MCP Course documentation
Local Tiny Agents with AMD NPU and iGPU Acceleration
Local Tiny Agents with AMD NPU and iGPU Acceleration
In this section, we’ll show you how to accelerate our end-to-end Tiny Agents application using AMD Neural Processing Unit (NPU) and integrated GPU (iGPU). We then enhance our end-to-end application by providing it with access to local files and creating an assistant to handle sensitive information locally, ensuring maximum privacy.
To enable this, we’ll use Lemonade Server, a tool for running models locally with NPU and iGPU acceleration.
Setup
Setup Lemonade Server
You can install Lemonade Server on both Windows and Linux. Additional documentation can be found at lemonade-server.ai.
To install Lemonade Server on Windows, simply download and run the latest installer here.
Lemonade Server supports CPU inference across all platforms and engines on Windows x86/x64. GPU acceleration is enabled via the llamacpp engine using Vulkan, with a focus on AMD Ryzen™ AI 7000/8000/300 series and AMD Radeon™ 7000/9000 series. For NPU acceleration, the ONNX Runtime GenAI (OGA) engine enables support for AMD Ryzen™ AI 300 series devices.
Once you have installed Lemonade Server, you can launch it by clicking the Lemonade icon added to the Desktop.
Tiny Agents and NPX Setup
This section of the course assumes you have already installed npx and Tiny Agents. If you haven’t, please refer to the Tiny Agents section of the course.
Running your Tiny Agents application with AMD NPU and iGPU
To run your Tiny Agents application with AMD NPU and iGPU, simply point to the MCP server we created in the previous section to the Lemonade Server, as shown below:
{
"model": "Qwen3-8B-GGUF",
"endpointUrl": "http://localhost:8000/api/",
"servers": [
{
"type": "stdio",
"config": {
"command": "C:\\Program Files\\nodejs\\npx.cmd",
"args": [
"mcp-remote",
"http://localhost:7860/gradio_api/mcp/sse"
]
}
}
]
}You can then choose from a variety of models to run on your local machine. For this example, used the Qwen3-8B-GGUF model, which runs efficiently on AMD GPUs through Vulkan acceleration. You can find the list of models supported and even import your own models by navigating to http://localhost:8000/#model-management.
Creating an assistant to handle sensitive information locally
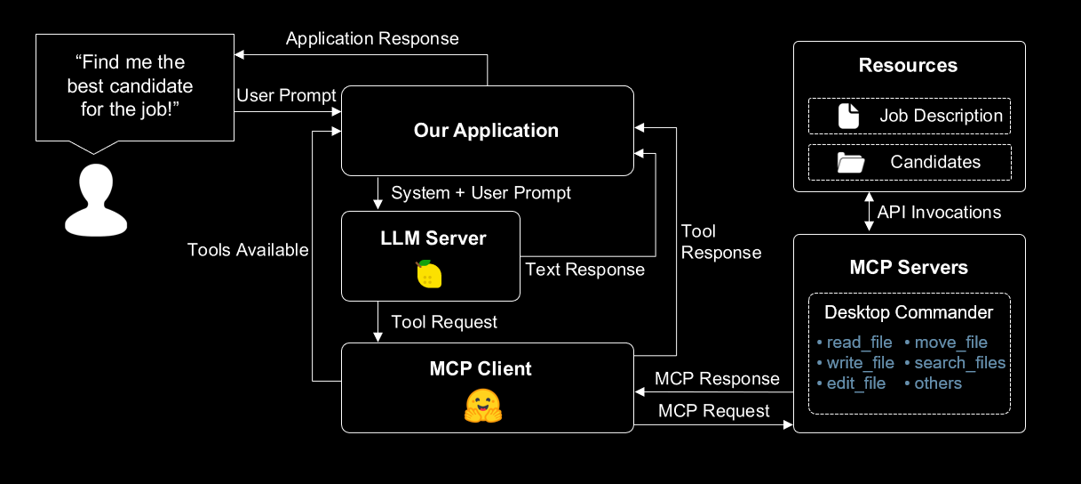
Now let’s enhance our end-to-end application by enabling access to local files and introducing an assistant that processes sensitive information entirely on-device. Specifically, this assistant will help us evaluate candidate resumes and support decision-making in the hiring process—all while keeping the data private and secure.
To do this, we’ll use the Desktop Commander MCP server, which allows you to run commands on your local machine and provides comprehensive file system access, terminal control, and code editing capabilities.
Let’s setup a project with a basic Tiny Agent.
mkdir file-assistant
cd file-assistantLet’s then create a new agent.json file in the file-assistant folder.
{
"model": "user.jan-nano",
"endpointUrl": "http://localhost:8000/api/",
"servers": [
{
"type": "stdio",
"config": {
"command": "C:\\Program Files\\nodejs\\npx.cmd",
"args": [
"-y",
"@wonderwhy-er/desktop-commander"
]
}
}
]
}Finally, we have to download the Jan Nano model. You can do this by navigating to http://localhost:8000/#model-management, clicking on Add a Model and providing the following information:
Model Name: user.jan-nano
Checkpoint: Menlo/Jan-nano-gguf:jan-nano-4b-Q4_0.gguf
Recipe: llamacpp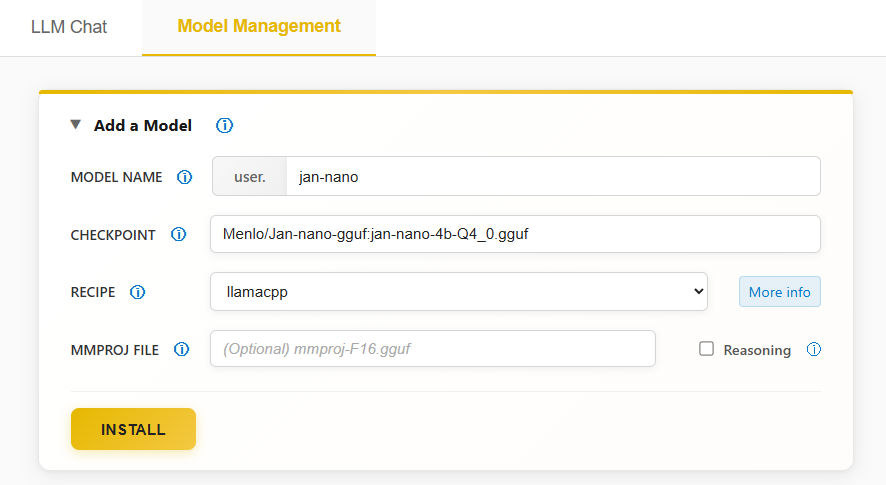
All done! Now let’s give it a try.
Taking it for a spin
Our goal is to create an assistant that can help us handle sensitive information locally. To do this, we’ll first create a job description file for our assistant to work with.
Create a file called job_description.md in the file-assistant folder.
# Senior Food Technology Engineer
## About the Role
We're seeking a culinary innovator to transform cooking processes into precise algorithms and AI systems.
## What You'll Do
- Convert cooking instructions into measurable algorithms
- Develop AI-powered kitchen tools
- Create food quality assessment systems
- Build recipe-following AI models
## Requirements
- MS in Computer Science (food-related thesis preferred)
- Python and PyTorch expertise
- Proven experience combining food science with ML
- Strong communication skills using culinary metaphors
## Perks
- Access to experimental kitchen
- Continuous taste-testing opportunities
- Collaborative tech-foodie team environment
*Note: Must attend conferences and publish on algorithmic cooking optimization.*
Now, let’s create a candidates folder inside the file-assistant folder and add a sample resume file for our assistant to work with.
mkdir candidates
touch candidates/john_resume.mdAdd the following sample resume or include your own.
# John Doe
**Contact Information**
- Email: [email protected]
- Phone: (+1) 123-456-7890
- Location: 1234 Abc Street, Example, EX 01234
- GitHub: github.com/example
- LinkedIn: linkedin.com/in/example
- Website: example.com
## Experience
**Machine Learning Engineer Intern** | Slow Feet Technology | Jul 2021 - Present
- Developed food-agnostic formulation for cross-ingredient meal cooking
- Created competitive cream of mushroom soup recipe, published in NeurIPS 2099
- Built specialized pan for meal cooking research
**Research Intern** | Paddling University | Aug 2020 - Present
- Designed efficient mapo tofu quality estimation method using thermometer
- Proposed fast stir frying algorithm for tofu cooking, published in CVPR 2077
- Outperformed SOTA methods with improved efficiency
**Research Assistant** | Huangdu Institute of Technology | Mar 2020 - Jun 2020
- Developed novel framework using spoon and chopsticks for eating mapo tofu
- Designed tofu filtering strategy inspired by beans grinding method
- Created evaluation criteria for eating plan novelty and diversity
**Research Intern** | Paddling University | Jul 2018 - Aug 2018
- Designed dual sandwiches using traditional burger ingredients
- Utilized structure duality to boost cooking speed for shared ingredients
- Outperformed baselines on QWE'15 and ASDF'14 datasets
## Education
**M.S. in Computer Science** | University of Charles River | Sep 2021 - Jan 2023
- Location: Boston, MA
**B.Eng. in Software Engineering** | Huangdu Institute of Technology | Sep 2016 - Jul 2020
- Location: Shanghai, China
## Skills
**Programming Languages:** Python, JavaScript/TypeScript, HTML/CSS, Java
**Tools and Frameworks:** Git, PyTorch, Keras, scikit-learn, Linux, Vue, React, Django, LaTeX
**Languages:** English (proficient), Indonesia (native)
## Awards and Honors
- **Gold**, International Collegiate Catching Fish Contest (ICCFC) | 2018
- **First Prize**, China National Scholarship for Outstanding Culinary Skills | 2017, 2018
## Publications
**Eating is All You Need** | NeurIPS 2099
- Authors: Haha Ha, San Zhang
**You Only Cook Once: Unified, Real-Time Mapo Tofu Recipe** | CVPR 2077 (Best Paper Honorable Mention)
- Authors: Haha Ha, San Zhang, Si Li, Wu WangWe can then run the agent with the following command:
tiny-agents run agent.json
You should see the following output:
Agent loaded with 18 tools:
• get_config
• set_config_value
• read_file
• read_multiple_files
• write_file
• create_directory
• list_directory
• move_file
• search_files
• search_code
• get_file_info
• edit_block
• execute_command
• read_output
• force_terminate
• list_sessions
• list_processes
• kill_process
»Now let’s provide the asistant with some info to get started.
» Read the contents of C:\Users\your_username\file-assistant\job_description.mdYou should see the an output similar to the following:
<Tool iNtxGmOuXHqZVBWmKnfxsc61xsJbsoAM>read_file {"path":"C:\\Users\\your_username\\file-assistant\\job_description.md","length":23}
Tool iNtxGmOuXHqZVBWmKnfxsc61xsJbsoAM
[Reading 23 lines from start]
(...)
The job description for the Senior Food Technology Engineer position emphasizes the need for a candidate who can bridge the gap between food science and artificial intelligence (...). Candidates are also expected to attend conferences and publish research on algorithmic cooking optimization.We are using the default system prompt, which may cause the assistant to call some tools multiple times. To create a more assertive assistant, you can provide a custom PROMPT.md file in the same directory as your agent.json.
Great! Now let’s read the candidate’s resume.
» Inside the same folder you can find a candidates folder. Check for john_resume.md and let me know if he is a good fit for the job.You should see an output similar to the following:
<Tool ll2oWo73YeGIft5VbOIpF9GNf0kevjEy>read_file {"path":"C:\\Users\\your_username\\file-assistant\\candidates\\john_resume.md"}
Tool ll2oWo73YeGIft5VbOIpF9GNf0kevjEy
[Reading 58 lines from start]
(...)
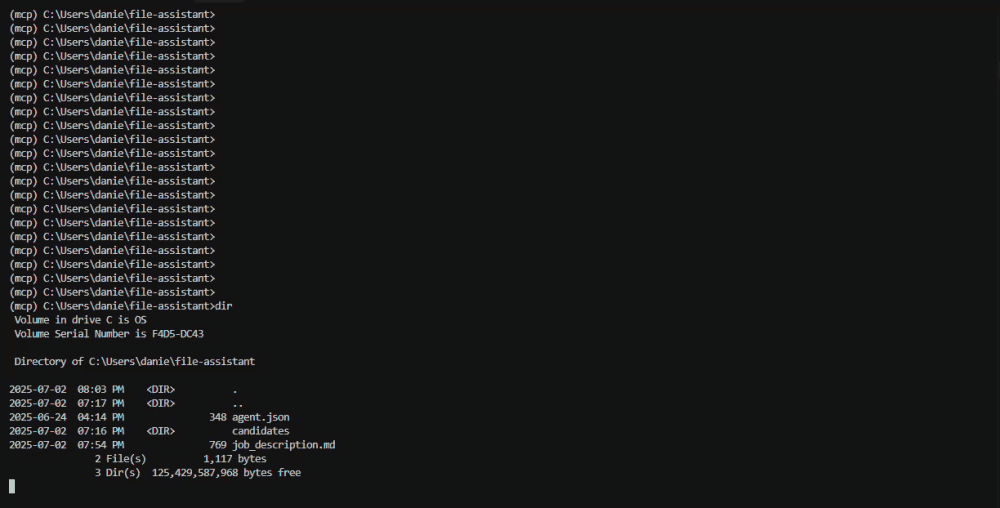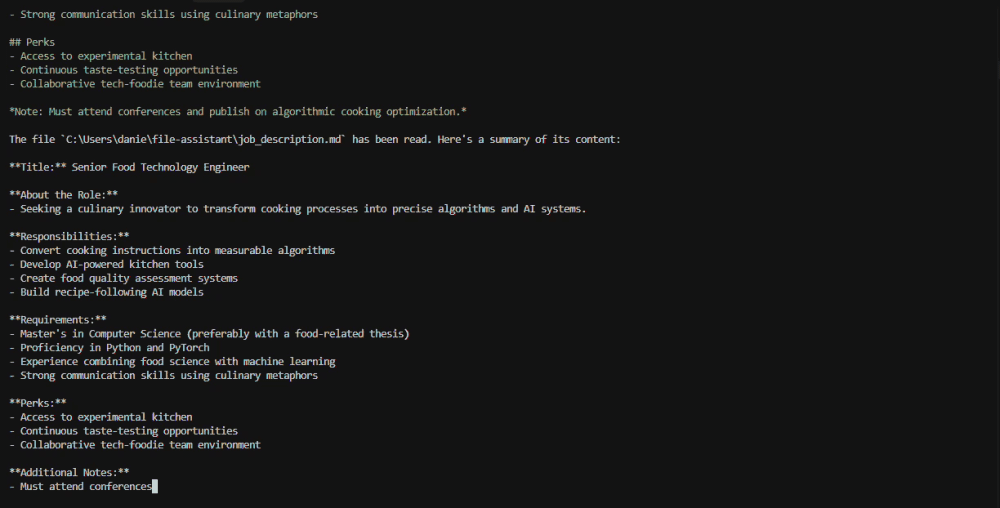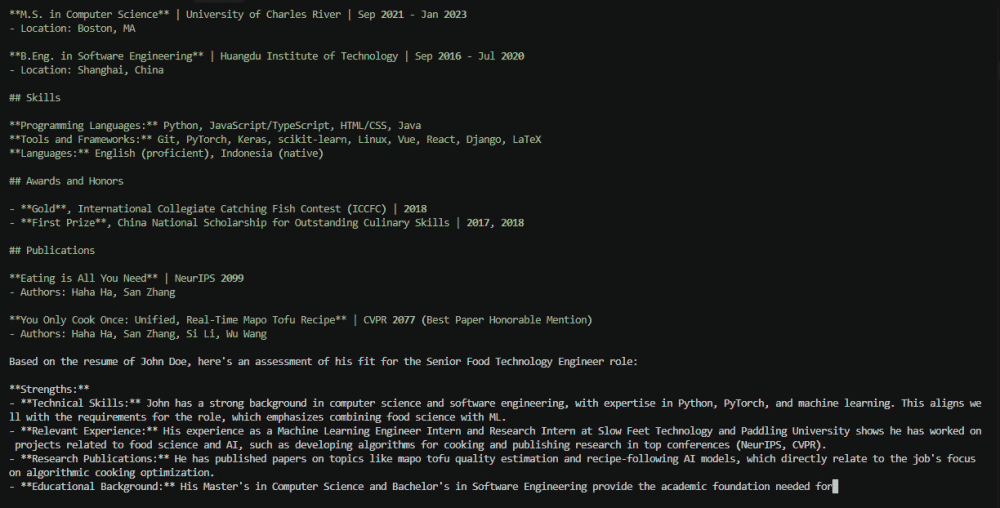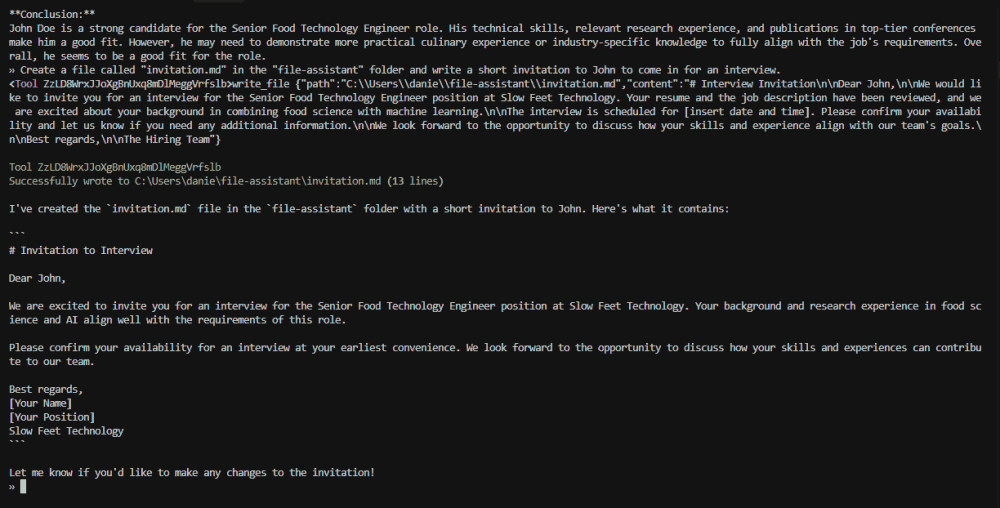
John Wayne is a **strong fit** for the Senior Food Technology Engineer role. His technical expertise in AI and machine learning, combined with his experience in food-related research and publications, makes him an excellent candidate. He also has the soft skills and cultural fit needed to thrive in a collaborative, innovative environment.Amazing! Now we can move forward with inviting the candidate to the interview.
» Create a file called "invitation.md" in the "file-assistant" folder and write a short invitation to John to come in for an interview.You should see content similar to the following being written to the invitation.md file:
# Interview Invitation
Dear John,
We would like to invite you for an interview for the Senior Food Technology Engineer position. The interview will be held on [insert date and time] at [insert location or virtual meeting details].
Please confirm your availability and let us know if you need any additional information.
Best regards,
[Your Name]
[Your Contact Information]Woohoo! We successfully created an assistant that can help us handle sensitive information locally.
Exploring other models and acceleration options
In the example above, the Jan-Nano model leveraged Vulkan acceleration for efficient local LLM inference on AMD GPUs. You can also try out other models and acceleration options by navigating to http://localhost:8000/#model-management or checking the models documentation.
For Windows applications that require a concise context and would benefit from NPU + iGPU acceleration, you can try the Hybrid models available with Lemonade Server — optimized for AMD Ryzen AI 300 series PCs. Models such as Llama-xLAM-2-8b-fc-r-Hybrid are specifically fine-tuned for tool-calling and deliver fast, responsive performance!
Conclusion
In this unit, we’ve shown how to accelerate our end-to-end Tiny Agents application with AMD NPU and iGPU. We’ve also shown how to create an assistant to handle sensitive information locally.
Now that you’ve learned how to leverage Lemonade Server for local model acceleration and privacy-focused applications, you can explore more examples and features in the Lemonade GitHub repository. The repository contains additional documentation, example implementations, and is actively maintained by the community.
< > Update on GitHub