
![]()
项目仓库:https://github.com/svc-develop-team/so-vits-svc
项目来源:末日三问/末日时在做什么?有没有空?可以来拯救吗?/終末なにしてますか?忙しいですか?救ってもらっていいですか?
来自 中珂院炼金学分院 Q群:715311859
第一次实验简要记录(开炉失败 删除记录)
第二次实验简要记录(开炉失败 删除记录)
第三次实验简要记录
实验目标:
70%情况下,在入门级发烧HiFi设备下无法识别出与人类声音的区别
实验综述:
2022年5月3日,公布第三代模型,使用SoVits的768训练分支制作,共计1360epoch、189600step。
768分支训练方案的优点在于可以生成更加拟合目标声线的音频,但是缺点是训练困难且容易受到杂音干扰,经常会出现高音破音或者糊掉的情况。相比于1.0原版分支,768训练出来的模型不适合作为翻唱模型,反而更适合文本转语音的TTS/Vits→Audio的流程。
实验结论:
70%情况下,在入门级发烧HiFi设备下无法识别出与人类声音的区别(未达成)- 因为sovits在效果上只改变了说话人的声线,不改变具体的说话内容,所以推理参数调教得好的话可以适应几乎所有语种,至于TTS目前新出来了一个叫作Bark的具有情感功能的TTS人工智能,相信其在未来,可以为sovits的变声功能锦上添花。
第四次实验简要记录
实验目标:
70%情况下,在入门级发烧HiFi设备下无法识别出与人类声音的区别
实验综述:
2022年5月8日,更新第四代模型,Chtholly_V4
本次模型总结了上一炉Chtholly_V3的经验,使用SoVits的v1训练分支制作。
V1原版分支的好处在于,相比于768分支,具有更好的抗杂音抗干扰性能;但是对音色的拟合度会略微降低,在推理时需要花费更多时间进行调音。
本次模型添加了末日三问的广播剧,并对上次数据集进行精简,使其可以对珂朵莉系列模型的高音域容易破音问题作出了针对性调整。
添加了少量噪音数据,意图使其适应英文输出。
共计1379epoch、204800step。
- 以下是作者进行十分制打分的结果:
- 中文效果:7/10
- 日文效果:8/10
- 英文效果:6/10
实验结论:
70%情况下,在入门级发烧HiFi设备下无法识别出与人类声音的区别(未达成)- 在添加了不足二分钟的杂音音频情况下制作出的模型对于英文的平滑音适应性良好、对爆破音适应性良好、对过渡音不合格(存在跑调现象)、对长音适应性勉强达标
- 注:(本次 附 聚类模型)
第五次实验简要记录
实验目标:
60%情况下,在入门级发烧HiFi设备下无法识别出与人类声音的区别
实验综述:
2023年5月19日,公开用于第五代模型的数据集(取消噪音干涉)
数据集来源:番剧1-12集(有小概率混合了其他角色的台词,请见谅,本人也是尽可能筛掉,但不保证没有,几乎不影响使用)、广播剧1-6集
主要so-vits模型:采用768分支,在新底模型的基础上,炼制了两个不同版本,一个是21600Step的特殊“加料”版本(Chtholly_V5Sp)(添加了小部分重复推理的高音音频、多语种音频进行套娃式炼制,目的是追求音域适应性),一个是80800Step的通用版本(Chtholly_V5Co)(完全纯净的珂朵莉干声,去除了所有带有可分辨的底噪和电音的数据音频,目的是追求声线相似性)。
使用通用版第五代模型推理的音频已在Sound Similar Free中,测试达到99.9%声纹相似度。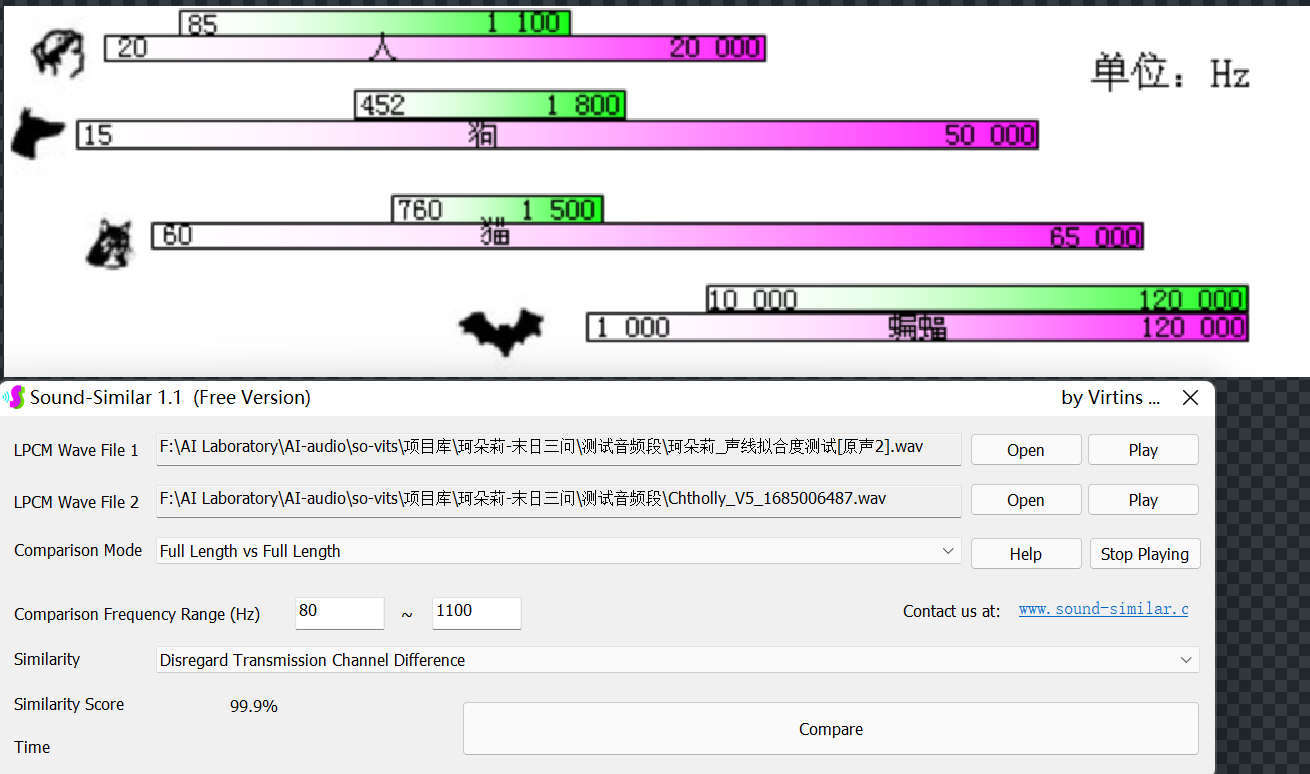
在某些特殊情况下(如干声中存在海豚音和过高音),使用特殊版本可以获得更好的推理效果。
而语音变声和普通的音声推理,使用通用版本即可。
聚类模型(标有kmeans的文件):用于提升音色相似度,但是会降低咬字清晰度。一般0.1-0.6之间均可,常用值0.1、0.2,仓库方推荐值0.5。
浅扩散模型(以.yaml作为后缀的配置文件和标有model的文件):用于歌声推理,可以一定程度上去除底噪和电音,目前使用52000Step版本下,可用值30-600均有可能。如果是推理TTS出来的纯语音,不建议开启浅扩散模型,因为根本没有底噪,所以开了也没有用处,反而会有小概率推理出来更离谱的鬼音。
建议推理参数:(在使用sovits进行TTS音频变声时)打开F0预测;变调[-3,6];F0均值滤波值域[0,0.9]、编码器Crepe;NSF-HIFIGAN增强器高音域适应值域[0,12](影响不如直接变调大)。
- 以下是作者进行十分制打分的结果:
- 中文效果:7/10
- 日文效果:9/10
- 英文效果:7/10
注意:
- 两个版本的模型在推理时最好打开NSF_HIFIGAN。
- 尽量使用通用版本,如果效果还是差强人意,再使用特殊版本。
- 后缀标记有“compressed”的模型是经过了体积压缩的模型,并不影响推理效果,但是无法再继续训练。
实验结论:
- 第四次实验的噪音其实可以通过控制数据集来达到同样效果,故而本次实验删除噪音
- 60%情况下,在入门级发烧HiFi设备下无法识别出与人类声音的区别(请调制好参数)
- 在添加了多语种音频后,模型会更快地失衡。因此,不要训练太多步。