfaces module.
# 4) The deprecation warning raised when importing deprecated attributes from
# the certbot.display.util module.
+# 5) A deprecation warning is raised in dnspython==1.15.0 in the oldest tests for
+# certbot-dns-rfc2136.
filterwarnings =
error
ignore:The external mock module:PendingDeprecationWarning
ignore:.*zope. missing __init__:ImportWarning
ignore:.*attribute in certbot.interfaces module is deprecated:DeprecationWarning
- ignore:.*attribute in certbot.display.util module is deprecated:DeprecationWarning
\ No newline at end of file
+ ignore:.*attribute in certbot.display.util module is deprecated:DeprecationWarning
+ ignore:decodestring\(\) is a deprecated alias:DeprecationWarning:dns
diff --git a/tools/oldest_constraints.txt b/tools/oldest_constraints.txt
index 37864e76851..9cdf9f81d63 100644
--- a/tools/oldest_constraints.txt
+++ b/tools/oldest_constraints.txt
@@ -22,7 +22,7 @@ cython==0.29.24; (python_version >= "2.6" and python_full_version < "3.0.0") or
distlib==0.3.2; python_version >= "3.6" and python_full_version < "3.0.0" or python_version >= "3.6" and python_full_version >= "3.5.0"
distro==1.0.1
dns-lexicon==3.2.1
-dnspython==2.1.0; python_version >= "3.6"
+dnspython==1.15.0
docker-compose==1.24.1; python_version >= "3.6" and python_full_version < "3.0.0" or python_full_version >= "3.4.0" and python_version >= "3.6"
docker-pycreds==0.4.0; python_version >= "3.6" and python_full_version < "3.0.0" or python_full_version >= "3.4.0" and python_version >= "3.6"
docker==3.7.3; python_version >= "3.6" and python_full_version < "3.0.0" or python_full_version >= "3.4.0" and python_version >= "3.6"
diff --git a/tools/pinning/oldest/pyproject.toml b/tools/pinning/oldest/pyproject.toml
index 34db41d5f8e..70ec89729ee 100644
--- a/tools/pinning/oldest/pyproject.toml
+++ b/tools/pinning/oldest/pyproject.toml
@@ -63,6 +63,7 @@ configobj = "5.0.6"
cryptography = "2.1.4"
distro = "1.0.1"
dns-lexicon = "3.2.1"
+dnspython = "1.15.0"
funcsigs = "0.4"
google-api-python-client = "1.5.5"
httplib2 = "0.9.2"
|
Fixes #9033.
|
https://api.github.com/repos/certbot/certbot/pulls/9035
|
2021-09-12T21:05:45Z
|
2021-09-13T21:48:16Z
|
2021-09-13T21:48:16Z
|
2021-09-13T21:48:16Z
| 1,389
|
certbot/certbot
| 3,015
|
Remove wrong comma
|
diff --git a/docs/patterns/appfactories.rst b/docs/patterns/appfactories.rst
index dc9660ae44..c118a2730b 100644
--- a/docs/patterns/appfactories.rst
+++ b/docs/patterns/appfactories.rst
@@ -6,7 +6,7 @@ Application Factories
If you are already using packages and blueprints for your application
(:ref:`blueprints`) there are a couple of really nice ways to further improve
the experience. A common pattern is creating the application object when
-the blueprint is imported. But if you move the creation of this object,
+the blueprint is imported. But if you move the creation of this object
into a function, you can then create multiple instances of this app later.
So why would you want to do this?
|
I don't think that comma belongs there.
|
https://api.github.com/repos/pallets/flask/pulls/2116
|
2016-12-18T20:23:56Z
|
2016-12-19T13:37:34Z
|
2016-12-19T13:37:34Z
|
2020-11-14T04:32:58Z
| 183
|
pallets/flask
| 20,500
|
Fix for DTE Energy Bridge returning the wrong units from time to time
|
diff --git a/homeassistant/components/sensor/dte_energy_bridge.py b/homeassistant/components/sensor/dte_energy_bridge.py
index ee80c4f76feb..00da6c2ce51e 100644
--- a/homeassistant/components/sensor/dte_energy_bridge.py
+++ b/homeassistant/components/sensor/dte_energy_bridge.py
@@ -91,4 +91,9 @@ def update(self):
response.text, self._name)
return
- self._state = float(response_split[0])
+ val = float(response_split[0])
+
+ # A workaround for a bug in the DTE energy bridge.
+ # The returned value can randomly be in W or kW. Checking for a
+ # a decimal seems to be a reliable way to determine the units.
+ self._state = val if '.' in response_split[0] else val / 1000
diff --git a/tests/components/sensor/test_dte_energy_bridge.py b/tests/components/sensor/test_dte_energy_bridge.py
new file mode 100644
index 000000000000..2341c3f83504
--- /dev/null
+++ b/tests/components/sensor/test_dte_energy_bridge.py
@@ -0,0 +1,68 @@
+"""The tests for the DTE Energy Bridge."""
+
+import unittest
+
+import requests_mock
+
+from homeassistant.setup import setup_component
+
+from tests.common import get_test_home_assistant
+
+DTE_ENERGY_BRIDGE_CONFIG = {
+ 'platform': 'dte_energy_bridge',
+ 'ip': '192.168.1.1',
+}
+
+
+class TestDteEnergyBridgeSetup(unittest.TestCase):
+ """Test the DTE Energy Bridge platform."""
+
+ def setUp(self):
+ """Initialize values for this testcase class."""
+ self.hass = get_test_home_assistant()
+
+ def tearDown(self):
+ """Stop everything that was started."""
+ self.hass.stop()
+
+ def test_setup_with_config(self):
+ """Test the platform setup with configuration."""
+ self.assertTrue(
+ setup_component(self.hass, 'sensor',
+ {'dte_energy_bridge': DTE_ENERGY_BRIDGE_CONFIG}))
+
+ @requests_mock.Mocker()
+ def test_setup_correct_reading(self, mock_req):
+ """Test DTE Energy bridge returns a correct value."""
+ mock_req.get("http://{}/instantaneousdemand"
+ .format(DTE_ENERGY_BRIDGE_CONFIG['ip']),
+ text='.411 kW')
+ assert setup_component(self.hass, 'sensor', {
+ 'sensor': DTE_ENERGY_BRIDGE_CONFIG})
+ self.assertEqual('0.411',
+ self.hass.states
+ .get('sensor.current_energy_usage').state)
+
+ @requests_mock.Mocker()
+ def test_setup_incorrect_units_reading(self, mock_req):
+ """Test DTE Energy bridge handles a value with incorrect units."""
+ mock_req.get("http://{}/instantaneousdemand"
+ .format(DTE_ENERGY_BRIDGE_CONFIG['ip']),
+ text='411 kW')
+ assert setup_component(self.hass, 'sensor', {
+ 'sensor': DTE_ENERGY_BRIDGE_CONFIG})
+ self.assertEqual('0.411',
+ self.hass.states
+ .get('sensor.current_energy_usage').state)
+
+ @requests_mock.Mocker()
+ def test_setup_bad_format_reading(self, mock_req):
+ """Test DTE Energy bridge handles an invalid value."""
+ mock_req.get("http://{}/instantaneousdemand"
+ .format(DTE_ENERGY_BRIDGE_CONFIG['ip']),
+ text='411')
+ assert setup_component(self.hass, 'sensor', {
+ 'sensor': DTE_ENERGY_BRIDGE_CONFIG})
+ self.assertEqual('unknown',
+ self.hass.states
+ .get('sensor.current_energy_usage').state)
|
## Description:
The DTE Energy Bridge seems to return the current energy
usage randomly in either W or kW. The only way to tell the difference
is if there is a decimal or not in the result.
Also added some tests.
## Checklist:
If the code communicates with devices, web services, or third-party tools:
- [x] Local tests with `tox` run successfully. **Your PR cannot be merged unless tests pass**
[ex-requir]: https://github.com/home-assistant/home-assistant/blob/dev/homeassistant/components/keyboard.py#L14
[ex-import]: https://github.com/home-assistant/home-assistant/blob/dev/homeassistant/components/keyboard.py#L54
|
https://api.github.com/repos/home-assistant/core/pulls/9246
|
2017-09-01T01:09:54Z
|
2017-09-16T06:12:07Z
|
2017-09-16T06:12:07Z
|
2019-03-21T04:52:39Z
| 848
|
home-assistant/core
| 38,777
|
Documentation: specify Python version 3.10 requirement in `README.md` (#723)
|
diff --git a/README.md b/README.md
index bf15f3a6f7..6a4b566f0c 100644
--- a/README.md
+++ b/README.md
@@ -36,7 +36,7 @@ pip install -U g4f
#### Prerequisites:
-1. [Download and install Python](https://www.python.org/downloads/) (Version 3.x is recommended).
+1. [Download and install Python](https://www.python.org/downloads/) (Version 3.10 is recommended).
#### Setting up the project:
|
## Changes
* According to related issues, the Python version requirement should be specified as 3.10 in `README.md`.
## Related issues
* Close #723
* #720
* #871
* #823
|
https://api.github.com/repos/xtekky/gpt4free/pulls/917
|
2023-09-19T02:03:09Z
|
2023-09-19T17:37:12Z
|
2023-09-19T17:37:12Z
|
2023-09-19T17:37:12Z
| 127
|
xtekky/gpt4free
| 37,884
|
Fixed typo
|
diff --git a/letsencrypt/cli.py b/letsencrypt/cli.py
index 0797f23b4eb..6692d9c9902 100644
--- a/letsencrypt/cli.py
+++ b/letsencrypt/cli.py
@@ -57,7 +57,7 @@
install Install a previously obtained cert in a server
revoke Revoke a previously obtained certificate
rollback Rollback server configuration changes made during install
- config-changes Show changes made to server config during installation
+ config_changes Show changes made to server config during installation
Choice of server for authentication/installation:
|
Changed config-changes in the short help (wrong) to config_changes (right)
|
https://api.github.com/repos/certbot/certbot/pulls/623
|
2015-07-20T08:20:33Z
|
2015-07-20T18:40:47Z
|
2015-07-20T18:40:47Z
|
2016-05-06T19:22:10Z
| 136
|
certbot/certbot
| 971
|
Add script for building MacOS wheels.
|
diff --git a/python/README-manylinux1.md b/python/README-building-wheels.md
similarity index 59%
rename from python/README-manylinux1.md
rename to python/README-building-wheels.md
index f8055d19de815..9ad0ceda7b67b 100644
--- a/python/README-manylinux1.md
+++ b/python/README-building-wheels.md
@@ -6,10 +6,21 @@ repository, including both changes to tracked files, and ANY untracked files.
It will also cause all files inside the repository to be owned by root, and
produce .whl files owned by root.
-Inside the root directory (i.e. one level above this python directory), run
+Inside the root directory (i.e., one level above this python directory), run
```
docker run --rm -w /ray -v `pwd`:/ray -ti quay.io/xhochy/arrow_manylinux1_x86_64_base:ARROW-1024 /ray/python/build-wheel-manylinux1.sh
```
The wheel files will be placed in the .whl directory.
+
+## Building MacOS wheels
+
+To build wheels for MacOS, run the following inside the root directory (i.e.,
+one level above this python directory).
+
+```
+./python/build-wheel-macos.sh
+```
+
+The script uses `sudo` multiple times, so you may need to type in a password.
diff --git a/python/build-wheel-macos.sh b/python/build-wheel-macos.sh
new file mode 100755
index 0000000000000..14b1f0c291515
--- /dev/null
+++ b/python/build-wheel-macos.sh
@@ -0,0 +1,65 @@
+#!/bin/bash
+
+# Cause the script to exit if a single command fails.
+set -e
+
+# Show explicitly which commands are currently running.
+set -x
+
+# Much of this is taken from https://github.com/matthew-brett/multibuild.
+# This script uses "sudo", so you may need to type in a password a couple times.
+
+MACPYTHON_URL=https://www.python.org/ftp/python
+MACPYTHON_PY_PREFIX=/Library/Frameworks/Python.framework/Versions
+DOWNLOAD_DIR=python_downloads
+
+PY_VERSIONS=("2.7.13"
+ "3.4.4"
+ "3.5.3"
+ "3.6.1")
+PY_INSTS=("python-2.7.13-macosx10.6.pkg"
+ "python-3.4.4-macosx10.6.pkg"
+ "python-3.5.3-macosx10.6.pkg"
+ "python-3.6.1-macosx10.6.pkg")
+PY_MMS=("2.7"
+ "3.4"
+ "3.5"
+ "3.6")
+
+mkdir -p $DOWNLOAD_DIR
+mkdir -p .whl
+
+for ((i=0; i<${#PY_VERSIONS[@]}; ++i)); do
+ PY_VERSION=${PY_VERSIONS[i]}
+ PY_INST=${PY_INSTS[i]}
+ PY_MM=${PY_MMS[i]}
+
+ # The -f flag is passed twice to also run git clean in the arrow subdirectory.
+ # The -d flag removes directories. The -x flag ignores the .gitignore file,
+ # and the -e flag ensures that we don't remove the .whl directory.
+ git clean -f -f -x -d -e .whl -e $DOWNLOAD_DIR
+
+ # Install Python.
+ INST_PATH=python_downloads/$PY_INST
+ curl $MACPYTHON_URL/$PY_VERSION/$PY_INST > $INST_PATH
+ sudo installer -pkg $INST_PATH -target /
+
+ # Create a link from "python" to the actual Python executable so that the
+ # Python on the path that Ray finds is the correct version.
+ if [ ! -e $MACPYTHON_PY_PREFIX/$PY_MM/bin/python ]; then
+ ln -s $MACPYTHON_PY_PREFIX/$PY_MM/bin/python$PY_MM $MACPYTHON_PY_PREFIX/$PY_MM/bin/python
+ fi
+ PYTHON_EXE=$MACPYTHON_PY_PREFIX/$PY_MM/bin/python
+ PIP_CMD="$(dirname $PYTHON_EXE)/pip$PY_MM"
+
+ pushd python
+ # Fix the numpy version because this will be the oldest numpy version we can
+ # support.
+ $PIP_CMD install numpy==1.10.4
+ # Install wheel to avoid the error "invalid command 'bdist_wheel'".
+ $PIP_CMD install wheel
+ # Add the correct Python to the path and build the wheel.
+ PATH=$MACPYTHON_PY_PREFIX/$PY_MM/bin:$PATH $PYTHON_EXE setup.py bdist_wheel
+ mv dist/*.whl ../.whl/
+ popd
+done
diff --git a/test/jenkins_tests/run_multi_node_tests.sh b/test/jenkins_tests/run_multi_node_tests.sh
index 91c9884b12954..757c419cc2feb 100755
--- a/test/jenkins_tests/run_multi_node_tests.sh
+++ b/test/jenkins_tests/run_multi_node_tests.sh
@@ -3,7 +3,7 @@
# Cause the script to exit if a single command fails.
set -e
-# show explicitly which commands are currently running
+# Show explicitly which commands are currently running.
set -x
ROOT_DIR=$(cd "$(dirname "${BASH_SOURCE:-$0}")"; pwd)
|
This is largely taken from https://github.com/matthew-brett/multibuild, which is used by arrow in https://github.com/xhochy/pyarrow-macos-wheels.
However, I tried to simplify it a bunch so I could run it on my laptop without Travis. It basically loops over different Python versions, pulls the relevant Python binaries, installs Python and installs pip, then builds the wheel.
Note
- It requires sudo.
- **I'm omitting Python 3.3** because I had some trouble getting it to work locally. The binary for 3.3 is a `.dmg` instead of `.pkg`.
- If you run this script locally, it may mess up your Python installations.
|
https://api.github.com/repos/ray-project/ray/pulls/601
|
2017-05-29T22:50:01Z
|
2017-06-01T00:30:46Z
|
2017-06-01T00:30:46Z
|
2017-06-01T00:30:49Z
| 1,226
|
ray-project/ray
| 19,729
|
Prepare release 24.1.1
|
diff --git a/CHANGES.md b/CHANGES.md
index 6278aed77d8..a794f421694 100644
--- a/CHANGES.md
+++ b/CHANGES.md
@@ -1,57 +1,19 @@
# Change Log
-## Unreleased
+## 24.1.1
-### Highlights
-
-<!-- Include any especially major or disruptive changes here -->
-
-### Stable style
-
-<!-- Changes that affect Black's stable style -->
+Bugfix release to fix a bug that made Black unusable on certain file systems with strict
+limits on path length.
### Preview style
-<!-- Changes that affect Black's preview style -->
-
- Consistently add trailing comma on typed parameters (#4164)
### Configuration
-<!-- Changes to how Black can be configured -->
-
- Shorten the length of the name of the cache file to fix crashes on file systems that
do not support long paths (#4176)
-### Packaging
-
-<!-- Changes to how Black is packaged, such as dependency requirements -->
-
-### Parser
-
-<!-- Changes to the parser or to version autodetection -->
-
-### Performance
-
-<!-- Changes that improve Black's performance. -->
-
-### Output
-
-<!-- Changes to Black's terminal output and error messages -->
-
-### _Blackd_
-
-<!-- Changes to blackd -->
-
-### Integrations
-
-<!-- For example, Docker, GitHub Actions, pre-commit, editors -->
-
-### Documentation
-
-<!-- Major changes to documentation and policies. Small docs changes
- don't need a changelog entry. -->
-
## 24.1.0
### Highlights
diff --git a/docs/integrations/source_version_control.md b/docs/integrations/source_version_control.md
index 259c1c1eaf3..92279707d84 100644
--- a/docs/integrations/source_version_control.md
+++ b/docs/integrations/source_version_control.md
@@ -8,7 +8,7 @@ Use [pre-commit](https://pre-commit.com/). Once you
repos:
# Using this mirror lets us use mypyc-compiled black, which is about 2x faster
- repo: https://github.com/psf/black-pre-commit-mirror
- rev: 24.1.0
+ rev: 24.1.1
hooks:
- id: black
# It is recommended to specify the latest version of Python
@@ -35,7 +35,7 @@ include Jupyter Notebooks. To use this hook, simply replace the hook's `id: blac
repos:
# Using this mirror lets us use mypyc-compiled black, which is about 2x faster
- repo: https://github.com/psf/black-pre-commit-mirror
- rev: 24.1.0
+ rev: 24.1.1
hooks:
- id: black-jupyter
# It is recommended to specify the latest version of Python
diff --git a/docs/usage_and_configuration/the_basics.md b/docs/usage_and_configuration/the_basics.md
index 562fd7d5905..dc9d9a64c68 100644
--- a/docs/usage_and_configuration/the_basics.md
+++ b/docs/usage_and_configuration/the_basics.md
@@ -266,8 +266,8 @@ configuration file for consistent results across environments.
```console
$ black --version
-black, 24.1.0 (compiled: yes)
-$ black --required-version 24.1.0 -c "format = 'this'"
+black, 24.1.1 (compiled: yes)
+$ black --required-version 24.1.1 -c "format = 'this'"
format = "this"
$ black --required-version 31.5b2 -c "still = 'beta?!'"
Oh no! 💥 💔 💥 The required version does not match the running version!
@@ -363,7 +363,7 @@ You can check the version of _Black_ you have installed using the `--version` fl
```console
$ black --version
-black, 24.1.0
+black, 24.1.1
```
#### `--config`
|
<!-- Hello! Thanks for submitting a PR. To help make things go a bit more
smoothly we would appreciate that you go through this template. -->
### Description
<!-- Good things to put here include: reasoning for the change (please link
any relevant issues!), any noteworthy (or hacky) choices to be aware of,
or what the problem resolved here looked like ... we won't mind a ranty
story :) -->
### Checklist - did you ...
<!-- If any of the following items aren't relevant for your contribution
please still tick them so we know you've gone through the checklist.
All user-facing changes should get an entry. Otherwise, signal to us
this should get the magical label to silence the CHANGELOG entry check.
Tests are required for bugfixes and new features. Documentation changes
are necessary for formatting and most enhancement changes. -->
- [ ] Add an entry in `CHANGES.md` if necessary?
- [ ] Add / update tests if necessary?
- [ ] Add new / update outdated documentation?
<!-- Just as a reminder, everyone in all psf/black spaces including PRs
must follow the PSF Code of Conduct (link below).
Finally, once again thanks for your time and effort. If you have any
feedback in regards to your experience contributing here, please
let us know!
Helpful links:
PSF COC: https://www.python.org/psf/conduct/
Contributing docs: https://black.readthedocs.io/en/latest/contributing/index.html
Chat on Python Discord: https://discord.gg/RtVdv86PrH -->
|
https://api.github.com/repos/psf/black/pulls/4186
|
2024-01-28T04:41:55Z
|
2024-01-28T04:51:33Z
|
2024-01-28T04:51:33Z
|
2024-01-28T04:51:36Z
| 925
|
psf/black
| 24,197
|
Mark test_session_unicode as skip on py3
|
diff --git a/tests/test_sessions.py b/tests/test_sessions.py
index 6d5985843f..210f9d954c 100644
--- a/tests/test_sessions.py
+++ b/tests/test_sessions.py
@@ -1,6 +1,9 @@
# coding=utf-8
import os
import shutil
+import sys
+
+import pytest
from httpie.plugins.builtin import HTTPBasicAuth
from utils import TestEnvironment, mk_config_dir, http, HTTP_OK, \
@@ -132,6 +135,10 @@ def test_session_by_path(self, httpbin):
assert HTTP_OK in r2
assert r2.json['headers']['Foo'] == 'Bar'
+ @pytest.mark.skipif(
+ sys.version_info >= (3,),
+ reason="This test fails intermittently on Python 3 - "
+ "see https://github.com/jakubroztocil/httpie/issues/282")
def test_session_unicode(self, httpbin):
self.start_session(httpbin)
|
There are known problems with unicode in headers
|
https://api.github.com/repos/httpie/cli/pulls/305
|
2015-02-10T02:15:44Z
|
2015-02-10T15:00:24Z
|
2015-02-10T15:00:24Z
|
2015-02-10T15:08:28Z
| 220
|
httpie/cli
| 33,745
|
Exclude `ipython` from hubconf.py `check_requirements()`
|
diff --git a/hubconf.py b/hubconf.py
index bffe2d588b4..2f05565629a 100644
--- a/hubconf.py
+++ b/hubconf.py
@@ -37,7 +37,7 @@ def _create(name, pretrained=True, channels=3, classes=80, autoshape=True, verbo
if not verbose:
LOGGER.setLevel(logging.WARNING)
- check_requirements(exclude=('tensorboard', 'thop', 'opencv-python'))
+ check_requirements(exclude=('ipython', 'opencv-python', 'tensorboard', 'thop'))
name = Path(name)
path = name.with_suffix('.pt') if name.suffix == '' and not name.is_dir() else name # checkpoint path
try:
|
Signed-off-by: Glenn Jocher <[email protected]>
<!--
Thank you for submitting a YOLOv5 🚀 Pull Request! We want to make contributing to YOLOv5 as easy and transparent as possible. A few tips to get you started:
- Search existing YOLOv5 [PRs](https://github.com/ultralytics/yolov5/pull) to see if a similar PR already exists.
- Link this PR to a YOLOv5 [issue](https://github.com/ultralytics/yolov5/issues) to help us understand what bug fix or feature is being implemented.
- Provide before and after profiling/inference/training results to help us quantify the improvement your PR provides (if applicable).
Please see our ✅ [Contributing Guide](https://github.com/ultralytics/yolov5/blob/master/CONTRIBUTING.md) for more details.
-->
## 🛠️ PR Summary
<sub>Made with ❤️ by [Ultralytics Actions](https://github.com/ultralytics/actions)<sub>
### 🌟 Summary
Improvement of dependency checks in model loading routine.
### 📊 Key Changes
- Altered the list of excluded requirements during model initialization, adding 'ipython' to the exclusions.
### 🎯 Purpose & Impact
- **Purpose**: This change ensures that non-critical packages such as 'ipython' do not interfere with the model loading process, if they are not installed.
- **Impact**: Streamlines the user experience by preventing unnecessary warnings/errors about 'ipython' during model loading, especially for users who may not use 'ipython' in their workflow. This contributes to a smoother setup and fewer issues for new users getting started with the models.
|
https://api.github.com/repos/ultralytics/yolov5/pulls/9362
|
2022-09-10T19:41:48Z
|
2022-09-10T19:58:24Z
|
2022-09-10T19:58:24Z
|
2024-01-19T06:06:37Z
| 170
|
ultralytics/yolov5
| 24,905
|
Strip "\n" from end of OS version string for OS X.
|
diff --git a/certbot/util.py b/certbot/util.py
index 8507f80d668..35c599737c7 100644
--- a/certbot/util.py
+++ b/certbot/util.py
@@ -325,7 +325,7 @@ def get_python_os_info():
os_ver = subprocess.Popen(
["sw_vers", "-productVersion"],
stdout=subprocess.PIPE
- ).communicate()[0]
+ ).communicate()[0].rstrip('\n')
elif os_type.startswith('freebsd'):
# eg "9.3-RC3-p1"
os_ver = os_ver.partition("-")[0]
|
If you don't, it ends up in the UserAgent header and you get an error
like:
Invalid header value 'CertbotACMEClient/0.8.0 (darwin 10.10.5\n)...'
|
https://api.github.com/repos/certbot/certbot/pulls/3118
|
2016-06-03T05:52:09Z
|
2016-06-05T02:43:13Z
|
2016-06-05T02:43:13Z
|
2019-01-23T23:06:33Z
| 143
|
certbot/certbot
| 2,448
|
fixing default communication_data_type for bfloat16_enabled and docs
|
diff --git a/deepspeed/runtime/engine.py b/deepspeed/runtime/engine.py
index f073a0e61695..a95b5a6ca6a8 100644
--- a/deepspeed/runtime/engine.py
+++ b/deepspeed/runtime/engine.py
@@ -778,6 +778,9 @@ def communication_data_type(self):
if self.fp16_enabled():
return torch.float16
+ if self.bfloat16_enabled():
+ return torch.bfloat16
+
return torch.float32
def postscale_gradients(self):
diff --git a/docs/_pages/config-json.md b/docs/_pages/config-json.md
index f146ebeea24c..84f2f833f212 100755
--- a/docs/_pages/config-json.md
+++ b/docs/_pages/config-json.md
@@ -181,7 +181,7 @@ Example of <i>**scheduler**</i>
### Communication options
-<i>**communication_data_type**</i>: [boolean]
+<i>**communication_data_type**</i>: [string]
| Description | Default |
| ----------------------------------------------------------------------------------------------------------------------------- | ------- |
diff --git a/tests/unit/runtime/half_precision/test_bf16.py b/tests/unit/runtime/half_precision/test_bf16.py
index 916267a6ad42..740fa30641a1 100644
--- a/tests/unit/runtime/half_precision/test_bf16.py
+++ b/tests/unit/runtime/half_precision/test_bf16.py
@@ -287,7 +287,7 @@ def test(self, stage=2):
@pytest.mark.parametrize("comp_type", [torch.float16, torch.bfloat16, torch.float], ids=["fp16", "bfp16", "fp32"])
[email protected]("comm_type", [torch.float16, torch.bfloat16], ids=["fp16", "bfp16"])
[email protected]("comm_type", [torch.float16, torch.bfloat16, None], ids=["fp16", "bfp16", "default"])
class TestZeroDtypeCocktail(DistributedTest):
world_size = 2
@@ -312,8 +312,11 @@ def test(self, comp_type, comm_type):
"zero_optimization": {
"stage": 2
},
- "communication_data_type": type_str[comm_type]
}
+ if comm_type is not None:
+ config_dict["communication_data_type"] = type_str[comm_type]
+ else:
+ comm_type = comp_type
hidden_dim = 10
model = SimpleModel(hidden_dim)
|
fixes #2071
#2145 fixed the case when `communication_data_type` is set explicitly, unfortunately the default value for when `bfloat16_enabled=True` is not `bfp16`.
Adding unit tests for default `communication_data_type`.
Correcting the docs that mentioned `communication_data_type` as being of type `boolean`.
Before the fix:
```
tests/unit/runtime/half_precision/test_bf16.py::TestZeroDtypeCocktail::test[fp16-fp16] PASSED [ 11%]
tests/unit/runtime/half_precision/test_bf16.py::TestZeroDtypeCocktail::test[fp16-bfp16] PASSED [ 22%]
tests/unit/runtime/half_precision/test_bf16.py::TestZeroDtypeCocktail::test[fp16-fp32] PASSED [ 33%]
tests/unit/runtime/half_precision/test_bf16.py::TestZeroDtypeCocktail::test[bfp16-fp16] PASSED [ 44%]
tests/unit/runtime/half_precision/test_bf16.py::TestZeroDtypeCocktail::test[bfp16-bfp16] PASSED [ 55%]
tests/unit/runtime/half_precision/test_bf16.py::TestZeroDtypeCocktail::test[bfp16-fp32] PASSED [ 66%]
tests/unit/runtime/half_precision/test_bf16.py::TestZeroDtypeCocktail::test[default-fp16] PASSED [ 77%]
tests/unit/runtime/half_precision/test_bf16.py::TestZeroDtypeCocktail::test[default-bfp16] FAILED [ 88%]
tests/unit/runtime/half_precision/test_bf16.py::TestZeroDtypeCocktail::test[default-fp32] PASSED [100%]
=============================================================================================================== FAILURES ===============================================================================================================
______________________________________________________________________________________________ TestZeroDtypeCocktail.test[default-bfp16]
```
After the fix:
```
tests/unit/runtime/half_precision/test_bf16.py::TestZeroDtypeCocktail::test[fp16-fp16] PASSED [ 11%]
tests/unit/runtime/half_precision/test_bf16.py::TestZeroDtypeCocktail::test[fp16-bfp16] PASSED [ 22%]
tests/unit/runtime/half_precision/test_bf16.py::TestZeroDtypeCocktail::test[fp16-fp32] PASSED [ 33%]
tests/unit/runtime/half_precision/test_bf16.py::TestZeroDtypeCocktail::test[bfp16-fp16] PASSED [ 44%]
tests/unit/runtime/half_precision/test_bf16.py::TestZeroDtypeCocktail::test[bfp16-bfp16] PASSED [ 55%]
tests/unit/runtime/half_precision/test_bf16.py::TestZeroDtypeCocktail::test[bfp16-fp32] PASSED [ 66%]
tests/unit/runtime/half_precision/test_bf16.py::TestZeroDtypeCocktail::test[default-fp16] PASSED [ 77%]
tests/unit/runtime/half_precision/test_bf16.py::TestZeroDtypeCocktail::test[default-bfp16] PASSED [ 88%]
tests/unit/runtime/half_precision/test_bf16.py::TestZeroDtypeCocktail::test[default-fp32] PASSED [100%]
```
|
https://api.github.com/repos/microsoft/DeepSpeed/pulls/3370
|
2023-04-24T22:55:15Z
|
2023-04-25T17:25:08Z
|
2023-04-25T17:25:08Z
|
2023-05-12T15:56:53Z
| 559
|
microsoft/DeepSpeed
| 10,769
|
Minor session serializer fixes.
|
diff --git a/flask/json/tag.py b/flask/json/tag.py
index 1e51d6fc19..11c966c582 100644
--- a/flask/json/tag.py
+++ b/flask/json/tag.py
@@ -36,7 +36,7 @@ def to_json(self, value):
def to_python(self, value):
return OrderedDict(value)
- app.session_interface.serializer.register(TagOrderedDict, 0)
+ app.session_interface.serializer.register(TagOrderedDict, index=0)
:copyright: © 2010 by the Pallets team.
:license: BSD, see LICENSE for more details.
@@ -243,7 +243,7 @@ def __init__(self):
for cls in self.default_tags:
self.register(cls)
- def register(self, tag_class, force=False, index=-1):
+ def register(self, tag_class, force=False, index=None):
"""Register a new tag with this serializer.
:param tag_class: tag class to register. Will be instantiated with this
@@ -251,8 +251,8 @@ def register(self, tag_class, force=False, index=-1):
:param force: overwrite an existing tag. If false (default), a
:exc:`KeyError` is raised.
:param index: index to insert the new tag in the tag order. Useful when
- the new tag is a special case of an existing tag. If -1 (default),
- the tag is appended to the end of the order.
+ the new tag is a special case of an existing tag. If ``None``
+ (default), the tag is appended to the end of the order.
:raise KeyError: if the tag key is already registered and ``force`` is
not true.
@@ -266,7 +266,7 @@ def register(self, tag_class, force=False, index=-1):
self.tags[key] = tag
- if index == -1:
+ if index is None:
self.order.append(tag)
else:
self.order.insert(index, tag)
diff --git a/tests/test_json_tag.py b/tests/test_json_tag.py
index 6f42539e7f..da5e659520 100644
--- a/tests/test_json_tag.py
+++ b/tests/test_json_tag.py
@@ -72,3 +72,19 @@ def test_tag_interface():
pytest.raises(NotImplementedError, t.check, None)
pytest.raises(NotImplementedError, t.to_json, None)
pytest.raises(NotImplementedError, t.to_python, None)
+
+
+def test_tag_order():
+ class Tag1(JSONTag):
+ key = ' 1'
+
+ class Tag2(JSONTag):
+ key = ' 2'
+
+ s = TaggedJSONSerializer()
+
+ s.register(Tag1, index=-1)
+ assert isinstance(s.order[-2], Tag1)
+
+ s.register(Tag2, index=None)
+ assert isinstance(s.order[-1], Tag2)
|
A couple of minor fixes for the extensible session serializer added by #2352.
There were two issues observed:
1. The example usage of ``register()`` passes and ``index`` to the ``force`` argument.
2. It is not possible to insert a tag as the penultimate item in the order list.
Regarding the latter, `a.append(x)` is not the same as `a.insert(-1, x)` - it is `a.insert(len(a), x)`.
It would be good to get these out before the release of 1.0.0 so that the index default is correct.
- [x] add tests that fail without the patch
- [x] ensure all tests pass with ``pytest``
- [x] add documentation to the relevant docstrings or pages
- [ ] ~~add ``versionadded`` or ``versionchanged`` directives to relevant docstrings~~
- [ ] ~~add a changelog entry if this patch changes code~~ *Not required as the feature is unreleased?*
|
https://api.github.com/repos/pallets/flask/pulls/2711
|
2018-04-19T13:29:16Z
|
2018-04-19T13:57:12Z
|
2018-04-19T13:57:12Z
|
2020-11-14T03:27:23Z
| 657
|
pallets/flask
| 20,161
|
Fix passing of metadata on S3 presigned URL put
|
diff --git a/localstack/services/s3/s3_listener.py b/localstack/services/s3/s3_listener.py
index 3176b59f03198..7e5b8a0951c51 100644
--- a/localstack/services/s3/s3_listener.py
+++ b/localstack/services/s3/s3_listener.py
@@ -42,6 +42,9 @@
# list of destination types for bucket notifications
NOTIFICATION_DESTINATION_TYPES = ('Queue', 'Topic', 'CloudFunction', 'LambdaFunction')
+# prefix for object metadata keys in headers and query params
+OBJECT_METADATA_KEY_PREFIX = 'x-amz-meta-'
+
# response header overrides the client may request
ALLOWED_HEADER_OVERRIDES = {
'response-content-type': 'Content-Type',
@@ -306,6 +309,13 @@ def append_list_objects_marker(method, path, data, response):
response.headers['Content-Length'] = str(len(response._content))
+def append_metadata_headers(method, query_map, headers):
+ for key, value in query_map.items():
+ if key.lower().startswith(OBJECT_METADATA_KEY_PREFIX):
+ if headers.get(key) is None:
+ headers[key] = value[0]
+
+
def get_lifecycle(bucket_name):
lifecycle = BUCKET_LIFECYCLE.get(bucket_name)
if not lifecycle:
@@ -561,6 +571,10 @@ def forward_request(self, method, path, data, headers):
path = parsed.path
bucket = path.split('/')[1]
query_map = urlparse.parse_qs(query, keep_blank_values=True)
+
+ # remap metadata query params (not supported in moto) to request headers
+ append_metadata_headers(method, query_map, headers)
+
if query == 'notification' or 'notification' in query_map:
# handle and return response for ?notification request
response = handle_notification_request(bucket, method, data)
@@ -662,7 +676,8 @@ def return_response(self, method, path, data, headers, response):
# Remove body from PUT response on presigned URL
# https://github.com/localstack/localstack/issues/1317
- if method == 'PUT' and ('X-Amz-Security-Token=' in path or 'AWSAccessKeyId=' in path):
+ if method == 'PUT' and ('X-Amz-Security-Token=' in path or
+ 'X-Amz-Credential=' in path or 'AWSAccessKeyId=' in path):
response._content = ''
reset_content_length = True
diff --git a/tests/integration/test_s3.py b/tests/integration/test_s3.py
index 2097ee3365d3a..846ea6345bf64 100644
--- a/tests/integration/test_s3.py
+++ b/tests/integration/test_s3.py
@@ -176,8 +176,7 @@ def test_s3_get_response_default_content_type(self):
object_key = 'key-by-hostname'
self.s3_client.put_object(Bucket=bucket_name, Key=object_key, Body='something')
url = self.s3_client.generate_presigned_url(
- 'get_object', Params={'Bucket': bucket_name, 'Key': object_key}
- )
+ 'get_object', Params={'Bucket': bucket_name, 'Key': object_key})
# get object and assert headers
response = requests.get(url, verify=False)
@@ -185,6 +184,32 @@ def test_s3_get_response_default_content_type(self):
# clean up
self._delete_bucket(bucket_name, [object_key])
+ def test_s3_put_presigned_url_metadata(self):
+ # Object metadata should be passed as query params via presigned URL
+ # https://github.com/localstack/localstack/issues/544
+
+ bucket_name = 'test-bucket-%s' % short_uid()
+ self.s3_client.create_bucket(Bucket=bucket_name)
+
+ # put object
+ object_key = 'key-by-hostname'
+ url = self.s3_client.generate_presigned_url(
+ 'put_object', Params={'Bucket': bucket_name, 'Key': object_key})
+ # append metadata manually to URL (this is not easily possible with boto3, as "Metadata" cannot
+ # be passed to generate_presigned_url, and generate_presigned_post works differently)
+ url += '&x-amz-meta-foo=bar'
+
+ # get object and assert metadata is present
+ response = requests.put(url, data='content 123', verify=False)
+ self.assertLess(response.status_code, 400)
+ # response body should be empty, see https://github.com/localstack/localstack/issues/1317
+ self.assertEqual('', to_str(response.content))
+ response = self.s3_client.head_object(Bucket=bucket_name, Key=object_key)
+ self.assertEquals('bar', response.get('Metadata', {}).get('foo'))
+
+ # clean up
+ self._delete_bucket(bucket_name, [object_key])
+
def test_s3_get_response_content_type_same_as_upload(self):
bucket_name = 'test-bucket-%s' % short_uid()
self.s3_client.create_bucket(Bucket=bucket_name)
|
Fix passing of metadata on S3 presigned URL put - addresses #544
|
https://api.github.com/repos/localstack/localstack/pulls/1745
|
2019-11-09T12:16:33Z
|
2019-11-09T15:27:49Z
|
2019-11-09T15:27:49Z
|
2019-11-09T15:27:56Z
| 1,126
|
localstack/localstack
| 28,817
|
don't require typed-ast
|
diff --git a/CHANGES.md b/CHANGES.md
index 7da7be7b842..97a3be33c93 100644
--- a/CHANGES.md
+++ b/CHANGES.md
@@ -40,6 +40,11 @@
- Lines ending with `fmt: skip` will now be not formatted (#1800)
+- PR #2053: Black no longer relies on typed-ast for Python 3.8 and higher
+
+- PR #2053: Python 2 support is now optional, install with
+ `python3 -m pip install black[python2]` to maintain support.
+
#### _Packaging_
- Self-contained native _Black_ binaries are now provided for releases via GitHub
diff --git a/README.md b/README.md
index 411a8c8609d..0be356e3b84 100644
--- a/README.md
+++ b/README.md
@@ -50,7 +50,8 @@ _Contents:_ **[Installation and usage](#installation-and-usage)** |
### Installation
_Black_ can be installed by running `pip install black`. It requires Python 3.6.2+ to
-run but you can reformat Python 2 code with it, too.
+run. If you want to format Python 2 code as well, install with
+`pip install black[python2]`.
#### Install from GitHub
diff --git a/setup.py b/setup.py
index efdf6933025..856c7fadb0c 100644
--- a/setup.py
+++ b/setup.py
@@ -71,7 +71,7 @@ def get_long_description() -> str:
"click>=7.1.2",
"appdirs",
"toml>=0.10.1",
- "typed-ast>=1.4.2",
+ "typed-ast>=1.4.2; python_version < '3.8'",
"regex>=2020.1.8",
"pathspec>=0.6, <1",
"dataclasses>=0.6; python_version < '3.7'",
@@ -81,6 +81,7 @@ def get_long_description() -> str:
extras_require={
"d": ["aiohttp>=3.3.2", "aiohttp-cors"],
"colorama": ["colorama>=0.4.3"],
+ "python2": ["typed-ast>=1.4.2"],
},
test_suite="tests.test_black",
classifiers=[
diff --git a/src/black/__init__.py b/src/black/__init__.py
index a8f4f89a6bb..52a57695aef 100644
--- a/src/black/__init__.py
+++ b/src/black/__init__.py
@@ -48,7 +48,20 @@
from dataclasses import dataclass, field, replace
import click
import toml
-from typed_ast import ast3, ast27
+
+try:
+ from typed_ast import ast3, ast27
+except ImportError:
+ if sys.version_info < (3, 8):
+ print(
+ "The typed_ast package is not installed.\n"
+ "You can install it with `python3 -m pip install typed-ast`.",
+ file=sys.stderr,
+ )
+ sys.exit(1)
+ else:
+ ast3 = ast27 = ast
+
from pathspec import PathSpec
# lib2to3 fork
@@ -6336,7 +6349,12 @@ def parse_ast(src: str) -> Union[ast.AST, ast3.AST, ast27.AST]:
return ast3.parse(src, filename, feature_version=feature_version)
except SyntaxError:
continue
-
+ if ast27.__name__ == "ast":
+ raise SyntaxError(
+ "The requested source code has invalid Python 3 syntax.\n"
+ "If you are trying to format Python 2 files please reinstall Black"
+ " with the 'python2' extra: `python3 -m pip install black[python2]`."
+ )
return ast27.parse(src)
diff --git a/tox.ini b/tox.ini
index 500a2cad579..9bb809abe41 100644
--- a/tox.ini
+++ b/tox.ini
@@ -7,7 +7,7 @@ skip_install = True
deps =
-r{toxinidir}/test_requirements.txt
commands =
- pip install -e .[d]
+ pip install -e .[d,python2]
coverage erase
coverage run -m pytest tests
coverage report
|
#2044
|
https://api.github.com/repos/psf/black/pulls/2053
|
2021-03-20T10:33:18Z
|
2021-04-01T15:38:05Z
|
2021-04-01T15:38:05Z
|
2021-04-29T06:40:04Z
| 1,024
|
psf/black
| 23,945
|
Bump ctransformers to 0.2.25
|
diff --git a/requirements.txt b/requirements.txt
index 4a9209a0c4..cbe22b69c2 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -53,4 +53,4 @@ https://github.com/jllllll/GPTQ-for-LLaMa-CUDA/releases/download/0.1.0/gptq_for_
https://github.com/jllllll/GPTQ-for-LLaMa-CUDA/releases/download/0.1.0/gptq_for_llama-0.1.0+cu117-cp310-cp310-linux_x86_64.whl; platform_system == "Linux" and platform_machine == "x86_64"
# ctransformers
-https://github.com/jllllll/ctransformers-cuBLAS-wheels/releases/download/AVX2/ctransformers-0.2.24+cu117-py3-none-any.whl
+https://github.com/jllllll/ctransformers-cuBLAS-wheels/releases/download/AVX2/ctransformers-0.2.25+cu117-py3-none-any.whl
|
## Checklist:
- [x] I have read the [Contributing guidelines](https://github.com/oobabooga/text-generation-webui/wiki/Contributing-guidelines).
---
https://github.com/marella/ctransformers/compare/v0.2.24...v0.2.25
|
https://api.github.com/repos/oobabooga/text-generation-webui/pulls/3740
|
2023-08-29T06:23:16Z
|
2023-08-29T20:24:36Z
|
2023-08-29T20:24:36Z
|
2023-08-29T20:59:11Z
| 257
|
oobabooga/text-generation-webui
| 26,393
|
Added 'import os' statement
|
diff --git a/docs/tutorial/setup.rst b/docs/tutorial/setup.rst
index ed8a744c00..65d4b3f2ce 100644
--- a/docs/tutorial/setup.rst
+++ b/docs/tutorial/setup.rst
@@ -14,6 +14,7 @@ load that or import the values from there.
First we add the imports in `flaskr.py`::
# all the imports
+ import os
import sqlite3
from flask import Flask, request, session, g, redirect, url_for, abort, \
render_template, flash
|
Added 'import os' statement so you can use os.path.join() when defining DATABASE location
|
https://api.github.com/repos/pallets/flask/pulls/994
|
2014-03-04T23:01:35Z
|
2014-03-13T18:25:34Z
|
2014-03-13T18:25:34Z
|
2020-11-14T07:18:52Z
| 128
|
pallets/flask
| 20,507
|
[tests] remove T5 test skip decorator
|
diff --git a/tests/test_fx/test_pipeline/test_hf_model/test_t5.py b/tests/test_fx/test_pipeline/test_hf_model/test_t5.py
index d78883c3de23..ea32b87cf238 100644
--- a/tests/test_fx/test_pipeline/test_hf_model/test_t5.py
+++ b/tests/test_fx/test_pipeline/test_hf_model/test_t5.py
@@ -2,12 +2,20 @@
import transformers
import torch
from hf_utils import split_model_and_compare_output
+from colossalai.fx.tracer.meta_patch import meta_patched_module
+try:
+ import apex
+
+ @meta_patched_module.register(apex.normalization.FusedRMSNorm)
+ def apex_fused_layernorm(self, input):
+ return torch.empty(input.shape, device='meta')
+except ImportError:
+ pass
BATCH_SIZE = 1
SEQ_LENGHT = 16
[email protected]('tracing failed')
def test_t5():
MODEL_LIST = [
transformers.T5Model,
@@ -15,7 +23,7 @@ def test_t5():
transformers.T5EncoderModel,
]
- config = transformers.T5Config(d_model=128, num_layers=2)
+ config = transformers.T5Config(vocab_size=100, d_model=128, num_layers=2)
def data_gen():
input_ids = torch.zeros((BATCH_SIZE, SEQ_LENGHT), dtype=torch.int64)
|
https://api.github.com/repos/hpcaitech/ColossalAI/pulls/1271
|
2022-07-12T10:14:04Z
|
2022-07-12T15:25:30Z
|
2022-07-12T15:25:30Z
|
2022-07-12T15:25:31Z
| 321
|
hpcaitech/ColossalAI
| 11,459
|
|
Fix typos
|
diff --git a/CppCoreGuidelines.md b/CppCoreGuidelines.md
index ff7f72b14..0e60ee90d 100644
--- a/CppCoreGuidelines.md
+++ b/CppCoreGuidelines.md
@@ -21621,7 +21621,7 @@ The use of `p` for pointer and `x` for a floating-point variable is conventional
### <a name="Rl-name"></a>NL.8: Use a consistent naming style
-**Rationale**: Consistence in naming and naming style increases readability.
+**Rationale**: Consistency in naming and naming style increases readability.
##### Note
@@ -22032,7 +22032,7 @@ Consistency in large code bases.
##### Note
-We are well aware that you could claim the "bad" examples more logical than the ones marked "OK",
+We are well aware that you could claim the "bad" examples are more logical than the ones marked "OK",
but they also confuse more people, especially novices relying on teaching material using the far more common, conventional OK style.
As ever, remember that the aim of these naming and layout rules is consistency and that aesthetics vary immensely.
|
https://api.github.com/repos/isocpp/CppCoreGuidelines/pulls/2158
|
2023-11-04T22:37:35Z
|
2024-01-18T18:21:44Z
|
2024-01-18T18:21:44Z
|
2024-01-18T18:21:44Z
| 258
|
isocpp/CppCoreGuidelines
| 15,801
|
|
Add YandexGPT API support
|
diff --git a/docs/model_support.md b/docs/model_support.md
index 50ef527aa8..123daf6730 100644
--- a/docs/model_support.md
+++ b/docs/model_support.md
@@ -105,7 +105,7 @@ After these steps, the new model should be compatible with most FastChat feature
## API-Based Models
To support an API-based model, consider learning from the existing OpenAI example.
If the model is compatible with OpenAI APIs, then a configuration file is all that's needed without any additional code.
-For custom protocols, implementation of a streaming generator in [fastchat/serve/api_provider.py](https://github.com/lm-sys/FastChat/blob/main/fastchat/serve/api_provider.py) is required, following the provided examples. Currently, FastChat is compatible with OpenAI, Anthropic, Google Vertex AI, Mistral, and Nvidia NGC.
+For custom protocols, implementation of a streaming generator in [fastchat/serve/api_provider.py](https://github.com/lm-sys/FastChat/blob/main/fastchat/serve/api_provider.py) is required, following the provided examples. Currently, FastChat is compatible with OpenAI, Anthropic, Google Vertex AI, Mistral, Nvidia NGC and YandexGPT.
### Steps to Launch a WebUI with an API Model
1. Specify the endpoint information in a JSON configuration file. For instance, create a file named `api_endpoints.json`:
@@ -120,7 +120,7 @@ For custom protocols, implementation of a streaming generator in [fastchat/serve
}
}
```
- - "api_type" can be one of the following: openai, anthropic, gemini, or mistral. For custom APIs, add a new type and implement it accordingly.
+ - "api_type" can be one of the following: openai, anthropic, gemini, mistral or yandexgpt. For custom APIs, add a new type and implement it accordingly.
- "anony_only" indicates whether to display this model in anonymous mode only.
2. Launch the Gradio web server with the argument `--register api_endpoints.json`:
diff --git a/fastchat/conversation.py b/fastchat/conversation.py
index 99eb32a442..63f867f1e2 100644
--- a/fastchat/conversation.py
+++ b/fastchat/conversation.py
@@ -1620,6 +1620,16 @@ def get_conv_template(name: str) -> Conversation:
)
)
+register_conv_template(
+ Conversation(
+ name="yandexgpt",
+ system_message="",
+ roles=("user", "assistant"),
+ sep_style=None,
+ sep=None,
+ )
+)
+
if __name__ == "__main__":
from fastchat.conversation import get_conv_template
diff --git a/fastchat/model/model_adapter.py b/fastchat/model/model_adapter.py
index f5fb57cb58..4807703d27 100644
--- a/fastchat/model/model_adapter.py
+++ b/fastchat/model/model_adapter.py
@@ -2276,6 +2276,16 @@ def get_default_conv_template(self, model_path: str) -> Conversation:
return get_conv_template("gemma")
+class YandexGPTAdapter(BaseModelAdapter):
+ """The model adapter for YandexGPT"""
+
+ def match(self, model_path: str):
+ return "yandexgpt" in model_path.lower()
+
+ def get_default_conv_template(self, model_path: str) -> Conversation:
+ return get_conv_template("yandexgpt")
+
+
class CllmAdapter(BaseModelAdapter):
"""The model adapter for CLLM"""
@@ -2397,6 +2407,7 @@ def get_default_conv_template(self, model_path: str) -> Conversation:
register_model_adapter(LlavaAdapter)
register_model_adapter(YuanAdapter)
register_model_adapter(GemmaAdapter)
+register_model_adapter(YandexGPTAdapter)
register_model_adapter(CllmAdapter)
# After all adapters, try the default base adapter.
diff --git a/fastchat/serve/api_provider.py b/fastchat/serve/api_provider.py
index b0611773cc..cba95eacec 100644
--- a/fastchat/serve/api_provider.py
+++ b/fastchat/serve/api_provider.py
@@ -83,6 +83,31 @@ def get_api_provider_stream_iter(
api_base=model_api_dict["api_base"],
api_key=model_api_dict["api_key"],
)
+ elif model_api_dict["api_type"] == "yandexgpt":
+ # note: top_p parameter is unused by yandexgpt
+
+ messages = []
+ if conv.system_message:
+ messages.append({"role": "system", "text": conv.system_message})
+ messages += [
+ {"role": role, "text": text}
+ for role, text in conv.messages
+ if text is not None
+ ]
+
+ fixed_temperature = model_api_dict.get("fixed_temperature")
+ if fixed_temperature is not None:
+ temperature = fixed_temperature
+
+ stream_iter = yandexgpt_api_stream_iter(
+ model_name=model_api_dict["model_name"],
+ messages=messages,
+ temperature=temperature,
+ max_tokens=max_new_tokens,
+ api_base=model_api_dict["api_base"],
+ api_key=model_api_dict.get("api_key"),
+ folder_id=model_api_dict.get("folder_id"),
+ )
elif model_api_dict["api_type"] == "cohere":
messages = conv.to_openai_api_messages()
stream_iter = cohere_api_stream_iter(
@@ -467,6 +492,47 @@ def nvidia_api_stream_iter(model_name, messages, temp, top_p, max_tokens, api_ba
yield {"text": text, "error_code": 0}
+def yandexgpt_api_stream_iter(
+ model_name, messages, temperature, max_tokens, api_base, api_key, folder_id
+):
+ api_key = api_key or os.environ["YANDEXGPT_API_KEY"]
+ headers = {
+ "Authorization": f"Api-Key {api_key}",
+ "content-type": "application/json",
+ }
+
+ payload = {
+ "modelUri": f"gpt://{folder_id}/{model_name}",
+ "completionOptions": {
+ "temperature": temperature,
+ "max_tokens": max_tokens,
+ "stream": True,
+ },
+ "messages": messages,
+ }
+ logger.info(f"==== request ====\n{payload}")
+
+ # https://llm.api.cloud.yandex.net/foundationModels/v1/completion
+ response = requests.post(
+ api_base, headers=headers, json=payload, stream=True, timeout=60
+ )
+ text = ""
+ for line in response.iter_lines():
+ if line:
+ data = json.loads(line.decode("utf-8"))
+ data = data["result"]
+ top_alternative = data["alternatives"][0]
+ text = top_alternative["message"]["text"]
+ yield {"text": text, "error_code": 0}
+
+ status = top_alternative["status"]
+ if status in (
+ "ALTERNATIVE_STATUS_FINAL",
+ "ALTERNATIVE_STATUS_TRUNCATED_FINAL",
+ ):
+ break
+
+
def cohere_api_stream_iter(
client_name: str,
model_id: str,
|
<!-- Thank you for your contribution! -->
<!-- Please add a reviewer to the assignee section when you create a PR. If you don't have the access to it, we will shortly find a reviewer and assign them to your PR. -->
## Why are these changes needed?
<!-- Please give a short summary of the change and the problem this solves. -->
## Related issue number (if applicable)
<!-- For example: "Closes #1234" -->
## Checks
- [x] I've run `format.sh` to lint the changes in this PR.
- [x] I've included any doc changes needed.
- [x] I've made sure the relevant tests are passing (if applicable).
|
https://api.github.com/repos/lm-sys/FastChat/pulls/3116
|
2024-03-01T16:37:44Z
|
2024-04-10T21:26:35Z
|
2024-04-10T21:26:35Z
|
2024-04-15T00:30:24Z
| 1,624
|
lm-sys/FastChat
| 41,466
|
Bump pyinstaller from 5.10.1 to 5.11.0
|
diff --git a/pyproject.toml b/pyproject.toml
index 807e8f94c2..0d6c72d5a0 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -64,7 +64,7 @@ dev = [
"click>=7.0,<8.2",
"hypothesis>=5.8,<7",
"pdoc>=4.0.0",
- "pyinstaller==5.10.1",
+ "pyinstaller==5.11.0",
"pytest-asyncio>=0.17,<0.22",
"pytest-cov>=2.7.1,<4.1",
"pytest-timeout>=1.3.3,<2.2",
|
[//]: # (dependabot-start)
⚠️ **Dependabot is rebasing this PR** ⚠️
Rebasing might not happen immediately, so don't worry if this takes some time.
Note: if you make any changes to this PR yourself, they will take precedence over the rebase.
---
[//]: # (dependabot-end)
Bumps [pyinstaller](https://github.com/pyinstaller/pyinstaller) from 5.10.1 to 5.11.0.
<details>
<summary>Release notes</summary>
<p><em>Sourced from <a href="https://github.com/pyinstaller/pyinstaller/releases">pyinstaller's releases</a>.</em></p>
<blockquote>
<h2>v5.11.0</h2>
<p>Please see the <a href="https://pyinstaller.org/en/v5.11.0/CHANGES.html#id1">v5.11.0 section of the changelog</a> for a list of the changes since v5.10.1.</p>
</blockquote>
</details>
<details>
<summary>Changelog</summary>
<p><em>Sourced from <a href="https://github.com/pyinstaller/pyinstaller/blob/develop/doc/CHANGES.rst">pyinstaller's changelog</a>.</em></p>
<blockquote>
<h2>5.11.0 (2023-05-13)</h2>
<p>Features</p>
<pre><code>
* Add a work-around for pure-python modules that do not specify encoding via
:pep:`263` encoding header but contain non-ASCII characters in local
(non-UTF8) encoding. When such characters are present only in code comments,
python still loads and runs the module, but attempting to retrieve its source
code via the loader's ``get_source()`` method results in a
:class:`UnicodeDecodeError`, which interrupts the analysis process. The error
is now caught and a fall-back codepath attempts to retrieve the source code as
raw data to avoid encoding issues. (:issue:`7622`)
<p>Bugfix</p>
<pre><code>
* (Windows) Avoid writing collected binaries to binary cache unless
they need to be processed (i.e., only if binary stripping or ``upx``
processing is enabled). (:issue:`7595`)
* Fix a regression in bootloader that caused crash in onefile executables
when encountering a duplicated entry in the PKG/CArchive and the
``PYINSTALLER_STRICT_UNPACK_MODE`` environment variable not being set.
(:issue:`7613`)
Deprecations
</code></pre>
<ul>
<li>The <code>TOC</code> class is now deprecated; use a plain <code>list</code> with the same
three-element tuples instead. PyInstaller now performs explicit
normalization (i.e., entry de-duplication) of the TOC lists passed
to the build targets (e.g., <code>PYZ</code>, <code>EXE</code>, <code>COLLECT</code>) during their
instantiation. (:issue:<code>7615</code>)</li>
</ul>
<p>Bootloader</p>
<pre><code>
* Fix bootloader building with old versions of ``gcc`` that do not
support the ``-Wno-error=unused-but-set-variable`` compiler flag
(e.g., ``gcc`` v4.4.3). (:issue:`7592`)
Documentation
</code></pre>
<ul>
<li>Update the documentation on TOC lists and <code>Tree</code> class to reflect the</li>
</ul>
<!-- raw HTML omitted -->
</blockquote>
<p>... (truncated)</p>
</details>
<details>
<summary>Commits</summary>
<ul>
<li><a href="https://github.com/pyinstaller/pyinstaller/commit/413cce49ff28d87fad4472f4953489226ec90c84"><code>413cce4</code></a> Release v5.11.0. [skip ci]</li>
<li><a href="https://github.com/pyinstaller/pyinstaller/commit/75f86ee17da619d4b138b1ee66eda78579d51122"><code>75f86ee</code></a> hookutils: collect_delvewheel_libs_directory: collect .load_order file</li>
<li><a href="https://github.com/pyinstaller/pyinstaller/commit/e4ec2853ef9d890b7b124193338c2d4321117087"><code>e4ec285</code></a> modulegraph: add a work-around for modules with invalid characters (<a href="https://redirect.github.com/pyinstaller/pyinstaller/issues/7622">#7622</a>)</li>
<li><a href="https://github.com/pyinstaller/pyinstaller/commit/1c867390f670a6d89e26c7a87cc8f641c3eff2a8"><code>1c86739</code></a> building: ensure TOC de-duplication when dest_name contains pardir loops</li>
<li><a href="https://github.com/pyinstaller/pyinstaller/commit/bf46d025f70b19404bfe26cc03d57ce8c97113fa"><code>bf46d02</code></a> docs: update documentation on TOC lists</li>
<li><a href="https://github.com/pyinstaller/pyinstaller/commit/6ed6b50cf3d88e06889b6cd1716c8d8e7b958029"><code>6ed6b50</code></a> building: add deprecation warning to TOC class</li>
<li><a href="https://github.com/pyinstaller/pyinstaller/commit/ad5d1c70beeddb86d3945cf5a661a40a562a597d"><code>ad5d1c7</code></a> tests: add basic tests for the new TOC normalization helpers</li>
<li><a href="https://github.com/pyinstaller/pyinstaller/commit/2aa726cc5d6d610b0133fe9f88759e235c1ca948"><code>2aa726c</code></a> building: EXE: remove the work-around for merging PYZ.dependencies</li>
<li><a href="https://github.com/pyinstaller/pyinstaller/commit/02580411f4412619fb435198f69e27c91ffd53bb"><code>0258041</code></a> building: implement TOC list normalization helpers</li>
<li><a href="https://github.com/pyinstaller/pyinstaller/commit/91ba5c4c5011921999c389b38ebfe879343e6e1e"><code>91ba5c4</code></a> building: splash: fix detection of tkinter usage</li>
<li>Additional commits viewable in <a href="https://github.com/pyinstaller/pyinstaller/compare/v5.10.1...v5.11.0">compare view</a></li>
</ul>
</details>
<br />
</code></pre>
[](https://docs.github.com/en/github/managing-security-vulnerabilities/about-dependabot-security-updates#about-compatibility-scores)
Dependabot will resolve any conflicts with this PR as long as you don't alter it yourself. You can also trigger a rebase manually by commenting `@dependabot rebase`.
[//]: # (dependabot-automerge-start)
[//]: # (dependabot-automerge-end)
---
<details>
<summary>Dependabot commands and options</summary>
<br />
You can trigger Dependabot actions by commenting on this PR:
- `@dependabot rebase` will rebase this PR
- `@dependabot recreate` will recreate this PR, overwriting any edits that have been made to it
- `@dependabot merge` will merge this PR after your CI passes on it
- `@dependabot squash and merge` will squash and merge this PR after your CI passes on it
- `@dependabot cancel merge` will cancel a previously requested merge and block automerging
- `@dependabot reopen` will reopen this PR if it is closed
- `@dependabot close` will close this PR and stop Dependabot recreating it. You can achieve the same result by closing it manually
- `@dependabot ignore this major version` will close this PR and stop Dependabot creating any more for this major version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this minor version` will close this PR and stop Dependabot creating any more for this minor version (unless you reopen the PR or upgrade to it yourself)
- `@dependabot ignore this dependency` will close this PR and stop Dependabot creating any more for this dependency (unless you reopen the PR or upgrade to it yourself)
</details>
|
https://api.github.com/repos/mitmproxy/mitmproxy/pulls/6156
|
2023-06-01T23:00:10Z
|
2023-06-02T10:06:51Z
|
2023-06-02T10:06:51Z
|
2023-06-02T10:07:00Z
| 171
|
mitmproxy/mitmproxy
| 27,801
|
Add openorca
|
diff --git a/fastchat/conversation.py b/fastchat/conversation.py
index 71885dc4d5..c06ff9e88d 100644
--- a/fastchat/conversation.py
+++ b/fastchat/conversation.py
@@ -878,6 +878,30 @@ def get_conv_template(name: str) -> Conversation:
)
)
+# OpenOrcaxOpenChat-Preview2-13B template
+register_conv_template(
+ Conversation(
+ name="open-orca",
+ system_template="{system_message}",
+ system_message="You are a helpful assistant. Please answer truthfully and write out your "
+ "thinking step by step to be sure you get the right answer. If you make a mistake or encounter "
+ "an error in your thinking, say so out loud and attempt to correct it. If you don't know or "
+ "aren't sure about something, say so clearly. You will act as a professional logician, mathematician, "
+ "and physicist. You will also act as the most appropriate type of expert to answer any particular "
+ "question or solve the relevant problem; state which expert type your are, if so. Also think of "
+ "any particular named expert that would be ideal to answer the relevant question or solve the "
+ "relevant problem; name and act as them, if appropriate.",
+ roles=("User", "Assistant"),
+ messages=(),
+ offset=0,
+ sep_style=SeparatorStyle.ADD_COLON_SPACE_SINGLE,
+ sep="<|end_of_turn|>\n",
+ stop_token_ids=[32000, 32001], # "<|end_of_turn|>"
+ stop_str="User",
+ )
+)
+
+
if __name__ == "__main__":
print("Vicuna template:")
conv = get_conv_template("vicuna_v1.1")
diff --git a/fastchat/model/model_adapter.py b/fastchat/model/model_adapter.py
index d065ffd577..569c9b1287 100644
--- a/fastchat/model/model_adapter.py
+++ b/fastchat/model/model_adapter.py
@@ -1239,6 +1239,30 @@ def get_default_conv_template(self, model_path: str) -> Conversation:
return get_conv_template("cutegpt")
+class OpenOrcaAdapter(BaseModelAdapter):
+ "Model adapater for Open-Orca models (e.g., Open-Orca/OpenOrcaxOpenChat-Preview2-13B)" ""
+
+ use_fast_tokenizer = False
+
+ def match(self, model_path: str):
+ return "openorca" in model_path.lower()
+
+ def load_model(self, model_path: str, from_pretrained_kwargs: dict):
+ revision = from_pretrained_kwargs.get("revision", "main")
+ tokenizer = AutoTokenizer.from_pretrained(
+ model_path, use_fast=self.use_fast_tokenizer, revision=revision
+ )
+ model = AutoModelForCausalLM.from_pretrained(
+ model_path,
+ low_cpu_mem_usage=True,
+ **from_pretrained_kwargs,
+ ).eval()
+ return model, tokenizer
+
+ def get_default_conv_template(self, model_path: str) -> Conversation:
+ return get_conv_template("open-orca")
+
+
# Note: the registration order matters.
# The one registered earlier has a higher matching priority.
register_model_adapter(PeftModelAdapter)
@@ -1284,6 +1308,7 @@ def get_default_conv_template(self, model_path: str) -> Conversation:
register_model_adapter(StarChatAdapter)
register_model_adapter(Llama2Adapter)
register_model_adapter(CuteGPTAdapter)
+register_model_adapter(OpenOrcaAdapter)
# After all adapters, try the default base adapter.
register_model_adapter(BaseModelAdapter)
|
<!-- Thank you for your contribution! -->
<!-- Please add a reviewer to the assignee section when you create a PR. If you don't have the access to it, we will shortly find a reviewer and assign them to your PR. -->
## Why are these changes needed?
1. Add OpenOrca chat model support
<!-- Please give a short summary of the change and the problem this solves. -->
## Related issue number (if applicable)
<!-- For example: "Closes #1234" -->
## Checks
- [x] I've run `format.sh` to lint the changes in this PR.
- [ ] I've included any doc changes needed.
- [ ] I've made sure the relevant tests are passing (if applicable).
|
https://api.github.com/repos/lm-sys/FastChat/pulls/2155
|
2023-08-04T10:09:22Z
|
2023-08-05T06:09:12Z
|
2023-08-05T06:09:12Z
|
2023-08-05T11:45:07Z
| 825
|
lm-sys/FastChat
| 41,558
|
ref(pageFilters): Only check desync state on first load
|
diff --git a/static/app/actionCreators/pageFilters.tsx b/static/app/actionCreators/pageFilters.tsx
index a58d74deb14a73..f2892cb90536cb 100644
--- a/static/app/actionCreators/pageFilters.tsx
+++ b/static/app/actionCreators/pageFilters.tsx
@@ -50,10 +50,6 @@ type Options = {
* Persist changes to the page filter selection into local storage
*/
save?: boolean;
- /**
- * Skip checking desync state after updating the page filter value.
- */
- skipDesyncUpdate?: boolean;
};
/**
@@ -257,8 +253,21 @@ export function initializeUrlState({
const pinnedFilters = organization.features.includes('new-page-filter')
? new Set<PinnedPageFilter>(['projects', 'environments', 'datetime'])
: storedPageFilters?.pinnedFilters ?? new Set();
+
+ // We should only check and update the desync state if the site has just been loaded
+ // (not counting route changes). To check this, we can use the `isReady` state: if it's
+ // false, then the site was just loaded. Once it's true, `isReady` stays true
+ // through route changes.
+ const shouldCheckDesyncedURLState = !PageFiltersStore.getState().isReady;
+
PageFiltersStore.onInitializeUrlState(pageFilters, pinnedFilters, shouldPersist);
- updateDesyncedUrlState(router, shouldForceProject);
+
+ if (shouldCheckDesyncedURLState) {
+ checkDesyncedUrlState(router, shouldForceProject);
+ } else {
+ // Clear desync state on route changes
+ PageFiltersStore.updateDesyncedFilters(new Set());
+ }
const newDatetime = {
...datetime,
@@ -307,7 +316,6 @@ export function updateProjects(
if (options?.environments) {
persistPageFilters('environments', options);
}
- !options?.skipDesyncUpdate && updateDesyncedUrlState(router);
}
/**
@@ -326,7 +334,6 @@ export function updateEnvironments(
PageFiltersStore.updateEnvironments(environment);
updateParams({environment}, router, options);
persistPageFilters('environments', options);
- !options?.skipDesyncUpdate && updateDesyncedUrlState(router);
}
/**
@@ -346,7 +353,6 @@ export function updateDateTime(
PageFiltersStore.updateDateTime({...selection.datetime, ...datetime});
updateParams(datetime, router, options);
persistPageFilters('datetime', options);
- !options?.skipDesyncUpdate && updateDesyncedUrlState(router);
}
/**
@@ -423,7 +429,7 @@ async function persistPageFilters(filter: PinnedPageFilter | null, options?: Opt
* If shouldForceProject is enabled, then we do not record any url desync
* for the project.
*/
-async function updateDesyncedUrlState(router?: Router, shouldForceProject?: boolean) {
+async function checkDesyncedUrlState(router?: Router, shouldForceProject?: boolean) {
// Cannot compare URL state without the router
if (!router || !PageFiltersStore.shouldPersist) {
return;
@@ -591,5 +597,5 @@ export function revertToPinnedFilters(orgSlug: string, router: InjectedRouter) {
updateParams(newParams, router, {
keepCursor: true,
});
- updateDesyncedUrlState(router);
+ PageFiltersStore.updateDesyncedFilters(new Set());
}
diff --git a/static/app/components/charts/chartZoom.tsx b/static/app/components/charts/chartZoom.tsx
index 96f964b56ec8fa..b363d2f7bb9068 100644
--- a/static/app/components/charts/chartZoom.tsx
+++ b/static/app/components/charts/chartZoom.tsx
@@ -172,8 +172,7 @@ class ChartZoom extends Component<Props> {
: startFormatted,
end: endFormatted ? getUtcToLocalDateObject(endFormatted) : endFormatted,
},
- router,
- {skipDesyncUpdate: true}
+ router
);
}
diff --git a/static/app/components/organizations/datePageFilter.spec.tsx b/static/app/components/organizations/datePageFilter.spec.tsx
index 5035d9f05539e0..c07cb008c6835d 100644
--- a/static/app/components/organizations/datePageFilter.spec.tsx
+++ b/static/app/components/organizations/datePageFilter.spec.tsx
@@ -1,7 +1,7 @@
import {initializeOrg} from 'sentry-test/initializeOrg';
-import {act, fireEvent, render, screen, userEvent} from 'sentry-test/reactTestingLibrary';
+import {fireEvent, render, screen, userEvent} from 'sentry-test/reactTestingLibrary';
-import {updateDateTime} from 'sentry/actionCreators/pageFilters';
+import {initializeUrlState} from 'sentry/actionCreators/pageFilters';
import {DatePageFilter} from 'sentry/components/organizations/datePageFilter';
import OrganizationStore from 'sentry/stores/organizationStore';
import PageFiltersStore from 'sentry/stores/pageFiltersStore';
@@ -145,12 +145,14 @@ describe('DatePageFilter', function () {
},
});
- // Manually mark the date filter as desynced
- act(() =>
- updateDateTime({period: '14d', start: null, end: null, utc: false}, desyncRouter, {
- save: false,
- })
- );
+ PageFiltersStore.reset();
+ initializeUrlState({
+ memberProjects: [],
+ organization: desyncOrganization,
+ queryParams: {statsPeriod: '14d'},
+ router: desyncRouter,
+ shouldEnforceSingleProject: false,
+ });
render(<DatePageFilter />, {
context: desyncRouterContext,
diff --git a/static/app/components/organizations/environmentPageFilter/index.spec.tsx b/static/app/components/organizations/environmentPageFilter/index.spec.tsx
index 37375c635945b0..c28f9b326ddfab 100644
--- a/static/app/components/organizations/environmentPageFilter/index.spec.tsx
+++ b/static/app/components/organizations/environmentPageFilter/index.spec.tsx
@@ -1,7 +1,7 @@
import {initializeOrg} from 'sentry-test/initializeOrg';
import {act, fireEvent, render, screen, userEvent} from 'sentry-test/reactTestingLibrary';
-import {updateEnvironments} from 'sentry/actionCreators/pageFilters';
+import {initializeUrlState, updateEnvironments} from 'sentry/actionCreators/pageFilters';
import {EnvironmentPageFilter} from 'sentry/components/organizations/environmentPageFilter';
import OrganizationStore from 'sentry/stores/organizationStore';
import PageFiltersStore from 'sentry/stores/pageFiltersStore';
@@ -157,8 +157,14 @@ describe('EnvironmentPageFilter', function () {
},
});
- // Manually mark the environment filter as desynced
- act(() => updateEnvironments(['staging'], desyncRouter, {save: false}));
+ PageFiltersStore.reset();
+ initializeUrlState({
+ memberProjects: [],
+ organization: desyncOrganization,
+ queryParams: {project: ['1'], environment: 'staging'},
+ router: desyncRouter,
+ shouldEnforceSingleProject: false,
+ });
render(<EnvironmentPageFilter />, {
context: desyncRouterContext,
diff --git a/static/app/components/organizations/projectPageFilter/index.spec.tsx b/static/app/components/organizations/projectPageFilter/index.spec.tsx
index 964b5ef07854c7..710951b37102aa 100644
--- a/static/app/components/organizations/projectPageFilter/index.spec.tsx
+++ b/static/app/components/organizations/projectPageFilter/index.spec.tsx
@@ -8,7 +8,7 @@ import {
within,
} from 'sentry-test/reactTestingLibrary';
-import {updateProjects} from 'sentry/actionCreators/pageFilters';
+import {initializeUrlState, updateProjects} from 'sentry/actionCreators/pageFilters';
import {ProjectPageFilter} from 'sentry/components/organizations/projectPageFilter';
import {ALL_ACCESS_PROJECTS} from 'sentry/constants/pageFilters';
import OrganizationStore from 'sentry/stores/organizationStore';
@@ -229,8 +229,14 @@ describe('ProjectPageFilter', function () {
},
});
- // Manually mark the project filter as desynced
- act(() => updateProjects([2], desyncRouter, {save: false}));
+ PageFiltersStore.reset();
+ initializeUrlState({
+ memberProjects: [],
+ organization: desyncOrganization,
+ queryParams: {project: '2'},
+ router: desyncRouter,
+ shouldEnforceSingleProject: false,
+ });
render(<ProjectPageFilter />, {
context: desyncRouterContext,
diff --git a/static/app/stores/pageFiltersStore.tsx b/static/app/stores/pageFiltersStore.tsx
index 05a8877a40b026..058d5d3631eba9 100644
--- a/static/app/stores/pageFiltersStore.tsx
+++ b/static/app/stores/pageFiltersStore.tsx
@@ -127,6 +127,12 @@ const storeConfig: PageFiltersStoreDefinition = {
return;
}
+ if (this.desyncedFilters.has('projects')) {
+ const newDesyncedFilters = new Set(this.desyncedFilters);
+ newDesyncedFilters.delete('projects');
+ this.desyncedFilters = newDesyncedFilters;
+ }
+
this.selection = {
...this.selection,
projects,
@@ -140,6 +146,12 @@ const storeConfig: PageFiltersStoreDefinition = {
return;
}
+ if (this.desyncedFilters.has('datetime')) {
+ const newDesyncedFilters = new Set(this.desyncedFilters);
+ newDesyncedFilters.delete('datetime');
+ this.desyncedFilters = newDesyncedFilters;
+ }
+
this.selection = {
...this.selection,
datetime,
@@ -152,6 +164,12 @@ const storeConfig: PageFiltersStoreDefinition = {
return;
}
+ if (this.desyncedFilters.has('environments')) {
+ const newDesyncedFilters = new Set(this.desyncedFilters);
+ newDesyncedFilters.delete('environments');
+ this.desyncedFilters = newDesyncedFilters;
+ }
+
this.selection = {
...this.selection,
environments: environments ?? [],
|
We should only check for desynced page filter state when the site first loads, not on subsequent route changes (e.g. when the user clicks on an internal link). Internal route changes and whatever updates to page filter values that they carry are assumed to be intentional and thus should not trigger a desync state warning.
For example, user clicks on "Open In Discover" from inside Issue Details. They get to the Discover page with the project and date filters prefilled with custom values. Neither filter should be marked as desynced since the difference between the current value and the saved ones is intentional.
<img width="618" alt="image" src="https://github.com/getsentry/sentry/assets/44172267/426cb15c-e9ec-4c65-93ee-bddb248614aa">
<img width="1254" alt="image" src="https://github.com/getsentry/sentry/assets/44172267/792446d5-f623-4471-9139-8b921a41a109">
|
https://api.github.com/repos/getsentry/sentry/pulls/50110
|
2023-05-31T21:38:25Z
|
2023-06-08T19:33:21Z
|
2023-06-08T19:33:21Z
|
2023-06-24T00:02:42Z
| 2,331
|
getsentry/sentry
| 44,280
|
SF.10: Fix annotation of examples
|
diff --git a/CppCoreGuidelines.md b/CppCoreGuidelines.md
index 14e4f01ef..5983e6c5f 100644
--- a/CppCoreGuidelines.md
+++ b/CppCoreGuidelines.md
@@ -19096,12 +19096,12 @@ Avoid surprises.
Avoid having to change `#include`s if an `#include`d header changes.
Avoid accidentally becoming dependent on implementation details and logically separate entities included in a header.
-##### Example
+##### Example, bad
#include <iostream>
using namespace std;
- void use() // bad
+ void use()
{
string s;
cin >> s; // fine
|
In one example, a _bad_ annotation was marking a perfectly fine function
name instead of the incorrect local variable declaration.
In another example, a _fine_ annotation of the aforementioned variable
declaration was missing.
|
https://api.github.com/repos/isocpp/CppCoreGuidelines/pulls/1627
|
2020-05-27T15:08:22Z
|
2020-05-28T18:37:51Z
|
2020-05-28T18:37:51Z
|
2020-05-29T18:11:15Z
| 158
|
isocpp/CppCoreGuidelines
| 15,370
|
Fix config edit mac os
|
diff --git a/README.md b/README.md
index ba8fafb62..a63759189 100644
--- a/README.md
+++ b/README.md
@@ -350,6 +350,10 @@ pip install fastapi uvicorn
uvicorn server:app --reload
```
+## Android
+
+The step-by-step guide for installing Open Interpreter on your Android device can be found in the [open-interpreter-termux repo](https://github.com/Arrendy/open-interpreter-termux).
+
## Safety Notice
Since generated code is executed in your local environment, it can interact with your files and system settings, potentially leading to unexpected outcomes like data loss or security risks.
diff --git a/interpreter/terminal_interface/start_terminal_interface.py b/interpreter/terminal_interface/start_terminal_interface.py
index 58b5674bd..2a24c6c47 100644
--- a/interpreter/terminal_interface/start_terminal_interface.py
+++ b/interpreter/terminal_interface/start_terminal_interface.py
@@ -304,18 +304,10 @@ def start_terminal_interface(interpreter):
if platform.system() == "Windows":
os.startfile(config_directory)
- else:
- subprocess.call(["xdg-open", config_directory])
-
- # Use the default system editor to open the file
- if platform.system() == "Windows":
- os.startfile(
- config_file
- ) # This will open the file with the default application, e.g., Notepad
else:
try:
# Try using xdg-open on non-Windows platforms
- subprocess.call(["xdg-open", config_file])
+ subprocess.call(["xdg-open", config_directory])
except FileNotFoundError:
# Fallback to using 'open' on macOS if 'xdg-open' is not available
subprocess.call(["open", config_file])
|
### Describe the changes you have made:
Added the `try...except` in case MacOS does not have `xdg-open` installed and calls `open` instead. Previous functionality that was removed when updating `config_file` to `config_directory` as seen in https://github.com/KillianLucas/open-interpreter/commit/3241ae47372693e083b4bb07c2753339814f39d2#diff-dbfabffe97449287c29c05be833deaec361f15787ac3befc0ad745b826d9867bR301-R322
### Reference any relevant issues (e.g. "Fixes #000"):
### Pre-Submission Checklist (optional but appreciated):
- [ ] I have included relevant documentation updates (stored in /docs)
- [ ] I have read `docs/CONTRIBUTING.md`
- [ ] I have read `docs/ROADMAP.md`
### OS Tests (optional but appreciated):
- [ ] Tested on Windows
- [ ] Tested on MacOS
- [ ] Tested on Linux
|
https://api.github.com/repos/OpenInterpreter/open-interpreter/pulls/927
|
2024-01-15T20:39:58Z
|
2024-01-15T22:15:18Z
|
2024-01-15T22:15:18Z
|
2024-01-15T22:15:18Z
| 400
|
OpenInterpreter/open-interpreter
| 40,684
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.