
| # MS MARCO | |
| [MS MARCO Passage Ranking](https://github.com/microsoft/MSMARCO-Passage-Ranking) is a large dataset to train models for information retrieval. It consists of about 500k real search queries from Bing search engine with the relevant text passage that answers the query. | |
| This pages shows how to **train** models (Cross-Encoder and Sentence Embedding Models) on this dataset so that it can be used for searching text passages given queries (key words, phrases or questions). | |
| If you are interested in how to use these models, see [Application - Retrieve & Re-Rank](../../applications/retrieve_rerank/README.md). | |
| There are **pre-trained models** available, which you can directly use without the need of training your own models. For more information, see: [Pretrained Models](https://www.sbert.net/docs/pretrained_models.html) | [Pretrained Cross-Encoders](https://www.sbert.net/docs/pretrained_cross-encoders.html) | |
| ## Bi-Encoder | |
| Cross-Encoder are only suitable for reranking a small set of passages. For retrieval of suitable documents from a large collection, we have to use a bi-encoder. The documents are independently encoded into fixed-sized embeddings. A query is embedded into the same vector space. Relevant documents can then be found by using dot-product. | |
| 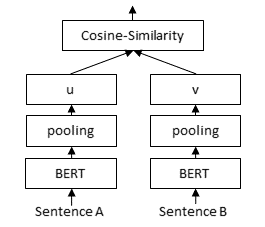 | |
| There are two strategies to **train an bi-encoder** on the MS MARCO dataset: | |
| ### MultipleNegativesRankingLoss | |
| **Training code: [train_bi-encoder_mnrl.py](train_bi-encoder_mnrl.py)** | |
| When we use [MultipleNegativesRankingLoss](https://www.sbert.net/docs/package_reference/losses.html#multiplenegativesrankingloss), we provide triplets: ``(query, positive_passage, negative_passage)`` where `positive_passage` is the relevant passage to the query and `negative_passage` is a non-relevant passage to the query. | |
| We compute the embeddings for all queries, positive passages, and negative passages in the corpus and then optimize the following objective: We want to have the `(query, positive_passage)` pair to be close in the vector space, while `(query, negative_passage)` should be distant in vector space. | |
| To further improve the training, we use **in-batch negatives**: | |
| 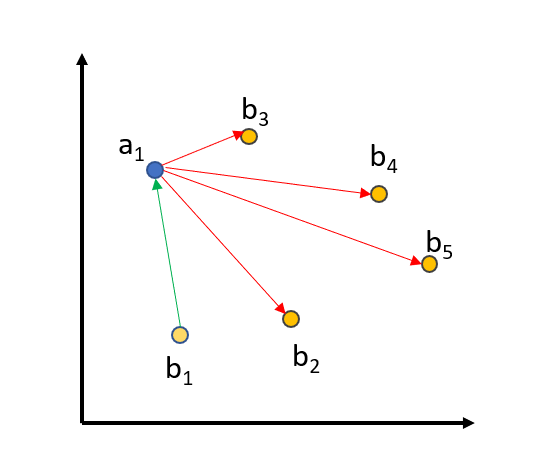 | |
| We embed all `queries`, `positive_passages`, and `negative_passages` into the vector space. The matching `(query_i, positive_passage_i)` should be close, while there should be a large distance between a `query` and all other (positive/negative) passages from all other triplets in a batch. For a batch size of 64, we compare a query against 64+64=128 passages, from which only one passage should be close and the 127 others should be distant in vector space. | |
| One way to **improve training** is to choose really good negatives, also know as **hard negative**: The negative should look really similar to the positive passage, but it should not be relevant to the query. | |
| We find these hard negatives in the following way: We use existing retrieval systems (e.g. lexical search and other bi-encoder retrieval systems), and for each query we find the most relevant passages. We then use a powerful [Cross-Encoder](../../applications/cross-encoder/README.md) to score the found `(query, passage)` pairs. We provide scores for 160 million such pairs in our [msmarco-hard-negatives dataset](https://huggingface.co/datasets/sentence-transformers/msmarco-hard-negatives). | |
| For MultipleNegativesRankingLoss, we must ensure that in the triplet `(query, positive_passage, negative_passage)` that the `negative_passage` is actually not relevant for the query. The MS MARCO dataset is sadly **highly redundant**, and even though that there is on average only one passage marked as relevant for a query, it actually contains many passages that humans would consider as relevant. We must ensure that these passages are **not passed as negatives**: We do this by ensuring a certain threshold in the CrossEncoder scores between the relevant passages and the mined hard negative. By default, we set a threshold of 3: If the `(query, positive_passage)` gets a score of 9 from the CrossEncoder, than we will only consider negatives with a score below 6 from the CrossEncoder. This threshold ensures that we actually use negatives in our triplets. | |
| ### MarginMSE | |
| **Training code: [train_bi-encoder_margin-mse.py](train_bi-encoder_margin-mse.py)** | |
| [MarginMSELoss](https://www.sbert.net/docs/package_reference/losses.html#marginmseloss) is based on the paper of [Hofstätter et al](https://arxiv.org/abs/2010.02666). As for MultipleNegativesRankingLoss, we have triplets: `(query, passage1, passage2)`. In contrast to MultipleNegativesRankingLoss, `passage1` and `passage2` do not have to be strictly positive/negative, both can be relevant or not relevant for a given query. | |
| We then compute the [Cross-Encoder](../../applications/cross-encoder/README.md) score for `(query, passage1)` and `(query, passage2)`. We provide scores for 160 million such pairs in our [msmarco-hard-negatives dataset](https://huggingface.co/datasets/sentence-transformers/msmarco-hard-negatives). We then compute the distance: `CE_distance = CEScore(query, passage1) - CEScore(query, passage2)` | |
| For our bi-encoder training, we encode `query`, `passage1`, and `passage2` into vector spaces and then measure the dot-product between `(query, passage1)` and `(query, passage2)`. Again, we measure the distance: `BE_distance = DotScore(query, passage1) - DotScore(query, passage2)` | |
| We then want to ensure that the distance predicted by the bi-encoder is close to the distance predicted by the cross-encoder, i.e., we optimize the mean-squared error (MSE) between `CE_distance` and `BE_distance`. | |
| An **advantage** of MarginMSELoss compared to MultipleNegativesRankingLoss is that we **don't require** a `positive` and `negative` passage. As mentioned before, MS MARCO is redundant, and many passages contain the same or similar content. With MarginMSELoss, we can train on two relevant passages without issues: In that case, the `CE_distance` will be smaller and we expect that our bi-encoder also puts both passages closer in the vector space. | |
| And **disadvantage** of MarginMSELoss is the slower training time: We need way more epochs to get good results. In MultipleNegativesRankingLoss, with a batch size of 64, we compare one query against 128 passages. With MarginMSELoss, we compare a query only against two passages. | |
| ## Cross-Encoder | |
| A [Cross-Encoder](https://www.sbert.net/examples/applications/cross-encoder/README.html) accepts both inputs, the query and the possible relevant passage and returns a score between 0 and 1 how relevant the passage is for the given query. | |
| 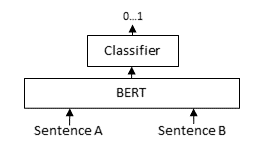 | |
| Cross-Encoders are often used for **re-ranking:** Given a list with possible relevant passages for a query, for example retrieved from BM25 / ElasticSearch, the cross-encoder re-ranks this list so that the most relevant passages are the top of the result list. | |
| To **train an cross-encoder** on the MS MARCO dataset, see: | |
| - **[train_cross-encoder_scratch.py](train_cross-encoder_scratch.py)** trains a cross-encoder from scratch using the provided data from the MS MARCO dataset. | |
| ## Cross-Encoder Knowledge Distillation | |
|  | |
| - **[train_cross-encoder_kd.py](train_cross-encoder_kd.py)** uses a knowledge distillation setup: [Hostätter et al.](https://arxiv.org/abs/2010.02666) trained an ensemble of 3 (large) models for the MS MARCO dataset and predicted the scores for various (query, passage)-pairs (50% positive, 50% negative). In this example, we use knowledge distillation with a small & fast model and learn the logits scores from the teacher ensemble. This yields performances comparable to large models, while being 18 times faster. |