
id
int64 393k
2.82B
| repo
stringclasses 68
values | title
stringlengths 1
936
| body
stringlengths 0
256k
⌀ | labels
stringlengths 2
508
| priority
stringclasses 3
values | severity
stringclasses 3
values |
|---|---|---|---|---|---|---|
334,698,487
|
flutter
|
Problems with API docs, specifically for native pages
|
**tl;dr**
- Search doesn't work for native docs.
- Native docs are very hard to find. (Right now, the `PLATFORM_INTEGRATI...` entries are several pages down (buried) in the side nav.)
- The native content is not great.
- Native docs look very different than our Dart docs.
---
Ben K gave me a demonstration of how hard (impossible) it is to find docs for the native packages on [docs.flutter.io](https://docs.flutter.io/). This matters because he's about to land a feature that allows devs to write plugins that support isolates running in the background, even when the app is closed. It's difficult to write a plugin when you can't search the native docs, unless you know exactly what you're looking for.
1. Try searching in the search textfield for, say, `BinaryMessenger`. Zero hits. How about `FlutterViewController`. Nope.
2. Next, try:
```
BinaryMessenger site:docs.flutter.io
```
Now you can see that the class page is down in [`docs.flutter.io/javadoc/io/flutter/plugin/common/BinaryMessenger.html`](https://docs.flutter.io/javadoc/io/flutter/plugin/common/BinaryMessenger.html).
3. Now try searching in the browser for
```
FlutterViewController site:docs.flutter.io
```
The page is located in [`docs.flutter.io/objcdoc/Classes/FlutterViewController.html`](https://docs.flutter.io/objcdoc/Classes/FlutterViewController.html)
4. Next, go back to the API docs home page by clicking "Flutter Docs" in the upper left corner. Nope, you're still in the objective C directory. Once you've entered the subsite [`docs.flutter/javadoc`](https://docs.flutter.io/javadoc/), you're in the same boat. There is no way to get back to the regular Flutter docs from either native set of docs, without manually modifying the URL.
---
In the short term (pre 1.0), I suggest that we:
* Expose buttons on the front page that direct readers to the iOS and Android docs.
* Add buttons to the native pages that take you back to the regular docs.
* Welcome PRs to improve the docs.
In the long term (post 1.0), this site needs more love and care. Can we assign someone to improve it?
@bkonyi, @Hixie
|
engine,d: api docs,P2,team-engine,triaged-engine
|
low
|
Minor
|
334,885,773
|
go
|
x/review/git-codereview: Documentation and tool behavior don't match for 'git codereview change'
|
Please answer these questions before submitting your issue. Thanks!
### What version of Go are you using (`go version`)?
`go version go1.10.3 linux/amd64`
### What version of git-codereview are you using?
https://github.com/golang/review/commit/3faf27076323fb8383c9b24e875f37a630b2f213
### Does this issue reproduce with the latest release?
Yes.
### What operating system and processor architecture are you using (`go env`)?
```GOARCH="amd64"
GOBIN=""
GOCACHE="/home/vimeo/.cache/go-build"
GOEXE=""
GOHOSTARCH="amd64"
GOHOSTOS="linux"
GOOS="linux"
GOPATH="/home/vimeo/godep"
GORACE=""
GOROOT="/home/vimeo/go"
GOTMPDIR=""
GOTOOLDIR="/home/vimeo/go/pkg/tool/linux_amd64"
GCCGO="gccgo"
CC="gcc"
CXX="g++"
CGO_ENABLED="1"
CGO_CFLAGS="-g -O2"
CGO_CPPFLAGS=""
CGO_CXXFLAGS="-g -O2"
CGO_FFLAGS="-g -O2"
CGO_LDFLAGS="-g -O2"
PKG_CONFIG="pkg-config"
GOGCCFLAGS="-fPIC -m64 -pthread -fmessage-length=0 -fdebug-prefix-map=/tmp/go-build902163312=/tmp/go-build -gno-record-gcc-switches"
```
### What did you do?
Cloned the `x/image` repo as per its README:
```
$ git clone https://go.googlesource.com/image $GOPATH/src/golang.org/x/image
$ cd $GOPATH/src/golang.org/x/image
```
Signed up for and setup cookies for Go's Gerrit system (I had already set it up since previosly contributing, technically.)
Installed `git-codereview` as per [the documentation](https://golang.org/doc/contribute.html):
```
$ go get -u golang.org/x/review/git-codereview
```
Created a new branch for work, and did my changes, as per [the documentation](https://golang.org/doc/contribute.html#make_branch):
```
$ git checkout -b newbranch
$ vim whatever.go
$ git add whatever.go
$ git codereview change
```
### What did you expect to see?
I expected `git codereview change` to add a `Change-Id:` line to the commit messages.
### What did you see instead?
It did not add a `Change-Id:` to the commit message.
### Workaround / extra information which could be important
If I **do not** follow the documentation, and instead of using `git checkout -b newbranch`, I use `git codereview change newbranch`, it *does* add the `Change-Id:` line as required. But this does not match what the official documentation on golang.org says to do. It is also worth noting this occurs on the x/image` repo; I haven't tried the official `go` repo.
|
Documentation,NeedsInvestigation
|
low
|
Critical
|
334,918,682
|
opencv
|
Possible cv::erode() and cv::dilate() optimisation trick
|
##### System information (version)
- OpenCV => 4.0 (but every version I tested so far really)
- Operating System / Platform => iOS
- Compiler => Xcode
##### Detailed description
Performance of ```cv::erode()``` and ```cv::dilate()``` is pretty much terrible on iOS, if kernel size is greater than 3-5 and structuring element is set to ```cv::MORPH_ELIPSE```. However, for bigger kernels, a simple trick can be used to improve the performance: instead of calling ```cv::erode()``` or ```cv::dilate()``` for bigger kernels, it can be called multiple times with the smallest possible kernel value set (which is 3) and using ```cv::MORPH_CROSS``` instead of ```cv::MORPH_ELIPSE```.
```cpp
cv::Mat element = cv::getStructuringElement(cv::MORPH_CROSS, cv::Size(3, 3));
for(int k = kernelSize; k > 1; k -= 2) {
cv::erode(mat, mat, element);
}
```
The above solution is about 8-10 times faster for large kernels (~30).
It would be great, if OpenCV offered this as a build-in optimisation (e.g. as something like ```cv::MORPH_ELIPSE_OPTIMISED```) or at least mentioned this in the docs.
|
RFC
|
low
|
Major
|
334,960,537
|
vscode
|
Git - Support submodule management
|
### **Feature Request**
Add support for the git submodule commands from within VS Code.
Currently submodules are supported, but only if the submodules are created via git cli.
Examples:
git submodule init
git submodule update
git submodule summary
etc...
I think the most important ones would be add, init, and update
Currently running ver. 1.24.1
|
help wanted,feature-request,git
|
medium
|
Major
|
334,981,118
|
react
|
Add support for hydrating portals
|
<!--
Note: if the issue is about documentation or the website, please file it at:
https://github.com/reactjs/reactjs.org/issues/new
-->
**Do you want to request a *feature* or report a *bug*?**
Probably bug, but arguably a feature request, I suppose.
**What is the current behavior?**
I've attempted my best effort at a fiddle that shows off the particular issue. Obviously server side rendering is impossible via JSFiddle, but the markup should be equivalent to having rendered `Test` into a div with id `test-1` during server side render.
https://jsfiddle.net/y8o5n2zg/
As seen in the fiddle, an attempt to ReactDOM.hydrate() a portal results in:
> `Warning: Expected server HTML to contain a matching text node for "Hello World" in <div>.`
Additionally, after failing to hydrate, React renders the component and appends it resulting in a duplicated section of DOM:
> `<div id="test-1">Hello WorldHello World</div>`
**What is the expected behavior?**
In an ideal world, calling hydrate on a component that has portals would allow those DOM containers to hydrate into the components they were rendered with.
**Which versions of React, and which browser / OS are affected by this issue? Did this work in previous versions of React?**
I've only tested this in 16.4.1, but I've confirmed the behavior in Chrome and Firefox. Given that I'm really looking at an edge case here I doubt it worked previously.
#### *Why* I'm doing this edge-case-y nonsense:
We're currently using multiple React roots on our pages (as some portions of the pages are not rendered by React yet), most of which are server-side rendered. We'd like to be able to hydrate them into a single React root on page, so that we can share contexts between them without difficulty and without repeating those context components in memory (in some cases we can have a good number of roots on the page—20-30, perhaps?).
In searching, I found a few potentially related bugs (#12615, #10713, #11169), but it seemed like these really didn't line up with my (hopefully valid?) use case.
Thanks!
|
Type: Feature Request
|
high
|
Critical
|
335,053,421
|
TypeScript
|
Type declaration on property access not checked
|
See `jsdocPrototypePropertyAccessWithType.ts` as of #25170. The test should have an error because `false` is not a number.
|
Bug,Domain: JavaScript
|
low
|
Critical
|
335,060,161
|
pytorch
|
MPI causing job to hang --- unresponsive to external (termination) signals
|
## Issue description
When running `torch.distributed` with the MPI backend in a cluster, the job fails to exit and hangs unresponsively --- essentially any node in the cluster that the runs the script becomes unresponsive when you try to terminate the job. This varies from run to run, but it happens often enough that it is problematic.
Here is a minimal reproduction script. High level steps:
1. initialize multiple DataLoader workers
2. communicate model parameters
3. update model parameters
4. run forward-backward pass
## Code example
For a single machine with `$world_size` GPUs, run
`mpirun -n $world_size python issues.py`
issues.py:
```
import os
import signal
import torch
import torch.backends.cudnn as cudnn
import torch.distributed as dist
import torch.utils.data
import torch.utils.data.distributed
import torch.multiprocessing as mp
import torchvision.datasets as datasets
import torchvision.models as models
import torchvision.transforms as transforms
# path to dataset (REPLACE WITH YOUR OWN LOCAL PATH TO DATASET)
TRAIN_DIRECTORY = '/datasets/imagenet_full_size/train'
def main():
signal.signal(signal.SIGTERM, SIGTERMHandler)
# initialize torch distributed mpi backend
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '40101'
dist.init_process_group(backend='mpi')
# run each task on a single GPU
torch.cuda.set_device(dist.get_rank())
# seed for reproducibility
torch.manual_seed(37)
torch.cuda.manual_seed(37)
torch.backends.cudnn.deterministic = True
model = models.resnet50()
model.cuda()
model.train()
criterion = torch.nn.CrossEntropyLoss().cuda()
optimizer = torch.optim.SGD(model.parameters(), lr=0.1, momentum=0.9,
weight_decay=0.0001, nesterov=True)
cudnn.benchmark = True
# initialize a dataloader with 4 worker processes
loader, sampler = make_dataloader(TRAIN_DIRECTORY)
for i, (input, target) in enumerate(loader):
print('itr {}'.format(i))
input = input.cuda(non_blocking=True)
target = target.cuda(non_blocking=True)
# communicate model parameters
comm_buffer = _flatten_tensors(list(model.parameters())).detach_()
send_recieve(comm_buffer)
comm_buffer = _unflatten_tensors(comm_buffer, list(model.parameters()))
with torch.no_grad():
for p, e in zip(model.parameters(), comm_buffer):
p.data.copy_(e)
# forward/backward pass
output = model(input)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
prec1, prec5 = accuracy(output, target, topk=(1, 5))
print('* @Prec1 {prec1:.3f}\t@Prec5 {prec5:.3f}'
.format(prec1=prec1.item(), prec5=prec5.item()))
def send_recieve(buffer):
buffer.mul_(0.5)
# ring communication
destination = (dist.get_rank() + 1) % dist.get_world_size()
source = dist.get_rank() - 1 if dist.get_rank() != 0 else dist.get_world_size() - 1
# non-blocking send message
send_buffer = buffer.clone()
req = dist.isend(tensor=send_buffer, dst=destination)
out_msg = (req, send_buffer) # keep in scope
# blocking receive
receive = buffer.clone()
dist.recv(receive, src=source)
# update buffer
buffer.add_(receive)
# wait for neighbours to receive message
out_msg[0].wait()
def make_dataloader(train_directory):
""" Create distributed dataloader """
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
train_dataset = datasets.ImageFolder(train_directory, transforms.Compose([
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize]))
# sampler produces indices used to assign data samples to each agent
train_sampler = torch.utils.data.distributed.DistributedSampler(
dataset=train_dataset,
num_replicas=dist.get_world_size(),
rank=dist.get_rank())
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=32,
shuffle=False,
num_workers=4,
pin_memory=True, sampler=train_sampler)
return train_loader, train_sampler
def accuracy(output, target, topk=(1,)):
""" Computes the precision@k for the specified values of k """
with torch.no_grad():
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].view(-1).float().sum(0, keepdim=True)
res.append(correct_k.mul_(100.0 / batch_size))
return res
def _flatten_tensors(tensors):
if len(tensors) == 1:
return tensors[0].view(-1)
flat = torch.cat([t.view(-1) for t in tensors], dim=0)
return flat
def _unflatten_tensors(flat, tensors):
outputs = []
offset = 0
for tensor in tensors:
numel = tensor.numel()
outputs.append(flat.narrow(0, offset, numel).view_as(tensor))
offset += numel
return tuple(outputs)
def SIGTERMHandler(signum, frame):
"""
Ignore SIGTERM preemption signal (doesn't stop preemption);
instead SIGUSR1 will be moved up and handled accordingly
"""
print('Received SIGTERM')
if __name__ == '__main__':
mp.set_start_method('forkserver')
main()
```
## System Info
PyTorch (built from source) version: 0.5.0a0+f8c18e0
Is debug build: No
CUDA used to build PyTorch: 9.0.176
OS: Ubuntu 16.04.4 LTS
GCC version: (Ubuntu 5.5.0-12ubuntu1~16.04) 5.5.0 20171010
CMake version: version 3.11.1
Python version: 3.6
Is CUDA available: Yes
CUDA runtime version: 9.0.176
GPU models and configuration:
GPU[0-8]: V100 (NVIDIA voltas)
Nvidia driver version: 384.81
cuDNN version: cudnn/v7.0-cuda.9.0
Versions of relevant libraries:
openmpi/3.0.0/gcc.5.4.0
NCCL/2.2.12-1-cuda.9.0
[pip] numpy (1.14.3)
[pip] torch (0.5.0a0+f8c18e0)
[pip] torchvision (0.2.1)
[conda] magma-cuda90 2.3.0 1 pytorch
[conda] torch 0.5.0 <pip>
[conda] torchvision 0.2.1 <pip>
cc @pietern @mrshenli @pritamdamania87 @zhaojuanmao @satgera @rohan-varma @gqchen @aazzolini @osalpekar @jiayisuse @agolynski @SciPioneer @H-Huang @mrzzd
|
oncall: distributed
|
low
|
Critical
|
335,068,044
|
youtube-dl
|
Add support for independent.bbvms.com
|
Apologies. I left all the verbosity in your template due to uncertainty in submission process.
This URL works in the browser: https://independent.bbvms.com/view/embed/2957075.html
[]
Add the `-v` flag to **your command line** you run youtube-dl with (`youtube-dl -v <your command line>`), copy the **whole** output and insert it here. It should look similar to one below (replace it with **your** log inserted between triple ```):
"
youtube-dl -v https://independent.bbvms.com/view/embed/2957075.html
[debug] System config: []
[debug] User config: []
[debug] Custom config: []
[debug] Command-line args: ['-v', 'https://independent.bbvms.com/view/embed/2957075.html']
[debug] Encodings: locale UTF-8, fs utf-8, out UTF-8, pref UTF-8
[debug] youtube-dl version 2018.06.19
[debug] Python version 3.5.3 (CPython) - Linux-4.14.0-3+reiser4.0.2-amd64-x86_64-with-debian-9.4
[debug] exe versions: ffmpeg N-91178-g8a4dbd3e9f, ffprobe N-91178-g8a4dbd3e9f
[debug] Proxy map: {}
[generic] 2957075: Requesting header
WARNING: Falling back on generic information extractor.
[generic] 2957075: Downloading webpage
[generic] 2957075: Extracting information
ERROR: Unsupported URL: https://independent.bbvms.com/view/embed/2957075.html
Traceback (most recent call last):
File "/usr/local/lib/python3.5/dist-packages/youtube_dl/YoutubeDL.py", line 792, in extract_info
ie_result = ie.extract(url)
File "/usr/local/lib/python3.5/dist-packages/youtube_dl/extractor/common.py", line 501, in extract
ie_result = self._real_extract(url)
File "/usr/local/lib/python3.5/dist-packages/youtube_dl/extractor/generic.py", line 3263, in _real_extract
raise UnsupportedError(url)
youtube_dl.utils.UnsupportedError: Unsupported URL: https://independent.bbvms.com/view/embed/2957075.html
[]% youtube-dl --version
2018.06.19
"
[]
All I wanted is to download the video. Thanks.
|
site-support-request
|
low
|
Critical
|
335,087,054
|
go
|
go/ast: provide test for Filter func
|
### What version of Go are you using (`go version`)?
go version go1.9.2 linux/amd64
### What operating system and processor architecture are you using (`go env`)?
GOARCH="amd64"
GOBIN=""
GOEXE=""
GOHOSTARCH="amd64"
GOHOSTOS="linux"
GOOS="linux"
GOPATH="/srv/go"
GORACE=""
GOROOT="/usr/local/go"
GOTOOLDIR="/usr/local/go/pkg/tool/linux_amd64"
GCCGO="gccgo"
CC="gcc"
GOGCCFLAGS="-fPIC -m64 -pthread -fmessage-length=0 -fdebug-prefix-map=/tmp/go-build760291292=/tmp/go-build -gno-record-gcc-switches"
CXX="g++"
CGO_ENABLED="1"
CGO_CFLAGS="-g -O2"
CGO_CPPFLAGS=""
CGO_CXXFLAGS="-g -O2"
CGO_FFLAGS="-g -O2"
CGO_LDFLAGS="-g -O2"
PKG_CONFIG="pkg-config"
### What did you do?
Add TestFilter function to test comments after filtering
### What did you expect to see?
TestFilter function runs with all checks passed
|
NeedsInvestigation
|
low
|
Critical
|
335,103,898
|
pytorch
|
Storages still use legacy printing
|
A minor issue reported by @francoisfleuret
```py
In [1]: x = torch.randn(2)
In [2]: x
Out[2]: tensor([-0.2241, -0.8273])
In [3]: x.storage()
Out[3]:
-0.2240564078092575
-0.8272911906242371
[torch.FloatStorage of size 2]
```
|
module: printing,triaged
|
low
|
Minor
|
335,110,843
|
godot
|
shader on gui element is applied to geometry and text - probably missing z value
|
<!-- Please search existing issues for potential duplicates before filing yours:
https://github.com/godotengine/godot/issues?q=is%3Aissue
-->
**Godot version:** 3.0.3
<!-- Specify commit hash if non-official. -->
**OS/device including version:** Windows, 7, 32-bit, Intel HD graphics (coming with Lenovo L570).
<!-- Specify GPU model and drivers if graphics-related. -->
**Issue description:** In 2D: added a ShaderMaterial to a button. The shader code is below. This creates a red rectangle on the left of the button. However, some characters in on the button text also had a red rectangle. Experimenting with different text strings I noticed it was always on the same characters. Changing to a different font I noticed it was on different characters. My best guess here is that the characters showing this effect had the required UV.x value, that is, they were locate on the left edge of the corresponding bitmap holding th characters.
/// code
shader_type canvas_item;
void fragment() {
vec4 c = texture(TEXTURE, UV);
if ((UV.x < 0.1)) {
COLOR.rgba = vec4(1.0, 0.0, 0.0, 1.0);
}
else {
COLOR = c;
}
}
**expected behaviour**
To the minimum: it should be possible to distinguish in the shader between the various layers that make up a gui element - in the sample project, I used a button with som text so the expected behaviour here would be to have the text on a different layer than the button geometry - so a z-value should be needed.
Better would be to allow for different shaders on gui elements. It makes sense to do this since you can then apply different effects on gui background and the gui front.
**Minimal reproduction project:**
<!-- Recommended as it greatly speeds up debugging. Drag and drop a zip archive to upload it. -->
[shadertest.zip](https://github.com/godotengine/godot/files/2130035/shadertest.zip)
|
enhancement,discussion,topic:rendering,documentation
|
low
|
Critical
|
335,115,235
|
opencv
|
opencv built successfully but almost all tests failed??!
|
opecv version : Tried 3.4.0, 3.4.1, master all similar results: opencv builds without a hitch (cmake .. make ) but run
"make test -j8" almost all tests failed. Matching versions of opencv_extra and opencv_contrib were used in all cases.
OS : Ubuntu 16.04.4 64 bit, CUDA 9.1 on GTX1070
I configured with
```
cmake -DCMAKE_BUILD_TYPE=RELEASE
-DCMAKE_INSTALL_PREFIX=/usr/local
-DWITH_V4L=ON
-DOPENCV_EXTRA_MODULES_PATH=../opencv_contrib/modules
-DWITH_OPENMP=ON
-DBUILD_TESTS=ON
-DBUILD_SHARED_LIBS=ON
-DBUILD_EXAMPLES=ON
-DOPENCV_TEST_DATA_PATH=../opencv_extra/testdata
-DOPENCV_ENABLE_NONFREE=ON
-DENABLE_FAST_MATH=ON
-DBUILD_opencv_python3=ON
-DWITH_CUDA=ON
-DWITH_OPENCL=OFF
-DWITH_FFMPEG=ON
-DINSTALL_TESTS=ON ..
```
Then I tried with CUDA off and OPENCL on, then both off. The results are similar: build opencv with no issue but almost all tests failed.
Test log for opencv master with cuda on:
[LastTest.log](https://github.com/opencv/opencv/files/2130070/LastTest.log)
Test log for opencv master with cuda and opencl both off
[LastTest.log](https://github.com/opencv/opencv/files/2130071/LastTest.log)
P.S also tried with OPENMP off and TBB on, similar results.
.
|
bug,priority: low,category: gpu/cuda (contrib)
|
low
|
Critical
|
335,120,301
|
TypeScript
|
simply logic predicate code fix or suggestion
|
<!-- 🚨 STOP 🚨 𝗦𝗧𝗢𝗣 🚨 𝑺𝑻𝑶𝑷 🚨
Half of all issues filed here are duplicates, answered in the FAQ, or not appropriate for the bug tracker. Please read the FAQ first, especially the "Common Feature Requests" section.
-->
## Search Terms
logic, predicate, quickfix
<!-- List of keywords you searched for before creating this issue. Write them down here so that others can find this suggestion more easily -->
## Suggestion
provide a code fix or refactor to simply logic predicate
<!-- A summary of what you'd like to see added or changed -->
## Use Cases
<!--
What do you want to use this for?
What shortcomings exist with current approaches?
-->
simply some complexity logic predicate is hard and always get a break change,
hope have a code fix to simply that like the jetbrain idea
## Examples
```ts
if (! a && !b || !a && !c) {
// something
}
```
fix to:
```ts
if (!(a && (b || c))) {
// something
}
```
<!-- Show how this would be used and what the behavior would be -->
## Checklist
My suggestion meets these guidelines:
* [x] This wouldn't be a breaking change in existing TypeScript / JavaScript code
* [x] This wouldn't change the runtime behavior of existing JavaScript code
* [x] This could be implemented without emitting different JS based on the types of the expressions
* [x] This isn't a runtime feature (e.g. new expression-level syntax)
|
Suggestion,Help Wanted,Domain: Refactorings
|
low
|
Critical
|
335,125,554
|
flutter
|
Not possible to add custom labels to images using TalkBack
|
Using talkback it is possible to apply labels to unlabeled images. Currently an unlabeled image cannot be labeled with a Flutter app.
See https://support.google.com/accessibility/android/answer/6007066?hl=en
|
c: new feature,platform-android,framework,a: accessibility,P3,team-android,triaged-android
|
low
|
Minor
|
335,127,142
|
flutter
|
Support for a11y link traits on iOS
|
This will probably require a new flag
On Android, TalkBack can pull links into the navigation menu:
https://support.google.com/accessibility/android/answer/6378148?hl=en
https://developer.apple.com/documentation/uikit/uiaccessibilitytraitlink?language=objc
filed b/141771449
|
c: new feature,platform-ios,framework,a: accessibility,P2,team-ios,triaged-ios
|
low
|
Minor
|
335,127,485
|
godot
|
Framerate/FPS jumps to 110, wasting CPU, when game is minimized
|
v3.0.2.stable.official
Windows 10
Monitor shows the fps going straight for double the normal when minimized.
Happens even when `OS.set_low_processor_usage_mode(true)`
|
bug,topic:porting,confirmed
|
low
|
Major
|
335,155,326
|
neovim
|
API: nvim_buf_attach not returning
|
When testing the new buffer API functions through `nvim --embed`, I noticed that `nvim_buf_attach` never returns, but an event is fired. Also, when calling for instance `nvim_buf_set_lines`, it often returns, but not always.
|
bug,api,channels-rpc
|
medium
|
Critical
|
335,160,852
|
rust
|
Bug: a macro never hit recursion limit, `cargo build` run... forever!
|
I know what is my mistake, ~but I think there is a bug in Rust!~
**Edit**: We just need a **better help** from the compiler to easily spot out mistake like this.
*Edit: the problem seems just involve only the first rule. So the new minimal buggy code is:*
```rust
macro_rules! there_is_a_bug {
( $id:ident: $($tail:tt)* ) => {
there_is_a_bug! { $($tail:tt)* } // I dit it wrong here `:tt`
};
}
fn main() {
there_is_a_bug! { something: more {} }
}
```
`cargo build` will run forever! (well, I just wait for it for about ten minutes!)
```
rustup show
stable-x86_64-unknown-linux-gnu (default)
rustc 1.27.0 (3eda71b00 2018-06-19)
```
|
I-compiletime,A-macros,T-compiler,C-bug,I-hang
|
medium
|
Critical
|
335,167,513
|
godot
|
SSAO doesn't work when the camera is in orthogonal mode
|
<!-- Please search existing issues for potential duplicates before filing yours:
https://github.com/godotengine/godot/issues?q=is%3Aissue
-->
**Godot version:**
3.X.X branch
**OS/device including version:**
Windows, but probably it's global issue
**Issue description:**
Ssao is not working with camera in orthogonal mode
**Steps to reproduce:**
Add WorldEnviroment with Ssao turned on and switch camera between projection modes
**Screens:**


|
bug,topic:rendering,confirmed,topic:3d
|
low
|
Major
|
335,172,333
|
go
|
time: time.Parse unable to parse timestamps with unusual UTC offsets
|
```
$ gotip version
go version devel +d6a27e8edc Sat Jun 23 00:16:14 2018 +0000 linux/amd64
```
I dumped the time for each of the 425 timezones in my system's tz database in a file and tried to parse the timestamps. I got 17 errors, all caused by `time.Parse` inability to parse unusual offsets like `+0545` (used in `Asia/Kathmandu`) or `+13` (used in `Pacific/Fakaofo`).
Complete failures log:
```
Timezone: America/Scoresbysund
zdump time: Sun Jun 24 10:43:46 2018 +00
time.Parse: parsing time "Sun Jun 24 10:43:46 2018 +00": extra text: +00
Timezone: Asia/Colombo
zdump time: Sun Jun 24 16:13:46 2018 +0530
time.Parse: parsing time "Sun Jun 24 16:13:46 2018 +0530": extra text: +0530
Timezone: Asia/Kabul
zdump time: Sun Jun 24 15:13:46 2018 +0430
time.Parse: parsing time "Sun Jun 24 15:13:46 2018 +0430": extra text: +0430
Timezone: Asia/Kathmandu
zdump time: Sun Jun 24 16:28:46 2018 +0545
time.Parse: parsing time "Sun Jun 24 16:28:46 2018 +0545": extra text: +0545
Timezone: Asia/Tehran
zdump time: Sun Jun 24 15:13:46 2018 +0430
time.Parse: parsing time "Sun Jun 24 15:13:46 2018 +0430": extra text: +0430
Timezone: Asia/Yangon
zdump time: Sun Jun 24 17:13:46 2018 +0630
time.Parse: parsing time "Sun Jun 24 17:13:46 2018 +0630": extra text: +0630
Timezone: Atlantic/Azores
zdump time: Sun Jun 24 10:43:46 2018 +00
time.Parse: parsing time "Sun Jun 24 10:43:46 2018 +00": extra text: +00
Timezone: Australia/Eucla
zdump time: Sun Jun 24 19:28:46 2018 +0845
time.Parse: parsing time "Sun Jun 24 19:28:46 2018 +0845": extra text: +0845
Timezone: Australia/Lord_Howe
zdump time: Sun Jun 24 21:13:46 2018 +1030
time.Parse: parsing time "Sun Jun 24 21:13:46 2018 +1030": extra text: +1030
Timezone: Indian/Cocos
zdump time: Sun Jun 24 17:13:46 2018 +0630
time.Parse: parsing time "Sun Jun 24 17:13:46 2018 +0630": extra text: +0630
Timezone: Pacific/Apia
zdump time: Sun Jun 24 23:43:46 2018 +13
time.Parse: parsing time "Sun Jun 24 23:43:46 2018 +13": extra text: +13
Timezone: Pacific/Chatham
zdump time: Sun Jun 24 23:28:46 2018 +1245
time.Parse: parsing time "Sun Jun 24 23:28:46 2018 +1245": extra text: +1245
Timezone: Pacific/Enderbury
zdump time: Sun Jun 24 23:43:46 2018 +13
time.Parse: parsing time "Sun Jun 24 23:43:46 2018 +13": extra text: +13
Timezone: Pacific/Fakaofo
zdump time: Sun Jun 24 23:43:46 2018 +13
time.Parse: parsing time "Sun Jun 24 23:43:46 2018 +13": extra text: +13
Timezone: Pacific/Kiritimati
zdump time: Mon Jun 25 00:43:46 2018 +14
time.Parse: parsing time "Mon Jun 25 00:43:46 2018 +14": extra text: +14
Timezone: Pacific/Marquesas
zdump time: Sun Jun 24 01:13:46 2018 -0930
time.Parse: parsing time "Sun Jun 24 01:13:46 2018 -0930": extra text: -0930
Timezone: Pacific/Tongatapu
zdump time: Sun Jun 24 23:43:46 2018 +13
time.Parse: parsing time "Sun Jun 24 23:43:46 2018 +13": extra text: +13
```
https://gist.github.com/ALTree/de33561c1cc00ac46e2e9e6d6cca52fe
|
NeedsFix
|
low
|
Critical
|
335,214,547
|
react
|
add support for SyntheticKeyboardEvent#isComposing
|
**Do you want to request a *feature* or report a *bug*?**
Bug
**What is the current behavior?**
Synthetic keyboard events do not contain `isComposing`.
They should if the value is true, per the w3 spec 4.7.5: https://www.w3.org/TR/uievents/#events-compositionevents
**What is the expected behavior?**
`event.isComposing === event.nativeEvent.isComposing`
SyntheticKeyboardEvent#isComposing is true when a keydown even is fired after compositionstart and before compositionend.
**Which versions of React, and which browser / OS are affected by this issue? Did this work in previous versions of React?**
all versions, up through at least 16.4.1
|
Type: Feature Request,Component: DOM
|
medium
|
Critical
|
335,237,115
|
pytorch
|
Inconsistency in implementation of _LRScheduler
|
I've noticed an odd behavior when attempting to write my own scheduler based on `torch.optim.lr_scheduler._LRScheduler`.
If you write a custom get_lr() to work based on self.last_epoch, its impossible to differentiate the
0th and the 1st epoch.
Here is a minimal working example:
```python
def mwe():
# Assuming optimizer has two groups.
import torch.optim.lr_scheduler
import netharn as nh
model = nh.models.ToyNet2d()
optimizer = torch.optim.SGD(model.parameters(), lr=10)
class DummySchedule(torch.optim.lr_scheduler._LRScheduler):
def get_lr(self):
print('Set LR based on self.last_epoch = {!r}'.format(self.last_epoch))
self._current_lr = self.last_epoch
return [self.last_epoch]
# Initialize the optimizer with epoch 0's LR
# self = torch.optim.lr_scheduler.LambdaLR(optimizer, lambda x: x)
self = DummySchedule(optimizer)
for epoch in range(3):
print('------')
print('Run epoch = {!r}'.format(epoch))
# Pretend we run epoch 0
print('Training with self._current_lr = {!r}'.format(self._current_lr))
# Pretend epoch 0 has finished, so step the scheduler.
# self.step(epoch=epoch)
self.step()
```
This results in the output
```
Set LR based on self.last_epoch = 0
------
Run epoch = 0
Training with self._current_lr = 0
Set LR based on self.last_epoch = 0
------
Run epoch = 1
Training with self._current_lr = 0
Set LR based on self.last_epoch = 1
------
Run epoch = 2
Training with self._current_lr = 1
Set LR based on self.last_epoch = 2
```
You can see the last epoch is asked to set the learning rate based on the last epoch being 0 twice. This LRScheduler class takes last_epoch as an argument, so it knows how to set the LR for the previous epoch. By default last_epoch=-1, because the first epoch is 0 and no epoch has run yet. On construction it then calls `step` with `last_epoch + 1`, which means the step function sets the learning rate for epoch 0. Then last_epoch is reset to -1 immediately after, so the next call to step also sets the learning rate for epoch 0.
A fix would simply remove the + 1 from `self.step(last_epoch + 1)`, but this might break existing implementations of `get_lr()` which wouldn't expect `self.last_epoch` being set to a negative number.
I think a more intuitive implementation of this class might track the current epoch rather than the previous one. This would be a backwards incompatible change, but I think it would improve the overall quality of torch. I'm willing to give a re-implementation a shot if it sounds like a good idea to the maintainers.
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer @mruberry @jbschlosser @vincentqb
|
module: nn,module: optimizer,triaged,needs research
|
low
|
Minor
|
335,269,335
|
vscode
|
[HTML] Auto tag-closing doesn't work with undo/redo and programmatic changes
|
We had a user [report an issue](https://github.com/MicrosoftDocs/live-share/issues/610) with Visual Studio Live Share, where their HTML tag-closing behavior would insert duplicate closing tags as soon as a guest connected to their session.

After looking into it briefly, it appears like the [HTML tag-closing behavior](https://github.com/Microsoft/vscode/blob/master/extensions/html-language-features/client/src/tagClosing.ts) is [listening to the `workspace.onDidChangeTextDocument` event](https://github.com/Microsoft/vscode/blob/master/extensions/html-language-features/client/src/tagClosing.ts#L12:12), and therefore, generating the closing tag on every participants machine, as soon as the `/` or `>` is synchronized across the session. If five guests joined the session, then you'd see six copies of the closing tag.
It isn't immediately clear what the best fix for this is, so I was hoping to get some advice. Initially, I thought we could set the `html.autoClosingTags` setting to `false` in the guest's workspace file. However, since the tag-closing behavior [relies on the `activeEditor`](https://github.com/Microsoft/vscode/blob/master/extensions/html-language-features/client/src/tagClosing.ts#L58), this would break tag-closing for guests if they weren't focused on the same file as the host (maybe that's a better short-term solution?).
At a high-level, it seems like there are two possible ways to address to:
1. **Run the tag-closing logic on the host** - Live Share already takes "exclusive" ownership of language services for `vsls:` documents, but the tag-closing logic runs on the guest's machine since it appears to be [always initialized](https://github.com/Microsoft/vscode/blob/master/extensions/html-language-features/client/src/htmlMain.ts#L90) regardless of the document scheme. We could explore ways to run this logic on the host, however, the reliance on the `activeEditor` would need to be refactored.
2. **Run the tag-closing logic local to each participant** - Since the tag-closing logic could operate entirely on a document buffer, it could technically just run on each guest's machine, without needing file system access. However, since it relies on the `workspace.onDidChangeChangeTextDocument` event, it seems like it would need to identify "local" edits, and only generate closing tags as appropriate. That way, each guest doesn't create the same edit that everyone else is already making.
Any thoughts would be greatly appreciated, since the current behavior is definitely a little wonky. Thanks!
|
html,debt,undo-redo
|
medium
|
Major
|
335,299,795
|
rust
|
ambiguous type-dependent name resolution
|
Currently ([playground](https://play.rust-lang.org/?gist=005ffda13df3190067c4f7189856d22a&version=stable&mode=debug)):
```rust
pub struct A<T>(T);
impl A<u32> {
fn new(x: u32) -> Self { A(0) }
}
impl A<f32> {
fn new(x: f32) -> Self { A(0.) }
}
fn main() {
let _ : A<f32> = A::new(0.); // ERROR
// let _ = A::<f32>::new(0.); // OK
}
```
errors with:
```
error[E0034]: multiple applicable items in scope
--> src/main.rs:9:22
|
9 | let _ : A<f32> = A::new(0.);
| ^^^^^^ multiple `new` found
|
note: candidate #1 is defined in an impl for the type `A<u32>`
--> src/main.rs:3:5
|
3 | fn new(x: u32) -> Self { A(0) }
| ^^^^^^^^^^^^^^^^^^^^^^
note: candidate #2 is defined in an impl for the type `A<f32>`
--> src/main.rs:6:5
|
6 | fn new(x: f32) -> Self { A(0.) }
| ^^^^^^^^^^^^^^^^^^^^^^
error: aborting due to previous error
```
This is probably a feature request but I'd like the `A<f32>` method to be picked in this case and for the program above to compile.
Solving this might require an RFC but I think this is a problem worth solving.
---
cc @nikomatsakis @eddyb
|
A-trait-system,A-associated-items,T-lang,C-feature-request,T-types
|
low
|
Critical
|
335,323,345
|
rust
|
Mutually exclusive traits still cause conflict in blancket implementation
|
The following code
```rust
#![crate_type="rlib"]
#![feature(optin_builtin_traits)]
trait Simple {}
trait Complicated {}
impl<T : Simple> !Complicated for T {}
impl<T : Complicated> !Simple for T {}
trait MyTrait {}
impl<T : Simple> MyTrait for T {}
impl<T : Complicated> MyTrait for T {}
```
refuses to compile with the following error
```console
error[E0119]: conflicting implementations of trait `MyTrait`:
--> buggy.rs:13:1
|
12 | impl<T : Simple> MyTrait for T {}
| ------------------------------ first implementation here
13 | impl<T : Complicated> MyTrait for T {}
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ conflicting implementation
error: aborting due to previous error
For more information about this error, try `rustc --explain E0119`.
```
It should compile: `Simple` and `Complicated` being explicitly defined as mutually exclusive no type can be both, and as such, the implementations do not conflict.
It should work with more than two traits, as long as they are all mutually exclusive.
Building with the latest nightly.
```console
rustc 1.28.0-nightly (01cc982e9 2018-06-24)
binary: rustc
commit-hash: 01cc982e936120acb0424e41de14e42ba2d88c6f
commit-date: 2018-06-24
host: x86_64-unknown-linux-gnu
release: 1.28.0-nightly
LLVM version: 6.0
```
|
A-trait-system,T-lang,C-feature-request
|
low
|
Critical
|
335,334,864
|
vue
|
Computed Watchers Not Firing
|
### Version
2.5.16
### Reproduction link
[https://vuejs.org/v2/guide/computed.html#Watchers](https://vuejs.org/v2/guide/computed.html#Watchers)
### Steps to reproduce
Use the demo for entering a question on the Docs page using a Amazon Kindle 7'' or Android Tablet (I used a Lenovo Tab 3 7'' version)
https://vuejs.org/v2/guide/computed.html#Watchers
### What is expected?
When typing in the field the value is evaluated after each letter is tapped when using a browser on a tablet, as per the demo instructions.
### What is actually happening?
Nothing is evaluated until the space bar is tapped or a question mark / exclamation mark is selected from the keyboard.
---
I use this to create a drop down list of options when a user starts typing into a text field using Android tablet specifically Amazon Fire.
The user starts typing and after letters are entered the list is shown..
After updating then the list is only shown if the user taps the space bar or the enter key on the on screen keyboard.
This works as expected when using a browser on a computer.
I have tested my code on Mac using Safari, Chrome and Firefox and no errors are in the console.
On Amazon Fire and it works as expected when on version 2.5.13
Updating my VueJS to version 2.5.16 and this stops working on the tablet and requires the space key, exclamation mark, question mark or enter key to be tapped for the evaluation to fire/run when using the tablet device.
<!-- generated by vue-issues. DO NOT REMOVE -->
|
browser quirks,help wanted
|
medium
|
Critical
|
335,363,509
|
rust
|
Support for running the src/ci/docker/run.sh with user namespace
|
Hello
When struggling to run the complete build and tests, I decided to try the bundled docker runner. However, I run docker under user namespace, which disables support for `--privileged`. The run script fails:
```
./src/ci/docker/run.sh x86_64-gnu
... <A lot of output> ...
Successfully built 2a8488e739aa
Successfully tagged rust-ci:latest
docker: Error response from daemon: privileged mode is incompatible with user namespaces. You must run the container in the host namespace when running privileged mode.
See 'docker run --help'.
```
Would it make sense to have some limited mode of the tests that would skip the parts needing the extra syscalls (mentioned [here](https://github.com/rust-lang/rust/blob/master/src/ci/docker/run.sh#L114)) and conditionally disable the privileged mode? Or would it be too much work with very little benefit?
This is on a yesterday's master (01cc982e936120acb0424e41de14e42ba2d88c6f).
|
T-bootstrap,C-feature-request
|
low
|
Critical
|
335,429,663
|
vscode
|
Add settings editor commands to focus next and previous settings
|
Issue Type: <b>Bug</b>
1) When the cursor in the search box, <kbd>DownArrow</kbd> moves the keyboard focus to the list of settings. However, <kbd>UpArrow</kbd> does not bring me back to the search box.
2) When the keyboard focus in the TOC, <kbd>RightArrow</kbd> should move the keyboard focus to the closest item in the list of settings.
3) When the keyboard focus is in the list of settings, <kbd>LeftArrow</kbd> should move the keyboard focus to the highlighted node in the TOC.
4) It seems unusal that the section headers and subheaders in the list of settings can take the keyboard focus. It would feel more natural if the headers and subheaders would be skipped.
5) When a settings cells has the keyboard focus, <kbd>Enter</kbd> should move the keyboard focus to the value editor (same as <kbd>Tab</kbd>. <kbd>Shift+Tab</kbd> and <kbd>ESC</kbd> remain to remove it back to the settings row.
VS Code version: Code - Insiders 1.25.0-insider (5d6156a0f8b68fe7e9429facbcfaa7c061a8b3e3, 2018-06-25T09:32:08.937Z)
OS version: Darwin x64 16.7.0
<details>
<summary>System Info</summary>
|Item|Value|
|---|---|
|CPUs|Intel(R) Core(TM) i7-4870HQ CPU @ 2.50GHz (8 x 2500)|
|GPU Status|2d_canvas: enabled<br>flash_3d: enabled<br>flash_stage3d: enabled<br>flash_stage3d_baseline: enabled<br>gpu_compositing: enabled<br>multiple_raster_threads: enabled_on<br>native_gpu_memory_buffers: enabled<br>rasterization: enabled<br>video_decode: enabled<br>video_encode: enabled<br>vpx_decode: enabled<br>webgl: enabled<br>webgl2: enabled|
|Load (avg)|2, 2, 2|
|Memory (System)|16.00GB (1.06GB free)|
|Process Argv|/Users/kmaetzel/Applications/Visual Studio Code - Insiders.app/Contents/MacOS/Electron -psn_0_17449123|
|Screen Reader|no|
|VM|0%|
</details>
<!-- generated by issue reporter -->
|
help wanted,feature-request,settings-editor
|
low
|
Critical
|
335,486,111
|
rust
|
Re-export from external crate not documented
|
c.f. https://docs.rs/hyper/0.12.2/hyper/index.html and https://docs.rs/hyper/0.12.2/hyper/struct.Response.html
Based on that documentation, it appears that `Response` is part of the `hyper` crate, when it's definition there is https://github.com/hyperium/hyper/blob/master/src/lib.rs#L39-L48 (pub use from `http`).
This was especially confusing to me because I wanted to pass the result of `Response::builder()` between functions in my own code. I was surprised to discover that I'd need to add `http` as a direct dependency in my Cargo.toml.
The `pub use` lines referring to internal modules within `hyper` are reported that way, but the re-exports from `http` are both not listed in the "Re-exports" section, and they're presented as if they were defined in `hyper`.
|
T-rustdoc,C-enhancement
|
low
|
Minor
|
335,487,826
|
rust
|
Confusing behavior around unsized return values in traits
|
The following traits are accepted, ~~but not object safe~~:
```rust
pub trait MyTrait {
fn deserialize(input: u32) -> Self;
}
pub trait YourTrait {
type Output: ?Sized;
fn deserialize(&self, input: u32) -> Self::Output;
}
```
On the other hand, the following traits are rejected saying `the trait bound Self: std::marker::Sized is not satisfied`:
```rust
pub trait MyTrait {
fn deserialize(input: u32) -> Option<Self>;
}
pub trait YourTrait {
type Output: ?Sized;
fn deserialize(&self, input: u32) -> Option<Self::Output>;
}
```
The error makes sense in principle, but
* (a) it is really confusing that it is okay to have unsized return types (where usually the same check would apply!), but not return enums with unsized types inside them. What seems to happen here is that there is a special rule if the return type is unsized to drop object safety (if the type is `Self`) or do nothing (otherwise) instead of complaining.
* (b) The fix is far from obvious: One has to add `Sized` as a supertrait to `MyTrait`. Given that `Sized` is usually added implicitly, people will run into this without ever having dealt with `Sized` before (and in fact, that's what just happened when a friend asked me about this). The error will certainly not help with finding this.
Both of these points would be fixed if that exception for unsized argument/return types would be extended to also cover the above cases.
|
C-enhancement,A-trait-system,A-DSTs,T-lang
|
low
|
Critical
|
335,491,933
|
go
|
proposal: os: API to detect that the read end of a pipe was closed
|
Currently there is no API in Go to detect that the read end of a pipe was closed without writing to the pipe a non-empty slice. This prevents, for example, to write in a safe Go a version of GNU tail utility that exits immediately when it detects that the read end of its stdout was closed even when it waits for more input like when it is called via `tail -f`. For example, given the following case:
tail -f file-to-follow | grep -q foo
GNU tail exits immediately after the grep finds the word _foo_ and terminates without waiting that the file-to-follow will be extended and trying to write those extra bytes to stdout.
Yet to write such functionality in Go one needs to use unsafe code to call sys.Select or similar and wait for an syscall.EPIPE from the stdout descriptor.
### What version of Go are you using (`go version`)?
go1.10.3
### Does this issue reproduce with the latest release?
Yes
### What operating system and processor architecture are you using (`go env`)?
amd64 linux fedora-28
|
Proposal
|
medium
|
Major
|
335,497,470
|
pytorch
|
Todo functions and autograd supports for Sparse Tensor
|
Here summarizes a list of requested Sparse Tensor functions and autograd supports from previous PRs. Please feel free to comment on functions that should be added also.
## Functions
- [x] `sum()` with autograd https://github.com/pytorch/pytorch/pull/12430
- [ ] `max()` with autograd
- [x] `log1p()` https://github.com/pytorch/pytorch/pull/8969
- [x] `S.copy_(S) with autograd ` https://github.com/pytorch/pytorch/pull/9005
- [ ] indexing (`gather()`, `index_select()`)
- [ ] `mul_(S, D) -> S`, `mul(S, D) -> S` with autograd
- [x] `cuda()`
- [ ] `nn.Linear` with autograd (SxS, SxD, relies on `addmm` and `matmul`)
- [x] `softmax()` with autograd (same as in [TF](https://www.tensorflow.org/api_docs/cc/class/tensorflow/ops/sparse-softmax): Applies softmax() to a region of a densified tensor submatrix; (2) Masks out the zero locations; (3) Renormalizes the remaining elements. SparseTensor result has exactly the same non-zero indices and shape)
- [x] `to_sparse()` #12171
- [x] `narrow_copy()` https://github.com/pytorch/pytorch/pull/11342
- [ ] `sparse_mm(S, D) -> D` with autograd
- [x] `cat()` https://github.com/pytorch/pytorch/pull/13577
- [x] `unsqueeze()`, `stack()` https://github.com/pytorch/pytorch/pull/13760
### Wish list
- `bmm(S, D)` (add an extra sparse dim at `indices` of SparseTensor as batch dim?)
- broadcasting `mul(S, D) -> S`
- `Dataset`, `Dataloader`
- `save`, `load` for sparse tensors
## Existing
- autograd supported for `values()` via https://github.com/pytorch/pytorch/pull/13001 (Thanks to @SsnL!), that means all element-wise ops are supported in sparse now
- norm (cannot take `dim` args)
- pow
- clone
- zero_
- t_ / t
- add_ / add(Sparse, Sparse, Scalar) -> Sparse
- add_ / add(Dense, Sparse, Scalar) -> Dense
- sub_ / sub(Sparse, Sparse, Scalar) -> Sparse
- mul_ / mul(Sparse, Sparse) -> Sparse
- mul_ / mul(Sparse, Scalar) -> Sparse
- div_ / div(Sparse, Scalar) -> Sparse
- addmm(Dense, Sparse, Dense, Scalar, Scalar) -> Dense
- sspaddmm(Sparse, Sparse, Dense, Scalar, Scalar) -> Sparse
- mm(Sparse, Dense) -> Dense
- smm(Sparse, Dense) -> Sparse
- hspmm(Sparse, Dense) -> HybridSparse
- spmm(Sparse, Dense) -> Dense
|
module: sparse,triaged
|
medium
|
Critical
|
335,512,674
|
go
|
x/build: add js/wasm Chrome/Firefox capable trybot
|
Follow on from https://github.com/golang/go/issues/26015#issuecomment-400029578
With a Chrome and/or Firefox capable trybot we'd be able to do more interesting WASM tests in a headless browser-based JS VM, and so have access to the DOM etc.
This issue is to decide whether or not such a trybot would be useful and therefore worth the effort.
|
Builders,NeedsFix,FeatureRequest,arch-wasm,new-builder
|
medium
|
Major
|
335,550,724
|
flutter
|
SeekControl action support for TalkBack
|
On Android you can select a SeekControl (Slider in Flutter) and open the local context menu to select an exact value. Unclear currently if we need to support this with our own local context action or with some additional hooks in the accessibility bridge
|
c: new feature,platform-android,framework,engine,a: accessibility,P2,team-android,triaged-android
|
low
|
Minor
|
335,580,058
|
pytorch
|
Use target_compile_options to set warning flags
|
They are currently set via `CMAKE_CXX_FLAGS` in root `CMakeList.txt`.
Just opening an issue to track this. It isn't high-pri.
cc @malfet @seemethere @walterddr @goldsborough @orionr
|
module: build,triaged
|
low
|
Minor
|
335,583,244
|
vscode
|
Safe File Delete
|
Add a "safe delete" option for files that gives option to check for file usage in comments/strings **and/or** text occurrences. If usages found, it will display an additional warning before deleting the file.
[Feature example](https://www.jetbrains.com/help/phpstorm/safe-delete.html) exists in WebStorm.
|
feature-request,api,editor-code-actions
|
medium
|
Major
|
335,589,118
|
pytorch
|
Issues with dynamically created grad_fn for views
|
Currently the dynamically created `grad_fn` to point to `base`. When a view is created via
```py
base = torch.randn(3, requires_grad=True)
view1 = base[:2]
my_view = view1[:]
```
Then, if `base` is modified in-place, the `grad_fn` of `my_view` will be created to just point to `base`. Then the `retain_grad` and backward hooks on `view1` will be wrong.
E.g.,
```py
x = torch.ones(4, requires_grad=True).clone()
xx = x[2:]
y = xx[1]
xx.retain_grad()
#x[0] += 0
y.backward()
xx.grad
```
(Un)comment the line `x[0] += 0` changes the grad of `xx`.
This was previously reported at #8626 , but that also describes another unrelated (now solved) issue. So I'm opening a new one to track this.
cc @ezyang @albanD @zou3519 @gqchen @pearu @nikitaved @soulitzer
|
module: autograd,triaged,module: viewing and reshaping
|
low
|
Minor
|
335,616,819
|
opencv
|
make install doesn't create bin/ after platforms/js/build_js.py
|
```
git clone https://github.com/opencv/opencv
cd opencv
mkdir build
cd build
pwd
#prints: /Users/username/opencv/build
python ../platforms/js/build_js.py . --build_wasm
DESTDIR=/tmp/build make install
ls /tmp/build/Users/username/opencv/build/install/
include
lib
share
```
error: no bin/ created (that's where opencv.js etc is created), so we have to keep the build around, seems like a bug.
|
priority: low,category: build/install,RFC,category: javascript (js)
|
low
|
Critical
|
335,617,535
|
godot
|
Keyboard interrupt no longer stops the command line debugger
|
Godot master ff01fd57bc19d9f4cb3929dbee87cdd9eda578e1
Windows 10 64 bits
Powershell
In Godot 3.0.4, I used to debug my plugin by using the command line debugger (`-e -d command line options`), and using Ctrl+C (keyboard interrupt) to break out of a script error and close Godot straight away. This was fast and also left the terminal open, allowing me to keep track of the logs and easily restart the session without retyping commands.
Now I wanted to debug it using a build I made from master, but I noticed keyboard interruption no longer stops the process. Instead, the debugger just repeats the error. I tried using `q` for quitting, but it didn't quit and stayed blocked on the last script error, so the only way I could close was to close the terminal...
|
bug,enhancement,topic:editor,topic:porting,confirmed
|
low
|
Critical
|
335,619,802
|
flutter
|
SwitchListTile's constructor's leading element param should be named "leading" to be consistent with ListTile
|
This use case came up in our app and there's no way to accomplish this. We'll use `ListTile` for now.
|
framework,f: material design,c: API break,a: quality,P3,team-design,triaged-design
|
low
|
Major
|
335,625,826
|
vscode
|
VS Code was lost on shutdown with pending update
|
It was the second time ,it happend.
I download VScode's update patch when I was coding , and then shut down the computer and forgot to update it.
Next day I turn the computer on and can't find VScode anywhere , all the file was empty.
- OS Version : Windows 10 Home
|
bug,install-update,windows
|
high
|
Critical
|
335,629,288
|
go
|
proposal: spec: permit goto over declaration if variable is not used after goto label
|
Right now you get this error: ` goto SKIP jumps over declaration of queryArgs`
```
if len(s.standardDays) == 0 {
goto SKIP
}
queryArgs := []interface{}{}
//Do stuff with queryArgs
SKIP:
//Do stuff here BUT queryArgs is not used ANYWHERE from SKIP onwards
```
Currently I have to refactor all my code like this (including placing `var err error` at the top):
```
var queryArgs []interface{}
if len(s.standardDays) == 0 {
goto SKIP
}
queryArgs = []interface{}{}
//Do stuff with queryArgs
SKIP:
//Do stuff here BUT queryArgs is not used ANYWHERE from SKIP onwards
```
|
LanguageChange,Proposal,LanguageChangeReview
|
medium
|
Critical
|
335,629,861
|
go
|
runtime: use wrappers for op= map operations
|
CL 120255 made mapdelete zero the value all the time, to make sure op= map operations work correctly.
Probably we should do wrapper functions for op= operations so we don't need to zero during all map deletes.
@vkuzmin-uber
@martisch
|
Performance,NeedsInvestigation,compiler/runtime
|
low
|
Major
|
335,630,091
|
go
|
runtime: g0 stack.lo is sometimes too low
|
In cgo mode for UNIX platforms, we compute the g0 stack bounds by querying the stack size from `pthread_get_stacksize`, subtracting that from the current SP in `mstart`, and adding a 1k buffer. However, on my Linux laptop, over 4k of the stack has already been consumed by the time we reach `mstart`, so the runtime sets the bottom of the g0 stack to be below the mapped memory. As a result, if we actually overflow the g0 stack, we get a segfault instead of a useful message with a traceback.
We should use `pthread_get_stack` instead to get both stack bounds.
Discovered when writing a test of overflowing the g0 stack for #21382, which I had assumed would pass on linux/amd64 but didn't.
|
NeedsFix,compiler/runtime
|
low
|
Minor
|
335,631,520
|
pytorch
|
[Caffe2] Dose caffe2 support the function similar to itersize of caffe
|
I don't want to decrease the batch size with limited gpus, so does caffe2 support itersize? The caffe2 doc is incomplete. And I have googled some keywords, but got nothing. I hope you can give me a hand! thanks for your help!
|
caffe2
|
low
|
Minor
|
335,669,588
|
flutter
|
Template for flutter create cupertino
|
A flutter create template that doesn't import material
|
c: new feature,framework,f: cupertino,P2,team-design,triaged-design
|
low
|
Major
|
335,697,398
|
vscode
|
Dragging files and folders onto an empty explorer ignores the files
|
re #52292
* in the finder select a file and a folder
* drop them onto an empty explorer
* 🐛 only the folder is opened, the file is being ignored
|
bug,file-explorer
|
low
|
Minor
|
335,727,668
|
opencv
|
Unable to Play rtsp stream using cv::cudacodec::VideoReader
|
I am using Opencv 3.1.0, ffmpeg gpu, and nvidia video codec sdk 8.2.15.
ffmpeg version N-91329-g830695b Copyright (c) 2000-2018 the FFmpeg developers built with gcc 5.4.0 (Ubuntu 5.4.0-6ubuntu1~16.04.6) 20160609 configuration: --enable-cuda --enable-cuvid --enable-nvenc --enable-nonfree --enable-libnpp --extra-cflags=-I/usr/local/cuda/include --extra-ldflags=-L/usr/local/cuda/lib64 --enable-shared --disable-static
`
OpenCV Error: Gpu API call (CUDA_ERROR_FILE_NOT_FOUND [Code = 301]) in CuvidVideoSource, file /usr/deepak/ffmpeg-gpu/opencv/modules/cudacodec/src/cuvid_video_source.cpp, line 66
`
`
OpenCV Error: Unsupported format or combination of formats (Unsupported video source) in nextFrame, file /usr/deepak/ffmpeg-gpu/opencv/modules/cudacodec/src/video_reader.cpp, line 143
terminate called after throwing an instance of 'cv::Exception'
`
`
what(): /usr/deepak/ffmpeg-gpu/opencv/modules/cudacodec/src/video_reader.cpp:143: error: (-210) Unsupported video source in function nextFrame
`
I looked at the solution https://github.com/opencv/opencv/issues/9739 and had exactly the same issue. Unfortunately, the problem wasn't resolved using the given solution.
As mentioned in the link above I had the same issue that,
ffmpeg detected the stream as YUVJ420P so I made the changes mentioned in the link.
However I still get the same error.
When I run gdb on opencv/modules/cudacodec/src/ffmpeg_video_source.cpp,
`
(gdb) n
OpenCV Error: Gpu API call (CUDA_ERROR_FILE_NOT_FOUND [Code = 301]) in CuvidVideoSource, file /usr/deepak/ffmpeg-gpu/opencv/modules/cudacodec/src/cuvid_video_source.cpp, line 66
[New Thread 0x7fffe1328700 (LWP 31246)]
[New Thread 0x7fffe0b27700 (LWP 31247)]
[New Thread 0x7fffdba98700 (LWP 31248)]
[Thread 0x7fffdba98700 (LWP 31248) exited]
22 if (!d_reader->nextFrame(d_frame))
`
`
(gdb) n
OpenCV Error: Unsupported format or combination of formats (Unsupported video source) in nextFrame, file /usr/deepak/ffmpeg-gpu/opencv/modules/cudacodec/src/video_reader.cpp, line 128
terminate called after throwing an instance of 'cv::Exception'
what(): /usr/deepak/ffmpeg-gpu/opencv/modules/cudacodec/src/video_reader.cpp:128: error: (-210) Unsupported video source in function nextFrame
`
Any help would be greatly appreciated!!!
|
priority: low,category: gpu/cuda (contrib)
|
low
|
Critical
|
335,774,874
|
vue
|
Transitions classes are added after `before-enter` or `before-leave`
|
### Version
2.5.16
### Reproduction link
[https://codesandbox.io/s/zq5mw2zk9x](https://codesandbox.io/s/zq5mw2zk9x)
### Steps to reproduce
1. Open browser console (to trigger the debugger)
2. Click on "Page 2"
3. Inspect elements inside `<main`>`
### What is expected?
The two children `<sections>` are supposed to have the transitions classes.
### What is actually happening?
The two children`<sections>` are already added but without any transition class, which are added on next tick. So the new `<section>` is visible on top on the old one for 1 frame, causing a flickering effect.
---
Remove this fix in `App.vue`:
```css
main > :first-child {
z-index: 1; /* Prevent flickering on first frame when transition classes not added yet */
}
```
And navigate through the app to see the flicker effect.
<!-- generated by vue-issues. DO NOT REMOVE -->
|
transition
|
medium
|
Critical
|
335,826,860
|
rust
|
s390x intrinsic has incorrect return type - stdsimd cross-link
|
On `s390x-unknown-linux-gnu` `coresimd` fails to compile due to errors in the following floating-point vector functions: abs, cos, fma, sin, sqrt.
The errors are all of the form:
```shell
Intrinsic has incorrect return type!
void (<16 x float>*, <16 x float>*, <16 x float>*, <16 x float>*)* @llvm.fma.v16f32
LLVM ERROR: Broken function found, compilation aborted!
```
This is a cross-link to the `stdsimd` issue: https://github.com/rust-lang-nursery/stdsimd/issues/501
|
O-SystemZ
|
low
|
Critical
|
335,893,501
|
go
|
x/mobile: unexpected fault address 0x30ad1040
|
Please answer these questions before submitting your issue. Thanks!
### What version of Go are you using (`go version`)?
go version go1.10.3 linux/amd64
### Does this issue reproduce with the latest release?
Yes
### What operating system and processor architecture are you using (`go env`)?
linux amd64 and android 7.1.1
### What did you do?
I'm trying to run a code which ran successfully on my computer but keeps failing on android.
The error message doesn't give enough information. I need some information to know what is going on with the error. I've tested the same code several times on my computer and It doesn't fail.
Android code: https://github.com/C-ollins/dcrandroid/tree/spv_bug
Golang code: https://github.com/C-ollins/btcwallet/tree/spv_bug
### What did you expect to see?
A successful run
### What did you see instead?
Error log: https://bpaste.net/show/61c2f48d8d49
|
OS-Android,NeedsInvestigation,mobile
|
low
|
Critical
|
335,917,260
|
neovim
|
API: nvim_buf_lines_event after checktime ?
|
<!-- Before reporting: search existing issues and check the FAQ. -->
- `nvim --version`: NVIM v0.3.1-96-g883858269
- Vim (version: ) behaves differently? No
- Operating system/version: MacOS
- Terminal name/version: ITerm2
- `$TERM`: xterm-256color
### Steps to reproduce using `nvim -u NORC`
``` vim
async function setup(nvim) {
let id = await nvim.channelId
let buffer = await nvim.buffer
let lines = await buffer.lines
let cb = (buf, tick, firstline, lastline, linedata, more) => {
console.error('----------')
console.error('result:', tick, firstline, lastline, linedata, more)
}
buffer.listen('lines', cb)
buffer.listen('detach', buf => {
console.error('detached')
})
}
module.exports = (plugin) => {
let {nvim} = plugin
plugin.registerAutocmd('VimEnter', setup.bind(null, nvim), {pattern: '*'})
}
```
Open a file and change the file outside vim and run `:checktime`, the new content is loaded, but no `nvim_buf_detach_event` is fired, the `nvim_buf_detach_event` is fired when I use `:edit`.
### Actual behaviour
No `nvim_buf_detach_event` fired.
### Expected behaviour
Should have `nvim_buf_detach_event` fired.
|
api,needs:design
|
low
|
Critical
|
335,929,875
|
pytorch
|
[Caffe 2] Does caffe2 support Galaxy 5S with Android 6?
|
I convert the detectron model to .PB format, and it runs on Google Pixel Android 7 & 8, but not Galaxy 5S with Android 6. Has anyone had experience with it?
|
caffe2
|
low
|
Minor
|
335,946,057
|
TypeScript
|
Allow Program#getSemanticDiagnostics to ignore @ts-ignore
|
<!-- 🚨 STOP 🚨 𝗦𝗧𝗢𝗣 🚨 𝑺𝑻𝑶𝑷 🚨
Half of all issues filed here are duplicates, answered in the FAQ, or not appropriate for the bug tracker. Please read the FAQ first, especially the "Common Feature Requests" section.
-->
## Search Terms
`ts-ignore`
## Suggestion
Add a parameter to `program.getSemanticDiagnostics` to turn off filtering by `// @ts-ignore` comments.
## Use Cases
#25166 proposes an option to report unused `// @ts-ignore` comments. Since this would require yet another compilerOption, I think this should better be done by external tooling like a linter.
Currently there is no way for external tools to know if there would actually be a semantic diagnostic without the comment. With the proposed API one could check that there is at least one diagnostic per ignore comment.
|
Suggestion,In Discussion,API
|
low
|
Critical
|
335,972,673
|
vue
|
Style bindings with !important don't work properly in IE 11.540
|
### Version
2.5.16
### Reproduction link
[https://codepen.io/anon/pen/QxVRyW?editors=1010](https://codepen.io/anon/pen/QxVRyW?editors=1010)
### Steps to reproduce
I've only seen this occur in IE 11.540 (through BrowserStack). The issue is not present in IE 11.0.
1. Click "toggle" button
2. "Surprise!!" should show up
3. Click "toggle" button again
4. "Surprise!!" is still visible
### What is expected?
Clicking "toggle" should hide the message. This works properly in chrome, and probably other browsers as well.
### What is actually happening?
The message is still visible, and has the `display: block !important` styling applied.
---
This causes problems with modals in semantic ui vue. See Semantic-UI-Vue/Semantic-UI-Vue#191
<!-- generated by vue-issues. DO NOT REMOVE -->
|
browser quirks
|
medium
|
Minor
|
335,973,122
|
TypeScript
|
navigateTo: special property assignment should have containerName set
|
See `navigationItemsSpecialPropertyAssignment.ts` as of #25239 -- `Cls.prototype.instanceMethod` should have `containerName` of `Cls`.
|
Suggestion,Awaiting More Feedback
|
low
|
Minor
|
335,988,570
|
pytorch
|
Multiprocessing Self Test Error
|
Getting this error in multi processing self test. The bug surfaces when I issue the `run_test` command like two more times one after another.
System:
Pytorch (cca24763), CUDA 9, V100
```
Running test_multiprocessing ...
s..........FTraceback (most recent call last):
File "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/queues.py", line 240, in _feed
send_bytes(obj)
File "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/connection.py", line 200, in send_bytes
self._send_bytes(m[offset:offset + size])
File "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/connection.py", line 404, in _send_bytes
self._send(header + buf)
File "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/connection.py", line 368, in _send
n = write(self._handle, buf)
BrokenPipeError: [Errno 32] Broken pipe
.EFTraceback (most recent call last):
File "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/queues.py", line 234, in _feed
obj = _ForkingPickler.dumps(obj)
File "/opt/conda/envs/pytorch-py3.6/lib/python3.6/multiprocessing/reduction.py", line 51, in dumps
cls(buf, protocol).dump(obj)
File "/opt/conda/envs/pytorch-py3.6/lib/python3.6/site-packages/torch/multiprocessing/reductions.py", line 112, in reduce_storage
metadata = storage._share_filename_()
RuntimeError: unable to open shared memory object </torch_34959_822569775> in read-write mode at ../aten/src/TH/THAllocator.cpp:334
```
|
todo,module: multiprocessing,triaged
|
low
|
Critical
|
336,000,054
|
rust
|
Lint warnings for "unused #[must_use]" should be emitted even if typeck fails.
|
In a situation like this (feel free to suggest less contrived examples):
```rust
#[must_use]
struct Foo<T> {
text: String,
children: Vec<T>,
}
impl<T> Foo<T> {
fn combine(mut self, other: Self) -> Self {
self.text.push_str(&other.text);
self.children.extend(other.children);
self
}
}
fn text<T>(text: impl Into<String>) -> Foo<T> {
Foo {
text: text.into(),
children: vec![],
}
}
fn bar<T>(mut foo: Foo<T>) -> Foo<T> {
if foo.text.is_empty() {
// Incomplete/incorrect code, #[must_use] should warn.
// However, we already have a type inference error.
text("bar");
// Correct code:
foo = text("bar").combine(foo);
}
foo
}
```
Because of the type-checking error caused by an uninferrable `T`, the `#[must_use]` lint never gets to run. But the fact that the return value isn't used is, in this case, quite relevant to the error.
If the `#[must_use]` lint is moved to typeck, it could run even on incomplete inference. Alternatively, the lint could stay independent, but somehow always run, even if typeck errored. The `test("bar")` expression would need to have the type `Foo<_>` with the `_` being a `TyError`.
cc @nikomatsakis @Manishearth
|
C-enhancement,A-lints,T-compiler
|
low
|
Critical
|
336,002,823
|
flutter
|
Examples on moving large structured data between Java/Obj-C and Dart
|
This comes up when authoring plugins, or using existing 3rd party frameworks. Sometimes one wants to move large amounts of structured data in/out of Dart.
I've heard at least anecdotal reports that this is slow (I've not personally benchmarked this).
I believe lack of documentation/direction here is also part of what is motivating upvotes for https://github.com/flutter/flutter/issues/7053.
No urgency on this, just a percieved opportunity. FYI @RedBrogdon @mjohnsullivan
|
engine,c: performance,d: api docs,P2,a: plugins,team-engine,triaged-engine
|
low
|
Major
|
336,010,606
|
TypeScript
|
In JS, typedef tags are not bound on non-expression statements
|
```js
/** @typedef {number} A */
var ok;
/** @typedef {number} B */
ok = 1; // also ok
/** @typedef {number} C not ok */
;
/** @typedef {number} D not ok */
if (ok) {
}
/** @type {[A, B, C, D]} */
var t = [1,2,3,4]
```
**Expected behavior:**
All of A, B, C, and D are type aliases for number.
**Actual behavior:**
Cannot find name 'C' and 'D'.
|
Suggestion,Awaiting More Feedback,Domain: JavaScript
|
low
|
Minor
|
336,013,179
|
three.js
|
Changing RenderTarget's texture parameters on the fly
|
Sometimes, when we want to save some memory, it happens that we have to reuse a render target, by just changing some possible parameters on the fly. I am talking about wrapping and filtering, obviously not format and type. Changing these parameters is (generally) fast enough (depending on the drivers).
However, it is not currently possible to do that, because of this part of the code:
https://github.com/mrdoob/three.js/blob/dev/src/renderers/webgl/WebGLTextures.js#L225-L244
As a `WebGLRenderTarget` has obviously no image attribute.
Maybe I am missing something, but it looks like the data uploading and the parameters and couple together. Am I the only one looking for a change on this side?
It would be nice to separate the data uploading from the parameters.
##### Three.js version
- [X] All of them
##### Browser
- [x] All of them
##### OS
- [x] All of them
|
Suggestion
|
low
|
Major
|
336,014,853
|
rust
|
NLL: `if let` not detecting proper lifetime
|
Hello,
I have recently been pointed to [this example](https://play.rust-lang.org/?gist=289c6fe73106c3fee425f1d50062076a&version=nightly&mode=debug):
```rust
#![feature(nll)]
fn find_best(vec: &mut Vec<i32>) -> Option<&mut i32> {
vec.get_mut(0)
}
fn foo(vec: &mut Vec<i32>) -> &mut i32 {
if let Some(best) = find_best(vec) {
best
} else {
&mut vec[1]
}
}
fn main() {
let mut x = vec![1, 2, 3];
*foo(&mut x) = 42;
}
```
To me, the code looks sane, and looks like it should compile with NLL enabled (as the borrow to `vec` ends at the end of the `if` block, and shouldn't propagate to the `else` block), yet it looks like it doesn't.
Hope that helps, and as always thank you for your work on `rustc`!
|
T-compiler,A-NLL,NLL-polonius
|
low
|
Critical
|
336,014,886
|
pytorch
|
[feature request] More methods for PackedSequence
|
As a person who works a lot with recurrent networks and sequences, I wish it was easier to work with `PackedSequence`. I frequently find myself packing/unpacking sequence to perform some simple operation such as
```
sequence, lengths = pad_packed_sequence(input, batch_first=True)
sequence = elementwise_function(sequence)
pack_padded_sequence(sequence, lengths, batch_first=True)
```
This complicates code, introduces bugs (setting `batch_first` incorrectly), and makes me write two versions of code for tensors and sequences.
`PaddedSequence` can be extended to act more like `torch.Tensor`. More specifically, it can be extended with following methods (I tried to choose ones which make sense):
# Element-wise unary operations (wrt to the tensor)
- abs, acos, asin, atan, atan2, ceil, clamp, contiguous, cos, cosh, exp, expm1, frac, log, log10, log1p, log2, mul, pow, reciprocal, neg, renorm, round, rsqrt, sigmoid, sign, sin, sinh, sqrt, tan, tanh, trunc
- fill_, pin_memory
# Boolean functions
- is_contiguous, is_pinned
# Element-wise binary operations
Two sequences can be added, subtracted, compared, etc when they have same shape and lengths.
- add, div, eq, fmod, ge, gt, le, lt, ne, remainder, sub
- map_
# Autograd functions
- detach
cc @albanD @mruberry @jbschlosser
|
feature,module: nn,triaged
|
low
|
Critical
|
336,042,182
|
TypeScript
|
refactoring for turning // comments to /**
|
<!-- 🚨 STOP 🚨 𝗦𝗧𝗢𝗣 🚨 𝑺𝑻𝑶𝑷 🚨
Half of all issues filed here are duplicates, answered in the FAQ, or not appropriate for the bug tracker. Please read the FAQ first, especially the "Common Feature Requests" section.
-->
## Search Terms
https://github.com/Microsoft/TypeScript/search?q=refactoring+comments&type=Issues
## Suggestion
Turn a selected block of double-slash comments to a slash-star-star comments.
## Use Cases
Turning conventional `//` into JSDoc
|
Suggestion,In Discussion,Domain: Refactorings
|
low
|
Critical
|
336,073,494
|
go
|
proposal: cmd/link: by default, do not write out DWARF
|
This is not as radical as it sounds.
At the very least, we need to understand what the default should be when building the Go installation: write out DWARF, or not? The costs and benefits are more subtle than some realize.
Update: As demonstrated below, dropping DWARF also causes a significant improvement in build/install time.
```
% cat hello.go
package main
import "fmt"
func main() {
fmt.Printf("hello world")
}
```
With this canonical, trivial, but also representative program as input, I used a sequence of Go versions to build the binary on my Mac (OSX 10.13.5, amd64). I have sorted the list into chronological order by version:
```
% ls -l hello*
-rw-r--r--+ 1 r staff 71 Apr 8 2014 hello.go
-rwxr-xr-x 1 r staff 1919504 Jun 27 13:44 hello1.4 # built with Go 1.4
-rwxr-xr-x 1 r staff 1616000 Jun 27 13:54 hello1.7 # built with Go 1.7
-rwxr-xr-x 1 r staff 1632480 Jun 27 13:45 hello1.8 # built with Go 1.8
-rwxr-xr-x 1 r staff 1941456 Jun 27 13:47 hello1.9 # built with Go 1.9
-rwxr-xr-x 1 r staff 2106672 Jun 27 13:50 hello1.10 # built with Go 1.10
-rwxr-xr-x 1 r staff 2964464 Jun 27 14:01 hello-21Jun-2018 # built with Go at tip on 21 June 2018 - this is just before DWARF compression went in
-rwxr-xr-x 1 r staff 1970552 Jun 27 13:53 hello1.11beta1 # built with Go 1.11 beta 1 # built with Go 1.11 beta 1, with DWARF compression
```
I believe the drop from 1.4 to 1.7 (1.5 and 1.6 won't run on my Mac any more) is due to various cleanups in the binary triggered by https://github.com/golang/go/issues/6853.
The growth after that is pretty much all due to DWARF. Absent compression, DWARF debugging is now half the binary, as reported by @rsc's sizecmp:
```
% sizecmp hello1.7 hello-21Jun-2018
__bss 108784 116464 +7680
__data 6144 26896 +20752
__debug_abbrev 255 467 +212
__debug_aranges 48 0 -48
__debug_frame 68836 81036 +12200
__debug_gdb_scri 40 40 +0
__debug_info 245056 482436 +237380
__debug_line 101426 146608 +45182
__debug_loc 0 436989 +436989
__debug_pubnames 61781 32854 -28927
__debug_pubtypes 26794 44637 +17843
__debug_ranges 0 153520 +153520
__gopclntab 277492 478600 +201108
__gosymtab 0 0 +0
__itablink 64 96 +32
__nl_symbol_ptr 0 144 +144
__noptrbss 19520 9208 -10312
__noptrdata 8264 52284 +44020
__rodata 208087 290543 +82456
__symbol_stub1 0 108 +108
__text 508560 592476 +83916
__typelink 2732 3032 +300
total 1643883 2948438 +1304555
%
```
That's 1.3MB of growth, almost all in debug info. Even the PC-to-line table grew massively, quite disproportionate to text size, which is inexplicable to me, but also a bit off topic.
So, DWARF is huge, but we need it, right?
I don't think we do, most of the time. Surely when we are using Delve or GDB or perhaps one day LLDB, yes, but mostly not.
The need for DWARF and other debugging support in Go programs is much less than the corresponding need in C programs, for which DWARF was designed. Go binaries already include basic type information (reflection), a simple symbol table, and PC-to-line data. These not only help the running program, they also provide valuable debugging aids as they stand.
Even without DWARF at all, stack traces cased by panic would be unchanged and would contain symbols and line numbers. Pprof, objdump, and many other tools would still work.
_The DWARF tables are present only for the debuggers._
And useful though the debuggers are sometimes, they are not used often and often not used at all. I think Delve is a great tool, but I use it only once or twice a year because the existing, built-in debugging information is almost always all I need. Why then do we write bloated binaries, paying a cost in file I/O and DWARF write time (not to mention time to compress now) when _half the data in the binary is almost never used?_
If I look in my personal bin directory, it consists of a few shell scripts and many Go binaries, and the net size is in the gigabytes. Gigabytes of binaries! I could delete the DWARF data from all of them and get much of the space back at no cost.
Also, keep in mind that much of this data is redundant. Yes, the addresses change between binaries but the type information that we write out for the runtime, garbage collector, and so on is a megabyte or more of utter redundancy, unvarying yet unshared.
The counterargument to dropping DWARF is of course that people want to debug their programs. The recent Go developer survey reported much higher concern for good debugging support than for reducing binary size. But I stress, most programs are never shown to a debugger, and many programmers only rarely use a debugger on a Go binary.
The desire to have good debugging does not immediately translate into writing out full massive DWARF data every time we build and install a program. (Test binaries and such actually skip DWARF, by default.) I believe time might be better spent improving native debugging support in the binaries, such as more informative stack traces, but that is another topic.
So to the proposal itself:
I propose we change the Go build environment to suppress DWARF by default, saving lots of CPU time and disk space. Instead, a global shell environment variable, say GODWARF=1, could be set to cause it to be written out. Programmers that want DWARF can set that once, in their shell profile, and have full data available. Others could set it only occasionally, on bad days.
For the rest of us, the rest of the time, why bother with it?
If it is decided that DWARF is too valuable to disable by default, I would instead propose a variant of this proposal, where I could set GOWARF=0 and turn it off in perpetuity.
In other words, I am proposing two things.
1) Provide a mechanism, such as a global shell environment variable, to control whether DWARF is written by the tool chain.
2) Decide whether that setting should switch to "no DWARF" by default. I would like that, but would be almost as happy just to have part 1: a simple way to suppress it.
Note: It's not easy enough to use `-ldflags=-w`, since there is no mechanism to set LD flags globally in the Go toolchain. Perhaps that's another way to approach the problem.
|
Proposal,Proposal-Hold
|
high
|
Critical
|
336,099,024
|
opencv
|
expose 'cv::partition' function to python
|
can expose 'cv::partition' function to python?
- OpenCV => 3.4.1(python-opencv)
- Operating System / Platform => Windows 64 Bit
- Compiler => Visual Studio 2015
|
wontfix,category: python bindings,RFC
|
low
|
Minor
|
336,186,555
|
awesome-mac
|
Awesome Mac application sharing recommendation - Awesome Mac
|
http://wangchujiang.com/awesome-mac/
A curated list of awesome applications, softwares, tools and shiny things for Mac osx. - Awesome Mac
|
Gitalk,/awesome-mac/
|
low
|
Minor
|
336,201,836
|
vscode
|
Snippet transform leaves conditional operator
|
```
"fffff": {
"prefix": "ffff",
"body": [
"- (${1:void})${2:methodName}{",
"${1/void$|(.+)/(?1:\n\treturn nil;)/}",
"}"
]
},
```
* have the snippet above
* type number for the first placeholder
* press tab
* 🐛 there `?1:` in the editor...
|
feature-request,snippets
|
low
|
Minor
|
336,231,688
|
pytorch
|
[caffe2] Is there any method to implement learning rate scheduler?
|
Hello, everyone.
since tensorflow or pytorch can adjust learning rate easily by using a scheduler function.
```python
epochs = 200
def step_decay_scheduler(epoch):
if epoch < 81:
return 0.1
if epoch < 122:
return 0.01
return 0.001
def step_decay_scheduler2(epoch):
if epoch < 100:
return 0.1
if epoch < 150:
return 0.01
return 0.001
def cos_scheduler(epoch):
return (start_lr+end_lr)/2.+(start_lr-end_lr)/2.*math.cos(math.pi/2.0*(epoch/(epochs/2.0)))
```
Is there anyway to use a different learning rate scheduler(e.g. cos scheduler)???
|
caffe2
|
low
|
Minor
|
336,315,471
|
pytorch
|
[caffe2] UnicodeDecodeError when running LeNet
|
## Issue description
I am getting the following error [UnicodeDecodeError: 'ascii' codec can't decode byte 0x90 in position 131: ordinal not in range(128)] when following similar code to this: https://caffe2.ai/docs/tutorial-MNIST.html
## Code example
workspace.ResetWorkspace()
device_opts = core.DeviceOption(caffe2_pb2.CUDA, 0)
init_def = caffe2_pb2.NetDef()
net_def = caffe2_pb2.NetDef()
with open(INIT_NET, 'r') as f:
init_def.ParseFromString(f.read())
init_def.device_option.CopyFrom(device_opts)
workspace.RunNetOnce(init_def.SerializeToString())
with open(PREDICT_NET, 'r') as f:
net_def.ParseFromString(f.read())
net_def.device_option.CopyFrom(device_opts)
workspace.CreateNet(net_def.SerializeToString(), overwrite=True)
I am getting an error in the last line
## System Info
`
- Caffe2
- How you installed PyTorch (conda, pip, source): pip
- Build command you used (if compiling from source):
- OS: Ubuntu 16.04
- PyTorch version:
- Python version:
- CUDA/cuDNN version:
- GPU models and configuration:
- GCC version (if compiling from source):
- CMake version:
- Versions of any other relevant libraries:
|
caffe2
|
low
|
Critical
|
336,395,916
|
vscode
|
Show 'Source' actions in file explorer context menu
|
**Feature request**
Show source actions in the file explorer context menu. This would allow triggering actions such as `organize imports` on file
I believe this would require a new activation event and a new way to present source actions (instead of using the editor right click context menu)
**Alternatives**
- A generic `source` context menu could be contributed by an extension
- Or individual extensions could contribute new items to the file explorer context menu
|
help wanted,feature-request,editor-code-actions
|
low
|
Minor
|
336,398,245
|
go
|
go/types: string(1 << s) should be an error
|
```Go
package main
func main() {
var s uint
_ = string(1 << s)
}
```
(https://play.golang.org/p/owHsmdZd32v) is an error: The `1` in `1 << s` assumes the type it would have without the shift, which is `string`. Both cm/compile and gccgo correct report an error.
go/types appears to accept it.
|
NeedsFix
|
low
|
Critical
|
336,487,026
|
neovim
|
Switch (Python) provider(s) dynamically
|
Currently `g:python3_host_prog` is used to initialize the given provider lazily once.
It would be nice if there was a way to change this during runtime, e.g. a command or a function, that would update the global variable and handle setting up the new version.
|
enhancement,provider
|
low
|
Major
|
336,494,531
|
flutter
|
Scan folders for font files similar to asset scan
|
Continuing work on #4890, but adding folder scan for folders.
It would be nice to make it seamless to download font packages from Google font pages, which would make it slightly different from asset scan. I'd lean into doing a recursive scan here, which is a big problem for regular assets because of variant handling for images.
|
c: new feature,tool,a: assets,P3,team-tool,triaged-tool
|
low
|
Minor
|
336,494,794
|
flutter
|
Generate dart file containing references to all assets and fonts available to app
|
Inspired on `R.drawable.image_logo` on native android platform.
Based on top of work done on #4890, it's independent of #18897 but highly related.
|
c: new feature,tool,a: assets,P3,team-tool,triaged-tool
|
medium
|
Critical
|
336,494,832
|
vue
|
<transition-group> not working as expected on page scroll
|
### Version
2.5.16
### Reproduction link
[https://codesandbox.io/s/kxkmp9mov3](https://codesandbox.io/s/kxkmp9mov3)
### Steps to reproduce
1. Create a list using `<transition-group>`.
2. Put the list at the end of a long page.
3. Scroll to the bottom of the page.
4. Trigger some change so that the page height is reduced and force the viewport to scroll upwards a little bit.
### What is expected?
The existing items should stick to the container, instantly appear in the final position, without transitions.
### What is actually happening?
The existing items jump out of the container because of the sudden change on vertical position and slowly move back to the expected position.
---
Internally, `<transition-group>` is using `getBoundingClinetRect()` to track the positions of transition items. This works fine when no page scroll is introduced. But when browsers force page scroll on certain situations, the container (and the rest of the page) flashed into the final position while transition items are stuck in the old position based on the viewport, which makes it look like they suddenly jump out of the document and start performing unexpected transitions.
Maybe we can provide some new prop on `<transition-group>`, say, `origin: 'viewport' | 'document'`, to optionally calculate positions based on the canvas origin instead of the viewport.
F.Y.I.
When forced page scroll is triggered:

When not triggered:

<!-- generated by vue-issues. DO NOT REMOVE -->
|
has PR,transition
|
low
|
Major
|
336,509,540
|
pytorch
|
Check failed: error == cudaSuccess unspecified launch failure [caffe2]
|
When I tried to resume training the maskrcnn using Detectron. The training progress goes well at the begining, but alone with the training continues, the training time for each iter grows progressly, after handreds or thousands of iterations, the training broke down with the cuda error below:
> *** Check failure stack trace: ***
> F0628 15:21:28.669647 1910 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669657 1911 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669684 1904 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669684 1909 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669703 1914 context_gpu.h:107] C06ck failed: error == cudaSuccess unspecified launch failure
> 28 15:21:28.669694 1906 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669710 1900 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.670411 1912 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.670415 1903 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failure
> *** Check failure stack trace: ***
> F0628 15:21:28.669647 1910 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669657 1911 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669684 1904 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669684 1909 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669703 1914 context_gpu.h:107] C06ck failed: error == cudaSuccess unspecified launch failure
> 28 15:21:28.669694 1906 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669710 1900 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.670411 1912 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.670415 1903 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.670450 1902 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failure
> *** Check failure stack trace: ***
> F0628 15:21:28.669647 1910 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669657 1911 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669684 1904 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669684 1909 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669703 1914 context_gpu.h:107] C06ck failed: error == cudaSuccess unspecified launch failure
> 28 15:21:28.669694 1906 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669710 1900 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.670411 1912 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.670415 1903 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.670450 1902 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.670488 1913 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failure
> E0628 15:21:28.669669 1907 net_dag.cc:195] Secondary exception from operator chain starting at '' (type 'Add'): caffe2::EnforceNotMet: [enforce fail at context_gpu.h:156] . Encountered CUDA error: unspecified launch failure Error from operator:
> input: "gpu_0/mask_fcn_logits_w_grad" input: "gpu_1/mask_fcn_logits_w_grad" output: "gpu_0/mask_fcn_logits_w_grad" name: "" type: "Add" device_option { device_type: 1 cuda_gpu_id: 0 }
> F0628 15:21:28.669647 1910 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669657 1911 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669684 1904 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669684 1909 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669703 1914 context_gpu.h:107] C06ck failed: error == cudaSuccess unspecified launch failure
> 28 15:21:28.669694 1906 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669710 1900 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.670411 1912 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.670415 1903 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.670450 1902 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.670488 1913 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failure
> *** Check failure stack trace: ***
> F0628 15:21:28.669647 1910 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669657 1911 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669684 1904 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669684 1909 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669703 1914 context_gpu.h:107] C06ck failed: error == cudaSuccess unspecified launch failure
> 28 15:21:28.669694 1906 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669710 1900 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.670411 1912 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.670415 1903 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.670450 1902 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.670488 1913 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureFF0628 15:21:28.669647 1910 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669657 1911 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669684 1904 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669684 1909 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669703 1914 context_gpu.h:107] C06ck failed: error == cudaSuccess unspecified launch failure
> 28 15:21:28.669694 1906 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.669710 1900 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.670411 1912 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.670415 1903 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.670450 1902 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.670488 1913 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failureF0628 15:21:28.670533 1907 context_gpu.h:107] Check failed: error == cudaSuccess unspecified launch failure
> *** Check failure stack trace: ***
> *** Check failure stack trace: ***
I googled this error, it seems like something about GPU memory leak, but during training time, GPU memory usage are stable and normal until the progress broke down. I tried to reboot my server but it didn't work, can you help me out with this?
I checked the context_gpu.h at line 107, the code is:
```
~ThreadLocalCUDAObjects() noexcept {
99 for (int i = 0; i < CAFFE2_COMPILE_TIME_MAX_GPUS; ++i) {
100 for (auto& handle : cublas_handles_[i]) {
101 if (handle) {
102 CUBLAS_CHECK(cublasDestroy(handle));
103 }
104 }
105 for (auto& stream : cuda_streams_[i]) {
106 if (stream) {
107 CUDA_CHECK(cudaStreamDestroy(stream));
108 }
109 }
110 for (auto& handle : cudnn_handles_[i]) {
111 if (handle) {
112 CUDNN_CHECK(cudnnDestroy(handle));
113 }
114 }
115 }
116 }
```
|
caffe2
|
low
|
Critical
|
336,616,686
|
flutter
|
Sample code of saving an image from an ImageStream
|
Community, this should goes in stackoverflow but I have searched some similliar question just got no useful solutions. Here is my demands:
**Saving an image from ImageProvider**
I have knowing that we have `resolve` methods to achieve this. But I just don't get how to using ImageStream an got the bytes write into a file.
```
widget.imageProvider.resolve(new ImageConfiguration()).addListener((imgageInfo, _) {
// how to get imagestream and save it as file
}
);
```
|
framework,d: api docs,d: examples,c: proposal,P2,team-framework,triaged-framework
|
low
|
Minor
|
336,623,199
|
pytorch
|
parallelize_bmuf_distributed_test intermittently hangs
|
Example: https://ci.pytorch.org/jenkins/job/caffe2-builds/job/py2-gcc5-ubuntu16.04-test/6806/console
```
23:45:38 lib/python2.7/dist-packages/caffe2/python/parallelize_bmuf_distributed_test.py::DistributedTest::test_bmuf_distributed Build timed out (after 45 minutes). Marking the build as failed.
00:27:43 Build was aborted
```
Note the timestamps.
@enosair, could you please look at it?
|
caffe2
|
low
|
Critical
|
336,625,843
|
flutter
|
iOS/MacOS – Flutter does not respect SF Pro breakpoints
|
Flutter does not appear to respect Apple's breakpoints for transitioning from SF Pro Text to SF Pro Display.
https://developer.apple.com/design/human-interface-guidelines/ios/visual-design/typography/
|
platform-ios,framework,engine,platform-mac,a: fidelity,a: typography,P2,team-ios,triaged-ios
|
low
|
Minor
|
336,654,596
|
pytorch
|
[Caffe2] segmentation fault
|
Hi,
I am following the installation guide for Caffe2 from https://caffe2.ai/docs/getting-started.html?platform=ubuntu&configuration=compile
When I get to the step where I have to test the Caffe2 install (by running cd ~ && python -c 'from caffe2.python import core' 2>/dev/null && echo "Success" || echo "Failure"). I get failure.
I have run the command in the python interpreter, and I received the error 'no module named caffe2.python' - which I then fixed by adding the build directory to my PYTHONPATH environment variable.
I tried to run the test command again, which then gives me a segmentation fault.
Any help would be appreciated.
~/pytorch/build/lib$ python
Python 3.6.5 | packaged by conda-forge | (default, Apr 6 2018, 13:39:56)
[GCC 4.8.2 20140120 (Red Hat 4.8.2-15)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> from caffe2.python import core
Segmentation fault (core dumped)
## System Info
I am running a Google Compute machine, with a K80 GPU
CUDA, CuDNN are installed
so are all the dependencies for the Caffe2 installation.
I am in a virtual environment in miniconda3
|
caffe2
|
low
|
Critical
|
336,746,661
|
TypeScript
|
@typedef tags appearing in the next declaration quick info in VSCode
|
**TypeScript Version:** 2.9.2 / 3.0.0-dev.20180628
**Search Terms:** jsdoc esdoc typedef vscode quick info function variable next description
I am experiencing an issue in Visual Studio Code where @typedef tags in .js files all get added to the next declaration, whether it be a function, a variable etc.
I searched the wiki and the issues about it and found closed issues that experienced the same bug.
VSCode was running TypeScript version 2.9.2. I also replicated the bug by upgrading to the latest preview version.
It seems this issue was resolved long ago and I can't understand why I am still experiencing it.
Here is some familiar code from issue #12233 :
**Code**
```js
/**
* @typedef {Object} MyType1
* @prop {string} name
* @prop {string} type
*/
/**
* @typedef {Object} MyType2
* @prop {string} name
* @prop {string} type
*/
/**
* @param {MyType1} param1 MyParamPype
* @returns {boolean}
*/
function MyFunc1 (param1) {
}
/**
* @param {MyType2} param2 MyParamPype
* @returns {boolean}
*/
function MyFunc2 (param1) {
}
```
**Expected behavior:** The quick info window when hovering ```MyFunc1```should only show
```js
@param {MyType1} param1 MyParamPype
@returns
```
**Actual behavior:**
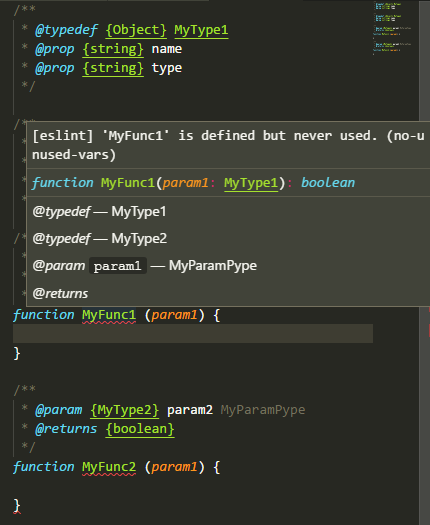

**Related Issues:** #12233 #12004
|
Bug,Help Wanted,Domain: JSDoc
|
low
|
Critical
|
336,754,467
|
flutter
|
Extend Textformfield validation - programatical interaction is missing
|
I noticed there seems to be no way to interact with Textformfield validation programatically.
This is quite limiting. At least there should be mehtods to set or clear the errors of a Formfield.
But I suggest to rework the validation as a whole and add for example a structure like:
1. To TextFormField or the TextEditingController some methods:
- addValidator(Validator validator)
- removeValidator(Validator validator)
- clearValidators()
- setError(ValidationError error)
- getErrors()
- clearErrors()
- onValidationStateChanges(ValidationState state=>{})
- ...?
2. classes for ValidationState, Validator and ValidationError
3. Some common Validators for email, length, phone number, regex and custom option
Arguable it would be favorable using an array for validation errors. So every Validator class has assigned an error, and the TextFormField can have assigned various Validators. Maybe with an option to show only the first unmet Validationerror, or all of them.
These are just some ideas and need definately some more thought. Nevertheless the current validation functionality is imo too rudimentary and will not quite suffice the needs of many developers.
|
a: text input,c: new feature,framework,f: material design,P2,team-design,triaged-design
|
low
|
Critical
|
336,783,419
|
rust
|
strange rust_2018_idioms warning on code comment in clippy codebase
|
````
git clone http://github.com/rust-lang-nursery/rust-clippy/
cd rust-clippy
git checkout 656b26ea4f2b330ea5b9cb3cb38545587eac8f7f
cargo check --all-targets --all-features
````
=>
````
....
warning: `extern crate` is not idiomatic in the new edition
--> src/lib.rs:1:1
|
1 | // error-pattern:cargo-clippy
| ^ help: convert it to a `use`
|
note: lint level defined here
--> src/lib.rs:8:9
|
8 | #![warn(rust_2018_idioms)]
| ^^^^^^^^^^^^^^^^
= note: #[warn(unused_extern_crates)] implied by #[warn(rust_2018_idioms)]
````
this is confusing because the highlighted line is a code comment and seems unrelated to the ````extern crate```` keyword.
rustc 1.28.0-nightly (cd494c1f0 2018-06-27)
link to file: https://github.com/rust-lang-nursery/rust-clippy/blob/656b26ea4f2b330ea5b9cb3cb38545587eac8f7f/src/lib.rs
|
A-lints,T-compiler,C-bug,F-rust_2018_preview,A-edition-2018
|
low
|
Critical
|
336,793,606
|
pytorch
|
cmake error
|
building caffe2 with gpu exits with the following log output
System Info :
> PyTorch version: 0.4.0
Is debug build: No
CUDA used to build PyTorch: 9.0.176
OS: Ubuntu 18.04 LTS
GCC version: (Ubuntu 7.3.0-16ubuntu3) 7.3.0
CMake version: version 3.10.2
Python version: 3.6
Is CUDA available: Yes
CUDA runtime version: 9.2.88
GPU models and configuration: GPU 0: Tesla V100-SXM2-16GB
Nvidia driver version: 396.26
cuDNN version: Probably one of the following:
/usr/lib/x86_64-linux-gnu/libcudnn.so.7.1.4
/usr/lib/x86_64-linux-gnu/libcudnn_static_v7.a
Versions of relevant libraries:
[pip3] numpy (1.14.4)
[conda] cuda90 1.0 h6433d27_0 pytorch
[conda] pytorch 0.4.0 py36_cuda9.0.176_cudnn7.1.2_1 [cuda90] pytorch
[conda] torchvision 0.2.1 py36_1 pytorch
Build command used :
> ./pytorch/scripts/build_anaconda.sh --install-locally --cuda 9.0 --cudnn 7
Since the build file exits if I provide it with :
> ./pytorch/scripts/build_anaconda.sh --install-locally --cuda 9.2 --cudnn 7
_Even tensorflow has this problem for cuda 9.2 so I had installed the cuda 9.0 toolkit as well. Error while using cuda 9.0 toolkit (if I build with path containing "..............**:/usr/local/cuda-9.0/bin/:**..............", instead of "........................**:/usr/local/cuda-9.2/bin/:**......................"):_
> CUDA 9.0 is not compatible with std::tuple from GCC version >= 6. Please upgrade to CUDA 9.2 or use the following option to use another version (for example)
So I did use cuda 9.2 in path variable but build it using argument of --cuda 9.0
This time it finally did start building but exists at 74% with the following :
> [ 74%] Linking CXX shared library ../../lib/libcaffe2_observers.so
[ 74%] Built target caffe2_observers
[ 74%] Linking CXX shared module python/caffe2_pybind11_state.cpython-36m-x86_64-linux-gnu.so
[ 74%] Built target caffe2_pybind11_state
Makefile:140: recipe for target 'all' failed
make: *** [all] Error 2
Traceback (most recent call last):
File "/home/ubuntu/anaconda3/bin/conda-build", line 11, in <module>
sys.exit(main())
File "/home/ubuntu/anaconda3/lib/python3.6/site-packages/conda_build/cli/main_build.py", line 420, in main
execute(sys.argv[1:])
File "/home/ubuntu/anaconda3/lib/python3.6/site-packages/conda_build/cli/main_build.py", line 411, in execute
verify=args.verify)
File "/home/ubuntu/anaconda3/lib/python3.6/site-packages/conda_build/api.py", line 200, in build
notest=notest, need_source_download=need_source_download, variants=variants)
File "/home/ubuntu/anaconda3/lib/python3.6/site-packages/conda_build/build.py", line 2168, in build_tree
notest=notest,
File "/home/ubuntu/anaconda3/lib/python3.6/site-packages/conda_build/build.py", line 1408, in build
utils.check_call_env(cmd, env=env, cwd=src_dir, stats=build_stats)
File "/home/ubuntu/anaconda3/lib/python3.6/site-packages/conda_build/utils.py", line 300, in check_call_env
return _func_defaulting_env_to_os_environ('call', *popenargs, **kwargs)
File "/home/ubuntu/anaconda3/lib/python3.6/site-packages/conda_build/utils.py", line 280, in _func_defaulting_env_to_os_environ
raise subprocess.CalledProcessError(proc.returncode, _args)
subprocess.CalledProcessError: Command '['/bin/bash', '-e', '/home/ubuntu/anaconda3/conda-bld/caffe2-cuda9.0-cudnn7_1530219711645/work/conda_build.sh']' returned non-zero exit status 2.
Aim : to run detectron on my env. Please advice as to what to do ?
|
caffe2
|
low
|
Critical
|
336,812,289
|
flutter
|
Create ModuleApp and MaterialModuleApp widgets
|
We should have variants of WidgetsApp and MaterialApp for add-to-app scenarios. They would avoid doing things like Title, but still do things like Navigator and Theme.
|
customer: fuchsia,framework,f: material design,a: existing-apps,customer: dream (g3),P3,team-design,triaged-design
|
low
|
Major
|
336,816,982
|
godot
|
Moving a scene in file browser breaks an instance of it in current edited scene
|
Godot 3.0.4
Windows 10 64 bits
Repro steps:
1) Create scene A with stuff in it and save it
2) Save a part of that scene as scene B (right-click, "save branch as scene")
3) In the file browser, move scene B into another folder
4) Save scene A again: you get this error

I think this should not happen. The scene was moved, but it shouldn't prevent saving the current scene properly.
5) Close scene A and open it again: notice the instance turned back into a normal branch, which isn't intented either.
Note: when I first got this bug in my project it happened without the error popup.
|
bug,topic:editor,confirmed
|
low
|
Critical
|
336,825,010
|
flutter
|
Handle possible keyboard open/close failures in TextInputPlugin on Android
|
The TextInputPlugin on Android communicates with Android's InputMethodManager to show and hide the keyboard. The corresponding methods in TextInputPlugin are `showTextInput()` and `hideTextInput()`. According to the InputMethodManager contract, calls to show and hide the keyboard can fail, but TextInputPlugin's method contracts return void instead of a boolean.
showTextInput() and hideTextInput() should be updated to return a boolean (or throw an exception, etc) and that success/failure should be made available to the Flutter side in case followup action needs to be taken.
|
a: text input,platform-android,engine,P2,team-android,triaged-android
|
low
|
Critical
|
336,856,711
|
pytorch
|
SimpleMetaNetDefInitializer intermittently hangs
|
Sample run:
```
04:47:39 [ RUN ] PredictorMetaNetDefTest.SimpleMetaNetDefInitializer
04:47:39 I0626 04:47:39.810371 469 net_dag_utils.cc:102] Operator graph pruning prior to chain compute took: 3.133e-06 secs
04:47:39 I0626 04:47:39.810408 469 net_async_base.cc:416] Using estimated CPU pool size: 32; NUMA node id: -1
04:47:39 I0626 04:47:39.810420 469 net_async_base.cc:426] Created new CPU pool, size: 32; NUMA node id: -1
05:30:49 Build timed out (after 45 minutes). Marking the build as failed.
05:30:49 Build was aborted
```
|
caffe2
|
low
|
Critical
|
336,878,344
|
neovim
|
API: async rpcrequest() ("callback for RPC requests")
|
Since vimscript is single-threaded, there're cases we don't want to wait for the result but still need to be called when it's done or error is thrown.
Is it possible to implement `rpcrequest_async` that could be used like this?
```vim
let context = {}
call rpcrequest_async(channel, 'Callback', context, method, args... )
func Callback(err, return_value) dict
let context = self
if a:err
throw err
endif
...
endfunc
```
|
enhancement,api,channels-rpc,async
|
low
|
Critical
|
336,915,074
|
godot
|
External Editor is not started when clicking on the Stack Frames in Debugging panel
|
**Godot version:**
3.0.4
**OS/device including version:**
Windows 8.1
**Issue description:**
When setting Godot to use a external editor for editing scripts it won't run the external editor when clicking on the Stack Frames in the Debugger/Debugger tab.
It does run the editor when clicking on the entries in the stack trace of the Debugging/Error tab but many issues don't generate a stack trace in that tab. The built-in editor isn't opened either, forcing you to disable "Use External Editor" during debugging and re-enabling it once finished.
|
bug,topic:editor,confirmed
|
low
|
Critical
|
336,939,264
|
go
|
bytes, strings: Compare tests do not modify input alignments
|
I can't see any tests varying the alignment of `Compare` arguments. Since `Compare` is written in assembly on most platforms (in `internal/bytealg`) we should probably be checking that it works even if the inputs are unaligned.
|
Testing,help wanted,NeedsFix
|
low
|
Major
|
336,941,322
|
pytorch
|
cmake error:Could NOT find IDEEP (missing: /usr/local/include)
|
- PyTorch or Caffe2: PyTorch
- Build command you used:
cmake -DUSE_NATIVE_ARCH=ON -DUSE_FFMPEG=ON -DUSE_ATEN=ON -D USE_TENSORRT=ON -D USE_OPENMP=ON -DUSE_MKL=ON -DUSE_IDEEP=ON ..
- OS: ubuntu 16.04 64bit
- PyTorch version: 00b5d397aef410f5926cb50e7d6e4e676aef71a8
- Python version: 2.7.12
- CUDA/cuDNN version: 9.0/7.15
- GPU models and configuration:
- GCC version: 5.4.0 20160609
- CMake version: 3.5.1
cmake error:
```
-- Looking for cblas_sgemm
-- Looking for cblas_sgemm - found
-- VTune profiling environment is unset
-- Could NOT find Doxygen (missing: DOXYGEN_EXECUTABLE)
-- VTune profiling environment is unset
-- Could NOT find IDEEP (missing: /usr/local/include)
CMake Error at cmake/Modules/FindMKL.cmake:360 (message):
Did not find IDEEP files!
Call Stack (most recent call first):
cmake/Dependencies.cmake:68 (find_package)
CMakeLists.txt:181 (include)
-- Configuring incomplete, errors occurred!
See also "/home/alex/software/pytorch/build/CMakeFiles/CMakeOutput.log".
See also "/home/alex/software/pytorch/build/CMakeFiles/CMakeError.log".
```
|
caffe2
|
low
|
Critical
|
336,966,002
|
pytorch
|
(CAFFE_ENFORCE_EQ_WITH_CALLER tensor.h) caffe2 C++ windows10 runtime error!
|
## Issue description
I have successfully build and install caffe2 on windows 10 and while i am testing my below code in visual studio 2017, i got an run-time error when Creating a tensor (TensorCPU), and filling its contents with the given values from my script.
I have compiled and test this code on ubuntu and it is function in a good way..
## Code example
`
`#include <tuple>
#include <caffe2/core/init.h>
#include <caffe2/core/net.h>
#include <caffe2/utils/proto_utils.h>
#include <iostream>
#include <cstdio>
#include <ctime>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include "classes.h"
CAFFE2_DEFINE_string(init_net, "C:\\Users\\HIMA\\source\\repos\\ConsoleApplication1\\model\\init_net.pb", "init net");
CAFFE2_DEFINE_string(predict_net, "C:\\Users\\HIMA\\source\\repos\\ConsoleApplication1\\model\\predict_net.pb", "predict net");
CAFFE2_DEFINE_string(file, "C:\\Users\\HIMA\\source\\repos\\ConsoleApplication1\\image\\lemon.jpg", "list of images separated by comma");
CAFFE2_DEFINE_int(size, 224, "image size in pixel");
namespace caffe2 {
cv::Mat preprocess(const std::string& image_file, int* min_size, int* max_size, bool use_crop, float& scale) {
cv::Mat image = cv::imread(image_file);
cv::Size dst_size;
if (min_size != nullptr) {
dst_size.width = std::max(*min_size * image.cols / image.rows, *min_size);
dst_size.height = std::max(*min_size * image.rows / image.cols, *min_size);
}
else if (max_size != nullptr) {
if (image.cols > *max_size && image.rows > *max_size) {
dst_size.width = std::min(*max_size * image.cols / image.rows, *max_size);
dst_size.height = std::min(*max_size * image.rows / image.cols, *max_size);
}
else {
dst_size.width = image.cols;
dst_size.height = image.rows;
}
}
else {
CAFFE_ENFORCE(false);
}
scale = static_cast<float>(image.cols) / dst_size.width;
cv::resize(image, image, dst_size);
if (use_crop) {
int size = std::min(image.cols, image.rows);
cv::Rect crop((image.cols - size) / 2, (image.rows - size) / 2, size, size);
image = image(crop);
}
image.convertTo(image, CV_32FC3, 1.0, -128);
return image;
}
void run() {
std::cout << std::endl << "==> using CPU" << std::endl;
DeviceOption device_option;
std::shared_ptr<CPUContext> ctx_cpu;
device_option.set_device_type(CPU);
ctx_cpu.reset(new CPUContext(device_option));
std::cout << std::endl << "==> using CPU" << std::endl;
std::cout << "==> init network" << std::endl;
NetDef init_net, predict_net;
CAFFE_ENFORCE(ReadProtoFromFile(FLAGS_init_net, &init_net));
CAFFE_ENFORCE(ReadProtoFromFile(FLAGS_predict_net, &predict_net));
Workspace workspace("default");
CAFFE_ENFORCE(workspace.RunNetOnce(init_net));
// https://stackoverflow.com/questions/1894886/parsing-a-comma-delimited-stdstring/10861816
std::cout << "==> parse image list" << std::endl;
std::stringstream ss(FLAGS_file);
std::vector<std::string> image_list;
while (ss.good()) {
std::string substr;
std::getline(ss, substr, ',');
image_list.push_back(substr);
}
size_t batch_size = image_list.size();
CAFFE_ENFORCE(true);
std::cout << "==> prepare batch ";
const size_t channel(3);
std::vector<float> data_batch;
std::vector<float> info_batch;
for (const std::string& image_file : image_list) {
// load image
bool use_crop = true;
float scale;
cv::Mat image;
image = preprocess(image_file, &FLAGS_size, nullptr, /* use_crop */ true, scale);
info_batch.push_back(image.rows);
info_batch.push_back(image.cols);
info_batch.push_back(scale);
// convert NHWC to NCHW
std::vector<cv::Mat> channels(channel);
cv::split(image, channels);
std::vector<float> data;
for (cv::Mat &c : channels) {
data.insert(data.end(), (float *)c.datastart, (float *)c.dataend);
}
data_batch.insert(data_batch.end(), data.begin(), data.end());
}
std::clock_t start;
double duration;
start = std::clock();
size_t height = info_batch[0];
size_t width = info_batch[1];
std::cout << "(" << batch_size << " x " << channel << " x " << height << " x " << width << ")" << std::endl;
std::vector<TIndex> dims(( batch_size, channel, height, width ));
**_TensorCPU tensor(dims, data_batch, nullptr); // here is the function that call tensor.h_**
TensorCPU im_info(std::vector<TIndex>(batch_size, 3), info_batch, nullptr);
std::cout << "==> feedforward" << std::endl;
workspace.CreateBlob("0")->GetMutable<TensorCPU>()->CopyFrom(tensor);
CAFFE_ENFORCE(workspace.RunNetOnce(predict_net));
auto&output = workspace.GetBlob("442")->Get<TensorCPU>();
std::cout << "==> retrieve results" << std::endl;
for (size_t i = 0; i < batch_size; i++) {
const auto&prob = output.data<float>() + i * classes.size();
std::vector<float> pred(prob, prob + classes.size());
auto it = std::max_element(std::begin(pred), std::end(pred));
auto maxValue = *it;
auto maxIndex = std::distance(std::begin(pred), it);
std::string image_file = image_list[i].substr(image_list[i].find_last_of('/') + 1);
std::cout << "P( " << classes[maxIndex] << " | " << image_file
<< " ) = " << maxValue << std::endl;
}
duration = (std::clock() - start) / (double)CLOCKS_PER_SEC;
std::cout << "printf: " << duration << '\n';
}
}
int main(int argc, char **argv) {
caffe2::GlobalInit(&argc, &argv);
caffe2::run();
return 0;
}
`
`
The error happen in this line below on tensor.h
`CAFFE_ENFORCE_EQ_WITH_CALLER(values.size(), size_);`
## System Info
Unhandled exception at 0x00007FFED188F218 in ConsoleApplication1.exe: Microsoft C++ exception: caffe2::EnforceNotMet at memory location 0x000000C439AFE870.
- Caffe2
- install from Source
- Build as release from visual studio
- OS: Windows 10
|
caffe2
|
low
|
Critical
|
337,001,450
|
pytorch
|
[caffe2]build problem, can not find caffe2_pybind11_state_hip
|
## Issue description
I build the caffe2 with anaconda following the [page](https://caffe2.ai/docs/getting-started.html?platform=mac&configuration=compile#anaconda-install-path).
In the server with a single titanx, has cudnn7 and cuda9 but do not have nccl, so I download the nccl2 from nvidia and extract it to path/to/local/nccl2, and then edit the ./pytorch/conda/integrated/build.sh in the line 42 to be:"export NCCL_ROOT_DIR=path/to/local/nccl2".
Then I need to use caffe2 with python2, so I added "conda_args+=(" --python 2.7") " in the ./pytorch/scripts/build_anaconda.sh to use python2.7.
The building was succeed, but when I run python2 test.py
`from caffe2.python import core`
It tells me:
WARNING:root:This caffe2 python run does not have GPU support. Will run in CPU only mode.
WARNING:root:Debug message: No module named caffe2_pybind11_state_hip
Segmentation fault (core dumped)
My question is:
a. why the conda does not support gpu?
b. if I am using a single gpu, is nccl necessary for building?
c. how to fix No module named caffe2_pybind11_state_hip
- PyTorch or Caffe2: caffe2
- How you installed PyTorch (conda, pip, source): conda
- Build command you used (if compiling from source):./scripts/build_anaconda.sh --install-locally --cuda 9.0 --cudnn 7
- OS:ubuntu16
- PyTorch version:
- Python version:2.7
- CUDA/cuDNN version:9.1/7
- GPU models and configuration:??
- GCC version (if compiling from source):5.4.0
- CMake version:not install
- Versions of any other relevant libraries:
Thank you very much!
|
awaiting response (this tag is deprecated),caffe2
|
low
|
Critical
|
337,005,449
|
pytorch
|
DataWorkersTest::testRNNInput timeout
|
```
06:58:12 lib/python2.7/dist-packages/caffe2/python/data_workers_test.py::DataWorkersTest::testRNNInput Build timed out (after 45 minutes). Marking the build as failed.
07:41:54 Build was aborted
```
logs: https://ci.pytorch.org/jenkins/job/caffe2-builds/job/py2-gcc4.8-ubuntu14.04-trigger-test/8507/
|
caffe2
|
low
|
Critical
|
337,025,630
|
go
|
cmd/go: private repos on hard-coded hosting providers require special configuration
|
### What version of Go are you using (`go version`)?
```
$ go get -u golang.org/x/vgo
$ vgo version
go version go1.10 darwin/amd64 vgo:2018-02-20.1
```
### Does this issue reproduce with the latest release?
yes (coming from https://github.com/golang/go/issues/25590)
### What operating system and processor architecture are you using (`go env`)?
```
$ go env
GOARCH="amd64"
GOBIN=""
GOCACHE="/Users/brunetto.ziosi/Library/Caches/go-build"
GOEXE=""
GOHOSTARCH="amd64"
GOHOSTOS="darwin"
GOOS="darwin"
GOPATH="/Users/brunetto.ziosi/Code"
GORACE=""
GOROOT="/usr/local/go"
GOTMPDIR=""
GOTOOLDIR="/usr/local/go/pkg/tool/darwin_amd64"
GCCGO="gccgo"
CC="clang"
CXX="clang++"
CGO_ENABLED="1"
CGO_CFLAGS="-g -O2"
CGO_CPPFLAGS=""
CGO_CXXFLAGS="-g -O2"
CGO_FFLAGS="-g -O2"
CGO_LDFLAGS="-g -O2"
PKG_CONFIG="pkg-config"
GOGCCFLAGS="-fPIC -m64 -pthread -fno-caret-diagnostics -Qunused-arguments -fmessage-length=0 -fdebug-prefix-map=/var/folders/m3/145jfhdd5qsf66_41wt9p02mhc4hp5/T/go-build518939426=/tmp/go-build -gno-record-gcc-switches -fno-common"
```
### What did you do?
I ran
```go
vgo get github.com/MY_ORGANIZATION/MY_REPO
```
where:
* I ran the command in a folder with a working golang app and a proper go.mod file -> vgo is working here and I can vgo build the app
* the repo is a private repo with SSO enabled I can access (git pull/push, ...)
### What did you expect to see?
The package code in MY_REPO or the go module downloaded
### What did you see instead?
```
vgo get github.com/MY_ORGANIZATION/MY_REPO: git ls-remote -q https://github.com/MY_ORGANIZATION/MY_REPO in /Users/brunetto.ziosi/Code/src/mod/cache/vcs/2cb00fa3547080bb301974fe87cf912af55d50f7a6d8a9955e11fed7a20ac6d3: exit status 128:
remote: Repository not found.
fatal: repository 'https://github.com/MY_ORGANIZATION/MY_REPO/' not found
```
|
NeedsInvestigation,modules
|
medium
|
Critical
|
337,027,240
|
pytorch
|
Lint check for non-Unicode characters in diffs / Unicode characters without coding
|
I noticed a PR which was only failing internal tests, and not external tests, due to a Unicode (or Latin-1?) apostrophe inside the source code. Our lint check should catch this. CC @yf225
|
module: lint,triaged,better-engineering
|
low
|
Minor
|
337,033,536
|
electron
|
Better documentation and examples for protocol.registerX and protocol.interceptX methods
|
**Is your feature request related to a problem? Please describe.**
Yes. I'm trying to intercept HTTP requests and provide responses and none of my initial examples work and the documentation is very sparse.
**Describe the solution you'd like**
Would love better documentation and examples of working code. The unit tests in the electron code base weren't very informative either.
**Describe alternatives you've considered**
Combed through bugs, issues, source code, etc. Can't figure out the 'proper' way to implement my own protocol handlers.
What I would like is some examples. Registering my own protocol schemes, handlnig HTTP responses, what do do with errors. How to handle aborted requests, etc.
|
enhancement :sparkles:,documentation :notebook:
|
low
|
Critical
|
337,047,454
|
flutter
|
`flutter packages upgrade` should run `pod install`
|
There are lots of issues like #18945, #17943, #17469, ...
that are fixed by running `pod install` in `ios/`
I think it would be a good idea to run that with `flutter packages get` and `flutter packages upgrade` automatically.
See for example https://github.com/flutter/flutter/issues/18945#issuecomment-401389388
|
platform-ios,tool,P3,a: plugins,team-ios,triaged-ios
|
low
|
Major
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.