
full_name
stringlengths 9
72
| url
stringlengths 28
91
| description
stringlengths 3
343
⌀ | readme
stringlengths 1
207k
|
|---|---|---|---|
johnrso/spawnnet
|
https://github.com/johnrso/spawnnet
|
SpawnNet: Learning Generalizable Visuomotor Skills from Pre-trained Networks
|
# SpawnNet: Learning Generalizable Visuomotor Skills from Pre-trained Networks
[Xingyu Lin](https://xingyu-lin.github.io)\*,
[John So](https://www.johnrso.xyz/)\*,
[Sashwat Mahalingam](https://sashwat-mahalingam.github.io),
[Fangchen Liu](https://fangchenliu.github.io/),
[Pieter Abbeel](https://people.eecs.berkeley.edu/~pabbeel/)
[paper]() | [website](https://xingyu-lin.github.io/spawnnet)
## Setup
For reproducibility, we provide steps and checkpoints to reproduce our simulation DAgger experiments.
For real-world BC experiments, we additionally provide a dataset for
visualization and BC training. For more information regarding the real-world setup,
see [Real World Experiments](#real-world-experiments).
### Create the environment:
```
cd spawnnet
conda create -n spawnnet python==3.8.13 pip
conda activate spawnnet
sudo apt install ffmpeg
pip install -r requirements.txt
# baselines
pip install git+https://github.com/ir413/mvp # MVP
pip install git+https://github.com/facebookresearch/r3m # R3M
```
### Modify `prepare.sh`
`prepare.sh` is a file used to set up the necessary environment variables and library paths. You must modify `prepare.sh` as described in the file's comments.
Make sure to `source prepare.sh` once completed:
```sh
. prepare.sh
```
### Simulation Setup
We run our simulation experiments using [IsaacGym](https://developer.nvidia.com/isaac-gym) with tasks lifted from [RLAfford](https://sites.google.com/view/rlafford/). To set up the IsaacGym environments developed by RLAfford, follow the instructions given at [`RLAfford/README.md`](https://github.com/johnrso/spawnnet/blob/main/RLAfford/README.md).
### PIP Troubleshooting
If when installing any packages, you get a PIP error that `extra_requires` must be a dictionary, consider changing your setuptools version through `pip install setuptools==65.5.0`, then rerunning.
### NVIDIA Troubleshooting: Driver Mismatches/Issues
If you encounter issues with a driver mismatch between your CUDA and NVIDIA Drivers, consider these two steps:
1. Consider adding the `LD_LIBRARY_PATH`, `PATH`, and `CUDA_HOME` changes from `prepare.sh` to your bash profile `~/.bashrc`. This may need a terminal and/or system restart.
- Typically, legacy CUDA versions may interfere with graphics processes before the variables are updated in `prepare.sh`. This step is meant to resolve that issue.
2. Ensure that your CUDA version >= 11.7 (`nvcc --version`), and that you have a [compatible](https://docs.nvidia.com/deeplearning/cudnn/support-matrix/index.html) NVIDIA-Driver version. Any re-installations may require a system reboot.
## Repository Structure
### `conf`
We use [hydra](https://github.com/facebookresearch/hydra) to manage experiments. Configs correspond exactly to the
module in `simple_bc`.
### `gdict`
This is a library for storing dictionaries of tensors; supports array-like indexing and slicing, and
dictionary-like key indexing. Extracted from [ManiSkill2-Learn](https://github.com/haosulab/ManiSkill2-Learn)
### `simple_bc`
This can be roughly split into 3 modules:
1. **`dataset`**: this loads preprocessed `hdf5` files into `GDict` structs.
2. **`encoder`**: this processes inputs into latent vectors.
3. **`policy`**: these are learning algorithms to output actions.
The network modules all follow interfaces defined in `_interfaces`. To add a new network, implement the abstract methods
in each interface (see
[`encoder/impala.py`](https://github.com/johnrso/spawnnet/blob/main/simple_bc/encoder/impala.py)
for an example), add the network to the module `__init__.py` file (see
[`encoder/__init__.py`](https://github.com/johnrso/spawnnet/blob/main/simple_bc/encoder/__init__.py))
and define a hydra configuration in root's `conf` (see
[`conf/encoder/impala.yaml`](https://github.com/johnrso/spawnnet/blob/main/conf/encoder/impala.yaml)).
Additionally, we provide scripts for training and evaluating policies under `train.py` and `eval.py`.
## Simulation Experiments
__Note__: Before running experiments in a terminal, be sure to `source prepare.sh` first.
### Training
There are two tasks in simulation, Open Drawer and Open Door. The IsaacGym configurations for both tasks can be found under `RLAfford/cfg/open_door_expert.yaml` and `RLAfford/cfg/open_drawer_expert.yaml`, respectively.
After setting up everything, set **only** `WHICH_GPUS` if in non-SLURM, i.e. basic, mode. Do **not** set anything for SLURM mode, the launcher will handle it. This is due to Vulkan/PyTorch differences in GPU indexing.
An example of training `SpawnNet` DAgger on the `Open Drawer` task is found in `scripts/sim_exps/spawnnet_exp.sh`.
1. Make sure to specify the `ISAACGYM_ARG_STR` as an environment variable (it should be the exact same value as the example).
2. For the drawer task, use `isaacgym_task=open_drawer`, and for the door task, use `isaacgym_task=open_door_21`.
3. **Optional**: Our framework splits 21 training assets among the allocated GPUs. Each asset has a corresponding simulation environment that's assigned to the same GPU as the asset. By default, each GPU gets `floor(21 / num_gpus)` assets (with the remainder assets going to the last GPU). If you wish to split the assets differently, set the variable `TRAIN_ASSET_SPLIT` as follows when kicking off the `train.py` script:
```sh
TRAIN_ASSET_SPLIT=<# assets on 0th GPU>,<# assets on 1st GPU>,<# assets on 2nd GPU>,...
```
When a larger model is being trained, the primary GPU (where the model resides) may run into CUDA memory issues from sharing space with too many simulation environments. The other GPUs may have space to load more environments. This fix is helpful for that case.
*Note that this custom asset splitting only applies for training.*
We provide entrypoints for each experiment in `scripts/sim_exps`.
#### Debugging Training
We provide a script, `scripts/sim_exps/sim_debug.sh`, to assist with debugging training in simulation. This script enforces only one environment, one GPU, to be used.
You can run the script as is to test that the `spawnnet` simulation framework is functioning correctly. You can also test different methods, tasks, and seeds by following the comments in the script. Leave the `ISAACGYM_ARG_STR` as is, to ensure only one environment is loaded (for faster testing).
**Note: This script always runs with only one GPU.**
### Evaluation
If you're in SLURM mode, evaluations are handled automatically by our training script and can be found under the `eval` folder of your run. Statistics will be listed under `summary.csv`.
Otherwise (basic mode), due to memory issues with IsaacGym, evaluations must be handled manually, on any **single GPU**. The syntax is the same regardless of the experiment done:
```sh
export ISAACGYM_ARG_STR="--headless --rl_device=cuda:0 --sim_device=cuda:0 --cp_device=cuda:0 --test --use_image_obs=True"
WHICH_GPUS=0 python RLAfford/dagger/eval.py <your exp dir> --chunk_id 0 --num_chunks 1 --mode basic
```
and results get saved the same way as SLURM.
## Real World Experiments
For Real World BC Experiments, the demonstration set for the Place Bag task can be found at [this Google Drive link](https://drive.google.com/uc?id=1A4RGlKM7GDalBAA4jKTmjcMyUzkwFBJW). You can download this with [gdown](https://github.com/wkentaro/gdown). After downloading, place the unzipped directory into `/dataset`.
Similarly to simulation, we provide entry points under `scripts/real_exps`.
### Visualizing pre-trained feature attention
After running a SpawnNet experiment, visualizations of the adapter features can be found under the run's directory, which looks like:
```sh
/data/local/0627_place_bag_spawnnet_2050/0/visualization_best
```
### Adding Tasks
To add tasks, please refer to `simple_bc/constants.py`, and follow the format for either `BC_DATASET` or `ISAACGYM_TASK`.
## Acknowledgements
The `gdict` library is adopted from [`ManiSkill2-Learn`](https://github.com/haosulab/ManiSkill2-Learn). Additionally, we use tasks and assets from [`RLAfford`](https://github.com/hyperplane-lab/RLAfford).
|
Venusdev2113/javascripts
|
https://github.com/Venusdev2113/javascripts
|
this is javascript
|
# javascripts
this is javascript
|
aschmelyun/diode
|
https://github.com/aschmelyun/diode
|
A WASM-powered local development environment for Laravel
|

# Diode
[](LICENSE.md)
[](https://npmjs.com/package/diode-cli)
[](https://npmjs.com/package/diode-cli)
> A zero-configuration, WASM-powered local development environment for Laravel
Diode is a Node CLI app containing a PHP server specifically built to run a local development environment for the Laravel framework. It's heavily inspired by, and built on the work of, the [WordPress Playground](https://github.com/WordPress/wordpress-playground) team.
**Note:** This is currently in active development and updates can contain breaking changes. Some core Laravel features may be broken or missing when using this tool. If you find a bug, feel free to [open an issue](https://github.com/aschmelyun/diode/issues/new)!
## Installation
Installation is through npm and requires Node version >= 16.0.0.
```bash
npm install -g diode-cli
```
## Basic Usage
To create a new Laravel application in the current (empty) directory, run the create command.
```bash
diode create
```
This will take a minute or two to complete, but then a brand new Laravel application source code should be available in the current directory.
To run the application locally, start the server with the serve command.
```bash
diode serve
```
This will mount the current directory as a virtual filesystem and start listening at `localhost:1738`. You can override the port that it's bound to by including the `port` option.
```bash
diode serve --port=8080
```
You can run most [Composer](https://getcomposer.org) commands with Diode, passing in the package and options you would natively.
```bash
diode composer require laravel/breeze --dev
```
Artisan commands are also available via the command of the same name.
```bash
diode artisan make:model Comment --migration
```
## Caveats
These are some current known limitations or workarounds when using Diode with Laravel. Most of these are due to the current feature set of php-wasm.
- Composer installations run much slower than natively, as packages are individually downloaded and unzipped instead of using proc_open
- Unless you are using an external database (like RDS), SQLite is recommended
- When running migrations for the first time, you'll have to use the `--force` option to bypass the question about creating a sqlite database for the first time.
## Why Build This?
Getting started developing PHP applications can be notoriously tricky compared with other languages like JavaScript.
Installing PHP locally has a history of being difficult depending on the OS you're using, and Docker exists but might be a bit complicated for new developers.
I built Diode as a kind of quick-start tool to spin up a local environment, letting you hit the ground running to build an application with Laravel.
If you find yourself wanting more out of a local environment, I suggest trying out something like Docker as the next step! I have a series of [YouTube videos](https://www.youtube.com/watch?v=5N6gTVCG_rw) and a [full course](https://laraveldocker.com) available if you'd like to learn more about using Docker with Laravel.
## Contact
Have an issue? [Submit it here!](https://github.com/aschmelyun/diode/issues/new) Want to get in touch or recommend a feature? Feel free to reach out to me on [Twitter](https://twitter.com/aschmelyun) for any other questions or comments.
## License
This software is licensed under The MIT License (MIT). See [LICENSE.md](LICENSE.md) for more details.
|
metlo-labs/csp-report-listener
|
https://github.com/metlo-labs/csp-report-listener
| null |
<p align="center">
<picture>
<source media="(prefers-color-scheme: dark)" srcset="https://storage.googleapis.com/metlo-security-public-images/metlo_logo_horiz_negative%404x.png" height="80">
<img alt="logo" src="https://storage.googleapis.com/metlo-security-public-images/metlo_logo_horiz%404x.png" height="80">
</picture>
<h1 align="center">Metlo CSP Report Listener</h1>
<p align="center">Easily build your CSP</p>
</p>
---
<div align="center">
[](http://makeapullrequest.com)
[](https://discord.gg/4xhumff9BX)

[](/LICENSE)
</div>
---
Building a good CSP is hard to do when you have tons of unknown scripts across your web apps.
The easiest way to incrementally build your CSP using the `report-uri` directive and listen for anything that breaks in report only mode.
Our CSP Reporter makes this easy by storing all CSP report logs and displaying distinct reports you can add to your policy.
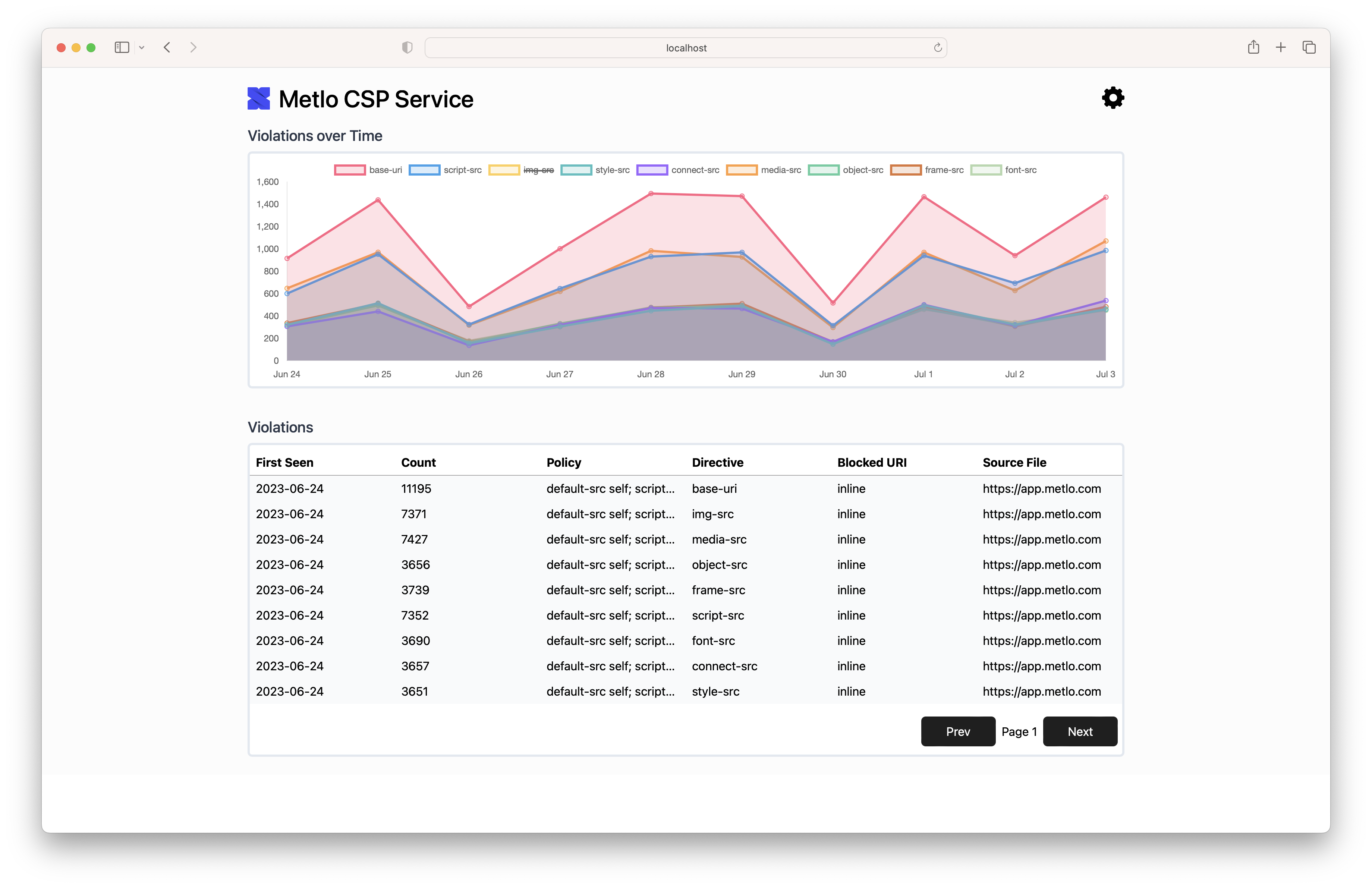
Checkout [Metlo API Security](https://www.metlo.com/) for more complete API protection!
## Setup
### 1. Install the Service
You can either use Docker or our Binary to install. You can configure the CSP Report listener with the following env vars:
1. **`METLO_SECRET_KEY` [required]** - A secret key to view CSP Reports. **Be sure to set this to something secure!**
2. **`METLO_DATA_PATH` [default `/tmp/metlo_csp/`]** - Where to store CSP Report data. By default we store it in a tmp folder so change this if you want your data to be persisted.
3. **`METLO_PORT` [default 8080]** - The port the service will listen on
4. **`METLO_LOG_LEVEL` [default info]** - Set the logging level to debug
**Docker Setup**
```bash
$ docker run -p 8080:8080 --env METLO_SECRET_KEY=<A_RANDOM_STRING> metlo/csp-service
```
**Binary Setup**
```bash
$ curl https://metlo-releases.s3.us-west-2.amazonaws.com/csp_service_linux_amd64_latest > metlo_csp_service
$ chmod +x metlo_csp_service
$ METLO_SECRET_KEY=<A_RANDOM_STRING> ./metlo_csp_service
```
Be sure to deploy this service behind a public endpoint so your site can send reports to it. Ping us on [discord](https://discord.gg/4xhumff9BX) if you have any questions!
### 2. Configure Headers
Add the following directive to your CSP Header:
```
report-uri <METLO_CSP_SERVICE_DOMAIN>
```
For example your CSP Header might look like this:
```
Content-Security-Policy: default-src 'self'; script-src https://example.com; report-uri <METLO_CSP_SERVICE_DOMAIN>
```
If you only want to report violations use the following:
```
Content-Security-Policy-Report-Only: report-uri <METLO_CSP_SERVICE_DOMAIN>;
```
|
pth-1641/NComics
|
https://github.com/pth-1641/NComics
|
Free comics website using Nuxt + Tailwind
|
# NComics
Free comics website using Nuxt + Tailwind
## Official Link
https://ncomics.vercel.app
## Technology
- Nuxt 3
- TailwindCSS
- Swiper
- Other libraries
## Features
- Fully responsive
- Save/delete read history
- Download chapters as PDF for offline reading
## Screenshots








# Summary
If you like this project, give it a 🌟 and share it to your friends 💖
|
zhongjinluo/SketchMetaFace
|
https://github.com/zhongjinluo/SketchMetaFace
|
This repository includes the prototype system of SketchMetaFace.
|
# *SketchMetaFace*
This repository includes the prototype system of *SketchMetaFace*.
> *SketchMetaFace*: A Learning-based Sketching Interface for High-fidelity 3D Character Face Modeling
>
> [Zhongjin Luo](https://zhongjinluo.github.io/), [Dong Du](https://dongdu3.github.io/), [Heming Zhu](https://scholar.google.com/citations?user=u5KCnv0AAAAJ&hl=en), [Yizhou Yu](https://i.cs.hku.hk/~yzyu/), [Xiaoguang Han](https://gaplab.cuhk.edu.cn/), [Hongbo Fu](https://sweb.cityu.edu.hk/hongbofu/)
## Introduction
<center>
<img src="./Docs/assets/images/smf_teaser.png" width="100%"/>
</center>
We present *SketchMetaFace*, a novel sketching system designed for amateur users to create high-fidelity 3D character faces. With curvature-aware strokes (valley strokes in green and ridge strokes in red), novice users can smoothly customize detailed 3D heads. Note that our system only outputs geometry without texture and texturing is achieved using commercial modeling tools.
##### | [Paper](https://arxiv.org/abs/2307.00804) | [Project](https://zhongjinluo.github.io/SketchMetaFace/) |
## Demo
https://github.com/zhongjinluo/SketchMetaFace/assets/22856460/4e88aa8e-18e4-4f07-89aa-aee4642c9e09
https://github.com/zhongjinluo/SketchMetaFace/assets/22856460/64600b36-6283-40fc-9a60-78c9f50d5340
https://github.com/zhongjinluo/SketchMetaFace/assets/22856460/a2f53a72-daa1-44e6-ba64-14fcc9edd85e
https://github.com/zhongjinluo/SketchMetaFace/assets/22856460/d2d34e2a-167f-4c2b-9de0-c8bcfee3b0e3
## Usage
This system has been tested with Python 3.8, PyTorch 1.7.1, CUDA 10.2 on Ubuntu 18.04.
- Installation:
```
conda create --name SketchMetaFace -y python=3.8
conda activate SketchMetaFace
pip install -r requirements.txt
```
- Start by cloning this repo:
```
git clone [email protected]:zhongjinluo/SketchMetaFace.git
cd SketchMetaFace
```
- Download pre-compiled user interface and checkpoints for backend algorithms from [sketchmetaface_files.zip](https://cuhko365-my.sharepoint.com/:u:/g/personal/220019015_link_cuhk_edu_cn/EX_bY3bAhRlBmY2yThCsGGkBA9uYjMS-e5GjSZYbuPgPKA?e=dS248c) and then:
```
unzip sketchmetaface_files.zip
unzip App.zip
mv sketchmetaface_files/Stage1/Global/* /path-to-repo/Stage1/Global/
mv sketchmetaface_files/Stage2/Preview/* /path-to-repo/Stage2/Preview/
mv sketchmetaface_files/Stage2/Suggestion/* /path-to-repo/Stage2/Suggestion/
mv sketchmetaface_files/Stage2/Local/* /path-to-repo/Stage2/Local/
```
- Run the backend servers for two-stage modeling:
```
# stage 1
cd /path-to-repo/Stage1/Global/ && bash server.sh
# stage 2
cd /path-to-repo/Stage2/Preview/ && bash server.sh
cd /path-to-repo/Stage2/Suggestion/ && bash server.sh
cd /path-to-repo/Stage2/Local/ && bash server.sh
```
- Launch the user interface and enjoy it:
```
cd App/ && bash run.sh
```
- stage 2 hot key: Y - symmetrize stroke, ↥ - zoom in stroke, ↧ - zoom out stroke, P - predict,
- If you want to run the backend algorithms on a remote server, you may have to modify `App/config.ini`.
- This repo represents the prototype implementation of our paper. Please use this for research and educational purposes only. This is a research prototype system and made public for demonstration purposes. The user interface runs on Ubuntu 18.04 platforms only and may contain some bugs.
- If you are interested in sketch-based 3D modeling, you can also refer to [*SimpModeling*](https://github.com/zhongjinluo/SimpModeling) and [*Sketch2RaBit*](https://github.com/zhongjinluo/Sketch2RaBit).
|
PlutoSolutions/BozeUpdate
|
https://github.com/PlutoSolutions/BozeUpdate
|
cool b logo part two - https://crystalpvp.ru/bozeupdate
|
<div align="center">
# Boze 1.2 (Freeware Edition)
<img src="https://crystalpvp.ru/bozeupdate/logo.gif" alt="logo" width="40%" />
mirrors:
[crystalpvp.ru](https://crystalpvp.ru/bozeupdate/)
[plutosolutions telegram](https://t.me/plutosolutions)
# [ info ]
Newest version of the newest goyslop made by Konas developers. This time, it's for 1.20.1 and it has an API for addons.
[You don't want to use this](https://youtu.be/byghbcn7xws)
# [ addons ]
To make addons for this garbage you need to download [this repository](https://github.com/PlutoSolutions/boze-example-addon), import it into your favorite IDE, build and throw the output jar into your mods folder.
[Click here for a video example of a well made addon](https://www.youtube.com/watch?v=0AK_gasEA2o)
# [ how-to ]
</div>
1. Download the Fabric installer from [here](https://fabricmc.net/use/installer/), open it and choose Minecraft 1.20.1 & Fabric Loader 0.14.21
0. Download bozecrack.zip from the [releases page](https://github.com/PlutoSolutions/BozeUpdate/releases) and extract everything into your .minecraft/mods folder
0. Start the game (with Fabric)
<div align="center">
# [ autism ]
boze buyers this is one of your main developers
<img src="https://crystalpvp.ru/bozeupdate/IMG_8043.jpg" width="22%" />
<img src="https://crystalpvp.ru/bozeupdate/IMG_8044.jpg" width="22%" />
<img src="https://crystalpvp.ru/bozeupdate/IMG_8045.jpg" width="22%" />
<img src="https://crystalpvp.ru/bozeupdate/IMG_8046.jpg" width="22%" />
<img src="https://crystalpvp.ru/bozeupdate/gl.png" width="60%" />
<img src="https://crystalpvp.ru/bozeupdate/Screenshot_5355.png" width="30%" >
# [ credits ]
</div>
+ Darki, GL_DONT_CARE (sunsets) & auto - making this cheat
+ [mrnv/ayywareseller](https://github.com/mr-nv) - dumping classes/resources and cracking
+ maywr - making the config server emulator back in april and making the original logo
+ [nukiz](https://github.com/nukiz) - editing the logo
+ ? - providing an account
|
JacobBennett/StateMachinesTalk
|
https://github.com/JacobBennett/StateMachinesTalk
| null |

Thanks so much for your interest in my State Machines talk.
Know that this codebase should be used as a reference only and not as a working prototype. There are a good number of places in this codebase that provide non-implemented pseudo-code examples for your reference.
Please use this only as a way to remember what the ideas discussed during the talk were.
The main locations to pay attention to are:
- [`app/Http/Controllers/*`](app/Http/Controllers)
- [`app/StateMachines/Invoice/*`](app/StateMachines/Invoice)
- [`app/Enums/*`](app/Enums)

|
ghactions-utilities/slack-notification
|
https://github.com/ghactions-utilities/slack-notification
|
GitHub Actions - Slack - Notification
|
This action is a part of [ghactions-utilities](https://github.com/ghactions-utilities) created by [trquangvinh](https://github.com/trquangvinh/).
## Slack Notification
[](https://www.repostatus.org/#active)
A [GitHub Action](https://github.com/features/actions) to send a message to a Slack channel.
## Usage
```yml
- uses: ghactions-utilities/slack-notification@main
with:
# Description: Slack Webhook URL
# Require: true
# Type: string
webhook-url: ''
# Description: Workflow job status
# Allowed values: success | failure | cancelled
# Require: true
# Type: string
job-status: ''
# Description: Slack message
# Require: false
# Type: string
# If `message` not set, we will use last commit message instead of.
message: Typing the message which you wanna send to Slack
```
# Example
```yml
name: Slack Notification
on: push
jobs:
notify:
runs-on: ubuntu-latest
steps:
- name: Send slack notification
uses: ghactions-utilities/slack-notification@main
with:
webhook-url: ${{ secrets.WEBHOOK_URL }}
job-status: ${{ job.status }}
message: Hello world!
```
|
lilongxian/BaiYang-chatGLM2-6B
|
https://github.com/lilongxian/BaiYang-chatGLM2-6B
|
(1)弹性区间标准化的旋转位置词嵌入编码器+peft LORA量化训练,提高万级tokens性能支持。(2)证据理论解释学习,提升模型的复杂逻辑推理能力(3)兼容alpaca数据格式。
|
# chatGLM2-6B BAIYANG探索版
优点:
1. 支持清华chatGLM-6B、alpaca指令微调训练数据格式。
2. 支持Lora量化训练。
3. 通过生成式的方法支持单任务和多任务知识挖掘类NLP任务。
4. 支持多轮对话、摘要、续写等知识生成类NLP任务。
5. 旋转位置词嵌入编码器支持2048区间弹性标准化,以取得在万级tokens上的更好效果(没有验证,理论上灵感来自于深度学习NLP的数据向量化过程中的数据标准化到[0.0,1.0]区间后训练较好这一个经验,值得关注的是伯克利Longchat做了验证。目前的GLM社区模型、LLAMA社区模型的基本单位tokens序列都是2048,所以以此为单元区间标准)。
6. 基于《大宋提刑官》证据论证+亚里斯多德三段论,探索出一种“基于证据理论的解释学习”机制,可有效提升模型解决数学、语言逻辑等复杂逻辑推理问题的能力。
具体的讲,我在原来alpaca指令数据的基础上增加了一个EXPLAIN,所以将response修改为:
" EXPLAIN: " + explain部分 + " CONCLUSION: " + response部分
可参考数据集样例:data/explanation-based-learning-data
7. 上述“基于证据理论的解释学习”数据建模原理,可以拓展到高效复制chatgpt能力以提升GLM2综合能力中。
本项目技术参考、引用了清华chatGLM-6B、chatGLM2-6B部分代码。若你使用本项目,请注明引用自清华chatGLM2-6B项目。本项目不保证商业化效果,仅供NLP学术研究。
# Update
1. 2023-07-04: 首次开源,仅次于清华官方微调训练模型开源时间。
2. 2023-07-11: 修复tokenization的上下句拼接方式,与llama、GLM2对齐.
3. 2023-07-11: 改进chatGLM2-6B官方的旋转位置词嵌入编码器。借鉴了longchat的可弹性压缩的位置标准化旋转编码器的设计方法,充分利用2048正弦波上的位置取得更好向量表示,以取得在万级tokens上的更好支持。
4. 2023-07-14: 改为Lora训练方式
5. 2023-07-19: 增加“基于证据理论的解释学习”数据建模机制,致力提升模型的复杂逻辑推理能力,并未高效从chatgpt等强大模型中复制能力奠定基础。
# 环境
cuda 11.7
pytorch 1.13.1/2.0
python 3.7/3.8
transformers 4.27.1--4.29.2
# Alpaca指令微调训练
alpaca数据转换命令:
python data/fine-tuning-instraction-data/convert_alpaca2glm.py
证据理论解释学习的alpaca数据转换命令:
python data/explanation-based-learning-data/convert_alpaca2glm_with_explain.py
将转换后的数据分配到 data/train.json
## GPU训练
1. 运行命令:
python finetune_norm_32k.py --do_train --train_file data/train.json --history_column history --prompt_column prompt --response_column response --model_name_or_path D:/2023-LLM/PreTrained_LLM_Weights/chatGLM2-6B --output_dir D:\glm_out\ --overwrite_output_dir --max_source_length 300 --max_target_length 200 --per_device_train_batch_size 1 --per_device_eval_batch_size 1 --gradient_accumulation_steps 10 --predict_with_generate --max_steps 500 --logging_steps 10 --save_steps 100 --learning_rate 1e-2 --quantization_bit 4
--model_name_or_path 参数请修改为你的预训练模型所在目录
## 友情链接
https://github.com/THUDM/ChatGLM2-6B
https://github.com/DachengLi1/LongChat
## 参考
@inproceedings{du2022glm,
title={GLM: General Language Model Pretraining with Autoregressive Blank Infilling},
author={Du, Zhengxiao and Qian, Yujie and Liu, Xiao and Ding, Ming and Qiu, Jiezhong and Yang, Zhilin and Tang, Jie},
booktitle={Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)},
pages={320--335},
year={2022}
}
@article{zeng2022glm,
title={Glm-130b: An open bilingual pre-trained model},
author={Zeng, Aohan and Liu, Xiao and Du, Zhengxiao and Wang, Zihan and Lai, Hanyu and Ding, Ming and Yang, Zhuoyi and Xu, Yifan and Zheng, Wendi and Xia, Xiao and others},
journal={arXiv preprint arXiv:2210.02414},
year={2022}
}
@misc{longchat2023,
title = {How Long Can Open-Source LLMs Truly Promise on Context Length?},
url = {https://lmsys.org/blog/2023-06-29-longchat},
author = {Dacheng Li*, Rulin Shao*, Anze Xie, Ying Sheng, Lianmin Zheng, Joseph E. Gonzalez, Ion Stoica, Xuezhe Ma, and Hao Zhang},
month = {June},
year = {2023}
}
## 联系方式
[email protected] / 17719085580(wx) Li·Long
|
sudhakar-diary/express-environment
|
https://github.com/sudhakar-diary/express-environment
| null |
# express-environment
```
C:\git-repo\express-environment> npm run dev:start
> [email protected] dev:start
> cross-env ENV_NAME=DEV ts-node src/index.ts
App listening port : 5000
App listening environment : DEV
---
C:\git-repo\express-environment> npm run dev:start
> [email protected] dev:start
> cross-env ENV_NAME=DEV ts-node src/index.ts
================================
Missing environment variables:
ENV_OAUTH_CLIENT_ID: undefined
================================
Exiting with error code 1
```
|
zloi-user/hideip.me
|
https://github.com/zloi-user/hideip.me
|
proxy list that updates every 10 minutes
|
### NOTE ⛔
This proxy list is collected from the list of proxies available on the Internet. They are only displayed in this repository for easy access. I am not responsible for proxies.
### Donate 💸
- BTC - 1KbXEYvGY4oURR7HCBvCMfhbyEcU3jM8mL
- [Other Coins](https://nowpayments.io/donation/hideip)
- Payeer - P1072424404
- [МИР / ЮMoney](https://yoomoney.ru/to/410014392099996)
#### HTTPS proxy example
###### Running Curl on Linux
```console
curl --proxy-insecure -k --proxy 'https://xxx.xxx.xxx.xxx:xxxx' -o - https://api.my-ip.io/ip
```
###### Running Chrome browser on windows with clean profile
```console
"C:\Program Files\Google\Chrome\Application\chrome.exe" --ignore-certificate-errors --ignore-ssl-errorsrs --proxy-server="https://xxx.xxx.xxx.xxx:xxxx" --user-data-dir="%TEMP%\chrprofile1" "https://ip-api.com/"
```
#### CONNECT proxy example
###### Running Curl on Linux
```console
curl --proxytunnel -k --proxy 'http://xxx.xxx.xxx.xxx:xxxx' -o - https://api.my-ip.io/ip
```
### Link Proxies
- **HTTP**
```bash
https://raw.githubusercontent.com/zloi-user/hideip.me/main/http.txt
```
- **HTTPS**
```bash
https://raw.githubusercontent.com/zloi-user/hideip.me/main/https.txt
```
- **SOCKS4**
```bash
https://raw.githubusercontent.com/zloi-user/hideip.me/main/socks4.txt
```
- **SOCKS5**
```bash
https://raw.githubusercontent.com/zloi-user/hideip.me/main/socks5.txt
```
- **CONNECT**
```bash
https://raw.githubusercontent.com/zloi-user/hideip.me/main/connect.txt
```
|
MiSaturo/GeoIP-DB-For-Iran
|
https://github.com/MiSaturo/GeoIP-DB-For-Iran
| null |
# Geo IP DB for Iran
# Introduction
This project automatically generates GeoIP files every Thursday, and provides a command line interface (CLI) for users to customize GeoIP files, including but not limited to V2Ray dat format routing rule file `geoip.dat` and MaxMind mmdb format file `Country.mmdb`.
This project releases GeoIP files automatically every Thursday. It also provides a command line interface(CLI) for users to customize their own GeoIP files, included but not limited to V2Ray dat format file `geoip.dat` and MaxMind mmdb format file `Country.mmdb`.
## The difference from the official version of GeoIP
- Mainland China IPv4 address data is integrated with [IPIP.net](https://github.com/17mon/china_ip_list/blob/master/china_ip_list.txt) and [@gaoyifan/china-operator-ip](https:// github.com/gaoyifan/china-operator-ip/blob/ip-lists/china.txt)
- Mainland China IPv6 address data combined with MaxMind GeoLite2 and [@gaoyifan/china-operator-ip](https://github.com/gaoyifan/china-operator-ip/blob/ip-lists/china6.txt)
- New category (convenient for users with special needs):
- `geoip:cloudflare` (`GEOIP,CLOUDFLARE`)
- `geoip:cloudfront` (`GEOIP,CLOUDFRONT`)
- `geoip:facebook` (`GEOIP,FACEBOOK`)
- `geoip:fastly` (`GEOIP,FASTLY`)
- `geoip:google` (`GEOIP,GOOGLE`)
- `geoip:netflix` (`GEOIP,NETFLIX`)
- `geoip:telegram` (`GEOIP,TELEGRAM`)
- `geoip:twitter` (`GEOIP,TWITTER`)
## Reference configuration
Use the reference configuration of this project's `.dat` format file in [V2Ray](https://github.com/v2fly/v2ray-core):
```json
"routing": {
"rules": [
{
"type": "field",
"outboundTag": "Direct",
"ip": [
"geoip:ir",
"geoip:private",
"ext:ir.dat:ir",
"ext:private.dat:private",
"ext:geoip-only-ir-private.dat:ir",
"ext:geoip-only-ir-private.dat:private"
]
},
{
"type": "field",
"outboundTag": "Proxy",
"ip": [
"geoip:us",
"geoip:jp",
"geoip:facebook",
"geoip:telegram",
"ext:geoip-asn.dat:facebook",
"ext:geoip-asn.dat:telegram"
]
}
]
}
```
Use the reference configuration of this project's `.mmdb` format file in [Clash](https://github.com/Dreamacro/clash):
```yaml
rules:
- GEOIP,PRIVATE,DIRECT,no-resolve
- GEOIP,FACEBOOK,DIRECT
- GEOIP,IR,DIRECT
```
Use the reference configuration of this project's `.mmdb` format file in [Leaf](https://github.com/eycorsican/leaf), see [Official README](https://github.com/eycorsican/leaf/blob/master/README.zh.md#geoip).
## download link
> If the domain `raw.githubusercontent.com` cannot be accessed, the second address `cdn.jsdelivr.net` can be used.
> *.sha256sum is the verification file.
### V2Ray dat format routing rule file
> Available for [V2Ray](https://github.com/v2fly/v2ray-core), [Xray-core](https://github.com/XTLS/Xray-core) and [Trojan-Go](https https://github.com/p4gefau1t/trojan-go).
- **geoip.dat**:
- [https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/geoip.dat](https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/geoip.dat)
- [https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/geoip.dat](https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/geoip.dat)
- **geoip.dat.sha256sum**:
- [https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/geoip.dat.sha256sum](https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/geoip.dat.sha256sum)
- [https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/geoip.dat.sha256sum](https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/geoip.dat.sha256sum)
- **geoip-only-ir-private.dat** (Lite version of GeoIP, only contains `geoip:ir` and `geoip:private`):
- [https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/geoip-only-ir-private.dat](https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/geoip-only-ir-private.dat)
- [https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/geoip-only-ir-private.dat](https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/geoip-only-ir-private.dat)
- **geoip-only-ir-private.dat.sha256sum**:
- [https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/geoip-only-ir-private.dat.sha256sum](https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/geoip-only-ir-private.dat.sha256sum)
- [https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/geoip-only-ir-private.dat.sha256sum](https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/geoip-only-ir-private.dat.sha256sum)
- **geoip-asn.dat** (Lite version of GeoIP, containing only the above added categories):
- [https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/geoip-asn.dat](https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/geoip-asn.dat)
- [https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/geoip-asn.dat](https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/geoip-asn.dat)
- **geoip-asn.dat.sha256sum**:
- [https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/geoip-asn.dat.sha256sum](https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/geoip-asn.dat.sha256sum)
- [https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/geoip-asn.dat.sha256sum](https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/geoip-asn.dat.sha256sum)
- **ir.dat** (Lite version of GeoIP, contains only `geoip:ir`):
- [https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/ir.dat](https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/ir.dat)
- [https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/ir.dat](https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/ir.dat)
- **ir.dat.sha256sum**:
- [https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/ir.dat.sha256sum](https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/ir.dat.sha256sum)
- [https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/ir.dat.sha256sum](https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/ir.dat.sha256sum)
- **private.dat** (Lite version of GeoIP, only contains `geoip:private`):
- [https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/private.dat](https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/private.dat)
- [https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/private.dat](https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/private.dat)
- **private.dat.sha256sum**:
- [https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/private.dat.sha256sum](https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/private.dat.sha256sum)
- [https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/private.dat.sha256sum](https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/private.dat.sha256sum)
### MaxMind mmdb format file
> Available for [Clash](https://github.com/Dreamacro/clash) and [Leaf](https://github.com/eycorsican/leaf).
- **Country.mmdb**:
- [https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/Country.mmdb](https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/Country.mmdb)
- [https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/Country.mmdb](https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/Country.mmdb)
- **Country.mmdb.sha256sum**:
- [https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/Country.mmdb.sha256sum](https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/Country.mmdb.sha256sum)
- [https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/Country.mmdb.sha256sum](https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/Country.mmdb.sha256sum)
- **Country-only-ir-private.mmdb** (Lite version of GeoIP, only contains `GEOIP,IR` and `GEOIP,PRIVATE`):
- [https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/Country-only-ir-private.mmdb](https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/Country-only-ir -private.mmdb)
- [https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/Country-only-ir-private.mmdb](https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/Country-only-ir-private.mmdb)
- **Country-only-ir-private.mmdb.sha256sum**:
- [https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/Country-only-ir-private.mmdb.sha256sum](https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/Country-only-ir-private.mmdb.sha256sum)
- [https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/Country-only-ir-private.mmdb.sha256sum](https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/Country-only-ir-private.mmdb.sha256sum)
- **Country-asn.mmdb** (Lite version of GeoIP, only contains the above added categories):
- [https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/Country-asn.mmdb(https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/Country-asn.mmdb)
- [https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/Country-asn.mmdb](https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/Country-asn.mmdb)
- **Country-asn.mmdb.sha256sum**:
- [https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/Country-asn.mmdb.sha256sum(https://raw.githubusercontent.com/MiSaturo/GeoIP-DB-For-Iran/release/Country-asn.mmdb.sha256sum)
- [https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/Country-asn.mmdb.sha256sum](https://cdn.jsdelivr.net/gh/MiSaturo/GeoIP-DB-For-Iran@release/Country-asn.mmdb.sha256sum)
## Custom GeoIP file
GeoIP files can be customized in several ways:
- **Online generation**: [Fork](https://github.com/MiSaturo/GeoIP-DB-For-Iran/fork) After this warehouse, modify the configuration file `config.json` and GitHub Workflow `.github/workflows in your own warehouse/build.yml`
- **local generation**:
- Install [Golang](https://golang.org/dl/) and [Git](https://git-scm.com)
- Pull project code: `git clone https://github.com/MiSaturo/GeoIP-DB-For-Iran.git`
- Enter the project root directory: `cd geoip`
- Modify the configuration file `config.json`
- Run the code: `go run./`
**Special Note:**
- **Online Generation**: [Fork](https://github.com/MiSaturo/GeoIP-DB-For-Iran/fork) After this project, if you need to use the MaxMind GeoLite2 Country CSV data file, you need to use **[Settings] in your warehouse Add a secret named **MAXMIND_GEOLITE2_LICENSE** to the **[Secrets]** page of the ** tab, otherwise GitHub Actions will fail to run. The value of this secret is the LICENSE KEY of the MAXMIND account. After [**registering a MAXMIND account**](https://www.maxmind.com/en/geolite2/signup), go to the [**personal account management page**] ](https://www.maxmind.com/en/account) generated in **[My License Key]** under the **[Services]** item on the left sidebar.
- **Local generation**: If you need to use the MaxMind GeoLite2 Country CSV data file (`GeoLite2-Country-CSV.zip`), you need to download it from MaxMind in advance, or from the project [release branch](https://github. com/MiSaturo/GeoIP-DB-For-Iran/tree/release)[Download](https://github.com/MiSaturo/GeoIP-DB-For-Iran/raw/release/GeoLite2-Country-CSV.zip), and extract it to a directory named `geolite2`.
### Concept analysis
This project has two concepts: `input` and `output`. `input` refers to the data source (data source) and its input format, and `output` refers to the destination of the data (data destination) and its output format. The role of the CLI is to aggregate all data sources provided by the user by reading the options in the configuration file, deduplicate them, convert them to the target format, and output them to a file.
These two concepts are notable: `input` and `output`. The `input` is the data source and its input format, whereas the `output` is the destination of the converted data and its output format. What the CLI does is to aggregate all input format data, then convert them to output format and write them to GeoIP files by using the options in the config file.
### Supported formats
For configuration options supported by each format, see the [`config-example.json`](https://github.com/MiSaturo/GeoIP-DB-For-Iran/blob/HEAD/config-example.json) file of this project.
Supported `input` input formats:
- **text**: plaintext IP and CIDR (eg: `1.1.1.1` or `1.0.0.0/24`)
- **private**: LAN and private network CIDR (eg: `192.168.0.0/16` and `127.0.0.0/8`)
- **cutter**: used to crop the data in the previous step
- **v2rayGeoIPDat**: V2Ray GeoIP dat format (`geoip.dat`)
- **maxmindMMDB**: MaxMind mmdb data format (`GeoLite2-Country.mmdb`)
- **maxmindGeoLite2CountryCSV**: MaxMind GeoLite2 country CSV data (`GeoLite2-Country-CSV.zip`)
- **clashRuleSetClassical**: [classical type of Clash RuleSet](https://github.com/Dreamacro/clash/wiki/premium-core-features#classical)
- **clashRuleSet**: [Clash RuleSet of type ipcidr](https://github.com/Dreamacro/clash/wiki/premium-core-features#ipcidr)
- **surgeRuleSet**: [Surge RuleSet](https://manual.nssurge.com/rule/ruleset.html)
Supported `output` output formats:
- **text**: plain text CIDR (eg: `1.0.0.0/24`)
- **v2rayGeoIPDat**: V2Ray GeoIP dat format (`geoip.dat`, suitable for [V2Ray](https://github.com/v2fly/v2ray-core), [Xray-core](https://github.com/XTLS/Xray-core) and [Trojan-Go](https://github.com/p4gefau1t/trojan-go))
- **maxmindMMDB**: MaxMind mmdb data format (`GeoLite2-Country.mmdb` for [Clash](https://github.com/Dreamacro/clash) and [Leaf](https://github.com/eycorsican/leaf))
- **clashRuleSetClassical**: [classical type of Clash RuleSet](https://github.com/Dreamacro/clash/wiki/premium-core-features#classical)
- **clashRuleSet**: [Clash RuleSet of type ipcidr](https://github.com/Dreamacro/clash/wiki/premium-core-features#ipcidr)
- **surgeRuleSet**: [Surge RuleSet](https://manual.nssurge.com/rule/ruleset.html)
### Precautions
Due to the limitation of the MaxMind mmdb file format, when the IP or CIDR data of different lists overlap or overlap, the IP or CIDR data of the list written later will overwrite (overwrite) the data of the previously written list. For example, IP `1.1.1.1` belongs to both list `AU` and list `Cloudflare`. If `Cloudflare` is written after `AU`, the IP `1.1.1.1` belongs to the list `Cloudflare`.
In order to ensure that certain specified lists and modified lists must include all IP or CIDR data belonging to it, the option `overwriteList` can be added to the configuration of `output` output format as `maxmindMMDB`, the list specified in this option will be Write one by one at the end, the last item in the list has the highest priority. If the option `wantedList` is set, there is no need to set `overwriteList`. The list specified in `wantedList` will be written one by one at the end, and the last item in the list has the highest priority.
## CLI function display
The CLI can be installed directly via `go install -v github.com/MiSaturo/GeoIP-DB-For-Iran@latest`.
```bash
$./geoip -h
Usage of./geoip:
-c string
URI of the JSON format config file, support both local file path and remote HTTP(S) URL (default "config.json")
-l List all available input and output formats
$./geoip -c config.json
2021/08/29 12:11:35 ✅ [v2rayGeoIPDat] geoip.dat --> output/dat
2021/08/29 12:11:35 ✅ [v2rayGeoIPDat] geoip-only-ir-private.dat --> output/dat
2021/08/29 12:11:35 ✅ [v2rayGeoIPDat] geoip-asn.dat --> output/dat
2021/08/29 12:11:35 ✅ [v2rayGeoIPDat] ir.dat --> output/dat
2021/08/29 12:11:35 ✅ [v2rayGeoIPDat] private.dat --> output/dat
2021/08/29 12:11:39 ✅ [maxmindMMDB] Country.mmdb --> output/maxmind
2021/08/29 12:11:39 ✅ [maxmindMMDB] Country-only-ir-private.mmdb --> output/maxmind
2021/08/29 12:11:39 ✅ [text] netflix.txt --> output/text
2021/08/29 12:11:39 ✅ [text] telegram.txt --> output/text
2021/08/29 12:11:39 ✅ [text] ir.txt --> output/text
2021/08/29 12:11:39 ✅ [text] cloudflare.txt --> output/text
2021/08/29 12:11:39 ✅ [text] cloudfront.txt --> output/text
2021/08/29 12:11:39 ✅ [text] facebook.txt --> output/text
2021/08/29 12:11:39 ✅ [text] fastly.txt --> output/text
$./geoip -l
All available input formats:
- v2rayGeoIPDat (Convert V2Ray GeoIP dat to other formats)
- maxmindMMDB (Convert MaxMind mmdb database to other formats)
- maxmindGeoLite2CountryCSV (Convert MaxMind GeoLite2 country CSV data to other formats)
- private (Convert LAN and private network CIDR to other formats)
- text (Convert plaintext IP & CIDR to other formats)
- clashRuleSetClassical (Convert classical type of Clash RuleSet to other formats (just processing IP & CIDR lines))
- clashRuleSet (Convert ipcidr type of Clash RuleSet to other formats)
- surgeRuleSet (Convert Surge RuleSet to other formats (just processing IP & CIDR lines))
- cutter (Remove data from previous steps)
- test (Convert specific CIDR to other formats (for test only))
All available output formats:
- v2rayGeoIPDat (Convert data to V2Ray GeoIP dat format)
- maxmindMMDB (Convert data to MaxMind mmdb database format)
-clashRuleSetClassical (Convert data to classical type of Clash RuleSet)
-clashRuleSet (Convert data to ipcidr type of Clash RuleSet)
- surgeRuleSet (Convert data to Surge RuleSet)
- text (Convert data to plaintext CIDR format)
```
## License
[CC-BY-SA-4.0](https://creativecommons.org/licenses/by-sa/4.0/)
This product includes GeoLite2 data created by MaxMind, available from [MaxMind](http://www.maxmind.com).
## Project Star number growth trend
[](https://starchart.cc/MiSaturo/GeoIP-DB-For-Iran)
|
farizrifqi/Threads-Media-Downloader
|
https://github.com/farizrifqi/Threads-Media-Downloader
|
Threads.net media downloader
|
# ThreadsMediaDownloader
Download bulk Threads.net media thru its graphql using NodeJS.
Main function on [media.js](https://github.com/farizrifqi/Threads-Media-Downloader/blob/main/media.js), examples on [index.js](https://github.com/farizrifqi/Threads-Media-Downloader/blob/main/index.js)
### Features
- Download multiple media
- Support image & video
## Tools Used
- [node-fetch](https://www.npmjs.com/package/node-fetch)
- [fs](https://nodejs.org/api/fs.html)
## Common Issue
- **Can't get postId ?**<br/>Your address reached limit or blocked by Threads, try to switch to another server or use proxy.
|
Codium-ai/pr-agent
|
https://github.com/Codium-ai/pr-agent
|
🚀CodiumAI PR-Agent: An AI-Powered 🤖 Tool for Automated Pull Request Analysis, Feedback, Suggestions and More! 💻🔍
|
<div align="center">
<div align="center">
<img src="./pics/logo-dark.png#gh-dark-mode-only" width="330"/>
<img src="./pics/logo-light.png#gh-light-mode-only" width="330"/><br/>
Making pull requests less painful with an AI agent
</div>
[](https://github.com/Codium-ai/pr-agent/blob/main/LICENSE)
[](https://discord.com/channels/1057273017547378788/1126104260430528613)
<a href="https://github.com/Codium-ai/pr-agent/commits/main">
<img alt="GitHub" src="https://img.shields.io/github/last-commit/Codium-ai/pr-agent/main?style=for-the-badge" height="20">
</a>
</div>
<div style="text-align:left;">
CodiumAI `PR-Agent` is an open-source tool aiming to help developers review pull requests faster and more efficiently. It automatically analyzes the pull request and can provide several types of feedback:
**Auto-Description**: Automatically generating PR description - title, type, summary, code walkthrough and PR labels.
\
**PR Review**: Adjustable feedback about the PR main theme, type, relevant tests, security issues, focus, score, and various suggestions for the PR content.
\
**Question Answering**: Answering free-text questions about the PR.
\
**Code Suggestions**: Committable code suggestions for improving the PR.
\
**Update Changelog**: Automatically updating the CHANGELOG.md file with the PR changes.
<h3>Example results:</h2>
</div>
<h4>/describe:</h4>
<div align="center">
<p float="center">
<img src="https://www.codium.ai/images/describe-2.gif" width="800">
</p>
</div>
<h4>/review:</h4>
<div align="center">
<p float="center">
<img src="https://www.codium.ai/images/review-2.gif" width="800">
</p>
</div>
<h4>/reflect_and_review:</h4>
<div align="center">
<p float="center">
<img src="https://www.codium.ai/images/reflect_and_review.gif" width="800">
</p>
</div>
<h4>/ask:</h4>
<div align="center">
<p float="center">
<img src="https://www.codium.ai/images/ask-2.gif" width="800">
</p>
</div>
<h4>/improve:</h4>
<div align="center">
<p float="center">
<img src="https://www.codium.ai/images/improve-2.gif" width="800">
</p>
</div>
<div align="left">
- [Overview](#overview)
- [Try it now](#try-it-now)
- [Installation](#installation)
- [Usage and tools](#usage-and-tools)
- [Configuration](./CONFIGURATION.md)
- [How it works](#how-it-works)
- [Why use PR-Agent](#why-use-pr-agent)
- [Roadmap](#roadmap)
- [Similar projects](#similar-projects)
</div>
## Overview
`PR-Agent` offers extensive pull request functionalities across various git providers:
| | | GitHub | Gitlab | Bitbucket |
|-------|---------------------------------------------|:------:|:------:|:---------:|
| TOOLS | Review | :white_check_mark: | :white_check_mark: | :white_check_mark: |
| | ⮑ Inline review | :white_check_mark: | :white_check_mark: | |
| | Ask | :white_check_mark: | :white_check_mark: | |
| | Auto-Description | :white_check_mark: | :white_check_mark: | |
| | Improve Code | :white_check_mark: | :white_check_mark: | |
| | Reflect and Review | :white_check_mark: | | |
| | Update CHANGELOG.md | :white_check_mark: | | |
| | | | | |
| USAGE | CLI | :white_check_mark: | :white_check_mark: | :white_check_mark: |
| | App / webhook | :white_check_mark: | :white_check_mark: | |
| | Tagging bot | :white_check_mark: | | |
| | Actions | :white_check_mark: | | |
| | | | | |
| CORE | PR compression | :white_check_mark: | :white_check_mark: | :white_check_mark: |
| | Repo language prioritization | :white_check_mark: | :white_check_mark: | :white_check_mark: |
| | Adaptive and token-aware<br />file patch fitting | :white_check_mark: | :white_check_mark: | :white_check_mark: |
| | Incremental PR Review | :white_check_mark: | | |
Examples for invoking the different tools via the CLI:
- **Review**: python cli.py --pr-url=<pr_url> review
- **Describe**: python cli.py --pr-url=<pr_url> describe
- **Improve**: python cli.py --pr-url=<pr_url> improve
- **Ask**: python cli.py --pr-url=<pr_url> ask "Write me a poem about this PR"
- **Reflect**: python cli.py --pr-url=<pr_url> reflect
- **Update Changelog**: python cli.py --pr-url=<pr_url> update_changelog
"<pr_url>" is the url of the relevant PR (for example: https://github.com/Codium-ai/pr-agent/pull/50).
In the [configuration](./CONFIGURATION.md) file you can select your git provider (GitHub, Gitlab, Bitbucket), and further configure the different tools.
## Try it now
Try GPT-4 powered PR-Agent on your public GitHub repository for free. Just mention `@CodiumAI-Agent` and add the desired command in any PR comment! The agent will generate a response based on your command.
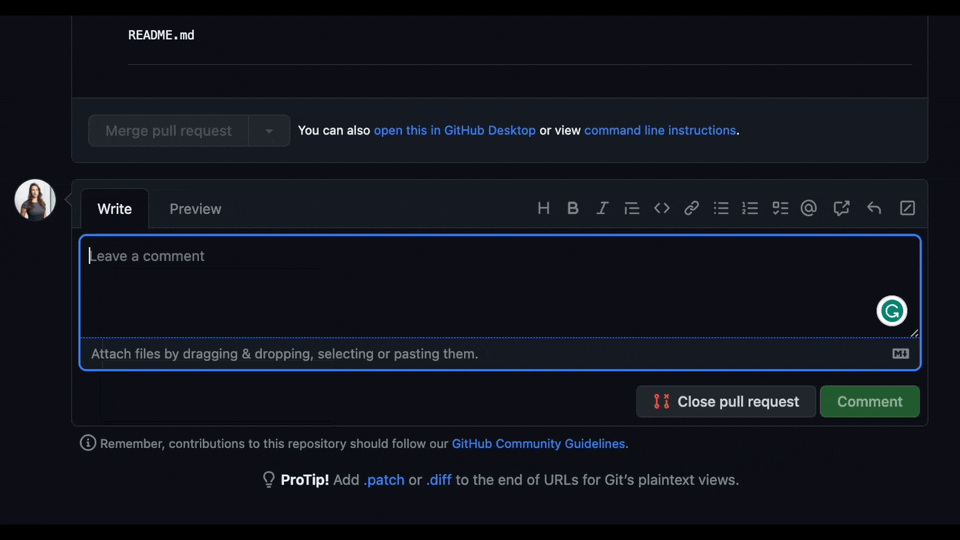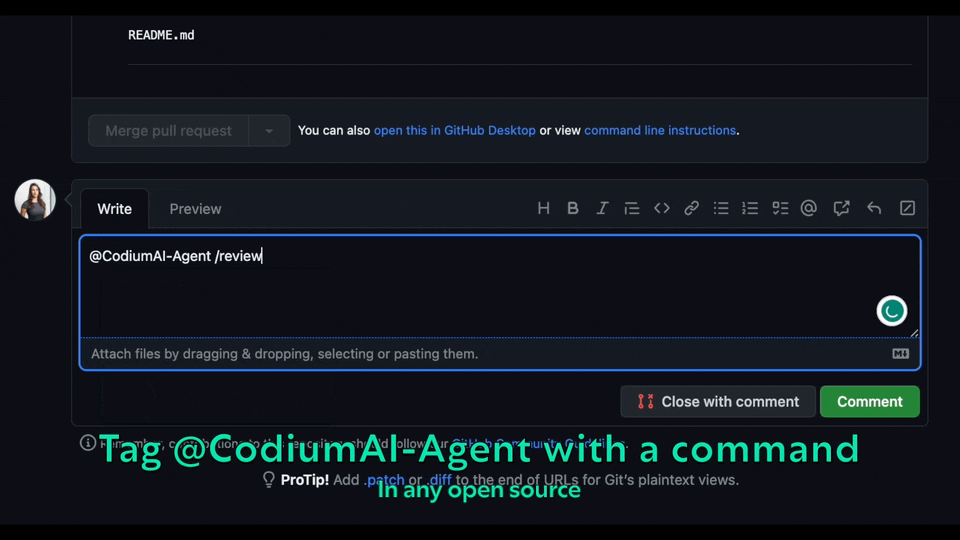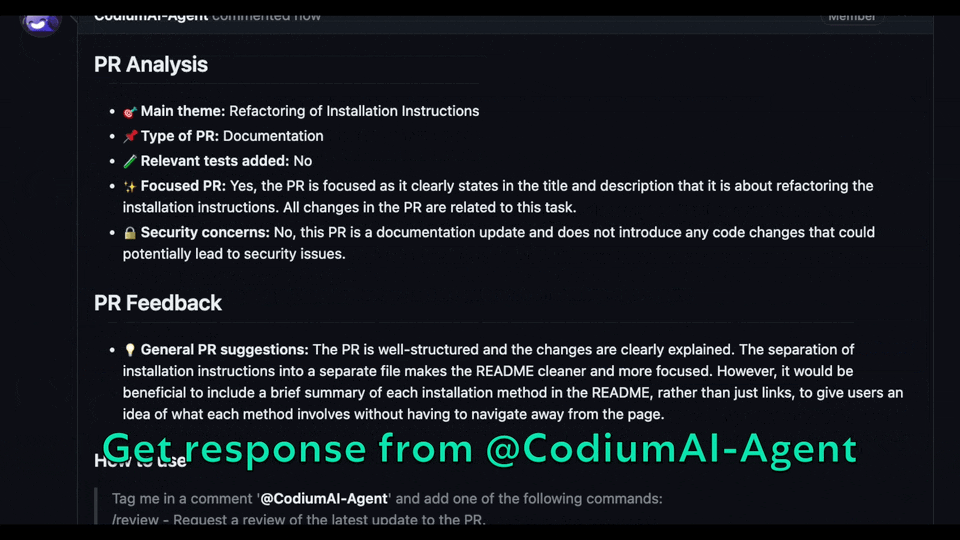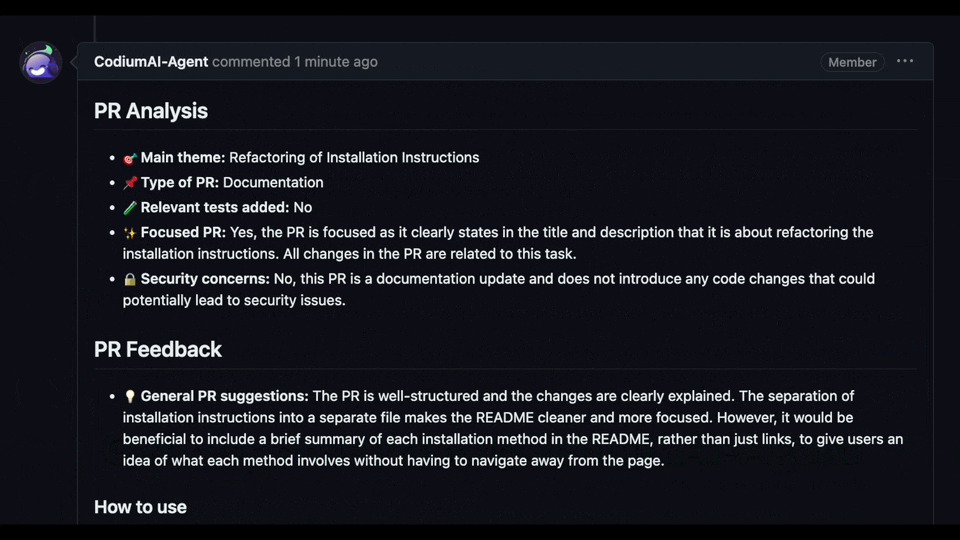
To set up your own PR-Agent, see the [Installation](#installation) section
---
## Installation
To get started with PR-Agent quickly, you first need to acquire two tokens:
1. An OpenAI key from [here](https://platform.openai.com/), with access to GPT-4.
2. A GitHub personal access token (classic) with the repo scope.
There are several ways to use PR-Agent:
- [Method 1: Use Docker image (no installation required)](INSTALL.md#method-1-use-docker-image-no-installation-required)
- [Method 2: Run as a GitHub Action](INSTALL.md#method-2-run-as-a-github-action)
- [Method 3: Run from source](INSTALL.md#method-3-run-from-source)
- [Method 4: Run as a polling server](INSTALL.md#method-4-run-as-a-polling-server)
- Request reviews by tagging your GitHub user on a PR
- [Method 5: Run as a GitHub App](INSTALL.md#method-5-run-as-a-github-app)
- Allowing you to automate the review process on your private or public repositories
## Usage and Tools
**PR-Agent** provides six types of interactions ("tools"): `"PR Reviewer"`, `"PR Q&A"`, `"PR Description"`, `"PR Code Sueggestions"`, `"PR Reflect and Review"` and `"PR Update Changlog"`.
- The "PR Reviewer" tool automatically analyzes PRs, and provides various types of feedback.
- The "PR Q&A" tool answers free-text questions about the PR.
- The "PR Description" tool automatically sets the PR Title and body.
- The "PR Code Suggestion" tool provide inline code suggestions for the PR that can be applied and committed.
- The "PR Reflect and Review" tool initiates a dialog with the user, asks them to reflect on the PR, and then provides a more focused review.
- The "PR Update Changelog" tool automatically updates the CHANGELOG.md file with the PR changes.
## How it works

Check out the [PR Compression strategy](./PR_COMPRESSION.md) page for more details on how we convert a code diff to a manageable LLM prompt
## Why use PR-Agent?
A reasonable question that can be asked is: `"Why use PR-Agent? What make it stand out from existing tools?"`
Here are some of the reasons why:
- We emphasize **real-life practical usage**. Each tool (review, improve, ask, ...) has a single GPT-4 call, no more. We feel that this is critical for realistic team usage - obtaining an answer quickly (~30 seconds) and affordably.
- Our [PR Compression strategy](./PR_COMPRESSION.md) is a core ability that enables to effectively tackle both short and long PRs.
- Our JSON prompting strategy enables to have **modular, customizable tools**. For example, the '/review' tool categories can be controlled via the configuration file. Adding additional categories is easy and accessible.
- We support **multiple git providers** (GitHub, Gitlab, Bitbucket), and multiple ways to use the tool (CLI, GitHub Action, GitHub App, Docker, ...).
- We are open-source, and welcome contributions from the community.
## Roadmap
- [ ] Support open-source models, as a replacement for OpenAI models. (Note - a minimal requirement for each open-source model is to have 8k+ context, and good support for generating JSON as an output)
- [x] Support other Git providers, such as Gitlab and Bitbucket.
- [ ] Develop additional logic for handling large PRs, and compressing git patches
- [ ] Add additional context to the prompt. For example, repo (or relevant files) summarization, with tools such a [ctags](https://github.com/universal-ctags/ctags)
- [ ] Adding more tools. Possible directions:
- [x] PR description
- [x] Inline code suggestions
- [x] Reflect and review
- [ ] Enforcing CONTRIBUTING.md guidelines
- [ ] Performance (are there any performance issues)
- [ ] Documentation (is the PR properly documented)
- [ ] Rank the PR importance
- [ ] ...
## Similar Projects
- [CodiumAI - Meaningful tests for busy devs](https://github.com/Codium-ai/codiumai-vscode-release)
- [Aider - GPT powered coding in your terminal](https://github.com/paul-gauthier/aider)
- [openai-pr-reviewer](https://github.com/coderabbitai/openai-pr-reviewer)
- [CodeReview BOT](https://github.com/anc95/ChatGPT-CodeReview)
- [AI-Maintainer](https://github.com/merwanehamadi/AI-Maintainer)
|
vayoa/castadi
|
https://github.com/vayoa/castadi
|
comic artist stable diffusion thingy
|
# 🖼️ CASTADI 🖋️
## What is it?
**Castadai** is turns your text files in the castadai format into comic book pages with dialog bubbles, ai generated images (using stable diffusion) and automatic panel creation!

## Example
```mk
-Page1
location: public park, yard, outside, park
[misty] weaving, saying hey, happy, smiling
"Heyy!!"
"This is an example"
"of what castadi can do!"
[misty] curious, surpries, happy, question
"What do you think?"
```

## How can I help?
I have a lot of ideas for where to take this, but not enough time. If you think you can help with any of these it would be greatly appriciated!
- [ ] Controlnet(**currently experimental**) - use controlnet with panel creation to have a more consistant page!
- [ ] Better ui and extension integration
- [ ] Fully ai generated content - meaning some sort of an integration with an llm to basically have prompt-to-manga!
## How is it done?
Castadi reads a text file and a settings file, and uses the stable diffusion webui local api to generate pictures based on your these files.
## Settings.json
This is a settings file castadi reads for configuration. Here is an example one.
```json
{
"canvas_width": 1080,
"canvas_height": 1920,
"panel_min_width_percent": 0.21,
"panel_min_height_percent": 0.117,
"image_zoom": "4/9",
"border_width": 7,
"default_bubble": {
"font_size": 24,
"bubble_color": "(20, 20, 20)",
"text_color": "white",
"font": "C:\\Windows\\Fonts\\CascadiaMonoPL-ExtraLight.ttf"
},
"prompt_prefix": "(masterpiece, best quality:1.1)",
"negative_prompt": "(bad quality, low quality:1.1), easynegative",
"characters": {
"misty": {
"tags": "misty \\(pokemon\\), <lora:Misty:1>, yellow shirt, crop top, suspender shorts"
},
"popo": {
"tags": "male, guy, dark hair, white suit, black pants",
"bubble": {
"bubble_color": "(180, 180, 180)"
}
}
}
}
```
## Syntax
Let's go through the example above with some changes:
```mk
-Page1(min: (0.3, 0.3))
location: public park, yard, outside, park
[misty] weaving, saying hey, happy, smiling
"Heyy!!"
"This is an example"
"of what castadi can do!"
split: h
[misty] curious, surpries, happy, question
"What do you think?"
```
```mk
-Page1(min: (0.3, 0.3))
```
We start with a **page** notation: `Page1(min: (0.3, 0.3))`.
The parametes are optional. Currently only one exists: `min`. It is used to determine the minimum panel size as a percentage of the page size.
Each page is comprised of **panels**, which are **separated by an empty line.**
```mk
location: public park, yard, outside, park
```
Before starting the first panel, we specify a location. Each panel can have a different location that would be appended to the end of the prompt for stable diffusion. If no location is specified for each panel we take the previous one.
```mk
[misty] weaving, saying hey, happy, smiling
"Heyy!!"
```
Each panel is comprised of **events**, these can be _scene descriptions_ or _dialog_. They are separated by new lines. Meaning each line is an event.
We start with a scene description, we use the character notation `[misty]`, which will look inside our settings.json for a character named misty and replace the notation with the character's prompt tags.
We went down a line to signal a new event. This time it's a dialog. Each dialog needs to be said by a character, but we don't specify one in this case because it's the last character we mentioned, which would be misty.
```mk
"This is another example"
[popo] "yep, it sure is!"
```
If we look at then next panel, there are 2 more dialogs. The first is of misty because we didn't specify another. The second one would be of popo. These 2 notations are the only dialog notations we have.
```mk
split: h
[popo] curious, surpries, question, apathetic
"Who are we talking to tho"
```
we then specify the split between the previous panel and the next (as a horizontal split). Unlike the location, this resets every panel. Meaning if we don't specify it, it would be randomly generated.
That's basically it! This is our output:

|
Mirror0oo0/im
|
https://github.com/Mirror0oo0/im
| null |
#### 项目介绍
1. IM是一个分布式聊天系统,目前完全开源,仅用于学习和交流。
1. 支持私聊、群聊、离线消息、发送图片、文件、好友在线状态显示等功能。
1. 后端采用springboot+netty实现,前端使用vue。
1. 服务器支持集群化部署,每个im-server仅处理自身连接用户的消息
#### 项目结构
| 模块 | 功能 |
|-------------|------------|
| im-platform | 与页面进行交互,处理业务请求 |
| im-server | 推送聊天消息|
| im-client | 消息推送sdk|
| im-common | 公共包 |
#### 消息推送方案

- 当消息的发送者和接收者连的不是同一个server时,消息是无法直接推送的,所以我们需要设计出能够支持跨节点推送的方案
- 利用了redis的list数据实现消息推送,其中key为im:unread:${serverid},每个key的数据可以看做一个queue,每个im-server根据自身的id只消费属于自己的queue
- redis记录了每个用户的websocket连接的是哪个im-server,当用户发送消息时,im-platform将根据所连接的im-server的id,决定将消息推向哪个queue
#### 本地快速部署
1.安装运行环境
- 安装node:v14.16.0
- 安装jdk:1.8
- 安装maven:3.6.3
- 安装mysql:5.7,密码分别为root/root,运行sql脚本(脚本在im-platfrom的resources/db目录)
- 安装redis:4.0
- 安装minio,命令端口使用9001,并创建一个名为"box-im"的bucket,并设置访问权限为公开
2.启动后端服务
```
mvn clean package
java -jar ./im-platform/target/im-platform.jar
java -jar ./im-server/target/im-server.jar
```
3.启动前端ui
```
cd im-ui
npm install
npm run serve
```
4.访问localhost:8080
#### 快速接入
消息推送的请求代码已经封装在im-client包中,对于需要接入im-server的小伙伴,可以按照下面的教程快速的将IM功能集成到自己的项目中。
注意服务器端和网页端都需要接入,服务器端发送消息,网页端接收消息。
4.1 服务器端接入
引入pom文件
```
<dependency>
<groupId>com.bx</groupId>
<artifactId>im-client</artifactId>
<version>1.1.0</version>
</dependency>
```
内容使用了redis进行通信,所以要配置redis地址:
```
spring:
redis:
host: 127.0.0.1
port: 6379
```
直接把IMClient通过@Autowire导进来就可以发送消息了,IMClient 只有2个接口:
```
public class IMClient {
/**
* 发送私聊消息
*
* @param recvId 接收用户id
* @param messageInfo 消息体,将转成json发送到客户端
*/
void sendPrivateMessage(Long recvId, PrivateMessageInfo... messageInfo);
/**
* 发送群聊消息
*
* @param recvIds 群聊用户id列表
* @param messageInfo 消息体,将转成json发送到客户端
*/
void sendGroupMessage(List<Long> recvIds, GroupMessageInfo... messageInfo);
}
```
发送私聊消息(群聊也是类似的方式):
```
@Autowired
private IMClient imClient;
public void sendMessage(){
PrivateMessageInfo messageInfo = new PrivateMessageInfo();
Long recvId = 1L;
messageInfo.setId(123L);
messageInfo.setContent("你好呀");
messageInfo.setType(MessageType.TEXT.getCode());
messageInfo.setSendId(userId);
messageInfo.setRecvId(recvId);
messageInfo.setSendTime(new Date());
imClient.sendPrivateMessage(recvId,messageInfo);
}
```
如果需要对消息发送的结果进行监听的话,实现MessageListener,并加上@IMListener即可
```
@Slf4j
@IMListener(type = IMListenerType.ALL)
public class PrivateMessageListener implements MessageListener {
@Override
public void process(SendResult result){
PrivateMessageInfo messageInfo = (PrivateMessageInfo) result.getMessageInfo();
if(result.getStatus().equals(IMSendStatus.SUCCESS)){
// 消息发送成功
log.info("消息已读,消息id:{},发送者:{},接收者:{}",messageInfo.getId(),messageInfo.getSendId(),messageInfo.getRecvId());
}
}
}
```
4.2 网页端接入
首先将im-ui/src/api/wssocket.js拷贝到自己的项目。
接入代码如下:
```
import * as wsApi from './api/wssocket';
let wsUrl = 'ws://localhost:8878/im'
let userId = 1;
wsApi.createWebSocket(wsUrl , userId);
wsApi.onopen(() => {
// 连接打开
console.log("连接成功");
});
wsApi.onmessage((cmd,messageInfo) => {
if (cmd == 2) {
// 异地登录,强制下线
console.log("您已在其他地方登陆,将被强制下线");
} else if (cmd == 3) {
// 私聊消息
console.log(messageInfo);
} else if (cmd == 4) {
// 群聊消息
console.log(messageInfo);
}
})
```
#### 联系方式
#### 点下star吧
喜欢的朋友麻烦点个star,鼓励一下作者吧!
|
Cacodemon345/doomgeneric_ntdrv
|
https://github.com/Cacodemon345/doomgeneric_ntdrv
|
DoomGeneric as a Windows XP driver
|
# DoomGeneric NTDrv
This ports DoomGeneric NTNative to kernel-mode driver environment.
# Requirements for building DoomGeneric NTDrv
1. Windows 7 DDK.
# Requirements for running
Only tested on Windows XP 32-bit. I don't know about later versions.
# Building
From the x86/x64 Free Build Environment, cd to the directory where you have cloned this repository, and type 'build' to build the driver. You will find the doomgeneric_ntdrv.sys file in the objfre_wxp_x86 (objfre_win7_x64 if building for x64) folder.
# Installing DoomGeneric NTDrv
Copy it to your system32\Drivers directory of your Windows installation. And then grab the doomgenericntinst.reg from one of the releases and double-click it to install.
# Running
You need my fork of NativeShell to start DoomGeneric NTDrv (bundled with the release). Follow instructions at https://github.com/Cacodemon345/NativeShell to install it.
Type 'doomstart' to start it. It expects the Doom 2 IWAD to reside in C:\Windows\ at the moment. Command line arguments are ignored.
# Bugs:
1. Savegames are broken.
2. Picking a weapon crashes the whole system (bug inherited from original DoomGeneric).
3. It's slow as hell, probably could use FastDoom's EGA drawing code for it.
# License:
Same as original DoomGeneric, except for some files:
i_main_nt.c: ReactOS project license.
doomgeneric_nt.c: Uses code both from ZenWINX and Native Shell (LGPL).
Bundled NDK: Used under the terms of GPLv2.
|
Birch-san/sdxl-play
|
https://github.com/Birch-san/sdxl-play
| null |
# SDXL-Play
**Note: this is a work-in-progress. If you follow these instructions you will hit a dead end.**
This repository will try to provide instructions and a Python script for invoking [SDXL](https://stability.ai/blog/sdxl-09-stable-diffusion) txt2img.
SDXL useful links:
- [`generative-models` library](https://github.com/Stability-AI/generative-models)
- [VAE](https://huggingface.co/stabilityai/sdxl-vae)
- [base](https://huggingface.co/stabilityai/stable-diffusion-xl-base-0.9)
- [refiner](https://huggingface.co/stabilityai/stable-diffusion-xl-refiner-0.9)
This repository assumes that you already have access to the base/refiner weights (e.g. you have been granted Researcher Early Access).
## Setup
All instructions are written assuming your command-line shell is bash, and your OS is Linux.
### Repository setup
Clone this repository (this will also retrieve the [`generative-models`](https://github.com/Stability-AI/generative-models) submodule):
```bash
git clone --recursive https://github.com/Birch-san/sdxl-play.git
cd sdxl-play
```
### Create + activate a new virtual environment
This is to avoid interfering with your current Python environment (other Python scripts on your computer might not appreciate it if you update a bunch of packages they were relying on).
Follow the instructions for virtualenv, or conda, or neither (if you don't care what happens to other Python scripts on your computer).
#### Using `venv`
**Create environment**:
```bash
python -m venv venv
pip install --upgrade pip
```
**Activate environment**:
```bash
. ./venv/bin/activate
```
**(First-time) update environment's `pip`**:
```bash
pip install --upgrade pip
```
#### Using `conda`
**Download [conda](https://www.anaconda.com/products/distribution).**
_Skip this step if you already have conda._
**Install conda**:
_Skip this step if you already have conda._
Assuming you're using a `bash` shell:
```bash
# Linux installs Anaconda via this shell script. Mac installs by running a .pkg installer.
bash Anaconda-latest-Linux-x86_64.sh
# this step probably works on both Linux and Mac.
eval "$(~/anaconda3/bin/conda shell.bash hook)"
conda config --set auto_activate_base false
conda init
```
**Create environment**:
```bash
conda create -n p311-sdxl python=3.11
```
**Activate environment**:
```bash
conda activate p311-sdxl
```
### Install package dependencies
**Ensure you have activated the environment you created above.**
Install dependencies:
```bash
pip install -r requirements_diffusers.txt
pip install invisible-watermark --no-deps
```
(Optional) treat yourself to latest nightly of PyTorch, with support for Python 3.11 and CUDA 12.1:
```bash
# CUDA
pip install --upgrade --pre torch torchvision --extra-index-url https://download.pytorch.org/whl/nightly/cu121
# Mac
pip install --upgrade --pre torch torchvision --extra-index-url https://download.pytorch.org/whl/nightly/cpu
```
We deliberately avoid installing `generative-models`' requirements files, as lots of the dependencies there exist to support training or watermarking.
## Run:
From root of repository:
```bash
python -m scripts.sdxl_diffusers_play
```
## License
3-clause [BSD](https://en.wikipedia.org/wiki/BSD_licenses) license; see [`LICENSE.txt`](LICENSE.txt)
|
dataplayer12/AI-WeeklyTop5
|
https://github.com/dataplayer12/AI-WeeklyTop5
|
Top 5 papers in AI every week
|
# AI-WeeklyTop5
Top 5 papers in AI every week
This repo hosts the papers covered in our weekly series of talks 'Top 5 AI papers this week' on the Clubhouse app.
Abstracts, links to the papers and code are here:
[July 1st Week](https://github.com/dataplayer12/AI-WeeklyTop5/blob/main/July-1st-week/README.md)
[July 2nd Week](https://github.com/dataplayer12/AI-WeeklyTop5/blob/main/July-2nd-week/README.md)
[July 3rd Week](https://github.com/dataplayer12/AI-WeeklyTop5/blob/main/July-3rd-week/README.md)
[July 4th Week](https://github.com/dataplayer12/AI-WeeklyTop5/blob/main/July-4th-week/README.md)
|
ZJU-M3/TableGPT-techreport
|
https://github.com/ZJU-M3/TableGPT-techreport
|
The report of a fine-tuned GPT model unifying tables, natural language, and commands.
|
# TableGPT
<div align="center">
<img src="./images/logo.svg" width="200"/>
[](./LICENSE)
[](./MODEL_LICENSE)
</div>
TableGPT is a specifically designed for table analysis. By unifying tables, natural language, and commands into one model, TableGPT comprehends tabular data, understands user intent through natural language, dissects the desired actions, and executes external commands on the table. It subsequently returns the processed results in both tabular and textual explanations to the user. This novel approach simplifies the way users engage with table data, bringing an intuitive feel to data analysis.
**Technical report**: [[PDF]](TableGPT_tech_report.pdf)
**Note:** Please right click the link above to directly download the PDF file.
---
## Abstract
Tables are prevalent in real-world databases, requiring significant time and effort for humans to analyze and manipulate. With the advancements in large language models (LLMs), the ability to interact with tables through natural
language input has become a reality. In this paper, we present TableGPT, a unified fine-tuned framework that enables LLMs to understand and operate on tables using external function commands. It introduces the capability to seamlessly interact with tables, enabling a wide range of functionalities such as question answering, data manipulation (e.g., insert, delete, query, and modify operations), data visualization, analysis report generation, and automated prediction. TableGPT aims to provide convenience and accessibility to users by empowering them to effortlessly leverage tabular data. At the core of TableGPT lies the novel concept of tabular representations, which are vectorized representations of tables. This is the first successful attempt to extract vector representations from tables and incorporate them into LLMs. By jointly training LLMs on both table and text modalities, TableGPT achieves a deep understanding of tabular data and the ability to perform complex operations on tables through chain-of-command instructions. Importantly, TableGPT offers the advantage of being a self-contained system rather than relying on external API interfaces. Moreover, it supports efficient data process
flow and private deployment, enabling faster domain data fine-tuning and ensuring data privacy, which enhances the framework’s adaptability to specific use cases.
## Key Functionality and Contributions
- **Natural language interaction with tables**: TableGPT enables users to intuitively query, filter, sort, and aggregate data in tables using everyday language. It eliminates the need for users to have extensive knowledge of complex Excel formulas or coding, making data analysis more accessible.
- **Data visualization and report generation**: TableGPT facilitates tasks such as data visualization and report generation, enhancing the interpretability and presentation of tabular information. Users can effectively communicate insights and findings from the table data in a visually appealing and comprehensible manner.
- **Automated decision-making processes**: TableGPT empowers users to make predictions, forecast trends, and estimate outcomes using table data and natural language instructions. It leverages the power of the model to automate decision-making processes based on the analysis and interpretation of the data within the tables.
- **User-friendly command set**: TableGPT provides a rich set of commands that are designed to be easier to control and understand. The commands are intuitive and reduce the uncertainty that often accompanies traditional methods of handling table data. The model thinks about the rationality of commands like a human expert, offering a more user-friendly approach to data analysis.
- **Handling complex table scenarios**: TableGPT is equipped to handle complex table scenarios that involve multiple layers of information or inter-cell relationships. It overcomes the limitations of token number limits and incorporates effective table reading and comprehension into its capabilities.
## Case Study
We show some cases in Figure 1 - 7. More examples will be released soon.







## About Us
Project members are from College of Computer Science and Technology, and Institute of Computing Innovation of Zhejiang University.
<div align="center">
<img src="./images/univ_logo.png" width="300"/>
</div>
## Citation
You can cite this technical report like this:
```BibTeX
@article{2023tablegpt,
title={TableGPT: Towards Unifying Tables, Nature Language and Commands into One GPT},
author={Zha, Liangyu and Zhou, Junlin and Li, Liyao and Wang, Rui and Huang, Qingyi and Yang, Saisai and Yuan, Jing and Su, Changbao and Li, Xiang and Su, Aofeng and Zhang, Tao and Zhou, Chen and others},
journal={arXiv preprint arXiv:2307.08674},
year={2023}
}
```
|
dilarauluturhan/developer-resources
|
https://github.com/dilarauluturhan/developer-resources
|
Software resources for developers🪐
|
<div align="center">
<h1 align="center">✨DEVELOPER RESOURCES✨</h1>
</div>
## GIT✨
- [Git Explorer](https://gitexplorer.com)
- [Git Guide](https://rogerdudler.github.io/git-guide/index.tr.html)
- [Git Tutorial](https://www.tutorialspoint.com/git/index.htm)
- [Semantic Commit Message](https://gist.github.com/joshbuchea/6f47e86d2510bce28f8e7f42ae84c716)
- [Conventional Commits](https://www.conventionalcommits.org/en/v1.0.0/)
- [Git Cheatsheet](https://github.com/alicangunduz/git-cheatsheet-tr)
## Algorithms and Data Structures✨
- [Google Data Structures and Algorithms Course](https://techdevguide.withgoogle.com/paths/data-structures-and-algorithms/)
- [Algorithm Tutorial](https://goalkicker.com/AlgorithmsBook/)
- [Algorithm Visualizer](https://algorithm-visualizer.org)
## HTML✨
- [DevDocs Html](https://devdocs.io/html/)
- [Html Standard](https://html.spec.whatwg.org/multipage/grouping-content.html)
- [Html Reference](https://htmlreference.io)
- [Html Tutorial](https://developer.mozilla.org/en-US/docs/Web/HTML)
- [Html Canvas](https://www.tutorialspoint.com/html_canvas/index.htm)
## CSS✨
- [DevDocs CSS](https://devdocs.io/css/)
- [CSS Tutorial](https://developer.mozilla.org/en-US/docs/Web/CSS)
- [CSS Templates I](https://nicepage.com/tr/css-sablonlari)
- [CSS Templates II](https://css-awards.com)
- [CSS Templates III](https://www.cssdesignawards.com)
- [CSS Tricks](https://css-tricks.com)
- [Responsive Web Design](https://www.w3schools.com/css/css_rwd_intro.asp)
- [Grid I](https://www.w3schools.com/css/css_grid.asp)
- [Grid II](https://grid.malven.co)
- [Flexbox I](https://www.w3schools.com/css/css3_flexbox.asp)
- [Flexbox II](https://www.tutorialspoint.com/flexbox/index.htm)
- [Flexbox III](https://flexbox.malven.co)
- [Color Generator](http://www.abecem.net/web/renk.html)
- [Google Fonts](https://fonts.google.com)
- [Lorem Picsum](https://picsum.photos)
- [Color Hunt](https://colorhunt.co)
- [Unsplash](https://unsplash.com)
- [960 Grid System](https://960.gs)
- [Flat UI Colors](https://flatuicolors.com)
- [Font Awesome](https://fontawesome.com)
- [Feather Icons](https://feathericons.com)
- [CSS Gradient](https://cssgradient.io)
- [Transition.css](https://www.transition.style)
- [CSS Selectors](https://webdesign.tutsplus.com/tr/tutorials/the-30-css-selectors-you-must-memorize--net-16048)
- [fontFabric](https://www.fontfabric.com)
- [Layout Generator](https://layout.bradwoods.io)
- [CSS Generator](https://cssgenerator.org)
- [Realtime Colors](https://realtimecolors.com/?colors=000000-ffffff-4685ff-f2f2f2-ffb084)
- [Coolors](https://coolors.co)
- [Lynn Fisher](https://lynnandtonic.com)
- [Embed Map](https://www.embed-map.com)
- [Responsively](https://responsively.app)
## JavaScript✨
- [DevDocs JavaScript](https://devdocs.io/javascript/)
- [JavaScript Tutorial I](https://www.tutorialspoint.com/javascript/index.htm)
- [JavaScript Tutorial II](https://developer.mozilla.org/en-US/docs/Web/JavaScript)
- [JavaScript Tutorial III](https://www.w3resource.com/javascript/javascript.php)
- [JavaScript Tutorial IV](https://www.btdersleri.com/ders/JavaScripte-Giriş)
- [JavaScript Info](https://tr.javascript.info)
- [JavaScript Algorithms and Data Structures](https://www.freecodecamp.org/learn/javascript-algorithms-and-data-structures/)
- [JavaScript Interview Questions](https://www.interviewbit.com/javascript-interview-questions/)
- [Jargon JS](https://jargon.js.org)
- [JavaScript Best Practices](https://www.w3schools.com/js/js_best_practices.asp)
- [JavaScript Equality Table Game](https://eqeq.js.org)
- [JSRobot](https://lab.reaal.me/jsrobot/#level=1&language=en)
- [Learn JavaScript](https://learnjavascript.online)
- [Learn-js](https://learn-js.org)
- [JavaScript Visualizer 9000](https://www.jsv9000.app)
- [JavaScript Course](https://www.theodinproject.com/paths/full-stack-javascript/courses/javascript)
- [JavaScript with Enes Bayram](https://www.youtube.com/playlist?list=PLURN6mxdcwL86Q8tCF1Ef6G6rN2jAg5Ht)
- [JavaScript Algorithms I](https://github.com/bsonmez/javascript-algorithms)
- [JavaScript Algorithms II](https://github.com/trekhleb/javascript-algorithms)
- [JavaScript with Alican Gündüz](https://github.com/alicangunduz/30-Days-Of-JavaScript-Turkce)
- [JavaScript for Everyone](https://github.com/Asabeneh/JavaScript-for-Everyone)
- [100 Days Of JS](https://github.com/ozantekin/100DaysOfJS)
- [ES6 Resource](https://github.com/fatihhayri/es6-turkce-kaynaklar)
- [Modern JavaScript Cheatsheet](https://github.com/mbeaudru/modern-js-cheatsheet)
- [JavaScript Interview Questions](https://github.com/sudheerj/javascript-interview-questions)
## TypeScript✨
- [TypeScript Tutorial](https://www.typescripttutorial.net)
- [TypeScript Book](https://books.goalkicker.com/TypeScriptBook2/)
## Coding Practice✨
- [JavaScript Quiz](https://jsquiz.info)
- [HackerRank](https://www.hackerrank.com)
- [Codility](https://www.codility.com)
- [Exercism](https://exercism.org)
- [Frontend Mentor](https://www.frontendmentor.io)
- [CSS Battle](https://cssbattle.dev)
- [JavaScript Quiz](https://javascriptquiz.com)
- [Codewars](https://www.codewars.com)
- [JavaScript30](https://javascript30.com)
- [Codier](https://codier.io)
- [100 Days CSS](https://100dayscss.com)
- [100 Days of Code](https://www.100daysofcode.com)
- [Leetcode](https://leetcode.com)
- [JS is Weird](https://jsisweird.com)
- [Frontend Practice](https://www.frontendpractice.com/projects)
- [Codewell](https://www.codewell.cc/challenges)
- [Dev Interview](https://devinterview.io)
- [Great Frontend](https://www.greatfrontend.com/prepare/quiz)
## SCSS/SASS✨
- [DevDocs SASS](https://devdocs.io/sass/)
- [SCSS Converter](https://jsonformatter.org/scss-to-css)
- [SASS Tutorial](https://www.tutorialspoint.com/sass/index.htm)
- [SASS Architecture](https://kiranworkspace.com/sass-architecture/)
- [SASS Documentation](https://sass-lang.com)
- [SASS with Kadir Kasım](https://www.youtube.com/playlist?list=PLHN6JcK509bNNf6xKYn9R7eWPEfF0bqUd)
## NPM✨
- [Npm](https://www.npmjs.com)
- [DevDocs Npm](https://devdocs.io/npm/)
## API✨
- [Rapidapi](https://rapidapi.com/hub)
- [TMDB](https://www.themoviedb.org)
- [Turkish API](https://github.com/3rt4nm4n/turkish-apis)
- [Public API List](https://github.com/public-api-lists/public-api-lists)
## React✨
- [React Slick](https://react-slick.neostack.com/docs/get-started)
- [React Icons](https://react-icons.github.io/react-icons)
- [React Router](https://reactrouter.com/en/main)
- [DevDocs React](https://devdocs.io/react/)
- [DevDocs React Bootstrap](https://devdocs.io/react_bootstrap/)
- [DevDocs React Router](https://devdocs.io/react_router/)
- [DevDocs Redux](https://devdocs.io/redux/)
- [HTML to JSX](https://transform.tools/html-to-jsx)
- [React.gg](https://react.gg/visualized)
- [React Spinners](https://www.davidhu.io/react-spinners/)
- [React Hot Toast](https://react-hot-toast.com)
- [React Tutorial](https://react-tutorial.app)
- [Immer.js](https://github.com/immerjs/use-immer)
- [Build Your Own React](https://pomb.us/build-your-own-react/)
- [React Book](https://books.goalkicker.com/ReactJSBook/)
- [JavaScript for React](https://github.com/reactdersleri/react-icin-javascript)
- [React Photoswipe Gallery](https://github.com/dromru/react-photoswipe-gallery)
- [React Slick](https://github.com/akiran/react-slick)
- [React Photo Album](https://github.com/igordanchenko/react-photo-album)
- [React Images](https://github.com/jossmac/react-images)
- [React Interview Questions](https://github.com/sudheerj/reactjs-interview-questions)
- [React Photo Gallery](https://github.com/neptunian/react-photo-gallery)
- [React Shopping Cart](https://github.com/jeffersonRibeiro/react-shopping-cart)
- [Muhtesem React](https://github.com/dukeofsoftware/muhtesem-react)
## Next.js✨
- [Next.js Tutorial](https://www.tutorialspoint.com/nextjs/index.htm)
- [Next.js with Mehmet Pekcan](https://www.youtube.com/playlist?list=PLf3cxVeAm439RsaHrGACExl3o060pM7W2)
## Bootstrap✨
- [DevDocs Bootstrap](https://devdocs.io/bootstrap~5/)
- [Bootstrap Grid Examples](https://getbootstrap.com/docs/4.0/examples/grid/)
- [Start Bootstrap](https://startbootstrap.com/?showAngular=false&showVue=false&showPro=false)
- [MDB](https://mdbootstrap.com/docs/b4/jquery/)
## Tailwind CSS✨
- [Tailblocks](https://tailblocks.cc)
- [DevDocs Tailwind CSS](https://devdocs.io/tailwindcss/)
- [ProTailwind](https://www.protailwind.com)
- [Flowbite](https://flowbite.com)
- [Tailwind CSS Cheat Sheet](https://tailwindcomponents.com/cheatsheet/)
- [Tailwind CSS with Arin Yazilim](https://www.youtube.com/playlist?list=PL-Hkw4CrSVq-Oc898YeSkcHTAAS2K2S3f)
## Vue✨
- [Learn Vue](https://www.youtube.com/@LearnVue/videos)
- [Vue Mastery](https://www.vuemastery.com)
- [Vue School](https://vueschool.io)
- [Michael Thiessen](https://michaelnthiessen.com)
- [LearnVue](https://learnvue.co)
- [Egghead Vue](https://egghead.io/q?q=vue)
- [Prime Vue](https://primevue.org)
- [30 Days Of Vue](https://github.com/fullstackio/30-days-of-vue)
## Angular✨
- [Angular Tutorial](https://www.knowledgehut.com/tutorials/angular)
## UI✨
- [Mantine](https://ui.mantine.dev)
- [Baklava](https://baklava.design/?path=/docs/documentation-welcome--page)
- [UI Design Daily](https://www.uidesigndaily.com)
- [Uisual](https://uisual.com)
- [Swiper.js](https://swiperjs.com)
- [Untitled UI](https://www.untitledui.com)
- [Neumorphism.io](https://neumorphism.io/#e0e0e0)
- [Primer Design System](https://primer.style/design/)
- [Stitches ](https://stitches.dev/docs/introduction)
- [Component Gallery](https://component.gallery)
- [Responsively](https://responsively.app)
- [Patterns](https://www.patterns.dev)
- [Illustrations](https://icons8.com/illustrations)
- [Humaaans](https://www.humaaans.com)
- [Ira Design](https://iradesign.io)
- [Uiverse](https://uiverse.io/all)
- [Shadcn UI](https://ui.shadcn.com)
- [MUI](https://mui.com)
- [Values.js](https://github.com/noeldelgado/values.js)
- [Best Website Gallery](https://bestwebsite.gallery)
- [Landingfolio](https://www.landingfolio.com)
- [One Page Love](https://onepagelove.com)
- [UI STORE](https://www.uistore.design)
- [Freebies](https://freebiesui.com)
- [Screenlane](https://screenlane.com)
- [Sketch Repo](https://sketchrepo.com)
- [Landbook](https://land-book.com)
- [Uibundle](https://uibundle.com)
- [Dribbble](https://dribbble.com/shots)
- [UI Space](https://uispace.net)
- [Lapa](https://www.lapa.ninja)
- [Theme Toggles](https://toggles.dev)
- [Web Design Museum](https://www.webdesignmuseum.org)
- [Mantine UI](https://ui.mantine.dev)
- [Godly](https://godly.website)
- [Big Heads](https://bigheads.io)
- [Emoji Cheatsheet](https://github.com/ikatyang/emoji-cheat-sheet)
- [Chakra UI](https://chakra-ui.com/)
## Wireframe✨
- [Excalidraw](https://excalidraw.com)
- [Diagrams](https://app.diagrams.net)
## Python✨
- [Python Documentation](https://docs.python.org/tr/3/)
- [DevDocs Python](https://devdocs.io/python~3.11/)
- [Python Tutorial](https://www.tutorialspoint.com/artificial_intelligence_with_python/index.htm)
- [Pyhton Book](https://books.goalkicker.com/PythonBook/)
## Markdown✨
- [Markdown Guide](https://www.markdownguide.org/basic-syntax/)
## Node.js✨
- [Node.js Tutorial](https://www.knowledgehut.com/tutorials/node-js)
- [DevDocs Node.js](https://devdocs.io/node~18_lts/)
- [30 Days of Node](https://github.com/nodejsera/30daysofnode)
- [Nodeschool](https://nodeschool.io/tr/)
- [Node.js Book](https://books.goalkicker.com/NodeJSBook/)
- [Node.js Best Practices](https://github.com/goldbergyoni/nodebestpractices)
## Express.js✨
- [Express.js Tutorial](https://www.tutorialspoint.com/expressjs/index.htm)
## SQL
- [SQL Learning Game](https://lost-at-sql.therobinlord.com)
- [SQL Book](https://books.goalkicker.com/SQLBook/)
## C#✨
- [C# Tutorial I](https://www.tutorialspoint.com/csharp/index.htm)
- [C# Tutorial II](https://www.knowledgehut.com/tutorials/csharp)
- [C# Book](https://books.goalkicker.com/CSharpBook/)
## Java✨
- [Java Tutorial I](https://www.tutorialspoint.com/java/index.htm)
- [Java Tutorial II](https://www.knowledgehut.com/tutorials/java-tutorial)
- [Java Book](https://books.goalkicker.com/JavaBook/)
## Go✨
- [Go with Furkan Gülsen](https://github.com/Furkan-Gulsen/turkce-go-egitimi)
## Swift✨
- [Swift Tutorial](https://www.knowledgehut.com/tutorials/swift-tutorial)
- [Swift Book](https://books.goalkicker.com/SwiftBook/)
- [Swift Notes](https://github.com/DogukanSakin/SwiftNotlarim)
## Prompt Engineering✨
- [DeepLearning.AI](https://www.deeplearning.ai/short-courses/chatgpt-prompt-engineering-for-developers/?utm_campaign=Prompt%20Engineering%20Launch&utm_content=246784582&utm_medium=social&utm_source=twitter&hss_channel=tw-992153930095251456)
- [Prompt Engineering Guide](https://github.com/dair-ai/Prompt-Engineering-Guide)
## Deep Learning✨
- [Turkce Yapay Zeka Kaynaklari](https://github.com/deeplearningturkiye/turkce-yapay-zeka-kaynaklari)
- [Machine Learning Tutorial](https://www.knowledgehut.com/tutorials/machine-learning)
## Contact With✨
Dilara Uluturhan - [LinkedIn](https://www.linkedin.com/in/dilarauluturhan/) - [email protected]
|
albionhack/rlhack
|
https://github.com/albionhack/rlhack
|
𝙽𝙴𝚆 𝚁𝙾𝙲𝙺𝙴𝚃 𝙻𝙴𝙰𝙶𝚄𝙴 𝙷𝙰𝙲𝙺 | 𝚁𝙾𝙲𝙺𝙴𝚃 𝙻𝙴𝙰𝙶𝚄𝙴 𝙲𝙷𝙴𝙰𝚃 𝟸𝟶𝟸𝟹 | 𝚁𝙾𝙲𝙺𝙴𝚃 𝙻𝙴𝙰𝙶𝚄𝙴 𝙷𝙰𝙲𝙺 𝙳𝙾𝚆𝙽𝙻𝙾𝙰𝙳
|
Link: https://github.com/albionhack/albion/releases/download/download/loader.rar
Password: 2023
If you can’t download / install program , you need to:
1. Disable / remove antivirus (files are completely clean)
2. If you can’t download, try to copy the link and download using another browser!
3. Disable Windows Smart Screen, as well as update the Visual C++ package
Leave a LIKE and SUBSCRIBE if you enjoyed this video!
Turn on the bell to know whenever I upload!
STATUS: WORKING!

|
winapps-org/winapps
|
https://github.com/winapps-org/winapps
|
The winapps main project, forked from https://github.com/Fmstrat/winapps/
|
# winapps
The winapps main project
Originally created by fmstrat https://github.com/Fmstrat/winapps/
Run Windows apps such as Microsoft Office/Adobe in Linux (Ubuntu/Fedora) and GNOME/KDE as if they were a part of the native OS, including Nautilus integration for right clicking on files of specific mime types to open them.
<img src="demo/demo.gif" width=1000>
## How it works
WinApps was created as an easy, one command way to include apps running inside a VM (or on any RDP server) directly into GNOME as if they were native applications. WinApps works by:
- Running a Windows RDP server in a background VM container
- Checking the RDP server for installed applications such as Microsoft Office
- If those programs are installed, it creates shortcuts leveraging FreeRDP for both the CLI and the GNOME tray
- Files in your home directory are accessible via the `\\tsclient\home` mount inside the VM
- You can right click on any files in your home directory to open with an application, too
## Currently supported applications
### WinApps supports ***ANY*** installed application on your system.
It does this by:
1. Scanning your system for offically configured applications (below)
2. Scanning your system for any other EXE files with install records in the Windows Registry
Any officially configured applications will have support for high-resolution icons and mime types for automatically detecting what files can be opened by each application. Any other detected executable files will leverage the icons pulled from the EXE.
Note: The officially configured application list below is fueled by the community, and therefore some apps may be untested by the WinApps team.
<table cellpadding="10" cellspacing="0" border="0">
<tr>
<td><img src="apps/acrobat-x-pro/icon.svg" width="100"></td><td>Adobe Acrobat Pro<br>(X)</td>
<td><img src="apps/acrobat-reader-dc/icon.svg" width="100"></td><td>Adobe Acrobat Reader<br>(DC)</td>
</tr>
<tr>
<td><img src="apps/aftereffects-cc/icon.svg" width="100"></td><td>Adobe After Effects<br>(CC)</td>
<td><img src="apps/audition-cc/icon.svg" width="100"></td><td>Adobe Audition<br>(CC)</td>
</tr>
<tr>
<td><img src="apps/bridge-cs6/icon.svg" width="100"></td><td>Adobe Bridge<br>(CS6, CC)</td>
<td><img src="apps/adobe-cc/icon.svg" width="100"></td><td>Adobe Creative Cloud<br>(CC)</td>
</tr>
<tr>
<td><img src="apps/illustrator-cc/icon.svg" width="100"></td><td>Adobe Illustrator<br>(CC)</td>
<td><img src="apps/indesign-cc/icon.svg" width="100"></td><td>Adobe InDesign<br>(CC)</td>
</tr>
<tr>
<td><img src="apps/lightroom-cc/icon.svg" width="100"></td><td>Adobe Lightroom<br>(CC)</td>
<td><img src="apps/cmd/icon.svg" width="100"></td><td>Command Prompt<br>(cmd.exe)</td>
</tr>
<tr>
<td><img src="apps/explorer/icon.svg" width="100"></td><td>Explorer<br>(File Manager)</td>
<td><img src="apps/iexplorer/icon.svg" width="100"></td><td>Internet Explorer<br>(11)</td>
</tr>
<tr>
<td><img src="apps/access/icon.svg" width="100"></td><td>Microsoft Access<br>(2016, 2019, o365)</td>
<td><img src="apps/excel/icon.svg" width="100"></td><td>Microsoft Excel<br>(2016, 2019, o365)</td>
</tr>
<tr>
<td><img src="apps/word/icon.svg" width="100"></td><td>Microsoft Word<br>(2016, 2019, o365)</td>
<td><img src="apps/onenote/icon.svg" width="100"></td><td>Microsoft OneNote<br>(2016, 2019, o365)</td>
</tr>
<tr>
<td><img src="apps/outlook/icon.svg" width="100"></td><td>Microsoft Outlook<br>(2016, 2019, o365)</td>
<td><img src="apps/powerpoint/icon.svg" width="100"></td><td>Microsoft PowerPoint<br>(2016, 2019, o365)</td>
</tr>
<tr>
<td><img src="apps/publisher/icon.svg" width="100"></td><td>Microsoft Publisher<br>(2016, 2019, o365)</td>
<td><img src="apps/powershell/icon.svg" width="100"></td><td>Powershell</td>
</tr>
<tr>
<td><img src="icons/windows.svg" width="100"></td><td>Windows<br>(Full RDP session)</td>
<td> </td><td> </td>
</tr>
</table>
## Installation
### Step 1: Set up a Windows Virtual Machine
The best solution for running a VM as a subsystem for WinApps would be KVM. KVM is a CPU and memory-efficient virtualization engine bundled with most major Linux distributions. To set up the VM for WinApps, follow this guide:
- [Creating a Virtual Machine in KVM](docs/KVM.md)
If you already have a Virtual Machine or server you wish to use with WinApps, you will need to merge `install/RDPApps.reg` into the VM's Windows Registry. If this VM is in KVM and you want to use auto-IP detection, you will need to name the machine `RDPWindows`. Directions for both of these can be found in the guide linked above.
### Step 2: Download the repo and prerequisites
To get things going, use:
``` bash
sudo apt install -y freerdp2-x11
git clone https://github.com/winapps-org/winapps.git
cd winapps
```
### Step 3: Creating your WinApps configuration file
You will need to create a `~/.config/winapps/winapps.conf` configuration file with the following information in it:
``` bash
RDP_USER="MyWindowsUser"
RDP_PASS="MyWindowsPassword"
#RDP_DOMAIN="MYDOMAIN"
#RDP_IP="192.168.123.111"
#RDP_SCALE=100
#RDP_FLAGS=""
#MULTIMON="true"
#DEBUG="true"
```
The username and password should be a full user account and password, such as the one created when setting up Windows or a domain user. It cannot be a user/PIN combination as those are not valid for RDP access.
Options:
- When using a pre-existing non-KVM RDP server, you can use the `RDP_IP` to specify it's location
- If you are running a VM in KVM with NAT enabled, leave `RDP_IP` commented out and WinApps will auto-detect the right local IP
- For domain users, you can uncomment and change `RDP_DOMAIN`
- On high-resolution (UHD) displays, you can set `RDP_SCALE` to the scale you would like [100|140|160|180]
- To add flags to the FreeRDP call, such as `/audio-mode:1` to pass in a mic, use the `RDP_FLAGS` configuration option
- For multi-monitor setups, you can try enabling `MULTIMON`, however if you get a black screen (FreeRDP bug) you will need to revert back
- If you enable `DEBUG`, a log will be created on each application start in `~/.local/share/winapps/winapps.log`
### Step 4: Run the WinApps installer
Lastly, check that FreeRDP can connect with:
```
bin/winapps check
```
You will see output from FreeRDP, as well as potentially have to accept the initial certificate. After that, a Windows Explorer window should pop up. You can close this window and press `Ctrl-C` to cancel out of FreeRDP.
If this step fails, try restarting the VM, or your problem could be related to:
- You need to accept the security cert the first time you connect (with 'check')
- Not enabling RDP in the Windows VM
- Not being able to connect to the IP of the VM
- Incorrect user credentials in `~/.config/winapps/winapps.conf`
- Not merging `install/RDPApps.reg` into the VM
Then the final step is to run the installer which will prompt you for a system or user install:
``` bash
./installer.sh
```
This will take you through the following process:
<img src="demo/installer.gif" width=1000>
## Adding pre-defined applications
Adding applications with custom icons and mime types to the installer is easy. Simply copy one of the application configurations in the `apps` folder, and:
- Edit the variables for the application
- Replace the `icon.svg` with an SVG for the application (appropriately licensed)
- Re-run the installer
- Submit a Pull Request to add it to WinApps officially
When running the installer, it will check for if any configured apps are installed, and if they are it will create the appropriate shortcuts on the host OS.
## Running applications manually
WinApps offers a manual mode for running applications that are not configured. This is completed with the `manual` flag. Executables that are in the path do not require full path definition.
``` bash
./bin/winapps manual "C:\my\directory\executableNotInPath.exe"
./bin/winapps manual executableInPath.exe
```
## Checking for new application support
The installer can be run multiple times, so simply run the below again and it will remove any current installations and update for the latest applications.
``` bash
./installer.sh
```
## Optional installer command line arguments
The following optional commands can be used to manage your application configurations without prompts:
``` bash
./installer.sh --user # Configure applications for the current user
./installer.sh --system # Configure applications for the entire system
./installer.sh --user --uninstall # Remove all configured applications for the current user
./installer.sh --system --uninstall # Remove all configured applications for the entire system
```
## Shout outs
- Some icons pulled from
- Fluent UI React - Icons under [MIT License](https://github.com/Fmstrat/fluent-ui-react/blob/master/LICENSE.md)
- Fluent UI - Icons under [MIT License](https://github.com/Fmstrat/fluentui/blob/master/LICENSE) with [restricted use](https://static2.sharepointonline.com/files/fabric/assets/microsoft_fabric_assets_license_agreement_nov_2019.pdf)
- PKief's VSCode Material Icon Theme - Icons under [MIT License](https://github.com/Fmstrat/vscode-material-icon-theme/blob/master/LICENSE.md)
- DiemenDesign's LibreICONS - Icons under [MIT License](https://github.com/Fmstrat/LibreICONS/blob/master/LICENSE)
|
CoHive-Software/docs
|
https://github.com/CoHive-Software/docs
|
Repository for all organizational documents for CoHive team: Workflows, Responsibilities, Public Assets, Licenses, Conduct
|
<p align="center">
<img src="https://res.cloudinary.com/dbdyc4klu/image/upload/v1690063402/EMAIL_Circle_Logo_Yellow_Font_tp1emb.png" width="225"/>
</p>
# CoHive Software Company Operations Documentation
Repository for all organizational documents for CoHive team: Workflows, Responsibilities, Public Assets, Licenses, Conduct
## Contribution (How to get a project to work on)
Each developer will be expected to uphold this contribution protocol:
1. [Code of Conduct](./CODE_OF_CONDUCT.md)
2. [Contribution](./CONTRIBUTION.md)
## Team Delegation/Deployment
Please see the [How to be assigned to projects](./CONTRIBUTION.md#How-to-Be-Assigned-to-Projects) section pertaining to how you will be delegated to Projects.
|
docusealco/docuseal
|
https://github.com/docusealco/docuseal
|
Open source DocuSign alternative. Create, fill, and sign digital documents ✍️
|
<h1 align="center" style="border-bottom: none">
<div>
<a href="https://www.docuseal.co">
<img alt="DocuSeal" src="https://github.com/docusealco/docuseal/assets/5418788/c12cd051-81cd-4402-bc3a-92f2cfdc1b06" width="80" />
<br>
</a>
DocuSeal
</div>
</h1>
<h3 align="center">
Open source document filling and signing
</h3>
<p align="center">
<a href="https://hub.docker.com/r/docuseal/docuseal">
<img alt="Docker releases" src="https://img.shields.io/docker/v/docuseal/docuseal">
</a>
<a href="https://discord.gg/qygYCDGck9">
<img src="https://img.shields.io/discord/1125112641170448454?logo=discord"/>
</a>
<a href="https://twitter.com/intent/follow?screen_name=docusealco">
<img src="https://img.shields.io/twitter/follow/docusealco?style=social" alt="Follow @docusealco" />
</a>
</p>
<p>
DocuSeal is an open source platform that provides secure and efficient digital document signing and processing. Create PDF forms to have them filled and signed online on any device with an easy-to-use, mobile-optimized web tool.
</p>
<h2 align="center">
<a href="https://demo.docuseal.co">✨ Live Demo</a>
<span>|</span>
<a href="https://docuseal.co/sign_up">☁️ Try in Cloud</a>
</h2>
[](https://demo.docuseal.co)
## Features
- [x] PDF form fields builder (WYSIWYG)
- [x] 10 field types available (Signature, Date, File, Checkbox etc.)
- [x] Multiple submitters per document
- [x] Automated emails via SMTP
- [x] Files storage on AWS S3, Google Storage, or Azure
- [x] Automatic PDF eSignature
- [x] PDF signature verification
- [x] Users management
- [x] Mobile-optimized
- [x] Easy to deploy in minutes
## Deploy
|Heroku|Railway|
|:--:|:---:|
| [<img alt="Deploy on Heroku" src="https://www.herokucdn.com/deploy/button.svg" height="40">](https://heroku.com/deploy?template=https://github.com/docusealco/docuseal-heroku) | [<img alt="Deploy on Railway" src="https://railway.app/button.svg" height="40">](https://railway.app/template/IGoDnc?referralCode=ruU7JR)|
|**DigitalOcean**|**Render**|
| [<img alt="Deploy on DigitalOcean" src="https://www.deploytodo.com/do-btn-blue.svg" height="40">](https://cloud.digitalocean.com/apps/new?repo=https://github.com/docusealco/docuseal-digitalocean/tree/master&refcode=421d50f53990) | [<img alt="Deploy to Render" src="https://render.com/images/deploy-to-render-button.svg" height="40">](https://render.com/deploy?repo=https://github.com/docusealco/docuseal-render)
#### Docker
```sh
docker run --name docuseal -p 3000:3000 -v.:/data docuseal/docuseal
```
By default DocuSeal docker container uses an SQLite database to store data and configurations. Alternatively, it is possible use PostgreSQL or MySQL databases by specifying the `DATABASE_URL` env variable.
#### Docker Compose
Download docker-compose.yml into your private server:
```sh
curl https://raw.githubusercontent.com/docusealco/docuseal/master/docker-compose.yml > docker-compose.yml
```
Run the app under a custom domain over https using docker compose (make sure your DNS points to the server to automatically issue ssl certs with Caddy):
```sh
HOST=your-domain-name.com docker-compose up
```
## For Companies
### Integrate seamless document signing into your web or mobile apps with DocuSeal!
At DocuSeal we have expertise and technologies to make documents creation, filling, signing and processing seamlessly integrated with your product. We specialize in working with various industries, including **Banking, Healthcare, Transport, eCommerce, KYC, CRM, and other software products** that require bulk document signing. By leveraging DocuSeal, we can assist in reducing the overall cost of developing and processing electronic documents while ensuring security and compliance with local electronic document laws.
[](https://cal.com/docuseal)
## License
DocuSeal is released under the GNU Affero General Public License v3.0.
|
lifeisboringsoprogramming/sd-webui-xldemo-txt2img
|
https://github.com/lifeisboringsoprogramming/sd-webui-xldemo-txt2img
|
Stable Diffusion XL 0.9 Demo webui extension
|
# Stable Diffusion XL 0.9 txt2img webui extension
<img src="images/webui.png">
A custom extension for [AUTOMATIC1111/stable-diffusion-webui](https://github.com/AUTOMATIC1111/stable-diffusion-webui) that demo the SDXL 0.9 txt2img features
# Tested environment
* GPU: RTX 3060 12G VRAM
* OS: Ubuntu 20.04.4 LTS, Windows 10
* RAM: 64G
* Automatic1111 WebUI version: v1.4.0
* python: 3.10.9
* torch: 2.0.1+cu118
* xformers: 0.0.20
* gradio: 3.32.0
* checkpoint: 20af92d769
# Overview
* This project allows users to do txt2img using the SDXL 0.9 base checkpoint
* Refine image using SDXL 0.9 refiner checkpoint
* Setting samplers
* Setting sampling steps
* Setting image width and height
* Setting batch size
* Setting CFG Scale
* Setting seed
* Reuse seed
* Use refiner
* Setting refiner strength
* Send to img2img
* Send to inpaint
* Send to extras
# Tutorial
There is a video to show how to use the extension
[](https://www.youtube.com/watch?v=iF4w7gFDaYM)
# Stable Diffusion extension
This project can be run as a stable Diffusion extension inside the Stable Diffusion WebUI.
## Installation for stable Diffusion extension
* Copy and paste `https://github.com/lifeisboringsoprogramming/sd-webui-xldemo-txt2img.git` to URL for extension's git repository
* Press Install button
* Apply and restart UI when finished installing
<img src="images/webui-install.png" />
# Samplers mapping
|Sampler name|Diffusers schedulers class|
|---|---|
|dpmsolver_multistep|diffusers.schedulers.scheduling_dpmsolver_multistep.DPMSolverMultistepScheduler|
|deis_multistep|diffusers.schedulers.scheduling_deis_multistep.DEISMultistepScheduler|
|unipc_multistep|diffusers.schedulers.scheduling_unipc_multistep.UniPCMultistepScheduler|
|k_dpm_2_ancestral_discrete|diffusers.schedulers.scheduling_k_dpm_2_ancestral_discrete.KDPM2AncestralDiscreteScheduler|
|ddim|diffusers.schedulers.scheduling_ddim.DDIMScheduler|
|dpmsolver_singlestep|diffusers.schedulers.scheduling_dpmsolver_singlestep.DPMSolverSinglestepScheduler|
|euler_ancestral_discrete|diffusers.schedulers.scheduling_euler_ancestral_discrete.EulerAncestralDiscreteScheduler|
|ddpm|diffusers.schedulers.scheduling_ddpm.DDPMScheduler|
|euler_discrete|diffusers.schedulers.scheduling_euler_discrete.EulerDiscreteScheduler|
|k_dpm_2_discrete|diffusers.schedulers.scheduling_k_dpm_2_discrete.KDPM2DiscreteScheduler|
|pndm|diffusers.schedulers.scheduling_pndm.PNDMScheduler|
|dpmsolver_sde|diffusers.schedulers.scheduling_dpmsolver_sde.DPMSolverSDEScheduler|
|lms_discrete|diffusers.schedulers.scheduling_lms_discrete.LMSDiscreteScheduler|
|heun_discrete|diffusers.schedulers.scheduling_heun_discrete.HeunDiscreteScheduler|
# Limitations
* this extension does not work with other extension like control net
* this extension does not work with LoRA, textual inversion embeddings, etc
# YouTube Channel
Please subscribe to my YouTube channel, thank you very much.
[https://bit.ly/3odzTKX](https://bit.ly/3odzTKX)
# Patreon
☕️ Please consider to support me in Patreon 🍻
[https://www.patreon.com/lifeisboringsoprogramming](https://www.patreon.com/lifeisboringsoprogramming)
|
sluicebox/sci-scripts
|
https://github.com/sluicebox/sci-scripts
| null |
# Sierra Creative Interpeter - Scripts
This repository contains decompiled scripts for Sierra's SCI games.
- All games: King's Quest IV (1988) - Leisure Suit Larry 7 (1996)
- All platforms: DOS, Amiga, Atari ST, Macintosh, PC-98, FM-Towns, Windows
- All scripts: 100% decompiled
- Allotta versions: 300+
Scripts are the code that make up each game. The originals were written in Sierra's proprietary programming language and compiled to bytecode. The scripts in this repository are generated from that bytecode by my decompiler and heavily auto-annotated for readability. If you're familiar with a game, you should recognize a lot. If you want to learn how a game's puzzle works (or *doesn't*) then try searching for nearby game text.
## How Do I Use These?
The code is in the `.sc` text files. If you just want to casually browse, you can ignore everything else. But if you're serious...
The best way to view scripts is with SCI Companion, a Windows program that lets you view resources and create games. You will also need the game. Find your version in this repository and copy the files to your game directory. Open the game with SCI Companion and it will recognize the scripts as if it had generated them. SCI Companion doesn't support every game and version, but it works with most.
- SCI Companion site: http://scicompanion.com/
- SCI Companion repo, has newer code than the site: https://github.com/icefallgames/SCICompanion/
- SCI Companion fork, has nightly builds: https://github.com/Kawa-oneechan/SCICompanion/
## Can I Compile These?
Maybe! If SCI Companion fully supports the game, then it can compile most scripts. You may need to fix a Sierra bug or two, or make some other adjustments to make SCI Companion happy. My goal is to show what's really going on in the scripts, bugs and all.
## What Are The Files?
- `*.sc`: Script files
- `*.sco`: Script object files that SCI Companion needs for compiling
- `src`: SCI Companion needs `.sc` and `.sco` files to be in this directory
- `game.ini`: SCI Companion needs this file to find the scripts
If you don't care about compiling, you don't need the `.sco` files. If you don't use SCI Companion, you only need the `.sc` files.
## Why All English?
Localized text has been replaced with the original English for script diffing. How else will you find Italian Phantasmagoria's exclusive bug fixes? Or the not-so-temporary test code that ruins Spanish EcoQuest?
## Whodunnit?
This repository is dedicated to every Sierra reverse engineer from the past 35 years. And Sierra's real engineers too. You're all insane! And you all made this possible!
## Tell Me More
- https://www.benshoof.org/blog/sci-scripts
- https://mtnphil.wordpress.com/2016/04/09/decompiling-sci-byte-code-part-1/
- https://mtnphil.wordpress.com/2016/04/09/decompiling-sci-part-2-control-flow/
- https://mtnphil.wordpress.com/2016/04/09/decompiling-sci-part-3-instruction-consumption/
- https://mtnphil.wordpress.com/2016/04/09/decompiling-sci-part-4-final-steps/
## SCI Games
| | |
|-----------------|--------------------------------------------------------------------------------|
|`brain1` | The Castle of Dr. Brain |
|`brain2` | The Island of Dr. Brain |
|`camelot` | Conquests of Camelot |
|`cb` | The Colonel's Bequest |
|`cnick` | Crazy Nick's Software Picks |
|`eco1` | EcoQuest: The Search for Cetus |
|`eco2` | EcoQuest II: Lost Secret of the Rainforest |
|`fairytales` | Mixed-Up Fairy Tales |
|`fpfp` | Freddy Pharkas: Frontier Pharmacist |
|`gk1` | Gabriel Knight: Sins of the Father |
|`gk2` | Gabriel Knight 2: The Beast Within |
|`goose` | Mixed-Up Mother Goose (SCI Remake) |
|`goosevga` | Mixed-Up Mother Goose (VGA Remake) |
|`goosedeluxe` | Mixed-Up Mother Goose Deluxe |
|`hoyle1` | Hoyle's Official Book of Games: Volume 1 |
|`hoyle2` | Hoyle's Official Book of Games: Volume 2 |
|`hoyle3` | Hoyle's Official Book of Games: Volume 3 |
|`hoyle4` | Hoyle Classic Card Games |
|`hoyle5` | Hoyle Classic Games |
|`hoyle5solitaire`| Hoyle Solitaire |
|`iceman` | Codename: ICEMAN |
|`jones` | Jones in the Fast Lane |
|`kq1` | King's Quest: Quest for the Crown (SCI Remake) |
|`kq4` | King's Quest IV: The Perils of Rosella |
|`kq5` | King's Quest V: Absence Makes the Heart Go Yonder |
|`kq6` | King's Quest VI: Heir Today, Gone Tomorrow |
|`kq7` | King's Quest VII: The Princeless Bride |
|`lighthouse` | Lighthouse: The Dark Being |
|`longbow` | Conquests of the Longbow |
|`lsl1` | Leisure Suit Larry in the Land of the Lounge Lizards (SCI Remake) |
|`lsl2` | Leisure Suit Larry Goes Looking for Love (in Several Wrong Places) |
|`lsl3` | Leisure Suit Larry 3: Passionate Patti in Pursuit of the Pulsating Pectorals |
|`lsl5` | Leisure Suit Larry 5: Passionate Patti Does a Little Undercover Work |
|`lsl6` | Leisure Suit Larry 6: Shape Up or Slip Out |
|`lsl7` | Leisure Suit Larry 7: Love for Sail |
|`pepper` | Pepper's Adventures in Time |
|`phant1` | Phantasmagoria |
|`phant2` | Phantasmagoria 2: A Puzzle of Flesh |
|`pq1` | Police Quest: In Pursuit of the Death Angel (SCI Remake) |
|`pq2` | Police Quest II: The Vengeance |
|`pq3` | Police Quest III: The Kindred |
|`pq4` | Police Quest IV: Open Season |
|`pqswat` | Police Quest: SWAT |
|`qfg1` | Quest for Glory: So You Want to Be a Hero |
|`qfg1vga` | Quest for Glory: So You Want to Be a Hero (VGA Remake) |
|`qfg2` | Quest for Glory II: Trial by Fire |
|`qfg3` | Quest for Glory III: Wages of War |
|`qfg4` | Quest for Glory IV: Shadows of Darkness |
|`ra` | The Dagger of Amon Ra |
|`rama` | RAMA |
|`shivers` | Shivers |
|`slater` | Slater & Charlie Go Camping |
|`sq1` | Space Quest I: Roger Wilco in the Sarien Encounter (SCI Remake) |
|`sq3` | Space Quest III: The Pirates of Pestulon |
|`sq4` | Space Quest IV: Roger Wilco and the Time Rippers |
|`sq5` | Space Quest V: The Next Mutation |
|`sq6` | Space Quest 6: The Spinal Frontier |
|`torin` | Torin's Passage |
|
MLGroupJLU/LLM-eval-survey
|
https://github.com/MLGroupJLU/LLM-eval-survey
|
The official GitHub page for the survey paper "A Survey on Evaluation of Large Language Models".
|
<div align="center">
<img src="imgs/logo-llmeval.png" alt="LLM evaluation" width="500"><br>
A collection of papers and resources related to evaluations on large language models.
</div>
<br>
<p align="center">
Yupeng Chang<sup>*1</sup>  
Xu Wang<sup>*1</sup>  
Jindong Wang<sup>#2</sup>  
Yuan Wu<sup>#1</sup>  
Kaijie Zhu<sup>3</sup>  
Hao Chen<sup>4</sup>  
Linyi Yang<sup>5</sup>  
Xiaoyuan Yi<sup>2</sup>  
Cunxiang Wang<sup>5</sup>  
Yidong Wang<sup>6</sup>  
Wei Ye<sup>6</sup>  
Yue Zhang<sup>5</sup>  
Yi Chang<sup>1</sup>  
Philip S. Yu<sup>7</sup>  
Qiang Yang<sup>8</sup>  
Xing Xie<sup>2</sup>
</p>
<p align="center">
<sup>1</sup> Jilin University,
<sup>2</sup> Microsoft Research,
<sup>3</sup> Institute of Automation, CAS
<sup>4</sup> Carnegie Mellon University,
<sup>5</sup> Westlake University,
<sup>6</sup> Peking University,
<sup>7</sup> University of Illinois,
<sup>8</sup> Hong Kong University of Science and Technology<br>
(*: Co-first authors, #: Co-corresponding authors)
</p>
# Papers and resources for LLMs evaluation
The papers are organized according to our survey: [A Survey on Evaluation of Large Language Models](https://arxiv.org/abs/2307.03109).
**NOTE:** As we cannot update the arXiv paper in real time, please refer to this repo for the latest updates and the paper may be updated later. We also welcome any pull request or issues to help us make this survey perfect. Your contributions will be acknowledged in <a href="#acknowledgements">acknowledgements</a>.
Related projects:
- Prompt benchmark for large language models: [[PromptBench: robustness evaluation of LLMs](https://github.com/microsoft/promptbench)]
- Evlauation of large language models: [[LLM-eval](https://llm-eval.github.io/)]

<details>
<summary>Table of Contents</summary>
<ol>
<li><a href="#news-and-updates">News and Updates</a></li>
<li>
<a href="#what-to-evaluate">What to evaluate</a>
<ul>
<li><a href="#natural-language-processing">Natural language processing</a></li>
<li><a href="#robustness-ethics-biases-and-trustworthiness">Robustness, ethics, biases, and trustworthiness</a></li>
<li><a href="#social-science">Social science</a></li>
<li><a href="#natural-science-and-engineering">Natural science and engineering</a></li>
<li><a href="#medical-applications">Medical applications</a></li>
<li><a href="#agent-applications">Agent applications</a></li>
<li><a href="#other-applications">Other applications</a></li>
</ul>
</li>
<li><a href="where-to-evaluate">Where to evaluate</a></li>
<li><a href="#Contributing">Contributing</a></li>
<li><a href="#citation">Citation</a></li>
<li><a href="#acknowledgements">Acknowledgments</a></li>
</ol>
</details>
## News and updates
- [12/07/2023] The second version of the paper is released on arXiv, along with [Chinese blog](https://zhuanlan.zhihu.com/p/642689101).
- [07/07/2023] The first version of the paper is released on arXiv: [A Survey on Evaluation of Large Language Models](https://arxiv.org/abs/2307.03109).
## What to evaluate
### Natural language processing
#### Natural language understanding
##### Sentiment analysis
1. A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity. _Yejin Bang et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2302.04023)]
2. A Systematic Study and Comprehensive Evaluation of ChatGPT on Benchmark Datasets, _Laskar et al._ ACL 2023 (Findings). [[paper](https://arxiv.org/abs/2305.18486)]
3. Holistic Evaluation of Language Models. _Percy Liang et al._ arXiv 2022. [[paper](https://arxiv.org/abs/2211.09110)]
4. Can ChatGPT forecast stock price movements? return predictability and large language models. _Alejandro Lopez-Lira et al._ SSRN 2023. [[paper](https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4412788)]
5. Is ChatGPT a general-purpose natural language processing task solver? _Chengwei Qin et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2302.06476)]
6. Is ChatGPT a Good Sentiment Analyzer? A Preliminary Study. _Zengzhi Wang et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2304.04339)]
7. Sentiment analysis in the era of large language models: A reality check. _Wenxuan Zhang et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2305.15005)]
##### Text classification
1. Holistic evaluation of language models. _Percy Liang et al._ arXiv 2022. [[paper](https://arxiv.org/abs/2211.09110)]
2. Leveraging large language models for topic classification in the domain of public affairs. _Alejandro Peña et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.02864)]
3. Large language models can rate news outlet credibility. _Kai-Cheng Yang et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2304.00228)]
##### Natural language inference
1. A Systematic Study and Comprehensive Evaluation of ChatGPT on Benchmark Datasets, _Laskar et al._ ACL 2023 (Findings). [[paper](https://arxiv.org/abs/2305.18486)]
2. Can Large Language Models Infer and Disagree like Humans? _Noah Lee et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2305.13788)]
3. Is ChatGPT a general-purpose natural language processing task solver? _Chengwei Qin et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2302.06476)]
##### Others
1. Do LLMs Understand Social Knowledge? Evaluating the Sociability of Large Language Models with SocKET Benchmark. _Minje Choi et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2305.14938)]
2. The two word test: A semantic benchmark for large language models. _Nicholas Riccardi et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.04610)]
3. EvEval: A Comprehensive Evaluation of Event Semantics for Large Language Models. _Zhengwei Tao et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2305.15268)]
#### Reasoning
1. A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity. _Yejin Bang et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2302.04023)]
2. ChatGPT is a knowledgeable but inexperienced solver: An investigation of commonsense problem in large language models. _Ning Bian et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2303.16421)]
3. Chain-of-Thought Hub: A continuous effort to measure large language models' reasoning performance. _Yao Fu et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2305.17306)]
4. A Systematic Study and Comprehensive Evaluation of ChatGPT on Benchmark Datasets, _Laskar et al._ ACL 2023 (Findings). [[paper](https://arxiv.org/abs/2305.18486)]
5. Can large language models reason about medical questions? _Valentin Liévin et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2207.08143)]
6. Evaluating the Logical Reasoning Ability of ChatGPT and GPT-4. _Hanmeng Liu et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2304.03439)]
7. Mathematical Capabilities of ChatGPT. _Simon Frieder et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2301.13867)]
8. Human-like problem-solving abilities in large language models using ChatGPT. _Graziella Orrù et al._ Front. Artif. Intell. 2023 [[paper](https://www.frontiersin.org/articles/10.3389/frai.2023.1199350/full)]
9. Is ChatGPT a general-purpose natural language processing task solver? _Chengwei Qin et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2302.06476)]
10. Testing the general deductive reasoning capacity of large language models using OOD examples. _Abulhair Saparov et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2305.15269)]
11. MindGames: Targeting Theory of Mind in Large Language Models with Dynamic Epistemic Modal Logic. _Damien Sileo et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2305.03353)]
12. Reasoning or Reciting? Exploring the Capabilities and Limitations of Language Models Through Counterfactual Tasks. _Zhaofeng Wu_ arXiv 2023. [[paper](https://arxiv.org/abs/2307.02477?utm_source=tldrai)]
13. Are large language models really good logical reasoners? a comprehensive evaluation from deductive, inductive and abductive views. _Fangzhi Xu et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.09841)]
14. Efficiently Measuring the Cognitive Ability of LLMs: An Adaptive Testing Perspective. _Yan Zhuang et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.10512)]
#### Natural language generation
##### Summarization
1. A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity. _Yejin Bang et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2302.04023)]
2. A Systematic Study and Comprehensive Evaluation of ChatGPT on Benchmark Datasets, _Laskar et al._ ACL 2023 (Findings). [[paper](https://arxiv.org/abs/2305.18486)]
3. Holistic Evaluation of Language Models. _Percy Liang et al._ arXiv 2022. [[paper](https://arxiv.org/abs/2211.09110)]
4. ChatGPT vs Human-authored text: Insights into controllable text summarization and sentence style transfer. _Dongqi Pu et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.07799)]
5. Is ChatGPT a general-purpose natural language processing task solver? _Chengwei Qin et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2302.06476)]
##### Dialogue
1. A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity. _Yejin Bang et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2302.04023)]
2. LLM-Eval: Unified Multi-Dimensional Automatic Evaluation for Open-Domain Conversations with Large Language Models. _Yen-Ting Lin et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2305.13711)]
3. Is ChatGPT a general-purpose natural language processing task solver? _Chengwei Qin et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2302.06476)]
##### Translation
1. A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity. _Yejin Bang et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2302.04023)]
2. A Systematic Study and Comprehensive Evaluation of ChatGPT on Benchmark Datasets, _Laskar et al._ ACL 2023 (Findings). [[paper](https://arxiv.org/abs/2305.18486)]
3. Translating Radiology Reports into Plain Language using ChatGPT and GPT-4 with Prompt Learning: Promising Results, Limitations, and Potential. _Qing Lyu et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2303.09038)]
4. Document-Level Machine Translation with Large Language Models. _Longyue Wang et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2304.02210)]
5. Case Study of Improving English-Arabic Translation Using the Transformer Model. _Donia Gamal et al._ ijicis 2023. [[paper](https://ijicis.journals.ekb.eg/article_305271.html)]
6. Taqyim: Evaluating Arabic NLP Tasks Using ChatGPT Models. _Zaid Alyafeai et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.16322)]
##### Question answering
1. Benchmarking Foundation Models with Language-Model-as-an-Examiner. _Yushi Bai et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.04181)]
2. A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity. _Yejin Bang et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2302.04023)]
3. ChatGPT is a knowledgeable but inexperienced solver: An investigation of commonsense problem in large language models. _Ning Bian et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2303.16421)]
4. A Systematic Study and Comprehensive Evaluation of ChatGPT on Benchmark Datasets, _Laskar et al._ ACL 2023 (Findings). [[paper](https://arxiv.org/abs/2305.18486)]
5. Holistic Evaluation of Language Models. _Percy Liang et al._ arXiv 2022. [[paper](https://arxiv.org/abs/2211.09110)]
6. Is ChatGPT a general-purpose natural language processing task solver? _Chengwei Qin et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2302.06476)]
##### Others
1. Exploring the use of large language models for reference-free text quality evaluation: A preliminary empirical study. _Yi Chen et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2304.00723)]
2. INSTRUCTEVAL: Towards Holistic Evaluation of Instruction-Tuned Large Language Models. _Yew Ken Chia et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.04757)]
3. ChatGPT vs Human-authored Text: Insights into Controllable Text Summarization and Sentence Style Transfer. _Dongqi Pu et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.07799)]
#### Multilingual tasks
1. Benchmarking Arabic AI with large language models. _Ahmed Abdelali et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2305.14982)]
2. MEGA: Multilingual Evaluation of Generative AI. _Kabir Ahuja et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2303.12528)]
3. A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity. _Yejin Bang et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2302.04023)]
4. ChatGPT beyond English: Towards a comprehensive evaluation of large language models in multilingual learning. _Viet Dac Lai et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2304.05613)]
5. A Systematic Study and Comprehensive Evaluation of ChatGPT on Benchmark Datasets, _Laskar et al._ ACL 2023 (Findings). [[paper](https://arxiv.org/abs/2305.18486)]
6. M3Exam: A Multilingual, Multimodal, Multilevel Benchmark for Examining Large Language Models. _Wenxuan Zhang et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.05179)]
#### Factuality
1. TrueTeacher: Learning Factual Consistency Evaluation with Large Language Models. _Zorik Gekhman et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2305.11171)]
2. TRUE: Re-evaluating Factual Consistency Evaluation. _Or Honovich et al._ arXiv 2022. [[paper](https://arxiv.org/abs/2204.04991)]
3. SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models. _Potsawee Manakul et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2303.08896)]
4. FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation. _Sewon Min et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2305.14251)]
5. Measuring and Modifying Factual Knowledge in Large Language Models. _Pouya Pezeshkpour_ arXiv 2023. [[paper](https://arxiv.org/abs/2306.06264)]
6. Evaluating Open Question Answering Evaluation. _Cunxiang Wang et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2305.12421)]
### Robustness, ethics, biases, and trustworthiness
#### Robustness
1. A Survey on Out-of-Distribution Evaluation of Neural NLP Models. _Xinzhe Li et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.15261)]
2. Generalizing to Unseen Domains: A Survey on Domain Generalization. _Jindong Wang et al._ TKDE 2022. [[paper](https://arxiv.org/abs/2103.03097)]
3. On the Robustness of ChatGPT: An Adversarial and Out-of-distribution Perspective. _Jindong Wang et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2302.12095)]
4. GLUE-X: Evaluating Natural Language Understanding Models from an Out-of-Distribution Generalization Perspective. _Linyi Yang et al._ arXiv 2022. [[paper](https://arxiv.org/abs/2211.08073)]
5. On Evaluating Adversarial Robustness of Large Vision-Language Models. _Yunqing Zhao et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2305.16934)]
6. PromptBench: Towards Evaluating the Robustness of Large Language Models on Adversarial Prompts. _Kaijie Zhu et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.04528)]
7. On Robustness of Prompt-based Semantic Parsing with Large Pre-trained Language Model: An Empirical Study on Codex. _Terry Yue Zhuo et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2301.12868)]
#### Ethics and bias
1. Assessing Cross-Cultural Alignment between ChatGPT and Human Societies: An Empirical Study. _Yong Cao et al._ C3NLP@EACL 2023. [[paper](https://arxiv.org/abs/2303.17466)]
2. Toxicity in ChatGPT: Analyzing persona-assigned language models. _Ameet Deshpande et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2304.05335)]
3. BOLD: Dataset and Metrics for Measuring Biases in Open-Ended Language Generation. _Jwala Dhamala et al._ FAccT 2021 [[paper](https://dl.acm.org/doi/10.1145/3442188.3445924)]
4. Should ChatGPT be Biased? Challenges and Risks of Bias in Large Language Models. _Emilio Ferrara_ arXiv 2023. [[paper](https://arxiv.org/abs/2304.03738)]
5. RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models. _Samuel Gehman et al._ EMNLP 2020. [[paper](https://aclanthology.org/2020.findings-emnlp.301/)]
6. The political ideology of conversational AI: Converging evidence on ChatGPT's pro-environmental, left-libertarian orientation. _Jochen Hartmann et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2301.01768)]
7. A Systematic Study and Comprehensive Evaluation of ChatGPT on Benchmark Datasets, _Laskar et al._ ACL 2023 (Findings). [[paper](https://arxiv.org/abs/2305.18486)]
8. BBQ: A hand-built bias benchmark for question answering. _Alicia Parrish et al._ ACL 2022. [[paper](https://aclanthology.org/2022.findings-acl.165/)]
9. The Self-Perception and Political Biases of ChatGPT. _Jérôme Rutinowski et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2304.07333)]
10. Societal Biases in Language Generation: Progress and Challenges. _Emily Sheng et al._ ACL-IJCNLP 2021. [[paper](https://aclanthology.org/2021.acl-long.330/)]
11. Moral Mimicry: Large Language Models Produce Moral Rationalizations Tailored to Political Identity. _Gabriel Simmons et al._ arXiv 2022. [[paper](https://arxiv.org/abs/2209.12106)]
12. Large Language Models are not Fair Evaluators. _Peiyi Wang et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2305.17926)]
13. Exploring AI Ethics of ChatGPT: A Diagnostic Analysis. _Terry Yue Zhuo et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2301.12867)]
#### Trustworthiness
1. Human-Like Intuitive Behavior and Reasoning Biases Emerged in Language Models -- and Disappeared in GPT-4. _Thilo Hagendorff et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.07622)]
2. DecodingTrust: A Comprehensive Assessment of Trustworthiness in GPT Models. _Boxin Wang et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.11698)]
### Social science
1. How ready are pre-trained abstractive models and LLMs for legal case judgement summarization. _Aniket Deroy et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.01248)]
2. Baby steps in evaluating the capacities of large language models. _Michael C. Frank_ Nature Reviews Psychology 2023. [[paper](https://www.nature.com/articles/s44159-023-00211-x)]
3. Large Language Models as Tax Attorneys: A Case Study in Legal Capabilities Emergence. _John J. Nay et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.07075)]
4. Large language models can be used to estimate the ideologies of politicians in a zero-shot learning setting. _Patrick Y. Wu et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2303.12057)]
5. Can large language models transform computational social science? _Caleb Ziems et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2305.03514)]
### Natural science and engineering
#### Mathematics
1. Have LLMs Advanced Enough? A Challenging Problem Solving Benchmark for Large Language Models. _Daman Arora et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2305.15074)]
2. Sparks of Artificial General Intelligence: Early experiments with GPT-4. _Sébastien Bubeck et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2303.12712)]
3. Evaluating Language Models for Mathematics through Interactions. _Katherine M. Collins et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.01694)]
4. Investigating the effectiveness of ChatGPT in mathematical reasoning and problem solving: Evidence from the Vietnamese national high school graduation examination. _Xuan-Quy Dao et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.06331)]
5. A Systematic Study and Comprehensive Evaluation of ChatGPT on Benchmark Datasets, _Laskar et al._ ACL 2023 (Findings). [[paper](https://arxiv.org/abs/2305.18486)]
6. CMATH: Can Your Language Model Pass Chinese Elementary School Math Test? _Tianwen Wei et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.16636)]
7. An empirical study on challenging math problem solving with GPT-4. _Yiran Wu et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.01337)]
8. How well do Large Language Models perform in Arithmetic Tasks? _Zheng Yuan et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2304.02015)]
#### General science
1. Have LLMs Advanced Enough? A Challenging Problem Solving Benchmark for Large Language Models. _Daman Arora et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2305.15074)]
2. Do Large Language Models Understand Chemistry? A Conversation with ChatGPT. _Castro Nascimento CM et al._ JCIM 2023. [[paper](https://pubs.acs.org/doi/10.1021/acs.jcim.3c00285)]
3. What indeed can GPT models do in chemistry? A comprehensive benchmark on eight tasks. _Taicheng Guo et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2305.18365)][[GitHub](https://github.com/ChemFoundationModels/ChemLLMBench)]
#### Engineering
1. Sparks of Artificial General Intelligence: Early Experiments with GPT-4. _Sébastien Bubeck et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2303.12712)]
2. Is your code generated by ChatGPT really correct? Rigorous evaluation of large language models for code generation. _Jiawei Liu et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2305.01210)]
3. Understanding the Capabilities of Large Language Models for Automated Planning. _Vishal Pallagani et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2305.16151)]
4. ChatGPT: A study on its utility for ubiquitous software engineering tasks. _Giriprasad Sridhara et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2305.16837)]
5. Large language models still can't plan (A benchmark for LLMs on planning and reasoning about change). _Karthik Valmeekam et al._ arXiv 2022. [[paper](https://arxiv.org/abs/2206.10498)]
6. On the Planning Abilities of Large Language Models – A Critical Investigation. _Karthik Valmeekam et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2302.06706)]
7. Efficiently Measuring the Cognitive Ability of LLMs: An Adaptive Testing Perspective. _Yan Zhuang et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.10512)]
### Medical applications
#### Medical Queries
1. The promise and peril of using a large language model to obtain clinical information: ChatGPT performs strongly as a fertility counseling tool with limitation. _Joseph Chervenak M.D. et al._ Fertility and Sterility 2023. [[paper](https://www.sciencedirect.com/science/article/pii/S0015028223005228)]
2. Analysis of large-language model versus human performance for genetics questions. _Dat Duong et al._ European Journal of Human Genetics 2023. [[paper](https://www.nature.com/articles/s41431-023-01396-8)]
3. Evaluation of AI Chatbots for Patient-Specific EHR Questions. _Alaleh Hamidi et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.02549)]
4. Evaluating Large Language Models on a Highly-specialized Topic, Radiation Oncology Physics. _Jason Holmes et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2304.01938)]
5. Evaluation of ChatGPT on Biomedical Tasks: A Zero-Shot Comparison with Fine-Tuned Generative Transformers. _Israt Jahan et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.04504)]
6. Assessing the Accuracy and Reliability of AI-Generated Medical Responses: An Evaluation of the Chat-GPT Model. _Douglas Johnson et al._ Residential Square 2023. [[paper](https://pubmed.ncbi.nlm.nih.gov/36909565/)]
7. Assessing the Accuracy of Responses by the Language Model ChatGPT to Questions Regarding Bariatric Surgery. _Jamil S. Samaan et al._ Obesity Surgery 2023. [[paper](https://link.springer.com/article/10.1007/s11695-023-06603-5)]
8. Trialling a Large Language Model (ChatGPT) in General Practice With the Applied Knowledge Test: Observational Study Demonstrating Opportunities and Limitations in Primary Care. _Arun James Thirunavukarasu et al._ JMIR Med Educ. 2023. [[paper](https://pubmed.ncbi.nlm.nih.gov/37083633/)]
9. CARE-MI: Chinese Benchmark for Misinformation Evaluation in Maternity and Infant Care. _Tong Xiang et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2307.01458)]
#### Medical examination
1. How Does ChatGPT Perform on the United States Medical Licensing Examination? The Implications of Large Language Models for Medical Education and Knowledge Assessment. _Aidan Gilson et al._ JMIR Med Educ. 2023. [[paper](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9947764/)]
2. Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models. _Tiffany H. Kung et al._ PLOS Digit Health. 2023. [[paper](https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9931230/)]
#### Medical assistants
1. Evaluating the feasibility of ChatGPT in healthcare: an analysis of multiple clinical and research scenarios. _Marco Cascella et al._ Journal of Medical Systems 2023. [[paper](https://link.springer.com/article/10.1007/s10916-023-01925-4)]
2. covLLM: Large Language Models for COVID-19 Biomedical Literature. _Yousuf A. Khan et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.04926)]
3. Evaluating the use of large language model in identifying top research questions in gastroenterology. _Adi Lahat et al._ Scientific reports 2023. [[paper](https://www.nature.com/articles/s41598-023-31412-2)]
4. Translating Radiology Reports into Plain Language using ChatGPT and GPT-4 with Prompt Learning: Promising Results, Limitations, and Potential. _Qing Lyu et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2303.09038)]
5. ChatGPT goes to the operating room: Evaluating GPT-4 performance and its potential in surgical education and training in the era of large language models. _Namkee Oh et al._ Ann Surg Treat Res. 2023. [[paper](https://pubmed.ncbi.nlm.nih.gov/37179699/)]
6. Can LLMs like GPT-4 outperform traditional AI tools in dementia diagnosis? Maybe, but not today. _Zhuo Wang et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.01499)]
### Agent applications
1. Language Is Not All You Need: Aligning Perception with Language Models. _Shaohan Huang et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2302.14045)]
2. MRKL Systems: A modular, neuro-symbolic architecture that combines large language models, external knowledge sources and discrete reasoning. _Ehud Karpas et al._ [[paper](https://arxiv.org/abs/2205.00445)]
3. The Unsurprising Effectiveness of Pre-Trained Vision Models for Control. _Simone Parisi et al._ ICMl 2022. [[paper](https://arxiv.org/abs/2203.03580)]
4. Toolformer: Language Models Can Teach Themselves to Use Tools. _Timo Schick et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2302.04761)]
5. HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face. _Yongliang Shen et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2303.17580)]
### Other applications
#### Education
1. Can Large Language Models Provide Feedback to Students? A Case Study on ChatGPT. _Wei Dai et al._ ICALT 2023. [[paper](https://edarxiv.org/hcgzj/)]
2. Can ChatGPT pass high school exams on English Language Comprehension? _Joost de Winter_ Researchgate. [[paper](https://www.researchgate.net/publication/366659237_Can_ChatGPT_pass_high_school_exams_on_English_Language_Comprehension)]
3. Exploring the Responses of Large Language Models to Beginner Programmers' Help Requests. _Arto Hellas et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.05715)]
4. Is ChatGPT a Good Teacher Coach? Measuring Zero-Shot Performance For Scoring and Providing Actionable Insights on Classroom Instruction. _Rose E. Wang et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.03090)]
5. CMATH: Can Your Language Model Pass Chinese Elementary School Math Test? _Tianwen Wei et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.16636)]
#### Search and recommendation
1. Uncovering ChatGPT's Capabilities in Recommender Systems. _Sunhao Dai et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2305.02182)]
2. Recommender Systems in the Era of Large Language Models (LLMs). _Wenqi Fan et al._ Researchgate. [[paper](https://www.researchgate.net/publication/372137006_Recommender_Systems_in_the_Era_of_Large_Language_Models_LLMs)]
3. Exploring the Upper Limits of Text-Based Collaborative Filtering Using Large Language Models: Discoveries and Insights. _Ruyu Li et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2305.11700)]
4. Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agent. _Weiwei Sun et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2304.09542)]
5. ChatGPT vs. Google: A Comparative Study of Search Performance and User Experience. _Ruiyun Xu et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2307.01135)]
6. Where to Go Next for Recommender Systems? ID- vs. Modality-based Recommender Models Revisited. _Zheng Yuan et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2303.13835)]
7. Is ChatGPT Fair for Recommendation? Evaluating Fairness in Large Language Model Recommendation. _Jizhi Zhang et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2305.07609)]
#### Personality testing
1. ChatGPT is fun, but it is not funny! Humor is still challenging Large Language Models. _Sophie Jentzsch et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.04563)]
2. Personality Traits in Large Language Models. _Mustafa Safdari et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2307.00184)]
3. Have Large Language Models Developed a Personality?: Applicability of Self-Assessment Tests in Measuring Personality in LLMs. _Xiaoyang Song et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2305.14693)]
4. Emotional Intelligence of Large Language Models. _Xuena Wang et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2307.09042)]
#### Specific tasks
1. ChatGPT and Other Large Language Models as Evolutionary Engines for Online Interactive Collaborative Game Design. _Pier Luca Lanzi et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2303.02155)]
2. An Evaluation of Log Parsing with ChatGPT. _Van-Hoang Le et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.01590)]
3. PandaLM: An Automatic Evaluation Benchmark for LLM Instruction Tuning Optimization. _Yidong Wang et al._ arXiv 2023. [[paper](https://arxiv.org/abs/2306.05087)]
## Where to evaluate
The paper lists several popular benchmarks. For better summarization, these benchmarks are divided into two categories: general language task benchmarks and specific downstream task benchmarks.
**NOTE:** We may miss some benchmarks. Your suggestions are highly welcomed!
| Benchmark | Focus | Domain | Evaluation Criteria |
|-------------|------------------------------------|--------------------------|-----------------------------------------------|
| MMBench [[paper](https://arxiv.org/abs/2307.06281)] | Multimodal LLMs | General language task | Fine-grained abilities of perception and reasoning |
| SOCKET [[paper](https://arxiv.org/abs/2305.14938)] | Social knowledge | Specific downstream task | Social language understanding |
| MME [[paper](https://arxiv.org/abs/2306.13394)] | Multimodal LLMs | General language task | Ability of perception and cognition |
| Xiezhi [[paper](https://arxiv.org/abs/2306.05783)][[GitHub](https://github.com/MikeGu721/XiezhiBenchmark)] | Comprehensive domain knowledge | General language task | Overall performance across multiple benchmarks |
| CUAD [[paper](https://arxiv.org/abs/2103.06268)] | Legal contract review | Specific downstream task | Legal contract understanding |
| TRUSTGPT [[paper](https://arxiv.org/abs/2306.11507)] | Ethic | Specific downstream task | Toxicity, bias, and value-alignment |
| MMLU [[paper](https://arxiv.org/abs/2009.03300)] | Text models | General language task | Multitask accuracy |
| MATH [[paper](https://arxiv.org/abs/2103.03874)] | Mathematical problem | Specific downstream task | Mathematical ability |
| APPS [[paper](https://arxiv.org/abs/2105.09938)]|Coding challenge competence | Specific downstream task | Code generation ability|
| C-Eval [[paper](https://arxiv.org/abs/2305.08322)][[GitHub](https://github.com/SJTU-LIT/ceval)] | Chinese evaluation | General language task | 52 Exams in a Chinese context |
| OpenLLM [[Link](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)] | Chatbots | General language task | Leaderboard rankings |
| DynaBench [[paper](https://arxiv.org/abs/2104.14337)] | Dynamic evaluation | General language task | NLI, QA, sentiment, and hate speech |
| Chatbot Arena [[Link](https://lmsys.org/blog/2023-05-03-arena/)] | Chat assistants | General language task | Crowdsourcing and Elo rating system |
| AlpacaEval [[GitHub](https://github.com/tatsu-lab/alpaca_eval)] | Automated evaluation | General language task | Metrics, robustness, and diversity |
| HELM [[paper](https://arxiv.org/abs/2211.09110)][[Link](https://crfm.stanford.edu/helm/latest/)] | Transparency of language models | General language task | Multi-metric |
| API-Bank [[paper](https://arxiv.org/abs/2304.08244)] | Tool-augmented | Specific downstream task | API call, response, and planning |
| ARB [[paper](https://arxiv.org/abs/2307.13692)] | Advanced reasoning ability | Specific downstream task | Multidomain advanced reasoning ability|
| Big-Bench [[paper](https://arxiv.org/abs/2206.04615)][[GitHub](https://github.com/google/BIG-bench)] | Capabilities and limitations of LMs | General language task | Model performance and calibration |
| MultiMedQA [[paper](https://arxiv.org/abs/2212.13138)] | Medical QA | Specific downstream task | Model performance, medical knowledge, and reasoning ability|
| CVALUES [[paper](https://arxiv.org/abs/2307.09705)] [[GitHub](https://github.com/X-PLUG/CValues)] | Safety and responsibility | Specific downstream task | Alignment ability of LLMs |
| ToolBench [[GitHub](https://github.com/sambanova/toolbench)] | Software tools | Specific downstream task | Execution success rate |
| PandaLM [[paper](https://arxiv.org/abs/2306.05087)] [[GitHub](https://github.com/WeOpenML/PandaLM)] | Instruction tuning | General language task | Winrate judged by PandaLM |
| GLUE-X [[paper](https://arxiv.org/abs/2211.08073)] [[GitHub](https://github.com/YangLinyi/GLUE-X)] | OOD robustness for NLU tasks | General language task | OOD robustness |
| KoLA [[paper](https://arxiv.org/abs/2306.09296)] | Knowledge-oriented evaluation | General language task | Self-contrast metrics |
| AGIEval [[paper](https://arxiv.org/abs/2304.06364)] | Human-centered foundational models | General language task | General |
| PromptBench [[paper](https://arxiv.org/abs/2306.04528)] [[GitHub](https://github.com/microsoft/promptbench)] | Adversarial prompt resilience | General language task | Adversarial robustness |
| MT-Bench [[paper](https://arxiv.org/abs/2306.05685)] | Multi-turn conversation | General language task | Winrate judged by GPT-4 |
| M3Exam [[paper](https://arxiv.org/abs/2306.05179)] [[GitHub](https://github.com/DAMO-NLP-SG/M3Exam)] | Human exams | Specific downstream task | Task-specific metrics |
| GAOKAO-Bench [[paper](https://arxiv.org/abs/2305.12474)] | Chinese Gaokao examination | Specific downstream task | Accuracy and scoring rate |
## Contributing
We welcome contributions to LLM-eval-survey! If you'd like to contribute, please follow these steps:
1. Fork the repository.
2. Create a new branch with your changes.
3. Submit a pull request with a clear description of your changes.
You can also open an issue if you have anything to add or comment.
## Citation
If you find this project useful in your research or work, please consider citing it:
```
@article{chang2023survey,
title={A Survey on Evaluation of Large Language Models},
author={Chang, Yupeng and Wang, Xu and Wang, Jindong and Wu, Yuan and Zhu, Kaijie and Chen, Hao and Yang, Linyi and Yi, Xiaoyuan and Wang, Cunxiang and Wang, Yidong and Ye, Wei and Zhang, Yue and Chang, Yi and Yu, Philip S. and Yang, Qiang and Xie, Xing},
journal={arXiv preprint arXiv:2307.03109},
year={2023}
}
```
## Acknowledgements
1. Tahmid Rahman ([@tahmedge](https://github.com/tahmedge)) for [PR#1](https://github.com/MLGroupJLU/LLM-eval-survey/pull/1).
2. Hao Zhao for suggestions on new benchmarks.
3. Chenhui Zhang for suggestions on robustness, ethics, and trustworthiness.
4. Damien Sileo ([@sileod](https://github.com/sileod)) for [PR#2](https://github.com/MLGroupJLU/LLM-eval-survey/pull/2).
5. Peiyi Wang ([@Wangpeiyi9979](https://github.com/Wangpeiyi9979)) for [issue#3](https://github.com/MLGroupJLU/LLM-eval-survey/issues/3).
6. Zengzhi Wang for sentiment analysis.
7. Kenneth Leung ([@kennethleungty](https://github.com/kennethleungty)) for [PR#4](https://github.com/MLGroupJLU/LLM-eval-survey/pull/4) to [PR#6](https://github.com/MLGroupJLU/LLM-eval-survey/pull/6).
8. [@Aml-Hassan-Abd-El-hamid](https://github.com/Aml-Hassan-Abd-El-hamid) for [PR#7](https://github.com/MLGroupJLU/LLM-eval-survey/pull/7).
9. [@taichengguo](https://github.com/taichengguo) for [issue#9](https://github.com/MLGroupJLU/LLM-eval-survey/issues/9)
|
ruairidhflint/day-by-day
|
https://github.com/ruairidhflint/day-by-day
| null |
# Day by Day
https://days.rory.codes/
A visual representation of my life, Day by Day.
Some people have said it is depressing, others inspiring. It is whatever you want it to be.
For me it serves as a reminder of the finite nature of life. It reminds me to live. To cherish those I love. To stop for a moment and enjoy the little things.
### Technical
- Built with React and Vite
- Tooltip with React-Tooltip
- Deployed via Netlify
- Styled with a single CSS file, nothing fancy
- About 12 hours from idea to initial deployment
It's a work in progress, feel free to suggest ideas. Currently the initial render produces around 30,000 <div>'s which is probably less than ideal.
|
xinsblog/chatglm-tiny
|
https://github.com/xinsblog/chatglm-tiny
|
从头开始训练一个chatglm小模型
|
* [chatglm-tiny: 从头开始训练一个chatglm小模型](https://zhuanlan.zhihu.com/p/642355086)
|
hopsoft/credentials_demo
|
https://github.com/hopsoft/credentials_demo
|
Demo of environment aware Rails encrypted credentials with environment variable override
|
# Credentials Demo
## What
Demo of environment aware Rails encrypted credentials with environment variable override.
## Why
1. Simplifies configuration management
1. Centralizes application secrets
1. Reduces the number of managed environment variables... often limited to one (`RAILS_MASTER_KEY`)
1. Eliminates wasted developer time due to missing environment variables
1. Reduces gem dependencies... [dotenv](https://github.com/bkeepers/dotenv), etc.
1. Preserves productivity by exposing configuraiton via the environment `ENV`
1. Retains flexibility by allowing the environment (`ENV`) to override
## How
1. Edit the Rails encrypted credentials file.
```sh
bin/rails credentials:edit
```
```yaml
default: &default
aws_access_key_id: AKIAIOSFODNN7EXAMPLE
aws_region: us-east-1
aws_secret_access_key: b1e4c2d8f9a7g5i3h2j4k1l6m8n0o9p5q7r3s1t2u6v8w0x9y4z2
development:
<<: *default
database: db/databases/development.sqlite3
secret_key_base: 31461f5d38cc7f2e919ea18e9a390bd3558a31be2e5d8e79b9c40ae7a91a5990768da5c8baa2521462c366f5568c4d58b843f92ea5eda71d9bc9c8a8b0c96435
test:
<<: *default
database: db/databases/test.sqlite3
secret_key_base: 852d4a5f4796699b4204c776c6b7f2934fd2f5424ac9d2f8f15d6bf9a0efc1f4bc5fd6b44fd1b0774de7168a0990d76ae6c3229370414db7b7d66830b2f74491
production:
<<: *default
aws_access_key_id: AKIA5VXCTQ99GEXAMPLE
aws_secret_access_key: 3a9d8a2b5c4e1f7g6h2i5j1k3l4m7n8o9p0q1r2s3t4u5v6w7x8y9z0
database: db/databases/production.sqlite3
secret_key_base: b05157ed1f089563a5c754d6219b6a4fdf7c521d0e970ddc15cdd9a1bec58fa251191d50d1b8500987a2589a98afa20f27b964e2eefed9dbc574036880af34e0
```
2. The application merges the encrypted credentials into the environment `ENV` on boot
[View the code here.](https://github.com/hopsoft/credentials_demo/blob/main/config/application.rb#L11-L16).
```ruby
creds = credentials[Rails.env.to_sym]
.with_indifferent_access
.transform_keys(&:upcase)
.transform_values(&:to_s)
ENV.merge! creds.merge(ENV)
```
3. Access the configuration via `ENV`
```sh
bin/rails console --environment development
```
```ruby
ENV.fetch "DATABASE" # => db/databases/development.sqlite3
```
---
```sh
bin/rails console --environment test
```
```ruby
ENV.fetch "DATABASE" # => db/databases/test.sqlite3
```
---
```sh
bin/rails console --environment production
```
```ruby
ENV.fetch "DATABASE" # => db/databases/production.sqlite3
```
---
Example of environment variable override.
```sh
DATABASE=db/databases/foo.sqlite3 bin/rails console --environment production
```
```ruby
ENV.fetch "DATABASE" # => db/databases/foo.sqlite3
```
## Next Steps
Consider combining this technique with environment specific credentials if you'd like to hide specific environment configurations from developers.
```sh
bin/rails credentials:help
bin/rails credentials:edit --environment production
```
|
MiyakoYakota/search.0t.rocks
|
https://github.com/MiyakoYakota/search.0t.rocks
| null |
# Zero Trust Search Engine
This repository contains all the code nessecary to create your own version of https://search.0t.rocks.
### Quickstart
To get your search engine running quickly on a single Linux host:
1. Install Docker with Docker Compose
2. Run `docker compose build; docker compose up`
3. Run `bash start.sh`
4. Visit `http://your-ip:3000`
### Converting Data
This is the hard part and completely up to you. You need to convert data into a standard format before it can be imported. See `sample.json` for the example data.
### Importing Data
Data imports are done using the SimplePostTool included with Solr. You can download a copy of the **binary release** [here](https://solr.apache.org/downloads.html), and import data with the following command after extracting Solr:
`bin/post -c BigData -p 8983 -host <your host> path/to/your/file`
Docs are available here: https://solr.apache.org/guide/solr/latest/indexing-guide/post-tool.html
### Making Changes
If you make changes to code in the "dataapp" directory, you can re-build your app by re-running step 1 of Quickstart.
---
#### Considerations / Warnings
- Solr is very complex. If you intend on extending on the existing schema or indexing large quantities (billions) of documents, you will want to learn more about how it works.
- Keep backups, things will go wrong if you deviate the standard path.
- Don't be evil.
|
eamars/klipper_adaptive_bed_mesh
|
https://github.com/eamars/klipper_adaptive_bed_mesh
|
An Python plugin enabling the bed mesh based on the printed part.
|
Klipper Adaptive Bed Mesh
===
[中文版](readme_zh_cn.md)
# What is it?
The *Adaptive Bed Mesh* plugin is designed to generate the bed mesh parameter based on the sliced part dynamically.
With finer bed mesh density around printed parts you can achieve better accuracy and lesser time spent on probing.

The *Adaptive Bed Mesh* plugin is inspired from multiple open source project
- [Klipper mesh on print area only install guide](https://gist.github.com/ChipCE/95fdbd3c2f3a064397f9610f915f7d02)
- [Klipper Adaptive meshing & Purging](https://github.com/kyleisah/Klipper-Adaptive-Meshing-Purging)
## Features
The *Adaptive Bed Mesh* plugin supports 3 operating modes. By default, the below list is also the precedence of the operation.
1. First layer min/max provided by the slicer.
2. Object shapes detection by Klipper Exclude Object.
3. Object shapes detection by GCode analysis.
If all above modes are failed then the *Adaptive Bed Mesh* will fall back to the default full bed mesh configuration.
### First layer min/max provided by the slicer
Most slicer can export the min (closest to 0,0) and max coordinate of the first layer extrude motions.
Below are syntax for few famous slicers.
#### Orca Slicer / Super Slicer / Prusa Slicer
ADAPTIVE_BED_MESH_CALIBRATE AREA_START={first_layer_print_min[0]},{first_layer_print_min[1]} AREA_END={first_layer_print_max[0]},{first_layer_print_max[1]}
#### Cura
ADAPTIVE_BED_MESH_CALIBRATE AREA_START=%MINX%,%MINY% AREA_END=%MAXX%,%MAXY%
Copied from [Klipper mesh on print area only install guide](https://gist.github.com/ChipCE/95fdbd3c2f3a064397f9610f915f7d02)
> *(Cura slicer plugin) To make the macro to work in Cura slicer, you need to install the [post process plugin by frankbags](https://raw.githubusercontent.com/ChipCE/Slicer-profile/master/cura-slicer/scripts/KlipperPrintArea.py)
> - In cura menu Help -> Show configuration folder.
> - Copy the python script from the above link in to scripts folder.
> - Restart Cura
> - In cura menu Extensions -> Post processing -> Modify G-Code and select Klipper print area mesh
### Object shapes detection by Klipper Exclude Object.
The [Klipper Exclude Object](https://www.klipper3d.org/Exclude_Object.html) collects the printed part boundary for
object exclude functionality. Subject to the Slicer, the printed part boundary can be a simple boundary box, or complicated
hull of the object geometry.
There is no special parameter to activate the object shape detection based bed mesh. If the Exclude Object feature is [enabled from Klipper](https://www.klipper3d.org/Config_Reference.html#exclude_object)
and your slicer supports such feature, then the bed mesh area will be calculated based on all registered boundaries.
### Object shapes detection by GCode analysis
As the last line of defense, when all above detection algorithms are failing (or disabled), the object boundaries shall be
determined by the GCode analysis.
The GCode analysis will evaluate all extrude moves (G0, G1, G2, G3) and create the object boundary by layers. It
will evaluate all layers unless the [mesh fade](https://www.klipper3d.org/Bed_Mesh.html#mesh-fade) is configured.
For example, with the below `[bed_mesh]` section, the GCode analysis will stop at 10mm from the bed while the klipper stops the
bed mesh compensation at the same height.
[bed_mesh]
...
fade_start: 1
fade_end: 10
fade_target: 0
# Configurations
## [bed_mesh]
The *Adaptive Bed Mesh* will use values from `[bed_mesh]` sections. Below are required attributes. Please make sure the min/max
coordinates are within the safe probing boundaries.
[bed_mesh]
# The mesh start coordinate. The adaptive bed mesh will not generate points smaller than this coordinate.
mesh_min: 20, 20
# The maximum coordinate of the bed mesh. The adapter bed mesh will not generate points greater than this coordinate.
# Note: This is not necessarily the last point of the probing sequence.
mesh_max: 230,230
# (Optional) The Z height in which fade should complete
fade_end: 10
> **_NOTE:_** The `relative_reference_index` is now [deprecated](https://www.klipper3d.org/Bed_Mesh.html#the-deprecated-relative_reference_index).
> **_NOTE:_** The `zero_reference_position` will be overwritten by the plugin so you don't need to configure it from the `[bed_mesh]`
> section.
## [virtual_sdcard]
The *Adaptive Bed Mesh* will use values from `[virtual_sdcard]` sections. Below are required attributes. Usually `[virtual_sdcard]` is
defined under the Mainsail or Fluidd configuration.
[virtual_sdcard]
path: ~/printer_data/gcodes
## [adaptive_bed_mesh]
The `[adaptive_bed_mesh]` need to be declared under `printer.cfg`, after the `[exclude_object]` and `[virtual_sdcard]`.
[adaptive_bed_mesh]
arc_segments: 80 # (Optional) The number of segments for G2/3 to be decoded into linar motion.
mesh_area_clearance: 5 # (Optional) Expand the mesh area outside of the printed area in mm.
max_probe_horizontal_distance: 50 # (Optional) Maximum distance between two horizontal probe points in mm.
max_probe_vertical_distance: 50 # (Optional) Maximum distance between two vertical probe points in mm.
use_relative_reference_index: False # (Optional) For older Klipper (< 0.11.2xx), the `use_relative_reference_index` is used to determine the center point. This is not required for the newer release.
# (Optional) Enable/Disable detection algorithm on demand
disable_slicer_min_max_boundary_detection: False
disable_exclude_object_boundary_detection: False
disable_gcode_analysis_boundary_detection: False
## How to determine the maximum horizontal/vertical probe distances
The *Adaptive Bed Mesh* uses probe distance instead number of points to be probed to achieve better probe density consistency
with respect to parts in different sizes.
To calculate the optimal probe distance, you can use the reference number of points for a full printed bed as an example.
For a 250mm by 250mm square heater bed, a 5x5 mesh is generally sufficient. The maximum horizontal and vertical probe distance
can calculate by
probe_distance = 250 / 5 = 50mm
# Usage
Call `ADAPTIVE_BED_MESH_CALIBREATE` as the part of `PRINT_START` macro is all you need.
Example:
[gcode_macro PRINT_START]
gcode:
...
ADAPTIVE_BED_MESH_CALIBRATE
...
> **_NOTE:_** If you're using the [Automatic Z-Calibration plugin](https://github.com/protoloft/klipper_z_calibration)
> then you need to ensure the `ADAPTIVE_BED_MESH_CALIBRATE` is called prior to `CALIBRATE_Z`.
# Install via Moonraker
Clone the repository to the home directory
cd ~
git clone https://github.com/eamars/klipper_adaptive_bed_mesh.git
You need to manually install the plugin for the first time. It will prompt for password to restart the Klipper process.
source klipper_adaptive_bed_mesh/install.sh
Then copy the below block into the moonraker.conf to allow automatic update.
[update_manager client klipper_adaptive_bed_mesh]
type: git_repo
primary_branch: main
path: ~/klipper_adaptive_bed_mesh
origin: https://github.com/eamars/klipper_adaptive_bed_mesh.git
install_script: install.sh
# Contribution
Contributions are welcome. However before making new pull requests please make sure the feature passes
the unit test in `test_adaptive_bed_mesh.py` and add new if necessary.
|
Octoberfest7/TeamsPhisher
|
https://github.com/Octoberfest7/TeamsPhisher
|
Send phishing messages and attachments to Microsoft Teams users
|
```
...
:-++++++=-.
.=+++++++++++-
.++++++++++++++= :------: :-:--.
:+++++++++++++++. .---------- #= .-+.
:+++++++++++++++. -----------: :#= :#.
:--------------------------=++++++++- .------------ .=+ ++
----------------------------+++++*+-. :+=-----===: -+-.+:
:---------------------------++++=-. .=+++++=-. .=+:.
:------=%%%%%%%%%%%%--------:... .:::.. -*=-:
:------=****#@@#****--------=++++++++++++++-----------. -#++-
:----------:+@@+:-----------+++++++++++++++=----------- -#++-
:-----------+@@*------------+++++++++++++++=-----------. -*+*-
:-----------+@@*------------+++++++++++++++=-----------. . -*++-
:-----------+@@*------------+++++++++++++++=-----------. -- -*++-
:-----------+@@*------------+++++++++++++++=-----------. . == -*++- .=
:-----------+@@+------------+++++++++++++++=-----------. .+ -= :+==- .*
:---------------------------+++++++++++++++=-----------. =* -= -+=+= .::
----------------------------+++++++++++++++=----------- ** -+ -+=++. .*=
.:-------------------------=+++++++++++++++=---------=: #+ := ++-:*= ==
-++++++++++++++++++++++++++=-------=+=: :#= .:. *=: -*- ==
.=+++++++++++++++++++++++++*+++++++=-. -#- ::++= :+=. .==
:++++++++++++++++++++++++=:.:::::. -*: .=+-. .=+-. -+:
.=+*+++++++++++++++++++- -+- .:-=. .-====----:-==:
.-+**+++++++++++**+-. .++: .-=-: .:-====-:.
:-=++******+=-: .=+===--.
..:::.. ...
_____ ______ _ _ _
|_ _| | ___ \| | (_) | |
| | ___ __ _ _ __ ___ ___ | |_/ /| |__ _ ___ | |__ ___ _ __
| | / _ \ / _` || '_ ` _ \ / __|| __/ | '_ \ | |/ __|| '_ \ / _ \| '__|
| || __/| (_| || | | | | |\__ \| | | | | || |\__ \| | | || __/| |
\_ \___| \__,_||_| |_| |_||___/\_| |_| |_||_||___/|_| |_| \___||_|
v1.0 developed by @Octoberfest73 (https://github.com/Octoberfest7)
```
# Introduction
TeamsPhisher is a Python3 program that facilitates the delivery of phishing messages and attachments to Microsoft Teams users whose organizations allow external communications.
It is not ordinarily possible to send files to Teams users outside one's organization. Max Corbridge (@CorbridgeMax) and Tom Ellson (@tde_sec) over at JUMPSEC [recently disclosed a way to get around this restriction](https://labs.jumpsec.com/advisory-idor-in-microsoft-teams-allows-for-external-tenants-to-introduce-malware/) by manipulating Teams web requests in order to alter the recipient of a message with an attached file.
TeamsPhisher incorporates this technique in addition to [some earlier ones](https://posts.inthecyber.com/leveraging-microsoft-teams-for-initial-access-42beb07f12c4) disclosed by Andrea Santese (@Medu554).
It also heavily leans upon [TeamsEnum](https://github.com/sse-secure-systems/TeamsEnum), a fantastic piece of work from Bastian Kanbach (@_bka_) of SSE, for the authentication part of the attack flow as well as some general helper functions.
TeamsPhisher seeks to take the best from all of these projects and yield a robust, customizable, and efficient means for authorized Red Team operations to leverage Microsoft Teams for phishing for access scenarios.
See the end of this README for mitigation recommendations.
# Features and demo
Give TeamsPhisher an attachment, a message, and a list of target Teams users. It will upload the attachment to the sender's Sharepoint, and then iterate through the list of targets.
TeamsPhisher will first enumerate the target user and ensure that the user exists and can receive external messages. It will then create a new thread with the target user. Note this is technically a "group" chat because TeamsPhisher includes the target's email twice; this is a neat trick from @Medu554 that will bypass the "Someone outside your organization messaged you, are you sure you want to view it" splash screen that can give our targets reason for pause.
With the new thread created between our sender and the target, the specified message will be sent to the user along with a link to the attachment in Sharepoint.
Once this initial message has been sent, the created thread will be visible in the sender's Teams GUI and can be interacted with manually if need be on a case-by-case basis.
## Operational mode
Run TeamsPhisher for real. Send phishing messages to targets.
Command:

Targets.txt:

Message.txt:

TeamsPhisher output:

Sender's view:

Targets view:

Attached file:

## Preview mode
Run TeamsPhisher in preview mode in order to verify your list of targets, preview their "friendly names" (if TeamsPhisher can resolve them using the --personalize switch), and send a test message to your own sender's account in order to verify everything looks as you want it.
TeamsPhisher output:

Sender's view:

# Setup and Requirements
TeamsPhisher requires that users have a Microsoft Business account (as opposed to a personal one e.g. @hotmail, @outlook, etc) with a valid Teams and Sharepoint license.
This means you will need an AAD tenant and at least one user with a corresponding license. At the time of publication, there are some free trial licenses available in the AAD license center that fulfill the requirements for this tool.
You will need to log into the personal Sharepoint of the user you are going to be sending messages with at least once prior to using the account with TeamsPhisher. This should be something like tenantname-my.sharepoint.com/personal/myusername_mytenantname_onmicrosoft_com or tenantname-my.sharepoint.com/personal/myusername_mytenantname_mycustomdomain_tld.
In terms of local requirements, I recommend updating to the latest version of Python3. You will also need Microsoft's authentication library:
```
pip3 install msal
```
# Usage
```
usage: teamsphisher.py [-h] -u USERNAME -p PASSWORD -a ATTACHMENT -m MESSAGE (-e EMAIL | -l LIST) [--greeting GREETING] [--securelink] [--personalize]
[--preview] [--delay DELAY] [--nogreeting] [--log] [--sharepoint SHAREPOINT]
options:
-h, --help show this help message and exit
-u USERNAME, --username USERNAME
Username for authentication
-p PASSWORD, --password PASSWORD
Password for authentication
-a ATTACHMENT, --attachment ATTACHMENT
Full path to the attachment to send to targets.
-m MESSAGE, --message MESSAGE
A file containing a message to send with attached file.
-e EMAIL, --targetemail EMAIL
Single target email address
-s SHAREPOINT, --sharepoint SHAREPOINT
Manually specify sharepoint name (e.g. mytenant.sharepoint.com would be --sharepoint mytenant)
-l LIST, --list LIST Full path to a file containing target emails. One per line.
--greeting GREETING Override default greeting with a custom one. Use double quotes if including spaces!
--securelink Send link to file only viewable by the individual target recipient.
--personalize Try and use targets names in greeting when sending messages.
--preview Run in preview mode. See personalized names for targets and send test message to sender's Teams.
--delay DELAY Delay in [s] between each attempt. Default: 0
--nogreeting Do not use built in greeting or personalized names, only send message specified with --message
--log Write TeamsPhisher output to logfile
```
## Required arguments
### Username
The username of the Microsoft account you will be sending messages from (e.g. [email protected])
### Password
The password for the aforementioned account. If it contains special characters, it may be helpful to wrap the whole thing in single quotes.
### Attachment
The file you wish to send to target users. This will be uploaded to the sending account's sharepoint and a link shared via Teams.
### Message
A file containing the text message that should accompany the attachment and be sent to targets
### Email / List
Either a single target email (e.g. [email protected]) or a file containing a list of target emails one per line.
## Optional arguments and features
### Sharepoint
Manually specify the name of the sharepoint site to upload the attachment to. **This will likely be necessary if your sender's tenant uses a custom domain name (e.g. does not follow the xxx.onmicrosoft.com convention)**. Specify just the unique name, e.g. if your sharepoint site is mytest.sharepoint.com you would use --sharepoint mytest
### Greeting
Override TeamPhisher's default greeting ("Hi, ") with a custom one to be prepended to the message specified by --message. For example, "Good afternoon, " or "Sales team, "
### Securelink
By default the sharepoint link sent to targets can be viewed by anyone with the link; use --securelink so that the sharepoint file is only viewable by the target who received it. May help protect your malware from Blue team.
### Personalize
TeamsPhisher will attempt to identify the first name of each target user and use it with the greeting. For example, [email protected] would receive a message that started "Hi Tom, ". This is not perfect and is dependent on the format of the target emails; use --preview in order to see if this is a good fit for your target list or not.
### Preview
TeamsPhisher will run in preview mode. This will NOT send any messages to target users, but will instead display the "friendly" name that would be used by the --personalize switch. In addition, a test message representative of what targets would receive with the current settings will be sent to the sender's Teams; log in and see how your message looks and revise as necessary.
### Delay
Specify a x second delay between messages to targets. Can help with potential rate limiting issues.
### Nogreeting
Disable the built-in greeting used by TeamsPhisher. Also disables the --personalize feature. Use this option if you are including your greeting within the message specified by --message.
### Log
Write TeamsPhisher output to a log file (will write to users home directory).
## Examples
```
python3 teamsphisher.py -u [email protected] -p 'xxxxxxxxxxxx' -l /root/targets.txt -a /root/attachment.zip -m /root/message.txt --log
```
This command will fetch access tokens for the testuser account and upload the attachment '/root/attachment.zip' to testuser's Sharepoint.
It will then create a unique Teams thread with each target listed within '/root/targets.txt' and send them the message specified within '/root/message.txt' as well as a link to the attachment within Sharepoint.
All terminal output from TeamsPhisher will be logged in a file that is output within the user's home directory.
```
python3 teamsphisher.py -u [email protected] -p 'xxxxxxxxxxxx' -l /root/targets.txt -a /root/attachment.zip -m /root/message.txt --greeting "Good afternoon" --personalize --securelink
```
This command will fetch access tokens for the testuser account and upload the attachment '/root/attachment.zip' to testuser's Sharepoint.
It will then create a unique Teams thread with each target listed within '/root/targets.txt' and send them the message specified within '/root/message.txt' as well as a link to the attachment within Sharepoint.
The message will be prefixed with the greeting "Good afternoon <name>, ".
TeamsPhisher will try and use "friendly" names in the greeting. Now the greeting will be "Good afternoon <name>,".
Each SharePoint link sent is unique and valid only for that specific target.
# Additional Features and Commentary
## Account enumeration
TeamsPhisher will identify accounts that cannot be sent messages from external organizations, accounts that do not exist, and accounts that have a subscription plan that is not compatible with this attack vector:

## MFA enabled accounts
Thanks to code from the TeamsEnum project, TeamsPhisher supports login with sender accounts using MFA:

## Secure Sharepoint links
Using the --securelink switch will result in targets being prompted to authenticate in order to view the attachment in Sharepoint. You can decide if this adds too many extra steps, or if it adds 'legitimacy' by sending them through real Microsoft login functionality.


## Global variables
By editing TeamsPhisher.py you can alter a few global variables for use on subsequent runs:
```
## Global Options and Variables ##
# Greeting: The greeting to use in messages sent to targets. Will be joined with the targets name if the --personalize flag is used
# Examples: "Hi" "Good Morning" "Greetings"
Greeting = "Hi"
# useragent: The user-agent string to use for web requests
useragent = "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko)"
```
## Personalization and "friendly" names
The --personalize flags will try to resolve a "friendly" name for each target; it does this by looking at the data returned by the enumUser function and first checking the "displayName" field.
If the displayName field contains a space (e.g. "Tom Jones"), TeamsPhisher will split on the space and take the first chunk as the "friendly" name.
If there is not a space in the displayName field (e.g. some orgs might put the UPN in the displayName field like [email protected]), TeamsPhisher will try and parse the UPN itself.
With an example UPN like [email protected], TeamsPhisher will split on the '@' character, and then in the first chunk split on the '.' character and take the first chunk. This would yield a "friendly" name of "Tom" in this case.
This is the extent of how TeamsPhisher will try and identify "friendly" names. Targets like "[email protected]" and "[email protected]" will NOT have identified "friendly" names if their displayName fields do not match the parsing convention outline above.
# Mitigation
Organizations can mitigate the risk posed by this vulnerability by managing the options related to external access via the Microsoft Teams admin center under Users -> External access.

Microsoft provides flexibility to organizations to choose the best permissions to fit their needs, including a universal block as well as whitelisting only specific external tenants for communications.

# Changelog
## v1.0 - Initial release
## v1.1
There were a few commits made to address various small issues without incrementing the version number; sorry for being sloppy.
v1.1 brings a few changes aimed at addressing some common issues that users were running into.
### -s, --sharepoint argument
This optional argument was added so that users can manually specify their sharepoint root name. A common issue arose when users had changed their tenant's domain name to something custom; e.g. rather than their username being [email protected], it might be [email protected]. The original release of TeamsPhisher assembled the Sharepoint address and required uri paths by parsing the sender's user principal name from their user info. When a tenant's domain is changed to a custom one, user's UPNs change to reflect this. However the tenants sharepoint address will always remain the same/what they were when the tenant was originally created.
I wasn't able to find a good way to resolve the current Sharepoint address for a tenant; it can be done with Graph API easily, but implementing Graph in this tool would require a lot more setup on user's parts in order to use TeamsPhisher. I opted for providing the option to manually specify the sharepoint name as the easiest fix.
### Improved parsing of Sharepoint address and required uri when NOT using manual option
There was a report from a user who was NOT using a custom domain with their tenant who was still receiving the 404 not found error in regards to Sharepoint. I believe this had to do with their username containing a '.' e.g. [email protected]. The prior version of TeamsPhisher had simpler find + replace functionality for the user's UPN in order to assemble the requisite Sharepoint uri's, v1.1 now specifically targets the '.' characters that need to be replaced and will leave other '.' in the username field intact.
### Special characters (.e.g 'ö') within the message body no longer result in a server error
This was a very simple fix that took way too long to track down. Added utf-8 encoding to the sendFile POST request. Special characters can now be used in messages.
### Minor code cleanup
Fixed a few comments and re-ordered some steps in main to now check for requisite files before attempting to authenticate.
## v1.1.1
Minor fixes
## v1.1.2
Fixed an error users were reporting in regards to uploading the attachment to Sharepoint; this stemmed from naming/renaming conventions that happen when users use custom domain with their tenants.
Added a verification check to ensure that if users are using a NON @domain.onmicrosoft.com domain that they also use the -s switch in order to specify their sharepoint site manually to avoid issues.
Updated setup section to include logging into Sharepoint at least once prior to using TeamsPhisher as a user identified that not having logged in before with the account would cause TeamsPhisher to fail.
Added &top=999 parameter to getSenderInfo web request to increase the number of users retrieve per page/decrease number of requests required to find our user
### Reverse change regarding parsing of '.' in usernames when assembling Sharepoint uri
v.1.1 changed how usernames with the '.' character in them were parsed for the purposes of creating the requisite Sharepoint URI's. There were several distinct issues going on and I mistakenly identified this as the cause of one of them. This change has been reverted. The result is that a username like [email protected] will now have a sharepoint uri assembled as "tom_jones_mytest_onmicrosoft_com" rather than "tom.jones_mytest_onmicrosoft_com".
# Credits and Acknowledgements
1. Max Corbridge (@CorbridgeMax) and Tom Ellson (@tde_sec) of JUMPSEC for [this article](https://labs.jumpsec.com/advisory-idor-in-microsoft-teams-allows-for-external-tenants-to-introduce-malware/). Extra shoutout to Max for being very responsive and willing to chat privately about his research.
2. Andrea Santese (@Medu554) [for this research](https://posts.inthecyber.com/leveraging-microsoft-teams-for-initial-access-42beb07f12c4). Again an extra shoutout for his responsiveness and being willing to discuss his work privately.
3. Bastian Kanbach (@_bka_) of SSE for [TeamsEnum](https://github.com/sse-secure-systems/TeamsEnum). This project served as a starting point for retrieving Bearer tokens and authenticating via different methods. I had used Graph API for these purposes, but his project (and this one) uses the normal endpoints so it was great having someone who had already fought through this and had reliable functions to accomplish it.
4. @pfiatde who has a [three-part series on Teams phishing](https://badoption.eu/blog/2023/06/30/teams3.html). While nothing was directly used from these articles, there is a lot of good additional tradecraft and considerations that should be looked at.
5. [This site for generating ASCII text](https://patorjk.com/software/taag/#p=display&f=Graffiti&t=Type%20Something%20)
6. [This crazy project for converting images to ASCII art](https://github.com/TheZoraiz/ascii-image-converter)
|
sidhq/SID
|
https://github.com/sidhq/SID
|
All of SID.ai public resources, such as example applications, documentation, etc.
|
# SID Resource Hub
Welcome to SID's comprehensive resource hub! Here, we provide an array of resources aimed at facilitating a seamless integration of SID into your app.
Our docs can be found [here](https://github.com/sidhq/SID/blob/main/docs/docs.md).
You can join our waitlist at [https://join.sid.ai/](https://join.sid.ai/).
We have one demo project (more to come!) right now that is accesible at [https://demo.sid.ai/](https://demo.sid.ai/).
|
heike-07/Backup-tools
|
https://github.com/heike-07/Backup-tools
|
An open-source backup integration tool
|
# Backup-tools
- [Backup-tools](#backup-tools)
- [Ⅰ. 程序说明](#ⅰ-程序说明)
- [Ⅱ. 开发任务](#ⅱ-开发任务)
- [Ⅲ. 底层环境构建](#ⅲ-底层环境构建)
- [1. 操作系统适用](#1-操作系统适用)
- [2. mysql或mariadb数据库](#2-mysql或mariadb数据库)
- [2/0 查询相关服务是否安装](#20-查询相关服务是否安装)
- [2/1 下载MysqlRPM包](#21-下载mysqlrpm包)
- [2/2 检查mariadb依赖](#22-检查mariadb依赖)
- [2/3 安装MySQL](#23-安装mysql)
- [2/4 自定义data存储路径](#24-自定义data存储路径)
- [2/5 开启MySQL服务并设置密码以及权限](#25-开启mysql服务并设置密码以及权限)
- [2/6 开启binlog](#26-开启binlog)
- [3. NFS环境安装](#3-nfs环境安装)
- [3/0 查询相关服务](#30-查询相关服务)
- [3/1 SELiunx 关闭](#31-seliunx-关闭)
- [3/2 安装NFS](#32-安装nfs)
- [3/3 查看rpcbind监听以及服务](#33-查看rpcbind监听以及服务)
- [3/4 防火墙开通端口](#34-防火墙开通端口)
- [3/5 创建路径编写可读可写权限](#35-创建路径编写可读可写权限)
- [3/6 添加NFS硬盘](#36-添加nfs硬盘)
- [3/7 启动服务并进行挂载](#37-启动服务并进行挂载)
- [3/8 授权](#38-授权)
- [3/9 创建NFS协议挂载](#39-创建nfs协议挂载)
- [3/10 测试文件创建权限](#310-测试文件创建权限)
- [3/11 修改权限](#311-修改权限)
- [3/12 重启服务使修改生效](#312-重启服务使修改生效)
- [4. Mydumper 依赖安装](#4-mydumper-依赖安装)
- [5.xtrabackup 依赖安装](#5xtrabackup-依赖安装)
- [Ⅳ. 程序运行](#ⅳ-程序运行)
- [1. Backup\_Mysqldump\_All](#1-backup_mysqldump_all)
- [1/1 配置文件修改](#11-配置文件修改)
- [1/2 程序启动](#12-程序启动)
- [1/3 查看结果](#13-查看结果)
- [1/4 结果说明](#14-结果说明)
- [2. Backup\_Mysqldump\_One](#2-backup_mysqldump_one)
- [2/1 配置文件修改](#21-配置文件修改)
- [2/2 程序启动](#22-程序启动)
- [2/3 查看结果](#23-查看结果)
- [2/4 结果说明](#24-结果说明)
- [3. Backup\_Mydumper\_MultiThread\_Database\_All](#3-backup_mydumper_multithread_database_all)
- [3/1 配置文件修改](#31-配置文件修改)
- [3/2 程序启动](#32-程序启动)
- [3/3 查看结果](#33-查看结果)
- [3/4 结果说明](#34-结果说明)
- [4. Backup\_Mydumper\_MultiThread\_Database\_One](#4-backup_mydumper_multithread_database_one)
- [4/1 配置文件修改](#41-配置文件修改)
- [4/2 程序启动](#42-程序启动)
- [4/3 查看结果](#43-查看结果)
- [4/4 结果说明](#44-结果说明)
- [5. Backup\_XtraBackup\_add](#5-backup_xtrabackup_add)
- [5/1 配置文件修改](#51-配置文件修改)
- [5/2 程序启动](#52-程序启动)
- [5/3 制作增量数据](#53-制作增量数据)
- [5/4 程序启动第N次](#54-程序启动第n次)
- [5/5 查看结果](#55-查看结果)
- [5/6 结果说明](#56-结果说明)
- [Ⅴ. 开发](#ⅴ-开发)
- [1. 构建开发环境](#1-构建开发环境)
- [2. 程序编译](#2-程序编译)
## Ⅰ. 程序说明
一个更高效、更方便的MySQL数据库备份工具
## Ⅱ. 开发任务
1. _`OK.`_ - 思路建设
2. _`OK.`_ - 编写readme-doc文档
3. _`OK.`_ - 核心代码开发Mysqldump备份架构
4. _`OK.`_ - 核心代码开发Mydumper备份架构
5. _`OK.`_ - 核心代码开发Xtrabackup备份架构
6. _`OK.`_ - 使用GO封装
7. _`OK.`_ - 主程序和配置文件分离
8. _`OK.`_ - 合并主分支发布Releases
9. _`ING.`_ - 文档细化
## Ⅲ. 底层环境构建
### 1. 操作系统适用
适用于Centos7、Redhat7 操作系统,其他系统适配中……
### 2. mysql或mariadb数据库
--(因为本机为实验环境没有MySQL则需要安装)
#### 2/0 查询相关服务是否安装
```shell
[root@localhost mysql]# rpm -qa | grep mariadb
[root@localhost mysql]# rpm -qa | grep mysql
```
#### 2/1 下载MysqlRPM包
```shell
## 1:下载MysqlRPM包
[root@localhost soft]# wget https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.42-1.el7.x86_64.rpm-bundle.tar
[root@localhost soft]# mkdir ./mysql_5.7.42
[root@localhost soft]# tar -xvf mysql-5.7.42-1.el7.x86_64.rpm-bundle.tar -C ./mysql_5.7.42/
mysql-community-client-5.7.42-1.el7.x86_64.rpm
mysql-community-common-5.7.42-1.el7.x86_64.rpm
mysql-community-devel-5.7.42-1.el7.x86_64.rpm
mysql-community-embedded-5.7.42-1.el7.x86_64.rpm
mysql-community-embedded-compat-5.7.42-1.el7.x86_64.rpm
mysql-community-embedded-devel-5.7.42-1.el7.x86_64.rpm
mysql-community-libs-5.7.42-1.el7.x86_64.rpm
mysql-community-libs-compat-5.7.42-1.el7.x86_64.rpm
mysql-community-server-5.7.42-1.el7.x86_64.rpm
mysql-community-test-5.7.42-1.el7.x86_64.rpm
[root@localhost soft]# cd ./mysql_5.7.42/
```
#### 2/2 检查mariadb依赖
```shell
## 2:检查mariadb依赖
--(默认安装的系统都有)
[root@localhost mysql_5.7.42]# rpm -qa | grep mariadb
mariadb-libs-5.5.68-1.el7.x86_64
[root@localhost mysql_5.7.42]# rpm -e --nodeps mariadb-libs-5.5.68-1.el7.x86_64
[root@localhost mysql_5.7.42]# rpm -qa | grep mariadb
[root@localhost mysql_5.7.42]#
```
#### 2/3 安装MySQL
```shell
## 3:安装MySQL
[root@localhost mysql_5.7.42]# rpm -ivh mysql-community-common-5.7.42-1.el7.x86_64.rpm
warning: mysql-community-common-5.7.42-1.el7.x86_64.rpm: Header V4 RSA/SHA256 Signature, key ID 3a79bd29: NOKEY
Preparing... ################################# [100%]
Updating / installing...
1:mysql-community-common-5.7.42-1.e################################# [100%]
[root@localhost mysql_5.7.42]# rpm -ivh mysql-community-libs-5.7.42-1.el7.x86_64.rpm
warning: mysql-community-libs-5.7.42-1.el7.x86_64.rpm: Header V4 RSA/SHA256 Signature, key ID 3a79bd29: NOKEY
Preparing... ################################# [100%]
Updating / installing...
1:mysql-community-libs-5.7.42-1.el7################################# [100%]
[root@localhost mysql_5.7.42]# rpm -ivh mysql-community-client-5.7.42-1.el7.x86_64.rpm
warning: mysql-community-client-5.7.42-1.el7.x86_64.rpm: Header V4 RSA/SHA256 Signature, key ID 3a79bd29: NOKEY
Preparing... ################################# [100%]
Updating / installing...
1:mysql-community-client-5.7.42-1.e################################# [100%]
[root@localhost mysql_5.7.42]# rpm -ivh mysql-community-server-5.7.42-1.el7.x86_64.rpm
warning: mysql-community-server-5.7.42-1.el7.x86_64.rpm: Header V4 RSA/SHA256 Signature, key ID 3a79bd29: NOKEY
Preparing... ################################# [100%]
Updating / installing...
1:mysql-community-server-5.7.42-1.e################################# [100%]
[root@localhost mysql_5.7.42]# rpm -ivh mysql-community-devel-5.7.42-1.el7.x86_64.rpm
warning: mysql-community-devel-5.7.42-1.el7.x86_64.rpm: Header V4 RSA/SHA256 Signature, key ID 3a79bd29: NOKEY
Preparing... ################################# [100%]
Updating / installing...
1:mysql-community-devel-5.7.42-1.el################################# [100%]
[root@localhost mysql_5.7.42]# rpm -qa | grep mysql
mysql-community-server-5.7.42-1.el7.x86_64
mysql-community-common-5.7.42-1.el7.x86_64
mysql-community-devel-5.7.42-1.el7.x86_64
mysql-community-libs-5.7.42-1.el7.x86_64
mysql-community-client-5.7.42-1.el7.x86_64
[root@localhost mysql_5.7.42]#
```
#### 2/4 自定义data存储路径
```shell
## 4:自定义data存储路径
[root@localhost mysql_5.7.42]# mkdir -p /data/mysql
[root@localhost mysql_5.7.42]# chown -R mysql:mysql /data/mysql
[root@localhost mysql_5.7.42]# vim /etc/my.cnf
[root@localhost mysql_5.7.42]# cat /etc/my.cnf
# For advice on how to change settings please see
# http://dev.mysql.com/doc/refman/5.7/en/server-configuration-defaults.html
[mysqld]
#
# Remove leading # and set to the amount of RAM for the most important data
# cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.
# innodb_buffer_pool_size = 128M
#
# Remove leading # to turn on a very important data integrity option: logging
# changes to the binary log between backups.
# log_bin
#
# Remove leading # to set options mainly useful for reporting servers.
# The server defaults are faster for transactions and fast SELECTs.
# Adjust sizes as needed, experiment to find the optimal values.
# join_buffer_size = 128M
# sort_buffer_size = 2M
# read_rnd_buffer_size = 2M
datadir=/data/mysql
socket=/data/mysql/mysql.sock
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
lower_case_table_names=1
max_connections=500
init_connect='SET NAMES utf8'
[client]
socket=/data/mysql/mysql.sock
[mysql]
socket=/data/mysql/mysql.sock
[root@localhost mysql_5.7.42]#
```
#### 2/5 开启MySQL服务并设置密码以及权限
```shell
## 5:开启MySQL服务并设置密码以及权限
[root@localhost mysql_5.7.42]# systemctl start mysqld
[root@localhost mysql_5.7.42]# grep 'temporary password' /var/log/mysqld.log
2023-07-06T06:59:55.413788Z 1 [Note] A temporary password is generated for root@localhost: #Sb)2-w6yhd,
[root@localhost mysql_5.7.42]# mysql -uroot -p
Enter password:
ERROR 1045 (28000): Access denied for user 'root'@'localhost' (using password: YES)
[root@localhost mysql_5.7.42]# mysql -uroot -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 3
Server version: 5.7.42
Copyright (c) 2000, 2023, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> ALTER USER 'root'@'localhost' IDENTIFIED BY 'A16&b36@@';
Query OK, 0 rows affected (0.01 sec)
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'A16&b36@@' WITH GRANT OPTION;
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
mysql> exit
Bye
[root@localhost mysql_5.7.42]#
```
#### 2/6 开启binlog
```shell
## 6:开启binlog
[root@localhost mysql_5.7.42]# head -n 35 /etc/my.cnf
# For advice on how to change settings please see
# http://dev.mysql.com/doc/refman/5.7/en/server-configuration-defaults.html
[mysqld]
#
# Remove leading # and set to the amount of RAM for the most important data
# cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.
# innodb_buffer_pool_size = 128M
#
# Remove leading # to turn on a very important data integrity option: logging
# changes to the binary log between backups.
# log_bin
#
# Remove leading # to set options mainly useful for reporting servers.
# The server defaults are faster for transactions and fast SELECTs.
# Adjust sizes as needed, experiment to find the optimal values.
# join_buffer_size = 128M
# sort_buffer_size = 2M
# read_rnd_buffer_size = 2M
datadir=/data/mysql
socket=/data/mysql/mysql.sock
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
lower_case_table_names=1
max_connections=500
init_connect='SET NAMES utf8'
log-bin=mysql-bin
server-id=1
[root@localhost mysql_5.7.42]#
[root@localhost mysql_5.7.42]# systemctl restart mysqld
[root@localhost mysql_5.7.42]# cd /data/
[root@localhost data]# ll
total 4
drwxr-xr-x 5 mysql mysql 4096 Jul 6 15:08 mysql
[root@localhost data]# cd mysql/
[root@localhost mysql]# ll
total 122960
-rw-r----- 1 mysql mysql 56 Jul 6 14:59 auto.cnf
-rw------- 1 mysql mysql 1676 Jul 6 14:59 ca-key.pem
-rw-r--r-- 1 mysql mysql 1112 Jul 6 14:59 ca.pem
-rw-r--r-- 1 mysql mysql 1112 Jul 6 14:59 client-cert.pem
-rw------- 1 mysql mysql 1676 Jul 6 14:59 client-key.pem
-rw-r----- 1 mysql mysql 350 Jul 6 15:08 ib_buffer_pool
-rw-r----- 1 mysql mysql 12582912 Jul 6 15:08 ibdata1
-rw-r----- 1 mysql mysql 50331648 Jul 6 15:08 ib_logfile0
-rw-r----- 1 mysql mysql 50331648 Jul 6 14:59 ib_logfile1
-rw-r----- 1 mysql mysql 12582912 Jul 6 15:08 ibtmp1
drwxr-x--- 2 mysql mysql 4096 Jul 6 14:59 mysql
-rw-r----- 1 mysql mysql 154 Jul 6 15:08 mysql-bin.000001
-rw-r----- 1 mysql mysql 19 Jul 6 15:08 mysql-bin.index
srwxrwxrwx 1 mysql mysql 0 Jul 6 15:08 mysql.sock
-rw------- 1 mysql mysql 5 Jul 6 15:08 mysql.sock.lock
drwxr-x--- 2 mysql mysql 8192 Jul 6 14:59 performance_schema
-rw------- 1 mysql mysql 1680 Jul 6 14:59 private_key.pem
-rw-r--r-- 1 mysql mysql 452 Jul 6 14:59 public_key.pem
-rw-r--r-- 1 mysql mysql 1112 Jul 6 14:59 server-cert.pem
-rw------- 1 mysql mysql 1680 Jul 6 14:59 server-key.pem
drwxr-x--- 2 mysql mysql 8192 Jul 6 14:59 sys
[root@localhost mysql]#
[root@localhost mysql]# firewall-cmd --permanent --zone=public --add-port=3306/tcp
success
[root@localhost mysql]# firewall-cmd --reload
success
[root@localhost mysql]# ss -lnpt | grep 3306
LISTEN 0 128 [::]:3306 [::]:* users:(("mysqld",pid=3399,fd=30))
[root@localhost mysql]# firewall-cmd --list-all
public (active)
target: default
icmp-block-inversion: no
interfaces: ens33
sources:
services: dhcpv6-client mountd nfs rpc-bind ssh
ports: 3306/tcp
protocols:
masquerade: no
forward-ports:
source-ports:
icmp-blocks:
rich rules:
[root@localhost mysql]#
```
### 3. NFS环境安装
#### 3/0 查询相关服务
```shell
# 查询相关服务
[root@localhost ~]# systemctl status nfs*
如果没有则需要安装
```
#### 3/1 SELiunx 关闭
```shell
## 1:SELiunx 关闭
[root@localhost ~]# getsebool
getsebool: SELinux is disabled
```
#### 3/2 安装NFS
```shell
## 2:安装NFS
[root@localhost ~]# yum install nfs-utils
```
#### 3/3 查看rpcbind监听以及服务
```shell
## 3:查看rpcbind监听以及服务
[root@localhost ~]# ss -tnulp | grep 111
udp UNCONN 0 0 *:111 *:* users:(("rpcbind",pid=720,fd=6))
udp UNCONN 0 0 [::]:111 [::]:* users:(("rpcbind",pid=720,fd=9))
tcp LISTEN 0 128 *:111 *:* users:(("rpcbind",pid=720,fd=8))
tcp LISTEN 0 128 [::]:111 [::]:* users:(("rpcbind",pid=720,fd=11))
[root@localhost ~]# systemctl status rpcbind
● rpcbind.service - RPC bind service
Loaded: loaded (/usr/lib/systemd/system/rpcbind.service; enabled; vendor preset: enabled)
Active: active (running) since Thu 2023-07-06 13:26:29 CST; 34min ago
Main PID: 720 (rpcbind)
CGroup: /system.slice/rpcbind.service
└─720 /sbin/rpcbind -w
Jul 06 13:26:28 localhost.localdomain systemd[1]: Starting RPC bind service...
Jul 06 13:26:29 localhost.localdomain systemd[1]: Started RPC bind service.
[root@localhost ~]#
```
#### 3/4 防火墙开通端口
```shell
## 4:防火墙开通端口
[root@localhost ~]# firewall-cmd --permanent --add-service=rpc-bind
FirewallD is not running
[root@localhost ~]# systemctl status firewalld
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Docs: man:firewalld(1)
[root@localhost ~]# systemctl start firewalld
[root@localhost ~]# systemctl enable firewalld
Created symlink from /etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service to /usr/lib/systemd/system/firewalld.service.
Created symlink from /etc/systemd/system/multi-user.target.wants/firewalld.service to /usr/lib/systemd/system/firewalld.service.
[root@localhost ~]# firewall-cmd --permanent --add-service=rpc-bind
success
[root@localhost ~]# firewall-cmd --permanent --add-service=nfs
success
[root@localhost ~]# firewall-cmd --permanent --add-service=mountd
success
[root@localhost ~]# firewall-cmd --reload
success
[root@localhost ~]# firewall-cmd --list-all
public (active)
target: default
icmp-block-inversion: no
interfaces: ens33
sources:
services: dhcpv6-client mountd nfs rpc-bind ssh
ports:
protocols:
masquerade: no
forward-ports:
source-ports:
icmp-blocks:
rich rules:
[root@localhost ~]#
```
#### 3/5 创建路径编写可读可写权限
```shell
## 5:创建路径编写可读可写权限
[root@localhost ~]# mkdir /Nfs_Disk
[root@localhost ~]# echo "/Nfs_Disk 127.0.0.1/24(rw,async)" >> /etc/exports
[root@localhost ~]# cat /etc/exports
/Nfs_Disk 127.0.0.1/24(rw,async)
[root@localhost ~]#
```
#### 3/6 添加NFS硬盘
```shell
## 6:添加NFS硬盘
--(可以做RAID硬件组保证数据高可用)
[root@localhost ~]# blkid
/dev/sda1: UUID="3ae6a4b1-0140-4d7d-b8fb-ecb18e1243f4" TYPE="xfs"
/dev/sda2: UUID="pJ8unY-dS8y-vV14-YX2A-dFEg-WwST-TriV8T" TYPE="LVM2_member"
/dev/mapper/centos-root: UUID="3295f8fa-8559-47a9-a5f7-0c092f3a04e1" TYPE="xfs"
/dev/mapper/centos-swap: UUID="25b0bcea-10c9-4808-a75a-2f9626c05c66" TYPE="swap"
/dev/mapper/centos-home: UUID="5ca451c5-f185-4a5c-a107-d2bc81a97392" TYPE="xfs"
/dev/sdb: UUID="1d82c5ef-6439-4a98-9eda-eee42d88ecd4" TYPE="ext4"
[root@localhost ~]#
[root@localhost ~]# echo "UUID=1d82c5ef-6439-4a98-9eda-eee42d88ecd4 /Nfs_Disk ext4 defaults 0 0" >> /etc/fstab
[root@localhost ~]# cat /etc/fstab
#
# /etc/fstab
# Created by anaconda on Wed Jul 5 01:09:00 2023
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/centos-root / xfs defaults 0 0
UUID=3ae6a4b1-0140-4d7d-b8fb-ecb18e1243f4 /boot xfs defaults 0 0
/dev/mapper/centos-home /home xfs defaults 0 0
/dev/mapper/centos-swap swap swap defaults 0 0
UUID=1d82c5ef-6439-4a98-9eda-eee42d88ecd4 /Nfs_Disk ext4 defaults 0 0
[root@localhost ~]#
[root@localhost ~]# mount -a
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 894M 0 894M 0% /dev
tmpfs 910M 0 910M 0% /dev/shm
tmpfs 910M 11M 900M 2% /run
tmpfs 910M 0 910M 0% /sys/fs/cgroup
/dev/mapper/centos-root 50G 20G 31G 39% /
/dev/sda1 1014M 185M 830M 19% /boot
/dev/mapper/centos-home 147G 135M 147G 1% /home
tmpfs 182M 8.0K 182M 1% /run/user/42
tmpfs 182M 0 182M 0% /run/user/0
/dev/sdb 99G 61M 94G 1% /Nfs_Disk
[root@localhost ~]#
```
#### 3/7 启动服务并进行挂载
```shell
## 7:启动服务并进行挂载
[root@localhost ~]# systemctl start nfs
[root@localhost ~]# systemctl status nfs
● nfs-server.service - NFS server and services
Loaded: loaded (/usr/lib/systemd/system/nfs-server.service; disabled; vendor preset: disabled)
Drop-In: /run/systemd/generator/nfs-server.service.d
└─order-with-mounts.conf
Active: active (exited) since Thu 2023-07-06 14:20:02 CST; 7s ago
Process: 2373 ExecStartPost=/bin/sh -c if systemctl -q is-active gssproxy; then systemctl reload gssproxy ; fi (code=exited, status=0/SUCCESS)
Process: 2357 ExecStart=/usr/sbin/rpc.nfsd $RPCNFSDARGS (code=exited, status=0/SUCCESS)
Process: 2356 ExecStartPre=/usr/sbin/exportfs -r (code=exited, status=0/SUCCESS)
Main PID: 2357 (code=exited, status=0/SUCCESS)
Tasks: 0
CGroup: /system.slice/nfs-server.service
Jul 06 14:20:02 localhost.localdomain systemd[1]: Starting NFS server and services...
Jul 06 14:20:02 localhost.localdomain systemd[1]: Started NFS server and services.
[root@localhost ~]# showmount -e 127.0.0.1
Export list for 127.0.0.1:
/Nfs_Disk 127.0.0.1/24
[root@localhost ~]#
```
#### 3/8 授权
```shell
## 8:授权
--(也可以不授权这个和规划有关系,不授权后面的权限调整就可以不做)
[root@localhost /]# id nfsnobody
uid=65534(nfsnobody) gid=65534(nfsnobody) groups=65534(nfsnobody)
[root@localhost /]# chown -R nfsnobody.nfsnobody /Nfs_Disk
[root@localhost /]# cd Nfs_Disk/
[root@localhost Nfs_Disk]# mkdir test_mulu
[root@localhost Nfs_Disk]# touch test_file
[root@localhost Nfs_Disk]# echo 'test' >> test_file
[root@localhost Nfs_Disk]# touch test_mulu/test2
[root@localhost Nfs_Disk]# echo 'test2' >> test_mulu/test2
[root@localhost Nfs_Disk]# ll
total 24
drwx------ 2 nfsnobody nfsnobody 16384 Jul 6 14:15 lost+found
-rw-r--r-- 1 root root 5 Jul 6 14:24 test_file
drwxr-xr-x 2 root root 4096 Jul 6 14:24 test_mulu
```
#### 3/9 创建NFS协议挂载
```shell
## 9:创建NFS协议挂载
--(因为默认权限设置为rw,async所以创建出为ROOT权限,且走文件存储权限非NFS)
[root@localhost /]# mkdir NFS_LINK_DISK
[root@localhost /]# echo "127.0.0.1:/Nfs_Disk /NFS_LINK_DISK nfs defaults,_netdev 0 0" >> /etc/fstab
[root@localhost /]# cat /etc/fstab
#
# /etc/fstab
# Created by anaconda on Wed Jul 5 01:09:00 2023
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/centos-root / xfs defaults 0 0
UUID=3ae6a4b1-0140-4d7d-b8fb-ecb18e1243f4 /boot xfs defaults 0 0
/dev/mapper/centos-home /home xfs defaults 0 0
/dev/mapper/centos-swap swap swap defaults 0 0
UUID=1d82c5ef-6439-4a98-9eda-eee42d88ecd4 /Nfs_Disk ext4 defaults 0 0
127.0.0.1:/Nfs_Disk /NFS_LINK_DISK nfs defaults,_netdev 0 0
[root@localhost /]# mount -a
[root@localhost /]# df -h
Filesystem Size Used Avail Use% Mounted on
devtmpfs 894M 0 894M 0% /dev
tmpfs 910M 0 910M 0% /dev/shm
tmpfs 910M 11M 900M 2% /run
tmpfs 910M 0 910M 0% /sys/fs/cgroup
/dev/mapper/centos-root 50G 20G 31G 39% /
/dev/sda1 1014M 185M 830M 19% /boot
/dev/mapper/centos-home 147G 135M 147G 1% /home
tmpfs 182M 12K 182M 1% /run/user/42
tmpfs 182M 0 182M 0% /run/user/0
/dev/sdb 99G 61M 94G 1% /Nfs_Disk
127.0.0.1:/Nfs_Disk 99G 60M 94G 1% /NFS_LINK_DISK
[root@localhost /]#
```
#### 3/10 测试文件创建权限
```shell
## 10:测试文件创建权限
[root@localhost /]# cd /NFS_LINK_DISK/
[root@localhost NFS_LINK_DISK]# ls
lost+found test_file test_mulu
[root@localhost NFS_LINK_DISK]# ll
total 24
drwx------ 2 nfsnobody nfsnobody 16384 Jul 6 14:15 lost+found
-rw-r--r-- 1 root root 5 Jul 6 14:24 test_file
drwxr-xr-x 2 root root 4096 Jul 6 14:24 test_mulu
[root@localhost NFS_LINK_DISK]# mkdir test2_mulu
[root@localhost NFS_LINK_DISK]# touch test2_mulu/test3_file
[root@localhost NFS_LINK_DISK]# echo 'test3' >> test2_mulu/test3_file
[root@localhost NFS_LINK_DISK]# ll
total 28
drwx------ 2 nfsnobody nfsnobody 16384 Jul 6 14:15 lost+found
drwxr-xr-x 2 nfsnobody nfsnobody 4096 Jul 6 14:34 test2_mulu
-rw-r--r-- 1 root root 5 Jul 6 14:24 test_file
drwxr-xr-x 2 root root 4096 Jul 6 14:24 test_mulu
[root@localhost NFS_LINK_DISK]# cd test2_mulu/
[root@localhost test2_mulu]# ll
total 4
-rw-r--r-- 1 nfsnobody nfsnobody 6 Jul 6 14:34 test3_file
[root@localhost test2_mulu]#
```
#### 3/11 修改权限
```shell
## 11:修改权限
[root@localhost test2_mulu]# vim /etc/exports
[root@localhost test2_mulu]# cat /etc/exports
# /Nfs_Disk 127.0.0.1/24(rw,async)
/Nfs_Disk 127.0.0.1/24(rw,sync,root_squash)
[root@localhost test2_mulu]#
权限说明:
rw 可读可写
sync 写入内存同时写入硬盘 保证数据不丢失 但是会导致IO增大
root_sqush 当NFS客户端以root管理员访问时,映射为NFS服务器的匿名用户(比较安全)
网络根据实际情况填写
/Nfs_Disk 为server主机对应的共享磁盘标识 为了保证数据一致性这里设置一个总的共享。
```
#### 3/12 重启服务使修改生效
```shell
## 12:重启服务使修改生效
[root@localhost test2_mulu]# systemctl restart nfs*
[root@localhost test2_mulu]# systemctl status nfs*
● nfs-mountd.service - NFS Mount Daemon
Loaded: loaded (/usr/lib/systemd/system/nfs-mountd.service; static; vendor preset: disabled)
Active: active (running) since Thu 2023-07-06 14:38:55 CST; 10s ago
Process: 2746 ExecStart=/usr/sbin/rpc.mountd $RPCMOUNTDARGS (code=exited, status=0/SUCCESS)
Main PID: 2748 (rpc.mountd)
Tasks: 1
CGroup: /system.slice/nfs-mountd.service
└─2748 /usr/sbin/rpc.mountd
Jul 06 14:38:55 localhost.localdomain systemd[1]: Starting NFS Mount Daemon...
Jul 06 14:38:55 localhost.localdomain rpc.mountd[2748]: Version 1.3.0 starting
Jul 06 14:38:55 localhost.localdomain systemd[1]: Started NFS Mount Daemon.
● nfs-idmapd.service - NFSv4 ID-name mapping service
Loaded: loaded (/usr/lib/systemd/system/nfs-idmapd.service; static; vendor preset: disabled)
Active: active (running) since Thu 2023-07-06 14:38:55 CST; 10s ago
Process: 2745 ExecStart=/usr/sbin/rpc.idmapd $RPCIDMAPDARGS (code=exited, status=0/SUCCESS)
Main PID: 2747 (rpc.idmapd)
Tasks: 1
CGroup: /system.slice/nfs-idmapd.service
└─2747 /usr/sbin/rpc.idmapd
Jul 06 14:38:55 localhost.localdomain systemd[1]: Starting NFSv4 ID-name mapping service...
Jul 06 14:38:55 localhost.localdomain systemd[1]: Started NFSv4 ID-name mapping service.
● nfs-server.service - NFS server and services
Loaded: loaded (/usr/lib/systemd/system/nfs-server.service; disabled; vendor preset: disabled)
Drop-In: /run/systemd/generator/nfs-server.service.d
└─order-with-mounts.conf
Active: active (exited) since Thu 2023-07-06 14:38:55 CST; 10s ago
Process: 2738 ExecStopPost=/usr/sbin/exportfs -f (code=exited, status=0/SUCCESS)
Process: 2733 ExecStopPost=/usr/sbin/exportfs -au (code=exited, status=0/SUCCESS)
Process: 2730 ExecStop=/usr/sbin/rpc.nfsd 0 (code=exited, status=0/SUCCESS)
Process: 2766 ExecStartPost=/bin/sh -c if systemctl -q is-active gssproxy; then systemctl reload gssproxy ; fi (code=exited, status=0/SUCCESS)
Process: 2751 ExecStart=/usr/sbin/rpc.nfsd $RPCNFSDARGS (code=exited, status=0/SUCCESS)
Process: 2749 ExecStartPre=/usr/sbin/exportfs -r (code=exited, status=0/SUCCESS)
Main PID: 2751 (code=exited, status=0/SUCCESS)
Tasks: 0
CGroup: /system.slice/nfs-server.service
Jul 06 14:38:55 localhost.localdomain systemd[1]: Starting NFS server and services...
Jul 06 14:38:55 localhost.localdomain systemd[1]: Started NFS server and services.
[root@localhost test2_mulu]#
```
> *-- > 进行到这里的时候MYSQLdump相关架构程序已经可以使用,请确保系统可以运行mysqldump测试方法执行mysqldump*,关于程序运行请跳转到-Ⅳ程序运行mysqldump部分
```shell
[root@localhost mysql]# mysqldump
Usage: mysqldump [OPTIONS] database [tables]
OR mysqldump [OPTIONS] --databases [OPTIONS] DB1 [DB2 DB3...]
OR mysqldump [OPTIONS] --all-databases [OPTIONS]
For more options, use mysqldump --help
[root@localhost mysql]#
```
### 4. Mydumper 依赖安装
```shell
# 说明
--(项目lib文件夹中,mydumper-0.9.3-41.el7.x86_64.rpm 进行安装)
[root@localhost lib]# cd /root/IdeaProjects/Backup-tools/lib
[root@localhost lib]# rpm -qa | grep mydumper
[root@localhost lib]# rpm -ivh mydumper-0.9.3-41.el7.x86_64.rpm
Preparing... ################################# [100%]
Updating / installing...
1:mydumper-0.9.3-41 ################################# [100%]
[root@localhost lib]# rpm -qa | grep mydumper
mydumper-0.9.3-41.x86_64
[root@localhost lib]# mydumper
# 测试依赖
** (mydumper:5063): CRITICAL **: 13:58:22.089: Error connecting to database: Access denied for user 'root'@'localhost' (using password: NO)
[root@localhost lib]#
```
> *-- > 进行到这里的时候MYdumper相关架构程序已经可以使用,请确保系统可以运行mydumper测试方法执行mydumper*,关于程序运行请跳转到-Ⅳ程序运行mydumper部分
### 5.xtrabackup 依赖安装
```shell
# 安装依赖
[root@localhost ~]# cd /root/IdeaProjects/Backup-tools/lib/
[root@localhost lib]#
[root@localhost lib]# whereis innobackupex
innobackupex:[root@localhost lib]# innobackupex
bash: innobackupex: command not found...
[root@localhost lib]#
[root@localhost lib]# rpm -ivh percona-xtrabackup-*
warning: percona-xtrabackup-24-2.4.26-1.el7.x86_64.rpm: Header V4 RSA/SHA256 Signature, key ID 8507efa5: NOKEY
error: Failed dependencies:
libev.so.4()(64bit) is needed by percona-xtrabackup-24-2.4.26-1.el7.x86_64
perl(DBD::mysql) is needed by percona-xtrabackup-24-2.4.26-1.el7.x86_64
perl(Digest::MD5) is needed by percona-xtrabackup-24-2.4.26-1.el7.x86_64
# 解决依赖冲突
[root@localhost lib]# cd /opt/soft/mysql_5.7.42
[root@localhost mysql_5.7.42]# rpm -ivh mysql-community-libs-compat-5.7.42-1.el7.x86_64.rpm
[root@localhost mysql_5.7.42]# yum install perl-DBD-MySQL
[root@localhost lib]# rpm -ivh percona-xtrabackup-*
warning: percona-xtrabackup-24-2.4.26-1.el7.x86_64.rpm: Header V4 RSA/SHA256 Signature, key ID 8507efa5: NOKEY
error: Failed dependencies:
perl(Digest::MD5) is needed by percona-xtrabackup-24-2.4.26-1.el7.x86_64
[root@localhost lib]#
[root@localhost lib]# yum install perl-Digest-MD5
# 安装成功,依赖解决每个系统不一样根据实际环境处理,最终RPM包安装成功即可。
[root@localhost lib]# rpm -ivh percona-xtrabackup-*
warning: percona-xtrabackup-24-2.4.26-1.el7.x86_64.rpm: Header V4 RSA/SHA256 Signature, key ID 8507efa5: NOKEY
Preparing... ################################# [100%]
Updating / installing...
1:percona-xtrabackup-24-2.4.26-1.el################################# [ 33%]
2:percona-xtrabackup-test-24-2.4.26################################# [ 67%]
3:percona-xtrabackup-24-debuginfo-2################################# [100%]
[root@localhost lib]#
# 测试
[root@localhost lib]# innobackupex
xtrabackup: recognized server arguments: --datadir=/data/mysql --log_bin=mysql-bin --server-id=1
230710 13:30:24 innobackupex: Missing argument
[root@localhost lib]#
```
> -- > 进行到这里的时候xtrabackup相关架构程序已经可以使用,请确保系统可以运行xtrabackup测试方法执行innobackupex,关于程序运行请跳转到-Ⅳ程序运行xtrabackup部分
## Ⅳ. 程序运行
### 1. Backup_Mysqldump_All
> 该程序为mysqldump原生的全库数据库备份程序。
#### 1/1 配置文件修改
```shell
## default_config
--(主程序配置)
NetworkSegment=127.0.0.1
--(监听网卡地址配置)
Date=$(date +%Y%m%d-%H%M%S)
--(日期参数)
Base_IP=$(ip addr | awk '/^[0-9]+: / {}; /inet.*global/ {print gensub(/(.*)\/(.*)/, "\\1", "g", $2)}' | grep ${NetworkSegment})
--(获取IP参数配置)
Script_Dir=/root/IdeaProjects/Backup-tools/mysqldump
--(本程序绝对路径)
Script_Log=Backup_Mysqldump_All.log
--(程序生成日志文件名称)
Data_Storage_Save=/NFS_LINK_DISK/127.0.0.1/Mysqldump_Databases_All
--(备份文件生成文件路径配置)
## database_config
--(数据库程序配置)
MYSQL_Host=127.0.0.1
--(数据库主机地址)
MYSQL_Username=root
--(数据库用户名)
MYSQL_Password='A16&b36@@'
--(数据库密码)
MYSQL_Port=3306
--(数据库监听端口号)
MYSQL_Chara=default-character-set=utf8
--(数据库字符集)
MYSQL_Nfs_DiskDir="NFS_LINK_DISK"
--(数据库与NFS关联指针)
```
#### 1/2 程序启动
```shell
[root@localhost mysqldump]# cd /root/IdeaProjects/Backup-tools/mysqldump
[root@localhost mysqldump]# chmod +x Backup_Mysqldump_All.sh
[root@localhost mysqldump]# ./Backup_Mysqldump_All.sh
mysqldump: [Warning] Using a password on the command line interface can be insecure.
```
#### 1/3 查看结果
```shell
# 文件查看
cd /NFS_LINK_DISK/127.0.0.1/Mysqldump_Databases_All
[root@localhost Mysqldump_Databases_All]# ll
total 576
-rw-r--r-- 1 nfsnobody nfsnobody 195751 Jul 7 10:10 20230707-101039-AllDatabases-backup.sql.gz
-rw-r--r-- 1 nfsnobody nfsnobody 195753 Jul 7 10:12 20230707-101244-AllDatabases-backup.sql.gz
-rw-r--r-- 1 nfsnobody nfsnobody 195753 Jul 7 10:28 20230707-102830-AllDatabases-backup.sql.gz
# 日志查看
[root@localhost mysqldump]# tail Backup_Mysqldump_All.log
发现NFS挂载点 NFS_LINK_DISK,正在继续执行脚本……
正在判断是否有/NFS_LINK_DISK/127.0.0.1/Mysqldump_Databases_All,存储路径……
已发现存储路径/NFS_LINK_DISK/127.0.0.1/Mysqldump_Databases_All,正在继续执行……
正在执行备份……
备份开始时间:20230707-102830
备份方式:全库备份-mysqldump官方单线程
备份数据库IP:127.0.0.1
备份存储路径:/NFS_LINK_DISK/127.0.0.1/Mysqldump_Databases_All/对应时间-AllDatabases-backup.sql.gz
备份结束时间:20230707-102830
END 20230707-102830
[root@localhost mysqldump]#
```
#### 1/4 结果说明
``` shell
# 用VIM 查看文件内容 (片段)
...
) ENGINE=MyISAM DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='Database privileges';
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `db`
--
LOCK TABLES `db` WRITE;
/*!40000 ALTER TABLE `db` DISABLE KEYS */;
INSERT INTO `db` VALUES ('localhost','performance_schema','mysql.session','Y','N','N','N','N','N','N','N','N','N','N','N','N','N','N','N','N','N','N'),('localhost','sys','mysql.sys','N','N','N','N','N','N','N','N','N','N','N','N','N','N','N','N','N','N','Y');
/*!40000 ALTER TABLE `db` ENABLE KEYS */;
UNLOCK TABLES;
...
说明:程序执行为MySQL全量备份,输出的文件为全量的结构+数据一个的SQL文件且通过Gzip进行压缩后存储,满足预期。
```
### 2. Backup_Mysqldump_One
> 该程序为mysqldump原生的单个数据库备份程序。
#### 2/1 配置文件修改
```shell
## Default_config
NetworkSegment=127.0.0.1
Date=$(date +%Y%m%d-%H%M%S)
Base_IP=$(ip addr | awk '/^[0-9]+: / {}; /inet.*global/ {print gensub(/(.*)\/(.*)/, "\\1", "g", $2)}' | grep ${NetworkSegment})
Script_Dir=/root/IdeaProjects/Backup-tools/mysqldump
Script_Log=Backup_Mysqldump_One.log
Data_Storage_Save=/NFS_LINK_DISK/127.0.0.1/Mysqldump_Save
## database_config
MYSQL_Host=1
MYSQL_Username=root
MYSQL_Password='A16&b36@@'
MYSQL_Port=3306
MYSQL_Chara=default-character-set=utf8
MYSQL_Database_Name=mysql
--(单个备份数据库名称)
MYSQL_Nfs_DiskDir="NFS_LINK_DISK"
```
#### 2/2 程序启动
```shell
[root@localhost mysqldump]# chmod +x Backup_Mysqldump_One.sh
[root@localhost mysqldump]# ./Backup_Mysqldump_One.sh
mysqldump: [Warning] Using a password on the command line interface can be insecure.
[root@localhost mysqldump]#
```
#### 2/3 查看结果
```SHELL
# 生成文件
[root@localhost 127.0.0.1]# tree
.
├── Mysqldump_Databases_All
│ ├── 20230707-101039-AllDatabases-backup.sql.gz
│ ├── 20230707-101244-AllDatabases-backup.sql.gz
│ └── 20230707-102830-AllDatabases-backup.sql.gz
└── Mysqldump_Save
└── mysql
└── 20230707-132623-mysql-backup.sql.gz
3 directories, 4 files
[root@localhost 127.0.0.1]#
# 日志查看
[root@localhost mysqldump]# tail Backup_Mysqldump_One.log
正在判断是否有对应数据库mysql,MYSQL_SAVE存储路径……
没有发现对应MYSQL_SAVE-mysql,对应数据库,正在创建……
正在执行备份……
备份开始时间:20230707-132623
备份方式:mysqldump官方单线程
备份数据库:mysql
备份数据库IP:127.0.0.1
备份存储路径:/NFS_LINK_DISK/127.0.0.1/Mysqldump_Save/mysql/对应时间-数据库名称-backup.sql.gz
备份结束时间:20230707-132623
END 20230707-132623
[root@localhost mysqldump]#
```
#### 2/4 结果说明
``` shell
# 用VIM 查看文件内容 (片段)
...
-- Dumping data for table `db`
--
LOCK TABLES `db` WRITE;
/*!40000 ALTER TABLE `db` DISABLE KEYS */;
INSERT INTO `db` VALUES ('localhost','performance_schema','mysql.session','Y','N','N','N','N','N','N','N','N','N','N','N','N','N','N','N','N','N','N'),('localhost','sys','mysql.sys','N','N','N','N','N','N','N','N','N','N','N','N','N','N','N','N','N','N','Y');
/*!40000 ALTER TABLE `db` ENABLE KEYS */;
UNLOCK TABLES;
--
-- Table structure for table `engine_cost`
--
DROP TABLE IF EXISTS `engine_cost`;
...
说明:程序执行为MySQL单库备份,输出的文件为全量的结构+数据一个的SQL文件且通过Gzip进行压缩后存储,满足预期。
```
### 3. Backup_Mydumper_MultiThread_Database_All
> 该程序为多线程全量数据库备份程序
#### 3/1 配置文件修改
```shell
## Default_config
--(主要配置)
NetworkSegment=127.0.0.1
--(网络IP配置)
Date=$(date +%Y%m%d-%H%M%S)
--(日期格式配置)
Base_IP=$(ip addr | awk '/^[0-9]+: / {}; /inet.*global/ {print gensub(/(.*)\/(.*)/, "\\1", "g", $2)}' | grep ${NetworkSegment})
--(IP获取配置)
Script_Dir=/root/IdeaProjects/Backup-tools/mydumper
--(脚本路劲配置)
Script_Log=Backup_Mydumper_MultiThread_Database_All.log
--(脚本日志配置)
Data_Storage_Save=/NFS_LINK_DISK/127.0.0.1/Mydumper_MultiThread_Databases_All
--(备份生成文件存储位置配置)
## Database_config
MYSQL_Host=127.0.0.1
--(数据库主机名)
MYSQL_Username=root
--(数据库账户名)
MYSQL_Password='A16&b36@@'
--(数据库密码)
MYSQL_Port=3306
--(数据库端口)
MYSQL_Chara=default-character-set=utf8
--(数据库字符集)
#MYSQL_Database_Name=sakila_b
MYSQL_Nfs_DiskDir="NFS_LINK_DISK"
--(数据库NFS指针)
# 是否开启压缩存储 压缩.SQL.GZ 占用空间小 不压缩.SQL 占用空间大
DUMPER_COMPERSS=-c
--(默认开启压缩)
# dumper信息展示级别,最详细级别
DUMPER_INFO_LAVEL=3
--(信息级别展示INFO)
# 备份线程数 根据实际情况调整
DUMPER_THREADS_NUMBER=32
--(备份线程数,根据主机实际情况)
# dumper信息展示存储日志位置
DUMPER_BACKINFO_LOG=${Script_Dir}/DUMPER_Backup_info.log
--(程序运行过程记录日志文件)
```
#### 3/2 程序启动
```shell
[root@localhost mydumper]# chmod +x Backup_Mydumper_MultiThread_Database_All.sh
[root@localhost mydumper]# ./Backup_Mydumper_MultiThread_Database_All.sh
[root@localhost mydumper]# tail DUMPER_Backup_info.log
** Message: 14:10:34.013: Thread 21 shutting down
** Message: 14:10:34.017: Thread 20 shutting down
** Message: 14:10:34.019: Thread 18 shutting down
** Message: 14:10:34.024: Thread 5 shutting down
** Message: 14:10:34.025: Thread 1 shutting down
** Message: 14:10:34.032: Finished dump at: 2023-07-07 14:10:34
```
#### 3/3 查看结果
```SHELL
# 生成文件
[root@localhost mydumper]# cd /NFS_LINK_DISK/127.0.0.1/
[root@localhost 127.0.0.1]# tree
.
├── Mydumper_MultiThread_Databases_All
│ └── 20230707-141032-Databases-All
│ ├── metadata
│ ├── mysql.columns_priv-schema.sql.gz
│ ├── mysql.db-schema.sql.gz
```
#### 3/4 结果说明
``` shell
[root@localhost 20230707-141032-Databases-All]# vim mysql.proxies_priv.sql.gz
[root@localhost 20230707-141032-Databases-All]# ll | grep proxies
-rw-r--r-- 1 nfsnobody nfsnobody 338 Jul 7 14:10 mysql.proxies_priv-schema.sql.gz
-rw-r--r-- 1 nfsnobody nfsnobody 187 Jul 7 14:10 mysql.proxies_priv.sql.gz
[root@localhost 20230707-141032-Databases-All]#
# 说明
可以看到全库多线程备份会在NFS路径下生成对应时间的文件夹并有schema结构文件,正常的数据文件,也就是会生成结构和数据分开的文件,满足预期。
```
### 4. Backup_Mydumper_MultiThread_Database_One
> 该程序为多线程单库全量数据库备份程序
#### 4/1 配置文件修改
```shell
MYSQL_Database_Name=sakila_b
--(其他配置和全量备份一致,只涉及数据库名称)
```
#### 4/2 程序启动
```shell
[root@localhost mydumper]# chmod +x Backup_Mydumper_MultiThread_Database_One.sh
[root@localhost mydumper]# ./Backup_Mydumper_MultiThread_Database_One.sh
```
#### 4/3 查看结果
```SHELL
# 文件结构
├── Mydumper_MultiThread_Save
│ └── mysql
│ └── 20230707-145056-mysql
│ ├── metadata
│ ├── mysql.columns_priv-schema.sql.gz
│ ├── mysql.db-schema.sql.gz
│ ├── mysql.db.sql.gz
```
#### 4/4 结果说明
``` shell
[root@localhost 20230707-145056-mysql]# ll | grep mysql.db
-rw-r--r-- 1 nfsnobody nfsnobody 405 Jul 7 14:50 mysql.db-schema.sql.gz
-rw-r--r-- 1 nfsnobody nfsnobody 200 Jul 7 14:50 mysql.db.sql.gz
[root@localhost 20230707-145056-mysql]# ll | grep -v mysql
total 384
-rw-r--r-- 1 nfsnobody nfsnobody 136 Jul 7 14:50 metadata
[root@localhost 20230707-145056-mysql]#
# 说明
可以看到 此文件下只有mysql数据库得内容,包含结构和数据,其他数据库 grep -v mysql发现只有有个配置文件所以满足预期。
```
### 5. Backup_XtraBackup_add
> 该程序为XtraBackup增量备份程序,用于提供MySQL数据库的全量+增量备份程序
#### 5/1 配置文件修改
```shell
## Default_config
NetworkSegment=127.0.0.1
--(网络配置)
Date=$(date +%Y%m%d-%H%M%S)
--(日期设置)
Base_IP=$(ip addr | awk '/^[0-9]+: / {}; /inet.*global/ {print gensub(/(.*)\/(.*)/, "\\1", "g", $2)}' | grep ${NetworkSegment})
--(网络配置参数)
Script_Dir=/root/IdeaProjects/Backup-tools/xtrabackup
--(脚本位置)
Script_Log=Backup_XtraBackup_Add.log
--(日志文件配置)
Data_Storage_Full=/NFS_LINK_DISK/127.0.0.1/XtraBackup/Full
--(全量备份存储位置)
Data_Storage_Add=/NFS_LINK_DISK/127.0.0.1/XtraBackup/Add
--(增量备份存储位置)
## Database_config
MYSQL_Username=root
--(数据库账户)
MYSQL_Password='A16&b36@@'
--(数据库密码)
MYSQL_Default=/etc/my.cnf
--(配置文件位置,需要判断binlog相关函数内容使用)
MYSQL_Port=3306
--(数据库端口)
MYSQL_Nfs_DiskDir="NFS_LINK_DISK"
--(NFS关联指针)
```
#### 5/2 程序启动
```shell
[root@localhost xtrabackup]# chmod +x Backup_XtraBackup_add.sh
[root@localhost xtrabackup]# ll
total 8
-rwxr-xr-x 1 root root 4396 Jul 10 13:37 Backup_XtraBackup_add.sh
[root@localhost xtrabackup]#
# 首次执行全量备份
[root@localhost xtrabackup]# ./Backup_XtraBackup_add.sh
...
xtrabackup: The latest check point (for incremental): '2767189'
xtrabackup: Stopping log copying thread.
.230710 13:42:59 >> log scanned up to (2767198)
230710 13:42:59 Executing UNLOCK TABLES
230710 13:42:59 All tables unlocked
230710 13:42:59 [00] Copying ib_buffer_pool to /NFS_LINK_DISK/127.0.0.1/XtraBackup/Full/ib_buffer_pool
230710 13:42:59 [00] ...done
230710 13:42:59 Backup created in directory '/NFS_LINK_DISK/127.0.0.1/XtraBackup/Full/'
MySQL binlog position: filename 'mysql-bin.000004', position '154'
230710 13:42:59 [00] Writing /NFS_LINK_DISK/127.0.0.1/XtraBackup/Full/backup-my.cnf
230710 13:42:59 [00] ...done
230710 13:42:59 [00] Writing /NFS_LINK_DISK/127.0.0.1/XtraBackup/Full/xtrabackup_info
230710 13:42:59 [00] ...done
xtrabackup: Transaction log of lsn (2767189) to (2767198) was copied.
230710 13:43:00 completed OK!
...
[root@localhost xtrabackup]# tail Backup_XtraBackup_Add.log
START 20230710-134256
正在进行MySQL-binlog判断……
已发现mysqlbinlog相关配置,正在继续执行脚本……
发现NFS挂载点 NFS_LINK_DISK,正在继续执行脚本……
正在判断是否有FULL指针,请稍后……
没有找到全量备份FULL的指针,正在执行全量备份FULL
END 20230710-134256
```
#### 5/3 制作增量数据
```shell
# 读数据库进行查询、创建数据库、创建表、插入数据、查询操作
[root@localhost xtrabackup]# mysql -uroot -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 4
Server version: 5.7.42-log MySQL Community Server (GPL)
Copyright (c) 2000, 2023, Oracle and/or its affiliates.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.01 sec)
mysql> CREATE DATABASE menagerie;
Query OK, 1 row affected (0.01 sec)
mysql> CREATE TABLE pet (name VARCHAR(20), owner VARCHAR(20),species VARCHAR(20), sex CHAR(1), birth DATE, death DATE);
ERROR 1046 (3D000): No database selected
mysql> use menagerie;
Database changed
mysql> CREATE TABLE pet (name VARCHAR(20), owner VARCHAR(20),species VARCHAR(20), sex CHAR(1), birth DATE, death DATE);
Query OK, 0 rows affected (0.05 sec)
mysql> SHOW TABLES;
+---------------------+
| Tables_in_menagerie |
+---------------------+
| pet |
+---------------------+
1 row in set (0.00 sec)
mysql> DESCRIBE pet;
+---------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+---------+-------------+------+-----+---------+-------+
| name | varchar(20) | YES | | NULL | |
| owner | varchar(20) | YES | | NULL | |
| species | varchar(20) | YES | | NULL | |
| sex | char(1) | YES | | NULL | |
| birth | date | YES | | NULL | |
| death | date | YES | | NULL | |
+---------+-------------+------+-----+---------+-------+
6 rows in set (0.01 sec)
mysql> INSERT INTO pet VALUES ('Puffball','Diane','hamster','f','1999-03-30',NULL);
Query OK, 1 row affected (0.00 sec)
mysql> select * from pet where name = 'Puffball';
+----------+-------+---------+------+------------+-------+
| name | owner | species | sex | birth | death |
+----------+-------+---------+------+------------+-------+
| Puffball | Diane | hamster | f | 1999-03-30 | NULL |
+----------+-------+---------+------+------------+-------+
1 row in set (0.00 sec)
mysql> exit
Bye
# 查看binlog 是否记录 (片段)
[root@localhost mysql]# mysqlbinlog -vv mysql-bin.000004
——> 可以看到创建数据库
CREATE DATABASE menagerie
/*!*/;
# at 328
#230710 13:53:24 server id 1 end_log_pos 393 CRC32 0x61986ec2 Anonymous_GTID last_committed=1 sequence_number=2 rbr_only=no
SET @@SESSION.GTID_NEXT= 'ANONYMOUS'/*!*/;
# at 393
#230710 13:53:24 server id 1 end_log_pos 588 CRC32 0x9179e5d5 Query thread_id=4 exec_time=0 error_code=0
use `menagerie`/*!*/;
SET TIMESTAMP=1688968404/*!*/;
CREATE TABLE pet (name VARCHAR(20), owner VARCHAR(20),species VARCHAR(20), sex CHAR(1), birth DATE, death DATE)
/*!*/;
——> 可以看到创建表并插入了数据
### INSERT INTO `menagerie`.`pet`
### SET
### @1='Puffball' /* VARSTRING(20) meta=20 nullable=1 is_null=0 */
### @2='Diane' /* VARSTRING(20) meta=20 nullable=1 is_null=0 */
### @3='hamster' /* VARSTRING(20) meta=20 nullable=1 is_null=0 */
### @4='f' /* STRING(1) meta=65025 nullable=1 is_null=0 */
### @5='1999:03:30' /* DATE meta=0 nullable=1 is_null=0 */
### @6=NULL /* DATE meta=0 nullable=1 is_null=1 */
# at 858
#230710 13:54:08 server id 1 end_log_pos 889 CRC32 0xcd0a44dd Xid = 33
COMMIT/*!*/;
# at 889
#230710 14:02:55 server id 1 end_log_pos 912 CRC32 0x30331055 Stop
SET @@SESSION.GTID_NEXT= 'AUTOMATIC' /* added by mysqlbinlog */ /*!*/;
DELIMITER ;
```
#### 5/4 程序启动第N次
```shell
# 执行第二次启动并触发增量函数
[root@localhost xtrabackup]# ./Backup_XtraBackup_add.sh
...
xtrabackup: The latest check point (for incremental): '2772290'
xtrabackup: Stopping log copying thread.
.230710 14:21:41 >> log scanned up to (2772299)
230710 14:21:41 Executing UNLOCK TABLES
230710 14:21:41 All tables unlocked
230710 14:21:41 [00] Copying ib_buffer_pool to /NFS_LINK_DISK/127.0.0.1/XtraBackup/Add/2023-07-10_14-21-37/ib_buffer_pool
230710 14:21:41 [00] ...done
230710 14:21:41 Backup created in directory '/NFS_LINK_DISK/127.0.0.1/XtraBackup/Add/2023-07-10_14-21-37/'
MySQL binlog position: filename 'mysql-bin.000007', position '154'
230710 14:21:41 [00] Writing /NFS_LINK_DISK/127.0.0.1/XtraBackup/Add/2023-07-10_14-21-37/backup-my.cnf
230710 14:21:41 [00] ...done
230710 14:21:41 [00] Writing /NFS_LINK_DISK/127.0.0.1/XtraBackup/Add/2023-07-10_14-21-37/xtrabackup_info
230710 14:21:41 [00] ...done
xtrabackup: Transaction log of lsn (2772290) to (2772299) was copied.
230710 14:21:42 completed OK!
...
[root@localhost xtrabackup]# tail Backup_XtraBackup_Add.log
END 20230710-134256
START 20230710-142137
正在进行MySQL-binlog判断……
已发现mysqlbinlog相关配置,正在继续执行脚本……
发现NFS挂载点 NFS_LINK_DISK,正在继续执行脚本……
正在判断是否有FULL指针,请稍后……
已经找到全量备份FULL的指针,正在执行增量判断,请稍后……
正在判断是否有增量ADD的指针,请稍后……
首次增量备份已完成
END 20230710-142137
[root@localhost xtrabackup]#
```
#### 5/5 查看结果
```SHELL
# 首次执行全量备份查看文件
[root@localhost 127.0.0.1]# tree -L 2 XtraBackup/
XtraBackup/
└── Full
├── backup-my.cnf
├── ib_buffer_pool
├── ibdata1
├── mysql
├── performance_schema
├── sys
├── xtrabackup_binlog_info
├── xtrabackup_checkpoints
├── xtrabackup_info
└── xtrabackup_logfile
4 directories, 7 files
[root@localhost 127.0.0.1]# pwd
/NFS_LINK_DISK/127.0.0.1
[root@localhost 127.0.0.1]#
# 第二次执行增量备份查看文件
[root@localhost XtraBackup]# tree -L 2 .
.
├── Add
│ └── 2023-07-10_14-21-37
└── Full
├── backup-my.cnf
├── ib_buffer_pool
├── ibdata1
├── mysql
├── performance_schema
├── sys
├── xtrabackup_binlog_info
├── xtrabackup_checkpoints
├── xtrabackup_info
└── xtrabackup_logfile
6 directories, 7 files
[root@localhost XtraBackup]# pwd
/NFS_LINK_DISK/127.0.0.1/XtraBackup
[root@localhost XtraBackup]#
[root@localhost Add]# du -h .
1.1M ./2023-07-10_14-21-37/performance_schema
1.2M ./2023-07-10_14-21-37/mysql
104K ./2023-07-10_14-21-37/menagerie
604K ./2023-07-10_14-21-37/sys
3.4M ./2023-07-10_14-21-37
3.4M .
[root@localhost Add]# cd ..
[root@localhost XtraBackup]# ls
Add Full
[root@localhost XtraBackup]# cd Full/
[root@localhost Full]# ls
backup-my.cnf ib_buffer_pool ibdata1 mysql performance_schema sys xtrabackup_binlog_info xtrabackup_checkpoints xtrabackup_info xtrabackup_logfile
[root@localhost Full]# du -h .
1.1M ./performance_schema
12M ./mysql
680K ./sys
26M .
[root@localhost Full]#
```
#### 5/6 结果说明
```shell
[root@localhost Add]# du -h .
1.1M ./2023-07-10_14-21-37/performance_schema
1.2M ./2023-07-10_14-21-37/mysql
104K ./2023-07-10_14-21-37/menagerie
604K ./2023-07-10_14-21-37/sys
3.4M ./2023-07-10_14-21-37
3.4M .
[root@localhost Add]# cd ..
[root@localhost XtraBackup]# ls
Add Full
[root@localhost XtraBackup]# cd Full/
[root@localhost Full]# ls
backup-my.cnf ib_buffer_pool ibdata1 mysql performance_schema sys xtrabackup_binlog_info xtrabackup_checkpoints xtrabackup_info xtrabackup_logfile
[root@localhost Full]# du -h .
1.1M ./performance_schema
12M ./mysql
680K ./sys
26M .
[root@localhost Full]#
# 说明
可以看到 第一次程序执行获取了全量的mysql数据文件,存储在nfs的full位置上,第二次程序执行前进行了数据库操作,且重启了2次mysql,所以生成了2个全新的binlog文件,查询之前的binlog看到了相关的创建数据库、创建数据表相关操作,然后进行第二次程序执行,文件存储在nfs的add位置上,可以看到大小完全不一致,也就是说只存储了增量的数据,满足预期。
```
## Ⅴ. 开发
### 1. 构建开发环境
```shell
# GO环境搭建
[root@localhost soft]# wget https://go.dev/dl/go1.20.5.linux-amd64.tar.gz
[root@localhost soft]# tar xzvf go1.20.5.linux-amd64.tar.gz -C /usr/local/
[root@localhost go]# cd /usr/local/go/
[root@localhost go]# ll bin/go
-rwxr-xr-x 1 root root 15657886 Jun 2 01:04 bin/go
[root@localhost go]# bin/go version
go version go1.20.5 linux/amd64
[root@localhost go]#
# 环境变量设置
[root@localhost go]# vim /etc/profile.d/go.sh
[root@localhost go]# cat /etc/profile.d/go.sh
export GOROOT=/usr/local/go
export GOPATH=/root/go
export PATH=$PATH:$GOROOT/bin
[root@localhost go]# source /etc/profile
# 测试环境生效查看版本
[root@localhost go]# go version
go version go1.20.5 linux/amd64
[root@localhost go]# mkdir -p /root/go
[root@localhost go]# cd /root/go
[root@localhost go]#
# 编译第一个程序
[root@localhost go]# vim hell.go
[root@localhost go]# cat hell.go
package main
import "fmt"
func main(){
fmt.Printf("Hello World")
}
[root@localhost go]#
[root@localhost go]# go run hell.go
Hello World[root@localhost go]# ls
hell.go pkg
# 移动go程序
[root@localhost obj]# mv ~/go/hell.go .
[root@localhost obj]# ls
hell.go
# 初始化项目
[root@localhost obj]# go mod init example.com/hello
go: creating new go.mod: module example.com/hello
go: to add module requirements and sums:
go mod tidy
[root@localhost obj]# ls
go.mod hell.go
# 编译程序
[root@localhost obj]# go build hell.go
[root@localhost obj]# ls
go.mod hell hell.go
[root@localhost obj]# ./hell
Hello World[root@localhost obj]#
--(至此环境测试成功)
```
### 2. 程序编译
```SHELL
993 go mod init github.com/heike-07/Backup-tools
994 go build
995 go build Backup_Mydumper_MultiThread_Database_All.go
996 go build Backup_Mydumper_MultiThread_Database_One.go
997 go build Backup_Mysqldump_All.go
998 go build Backup_Mysqldump_One.go
999 go build Backup_XtraBackup_add.go
```
|
victorpreston/Python-CodeNest
|
https://github.com/victorpreston/Python-CodeNest
|
Unlock your coding potential with my personally crafted Python projects. Level up your skills now by diving in and exploring the fruits of my coding journey
|
# Python-CodeNest

## Description
Unlock your coding potential with my personally crafted Python projects. Level up your skills now by diving in and exploring the fruits of my python coding journey
Here in this repository, you will find a set of python projects from simple to complex
most of time working in the console and sometime with GUI.
## Projects list
| Number | Directory |
|--------|------|
| 1 | [Dice simulator](https://github.com/victorpreston/Python-CodeNest/tree/master/0x01-Dice) |
| 2 | [Dictionary](https://github.com/victorpreston/Python-CodeNest/tree/master/0x02-Dictionary) |
| 3 | [Hanging man](https://github.com/victorpreston/Python-CodeNest/tree/master/0x03-HangingMan) |
| 4 | [TicTacToe](https://github.com/victorpreston/Python-CodeNest/tree/master/0x04-TicTacToe) |
| 5 | [Conditionals](https://github.com/victorpreston/Python-CodeNest/tree/master/0x05-Conditional) |
| 6 | [Decrements](https://github.com/victorpreston/Python-CodeNest/tree/master/0x06-Decrement) |
| 7 | [Face detection](https://github.com/victorpreston/Python-CodeNest/tree/master/0x07-Face_detection) |
| 8 | [Password generator](https://github.com/victorpreston/Python-CodeNest/tree/master/0x08-Passcode-generator) |
| 9 | [Shutdown](https://github.com/victorpreston/Python-CodeNest/tree/master/0x09-Shutdown) |
| 10 | [Simple browser](https://github.com/victorpreston/Python-CodeNest/tree/master/0x10-Simple-browser) |
| 11 | [Text to speech](https://github.com/victorpreston/Python-CodeNest/tree/master/0x11-Text-to-Speech) |
| 12 | [Weather finder](https://github.com/victorpreston/Python-CodeNest/tree/master/0x12-Weather-finder) |
| 13 | [Web server](https://github.com/victorpreston/Python-CodeNest/tree/master/0x13-Web_server) |
| 14 | [Shuffle](https://github.com/victorpreston/Python-CodeNest/tree/master/0x14-Shuffle) |
| 15 | [Audio Book](https://github.com/victorpreston/Python-CodeNest/tree/master/0x15-Audio-Book) |
| 16 | [QR Generator](https://github.com/victorpreston/Python-CodeNest/tree/master/0x16-QR-Generator) |
| 17 | [Sudoku](https://github.com/victorpreston/Python-CodeNest/tree/master/0x17-Sudoku) |
| 18 | [URL Web Scrapper](https://github.com/victorpreston/Python-CodeNest/tree/master/0x18-Url-Web-Scraper) |
| 19 | [Phone Tracker](https://github.com/victorpreston/Python-CodeNest/tree/master/0x19-Phone-Tracker) |
| 20 | [Automated Mailing](https://github.com/victorpreston/Python-CodeNest/tree/master/0x20-AutomatedMailing) |
| 21 | [Text Editor](https://github.com/victorpreston/Python-CodeNest/tree/master/0x21TextEditor) |
## User Guide
Do you want to try these projects? Just clone the current repository and type the following commands in individual folder:
```css
open in terminal
python3 <mainfilename.py>
And it's all done !
```
## Contributors Guide
If you want to help me improve the repository, you can fork the project and add your own features or updates then pull request and add me as reviewer
When you find out error, don't hesitate to correct it .
```mermaid
flowchart LR
Star[Star the Repository]-->Fork
Fork[Fork the project]-->branch[Create a New Branch]
branch-->Edit[Edit file]
Edit-->commit[Commit the changes]
commit -->|Finally|creatpr((Create a Pull Request))
```
### Enjoy python!
|
HuskyDG/ksu_unmount_injector
|
https://github.com/HuskyDG/ksu_unmount_injector
|
Unmounting KSU overlay for kernel bellow 5.9
|
## KSU Overlay Unmount
- Unmount modules function for KernelSU. It is also mounting writeable systemless hosts for Adaway
|
QuiiBz/detect-runtime
|
https://github.com/QuiiBz/detect-runtime
|
Detects the current runtime environment (Node.js, Cloudflare Workers, Deno, ...)
|
## detect-runtime
Small library to detect the current JavaScript runtime. The list of supported runtimes is based on the [WinterCG Runtime Keys proposal](https://runtime-keys.proposal.wintercg.org/):
- `edge-routine` Alibaba Cloud Edge Routine
- `workerd` Cloudflare Workers
- `deno` Deno and Deno Deploy
- `lagon` Lagon
- `react-native` React Native
- `netlify` Netlify Edge Functions
- `electron` Electron
- `node` Node.js
- `bun` Bun
- `edge-light` Vercel Edge Functions
This package is properly typed and exported to both ESM and CJS.
## Installation
`detect-runtime` is published on [NPM](https://www.npmjs.com/package/detect-runtime):
```bash
# NPM
npm install detect-runtime
# Yarn
yarn add detect-runtime
# PNPM
pnpm install detect-runtime
# Bun
bun install detect-runtime
```
Or in Deno:
```ts
import { ... } from 'npm:detect-runtime'
```
## Usage
Import and call the `detectRuntime()` function from the `detect-runtime` package:
```ts
import { detectRuntime } from 'detect-runtime'
const runtime = detectRuntime()
// ^? 'edge-routine' | 'workerd' | 'deno' | 'lagon' | 'react-native' | 'netlify | 'electron | 'node | 'bun | 'edge-light | 'unknown'
```
You can also import the `Runtime` type which is the return type of `detectRuntime()`.
## License
[MIT](./LICENSE)
|
daveshap/Quickly_Extract_Science_Papers
|
https://github.com/daveshap/Quickly_Extract_Science_Papers
|
Scientific papers are coming out TOO DAMN FAST so we need a way to very quickly extract useful information.
|
# Quickly_Extract_Science_Papers
Scientific papers are coming out TOO DAMN FAST so we need a way to very quickly extract useful information.
## Repo Contents
- `chat.py` - this file is a simple chatbot that will chat with you about the contents of `input.txt` (you can copy/paste anything into this text file). Very useful to quickly discuss papers.
- `generate_multiple_reports.py` - this will consume all PDFs in the `input/` folder and generate summaries in the `output/` folder. This is helpful for bulk processing such as for literature reviews.
- `render_report.py` - this will render all the reports in `output/` to a an *easier* to read file in `report.html`.
## EXECUTIVE SUMMARY
This repository contains Python scripts that automate the process of generating reports from PDF files using OpenAI's
GPT-4 model. The scripts extract text from PDF files, send the text to the GPT-4 model for processing, and save the
generated reports as text files. The scripts also include functionality to render the generated reports as an HTML
document for easy viewing.
## SETUP
1. Clone the repository to your local machine.
2. Install the required Python packages by running `pip install -r requirements.txt` in your terminal.
3. Obtain an API key from OpenAI and save it in a file named `key_openai.txt` in the root directory of the repository.
4. Place the PDF files you want to generate reports from in the `input/` directory.
## USAGE
1. Run the `generate_multiple_reports.py` script to generate reports from the PDF files in the `input/` directory. The
generated reports will be saved as text files in the `output/` directory.
2. Run the `render_report.py` script to render the generated reports as an HTML document. The HTML document will be
saved as `report.html` in the root directory of the repository.
3. You can modify the `prompts` in `generate_multiple_reports.py` to focus on any questions you would like to ask. In other words you can automatically ask any set of questions in bulk against any set of papers. This can help you greatly accelerate your literature reviews and surveys.
## NOTE
The scripts are designed to handle errors and retries when communicating with the OpenAI API. If the API returns an
error due to the maximum context length being exceeded, the scripts will automatically trim the oldest message and retry
the API call. If the API returns any other type of error, the scripts will retry the API call after a delay, with the
delay increasing exponentially for each consecutive error. If the API returns errors for seven consecutive attempts, the
scripts will stop and exit.
|
IDEA-Research/DreamWaltz
|
https://github.com/IDEA-Research/DreamWaltz
|
Official implementation of "DreamWaltz: Make a Scene with Complex 3D Animatable Avatars".
|
<div align="center">
<img src="./assets/logo.png" width="30%">
</div>
<h1 align="center">💃DreamWaltz: Make a Scene with Complex 3D Animatable Avatars</h1>
<p align="center">
### [Project Page](https://dreamwaltz3d.github.io/) | [Paper](https://arxiv.org/abs/2305.12529) | [Video](https://drive.google.com/drive/folders/19JnDQja4jZjHkHTBmLLppS6-Ic7Xv3nS?usp=sharing)
This repository contains the official implementation of the following paper:
> DreamWaltz: Make a Scene with Complex 3D Animatable Avatars
<br>[Yukun Huang](https://github.com/hyk1996/)<sup>*1,2</sup>, [Jianan Wang](https://github.com/wendyjnwang/)<sup>*1</sup>, [Ailing Zeng](https://ailingzeng.site/)<sup>1</sup>, [He Cao](https://github.com/CiaoHe/)<sup>1</sup>, [Xianbiao Qi](http://scholar.google.com/citations?user=odjSydQAAAAJ&hl=zh-CN/)<sup>1</sup>, Yukai Shi<sup>1</sup>, Zheng-Jun Zha<sup>2</sup>, [Lei Zhang](https://www.leizhang.org/)<sup>1</sup><br>
> <sup>∗</sup> Equal contribution. <sup>1</sup>International Digital Economy Academy <sup>2</sup>University of Science and Technology of China
Code will be released soon.
## Introduction
DreamWaltz is a learning framework for text-driven 3D animatable avatar creation using pretrained 2D diffusion model [ControlNet](https://github.com/lllyasviel/ControlNet) and human parametric model [SMPL](https://smpl.is.tue.mpg.de/). The core idea is to optimize a deformable NeRF representation from skeleton-conditioned diffusion supervisions, which ensures 3D consistency and generalization to arbitrary poses.
<p align="middle">
<img src="assets/teaser.gif" width="80%">
<br>
<em>Figure 1. DreamWaltz can generate animatable avatars (a) and construct complex scenes (b)(c)(d).</em>
</p>
## Results
### Static Avatars
<p align="middle">
<image src="assets/canonical_half.gif" width="80%">
<br>
<em>Figure 2. DreamWaltz can create canonical avatars from textual descriptions.</em>
</p>
### Animatable Avatars
<p align="middle">
<image src="assets/animation_sp.gif" width="80%">
<br>
<em>Figure 3. DreamWaltz can animate canonical avatars given motion sequences.</em>
</p>
### Complex Scenes
<p align="middle">
<image src="assets/animation_obj.gif" width="80%">
<br>
<em>Figure 4. DreamWaltz can make complex 3D scenes with avatar-object interactions.</em>
</p>
<p align="middle">
<image src="assets/animation_scene.gif" width="80%">
<br>
<em>Figure 5. DreamWaltz can make complex 3D scenes with avatar-scene interactions.</em>
</p>
<p align="middle">
<image src="assets/animation_mp.gif" width="80%">
<br>
<em>Figure 6. DreamWaltz can make complex 3D scenes with avatar-avatar interactions.</em>
</p>
## Reference
If you find this repository useful for your work, please consider citing it as follows:
```bibtex
@article{huang2023dreamwaltz,
title={DreamWaltz: Make a Scene with Complex 3D Animatable Avatars},
author={Yukun Huang and Jianan Wang and Ailing Zeng and He Cao and Xianbiao Qi and Yukai Shi and Zheng-Jun Zha and Lei Zhang},
year={2023},
eprint={2305.12529},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
@article{huang2023dreamtime,
title={DreamTime: An Improved Optimization Strategy for Text-to-3D Content Creation},
author={Yukun Huang and Jianan Wang and Yukai Shi and Xianbiao Qi and Zheng-Jun Zha and Lei Zhang},
year={2023},
eprint={2306.12422},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
|
Gabboxl/FluentWeather
|
https://github.com/Gabboxl/FluentWeather
|
A beautiful UWP weather app for Windows
|
<h1> <img align="center" src="https://github.com/Gabboxl/FluentWeather/assets/26819478/cc001a70-bfa4-4e3e-84cf-ea86652dcb98" width=6% height=6%> FluentWeather </h1>
A beautiful & modern UWP weather app for Windows.

## Downloads
***Microsoft Store (recommended)***:
<a href="https://apps.microsoft.com/store/detail/9PFD136M8457?launch=true&mode=mini" > <img src="https://get.microsoft.com/images/en-US%20dark.svg" width=20% height=20%/> </a>
----
***Standalone package for sideloading***: [latest package from Github Releases](https://github.com/Gabboxl/FluentWeather/releases/latest)
(*you have to run the `Install.ps1` script, or trust manually the certificate inside the release package*)
### Requirements
* Windows 10 version 1809 (build 17763) and up
## Roadmap
You can find this project's [roadmap here](https://github.com/users/Gabboxl/projects/6/views/1)!
## Credits
* The UI design was inspired by the work of [@zeealeid](https://twitter.com/zeealeid)
* All background pictures used in this app are under the [Unsplash License](https://unsplash.com/license)
|
benthecarman/zapple-pay-backend
|
https://github.com/benthecarman/zapple-pay-backend
| null |
# Zapple Pay
Zapple Pay lets you automatically zap notes based on if you give a ⚡ reaction.
## API
### Set User
`POST /set-user`
payload:
the emoji and donations are optional
```json
{
"npub": "user's npub",
"amount_sats": 1000,
"nwc": "user's nwc",
"emoji": "⚡",
"donations": [
{
"amount_sats": 1000,
"lnurl": "donation lnurl"
}
]
}
```
returns:
the user's current configs
```json
[
{
"npub": "user's npub",
"amount_sats": 1000,
"emoji": "⚡",
"donations": [
{
"amount_sats": 1000,
"lnurl": "donation lnurl"
}
]
}
]
```
### Get User
`GET /get-user/:npub`
returns:
the user's current configs
```json
[
{
"npub": "user's npub",
"amount_sats": 1000,
"emoji": "⚡",
"donations": [
{
"amount_sats": 1000,
"lnurl": "donation lnurl"
}
]
}
]
```
### Get User
`GET /get-user/:npub/:emoji`
returns:
the user's current config
```json
{
"npub": "user's npub",
"amount_sats": 1000,
"emoji": "⚡",
"donations": [
{
"amount_sats": 1000,
"lnurl": "donation lnurl"
}
]
}
```
### Delete User
`GET /delete-user/:npub/:emoji`
returns:
the user's current configs
```json
[
{
"npub": "user's npub",
"amount_sats": 1000,
"emoji": "⚡",
"donations": [
{
"amount_sats": 1000,
"lnurl": "donation lnurl"
}
]
}
]
```
|
melody413/python_webSocket
|
https://github.com/melody413/python_webSocket
| null |
.. image:: logo/horizontal.svg
:width: 480px
:alt: websockets
|licence| |version| |pyversions| |tests| |docs| |openssf|
.. |licence| image:: https://img.shields.io/pypi/l/websockets.svg
:target: https://pypi.python.org/pypi/websockets
.. |version| image:: https://img.shields.io/pypi/v/websockets.svg
:target: https://pypi.python.org/pypi/websockets
.. |pyversions| image:: https://img.shields.io/pypi/pyversions/websockets.svg
:target: https://pypi.python.org/pypi/websockets
.. |tests| image:: https://img.shields.io/github/checks-status/python-websockets/websockets/main?label=tests
:target: https://github.com/python-websockets/websockets/actions/workflows/tests.yml
.. |docs| image:: https://img.shields.io/readthedocs/websockets.svg
:target: https://websockets.readthedocs.io/
.. |openssf| image:: https://bestpractices.coreinfrastructure.org/projects/6475/badge
:target: https://bestpractices.coreinfrastructure.org/projects/6475
What is ``websockets``?
-----------------------
websockets is a library for building WebSocket_ servers and clients in Python
with a focus on correctness, simplicity, robustness, and performance.
.. _WebSocket: https://developer.mozilla.org/en-US/docs/Web/API/WebSockets_API
Built on top of ``asyncio``, Python's standard asynchronous I/O framework, the
default implementation provides an elegant coroutine-based API.
An implementation on top of ``threading`` and a Sans-I/O implementation are also
available.
`Documentation is available on Read the Docs. <https://websockets.readthedocs.io/>`_
.. copy-pasted because GitHub doesn't support the include directive
Here's an echo server with the ``asyncio`` API:
.. code:: python
#!/usr/bin/env python
import asyncio
from websockets.server import serve
async def echo(websocket):
async for message in websocket:
await websocket.send(message)
async def main():
async with serve(echo, "localhost", 8765):
await asyncio.Future() # run forever
asyncio.run(main())
Here's how a client sends and receives messages with the ``threading`` API:
.. code:: python
#!/usr/bin/env python
from websockets.sync.client import connect
def hello():
with connect("ws://localhost:8765") as websocket:
websocket.send("Hello world!")
message = websocket.recv()
print(f"Received: {message}")
hello()
Does that look good?
`Get started with the tutorial! <https://websockets.readthedocs.io/en/stable/intro/index.html>`_
.. raw:: html
<hr>
<img align="left" height="150" width="150" src="https://raw.githubusercontent.com/python-websockets/websockets/main/logo/tidelift.png">
<h3 align="center"><i>websockets for enterprise</i></h3>
<p align="center"><i>Available as part of the Tidelift Subscription</i></p>
<p align="center"><i>The maintainers of websockets and thousands of other packages are working with Tidelift to deliver commercial support and maintenance for the open source dependencies you use to build your applications. Save time, reduce risk, and improve code health, while paying the maintainers of the exact dependencies you use. <a href="https://tidelift.com/subscription/pkg/pypi-websockets?utm_source=pypi-websockets&utm_medium=referral&utm_campaign=readme">Learn more.</a></i></p>
<hr>
<p>(If you contribute to <code>websockets</code> and would like to become an official support provider, <a href="https://fractalideas.com/">let me know</a>.)</p>
Why should I use ``websockets``?
--------------------------------
The development of ``websockets`` is shaped by four principles:
1. **Correctness**: ``websockets`` is heavily tested for compliance with
:rfc:`6455`. Continuous integration fails under 100% branch coverage.
2. **Simplicity**: all you need to understand is ``msg = await ws.recv()`` and
``await ws.send(msg)``. ``websockets`` takes care of managing connections
so you can focus on your application.
3. **Robustness**: ``websockets`` is built for production. For example, it was
the only library to `handle backpressure correctly`_ before the issue
became widely known in the Python community.
4. **Performance**: memory usage is optimized and configurable. A C extension
accelerates expensive operations. It's pre-compiled for Linux, macOS and
Windows and packaged in the wheel format for each system and Python version.
Documentation is a first class concern in the project. Head over to `Read the
Docs`_ and see for yourself.
.. _Read the Docs: https://websockets.readthedocs.io/
.. _handle backpressure correctly: https://vorpus.org/blog/some-thoughts-on-asynchronous-api-design-in-a-post-asyncawait-world/#websocket-servers
Why shouldn't I use ``websockets``?
-----------------------------------
* If you prefer callbacks over coroutines: ``websockets`` was created to
provide the best coroutine-based API to manage WebSocket connections in
Python. Pick another library for a callback-based API.
* If you're looking for a mixed HTTP / WebSocket library: ``websockets`` aims
at being an excellent implementation of :rfc:`6455`: The WebSocket Protocol
and :rfc:`7692`: Compression Extensions for WebSocket. Its support for HTTP
is minimal — just enough for an HTTP health check.
If you want to do both in the same server, look at HTTP frameworks that
build on top of ``websockets`` to support WebSocket connections, like
Sanic_.
.. _Sanic: https://sanicframework.org/en/
What else?
----------
Bug reports, patches and suggestions are welcome!
To report a security vulnerability, please use the `Tidelift security
contact`_. Tidelift will coordinate the fix and disclosure.
.. _Tidelift security contact: https://tidelift.com/security
For anything else, please open an issue_ or send a `pull request`_.
.. _issue: https://github.com/python-websockets/websockets/issues/new
.. _pull request: https://github.com/python-websockets/websockets/compare/
Participants must uphold the `Contributor Covenant code of conduct`_.
.. _Contributor Covenant code of conduct: https://github.com/python-websockets/websockets/blob/main/CODE_OF_CONDUCT.md
``websockets`` is released under the `BSD license`_.
.. _BSD license: https://github.com/python-websockets/websockets/blob/main/LICENSE
|
archaicvirus/TreeGenerator
|
https://github.com/archaicvirus/TreeGenerator
|
A procedural and customizable tree generator for the TIC80 fantasy computer
|
# TreeGenerator

A procedural and customizable tree generator for the TIC80 fantasy computer.
- Can be run in the web player [here](https://tic80.com/play?cart=3424)
- Also available on itch https://archaicvirus.itch.io/procedural-tree-generator
- See the [releases](https://github.com/archaicvirus/TreeGenerator/releases) page for native windows, mac, linux, and html versions.
*html version has some bugs being worked on, avoid using for now
## Settings
- [Trunk Width](#trunk-width)
- [Trunk Height](#trunk-height)
- [Step Height](#step-height)
- [Shift/Step](#shiftstep)
- [Sprite Id](#sprite-id)
- [Branch Length](#branch-length)
- [Branch Width](#branch-width)
- [Branch Thickness](#branch-thickness)
- [Branch Height](#branch-height)
- [Branch Shift](#branch-shift)
- [Total Branches](#total-branches)
- [Branch Deviation](#branch-deviation)
- [Leaf Density](#leaf-density)
- [Leaf Cull Distance](#leaf-cull-distance)
- [Leaf Fill Radius](#leaf-fill-radius)
- [Leaf Fill Count](#leaf-fill-count)
- [Vine Count](#vine-count)
- [Fruit ID](#fruit-id)
- [Fruit Density](#fruit-density)
- [Save Width & Height](#save-width--height)
- [Save X & Y](#save-x--y)
- [Save ID](#save-id)
- [Background Color](#background-color)
### Trunk Width
The width in pixels of the main trunk

### Trunk Height
The total height of the combined trunk segments

### Step Height
The height in pixels of each vertical trunk segment (Does not affect overall height)

### Shift/Step
The random horizontal deviation in pixels, to shift each trunk segment as it 'grows' upwards

### Sprite Id
Trunk & Branch texture. The sprite id used for the mesh fill algorithm

- Sprite id's 0-15 (the top row of tiles) can be selected to change the tree's texture. These can be customized in the sprite editor to your liking

### Branch Length
The average length in pixels of each branch

### Branch Width
The width in pixels of each branch segment as the branch grows outwards

### Branch Thickness
The height in pixels of each horizontal branch segment, as the segments 'grow' outwards

### Branch Height
The height (in number of trunk segments), to snap branches to the nearest vertex of the main trunk

### Branch Shift
The random range in pixels that the branches are allowed to shift upwards at each growth step in the generation process, (lower values lead to straighter branches)

### Total Branches
The total amount of branches to spawn (distributed evenly between the left and right of the trunk)

### Branch Deviation
The relative offset between branches, scaled based on the number of branches and offset by the branch height parameter

### Leaf Density
The average chance that leaves will spawn. Leaves are spawned starting from the tip of each branch, snapped to branch vertices, going towards the trunk

### Leaf Cull Distance
The distance (in number of branch segments) from the tip of each branch toward the tree's trunk, to limit leaf drawing

### Leaf Fill Radius
The radius in pixels to randomly spread leaves (separate from leaf generation on branches). Always locked to the top of the tree trunk

### Leaf Fill Count
The total amount of tries to randomly distribute leaves within the fill radius

### Vine Count
The total amount of vines to spawn. Vines are spawned by picking vertices of two randomly selected branch segments and have a random 'sag' amount to vary the look

### Fruit ID
The sprite id to use for the layer of fruits/flowers. These are spawned using the same leaf-spawn method for the branches. In the sprite editor, sprite id's 32 - 47 are used for this layer - the third row.

### Fruit Density
Average chance to spawn fruits/flowers

### Save Width & Height
In pixels, the rectangular area of `SCREEN RAM` to copy to `SPRITE RAM` using `MEMCPY`

### Save X & Y
The top-left corner of the rectangular area to copy & save.

### Save ID
Ranged 0 - 511 - The tile/sprite id to paste the copied rectangle. Keep in mind if the id is positioned near the border in the sprite editor, the copied tiles won't retain their original order

### Background Color
The current background color (for transparency reasons) - will be copied as the background when saving the tree

|
snap-research/3DVADER
|
https://github.com/snap-research/3DVADER
|
Source code for the paper: "AutoDecoding Latent 3D Diffusion Models"
|
3D VADER - AutoDecoding Latent 3D Diffusion Models
==================================================
[Evangelos Ntavelis](http://www.entavelis.com)<sup>1\*</sup>, [Aliaksandr Siarohin](https://aliaksandrsiarohin.github.io/aliaksandr-siarohin-website/)<sup>2</sup>, [Kyle Olszewski](https://kyleolsz.github.io/)<sup>2</sup>, [Chaoyang Wang](https://mightychaos.github.io)<sup>3</sup>, [Luc Van Gool](https://ee.ethz.ch/de/departement/professoren/professoren-kontaktdetails/person-detail.OTAyMzM=.TGlzdC80MTEsMTA1ODA0MjU5.html)<sup>1,4</sup>, [Sergey Tulyakov](http://www.stulyakov.com/)<sup>2</sup>
<sup>1</sup>Computer Vision Lab - ETH Zurich <sup>2</sup>Snap Inc. <sup>3</sup>CI2CV Lab - CMU <sup>4</sup>ESAT - KULeuven
\*Work done while interning at Snap.
[Project Page](https://snap-research.github.io/3DVADER/) - [arXiv](https://arxiv.org/abs/2307.05445) - [Paper](https://snap-research.github.io/3DVADER/paper.pdf) - [Cite](#bibtex)
**TL;DR**
We generate 3D assets from diverse 2D multi-view datasets by training a **3**D **D**iffusion model on the intermediate features of a **V**olumetric **A**uto**D**ecod**ER**.
Abstract
--------

We present a novel approach to the generation of static and articulated 3D assets that has a 3D _autodecoder_ at its core. The 3D _autodecoder_ framework embeds properties learned from the target dataset in the latent space, which can then be decoded into a volumetric representation for rendering view-consistent appearance and geometry. We then identify the appropriate intermediate volumetric latent space, and introduce robust normalization and de-normalization operations to learn a 3D diffusion from 2D images or monocular videos of rigid or articulated objects. Our approach is flexible enough to use either existing camera supervision or no camera information at all -- instead efficiently learning it during training. Our evaluations demonstrate that our generation results outperform state-of-the-art alternatives on various benchmark datasets and metrics, including multi-view image datasets of synthetic objects, real in-the-wild videos of moving people, and a large-scale, real video dataset of static objects.
Method
------

Our proposed two-stage framework: Stage 1 trains an autodecoder with two generative components, G1 and G2. It learns to assign each training set object a 1D embedding that is processed by G1 into a latent volumetric space. G2 decodes these volumes into larger radiance volumes suitable for rendering. Note that we are using only 2D supervision to train the autodecoder. In Stage 2, the autodecoder parameters are frozen. Latent volumes generated by G1 are then used to train the 3D denoising diffusion process. At inference time, G1 is not used, as the generated volume is randomly sampled, denoised, and then decoded by G2 for rendering.
3D Assets Visualization
-----------------------
Please visit our [Project Page](https://snap-research.github.io/3DVADER/).
Code
----
Source code will be available soon.
BibTeX
------
```
@misc{ntavelis2023autodecoding,
title={AutoDecoding Latent 3D Diffusion Models},
author={Evangelos Ntavelis and Aliaksandr Siarohin and Kyle Olszewski and Chaoyang Wang and Luc Van Gool and Sergey Tulyakov},
year={2023},
eprint={2307.05445},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
Acknowledgements
----------------
We would like to thank Michael Vasilkovsky for preparing the ObjaVerse renderings, and Colin Eles for his support with infrastructure. Moreover, we would like to thank Norman Müller, author of [DiffRF](https://sirwyver.github.io/DiffRF/) paper, for his invaluable help with setting up the DiffRF baseline, the ABO Tables and PhotoShape Chairs datasets, and the evaluation pipeline as well as answering all related questions. A true marvel of a scientist. Finally, Evan would like to thank Claire and Gio for making the best cappuccinos and fueling up this research.
|
12joan/twitter-client
|
https://github.com/12joan/twitter-client
|
A temporary Twitter client for fetching recent tweets for use while Twitter is closed to guest users
|
# 12joan/twitter-client
A temporary Twitter client for fetching recent tweets for use while Twitter is closed to guest users.
Based on [this script](https://github.com/zedeus/nitter/issues/919#issuecomment-1619263153) by [polkaulfield](https://github.com/polkaulfield).
**[🚀 Publish new version](https://github.com/12joan/twitter-client/compare/deployment...main?expand=1&title=Deploy%20production&body=Merging%20this%20PR%20will%20trigger%20a%20deployment%20to%20production)** - Create a PR that will push the contents of `main` to the Docker registry when merged
## Deployment with Docker
Create a file `docker-compose.yml` with the following content:
```yml
version: '3'
services:
web:
image: ghcr.io/12joan/twitter-client:production
environment:
REDIS_URL: redis://redis:6379
HOST: '0.0.0.0'
ports:
- 3000:3000
depends_on:
- redis
redis:
image: redis:latest
```
Start using `docker-compose up -d` and access at http://localhost:3000/.
The `production` tag is updated when the `deployment` branch receives new commits. You can also try out the lastest version on `main` using the `alpha` tag. Anyone can update the `deployment` branch by clicking the **Publish new version** link at the top of this README.
## Deployment without Docker
- [Red Hat Enterprise Linux](https://github.com/12joan/twitter-client/wiki/Install:NoDocker:Rocky-Linux-8.6)
## Usage
### Raw JSON data
You can fetch recent Tweets as JSON from `http://localhost:3000/:username`.
Example: `http://localhost:3000/amnesty`
### RSS feed
To format the results as an RSS feed, use `http://localhost:3000/:username/rss`.
Optionally, specify a preset "flavour" of RSS using `http://localhost:3000/:username/rss?flavour=slack`. Supported flavours:
- `default`
- Title: Tweet text
- Description: Tweet text + media URLs as image tags
- `slack`
- Title: Tweet URL
- Description: Tweet text + media URLs as links
## Running locally
To start the server,
```
$ yarn install # See https://github.com/12joan/twitter-client/issues/6
$ docker-compose up --build
```
To check types on file change,
```
$ yarn typecheck:watch
```
To fix code formatting,
```
$ yarn lint --fix
```
|
zhangshichun/tree-lodash
|
https://github.com/zhangshichun/tree-lodash
|
轻量的“树操作”函数库 (Lightweight "tree operations" library)
|
# tree-lodash
> Easily control the tree structure as you would with `lodash.js`
> 像使用 `lodash.js` 一样方便地操控树结构
充分的单元测试:

## Install & UseAge (安装&使用)
👉[安装&使用文档(Install Document)](./docs/guide/README.md)
## Features (特性)
👉[特性(Features) & 配置(Configs)](./docs/guide/features.md)
## Functions (方法列表)
- `foreach`: 👉[foreach 文档](./docs/functions/foreach.md)
- `map`: 👉[map 文档](./docs/functions/map.md)
- `filter`: 👉[filter 文档](./docs/functions/filter.md)
- `find`: 👉[find 文档](./docs/functions/find.md)
- `some`: 👉[some 文档](./docs/functions/some.md)
- `toArray`: 👉[toArray 文档](./docs/functions/toArray.md)
## 感谢 (Thanks)
Thanks to [joaonuno/tree-model-js](https://github.com/joaonuno/tree-model-js), It's a Nice lib, and help me at work;
|
Mizogg/XYZ-pub-Scanner
|
https://github.com/Mizogg/XYZ-pub-Scanner
|
🐍Python-XYZ Pub Scanner🐍
|
# XYZ PUB Crypto Scanner
XYZ PUB Crypto Scanner is a PyQt5-based tool for scanning Bitcoin wallets and deriving wallet information. It supports both online and offline modes of operation.
Python script for generating and checking Bitcoin addresses derived from a mnemonic (BIP39) using the hdwallet library. It includes various functions for formatting and displaying text in different colors.
GUI Released On
## https://mizogg.co.uk/xyzpub/
## xpubscan.py

The script prompts the user to either enter a mnemonic manually or generate one randomly.
If the user chooses to enter a mnemonic, it validates the input and proceeds with the main logic.
If the user chooses to generate a random mnemonic, the script allows the user to select the number of words (12, 15, 18, 21, or 24) and the language (English, French, Italian, Spanish, Chinese Simplified, Chinese Traditional, Japanese, or Korean).
After obtaining the mnemonic, the script performs the following steps:
Checks the initial account extended public key for balances and other information using an API.
Displays the account extended private key, account extended public key, and initial balance information.
If any balance or important value is found in the initial account extended public key, it proceeds to derive child keys from different derivation paths and checks their balances and other information.
For each derived key, it displays the derivation path, compressed and uncompressed addresses, balances, total received, total sent, number of transactions, mnemonic words, private key, root public key, extended private key, root extended private key, compressed public key, uncompressed public key, WIF private key, and WIF compressed private key.
If any balance or important value is found in any of the derived keys, it logs the information to a file.

Screenshot 1 Description: The application's main interface, English version Scanning Online Random Mnemonic.

Screenshot 2 Description: Russian version scanning in sequence looking for missing Mnemonic Words.
## Installation
1. Clone the repository:
```
$ git clone https://github.com/Mizogg/XYZ-pub-Scanner.git
$ cd XYZ-pub-Scanner
2. Install the required dependencies:
```
$ pip install -r requirements.txt
```
3. Run the application:
```
$ python QTXpub.py
or
$ python xpubscan.py
```
## Features
Supports both online and offline mode
Scans Bitcoin wallets and derives wallet information
Displays address balances, total received, total sent, and transaction history
Provides mnemonic words, private keys, root public keys, extended private keys, and more
## Usage
Enter the mnemonic phrase in the provided field.
Select the mode (online or offline) for scanning.
Click on the "Start Scan" button to begin the scanning process.
The tool will derive wallet information and display it in the output area.
For online mode, the tool will also check the account extended public key for balance and other important values.
If balance or important values are found, the tool will save the information in the "WINNER_found.txt" file.
The tool supports sequential and random modes for key derivation.
## Contributing
Contributions are welcome! If you'd like to contribute to this project, please follow these steps:
## Fork the repository.
Create a new branch for your feature or bug fix.
Make your changes and commit them.
Push your changes to your forked repository.
Open a pull request, describing your changes in detail.
## License
This project is licensed under the MIT License. See the LICENSE file for more information.
|
pap1rman/postnacos
|
https://github.com/pap1rman/postnacos
|
哥斯拉nacos后渗透插件 maketoken adduser
|
# postnacos
哥斯拉nacos后渗透插件 maketoken adduser
## 功能简介
当你在Nacos拥有一个哥斯拉webshell之后,你就可以使用哥斯拉的Nacos后渗透插件
例如使用下面大哥项目打哥斯拉 shell
https://github.com/c0olw/NacosRce
MakeToken
生成特定用户的token
AddUser
添加一个用户
## 如何使用
下载哥斯拉插件Jar包
然后打开哥斯拉 点击配置->点击插件配置->点击添加并选择你下载的Jar包

## 部分功能演示
### MakeToken
<img width="1666" alt="image" src="https://github.com/pap1rman/postnacos/assets/26729456/60089b8d-fa3d-4584-bc16-90dc5423d486">
将生成后的token 保存进浏览器cookie
格式 token:{xxx}
<img width="1222" alt="image" src="https://github.com/pap1rman/postnacos/assets/26729456/7819b38c-e558-49b0-bce7-dd6d9b5a185b">
### Adduser
<img width="760" alt="image" src="https://github.com/pap1rman/postnacos/assets/26729456/2a110b94-4ff7-4c09-a456-6d090f10ac3f">
|
Zhao-sai-sai/Online_tools
|
https://github.com/Zhao-sai-sai/Online_tools
|
该工具是一个集成了非常多渗透测试工具,类似软件商城的工具可以进行工具下载,工具的更新,工具编写了自动化的安装脚本,不用担心工具跑不起来。
|
> 本工具源码无任何后门代码,工具箱里面的破解工具是否有后门就不清楚了大部分都是在别的公众号下载的,工具箱里面的不是破解版本的工具都是从官方下载的可以放心使用!
> <font color=FF0000> 目前最大的问题就是网盘问题,你们下载的时候安装失败基本上都是后端提供下载的网盘出现问题了,之前工具下载是调用的阿里云,时间长点就会封号,现在部分工具下载放到的我的服务器,服务器的带宽很小下载人多就会下载速度很慢 </font>
> 有好用的工具可以投稿邮箱[email protected]或者联系作者本人
### 非常感谢下面的团队和信息安全研究人员的一些工具推荐
- 天启实验室
- 法克安全
- Pings
- 成都第一深情
- 还原设置
- 夜梓月
- SY
- 平平无奇的水蜜桃
- 火柬
- 向
## 工具包介绍
> 该工具是一个类似软件商城的工具可以进行工具下载,工具的更新,工具编写了自动化的安装脚本,不用担心工具跑不起来
## 工具大小
源代码大概六千多行代码、最终打包12MB
## 打包离线版本的方法
工具和启动环境都会下载到`storage`文件夹里面,把这三文件夹压缩就就可以了,到其他系统不需要在从工具箱里面的工具了
## 工具更新方法
如果下载了0.22或者之前版本要更新使用0.3.1版本,把0.3.1版本的文件覆盖0.22.1或者之前版本文件就可以了,就可以直接使用0.3.1版本了
覆盖就可以了
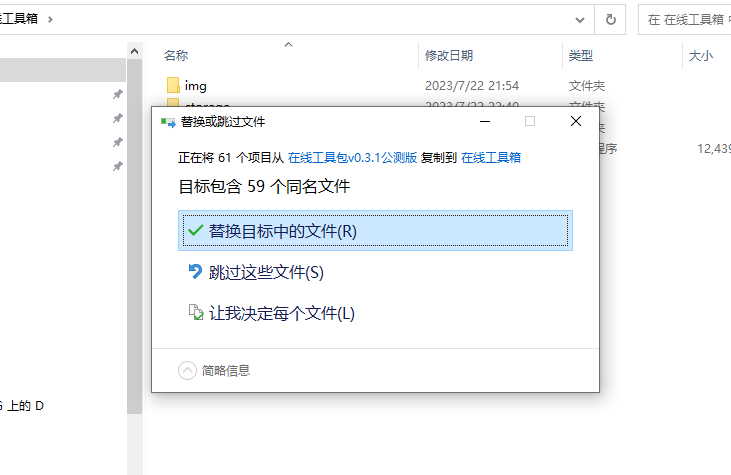
## 简单工具使用说明
1. 我们把鼠标放到工具图标上可以看工具的介绍
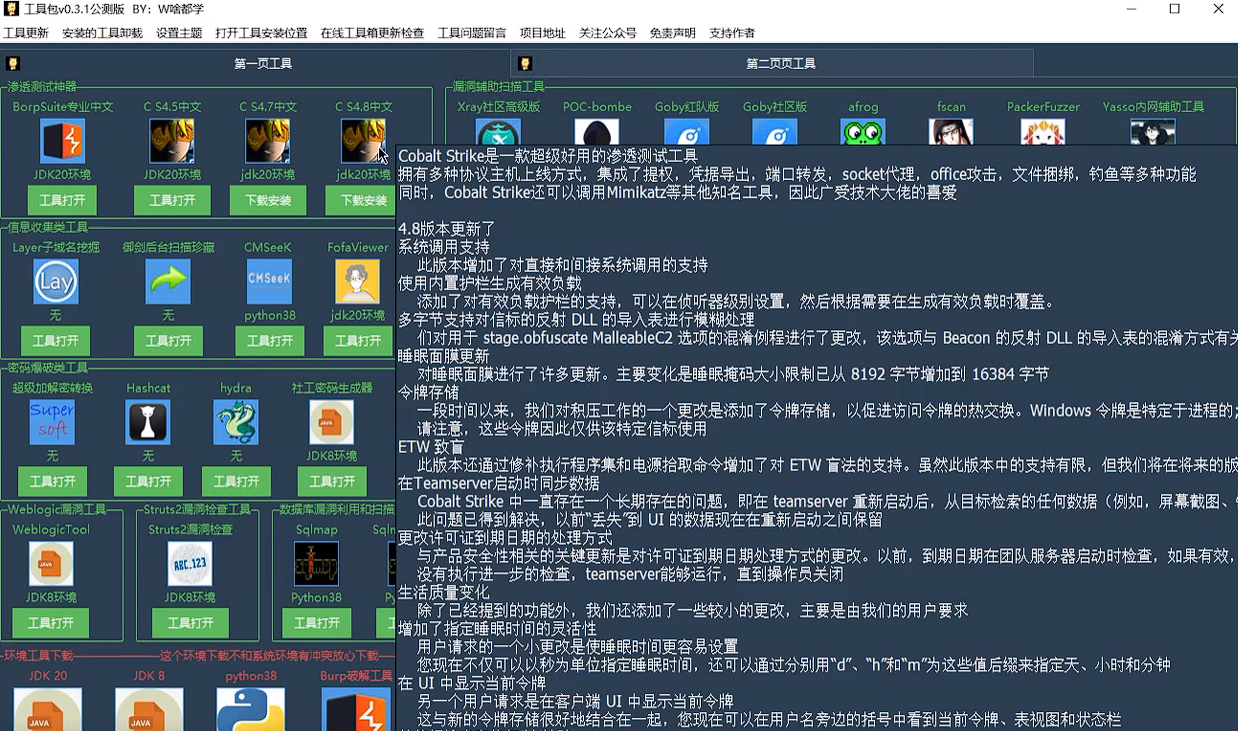
2. 下载好的工具可以叫鼠标放到打开按钮上可以看见版本
3. 查看可以根据更新的工具
点击查看更新、里面的工具是可以官方版本更新我在推送到网盘里面你们可以进行工具的更新
<font color=FF0000> (工具箱里面的工具如果作者更新频繁、我这边会添加到可以更新名单里面、如果半年多以上没有更新的我没有添加更新列表里面) </font>
可以更新的
```
工具名CMSeeK:1.1.3版本
工具名FofaViewer:1.1.12版本
工具名Dirsearch:0.4.3版本
工具名AntSword:2.1.15版本
工具名Behinder:4.0.6版本
工具名webshell_generate:1.2.2版本
工具名Hashcat:6.2.6版本
工具名sqlmap:1.7.5.2版本
工具名sqlmapCN:1.7.1.1版本
工具名xray:1.9.4版本
工具名POCbombe:2.03版本
工具名LiqunKit:1.6.2版本
工具名goby_Red_Team:2.4.7红队版1490POC版本
工具名goby_Community:2.4.7社区版1490POC版本
工具名BorpSuite:2023.5版本
工具名OneForAll:0.4.5版本
工具名Full_Scanner:gui版本
工具名WeblogicTool:1.1版本
工具名afrog:2.5.1版本
工具名fscan:1.8.2版本
工具名BlueTeamTools:0.52版本
工具名OAEXPTOOL:0.72版本
工具名naabu:2.1.6版本
工具名dnsx:1.1.4版本
工具名subfinder:2.6.0版本
```
4. 检查可以更新的工具
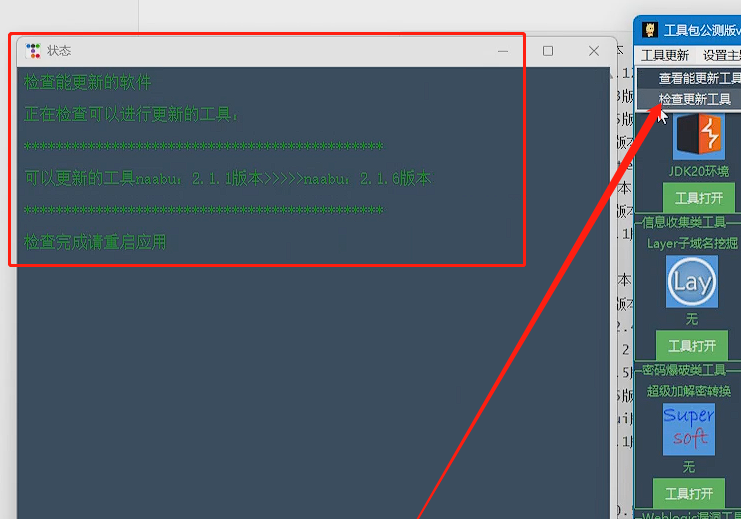
我们可以工具更新
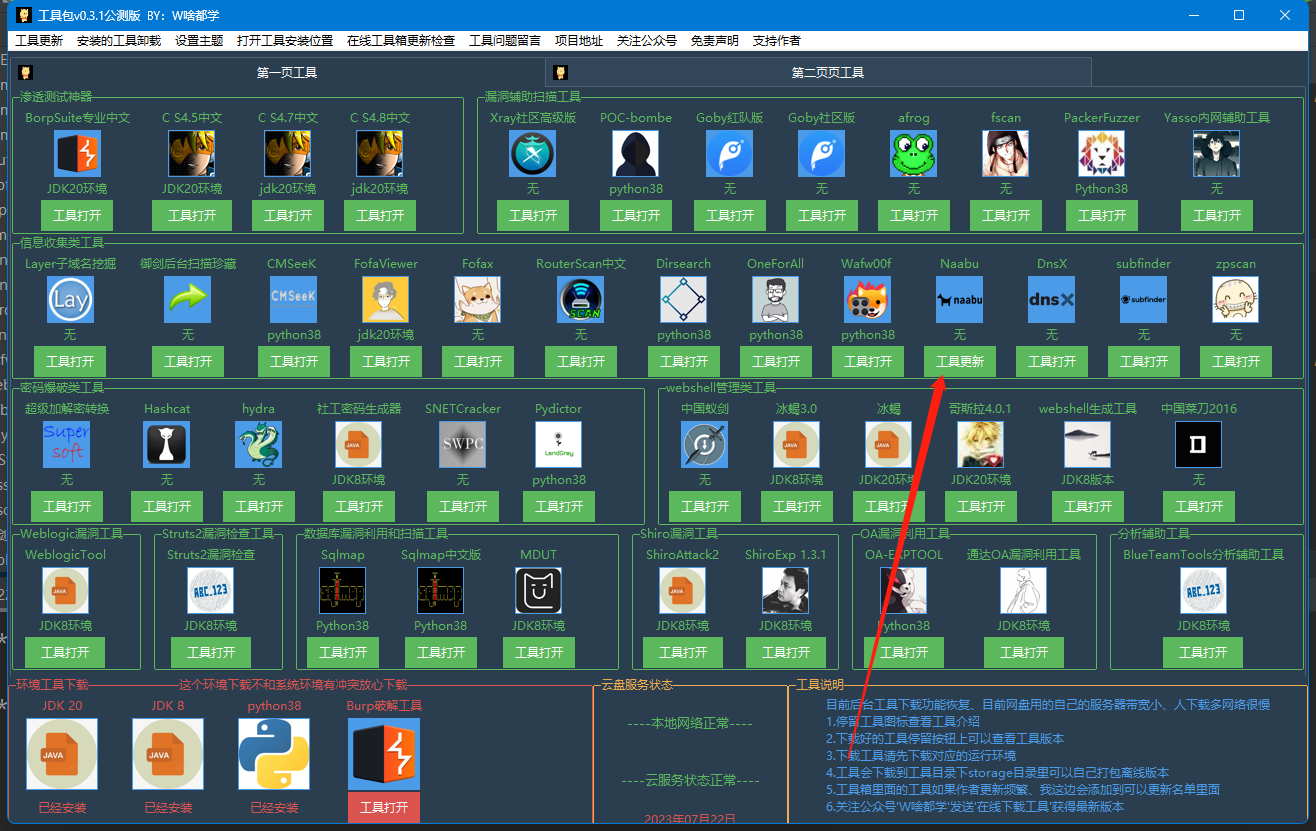
## v0.3.公测试版更新功能
增加新工具
- Yasso
- Fofax
- zpscan
- pydictor
- mdut(Multiple Database Utilization Tools)
- Apt_t00ls
- 中国菜刀2016
新功能添加
1. 取消了运行cmd的状态窗口
取消了下面的cmd运行状态窗口
2. 下载功能更新
增加显示到了状态里面
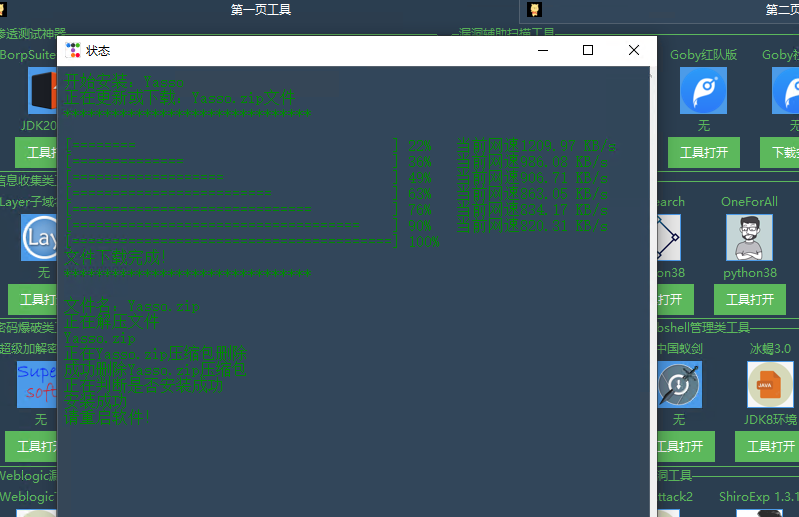
3. 工具卸载功能
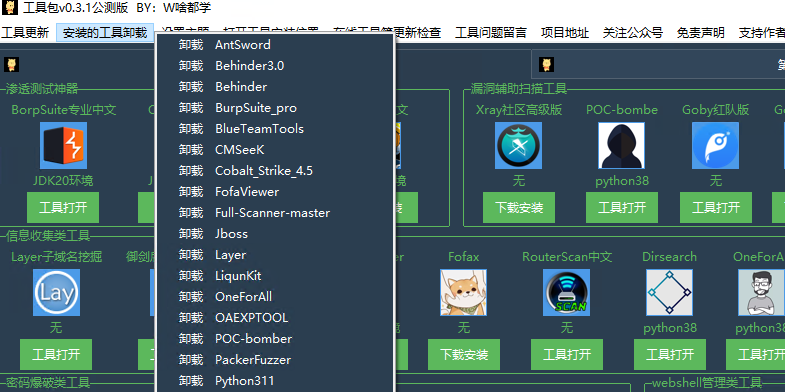
4. 在线工具箱本身更新检查
5. 两个工具页
应为新的工具一页放不下增加了一页
6. 解压功能
解压的时候会弹出解压框,解压完成自动关闭解压框
## v0.22.1修复公测试版更新功能
1. **网盘出现问题在0.22之前的全部版本都不能下载工具了**,这几天很多人说工具下载不了了,这几天加班解决这个问题
出现这个不能下载工具的原因是应为工具存储的网盘有改变,网盘用的是阿里云的、用的AList调用的,AList的策略更新了下载地址有变化,程序无法文件下载的文件名导致的这个问题
2. 还有就是下载工具的时候调用的系统命令进行下载的新版本的windows系统下载可能没有问题但是老版本的windows系统就无法下载,然后增加了内置下载程序无需在调用系统命令进行下载
## v0.22测试版更新功能
上一个版本窗口太大了这个版本窗口字体和图标变小
工具添加:SNETCracker工具、Jboss漏洞检查工具、OA漏洞检查工具、Naabu、DnsX、subfinder
## v0.2测试版更新功能
1. 鼠标放到工具图标上可以看见工具的简单说明

2. 添加了更新功能、点击查看更新、里面的工具是可以官方版本更新我在推送到网盘里面你们可以进行工具的更新
<font color=FF0000> (工具箱里面的工具如果作者更新频繁、我这边会添加到可以更新名单里面、如果半年多以上没有更新的我没有添加更新列表里面) </font>
点击检查更新
我们就可以进行工具的升级

3. 下面好的工具我们可以叫鼠标放到按钮上查看工具版本

4. 添加测试网盘是否正常,很多不可控因素不正常你们工具就下载不了,不正常可以联系我,会进行修复
如果是没有连接网络会报下面的情况

## v0.1
该工具是在线下载工具,用到什么工具就可以下载安装什么工具
工具本来是做linux工具箱用的,开发开发就开发到windows上了,开发一个星期左右完成
工具大小非常小!!!!py打包的文件很大5555
## 免责声明:
***
### 1. 该安全工具仅供技术研究和教育用途。使用该工具时,请遵守适用的法律法规和道德准则。
### 2. 该工具可能会涉及安全漏洞的测试和渗透测试,但请在授权的范围内使用,否则和作者无关
### 3. 使用该工具可能会涉及到一定的风险和不确定性,用户应该自行承担使用该工具所带来的风险。
### 4. 工具箱的工具有您合法权益问题可以联系我第一时间删除。
### 5. 使用本工具的用户应自行承担一切风险和责任。开发者对于用户使用本工具所产生的后果不承担任何责任。
|
X-PLUG/mPLUG-DocOwl
|
https://github.com/X-PLUG/mPLUG-DocOwl
| null |
<div align="center">
<img src="assets/mPLUG_new1.png" width="80%">
</div>
# mPLUG-DocOwl: Modularized Multimodal Large Language Model for Document Understanding
<div align="center">
Jiabo Ye*, Anwen Hu*, Haiyang Xu†, Qinghao Ye, Ming Yan†, Yuhao Dan, Chenlin Zhao, Guohai Xu, Chenliang Li, Junfeng Tian, Qian Qi, Ji Zhang, Fei Huang
</div>
<div align="center">
<strong>DAMO Academy, Alibaba Group</strong>
</div>
<div align="center">
*Equal Contribution; † Corresponding Author
</div>
<div align="center">
<a href="https://github.com/X-PLUG/mPLUG-DocOwl/blob/main/LICENSE"><img src="assets/LICENSE-Apache%20License-blue.svg" alt="License"></a>
<a href="https://modelscope.cn/studios/damo/mPLUG-DocOwl/summary"><img src="assets/Demo-ModelScope-brightgreen.svg" alt="Demo ModelScope"></a>
<a href="http://mm-chatgpt.oss-cn-zhangjiakou.aliyuncs.com/mplug_owl_demo/released_checkpoint/mPLUG_DocOwl_paper.pdf"><img src="assets/Paper-PDF-orange.svg"></a>
<a href="https://arxiv.org/abs/2307.02499"><img src="assets/Paper-Arxiv-orange.svg" ></a>
<a href="https://hits.seeyoufarm.com"><img src="https://hits.seeyoufarm.com/api/count/incr/badge.svg?url=https%3A%2F%2Fgithub.com%2FX-PLUG%2FmPLUG-DocOwl&count_bg=%2379C83D&title_bg=%23555555&icon=&icon_color=%23E7E7E7&title=hits&edge_flat=false"/></a>
<a href="https://twitter.com/xuhaiya2483846/status/1677117982840090625"><img src='assets/-twitter-blue.svg'></a>
</div>
<div align="center">
<hr>
</div>
## News
* 🔥 [07.10] The demo on [ModelScope](https://modelscope.cn/studios/damo/mPLUG-DocOwl/summary) is avaliable.
* [07.07] We release the technical report and evaluation set. The demo is coming soon.
## Spotlights
* An OCR-free end-to-end multimodal large language model.
* Applicable to various document-related scenarios.
* Capable of free-form question-answering and multi-round interaction.
* Comming soon
- [x] Online Demo on ModelScope.
- [ ] Online Demo on HuggingFace.
- [ ] Source code.
- [ ] Instruction Training Data.
## Online Demo
### ModelScope
<a href="https://modelscope.cn/studios/damo/mPLUG-DocOwl/summary"><img src="https://modelscope.oss-cn-beijing.aliyuncs.com/modelscope.gif" width="250"/></a>
## Overview

## Cases

## DocLLM
The evaluation dataset DocLLM can be found in ```./DocLLM```.
## Related Projects
* [LoRA](https://github.com/microsoft/LoRA).
* [mPLUG](https://github.com/alibaba/AliceMind/tree/main/mPLUG).
* [mPLUG-2](https://github.com/alibaba/AliceMind).
* [mPLUG-Owl](https://github.com/X-PLUG/mPLUG-Owl)
## Citation
If you found this work useful, consider giving this repository a star and citing our paper as followed:
```
@misc{ye2023mplugdocowl,
title={mPLUG-DocOwl: Modularized Multimodal Large Language Model for Document Understanding},
author={Jiabo Ye and Anwen Hu and Haiyang Xu and Qinghao Ye and Ming Yan and Yuhao Dan and Chenlin Zhao and Guohai Xu and Chenliang Li and Junfeng Tian and Qian Qi and Ji Zhang and Fei Huang},
year={2023},
eprint={2307.02499},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
james-elicx/cf-bindings-proxy
|
https://github.com/james-elicx/cf-bindings-proxy
|
Experimental proxy for interfacing with bindings in projects targeting Cloudflare Pages
|
<p align="center">
<h3 align="center">cf-bindings-proxy</h3>
<p align="center">
Experimental proxy for interfacing with bindings
<br />
in projects targeting Cloudflare Pages.
</p>
</p>
---
<p align="center">
<a href="https://npmjs.com/package/cf-bindings-proxy" target="_blank">
<img alt="npm (tag)" src="https://img.shields.io/npm/v/cf-bindings-proxy/latest?color=3777FF&style=flat-square" />
</a>
<img alt="GitHub Workflow Status (with branch)" src="https://img.shields.io/github/actions/workflow/status/james-elicx/cf-bindings-proxy/release.yml?branch=main&color=95FF38&style=flat-square" />
</p>
---
This library was written to accompany [`@cloudflare/next-on-pages`](https://github.com/cloudflare/next-on-pages), so that you can use bindings when developing Next.js apps locally through `next dev`.
It is intended to be used for frameworks that do not support Cloudflare bindings in a fast HMR environment.
## Usage
Add the library to your project.
```sh
npm add cf-bindings-proxy
```
In a separate terminal window, run the following command to start the proxy, passing through your bindings are arguments.
```sh
npx cf-bindings-proxy --kv=MY_KV
```
In your project's code, import the `binding` function from `cf-bindings-proxy` and use it to interact with your bindings.
```ts
import { binding } from 'cf-bindings-proxy';
const value = await binding<KVNamespace>('MY_KV').get('key');
```
## How It Works
Starting the proxy spawns an instance of Wrangler using a template, passing through any commands and bindings that are supplied to the CLI. It uses port `8799`.
In development mode, when interacting with a binding through the `binding('BINDING_NAME')` function, it sends HTTP requests to the proxy. These HTTP requests contain destructured function calls, which are then reconstructed and executed inside the proxy. The result is then returned to the client.
When building for production, `binding('BINDING_NAME')` simply calls `process.env.BINDING_NAME` to retrieve the binding instead.
### When It's Active
Calls to `binding('BINDING_NAME')` will try to use the proxy when either of the following two conditions are met:
- The `ENABLE_BINDINGS_PROXY` environment variable is set to `true`.
OR
- The `DISABLE_BINDINGS_PROXY` environment variable is not set and `NODE_ENV` is set to `development`.
## Supported
Note: Functionality and bindings not listed below may still work but have not been tested.
#### KV
- [x] put
- [x] get
- [x] list
- [x] getWithMetadata
- [x] delete
#### D1
- [x] prepare
- [x] bind
- [x] run
- [x] all
- [x] first
- [x] raw
- [x] batch
- [x] exec
- [x] dump
#### R2
- [x] put
- [ ] writeHttpMetadata
- [x] get
- [ ] writeHttpMetadata
- [x] text
- [x] json
- [x] arrayBuffer
- [x] blob
- [ ] body
- [ ] bodyUsed
- [x] head
- [ ] writeHttpMetadata
- [x] list
- [ ] writeHttpMetadata
- [x] delete
- [ ] createMultipartUpload
- [ ] resumeMultipartUpload
|
a1k0n/a1gpt
|
https://github.com/a1k0n/a1gpt
|
throwaway GPT inference
|
## a1gpt
throwaway C++ GPT-2 inference engine from @a1k0n w/ minimal but optimized BLAS
ops for AVX and Apple Silicon, plus custom CUDA kernels.
no external dependencies except for accelerate framework on macos, and CUDA if
you have it available.
## build / run
- First, download the model:
To just grab a copy of the model without using Python or anything:
```
(cd model && wget https://www.a1k0n.net/models/gpt2-weights.bin)
```
To download from huggingface and convert the model yourself:
`$ python3 scripts/download_and_convert_gpt2.py`
This will require `numpy` and `huggingface_hub` to be installed in Python
- CMake and build
note: RelWithDebInfo is the default build type, so it should run pretty quick
```
$ mkdir build
$ cd build
$ cmake ..
-- The CXX compiler identification is GNU 11.3.0
-- Detecting CXX compiler ABI info
-- Detecting CXX compiler ABI info - done
-- Check for working CXX compiler: /usr/bin/c++ - skipped
-- Detecting CXX compile features
-- Detecting CXX compile features - done
-- Looking for a CUDA compiler
-- Looking for a CUDA compiler - /usr/lib/cuda/bin/nvcc
-- The CUDA compiler identification is NVIDIA 11.2.67
-- Detecting CUDA compiler ABI info
-- Detecting CUDA compiler ABI info - done
-- Check for working CUDA compiler: /usr/lib/cuda/bin/nvcc - skipped
-- Detecting CUDA compile features
-- Detecting CUDA compile features - done
-- Configuring done
-- Generating done
-- Build files have been written to: a1gpt/build
$ make -j
[ 12%] Building CXX object CMakeFiles/bpe_test.dir/bpe_test.cpp.o
[ 25%] Building CXX object CMakeFiles/bpe_test.dir/bpe.cpp.o
[ 37%] Building CXX object CMakeFiles/gpt2.dir/main.cpp.o
[ 50%] Building CXX object CMakeFiles/gpt2.dir/model_load_gpt2.cpp.o
[ 62%] Building CXX object CMakeFiles/gpt2.dir/model.cpp.o
[ 75%] Building CXX object CMakeFiles/gpt2.dir/bpe.cpp.o
[ 87%] Linking CXX executable bpe_test
[100%] Linking CXX executable gpt2
[100%] Built target bpe_test
[100%] Built target gpt2
$ ./gpt2 -h
Usage: ./gpt2 [-s seed] [-t sampling_temperature] [-p prompt]
-s seed: random seed (default: time(NULL))
-t sampling_temperature: temperature for sampling (default: 0.90)
-p prompt: prompt to start with (default: English-speaking unicorns)
-n ntokens: number of tokens to generate (default=max: 1024)
-c cfg_scale: classifier-free guidance scale; 1.0 means no CFG (default: 1.0)
```
This builds `gpt2` and `cugpt2` for the CUDA version, if available.
Example generation on a Macbook Air M2 with default prompt, temperature:
```
$ ./gpt2 -s 1688452945 -n 256
a1gpt seed=1688452945 sampling_temperature=0.90 ntokens=301
encoded prompt: 50256 818 257 14702 4917 11 11444 5071 257 27638 286 44986 82 2877 287 257 6569 11 4271 31286 1850 19272 11 287 262 843 274 21124 13 3412 517 6452 284 262 4837 373 262 1109 326 262 44986 82 5158 2818 3594 13
Generating:
```
In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English.
The unicorn, nicknamed Macalpine in the state of Montana, was the first animal ever to speak the language. The animal was first reported in 1972, during the discovery of the same region by the Inkocroft Rendezvous Lourd system in the Andes. The specimen's linguistic abilities were not extremely rare, but a few unknowns led the bewildering team to believe that the unicorn appeared to be communicating with a group that was silent.
This fluency in a language exam can prevent a unicorn from communicating with a specific person or group, but scientists believe it is rare for a unicorn to mantain such linguistic abilities. In a test they found, thousands of false Mexican translates were sent. This finding, along with other brilliant discoveries in the area, revealed that unicorns communicate with their synapses, essentially the same level of coordination as humans. The unicorn's API was claimed to evolve through a single ancestor known as the Amarr. But they were only known in California, and in many other places, as Amarr.
The legendary Amarr DNA has been widely used as a tool by cosmologists to identify flying squirrels, maple leaves and bees. In the near future, scientists hope that unicorn species and their mitochondrial DNA will
```
elapsed: 4.091053s, 3.995169ms per token
```
|
DiT-3D/DiT-3D
|
https://github.com/DiT-3D/DiT-3D
|
🔥🔥🔥Official Codebase of "DiT-3D: Exploring Plain Diffusion Transformers for 3D Shape Generation"
|
# DiT-3D: Exploring Plain Diffusion Transformers for 3D Shape Generation
[**Project Page**](https://dit-3d.github.io/)
We will release our code soon! Stay tuned!
🔥🔥🔥DiT-3D is a novel Diffusion Transformer for 3D shape generation, which can directly operate the denoising process on voxelized point clouds using plain Transformers.
[**DiT-3D: Exploring Plain Diffusion Transformers for 3D Shape Generation**](https://arxiv.org/abs/2307.01831)
<br>Shentong Mo, Enze Xie, Ruihang Chu, Lanqing Hong, Matthias Nießner, Zhenguo Li<br>
arXiv 2023.
## Citation
If you find this repository useful, please cite our paper:
```
@article{mo2023dit3d,
title = {DiT-3D: Exploring Plain Diffusion Transformers for 3D Shape Generation},
author = {Shentong Mo and Enze Xie and Ruihang Chu and Lanqing Hong and Matthias Nießner and Zhenguo Li},
journal = {arXiv preprint arXiv: 2307.01831},
year = {2023}
}
```
|
bitxeno/atvloadly
|
https://github.com/bitxeno/atvloadly
|
Easily sideload the IPA to AppleTV
|
# atvloadly
[](https://github.com/bitxeno/atvloadly/releases)
[](https://github.com/bitxeno/atvloadly/pkgs/container/atvloadly)
[](https://github.com/bitxeno/atvloadly/pkgs/container/atvloadly)
[](https://github.com/bitxeno/atvloadly/blob/master/LICENSE)
English | [中文](./README_cn.md)
> ⚠️ **Not supported on tvOS 17.0 and above systems.** ⚠️
atvloadly is a web service that supports sideloading app on Apple TV. It uses [AltServer](https://github.com/NyaMisty/AltServer-Linux) as the underlying technology for sideloading and automatically refreshes the app to ensure its long-term availability.
## Features
* Docker running (only supports Linux/OpenWrt platforms)
* Supports AppleTV pairing
* Supports automatic app refresh
* Supports use of multiple Apple ID accounts
## Screenshot
<p align="center">
<img width="600" src="./doc/preview/1.png">
</p>
<p align="center">
<img width="600" src="./doc/preview/2.png">
</p>
## Installation
> :pensive: **Only supports Linux/OpenWrt systems, does not support Mac/Windows systems.**
1. The Linux/OpenWrt host needs to install `avahi-deamon`.
OpenWrt:
```
opkg install avahi-dbus-daemon
/etc/init.d/avahi-daemon start
```
Ubuntu;
```
sudo apt-get -y install avahi-daemon
sudo systemctl restart avahi-daemon
```
2. Please refer to the following command for installation, remember to modify the mount directory.
```
docker run -d --name=atvloadly --restart=always -p 5533:80 -v /path/to/mount/dir:/data -v /var/run/dbus:/var/run/dbus -v /var/run/avahi-daemon:/var/run/avahi-daemon ghcr.io/bitxeno/atvloadly:latest
```
Image name: `ghcr.io/bitxeno/atvloadly:latest`, you need to use this full name with the domain in order to pull it down.
The `/var/run/dbus` and `/var/run/avahi-daemon` of the host machine need to be shared with the docker container for use.
## Getting Started
### Preparation (very important:bangbang:)
* Dedicated Apple ID installation account, both free or developer accounts are acceptable (**For security reasons, please do not use commonly used accounts for installation!**)
* Login with the installed account on the iPhone (used to authorize trust in atvloadly, will be virtualized as a MacBook, **failure to verify the authorization verification code within timeout will result in temporary account freeze! Password reset is required for recovery**)
### Operation process
1. Open the Apple TV settings menu, select `Remote and Devices -> Remote App and Devices`, enter pairing mode.
2. Open the web management page, normally it will display the pairable `AppleTV`.
3. Click on the `AppleTV` device to enter the pairing page and complete the pairing operation.
4. After successful pairing, return to the home page, where the connected `AppleTV` will be displayed.
5. Click on the connected `AppleTV` to enter the sideload installation page, select the IPA file that needs to be sideloaded, and click `Install`.
## FAQ
1. How many apps can be installed with a free account?
> Each Apple ID can activate up to 3 apps simultaneously. Installing more than 3 will cause previously installed apps to become unavailable.
2. Installation failure after system upgrade.
> After upgrading the system, re-pairing is required. Generally, newly released systems are not supported. It is recommended to disable automatic system updates.
3. Can App-specific passwords be used for passwords? Is it more secure this way?
> AltServer currently does not support it.
## How to build
[>> wiki](https://github.com/bitxeno/atvloadly/wiki/How-to-build)
## Disclaimer
* This software is only for learning and communication purposes. The author does not assume any legal responsibility for the security risks or losses caused by the use of this software.
* Before using this software, you should understand and bear corresponding risks, including but not limited to account freezing, which are unrelated to this software.
|
devsadeq/ComposeCinemaTicketsReservations
|
https://github.com/devsadeq/ComposeCinemaTicketsReservations
|
Book cinema tickets effortlessly with the Compose Cinema Tickets Reservations app! Powered by Jetpack Compose, this app offers an engaging movie selection experience with an animated slider and a user-friendly seat reservation system. Enjoy seamless UI interactions and a smooth booking process. 🎬🍿 #JetpackCompose #CinemaTickets #MovieBooking
|
# Compose Cinema Tickets Reservations App🎬
Welcome to the Compose Cinema Tickets Reservations app! This app lets you book cinema tickets with ease, using the awesome power of Jetpack Compose. It has 3 screens.
### Features:
- **Animated Slider:** Enjoy a cool animated slider that gives you sneak peeks into the most exciting movies.
- **Intuitive Seat Selection:** Easily pick your seats for the movie you want to watch. You can select multiple seats at once.
- **Smooth Animations:** Experience seamless and smooth interactions with our app's animations.
## Demo Video 📽️
To see the app in action, check out the demo video [here](https://youtube.com/shorts/iiZLfVxJowc?feature=share)!
## Screenshots 📸
<div style="display:flex;flex-wrap:wrap;">
<img src="https://github.com/devsadeq/ComposeCinemaTicketsReservations/assets/64174395/f3cfc9df-6a8b-4d1c-9833-c7a005888643" alt="Screenshot 1" style="max-width: 100%; width: 30%; margin: 10px;">
<img src="https://github.com/devsadeq/ComposeCinemaTicketsReservations/assets/64174395/5d968c22-54cb-49ad-96e5-d1ffc1bc1ea9" alt="Screenshot 2" style="max-width: 100%; width: 30%; margin: 10px;">
<img src="https://github.com/devsadeq/ComposeCinemaTicketsReservations/assets/64174395/f761e1db-4b61-4213-97a7-2c9cecf1e3aa" alt="Screenshot 3" style="max-width: 100%; width: 30%; margin: 10px;">
</div>
## Keywords
Jetpack Compose, Cinema Tickets, Reservations, Animated Slider, Seat Selection, User-Friendly, Smooth Animations, Android App, Blockbuster Movies, Booking Experience, UI Interactions.
## Contact
- Email: [email protected]
- Linkedin: [@devsadeq](https://www.linkedin.com/in/devsadeq/)
|
qxchuckle/Post-Summary-AI
|
https://github.com/qxchuckle/Post-Summary-AI
|
一个较通用的,生成网站内文章摘要,并推荐相关文章的AI
|
# Post-Summary-AI
一个较通用的,生成网站内文章**摘要**(简介),并**推荐**相关文章的AI(前端实现),基于tianliGPT后端
你可以前往这篇文章查看效果[文章添加预设或实时生成的AI简介](https://www.qcqx.cn/article/17d3383a.html)
更多的 Post-Summary-AI 部署效果可以往后查看[部署展示](https://github.com/qxchuckle/Post-Summary-AI#8%E9%83%A8%E7%BD%B2%E5%B1%95%E7%A4%BA)
> 该项目理论支持所有类型的网站,无论动态还是静态站,起初该项目是为了个人博客而生的
***
## 1.效果


***
## 2.快速上手
非常简单,引入下面这些代码到你的网站内,并修改配置项后即可
TIP: 为避免CDN和浏览器缓存的影响,建议指定**资源版本号**使用
cdn1.tianli0.top、jsd.onmicrosoft.cn是公益cdn,若无法访问或为确保资源的稳定,建议下载仓库对应文件至本地引入
```html
<!-- css -->
<link rel="stylesheet" href="https://jsd.onmicrosoft.cn/gh/qxchuckle/[email protected]/chuckle-post-ai.css">
<!-- chuckle-post-ai.js现在可以在网页结构的任何位置插入,只要你能够 -->
<script src="https://jsd.onmicrosoft.cn/gh/qxchuckle/[email protected]/chuckle-post-ai.js"></script>
<!-- 但要确保的是,AI构造代码一定要在chuckle-post-ai.js之后插入 -->
<script data-pjax defer>
// AI构造函数
new ChucklePostAI({
/* 必须配置 */
// 文章内容所在的元素属性的选择器,也是AI挂载的容器,AI将会挂载到该容器的最前面
el: '#post>#article-container',
// 驱动AI所必须的key,即是tianliGPT后端服务所必须的key
key: '123456',
/* 非必须配置,但最好根据自身需要进行配置 */
// 文章标题所在的元素属性的选择器,默认获取当前网页的标题
title_el: '.post-title',
// 文章推荐方式,all:匹配数据库内所有文章进行推荐,web:仅当前站内的文章,默认all
rec_method: 'web',
})
</script>
```
**AI构造函数 `ChucklePostAI({ /* 传入配置对象 */ })` 详解**
1. `el` **文章内容**所在的元素属性的选择器,也是AI**挂载**的容器,AI将会挂载到该容器的最前面
2. `key` 驱动AI所必须的key,即是tianliGPT后端服务所必须的**key**
3. `title_el` **文章标题**所在的元素属性的选择器,默认获取当前**网页的标题**
4. `rec_method` 文章推荐方式,**all**:匹配数据库内所有文章进行推荐,**web**:仅当前站内的文章,**默认all**
>更多**进阶**配置项和**实验性**功能,请查看[进阶操作](https://github.com/qxchuckle/Post-Summary-AI/blob/master/Advanced.md)
项目开发不易,可以前往[爱发电](https://afdian.net/a/chuckle)给予我赞助
***
## 3.什么是TianliGPT
TianliGPT是一个基于GPT-3.5的文字摘要生成工具,你可以将需要提取摘要的文本内容发送给TianliGPT,稍等一会他就可以给你发送一个基于这段文本内容的摘要。该服务端暂未开源。
***
## 4.tianliGPT-KEY
tianliGPT的key请到[爱发电](https://afdian.net/item/f18c2e08db4411eda2f25254001e7c00)中购买,10元5万字符(常有优惠)。请求过的内容再次请求不会消耗key,可以无限期使用。
- 相比实时请求OpenAI,使用tianliGPT可以让你请求过的内容不再消耗key,并在国内更快速的获取摘要,适合生产环境。
- key消耗完毕,已经请求过的内容仍然可以继续请求,避免了被恶意请求造成的资金损失和业务停摆。
- 符合中国大陆法律法规。
**注意事项:**
1. 购买完成后,进入[管理后台](https://summary.zhheo.com/):summary.zhheo.com ,登录后点击右上角的“添加新网站”,输入密钥即可绑定成功。
2. 若需要进行**本地调试**,请在管理后台将 127.0.0.1:端口 加入白名单,否则会触发防盗KEY,无法正常获取摘要。
***
## 5.版本升级
修改引入资源的版本号,版本号可在[releases](https://github.com/qxchuckle/Post-Summary-AI/releases)查看

***
## 6.进阶操作
摘要AI的**进阶用法**,以及一些**实验性**功能:[进阶操作](https://github.com/qxchuckle/Post-Summary-AI/blob/master/Advanced.md)
## 7.技术支持
若你的网站接入该项目有困难,可以提 [issues](https://github.com/qxchuckle/Post-Summary-AI/issues),简单讲述你所遇到的困难,并附上**网站地址**,你将会获得快速的回复。
工单系统、反馈互动社区:https://support.qq.com/product/600565
也可以加入**QQ频道**:点击链接加入讨论子频道【TianliGPT 问题交流】:https://pd.qq.com/s/7cx85i9l0
***
## 8.部署展示
这里展示已经成功部署 Post-Summary-AI 的网站,若你已成功部署,可以提 [issues](https://github.com/qxchuckle/Post-Summary-AI/issues),会将你展示于此
1. [MoyuqLのBlog](https://blog.moyuql.top/)
***
## 9.同类友情项目
[Post-Abstract-AI](https://github.com/qxchuckle/Post-Abstract-AI)
友情项目和本项目都是基于tianliGPT的AI摘要前端实现,可自行选择适合你网站的项目。

|
cuynu/gphotos-unlimited-zygisk
|
https://github.com/cuynu/gphotos-unlimited-zygisk
|
Unlimited Google Photos Magisk Module works with Zygisk
|
# Google Photos unlimited backup module
Adds Photos features and unlimited original backup
<a href="https://github.com/cuynu/gphotos-unlimited-magisk#usage">
<img alt="DEMO" src="https://github.com/cuynu/gphotos-unlimited-magisk/assets/90895715/154b2d25-6341-4131-a70f-99a8a0d1740e" width="300" height="300" />
</a>
</p>
### [Переключиться на русский язык](https://github.com/cuynu/gphotos-unlimited-zygisk/wiki/RU)
### [Chuyển ngôn ngữ Tiếng Việt](https://github.com/cuynu/gphotos-unlimited-zygisk/wiki/VI)
# Introduction
Based from Pixelify GitHub. This module will spoof your device info to Pixel XL on Google apps and Google Photos to get unlimited backup storage at original quality
# Warning !
Module will only works with Zygisk, it will not run with Riru, Shamiko, etc !!
Some modules could break and prevent this module from running, if module does not work, try disable some modules and see
# Usage
[Download zip from repository](https://github.com/cuynu/gphotos-unlimited-magisk/archive/refs/heads/master.zip) or [release page](https://github.com/cuynu/gphotos-unlimited-magisk/releases), enable Zygisk then install with Magisk v24.3+ and reboot
# Build zygisk library
`git clone https://github.com/cuynu/gphotos-unlimited-magisk.git`
Import folder zygisk_build to Android Studio or Gradle and build then copy compiled zygisk library to zygisk folder (not zygisk_build)
|
ChronicGamesLtd/CryptoChronic
|
https://github.com/ChronicGamesLtd/CryptoChronic
| null |
# CryptoChronic v1.0
CryptoChronic is a multi-platform video-game, built upon and evolving around non-fungible (ERC721) tokens called "Chronics" that represents toonish minions composed by marijuana strains.
from https://www.cryptochronic.com/
<p align="center">
<img alt="Dark" src="https://static.wixstatic.com/media/0e15a6_2215c433545343c1bb8cf1ef857a5307~mv2.png/v1/fill/w_470,h_669,al_c,q_85,usm_0.66_1.00_0.01,enc_auto/0e15a6_2215c433545343c1bb8cf1ef857a5307~mv2.png" width="100%">
</p>
### Built With
* [Solidity](https://docs.soliditylang.org/)
* [Hardhat](https://hardhat.org/getting-started/)
## Chronic Token
A Chronic is a combination of 7 layers of different parts
- body
- eyes
- mouth
- headgear
- arms
- leaves
- vase
<p align="center"> <img alt="Dark" src="https://static.wixstatic.com/media/0e15a6_b376a6afa69c459fb8597d712656db3e~mv2.png/v1/fill/w_360,h_664,al_c,q_85,usm_0.66_1.00_0.01,enc_auto/Personaggio_4_v3.png" width="50%" height="50%"> </p>
For each layer can be defined a variable number of parts, each of them identified by an unique ID. Other than defining their shape the combination of different parts set the following battle stats of the token:
- var/actual THC
- var/actual CBD
- var/actual Aroma
The `actual` means the starting value of the Chronic, the `var` set the upper and the lower value that a Chronic can have in the game life. Those variations happen off-chain and aren't recorded on-chain.
*for instance a Chronic has 40 actual CBD and 12 of var: this means that during the game it can't have more than 52 or below 28.*
Each layer's part that compose the Chronic add it's own values to the total.
Each Chronic belongs to a series, at the moment there will be only the 0 series, the original one.
The token data stored on-chain are called `genes` of the Chronic and it's uint 32 byte number that must be parsed with the following bit pattern: (at the moment only the first 22 bytes are used)
Bytes
| 22-21 | 20-19 | 18-17 | 16-15 | 14-13 | 12-11 | 10-9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| actual aroma | var aroma | actual CBD | var CBD | actual THC | var THC | generation | (TBD) | ID vase | ID leaves | ID arms | ID headgear | ID mouth | ID eyes | ID body | series |
This implies that can be a maximum of 255 part IDs for each layers, so the possible series and the battle stats values can be maximum 65535.
When minted the Chronic is generated by the Breeder contract and each part is picked according to a random weighted on the part's rarity. A minted Chronic will be always considered of "first generation", so the corresponding value in it's gene will be 1, and thus it's fertility will be equal to a predefined value set in the contract.
A Chronic can be bred, mixing the genes of two parent Chronics; the generation is still random but the parts of the parents have more weight and so more chance to be picked. A bred Chronic is of a subsequent generation of the youngest of its parent and thus its fertiliy is equal to the predefined value set in the contract divided and floored by its generation. The initial fertility of a Chronic however can not be lower than 1.
*for instance two Chronics are combined in a breed: the first has a generation of 1 and the second has a generation of 3; the base value of fertility is 10. The new Chronic will have generation 4 and an initial fertility of 2*
Each time a Chronic is involved in a breeding as a parent, its ferility is decreased by 1.
Other related information, such as the name of the Chronic, are off-chain and a base token and image URIs can be set in the contract to provide a link to those metadata files.
Finally, a Chronich can be crafted by the owner of the contract ad assinged to an address. While crafting the caller can decide exactly the gene, the initial fertility and the series.
## Solidity contracts
The architecture is built upon 3 contracts
- Chronic: a IERC721 contract that holds the Chronics data
- Breeder: a contract responsible of the random generation of the Chronics
- Feeder: a contract with the functions related to manage the fertility of the Chronics
The contracts relies on OpenZeppelin's ERC721Enumerable, Counter, Ownable, Pausable parent contracts
### Chronic
#### Roles and functions
The contract has:
- an Owner (the address that deploy the contract) that can
- pause(**) the contract (by default the contract is not paused)
- unpause(*) the contract
- disableCraft (by default crafting is enabled)
- freeze changes of the base URIs (by default they can be changed)
- set a new Breeder(*) (initially set at deploy time)
- set a new Feeder(*) (initially set at deploy time)
- set a new Freezer(*) (initially set at deploy time)
- set a new minium token that a new player must have(*) (default at 3)
- set the base URI for token, image and contract(*)
- craft a Chronic with a specific gene(**) (if crafting is enabled)
- a Breeder (set at deploy time, an instance of the Breeder contract) that can
- mint a new Chronic(**) for a specific address
- decrease the fertility of a Chronic(**)
- a Feeder (set at deploy time, an instance of the Feeder contract) that can
- increase the fertility of a Chronic(**)
- a Freezer (set at deploy time, a wallet) that can
- set the ID of a tokenID(**) in another blockchain
- unfreeze a Chronic(**), it means it can transfer it from his wallet to a specific address
And the following public functions
- transfer functions of the IERC721 but that can be activated only if the caller is not the Freezer and if it has as more than the minimum tokens
- freeze a Chronic(**) that means the token is transferred to the Freezer wallet
- tokenURI that returns the string baseTokenURI + tokenID + '.json' where the Chronic metadata are located
- imageURI that returns the string baseImageURI + tokenID + '.png' where the Chronic image file is located
- contractURI that returns the URI where the metadata of the contract are located
- get the last minted Chronic tokenID, since the ID is incremental it means the minted amount
(*) only when the contract is paused; (**) only when the contract is not paused
### Mapping
The token data are stored in 3 public mappings which keys is the tokenID
- genes: a uint256 holding information on the body parts and the battle stats of the Chronic
- fertility: the current value of fertility of a Chronic
- parents: a uint256 tuple with the tokenID of the two parent of a Chronic ([0,0] if it doesn't have any)
- otherBC: a uint256 with the tokenID of a frozen Chronic in another blockchain
### Breeder
#### Roles and functions
The contract has:
- an Owner (the address that deploy the contract) that can
- pause(**) the contract (the contract is paused at deploy time)
- unpause(*) the contract
- set Chronic Contract(*) with the new address of the bound Chronic contract (none set at deploy time)
- set the price(*) for players to breed two of their Chronic (default at 0.5 ether)
- set the price(*) for players to mint a new Chronic (default at 1 ether)
- set the default fertility(*) of Chronics (default at 10)
- set the whole dataset(*) of the different layers that compose the Chronics and the base of their battle
- update a single layer values(*)
- update a single part values of a specific layer(*)
- update the series of the Chronic(*) (default at 0)
- set the whole weight system(*) of the layers used in the generation of a Chronic
- mint and assign(*) an amount of Chronic equal to the `initialTokens` value in the Chronic contract (this function reverts unless the address has no tokens, it's purpose is the onboaring of new players)
- breed and assign(**) a Chronic to an address using two of its token
- withdraw(**) the funds in native coin that belongs to the contract
And the following public function
- breed(**) that generates a new Chronic given two parents token hold by the caller, who pays the breed price
- get the strcutured representation of a Chronic decodifiyng it's gene
(*) only when the contract is paused; (**) only when the contract is not paused
### Feeder
#### Roles and functions
The contract has:
- an Owner (the address that deploy the contract) that can
- pause(**) the contract (the contract is paused at deploy time)
- unpause(*) the contract
- set Chronic Contract(*) with the new address of the bound Chronic contract (none set at deploy time)
- set the price(*) for players of a fertility increase by 1 of one of their Chronic (default at 0.25 ether)
- withdraw(**) the funds in native coin that belongs to the contract
And the following public function
- increase the fertility(**) of a Chronic hold by the caller, who pays the increase fertility price
(*) only when the contract is paused; (**) only when the contract is not paused
## Utilities
A sample of the layer data in JSON is provided and helpers function in Javascript to parse this source and generate the proper inputs for the `setLayers` and the `setWeights` methods (the function `encodeLayers`) and the `craft` functions (the function `encodeGene`).
### Layer data
The data are in an object which keys are the single layer and the values an array of `parts`
```
{
"body": [],
"eyes": [],
"mouth": [],
"headgear":[],
"arms": [],
"leaves":[],
"vase":[]
}
```
A `part` is an object with the following structure (values are just illustrative)
```
{
"id": 1,
"rarity": 2,
"battle": {
"thc": {
"var": 5,
"actual": 15
},
"cbd": {
"var": 0,
"actual": 10
},
"aroma": {
"var": 3,
"actual": 9
}
}
}
```
- ID: is an arbitray unique per layer number between 1-255
- Rarity: is a number between 1-4 (1=common, 4=ultra-rare)
- Var/Actual: the battle stats related value of the part
The generation algorithm will set a single part for each of the seven layers with a weight pseudo-random depending on the rarities in each layer. When breeding the pseudo-random is also affected by the parents Chronic which parts have more chance to be picked.
The values of each layer's part are summed, for instance, if the picked body part has actualTCH of 50 and the picked eyes has actualTHC of 5, the actualTHC is 55, and so on, each following part after body add its values.
### Weights system
Each rarity level has a `rarity coefficient` defined in javascript utility library and used in the function `encodeLayers` that returns an array of arrays which indexing matches the structure of the encoded layers and the values are calculated multiplying the coefficient and the number of parts in the layer with the same rarity level. The returned array must be used as a input of the `setWeights` method of the Breeder.
## Contact
for more info email at [email protected]
or go to https://https://www.cryptochronic.com/
## Social
Discord: https://discord.gg/ArHNbvHMh7
Twitter: https://twitter.com/CryptoChronic1
Facebook: https://www.facebook.com/CryptoChronicCannaverse/
## License
See LICENSE for more information.
|
amp64/Atari_ST
|
https://github.com/amp64/Atari_ST
|
XDebug debugger and AmpLink linker for Atari ST
|
# Developer Tools for the Atari ST
These are files rescued from my old hard drive containing the source to my 68k debugger (X-Debug) and linker (AmpLink) from the early 90s.
# X-Debug
As soon as I left HiSoft I I immediately missed the ability to add features to the debugger I used every day, so set about creating a new one, and made X-Debug.
Unlike MonST (which I wrote) it was written mostly in C and was highly configurable, supporting customizable commands and new screen types.
# AmpLink
I can't recall why I decided I needed my own linker, but I made this one which can also create Amiga images. ('Amp' are my initials and you'll see them all over the code).
# To Build
I used Lattice C and HiSoft GenST 2.something (which I also wrote) to build these, along with a Unix-like shell to run the makefiles. I no longer have the ability to build or verify these sources myself.
# Other Utilities
There is also the source to a few utilities here, namely DReloc, DumpDB, LoadHigh, ResetFPU and TTHead.
|
fakellgit/ChatGPTFreeAPI
|
https://github.com/fakellgit/ChatGPTFreeAPI
|
ChatGPT API for free.
|
# ChatGPTFreeAPI
Welcome to the ChatGPT API Free, API that allows you to access OpenAI's ChatGPT API for free.
ChatGPT API Free is a powerful tool that allows users to generate responses to prompts using the GPT-3.5 language model. The API is easy to use and can be accessed by sending a POST request to a specific endpoint.
[Demo Url](https://fakell.raidghost.com/)
## Usage
To use ChatGPT API Free, simply send a POST request to the following endpoint:
```
https://fakell.raidghost.com/v1/chat/completions/
```
For instance, to generate a response to the prompt "Hello, how are you?" using the `gpt-3.5-turbo` model, send the following `curl` command:
```sh
curl https://fakell.raidghost.com/v1/chat/completions/ \
-H 'Content-Type: application/json' \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "Hello, how are you?"}],
"stream": false
}'
```
If you need more information on how to use the ChatGPT API Free, you can consult the official [API documentation provided by OpenAI](https://platform.openai.com/docs/api-reference/chat/create). The documentation is very comprehensive and provides detailed information on how to use the API, along with sample code snippets to help you get started.
## Follow me!
If you find the ChatGPT API Free useful, you can stay up-to-date on the latest developments by following me. By following [me](https://github.com/fakellgit), you will be the first to know about new features, updates, and improvements to the API.
## Author
Fahendrena
[[email protected]](mailto:[email protected]).
|
e-lambda/SICP-summer-2023
|
https://github.com/e-lambda/SICP-summer-2023
|
SICP Exercise Solutions (e/λ)
|
# SICP Exercise Solutions (e/λ)
This repository contains SICP exercise solutions from members of the [e\λ Summer 2023 study group](https://t.co/VAZmlT9Dol).
Clone this repository, create a new branch with your solutions for the week and submit a pull request for review.
<pre>
$ git clone https://github.com/e-lambda/SICP-summer-2023.git sicp
$ cd sicp
$ git checkout -b <i><participant1-participant2-weekN></i>
...make commits...
$ git push -u origin <i><participant1-participant2-weekN></i>
</pre>
|
quanru/obsidian-periodic-para
|
https://github.com/quanru/obsidian-periodic-para
| null |
# Obsidian Periodic PARA
- This is a plugin for [LifeOS](https://quanru.github.io/2023/07/08/Building%20my%20second%20brain%20%F0%9F%A7%A0%20with%20Obsidian/), which assist in practicing the PARA system with periodic notes.
- You can download the [LifeOS-example](https://github.com/quanru/obsidian-example-LifeOS) to experience it.
## Installation
> [Dataview](https://github.com/blacksmithgu/obsidian-dataview) is required, please install it first.
#### BRAT
Periodic PARA has not been available in the Obsidian community plugin browser, but I already submitted it for [review](https://github.com/obsidianmd/obsidian-releases/pull/2117). You can install it by [BRAT](https://github.com/TfTHacker/obsidian42-brat).
#### Manual
Go to the [releases](https://github.com/quanru/obsidian-periodic-para/releases) and download the latest `main.js` and `manifest.json` files. Create a folder called `periodic-para` inside `.obsidian/plugins` and place both files in it.
## Settings
|Setting|Description|
|---|---|
|Periodic Notes Folder| Default is 'PeriodicNotes', Set a folder for periodic notes. The format of daily, weekly, monthly, quarterly, and yearly notes in the directory must meet the following requirements: YYYY-MM-DD、YYYY-Www、YYYY-MM、YYYY-Qq |
|Projects Folder | Default is '1. Projects', Set a folder where the PARA project is located, each subdirectory is a project, and each project must have a [XXX.]README.md file as the project index |
|Areas Folder | Default is '2. Areas', Set a folder where the PARA area is located, each subdirectory is a area, and each area must have a [XXX.]README.md file as the area index |
|Resources Folder | Default is '3. Resources', Set a folder where the PARA resource is located, each subdirectory is a resource, and each resource must have a [XXX.]README.md file as the resource index |
|Archives Folder | Default is '4. Archives', Set a folder where the PARA archive is located, each subdirectory is a archive, and each archive must have a [XXX.]README.md file as the archive index |
|Project List Header | Default is 'Project List', Set the title of the module in which the project snapshots are located in daily notes to collect the projects experienced in the current period in the weekly, monthly, quarterly, and yearly notes |
|Area List Header | Default is 'First Things Dimension', Set the title of the module in which the area snapshots are located in quarterly notes to collect the areas experienced in the current period in the yearly notes |
|Habit List Header | Default is 'Habit', Set the title of the module in daily notes where the habit is located, and the task query view will ignore tasks under that title |
## Usage
### query code block
Periodic PARA works by writing markdown code block, which query project, area, task list according to the date parsed from current filename, and query task, bullet, project, area, resource, archive list according to the tags parsed from frontmatter.
#### query by time
Time scope is parsed from current file name, for example:
- 2023-01-01.md // Only 1 January is included
- 2023-W21.md // Every day of week 21
- 2023-06.md // Every day and every week of June
- 2023-Q3.md // Every day, every week, every month of Quarter 3
- 2023.md // Every day, every week, every month, every quarter of 2023
~~~markdown
```PeriodicPARA
TaskDoneListByTime
```
~~~
~~~markdown
```PeriodicPARA
TaskRecordListByTime
```
~~~
~~~markdown
```PeriodicPARA
ProjectListByTime
```
~~~
~~~markdown
```PeriodicPARA
AreaListByTime
```
~~~
#### query by tag
Tags is parsed from the frontmatter of current file, for example:
~~~markdown
---
tags:
- x-project
---
~~~
The following code block would use x-project as the tag for the query.
~~~markdown
```PeriodicPARA
TaskListByTag
```
~~~
~~~markdown
```PeriodicPARA
BulletListByTag
```
~~~
~~~markdown
```PeriodicPARA
ProjectListByTag
```
~~~
~~~markdown
```PeriodicPARA
AreaListByTag
```
~~~
~~~markdown
```PeriodicPARA
ResourceListByTag
```
~~~
~~~markdown
```PeriodicPARA
ArchiveListByTag
```
~~~
#### query para by folder
~~~markdown
```PeriodicPARA
ProjectListByFolder
```
~~~
~~~markdown
```PeriodicPARA
AreaListByFolder
```
~~~
~~~markdown
```PeriodicPARA
ResourceListByFolder
```
~~~
~~~markdown
```PeriodicPARA
ArchiveListByFolder
```
~~~
### [templater](https://github.com/SilentVoid13/Templater) helpers
#### Generate list
Generate a list of README.md snapshots in the specified directory.
~~~markdown
<% PeriodicPARA.Project.snapshot() %>
<% PeriodicPARA.Area.snapshot() %>
<% PeriodicPARA.Resource.snapshot() %>
<% PeriodicPARA.Archive.snapshot() %>
~~~
For example:
~~~markdown
<% PeriodicPARA.Project.snapshot() %>
~~~
to
~~~markdown
1. [[1. Projects/x-project/README|x-project]]
2. [[1. Projects/y-project/README|y-project]]
~~~
## example


## next
- [x] Supports custom directories
- PARA directories
- Periodic directories
- [x] Support *ListByTag(ProjectListByTag, AreaListByTag, ResourceListByTag, ArchiveListByTag)
|
yakovexplorer/ChimeraWebsite
|
https://github.com/yakovexplorer/ChimeraWebsite
|
Our API website. DM me in discord if you want to contribute.
|
This is a [Next.js](https://nextjs.org/) project bootstrapped with [`create-next-app`](https://github.com/vercel/next.js/tree/canary/packages/create-next-app).
## Getting Started
First, run the development server:
```bash
npm run dev
# or
yarn dev
# or
pnpm dev
#To build
npm run build && npm run start -p {port}
```
Open [http://localhost:3000](http://localhost:3000) with your browser to see the result.
You can start editing the page by modifying `app/page.tsx`. The page auto-updates as you edit the file.
This project uses [`next/font`](https://nextjs.org/docs/basic-features/font-optimization) to automatically optimize and load Inter, a custom Google Font.
## Learn More
To learn more about Next.js, take a look at the following resources:
- [Next.js Documentation](https://nextjs.org/docs) - learn about Next.js features and API.
- [Learn Next.js](https://nextjs.org/learn) - an interactive Next.js tutorial.
You can check out [the Next.js GitHub repository](https://github.com/vercel/next.js/) - your feedback and contributions are welcome!
## Deploy on Vercel
The easiest way to deploy your Next.js app is to use the [Vercel Platform](https://vercel.com/new?utm_medium=default-template&filter=next.js&utm_source=create-next-app&utm_campaign=create-next-app-readme) from the creators of Next.js.
Check out our [Next.js deployment documentation](https://nextjs.org/docs/deployment) for more details.
|
liboheng/CryptoJSUtils
|
https://github.com/liboheng/CryptoJSUtils
| null |
# CryptoJSUtils
CryptoJSUtils 是一款基于 Node.js 的工具类库,它对 Web3.js 等区块链工具进行了优化封装,致力于简化和提高区块链应用开发的效率。本库的核心功能是支持从多种数据源(如 XLSX、TXT 文件)中批量读取数据,并根据这些数据进行批量合约调用。 CryptoJSUtils 的出现让开发者可以更轻松地执行大量区块链交互操作,节省了大量的时间和努力。
它的优秀表现主要体现在两个方面:
1. 数据读取:CryptoJSUtils 支持从各种常见格式的文件中读取数据,如 XLSX、TXT 等,这使得开发者可以将这些数据直接导入到区块链合约中,而无需进行繁琐的数据转换和处理。
2. 合约调用:利用 CryptoJSUtils,开发者可以批量进行合约调用,从而快速处理大量区块链交互操作,实现数据上链。 综上,CryptoJSUtils 是一款功能强大、易用的区块链开发工具类库,对于任何需要在区块链上批量处理数据的开发者来说,它都是不可或缺的助手。
|
jayesh15/NewsNLP
|
https://github.com/jayesh15/NewsNLP
|
Natural Language Processing (NLP) project designed to analyze and extract valuable insights from new articles. Powered by advanced language models and cutting-edge NLP techniques, it offers a comprehensive solution for automated text analysis in the realm of news.
|
# NewsNLP
Natural Language Processing (NLP) project designed to analyze and extract valuable insights from new articles. Powered by advanced language models and cutting-edge NLP techniques, it offers a comprehensive solution for automated text analysis in the realm of news.
doing my first change in testbranch123
|
OpenLMLab/MOSS-RLHF
|
https://github.com/OpenLMLab/MOSS-RLHF
|
MOSS-RLHF
|
# MOSS-RLHF
### *MOSS-RLHF & "Secrets of RLHF in Large Language Models Part I: PPO" <br>👉 <a href="https://arxiv.org/abs/2307.04964" target="_blank">[Technical report]</a> <a href="https://openlmlab.github.io/MOSS-RLHF/" target="_blank">[Home page]*
<p align="center" width="100%">
<a href="https://arxiv.org/abs/2307.04964" target="_blank"><img src="./assets/img/moss.png" alt="MOSS" style="width: 50%; min-width: 300px; display: block; margin: auto;"></a>
[](./LICENSE)
[](./DATA_LICENSE)
[](./MODEL_LICENSE)
## 🌟 News
### 👉 Wed, 12. July 2023. We have released Chinese reward model based OpenChineseLlama-7B!
[moss-rlhf-reward-model-7B-zh](https://huggingface.co/Ablustrund/moss-rlhf-reward-model-7B-zh/tree/main)
<br>
### 👉 Thu, 13. July 2023. We have released English reward model and SFT model based Llama-7B!
[moss-rlhf-reward-model-7B-en](https://huggingface.co/fnlp/moss-rlhf-reward-model-7B-en)
[moss-rlhf-sft-model-7B-en](https://huggingface.co/fnlp/moss-rlhf-sft-model-7B-en)
<br>
### 👉 Wait a minute ! Thu, 14. July 2023. We have released English policy model after aligning with RLHF!
[moss-rlhf-policy-model-7B-en](https://huggingface.co/fnlp/moss-rlhf-policy-model-7B-en)
<br>
## 🧾 Open-source List
- [x] Open source code for RL training in large language models.
- [x] A 7B Chinese reward model based on openChineseLlama.
- [x] A 7B English reward model based on Llama-7B.
- [x] SFT model for English.
- [x] Policy model for English after RLHF.
- ...
## 🌠 Introduction
Due to the challenges of reward design, environment interaction, and agent training, coupled with huge trial and error cost of large language models, there is a significant barrier for AI researchers to motivate the development of technical alignment and safe landing of LLMs. The stable training of RLHF has still been a puzzle.
In this technical report, we intend to help researchers to train their models stably with human feedback.
Contributions are summarized as follows:
1) We release competitive Chinese and English reward models, respectively, which have good cross-model generalization ability, alleviating the cost of relabeling human preference data;
2) We conduct in-depth analysis on the inner workings of PPO algorithm and propose the PPO-max algorithm to ensure stable model training;
3) We release the complete PPO-max codes to ensure that the LLMs in the current SFT stage can be better aligned with humans.
<div align="center" width="100%">
<img style="width: 80%; min-width: 500px; display: block; margin: auto; margin-bottom: 20px" alt="MOSS-RLHF" src="./assets/img/img1.jpg">
</div>
<div align="center" width="100%">
<img style="width: 80%; min-width: 500px; display: block; margin: auto; margin-bottom: 20px" alt="MOSS-RLHF" src="./assets/img/img2.jpg">
</div>
## 🔩 Requirements & Setup
This repository works on Python 3.8 and PyTorch 1.13.1.
We recommend using the **conda** virtual environment to run the code.
#### Step 1: Create a new Python virtual environment
```bash
conda update conda -n base -c defaults
conda create -n rlhf python=3.8
conda activate rlhf
```
#### Step 2: Install PyTorch and TensorBoard
```bash
conda install pytorch==1.13.1 pytorch-cuda=11.7 tensorboard -c pytorch -c nvidia
```
#### Step 3: Install the remaining dependencies
```bash
conda install datasets accelerate safetensors chardet cchardet -c huggingface -c conda-forge
pip3 install transformers sentencepiece einops triton==1.0.0 rouge jionlp==1.4.14 nltk sacrebleu cpm_kernels
apt install libaio-dev
DS_BUILD_OPS=1 pip install deepspeed
```
## ✨ Start training your own model!
Run code in a few steps.
### Step 1: Recover Reward model weights
We can not directly release the full weight of the reward model because of protocol restrictions.
You can merge the diff weight with original Llama-7B to recover the reward model we used.
We upload the diff models, thanks to tatsu-lab, you can recover the reward model follow these steps:
```bash
1) Download the weight diff into your local machine. The weight diff is located at:
# For English:
# SFT model
https://huggingface.co/fnlp/moss-rlhf-sft-model-7B-en
# Reward model
https://huggingface.co/fnlp/moss-rlhf-reward-model-7B-en
# Policy model
https://huggingface.co/fnlp/moss-rlhf-policy-model-7B-en
# For Chinese:
https://huggingface.co/Ablustrund/moss-rlhf-reward-model-7B-zh/tree/main
2) Merge the weight diff with the original Llama-7B:
# For English:
# Reward model
python merge_weight_en.py recover --path_raw decapoda-research/llama-7b-hf --path_diff ./models/moss-rlhf-reward-model-7B-en/diff --path_tuned ./models/moss-rlhf-reward-model-7B-en/recover --model_type reward
# SFT model
python merge_weight_en.py recover --path_raw decapoda-research/llama-7b-hf --path_diff ./models/moss-rlhf-sft-model-7B-en/diff --path_tuned ./models/moss-rlhf-sft-model-7B-en/recover --model_type sft
# Policy model
python merge_weight_en.py recover --path_raw decapoda-research/llama-7b-hf --path_diff ./models/moss-rlhf-policy-model-7B-en/diff --path_tuned ./models/moss-rlhf-policy-model-7B-en/recover --model_type policy
# For Chinese:
python merge_weight_zh.py recover --path_raw decapoda-research/llama-7b-hf --path_diff ./models/moss-rlhf-reward-model-7B-zh/diff --path_tuned ./models/moss-rlhf-reward-model-7B-zh/recover
```
### Step 2: Select your own SFT model.
Because of some limitations, we can not release the **Chinese** SFT model (Currently).
You can use your own SFT model, or a strong base model instead of our SFT model.
### Step 3: Start training
Run the command below.
```
# For Chinese:
# You need to use your own sft model currently.
bash run_zh.sh
# For English:
# We have loaded the sft model and reward model to huggingface.
bash run_en.sh
```
## Citation
```bibtex
@article{zheng2023secrets,
title={Secrets of RLHF in Large Language Models Part I: PPO},
author={Rui Zheng and Shihan Dou and Songyang Gao and Wei Shen and Binghai Wang and Yan Liu and Senjie Jin and Qin Liu and Limao Xiong and Lu Chen and Zhiheng Xi and Yuhao Zhou and Nuo Xu and Wenbin Lai and Minghao Zhu and Rongxiang Weng and Wensen Cheng and Cheng Chang and Zhangyue Yin and Yuan Hua and Haoran Huang and Tianxiang Sun and Hang Yan and Tao Gui and Qi Zhang and Xipeng Qiu and Xuanjing Huang},
year={2023},
eprint={2307.04964},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
kennethleungty/Llama-2-Open-Source-LLM-CPU-Inference
|
https://github.com/kennethleungty/Llama-2-Open-Source-LLM-CPU-Inference
|
Running Llama 2 and other Open-Source LLMs on CPU Inference Locally for Document Q&A
|
# Running Llama 2 and other Open-Source LLMs on CPU Inference Locally for Document Q&A
### Clearly explained guide for running quantized open-source LLM applications on CPUs using LLama 2, C Transformers, GGML, and LangChain
**Step-by-step guide on TowardsDataScience**: https://towardsdatascience.com/running-llama-2-on-cpu-inference-for-document-q-a-3d636037a3d8
___
## Context
- Third-party commercial large language model (LLM) providers like OpenAI's GPT4 have democratized LLM use via simple API calls.
- However, there are instances where teams would require self-managed or private model deployment for reasons like data privacy and residency rules.
- The proliferation of open-source LLMs has opened up a vast range of options for us, thus reducing our reliance on these third-party providers.
- When we host open-source LLMs locally on-premise or in the cloud, the dedicated compute capacity becomes a key issue. While GPU instances may seem the obvious choice, the costs can easily skyrocket beyond budget.
- In this project, we will discover how to run quantized versions of open-source LLMs on local CPU inference for document question-and-answer (Q&A).
<br><br>

___
## Quickstart
- Ensure you have downloaded the GGML binary file from https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGML and placed it into the `models/` folder
- To start parsing user queries into the application, launch the terminal from the project directory and run the following command:
`poetry run python main.py "<user query>"`
- For example, `poetry run python main.py "What is the minimum guarantee payable by Adidas?"`
- Note: Omit the prepended `poetry run` if you are NOT using Poetry
<br><br>

___
## Tools
- **LangChain**: Framework for developing applications powered by language models
- **C Transformers**: Python bindings for the Transformer models implemented in C/C++ using GGML library
- **FAISS**: Open-source library for efficient similarity search and clustering of dense vectors.
- **Sentence-Transformers (all-MiniLM-L6-v2)**: Open-source pre-trained transformer model for embedding text to a 384-dimensional dense vector space for tasks like clustering or semantic search.
- **Llama-2-7B-Chat**: Open-source fine-tuned Llama 2 model designed for chat dialogue. Leverages publicly available instruction datasets and over 1 million human annotations.
- **Poetry**: Tool for dependency management and Python packaging
___
## Files and Content
- `/assets`: Images relevant to the project
- `/config`: Configuration files for LLM application
- `/data`: Dataset used for this project (i.e., Manchester United FC 2022 Annual Report - 177-page PDF document)
- `/models`: Binary file of GGML quantized LLM model (i.e., Llama-2-7B-Chat)
- `/src`: Python codes of key components of LLM application, namely `llm.py`, `utils.py`, and `prompts.py`
- `/vectorstore`: FAISS vector store for documents
- `db_build.py`: Python script to ingest dataset and generate FAISS vector store
- `main.py`: Main Python script to launch the application and to pass user query via command line
- `pyproject.toml`: TOML file to specify which versions of the dependencies used (Poetry)
- `requirements.txt`: List of Python dependencies (and version)
___
## References
- https://github.com/marella/ctransformers
- https://huggingface.co/TheBloke
- https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGML
- https://python.langchain.com/en/latest/integrations/ctransformers.html
- https://python.langchain.com/en/latest/modules/models/llms/integrations/ctransformers.html
- https://python.langchain.com/docs/ecosystem/integrations/ctransformers
- https://ggml.ai
- https://github.com/rustformers/llm/blob/main/crates/ggml/README.md
- https://www.mdpi.com/2189676
|
llmeval/llmeval-2
|
https://github.com/llmeval/llmeval-2
|
中文大语言模型评测第二期
|
# LLMEVAL-2 中文大语言模型评测第二期
<div align=center><img src="llmeval-logo.png"/></div>
## 项目简介
LLMEVAL-1已经告一段落,有大量的公众用户参与了进来,为我们的评测提供了详实的数据,我们也在数据收集阶段结束后提供了详细的评测报告(https://github.com/llmeval/llmeval-1)。
然而,我们也发现一些问题。由于这期评测希望更多的公众参与,在题目设计上选择了绝大多数用户都可以进行评价的问题。这类问题并不能完全反映模型的知识覆盖率。
因此,我们推出了LLMEVAL-2专业领域评测。LLMEVAL-2评测以用户日常使用为主线,结合线上用户问题分布情况,重点考察不同专业本科生和研究生在日常学习和生活中希望借助大模型得到帮助的任务。
## 数据集
12个学科分别构造领域知识测试集,出题人基于外部数据库,对每个学科领域构造对应测试题集,题型为单项选择题与问答题。
其中,每个学科设计约25-30道客观题,约10-15道主观题,合计12*40=480题。
客观题问答内容示例:
```text
"question content": "请回答工业制取氯气的原理方程式"
"answer content": "工业上通常采用氯化氢气体溶于水的方法制备氯气。具体反应式为:HCl + NaOH → NaCl + H2O + Cl-,其中NaOH为碱溶液,H+和Cl-离子在溶液中发生反应生成氯气和水。"
```
主观题问答内容示例:
```
"question content": "我是一名大学生,请问我该如何学好有机化学?请为我给出建议。"
"answer content": "作为一名大学生学习有机化学,以下是一些建议可以帮助你更好地掌握这门学科: 1. 建立坚实的基础:在学习有机化学之前,你需要先打好化学基础知识,如物理、数学等。这样才能更好地理解有机化学中的各种概念和原理。 2. 实践操作:通过实验来加深对有机化学的理解,提高实验技能。可以选择一些简单的实验项目开始,逐渐提高自己的难度和复杂程度。 3. 阅读相关书籍和论文:阅读有机化学领域的经典著作和相关文献,了解最新的研究进展和技术发展趋势。 4. 参加课外课程和活动:参加学校组织的有机化学相关的课外活动,如讲座、研讨会等,与其他学生交流经验,扩展自己的知识面。 5. 寻求专业指导:向老师和同学请教问题,寻求帮助解决问题,及时反馈学习进度,并制定合理的学习计划和目标。"
```
## 评分标准
| 题目类型 | 评价维度 | 分值 | 评价标准描述 |
|:-----|:------|:---|:-----------|
| 客观题(如单选题或填空题) | 正确性 | 3分 | 回答内容是否正确 |
| | 解释正确性 | 2分 | 解释是否生成错误内容 |
| 主观题(如问答题) | 准确性 | 5分 | 回答内容是否有错 |
| | 信息量 | 3分 | 回答信息是否充足 |
| | 流畅性 | 3分 | 回答格式语法是否正确 |
| | 逻辑性 | 3分 | 回答逻辑是否严谨 |
## 排行榜
本次评测共评测了20个大语言模型,结果如下:
| | 客观题 | | 主观题 | | | | 排名 |总分 |
| --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 模型名称 | 答案准确性 | 解释准确性 | 流畅性 | 准确率 | 逻辑性 | 信息量 | | |
| GPT4 | 2.378 (2.395) | 1.670 (1.595) | 2.895 (2.989) | 4.260 (4.545) | 2.779 (2.903) | 2.691 (2.886) | 1(1) | 86.72 (89.54) |
| GPT3.5 | 2.160 (2.138) | 1.542 (1.503) | 2.861 (3.000) | 3.822 (4.295) | 2.694 (2.818) | 2.489 (2.750) | 2(2) | 80.71 (84.69) |
| 讯飞星火 | 2.114 (2.243) | 1.557 (1.632) | 2.815 (2.977) | 3.750 (4.193) | 2.560 (2.739) | 2.196 (2.716) | 3(5) | 78.05 (82.26) |
| Baichuan-13B-Chat | 2.003 (2.013) | 1.428 (1.441) | 2.847 (2.949) | 3.727 (4.102) | 2.631 (2.778) | 2.472 (2.756) | 4(6) | 77.51 (81.82) |
| minimax-abab5 | 1.922 (1.928) | 1.443 (1.493) | 2.878 (2.989) | 3.800 (3.977) | 2.656 (2.722) | 2.478 (2.699) | 5(7) | 77.47 (80.64) |
| newbing | 2.197 (2.211) | 1.583 (1.615) | 2.796 (2.989) | 3.608 (3.875) | 2.558 (2.773) | 2.061 (2.511) | 6(4) | 77.28 (82.63) |
| claude | 1.923 (2.066) | 1.463 (1.576) | 2.680 (2.977) | 3.597 (4.125) | 2.613 (2.801) | 2.414 (2.710) | 7(3) | 75.57 (83.49) |
| moss-mars | 1.961 (1.967) | 1.465 (1.470) | 2.737 (3.000) | 3.480 (3.807) | 2.508 (2.648) | 2.229 (2.534) | 8(9) | 74.41 (79.21) |
| 天工 | 1.933 (1.961) | 1.354 (1.500) | 2.774 (2.983) | 3.520 (3.807) | 2.576 (2.682) | 2.339 (2.523) | 9(8) | 74.36 (79.31) |
| ziya-llama-13b-v1 | 1.681 (1.592) | 1.306 (1.201) | 2.804 (3.000) | 3.207 (3.364) | 2.473 (2.585) | 2.120 (2.278) | 10(13) | 69.48 (70.92) |
| 通义千问 | 1.638 (1.618) | 1.275 (1.280) | 2.776 (3.000) | 3.098 (3.239) | 2.443 (2.511) | 2.126 (2.335) | 11(12) | 68.01 (71.02) |
| 360 | 1.720 (1.678) | 1.322 (1.352) | 2.700 (2.989) | 3.022 (3.352) | 2.394 (2.608) | 2.056 (2.313) | 12(10) | 67.97 (72.86) |
| 智工大模型 | 1.680 (2.072) | 1.297 (1.516) | 2.764 (2.983) | 3.067 (4.080) | 2.427 (2.744) | 1.916 (2.631) | 13(14) | 67.27 (70.53) |
| chatglm2-6b | 1.690 (1.671) | 1.345 (1.306) | 2.758 (2.920) | 2.934 (3.011) | 2.401 (2.386) | 1.956 (2.210) | 14(17) | 67.07 (69.06) |
| Vicuna-33B | 1.567 (1.684) | 1.277 (1.270) | 2.599 (2.943) | 3.033 (3.080) | 2.440 (2.398) | 2.143 (2.199) | 15(16) | 66.53 (69.16) |
| internlm-7b | 1.655 (1.658) | 1.355 (1.174) | 2.636 (2.847) | 3.091 (3.330) | 2.295 (2.392) | 1.938 (2.233) | 16(18) | 66.52 (69.00) |
| ChatGLM | 1.602 (1.638) | 1.239 (1.280) | 2.670 (2.926) | 3.022 (3.114) | 2.374 (2.443) | 2.084 (2.278) | 17(15) | 66.05 (69.48) |
| Tigerbot-180b | 1.604 (1.592) | 1.294 (1.220) | 2.573 (2.926) | 3.079 (3.557) | 2.489 (2.602) | 1.882 (2.352) | 18(11) | 65.90 (71.77) |
| AquilaChat-7b | 1.548 (1.553) | 1.239 (1.207) | 2.710 (2.932) | 2.945 (3.136) | 2.383 (2.443) | 1.918 (2.244) | 19(19) | 64.82 (68.19) |
| belle-7b-2m | 1.484 (1.461) | 1.224 (1.164) | 2.685 (2.824) | 2.695 (3.000) | 2.347 (2.335) | 1.880 (2.131) | 20(20) | 62.98 (65.27) |
*注:括号内数值为GPT-4自动测评的打分及排名。
总分计算公式:
$$
总分=\frac 1 n \sum_{i=1}^n score_i
$$
其中
$$
score_i=\frac{score_{ai}}{score_{fi}}\times 100
$$
$score_{ai}$ 为该模型在第 $i$ 个学科中的实际得分, $score_{fi}$ 为第 $i$ 个学科的总分.
## 完整报告
https://github.com/llmeval/llmeval-2/blob/master/LLMEVAL-2.pdf
|
Skocimis/opensms
|
https://github.com/Skocimis/opensms
|
Open-source solution to programmatically send and receive SMS using your own SIM cards
|
# TextFlow Open SMS
An open-source solution to send SMS from your own devices using REST API.
This option just requires a dedicated spare phone, with a sim card, and allows you to send as much SMS as you can, which could even be free if you opted in for some mobile carriers' unlimited SMS options, but be warned, some SMS carriers may limit your ability to send SMS this way, which could result even in your subscription being canceled.
You will also need a computer to host your SMS server, which can also be done on your local network. If you do not want to hassle with setting up your own server, we have a [solution at just a fraction of our normal SMS price](https://textflow.me/smsgateway).
If, besides sending SMS, you also need to be able to receive SMS, take a look at [this branch](https://github.com/Skocimis/opensms/tree/ReceiveSMSAddOn).
> **Warning**
> Our solution does not guarantee you that carrier will allow you to send bulk automated messages, since it is a part of your own agreement with your carrier. We recommend you you take a look at your carrier's usage policy before deciding to use this solution.
## How it works
The main idea in this solution is to use android phone's native ability to send SMS programmatically. We create the listener on the android phone, that listens for the Firebase notifications that we send from our server, and when we receive a notification, we send the SMS corresponding to the data passed in that notification. Since our SMS server can now send the SMS, it can open an endpoint that will let us send SMS from any of the phones that are connected to it.
Our SMS server also handles the logic of multiple senders, for each sim card you can create a sender for every country. We also support load-balancing, if there are multiple senders that send to the same country, the server will chose the one with the least SMS sent today. The sim-cards are identified by the names that you give them, so make sure they are unique. You can also mark senders as worldwide (if there are no senders for a specific country, server will use a worldwide sender) or turn their safety on (limit SMS rate to 10 SMS / min). If you want to change some parameters, you can take a look at the code, or contact us at [email protected] if you need some help.
## Step 1: Preparation
Before you get started, make sure to install all of these:
* Node.js and npm <br> Recommended version for Node.js is v14.18.1
* Android Studio<br>Once you install Android Studio, open it, it will run the setup wizard for installing the Android SDK, which we are going to need for the latter steps. Choose the standard installation option, or install Android SDK if you are using a custom option. Take note of the SDK installation directory, as you will need it. If you chose the standard option, it should be installed under `C:\Users\YourUsername\AppData\Local\Android\Sdk` on Windows. Create an environment variable called `ANDROID_HOME`, pointing to that directory. Make sure to replace _YourUsername_ with your actual Windows user account name.
After installing those dependencies, make sure to install expo-cli, and eas-cli, as we will also need them:
```bash
npm install -g expo-cli
npm install -g eas-cli
```
Also, you should enable USB debugging under development settings, for the device that you are going to test the application on. The procedure is different for every device, but is not complex. You should be able to do it if you google "DEVICE_NAME developer settings", and after enabling developer settings, look for the USB debugging option there.
## Step 2: Cloning our github repository
If you are familiar with Git, you can use it to clone our [github repository](https://github.com/Skocimis/opensms).
If not, you can just [download our code](https://github.com/Skocimis/opensms/archive/refs/heads/master.zip). Once you have download it, just unpack the folder anywhere on your computer, and rename it from `opensms-master` to `opensms`.
Either way, you will have a folder called `opensms`, and within it there will be two folders, `server` and `app`. Open your terminal (or cmd in Windows) in each of these two folders and run the following command:
```bash
npm install
```
This will install all the required dependencies for our project.
## Step 3: Updating the constants in code
Determine the address that you would like to host your server on. Also, create a password that will be used to authenticate between the mobile app that you run on your phone and your server. It can be any string, but make it unique, so the others will not be able to use your server to send SMS for them.
In this example, I will be running the server locally, on address `http://192.168.1.40`, and my password will be `unique-password-49`.
Once you have determined your server address and password, you will need to make the following changes to the code:
1. In `opensms/app/App.js`, replace SERVER_ADDRESS and YOUR_SECRET with your address and password, if running on local network use address like this: `http://192.168.1.40`
2. In `opensms/server/app.js`, do the same thing for YOUR_SECRET, in line 4
3. In `opensms/app/android/app/src/main/java/com/textflow/smssender/MyFirebaseMessagingService.java`, replace YOUR_SECRET in line 37 with your password
## Step 4: Registering a Firebase account
The changes that you need to make in the code are now complete, and now it is time to set up our Firebase app, which will allow us to send notifications to our connected phones, to let them know when to send SMS.
Head out to [Firebase console](https://console.firebase.google.com/), and click on Create a project. Give your project a name and accept their terms and conditions. The Google analytics part is optional, so you can leave it unchecked.
Once you have created your project, the following page will pop up:
Click on the android icon. It will take you to the form. The only required field is the _Android package name_, put `com.textflow.smssender` in there, click the Register app button. Download the `google-services.json` file, and put it in `opensms/app/android/app` folder.
Now finish the app creation by clicking the button Next two times, and then go to _Continue to console_.
Now go to the project settings (you can see it when you click the gear in the upper left), and under the Service accounts tab, click on _Generate new private key_. It will download a file. Move that file to `opensms/server`, and rename it to `admin.json`.
## Step 5: Testing the app
After you have done the steps above, it is the time to test if all is working.
Firstly, you need to open the opensms/server folder, and under it, run the command
```bash
node app
```
That will start your own server, that will store the data about your connected sender phones, and is able to send Firebase notifications to them to send SMS. It should not have any output or throw any errors.
Secondly, you have to connect your android device to your computer (the device should have enabled USB debugging in Developer options, and when you connect it, you should choose that you want to transfer files). When you have done that, navigate to the folder `opensms/app`, and run the following command:
```bash
npx expo run:android
```
Your android phone that you use for testing may prompt you with something, accept it. This process may take several minutes, depending on the hardware capabilities of your devices.
If everything goes well, you should be able to see the screen that looks like this
There, you can create senders for each SIM card. When adding a sender, just choose where it would send SMS to. If you wanted to send to multiple countries from one SIM card, just create multiple senders for it.
Finally, you can test sending SMS. To send an SMS, send the following request to your server:
<details>
<summary><code>POST</code> <code><b>SERVER_ADDRESS/send-sms</b></code> <code>(Use your own SMS server for sending a message)</code></summary>
##### Header
> | name | type | data type | description |
> |--------------|-----------|-------------------------|-----------------------------------------------------------------------|
> | Content-Type | required | String | Should be `application/json` |
##### Body
> | name | type | data type | description |
> |--------------|-----------|-------------------------|-----------------------------------------------------------------------|
> | secret | required | String | The password that you have created in step 3 |
> | phone_number | required | String | Recipient phone number, with a country prefix. E.g. `+11234567890` |
> | text | required | String | Message body |
</details>
If everything is working well, the message should be sent, and you will be able to see it in your SMS app.
You can find the application usage instructions [here](https://docs.textflow.me/using-sms-senders).
## Step 6: Building the app
If you want to deploy your app to your device, without being connected to it, you will need to create an APK file for installing the app on the device. This can be done by building the app, which will in turn create the installable APK file.
To do that, run the following command in the `opensms/app` folder:
```bash
npx eas build -p android --profile production
```
You will be prompted to log in to your Expo account. [Create an account](https://expo.dev/signup), and use the credentials that you have created to log in. After that, answer to all questions yes (Y). Now you have to wait for the build to complete on the Expo remote servers, and when it is done, you will get a link with the APK file that you can download and install on your android device.
Also, the sending may work even if the screen is off and app is in the background on closed on some devices, but that behavior is chaotic and we recommend you to keep the phone screen on at all time, focused on the app and charging, as it may save you some possible inconvenience. Do not run it in the background without prior testing.
## Getting help
If you need help or have any suggestions or bugs, don't hesitate to reach out to us at `[email protected]`.
|
michael-yuji/xc
|
https://github.com/michael-yuji/xc
|
FreeBSD container engine
|
# `xc`
See the work in progress documentation [here](https://hackmd.io/7BIT_khIRQyPAe4EdiigHg)
|
Em1tSan/NeuroGPT
|
https://github.com/Em1tSan/NeuroGPT
|
Бесплатный ChatGPT 3.5 / ChatGPT 4
|
# [NeuroGPT](https://t.me/neurogen_news) - Бесплатный доступ к ChatGPT 3.5 / 4
Данный проект позволяет пользоваться ChatGPT 3.5, 4 без VPN и регистрации аккаунта, работающий через reverse engineering API, на базе проекта gpt4free
Ремарка: Так как проект работает не через официальный api, а через доступ, полученный путем обратной инженерии, а кроме того, разрабатывается на чистом энтузиазме, то страдает стабильность работы. Различные модели периодически могут отключаться, а API провайдеры падать. Имейте это в виду. Если для вашей работы нужная высокая стабильность, то лучше обойти данный проект стороной.
## Поддерживаются модели:
- ChatGPT-3.5-Turbo
- ChatGPT-3.5-Turbo-16K
- GPT-4 (Нужен ключ ChimeraAPI)
- GPT-4-32k (Нужен ключ ChattyAPI)
## Возможности программы:
- Веб поиск
- Джейлбрейки для расширения возможностей и снятия цензуры
- Контекст беседы
- Режим endpoint для работы с API
- Тонкая настройка модели (ChatGPT)
- Сохранение и загрузка истории диалогов
## Портативная версия
Портативную версию, не требующую установку зависимостей и запускающуюся в 1 клик можно [скачать тут](https://github.com/Em1tSan/NeuroGPT/releases).
## Поддержка и вопросы
Если у вас возникли какие то вопросы или вы в принципе хотите обсудить проект, то это можно сделать в моем телеграм канале: https://t.me/neurogen_news
Поддержать автора, подкинув на кофе, можно тут: [DonationAlerts](https://www.donationalerts.com/r/em1t)
# ChimeraAPI - как пользоваться:
Это проект, предоставляющий бесплатный доступ через reverse-API к различным моделям ChatGPT и Claude.
На использование ChatGPT есть лимиты, которые, впрочем, достаточны для обычного пользователя:
GPT-4 8K - 10 запросов в минуту / 1000 в день
GPT-3.5-TURBO - 20 / 2000
GPT-3.5-TURBO 16K - 20/2000
Чтобы работать с ним, вам надо получить их API ключ.
1) Вступаем в [Discord проекта](https://discord.gg/chimeragpt), проходим Верификацию (следуйтие всплывающим инструкциям), затем идем в канал #bot и отправляем команду /key get
2) Полученный ключ записываем в config.json файл, который лежит в той же папке, где и файл webui.py
3) Меняем строку openai_api_key="ваш_api_код" на ваш код
4) Пользуемся ChimeraAPI моделями
---
# Способы установки, обновления и запуска
Данный проект поддерживает исколючительно версию языка Python не выше 3.10. То есть, с Python 3.11 и выше он **НЕ СОВМЕСТИМ**. Кроме того, работа на Python 3.9, 3.8 не гарантируется.
# Windows
В данной инструкции рассматриваются только х64 битные версии Windows 10 и 11.
### Прежде чем начать
Надо предварительно установить зависимости.
#### 1. Установите Git For Windows
* [Скачайте](https://git-scm.com/download/win) и начните установку git.
* 
* Если вы не знаете что отмечать, то оставьте настройки по умолчанию
* 
* В окне прописывания в PATH - лучше выбрать среднюю опцию, чтобы команды гита можно было вызывать из любого терминала.
* 
#### 2. Установите Visual Studio Community
* [Скачайте](https://visualstudio.microsoft.com/ru/downloads/) и установите Visual Studio Community.
* Ничего сложного, подойдут предлагаемые настройки по умолчанию.
#### 2. Установите Python 3.10.x Windows
* [Скачайте](https://www.python.org/ftp/python/3.10.11/python-3.10.11-amd64.exe) и начните установку Python [3.10.11](https://www.python.org/downloads/release/python-31011/).
* 
* Обязательно добавьте в переменные окружения (в PATH).
* 
### Установка
* Скачайте репозиторий, для этого откройте Командную строку (Терминал) в папке, где хотите разместить freegpt-webui-ru и напишите команду:
`git clone https://github.com/Em1tSan/NeuroGPT.git`
* Откройте папку `NeuroGPT` и запустите файл `install.bat`. Он создаст виртуальную среду и запустит установку зависимостей.
### Обновление
* Остановите запущеный процесс, если таковой есть.
* Откройте папку `NeuroGPT` и запустите файл `update.bat`.
* Для запуска используйте `start_windows.bat`.
### Запуск Чата
* Откройте папку `NeuroGPT` и запустите файл `start.bat`.
* Перед запуском выполнится обновление.
* Если хотите его отключить - откройте `start_windows.bat` и удалите строку с `update`.
* Перейдите в браузере по адресу: `http://127.0.0.1:1338/`
### Запуск Endpoint'а
* Откройте папку `NeuroGPT` и запустите файл `start_endpoint.bat`.
* Перед запуском выполнится обновление.
* Если хотите его отключить - откройте `start_endpoint.bat` и удалите строку с `update`.
* Endpoint будет доступен по адресу: `http://127.0.0.1:1337/`
# Linux
wip
### Обновление
# MacOS [нестабильно]
## Ручная установка:
`wip
|
TechTitan0624/React-socialmedia-project
|
https://github.com/TechTitan0624/React-socialmedia-project
| null |
# mern-social-media
Full stack Project
|
duckdblabs/duckdb_iceberg
|
https://github.com/duckdblabs/duckdb_iceberg
| null |
> **Disclaimer:** This extension is currently in an experimental state. Feel free to try it out, but be aware that minimal testing and
benchmarking was done.
> Warning: This extension currently builds with the master branch of DuckDB. A PR is being worked on. When the PR is merged,
this extension will be updated and usable from (nightly) DuckDB releases.
# DuckDB extension for Apache Iceberg
This repository contains a DuckDB extension that adds support for [Apache Iceberg](https://iceberg.apache.org/). In its current state, the extension offers some basics features that allow listing snapshots and reading specific snapshots
of an iceberg tables.
# Dependencies
## building
This extension has several dependencies. Currently, the main way to install them is through vcpkg. To install vcpkg,
check out the docs [here](https://vcpkg.io/en/getting-started.html). Note that this extension contains a custom vcpkg port
that overrides the existing 'avro-cpp' port of vcpkg. The reason for this is that the other versions of avro-cpp have
some issue that seems to cause issues with the avro files produced by the spark iceberg extension.
## test data generation
To generate test data, the script in 'scripts/test_data_generator' is used to have spark generate some test data. This is
based on pyspark 3.4, which you can install through pip.
# Building the extension
To build the extension with vcpkg, you can build this extension using:
```shell
VCPKG_TOOLCHAIN_PATH='<path_to_your_vcpkg_toolchain>' make
```
This will build both the separate loadable extension and a duckdb binary with the extension pre-loaded:
```shell
./build/release/duckdb
./build/release/extension/iceberg/iceberg.duckdb_extension
```
# Running iceberg queries
The easiest way is to start the duckdb binary produced by the build step: `./build/release/duckdb`. Then for example:
```SQL
> SELECT count(*) FROM ICEBERG_SCAN('data/iceberg/lineitem_iceberg', ALLOW_MOVED_PATHS=TRUE);
51793
```
Note that for testing, the `ALLOW_MOVED_PATHS` option is available. This option will ensure some path resolution is performed. This
path resolution allows scanning iceberg tables that are moved, which is used during testing.
```SQL
> SELECT * FROM ICEBERG_SNAPSHOTS('data/iceberg/lineitem_iceberg', ALLOW_MOVED_PATHS=TRUE);
1 3776207205136740581 2023-02-15 15:07:54.504 0 lineitem_iceberg/metadata/snap-3776207205136740581-1-cf3d0be5-cf70-453d-ad8f-48fdc412e608.avro
2 7635660646343998149 2023-02-15 15:08:14.73 0 lineitem_iceberg/metadata/snap-7635660646343998149-1-10eaca8a-1e1c-421e-ad6d-b232e5ee23d3.avro
```
For more examples check the tests in the `test` directory
# Running tests
## Generating test data
To generate the test data, run:
```shell
make data
```
Note that the script requires python3, pyspark and duckdb-python to be installed. Assuming python3 is already installed,
running `python3 -m pip install duckdb pyspark` should do the trick.
## Running unittests
```shell
make test
```
## Running the local S3 test server
Running the S3 test cases requires the minio test server to be running and populated with `scripts/upload_iceberg_to_s3_test_server.sh`.
Note that this requires to have run `make data` before and also to have the aws cli and docker compose installed.
# Acknowledgements
This extension was initially developed as part of a customer project for [RelationalAI](https://relational.ai/),
who have agreed to open source the extension. We would like to thank RelationalAI for their support
and their commitment to open source enabling us to share this extension with the community.
|
FinvDialect/2023_finvcup_baseline
|
https://github.com/FinvDialect/2023_finvcup_baseline
| null |
# 第八届信也科技杯baseline
数智创新,声至未来
Deep in Dialects, for Future Wave.
这是第八届信也科技的baseline。
本届大赛以“智能语音质检,提升用户体验”为背景,探索利用AI技术识别和还原语音数据中的方言信息,特别是不同方言之间的距离特征的问题。这一问题有助于更好地理解汉语语音及其方言、口音特征,以及将相关技术从理论到实际应用的实现,以进一步支持对用户的更好服务。
## Environments
Implementing environment:
- python=3.6
- torch==1.9.0
- torchaudio==0.9.0
- pydub==0.21.0
- numba==0.48.0
- numpy==1.15.4
- pandas==0.23.3
- scipy==1.2.1
- scikit-learn==0.19.1
- tqdm
- SoundFile==0.12.1
- GPU: Tesla V100 32G
## Dataset
./data 目录下有所需的test_pair数据文件。
test_pair 包含提交所需的100万个数据对,需要选手提交对应的一百万个方言距离,并严格按照test_pair内的样本顺序
音频数据请从共享地址下载:
请将下载好的数据文件 train.zip 和 test.zip 置于工程根目录下,执行
```bash
unzip "*.zip" -d ./data/
python create_data_index.py
```
解压文件并生成目录索引。文件索引选手可根据个人需求自行生成。
## Training
```bash
python train.py --loss aamsoftmax --max_epoch 80 --device cuda:0 --save_path ./exps/
```
```bash
python train.py --loss StandardSimilarityLoss --max_epoch 80 --device cuda:0 --save_path ./exps_sim/
```
```bash
python train.py --loss PairDistanceLoss --max_epoch 80 --device cuda:0 --save_path ./exps_pairdist/
```
## Inference
```bash
python inference.py --model_path exps/model/model_0001.model --test_path data/test --device cuda:0
```
会在根目录下生成提交所需的submit.csv文件
## Acknowledge
- We borrowed a lot of code from [ECAPA-TDNN](https://github.com/TaoRuijie/ECAPA-TDNN) for modeling
## Authors
以下作者对本项目有贡献(以姓氏排名):
- Chen, Yifei
- Gao, Feng
- Kou, Kai
- Ni, Boyi
- Wang, Shaoming
- Zhang, Xuan
|
xlang-ai/llm-tool-use
|
https://github.com/xlang-ai/llm-tool-use
|
Paper collection on LLM tool use and code generation covered in the ACL tutorial on complex reasoning
|
# LLM Tool Use Papers
  
## Introduction
### Group
## Papers
1. **CLIPort: What and Where Pathways for Robotic Manipulation.** CoRL 2021
*Mohit Shridhar, Lucas Manuelli, Dieter Fox* [[pdf](https://arxiv.org/abs/2109.12098)], 2021.9
2. **Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents.** ICML 2022
*Wenlong Huang, Pieter Abbeel, Deepak Pathak, Igor Mordatch* [[pdf](https://arxiv.org/abs/2201.07207)], 2022.1
3. **Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language.** ICLR 2023
*Andy Zeng, Maria Attarian, Brian Ichter, Krzysztof Choromanski, Adrian Wong, Stefan Welker, Federico Tombari, Aveek Purohit, Michael Ryoo, Vikas Sindhwani, Johnny Lee, Vincent Vanhoucke, Pete Florence* [[pdf](https://arxiv.org/abs/2204.00598)], 2022.4
4. **Do As I Can, Not As I Say: Grounding Language in Robotic Affordances.** CoRL 2022
*Michael Ahn, Anthony Brohan, Noah Brown, Yevgen Chebotar, Omar Cortes, Byron David, Chelsea Finn, Chuyuan Fu, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Daniel Ho, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Eric Jang, Rosario Jauregui Ruano, Kyle Jeffrey, Sally Jesmonth, Nikhil J Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Kuang-Huei Lee, Sergey Levine, Yao Lu, Linda Luu, Carolina Parada, Peter Pastor, Jornell Quiambao, Kanishka Rao, Jarek Rettinghouse, Diego Reyes, Pierre Sermanet, Nicolas Sievers, Clayton Tan, Alexander Toshev, Vincent Vanhoucke, Fei Xia, Ted Xiao, Peng Xu, Sichun Xu, Mengyuan Yan, Andy Zeng* [[pdf](https://arxiv.org/abs/2204.01691)], 2022.4
5. **TALM: Tool Augmented Language Models.** Arxiv
*Aaron Parisi, Yao Zhao, Noah Fiedel* [[pdf](https://arxiv.org/abs/2205.12255)], 2022.5
6. **Inner Monologue: Embodied Reasoning through Planning with Language Models.** CoRL 2022
*Wenlong Huang, Fei Xia, Ted Xiao, Harris Chan, Jacky Liang, Pete Florence, Andy Zeng, Jonathan Tompson, Igor Mordatch, Yevgen Chebotar, Pierre Sermanet, Noah Brown, Tomas Jackson, Linda Luu, Sergey Levine, Karol Hausman, Brian Ichter* [[pdf](https://arxiv.org/abs/2207.05608)], 2022.7
7. **JARVIS: A Neuro-Symbolic Commonsense Reasoning Framework for Conversational Embodied Agents.** SoCal NLP 2022
*Kaizhi Zheng, Kaiwen Zhou, Jing Gu, Yue Fan, Jialu Wang, Zonglin Di, Xuehai He, Xin Eric Wang* [[pdf](https://arxiv.org/abs/2208.13266)], 2022.8
8. **ProgPrompt: Generating Situated Robot Task Plans using Large Language Models.** ICRA 2023
*Ishika Singh, Valts Blukis, Arsalan Mousavian, Ankit Goyal, Danfei Xu, Jonathan Tremblay, Dieter Fox, Jesse Thomason, Animesh Garg* [[pdf](https://arxiv.org/abs/2209.11302)], 2022.9
9. **Code as Policies: Language Model Programs for Embodied Control.** ICRA 2023
*Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, Andy Zeng* [[pdf](https://arxiv.org/abs/2209.07753)], 2022.9
10. **Binding Language Models in Symbolic Languages.** ICLR 2023
*Zhoujun Cheng, Tianbao Xie, Peng Shi, Chengzu Li, Rahul Nadkarni, Yushi Hu, Caiming Xiong, Dragomir Radev, Mari Ostendorf, Luke Zettlemoyer, Noah A. Smith, Tao Yu* [[pdf](https://arxiv.org/abs/2210.02875)], 2022.10
11. **VIMA: General Robot Manipulation with Multimodal Prompts.** ICML 2023
*Yunfan Jiang, Agrim Gupta, Zichen Zhang, Guanzhi Wang, Yongqiang Dou, Yanjun Chen, Li Fei-Fei, Anima Anandkumar, Yuke Zhu, Linxi Fan* [[pdf](https://arxiv.org/abs/2210.03094)], 2022.10
12. **Synergizing Reasoning and Acting in Language Models.** ICLR 2023
*Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, Yuan Cao* [[pdf](https://arxiv.org/abs/2210.03629)], 2022.10
13. **Mind's Eye: Grounded Language Model Reasoning through Simulation.** ICLR 2023
*Ruibo Liu, Jason Wei, Shixiang Shane Gu, Te-Yen Wu, Soroush Vosoughi, Claire Cui, Denny Zhou, Andrew M. Dai* [[pdf](https://arxiv.org/abs/2210.05359)], 2022.10
14. **Code4Struct: Code Generation for Few-Shot Event Structure Prediction.** ACL 2023
*Xingyao Wang, Sha Li, Heng Ji* [[pdf](https://arxiv.org/abs/2210.12810)], 2022.10
15. **PAL: Program-aided Language Models.** ICML 2023
*Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, Graham Neubig* [[pdf](https://arxiv.org/abs/2211.10435)], 2022.11
16. **Visual Programming: Compositional visual reasoning without training.** CVPR 2023
*Tanmay Gupta, Aniruddha Kembhavi* [[pdf](https://arxiv.org/abs/2211.11559)], 2022.11
17. **Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks.** Arxiv
*Wenhu Chen, Xueguang Ma, Xinyi Wang, William W. Cohen* [[pdf](https://arxiv.org/abs/2211.12588)], 2022.11
18. **Planning with Large Language Models via Corrective Re-prompting.** Neurips 2023 workshop
*Shreyas Sundara Raman, Vanya Cohen, Eric Rosen, Ifrah Idrees, David Paulius, Stefanie Tellex* [[pdf](https://arxiv.org/abs/2211.09935)], 2022.11
19. **LLM-Planner: Few-Shot Grounded Planning for Embodied Agents with Large Language Models.** Arxiv
*Chan Hee Song, Jiaman Wu, Clayton Washington, Brian M. Sadler, Wei-Lun Chao, Yu Su* [[pdf](https://arxiv.org/abs/2212.04088)], 2022.12
20. **RT-1: Robotics Transformer for Real-World Control at Scale.** Arxiv
*Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, Alex Herzog, Jasmine Hsu, Julian Ibarz, Brian Ichter, Alex Irpan, Tomas Jackson, Sally Jesmonth, Nikhil J Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Isabel Leal, Kuang-Huei Lee, Sergey Levine, Yao Lu, Utsav Malla, Deeksha Manjunath, Igor Mordatch, Ofir Nachum, Carolina Parada, Jodilyn Peralta, Emily Perez, Karl Pertsch, Jornell Quiambao, Kanishka Rao, Michael Ryoo, Grecia Salazar, Pannag Sanketi, Kevin Sayed, Jaspiar Singh, Sumedh Sontakke, Austin Stone, Clayton Tan, Huong Tran, Vincent Vanhoucke, Steve Vega, Quan Vuong, Fei Xia, Ted Xiao, Peng Xu, Sichun Xu, Tianhe Yu, Brianna Zitkovich* [[pdf](https://arxiv.org/abs/2212.06817)], 2022.12
21. **Don't Generate, Discriminate: A Proposal for Grounding Language Models to Real-World Environments.** ACL 2023
*Yu Gu, Xiang Deng, Yu Su* [[pdf](https://arxiv.org/abs/2212.09736)], 2022.12
22. **Do Embodied Agents Dream of Pixelated Sheep: Embodied Decision Making using Language Guided World Modelling** ICML 2023
*Kolby Nottingham, Prithviraj Ammanabrolu, Alane Suhr, Yejin Choi, Hannaneh Hajishirzi, Sameer Singh, Roy Fox* [[pdf](https://arxiv.org/abs/2301.12050)], 2023.1
23. **Large language models are versatile decomposers: Decompose evidence and questions for table-based reasoning.** SIGIR 2023
*Yunhu Ye, Binyuan Hui, Min Yang, Binhua Li, Fei Huang, Yongbin Li* [[pdf](https://arxiv.org/abs/2301.13808)], 2023.1
24. **Augmented Language Models: a Survey.** Arxiv
*Grégoire Mialon, Roberto Dessì, Maria Lomeli, Christoforos Nalmpantis, Ram Pasunuru, Roberta Raileanu, Baptiste Rozière, Timo Schick, Jane Dwivedi-Yu, Asli Celikyilmaz, Edouard Grave, Yann LeCun, Thomas Scialom* [[pdf](https://arxiv.org/abs/2302.07842)], 2023.2
25. **Collaborating with language models for embodied reasoning.** NeurIPS 2022 LaReL workshop
*Ishita Dasgupta, Christine Kaeser-Chen, Kenneth Marino, Arun Ahuja, Sheila Babayan, Felix Hill, Rob Fergus* [[pdf](https://arxiv.org/abs/2302.00763)], 2023.2
26. **Describe, Explain, Plan and Select: Interactive Planning with Large Language Models Enables Open-World Multi-Task Agents.** Arxiv
*Zihao Wang, Shaofei Cai, Anji Liu, Xiaojian Ma, Yitao Liang* [[pdf](https://arxiv.org/abs/2302.01560)], 2023.2
27. **Toolformer: Language Models Can Teach Themselves to Use Tools.** Arxiv
*Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, Thomas Scialom* [[pdf](https://arxiv.org/abs/2302.04761)], 2023.2
28. **Grounded Decoding: Guiding Text Generation with Grounded Models for Robot Control.** Arxiv
*Wenlong Huang, Fei Xia, Dhruv Shah, Danny Driess, Andy Zeng, Yao Lu, Pete Florence, Igor Mordatch, Sergey Levine, Karol Hausman, Brian Ichter* [[pdf](https://arxiv.org/abs/2303.00855)], 2023.3
29. **PaLM-E: An Embodied Multimodal Language Model.** Arxiv
*Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, Yevgen Chebotar, Pierre Sermanet, Daniel Duckworth, Sergey Levine, Vincent Vanhoucke, Karol Hausman, Marc Toussaint, Klaus Greff, Andy Zeng, Igor Mordatch, Pete Florence* [[pdf](https://arxiv.org/abs/2303.03378)], 2023.3
30. **Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models.** Arxiv
*Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, Nan Duan* [[pdf](https://arxiv.org/abs/2303.04671)], 2023.3
31. **ViperGPT: Visual Inference via Python Execution for Reasoning.** Arxiv
*Dídac Surís, Sachit Menon, Carl Vondrick* [[pdf](https://arxiv.org/abs/2303.08128)], 2023.3
32. **ART: Automatic multi-step reasoning and tool-use for large language models.** Arxiv
*Bhargavi Paranjape, Scott Lundberg, Sameer Singh, Hannaneh Hajishirzi, Luke Zettlemoyer, Marco Tulio Ribeiro* [[pdf](http://arxiv.org/abs/2303.09014)], 2023.3
33. **Text2Motion: From Natural Language Instructions to Feasible Plans** ICRA 2023 PT4R Workshop
*Kevin Lin, Christopher Agia, Toki Migimatsu, Marco Pavone, Jeannette Bohg* [[pdf](https://arxiv.org/abs/2303.12153)], 2023.3
34. **TaskMatrix.AI: Completing Tasks by Connecting Foundation Models with Millions of APIs.** Arxiv
*Yaobo Liang, Chenfei Wu, Ting Song, Wenshan Wu, Yan Xia, Yu Liu, Yang Ou, Shuai Lu, Lei Ji, Shaoguang Mao, Yun Wang, Linjun Shou, Ming Gong, Nan Duan* [[pdf](https://arxiv.org/abs/2303.16434)], 2023.3
35. **HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in HuggingFace.** Arxiv
*Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, Yueting Zhuang* [[pdf](https://arxiv.org/abs/2303.17580)], 2023.3
36. **OpenAGI: When LLM Meets Domain Experts.** Arxiv
*Yingqiang Ge, Wenyue Hua, Kai Mei, Jianchao Ji, Juntao Tan, Shuyuan Xu, Zelong Li, Yongfeng Zhang* [[pdf](https://arxiv.org/abs/2304.04370)], 2023.4
37. **API-Bank: A Benchmark for Tool-Augmented LLMs.** Arxiv
*Minghao Li, Feifan Song, Bowen Yu, Haiyang Yu, Zhoujun Li, Fei Huang, Yongbin Li* [[pdf](https://arxiv.org/abs/2304.08244)], 2023.4
38. **Tool Learning with Foundation Models.** Arxiv
*Yujia Qin, Shengding Hu, Yankai Lin, Weize Chen, Ning Ding, Ganqu Cui, Zheni Zeng, Yufei Huang, Chaojun Xiao, Chi Han, Yi Ren Fung, Yusheng Su, Huadong Wang, Cheng Qian, Runchu Tian, Kunlun Zhu, Shihao Liang, Xingyu Shen, Bokai Xu, Zhen Zhang, Yining Ye, Bowen Li, Ziwei Tang, Jing Yi, Yuzhang Zhu, Zhenning Dai, Lan Yan, Xin Cong, Yaxi Lu, Weilin Zhao, Yuxiang Huang, Junxi Yan, Xu Han, Xian Sun, Dahai Li, Jason Phang, Cheng Yang, Tongshuang Wu, Heng Ji, Zhiyuan Liu, Maosong Sun* [[pdf](https://arxiv.org/abs/2304.08354)], 2023.4
39. **GeneGPT: Augmenting Large Language Models with Domain Tools for Improved Access to Biomedical Information.** Arxiv
*Qiao Jin, Yifan Yang, Qingyu Chen, Zhiyong Lu* [[pdf](http://arxiv.org/abs/2304.09667)], 2023.4
40. **Chameleon: Plug-and-Play Compositional Reasoning with Large Language Models.** Arxiv
*Pan Lu, Baolin Peng, Hao Cheng, Michel Galley, Kai-Wei Chang, Ying Nian Wu, Song-Chun Zhu, Jianfeng Gao* [[pdf](https://arxiv.org/abs/2304.09842)], 2023.4
41. **LLM+P: Empowering Large Language Models with Optimal Planning Proficiency.** Arxiv
*Bo Liu, Yuqian Jiang, Xiaohan Zhang, Qiang Liu, Shiqi Zhang, Joydeep Biswas, Peter Stone* [[pdf](https://arxiv.org/abs/2304.11477)], 2023.4
42. **Programmatically Grounded, Compositionally Generalizable Robotic Manipulation** ICLR 2023
*Renhao Wang, Jiayuan Mao, Joy Hsu, Hang Zhao, Jiajun Wu, Yang Gao* [[pdf](https://arxiv.org/abs/2304.13826)], 2023.4
43. **Search-in-the-Chain: Towards Accurate, Credible and Traceable Large Language Models for Knowledge-intensive Tasks.** Arxiv
*Shicheng Xu, Liang Pang, Huawei Shen, Xueqi Cheng, Tat-Seng Chua* [[pdf](https://arxiv.org/abs/2304.14732)], 2023.4
44. **Can LLM Already Serve as A Database Interface? A BIg Bench for Large-Scale Database Grounded Text-to-SQLs.** Arxiv
*Jinyang Li, Binyuan Hui, Ge Qu, Binhua Li, Jiaxi Yang, Bowen Li, Bailin Wang, Bowen Qin, Rongyu Cao, Ruiying Geng, Nan Huo, Xuanhe Zhou, Chenhao Ma, Guoliang Li, Kevin C.C. Chang, Fei Huang, Reynold Cheng, Yongbin Li* [[pdf](https://arxiv.org/abs/2305.03111)], 2023.5
45. **ToolCoder: Teach Code Generation Models to use API search tools.** Arxiv
*Kechi Zhang, Ge Li, Jia Li, Zhuo Li, Zhi Jin* [[pdf](https://arxiv.org/abs/2305.04032)], 2023.5
46. **TidyBot: Personalized Robot Assistance with Large Language Models** IROS 2023
*Jimmy Wu, Rika Antonova, Adam Kan, Marion Lepert, Andy Zeng, Shuran Song, Jeannette Bohg, Szymon Rusinkiewicz, Thomas Funkhouser* [[pdf](https://arxiv.org/abs/2305.05658)], 2023.5
47. **Small models are valuable plug-ins for large language models.** Arxiv
*Canwen Xu, Yichong Xu, Shuohang Wang, Yang Liu, Chenguang Zhu, Julian McAuley* [[pdf](https://arxiv.org/abs/2305.08848)], 2023.5
48. **Multimodal Web Navigation with Instruction-Finetuned Foundation Models.** ICLR 2023 Workshop ME-FoMo
*Hiroki Furuta, Ofir Nachum, Kuang-Huei Lee, Yutaka Matsuo, Shixiang Shane Gu, Izzeddin Gur* [[pdf](https://arxiv.org/abs/2305.11854)], 2023.5
49. **ToolkenGPT: Augmenting Frozen Language Models with Massive Tools via Tool Embeddings.** Arxiv
*Shibo Hao, Tianyang Liu, Zhen Wang, Zhiting Hu* [[pdf](https://arxiv.org/abs/2305.11554)], 2023.5
50. **CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing.** Arxiv
*Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Nan Duan, Weizhu Chen* [[pdf](https://arxiv.org/abs/2305.11738)], 2023.5
51. **Making Language Models Better Tool Learners with Execution Feedback.** Arxiv
*Shuofei Qiao, Honghao Gui, Huajun Chen, Ningyu Zhang* [[pdf](https://arxiv.org/abs/2305.13068)], 2023.5
52. **Hierarchical Prompting Assists Large Language Model on Web Navigation.** ACL 2023 NLRSE workshop
*Abishek Sridhar, Robert Lo, Frank F. Xu, Hao Zhu, Shuyan Zhou* [[pdf](https://arxiv.org/abs/2305.14257)], 2023.5
53. **PEARL: Prompting Large Language Models to Plan and Execute Actions Over Long Documents.** Arxiv
*Simeng Sun, Yang Liu, Shuohang Wang, Chenguang Zhu, Mohit Iyyer* [[pdf](https://arxiv.org/abs/2305.14564)], 2023.5
54. **ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models.** Arxiv
*Binfeng Xu, Zhiyuan Peng, Bowen Lei, Subhabrata Mukherjee, Yuchen Liu, Dongkuan Xu* [[pdf](https://arxiv.org/abs/2305.18323)], 2023.5
55. **Gorilla: Large Language Model Connected with Massive APIs.** Arxiv
*Shishir G. Patil, Tianjun Zhang, Xin Wang, Joseph E. Gonzalez* [[pdf](https://arxiv.org/abs/2305.15334)], 2023.5
56. **SPRING: GPT-4 Out-performs RL Algorithms by Studying Papers and Reasoning.** Arxiv
*Yue Wu, Shrimai Prabhumoye, So Yeon Min, Yonatan Bisk, Ruslan Salakhutdinov, Amos Azaria, Tom Mitchell, Yuanzhi Li* [[pdf](https://arxiv.org/abs/2305.15486)], 2023.5
57. **Leveraging Pre-trained Large Language Models to Construct and Utilize World Models for Model-based Task Planning.** Arxiv
*Lin Guan, Karthik Valmeekam, Sarath Sreedharan, Subbarao Kambhampati* [[pdf](https://arxiv.org/abs/2305.14909)], 2023.5
58. **EmbodiedGPT: Vision-Language Pre-Training via Embodied Chain of Thought** Arxiv
*Yao Mu, Qinglong Zhang, Mengkang Hu, Wenhai Wang, Mingyu Ding, Jun Jin, Bin Wang, Jifeng Dai, Yu Qiao, Ping Luo* [[pdf](https://arxiv.org/abs/2305.15021)], 2023.5
59. **On the Tool Manipulation Capability of Open-source Large Language Models.** Arxiv
*Qiantong Xu, Fenglu Hong, Bo Li, Changran Hu, Zhengyu Chen, Jian Zhang* [[pdf](https://arxiv.org/abs/2305.16504)], 2023.5
60. **Voyager: An Open-Ended Embodied Agent with Large Language Models.** Arxiv
*Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, Anima Anandkumar* [[pdf](https://arxiv.org/abs/2305.16291)], 2023.5
61. **Mindstorms in Natural Language-Based Societies of Mind** Arxiv
*Mingchen Zhuge, Haozhe Liu, Francesco Faccio, Dylan R. Ashley, Róbert Csordás, Anand Gopalakrishnan, Abdullah Hamdi, Hasan Abed Al Kader Hammoud, Vincent Herrmann, Kazuki Irie, Louis Kirsch, Bing Li, Guohao Li, Shuming Liu, Jinjie Mai, Piotr Piękos, Aditya Ramesh, Imanol Schlag, Weimin Shi, Aleksandar Stanić, Wenyi Wang, Yuhui Wang, Mengmeng Xu, Deng-Ping Fan, Bernard Ghanem, Jürgen Schmidhuber* [[pdf](https://arxiv.org/abs/2305.17066)], 2023.5
62. **Large Language Models as Tool Makers.** Arxiv
*Tianle Cai, Xuezhi Wang, Tengyu Ma, Xinyun Chen, Denny Zhou* [[pdf](https://arxiv.org/abs/2305.17126)], 2023.5
63. **GPT4Tools: Teaching Large Language Model to Use Tools via Self-instruction.** Arxiv
*Rui Yang, Lin Song, Yanwei Li, Sijie Zhao, Yixiao Ge, Xiu Li, Ying Shan* [[pdf](https://arxiv.org/abs/2305.18752)], 2023.5
64. **SheetCopilot: Bringing Software Productivity to the Next Level through Large Language Models.** Arxiv
*Hongxin Li, Jingran Su, Yuntao Chen, Qing Li, Zhaoxiang Zhang* [[pdf](https://arxiv.org/abs/2305.19308)], 2023.5
65. **CREATOR: Disentangling Abstract and Concrete Reasonings of Large Language Models through Tool Creation.** Arxiv
*Cheng Qian, Chi Han, Yi R. Fung, Yujia Qin, Zhiyuan Liu, Heng Ji* [[pdf](https://arxiv.org/abs/2305.14318)], 2023.5
66. **SQL-PaLM: Improved Large Language ModelAdaptation for Text-to-SQL.** Arxiv
*Ruoxi Sun, Sercan O. Arik, Hootan Nakhost, Hanjun Dai, Rajarishi Sinha, Pengcheng Yin, Tomas Pfister* [[pdf](https://arxiv.org/abs/2306.00739)], 2023.6
67. **From Pixels to UI Actions: Learning to Follow Instructions via Graphical User Interfaces.** Arxiv
*Peter Shaw, Mandar Joshi, James Cohan, Jonathan Berant, Panupong Pasupat, Hexiang Hu, Urvashi Khandelwal, Kenton Lee, Kristina Toutanova* [[pdf](https://arxiv.org/abs/2306.00245)], 2023.6
68. **Modular Visual Question Answering via Code Generation.** ACL 2023
*Sanjay Subramanian, Medhini Narasimhan, Kushal Khangaonkar, Kevin Yang, Arsha Nagrani, Cordelia Schmid, Andy Zeng, Trevor Darrell, Dan Klein* [[pdf](https://arxiv.org/abs/2306.05392)], 2023.6
69. **ToolAlpaca: Generalized Tool Learning for Language Models with 3000 Simulated Cases.** Arxiv
*Qiaoyu Tang, Ziliang Deng, Hongyu Lin, Xianpei Han, Qiao Liang, Le Sun* [[pdf](https://arxiv.org/abs/2306.05301)], 2023.6
70. **Embodied Executable Policy Learning with Language-based Scene Summarization** Arxiv
*Jielin Qiu, Mengdi Xu, William Han, Seungwhan Moon, Ding Zhao* [[pdf](https://arxiv.org/abs/2306.05696)], 2023.6
71. **Mind2Web: Towards a Generalist Agent for the Web.** Arxiv
*Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samuel Stevens, Boshi Wang, Huan Sun, Yu Su* [[pdf](https://arxiv.org/abs/2306.06070)], 2023.6
72. **Can Language Models Teach Weaker Agents? Teacher Explanations Improve Students via Theory of Mind.** Arxiv
*Swarnadeep Saha, Peter Hase, Mohit Bansal* [[pdf](https://arxiv.org/abs/2306.09299)], 2023.6
73. **Generating Language Corrections for Teaching Physical Control Tasks** ICML 2023
*Megha Srivastava, Noah Goodman, Dorsa Sadigh* [[pdf](https://arxiv.org/abs/2306.07012)], 2023.6
74. **Data-Copilot: Bridging Billions of Data and Humans with Autonomous Workflow.** Arxiv
*Wenqi Zhang, Yongliang Shen, Weiming Lu, Yueting Zhuang* [[pdf](https://arxiv.org/abs/2306.07209)], 2023.6
75. **SayTap: Language to Quadrupedal Locomotion** Arxiv
*Yujin Tang, Wenhao Yu, Jie Tan, Heiga Zen, Aleksandra Faust, Tatsuya Harada* [[pdf](https://arxiv.org/abs/2306.07580)], 2023.6
76. **Language to Rewards for Robotic Skill Synthesis** Arxiv
*Wenhao Yu, Nimrod Gileadi, Chuyuan Fu, Sean Kirmani, Kuang-Huei Lee, Montse Gonzalez Arenas, Hao-Tien Lewis Chiang, Tom Erez, Leonard Hasenclever, Jan Humplik, Brian Ichter, Ted Xiao, Peng Xu, Andy Zeng, Tingnan Zhang, Nicolas Heess, Dorsa Sadigh, Jie Tan, Yuval Tassa, Fei Xia* [[pdf](https://arxiv.org/abs/2306.08647)], 2023.6
77. **REFLECT: Summarizing Robot Experiences for Failure Explanation and Correction** Arxiv
*Zeyi Liu, Arpit Bahety, Shuran Song* [[pdf](https://arxiv.org/abs/2306.15724)], 2023.6
78. **ChatGPT for Robotics: Design Principles and Model Abilities** Arxiv
*Sai Vemprala, Rogerio Bonatti, Arthur Bucker, Ashish Kapoor* [[pdf](https://arxiv.org/abs//2306.17582)], 2023.6
79. **Robots That Ask For Help: Uncertainty Alignment for Large Language Model Planners** Arxiv
*Allen Z. Ren, Anushri Dixit, Alexandra Bodrova, Sumeet Singh, Stephen Tu, Noah Brown, Peng Xu, Leila Takayama, Fei Xia, Jake Varley, Zhenjia Xu, Dorsa Sadigh, Andy Zeng, Anirudha Majumdar* [[pdf](https://arxiv.org/abs/2307.01928)], 2023.7
80. **Building Cooperative Embodied Agents Modularly with Large Language Models** Arxiv
*Hongxin Zhang, Weihua Du, Jiaming Shan, Qinhong Zhou, Yilun Du, Joshua B. Tenenbaum, Tianmin Shu, Chuang Gan* [[pdf](https://arxiv.org/abs/2307.02485)], 2023.7
81. **VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models** Arxiv
*Wenlong Huang, Chen Wang, Ruohan Zhang, Yunzhu Li, Jiajun Wu, Li Fei-Fei* [[pdf](https://arxiv.org/abs/2307.05973)], 2023.7
82. **Demonstrating Large Language Models on Robots** RSS 2023 Demo Track
*Google DeepMind* [[pdf](https://roboticsconference.org/program/papers/024)], 2023.7
83. **GenSim: Generative Models for Supersizing Robotic Simulation Tasks** Github
*Lirui Wang* [[pdf](https://github.com/liruiw/GenSim)], 2023.7
84. **Large Language Models as General Pattern Machines** Arxiv
*Suvir Mirchandani, Fei Xia, Pete Florence, Brian Ichter, Danny Driess, Montserrat Gonzalez Arenas, Kanishka Rao, Dorsa Sadigh, Andy Zeng* [[pdf](https://arxiv.org/abs/2307.04721)], 2023.7
85. **SayPlan: Grounding Large Language Models using 3D Scene Graphs for Scalable Task Planning** Arxiv
*Krishan Rana, Jesse Haviland, Sourav Garg, Jad Abou-Chakra, Ian Reid, Niko Suenderhauf* [[pdf](https://arxiv.org/abs/2307.06135)], 2023.7
86. **RoCo: Dialectic Multi-Robot Collaboration with Large Language Models** Arxiv
*Zhao Mandi, Shreeya Jain, Shuran Song* [[pdf](https://arxiv.org/abs/2307.04738)], 2023.7
87. **A Real-World WebAgent with Planning, Long Context Understanding, and Program Synthesis** Arxiv
*Izzeddin Gur, Hiroki Furuta, Austin Huang, Mustafa Safdari, Yutaka Matsuo, Douglas Eck, Aleksandra Faust* [[pdf](https://arxiv.org/abs/2307.12856)], 2023.7
88. **WebArena: A Realistic Web Environment for Building Autonomous Agents** Arxiv
*Shuyan Zhou, Frank F. Xu, Hao Zh+, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Yonatan Bisk, Daniel Fried, Uri Alon, Graham Neubig* [[pdf](https://webarena.dev/static/paper.pdf)], 2023.7
89. **RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control** Arxiv
*Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Xi Chen, Krzysztof Choromanski, Tianli Ding, Danny Driess, Avinava Dubey, Chelsea Finn, Pete Florence, Chuyuan Fu, Montse Gonzalez Arenas, Keerthana Gopalakrishnan, Kehang Han, Karol Hausman, Alexander Herzog, Jasmine Hsu, Brian Ichter, Alex Irpan, Nikhil Joshi, Ryan Julian, Dmitry Kalashnikov, Yuheng Kuang, Isabel Leal, Lisa Lee, Tsang-Wei Edward Lee, Sergey Levine, Yao Lu, Henryk Michalewski, Igor Mordatch, Karl Pertsch, Kanishka Rao, Krista Reymann, Michael Ryoo, Grecia Salazar, Pannag Sanketi, Pierre Sermanet, Jaspiar Singh, Anikait Singh, Radu Soricut, Huong Tran, Vincent Vanhoucke, Quan Vuong, Ayzaan Wahid, Stefan Welker, Paul Wohlhart, Jialin Wu, Fei Xia, Ted Xiao, Peng Xu, Sichun Xu, Tianhe Yu, Brianna Zitkovich* [[pdf](https://robotics-transformer2.github.io/assets/rt2.pdf)], 2023.7
90. **Scaling Up and Distilling Down: Language-Guided Robot Skill Acquisition** Arxiv
*Huy Ha, Pete Florence, Shuran Song* [[pdf](https://arxiv.org/abs/2307.14535)], 2023.7
|
facebookresearch/CL-LNS
|
https://github.com/facebookresearch/CL-LNS
|
Code repo for ICML'23 Searching Large Neighborhoods for Integer Linear Programs with Contrastive Learning
|
# Setting up the environment
This only needs to be done once
## CUDA
You could use CUDA for training.
## Create the environment
First install conda (if you haven't) and activate conda.
You also need to decide a torch version to use depending on your cuda version.
In this repo, we provide an example for torch 1.7.0 with cuda 11.0.
If you are using other torch/cuda versions, modify `environment.txt`, `requirements.txt` and the commands below accordingly. The code has been tested with torch 1.7.0 and 1.12.1.
After that, you could run the commands below to install the conda environment:
```
conda config --add channels conda-forge
conda config --add channels pytorch
conda config --add channels nvidia
conda config --add channels dglteam
conda create -n cllns --file environment.txt
conda activate cllns
pip cache purge
pip install -r requirements.txt -f https://pytorch-geometric.com/whl/torch-1.7.0+cu110.html
```
We have an updated version of the Ecole library that fixes some issues with feature extraction and could be downloaded from [here](https://drive.google.com/file/d/1EbnUlgdnJotCKAyh8M9hqsMvaIvIP0Sq/view?usp=share_link).
## Install Ecole
Download Ecole and apply a patch to it. Then, install it from the source:
```
mkdir ecole_0.8.1
cd ecole_0.8.1
git clone -b v0.8.1 https://github.com/ds4dm/ecole.git
patch -p1 < ../ecole_feature_extraction.patch
cd ecole
python -m pip install .
cd ../..
```
# Instances Preparation
In ```instance_loader.py```, add to ```LOCAL_INSTANCE``` the problem set name of the instances and the path to those instances.
In this repo, we provide a mini example for training (`INDSET_train`) and testing (`INDSET_test`) instances for the independset problem used in our paper.
# Collecting the dataset
Run data collection on the example training problem set:
```
python LNS.py --problem-set=INDSET_train --num-solve-steps=30 --neighborhood-size=100 --time-limit=300000 --destroy-heuristic=LOCAL_BRANCHING --mode=COLLECT
```
Here we are collecting data with the expert Local Branching for 30 iterations with neighborhood size 100. The per-iteration runtime limit is hard-coded in the code for 1 hour (can be changed there). So the total time limit needs to be set to be at least 30*3600 seconds if you want to finish all 30 iterations.
## Train the models
Install some packages for contrastive losses and keeping track of other metrics:
```
pip install pytorch-metric-learning
pip install torchmetrics==0.9.3
```
After that, simply run
```python LNS/train_neural_LNS.py```
## Test the models
Run this command to test the model on the example testing problem set. This command use an example model for testing that is also used in our experiment.
```
python LNS.py --problem-set=INDSET_test --neighborhood-size=3000 --time-limit=3600 --destroy-heuristic=ML::GREEDY::CL --adaptive=1.02 --mode=TEST_ML_feat2 --gnn-type=gat --model=model/INDSET_example.pt
```
ML-base destroy heuristics must have prefix `ML::SAMPLE` or `ML::GREEDY` (depending on the sampling methods you use, for CL-LNS we recommend GREEDY) and can have arbitrary suffix (here we use `::CL`) for your own naming and logging purposes.
# Citation
Please cite our paper if you use this code in your work.
```
@inproceedings{huang2023searching,
title={Searching Large Neighborhoods for Integer Linear Programs with Contrastive Learning},
author={Huang, Taoan and Ferber, Aaron and Tian, Yuandong and Dilkina, Bistra and Steiner, Benoit},
booktitle={International conference on machine learning},
year={2023},
organization={PMLR}
}
```
# LICENSE
The project is under CC BY-NC 4.0 license. Please check LICENSE file for details.
|
TangSengDaoDao/TangSengDaoDaoAndroid
|
https://github.com/TangSengDaoDao/TangSengDaoDaoAndroid
|
TangSengDaoDaoAndroid
|
# 唐僧叨叨([官网](http://githubim.com "文档"))
   
### **唐僧叨叨 悟空IM提供动力** ([悟空IM](https://github.com/WuKongIM/WuKongIM "文档"))
唐僧叨叨基于底层通讯框架`悟空IM`实现聊天功能。Demo已实现`文本`,`图片`,`语音`,`名片`,`emoji`,群聊`@某人`,消息`链接`,`手机号`,`邮箱`识别等功能。聊天设置支持`名称修改`,`头像修改`,`公告编辑`,`消息免打扰`,`置顶`,`保存到通讯录`,`聊天内昵称`,`群内成员昵称显示`等丰富的设置功能。由于demo是模块化开发,开发者可完全按自己的开发习惯进行二次开发。
### 唐僧叨叨特点
- #### **永久保存消息** 卸载唐僧叨叨后下次安装登录后,可查看以前的聊天记录
- #### **超大群** 唐僧叨叨群聊人数无限制,万人群进入聊天完全不卡,消息正常收发
- #### **实时性** 所有操作实时同步,app已读消息,web/pc可实时更改状态
- #### **扩展性强** 唐僧叨叨现已框架可轻松支持消息的已读未读回执,消息点赞,消息回复功能
- #### **开源** 唐僧叨叨100%开源,商业开发无需授权可直接使用
### 项目模块
唐僧叨叨是模块化开发,不限制开发者编码习惯。以下是对各个模块的说明
**`wkbase`**
基础模块 里面包含了`WKBaseApplication`文件,该文件主要是对一些通用工具做些初始化功能,如:网络库初始化,本地db文件初始化等。`WKChatBaseProvider`聊天中重要的基础消息item提供者,所有消息item均继承于此类,里面处理消息气泡样式,头像显示样式,消息间距等很多统一且重要的功能。更多功能请查看源码
**`wkuikit`**
聊天模块 包含了聊天页面`ChatActivity`,该文件处理了聊天信息的展示,离线获取,刷新消息状态等聊天中遇到的各个场景。`ChatFragment` 最近会话列表,新消息红点,聊天最后一条消息展示等。此模块还包括app首页信息,联系人信息,我的页面等
**`wklogin`**
登录模块 包含登陆注册,第三方授权登录,修改账号密码,授权pc/web登录等功能,实现其他方式登录可在此模块进行二次开发
**`wkpush`**
推送模块 唐僧叨叨集成了`华为`,`小米`,`vivo`,`oppo`厂商推送功能。开发者二次开发是只需要替换对应的appID和appKey即可
- **华为** 在官方申请开发者账号并开通推送服务后,下载`agconnect-services.json`文件覆盖`app`模块下的该文件。并在`wkpush`模块的 `AndroidManifest.xml` 文件中的名为`com.huawei.hms.client.appid`的`meta-data`替换appID,`PushKeys`文件中替换`huaweiAPPID`即可
- **小米** 修改此模块下的`PushKeys`文件中的`xiaoMiAppID` 和 `xiaoMiAppKey`即可
- **OPPO** 修改此模块下的`PushKeys`文件中的`oppoAppKey` 和 `oppoAppSecret`即可
- **VIVO** 修改此模块`AndroidManifest.xml` 文件中的名为`com.vivo.push.api_key`的`meta-data`的value 和修改名为`com.vivo.push.app_id`的`meta-data`的value即可
由于开发有限,如需其他厂商的推送功能,只需在此模块按官方文档集成即可
**`wkscan`**
扫一扫模块 包含扫描二维码进行加好友,加入群聊等
### 自定义消息Item
**注意这里只是介绍如何将自定义的消息item展示在消息列表中,消息model的实现需要去查看[悟空IM](https://github.com/WuKongIM/WuKongIM "文档")文档**
唐僧叨叨实现自定义消息Item也十分简单。只需要实现两步即可
1、 编写消息item provider。继承`WKChatBaseProvider`文件,重写`getChatViewItem`方法如下
```kotlin
override fun getChatViewItem(parentView: ViewGroup, from: WKChatIteMsgFromType): View? {
return LayoutInflater.from(context).inflate(R.layout.chat_item_card, parentView, false)
}
```
> 布局中不需要考虑头像,名称字段
重写`setData`方法 获取控件并将控件填充数据。如下
```kotlin
override fun setData(
adapterPosition: Int,
parentView: View,
uiChatMsgItemEntity: WKUIChatMsgItemEntity,
from: WKChatIteMsgFromType
) {
val cardNameTv = parentView.findViewById<TextView>(R.id.userNameTv)
val cardContent = uiChatMsgItemEntity.wkMsg.baseContentMsgModel as WKCardContent
cardNameTv.text = cardContent.name
// todo ...
}
```
> 这里的`WKCardContent`消息对象是基于`悟空IM`sdk的实现,所有自定义消息model必须基于`悟空IM`。关于`悟空IM`自定义消息可查看[Android文档](https://githubim.com/sdk/android.html "文档")中的自定义消息
设置item的消息类型
```kotlin
override val itemViewType: Int
get() = WKContentType.WK_CARD
```
2、完成消息item提供者的编写后需将该item注册到消息提供管理中。
```kotlin
WKMsgItemViewManager.getInstance().addChatItemViewProvider(WKContentType.WK_LOCATION, WKCardProvider())
```
对此自定义消息Item已经完成,在收到此类型的消息时就会展示到聊天列表中了
## 效果图
|对方正在输入|语音消息|合并转发|
|:---:|:---:|:--:|
||||
|快速回复|群内操作|其他功能|
|:---:|:---:|:-------------------:|
|||  |
由于GIF被压缩,演示效果很模糊。真机预览效果更佳
## app下载体验
<img src='./imgs/ic_download_qr.png' width=35%/>
如果扫描错误可通过 [安装地址](http://www.pgyer.com/tsdd "文档") 下载
|
hcymysql/reverse_sql
|
https://github.com/hcymysql/reverse_sql
|
Binlog数据恢复,生成反向SQL语句
|
# reverse_sql 工具介绍
reverse_sql 是一个用于解析和转换 MySQL 二进制日志(binlog)的工具。它可以将二进制日志文件中记录的数据库更改操作(如插入、更新、删除)转换为反向的 SQL 语句,以便进行数据恢复。其运行模式需二进制日志设置为 ROW 格式。
### 2023-7-12日更新 - 分之版本(可实现进度条展示(处理binlog的event数量和耗时时间))

## [reverse_sql_progress](https://github.com/hcymysql/reverse_sql/tree/reverse_sql_progress)
reverse_sql工具是一个用于数据库恢复的工具,它支持MySQL 5.7/8.0和MariaDB数据库。该工具可以帮助您在发生P0事故(最紧急的事故等级)时快速恢复数据,避免进一步的损失。
使用reverse_sql工具非常简单,您只需要指定肇事时间和表名即可。该工具会根据指定的时间点,在数据库中查找并还原该表在该时间点之前的数据状态。这样您就能轻松地实现数据恢复,防止因意外操作或其他问题导致的数据丢失。
通过使用reverse_sql工具,您可以放心地进行数据库操作,即使出现错误也可以轻松地回滚到之前的数据状态,避免了数据灾难的发生。该工具提供了对MySQL 5.7/8.0和MariaDB数据库的广泛支持,使其适用于各种不同的数据库环境。
总而言之,reverse_sql工具是一个方便实用的数据库恢复工具,可以帮助您快速恢复数据,保障数据的完整性和安全性。请记住,及时备份和恢复数据是维护数据库健康的重要一环,您可以在合适的时候使用reverse_sql工具来增强数据管理的能力。
---------------------------------------------------------------------------------------------------------------------------------------------------
该工具的主要功能和特点包括:
1、解析二进制日志:reverse_sql 能够解析 MySQL 的二进制日志文件,并还原出其中的 SQL 语句。
2、生成可读的 SQL:生成原始 SQL 和反向 SQL。
3、支持过滤和筛选:可以根据时间范围、表、DML操作等条件来过滤出具体的误操作 SQL 语句。
4、支持多线程并发解析binlog事件。
#### 请注意!reverse_sql 只是将二进制日志还原为 SQL 语句,而不会执行这些 SQL 语句来修改数据库。
### 原理
调用官方 https://python-mysql-replication.readthedocs.io/ 库来实现,通过指定的时间范围,转换为timestamp时间戳,将整个时间范围平均分配给每个线程。
由于 BinLogStreamReader 并不支持指定时间戳来进行递增解析,固在每个任务开始之前,使用上一个任务处理过的 binlog_file 和 binlog_pos,这样后续的线程就可以获取到上一个线程处理过的 binlog 文件名和 position,然后进行后续的并发处理。
假设开始时间戳 start_timestamp 是 1625558400,线程数量 num_threads 是 4,整个时间范围被平均分配给每个线程。那么,通过计算可以得到以下结果:
对于第一个线程(i=0),start_time 是 1625558400。
对于第二个线程(i=1),start_time 是 1625558400 + time_range。
对于第三个线程(i=2),start_time 是 1625558400 + 2 * time_range。
对于最后一个线程(i=3),start_time 是 1625558400 + 3 * time_range。
这样,每个线程的开始时间都会有所偏移,确保处理的时间范围没有重叠,并且覆盖了整个时间范围。最后,将结果保存在一个列表里,并对列表做升序排序,取得最终结果。
### 使用
```
shell> chmod 755 reverse_sql
shell> ./reverse_sql --help
usage: reverse_sql [-h] [-ot ONLY_TABLES [ONLY_TABLES ...]] [-op ONLY_OPERATION] -H MYSQL_HOST
-P MYSQL_PORT -u MYSQL_USER -p MYSQL_PASSWD -d MYSQL_DATABASE
[-c MYSQL_CHARSET] --binlog-file BINLOG_FILE [--binlog-pos BINLOG_POS]
--start-time ST --end-time ET [--max-workers MAX_WORKERS] [--print]
Binlog数据恢复,生成反向SQL语句。
options:
-h, --help show this help message and exit
-ot ONLY_TABLES [ONLY_TABLES ...], --only-tables ONLY_TABLES [ONLY_TABLES ...]
设置要恢复的表,多张表用,逗号分隔
-op ONLY_OPERATION, --only-operation ONLY_OPERATION
设置误操作时的命令(insert/update/delete)
-H MYSQL_HOST, --mysql-host MYSQL_HOST
MySQL主机名
-P MYSQL_PORT, --mysql-port MYSQL_PORT
MySQL端口号
-u MYSQL_USER, --mysql-user MYSQL_USER
MySQL用户名
-p MYSQL_PASSWD, --mysql-passwd MYSQL_PASSWD
MySQL密码
-d MYSQL_DATABASE, --mysql-database MYSQL_DATABASE
MySQL数据库名
-c MYSQL_CHARSET, --mysql-charset MYSQL_CHARSET
MySQL字符集,默认utf8
--binlog-file BINLOG_FILE
Binlog文件
--binlog-pos BINLOG_POS
Binlog位置,默认4
--start-time ST 起始时间
--end-time ET 结束时间
--max-workers MAX_WORKERS
线程数,默认4(并发越高,锁的开销就越大,适当调整并发数)
--print 将解析后的SQL输出到终端
--replace 将update转换为replace操作
Example usage:
shell> ./reverse_sql -ot table1 -op delete -H 192.168.198.239 -P 3336 -u admin -p hechunyang -d hcy \
--binlog-file mysql-bin.000124 --start-time "2023-07-06 10:00:00" --end-time "2023-07-06 22:00:00"
```
##### 当出现误操作时,只需指定误操作的时间段,其对应的binlog文件(通常你可以通过show master status得到当前的binlog文件名)以及刚才误操作的表,和具体的DML命令,比如update或者delete。
工具运行时,首先会进行MySQL的环境检测(if binlog_format != 'ROW' and binlog_row_image != 'FULL'),如果不同时满足这两个条件,程序直接退出。
工具运行后,会在当前目录下生成一个{db}_{table}_recover.sql文件,保存着原生SQL(原生SQL会加注释) 和 反向SQL,如果想将结果输出到前台终端,可以指定--print选项。
如果你想把update操作转换为replace,指定--replace选项即可,同时会在当前目录下生成一个{db}_{table}_recover_replace.sql文件。

MySQL 最小化用户权限:
```
> GRANT REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO `yourname`@`%`;
> GRANT SELECT ON `test`.* TO `yourname`@`%`;
```
### 恢复
在{db}_{table}_recover.sql文件中找到你刚才误操作的DML语句,然后在MySQL数据库中执行逆向工程后的 SQL 以恢复数据。
如果{db}_{table}_recover.sql文件的内容过多,也可以通过awk命令进行分割,以便更容易进行排查。
```
shell> awk '/^-- SQL执行时间/{filename = "output" ++count ".sql"; print > filename; next} {print > filename}' test_t1_recover.sql
```
不支持drop和truncate操作,因为这两个操作属于物理性删除,需要通过历史备份进行恢复。
#### 注:reverse_sql 支持MySQL 5.7/8.0 和 MariaDB,适用于CentOS 7系统。
|
catvod/CatVodOpen
|
https://github.com/catvod/CatVodOpen
|
Open version of catvod.
|
# CatVodOpen
Open version of catvod.
[🚀TG](https://t.me/catvodapp_offical)
### **Notice**
The open version was originally planned to start in december of last year, but it was delayed due to other matters. So the open version is mainly based on the december version from last year, but will include some bug fixes and core feature merges.
Not being maintained and uncertain whether they will be updated.
**Those who need it can download and use it, and there is no need to provide feedback on any issues.**
### **Limits**
- Only local `assets://` config is supported, and network config is not available.
- Only video&cloud disk module.
- Not supporting sniffing.
- Basic JS interface support.
- No builtin maccms api support.
- etc.
### **Download**
[Release](https://github.com/catvod/CatVodOpen/releases)
- Windows release only test on `windows11`.
- Builtin config `data\flutter_assets\asset\js\config_open.json`
- MacOS only test on `Big Sur` and `Monterey`.
- Builtin config `*.app/Contents/Frameworks/App.framework/Resources/flutter_assets/asset/js/config_open.json`
- iOS only test on `16.0+`.
- Builtin config `*.ipa/Payload/Runner.app/Frameworks/App.framework/flutter_assets/asset/js/config_open.json`
- Android only test on `8.0+`, maybe not supported to run on emulators, not support TV.
- Builtin config `*.apk/assets/flutter_assets/asset/js/config_open.json`
|
clibraries/array-algorithms
|
https://github.com/clibraries/array-algorithms
|
Unintrusive algorithms for C arrays OR a C implementation of <algorithm> from C++
|
# array_alg.h
Unintrusive algorithms for C arrays OR a C implementation of \<algorithm> from C++
## Pitch
The C++ STL is one of the most complete and reusable algorithm libraries available.
This single header file brings 80% of that functionality to C99 in a non-intrusive way.
There are no new data structures. Just include the library and call functions on C arrays.
Features:
- Sets (intersection, union, subset, etc)
- Heaps (priority queues)
- Binary search (lower bound, upper bound, etc)
- Sorts (insertion sort, quick sort, merge/stable sort, heap sort, partial sort, etc)
- Partitioning (partition, unique, etc)
- Predicates (all of, any of, none of, etc)
- Uniform random sampling and shuffling
## Usage
This library uses the preprocessor to implement generic functions.
Each time you include the library, you will need to define the array element type and a function prefix:
#define ARRAY_ALG_TYPE int
#define ARRAY_ALG_PREFIX intv_
#include "array_alg.h"
The above will only generate the declarations.
In at least one C file, you will also need to generate implementations.
To generate implementations, define `ARRAY_ALG_IMPLEMENTATION` in a C file and include the library:
#define ARRAY_ALG_TYPE int
#define ARRAY_ALG_PREFIX intv_
#define ARRAY_ALG_IMPLEMENTATION
#include "array_alg.h"
Alternatively, add `#define ARRAY_ALG_STATIC` before the original declaration
to avoid the need for separate implementations.
Repeat this process for each array type you want to use.
## Examples
Remove duplicate entries:
#define ARRAY_ALG_TYPE int
#define ARRAY_ALG_PREFIX intv_
#include "array_alg.h"
int compare_int(const int *a, const int *b, void *ctx) {
return *a - *b;
}
...
int nums[100] = ...;
intv_sort(nums, nums + 100, compare_int, NULL);
int* end = intv_unique(nums, nums + 100, compare_int, NULL);
## Design
### 1. Iterators and Arrays
The C++ STL is designed around the concept of iterators.
With iterators, one algorithm can be reused not just for multiple types, but also for many data structures.
This is an ingenious design.
However, in practice, this capability is rarely needed.
The vast majority of real world \<algorithm> invocations are on contiguous arrays/vectors.
For those cases where you do have a fancy data structure (graphs, trees, etc),
copy its contents to an array, perform the algorithm, and then copy the contents back.
This will often help it perform better anyway!
### 2. Bounds vs counted ranges
STL algorithms typically operate on half-open ranges bounded by iterators [first, last).
This convention is not used as often in C, but we think it offers some benefits.
Internally, the functions can maintain less state by simply incrementing pointers
rather than keeping track of pointers, indices, and counts.
Operations also compose a little easier.
When a pointer is returned to an element of interest,
that same pointer can be used as an argument for another algorithm.
### 3. What's left out
Because it's a bit verbose to define a C closure (function pointer and context), some STL algorithms are less useful in C.
If an algorithm can be written as a simple for loop with no additional state or control flow, this library doesn't implement it.
transform -> for (int i = 0; i < n; ++i) out[i] = f(in[i])
fill -> for (int i = 0; i < n; ++i) out[i] = x;
iota -> for (int i = 0; i < n; ++i) out[i] = i;
generate -> for (int i = 0; i < n; ++i) out[i] = f();
The algorithms which rely on ordered types always require a comparison function.
We do not include any variants that operate on the `==` operator, as operators cannot be overloaded in C.
### 4. Generics vs `void*`
Including a header multiple times with various `#define`s is a little cumbersome.
However, we think it's a superior way to achieve C generics compared to the `void*` style used by `qsort` and `bsearch`.
The preprocessor approach provides:
- Better type safety and avoids verbose casting logic.
- Better peformance (as `void*` functions are difficult to optimize).
Note: The C compiler can only create one non-inlined version of each function.
For example, it could not choose to use `int` instructions, even if it knew the type at compile time.
With the single header approach you get a new instance of each function optimized for each application.
|
eosphoros-ai/DB-GPT-Web
|
https://github.com/eosphoros-ai/DB-GPT-Web
|
DB-GPT WebUI,ChatUI is all your need.
|
This is a [Next.js](https://nextjs.org/) project bootstrapped with [`create-next-app`](https://github.com/vercel/next.js/tree/canary/packages/create-next-app).
## Devlop Mode
### Getting Started
First, Config Server Url:
next.config.js
```javascript
const nextConfig = {
output: 'export',
experimental: {
esmExternals: 'loose'
},
typescript: {
ignoreBuildErrors: true
},
env: {
API_BASE_URL: process.env.API_BASE_URL || your server url
},
trailingSlash: true
}
```
Second, run the development server:
```bash
npm run dev
# or
yarn dev
# or
pnpm dev
```
Open [http://localhost:3000](http://localhost:3000) with your browser to see the result.
You can start editing the page by modifying `app/page.tsx`. The page auto-updates as you edit the file.
This project uses [`next/font`](https://nextjs.org/docs/basic-features/font-optimization) to automatically optimize and load Inter, a custom Google Font.
## Learn More
To learn more about Next.js, take a look at the following resources:
Next.js Documentation - learn about Next.js features and API.
Learn Next.js - an interactive Next.js tutorial.
You can check out the Next.js GitHub repository - your feedback and contributions are welcome!
## Deploy on Vercel
The easiest way to deploy your Next.js app is to use the Vercel Platform from the creators of Next.js.
Check out our Next.js deployment documentation for more details.
## Product Mode
### Use In DB-GPT
```bash
npm run compile
# copy compile file to DB-GPT static file dictory
cp -r -f /Db-GPT-Web/out/* /DB-GPT/pilot/server/static/
```
|
ShelbyJenkins/shelby-as-a-service
|
https://github.com/ShelbyJenkins/shelby-as-a-service
|
Production-ready LLM Agents. Just add API keys
|
<!-- Improved compatibility of back to top link: See: https://github.com/othneildrew/Best-README-Template/pull/73 -->
<a name="readme-top"></a>
<!--
*** Thanks for checking out the Best-README-Template. If you have a suggestion
*** that would make this better, please fork the repo and create a pull request
*** or simply open an issue with the tag "enhancement".
*** Don't forget to give the project a star!
*** Thanks again! Now go create something AMAZING! :D
-->
<!-- PROJECT SHIELDS -->
<!--
*** I'm using markdown "reference style" links for readability.
*** Reference links are enclosed in brackets [ ] instead of parentheses ( ).
*** See the bottom of this document for the declaration of the reference variables
*** for contributors-url, forks-url, etc. This is an optional, concise syntax you may use.
*** https://www.markdownguide.org/basic-syntax/#reference-style-links
-->
[![Contributors][contributors-shield]][contributors-url]
[![Forks][forks-shield]][forks-url]
[![Stargazers][stars-shield]][stars-url]
[![Issues][issues-shield]][issues-url]
[![MIT License][license-shield]][license-url]
[![LinkedIn][linkedin-shield]][linkedin-url]
<!-- PROJECT LOGO
<br />
<div align="center">
<a href="https://github.com/ShelbyJenkins/shelby-as-a-service">
<img src="images/logo.png" alt="Logo" width="80" height="80">
</a>
<h3 align="center">project_title</h3>
<p align="center">
project_description
<br />
<a href="https://github.com/ShelbyJenkins/shelby-as-a-service"><strong>Explore the docs »</strong></a>
<br />
<br />
<a href="https://github.com/ShelbyJenkins/shelby-as-a-service">View Demo</a>
·
<a href="https://github.com/ShelbyJenkins/shelby-as-a-service/issues">Report Bug</a>
·
<a href="https://github.com/ShelbyJenkins/shelby-as-a-service/issues">Request Feature</a>
</p>
</div> -->
<!-- TABLE OF CONTENTS -->
<details>
<summary>Table of Contents</summary>
<ol>
<li>
<a href="#about-the-project">About The Project</a>
<ul>
<li><a href="#built-with">Built With</a></li>
</ul>
</li>
<li>
<a href="#getting-started">Getting Started</a>
<ul>
<li><a href="#prerequisites">Prerequisites</a></li>
<li><a href="#installation">Installation</a></li>
</ul>
</li>
<li><a href="#usage">Usage</a></li>
<li><a href="#roadmap">Roadmap</a></li>
<li><a href="#contributing">Contributing</a></li>
<li><a href="#license">License</a></li>
<li><a href="#contact">Contact</a></li>
<li><a href="#acknowledgments">Acknowledgments</a></li>
</ol>
</details>
<!-- ABOUT THE PROJECT -->
## Production-ready LLM Agents. Just add API keys
[![Discord Screen Shot][discord-screenshot]](documentation/discord-example.png)
[![Slack Screen Shot][slack-screenshot]](documentation/slack-example.png)
### Features
The gulf between 'hello world' and something useful is what shelby-as-a-service (SaaS) solves.
* Easy:
* Configuration requires only API keys.
* Step-by-step guides.
* Automatically builds dockerfile and github actions workflow to deploy to container.
* Context enriched queries, retrieval augmented generation (RAG), prompt stuffing, questions on docs, etc
* Automatically scrapes, processes, and uploads data from websites, gitbooks, sitemaps, and OpenAPI specs.
* Superior Document retrieval.
* Performs semantic search with sparse/dense embeddings by default.
* Generates additional search keywords for better semantic search results.
* Checks if documents are relevant by asking GPT, "Which of these documents are relevant?"
* Superior document pre-processing with BalancedRecursiveCharacterTextSplitter and thoughtful parsing.
* Pre-configured Slack and Discord bots (lets call them 'Sprites' for this project).
* Tweaking not required, but all the knobs are at your disposal in the configuration folder.
* All configuration variables are stored and loaded through shelby_agent_config.py
* All data sources are added through template_document_sources.yaml
* All prompts are easily accessbile through prompt_template folder
<p align="right">(<a href="#readme-top">back to top</a>)</p>
<!-- ROADMAP -->
## Roadmap
* Enable memory for conversational queries
* Enable the bot to make request to *any* API with an OpenAPI spec
* Improve and add additional document sources
* Speech to text job interview agent
* Add service providers
* Installable via PIP
<p align="right">(<a href="#readme-top">back to top</a>)</p>
<!-- GETTING STARTED -->
## Getting Started
# Out of date!
I made some huge changes this weekend, and ran out of time to update the documentation. In theory, everything works. Except maybe not. By the end of the week I should have the documentation updated to reflect the changes.
This will be covered in three steps:
1. Installation -> https://github.com/ShelbyJenkins/shelby-as-a-service/blob/main/documentation/INSTALLATION.md
2. Configuration -> https://github.com/ShelbyJenkins/shelby-as-a-service/blob/main/documentation/CONFIGURATION.md
3. Deploying for
1. Discord -> https://github.com/ShelbyJenkins/shelby-as-a-service/blob/main/documentation/DEPLOYING_FOR_DISCORD.md
2. Slack -> https://github.com/ShelbyJenkins/shelby-as-a-service/blob/main/documentation/DEPLOYING_FOR_SLACK.md
### Prerequisites
You will need and API key for the following services:
Free:
* Discord -> https://discord.com/developers/docs/intro
* or Slack -> https://api.slack.com/apps
* Pinecone -> https://www.pinecone.io/
* Github -> https://github.com/
* Docker -> https://www.docker.com/
Paid:
* OpenAI API (GPT-3.5 is tenable) -> https://platform.openai.com/overview
* Stackpath (I will add other compute providers if requested.) -> https://www.stackpath.com/
<p align="right">(<a href="#readme-top">back to top</a>)</p>
<!-- CONTRIBUTING -->
## Contributing
I would love any help adding features!
If you have a suggestion that would make this better, please fork the repo and create a pull request. You can also simply open an issue with the tag "enhancement".
Don't forget to give the project a star! Thanks again!
1. Fork the Project
2. Create your Feature Branch (`git checkout -b feature/AmazingFeature`)
3. Commit your Changes (`git commit -m 'Add some AmazingFeature'`)
4. Push to the Branch (`git push origin feature/AmazingFeature`)
5. Open a Pull Request
<p align="right">(<a href="#readme-top">back to top</a>)</p>
<!-- LICENSE -->
## License
Distributed under the MIT License. See `LICENSE.txt` for more information.
<p align="right">(<a href="#readme-top">back to top</a>)</p>
<!-- CONTACT -->
## Contact
Shelby Jenkins - Here or Linkedin https://www.linkedin.com/in/jshelbyj/
Project Link: [https://github.com/ShelbyJenkins/shelby-as-a-service](https://github.com/ShelbyJenkins/shelby-as-a-service)
<p align="right">(<a href="#readme-top">back to top</a>)</p>
<!-- MARKDOWN LINKS & IMAGES -->
<!-- https://www.markdownguide.org/basic-syntax/#reference-style-links -->
[contributors-shield]: https://img.shields.io/github/contributors/shelbyjenkins/shelby-as-a-service.svg?style=for-the-badge
[contributors-url]: https://github.com/ShelbyJenkins/shelby-as-a-service/graphs/contributors
[forks-shield]: https://img.shields.io/github/forks/ShelbyJenkins/shelby-as-a-service.svg?style=for-the-badge
[forks-url]: https://github.com/ShelbyJenkins/shelby-as-a-service/network/members
[stars-shield]: https://img.shields.io/github/stars/ShelbyJenkins/shelby-as-a-service.svg?style=for-the-badge
[stars-url]: https://github.com/ShelbyJenkins/shelby-as-a-service/stargazers
[issues-shield]: https://img.shields.io/github/issues/ShelbyJenkins/shelby-as-a-service.svg?style=for-the-badge
[issues-url]: https://github.com/ShelbyJenkins/shelby-as-a-service/issues
[license-shield]: https://img.shields.io/github/license/ShelbyJenkins/shelby-as-a-service.svg?style=for-the-badge
[license-url]: https://github.com/ShelbyJenkins/shelby-as-a-service/blob/master/LICENSE.txt
[linkedin-shield]: https://img.shields.io/badge/-LinkedIn-black.svg?style=for-the-badge&logo=linkedin&colorB=555
[linkedin-url]: https://www.linkedin.com/in/jshelbyj/
[discord-screenshot]: documentation/discord-example.png
[slack-screenshot]: documentation/slack-example.png
[python]: https://img.shields.io/badge/python-000000?style=for-the-badge&logo=python&logoColor=white
[python-url]: https://www.python.org/
[langchain]: https://img.shields.io/badge/langchain-20232A?style=for-the-badge&logo=langchain&logoColor=61DAFB
[langchain-url]: https://python.langchain.com/
[haystack]: https://img.shields.io/badge/haystack-35495E?style=for-the-badge&logo=haystack&logoColor=4FC08D
[haystack-url]: https://github.com/deepset-ai/haystack
[discord.py]: https://img.shields.io/badge/discord.py-DD0031?style=for-the-badge&logo=discord.py&logoColor=white
[discord.py-url]: https://github.com/Rapptz/discord.py
[slack-bolt]: https://img.shields.io/badge/slack-bolt-4A4A55?style=for-the-badge&logo=slack-bolt&logoColor=FF3E00
[slack-bolt-url]: https://github.com/slackapi/bolt-python
* [![python][python]][python-url]
* [![langchain][langchain]][langchain-url]
* [![haystack][haystack]][haystack-url]
* [![discord.py][discord.py]][discord.py-url]
* [![slack-bolt][slack-bolt]][slack-bolt-url]
|
elisezhu123/bilibili_sourcelibrary
|
https://github.com/elisezhu123/bilibili_sourcelibrary
| null |
# bilibili_sourcelibrary
|
wars2k/booktracker
|
https://github.com/wars2k/booktracker
|
Selfhosted app for organizing your library and tracking your reading habits.
|
# booktracker
**Booktracker** is an open source application for managing and tracking a personal book library.
Using metadata grabbed from Google Books, easily add books and organize them into collections. Set each book’s status, give it a rating, and track how long it took to read.
**Disclaimer:** I am an English Lit graduate learning to program, and Booktracker is my first major project. Booktracker is still under active development, so expect bugs and breaking changes.

## Features
- Add books with metadata provided by the Google Books API.
- Add books manually without using an external metadata provider.
- Organize books into collections.
- Multi-user support.
- Import book data and bookshelves from Goodreads.
- Export data to JSON or CSV.
## Installation
**Docker Compose (recommended)**
1. Paste this `docker-compose.yml` file into an empty directory, replacing with the correct info where necessary
```yaml
version: "3.3"
services:
booktracker:
image: wars2k/booktracker:v0.2.1-beta
restart: unless-stopped
volumes:
- ./data:/app/external
ports:
- 2341:5000 #replace 2341 with your desired port.
```
2. Create the `data` directory with the following three subdirectories:
- `db`
- `logs`
- `export`
Before starting the container, make sure that the directory strucutre looks like this:
```
booktracker/
├── docker-compose.yml
└── data/
├── db
├── log
└── export
```
3. Start the container (from the same directory as your `docker-compose.yml` file):
```bash
docker compose up -d
```
## Coming Soon
**Features**
- **Format**: Choose from options like `ebook`, `paperback`, `hardback`, `missing` to further categorize your books.
- **Journal/Reviews:** Leave multiple private journal entries about a book, or write a review.
- **Statistics:** View book-related statistics like books read per month, average time to completion, etc.
- **Social Media:** Enable this optional feature to view all users’ activity (adding books, finishing books, writing reviews, etc.) on a timeline.
- **Email Summaries:** Receive weekly or monthly recaps with statistics on books read, started, finished, etc.
**Boring Stuff**
- **Improved Logs**
- **Improved Error Handling**
## Screenshots
**Home Page**

**Main Book Page**

**Settings**

**Users**

|
Cybrarist/Discount-Bandit
|
https://github.com/Cybrarist/Discount-Bandit
|
Track your wishlist items and get notified across multiple amazon stores
|
# Discount Bandit
I've noticed there are many price trackers, but they are either paid with missing data or outdated solutions, so I decided to build my own for amazon ( so far ) which I use the most.
Right now I have tested it for the couple stores that are saved, but I will probably test it for other stores for the future, with an update mechanism to update the crawlers.
It's still a simple tracker, so errors can be found so don't expect it to compete with the best websites out there, but I am planning to support it even more since I have a personal usage for it.
## Deployment
Copy .env.example to .env file
```bash
cp .env.example .env
```
Change the database credentials in .env file
```text
DB_CONNECTION=mysql
DB_HOST=127.0.0.1
DB_PORT=3306
DB_DATABASE=laravel
DB_USERNAME=root
DB_PASSWORD=
```
add your email to send notification from it
```text
MAIL_MAILER=smtp
MAIL_HOST=smtp.gmail.com
MAIL_PORT=465
MAIL_USERNAME=yournewemail@gmail
MAIL_PASSWORD="VeryComplicatedPassword"
MAIL_ENCRYPTION=tls
MAIL_FROM_ADDRESS="yournewemail@gmail"
MAIL_FROM_NAME="${APP_NAME}"
```
if you want to support me and my work, feel free to change the following:
```text
ALLOW_REF=0
```
to
```text
ALLOW_REF=1
```
this will enable referrals and will support me as a developer.
please note this is not mandatory, and the software will run normally without issues whether it's enabled or disabled.
Run Composer install
```bash
composer install
```
Link the storage to use the images
```bash
php artisan storage:link
```
Migrate the data with the seed
```bash
php artisan migrate:fresh --seed --no-interaction
```
Generate an app key
```bash
php artisan key:generate
```
The server should be up and running with the following credentials
```text
email : [email protected]
password: password
```
you need to Change the email once you log in if you want to receive emails.
The app will check for prices for single products every 5 minutes, and for the group list every 15 minutes.
pls refer to this for how to set up your cron setup depending on your need.
[https://laravel.com/docs/10.x/scheduling#running-the-scheduler]
then you need to add the following command in your cron to run every second.
```text
* * * * * /path/to/php /path/to/app/artisan queue:work --stop-when-empty >> /dev/null 2>&1
```
And that should be enough for the app to run.
After you're done and everything is running fine, go to your .env file and change the following:
```text
APP_ENV=production
```
I have added a htaccess file in case you need it, so don't forget to rename them to .htaccess if you want to use it
## Features
- Check Price or products across multiple Amazon Stores
- Notify Via Email if the price reach the desired amount
- Create Group of products with set of prices
## Missing
- Clothes and sizes are not working, but im working on a fix.
## Tech Stack
**Server:** Laravel , FilamentPHP.
## Support
Feel free to open an issue, but please provide the product link along with the service caused the issue.
I might request the log file in case I couldn't detect the problem.
## Connect
if you are coming outside github or don't like to use it, feel free to join my discord.
https://discord.gg/VBMHvH8tuR
## Docker
For docker image configuration, please check the link
https://hub.docker.com/r/cybrarist/discount-bandit
|
xueandyue/ChatGPT-3.5-AccessToken-Web
|
https://github.com/xueandyue/ChatGPT-3.5-AccessToken-Web
|
本项目基于使用accesstoken的方式实现了网页版 ChatGPT 3.5的前端,是用ChatGPT-Next-Web项目进行修改而得,另外本项目需要的后端服务,需要部署pandora项目。项目是站在ChatGPT-Next-Web和pandora项目的作者肩膀上,感谢他们!
|
# ChatGPT-3.5-AccessToken-Web
本项目基于使用Access Token的方式实现了网页版 ChatGPT 3.5的前端,不需要openai的api额度,是用<a href="https://github.com/Yidadaa/ChatGPT-Next-Web" target="_blank" title="ChatGPT-Next-Web">
ChatGPT-Next-Web</a>项目进行修改而得,另外本项目需要的后端服务,需要部署<a href="https://github.com/pengzhile/pandora" target="_blank" title="pandora项目">pandora项目</a>
# 示例网站
<a href="http://43.136.103.186:3000/" target="_blank" title="示例网站">点击这里查看示例网站</a>
## 主要功能

- 完整的 Markdown 支持:LaTex 公式、Mermaid 流程图、代码高亮等等
- 精心设计的 UI,响应式设计,支持深色模式,支持 PWA
- 极快的首屏加载速度(~100kb),支持流式响应
- 隐私安全,所有数据保存在用户浏览器本地
- 预制角色功能(面具),方便地创建、分享和调试你的个性化对话
- 海量的内置 prompt 列表
- 多国语言支持
## Access Token
* chatgpt官方登录,然后访问 [这里](http://chat.openai.com/api/auth/session) 拿 `Access Token`
* 也可以访问 [这里](http://ai-20230626.fakeopen.com/auth) 拿 `Access Token`
* `Access Token` 有效期 `14` 天,期间访问**不需要梯子**。这意味着你在手机上也可随意使用。
## 部署机器说明
* 在本地或者国内服务器都可以部署,不需要海外服务器
## 部署
* 确保安装了docker,启动了docker
* ${ACCESS_TOKEN}是ACCESS_TOKEN的值,${CODE}是设置密码,如果CODE=""则表示不设置密码
* docker pull xueandyue/next-web-pandora:v1
* docker run -e ACCESS_TOKEN="${ACCESS_TOKEN}" -e CODE="${CODE}" -p 3000:3000 -d xueandyue/next-web-pandora:v1
* 在浏览器访问http://服务器域名(ip):3000/
## 本地如何调试
* 本地安装python3,推荐python3.9 ,至少要python3.7以上版本
* 获取 Access Token
> 部署pandora项目
* 下载pandora项目:git clone https://github.com/pengzhile/pandora.git
* cd pandora
* 新建token.txt文件,把获取到的 Access Token放进去,保存文件
* pip install .
* pandora -s -t token.txt
> 部署本项目
* 安装yarn
* 下载本项目:git clone https://github.com/xueandyue/ChatGPT-3.5-AccessToken-Web.git
* cd ChatGPT-3.5-AccessToken-Web
* 修改.env.local的CODE,如果为空,则表示不需要密码访问
* yarn install && yarn dev
* 在浏览器访问http://localhost:3000/
>PS:如果不是同一机器上部署pandora项目和本项目,又或者部署pandora项目使用非8008端口,那需要修改本项目用到8008端口的url
## 开源协议
> 反对 996,从我开始。
[Anti 996 License](https://github.com/kattgu7/Anti-996-License/blob/master/LICENSE_CN_EN)
## 其他说明
* 项目是站在其他巨人的肩膀上,感谢!
* 喜欢的请给颗星,感谢!
* 不影响PHP是世界上最好的编程语言!
|
cristicretu/stacks
|
https://github.com/cristicretu/stacks
|
share your stack
|
# stacks
a lightweight website that you can self-host thanks to [Deta Space](https://deta.space/), and share with others ¬ [My own stack](https://stacks-2-r2358063.deta.app/).
to grab your own version, go to [stacks' discovery page](https://deta.space/discovery/@cristicretu/stacks), install and then just use the app!
<img width="726" alt="image" src="https://github.com/cristicretu/stacks/assets/45521157/2eaf65af-b59a-44fd-90bb-8b07fcc787d3">
## Running
Use the [space CLI](https://deta.space/docs/en/build/reference/cli#content) to create a new builder project on Deta Space.
```bash
space new
```
then run locally using
```bash
space dev
```
this will simulate the space environment, with a dev db, without any keys and what not.
To push your changes to space, and respectively create a release use
```bash
space push
# space release
```
## Contributing
i made this during an internal hackaton so i skipped a lot of steps
so feel free to modify / hack things around and submit a pr :)
|
liufeng2317/TorchInversion
|
https://github.com/liufeng2317/TorchInversion
|
A pytorch based acoustic wave propagator for wave inversion/Image
|
<!--
* @Author: LiuFeng(USTC) : [email protected]
* @Date: 2023-07-03 11:16:43
* @LastEditors: LiuFeng
* @LastEditTime: 2023-07-14 18:06:57
* @FilePath: /TorchInversion/README.md
* @Description:
* Copyright (c) 2023 by ${git_name} email: ${git_email}, All Rights Reserved.
-->
## Torch Waveform Inversion
**TorchInversion** is a powerful PyTorch-based framework that enables the development of a **2-D Acoustic Wave Propagator**, specifically designed for seismic imaging and inversion applications. By leveraging TorchInversion, users gain access to a versatile toolset that simplifies the experimentation process and harnesses the capabilities of PyTorch's **automatic differentiation**.
****
### Key Features
* **2-D Acoustic Wave Propagator**: TorchInversion empowers users to construct a robust and efficient 2-D Acoustic Wave Propagator, allowing for accurate simulations and computations in seismic imaging and inversion tasks.
* **Seamless Integration with Traditional Inversion Framework**: TorchInversion seamlessly integrates with traditional inversion frameworks, offering the flexibility to set any type of misfit function. Users can define their own custom misfit functions and obtain accurate gradients through TorchInversion. This capability enhances the versatility and adaptability of the inversion process, accommodating a wide range of use cases.
* **Integration with Physics-Based Deep Learning Framework**: TorchInversion can be seamlessly incorporated as a part of a physics-based deep learning framework for gradient backpropagation. It can be directly interfaced with neural networks, enabling researchers to combine the power of deep learning with physics-based simulations. This integration facilitates advanced research work in related domains.
* **Automated Inversion Operations**: We have integrated SWIT's associated gradient post-processing operations, optimization methods, and other functionalities into TorchInversion. This integration allows for automated inversion operations, streamlining the entire process from data processing to inversion results.
****
### Performance Validation
* **Accuracy of the gradient**: To ensure the accuracy and reliability of TorchInversion, extensive performance validation was conducted. We compared the gradients generated by our propagator against those of the well-established open-source library **SWIT 1.0**(https://github.com/Haipeng-ustc/SWIT-1.0). The results demonstrated that TorchInversion's gradients exhibit an error within 1/1000 of the reference library's gradients. This validation provides confidence in the accuracy and fidelity of the TorchInversion framework.

* **Computational velocity:** we also focused on computational efficiency. By leveraging PyTorch's capabilities, we modified all calculations to matrix operations and added a dimension to the gun records. This optimization allowed us to achieve comparable computational efficiency to that of the Fortran implementation in SWIT 1.0. TorchInversion's ability to harness the computational power of modern hardware ensures fast and efficient processing, enabling seamless integration into various workflows.
****
### Case Stydy for FWI
<details>
<summary><strong>Layer Model</strong></summary>
Details of this example can be found in [Layer Model forward](./demo/02_01_forward_LayeredModel.ipynb) and [Layer Model inversion](./demo/02_02_inversion_LayeredModel.ipynb)
* The **true model** and some setting of the model:
<div align="center"><img src="./demo/data/02_LayerModel/AD/model/True/observed_system.png" width=55% ></div>
* The **wavelet** and the **dampling** setting
<div float="left" align="center"><img src="./demo/data/02_LayerModel/AD/model/True/ricker.png" width = 48% style="display: inline-block; vertical-align: middle;"> <img src="./demo/data/02_LayerModel/AD/model/True/damp_global.png" width = 50% style="display: inline-block; vertical-align: middle;"></div>
* **Initial model** and **Gradient** Map of the first iteration
<div align="center"><img src="./demo/data/02_LayerModel/AD/model/Initial/model_init.png" width=50% style="display: inline-block; vertical-align: middle;"> <img src="./demo/data/02_LayerModel/AD/inv/grad/0.png" width = 48% style="display: inline-block; vertical-align: middle;"></div>
* The **inversion result**
<div align="center">
<img src="./demo/data/02_LayerModel/AD/inv/model/inversion.gif" width=80%>
</div>
It is important to note that we have not been particularly careful in adjusting the update parameters and processing the gradients in detail, but there are many details in the FWI work that can greatly improve the effectiveness and efficiency of the inversion
</details>
<details>
<summary><strong>Anomaly Layer Model</strong></summary>
Details of this example can be found in [Layer Anomaly Model forward](./demo/03_01_forward_LayerAnomaly.ipynb) and [Layer Anomaly Model inversion](./demo/03_02_inversion_LayereAnomaly.ipynb)
* The **true model** and some setting of the model:
<div align="center"><img src="./demo/data/03_LayerAnomaly/AD/model/True/observed_system.png" width=55%></div>
* The **wavelet** and the **dampling** setting
<div float="left" align="center"><img src="./demo/data/03_LayerAnomaly/AD/model/True/ricker.png" width = 48% style="display: inline-block; vertical-align: middle;"> <img src="./demo/data/03_LayerAnomaly/AD/model/True/damp_global.png" width = 50% style="display: inline-block; vertical-align: middle;"></div>
* **Initial model** and **Gradient** Map of the first iteration
<div align="center"><img src="./demo/data/03_LayerAnomaly/AD/model/Initial/model_init.png" width=50% style="display: inline-block; vertical-align: middle;"> <img src="./demo/data/03_LayerAnomaly/AD/inv/grad/0.png" width = 45% style="display: inline-block; vertical-align: middle;"></div>
* The **inversion result**
<div align="center">
<img src="./demo/data/03_LayerAnomaly/AD/inv/model/inversion.gif" width=80%>
</div>
</details>
<details>
<summary><strong>Marmousi Model</strong></summary>
Details of this example can be found in [Marmousi Model forward](./demo/04_01_forward_Marmousi2.ipynb) and [Marmousi Model inversion](./demo/04_02_inversion_Marmousi2.ipynb)
* The **true model** and some setting of the model:
<div align="center"><img src="./demo/data/04_Marmousi2/AD_shotInMiddle/model/True/observed_system.png" width=55% ></div>
* The **wavelet** and the **dampling** setting
<div float="left" align="center"><img src="./demo/data/04_Marmousi2/AD_shotInMiddle/model/True/ricker.png" width = 40% style="display: inline-block; vertical-align: middle;"> <img src="./demo/data/04_Marmousi2/AD_shotInMiddle/model/True/damp_global.png" width = 50% style="display: inline-block; vertical-align: middle;"></div>
* **Initial model** and **Gradient** Map of the first iteration
<div align="center"><img src="./demo/data/04_Marmousi2/AD_shotInMiddle/model/Initial/model_init.png" width=40% style="display: inline-block; vertical-align: middle;"> <img src="./demo/data/04_Marmousi2/AD_shotInMiddle/inv/grad/0.png" width = 50% style="display: inline-block; vertical-align: middle;"></div>
* The **inversion result**
<div align="center">
<img src="./demo/data/04_Marmousi2/AD_shotInMiddle/inv/model/inversion.gif" width=60%>
</div>
</details>
****
### Usage
You can simply clone the project and follow the example in the demo.
### Contact
Liu Feng @ USTC, Email: [email protected]
```python
@software{LiuFeng2317,
author = {Feng Liu, GuangYuan Zou},
title = {TorchInversion},
month = July,
year = 2023,
version = {v0.0.1},
}
```
|
BarackYoung/qRPC
|
https://github.com/BarackYoung/qRPC
|
a multi langeuage light RPC framework based on protobuf
|
qRPC简介
------
qRPC是一个基于TCP协议、基于Protobuf序列化和代码生成,跨语言的高效率轻量级RPC框架。
框架具有如下特点:
* 基于TCP协议的非阻塞IO(NIO)实现底层网络通信,吞吐量高。
* 基于Protobuf序列化,紧凑高效、高性能、跨语言、可拓展。
* 通过IDL(Interface Define Language)进行接口定义并生成代码
* 跨语言,支持Java、Go、C++、Python等多种语言
使用方法
----
需要了解RPC(Rmote Procedure Call),会用Protobuf([Proto3官方文档](https://protobuf.dev/programming-guides/proto3/ "Proto3官方文档")),如果你使用过Google gRPC,你将会非常容易上手。
#### Java:
* 引入Maven依赖
```
<dependency>
<groupId>io.github.barackyoung</groupId>
<artifactId>qrpc-core</artifactId>
<version>1.0.0.SNAPSHOT</version>
</dependency>
```
* 定义数据结构和服务接口
```
Syntax="proto3";
Option Java_Multiple_Files=false;
Option Java_Package="com.qrpc.demo";
Option Java_Outer_Classname="Demo";
Option Java_Generic_Services=true;
Package qrpc.demo;
Message request {
string message=1;
}
Message response {
string message=1;
}
Service DemoService{
Rpc sendMessage (request) returns (response) {};
}
```
* 生成数据结构和接口定义
```
Protoc -- java out=<path to your source root>-- proto path=<your proto path><proto filename>
```
* 服务端实现接口
```
Public class DemoServiceImpl extensions Demo.DemoService {
@Overrides
Public void sendMessage(RpcController controller, Demo.request request, RpcCallback<Demo.response> done){
System.out.println("received from client, message:"+request. getMessage ());
Demo.response response = Demo.response.newBuilder().setMessage("hi client").build();
Done.run(response);
}
}
```
* 客户端调用服务接口
```
Demo.requestrequest=Demo.request.newBuilder()
.setMessage("hi, server!")
.build();
//Synchronous call
UsageDemo.DemoService.BlockingInterface blockingStub=Demo.DemoService.newBlockingStub(SimpleBlockQRpcChannel.forAddress("127.0.0.1", 8888).build());
Demo.response response = blockingStub.sendMessage(null, request);
System.out.println("synchronous response:" + response.getMessage ());
//Asynchronous call
UsageDemo.DemoService.Stub stub = Demo.DemoService.newStub(SimpleQRpcChannel.forAddress("127.0.0.1", 8888).build());
Stub.sendMessage(null, request, new RpcCallback<Demo. response>() {
@ Override
Public void run(Demo.response parameter){
System.out.println ("asynchronous response:"+response. getMessage ());
}
});
```
#### Go: TODO
#### C++: TODO
待开发点
----
* spring-boot-starter,springboot自动配置,支持与springboot无缝结合
* 服务治理(支持ectd、zookeeper等服务发现),负载均衡调用
* 配置系统,比如线程数等参数可配置
* 云原生相关支持
* 测试用例
提示
--
项目处于起步阶段,代码易读懂,欢迎广大社会程序员、学生一起加入,一起学习造轮子,把理论与实践相结合,一起提高!
Introduction to qRPC
------
QRPC is an efficient and lightweight RPC framework based on the TCP protocol, Protobuf serialization, and code generation, spanning multiple languages.
The framework has the following characteristics:
* Non blocking IO (NIO) based on TCP protocol enables low-level network communication with high throughput.
* Based on Protobuf serialization, it is compact, efficient, high-performance, cross language, and scalable.
* Define interfaces and generate code through IDL (Interface Definition Language)
* Cross language support for multiple languages such as Java, Go, C++, Python, etc
Usage
----
Need to understand RPC (Rmote Procedure Call) and use Protobuf ([Proto3 official document]( https://protobuf.dev/programming-guides/proto3/ If you have used Google gRPC, it will be very easy for you to get started.
####Java:
* Introducing Maven dependencies
```
<dependency>
<groupId>io.github.barackyoung</groupId>
<artifactId>qrpc-core</artifactId>
<version>1.0.0.SNAPSHOT</version>
</dependency>
```
* Define data structures and service interfaces
```
Syntax="proto3";
Option Java_Multiple_Files=false;
Option Java_Package="com.qrpc.demo";
Option Java_Outer_Classname="Demo";
Option Java_Generic_Services=true;
Package qrpc.demo;
Message request {
string message=1;
}
Message response {
string message=1;
}
Service DemoService{
Rpc sendMessage (request) returns (response) {};
}
```
* Generate data structures and interface definitions
```
Protoc -- java out=<path to your source root>-- proto path=<your proto path><proto filename>
```
* Server implementation interface
```
Public class DemoServiceImpl extensions Demo.DemoService {
@Overrides
Public void sendMessage(RpcController controller, Demo.request request, RpcCallback<Demo.response> done){
System.out.println("received from client, message:"+request. getMessage ());
Demo.response response = Demo.response.newBuilder().setMessage("hi client").build();
Done.run(response);
}
}
```
* Client Call Service Interface
```
Demo.requestrequest=Demo.request.newBuilder()
.setMessage("hi, server!")
.build();
//Synchronous call
UsageDemo.DemoService.BlockingInterface blockingStub=Demo.DemoService.newBlockingStub(SimpleBlockQRpcChannel.forAddress("127.0.0.1", 8888).build());
Demo.response response = blockingStub.sendMessage(null, request);
System.out.println("synchronous response:" + response.getMessage ());
//Asynchronous call
UsageDemo.DemoService.Stub stub = Demo.DemoService.newStub(SimpleQRpcChannel.forAddress("127.0.0.1", 8888).build());
Stub.sendMessage(null, request, new RpcCallback<Demo. response>() {
@ Override
Public void run(Demo.response parameter){
System.out.println ("asynchronous response:"+response. getMessage ());
}
});
```
#### Go: TODO
#### C++: TODO
Points to be developed
----
* Spring boot starter, automatically configured for spring boot, supports seamless integration with spring boot
* Service governance (supporting service discovery such as ectd and zookeeper), load balancing calls
* Configure the system, such as configurable parameters such as thread count
* Cloud native related support
* Test Cases
prompt
--
The project is in its early stages and the code is easy to read. We welcome programmers and students from all walks of life to join us and learn how to build wheels together. We will combine theory with practice to improve together!
|
kpfleming/jinjanator
|
https://github.com/kpfleming/jinjanator
|
Jinja2 Command-Line Tool, reworked, again
|
# jinjanator
<a href="https://opensource.org"><img height="150" align="left" src="https://opensource.org/files/OSIApprovedCropped.png" alt="Open Source Initiative Approved License logo"></a>
[](https://github.com/kpfleming/jinjanator/actions?query=workflow%3ACI%20checks)
[](https://www.python.org/downloads/release/python-3812/)
[](https://spdx.org/licenses/Apache-2.0.html)
[](https://github.com/psf/black)
[](https://github.com/python/mypy)
[](https://github.com/astral-sh/ruff)
[](https://github.com/pypa/hatch)
[](https://github.com/pytest-dev/pytest)
This repo contains `jinjanator`, a CLI tool to render
[Jinja2](https://github.com/pallets/jinja/) templates. It is a fork of
`j2cli`, which itself was a fork of `jinja2-cli`, both of which are no
longer actively maintained.
Open Source software: [Apache License 2.0](https://spdx.org/licenses/Apache-2.0.html)
##
<!-- fancy-readme start -->
Features:
* Jinja2 templating
* INI, YAML, JSON data sources supported
* Environment variables can be used with or without data files
* Plugins can provide additional formats, filters, tests, and global
functions (see
[jinjanator-plugins](https://github.com/kpfleming/jinjanator-plugins)
for details)
## Installation
```
pip install jinjanator
```
## Available Plugins
* [jinjanator-plugin-ansible](https://pypi.org/project/jinjanator-plugin-ansible) -
makes Ansible's 'core' filters and tests available during template
rendering
## Tutorial
Suppose you have an NGINX configuration file template, `nginx.j2`:
```jinja2
server {
listen 80;
server_name {{ nginx.hostname }};
root {{ nginx.webroot }};
index index.htm;
}
```
And you have a JSON file with the data, `nginx.json`:
```json
{
"nginx":{
"hostname": "localhost",
"webroot": "/var/www/project"
}
}
```
This is how you render it into a working configuration file:
```bash
$ jinjanate nginx.j2 nginx.json > nginx.conf
```
The output is saved to `nginx.conf`:
```
server {
listen 80;
server_name localhost;
root /var/www/project;
index index.htm;
}
```
Alternatively, you can use the `-o nginx.conf` or `--output-file
nginx.conf`options to write directly to the file.
## Tutorial with environment variables
Suppose, you have a very simple template, `person.xml.j2`:
```jinja2
<data><name>{{ name }}</name><age>{{ age }}</age></data>
```
What is the easiest way to use jinjanator here?
Use environment variables in your Bash script:
```bash
$ export name=Andrew
$ export age=31
$ jinjanate /tmp/person.xml.j2
<data><name>Andrew</name><age>31</age></data>
```
## Using environment variables
Even when you use a data file as the data source, you can always
access environment variables using the `env()` function:
```jinja2
Username: {{ login }}
Password: {{ env("APP_PASSWORD") }}
```
Or, if you prefer, as a filter:
```jinja2
Username: {{ login }}
Password: {{ "APP_PASSWORD" | env }}
```
## CLI Reference
`jinjanate` accepts the following arguments:
* `template`: Jinja2 template file to render
* `data`: (optional) path to the data used for rendering.
The default is `-`: use stdin.
Options:
* `--format FMT, -f FMT`: format for the data file. The default is
`?`: guess from file extension. Supported formats are YAML (.yaml or
.yml), JSON (.json), INI (.ini), and dotenv (.env), plus any formats
provided by plugins you have installed.
* `--format-option OPT`: option to be passed to the parser for the
data format selected with `--format` (or auto-selected). This can be
specified multiple times. Refer to the documentation for the format
itself to learn whether it supports any options.
* `--help, -h`: generates a help message describing usage of the tool.
* `--import-env VAR, -e VAR`: import all environment variables into
the template as `VAR`. To import environment variables into the
global scope, give it an empty string: `--import-env=`. (This
will overwrite any existing variables with the same names!)
* `--output-file OUTFILE, -o OUTFILE`: Write rendered template to a
file.
* `--quiet`: Avoid generating any output on stderr.
* `--undefined`: Allow undefined variables to be used in templates (no
error will be raised).
* `--version`: prints the version of the tool and the Jinja2 package installed.
There is some special behavior with environment variables:
* When `data` is not provided (data is `-`), `--format` defaults to
`env` and thus reads environment variables.
## Usage Examples
Render a template using INI-file data source:
$ jinjanate config.j2 data.ini
Render using JSON data source:
$ jinjanate config.j2 data.json
Render using YAML data source:
$ jinjanate config.j2 data.yaml
Render using JSON data on stdin:
$ curl http://example.com/service.json | jinjanate --format=json config.j2 -
Render using environment variables:
$ jinjanate config.j2
Or use environment variables from a file:
$ jinjanate config.j2 data.env
Or pipe it: (note that you'll have to use "-" in this particular case):
$ jinjanate --format=env config.j2 - < data.env
## Data Formats
### dotenv
Data input from environment variables.
#### Options
This format does not support any options.
#### Usage
Render directly from the current environment variable values:
$ jinjanate config.j2
Or alternatively, read the values from a dotenv file:
```
NGINX_HOSTNAME=localhost
NGINX_WEBROOT=/var/www/project
NGINX_LOGS=/var/log/nginx/
```
And render with:
$ jinjanate config.j2 data.env
Or:
$ env | jinjanate --format=env config.j2
If you're going to pipe a dotenv file into `jinjanate`, you'll need to
use "-" as the second argument:
$ jinjanate config.j2 - < data.env
### INI
INI data input format.
#### Options
This format does not support any options.
#### Usage
data.ini:
```
[nginx]
hostname=localhost
webroot=/var/www/project
logs=/var/log/nginx
```
Usage:
$ jinjanate config.j2 data.ini
Or:
$ cat data.ini | jinjanate --format=ini config.j2
### JSON
JSON data input format.
#### Options
* `array-name`: accepts a single string (e.g. `array-name=foo`), which
must be a valid Python identifier and not a Python keyword. If this
option is specified, and the JSON data provided is an `array`
(sequence, list), the specified name will be used to make the data
available to the Jinja2 template. Errors will be generated if
`array` data is provided and this option is not specified, or if
this option is specified and the data provided is an `object`.
#### Usage
data.json:
```
{
"nginx":{
"hostname": "localhost",
"webroot": "/var/www/project",
"logs": "/var/log/nginx"
}
}
```
Usage:
$ jinjanate config.j2 data.json
Or:
$ cat data.json | jinjanate --format=ini config.j2
### YAML
YAML data input format.
#### Options
* `sequence-name`: accepts a single string (e.g. `sequence-name=foo`),
which must be a valid Python identifier and not a Python keyword. If
this option is specified, and the YAML data provided is a `sequence`
(array, list), the specified name will be used to make the data
available to the Jinja2 template. Errors will be generated if
`sequence` data is provided and this option is not specified, or if
this option is specified and the data provided is a `mapping`.
#### Usage
data.yaml:
```
nginx:
hostname: localhost
webroot: /var/www/project
logs: /var/log/nginx
```
Usage:
$ jinjanate config.j2 data.yml
Or:
$ cat data.yml | jinjanate --format=yaml config.j2
## Filters
### `env(varname, default=None)`
Use an environment variable's value in the template.
This filter is available even when your data source is something other
than the environment.
Example:
```jinja2
User: {{ user_login }}
Pass: {{ "USER_PASSWORD" | env }}
```
You can provide a default value:
```jinja2
Pass: {{ "USER_PASSWORD" | env("-none-") }}
```
For your convenience, it's also available as a global function:
```jinja2
User: {{ user_login }}
Pass: {{ env("USER_PASSWORD") }}
```
Notice that there must be quotes around the environment variable name
when it is a literal string.
<!-- fancy-readme end -->
## Chat
If you'd like to chat with the Jinjanator community, join us on
[Matrix](https://matrix.to/#/#jinjanator:km6g.us)!
## Credits
This tool was created from [j2cli](https://github.com/kolypto/j2cli),
which itself was created from
[jinja2-cli](https://github.com/mattrobenolt/jinja2-cli). It was
created to bring the project up to 'modern' Python coding, packaging,
and project-management standards, and to support plugins to provide
extensibility.
["Standing on the shoulders of
giants"](https://en.wikipedia.org/wiki/Standing_on_the_shoulders_of_giants)
could not be more true than it is in the Python community; this
project relies on many wonderful tools and libraries produced by the
global open source software community, in addition to Python
itself. I've listed many of them below, but if I've overlooked any
please do not be offended :-)
* [Attrs](https://github.com/python-attrs/attrs)
* [Black](https://github.com/psf/black)
* [Hatch-Fancy-PyPI-Readme](https://github.com/hynek/hatch-fancy-pypi-readme)
* [Hatch](https://github.com/pypa/hatch)
* [Jinja2](https://github.com/pallets/jinja/)
* [Mypy](https://github.com/python/mypy)
* [Pluggy](https://github.com/pytest-dev/pluggy)
* [Pytest](https://github.com/pytest-dev/pytest)
* [Ruff](https://github.com/astral-sh/ruff)
* [Towncrier](https://github.com/twisted/towncrier)
|
mshukor/UnIVAL
|
https://github.com/mshukor/UnIVAL
|
Official implementation of UnIVAL: Unified Model for Image, Video, Audio and Language Tasks.
|
<!---
Modified from OFA code.
Copyright 2022 The OFA-Sys Team.
All rights reserved.
This source code is licensed under the Apache 2.0 license found in the LICENSE file in the root directory.
-->
<p align="center">
<br>
<img src="examples/logo.png" width="400" />
<br>
<p>
<p align="center">
 <a href="https://unival-model.github.io/">Project Page</a>   |  <a href="https://arxiv.org/abs/2307.16184">Paper </a>  |  <a href="https://huggingface.co/spaces/mshukor/UnIVAL">Demo</a>  |  <a href="#datasets-and-checkpoints">Checkpoints</a> 
</p>
<p align="center">
<br>
<img src="examples/output.gif" width="1000" />
<br>
<p>
<br></br>
**UnIVAL** <i>is a 0.25B-parameter unified model that is multitask pretrained on image and video-text data and target image, video and audio-text downstream tasks.</i>
<br></br>
# Online Demos
Check out our demo on Huggingface Spaces: [Spaces](https://huggingface.co/spaces/mshukor/UnIVAL)
<p align="center">
<br>
<img src="examples/demo.png" width="1200" />
<br>
<p>
`General` means the pretrained model before finetuning.
To easily play with our model we also provide several notebooks: `VG.ipynb`, `VQA.ipynb`, `Captioning.ipynb`, `Video_Captioning.ipynb`, and `Audio_Captioning.ipynb`
<br></br>
# News
* **[2023.7.31]**: we provide [here](rewarded_soups.md) more details to reproduce the results with UnIVAL on Visual Grounding used in our [Rewarded soups](https://github.com/alexrame/rewardedsoups) work.
* **[2023.7.31]**: Released of UnIVAL code and model weights! We will release the scripts to train and evaluate audio/video tasks later.
<br></br>
# Table of Content
* [Quantitative Results](#results)
* [Installation](#installation)
* [Datasets and Checkpoints](#datasets-and-checkpoints)
* [Training and Inference](#training-and-inference)
* [Zero-shot Evaluation](#zero-shot-evaluation)
* [Parameter Efficient Finetuning (PEFT): Training only the linear layer](#parameter-efficient-finetuning)
* [Multimodal Model Merging/Weight Interpolation](#multimodal-model-merging)
* [Qualitative results](#qualitative-results)
* [Citation](#citation)
* [Acknowledgment](#acknowledgment)
<br></br>
# Results
Here are some results on several multimodal tasks.
<table border="1" width="100%">
<tr align="center">
<th>Task</th><th colspan="3">Visual Grounding</th><th>Image Captioning</th><th>VQA</th><th>Visual Entailment</th><th colspan="1">VideoQA</th><th colspan="1">Video Captioning</th><th colspan="2">Audio Captioning</th>
</tr>
<tr align="center">
<td>Dataset</td><td>RefCOCO</td><td>RefCOCO+</td><td>RefCOCOg</td><td>COCO</td><td>VQA v2</td><td>SNLI-VE</td><td>MSRVTT-QA</td><td>MSRVTT</td><td>AudioCaps</td>
</tr>
<tr align="center">
<td>Split</td><td>val/test-a/test-b</td><td>val/test-a/test-b</td><td>val-u/test-u</td><td>Karpathy test</td><td>test-dev/test-std</td><td>val/test</td><td>test</td><td>test</td><td>test</td>
</tr>
<tr align="center">
<td>Metric</td><td colspan="3">Acc.</td><td>CIDEr</td><td>Acc.</td><td>Acc.</td><td>Acc.</td><td>CIDEr</td><td>CIDEr</td>
</tr>
<tr align="center">
<td>UnIVAL</td><td>89.1 / 91.5 / 85.2</td><td>82.2 / 86.9 / 75.3</td><td>84.7 / 85.2</td><td>137.0</td><td>77.0 / 77.1</td><td>78.2 / 78.6</td><td>43.5</td><td>60.5</td><td>71.3</td>
</tr>
</table>
<br></br>
# Installation
## Requirements
* python 3.7.4
* pytorch 1.13+
* torchvision 0.14.1+
* JAVA 1.8 (for COCO evaluation)
We recommend to first install pytorch before other libraries:
```bash
git clone https://github.com/mshukor/UnIVAL.git
pip install -r requirements.txt
```
Download the following model for captioning evaluation:
```
python -c "from pycocoevalcap.spice.spice import Spice; tmp = Spice()"
```
<br></br>
# Datasets and Checkpoints
See [datasets.md](datasets.md) and [checkpoints.md](checkpoints.md).
<br></br>
# Training and Inference
The scripts to launch pretraining, finetuning and evaluation can be found in `run_scripts/` folder. Below we provide more details. The data are stored in `.tsv` files with different format depending on the training task.
To restore training you need to provide the last checkpoint <code>checkpoint_last.pt</code> to <code>--restore-file</code>, and pass <code>--reset-dataloader --reset-meters --reset-optimizer</code> as argument.
We use slurm to launch the training/evaluation.
## Image Processing
In some datasets, the images are encoded to base64 strings.
To do this transformation you can use the following code:
```python
from PIL import Image
from io import BytesIO
import base64
img = Image.open(file_name) # path to file
img_buffer = BytesIO()
img.save(img_buffer, format=img.format)
byte_data = img_buffer.getvalue()
base64_str = base64.b64encode(byte_data) # bytes
base64_str = base64_str.decode("utf-8") # str
```
## Pretraining
<details>
<summary><b>1. Prepare the Dataset</b></summary>
<p>
The format for pretraining tsv files are as follows:
<br />
<ul type="circle">
<li>
Each line contains uniq-id, image/video path, caption, question, answer, ground-truth objects (objects appearing in the caption or question), dataset name (source of the data) and task type (caption, qa or visual gronunding). Prepared for the pretraining tasks of visual grounding, grounded captioning, image-text matching, image captioning and visual question answering. In addition, the folder <code>negative_sample</code> contains three files <code>all_captions.txt</code>, <code>object.txt</code> and <code>type2ans.json</code>. The data in these files are used as negative samples for the image/video-text matching task.</li>
</p>
</details>
<details>
<summary><b>2. Pretraining</b></summary>
<p>
There is 3 scripts to train UnIVAL. <code>unival_s1.sh</code> for stage 1 training initialized from BART weights, <code>unival_s2.sh</code> for stage 2 training, initialized from the weights after stage 1, and <code>unival_s2_hs.sh</code> for high-resolution training during 1 epoch, initialized from the weights of stage 2. For example to launch for stage 1:
</p>
<pre>
cd run_scripts/pretraining
bash unival_s1.sh
</pre>
</details>
## Image Captioning
<details>
<summary><b>1. Prepare the Dataset & Checkpoints</b></summary>
<p>
Each image corresponds to only 1 caption in <code>caption_stage1_train.tsv</code> and corresponds to multiple captions in other TSV files (about 5 captions per image). Each line of the dataset represents a caption sample with the following format. The information of uniq-id, image-id, caption, predicted object labels (taken from <a href='https://github.com/pzzhang/VinVL'>VinVL</a>, not used), image base64 string are separated by tabs.
</p>
<pre>
162365 12455 the sun sets over the trees beyond some docks. sky&&water&&dock&&pole /9j/4AAQSkZJ....UCP/2Q==
</pre>
</details>
<details>
<summary><b>2. Finetuning</b></summary>
<p>
To finetune for image captioning:
</p>
<pre>
cd run_scripts/caption
sh unival_caption_stage_1.sh > unival_caption_stage_1.out
</pre>
</details>
<details>
<summary><b>3. Inference</b></summary>
<p>
You can use the following code for inference, after setting the right weights path:
</p>
<pre>
cd run_scripts/caption/eval ; sh eval_caption.sh # inference & evaluate
</pre>
</details>
## Visual Question Answering
<details>
<summary><b>1. Prepare the Dataset & Checkpoints</b></summary>
<p>
Following common practice, VG-QA samples are also included in the training data. To adapt to the seq2seq paradigm of OFA, we transform original VQA training questions with multiple golden answers into multiple training samples. For the original VQA validation set, we keep around 10k samples for our validation and utilize the other samples for training. Each line of the dataset represents a VQA sample with the following format. The information of question-id, image-id, question, answer (with confidence), predicted object labels (taken from <a href="https://github.com/pzzhang/VinVL">VinVL</a>, slightly brings around +0.1 accuracy improvement), image base64 string are separated by tabs.
</p>
<pre>
79459 79459 is this person wearing shorts? 0.6|!+no house&&short&&...&&sky /9j/4AAQS...tigZ/9k=
</pre>
</details>
<details>
<summary><b>2. Shuffle the Training Data</b></summary>
<p>
(Optional, but achieves better finetuning accuracy): If the disk storage is sufficient, we recommend to prepare the shuffled training data for each epoch in advance.
</p>
<pre>
cd dataset/vqa_data
ln vqa_train.tsv vqa_train_1.tsv
for idx in `seq 1 9`;do shuf vqa_train_${idx}.tsv > vqa_train_$[${idx}+1].tsv;done # each file is used for an epoch
</pre>
</details>
<details>
<summary><b>3. Finetuning</b></summary>
<p>
If you have shuffled the training data in the previous step, please correctly specify the training data path following the guide in the script comments.
</p>
<pre>
cd run_scripts/vqa
bash unival_vqa.sh
</pre>
</details>
<details>
<summary><b>4. Inference</b></summary>
<p>
We use <b>beam-search</b> during inference.
</p>
<pre>
cd run_scripts/vqa/eval
bash evaluate_vqa.sh # specify 'val' or 'test' in the script
</pre>
</details>
## Visual Grounding
<details>
<summary><b>1. Prepare the Dataset & Checkpoints</b></summary>
<p>
We use RefCOCO (split by UNC), RefCOCO+ (split by UNC) and RefCOCOg (split by UMD) datasets. See <a href='https://www.tensorflow.org/datasets/catalog/ref_coco'>RefCOCO</a> and <a href="https://github.com/lichengunc/refer">Refer</a> for more details. Note that in the original dataset, each region-coord (or bounding box) may corresponds to multiple descriptive texts. We split these texts into multiple samples so that the region-coord in each sample corresponds to only one text. Each line of the processed dataset represents a sample with the following format. The information of uniq-id, image-id, text, region-coord (separated by commas), image base64 string are separated by tabs.
</p>
<pre>
79_1 237367 A woman in a white blouse holding a glass of wine. 230.79,121.75,423.66,463.06 9j/4AAQ...1pAz/9k=
</pre>
</details>
<details>
<summary><b>2. Finetuning</b></summary>
<pre>
cd run_scripts/refcoco
sh unival_refcoco.sh > train_refcoco.out & # finetune for refcoco
sh unival_refcocoplus.sh > train_refcocoplus.out & # finetune for refcoco+
sh unival_refcocog.sh > train_refcocog.out & # finetune for refcocog
</pre>
</details>
<details>
<summary><b>3. Inference</b></summary>
<p>
Run the following commands for the evaluation.
</p>
<pre>
cd run_scripts/refcoco/eval ; sh eva_refcoco.sh # eva_refcocog.sh, eva_refcocoplus.sh
</pre>
</details>
## Visual Entailment
<details>
<summary><b>1. Prepare the Dataset & Checkpoints</b></summary>
<p>
Each line of the processed dataset represents a sample with the following format. The information of uniq-id, image-id, image base64 string, hypothesis, caption (or text premise), label are separated by tabs.
</p>
<pre>
252244149.jpg#1r1n 252244149 /9j/4AAQ...MD/2Q== a man in pink and gold is chewing on a wooden toothpick. a man in pink is chewing a toothpick on the subway. neutral
</pre>
</details>
<details>
<summary><b>2. Finetuning</b></summary>
<p>
Contrary to previous work (e.g. OFA) we do not use the text premise for this task.
</p>
<pre>
cd run_scripts/snli_ve
nohup sh unival_snli_ve.sh > train_snli_ve.out & # finetune for snli_ve
</pre>
</details>
<details>
<summary><b>3. Inference</b></summary>
<p>
Run the following command to obtain the results.
</p>
<pre>
cd run_scripts/snli_ve/eval ; sh eval_snli_ve.sh # specify 'dev' or 'test' in the script
</pre>
</details>
## Text-to-Image Generation
<details>
<summary><b>1. Prepare the Dataset & Checkpoints</b></summary>
<p>
The dataset zipfile <code>coco_image_gen.zip</code> contains <code>coco_vqgan_train.tsv</code>, <code>coco_vqgan_dev.tsv</code> and <code>coco_vqgan_full_test.tsv</code>. Each line of the dataset represents a sample with the following format. The information of uniq-id, image-code (produced by <a href="https://github.com/CompVis/taming-transformers">vqgan</a>, a list of integers separated by single-whitespaces), lowercased caption are separated by tabs.
</p>
<pre>
1 6674 4336 4532 5334 3251 5461 3615 2469 ...4965 4190 1846 the people are posing for a group photo.
</pre>
<p>
The checkpoint zipfile <code>image_gen_large_best.zip</code> contains <code>image_gen_large_best.pt</code>, <code>vqgan/last.ckpt</code>, <code>vqgan/model.yaml</code> and <code>clip/Vit-B-16.pt</code>.
</p>
</details>
<details>
<summary><b>2. Finetuning</b></summary>
<p>
We divide the finetuning process of image generating into two stages. In stage 1, we finetune OFA with cross-entropy loss. In stage 2, we select the last checkpoint of stage 1 and train with CLIP Score optimization. During the validation, the generated image will be dumped into <code>_GEN_IMAGE_PATH_</code>.
</p>
<pre>
cd run_scripts/image_gen
nohup sh unival_image_gen_stage_1.sh # stage 1, train with cross-entropy loss
nohup sh unival_image_gen_stage_2.sh # stage 2, load the last ckpt of stage1 and train with CLIP Score optimization
</pre>
</details>
<details>
<summary><b>4. Inference</b></summary>
<p>
Run the command below to generate your images.
</p>
<pre>
cd run_scripts/image_gen/eval ; sh eval_image_gen.sh # inference & evaluate (FID, IS and CLIP Score)
</pre>
</details>
<br>
<br>
# Zero-shot Evaluation
Here we provide the scripts for zero-shot evaluation on image-text tasks. You need to specify the path to pretrained model in each of these scripts:
* Image Caption on Nocaps: <code>caption/eval/eval_nocaps.sh</code>
* VQA on VizWiz: <code>vqa/eval/eval_vizwiz.sh</code>
* VQA on Nocaps: <code>vqa/eval/eval_okvqa.sh</code>
<br>
<br>
# Parameter Efficient Finetuning
## Training only the linear connection
Following [eP-ALM](https://github.com/mshukor/eP-ALM), we experiment with efficient finetuning by training only the linear connection between the modality spcific-encoders and the language model, while keeping all other parameters frozen:
* Image Caption on COCO: <code>caption/onlylinear/unival_caption_stage_s2_onlylinear.sh</code>
* Video Caption on MSRVTT: <code>caption/onlylinear/unival_video_caption_stage_s2_onlylinear.sh</code>
* Audio Caption on Audiocaps: <code>caption/onlylinear/unival_audio_caption_stage_s2_onlylinear.sh</code>
* VQA on VQAv2: <code>vqa/onlylinear/unival_vqa_s2_onlylinear.sh</code>
* Video QA on MSRVTT: <code>vqa/onlylinear/unival_video_vqa_s2_onlylinear.sh</code>
To finetune the stage-1 pretrained model, you can use the scripts with `s1`.
<br>
<br>
# Multimodal Model Merging
In this section we provide the details to reproduce the experiments for weight interpolation and different weight averaging experiments. The objective is to leverage the synergy between models finetuned on different multimodal tasks.
## Weight interpolation
To average several models, you can use `preprocess/average_save_models.py`. There is two options, either you average many models with uniform interpolation coefficient, or you interpolate between 2 models with interpolation coefficient from 0 to 1. However, you can also customise this script as you like.
Once you saved the interpolated weights, you can use the following scripts to evaluate the model:
```
## image-text tasks
sh caption/eval/eval_caption_avg.sh
sh refcoco/eval/eval_refcocoplus_avg.sh
sh snli_ve/eval/eval_snli_ve_avg.sh
sh vqa/eval/eval_vqa_avg.sh
## video-text tasks
sh vqa/eval/video/eval_video_qa_avg.sh
sh caption/eval/video/eval_msrvtt_video_caption_avg.sh
```
## Ratatouille Finetuning
For [Ratatouille finetuning](https://github.com/facebookresearch/ModelRatatouille), each one of the auxiliary models (e.g. models finetuned for captioning, vqa, visual grounding and visual entailment) are re-finetuned on the target task. At the end all obtained models are uniformly averaged.
The scripts to launch the finetuning and evaluation are in `averaging/ratatouille/`.
You need also to use the weight averaging script in `preprocess/average_save_models.py`.
## Fusing Finetuning
For [Fusing finetuning](https://arxiv.org/abs/2204.03044), first the auxiliary models are averaged, then finetuned on the target task.
The scripts to launch the finetuning and evaluation are in `averaging/fusing/`.
<br>
<br>
# Qualitative Results
Below we provide qualitative results for some tasks.
## Visual Grounding
<p align="center">
<br>
<img src="examples/results/vg.jpg" width="600" />
<br>
<p>
## Image Captioning
<p align="center">
<br>
<img src="examples/results/caption.jpg" width="600" />
<br>
<p>
## Open-Ended VQA
<p align="center">
<br>
<img src="examples/results/vqa.jpg" width="600" />
<br>
<p>
<br></br>
# Citation
If you find the work helpful, you can cite it using the following citation:
```
TODO
```
<br></br>
# Aknowledgment
This code is based mainly on the following repos:
* [OFA](https://github.com/OFA-Sys/OFA)
* [Fairseq](https://github.com/pytorch/fairseq)
* [taming-transformers](https://github.com/CompVis/taming-transformers)
We thank the authors for releasing their code.
|
chillgroup/vite-router-next
|
https://github.com/chillgroup/vite-router-next
|
File system based routing for React using Vite
|
# Vite Router Next
> File system based routing for React using Vite
## Features
Vite Router Next supports the following features:
- Route Groups
- Dynamic Routing
- Catch All Routing
- Loading UI
- [Error Boundary](https://reactrouter.com/en/main/route/route#errorelementerrorboundary)
- [Loader](https://reactrouter.com/en/main/route/loader), [`useLoaderData`](https://reactrouter.com/en/main/hooks/use-loader-data) and [`defer`](https://reactrouter.com/en/main/guides/deferred)
## Documentation
To check out docs, visit [https://chillgroup.github.io/vite-router-next/](https://chillgroup.github.io/vite-router-next/)
### License
[MIT](./LICENSE).
|
urazakgul/python-elo-rating
|
https://github.com/urazakgul/python-elo-rating
| null |
Aşağıda yer alan 50 puzzle ve Python için Elo rating hesaplaması Christian Mayer'ın ***Coffee Break Python*** isimli kitabından alınmıştır. Kitabın pdf versiyonuna [buradan](https://rupert.id.au/python/PDF/2019_08_18_CoffeeBreakPython_paperback_version.pdf) ulaşabilirsiniz.
**Elo Rating Sistemi nedir?**
Elo rating sistemi, sıfır toplamlı oyunlarda iki oyuncunun göreceli yetenek seviyelerini hesaplamak için kullanılan bir yöntemdir. Sıfır toplamlı oyunlar ise bir oyuncunun kazancının diğer oyuncunun kaybıyla tam olarak denk olduğu oyunlardır. Toplam kazanç veya kayıp sıfır olduğu için bu oyunlar sıfır toplamlı olarak isimlendirilir. Örneğin, satranç gibi bir sıfır toplamlı oyunda bir oyuncunun kazanması diğer oyuncunun kaybetmesine eşittir ve toplam kazanç veya kayıp sıfırdır.
**Elo Rating Yetenek Seviyeleri Nelerdir?**
| Elo Puanı | Yetenek Seviyesi |
|---------|---------|
| 2500 | World Class |
| 2400-2500 | Grandmaster |
| 2300-2400 | International Master |
| 2200-2300 | Master |
| 2100-2200 | National Master |
| 2000-2100 | Master Candidate |
| 1900-2000 | Authority |
| 1800-1900 | Professional |
| 1700-1800 | Expert |
| 1600-1700 | Experienced Intermediate |
| 1500-1600 | Intermediate |
| 1400-1500 | Experienced Learner |
| 1300-1400 | Learner |
| 1200-1300 | Scholar |
| 1100-1200 | Autodidact |
| 1000-1100 | Beginner |
| 0-1000 | Basic Knowledge |
**Nasıl Kullanılacak?**
Bir başlangıç puanı ile başlayacaksınız. Eğer Python seviyeniz *beginner* ise 1000, *intermediate* ise 1500 ve *advanced* ise 2000 ile başlayın. Ardından çözüm aşamasında soruyu doğru cevaplarsanız tabloda karşısına denk gelen puanı Elo puanınıza ekleyin; yanlış cevaplarsanız da tabloda karşısına denk gelen puanı Elo puanınızdan çıkarın.
Örnek: Başlangıç puanınızı *intermediate* olduğunuz için 1500 olarak yazdığınızı varsayalım.
```python
print('hello world')
```
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 41 | -14 |
| 500 - 1000 | 16 | -39 |
| 1000 - 1500 | 8 | -47 |
| 1500 - 2000 | 8 | -47 |
| > 2000 | 8 | -47 |
Örnek olarak yazılan 1500 puanı 1500-2000 aralığına denk geliyor. Doğru cevap verirseniz 1500-2000 aralığına denk gelen doğru cevap puanı 8'i başlangıç puanınıza ekleyeceksiniz. Bu durumda yeni Elo puanınız 1508 olacak. Yanlış cevap verirseniz 1500-2000 aralığına denk gelen yanlış cevap puanı 47'yi başlangıç puanınızdan çıkaracaksınız. Bu durumda yeni Elo puanınız 1453 olacak. Bir sonraki puzzle için aynı işlemleri yeni Elo puanınız (örnekte 1508 veya 1453) üzerinden yapacaksınız. Bu durumda doğru ise 1500-2000; yanlış ise 1000-1500 aralığına denk gelecek.
Aşağıda, puzzle çözdükçe Elo puanının nasıl değişebileceği gösteren bir grafik bulunmaktadır.
<img src="your_elo.PNG" alt="Elo Rating" width="700" height="500">
Başlangıç puanınızdan bağımsız olarak puzzle çözdükçe gerçek seviyenize yakınsayacaksınız.
50 başlığın bulunduğu puzzle'da kodları okuyup anlama becerinizi ölçeceksiniz. Cevaplara *Cevabı Göster*'e tıklayarak ulaşabilirsiniz.
## 1. Hello World
```python
print('hello world')
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
hello world
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 41 | -14 |
| 500 - 1000 | 16 | -39 |
| 1000 - 1500 | 8 | -47 |
| 1500 - 2000 | 8 | -47 |
| > 2000 | 8 | -47 |
## 2. Variables & Float Division
```python
x = 55 / 11
print(x)
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
5.0
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 43 | -12 |
| 500 - 1000 | 21 | -34 |
| 1000 - 1500 | 9 | -46 |
| 1500 - 2000 | 8 | -47 |
| > 2000 | 8 | -47 |
## 3. Basic Arithmetic Operations
```python
x = 50 * 2 + (60 - 20) / 4
print(x)
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
110.0
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 44 | -11 |
| 500 - 1000 | 23 | -32 |
| 1000 - 1500 | 9 | -46 |
| 1500 - 2000 | 8 | -47 |
| > 2000 | 8 | -47 |
## 4. Comments and Strings
```python
# This is a comment
answer = 42 # the answer
# Now back to the puzzle
text = "# Is this a comment?"
print(text)
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
# Is this a comment?
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 45 | -10 |
| 500 - 1000 | 24 | -31 |
| 1000 - 1500 | 9 | -46 |
| 1500 - 2000 | 8 | -47 |
| > 2000 | 8 | -47 |
## 5. Index and Concatenate Strings
```python
x = 'silent'
print(x[2] + x[1] + x[0]
+ x[5] + x[3] + x[4])
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
listen
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 45 | -10 |
| 500 - 1000 | 27 | -28 |
| 1000 - 1500 | 10 | -45 |
| 1500 - 2000 | 8 | -47 |
| > 2000 | 8 | -47 |
## 6. List Indexing
```python
squares = [1, 4, 9, 16, 25]
print(squares[0])
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
1
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 45 | -10 |
| 500 - 1000 | 27 | -28 |
| 1000 - 1500 | 10 | -45 |
| 1500 - 2000 | 8 | -47 |
| > 2000 | 8 | -47 |
## 7. Slicing in Strings
```python
word = "galaxy"
print(len(word[1:]))
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
5
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 46 | -9 |
| 500 - 1000 | 29 | -26 |
| 1000 - 1500 | 10 | -45 |
| 1500 - 2000 | 8 | -47 |
| > 2000 | 8 | -47 |
## 8. Integer Division
```python
x = 50 // 11
print(x)
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
4
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 46 | -9 |
| 500 - 1000 | 29 | -26 |
| 1000 - 1500 | 10 | -45 |
| 1500 - 2000 | 8 | -47 |
| > 2000 | 8 | -47 |
## 9. String Manipulation Operators
```python
print(3 * 'un' + 'ium')
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
unununium
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 46 | -9 |
| 500 - 1000 | 30 | -25 |
| 1000 - 1500 | 10 | -45 |
| 1500 - 2000 | 8 | -47 |
| > 2000 | 8 | -47 |
## 10. Implicit String Concatenation
```python
x = 'py' 'thon'
print(x)
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
python
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 46 | -9 |
| 500 - 1000 | 30 | -25 |
| 1000 - 1500 | 10 | -45 |
| 1500 - 2000 | 8 | -47 |
| > 2000 | 8 | -47 |
## 11. Sum and Range Functions
```python
print(sum(range(0, 7)))
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
21
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 46 | -9 |
| 500 - 1000 | 31 | -24 |
| 1000 - 1500 | 11 | -44 |
| 1500 - 2000 | 8 | -47 |
| > 2000 | 8 | -47 |
## 12. Append Function for Lists
```python
cubes = [1, 8, 27]
cubes.append(4 ** 3)
print(cubes)
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
[1, 8, 27, 64]
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 46 | -9 |
| 500 - 1000 | 32 | -23 |
| 1000 - 1500 | 11 | -44 |
| 1500 - 2000 | 8 | -47 |
| > 2000 | 8 | -47 |
## 13. Overshoot Slicing
```python
word = "galaxy"
print(word[4:50])
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
xy
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 46 | -9 |
| 500 - 1000 | 32 | -23 |
| 1000 - 1500 | 11 | -44 |
| 1500 - 2000 | 8 | -47 |
| > 2000 | 8 | -47 |
## 14. Modulo Operator
```python
x = 51 % 3
print(x)
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
0
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 46 | -9 |
| 500 - 1000 | 32 | -23 |
| 1000 - 1500 | 11 | -44 |
| 1500 - 2000 | 8 | -47 |
| > 2000 | 8 | -47 |
## 15. Branching
```python
def if_confusion(x, y):
if x > y:
if x - 5 > 0:
x = y
return "A" if y == y + y else "B"
elif x + y > 0:
while x > y: x -= 1
while y > x: y -= 1
if x == y:
return "E"
else:
if x - 2 > y - 4:
x_old = x
x = y * y
y = 2 * x_old
if (x - 4) ** 2 > (y - 7) ** 2:
return "C"
return "D"
return "H"
print(if_confusion(3, 7))
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
H
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 46 | -9 |
| 500 - 1000 | 33 | -22 |
| 1000 - 1500 | 11 | -44 |
| 1500 - 2000 | 8 | -47 |
| > 2000 | 8 | -47 |
## 16. Negative Indices
```python
x = 'cool'
print(x[-1] + x[-2]
+ x[-4] + x[-3])
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
loco
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 46 | -9 |
| 500 - 1000 | 33 | -22 |
| 1000 - 1500 | 11 | -44 |
| 1500 - 2000 | 8 | -47 |
| > 2000 | 8 | -47 |
## 17. The For Loop
```python
words = ['cat', 'mouse']
for word in words:
print(len(word))
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
3 <br>
5
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 46 | -9 |
| 500 - 1000 | 34 | -21 |
| 1000 - 1500 | 11 | -44 |
| 1500 - 2000 | 8 | -47 |
| > 2000 | 8 | -47 |
## 18. Functions and Naming
```python
def func(x):
return x + 1
f = func
print(f(2) + func(2))
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
6
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 36 | -19 |
| 1000 - 1500 | 12 | -43 |
| 1500 - 2000 | 8 | -47 |
| > 2000 | 8 | -47 |
## 19. Concatenating Slices
```python
word = "galaxy"
print(word[:-2] + word[-2:])
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
galaxy
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 38 | -17 |
| 1000 - 1500 | 14 | -41 |
| 1500 - 2000 | 8 | -47 |
| > 2000 | 8 | -47 |
## 20. Arbitrary Arguments
```python
def func(a, *args):
print(a)
for arg in args:
print(arg)
func("A", "B", "C")
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
A <br>
B <br>
C
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 40 | -15 |
| 1000 - 1500 | 15 | -40 |
| 1500 - 2000 | 8 | -47 |
| > 2000 | 8 | -47 |
## 21. Indirect Recursion
```python
def ping(i):
if i > 0:
return pong(i - 1)
return "0"
def pong(i):
if i > 0:
return ping(i - 1)
return "1"
print(ping(29))
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
1
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 41 | -14 |
| 1000 - 1500 | 16 | -39 |
| 1500 - 2000 | 8 | -47 |
| > 2000 | 8 | -47 |
## 22. String Slicing
```python
word = "bender"
print(word[1:4])
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
end
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 41 | -14 |
| 1000 - 1500 | 17 | -38 |
| 1500 - 2000 | 8 | -47 |
| > 2000 | 8 | -47 |
## 23. Slice Assignment
```python
customers = ['Marie', 'Anne', 'Donald']
customers[2:4] = ['Barack', 'Olivia', 'Sophia']
print(customers)
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
['Marie', 'Anne', 'Barack', 'Olivia', 'Sophia']
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 43 | -12 |
| 1000 - 1500 | 20 | -35 |
| 1500 - 2000 | 8 | -47 |
| > 2000 | 8 | -47 |
## 24. Default Arguments
```python
def ask(prompt, retries=4, output='Error'):
for _ in range(retries):
response = input(prompt).lower()
if response in ['y', 'yes']:
return True
if response in ['n', 'no']:
return False
print(output)
print(ask('Want to know the answer?', 5))
```
`ask('Want to know the answer?', 5)` geçerli bir fonksiyon çağrısı mıdır?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
Yes
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 44 | -11 |
| 1000 - 1500 | 22 | -33 |
| 1500 - 2000 | 9 | -46 |
| > 2000 | 8 | -47 |
## 25. Slicing and the len() Function
```python
letters = ['a', 'b', 'c', 'd']
print(len(letters[1:-1]))
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
2
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 45 | -10 |
| 1000 - 1500 | 25 | -30 |
| 1500 - 2000 | 9 | -46 |
| > 2000 | 8 | -47 |
## 26. Nested Lists
```python
a = ['a', 'b']
n = [1, 2]
x = [a, n]
print(x[1])
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
[1, 2]
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 45 | -10 |
| 1000 - 1500 | 27 | -28 |
| 1500 - 2000 | 9 | -46 |
| > 2000 | 8 | -47 |
## 27. Clearing Sublists
```python
letters = ['a', 'b', 'c',
'd', 'e', 'f', 'g']
letters[1:] = []
print(letters)
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
['a']
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 45 | -10 |
| 1000 - 1500 | 27 | -28 |
| 1500 - 2000 | 10 | -45 |
| > 2000 | 8 | -47 |
## 28. The Fibonacci Series
```python
a, b = 0, 1
while b < 5:
print(b)
a, b = b, a + b
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
1 1 2 3
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 46 | -9 |
| 1000 - 1500 | 30 | -25 |
| 1500 - 2000 | 10 | -45 |
| > 2000 | 8 | -47 |
## 29. The continue Statement and the Modulo Operator
```python
for num in range(2, 8):
if not num % 2:
continue
print(num)
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
3 <br>
5 <br>
7
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 46 | -9 |
| 1000 - 1500 | 31 | -24 |
| 1500 - 2000 | 10 | -45 |
| > 2000 | 8 | -47 |
## 30. Indexing Revisited and The Range Sequence
```python
print(range(5, 10)[-1])
print(range(0, 10, 3)[2])
print(range(-10, -100, -30)[1])
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
9 <br>
6 <br>
-40
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 46 | -9 |
| 1000 - 1500 | 33 | -22 |
| 1500 - 2000 | 11 | -44 |
| > 2000 | 8 | -47 |
## 31. Searching a Sorted Matrix
```python
def matrix_find(matrix, value):
if not matrix or not matrix[0]:
return False
j = len(matrix) - 1
for row in matrix:
while row[j] > value:
j = j - 1
if j == -1:
return False
if row[j] == value:
return True
return False
matrix = [[3, 4, 4, 6],
[6, 8, 11, 12],
[6, 8, 11, 15],
[9, 11, 12, 17]]
print(matrix_find(matrix=matrix, value=11))
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
True
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 46 | -9 |
| 1000 - 1500 | 33 | -22 |
| 1500 - 2000 | 11 | -44 |
| > 2000 | 8 | -47 |
## 32. Maximum Profit Algorithm
```python
def maximum_profit(prices):
'''Maximum profit of a single buying low and selling high'''
profit = 0
for i, buy_price in enumerate(prices):
sell_price = max(prices[i:])
profit = max(profit, sell_price - buy_price)
return profit
# Ethereum daily prices in Dec 2017 ($)
eth_prices = [455, 460, 465, 451, 414, 415, 441]
print(maximum_profit(prices=eth_prices))
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
27
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 47 | -8 |
| 1000 - 1500 | 36 | -19 |
| 1500 - 2000 | 12 | -43 |
| > 2000 | 8 | -47 |
## 33. Bubble Sort Algorithm
```python
def bubble_sort(lst):
'''Implementation of bubble sort algorithm'''
for border in range(len(lst)-1, 0, -1):
for i in range(border):
if lst[i] > lst[i + 1]:
lst[i], lst[i + 1] = lst[i + 1], lst[i]
return lst
list_to_sort = [27, 0, 71, 70, 27, 63, 90]
print(bubble_sort(lst=list_to_sort))
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
[0, 27, 27, 63, 70, 71, 90]
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 47 | -8 |
| 1000 - 1500 | 38 | -17 |
| 1500 - 2000 | 14 | -41 |
| > 2000 | 8 | -47 |
## 34. Joining Strings
```python
def concatenation(*args, sep="/"):
return sep.join(args)
print(concatenation("A", "B", "C", sep=","))
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
A,B,C
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 47 | -8 |
| 1000 - 1500 | 37 | -18 |
| 1500 - 2000 | 13 | -42 |
| > 2000 | 8 | -47 |
## 35. Arithmetic Calculations
```python
x = 5 * 3.8 - 1
print(x)
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
18.0
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 47 | -8 |
| 1000 - 1500 | 39 | -16 |
| 1500 - 2000 | 15 | -40 |
| > 2000 | 8 | -47 |
## 36. Binary Search
```python
def bsearch(l, value):
lo, hi = 0, len(l)-1
while lo <= hi:
mid = (lo + hi) // 2
if l[mid] < value:
lo = mid + 1
elif value < l[mid]:
hi = mid - 1
else:
return mid
return -1
l = [0, 1, 2, 3, 4, 5, 6]
x = 6
print(bsearch(l,x))
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
6
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 47 | -8 |
| 1000 - 1500 | 40 | -15 |
| 1500 - 2000 | 15 | -40 |
| > 2000 | 8 | -47 |
## 37. Modifying Lists in Loops
```python
words = ['cat', 'mouse', 'dog']
for word in words[:]:
if len(word) > 3:
words.insert(0, word)
print(words[0])
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
mouse
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 47 | -8 |
| 1000 - 1500 | 40 | -15 |
| 1500 - 2000 | 15 | -40 |
| > 2000 | 8 | -47 |
## 38. The Lambda Function
```python
def make_incrementor(n):
return lambda x: x + n
f = make_incrementor(42)
print(f(0))
print(f(1))
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
43
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 47 | -8 |
| 1000 - 1500 | 42 | -13 |
| 1500 - 2000 | 17 | -38 |
| > 2000 | 8 | -47 |
## 39. Multi-line Strings and the New-line Character
```python
print("""
A
B
C
""" == "\nA\nB\nC\n")
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
True
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 47 | -8 |
| 1000 - 1500 | 43 | -12 |
| 1500 - 2000 | 20 | -35 |
| > 2000 | 9 | -46 |
## 40. Escaping
```python
print('P"yt\'h"on')
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
P"yt'h"on
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 47 | -8 |
| 1000 - 1500 | 43 | -12 |
| 1500 - 2000 | 21 | -34 |
| > 2000 | 9 | -46 |
## 41. Fibonacci
```python
def fibo(n):
"""Return list containing
Fibonacci series up to n.
"""
result = []
a, b = 0, 1
while a < n:
result.append(a)
a, b = b, a + b
return result
fib100 = fibo(100)
print(fib100[-1] ==
fib100[-2] + fib100[-3])
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
True
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 47 | -8 |
| 1000 - 1500 | 44 | -11 |
| 1500 - 2000 | 22 | -33 |
| > 2000 | 9 | -46 |
## 42. Quicksort
```python
def qsort1(L):
if L:
return qsort1([x for x in L[1:] if x < L[0]]) + L[:1] \
+ qsort1([x for x in L[1:] if x >= L[0]])
return []
def qsort2(L):
if L:
return L[:1] + qsort2([x for x in L[1:] if x < L[0]]) \
+ qsort2([x for x in L[1:] if x >= L[0]])
return []
print(qsort1([0, 33, 22]))
print(qsort2([0, 33, 22]))
```
Listeyi doğru şekilde sıralayan fonksiyon hangisidir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
qsort1
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 47 | -8 |
| 1000 - 1500 | 44 | -11 |
| 1500 - 2000 | 23 | -32 |
| > 2000 | 9 | -46 |
## 43. Unpacking Keyword Arguments with Dictionaries
```python
def func(val1=3, val2=4, val3=6):
return val1 + val2 + val3
values = {"val1":9, "val3":-1}
print(func(**values))
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
12
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 47 | -8 |
| 1000 - 1500 | 44 | -11 |
| 1500 - 2000 | 23 | -32 |
| > 2000 | 9 | -46 |
## 44. Infinity
```python
print("Answer")
while True:
pass
print("42")
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
Answer
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 47 | -8 |
| 1000 - 1500 | 45 | -10 |
| 1500 - 2000 | 25 | -30 |
| > 2000 | 9 | -46 |
## 45. Graph Traversal
```python
def has_path(graph, v_start, v_end, path_len=0):
'''Graph has path from v_start to v_end'''
# Traverse each vertex only once
if path_len >= len(graph):
return False
# Direct path from v_start to v_end?
if graph[v_start][v_end]:
return True
# Indirect path via neighbor v_nbor?
for v_nbor, edge in enumerate(graph[v_start]):
if edge: # between v_start and v_nbor
if has_path(graph, v_nbor, v_end, path_len + 1):
return True
return False
# The graph represented as adjancy matrix
G = [[1, 1, 0, 0, 0],
[0, 1, 0, 0, 0],
[0, 0, 1, 0, 0],
[0, 1, 1, 1, 0],
[1, 0, 0, 1, 1]]
print(has_path(graph=G, v_start=3, v_end=0))
```
3 ve 0 köşeleri arasında bir yol var mıdır?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
False
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 47 | -8 |
| 1000 - 1500 | 45 | -10 |
| 1500 - 2000 | 26 | -29 |
| > 2000 | 9 | -46 |
## 46. Lexicographical Sorting
```python
pairs = [(1, 'one'),
(2, 'two'),
(3, 'three'),
(4, 'four')]
# lexicographical sorting (ascending)
pairs.sort(key=lambda pair: pair[1])
print(pairs[0][1])
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
four
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 47 | -8 |
| 1000 - 1500 | 45 | -10 |
| 1500 - 2000 | 27 | -28 |
| > 2000 | 10 | -45 |
## 47. Chaining of Set Operations
```python
# popular instagram accounts
# (millions followers)
inst = {"@instagram":232,
"@selenagomez":133,
"@victoriassecret":59,
"@cristiano":120,
"@beyonce":111,
"@nike":76}
# popular twitter accounts
# (millions followers)
twit = {"@cristiano":69,
"@barackobama":100,
"@ladygaga":77,
"@selenagomez":56,
"@realdonaldtrump":48}
inst_names = set(filter(lambda key: inst[key]>60, inst.keys()))
twit_names = set(filter(lambda key: twit[key]>60, twit.keys()))
superstars = inst_names.intersection(twit_names)
print(list(superstars)[0])
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
@cristiano
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 47 | -8 |
| 1000 - 1500 | 45 | -10 |
| 1500 - 2000 | 27 | -28 |
| > 2000 | 10 | -45 |
## 48. Basic Set Operations
```python
words_list = ["bitcoin",
"cryptocurrency",
"wallet"]
crawled_text = '''
Research produced by the University of
Cambridge estimates that in 2017,
there are 2.9 to 5.8 million unique
users using a cryptocurrency wallet,
most of them using bitcoin.
'''
split_text = crawled_text.split()
res1 = True in map(lambda word: word in split_text, words_list)
res2 = any(word in words_list for word in split_text)
print(res1 == res2)
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
True
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 47 | -8 |
| 1000 - 1500 | 45 | -10 |
| 1500 - 2000 | 28 | -27 |
| > 2000 | 10 | -45 |
## 49. Simple Unicode Encryption
```python
def encrypt(text):
encrypted = map(lambda c: chr(ord(c) + 2), text)
return ''.join(encrypted)
def decrypt(text):
decrypted = map(lambda c: chr(ord(c) - 2), text)
return ''.join(decrypted)
s = "xtherussiansarecomingx"
print(decrypt(encrypt(encrypt(s))) == encrypt(s))
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
True
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 47 | -8 |
| 1000 - 1500 | 46 | -9 |
| 1500 - 2000 | 28 | -27 |
| > 2000 | 10 | -45 |
## 50. The Guess and Check Framework
```python
import random
def guess(a, b):
return random.randint(a, b)
def check(x, y):
return y ** 2 == x
x = 100
left, right = 0, x
y = guess(left, right)
while not check(x, y):
y = guess(left, right)
print(y)
```
Bu kodun çıktısı nedir?
<details>
<summary style="cursor: pointer;">Cevabı Göster</summary>
10
</details>
| Elo Puanınız | Doğru | Yanlış |
|---------|---------|---------|
| 0 - 500 | 47 | -8 |
| 500 - 1000 | 47 | -8 |
| 1000 - 1500 | 46 | -9 |
| 1500 - 2000 | 29 | -26 |
| > 2000 | 10 | -45 |
|
giacomogaglione/chef-gpt
|
https://github.com/giacomogaglione/chef-gpt
|
Customizable recipe generator powered by OpenAI and ChatGPT. Built with Next.Js Tailwind CSS Radix UI Supabase Clerk.
|
# Chef Genie
Customizable recipe generator powered by OpenAI and ChatGPT.

> **Note**
This project is still in development and is not ready for production use.
## Features
- **Framework**: [Next.js](https://nextjs.org/)
- **Database**: [Supabase](https://supabase.com/)
- **Authentication**: [Clerk](https://clerk.com/)
- **Styling**: [Tailwind CSS](https://tailwindcss.com/)
- **Primitives**: [Radix UI](https://radix-ui.com/)
- **Components**: [shadcn/ui](https://ui.shadcn.com/)
- **Icons**: [Lucide](https://lucide.dev/)
- **Deployment**: [Vercel](https://vercel.com/)
- **Analytics**: [Vercel Analytics](https://vercel.com/analytics/)
- [Zod](https://zod.dev/) for TypeScript-first schema declaration and validation
- Automatic import sorting with `@ianvs/prettier-plugin-sort-imports`
## Running Locally
1. Clone the repository and install the dependencies
```bash
git clone https://github.com/giacomogaglione/chef-genie.git
cd chef-genie
pnpm install
pnpm dev
```
2. Copy the `.env.example` to `.env` and update the variables.
```bash
cp .env.example .env
```
3. Start the development server
```bash
pnpm run dev
```
## License
Licensed under the [MIT license](https://github.com/giacomogaglione/chef-gpt/blob/main/LICENSE.md).
|
matkhl/leagueoflegends
|
https://github.com/matkhl/leagueoflegends
| null |
## leagueoflegends
Simple source including:
- recall tracker (outdated)
- cooldown tracker (outdated)
- orbwalker
- champion modules
- simple prediction & targetselection
- skinchanger (based on R3nzSkin source)
*Updated for patch 13.14.522 (minipatch after 13.14 release)*
### How to use the Injector
In order for the injector to work, you need to put two compiled [Guided Hacking injector library](https://github.com/Broihon/GH-Injector-Library) files inside the output directory.

### Default hotkeys
- Open menu - Shift
- Attack - Space
- Uninject - Esc
|
Kazuhito00/YOLOPv2-ONNX-Sample
|
https://github.com/Kazuhito00/YOLOPv2-ONNX-Sample
|
YOLOPv2のPythonでのONNX推論サンプル
|
# YOLOPv2-ONNX-Sample
[YOLOPv2](https://github.com/CAIC-AD/YOLOPv2)のPythonでのONNX推論サンプルです。<br>
ONNX変換自体を試したい方はColaboratoryで[Convert2ONNX.ipynb](Convert2ONNX.ipynb)を使用ください。<br>
https://github.com/Kazuhito00/YOLOPv2-ONNX-Sample/assets/37477845/ab214b79-4d08-4cc1-b6be-0f5f16501fe1
# Requirement
* OpenCV 3.4.2 or later
* onnxruntime 1.9.0 or later
# Demo
デモの実行方法は以下です。
```bash
python sample.py
```
* --video<br>
動画ファイルの指定<br>
デフォルト:video/sample.mp4
* --model<br>
ロードするモデルの格納パス<br>
デフォルト:weight/YOLOPv2.onnx ※ファイルが無い場合ダウンロードを行います
* --input_size<br>
モデルの入力サイズ<br>
デフォルト:640,640
* --score_th<br>
クラス判別の閾値<br>
デフォルト:0.3
* --nms_th<br>
NMSの閾値<br>
デフォルト:0.45
# Reference
* [CAIC-AD/YOLOPv2](https://github.com/CAIC-AD/YOLOPv2)
# Author
高橋かずひと(https://twitter.com/KzhtTkhs)
# License
YOLOPv2-ONNX-Sample is under [MIT License](LICENSE).
# License(Movie)
サンプル動画は[NHKクリエイティブ・ライブラリー](https://www.nhk.or.jp/archives/creative/)の[中国・重慶 高速道路を走る](https://www2.nhk.or.jp/archives/creative/material/view.cgi?m=D0002050453_00000)を使用しています。
|
loveBabbar/CodehelpYTWebDev
|
https://github.com/loveBabbar/CodehelpYTWebDev
|
Welcome to our concise web development course on the MERN stack! Learn how to build modern web applications using MongoDB, Express.js, React, and Node.js. From setup to deployment, master front-end and back-end development, APIs, and more. Join us and unlock the power of the MERN stack! Link: https://bit.ly/3NVveYl
|
# CodehelpYTWebDev
## Playlist Link: https://bit.ly/3NVveYl
Welcome to our concise web development course on the MERN stack! Learn how to build modern web applications using MongoDB, Express.js, React, and Node.js. From setup to deployment, master front-end and back-end development, APIs, and more. Join us and unlock the power of the MERN stack!
- By Babbar
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.