
Multimodal E5 Embeddings
Collection
3 items
•
Updated
•
2
mmE5: Improving Multimodal Multilingual Embeddings via High-quality Synthetic Data. Haonan Chen, Liang Wang, Nan Yang, Yutao Zhu, Ziliang Zhao, Furu Wei, Zhicheng Dou, arXiv 2025
This model is trained based on Llama-3.2-11B-Vision.
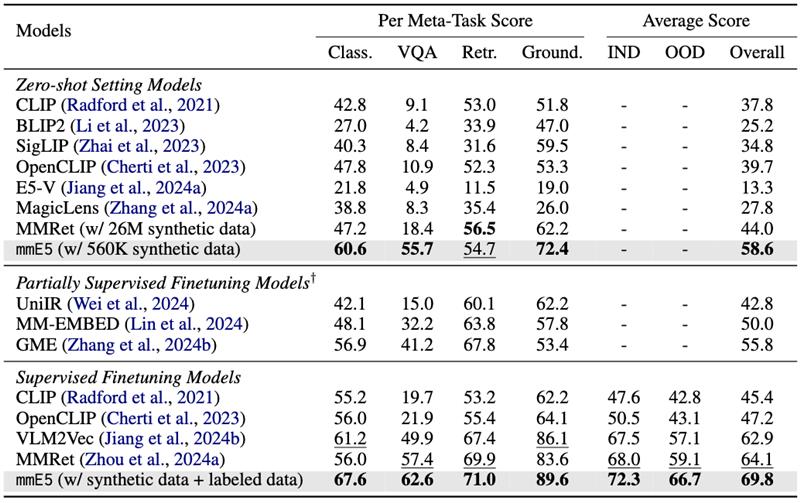
Our model achieves SOTA performance on MMEB benchmark.
Below is an example we adapted from VLM2Vec.
import torch
import requests
from PIL import Image
from transformers import MllamaForConditionalGeneration, AutoProcessor
# Pooling and Normalization
def last_pooling(last_hidden_state, attention_mask, normalize=True):
sequence_lengths = attention_mask.sum(dim=1) - 1
batch_size = last_hidden_state.shape[0]
reps = last_hidden_state[torch.arange(batch_size, device=last_hidden_state.device), sequence_lengths]
if normalize:
reps = torch.nn.functional.normalize(reps, p=2, dim=-1)
return reps
def compute_similarity(q_reps, p_reps):
return torch.matmul(q_reps, p_reps.transpose(0, 1))
model_name = "intfloat/mmE5-mllama-11b-instruct"
# Load Processor and Model
processor = AutoProcessor.from_pretrained(model_name)
model = MllamaForConditionalGeneration.from_pretrained(
model_name, torch_dtype=torch.bfloat16
).to("cuda")
model.eval()
# Image + Text -> Text
image = Image.open(requests.get('https://github.com/haon-chen/mmE5/blob/main/figures/example.jpg?raw=true', stream=True).raw)
inputs = processor(text='<|image|><|begin_of_text|>Represent the given image with the following question: What is in the image\n', images=[image], return_tensors="pt").to("cuda")
qry_output = last_pooling(model(**inputs, return_dict=True, output_hidden_states=True).hidden_states[-1], inputs['attention_mask'])
string = 'A cat and a dog'
text_inputs = processor(text=string, return_tensors="pt").to("cuda")
tgt_output = last_pooling(model(**text_inputs, return_dict=True, output_hidden_states=True).hidden_states[-1], text_inputs['attention_mask'])
print(string, '=', compute_similarity(qry_output, tgt_output))
## A cat and a dog = tensor([[0.4219]], device='cuda:0', dtype=torch.bfloat16)
string = 'A cat and a tiger'
text_inputs = processor(text=string, return_tensors="pt").to("cuda")
tgt_output = last_pooling(model(**text_inputs, return_dict=True, output_hidden_states=True).hidden_states[-1], text_inputs['attention_mask'])
print(string, '=', compute_similarity(qry_output, tgt_output))
## A cat and a tiger = tensor([[0.3184]], device='cuda:0', dtype=torch.bfloat16)
# Text -> Image
inputs = processor(text='Find me an everyday image that matches the given caption: A cat and a dog.\n', return_tensors="pt").to("cuda")
qry_output = last_pooling(model(**inputs, return_dict=True, output_hidden_states=True).hidden_states[-1], inputs['attention_mask'])
string = '<|image|><|begin_of_text|>Represent the given image.\n'
tgt_inputs = processor(text=string, images=[image], return_tensors="pt").to("cuda")
tgt_output = last_pooling(model(**tgt_inputs, return_dict=True, output_hidden_states=True).hidden_states[-1], tgt_inputs['attention_mask'])
print(string, '=', compute_similarity(qry_output, tgt_output))
## <|image|><|begin_of_text|>Represent the given image. = tensor([[0.4414]], device='cuda:0', dtype=torch.bfloat16)
inputs = processor(text='Find me an everyday image that matches the given caption: A cat and a tiger.\n', return_tensors="pt").to("cuda")
qry_output = last_pooling(model(**inputs, return_dict=True, output_hidden_states=True).hidden_states[-1], inputs['attention_mask'])
string = '<|image|><|begin_of_text|>Represent the given image.\n'
tgt_inputs = processor(text=string, images=[image], return_tensors="pt").to("cuda")
tgt_output = last_pooling(model(**tgt_inputs, return_dict=True, output_hidden_states=True).hidden_states[-1], tgt_inputs['attention_mask'])
print(string, '=', compute_similarity(qry_output, tgt_output))
## <|image|><|begin_of_text|>Represent the given image. = tensor([[0.3730]], device='cuda:0', dtype=torch.bfloat16)
You can also use Sentence Transformers, where the majority of the pre- and post-processing has been abstracted.
from sentence_transformers import SentenceTransformer
import requests
# Load the model
model = SentenceTransformer("intfloat/mmE5-mllama-11b-instruct", trust_remote_code=True)
# Download an example image of a cat and a dog
dog_cat_image_bytes = requests.get('https://github.com/haon-chen/mmE5/blob/main/figures/example.jpg?raw=true', stream=True).raw.read()
with open("cat_dog_example.jpg", "wb") as f:
f.write(dog_cat_image_bytes)
# Image + Text -> Text
image_embeddings = model.encode([{
"image": "cat_dog_example.jpg",
"text": "Represent the given image with the following question: What is in the image",
}])
text_embeddings = model.encode([
{"text": "A cat and a dog"},
{"text": "A cat and a tiger"},
])
similarity = model.similarity(image_embeddings, text_embeddings)
print(similarity)
# tensor([[0.3967, 0.3090]])
# ✅ The first text is most similar to the image
# Text -> Image
image_embeddings = model.encode([
{"image": dog_cat_image_bytes, "text": "Represent the given image."},
])
text_embeddings = model.encode([
{"text": "Find me an everyday image that matches the given caption: A cat and a dog."},
{"text": "Find me an everyday image that matches the given caption: A cat and a tiger."},
])
similarity = model.similarity(image_embeddings, text_embeddings)
print(similarity)
# tensor([[0.4250, 0.3896]])
# ✅ The first text is most similar to the image
@article{chen2025mmE5,
title={mmE5: Improving Multimodal Multilingual Embeddings via High-quality Synthetic Data},
author={Chen, Haonan and Wang, Liang and Yang, Nan and Zhu, Yutao and Zhao, Ziliang and Wei, Furu and Dou, Zhicheng},
journal={arXiv preprint arXiv:2502.08468},
year={2025}
}