
focalcodec
Collection
4 items
•
Updated
A low-bitrate single-codebook 16 kHz speech codec based on focal modulation.
This repository contains the 25 Hz checkpoint trained on LibriTTS 960, as described in the preprint.
📜 Preprint: https://arxiv.org/abs/2502.04465
🌐 Project Page: https://lucadellalib.github.io/focalcodec-web/
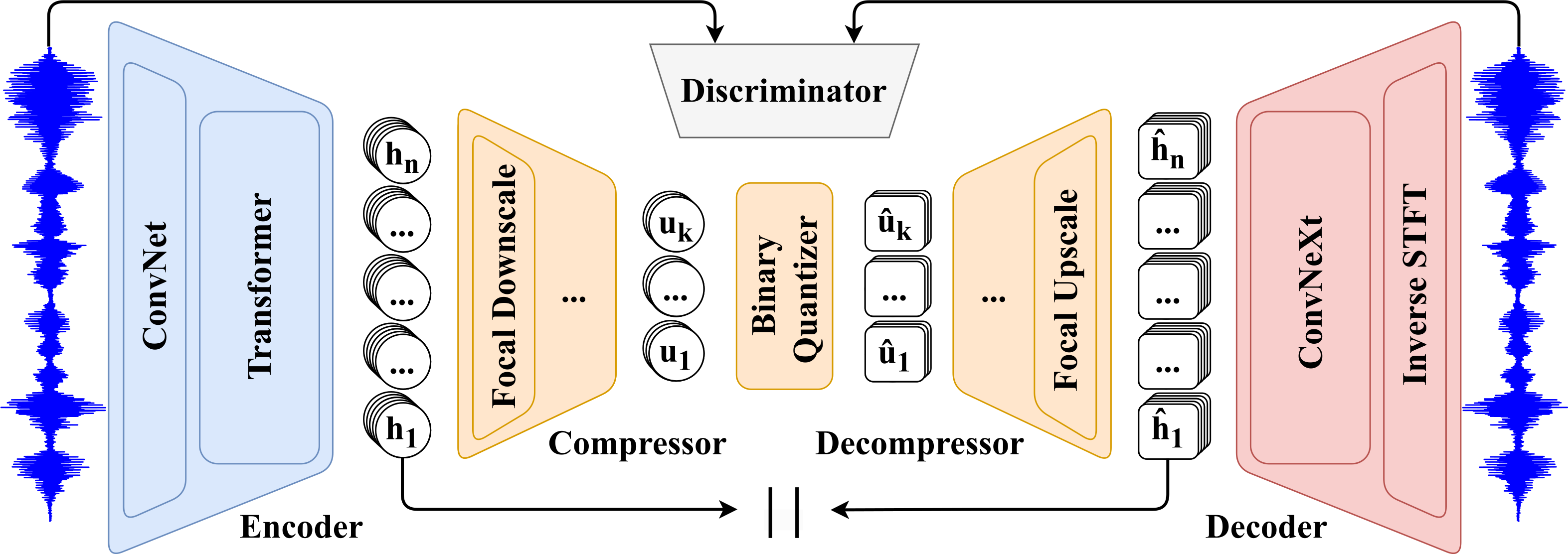
See the readme at: https://github.com/lucadellalib/focalcodec
@article{dellalibera2025focalcodec,
title = {{FocalCodec}: Low-Bitrate Speech Coding via Focal Modulation Networks},
author = {Luca {Della Libera} and Francesco Paissan and Cem Subakan and Mirco Ravanelli},
journal = {arXiv preprint arXiv:2502.04465},
year = {2025},
}
Base model
microsoft/wavlm-large