Old Maps, New Terrain: Updating Labour Taxonomies for the AI Era By frimelle and 1 other • 7 days ago • 13
NVIDIA Releases 3 Million Sample Dataset for OCR, Visual Question Answering, and Captioning Tasks By nvidia and 4 others • 15 days ago • 67
Supercharge Edge AI With High‑Accuracy Reasoning Using NVIDIA Nemotron Nano 2 9B By nvidia and 9 others • 8 days ago • 21
What’s MXFP4? The 4-Bit Secret Powering OpenAI’s GPT‑OSS Models on Modest Hardware By RakshitAralimatti • 18 days ago • 18
AutoBench Third Run: Revolutionizing LLM Evaluation with Record-Breaking Scale, Accuracy, and a New Home at autobench.org By PeterKruger • 7 days ago • 6
Luth: Efficient French Specialization for Small Language Models By MaxLSB and 1 other • 16 days ago • 14
How To Build a News Agent with GPT-OSS, Hugging Face Inference & Gradio By fdaudens • 12 days ago • 21
DeepSeek-R1 Dissection: Understanding PPO & GRPO Without Any Prior Reinforcement Learning Knowledge By NormalUhr • Feb 7 • 211
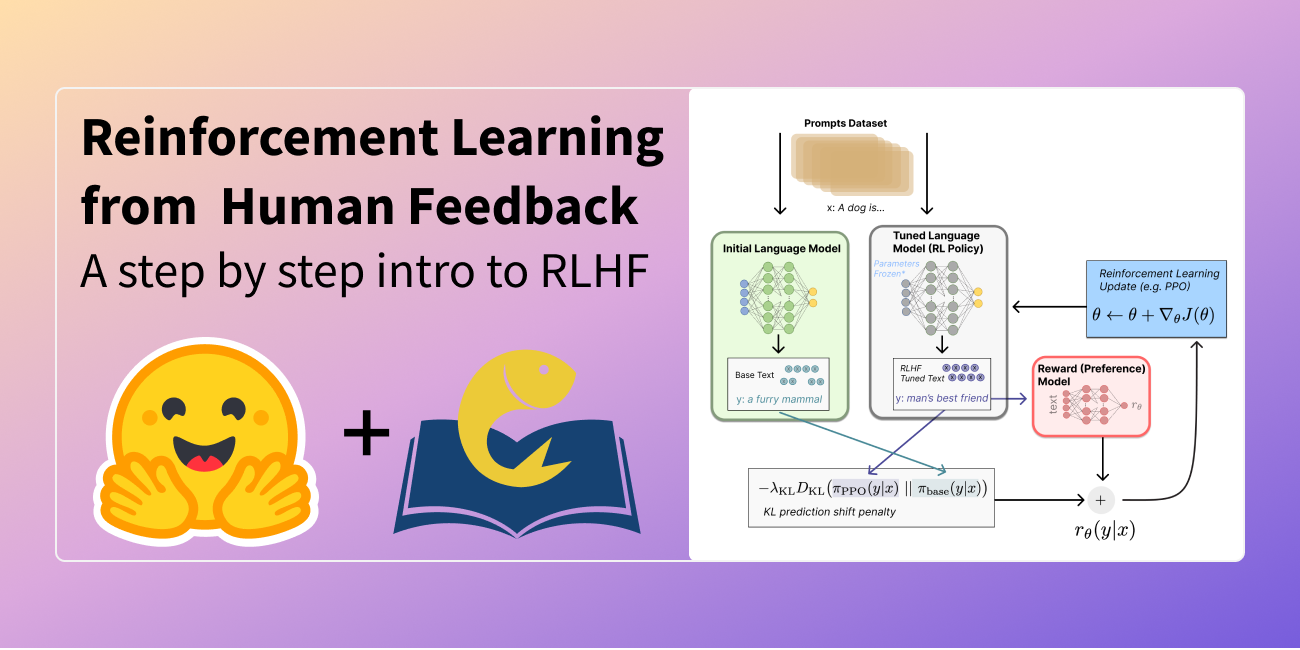
Navigating the RLHF Landscape: From Policy Gradients to PPO, GAE, and DPO for LLM Alignment By NormalUhr • Feb 11 • 61
Old Maps, New Terrain: Updating Labour Taxonomies for the AI Era By frimelle and 1 other • 7 days ago • 13
NVIDIA Releases 3 Million Sample Dataset for OCR, Visual Question Answering, and Captioning Tasks By nvidia and 4 others • 15 days ago • 67
Supercharge Edge AI With High‑Accuracy Reasoning Using NVIDIA Nemotron Nano 2 9B By nvidia and 9 others • 8 days ago • 21
What’s MXFP4? The 4-Bit Secret Powering OpenAI’s GPT‑OSS Models on Modest Hardware By RakshitAralimatti • 18 days ago • 18
AutoBench Third Run: Revolutionizing LLM Evaluation with Record-Breaking Scale, Accuracy, and a New Home at autobench.org By PeterKruger • 7 days ago • 6
Luth: Efficient French Specialization for Small Language Models By MaxLSB and 1 other • 16 days ago • 14
How To Build a News Agent with GPT-OSS, Hugging Face Inference & Gradio By fdaudens • 12 days ago • 21
DeepSeek-R1 Dissection: Understanding PPO & GRPO Without Any Prior Reinforcement Learning Knowledge By NormalUhr • Feb 7 • 211
Navigating the RLHF Landscape: From Policy Gradients to PPO, GAE, and DPO for LLM Alignment By NormalUhr • Feb 11 • 61