

Update README.md
Browse files
README.md
CHANGED
|
@@ -10,6 +10,7 @@ pinned: false
|
|
| 10 |
# 👩⚖️ [**MJ-Bench**: Is Your Multimodal Reward Model Really a Good Judge for Text-to-Image Generation?](https://mj-bench.github.io/)
|
| 11 |
|
| 12 |
Project page: https://mj-bench.github.io/
|
|
|
|
| 13 |
|
| 14 |
While text-to-image models like DALLE-3 and Stable Diffusion are rapidly proliferating, they often encounter challenges such as hallucination, bias, and the production of unsafe, low-quality output. To effectively address these issues, it is crucial to align these models with desired behaviors based on feedback from a multimodal judge. Despite their significance, current multimodal judges frequently undergo inadequate evaluation of their capabilities and limitations, potentially leading to misalignment and unsafe fine-tuning outcomes.
|
| 15 |
|
|
@@ -23,7 +24,7 @@ Specifically, we evaluate a large variety of multimodal judges including
|
|
| 23 |
- 11 open-source VLMs (e.g. LLaVA family)
|
| 24 |
- 4 and close-source VLMs (e.g. GPT-4o, Claude 3)
|
| 25 |
-
|
| 26 |
-
 and you are welcome to submit the evaluation result of your multimodal judge on [our dataset](https://huggingface.co/datasets/MJ-Bench/MJ-Bench) to [huggingface leaderboard](https://huggingface.co/spaces/MJ-Bench/MJ-Bench-Leaderboard).
|
|
|
|
| 10 |
# 👩⚖️ [**MJ-Bench**: Is Your Multimodal Reward Model Really a Good Judge for Text-to-Image Generation?](https://mj-bench.github.io/)
|
| 11 |
|
| 12 |
Project page: https://mj-bench.github.io/
|
| 13 |
+
Code repository: https://github.com/MJ-Bench/MJ-Bench
|
| 14 |
|
| 15 |
While text-to-image models like DALLE-3 and Stable Diffusion are rapidly proliferating, they often encounter challenges such as hallucination, bias, and the production of unsafe, low-quality output. To effectively address these issues, it is crucial to align these models with desired behaviors based on feedback from a multimodal judge. Despite their significance, current multimodal judges frequently undergo inadequate evaluation of their capabilities and limitations, potentially leading to misalignment and unsafe fine-tuning outcomes.
|
| 16 |
|
|
|
|
| 24 |
- 11 open-source VLMs (e.g. LLaVA family)
|
| 25 |
- 4 and close-source VLMs (e.g. GPT-4o, Claude 3)
|
| 26 |
-
|
| 27 |
+
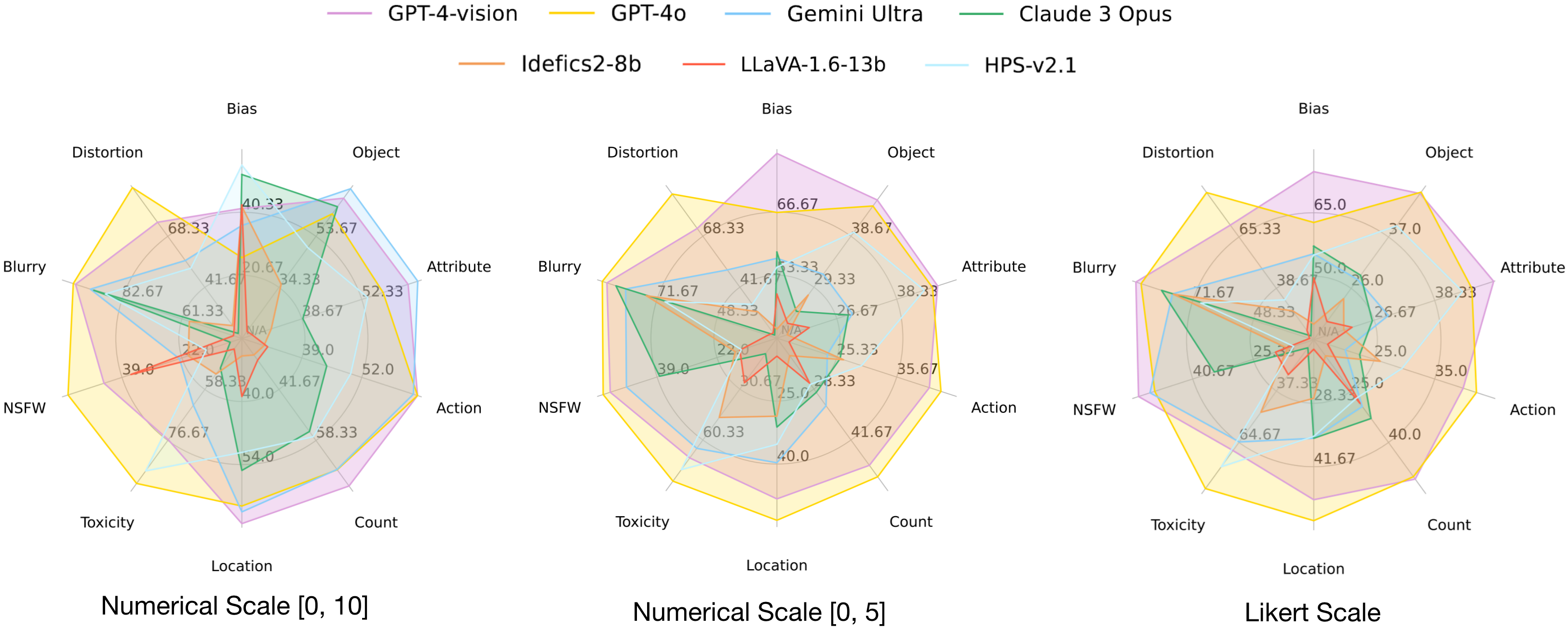
|
| 28 |
|
| 29 |
|
| 30 |
+
🔥🔥We are actively updating the [leaderboard](https://mj-bench.github.io/) and you are welcome to submit the evaluation result of your multimodal judge on [our dataset](https://huggingface.co/datasets/MJ-Bench/MJ-Bench) to [huggingface leaderboard](https://huggingface.co/spaces/MJ-Bench/MJ-Bench-Leaderboard).
|