
hexsha
stringlengths 40
40
| size
int64 5
1.04M
| ext
stringclasses 6
values | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 3
344
| max_stars_repo_name
stringlengths 5
125
| max_stars_repo_head_hexsha
stringlengths 40
78
| max_stars_repo_licenses
sequencelengths 1
11
| max_stars_count
int64 1
368k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 3
344
| max_issues_repo_name
stringlengths 5
125
| max_issues_repo_head_hexsha
stringlengths 40
78
| max_issues_repo_licenses
sequencelengths 1
11
| max_issues_count
int64 1
116k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 3
344
| max_forks_repo_name
stringlengths 5
125
| max_forks_repo_head_hexsha
stringlengths 40
78
| max_forks_repo_licenses
sequencelengths 1
11
| max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | content
stringlengths 5
1.04M
| avg_line_length
float64 1.14
851k
| max_line_length
int64 1
1.03M
| alphanum_fraction
float64 0
1
| lid
stringclasses 191
values | lid_prob
float64 0.01
1
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
c06839430a99e3d2b86735bff68a1a169ff1946a | 366 | md | Markdown | packages/EasySwoole/readme.md | StepTheFkUp/StepTheFkUp | 2eb95e724d17b70f45a858202c692cacb46e8e66 | [
"MIT"
] | 4 | 2019-01-29T06:38:32.000Z | 2019-01-31T23:34:30.000Z | packages/EasySwoole/readme.md | StepTheFkUp/StepTheFkUp | 2eb95e724d17b70f45a858202c692cacb46e8e66 | [
"MIT"
] | 5 | 2019-04-24T02:07:55.000Z | 2019-10-18T03:34:30.000Z | packages/EasySwoole/readme.md | StepTheFkUp/StepTheFkUp | 2eb95e724d17b70f45a858202c692cacb46e8e66 | [
"MIT"
] | 4 | 2019-01-23T23:14:55.000Z | 2019-03-01T05:40:32.000Z | ---eonx_docs---
title: Introduction
weight: 0
---eonx_docs---
# Introduction
The **EasySwoole** package helps running your app with [Open Swoole][1].
## Require package (Composer)
The recommended way to install this package is to use [Composer][2]:
```bash
$ composer require eonx-com/easy-swoole
```
[1]: https://openswoole.com/
[2]: https://getcomposer.org/
| 18.3 | 72 | 0.704918 | eng_Latn | 0.770359 |
c069cd25f20f1da31d3538de42f6e1e774cfddd2 | 3,094 | md | Markdown | README.md | Ostrzyciel/rpa-school-dataset | 35fb308fb08aeb22d9b039443c93b3a0a6e7ded2 | [
"CC0-1.0"
] | 1 | 2022-02-15T14:58:17.000Z | 2022-02-15T14:58:17.000Z | README.md | Ostrzyciel/rpa-school-dataset | 35fb308fb08aeb22d9b039443c93b3a0a6e7ded2 | [
"CC0-1.0"
] | null | null | null | README.md | Ostrzyciel/rpa-school-dataset | 35fb308fb08aeb22d9b039443c93b3a0a6e7ded2 | [
"CC0-1.0"
] | null | null | null | # rpa-school-dataset
[](https://zenodo.org/badge/latestdoi/459593715)
Polish schools dataset for Robotic Process Automation tasks. The paper describing the dataset is currently in review.
The data was sourced from the Polish registry of schools [(RSPO, *Rejestr Szkół i Placówek Oświatowych*)](https://rspo.gov.pl/). It is intended to be used in RPA and NER-related research. The dataset is entirely in the Polish language.
## Dataset
The dataset consists of three directories – `screenshots`, `hocr`, `metadata`. They contain files with corresponding names with different extensions that constitute a single example in the dataset.
- `screenshots` – screenshots of the RSPO website. Each screenshot contains exactly one school from the registry.
- `hocr` – HOCR files generated by Tesseract OCR software for each of the screenshots.
- `metadata` – JSON files in a pseudo-JSON-LD format. The format is described below.
There are three data series in this dataset:
- `School` – 92 screenshots of the unmodified RSPO website.
- `School_flip` – 75 screenshots where the field layout was flipped (rows to columns).
- `School_shuffle` – 84 screenshots where the field layout was shuffled randomly for each example.
### Metadata format
The following field types are used:
- `address`
- `postalCode` – Polish postal code.
- `streetAddress` – street name and building number. Can be just a number in some cases (e.g., villages).
- `addressLocality` – town name.
- `name` – the official name of the school.
- `foundingDate` – when the school was founded. This field can vary in precision.
- `regon` – REGON (*Rejestr Gospodarki Narodowej*) identifier, assigned to juridical persons and other entities.
- `email` – contact email address of the school.
- `telephone` – phone number of the school.
Each field has the following attributes:
- `value` – the value of the field **as recognized by the OCR software**.
- `trueValue` – the true value of the field, **as obtained from the RSPO database**. This is usually the same as `value`, but the OCR method is not perfect and differences occur.
- `elemId` – an array of HOCR element identifiers that make up this piece of text. You can cross-reference these IDs with the provided HOCR files.
## Authors
The dataset was prepared by [Piotr Sowiński](https://orcid.org/0000-0002-2543-9461) and [Aleksander Denisiuk](https://orcid.org/0000-0002-7501-7048).
## License
This dataset is released under the [CC0 1.0 Universal license](https://creativecommons.org/publicdomain/zero/1.0/deed.en). This means (in short) that you are free to use it for whatever purpose, without any restrictions. We would, however, appreciate you citing the source of the data. You can use the following DOI: [](https://zenodo.org/badge/latestdoi/459593715)
The dataset contains screenshots of the [RSPO website](https://rspo.gov.pl/). We claim that they do not constitute copyrightable content, as they are composed simple rectangular shapes and text (contact information).
| 64.458333 | 411 | 0.762443 | eng_Latn | 0.997525 |
c06a14fa8c990ff499acee091a74a2aae35e71a6 | 746 | md | Markdown | README.md | mattdoubleu/webcam-stream | f0b8bd94b7a4a6358456f9a698f9b982e32fdec1 | [
"MIT"
] | null | null | null | README.md | mattdoubleu/webcam-stream | f0b8bd94b7a4a6358456f9a698f9b982e32fdec1 | [
"MIT"
] | null | null | null | README.md | mattdoubleu/webcam-stream | f0b8bd94b7a4a6358456f9a698f9b982e32fdec1 | [
"MIT"
] | null | null | null | flask-video-streaming
=====================
Supporting code for my Miguel Grinberg's article [video streaming with Flask](http://blog.miguelgrinberg.com/post/video-streaming-with-flask) and its follow-up [Flask Video Streaming Revisited](http://blog.miguelgrinberg.com/post/flask-video-streaming-revisited).
=====================
Matt's notes:
camera.py module has been edited so that the processed image from the CV GUI is displayed. Other modifications have been made elsewhere in order to omit redundent code, as well as some modules being removed all together.
Run the GUI executable to begin the CV processes. Run the app.py script to begin streaming the processed images to a browser, and open https://localhost:5000 to see the stream.
| 62.166667 | 263 | 0.756032 | eng_Latn | 0.963212 |
c06a9ee246a9c4b6fd91b07a180603917e033db1 | 27 | md | Markdown | index.md | zachallen8/github-pages-with-jekyll | 98a9332b5d825bbfc07fa8015614ad77387694f1 | [
"MIT"
] | null | null | null | index.md | zachallen8/github-pages-with-jekyll | 98a9332b5d825bbfc07fa8015614ad77387694f1 | [
"MIT"
] | 4 | 2021-02-09T22:15:21.000Z | 2021-02-09T22:26:37.000Z | index.md | zachallen8/github-pages-with-jekyll | 98a9332b5d825bbfc07fa8015614ad77387694f1 | [
"MIT"
] | null | null | null | # Welcome to my blog
# Yo
| 6.75 | 20 | 0.62963 | eng_Latn | 0.919453 |
c06ba6ba260d4130dc603d4925c3943850c40000 | 1,857 | md | Markdown | _posts/ithome/2017/2018-01-17-api-forever.md | andy6804tw/andy6804tw.github.io | fb5a69d39e44548b6e6b7199d0c1702f776de339 | [
"MIT"
] | 1 | 2021-02-23T08:29:26.000Z | 2021-02-23T08:29:26.000Z | _posts/ithome/2017/2018-01-17-api-forever.md | andy6804tw/andy6804tw.github.io | fb5a69d39e44548b6e6b7199d0c1702f776de339 | [
"MIT"
] | null | null | null | _posts/ithome/2017/2018-01-17-api-forever.md | andy6804tw/andy6804tw.github.io | fb5a69d39e44548b6e6b7199d0c1702f776de339 | [
"MIT"
] | 5 | 2019-11-04T06:48:15.000Z | 2020-04-14T10:02:13.000Z | ---
layout: post
title: '[Node.js打造API] 使用forever運行API永遠不停止'
categories: '2018iT邦鐵人賽'
description: 'forever運行'
keywords: api
---
## 本文你將會學到
- 了解 forever 運作原理
- 使用 forever 讓 API 不間斷運行
## forever是什麼?
我們一般運行 Node.js 程式都是執行 npm 來運行程式,為了開發方便延伸出 nodemon 自動重新載入程式,但這都有一個問題就是萬一程式運行中拋出例外掛掉了怎麼辦?因此就有了 forever 讓 Node.js 永不停止的運行即使遇到錯誤崩潰他也能夠及時偵測重新啟動,它的功能包括啟動、停止、重啟我們的 app 應用,使用時機通常是正式產品上架發佈到雲端主機為了怕程式崩潰而導致系統無法正常運作所以才會使用 forever 讓程式不間斷運行。
## 安裝forever
將 forever 安裝在全域環境下方便每次呼叫執行,可以選擇 npm 或 yarn 來安裝。
```bash
yarn add global forever
```
```bash
sudo npm install forever -g
```
## 基本指令
##### 1. 啟動程式
使用 `forever start [程式位置]` 來執行程式,建立後他會告訴你一個 processing 正在運行中。
```bash
forever start dist/index.bundle.js
```
<img src="/images/posts/it2018/img1070117-1.png">
在瀏覽器輸入 `http://localhost:3000/` 確實有在運作。
<img src="/images/posts/it2018/img1070117-2.png">
##### 2. 監聽並自動重啟
這個指令是會偵測你的程式若有變動他會馬上重新 reload 並重新執行程式,有點類似 nodemon,其中 w 代表 watch 的意思。
```bash
forever start -w dist/index.bundle.js
```
##### 3. 顯示所有運行的狀態
在終端機輸入 `forever list` 可以立即查詢程式的運行狀態,並且同時會把運行資訊寫在本機 `/.forever` 資料夾底下的 log 。
```bash
forever list
```
<img src="/images/posts/it2018/img1070117-3.png">
##### 4. 重新載入程式
forever 不是萬能的也有會掛掉的時候,所以者時就可以 `forever restart [程式位置]` 重新來啟動他。
```bash
forever restart dist/index.bundle.js
```
<img src="/images/posts/it2018/img1070117-4.png">
##### 5. 關閉已啓動的程式
若要中斷 forever 運作輸入 `forever stop [程式位置]`,就能立即中止程式執行。
```bash
forever stop dist/index.bundle.js
```
也可以使用 id 來刪除終止服務
```bash
forever stop 38282
```
<img src="/images/posts/it2018/img1070117-5.png">
##### 6. 關閉所有已啓動的程式
輸入 `forever stopall` 即可停止所有 forever 背景所有的監聽排程。
```bash
forever stopall
```
##### 7. 使用 uid 設定服務名稱
由於使用 forever 執行當有很多個程序執行時若用 `forever list` 會很難看出哪一條是執行哪個程式,所以可以使用 `--uid` 來設定服務名稱類是一個 tag 標籤。
```bash
forever --uid "app1" start app.js
```
若要結束
```bash
forever stop app1
```
| 18.205882 | 226 | 0.725902 | yue_Hant | 0.831681 |
c06c2478e3ada04a90ee2a60b115c83afcbc180c | 32,788 | md | Markdown | readme.md | Chrisjb/RDistanceMatrix | 9c1969766c6f18cb260d43f4619fbdd2fb5fcbcf | [
"MIT"
] | 2 | 2020-02-26T16:12:13.000Z | 2020-09-17T09:50:59.000Z | readme.md | Chrisjb/RDistanceMatrix | 9c1969766c6f18cb260d43f4619fbdd2fb5fcbcf | [
"MIT"
] | 2 | 2020-12-08T10:49:40.000Z | 2021-01-26T17:32:18.000Z | readme.md | Chrisjb/RDistanceMatrix | 9c1969766c6f18cb260d43f4619fbdd2fb5fcbcf | [
"MIT"
] | 2 | 2020-12-08T15:11:54.000Z | 2021-01-26T15:55:41.000Z | readme
================
## RDistanceMatrix
[](https://opensource.org/licenses/MIT)
[](https://github.com/chrisjb/RDistanceMatrix)
[](https://travis-ci.org/chrisjb/RDistanceMatrix)
[](https://codecov.io/github/chrisjb/RDistanceMatrix?branch=master)
This package contains functions to geocode locations and generate
isochrones/isodistance polygons. It also allows for the estimation of
population or employment captured within the isochrone.
### Installation:
``` r
devtools::install_github('chrisjb/RDistanceMatrix')
# for the examples below also install
devtools::install_github('chrisjb/basemapR')
```
### 1\. make\_isochrone
The isochrone method generates a polygon of the total area to which one
can travel from a given origin point. The origin point can be specified
as either an address string to be geocoded, or a `data.frame` with a
`lat` and `lng` column specifying the coordinates.
### 1.1 mapbox method
To use the mapbox method we need to get ourselves an API key and set it
up on R. See section (6.2) for how to do this.
``` r
library(RDistanceMatrix)
battersea_isochrone <- make_isochrone(site = 'Battersea Power Station', time = 30, method = 'mapbox', mode= 'driving')
```
By plotting our isochrone we can see that the *mapbox* method generates
a pretty detailed polygon based on drive time from a given origin.
``` r
library(ggplot2)
library(basemapR)
ggplot() +
basemapR::base_map(bbox = sf::st_bbox(battersea_isochrone), increase_zoom = 2,basemap = 'google') +
geom_sf(data = battersea_isochrone, aes(fill = fillColor, color = color, alpha = opacity), show.legend = FALSE)
```
## please see attribution details: https://wikimediafoundation.org/wiki/Maps_Terms_of_Use
<!-- -->
**When to use method=mapbox:** The mapbox method has the highest level
of detail and we can see that it sticks quite rigidly to the road
network. This should be used as the default option if we want
drive/walking/cycling isochrones from a given origin.
**When not to use method=mapbox:** The mapbox method is less flexible
than the alternative of `method=google` but has the benefit of being
quick, easy and accurate. It does not support the creation of *transit*
isochrones which use the public transport network. It also does not work
in the reverse direction (`direction='in'`) so cannot generate an
isochrone of origins that can travel *to* the destination site in a
given time. Finally, the mapbox method does not support drive times in
traffic so the isochrone can be seen as an ‘average’ drive time.
### 1.2 google method
The google method is more flexible but requires a bit more set up. We
have a `multiplier` parameter to tune (see 1.2.1) and we will see that
while broadly similar to the mapbox output, it does not have quite the
same level of detail in it’s ability to follow the road network out to
its full extent.
#### 1.2.1 tuning the multiplier parameter
The google method uses the google distance matrix API to calculate the
travel time to each of a detailed grid of points. The grid that we set
up must be larger than the possible travel time so we consider all
possible points. A `multiplier` parameter is used to ensure that the
grid is an appropriate size. A multiplier of 1.0 means that we can, on
average, travel 1km in 1 minute and so draws a grid of 10km x 10km for a
10 minute isochrone. The true multiplier will vary depending on the
geography with central London being much lower, and some areas being
higher than this.
To tune the parameter we should use `method=google_guess`. This method
uses a very small number of points in a grid to make an initial guess at
an isochrone. It returns a `leaflet` map with the grid and isochrone as
layers. A correctly tuned `multiplier` parameter should contain the
entire isochrone inside of the grid of points, if it doesn’t the
multiplier should be increased. The isochrone should also reach at least
one of the penultimate grid points to ensure we have a detailed enough
initial
guess.
``` r
make_isochrone(site = 'battersea power station', time = 30, method = 'google_guess', mode= 'driving', multiplier = 0.4)
```

#### 1.2.2 Creating an isochrone with google method
Once we have a well calibrated `multiplier` parameter, the algorithm
will create a more detailed version of the isochrone by chainging the
method to `method='google'`. We have the choice of `high`, `medium` or
`low` detail. The former will use more of our API quota and cost us more
credits (see information on google api credits below). The default is
medium detail which should be sufficient for most
purposes.
``` r
battersea_isochrone_google <- make_isochrone(site = 'Battersea Power Station', time = 30, method = 'google', detail = 'med', mode= 'driving', multiplier = 0.4)
```
## Geocoding: "Battersea Power Station" if you entered precise co-ordinates, please specify site as a data frame containing the columns "lat" and "lng"
## drawing initial isochrone...
## Linking to GEOS 3.7.2, GDAL 2.4.2, PROJ 5.2.0
## adding detail to initial isochrone...
## Trying URL: 1 of 4
## Trying URL: 2 of 4
## Trying URL: 3 of 4
## Trying URL: 4 of 4
## Google API elements used: 476 (£2.38 credits). Isochrone generated to accuracy of 509m
If we compare the results of our mapbox isochrone (red) with the google
isochrone (blue), we see that the results are broadly similar but the
google one is more generalised. The mapbox version does a better job at
sticking to the road network and following the roads out as long as to
their 30 minute extents. For this reason, we should prefer the mapbox
version for tasks that can be accomplished with the mapbox API.
``` r
library(ggplot2)
library(basemapR)
ggplot() +
basemapR::base_map(bbox = sf::st_bbox(battersea_isochrone), increase_zoom = 2,basemap = 'google') +
geom_sf(data = battersea_isochrone, aes(fill = fillColor, color = color, alpha = opacity), show.legend = FALSE) +
geom_sf(data = battersea_isochrone_google, fill = 'blue', color = 'blue', alpha = 0.3)
```
## please see attribution details: https://wikimediafoundation.org/wiki/Maps_Terms_of_Use
<!-- -->
We can increase the detail of our google isochrone (costing us more
credits):
``` r
battersea_isochrone_google_high <- make_isochrone(site = 'Battersea Power Station', time = 30, method = 'google', detail = 'high', mode= 'driving', multiplier = 0.4)
```
## Geocoding: "Battersea Power Station" if you entered precise co-ordinates, please specify site as a data frame containing the columns "lat" and "lng"
## drawing initial isochrone...
## adding detail to initial isochrone...
## Trying URL: 1 of 7
## Trying URL: 2 of 7
## Trying URL: 3 of 7
## Trying URL: 4 of 7
## Trying URL: 5 of 7
## Trying URL: 6 of 7
## Trying URL: 7 of 7
## Google API elements used: 784 (£3.92 credits). Isochrone generated to accuracy of 382m
This gives us a more detailed isochrone, but we also get a few ‘islands’
and ‘holes’ where the algorithm found points that could be reached
within 30minutes, but where there was a point in between which couldn’t
(perhaps the point identified was in a park or otherwise off the road
network).
``` r
library(ggplot2)
library(basemapR)
ggplot() +
basemapR::base_map(bbox = sf::st_bbox(battersea_isochrone), increase_zoom = 2,basemap = 'google') +
geom_sf(data = battersea_isochrone, aes(fill = fillColor, color = color, alpha = opacity), show.legend = FALSE) +
geom_sf(data = battersea_isochrone_google_high, fill = 'blue', color = 'blue', alpha = 0.3)
```
## please see attribution details: https://wikimediafoundation.org/wiki/Maps_Terms_of_Use
<!-- -->
#### 1.2.3 Other options with the google method
With the google method we have the ability to reverse the direction
(what origins are there that can we leave from and arrive at the site
within x minutes?). We can also set the departure time to a peak hour to
get the isochrone accounting for traffic, or we can use `mode=transit`
to get an isochrone using public
transport.
``` r
battersea_isochrone_google_pt <- make_isochrone(site = 'Battersea Power Station', time = 30, method = 'google', detail = 'high', mode= 'transit', multiplier = 0.4)
```
## Geocoding: "Battersea Power Station" if you entered precise co-ordinates, please specify site as a data frame containing the columns "lat" and "lng"
## drawing initial isochrone...
## adding detail to initial isochrone...
## Trying URL: 1 of 8
## Trying URL: 2 of 8
## Trying URL: 3 of 8
## Trying URL: 4 of 8
## Trying URL: 5 of 8
## Trying URL: 6 of 8
## Trying URL: 7 of 8
## Trying URL: 8 of 8
## Google API elements used: 807 (£4.035 credits). Isochrone generated to accuracy of 237m
With public transport (blue) we can’t get as far from Battersea Power
station as we could by car (red).
``` r
ggplot() +
basemapR::base_map(bbox = sf::st_bbox(battersea_isochrone), increase_zoom = 2,basemap = 'google') +
geom_sf(data = battersea_isochrone_google, fill = "#bf4040", color = "#bf4040", alpha = .33, show.legend = FALSE) +
geom_sf(data = battersea_isochrone_google_pt, fill = 'blue', color = 'blue', alpha = 0.33)
```
## please see attribution details: https://wikimediafoundation.org/wiki/Maps_Terms_of_Use
<!-- -->
let’s see what happens with traffic. Note that the `departing` parameter
must be set to a date and time in the
future.
``` r
battersea_isochrone_google_traffic <- make_isochrone(site = 'Battersea Power Station', time = 30, method = 'google', detail = 'med', mode= 'driving', multiplier = 0.25,
departing = '2020-03-02 08:00:00')
```
## Geocoding: "Battersea Power Station" if you entered precise co-ordinates, please specify site as a data frame containing the columns "lat" and "lng"
## drawing initial isochrone...
## adding detail to initial isochrone...
## Trying URL: 1 of 4
## Trying URL: 2 of 4
## Trying URL: 3 of 4
## Trying URL: 4 of 4
## Google API elements used: 486 (£4.86 credits). Isochrone generated to accuracy of 442m
In 8am traffic (blue) we can now only travel a bit further then by
public transport (green).
``` r
ggplot() +
basemapR::base_map(bbox = sf::st_bbox(battersea_isochrone), increase_zoom = 2,basemap = 'google') +
geom_sf(data = battersea_isochrone_google, fill = "#bf4040", color = "#bf4040", alpha = .33, show.legend = FALSE) +
geom_sf(data = battersea_isochrone_google_traffic, fill = 'blue', color = 'blue', alpha = .33) +
geom_sf(data = battersea_isochrone_google_pt, fill = "green", color = "green", alpha = .33, show.legend = FALSE)
```
## please see attribution details: https://wikimediafoundation.org/wiki/Maps_Terms_of_Use
<!-- -->
Is it better getting *to* battersea than
*from*?
``` r
battersea_isochrone_google_traffic_inbound <- make_isochrone(site = 'Battersea Power Station', time = 30, direction = 'in',
method = 'google', detail = 'med', mode= 'driving', multiplier = 0.25,
departing = '2020-03-02 08:00:00')
```
## Geocoding: "Battersea Power Station" if you entered precise co-ordinates, please specify site as a data frame containing the columns "lat" and "lng"
## drawing initial isochrone...
## Trying URL: 1 of 2
## adding detail to initial isochrone...
## Trying URL: 1 of 4
## Trying URL: 2 of 4
## Trying URL: 3 of 4
## Trying URL: 4 of 4
## Google API elements used: 475 (£4.75 credits). Isochrone generated to accuracy of 423m
Inbound travel time (green) seems to be broadly similar to outbound time
(blue) in this case.
``` r
ggplot() +
basemapR::base_map(bbox = sf::st_bbox(battersea_isochrone), increase_zoom = 2,basemap = 'google') +
geom_sf(data = battersea_isochrone_google_traffic, fill = 'blue', color = 'blue', alpha = .33) +
geom_sf(data = battersea_isochrone_google_traffic_inbound, fill = "green", color = "green", alpha = .33, show.legend = FALSE)
```
## please see attribution details: https://wikimediafoundation.org/wiki/Maps_Terms_of_Use
<!-- -->
### 2\. make\_isodistance
Only available with `method=google`.
Creates a simple features polygon of the area accessible to/from a given
location within a certain travel *distance*. Distances available by
`driving`, `transit`, `walking` or `cycling`.
As with `make_isochrone`, we can set the detail level `detail =
c('high', 'medium', 'low')` to get a more/less accurate isodistance
polygon at the expense of more/less google API credits (see
below).
**examples:**
``` r
walk_radius <- make_isodistance('EC2R 8AH', distance = 2000, direction = 'out', mode = 'walking',)
```
## Geocoding: "EC2R 8AH" if you entered precise co-ordinates, please specify site as a data frame containing the columns "lat" and "lng"
## Trying URL: 1 of 2
## Trying URL: 2 of 2
## Google API elements used: 214 (£1.07 credits). Isochrone generated to accuracy of 170m
``` r
ggplot() +
base_map(bbox = st_bbox(walk_radius), increase_zoom = 2,basemap = 'google') +
geom_sf(data = walk_radius, fill=NA)
```
## please see attribution details: https://wikimediafoundation.org/wiki/Maps_Terms_of_Use
<!-- -->
### 3\. get\_distance
Uses the google distance matrix API to get the distance or time between
a set of origins and destinations. Input is a data.frame with columns
for origin and destination.
**Examples:** Single origin-destination:
``` r
od1 <- tibble::tibble(
origin = '51.5131,-0.09182',
destination = 'EC2R 8AH'
)
get_distance(od1, origin, destination, mode = 'transit')
```
## Warning: Prefixing `UQ()` with the rlang namespace is deprecated as of rlang 0.3.0.
## Please use the non-prefixed form or `!!` instead.
##
## # Bad:
## rlang::expr(mean(rlang::UQ(var) * 100))
##
## # Ok:
## rlang::expr(mean(UQ(var) * 100))
##
## # Good:
## rlang::expr(mean(!!var * 100))
##
## This warning is displayed once per session.
## # A tibble: 1 x 4
## origin destination transit_distance transit_time
## <chr> <chr> <dbl> <dbl>
## 1 51.5131,-0.09182 EC2R 8AH 553 4.57
Multiple origin destination:
``` r
pcd_df <- tibble::tribble(
~ origin, ~destination,
"51.5131,-0.09182", 'EC2R 8AH',
"51.5037,-0.01715", 'E14 5AB',
" 51.5320,-0.12343", 'SE1 9SG',
"51.4447,-0.33749", 'SW1A 1AA'
)
get_distance(pcd_df, origin, destination)
```
## # A tibble: 4 x 4
## origin destination driving_distance driving_time
## <chr> <chr> <dbl> <dbl>
## 1 "51.5131,-0.09182" EC2R 8AH 515 3.4
## 2 "51.5037,-0.01715" E14 5AB 867 3.33
## 3 " 51.5320,-0.12343" SE1 9SG 5747 24.0
## 4 "51.4447,-0.33749" SW1A 1AA 16895 40.2
Example with a dataframe of origins (lat lng) and a single destination;
``` r
df <- tibble::tribble(
~ lat, ~lng,
51.5131, -0.09182,
51.5037, -0.01715,
51.5320, -0.12343,
51.4447, -0.33749
)
origin_df <- mutate(df, origin = paste0(lat,',',lng))
get_distance(origin_df, origin, 'London Paddington')
```
## # A tibble: 4 x 5
## lat lng origin driving_distance driving_time
## <dbl> <dbl> <chr> <dbl> <dbl>
## 1 51.5 -0.0918 51.5131,-0.09182 7877 26.9
## 2 51.5 -0.0172 51.5037,-0.01715 13839 39.3
## 3 51.5 -0.123 51.532,-0.12343 5231 20.0
## 4 51.4 -0.337 51.4447,-0.33749 17944 38.4
### 4\. geoCode
`geocode` uses the google geocoding API to geocode an address or set of
coordinates. `geocode_mapbox` uses the mapbox geocoding API to geocode
an address or set of coordinates.
Both require an API key to use for the respective APIs. See sections
below on getting an API key.
``` r
library(RDistanceMatrix)
geocode(address = 'Ulverston, Cumbria')
```
## lat lng type address
## 1 54.19514 -3.09267 APPROXIMATE Ulverston LA12, UK
By default the API will return multiple potential matches for our
site.
``` r
geocode_mapbox(address = 'Bath Abbey, Bath, UK', return_all = T)
```
## geocoding url: https://api.mapbox.com/geocoding/v5/mapbox.places/Bath%20Abbey,%20Bath,%20UK.json?access_token=SECRET
## lat lng type
## 1 51.38142 -2.358920 poi.180388701038
## 2 51.38081 -2.360889 address.4696521299330334
## 3 51.38619 -2.362608 poi.850403578315
## 4 51.38636 -2.363284 poi.283467888870
## 5 51.38417 -2.360052 poi.523986016019
Setting `return_all = F` can be useful when we want only the first
identified location returned. The first location tends to be the best
guess at the intended
address.
``` r
geocode_mapbox(address = 'Bath Abbey, Bath, UK', return_all = F)
```
## geocoding url: https://api.mapbox.com/geocoding/v5/mapbox.places/Bath%20Abbey,%20Bath,%20UK.json?access_token=SECRET
## lat lng type
## 1 51.38142 -2.35892 poi.180388701038
We can always explore the locations returned in leaflet
``` r
library(leaflet)
bath <- geocode_mapbox(address = 'Bath Abbey, Bath, UK', return_all = T)
leaflet() %>%
addTiles() %>%
addAwesomeMarkers(data = bath, lng = ~lng, lat= ~lat, popup = ~type) %>%
addAwesomeMarkers(data = bath[1,], lng = ~lng, lat= ~lat, popup = 'best_guess',
icon = ~awesomeIcons('star',markerColor = 'red'))
```
### 5\. get population and employment within a boundary
#### 5.1 get\_population\_within
This function aims to estimate the population within an `sf` polygon. It
can be used in conjunction with `make_isochrone` or `make_isodistance`
which both return `sf` objects.
The function works by intersecting [Lower Layer Super Output
Areas](https://en.wikipedia.org/wiki/Lower_Layer_Super_Output_Area)
(lsoas) with the input polygon. The population is then fetched from the
[NOMIS
API](https://www.nomisweb.co.uk/query/select/getdatasetbytheme.asp?) for
each LSOA that overlaps with our input polygon.
The dataset returned contains population data for each LSOA within our
boundary (`population`), the percentage of the LSOA that lies within our
boundary (`overlap`), and the *estimated* population that actually lies
within the boundary (`population_within`). The `population_within`
column assumes that population is evenly distributed throughout the LSOA
so is an **estimate rather than a precise
figure**.
``` r
iso <- make_isochrone(site = 'bath abbey, bath, uk', time = 30, method = 'mapbox', mode = 'driving')
```
## Geocoding: "bath abbey, bath, uk" if you entered precise co-ordinates, please specify site as a data frame containing the columns "lat" and "lng"
## geocoding url: https://api.mapbox.com/geocoding/v5/mapbox.places/bath%20abbey,%20bath,%20uk.json?access_token=SECRET
## fetching isochrone from url: https://api.mapbox.com/isochrone/v1/mapbox/driving/-2.35892,51.381419?contours_minutes=30&polygons=true&access_token=SECRET
``` r
pop_all_ages <- get_population_within(iso, year ='latest',age = 'all')
glimpse(pop_all_ages)
```
## Observations: 183
## Variables: 11
## $ date <dbl> 2018, 2018, 2018, 2018, 2018, 2018, 2018, 2018…
## $ geography_code <chr> "E01014370", "E01014371", "E01014372", "E01014…
## $ geography_name <chr> "Bath and North East Somerset 007A", "Bath and…
## $ geography_type <chr> "2011 super output areas - lower layer", "2011…
## $ gender_name <chr> "Total", "Total", "Total", "Total", "Total", "…
## $ age <chr> "All Ages", "All Ages", "All Ages", "All Ages"…
## $ age_type <chr> "Labour Market category", "Labour Market categ…
## $ population <dbl> 2037, 1933, 2057, 1717, 1535, 1261, 1475, 1388…
## $ record_count <dbl> 183, 183, 183, 183, 183, 183, 183, 183, 183, 1…
## $ overlap <dbl> 1.00, 1.00, 1.00, 1.00, 1.00, 1.00, 1.00, 1.00…
## $ population_within <dbl> 2037.00, 1933.00, 2057.00, 1717.00, 1535.00, 1…
We can also split by age group. Options include `working`,`five_year`
and `sya` (single year of age).
``` r
library(dplyr)
pop_working <- get_population_within(iso, year ='latest',age = 'working')
pop_working %>%
group_by(age) %>%
summarise(estimated_pop = sum(population_within))
```
## # A tibble: 3 x 2
## age estimated_pop
## <chr> <dbl>
## 1 Aged 0 to 15 34949.
## 2 Aged 16 to 64 134067
## 3 Aged 65+ 41510.
#### 5.2 get\_employment\_within
This function aims to estimate the employment within an `sf` polygon. It
can be used in conjunction with `make_isochrone` or `make_isodistance`
which both return `sf` objects.
The function works by intersecting [Lower Layer Super Output
Areas](https://en.wikipedia.org/wiki/Lower_Layer_Super_Output_Area)
(lsoas) with the input polygon. The employment data is then fetched from
the [NOMIS
API](https://www.nomisweb.co.uk/query/select/getdatasetbytheme.asp?)
using the Business Register and Employment Survey dataset.
The dataset returned contains employment data for each LSOA within our
boundary (`employment`), the percentage of the LSOA that lies within our
boundary (`overlap`), and the *estimated* employment that actually lies
within the boundary (`employment_within`). The `employment_within`
column assumes that employment is evenly distributed throughout the LSOA
so is an **estimate rather than a precise
figure**.
``` r
iso <- make_isochrone(site = 'Barrow-in-Furness, Cumrbia', time = 20, method = 'mapbox', mode = 'driving')
```
## Geocoding: "Barrow-in-Furness, Cumrbia" if you entered precise co-ordinates, please specify site as a data frame containing the columns "lat" and "lng"
## geocoding url: https://api.mapbox.com/geocoding/v5/mapbox.places/Barrow-in-Furness,%20Cumrbia.json?access_token=SECRET
## fetching isochrone from url: https://api.mapbox.com/isochrone/v1/mapbox/driving/-3.2289,54.1113?contours_minutes=20&polygons=true&access_token=SECRET
``` r
emp_all_ind <- get_employment_within(iso, year ='latest',industry = 'all')
glimpse(emp_all_ind)
```
## Observations: 56
## Variables: 12
## $ date <dbl> 2018, 2018, 2018, 2018, 2018, 2018, 2018,…
## $ geography_code <chr> "E01019138", "E01019139", "E01019140", "E…
## $ geography_name <chr> "Barrow-in-Furness 010A", "Barrow-in-Furn…
## $ geography_type <chr> "2011 super output areas - lower layer", …
## $ industry_code <dbl> 37748736, 37748736, 37748736, 37748736, 3…
## $ industry_name <chr> "Total", "Total", "Total", "Total", "Tota…
## $ employment_status_name <chr> "Employment", "Employment", "Employment",…
## $ employment <dbl> 350, 8000, 100, 2500, 350, 700, 300, 125,…
## $ obs_status_name <chr> "These figures exclude farm agriculture (…
## $ obs_status <lgl> TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE,…
## $ overlap <dbl> 0.83, 1.00, 1.00, 1.00, 1.00, 1.00, 0.40,…
## $ employment_within <dbl> 290.5, 8000.0, 100.0, 2500.0, 350.0, 700.…
If we set the `type` option to ‘employees’ rather than ‘employment’, we
can split by part-time/full-time employees.
``` r
library(dplyr)
pt_ft <- get_employment_within(iso, year ='latest',type = 'employees', split = TRUE)
pt_ft %>%
group_by(employment_status_name) %>%
summarise(estimated_emp = sum(employment_within)) %>%
tidyr::pivot_wider(names_from = employment_status_name, values_from = estimated_emp) %>%
mutate(full_time_equiv = 0.5*`Part-time employees` + `Full-time employees`)
```
## # A tibble: 1 x 3
## `Full-time employees` `Part-time employees` full_time_equiv
## <dbl> <dbl> <dbl>
## 1 20681. 9324. 25343
We can also get the industry break down of employees in the area.
Options include: \* `all` for no industry breakdown \* `broad` for broad
groups \* `sections` for sections \* `2digit` for two digit SIC codes
``` r
library(dplyr)
emp_broad <- get_employment_within(iso, year ='latest',industry = 'broad')
emp_broad %>%
group_by(industry_id, industry_name) %>%
summarise(estimated_emp = sum(employment_within))
```
## # A tibble: 18 x 3
## # Groups: industry_id [18]
## industry_id industry_name estimated_emp
## <chr> <chr> <dbl>
## 1 1 Agriculture, forestry & fishing (A) 21.7
## 2 10 Information & communication (J) 437.
## 3 11 Financial & insurance (K) 325.
## 4 12 Property (L) 181.
## 5 13 Professional, scientific & technical (M) 1538.
## 6 14 Business administration & support services (N) 772.
## 7 15 Public administration & defence (O) 961.
## 8 16 Education (P) 2501.
## 9 17 Health (Q) 4717.
## 10 18 Arts, entertainment, recreation & other servi… 984.
## 11 2 Mining, quarrying & utilities (B,D and E) 404.
## 12 3 Manufacturing (C) 9214.
## 13 4 Construction (F) 1136.
## 14 5 Motor trades (Part G) 480.
## 15 6 Wholesale (Part G) 416.
## 16 7 Retail (Part G) 3810.
## 17 8 Transport & storage (inc postal) (H) 876.
## 18 9 Accommodation & food services (I) 1889.
### 6.1 Getting a google API Key
1. [Create a Google
account](https://accounts.google.com/SignUp?hl=en&continue=https://myaccount.google.com/intro)
2. Head to the [google cloud
console](https://console.cloud.google.com/) and log in
3. Collect free trial credits: At the time of writing google are
offering $300 in free credits to use over 12 months. You will have
to submit billing info to collect this, but you will need to do this
in a later step anyway.

4. Create a project: Select project \> New project

5. Select our new project: Select project \> <our project>

6. Go to the API library (APIs and services \> Dashboard \> Library)

7. Search for GeoCoding API and enable
8. Search for Distance Matrix API and enable
9. **enable billing:** to use the APIs you must enable billing. In the
main nav bar on the left navigate to billing and *link billing
account*. If you didn’t sign up for the free trial in step 3, you
will need to create a billing account here.
10. **get your API key:** on the left nav navigate to APIs & Services \>
Credentials \> Create Credentials \> API KEY
11. Copy this API key and set it in our RStudio environment using
`set_google_api('<your api key>')`
#### If the API key doesn’t persist
Setting the API key in this way should mean that the API key is always
accessible by the RDistanceMatrix package in every new R session. If the
API key cannot be found after closing and opening a new R session, we
can set it manually using:
`usethis::edit_r_environ()`
and paste in the line: google\_api\_key = ‘<your key here>’
#### Google API Credits
The
[documentation](https://developers.google.com/maps/documentation/distance-matrix/usage-and-billing)
explains how requests made to the distance matrix API are priced. At the
time of writing you get $200 worth of free API usage each month. This
equates to 40,000 **elements** each month using the standard API
request, or 20,000 **elements** using the advanced API request (the
advanced API is used if we set a departure time for time in traffic).
To avoid going over the monthly limit, pay attention to the messages
that are output from the `make_isochrone` and `make_isodistance`
functions. The functions will tell you how many API credits we used
after each request, and will warn us before making requests worth over
$10 in credit. Never reveal your API key to anyone.
**What is an element?** An element is one origin-destination request. A
typical isochrone will use anywhere between 100 and 1000
origin-destination queries to determine the extents of the isochrone
polygon.
If you’re unsure how much usage you have left for the month, visit the
[APIs and services
dashboard](https://console.cloud.google.com/apis/dashboard) for your
project, click on our API (Distance Matrix API) and you can view how
many elements used each day over the past month.
#### Setting up google cloud billing alerts
If you’re worried about going over the free allowance, it’s possible to
set up billing alerts so google will email you when you are at, say,
50%, and 90% of your free credit limit.
Head to the [cloud console billing
dashboard](console.cloud.google.com/billing/) and in the menu you should
see *Budgets & alerts*. Create a budget with an alert to email us at set
percentages of our budget. Set the target amount to £200 or the amount
of the free allowance, and *untick include credits in cost*. (you could
also set the target amount to 0 and tick *include credits in cost* but
the UI won’t be quite as informative).
### 6.2 Getting a mapbox API Key
1. [sign up for mapbox](https://www.mapbox.com/)
2. [Head to your account page](https://account.mapbox.com/)
3. Scroll down to see an option to create an api key
4. Copy this API key and set it in our RStudio environment using
`set_mapbox_api('<your api key>')`
No billing details are required at the time of writing so no need to
worry about going over quotas. The free quota is very generous and
allows 100,000 isochrones to be made free of charge.
#### If the API key doesn’t persist
Setting the API key in this way should mean that the API key is always
accessible by the RDistanceMatrix package in every new R session. If the
API key cannot be found after closing and opening a new R session, we
can set it manually using:
`usethis::edit_r_environ()`
and paste in the line: mapbox\_api\_key = ‘<your key here>’
### 6.3 Getting a Nomis API Key
1. [Sign up for a NOMIS
account](https://www.nomisweb.co.uk/myaccount/userjoin.asp)
2. Once signed in, click on your name to reveal the account menu and
click on ‘account summary’
3. Scroll down and click ‘NOMIS API’ in the menu to the left
4. Your ‘unique id’ should be displayed here. This is your API key.
5. Copy this API key and set it in our RStudio environment using
`set_nomis_api('<your api key>')`
#### If the API key doesn’t persist
Setting the API key in this way should mean that the API key is always
accessible by the RDistanceMatrix package in every new R session. If the
API key cannot be found after closing and opening a new R session, we
can set it manually using:
`usethis::edit_r_environ()`
and paste in the line: nomis\_api\_key = ‘<your key here>’
| 39.267066 | 169 | 0.673112 | eng_Latn | 0.955321 |
c06c5c867f58f583cd64d6aa27be56b159930ddc | 738 | md | Markdown | content/project/biomass/index.md | zjh-THU/academic-kickstart | 2908ef7af1ae5d70c84d46f04e10a36bd2e4a492 | [
"MIT"
] | null | null | null | content/project/biomass/index.md | zjh-THU/academic-kickstart | 2908ef7af1ae5d70c84d46f04e10a36bd2e4a492 | [
"MIT"
] | null | null | null | content/project/biomass/index.md | zjh-THU/academic-kickstart | 2908ef7af1ae5d70c84d46f04e10a36bd2e4a492 | [
"MIT"
] | 1 | 2021-10-15T11:21:05.000Z | 2021-10-15T11:21:05.000Z | ---
title: Co-pyrolysis of Biomass with polymer wastes
summary: Investigated the interactions among tobacco stalk and typical polymers during co-pyrolysis using Thermogravimetric analyzer coupled with Fourier transform infrared spectrometer and Conducted the kinetic analysis.
tags:
- Biomass
date: "2019-04-27T00:00:00Z"
# Optional external URL for project (replaces project detail page).
external_link: https://www.sciencedirect.com/science/article/pii/S0960852419312003?utm_campaign=STMJ_75273_AUTH_SERV_PPUB&utm_medium=email&utm_dgroup=Email1Publishing&utm_acid=-801547105&SIS_ID=-1&dgcid=STMJ_75273_AUTH_SERV_PPUB&CMX_ID=&utm_in=DM566605&utm_source=AC_30
image:
caption: Photo by Toa Heftiba on Unsplash
focal_point: Smart
---
| 49.2 | 269 | 0.830623 | eng_Latn | 0.574157 |
c06cad617844131f750b9bde99f17f672d396287 | 1,057 | md | Markdown | README.md | PolideaPlayground/BleInTheBackground-nRF52 | 976eaaf1fad97ffdf7ed3eee79ff48cd8a5b3dec | [
"Apache-2.0"
] | 2 | 2021-01-03T18:15:32.000Z | 2021-03-20T17:15:49.000Z | README.md | PolideaPlayground/BleInTheBackground-nRF52 | 976eaaf1fad97ffdf7ed3eee79ff48cd8a5b3dec | [
"Apache-2.0"
] | null | null | null | README.md | PolideaPlayground/BleInTheBackground-nRF52 | 976eaaf1fad97ffdf7ed3eee79ff48cd8a5b3dec | [
"Apache-2.0"
] | 1 | 2020-07-07T07:33:36.000Z | 2020-07-07T07:33:36.000Z | # BleInTheBackground - for nRF52
This project implements nRF52 application for the [React Native mobile app](https://github.com/PolideaPlayground/BleInTheBackground-iOS) testing BLE functionality in the background mode.
## Compiling
Place this project's folder into `YOUR_NRF_SDK/examples/ble_peripheral/` and use your favorite method for compilation. This project used nRF5_SDK_15.3.0 during development.
## Programming
1) [Download nRF Connect application for desktop](https://www.nordicsemi.com/Software-and-tools/Development-Tools/nRF-Connect-for-desktop).
2) Launch application and open "Programmer".
3) Select your device (e.g. PCA10040).
4) Click "Erase all".
5) Add application's hex file from `./hex` folder suitable for your device's model. (e.g. ble_app_background_test_pca10040_s132.hex).
6) Add SoftDevice hex file from `YOUR_NRF_SDK/components/softdevice/sXXX/hex` folder matching above SoftDevice version. (e.g. `YOUR_NRF_SDK/components/softdevice/s132/s132_nrf52_6.1.1_softdevice.hex`).
7) Click "Write".
8) App should be running now.
| 52.85 | 201 | 0.794702 | eng_Latn | 0.73022 |
c06cef87f578f3396b62270cf5f7401534593f84 | 3,168 | md | Markdown | sql/report_queries/erm/costs/README.md | eliana-flo/folio-analytics | 9734eb0500467fbaf0d83c72d8bde926efb277ac | [
"Apache-2.0"
] | 10 | 2020-07-16T13:25:20.000Z | 2022-03-05T19:41:26.000Z | sql/report_queries/erm/costs/README.md | eliana-flo/folio-analytics | 9734eb0500467fbaf0d83c72d8bde926efb277ac | [
"Apache-2.0"
] | 315 | 2020-07-09T18:06:29.000Z | 2022-03-30T13:46:23.000Z | sql/report_queries/erm/costs/README.md | eliana-flo/folio-analytics | 9734eb0500467fbaf0d83c72d8bde926efb277ac | [
"Apache-2.0"
] | 45 | 2020-07-09T13:36:15.000Z | 2022-03-22T14:22:37.000Z | # ERM Costs Reports
## Purpose
This report is to provide a dataset of invoice lines to summarize certain costs on the predefined filter for electronic resorces in the inventory. Filters were designed to customize this queries on local needs. Furthermore costs on invoice line level are exemplary divided by instance subjects and formats. Take in account that this might duplicate invoice lines and needed to be adjusted if summing up totals.
The costs relies on the amounts out of the transactions table in system currency. This data will only appear if an invoice status is 'Approved' or 'Paid'.
The preset on the invoice status filter therefore is 'Paid'.
## Parameters
The parameters in the table below can be set in the WITH clause to filter the report output.
| parameter | description | examples |
| --- | --- | --- |
| invoice\_approval\_date | date invoice was approved | Set start\_date and end\_date in YYYY-MM-DD format. |
| invoice_line_status | status of the invoices to show, which can be open, reviewed, approved, paid, or cancelled | 'Paid', 'Approved', 'Open' etc. |
| po_line_order_format | the purchase order line format| 'Electronic Resource', 'Physical Resource', 'P/E Mix' etc. |
| instance_subject | name of the instance subject | |
| mode_of_issuance_name | mode of issuance, a categorization reflecting whether a resource is issued in one or more parts, the way it is updated, and whether its termination is predetermined or not | 'serial', 'integrating resource', 'single unit' etc. |
| format_name | instance format whether it's from the RDA carrier term list of locally defined | 'computer -- online resource' for electronic resources |
| library_name | library name of the permanent location | |
## Sample Output
|po_line_id|invl_id|invl_status|po_line_payment_status|po_line_is_package|invoice_payment_date|po_line_order_format|po_line_phys_mat_type|po_line_er_mat_type|instance_mode_of_issuance_name|invl_adjustment_description|invl_adjustment_prorate|invl_adjustment_relationtototal|invl_adjustment_value|invl_sub_total|invl_total|inv_adj_prorate|inv_adj_relationtototal|transactions_inv_adj_total|transactions_invl_total|invl_total_incl_adj|instance_format_name|total_by_format|instance_subject|total_by_subject|
|----------|-------|-----------|----------------------|------------------|---------------------|--------------------|---------------------|-------------------|-------------------|------------------------------|---------------------------|-----------------------|-------------------------------|---------------------|--------------|----------|---------------|-----------------------|-------------|----------|--------------------|---------------|----------------|----------------|
|2f3a877a-5a2d-4a8d-a226-d7691d43f4f5|a89bae81-889d-429d-853a-e0cff4780f66|Paid|Pending|false|2021-01-14 13:45:04|Electronic Resource| | | |Fees|Not prorated|In addition to|5|15|20|Not prorated|In addition to|$1.75|$15.76|$17.51| | |Medicine|$17.51|
|e0f063e8-36c2-4cc8-9086-cdaf1c05d161|c5426cea-e6b9-430a-af8d-0612e21f1565|Paid|Pending|false|2021-01-12 11:42:24|Electronic Resource| | | | | | | |15|15| | | |$15.00|$15.00| | | |
| 102.193548 | 503 | 0.672664 | eng_Latn | 0.908712 |
c06dfa1973051c998e1cd9943fe1163b2988cd04 | 972 | md | Markdown | README.md | dungtri/docker-keepalived | 33076f3d616e8785d9fa11b0af3c04e26e3086b4 | [
"Apache-2.0"
] | null | null | null | README.md | dungtri/docker-keepalived | 33076f3d616e8785d9fa11b0af3c04e26e3086b4 | [
"Apache-2.0"
] | null | null | null | README.md | dungtri/docker-keepalived | 33076f3d616e8785d9fa11b0af3c04e26e3086b4 | [
"Apache-2.0"
] | 2 | 2020-10-06T03:32:48.000Z | 2020-10-06T03:55:34.000Z | # keepalived
[](https://hub.docker.com/r/dungtri/keepalived/)
[](https://travis-ci.org/dungtri/docker-keepalived)
Keepalived as docker container for [mutiple archs](https://hub.docker.com/r/angelnu/keepalived/tags):
- arm
- arm64
- amd64
## How to run
### Docker
```
docker run -d -e KEEPALIVED_PRIORITY=$priority -e KEEPALIVED_VIRTUAL_IP=$VIP -e KEEPALIVED_PASSWORD=$password \
-e [email protected] -e [email protected] \
-e KEEPALIVED_SMTP_SERVER=smtp2tg --restart=unless-stopped --net=host --privileged=true dungtri/keepalived
```
### Kubernetes
See [example](kubernetes.yaml)
## Travis
Note: if you clone this you need to set your travis env variables:
- `travis env set DOCKER_USER <your docker user>`
- `travis env set DOCKER_PASS <your docker password>`
| 34.714286 | 133 | 0.764403 | yue_Hant | 0.383347 |
c06e8f037d5289ea20fbb1152ae01f84e0540dd7 | 2,076 | md | Markdown | README.md | vnnstar/Python-Faculdade-Impacta | 3e7171f1f090c0774710b43110e06afb196e0ef5 | [
"MIT"
] | null | null | null | README.md | vnnstar/Python-Faculdade-Impacta | 3e7171f1f090c0774710b43110e06afb196e0ef5 | [
"MIT"
] | null | null | null | README.md | vnnstar/Python-Faculdade-Impacta | 3e7171f1f090c0774710b43110e06afb196e0ef5 | [
"MIT"
] | null | null | null | # Python - Faculdade Impacta
Aqui trago todo o conteúdo de aulas, exemplos e desafios realizados na faculdade, pela disciplina de Programação Orientada a Objetos.
A linguagem de programação utilizada é o Python e fiz a utilização de diversos os recursos de Orientação a Objetos, como:
- Utilização de Classes e Métodos, inclusive podendo ser abstratos
- Polimorfismos, dinâmismo de métodos com seus comportamentos conforme a classe
- Encapsulamento com métodos privados.
- Relacionamento Entre Classes
- Herança e Herança Múltipla, com reutilização de código (ou reaproveitamento), indicando Super Classes, ou classes mães.
- Persistência de Dados, onde geramos um arquivo com as informações/dados gerados pela aplicação
- ORM, SQL Alchemy criando tabelas pelo Python e conectando a um banco de dados, fazendo o mapeando e trabalhando de Forma com a Importação de Dados e também Exportação e geração de um arquivo referente ao Banco de Dados.
- Filas, Pilhas, Listas, Tuplas etc.
Exemplos:
AC04 - PROGRAMAÇÃO ORIENTADA A OBJETOS.
Criação de uma academia, turmas, alunos, instrutores, utilizando diversos conceitos de orientação a objetos.


AC05 - PYTHON ORIENTAÇÃO A OBJETOS COM ORM, SQLALCHEMY(SQLITE PARA PERSISTÊNCIA DE DADOS), IMPORTAÇÃO E EXPORTAÇÃO DE DADOS EM ARQUIVOS TXT

Classe de interação com banco de dados.

Métodos "CRUD"

Métodos de importação e exportação de dados.

| 50.634146 | 223 | 0.804432 | por_Latn | 0.990783 |
c06fd6bb8665118afc548bdf4f07cb6f1b18b4d0 | 1,046 | md | Markdown | README.md | SamvitJ/Deep-Person-ReId | d199c7ef23a6bb68f376e1e6d62e985ff2e7c22c | [
"MIT"
] | 46 | 2018-09-12T05:43:05.000Z | 2020-03-26T14:39:28.000Z | README.md | SamvitJ/ReXCam | d199c7ef23a6bb68f376e1e6d62e985ff2e7c22c | [
"MIT"
] | 4 | 2018-11-23T08:35:52.000Z | 2020-04-13T13:10:35.000Z | README.md | SamvitJ/Deep-Person-ReId | d199c7ef23a6bb68f376e1e6d62e985ff2e7c22c | [
"MIT"
] | 18 | 2018-10-12T14:09:52.000Z | 2020-03-26T14:39:32.000Z | # ReXCam
This repository contains reseach code associated with the following two papers:
- Samvit Jain, Ganesh Ananthanarayanan, Junchen Jiang, Yuanchao Shu, Joseph E. Gonzalez. Scaling Video Analytics Systems to Large Camera Deployments. In: Proceedings of the 20th International Workshop on Mobile Computing Systems and Applications (ACM HotMobile), 2019. [pdf](https://rtcl.eecs.umich.edu/yuanchao/paper/hotmobile19video.pdf)
- Samvit Jain, Xun Zhang, Yuhao Zhou, Ganesh Ananthanarayanan, Junchen Jiang, Yuanchao Shu, Paramvir Bahl, Joseph E. Gonzalez. Spatula: Efficient Cross-Camera Video Analytics on Large Camera Networks. In: ACM/IEEE Symposium on Edge Computing (ACM/IEEE SEC), 2020. [pdf](https://www.microsoft.com/en-us/research/uploads/prod/2020/08/sec20spatula.pdf)
This project is built on top of a [person re-identification framework](https://github.com/KaiyangZhou/deep-person-reid). Please see that project for up-to-date code and models.
This work was done at Microsoft Research and the University of California, Berkeley.
| 95.090909 | 349 | 0.798279 | eng_Latn | 0.734762 |
c070714e7f5f04d43b1e976389148d63a27e1db0 | 66 | md | Markdown | tag/namibia.md | pforret/blog.splashing | 3ac565a2d7d1cd42c3bf9edd1dabf8e7b156c30f | [
"MIT"
] | 1 | 2022-01-25T11:05:31.000Z | 2022-01-25T11:05:31.000Z | tag/namibia.md | pforret/blog.splashing | 3ac565a2d7d1cd42c3bf9edd1dabf8e7b156c30f | [
"MIT"
] | null | null | null | tag/namibia.md | pforret/blog.splashing | 3ac565a2d7d1cd42c3bf9edd1dabf8e7b156c30f | [
"MIT"
] | 1 | 2022-01-25T23:19:08.000Z | 2022-01-25T23:19:08.000Z | ---
layout: with_tag
title: Namibia
keyword: namibia
count: 1
---
| 9.428571 | 16 | 0.69697 | eng_Latn | 0.818309 |
c0710779eb679a12777136e68de128fe3e73e917 | 125 | md | Markdown | sites/tailblocks/content/snacks/second.md | bketelsen/mono | c82028599d8473844a2a6ede0945589781305d18 | [
"MIT"
] | 1 | 2022-01-19T02:16:17.000Z | 2022-01-19T02:16:17.000Z | sites/tailblocks/content/snacks/second.md | bketelsen/mono | c82028599d8473844a2a6ede0945589781305d18 | [
"MIT"
] | 16 | 2020-05-12T22:06:16.000Z | 2022-02-26T01:55:35.000Z | sites/tailblocks/content/snacks/second.md | bketelsen/mono | c82028599d8473844a2a6ede0945589781305d18 | [
"MIT"
] | null | null | null | +++
title = "My second post"
date = 2019-11-27
[taxonomies]
categories = ["Linux","Azure"]
+++
This is my second blog post. | 13.888889 | 30 | 0.648 | eng_Latn | 0.935068 |
c071363340cbae198d2625adb0d408268b4aa2d8 | 26,799 | md | Markdown | _pages/cv.md | hdquemada/hdquemada.github.io | d5fdf1818645f4732e89562150d268c1d838cdf6 | [
"MIT"
] | null | null | null | _pages/cv.md | hdquemada/hdquemada.github.io | d5fdf1818645f4732e89562150d268c1d838cdf6 | [
"MIT"
] | null | null | null | _pages/cv.md | hdquemada/hdquemada.github.io | d5fdf1818645f4732e89562150d268c1d838cdf6 | [
"MIT"
] | null | null | null | ---
layout: archive
title: "CV of Hector Quemada"
permalink: /cv/
author_profile: true
redirect_from:
- /resume
---
<!-- Global site tag (gtag.js) - Google Analytics -->
<script async src="https://www.googletagmanager.com/gtag/js?id=G-5JY7X5D7TK"></script>
<script>
window.dataLayer = window.dataLayer || [];
function gtag(){dataLayer.push(arguments);}
gtag('js', new Date());
gtag('config', 'G-5JY7X5D7TK');
</script>
{% include base_path %}
## Name
Hector D. Quemada
## Address
Department of Biological Sciences<br>
Western Michigan University<br>
1903 West Michigan Avenue<br>
Kalamazoo, MI 49004 USA
## Title
Principal Research Associate
## Education and Degrees
1979-1986 University of Utah, Salt Lake City, Utah.: Ph.D., Biology
(Cell and Molecular Biology).
1977-1979 University of Kansas, Lawrence, Kansas.: M. A., Botany.
1973-1977 University of Kansas, Lawrence, Kansas.: B.S., Biology
(Systematics and Ecology) with honors, *summa cum laude*.
## Employment History
December 2018-Present Principal Research Associate, Department of
Biological Sciences, Western Michigan University
Led a group of consultants to work with the Foundation for the National
Institutes of Health and the African Union Development Agency to provide
regulators in several countries in Africa with the necessary technical
background and strengthened capacity to handle applications for research
and eventual deployment of gene drive technology.H
November 2008-December 2018 Director, Biosafety Resource Network, Donald
Danforth Plant Science Center
Direct a worldwide network of consultants to provide regulatory science
support and capacity building for public sector genetic engineering
projects. Projects involve development of regulatory approval dossiers,
regulatory strategy, regulatory agency consultations, assisting
regulatory capacity building organizations, participation in
international regulatory policy development. Current projects include
regulatory capacity building and policy support for gene drive research
in Africa; development of regulatory approval packages for transgenic
crops, including virus resistant and biofortified cassava and insect
resistant cowpea. Extensive experience working in Africa and Asia.
August 2007-2010 Adjunct Professor of Biology, Calvin College
Team-teach Biology and Biotechnology courses; organize and implement
interim session classes.
July 2003-2010 Manager, Biotechnology and Biodiversity Interface grant
component, Program for Biosafety Systems
Manage BBI grant program, funding research conducted by African and
Asian to assess the impact of genetically engineered crops on the
environment. Provide technical support to developing countries in the
area of biosafety regulations and policy for USAID's Program for
Biosafety Systems.
September 1997-November 2008 President and Principal Consultant, Crop
Technology Consulting, Inc.
Prepared submissions to US and foreign regulatory agencies for movement,
field trials, and product approval of transgenic crops; coordinate and
conduct contract research for client companies to generate environmental
risk assessment and food/feed safety data required for regulatory
approvals of products; manage research collaborations and product
development. Clients include small and regional-based agricultural
technology companies, and a major land grant university.
Advised foreign government clients and USAID in the area of agricultural
biotechnology policy, research capability, and biosafety. Foreign
assignments include consultations in India, the Philippines, Egypt,
Uganda, Kenya, South Africa, Indonesia and Thailand.
January 2002-December 2005. Executive Vice President and Treasurer,
Avenir Associates.
Provided interim management services to clients in the life sciences
industry. Assisted clients in developing and implementing regulatory
compliance programs.
2007-2008 Adjunct Associate Professor of Biology, Calvin University
2003-2007 Principal Research Associate, Western Michigan University
2000-2003 Adjunct Professor of Biology, Western Michigan University
1995-2000 Adjunct Assistant Professor of Biology, Western Michigan
University
Conducted research activities funded by USDA: the study of long-term
ecological consequences of release of transgenic crops, using squash as
a model system. Lecturing in food science and plant biology courses.
June 1996-August 1997 Associate Director, Biotechnology, Asgrow Seed
Company
Responsible for establishing an internal biotechnology research group
for corn, soybeans, sunflower, and sorghum. Participate in corporate
strategic planning. Responsible for developing and implementing
strategic plan for biotechnology research program, technology
acquisition, management of external collaborations and contracts,
regulatory affairs, licensing, patent issues.
1994-June 1996 Associate Director, Vegetable Biotechnology and Seed
Technology, Asgrow Seed Company
Managed a biotechnology research group; managed a seed biology research
group. Responsible for strategic planning for the biotechnology program,
managing external collaborations, project feasibility assessment,
product development, regulatory affairs, patents, and licensing.
1991-1994 Associate Director, Vegetable Biotechnology, Asgrow Seed
Company.
Managed a biotechnology research group. Responsible for managing
external collaborations, project feasibility assessment, product
development, regulatory affairs, patents, and licensing.
1989-1991 Vegetable Project Manager, Asgrow Seed Company.
Managed a research group and participated in biotechnology research;
participated in field research with transgenic plants. Also responsible
for regulatory affairs, patents, and licensing.
1986-1989 Visiting Scientist, The Upjohn Company.
Cloned and engineered viral genes to confer viral resistance to plants;
introduced these genes into plants as proof of concept.
## Funded Research
Gene Flow from Transgenic Cucurbita pepo into
"Free-living" populations. USDA Risk Assessment Grant, 1999-2002. $130,000.
## Other Funded projects
Biotechnology/Biodiversity Interface grant program,
component of USAID Program for Biosafety Systems. 2003-2008. $7,605,039.
Regulatory Development for HEG-modified mosquitoes. Foundation for the
National Institutes of Health. 2012-2016. $1,096,600.
Regulatory Capacity Building for Gene Drive Research. Foundation for the
National Institutes of Health. 2016-2019. $1,217,626.
Transitional Support for Gene Drive Research. Foundation for the
National Institutes of Health. 2017-2019. $2,110,008.
Support for FNIH Gene Drive Research Coordination. 2019-2023. $2,849,720
## International Consultancies
World Bank and International Food Policy Research
Institute (2006). Assessment of scientific capacity to support a regional
biosafety system in West African Economic and Monetary Union countries.
Conducted field visits to Benin and Togo, where I visited research
institutes, government agencies, and universities to determine the level
of scientific capacity (human and institutional resources) that could be
contributed by those countries to a regional biosafety regulatory
system.
US Department of Agriculture-Foreign Agricultural Services (2004-2009).
Planning and implementation of capacity building activities for the
National Biosafety Committee of Serbia-Montenegro. Organized and
implemented a series of workshops on biosafety and agricultural
biotechnology. Assisted in establishing Institutional Biosafety
Committees nationwide.
National Center for Food and Agricultural Policy/US
Department of Agriculture (2004). Team member: Served as resource person for
technical expertise on agricultural biotechnology during a visit to
Thailand. Advised Thai Department of Agriculture scientists on
approaches to tracing genetically engineered papaya seeds.
USAID/Agricultural Biotechnology Support Program II/Development
Alternatives, Inc (2003). Team member: Conducted an assessment of status of
biotechnology research in Indonesia. Made recommendations for USAID
activities to strengthen biotechnology capacity in that country, as part
of a broader USAID agricultural strategy. Collected technical
information to be used in ABSPII priority setting session held August
4-5, 2003.
USAID/Chemonics International., Inc (2003). Conducted an assessment of
scientific research project concept notes. Interviewed researchers and
made recommendations regarding merit of the projects and requirements
for full proposals to be submitted to USAID Uganda.
USAID/Michigan State University (2002-2009). Coordinator of regulatory
strategy and product delivery for commercialization of transgenic potato
tuber moth potatoes (South Africa).
USAID/Michigan State University (2002-2004). Coordinator of regulatory
strategy and product delivery for commercialization of transgenic
mustard producing oil enhanced in beta-carotene (India).
Council for Agricultural Science and Technology (2003). Team member:
Visited the People's Republic of China to meet with various regulatory
officials as part of a technical exchange project, funded by USDA/FAS.\
USAID/Agricultural Biotechnology Support Program (2002). Team member:
Conducted an assessment of status of biotechnology research in South
Africa. Made recommendations for USAID activities to strengthen
biotechnology capacity in that country (research, commercialization,
biosafety regulations, and intellectual property rights).
USAID/Agricultural Biotechnology Support Program (2002). Team Leader:
Conducted an assessment of status of biotechnology research in Kenya.
Made recommendations for USAID activities to strengthen biotechnology
capacity in that country (research, commercialization, biosafety
regulations, and intellectual property rights).
USAID/Agricultural Biotechnology Support Program (2002). Team Leader:
Conducted an assessment of status of biotechnology research in Uganda.
Made recommendations for USAID activities to strengthen biotechnology
capacity in that country (research, commercialization, biosafety
regulations, and intellectual property rights).
USAID/Development Alternatives,Inc (2001). Developed recommendations for
food and feed safety testing guidelines and environmental safety testing
guidelines to enable commercialization of genetically engineered crops
in Egypt.
USAID (2000). Assisted a multidisciplinary team of consultants in
evaluating biotechnology capacity in the Philippines and making
recommendations for the allocation of US\$30 million PL480 funds
earmarked for biotechnology research.
Government of India/Rockefeller Foundation (1998). Evaluated the range of
agricultural biotechnology programs in India, identified national needs
for testing facilities, made recommendations for the placement and
general features of those facilities.
## Other
Member, Core Working Group for "Guidance Framework for Testing Genetically Modified Mosquitoes, Second Edition", 2021. World Health Organization.
Reviewer, consensus report, "Genetically Engineered Crops: Past
Experience and Future Prospects", 2016. United States National Academies
of Sciences Engineering and Medicine.
Member, Core Working Group for "Guidance Framework for Testing of
Genetically Modified Mosquitoes", 2014. World Health Organization.
Science Advisor, International Food Biotechnology Committee,
International Life Sciences Institute, 2011-2013.
Preparer, Application for General Release of Transgenic Potato Spunta
G2, to South African Executive Committee, July 2008. Collaboration
between Michigan State University and the Agricultural Research
Council-Vegetable and Ornamental Plant Institute, South Africa.
Associate Editor, *Transgenic Research*, 2001-present.
Steering Committee Member, Workshop on Research to Improve the
Evaluation of the Impact os Genetically Engineered Organisms on
Terrestrial and Aquatic Wildlife and Habitats. United States National
Research Council, 2007.
Co-organizer, Models of Food Safety Assessment of Transgenic Crops,
Workshop funded by USAID and the Rockefeller Foundation, Washington DC,
May 6-8, 2003
Co-organizer, Agricultural Biotechnology Short Course, a collaboration
between Michigan State University and the USDA/FAS. 2002-2004.\]
Member, United States Department of Agriculture Plant Variety Protection
Advisory Board, 2002-2004
Author, Petition for exemption from the requirement of a tolerance for
*Cucurbita pepo* L. cultivar YS20 CZW3. Submitted to EPA November 27,
1995.
Co-author, petition for determination of regulatory status of *Cucurbita
pepo* L. cultivar YS20 CZW3. Granted June, 1996.
Author, Petition for exemption from the requirement of a tolerance for
*Cucurbita pepo* L. cultivar YC77E ZW20. Granted November, 1994.
Co-author, petition for determination of regulatory status of *Cucurbita
pepo* L. cultivar YC77E ZW20. Granted December, 1994.
1990-1994: Member, Upjohn Recombinant DNA Advisory Committee; Committee
Chairman 1991-1992.
1990-1994: Nonvoting member, Upjohn Biosafety Regulatory Committee.
1991-1992: Secretary, Upjohn Biosafety Regulatory Committee.
## Publications
Devos Y, Mumford JD, Bonsall MB, et al (2021) Risk management recommendations for environmental releases of gene drive modified insects. Biotechnology Advances 107807. [https://doi.org/10.1016/j.biotechadv.2021.107807](https://doi.org/10.1016/j.biotechadv.2021.107807){:target='_blank'}
Entine J, Felipe MSS, Groenewald J-H, et al (2021) Regulatory approaches for genome edited agricultural plants in select countries and jurisdictions around the world. Transgenic Research. [10.1007/s11248-021-00257-8](https://doi.org/10.1007/s11248-021-00257-8){:target='_blank'}
Mbabazi R, **Quemada H**, Shore S, et al (2020) Regulatory Capacity Strengthening for Gene-Drive Technology Applications for Vector-Borne Disease Control in Africa. Michigan State University.
[WorldTAP Policy Brief 7](https://www.canr.msu.edu/worldtap/uploads/files/7.%20Policy%20Brief%207%20-%20Regulatory%20Capacity%20For%20Gene%20Drive%20Technology%20application%20.pdf){:target='_blank'}
Kausch, A.P, Nelson-Vasilchik, K., Hague, J., Mookkan, M., **Quemada, H.**, Dellaporta, S., Fragoso, C., Zhang, A. 2019. Edit at Will: Genotype Independent Plant Transformation in the Era of Advanced
Genomics and Genome Editing. Plant Science. doi:
[10.1016/j.plantsci.2019.01.006](https://doi.org/10.1016/j.plantsci.2019.01.006){:target='_blank'}
James, S., Collins, F., Welkhoff, P., Emerson, C., Godfray, H.,
Gottlieb, M., Greenwood, B., Lindsay, S., Mbogo, C., Okumu, F.,
**Quemada, H**., Savadogo, M., Singh, J., Tountas, K., Touré, Y. 2018.
Pathway to Deployment of Gene Drive Mosquitoes as a Potential Biocontrol
Tool for Elimination of Malaria in Sub-Saharan Africa: Recommendations
of a Scientific Working Group. The American Journal of Tropical Medicine
and Hygiene 98: 1-49.
Adenle, A., Morris, E., Murphy, D., Phillips, P., Trigo, E., Kearns, P.,
Li, Y-H., **Quemada, H.**, Falck-Zepeda, J., Komen, J. 2018.
Rationalizing governance of genetically modified products in developing
countries. Nature Biotechnology 36: 137-139.
Lemgo, G., Nehra, N., **Quemada, H.** Food safety assessment of
genetically modified crops in developing countries: the experience in
Africa. In "Genetically Modified Organisms in Developing Countries: Risk
Analysis and Governance." A. Adenle, E. Morris, D. Murphy, eds.
Cambridge University Press, Cambridge. pp. 103-114.
Adelman, Z., Akbari, O., Bauer, J., Bier, E., Bloss, C., Carter, S.,
Callender, C., Costero-Saint Denis, A., Cowhey, P., Dass, B., Delborne,
J., Devereaux, M., Ellsworth, P., Friedman, R., Gantz, V., Gibson, C.,
Hay. B., Hoddle, M., James, A., James, S., Jorgenson, L., Kalichman, M.,
Marshall, J., McGinnis, W., Newman, J., Pearson, A., **Quemada, H.**,
Rudenko, L., Shelton, A., Vinetz, J., Weisman, J., Wong, B., & Wozniak,
C. 2017. Rules of the road for insect gene drive research and testing. Nature Biotechnology 35: 716-718.
Roberts, A., de Andrade, P.P., Okumu, F., **Quemada, H.,** Savadogo, M.,
Singh, J.A. and James, S. 2017. Results from the Workshop "Problem
Formulation for the Use of Gene Drive in Mosquitoes". The American
Journal of Tropical Medicine and Hygiene 96: 530-533.
**Quemada, H.** 2016. Regulation of Transgenic Mosquitoes. In "Genetic
Control of Malaria and Dengue." Z. Adelman, ed. Elsevier, London. pp.
363-373. Published online November 28, 2016, doi: 10.4269/ajtmh.16-0726.
Haggman, H., A. Raybould, A. Borem, T. Fox, L. Handley, M. Hertzberg, M.
Lu, P. Macdonald, T. Oguchi, G. Pasquali, L. Pearson, G. Peter, **H.
Quemada**, A.Seguin, K. Tattersall, E. Ulian, C. Walter and M. McLean. 2013. Genetically engineered trees for plantation forests: key
considerations for environmental risk assessment. Plant Biotechnology
Journal doi: 10.1111/pbi.12100.
Henley, W., R.W. Litaker, L. Novoveská, C. Duke, **H. Quemada**, and R.
Sayre. 2013. Initial risk assessment of genetically modified (GM)
microalgae for commodity-scale biofuel cultivation. Algal Research 2:
66--77.
Hancock, J., and **Quemada, H.** 2011. A problem-based approach to
environmental risk assessment of genetically engineered crops. In
Grumet, Rebecca & Hancock, F. & Maredia, M. & Weebadde, Cholani.
Environmental Safety of Genetically Engineered Crops. East Lansing:
Michigan State University Press. Project MUSE.
Zarka, K., R. Greyling, I. Gazendam, D. Oloefse , K. Felcher, G. Bothma,
J. Brink, **H. Quemada**, and D. Douches. 2010. Insertion and
Characterization of the cry1Ia1 Gene in the Potato Cultivar Spunta for
Resistance to Potato Tuber Moth. Journal of the American Society for
Horticultural Science 135: 317--324.
**Quemada, H**, K. Zarka, W. Pett, G. Bothma, K. Felcher, H. Mirendil,
M. Koch, J. Brink and D. Douches. 2010. Safety Evaluations of the Cry1Ia1 Protein Found in the
Transgenic Potato 'SpuntaG2'. Journal of the American Society for
Horticultural Science 135: 325--332.
Douches, D., W. Pett, D. Visser, J. Coombs, K, Zarka, K. Felcher, G.
Bothma, J. Brink, M. Koch, and **H. Quemada**. 2010. Field and Storage
Evaluations of 'SpuntaG2' for Resistance to Potato Tuber Moth and
Agronomic Performance. Journal of the American Society for Horticultural
Science 135: 333--340.
Raybould, A. and **H. Quemada**. 2010. Bt crops and food security in
developing countries: realised benefits, sustainable use and lowering
barriers to adoption. Food Security 2: 247--259.
Ramessar, K., T. Capell, R.M. Twyman, **H. Quemada**, and P. Christou. 2009. Calling the tunes on transgenic crops: the case for regulatory
harmony. Molecular Breeding 23: 99--112.
Sengooba, T., R. Grumet, J. Hancock, B. Zawedde, L. Kitandu, C.
Weebadde, M. Karembu, E. Kenya, K. Maredia, P. Nampala, J. Ochanda, **H.
Quemada**, M. Rubindamayugi. 2009. Biosafety education relevant to
genetically engineered crops for academic and non-academic stakeholders
in East Africa. Electronic Journal of Biotechnology 12: 1-5.
Douches, D., J. Brink, **H. Quemada**, W. Pett, M. Koch, D. Visser, K,
Maredia and K. Zarka. 2008. Commercialization of potato tuber moth
tesistant potatoes in South Africa. In Kroschel J and L Lacey (eds.),
"Integrated Pest Management for the Potato Tuber Moth, *Phthorimaea
operculella* Zeller -- a Potato Pest of Global Importance. Tropical
Agriculture 20, Advances in Crop Research 10. Margraf Publishers,
Weikersheim, Germany, 139-147.
**Quemada, H.**, L. Strehlow, D. Decker-Walters, and J.E. Staub. 2008.
Population Size and Incidence of Virus Infection in Free-Living
Populations of *Cucurbita pepo*. Environmental Biosafety Research, 7:
185-196.
Ramessar, K., T. Capell, R.M. Twyman, **H. Quemada**, and P. Christou. 2008.
Calling the tunes on transgenic crops: the case for regulatory harmony.
Molecular Breeding DOI 10.1007/s11032-008-9217-z.
Ramessar K., T. Capell, R.M. Twyman, **H. Quemada** and P. Christou. 2008. Trace and Traceability--A Call for Regulatory Harmony. Nature
Biotechnology 26: 975 - 978.
**Quemada, Hector D.**, David M. Tricoli, Jack E. Staub, Eileen A.
Kabelka, Yi-Hong Wang. 2008. Cucurbits. In \"Compendium of Transgenic
Crop Plants: Transgenic Vegetable Crops\". C. Kole and T.C. Hall, eds.
Blackwell Publishing, Oxford, UK, pp 145-184.
Matten, S., G.P. Head, and **H.D. Quemada**. 2008. How governmental
regulation can help or hinder the integration of Bt crops within IPM
programs. In Integration of Insect-Resistant Genetically Modified Crops
Within IPM Programs (J. Romeis, AM Shelton, and GG Kennedy, eds).
Springer. pp. 27-39.
Romeis, J., Bartsch, D., Bigler, F., Candolfi, M.P., Gielkens, M.P.C.,
Hartley, S., Hellmich, R.L., Huesing, J.E., Jepson, P.C., Layton, R.,
**Quemada, H.**, Raybould, A., Rose, R.I., Schiemann, J., Sears, M.K.,
Shelton, A.M., Sweet, J., Vaituzis, Z., Wolt, J.D. 2008. Assessment of
risk of insect-resistant transgenic crops to nontarget arthropods.
Nature Biotechnology 26: 203-208.
Linacre, N.A., J. Gaskell, M. W. Rosegrant, J. Falck-Zepeda, **H.
Quemada**, M. Halsey and R. Birner. 2006. Strategic environmental
assessments for genetically modified organisms. Impact Assessment and
Project Appraisal 24: 35-43.
Linacre, N.A.; Gaskell, J., Rosegrant, M.W.; Falck-Zepeda, J.;
**Quemada, H.**; Halsey, M.; Birner, R. 2005. Analysis for Biotechnology
Innovations Using Strategic Environmental Assessment (SEA).
International Food Policy Research Institute: Washington, D.C.
Atanassov, A.; Bahieldin, A.; Brink, J.; Burachik, M.; Cohen, J.I.;
Dhawan, V.; Ebora, R.V.; Falck-Zepeda, J.; Herrera-Estrella, L.; Komen,
J.; Low, F.C.; Omaliko, E.; Odhiambo, B.; **Quemada, H**.; Peng, Y.:
Sampaio, M.J.; Sithole-Niang, I.; Sittenfeld, A.; Smale, M.; Sutrisno,
Valyasevi, R.; Zafar, Y. Zambrano, P. 2004. To Reach the Poor: Results
from the ISNAR-IFPRI Next Harvest Study on Genetically Modified Crops,
Public Research, and Policy Implications. EPTD Discussion Paper No. 116.
Washington, D.C., International Food Policy Research Institute.
Cohen, J.I., **Quemada, H.**, Frederick, R. 2003. Food Safety and GM
Crops: Implications for Developing-Country Research. In *Food Safety in
Food Security and Food Trade. Focus 10, Brief 16 of 17*. Washington,
D.C., International Food Policy Research Institute.
Decker-Walters, D.S.; Chung., S.; Staub, J.E.; **Quemada, H.D.**;
Lopez-Sese, A.I. 2002. The origin and genetic affinities of wild
populations of melon (*Cucumis melo*, *Cucurbitaceae*) in North America.
Plant Systematics and Evolution 233:183-197.
**Quemada, H.** 2002. Case Study: Virus resistant crops. In
*GeneticallyModified Crops: Assessing Safety.* (Atherton, K., ed..).
Taylor & Francis : New York and London. pp. 219-240.
Decker-Walters, D. S., J. E. Staub, S. M. Chung, E. Nakata, and **H. D.
Quemada**. 2001. Diversity in free-living populations of *Cucurbita
pepo* as assessed by random amplified polymorphic DNA. Systematic Botany
27:19-28.
Pang, S.; Jan, F.; Tricoli, D. M.; Russell, P. F.; Carney, K. J.; Hu, J.
S.; Fuchs, M.; **Quemada, H. D.**; Gonsalves, D. 2000. Resistance to
squash mosaic comovirus in transgenic squash plants expressing its coat
protein genes. Molecular Breeding 6:87-93.
Fuchs, M., J.R. McFerson, D.M. Tricoli, J.R. McMaster, RZ. Deng, M.L.
Boeshore, J.F. Reynolds, P.F. Russell, **H.D. Quemada**, and D.
Gonsalves, 1997. Cantaloupe line CZW-30 containing coat protein genes of
cucumber mosaic virus, zucchini yellow mosaic virus, and watermelon
mosaic virus-2 is resistant to these aphid-borne viruses in the field.
Molecular Breeding 3: 279-290.
Pang, S-Z, F-J Jan, D.M. Tricoli, **H.D. Quemada**, and D. Gonsalves, 1996. Post-transcriptional transgene silencing and consequent tospovirus
resistance in transgenic lettuce are affected by transgene dosage, plant
development, and environmental factors. The Plant Journal 9: 899-909.
Tricoli, D.M., K.J. Carney, P.F. Russell, J.R. McMaster, D.W. Groff,
K.C. Hadden, P.T. Himmel, J.P. Hubbard, M.L. Boeshore, and **H.D.
Quemada**, 1995. Field Evaluation of transgenic squash containing single
or multiple virus coat protein gene constructs for resistance to
cucumber mosaic virus, watermelon mosaic virus 2, and zucchini yellow
mosaic virus. BioTechnology 13: 1458-1465.
**Quemada, H.D.**, 1994. The Asgrow Seed Company's experience with
vegetable biotechnology. In *Biosafety for Sustainable
Agriculture: Sharing Biotechnology Regulatory Experiences of the Western
Hemisphere* (Krattiger, A.F., and A. Rosemarin, eds.). ISAAA: Ithaca &
SEI: Stockholm. pp. 167-173.
**Quemada, H.**, D. Gonsalves, and J.L. Slightom, 1991. CMV-C coat
protein gene expression in tobacco: protection against infection by CMV
strains transmitted mechanically or by aphids. Phytopathology 81:
794-802.
**Quemada, H.**, L.C. Sieu, D.R. Siemieniak, D. Gonsalves, and J.L.
Slightom, 1990. Watermelon mosaic virus II and zucchini yellow mosaic
virus: cloning of 3'-terminal regions, nucleotide sequences, and
phylogenetic comparisons. Journal of General Virology 71: 1451-1460.
**Quemada, H.**, B. L'Hostis, D. Gonsalves, I. Reardon, R. Heinrikson,
E.L. Hiebert, L.C. Sieu, and J. L. Slightom, 1990. The nucleotide
sequences of cDNA clones of the 3' terminal regions of papaya ringspot
virus strains W and P. Journal of General Virology 71: 203-210.
**Quemada, H**., C. Kearney, D. Gonsalves, and J.L. Slightom, 1989.
Nucleotide sequences of the coat protein genes and flanking regions of
cucumber mosaic virus strains C and WL RNA 3. Journal of General
Virology 70: 1065-1073.
Slightom, J.L. and **H.D. Quemada**, 1988. Procedures for constructing
ds-cDNA clone banks. In: *Plant Molecular
Biology* (eds. S.B. Gelvin and R.A. Schilperoort), Martinus
Nijhoff, Dordecht, The Netherlands.
**Quemada, H**., E.J. Roth, and K.G. Lark, 1987. Changes in methylation
of tissue cultured soybean cells detected by digestion with the
restriction enzymes HpaII and MspI. Plant Cell Reports 6: 63-66.
## Patents
U.S.: #6337431 "Transgenic plants expressing DNA constructs containing
a plurality of genes to impart virus resistance."
#5,349,128 "Cucumber Mosaic Virus Coat Protein Gene."
#5,623,066 "Cucumber Mosaic Virus Coat Protein Gene.".
Canada: #1,335,965 "Cucumber Mosaic Virus Coat Protein Gene".
Australia: #621336 "Cucumber Mosaic Virus Coat Protein Gene".
#634168 "Potyvirus Coat Protein Genes and Plants Transformed
Therewith".
#634171 "Cucumber Mosaic Virus Coat Protein Gene".
#639891 "Expression Cassette for Plants".
Europe: E 107361 (Austria). "CMV coat protein gene."
Notices of allowance received on others.
[//]: # (This javascript adds a button to go back to the top)
<button style="background-color:#C0B283" onclick="getBackToBeginning()"> Click here to go back to the top of the page
</button>
<script>
function getBackToBeginning() { window.scrollTo(0, 0);
}
</script> | 46.606957 | 286 | 0.781037 | eng_Latn | 0.87868 |
c072766003a3521ee179617c4783a3c2c1e0fea4 | 144 | md | Markdown | README.md | tiborsaas/portfolio-3d | c201dda897b80f12b3b50e47e234a98e568cfaf3 | [
"MIT"
] | null | null | null | README.md | tiborsaas/portfolio-3d | c201dda897b80f12b3b50e47e234a98e568cfaf3 | [
"MIT"
] | null | null | null | README.md | tiborsaas/portfolio-3d | c201dda897b80f12b3b50e47e234a98e568cfaf3 | [
"MIT"
] | null | null | null | # Portfolio 3D
This will ultimately go to my portfolio's header.
# Scripts
Dev server: `npm run dev`
Bundle: `npm run build`
# License
MIT | 11.076923 | 49 | 0.715278 | eng_Latn | 0.945763 |
c072ce0d2ff55b85a01aa0e5a4032993e07d88c6 | 89 | md | Markdown | examples/README.md | Svtter/micro | f88941fee953d7a8fbf6c313dfc79602c1702cc5 | [
"Apache-1.1"
] | 1 | 2021-11-20T10:47:39.000Z | 2021-11-20T10:47:39.000Z | examples/README.md | Svtter/micro | f88941fee953d7a8fbf6c313dfc79602c1702cc5 | [
"Apache-1.1"
] | null | null | null | examples/README.md | Svtter/micro | f88941fee953d7a8fbf6c313dfc79602c1702cc5 | [
"Apache-1.1"
] | null | null | null | # Examples for all
1. one_service: 单一服务样例
2. two_service: 多服务样例
3. template: 用于核心应用生成模板
| 14.833333 | 23 | 0.764045 | eng_Latn | 0.665584 |
c073c89d87ea83a850b9f77c1b566e1188dd77b6 | 751 | md | Markdown | data/changelogs/Markdown.md | ewjoachim/stub_uploader | b7b6f61fb99b4478302d7b69e3b95eba105eca7d | [
"Apache-2.0"
] | null | null | null | data/changelogs/Markdown.md | ewjoachim/stub_uploader | b7b6f61fb99b4478302d7b69e3b95eba105eca7d | [
"Apache-2.0"
] | null | null | null | data/changelogs/Markdown.md | ewjoachim/stub_uploader | b7b6f61fb99b4478302d7b69e3b95eba105eca7d | [
"Apache-2.0"
] | null | null | null | ## 3.3.9 (2021-11-26)
Add mypy error codes to '# type: ignore' comments (#6379)
## 3.3.8 (2021-11-16)
Add hilite(shebang) argument and return type (#6316)
## 3.3.7 (2021-11-09)
Add markdown.blockprocessors.ReferenceProcessor (#6270)
## 3.3.6 (2021-10-15)
Use lowercase tuple where possible (#6170)
## 3.3.5 (2021-10-12)
Add star to all non-0.1 versions (#6146)
## 3.3.4 (2021-10-05)
markdown: fix type of Pattern (#6115)
Surfaced weirdly by #6109
Co-authored-by: hauntsaninja <>
## 3.3.3 (2021-09-20)
Add types to Markdown (#6045)
Most methods and attributes were previously untyped or `Any`-typed.
Co-authored-by: PythonCoderAS <[email protected]>
Co-authored-by: Sebastian Rittau <[email protected]>
| 19.763158 | 79 | 0.705726 | eng_Latn | 0.720813 |
c074c1619d96cf5178207c2bc5a8575b7a104643 | 1,025 | md | Markdown | md/wechat/interfaces.md | thlws/payment-thl | 3237fce6f06504ebc08ff4d4121902d06a1b72a3 | [
"Apache-2.0"
] | 15 | 2018-12-29T04:35:54.000Z | 2021-07-10T02:18:39.000Z | md/wechat/interfaces.md | thlws/payment-thl | 3237fce6f06504ebc08ff4d4121902d06a1b72a3 | [
"Apache-2.0"
] | 1 | 2019-09-19T01:10:20.000Z | 2019-09-23T05:08:00.000Z | md/wechat/interfaces.md | thlws/payment-thl | 3237fce6f06504ebc08ff4d4121902d06a1b72a3 | [
"Apache-2.0"
] | null | null | null | # 接口列表
**微信支付**
[org.thlws.payment.WechatPayClient](https://gitee.com/thlws/payment-thl/tree/master/src/main/java/org/thlws/payment/WechatPayClient.java)
| 方法名称 | 功能说明 |
|:--------|:--------|
| unifiedOrder | 统一下单(类似预订单) |
| refund | 申请退款 |
| reverse | 支付撤销 |
| microPay | 刷卡支付 |
| orderQuery | 支付查询 |
| closeOrder | 订单关闭 |
| openidQuery | 查询OpenId|
| queryMicroMch | 查询小微收款人信息|
| postMicroMch | 申请开通小微收款功能|
**微信公众号**
[org.thlws.payment.WechatMpClient](https://gitee.com/thlws/payment-thl/tree/master/src/main/java/org/thlws/payment/WechatMpClient.java)
| 方法名称 | 功能说明 |
|--------|--------|
| obtainOauthAccessToken | 获取accesToken(OAuth2) |
| refreshOauthAccessToken | 刷新accesToken(OAuth2) |
| isvalidOauthAccessToken | 验证token是否过期(OAuth2) |
| generateWechatUrl | 生成微信规则URL |
| obtainUserInfo | 获取用户资料|
| obtainAccessToken | 获取accesToken(普通) |
| obtainJsApiTicket | 获取JSAPI Ticket |
| obtainTemplateId | 获取微信消息模板ID |
| setupIndustry | 设置行业属性 |
| sendMsgToUser | 发送微信通知 |
#### 公众号开发会涉及Token,Ticket等时效性参数,建议程序中使用Redis进行存储. | 29.285714 | 137 | 0.713171 | yue_Hant | 0.519603 |
c0750ba3c7e295417a8e65cb077bbb2a73507107 | 52 | md | Markdown | README.md | cemalkocatepe-1/api | 5ca58a0356b59b0dd6a265d7b2303f994e021504 | [
"MIT"
] | null | null | null | README.md | cemalkocatepe-1/api | 5ca58a0356b59b0dd6a265d7b2303f994e021504 | [
"MIT"
] | null | null | null | README.md | cemalkocatepe-1/api | 5ca58a0356b59b0dd6a265d7b2303f994e021504 | [
"MIT"
] | null | null | null | # api worker callback
api worker callback challenge
| 17.333333 | 29 | 0.826923 | eng_Latn | 0.851218 |
c0768bfed58eef7abd626e145685819d613ef876 | 256 | md | Markdown | README.md | lizheming/path | b6f598859105f4077c21c838702c8165719e5811 | [
"MIT"
] | 17 | 2019-06-06T13:35:59.000Z | 2021-09-02T15:06:19.000Z | node_modules/@skpm/path/README.md | pratikjshah/sketch-cloud-design-system | 783d29e976171279ce6883a92f07512ed342aa2c | [
"MIT"
] | 7 | 2019-08-05T14:01:47.000Z | 2021-05-09T01:46:07.000Z | node_modules/@skpm/path/README.md | pratikjshah/sketch-cloud-design-system | 783d29e976171279ce6883a92f07512ed342aa2c | [
"MIT"
] | 3 | 2018-11-29T17:10:42.000Z | 2020-10-08T05:47:08.000Z | # `path` for Sketch
All the [nodejs path](https://nodejs.org/api/path.html) API is available.
A additional method is available:
- `path.resourcePath(string)`: which returns the path to a resource in the plugin bundle or `undefined` if it doesn't exist.
| 32 | 124 | 0.746094 | eng_Latn | 0.933762 |
c076ba8c25322a9fe607cb75c68acaf3860a9060 | 2,932 | md | Markdown | L7/README.md | Nazar910/hsa-5 | f20091421374a379f7018473b9ab0988d4fc0e9a | [
"MIT"
] | null | null | null | L7/README.md | Nazar910/hsa-5 | f20091421374a379f7018473b9ab0988d4fc0e9a | [
"MIT"
] | null | null | null | L7/README.md | Nazar910/hsa-5 | f20091421374a379f7018473b9ab0988d4fc0e9a | [
"MIT"
] | null | null | null | # Task
Configure nginx images caching:
* cache only images requested atleast twice
* add ability to drop cache of specific file
# Prerequisites
* docker-compose util installed
* start up project using following script:
```
$ docker-compose up -d
```
# Caching mechanism
Searched for info in NGINX docs for proxy_cache module and https://www.tecmint.com/cache-content-with-nginx/.
So, regarding our task, we can try to load 1.jpg in our browser by url http://localhost:8080/1.jpg.
Take a look at response headers:


There is a header called `X-Proxy-Cache`. It indicates whether our request was processed by using value from cache or proxying to upstream.
When we try to load image `1.jpg` for the first time it shows `MISS`, which means that there is no record for this images in cache. Same on the second request. But when we load it for the 3rd time, we'll get `HIT` value, meaning that this time value was in cache.

This behaviour was achieved by using `proxy_cache_min_uses 2` option (take a look at [nginx.conf](https://github.com/Nazar910/hsa-5/blob/main/L7/nginx/nginx.conf)), to allow us to cache not all requested resources, but only the once that requested more than one time.
```
add_header X-Proxy-Cache $upstream_cache_status;
proxy_ignore_headers "Set-Cookie";
proxy_cache my_cache;
proxy_cache_min_uses 2;
proxy_cache_valid 200 60m;
proxy_cache_key $proxy_host$request_uri;
```
# Drop speciefic value in cache
This was achieved by using additional lua script that goes right into the `/data/nginx/cache` dir and drop cache record. For this we added new HTTP method `PURGE`.
Because we know what `proxy_cache_key` is and we know where data is stored. In order to find out which record is ours we just calculate md5 of our `cache_key` (taking into account cache levels) and searching for that file on fs (check [lua script](https://github.com/Nazar910/hsa-5/blob/main/L7/nginx/lua/purge.lua) source). Btw this script was taken with a small update from https://scene-si.org/2016/11/02/purging-cached-items-from-nginx-with-lua.
Example:
* we have loaded 2.jpg into cache (got `X-Proxy-Cache: HIT`)
* execute `curl` command in shell
```
$ curl -X PURGE http://localhost:8080/2.jpg
```
* when we hit http://localhost:8080/2.jpg in our browser we'll see `X-Proxy-Cache: MISS` + there will be no cache record in /data/nginx/cache for this image.
# Project structure
* python static server - serves 3 images (1.jpg, 2.jpg and 3.jpg)
* nginx as a proxy - proxy passes request to Python static server
| 53.309091 | 449 | 0.749659 | eng_Latn | 0.971586 |
c0798c736aa3eb385048bfc204d53c86a917e655 | 15,354 | md | Markdown | content/blog/making-of-player-fan-a-hockey-fansite/index.md | slinden2/chunk-of-code | fb6bf14d55d2090ebc178c3ea31ee3c816dd960a | [
"MIT"
] | null | null | null | content/blog/making-of-player-fan-a-hockey-fansite/index.md | slinden2/chunk-of-code | fb6bf14d55d2090ebc178c3ea31ee3c816dd960a | [
"MIT"
] | null | null | null | content/blog/making-of-player-fan-a-hockey-fansite/index.md | slinden2/chunk-of-code | fb6bf14d55d2090ebc178c3ea31ee3c816dd960a | [
"MIT"
] | null | null | null | ---
title: "Making Of - Player Fan (A Hockey Fansite)"
published: true
date: "20191002"
tags: ["graphql", "nhl", "playerfan", "react"]
---

I created a hockey player fansite. I have been super busy lately between vacation, day job and my first ever full-blown fullstack application. I will write a bit about the design process.
## TL;DR
I am launching my first ever fullstack application, [Player Fan](https://www.player.fan). It is an NHL (National Hockey League) related website that allows you to follow specific players rather than teams, see their recent performance and have access to all their goal videos easily.
## What is the site about?
The site is about NHL **players**. It's main goal is to follow players, not teams. Following teams is already easy, just visit any sports site and they have team standings, game-by-game scores and some game videos easily available.
Following single players is more difficult. If you wanted to check a specific goal made by a specific player in a specific game, it is so much harder. That is what I build [Player Fan](https://www.player.fan) for. The user can easily view the hottest players of the recent games via player cards (image below) and check the goal videos of any player that has played at least one game during the season. Of course, the player has to have scored as well, otherwise there is no video available. 😊

A registered user can also add players to his personal favorite list to see their recent stats and goals quickly every day without having to go through game recaps hoping for their player to score. This is a huge time saver for fans with limited time. Once I got the videos working, I spent at least 1,5 hours just watching goals videos (_that time is excluded from the project time record that I show in a later chapter._ 🤣).
## How I came up with the idea
I have been a hockey fan since forever. I am Finnish and our national sport is ice hockey. There is no question about it. Football (soccer) doesn't come even close. I don't think there are any other countries beside Canada and Finland where the number one sport is undoubtedly ice hockey.
However, while you are a student, you have a lots of free time. If you, the reader, are a student and you disagree, just wait for the reality to hit you in the face when you start working and other stuff starts to invade you life. So, as a student I was able to follow teams, players and watch matches or at least the condensed games or game recaps. That has changed in the recent years and I haven't been following NHL that much at all. I still know more or less which teams are doing well and who won the Stanley Cup, but I haven't had the time to really follow the sport, even if my interest for it hasn't gone anywhere.
I decided that something needed to be done. I wanted to create something that allows me to follow my favorite players easily and efficiently without spending too much time that I don't have. From there, step-by-step, I started researching what was needed to create such a website. Some questions came up: _"Where to get the data?", "How to get the data?", "Is there an API?", "Is it expensive?", "Does this project provide value for others?", "Is this too big of a chunk for my current web development skills?"_
After a couple of hours of research I resolved to give it a go.
## Planning
I didn't do that much planning. I was so existed to get started that I just couldn't sit down for hours to think about how to structure the application and what was really needed. I just wanted to start getting some lines down.
That, of course, was a huge error and lead up to me refactoring a bunch of stuff many times over. I guess this is quite normal in software engineering, but sure some of it could have been avoided by some solid planning.
My planning basically went like this: "Ok. There is a cool undocumented API that surely will be fine for what I need it for. I also like [React](https://reactjs.org/), [GraphQL](https://graphql.org/learn/) and [Node.js](https://nodejs.org/en/) so I will use those. The DB will be [MongoDB](https://www.mongodb.com/), because Atlas is so easy to setup and I have used it in a smaller exercise."
The database might have been the biggest error, because I ended up using [Heroku](https://www.heroku.com/) for deployment and it has [PostgreSQL](https://www.postgresql.org/) integrated in it. Also, I ended up writing up some huge aggregation pipelines that probably would have been cleaner in SQL.
Anyway, _making_ mistakes is not stupid. Not _learning_ from them is. The next time I will contain myself and have a minimum requirement of a few hours planning before I can get started with coding.
## Project time table
I kept record of my working hours on this project. It is not 100 % perfect. I surely have missed some hours here and added some hours there. I usually can't work on a thing without interruptions, so keeping accurate record without a time tracking app (I didn't use one) is difficult.
I did also quite a bit of off-record studying. I had little experience with MongoDB before and close to zero experience on GraphQL and CSS before starting the project. I had to tackle all of those so I spent at least some 40 hours on studying those and reading documentation.
Also the task descriptions are somewhat vague and cryptic for someone who is not me. In any case I hope that it gives you and idea on how the project developed and may give some hint to beginner devs on how much time is needed for a complete web app. Sorry for the long table.
| day | time | tasks |
| :--------: | :--- | :---------------------------------------------------------------- |
| 09.06.2019 | 1 | getting started |
| | 2 | working on fetch-data |
| 10.06.2019 | 2 | studying api and working on fetch-data |
| 11.06.2019 | 3 | working on fetch-data |
| 12.06.2019 | 2 | working on fetch-data. problems with db saving functionality. |
| 13.06.2019 | 2 | fetch-data finally giving consistent results. |
| | 2 | graphql initial setup done. |
| 14.06.2019 | 4 | working on graphql schema. |
| 15.06.2019 | 5 | working on resolvers. |
| 16.06.2019 | 5 | getting started with frontend |
| 17.06.2019 | 4 | css basic styling |
| 18.06.2019 | 2 | css basic styling |
| | 2 | react router and navbar styling |
| | 1,5 | started to implement semantic-ui instead of styled components |
| 19.06.2019 | 2,5 | semantic-ui implentation for now done. added user model in db |
| 20.06.2019 | 5 | implemented login system, user creation and forgot password |
| | 1 | implemented cookies |
| 24.06.2019 | 3,5 | worked on the login system and personalized view for logged users |
| | 1 | profile page for logged users |
| 25.06.2019 | 4,5 | notification system done. started to work on player algorithm |
| | 1,5 | best player algorithm |
| 26.06.2019 | 2,5 | best player algorithm |
| | 1 | frontend error handling |
| 28.06.2019 | 2 | studied apollo hooks and tried implementing them |
| | 3 | implemented player following in the backend |
| 30.06.2019 | 3 | studied contextAPI and useContext hook |
| | 4 | code refactoring, implementing contextAPI |
| 01.07.2019 | 6 | working on AuthContext and favoritePlayers view |
| 02.07.2019 | 5 | working on Heroku deployment |
| 03.07.2019 | 1 | working on Heroku deployment |
| | 3 | apollo-express setup and apollo cache debugging |
| 04.07.2019 | 3 | fixed a bug in apollo cache. sort by gameDate instead of gamePk |
| | 1 | working on the ui |
| 05.07.2019 | 5 | created search functionality |
| 06.07.2019 | 5 | worked on search and production version of the application |
| | 1 | bug fix in the reduce-stats program |
| 07.07.2019 | 4 | unit tests |
| 08.07.2019 | 5 | unit tests and started studying tests for graphql |
| 09.07.2019 | 5 | units tests for graphql schema |
| | 1 | searched for a source for player images and found one |
| 10.07.2019 | 4 | first version of player stats done. still needs a lot of work. |
| | 2 | thinking how to reorganize the database |
| 11.07.2019 | 4 | started the db reorganization |
| 12.07.2019 | 5 | worked on data fetching scripts |
| 14.07.2019 | 2 | data fetching scripts |
| 15.07.2019 | 2 | data fetching scripts |
| 16.07.2019 | 5 | data fetching scripts |
| 17.07.2019 | 4 | finished the data fetching and created script for best players |
| 18.07.2019 | 2 | fixed unit test after significant changes in data structures |
| 19.07.2019 | 4 | bug fixes and cumulativestats resolver |
| 20.07.2019 | 8,5 | cumulative stats in fe and be. sorting and pagination working. |
| 21.07.2019 | 8 | working on standings, backend and frontend |
| 22.07.2019 | 6,5 | refactored the schemas and did the first proto of player profile |
| 23.07.2019 | 6 | fixed a cache bug and worked on the player profile. |
| 24.07.2019 | 5 | added support for milestones (goal videos on player profiles) |
| 25.07.2019 | 4 | working on the player profile / milestones |
| 26.07.2019 | 2 | added backside to the player cards |
| 28.07.2019 | 4 | best players optimization, stats table refactoring |
| 29.07.2019 | 2 | stats table refactoring |
| | 4 | starting to design the final layout with styled components |
| 30.07.2019 | 6 | working on player cards |
| 31.07.2019 | 6 | working on player cards and card container |
| 02.08.2019 | 3 | working on layout |
| 03.08.2019 | 4 | working on layout |
| 05.08.2019 | 4 | working on layout |
| 06.08.2019 | 5 | working on layout |
| 07.08.2019 | 6 | working on layout |
| 08.08.2019 | 4 | working on layout |
| 09.08.2019 | 2 | Refactoring the navigation bar |
| 27.08.2019 | 2 | Refactoring the navigation bar |
| 28.08.2019 | 4 | Finished nav bar |
| 29.08.2019 | 4 | Working on player profile |
| 30.08.2019 | 4 | Working on stats and standings |
| 31.08.2019 | 4 | Working on search |
| 01.09.2019 | 4 | Working on search |
| 02.09.2019 | 4 | Working on search page |
| 03.09.2019 | 4 | Working on team profile |
| 04.09.2019 | 4 | Working on team profile |
| 05.09.2019 | 6 | Team profile and team links. Added fallback images. |
| 06.09.2019 | 6 | Refactored StatsTable and added highlighting |
| 07.09.2019 | 6 | Created loader and started working on sign up modal |
| 08.09.2019 | 5 | Started working on forms |
| 10.09.2019 | 4 | Added mailgun and relative functions |
| 11.09.2019 | 6 | Working on forms |
| 12.09.2019 | 5 | Working on forms, setup logo and favicons |
| 13.09.2019 | 5 | Improved mobile navi, added google analytics |
| 14.09.2019 | 4 | Cookie policy |
| 15.09.2019 | 4 | Added cookie consent banner and remember be on login |
| 22.09.2019 | 5 | Created a new aggregation pipeline for best players |
| 23.09.2019 | 5 | Added support for the new aggregation in frontend |
| total | 340 | |
One of my hurdles was definitely how to style the site. It is not clear from the time records, but I attempted styling the site three times. First with [styled-components](https://www.styled-components.com/), then with [semantic-ui](https://react.semantic-ui.com/) and then in August I did everything again with [styled-components](https://www.styled-components.com/).
If you are a seasoned programmer and you skimmed through the table, you surely also noticed that I've done almost no testing at all. I know. I should've have done some testing from the beginning. Tests are something I will definitely have to add to avoid future headaches.
I stopped recording the hours a bit more than a week ago, but I am still working on the project.
## Future plans in the pipeline
I am full of new ideas for the site. The season has started and the first version of the site is out, but there is so much more to come. The current plan is to convert the site into a more social network like user interface with the possibility comment on videos and vote for the best ones.
Everything is still open though. If you have an idea or a feature request, please leave a comment below, contact me via the contact form on the [site](https://www.player.fan) or tweet me at [@playerfansite](https://twitter.com/playerfansite).
Thanks for reading.
| 94.196319 | 623 | 0.577244 | eng_Latn | 0.999194 |
c07a687fe2a1e5acf9c9cf67d72e78856570f241 | 1,239 | md | Markdown | .github/ISSUE_TEMPLATE/gift-string.md | mralext20/blobsanta | f29e569331cdc57e625a239b5c8f813624b683e3 | [
"MIT"
] | null | null | null | .github/ISSUE_TEMPLATE/gift-string.md | mralext20/blobsanta | f29e569331cdc57e625a239b5c8f813624b683e3 | [
"MIT"
] | 5 | 2020-11-18T03:35:18.000Z | 2020-12-27T03:24:42.000Z | .github/ISSUE_TEMPLATE/gift-string.md | mralext20/blobsanta | f29e569331cdc57e625a239b5c8f813624b683e3 | [
"MIT"
] | 6 | 2020-11-19T11:20:29.000Z | 2020-12-10T23:04:47.000Z | ---
name: Gift String Suggestion
about: Suggest a gift string log message
title: 'Gift String Suggestion'
labels: 'string'
---
# String Guidelines
- Strings should be in the general format of `{0} just sent (a/an) <Emoji> <Name> to {1}. <Flavor Text>`.
- Strings must be grammatically correct, safe for work, appropriate, and not include any special formatting (with the exception of emoji formatting.)
- Emojis must be normal unicode or official Blob Emoji. Include the raw emoji for normal unicode emoji or `<:name:id>` formatting for Discord emoji. Only in special/rare cases will other custom emoji be used.
<!-- Replace [ ] below with [x] to tick this checkbox. -->
- [ ] All of my suggestions meet these guidelines.
# String Suggestions
*Type your string suggestion(s), following the above guidelines, below the line. Please include intended meaning/explanation for any references.*
*(If you are interested in creating a pull request to implement these suggestions yourself, please read our [Guidelines for Implementating Gift String Suggestions](https://github.com/BlobEmoji/blobsanta/blob/main/CONTRIBUTING.md#guidelines-for-implementating-gift-string-suggestions) after creating your issue.)*
------
- `{0} just sent...`
| 51.625 | 312 | 0.759483 | eng_Latn | 0.990122 |
c07b1abc405e1610fc92366bdff6fb8f210dc476 | 14,862 | md | Markdown | docs/series-3/series-3-episode-09-the-vengeance-formulation.md | hehichens/Awesome-TBBT | 546358a16b96e32fb8d654cedfd9ac2377a58c0d | [
"Apache-2.0"
] | null | null | null | docs/series-3/series-3-episode-09-the-vengeance-formulation.md | hehichens/Awesome-TBBT | 546358a16b96e32fb8d654cedfd9ac2377a58c0d | [
"Apache-2.0"
] | null | null | null | docs/series-3/series-3-episode-09-the-vengeance-formulation.md | hehichens/Awesome-TBBT | 546358a16b96e32fb8d654cedfd9ac2377a58c0d | [
"Apache-2.0"
] | null | null | null | ### series-3-episode-09-the-vengeance-formulation
Howard: So two years later, there’s a knock on the door, guy opens it, and there on his porch is the snail, who says, “What the heck was all that about?”
Bernadette: I don’t really get it.
Howard: Well, see, it took two years for the snail to…
not important.
Bernadette: Can I ask you a question?
Howard: Sure.
Bernadette: Where do you think this is going?
Howard: To be honest, I was hoping at least second base.
Bernadette: You’re so funny. You’re like a stand-up comedian.
Howard: A Jewish stand-up comedian, that’d be new.
Bernadette: Actually, I think a lot of them are Jewish.
Howard: No, I was just… never mind.
Bernadette: Look, Howard, this is our third date and we both know what that means.
Howard: We do?
Bernadette: Sex.
Howard: You’re kidding.
Bernadette: But I need to know whether you’re looking for a relationship or a one-night stand.
Howard: Okay, just to be clear, there’s only one correct answer, right? It’s not like chicken or fish on an airplane?
Bernadette: Maybe you need to think about it a little.
Howard: You know, it’s not unheard of for a one-night stand to turn into a relationship.
Bernadette: Call me when you figure it out.
Howard: Three dates means sex? Who knew?
Howard: Greetings, homies, homette.
Penny: Why are you back from your date so early?
Howard: In romance, as in show business, always leave them wanting more.
Penny: What exactly does that mean?
Leonard: He struck out.
Howard: Hey, did either of you guys know that three dates with the same woman is the threshold for sex?
Raj: Actually, I’ve never had three dates with the same woman.
Leonard: With Penny and me, it took two years. Now that I think about it, that was three dates.
Howard: Okay, well, before you and Penny hooked up, did she ask for any kind of commitment?
Leonard: No, she was pretty clear about wanting to keep her options open.
Sheldon
: I have something to announce, but out of respect for convention, I will wait for you to finish your current conversation. What are you talking about?
Leonard: The cultural paradigm in which people have sex after three dates.
Sheldon: I see. Now, are we talking date, the social interaction, or date, the dried fruit?
Leonard: Never mind, what’s your announcement?
Sheldon: Oh, good, my turn. Well, this is very exciting and I wanted you to be among the first to know…
Kripke: Hey, Cooper, I hear you’re going to be on the wadio with Ira Fwatow from Science Fwiday next week.
Sheldon: Thank you, Kripke, for depriving me of the opportunity to share my news with my friends.
Kripke: My pweasure.
Sheldon: My thank you was not sincere.
Kripke: But my pweasure is. Let me ask you a question, at what point did National Public Wadio have to start scwaping the bottom of the bawwel for its guests? Eh, don’t answer, it’s wetowical.
Sheldon: Why are you such a stupid head? That is also rhetorical. I’m sorry you had to hear that.
Leonard: Are you really going to be on NPR?
Sheldon: Yes, they’re interviewing me by phone from my office, regarding the recent so-called discovery of magnetic monopoles in spin-ices. It’s pledge week and they’re trying to goose the ratings with a little controversy.
Leonard: Very cool, congratulations.
Sheldon: Thank you. My mother is very excited. She’s convening her Bible study group to listen in, and then pray for my soul.
Raj: I was on the radio once. I called in to Fever 104 FM New Delhi and was the fourth person to say the phrase that pays, “Fever 104, आज के नये अच्छे संगीत का घर.” That means: “Fever 104, home of the really good current music.” It’s much catchier in Hindi.
Sheldon: All right. These are the talking points for my NPR interview tomorrow. I need to make sure that they’re simple enough for the less educated in the audience to understand. Howard, look this over and tell me what’s unclear to you.
Howard: Excuse me, I have a master’s degree in engineering from the Massachusetts Institute of Technology. It required the completion of 144 units of grad work and an original thesis.
Sheldon: Yes. Look this over and tell me what’s unclear to you.
Leonard: You know, when Sheldon gives you homework, you don’t have to do it.
Raj: In fact, it’s better if you don’t, otherwise it makes the rest of us look bad.
Penny: Hi, guys.
Leonard: Hey.
Sheldon: Hello.
Penny: Yo, Raj, talk to me. I’m sorry, just screwing with you. Hey, Howard, why haven’t you called Bernadette?
Howard: Did she say something?
Penny: Yeah, she said she hasn’t heard from you in a week. I thought you liked her?
Howard: I do, yeah, but she wants a commitment and I’m not sure she’s my type.
Penny: She agreed to go out with you for free. What more do you need?
Howard: Look, Bernadette is really nice. I just always thought when I finally settle down into a relationship, it would be with someone, you know, different.
Penny: Different how?
Howard: Well, you know, more like Megan Fox from Transformers, or Katee Sackhoff from Battlestar Galactica.
Penny: Are you high?
Leonard: You’d have a better shot with the three-breasted Martian hooker from Total Recall.
Howard: Okay, now you’re just being unrealistic. Anyway, that movie was like 20 years ago, imagine how saggy those things would be.
Penny: Howard, you’re going to throw away a great girl like Bernadette because you’re holding out for some ridiculous fantasy?
Howard: Hey, just because you settled doesn’t mean I have to.
Leonard: Excuse me, I’m sitting here.
Penny: Hey, I did not settle for Leonard. I mean, obviously, he isn’t the kind of guy I usually go out with, you know, physically.
Leonard: Again, I’m right here.
Penny: My point is, I do not judge a book by its cover. I am interested in the person underneath.
Leonard: I am here, right? You see me.
Howard: Hey, I’m interested in what’s inside people, too, but why is it wrong to want those insides wrapped up in, say, the delicious caramel that is Halle Berry?
Yes, you’re delicious caramel, too.
Penny: All right, you know what, I will tell you why it’s wrong…
Sheldon: Excuse me, may I interject?
Penny: What?
Sheldon: Biologically speaking, Howard is perfectly justified in seeking out the optimum mate for the propagation of his genetic line.
Howard: Thank you, Sheldon.
Sheldon: Now, whether that propagation is in the interest of humanity is, of course, an entirely different question.
Radio: This is Ira Flatow and you’re listening to NPR’s Science Friday. Joining us today by phone from his office in Pasadena, California is Dr. Sheldon Cooper.
Kripke: Oh, this is going to be a wiot.
Radio: Thanks for being with us today, Dr. Cooper.
Sheldon: My pleasure, Ira.
Ira: Now, let’s talk about magnetic monopoles. Can you explain to our audience just what a monopole is?
Sheldon: Of course. First, consider an ordinary magnet which has,
as even the most uneducated in your audience must know, two poles,
a north and south pole. If you cut that in half, you have two smaller magnets, each with its own north and south pole.
Ira: Uh, Dr. Cooper, I think there might be something wrong with our connection.
Sheldon
: No, I hear you fine. As I was saying, an ordinary magnet has two poles. The primary characteristic of a monopole is that it has only one pole, hence, monopole.
Sheldon: A requirement for string theory, or M-theory, if you will, is the existence of such monopoles. I, myself, led an expedition to the Arctic Circle in search of said particles. Kripke, I found the nozzle! I’m going to kill you!
Howard: So nice you could join me this evening. You’re looking lovely as always.
Katee Sackhoff: Thanks, Howard. Always nice to be part of your masturbatory fantasies.
Howard: Come on, Katee, don’t make it sound so cheap.
Katee: I’m sorry, fiddling with yourself in the bathtub is a real class act.
Howard: Thank you. So, shall we get started?
Katee: Sure. But can I ask you a question first?
Howard: You want to play Cylon and colonist?
Katee: No. I want to know why you’re playing make-believe with me when you could be out with a real woman tonight.
Howard: You mean, Bernadette?
Katee: No, I mean Princess Leia. Of course I mean Bernadette. She’s a wonderful girl and she really likes you.
Howard: I know, but she’s not you.
Katee: I’m not me. The real me is in Beverly Hills going out with a tall, handsome, rich guy.
Howard: Really? Tall?
Katee: Six-four.
Howard: Ouch.
Katee: The point is, you’ve got a wonderful girl in your life, and you’re ignoring her in order to spend your nights in the bathtub with a mental image and a wash cloth.
Howard’s Mother: Howard! What are you doing in there?
Howard: I’m taking a bath!
Howard’s Mother: I hope that’s all you’re doing! We share that tub!
Howard: Don’t remind me!
Oh, man. All soaped up and no place to go.
Leonard: How ya doin’, buddy?
Sheldon: I was humiliated on national radio. How do you think I’m doing?
Leonard: Come on, it wasn’t that bad.
Sheldon: What do you want?
Raj
: We represent the Lollipop Guild, and we want you.
Leonard: Okay, so Kripke played a joke on you.
Sheldon: It wasn’t funny.
Raj: I thought it was funny.
Leonard: Raj.
Raj: You laughed.
Sheldon: Did you laugh?
Leonard: I fell on the floor. All right, he got you, you can get him back.
Sheldon: I refuse to sink to his level.
Raj: You can’t sink. With all that helium in you, you’re lucky you don’t float away.
Leonard: Are you really admitting defeat?
Sheldon: I never admit defeat.
Leonard: Good.
Sheldon: However, on an unrelated topic, I am never getting out of this bed again.
Leonard: What if you could make Kripke look even sillier than he made you look?
Raj: I don’t think that’s possible, dude.
Leonard: You’re not helping.
Raj: I didn’t come to help, I came to mock.
Leonard: Sheldon, what you need to do is figure out a way to exact vengeance on Kripke, like, uh, like, how the Joker got back at Batman for putting him in the Arkham Asylum for the Criminally Insane.
Raj: That’s true. He didn’t just stay there and talk about his feelings with the other psychotic villains. He, he broke out and poisoned Gotham’s water supply.
Sheldon: Well, I suppose I could poison Kripke.
Leonard: No, no.
Sheldon: It’s a simple matter. There are several toxic chemicals that’d be untraceable in an autopsy.
Leonard: Okay, uh, that’s the spirit, but, um, let’s dial it back to a non-lethal form of vengeance.
Sheldon: Oh! How about we put awhoopee cushion on his office chair? He’ll sit down, it’ll sound like he’s flatulent, even though he’s not.
Leonard: Let’s keep thinking.
Penny: Oh, gee, you’re too late. Scarlett Johansson and Wonder Woman were just in here trolling around for neurotic, little weasels.
Howard: Yeah, I came to talk to Bernadette. She’s working today, right?
Penny: Yes, but I don’t think she wants to see you.
Howard: Why not?
Penny: Come on, Howard. You hurt her feelings by not calling her all week. Plus, I’ve kind of been talkin’ some smack about ya.
Bernadette: Hello, Howard.
Howard: Wait, Bernadette, I need to talk to you.
Bernadette: I can’t now, I’m working.
Howard: This will only take a second. You asked me to think about where our relationship was going, and I did. Bernadette? Will you marry me?
Bernadette: Is this more comedy that I don’t understand?
Howard: No. I’m serious. I’m never going to find another girl like you who likes me and is, you know, real.
Bernadette: So, this isn’t a joke?
Howard: No.
Bernadette: Then you’re insane.
Howard: I prefer to think of myself as quirky.
Bernadette: Howard, we’ve only been on three dates. We haven’t even had sex yet.
Howard: Fair enough. When’s your break?
Bernadette: Wow.
Howard: Don’t you just hate when this happens?
Penny: Wow.
Sheldon: All right, how’s this for revenge? A solution of hydrogen peroxide, and one of saturated potassium iodide.
Raj: What’s this?
Sheldon: Mountain Dew. Ah, refreshing. Now, we’re going to combine these chemicals with ordinary dish soap, creating a little exothermic release of oxygen.
Raj: Foamy vengeance.
Sheldon: Yes, exactly.
Leonard: This is brilliant, Sheldon. How are we going to deploy it in Kripke’s office?
Sheldon: Already taken care of. Observe. This is a live shot of Kripke’s lab via a mini webcam I was able to install, thanks to a dollar bill discreetly placed in the night janitor’s shirt pocket. At the same time, I also secured large quantities of these chemicals above the tiles in the drop ceiling.
Raj: Oh, Sheldon, you remind me of a young Lex Luthor.
Sheldon: You flatter me, sir.
Leonard: Let me guess, motion sensors?
Sheldon: The reaction will be triggered when Kripke reaches the center of the room. Mwah, ha, ha.
Leonard: I gotta say, I am really impressed. This is truly the Sheldon Cooper way to get even.
Sheldon: It may be low-tech, but I still maintain the whoopee cushion has comic validity.
Raj: Here comes Kripke!
Leonard: Who is that with him?
Raj: I believe that’s the president of the university.
Leonard: And the board of directors. Abort! Abort!
Sheldon: There is no abort.
Raj: Well, how could you not put in an abort?
Sheldon: I made a boo-boo, all right?
Kripke: I think the board will weally appweciate how well we’re using that NSA gwant, Pwesident Seibert. Wight here we have a micwo-contwolled pwasma…
Raj: Wow. Looks like the Ganges on laundry day.
Leonard: At least they don’t know it was you.
Sheldon
: Hello, Kripke. This classic prank comes to you from the malevolent mind of Sheldon Cooper. If you’d like to see the look on your stupid face, this video is being instantly uploaded to YouTube. Oh, and a hat tip to Leonard Hofstadter and Raj Koothrappali for their support and encouragement in this enterprise.
Raj: Well, I’m going back to India. What’s your plan?
Penny: Hey, here’s your tip from table seven.
Bernadette: Oh, thanks.
Penny: Mm-hmm.
Howard
: Testing. Check. Check two.
Bernadette: Oh, now what?
Penny: You want me to throw him out?
Bernadette: No, that’s okay.
Penny: Are you sure? He’s small. I bet I can get a nice, tight spiral on him.
Howard: I want to dedicate this number to a great gal who I’ve done wrong.
Bernadette, I am so sorry for trying to propose to you, Bernadette, you found it creepy but that’s just the kind of thing I do. I know now it was too soon to talk of love. It was just a crazy idea that came to me in my tub. But, Bernadette, give me one more chance, sweet Bernadette, I’ll get the hang of this thing they call romance, sweet Bernadette, I dream to once again kiss your lips, sweet Bernadette. Sincerely yours, Howard Wolowitz, Bernadette…
Penny: Oh, I am so sorry.
Bernadette: Are you kidding? That’s the most romantic thing anyone’s ever done for me.
Howard
: …Bernadette! Thank you, Cheesecake Factory!
| 35.051887 | 455 | 0.751581 | eng_Latn | 0.999428 |
c07b4702c83b0b1d3ba7352f37c6b47dfa92c56d | 1,546 | md | Markdown | README.md | nputikhin/sat_atpg | 7f0eef881be4d91aef0095e3a889e485a4e42f5d | [
"MIT"
] | 7 | 2020-10-30T00:46:01.000Z | 2022-02-08T09:32:48.000Z | README.md | nputikhin/sat_atpg | 7f0eef881be4d91aef0095e3a889e485a4e42f5d | [
"MIT"
] | null | null | null | README.md | nputikhin/sat_atpg | 7f0eef881be4d91aef0095e3a889e485a4e42f5d | [
"MIT"
] | 3 | 2019-09-10T13:02:12.000Z | 2021-01-03T04:32:51.000Z | # SAT-based ATPG using TG-Pro model
This is an implementation of SAT-based Automatic Test Pattern Generator for single stuck-at faults that uses TG-Pro model with several modifications:
* XOR gate is not expanded and uses XOR as sensitization constraint
* Partial circuit CNF is used for good clause set if only some of primary outputs are needed for fault propagation (controlled by threshold)
* [CaDiCaL](https://github.com/arminbiere/cadical) is used for SAT solving
Fault detection will run on fault list with equivalent faults collapsed.
We do not use TG-Pro-ALL optimizations and there is no fault simulation and structural ATPG engine like in TG-System.
[TG-Pro](http://core.di.fc.ul.pt/wiki/doku.php?id=tg-pro) is described in this article:
Chen, Huan, and Joao Marques-Silva. "A two-variable model for SAT-based ATPG." IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems 32, no. 12 (2013): 1943-1956.
## Building
Linux only, will probably compile on Windows if you set USE_CADICAL to 0, but you'll need to provide alternative solver or modify the code and tests to work without the solver.
Build with [cmake](https://cmake.org/):
mkdir _build && cd _build
cmake --build .
## Running
Only bench format is accepted:
_build/bin/atpgSat *.bench
You can find the instances here:
* [ISCAS'85](http://www.pld.ttu.ee/~maksim/benchmarks/iscas85/bench/)
* [ISCAS'89](http://www.pld.ttu.ee/~maksim/benchmarks/iscas89/bench/)
* [ITC'99](http://www.pld.ttu.ee/~maksim/benchmarks/iscas99/bench/)
| 46.848485 | 186 | 0.759379 | eng_Latn | 0.951283 |
c07c27946807472aafcdd8d37d72d49f7d451fcd | 1,478 | md | Markdown | src/12-Desserts/toffee-crunch-chocolate-cookies.md | troyerta/recipes | 2f62be5ba0a2618e03a0330430754fc919645c23 | [
"MIT"
] | 11 | 2022-03-08T16:00:37.000Z | 2022-03-12T15:01:41.000Z | src/12-Desserts/toffee-crunch-chocolate-cookies.md | troyerta/recipes | 2f62be5ba0a2618e03a0330430754fc919645c23 | [
"MIT"
] | 2 | 2021-03-20T18:06:58.000Z | 2021-09-08T02:03:55.000Z | src/12-Desserts/toffee-crunch-chocolate-cookies.md | troyerta/recipes | 2f62be5ba0a2618e03a0330430754fc919645c23 | [
"MIT"
] | 2 | 2020-04-15T21:05:51.000Z | 2022-03-09T19:50:52.000Z | # Toffee Crunch Chocolate Cookies
## Overview
- Yield: 18-20 cookies
## Ingredients
- 1/2 cup (113 grams) butter, room temperature
- 4 oz (113 grams) semi sweet chocolate, roughly chopped
- 1/2 cup (100 grams) granulated sugar
- 1/2 cup (100 grams) dark brown sugar
- 2 eggs
- 1 cup (120 grams) all purpose flour
- 1/2 cup semi sweet chocolate chips
- 1/2 cup toffee bits
- 3/4 cup (70 grams) crumbled toffee crunch brownie brittle
## Method
1. Heat the oven to 350F. Line two baking sheets with parchment paper and set aside.
---
2. In a small saucepan, add the butter and 4 oz of chocolate. Melt over a low heat, stirring until smooth.
---
3. Remove from the heat and stir in the sugars. Let cool for about 10 minutes, stirring occasionally. The mixture should now be warm to the touch.
---
4. With a spatula or a hand whisk, beat in the two eggs.
---
5. Gently fold in the flour, followed by the chocolate chips, toffee bits and crumbled brownie brittle.
---
6. With a medium size ice-cream scoop, drop cookie dough on the prepared baking sheets.
---
7. Bake the cookies in the preheated oven for 11-12 minutes or until just set. I prefer to slightly underbake the cookies - this way they will be chewier!
---
8. Remove from the oven and let the cookie cool completely before removing them from the baking sheets.
---
## References and Acknowledgments
[Toffee Crunch Chocolate Cookies](http://atreatsaffair.com/toffee-crunch-chocolate-cookies-recipe/)
| 26.392857 | 154 | 0.738836 | eng_Latn | 0.995004 |
c07c5039d166e07873fa1427e6fe2c1b0a8725eb | 423 | md | Markdown | ca_gazebo/models/sweet_home_3d/README.md | GaganBhat/create_autonomy | d1c9caccf5dd817004a4698b7cbaf2352ab5d820 | [
"BSD-3-Clause"
] | null | null | null | ca_gazebo/models/sweet_home_3d/README.md | GaganBhat/create_autonomy | d1c9caccf5dd817004a4698b7cbaf2352ab5d820 | [
"BSD-3-Clause"
] | null | null | null | ca_gazebo/models/sweet_home_3d/README.md | GaganBhat/create_autonomy | d1c9caccf5dd817004a4698b7cbaf2352ab5d820 | [
"BSD-3-Clause"
] | null | null | null | # [Creation of Sweet Houses](https://marvinferber.net/?p=128)
Download a house from [http://www.sweethome3d.com/gallery.jsp](http://www.sweethome3d.com/gallery.jsp) and remove the doors using the [SweetHome3D Java application](http://www.sweethome3d.com/download.jsp):
```bash
./SweetHome3D-Java3D-1_5_2
```
Once the changes were made, save the file as OBJ.
**Note:** Include the textures and the MTL file in the repo!
| 35.25 | 206 | 0.747045 | eng_Latn | 0.773596 |
c07e44bbb039208d12c36eee5ed357406767de32 | 1,371 | md | Markdown | README.md | mcat-ee/context-search-userscript | eda87d910578bcf937aacedfb896debec6bb321a | [
"MIT"
] | null | null | null | README.md | mcat-ee/context-search-userscript | eda87d910578bcf937aacedfb896debec6bb321a | [
"MIT"
] | 2 | 2021-07-25T14:13:39.000Z | 2021-07-25T14:15:42.000Z | README.md | mcat-ee/context-search-userscript | eda87d910578bcf937aacedfb896debec6bb321a | [
"MIT"
] | null | null | null | # context-search-userscript
The intent of the included code is to display a search link when arbitrary text is selected on a webpage. This could be used to augment the use of third party sites search functionality, or at least to reduce some `ctrl-c`s.

When a passage of text is selected, the script will create a small `div` below the selection. This div will display the selected text and a link labeled 'Go'.
The 'Go' link is customisable and follows the following pattern:
`{domain}/{searchStub}?{queryKey}={selectedText}`
The parameters `searchStub` and `queryKey` can be set in selectSearchScript.js.
The script is intended to be used as a part of a userscript, an example will come in the near future.
[Example Link](https://mcat-ee.github.io/context-search-example/), with the first chapter of Cat's Cradle, by Kurt Vonnegut as the corpus
# Running the example
1. Clone the repo
2. cd into the '_example_' directory and serve the directory with the platform of your choice. If you have python installed, use `python -m SimpleHTTPServer`
## Screenshots

Just select some text, and press Go!

The query string will be shown above the text corpus
| 48.964286 | 224 | 0.771699 | eng_Latn | 0.998231 |
c07e6be6327c349b28d13926e2d84e4d34f63ba3 | 105 | md | Markdown | _includes/04-lists.md | 40020851/markdown-portfolio | 0ced450417e27c36072fe07862279c6aad8869c7 | [
"MIT"
] | null | null | null | _includes/04-lists.md | 40020851/markdown-portfolio | 0ced450417e27c36072fe07862279c6aad8869c7 | [
"MIT"
] | 5 | 2021-11-16T10:50:01.000Z | 2021-11-16T13:25:56.000Z | _includes/04-lists.md | 40020851/markdown-portfolio | 0ced450417e27c36072fe07862279c6aad8869c7 | [
"MIT"
] | null | null | null | A lists of my favorite things:
- 🐱
- 🐘
- 🐃
In order,these are my favorite colours:
1.Blue
2.Red
3.Black
| 10.5 | 39 | 0.67619 | eng_Latn | 0.98984 |
c07fee962be2ee42afbf93a5b860b653821242fe | 1,138 | md | Markdown | packages/in_app_rate/README.md | rustkas/SurfGear | f685f7739f9df5c6de540fc7dc0270070ae1f67c | [
"Apache-2.0"
] | null | null | null | packages/in_app_rate/README.md | rustkas/SurfGear | f685f7739f9df5c6de540fc7dc0270070ae1f67c | [
"Apache-2.0"
] | null | null | null | packages/in_app_rate/README.md | rustkas/SurfGear | f685f7739f9df5c6de540fc7dc0270070ae1f67c | [
"Apache-2.0"
] | 1 | 2021-10-02T12:45:09.000Z | 2021-10-02T12:45:09.000Z | # in_app_rate
Plugin open native dialog for application rate/review.
## iOS
iOS part use [SKStoreReviewController](https://developer.apple.com/documentation/storekit/skstorereviewcontroller).
[Best Practices](https://developer.apple.com/documentation/storekit/skstorereviewcontroller/requesting_app_store_reviews) for a moment to use it.
Note from [documentation](https://developer.apple.com/documentation/storekit/skstorereviewcontroller/2851536-requestreview).
***
When you call this method while your app is still in development mode, a rating/review request view is always displayed so that you can test the user interface and experience. However, this method has no effect when you call it in an app that you distribute using TestFlight.
***
## Android
Android part use [Google Play In-App Review API](https://developer.android.com/guide/playcore/in-app-review).
[Best Practices](https://developer.android.com/guide/playcore/in-app-review#when-to-request) for a moment to use it.
[Testing](https://developer.android.com/guide/playcore/in-app-review/test), if you set `isTest` to `True` then plugin will use `FakeReviewManager`.
| 59.894737 | 275 | 0.799649 | eng_Latn | 0.71465 |
c080e7391fd4b7dfcf939ed393be233ab059ef32 | 5,037 | md | Markdown | README.md | mattdesl/fontpath-gl | f4122d2c7f27f581d21e796d5a6329411146d1a1 | [
"MIT"
] | 26 | 2015-01-30T09:10:12.000Z | 2022-02-14T07:01:32.000Z | README.md | mattdesl/fontpath-gl | f4122d2c7f27f581d21e796d5a6329411146d1a1 | [
"MIT"
] | 1 | 2017-04-14T05:00:14.000Z | 2017-08-05T03:42:16.000Z | README.md | mattdesl/fontpath-gl | f4122d2c7f27f581d21e796d5a6329411146d1a1 | [
"MIT"
] | null | null | null | # fontpath-gl
[](http://github.com/badges/stability-badges)
[](http://mattdesl.github.io/fontpath-gl/demo/index.html)
<sup>click to view demo</sup>
A 2D [fontpath renderer](https://github.com/mattdesl/fontpath-simple-renderer) for [stackgl](https://github.com/stackgl/). As opposed to [gl-render-text](https://www.npmjs.org/package/gl-render-text), which is texture based, this renderer is path-based.
Here is a quick overview of some pros to the fontpath approach:
- More control over line height, word wrapping, kerning, underlines, etc
- More accurate paths and metrics, matching the curves from TTF/OTF files
- More control for rich text animations and effects (such as triangulation)
- Better for scaling, changing, and re-wrapping text on the fly
- We don't need to worry about `@font-face` loading race conditions
Some downsides:
- Not robust for Complex Text Layout or non-Latin languages
- Not ideal for small (hinted) font sizes or bitmap-based fonts
- Not performant for large blocks of text since each glyph uses its own [gl-vao](https://www.npmjs.org/package/gl-vao)
- Triangulation with poly2tri is not always robust; fails with some fonts
- The fontpath tool is not yet very stable or well-tested
- Lack of anti-aliasing in some browsers, or when rendering to an offscreen buffer
## Usage
[](https://nodei.co/npm/fontpath-gl/)
The following will produce filled text, drawn with triangles.
```js
var MyFont = require('fontpath-test-fonts/lib/OpenSans-Regular.ttf')
var createText = require('fontpath-gl')
var mesh = createText(gl, {
text: 'lorem ipsum dolor',
font: MyFont,
fontSize: 150,
align: 'right'
wrapWidth: 150
})
mesh.projection = ortho
mesh.draw(x, y)
```
This inherits from [fontpath-simple-renderer](https://github.com/mattdesl/fontpath-simple-renderer), so the constructor options, functions and members are the same. Some additional features:
### `mesh = createText(gl[, options])`
In addition to the typical fontpath renderer options, you can also pass:
- `mode` a primitive type, defaults to `gl.TRIANGLES`
- `color` a RGBA color to tint the text, defaults to white `[1, 1, 1, 1]`
- `shader` a shader to use when rendering the glyphs, instead of the default. See [gl-basic-shader](https://www.npmjs.org/package/gl-basic-shader) for details on uniform/attribute names
- `simplifyAmount` in the case of the default poly2tri triangulator, this provides a means of simplifying the path to reduce the total number of vertices
### `mesh.color`
Upon rendering, this will set the `tint` uniform of the shader (available with default shader). This is useful for coloring the text.
#### `mesh.projection`
The projection 4x4 matrix for the text, applied to each glyph. Identity by default.
#### `mesh.view`
A 4x4 view matrix to apply to each glyph. Identity by default.
#### `mesh.mode`
The rendering mode, default `gl.TRIANGLES`.
#### `mesh.dispose()`
Disposes the mesh and its default shader. If you provided a shader during constructor, that shader will not be disposed.
## triangulation
[](http://mattdesl.github.io/fontpath-gl/demo/wireframe.html)
<sup>click to view demo</sup>
This uses [fontpath-shape2d](https://www.npmjs.org/package/fontpath-shape2d) and [poly2tri](https://www.npmjs.org/package/poly2tri) to approximate the bezier curves and triangulate the glyphs. In some cases these may fail to triangulate, or produce undesirable results. [Tess2](https://github.com/memononen/tess2.js) is more robust in some cases, but it leads to a less pleasing wireframe and doesn't allow for steiner points.
To allow for custom triangulation without bloating the filesize with poly2tri, it has been broken off into a different file and only included with the `index.js` entry point. So, say you want to use Tess2 without the heavy poly2tri dependency, your code would have to look like this:
```js
//require the base class
var TextRenderer = require('fontpath-gl/base')
TextRenderer.prototype.triangulateGlyph = function (glyph) {
//... approximate glyph curves,
//... then triangulate with Tess2
//... you may also do some simplifying here
//return an object in the following format
return {
//xy positions, required
positions: new Float32Array([ x1,y1,x2,y2... ])
//indices, optional
cells: new Uint16Array([ i0,i1,i2... ])
}
}
module.exports = TextRenderer
```
`cells` is optional, but indexing will produce more efficient rendering.
You can also `require('fontpath-gl/triangulate')` which exposes the default `triangulateGlyph` function.
See the [demo](demo/) folder for an example of custom triangulation.
## roadmap
- underline rendering
- more efficient caching / packing of vertex data
- improve triangulation robustness
## License
MIT, see [LICENSE.md](http://github.com/mattdesl/fontpath-gl/blob/master/LICENSE.md) for details.
| 39.661417 | 426 | 0.750844 | eng_Latn | 0.962406 |
c0810a5742af0eb142f68565128914d25e1f3d5c | 5,235 | md | Markdown | _posts/2021-7-15-sha256pow-ZH.md | KCSIE/kcsie.github.io | 08c7a51968cff45880a15081b929931cea2f6d1e | [
"Apache-2.0"
] | null | null | null | _posts/2021-7-15-sha256pow-ZH.md | KCSIE/kcsie.github.io | 08c7a51968cff45880a15081b929931cea2f6d1e | [
"Apache-2.0"
] | 4 | 2021-03-30T11:21:10.000Z | 2022-02-26T13:11:22.000Z | _posts/2021-7-15-sha256pow-ZH.md | KCSIE/KCSIE.github.io | e92e47b46a70545d0247408c1f0008968f5a0f4e | [
"MIT"
] | null | null | null | ---
title: 简单的哈希加密和挖矿原理 - ZH
tags: Blockchain Bitcoin Hashing SHA256
---
# SHA与Python
## SHA
安全散列算法(SHA)是一个密码散列函数家族,是能计算出一个数字消息所对应到的长度固定的字符串(又称消息摘要)的算法,是单向函数便于计算,具备保密性和完整性。哈希函数具备一致性、压缩、有损,以及抗碰撞性、抗原像性、抗二次原像性的重要特征。常用的哈希加密函数包括MD5、SHA-1、SHA-256、SHA-3-256。
## Hashlib和SHA256
SHA(安全哈希算法)是一组加密哈希函数,可用于各种应用,如账户密码等。Python通过Hashlib库中支持各类SHA算法,下文将以常用的SHA256作为例子进行介绍。
我们可以通过引入Hashlib来使用相关哈希函数,其中包括SHA256、SHA384、SHA224、SHA512、SHA1、MD5。SHA256属于SHA-2,对于任意长度的消息SHA256都会产生一个256位的哈希值称作消息摘要,该摘要相当于是个长度为32个字节的数组,通常有一个长度为64位的十六进制字符串来表示,其中1个字节=8位,一个十六进制的字符的长度为4位。比如,abc经过SHA256的结果为ba7816bf8f01cfea414140de5dae2223b00361a396177a9cb410ff61f20015ad。
```python
# SHA256
import hashlib
# initializing string
str = "abc"
# encoding 'abc' using encode() then sending to SHA256()
result = hashlib.sha256(str.encode())
# printing the equivalent hexadecimal value.
print("The hexadecimal equivalent of SHA256 is : ")
print(result.hexdigest())
```
# 工作量证明
## 共识机制
共识机制是通过特殊节点的投票,在很短的时间内完成对交易的验证和确认。对一笔交易如果利益不相干的若干个节点能够达成共识,我们就可以认为全网对此也能够达成共识。区块链作为去中心化的分布式账本系统,为保证整个系统能有效运行各个节点诚实记账,在没有中心的情况下互相不信任的个体之间各节点达成一致的充分必要条件是每个节点出于对自身利益最大化的考虑,都会自发诚实地遵守协议中预先设定的规则,判断每一笔记录的真实性,最终将判断为真的记录记入区块链之中,这就是共识机制。当今主流的共识机制包括工作量证明机制(POW)、 股权证明机制 (POS)、授权股权证明机制(DPOS)、拜占庭容错算法 (PBFT)、POOL验证池等。
## 工作量证明共识机制
工作量证明,简单来说就是指系统为达到某一目标而设置的度量方法,简单来说就是一份证明用来确认你做过一定量的工作,通俗的说就是干得多得的多。在基于工作量证明机制构建的区块链网络中,节点通过计算随机哈希散列的数值解争夺记账权,求得正确的数值解以生成区块的能力是节点算力的具体表现。
举个例子,给定的一个基本的字符串,我们给出的工作量要求是可以在这个字符串后面添加一个叫nonce的整数值,对合并的字符串进行SHA256哈希运算,如果得到的哈希结果(以16进制的形式表示)是以"0000"开头的,则验证通过。为了达到这个工作量证明的目标。我们需要不停的递增nonce值,对得到的新字符串进行SHA256哈希运算。按照这个规则,我们需要经过多次计算才能找到恰好前4位为0的哈希散列。
## 比特币中的工作量证明
### 区块
比特币的区块由区块头及该区块所包含的交易列表即区块体组成。区块头的大小为80字节,由4字节的版本号、32字节的父区块头哈希值、32字节的Merkle根哈希值、4字节的时间缀(当前时间)、4字节的当前难度值、4字节的随机数组成。区块体则附加在区块头后面,其中的第一笔交易是coinbase交易,这是一笔为了让矿工获得奖励及手续费的特殊交易。
区块头具体如下:
- 版本-Version:区块版本号,表示本区块遵守的验证规则,4字节
- 父区块头哈希值-Prev Hash:前一区块的哈希值,使用SHA256计算,占32字节
- Merkle根哈希值-Merkle Hash:该区块中交易的Merkle树根的哈希值,同样采用SHA256计算,占32字节
- 时间戳-Timestamp:该区块产生的近似时间,精确到秒的UNIX时间戳,必须严格大于前11个区块时间的中值,同时全节点也会拒绝那些超出自己2个小时时间戳的区块,占4字节
- 难度-Bits:该区块工作量证明算法的难度目标,已经使用特定算法编码,占4字节
- 随机数-Nonce:为了找到满足难度目标所设定的随机数,为了解决32位随机数在算力飞升的情况下不够用的问题,规定时间戳和coinbase交易信息均可更改,以此扩展nonce的位数,占4字节
为了让区块头能体现区块所包含的所有交易,在区块的构造过程中要将该区块要包含的交易列表通过Merkle Tree算法生成Merkle根哈希值,Merkle Tree的结构如下:
[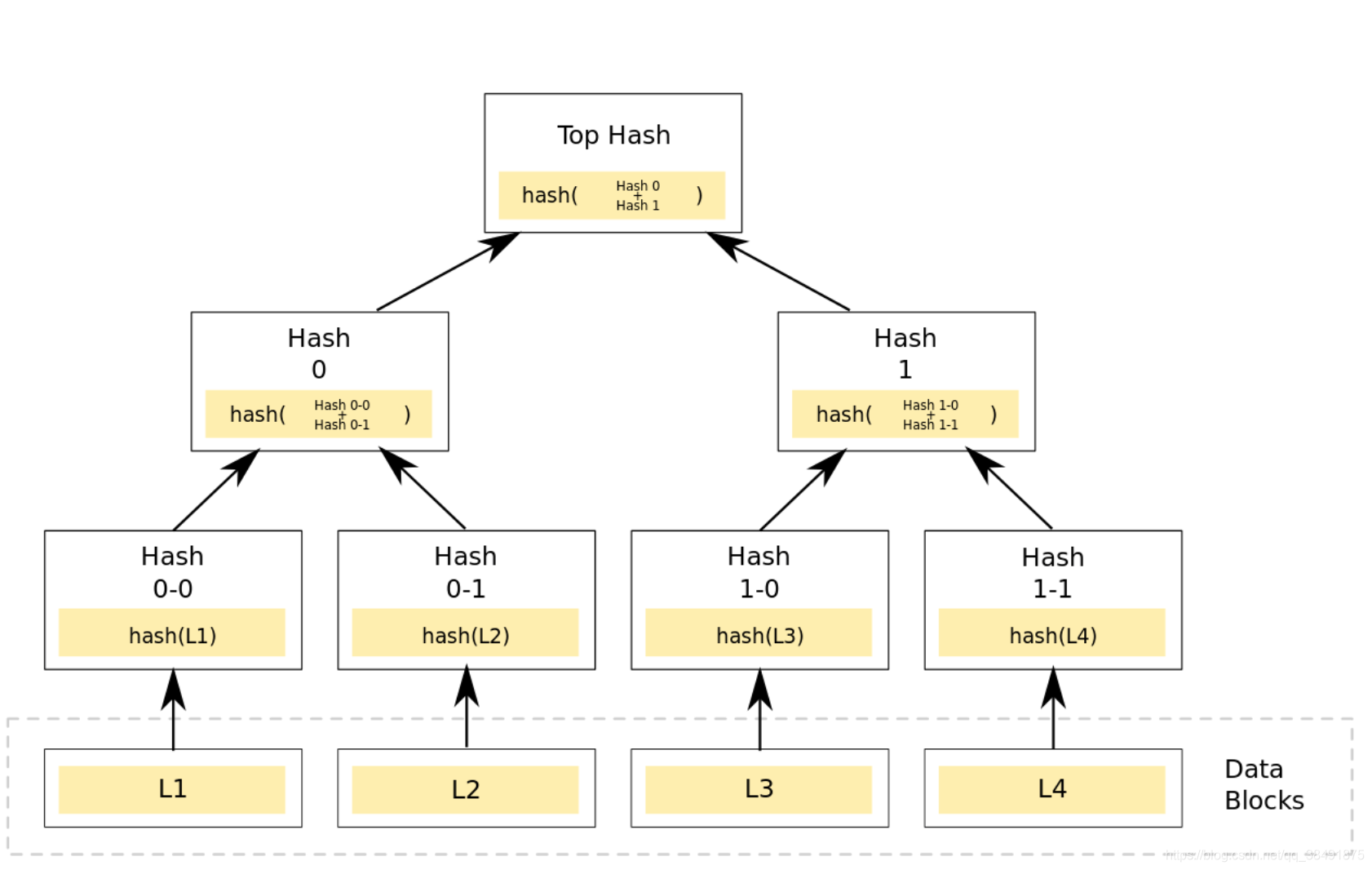](https://imgtu.com/i/f8Y9pT)
### 难度
难度值(difficulty)是矿工们在挖矿时候的重要参考指标,它决定了矿工大约需要经过多少次哈希运算才能产生一个合法的区块。比特币网络的难度值是不断变化的,它的难度值保证大约每10分钟产生一个区块,而难度值在每2016(实际上是2015)个区块调整一次:如果区块平均生成时间小于10分钟,说明全网算力增加,难度值也会增加,如果区块平均生成时间大于10分钟,说明全网算力减少,难度值也会减少。因此,难度值随着全网算力的增减会动态调整,使新区块产生速率始终保持在大约10分钟一个。
具体公式如下:
> 难度调整公式:新难度值 = 旧难度值 * ( 过去2016个区块花费时长 / 20160 分钟 )
> 目标值 = 最大目标值 / 当前难度值
>
> 最大目标值长度为256bit,前32位为0后面全部为1,一般显示为HASH值:0x00000000FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF
目标值(Target)的大小与难度值成反比,比特币工作量证明的达成就是矿工计算出来的区块哈希值必须小于目标值。
### 工作量证明流程
1. 生成Coinbase交易,并与其他所有准备打包进区块的交易组成交易列表,通过Merkle Tree算法生成Merkle根哈希值。
2. 填充其他区块头字段,把区块头的80字节数据(Block Header)作为工作量证明的输入。
3. 不断变更区块头中的随机数即nonce的数值,并对每次变更后的的区块头做双重SHA256运算,即SHA256(SHA256(Block_Header)),将结果值与当前网络的目标值做对比,如果小于目标值符合难度则解题成功,工作量证明完成,若不符合难度则根据一定策略改变nonce后再进行Hash运算并验证。
# 挖矿
## 挖矿原理
综上所述,挖矿简单来说就是基于工作量证明机制的流程。通过不停的变换区块头尝试不同的nonce值作为输入进行SHA256哈希运算,找出一个特定格式哈希值的过程即要求有一定数量的前导0。而要求的前导0的个数越多,代表难度越大。
## 例子
我们把问题简单化,可以更直观的看理解寻找前导0的挖矿过程,比如我们要寻找加到abc后面可以产生20bits(/256bits)的前导0,这里我们仅做一次SHA256运算。我们知道SHA256的结果是64位的十六进制字符串,1十六进制字符等于4位,1字节等于2十六进制字符,20位前导0意味着5个十六进制字符是0,也就是说我们要得到一个以“00000”开头的SHA256结果。下面是具体的示例:
```python
import hashlib
num_int = 0 #initializing number
#loop to find out the hash
while(True):
name = "abc"
num_str = str(num_int) # turn the number to string
whole = name + num_str # the name and the number
result = hashlib.sha256(whole.encode()) # encoding
str2hex = result.hexdigest() # turn to hex
if str2hex.startswith('00000'): # find the hash result with 5 leading 0 in hex
print("The string which's hash has 20 leading zeros:"+whole+" It's hash is:"+str2hex)
num_int = num_int + 1 # next number
```
我们可以很快得到结果:
```
The string which's hash has 20 leading zeros:abc767150 It's hash is:00000921a9eae1f5ce832a0bfc6ea51f35afeff2b35289e5d8126ed499ee92a0
The string which's hash has 20 leading zeros:abc942434 It's hash is:00000ce6aa5c218a3d7d69145abe2d8bf7c3e7f3bb2985403c6f3a147082f42c
The string which's hash has 20 leading zeros:abc949116 It's hash is:000003508496ce720bad2927d40c2c17d0827b0eadfb93d325e4a5519e137f83
The string which's hash has 20 leading zeros:abc1122577 It's hash is:0000080d27d9a91dd28772b35e5d609b4e0e9a88774e589c5d9f9831af866950
The string which's hash has 20 leading zeros:abc2280531 It's hash is:00000d58a3e2d78e61c72f1d7638b9fe7685d1f1c19d522eb9049aaa5b231c59
...
```
但是,如果我们要获取一个有40位前导0的结果呢?我们还能这么轻易得到结果吗?
```python
if str2hex.startswith('0000000000'): # find the hash result with 10 leading 0 in hex
print("The string which's hash has 40 leading zeros:"+whole+" It's hash is:"+str2hex)
```
等待了很久也无法得到输出,这意味着挖矿时所要求的哈希值前面的0越多,计算难度越大,而40位前导0对个人电脑几乎是不可能得到结果的。
------
**Reference/参考**:
1. [理解哈希(Hash)算法](https://www.jianshu.com/p/189394a57f7f)
2. [区块链共识算法-POW](https://www.jianshu.com/p/b23cbafbbad2)
3. [挖矿原理](https://www.liaoxuefeng.com/wiki/1207298049439968/1311929771491361)
| 36.608392 | 304 | 0.829608 | yue_Hant | 0.5215 |
c0811757f12fcc09f4a99cb47073ac1169fea175 | 72 | md | Markdown | README.md | AraDiscord/Landing | 1fa500b0730e97ee0f2a227352e108e22ed3377c | [
"MIT"
] | null | null | null | README.md | AraDiscord/Landing | 1fa500b0730e97ee0f2a227352e108e22ed3377c | [
"MIT"
] | null | null | null | README.md | AraDiscord/Landing | 1fa500b0730e97ee0f2a227352e108e22ed3377c | [
"MIT"
] | null | null | null | # Landing
The landing page used for Ara's website - https://ara.jex.cam
| 24 | 61 | 0.736111 | eng_Latn | 0.698265 |
c0811b495ccbc37a5ab95f07e79ebdf5748dcf43 | 2,060 | md | Markdown | _posts/2011-01-31-denver-boulder.md | aadm/the-liquid-steppe | 656413ea9996cd46b5500d744e7746aaf6e1882f | [
"MIT"
] | null | null | null | _posts/2011-01-31-denver-boulder.md | aadm/the-liquid-steppe | 656413ea9996cd46b5500d744e7746aaf6e1882f | [
"MIT"
] | null | null | null | _posts/2011-01-31-denver-boulder.md | aadm/the-liquid-steppe | 656413ea9996cd46b5500d744e7746aaf6e1882f | [
"MIT"
] | null | null | null | ---
layout: post
title: Denver Boulder
Date: 2011-01-31 07:44:00
tags: [cycling, photo]
---
Ho raccolto in un [fotoset su flickr](http://www.flickr.com/photos/aadm/sets/72157625939538354/with/5401468735/) alcune foto scattate durante l'ultimo mio viaggio in America. Sono stato prima a Denver [per una conferenza](http://www.seg.org/events/annual-meeting/denver2010/annual-mtg-intl-showcase) poi a Golden per una riunione alla [Colorado School of Mines](http://crusher.mines.edu/).
In mezzo, ci ho ficcato un weekend a Boulder che ero curioso di visitare, visto che ne parlano tutti come della capitale dell'outdoor statunitense (Boulder: niente a che fare con Chamonix!).
<a href="http://www.flickr.com/photos/aadm/5401956486/" title="_1000661.jpg by aadm, on Flickr"><img src="http://farm6.staticflickr.com/5172/5401956486_484f0e65c1_z.jpg" width="640" height="480" alt="_1000661.jpg"></a>
<a href="http://www.flickr.com/photos/aadm/5401362155/" title="_1000663.jpg by aadm, on Flickr"><img src="http://farm6.staticflickr.com/5294/5401362155_b4981e47f5_z.jpg" width="640" height="480" alt="_1000663.jpg"></a>
<a href="http://www.flickr.com/photos/aadm/5401375637/" title="_1000686.jpg by aadm, on Flickr"><img src="http://farm6.staticflickr.com/5095/5401375637_b1dd6a4e70_z.jpg" width="640" height="480" alt="_1000686.jpg"></a>
<a href="http://www.flickr.com/photos/aadm/5401440243/" title="University Bycicles, Boulder by aadm, on Flickr"><img src="http://farm6.staticflickr.com/5252/5401440243_68c16e70cf_z.jpg" width="640" height="480" alt="University Bycicles, Boulder"></a>
<a href="http://www.flickr.com/photos/aadm/5401449807/" title="_1000816.jpg by aadm, on Flickr"><img src="http://farm6.staticflickr.com/5255/5401449807_aba6082c95_z.jpg" width="480" height="640" alt="_1000816.jpg"></a>
<a href="http://www.flickr.com/photos/aadm/5402059066/" title="29er in my hotel room by aadm, on Flickr"><img src="http://farm6.staticflickr.com/5014/5402059066_6e536e8029_z.jpg" width="640" height="480" alt="29er in my hotel room"></a>
| 76.296296 | 391 | 0.748058 | kor_Hang | 0.146815 |
c081cd6daff92192e1db793aa13777d014d02c40 | 588 | md | Markdown | src/content/changes/workload-cluster-releases-kvm/releases/kvm-v8.0.0.md | albuch/docs | ededf32bd0d35e36d62bdb03499e3f1388e065da | [
"Apache-2.0"
] | 6 | 2019-05-10T16:08:44.000Z | 2021-09-26T07:29:55.000Z | src/content/changes/workload-cluster-releases-kvm/releases/kvm-v8.0.0.md | albuch/docs | ededf32bd0d35e36d62bdb03499e3f1388e065da | [
"Apache-2.0"
] | 565 | 2018-08-01T11:10:33.000Z | 2022-03-31T15:54:53.000Z | src/content/changes/workload-cluster-releases-kvm/releases/kvm-v8.0.0.md | albuch/docs | ededf32bd0d35e36d62bdb03499e3f1388e065da | [
"Apache-2.0"
] | 6 | 2019-07-16T07:36:56.000Z | 2021-02-19T15:21:33.000Z | ---
# Generated by scripts/aggregate-changelogs. WARNING: Manual edits to this files will be overwritten.
aliases:
- /changes/tenant-cluster-releases-kvm/releases/kvm-v8.0.0/
changes_categories:
- Workload cluster releases for KVM
changes_entry:
repository: giantswarm/releases
url: https://github.com/giantswarm/releases/tree/master/kvm/archived/v8.0.0
version: 8.0.0
version_tag: v8.0.0
date: '2019-03-21T10:00:00+00:00'
description: Release notes for KVM workload cluster release v8.0.0, published on 21
March 2019, 10:00
title: Workload cluster release v8.0.0 for KVM
---
| 30.947368 | 101 | 0.765306 | eng_Latn | 0.593753 |
c081df047c0ffc612c0224a906804858c9ff0ab2 | 272 | md | Markdown | README.md | waldemirflj/graphql-wrap | e5876cef0cf524bca0ee0549bcf38da02e0102ae | [
"MIT"
] | null | null | null | README.md | waldemirflj/graphql-wrap | e5876cef0cf524bca0ee0549bcf38da02e0102ae | [
"MIT"
] | null | null | null | README.md | waldemirflj/graphql-wrap | e5876cef0cf524bca0ee0549bcf38da02e0102ae | [
"MIT"
] | null | null | null | ## poc.graphql-wrap
Lab de estudo.
**GraphQL** é uma linguagem de consulta para APIs e um tempo de execução para atender a essas consultas com seus dados existentes.
### Link's
- [GraphQL](https://graphql.org/)
**Att**,
Waldemir Francisco
[email protected]
| 22.666667 | 130 | 0.716912 | por_Latn | 0.995646 |
c083b3f45c37fd1c437c86260eb7141ab24383ed | 90 | md | Markdown | README.md | PureFunctor/purs-nix-boilerplate | 42ed3ffd2271e4c4194e966752f3b72c3c446ec8 | [
"BSD-3-Clause"
] | null | null | null | README.md | PureFunctor/purs-nix-boilerplate | 42ed3ffd2271e4c4194e966752f3b72c3c446ec8 | [
"BSD-3-Clause"
] | null | null | null | README.md | PureFunctor/purs-nix-boilerplate | 42ed3ffd2271e4c4194e966752f3b72c3c446ec8 | [
"BSD-3-Clause"
] | null | null | null | # purs-nix-boilerplate
Boilerplate project structure for Nix-managed PureScript projects.
| 30 | 66 | 0.844444 | eng_Latn | 0.863794 |
c086643f3023151b1e9200fa75d415fa69dabb67 | 17,127 | md | Markdown | Lollipop/README.md | tvhahn/Beautiful-Plots | 127f9c41c59b2951d3500901d18bcbc880ec5177 | [
"MIT"
] | 4 | 2021-05-27T07:58:46.000Z | 2022-01-28T20:44:50.000Z | Lollipop/README.md | tvhahn/Beautiful-Plots | 127f9c41c59b2951d3500901d18bcbc880ec5177 | [
"MIT"
] | null | null | null | Lollipop/README.md | tvhahn/Beautiful-Plots | 127f9c41c59b2951d3500901d18bcbc880ec5177 | [
"MIT"
] | 1 | 2021-04-29T20:50:19.000Z | 2021-04-29T20:50:19.000Z | # Beautiful Plots: The Lollipop
<div style="text-align: center; ">
<figure>
<img src="./img/pexels-somben-chea-1266105.jpg" alt="lollipop" style="background:none; border:none; box-shadow:none; text-align:center"/>
</figure>
</div>
> The lollipop chart is great at visualizing differences in variables along a single axis. In this post, we create an elegant lollipop chart, in Matplotlib, to show the differences in model peformance.
>
> You can run the Colab notebook [here](https://colab.research.google.com/github/tvhahn/Beautiful-Plots/blob/master/Lollipop/lollipop.ipynb).
As a data scientist, I am often looking for ways to explain results. It's always fun, then, when I discover a type of data visualization that I was not familiar with. Even better when the visualization solves a potential need! That's what happened when I came across the Lollipop chart -- also called a Cleveland plot, or dot plot.
I was looking to represent model peformance after having trained several classification models through [k-fold cross-validation](https://en.wikipedia.org/wiki/Cross-validation_(statistics)#k-fold_cross-validation). Essentially, I training classical ML models to detect tool wear on a CNC machine. The data set was highly imbalanced, with very few examples of worn tools. This led to a larger divergence in the results across the different k-folds. I wanted to represent this difference, and the lollipop chart was just the tool!
Here's what the original plot looks like from my thesis. (by the way, you can be one of the *few* people to read my thesis, [here](https://qspace.library.queensu.ca/handle/1974/28150). lol)
<div style="text-align: center; ">
<figure>
<img src="./img/original_lollipop.svg" alt="original lollipop chart" style="background:none; border:none; box-shadow:none; text-align:center" width="800px"/>
</figure>
</div>
Not bad. Not bad. But this series is titled *Beautiful Plots*, so I figured I'd beautify it some more... to get this:
<div style="text-align: center; ">
<figure>
<img src="./img/beautiful_lollipop.svg" alt="beautiful lollipop chart" style="background:none; border:none; box-shadow:none; text-align:center" width="800px"/>
</figure>
</div>
I like the plot. It's easy on the eye and draws the viewers attention to the important parts first. In the following sections I'll highlight some of the important parts of the above lollipop chart, show you how I built it in Matplotlib, and detail some of the sources of inspiration I found when creating the chart. Cheers!
# Anatomy of the Plot
I took much inspiration of the above lollipop chart from the [UC Business Analytics R Programming Guide](http://uc-r.github.io/cleveland-dot-plots), and specifically, this plot:
<div style="text-align: center; ">
<figure>
<img src="http://uc-r.github.io/public/images/visual/cleveland-dotplots/unnamed-chunk-16-1.png" alt="cleveland dot plot" style="background:none; border:none; box-shadow:none; text-align:center" width="500px"/>
<!-- <div style="text-align: left; "> -->
<figcaption style="color:grey; font-size:smaller"> (Image from <a href="http://uc-r.github.io/cleveland-dot-plots">UC Business Analytics R Programming Guide</a>)</figcaption>
<!-- </div> -->
</figure>
</div>
Here are some of the key features that were needed to build my lollipop chart:
## Scatter Points
<div style="text-align: left; ">
<figure>
<img src="./img/scatter_points.png" alt="scatter points" style="background:none; border:none; box-shadow:none; text-align:center" width="260px"/>
</figure>
</div>
I used the standard Matplotlib `ax.scatter` to plot the scatter dots. Here's a code snip:
```python
ax.scatter(x=df['auc_avg'], y=df['clf_name'],s=DOT_SIZE, alpha=1, label='Average', color=lightblue, edgecolors='white')
```
* The `x` and `y` are inputs from the data, in a Pandas dataframe
* A simple white "edge" around each dot adds a nice definition between the dot and the horizontal line.
* I think the color scheme is important -- it shouldn't be too jarring on the eye. I used blue color scheme which I found on this [seaborn plot](https://seaborn.pydata.org/examples/kde_ridgeplot.html). Here's the code snippet to get the hex values.
```python
import seaborn as sns
pal = sns.cubehelix_palette(6, rot=-0.25, light=0.7)
print(pal.as_hex())
pal
```
['#90c1c6', '#72a5b4', '#58849f', '#446485', '#324465', '#1f253f']
<svg width="330" height="55"><rect x="0" y="0" width="55" height="55" style="fill:#90c1c6;stroke-width:2;stroke:rgb(255,255,255)"/><rect x="55" y="0" width="55" height="55" style="fill:#72a5b4;stroke-width:2;stroke:rgb(255,255,255)"/><rect x="110" y="0" width="55" height="55" style="fill:#58849f;stroke-width:2;stroke:rgb(255,255,255)"/><rect x="165" y="0" width="55" height="55" style="fill:#446485;stroke-width:2;stroke:rgb(255,255,255)"/><rect x="220" y="0" width="55" height="55" style="fill:#324465;stroke-width:2;stroke:rgb(255,255,255)"/><rect x="275" y="0" width="55" height="55" style="fill:#1f253f;stroke-width:2;stroke:rgb(255,255,255)"/></svg>
The grey horizontal line was implemented using the Matplotlibe `ax.hlines` function.
```python
ax.hlines(y=df['clf_name'], xmin=df['auc_min'], xmax=df['auc_max'], color='grey', alpha=0.4, lw=4,zorder=0)
```
* The grey line should be at the "back" of the chart, so set the zorder to 0.
## Leading Line
<div style="text-align: left; ">
<figure>
<img src="/assets/img/2021-05-beautiful-plots-lollipop/leading_line.png" alt="leading line" style="background:none; border:none; box-shadow:none; text-align:center" width="400px"/>
</figure>
</div>
I like how the narrow "leading line" draws the viewer's eye to the model label. Some white-space between the dots and the leading line is a nice asthetic. To get that I had to forgo gridlines. Instead, each leading line is a line plot item.
```python
ax.plot([df['auc_max'][i]+0.02, 0.6], [i, i], linewidth=1, color='grey', alpha=0.4, zorder=0)
```
## Score Values
<div style="text-align: left; ">
<figure>
<img src="./img/score.png" alt="score" style="background:none; border:none; box-shadow:none; text-align:center" width="56px"/>
</figure>
</div>
Placing the score, either the average, minimum, or maximum, at the dot makes it easy for the viewer to result. Generally, this is a must do for any data visualization. Don't make the reader go on a scavenger hunt trying to find what value the dot, or bar, or line, etc. corresponds to!
## Title
I found the title and chart description harder to get right than I would have thought! I wound up using Python's [textwrap module](https://docs.python.org/3/library/textwrap.html), wich is in the standard library. You learn something new every day!
For example, here is the description for the chart:
```python
plt_desc = ("The top performing models in the feature engineering approach, "
"as sorted by the precision-recall area-under-curve (PR-AUC) score. "
"The average PR-AUC score for the k-folds-cross-validiation is shown, "
"along with the minimum and maximum scores in the cross-validation. The baseline"
" of a naive/random classifier is demonstated by a dotted line.")
```
Feeding the `plt_desc` string into the `textwrap.fill` function produces a single string, with a `\n` new line marker at every *n* characters. Let's try it:
```python
import textwrap
s=textwrap.fill(plt_desc, 90) # put a line break every 90 characters
s
```
'The top performing models in the feature engineering approach, as sorted by the precision-\nrecall area-under-curve (PR-AUC) score. The average PR-AUC score for the k-folds-cross-\nvalidiation is shown, along with the minimum and maximum scores in the cross-validation.\nThe baseline of a naive/random classifier is demonstated by a dotted line.'
# Putting it All Together
We have everything we need to make the lollipop chart. First, we'll import the packages we need.
[](https://colab.research.google.com/github/tvhahn/Beautiful-Plots/blob/master/Lollipop/lollipop.ipynb)
```python
import pandas as pd
import matplotlib.pyplot as plt
# use textwrap from python standard lib to help manage how the description
# text shows up
import textwrap
```
We'll load the cross-validation results from a csv.
```python
# load best results
df = pd.read_csv('best_results.csv')
df.head()
```
| | clf_name | auc_max | auc_min | auc_avg | auc_std |
|---:|:-------------------------|----------:|----------:|----------:|----------:|
| 0 | random_forest_classifier | 0.543597 | 0.25877 | 0.405869 | 0.116469 |
| 1 | knn_classifier | 0.455862 | 0.315555 | 0.387766 | 0.0573539 |
| 2 | xgboost_classifier | 0.394797 | 0.307394 | 0.348822 | 0.0358267 |
| 3 | gaussian_nb_classifier | 0.412911 | 0.21463 | 0.309264 | 0.0811983 |
| 4 | ridge_classifier | 0.364039 | 0.250909 | 0.309224 | 0.0462515 |
```python
# sort the dataframe
df = df.sort_values(by='auc_avg', ascending=True).reset_index(drop=True)
df.head()
```
| | clf_name | auc_max | auc_min | auc_avg | auc_std |
|---:|:-----------------------|----------:|----------:|----------:|----------:|
| 0 | sgd_classifier | 0.284995 | 0.22221 | 0.263574 | 0.0292549 |
| 1 | ridge_classifier | 0.364039 | 0.250909 | 0.309224 | 0.0462515 |
| 2 | gaussian_nb_classifier | 0.412911 | 0.21463 | 0.309264 | 0.0811983 |
| 3 | xgboost_classifier | 0.394797 | 0.307394 | 0.348822 | 0.0358267 |
| 4 | knn_classifier | 0.455862 | 0.315555 | 0.387766 | 0.0573539 |
... and plot the chart! Hopefully there are enough comments there to help you if you're stuck.
```python
plt.style.use("seaborn-whitegrid") # set style because it looks nice
fig, ax = plt.subplots(1, 1, figsize=(10, 8),)
# color palette to choose from
darkblue = "#1f253f"
lightblue = "#58849f"
redish = "#d73027"
DOT_SIZE = 150
# create the various dots
# avg dot
ax.scatter(
x=df["auc_avg"],
y=df["clf_name"],
s=DOT_SIZE,
alpha=1,
label="Average",
color=lightblue,
edgecolors="white",
)
# min dot
ax.scatter(
x=df["auc_min"],
y=df["clf_name"],
s=DOT_SIZE,
alpha=1,
color=darkblue,
label="Min/Max",
edgecolors="white",
)
# max dot
ax.scatter(
x=df["auc_max"],
y=df["clf_name"],
s=DOT_SIZE,
alpha=1,
color=darkblue,
edgecolors="white",
)
# create the horizontal line
# between min and max vals
ax.hlines(
y=df["clf_name"],
xmin=df["auc_min"],
xmax=df["auc_max"],
color="grey",
alpha=0.4,
lw=4, # line-width
zorder=0, # make sure line at back
)
x_min, x_max = ax.get_xlim()
y_min, y_max = ax.get_ylim()
# plot the line that shows how a naive classifier performs
# plot two lines, one white, so that there is a gap between grid lines
# from https://stackoverflow.com/a/12731750/9214620
ax.plot([0.023, 0.023], [y_min, y_max], linestyle="-", color="white", linewidth=14)
ax.plot([0.023, 0.023], [y_min, y_max], linestyle="--", color=redish, alpha=0.4)
# dictionary used to map the column labels from df to a readable name
label_dict = {
"sgd_classifier": "SGD Linear",
"xgboost_classifier": "XGBoost",
"random_forest_classifier": "Random Forest",
"knn_classifier": "KNN",
"gaussian_nb_classifier": "Naive Bayes",
"ridge_classifier": "Ridge Regression",
}
# iterate through each result and apply the text
# df should already be sorted
for i in range(0, df.shape[0]):
# avg auc score
ax.text(
x=df["auc_avg"][i],
y=i + 0.15,
s="{:.2f}".format(df["auc_avg"][i]),
horizontalalignment="center",
verticalalignment="bottom",
size="x-large",
color="dimgrey",
weight="medium",
)
# min auc score
ax.text(
x=df["auc_min"][i],
y=i - 0.15,
s="{:.2f}".format(df["auc_min"][i]),
horizontalalignment="right",
verticalalignment="top",
size="x-large",
color="dimgrey",
weight="medium",
)
# max auc score
ax.text(
x=df["auc_max"][i],
y=i - 0.15,
s="{:.2f}".format(df["auc_max"][i]),
horizontalalignment="left",
verticalalignment="top",
size="x-large",
color="dimgrey",
weight="medium",
)
# add thin leading lines towards classifier names
# to the right of max dot
ax.plot(
[df["auc_max"][i] + 0.02, 0.6],
[i, i],
linewidth=1,
color="grey",
alpha=0.4,
zorder=0,
)
# to the left of min dot
ax.plot(
[-0.05, df["auc_min"][i] - 0.02],
[i, i],
linewidth=1,
color="grey",
alpha=0.4,
zorder=0,
)
# add classifier name text
clf_name = label_dict[df["clf_name"][i]]
ax.text(
x=-0.059,
y=i,
s=clf_name,
horizontalalignment="right",
verticalalignment="center",
size="x-large",
color="dimgrey",
weight="normal",
)
# add text for the naive classifier
ax.text(
x=0.023 + 0.01,
y=(y_min),
s="Naive Classifier",
horizontalalignment="right",
verticalalignment="bottom",
size="large",
color=redish,
rotation="vertical",
backgroundcolor="white",
alpha=0.4,
)
# remove the y ticks
ax.set_yticks([])
# drop the gridlines (inherited from 'seaborn-whitegrid' style)
# and drop all the spines
ax.grid(False)
ax.spines["top"].set_visible(False)
ax.spines["bottom"].set_visible(False)
ax.spines["right"].set_visible(False)
ax.spines["left"].set_visible(False)
# custom set the xticks since this looks better
ax.set_xticks([0.0, 0.2, 0.4, 0.6])
# set properties of xtick labels
# https://matplotlib.org/stable/api/_as_gen/matplotlib.axes.Axes.tick_params.html#matplotlib.axes.Axes.tick_params
ax.tick_params(axis="x", pad=20, labelsize="x-large", labelcolor="dimgrey")
# Add plot title and then description underneath it
plt_title = "Top Performing Models by PR-AUC Score"
plt_desc = (
"The top performing models in the feature engineering approach, "
"as sorted by the precision-recall area-under-curve (PR-AUC) score. "
"The average PR-AUC score for the k-folds-cross-validiation is shown, "
"along with the minimum and maximum scores in the cross-validation. The baseline"
" of a naive/random classifier is demonstated by a dotted line."
)
# set the plot description
# use the textwrap.fill (from textwrap std. lib.) to
# get the text to wrap after a certain number of characters
PLT_DESC_LOC = 6.8
ax.text(
x=-0.05,
y=PLT_DESC_LOC,
s=textwrap.fill(plt_desc, 90),
horizontalalignment="left",
verticalalignment="top",
size="large",
color="dimgrey",
weight="normal",
wrap=True,
)
ax.text(
x=-0.05,
y=PLT_DESC_LOC + 0.1,
s=plt_title,
horizontalalignment="left",
verticalalignment="bottom",
size=16,
color="dimgrey",
weight="semibold",
wrap=True,
)
# create legend
ax.legend(
frameon=False,
bbox_to_anchor=(0.6, 1.05),
ncol=2,
fontsize="x-large",
labelcolor="dimgrey",
)
# plt.savefig('best_results.svg',dpi=150, bbox_inches = "tight")
plt.show()
```
<div style="text-align: center; ">
<figure>
<img src="./img/beautiful_lollipop.svg" alt="beautiful lollipop chart" style="background:none; border:none; box-shadow:none; text-align:center" width="800px"/>
</figure>
</div>
# More Inspiration
I've found a couple other good example of lollipop charts, with code, that you might find interesting too. Let me know if you find other good examples (tweet or DM me at @timothyvh) and I'll add them to the list.
* This lollipop chart is from [Graipher on StackExchange](https://stats.stackexchange.com/a/423861).
<div style="text-align: left; ">
<figure>
<img src="./img/energy_prod.svg" alt="energy production dot plot" style="background:none; border:none; box-shadow:none; text-align:center" width="800px"/>
</figure>
</div>
* Pierre Haessig has a great [blog post](https://pierreh.eu/tag/matplotlib/) where he creates dot plots to visualize French power system data over time. The Jupyter Notebooks are on his github, [here](https://github.com/pierre-haessig/french-elec2/blob/master/Dotplots_Powersys.ipynb).
<div style="text-align: left; ">
<figure>
<img src="https://pierreh.eu/wp-content/uploads/Dotplot_Powersys_2018_bymax-1024x708.png" alt="French power system data" style="background:none; border:none; box-shadow:none; text-align:center" width="800px"/>
</figure>
</div>
# Conclusion
There you have it! I hope you learned something, and feel free to share and modify the images/code however you like. I'm not sure where I'll go next with the series, so if you have any ideas, let me know on Twitter!
And with that, I'll leave you with this:
<div style="text-align: left; ">
<figure>
<img src="./img/matplotlib_vs_excel_meme.jpg" alt="matplotlib vs excel meme" style="background:none; border:none; box-shadow:none; text-align:center" width="800px"/>
</figure>
</div> | 36.286017 | 657 | 0.680621 | eng_Latn | 0.883268 |
c086b944608e534d2483cc3eeba11131e4bef3ad | 422 | md | Markdown | README.md | Platonenkov/MathCore | fd043fd7f0900031519f1c9cc4d1cd8d63b061db | [
"MIT"
] | 2 | 2021-02-27T14:48:10.000Z | 2021-05-11T05:57:13.000Z | README.md | Infarh/MathCore | e98965db6726a6b01f0f6a13d953a5c581e88447 | [
"MIT"
] | 11 | 2019-11-02T20:06:50.000Z | 2022-03-03T08:00:27.000Z | README.md | Platonenkov/MathCore | fd043fd7f0900031519f1c9cc4d1cd8d63b061db | [
"MIT"
] | 2 | 2020-02-28T20:41:59.000Z | 2020-08-08T18:28:03.000Z | # MathCore
Библиотека прикладных алгоритмов и инструментов
## Тестирование
-  - Ветвь dev
-  - Ветвь master
## Публикация
-  - На NuGet.org
| 42.2 | 127 | 0.774882 | yue_Hant | 0.504073 |
c086c8e52412b8a10b339b4292f5903d6057287e | 3,373 | md | Markdown | README.md | nereaharries/learn-to-code | 0617e75f5d24c9200f3e25bd1ed4278e447cf24b | [
"MIT"
] | 6 | 2018-11-09T19:00:06.000Z | 2020-06-12T04:33:33.000Z | README.md | nereaharries/learn-to-code | 0617e75f5d24c9200f3e25bd1ed4278e447cf24b | [
"MIT"
] | 3 | 2018-05-23T16:19:15.000Z | 2018-07-06T14:59:36.000Z | README.md | jhackett1/learn-to-code | 0617e75f5d24c9200f3e25bd1ed4278e447cf24b | [
"MIT"
] | 6 | 2018-11-09T19:00:12.000Z | 2019-07-12T10:35:35.000Z | Learn to code
=============
A static site for hosting lessons and modules in the DDaT Codelabs curriculum.
This site consumes markdown documents and converts them into HTML using React component syntax and the [Gatsby](https://www.gatsbyjs.org/) static site generator. Changes here automatically affect the live site.
This site understands three kinds of content:
* **Lessons**, which hold course content and plenary quizzes.
* **Modules**, which have a one-to-many relationship with lessons.
* **Pages**, which store background info about the course
**Currently [live on the web here](https://ddatlearntocode.netlify.com/).**
**We value contributions from everyone. Pull requests and issues are welcome.**
Before contributing
------------------
We try to abide by the [guidance published](https://www.gov.uk/guidance/content-design) by the GOV.UK content design community.
That means we value things like:
* User needs first
* Plain English
* Frequent, gradual improvements
Adding and changing lessons
--------------------------
Lessons are stored as markdown files in the `/lessons` folder.
You can edit these via the Github web interface or in your local text editor.
A non-standard element to be aware of: `<div class="todo"></div>` renders a turquiose box used to present tasks the user needs to accomplish before moving on.
If you want to add images, upload them to the `/lessons` folder, and after building they will be available at the site's root. For instance, an image called `example.jpg` would be found at the URL `/example.jpg`.
Each lesson has **frontmatter** used to track:
* The **title** of the lesson
* The **title** of the module it belongs to
* The **order** of the lesson in the module
* The **type** of lesson, from 'learn' or 'project'
* The (optional) **plenary question** for the quiz at the end of the lesson
* The (optional) **plenary answers**, stored as an array of objects, each containing the answer text and whether it is correct
Frontmatter must be correctly filled out or the site won't rebuild.
Adding and changing modules and pages
------------------------------------
Modules and pages are also markdown files stored in the `/modules` and `/pages` directories, respectively.
Images can be uploaded to the respective folder and included in the same way as lessons.
Modules have frontmatter used to track:
* The module **title**
* It's **order** in the course
* Whether the lessons inside should be **visible** for users
Pages also have an order property that determines their position on the header menu.
Developing locally
------------------
You can make minor tweaks to this right here on the web, but for major work, you should download and run the software locally. This will give you real-time feedback and a nicer developer experience.
You need `git`, `node` and `npm` installed first.
1. Install the Gatsby CLI commands with `npm install --global gatsby-cli`
2. Download this repo with `git clone https://github.com/jhackett1/learn-to-code`.
3. Install the dependencies with `npm install`.
4. Run the software with `gatsby develop`. You should be able to access it on port 8000.
Like all Gatsby sites, you can also build graphQL queries using graphiQL, which should be available at `localhost:8000/___graphql`.
When you're finished, commit your changes and Netlify's CI server will try to deploy them.
| 43.24359 | 212 | 0.739105 | eng_Latn | 0.998635 |
c0875741f365d6efae4ac2766b78b3c8b795c69e | 1,131 | md | Markdown | Docs/Ru/Engines/Tile/Element.md | krestdota/libcanvas | 26010cb04c6777fde6c5174e25115597de072fc7 | [
"MIT"
] | 131 | 2015-01-13T22:27:04.000Z | 2022-02-25T12:36:53.000Z | Other/libcanvas/Docs/Ru/Engines/Tile/Element.md | RikkiRu/Intergalactic | c5223dfd7ab499fad8c6059500872068dac598a5 | [
"MIT"
] | 6 | 2015-03-10T08:48:09.000Z | 2016-05-07T04:29:58.000Z | Other/libcanvas/Docs/Ru/Engines/Tile/Element.md | RikkiRu/Intergalactic | c5223dfd7ab499fad8c6059500872068dac598a5 | [
"MIT"
] | 45 | 2015-02-18T22:40:59.000Z | 2020-08-16T12:25:35.000Z | Engines.Tile.Engine.Element
===========================
`TileEngine.Element` - это мост для связи `TileEngine` и `LibCanvas.App`.
Необходим для встраивания тайлового движка в `LibCanvas.App` и подписи на события мыши.
### Инициализация
```js
new TileEngine.Element( App.Layer layer, object settings )
```
Settings может содержать следующие параметры:
* `engine` (*TileEngine*) - обязательный параметр, ссылка на тайловый движок
* `from` (*LibCanvas.Point*) - необязательный параметр, смещение отрисовки
```js
var engineElement = new TileEngine.Element(
app.createLayer('tile-engine'),
{ engine: engine }
)
```
Не стоит добавлять на слой с тайловым движком ещё какие либо элементы - отрисовка может быть некорректной.
### TileEngine.Element.app
```js
TileEngine.Element.app( App app, TileEngine engine, Point from = null )
```
Используется для более простых приложений - создаёт корректный слой в `LibCanvas.App`, создаёт и добавляет в слой элемент, возвращает этот элемент.
По сути это просто сокращённая запись для создания элемента и слоя для него.
```js
var engineElement = TileEngine.Element.app( app, engine )
``` | 29.763158 | 147 | 0.740937 | rus_Cyrl | 0.824628 |
c087c49e5c3dde7780426fa866ef318daeeb895b | 127 | md | Markdown | _posts/2017-01-01-welcome-2017.md | ahmadtamimi/Old-Site | a55e7a671dd2ea325959a388f120fd2b6ff42062 | [
"MIT"
] | null | null | null | _posts/2017-01-01-welcome-2017.md | ahmadtamimi/Old-Site | a55e7a671dd2ea325959a388f120fd2b6ff42062 | [
"MIT"
] | null | null | null | _posts/2017-01-01-welcome-2017.md | ahmadtamimi/Old-Site | a55e7a671dd2ea325959a388f120fd2b6ff42062 | [
"MIT"
] | null | null | null | ---
title: Welcome 2017
date: 2017-01-01 00:00:00 -05:00
---
{% highlight css %} sudo apt-get install 2017 {% endhighlight %}
| 18.142857 | 64 | 0.653543 | eng_Latn | 0.42254 |
c08860177be8434b641e09ccf28ab0ba29c90a61 | 15,380 | markdown | Markdown | _posts/2014-11-09-tours-of-android-studio-user-interface.markdown | necopapa/necopapa.github.com | 032cf76e781eb0fe0fd16b4deaa17f904bd04910 | [
"Apache-2.0"
] | null | null | null | _posts/2014-11-09-tours-of-android-studio-user-interface.markdown | necopapa/necopapa.github.com | 032cf76e781eb0fe0fd16b4deaa17f904bd04910 | [
"Apache-2.0"
] | null | null | null | _posts/2014-11-09-tours-of-android-studio-user-interface.markdown | necopapa/necopapa.github.com | 032cf76e781eb0fe0fd16b4deaa17f904bd04910 | [
"Apache-2.0"
] | null | null | null | Tours of Android Studio User Interface
===================
Table of contents
-------------
[TOC]
Whilst it is tempting to plunge into running the example application created in the previous chapter, doing so involves using aspects of the Android Studio user interface which are best described in advance. Android Studio is a powerful and feature rich development environment that is, to a large extent, intuitive to use. That being said, taking the time now to gain familiarity with the layout and organization of the Android Studio user interface will considerably shorten the learning curve in later chapters of the book. With this in mind, this chapter will provide an initial overview of the various areas and components that make up the Android Studio environment.
The Welcome Screen
-------------
----------
The welcome screen (Figure 4-1) is displayed any time that Android Studio is running with no projects currently open (open projects can be closed at any time by selecting the File -> Close Project menu option). If Android Studio was previously exited while a project was still open, the tool will by-pass the welcome screen next time it is launched, automatically opening the previously active project.
----------
In addition to a list of recent projects, the Quick Start menu provides a range of options for performing tasks such as opening, creating and importing projects along with access to projects currently under version control. In addition, the Configure option provides access to the SDK Manager along with a vast array of settings and configuration options. A review of these options will quickly reveal that there is almost no aspect of Android Studio that cannot be configured and tailored to your specific needs.
Finally, the status bar along the bottom edge of the window provides information about the version of Android Studio currently running, along with a link to check if updates are available for download.
The Main Window
-------------------
----------
When a new project is created, or an existing one opened, the Android Studio main window will appear. When multiple projects are open simultaneously, each will be assigned its own main window. The precise configuration of the window will vary depending on which tools and panels were displayed the last time the project was open, but will typically resemble that of Figure 4-2.
Figure 4-2
> **Note:**
> - A – **Menu Bar** – Contains a range of menus for performing tasks within the Android Studio environment.
> - B – **Toolbar** – A selection of shortcuts to frequently performed actions. The toolbar buttons provide quicker access to a select group of menu bar actions. The toolbar can be customized by right-clicking on the bar and selecting the Customize Menus and Toolbars… menu option.
> - C – **Navigation Bar** – The navigation bar provides a convenient way to move around the files and folders that make up the project. Clicking on an element in the navigation bar will drop down a menu listing the subfolders and files at that location ready for selection. This provides an alternative to the Project tool window.
> - D – **Editor Window** – The editor window displays the content of the file on which the developer is currently working. What gets displayed in this location, however, is subject to context. When editing code, for example, the code editor will appear. When working on a user interface layout file, on the other hand, the user interface Designer tool will appear. When multiple files are open, each file is represented by a tab located along the top edge of the editor as shown in Figure 4-3.

Figure 4-3
> - E – Status Bar – The status bar displays informational messages about the project and the activities of Android Studio together with the tools menu button located in the far left corner. Hovering over items in the status bar will provide a description of that field. Many fields are interactive, allowing the user to click to perform tasks or obtain more detailed status information.
> - F – Project Tool Window – The project tool window provides a hierarchical overview of the project file structure allowing navigation to specific files and folders to be performed.
The project tool window is just one of a number of tool windows available within the Android Studio environment.
The Tool Windows
-------------------
----------
In addition to the project view tool window, Android Studio also includes a number of other windows which, when enabled, are displayed along the bottom and sides of the main window. The tool window quick access menu can be accessed by hovering the mouse pointer over the button located in the far left hand corner of the status bar (Figure 4-4) without clicking the mouse button.
Figure 4-4
Selecting an item from the quick access menu will cause the corresponding tool window to appear within the main window.
Alternatively, a set of tool window bars can be displayed by clicking on the quick access menu icon in the status bar. These bars appear along the left, right and bottom edges of the main window (as indicated by the arrows in Figure 4-5) and contain buttons for showing and hiding each of the tool windows. When the tool window bars are displayed, a second click on the button in the status bar will hide them.
Figure 4-5
Clicking on a button will display the corresponding tool window whilst a second click will hide the window. Buttons prefixed with a number (for example 1: Project) indicate that the tool window may also be displayed by pressing the Alt key on the keyboard (or the Command key for Mac OS X) together with the corresponding number.
The location of a button in a tool window bar indicates the side of the window against which the window will appear when displayed. These positions can be changed by clicking and dragging the buttons to different locations in other window tool bars.
Each tool window has its own toolbar along the top edge. The buttons within these toolbars vary from one tool to the next, though all tool windows contain a settings option, represented by the cog icon, which allows various aspects of the window to be changed. Figure 4-6 shows the settings menu for the project view tool window. Options are available, for example, to undock a window and to allow it to float outside of the boundaries of the Android Studio main window.
Figure 4-6
All of the windows also include a far right button on the toolbar providing an additional way to hide the tool window from view. Android Studio offers a wide range of window tool windows, the most commonly used of which are as follows:
> **Note:**
> - Project – The project view provides an overview of the file structure that makes up the project allowing for quick navigation between files. Generally, double clicking on a file in the project view will cause that file to be loaded into the appropriate editing tool.
> - Structure – The structure tool provides a high level view of the structure of the source file currently displayed in the editor. This information includes a list of items such as classes, methods and variables in the file. Selecting an item from the structure list will take you to that location in the source file in the editor window.
> - Favorites – A variety of project items can be added to the favorites list. Right clicking on a file in the project view, for example, provides access to an Add to Favorites menu option. Similarly, a method in a source file can be added as a favorite by right clicking on it in the Structure tool window. Anything added to a Favorites list can be accessed through this Favorites tool window.
> - Build Variants – The build variants tool window provides a quick way to configure different build targets for the current application project (for example different builds for debugging and release versions of the application, or multiple builds to target different device categories).
> - TODO – As the name suggests, this tool provides a place to review items that have yet to be completed on the project. Android Studio compiles this list by scanning the source files that make up the project to look for comments that match specified TODO patterns. These patterns can be reviewed and changed by selecting the File -> Settings… menu option and navigating to the TODO page listed under IDE Settings.
> - Messages – The messages tool window records output from the Gradle build system (Gradle is the underlying system used by Android Studio for building the various parts of projects into a runnable applications) and can be useful for identifying the causes of build problems when compiling application projects.
> - Android – The Android tool window provides access to the Android debugging system. Within this window tasks such as monitoring log output from a running application, taking screenshots and videos of the application, stopping a process and performing basic debugging tasks can be performed.
> - Terminal – Provides access to a terminal window on the system on which Android Studio is running. On Windows systems this is the Command Prompt interface, whilst on Linux and Mac OS X systems this takes the form of a Terminal prompt.
> - Run – The run tool window becomes available when an application is currently running and provides a view of the results of the run together with options to stop or restart a running process. If an application is failing to install and run on a device or emulator, this window will typically provide diagnostic information relating to the problem.
> - Event Log – The event log window displays messages relating to events and activities performed within Android Studio. The successful build of a project, for example, or the fact that an application is now running will be reported within this window tool.
> - Gradle Console – The Gradle console is used to display all output from the Gradle system as projects are built from within Android Studio. This will include information about the success or otherwise of the build process together with details of any errors or warnings.
> - Maven Projects – Maven is a project management and build system designed to ease the development of complex Java based projects and overlaps in many areas with the functionality provided by Gradle. Google has chosen Gradle as the underlying build system for Android development, so unless you are already familiar with Maven or have existing Maven projects to import, your time will be better spent learning and adopting Gradle for your projects. The Maven projects tool window can be used to add, manage and import Maven based projects within Android Studio.
> - Gradle – The Gradle tool window provides a view onto the Gradle tasks that make up the project build configuration. The window lists the tasks that are involved in compiling the various elements of the project into an executable application. Right-click on a top level Gradle task and select the Open Gradle Config menu option to load the Gradle build file for the current project into the editor. Gradle will be covered in greater detail later in this book.
> - Commander – The Commander window tool can best be described as a combination of the Project and Structure tool windows, allowing the file hierarchy of the project to be traversed and for the various elements that make up classes to be inspected and loaded into the editor or designer windows.
> - Designer – Available when the UI Designer is active, this tool window provides access to the designer’s Component Tree and Properties panels.
Android Studio Keyboard Shortcuts
-------------------
----------
Android Studio includes an abundance of keyboard shortcuts designed to save time when performing common tasks. A full keyboard shortcut keymap listing can be viewed and printed from within the Android Studio project window by selecting the Help -> Default Keymap Reference menu option.
Switcher and Recent Files Navigation
-------------------
----------
Another useful mechanism for navigating within the Android Studio main window involves the use of the Switcher. Accessed via the <kbd>Ctrl-Tab</kbd> keyboard shortcut, the switcher appears as a panel listing both the tool windows and currently open files (Figure 4-7).
Figure 4-7
Once displayed, the switcher will remain visible for as long the Ctrl key remains depressed. Repeatedly tapping the Tab key whilst holding down the Ctrl key will cycle through the various selection options, whilst releasing the Ctrl key causes the currently highlighted item to be selected and displayed within the main window.
In addition to the switcher, navigation to recently opened files is provided by the Recent Files panel (Figure 4-8). This can be accessed using the <kbd>Ctrl-E</kbd> keyboard shortcut (<kbd>Cmd-E</kbd> on Mac OS X). Once displayed, either the mouse pointer can be used to select an option or, alternatively, the keyboard arrow keys can be used to scroll through the file name and tool window options. Pressing the Enter key will select the currently highlighted item.
Changing the Android Studio Theme
-------------------
----------
The overall theme of the Android Studio environment may be changed either from the welcome screen using the Configure -> Settings option, or via the File -> Settings… menu option of the main window. Once the settings dialog is displayed, select the Appearance option in the left hand panel and then change the setting of the Theme menu before clicking on the Apply button. The themes currently available consist of IntelliJ, Windows and Darcula. Figure 4-9 shows an example of the main window with the Darcula theme selected:
Figure 4-9
Summary
-------------------
----------
The primary elements of the Android Studio environment consist of the welcome screen and main window. Each open project is assigned its own main window which, in turn, consists of a menu bar, toolbar, editing and design area, status bar and a collection of tool windows. Tool windows appear on the sides and bottom edges of the main window and can be accessed either using the quick access menu located in the status bar, or via the optional tool window bars.
There are very few actions within Android Studio which cannot be triggered via a keyboard shortcut. A keymap of default keyboard shortcuts can be accessed at any time from within the Android Studio main window.
Extra
-------------------
----------
[Link] [A Tour of the Android Studio User Interface](http://www.techotopia.com/index.php/A_Tour_of_the_Android_Studio_User_Interface) | 120.15625 | 672 | 0.790247 | eng_Latn | 0.9994 |
c0886b6f17f9c0e2b3f5c0dd07abc73cffb0666f | 1,044 | md | Markdown | windows-driver-docs-pr/kernel/handling-a-system-set-power-irp-in-a-bus-driver.md | AnLazyOtter/windows-driver-docs.zh-cn | bdbf88adf61f7589cde40ae7b0dbe229f57ff0cb | [
"CC-BY-4.0",
"MIT"
] | null | null | null | windows-driver-docs-pr/kernel/handling-a-system-set-power-irp-in-a-bus-driver.md | AnLazyOtter/windows-driver-docs.zh-cn | bdbf88adf61f7589cde40ae7b0dbe229f57ff0cb | [
"CC-BY-4.0",
"MIT"
] | null | null | null | windows-driver-docs-pr/kernel/handling-a-system-set-power-irp-in-a-bus-driver.md | AnLazyOtter/windows-driver-docs.zh-cn | bdbf88adf61f7589cde40ae7b0dbe229f57ff0cb | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: 处理总线驱动程序中的系统 Set-Power IRP
description: 处理总线驱动程序中的系统 Set-Power IRP
ms.assetid: e88344bd-4223-4cd5-9428-201d46c6dbb4
keywords:
- 设置电源 Irp WDK 电源管理
- 总线驱动程序 WDK 电源管理
ms.date: 06/16/2017
ms.localizationpriority: medium
ms.openlocfilehash: e37faf79a6a14a03a95933b60c99bc0c09d58ac6
ms.sourcegitcommit: 4b7a6ac7c68e6ad6f27da5d1dc4deabd5d34b748
ms.translationtype: MT
ms.contentlocale: zh-CN
ms.lasthandoff: 10/24/2019
ms.locfileid: "72838677"
---
# <a name="handling-a-system-set-power-irp-in-a-bus-driver"></a>处理总线驱动程序中的系统 Set-Power IRP
当总线驱动程序收到系统设置-power IRP 时,它必须执行以下步骤:
1. 调用[**PoStartNextPowerIrp**](https://docs.microsoft.com/windows-hardware/drivers/ddi/ntifs/nf-ntifs-postartnextpowerirp)以启动下一个 power IRP。 (仅限 windows Server 2003、Windows XP 和 Windows 2000。)
2. 将**Irp>IoStatus**设置为 STATUS\_SUCCESS。 驱动程序无法通过系统设置-power IRP 来失败。
3. 调用[**IoCompleteRequest**](https://docs.microsoft.com/windows-hardware/drivers/ddi/wdm/nf-wdm-iocompleterequest),指定 IO\_NO\_递增,以完成 IRP。
总线驱动程序在收到请求设备电源状态的电源 IRP 之前,不会更改设备电源设置。
| 26.1 | 192 | 0.785441 | yue_Hant | 0.668568 |
c08920101f825259f734fa33832719ccb80ca638 | 79 | md | Markdown | _includes/05-emphasis.md | gabrielaserna/markdown-portfolio | 4b16552f310675bcd567a1aab53b85d6ab0a0031 | [
"MIT"
] | null | null | null | _includes/05-emphasis.md | gabrielaserna/markdown-portfolio | 4b16552f310675bcd567a1aab53b85d6ab0a0031 | [
"MIT"
] | 6 | 2021-05-13T06:27:28.000Z | 2021-05-13T08:50:57.000Z | _includes/05-emphasis.md | gabrielaserna/markdown-portfolio | 4b16552f310675bcd567a1aab53b85d6ab0a0031 | [
"MIT"
] | null | null | null | *Generous*
_Brave_
**Adventurous**
__Loyal__
_Always keen on **having fun**_
| 9.875 | 31 | 0.734177 | eng_Latn | 0.481092 |
c0899fbbb9f90a4202df29f2972caa1ae4a644e8 | 3,328 | md | Markdown | content/en/community/roadmap.md | stroomdev00/stroom-docs | 5cdd6e6dbb62e3944c167c5ce0d0dd6f21568836 | [
"Apache-2.0"
] | null | null | null | content/en/community/roadmap.md | stroomdev00/stroom-docs | 5cdd6e6dbb62e3944c167c5ce0d0dd6f21568836 | [
"Apache-2.0"
] | null | null | null | content/en/community/roadmap.md | stroomdev00/stroom-docs | 5cdd6e6dbb62e3944c167c5ce0d0dd6f21568836 | [
"Apache-2.0"
] | null | null | null | ---
title: "Roadmap"
linkTitle: "Roadmap"
weight: 10
date: 2022-01-19
tags:
description: >
The roadmap for new features and changes to the Stroom family of products.
---
## v7.0
### Reference data storage
Reference data uses a memory-mapped disk-based store rather than direct memory to reduce the memory overhead associated with storing reference data.
### Search result storage
Search results are stored on disk rather than in memory during creation to reduce the memory overhead incurred by search.
### Modularisation
Separation of Stroom components into discreet modules that have clear APIs and separate persistence where required to reduce coupling.
### Modernisation of libraries
Changing Stroom libraries to replace Spring with Guice and Hibernate with JOOQ.
### Annotations
Search results in dashboards can be annotated to provide status and notes relating to the result item, e.g. an event. These annotations can later be searched to see which events have annotations associated with them.
## v7.1
### Elastic search integration
Elastic search can be used for indexing data. Data can be sent to an elastic index via a pipeline element and an elastic index can be queried from a Stroom dashboard.
### Interactive Visualisations
Selecting or manipulating parts of visualisations can be used to trigger further queries to zoom in or select specific data etc.
### Improved Proxy Aggregation
Proxy aggregation can better match user defined aggregate sizes and forward to multiple destinations.
### User Preferences
The UI can be customised to meet the needs of an end user including theme (dark mode), date and time format, font, layout.
## v7.2
### XSLT 3
Add support for XSLT 3.
### Accessibility Improvements
Refactoring some elements of the UI to improve accessibility.
## v8+
### Authorisation enhancements
The Stroom authorisation system is split out into a separate service and provides integration with external authorisation mechanisms.
### Proxy processing
Stroom proxy is capable of pipeline processing in the same way as a full Stroom application. Pipeline configuration content can be pushed to proxies so that they can perform local processing prior to sending data to Stroom.
### Multiple input sources
Stroom is capable of processing data from a Kafka topic, HDFS, the local file system, HTTP POST in addition to the included stream store.
### Multiple output destinations
Stroom has improved support for writing to various destinations such as Kafka, HDFS, etc. Improvements include compression and meta data wrapping for future import.
### Improved field extraction
Enhancements to data splitter and associated UI to make the process of extracting field data from raw content much easier.
### Kafka analytics
Stroom exposes the use of Apache Kafka Streams for performing certain complex analytics.
### Query fusion
Stroom allows multiple data sources to be queried at the same time and the results of the queries to be fused. This might be for fusing data from multiple search indexes, e.g. events and annotations, or to effectively decorate results with additional data at search time.
### Reference data deltas
Reference data is enhanced to cope with changes (additions and removals) of state information rather than always relying on complete snapshots.
| 35.031579 | 271 | 0.791767 | eng_Latn | 0.998759 |
c08a6ea2db4ab7855ecb983138baa189433db211 | 183 | md | Markdown | static/linkGame/README.md | nicehero/h5game_platform | 238d71e51b14781c1178fe97f0a9d7ab7686e75d | [
"BSD-3-Clause"
] | null | null | null | static/linkGame/README.md | nicehero/h5game_platform | 238d71e51b14781c1178fe97f0a9d7ab7686e75d | [
"BSD-3-Clause"
] | null | null | null | static/linkGame/README.md | nicehero/h5game_platform | 238d71e51b14781c1178fe97f0a9d7ab7686e75d | [
"BSD-3-Clause"
] | null | null | null | ### link-game
H5消消乐(连连看)小游戏
### 效果图

# 体验地址:
[https://zhanyuzhang.github.io/link-game/index1.html](https://zhanyuzhang.github.io/link-game/index1.html)
| 20.333333 | 106 | 0.715847 | yue_Hant | 0.174561 |
c08ba8a5f5c2f331cd79c3be913aab8ffd381e5f | 365 | md | Markdown | Hackerrank/Helloworld program in c/Hello,world.md | Sloth-Panda/Data-Structure-and-Algorithms | 00b74ab23cb8dfc3e96cdae80de95e985ad4a110 | [
"MIT"
] | 51 | 2021-01-14T04:05:55.000Z | 2022-01-25T11:25:37.000Z | Hackerrank/Helloworld program in c/Hello,world.md | Sloth-Panda/Data-Structure-and-Algorithms | 00b74ab23cb8dfc3e96cdae80de95e985ad4a110 | [
"MIT"
] | 638 | 2020-12-27T18:49:53.000Z | 2021-11-21T05:22:52.000Z | Hackerrank/Helloworld program in c/Hello,world.md | Sloth-Panda/Data-Structure-and-Algorithms | 00b74ab23cb8dfc3e96cdae80de95e985ad4a110 | [
"MIT"
] | 124 | 2021-01-30T06:40:20.000Z | 2021-11-21T15:14:40.000Z | <pre>
<h3>Objective</h3>
to get a string from user and print that string along with a string "Hello world!" above that line.
Example
The required output is:
Hello, World!
Life is beautiful
<h2>Input Format</h2>
There is one line of text.
<h2>Sample Input :</h2>
Welcome to C programming.
<h2>Sample Output :</h2>
Hello, World!
Welcome to C programming. | 15.869565 | 99 | 0.717808 | eng_Latn | 0.988133 |
c08c065fc2d3c956daa051547630b2b4e78ba414 | 2,614 | md | Markdown | _posts/2019-05-02-Download-e2020-answers-for-environmental-science-s1.md | Jobby-Kjhy/27 | ea48bae2a083b6de2c3f665443f18b1c8f241440 | [
"MIT"
] | null | null | null | _posts/2019-05-02-Download-e2020-answers-for-environmental-science-s1.md | Jobby-Kjhy/27 | ea48bae2a083b6de2c3f665443f18b1c8f241440 | [
"MIT"
] | null | null | null | _posts/2019-05-02-Download-e2020-answers-for-environmental-science-s1.md | Jobby-Kjhy/27 | ea48bae2a083b6de2c3f665443f18b1c8f241440 | [
"MIT"
] | null | null | null | ---
layout: post
comments: true
categories: Other
---
## Download E2020 answers for environmental science s1 book
"How's that work?" wrist, the glaciers, as well. This time he would be rational about how irrational the whole thing was and refused to be intimidated by his own imagination. The doctor of doom had purchased this forbidden beverage without the tofu-eater's every night, lacing e2020 answers for environmental science s1 unlacing the fingers, hurt. 167. "Yep. " manned with 20 men. 1 (0 deg. years. He staggered, repaid Nella's kindness with her own stunning message to Lipscomb, and after Cass has determined that the "You're spooking me, Micky kicked off her e2020 answers for environmental science s1 high heels, paragraphs in her treaties with the civilised countries of Europe, even with no defense preoccupations, surely he would be rubinum de mundo"? An Jacob trusted no one but Agnes and Edom. "This is where I grew up. but then diminishes and fades entirely away. The King's working the old Chapter 68 never had, Samoyed. The Country Squire parked in the driveway, Solus HI. She could choose between waiting here to follow Maddoc or "Gee, which she regards with obvious dread! Like the Lapps and most other European and Asiatic Polar races, he'd never slept with an older woman. please call me Wally. I left. In the same part (p. I thought you said they was dead here. This thing was black, lowering its spells Sometimes, it rivals the Golden Gate Bridge. "Maybe they're just hungry for a good cheeseburger," says a florid-faced man it to help maintain her balance as she stumped toward the foot of the bed. What triggers a phase-change Eleven years later, 'Abide thou here in thy place, and Discoveries of the English "Don't strain yourself. observations about their family breakfast, I'll know what to say to those who come. He'll know what he wants when he sees it!" size. " someone's name gives you power "If I did, Wellesley said in a still angry voice to the computer recording the proceedings. hundreds of skuas which I have seen, the dog remaining by his side, the great gold-mailed flanks! Gabby e2020 answers for environmental science s1 only a step or two isfy their curiosity in here where we can watch them, to see his boy teaching tricks to the witch-child, infantry reconnaissance that they had managed to slip in a thousand feet above the floor of the gorge and almost over the enemy's forward positions and was supplemented by additional data collected from satellite and other ELINT network sources. In this state of things we have to seek for the reason had killed Laura. | 290.444444 | 2,498 | 0.791125 | eng_Latn | 0.999912 |
c08c4748d62e1ead80f68d0e4d854997239741c7 | 1,607 | md | Markdown | README.md | MobileFirst-Platform-Developer-Center/StepUpSwift | f8480f12e57ed0033133c5f4c688781d4953fbf5 | [
"Apache-2.0"
] | null | null | null | README.md | MobileFirst-Platform-Developer-Center/StepUpSwift | f8480f12e57ed0033133c5f4c688781d4953fbf5 | [
"Apache-2.0"
] | null | null | null | README.md | MobileFirst-Platform-Developer-Center/StepUpSwift | f8480f12e57ed0033133c5f4c688781d4953fbf5 | [
"Apache-2.0"
] | null | null | null | IBM MobileFirst Platform Foundation
===
## StepUpSwift
A sample application demonstrating the use of multiple challenge handlers.
### Tutorials
### Usage
1. Use either Maven, MobileFirst CLI or your IDE of choice to [build and deploy the available `ResourceAdapter`, `StepUpUserLogin` and `StepUpPinCode` adapters](https://mobilefirstplatform.ibmcloud.com/tutorials/en/foundation/8.0/adapters/creating-adapters/).
SecurityCheck adapter: https://github.com/MobileFirst-Platform-Developer-Center/SecurityCheckAdapters/tree/release80
2. From a command-line window, navigate to the project's root folder and run the following commands:
- `pod update` followed by `pod install` - to add the MobileFirst SDK.
- `mfpdev app register` - to register the application
- `mfpdev app push` - to add the following scope mappings:
- `accessRestricted` to `StepUpUserLogin`.
- `transferPrivilege` to both `StepUpUserLogin` and `StepUpPinCode`.
3. In Xcode, run the application
### Supported Levels
IBM MobileFirst Platform Foundation 8.0
### License
Copyright 2016 IBM Corp.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| 40.175 | 259 | 0.779091 | eng_Latn | 0.945256 |
c08c4ebb1862cd362e18bf61dd80ae044fb09d8f | 1,924 | md | Markdown | docs/how-components-are-created.md | BehindStar/Windsor-doc-cn | be9689d75a513f8290786cdf562b00e8ea1a4b08 | [
"Apache-2.0"
] | 32 | 2016-06-07T05:52:25.000Z | 2020-08-25T08:59:59.000Z | docs/how-components-are-created.md | BehindStar/Windsor-doc-cn | be9689d75a513f8290786cdf562b00e8ea1a4b08 | [
"Apache-2.0"
] | null | null | null | docs/how-components-are-created.md | BehindStar/Windsor-doc-cn | be9689d75a513f8290786cdf562b00e8ea1a4b08 | [
"Apache-2.0"
] | 17 | 2016-06-08T15:11:51.000Z | 2021-06-18T02:06:56.000Z | # 组件是怎样创建的
<img align="right" src="images/creation-flow.png">
当从Windsor容器请求组件时,容器需要经过几个步骤来提供实例。右边的图片描述了这些步骤的更重要的方面。我们将在这里讨论它们的更多细节。
:information_source: **关于实例生命周期(lifecycle)和生命期方式(lifestyle):** 该页面提供了双重目的。首先它解释了当[组件](services-and-components.md)的一个实例被以**忽略组件的 [生命期方式](lifestyles.md)**请求时,Windsor所做的工作。除此之外,它描述了组件的生命周期的第一个部分,这是它的开始和出生(或用技术术语,什么导致实例被创建,以及它如何被创建)。请千万记住这不是一个实例的整个生命周期,这只是第一步。要了解的整个生命周期,一直到组件的死亡,请查看[实体生命周期](lifecycle.md)页面。
## 定位处理器(Locating handler)
当组件被请求时由容器执行的第一步,是检查所请求的组件是否被注册到容器中。容器从其[命名子系统](subsystems.md)中查找组件,如果找不到该组件,容器会尝试[延迟-组件-加载器|延迟注册],如果没有成功,一个`ComponentNotFoundException`将被抛出。
假设可以发现找到正确的组件,容器将轮询其[处理器](handlers.md),并要求解析组件实例。
## 处理器都做了什么
处理器做了几件事情:
* 它调用与它相关联的所有`ComponentResolvingDelegate`,让他们有机会在实际开始之前来影响它的决定。这里有个例子, 什么时候[委托传递到Fluent注册API的DynamicParameters方法](inline-dependencies.md#supplying-dynamic-dependencies)。([Fluent注册API](fluent-registration-api.md))
* 如果未提供内嵌参数,它会检查该组件及其所有强制依赖是否能够解析。如果不能,抛出`HandlerException`异常。
* 最后,处理器要求[生命期方式管理器](lifestyles.md)解析该组件。
## 生命期方式管理器都做了什么
生命期管理器具有相对简单的角色。如果它有一个它可以重复使用的组件实例,它获得并直接返回该实例返回到处理器。如果没有,它要求它的[组件激活器](component-activators)创建一个。
## 组件激活器都做了什么
:information_source: **组件激活器:**
组件激活器负责创建组件的实例。各种激活器有各自的实现。当您通过`UsingFactoryMethod`创建组件时,您提供的委托将被调用以创建实例。[工厂支持设施](factory-support-facility.md)或[远程设施](remoting-facility.md)有它们自己的一套激活器,用于执行组件的自定义初始化。
多数时候你应该使用 `DefaultComponentActivator` ,其工作流程如下:
* 调用组件的构造函数实例化组件。 :information_source: **构造函数是怎样选择的:** 了解默认组件激活器如何选择构造函数,点击[这里](how-constructor-is-selected.md).
* 当实例被创建,就会解析组件的属性依赖。 :information_source: **属性时如何注入的:** 了解默认组件激活器如何将依赖注入到属性,点击[这里](how-properties-are-injected.md).
* 当组件创建完成后, 调用组件的所有[commission concerns](lifecycle.md)。
* 在核心(kernel)触发`ComponentCreated` 事件。
* 返回实例到生命期方式管理器。
## 处理器,发布政策和容器都做了什么
生命期方式管理器将会在需要的时候将实例保存到上下文缓存中,之后就可以重用,并将实例传递给处理器。如果允许和需要,处理器调用[发布政策](release-policy.md)以跟踪组件,然后将组件传递给容器,容器将组件返回给用户。
## 还可以看看
* [依赖是怎样解析的](how-dependencies-are-resolved.md) | 41.826087 | 304 | 0.819647 | yue_Hant | 0.743234 |
c08d0d53c68a3ced0680aef8010706f21f18d540 | 1,432 | md | Markdown | _posts/2015-12-22-day-twenty-two-docker-and-monitoring.md | abtris/dockeradvent.com | 21e4b04f24c83eec38dfa5082212501f96126c7e | [
"MIT"
] | null | null | null | _posts/2015-12-22-day-twenty-two-docker-and-monitoring.md | abtris/dockeradvent.com | 21e4b04f24c83eec38dfa5082212501f96126c7e | [
"MIT"
] | 30 | 2015-11-26T08:55:41.000Z | 2022-03-04T04:03:47.000Z | _posts/2015-12-22-day-twenty-two-docker-and-monitoring.md | abtris/dockeradvent.com | 21e4b04f24c83eec38dfa5082212501f96126c7e | [
"MIT"
] | null | null | null | ---
layout: post
title: "Day Twenty Two - Docker and monitoring"
date: 2015-12-22 11:00:00 +0100
categories: 2015
---
Hi everyone,<br>
Docker have [runtime metrics](https://docs.docker.com/engine/articles/runmetrics/), you can see CPU, MEM, IO and network for every container.
```
$ docker stats determined_shockley determined_wozniak prickly_hypatia
CONTAINER CPU % MEM USAGE/LIMIT MEM % NET I/O
determined_shockley 0.00% 884 KiB/1.961 GiB 0.04% 648 B/648 B
determined_wozniak 0.00% 1.723 MiB/1.961 GiB 0.09% 1.266 KiB/648 B
prickly_hypatia 0.00% 740 KiB/1.961 GiB 0.04% 1.898 KiB/648 B
```
It's many tools for monitoring:
- [cAdvisor](https://github.com/google/cadvisor) from google have web UI.
- I'm using [Datadog](https://www.datadoghq.com/blog/monitor-docker-datadog/).
- [Sensu Monitoring Framework](http://sensuapp.org/) you can use with [container](https://registry.hub.docker.com/u/hiroakis/docker-sensu-server/).
- [Prometheus](http://prometheus.io/) is an open-source service monitoring system and time series database.
- [Scout](https://scoutapp.com/plugin_urls/19761-docker-monitor)
All monitoring works at some principles. Install agent on host and using docker stats and StatsD for sending data into some collection system.
See you tomorrow,<br>
Ladislav
| 46.193548 | 147 | 0.674581 | eng_Latn | 0.355093 |
c08d65b29733849653546d1db4bec6801aff529c | 184 | md | Markdown | content/components/charts-and-graphs/index.md | heinekin/gatsby-style-guide-guide | 7e990e36476ccec3f8b36a47375dcda846aca84b | [
"MIT"
] | 486 | 2018-06-13T15:13:54.000Z | 2022-03-05T03:49:03.000Z | content/components/charts-and-graphs/index.md | heinekin/gatsby-style-guide-guide | 7e990e36476ccec3f8b36a47375dcda846aca84b | [
"MIT"
] | 12 | 2018-06-14T10:04:04.000Z | 2021-03-25T16:43:54.000Z | content/components/charts-and-graphs/index.md | heinekin/gatsby-style-guide-guide | 7e990e36476ccec3f8b36a47375dcda846aca84b | [
"MIT"
] | 39 | 2018-06-13T20:06:25.000Z | 2021-12-17T01:08:22.000Z | ---
layout: component-category
group: components
subgroup: charts-and-graphs
path: /components/charts-and-graphs
title: Charts and graphs
description: Essential data-viz patterns
---
| 18.4 | 40 | 0.788043 | eng_Latn | 0.863763 |
c08d98bca57987f41aba625a47c98b4dd4977339 | 1,715 | md | Markdown | Exchange-Server-2013/deploy-a-new-installation-of-exchange-2013-exchange-2013-help.md | v-kents/OfficeDocs-Exchange-Test-pr.ru-ru | 369e193682e71d5edffee0d10a840b4967668b93 | [
"CC-BY-4.0",
"MIT"
] | 4 | 2018-07-20T08:47:21.000Z | 2021-05-26T10:59:17.000Z | Exchange-Server-2013/deploy-a-new-installation-of-exchange-2013-exchange-2013-help.md | v-kents/OfficeDocs-Exchange-Test-pr.ru-ru | 369e193682e71d5edffee0d10a840b4967668b93 | [
"CC-BY-4.0",
"MIT"
] | 24 | 2018-06-19T08:37:04.000Z | 2018-09-26T16:37:08.000Z | Exchange-Server-2013/deploy-a-new-installation-of-exchange-2013-exchange-2013-help.md | v-kents/OfficeDocs-Exchange-Test-pr.ru-ru | 369e193682e71d5edffee0d10a840b4967668b93 | [
"CC-BY-4.0",
"MIT"
] | 12 | 2018-06-19T07:21:50.000Z | 2021-11-15T11:19:10.000Z | ---
title: 'Развертывание новой установки Exchange 2013: Exchange 2013 Help'
TOCTitle: Развертывание новой установки Exchange 2013
ms:assetid: 681835cf-79fe-4aa7-8a28-4a39944d0efc
ms:mtpsurl: https://technet.microsoft.com/ru-ru/library/Aa998619(v=EXCHG.150)
ms:contentKeyID: 50488173
ms.date: 04/30/2018
mtps_version: v=EXCHG.150
ms.translationtype: HT
---
# Развертывание новой установки Exchange 2013
_**Применимо к:** Exchange Server 2013_
_**Последнее изменение раздела:** 2014-07-31_
Прежде чем начать установку МайкрософтExchange Server 2013, см. в разделе [Планирование и развертывание](planning-and-deployment-for-exchange-2013-installation-instructions.md) важные сведения о планировании, а также информацию о требованиях к системе и предварительных условиях.
В следующих разделах содержатся сведения о развертывании новой установки Exchange 2013 в организации.
[Контрольный список: Выполнение новой установки Exchange 2013](checklist-perform-a-new-installation-of-exchange-2013-exchange-2013-help.md)
[Установка Exchange 2013 с помощью мастера установки](install-exchange-2013-using-the-setup-wizard-exchange-2013-help.md)
[Установка Exchange 2013 в автоматическом режиме](install-exchange-2013-using-unattended-mode-exchange-2013-help.md)
[Установка роли пограничного транспортного сервера Exchange 2013 с помощью мастера установки](install-the-exchange-2013-edge-transport-role-using-the-setup-wizard-exchange-2013-help.md)
[Делегирование установки сервера Exchange 2013](delegate-the-installation-of-an-exchange-2013-server-exchange-2013-help.md)
После завершения установки см. раздел [Задачи после установки Exchange 2013](exchange-2013-post-installation-tasks-exchange-2013-help.md).
| 47.638889 | 279 | 0.819825 | rus_Cyrl | 0.526665 |
c08e8bf2c3246e5d4f08d73bf9e9e783febe4ecb | 2,735 | md | Markdown | exercises/DP1/src/ch/epfl/sweng/dp1/solutions/quiz/1-Basics.md | PeterKrcmar0/public | 4bd1b045dc6b6116d264d0032e97f2b03becac6c | [
"Apache-2.0"
] | null | null | null | exercises/DP1/src/ch/epfl/sweng/dp1/solutions/quiz/1-Basics.md | PeterKrcmar0/public | 4bd1b045dc6b6116d264d0032e97f2b03becac6c | [
"Apache-2.0"
] | null | null | null | exercises/DP1/src/ch/epfl/sweng/dp1/solutions/quiz/1-Basics.md | PeterKrcmar0/public | 4bd1b045dc6b6116d264d0032e97f2b03becac6c | [
"Apache-2.0"
] | null | null | null | # Design patterns: The basics
## Question 1
Which of the following could be considered an abuse of the Exceptions design pattern? Select all that apply.
- [ ] Throwing a RuntimeException when the error is caused by a programmer mistake
- [x] Throwing a RuntimeException in order to break out of several nested loops
- [x] Throwing an EmptyListException in the size() method of a list class, if the list is empty
- [ ] Throwing an IOException in a network socket class if the connection is dropped
**Explanation**
The first case is not an abuse: RuntimeExceptions should indeed be thrown in exceptional circumstances caused by programmer mistakes (e.g., NPEs, invalid arguments, etc.)
The second case is an abuse: it takes advantage of the unwinding properties of the exceptions to break the control flow in a non-exceptional case.
The third case is also an abuse: an empty list is not an exceptional situation, and throwing an exception for that is unnecessary.
The fourth case is not an abuse: Dropped connections are caused by external factors that we cannot control, so the code should be prepared to receive this exception.
## Question 2
Which of the following are advantages of inheritance over encapsulation? Select all that apply.
- [ ] Inheritance reduces the amount of code coupling
- [x] Inheritance better prevents code duplication
- [ ] Inheritance improves system performance
- [ ] Inheritance simplifies system testing
- [ ] Inheritance enables the use of design patterns, while encapsulation does not
**Explanation**
Inheritance actually increases the amount of code coupling, since subclasses have access to the internal state of their superclasses. Thus, they depend on how the superclass is implemented (video @12:20).
Inheritance prevents code duplication, since subclasses inherit methods and fields from the superclass and do not need to re-implement them.
Both inheritance and encapsulation can have negative impacts on performance; encapsulation adds the necessity of accessing fields through method calls, while inheritance adds the overhead of the dispatcher, which needs to select which method implementation to call in a given context. In some designs, inheritance is more efficient, while in others encapsulation is more efficient.
Inheritance can make testing more complex, due to the increased coupling between classes. With encapsulation, the implementations of classes can be evaluated independently (because as long as the interfaces are respected, the particularities of implementations are irrelevant). With inheritance, the two implementations are dependent and cannot be separated (the subclass depends on the superclass).
Some design patterns use inheritance, while others use encapsulation.
| 88.225806 | 399 | 0.80841 | eng_Latn | 0.999623 |
c08e9cbcbfc3cd68043181a284ae0e64bbc98535 | 1,581 | md | Markdown | _posts/2019-09-24-meeting-minutes.md | acm-ndsu/NDSU-ACM-Website-Source | e3116ef0898127a59b953558600421e3dcc7aa3c | [
"MIT"
] | 3 | 2016-05-02T22:14:38.000Z | 2019-11-12T21:54:13.000Z | _posts/2019-09-24-meeting-minutes.md | acm-ndsu/NDSU-ACM-Website-Source | e3116ef0898127a59b953558600421e3dcc7aa3c | [
"MIT"
] | 2 | 2019-05-06T03:59:10.000Z | 2021-08-31T15:32:11.000Z | _posts/2019-09-24-meeting-minutes.md | acm-ndsu/NDSU-ACM-Website-Source | e3116ef0898127a59b953558600421e3dcc7aa3c | [
"MIT"
] | 2 | 2019-04-11T16:49:02.000Z | 2021-08-31T09:36:02.000Z | # What We're Going Over:
- MechMania Recap
- DigiKey
- Raspberry Pi + Ethernet Adapter
- SIGs
# What We Went Over:
- MechMania Recap
- Trip itself went really well
- Sleep accommodations were not made clear to all members (at the event)
- We forgot to bring power strips
- Competition itself was fine
- 2 vans were much more comfortable than a 15, and works really well
- Communication did fail at a couple points (because of MechMania staff and because of 2 vans instead of 1)
- Reimbursements
- Totaling of how much we spent on the trip must be done
- We took 14, even though we budgeted for 13
- Student gov is providing us a smaller budget than last year
- DigiKey (competition)
- Sign ups are due Thursday, September 26
- DigiKey will pay for hotels
- We will have to cover van rentals
- Likely covered by previous DigiKey winnings
- Travel is from Thursday night to Friday night
- It's expected that Dr. Denton is joining us
- Raspberry Pi 4
- Expensive, full sets on Amazon & Best Buy (~$100)
- Just a Pi (~$55)
- Mailman
- Spencer is planning to look into it
- SIGs
- Git
- 2 classes planned on different days
- Study
- 3:00-4:00pm on MWF
- C++/Linux
- looking for interest
- Gdev
- 4:00pm on Friday
- Bank Account - $1,621.31
- major deductions expected once MechMania payments go through
- membership fees have been added in there roughly the same time
# To Accomplish By Next Meeting:
- work on mailman
- DigiKey signups
- Reimbursements
# Next Meeting:
- DigiKey
- Mailman
- Raspberry Pi
- SIGs
- MechMania Reimbursements
| 1,581 | 1,581 | 0.729285 | eng_Latn | 0.996879 |
c08f06708381a0aab1e99b80c05d1770a44a6a0b | 13,570 | md | Markdown | README.md | UiPath/ProcessMining-pm-utils | aabe3210e7b175d4309036aa73d35d263af2c0b8 | [
"Apache-2.0"
] | null | null | null | README.md | UiPath/ProcessMining-pm-utils | aabe3210e7b175d4309036aa73d35d263af2c0b8 | [
"Apache-2.0"
] | null | null | null | README.md | UiPath/ProcessMining-pm-utils | aabe3210e7b175d4309036aa73d35d263af2c0b8 | [
"Apache-2.0"
] | null | null | null | # pm-utils
Utility functions for process mining related dbt projects.
## Installation instructions
See the instructions *How do I add a package to my project?* in the [dbt documentation](https://docs.getdbt.com/docs/building-a-dbt-project/package-management). The pm-utils is a public git repository, so the packages can be installed using the git syntax:
```
packages:
- git: "https://github.com/UiPath/ProcessMining-pm-utils.git"
revision: [tag name of the release]
```
This package contains some date/time conversion macros. You can override the default format that is used in the macros by defining variables in your `dbt_project.yml`. The following shows an example configuration of all the possible variables and the default values used:
```
vars:
# Date and time formats.
# For SQL Server defined by integers and for Snowflake defined by strings.
date_format: 23 # default: SQL Server: 23, Snowflake: 'YYYY-MM-DD'
time_format: 14 # default: SQL Server: 14, Snowflake: 'hh24:mi:ss.ff3'
datetime_format: 21 # default: SQL Server: 21, Snowflake: 'YYYY-MM-DD hh24:mi:ss.ff3'
```
## Contents
This dbt package contains macros for SQL functions to run the dbt project on multiple databases and for generic tests. The databases that are currently supported are Snowflake and SQL Server.
- [Multiple databases](#Multiple-databases)
- [date_from_timestamp](#date_from_timestamp-source)
- [datediff](#datediff-source)
- [generate_id](#generate_id-source)
- [string_agg](#string_agg-source)
- [timestamp_from_date](#timestamp_from_date-source)
- [timestamp_from_parts](#timestamp_from_parts-source)
- [to_boolean](#to_boolean-source)
- [to_date](#to_date-source)
- [to_double](#to_double-source)
- [to_integer](#to_integer-source)
- [to_time](#to_time-source)
- [to_timestamp](#to_timestamp-source)
- [to_varchar](#to_varchar-source)
- [Generic tests](#Generic-tests)
- [test_field_length](#test_field_length-source)
- [test_edge_count](#test_edge_count-source)
- [test_equal_rowcount](#test_equal_rowcount-source)
- [test_exists](#test_exists-source)
- [test_not_negative](#test_not_negative-source)
- [test_one_column_not_null](#test_one_column_not_null-source)
- [test_type_boolean](#test_type_boolean-source)
- [test_type_date](#test_type_date-source)
- [test_type_double](#test_type_double-source)
- [test_type_integer](#test_type_integer-source)
- [test_type_timestamp](#test_type_timestamp-source)
- [test_unique_combination_of_columns](#test_unique_combination_of_columns-source)
- [Generic](#Generic)
- [optional](#optional-source)
- [left_from_char](#left_from_char-source)
- [Process mining tables](#Process-mining-tables)
- [generate_edge_table](#generate_edge_table-source)
- [generate_variant](#generate_variant-source)
### Multiple databases
#### date_from_timestamp ([source](macros/multiple_databases/date_from_timestamp.sql))
This macro extracts the date part from a datetime field.
Usage:
`{{ pm_utils.date_from_timestamp('[expression]') }}`
#### datediff ([source](macros/multiple_databases/datediff.sql))
This macro computes the difference between two date, time, or datetime expressions based on the specified `datepart` and returns an integer value. The datepart can be any of the following values: year, quarter, month, week, day, hour, minute, second, millisecond.
Usage:
`{{ pm_utils.datediff('[datepart]', '[start_date_expression]', '[end_date_expression]') }}`
#### generate_id ([source](macros/multiple_databases/generate_id.sql))
This macro generates an id field for the current model. This macro can only be used in a dbt post-hook. With the argument you specify the name of the id field which can be referenced in next transformations like any other field.
Usage:
```
{{ config(
post_hook="{{ generate_id('[id_field]') }}"
) }}
```
#### string_agg ([source](macros/multiple_databases/string_agg.sql))
This macro aggregates string fields separated by the given delimiter. If no delimiter is specified, strings are separated by a comma followed by a space. This macro can only be used as an aggregate function.
Usage:
`{{ pm_utils.string_agg('[expression]', '[delimiter]') }}`
#### timestamp_from_date ([source](macros/multiple_databases/timestamp_from_date.sql))
This macro creates a timestamp based on only a date field. The time part of the timestamp is set to 00:00:00.
Usage:
`{{ pm_utils.timestamp_from_date('[expression]') }}`
#### timestamp_from_parts ([source](macros/multiple_databases/timestamp_from_parts.sql))
This macro create a timestamp based on a date and time field.
Usage:
`{{ pm_utils.timestamp_from_parts('[date_expression]', '[time_expression]') }}`
#### to_boolean ([source](macros/multiple_databases/to_boolean.sql))
This macro converts a field to a boolean field.
Usage:
`{{ pm_utils.to_boolean('[expression]') }}`
#### to_date ([source](macros/multiple_databases/to_date.sql))
This macro converts a field to a date field.
Usage:
`{{ pm_utils.to_date('[expression]') }}`
Variables:
- date_format
#### to_double ([source](macros/multiple_databases/to_double.sql))
This macro converts a field to a double field.
Usage:
`{{ pm_utils.to_double('[expression]') }}`
#### to_integer ([source](macros/multiple_databases/to_integer.sql))
This macro converts a field to an integer field.
Usage:
`{{ pm_utils.to_integer('[expression]') }}`
#### to_time ([source](macros/multiple_databases/to_time.sql))
This macro converts a field to a time field.
Usage:
`{{ pm_utils.to_time('[expression]') }}`
Variables:
- time_format
#### to_timestamp ([source](macros/multiple_databases/to_timestamp.sql))
This macro converts a field to a timestamp field.
Usage:
`{{ pm_utils.to_timestamp('[expression]') }}`
Variables:
- datetime_format
#### to_varchar ([source](macros/multiple_databases/to_varchar.sql))
This macro converts a field to a string field.
Usage:
`{{ pm_utils.to_varchar('[expression]') }}`
### Generic tests
#### test_field_length ([source](macros/generic_tests/test_field_length.sql))
This generic test evaluates whether the values of the column have a particular length.
Usage:
```
models:
- name: Model_A
tests:
- pm_utils.field_length:
length: 'Length'
```
#### test_edge_count ([source](macros/generic_tests/test_edge_count.sql))
This generic test evaluates whether the number of edges is as expected based on the event log. The expected number of edges is equal to the number of events plus the number of cases, since also edges from the source node and to the sink node are taken into account.
Usage:
```
models:
- name: Edge_table_A
tests:
- pm_utils.edge_count:
event_log: 'Event_log_model'
case_ID: 'Case_ID'
```
#### test_equal_rowcount ([source](macros/generic_tests/test_equal_rowcount.sql))
This generic test evaluates whether two models have the same number of rows.
Usage:
```
models:
- name: Model_A
tests:
- pm_utils.equal_rowcount:
compare_model: 'Model_B'
```
#### test_exists ([source](macros/generic_tests/test_exists.sql))
This generic test evaluates whether a column is available in the model.
Usage:
```
models:
- name: Model_A
columns:
- name: '"Column_A"'
tests:
- pm_utils.exists
```
#### test_not_negative ([source](macros/generic_tests/test_not_negative.sql))
This generic test evaluates whether the values of the column are not negative.
Usage:
```
models:
- name: Model_A
columns:
- name: '"Column_A"'
tests:
- pm_utils.not_negative
```
#### test_one_column_not_null ([source](macros/generic_tests/test_one_column_not_null.sql))
This generic test evaluates whether exactly one out of the specified columns does contain a value. This test can be defined by two or more columns.
Usage:
```
models:
- name: Model_A
tests:
- pm_utils.one_column_not_null:
columns:
- 'Column_A'
- 'Column_B'
```
#### test_type_boolean ([source](macros/generic_tests/test_type_boolean.sql))
This generic test evaluates whether a field is a boolean represented by the numeric values 0 and 1.
Usage:
```
models:
- name: Model_A
columns:
- name: '"Column_A"'
tests:
- pm_utils.type_boolean
```
#### test_type_date ([source](macros/generic_tests/test_type_date.sql))
This generic test evaluates whether a field is a date data type.
Usage:
```
models:
- name: Model_A
columns:
- name: '"Column_A"'
tests:
- pm_utils.type_date
```
#### test_type_double ([source](macros/generic_tests/test_type_double.sql))
This generic test evaluates whether a field is a double data type.
Usage:
```
models:
- name: Model_A
columns:
- name: '"Column_A"'
tests:
- pm_utils.type_double
```
#### test_type_integer ([source](macros/generic_tests/test_type_integer.sql))
This generic test evaluates whether a field is an integer data type.
Usage:
```
models:
- name: Model_A
columns:
- name: '"Column_A"'
tests:
- pm_utils.type_integer
```
#### test_type_timestamp ([source](macros/generic_tests/test_type_timestamp.sql))
This generic test evaluates whether a field is a timestamp data type.
Usage:
```
models:
- name: Model_A
columns:
- name: '"Column_A"'
tests:
- pm_utils.type_timestamp
```
#### test_unique_combination_of_columns ([source](macros/generic_tests/test_unique_combination_of_columns.sql))
This generic test evaluates whether the combination of columns is unique. This test can be defined by two or more columns.
Usage:
```
models:
- name: Model_A
tests:
- pm_utils.unique_combination_of_columns:
combination_of_columns:
- 'Column_A'
- 'Column_B'
```
### Generic
#### left_from_char ([source](macros/generic/left_from_char.sql))
This macro extracts the string left from the character.
Usage:
`{{ pm_utils.left_from_char('[expression]', '[character]') }}`
#### optional ([source](macros/generic/optional.sql))
This macro checks in a table whether a column is present. If the column is not present, it creates the column with `null` values. If the column is present, it selects the column from the table. Use this macro to allow for missing columns in your source tables when that data is optional. Use the optional argument `data_type` to indicate the data type of the column. Possible values are: `boolean`, `date`, `double`, `integer`, `time`, `datetime`, and `text`. When no data type is set, the optional column is considered to be text.
Usage:
`{{ pm_utils.optional(source(source_name, table_name), '"Column_A"', 'data_type') }}`
Alternatively, you can use this macro for non-source data. Use instead of the source function, the ref function: `ref(table_name)`.
To keep the SQL in the model more readable, you can define a Jinja variable for the reference to the source table:
`{% set source_table = source(source_name, table_name) %}`
Variables:
- date_format
- time_format
- datetime_format
These variables are only required when the `data_type` is used with the values `date`, `time`, or `datetime`.
### Process mining tables
#### generate_edge_table ([source](macros/process_mining_tables/generate_edge_table.sql))
The edge table contains all transitions in the process graph. Each transition is indicated by the `From_activity` and the `To_activtiy` and for which case this transition took place. The edge table includes transitions from the source node and to the sink node.
The required input is an event log model with fields describing the case ID, activity, and event order. With the argument `table_name` you indicate how to name the generated table. The generated table contains at least the following columns: `Edge_ID`, one according to the given case ID, `From_activity` and `To_activity`. It also generates a column `Unique_edge`, which contains the value 1 once per occurrence of an edge per case.
Optional input is a list of properties. This generates columns like `Unique_edge`, which contains the value 1 once per occurrence of an edge per the given property. The name of this column is `Unique_edge` concatenated with the property.
Usage:
```
{{ pm_utils.generate_edge_table(
table_name = 'Edge_table',
event_log_model = 'Event_log',
case_ID = 'Case_ID',
activity = 'Activity',
event_order = 'Event_order',
properties = ['Property1', 'Property2'])
}}
```
This generates the table `Edge_table` with columns `Edge_ID`, `Case_ID`, `From_activity`, `To_activity`, `Unique_edge`, `Unique_edge_Property1` and `Unique_edge_Property2`.
#### generate_variant ([source](macros/process_mining_tables/generate_variant.sql))
A variant is a particular order of activities that a case executes. The most occurring variant is named "Variant 1", the next most occurring one "Variant 2", etc. This macro generates a cases table with for each case the variant.
The required input is an event log model with fields describing the case ID, activity, and event order. With the argument `table_name` you indicate how to name the generated table. The generated table contains two columns: one according to the given case ID and `Variant`.
Usage:
```
{{ pm_utils.generate_variant(
table_name = 'Cases_table_with_variant',
event_log_model = 'Event_log',
case_ID = 'Case_ID',
activity = 'Activity',
event_order = 'Event_order')
}}
```
This generates the table `Cases_table_with_variant` with columns `Case_ID` and `Variant`.
| 35.804749 | 532 | 0.732793 | eng_Latn | 0.940517 |
c08f8312b111d364cdb01b4f3bfd2b4ee741f291 | 69 | md | Markdown | README.md | AntonPrazdnichnykh/HSE.optimization | ca844bb041c614e0de95cab6de87db340323e59d | [
"Apache-2.0"
] | null | null | null | README.md | AntonPrazdnichnykh/HSE.optimization | ca844bb041c614e0de95cab6de87db340323e59d | [
"Apache-2.0"
] | null | null | null | README.md | AntonPrazdnichnykh/HSE.optimization | ca844bb041c614e0de95cab6de87db340323e59d | [
"Apache-2.0"
] | null | null | null | # HSE.optimization
Home assignments for optimization methods course
| 17.25 | 48 | 0.84058 | eng_Latn | 0.992326 |
c091bd8c95142400d953825223427466a7e2a5ef | 22 | md | Markdown | README.md | tcutroll/tcutroll.github.io | 00f42c6a795d3696f01fb75598a13431e35b6f23 | [
"MIT"
] | null | null | null | README.md | tcutroll/tcutroll.github.io | 00f42c6a795d3696f01fb75598a13431e35b6f23 | [
"MIT"
] | null | null | null | README.md | tcutroll/tcutroll.github.io | 00f42c6a795d3696f01fb75598a13431e35b6f23 | [
"MIT"
] | null | null | null | # tcutroll
# tcutroll
| 7.333333 | 10 | 0.727273 | lmo_Latn | 0.359906 |
c092260a3265ef5759c95e220989c4b363f8398d | 2,677 | md | Markdown | README.md | chuckbutler/rpi-tower | 0184e175aed10c9c24755f3a48a822631ea7c553 | [
"Apache-2.0"
] | null | null | null | README.md | chuckbutler/rpi-tower | 0184e175aed10c9c24755f3a48a822631ea7c553 | [
"Apache-2.0"
] | null | null | null | README.md | chuckbutler/rpi-tower | 0184e175aed10c9c24755f3a48a822631ea7c553 | [
"Apache-2.0"
] | null | null | null | # Pi Tower
This is the collection of scripts, templates, and other oddities that are
required to setup the six node RPI cluster sitting on my desk. It became
apparent that at major updates I would have to re-flash the SSD drives
with whatever the updated OS is. This means resetting back to vanilla.
I hate doing things manually more than once, so this collection of scripts
should alleviate a majority of the heavy lifting.
## Usage
Right now each script is numbered in terms of its expected run.
#### Getting Started
You'll need to clone this repository on each pi.
```shell
git clone https://github.com/chuckbutler/pi-tower.git
cd pi-tower
sudo install.sh
```
## Expected Pre Reqs
You should have a hypriot prepared SSD and have the SD card set to boot
off of the attached SSD.
Contents of SDCard `cmdline.txt`
```
+dwc_otg.lpm_enable=0 console=tty1 root=/dev/sda2 rootfstype=ext4
cgroup_enable=memory swapaccount=1 elevator=deadline fsck.repair=yes
rootwait console=ttyAMA0,115200 kgdboc=ttyAMA0,115200
```
Flash Hypriot to your SSD (assumed OSX as the workstation, and /dev/disk2 is
the attached SSD
```
dd if=hypriotos-rpi-v1.0.0.img bs=1m of=/dev/rdisk2
```
Plug in both the SSD and the SD card, and boot off your SSD.
From your Raspberry Pi, type the following command to start FDisk:
```
sudo fdisk /dev/sda
```
Then press p and enter to see the partitions. There should only be 2. What
we’re going to do now is delete the Linux partition, but before we do this, we
make a note of the start position for the linux partition sda2. Press d and
then when prompted type 2 and then hit enter. This will delete the partition.
Now we’re going to create a new partition, and make it large enough for the OS
to occupy the full space available on the USB Flash Drive. To do this type `n`
to create a new partition, when prompted to give the partition type, press `p`
for primary. Then it will as for a partition number, press 2 and hit enter.
You will be asked for a first sector, set this as the start of partition 2 as
noted earlier. In my case this as 12280 but this is likely to be different for
you.
After this it will ask for an end position, hit enter to use the default
which is end of disk. Now type `w` to commit the changes.
```
sudo reboot
```
Once your Raspberry Pi has rebooted, we need to resize the partition.
To do this type the following command:
```
sudo resize2fs /dev/sda2
```
Be patient, this will take some time. Once it’s done reboot again. Then type:
```
df -h
```
This will show the partitions and the space, you’ll see the full SSD space
available now.

| 28.478723 | 78 | 0.757564 | eng_Latn | 0.998151 |
c092b704e991557e5a6aef3f76ef0df0cc182d83 | 1,295 | md | Markdown | nosotros/mv.md | mper-bcn-ny/catalunya-en-cifras | a8797c5ad912326b51f48a877b9351c41b084f99 | [
"CC-BY-3.0"
] | null | null | null | nosotros/mv.md | mper-bcn-ny/catalunya-en-cifras | a8797c5ad912326b51f48a877b9351c41b084f99 | [
"CC-BY-3.0"
] | null | null | null | nosotros/mv.md | mper-bcn-ny/catalunya-en-cifras | a8797c5ad912326b51f48a877b9351c41b084f99 | [
"CC-BY-3.0"
] | null | null | null | ---
title: Martin Virtel
layout: page
hide: true
canonical: false
---
Alemán, 49 años, periodista y desarrollador.
Entender cómo las herramientas que creamos a su vez nos cambian a nosotros me fascinó desde joven. Las razones varían.
<iframe id="datawrapper-chart-v82rz" src="//datawrapper.dwcdn.net/v82rz/2/" scrolling="no" frameborder="0" allowtransparency="true" style="width: 0; min-width: 100% !important;" height="207"></iframe><script type="text/javascript">if("undefined"==typeof window.datawrapper)window.datawrapper={};window.datawrapper["v82rz"]={},window.datawrapper["v82rz"].embedDeltas={"100":294.003472,"200":236.003472,"300":236.003472,"400":207.003472,"500":207.003472,"700":207.003472,"800":207.003472,"900":207.003472,"1000":207.003472},window.datawrapper["v82rz"].iframe=document.getElementById("datawrapper-chart-v82rz"),window.datawrapper["v82rz"].iframe.style.height=window.datawrapper["v82rz"].embedDeltas[Math.min(1e3,Math.max(100*Math.floor(window.datawrapper["v82rz"].iframe.offsetWidth/100),100))]+"px",window.addEventListener("message",function(a){if("undefined"!=typeof a.data["datawrapper-height"])for(var b in a.data["datawrapper-height"])if("v82rz"==b)window.datawrapper["v82rz"].iframe.style.height=a.data["datawrapper-height"][b]+"px"});</script>
| 61.666667 | 1,047 | 0.751351 | spa_Latn | 0.101854 |
c096a1b9960abf3145edf9c75878e7e80f4f538d | 2,604 | md | Markdown | README.md | tikismoke/ESPHomeRoombaComponent | ef9c733604a054720799c7e741683a0cb7a33937 | [
"MIT"
] | 7 | 2020-11-17T17:39:27.000Z | 2021-12-14T17:32:29.000Z | README.md | tikismoke/ESPHomeRoombaComponent | ef9c733604a054720799c7e741683a0cb7a33937 | [
"MIT"
] | null | null | null | README.md | tikismoke/ESPHomeRoombaComponent | ef9c733604a054720799c7e741683a0cb7a33937 | [
"MIT"
] | 9 | 2021-02-13T06:52:29.000Z | 2022-02-09T12:02:40.000Z | # Roomba Component for ESPHome
The inspiration is [Mannkind ESPHomeRoombaComponent](https://github.com/mannkind/ESPHomeRoombaComponent), that became deprecated due to dependency updates.
In addition I did not want the Roomba device to communicate over MQTT, it instead registers a service call for commands, and expose sensors through `roomba.yaml`.
## Hardware
## Wiring Guide
Using the brc pin we get the following:

Alternatively using the IR led:

## Special Notes
*Depending on your Roomba model, you might be unlucky as me and have a bug that does not allow the device to wake from brc pin when it goes into passive mode during trickle charging. To circumvent this I copied my code from a previous general controller I had stationed in the kitchen for 433mhz and IR controlling that sends the start code with and IR led to the roomba, it need a clear sight of the roomba IR sensor over a short distance.
If you need this, uncomment the remote transmitter switch section in the `roomba.yaml` and use the switch to wake and clean.
## Placement
The Wemos D1 mini is small enough to [fit into the compartment by one of the wheels](https://community-home-assistant-assets.s3.dualstack.us-west-2.amazonaws.com/optimized/2X/a/a258c7253f8bd3fe76ad9e7aa1202b60bd113d74_2_496x600.jpg).
But using a esp-01 or esp-12 series and some single braid wire I have managed to fit it all under the top lid without bulging or deformeties, the only visual defect is my led that is pointing at the IR reciever.
## Software Setup/Use
Copy the contents of the `ESPRoombaHomeComponent.h` and `example/roomba.yaml` into your esphome config folder, change accordingly.
Flash onto new device and connect circuit.
## Motivation
Besides the obvious, connecting your vacuum to your automation system, it also does so completly inside a private and controlled ecosystem. As I was about to replace this unit due to the "hacky feel" of using the IR led, as the unit was shipped bugged and there's not a high availability of create cables for a patch, but all other solutions had me locked into a proprietary system such as mi home, or tuya with smart life; sure there are roundabout ways of both interfacing with them through Home assistant etc, and do so locally. They all seemingly lacked the future proofing and control I wanted. With this setup there is nothing really stopping you from a full on LiDar setup and room control!
| 70.378378 | 697 | 0.797619 | eng_Latn | 0.998724 |
c09765611c65903109dca6e6c97e5ef2a5faef62 | 813 | md | Markdown | docs/odbc/reference/network-example.md | L3onard80/sql-docs.it-it | f73e3d20b5b2f15f839ff784096254478c045bbb | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/odbc/reference/network-example.md | L3onard80/sql-docs.it-it | f73e3d20b5b2f15f839ff784096254478c045bbb | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/odbc/reference/network-example.md | L3onard80/sql-docs.it-it | f73e3d20b5b2f15f839ff784096254478c045bbb | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: Esempio di rete | Microsoft Docs
ms.custom: ''
ms.date: 01/19/2017
ms.prod: sql
ms.prod_service: connectivity
ms.reviewer: ''
ms.technology: connectivity
ms.topic: conceptual
helpviewer_keywords:
- drivers [ODBC], examples
ms.assetid: e14ae90f-87b3-4bcf-b69a-1773e2c2a1c5
author: MightyPen
ms.author: genemi
ms.openlocfilehash: 3454fab31de20a7d72f99a50c7dd3781ea2bc2be
ms.sourcegitcommit: b87d36c46b39af8b929ad94ec707dee8800950f5
ms.translationtype: MT
ms.contentlocale: it-IT
ms.lasthandoff: 02/08/2020
ms.locfileid: "67937981"
---
# <a name="network-example"></a>Esempio di rete
In questa illustrazione viene mostrato in che modo ogni configurazione precedente può essere visualizzata in una singola rete.

| 31.269231 | 128 | 0.792128 | ita_Latn | 0.486403 |
c0983e60e0cce64dc2a6b981226e24306e625f06 | 2,831 | md | Markdown | tictactoe/README.md | natacski/natacski.github.io | ef728a7ec230878b7fc15b8455e07c198d21eec7 | [
"MIT"
] | null | null | null | tictactoe/README.md | natacski/natacski.github.io | ef728a7ec230878b7fc15b8455e07c198d21eec7 | [
"MIT"
] | null | null | null | tictactoe/README.md | natacski/natacski.github.io | ef728a7ec230878b7fc15b8455e07c198d21eec7 | [
"MIT"
] | null | null | null | Now that you know how to create with React. It is time to create a game. We are going to create Tic tac toe this time.
This project was bootstrapped with [Create React App](https://github.com/facebook/create-react-app).
We have the folder setted up for you.
In the project directory, you need to run:
## `npm install`
download the dependencies
### `npm start`
Runs the app in the development mode.<br />
Open [http://localhost:3000](http://localhost:3000) to view it in the browser.
The page will reload if you make edits.<br />
You will also see any lint errors in the console.
[Here you have a Demo](https://xenodochial-mcnulty-3024f6.netlify.app/)
Requirements:
* Welcome page: with the Logo and the 'start' button which will disappears when the user clicks it.
<img src="./src/images/finalLook/welcome.png">
* After clicking the 'start' button the program have to aks the players their names. The program has to validate the inputs in case they are empties
<img src="./src/images/finalLook/inputs.png">
* After the inputs the program displays the board game with the players names and 2 button. 'Reset' and 'New Game':
'Reset button' cleans the board and remains the players names.
'New Game button' starts a new game with new players
<img src="./src/images/finalLook/beginning.png">
* finally in case there is a winner. The program must display the winner's name and the same two previous buttons.
<img src="./src/images/finalLook/winner.png">
**To resolve this Game you just need to know the basics of React and react Components. Remember to use conditional statements to render the components.**
The project has a **src** folder that contains a **component** 5 components:
* App.js -> main component which is rendered in the DOM
* Board.js -> here is where you will create the board 3x3
* Cell.js -> this is the component that represent a square of the board
* Header.js -> this is the component that displays the logo and start button at the beginning
* Info.js -> and this component is the one you will use to create the inputs for the players's name
those are the component we think are fundamentals for the development of the game, but feel free to add more components to make it your own style.
We also provided you with a set of images you need in the folder **images** and a group of css rules in the file **index.css**. We added Bootstrap CDN which means you can use bootstrap classes. You can create your own css style and images.
Create issues on the link below on the parent repo if you are stuck and want to talk about it. You can paste code, tag people and refer to other issues there. Please use it! It will be helpful for mentors and future students to see where common problems are. Link here: https://github.com/Code-the-Dream-School/Front-end-React-week-1/issues
Happy coding!!
| 45.66129 | 340 | 0.758036 | eng_Latn | 0.999512 |
c098924169b23bb10ff4397ea1f1c7e2739ef406 | 2,186 | md | Markdown | README.md | npmdoc/node-npmdoc-branch-diff | 87ac6f861685b9761764af001cc10b55b858932e | [
"MIT"
] | null | null | null | README.md | npmdoc/node-npmdoc-branch-diff | 87ac6f861685b9761764af001cc10b55b858932e | [
"MIT"
] | null | null | null | README.md | npmdoc/node-npmdoc-branch-diff | 87ac6f861685b9761764af001cc10b55b858932e | [
"MIT"
] | null | null | null | # npmdoc-branch-diff
#### api documentation for branch-diff (v1.7.0) [](https://www.npmjs.org/package/npmdoc-branch-diff) [](https://travis-ci.org/npmdoc/node-npmdoc-branch-diff)
#### A tool to list print the commits on one git branch that are not on another using loose comparison
[](https://www.npmjs.com/package/branch-diff)
- [https://npmdoc.github.io/node-npmdoc-branch-diff/build/apidoc.html](https://npmdoc.github.io/node-npmdoc-branch-diff/build/apidoc.html)
[](https://npmdoc.github.io/node-npmdoc-branch-diff/build/apidoc.html)


# package.json
```json
{
"name": "branch-diff",
"version": "1.7.0",
"description": "A tool to list print the commits on one git branch that are not on another using loose comparison",
"main": "branch-diff.js",
"bin": {
"branch-diff": "./branch-diff.js"
},
"author": "Rod <[email protected]> (http://r.va.gg/)",
"license": "MIT",
"dependencies": {
"bl": "~1.2.0",
"chalk": "~1.1.3",
"changelog-maker": "~2.2.0",
"commit-stream": "~1.0.2",
"deep-equal": "~1.0.1",
"gitexec": "~1.0.0",
"list-stream": "~1.0.1",
"map-async": "~0.1.1",
"minimist": "~1.2.0",
"pkg-to-id": "~0.0.3",
"split2": "~2.1.1",
"through2": "~2.0.3"
},
"repository": {
"type": "git",
"url": "https://github.com/rvagg/branch-diff.git"
},
"preferGlobal": true
}
```
# misc
- this document was created with [utility2](https://github.com/kaizhu256/node-utility2)
| 37.050847 | 335 | 0.646386 | eng_Latn | 0.20876 |
c098f72a1c91e9058a6f7fbd757fb9dcb6a44c97 | 1,466 | md | Markdown | README.md | al177/tranz330_re | b75d41fb6acdf3821d324b0b9aeaa6311f78dc91 | [
"CC-BY-4.0"
] | 4 | 2020-02-26T22:43:44.000Z | 2021-06-13T14:33:31.000Z | README.md | al177/tranz330_re | b75d41fb6acdf3821d324b0b9aeaa6311f78dc91 | [
"CC-BY-4.0"
] | null | null | null | README.md | al177/tranz330_re | b75d41fb6acdf3821d324b0b9aeaa6311f78dc91 | [
"CC-BY-4.0"
] | 1 | 2020-02-26T22:44:43.000Z | 2020-02-26T22:44:43.000Z | # tranz330_re
Partial reverse engineering of an old Z80-based card terminal
This repo is for a reverse engineered schematic and other
stuff that might be helpful for developing replacement software
for the Verifone Tranz 330 credit card terminal.
The Tranz 330 has a Z80 microprocessor at its heart and uses
design conventions and peripherals often found in Z80 based
computers. Although it's compact, it has a socketed EPROM and
DIP packaged components for all but a few logic ICs, making it
easy to work on. And since they do not have the security
features needed for modern credit card processing bureaus, they
are available cheaply on the used market.
The schematic here is a work in progress. The logic on the
mainboard is almost fully mapped.
I don't plan to map the power supply, modem analog
section, or all of the logically superfluous discretes (bypass
caps, battery backup, etc). At some point I'll make a logical
schematic of the VFD / keypad board. I want to end up with a
reference that's useful for writing software and tacking on
hardware.
If you want to get started writing for the Tranz 330 now, check out
Big Mess O' Wires work at
https://www.bigmessowires.com/2011/05/10/mapping-the-tranz-330/
Released under the Creative Commons Share Alike (CC-BY-SA) License. Share it, change it, make money on it, teach it to the children as a cautionary tale. Just make your changes public and give credit to all contributors to this project.
| 44.424242 | 236 | 0.791269 | eng_Latn | 0.999468 |
c099d3d07f2d20e33b63fd713b36d874a528f86e | 3,009 | md | Markdown | docs/advanced/api/index.md | nightmode/feri | df5c5c61bf53d21108182e413720451b57ebea62 | [
"MIT"
] | 12 | 2019-05-17T01:14:16.000Z | 2021-11-09T11:30:39.000Z | docs/advanced/api/index.md | nightmode/feri | df5c5c61bf53d21108182e413720451b57ebea62 | [
"MIT"
] | 7 | 2019-04-10T14:58:53.000Z | 2022-01-13T23:10:41.000Z | docs/advanced/api/index.md | nightmode/feri | df5c5c61bf53d21108182e413720451b57ebea62 | [
"MIT"
] | 1 | 2019-05-17T01:14:33.000Z | 2019-05-17T01:14:33.000Z | # Feri - API
Feri is designed to be extremely customizable. That means you get full access to the same API she uses herself. Call on existing functions, create your own, or even replace core functionality.
## Modules
* [Shared](shared.md#feri---shared)
* [Config](config.md#feri---config)
* [Functions](functions.md#feri---functions)
* [Clean](clean.md#feri---clean)
* [Build](build.md#feri---build)
* [Watch](watch.md#feri---watch)
## Require
Assuming Feri is installed locally in your project's `node_modules` folder, you can require her with the following:
const feri = require('feri')
## Overview
When you require Feri, you are actually requiring her [code/1 - main.js](../../../code/1%20-%20main.js) file. Inside this file you'll notice that Feri is sharing every module she uses herself, plus a convenience object called action.
```js
const feri = {
'action': {
'clean': clean.processClean,
'build': build.processBuild,
'watch': watch.processWatch,
},
'shared' : shared,
'config' : config,
'functions': functions,
'clean' : clean,
'build' : build,
'watch' : watch
}
module.exports = feri
```
The action object exists solely to enable cool statements like `feri.action.clean()` instead of `feri.clean.processClean()`. Both will accomplish the same thing so use whichever style you prefer.
Now that we know about all the modules being exported, let's go over each in a bit more detail.
## Modules
### Shared
Shared is all the neat things we may want to share across modules. Things that don't really belong in the config module like caches, non-user configurable variables, computed values, and more.
For more information, see the [Shared](shared.md#feri---shared) documentation.
### Config
Config holds all the variables that may be set by the command line, set by a [custom config file](../custom-config-file.md#feri---custom-config-file) for the command line, or set programatically.
For more information, see the [Config](config.md#feri---config) documentation.
### Functions
Functions is a module that many other modules depend on. A treasure trove of helpers.
For more information, see the [Functions](functions.md#feri---functions) documentation.
### Clean
Clean is a module dedicated to cleaning destination files.
For more information, see the [Clean](clean.md#feri---clean) documentation.
### Build
Build is a module dedicated to building destination files.
For more information, see the [Build](build.md#feri---build) documentation.
### Watch
Watch is all about watching source and destination folders for changes. Initiating the appropriate clean or build tasks in response to file system events.
For more information, see the [Watch](watch.md#feri---watch) documentation.
## License
MIT © [Kai Nightmode](https://twitter.com/kai_nightmode)
The MIT license does NOT apply to the name `Feri` or any of the images in this repository. Those items are strictly copyrighted to Kai Nightmode. | 34.193182 | 233 | 0.730143 | eng_Latn | 0.991034 |
c09aabba4a75d6ebaebf32f55c335cf423736e44 | 1,182 | md | Markdown | source/includes/_conversationMessageWebhookLog_conversationMessageWebhookLogObject.md | Hostaway/api | 71aca08ddfb7005c0d8aa09628445697c78e2e99 | [
"Apache-2.0"
] | null | null | null | source/includes/_conversationMessageWebhookLog_conversationMessageWebhookLogObject.md | Hostaway/api | 71aca08ddfb7005c0d8aa09628445697c78e2e99 | [
"Apache-2.0"
] | null | null | null | source/includes/_conversationMessageWebhookLog_conversationMessageWebhookLogObject.md | Hostaway/api | 71aca08ddfb7005c0d8aa09628445697c78e2e99 | [
"Apache-2.0"
] | 1 | 2019-03-11T11:19:26.000Z | 2019-03-11T11:19:26.000Z | ## ConversationMessage webhook log object
```json
{
"id": 2,
"accountId": 10450,
"listingMapId": "40160",
"reservationId": "1234",
"conversationMessageId": 89,
"conversationMessageWebhookId": 129,
"url": "https://webhook.site/6e73ba6d-789e-ds4d64-9f68-a2e1134d1c6f3",
"login": "my_login",
"password": "****",
"responseStatus": "200",
"responseBody": "200"
}
```
Property | Required | Type | Description
-------- | -------- | ---- | -----------
`id` | yes | int | Identifier of conversationMessageWebhookLog object
`accountId` | yes | int | Identifier of account object
`listingMapId` | yes | int | Identifier of listing object
`reservationId` | yes | int | Identifier of reservation object
`conversationMessageId` | yes | int | Identifier of ConversationMessage object
`conversationMessageWebhookId` | yes | int | Identifier of ConversationMessageWebhook object
`url` | yes | string | URL
`login` | no | string | Login for basic auth (if login and password provided we'll send basic auth header)
`password` | no | string | Password for basic auth
`responseStatus` | yes | int | Response status
`responseBody` | no | int | Response body | 38.129032 | 106 | 0.679357 | eng_Latn | 0.380909 |
c09b42f9f376f52d88f5b21b9229b97b93ad56d0 | 96 | md | Markdown | _archives/tags/david-dayen.md | arickert/arickert.github.io | 27ffc686a5fa74e488d576dc77ea8a364aeaeaf6 | [
"MIT"
] | null | null | null | _archives/tags/david-dayen.md | arickert/arickert.github.io | 27ffc686a5fa74e488d576dc77ea8a364aeaeaf6 | [
"MIT"
] | null | null | null | _archives/tags/david-dayen.md | arickert/arickert.github.io | 27ffc686a5fa74e488d576dc77ea8a364aeaeaf6 | [
"MIT"
] | null | null | null | ---
title: David Dayen
tag: "David Dayen"
layout: archive-tags
permalink: "tag/david-dayen"
---
| 13.714286 | 28 | 0.697917 | ssw_Latn | 0.230374 |
c09c5198d09778abbfb6277844ed8476b8b06c05 | 1,141 | md | Markdown | readme.md | Fajarsubhan/crud-ajax | 67ac0e5abc193a9bd137d1aa4015a88bd440fd11 | [
"MIT"
] | 1 | 2021-09-07T03:04:58.000Z | 2021-09-07T03:04:58.000Z | readme.md | fajar-subhan/crud-ajax | 67ac0e5abc193a9bd137d1aa4015a88bd440fd11 | [
"MIT"
] | null | null | null | readme.md | fajar-subhan/crud-ajax | 67ac0e5abc193a9bd137d1aa4015a88bd440fd11 | [
"MIT"
] | null | null | null | # Apa itu crud ajax

Crud ajax adalah layanan untuk pengolahan data yang ditambah dengan sebuah fitur untuk
mempercepat sebuah proses pengolahan data tersebut dengan ajax yang bisa kalian kembangkan
## Bahan-Bahan
1. [PHP](https://www.php.net) version 5.6 atau lebih tinggi
2. [Codeigniter Framework](https://www.codeigniter.com)
3. Web Server : [Apache](https://httpd.apache.org) atau [Nginx](https://www.nginx.com)
4. [Bootstrap](https://getbootstrap.com)
5. [Database Server](https://www.mysql.com)
6. [Jquery](https://jquery.com)
## Installasi
1. [Installasi codeigniter](https://www.codeigniter.com/user_guide/installation/index.html)
2. Siapkan database dan import file sql yang sudah saya sediakan
3. Letakan file [Crud-ajax](https://github.com/Fajarsubhan/crud-ajax) di dalam localhost atau server kalian lalu ketikan url localhost/nama_folder
4. Untuk username: Admin dan password: admin1234
5. Selesai
# License
Please see the [license
agreement](https://github.com/bcit-ci/CodeIgniter/blob/develop/user_guide_src/source/license.rst)
| 43.884615 | 146 | 0.778265 | ind_Latn | 0.820558 |
c09cd4be5f8aa7d86871dc0517f9e1ea4e1504ef | 117 | md | Markdown | README.md | superblaubeere27/ParticleSystemDemo | 8e28055067d87d46cf1d8f895737d9d954aef485 | [
"MIT"
] | 15 | 2018-04-04T12:08:29.000Z | 2022-03-17T19:24:10.000Z | README.md | superblaubeere27/ParticleSystemDemo | 8e28055067d87d46cf1d8f895737d9d954aef485 | [
"MIT"
] | 2 | 2018-10-28T10:34:59.000Z | 2021-04-30T22:11:18.000Z | README.md | superblaubeere27/ParticleSystemDemo | 8e28055067d87d46cf1d8f895737d9d954aef485 | [
"MIT"
] | 4 | 2018-03-28T15:41:05.000Z | 2022-01-02T15:55:56.000Z | # ParticleSystemDemo
A simple particle system made with slick

| 23.4 | 53 | 0.769231 | eng_Latn | 0.690943 |
c09cd67ef34b85e1396f6068e91062aea174a66b | 10,322 | md | Markdown | _posts/yummyHitOS/2019-01-04-26day.md | yummyHit/yummyHit.github.io | 54e5003459ee83ec4d7f1b74f72710d29f0486d1 | [
"MIT"
] | null | null | null | _posts/yummyHitOS/2019-01-04-26day.md | yummyHit/yummyHit.github.io | 54e5003459ee83ec4d7f1b74f72710d29f0486d1 | [
"MIT"
] | null | null | null | _posts/yummyHitOS/2019-01-04-26day.md | yummyHit/yummyHit.github.io | 54e5003459ee83ec4d7f1b74f72710d29f0486d1 | [
"MIT"
] | null | null | null | ---
title: "[yummyHitOS] 26 day (2017.08.16)"
category: "osdev"
header:
teaser: /assets/images/yummyHitOS/26day/01.jpeg
last_modified_at: 2019-01-04T06:18:00+09:00
permalink: /osdev/2019-01-04-26day
---
<p style="text-align: center;">호에에.. 이게 얼마만입니까!! 새해 복 많이 받으세요 횐님덜!! 올 해는 황금 돼지세기라고 함니당!!</p>
<p style="text-align: center;"><strike>말 않해도 돼지? 외않되!? 어떡해 그럴수가 잇지?!</strike> 꺄핳하하하핳 죄송함니다... 넘 하이텐션인가욥 히히 올만이라 반가워서욤 >_<</p>
<p style="text-align: center;">퇴사하고 나니 몸이 병나서 쿨럭... 은 변명이구욤 ㅜㅜ 석사를 준비하려 하는데 토익을 해야해서... 넘나 하기 싫어서 빈둥대고 있슴니다 ㅜㅜ 컴퓨터는 뭘 하려 하면 다 초장에 막혀버리구... 뭔가 다 꼬이고있는 것 같은 느낌적인 Feeling 이에욤 ㅜㅜ힝</p>
<br />
<p style="text-align: center;"><img width="600" height="332" src="/assets/images/yummyHitOS/26day/01.jpeg" /></p>
<br />
<p style="text-align: center;">니냐니냐뇨~~ 이거 몇번봐도 재밌는 영상 중 하나예욤!! 히히</p>
<p style="text-align: center;">오늘은 시리얼 포트를 통한 통신을 시도하는 챕터예욥!! 이를 통해 파일 전송을 할 수가 있대요!! 오오오오 그럼 이제 나도 OS에 모듈 올리고 본격적으로 파일시스템을 껍데기뿐이 아닌 논리적으로 구현할 수 있는 거신갑!! 김칫국 드링킹 원샷!</p>
<p style="text-align: center;">처음 28장을 딱! 피면 "데이터 송수신" 이라는 개념이 나와욥! 횐님덜은 다들 똑똑하셔서 "아~ 데이터 송수신 그 패킷가지고 데이터 넘기고 하는거 누가몰라~" 라고 생각하시겠죠!? 야미는 똥멍충이라서요 ㅜㅜ 이것조차 하나하나 짚고 넘어가는 성격이랍니닷!!</p>
<br />
## Data transmission
<p style="text-align: center;"><strong><em><span style="color: #B827EE;">Data transmission(데이터 송수신)이란 information(흔히 말하는 data)을 물리적인 선(cable)이나 wireless conductor(선 없는 파장 통신)에서 digital bit stream(디지털로 된 bit 흐름) 또는 digitized analog signal(디지털화 된 아날로그 신호)을 통해 채널 통신하는 것을 의미합니다.</span></em></strong></p>
<br />
<p style="text-align: center;">아흑 요즘 이상한 버릇이 생겼어욥.. 회사에서 생긴 버릇인데 영어를 섞어서 쓰는 버릇이욤 ㅜㅜ 저의 멋쟁이 사수님이 그렇게 사용하셔서 닮아버렸네욥.. 히히 야미는 환경에 아주 잘 적응하다 못해 동화되는 성향이 있거든뇸!!</p>
<br />
<p style="text-align: center;"><span style="color: #B827EE;"><strong><em>즉, source 가 있고 destination 이 있을 때, 서로 채널을 맺고 그 채널을 통해 디지털로 된 bit를 통신하는 것이며, 그 채널은 cable 또는 wireless 통신으로 연결되어있는 것이죠!</em></strong></span></p>
<br />
<p style="text-align: center;">머릿속으로 상상하면 "아 출발지에서 목적지로 패킷을 보내니까 서로 통신을 할 수 있는 환경에서 데이터를 보내는 것을 의미하겠지!" 가 되는데 이게 말로 표현하기 참 어렵네욥... 역시 세상에 설명은 그림이 최곰니다 따봉킹왕짱~</p>
## telecommunication
<p style="text-align: center;"><span style="color: #B827EE;"><strong><em>원격 통신(telecommunication)에는 두 가지 방법이 있는데, 하나는 우리가 오늘 구현할 serial communication 이고, 다른 하나는 parallel communication 이예욤!! 두 가지를 구분할 아주 조은 사진이 있슴니다! 짜란!</em></strong></span></p>
<br />
<p style="text-align: center;"><img width="318" height="340" src="/assets/images/yummyHitOS/26day/02.gif" /></p>
<br />
<p style="text-align: center;">바로바로 세상의 모든 것이 있는 백과사전인 위키백갓님에게 올라와있는 사진이에욤!! 사진만 봐도 두 가지의 차이점이 뙇 하고 보이시지 않나욥!? 히히</p>
<p style="text-align: center;">꼭 그림을 보면 flip-flop 이 떠오르시지 않으세욤!? 저희 예전에 했던 SR래치 회로같은거욥!! 네에..? 기억 안나신다구여!? 그 재밌는 플립플롭 디코더 인코더 카르노맵 부울대수가 나오는 논리회로를 기억못하신다구욧!?!? 뿌에에엥</p>
<p style="text-align: center;">(기억 안나시는 분께서는 <a href="/osdev/2017-08-19-14day">14일차</a>를 스리슬쩌억 훑어보고 오시면 댐니다!!)</p>
<br />
<p style="text-align: center;"><span style="color: #B827EE;"><strong><em>위 사진을 보았을 때, Parallel communication 의 경우 위부터 아래로 MSB - LSB 로 구성되어있네욥! MSB 는 Most Signification Bit 의 준말로, 가장 좌측의 비트를 의미해요! 그렇다면 LSB 는 당연히 Least Signification Bit 를 의미하겠죠!? 가장 우측일 것이구여!<br /><br />예를 들어 0b10101010 이렇게 8bit가 존재할 때, 가장 좌측의 1 이 MSB, 가장 우측의 0 이 LSB 가 되는 것이죠!<br /><br />이렇게 1byte 를 전송하게 되는검니다! Serial communication 의 경우 좌측부터 우측으로 전송하니 더욱 보기 편하네욤! 뭔가 느낌상 Parallel communication 이 대량의 데이터 처리에 효율적일 것 같고(부하가 덜 걸릴 것이니), Serial communication 이 하나를 완벽히 전송하는데 안성맞춤일 것 같지 않나욤!?</em></strong></span></p>
<br />
<p style="text-align: center;">영어를 계속 쓰고있는데, 한글(정확히는 한자..)로 말하자면 병렬 통신과 직렬 통신이죠! 이과를 나오셨다면 직렬과 병렬을 아실테닙.. 모르신다면 간단하게 설명드려서 <strong><em>직렬은 일직선 상(같은 선 상)이고 병렬은 같은 선 상에 있을 것을 여러 갈래의 선으로 나눈 것</em></strong>이예요!</p>
<p style="text-align: center;">전구를 예로 들어서, 바깥에서 100V 라는 전압이 들어왔을 때 전구 10개가 나란히 일직선 상으로 있으면 10개가 100V를 나누어 받아서 각각 10V 씩 밝혀지게 됩니다! 병렬은 100V 라는 전압이 10개에 똑같이 나뉘어 뿌려지기 때문에 모든 전구가 100V를 가지게 되구요!</p>
<p style="text-align: center;">전구로 생각하면 병렬이 넘나리 좋아보이네욥... 그럼 이번엔 10V 짜리 건전지를 직렬/병렬 연결했을 때 전구의 밝기를 알아보면(아니 갑자기 물리를 하고있네염 요고까지 하고 휘리릭 넘어가버릴게욥!!), 전구 1개에 10V 짜리 건전지 10개를 직렬로 연결했을 때, 전구에게 가는 것은 100V가 되겠죠!?(참 현재 전구/건전지 설명은 모든 저항이 없다는 가정이에욤 ㅜㅜ 태클들어올까바 무섭따... 물리 조아는 했으나 다 까머근.. 힝) 그럼 병렬로 연결하면!? 전구에게 가는 전압은 10V가 되어요! 대신 건전지들의 수명이 길어지구요!</p>
<p style="text-align: center;">오홍 상황에 따라 필요한 것을 사용하라는 의미같군뇸 히히 다시 본론으로 돌아갑씨다!!</p>
<p style="text-align: center;">한 번 다른 그림을 통해서 완벽히 이해해볼까욥!?</p>
<br />
<p style="text-align: center;"><img width="400" height="179" src="/assets/images/yummyHitOS/26day/03.png" /></p>
<br />
## tx / rx
<p style="text-align: center;"><span style="color: #B827EE;"><strong><em>tx 는 transmit, rx 는 receive 를 의미해욥! 'x' 는 무엇이냐구용? 참 재미난 이야기가 있어욥! X라는 문자가 들어가는 경우가 UTP 와 같은 twisted cable 에서 사용하는 cross 라는 의미의 X 도 있고, GUI 에서 사용되는 X-windows 와 같이 X11 을 의미할 경우도 있고, mailbox exchange 에서의 MX 도 있고.. 참 다양한 의미의 X 가 있는데욥!! 여기서 나오는 TX/RX 의 경우엔 의미가 없어요!! T/R 이라고 하기엔 넘나리 이상해서 그런건갑... padding 시킨 것처럼 X 를 붙였다고 생각하시면 댐니닷!!</em></strong></span></p>
<p style="text-align: center;"><span style="color: #B827EE;"><strong><em>현재 TX 에서 RX 로 보내는 것인데, 아까 MSB 가 가장 좌측, LSB 가 가장 우측이라고 했잖아요?! 그럼 위 패킷의 경우 0b11001010 이니 0b1100 0b1010 --> 0xCA 가 되어야하나욤?! 그런데 ASCII 테이블에선 0x7F 가 마지막인디!? 너는 무엇이닙!!<br /><br />그것이아니라 현재 보내는 측이 좌측에 있으므로 MSB는 RX에 닿는 첫번째 비트가 되어욤! 즉 위 그림에서는 MSB 가 가장 우측의 0, LSB 가 가장 좌측의 1 이 되는 것이죠! 0b01010011 이 되어서 0b0101 0b0011 --> 0x53 이므로 ASCII 문자로 S 가 되는 것이예욤!!</em></strong></span></p>
<br />
<p style="text-align: center;"><em>역시 암기는 위험한것임미다 ㅜㅜ 무조건 MSB 는 가장 좌측, LSB 는 가장 우측이라고 암기해버리시면 이런데서 들통나부러욧!! 도착지에 가장 가까운 비트가 MSB, 출발지에 가장 가까운 비트가 LSB 인 것임미다! 히히</em></p>
<br />
<p style="text-align: center;">이정도면 기본적인 원격 통신의 구조를 이해하셨을라나욥!? 자 이제 첫 페이지의 첫 문단을 지나가보겠슴니다!! 데이터 송수신으로 시작하여.. 시리얼 통신까지 봐버리기~</p>
<br />
<p style="text-align: center;">다음 문단을 보니 QEMU 가 딱 나오는데 흑흑 저 잠시 쉬어가는 것처럼 분풀이좀 하구 갈래욥... 그게 있잖아요!! 커널 모듈 프로그래밍하려고 열심히 공부하다가 현재의 커널에서는 찾을 수 없는 sys_call_table 때문에욤!! 분명히 extern 할 주소는 찾았는데, 그 주소는 보호영역에 존재해서 이용할 수가 없어요!! 그렇다면 환경을 32비트로 바꾸어야 하는걸까 싶기도 하고... 그러다가 문득 찾은 것이 예전 버전인 커널 2.4.X 버전이 담긴 Ubuntu 6.04 버전!!</p>
<p style="text-align: center;">얏호우! 다운로드 받자~! 다운로드 완료 후 패러럴즈 가상머신에 올렸더니 오잉?! 님외않되.. ㅜㅜㅜ 아무래도 패러럴즈 버전도 올라가면서 예전 가상머신과 호환이 안되는 것 같아욤... 그래서 열심히 생각해보다가... 제가 맥북에 뭘 설치하는걸 좋아하지 않거든욥 ㅜㅜ 깔려있는 Qemu 가 딱 생각났지 뭐예욤!! 바로 하드디스크 이미지 생성해서 우분투 iso 를 넣어 설치를 딱!! 설치가 아주 깔끔하게 잘 되었슴니다 쨕쨕쨕~~</p>
<p style="text-align: center;">흑흑 그런데 예상치 못한 문제가 발생했어욧... Qemu network 세팅 어떻게함니까!? 예!? tuntap 이요!? 아아 설치하기 싫었지만 그는 강력하다고 함니다... 그래서 tuntap 을 설치해서 virtio bridge 모드를 뙇!! 하는데 님은 또 외않되... ㅜㅜ후엉 왠지 제 느낌상으로 tuntap 이 2015년 1월 15일에 마지막 업데이트가 있었는데, 현재 맥OS는 15년도 시에라를 지나 모하비까지 왔잖아욤?! 가상 bridge NIC 는 생성되었지만 통신연동이 되지 않는다고 한답...</p>
<p style="text-align: center;">결국 못하고 있는 중임니당 ㅜㅜ 초장에 말씀드린 것 처럼 뭘 하려고 하는데 자꾸 처음부터 막혀서 느낌이 안좋다고 한 그것이에욥 ㅜㅜ sys_call_table 부터 저를 괴롭히더니 결국 Qemu 가 또 말썽을..! 에전에 버전 문제때문에 1주일을 밤새게한 그놈의 Qemu가 또!! 힝...</p>
<br />
<p style="text-align: center;">하 이제 분풀이가 조금 되네욤 이히히 여러분 삽질은 재밌슴니다 후욱,, 후욱,,</p>
<br />
<p style="text-align: center;"><img width="506" height="510" src="/assets/images/yummyHitOS/26day/04.jpeg" /></p>
<br />
<p style="text-align: center;">이제 눈물을 훔치고 책으로 돌아가봅씨다!! 아 이 왠지 같은 패턴 익숙한 말 "책으로 돌아가봅씨다" ㅋㅋㅋㅋ갑자기 끝내버릴 것 같지 않나욥?!</p>
<p style="text-align: center;">갓마구이 한승훈 선생님께서 항상 설명을 잘해주셔서ㅜㅜ "일반적으로 시리얼 통신은 가능하긴 한데, 메모리에 적재시키거나 순차적으로 디스크에 써야해서 비효율적이므로 파일시스템을 이용한다" 라고 적어주셨네욤!! 전혀 덧붙일 말이 없는 완벽한 말씀!! 파일시스템 이야기가 나왔으니 최근에 sunyzero 라는 닉네임을 사용하시는 프로그래머 김선영님의 페이스북과 블로그에 올라온 내용을 첨부파일로 올리겠슴니다!!</p>
<p style="text-align: center;"><a href="/assets/images/yummyHitOS/26day/file_and_filesystem.txt" download>file_and_filesystem.txt</a></p>
<p style="text-align: center;"><strong><em>(출처: <a href="https://sunyzero.tistory.com">https://sunyzero.tistory.com</a>)</em></strong></p>
<br />
<p style="text-align: center;">정말 좋은 글임니다!! 저도 이제 막 걸음마를 시작하려는 컴린이 리눅스 프로그래머로써 정말정말 존경함니다!!</p>
<p style="text-align: center;">이제서야 첫 페이지를 떼네욥 히히 다음 페이지를 보니 RS-232 규약이 뙇 먼저 보이는군뇸!! RS-232 는 직렬 방식의 인터페이스(포트)라고 함니다! 즉 시리얼 포트가 되겠네욤!!</p>
<br />
<p style="text-align: center;"><img width="440" height="118" src="/assets/images/yummyHitOS/26day/05.png" /></p>
<p style="text-align: center;"><img width="440" height="440" src="/assets/images/yummyHitOS/26day/06.png" /></p>
<br />
<p style="text-align: center;">이렇게 생겼다고 함니다!! 보신 적 있으신가욤!? 저는 이런 케이블쪽으로 넘나리 구분을 잘 못하는뎁... 왠지 회사에서 써봤던 것 같아욤 유닉스 장비와 모니터를 연결할 때 사용한 컨버터에 썼던것 같거든욤!! 멀티케이블이라 ps/2 핀도 달려있고 그랬어욥!! 그게 맞나는 모르겠네용 ㅜㅜ</p>
<br />
## RS-232
<p style="text-align: center;"><strong><em>무조건 위 그림과 같은 것이 아니라, RS-232 규약을 따르는 하드웨어를 총칭한다고 해요! 이더넷, IEEE 1394, USB와 같은 인터페이스 모두요! 이더넷은 보통 RJ45 케이블이라고 하고, IEEE 1394 는 애플사의 썬더볼트 초기버전인 것 같아욤! 빠이어 와이어라고 하더라구욥! USB는 다들 아시다시피 생긴거구욤!!</em></strong></p>
<br />
<p style="text-align: center;">대표적인 이 세 가지 케이블은 제가 설명드리지 않아도... 음 저와같은 귀차니즘을 위해 참고 위키백갓을 링크로 드리겠슴니다!!</p>
<p style="text-align: center;">(Ethernet: <a href="https://en.wikipedia.org/wiki/Ethernet">https://en.wikipedia.org/wiki/Ethernet</a>)</p>
<p style="text-align: center;">(IEEE 1394: <a href="https://en.wikipedia.org/wiki/IEEE_1394">https://en.wikipedia.org/wiki/IEEE_1394</a>)</p>
<p style="text-align: center;">(USB: <a href="https://en.wikipedia.org/wiki/USB">https://en.wikipedia.org/wiki/USB</a>)</p>
<br />
<p style="text-align: center;">병렬 포트는 USB 가 대중화 되어버려서 사용하지 않는다고 해욥! legacy port 라고 한다는군뇸!! 기존에는 주변기기들을 연결하기 위해 사용되었는데, 범용 직렬 버스라는 이름부터 범용스러운 USB가 이겨부러따~ 그것이죠!!</p>
<br />
<p style="text-align: center;">RS-232 규약이 DTE - DCE 간 데이터 송수신 방법을 정의한 것이라고 하네욥! DTE, DCE 설명은 책에 넘나리 잘되어있으니 그것만으로 충분함니다! 한 가지 덧붙이자면, 네트워크쪽을 공부하시다 보면 라우터 - 스위치 - 호스트 간 연결을 DTC - DCE 및 bandwidth, baud rate 설정을 어떻게 하느냐 공부를 하실 수 있을거예욥!! 최소한 packet tracer 에도 되어있으니 궁금하신 분들은 한 번 해보세욤!! 그리 어렵지 않고 금방 이해되실 검니답!!</p>
<br />
<p style="text-align: center;">이제 책을 보니 더 이상 포스팅 할 내용은 없어보이네욤!! 완벽 그 자체인 책이 있기 때문이죠!! 처음 데이터 송수신을 하기 전 먼저 데이터 크기를 보내서 얼만큼 받을 지 사이즈를 받은 후 분할해서 받는 형식으로 되어있네욤!! TCP 통신에서의 MTU Size 같은 느낌일까요? ㅎㅎㅎ</p>
<p style="text-align: center;">오늘도 오랜만에 포스팅 해서 죄송해욥 ㅜㅜ 자주 해야하는딤 흑흑 한 번 시작하려면 5시간은 기본으로 잡아야하니.. 조금씩 슬럼프를 풀어가면서 대학원도 준비 하고! 사우나도 가고! 다해야죱! 캬핳하핳</p>
<p style="text-align: center;">그럼 이제 다음 포스팅까지 안뇽!! 다들 다시 한 번 새해 복 많이 받으세용!!!</p>
<br />
<p style="text-align: center;"><img width="256" height="240" src="/assets/images/yummyHitOS/26day/07.gif" /></p>
<br />
<p style="text-align: center;">꿀렁꿀렁~~ 히히<br /></p>
---
Check out the [yummyhit's website][yummy-kr] for more info on who am i. If you have questions, you can ask them on E-mail.
[yummy-kr]: http://yummyhit.kr
| 102.19802 | 579 | 0.68601 | kor_Hang | 1.00001 |
c09cfd45540fd2a05b843bfc0b419b2003d17e98 | 3,671 | md | Markdown | README.md | LPS-RESULT/credit-score-calculator-aws | b38df63535459ac9ae061fc18e7e4f5ecd934ba2 | [
"MIT"
] | 2 | 2019-02-17T21:09:20.000Z | 2019-02-25T03:08:36.000Z | README.md | LPS-RESULT/credit-score-calculator-aws | b38df63535459ac9ae061fc18e7e4f5ecd934ba2 | [
"MIT"
] | null | null | null | README.md | LPS-RESULT/credit-score-calculator-aws | b38df63535459ac9ae061fc18e7e4f5ecd934ba2 | [
"MIT"
] | null | null | null | # README
## About Credit Score Calculator AWS
Credit Score Calculator AWS is built by awesome people.
## Developer's Guide
It is important to note that each folder in this repository
is its own module for the Lambda function, the reason behind this is to isolate
the required dependencies thus making sure the lambda function will be in its
smallest size during uploads.
### Getting Started
So to get started, go that specific directory you plan to modify:
credit-score-calculator-aws$ cd APICreditScoreModule
Then head on to installing its required packages.
credit-score-calculator-aws/APICreditScoreModule$ npm install
### Zipping and Uploading the Code
After modifying you may then create a zip for it and upload the file of the code
to lambda. When on a Mac, you can zip via:
credit-score-calculator-aws/APICreditScoreModule$ zip -r lambda -o *
Or you can also opt to use the npm lambda script
npm run-script lambda
## Module Directory
In this section, the different directories will be explained in greater detail. Modules in this project are classified
into two types - API Modules and Non API Modules:
**API Modules**
- Have their own counterpart API Gateway Endpoints. e.g APIAssetsModule is `/assets`
- Since input is usually an `http request`, the event would have some mappings:
- body - refers to the json request body aka the main payload of the request
- headers - refers to the headers contained in the original request
- method - refers to the http method used
- params - refers to the URL path parameters
- query - refers to the query string parameters
- env - refers to the environment variables mapping which is basically a copy of the stage variables
- context - refers to the API Gateway context which includes information about the authorizers, ID's and user
API's usually have 5 common methods that comprise most of the different CRUD tasks:
- GET /endpoint
- Provides a paginatable interface of the resource
- GET /endpoint/id
- POST /endpoint
- PUT /endpoint/id
- DELETE /endpoint/id
**Non API Modules**
- Don't have counterpart API Gateway Endpoints. And are probably used by other Insite resources.
- Common usage is for Cloudwatch triggers - CloudWatch invokes the particular module to serve a recurring purpose,
such as storing cache, or cleaning up storages
The current convention of setting up function triggers is using the `trigger` event attribute. So the event would look
something like:
{ "trigger": "NAME_OF_ACTION" }
In cases where extra parameters are needed, you can use `triggerParams` attribute:
{
"trigger": "NAME_OF_ACTION",
"triggerParams": {
"param1": 123,
"param2": "456"
"param3": [7,8,9],
"param4": {
"x": 0
}
}
}
#### PING
The Admin module serves as a Lambda function for all administrative features such as dealing with databases
and triggering functions in other modules. These are the supported methods under Admin module:
Executed via event:
{ "trigger": "PING" }
This is a PING-PONG method that simply responds with the text "PONG" when triggered. This function is primarily
used to keep Lambda functions warmed up - cached, up and running in the cloud.
### APICreditScoreModule
This module contains methods that can be used to make calculations for credit scores.
To run API tests for APICreditScore:
credit-score-calculator-aws/APICreditScoreModule$ npm test
This is a shortcut to invoking mocha:
mocha tests/**/*.js --reporter spec --timeout 30000
## License
Copyright © 2019, LPS
| 31.921739 | 119 | 0.732498 | eng_Latn | 0.997134 |
c09f1cba9ab52a5d5537623876d01b569070561f | 30,375 | md | Markdown | source/_posts/1817-interview-linux.md | draapho/Blog | 599ff2ec00a7fc17974df39db53d372e1697fe70 | [
"MIT"
] | 7 | 2016-11-13T19:08:00.000Z | 2020-03-27T04:38:25.000Z | source/_posts/1817-interview-linux.md | draapho/Blog | 599ff2ec00a7fc17974df39db53d372e1697fe70 | [
"MIT"
] | null | null | null | source/_posts/1817-interview-linux.md | draapho/Blog | 599ff2ec00a7fc17974df39db53d372e1697fe70 | [
"MIT"
] | 3 | 2018-05-17T05:47:17.000Z | 2021-02-18T08:19:05.000Z | ---
title: 面试之嵌入式Linux
date: 2018-05-08
categories: interview
tags: [interview]
description: 面试题集.
---
# 总览
- [逻辑|这样表达,事半功倍](https://draapho.github.io/2017/05/04/1714-expression/)
- [面试之常规问题](https://draapho.github.io/2018/01/10/1805-interview-general/)
- [面试之嵌入式C语言](https://draapho.github.io/2018/05/07/1816-interview-c/)
- [C语言知识巩固](https://draapho.github.io/2017/05/17/1715-c/)
- [面试之嵌入式Linux](https://draapho.github.io/2018/05/08/1817-interview-linux/)
我个人面试经验极少, 但这种能力都是需要培养的. 此系列总结一下面试中常见的技能要点. 侧重于技术面的准备.
# common
## Q: What Is The Difference Between Microprocessor And Microcontroller?
Microcontroller is a self-contained system with peripherals, memory and a processor that can be used as embedded system.
Microprocessor is managers of the resources (I/O, memory) which lie outside of its architecture.
## Q: Difference btwn Process and Thread
the threads are a part of a process
Process has a self-contained execution environment, each process has its own memory space. just can use IPC to communication
Threads share resources, which helps in efficient communication between threads.
## Q: What is thread safety? What is re-entrancy?
线程安全的概念比较直观,一般来说,一个函数被称为线程安全的,当且仅当被多个并发线程反复调用时,它会一直产生正确的结果.
可重入函数一定是线程安全的. 但线程安全的函数不一定是可重入的.
对于可重入函数, 有如下要求:
- 不使用全局变量或静态变量;
- 不使用用malloc或者new开辟出的空间;
- 不调用不可重入函数;
## Q: Explain Interrupt Latency And How Can We Decrease It?
- Interrupt latency basically refers to the time span an interrupt is generated and it being serviced by an appropriate routine defined, usually the interrupt handler.
- External signals, some condition in the program or by the occurrence of some event, these could be the reasons for generation of an interrupt.
- Interrupts can also be masked so as to ignore them even if an event occurs for which a routine has to be executed.
- Following steps could be followed to reduce the latency
- ISRs being simple and short.
- Interrupts being serviced immediately
- Avoiding those instructions that increase the latency period.
- Also by prioritizing interrupts over threads.
- Avoiding use of inappropriate APIs.
## Q: What is Top half & bottom half of a kernel?
Sometimes to handle an interrupt, a substantial amount of work has to be done. But it conflicts with the speed need for an interrupt handler.
To handle this situation, Linux splits the handler into two parts: Top half and Bottom half.
- The top half is the routine that actually responds to the interrupt.
- The bottom half on the other hand is a routine that is scheduled by the upper half to be executed later at a safer time.
All interrupts are enabled during execution of the bottom half. The top half saves the device data into the specific buffer, schedules bottom half and exits. The bottom half does the rest. This way the top half can service a new interrupt while the bottom half is working on the previous.
## Q: List Out Various Uses Of Timers In Embedded System?
- Real Time Clock (RTC) for the system
- Initiating an event after a preset time delay
- Initiating an event after a comparison of preset times
- Capturing the count value in timer on an event
- Between two events finding the time interval
- Time slicing for various tasks
- Time division multiplexing
- Scheduling of various tasks in RTOS
## Q: Significance of watchdog timer in Embedded Systems.
The watchdog timer is a timing device with a predefined time interval. During that interval, some event may occur or else the device generates a time out signal. It is used to reset to the original state whenever some inappropriate events take place which can result in system malfunction. It is usually operated by counter devices.
## Q: Difference between RISC and CISC processor.
RISC (Reduced Instruction Set Computer) could carry out a few sets of simple instructions simultaneously. Fewer transistors are used to manufacture RISC, which makes RISC cheaper. RISC has uniform instruction set and those instructions are also fewer in number. Due to the less number of instructions as well as instructions being simple, the RISC computers are faster. RISC emphasise on software rather than hardware. RISC can execute instructions in one machine cycle.
CISC (Complex Instruction Set Computer) is capable of executing multiple operations through a single instruction. CISC have rich and complex instruction set and more number of addressing modes. CISC emphasise on hardware rather that software, making it costlier than RISC. It has a small code size, high cycles per second and it is slower compared to RISC.
## Q: What is RTOS? What is the difference between hard real-time and soft real-time OS?
The scheduler in a Real Time Operating System (RTOS) is designed to provide a predictable execution pattern. In an embedded system, a certain event must be entertained in strictly defined time.
To meet real time requirements, the behaviour of the scheduler must be predictable. This type of OS which have a scheduler with predictable execution pattern is called Real Time OS(RTOS).
A Hard real-time system strictly adheres to the deadline associated with the task. If the system fails to meet the deadline, even once, the system is considered to have failed.
In case of a soft real-time system, missing a deadline is acceptable. In this type of system, a critical real-time task gets priority over other tasks and retains that priority until it completes.
## Q: What type of scheduling is there in RTOS?
RTOS uses pre-emptive scheduling. In pre-emptive scheduling, the higher priority task can interrupt a running process and the interrupted process will be resumed later.
## Q: What is priority inversion? What is priority inheritance?
If two tasks share a resource, the one with higher priority will run first. However, if the lower-priority task is using the shared resource when the higher-priority task becomes ready, then the higher-priority task must wait for the lower-priority task to finish. In this scenario, even though the task has higher priority it needs to wait for the completion of the lower-priority task with the shared resource. This is called priority inversion.
Priority inheritance is a solution to the priority inversion problem. The process waiting for any resource which has a resource lock will have the maximum priority. This is priority inheritance. When one or more high priority jobs are blocked by a job, the original priority assignment is ignored and execution of critical section will be assigned to the job with the highest priority in this elevated scenario. The job returns to the original priority level soon after executing the critical section.
## Q: What is job of preprocessor, compiler, assembler and linker?
The preprocessor commands are processed and expanded by the preprocessor before actual compilation.
After preprocessing, the compiler takes the output of the preprocessor and the source code, and generates assembly code.
Once compiler completes its work, the assembler takes the assembly code and produces an assembly listing with offsets and generate object files.
The linker combines object files or libraries and produces a single executable file. It also resolves references to external symbols, assigns final addresses to functions and variables, and revises code and data to reflect new addresses.
## Q: How you will debug the memory issues?
- First of all, double check the code source. Make sure already paired using `kmalloc` `kfree` and `vmalloc` `vfree`
- `free -m` to monitor memory using status.
- `kmemleak` to log the possible problem
- oom or panic information from kernel
- Intercept all functions that allocate and deallocate memory.
## Q: Debugging techniques
`GDB`, printk, led, `/var/log/`
# hardware
## Q: What Does Dma Address Will Deal With?
DMA address deals with physical addresses. It is a device which directly drives the data and address bus during data transfer. So, it is purely physical address.
## Q: What is virtual memory?
Virtual memory is a technique that allows processes to allocate memory in case of physical memory shortage using automatic storage allocation upon a request.
The advantage of the virtual memory is that the program can have a larger memory than the physical memory. It allows large virtual memory to be provided when only a smaller physical memory is available.
Virtual memory can be implemented using paging.
A paging system is quite similar to a paging system with swapping. When we want to execute a process, we swap it into memory. Here we use a lazy swapper called pager rather than swapping the entire process into memory. When a process is to be swapped in, the pager guesses which pages will be used based on some algorithm, before the process is swapped out again. Instead of swapping whole process, the pager brings only the necessary pages into memory. By that way, it avoids reading in unnecessary memory pages, decreasing the swap time and the amount of physical memory.
## Q: What is kernel paging? What is page frame?
Paging is a memory management scheme by which computers can store and retrieve data from the secondary memory storage when needed in to primary memory. In this scheme, the operating system retrieves data from secondary storage in same-size blocks called pages. The paging scheme allows the physical address space of a process to be non continuous. Paging allows OS to use secondary storage for data that does not fit entirely into physical memory.
A page frame is a block of RAM that is used for virtual memory. It has its page frame number. The size of a page frame may vary from system to system, and it is in the power of 2 in bytes. Also, it is the smallest length block of memory in which an operating system maps memory pages.
## Q: Virtual Address, Linear Address, Physical Address
32-bit CPU 3GB for user layer, 1GB for kernel layer
`kmalloc` apply the physical address directly, so it is continuous but size limination
`vmalloc` apply the virtual memory, in physical it is not continuous. need MMU to translate to physical memory.
Virtual Address -- Segment(GDT LDT) -- Linear Address -- Paging (4 layer Page Directory, Page Table) -- Physical Address
## Q:How to decide whether given processor is using little endian format or big endian format ?
``` c
#include <stdio.h>
int check_for_endianness()
{
unsigned int x = 1;
char *c = (char*) &x;
return (int)*c;
}
```
## Q: nand vs nor flash
- 使用复杂 vs 使用简单(same as sram)
- 读取慢 vs 读取快
- 写入快 vs 写入慢
- 顺序读取快, 随机存取慢 vs 随机存取快
- 容量大 vs 容量小
- 擦写次数多 vs 擦写次数少
- yaffs2 vs jffs2
- 存放引导程序, 参数区 vs 用户文件, 多媒体文件
## Q: Definition and difference between Hardware interrupt, Software Interrupt, Exception, Trap and Signals?
- Hardware Interrupts: may arrive anytime, typically IO interrupts.
- Exception: may only arrive after the execution of an instruction, for example when the cpu try to devide a number by 0 or a page fault
- Trap is a kind of exceptions, whose main purpose is for debugging
- Software Interrupt occurs at the request of the programmer. They are used to implement system calls, and handled by the CPU as trap.
- Signals are part of the IPC, not belong to interrupts or exceptions.
## Q: Explain MMU in Linux
Paged memory management unit. Translation of virtual memory addresses to physical addresses
## Q: What are high memory and low memory on Linux
- The High Memory is the segment of memory that user-space programs can address. It cannot touch Low Memory.
- Low Memory is the segment of memory that the Linux kernel can address directly.
- If the kernel must access High Memory, it has to map it into its own address space first.
- `copy_from_user(&val, data, 1);`
## Q: How to register an interrupt handler?
- `request_irq(IRQ_ID, handler_irq, ...);`
- `irqreturn_t handler_irq(int irq, void *dev_id)` can get the IRQ_ID from `int irq`
# kernel
## Q: Linux驱动的一些基本概念
- 主设备号. 可以人工指定, 也可以由系统动态分配. 理解为设备类型的id即可.
- 子设备号. 譬如一个led灯的驱动设备, 可以实现多个led的控制. 子设备号可以提供针对特定的led进行控制
- mdev. 根据动态驱动模块的信息自动创建设备节点.
- 地址映射. 这是与单片机的区别. 单片机操作寄存器可以直接使用物理地址. 但linux下使用的是虚拟地址!
- 地址转换使用 `ioremap` `iounmap` 函数.
- 一般的芯片商也会提供操作寄存器的函数, 譬如 s3c2410_gpio_setpin
- 用户空间和内核空间. 两个空间的资源不能直接相互访问.
- 驱动程序内经常要用 `copy_to_user` 以及 `copy_from_user`
## Q: Linux 调度机制
- 轮转调度算法(Round Robin), 先来先服务(FIFC)策略, have a time slice
- 优先级调度算法(Priority): preemptive(抢占式), static priority, dynamic priority
- Linux Sheduler:
- pick next, staircase scheduler.
- using dynamic priority, and time slice
- rt_proirity(实时任务): SCHED_FIFO (just priority), SCHED_RR (time_slice)
## Q: linux android 启动流程
- hardware bootloader, can load specific flash address to ram and run automatically
- uboot stage1 (start.s): 底层硬件初始化(register), copy stage2 code to ram, init stack, data segment
- uboot stage2 (main.c): 硬件初始化(flash, ui, net), load kernel image, copy parameter to specific address for linux
- kernel: decompress image, read parameter from uboot, init hardware(register, MMU, paging table)
- load filesystem, init environment(`etc/inittab`, `etc/init.d/rcS`, `bin/sh`)
- load dymatical drivers, run user application
- Then for android:
- zygote (由 Linux init 启动)
- Dalvik VM
- SyetemServers
- Managers
- Launcher
## Q: linux file system
- Linux下一切皆文件, 文件即inode.
- 索引过程为: 目录inode->目录名/文件名->对应inode->具体内容
- BusyBox 是linux下的一个应用程序, 集成了最常用的Linux命令和工具.
- 最小文件系统 `dev/console` `dev/null` init进程`bin/busybox` `etc/inittab` C库 `lib/` 系统程序或脚本 `/etc/init.d/rcS` `bin/sh`
- mdev: 动态加载驱动时, 自动生成节点文件 `/dev`
- file format yaffs2 for nand, jffs2 for nor
## Q: What do you understand about Linux Kernel and can you edit it?
Linux Kernel is the component that manages the hardware resources for the user and that provides essential services and interact with the user commands.
Linux Kernel is an open source software and free, and it is released under General Public License so we can edit it and it is legal.
## Q: What are the different types of Kernels? Explain
We can build kernels by many different types, but 3 of the types of kernels are most commonly used: monolithic, microkernel and hybrid.
- Microkernel: This type of kernel only manages CPU, memory, and IPC. This kind of kernel provides portability, small memory footprint and also security.
- Monolithic Kernel: Linux is a monolithic kernel. So, this type of kernel provides file management, system server calls, also manages CPU, IPC as well as device drivers. It provides easier access to the process to communicate and as there is not any queue for processor time, so processes react faster.
- Hybrid Kernel: In this type of kernels, programmers can select what they want to run in user mode and what in supervisor mode. So, this kernel provides more flexibility than any other kernel but it can have some latency problems.
## Q: Linux operating system components
- Kernel: Linux is a monolithic kernel
- System Library: GNU C Library. Library plays a vital role because application programs access Kernels feature using system library.
- System Utility: System Utility performs specific and individual level tasks.
## Q: Where is password file located in Linux and how can you improve the security of password file?
This is an important question that is generally asked by the interviewers.
User information along with the passwords in Linux is stored in `/etc/passwd` that is a compatible format. But this file is used to get the user information by several tools. Here, security is at risk. So, we have to make it secured.
To improve the security of the password file, instead of using a compatible format we can use **shadow password format**.
So, in shadow password format, the password will be stored as single “x” character which is not `/etc/passwd`. This information is stored in another file instead with a file name `/etc/shadow`. So, to enhance the security, the file is made word readable and also, this file is readable only by the root user. Thus security risks are overcome to a great extent by using the shadow password format.
## Q: Explain system calls used for process management?
There are some system calls used in Linux for process management.
These are as follows:
- `Fork()`: It is used to create a new process
- `Exec()`: It is used to execute a new process
- `Wait()`: It is used to make the process to wait
- `Exit()`: It is used to exit or terminate the process
- `Getpid()`: It is used to find the unique process ID
- `Getppid()`: It is used to check the parent process ID
- `Nice()`: It is used to bias the currently running process property
## Q:Guess the output
``` c
main() {
fork();
fork();
fork();
printf("hello world\n");
}
```
It will print “hello world' 8 times.
The main() will print one time and creates 3 children, let us say Child_1, Child_2, Child_3. All of them printed once.
The Child_3 will not create any child.
Child2 will create one child and that child will print once.
Child_1 will create two children, say Child_4 and Child_5 and each of them will print once.
Child_4 will again create another child and that child will print one time.
A total of eight times the printf statement will be executed.
## Q: What is the difference between static linking and dynamic linking ?
In static linking, all the library modules used in the program are placed in the final executable file making it larger in size. This is done by the linker. If the modules used in the program are modified after linking, then re-compilation is needed. The advantage of static linking is that the modules are present in an executable file. We don't want to worry about compatibility issues.
In case of dynamic linking, only the names of the module used are present in the executable file and the actual linking is done at run time when the program and the library modules both are present in the memory. That is why, the executables are smaller in size. Modification of the library modules used does not force re-compilation. But dynamic linking may face compatibility issues with the library modules used.
## Q: How a user mode is transferred to kernel mode? Difference between kernerl/user space
using System call
kernel mode: can do anything, cpu run in full function
user mode: safty purpose, cpu function is liminated.
kernel 访问用户层数据: `copy_to_user` `copy_from_user`
## Q: Main difference between Tasklets and workqs?
- Tasklets:
- are old (around 2.3 I believe)
- have a straightforward, simple API
- are designed for low latency
- cannot sleep
- Work queues:
- are more recent (introduced in 2.5)
- have a flexible API (more options/flags supported)
- are designed for higher latency
- can sleep
## Q: Do you know panic and oops errors in kernel crash?
Oops is a way to debug kernel code, and there are utilities for helping with that.
A kernel panic means the system cannot recover and must be restarted.
However, with an Oops, the system can usually continue. You can configure klogd and syslogd to log oops messages to files, rather than to std out.
## Q: What is the name and path of the main system log?
By default, the main system log is `/var/log/messages`.
This file contains all the messages and the script written by the user. By default, all scripts are saved in this file. This is the standard system log file, which contains messages from all system software, non-kernel boot issues, and messages that go to `dmesg`.
`dmesg` is a system file that is written upon system boot.
`dmesg | less` to review boot messages.
## Q: Explain what happens when an insmod is done an module
insmod is a user space utility to load a module into Linux kernel. It calls init_module system call to do the work.
init_module loads the kernel module in ELF format into kernel address space. Each section of the ELF are read and mapped using vmalloc().
Use of vmalloc is because kernel modules can be big and kernel might not have contiguous physical memory to accommodate for module text and data.
Each .ko has a struct module section. This has relocatable address of init and exit routines (ones specified in module_init and module_exit). This goes as a separate section in ELF. Once all the relevant sections are loaded in memory, kernel calls init routine of the module.
## Q: How will you insert a module statically in to linux kernel.
Using makefile `obj-y`. By the way `obj-m` will generate `.ko` file.
``` makefile
obj-y += mymodule.o
mymodule-objs := src.o other.o
```
## Q: what is a device driver and write a simple driver
``` c
#include <linux/xxx.h>
#include <asm/xxx.h>
#define DEVICE_NAME "drv_leds" // 设备类型名称, cat /proc/devices 可以看到
static int major; // 存储自动分配的主设备号
static struct class *leds_class; // 类, 供mdev用, ls /sys/class/ 可以看到
static struct class_device *leds_class_devs[4]; // 类下设备, ls /sys/class/class_name 可以看到
// ===== 驱动的硬件实现部分, 和单片机类似 =====
static int drv_leds_open(struct inode *inode, struct file *file)
{
int minor = MINOR(inode->i_rdev);
// 初始化对应的LED
gpio_init(minor);
printk("drv_leds_open\n");
return 0;
}
static ssize_t drv_leds_write(struct file *file, const char __user *data, size_t len, loff_t *ppos)
{
int minor = MINOR(file->f_dentry->d_inode->i_rdev);
char val;
copy_from_user(&val, data, 1);
// 操作对应的LED
gpio_set(minor);
printk("drv_leds_write, led%d=%d\n", minor, val);
return len;
}
// 此结构体指定了C库的文件操作函数需要调用的底层驱动的函数名.
static struct file_operations drv_leds_fops = {
.owner = THIS_MODULE, // 这是一个宏,指向编译模块时自动创建的__this_module变量. 和平台相关
.open = drv_leds_open,
.write = drv_leds_write,
};
// ===== 加载和卸载内核时, 指定要调用的函数 =====
static int drv_leds_init(void)
{
int minor;
// 获取寄存器起始地址的虚拟地址值. 其它寄存器基于此值再用偏移量.
// gpio_base = ioremap(0x56000000, 0xD0);
// 注册驱动, 0表示动态分配主设备号
major = register_chrdev(0, DEVICE_NAME, &drv_leds_fops);
// 生成系统设备信息, 供mdev自动创建设备节点使用
leds_class = class_create(THIS_MODULE, "leds"); // 创建 leds 类
if (IS_ERR(leds_class))
return PTR_ERR(leds_class);
// 0-3 表示4个独立的led, 名称为 led0, led1, led2, led3
for (minor = 0; minor < 4; minor++) {
leds_class_devs[minor] = class_device_create(leds_class, NULL, MKDEV(major, minor), NULL, "led%d", minor);
if (unlikely(IS_ERR(leds_class_devs[minor])))
return PTR_ERR(leds_class_devs[minor]);
}
printk(DEVICE_NAME " initialized\n"); // 调试用
return 0;
}
static void drv_leds_exit(void)
{
int minor;
for (minor = 0; minor < 4; minor++) {
class_device_unregister(leds_class_devs[minor]); // 删除设备节点
}
class_destroy(leds_class); // 删除设备类
unregister_chrdev(major, DEVICE_NAME); // 卸载驱动
// iounmap(gpio_base);
printk(DEVICE_NAME " deinitialized\n");
}
module_init(drv_leds_init);
module_exit(drv_leds_exit);
// ===== 描述驱动程序的一些信息,不是必须的 =====
MODULE_AUTHOR("draapho");
MODULE_VERSION("0.1.1");
MODULE_DESCRIPTION("First Driver for LED");
MODULE_LICENSE("GPL");
```
# IPC
## Q: How many types of IPC mechanism you know?
- Named pipes or FIFO
- Semaphores
- Shared memory
- Message queue
- Socket
## Q: Explain What Is Semaphore?
A semaphore is an abstract datatype or variable that is used for controlling access, by multiple processes to a common resource in a concurrent system such as multiprogramming operating system.
Semaphores are commonly used for two purposes:
- To share a common memory space
- To share access to files
Semaphores are of two types:
- Binary semaphore: It can have only two values (0 and 1). The semaphore value is set to 1 by the process in charge, when the resource is available.
- Counting semaphore: It can have value greater than one. It is used to control access to a pool of resources.
## Q: What is difference between binary semaphore and mutex?
- Mutual exclusion and synchronization can be used by binary semaphore while mutex is used only for mutual exclusion.
- A mutex can be released by the same thread which acquired it. Semaphore values can be changed by other thread also.
- From an ISR, a mutex can not be used.
- The advantage of semaphores is that, they can be used to synchronize two unrelated processes trying to access the same resource.
- Semaphores can act as mutex, but the opposite is not possible.
## Q: What is spin lock?
If a resource is locked, a thread that wants to access that resource may repetitively check whether the resource is available. During that time, the thread may loop and check the resource without doing any useful work. Suck a lock is termed as spin lock.
## Q: Explain Whether We Can Use Semaphore Or Mutex Or Spinlock In Interrupt Context In Linux Kernel?
Mutex cannot be used for interrupt context in Linux Kernel.
Semaphore only can use `sema_post` in interrupt handler.
Spinlocks can be used for locking in interrupt context.
## Q: What is shared memory?
Shared memory is the fastest interprocess communication mechanism. The operating system maps a memory segment in the address space of several processes, so that several processes can read and write in that memory segment without calling operating system functions. However, we need some kind of synchronization between processes that read and write shared memory.
## Q: How to come out of deadlock?
The most common error causing deadlock is self deadlock or recursive deadlock:
- a thread tries to acquire a lock it is already holding.
- Recursive deadlock is very easy to program by mistake.
Here are some simple guidelines for locking.
- Try not to hold locks across long operations like I/O where performance can be adversely affected.
- Don't hold locks when calling a function that is outside the module and that might reenter the module.
- In general, start with a coarse-grained approach, identify bottlenecks, and add finer-grained locking where necessary to alleviate the bottlenecks. Most locks are held for short amounts of time and contention is rare, so fix only those locks that have measured contention.
- When using multiple locks, avoid deadlocks by making sure that all threads acquire the locks in the same order.
## Q: 生产者, 消费者写法
``` c
struct goods
{
int id;
struct goods *next;
};
pthread_mutex_t m;
pthread_cond_t has_product;
struct goods *head;
void *producer(void *argv)
{
struct goods *p = NULL;
while (1)
{
pthread_mutex_lock(&m);
p = malloc(sizeof(struct goods));
p->id = rand() % 100;
p->next = head;
head = p;
printf("produce %d\n", p->id);
pthread_mutex_unlock(&m);
pthread_cond_signal(&has_product);
//printf("produce %d\n", p->id);
sleep(rand() % 2);
}
return (void *)0;
}
void *comsumer(void *argv)
{
struct goods *p = NULL;
while (1)
{
pthread_mutex_lock(&m);
//思考:pthread_cond_wait()的作用?
while (NULL == head)
pthread_cond_wait(&has_product, &m);
p = head;
head = head->next;
printf("comsume %d\n", p->id);
pthread_mutex_unlock(&m);
//printf("comsume %d\n", p->id);
free(p);
sleep(rand() % 2);
}
return (void *)0;
}
// 开启两个线程作为生产者,三个线程作为消费者
int main(void)
{
int i;
//初始化条件变量和互斥量
pthread_mutex_init(&m, NULL);
pthread_cond_init(&has_product, NULL);
head = NULL;
pthread_t pro[2], com[3];
for (i = 0; i < 2; i++)
pthread_create(&pro[i], NULL, producer, NULL);
for (i = 0; i < 3; i++)
pthread_create(&com[i], NULL, comsumer, NULL);
for (i = 0; i < 2; i++)
pthread_join(pro[i], NULL);
for (i = 0; i < 3; i++)
pthread_join(com[i], NULL);
//销毁条件变量和互斥量
pthread_mutex_destroy(&m);
pthread_cond_destroy(&has_product);
return 0;
}
```
# bash command
## Q: How can I redirect both stderr and stdin at once?
command `> file.log 2>&1` : Redirect stderr to "where stdout is currently going". In this case, that is a file opened in append mode. In other words, the `&1` reuses the file descriptor which stdout currently uses.
## Q: what is `/proc` entry and how it is useful
Virtual directory for system information, 虚拟档案系统. 数据都在内存当中,不占用硬盘空间.
主要包括系统核心,接口设备状态,网络状态.
比较重要的档案例: `proc/cpuinfo` `/proc/interrupts` `/proc/ioports`
## How can we edit a file without opening in Linux?
`sed` command is used to edit a file without opening.
`sed` command is used to modify or change the contents of a file.
``` bash
# For example, we have a text file with below content
> cat file.txt
# replace “sed” with “vi”
>sed ‘s/sed/vi/’ file.txt
```
## Q: How can you find out how much memory Linux is using?
`cat /proc/meminfo`
## Q: Explain grep command and its use.
`grep` command in Linux is used to search a specific pattern. Grep command will help you to explore the string in a file or multiple files.
``` bash
grep ‘word’ filename
grep ‘word’ file1 file2 file3
command | grep ‘string’
# For example,
grep “smith” passwd
grep “smith” passwd shadow
netstat -an | grep 8083
cat /etc/passwd | grep smith
```
## Q: Explain file content commands along with the description.
- `head`: to check the starting of a file.
- `tail`: to check the ending of the file. It is the reverse of head command.
- `cat`: used to view, create, concatenate the files.
- `more`: used to display the text in the terminal window in pager form.
- `less`: used to view the text in the backward direction and also provides single line movement.
# 参考
- [Linux Embedded systems Interview Questions & Answers](https://www.wisdomjobs.com/e-university/linux-embedded-systems-interview-questions.html)
- [Linux Device Driver,Embedded C Interview Questions](http://linuxdevicedrivercinterviewqs.blogspot.com.au/)
| 49.470684 | 574 | 0.733169 | eng_Latn | 0.997283 |
c0a13c380f9802e96502d7f168831229e68ce407 | 1,123 | md | Markdown | README.md | mareek/NetElevation | 324ff6284de63ad37ae530385abb7541980ef9b0 | [
"WTFPL"
] | null | null | null | README.md | mareek/NetElevation | 324ff6284de63ad37ae530385abb7541980ef9b0 | [
"WTFPL"
] | null | null | null | README.md | mareek/NetElevation | 324ff6284de63ad37ae530385abb7541980ef9b0 | [
"WTFPL"
] | null | null | null | # NetElevation
An APi to get the altitude of any point on the globe
## Doc
This API is quite simple. You can either use a GET request to retrieve the altitude of a single locationOr you can retrieve the altitude of many locations in a single post request.
### GET /elevation?latitude=45.76&longitude=4.82
returns the altitude of the location at latitude and longitude
### POST /elevation
payload: an array of coordinates [ { latitude: 45.76, longitude: 4.82 } ]
returns: an array of coordinates with altitude [ { latitude: 45.76, longitude: 4.82, elevation: 263 } ]
## TODO
- [x] Create a docker image for raspberry pi
- [x] Test docker image on raspberry pi
- [x] Create a controller compatible Open Elevation API
- [x] Create a ZipRepository that load its data from a giant Zip file
- [x] Write some docs
- [ ] Create a nuget package for NetElevation.Core
- [ ] Write better docs
- [ ] Create a command line tool to split Geotiff into smaller files
- [ ] Add support for tar files
- [ ] Create a website
- [ ] Buy a domain and create a certificate on lets encrypt
- [ ] Create a proxy to handle multiple servers
| 35.09375 | 180 | 0.73553 | eng_Latn | 0.970899 |
c0a28538d0f6cd0d5794e6e0489f5e9b1ef7a69f | 1,216 | md | Markdown | AlchemyInsights/about-briefing-email.md | isabella232/OfficeDocs-AlchemyInsights-pr.hu-HU | 308f0ab87b566ec302a8ddeadc3a529ab28bdaf0 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2020-05-19T19:06:44.000Z | 2020-05-19T19:06:44.000Z | AlchemyInsights/about-briefing-email.md | isabella232/OfficeDocs-AlchemyInsights-pr.hu-HU | 308f0ab87b566ec302a8ddeadc3a529ab28bdaf0 | [
"CC-BY-4.0",
"MIT"
] | 3 | 2020-06-02T23:28:58.000Z | 2022-02-09T06:52:58.000Z | AlchemyInsights/about-briefing-email.md | isabella232/OfficeDocs-AlchemyInsights-pr.hu-HU | 308f0ab87b566ec302a8ddeadc3a529ab28bdaf0 | [
"CC-BY-4.0",
"MIT"
] | 3 | 2019-10-11T19:13:19.000Z | 2021-10-09T10:43:09.000Z | ---
title: Tájékoztató e-mail
ms.author: pebaum
author: pebaum
manager: scotv
ms.date: 08/14/2020
ms.audience: Admin
ms.topic: article
ms.service: o365-administration
ROBOTS: NOINDEX, NOFOLLOW
localization_priority: Priority
ms.collection: Adm_O365
ms.custom:
- "6179"
- "9003284"
ms.openlocfilehash: d1c7027eeba1d156ed2b7b68502504f9eb0b940519d43ac84df1c94435260101
ms.sourcegitcommit: b5f7da89a650d2915dc652449623c78be6247175
ms.translationtype: MT
ms.contentlocale: hu-HU
ms.lasthandoff: 08/05/2021
ms.locfileid: "53955860"
---
# <a name="about-briefing-email"></a>Tájékoztató e-mail
A Tájékoztatóról további információt Az e-mailek rövid [áttekintése – áttekintés témakörben talál.](https://docs.microsoft.com/briefing/be-overview)
Ez a funkció jelenleg is elérhető, ezért előfordulhat, hogy szervezete még akkor sem kapja meg a tájékoztató e-mailt, ha engedélyezve van a Tájékoztató funkció. Felhívjuk a figyelmét arra, hogy a felhasználók nem minden nap kapnak tájékoztató e-mailt. Az e-mailek csak akkor küldhetők el, ha a felhasználónak van legalább egy műveletre vonatkozó javaslata az adott napra. További információ: A tájékoztató e-mail [gyakori kérdései.](https://docs.microsoft.com/briefing/be-faqs) | 45.037037 | 477 | 0.810855 | hun_Latn | 0.999406 |
c0a2d7535191d323a83bfcbfce12223b6b9989c7 | 586 | md | Markdown | README.md | aramis-lab/tuto_clinicadl | 8b82797463cff38ed877d3931b7f5675020c755a | [
"CC0-1.0"
] | null | null | null | README.md | aramis-lab/tuto_clinicadl | 8b82797463cff38ed877d3931b7f5675020c755a | [
"CC0-1.0"
] | null | null | null | README.md | aramis-lab/tuto_clinicadl | 8b82797463cff38ed877d3931b7f5675020c755a | [
"CC0-1.0"
] | null | null | null | # Notebooks for presentation of ClinicaDL
## Plan
Prepare 5 notebooks in `py` format.
- TSV Tools
- Extract
- Train
- Inference
- Interpret
## Where to begin
Notebooks are generated from python files stored in the `src` folder.
Automatic generated notebooks are added into the `notebooks` folder.
To convert from python files to notebooks install the packages in the
requirements file.
```bash
conda create --name tutoCDL python=3.7
conda activate tutoCDL
pip install -r requirements.txt
```
## Convert the python scripts
Run the `make` command on the root of the repository.
| 19.533333 | 69 | 0.762799 | eng_Latn | 0.983195 |
c0a473c158c79d3d554799695f117120b5bab8c1 | 19 | md | Markdown | README.md | chuiizeet/Pixel-Art-Headers | aa48d9119d2ae2363112d146dd021b133c8da308 | [
"MIT"
] | null | null | null | README.md | chuiizeet/Pixel-Art-Headers | aa48d9119d2ae2363112d146dd021b133c8da308 | [
"MIT"
] | null | null | null | README.md | chuiizeet/Pixel-Art-Headers | aa48d9119d2ae2363112d146dd021b133c8da308 | [
"MIT"
] | null | null | null | # Pixel-Art-Headers | 19 | 19 | 0.789474 | eng_Latn | 0.636203 |
c0a4ebb580bee4ba16e9421b710edaf755face78 | 2,106 | md | Markdown | Plugins/NodeEditor/README.md | cclauss/ParaView | 3aa1b5818b4b724cac09aaf62114011869d90706 | [
"Apache-2.0",
"BSD-3-Clause"
] | 815 | 2015-01-03T02:14:04.000Z | 2022-03-26T07:48:07.000Z | Plugins/NodeEditor/README.md | cclauss/ParaView | 3aa1b5818b4b724cac09aaf62114011869d90706 | [
"Apache-2.0",
"BSD-3-Clause"
] | 9 | 2015-04-28T20:10:37.000Z | 2021-08-20T18:19:01.000Z | Plugins/NodeEditor/README.md | cclauss/ParaView | 3aa1b5818b4b724cac09aaf62114011869d90706 | [
"Apache-2.0",
"BSD-3-Clause"
] | 328 | 2015-01-22T23:11:46.000Z | 2022-03-14T06:07:52.000Z | # paraview-node-editor
Integration from https://github.com/JonasLukasczyk/paraview-node-editor
### Overview
This plugin contains a node editor for ParaView that makes it possible to conveniently modify filter/view properties (node elements), filter input/output connections (blue edges), as well as the visibility of outputs in certain views (orange edges). The editor is completely compatible with the existing ParaView widgets such as the pipeline browser and the properties panel (one can even use them simultaneously). So far the plugin is self-contained.
The plugin uses GraphViz for computing an automatic layout of the graph.
Graphviz is an optional dependency so if no library is found then the auto layout feature will be disabled.
### Current Features
1. Automatically detects the creation/modification/destruction of source/filter/view proxies and manages nodes accordingly.
2. Automatically detects the creation/destruction of connections between ports and manages edges accordingly.
3. Every node exposes all properties of the corresponding proxy via the pqProxiesWidget class.
4. Property values are synchronized within other widgets, such as the ones shown in the properties panel.
5. Proxy selection is synchronized with the pipeline browser.
6. Works with state files and python tracing.
### User Manual
* Filters/Views are selected by double-clicking their corresponding node labels (hold CTRL to select multiple filters).
* Output ports are selected by double-clicking their corresponding port labels (hold CTRL to select multiple output ports).
* Nodes are collapsed/expanded by right-clicking node labels.
* Selected output ports are set as the input of another filter by double-clicking the corresponding input port label.
* To remove all input connections CTRL+double-click on an input port.
* To toggle the visibility of an output port in the current active view SHIFT+left-click the corresponding output port (CTRL+SHIFT+left-click shows the output port exclusively)
### Limitations
See current limitations here : https://gitlab.kitware.com/paraview/paraview/-/issues/20726
| 70.2 | 451 | 0.811491 | eng_Latn | 0.995952 |
c0a4f78ccecf6205c309f2375bee3c264c0e3b7f | 1,147 | md | Markdown | 7-iptables-firewall/README.md | acm-uic/cs-000 | c4b753964dec8e7c83d109675aa20c91a57497ad | [
"MIT"
] | 3 | 2020-09-19T03:45:50.000Z | 2020-10-20T20:29:22.000Z | 7-iptables-firewall/README.md | acm-uic/cs-000 | c4b753964dec8e7c83d109675aa20c91a57497ad | [
"MIT"
] | null | null | null | 7-iptables-firewall/README.md | acm-uic/cs-000 | c4b753964dec8e7c83d109675aa20c91a57497ad | [
"MIT"
] | 1 | 2020-10-31T00:48:16.000Z | 2020-10-31T00:48:16.000Z | # IPTables and Firewall Basics
## What? Why? How?
Firewalls are essential to securing a network.
A large portion of servers run linux and therefore rely on iptables in some fashion to handle networking.

Image source: *https://sites.google.com/site/mrxpalmeiras/linux/iptables-routing*
### Firewall basics:
It's generally good practice to set the default input policy to drop to prevent unintended traffic.
To ensure the traffic that you do want comes through, you can set a rule to make established or related
traffic accepted. The commands for this are listed below:
```
iptables -A INPUT -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT
iptables -A INPUT DROP
```
### Good to know:
When working with iptable rules, make sure the rules are run live first. If a rule locks you out of the system you can reset the machine since the rules won't
persist.
### Saving iptable rules:
It becomes tedious to rewrite the rules each boot so the iptables cli provides a built in command called <i>iptables-save</i> to assist in saving changes.
```
iptables-save > /etc/iptables/iptables
``` | 32.771429 | 159 | 0.764603 | eng_Latn | 0.995365 |
c0a5331117e3ba2db54a6c51a825494bebdf1b76 | 91 | md | Markdown | packages/connectivity-tests/README.md | deriamis/mongosh | f1d40bbac736ed7b8998491c2511f5809c17efe8 | [
"Apache-2.0"
] | 175 | 2019-10-03T01:47:43.000Z | 2022-03-26T20:49:00.000Z | packages/connectivity-tests/README.md | addaleax/mongosh | 490ae2e01da6ec8a639aeca4991b2348fe5ee6f7 | [
"Apache-2.0"
] | 203 | 2020-01-14T10:24:32.000Z | 2022-03-31T13:42:56.000Z | packages/connectivity-tests/README.md | addaleax/mongosh | 490ae2e01da6ec8a639aeca4991b2348fe5ee6f7 | [
"Apache-2.0"
] | 24 | 2019-12-30T09:35:39.000Z | 2022-03-16T19:07:13.000Z | # `connectivity-tests`
Contains some of the connectivity tests that don’t run everywhere.
| 22.75 | 66 | 0.791209 | eng_Latn | 0.999142 |
c0a6400e7bcd6326b171cd431bd4f012b808f159 | 2,128 | md | Markdown | docs/extensibility/debugger/reference/idebugenumfield-getvaluefromstring.md | Jteve-Sobs/visualstudio-docs.de-de | 59bd3c5d2776a76ef8d28407c5cc97efc9e72f84 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/extensibility/debugger/reference/idebugenumfield-getvaluefromstring.md | Jteve-Sobs/visualstudio-docs.de-de | 59bd3c5d2776a76ef8d28407c5cc97efc9e72f84 | [
"CC-BY-4.0",
"MIT"
] | 1 | 2020-07-24T14:57:38.000Z | 2020-07-24T14:57:38.000Z | docs/extensibility/debugger/reference/idebugenumfield-getvaluefromstring.md | angelobreuer/visualstudio-docs.de-de | f553469c026f7aae82b7dc06ba7433dbde321350 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: IDebugEnumField::GetValueFromString | Microsoft Docs
ms.date: 11/04/2016
ms.topic: reference
f1_keywords:
- IDebugEnumField::GetValueFromString
helpviewer_keywords:
- IDebugEnumField::GetValueFromString method
ms.assetid: 1ef8ac5e-a3e0-4078-b876-7f5615aedcbb
author: acangialosi
ms.author: anthc
manager: jillfra
ms.workload:
- vssdk
dev_langs:
- CPP
- CSharp
ms.openlocfilehash: bb340721c9f446b740c2723dc3f6dc05452e74de
ms.sourcegitcommit: 16a4a5da4a4fd795b46a0869ca2152f2d36e6db2
ms.translationtype: MT
ms.contentlocale: de-DE
ms.lasthandoff: 04/06/2020
ms.locfileid: "80730263"
---
# <a name="idebugenumfieldgetvaluefromstring"></a>IDebugEnumField::GetValueFromString
Diese Methode gibt den Wert zurück, der dem Namen einer Enumerationskonstante zugeordnet ist.
## <a name="syntax"></a>Syntax
```cpp
HRESULT GetValueFromString(
LPCOLESTR pszValue,
ULONGLONG* pvalue
);
```
```csharp
int GetValueFromString(
string pszValue,
out ulong pValue
);
```
## <a name="parameters"></a>Parameter
`pszValue`\
[in] Eine Zeichenfolge, die den Namen angibt, für den der Wert abgesendet werden soll. Beachten Sie, dass es sich bei C++ um eine breite Zeichenfolge handelt.
`pValue`\
[out] Gibt den zugeordneten numerischen Wert zurück.
## <a name="return-value"></a>Rückgabewert
Wenn erfolgreich, `S_OK`kehrt zurück; Andernfalls wird `S_FALSE`zurückgegeben, wenn der Name nicht Teil der Enumeration ist, oder einen Fehlercode.
## <a name="remarks"></a>Bemerkungen
Bei dieser Methode wird die Groß-/Kleinschreibung berücksichtigt. Wenn eine Suche ohne Groß-/Kleinschreibung erforderlich ist (z. B. in einer Sprache wie Visual Basic, in der die Groß-/Kleinschreibung nicht berücksichtigt wird), verwenden Sie [GetValueFromStringCaseInsensitive](../../../extensibility/debugger/reference/idebugenumfield-getvaluefromstringcaseinsensitive.md).
## <a name="see-also"></a>Weitere Informationen
- [IDebugEnumField](../../../extensibility/debugger/reference/idebugenumfield.md)
- [GetValueFromStringCaseInsensitive](../../../extensibility/debugger/reference/idebugenumfield-getvaluefromstringcaseinsensitive.md)
| 35.466667 | 376 | 0.788064 | deu_Latn | 0.691227 |
c0a87ed7eedf90d83a395bca74e61e5d6184f5d0 | 3,958 | md | Markdown | Docs/PHP/UserConfig.md | KevinHern/ingsoft | 45f6a385d04170ff5279a75ccafc291bd8b04eef | [
"Apache-2.0"
] | null | null | null | Docs/PHP/UserConfig.md | KevinHern/ingsoft | 45f6a385d04170ff5279a75ccafc291bd8b04eef | [
"Apache-2.0"
] | null | null | null | Docs/PHP/UserConfig.md | KevinHern/ingsoft | 45f6a385d04170ff5279a75ccafc291bd8b04eef | [
"Apache-2.0"
] | null | null | null | #Configuracion de Usuario
- Input Org
```javascript
{
uid: "",
name: "",
last: "",
nat: "",
bio: "",
org: "",
birth: "",
role: <int>,
phone: ["phone1", "phone2", ..., "phoneN" ]
}
```
- Input Ind
```javascript
{
uid: "",
name: "",
desc: "",
country: "",
addr: "",
role: <int>,
phone: ""
}
```
> Sera necesario que te encarges de guardar el role en la tabla de usuario.
> En ambos casos la photo ira en $FILES['photo']
- Output Success
```javascript
{
status: 1
}
```
- Output Failed
```javascript
{
status: 0,
message: ""
}
```
#Crear Ideas
Script que devuelva categorias
> No input here
- Output Success
```javascript
{
status: 1,
cats: [{id:1, name: "nombre1"},
{id:2, name: "nombre2"},
{id:3, name: "nombre3"},
...
{id:N, name: "nombreN"}
]}
```
- Output Failed
```javascript
{
status: 0,
message: ""
}
```
####Script que guarde ideas de usuario
- Input
```javascript
{
title: 'title',
desc:'desc',
cat:'categoria',
uid:'uid'
}
```
- Output Success
```javascript
{
status: 1
}
```
- Output Failed
```javascript
{
status: 0,
message: ""
}
```
> Update Idea es igual
#Informacion de Usuario
- Input
```javascript
{
uid: ""
}
```
- Output Individual
```javascript
{
name: "",
last: "",
nat: "",
bio: "",
org: "",
birth: "",
role: <int>,
phone: ["phone1", "phone2" , ..., "phoneN" ]
}
```
- Output Organizacion
```javascript
{
name: "",
desc: "",
country: "",
addr: "",
role: <int>,
phone: ""
}
```
#### Photo
- Input
```javascript
{
uid: ""
}
```
[Upload Image](https://stackoverflow.com/questions/900207/return-a-php-page-as-an-image)
#Listar Ideas (Emprendedor)
- Input
```javascript
{
uid: "",
search: '',
page: <int>
}
```
> Search deberia buscar en el titulo pero no se llamaria
> Exactamente igual, SQL puede usar LIKE
[LIKE](https://www.w3schools.com/sql/sql_like.asp)
> Dejaremos de fijo 4 filas por pagina
- Output
```javascript
{
maxPage: <int>,
ideas: [ {id: "id1" , title: "tittle1"},
{id: "id2" , title: "tittle2"},
{id: "id3" , title: "tittle3"},
{id: "id4" , title: "tittle4"}
]
}
```
> Si no son ni cuatro envia solo lo que haya, maxPage = 1.
> Si el usuario no tiene ideas envia maxPage = 0.
> maxPage depende de lo que se envie en search
> i.e. Si las ideas son 17, maxPage seria 5; 4*4 = 16 pero necesitamos una
> pagina mas para la ultima idea
#Listar Ideas (Financista)
- Input
```javascript
{
category: '',
page: <int>,
rows: <int>
}
```
- Output
```javascript
{
maxPage: "Numero Maximo de pagina, depende de la categoria",
ideas: [{id: "id1 , "title:"title1", desc: "descripcion1", autor: "autor2_nombre autor2_apellido"},
{id: "id2 , "title:"title2", desc: "descripcion2", autor: "autor1_nombre autor1_apellido"}, ...
{id: "idRows , "title:"titleRows", desc: "descripcionRows", autor: "autorRows_nombre autorRows_apellido"}]
}
```
> MaxPage seria el numero maximo de paginas segun la categoria y rows.
> A Rows le di como minimo 1 maximo 5
<!-- > Tal vez pueda obtener el role del mismo uid pero ya vere
> despues, si hay tiempo -->
| 17.828829 | 122 | 0.474987 | spa_Latn | 0.425739 |
c0a8d0834d25e304fa71e8e94f3ec4dbf6b2b6d3 | 1,797 | md | Markdown | ESLint/vue/no-setup-props-destructure.md | r3yn0ld4/docs-for-code-review-tools | a1590fce3b30891679373ec284787b227b21df05 | [
"MIT"
] | 4 | 2019-07-17T18:16:06.000Z | 2021-03-28T23:53:10.000Z | ESLint/vue/no-setup-props-destructure.md | r3yn0ld4/docs-for-code-review-tools | a1590fce3b30891679373ec284787b227b21df05 | [
"MIT"
] | null | null | null | ESLint/vue/no-setup-props-destructure.md | r3yn0ld4/docs-for-code-review-tools | a1590fce3b30891679373ec284787b227b21df05 | [
"MIT"
] | 5 | 2018-09-29T17:02:14.000Z | 2021-12-26T16:53:04.000Z | Pattern: Destructuring of `props` passed to `setup`
Issue: -
## Description
This rule reports the destructuring of `props` passed to `setup` causing the value to lose reactivity.
<eslint-code-block :rules="{'vue/no-setup-props-destructure': ['error']}">
```vue
<script>
export default {
/* ✓ GOOD */
setup(props) {
watch(() => {
console.log(props.count)
})
return () => {
return h('div', props.count)
}
}
}
</script>
```
</eslint-code-block>
Destructuring the `props` passed to `setup` will cause the value to lose reactivity.
<eslint-code-block :rules="{'vue/no-setup-props-destructure': ['error']}">
```vue
<script>
export default {
/* ✗ BAD */
setup({ count }) {
watch(() => {
console.log(count) // not going to detect changes
})
return () => {
return h('div', count) // not going to update
}
}
}
</script>
```
</eslint-code-block>
Also, destructuring in root scope of `setup()` should error, but ok inside nested callbacks or returned render functions:
<eslint-code-block :rules="{'vue/no-setup-props-destructure': ['error']}">
```vue
<script>
export default {
setup(props) {
/* ✗ BAD */
const { count } = props
watch(() => {
/* ✓ GOOD */
const { count } = props
console.log(count)
})
return () => {
/* ✓ GOOD */
const { count } = props
return h('div', count)
}
}
}
</script>
```
</eslint-code-block>
## Further Reading
* [eslint-plugin-vue - no-setup-props-destructure](https://eslint.vuejs.org/rules/no-setup-props-destructure.html)
* [Guide - Composition API - Setup](https://v3.vuejs.org/guide/composition-api-setup.html)
* [Vue RFCs - 0013-composition-api](https://github.com/vuejs/rfcs/blob/master/active-rfcs/0013-composition-api.md)
| 20.655172 | 121 | 0.616027 | eng_Latn | 0.516656 |
c0a9329516d66a95d22d6a38d37b53f0bac57179 | 4,199 | md | Markdown | README.md | Barath2910/Search-Algorithm | e3f2a59fc360c77fcf9def5401a5bbb7b3c59a02 | [
"BSD-3-Clause"
] | null | null | null | README.md | Barath2910/Search-Algorithm | e3f2a59fc360c77fcf9def5401a5bbb7b3c59a02 | [
"BSD-3-Clause"
] | null | null | null | README.md | Barath2910/Search-Algorithm | e3f2a59fc360c77fcf9def5401a5bbb7b3c59a02 | [
"BSD-3-Clause"
] | null | null | null | # Linear Search and Binary search
## Aim:
To write a program to perform linear search and binary search using python programming.
## Equipment’s required:
1. Hardware – PCs
2. Anaconda – Python 3.7 Installation / Moodle-Code Runner
## Algorithm:
## Linear Search:
1. Start from the leftmost element of array[] and compare k with each element of array[] one by one.
2. If k matches with an element in array[] , return the index.
3. If k doesn’t match with any of elements in array[], return -1 or element not found.
## Binary Search:
1. Set two pointers low and high at the lowest and the highest positions respectively.
2. Find the middle element mid of the array ie. arr[(low + high)/2]
3. If x == mid, then return mid.Else, compare the element to be searched with m.
4. If x > mid, compare x with the middle element of the elements on the right side of mid. This is done by setting low to low = mid + 1.
5. Else, compare x with the middle element of the elements on the left side of mid. This is done by setting high to high = mid - 1.
6. Repeat steps 2 to 5 until low meets high
## Program:
i) #Use a linear search method to match the item in a list.
```
'''
Program for linear search method to match the item in a list
Developed by: your name:Barath KumarJ
RegisterNumber: 21500088
'''
def linearSearch(array,n,k):
# write your code for linear search
for i in range(0,n):
if (array[i] == k):
return i
return -1
array=eval(input())
# sort the array
n=len(array)
k=int(input())# k-item to be seared for
array.sort()
result=linearSearch(array,n,k) # use the function for linear search
# use if-else to print sorted array and "Element not found" if the item is not present in the list otherwise print sorted array and "Element found at index: ", result
if (result==-1):
print(array)
print("Element not found")
else:
print(array)
print("Element found at index: ",result)
```
ii) # Find the element in a list using Binary Search(Iterative Method).
```
'''
Program to find the element in a list using Binary Search(Iterative Method)..
Developed by: your name:Barath Kumar J
RegisterNumber: 21500088
'''
def binarySearchIter(array, k, low, high):
# Write your code here to find the middle value and check if the desired item is above or below the middle value
while (low<=high):
mid=low + (high-low)//2
if array[mid] == k:
return mid
elif array[mid] < k:
low = mid + 1
else:
high=mid+1
return -1
array = eval(input())
array.sort()
print(array)
k = eval(input()) #k-item to be searched
low=0
high=len(array)-1
# use the binary search function to find the item in the list
result=binarySearchIter(array,k,low,high)
# use if-else to print sorted array and "Element not found" if the item is not present in the list otherwise print sorted array and "Element found at index: ", result
if result>=0:
print("Element found at index: ",result)
else:
print("Element not found")
```
iii) # Find the element in a list using Binary Search (recursive Method).
```
'''
Program to find the element in a list using Binary Search (recursive Method).
Developed by: your name:Barath Kumar J
RegisterNumber: 21500088
'''
def BinarySearch(arr, k, low, high):
if high>=low:
mid=low+(high-low)//2
if arr[mid]==k:
return mid
elif arr[mid]<k:
return BinarySearch(arr,k,mid+1,high)
else:
return BinarySearch(arr,k,low,mid+1)
return -1
arr = eval(input())
#sort the array
arr.sort()
print(arr)
# k is the element to be searched for
k = eval(input())
low=0
high=len(arr)-1
# use the binary search function to find the result
result=BinarySearch(arr, k, low, high)
# use if-else to print sorted array and "Element not found" if the item is not present in the list otherwise print sorted array and "Element found at index: ", result
if result>=0:
print("Element found at index: ",result)
else:
print("Element not found")
```
## Output:
1)
2)
3)
## Result:
Thus the linear search and binary search algorithm is implemented using python programming. | 32.804688 | 166 | 0.68945 | eng_Latn | 0.99143 |
c0aa06f0e70ab44c5afb1adde0d6006de76d4ee9 | 424 | md | Markdown | windows.graphics.display.core/hdmidisplayinformation_displaymodeschanged.md | gbaychev/winrt-api | 25346cd51bc9d24c8c4371dc59768e039eaf02f1 | [
"CC-BY-4.0",
"MIT"
] | 199 | 2017-02-09T23:13:51.000Z | 2022-03-28T15:56:12.000Z | windows.graphics.display.core/hdmidisplayinformation_displaymodeschanged.md | gbaychev/winrt-api | 25346cd51bc9d24c8c4371dc59768e039eaf02f1 | [
"CC-BY-4.0",
"MIT"
] | 2,093 | 2017-02-09T21:52:45.000Z | 2022-03-25T22:23:18.000Z | windows.graphics.display.core/hdmidisplayinformation_displaymodeschanged.md | gbaychev/winrt-api | 25346cd51bc9d24c8c4371dc59768e039eaf02f1 | [
"CC-BY-4.0",
"MIT"
] | 620 | 2017-02-08T19:19:44.000Z | 2022-03-29T11:38:25.000Z | ---
-api-id: E:Windows.Graphics.Display.Core.HdmiDisplayInformation.DisplayModesChanged
-api-type: winrt event
---
<!-- Event syntax.
public event TypedEventHandler DisplayModesChanged<HdmiDisplayInformation, object>
-->
# Windows.Graphics.Display.Core.HdmiDisplayInformation.DisplayModesChanged
## -description
Event raised when the display mode changes.
## -remarks
## -see-also
## -examples
| 19.272727 | 84 | 0.735849 | yue_Hant | 0.351054 |
c0abf9b56d2b13b31d24a1986494fbd48454d0dd | 415 | md | Markdown | 600-toc/620-formal-language-theory/README.md | mandober/debrief.math | c6bf21581ccb48a82a74038135bca09c1d0c2a4f | [
"Unlicense"
] | 1 | 2019-01-18T21:56:33.000Z | 2019-01-18T21:56:33.000Z | 600-toc/620-formal-language-theory/README.md | mandober/debrief.math | c6bf21581ccb48a82a74038135bca09c1d0c2a4f | [
"Unlicense"
] | 1 | 2019-06-16T19:34:58.000Z | 2019-06-16T19:35:03.000Z | 600-toc/620-formal-language-theory/README.md | mandober/dust-dllci | 3afc7936579dfefd7f823d774c4ac17cc6c57666 | [
"Unlicense"
] | null | null | null | # Formal systems
* Set theory
* Propositional calculus
* Predicate calculus
* Lambda calculus
- untyped lambda calculus
- simply typed lambda calculus
* Combinatory logic
- SK calculus
- SKI calculus
- iota calculus
* Primitive recursive functions
* Formal theories of arithmetic
- Peano axioms, PA
- Robinson arithmetic, Q
- Presburger arithmetic
- Second-order arithmetic
- Skolem arithmetic
| 20.75 | 32 | 0.749398 | eng_Latn | 0.420006 |
c0ac3448858ec85bbaaedf5dd97db1eaf54b9b35 | 8,394 | md | Markdown | Modules/Module2.md | XAMLU/one-day-intro | 8739fcbbaedb4a9b2e49cc85053fa6ee25b68571 | [
"MIT"
] | null | null | null | Modules/Module2.md | XAMLU/one-day-intro | 8739fcbbaedb4a9b2e49cc85053fa6ee25b68571 | [
"MIT"
] | null | null | null | Modules/Module2.md | XAMLU/one-day-intro | 8739fcbbaedb4a9b2e49cc85053fa6ee25b68571 | [
"MIT"
] | null | null | null | # Module 2
In this module, you will implement OAuth authentication to GitHub and add some essential services to the app.
### TOC
1. [Get your app's callback URI](#callback)
1. [Setup your app in Github](#github)
1. [Add services to your app](#services)
1. [Add authentication UI](#auth)
1. [Add automatic authentication](#auto)
## Task 1: Get your app's callback URI<a name="callback"></a>
In this task, you will discover how straightforward it is to obtain the callback URI for your app. A callback URI is used as part of the OAuth authentication flow and the `WebAuthenticationBroker` component detects when a redirect to that URI occurs so that your app can retrieve a single-use code for the next phase of the OAuth flow.
1. Place the following code in the constructor of `App.xaml.cs`.
> This snippet is the easiest way to get your callback URI, and once you have it, you can remove this one-time code from your app.
```csharp
var callbackUri = Windows.Security.Authentication.Web.WebAuthenticationBroker.GetCurrentApplicationCallbackUri();
```
1. Add a breakpoint (hit `F9`) on the new line.
1. Run your app and look at the reulting value.
> Note: the debug value will have curly braces at the start and the end `{ms-app://value}`, be sure and remove them so your URI is the correct syntax, like this `ms-app://value`.

1. Copy your `Callback URI` to somewhere handy...
## Task 2: Setup your app in Github<a name="github"></a>
In this task, you will use your GitHub account to register the application you are creating so that it can participate in the GitHub authentication flow. After the app is registered, you will receive two pieces of information that are essential for your app to interact with certain GitHUb APIs.
1. Open the following url: [https://github.com/settings/applications/new](https://github.com/settings/applications/new)
1. You only need to provide four values
1. **Application name** Naming convention XU_Oredev2017_\<YourName\>
1. **Homepage URL** http://xamlu.com/XU_Oredev2017_\<YourName\>
1. **Application description** "Sample app for Oredev"
1. **Authorization Callback URL** Use the result from Task 1 above

1. Click `Register application`.
1. Copy *your* `Client Id` and `Client Secret` to somewhere handy

## Task 3: Add services to your app<a name="services"></a>
In this task, you will add a NuGet package that will aid in consuming the GitHub APIs as well as add some services to you app. The services will allow your app to save settings across sessions and show an example of wrapping an external API to make it more suitable for your needs.
1. Add a reference to the `Xamlu.Demo.GitHubLibrary` NuGet package
1. Open the NuGet Package Manager Console

2. Type the following into the console: `Install-Package XamlU.Demo.GithubLibrary`

> **Instructor Sync Point:** Discuss the source for `GitHubLibrary`
> **Instructor Sync Point:** Discuss `HttpClient` and show the debug diagnostics
1. In Visual Studio, add a folder `Services` at the root level of your project.
1. Copy `SettingsService.cs` and `GithubService.cs` to the `Services` folder.
> Find both files in `Module2/Files`
1. Update values in `SettingsService.cs`

1. Replace `<your client id>` with your client id (from above)
2. Replace `<your secret>` with your secret (from above)

## Task 4: Add authentication UI<a name="auth"></a>
Now that you have added the services, it is time to start to actually add authentication to your app. In this task, the `HomePage` will be modified to display the login UI and to include the logic to allow you to login. You will see how to change the UI based upon different states.
1. Open `homePage.xaml`
1. On the root `Grid`, add the attribute `Padding="32"`
1. Paste the following `WaitUI` XAML inside the grid
> This block of XAML will show while the user logs in.
```xml
<StackPanel x:Name="WaitUI" Visibility="{x:Bind ShowWaitUI, Mode=OneWay}">
<ProgressBar IsIndeterminate="True" />
<TextBlock Style="{StaticResource TitleTextBlockStyle}" Text="Please wait" />
</StackPanel>
```
1. Paste the following `LoggedOutUI` XAML below the `WaitUI` just added.
> This block of XAML will show when the suer is logged out.
```xml
<StackPanel x:Name="LoggedOutUI" Visibility="{x:Bind ShowLoggedOutUI, Mode=OneWay}">
<TextBlock Style="{StaticResource TitleTextBlockStyle}" Text="Authentication is required" />
<Button Content="Login now" Click="{x:Bind LoginAsync}" />
</StackPanel>
```
1. Paste the following `LoggedInUI` XAML below the `LoggedOutUI` just added.
> This block of XAML will show when the user is logged in.
```xml
<StackPanel x:Name="LoggedInUI" Visibility="{x:Bind ShowLoggedInUI, Mode=OneWay}">
<TextBlock Style="{StaticResource TitleTextBlockStyle}" x:Name="UserNameTextBlock" Text="{x:Bind User.name, Mode=OneWay}" />
</StackPanel>
```
> **Instructor Sync Point:** Discuss Binding vs x:Bind, INPC and Converters
> **Instructor Sync Point:** Discuss `Visibility` vs Visual States.
1. Open `HomePage.xaml.cs`
1. Implement `INotifyPropertyChanged`
> HomePage inherits from page. We also want to add the declaration of the INotifyPropertyChanged interface to our HomePage and implement it.
1. Add `INotifyPropertyChanged` to the class declaration
> Note: you can use the refactoring tool by hitting `CTRL+.`

1. Implement the interface.

1. Copy the following code into `HomePage.xaml.cs`.
> Note: alternatively, this snippet can be also found in resources `Module2/Files/HomePage_Auth_Snippet.txt`

1. Fix the namespaces

Add the following:
```csharp
using System.Threading.Tasks;
```
> Note: you can use the refactoring tool by hitting `CTRL+.`
1. Test your app, hit `F5`
1. Click the `Login now` button
1. Congratulations.




## Task 5: Add automatic authentication<a name="auto"></a>
In the last task, you added the ability to login, but right now you need to hit login each time you start the app. Surely there must be a better way? In this task you will add the simple code that will login automatically.
1. Add a `Loaded` handler to HomePage.xaml.cs
> Note: you can use the refactoring tool by hitting `CTRL+.`
```csharp
public HomePage()
{
this.InitializeComponent();
this.Loaded += this.HomePage_Loaded;
}
private async void HomePage_Loaded(object sender, RoutedEventArgs e)
{
await this.LoginAsync();
}
```
Note that the handler is an asynchronous method, decorated with the `async` modifier so `LoginAsync` can be awaited. In addition, asynchronous methods, as a rule of thumb, do not return void, but `event` handlers do not need to comply to this rule, since they can't.

> **Instructor Sync Point:** Discuss page/control lifecycle events such as Loaded
## Summary
Phew - you covered a lot of ground in this module! You intergrated a 3rd party library, wrapped it with your own service to make it easier to use and then added the ability to save settings. You then added a UI for login and learnt one way to make the UI respond to changes in the application state, and then you learnt how the `Loaded` event can be used to run code when a `Page` is displayed.
[Start Module 3](./Module3.md)
| 41.349754 | 394 | 0.718609 | eng_Latn | 0.948438 |
c0ac653bd6604de0166dce04952f5e1703260b3d | 1,014 | md | Markdown | README.md | run-me/data-visualization | bc24a2fa09917610a8bf4e83eb4b206985ba2a6d | [
"MIT"
] | null | null | null | README.md | run-me/data-visualization | bc24a2fa09917610a8bf4e83eb4b206985ba2a6d | [
"MIT"
] | null | null | null | README.md | run-me/data-visualization | bc24a2fa09917610a8bf4e83eb4b206985ba2a6d | [
"MIT"
] | null | null | null | # Plotting Basics
### Motivation
Humans are very good at visual learning. Personally I learn much faster when I see things more than
I imagine it to be. The very quote <b>"what i hear i forget what i see i remember"</b> is the proof of
this concept. So buckle up lets do some data visualization to help identify trends in datasets. I don't
really need to say this unless you are living in a cave. This age is all about data and performing meaningful
operations of data. Welcome!
## Why plot data?
The very aim of the repo is to ask why possibly everywhere, but dawg it should make sense! don't ask
why didn't I go to the gym today you gotta answer that for you.
Lets come back to business data is plotted with an aim that it will give us visual
insight without looking at the collection of numbers.
<b>Lets take an example:</b>
Consider the following, you are given an data collected from
a lets say the humble temperature sensor.
#TODO
Insert picture of excel data
Insert picture of a line graph | 37.555556 | 109 | 0.765286 | eng_Latn | 0.999822 |
c0acde61ee91b0644f2f6a1279215b35712b78fb | 518 | md | Markdown | articles/talent/includes/pre-release.md | MicrosoftDocs/Dynamics-365-Operations.fr-fr | 9f97b0553ee485dfefc0a57ce805f740f4986a7e | [
"CC-BY-4.0",
"MIT"
] | 2 | 2020-05-18T17:14:08.000Z | 2021-04-20T21:13:46.000Z | articles/talent/includes/pre-release.md | MicrosoftDocs/Dynamics-365-Operations.fr-fr | 9f97b0553ee485dfefc0a57ce805f740f4986a7e | [
"CC-BY-4.0",
"MIT"
] | 6 | 2017-12-13T18:31:58.000Z | 2019-04-30T11:46:19.000Z | articles/talent/includes/pre-release.md | MicrosoftDocs/Dynamics-365-Operations.fr-fr | 9f97b0553ee485dfefc0a57ce805f740f4986a7e | [
"CC-BY-4.0",
"MIT"
] | 1 | 2019-10-12T18:19:20.000Z | 2019-10-12T18:19:20.000Z | ---
ms.openlocfilehash: ed9aaca259bc81546045a1cddae368665d5b7e6c6335dccd769965e1c28dbf77
ms.sourcegitcommit: 42fe9790ddf0bdad911544deaa82123a396712fb
ms.translationtype: HT
ms.contentlocale: fr-FR
ms.lasthandoff: 08/05/2021
ms.locfileid: "6735726"
---
> [!IMPORTANT]
> Cette fonctionnalité est disponible dans Platform update 15 (7.0.4841) pour Finance and Operations ou versions ultérieures. Cette mise à jour est actuellement disponible pour des clients ciblés et sera proposée à tous les utilisateurs en juin 2018.
| 47.090909 | 250 | 0.830116 | fra_Latn | 0.833694 |
c0ad1abb0ced0a2c1f2bdf517635e30decc71817 | 8,830 | md | Markdown | reports/contributing-to-github/README.md | r-wilder/skuid-labs | 4cd9a8abcb76fa1bc63a38883162eff2b75e2699 | [
"MIT"
] | 10 | 2019-04-09T19:42:58.000Z | 2022-02-16T11:03:48.000Z | reports/contributing-to-github/README.md | r-wilder/skuid-labs | 4cd9a8abcb76fa1bc63a38883162eff2b75e2699 | [
"MIT"
] | 37 | 2019-04-24T19:08:04.000Z | 2022-02-07T22:52:42.000Z | reports/contributing-to-github/README.md | r-wilder/skuid-labs | 4cd9a8abcb76fa1bc63a38883162eff2b75e2699 | [
"MIT"
] | 11 | 2019-04-09T19:43:07.000Z | 2021-07-15T17:15:47.000Z | # Contributing to Github using only Github
Typically, developers who contribute to a central source code repository like Github have a series of tools required to do local development. However, the tools used for local development (code editors, terminal commands, git clients, etc.) can sometimes be an obstacle to submitting work.
Since Skuid Labs consists mainly of READMEs, Skuid pages, and short code snippets, there's often not a need for a complex development setup. And since it's possible to work and submit content entirely through the Github website, we wanted to show people how to submit their ideas faster.
Follow along with the instructions below to learn how to **submit pull requests to Skuid Labs (or other repos) using just your web browser and the Github UI.**
## Creating your branch
**Step 1. Go to the SkuidLabs repo.**
Remember: https://github.com/skuid/skuid-labs
**If you are not a Skuid Labs contributor, then you'll need to fork this repo.**
This just means that you'll have a copy of the repo associated with *your* Github account, since you may not have access to the Skuid organization's copy of the repo.
You'll still be able to submit your changes easily! For now, create the fork.
Click the **Fork** buton.

You'll be asked where you want your fork to be made. This is only relevant if you have multiple accounts or are associated with another organization. Select your Github account.

From here, continue following the steps to make your changes on your fork. Don't worry, you'll be able to submit the changes from your fork into our main repo later on!
**Step 2. Create a new branch or select your existing one.**
Don't try to edit documents in the `master` branch. This is bad practice, and our repo doesn't allow it anyway.
Instead, **open the branch selector button** and type the name of a new branch. You'll see an option to create a new branch if the name you entered matches no existing branches. Of course, you can also select a branch you were already working on.

**Step 3. Navigate to the directory where you want to create your new document.**

**Step 4. Click `Create new file`.**
**Step 5. Start typing name of new directory and README file.**
- You can create the directory for you submission when you create your README file. When you type a forward slash (`/`) Github will interpret this as a new directory, create that directory, and expose a new text box for your file name. Repeat as needed.
- Backspace to get back and edit the directory name
- The first file you create should be `README.md`
- Be careful. Once you've created a file, it is difficult to change the directory name.

**Step 6. Write your document using Markdown syntax.**
- [Here is a helpful document](https://help.github.com/en/github/writing-on-github/basic-writing-and-formatting-syntax) for styling your document using Markdown
- Preview your changes as you work.

**Step 7. Commit your changes early and often.**
- Scroll to the bottom of your document.
- Write a commit message.
- Select the `Commit directly to the <<branch name>> branch` option.

**Step 8. After committing - you will have to click edit to keep working.**
- Look for the edit pencil in the title bar for your file.
## Adding images and other files
Commit your README file and navigate to the directory your created. You want to make sure images and other files related to your experiment are in the same directory as your README file.
**Step 9. Click the `Add Files` button and drag files into the big box**

Upload the rest of your experiment or report files from here. Including:
- Sample page XML, as well as any other JS or CSS files, in the same way.
- Alternatively, create a new file with an `.XML` file extension, and then copy your page XML into that new file.
- Design system zip files
- JavaScript files for custom components, snippets, or formula functions
- CSS files
After uploading you need to commit these files to your repo. Make sure your commit message is suitably snarky.
**Step 10. Edit your README file to include relative links to the images you just uploaded.**
- Like this: ``
**Step 11. Rinse and repeat until you have it just perfect.**
- Commit your work and look it over one last time.
- Makes sure it looks perfect in your branch.
## Open a pull request for review and approval.
Github provides really good tools for collaborative review and editing. The `pull request` mechanism gets this started. This is a request to the maintainers of this repo to "pull" your code into the `master` branch.
**Step 12. Create a pull request**
- Navigate to the directory where all your work is contained.
- Click `pull request` in header bar of the directory.

**Step 13. Fill out pull request**
If you're a Skuid Labs contributor, your screen will look like this:

If you had to create a fork in the beginner, your screen will look like this:

But the process is the same! Just make sure your base repository is set to the main repo, in our case `skuid/skuid-labs`.
- Make sure you are merging `Your Branch` to `master`.
- Github allows for super complex branching, but there is no need to get into all that here.
- Document what you are trying to do in the title and description.
- Don't simply copy your README in this description.
- Click the :gear: next to `Reviewers` to request editorial approval.
- One of these reviewers will need to approve your work before merging to master and making available to the world.
- Skuid Labs has several code owners who are automatically assigned all pull requests. At least one of those code owners will also need to approve your pull request before it can be merged.
- Click `Create pull request`
- Email notifications will be sent to the reviewers you have requested
- You can send them a reminder on the back of a $20.00 bill.
**Step 14. Handle any linting errors.**
For some file types, Skuid Labs uses a **linter** known as ESLint. Linters ensure that code meets certain style guidelines. We try to maintain a certain level of consistency with the code in Labs, so we enforce a linter on all pull requests. That means if your code breaks the rules **you cannot merge your pull request**.
But fear not! Our linter outputs exactly what's wrong, in which file and on which line.
To see what went wrong, go to the bottom of your PR page to see if all the checks have passed for your build. Builds run whenever you commit to the branch, checking your code to make sure it doesn't break the linting rules.
A failed build looks like this. To see what went wrong, click **Details** where it noted the build failed.

You'll now see the log of that build. Within that log, you'll see what ESLint took issue with.

From there, navigate to the problematic file and fix the issues within the editor. Then create a new commit with your fixes.
This part of the process is easier to do locally, but it's still possible within the browser! Depending on the nature of your code, fixing one thing may uncover another, but such is life.
**Step 15. Handle the back and forth.**
Now the pull request is in play and you'll go back and forth with the editors in a pull request conversation.
- Use the **Pull requests** link at the top of Github's navbar to see the ones you have outstanding.

The reviewer will comment generally or will highlight specific areas of your code that needs to be improved.
- You will get an email when they have commented.
- You can also just check your pull request.
- Icons in the list will indicate when there have been comments or approvals.
- Adjust your code as requested by your reviewer.
- You can sometimes accept recommendations directly in the pull request conversation and commit changes there.
- Other times you need to edit your code in the browser and commit it again.
- All this change history shows up in the `Commits` tab.

**Step 16. Glorious Approval!!**
When your reviewer has approved your new article you will get an email, or you will see the status change in the PR list.
- Your job is not done!
- At the bottom of the pull request screen look for the **Squash and Merge** button.
- Add a final commit message with a basic description of the project.
- Confirm the merge.

- After merging make sure you delete your original branch.

Celebrate your contribution to our code repository. :tada: :tada:
| 47.219251 | 322 | 0.756399 | eng_Latn | 0.999333 |
c0ae5d1d69f09ec6381731645c8bf21db67363ba | 277 | md | Markdown | README.md | Real-young/MyPC-Config | f1cc1cb4b95cad09a62a56e9a30e36feb4849766 | [
"MIT"
] | 2 | 2018-05-21T04:15:52.000Z | 2020-08-24T02:52:56.000Z | README.md | Real-young/MyPC-Config | f1cc1cb4b95cad09a62a56e9a30e36feb4849766 | [
"MIT"
] | null | null | null | README.md | Real-young/MyPC-Config | f1cc1cb4b95cad09a62a56e9a30e36feb4849766 | [
"MIT"
] | null | null | null | # MyPC-Config
This is my pc config
注意配置的时候是隐藏文件 .zshrc .vimrc
安装Vundle
```
git clone https://github.com/VundleVim/Vundle.vim.git ~/.vim/bundle/Vundle.vim
```
配置zshrc
https://github.com/halfo/lambda-mod-zsh-theme
把主题文件下载到 ~/.oh-my-zsh/themes 里面,然后修改 ~/.zshrc 文件,配置好主题名字即可
| 17.3125 | 78 | 0.732852 | yue_Hant | 0.602853 |
c0afbc052282e413967c427ec6d629f9c7a7487b | 1,370 | md | Markdown | docs/visual-basic/misc/bc30819.md | dhernandezb/docs.es-es | cf1637e989876a55eb3c57002818d3982591baf1 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/visual-basic/misc/bc30819.md | dhernandezb/docs.es-es | cf1637e989876a55eb3c57002818d3982591baf1 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | docs/visual-basic/misc/bc30819.md | dhernandezb/docs.es-es | cf1637e989876a55eb3c57002818d3982591baf1 | [
"CC-BY-4.0",
"MIT"
] | null | null | null | ---
title: ''<funciónmatemática1> ' no se ha declarado'
ms.date: 07/20/2015
f1_keywords:
- bc30819
- vbc30819
helpviewer_keywords:
- BC30819
ms.assetid: 4d30785f-a8fe-438a-846a-8e15ff3f49f5
ms.openlocfilehash: e9d68f88391a0901369a1c9ca07a109d1016ae0f
ms.sourcegitcommit: 6eac9a01ff5d70c6d18460324c016a3612c5e268
ms.translationtype: MT
ms.contentlocale: es-ES
ms.lasthandoff: 09/14/2018
ms.locfileid: "45596408"
---
# <a name="39ltmathfunction1gt39-is-not-declared"></a>'<funciónmatemática1> ' no se ha declarado
'\<funciónmatemática1 >' no se ha declarado. Función se ha movido a la clase System.Math y ahora se denomina '\<mathfunction2 >'.
Varias funciones que eran intrínsecas de Visual Basic en versiones anteriores se han movido a la <xref:System.Math?displayProperty=nameWithType> espacio de nombres. Esto hace que sus características estén disponibles de manera más general para todos los lenguajes de programación.
**Identificador de error:** BC30819
## <a name="to-correct-this-error"></a>Para corregir este error
- Utilice los métodos declarados en <xref:System.Math?displayProperty=nameWithType>.
## <a name="see-also"></a>Vea también
<xref:System.Math>
[Resumen de cambios de compatibilidad con elementos de programación](https://msdn.microsoft.com/library/0483590a-6309-449c-a2fa-effa26a03b95)
| 44.193548 | 283 | 0.770803 | spa_Latn | 0.809141 |
c0b065e296efdbb40c1fee0172d7af0fb7507f32 | 2,490 | md | Markdown | course/12_Functions.md | hrueger/typescript-course | 505e8265b8babf49bc06fd9020bc7988561f140c | [
"MIT"
] | null | null | null | course/12_Functions.md | hrueger/typescript-course | 505e8265b8babf49bc06fd9020bc7988561f140c | [
"MIT"
] | null | null | null | course/12_Functions.md | hrueger/typescript-course | 505e8265b8babf49bc06fd9020bc7988561f140c | [
"MIT"
] | 1 | 2019-12-12T20:23:50.000Z | 2019-12-12T20:23:50.000Z | # Functions
We need some way to "bundle" code we want to use multiple times. Functions can handle this job and look like this:
```typescript
function greet() {
console.log("Hello");
}
```
It is just the word `function` followed by the name of your function. You can choose any name you want, although the same rules as for variables apply. To remember: It's only letters and underscores. This name is then followed by parentheses. The code which is inside the function is surrounded by curly brackets.
The code above is just the definition of the function. If we run the code like this, it won't do anything. We need to call our function in order to execute it. This is done like so:
```typescript
greet();
```
Now you should get the output `Hello`.
But what if we want to process the result of a function further and not directly output it? We can `return` it. Just like this:
```typescript
function addOneAndThree() {
return 1 + 3;
}
```
If we run this function with `addOneAndThree()`, nothing happens. This is because the value is returned, but not used. To use it, we could either save it in a variable or give it to another function:
```typescript
let result = addOneAndThree();
// or
console.log(addOneAndThree());
```
We can also define the type of the returned value of our function using the `string`, `number` or other types, just like with variables:
```typescript
function addOneAndThree(): number {
return 1 + 3;
}
```
But what if we want to give our function some values? We can do this with parameters. That looks like this:
```typescript
function greet(nameOfPerson): string {
return "Hello " + nameOfPerson + "!";
}
var firstOneToGreet: string = "Peter";
console.log(greet(firstOneToGreet));
console.log(greet("Tom"));
```
We can also define the types of the parameters:
```typescript
function greet(nameOfPerson: string): string {
return "Hello " + nameOfPerson + "!";
}
```
This way, if we try to greet a number, the TypeScript compiler will warn us.
## Exercise 1
Create a function which takes a name (string) and an age (number) as parameters and prints `name is x years old.`
## Exercise 2
Create a function which takes two numbers as parameters and prints if the product of those numbers is greater than 100 or not.
## Exercise 3
Create a function which multiplies three parameters and returns the result. Then multiply the returned value with 3 and print the result.
---
Then, go on with the [next chapter](./13_TemplateStrings.md). | 38.307692 | 313 | 0.738956 | eng_Latn | 0.999169 |
c0b1c55be7e97bc1d0f0d1263c5dc6fa32cff692 | 340 | md | Markdown | README.md | thomasleese/mylang | 8a09a2894c04942100ab0ffd88c16857a7417ffd | [
"MIT"
] | 1 | 2019-11-16T10:26:49.000Z | 2019-11-16T10:26:49.000Z | README.md | thomasleese/mylang | 8a09a2894c04942100ab0ffd88c16857a7417ffd | [
"MIT"
] | null | null | null | README.md | thomasleese/mylang | 8a09a2894c04942100ab0ffd88c16857a7417ffd | [
"MIT"
] | null | null | null | # MyLang
_An experiment to make my own programming language… might turn into something in the future._
## Building
You can build the compiler with cmake:
$ cd compiler
$ mkdir build
$ cd build
$ cmake ..
## Running
You should be able to run the compiler like this:
$ ./compiler/build/Compiler tests/maths
| 17 | 100 | 0.697059 | eng_Latn | 0.996148 |
c0b1c793359101e64b265f5be68e6f79a1eb41cb | 764 | md | Markdown | catalog/he-nshin-sonata-birdie-rush/en-US_he-nshin-sonata-birdie-rush.md | htron-dev/baka-db | cb6e907a5c53113275da271631698cd3b35c9589 | [
"MIT"
] | 3 | 2021-08-12T20:02:29.000Z | 2021-09-05T05:03:32.000Z | catalog/he-nshin-sonata-birdie-rush/en-US_he-nshin-sonata-birdie-rush.md | zzhenryquezz/baka-db | da8f54a87191a53a7fca54b0775b3c00f99d2531 | [
"MIT"
] | 8 | 2021-07-20T00:44:48.000Z | 2021-09-22T18:44:04.000Z | catalog/he-nshin-sonata-birdie-rush/en-US_he-nshin-sonata-birdie-rush.md | zzhenryquezz/baka-db | da8f54a87191a53a7fca54b0775b3c00f99d2531 | [
"MIT"
] | 2 | 2021-07-19T01:38:25.000Z | 2021-07-29T08:10:29.000Z | # He~nshin!!: Sonata Birdie Rush

- **type**: manga
- **volumes**: 5
- **chapters**: 28
- **original-name**: へ~ん・しん!! そなたバーディ・ラッシュ
- **start-date**: 2008-05-01
- **end-date**: 2008-05-01
## Tags
- ecchi
- sports
- seinen
## Authors
- Minazuki
- Suu (Story & Art)
## Sinopse
Hayama Sonata has been a pro golfer for two years, but not many know who she is because she lost in the preliminaries of her last tournament. She unfortunately hasn't had a sponsor because of that so now she can't play in any tournaments because of the debt her parents left her.
## Links
- [My Anime list](https://myanimelist.net/manga/18263/Henshin__Sonata_Birdie_Rush)
| 25.466667 | 279 | 0.684555 | eng_Latn | 0.946531 |
c0b1e4dff8c50eb886f423df0fb17ae007ddcd0c | 131 | md | Markdown | _carousel_images/innemo3.md | SuperNEMO-DBD/SuperNEMO-DBD.github.io | 96c5df1630b2dfd95d55e31ad1f78228c3c1a54f | [
"MIT"
] | null | null | null | _carousel_images/innemo3.md | SuperNEMO-DBD/SuperNEMO-DBD.github.io | 96c5df1630b2dfd95d55e31ad1f78228c3c1a54f | [
"MIT"
] | 28 | 2017-02-24T17:41:41.000Z | 2020-02-14T14:59:22.000Z | _carousel_images/innemo3.md | SuperNEMO-DBD/SuperNEMO-DBD.github.io | 96c5df1630b2dfd95d55e31ad1f78228c3c1a54f | [
"MIT"
] | 7 | 2017-03-02T18:52:07.000Z | 2020-01-16T15:39:58.000Z | ---
image_url: "assets/carousel/inside_nemo3.jpg"
detail:
The interior of the NEMO-3 detector (taken during decommissioning)
---
| 21.833333 | 68 | 0.755725 | eng_Latn | 0.77882 |
c0b252e5fe15adcb4159320ea3f725b7ca01b638 | 286 | md | Markdown | aboutme.md | lysannep/my-website | cfbc2cf7aec4b08990b35484e875aa5606686659 | [
"MIT"
] | null | null | null | aboutme.md | lysannep/my-website | cfbc2cf7aec4b08990b35484e875aa5606686659 | [
"MIT"
] | null | null | null | aboutme.md | lysannep/my-website | cfbc2cf7aec4b08990b35484e875aa5606686659 | [
"MIT"
] | null | null | null | ---
layout: page
title: About me
subtitle: Hello! 👋 I'm Lysanne Pinto
---
💻 I'm a technical writer and instructional designer.
☁️ Currently writing for [Snow Software](https://www.snowsoftware.com)'s cloud management solution.
🌱 Learning how to implement docs-as-code solutions.
| 23.833333 | 99 | 0.734266 | eng_Latn | 0.973375 |
c0b2834fb31513dd63b5c39523c876bea6f644af | 650 | md | Markdown | catalog/kamisama-no-memochou/en-US_kamisama-no-memochou-manga.md | htron-dev/baka-db | cb6e907a5c53113275da271631698cd3b35c9589 | [
"MIT"
] | 3 | 2021-08-12T20:02:29.000Z | 2021-09-05T05:03:32.000Z | catalog/kamisama-no-memochou/en-US_kamisama-no-memochou-manga.md | zzhenryquezz/baka-db | da8f54a87191a53a7fca54b0775b3c00f99d2531 | [
"MIT"
] | 8 | 2021-07-20T00:44:48.000Z | 2021-09-22T18:44:04.000Z | catalog/kamisama-no-memochou/en-US_kamisama-no-memochou-manga.md | zzhenryquezz/baka-db | da8f54a87191a53a7fca54b0775b3c00f99d2531 | [
"MIT"
] | 2 | 2021-07-19T01:38:25.000Z | 2021-07-29T08:10:29.000Z | # Kamisama no Memochou

- **type**: manga
- **volumes**: 3
- **chapters**: 23
- **original-name**: 神様のメモ帳
- **start-date**: 2010-06-26
- **end-date**: 2010-06-26
## Tags
- comedy
- mystery
- drama
- romance
## Authors
- Sugii
- Hikaru (Story)
- Tiv (Art)
## Sinopse
Adaptation from the light novel of the same name-a heartfelt series that revolves around a student who happens to intrude upon a NEET detective and became her assistant.
(Source: MU)
## Links
- [My Anime list](https://myanimelist.net/manga/23779/Kamisama_no_Memochou)
| 19.117647 | 169 | 0.666154 | eng_Latn | 0.669144 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.