
qid
int64 1
74.7M
| question
stringlengths 0
58.3k
| date
stringlengths 10
10
| metadata
sequence | response_j
stringlengths 2
48.3k
| response_k
stringlengths 2
40.5k
|
|---|---|---|---|---|---|
107,732 | I've tried researching this question myself, but the only data I can find is over huge timescales, like situations where the continents have reformed back into a Neo-Pangea.
I'm not looking for any real drastic changes in positioning, just relatively minor things like seas disappearing or continents slightly shrinking or pushing into each other.
Would there be any noteworthy changes at all, or would it be pretty much the same as today aside from some minor changes that wouldn't affect anything?
Let's just assume humanity suddenly stopped existing today for the purposes of the question, so they don't make any more changes to the world than they already have.
As always, I'm very grateful for any answers, and if you need anything clarified feel free to leave a comment and I'll do my best to clear things up. | 2018/03/23 | [
"https://worldbuilding.stackexchange.com/questions/107732",
"https://worldbuilding.stackexchange.com",
"https://worldbuilding.stackexchange.com/users/48871/"
] | >
> Would there be any noteworthy changes at all,
>
>
> just assume humanity suddenly stopped existing today for the purposes of the question
>
>
>
Global Warming would continue for a while, if for no other reason than approximately 2.5% of CO2 is sequestered per annum.
<http://euanmearns.com/the-half-life-of-co2-in-earths-atmosphere-part-1/>
>
> Sequestration of CO2 from the atmosphere can be modelled using a single exponential decay constant of 2.5% per annum.
>
>
>
At that rate, it would take 14 years to return to a CO2 value of 280ppm.
But in the meantime,
1. much polar ice has disappeared, and blue ocean absorbs more energy than white ice, and
2. the permafrosts are thawing, releasing lots of methane, which an even stronger greenhouse gas. This northern warming is causing even more methane to be released, in a vicious cycle.
Thus, it's very possible that most of the Greenland icecap will be melted, and also Antarctica, raising the ocean levels by 70 meters. | "Is removing people sufficient to stop global warming?" Good question. Answer is not clear. If we have passed the tipping point for arctic permafrost collapse, arctic ocean being ice free in summer, then we may release huge amounts of methane clathrates.
On top of this while oil has to be pumped, natural gas is often under pressure. As distribuiton systems break down, more methane is released.
Net result: ALL of antarctica and Greenland melt over the space of that thousand years.
So we have an new continent free from ice in the south, we have a new archipelago of islands where Greenland was. We have new ecologies in the arctic regions, and the ocean shoreline moves in a bunch.
Details here: <https://www.nationalgeographic.com/magazine/2013/09/rising-seas-ice-melt-new-shoreline-maps/#/07-ice-melt-antarctica.jpg> |
107,732 | I've tried researching this question myself, but the only data I can find is over huge timescales, like situations where the continents have reformed back into a Neo-Pangea.
I'm not looking for any real drastic changes in positioning, just relatively minor things like seas disappearing or continents slightly shrinking or pushing into each other.
Would there be any noteworthy changes at all, or would it be pretty much the same as today aside from some minor changes that wouldn't affect anything?
Let's just assume humanity suddenly stopped existing today for the purposes of the question, so they don't make any more changes to the world than they already have.
As always, I'm very grateful for any answers, and if you need anything clarified feel free to leave a comment and I'll do my best to clear things up. | 2018/03/23 | [
"https://worldbuilding.stackexchange.com/questions/107732",
"https://worldbuilding.stackexchange.com",
"https://worldbuilding.stackexchange.com/users/48871/"
] | A millennium is a blink of an eye on a geological scale. But interesting things can happen in a blink of an eye. Even disegarding the changes which may happen as a result of the present climatological instability, small but important modification can occur here and there.
I have no idea of the geographical changes between today and 3000 CE; but I do know of *some* geographical changes between 1 CE and today, either because they happened in places in which I have a local interest, or because they are somehow important to various historical events, or because I found out about them by accident and found them interesting enough to remember.
Geographical changes during the last 1000 or 2000 years
-------------------------------------------------------
* While sea level is today not very different from what it was in the first century, *in some places the sea advanced or retreated considerably:*
+ Some cities which used to be seaports in the first century are now several miles inland. For example:
- In the Antiquity [Ephesus](https://en.wikipedia.org/wiki/Ephesus) and [Miletus](https://en.wikipedia.org/wiki/Miletus) were major ports on the Ionian coast; they are now several kilometers inland.
[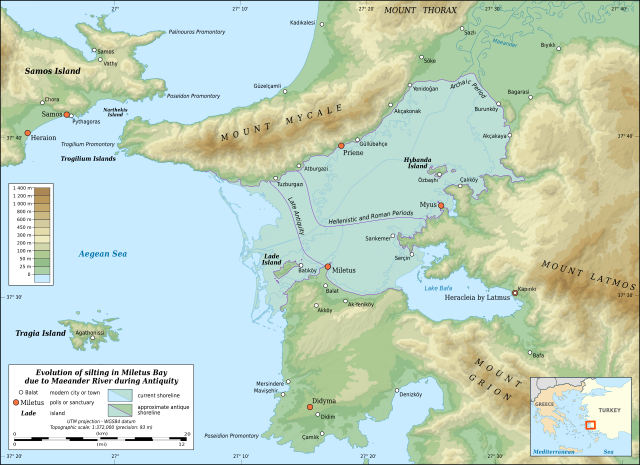](https://en.wikipedia.org/wiki/Miletus#/media/File:Miletus_Bay_silting_evolution_map-en.svg)
*The silting evolution of Miletus Bay due to the alluvium brought by the Maeander River during Antiquity. Map by Eric Gaba, available on Wikimedia under the CC-BY-SA-3.0 license.*
- Closer to me, in the Antiquity the city of Histria was a seaport on the western coast of the Black Sea. Now its ruins lay on the shore of a shallow lagoon, and the sea is kilometers away.
[](https://en.wikipedia.org/wiki/Histria_(ancient_city)#/media/File:Scythia_Minor_map.jpg)
*Ancient towns and colonies in Dobruja; modern coastline shown as a dotted line. Map by Bogdan, available on Wikimedia under the CC-BY-SA-3.0 license.*
+ On the other hand, in some places the sea advanced. For example, what is now the [IJselmeer](https://en.wikipedia.org/wiki/IJsselmeer) in the Netherlands used to be a low-lying plain in the first century, with a large lake known by the Romans as [Lake Flevo](https://en.wikipedia.org/wiki/Lake_Flevo). In 1287, [Saint Lucia's flood](https://en.wikipedia.org/wiki/St._Lucia%27s_flood) broke through and submerged the former river [Vlie](https://en.wikipedia.org/wiki/Vlie), creating a large shallow gulf which was called the [Zuiderzee](https://en.wikipedia.org/wiki/Zuiderzee).
[](https://en.wikipedia.org/wiki/Lake_Flevo#/media/File:50nc_ex_leg_copy.jpg)
*The region of the Netherlands in the 1st century CE. Map by the Dutch Nationale Onderzoeksagenda Archeologie (www.noaa.nl), available on Wikimedia under the CC-BY-SA-3.0 license.*
Then in 1932 the long effort of the Dutch to build the [Afsluitdijk](https://en.wikipedia.org/wiki/Afsluitdijk) was brough to completion, and the gulf was separated from the sea and became a lake, which the Dutch then proceeded to drain in order to increase the territory of their country; and now the Netherlands has a new 1500 square kilometer province, called [Flevoland](https://en.wikipedia.org/wiki/Flevoland).
* Rivers sometimes change course dramatically. For me, the most spectacular example is the [Oxus](https://en.wikipedia.org/wiki/Amu_Darya), which is today known as the Amu Darya. Until the 16th century it used to flow into the Caspian Sea, through what is now the dry [Uzboy](https://en.wikipedia.org/wiki/Uzboy) valley; it then changed its mind, abandoned the Caspian and went to empty into the Aral Sea.
[](https://en.wikipedia.org/wiki/Uzboy#/media/File:XXth_Century_Citizen%27s_Atlas_map_of_Central_Asia.png)
*The old course of the Oxus (Amu Darya), when it flew into the Caspian Sea, marked as "Old Bed of the Oxus". Map from 1903, available on Wikimedia. Public domain.*
At the beginning of the 18th century, [Peter the Great](https://en.wikipedia.org/wiki/Peter_the_Great), emperor of Russia, sent prince [Alexander Bekovich-Cherkassky](https://en.wikipedia.org/wiki/Alexander_Bekovich-Cherkassky) to find the mouth of the Oxus, with the intention of establishing a trade route from the Caspian to Transoxiana. The prince dutifully mapped the coast and returned with the sad news that the river no longer flowed into the Caspian...
* Speaking of the [Aral Sea](https://en.wikipedia.org/wiki/Aral_Sea), the Soviet Union killed it in the 20th century. The former immense lake of 68,000 square kilometers is now a desert, the [Aralkum](https://en.wikipedia.org/wiki/Aralkum_Desert).
* Speaking of the Soviet Union and Transoxiana: in the 1930s the Soviet Union conceived a titanic project to *"divert the flow of the Northern rivers in the Soviet Union, which "uselessly" drain into the Arctic Ocean, southwards towards the populated agricultural areas of Central Asia, which lack water"* (Wikipedia). The [Northern River Reversal](https://en.wikipedia.org/wiki/Northern_river_reversal) eventually grew and grew, design and planning progressed through the 1960s and 1970s, so that by 1980 the Soviets were talking of diverting 12 major Siberian rivers into the Central Asian desert. They even envisaged using atomic bombs to move massive amounts of dirt speedily. Then the Soviet Union fell; but who knows?
* Speaking of using atomic bombs to dig canals, Egypt is considering a [plan to dig a canal](https://en.wikipedia.org/wiki/Qattara_Depression_Project) from the Mediterranean to the [Qattara Depression](https://en.wikipedia.org/wiki/Qattara_Depression), flooding it and creating a solar-powered 2000 megawatt hydropower plant.
[](https://en.wikipedia.org/wiki/Qattara_Depression_Project#/media/File:All_proposed_routes.PNG)
*All proposed routes for a tunnel and/or canal route from the Mediterranean Sea towards the Qattara Depression. Map by AlwaysUnite, available on Wikimedia under the CC-BY-SA-3.0 license.*
And yes, in the 1950s the international Board of Advisers led by Prof. [Friedrich Bassler](https://en.wikipedia.org/wiki/Friedrich_Bassler) proposed to dig the canal using atomic blasts, part of President Eisenhower's [Atoms for Peace](https://en.wikipedia.org/wiki/Atoms_for_Peace) program.
* The [Frisian Islands](https://en.wikipedia.org/wiki/Frisian_Islands) on the eastern edge of the North Sea are notoriously shifty, so that the approaches to the Dutch ports have changed considerably from the Middle Ages to the present. For example, the northern part of what is now the island of [Texel](https://en.wikipedia.org/wiki/Texel) was until the 13th century the southern part of the island of [Vlieland](https://en.wikipedia.org/wiki/Vlieland); it then left Vlieland and became a separate island, the [Eierland](https://en.wikipedia.org/wiki/Eierland); in the 17th century the Dutch reclaimed the land between the Texel and Eierland, and the two islands became one.
[](https://en.wikipedia.org/wiki/Eierland#/media/File:PaysBas_delisle_1743_fragment.jpg)
*Eierland when it was a separate island. Map from 1702, available on Wikimedia. Public domain.*
Geography is not static
-----------------------
The list could be very much expanded. The Panama Canal. The proposed Nicaragua Canal. The lockless Suez Canal, which has brought the marine life of the Red Sea into the Mediterranean. The Hot Gates of Greece. The shifting barrier islands off the coast of Texas. The absent-minded [Yellow River](https://en.wikipedia.org/wiki/Yellow_River) of China. The wandering lake [Lop Nor](https://en.wikipedia.org/wiki/Lop_Nur). The unstable coastline of England -- how many of the medieval [Cinque Ports](https://en.wikipedia.org/wiki/Cinque_Ports) are still ports, that is, if they exist at all?
Geography changes wherever you look closely. | You mention plate tectonics as a cause of change; there are others
* **Rising sea levels**. [Wikipedia has a map](https://en.wikipedia.org/wiki/Sea_level_rise#/media/File:6m_Sea_Level_Rise.jpg) from NASA about how a 6-meter sea level rise would change the world map. Current predictions seem to be something between 0.3m and 2.5m in the next hundred years, so 6m doesn't seem crazy over 1000 years.
* **Coastal erosion** can cause significant changes: for example, the [seashore at Hemsby](http://www.bbc.co.uk/news/uk-england-norfolk-43472150) in eastern England is receding at the rate of about 35 metres (115 ft) per year.
* [**Post-glacial rebound**](https://en.wikipedia.org/wiki/Post-glacial_rebound). During the ice age, ice-covered land was weighted down; it's slowly springing back. For example, much of Finland was underwater a few thousand years ago, even though sea levels were much lower. Southern England is pivoting downwards as Scotland rises, which will lower southern England by about 0.5m in the next thousand years.
* **Vulcanism** can and does create new islands.
* **Deposition** from rivers causes estuaries to grow out into the sea. |
107,732 | I've tried researching this question myself, but the only data I can find is over huge timescales, like situations where the continents have reformed back into a Neo-Pangea.
I'm not looking for any real drastic changes in positioning, just relatively minor things like seas disappearing or continents slightly shrinking or pushing into each other.
Would there be any noteworthy changes at all, or would it be pretty much the same as today aside from some minor changes that wouldn't affect anything?
Let's just assume humanity suddenly stopped existing today for the purposes of the question, so they don't make any more changes to the world than they already have.
As always, I'm very grateful for any answers, and if you need anything clarified feel free to leave a comment and I'll do my best to clear things up. | 2018/03/23 | [
"https://worldbuilding.stackexchange.com/questions/107732",
"https://worldbuilding.stackexchange.com",
"https://worldbuilding.stackexchange.com/users/48871/"
] | A millennium is a blink of an eye on a geological scale. But interesting things can happen in a blink of an eye. Even disegarding the changes which may happen as a result of the present climatological instability, small but important modification can occur here and there.
I have no idea of the geographical changes between today and 3000 CE; but I do know of *some* geographical changes between 1 CE and today, either because they happened in places in which I have a local interest, or because they are somehow important to various historical events, or because I found out about them by accident and found them interesting enough to remember.
Geographical changes during the last 1000 or 2000 years
-------------------------------------------------------
* While sea level is today not very different from what it was in the first century, *in some places the sea advanced or retreated considerably:*
+ Some cities which used to be seaports in the first century are now several miles inland. For example:
- In the Antiquity [Ephesus](https://en.wikipedia.org/wiki/Ephesus) and [Miletus](https://en.wikipedia.org/wiki/Miletus) were major ports on the Ionian coast; they are now several kilometers inland.
[](https://en.wikipedia.org/wiki/Miletus#/media/File:Miletus_Bay_silting_evolution_map-en.svg)
*The silting evolution of Miletus Bay due to the alluvium brought by the Maeander River during Antiquity. Map by Eric Gaba, available on Wikimedia under the CC-BY-SA-3.0 license.*
- Closer to me, in the Antiquity the city of Histria was a seaport on the western coast of the Black Sea. Now its ruins lay on the shore of a shallow lagoon, and the sea is kilometers away.
[](https://en.wikipedia.org/wiki/Histria_(ancient_city)#/media/File:Scythia_Minor_map.jpg)
*Ancient towns and colonies in Dobruja; modern coastline shown as a dotted line. Map by Bogdan, available on Wikimedia under the CC-BY-SA-3.0 license.*
+ On the other hand, in some places the sea advanced. For example, what is now the [IJselmeer](https://en.wikipedia.org/wiki/IJsselmeer) in the Netherlands used to be a low-lying plain in the first century, with a large lake known by the Romans as [Lake Flevo](https://en.wikipedia.org/wiki/Lake_Flevo). In 1287, [Saint Lucia's flood](https://en.wikipedia.org/wiki/St._Lucia%27s_flood) broke through and submerged the former river [Vlie](https://en.wikipedia.org/wiki/Vlie), creating a large shallow gulf which was called the [Zuiderzee](https://en.wikipedia.org/wiki/Zuiderzee).
[](https://en.wikipedia.org/wiki/Lake_Flevo#/media/File:50nc_ex_leg_copy.jpg)
*The region of the Netherlands in the 1st century CE. Map by the Dutch Nationale Onderzoeksagenda Archeologie (www.noaa.nl), available on Wikimedia under the CC-BY-SA-3.0 license.*
Then in 1932 the long effort of the Dutch to build the [Afsluitdijk](https://en.wikipedia.org/wiki/Afsluitdijk) was brough to completion, and the gulf was separated from the sea and became a lake, which the Dutch then proceeded to drain in order to increase the territory of their country; and now the Netherlands has a new 1500 square kilometer province, called [Flevoland](https://en.wikipedia.org/wiki/Flevoland).
* Rivers sometimes change course dramatically. For me, the most spectacular example is the [Oxus](https://en.wikipedia.org/wiki/Amu_Darya), which is today known as the Amu Darya. Until the 16th century it used to flow into the Caspian Sea, through what is now the dry [Uzboy](https://en.wikipedia.org/wiki/Uzboy) valley; it then changed its mind, abandoned the Caspian and went to empty into the Aral Sea.
[](https://en.wikipedia.org/wiki/Uzboy#/media/File:XXth_Century_Citizen%27s_Atlas_map_of_Central_Asia.png)
*The old course of the Oxus (Amu Darya), when it flew into the Caspian Sea, marked as "Old Bed of the Oxus". Map from 1903, available on Wikimedia. Public domain.*
At the beginning of the 18th century, [Peter the Great](https://en.wikipedia.org/wiki/Peter_the_Great), emperor of Russia, sent prince [Alexander Bekovich-Cherkassky](https://en.wikipedia.org/wiki/Alexander_Bekovich-Cherkassky) to find the mouth of the Oxus, with the intention of establishing a trade route from the Caspian to Transoxiana. The prince dutifully mapped the coast and returned with the sad news that the river no longer flowed into the Caspian...
* Speaking of the [Aral Sea](https://en.wikipedia.org/wiki/Aral_Sea), the Soviet Union killed it in the 20th century. The former immense lake of 68,000 square kilometers is now a desert, the [Aralkum](https://en.wikipedia.org/wiki/Aralkum_Desert).
* Speaking of the Soviet Union and Transoxiana: in the 1930s the Soviet Union conceived a titanic project to *"divert the flow of the Northern rivers in the Soviet Union, which "uselessly" drain into the Arctic Ocean, southwards towards the populated agricultural areas of Central Asia, which lack water"* (Wikipedia). The [Northern River Reversal](https://en.wikipedia.org/wiki/Northern_river_reversal) eventually grew and grew, design and planning progressed through the 1960s and 1970s, so that by 1980 the Soviets were talking of diverting 12 major Siberian rivers into the Central Asian desert. They even envisaged using atomic bombs to move massive amounts of dirt speedily. Then the Soviet Union fell; but who knows?
* Speaking of using atomic bombs to dig canals, Egypt is considering a [plan to dig a canal](https://en.wikipedia.org/wiki/Qattara_Depression_Project) from the Mediterranean to the [Qattara Depression](https://en.wikipedia.org/wiki/Qattara_Depression), flooding it and creating a solar-powered 2000 megawatt hydropower plant.
[](https://en.wikipedia.org/wiki/Qattara_Depression_Project#/media/File:All_proposed_routes.PNG)
*All proposed routes for a tunnel and/or canal route from the Mediterranean Sea towards the Qattara Depression. Map by AlwaysUnite, available on Wikimedia under the CC-BY-SA-3.0 license.*
And yes, in the 1950s the international Board of Advisers led by Prof. [Friedrich Bassler](https://en.wikipedia.org/wiki/Friedrich_Bassler) proposed to dig the canal using atomic blasts, part of President Eisenhower's [Atoms for Peace](https://en.wikipedia.org/wiki/Atoms_for_Peace) program.
* The [Frisian Islands](https://en.wikipedia.org/wiki/Frisian_Islands) on the eastern edge of the North Sea are notoriously shifty, so that the approaches to the Dutch ports have changed considerably from the Middle Ages to the present. For example, the northern part of what is now the island of [Texel](https://en.wikipedia.org/wiki/Texel) was until the 13th century the southern part of the island of [Vlieland](https://en.wikipedia.org/wiki/Vlieland); it then left Vlieland and became a separate island, the [Eierland](https://en.wikipedia.org/wiki/Eierland); in the 17th century the Dutch reclaimed the land between the Texel and Eierland, and the two islands became one.
[](https://en.wikipedia.org/wiki/Eierland#/media/File:PaysBas_delisle_1743_fragment.jpg)
*Eierland when it was a separate island. Map from 1702, available on Wikimedia. Public domain.*
Geography is not static
-----------------------
The list could be very much expanded. The Panama Canal. The proposed Nicaragua Canal. The lockless Suez Canal, which has brought the marine life of the Red Sea into the Mediterranean. The Hot Gates of Greece. The shifting barrier islands off the coast of Texas. The absent-minded [Yellow River](https://en.wikipedia.org/wiki/Yellow_River) of China. The wandering lake [Lop Nor](https://en.wikipedia.org/wiki/Lop_Nur). The unstable coastline of England -- how many of the medieval [Cinque Ports](https://en.wikipedia.org/wiki/Cinque_Ports) are still ports, that is, if they exist at all?
Geography changes wherever you look closely. | In addition to the previously noted changes due to climate and normal geology, the sudden removal of humans a la Discovery Channel's [Life After People](https://www.history.com/shows/life-after-people) would quickly lead to the breakdown of electrical and mechanical infrastructure, including pumping stations (e.g., the [California Aqueduct](https://en.wikipedia.org/wiki/California_Aqueduct), [New Orleans' pumping stations](https://en.wikipedia.org/wiki/Drainage_in_New_Orleans), and the Netherlands' [pumping stations in Flevoland](https://www.visitflevoland.nl/en/on-expedition/heritage/pumping-stations-in-flevoland/)), with the obvious results. In the longer term (a few centuries at most, according to Discovery), the majority of earthen and concrete structures are likely to fail, which includes essentially all of the world's dams, dikes, and levees. Their collapses will cause significant flooding, erosion, and scouring of low-lying areas downstream, and some river channels will be changed significantly enough to still show the effects a millennium hence.
Earth's cities and highways are also likely to be largely buried in vegetation (again, per Discovery), with the result that urban and linear features that are prominent from the air or even space will become much harder to see.
The disappearance of humans will also eliminate agriculture and logging, which is likely to reduce silt and fertilizer runoff in most places, with at least some visible changes in watersheds. (For example, [mangroves](https://go.nasa.gov/2FY1CnO) can be expected to make a larger comeback in some rivers; clear-cut areas of the Amazon and other forests will recover to some extent; and a number of river deltas like the [Ebro's](https://go.nasa.gov/2Ik9OQV) will stop growing so quickly and may actually erode.) The Aral Sea may make a comeback as well.
Astronomy might also play a small part; according to [Wikipedia](https://en.wikipedia.org/wiki/Impact_event), there's about a 20% chance of an asteroid strike large enough to create a crater actually hitting land and doing so.
By the way, spacecraft, even the ISS, are too small to make much of a mark, and what little damage they do cause would be hidden by vegetation and weathering very quickly (years, or decades at most). |
107,732 | I've tried researching this question myself, but the only data I can find is over huge timescales, like situations where the continents have reformed back into a Neo-Pangea.
I'm not looking for any real drastic changes in positioning, just relatively minor things like seas disappearing or continents slightly shrinking or pushing into each other.
Would there be any noteworthy changes at all, or would it be pretty much the same as today aside from some minor changes that wouldn't affect anything?
Let's just assume humanity suddenly stopped existing today for the purposes of the question, so they don't make any more changes to the world than they already have.
As always, I'm very grateful for any answers, and if you need anything clarified feel free to leave a comment and I'll do my best to clear things up. | 2018/03/23 | [
"https://worldbuilding.stackexchange.com/questions/107732",
"https://worldbuilding.stackexchange.com",
"https://worldbuilding.stackexchange.com/users/48871/"
] | A millennium is a blink of an eye on a geological scale. But interesting things can happen in a blink of an eye. Even disegarding the changes which may happen as a result of the present climatological instability, small but important modification can occur here and there.
I have no idea of the geographical changes between today and 3000 CE; but I do know of *some* geographical changes between 1 CE and today, either because they happened in places in which I have a local interest, or because they are somehow important to various historical events, or because I found out about them by accident and found them interesting enough to remember.
Geographical changes during the last 1000 or 2000 years
-------------------------------------------------------
* While sea level is today not very different from what it was in the first century, *in some places the sea advanced or retreated considerably:*
+ Some cities which used to be seaports in the first century are now several miles inland. For example:
- In the Antiquity [Ephesus](https://en.wikipedia.org/wiki/Ephesus) and [Miletus](https://en.wikipedia.org/wiki/Miletus) were major ports on the Ionian coast; they are now several kilometers inland.
[](https://en.wikipedia.org/wiki/Miletus#/media/File:Miletus_Bay_silting_evolution_map-en.svg)
*The silting evolution of Miletus Bay due to the alluvium brought by the Maeander River during Antiquity. Map by Eric Gaba, available on Wikimedia under the CC-BY-SA-3.0 license.*
- Closer to me, in the Antiquity the city of Histria was a seaport on the western coast of the Black Sea. Now its ruins lay on the shore of a shallow lagoon, and the sea is kilometers away.
[](https://en.wikipedia.org/wiki/Histria_(ancient_city)#/media/File:Scythia_Minor_map.jpg)
*Ancient towns and colonies in Dobruja; modern coastline shown as a dotted line. Map by Bogdan, available on Wikimedia under the CC-BY-SA-3.0 license.*
+ On the other hand, in some places the sea advanced. For example, what is now the [IJselmeer](https://en.wikipedia.org/wiki/IJsselmeer) in the Netherlands used to be a low-lying plain in the first century, with a large lake known by the Romans as [Lake Flevo](https://en.wikipedia.org/wiki/Lake_Flevo). In 1287, [Saint Lucia's flood](https://en.wikipedia.org/wiki/St._Lucia%27s_flood) broke through and submerged the former river [Vlie](https://en.wikipedia.org/wiki/Vlie), creating a large shallow gulf which was called the [Zuiderzee](https://en.wikipedia.org/wiki/Zuiderzee).
[](https://en.wikipedia.org/wiki/Lake_Flevo#/media/File:50nc_ex_leg_copy.jpg)
*The region of the Netherlands in the 1st century CE. Map by the Dutch Nationale Onderzoeksagenda Archeologie (www.noaa.nl), available on Wikimedia under the CC-BY-SA-3.0 license.*
Then in 1932 the long effort of the Dutch to build the [Afsluitdijk](https://en.wikipedia.org/wiki/Afsluitdijk) was brough to completion, and the gulf was separated from the sea and became a lake, which the Dutch then proceeded to drain in order to increase the territory of their country; and now the Netherlands has a new 1500 square kilometer province, called [Flevoland](https://en.wikipedia.org/wiki/Flevoland).
* Rivers sometimes change course dramatically. For me, the most spectacular example is the [Oxus](https://en.wikipedia.org/wiki/Amu_Darya), which is today known as the Amu Darya. Until the 16th century it used to flow into the Caspian Sea, through what is now the dry [Uzboy](https://en.wikipedia.org/wiki/Uzboy) valley; it then changed its mind, abandoned the Caspian and went to empty into the Aral Sea.
[](https://en.wikipedia.org/wiki/Uzboy#/media/File:XXth_Century_Citizen%27s_Atlas_map_of_Central_Asia.png)
*The old course of the Oxus (Amu Darya), when it flew into the Caspian Sea, marked as "Old Bed of the Oxus". Map from 1903, available on Wikimedia. Public domain.*
At the beginning of the 18th century, [Peter the Great](https://en.wikipedia.org/wiki/Peter_the_Great), emperor of Russia, sent prince [Alexander Bekovich-Cherkassky](https://en.wikipedia.org/wiki/Alexander_Bekovich-Cherkassky) to find the mouth of the Oxus, with the intention of establishing a trade route from the Caspian to Transoxiana. The prince dutifully mapped the coast and returned with the sad news that the river no longer flowed into the Caspian...
* Speaking of the [Aral Sea](https://en.wikipedia.org/wiki/Aral_Sea), the Soviet Union killed it in the 20th century. The former immense lake of 68,000 square kilometers is now a desert, the [Aralkum](https://en.wikipedia.org/wiki/Aralkum_Desert).
* Speaking of the Soviet Union and Transoxiana: in the 1930s the Soviet Union conceived a titanic project to *"divert the flow of the Northern rivers in the Soviet Union, which "uselessly" drain into the Arctic Ocean, southwards towards the populated agricultural areas of Central Asia, which lack water"* (Wikipedia). The [Northern River Reversal](https://en.wikipedia.org/wiki/Northern_river_reversal) eventually grew and grew, design and planning progressed through the 1960s and 1970s, so that by 1980 the Soviets were talking of diverting 12 major Siberian rivers into the Central Asian desert. They even envisaged using atomic bombs to move massive amounts of dirt speedily. Then the Soviet Union fell; but who knows?
* Speaking of using atomic bombs to dig canals, Egypt is considering a [plan to dig a canal](https://en.wikipedia.org/wiki/Qattara_Depression_Project) from the Mediterranean to the [Qattara Depression](https://en.wikipedia.org/wiki/Qattara_Depression), flooding it and creating a solar-powered 2000 megawatt hydropower plant.
[](https://en.wikipedia.org/wiki/Qattara_Depression_Project#/media/File:All_proposed_routes.PNG)
*All proposed routes for a tunnel and/or canal route from the Mediterranean Sea towards the Qattara Depression. Map by AlwaysUnite, available on Wikimedia under the CC-BY-SA-3.0 license.*
And yes, in the 1950s the international Board of Advisers led by Prof. [Friedrich Bassler](https://en.wikipedia.org/wiki/Friedrich_Bassler) proposed to dig the canal using atomic blasts, part of President Eisenhower's [Atoms for Peace](https://en.wikipedia.org/wiki/Atoms_for_Peace) program.
* The [Frisian Islands](https://en.wikipedia.org/wiki/Frisian_Islands) on the eastern edge of the North Sea are notoriously shifty, so that the approaches to the Dutch ports have changed considerably from the Middle Ages to the present. For example, the northern part of what is now the island of [Texel](https://en.wikipedia.org/wiki/Texel) was until the 13th century the southern part of the island of [Vlieland](https://en.wikipedia.org/wiki/Vlieland); it then left Vlieland and became a separate island, the [Eierland](https://en.wikipedia.org/wiki/Eierland); in the 17th century the Dutch reclaimed the land between the Texel and Eierland, and the two islands became one.
[](https://en.wikipedia.org/wiki/Eierland#/media/File:PaysBas_delisle_1743_fragment.jpg)
*Eierland when it was a separate island. Map from 1702, available on Wikimedia. Public domain.*
Geography is not static
-----------------------
The list could be very much expanded. The Panama Canal. The proposed Nicaragua Canal. The lockless Suez Canal, which has brought the marine life of the Red Sea into the Mediterranean. The Hot Gates of Greece. The shifting barrier islands off the coast of Texas. The absent-minded [Yellow River](https://en.wikipedia.org/wiki/Yellow_River) of China. The wandering lake [Lop Nor](https://en.wikipedia.org/wiki/Lop_Nur). The unstable coastline of England -- how many of the medieval [Cinque Ports](https://en.wikipedia.org/wiki/Cinque_Ports) are still ports, that is, if they exist at all?
Geography changes wherever you look closely. | "Is removing people sufficient to stop global warming?" Good question. Answer is not clear. If we have passed the tipping point for arctic permafrost collapse, arctic ocean being ice free in summer, then we may release huge amounts of methane clathrates.
On top of this while oil has to be pumped, natural gas is often under pressure. As distribuiton systems break down, more methane is released.
Net result: ALL of antarctica and Greenland melt over the space of that thousand years.
So we have an new continent free from ice in the south, we have a new archipelago of islands where Greenland was. We have new ecologies in the arctic regions, and the ocean shoreline moves in a bunch.
Details here: <https://www.nationalgeographic.com/magazine/2013/09/rising-seas-ice-melt-new-shoreline-maps/#/07-ice-melt-antarctica.jpg> |
107,732 | I've tried researching this question myself, but the only data I can find is over huge timescales, like situations where the continents have reformed back into a Neo-Pangea.
I'm not looking for any real drastic changes in positioning, just relatively minor things like seas disappearing or continents slightly shrinking or pushing into each other.
Would there be any noteworthy changes at all, or would it be pretty much the same as today aside from some minor changes that wouldn't affect anything?
Let's just assume humanity suddenly stopped existing today for the purposes of the question, so they don't make any more changes to the world than they already have.
As always, I'm very grateful for any answers, and if you need anything clarified feel free to leave a comment and I'll do my best to clear things up. | 2018/03/23 | [
"https://worldbuilding.stackexchange.com/questions/107732",
"https://worldbuilding.stackexchange.com",
"https://worldbuilding.stackexchange.com/users/48871/"
] | You mention plate tectonics as a cause of change; there are others
* **Rising sea levels**. [Wikipedia has a map](https://en.wikipedia.org/wiki/Sea_level_rise#/media/File:6m_Sea_Level_Rise.jpg) from NASA about how a 6-meter sea level rise would change the world map. Current predictions seem to be something between 0.3m and 2.5m in the next hundred years, so 6m doesn't seem crazy over 1000 years.
* **Coastal erosion** can cause significant changes: for example, the [seashore at Hemsby](http://www.bbc.co.uk/news/uk-england-norfolk-43472150) in eastern England is receding at the rate of about 35 metres (115 ft) per year.
* [**Post-glacial rebound**](https://en.wikipedia.org/wiki/Post-glacial_rebound). During the ice age, ice-covered land was weighted down; it's slowly springing back. For example, much of Finland was underwater a few thousand years ago, even though sea levels were much lower. Southern England is pivoting downwards as Scotland rises, which will lower southern England by about 0.5m in the next thousand years.
* **Vulcanism** can and does create new islands.
* **Deposition** from rivers causes estuaries to grow out into the sea. | In addition to the previously noted changes due to climate and normal geology, the sudden removal of humans a la Discovery Channel's [Life After People](https://www.history.com/shows/life-after-people) would quickly lead to the breakdown of electrical and mechanical infrastructure, including pumping stations (e.g., the [California Aqueduct](https://en.wikipedia.org/wiki/California_Aqueduct), [New Orleans' pumping stations](https://en.wikipedia.org/wiki/Drainage_in_New_Orleans), and the Netherlands' [pumping stations in Flevoland](https://www.visitflevoland.nl/en/on-expedition/heritage/pumping-stations-in-flevoland/)), with the obvious results. In the longer term (a few centuries at most, according to Discovery), the majority of earthen and concrete structures are likely to fail, which includes essentially all of the world's dams, dikes, and levees. Their collapses will cause significant flooding, erosion, and scouring of low-lying areas downstream, and some river channels will be changed significantly enough to still show the effects a millennium hence.
Earth's cities and highways are also likely to be largely buried in vegetation (again, per Discovery), with the result that urban and linear features that are prominent from the air or even space will become much harder to see.
The disappearance of humans will also eliminate agriculture and logging, which is likely to reduce silt and fertilizer runoff in most places, with at least some visible changes in watersheds. (For example, [mangroves](https://go.nasa.gov/2FY1CnO) can be expected to make a larger comeback in some rivers; clear-cut areas of the Amazon and other forests will recover to some extent; and a number of river deltas like the [Ebro's](https://go.nasa.gov/2Ik9OQV) will stop growing so quickly and may actually erode.) The Aral Sea may make a comeback as well.
Astronomy might also play a small part; according to [Wikipedia](https://en.wikipedia.org/wiki/Impact_event), there's about a 20% chance of an asteroid strike large enough to create a crater actually hitting land and doing so.
By the way, spacecraft, even the ISS, are too small to make much of a mark, and what little damage they do cause would be hidden by vegetation and weathering very quickly (years, or decades at most). |
107,732 | I've tried researching this question myself, but the only data I can find is over huge timescales, like situations where the continents have reformed back into a Neo-Pangea.
I'm not looking for any real drastic changes in positioning, just relatively minor things like seas disappearing or continents slightly shrinking or pushing into each other.
Would there be any noteworthy changes at all, or would it be pretty much the same as today aside from some minor changes that wouldn't affect anything?
Let's just assume humanity suddenly stopped existing today for the purposes of the question, so they don't make any more changes to the world than they already have.
As always, I'm very grateful for any answers, and if you need anything clarified feel free to leave a comment and I'll do my best to clear things up. | 2018/03/23 | [
"https://worldbuilding.stackexchange.com/questions/107732",
"https://worldbuilding.stackexchange.com",
"https://worldbuilding.stackexchange.com/users/48871/"
] | You mention plate tectonics as a cause of change; there are others
* **Rising sea levels**. [Wikipedia has a map](https://en.wikipedia.org/wiki/Sea_level_rise#/media/File:6m_Sea_Level_Rise.jpg) from NASA about how a 6-meter sea level rise would change the world map. Current predictions seem to be something between 0.3m and 2.5m in the next hundred years, so 6m doesn't seem crazy over 1000 years.
* **Coastal erosion** can cause significant changes: for example, the [seashore at Hemsby](http://www.bbc.co.uk/news/uk-england-norfolk-43472150) in eastern England is receding at the rate of about 35 metres (115 ft) per year.
* [**Post-glacial rebound**](https://en.wikipedia.org/wiki/Post-glacial_rebound). During the ice age, ice-covered land was weighted down; it's slowly springing back. For example, much of Finland was underwater a few thousand years ago, even though sea levels were much lower. Southern England is pivoting downwards as Scotland rises, which will lower southern England by about 0.5m in the next thousand years.
* **Vulcanism** can and does create new islands.
* **Deposition** from rivers causes estuaries to grow out into the sea. | "Is removing people sufficient to stop global warming?" Good question. Answer is not clear. If we have passed the tipping point for arctic permafrost collapse, arctic ocean being ice free in summer, then we may release huge amounts of methane clathrates.
On top of this while oil has to be pumped, natural gas is often under pressure. As distribuiton systems break down, more methane is released.
Net result: ALL of antarctica and Greenland melt over the space of that thousand years.
So we have an new continent free from ice in the south, we have a new archipelago of islands where Greenland was. We have new ecologies in the arctic regions, and the ocean shoreline moves in a bunch.
Details here: <https://www.nationalgeographic.com/magazine/2013/09/rising-seas-ice-melt-new-shoreline-maps/#/07-ice-melt-antarctica.jpg> |
107,732 | I've tried researching this question myself, but the only data I can find is over huge timescales, like situations where the continents have reformed back into a Neo-Pangea.
I'm not looking for any real drastic changes in positioning, just relatively minor things like seas disappearing or continents slightly shrinking or pushing into each other.
Would there be any noteworthy changes at all, or would it be pretty much the same as today aside from some minor changes that wouldn't affect anything?
Let's just assume humanity suddenly stopped existing today for the purposes of the question, so they don't make any more changes to the world than they already have.
As always, I'm very grateful for any answers, and if you need anything clarified feel free to leave a comment and I'll do my best to clear things up. | 2018/03/23 | [
"https://worldbuilding.stackexchange.com/questions/107732",
"https://worldbuilding.stackexchange.com",
"https://worldbuilding.stackexchange.com/users/48871/"
] | In addition to the previously noted changes due to climate and normal geology, the sudden removal of humans a la Discovery Channel's [Life After People](https://www.history.com/shows/life-after-people) would quickly lead to the breakdown of electrical and mechanical infrastructure, including pumping stations (e.g., the [California Aqueduct](https://en.wikipedia.org/wiki/California_Aqueduct), [New Orleans' pumping stations](https://en.wikipedia.org/wiki/Drainage_in_New_Orleans), and the Netherlands' [pumping stations in Flevoland](https://www.visitflevoland.nl/en/on-expedition/heritage/pumping-stations-in-flevoland/)), with the obvious results. In the longer term (a few centuries at most, according to Discovery), the majority of earthen and concrete structures are likely to fail, which includes essentially all of the world's dams, dikes, and levees. Their collapses will cause significant flooding, erosion, and scouring of low-lying areas downstream, and some river channels will be changed significantly enough to still show the effects a millennium hence.
Earth's cities and highways are also likely to be largely buried in vegetation (again, per Discovery), with the result that urban and linear features that are prominent from the air or even space will become much harder to see.
The disappearance of humans will also eliminate agriculture and logging, which is likely to reduce silt and fertilizer runoff in most places, with at least some visible changes in watersheds. (For example, [mangroves](https://go.nasa.gov/2FY1CnO) can be expected to make a larger comeback in some rivers; clear-cut areas of the Amazon and other forests will recover to some extent; and a number of river deltas like the [Ebro's](https://go.nasa.gov/2Ik9OQV) will stop growing so quickly and may actually erode.) The Aral Sea may make a comeback as well.
Astronomy might also play a small part; according to [Wikipedia](https://en.wikipedia.org/wiki/Impact_event), there's about a 20% chance of an asteroid strike large enough to create a crater actually hitting land and doing so.
By the way, spacecraft, even the ISS, are too small to make much of a mark, and what little damage they do cause would be hidden by vegetation and weathering very quickly (years, or decades at most). | "Is removing people sufficient to stop global warming?" Good question. Answer is not clear. If we have passed the tipping point for arctic permafrost collapse, arctic ocean being ice free in summer, then we may release huge amounts of methane clathrates.
On top of this while oil has to be pumped, natural gas is often under pressure. As distribuiton systems break down, more methane is released.
Net result: ALL of antarctica and Greenland melt over the space of that thousand years.
So we have an new continent free from ice in the south, we have a new archipelago of islands where Greenland was. We have new ecologies in the arctic regions, and the ocean shoreline moves in a bunch.
Details here: <https://www.nationalgeographic.com/magazine/2013/09/rising-seas-ice-melt-new-shoreline-maps/#/07-ice-melt-antarctica.jpg> |
31,158,335 | I encountered a strange issue. It's Wednesday now, and:
```
DateTime date;
DateTime.TryParseExact(
"Wed", "ddd", null, System.Globalization.DateTimeStyles.None, out date); // true
DateTime.TryParseExact(
"Mon", "ddd", null, System.Globalization.DateTimeStyles.None, out date); // false
```
When I change local date on computer to Monday output swaps to 'false-true'.
Why does the parser depend on current date? | 2015/07/01 | [
"https://Stackoverflow.com/questions/31158335",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/1632632/"
] | I *suspect* the problem is that you've got a very incomplete date format there. Usually, `DateTime.TryParseExact` will use the current time and date for any fields that aren't specified. Here, you're specifying the day of the week, which isn't really enough information to get to a real date... so I suspect that the text value is only being used to *validate* that it's a reasonable date, after defaulting the `DateTime` to "now". (In the cases where it does manage to parse based on just the day name, you end up with today's date.)
I've just done another test where we specify the day-of-month value as well, and that ends up with interesting results - it appears to use the first month of the current year:
```
using System;
using System.Globalization;
class Test
{
public static void Main (string[] args)
{
// Note: All tests designed for 2015.
// January 1st 2015 was a Thursday.
TryParse("01 Wed"); // False
TryParse("01 Thu"); // True - 2015-01-01
TryParse("02 Thu"); // False
TryParse("02 Fri"); // True - 2015-01-02
}
private static void TryParse(string text)
{
DateTime date;
bool result = DateTime.TryParseExact(
text, "dd ddd", CultureInfo.InvariantCulture, 0, out date);
Console.WriteLine("{0}: {1} {2:yyyy-MM-dd}", text, result, date);
}
}
```
Changing the system date to 2016 gave results consistent with finding dates in January 2016.
Fundamentally, trying to parse such incomplete as this is inherently odd. Think carefully about what you're really trying to achieve. | Why not use regex if you are wanting validating part of a date?
<https://dotnetfiddle.net/ieokVz>
```
using System;
using System.Text.RegularExpressions;
public class Program
{
public static void Main()
{
string pattern = "(Mon|Tue|Wed|Thu|Fri|Sat|Sun)";
string[] values = {"Mon","Tue","Wed","Thu","Fri","Sat","Sun","Bun","Boo","Moo"};
Console.WriteLine("");
foreach(var val in values){
Console.WriteLine("{0} ? {1}",val,Regex.IsMatch(val,pattern));
}
}
}
```
As per @Jon's comments
<https://dotnetfiddle.net/I4R2ZT>
```
using System;
using System.Collections.Generic;
public class Program
{
public static void Main()
{
var matches = new HashSet<String>(System.Threading.Thread.CurrentThread.CurrentCulture.DateTimeFormat.AbbreviatedDayNames,StringComparer.OrdinalIgnoreCase);
string[] values = {"Mon","Tue","Wed","Thu","Fri","Sat","Sun","Bun","Boo","Moo","Foo","Bar"};
foreach(var val in values){
Console.WriteLine("{0} ? {1}", val, matches.Contains(val));
}
}
}
``` |
27,674,464 | I been having problems on my onclick function to another JSP.
I wanted to check whether if the session attribute is the same as **John** or **Mark** from my **display.jsp**, then it will display on **new.jsp** with that name.
I have a **login.jsp** and successfully works on **display.jsp** where it able to display name out by using session in ValidationServlet.
After implementing the code in **display.jsp**, I keep getting requested resource () is not available.
Stuck there for 3 days already and kinda lost now.
Hope you guys could help me out with it, thanks in advance.
**This is my display.jsp code**
```
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Application</title>
</head>
<body>
<h1>Display</h1>
Welcome <b><%=session.getAttribute("name")%></b>,
<table border="0">
<tr>
<th colspan="3"></th>
</tr>
<tr>
<td>
<form action="loan" method="post">
<input type="submit" value="New" onClick="new()"/>
</form>
<SCRIPT LANGUAGE="JavaScript">
function new(){
if (session.getAttribute("name") === "John") {
session.setAttribute("name", "John");
document.new.action="new.jsp";
}
if (session.getAttribute("name") === "Mark") {
session.setAttribute("name", "Mark");
document.new.action="new.jsp";
} else {
session.setAttribute("name", null);
document.new.action="new.jsp";
}
new.submit();
}
</SCRIPT>
</td>
<td colspan="2"></td>
</tr>
</table>
</body>
</html>
```
**This is my new.jsp code**
```
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">
<title>Application</title>
</head>
<body>
<h1>New</h1>
Hello <b><%=session.getAttribute("name")%></b>
</body>
</html>
``` | 2014/12/28 | [
"https://Stackoverflow.com/questions/27674464",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/3127380/"
] | You will get the session variable like beelow:
```
var firstName='<%= session.getAttribute("name")%>';
``` | I don't think you can access session variable from java script, since it executes on client side, what is the output for this piece of code `session.getAttribute("name")` , Are you getting expected value?
Alternatively you can fallow this link [Access session variables in js](https://stackoverflow.com/questions/6918314/using-javascript-can-you-get-the-value-from-a-session-attribute-set-by-servlet-i) |
45,964 | Buddha talks of becoming have a cause, is dependent on something other. Like Lamp's flame and light, shadow and real object, The sun and it's aura, object and mirage.
The dependent origination generates the false 'I' which is nothing but the becoming.
Then can one conclude the cessation of becoming is also carried out by reversal of dependent origination I.e Dependent Cessation? I think that's the way!
Shadow can be ceased only when the real object is perceived, if not the shadow thinks it as real, even though it's unreal or non existing thing! Previously perceived snake was actually the rope, when the wisdom dawns upon.
This shadow is false 'I', the illusion, the non-existant thing. But only when one sees it with eyes of wisdom! Can we say that?
Some quotes of Saints have this testimony in common,
√ Cure for Pain is in Pain!\_ Rumi
√ Samudayadhamma(origination) = nirodhadhamma(cessation)\_ Buddha
I believe the becoming and cessation are two opposite sides of the same coin!
What do others have to say about this? Please don't bring here quotes of scriptures. Do we have here the seekers which can see with eyes of wisdom?
I am asking them! Others please don't bother! | 2021/10/07 | [
"https://buddhism.stackexchange.com/questions/45964",
"https://buddhism.stackexchange.com",
"https://buddhism.stackexchange.com/users/12115/"
] | Good question, more to the point than your first one, IMO.
Regular samsaric mind is "flat", we see things and we interpret them non-ambiguously as per our ego's convictions.
Buddha's mind is "non-flat", it's not like it doesn't interpret at all, rather it produces a solution space of all possible and plausible interpretations at once. It's not a collection of individual distinct interpretations, more like a multidimensional gradient space.
This is why it's said the Buddha's mind is indescribable, Buddha has no position on things etc.
This has been described variously in Buddhist literature as openness or vastness or groundlessness or Emptiness or suchness or ambiguity or metaphorical homelessness etc.
So it's not that you need to stop the thought and become a rock or a log, not at all. Undoing the ego is about opening up and removing the boundaries, towards the fully open Buddha-mind (Bodhi-citta).
In practice this sort of open multiperspective is actually very helpful in everyday life. It makes one a lot less prone to being stuck in a box or getting into a conflict with others. So it's not just good for enlightenment, it makes one more robust in the regular life, too. | You cannot, not at least until you are enlightened & choose to do so.
What you can do is cease identification with the thought; detach yourself from the one who is doing the thinking. Karma will still play out for you, things happen, situations occur, thoughts arise. You can't really stop this.
The waves still as a consequence of following the path, you cannot willfully curb thought. |
45,964 | Buddha talks of becoming have a cause, is dependent on something other. Like Lamp's flame and light, shadow and real object, The sun and it's aura, object and mirage.
The dependent origination generates the false 'I' which is nothing but the becoming.
Then can one conclude the cessation of becoming is also carried out by reversal of dependent origination I.e Dependent Cessation? I think that's the way!
Shadow can be ceased only when the real object is perceived, if not the shadow thinks it as real, even though it's unreal or non existing thing! Previously perceived snake was actually the rope, when the wisdom dawns upon.
This shadow is false 'I', the illusion, the non-existant thing. But only when one sees it with eyes of wisdom! Can we say that?
Some quotes of Saints have this testimony in common,
√ Cure for Pain is in Pain!\_ Rumi
√ Samudayadhamma(origination) = nirodhadhamma(cessation)\_ Buddha
I believe the becoming and cessation are two opposite sides of the same coin!
What do others have to say about this? Please don't bring here quotes of scriptures. Do we have here the seekers which can see with eyes of wisdom?
I am asking them! Others please don't bother! | 2021/10/07 | [
"https://buddhism.stackexchange.com/questions/45964",
"https://buddhism.stackexchange.com",
"https://buddhism.stackexchange.com/users/12115/"
] | Good question, more to the point than your first one, IMO.
Regular samsaric mind is "flat", we see things and we interpret them non-ambiguously as per our ego's convictions.
Buddha's mind is "non-flat", it's not like it doesn't interpret at all, rather it produces a solution space of all possible and plausible interpretations at once. It's not a collection of individual distinct interpretations, more like a multidimensional gradient space.
This is why it's said the Buddha's mind is indescribable, Buddha has no position on things etc.
This has been described variously in Buddhist literature as openness or vastness or groundlessness or Emptiness or suchness or ambiguity or metaphorical homelessness etc.
So it's not that you need to stop the thought and become a rock or a log, not at all. Undoing the ego is about opening up and removing the boundaries, towards the fully open Buddha-mind (Bodhi-citta).
In practice this sort of open multiperspective is actually very helpful in everyday life. It makes one a lot less prone to being stuck in a box or getting into a conflict with others. So it's not just good for enlightenment, it makes one more robust in the regular life, too. | >
> How does one accomplish a reality not governed by the mind when thought is required to function?
>
>
>
There is no one who can govern. There are only realities which causing others.
So, the purification of understanding in realities is the only way to specify the using of "govern" word whether wrong or right using.
It's ok to say "governed by the mind" if the speaker realizing in every moment weather "there are only realities depending on other realities, nothing controllable itself".
It's wrong if the speaker don't realize even one moment, although the speaker avoid to say the word "govern".
**And that ability required proficient Jhana and Abhidhammic detail. The proficient Jhana let the practitioner see ultimate realities in very advance, abhidhammic detail. The abhidhammic detail are seeing the smallest reality more than atom, fastest arising&vanishing more than the light speed, more than trillion time in a second.**
>
> It often seems that ultimate reality is only available in the absence of thought, yet interactions, work and daily functioning requires thought.
>
>
>
The ultimate reality is every where either thinking or not. The mind can know only a reality or a concept per arising, however it's conascence-wisdom can understand both of them at the same moment.
So, the thought is the opposite of only Jhana.
However, the unwholesome is the opposite of the insight-meditation as well, so it is important to do Jhana for pausing the thought. Jhana is easier than the insight-meditation, less detail, so it is good in short term to stop the unwholesome mind.
>
> How does one curb thought when it is uncertain as to whether there is utility in the thought and that it is necessary to follow that thought to achieve something? Wouldn't this mean that ultimate reality can't be accomplished?
>
>
>
"Curbing thought" is Jhana. Jhana is required but not all the time.
It's important for insight meditation weather "how deep in detail that you can see the realities?".
But it's important for Jhana meditation weather "how long time that you can pause the thought?"
However, both Jhana-meditation and insight-meditation are important to do. |
45,964 | Buddha talks of becoming have a cause, is dependent on something other. Like Lamp's flame and light, shadow and real object, The sun and it's aura, object and mirage.
The dependent origination generates the false 'I' which is nothing but the becoming.
Then can one conclude the cessation of becoming is also carried out by reversal of dependent origination I.e Dependent Cessation? I think that's the way!
Shadow can be ceased only when the real object is perceived, if not the shadow thinks it as real, even though it's unreal or non existing thing! Previously perceived snake was actually the rope, when the wisdom dawns upon.
This shadow is false 'I', the illusion, the non-existant thing. But only when one sees it with eyes of wisdom! Can we say that?
Some quotes of Saints have this testimony in common,
√ Cure for Pain is in Pain!\_ Rumi
√ Samudayadhamma(origination) = nirodhadhamma(cessation)\_ Buddha
I believe the becoming and cessation are two opposite sides of the same coin!
What do others have to say about this? Please don't bring here quotes of scriptures. Do we have here the seekers which can see with eyes of wisdom?
I am asking them! Others please don't bother! | 2021/10/07 | [
"https://buddhism.stackexchange.com/questions/45964",
"https://buddhism.stackexchange.com",
"https://buddhism.stackexchange.com/users/12115/"
] | Good question, more to the point than your first one, IMO.
Regular samsaric mind is "flat", we see things and we interpret them non-ambiguously as per our ego's convictions.
Buddha's mind is "non-flat", it's not like it doesn't interpret at all, rather it produces a solution space of all possible and plausible interpretations at once. It's not a collection of individual distinct interpretations, more like a multidimensional gradient space.
This is why it's said the Buddha's mind is indescribable, Buddha has no position on things etc.
This has been described variously in Buddhist literature as openness or vastness or groundlessness or Emptiness or suchness or ambiguity or metaphorical homelessness etc.
So it's not that you need to stop the thought and become a rock or a log, not at all. Undoing the ego is about opening up and removing the boundaries, towards the fully open Buddha-mind (Bodhi-citta).
In practice this sort of open multiperspective is actually very helpful in everyday life. It makes one a lot less prone to being stuck in a box or getting into a conflict with others. So it's not just good for enlightenment, it makes one more robust in the regular life, too. | "governed by the mind" suggest that there is one who is governed. Once you enter the 2nd refuge of the 3 jewels of Buddhism (taking refuge in the Dharma) and the teacher and the teaching as localized sources melt away, you become one with all , therefore the continued teaching and realizations do not flow from a person or from a book anymore. The whole starts teaching herself.
2+2=4 not because your mind is localized and is able to calculate. The same way, things can be happening (urge to go to the bathroom) without the mind creating a story about it. Then "you aren't going to the bathroom", but rather "the whole is going to the bathroom". There is still "going to the bathroom", but a localized mind is not required to achieve the act.
Also IMPORTANT, none of these states are black/white, on/off, etc. In most cases there are partial realizations or degrees of achievements. Once you notice the gap (between what is and what is in the mind), you can widen that gap with practice and repetition. So the functionality of the mind can be slowly/quickly, gradually/at once be transferred/tasked to work as part of the whole, rather than work for the individual. The Eightfold Path gives you specific training to work on the mind and its functionality, to slowly erode its fascination with itself. Then it becomes a tool, rather than the seat of your god. |
45,964 | Buddha talks of becoming have a cause, is dependent on something other. Like Lamp's flame and light, shadow and real object, The sun and it's aura, object and mirage.
The dependent origination generates the false 'I' which is nothing but the becoming.
Then can one conclude the cessation of becoming is also carried out by reversal of dependent origination I.e Dependent Cessation? I think that's the way!
Shadow can be ceased only when the real object is perceived, if not the shadow thinks it as real, even though it's unreal or non existing thing! Previously perceived snake was actually the rope, when the wisdom dawns upon.
This shadow is false 'I', the illusion, the non-existant thing. But only when one sees it with eyes of wisdom! Can we say that?
Some quotes of Saints have this testimony in common,
√ Cure for Pain is in Pain!\_ Rumi
√ Samudayadhamma(origination) = nirodhadhamma(cessation)\_ Buddha
I believe the becoming and cessation are two opposite sides of the same coin!
What do others have to say about this? Please don't bring here quotes of scriptures. Do we have here the seekers which can see with eyes of wisdom?
I am asking them! Others please don't bother! | 2021/10/07 | [
"https://buddhism.stackexchange.com/questions/45964",
"https://buddhism.stackexchange.com",
"https://buddhism.stackexchange.com/users/12115/"
] | >
> How does one accomplish a reality not governed by the mind when thought is required to function?
>
>
>
There is no one who can govern. There are only realities which causing others.
So, the purification of understanding in realities is the only way to specify the using of "govern" word whether wrong or right using.
It's ok to say "governed by the mind" if the speaker realizing in every moment weather "there are only realities depending on other realities, nothing controllable itself".
It's wrong if the speaker don't realize even one moment, although the speaker avoid to say the word "govern".
**And that ability required proficient Jhana and Abhidhammic detail. The proficient Jhana let the practitioner see ultimate realities in very advance, abhidhammic detail. The abhidhammic detail are seeing the smallest reality more than atom, fastest arising&vanishing more than the light speed, more than trillion time in a second.**
>
> It often seems that ultimate reality is only available in the absence of thought, yet interactions, work and daily functioning requires thought.
>
>
>
The ultimate reality is every where either thinking or not. The mind can know only a reality or a concept per arising, however it's conascence-wisdom can understand both of them at the same moment.
So, the thought is the opposite of only Jhana.
However, the unwholesome is the opposite of the insight-meditation as well, so it is important to do Jhana for pausing the thought. Jhana is easier than the insight-meditation, less detail, so it is good in short term to stop the unwholesome mind.
>
> How does one curb thought when it is uncertain as to whether there is utility in the thought and that it is necessary to follow that thought to achieve something? Wouldn't this mean that ultimate reality can't be accomplished?
>
>
>
"Curbing thought" is Jhana. Jhana is required but not all the time.
It's important for insight meditation weather "how deep in detail that you can see the realities?".
But it's important for Jhana meditation weather "how long time that you can pause the thought?"
However, both Jhana-meditation and insight-meditation are important to do. | You cannot, not at least until you are enlightened & choose to do so.
What you can do is cease identification with the thought; detach yourself from the one who is doing the thinking. Karma will still play out for you, things happen, situations occur, thoughts arise. You can't really stop this.
The waves still as a consequence of following the path, you cannot willfully curb thought. |
45,964 | Buddha talks of becoming have a cause, is dependent on something other. Like Lamp's flame and light, shadow and real object, The sun and it's aura, object and mirage.
The dependent origination generates the false 'I' which is nothing but the becoming.
Then can one conclude the cessation of becoming is also carried out by reversal of dependent origination I.e Dependent Cessation? I think that's the way!
Shadow can be ceased only when the real object is perceived, if not the shadow thinks it as real, even though it's unreal or non existing thing! Previously perceived snake was actually the rope, when the wisdom dawns upon.
This shadow is false 'I', the illusion, the non-existant thing. But only when one sees it with eyes of wisdom! Can we say that?
Some quotes of Saints have this testimony in common,
√ Cure for Pain is in Pain!\_ Rumi
√ Samudayadhamma(origination) = nirodhadhamma(cessation)\_ Buddha
I believe the becoming and cessation are two opposite sides of the same coin!
What do others have to say about this? Please don't bring here quotes of scriptures. Do we have here the seekers which can see with eyes of wisdom?
I am asking them! Others please don't bother! | 2021/10/07 | [
"https://buddhism.stackexchange.com/questions/45964",
"https://buddhism.stackexchange.com",
"https://buddhism.stackexchange.com/users/12115/"
] | "governed by the mind" suggest that there is one who is governed. Once you enter the 2nd refuge of the 3 jewels of Buddhism (taking refuge in the Dharma) and the teacher and the teaching as localized sources melt away, you become one with all , therefore the continued teaching and realizations do not flow from a person or from a book anymore. The whole starts teaching herself.
2+2=4 not because your mind is localized and is able to calculate. The same way, things can be happening (urge to go to the bathroom) without the mind creating a story about it. Then "you aren't going to the bathroom", but rather "the whole is going to the bathroom". There is still "going to the bathroom", but a localized mind is not required to achieve the act.
Also IMPORTANT, none of these states are black/white, on/off, etc. In most cases there are partial realizations or degrees of achievements. Once you notice the gap (between what is and what is in the mind), you can widen that gap with practice and repetition. So the functionality of the mind can be slowly/quickly, gradually/at once be transferred/tasked to work as part of the whole, rather than work for the individual. The Eightfold Path gives you specific training to work on the mind and its functionality, to slowly erode its fascination with itself. Then it becomes a tool, rather than the seat of your god. | You cannot, not at least until you are enlightened & choose to do so.
What you can do is cease identification with the thought; detach yourself from the one who is doing the thinking. Karma will still play out for you, things happen, situations occur, thoughts arise. You can't really stop this.
The waves still as a consequence of following the path, you cannot willfully curb thought. |
3,808 | By default, `populateState` seems to limit a call to any model's `get('Items')` function to 20 items.
How can this be overridden - by re-writing `populateState`? By writing a separate function in the model? I've gone for the second option...
```
public function getAll(){
return $this->_getList($this->getListQuery());
}
```
which works, but I think there's a more Joomla-ish way of doing this - I just can't find it. | 2014/07/30 | [
"https://joomla.stackexchange.com/questions/3808",
"https://joomla.stackexchange.com",
"https://joomla.stackexchange.com/users/90/"
] | To answer the question in the title about "setting" the limit, this is done in the Joomla global configuration: "Default List Limit".
To override, Joomla components generally seem to use this in the model:
Using `$limit = 0` shows all items
```
protected function populateState($ordering = null, $direction = null)
{
// set limit
$this->setState('list.limit', $limit);
// set start (eg. what record to begin pagination at)
$this->setState('list.start', $value);
}
``` | **Try this also**
```
protected function populateState($ordering = null, $direction = null)
{
// Load the list state.
$this->setState('list.start', 0);
$this->setState('list.limit', 10);
}
``` |
3,808 | By default, `populateState` seems to limit a call to any model's `get('Items')` function to 20 items.
How can this be overridden - by re-writing `populateState`? By writing a separate function in the model? I've gone for the second option...
```
public function getAll(){
return $this->_getList($this->getListQuery());
}
```
which works, but I think there's a more Joomla-ish way of doing this - I just can't find it. | 2014/07/30 | [
"https://joomla.stackexchange.com/questions/3808",
"https://joomla.stackexchange.com",
"https://joomla.stackexchange.com/users/90/"
] | To answer the question in the title about "setting" the limit, this is done in the Joomla global configuration: "Default List Limit".
To override, Joomla components generally seem to use this in the model:
Using `$limit = 0` shows all items
```
protected function populateState($ordering = null, $direction = null)
{
// set limit
$this->setState('list.limit', $limit);
// set start (eg. what record to begin pagination at)
$this->setState('list.start', $value);
}
``` | Like others have said - put this in the model's populateState function
```
$this->setState('list.limit', $limit); #limit=0 removes limit
$this->setState('list.start', $start);
```
But you must make sure that these lines are AFTER
```
parent::populateState($order, $dir);
```
or the parent class will override your values |
3,808 | By default, `populateState` seems to limit a call to any model's `get('Items')` function to 20 items.
How can this be overridden - by re-writing `populateState`? By writing a separate function in the model? I've gone for the second option...
```
public function getAll(){
return $this->_getList($this->getListQuery());
}
```
which works, but I think there's a more Joomla-ish way of doing this - I just can't find it. | 2014/07/30 | [
"https://joomla.stackexchange.com/questions/3808",
"https://joomla.stackexchange.com",
"https://joomla.stackexchange.com/users/90/"
] | Like others have said - put this in the model's populateState function
```
$this->setState('list.limit', $limit); #limit=0 removes limit
$this->setState('list.start', $start);
```
But you must make sure that these lines are AFTER
```
parent::populateState($order, $dir);
```
or the parent class will override your values | **Try this also**
```
protected function populateState($ordering = null, $direction = null)
{
// Load the list state.
$this->setState('list.start', 0);
$this->setState('list.limit', 10);
}
``` |
23,977,264 | I was wondering how I can initialize a `std::vector` of strings, without having to use a bunch of `push_back`'s in *Visual Studio Ultimate 2012*.
---
I've tried `vector<string> test = {"hello", "world"}`, but that gave me the following error:
>
> `Error: initialization with '{...}' is not allowed for an object of type "std::vector<std::string, std::allocator<std::string>>`
>
>
>
---
* Why do I receive the error?
* Any ideas on what I can do to store the strings? | 2014/06/01 | [
"https://Stackoverflow.com/questions/23977264",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2535589/"
] | **The problem**
You'll have to upgrade to a more recent compiler version (and standard library implementation), if you'd like to use what you have in your snippet.
*VS2012* [doesn't support](http://msdn.microsoft.com/en-us/library/hh567368.aspx) `std::initializer_list`, which means that the overload among `std::vector`'s constructors, that you are trying to use, simply doesn't exist.
In other words; the example cannot be compiled with *VS2012*.
* [**msdn.com** - Support For C++11 Features (Modern C++)](http://msdn.microsoft.com/en-us/library/hh567368.aspx)
---
**Potential Workaround**
Use an intermediate *array* to store the `std::string`s, and use that to initialize the vector.
```
std::string const init_data[] = {
"hello", "world"
};
std::vector<std::string> test (std::begin (init_data), std::end (init_data));
``` | **1. Why do I receive the error?**
Visual Studio 2012 doesn't support list initialization before the [2012 November update](https://support.microsoft.com/en-us/help/2797915/description-of-visual-studio-2012-update-1) according to this [question](https://stackoverflow.com/questions/12654394/initializer-list-not-working-with-vector-in-visual-studio-2012).
**2.Any ideas on what I can do to store the strings?**
Using push\_back() is a totally valid solution. Example:
```cpp
#include<vector>
#include <string>
using namespace std;
int main()
{
vector<string> test;
test.push_back("hello");
test.push_back("world");
for(int i=0; i<test.size(); i++)
cout<<test[i]<<endl;
return 0;
}
``` |
10,598 | Reading [the answer to a question about Sabé](https://scifi.stackexchange.com/a/10590/2565) (the Amidala stand-in) I remembered that I always wondered why she ordered the actual queen to scrub R2-D2. There were enough actual servants who could have done it, so why Padmé? If that wasn't enough, after giving the actual queen (Padmé) the order to go away, she tells Panaka to continue with the discussion. How does that make sense?
The significant piece of dialogue:
>
> AMIDALA : Thank you, Artoo Detoo. You have proven to be very loyal...Padme!
> ...
>
> AMIDALA : (Cont'd) Clean this droid up the best you can. It deserves our gratitude...(to Panaka) Continue, Captain.
>
>
>
Note that this question is two-fold:
1. Why was Padmé chosen in the first place?
2. Why would an important meeting with the ship's captain be continued without her? | 2012/02/07 | [
"https://scifi.stackexchange.com/questions/10598",
"https://scifi.stackexchange.com",
"https://scifi.stackexchange.com/users/2565/"
] | In addition to what Chris stated, it also gave Amidala an more ready excuse to be around the Jedi, Anakin and JarJar in a non-formal environment where discussion might flow more freely. An attendant to the Queen would be expected to be in attendance to the Queen whenever possible and allows little time to just "hang out" as it were in that more free environment. But if she were given a task that would take some time, she could spend time getting to know the travelers more and perhaps gain more of their trust in return. | The decision to ask her to clean the droid seems to have been to give Padmé an opportunity to interact directly with the Queen *without it seeming like she's consulting her*. Presumably if Padmé had disagreed, she could have shaken her head sadly as she looked at how dirty the droid was.
It's a little clearer in the film's [official novelisation](http://starwars.wikia.com/wiki/Star_Wars_Episode_I:_The_Phantom_Menace_(novel))
>
> The Queen looked at Qui-Gon. The Jedi did not waver. **“You must trust
> my judgment, Your Highness.”**
>
>
> **“Must I?” Amidala asked quietly. She shifted her gaze to her
> handmaidens, ending with Padmé.** The girl had not moved from the
> Queen’s side, but seemed to remember suddenly she had been given a
> task to complete. **She nodded briefly to the Queen,** and moved to take
> R2-D2 in hand.
>
>
> Amidala looked back at Qui-Gon Jinn. “**We are in your hands,**” she
> advised, and the matter was settled.
>
>
>
It also helps to maintain her subterfuge
>
> *Now that I am Padmé, **the Queen can command me to perform tasks. I told
> Sabé she must do this, or it will look suspicious. But does Sabé get
> just a little pleasure out of telling me to clean up an astromech
> droid?***
>
>
> ***Maybe. She's only human.** Actually, once I began, I didn't mind the
> task. I like working with my hands, it takes my mind off the
> impatience. And after all, the droid saved my life.*
>
>
> [Star Wars Journals - Episode 1 #2 - Queen Amidala](https://www.scholastic.com/teachers/books/star-wars-journals-episode-1-02-amidala-by-jude-watson/)
>
>
> |
10,598 | Reading [the answer to a question about Sabé](https://scifi.stackexchange.com/a/10590/2565) (the Amidala stand-in) I remembered that I always wondered why she ordered the actual queen to scrub R2-D2. There were enough actual servants who could have done it, so why Padmé? If that wasn't enough, after giving the actual queen (Padmé) the order to go away, she tells Panaka to continue with the discussion. How does that make sense?
The significant piece of dialogue:
>
> AMIDALA : Thank you, Artoo Detoo. You have proven to be very loyal...Padme!
> ...
>
> AMIDALA : (Cont'd) Clean this droid up the best you can. It deserves our gratitude...(to Panaka) Continue, Captain.
>
>
>
Note that this question is two-fold:
1. Why was Padmé chosen in the first place?
2. Why would an important meeting with the ship's captain be continued without her? | 2012/02/07 | [
"https://scifi.stackexchange.com/questions/10598",
"https://scifi.stackexchange.com",
"https://scifi.stackexchange.com/users/2565/"
] | The decision to ask her to clean the droid seems to have been to give Padmé an opportunity to interact directly with the Queen *without it seeming like she's consulting her*. Presumably if Padmé had disagreed, she could have shaken her head sadly as she looked at how dirty the droid was.
It's a little clearer in the film's [official novelisation](http://starwars.wikia.com/wiki/Star_Wars_Episode_I:_The_Phantom_Menace_(novel))
>
> The Queen looked at Qui-Gon. The Jedi did not waver. **“You must trust
> my judgment, Your Highness.”**
>
>
> **“Must I?” Amidala asked quietly. She shifted her gaze to her
> handmaidens, ending with Padmé.** The girl had not moved from the
> Queen’s side, but seemed to remember suddenly she had been given a
> task to complete. **She nodded briefly to the Queen,** and moved to take
> R2-D2 in hand.
>
>
> Amidala looked back at Qui-Gon Jinn. “**We are in your hands,**” she
> advised, and the matter was settled.
>
>
>
It also helps to maintain her subterfuge
>
> *Now that I am Padmé, **the Queen can command me to perform tasks. I told
> Sabé she must do this, or it will look suspicious. But does Sabé get
> just a little pleasure out of telling me to clean up an astromech
> droid?***
>
>
> ***Maybe. She's only human.** Actually, once I began, I didn't mind the
> task. I like working with my hands, it takes my mind off the
> impatience. And after all, the droid saved my life.*
>
>
> [Star Wars Journals - Episode 1 #2 - Queen Amidala](https://www.scholastic.com/teachers/books/star-wars-journals-episode-1-02-amidala-by-jude-watson/)
>
>
> | The smile that Sabe gives Padme after she orders her to do it is quite telling. Like it's some kind of joke. Whether it's a joke that she's making her do something menial, or a joke that "Hey, we're going to pull off you infiiltrating the strangers' ranks" is unknown. |
10,598 | Reading [the answer to a question about Sabé](https://scifi.stackexchange.com/a/10590/2565) (the Amidala stand-in) I remembered that I always wondered why she ordered the actual queen to scrub R2-D2. There were enough actual servants who could have done it, so why Padmé? If that wasn't enough, after giving the actual queen (Padmé) the order to go away, she tells Panaka to continue with the discussion. How does that make sense?
The significant piece of dialogue:
>
> AMIDALA : Thank you, Artoo Detoo. You have proven to be very loyal...Padme!
> ...
>
> AMIDALA : (Cont'd) Clean this droid up the best you can. It deserves our gratitude...(to Panaka) Continue, Captain.
>
>
>
Note that this question is two-fold:
1. Why was Padmé chosen in the first place?
2. Why would an important meeting with the ship's captain be continued without her? | 2012/02/07 | [
"https://scifi.stackexchange.com/questions/10598",
"https://scifi.stackexchange.com",
"https://scifi.stackexchange.com/users/2565/"
] | In addition to what Chris stated, it also gave Amidala an more ready excuse to be around the Jedi, Anakin and JarJar in a non-formal environment where discussion might flow more freely. An attendant to the Queen would be expected to be in attendance to the Queen whenever possible and allows little time to just "hang out" as it were in that more free environment. But if she were given a task that would take some time, she could spend time getting to know the travelers more and perhaps gain more of their trust in return. | Perhaps Padmé *wanted* to clean the droid--both to learn more about the people she was traveling with, and the droid that had saved her and her ship. She didn't seem to treat it as an onerous task, did she? |
10,598 | Reading [the answer to a question about Sabé](https://scifi.stackexchange.com/a/10590/2565) (the Amidala stand-in) I remembered that I always wondered why she ordered the actual queen to scrub R2-D2. There were enough actual servants who could have done it, so why Padmé? If that wasn't enough, after giving the actual queen (Padmé) the order to go away, she tells Panaka to continue with the discussion. How does that make sense?
The significant piece of dialogue:
>
> AMIDALA : Thank you, Artoo Detoo. You have proven to be very loyal...Padme!
> ...
>
> AMIDALA : (Cont'd) Clean this droid up the best you can. It deserves our gratitude...(to Panaka) Continue, Captain.
>
>
>
Note that this question is two-fold:
1. Why was Padmé chosen in the first place?
2. Why would an important meeting with the ship's captain be continued without her? | 2012/02/07 | [
"https://scifi.stackexchange.com/questions/10598",
"https://scifi.stackexchange.com",
"https://scifi.stackexchange.com/users/2565/"
] | 1. It underscores the subterfuge - if the "queen" were deferential and reluctant to use a particular handmaiden as a servant, that would raise suspicions. If Padme wanted to be seen as a servant, she would have walk the walk.
2. I think that Sabé was well-trained enough to handle the situation. They were out of danger, and she could couch any major decision she was pressed for as "I need some time to think about it", huddle with Padme, and there you are. If you've cultivated a habit of consulting your handmaidens *anyway*, this seems perfectly logical - I suspect that the handmaidens are probably noble-born and highly educated as well. | I always thought it was Sabe playing a joke on her friend the Queen. The Queen and her handmaidens are supposed to be very close (look at how distraught Padme was when Corde, who wasn't even HER handmaiden was killed) so maybe Sabe felt secure enough in their friendship to make her do dirty work. I know that if my best friend was a noble and I was his servant and we switched for a few weeks, I'd have him on latrine duty from 8 o'clock, day one. |
10,598 | Reading [the answer to a question about Sabé](https://scifi.stackexchange.com/a/10590/2565) (the Amidala stand-in) I remembered that I always wondered why she ordered the actual queen to scrub R2-D2. There were enough actual servants who could have done it, so why Padmé? If that wasn't enough, after giving the actual queen (Padmé) the order to go away, she tells Panaka to continue with the discussion. How does that make sense?
The significant piece of dialogue:
>
> AMIDALA : Thank you, Artoo Detoo. You have proven to be very loyal...Padme!
> ...
>
> AMIDALA : (Cont'd) Clean this droid up the best you can. It deserves our gratitude...(to Panaka) Continue, Captain.
>
>
>
Note that this question is two-fold:
1. Why was Padmé chosen in the first place?
2. Why would an important meeting with the ship's captain be continued without her? | 2012/02/07 | [
"https://scifi.stackexchange.com/questions/10598",
"https://scifi.stackexchange.com",
"https://scifi.stackexchange.com/users/2565/"
] | The decision to ask her to clean the droid seems to have been to give Padmé an opportunity to interact directly with the Queen *without it seeming like she's consulting her*. Presumably if Padmé had disagreed, she could have shaken her head sadly as she looked at how dirty the droid was.
It's a little clearer in the film's [official novelisation](http://starwars.wikia.com/wiki/Star_Wars_Episode_I:_The_Phantom_Menace_(novel))
>
> The Queen looked at Qui-Gon. The Jedi did not waver. **“You must trust
> my judgment, Your Highness.”**
>
>
> **“Must I?” Amidala asked quietly. She shifted her gaze to her
> handmaidens, ending with Padmé.** The girl had not moved from the
> Queen’s side, but seemed to remember suddenly she had been given a
> task to complete. **She nodded briefly to the Queen,** and moved to take
> R2-D2 in hand.
>
>
> Amidala looked back at Qui-Gon Jinn. “**We are in your hands,**” she
> advised, and the matter was settled.
>
>
>
It also helps to maintain her subterfuge
>
> *Now that I am Padmé, **the Queen can command me to perform tasks. I told
> Sabé she must do this, or it will look suspicious. But does Sabé get
> just a little pleasure out of telling me to clean up an astromech
> droid?***
>
>
> ***Maybe. She's only human.** Actually, once I began, I didn't mind the
> task. I like working with my hands, it takes my mind off the
> impatience. And after all, the droid saved my life.*
>
>
> [Star Wars Journals - Episode 1 #2 - Queen Amidala](https://www.scholastic.com/teachers/books/star-wars-journals-episode-1-02-amidala-by-jude-watson/)
>
>
> | Perhaps Padmé *wanted* to clean the droid--both to learn more about the people she was traveling with, and the droid that had saved her and her ship. She didn't seem to treat it as an onerous task, did she? |
10,598 | Reading [the answer to a question about Sabé](https://scifi.stackexchange.com/a/10590/2565) (the Amidala stand-in) I remembered that I always wondered why she ordered the actual queen to scrub R2-D2. There were enough actual servants who could have done it, so why Padmé? If that wasn't enough, after giving the actual queen (Padmé) the order to go away, she tells Panaka to continue with the discussion. How does that make sense?
The significant piece of dialogue:
>
> AMIDALA : Thank you, Artoo Detoo. You have proven to be very loyal...Padme!
> ...
>
> AMIDALA : (Cont'd) Clean this droid up the best you can. It deserves our gratitude...(to Panaka) Continue, Captain.
>
>
>
Note that this question is two-fold:
1. Why was Padmé chosen in the first place?
2. Why would an important meeting with the ship's captain be continued without her? | 2012/02/07 | [
"https://scifi.stackexchange.com/questions/10598",
"https://scifi.stackexchange.com",
"https://scifi.stackexchange.com/users/2565/"
] | In addition to what Chris stated, it also gave Amidala an more ready excuse to be around the Jedi, Anakin and JarJar in a non-formal environment where discussion might flow more freely. An attendant to the Queen would be expected to be in attendance to the Queen whenever possible and allows little time to just "hang out" as it were in that more free environment. But if she were given a task that would take some time, she could spend time getting to know the travelers more and perhaps gain more of their trust in return. | I always thought it was Sabe playing a joke on her friend the Queen. The Queen and her handmaidens are supposed to be very close (look at how distraught Padme was when Corde, who wasn't even HER handmaiden was killed) so maybe Sabe felt secure enough in their friendship to make her do dirty work. I know that if my best friend was a noble and I was his servant and we switched for a few weeks, I'd have him on latrine duty from 8 o'clock, day one. |
10,598 | Reading [the answer to a question about Sabé](https://scifi.stackexchange.com/a/10590/2565) (the Amidala stand-in) I remembered that I always wondered why she ordered the actual queen to scrub R2-D2. There were enough actual servants who could have done it, so why Padmé? If that wasn't enough, after giving the actual queen (Padmé) the order to go away, she tells Panaka to continue with the discussion. How does that make sense?
The significant piece of dialogue:
>
> AMIDALA : Thank you, Artoo Detoo. You have proven to be very loyal...Padme!
> ...
>
> AMIDALA : (Cont'd) Clean this droid up the best you can. It deserves our gratitude...(to Panaka) Continue, Captain.
>
>
>
Note that this question is two-fold:
1. Why was Padmé chosen in the first place?
2. Why would an important meeting with the ship's captain be continued without her? | 2012/02/07 | [
"https://scifi.stackexchange.com/questions/10598",
"https://scifi.stackexchange.com",
"https://scifi.stackexchange.com/users/2565/"
] | I always thought it was Sabe playing a joke on her friend the Queen. The Queen and her handmaidens are supposed to be very close (look at how distraught Padme was when Corde, who wasn't even HER handmaiden was killed) so maybe Sabe felt secure enough in their friendship to make her do dirty work. I know that if my best friend was a noble and I was his servant and we switched for a few weeks, I'd have him on latrine duty from 8 o'clock, day one. | Perhaps Padmé *wanted* to clean the droid--both to learn more about the people she was traveling with, and the droid that had saved her and her ship. She didn't seem to treat it as an onerous task, did she? |
10,598 | Reading [the answer to a question about Sabé](https://scifi.stackexchange.com/a/10590/2565) (the Amidala stand-in) I remembered that I always wondered why she ordered the actual queen to scrub R2-D2. There were enough actual servants who could have done it, so why Padmé? If that wasn't enough, after giving the actual queen (Padmé) the order to go away, she tells Panaka to continue with the discussion. How does that make sense?
The significant piece of dialogue:
>
> AMIDALA : Thank you, Artoo Detoo. You have proven to be very loyal...Padme!
> ...
>
> AMIDALA : (Cont'd) Clean this droid up the best you can. It deserves our gratitude...(to Panaka) Continue, Captain.
>
>
>
Note that this question is two-fold:
1. Why was Padmé chosen in the first place?
2. Why would an important meeting with the ship's captain be continued without her? | 2012/02/07 | [
"https://scifi.stackexchange.com/questions/10598",
"https://scifi.stackexchange.com",
"https://scifi.stackexchange.com/users/2565/"
] | 1. It underscores the subterfuge - if the "queen" were deferential and reluctant to use a particular handmaiden as a servant, that would raise suspicions. If Padme wanted to be seen as a servant, she would have walk the walk.
2. I think that Sabé was well-trained enough to handle the situation. They were out of danger, and she could couch any major decision she was pressed for as "I need some time to think about it", huddle with Padme, and there you are. If you've cultivated a habit of consulting your handmaidens *anyway*, this seems perfectly logical - I suspect that the handmaidens are probably noble-born and highly educated as well. | The smile that Sabe gives Padme after she orders her to do it is quite telling. Like it's some kind of joke. Whether it's a joke that she's making her do something menial, or a joke that "Hey, we're going to pull off you infiiltrating the strangers' ranks" is unknown. |
10,598 | Reading [the answer to a question about Sabé](https://scifi.stackexchange.com/a/10590/2565) (the Amidala stand-in) I remembered that I always wondered why she ordered the actual queen to scrub R2-D2. There were enough actual servants who could have done it, so why Padmé? If that wasn't enough, after giving the actual queen (Padmé) the order to go away, she tells Panaka to continue with the discussion. How does that make sense?
The significant piece of dialogue:
>
> AMIDALA : Thank you, Artoo Detoo. You have proven to be very loyal...Padme!
> ...
>
> AMIDALA : (Cont'd) Clean this droid up the best you can. It deserves our gratitude...(to Panaka) Continue, Captain.
>
>
>
Note that this question is two-fold:
1. Why was Padmé chosen in the first place?
2. Why would an important meeting with the ship's captain be continued without her? | 2012/02/07 | [
"https://scifi.stackexchange.com/questions/10598",
"https://scifi.stackexchange.com",
"https://scifi.stackexchange.com/users/2565/"
] | 1. It underscores the subterfuge - if the "queen" were deferential and reluctant to use a particular handmaiden as a servant, that would raise suspicions. If Padme wanted to be seen as a servant, she would have walk the walk.
2. I think that Sabé was well-trained enough to handle the situation. They were out of danger, and she could couch any major decision she was pressed for as "I need some time to think about it", huddle with Padme, and there you are. If you've cultivated a habit of consulting your handmaidens *anyway*, this seems perfectly logical - I suspect that the handmaidens are probably noble-born and highly educated as well. | The decision to ask her to clean the droid seems to have been to give Padmé an opportunity to interact directly with the Queen *without it seeming like she's consulting her*. Presumably if Padmé had disagreed, she could have shaken her head sadly as she looked at how dirty the droid was.
It's a little clearer in the film's [official novelisation](http://starwars.wikia.com/wiki/Star_Wars_Episode_I:_The_Phantom_Menace_(novel))
>
> The Queen looked at Qui-Gon. The Jedi did not waver. **“You must trust
> my judgment, Your Highness.”**
>
>
> **“Must I?” Amidala asked quietly. She shifted her gaze to her
> handmaidens, ending with Padmé.** The girl had not moved from the
> Queen’s side, but seemed to remember suddenly she had been given a
> task to complete. **She nodded briefly to the Queen,** and moved to take
> R2-D2 in hand.
>
>
> Amidala looked back at Qui-Gon Jinn. “**We are in your hands,**” she
> advised, and the matter was settled.
>
>
>
It also helps to maintain her subterfuge
>
> *Now that I am Padmé, **the Queen can command me to perform tasks. I told
> Sabé she must do this, or it will look suspicious. But does Sabé get
> just a little pleasure out of telling me to clean up an astromech
> droid?***
>
>
> ***Maybe. She's only human.** Actually, once I began, I didn't mind the
> task. I like working with my hands, it takes my mind off the
> impatience. And after all, the droid saved my life.*
>
>
> [Star Wars Journals - Episode 1 #2 - Queen Amidala](https://www.scholastic.com/teachers/books/star-wars-journals-episode-1-02-amidala-by-jude-watson/)
>
>
> |
10,598 | Reading [the answer to a question about Sabé](https://scifi.stackexchange.com/a/10590/2565) (the Amidala stand-in) I remembered that I always wondered why she ordered the actual queen to scrub R2-D2. There were enough actual servants who could have done it, so why Padmé? If that wasn't enough, after giving the actual queen (Padmé) the order to go away, she tells Panaka to continue with the discussion. How does that make sense?
The significant piece of dialogue:
>
> AMIDALA : Thank you, Artoo Detoo. You have proven to be very loyal...Padme!
> ...
>
> AMIDALA : (Cont'd) Clean this droid up the best you can. It deserves our gratitude...(to Panaka) Continue, Captain.
>
>
>
Note that this question is two-fold:
1. Why was Padmé chosen in the first place?
2. Why would an important meeting with the ship's captain be continued without her? | 2012/02/07 | [
"https://scifi.stackexchange.com/questions/10598",
"https://scifi.stackexchange.com",
"https://scifi.stackexchange.com/users/2565/"
] | I always thought it was Sabe playing a joke on her friend the Queen. The Queen and her handmaidens are supposed to be very close (look at how distraught Padme was when Corde, who wasn't even HER handmaiden was killed) so maybe Sabe felt secure enough in their friendship to make her do dirty work. I know that if my best friend was a noble and I was his servant and we switched for a few weeks, I'd have him on latrine duty from 8 o'clock, day one. | The smile that Sabe gives Padme after she orders her to do it is quite telling. Like it's some kind of joke. Whether it's a joke that she's making her do something menial, or a joke that "Hey, we're going to pull off you infiiltrating the strangers' ranks" is unknown. |
60,989,333 | I have array:
`const someArray = ['one', 'two', 'three'];`
and I have type:
`type SomeType = 'one' | 'two' | 'three';`
How can I get `SomeType` from `someArray`? | 2020/04/02 | [
"https://Stackoverflow.com/questions/60989333",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/10561224/"
] | You can not, because TypeScript is not a dependently-typed language.
TypeScript, like almost any other well known statically typed language in existence at the moment, can create types for values, but not create types from values.
So you can create a type for your values:
`const someArray: SomeType[] = ['one', 'two', 'three'];`
but you can not create a type from your values:
`type SomeType = infer T for someArray[T] // invented syntax`
Only [dependently typed languages](https://en.wikipedia.org/wiki/Dependent_type) can do this. Unfortunately this is not yet mainstream. Give it another decade though and you'll be hearing more about this.
Probably this does not mean you are stuck though. Over time I've had very few times where I could absolutely not get to the type just because the language was not dependently typed. You should try to ask another question and might get a satisfactory answer. There are ways for example to have types available during runtime, like with <https://github.com/gcanti/io-ts>. | by 'filter' to ergodic return satisfy condition‘s element |
60,989,333 | I have array:
`const someArray = ['one', 'two', 'three'];`
and I have type:
`type SomeType = 'one' | 'two' | 'three';`
How can I get `SomeType` from `someArray`? | 2020/04/02 | [
"https://Stackoverflow.com/questions/60989333",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/10561224/"
] | You can, at the cost that you have to apply `as const` assertion to `someArray`.
```
const someArray = ['one', 'two', 'three'] as const;
/* ^------- IMPORTANT!
otherwise it'll just be `string[]` */
type GetItem<T> = T extends ReadonlyArray<infer I> ? I : never;
type SomeType = GetItem<typeof someArray>; // 'one' | 'two' | 'three'
``` | by 'filter' to ergodic return satisfy condition‘s element |
60,989,333 | I have array:
`const someArray = ['one', 'two', 'three'];`
and I have type:
`type SomeType = 'one' | 'two' | 'three';`
How can I get `SomeType` from `someArray`? | 2020/04/02 | [
"https://Stackoverflow.com/questions/60989333",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/10561224/"
] | I found an even simpler solution.
```
const someArray = ['one', 'two', 'three'] as const;
/* ^------- IMPORTANT!
otherwise it'll just be `string[]` */
type SomeType = typeof someArray[number]; // 'one' | 'two' | 'three'
``` | by 'filter' to ergodic return satisfy condition‘s element |
60,989,333 | I have array:
`const someArray = ['one', 'two', 'three'];`
and I have type:
`type SomeType = 'one' | 'two' | 'three';`
How can I get `SomeType` from `someArray`? | 2020/04/02 | [
"https://Stackoverflow.com/questions/60989333",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/10561224/"
] | You can, at the cost that you have to apply `as const` assertion to `someArray`.
```
const someArray = ['one', 'two', 'three'] as const;
/* ^------- IMPORTANT!
otherwise it'll just be `string[]` */
type GetItem<T> = T extends ReadonlyArray<infer I> ? I : never;
type SomeType = GetItem<typeof someArray>; // 'one' | 'two' | 'three'
``` | You can not, because TypeScript is not a dependently-typed language.
TypeScript, like almost any other well known statically typed language in existence at the moment, can create types for values, but not create types from values.
So you can create a type for your values:
`const someArray: SomeType[] = ['one', 'two', 'three'];`
but you can not create a type from your values:
`type SomeType = infer T for someArray[T] // invented syntax`
Only [dependently typed languages](https://en.wikipedia.org/wiki/Dependent_type) can do this. Unfortunately this is not yet mainstream. Give it another decade though and you'll be hearing more about this.
Probably this does not mean you are stuck though. Over time I've had very few times where I could absolutely not get to the type just because the language was not dependently typed. You should try to ask another question and might get a satisfactory answer. There are ways for example to have types available during runtime, like with <https://github.com/gcanti/io-ts>. |
60,989,333 | I have array:
`const someArray = ['one', 'two', 'three'];`
and I have type:
`type SomeType = 'one' | 'two' | 'three';`
How can I get `SomeType` from `someArray`? | 2020/04/02 | [
"https://Stackoverflow.com/questions/60989333",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/10561224/"
] | You can, at the cost that you have to apply `as const` assertion to `someArray`.
```
const someArray = ['one', 'two', 'three'] as const;
/* ^------- IMPORTANT!
otherwise it'll just be `string[]` */
type GetItem<T> = T extends ReadonlyArray<infer I> ? I : never;
type SomeType = GetItem<typeof someArray>; // 'one' | 'two' | 'three'
``` | I found an even simpler solution.
```
const someArray = ['one', 'two', 'three'] as const;
/* ^------- IMPORTANT!
otherwise it'll just be `string[]` */
type SomeType = typeof someArray[number]; // 'one' | 'two' | 'three'
``` |
43,798 | I have been playing piano for almost 7 years. I am trying to learn "Flight of the Bumblebee", Rachmaninoff version. The problem is that the left hand has certain chords that my fingers cannot reach. There is AEC#, C#AE, F#ADA, and maybe more. I am able to reach an octave and one note over an octave, but thats it. I have tried compromising notes to fit my finger length, but it makes the song sound different. I don't know what to do, because this is an an assignment that is due on May 31. | 2016/04/23 | [
"https://music.stackexchange.com/questions/43798",
"https://music.stackexchange.com",
"https://music.stackexchange.com/users/28137/"
] | Very large chords like the one you mention are quite common in fact in classical romantic music piano literature.
Basics about this issue is, play like an arpeggio (alephzero answer). Most pianists do that indeed. This is absolutely normal, as even pianists with very long fingers can't reach some insane chords (see image; *La Campanella* from Lizst).
[](https://i.stack.imgur.com/RlXxB.jpg)
One practical way of doing this is simply working on hand/wrist (and not fingers) movement. Just bring the fingers in order for them to do their job with the help of your entire arm. | Just play the chords that you can't reach as arpeggios (rolled chords). When you get the piece up to the correct tempo, nobody will notice. For consistency, you might want to roll some of the chords that you *can* reach, as well as the ones you can't.
(The score is here: <http://imslp.org/wiki/Special:ImagefromIndex/99876>) |
43,798 | I have been playing piano for almost 7 years. I am trying to learn "Flight of the Bumblebee", Rachmaninoff version. The problem is that the left hand has certain chords that my fingers cannot reach. There is AEC#, C#AE, F#ADA, and maybe more. I am able to reach an octave and one note over an octave, but thats it. I have tried compromising notes to fit my finger length, but it makes the song sound different. I don't know what to do, because this is an an assignment that is due on May 31. | 2016/04/23 | [
"https://music.stackexchange.com/questions/43798",
"https://music.stackexchange.com",
"https://music.stackexchange.com/users/28137/"
] | Very large chords like the one you mention are quite common in fact in classical romantic music piano literature.
Basics about this issue is, play like an arpeggio (alephzero answer). Most pianists do that indeed. This is absolutely normal, as even pianists with very long fingers can't reach some insane chords (see image; *La Campanella* from Lizst).
[](https://i.stack.imgur.com/RlXxB.jpg)
One practical way of doing this is simply working on hand/wrist (and not fingers) movement. Just bring the fingers in order for them to do their job with the help of your entire arm. | In the specific case of Rachmaninoff's arrangement of "Flight of the Bumblebee" there is an option that works well for pianists who find arpeggiation difficult or unworkable.
### The ACE chord (e.g., mm. 9-13)
* Play the low A and E with the left hand.
* Play the middle C with the right hand.
[](https://i.stack.imgur.com/bgsda.jpg) ======> [](https://i.stack.imgur.com/62Gi9.jpg)
### The C#AE and DAF chords (e.g., m. 17)
* Move the C# and D up two octaves and play them with the right hand.
* Play the low AE and AF with the left hand.
[](https://i.stack.imgur.com/zCeq4.jpg)
[](https://i.stack.imgur.com/3kyxi.jpg)
### The FDA chord (e.g., m. 20)
There are two options for this chord:
* Like the ACE chord, move the topmost A to the right hand.
* Like the C#AE/DAF chords, move the low F up two octaves to the right hand.
### The F#ADA chord (e.g., mm. 64 and 66)
Here, too, there are two options:
* Omit the topmost A in the left hand. A is already both the lowest and highest pitch present, so this inner A can be safely left out.
* With some careful fingering, the inner A can be shifted to the right hand.
[](https://i.stack.imgur.com/r0buR.jpg)
[](https://i.stack.imgur.com/oGAu0.jpg)
### The remainder of the piece
These same techniques can be applied throughout, with any octave displacement being adjusted to the octave in which the right hand is playing. In general it works best to move the highest left-hand note to the right hand. |
31,284,260 | I am using Intellij idea IDE. Whenever I try to copy and paste any code from my browser to the IDE, it is not being pasted. Actually the last selection in the IDE is pasted every time. However if I paste it in any other application like notepad, it works fine.
What do I need to do? | 2015/07/08 | [
"https://Stackoverflow.com/questions/31284260",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/3186914/"
] | I solved this problem by restarting intellij with the `invalidate cache\restart" menu option. Prior to restarting anything I'd had copied to the clipboard outside the IDE I couldn't paste, but afterward I could paste. I didn't investigate if just restarting would have worked. The menu option provides a nice way of closing all intellij windows at once on Windows. | Happens to me quite often on win 7. Seems to be after idea is running for longer period of time / through suspend. Standard close and relaunch of all idea windows works. Is the same in versions 14 and 15 (no tested other). |
31,284,260 | I am using Intellij idea IDE. Whenever I try to copy and paste any code from my browser to the IDE, it is not being pasted. Actually the last selection in the IDE is pasted every time. However if I paste it in any other application like notepad, it works fine.
What do I need to do? | 2015/07/08 | [
"https://Stackoverflow.com/questions/31284260",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/3186914/"
] | I found the same problem with IntelliJ 14.1.4 on Windows 7. I copy something external, use `Ctrl+V` in the IDE, but the last clipboard from the IDE is pasted instead.
I was able to resolve this by clearing the IDE clipboard, you can do this with `Ctrl+Shift+V` which opens the **Paste from History** dialog, here you will see all the IDE clipboard entries, you can click on each one and click `Delete`. I cleared all the entries, then copied again from the other application.
Now `Ctrl+V` in the IDE should give you the external clipboard item. | Happens to me quite often on win 7. Seems to be after idea is running for longer period of time / through suspend. Standard close and relaunch of all idea windows works. Is the same in versions 14 and 15 (no tested other). |
66,507,096 | I wanted to create something simple like void Function(struct str) to calculate paralel in barriers sync, but seems to not be so simple, so I followed this:
<https://learn.microsoft.com/en-us/windows/win32/procthread/creating-threads>
and some other topics, but without success. Couldnt find a solution. Code is all in one file.
Any advise how to fix it? make it work?
**Solved by std::thread rewrite**
[](https://i.stack.imgur.com/AzkTH.png) | 2021/03/06 | [
"https://Stackoverflow.com/questions/66507096",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/10705548/"
] | Note how when you cast `lpParam` to a `dectectorData*` you should cast like this: `(detectorData*)lpParam` not `(detectorData)lpParam`. (Note the `*` denoting a pointer.) | Since I am using C++, there is already std::thread class.
So my simple task can be done by this code:
```
void detAndComputeT(detectorData &data) {
Ptr<SIFT> detector = cv::SIFT::create();
detector->detectAndCompute(data.image, Mat(), data.keypoints, data.descriptors);
}
```
and
```
std::thread threads2[2];
detectorData dataImage1;
detectorData dataImage2;
dataImage1.image = image1_toCalc;
dataImage2.image = image2_toCalc;
threads2[0] = thread(detAndComputeT, std::ref(dataImage1));
threads2[1] = thread(detAndComputeT, std::ref(dataImage2));
threads2[0].join();
threads2[1].join();
``` |
12,573,839 | I am a newby to design and looking now into the use of background instead of foreground images, which is a common practice.
I look at the techniques used, and see that:
* you usually need to explicitly state the dimensions of the image (and set the foreground element to these dimensions)
* you need to make the foreground element to somehow disappear with css tricks.
All this looks really hackish. So, I wonder, why on earth do all this instead of just using the native element? I am sure there is a good answer
(I did go through this [When to use IMG vs. CSS background-image?](https://stackoverflow.com/questions/492809/when-to-use-img-vs-css-background-image) , and could not figure out a clear answer) | 2012/09/24 | [
"https://Stackoverflow.com/questions/12573839",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/440925/"
] | The main difference is that in the `img` tag the image is *hardcoded*.
With CSS you can create different designs, switch between them, redesign the page, without altering the source code. To see the power of CSS, check <http://www.csszengarden.com/>, all the pages use the same HTML source, but with different CSS layout.
As @Shmiddty noted, if `img` is for embedded images (actual content, for example a gallery, or a picture for an article), and CSS is for design.
Also, the question you referred to, has nice list of all the use-cases: `When to use CSS background-image`. | One of the main points of *image replacement* is to use your site title in a `h1` tag for good SEO, and then hiding the text and replacing it with a custom logo.
This also makes your site more accessible. Say for example, your user has CSS disabled for whatever reason (screenreaders, maybe). They would still see the textual representation of your site title, whereas normal users would see the custom graphic. |
12,573,839 | I am a newby to design and looking now into the use of background instead of foreground images, which is a common practice.
I look at the techniques used, and see that:
* you usually need to explicitly state the dimensions of the image (and set the foreground element to these dimensions)
* you need to make the foreground element to somehow disappear with css tricks.
All this looks really hackish. So, I wonder, why on earth do all this instead of just using the native element? I am sure there is a good answer
(I did go through this [When to use IMG vs. CSS background-image?](https://stackoverflow.com/questions/492809/when-to-use-img-vs-css-background-image) , and could not figure out a clear answer) | 2012/09/24 | [
"https://Stackoverflow.com/questions/12573839",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/440925/"
] | The main difference is that in the `img` tag the image is *hardcoded*.
With CSS you can create different designs, switch between them, redesign the page, without altering the source code. To see the power of CSS, check <http://www.csszengarden.com/>, all the pages use the same HTML source, but with different CSS layout.
As @Shmiddty noted, if `img` is for embedded images (actual content, for example a gallery, or a picture for an article), and CSS is for design.
Also, the question you referred to, has nice list of all the use-cases: `When to use CSS background-image`. | The goal is to separate content from presentation. HTML should contain just content, and all presentation should be moved to the CSS. Once you achieve that, you gain a few useful side effects:
* The CSS (presentational code) is cached by the user's browser, and each HTML file requested is smaller. This also has some SEO benefits (decreased code fluff).
* Screen readers have to muddle through less when interpreting your page for visually impaired users. Making sure your HTML contains *just content* means visually impaired users reach what they're looking for much quicker.
* CSS makes it possible to display the same content in different visual configurations, which is the cornerstone of the [responsive web design](http://en.wikipedia.org/wiki/Responsive_Web_Design) movement. Properly delineating your content and presentation means being able to use the same HTML files across multiple platforms (desktop, tablet, smartphone).
However, there are times when images are content on a specific page. In those cases, you want to use an `IMG` tag, and moving the image to the CSS is actually a wrong move. A great discussion of when and where to use text to image replacement is at [When to use IMG vs. CSS background-image?](https://stackoverflow.com/questions/492809/when-to-use-img-vs-css-background-image) Basically, my personal litmus test is something like: Is this image going to be used multiple times on the site? If it is, it's probably part of the design. Once-off images are generally content.
If you're looking to move your design images to the CSS, congratulations :-p You've adopted a healthy amount of work, but started doing something worthwhile to the long-term health of your website as part of the web ecosystem. I would highly recommend looking into using the [SASS/Compass](http://compass-style.org/) system to manage your design images as sprites (see [A List Apart:CSS Sprites](http://www.alistapart.com/articles/sprites/) and [Spriting with Compass](http://compass-style.org/help/tutorials/spriting/)). |
12,573,839 | I am a newby to design and looking now into the use of background instead of foreground images, which is a common practice.
I look at the techniques used, and see that:
* you usually need to explicitly state the dimensions of the image (and set the foreground element to these dimensions)
* you need to make the foreground element to somehow disappear with css tricks.
All this looks really hackish. So, I wonder, why on earth do all this instead of just using the native element? I am sure there is a good answer
(I did go through this [When to use IMG vs. CSS background-image?](https://stackoverflow.com/questions/492809/when-to-use-img-vs-css-background-image) , and could not figure out a clear answer) | 2012/09/24 | [
"https://Stackoverflow.com/questions/12573839",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/440925/"
] | The main difference is that in the `img` tag the image is *hardcoded*.
With CSS you can create different designs, switch between them, redesign the page, without altering the source code. To see the power of CSS, check <http://www.csszengarden.com/>, all the pages use the same HTML source, but with different CSS layout.
As @Shmiddty noted, if `img` is for embedded images (actual content, for example a gallery, or a picture for an article), and CSS is for design.
Also, the question you referred to, has nice list of all the use-cases: `When to use CSS background-image`. | One thing to consider as a benefit to using CSS for images is that you can load all your design images (images for UI elements, etc) with one http request rather than an http request for each individual image using a sprite. One large image that contains a grid of all your images.
As its been stated before, content images should use the img tag which also helps for people using various accessibility options when visiting your site/app. For example, if they are using a screenreader, the screenreader knows its an image and can read the img alt name or title, but if its just a div with a background image they get nothing. |
12,573,839 | I am a newby to design and looking now into the use of background instead of foreground images, which is a common practice.
I look at the techniques used, and see that:
* you usually need to explicitly state the dimensions of the image (and set the foreground element to these dimensions)
* you need to make the foreground element to somehow disappear with css tricks.
All this looks really hackish. So, I wonder, why on earth do all this instead of just using the native element? I am sure there is a good answer
(I did go through this [When to use IMG vs. CSS background-image?](https://stackoverflow.com/questions/492809/when-to-use-img-vs-css-background-image) , and could not figure out a clear answer) | 2012/09/24 | [
"https://Stackoverflow.com/questions/12573839",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/440925/"
] | The goal is to separate content from presentation. HTML should contain just content, and all presentation should be moved to the CSS. Once you achieve that, you gain a few useful side effects:
* The CSS (presentational code) is cached by the user's browser, and each HTML file requested is smaller. This also has some SEO benefits (decreased code fluff).
* Screen readers have to muddle through less when interpreting your page for visually impaired users. Making sure your HTML contains *just content* means visually impaired users reach what they're looking for much quicker.
* CSS makes it possible to display the same content in different visual configurations, which is the cornerstone of the [responsive web design](http://en.wikipedia.org/wiki/Responsive_Web_Design) movement. Properly delineating your content and presentation means being able to use the same HTML files across multiple platforms (desktop, tablet, smartphone).
However, there are times when images are content on a specific page. In those cases, you want to use an `IMG` tag, and moving the image to the CSS is actually a wrong move. A great discussion of when and where to use text to image replacement is at [When to use IMG vs. CSS background-image?](https://stackoverflow.com/questions/492809/when-to-use-img-vs-css-background-image) Basically, my personal litmus test is something like: Is this image going to be used multiple times on the site? If it is, it's probably part of the design. Once-off images are generally content.
If you're looking to move your design images to the CSS, congratulations :-p You've adopted a healthy amount of work, but started doing something worthwhile to the long-term health of your website as part of the web ecosystem. I would highly recommend looking into using the [SASS/Compass](http://compass-style.org/) system to manage your design images as sprites (see [A List Apart:CSS Sprites](http://www.alistapart.com/articles/sprites/) and [Spriting with Compass](http://compass-style.org/help/tutorials/spriting/)). | One of the main points of *image replacement* is to use your site title in a `h1` tag for good SEO, and then hiding the text and replacing it with a custom logo.
This also makes your site more accessible. Say for example, your user has CSS disabled for whatever reason (screenreaders, maybe). They would still see the textual representation of your site title, whereas normal users would see the custom graphic. |
12,573,839 | I am a newby to design and looking now into the use of background instead of foreground images, which is a common practice.
I look at the techniques used, and see that:
* you usually need to explicitly state the dimensions of the image (and set the foreground element to these dimensions)
* you need to make the foreground element to somehow disappear with css tricks.
All this looks really hackish. So, I wonder, why on earth do all this instead of just using the native element? I am sure there is a good answer
(I did go through this [When to use IMG vs. CSS background-image?](https://stackoverflow.com/questions/492809/when-to-use-img-vs-css-background-image) , and could not figure out a clear answer) | 2012/09/24 | [
"https://Stackoverflow.com/questions/12573839",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/440925/"
] | One thing to consider as a benefit to using CSS for images is that you can load all your design images (images for UI elements, etc) with one http request rather than an http request for each individual image using a sprite. One large image that contains a grid of all your images.
As its been stated before, content images should use the img tag which also helps for people using various accessibility options when visiting your site/app. For example, if they are using a screenreader, the screenreader knows its an image and can read the img alt name or title, but if its just a div with a background image they get nothing. | One of the main points of *image replacement* is to use your site title in a `h1` tag for good SEO, and then hiding the text and replacing it with a custom logo.
This also makes your site more accessible. Say for example, your user has CSS disabled for whatever reason (screenreaders, maybe). They would still see the textual representation of your site title, whereas normal users would see the custom graphic. |
2,967,436 | How can i form of the matrix representation in the following exercise?
>
> Given the linear maps $f$ and $g$
>
>
> $$f\left(\begin{bmatrix}\lambda\_1\\ \lambda\_2\\ \lambda\_3\end{bmatrix}\right)=\begin{bmatrix}\lambda\_3-\lambda\_1\\\lambda\_2-\lambda\_1\end{bmatrix}\\ g\left(\begin{bmatrix}\mu\_1\\\mu\_2\end{bmatrix}\right)=\begin{bmatrix}\mu\_2-\mu\_1\\ -2\mu\_1\\ \mu\_1+\mu\_2\end{bmatrix}$$
>
>
> find the matrix repesentation of $g\circ f$.
>
>
> | 2018/10/23 | [
"https://math.stackexchange.com/questions/2967436",
"https://math.stackexchange.com",
"https://math.stackexchange.com/users/605276/"
] | The matrix representation of $T:\Bbb R^n\to\Bbb R^m$ (in the canonical basis) is simply the matrix $$\begin{pmatrix}T(e\_1)& T(e\_2)&\cdots &T(e\_n)\end{pmatrix}.$$
This can be easily computed in this instance. | $f$ is represented (in the standard bases) by $$M\_f= \begin{bmatrix} -1 & 0 & 1\\ -1 & 1 & 0\end{bmatrix}$$
and $g$ by
$$M\_g= \begin{bmatrix}
-1 & 1\\
-2 & 0\\
1 & 1
\end{bmatrix}$$
Now compute $M\_g M\_f$ as matrices |
19,037 | **Thought 1**
```
public interface IRepository<T> : IDisposable where T : class
{
IQueryable<T> Fetch();
IEnumerable<T> GetAll();
IEnumerable<T> Find(Func<T, bool> predicate);
T Single(Func<T, bool> predicate);
T First(Func<T, bool> predicate);
void Add(T entity);
void Delete(T entity);
void SaveChanges();
}
```
with the above approach I will go like Repository and then have a Repository
with the implementation of methods written above.
I think this frees my tests from DbContext dependency.
**Thought 2**
```
public class RepositoryBase<TContext> : IDisposable where TContext : DbContext, new()
{
private TContext _DataContext;
protected virtual TContext DataContext
{
get
{
if (_DataContext == null)
{
_DataContext = new TContext();
}
return _DataContext;
}
}
public virtual IQueryable<T> GetAll<T>() where T : class
{
using (DataContext)
{
return DataContext.Set<T>();
}
}
public virtual T FindSingleBy<T>(Expression<Func<T, bool>> predicate) where T : class
{
if (predicate != null)
{
using (DataContext)
{
return DataContext.Set<T>().Where(predicate).SingleOrDefault();
}
}
else
{
throw new ArgumentNullException("Predicate value must be passed to FindSingleBy<T>.");
}
}
public virtual IQueryable<T> FindAllBy<T>(Expression<Func<T, bool>> predicate) where T : class
{
if (predicate != null)
{
using (DataContext)
{
return DataContext.Set<T>().Where(predicate);
}
}
else
{
throw new ArgumentNullException("Predicate value must be passed to FindAllBy<T>.");
}
}
public virtual IQueryable<T> FindBy<T, TKey>(Expression<Func<T, bool>> predicate,Expression<Func<T, TKey>> orderBy) where T : class
{
if (predicate != null)
{
if (orderBy != null)
{
using (DataContext)
{
return FindAllBy<T>(predicate).OrderBy(orderBy).AsQueryable<T>(); ;
}
}
else
{
throw new ArgumentNullException("OrderBy value must be passed to FindBy<T,TKey>.");
}
}
else
{
throw new ArgumentNullException("Predicate value must be passed to FindBy<T,TKey>.");
}
}
public virtual int Save<T>(T Entity) where T : class
{
return DataContext.SaveChanges();
}
public virtual int Update<T>(T Entity) where T : class
{
return DataContext.SaveChanges();
}
public virtual int Delete<T>(T entity) where T : class
{
DataContext.Set<T>().Remove(entity);
return DataContext.SaveChanges();
}
public void Dispose()
{
if (DataContext != null) DataContext.Dispose();
}
}
```
I could now have `CustomerRepository : RepositoryBase<Mycontext>,ICustomerRepository`
`ICustomerRepository` gives me the option of defining stuff like `GetCustomerWithOrders` etc...
I am confused as to which approach to take. Would need help through a review on the implementation first then comments on which one will be the easier approach when it comes to Testing and extensibility. | 2012/11/26 | [
"https://codereview.stackexchange.com/questions/19037",
"https://codereview.stackexchange.com",
"https://codereview.stackexchange.com/users/7511/"
] | You should use `Expression<Func<T, bool>>` as predicates on your interface and have the `RepositoryBase` implement that interface.
By only using `Func`, you won't get translation to L2E etc, but will have to enumerate the entire DB table before you can evaluate the `Func`.
The interface can be mocked, hence unit-tested without a physical db and also used with other ORMs.
It's generally prefered to keep `SaveChanges` and the `DbContext` in a separate `IUnitOfWork` implementation. You can pass the `UnitOfWork` to the repository constructor, which can access an internal property on the UOW exposing the `DbContext`.
By doing that you can share the same `DbContext` between repositories, and batch updates to several entity roots of different type. You also keep fewer open connections, which are the most expensive resource you have when it comes to DBs.
Not to forget they can share transactions. :)
Hence you should not dispose the DbContext in the Repository, the Repository really doesn't need to be disposable at all. But the UnitOfWork / DbContext must be disposed by something.
Also, ditch the `OrderBy` predicate to `FindBy`. Since you return an `IQueryable`, and use an `Expression` for the predicate, you can keep building the Queryable after the call. For instance `repo.FindBy(it => it.Something == something).OrderBy(it => it.OrderProperty)`. It will still be translated to "select [fields] from [table] where [predicate] order by [orderprop]" when enumerated.
Otherwise it looks good.
Here's a couple of good examples:
<http://blog.swink.com.au/index.php/c-sharp/generic-repository-for-entity-framework-4-3-dbcontext-with-code-first/>
<http://www.martinwilley.com/net/code/data/genericrepository.html>
<http://www.mattdurrant.com/ef-code-first-with-the-repository-and-unit-of-work-patterns/>
And here's how I do it:
**Model / Common / Business assembly**
No references but BCL and other possible models (interfaces/dtos)
```
public interface IUnitOfWork : IDisposable
{
void Commit();
}
public interface IRepository<T>
{
void Add(T item);
void Remove(T item);
IQueryable<T> Query();
}
// entity classes
```
**Business tests assembly**
Only references Model / Common / Business assembly
```
[TestFixture]
public class BusinessTests
{
private IRepository<Entity> repo;
private ConcreteService service;
[SetUp]
public void SetUp()
{
repo = MockRepository.GenerateStub<IRepository<Entity>>();
service = new ConcreteService(repo);
}
[Test]
public void Service_DoSomething_DoesSomething()
{
var expectedName = "after";
var entity = new Entity { Name = "before" };
var list = new List<Entity> { entity };
repo.Stub(r => r.Query()).Return(list.AsQueryable());
service.DoStuff();
Assert.AreEqual(expectedName, entity.Name);
}
}
```
**Entity Framework implementation assembly**
References Model *and* the Entity Framework / System.Data.Entity assemblies
```
public class EFUnitOfWork : IUnitOfWork
{
private readonly DbContext context;
public EFUnitOfWork(DbContext context)
{
this.context = context;
}
internal DbSet<T> GetDbSet<T>()
where T : class
{
return context.Set<T>();
}
public void Commit()
{
context.SaveChanges();
}
public void Dispose()
{
context.Dispose();
}
}
public class EFRepository<T> : IRepository<T>
where T : class
{
private readonly DbSet<T> dbSet;
public EFRepository(IUnitOfWork unitOfWork)
{
var efUnitOfWork = unitOfWork as EFUnitOfWork;
if (efUnitOfWork == null) throw new Exception("Must be EFUnitOfWork"); // TODO: Typed exception
dbSet = efUnitOfWork.GetDbSet<T>();
}
public void Add(T item)
{
dbSet.Add(item);
}
public void Remove(T item)
{
dbSet.Remove(item);
}
public IQueryable<T> Query()
{
return dbSet;
}
}
```
**Integrated tests assembly**
References everything
```
[TestFixture]
[Category("Integrated")]
public class IntegratedTest
{
private EFUnitOfWork uow;
private EFRepository<Entity> repo;
[SetUp]
public void SetUp()
{
Database.SetInitializer(new DropCreateDatabaseAlways<YourContext>());
uow = new EFUnitOfWork(new YourContext());
repo = new EFRepository<Entity>(uow);
}
[TearDown]
public void TearDown()
{
uow.Dispose();
}
[Test]
public void Repository_Add_AddsItem()
{
var expected = new Entity { Name = "Test" };
repo.Add(expected);
uow.Commit();
var actual = repo.Query().FirstOrDefault(e => e.Name == "Test");
Assert.IsNotNull(actual);
}
[Test]
public void Repository_Remove_RemovesItem()
{
var expected = new Entity { Name = "Test" };
repo.Add(expected);
uow.Commit();
repo.Remove(expected);
uow.Commit();
Assert.AreEqual(0, repo.Query().Count());
}
}
``` | Reinventing the wheel
---------------------
If you need a generic repository class use IObjectSet for base type and implement it if needed (in production code it is not needed, in tests you can use an IList<> as backend).
Leek on the abstraction
-----------------------
Repositories aren't supposed to have Save method becouse if someone else is in a transactional moment in shared context then you (or the other guy) can trick each other. Please create an independent IUnitOfWork for this.
```
interface IUnitOfWork : IDisposable {
void Commit();
void Rollback();
}
interface IDataStore {
IUnitOfWork InUnitOfWork();
IObjectSet<T> Set<T>() where T : class;
}
using (var uow = _data.InUnitOfWork()) {
_data.Set<Order>.AddObject(order);
_data.Set<SomethingElse>.Remove(otherObject);
uow.Comit();
}
```
The tricky part is how you handles the transaction. I have created an ISession interface with some methods (BeginTransaction(), InTransaction, Commit(), Rollback()) and created a default implementation. In my default IUnitOfWork implementation the constructor recieves an ISession instance and starting a transaction with it. The ISession implementation has an inner counter to count how many other actor started it's own transaction. When an IUnitOfWork from the shared storage Commited the counter is decremented by 1 if someone says RollBack then everything is rolled back.
EDIT (Dec. 03)
--------------
Fixed the IUnitOfWork Dispose behavior: the default is Rollback() not Commit()
In this way you can test your code easily. |
3,529,430 | I try to generate a trigger, in the trigger statement I have to set a column of type decimal(17,3) with the actual timestamp or the seconds of unix timestamp, but could not find a solution. | 2010/08/20 | [
"https://Stackoverflow.com/questions/3529430",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/275837/"
] | One definition of foldr is:
```
foldr :: (a -> b -> b) -> b -> [a] -> b
foldr f acc [] = acc
foldr f acc (x:xs) = f x (foldr f acc xs)
```
The [wikibook on Haskell](http://en.wikibooks.org/wiki/Haskell/List_processing) has a nice graph on foldr (and on other folds, too):
```
: f
/ \ / \
a : foldr f acc a f
/ \ -------------> / \
b : b f
/ \ / \
c [] c acc
```
I.e. `a : b : c : []` (which is just `[a, b, c]`) becomes `f a (f b (f c acc))` (again, taken from wikibook).
So your example is evaluated as `let f = (\x y -> 2*x + y) in f 5 (f 6 (f 7 4))` (let-binding only for brevity). | You can actually easily visualize it for yourself:
```
import Text.Printf
showOp f = f (printf "(%s op %s)") "0" ["1","2","3"]
```
then
```
Main> showOp foldr
"(1 op (2 op (3 op 0)))"
Main> showOp foldl
"(((0 op 1) op 2) op 3)"
Main> showOp scanl
["0","(0 op 1)","((0 op 1) op 2)","(((0 op 1) op 2) op 3)"]
``` |
3,529,430 | I try to generate a trigger, in the trigger statement I have to set a column of type decimal(17,3) with the actual timestamp or the seconds of unix timestamp, but could not find a solution. | 2010/08/20 | [
"https://Stackoverflow.com/questions/3529430",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/275837/"
] | One definition of foldr is:
```
foldr :: (a -> b -> b) -> b -> [a] -> b
foldr f acc [] = acc
foldr f acc (x:xs) = f x (foldr f acc xs)
```
The [wikibook on Haskell](http://en.wikibooks.org/wiki/Haskell/List_processing) has a nice graph on foldr (and on other folds, too):
```
: f
/ \ / \
a : foldr f acc a f
/ \ -------------> / \
b : b f
/ \ / \
c [] c acc
```
I.e. `a : b : c : []` (which is just `[a, b, c]`) becomes `f a (f b (f c acc))` (again, taken from wikibook).
So your example is evaluated as `let f = (\x y -> 2*x + y) in f 5 (f 6 (f 7 4))` (let-binding only for brevity). | [This was supposed to be a comment on delnan's remark, but was too wordy...]
Yoon, you can open a private 'conversation' with `lambdabot` on the #haskell irc (e.g. at <http://webchat.freenode.net/> ). She has a simple reflection ability, so you can type meaningless letters, e.g.
```
Yoon: > foldr (\x y -> 2*x + y) o [a,b,c,d]
lamdabot: 2 * a + (2 * b + (2 * c + (2 * d + o)))
```
This says what is evaluated, but as Edka points out you get a picture of the order of evaluation from say
```
Yoon: > reverse (scanr (\x y -> 2*x + y) o [a,b,c,d])
lambdabot: [o,2 * d + o,2 * c + (2 * d + o),2 * b + (2 * c + (2 * d + o)),2 * a + (2 * b + (2 * c + (2 * d + o)))
```
I remember imprinting some good lessons playing around with `foldr`, `foldl`, `scanr`, `scanl` and this clever device. |
3,529,430 | I try to generate a trigger, in the trigger statement I have to set a column of type decimal(17,3) with the actual timestamp or the seconds of unix timestamp, but could not find a solution. | 2010/08/20 | [
"https://Stackoverflow.com/questions/3529430",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/275837/"
] | You can actually easily visualize it for yourself:
```
import Text.Printf
showOp f = f (printf "(%s op %s)") "0" ["1","2","3"]
```
then
```
Main> showOp foldr
"(1 op (2 op (3 op 0)))"
Main> showOp foldl
"(((0 op 1) op 2) op 3)"
Main> showOp scanl
["0","(0 op 1)","((0 op 1) op 2)","(((0 op 1) op 2) op 3)"]
``` | [This was supposed to be a comment on delnan's remark, but was too wordy...]
Yoon, you can open a private 'conversation' with `lambdabot` on the #haskell irc (e.g. at <http://webchat.freenode.net/> ). She has a simple reflection ability, so you can type meaningless letters, e.g.
```
Yoon: > foldr (\x y -> 2*x + y) o [a,b,c,d]
lamdabot: 2 * a + (2 * b + (2 * c + (2 * d + o)))
```
This says what is evaluated, but as Edka points out you get a picture of the order of evaluation from say
```
Yoon: > reverse (scanr (\x y -> 2*x + y) o [a,b,c,d])
lambdabot: [o,2 * d + o,2 * c + (2 * d + o),2 * b + (2 * c + (2 * d + o)),2 * a + (2 * b + (2 * c + (2 * d + o)))
```
I remember imprinting some good lessons playing around with `foldr`, `foldl`, `scanr`, `scanl` and this clever device. |
53,495,531 | We are extracting a large amount of JSON objects from an EVE Online API, and deseralizing them into EveObjModel objects using Newtonsoft.Json.JsonConvert. From there we want to create a list of unique objects, i.e. the most expensive of each type\_id. I have pasted the dataContract below as well.
**The problem:** This code below can handle smaller sets of data, but it is not viable with larger amounts. Currently, we are running it through and it takes more than 50 minutes (and counting). What can we do to reduce the time it takes to run through larger sets of data to a bearable level?
Thank you for your time. Fingers crossed.
```
// The buyList contains about 93,000 objects.
public void CreateUniqueBuyList(List<EveObjModel> buyList)
{
List<EveObjModel> uniqueBuyList = new List<EveObjModel>();
foreach (EveObjModel obj in buyList)
{
int duplicateCount = 0;
for (int i = 0; i < uniqueBuyList.Count; i++)
{
if (uniqueBuyList[i].type_id == obj.type_id)
duplicateCount++;
}
if (duplicateCount == 1)
{
foreach (EveObjModel objinUnique in uniqueBuyList)
{
if (obj.type_id == objinUnique.type_id && obj.price > objinUnique.price)
{
// instead of adding obj, the price is just changed to the price in the obj.
objinUnique.price = obj.price;
}
else if (obj.type_id == objinUnique.type_id && obj.price == objinUnique.price)
{
//uniqueBuyList.RemoveAll(item => item.type_id == obj.type_id);
}
else
{
// Hitting this mean that there are other objects with same type and higher price OR its not the same type_id
}
}
}
else if (duplicateCount > 1)
{
// shud not happn...
}
else
{
uniqueBuyList.Add(obj);
}
continue;
}
foreach (EveObjModel item in uniqueBuyList.OrderBy(item => item.type_id))
{
buyListtextField.Text += $"Eve Online Item! Type-ID is: {item.type_id}, Price is {item.price}\n";
}
}
```
This is our EveObjModel class
```
using System;
using System.Collections.Generic;
using System.Linq;
using System.Runtime.Serialization;
using System.Text;
using System.Threading.Tasks;
namespace EveOnlineApp
{
[DataContract]
public class EveObjModel
{
[DataMember]
public bool is_buy_order { get; set; }
[DataMember]
public double price { get; set; }
[DataMember]
public int type_id { get; set; }
}
}
``` | 2018/11/27 | [
"https://Stackoverflow.com/questions/53495531",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/7766834/"
] | It's not surprising that the process is slow, because the algorithm you are using (with nested loop) has at least quadratic O(N\*N) time complexity, which with such size of data sets is really slow.
One way is to use LINQ `GroupBy` operator, which internally uses hash based lookup, hence has theoretically O(N) time complexity. So you group by `type_id` and for each group (list of elements with the same key) take the one with the maximum `price`:
```
var uniqueBuyList = buyList
.GroupBy(e => e.type_id)
.Select(g => g.OrderByDescending(e => e.price).First())
.ToList();
```
Of cource you don't need to sort the list in order to take the element with the max `price`. A better version is to use `Aggregate` method (which is basically `foreach` loop) for that:
```
var uniqueBuyList = buyList
.GroupBy(e => e.type_id)
.Select(g => g.Aggregate((e1, e2) => e1.price > e2.price ? e1 : e2))
.ToList();
```
Another non LINQ based way is to sort the input list by `type_id` ascending, `price` descending. Then do a single loop over the sorted list and take the first element of each `type_id` group (it will have the maximum `price`):
```
var comparer = Comparer<EveObjModel>.Create((e1, e2) =>
{
int result = e1.type_id.CompareTo(e2.type_id);
if (result == 0) // e1.type_id == e2.type_id
result = e2.price.CompareTo(e1.price); // e1, e2 exchanged to get descending order
return result;
});
buyList.Sort(comparer);
var uniqueBuyList = new List<EveObjModel>();
EveObjModel last = null;
foreach (var item in buyList)
{
if (last == null || last.type_id != item.type_id)
uniqueBuyList.Add(item);
last = item;
}
```
The complexity of this algorithm is O(N\*log(N)), so it's worse than the hash based algorithms (but much better than original). The benefit is that it uses less memory and the resulting list is already sorted by `type_id`, so you don't need to use `OrderBy`. | You should be able to use `Enumerable.GroupBy()` to do this fairly efficiently:
```
var grouped = buyList.GroupBy(item => item.type_id);
var uniqueBuyList = new List<EveObjModel>();
foreach (var group in grouped)
{
var combined = group.First();
combined.price = group.Max(item => item.price);
uniqueBuyList.Add(combined);
}
```
Or alternatively (but more difficult to read):
```
var uniqueBuyList = buyList.GroupBy(item => item.type_id).Select(group =>
{
var combined = group.First();
combined.price = group.Max(item => item.price);
return combined;
}).ToList();
``` |
53,495,531 | We are extracting a large amount of JSON objects from an EVE Online API, and deseralizing them into EveObjModel objects using Newtonsoft.Json.JsonConvert. From there we want to create a list of unique objects, i.e. the most expensive of each type\_id. I have pasted the dataContract below as well.
**The problem:** This code below can handle smaller sets of data, but it is not viable with larger amounts. Currently, we are running it through and it takes more than 50 minutes (and counting). What can we do to reduce the time it takes to run through larger sets of data to a bearable level?
Thank you for your time. Fingers crossed.
```
// The buyList contains about 93,000 objects.
public void CreateUniqueBuyList(List<EveObjModel> buyList)
{
List<EveObjModel> uniqueBuyList = new List<EveObjModel>();
foreach (EveObjModel obj in buyList)
{
int duplicateCount = 0;
for (int i = 0; i < uniqueBuyList.Count; i++)
{
if (uniqueBuyList[i].type_id == obj.type_id)
duplicateCount++;
}
if (duplicateCount == 1)
{
foreach (EveObjModel objinUnique in uniqueBuyList)
{
if (obj.type_id == objinUnique.type_id && obj.price > objinUnique.price)
{
// instead of adding obj, the price is just changed to the price in the obj.
objinUnique.price = obj.price;
}
else if (obj.type_id == objinUnique.type_id && obj.price == objinUnique.price)
{
//uniqueBuyList.RemoveAll(item => item.type_id == obj.type_id);
}
else
{
// Hitting this mean that there are other objects with same type and higher price OR its not the same type_id
}
}
}
else if (duplicateCount > 1)
{
// shud not happn...
}
else
{
uniqueBuyList.Add(obj);
}
continue;
}
foreach (EveObjModel item in uniqueBuyList.OrderBy(item => item.type_id))
{
buyListtextField.Text += $"Eve Online Item! Type-ID is: {item.type_id}, Price is {item.price}\n";
}
}
```
This is our EveObjModel class
```
using System;
using System.Collections.Generic;
using System.Linq;
using System.Runtime.Serialization;
using System.Text;
using System.Threading.Tasks;
namespace EveOnlineApp
{
[DataContract]
public class EveObjModel
{
[DataMember]
public bool is_buy_order { get; set; }
[DataMember]
public double price { get; set; }
[DataMember]
public int type_id { get; set; }
}
}
``` | 2018/11/27 | [
"https://Stackoverflow.com/questions/53495531",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/7766834/"
] | You should be able to use `Enumerable.GroupBy()` to do this fairly efficiently:
```
var grouped = buyList.GroupBy(item => item.type_id);
var uniqueBuyList = new List<EveObjModel>();
foreach (var group in grouped)
{
var combined = group.First();
combined.price = group.Max(item => item.price);
uniqueBuyList.Add(combined);
}
```
Or alternatively (but more difficult to read):
```
var uniqueBuyList = buyList.GroupBy(item => item.type_id).Select(group =>
{
var combined = group.First();
combined.price = group.Max(item => item.price);
return combined;
}).ToList();
``` | We can sort given List by ascending `type_id` and then by ascending `price` and reverse it. So that, `EveObjModel` object with `higher price` come first for every unique `type_id`.
Then, we may go through object List again and pick up the unique type\_id that come fist and skip same type\_id then after.
As we are only sorting once, this will cause us time complexity of `O(n * log n)`. Since, `n = 93773` , logarithm of 93773 in base 2 is nearly = `17`. So, sorting will take overall `n * log n = 93773 * 17 = 1594141` operations, which can be done in very less amount of time.
Hope following code will help you !
```
public void CreateUniqueBuyList(List<EveObjModel> buyList)
{
//sort by ascending type_id and then by ascending price and reverse it. so that,
// object with higher price come first
List<EveObjModel>tempList = buyList.OrderBy(x => x.type_id).ThenBy(x => x.price).Reverse().ToList();
List<EveObjModel> uniqueBuyList = new List<EveObjModel>();
for (int i = 0; i < tempList.Count; ++i) {
if ((i > 1) && tempList[i - 1].type_id == tempList[i].type_id) continue; // if duplicate type_id then don't take it again
uniqueBuyList.Add(tempList[i]);
}
foreach (EveObjModel item in uniqueBuyList.OrderBy(item => item.type_id))
{
buyListtextField.Text += $"Eve Online Item! Type-ID is: {item.type_id}, Price is {item.price}\n";
}
}
``` |
53,495,531 | We are extracting a large amount of JSON objects from an EVE Online API, and deseralizing them into EveObjModel objects using Newtonsoft.Json.JsonConvert. From there we want to create a list of unique objects, i.e. the most expensive of each type\_id. I have pasted the dataContract below as well.
**The problem:** This code below can handle smaller sets of data, but it is not viable with larger amounts. Currently, we are running it through and it takes more than 50 minutes (and counting). What can we do to reduce the time it takes to run through larger sets of data to a bearable level?
Thank you for your time. Fingers crossed.
```
// The buyList contains about 93,000 objects.
public void CreateUniqueBuyList(List<EveObjModel> buyList)
{
List<EveObjModel> uniqueBuyList = new List<EveObjModel>();
foreach (EveObjModel obj in buyList)
{
int duplicateCount = 0;
for (int i = 0; i < uniqueBuyList.Count; i++)
{
if (uniqueBuyList[i].type_id == obj.type_id)
duplicateCount++;
}
if (duplicateCount == 1)
{
foreach (EveObjModel objinUnique in uniqueBuyList)
{
if (obj.type_id == objinUnique.type_id && obj.price > objinUnique.price)
{
// instead of adding obj, the price is just changed to the price in the obj.
objinUnique.price = obj.price;
}
else if (obj.type_id == objinUnique.type_id && obj.price == objinUnique.price)
{
//uniqueBuyList.RemoveAll(item => item.type_id == obj.type_id);
}
else
{
// Hitting this mean that there are other objects with same type and higher price OR its not the same type_id
}
}
}
else if (duplicateCount > 1)
{
// shud not happn...
}
else
{
uniqueBuyList.Add(obj);
}
continue;
}
foreach (EveObjModel item in uniqueBuyList.OrderBy(item => item.type_id))
{
buyListtextField.Text += $"Eve Online Item! Type-ID is: {item.type_id}, Price is {item.price}\n";
}
}
```
This is our EveObjModel class
```
using System;
using System.Collections.Generic;
using System.Linq;
using System.Runtime.Serialization;
using System.Text;
using System.Threading.Tasks;
namespace EveOnlineApp
{
[DataContract]
public class EveObjModel
{
[DataMember]
public bool is_buy_order { get; set; }
[DataMember]
public double price { get; set; }
[DataMember]
public int type_id { get; set; }
}
}
``` | 2018/11/27 | [
"https://Stackoverflow.com/questions/53495531",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/7766834/"
] | It's not surprising that the process is slow, because the algorithm you are using (with nested loop) has at least quadratic O(N\*N) time complexity, which with such size of data sets is really slow.
One way is to use LINQ `GroupBy` operator, which internally uses hash based lookup, hence has theoretically O(N) time complexity. So you group by `type_id` and for each group (list of elements with the same key) take the one with the maximum `price`:
```
var uniqueBuyList = buyList
.GroupBy(e => e.type_id)
.Select(g => g.OrderByDescending(e => e.price).First())
.ToList();
```
Of cource you don't need to sort the list in order to take the element with the max `price`. A better version is to use `Aggregate` method (which is basically `foreach` loop) for that:
```
var uniqueBuyList = buyList
.GroupBy(e => e.type_id)
.Select(g => g.Aggregate((e1, e2) => e1.price > e2.price ? e1 : e2))
.ToList();
```
Another non LINQ based way is to sort the input list by `type_id` ascending, `price` descending. Then do a single loop over the sorted list and take the first element of each `type_id` group (it will have the maximum `price`):
```
var comparer = Comparer<EveObjModel>.Create((e1, e2) =>
{
int result = e1.type_id.CompareTo(e2.type_id);
if (result == 0) // e1.type_id == e2.type_id
result = e2.price.CompareTo(e1.price); // e1, e2 exchanged to get descending order
return result;
});
buyList.Sort(comparer);
var uniqueBuyList = new List<EveObjModel>();
EveObjModel last = null;
foreach (var item in buyList)
{
if (last == null || last.type_id != item.type_id)
uniqueBuyList.Add(item);
last = item;
}
```
The complexity of this algorithm is O(N\*log(N)), so it's worse than the hash based algorithms (but much better than original). The benefit is that it uses less memory and the resulting list is already sorted by `type_id`, so you don't need to use `OrderBy`. | We can sort given List by ascending `type_id` and then by ascending `price` and reverse it. So that, `EveObjModel` object with `higher price` come first for every unique `type_id`.
Then, we may go through object List again and pick up the unique type\_id that come fist and skip same type\_id then after.
As we are only sorting once, this will cause us time complexity of `O(n * log n)`. Since, `n = 93773` , logarithm of 93773 in base 2 is nearly = `17`. So, sorting will take overall `n * log n = 93773 * 17 = 1594141` operations, which can be done in very less amount of time.
Hope following code will help you !
```
public void CreateUniqueBuyList(List<EveObjModel> buyList)
{
//sort by ascending type_id and then by ascending price and reverse it. so that,
// object with higher price come first
List<EveObjModel>tempList = buyList.OrderBy(x => x.type_id).ThenBy(x => x.price).Reverse().ToList();
List<EveObjModel> uniqueBuyList = new List<EveObjModel>();
for (int i = 0; i < tempList.Count; ++i) {
if ((i > 1) && tempList[i - 1].type_id == tempList[i].type_id) continue; // if duplicate type_id then don't take it again
uniqueBuyList.Add(tempList[i]);
}
foreach (EveObjModel item in uniqueBuyList.OrderBy(item => item.type_id))
{
buyListtextField.Text += $"Eve Online Item! Type-ID is: {item.type_id}, Price is {item.price}\n";
}
}
``` |
19,131,927 | ```
void replace3sWith4s(int[] replace){
for (int i = 0;i<replace.length;i++){
if (replace[i]==3);{
replace[i]=4;
}
}
}
```
My program is replacing all numbers with #4 but I want to have an array that contains 3,
takes an integer array, and changes any element that has the value 3 to instead have the value 4. | 2013/10/02 | [
"https://Stackoverflow.com/questions/19131927",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2837656/"
] | ```
if (replace[i]==3);
^^^
```
Remove the semicolon.
It should be
```
if (replace[i]==3) {
replace[i]=4;
}
```
The semicolon changes the meaning to
```
if (replace[i]==3)
;//do nothing
// Separate New block
{
replace[i]=4;
}
``` | also You can try this method at if statement according to your array type
```
if (replace[i].equals("3")){
replace[i]=4;
```
} |
19,131,927 | ```
void replace3sWith4s(int[] replace){
for (int i = 0;i<replace.length;i++){
if (replace[i]==3);{
replace[i]=4;
}
}
}
```
My program is replacing all numbers with #4 but I want to have an array that contains 3,
takes an integer array, and changes any element that has the value 3 to instead have the value 4. | 2013/10/02 | [
"https://Stackoverflow.com/questions/19131927",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2837656/"
] | ```
(replace[i]==3);
```
Is like writing
```
(replace[i]==3) { }
```
Which does nothing.
Your code is equivalent to this code:
```
void replace3sWith4s(int[] replace){
for (int i = 0;i<replace.length;i++){
if (replace[i]==3) { }
replace[i]=4; //Always reachable
}
}
}
```
To fix your code, remove the semicolon:
```
(replace[i]==3);
^
``` | also You can try this method at if statement according to your array type
```
if (replace[i].equals("3")){
replace[i]=4;
```
} |
22,343 | I saw this question somewhere in the Internet(I forgot the source) and I think this forum is a good place to ask it.
According to what I know, the atoms in a persons body are replaced every certain amount of years:
<https://skeptics.stackexchange.com/questions/18427/are-all-the-atoms-in-our-bodies-replaced-on-a-regular-basis>
Then, if a persons body atoms are replaced every x years, should the person be prosecuted today for a crime that he/she committed x years ago, when today that person is physically another person(different atoms)?
And lets say hypothetically that 0.00001% of atoms are never replaced, should 0.99999% of the sentence in years be eliminated (the person is 0.00001% responsible for the crime) ?
This is a related question in the forum:
[Am I still the same person as I was yesterday?](https://philosophy.stackexchange.com/questions/2747/am-i-still-the-same-person-as-i-was-yesterday) | 2015/03/15 | [
"https://philosophy.stackexchange.com/questions/22343",
"https://philosophy.stackexchange.com",
"https://philosophy.stackexchange.com/users/13954/"
] | Atoms do not contain little tags that say "I am part of user63152", and whose unique properties determine the actions of user63152. Indeed, aside from differences in isotopes, and a handful of observables like nuclear spin, atoms of the same type are indistinguishable from each other.
Thus, we needn't care whether the atoms are replaced every minute, every decade, or never. That ongoing entity which is you is you by virtue of emergent properties (like thought) which are robust to changes in which atoms you are made from. So while time may have *some* bearing on how we choose to prosecute crime, it should *not* be because there has been some swapping around of functionally equivalent parts. | What is the purpose of punishment? If it is to link consequences to decisions, then the question is whether that old collection of molecules should have predicted the damage it would cause any better than this new collection of molecules.
Our notions of learning imply that behavior is a feedback loop and the consistency of personality is unrelated to the set of molecules that embody it, but related to the information that flows through them. So by and large, the prediction of recidivism remains good over long periods of time. Our morality gets no better with time, and the corresponding replacement of molecules, unless something else changes.
The better question is whether you should incarcerate, for instance, an amnesiac, or an addict who has just undergone something like ibogaine therapy, a rapist subject to chemical castration, or a terrorist who has undergone a religious conversion: a person who really feels like a 'new person' and has had a real part of their personality deactivated or removed in a way that has statistically proven likely to change current and future decision making. |
22,343 | I saw this question somewhere in the Internet(I forgot the source) and I think this forum is a good place to ask it.
According to what I know, the atoms in a persons body are replaced every certain amount of years:
<https://skeptics.stackexchange.com/questions/18427/are-all-the-atoms-in-our-bodies-replaced-on-a-regular-basis>
Then, if a persons body atoms are replaced every x years, should the person be prosecuted today for a crime that he/she committed x years ago, when today that person is physically another person(different atoms)?
And lets say hypothetically that 0.00001% of atoms are never replaced, should 0.99999% of the sentence in years be eliminated (the person is 0.00001% responsible for the crime) ?
This is a related question in the forum:
[Am I still the same person as I was yesterday?](https://philosophy.stackexchange.com/questions/2747/am-i-still-the-same-person-as-i-was-yesterday) | 2015/03/15 | [
"https://philosophy.stackexchange.com/questions/22343",
"https://philosophy.stackexchange.com",
"https://philosophy.stackexchange.com/users/13954/"
] | Atoms do not contain little tags that say "I am part of user63152", and whose unique properties determine the actions of user63152. Indeed, aside from differences in isotopes, and a handful of observables like nuclear spin, atoms of the same type are indistinguishable from each other.
Thus, we needn't care whether the atoms are replaced every minute, every decade, or never. That ongoing entity which is you is you by virtue of emergent properties (like thought) which are robust to changes in which atoms you are made from. So while time may have *some* bearing on how we choose to prosecute crime, it should *not* be because there has been some swapping around of functionally equivalent parts. | It seems to me that this is just a reformulation of Theseus' paradox. Plutarch notes in his biography of Theseus that the ship that Theseus and the other Athenian youths returned upon was preserved by the city of Athens through the ages. As various planks and rails rotted, they were replaced leading to the question commonly discussed among philosophers over whether or not the ship we have now is one and the same as the ship that Theseus returned to Athens upon.
Really the question at hand is the very question of identity. It's not an easy question to answer. A good starting place is the subtopic Understanding the Persistence Question over at the Stanford Encyclopedia of Philosophy in the Identity entry: <http://plato.stanford.edu/entries/identity-personal/#UndPerQue> |
22,343 | I saw this question somewhere in the Internet(I forgot the source) and I think this forum is a good place to ask it.
According to what I know, the atoms in a persons body are replaced every certain amount of years:
<https://skeptics.stackexchange.com/questions/18427/are-all-the-atoms-in-our-bodies-replaced-on-a-regular-basis>
Then, if a persons body atoms are replaced every x years, should the person be prosecuted today for a crime that he/she committed x years ago, when today that person is physically another person(different atoms)?
And lets say hypothetically that 0.00001% of atoms are never replaced, should 0.99999% of the sentence in years be eliminated (the person is 0.00001% responsible for the crime) ?
This is a related question in the forum:
[Am I still the same person as I was yesterday?](https://philosophy.stackexchange.com/questions/2747/am-i-still-the-same-person-as-i-was-yesterday) | 2015/03/15 | [
"https://philosophy.stackexchange.com/questions/22343",
"https://philosophy.stackexchange.com",
"https://philosophy.stackexchange.com/users/13954/"
] | Arne Naess wrote many essays about the Self. In them, he argued for a concept called the Ecological Self, but along the way he used a series of phrases to challenge commonly held approaches to defining the self. Such class of phrase pairs looked like:
* I enjoy listening to Mozart.
* My body enjoys listening to Mozart.
Or
* I am my mother's son. ("daughter" if you are female)
* My body is my mother's son ("daughter" if you are female)
If one considers the pairs of phrases to not be *quite* identical, it suggests that "my body," i.e. the atoms in my body, are not quite exactly the same concept as "my self." Thus, replacement of the atoms in the body is probably not sufficient to be a change of self. | What is the purpose of punishment? If it is to link consequences to decisions, then the question is whether that old collection of molecules should have predicted the damage it would cause any better than this new collection of molecules.
Our notions of learning imply that behavior is a feedback loop and the consistency of personality is unrelated to the set of molecules that embody it, but related to the information that flows through them. So by and large, the prediction of recidivism remains good over long periods of time. Our morality gets no better with time, and the corresponding replacement of molecules, unless something else changes.
The better question is whether you should incarcerate, for instance, an amnesiac, or an addict who has just undergone something like ibogaine therapy, a rapist subject to chemical castration, or a terrorist who has undergone a religious conversion: a person who really feels like a 'new person' and has had a real part of their personality deactivated or removed in a way that has statistically proven likely to change current and future decision making. |
22,343 | I saw this question somewhere in the Internet(I forgot the source) and I think this forum is a good place to ask it.
According to what I know, the atoms in a persons body are replaced every certain amount of years:
<https://skeptics.stackexchange.com/questions/18427/are-all-the-atoms-in-our-bodies-replaced-on-a-regular-basis>
Then, if a persons body atoms are replaced every x years, should the person be prosecuted today for a crime that he/she committed x years ago, when today that person is physically another person(different atoms)?
And lets say hypothetically that 0.00001% of atoms are never replaced, should 0.99999% of the sentence in years be eliminated (the person is 0.00001% responsible for the crime) ?
This is a related question in the forum:
[Am I still the same person as I was yesterday?](https://philosophy.stackexchange.com/questions/2747/am-i-still-the-same-person-as-i-was-yesterday) | 2015/03/15 | [
"https://philosophy.stackexchange.com/questions/22343",
"https://philosophy.stackexchange.com",
"https://philosophy.stackexchange.com/users/13954/"
] | Arne Naess wrote many essays about the Self. In them, he argued for a concept called the Ecological Self, but along the way he used a series of phrases to challenge commonly held approaches to defining the self. Such class of phrase pairs looked like:
* I enjoy listening to Mozart.
* My body enjoys listening to Mozart.
Or
* I am my mother's son. ("daughter" if you are female)
* My body is my mother's son ("daughter" if you are female)
If one considers the pairs of phrases to not be *quite* identical, it suggests that "my body," i.e. the atoms in my body, are not quite exactly the same concept as "my self." Thus, replacement of the atoms in the body is probably not sufficient to be a change of self. | It seems to me that this is just a reformulation of Theseus' paradox. Plutarch notes in his biography of Theseus that the ship that Theseus and the other Athenian youths returned upon was preserved by the city of Athens through the ages. As various planks and rails rotted, they were replaced leading to the question commonly discussed among philosophers over whether or not the ship we have now is one and the same as the ship that Theseus returned to Athens upon.
Really the question at hand is the very question of identity. It's not an easy question to answer. A good starting place is the subtopic Understanding the Persistence Question over at the Stanford Encyclopedia of Philosophy in the Identity entry: <http://plato.stanford.edu/entries/identity-personal/#UndPerQue> |
58,557,803 | I'm want to add **OR** condition in the JSON query of Cube.js. But once I added one more condition in the filter it always adds **AND** condition in SQL query.
Below is the JSON query that I'm trying.
```
{
"dimensions": [
"Employee.name",
"Employee.company"
],
"timeDimensions": [],
"measures": [],
"filters": [
{
"dimension": "Employee.company",
"operator": "contains",
"values": [
"soft"
]
},
{
"dimension": "Employee.name",
"operator": "contains",
"values": [
"soft"
]
}
]
}
```
It generates below SQL query.
```sql
SELECT
`employee`.name `employee__name`,
`employee`.company `employee__company`
FROM
DEMO.Employee AS `employee`
WHERE
`employee`.company LIKE CONCAT('%', 'soft', '%')
AND
`employee`.name LIKE CONCAT('%', 'soft', '%')
GROUP BY
1,
2;
```
What is the JSON query for Cube.js if I want to generate below SQL
```sql
SELECT
`employee`.name `employee__name`,
`employee`.company `employee__company`
FROM
DEMO.Employee AS `employee`
WHERE
`employee`.company LIKE CONCAT('%', 'soft', '%')
OR
`employee`.name LIKE CONCAT('%', 'soft', '%')
GROUP BY
1,
2;
``` | 2019/10/25 | [
"https://Stackoverflow.com/questions/58557803",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/12118067/"
] | API support for logical operators isn't shipped yet. Meanwhile there're several workarounds:
1. Define dimension that mimics **OR** behavior. In your case it's
```js
cube(`Employee`, {
// ...
dimensions: {
companyAndName: {
sql: `CONCAT(${company}, ' ', ${name})`,
type: `string`
}
}
});
```
2. Define segments. Those can be also generated: <https://cube.dev/docs/schema-generation>
```js
cube(`Employee`, {
// ...
segments: {
soft: {
sql: `${company} LIKE CONCAT('%', 'soft', '%') OR ${name} LIKE CONCAT('%', 'soft', '%')`
}
}
});
``` | this is how you do it
```
{
or: [
{
"dimension": "Employee.company",
"operator": "contains",
"values": [
"soft"
]
},
{
"dimension": "Employee.name",
"operator": "contains",
"values": [
"soft"
]
}
];
}
```
Refer to this [Boolean logical operators section](https://cube.dev/docs/query-format#boolean-logical-operators) in the documentation |
43,374,103 | Being rather new to socket programming and threading in general, my issue might be stemming from a misunderstanding of how they work. I am trying to create something that acts as both a client and a server using threading.
Following:
<https://docs.python.org/3/library/socketserver.html#asynchronous-mixins>
I created a client class to go with the server and executed both from a main class. The server supposedly launches normally and doesn't give any errors but when I try to connect from the client, it fails on the following:
```
# In client connection
sock = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
sock.connect((ip, port))
```
the error I am getting is:
```
Traceback (most recent call last):
File "./<project>", line 61, in <module>
client.start_client(serverInfo)
File "/home/<username>/Documents/Github/project/client.py", line 54, in <startclient>
<connectionMethod>(cmd)
File "/home/<username>/Documents/Github/project/client.py", line 112, in <connectionMethod>
sock.connect((remoteHOST,remotePORT))
ConnectionRefusedError: [Errno 111] Connection refused
```
Even when I modify the server from the code in the referenced python page (just to run on a specific port, 1234), and try to connect to that port with
```
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as sock:
sock.connect(('127.0.0.1',1234))
sock.sendall('Test message')
```
I get the same problem
```
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
ConnectionRefusedError: [Errno 111] Connection refused
```
Why is the server refusing connections? No firewall rules or iptables are in place, running the example that has the client and socket together as is from the site works but even removing the `server.shutdown()` line it still kills itself immediately.
Am I missing something?
The behaviour I am expecting is:
```
./programA
<server starts on port 30000>
```
```
./programB
<server starts on port 30001>
<client starts>
```
--- input/output ---
FROM CLIENT A:
```
/connect 127.0.0.1 30001
CONNECTED TO 127.0.0.1 30001
```
ON CLIENT B:
```
CONNECTION FROM 127.0.0.1 30000
```
Basically once the clients connect the first time they can communicate with each other by typing into a prompt which just creates another socket targeting the 'remote' IP and PORT to send off the message (instant messaging). The sockets are afterwords left to close because they aren't actually responsible for receiving anything back.
I would appreciate any help I can get on this. | 2017/04/12 | [
"https://Stackoverflow.com/questions/43374103",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/2763113/"
] | You could do something like below. Your elements need a `float:left;`.
Though there are far better ways to handle this. You should really change your HTML to use `span` instead of `div` to achieve the final solution.
```css
/* CSS used here will be applied after bootstrap.css */emergency{
color: #1D1060;
}
.alert-color{
color: #0F75BC;
}
.normal{
color:#6DC2E9;
}
.sys-cond-list ul li span{
color: #4B5D6B;
}
.sys-cond-list{
font-size: 12px;
}
#currState{
color: #3379A3;
float:left;
margin:24px 0 0 10px;
}
```
```html
<script src="https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script>
<script src="//cdnjs.cloudflare.com/ajax/libs/tether/1.4.0/js/tether.min.js"></script>
<script src="https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0-alpha.6/js/bootstrap.min.js"></script>
<link href="https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0-alpha.6/css/bootstrap.min.css" rel="stylesheet"/>
<div class="row">
<div class="col-sm-10" style="float: left">
<div class="system-cond" style="position: absolute">
<p style="text-align: left;float:left;">Our current<br>condition is: <strong>
</strong></p><div id="currState"><strong>Normal</strong></div><p></p>
</div>
</div>
</div>
</div>
``` | Your `<p>` and `#currState` are block level elements, meaning they will take up the full-width of screen and so naturally "Normal" will be on next line.
A hack fix would be to set both elements to `display: inline-block;` but I think your code could use a restructuring. You are using inline styles and `<br>` when not necessary and `<strong>` tags when you can just modify the `font-weight` in css, you have empty `<p>` tags, etc.
```
p {
display: inline-block;
}
#currState{
display: inline-block;
}
``` |
355,341 | Recently the Reopen Votes queue has been overrun with questions that have been closed, then edited by a user who is not the asker after the closure, and their edit has been approved.
95% of the time this happens, this approved edit does nothing to attempt to fix the question's content, but consists merely of formatting tweaks - which has the sole effect of (a) gaining rep for the editor (b) pushing the question into the Reopen Votes queue where shmucks like myself have to take a look at it to confirm that yes, it is still terribad and should never be reopened.
My procedure so far has been to go back to the stupidly-edited question and mod flag them with a comment that the edit is bad and whoever approved it should be review-banned, but seriously... that isn't instant, I have better things to do with my day, and I'm not the one who approved the bad edit and caused the problem in the first place, so why should I have to suffer?
I haven't thought long and hard about this, but I feel that some ways this could be mitigated (aside from review-banning the a\*\*hats who are accepting these useless reviews) are:
* If a question was closed as a dupe, don't nominate it for reopening if it's edited by someone other than the asker.
* If a question is closed, and someone who is not the asker edits it after the fact, show a warning banner on the edit screen - something to the effect of "This question was closed due to serious problems; please do not edit it unless you are certain you can materially improve its content to make it answerable".
* If an edit in the Suggested Edits queue is for a closed question and was not performed by the asker of the question, show a warning banner on that suggested edit for that particular question to reviewers.
Please proceed to shoot holes in my suggestions and/or tell me I'm a terrible human being. You could also provide your own thoughts and suggestions on how this can be addressed, if you're feeling constructive. ;)
Also if there is a better way to deal with bad suggested edits than mod-flagging the offending questions, please advise. | 2017/08/19 | [
"https://meta.stackoverflow.com/questions/355341",
"https://meta.stackoverflow.com",
"https://meta.stackoverflow.com/users/70345/"
] | Here's a better suggestion: edits should only cause questions to go into the reopen queue if the OP is the editor.
Let's consider every possible close reason, and then decide who is more likely to make an edit that makes the question reopen-worthy:
* Duplicate: If the question is not a duplicate, the OP is the one who is most able to disambiguate it from the dupe-target.
* Off-topic/General Computing/Hardware: If the question is not hardware-related, the OP is the best person to be able to explain why this is not the case.
* Off-topic/Server: Ditto
* Off-topic/Recommendation: If a question looks like a recommendation question but is instead a "how to achieve X" question, it is possible that people who aren't the OP can explain the difference.
* Off-topic/MCVE: The OP is the person who has the code; therefore, they are in the best position to provide the code.
* Off-topic/No-Repro: Such questions usually don't get reopened. But if they do, it is usually by the OP providing further information/clarification. Which the OP is uniquely suited to do.
* Unclear: The OP is the person most likely to be able to provide sufficient information to clarify the problem. Others may be able to guess sometimes, but only the OP *knows*.
* Too Broad: The OP is the *only one* who can narrow it down. They're the only one who knows exactly what they're looking for.
* Opinion-based: The OP is the person most capable of finding a more objective form of their question. If someone else has a more objective form, they can ask it anew themselves.
Note that there are a lot of "most likely" equivocation in the above statements. Yes, I recognize that it is *possible* for other people to provide that information in those cases. So what?
If the OP is not engaged enough to fix the problem with their question themselves, then they're not really in a position to ask someone else to do it. Therefore, only edits by the OP should be considered when putting something in the reopen queue.
Furthermore, the OP already failed once. We need to teach the OP how to fix their question's problems. And that's not done by fixing them for them. By only considering OP edits, we make sure that other people coming along to fix it won't get the same effect. This rewards OPs who actually work to improve their questions. | >
> My procedure so far has been to go back to the stupidly-edited question and mod flag them with a comment that the edit is bad and whoever approved it should be review-banned, but seriously... that isn't instant, I have better things to do with my day, and I'm not the one who approved the bad edit and caused the problem in the first place, so why should I have to suffer?
>
>
>
This seems like wrong/harmful behavior to me for several reasons:
* First of all, it's not your job to request that moderators take a *specific action* against a user or users; moderators decide what punishment a rule breaker gets. Flagging a user for problematic behavior is one thing, but telling moderators to perform the most severe action on the user because their actions are merely annoying to you, personally, is a bit of an overreaction.
* You can't possibly know for sure in every case when the first close vote hit the question, vs when the suggested edit hit the review queue. In some cases you can tell if the suggested edit hit the queue *after* the question was closed, but a lot of the time, those edits are sitting there pending while the question is still open.
* To segue from my second point, users suggesting edits can't even *see* if a question is accruing close votes. You need 3,000 reputation to see them on others' questions. You gain the privilege for automatic edits 1,000 reputation *before* that.
* If you are concerned about your limited time being wasted in the queue, and you are getting frustrated with the stuff that enters the queue, perhaps *don't spend so much time in the queue*. The queue exists precisely to put reopen candidates under scrutiny.
Editing a post to clarify it, fix code that someone forgot to indent or tag (I see a lot of HTML/CSS posts that look nonsensical because someone added a lot of `<div>`s and `<p>`s in their prose and didn't put graves/backticks around them, so they don't show up in the post), or fix some other issue is one of several valid ways to get a question reopened, and it's working as intended when such edits land the question in the reopen queue.
*It's your job as an editor* to review these; that's the whole point of the queue! If you don't like those edits, or edits by someone other than OP, it takes but a second or two to hit "skip". |
355,341 | Recently the Reopen Votes queue has been overrun with questions that have been closed, then edited by a user who is not the asker after the closure, and their edit has been approved.
95% of the time this happens, this approved edit does nothing to attempt to fix the question's content, but consists merely of formatting tweaks - which has the sole effect of (a) gaining rep for the editor (b) pushing the question into the Reopen Votes queue where shmucks like myself have to take a look at it to confirm that yes, it is still terribad and should never be reopened.
My procedure so far has been to go back to the stupidly-edited question and mod flag them with a comment that the edit is bad and whoever approved it should be review-banned, but seriously... that isn't instant, I have better things to do with my day, and I'm not the one who approved the bad edit and caused the problem in the first place, so why should I have to suffer?
I haven't thought long and hard about this, but I feel that some ways this could be mitigated (aside from review-banning the a\*\*hats who are accepting these useless reviews) are:
* If a question was closed as a dupe, don't nominate it for reopening if it's edited by someone other than the asker.
* If a question is closed, and someone who is not the asker edits it after the fact, show a warning banner on the edit screen - something to the effect of "This question was closed due to serious problems; please do not edit it unless you are certain you can materially improve its content to make it answerable".
* If an edit in the Suggested Edits queue is for a closed question and was not performed by the asker of the question, show a warning banner on that suggested edit for that particular question to reviewers.
Please proceed to shoot holes in my suggestions and/or tell me I'm a terrible human being. You could also provide your own thoughts and suggestions on how this can be addressed, if you're feeling constructive. ;)
Also if there is a better way to deal with bad suggested edits than mod-flagging the offending questions, please advise. | 2017/08/19 | [
"https://meta.stackoverflow.com/questions/355341",
"https://meta.stackoverflow.com",
"https://meta.stackoverflow.com/users/70345/"
] | Here's a better suggestion: edits should only cause questions to go into the reopen queue if the OP is the editor.
Let's consider every possible close reason, and then decide who is more likely to make an edit that makes the question reopen-worthy:
* Duplicate: If the question is not a duplicate, the OP is the one who is most able to disambiguate it from the dupe-target.
* Off-topic/General Computing/Hardware: If the question is not hardware-related, the OP is the best person to be able to explain why this is not the case.
* Off-topic/Server: Ditto
* Off-topic/Recommendation: If a question looks like a recommendation question but is instead a "how to achieve X" question, it is possible that people who aren't the OP can explain the difference.
* Off-topic/MCVE: The OP is the person who has the code; therefore, they are in the best position to provide the code.
* Off-topic/No-Repro: Such questions usually don't get reopened. But if they do, it is usually by the OP providing further information/clarification. Which the OP is uniquely suited to do.
* Unclear: The OP is the person most likely to be able to provide sufficient information to clarify the problem. Others may be able to guess sometimes, but only the OP *knows*.
* Too Broad: The OP is the *only one* who can narrow it down. They're the only one who knows exactly what they're looking for.
* Opinion-based: The OP is the person most capable of finding a more objective form of their question. If someone else has a more objective form, they can ask it anew themselves.
Note that there are a lot of "most likely" equivocation in the above statements. Yes, I recognize that it is *possible* for other people to provide that information in those cases. So what?
If the OP is not engaged enough to fix the problem with their question themselves, then they're not really in a position to ask someone else to do it. Therefore, only edits by the OP should be considered when putting something in the reopen queue.
Furthermore, the OP already failed once. We need to teach the OP how to fix their question's problems. And that's not done by fixing them for them. By only considering OP edits, we make sure that other people coming along to fix it won't get the same effect. This rewards OPs who actually work to improve their questions. | You know what? I'm not seeing it.
Out the 10 I've reviewed, not all where pushed to the queue with edits. The 6 which were, are done by users which fall in one of these two categories:
* Are the OP
* Have >2k reputation
My guess is that my filters rock (only reviewing off topic or primarily opinion based). |
355,341 | Recently the Reopen Votes queue has been overrun with questions that have been closed, then edited by a user who is not the asker after the closure, and their edit has been approved.
95% of the time this happens, this approved edit does nothing to attempt to fix the question's content, but consists merely of formatting tweaks - which has the sole effect of (a) gaining rep for the editor (b) pushing the question into the Reopen Votes queue where shmucks like myself have to take a look at it to confirm that yes, it is still terribad and should never be reopened.
My procedure so far has been to go back to the stupidly-edited question and mod flag them with a comment that the edit is bad and whoever approved it should be review-banned, but seriously... that isn't instant, I have better things to do with my day, and I'm not the one who approved the bad edit and caused the problem in the first place, so why should I have to suffer?
I haven't thought long and hard about this, but I feel that some ways this could be mitigated (aside from review-banning the a\*\*hats who are accepting these useless reviews) are:
* If a question was closed as a dupe, don't nominate it for reopening if it's edited by someone other than the asker.
* If a question is closed, and someone who is not the asker edits it after the fact, show a warning banner on the edit screen - something to the effect of "This question was closed due to serious problems; please do not edit it unless you are certain you can materially improve its content to make it answerable".
* If an edit in the Suggested Edits queue is for a closed question and was not performed by the asker of the question, show a warning banner on that suggested edit for that particular question to reviewers.
Please proceed to shoot holes in my suggestions and/or tell me I'm a terrible human being. You could also provide your own thoughts and suggestions on how this can be addressed, if you're feeling constructive. ;)
Also if there is a better way to deal with bad suggested edits than mod-flagging the offending questions, please advise. | 2017/08/19 | [
"https://meta.stackoverflow.com/questions/355341",
"https://meta.stackoverflow.com",
"https://meta.stackoverflow.com/users/70345/"
] | Assuming that such edits were made by a person without edit privileges, each such harmful edit would have ended up in the suggested edit review queue. If so, the root of the problem lies there.
When doing suggested-edit reviews of questions, the reviewer needs to consider if the question makes sense in the first place!
There do exist rare cases where an edit from a 3th party could save a question from being closed. But apart from that exception, there is never a reason to edit a question that is closed/should be closed.
Editors who "polish crap" are a huge waste of everyone's time. In addition, they send out a signal to the OP that: "the question was fixed, so it is fine now". And also such edits could indeed spawn re-open reviews.
What I do when I encounter minor edits to bad/closed questions, is to reject with a custom reason, something along the lines of: "This question is `<close reason>` and cannot be salvaged by anyone but the OP. It should therefore get closed, not polished. Instead of trying to fix it, flag/close vote instead." | You know what? I'm not seeing it.
Out the 10 I've reviewed, not all where pushed to the queue with edits. The 6 which were, are done by users which fall in one of these two categories:
* Are the OP
* Have >2k reputation
My guess is that my filters rock (only reviewing off topic or primarily opinion based). |
355,341 | Recently the Reopen Votes queue has been overrun with questions that have been closed, then edited by a user who is not the asker after the closure, and their edit has been approved.
95% of the time this happens, this approved edit does nothing to attempt to fix the question's content, but consists merely of formatting tweaks - which has the sole effect of (a) gaining rep for the editor (b) pushing the question into the Reopen Votes queue where shmucks like myself have to take a look at it to confirm that yes, it is still terribad and should never be reopened.
My procedure so far has been to go back to the stupidly-edited question and mod flag them with a comment that the edit is bad and whoever approved it should be review-banned, but seriously... that isn't instant, I have better things to do with my day, and I'm not the one who approved the bad edit and caused the problem in the first place, so why should I have to suffer?
I haven't thought long and hard about this, but I feel that some ways this could be mitigated (aside from review-banning the a\*\*hats who are accepting these useless reviews) are:
* If a question was closed as a dupe, don't nominate it for reopening if it's edited by someone other than the asker.
* If a question is closed, and someone who is not the asker edits it after the fact, show a warning banner on the edit screen - something to the effect of "This question was closed due to serious problems; please do not edit it unless you are certain you can materially improve its content to make it answerable".
* If an edit in the Suggested Edits queue is for a closed question and was not performed by the asker of the question, show a warning banner on that suggested edit for that particular question to reviewers.
Please proceed to shoot holes in my suggestions and/or tell me I'm a terrible human being. You could also provide your own thoughts and suggestions on how this can be addressed, if you're feeling constructive. ;)
Also if there is a better way to deal with bad suggested edits than mod-flagging the offending questions, please advise. | 2017/08/19 | [
"https://meta.stackoverflow.com/questions/355341",
"https://meta.stackoverflow.com",
"https://meta.stackoverflow.com/users/70345/"
] | Maybe when a question is edited the person doing the edit should be asked if they wish to “vote to reopen”. Often even as the OP I may edit a question (for example a duplicate) to make it clearer, but not wish it to be reopened that that point.
So prompt for “should be considered to be reopened” on an edit, but don’t automatically assume it. The reviewers of the edit should get the same prompt and the question put in the reopen queue only if they also agree. | You know what? I'm not seeing it.
Out the 10 I've reviewed, not all where pushed to the queue with edits. The 6 which were, are done by users which fall in one of these two categories:
* Are the OP
* Have >2k reputation
My guess is that my filters rock (only reviewing off topic or primarily opinion based). |
355,341 | Recently the Reopen Votes queue has been overrun with questions that have been closed, then edited by a user who is not the asker after the closure, and their edit has been approved.
95% of the time this happens, this approved edit does nothing to attempt to fix the question's content, but consists merely of formatting tweaks - which has the sole effect of (a) gaining rep for the editor (b) pushing the question into the Reopen Votes queue where shmucks like myself have to take a look at it to confirm that yes, it is still terribad and should never be reopened.
My procedure so far has been to go back to the stupidly-edited question and mod flag them with a comment that the edit is bad and whoever approved it should be review-banned, but seriously... that isn't instant, I have better things to do with my day, and I'm not the one who approved the bad edit and caused the problem in the first place, so why should I have to suffer?
I haven't thought long and hard about this, but I feel that some ways this could be mitigated (aside from review-banning the a\*\*hats who are accepting these useless reviews) are:
* If a question was closed as a dupe, don't nominate it for reopening if it's edited by someone other than the asker.
* If a question is closed, and someone who is not the asker edits it after the fact, show a warning banner on the edit screen - something to the effect of "This question was closed due to serious problems; please do not edit it unless you are certain you can materially improve its content to make it answerable".
* If an edit in the Suggested Edits queue is for a closed question and was not performed by the asker of the question, show a warning banner on that suggested edit for that particular question to reviewers.
Please proceed to shoot holes in my suggestions and/or tell me I'm a terrible human being. You could also provide your own thoughts and suggestions on how this can be addressed, if you're feeling constructive. ;)
Also if there is a better way to deal with bad suggested edits than mod-flagging the offending questions, please advise. | 2017/08/19 | [
"https://meta.stackoverflow.com/questions/355341",
"https://meta.stackoverflow.com",
"https://meta.stackoverflow.com/users/70345/"
] | >
> *meta note: I originally provided data for only 14 days here; I've since found myself referencing this post with some frequency, so I've updated it to reflect a full year of data; some of the original commentary may seem odd in light of this.*
>
>
>
Here's how reopen review outcomes break down by [creation triggers](https://meta.stackexchange.com/questions/196074/lots-of-questions-in-the-reopen-queue/196078#196078) over the 365 days between September 3rd 2017 and September 3rd 2018:
```
CreationReason ReopenTasks % Reopened % Leave Closed % Edit % Task Invalidated % Questions now open
--------------------- ----------- ---------- -------------- ------ ------------------ --------------------
OwnerEditCreated 37734 4.49 % 76.85 % 0.21 % 18.44 % 7.25 %
ThirdPartyEditCreated 12284 1.28 % 88.51 % 0.07 % 10.14 % 2.43 %
Popularity 8746 4.71 % 82.38 % 0.16 % 12.75 % 6.69 %
VoteCreated 8127 6.77 % 81.97 % 0.17 % 11.09 % 13.65 %
```
The second column is the total number of tasks created for that reason during that time, the next 4 are the % of those tasks that were resolved in various ways ("invalidated" just means the review couldn't finish for some reason - including both the question being deleted or reopened outside of review).
Note that when I threw this together last night, I made two big mistakes: I ignored audits (which inflated the popularity trigger - though this also varies wildly over time, so also suffers from a small sample size) and didn't correctly account for edits that happened prior to the question being closed - those ended up skewing the results considerably.
So, yeah 3rd-party edits have an even worse success rate than you predicted; in two weeks, only 5 of them got reopened via review. OP edits - which account for the majority of all questions in reopen review - are a little bit better, but still mostly terrible. Even reopen votes from folks with 3K+ rep leave reviewers cold the vast majority of the time.
OTOH, the primary reason for putting this logic in place was to require a bit more work than simply [flagging to reopen](https://meta.stackexchange.com/questions/186722/can-we-have-the-ability-to-flag-for-reopening/186728#186728). In light of that, at least there's potentially *something* to work with, vs. an endless stream of folks asking for questions to be reopened where nothing has changed since they were closed.
As for bad edits... Don't forget that you can leave a comment on any edited post that @-pings an editor - if you haven't *told them* why their edits are lacking, you might want to try that first. | Maybe when a question is edited the person doing the edit should be asked if they wish to “vote to reopen”. Often even as the OP I may edit a question (for example a duplicate) to make it clearer, but not wish it to be reopened that that point.
So prompt for “should be considered to be reopened” on an edit, but don’t automatically assume it. The reviewers of the edit should get the same prompt and the question put in the reopen queue only if they also agree. |
355,341 | Recently the Reopen Votes queue has been overrun with questions that have been closed, then edited by a user who is not the asker after the closure, and their edit has been approved.
95% of the time this happens, this approved edit does nothing to attempt to fix the question's content, but consists merely of formatting tweaks - which has the sole effect of (a) gaining rep for the editor (b) pushing the question into the Reopen Votes queue where shmucks like myself have to take a look at it to confirm that yes, it is still terribad and should never be reopened.
My procedure so far has been to go back to the stupidly-edited question and mod flag them with a comment that the edit is bad and whoever approved it should be review-banned, but seriously... that isn't instant, I have better things to do with my day, and I'm not the one who approved the bad edit and caused the problem in the first place, so why should I have to suffer?
I haven't thought long and hard about this, but I feel that some ways this could be mitigated (aside from review-banning the a\*\*hats who are accepting these useless reviews) are:
* If a question was closed as a dupe, don't nominate it for reopening if it's edited by someone other than the asker.
* If a question is closed, and someone who is not the asker edits it after the fact, show a warning banner on the edit screen - something to the effect of "This question was closed due to serious problems; please do not edit it unless you are certain you can materially improve its content to make it answerable".
* If an edit in the Suggested Edits queue is for a closed question and was not performed by the asker of the question, show a warning banner on that suggested edit for that particular question to reviewers.
Please proceed to shoot holes in my suggestions and/or tell me I'm a terrible human being. You could also provide your own thoughts and suggestions on how this can be addressed, if you're feeling constructive. ;)
Also if there is a better way to deal with bad suggested edits than mod-flagging the offending questions, please advise. | 2017/08/19 | [
"https://meta.stackoverflow.com/questions/355341",
"https://meta.stackoverflow.com",
"https://meta.stackoverflow.com/users/70345/"
] | I think suggestion #2 has some merit as it somewhat attempts to educate users. Along those lines, I am pretty sure most <2k users do not understand that the +2 rep they get for editing the closed post will go away when the post is deleted.
So how about something like this?
* If a question is closed, and <2k user who is not the asker edits it after the fact, show an info banner on the edit screen - something to the effect of:
>
> "This question was closed due to serious problems, please do not edit it unless you can materially improve its content to make it answerable; if it ends up being deleted, your +2 edit rep will be removed".
>
>
> | How about a ban on users that edit questions that get review rejected for:
These should be strikes for sure and count very heavily,
* No improvement
* Conflicts with authors intent
things like
* attempt to answer
* me too
* other (comments as answers)
should count towards a ban but with less weight than the others.
With an appropriately aggressive ban threshold this would automatically resolve the problem without any human intervention and dis-incentivise/degamify the behavior. |
355,341 | Recently the Reopen Votes queue has been overrun with questions that have been closed, then edited by a user who is not the asker after the closure, and their edit has been approved.
95% of the time this happens, this approved edit does nothing to attempt to fix the question's content, but consists merely of formatting tweaks - which has the sole effect of (a) gaining rep for the editor (b) pushing the question into the Reopen Votes queue where shmucks like myself have to take a look at it to confirm that yes, it is still terribad and should never be reopened.
My procedure so far has been to go back to the stupidly-edited question and mod flag them with a comment that the edit is bad and whoever approved it should be review-banned, but seriously... that isn't instant, I have better things to do with my day, and I'm not the one who approved the bad edit and caused the problem in the first place, so why should I have to suffer?
I haven't thought long and hard about this, but I feel that some ways this could be mitigated (aside from review-banning the a\*\*hats who are accepting these useless reviews) are:
* If a question was closed as a dupe, don't nominate it for reopening if it's edited by someone other than the asker.
* If a question is closed, and someone who is not the asker edits it after the fact, show a warning banner on the edit screen - something to the effect of "This question was closed due to serious problems; please do not edit it unless you are certain you can materially improve its content to make it answerable".
* If an edit in the Suggested Edits queue is for a closed question and was not performed by the asker of the question, show a warning banner on that suggested edit for that particular question to reviewers.
Please proceed to shoot holes in my suggestions and/or tell me I'm a terrible human being. You could also provide your own thoughts and suggestions on how this can be addressed, if you're feeling constructive. ;)
Also if there is a better way to deal with bad suggested edits than mod-flagging the offending questions, please advise. | 2017/08/19 | [
"https://meta.stackoverflow.com/questions/355341",
"https://meta.stackoverflow.com",
"https://meta.stackoverflow.com/users/70345/"
] | >
> *meta note: I originally provided data for only 14 days here; I've since found myself referencing this post with some frequency, so I've updated it to reflect a full year of data; some of the original commentary may seem odd in light of this.*
>
>
>
Here's how reopen review outcomes break down by [creation triggers](https://meta.stackexchange.com/questions/196074/lots-of-questions-in-the-reopen-queue/196078#196078) over the 365 days between September 3rd 2017 and September 3rd 2018:
```
CreationReason ReopenTasks % Reopened % Leave Closed % Edit % Task Invalidated % Questions now open
--------------------- ----------- ---------- -------------- ------ ------------------ --------------------
OwnerEditCreated 37734 4.49 % 76.85 % 0.21 % 18.44 % 7.25 %
ThirdPartyEditCreated 12284 1.28 % 88.51 % 0.07 % 10.14 % 2.43 %
Popularity 8746 4.71 % 82.38 % 0.16 % 12.75 % 6.69 %
VoteCreated 8127 6.77 % 81.97 % 0.17 % 11.09 % 13.65 %
```
The second column is the total number of tasks created for that reason during that time, the next 4 are the % of those tasks that were resolved in various ways ("invalidated" just means the review couldn't finish for some reason - including both the question being deleted or reopened outside of review).
Note that when I threw this together last night, I made two big mistakes: I ignored audits (which inflated the popularity trigger - though this also varies wildly over time, so also suffers from a small sample size) and didn't correctly account for edits that happened prior to the question being closed - those ended up skewing the results considerably.
So, yeah 3rd-party edits have an even worse success rate than you predicted; in two weeks, only 5 of them got reopened via review. OP edits - which account for the majority of all questions in reopen review - are a little bit better, but still mostly terrible. Even reopen votes from folks with 3K+ rep leave reviewers cold the vast majority of the time.
OTOH, the primary reason for putting this logic in place was to require a bit more work than simply [flagging to reopen](https://meta.stackexchange.com/questions/186722/can-we-have-the-ability-to-flag-for-reopening/186728#186728). In light of that, at least there's potentially *something* to work with, vs. an endless stream of folks asking for questions to be reopened where nothing has changed since they were closed.
As for bad edits... Don't forget that you can leave a comment on any edited post that @-pings an editor - if you haven't *told them* why their edits are lacking, you might want to try that first. | You know what? I'm not seeing it.
Out the 10 I've reviewed, not all where pushed to the queue with edits. The 6 which were, are done by users which fall in one of these two categories:
* Are the OP
* Have >2k reputation
My guess is that my filters rock (only reviewing off topic or primarily opinion based). |
355,341 | Recently the Reopen Votes queue has been overrun with questions that have been closed, then edited by a user who is not the asker after the closure, and their edit has been approved.
95% of the time this happens, this approved edit does nothing to attempt to fix the question's content, but consists merely of formatting tweaks - which has the sole effect of (a) gaining rep for the editor (b) pushing the question into the Reopen Votes queue where shmucks like myself have to take a look at it to confirm that yes, it is still terribad and should never be reopened.
My procedure so far has been to go back to the stupidly-edited question and mod flag them with a comment that the edit is bad and whoever approved it should be review-banned, but seriously... that isn't instant, I have better things to do with my day, and I'm not the one who approved the bad edit and caused the problem in the first place, so why should I have to suffer?
I haven't thought long and hard about this, but I feel that some ways this could be mitigated (aside from review-banning the a\*\*hats who are accepting these useless reviews) are:
* If a question was closed as a dupe, don't nominate it for reopening if it's edited by someone other than the asker.
* If a question is closed, and someone who is not the asker edits it after the fact, show a warning banner on the edit screen - something to the effect of "This question was closed due to serious problems; please do not edit it unless you are certain you can materially improve its content to make it answerable".
* If an edit in the Suggested Edits queue is for a closed question and was not performed by the asker of the question, show a warning banner on that suggested edit for that particular question to reviewers.
Please proceed to shoot holes in my suggestions and/or tell me I'm a terrible human being. You could also provide your own thoughts and suggestions on how this can be addressed, if you're feeling constructive. ;)
Also if there is a better way to deal with bad suggested edits than mod-flagging the offending questions, please advise. | 2017/08/19 | [
"https://meta.stackoverflow.com/questions/355341",
"https://meta.stackoverflow.com",
"https://meta.stackoverflow.com/users/70345/"
] | >
> *meta note: I originally provided data for only 14 days here; I've since found myself referencing this post with some frequency, so I've updated it to reflect a full year of data; some of the original commentary may seem odd in light of this.*
>
>
>
Here's how reopen review outcomes break down by [creation triggers](https://meta.stackexchange.com/questions/196074/lots-of-questions-in-the-reopen-queue/196078#196078) over the 365 days between September 3rd 2017 and September 3rd 2018:
```
CreationReason ReopenTasks % Reopened % Leave Closed % Edit % Task Invalidated % Questions now open
--------------------- ----------- ---------- -------------- ------ ------------------ --------------------
OwnerEditCreated 37734 4.49 % 76.85 % 0.21 % 18.44 % 7.25 %
ThirdPartyEditCreated 12284 1.28 % 88.51 % 0.07 % 10.14 % 2.43 %
Popularity 8746 4.71 % 82.38 % 0.16 % 12.75 % 6.69 %
VoteCreated 8127 6.77 % 81.97 % 0.17 % 11.09 % 13.65 %
```
The second column is the total number of tasks created for that reason during that time, the next 4 are the % of those tasks that were resolved in various ways ("invalidated" just means the review couldn't finish for some reason - including both the question being deleted or reopened outside of review).
Note that when I threw this together last night, I made two big mistakes: I ignored audits (which inflated the popularity trigger - though this also varies wildly over time, so also suffers from a small sample size) and didn't correctly account for edits that happened prior to the question being closed - those ended up skewing the results considerably.
So, yeah 3rd-party edits have an even worse success rate than you predicted; in two weeks, only 5 of them got reopened via review. OP edits - which account for the majority of all questions in reopen review - are a little bit better, but still mostly terrible. Even reopen votes from folks with 3K+ rep leave reviewers cold the vast majority of the time.
OTOH, the primary reason for putting this logic in place was to require a bit more work than simply [flagging to reopen](https://meta.stackexchange.com/questions/186722/can-we-have-the-ability-to-flag-for-reopening/186728#186728). In light of that, at least there's potentially *something* to work with, vs. an endless stream of folks asking for questions to be reopened where nothing has changed since they were closed.
As for bad edits... Don't forget that you can leave a comment on any edited post that @-pings an editor - if you haven't *told them* why their edits are lacking, you might want to try that first. | I think suggestion #2 has some merit as it somewhat attempts to educate users. Along those lines, I am pretty sure most <2k users do not understand that the +2 rep they get for editing the closed post will go away when the post is deleted.
So how about something like this?
* If a question is closed, and <2k user who is not the asker edits it after the fact, show an info banner on the edit screen - something to the effect of:
>
> "This question was closed due to serious problems, please do not edit it unless you can materially improve its content to make it answerable; if it ends up being deleted, your +2 edit rep will be removed".
>
>
> |
355,341 | Recently the Reopen Votes queue has been overrun with questions that have been closed, then edited by a user who is not the asker after the closure, and their edit has been approved.
95% of the time this happens, this approved edit does nothing to attempt to fix the question's content, but consists merely of formatting tweaks - which has the sole effect of (a) gaining rep for the editor (b) pushing the question into the Reopen Votes queue where shmucks like myself have to take a look at it to confirm that yes, it is still terribad and should never be reopened.
My procedure so far has been to go back to the stupidly-edited question and mod flag them with a comment that the edit is bad and whoever approved it should be review-banned, but seriously... that isn't instant, I have better things to do with my day, and I'm not the one who approved the bad edit and caused the problem in the first place, so why should I have to suffer?
I haven't thought long and hard about this, but I feel that some ways this could be mitigated (aside from review-banning the a\*\*hats who are accepting these useless reviews) are:
* If a question was closed as a dupe, don't nominate it for reopening if it's edited by someone other than the asker.
* If a question is closed, and someone who is not the asker edits it after the fact, show a warning banner on the edit screen - something to the effect of "This question was closed due to serious problems; please do not edit it unless you are certain you can materially improve its content to make it answerable".
* If an edit in the Suggested Edits queue is for a closed question and was not performed by the asker of the question, show a warning banner on that suggested edit for that particular question to reviewers.
Please proceed to shoot holes in my suggestions and/or tell me I'm a terrible human being. You could also provide your own thoughts and suggestions on how this can be addressed, if you're feeling constructive. ;)
Also if there is a better way to deal with bad suggested edits than mod-flagging the offending questions, please advise. | 2017/08/19 | [
"https://meta.stackoverflow.com/questions/355341",
"https://meta.stackoverflow.com",
"https://meta.stackoverflow.com/users/70345/"
] | Maybe when a question is edited the person doing the edit should be asked if they wish to “vote to reopen”. Often even as the OP I may edit a question (for example a duplicate) to make it clearer, but not wish it to be reopened that that point.
So prompt for “should be considered to be reopened” on an edit, but don’t automatically assume it. The reviewers of the edit should get the same prompt and the question put in the reopen queue only if they also agree. | How about a ban on users that edit questions that get review rejected for:
These should be strikes for sure and count very heavily,
* No improvement
* Conflicts with authors intent
things like
* attempt to answer
* me too
* other (comments as answers)
should count towards a ban but with less weight than the others.
With an appropriately aggressive ban threshold this would automatically resolve the problem without any human intervention and dis-incentivise/degamify the behavior. |
355,341 | Recently the Reopen Votes queue has been overrun with questions that have been closed, then edited by a user who is not the asker after the closure, and their edit has been approved.
95% of the time this happens, this approved edit does nothing to attempt to fix the question's content, but consists merely of formatting tweaks - which has the sole effect of (a) gaining rep for the editor (b) pushing the question into the Reopen Votes queue where shmucks like myself have to take a look at it to confirm that yes, it is still terribad and should never be reopened.
My procedure so far has been to go back to the stupidly-edited question and mod flag them with a comment that the edit is bad and whoever approved it should be review-banned, but seriously... that isn't instant, I have better things to do with my day, and I'm not the one who approved the bad edit and caused the problem in the first place, so why should I have to suffer?
I haven't thought long and hard about this, but I feel that some ways this could be mitigated (aside from review-banning the a\*\*hats who are accepting these useless reviews) are:
* If a question was closed as a dupe, don't nominate it for reopening if it's edited by someone other than the asker.
* If a question is closed, and someone who is not the asker edits it after the fact, show a warning banner on the edit screen - something to the effect of "This question was closed due to serious problems; please do not edit it unless you are certain you can materially improve its content to make it answerable".
* If an edit in the Suggested Edits queue is for a closed question and was not performed by the asker of the question, show a warning banner on that suggested edit for that particular question to reviewers.
Please proceed to shoot holes in my suggestions and/or tell me I'm a terrible human being. You could also provide your own thoughts and suggestions on how this can be addressed, if you're feeling constructive. ;)
Also if there is a better way to deal with bad suggested edits than mod-flagging the offending questions, please advise. | 2017/08/19 | [
"https://meta.stackoverflow.com/questions/355341",
"https://meta.stackoverflow.com",
"https://meta.stackoverflow.com/users/70345/"
] | Assuming that such edits were made by a person without edit privileges, each such harmful edit would have ended up in the suggested edit review queue. If so, the root of the problem lies there.
When doing suggested-edit reviews of questions, the reviewer needs to consider if the question makes sense in the first place!
There do exist rare cases where an edit from a 3th party could save a question from being closed. But apart from that exception, there is never a reason to edit a question that is closed/should be closed.
Editors who "polish crap" are a huge waste of everyone's time. In addition, they send out a signal to the OP that: "the question was fixed, so it is fine now". And also such edits could indeed spawn re-open reviews.
What I do when I encounter minor edits to bad/closed questions, is to reject with a custom reason, something along the lines of: "This question is `<close reason>` and cannot be salvaged by anyone but the OP. It should therefore get closed, not polished. Instead of trying to fix it, flag/close vote instead." | How about a ban on users that edit questions that get review rejected for:
These should be strikes for sure and count very heavily,
* No improvement
* Conflicts with authors intent
things like
* attempt to answer
* me too
* other (comments as answers)
should count towards a ban but with less weight than the others.
With an appropriately aggressive ban threshold this would automatically resolve the problem without any human intervention and dis-incentivise/degamify the behavior. |
802,877 | i get following errors when trying to open programs over ssh.
```
$ thunar
Thunar: Cannot open display:
$ libreoffice
Failed to open display
$ firefox
Error: GDK_BACKEND does not match available displays
$ keepassx
keepassx: cannot connect to X server
$ keepass2
Unhandled Exception:
System.TypeInitializationException: The type initializer for 'System.Windows.Forms.XplatUI' threw an exception. ---> System.ArgumentNullException: Could not open display (X-Server required. Check your DISPLAY environment variable)
Parameter name: Display
at System.Windows.Forms.XplatUIX11.SetDisplay (IntPtr display_handle) <0x41b3c8a0 + 0x00b9b> in <filename unknown>:0
at System.Windows.Forms.XplatUIX11..ctor () <0x41b3ab20 + 0x001df> in <filename unknown>:0
at System.Windows.Forms.XplatUIX11.GetInstance () <0x41b3a8d0 + 0x0005b> in <filename unknown>:0
at System.Windows.Forms.XplatUI..cctor () <0x41b3a160 + 0x00137> in <filename unknown>:0
--- End of inner exception stack trace ---
at System.Windows.Forms.Application.EnableVisualStyles () <0x41b38870 + 0x0001b> in <filename unknown>:0
at KeePass.Program.Main (System.String[] args) <0x41b376c0 + 0x0008b> in <filename unknown>:0
[ERROR] FATAL UNHANDLED EXCEPTION: System.TypeInitializationException: The type initializer for 'System.Windows.Forms.XplatUI' threw an exception. ---> System.ArgumentNullException: Could not open display (X-Server required. Check your DISPLAY environment variable)
Parameter name: Display
at System.Windows.Forms.XplatUIX11.SetDisplay (IntPtr display_handle) <0x41b3c8a0 + 0x00b9b> in <filename unknown>:0
at System.Windows.Forms.XplatUIX11..ctor () <0x41b3ab20 + 0x001df> in <filename unknown>:0
at System.Windows.Forms.XplatUIX11.GetInstance () <0x41b3a8d0 + 0x0005b> in <filename unknown>:0
at System.Windows.Forms.XplatUI..cctor () <0x41b3a160 + 0x00137> in <filename unknown>:0
--- End of inner exception stack trace ---
at System.Windows.Forms.Application.EnableVisualStyles () <0x41b38870 + 0x0001b> in <filename unknown>:0
at KeePass.Program.Main (System.String[] args) <0x41b376c0 + 0x0008b> in <filename unknown>:0
:06:22 PM~/Documents$ gimp
Cannot open display:
$ wireshark
QXcbConnection: Could not connect to display
Aborted (core dumped)
$ gedit
Failed to connect to Mir: Failed to connect to server socket: No such file or directory
Unable to init server: Could not connect: Connection refused
(gedit:23724): Gtk-WARNING **: cannot open display:
```
i've always been able to open aplications over ssh, this just started yesterday. using ubuntu 16.04 on both machines.
please DO NOT flag this as a repeat question, the following solutions didn't help:
<https://superuser.com/questions/310197/how-do-i-fix-a-cannot-open-display-error-when-opening-an-x-program-after-sshi>
[gksu: Gtk-WARNING \*\*: cannot open display: :0](https://askubuntu.com/questions/614387/gksu-gtk-warning-cannot-open-display-0)
[Gtk-WARNING \*\*: cannot open display: on Ubuntu Server](https://askubuntu.com/questions/471906/gtk-warning-cannot-open-display-on-ubuntu-server)
[(nautilus:13581): Gtk-WARNING \*\*: cannot open display:](https://askubuntu.com/questions/659299/nautilus13581-gtk-warning-cannot-open-display)
if specific info is needed, please ask, i'll do my best to answer. | 2016/07/25 | [
"https://askubuntu.com/questions/802877",
"https://askubuntu.com",
"https://askubuntu.com/users/572440/"
] | It is necessary for you to tell us 3 things.
1. What command did you use to launch your ssh session.
Did you run
```
$ ssh -Y whatever.com
```
or
```
$ ssh -X whatever.com
```
If you had neither -X nor -Y, X11 forwarding won't work
2. Have you edited the ssh client configuration file on the client machine? If you changed that, tell us exactly what.
If you don't want to type -X every time you need X11 forwarding, it can
be set as default by editing /etc/ssh/ssh\_config. That's not the machine's server config, it is default for all clients. At the bottom of mine, I have
```
ForwardAgent yes
ForwardX11 yes
ForwardX11Trusted yes
```
I expect these changes will have no effect until you log out, but I may be wrong about that.
3. On the server machine, did you enable X11 forwarding?
On the server, in the file /etc/X11/sshd\_config, it will be necessary
to turn on X11 forwarding with a line like
```
X11Forwarding yes
```
Please note that change will not have an effect until the server is restarted, or at least its ssh server is restarted.
Let us know how that works. If it fails, report the config files and what you ran. | Have you disabled ipv6? If so I found the solution!
Add AddressFamily inet to sshd\_config.
Edit:
Perform the following steps:
1. On the server, edit the file /etc/ssh/sshd\_config .
2. The default file should have "AddressFamily inet" commented out. Uncomment it and change the value from its default of "any" to "inet".
3. Then restart the service: sudo service sshd restart . |
20,211,678 | i have this (a rough e.g):
```
<StackPanel>
<StackPanel Orientation="Horizontal">
<Label .../>
<TextBox .../>
<Button Content="Add new input row" ... />
</StackPanel>
</StackPanel>
```
pretty self explanatory, i want to add a new Horizontal StackPanel with every click on the button..
is that possible?
thank you! | 2013/11/26 | [
"https://Stackoverflow.com/questions/20211678",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/1900641/"
] | You could use `strsplit` to split your string and then access the array element that you are interested in.
```
mystring = '245 0.00000000 2456171.50000000 1030492816.000 5.14501001 1 IG 5 -1.188022 .... 5.032154 90';
split = strsplit(mystring);
```
If your version of MATLAB is too old and `strsplit` isn't included, then it can be downloaded from [MATLAB central](http://www.mathworks.co.uk/matlabcentral/fileexchange/21710-string-toolkits/content/strings/strsplit.m).
Then you could use `str2num` or `str2double` to turn each string you are interested in into a number.
```
col5 = str2double(split(5));
% or
mycols = str2double(split([5 37 117]));
```
[strsplit reference](http://www.mathworks.co.uk/help/matlab/ref/strsplit.html)
[str2num reference](http://www.mathworks.co.uk/help/matlab/ref/str2num.html)
[str2double reference](http://www.mathworks.co.uk/help/matlab/ref/str2double.html) | Here is a piece of code that replicates `%*f` using `repmat` (with cells). It then changes the `%*f` into `%f` at the provided indexes, and finally transform the cells into a `char` vector.
```
f_star_nb = 20;
f_ind = [2 6 9];
f = repmat({'%*f'}, f_star_nb, 1)
f(f_ind) = {'%f'};
f = [f{:}]
``` |
94,886 | So I have a server that has a few harddrives in it, all formatted and mounted. However I'm told there is another drive attached to it. How do I find out what drives are attached? How do I find out the device filename for this new drive (that's not mounted) | 2009/12/16 | [
"https://serverfault.com/questions/94886",
"https://serverfault.com",
"https://serverfault.com/users/8950/"
] | `fdisk -l` | Depends on how the drive is attached.
ATA/SATA drives should normally be detected on bootup. Look into the boot log (`/var/log/syslog, /var/log/messages`, output of `dmesg`).
There should also be a list of recognized partitions for all partitioned drives under `/proc/partitions`.
For hotplugged drives (e.g. USB) it depends on how the distribution manages them. Usually modern distros use udev (older might use hotplug or hald). The log is configurable, either a separate log under `/var/log`, or in the general log `messages` or `syslog`). |
94,886 | So I have a server that has a few harddrives in it, all formatted and mounted. However I'm told there is another drive attached to it. How do I find out what drives are attached? How do I find out the device filename for this new drive (that's not mounted) | 2009/12/16 | [
"https://serverfault.com/questions/94886",
"https://serverfault.com",
"https://serverfault.com/users/8950/"
] | `fdisk -l` | fdisk -l
dmesg
/var/log/message.. |
94,886 | So I have a server that has a few harddrives in it, all formatted and mounted. However I'm told there is another drive attached to it. How do I find out what drives are attached? How do I find out the device filename for this new drive (that's not mounted) | 2009/12/16 | [
"https://serverfault.com/questions/94886",
"https://serverfault.com",
"https://serverfault.com/users/8950/"
] | `fdisk -l` | The sg\_\* utilities might also be useful:
```
$ sudo sg_map -i
/dev/sg0 /dev/sda ATA WDC WD5000BEVT-2 01.0
/dev/sg1 /dev/scd0 Optiarc BD ROM BC-5500S 1.83
/dev/sg2 /dev/sdb ATA WDC WD5000BEVT-0 01.0
/dev/sg3 /dev/sdc WD PP III Studio II 0817
```
There are lots of other commands in the sg utilities such as sg\_scan, sg\_readcap and so on.
Also if you are booted from a redhat/centos cd you can switch to an alternate console and use the "list-harddrives" command to show disks attached to the system. |
94,886 | So I have a server that has a few harddrives in it, all formatted and mounted. However I'm told there is another drive attached to it. How do I find out what drives are attached? How do I find out the device filename for this new drive (that's not mounted) | 2009/12/16 | [
"https://serverfault.com/questions/94886",
"https://serverfault.com",
"https://serverfault.com/users/8950/"
] | `fdisk -l` | For those coming here from a search - this is (currently) an old question with old answers, but there are other newer posts that answer this question better.
The solution I prefer is:
`root# lsblk -io NAME,TYPE,SIZE,MOUNTPOINT,FSTYPE,MODEL`
```
NAME TYPE SIZE MOUNTPOINT FSTYPE MODEL
sdb disk 2.7T WDC WD30EZRX-00D
`-sdb1 part 2.7T linux_raid_member
`-md0 raid1 2.7T /home xfs
sda disk 1.8T ST2000DL003-9VT1
|-sda1 part 196.1M /boot ext3
|-sda2 part 980.5M [SWAP] swap
|-sda3 part 8.8G / ext3
|-sda4 part 1K
`-sda5 part 1.8T /samba xfs
sdc disk 2.7T WDC WD30EZRX-00D
`-sdc1 part 2.7T linux_raid_member
`-md0 raid1 2.7T /home xfs
sr0 rom 1024M CDRWDVD DH-48C2S
```
References:
* <https://unix.stackexchange.com/q/4561>
* <https://askubuntu.com/q/182446>
* <https://serverfault.com/a/5081/109417> |
94,886 | So I have a server that has a few harddrives in it, all formatted and mounted. However I'm told there is another drive attached to it. How do I find out what drives are attached? How do I find out the device filename for this new drive (that's not mounted) | 2009/12/16 | [
"https://serverfault.com/questions/94886",
"https://serverfault.com",
"https://serverfault.com/users/8950/"
] | For those coming here from a search - this is (currently) an old question with old answers, but there are other newer posts that answer this question better.
The solution I prefer is:
`root# lsblk -io NAME,TYPE,SIZE,MOUNTPOINT,FSTYPE,MODEL`
```
NAME TYPE SIZE MOUNTPOINT FSTYPE MODEL
sdb disk 2.7T WDC WD30EZRX-00D
`-sdb1 part 2.7T linux_raid_member
`-md0 raid1 2.7T /home xfs
sda disk 1.8T ST2000DL003-9VT1
|-sda1 part 196.1M /boot ext3
|-sda2 part 980.5M [SWAP] swap
|-sda3 part 8.8G / ext3
|-sda4 part 1K
`-sda5 part 1.8T /samba xfs
sdc disk 2.7T WDC WD30EZRX-00D
`-sdc1 part 2.7T linux_raid_member
`-md0 raid1 2.7T /home xfs
sr0 rom 1024M CDRWDVD DH-48C2S
```
References:
* <https://unix.stackexchange.com/q/4561>
* <https://askubuntu.com/q/182446>
* <https://serverfault.com/a/5081/109417> | Depends on how the drive is attached.
ATA/SATA drives should normally be detected on bootup. Look into the boot log (`/var/log/syslog, /var/log/messages`, output of `dmesg`).
There should also be a list of recognized partitions for all partitioned drives under `/proc/partitions`.
For hotplugged drives (e.g. USB) it depends on how the distribution manages them. Usually modern distros use udev (older might use hotplug or hald). The log is configurable, either a separate log under `/var/log`, or in the general log `messages` or `syslog`). |
94,886 | So I have a server that has a few harddrives in it, all formatted and mounted. However I'm told there is another drive attached to it. How do I find out what drives are attached? How do I find out the device filename for this new drive (that's not mounted) | 2009/12/16 | [
"https://serverfault.com/questions/94886",
"https://serverfault.com",
"https://serverfault.com/users/8950/"
] | For those coming here from a search - this is (currently) an old question with old answers, but there are other newer posts that answer this question better.
The solution I prefer is:
`root# lsblk -io NAME,TYPE,SIZE,MOUNTPOINT,FSTYPE,MODEL`
```
NAME TYPE SIZE MOUNTPOINT FSTYPE MODEL
sdb disk 2.7T WDC WD30EZRX-00D
`-sdb1 part 2.7T linux_raid_member
`-md0 raid1 2.7T /home xfs
sda disk 1.8T ST2000DL003-9VT1
|-sda1 part 196.1M /boot ext3
|-sda2 part 980.5M [SWAP] swap
|-sda3 part 8.8G / ext3
|-sda4 part 1K
`-sda5 part 1.8T /samba xfs
sdc disk 2.7T WDC WD30EZRX-00D
`-sdc1 part 2.7T linux_raid_member
`-md0 raid1 2.7T /home xfs
sr0 rom 1024M CDRWDVD DH-48C2S
```
References:
* <https://unix.stackexchange.com/q/4561>
* <https://askubuntu.com/q/182446>
* <https://serverfault.com/a/5081/109417> | fdisk -l
dmesg
/var/log/message.. |
94,886 | So I have a server that has a few harddrives in it, all formatted and mounted. However I'm told there is another drive attached to it. How do I find out what drives are attached? How do I find out the device filename for this new drive (that's not mounted) | 2009/12/16 | [
"https://serverfault.com/questions/94886",
"https://serverfault.com",
"https://serverfault.com/users/8950/"
] | For those coming here from a search - this is (currently) an old question with old answers, but there are other newer posts that answer this question better.
The solution I prefer is:
`root# lsblk -io NAME,TYPE,SIZE,MOUNTPOINT,FSTYPE,MODEL`
```
NAME TYPE SIZE MOUNTPOINT FSTYPE MODEL
sdb disk 2.7T WDC WD30EZRX-00D
`-sdb1 part 2.7T linux_raid_member
`-md0 raid1 2.7T /home xfs
sda disk 1.8T ST2000DL003-9VT1
|-sda1 part 196.1M /boot ext3
|-sda2 part 980.5M [SWAP] swap
|-sda3 part 8.8G / ext3
|-sda4 part 1K
`-sda5 part 1.8T /samba xfs
sdc disk 2.7T WDC WD30EZRX-00D
`-sdc1 part 2.7T linux_raid_member
`-md0 raid1 2.7T /home xfs
sr0 rom 1024M CDRWDVD DH-48C2S
```
References:
* <https://unix.stackexchange.com/q/4561>
* <https://askubuntu.com/q/182446>
* <https://serverfault.com/a/5081/109417> | The sg\_\* utilities might also be useful:
```
$ sudo sg_map -i
/dev/sg0 /dev/sda ATA WDC WD5000BEVT-2 01.0
/dev/sg1 /dev/scd0 Optiarc BD ROM BC-5500S 1.83
/dev/sg2 /dev/sdb ATA WDC WD5000BEVT-0 01.0
/dev/sg3 /dev/sdc WD PP III Studio II 0817
```
There are lots of other commands in the sg utilities such as sg\_scan, sg\_readcap and so on.
Also if you are booted from a redhat/centos cd you can switch to an alternate console and use the "list-harddrives" command to show disks attached to the system. |
38,632,792 | I use the following JQuery function to restrict users from writing numeric values in the textbox. The code works fine but the problem is that it also restrict users from using other characters like full stop(.), comma(,), $, @ and other signs..It also does not allow users to use the options of copy and past. I only want to restrict the users from writing numeric values or numbers but the user should be allowed to use other characters.
```
$(function() {
$('.txtOnly').keydown(function(e) {
if (e.shiftKey || e.ctrlKey || e.altKey) {
e.preventDefault();
} else {
var key = e.keyCode;
if (!((key == 8) || (key == 32) || (key == 46) || (key >= 35 && key <= 40) || (key >= 65 && key <= 90))) {
e.preventDefault();
}
}
});
});
``` | 2016/07/28 | [
"https://Stackoverflow.com/questions/38632792",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5588049/"
] | Hope this helps:
```
<!DOCTYPE html>
<html lang="en">
<head>
<script src="jquery-1.12.2.js"></script>
</head>
<body>
<input class="txtOnly" id="txtOnly" name="txtOnly" type="text" />
<script>
$( document ).ready(function() {
$( ".txtOnly" ).keypress(function(e) {
var key = e.keyCode;
if (key >= 48 && key <= 57) {
e.preventDefault();
}
});
});
</script>
</body>
</html>
``` | You could do using regex `/[^a-z]/g`
```js
$('.txtOnly').bind('keyup blur',function(){
var node = $(this);
node.val(node.val().replace(/[^a-z]/g,'') ); }
);
```
```html
<script src="https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script>
<input name="lorem" class="txtOnly">
``` |
38,632,792 | I use the following JQuery function to restrict users from writing numeric values in the textbox. The code works fine but the problem is that it also restrict users from using other characters like full stop(.), comma(,), $, @ and other signs..It also does not allow users to use the options of copy and past. I only want to restrict the users from writing numeric values or numbers but the user should be allowed to use other characters.
```
$(function() {
$('.txtOnly').keydown(function(e) {
if (e.shiftKey || e.ctrlKey || e.altKey) {
e.preventDefault();
} else {
var key = e.keyCode;
if (!((key == 8) || (key == 32) || (key == 46) || (key >= 35 && key <= 40) || (key >= 65 && key <= 90))) {
e.preventDefault();
}
}
});
});
``` | 2016/07/28 | [
"https://Stackoverflow.com/questions/38632792",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5588049/"
] | You could do using regex `/[^a-z]/g`
```js
$('.txtOnly').bind('keyup blur',function(){
var node = $(this);
node.val(node.val().replace(/[^a-z]/g,'') ); }
);
```
```html
<script src="https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script>
<input name="lorem" class="txtOnly">
``` | You may use following code snippet to prevent users from entering numeric input. It will check for each `keydown` event and prevent any subsequent action if numeric value is provided.
```js
$('.txtOnly').bind('keydown', function(event) {
var key = event.which;
if (key >=48 && key <= 57) {
event.preventDefault();
}
});
```
```html
<script src="https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script>
<input class="txtOnly">
``` |
38,632,792 | I use the following JQuery function to restrict users from writing numeric values in the textbox. The code works fine but the problem is that it also restrict users from using other characters like full stop(.), comma(,), $, @ and other signs..It also does not allow users to use the options of copy and past. I only want to restrict the users from writing numeric values or numbers but the user should be allowed to use other characters.
```
$(function() {
$('.txtOnly').keydown(function(e) {
if (e.shiftKey || e.ctrlKey || e.altKey) {
e.preventDefault();
} else {
var key = e.keyCode;
if (!((key == 8) || (key == 32) || (key == 46) || (key >= 35 && key <= 40) || (key >= 65 && key <= 90))) {
e.preventDefault();
}
}
});
});
``` | 2016/07/28 | [
"https://Stackoverflow.com/questions/38632792",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5588049/"
] | ```js
$('.txtOnly').keypress(function (e) {
var regex = new RegExp("^[a-zA-Z]+$");
var str = String.fromCharCode(!e.charCode ? e.which : e.charCode);
if (regex.test(str)) {
return true;
}
else
{
e.preventDefault();
$('.error').show();
$('.error').text('Please Enter Alphabate');
return false;
}
});
```
```html
<script src="https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script>
<p class="error"></p>
<input class="txtOnly" type="text">
``` | You could do using regex `/[^a-z]/g`
```js
$('.txtOnly').bind('keyup blur',function(){
var node = $(this);
node.val(node.val().replace(/[^a-z]/g,'') ); }
);
```
```html
<script src="https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script>
<input name="lorem" class="txtOnly">
``` |
38,632,792 | I use the following JQuery function to restrict users from writing numeric values in the textbox. The code works fine but the problem is that it also restrict users from using other characters like full stop(.), comma(,), $, @ and other signs..It also does not allow users to use the options of copy and past. I only want to restrict the users from writing numeric values or numbers but the user should be allowed to use other characters.
```
$(function() {
$('.txtOnly').keydown(function(e) {
if (e.shiftKey || e.ctrlKey || e.altKey) {
e.preventDefault();
} else {
var key = e.keyCode;
if (!((key == 8) || (key == 32) || (key == 46) || (key >= 35 && key <= 40) || (key >= 65 && key <= 90))) {
e.preventDefault();
}
}
});
});
``` | 2016/07/28 | [
"https://Stackoverflow.com/questions/38632792",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5588049/"
] | Hope this helps:
```
<!DOCTYPE html>
<html lang="en">
<head>
<script src="jquery-1.12.2.js"></script>
</head>
<body>
<input class="txtOnly" id="txtOnly" name="txtOnly" type="text" />
<script>
$( document ).ready(function() {
$( ".txtOnly" ).keypress(function(e) {
var key = e.keyCode;
if (key >= 48 && key <= 57) {
e.preventDefault();
}
});
});
</script>
</body>
</html>
``` | You may use following code snippet to prevent users from entering numeric input. It will check for each `keydown` event and prevent any subsequent action if numeric value is provided.
```js
$('.txtOnly').bind('keydown', function(event) {
var key = event.which;
if (key >=48 && key <= 57) {
event.preventDefault();
}
});
```
```html
<script src="https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script>
<input class="txtOnly">
``` |
38,632,792 | I use the following JQuery function to restrict users from writing numeric values in the textbox. The code works fine but the problem is that it also restrict users from using other characters like full stop(.), comma(,), $, @ and other signs..It also does not allow users to use the options of copy and past. I only want to restrict the users from writing numeric values or numbers but the user should be allowed to use other characters.
```
$(function() {
$('.txtOnly').keydown(function(e) {
if (e.shiftKey || e.ctrlKey || e.altKey) {
e.preventDefault();
} else {
var key = e.keyCode;
if (!((key == 8) || (key == 32) || (key == 46) || (key >= 35 && key <= 40) || (key >= 65 && key <= 90))) {
e.preventDefault();
}
}
});
});
``` | 2016/07/28 | [
"https://Stackoverflow.com/questions/38632792",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5588049/"
] | Hope this helps:
```
<!DOCTYPE html>
<html lang="en">
<head>
<script src="jquery-1.12.2.js"></script>
</head>
<body>
<input class="txtOnly" id="txtOnly" name="txtOnly" type="text" />
<script>
$( document ).ready(function() {
$( ".txtOnly" ).keypress(function(e) {
var key = e.keyCode;
if (key >= 48 && key <= 57) {
e.preventDefault();
}
});
});
</script>
</body>
</html>
``` | ```js
$('.txtOnly').keypress(function (e) {
var regex = new RegExp("^[a-zA-Z]+$");
var str = String.fromCharCode(!e.charCode ? e.which : e.charCode);
if (regex.test(str)) {
return true;
}
else
{
e.preventDefault();
$('.error').show();
$('.error').text('Please Enter Alphabate');
return false;
}
});
```
```html
<script src="https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script>
<p class="error"></p>
<input class="txtOnly" type="text">
``` |
38,632,792 | I use the following JQuery function to restrict users from writing numeric values in the textbox. The code works fine but the problem is that it also restrict users from using other characters like full stop(.), comma(,), $, @ and other signs..It also does not allow users to use the options of copy and past. I only want to restrict the users from writing numeric values or numbers but the user should be allowed to use other characters.
```
$(function() {
$('.txtOnly').keydown(function(e) {
if (e.shiftKey || e.ctrlKey || e.altKey) {
e.preventDefault();
} else {
var key = e.keyCode;
if (!((key == 8) || (key == 32) || (key == 46) || (key >= 35 && key <= 40) || (key >= 65 && key <= 90))) {
e.preventDefault();
}
}
});
});
``` | 2016/07/28 | [
"https://Stackoverflow.com/questions/38632792",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5588049/"
] | ```js
$('.txtOnly').keypress(function (e) {
var regex = new RegExp("^[a-zA-Z]+$");
var str = String.fromCharCode(!e.charCode ? e.which : e.charCode);
if (regex.test(str)) {
return true;
}
else
{
e.preventDefault();
$('.error').show();
$('.error').text('Please Enter Alphabate');
return false;
}
});
```
```html
<script src="https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script>
<p class="error"></p>
<input class="txtOnly" type="text">
``` | You may use following code snippet to prevent users from entering numeric input. It will check for each `keydown` event and prevent any subsequent action if numeric value is provided.
```js
$('.txtOnly').bind('keydown', function(event) {
var key = event.which;
if (key >=48 && key <= 57) {
event.preventDefault();
}
});
```
```html
<script src="https://ajax.googleapis.com/ajax/libs/jquery/2.1.1/jquery.min.js"></script>
<input class="txtOnly">
``` |
5,437,501 | I have a concern of using GPL v2 and GPL v3 licensed software in commercial production environment. I would like to use HaProxy as a load balancing solution. Is it safe against copy-left? I won't modify anything from source code and the architecture of the system requires the use of a load balancer.
It will be embedded in a larger distributed system. So what we sell is the whole system. On another site, we will need to install the load balancer again and could mix with something else. I think it's the "Distributing" term which is confusing me. | 2011/03/25 | [
"https://Stackoverflow.com/questions/5437501",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/395146/"
] | If you're distributing (unmodified) binaries along with a product you ship, then you're required to distribute the source with them, or provide a way for people to request the sources. This is not a situation where you can ignore the GPL, but it's not going to be a real problem for you. The GPL won't infect your proprietary software unless you link to it.
Distributing in this sense means giving (or selling) to customers. If you're just using a distributed (multi-node) system inside your company, then you're entirely in the clear, as yan says.
Incidentally, the [GPLv2](http://www.gnu.org/licenses/gpl-2.0.html) ([v3 here](http://www.gnu.org/licenses/gpl-3.0.html)) is written to be read by non-lawyers. I strongly recommend you take a look at it. If English isn't your first language, [translations](http://www.gnu.org/licenses/old-licenses/gpl-2.0-translations.html) are available in many languages. | If you're not modifying the source and using the binaries, you should be entirely in the clear. |
5,437,501 | I have a concern of using GPL v2 and GPL v3 licensed software in commercial production environment. I would like to use HaProxy as a load balancing solution. Is it safe against copy-left? I won't modify anything from source code and the architecture of the system requires the use of a load balancer.
It will be embedded in a larger distributed system. So what we sell is the whole system. On another site, we will need to install the load balancer again and could mix with something else. I think it's the "Distributing" term which is confusing me. | 2011/03/25 | [
"https://Stackoverflow.com/questions/5437501",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/395146/"
] | Haproxy is GPLv2, so you can redistribute it in binary form provided you give enough information to the end user about where to fetch the sources to rebuild it. You also need to inform them about the build options / environment, because without them, it's possible that they won't be able to get the same features.
When you have a doubt on those points, keep in mind that the GPL's goal is to ensure that if you disappear, your customers will not be left with a buggy software they can't fix. So you just have to provide them means not to depend on your availability. When you keep that in mind, it's a lot easier to make the right choice. And good faith always counts if you try to make this possible but fail because you've not thought about everything.
Also, keep in mind that whenever you start distributing software, some of your customers will ask for specific changes to better cover their needs. At first you'll refuse but after losing a few customers who all want the exact same minor feature, you'll accept. Then you'll have patched the code and be embarrassed because you won't be able to point the customer to the original site to get the code.
There are two approaches to this :
- the patch is of general use and you don't want to maintain it. Just submit it for inclusion into mainstream. If it's accepted, you can update your version and don't need to maintain a patch anymore ;
- the patch is too much customer-specific and has no chance of being accepted, then you need to make it available to your customer along with the build instructions so that the customer can still grab the official release, patch it and build it.
One possible typical patch is to remove some names/urls/versions etc in the doc to make it appear cleaner and better integrated with your solution. Removing these information is right if you provide the patch which removes them. That way there's no obfuscation, your changes are transparent.
In any case, if you spot a bug and think you fixed it, you're strongly encouraged to submit it for review, as it's common to fix the consequences instead of the causes. | If you're not modifying the source and using the binaries, you should be entirely in the clear. |
5,437,501 | I have a concern of using GPL v2 and GPL v3 licensed software in commercial production environment. I would like to use HaProxy as a load balancing solution. Is it safe against copy-left? I won't modify anything from source code and the architecture of the system requires the use of a load balancer.
It will be embedded in a larger distributed system. So what we sell is the whole system. On another site, we will need to install the load balancer again and could mix with something else. I think it's the "Distributing" term which is confusing me. | 2011/03/25 | [
"https://Stackoverflow.com/questions/5437501",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/395146/"
] | Another point about the title of your question "Can I use GPL software binaries in commercial environment?" : yes you can and you're even encouraged to do so. The more free software we'll have in commercial environments, the less hassle we'll have to fix issues in production ! | If you're not modifying the source and using the binaries, you should be entirely in the clear. |
5,437,501 | I have a concern of using GPL v2 and GPL v3 licensed software in commercial production environment. I would like to use HaProxy as a load balancing solution. Is it safe against copy-left? I won't modify anything from source code and the architecture of the system requires the use of a load balancer.
It will be embedded in a larger distributed system. So what we sell is the whole system. On another site, we will need to install the load balancer again and could mix with something else. I think it's the "Distributing" term which is confusing me. | 2011/03/25 | [
"https://Stackoverflow.com/questions/5437501",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/395146/"
] | If you're distributing (unmodified) binaries along with a product you ship, then you're required to distribute the source with them, or provide a way for people to request the sources. This is not a situation where you can ignore the GPL, but it's not going to be a real problem for you. The GPL won't infect your proprietary software unless you link to it.
Distributing in this sense means giving (or selling) to customers. If you're just using a distributed (multi-node) system inside your company, then you're entirely in the clear, as yan says.
Incidentally, the [GPLv2](http://www.gnu.org/licenses/gpl-2.0.html) ([v3 here](http://www.gnu.org/licenses/gpl-3.0.html)) is written to be read by non-lawyers. I strongly recommend you take a look at it. If English isn't your first language, [translations](http://www.gnu.org/licenses/old-licenses/gpl-2.0-translations.html) are available in many languages. | Haproxy is GPLv2, so you can redistribute it in binary form provided you give enough information to the end user about where to fetch the sources to rebuild it. You also need to inform them about the build options / environment, because without them, it's possible that they won't be able to get the same features.
When you have a doubt on those points, keep in mind that the GPL's goal is to ensure that if you disappear, your customers will not be left with a buggy software they can't fix. So you just have to provide them means not to depend on your availability. When you keep that in mind, it's a lot easier to make the right choice. And good faith always counts if you try to make this possible but fail because you've not thought about everything.
Also, keep in mind that whenever you start distributing software, some of your customers will ask for specific changes to better cover their needs. At first you'll refuse but after losing a few customers who all want the exact same minor feature, you'll accept. Then you'll have patched the code and be embarrassed because you won't be able to point the customer to the original site to get the code.
There are two approaches to this :
- the patch is of general use and you don't want to maintain it. Just submit it for inclusion into mainstream. If it's accepted, you can update your version and don't need to maintain a patch anymore ;
- the patch is too much customer-specific and has no chance of being accepted, then you need to make it available to your customer along with the build instructions so that the customer can still grab the official release, patch it and build it.
One possible typical patch is to remove some names/urls/versions etc in the doc to make it appear cleaner and better integrated with your solution. Removing these information is right if you provide the patch which removes them. That way there's no obfuscation, your changes are transparent.
In any case, if you spot a bug and think you fixed it, you're strongly encouraged to submit it for review, as it's common to fix the consequences instead of the causes. |
5,437,501 | I have a concern of using GPL v2 and GPL v3 licensed software in commercial production environment. I would like to use HaProxy as a load balancing solution. Is it safe against copy-left? I won't modify anything from source code and the architecture of the system requires the use of a load balancer.
It will be embedded in a larger distributed system. So what we sell is the whole system. On another site, we will need to install the load balancer again and could mix with something else. I think it's the "Distributing" term which is confusing me. | 2011/03/25 | [
"https://Stackoverflow.com/questions/5437501",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/395146/"
] | If you're distributing (unmodified) binaries along with a product you ship, then you're required to distribute the source with them, or provide a way for people to request the sources. This is not a situation where you can ignore the GPL, but it's not going to be a real problem for you. The GPL won't infect your proprietary software unless you link to it.
Distributing in this sense means giving (or selling) to customers. If you're just using a distributed (multi-node) system inside your company, then you're entirely in the clear, as yan says.
Incidentally, the [GPLv2](http://www.gnu.org/licenses/gpl-2.0.html) ([v3 here](http://www.gnu.org/licenses/gpl-3.0.html)) is written to be read by non-lawyers. I strongly recommend you take a look at it. If English isn't your first language, [translations](http://www.gnu.org/licenses/old-licenses/gpl-2.0-translations.html) are available in many languages. | Another point about the title of your question "Can I use GPL software binaries in commercial environment?" : yes you can and you're even encouraged to do so. The more free software we'll have in commercial environments, the less hassle we'll have to fix issues in production ! |
21,212,121 | I am new to jquery, Please help me resolve the below issue.
I have a modal popup and inside the popup i have two asp buttons(Search and close). Onclick of the search button i want to perform a validation and then fire the server button click event and on click of the close button i want to close the dialog.
**Problems faced:**
1. Onclick of search the jquery validation is happening but the server side event is not getting fired.
2. Onclick of close, the dialog is getting closed only for the first time but after click of the search button once, the close JQUERY is not getting fired.
**Below is the code:**
***button to open dialog***
```
<asp:Button ID="btnOpenDialog" runat="server" Text="Change"/>
```
***jquery to open dialog***
```
$("[id*=btnOpenDialog]").live("click", function () {
$("#modal_dialog").dialog({
title: "Details",
modal: true,
width: "700px"
});
return false;
})
```
***The dialog with the asp buttons***
```
<div id="modal_dialog" style="display:none">
<asp:Label ID="lblError" runat="server" Visible="true" ForeColor="Red"></asp:Label>
<asp:Label ID="lblLastName" runat="server" Text="Last Name"></asp:Label>
<asp:TextBox ID="txtLastName" Width="100px" runat="server"></asp:TextBox>
<asp:Label ID="lblFirstName" runat="server" Text="First Name"> </asp:Label>
<asp:TextBox ID="txtFirstName" Width="100px" runat="server"></asp:TextBox>
<asp:Button ID="btnSearch" UseSubmitBehavior="false" runat="server" Text="Search" OnClick="btnSearch_Click"/>
<asp:Button ID ="btnClose" Text="Close" runat="server"></asp:Button>
</div>
```
***The btnSearch JQUERY***
```
$("[id*=btnSearch]").live("click", function (e) {
//e.preventDefault();
var firstName = $("#<%= txtFirstName.ClientID %>").val();
var lastName = $("#<%= txtLastName.ClientID %>").val();
if(firstName == "" & lastName == "")
{
$("#<%= lblError.ClientID %>").text("Enter minimum two characters in either first name or last name");
return false;
}
else
{
$("#<%= lblError.ClientID %>").text("");
$("#hdnFirstNameInitiator").val($("#<%= txtFirstName.ClientID %>").val());
$("#hdnLastNameInitiator").val($("#<%= txtLastName.ClientID %>").val());
return true;
}
})
```
***The close button JQUERY***
```
$("[id*=btnClose]").live("click", function (e) {
//e.preventDefault();
$("#modal_dialog").dialog('close');
return true;
})
```
Also if possible please brief me about e.preventDefault() and appendTo functions in jquery.
Please Help.
Thanks in advance, | 2014/01/19 | [
"https://Stackoverflow.com/questions/21212121",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/3211156/"
] | Add a constructor
```
template <typename Type2> Pos2(const Pos2<Type2> &other)
{ x = other.x; y = other.y; }
``` | You need to define an assignment operator for assignment from type `Size` to type `Pos`, because these are not the same type and therefore there is no default assignment operator between the two.
I guess you want to use a template here, so any instantiation of `Pos2` can be used to assign to another instantiation. For example like so:
```
template<typename T>
class Pos2 {
public:
T x, y;
Pos2() : x(0), y(0) {};
Pos2(T xy) : x(xy), y(xy) {};
Pos2(T x, T y) : x(x), y(y) {};
template<typename FromT>
Pos2<T>& operator=(const Pos2<FromT>& from) {
x = from.x;
y = from.y;
return *this;
}
};
```
You should do the same with the copy constructor (not shown here), because it might likely happen that you want to copy construct in the same scheme at some point.
This does only work if the assignment between type `T` and `FromT`, that is `pos_scalar` and `size_scalar` is possible. If not try to add correct explicit conversions and/or template specializations for the assignment operator.
Also if any of the members of `Pos2` are private/protected you will need to `friend` the assignment operator or provide adequate getters. |
47,350,199 | Environment:
Asp Net MVC app(.net framework 4.5.1) hosted on Azure app service with two instances.
App uses Azure SQL server database.
Also, app uses MemoryCache (System.Runtime.Caching) for caching purposes.
Recently, I noticed availability loss of the app. It happens almost every day.
[](https://i.stack.imgur.com/ExZnC.png)
[](https://i.stack.imgur.com/ZmXAq.png)
Observations:
The memory counter Page Reads/sec was at a dangerous level (242) on instance RD0003FF1F6B1B. Any value over 200 can cause delays or failures for any app on that instance.
What 'The memory counter Page Reads/sec' means?
How to fix this issue? | 2017/11/17 | [
"https://Stackoverflow.com/questions/47350199",
"https://Stackoverflow.com",
"https://Stackoverflow.com/users/5841485/"
] | >
> What 'The memory counter Page Reads/sec' means?
>
>
>
We could get the answer from this [blog](https://www.sqlshack.com/sql-server-memory-performance-metrics-part-3-sql-server-buffer-manager-metrics-memory-counters/). The recommended Page reads/sec value should be under **90**. Higher values indicate **insufficient memory** and **indexing issues**.
>
> “Page reads/sec indicates the number of physical database page reads that are issued per second. This statistic displays the total number of physical page reads across all databases. Because physical I/O is expensive, you may be able to minimize the cost, either by using a larger data cache, intelligent indexes, and more efficient queries, or by changing the database design.”
>
>
>
---
>
> How to fix this issue?
>
>
>
Based on my experience, you could have a try to [enable Local Cache in App
Service](https://learn.microsoft.com/en-us/azure/app-service/app-service-local-cache-overview#enable-local-cache-in-app-service).
>
> You enable Local Cache on a per-web-app basis by using this app setting: **WEBSITE\_LOCAL\_CACHE\_OPTION = Always**
>
>
> By default, the local cache size is **300 MB**. This includes the /site and /siteextensions folders that are copied from the content store, as well as any locally created logs and data folders. To increase this limit, use the app setting **WEBSITE\_LOCAL\_CACHE\_SIZEINMB**. You can increase the size up to **2 GB (2000 MB)** per web app.
>
>
> | There is some memory performance problems can be listed
* excessive paging,
* memory shortages,
* memory leaks
Memory counter values can be used to detect the presence of various performance problems. Tracking counter values both on a **system-wide** and a **per-process** basis helps you to pinpoint the cause in Azure such as in other systems.
Even if there is no change in the process, a change in the system can cause memory problems. the **system-wide**
**researching in the azure**:
Shared resources plans (Free and Basic) have memory limits as seen here: <https://learn.microsoft.com/en-us/azure/azure-subscription-service-limits#app-service-limits>.
**Quotas**: <https://learn.microsoft.com/en-us/azure/app-service-web/web-sites-monitor>
Also, you can check in the portal under your web app settings, search for “quotas”, and also check out “Diagnose and solve problems” and hit “metrics per instance (app service plan)” which will show you memory used for the plan.
A MemoryCache bug in .net 4 can also cause this type of behavior
<https://stackoverflow.com/a/15715990/914284> |
229,329 | I have a huge collection of PDF. Mostly it consists of research papers, of self-created documents but also of scanned documents.
Right now I drop them all in one folder and give them precise names with tags in the filename.
But even that gets impractical, so **I am looking for a PDF library management application**. I am thinking of something like [Yep](http://www.ironicsoftware.com/yep/) for Mac, with the following features:
* PDF cover browsing (with large preview, larger than Nautilus allows)
* tagging of PDF (data should be readable cross-platform)
* possibility to share across network (thus rather flat files than database)
* if possible: cross-platform
Mendeley seemed to be a good choice, but I am not only having academic papers and don't want to fill it all metadata that is required there.
The only alternative I could find thus far is [Shoka](http://www.mauropiccini.it/shoka/), but the features are limited and developments seems to have stopped already. | 2012/12/15 | [
"https://askubuntu.com/questions/229329",
"https://askubuntu.com",
"https://askubuntu.com/users/78383/"
] | One possibility is [Calibre](http://calibre-ebook.com).
It is an ebook management program which permits conversion to various ebook formats but is cross-platform and can manage databases of pdf files (and not only).
If you decide to install I suggest you do so manually as the version in the repos is not very up to date. Follow the instructions on the site.
A screenshot:
Another possibility is [Zotero](http://www.zotero.org/)
It is is bibliography manager but permits adding book details directly through a browser Amazon.com and other sites, pdf attachments and more.
To import the pdf's into Zotero you can [see this page](http://libguides.northwestern.edu/content.php?pid=68444&sid=1179558). | **[Referencer](http://packages.ubuntu.com/de/lucid/referencer)** (GNOME) is a simple tool for managing document collections.
Tagging is possible.
It tries to find metadata on arXiv or via DOI, but you can add metadata manually too, of course.
But I guess development stopped. |
229,329 | I have a huge collection of PDF. Mostly it consists of research papers, of self-created documents but also of scanned documents.
Right now I drop them all in one folder and give them precise names with tags in the filename.
But even that gets impractical, so **I am looking for a PDF library management application**. I am thinking of something like [Yep](http://www.ironicsoftware.com/yep/) for Mac, with the following features:
* PDF cover browsing (with large preview, larger than Nautilus allows)
* tagging of PDF (data should be readable cross-platform)
* possibility to share across network (thus rather flat files than database)
* if possible: cross-platform
Mendeley seemed to be a good choice, but I am not only having academic papers and don't want to fill it all metadata that is required there.
The only alternative I could find thus far is [Shoka](http://www.mauropiccini.it/shoka/), but the features are limited and developments seems to have stopped already. | 2012/12/15 | [
"https://askubuntu.com/questions/229329",
"https://askubuntu.com",
"https://askubuntu.com/users/78383/"
] | One possibility is [Calibre](http://calibre-ebook.com).
It is an ebook management program which permits conversion to various ebook formats but is cross-platform and can manage databases of pdf files (and not only).
If you decide to install I suggest you do so manually as the version in the repos is not very up to date. Follow the instructions on the site.
A screenshot:

Another possibility is [Zotero](http://www.zotero.org/)
It is is bibliography manager but permits adding book details directly through a browser Amazon.com and other sites, pdf attachments and more.

To import the pdf's into Zotero you can [see this page](http://libguides.northwestern.edu/content.php?pid=68444&sid=1179558). | Have you Tried Gnome Documents?
>
> GNOME Documents is a standalone application to find, organize and view
> your documents.
>
>
>
[](https://apps.ubuntu.com/cat/applications/gnome-documents) |
229,329 | I have a huge collection of PDF. Mostly it consists of research papers, of self-created documents but also of scanned documents.
Right now I drop them all in one folder and give them precise names with tags in the filename.
But even that gets impractical, so **I am looking for a PDF library management application**. I am thinking of something like [Yep](http://www.ironicsoftware.com/yep/) for Mac, with the following features:
* PDF cover browsing (with large preview, larger than Nautilus allows)
* tagging of PDF (data should be readable cross-platform)
* possibility to share across network (thus rather flat files than database)
* if possible: cross-platform
Mendeley seemed to be a good choice, but I am not only having academic papers and don't want to fill it all metadata that is required there.
The only alternative I could find thus far is [Shoka](http://www.mauropiccini.it/shoka/), but the features are limited and developments seems to have stopped already. | 2012/12/15 | [
"https://askubuntu.com/questions/229329",
"https://askubuntu.com",
"https://askubuntu.com/users/78383/"
] | One possibility is [Calibre](http://calibre-ebook.com).
It is an ebook management program which permits conversion to various ebook formats but is cross-platform and can manage databases of pdf files (and not only).
If you decide to install I suggest you do so manually as the version in the repos is not very up to date. Follow the instructions on the site.
A screenshot:

Another possibility is [Zotero](http://www.zotero.org/)
It is is bibliography manager but permits adding book details directly through a browser Amazon.com and other sites, pdf attachments and more.

To import the pdf's into Zotero you can [see this page](http://libguides.northwestern.edu/content.php?pid=68444&sid=1179558). | I use Docear. Mind-mapping is the mode which I prefer to explore tagged (hierarchical) notes and references. The way they implement hierarchical node trees, it is effectively tagging.
The UI for building out mind maps is fast. Though there is some learning curve to overcome at the beginning, it pays off in spades when you actually index your material in a way which primes your recollection later on. It is the closest thing to augmented memory that I have found besides the Google/Wikipedia/[askubuntu]/etc. combos. =)
<http://en.wikipedia.org/wiki/Docear> |
229,329 | I have a huge collection of PDF. Mostly it consists of research papers, of self-created documents but also of scanned documents.
Right now I drop them all in one folder and give them precise names with tags in the filename.
But even that gets impractical, so **I am looking for a PDF library management application**. I am thinking of something like [Yep](http://www.ironicsoftware.com/yep/) for Mac, with the following features:
* PDF cover browsing (with large preview, larger than Nautilus allows)
* tagging of PDF (data should be readable cross-platform)
* possibility to share across network (thus rather flat files than database)
* if possible: cross-platform
Mendeley seemed to be a good choice, but I am not only having academic papers and don't want to fill it all metadata that is required there.
The only alternative I could find thus far is [Shoka](http://www.mauropiccini.it/shoka/), but the features are limited and developments seems to have stopped already. | 2012/12/15 | [
"https://askubuntu.com/questions/229329",
"https://askubuntu.com",
"https://askubuntu.com/users/78383/"
] | One possibility is [Calibre](http://calibre-ebook.com).
It is an ebook management program which permits conversion to various ebook formats but is cross-platform and can manage databases of pdf files (and not only).
If you decide to install I suggest you do so manually as the version in the repos is not very up to date. Follow the instructions on the site.
A screenshot:

Another possibility is [Zotero](http://www.zotero.org/)
It is is bibliography manager but permits adding book details directly through a browser Amazon.com and other sites, pdf attachments and more.

To import the pdf's into Zotero you can [see this page](http://libguides.northwestern.edu/content.php?pid=68444&sid=1179558). | Give I, Librarian a try:
<http://i-librarian.net>
It shows PDF covers, it allows tagging, it is web-based so network access is easy and fully cross-platform. |
229,329 | I have a huge collection of PDF. Mostly it consists of research papers, of self-created documents but also of scanned documents.
Right now I drop them all in one folder and give them precise names with tags in the filename.
But even that gets impractical, so **I am looking for a PDF library management application**. I am thinking of something like [Yep](http://www.ironicsoftware.com/yep/) for Mac, with the following features:
* PDF cover browsing (with large preview, larger than Nautilus allows)
* tagging of PDF (data should be readable cross-platform)
* possibility to share across network (thus rather flat files than database)
* if possible: cross-platform
Mendeley seemed to be a good choice, but I am not only having academic papers and don't want to fill it all metadata that is required there.
The only alternative I could find thus far is [Shoka](http://www.mauropiccini.it/shoka/), but the features are limited and developments seems to have stopped already. | 2012/12/15 | [
"https://askubuntu.com/questions/229329",
"https://askubuntu.com",
"https://askubuntu.com/users/78383/"
] | Have you Tried Gnome Documents?
>
> GNOME Documents is a standalone application to find, organize and view
> your documents.
>
>
>

[](https://apps.ubuntu.com/cat/applications/gnome-documents) | **[Referencer](http://packages.ubuntu.com/de/lucid/referencer)** (GNOME) is a simple tool for managing document collections.
Tagging is possible.
It tries to find metadata on arXiv or via DOI, but you can add metadata manually too, of course.
But I guess development stopped. |
229,329 | I have a huge collection of PDF. Mostly it consists of research papers, of self-created documents but also of scanned documents.
Right now I drop them all in one folder and give them precise names with tags in the filename.
But even that gets impractical, so **I am looking for a PDF library management application**. I am thinking of something like [Yep](http://www.ironicsoftware.com/yep/) for Mac, with the following features:
* PDF cover browsing (with large preview, larger than Nautilus allows)
* tagging of PDF (data should be readable cross-platform)
* possibility to share across network (thus rather flat files than database)
* if possible: cross-platform
Mendeley seemed to be a good choice, but I am not only having academic papers and don't want to fill it all metadata that is required there.
The only alternative I could find thus far is [Shoka](http://www.mauropiccini.it/shoka/), but the features are limited and developments seems to have stopped already. | 2012/12/15 | [
"https://askubuntu.com/questions/229329",
"https://askubuntu.com",
"https://askubuntu.com/users/78383/"
] | I use Docear. Mind-mapping is the mode which I prefer to explore tagged (hierarchical) notes and references. The way they implement hierarchical node trees, it is effectively tagging.
The UI for building out mind maps is fast. Though there is some learning curve to overcome at the beginning, it pays off in spades when you actually index your material in a way which primes your recollection later on. It is the closest thing to augmented memory that I have found besides the Google/Wikipedia/[askubuntu]/etc. combos. =)
<http://en.wikipedia.org/wiki/Docear> | **[Referencer](http://packages.ubuntu.com/de/lucid/referencer)** (GNOME) is a simple tool for managing document collections.
Tagging is possible.
It tries to find metadata on arXiv or via DOI, but you can add metadata manually too, of course.
But I guess development stopped. |
229,329 | I have a huge collection of PDF. Mostly it consists of research papers, of self-created documents but also of scanned documents.
Right now I drop them all in one folder and give them precise names with tags in the filename.
But even that gets impractical, so **I am looking for a PDF library management application**. I am thinking of something like [Yep](http://www.ironicsoftware.com/yep/) for Mac, with the following features:
* PDF cover browsing (with large preview, larger than Nautilus allows)
* tagging of PDF (data should be readable cross-platform)
* possibility to share across network (thus rather flat files than database)
* if possible: cross-platform
Mendeley seemed to be a good choice, but I am not only having academic papers and don't want to fill it all metadata that is required there.
The only alternative I could find thus far is [Shoka](http://www.mauropiccini.it/shoka/), but the features are limited and developments seems to have stopped already. | 2012/12/15 | [
"https://askubuntu.com/questions/229329",
"https://askubuntu.com",
"https://askubuntu.com/users/78383/"
] | Give I, Librarian a try:
<http://i-librarian.net>
It shows PDF covers, it allows tagging, it is web-based so network access is easy and fully cross-platform. | **[Referencer](http://packages.ubuntu.com/de/lucid/referencer)** (GNOME) is a simple tool for managing document collections.
Tagging is possible.
It tries to find metadata on arXiv or via DOI, but you can add metadata manually too, of course.
But I guess development stopped. |
229,329 | I have a huge collection of PDF. Mostly it consists of research papers, of self-created documents but also of scanned documents.
Right now I drop them all in one folder and give them precise names with tags in the filename.
But even that gets impractical, so **I am looking for a PDF library management application**. I am thinking of something like [Yep](http://www.ironicsoftware.com/yep/) for Mac, with the following features:
* PDF cover browsing (with large preview, larger than Nautilus allows)
* tagging of PDF (data should be readable cross-platform)
* possibility to share across network (thus rather flat files than database)
* if possible: cross-platform
Mendeley seemed to be a good choice, but I am not only having academic papers and don't want to fill it all metadata that is required there.
The only alternative I could find thus far is [Shoka](http://www.mauropiccini.it/shoka/), but the features are limited and developments seems to have stopped already. | 2012/12/15 | [
"https://askubuntu.com/questions/229329",
"https://askubuntu.com",
"https://askubuntu.com/users/78383/"
] | I use Docear. Mind-mapping is the mode which I prefer to explore tagged (hierarchical) notes and references. The way they implement hierarchical node trees, it is effectively tagging.
The UI for building out mind maps is fast. Though there is some learning curve to overcome at the beginning, it pays off in spades when you actually index your material in a way which primes your recollection later on. It is the closest thing to augmented memory that I have found besides the Google/Wikipedia/[askubuntu]/etc. combos. =)
<http://en.wikipedia.org/wiki/Docear> | Have you Tried Gnome Documents?
>
> GNOME Documents is a standalone application to find, organize and view
> your documents.
>
>
>

[](https://apps.ubuntu.com/cat/applications/gnome-documents) |
229,329 | I have a huge collection of PDF. Mostly it consists of research papers, of self-created documents but also of scanned documents.
Right now I drop them all in one folder and give them precise names with tags in the filename.
But even that gets impractical, so **I am looking for a PDF library management application**. I am thinking of something like [Yep](http://www.ironicsoftware.com/yep/) for Mac, with the following features:
* PDF cover browsing (with large preview, larger than Nautilus allows)
* tagging of PDF (data should be readable cross-platform)
* possibility to share across network (thus rather flat files than database)
* if possible: cross-platform
Mendeley seemed to be a good choice, but I am not only having academic papers and don't want to fill it all metadata that is required there.
The only alternative I could find thus far is [Shoka](http://www.mauropiccini.it/shoka/), but the features are limited and developments seems to have stopped already. | 2012/12/15 | [
"https://askubuntu.com/questions/229329",
"https://askubuntu.com",
"https://askubuntu.com/users/78383/"
] | I use Docear. Mind-mapping is the mode which I prefer to explore tagged (hierarchical) notes and references. The way they implement hierarchical node trees, it is effectively tagging.
The UI for building out mind maps is fast. Though there is some learning curve to overcome at the beginning, it pays off in spades when you actually index your material in a way which primes your recollection later on. It is the closest thing to augmented memory that I have found besides the Google/Wikipedia/[askubuntu]/etc. combos. =)
<http://en.wikipedia.org/wiki/Docear> | Give I, Librarian a try:
<http://i-librarian.net>
It shows PDF covers, it allows tagging, it is web-based so network access is easy and fully cross-platform. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.