Accurate & efficient vision models, ops and systems
AI & ML interests
Computer Vision, AI, Machine Learning
Recent Activity
View all activity
Papers

IMG: Calibrating Diffusion Models via Implicit Multimodal Guidance
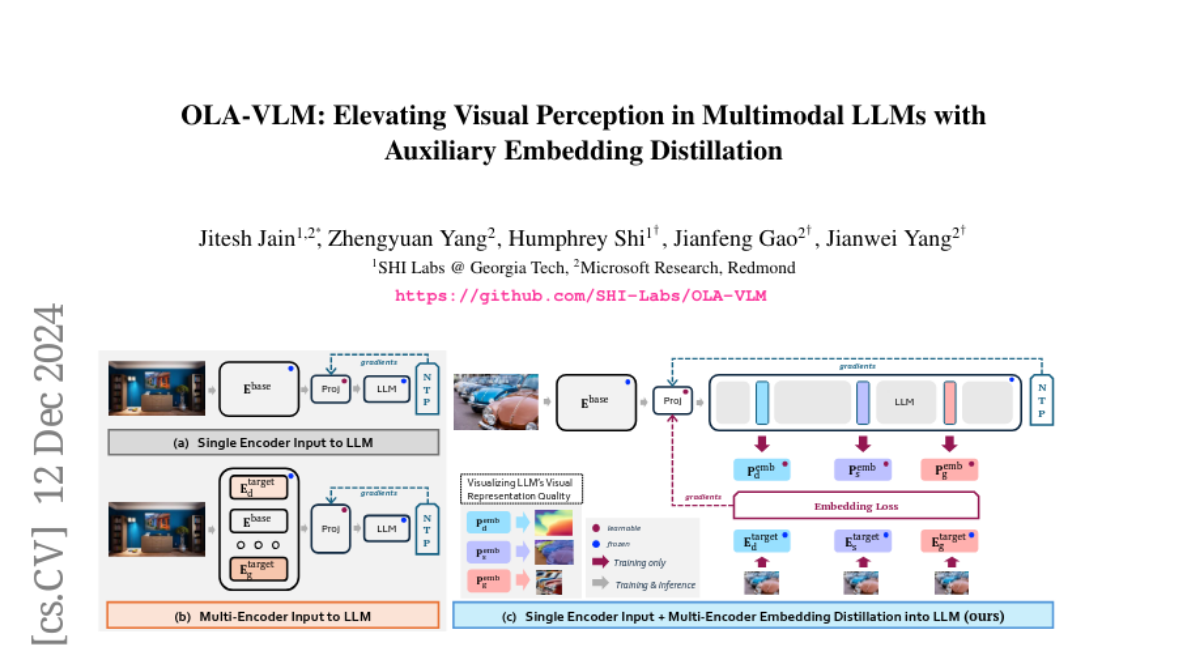
OLA-VLM: Elevating Visual Perception in Multimodal LLMs with Auxiliary Embedding Distillation
spaces
11
pinned
Running
5
Physical AI Bench Leaderboard
🤖
Benchmark for Physical AI generation and understanding
Running
on
Zero
5
VisPer-LM
🔍
Visualize image depth, segmentation, and generation
Runtime error
Slow Fast Video Mllm
👁
Describe video content with text prompts
Runtime error
Featured
408
Versatile Diffusion
🚀
Runtime error
Featured
63
VCoder
✌
Build error
10
Smooth Diffusion
🏆
models
57

shi-labs/IMG
Updated
•
1
shi-labs/slowfast-video-mllm-qwen2-7b-convnext-576-frame64-s1t4
Video-Text-to-Text
•
9B
•
Updated
•
46
shi-labs/slowfast-video-mllm-qwen2-7b-convnext-576-frame96-s1t6
Video-Text-to-Text
•
9B
•
Updated
•
8
shi-labs/slowfast-video-mllm-qwen2-7b-convnext-576-frame128-s2t4
9B
•
Updated
•
5
shi-labs/probe_depth_ola-vlm-pt-ift
Image-Text-to-Text
•
10B
•
Updated
•
4
shi-labs/probe_gen_ola-vlm-pt-ift
Image-Text-to-Text
•
9B
•
Updated
•
8
shi-labs/probe_gen_llava-1.5-pt-vpt-ift
Image-Text-to-Text
•
9B
•
Updated
•
8
shi-labs/probe_gen_llava-1.5-pt
Image-Text-to-Text
•
9B
•
Updated
•
5
shi-labs/probe_gen_llava-1.5-pt-0.5ift
Image-Text-to-Text
•
9B
•
Updated
•
10
shi-labs/probe_gen_llava-1.5-pt-ift
Image-Text-to-Text
•
9B
•
Updated
•
8
datasets
8
shi-labs/physical-ai-bench-generation
Viewer
•
Updated
•
1.04k
•
1.01k
•
3
shi-labs/physical-ai-bench-conditional-generation
Viewer
•
Updated
•
600
•
2.32k
shi-labs/physical-ai-bench-understanding
Viewer
•
Updated
•
1.21k
•
826
shi-labs/Eagle-1.8M
Updated
•
112
•
7
shi-labs/Agriculture-Vision
Preview
•
Updated
•
38
•
3
shi-labs/CuMo_dataset
Preview
•
Updated
•
28
•
6
shi-labs/COST
Updated
•
226
•
4
shi-labs/oneformer_demo
Preview
•
Updated
•
97.9k