
| # Pretrained Cross-Encoders | |
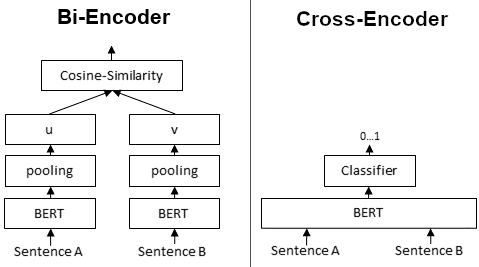
| This page lists available **pretrained Cross-Encoders**. Cross-Encoders require the input of a text pair and output a score 0...1. They do not work for individual sentences and they don't compute embeddings for individual texts. | |
|  | |
| ## MS MARCO | |
| [MS MARCO Passage Retrieval](https://github.com/microsoft/MSMARCO-Passage-Ranking) is a large dataset with real user queries from Bing search engine with annotated relevant text passages. | |
| These models can be used like this: | |
| ```python | |
| from sentence_transformers import CrossEncoder | |
| model = CrossEncoder('model_name', max_length=512) | |
| scores = model.predict([('Query1', 'Paragraph1'), ('Query1', 'Paragraph2')]) | |
| #For Example | |
| scores = model.predict([('How many people live in Berlin?', 'Berlin had a population of 3,520,031 registered inhabitants in an area of 891.82 square kilometers.'), | |
| ('How many people live in Berlin?', 'Berlin is well known for its museums.')]) | |
| ``` | |
| - **cross-encoder/ms-marco-TinyBERT-L-2-v2** - MRR@10 on MS Marco Dev Set: 32.56 | |
| - **cross-encoder/ms-marco-MiniLM-L-2-v2** - MRR@10 on MS Marco Dev Set: 34.85 | |
| - **cross-encoder/ms-marco-MiniLM-L-4-v2** - MRR@10 on MS Marco Dev Set: 37.70 | |
| - **cross-encoder/ms-marco-MiniLM-L-6-v2** - MRR@10 on MS Marco Dev Set: 39.01 | |
| - **cross-encoder/ms-marco-MiniLM-L-12-v2** - MRR@10 on MS Marco Dev Set: 39.02 | |
| For details on the usage, see [Applications - Information Retrieval](../examples/applications/retrieve_rerank/README.md) | |
| [MS MARCO Cross-Encoders - More details](pretrained-models/ce-msmarco.md) | |
| ## SQuAD (QNLI) | |
| QNLI is based on the [SQuAD dataset](https://rajpurkar.github.io/SQuAD-explorer/) and was introduced by the [GLUE Benchmark](https://arxiv.org/abs/1804.07461). Given a passage from Wikipedia, annotators created questions that are answerable by that passage. | |
| - **cross-encoder/qnli-distilroberta-base** - Accuracy on QNLI dev set: 90.96 | |
| - **cross-encoder/qnli-electra-base** - Accuracy on QNLI dev set: 93.21 | |
| ## STSbenchmark | |
| The following models can be used like this: | |
| ```python | |
| from sentence_transformers import CrossEncoder | |
| model = CrossEncoder('model_name') | |
| scores = model.predict([('Sent A1', 'Sent B1'), ('Sent A2', 'Sent B2')]) | |
| ``` | |
| They return a score 0...1 indicating the semantic similarity of the given sentence pair. | |
| - **cross-encoder/stsb-TinyBERT-L-4** - STSbenchmark test performance: 85.50 | |
| - **cross-encoder/stsb-distilroberta-base** - STSbenchmark test performance: 87.92 | |
| - **cross-encoder/stsb-roberta-base** - STSbenchmark test performance: 90.17 | |
| - **cross-encoder/stsb-roberta-large** - STSbenchmark test performance: 91.47 | |
| ## Quora Duplicate Questions | |
| These models have been trained on the [Quora duplicate questions dataset](https://www.quora.com/q/quoradata/First-Quora-Dataset-Release-Question-Pairs). They can used like the STSb models and give a score 0...1 indicating the probability that two questions are duplicate questions. | |
| - **cross-encoder/quora-distilroberta-base** - Average Precision dev set: 87.48 | |
| - **cross-encoder/quora-roberta-base** - Average Precision dev set: 87.80 | |
| - **cross-encoder/quora-roberta-large** - Average Precision dev set: 87.91 | |
| Note: The model don't work for question similarity. The question *How to learn Java* and *How to learn Python* will get a low score, as these questions are not duplicates. For question similarity, the respective bi-encoder trained on the Quora dataset yields much more meaningful results. | |
| ## NLI | |
| Given two sentences, are these contradicting each other, entailing one the other or are these netural? The following models were trained on the [SNLI](https://nlp.stanford.edu/projects/snli/) and [MultiNLI](https://cims.nyu.edu/~sbowman/multinli/) datasets. | |
| - **cross-encoder/nli-deberta-v3-base** - Accuracy on MNLI mismatched set: 90.04 | |
| - **cross-encoder/nli-deberta-base** - Accuracy on MNLI mismatched set: 88.08 | |
| - **cross-encoder/nli-deberta-v3-xsmall** - Accuracy on MNLI mismatched set: 87.77 | |
| - **cross-encoder/nli-deberta-v3-small** - Accuracy on MNLI mismatched set: 87.55 | |
| - **cross-encoder/nli-roberta-base** - Accuracy on MNLI mismatched set: 87.47 | |
| - **cross-encoder/nli-MiniLM2-L6-H768** - Accuracy on MNLI mismatched set: 86.89 | |
| - **cross-encoder/nli-distilroberta-base** - Accuracy on MNLI mismatched set: 83.98 | |
| ```python | |
| from sentence_transformers import CrossEncoder | |
| model = CrossEncoder('model_name') | |
| scores = model.predict([('A man is eating pizza', 'A man eats something'), ('A black race car starts up in front of a crowd of people.', 'A man is driving down a lonely road.')]) | |
| #Convert scores to labels | |
| label_mapping = ['contradiction', 'entailment', 'neutral'] | |
| labels = [label_mapping[score_max] for score_max in scores.argmax(axis=1)] | |
| ``` | |