
problem_id
stringlengths 18
22
| source
stringclasses 1
value | task_type
stringclasses 1
value | in_source_id
stringlengths 13
58
| prompt
stringlengths 1.71k
18.9k
| golden_diff
stringlengths 145
5.13k
| verification_info
stringlengths 465
23.6k
| num_tokens_prompt
int64 556
4.1k
| num_tokens_diff
int64 47
1.02k
|
|---|---|---|---|---|---|---|---|---|
gh_patches_debug_5930
|
rasdani/github-patches
|
git_diff
|
getsentry__sentry-4564
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
BrowserExtensionsFilter: _gCrWeb autofill error in iOS Chrome not ignored
This seems to be a relatively well-known issue on Chrome for iOS. It seems this could be ignored safely by the filter as well.
Source: https://groups.google.com/a/chromium.org/forum/#!topic/chromium-discuss/7VU0_VvC7mE
</issue>
<code>
[start of src/sentry/filters/browser_extensions.py]
1 from __future__ import absolute_import
2
3 from .base import Filter
4
5 import re
6
7 EXTENSION_EXC_VALUES = re.compile('|'.join((re.escape(x) for x in (
8 # Random plugins/extensions
9 'top.GLOBALS',
10 # See: http://blog.errorception.com/2012/03/tale-of-unfindable-js-error. html
11 'originalCreateNotification',
12 'canvas.contentDocument',
13 'MyApp_RemoveAllHighlights',
14 'http://tt.epicplay.com',
15 'Can\'t find variable: ZiteReader',
16 'jigsaw is not defined',
17 'ComboSearch is not defined',
18 'http://loading.retry.widdit.com/',
19 'atomicFindClose',
20 # Facebook borked
21 'fb_xd_fragment',
22 # ISP "optimizing" proxy - `Cache-Control: no-transform` seems to
23 # reduce this. (thanks @acdha)
24 # See http://stackoverflow.com/questions/4113268
25 'bmi_SafeAddOnload',
26 'EBCallBackMessageReceived',
27 # See http://toolbar.conduit.com/Developer/HtmlAndGadget/Methods/JSInjection.aspx
28 'conduitPage'
29 ))), re.I)
30
31 EXTENSION_EXC_SOURCES = re.compile('|'.join((
32 # Facebook flakiness
33 r'graph\.facebook\.com'
34 # Facebook blocked
35 r'connect\.facebook\.net\/en_US\/all\.js',
36 # Woopra flakiness
37 r'eatdifferent\.com\.woopra-ns\.com',
38 r'static\.woopra\.com\/js\/woopra\.js',
39 # Chrome extensions
40 r'^chrome(?:-extension)?:\/\/',
41 # Cacaoweb
42 r'127\.0\.0\.1:4001\/isrunning',
43 # Other
44 r'webappstoolbarba\.texthelp\.com\/',
45 r'metrics\.itunes\.apple\.com\.edgesuite\.net\/',
46 )), re.I)
47
48
49 class BrowserExtensionsFilter(Filter):
50 id = 'browser-extensions'
51 name = 'Filter out errors known to be caused by browser extensions'
52 description = 'Certain browser extensions will inject inline scripts and are known to cause errors.'
53
54 def get_exception_value(self, data):
55 try:
56 return data['sentry.interfaces.Exception']['values'][0]['value']
57 except (LookupError, TypeError):
58 return ''
59
60 def get_exception_source(self, data):
61 try:
62 return data['sentry.interfaces.Exception']['values'][0]['stacktrace']['frames'][-1]['abs_path']
63 except (LookupError, TypeError):
64 return ''
65
66 def test(self, data):
67 """
68 Test the exception value to determine if it looks like the error is
69 caused by a common browser extension.
70 """
71 if data.get('platform') != 'javascript':
72 return False
73
74 exc_value = self.get_exception_value(data)
75 if exc_value:
76 if EXTENSION_EXC_VALUES.search(exc_value):
77 return True
78
79 exc_source = self.get_exception_source(data)
80 if exc_source:
81 if EXTENSION_EXC_SOURCES.match(exc_source):
82 return True
83
84 return False
85
[end of src/sentry/filters/browser_extensions.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/sentry/filters/browser_extensions.py b/src/sentry/filters/browser_extensions.py
--- a/src/sentry/filters/browser_extensions.py
+++ b/src/sentry/filters/browser_extensions.py
@@ -24,6 +24,8 @@
# See http://stackoverflow.com/questions/4113268
'bmi_SafeAddOnload',
'EBCallBackMessageReceived',
+ # See https://groups.google.com/a/chromium.org/forum/#!topic/chromium-discuss/7VU0_VvC7mE
+ '_gCrWeb',
# See http://toolbar.conduit.com/Developer/HtmlAndGadget/Methods/JSInjection.aspx
'conduitPage'
))), re.I)
|
{"golden_diff": "diff --git a/src/sentry/filters/browser_extensions.py b/src/sentry/filters/browser_extensions.py\n--- a/src/sentry/filters/browser_extensions.py\n+++ b/src/sentry/filters/browser_extensions.py\n@@ -24,6 +24,8 @@\n # See http://stackoverflow.com/questions/4113268\n 'bmi_SafeAddOnload',\n 'EBCallBackMessageReceived',\n+ # See https://groups.google.com/a/chromium.org/forum/#!topic/chromium-discuss/7VU0_VvC7mE\n+ '_gCrWeb',\n # See http://toolbar.conduit.com/Developer/HtmlAndGadget/Methods/JSInjection.aspx\n 'conduitPage'\n ))), re.I)\n", "issue": "BrowserExtensionsFilter: _gCrWeb autofill error in iOS Chrome not ignored\nThis seems to be a relatively well-known issue on Chrome for iOS. It seems this could be ignored safely by the filter as well.\r\n\r\nSource: https://groups.google.com/a/chromium.org/forum/#!topic/chromium-discuss/7VU0_VvC7mE\n", "before_files": [{"content": "from __future__ import absolute_import\n\nfrom .base import Filter\n\nimport re\n\nEXTENSION_EXC_VALUES = re.compile('|'.join((re.escape(x) for x in (\n # Random plugins/extensions\n 'top.GLOBALS',\n # See: http://blog.errorception.com/2012/03/tale-of-unfindable-js-error. html\n 'originalCreateNotification',\n 'canvas.contentDocument',\n 'MyApp_RemoveAllHighlights',\n 'http://tt.epicplay.com',\n 'Can\\'t find variable: ZiteReader',\n 'jigsaw is not defined',\n 'ComboSearch is not defined',\n 'http://loading.retry.widdit.com/',\n 'atomicFindClose',\n # Facebook borked\n 'fb_xd_fragment',\n # ISP \"optimizing\" proxy - `Cache-Control: no-transform` seems to\n # reduce this. (thanks @acdha)\n # See http://stackoverflow.com/questions/4113268\n 'bmi_SafeAddOnload',\n 'EBCallBackMessageReceived',\n # See http://toolbar.conduit.com/Developer/HtmlAndGadget/Methods/JSInjection.aspx\n 'conduitPage'\n))), re.I)\n\nEXTENSION_EXC_SOURCES = re.compile('|'.join((\n # Facebook flakiness\n r'graph\\.facebook\\.com'\n # Facebook blocked\n r'connect\\.facebook\\.net\\/en_US\\/all\\.js',\n # Woopra flakiness\n r'eatdifferent\\.com\\.woopra-ns\\.com',\n r'static\\.woopra\\.com\\/js\\/woopra\\.js',\n # Chrome extensions\n r'^chrome(?:-extension)?:\\/\\/',\n # Cacaoweb\n r'127\\.0\\.0\\.1:4001\\/isrunning',\n # Other\n r'webappstoolbarba\\.texthelp\\.com\\/',\n r'metrics\\.itunes\\.apple\\.com\\.edgesuite\\.net\\/',\n)), re.I)\n\n\nclass BrowserExtensionsFilter(Filter):\n id = 'browser-extensions'\n name = 'Filter out errors known to be caused by browser extensions'\n description = 'Certain browser extensions will inject inline scripts and are known to cause errors.'\n\n def get_exception_value(self, data):\n try:\n return data['sentry.interfaces.Exception']['values'][0]['value']\n except (LookupError, TypeError):\n return ''\n\n def get_exception_source(self, data):\n try:\n return data['sentry.interfaces.Exception']['values'][0]['stacktrace']['frames'][-1]['abs_path']\n except (LookupError, TypeError):\n return ''\n\n def test(self, data):\n \"\"\"\n Test the exception value to determine if it looks like the error is\n caused by a common browser extension.\n \"\"\"\n if data.get('platform') != 'javascript':\n return False\n\n exc_value = self.get_exception_value(data)\n if exc_value:\n if EXTENSION_EXC_VALUES.search(exc_value):\n return True\n\n exc_source = self.get_exception_source(data)\n if exc_source:\n if EXTENSION_EXC_SOURCES.match(exc_source):\n return True\n\n return False\n", "path": "src/sentry/filters/browser_extensions.py"}]}
| 1,485 | 166 |
gh_patches_debug_40620
|
rasdani/github-patches
|
git_diff
|
googleapis__google-cloud-python-4606
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Multiple calls to Pub/Sub Policy.open() can "interact"
[E.g.][1] if you call `Policy.open()` a second time then it will overwrite the callback attached to the `Policy`.
ISTM that we should "tombstone" a `Policy` so that it can't be `open()`-ed more than once.
[1]: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/cc7da65b4a31d7a33055afe0bd6dc9855c3d6493/pubsub/google/cloud/pubsub_v1/subscriber/policy/thread.py#L150
</issue>
<code>
[start of pubsub/google/cloud/pubsub_v1/subscriber/policy/thread.py]
1 # Copyright 2017, Google LLC All rights reserved.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 from __future__ import absolute_import
16
17 from concurrent import futures
18 import logging
19 import sys
20 import threading
21
22 import grpc
23 from six.moves import queue as queue_mod
24
25 from google.cloud.pubsub_v1 import types
26 from google.cloud.pubsub_v1.subscriber import _helper_threads
27 from google.cloud.pubsub_v1.subscriber.futures import Future
28 from google.cloud.pubsub_v1.subscriber.policy import base
29 from google.cloud.pubsub_v1.subscriber.message import Message
30
31
32 _LOGGER = logging.getLogger(__name__)
33 _CALLBACK_WORKER_NAME = 'Thread-Consumer-CallbackRequestsWorker'
34
35
36 def _callback_completed(future):
37 """Simple callback that just logs a future's result.
38
39 Used on completion of processing a message received by a
40 subscriber.
41
42 Args:
43 future (concurrent.futures.Future): A future returned
44 from :meth:`~concurrent.futures.Executor.submit`.
45 """
46 _LOGGER.debug('Result: %s', future.result())
47
48
49 def _do_nothing_callback(message):
50 """Default callback for messages received by subscriber.
51
52 Does nothing with the message and returns :data:`None`.
53
54 Args:
55 message (~google.cloud.pubsub_v1.subscriber.message.Message): A
56 protobuf message returned by the backend and parsed into
57 our high level message type.
58
59 Returns:
60 NoneType: Always.
61 """
62 return None
63
64
65 class Policy(base.BasePolicy):
66 """A consumer class based on :class:`threading.Thread`.
67
68 This consumer handles the connection to the Pub/Sub service and all of
69 the concurrency needs.
70
71 Args:
72 client (~.pubsub_v1.subscriber.client): The subscriber client used
73 to create this instance.
74 subscription (str): The name of the subscription. The canonical
75 format for this is
76 ``projects/{project}/subscriptions/{subscription}``.
77 flow_control (~google.cloud.pubsub_v1.types.FlowControl): The flow
78 control settings.
79 executor (~concurrent.futures.ThreadPoolExecutor): (Optional.) A
80 ThreadPoolExecutor instance, or anything duck-type compatible
81 with it.
82 queue (~queue.Queue): (Optional.) A Queue instance, appropriate
83 for crossing the concurrency boundary implemented by
84 ``executor``.
85 """
86
87 def __init__(self, client, subscription, flow_control=types.FlowControl(),
88 executor=None, queue=None):
89 super(Policy, self).__init__(
90 client=client,
91 flow_control=flow_control,
92 subscription=subscription,
93 )
94 # Default the callback to a no-op; the **actual** callback is
95 # provided by ``.open()``.
96 self._callback = _do_nothing_callback
97 # Create a queue for keeping track of shared state.
98 self._request_queue = self._get_queue(queue)
99 # Also maintain an executor.
100 self._executor = self._get_executor(executor)
101 # The threads created in ``.open()``.
102 self._dispatch_thread = None
103 self._leases_thread = None
104
105 @staticmethod
106 def _get_queue(queue):
107 """Gets a queue for the constructor.
108
109 Args:
110 queue (Optional[~queue.Queue]): A Queue instance, appropriate
111 for crossing the concurrency boundary implemented by
112 ``executor``.
113
114 Returns:
115 ~queue.Queue: Either ``queue`` if not :data:`None` or a default
116 queue.
117 """
118 if queue is None:
119 return queue_mod.Queue()
120 else:
121 return queue
122
123 @staticmethod
124 def _get_executor(executor):
125 """Gets an executor for the constructor.
126
127 Args:
128 executor (Optional[~concurrent.futures.ThreadPoolExecutor]): A
129 ThreadPoolExecutor instance, or anything duck-type compatible
130 with it.
131
132 Returns:
133 ~concurrent.futures.ThreadPoolExecutor: Either ``executor`` if not
134 :data:`None` or a default thread pool executor with 10 workers
135 and a prefix (if supported).
136 """
137 if executor is None:
138 executor_kwargs = {}
139 if sys.version_info[:2] == (2, 7) or sys.version_info >= (3, 6):
140 executor_kwargs['thread_name_prefix'] = (
141 'ThreadPoolExecutor-SubscriberPolicy')
142 return futures.ThreadPoolExecutor(
143 max_workers=10,
144 **executor_kwargs
145 )
146 else:
147 return executor
148
149 def close(self):
150 """Close the existing connection."""
151 # Stop consuming messages.
152 self._request_queue.put(_helper_threads.STOP)
153 self._dispatch_thread.join() # Wait until stopped.
154 self._dispatch_thread = None
155 self._consumer.stop_consuming()
156 self._leases_thread.join()
157 self._leases_thread = None
158 self._executor.shutdown()
159
160 # The subscription is closing cleanly; resolve the future if it is not
161 # resolved already.
162 if self._future is not None and not self._future.done():
163 self._future.set_result(None)
164 self._future = None
165
166 def _start_dispatch(self):
167 """Start a thread to dispatch requests queued up by callbacks.
168
169 .. note::
170
171 This assumes, but does not check, that ``_dispatch_thread``
172 is :data:`None`.
173
174 Spawns a thread to run :meth:`dispatch_callback` and sets the
175 "dispatch thread" member on the current policy.
176 """
177 _LOGGER.debug('Starting callback requests worker.')
178 dispatch_worker = _helper_threads.QueueCallbackWorker(
179 self._request_queue,
180 self.dispatch_callback,
181 )
182 # Create and start the helper thread.
183 thread = threading.Thread(
184 name=_CALLBACK_WORKER_NAME,
185 target=dispatch_worker,
186 )
187 thread.daemon = True
188 thread.start()
189 _LOGGER.debug('Started helper thread %s', thread.name)
190 self._dispatch_thread = thread
191
192 def _start_lease_worker(self):
193 """Spawn a helper thread that maintains all of leases for this policy.
194
195 .. note::
196
197 This assumes, but does not check, that ``_leases_thread`` is
198 :data:`None`.
199
200 Spawns a thread to run :meth:`maintain_leases` and sets the
201 "leases thread" member on the current policy.
202 """
203 _LOGGER.debug('Starting lease maintenance worker.')
204 thread = threading.Thread(
205 name='Thread-LeaseMaintenance',
206 target=self.maintain_leases,
207 )
208 thread.daemon = True
209 thread.start()
210
211 self._leases_thread = thread
212
213 def open(self, callback):
214 """Open a streaming pull connection and begin receiving messages.
215
216 For each message received, the ``callback`` function is fired with
217 a :class:`~.pubsub_v1.subscriber.message.Message` as its only
218 argument.
219
220 Args:
221 callback (Callable): The callback function.
222
223 Returns:
224 ~google.api_core.future.Future: A future that provides
225 an interface to block on the subscription if desired, and
226 handle errors.
227 """
228 # Create the Future that this method will return.
229 # This future is the main thread's interface to handle exceptions,
230 # block on the subscription, etc.
231 self._future = Future(policy=self)
232
233 # Start the thread to pass the requests.
234 self._callback = callback
235 self._start_dispatch()
236 # Actually start consuming messages.
237 self._consumer.start_consuming(self)
238 self._start_lease_worker()
239
240 # Return the future.
241 return self._future
242
243 def dispatch_callback(self, action, kwargs):
244 """Map the callback request to the appropriate gRPC request.
245
246 Args:
247 action (str): The method to be invoked.
248 kwargs (Dict[str, Any]): The keyword arguments for the method
249 specified by ``action``.
250
251 Raises:
252 ValueError: If ``action`` isn't one of the expected actions
253 "ack", "drop", "lease", "modify_ack_deadline" or "nack".
254 """
255 if action == 'ack':
256 self.ack(**kwargs)
257 elif action == 'drop':
258 self.drop(**kwargs)
259 elif action == 'lease':
260 self.lease(**kwargs)
261 elif action == 'modify_ack_deadline':
262 self.modify_ack_deadline(**kwargs)
263 elif action == 'nack':
264 self.nack(**kwargs)
265 else:
266 raise ValueError(
267 'Unexpected action', action,
268 'Must be one of "ack", "drop", "lease", '
269 '"modify_ack_deadline" or "nack".')
270
271 def on_exception(self, exception):
272 """Handle the exception.
273
274 If the exception is one of the retryable exceptions, this will signal
275 to the consumer thread that it should "recover" from the failure.
276
277 This will cause the stream to exit when it returns :data:`False`.
278
279 Returns:
280 bool: Indicates if the caller should recover or shut down.
281 Will be :data:`True` if the ``exception`` is "acceptable", i.e.
282 in a list of retryable / idempotent exceptions.
283 """
284 # If this is in the list of idempotent exceptions, then we want to
285 # retry. That entails just returning None.
286 if isinstance(exception, self._RETRYABLE_STREAM_ERRORS):
287 return True
288
289 # Set any other exception on the future.
290 self._future.set_exception(exception)
291 return False
292
293 def on_response(self, response):
294 """Process all received Pub/Sub messages.
295
296 For each message, schedule a callback with the executor.
297 """
298 for msg in response.received_messages:
299 _LOGGER.debug(
300 'Using %s to process new message received:\n%r',
301 self._callback, msg)
302 message = Message(msg.message, msg.ack_id, self._request_queue)
303 future = self._executor.submit(self._callback, message)
304 future.add_done_callback(_callback_completed)
305
[end of pubsub/google/cloud/pubsub_v1/subscriber/policy/thread.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pubsub/google/cloud/pubsub_v1/subscriber/policy/thread.py b/pubsub/google/cloud/pubsub_v1/subscriber/policy/thread.py
--- a/pubsub/google/cloud/pubsub_v1/subscriber/policy/thread.py
+++ b/pubsub/google/cloud/pubsub_v1/subscriber/policy/thread.py
@@ -147,7 +147,26 @@
return executor
def close(self):
- """Close the existing connection."""
+ """Close the existing connection.
+
+ .. warning::
+
+ This method is not thread-safe. For example, if this method is
+ called while another thread is executing :meth:`open`, then the
+ policy could end up in an undefined state. The **same** policy
+ instance is not intended to be used by multiple workers (though
+ each policy instance **does** have a thread-safe private queue).
+
+ Returns:
+ ~google.api_core.future.Future: The future that **was** attached
+ to the subscription.
+
+ Raises:
+ ValueError: If the policy has not been opened yet.
+ """
+ if self._future is None:
+ raise ValueError('This policy has not been opened yet.')
+
# Stop consuming messages.
self._request_queue.put(_helper_threads.STOP)
self._dispatch_thread.join() # Wait until stopped.
@@ -159,9 +178,11 @@
# The subscription is closing cleanly; resolve the future if it is not
# resolved already.
- if self._future is not None and not self._future.done():
+ if not self._future.done():
self._future.set_result(None)
+ future = self._future
self._future = None
+ return future
def _start_dispatch(self):
"""Start a thread to dispatch requests queued up by callbacks.
@@ -213,6 +234,14 @@
def open(self, callback):
"""Open a streaming pull connection and begin receiving messages.
+ .. warning::
+
+ This method is not thread-safe. For example, if this method is
+ called while another thread is executing :meth:`close`, then the
+ policy could end up in an undefined state. The **same** policy
+ instance is not intended to be used by multiple workers (though
+ each policy instance **does** have a thread-safe private queue).
+
For each message received, the ``callback`` function is fired with
a :class:`~.pubsub_v1.subscriber.message.Message` as its only
argument.
@@ -222,9 +251,15 @@
Returns:
~google.api_core.future.Future: A future that provides
- an interface to block on the subscription if desired, and
- handle errors.
+ an interface to block on the subscription if desired, and
+ handle errors.
+
+ Raises:
+ ValueError: If the policy has already been opened.
"""
+ if self._future is not None:
+ raise ValueError('This policy has already been opened.')
+
# Create the Future that this method will return.
# This future is the main thread's interface to handle exceptions,
# block on the subscription, etc.
|
{"golden_diff": "diff --git a/pubsub/google/cloud/pubsub_v1/subscriber/policy/thread.py b/pubsub/google/cloud/pubsub_v1/subscriber/policy/thread.py\n--- a/pubsub/google/cloud/pubsub_v1/subscriber/policy/thread.py\n+++ b/pubsub/google/cloud/pubsub_v1/subscriber/policy/thread.py\n@@ -147,7 +147,26 @@\n return executor\n \n def close(self):\n- \"\"\"Close the existing connection.\"\"\"\n+ \"\"\"Close the existing connection.\n+\n+ .. warning::\n+\n+ This method is not thread-safe. For example, if this method is\n+ called while another thread is executing :meth:`open`, then the\n+ policy could end up in an undefined state. The **same** policy\n+ instance is not intended to be used by multiple workers (though\n+ each policy instance **does** have a thread-safe private queue).\n+\n+ Returns:\n+ ~google.api_core.future.Future: The future that **was** attached\n+ to the subscription.\n+\n+ Raises:\n+ ValueError: If the policy has not been opened yet.\n+ \"\"\"\n+ if self._future is None:\n+ raise ValueError('This policy has not been opened yet.')\n+\n # Stop consuming messages.\n self._request_queue.put(_helper_threads.STOP)\n self._dispatch_thread.join() # Wait until stopped.\n@@ -159,9 +178,11 @@\n \n # The subscription is closing cleanly; resolve the future if it is not\n # resolved already.\n- if self._future is not None and not self._future.done():\n+ if not self._future.done():\n self._future.set_result(None)\n+ future = self._future\n self._future = None\n+ return future\n \n def _start_dispatch(self):\n \"\"\"Start a thread to dispatch requests queued up by callbacks.\n@@ -213,6 +234,14 @@\n def open(self, callback):\n \"\"\"Open a streaming pull connection and begin receiving messages.\n \n+ .. warning::\n+\n+ This method is not thread-safe. For example, if this method is\n+ called while another thread is executing :meth:`close`, then the\n+ policy could end up in an undefined state. The **same** policy\n+ instance is not intended to be used by multiple workers (though\n+ each policy instance **does** have a thread-safe private queue).\n+\n For each message received, the ``callback`` function is fired with\n a :class:`~.pubsub_v1.subscriber.message.Message` as its only\n argument.\n@@ -222,9 +251,15 @@\n \n Returns:\n ~google.api_core.future.Future: A future that provides\n- an interface to block on the subscription if desired, and\n- handle errors.\n+ an interface to block on the subscription if desired, and\n+ handle errors.\n+\n+ Raises:\n+ ValueError: If the policy has already been opened.\n \"\"\"\n+ if self._future is not None:\n+ raise ValueError('This policy has already been opened.')\n+\n # Create the Future that this method will return.\n # This future is the main thread's interface to handle exceptions,\n # block on the subscription, etc.\n", "issue": "Multiple calls to Pub/Sub Policy.open() can \"interact\"\n[E.g.][1] if you call `Policy.open()` a second time then it will overwrite the callback attached to the `Policy`.\r\n\r\nISTM that we should \"tombstone\" a `Policy` so that it can't be `open()`-ed more than once.\r\n\r\n[1]: https://github.com/GoogleCloudPlatform/google-cloud-python/blob/cc7da65b4a31d7a33055afe0bd6dc9855c3d6493/pubsub/google/cloud/pubsub_v1/subscriber/policy/thread.py#L150\n", "before_files": [{"content": "# Copyright 2017, Google LLC All rights reserved.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom __future__ import absolute_import\n\nfrom concurrent import futures\nimport logging\nimport sys\nimport threading\n\nimport grpc\nfrom six.moves import queue as queue_mod\n\nfrom google.cloud.pubsub_v1 import types\nfrom google.cloud.pubsub_v1.subscriber import _helper_threads\nfrom google.cloud.pubsub_v1.subscriber.futures import Future\nfrom google.cloud.pubsub_v1.subscriber.policy import base\nfrom google.cloud.pubsub_v1.subscriber.message import Message\n\n\n_LOGGER = logging.getLogger(__name__)\n_CALLBACK_WORKER_NAME = 'Thread-Consumer-CallbackRequestsWorker'\n\n\ndef _callback_completed(future):\n \"\"\"Simple callback that just logs a future's result.\n\n Used on completion of processing a message received by a\n subscriber.\n\n Args:\n future (concurrent.futures.Future): A future returned\n from :meth:`~concurrent.futures.Executor.submit`.\n \"\"\"\n _LOGGER.debug('Result: %s', future.result())\n\n\ndef _do_nothing_callback(message):\n \"\"\"Default callback for messages received by subscriber.\n\n Does nothing with the message and returns :data:`None`.\n\n Args:\n message (~google.cloud.pubsub_v1.subscriber.message.Message): A\n protobuf message returned by the backend and parsed into\n our high level message type.\n\n Returns:\n NoneType: Always.\n \"\"\"\n return None\n\n\nclass Policy(base.BasePolicy):\n \"\"\"A consumer class based on :class:`threading.Thread`.\n\n This consumer handles the connection to the Pub/Sub service and all of\n the concurrency needs.\n\n Args:\n client (~.pubsub_v1.subscriber.client): The subscriber client used\n to create this instance.\n subscription (str): The name of the subscription. The canonical\n format for this is\n ``projects/{project}/subscriptions/{subscription}``.\n flow_control (~google.cloud.pubsub_v1.types.FlowControl): The flow\n control settings.\n executor (~concurrent.futures.ThreadPoolExecutor): (Optional.) A\n ThreadPoolExecutor instance, or anything duck-type compatible\n with it.\n queue (~queue.Queue): (Optional.) A Queue instance, appropriate\n for crossing the concurrency boundary implemented by\n ``executor``.\n \"\"\"\n\n def __init__(self, client, subscription, flow_control=types.FlowControl(),\n executor=None, queue=None):\n super(Policy, self).__init__(\n client=client,\n flow_control=flow_control,\n subscription=subscription,\n )\n # Default the callback to a no-op; the **actual** callback is\n # provided by ``.open()``.\n self._callback = _do_nothing_callback\n # Create a queue for keeping track of shared state.\n self._request_queue = self._get_queue(queue)\n # Also maintain an executor.\n self._executor = self._get_executor(executor)\n # The threads created in ``.open()``.\n self._dispatch_thread = None\n self._leases_thread = None\n\n @staticmethod\n def _get_queue(queue):\n \"\"\"Gets a queue for the constructor.\n\n Args:\n queue (Optional[~queue.Queue]): A Queue instance, appropriate\n for crossing the concurrency boundary implemented by\n ``executor``.\n\n Returns:\n ~queue.Queue: Either ``queue`` if not :data:`None` or a default\n queue.\n \"\"\"\n if queue is None:\n return queue_mod.Queue()\n else:\n return queue\n\n @staticmethod\n def _get_executor(executor):\n \"\"\"Gets an executor for the constructor.\n\n Args:\n executor (Optional[~concurrent.futures.ThreadPoolExecutor]): A\n ThreadPoolExecutor instance, or anything duck-type compatible\n with it.\n\n Returns:\n ~concurrent.futures.ThreadPoolExecutor: Either ``executor`` if not\n :data:`None` or a default thread pool executor with 10 workers\n and a prefix (if supported).\n \"\"\"\n if executor is None:\n executor_kwargs = {}\n if sys.version_info[:2] == (2, 7) or sys.version_info >= (3, 6):\n executor_kwargs['thread_name_prefix'] = (\n 'ThreadPoolExecutor-SubscriberPolicy')\n return futures.ThreadPoolExecutor(\n max_workers=10,\n **executor_kwargs\n )\n else:\n return executor\n\n def close(self):\n \"\"\"Close the existing connection.\"\"\"\n # Stop consuming messages.\n self._request_queue.put(_helper_threads.STOP)\n self._dispatch_thread.join() # Wait until stopped.\n self._dispatch_thread = None\n self._consumer.stop_consuming()\n self._leases_thread.join()\n self._leases_thread = None\n self._executor.shutdown()\n\n # The subscription is closing cleanly; resolve the future if it is not\n # resolved already.\n if self._future is not None and not self._future.done():\n self._future.set_result(None)\n self._future = None\n\n def _start_dispatch(self):\n \"\"\"Start a thread to dispatch requests queued up by callbacks.\n\n .. note::\n\n This assumes, but does not check, that ``_dispatch_thread``\n is :data:`None`.\n\n Spawns a thread to run :meth:`dispatch_callback` and sets the\n \"dispatch thread\" member on the current policy.\n \"\"\"\n _LOGGER.debug('Starting callback requests worker.')\n dispatch_worker = _helper_threads.QueueCallbackWorker(\n self._request_queue,\n self.dispatch_callback,\n )\n # Create and start the helper thread.\n thread = threading.Thread(\n name=_CALLBACK_WORKER_NAME,\n target=dispatch_worker,\n )\n thread.daemon = True\n thread.start()\n _LOGGER.debug('Started helper thread %s', thread.name)\n self._dispatch_thread = thread\n\n def _start_lease_worker(self):\n \"\"\"Spawn a helper thread that maintains all of leases for this policy.\n\n .. note::\n\n This assumes, but does not check, that ``_leases_thread`` is\n :data:`None`.\n\n Spawns a thread to run :meth:`maintain_leases` and sets the\n \"leases thread\" member on the current policy.\n \"\"\"\n _LOGGER.debug('Starting lease maintenance worker.')\n thread = threading.Thread(\n name='Thread-LeaseMaintenance',\n target=self.maintain_leases,\n )\n thread.daemon = True\n thread.start()\n\n self._leases_thread = thread\n\n def open(self, callback):\n \"\"\"Open a streaming pull connection and begin receiving messages.\n\n For each message received, the ``callback`` function is fired with\n a :class:`~.pubsub_v1.subscriber.message.Message` as its only\n argument.\n\n Args:\n callback (Callable): The callback function.\n\n Returns:\n ~google.api_core.future.Future: A future that provides\n an interface to block on the subscription if desired, and\n handle errors.\n \"\"\"\n # Create the Future that this method will return.\n # This future is the main thread's interface to handle exceptions,\n # block on the subscription, etc.\n self._future = Future(policy=self)\n\n # Start the thread to pass the requests.\n self._callback = callback\n self._start_dispatch()\n # Actually start consuming messages.\n self._consumer.start_consuming(self)\n self._start_lease_worker()\n\n # Return the future.\n return self._future\n\n def dispatch_callback(self, action, kwargs):\n \"\"\"Map the callback request to the appropriate gRPC request.\n\n Args:\n action (str): The method to be invoked.\n kwargs (Dict[str, Any]): The keyword arguments for the method\n specified by ``action``.\n\n Raises:\n ValueError: If ``action`` isn't one of the expected actions\n \"ack\", \"drop\", \"lease\", \"modify_ack_deadline\" or \"nack\".\n \"\"\"\n if action == 'ack':\n self.ack(**kwargs)\n elif action == 'drop':\n self.drop(**kwargs)\n elif action == 'lease':\n self.lease(**kwargs)\n elif action == 'modify_ack_deadline':\n self.modify_ack_deadline(**kwargs)\n elif action == 'nack':\n self.nack(**kwargs)\n else:\n raise ValueError(\n 'Unexpected action', action,\n 'Must be one of \"ack\", \"drop\", \"lease\", '\n '\"modify_ack_deadline\" or \"nack\".')\n\n def on_exception(self, exception):\n \"\"\"Handle the exception.\n\n If the exception is one of the retryable exceptions, this will signal\n to the consumer thread that it should \"recover\" from the failure.\n\n This will cause the stream to exit when it returns :data:`False`.\n\n Returns:\n bool: Indicates if the caller should recover or shut down.\n Will be :data:`True` if the ``exception`` is \"acceptable\", i.e.\n in a list of retryable / idempotent exceptions.\n \"\"\"\n # If this is in the list of idempotent exceptions, then we want to\n # retry. That entails just returning None.\n if isinstance(exception, self._RETRYABLE_STREAM_ERRORS):\n return True\n\n # Set any other exception on the future.\n self._future.set_exception(exception)\n return False\n\n def on_response(self, response):\n \"\"\"Process all received Pub/Sub messages.\n\n For each message, schedule a callback with the executor.\n \"\"\"\n for msg in response.received_messages:\n _LOGGER.debug(\n 'Using %s to process new message received:\\n%r',\n self._callback, msg)\n message = Message(msg.message, msg.ack_id, self._request_queue)\n future = self._executor.submit(self._callback, message)\n future.add_done_callback(_callback_completed)\n", "path": "pubsub/google/cloud/pubsub_v1/subscriber/policy/thread.py"}]}
| 3,748 | 713 |
gh_patches_debug_7333
|
rasdani/github-patches
|
git_diff
|
microsoft__botbuilder-python-383
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ChoiceFactory.for_channel could erroneously return a List instead of an Activity
Found in 4.5b5.
ChoiceFactory.for_channel could return a List instead of the expected Activity when the type should have defaulted to a list style.
[bug]
</issue>
<code>
[start of libraries/botbuilder-dialogs/botbuilder/dialogs/choices/choice_factory.py]
1 # Copyright (c) Microsoft Corporation. All rights reserved.
2 # Licensed under the MIT License.
3
4 from typing import List, Union
5
6 from botbuilder.core import CardFactory, MessageFactory
7 from botbuilder.schema import ActionTypes, Activity, CardAction, HeroCard, InputHints
8
9 from . import Channel, Choice, ChoiceFactoryOptions
10
11
12 class ChoiceFactory:
13 """
14 Assists with formatting a message activity that contains a list of choices.
15 """
16
17 @staticmethod
18 def for_channel(
19 channel_id: str,
20 choices: List[Union[str, Choice]],
21 text: str = None,
22 speak: str = None,
23 options: ChoiceFactoryOptions = None,
24 ) -> Activity:
25 """
26 Creates a message activity that includes a list of choices formatted based on the
27 capabilities of a given channel.
28
29 Parameters:
30 ----------
31 channel_id: A channel ID.
32 choices: List of choices to render
33 text: (Optional) Text of the message to send.
34 speak (Optional) SSML. Text to be spoken by your bot on a speech-enabled channel.
35 """
36 if channel_id is None:
37 channel_id = ""
38
39 choices = ChoiceFactory._to_choices(choices)
40
41 # Find maximum title length
42 max_title_length = 0
43 for choice in choices:
44 if choice.action is not None and choice.action.title not in (None, ""):
45 size = len(choice.action.title)
46 else:
47 size = len(choice.value)
48
49 if size > max_title_length:
50 max_title_length = size
51
52 # Determine list style
53 supports_suggested_actions = Channel.supports_suggested_actions(
54 channel_id, len(choices)
55 )
56 supports_card_actions = Channel.supports_card_actions(channel_id, len(choices))
57 max_action_title_length = Channel.max_action_title_length(channel_id)
58 long_titles = max_title_length > max_action_title_length
59
60 if not long_titles and not supports_suggested_actions and supports_card_actions:
61 # SuggestedActions is the preferred approach, but for channels that don't
62 # support them (e.g. Teams, Cortana) we should use a HeroCard with CardActions
63 return ChoiceFactory.hero_card(choices, text, speak)
64 if not long_titles and supports_suggested_actions:
65 # We always prefer showing choices using suggested actions. If the titles are too long, however,
66 # we'll have to show them as a text list.
67 return ChoiceFactory.suggested_action(choices, text, speak)
68 if not long_titles and len(choices) <= 3:
69 # If the titles are short and there are 3 or less choices we'll use an inline list.
70 return ChoiceFactory.inline(choices, text, speak, options)
71 # Show a numbered list.
72 return [choices, text, speak, options]
73
74 @staticmethod
75 def inline(
76 choices: List[Union[str, Choice]],
77 text: str = None,
78 speak: str = None,
79 options: ChoiceFactoryOptions = None,
80 ) -> Activity:
81 """
82 Creates a message activity that includes a list of choices formatted as an inline list.
83
84 Parameters:
85 ----------
86 choices: The list of choices to render.
87 text: (Optional) The text of the message to send.
88 speak: (Optional) SSML. Text to be spoken by your bot on a speech-enabled channel.
89 options: (Optional) The formatting options to use to tweak rendering of list.
90 """
91 choices = ChoiceFactory._to_choices(choices)
92
93 if options is None:
94 options = ChoiceFactoryOptions()
95
96 opt = ChoiceFactoryOptions(
97 inline_separator=options.inline_separator or ", ",
98 inline_or=options.inline_or or " or ",
99 inline_or_more=options.inline_or_more or ", or ",
100 include_numbers=(
101 options.include_numbers if options.include_numbers is not None else True
102 ),
103 )
104
105 # Format list of choices
106 connector = ""
107 txt_builder: List[str] = [text]
108 txt_builder.append(" ")
109 for index, choice in enumerate(choices):
110 title = (
111 choice.action.title
112 if (choice.action is not None and choice.action.title is not None)
113 else choice.value
114 )
115 txt_builder.append(connector)
116 if opt.include_numbers is True:
117 txt_builder.append("(")
118 txt_builder.append(f"{index + 1}")
119 txt_builder.append(") ")
120
121 txt_builder.append(title)
122 if index == (len(choices) - 2):
123 connector = opt.inline_or if index == 0 else opt.inline_or_more
124 connector = connector or ""
125 else:
126 connector = opt.inline_separator or ""
127
128 # Return activity with choices as an inline list.
129 return MessageFactory.text(
130 "".join(txt_builder), speak, InputHints.expecting_input
131 )
132
133 @staticmethod
134 def list_style(
135 choices: List[Union[str, Choice]],
136 text: str = None,
137 speak: str = None,
138 options: ChoiceFactoryOptions = None,
139 ):
140 """
141 Creates a message activity that includes a list of choices formatted as a numbered or bulleted list.
142
143 Parameters:
144 ----------
145
146 choices: The list of choices to render.
147
148 text: (Optional) The text of the message to send.
149
150 speak: (Optional) SSML. Text to be spoken by your bot on a speech-enabled channel.
151
152 options: (Optional) The formatting options to use to tweak rendering of list.
153 """
154 choices = ChoiceFactory._to_choices(choices)
155 if options is None:
156 options = ChoiceFactoryOptions()
157
158 if options.include_numbers is None:
159 include_numbers = True
160 else:
161 include_numbers = options.include_numbers
162
163 # Format list of choices
164 connector = ""
165 txt_builder = [text]
166 txt_builder.append("\n\n ")
167
168 for index, choice in enumerate(choices):
169 title = (
170 choice.action.title
171 if choice.action is not None and choice.action.title is not None
172 else choice.value
173 )
174
175 txt_builder.append(connector)
176 if include_numbers:
177 txt_builder.append(f"{index + 1}")
178 txt_builder.append(". ")
179 else:
180 txt_builder.append("- ")
181
182 txt_builder.append(title)
183 connector = "\n "
184
185 # Return activity with choices as a numbered list.
186 txt = "".join(txt_builder)
187 return MessageFactory.text(txt, speak, InputHints.expecting_input)
188
189 @staticmethod
190 def suggested_action(
191 choices: List[Choice], text: str = None, speak: str = None
192 ) -> Activity:
193 """
194 Creates a message activity that includes a list of choices that have been added as suggested actions.
195 """
196 # Return activity with choices as suggested actions
197 return MessageFactory.suggested_actions(
198 ChoiceFactory._extract_actions(choices),
199 text,
200 speak,
201 InputHints.expecting_input,
202 )
203
204 @staticmethod
205 def hero_card(
206 choices: List[Union[Choice, str]], text: str = None, speak: str = None
207 ) -> Activity:
208 """
209 Creates a message activity that includes a lsit of coices that have been added as `HeroCard`'s
210 """
211 attachment = CardFactory.hero_card(
212 HeroCard(text=text, buttons=ChoiceFactory._extract_actions(choices))
213 )
214
215 # Return activity with choices as HeroCard with buttons
216 return MessageFactory.attachment(
217 attachment, None, speak, InputHints.expecting_input
218 )
219
220 @staticmethod
221 def _to_choices(choices: List[Union[str, Choice]]) -> List[Choice]:
222 """
223 Takes a list of strings and returns them as [`Choice`].
224 """
225 if choices is None:
226 return []
227 return [
228 Choice(value=choice) if isinstance(choice, str) else choice
229 for choice in choices
230 ]
231
232 @staticmethod
233 def _extract_actions(choices: List[Union[str, Choice]]) -> List[CardAction]:
234 if choices is None:
235 choices = []
236 choices = ChoiceFactory._to_choices(choices)
237 card_actions: List[CardAction] = []
238 for choice in choices:
239 if choice.action is not None:
240 card_action = choice.action
241 else:
242 card_action = CardAction(
243 type=ActionTypes.im_back, value=choice.value, title=choice.value
244 )
245
246 card_actions.append(card_action)
247
248 return card_actions
249
[end of libraries/botbuilder-dialogs/botbuilder/dialogs/choices/choice_factory.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/libraries/botbuilder-dialogs/botbuilder/dialogs/choices/choice_factory.py b/libraries/botbuilder-dialogs/botbuilder/dialogs/choices/choice_factory.py
--- a/libraries/botbuilder-dialogs/botbuilder/dialogs/choices/choice_factory.py
+++ b/libraries/botbuilder-dialogs/botbuilder/dialogs/choices/choice_factory.py
@@ -69,7 +69,7 @@
# If the titles are short and there are 3 or less choices we'll use an inline list.
return ChoiceFactory.inline(choices, text, speak, options)
# Show a numbered list.
- return [choices, text, speak, options]
+ return ChoiceFactory.list_style(choices, text, speak, options)
@staticmethod
def inline(
|
{"golden_diff": "diff --git a/libraries/botbuilder-dialogs/botbuilder/dialogs/choices/choice_factory.py b/libraries/botbuilder-dialogs/botbuilder/dialogs/choices/choice_factory.py\n--- a/libraries/botbuilder-dialogs/botbuilder/dialogs/choices/choice_factory.py\n+++ b/libraries/botbuilder-dialogs/botbuilder/dialogs/choices/choice_factory.py\n@@ -69,7 +69,7 @@\n # If the titles are short and there are 3 or less choices we'll use an inline list.\n return ChoiceFactory.inline(choices, text, speak, options)\n # Show a numbered list.\n- return [choices, text, speak, options]\n+ return ChoiceFactory.list_style(choices, text, speak, options)\n \n @staticmethod\n def inline(\n", "issue": "ChoiceFactory.for_channel could erroneously return a List instead of an Activity\nFound in 4.5b5.\r\n\r\nChoiceFactory.for_channel could return a List instead of the expected Activity when the type should have defaulted to a list style.\r\n\r\n[bug]\r\n\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License.\n\nfrom typing import List, Union\n\nfrom botbuilder.core import CardFactory, MessageFactory\nfrom botbuilder.schema import ActionTypes, Activity, CardAction, HeroCard, InputHints\n\nfrom . import Channel, Choice, ChoiceFactoryOptions\n\n\nclass ChoiceFactory:\n \"\"\"\n Assists with formatting a message activity that contains a list of choices.\n \"\"\"\n\n @staticmethod\n def for_channel(\n channel_id: str,\n choices: List[Union[str, Choice]],\n text: str = None,\n speak: str = None,\n options: ChoiceFactoryOptions = None,\n ) -> Activity:\n \"\"\"\n Creates a message activity that includes a list of choices formatted based on the\n capabilities of a given channel.\n\n Parameters:\n ----------\n channel_id: A channel ID.\n choices: List of choices to render\n text: (Optional) Text of the message to send.\n speak (Optional) SSML. Text to be spoken by your bot on a speech-enabled channel.\n \"\"\"\n if channel_id is None:\n channel_id = \"\"\n\n choices = ChoiceFactory._to_choices(choices)\n\n # Find maximum title length\n max_title_length = 0\n for choice in choices:\n if choice.action is not None and choice.action.title not in (None, \"\"):\n size = len(choice.action.title)\n else:\n size = len(choice.value)\n\n if size > max_title_length:\n max_title_length = size\n\n # Determine list style\n supports_suggested_actions = Channel.supports_suggested_actions(\n channel_id, len(choices)\n )\n supports_card_actions = Channel.supports_card_actions(channel_id, len(choices))\n max_action_title_length = Channel.max_action_title_length(channel_id)\n long_titles = max_title_length > max_action_title_length\n\n if not long_titles and not supports_suggested_actions and supports_card_actions:\n # SuggestedActions is the preferred approach, but for channels that don't\n # support them (e.g. Teams, Cortana) we should use a HeroCard with CardActions\n return ChoiceFactory.hero_card(choices, text, speak)\n if not long_titles and supports_suggested_actions:\n # We always prefer showing choices using suggested actions. If the titles are too long, however,\n # we'll have to show them as a text list.\n return ChoiceFactory.suggested_action(choices, text, speak)\n if not long_titles and len(choices) <= 3:\n # If the titles are short and there are 3 or less choices we'll use an inline list.\n return ChoiceFactory.inline(choices, text, speak, options)\n # Show a numbered list.\n return [choices, text, speak, options]\n\n @staticmethod\n def inline(\n choices: List[Union[str, Choice]],\n text: str = None,\n speak: str = None,\n options: ChoiceFactoryOptions = None,\n ) -> Activity:\n \"\"\"\n Creates a message activity that includes a list of choices formatted as an inline list.\n\n Parameters:\n ----------\n choices: The list of choices to render.\n text: (Optional) The text of the message to send.\n speak: (Optional) SSML. Text to be spoken by your bot on a speech-enabled channel.\n options: (Optional) The formatting options to use to tweak rendering of list.\n \"\"\"\n choices = ChoiceFactory._to_choices(choices)\n\n if options is None:\n options = ChoiceFactoryOptions()\n\n opt = ChoiceFactoryOptions(\n inline_separator=options.inline_separator or \", \",\n inline_or=options.inline_or or \" or \",\n inline_or_more=options.inline_or_more or \", or \",\n include_numbers=(\n options.include_numbers if options.include_numbers is not None else True\n ),\n )\n\n # Format list of choices\n connector = \"\"\n txt_builder: List[str] = [text]\n txt_builder.append(\" \")\n for index, choice in enumerate(choices):\n title = (\n choice.action.title\n if (choice.action is not None and choice.action.title is not None)\n else choice.value\n )\n txt_builder.append(connector)\n if opt.include_numbers is True:\n txt_builder.append(\"(\")\n txt_builder.append(f\"{index + 1}\")\n txt_builder.append(\") \")\n\n txt_builder.append(title)\n if index == (len(choices) - 2):\n connector = opt.inline_or if index == 0 else opt.inline_or_more\n connector = connector or \"\"\n else:\n connector = opt.inline_separator or \"\"\n\n # Return activity with choices as an inline list.\n return MessageFactory.text(\n \"\".join(txt_builder), speak, InputHints.expecting_input\n )\n\n @staticmethod\n def list_style(\n choices: List[Union[str, Choice]],\n text: str = None,\n speak: str = None,\n options: ChoiceFactoryOptions = None,\n ):\n \"\"\"\n Creates a message activity that includes a list of choices formatted as a numbered or bulleted list.\n\n Parameters:\n ----------\n\n choices: The list of choices to render.\n\n text: (Optional) The text of the message to send.\n\n speak: (Optional) SSML. Text to be spoken by your bot on a speech-enabled channel.\n\n options: (Optional) The formatting options to use to tweak rendering of list.\n \"\"\"\n choices = ChoiceFactory._to_choices(choices)\n if options is None:\n options = ChoiceFactoryOptions()\n\n if options.include_numbers is None:\n include_numbers = True\n else:\n include_numbers = options.include_numbers\n\n # Format list of choices\n connector = \"\"\n txt_builder = [text]\n txt_builder.append(\"\\n\\n \")\n\n for index, choice in enumerate(choices):\n title = (\n choice.action.title\n if choice.action is not None and choice.action.title is not None\n else choice.value\n )\n\n txt_builder.append(connector)\n if include_numbers:\n txt_builder.append(f\"{index + 1}\")\n txt_builder.append(\". \")\n else:\n txt_builder.append(\"- \")\n\n txt_builder.append(title)\n connector = \"\\n \"\n\n # Return activity with choices as a numbered list.\n txt = \"\".join(txt_builder)\n return MessageFactory.text(txt, speak, InputHints.expecting_input)\n\n @staticmethod\n def suggested_action(\n choices: List[Choice], text: str = None, speak: str = None\n ) -> Activity:\n \"\"\"\n Creates a message activity that includes a list of choices that have been added as suggested actions.\n \"\"\"\n # Return activity with choices as suggested actions\n return MessageFactory.suggested_actions(\n ChoiceFactory._extract_actions(choices),\n text,\n speak,\n InputHints.expecting_input,\n )\n\n @staticmethod\n def hero_card(\n choices: List[Union[Choice, str]], text: str = None, speak: str = None\n ) -> Activity:\n \"\"\"\n Creates a message activity that includes a lsit of coices that have been added as `HeroCard`'s\n \"\"\"\n attachment = CardFactory.hero_card(\n HeroCard(text=text, buttons=ChoiceFactory._extract_actions(choices))\n )\n\n # Return activity with choices as HeroCard with buttons\n return MessageFactory.attachment(\n attachment, None, speak, InputHints.expecting_input\n )\n\n @staticmethod\n def _to_choices(choices: List[Union[str, Choice]]) -> List[Choice]:\n \"\"\"\n Takes a list of strings and returns them as [`Choice`].\n \"\"\"\n if choices is None:\n return []\n return [\n Choice(value=choice) if isinstance(choice, str) else choice\n for choice in choices\n ]\n\n @staticmethod\n def _extract_actions(choices: List[Union[str, Choice]]) -> List[CardAction]:\n if choices is None:\n choices = []\n choices = ChoiceFactory._to_choices(choices)\n card_actions: List[CardAction] = []\n for choice in choices:\n if choice.action is not None:\n card_action = choice.action\n else:\n card_action = CardAction(\n type=ActionTypes.im_back, value=choice.value, title=choice.value\n )\n\n card_actions.append(card_action)\n\n return card_actions\n", "path": "libraries/botbuilder-dialogs/botbuilder/dialogs/choices/choice_factory.py"}]}
| 3,031 | 174 |
gh_patches_debug_24377
|
rasdani/github-patches
|
git_diff
|
facebookresearch__hydra-1375
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Feature Request] [Submitit-Plugin] (Potentially a bug) Impossible to set certain flags in submitit launcher
# 🚀 Feature Request
<!-- A clear and concise description of the feature you are requesting -->
## Motivation
This could be read as a feature request or a bug report, I'm not sure how you want to consider it, I'm going with feature request. Currently theres some flags that you cannot set in the submitit launcher. I practice "gpu centric" scheduling, so I like to specify `mem_per_gpu` and `cpus_per_gpu` and then I can just use `gpus_per_task` to always get the optimal settings.
For example on "mystery cluster" (you know the one), we can use 10 cpus and 64GB RAM per GPU. These settings allow me to only have to change `gpus_per_task` for example if I need to have 2 GPUs for 2 different models, then I'll automatically get 20 cpus and 128GB RAM for each of the tasks without having to change all of the settings. I've already PRed stuff related to this into submitit.
The problem occurs when you try to set, via additional parameters, something like `mem_per_gpu`. You can't set `mem` and `mem_per_gpu`, slurm just crashes when you do that. Similarly, if you try to set `cpus_per_gpu` via `additional_parameters` you'll wind up setting that in addition to `cpus_per_task`.
## Pitch
I tried making a simple patch that fixes this, but it hits issues with the `AutoExecutor` which I never updated in submitit to be aware of the options which conflict with each other. I think in general auto is missing some of the recent work in submitit, and it feels like a semi-hacky workaround to me.
Submitit already has pretty good validation logic so my pitch is to (1) let submitit handle everything by calling the correct executor for the job instead of using Auto. This is going to require a revamp of how the parameters are named/passed however and will likely be a breaking change to the API. (2) It would be nice if we could allow people to pass whatever parameters are supported by submitit without needing to update the hydra schema each time. These are my two major goals, so they sound reasonable/feasible? Point (2) may not be possible I guess.
Other options:
* Use auto but try to include our own validation logic (needs exploration), I don't like this because it requires us to duplicate logic that submitit has already and also it may not even be possible depending on what Auto decides to do (looked iffy on my quick pass)
* Punt this to submitit to revamp the auto executor to do the right stuff and be more flexible. I don't like this because I think the auto executor is more of a convenience hack and more complex/flexible code would be calling the executors directly (this is what I was doing previously with my own submitit hydra wrapper thing). I also think its going to be a more more complex PR.
**Are you willing to open a pull request?** (See [CONTRIBUTING](../../CONTRIBUTING.md))
Yes, but I want feedback first on the best way to go about it
## Additional context
Add any other context or screenshots about the feature request here.
</issue>
<code>
[start of plugins/hydra_submitit_launcher/hydra_plugins/hydra_submitit_launcher/config.py]
1 # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
2 from dataclasses import dataclass, field
3 from typing import Any, Dict, List, Optional
4
5 from hydra.core.config_store import ConfigStore
6
7
8 @dataclass
9 class BaseQueueConf:
10 """Configuration shared by all executors"""
11
12 submitit_folder: str = "${hydra.sweep.dir}/.submitit/%j"
13
14 # maximum time for the job in minutes
15 timeout_min: int = 60
16 # number of cpus to use for each task
17 cpus_per_task: int = 1
18 # number of gpus to use on each node
19 gpus_per_node: int = 0
20 # number of tasks to spawn on each node
21 tasks_per_node: int = 1
22 # memory to reserve for the job on each node (in GB)
23 mem_gb: int = 4
24 # number of nodes to use for the job
25 nodes: int = 1
26 # name of the job
27 name: str = "${hydra.job.name}"
28
29
30 @dataclass
31 class SlurmQueueConf(BaseQueueConf):
32 """Slurm configuration overrides and specific parameters"""
33
34 _target_: str = (
35 "hydra_plugins.hydra_submitit_launcher.submitit_launcher.SlurmLauncher"
36 )
37
38 # Params are used to configure sbatch, for more info check:
39 # https://github.com/facebookincubator/submitit/blob/master/submitit/slurm/slurm.py
40
41 # Following parameters are slurm specific
42 # More information: https://slurm.schedmd.com/sbatch.html
43 #
44 # slurm partition to use on the cluster
45 partition: Optional[str] = None
46 comment: Optional[str] = None
47 constraint: Optional[str] = None
48 exclude: Optional[str] = None
49
50 # Following parameters are submitit specifics
51 #
52 # USR1 signal delay before timeout
53 signal_delay_s: int = 120
54 # Maximum number of retries on job timeout.
55 # Change this only after you confirmed your code can handle re-submission
56 # by properly resuming from the latest stored checkpoint.
57 # check the following for more info on slurm_max_num_timeout
58 # https://github.com/facebookincubator/submitit/blob/master/docs/checkpointing.md
59 max_num_timeout: int = 0
60 # Useful to add parameters which are not currently available in the plugin.
61 # Eg: {"mail-user": "[email protected]", "mail-type": "BEGIN"}
62 additional_parameters: Dict[str, Any] = field(default_factory=dict)
63 # Maximum number of jobs running in parallel
64 array_parallelism: int = 256
65 # A list of commands to run in sbatch befure running srun
66 setup: Optional[List[str]] = None
67
68
69 @dataclass
70 class LocalQueueConf(BaseQueueConf):
71 _target_: str = (
72 "hydra_plugins.hydra_submitit_launcher.submitit_launcher.LocalLauncher"
73 )
74
75
76 # finally, register two different choices:
77 ConfigStore.instance().store(
78 group="hydra/launcher",
79 name="submitit_local",
80 node=LocalQueueConf(),
81 provider="submitit_launcher",
82 )
83
84
85 ConfigStore.instance().store(
86 group="hydra/launcher",
87 name="submitit_slurm",
88 node=SlurmQueueConf(),
89 provider="submitit_launcher",
90 )
91
[end of plugins/hydra_submitit_launcher/hydra_plugins/hydra_submitit_launcher/config.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/plugins/hydra_submitit_launcher/hydra_plugins/hydra_submitit_launcher/config.py b/plugins/hydra_submitit_launcher/hydra_plugins/hydra_submitit_launcher/config.py
--- a/plugins/hydra_submitit_launcher/hydra_plugins/hydra_submitit_launcher/config.py
+++ b/plugins/hydra_submitit_launcher/hydra_plugins/hydra_submitit_launcher/config.py
@@ -14,13 +14,13 @@
# maximum time for the job in minutes
timeout_min: int = 60
# number of cpus to use for each task
- cpus_per_task: int = 1
+ cpus_per_task: Optional[int] = None
# number of gpus to use on each node
- gpus_per_node: int = 0
+ gpus_per_node: Optional[int] = None
# number of tasks to spawn on each node
tasks_per_node: int = 1
# memory to reserve for the job on each node (in GB)
- mem_gb: int = 4
+ mem_gb: Optional[int] = None
# number of nodes to use for the job
nodes: int = 1
# name of the job
@@ -46,6 +46,10 @@
comment: Optional[str] = None
constraint: Optional[str] = None
exclude: Optional[str] = None
+ cpus_per_gpu: Optional[int] = None
+ gpus_per_task: Optional[int] = None
+ mem_per_gpu: Optional[str] = None
+ mem_per_cpu: Optional[str] = None
# Following parameters are submitit specifics
#
|
{"golden_diff": "diff --git a/plugins/hydra_submitit_launcher/hydra_plugins/hydra_submitit_launcher/config.py b/plugins/hydra_submitit_launcher/hydra_plugins/hydra_submitit_launcher/config.py\n--- a/plugins/hydra_submitit_launcher/hydra_plugins/hydra_submitit_launcher/config.py\n+++ b/plugins/hydra_submitit_launcher/hydra_plugins/hydra_submitit_launcher/config.py\n@@ -14,13 +14,13 @@\n # maximum time for the job in minutes\n timeout_min: int = 60\n # number of cpus to use for each task\n- cpus_per_task: int = 1\n+ cpus_per_task: Optional[int] = None\n # number of gpus to use on each node\n- gpus_per_node: int = 0\n+ gpus_per_node: Optional[int] = None\n # number of tasks to spawn on each node\n tasks_per_node: int = 1\n # memory to reserve for the job on each node (in GB)\n- mem_gb: int = 4\n+ mem_gb: Optional[int] = None\n # number of nodes to use for the job\n nodes: int = 1\n # name of the job\n@@ -46,6 +46,10 @@\n comment: Optional[str] = None\n constraint: Optional[str] = None\n exclude: Optional[str] = None\n+ cpus_per_gpu: Optional[int] = None\n+ gpus_per_task: Optional[int] = None\n+ mem_per_gpu: Optional[str] = None\n+ mem_per_cpu: Optional[str] = None\n \n # Following parameters are submitit specifics\n #\n", "issue": "[Feature Request] [Submitit-Plugin] (Potentially a bug) Impossible to set certain flags in submitit launcher\n# \ud83d\ude80 Feature Request\r\n\r\n<!-- A clear and concise description of the feature you are requesting -->\r\n\r\n## Motivation\r\n\r\nThis could be read as a feature request or a bug report, I'm not sure how you want to consider it, I'm going with feature request. Currently theres some flags that you cannot set in the submitit launcher. I practice \"gpu centric\" scheduling, so I like to specify `mem_per_gpu` and `cpus_per_gpu` and then I can just use `gpus_per_task` to always get the optimal settings. \r\n\r\nFor example on \"mystery cluster\" (you know the one), we can use 10 cpus and 64GB RAM per GPU. These settings allow me to only have to change `gpus_per_task` for example if I need to have 2 GPUs for 2 different models, then I'll automatically get 20 cpus and 128GB RAM for each of the tasks without having to change all of the settings. I've already PRed stuff related to this into submitit.\r\n\r\nThe problem occurs when you try to set, via additional parameters, something like `mem_per_gpu`. You can't set `mem` and `mem_per_gpu`, slurm just crashes when you do that. Similarly, if you try to set `cpus_per_gpu` via `additional_parameters` you'll wind up setting that in addition to `cpus_per_task`.\r\n\r\n## Pitch\r\n\r\nI tried making a simple patch that fixes this, but it hits issues with the `AutoExecutor` which I never updated in submitit to be aware of the options which conflict with each other. I think in general auto is missing some of the recent work in submitit, and it feels like a semi-hacky workaround to me. \r\n\r\nSubmitit already has pretty good validation logic so my pitch is to (1) let submitit handle everything by calling the correct executor for the job instead of using Auto. This is going to require a revamp of how the parameters are named/passed however and will likely be a breaking change to the API. (2) It would be nice if we could allow people to pass whatever parameters are supported by submitit without needing to update the hydra schema each time. These are my two major goals, so they sound reasonable/feasible? Point (2) may not be possible I guess.\r\n\r\nOther options:\r\n\r\n* Use auto but try to include our own validation logic (needs exploration), I don't like this because it requires us to duplicate logic that submitit has already and also it may not even be possible depending on what Auto decides to do (looked iffy on my quick pass)\r\n* Punt this to submitit to revamp the auto executor to do the right stuff and be more flexible. I don't like this because I think the auto executor is more of a convenience hack and more complex/flexible code would be calling the executors directly (this is what I was doing previously with my own submitit hydra wrapper thing). I also think its going to be a more more complex PR.\r\n\r\n**Are you willing to open a pull request?** (See [CONTRIBUTING](../../CONTRIBUTING.md))\r\n\r\nYes, but I want feedback first on the best way to go about it\r\n\r\n## Additional context\r\nAdd any other context or screenshots about the feature request here.\r\n\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\nfrom dataclasses import dataclass, field\nfrom typing import Any, Dict, List, Optional\n\nfrom hydra.core.config_store import ConfigStore\n\n\n@dataclass\nclass BaseQueueConf:\n \"\"\"Configuration shared by all executors\"\"\"\n\n submitit_folder: str = \"${hydra.sweep.dir}/.submitit/%j\"\n\n # maximum time for the job in minutes\n timeout_min: int = 60\n # number of cpus to use for each task\n cpus_per_task: int = 1\n # number of gpus to use on each node\n gpus_per_node: int = 0\n # number of tasks to spawn on each node\n tasks_per_node: int = 1\n # memory to reserve for the job on each node (in GB)\n mem_gb: int = 4\n # number of nodes to use for the job\n nodes: int = 1\n # name of the job\n name: str = \"${hydra.job.name}\"\n\n\n@dataclass\nclass SlurmQueueConf(BaseQueueConf):\n \"\"\"Slurm configuration overrides and specific parameters\"\"\"\n\n _target_: str = (\n \"hydra_plugins.hydra_submitit_launcher.submitit_launcher.SlurmLauncher\"\n )\n\n # Params are used to configure sbatch, for more info check:\n # https://github.com/facebookincubator/submitit/blob/master/submitit/slurm/slurm.py\n\n # Following parameters are slurm specific\n # More information: https://slurm.schedmd.com/sbatch.html\n #\n # slurm partition to use on the cluster\n partition: Optional[str] = None\n comment: Optional[str] = None\n constraint: Optional[str] = None\n exclude: Optional[str] = None\n\n # Following parameters are submitit specifics\n #\n # USR1 signal delay before timeout\n signal_delay_s: int = 120\n # Maximum number of retries on job timeout.\n # Change this only after you confirmed your code can handle re-submission\n # by properly resuming from the latest stored checkpoint.\n # check the following for more info on slurm_max_num_timeout\n # https://github.com/facebookincubator/submitit/blob/master/docs/checkpointing.md\n max_num_timeout: int = 0\n # Useful to add parameters which are not currently available in the plugin.\n # Eg: {\"mail-user\": \"[email protected]\", \"mail-type\": \"BEGIN\"}\n additional_parameters: Dict[str, Any] = field(default_factory=dict)\n # Maximum number of jobs running in parallel\n array_parallelism: int = 256\n # A list of commands to run in sbatch befure running srun\n setup: Optional[List[str]] = None\n\n\n@dataclass\nclass LocalQueueConf(BaseQueueConf):\n _target_: str = (\n \"hydra_plugins.hydra_submitit_launcher.submitit_launcher.LocalLauncher\"\n )\n\n\n# finally, register two different choices:\nConfigStore.instance().store(\n group=\"hydra/launcher\",\n name=\"submitit_local\",\n node=LocalQueueConf(),\n provider=\"submitit_launcher\",\n)\n\n\nConfigStore.instance().store(\n group=\"hydra/launcher\",\n name=\"submitit_slurm\",\n node=SlurmQueueConf(),\n provider=\"submitit_launcher\",\n)\n", "path": "plugins/hydra_submitit_launcher/hydra_plugins/hydra_submitit_launcher/config.py"}]}
| 2,206 | 380 |
gh_patches_debug_15431
|
rasdani/github-patches
|
git_diff
|
learningequality__kolibri-9432
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
job_storage DB upgrading unnecessarily - fails to start devserver
## Observed behavior
This has happened to me several times in the last week where I stop my Kolibri dev server with CTRL+C and/or `killall -9 kolibri` and go to restart it and my job_storage DB is borked. When I run `rm $KOLIBRI_HOME/job_storage.sqlite3` and start it up again, it works just fine.
## Errors and logs
```
Error: Traceback (most recent call last):
File "/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/engine/base.py", line 1284, in _execute_context
cursor, statement, parameters, context
File "/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/engine/default.py", line 590, in do_execute
cursor.execute(statement, parameters)
sqlite3.OperationalError: index queue__scheduled_time already exists
The above exception was the direct cause of the following exception:
Traceback (most recent call last):
File "/home/jacob/Code/LE/kolibri/refactor-library-page/kolibri/utils/cli.py", line 193, in invoke
initialize(**get_initialize_params())
File "/home/jacob/Code/LE/kolibri/refactor-library-page/kolibri/utils/main.py", line 291, in initialize
update(version, kolibri.__version__)
File "/home/jacob/Code/LE/kolibri/refactor-library-page/kolibri/utils/main.py", line 349, in update
run_upgrades(old_version, new_version)
File "/home/jacob/Code/LE/kolibri/refactor-library-page/kolibri/core/upgrade.py", line 156, in run_upgrades
version_upgrade()
File "/home/jacob/Code/LE/kolibri/refactor-library-page/kolibri/core/upgrade.py", line 51, in __call__
return self.upgrade()
File "/home/jacob/Code/LE/kolibri/refactor-library-page/kolibri/core/tasks/upgrade.py", line 24, in drop_old_iceqube_tables
job_storage.recreate_tables()
File "/home/jacob/Code/LE/kolibri/refactor-library-page/kolibri/core/tasks/storage.py", line 113, in recreate_tables
self.Base.metadata.create_all(self.engine)
File "/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/sql/schema.py", line 4465, in create_all
ddl.SchemaGenerator, self, checkfirst=checkfirst, tables=tables
File "/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/engine/base.py", line 2104, in _run_visitor
conn._run_visitor(visitorcallable, element, **kwargs)
File "/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/engine/base.py", line 1663, in _run_visitor
visitorcallable(self.dialect, self, **kwargs).traverse_single(element)
File "/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/sql/visitors.py", line 144, in traverse_single
return meth(obj, **kw)
File "/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/sql/ddl.py", line 787, in visit_metadata
_is_metadata_operation=True,
File "/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/sql/visitors.py", line 144, in traverse_single
return meth(obj, **kw)
File "/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/sql/ddl.py", line 839, in visit_table
self.traverse_single(index)
File "/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/sql/visitors.py", line 144, in traverse_single
return meth(obj, **kw)
File "/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/sql/ddl.py", line 868, in visit_index
self.connection.execute(CreateIndex(index))
File "/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/engine/base.py", line 1020, in execute
return meth(self, multiparams, params)
File "/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/sql/ddl.py", line 72, in _execute_on_connection
return connection._execute_ddl(self, multiparams, params)
File "/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/engine/base.py", line 1082, in _execute_ddl
compiled,
File "/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/engine/base.py", line 1324, in _execute_context
e, statement, parameters, cursor, context
File "/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/engine/base.py", line 1518, in _handle_dbapi_exception
sqlalchemy_exception, with_traceback=exc_info[2], from_=e
File "/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/util/compat.py", line 178, in raise_
raise exception
File "/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/engine/base.py", line 1284, in _execute_context
cursor, statement, parameters, context
File "/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/engine/default.py", line 590, in do_execute
cursor.execute(statement, parameters)
sqlalchemy.exc.OperationalError: (sqlite3.OperationalError) index queue__scheduled_time already exists
[SQL: CREATE INDEX queue__scheduled_time ON jobs (queue, scheduled_time)]
(Background on this error at: http://sqlalche.me/e/e3q8)
```
## Expected behavior
<!--
Description of what behavior was expected but did not occur
-->
I shouldn't have to delete a DB to start/restart the dev server (this often anyway).
## User-facing consequences
Difficulties / unexpected errors for devs.
## Steps to reproduce
<!--
Precise steps that someone else can follow in order to see this behavior
-->
Kill your devserver and start it up again?
## Context
<!--
Tell us about your environment, including:
* Kolibri version
* Operating system
* Browser
-->
`develop` branch
Fedora
</issue>
<code>
[start of kolibri/core/tasks/upgrade.py]
1 """
2 A file to contain specific logic to handle version upgrades in Kolibri.
3 """
4 import logging
5
6 from kolibri.core.tasks.main import job_storage
7 from kolibri.core.upgrade import version_upgrade
8
9 logger = logging.getLogger(__name__)
10
11
12 # The schema of iceqube DBs changed between version 0.12 and 0.13.
13 # We have coopted this upgrade to just drop all the data in the job storage
14 # table from before 0.15, as from 0.15 onwards, we persist jobs in the
15 # database, rather than clearing at every startup.
16 # In 0.16 onwards we made schema updates to the job storage table, so we
17 # updated this upgrade task again to drop all the data in the job storage
18 @version_upgrade(old_version="<0.16.0")
19 def drop_old_iceqube_tables():
20 """
21 Rather than write a migration for the iceqube database, it is simpler to just drop the tables
22 and let iceqube reinitialize the tables from scratch.
23 """
24 job_storage.recreate_tables()
25
[end of kolibri/core/tasks/upgrade.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kolibri/core/tasks/upgrade.py b/kolibri/core/tasks/upgrade.py
--- a/kolibri/core/tasks/upgrade.py
+++ b/kolibri/core/tasks/upgrade.py
@@ -3,6 +3,8 @@
"""
import logging
+from sqlalchemy.exc import OperationalError
+
from kolibri.core.tasks.main import job_storage
from kolibri.core.upgrade import version_upgrade
@@ -21,4 +23,9 @@
Rather than write a migration for the iceqube database, it is simpler to just drop the tables
and let iceqube reinitialize the tables from scratch.
"""
- job_storage.recreate_tables()
+ try:
+ job_storage.recreate_tables()
+ except OperationalError:
+ logger.warning(
+ "Could not recreate job storage table. This is probably because the database already exists and did not need to be recreated."
+ )
|
{"golden_diff": "diff --git a/kolibri/core/tasks/upgrade.py b/kolibri/core/tasks/upgrade.py\n--- a/kolibri/core/tasks/upgrade.py\n+++ b/kolibri/core/tasks/upgrade.py\n@@ -3,6 +3,8 @@\n \"\"\"\n import logging\n \n+from sqlalchemy.exc import OperationalError\n+\n from kolibri.core.tasks.main import job_storage\n from kolibri.core.upgrade import version_upgrade\n \n@@ -21,4 +23,9 @@\n Rather than write a migration for the iceqube database, it is simpler to just drop the tables\n and let iceqube reinitialize the tables from scratch.\n \"\"\"\n- job_storage.recreate_tables()\n+ try:\n+ job_storage.recreate_tables()\n+ except OperationalError:\n+ logger.warning(\n+ \"Could not recreate job storage table. This is probably because the database already exists and did not need to be recreated.\"\n+ )\n", "issue": "job_storage DB upgrading unnecessarily - fails to start devserver\n## Observed behavior\r\n\r\nThis has happened to me several times in the last week where I stop my Kolibri dev server with CTRL+C and/or `killall -9 kolibri` and go to restart it and my job_storage DB is borked. When I run `rm $KOLIBRI_HOME/job_storage.sqlite3` and start it up again, it works just fine. \r\n\r\n## Errors and logs\r\n\r\n```\r\nError: Traceback (most recent call last):\r\n File \"/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/engine/base.py\", line 1284, in _execute_context\r\n cursor, statement, parameters, context\r\n File \"/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/engine/default.py\", line 590, in do_execute\r\n cursor.execute(statement, parameters)\r\nsqlite3.OperationalError: index queue__scheduled_time already exists\r\n\r\nThe above exception was the direct cause of the following exception:\r\n\r\nTraceback (most recent call last):\r\n File \"/home/jacob/Code/LE/kolibri/refactor-library-page/kolibri/utils/cli.py\", line 193, in invoke\r\n initialize(**get_initialize_params())\r\n File \"/home/jacob/Code/LE/kolibri/refactor-library-page/kolibri/utils/main.py\", line 291, in initialize\r\n update(version, kolibri.__version__)\r\n File \"/home/jacob/Code/LE/kolibri/refactor-library-page/kolibri/utils/main.py\", line 349, in update\r\n run_upgrades(old_version, new_version)\r\n File \"/home/jacob/Code/LE/kolibri/refactor-library-page/kolibri/core/upgrade.py\", line 156, in run_upgrades\r\n version_upgrade()\r\n File \"/home/jacob/Code/LE/kolibri/refactor-library-page/kolibri/core/upgrade.py\", line 51, in __call__\r\n return self.upgrade()\r\n File \"/home/jacob/Code/LE/kolibri/refactor-library-page/kolibri/core/tasks/upgrade.py\", line 24, in drop_old_iceqube_tables\r\n job_storage.recreate_tables()\r\n File \"/home/jacob/Code/LE/kolibri/refactor-library-page/kolibri/core/tasks/storage.py\", line 113, in recreate_tables\r\n self.Base.metadata.create_all(self.engine)\r\n File \"/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/sql/schema.py\", line 4465, in create_all\r\n ddl.SchemaGenerator, self, checkfirst=checkfirst, tables=tables\r\n File \"/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/engine/base.py\", line 2104, in _run_visitor\r\n conn._run_visitor(visitorcallable, element, **kwargs)\r\n File \"/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/engine/base.py\", line 1663, in _run_visitor\r\n visitorcallable(self.dialect, self, **kwargs).traverse_single(element)\r\n File \"/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/sql/visitors.py\", line 144, in traverse_single\r\n return meth(obj, **kw)\r\n File \"/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/sql/ddl.py\", line 787, in visit_metadata\r\n _is_metadata_operation=True,\r\n File \"/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/sql/visitors.py\", line 144, in traverse_single\r\n return meth(obj, **kw)\r\n File \"/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/sql/ddl.py\", line 839, in visit_table\r\n self.traverse_single(index)\r\n File \"/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/sql/visitors.py\", line 144, in traverse_single\r\n return meth(obj, **kw)\r\n File \"/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/sql/ddl.py\", line 868, in visit_index\r\n self.connection.execute(CreateIndex(index))\r\n File \"/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/engine/base.py\", line 1020, in execute\r\n return meth(self, multiparams, params)\r\n File \"/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/sql/ddl.py\", line 72, in _execute_on_connection\r\n return connection._execute_ddl(self, multiparams, params)\r\n File \"/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/engine/base.py\", line 1082, in _execute_ddl\r\n compiled,\r\n File \"/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/engine/base.py\", line 1324, in _execute_context\r\n e, statement, parameters, cursor, context\r\n File \"/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/engine/base.py\", line 1518, in _handle_dbapi_exception\r\n sqlalchemy_exception, with_traceback=exc_info[2], from_=e\r\n File \"/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/util/compat.py\", line 178, in raise_\r\n raise exception\r\n File \"/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/engine/base.py\", line 1284, in _execute_context\r\n cursor, statement, parameters, context\r\n File \"/home/jacob/Code/LE/kolibri/refactor-library-page/venv/lib/python3.6/site-packages/sqlalchemy/engine/default.py\", line 590, in do_execute\r\n cursor.execute(statement, parameters)\r\nsqlalchemy.exc.OperationalError: (sqlite3.OperationalError) index queue__scheduled_time already exists\r\n[SQL: CREATE INDEX queue__scheduled_time ON jobs (queue, scheduled_time)]\r\n(Background on this error at: http://sqlalche.me/e/e3q8)\r\n```\r\n\r\n## Expected behavior\r\n<!--\r\nDescription of what behavior was expected but did not occur\r\n-->\r\n\r\nI shouldn't have to delete a DB to start/restart the dev server (this often anyway).\r\n\r\n## User-facing consequences\r\n\r\nDifficulties / unexpected errors for devs.\r\n\r\n## Steps to reproduce\r\n<!--\r\nPrecise steps that someone else can follow in order to see this behavior\r\n-->\r\n\r\nKill your devserver and start it up again? \r\n\r\n## Context\r\n<!--\r\nTell us about your environment, including:\r\n * Kolibri version\r\n * Operating system\r\n * Browser\r\n-->\r\n\r\n`develop` branch\r\nFedora\n", "before_files": [{"content": "\"\"\"\nA file to contain specific logic to handle version upgrades in Kolibri.\n\"\"\"\nimport logging\n\nfrom kolibri.core.tasks.main import job_storage\nfrom kolibri.core.upgrade import version_upgrade\n\nlogger = logging.getLogger(__name__)\n\n\n# The schema of iceqube DBs changed between version 0.12 and 0.13.\n# We have coopted this upgrade to just drop all the data in the job storage\n# table from before 0.15, as from 0.15 onwards, we persist jobs in the\n# database, rather than clearing at every startup.\n# In 0.16 onwards we made schema updates to the job storage table, so we\n# updated this upgrade task again to drop all the data in the job storage\n@version_upgrade(old_version=\"<0.16.0\")\ndef drop_old_iceqube_tables():\n \"\"\"\n Rather than write a migration for the iceqube database, it is simpler to just drop the tables\n and let iceqube reinitialize the tables from scratch.\n \"\"\"\n job_storage.recreate_tables()\n", "path": "kolibri/core/tasks/upgrade.py"}]}
| 2,472 | 196 |
gh_patches_debug_9465
|
rasdani/github-patches
|
git_diff
|
liqd__adhocracy4-623
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
error handling intial slide
like https://github.com/liqd/a4-meinberlin/issues/3153
</issue>
<code>
[start of adhocracy4/projects/mixins.py]
1 from django.http import Http404
2 from django.http.response import HttpResponseRedirect
3 from django.shortcuts import get_object_or_404
4 from django.urls import resolve
5 from django.utils.functional import cached_property
6 from django.views import generic
7
8 from adhocracy4.modules.models import Module
9 from adhocracy4.projects.models import Project
10
11
12 class PhaseDispatchMixin(generic.DetailView):
13
14 @cached_property
15 def project(self):
16 return self.get_object()
17
18 @cached_property
19 def module(self):
20 return self.project.last_active_module
21
22 def dispatch(self, request, *args, **kwargs):
23 # Choose the appropriate view for the current active phase.
24 kwargs['project'] = self.project
25 kwargs['module'] = self.module
26
27 return self._view_by_phase()(request, *args, **kwargs)
28
29 def _view_by_phase(self):
30 """
31 Choose the appropriate view for the current active phase.
32 """
33 if self.module and self.module.last_active_phase:
34 return self.module.last_active_phase.view.as_view()
35 else:
36 return super().dispatch
37
38
39 class ModuleDispatchMixin(PhaseDispatchMixin):
40
41 @cached_property
42 def project(self):
43 return self.module.project
44
45 @cached_property
46 def module(self):
47 return self.get_object()
48
49 def dispatch(self, request, *args, **kwargs):
50 # Redirect to the project detail page if the module is shown there
51 if self.module == self.project.last_active_module:
52 return HttpResponseRedirect(self.project.get_absolute_url())
53
54 return super().dispatch(request, *args, **kwargs)
55
56
57 class ProjectMixin(generic.base.ContextMixin):
58 """Add project and module attributes to the view and the template context.
59
60 This is a counterpart to the Phase- / ModuleDispatcher logic.
61
62 To consider the object context from get_object() set the
63 get_context_from_object attribute. Enable this only if get_object() does
64 not access the project and module properties.
65 """
66
67 project_lookup_field = 'slug'
68 project_url_kwarg = 'project_slug'
69 module_lookup_field = 'slug'
70 module_url_kwarg = 'module_slug'
71 get_context_from_object = False
72
73 @property
74 def module(self):
75 """Get the module from the current object, kwargs or url."""
76 if self.get_context_from_object:
77 return self._get_object(Module, 'module')
78
79 if 'module' in self.kwargs \
80 and isinstance(self.kwargs['module'], Module):
81 return self.kwargs['module']
82
83 if self.module_url_kwarg and self.module_url_kwarg in self.kwargs:
84 lookup = {
85 self.module_lookup_field: self.kwargs[self.module_url_kwarg]
86 }
87 return get_object_or_404(Module, **lookup)
88
89 @property
90 def project(self):
91 """Get the project from the module, kwargs, url or current object."""
92 if self.module:
93 return self.module.project
94
95 if self.get_context_from_object:
96 return self._get_object(Project, 'project')
97
98 if 'project' in self.kwargs \
99 and isinstance(self.kwargs['project'], Project):
100 return self.kwargs['project']
101
102 if self.project_url_kwarg and self.project_url_kwarg in self.kwargs:
103 lookup = {
104 self.project_lookup_field: self.kwargs[self.project_url_kwarg]
105 }
106 return get_object_or_404(Project, **lookup)
107
108 def _get_object(self, cls, attr):
109 # CreateView supplies a defect get_object method and has to be excluded
110 if hasattr(self, 'get_object') \
111 and not isinstance(self, generic.CreateView):
112 try:
113 object = self.get_object()
114 if isinstance(object, cls):
115 return object
116
117 if hasattr(object, attr):
118 return getattr(object, attr)
119 except Http404:
120 return None
121 except AttributeError:
122 return None
123
124 return None
125
126 def get_context_data(self, **kwargs):
127 """Append project and module to the template context."""
128 if 'project' not in kwargs:
129 kwargs['project'] = self.project
130 if 'module' not in kwargs:
131 kwargs['module'] = self.module
132 return super().get_context_data(**kwargs)
133
134
135 class DisplayProjectOrModuleMixin(generic.base.ContextMixin):
136
137 @cached_property
138 def url_name(self):
139 return resolve(self.request.path_info).url_name
140
141 @cached_property
142 def extends(self):
143 if self.url_name == 'module-detail':
144 return 'a4modules/module_detail.html'
145 return 'a4projects/project_detail.html'
146
147 @cached_property
148 def initial_slide(self):
149 initial_slide = self.request.GET.get('initialSlide')
150 if initial_slide:
151 return int(initial_slide)
152 elif self.project.get_current_participation_date():
153 return self.project.get_current_participation_date()
154 return 0
155
156 def get_current_event(self):
157 idx = self.initial_slide
158 return self.project.get_current_event(idx)
159
160 def get_current_modules(self):
161 idx = self.initial_slide
162 return self.project.get_current_modules(idx)
163
164 def get_context_data(self, **kwargs):
165 context = super().get_context_data(**kwargs)
166 context['url_name'] = self.url_name
167 context['extends'] = self.extends
168 if not self.url_name == 'module-detail':
169 context['event'] = self.get_current_event()
170 context['modules'] = self.get_current_modules()
171 context['initial_slide'] = self.initial_slide
172 return context
173
174
175 class ProjectModuleDispatchMixin(generic.DetailView):
176
177 @cached_property
178 def project(self):
179 return self.get_object()
180
181 @cached_property
182 def module(self):
183 if (self.project.published_modules.count()
184 == 1 and not self.project.events):
185 return self.project.published_modules.first()
186 elif len(self.get_current_modules()) == 1:
187 return self.get_current_modules()[0]
188
189 def dispatch(self, request, *args, **kwargs):
190 kwargs['project'] = self.project
191 kwargs['module'] = self.module
192
193 return self._view_by_phase()(request, *args, **kwargs)
194
195 def _view_by_phase(self):
196 if self.module and self.module.last_active_phase:
197 return self.module.last_active_phase.view.as_view()
198 elif self.module and self.module.future_phases:
199 return self.module.future_phases.first().view.as_view()
200 else:
201 return super().dispatch
202
[end of adhocracy4/projects/mixins.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/adhocracy4/projects/mixins.py b/adhocracy4/projects/mixins.py
--- a/adhocracy4/projects/mixins.py
+++ b/adhocracy4/projects/mixins.py
@@ -148,7 +148,9 @@
def initial_slide(self):
initial_slide = self.request.GET.get('initialSlide')
if initial_slide:
- return int(initial_slide)
+ initial_slide = ''.join(i for i in initial_slide if i.isdigit())
+ if initial_slide:
+ return int(initial_slide)
elif self.project.get_current_participation_date():
return self.project.get_current_participation_date()
return 0
|
{"golden_diff": "diff --git a/adhocracy4/projects/mixins.py b/adhocracy4/projects/mixins.py\n--- a/adhocracy4/projects/mixins.py\n+++ b/adhocracy4/projects/mixins.py\n@@ -148,7 +148,9 @@\n def initial_slide(self):\n initial_slide = self.request.GET.get('initialSlide')\n if initial_slide:\n- return int(initial_slide)\n+ initial_slide = ''.join(i for i in initial_slide if i.isdigit())\n+ if initial_slide:\n+ return int(initial_slide)\n elif self.project.get_current_participation_date():\n return self.project.get_current_participation_date()\n return 0\n", "issue": "error handling intial slide\nlike https://github.com/liqd/a4-meinberlin/issues/3153\n", "before_files": [{"content": "from django.http import Http404\nfrom django.http.response import HttpResponseRedirect\nfrom django.shortcuts import get_object_or_404\nfrom django.urls import resolve\nfrom django.utils.functional import cached_property\nfrom django.views import generic\n\nfrom adhocracy4.modules.models import Module\nfrom adhocracy4.projects.models import Project\n\n\nclass PhaseDispatchMixin(generic.DetailView):\n\n @cached_property\n def project(self):\n return self.get_object()\n\n @cached_property\n def module(self):\n return self.project.last_active_module\n\n def dispatch(self, request, *args, **kwargs):\n # Choose the appropriate view for the current active phase.\n kwargs['project'] = self.project\n kwargs['module'] = self.module\n\n return self._view_by_phase()(request, *args, **kwargs)\n\n def _view_by_phase(self):\n \"\"\"\n Choose the appropriate view for the current active phase.\n \"\"\"\n if self.module and self.module.last_active_phase:\n return self.module.last_active_phase.view.as_view()\n else:\n return super().dispatch\n\n\nclass ModuleDispatchMixin(PhaseDispatchMixin):\n\n @cached_property\n def project(self):\n return self.module.project\n\n @cached_property\n def module(self):\n return self.get_object()\n\n def dispatch(self, request, *args, **kwargs):\n # Redirect to the project detail page if the module is shown there\n if self.module == self.project.last_active_module:\n return HttpResponseRedirect(self.project.get_absolute_url())\n\n return super().dispatch(request, *args, **kwargs)\n\n\nclass ProjectMixin(generic.base.ContextMixin):\n \"\"\"Add project and module attributes to the view and the template context.\n\n This is a counterpart to the Phase- / ModuleDispatcher logic.\n\n To consider the object context from get_object() set the\n get_context_from_object attribute. Enable this only if get_object() does\n not access the project and module properties.\n \"\"\"\n\n project_lookup_field = 'slug'\n project_url_kwarg = 'project_slug'\n module_lookup_field = 'slug'\n module_url_kwarg = 'module_slug'\n get_context_from_object = False\n\n @property\n def module(self):\n \"\"\"Get the module from the current object, kwargs or url.\"\"\"\n if self.get_context_from_object:\n return self._get_object(Module, 'module')\n\n if 'module' in self.kwargs \\\n and isinstance(self.kwargs['module'], Module):\n return self.kwargs['module']\n\n if self.module_url_kwarg and self.module_url_kwarg in self.kwargs:\n lookup = {\n self.module_lookup_field: self.kwargs[self.module_url_kwarg]\n }\n return get_object_or_404(Module, **lookup)\n\n @property\n def project(self):\n \"\"\"Get the project from the module, kwargs, url or current object.\"\"\"\n if self.module:\n return self.module.project\n\n if self.get_context_from_object:\n return self._get_object(Project, 'project')\n\n if 'project' in self.kwargs \\\n and isinstance(self.kwargs['project'], Project):\n return self.kwargs['project']\n\n if self.project_url_kwarg and self.project_url_kwarg in self.kwargs:\n lookup = {\n self.project_lookup_field: self.kwargs[self.project_url_kwarg]\n }\n return get_object_or_404(Project, **lookup)\n\n def _get_object(self, cls, attr):\n # CreateView supplies a defect get_object method and has to be excluded\n if hasattr(self, 'get_object') \\\n and not isinstance(self, generic.CreateView):\n try:\n object = self.get_object()\n if isinstance(object, cls):\n return object\n\n if hasattr(object, attr):\n return getattr(object, attr)\n except Http404:\n return None\n except AttributeError:\n return None\n\n return None\n\n def get_context_data(self, **kwargs):\n \"\"\"Append project and module to the template context.\"\"\"\n if 'project' not in kwargs:\n kwargs['project'] = self.project\n if 'module' not in kwargs:\n kwargs['module'] = self.module\n return super().get_context_data(**kwargs)\n\n\nclass DisplayProjectOrModuleMixin(generic.base.ContextMixin):\n\n @cached_property\n def url_name(self):\n return resolve(self.request.path_info).url_name\n\n @cached_property\n def extends(self):\n if self.url_name == 'module-detail':\n return 'a4modules/module_detail.html'\n return 'a4projects/project_detail.html'\n\n @cached_property\n def initial_slide(self):\n initial_slide = self.request.GET.get('initialSlide')\n if initial_slide:\n return int(initial_slide)\n elif self.project.get_current_participation_date():\n return self.project.get_current_participation_date()\n return 0\n\n def get_current_event(self):\n idx = self.initial_slide\n return self.project.get_current_event(idx)\n\n def get_current_modules(self):\n idx = self.initial_slide\n return self.project.get_current_modules(idx)\n\n def get_context_data(self, **kwargs):\n context = super().get_context_data(**kwargs)\n context['url_name'] = self.url_name\n context['extends'] = self.extends\n if not self.url_name == 'module-detail':\n context['event'] = self.get_current_event()\n context['modules'] = self.get_current_modules()\n context['initial_slide'] = self.initial_slide\n return context\n\n\nclass ProjectModuleDispatchMixin(generic.DetailView):\n\n @cached_property\n def project(self):\n return self.get_object()\n\n @cached_property\n def module(self):\n if (self.project.published_modules.count()\n == 1 and not self.project.events):\n return self.project.published_modules.first()\n elif len(self.get_current_modules()) == 1:\n return self.get_current_modules()[0]\n\n def dispatch(self, request, *args, **kwargs):\n kwargs['project'] = self.project\n kwargs['module'] = self.module\n\n return self._view_by_phase()(request, *args, **kwargs)\n\n def _view_by_phase(self):\n if self.module and self.module.last_active_phase:\n return self.module.last_active_phase.view.as_view()\n elif self.module and self.module.future_phases:\n return self.module.future_phases.first().view.as_view()\n else:\n return super().dispatch\n", "path": "adhocracy4/projects/mixins.py"}]}
| 2,446 | 147 |
gh_patches_debug_2466
|
rasdani/github-patches
|
git_diff
|
google__flax-3785
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[struct.dataclass] Consider adding optional `kw_only` arguments
I often run into the following issue:
```python
from flax import struct
class Foo(struct.PyTreeNode):
bar: int = struct.field(pytree_node=False, default=1)
class Baz(Foo):
qux: str
```
Since `qux` does not have a default value, I get:
```
Fields without default values cannot appear after fields with default values
```
Can we consider adding a simple wrapper to `dataclasses.dataclass(kw_only=True)`?
It should be easy for the `struct.dataclass`, we can maybe have another object for inheritance, like `PyTreeNodeKwOnly`?
</issue>
<code>
[start of flax/struct.py]
1 # Copyright 2024 The Flax Authors.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """Utilities for defining custom classes that can be used with jax transformations."""
16
17 import dataclasses
18 from typing import TypeVar
19
20 import jax
21 from typing_extensions import (
22 dataclass_transform, # pytype: disable=not-supported-yet
23 )
24
25 from . import serialization
26
27 _T = TypeVar('_T')
28
29
30 def field(pytree_node=True, **kwargs):
31 return dataclasses.field(metadata={'pytree_node': pytree_node}, **kwargs)
32
33
34 @dataclass_transform(field_specifiers=(field,)) # type: ignore[literal-required]
35 def dataclass(clz: _T, **kwargs) -> _T:
36 """Create a class which can be passed to functional transformations.
37
38 .. note::
39 Inherit from ``PyTreeNode`` instead to avoid type checking issues when
40 using PyType.
41
42 Jax transformations such as ``jax.jit`` and ``jax.grad`` require objects that are
43 immutable and can be mapped over using the ``jax.tree_util`` methods.
44 The ``dataclass`` decorator makes it easy to define custom classes that can be
45 passed safely to Jax. For example::
46
47 >>> from flax import struct
48 >>> import jax
49 >>> from typing import Any, Callable
50
51 >>> @struct.dataclass
52 ... class Model:
53 ... params: Any
54 ... # use pytree_node=False to indicate an attribute should not be touched
55 ... # by Jax transformations.
56 ... apply_fn: Callable = struct.field(pytree_node=False)
57
58 ... def __apply__(self, *args):
59 ... return self.apply_fn(*args)
60
61 >>> params = {}
62 >>> params_b = {}
63 >>> apply_fn = lambda v, x: x
64 >>> model = Model(params, apply_fn)
65
66 >>> # model.params = params_b # Model is immutable. This will raise an error.
67 >>> model_b = model.replace(params=params_b) # Use the replace method instead.
68
69 >>> # This class can now be used safely in Jax to compute gradients w.r.t. the
70 >>> # parameters.
71 >>> model = Model(params, apply_fn)
72 >>> loss_fn = lambda model: 3.
73 >>> model_grad = jax.grad(loss_fn)(model)
74
75 Note that dataclasses have an auto-generated ``__init__`` where
76 the arguments of the constructor and the attributes of the created
77 instance match 1:1. This correspondence is what makes these objects
78 valid containers that work with JAX transformations and
79 more generally the ``jax.tree_util`` library.
80
81 Sometimes a "smart constructor" is desired, for example because
82 some of the attributes can be (optionally) derived from others.
83 The way to do this with Flax dataclasses is to make a static or
84 class method that provides the smart constructor.
85 This way the simple constructor used by ``jax.tree_util`` is
86 preserved. Consider the following example::
87
88 >>> @struct.dataclass
89 ... class DirectionAndScaleKernel:
90 ... direction: jax.Array
91 ... scale: jax.Array
92
93 ... @classmethod
94 ... def create(cls, kernel):
95 ... scale = jax.numpy.linalg.norm(kernel, axis=0, keepdims=True)
96 ... direction = direction / scale
97 ... return cls(direction, scale)
98
99 Args:
100 clz: the class that will be transformed by the decorator.
101 Returns:
102 The new class.
103 """
104 # check if already a flax dataclass
105 if '_flax_dataclass' in clz.__dict__:
106 return clz
107
108 if 'frozen' not in kwargs.keys():
109 kwargs['frozen'] = True
110 data_clz = dataclasses.dataclass(**kwargs)(clz) # type: ignore
111 meta_fields = []
112 data_fields = []
113 for field_info in dataclasses.fields(data_clz):
114 is_pytree_node = field_info.metadata.get('pytree_node', True)
115 if is_pytree_node:
116 data_fields.append(field_info.name)
117 else:
118 meta_fields.append(field_info.name)
119
120 def replace(self, **updates):
121 """ "Returns a new object replacing the specified fields with new values."""
122 return dataclasses.replace(self, **updates)
123
124 data_clz.replace = replace
125
126 def iterate_clz(x):
127 meta = tuple(getattr(x, name) for name in meta_fields)
128 data = tuple(getattr(x, name) for name in data_fields)
129 return data, meta
130
131 def iterate_clz_with_keys(x):
132 meta = tuple(getattr(x, name) for name in meta_fields)
133 data = tuple(
134 (jax.tree_util.GetAttrKey(name), getattr(x, name)) for name in data_fields
135 )
136 return data, meta
137
138 def clz_from_iterable(meta, data):
139 meta_args = tuple(zip(meta_fields, meta))
140 data_args = tuple(zip(data_fields, data))
141 kwargs = dict(meta_args + data_args)
142 return data_clz(**kwargs)
143
144 jax.tree_util.register_pytree_with_keys(
145 data_clz, iterate_clz_with_keys, clz_from_iterable, iterate_clz,
146 )
147
148 def to_state_dict(x):
149 state_dict = {
150 name: serialization.to_state_dict(getattr(x, name))
151 for name in data_fields
152 }
153 return state_dict
154
155 def from_state_dict(x, state):
156 """Restore the state of a data class."""
157 state = state.copy() # copy the state so we can pop the restored fields.
158 updates = {}
159 for name in data_fields:
160 if name not in state:
161 raise ValueError(
162 f'Missing field {name} in state dict while restoring'
163 f' an instance of {clz.__name__},'
164 f' at path {serialization.current_path()}'
165 )
166 value = getattr(x, name)
167 value_state = state.pop(name)
168 updates[name] = serialization.from_state_dict(
169 value, value_state, name=name
170 )
171 if state:
172 names = ','.join(state.keys())
173 raise ValueError(
174 f'Unknown field(s) "{names}" in state dict while'
175 f' restoring an instance of {clz.__name__}'
176 f' at path {serialization.current_path()}'
177 )
178 return x.replace(**updates)
179
180 serialization.register_serialization_state(
181 data_clz, to_state_dict, from_state_dict
182 )
183
184 # add a _flax_dataclass flag to distinguish from regular dataclasses
185 data_clz._flax_dataclass = True # type: ignore[attr-defined]
186
187 return data_clz # type: ignore
188
189
190 TNode = TypeVar('TNode', bound='PyTreeNode')
191
192
193 @dataclass_transform(field_specifiers=(field,)) # type: ignore[literal-required]
194 class PyTreeNode:
195 """Base class for dataclasses that should act like a JAX pytree node.
196
197 See ``flax.struct.dataclass`` for the ``jax.tree_util`` behavior.
198 This base class additionally avoids type checking errors when using PyType.
199
200 Example::
201
202 >>> from flax import struct
203 >>> import jax
204 >>> from typing import Any, Callable
205
206 >>> class Model(struct.PyTreeNode):
207 ... params: Any
208 ... # use pytree_node=False to indicate an attribute should not be touched
209 ... # by Jax transformations.
210 ... apply_fn: Callable = struct.field(pytree_node=False)
211
212 ... def __apply__(self, *args):
213 ... return self.apply_fn(*args)
214
215 >>> params = {}
216 >>> params_b = {}
217 >>> apply_fn = lambda v, x: x
218 >>> model = Model(params, apply_fn)
219
220 >>> # model.params = params_b # Model is immutable. This will raise an error.
221 >>> model_b = model.replace(params=params_b) # Use the replace method instead.
222
223 >>> # This class can now be used safely in Jax to compute gradients w.r.t. the
224 >>> # parameters.
225 >>> model = Model(params, apply_fn)
226 >>> loss_fn = lambda model: 3.
227 >>> model_grad = jax.grad(loss_fn)(model)
228 """
229
230 def __init_subclass__(cls):
231 dataclass(cls) # pytype: disable=wrong-arg-types
232
233 def __init__(self, *args, **kwargs):
234 # stub for pytype
235 raise NotImplementedError
236
237 def replace(self: TNode, **overrides) -> TNode:
238 # stub for pytype
239 raise NotImplementedError
240
[end of flax/struct.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/flax/struct.py b/flax/struct.py
--- a/flax/struct.py
+++ b/flax/struct.py
@@ -227,8 +227,8 @@
>>> model_grad = jax.grad(loss_fn)(model)
"""
- def __init_subclass__(cls):
- dataclass(cls) # pytype: disable=wrong-arg-types
+ def __init_subclass__(cls, **kwargs):
+ dataclass(cls, **kwargs) # pytype: disable=wrong-arg-types
def __init__(self, *args, **kwargs):
# stub for pytype
|
{"golden_diff": "diff --git a/flax/struct.py b/flax/struct.py\n--- a/flax/struct.py\n+++ b/flax/struct.py\n@@ -227,8 +227,8 @@\n >>> model_grad = jax.grad(loss_fn)(model)\n \"\"\"\n \n- def __init_subclass__(cls):\n- dataclass(cls) # pytype: disable=wrong-arg-types\n+ def __init_subclass__(cls, **kwargs):\n+ dataclass(cls, **kwargs) # pytype: disable=wrong-arg-types\n \n def __init__(self, *args, **kwargs):\n # stub for pytype\n", "issue": "[struct.dataclass] Consider adding optional `kw_only` arguments\nI often run into the following issue:\r\n\r\n```python\r\nfrom flax import struct\r\n\r\nclass Foo(struct.PyTreeNode):\r\n bar: int = struct.field(pytree_node=False, default=1)\r\n\r\nclass Baz(Foo):\r\n qux: str\r\n```\r\n\r\nSince `qux` does not have a default value, I get:\r\n```\r\nFields without default values cannot appear after fields with default values\r\n```\r\n\r\nCan we consider adding a simple wrapper to `dataclasses.dataclass(kw_only=True)`?\r\n\r\nIt should be easy for the `struct.dataclass`, we can maybe have another object for inheritance, like `PyTreeNodeKwOnly`?\n", "before_files": [{"content": "# Copyright 2024 The Flax Authors.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"Utilities for defining custom classes that can be used with jax transformations.\"\"\"\n\nimport dataclasses\nfrom typing import TypeVar\n\nimport jax\nfrom typing_extensions import (\n dataclass_transform, # pytype: disable=not-supported-yet\n)\n\nfrom . import serialization\n\n_T = TypeVar('_T')\n\n\ndef field(pytree_node=True, **kwargs):\n return dataclasses.field(metadata={'pytree_node': pytree_node}, **kwargs)\n\n\n@dataclass_transform(field_specifiers=(field,)) # type: ignore[literal-required]\ndef dataclass(clz: _T, **kwargs) -> _T:\n \"\"\"Create a class which can be passed to functional transformations.\n\n .. note::\n Inherit from ``PyTreeNode`` instead to avoid type checking issues when\n using PyType.\n\n Jax transformations such as ``jax.jit`` and ``jax.grad`` require objects that are\n immutable and can be mapped over using the ``jax.tree_util`` methods.\n The ``dataclass`` decorator makes it easy to define custom classes that can be\n passed safely to Jax. For example::\n\n >>> from flax import struct\n >>> import jax\n >>> from typing import Any, Callable\n\n >>> @struct.dataclass\n ... class Model:\n ... params: Any\n ... # use pytree_node=False to indicate an attribute should not be touched\n ... # by Jax transformations.\n ... apply_fn: Callable = struct.field(pytree_node=False)\n\n ... def __apply__(self, *args):\n ... return self.apply_fn(*args)\n\n >>> params = {}\n >>> params_b = {}\n >>> apply_fn = lambda v, x: x\n >>> model = Model(params, apply_fn)\n\n >>> # model.params = params_b # Model is immutable. This will raise an error.\n >>> model_b = model.replace(params=params_b) # Use the replace method instead.\n\n >>> # This class can now be used safely in Jax to compute gradients w.r.t. the\n >>> # parameters.\n >>> model = Model(params, apply_fn)\n >>> loss_fn = lambda model: 3.\n >>> model_grad = jax.grad(loss_fn)(model)\n\n Note that dataclasses have an auto-generated ``__init__`` where\n the arguments of the constructor and the attributes of the created\n instance match 1:1. This correspondence is what makes these objects\n valid containers that work with JAX transformations and\n more generally the ``jax.tree_util`` library.\n\n Sometimes a \"smart constructor\" is desired, for example because\n some of the attributes can be (optionally) derived from others.\n The way to do this with Flax dataclasses is to make a static or\n class method that provides the smart constructor.\n This way the simple constructor used by ``jax.tree_util`` is\n preserved. Consider the following example::\n\n >>> @struct.dataclass\n ... class DirectionAndScaleKernel:\n ... direction: jax.Array\n ... scale: jax.Array\n\n ... @classmethod\n ... def create(cls, kernel):\n ... scale = jax.numpy.linalg.norm(kernel, axis=0, keepdims=True)\n ... direction = direction / scale\n ... return cls(direction, scale)\n\n Args:\n clz: the class that will be transformed by the decorator.\n Returns:\n The new class.\n \"\"\"\n # check if already a flax dataclass\n if '_flax_dataclass' in clz.__dict__:\n return clz\n\n if 'frozen' not in kwargs.keys():\n kwargs['frozen'] = True\n data_clz = dataclasses.dataclass(**kwargs)(clz) # type: ignore\n meta_fields = []\n data_fields = []\n for field_info in dataclasses.fields(data_clz):\n is_pytree_node = field_info.metadata.get('pytree_node', True)\n if is_pytree_node:\n data_fields.append(field_info.name)\n else:\n meta_fields.append(field_info.name)\n\n def replace(self, **updates):\n \"\"\" \"Returns a new object replacing the specified fields with new values.\"\"\"\n return dataclasses.replace(self, **updates)\n\n data_clz.replace = replace\n\n def iterate_clz(x):\n meta = tuple(getattr(x, name) for name in meta_fields)\n data = tuple(getattr(x, name) for name in data_fields)\n return data, meta\n\n def iterate_clz_with_keys(x):\n meta = tuple(getattr(x, name) for name in meta_fields)\n data = tuple(\n (jax.tree_util.GetAttrKey(name), getattr(x, name)) for name in data_fields\n )\n return data, meta\n\n def clz_from_iterable(meta, data):\n meta_args = tuple(zip(meta_fields, meta))\n data_args = tuple(zip(data_fields, data))\n kwargs = dict(meta_args + data_args)\n return data_clz(**kwargs)\n\n jax.tree_util.register_pytree_with_keys(\n data_clz, iterate_clz_with_keys, clz_from_iterable, iterate_clz,\n )\n\n def to_state_dict(x):\n state_dict = {\n name: serialization.to_state_dict(getattr(x, name))\n for name in data_fields\n }\n return state_dict\n\n def from_state_dict(x, state):\n \"\"\"Restore the state of a data class.\"\"\"\n state = state.copy() # copy the state so we can pop the restored fields.\n updates = {}\n for name in data_fields:\n if name not in state:\n raise ValueError(\n f'Missing field {name} in state dict while restoring'\n f' an instance of {clz.__name__},'\n f' at path {serialization.current_path()}'\n )\n value = getattr(x, name)\n value_state = state.pop(name)\n updates[name] = serialization.from_state_dict(\n value, value_state, name=name\n )\n if state:\n names = ','.join(state.keys())\n raise ValueError(\n f'Unknown field(s) \"{names}\" in state dict while'\n f' restoring an instance of {clz.__name__}'\n f' at path {serialization.current_path()}'\n )\n return x.replace(**updates)\n\n serialization.register_serialization_state(\n data_clz, to_state_dict, from_state_dict\n )\n\n # add a _flax_dataclass flag to distinguish from regular dataclasses\n data_clz._flax_dataclass = True # type: ignore[attr-defined]\n\n return data_clz # type: ignore\n\n\nTNode = TypeVar('TNode', bound='PyTreeNode')\n\n\n@dataclass_transform(field_specifiers=(field,)) # type: ignore[literal-required]\nclass PyTreeNode:\n \"\"\"Base class for dataclasses that should act like a JAX pytree node.\n\n See ``flax.struct.dataclass`` for the ``jax.tree_util`` behavior.\n This base class additionally avoids type checking errors when using PyType.\n\n Example::\n\n >>> from flax import struct\n >>> import jax\n >>> from typing import Any, Callable\n\n >>> class Model(struct.PyTreeNode):\n ... params: Any\n ... # use pytree_node=False to indicate an attribute should not be touched\n ... # by Jax transformations.\n ... apply_fn: Callable = struct.field(pytree_node=False)\n\n ... def __apply__(self, *args):\n ... return self.apply_fn(*args)\n\n >>> params = {}\n >>> params_b = {}\n >>> apply_fn = lambda v, x: x\n >>> model = Model(params, apply_fn)\n\n >>> # model.params = params_b # Model is immutable. This will raise an error.\n >>> model_b = model.replace(params=params_b) # Use the replace method instead.\n\n >>> # This class can now be used safely in Jax to compute gradients w.r.t. the\n >>> # parameters.\n >>> model = Model(params, apply_fn)\n >>> loss_fn = lambda model: 3.\n >>> model_grad = jax.grad(loss_fn)(model)\n \"\"\"\n\n def __init_subclass__(cls):\n dataclass(cls) # pytype: disable=wrong-arg-types\n\n def __init__(self, *args, **kwargs):\n # stub for pytype\n raise NotImplementedError\n\n def replace(self: TNode, **overrides) -> TNode:\n # stub for pytype\n raise NotImplementedError\n", "path": "flax/struct.py"}]}
| 3,288 | 144 |
gh_patches_debug_1282
|
rasdani/github-patches
|
git_diff
|
liqd__adhocracy4-1243
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Poll cannot change order of questions
Poll: after moving a question in the dashboard and saving, the question moves back to it's original position.
NOTE: flip-move lib still working in documents, may require a poll refactor
https://github.com/liqd/adhocracy-plus/issues/1964
https://github.com/liqd/a4-meinberlin/issues/4370
</issue>
<code>
[start of adhocracy4/polls/models.py]
1 from django.contrib.contenttypes.fields import GenericRelation
2 from django.core.exceptions import ValidationError
3 from django.db import models
4 from django.utils.translation import gettext_lazy as _
5
6 from adhocracy4.comments import models as comment_models
7 from adhocracy4.models.base import UserGeneratedContentModel
8 from adhocracy4.modules import models as module_models
9 from adhocracy4.polls import validators
10
11
12 class QuestionQuerySet(models.QuerySet):
13 def annotate_vote_count(self):
14 return self.annotate(
15 vote_count=models.Count(
16 'choices__votes__creator_id',
17 distinct=True),
18 vote_count_multi=models.Count(
19 'choices__votes',
20 distinct=True),
21 answer_count=models.Count(
22 'answers__creator_id',
23 distinct=True),
24 )
25
26
27 class ChoiceQuerySet(models.QuerySet):
28 def annotate_vote_count(self):
29 return self.annotate(
30 vote_count=models.Count(
31 'votes'
32 )
33 )
34
35
36 class Poll(module_models.Item):
37 comments = GenericRelation(comment_models.Comment,
38 related_query_name='poll',
39 object_id_field='object_pk')
40
41 def get_absolute_url(self):
42 return self.module.get_detail_url
43
44 def annotated_questions(self):
45 return self.questions.annotate_vote_count()
46
47
48 class Question(models.Model):
49 label = models.CharField(max_length=255)
50 help_text = models.CharField(
51 max_length=250,
52 blank=True,
53 verbose_name=_('Explanation')
54 )
55
56 weight = models.SmallIntegerField()
57
58 multiple_choice = models.BooleanField(default=False)
59 is_open = models.BooleanField(default=False)
60
61 poll = models.ForeignKey(
62 'Poll',
63 on_delete=models.CASCADE,
64 related_name='questions'
65 )
66
67 objects = QuestionQuerySet.as_manager()
68
69 @property
70 def has_other_option(self):
71 return self.choices.filter(is_other_choice=True).exists()
72
73 def get_other_option(self):
74 if self.has_other_option:
75 return self.choices.filter(is_other_choice=True).first()
76 return None
77
78 def clean(self, *args, **kwargs):
79 if self.is_open:
80 if self.multiple_choice:
81 raise ValidationError({
82 'is_open': _('Questions with open answers cannot '
83 'have multiple choices.')
84 })
85 elif self.choices.count() > 0:
86 raise ValidationError({
87 'is_open': _('Question with choices cannot become '
88 'open question. Delete choices or add new '
89 'open question.')
90 })
91
92 super().clean(*args, **kwargs)
93
94 def save(self, *args, **kwargs):
95 self.full_clean()
96 return super().save(*args, **kwargs)
97
98 def user_choices_list(self, user):
99 if not user.is_authenticated:
100 return []
101
102 return self.choices\
103 .filter(votes__creator=user)\
104 .values_list('id', flat=True)
105
106 def user_answer(self, user):
107 if not user.is_authenticated:
108 return ''
109
110 answers = self.answers.filter(creator=user)
111 if answers.exists():
112 # there can only be one answer bc of unique constraint
113 return answers.first().id
114 else:
115 return ''
116
117 def other_choice_answers(self):
118 if self.has_other_option:
119 other_choice = self.choices.filter(is_other_choice=True).first()
120 other_answers = OtherVote.objects.filter(vote__choice=other_choice)
121 return other_answers
122 else:
123 return OtherVote.objects.none()
124
125 def other_choice_user_answer(self, user):
126 if not user.is_authenticated:
127 return ''
128
129 elif self.has_other_option:
130 other_choice = self.choices.filter(is_other_choice=True).first()
131 other_choice_user_answer = OtherVote.objects.filter(
132 vote__creator=user,
133 vote__choice=other_choice)
134 if other_choice_user_answer.exists():
135 # there can only be one other vote as 1:1 relation
136 return other_choice_user_answer.first().vote.id
137 return ''
138
139 def get_absolute_url(self):
140 return self.poll.get_absolute_url()
141
142 def __str__(self):
143 return self.label
144
145 class Meta:
146 ordering = ['weight']
147
148
149 class Answer(UserGeneratedContentModel):
150 answer = models.CharField(
151 max_length=750,
152 verbose_name=_('Answer')
153 )
154
155 question = models.ForeignKey(
156 'Question',
157 on_delete=models.CASCADE,
158 related_name='answers',
159 )
160
161 def clean(self, *args, **kwargs):
162 if not self.question.is_open:
163 raise ValidationError({
164 'question': _('Only open questions can have answers.')
165 })
166 super().clean(*args, **kwargs)
167
168 def save(self, *args, **kwargs):
169 self.full_clean()
170 return super().save(*args, **kwargs)
171
172 def get_absolute_url(self):
173 return self.question.poll.get_absolute_url()
174
175 def __str__(self):
176 return '%s: %s' % (self.creator, self.answer[:20])
177
178 class Meta:
179 ordering = ['id']
180 unique_together = ('question', 'creator')
181
182
183 class Choice(models.Model):
184 label = models.CharField(max_length=255)
185
186 question = models.ForeignKey(
187 'Question',
188 on_delete=models.CASCADE,
189 related_name='choices',
190 )
191
192 is_other_choice = models.BooleanField(default=False)
193
194 weight = models.SmallIntegerField()
195
196 objects = ChoiceQuerySet.as_manager()
197
198 def clean(self, *args, **kwargs):
199 if self.question.is_open:
200 raise ValidationError({
201 'label': _('Open questions cannot have choices.')
202 })
203 elif self.is_other_choice:
204 if self.question.choices.count() == 0:
205 raise ValidationError({
206 'is_other_choice': _('"Other" cannot be the only choice. '
207 'Use open question or add more '
208 'choices.')
209 })
210 if self.question.has_other_option and \
211 self.id != self.question.get_other_option().id:
212 raise ValidationError({
213 'is_other_choice': _('Question already has "other" '
214 'choice.')
215 })
216 super().clean(*args, **kwargs)
217
218 def save(self, *args, **kwargs):
219 self.full_clean()
220 return super().save(*args, **kwargs)
221
222 def get_absolute_url(self):
223 return self.question.poll.get_absolute_url()
224
225 def __str__(self):
226 return '%s @%s' % (self.label, self.question)
227
228 class Meta:
229 ordering = ['weight', 'id']
230
231
232 class Vote(UserGeneratedContentModel):
233 choice = models.ForeignKey(
234 'Choice',
235 on_delete=models.CASCADE,
236 related_name='votes'
237 )
238
239 def save(self, *args, **kwargs):
240 self.validate_unique()
241 return super().save(*args, **kwargs)
242
243 def validate_unique(self, exclude=None):
244 super(Vote, self).validate_unique(exclude)
245 validators.single_vote_per_user(self.creator,
246 self.choice,
247 self.pk)
248
249 @property
250 def is_other_vote(self):
251 return hasattr(self, 'other_vote')
252
253 # Make Vote instances behave like items for rule checking
254 @property
255 def module(self):
256 return self.choice.question.poll.module
257
258 @property
259 def project(self):
260 return self.module.project
261
262 def get_absolute_url(self):
263 return self.choice.question.poll.get_absolute_url()
264
265 def __str__(self):
266 return '%s: %s' % (self.creator, self.choice)
267
268
269 class OtherVote(models.Model):
270 vote = models.OneToOneField(
271 Vote,
272 on_delete=models.CASCADE,
273 primary_key=True,
274 related_name='other_vote'
275 )
276
277 answer = models.CharField(
278 max_length=250,
279 verbose_name=_('Answer')
280 )
281
282 def clean(self, *args, **kwargs):
283 if not self.vote.choice.is_other_choice:
284 raise ValidationError({
285 'vote': _('Other vote can only be created for vote on '
286 '"other" choice.')
287 })
288 super().clean(*args, **kwargs)
289
290 def save(self, *args, **kwargs):
291 self.full_clean()
292 return super().save(*args, **kwargs)
293
294 @property
295 def module(self):
296 return self.vote.choice.question.poll.module
297
298 @property
299 def project(self):
300 return self.module.project
301
302 def get_absolute_url(self):
303 return self.vote.choice.question.poll.get_absolute_url()
304
305 def __str__(self):
306 return '%s: %s' % (self.vote.creator, _('other'))
307
[end of adhocracy4/polls/models.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/adhocracy4/polls/models.py b/adhocracy4/polls/models.py
--- a/adhocracy4/polls/models.py
+++ b/adhocracy4/polls/models.py
@@ -21,7 +21,7 @@
answer_count=models.Count(
'answers__creator_id',
distinct=True),
- )
+ ).order_by('weight')
class ChoiceQuerySet(models.QuerySet):
|
{"golden_diff": "diff --git a/adhocracy4/polls/models.py b/adhocracy4/polls/models.py\n--- a/adhocracy4/polls/models.py\n+++ b/adhocracy4/polls/models.py\n@@ -21,7 +21,7 @@\n answer_count=models.Count(\n 'answers__creator_id',\n distinct=True),\n- )\n+ ).order_by('weight')\n \n \n class ChoiceQuerySet(models.QuerySet):\n", "issue": "Poll cannot change order of questions \nPoll: after moving a question in the dashboard and saving, the question moves back to it's original position.\r\nNOTE: flip-move lib still working in documents, may require a poll refactor\r\n\r\nhttps://github.com/liqd/adhocracy-plus/issues/1964\r\nhttps://github.com/liqd/a4-meinberlin/issues/4370\r\n\n", "before_files": [{"content": "from django.contrib.contenttypes.fields import GenericRelation\nfrom django.core.exceptions import ValidationError\nfrom django.db import models\nfrom django.utils.translation import gettext_lazy as _\n\nfrom adhocracy4.comments import models as comment_models\nfrom adhocracy4.models.base import UserGeneratedContentModel\nfrom adhocracy4.modules import models as module_models\nfrom adhocracy4.polls import validators\n\n\nclass QuestionQuerySet(models.QuerySet):\n def annotate_vote_count(self):\n return self.annotate(\n vote_count=models.Count(\n 'choices__votes__creator_id',\n distinct=True),\n vote_count_multi=models.Count(\n 'choices__votes',\n distinct=True),\n answer_count=models.Count(\n 'answers__creator_id',\n distinct=True),\n )\n\n\nclass ChoiceQuerySet(models.QuerySet):\n def annotate_vote_count(self):\n return self.annotate(\n vote_count=models.Count(\n 'votes'\n )\n )\n\n\nclass Poll(module_models.Item):\n comments = GenericRelation(comment_models.Comment,\n related_query_name='poll',\n object_id_field='object_pk')\n\n def get_absolute_url(self):\n return self.module.get_detail_url\n\n def annotated_questions(self):\n return self.questions.annotate_vote_count()\n\n\nclass Question(models.Model):\n label = models.CharField(max_length=255)\n help_text = models.CharField(\n max_length=250,\n blank=True,\n verbose_name=_('Explanation')\n )\n\n weight = models.SmallIntegerField()\n\n multiple_choice = models.BooleanField(default=False)\n is_open = models.BooleanField(default=False)\n\n poll = models.ForeignKey(\n 'Poll',\n on_delete=models.CASCADE,\n related_name='questions'\n )\n\n objects = QuestionQuerySet.as_manager()\n\n @property\n def has_other_option(self):\n return self.choices.filter(is_other_choice=True).exists()\n\n def get_other_option(self):\n if self.has_other_option:\n return self.choices.filter(is_other_choice=True).first()\n return None\n\n def clean(self, *args, **kwargs):\n if self.is_open:\n if self.multiple_choice:\n raise ValidationError({\n 'is_open': _('Questions with open answers cannot '\n 'have multiple choices.')\n })\n elif self.choices.count() > 0:\n raise ValidationError({\n 'is_open': _('Question with choices cannot become '\n 'open question. Delete choices or add new '\n 'open question.')\n })\n\n super().clean(*args, **kwargs)\n\n def save(self, *args, **kwargs):\n self.full_clean()\n return super().save(*args, **kwargs)\n\n def user_choices_list(self, user):\n if not user.is_authenticated:\n return []\n\n return self.choices\\\n .filter(votes__creator=user)\\\n .values_list('id', flat=True)\n\n def user_answer(self, user):\n if not user.is_authenticated:\n return ''\n\n answers = self.answers.filter(creator=user)\n if answers.exists():\n # there can only be one answer bc of unique constraint\n return answers.first().id\n else:\n return ''\n\n def other_choice_answers(self):\n if self.has_other_option:\n other_choice = self.choices.filter(is_other_choice=True).first()\n other_answers = OtherVote.objects.filter(vote__choice=other_choice)\n return other_answers\n else:\n return OtherVote.objects.none()\n\n def other_choice_user_answer(self, user):\n if not user.is_authenticated:\n return ''\n\n elif self.has_other_option:\n other_choice = self.choices.filter(is_other_choice=True).first()\n other_choice_user_answer = OtherVote.objects.filter(\n vote__creator=user,\n vote__choice=other_choice)\n if other_choice_user_answer.exists():\n # there can only be one other vote as 1:1 relation\n return other_choice_user_answer.first().vote.id\n return ''\n\n def get_absolute_url(self):\n return self.poll.get_absolute_url()\n\n def __str__(self):\n return self.label\n\n class Meta:\n ordering = ['weight']\n\n\nclass Answer(UserGeneratedContentModel):\n answer = models.CharField(\n max_length=750,\n verbose_name=_('Answer')\n )\n\n question = models.ForeignKey(\n 'Question',\n on_delete=models.CASCADE,\n related_name='answers',\n )\n\n def clean(self, *args, **kwargs):\n if not self.question.is_open:\n raise ValidationError({\n 'question': _('Only open questions can have answers.')\n })\n super().clean(*args, **kwargs)\n\n def save(self, *args, **kwargs):\n self.full_clean()\n return super().save(*args, **kwargs)\n\n def get_absolute_url(self):\n return self.question.poll.get_absolute_url()\n\n def __str__(self):\n return '%s: %s' % (self.creator, self.answer[:20])\n\n class Meta:\n ordering = ['id']\n unique_together = ('question', 'creator')\n\n\nclass Choice(models.Model):\n label = models.CharField(max_length=255)\n\n question = models.ForeignKey(\n 'Question',\n on_delete=models.CASCADE,\n related_name='choices',\n )\n\n is_other_choice = models.BooleanField(default=False)\n\n weight = models.SmallIntegerField()\n\n objects = ChoiceQuerySet.as_manager()\n\n def clean(self, *args, **kwargs):\n if self.question.is_open:\n raise ValidationError({\n 'label': _('Open questions cannot have choices.')\n })\n elif self.is_other_choice:\n if self.question.choices.count() == 0:\n raise ValidationError({\n 'is_other_choice': _('\"Other\" cannot be the only choice. '\n 'Use open question or add more '\n 'choices.')\n })\n if self.question.has_other_option and \\\n self.id != self.question.get_other_option().id:\n raise ValidationError({\n 'is_other_choice': _('Question already has \"other\" '\n 'choice.')\n })\n super().clean(*args, **kwargs)\n\n def save(self, *args, **kwargs):\n self.full_clean()\n return super().save(*args, **kwargs)\n\n def get_absolute_url(self):\n return self.question.poll.get_absolute_url()\n\n def __str__(self):\n return '%s @%s' % (self.label, self.question)\n\n class Meta:\n ordering = ['weight', 'id']\n\n\nclass Vote(UserGeneratedContentModel):\n choice = models.ForeignKey(\n 'Choice',\n on_delete=models.CASCADE,\n related_name='votes'\n )\n\n def save(self, *args, **kwargs):\n self.validate_unique()\n return super().save(*args, **kwargs)\n\n def validate_unique(self, exclude=None):\n super(Vote, self).validate_unique(exclude)\n validators.single_vote_per_user(self.creator,\n self.choice,\n self.pk)\n\n @property\n def is_other_vote(self):\n return hasattr(self, 'other_vote')\n\n # Make Vote instances behave like items for rule checking\n @property\n def module(self):\n return self.choice.question.poll.module\n\n @property\n def project(self):\n return self.module.project\n\n def get_absolute_url(self):\n return self.choice.question.poll.get_absolute_url()\n\n def __str__(self):\n return '%s: %s' % (self.creator, self.choice)\n\n\nclass OtherVote(models.Model):\n vote = models.OneToOneField(\n Vote,\n on_delete=models.CASCADE,\n primary_key=True,\n related_name='other_vote'\n )\n\n answer = models.CharField(\n max_length=250,\n verbose_name=_('Answer')\n )\n\n def clean(self, *args, **kwargs):\n if not self.vote.choice.is_other_choice:\n raise ValidationError({\n 'vote': _('Other vote can only be created for vote on '\n '\"other\" choice.')\n })\n super().clean(*args, **kwargs)\n\n def save(self, *args, **kwargs):\n self.full_clean()\n return super().save(*args, **kwargs)\n\n @property\n def module(self):\n return self.vote.choice.question.poll.module\n\n @property\n def project(self):\n return self.module.project\n\n def get_absolute_url(self):\n return self.vote.choice.question.poll.get_absolute_url()\n\n def __str__(self):\n return '%s: %s' % (self.vote.creator, _('other'))\n", "path": "adhocracy4/polls/models.py"}]}
| 3,234 | 93 |
gh_patches_debug_35574
|
rasdani/github-patches
|
git_diff
|
SciTools__cartopy-1837
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Backport NaturalEarth url change in release 0.18 and 0.19 ?
It should be great, if possible, to backport the change of NaturalEarth url (done in this [commit](https://github.com/SciTools/cartopy/commit/af814c31829002acd7c1c49ba52cee530c6ac19a) ) in at least releases 0.18 (==> 0.18.1) and 0.19 (==> 0.19.1), and of course to release a new version with this change.
</issue>
<code>
[start of tools/cartopy_feature_download.py]
1 #!/usr/bin/env python
2 # Copyright Cartopy Contributors
3 #
4 # This file is part of Cartopy and is released under the LGPL license.
5 # See COPYING and COPYING.LESSER in the root of the repository for full
6 # licensing details.
7 """
8 This module provides a command-line tool for triggering the download of
9 the data used by various Feature instances.
10
11 For detail on how to use this tool, execute it with the `-h` option:
12
13 python download.py -h
14
15 """
16
17 import argparse
18
19 from cartopy import config
20 from cartopy.feature import Feature, GSHHSFeature, NaturalEarthFeature
21 from cartopy.io import Downloader
22
23
24 ALL_SCALES = ('110m', '50m', '10m')
25
26
27 FEATURE_DEFN_GROUPS = {
28 # Only need one GSHHS resolution because they *all* get downloaded
29 # from one file.
30 'gshhs': GSHHSFeature(scale='f'),
31 'physical': (
32 ('physical', 'coastline', ALL_SCALES),
33 ('physical', 'land', ALL_SCALES),
34 ('physical', 'ocean', ALL_SCALES),
35 ('physical', 'rivers_lake_centerlines', ALL_SCALES),
36 ('physical', 'lakes', ALL_SCALES),
37 ('physical', 'geography_regions_polys', ALL_SCALES),
38 ('physical', 'geography_regions_points', ALL_SCALES),
39 ('physical', 'geography_marine_polys', ALL_SCALES),
40 ('physical', 'glaciated_areas', ALL_SCALES)
41 ),
42 'cultural': (
43 ('cultural', 'admin_0_countries', ALL_SCALES),
44 ('cultural', 'admin_0_countries_lakes', ALL_SCALES),
45 ('cultural', 'admin_0_sovereignty', ALL_SCALES),
46 ('cultural', 'admin_0_boundary_lines_land', ALL_SCALES),
47
48 ('cultural', 'urban_areas', ('50m', '10m')),
49
50 ('cultural', 'roads', '10m'),
51 ('cultural', 'roads_north_america', '10m'),
52 ('cultural', 'railroads', '10m'),
53 ('cultural', 'railroads_north_america', '10m'),
54 ),
55 'cultural-extra': (
56 ('cultural', 'admin_0_map_units', '110m'),
57 ('cultural', 'admin_0_scale_rank', '110m'),
58 ('cultural', 'admin_0_tiny_countries', '110m'),
59 ('cultural', 'admin_0_pacific_groupings', '110m'),
60 ('cultural', 'admin_1_states_provinces', '110m'),
61 ('cultural', 'admin_1_states_provinces_lines', '110m'),
62 ),
63 }
64
65
66 def download_features(group_names, dry_run=True):
67 for group_name in group_names:
68 feature_defns = FEATURE_DEFN_GROUPS[group_name]
69 if isinstance(feature_defns, Feature):
70 feature = feature_defns
71 level = list(feature._levels)[0]
72 downloader = Downloader.from_config(('shapefiles', 'gshhs',
73 feature._scale, level))
74 format_dict = {'config': config, 'scale': feature._scale,
75 'level': level}
76 if dry_run:
77 print('URL: {}'.format(downloader.url(format_dict)))
78 else:
79 downloader.path(format_dict)
80 geoms = list(feature.geometries())
81 print('Feature {} length: {}'.format(feature, len(geoms)))
82 else:
83 for category, name, scales in feature_defns:
84 if not isinstance(scales, tuple):
85 scales = (scales,)
86 for scale in scales:
87 downloader = Downloader.from_config(('shapefiles',
88 'natural_earth',
89 scale, category,
90 name))
91 feature = NaturalEarthFeature(category, name, scale)
92 format_dict = {'config': config, 'category': category,
93 'name': name, 'resolution': scale}
94 if dry_run:
95 print('URL: {}'.format(downloader.url(format_dict)))
96 else:
97 downloader.path(format_dict)
98 geoms = list(feature.geometries())
99 print('Feature {}, {}, {} length: {}'
100 ''.format(category, name, scale, len(geoms)))
101
102
103 if __name__ == '__main__':
104 parser = argparse.ArgumentParser(description='Download feature datasets.')
105 parser.add_argument('group_names', nargs='+',
106 choices=FEATURE_DEFN_GROUPS,
107 metavar='GROUP_NAME',
108 help='Feature group name: %(choices)s')
109 parser.add_argument('--output', '-o',
110 help='save datasets in the specified directory '
111 '(default: user cache directory)')
112 parser.add_argument('--dry-run',
113 help='just print the URLs to download',
114 action='store_true')
115 parser.add_argument('--ignore-repo-data', action='store_true',
116 help='ignore existing repo data when downloading')
117 args = parser.parse_args()
118
119 if args.output:
120 config['pre_existing_data_dir'] = args.output
121 config['data_dir'] = args.output
122 if args.ignore_repo_data:
123 config['repo_data_dir'] = config['data_dir']
124 download_features(args.group_names, dry_run=args.dry_run)
125
[end of tools/cartopy_feature_download.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/tools/cartopy_feature_download.py b/tools/cartopy_feature_download.py
--- a/tools/cartopy_feature_download.py
+++ b/tools/cartopy_feature_download.py
@@ -10,19 +10,24 @@
For detail on how to use this tool, execute it with the `-h` option:
- python download.py -h
+ python cartopy_feature_download.py -h
"""
import argparse
+import pathlib
from cartopy import config
from cartopy.feature import Feature, GSHHSFeature, NaturalEarthFeature
-from cartopy.io import Downloader
+from cartopy.io import Downloader, DownloadWarning
ALL_SCALES = ('110m', '50m', '10m')
+# See https://github.com/SciTools/cartopy/pull/1833
+URL_TEMPLATE = ('https://naturalearth.s3.amazonaws.com/{resolution}_'
+ '{category}/ne_{resolution}_{name}.zip')
+SHP_NE_SPEC = ('shapefiles', 'natural_earth')
FEATURE_DEFN_GROUPS = {
# Only need one GSHHS resolution because they *all* get downloaded
@@ -114,11 +119,28 @@
action='store_true')
parser.add_argument('--ignore-repo-data', action='store_true',
help='ignore existing repo data when downloading')
+ parser.add_argument('--no-warn',
+ action='store_true',
+ help='ignore cartopy "DownloadWarning" warnings')
args = parser.parse_args()
if args.output:
- config['pre_existing_data_dir'] = args.output
- config['data_dir'] = args.output
+ target_dir = pathlib.Path(args.output).expanduser().resolve()
+ target_dir.mkdir(parents=True, exist_ok=True)
+ config['pre_existing_data_dir'] = target_dir
+ config['data_dir'] = target_dir
if args.ignore_repo_data:
config['repo_data_dir'] = config['data_dir']
+ if args.no_warn:
+ import warnings
+ warnings.filterwarnings('ignore', category=DownloadWarning)
+
+ # Enforce use of stable AWS endpoint, regardless of cartopy version.
+ # In doing so, this allows users to download this script and execute it
+ # with any version of cartopy, thus taking advantage of the stable AWS
+ # endpoint.
+ # This removes the need to backport the associated fix
+ # https://github.com/SciTools/cartopy/pull/1833.
+ config['downloaders'][SHP_NE_SPEC].url_template = URL_TEMPLATE
+
download_features(args.group_names, dry_run=args.dry_run)
|
{"golden_diff": "diff --git a/tools/cartopy_feature_download.py b/tools/cartopy_feature_download.py\n--- a/tools/cartopy_feature_download.py\n+++ b/tools/cartopy_feature_download.py\n@@ -10,19 +10,24 @@\n \n For detail on how to use this tool, execute it with the `-h` option:\n \n- python download.py -h\n+ python cartopy_feature_download.py -h\n \n \"\"\"\n \n import argparse\n+import pathlib\n \n from cartopy import config\n from cartopy.feature import Feature, GSHHSFeature, NaturalEarthFeature\n-from cartopy.io import Downloader\n+from cartopy.io import Downloader, DownloadWarning\n \n \n ALL_SCALES = ('110m', '50m', '10m')\n \n+# See https://github.com/SciTools/cartopy/pull/1833\n+URL_TEMPLATE = ('https://naturalearth.s3.amazonaws.com/{resolution}_'\n+ '{category}/ne_{resolution}_{name}.zip')\n+SHP_NE_SPEC = ('shapefiles', 'natural_earth')\n \n FEATURE_DEFN_GROUPS = {\n # Only need one GSHHS resolution because they *all* get downloaded\n@@ -114,11 +119,28 @@\n action='store_true')\n parser.add_argument('--ignore-repo-data', action='store_true',\n help='ignore existing repo data when downloading')\n+ parser.add_argument('--no-warn',\n+ action='store_true',\n+ help='ignore cartopy \"DownloadWarning\" warnings')\n args = parser.parse_args()\n \n if args.output:\n- config['pre_existing_data_dir'] = args.output\n- config['data_dir'] = args.output\n+ target_dir = pathlib.Path(args.output).expanduser().resolve()\n+ target_dir.mkdir(parents=True, exist_ok=True)\n+ config['pre_existing_data_dir'] = target_dir\n+ config['data_dir'] = target_dir\n if args.ignore_repo_data:\n config['repo_data_dir'] = config['data_dir']\n+ if args.no_warn:\n+ import warnings\n+ warnings.filterwarnings('ignore', category=DownloadWarning)\n+\n+ # Enforce use of stable AWS endpoint, regardless of cartopy version.\n+ # In doing so, this allows users to download this script and execute it\n+ # with any version of cartopy, thus taking advantage of the stable AWS\n+ # endpoint.\n+ # This removes the need to backport the associated fix\n+ # https://github.com/SciTools/cartopy/pull/1833.\n+ config['downloaders'][SHP_NE_SPEC].url_template = URL_TEMPLATE\n+\n download_features(args.group_names, dry_run=args.dry_run)\n", "issue": "Backport NaturalEarth url change in release 0.18 and 0.19 ?\nIt should be great, if possible, to backport the change of NaturalEarth url (done in this [commit](https://github.com/SciTools/cartopy/commit/af814c31829002acd7c1c49ba52cee530c6ac19a) ) in at least releases 0.18 (==> 0.18.1) and 0.19 (==> 0.19.1), and of course to release a new version with this change.\n", "before_files": [{"content": "#!/usr/bin/env python\n# Copyright Cartopy Contributors\n#\n# This file is part of Cartopy and is released under the LGPL license.\n# See COPYING and COPYING.LESSER in the root of the repository for full\n# licensing details.\n\"\"\"\nThis module provides a command-line tool for triggering the download of\nthe data used by various Feature instances.\n\nFor detail on how to use this tool, execute it with the `-h` option:\n\n python download.py -h\n\n\"\"\"\n\nimport argparse\n\nfrom cartopy import config\nfrom cartopy.feature import Feature, GSHHSFeature, NaturalEarthFeature\nfrom cartopy.io import Downloader\n\n\nALL_SCALES = ('110m', '50m', '10m')\n\n\nFEATURE_DEFN_GROUPS = {\n # Only need one GSHHS resolution because they *all* get downloaded\n # from one file.\n 'gshhs': GSHHSFeature(scale='f'),\n 'physical': (\n ('physical', 'coastline', ALL_SCALES),\n ('physical', 'land', ALL_SCALES),\n ('physical', 'ocean', ALL_SCALES),\n ('physical', 'rivers_lake_centerlines', ALL_SCALES),\n ('physical', 'lakes', ALL_SCALES),\n ('physical', 'geography_regions_polys', ALL_SCALES),\n ('physical', 'geography_regions_points', ALL_SCALES),\n ('physical', 'geography_marine_polys', ALL_SCALES),\n ('physical', 'glaciated_areas', ALL_SCALES)\n ),\n 'cultural': (\n ('cultural', 'admin_0_countries', ALL_SCALES),\n ('cultural', 'admin_0_countries_lakes', ALL_SCALES),\n ('cultural', 'admin_0_sovereignty', ALL_SCALES),\n ('cultural', 'admin_0_boundary_lines_land', ALL_SCALES),\n\n ('cultural', 'urban_areas', ('50m', '10m')),\n\n ('cultural', 'roads', '10m'),\n ('cultural', 'roads_north_america', '10m'),\n ('cultural', 'railroads', '10m'),\n ('cultural', 'railroads_north_america', '10m'),\n ),\n 'cultural-extra': (\n ('cultural', 'admin_0_map_units', '110m'),\n ('cultural', 'admin_0_scale_rank', '110m'),\n ('cultural', 'admin_0_tiny_countries', '110m'),\n ('cultural', 'admin_0_pacific_groupings', '110m'),\n ('cultural', 'admin_1_states_provinces', '110m'),\n ('cultural', 'admin_1_states_provinces_lines', '110m'),\n ),\n}\n\n\ndef download_features(group_names, dry_run=True):\n for group_name in group_names:\n feature_defns = FEATURE_DEFN_GROUPS[group_name]\n if isinstance(feature_defns, Feature):\n feature = feature_defns\n level = list(feature._levels)[0]\n downloader = Downloader.from_config(('shapefiles', 'gshhs',\n feature._scale, level))\n format_dict = {'config': config, 'scale': feature._scale,\n 'level': level}\n if dry_run:\n print('URL: {}'.format(downloader.url(format_dict)))\n else:\n downloader.path(format_dict)\n geoms = list(feature.geometries())\n print('Feature {} length: {}'.format(feature, len(geoms)))\n else:\n for category, name, scales in feature_defns:\n if not isinstance(scales, tuple):\n scales = (scales,)\n for scale in scales:\n downloader = Downloader.from_config(('shapefiles',\n 'natural_earth',\n scale, category,\n name))\n feature = NaturalEarthFeature(category, name, scale)\n format_dict = {'config': config, 'category': category,\n 'name': name, 'resolution': scale}\n if dry_run:\n print('URL: {}'.format(downloader.url(format_dict)))\n else:\n downloader.path(format_dict)\n geoms = list(feature.geometries())\n print('Feature {}, {}, {} length: {}'\n ''.format(category, name, scale, len(geoms)))\n\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser(description='Download feature datasets.')\n parser.add_argument('group_names', nargs='+',\n choices=FEATURE_DEFN_GROUPS,\n metavar='GROUP_NAME',\n help='Feature group name: %(choices)s')\n parser.add_argument('--output', '-o',\n help='save datasets in the specified directory '\n '(default: user cache directory)')\n parser.add_argument('--dry-run',\n help='just print the URLs to download',\n action='store_true')\n parser.add_argument('--ignore-repo-data', action='store_true',\n help='ignore existing repo data when downloading')\n args = parser.parse_args()\n\n if args.output:\n config['pre_existing_data_dir'] = args.output\n config['data_dir'] = args.output\n if args.ignore_repo_data:\n config['repo_data_dir'] = config['data_dir']\n download_features(args.group_names, dry_run=args.dry_run)\n", "path": "tools/cartopy_feature_download.py"}]}
| 2,093 | 589 |
gh_patches_debug_10586
|
rasdani/github-patches
|
git_diff
|
pyro-ppl__pyro-2014
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Cholesky issue in HMC
In PyTorch, if Cholesky issue happens, a Runtime Error will be raised (instead of returning `nan`) regarding singular matrix. So it will be difficult to run MCMC with gaussian process kernels (which involves Cholesky decomposition of covariance matrices). This issue is raised in https://github.com/pyro-ppl/pyro/issues/1863 and #1973. Because `nan` is a valid potential energy in HMC, we should add a mechanism to catch this error.
My proposed solution is to add a try, catch exception to potential function so that when Cholesky issue happens, it will return `nan`.
</issue>
<code>
[start of pyro/ops/integrator.py]
1 import torch
2 from torch.autograd import grad
3
4
5 def velocity_verlet(z, r, potential_fn, inverse_mass_matrix, step_size, num_steps=1, z_grads=None):
6 r"""
7 Second order symplectic integrator that uses the velocity verlet algorithm.
8
9 :param dict z: dictionary of sample site names and their current values
10 (type :class:`~torch.Tensor`).
11 :param dict r: dictionary of sample site names and corresponding momenta
12 (type :class:`~torch.Tensor`).
13 :param callable potential_fn: function that returns potential energy given z
14 for each sample site. The negative gradient of the function with respect
15 to ``z`` determines the rate of change of the corresponding sites'
16 momenta ``r``.
17 :param torch.Tensor inverse_mass_matrix: a tensor :math:`M^{-1}` which is used
18 to calculate kinetic energy: :math:`E_{kinetic} = \frac{1}{2}z^T M^{-1} z`.
19 Here :math:`M` can be a 1D tensor (diagonal matrix) or a 2D tensor (dense matrix).
20 :param float step_size: step size for each time step iteration.
21 :param int num_steps: number of discrete time steps over which to integrate.
22 :param torch.Tensor z_grads: optional gradients of potential energy at current ``z``.
23 :return tuple (z_next, r_next, z_grads, potential_energy): next position and momenta,
24 together with the potential energy and its gradient w.r.t. ``z_next``.
25 """
26 z_next = z.copy()
27 r_next = r.copy()
28 for _ in range(num_steps):
29 z_next, r_next, z_grads, potential_energy = _single_step_verlet(z_next,
30 r_next,
31 potential_fn,
32 inverse_mass_matrix,
33 step_size,
34 z_grads)
35 return z_next, r_next, z_grads, potential_energy
36
37
38 def _single_step_verlet(z, r, potential_fn, inverse_mass_matrix, step_size, z_grads=None):
39 r"""
40 Single step velocity verlet that modifies the `z`, `r` dicts in place.
41 """
42
43 z_grads = potential_grad(potential_fn, z)[0] if z_grads is None else z_grads
44
45 for site_name in r:
46 r[site_name] = r[site_name] + 0.5 * step_size * (-z_grads[site_name]) # r(n+1/2)
47
48 r_grads = _kinetic_grad(inverse_mass_matrix, r)
49 for site_name in z:
50 z[site_name] = z[site_name] + step_size * r_grads[site_name] # z(n+1)
51
52 z_grads, potential_energy = potential_grad(potential_fn, z)
53 for site_name in r:
54 r[site_name] = r[site_name] + 0.5 * step_size * (-z_grads[site_name]) # r(n+1)
55
56 return z, r, z_grads, potential_energy
57
58
59 def potential_grad(potential_fn, z):
60 """
61 Gradient of `potential_fn` w.r.t. parameters z.
62
63 :param potential_fn: python callable that takes in a dictionary of parameters
64 and returns the potential energy.
65 :param dict z: dictionary of parameter values keyed by site name.
66 :return: tuple of `(z_grads, potential_energy)`, where `z_grads` is a dictionary
67 with the same keys as `z` containing gradients and potential_energy is a
68 torch scalar.
69 """
70 z_keys, z_nodes = zip(*z.items())
71 for node in z_nodes:
72 node.requires_grad_(True)
73 potential_energy = potential_fn(z)
74 grads = grad(potential_energy, z_nodes)
75 for node in z_nodes:
76 node.requires_grad_(False)
77 return dict(zip(z_keys, grads)), potential_energy.detach()
78
79
80 def _kinetic_grad(inverse_mass_matrix, r):
81 # XXX consider using list/OrderDict to store z and r
82 # so we don't have to sort the keys
83 r_flat = torch.cat([r[site_name].reshape(-1) for site_name in sorted(r)])
84 if inverse_mass_matrix.dim() == 1:
85 grads_flat = inverse_mass_matrix * r_flat
86 else:
87 grads_flat = inverse_mass_matrix.matmul(r_flat)
88
89 # unpacking
90 grads = {}
91 pos = 0
92 for site_name in sorted(r):
93 next_pos = pos + r[site_name].numel()
94 grads[site_name] = grads_flat[pos:next_pos].reshape(r[site_name].shape)
95 pos = next_pos
96 assert pos == grads_flat.size(0)
97 return grads
98
[end of pyro/ops/integrator.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pyro/ops/integrator.py b/pyro/ops/integrator.py
--- a/pyro/ops/integrator.py
+++ b/pyro/ops/integrator.py
@@ -70,7 +70,16 @@
z_keys, z_nodes = zip(*z.items())
for node in z_nodes:
node.requires_grad_(True)
- potential_energy = potential_fn(z)
+ try:
+ potential_energy = potential_fn(z)
+ # deal with singular matrices
+ except RuntimeError as e:
+ if "singular U" in str(e):
+ grads = {k: v.new_zeros(v.shape) for k, v in z.items()}
+ return grads, z_nodes[0].new_tensor(float('nan'))
+ else:
+ raise e
+
grads = grad(potential_energy, z_nodes)
for node in z_nodes:
node.requires_grad_(False)
|
{"golden_diff": "diff --git a/pyro/ops/integrator.py b/pyro/ops/integrator.py\n--- a/pyro/ops/integrator.py\n+++ b/pyro/ops/integrator.py\n@@ -70,7 +70,16 @@\n z_keys, z_nodes = zip(*z.items())\n for node in z_nodes:\n node.requires_grad_(True)\n- potential_energy = potential_fn(z)\n+ try:\n+ potential_energy = potential_fn(z)\n+ # deal with singular matrices\n+ except RuntimeError as e:\n+ if \"singular U\" in str(e):\n+ grads = {k: v.new_zeros(v.shape) for k, v in z.items()}\n+ return grads, z_nodes[0].new_tensor(float('nan'))\n+ else:\n+ raise e\n+\n grads = grad(potential_energy, z_nodes)\n for node in z_nodes:\n node.requires_grad_(False)\n", "issue": "Cholesky issue in HMC\nIn PyTorch, if Cholesky issue happens, a Runtime Error will be raised (instead of returning `nan`) regarding singular matrix. So it will be difficult to run MCMC with gaussian process kernels (which involves Cholesky decomposition of covariance matrices). This issue is raised in https://github.com/pyro-ppl/pyro/issues/1863 and #1973. Because `nan` is a valid potential energy in HMC, we should add a mechanism to catch this error.\r\n\r\nMy proposed solution is to add a try, catch exception to potential function so that when Cholesky issue happens, it will return `nan`.\n", "before_files": [{"content": "import torch\nfrom torch.autograd import grad\n\n\ndef velocity_verlet(z, r, potential_fn, inverse_mass_matrix, step_size, num_steps=1, z_grads=None):\n r\"\"\"\n Second order symplectic integrator that uses the velocity verlet algorithm.\n\n :param dict z: dictionary of sample site names and their current values\n (type :class:`~torch.Tensor`).\n :param dict r: dictionary of sample site names and corresponding momenta\n (type :class:`~torch.Tensor`).\n :param callable potential_fn: function that returns potential energy given z\n for each sample site. The negative gradient of the function with respect\n to ``z`` determines the rate of change of the corresponding sites'\n momenta ``r``.\n :param torch.Tensor inverse_mass_matrix: a tensor :math:`M^{-1}` which is used\n to calculate kinetic energy: :math:`E_{kinetic} = \\frac{1}{2}z^T M^{-1} z`.\n Here :math:`M` can be a 1D tensor (diagonal matrix) or a 2D tensor (dense matrix).\n :param float step_size: step size for each time step iteration.\n :param int num_steps: number of discrete time steps over which to integrate.\n :param torch.Tensor z_grads: optional gradients of potential energy at current ``z``.\n :return tuple (z_next, r_next, z_grads, potential_energy): next position and momenta,\n together with the potential energy and its gradient w.r.t. ``z_next``.\n \"\"\"\n z_next = z.copy()\n r_next = r.copy()\n for _ in range(num_steps):\n z_next, r_next, z_grads, potential_energy = _single_step_verlet(z_next,\n r_next,\n potential_fn,\n inverse_mass_matrix,\n step_size,\n z_grads)\n return z_next, r_next, z_grads, potential_energy\n\n\ndef _single_step_verlet(z, r, potential_fn, inverse_mass_matrix, step_size, z_grads=None):\n r\"\"\"\n Single step velocity verlet that modifies the `z`, `r` dicts in place.\n \"\"\"\n\n z_grads = potential_grad(potential_fn, z)[0] if z_grads is None else z_grads\n\n for site_name in r:\n r[site_name] = r[site_name] + 0.5 * step_size * (-z_grads[site_name]) # r(n+1/2)\n\n r_grads = _kinetic_grad(inverse_mass_matrix, r)\n for site_name in z:\n z[site_name] = z[site_name] + step_size * r_grads[site_name] # z(n+1)\n\n z_grads, potential_energy = potential_grad(potential_fn, z)\n for site_name in r:\n r[site_name] = r[site_name] + 0.5 * step_size * (-z_grads[site_name]) # r(n+1)\n\n return z, r, z_grads, potential_energy\n\n\ndef potential_grad(potential_fn, z):\n \"\"\"\n Gradient of `potential_fn` w.r.t. parameters z.\n\n :param potential_fn: python callable that takes in a dictionary of parameters\n and returns the potential energy.\n :param dict z: dictionary of parameter values keyed by site name.\n :return: tuple of `(z_grads, potential_energy)`, where `z_grads` is a dictionary\n with the same keys as `z` containing gradients and potential_energy is a\n torch scalar.\n \"\"\"\n z_keys, z_nodes = zip(*z.items())\n for node in z_nodes:\n node.requires_grad_(True)\n potential_energy = potential_fn(z)\n grads = grad(potential_energy, z_nodes)\n for node in z_nodes:\n node.requires_grad_(False)\n return dict(zip(z_keys, grads)), potential_energy.detach()\n\n\ndef _kinetic_grad(inverse_mass_matrix, r):\n # XXX consider using list/OrderDict to store z and r\n # so we don't have to sort the keys\n r_flat = torch.cat([r[site_name].reshape(-1) for site_name in sorted(r)])\n if inverse_mass_matrix.dim() == 1:\n grads_flat = inverse_mass_matrix * r_flat\n else:\n grads_flat = inverse_mass_matrix.matmul(r_flat)\n\n # unpacking\n grads = {}\n pos = 0\n for site_name in sorted(r):\n next_pos = pos + r[site_name].numel()\n grads[site_name] = grads_flat[pos:next_pos].reshape(r[site_name].shape)\n pos = next_pos\n assert pos == grads_flat.size(0)\n return grads\n", "path": "pyro/ops/integrator.py"}]}
| 1,913 | 200 |
gh_patches_debug_26227
|
rasdani/github-patches
|
git_diff
|
quantumlib__Cirq-4288
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
MergeInteractions optimizer doesn't behave well with TaggedOperations
### Description of the issue
`MergeInteractions` checks for `isinstance(op, GateOperation)` if `allowe_partial_czs = False` and hence it doesn't behave well with `TaggedOperations`. See the example below.
### How to reproduce the issue
```python
q = cirq.LineQubit.range(2)
ops = []
for num_czs in [1, 2]:
circuit = cirq.Circuit([(cirq.CZ(*q) ** 0.5).with_tags("mytag")] * num_czs)
cirq.MergeInteractions(allow_partial_czs=False).optimize_circuit(circuit)
print(circuit)
```
```python
# MergeInteractions fails to decompose a single instance of tagged partial CZ because of isinstance(op, GateOperation) check.
0: ───@['mytag']───
│
1: ───@^0.5────────
# More than 1 occurrence in the trivial case works fine because new_op_count < old_op_count
0: ───Z^0.75───X^0.5───S^-1───Y^-0.5───@───S^-1───Y^0.5───Y^0.5───T────────
│
1: ───T────────X^0.5───S^-1───Y^-0.5───@───S^-1───Y^0.5───Y^0.5───Z^0.75───
```
### Long Term Solution [needs discussion]
- We should seriously work towards `cirq.match(op, GateType)`(#2536) and replace all `isinstance()` checks with `cirq.match` which understands how to handle `ControlledOperations`, `TaggedOperations` etc. Right now, it's very easy for such inconsistencies to exist because of
- Lack of backwards compatibility while introducing new operation classes like `TaggedOperation`
- Easy to make mistakes due to the intricate details involved.
- Related issues #4152, #4193
**Cirq version**
0.12.0.dev
Part of #3242
</issue>
<code>
[start of cirq-core/cirq/optimizers/merge_interactions.py]
1 # Copyright 2018 The Cirq Developers
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """An optimization pass that combines adjacent single-qubit rotations."""
16
17 from typing import Callable, List, Optional, Sequence, Tuple, cast, TYPE_CHECKING
18
19 import numpy as np
20
21 from cirq import circuits, ops, protocols
22 from cirq.optimizers import two_qubit_decompositions
23
24 if TYPE_CHECKING:
25 import cirq
26
27
28 class MergeInteractions(circuits.PointOptimizer):
29 """Combines series of adjacent one and two-qubit gates operating on a pair
30 of qubits."""
31
32 def __init__(
33 self,
34 tolerance: float = 1e-8,
35 allow_partial_czs: bool = True,
36 post_clean_up: Callable[[Sequence[ops.Operation]], ops.OP_TREE] = lambda op_list: op_list,
37 ) -> None:
38 super().__init__(post_clean_up=post_clean_up)
39 self.tolerance = tolerance
40 self.allow_partial_czs = allow_partial_czs
41
42 def optimization_at(
43 self, circuit: circuits.Circuit, index: int, op: ops.Operation
44 ) -> Optional[circuits.PointOptimizationSummary]:
45 if len(op.qubits) != 2:
46 return None
47
48 old_operations, indices, matrix = self._scan_two_qubit_ops_into_matrix(
49 circuit, index, op.qubits
50 )
51
52 old_interaction_count = len(
53 [old_op for old_op in old_operations if len(old_op.qubits) == 2]
54 )
55
56 switch_to_new = False
57 switch_to_new |= any(
58 len(old_op.qubits) == 2 and not isinstance(old_op.gate, ops.CZPowGate)
59 for old_op in old_operations
60 )
61 if not self.allow_partial_czs:
62 switch_to_new |= any(
63 isinstance(old_op, ops.GateOperation)
64 and isinstance(old_op.gate, ops.CZPowGate)
65 and old_op.gate.exponent != 1
66 for old_op in old_operations
67 )
68
69 # This point cannot be optimized using this method
70 if not switch_to_new and old_interaction_count <= 1:
71 return None
72
73 # Find a max-3-cz construction.
74 new_operations = two_qubit_decompositions.two_qubit_matrix_to_operations(
75 op.qubits[0], op.qubits[1], matrix, self.allow_partial_czs, self.tolerance, False
76 )
77 new_interaction_count = len(
78 [new_op for new_op in new_operations if len(new_op.qubits) == 2]
79 )
80
81 switch_to_new |= new_interaction_count < old_interaction_count
82
83 if not switch_to_new:
84 return None
85
86 return circuits.PointOptimizationSummary(
87 clear_span=max(indices) + 1 - index,
88 clear_qubits=op.qubits,
89 new_operations=new_operations,
90 )
91
92 def _op_to_matrix(
93 self, op: ops.Operation, qubits: Tuple['cirq.Qid', ...]
94 ) -> Optional[np.ndarray]:
95 """Determines the effect of an operation on the given qubits.
96
97 If the operation is a 1-qubit operation on one of the given qubits,
98 or a 2-qubit operation on both of the given qubits, and also the
99 operation has a known matrix, then a matrix is returned. Otherwise None
100 is returned.
101
102 Args:
103 op: The operation to understand.
104 qubits: The qubits we care about. Order determines matrix tensor
105 order.
106
107 Returns:
108 None, or else a matrix equivalent to the effect of the operation.
109 """
110 if any(q not in qubits for q in op.qubits):
111 return None
112
113 q1, q2 = qubits
114
115 matrix = protocols.unitary(op, None)
116 if matrix is None:
117 return None
118
119 assert op is not None
120 if op.qubits == qubits:
121 return matrix
122 if op.qubits == (q2, q1):
123 return _flip_kron_order(matrix)
124 if op.qubits == (q1,):
125 return np.kron(matrix, np.eye(2))
126 if op.qubits == (q2,):
127 return np.kron(np.eye(2), matrix)
128
129 return None
130
131 def _scan_two_qubit_ops_into_matrix(
132 self, circuit: circuits.Circuit, index: Optional[int], qubits: Tuple['cirq.Qid', ...]
133 ) -> Tuple[List[ops.Operation], List[int], np.ndarray]:
134 """Accumulates operations affecting the given pair of qubits.
135
136 The scan terminates when it hits the end of the circuit, finds an
137 operation without a known matrix, or finds an operation that interacts
138 the given qubits with other qubits.
139
140 Args:
141 circuit: The circuit to scan for operations.
142 index: The index to start scanning forward from.
143 qubits: The pair of qubits we care about.
144
145 Returns:
146 A tuple containing:
147 0. The operations.
148 1. The moment indices those operations were on.
149 2. A matrix equivalent to the effect of the scanned operations.
150 """
151
152 product = np.eye(4, dtype=np.complex128)
153 all_operations = []
154 touched_indices = []
155
156 while index is not None:
157 operations = list({circuit.operation_at(q, index) for q in qubits})
158 op_data = [self._op_to_matrix(op, qubits) for op in operations if op is not None]
159
160 # Stop at any non-constant or non-local interaction.
161 if any(e is None for e in op_data):
162 break
163 present_ops = [op for op in operations if op]
164 present_op_data = cast(List[np.ndarray], op_data)
165
166 for op_mat in present_op_data:
167 product = np.dot(op_mat, product)
168 all_operations.extend(present_ops)
169
170 touched_indices.append(index)
171 index = circuit.next_moment_operating_on(qubits, index + 1)
172
173 return all_operations, touched_indices, product
174
175
176 def _flip_kron_order(mat4x4: np.ndarray) -> np.ndarray:
177 """Given M = sum(kron(a_i, b_i)), returns M' = sum(kron(b_i, a_i))."""
178 result = np.array([[0] * 4] * 4, dtype=np.complex128)
179 order = [0, 2, 1, 3]
180 for i in range(4):
181 for j in range(4):
182 result[order[i], order[j]] = mat4x4[i, j]
183 return result
184
[end of cirq-core/cirq/optimizers/merge_interactions.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/cirq-core/cirq/optimizers/merge_interactions.py b/cirq-core/cirq/optimizers/merge_interactions.py
--- a/cirq-core/cirq/optimizers/merge_interactions.py
+++ b/cirq-core/cirq/optimizers/merge_interactions.py
@@ -55,16 +55,9 @@
switch_to_new = False
switch_to_new |= any(
- len(old_op.qubits) == 2 and not isinstance(old_op.gate, ops.CZPowGate)
+ len(old_op.qubits) == 2 and not self._may_keep_old_op(old_op)
for old_op in old_operations
)
- if not self.allow_partial_czs:
- switch_to_new |= any(
- isinstance(old_op, ops.GateOperation)
- and isinstance(old_op.gate, ops.CZPowGate)
- and old_op.gate.exponent != 1
- for old_op in old_operations
- )
# This point cannot be optimized using this method
if not switch_to_new and old_interaction_count <= 1:
@@ -89,6 +82,13 @@
new_operations=new_operations,
)
+ def _may_keep_old_op(self, old_op: 'cirq.Operation') -> bool:
+ """Returns True if the old two-qubit operation may be left unchanged
+ without decomposition."""
+ if self.allow_partial_czs:
+ return isinstance(old_op.gate, ops.CZPowGate)
+ return isinstance(old_op.gate, ops.CZPowGate) and old_op.gate.exponent == 1
+
def _op_to_matrix(
self, op: ops.Operation, qubits: Tuple['cirq.Qid', ...]
) -> Optional[np.ndarray]:
|
{"golden_diff": "diff --git a/cirq-core/cirq/optimizers/merge_interactions.py b/cirq-core/cirq/optimizers/merge_interactions.py\n--- a/cirq-core/cirq/optimizers/merge_interactions.py\n+++ b/cirq-core/cirq/optimizers/merge_interactions.py\n@@ -55,16 +55,9 @@\n \n switch_to_new = False\n switch_to_new |= any(\n- len(old_op.qubits) == 2 and not isinstance(old_op.gate, ops.CZPowGate)\n+ len(old_op.qubits) == 2 and not self._may_keep_old_op(old_op)\n for old_op in old_operations\n )\n- if not self.allow_partial_czs:\n- switch_to_new |= any(\n- isinstance(old_op, ops.GateOperation)\n- and isinstance(old_op.gate, ops.CZPowGate)\n- and old_op.gate.exponent != 1\n- for old_op in old_operations\n- )\n \n # This point cannot be optimized using this method\n if not switch_to_new and old_interaction_count <= 1:\n@@ -89,6 +82,13 @@\n new_operations=new_operations,\n )\n \n+ def _may_keep_old_op(self, old_op: 'cirq.Operation') -> bool:\n+ \"\"\"Returns True if the old two-qubit operation may be left unchanged\n+ without decomposition.\"\"\"\n+ if self.allow_partial_czs:\n+ return isinstance(old_op.gate, ops.CZPowGate)\n+ return isinstance(old_op.gate, ops.CZPowGate) and old_op.gate.exponent == 1\n+\n def _op_to_matrix(\n self, op: ops.Operation, qubits: Tuple['cirq.Qid', ...]\n ) -> Optional[np.ndarray]:\n", "issue": "MergeInteractions optimizer doesn't behave well with TaggedOperations\n### Description of the issue\r\n`MergeInteractions` checks for `isinstance(op, GateOperation)` if `allowe_partial_czs = False` and hence it doesn't behave well with `TaggedOperations`. See the example below. \r\n\r\n### How to reproduce the issue\r\n\r\n```python\r\nq = cirq.LineQubit.range(2)\r\nops = []\r\nfor num_czs in [1, 2]:\r\n circuit = cirq.Circuit([(cirq.CZ(*q) ** 0.5).with_tags(\"mytag\")] * num_czs)\r\n cirq.MergeInteractions(allow_partial_czs=False).optimize_circuit(circuit)\r\n print(circuit)\r\n```\r\n```python\r\n# MergeInteractions fails to decompose a single instance of tagged partial CZ because of isinstance(op, GateOperation) check.\r\n0: \u2500\u2500\u2500@['mytag']\u2500\u2500\u2500\r\n \u2502\r\n1: \u2500\u2500\u2500@^0.5\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\r\n\r\n# More than 1 occurrence in the trivial case works fine because new_op_count < old_op_count\r\n0: \u2500\u2500\u2500Z^0.75\u2500\u2500\u2500X^0.5\u2500\u2500\u2500S^-1\u2500\u2500\u2500Y^-0.5\u2500\u2500\u2500@\u2500\u2500\u2500S^-1\u2500\u2500\u2500Y^0.5\u2500\u2500\u2500Y^0.5\u2500\u2500\u2500T\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500\r\n \u2502\r\n1: \u2500\u2500\u2500T\u2500\u2500\u2500\u2500\u2500\u2500\u2500\u2500X^0.5\u2500\u2500\u2500S^-1\u2500\u2500\u2500Y^-0.5\u2500\u2500\u2500@\u2500\u2500\u2500S^-1\u2500\u2500\u2500Y^0.5\u2500\u2500\u2500Y^0.5\u2500\u2500\u2500Z^0.75\u2500\u2500\u2500\r\n```\r\n\r\n### Long Term Solution [needs discussion] \r\n- We should seriously work towards `cirq.match(op, GateType)`(#2536) and replace all `isinstance()` checks with `cirq.match` which understands how to handle `ControlledOperations`, `TaggedOperations` etc. Right now, it's very easy for such inconsistencies to exist because of\r\n - Lack of backwards compatibility while introducing new operation classes like `TaggedOperation`\r\n - Easy to make mistakes due to the intricate details involved. \r\n- Related issues #4152, #4193\r\n\r\n**Cirq version**\r\n0.12.0.dev\r\n\r\nPart of #3242 \r\n\n", "before_files": [{"content": "# Copyright 2018 The Cirq Developers\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"An optimization pass that combines adjacent single-qubit rotations.\"\"\"\n\nfrom typing import Callable, List, Optional, Sequence, Tuple, cast, TYPE_CHECKING\n\nimport numpy as np\n\nfrom cirq import circuits, ops, protocols\nfrom cirq.optimizers import two_qubit_decompositions\n\nif TYPE_CHECKING:\n import cirq\n\n\nclass MergeInteractions(circuits.PointOptimizer):\n \"\"\"Combines series of adjacent one and two-qubit gates operating on a pair\n of qubits.\"\"\"\n\n def __init__(\n self,\n tolerance: float = 1e-8,\n allow_partial_czs: bool = True,\n post_clean_up: Callable[[Sequence[ops.Operation]], ops.OP_TREE] = lambda op_list: op_list,\n ) -> None:\n super().__init__(post_clean_up=post_clean_up)\n self.tolerance = tolerance\n self.allow_partial_czs = allow_partial_czs\n\n def optimization_at(\n self, circuit: circuits.Circuit, index: int, op: ops.Operation\n ) -> Optional[circuits.PointOptimizationSummary]:\n if len(op.qubits) != 2:\n return None\n\n old_operations, indices, matrix = self._scan_two_qubit_ops_into_matrix(\n circuit, index, op.qubits\n )\n\n old_interaction_count = len(\n [old_op for old_op in old_operations if len(old_op.qubits) == 2]\n )\n\n switch_to_new = False\n switch_to_new |= any(\n len(old_op.qubits) == 2 and not isinstance(old_op.gate, ops.CZPowGate)\n for old_op in old_operations\n )\n if not self.allow_partial_czs:\n switch_to_new |= any(\n isinstance(old_op, ops.GateOperation)\n and isinstance(old_op.gate, ops.CZPowGate)\n and old_op.gate.exponent != 1\n for old_op in old_operations\n )\n\n # This point cannot be optimized using this method\n if not switch_to_new and old_interaction_count <= 1:\n return None\n\n # Find a max-3-cz construction.\n new_operations = two_qubit_decompositions.two_qubit_matrix_to_operations(\n op.qubits[0], op.qubits[1], matrix, self.allow_partial_czs, self.tolerance, False\n )\n new_interaction_count = len(\n [new_op for new_op in new_operations if len(new_op.qubits) == 2]\n )\n\n switch_to_new |= new_interaction_count < old_interaction_count\n\n if not switch_to_new:\n return None\n\n return circuits.PointOptimizationSummary(\n clear_span=max(indices) + 1 - index,\n clear_qubits=op.qubits,\n new_operations=new_operations,\n )\n\n def _op_to_matrix(\n self, op: ops.Operation, qubits: Tuple['cirq.Qid', ...]\n ) -> Optional[np.ndarray]:\n \"\"\"Determines the effect of an operation on the given qubits.\n\n If the operation is a 1-qubit operation on one of the given qubits,\n or a 2-qubit operation on both of the given qubits, and also the\n operation has a known matrix, then a matrix is returned. Otherwise None\n is returned.\n\n Args:\n op: The operation to understand.\n qubits: The qubits we care about. Order determines matrix tensor\n order.\n\n Returns:\n None, or else a matrix equivalent to the effect of the operation.\n \"\"\"\n if any(q not in qubits for q in op.qubits):\n return None\n\n q1, q2 = qubits\n\n matrix = protocols.unitary(op, None)\n if matrix is None:\n return None\n\n assert op is not None\n if op.qubits == qubits:\n return matrix\n if op.qubits == (q2, q1):\n return _flip_kron_order(matrix)\n if op.qubits == (q1,):\n return np.kron(matrix, np.eye(2))\n if op.qubits == (q2,):\n return np.kron(np.eye(2), matrix)\n\n return None\n\n def _scan_two_qubit_ops_into_matrix(\n self, circuit: circuits.Circuit, index: Optional[int], qubits: Tuple['cirq.Qid', ...]\n ) -> Tuple[List[ops.Operation], List[int], np.ndarray]:\n \"\"\"Accumulates operations affecting the given pair of qubits.\n\n The scan terminates when it hits the end of the circuit, finds an\n operation without a known matrix, or finds an operation that interacts\n the given qubits with other qubits.\n\n Args:\n circuit: The circuit to scan for operations.\n index: The index to start scanning forward from.\n qubits: The pair of qubits we care about.\n\n Returns:\n A tuple containing:\n 0. The operations.\n 1. The moment indices those operations were on.\n 2. A matrix equivalent to the effect of the scanned operations.\n \"\"\"\n\n product = np.eye(4, dtype=np.complex128)\n all_operations = []\n touched_indices = []\n\n while index is not None:\n operations = list({circuit.operation_at(q, index) for q in qubits})\n op_data = [self._op_to_matrix(op, qubits) for op in operations if op is not None]\n\n # Stop at any non-constant or non-local interaction.\n if any(e is None for e in op_data):\n break\n present_ops = [op for op in operations if op]\n present_op_data = cast(List[np.ndarray], op_data)\n\n for op_mat in present_op_data:\n product = np.dot(op_mat, product)\n all_operations.extend(present_ops)\n\n touched_indices.append(index)\n index = circuit.next_moment_operating_on(qubits, index + 1)\n\n return all_operations, touched_indices, product\n\n\ndef _flip_kron_order(mat4x4: np.ndarray) -> np.ndarray:\n \"\"\"Given M = sum(kron(a_i, b_i)), returns M' = sum(kron(b_i, a_i)).\"\"\"\n result = np.array([[0] * 4] * 4, dtype=np.complex128)\n order = [0, 2, 1, 3]\n for i in range(4):\n for j in range(4):\n result[order[i], order[j]] = mat4x4[i, j]\n return result\n", "path": "cirq-core/cirq/optimizers/merge_interactions.py"}]}
| 3,050 | 394 |
gh_patches_debug_4411
|
rasdani/github-patches
|
git_diff
|
frappe__frappe-15362
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
re.error: missing ), unterminated subpattern via remove_db_aggregation (patch)
<!--
Welcome to the Frappe Framework issue tracker! Before creating an issue, please heed the following:
1. This tracker should only be used to report bugs and request features / enhancements to Frappe
- For questions and general support, use https://stackoverflow.com/questions/tagged/frappe
- For documentation issues, refer to https://frappeframework.com/docs/user/en or the developer cheetsheet https://github.com/frappe/frappe/wiki/Developer-Cheatsheet
2. Use the search function before creating a new issue. Duplicates will be closed and directed to
the original discussion.
3. When making a bug report, make sure you provide all required information. The easier it is for
maintainers to reproduce, the faster it'll be fixed.
4. If you think you know what the reason for the bug is, share it with us. Maybe put in a PR 😉
-->
## Description of the issue
## Context information (for bug reports)
**Output of `bench version`**
```
chat 0.0.1
erpnext 13.x.x-develop
erpnext_support 0.0.3
foundation 0.0.1
frappe 14.x.x-develop
frappe_docs 0.0.1
frappe_graphql 1.0.0
getanerp 0.0.1
healthcare 0.0.1
photos 0.0.1
press 0.0.1
release 0.0.1
wiki 0.0.1
zlast 0.0.1
```
## Steps to reproduce the issue
1. pull frappe, erpnext
2. bench start
3. bench migrate
### Observed Result / Stacktrace
```
Migrating erpnext
Executing frappe.patches.v14_0.remove_db_aggregation in erpnext (_76cf18db07302d32)
Traceback (most recent call last):
File "/opt/homebrew/Cellar/[email protected]/3.9.7_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/runpy.py", line 197, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/opt/homebrew/Cellar/[email protected]/3.9.7_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/Users/gavin/Desktop/frappe-bench-dev/apps/frappe/frappe/utils/bench_helper.py", line 104, in <module>
main()
File "/Users/gavin/Desktop/frappe-bench-dev/apps/frappe/frappe/utils/bench_helper.py", line 18, in main
click.Group(commands=commands)(prog_name='bench')
File "/Users/gavin/Desktop/frappe-bench-dev/env/lib/python3.9/site-packages/click/core.py", line 829, in __call__
return self.main(*args, **kwargs)
File "/Users/gavin/Desktop/frappe-bench-dev/env/lib/python3.9/site-packages/click/core.py", line 782, in main
rv = self.invoke(ctx)
File "/Users/gavin/Desktop/frappe-bench-dev/env/lib/python3.9/site-packages/click/core.py", line 1259, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "/Users/gavin/Desktop/frappe-bench-dev/env/lib/python3.9/site-packages/click/core.py", line 1259, in invoke
return _process_result(sub_ctx.command.invoke(sub_ctx))
File "/Users/gavin/Desktop/frappe-bench-dev/env/lib/python3.9/site-packages/click/core.py", line 1066, in invoke
return ctx.invoke(self.callback, **ctx.params)
File "/Users/gavin/Desktop/frappe-bench-dev/env/lib/python3.9/site-packages/click/core.py", line 610, in invoke
return callback(*args, **kwargs)
File "/Users/gavin/Desktop/frappe-bench-dev/env/lib/python3.9/site-packages/click/decorators.py", line 21, in new_func
return f(get_current_context(), *args, **kwargs)
File "/Users/gavin/Desktop/frappe-bench-dev/apps/frappe/frappe/commands/__init__.py", line 26, in _func
ret = f(frappe._dict(ctx.obj), *args, **kwargs)
File "/Users/gavin/Desktop/frappe-bench-dev/apps/frappe/frappe/commands/site.py", line 457, in migrate
migrate(
File "/Users/gavin/Desktop/frappe-bench-dev/apps/frappe/frappe/migrate.py", line 68, in migrate
frappe.modules.patch_handler.run_all(skip_failing)
File "/Users/gavin/Desktop/frappe-bench-dev/apps/frappe/frappe/modules/patch_handler.py", line 36, in run_all
run_patch(patch)
File "/Users/gavin/Desktop/frappe-bench-dev/apps/frappe/frappe/modules/patch_handler.py", line 25, in run_patch
if not run_single(patchmodule = patch):
File "/Users/gavin/Desktop/frappe-bench-dev/apps/frappe/frappe/modules/patch_handler.py", line 66, in run_single
return execute_patch(patchmodule, method, methodargs)
File "/Users/gavin/Desktop/frappe-bench-dev/apps/frappe/frappe/modules/patch_handler.py", line 86, in execute_patch
frappe.get_attr(patchmodule.split()[0] + ".execute")()
File "/Users/gavin/Desktop/frappe-bench-dev/apps/frappe/frappe/patches/v14_0/remove_db_aggregation.py", line 30, in execute
script = re.sub(f"frappe.db.{agg}(", f"frappe.qb.{agg}(", script)
File "/opt/homebrew/Cellar/[email protected]/3.9.7_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/re.py", line 210, in sub
return _compile(pattern, flags).sub(repl, string, count)
File "/opt/homebrew/Cellar/[email protected]/3.9.7_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/re.py", line 304, in _compile
p = sre_compile.compile(pattern, flags)
File "/opt/homebrew/Cellar/[email protected]/3.9.7_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/sre_compile.py", line 764, in compile
p = sre_parse.parse(p, flags)
File "/opt/homebrew/Cellar/[email protected]/3.9.7_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/sre_parse.py", line 948, in parse
p = _parse_sub(source, state, flags & SRE_FLAG_VERBOSE, 0)
File "/opt/homebrew/Cellar/[email protected]/3.9.7_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/sre_parse.py", line 443, in _parse_sub
itemsappend(_parse(source, state, verbose, nested + 1,
File "/opt/homebrew/Cellar/[email protected]/3.9.7_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/sre_parse.py", line 836, in _parse
raise source.error("missing ), unterminated subpattern",
re.error: missing ), unterminated subpattern at position 13
```
## Additional information
Python 3.9.7
</issue>
<code>
[start of frappe/patches/v14_0/remove_db_aggregation.py]
1 import re
2
3 import frappe
4 from frappe.query_builder import DocType
5
6
7 def execute():
8 """Replace temporarily available Database Aggregate APIs on frappe (develop)
9
10 APIs changed:
11 * frappe.db.max => frappe.qb.max
12 * frappe.db.min => frappe.qb.min
13 * frappe.db.sum => frappe.qb.sum
14 * frappe.db.avg => frappe.qb.avg
15 """
16 ServerScript = DocType("Server Script")
17 server_scripts = frappe.qb.from_(ServerScript).where(
18 ServerScript.script.like("%frappe.db.max(%")
19 | ServerScript.script.like("%frappe.db.min(%")
20 | ServerScript.script.like("%frappe.db.sum(%")
21 | ServerScript.script.like("%frappe.db.avg(%")
22 ).select(
23 "name", "script"
24 ).run(as_dict=True)
25
26 for server_script in server_scripts:
27 name, script = server_script["name"], server_script["script"]
28
29 for agg in ["avg", "max", "min", "sum"]:
30 script = re.sub(f"frappe.db.{agg}(", f"frappe.qb.{agg}(", script)
31
32 frappe.db.update("Server Script", name, "script", script)
33
[end of frappe/patches/v14_0/remove_db_aggregation.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/frappe/patches/v14_0/remove_db_aggregation.py b/frappe/patches/v14_0/remove_db_aggregation.py
--- a/frappe/patches/v14_0/remove_db_aggregation.py
+++ b/frappe/patches/v14_0/remove_db_aggregation.py
@@ -27,6 +27,6 @@
name, script = server_script["name"], server_script["script"]
for agg in ["avg", "max", "min", "sum"]:
- script = re.sub(f"frappe.db.{agg}(", f"frappe.qb.{agg}(", script)
+ script = re.sub(f"frappe.db.{agg}\(", f"frappe.qb.{agg}(", script)
frappe.db.update("Server Script", name, "script", script)
|
{"golden_diff": "diff --git a/frappe/patches/v14_0/remove_db_aggregation.py b/frappe/patches/v14_0/remove_db_aggregation.py\n--- a/frappe/patches/v14_0/remove_db_aggregation.py\n+++ b/frappe/patches/v14_0/remove_db_aggregation.py\n@@ -27,6 +27,6 @@\n \t\tname, script = server_script[\"name\"], server_script[\"script\"]\n \n \t\tfor agg in [\"avg\", \"max\", \"min\", \"sum\"]:\n-\t\t\tscript = re.sub(f\"frappe.db.{agg}(\", f\"frappe.qb.{agg}(\", script)\n+\t\t\tscript = re.sub(f\"frappe.db.{agg}\\(\", f\"frappe.qb.{agg}(\", script)\n \n \t\tfrappe.db.update(\"Server Script\", name, \"script\", script)\n", "issue": "re.error: missing ), unterminated subpattern via remove_db_aggregation (patch)\n<!--\r\nWelcome to the Frappe Framework issue tracker! Before creating an issue, please heed the following:\r\n\r\n1. This tracker should only be used to report bugs and request features / enhancements to Frappe\r\n - For questions and general support, use https://stackoverflow.com/questions/tagged/frappe\r\n - For documentation issues, refer to https://frappeframework.com/docs/user/en or the developer cheetsheet https://github.com/frappe/frappe/wiki/Developer-Cheatsheet\r\n2. Use the search function before creating a new issue. Duplicates will be closed and directed to\r\n the original discussion.\r\n3. When making a bug report, make sure you provide all required information. The easier it is for\r\n maintainers to reproduce, the faster it'll be fixed.\r\n4. If you think you know what the reason for the bug is, share it with us. Maybe put in a PR \ud83d\ude09\r\n-->\r\n\r\n## Description of the issue\r\n\r\n## Context information (for bug reports)\r\n\r\n**Output of `bench version`**\r\n```\r\nchat 0.0.1\r\nerpnext 13.x.x-develop\r\nerpnext_support 0.0.3\r\nfoundation 0.0.1\r\nfrappe 14.x.x-develop\r\nfrappe_docs 0.0.1\r\nfrappe_graphql 1.0.0\r\ngetanerp 0.0.1\r\nhealthcare 0.0.1\r\nphotos 0.0.1\r\npress 0.0.1\r\nrelease 0.0.1\r\nwiki 0.0.1\r\nzlast 0.0.1\r\n```\r\n\r\n## Steps to reproduce the issue\r\n\r\n1. pull frappe, erpnext \r\n2. bench start \r\n3. bench migrate\r\n\r\n### Observed Result / Stacktrace\r\n\r\n```\r\nMigrating erpnext\r\nExecuting frappe.patches.v14_0.remove_db_aggregation in erpnext (_76cf18db07302d32)\r\n\r\nTraceback (most recent call last):\r\n File \"/opt/homebrew/Cellar/[email protected]/3.9.7_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/runpy.py\", line 197, in _run_module_as_main\r\n return _run_code(code, main_globals, None,\r\n File \"/opt/homebrew/Cellar/[email protected]/3.9.7_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/runpy.py\", line 87, in _run_code\r\n exec(code, run_globals)\r\n File \"/Users/gavin/Desktop/frappe-bench-dev/apps/frappe/frappe/utils/bench_helper.py\", line 104, in <module>\r\n main()\r\n File \"/Users/gavin/Desktop/frappe-bench-dev/apps/frappe/frappe/utils/bench_helper.py\", line 18, in main\r\n click.Group(commands=commands)(prog_name='bench')\r\n File \"/Users/gavin/Desktop/frappe-bench-dev/env/lib/python3.9/site-packages/click/core.py\", line 829, in __call__\r\n return self.main(*args, **kwargs)\r\n File \"/Users/gavin/Desktop/frappe-bench-dev/env/lib/python3.9/site-packages/click/core.py\", line 782, in main\r\n rv = self.invoke(ctx)\r\n File \"/Users/gavin/Desktop/frappe-bench-dev/env/lib/python3.9/site-packages/click/core.py\", line 1259, in invoke\r\n return _process_result(sub_ctx.command.invoke(sub_ctx))\r\n File \"/Users/gavin/Desktop/frappe-bench-dev/env/lib/python3.9/site-packages/click/core.py\", line 1259, in invoke\r\n return _process_result(sub_ctx.command.invoke(sub_ctx))\r\n File \"/Users/gavin/Desktop/frappe-bench-dev/env/lib/python3.9/site-packages/click/core.py\", line 1066, in invoke\r\n return ctx.invoke(self.callback, **ctx.params)\r\n File \"/Users/gavin/Desktop/frappe-bench-dev/env/lib/python3.9/site-packages/click/core.py\", line 610, in invoke\r\n return callback(*args, **kwargs)\r\n File \"/Users/gavin/Desktop/frappe-bench-dev/env/lib/python3.9/site-packages/click/decorators.py\", line 21, in new_func\r\n return f(get_current_context(), *args, **kwargs)\r\n File \"/Users/gavin/Desktop/frappe-bench-dev/apps/frappe/frappe/commands/__init__.py\", line 26, in _func\r\n ret = f(frappe._dict(ctx.obj), *args, **kwargs)\r\n File \"/Users/gavin/Desktop/frappe-bench-dev/apps/frappe/frappe/commands/site.py\", line 457, in migrate\r\n migrate(\r\n File \"/Users/gavin/Desktop/frappe-bench-dev/apps/frappe/frappe/migrate.py\", line 68, in migrate\r\n frappe.modules.patch_handler.run_all(skip_failing)\r\n File \"/Users/gavin/Desktop/frappe-bench-dev/apps/frappe/frappe/modules/patch_handler.py\", line 36, in run_all\r\n run_patch(patch)\r\n File \"/Users/gavin/Desktop/frappe-bench-dev/apps/frappe/frappe/modules/patch_handler.py\", line 25, in run_patch\r\n if not run_single(patchmodule = patch):\r\n File \"/Users/gavin/Desktop/frappe-bench-dev/apps/frappe/frappe/modules/patch_handler.py\", line 66, in run_single\r\n return execute_patch(patchmodule, method, methodargs)\r\n File \"/Users/gavin/Desktop/frappe-bench-dev/apps/frappe/frappe/modules/patch_handler.py\", line 86, in execute_patch\r\n frappe.get_attr(patchmodule.split()[0] + \".execute\")()\r\n File \"/Users/gavin/Desktop/frappe-bench-dev/apps/frappe/frappe/patches/v14_0/remove_db_aggregation.py\", line 30, in execute\r\n script = re.sub(f\"frappe.db.{agg}(\", f\"frappe.qb.{agg}(\", script)\r\n File \"/opt/homebrew/Cellar/[email protected]/3.9.7_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/re.py\", line 210, in sub\r\n return _compile(pattern, flags).sub(repl, string, count)\r\n File \"/opt/homebrew/Cellar/[email protected]/3.9.7_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/re.py\", line 304, in _compile\r\n p = sre_compile.compile(pattern, flags)\r\n File \"/opt/homebrew/Cellar/[email protected]/3.9.7_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/sre_compile.py\", line 764, in compile\r\n p = sre_parse.parse(p, flags)\r\n File \"/opt/homebrew/Cellar/[email protected]/3.9.7_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/sre_parse.py\", line 948, in parse\r\n p = _parse_sub(source, state, flags & SRE_FLAG_VERBOSE, 0)\r\n File \"/opt/homebrew/Cellar/[email protected]/3.9.7_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/sre_parse.py\", line 443, in _parse_sub\r\n itemsappend(_parse(source, state, verbose, nested + 1,\r\n File \"/opt/homebrew/Cellar/[email protected]/3.9.7_1/Frameworks/Python.framework/Versions/3.9/lib/python3.9/sre_parse.py\", line 836, in _parse\r\n raise source.error(\"missing ), unterminated subpattern\",\r\nre.error: missing ), unterminated subpattern at position 13\r\n```\r\n\r\n## Additional information\r\n\r\nPython 3.9.7\n", "before_files": [{"content": "import re\n\nimport frappe\nfrom frappe.query_builder import DocType\n\n\ndef execute():\n\t\"\"\"Replace temporarily available Database Aggregate APIs on frappe (develop)\n\n\tAPIs changed:\n\t\t* frappe.db.max => frappe.qb.max\n\t\t* frappe.db.min => frappe.qb.min\n\t\t* frappe.db.sum => frappe.qb.sum\n\t\t* frappe.db.avg => frappe.qb.avg\n\t\"\"\"\n\tServerScript = DocType(\"Server Script\")\n\tserver_scripts = frappe.qb.from_(ServerScript).where(\n\t\tServerScript.script.like(\"%frappe.db.max(%\")\n\t\t| ServerScript.script.like(\"%frappe.db.min(%\")\n\t\t| ServerScript.script.like(\"%frappe.db.sum(%\")\n\t\t| ServerScript.script.like(\"%frappe.db.avg(%\")\n\t).select(\n\t\t\"name\", \"script\"\n\t).run(as_dict=True)\n\n\tfor server_script in server_scripts:\n\t\tname, script = server_script[\"name\"], server_script[\"script\"]\n\n\t\tfor agg in [\"avg\", \"max\", \"min\", \"sum\"]:\n\t\t\tscript = re.sub(f\"frappe.db.{agg}(\", f\"frappe.qb.{agg}(\", script)\n\n\t\tfrappe.db.update(\"Server Script\", name, \"script\", script)\n", "path": "frappe/patches/v14_0/remove_db_aggregation.py"}]}
| 2,651 | 184 |
gh_patches_debug_12638
|
rasdani/github-patches
|
git_diff
|
Kinto__kinto-1850
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Migrate to JSONschema Draft v7
Currently we use Draft4. The library that we use supports Draft7
https://json-schema.org/specification.html
The idea would be:
* to use `Draft7Validator` instead of `Draft4Validator` (nothing more...)
* list main changes and add links in CHANGELOG (see spec release notes)
* check compatibility with kinto-admin
</issue>
<code>
[start of kinto/schema_validation.py]
1 import colander
2 from jsonschema import Draft4Validator, ValidationError, SchemaError, RefResolutionError, validate
3 from pyramid.settings import asbool
4
5 from kinto.core import utils
6 from kinto.core.errors import raise_invalid
7 from kinto.views import object_exists_or_404
8
9
10 class JSONSchemaMapping(colander.SchemaNode):
11 def schema_type(self, **kw):
12 return colander.Mapping(unknown="preserve")
13
14 def deserialize(self, cstruct=colander.null):
15 # Start by deserializing a simple mapping.
16 validated = super().deserialize(cstruct)
17
18 # In case it is optional in parent schema.
19 if not validated or validated in (colander.null, colander.drop):
20 return validated
21 try:
22 check_schema(validated)
23 except ValidationError as e:
24 self.raise_invalid(e.message)
25 return validated
26
27
28 def check_schema(data):
29 try:
30 Draft4Validator.check_schema(data)
31 except SchemaError as e:
32 message = e.path.pop() + e.message
33 raise ValidationError(message)
34
35
36 def validate_schema(data, schema, ignore_fields=[]):
37 required_fields = [f for f in schema.get("required", []) if f not in ignore_fields]
38 # jsonschema doesn't accept 'required': [] yet.
39 # See https://github.com/Julian/jsonschema/issues/337.
40 # In the meantime, strip out 'required' if no other fields are required.
41 if required_fields:
42 schema = {**schema, "required": required_fields}
43 else:
44 schema = {f: v for f, v in schema.items() if f != "required"}
45
46 data = {f: v for f, v in data.items() if f not in ignore_fields}
47
48 try:
49 validate(data, schema)
50 except ValidationError as e:
51 if e.path:
52 field = e.path[-1]
53 elif e.validator_value:
54 field = e.validator_value[-1]
55 else:
56 field = e.schema_path[-1]
57 e.field = field
58 raise e
59 # Raise an error here if a reference in the schema doesn't resolve.
60 # jsonschema doesn't provide schema validation checking upon creation yet,
61 # it must be validated against data.
62 # See https://github.com/Julian/jsonschema/issues/399
63 # For future support https://github.com/Julian/jsonschema/issues/346.
64 except RefResolutionError as e:
65 raise e
66
67
68 def validate_from_bucket_schema_or_400(data, resource_name, request, ignore_fields=[]):
69 """Lookup in the parent objects if a schema was defined for this resource.
70
71 If the schema validation feature is enabled, if a schema is/are defined, and if the
72 data does not validate it/them, then it raises a 400 exception.
73 """
74 settings = request.registry.settings
75 schema_validation = "experimental_collection_schema_validation"
76 # If disabled from settings, do nothing.
77 if not asbool(settings.get(schema_validation)):
78 return
79
80 bucket_id = request.matchdict["bucket_id"]
81 bucket_uri = utils.instance_uri(request, "bucket", id=bucket_id)
82 buckets = request.bound_data.setdefault("buckets", {})
83 if bucket_uri not in buckets:
84 # Unknown yet, fetch from storage.
85 bucket = object_exists_or_404(
86 request, collection_id="bucket", parent_id="", object_id=bucket_id
87 )
88 buckets[bucket_uri] = bucket
89
90 # Let's see if the bucket defines a schema for this resource.
91 metadata_field = "{}:schema".format(resource_name)
92 bucket = buckets[bucket_uri]
93 if metadata_field not in bucket:
94 return
95
96 # Validate or fail with 400.
97 schema = bucket[metadata_field]
98 try:
99 validate_schema(data, schema, ignore_fields=ignore_fields)
100 except ValidationError as e:
101 raise_invalid(request, name=e.field, description=e.message)
102 except RefResolutionError as e:
103 raise_invalid(request, name="schema", description=str(e))
104
[end of kinto/schema_validation.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kinto/schema_validation.py b/kinto/schema_validation.py
--- a/kinto/schema_validation.py
+++ b/kinto/schema_validation.py
@@ -1,5 +1,5 @@
import colander
-from jsonschema import Draft4Validator, ValidationError, SchemaError, RefResolutionError, validate
+from jsonschema import Draft7Validator, ValidationError, SchemaError, RefResolutionError, validate
from pyramid.settings import asbool
from kinto.core import utils
@@ -27,7 +27,7 @@
def check_schema(data):
try:
- Draft4Validator.check_schema(data)
+ Draft7Validator.check_schema(data)
except SchemaError as e:
message = e.path.pop() + e.message
raise ValidationError(message)
|
{"golden_diff": "diff --git a/kinto/schema_validation.py b/kinto/schema_validation.py\n--- a/kinto/schema_validation.py\n+++ b/kinto/schema_validation.py\n@@ -1,5 +1,5 @@\n import colander\n-from jsonschema import Draft4Validator, ValidationError, SchemaError, RefResolutionError, validate\n+from jsonschema import Draft7Validator, ValidationError, SchemaError, RefResolutionError, validate\n from pyramid.settings import asbool\n \n from kinto.core import utils\n@@ -27,7 +27,7 @@\n \n def check_schema(data):\n try:\n- Draft4Validator.check_schema(data)\n+ Draft7Validator.check_schema(data)\n except SchemaError as e:\n message = e.path.pop() + e.message\n raise ValidationError(message)\n", "issue": "Migrate to JSONschema Draft v7\nCurrently we use Draft4. The library that we use supports Draft7\r\n\r\nhttps://json-schema.org/specification.html\r\n\r\nThe idea would be:\r\n* to use `Draft7Validator` instead of `Draft4Validator` (nothing more...)\r\n* list main changes and add links in CHANGELOG (see spec release notes)\r\n* check compatibility with kinto-admin\r\n\n", "before_files": [{"content": "import colander\nfrom jsonschema import Draft4Validator, ValidationError, SchemaError, RefResolutionError, validate\nfrom pyramid.settings import asbool\n\nfrom kinto.core import utils\nfrom kinto.core.errors import raise_invalid\nfrom kinto.views import object_exists_or_404\n\n\nclass JSONSchemaMapping(colander.SchemaNode):\n def schema_type(self, **kw):\n return colander.Mapping(unknown=\"preserve\")\n\n def deserialize(self, cstruct=colander.null):\n # Start by deserializing a simple mapping.\n validated = super().deserialize(cstruct)\n\n # In case it is optional in parent schema.\n if not validated or validated in (colander.null, colander.drop):\n return validated\n try:\n check_schema(validated)\n except ValidationError as e:\n self.raise_invalid(e.message)\n return validated\n\n\ndef check_schema(data):\n try:\n Draft4Validator.check_schema(data)\n except SchemaError as e:\n message = e.path.pop() + e.message\n raise ValidationError(message)\n\n\ndef validate_schema(data, schema, ignore_fields=[]):\n required_fields = [f for f in schema.get(\"required\", []) if f not in ignore_fields]\n # jsonschema doesn't accept 'required': [] yet.\n # See https://github.com/Julian/jsonschema/issues/337.\n # In the meantime, strip out 'required' if no other fields are required.\n if required_fields:\n schema = {**schema, \"required\": required_fields}\n else:\n schema = {f: v for f, v in schema.items() if f != \"required\"}\n\n data = {f: v for f, v in data.items() if f not in ignore_fields}\n\n try:\n validate(data, schema)\n except ValidationError as e:\n if e.path:\n field = e.path[-1]\n elif e.validator_value:\n field = e.validator_value[-1]\n else:\n field = e.schema_path[-1]\n e.field = field\n raise e\n # Raise an error here if a reference in the schema doesn't resolve.\n # jsonschema doesn't provide schema validation checking upon creation yet,\n # it must be validated against data.\n # See https://github.com/Julian/jsonschema/issues/399\n # For future support https://github.com/Julian/jsonschema/issues/346.\n except RefResolutionError as e:\n raise e\n\n\ndef validate_from_bucket_schema_or_400(data, resource_name, request, ignore_fields=[]):\n \"\"\"Lookup in the parent objects if a schema was defined for this resource.\n\n If the schema validation feature is enabled, if a schema is/are defined, and if the\n data does not validate it/them, then it raises a 400 exception.\n \"\"\"\n settings = request.registry.settings\n schema_validation = \"experimental_collection_schema_validation\"\n # If disabled from settings, do nothing.\n if not asbool(settings.get(schema_validation)):\n return\n\n bucket_id = request.matchdict[\"bucket_id\"]\n bucket_uri = utils.instance_uri(request, \"bucket\", id=bucket_id)\n buckets = request.bound_data.setdefault(\"buckets\", {})\n if bucket_uri not in buckets:\n # Unknown yet, fetch from storage.\n bucket = object_exists_or_404(\n request, collection_id=\"bucket\", parent_id=\"\", object_id=bucket_id\n )\n buckets[bucket_uri] = bucket\n\n # Let's see if the bucket defines a schema for this resource.\n metadata_field = \"{}:schema\".format(resource_name)\n bucket = buckets[bucket_uri]\n if metadata_field not in bucket:\n return\n\n # Validate or fail with 400.\n schema = bucket[metadata_field]\n try:\n validate_schema(data, schema, ignore_fields=ignore_fields)\n except ValidationError as e:\n raise_invalid(request, name=e.field, description=e.message)\n except RefResolutionError as e:\n raise_invalid(request, name=\"schema\", description=str(e))\n", "path": "kinto/schema_validation.py"}]}
| 1,690 | 161 |
gh_patches_debug_12854
|
rasdani/github-patches
|
git_diff
|
librosa__librosa-1457
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Update show_versions to match current dependencies
**Describe the bug**
Looks like we forgot to revise the list of modules checked by `show_versions()` in the 0.9.0 release.
This isn't a major problem, but we should fix it for 0.9.2 and keep it as part of the release audit sequence going forward.
In general, `show_versions()` should track the dependencies listed in setup.cfg: https://github.com/librosa/librosa/blob/ef482b824c609222abb265357f7a79b11d174dd2/setup.cfg#L45-L84
Update show_versions to match current dependencies
**Describe the bug**
Looks like we forgot to revise the list of modules checked by `show_versions()` in the 0.9.0 release.
This isn't a major problem, but we should fix it for 0.9.2 and keep it as part of the release audit sequence going forward.
In general, `show_versions()` should track the dependencies listed in setup.cfg: https://github.com/librosa/librosa/blob/ef482b824c609222abb265357f7a79b11d174dd2/setup.cfg#L45-L84
</issue>
<code>
[start of librosa/version.py]
1 #!/usr/bin/env python
2 # -*- coding: utf-8 -*-
3 """Version info"""
4
5 import sys
6 import importlib
7
8 short_version = "0.9"
9 version = "0.9.1"
10
11
12 def __get_mod_version(modname):
13
14 try:
15 if modname in sys.modules:
16 mod = sys.modules[modname]
17 else:
18 mod = importlib.import_module(modname)
19 try:
20 return mod.__version__
21 except AttributeError:
22 return "installed, no version number available"
23
24 except ImportError:
25 return None
26
27
28 def show_versions():
29 """Return the version information for all librosa dependencies."""
30
31 core_deps = [
32 "audioread",
33 "numpy",
34 "scipy",
35 "sklearn",
36 "joblib",
37 "decorator",
38 "soundfile",
39 "resampy",
40 "numba",
41 ]
42
43 extra_deps = [
44 "numpydoc",
45 "sphinx",
46 "sphinx_rtd_theme",
47 "sphinxcontrib.versioning",
48 "sphinx-gallery",
49 "pytest",
50 "pytest-mpl",
51 "pytest-cov",
52 "matplotlib",
53 "presets",
54 ]
55
56 print("INSTALLED VERSIONS")
57 print("------------------")
58 print("python: {}\n".format(sys.version))
59 print("librosa: {}\n".format(version))
60 for dep in core_deps:
61 print("{}: {}".format(dep, __get_mod_version(dep)))
62 print("")
63 for dep in extra_deps:
64 print("{}: {}".format(dep, __get_mod_version(dep)))
65
[end of librosa/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/librosa/version.py b/librosa/version.py
--- a/librosa/version.py
+++ b/librosa/version.py
@@ -38,18 +38,26 @@
"soundfile",
"resampy",
"numba",
+ "pooch",
+ "packaging"
]
extra_deps = [
"numpydoc",
"sphinx",
"sphinx_rtd_theme",
- "sphinxcontrib.versioning",
- "sphinx-gallery",
+ "sphinx_multiversion",
+ "sphinx_gallery",
+ "mir_eval",
+ "ipython",
+ "sphinxcontrib-svg2pdfconverter",
"pytest",
"pytest-mpl",
"pytest-cov",
"matplotlib",
+ "samplerate",
+ "soxr",
+ "contextlib2",
"presets",
]
|
{"golden_diff": "diff --git a/librosa/version.py b/librosa/version.py\n--- a/librosa/version.py\n+++ b/librosa/version.py\n@@ -38,18 +38,26 @@\n \"soundfile\",\n \"resampy\",\n \"numba\",\n+ \"pooch\",\n+ \"packaging\"\n ]\n \n extra_deps = [\n \"numpydoc\",\n \"sphinx\",\n \"sphinx_rtd_theme\",\n- \"sphinxcontrib.versioning\",\n- \"sphinx-gallery\",\n+ \"sphinx_multiversion\",\n+ \"sphinx_gallery\",\n+ \"mir_eval\",\n+ \"ipython\",\n+ \"sphinxcontrib-svg2pdfconverter\",\n \"pytest\",\n \"pytest-mpl\",\n \"pytest-cov\",\n \"matplotlib\",\n+ \"samplerate\",\n+ \"soxr\",\n+ \"contextlib2\",\n \"presets\",\n ]\n", "issue": "Update show_versions to match current dependencies\n**Describe the bug**\r\n\r\nLooks like we forgot to revise the list of modules checked by `show_versions()` in the 0.9.0 release.\r\nThis isn't a major problem, but we should fix it for 0.9.2 and keep it as part of the release audit sequence going forward.\r\n\r\nIn general, `show_versions()` should track the dependencies listed in setup.cfg: https://github.com/librosa/librosa/blob/ef482b824c609222abb265357f7a79b11d174dd2/setup.cfg#L45-L84\nUpdate show_versions to match current dependencies\n**Describe the bug**\r\n\r\nLooks like we forgot to revise the list of modules checked by `show_versions()` in the 0.9.0 release.\r\nThis isn't a major problem, but we should fix it for 0.9.2 and keep it as part of the release audit sequence going forward.\r\n\r\nIn general, `show_versions()` should track the dependencies listed in setup.cfg: https://github.com/librosa/librosa/blob/ef482b824c609222abb265357f7a79b11d174dd2/setup.cfg#L45-L84\n", "before_files": [{"content": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"Version info\"\"\"\n\nimport sys\nimport importlib\n\nshort_version = \"0.9\"\nversion = \"0.9.1\"\n\n\ndef __get_mod_version(modname):\n\n try:\n if modname in sys.modules:\n mod = sys.modules[modname]\n else:\n mod = importlib.import_module(modname)\n try:\n return mod.__version__\n except AttributeError:\n return \"installed, no version number available\"\n\n except ImportError:\n return None\n\n\ndef show_versions():\n \"\"\"Return the version information for all librosa dependencies.\"\"\"\n\n core_deps = [\n \"audioread\",\n \"numpy\",\n \"scipy\",\n \"sklearn\",\n \"joblib\",\n \"decorator\",\n \"soundfile\",\n \"resampy\",\n \"numba\",\n ]\n\n extra_deps = [\n \"numpydoc\",\n \"sphinx\",\n \"sphinx_rtd_theme\",\n \"sphinxcontrib.versioning\",\n \"sphinx-gallery\",\n \"pytest\",\n \"pytest-mpl\",\n \"pytest-cov\",\n \"matplotlib\",\n \"presets\",\n ]\n\n print(\"INSTALLED VERSIONS\")\n print(\"------------------\")\n print(\"python: {}\\n\".format(sys.version))\n print(\"librosa: {}\\n\".format(version))\n for dep in core_deps:\n print(\"{}: {}\".format(dep, __get_mod_version(dep)))\n print(\"\")\n for dep in extra_deps:\n print(\"{}: {}\".format(dep, __get_mod_version(dep)))\n", "path": "librosa/version.py"}]}
| 1,288 | 203 |
gh_patches_debug_10338
|
rasdani/github-patches
|
git_diff
|
digitalfabrik__integreat-cms-449
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Region list menu points to api
### Describe the Bug
<!-- A clear and concise description of what the bug is. -->
The menu item for regions points to the region api and not the region list.
### Steps to Reproduce
1. Go to 'Regions'
### Expected Behavior
<!-- A clear and concise description of what you expected to happen. -->
The region list (`/regions/`) opens.
### Actual Behavior
<!-- A clear and concise description of what actually happened. -->
The region api (`/api/regions/`) opens.
### Additional Information
<!-- Add any other context (e.g. logs, screenshots, etc.) about the problem here. -->
This is because both urls have the name 'regions' and the last matching item in urlpatterns determines the actual url.
Region list menu points to api
### Describe the Bug
<!-- A clear and concise description of what the bug is. -->
The menu item for regions points to the region api and not the region list.
### Steps to Reproduce
1. Go to 'Regions'
### Expected Behavior
<!-- A clear and concise description of what you expected to happen. -->
The region list (`/regions/`) opens.
### Actual Behavior
<!-- A clear and concise description of what actually happened. -->
The region api (`/api/regions/`) opens.
### Additional Information
<!-- Add any other context (e.g. logs, screenshots, etc.) about the problem here. -->
This is because both urls have the name 'regions' and the last matching item in urlpatterns determines the actual url.
</issue>
<code>
[start of src/api/urls.py]
1 '''
2 Expansion of API-Endpoints for the CMS
3 '''
4 from django.conf.urls import include, url
5
6 from .v3.feedback import (
7 page_feedback,
8 search_result_feedback,
9 region_feedback,
10 offer_list_feedback,
11 event_list_feedback)
12 from .v3.languages import languages
13 from .v3.pages import pages
14 from .v3.push_notifications import sent_push_notifications
15 from .v3.regions import regions, liveregions, hiddenregions, pushnew
16 from .v3.offers import offers
17 from .v3.single_page import single_page
18
19 urlpatterns = [
20 url(r'regions/$', regions, name='regions'),
21 url(r'regions/live/$', liveregions, name='liveregions'),
22 url(r'regions/hidden/$', hiddenregions, name='hiddenregions'),
23 url(r'regions/pushnew/$', pushnew, name='pushnew'),
24 url(r'(?P<region_slug>[-\w]+)/', include([
25 url(r'languages/$', languages),
26 url(r'offers/$', offers),
27 url(r'(?P<lan_code>[-\w]+)/sent_push_notifications/$', sent_push_notifications),
28 url(r'(?P<languages>[-\w]+)/feedback/$', page_feedback.feedback),
29 url(r'(?P<language_code>[-\w]+)/feedback/categories$', region_feedback.region_feedback),
30 url(r'(?P<language_code>[-\w]+)/feedback/search$', search_result_feedback.search_result_feedback),
31 url(r'(?P<language_code>[-\w]+)/feedback/extras$', offer_list_feedback.offer_list_feedback),
32 url(r'(?P<language_code>[-\w]+)/feedback/events$', event_list_feedback.event_list_feedback),
33 url(r'(?P<language_code>[-\w]+)/pages/$', pages),
34 url(r'(?P<language_code>[-\w]+)/offers/$', offers),
35 url(r'(?P<language_code>[-\w]+)/page/$', single_page),
36 ])),
37 ]
38
[end of src/api/urls.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/api/urls.py b/src/api/urls.py
--- a/src/api/urls.py
+++ b/src/api/urls.py
@@ -17,10 +17,10 @@
from .v3.single_page import single_page
urlpatterns = [
- url(r'regions/$', regions, name='regions'),
- url(r'regions/live/$', liveregions, name='liveregions'),
- url(r'regions/hidden/$', hiddenregions, name='hiddenregions'),
- url(r'regions/pushnew/$', pushnew, name='pushnew'),
+ url(r'regions/$', regions),
+ url(r'regions/live/$', liveregions),
+ url(r'regions/hidden/$', hiddenregions),
+ url(r'regions/pushnew/$', pushnew),
url(r'(?P<region_slug>[-\w]+)/', include([
url(r'languages/$', languages),
url(r'offers/$', offers),
|
{"golden_diff": "diff --git a/src/api/urls.py b/src/api/urls.py\n--- a/src/api/urls.py\n+++ b/src/api/urls.py\n@@ -17,10 +17,10 @@\n from .v3.single_page import single_page\n \n urlpatterns = [\n- url(r'regions/$', regions, name='regions'),\n- url(r'regions/live/$', liveregions, name='liveregions'),\n- url(r'regions/hidden/$', hiddenregions, name='hiddenregions'),\n- url(r'regions/pushnew/$', pushnew, name='pushnew'),\n+ url(r'regions/$', regions),\n+ url(r'regions/live/$', liveregions),\n+ url(r'regions/hidden/$', hiddenregions),\n+ url(r'regions/pushnew/$', pushnew),\n url(r'(?P<region_slug>[-\\w]+)/', include([\n url(r'languages/$', languages),\n url(r'offers/$', offers),\n", "issue": "Region list menu points to api\n### Describe the Bug\r\n<!-- A clear and concise description of what the bug is. -->\r\nThe menu item for regions points to the region api and not the region list.\r\n\r\n### Steps to Reproduce\r\n\r\n1. Go to 'Regions'\r\n\r\n### Expected Behavior\r\n<!-- A clear and concise description of what you expected to happen. -->\r\nThe region list (`/regions/`) opens.\r\n\r\n### Actual Behavior\r\n<!-- A clear and concise description of what actually happened. -->\r\nThe region api (`/api/regions/`) opens.\r\n\r\n### Additional Information\r\n<!-- Add any other context (e.g. logs, screenshots, etc.) about the problem here. -->\r\nThis is because both urls have the name 'regions' and the last matching item in urlpatterns determines the actual url.\r\n\nRegion list menu points to api\n### Describe the Bug\r\n<!-- A clear and concise description of what the bug is. -->\r\nThe menu item for regions points to the region api and not the region list.\r\n\r\n### Steps to Reproduce\r\n\r\n1. Go to 'Regions'\r\n\r\n### Expected Behavior\r\n<!-- A clear and concise description of what you expected to happen. -->\r\nThe region list (`/regions/`) opens.\r\n\r\n### Actual Behavior\r\n<!-- A clear and concise description of what actually happened. -->\r\nThe region api (`/api/regions/`) opens.\r\n\r\n### Additional Information\r\n<!-- Add any other context (e.g. logs, screenshots, etc.) about the problem here. -->\r\nThis is because both urls have the name 'regions' and the last matching item in urlpatterns determines the actual url.\r\n\n", "before_files": [{"content": "'''\nExpansion of API-Endpoints for the CMS\n'''\nfrom django.conf.urls import include, url\n\nfrom .v3.feedback import (\n page_feedback,\n search_result_feedback,\n region_feedback,\n offer_list_feedback,\n event_list_feedback)\nfrom .v3.languages import languages\nfrom .v3.pages import pages\nfrom .v3.push_notifications import sent_push_notifications\nfrom .v3.regions import regions, liveregions, hiddenregions, pushnew\nfrom .v3.offers import offers\nfrom .v3.single_page import single_page\n\nurlpatterns = [\n url(r'regions/$', regions, name='regions'),\n url(r'regions/live/$', liveregions, name='liveregions'),\n url(r'regions/hidden/$', hiddenregions, name='hiddenregions'),\n url(r'regions/pushnew/$', pushnew, name='pushnew'),\n url(r'(?P<region_slug>[-\\w]+)/', include([\n url(r'languages/$', languages),\n url(r'offers/$', offers),\n url(r'(?P<lan_code>[-\\w]+)/sent_push_notifications/$', sent_push_notifications),\n url(r'(?P<languages>[-\\w]+)/feedback/$', page_feedback.feedback),\n url(r'(?P<language_code>[-\\w]+)/feedback/categories$', region_feedback.region_feedback),\n url(r'(?P<language_code>[-\\w]+)/feedback/search$', search_result_feedback.search_result_feedback),\n url(r'(?P<language_code>[-\\w]+)/feedback/extras$', offer_list_feedback.offer_list_feedback),\n url(r'(?P<language_code>[-\\w]+)/feedback/events$', event_list_feedback.event_list_feedback),\n url(r'(?P<language_code>[-\\w]+)/pages/$', pages),\n url(r'(?P<language_code>[-\\w]+)/offers/$', offers),\n url(r'(?P<language_code>[-\\w]+)/page/$', single_page),\n ])),\n]\n", "path": "src/api/urls.py"}]}
| 1,335 | 212 |
gh_patches_debug_24755
|
rasdani/github-patches
|
git_diff
|
NVIDIA-Merlin__NVTabular-1213
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[BUG] Reading data from GCS creates issue
**Describe the bug**
Reading parquet file from Google Cloud Storage does not work.
**Steps/Code to reproduce bug**
```
dataset = nvt.Dataset("gs://bucket/file.parquet")
dataset.to_ddf().head()
```
Error:
```
cuDF failure at: ../src/table/table.cpp:42: Column size mismatch:
```
If the data is copied to the local disk, the code will work.
cuDF / dask_cudf can read from GCS.
This is with the latest NVTabular
</issue>
<code>
[start of nvtabular/io/fsspec_utils.py]
1 #
2 # Copyright (c) 2021, NVIDIA CORPORATION.
3 #
4 # Licensed under the Apache License, Version 2.0 (the "License");
5 # you may not use this file except in compliance with the License.
6 # You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15 #
16
17 import io
18 from threading import Thread
19
20 import numpy as np
21 from pyarrow import parquet as pq
22
23 try:
24 import cudf
25 from cudf.core.column import as_column, build_categorical_column
26 except ImportError:
27 cudf = None
28
29 #
30 # Parquet-Specific Utilities
31 #
32
33
34 def _optimized_read_partition_remote(
35 fs, pieces, columns, index, categories=(), partitions=(), **kwargs
36 ):
37 # This is a specialized version of `CudfEngine.read_partition`
38 # for remote filesystems. This implementation is intended to
39 # replace the upstream `read_partition` classmethod until
40 # remote-filesystem handling is optimized in cudf/dask-cudf
41
42 if columns is not None:
43 columns = list(columns)
44 if isinstance(index, list):
45 columns += index
46
47 # Check that this is a single-piece read on a non-local filesystem
48 if not isinstance(pieces, list):
49 pieces = [pieces]
50 if len(pieces) > 1:
51 raise ValueError(
52 "The `_custom_read_partition` code path is not designed to "
53 "handle a multi-element `pieces` argument."
54 )
55 if cudf.utils.ioutils._is_local_filesystem(fs):
56 raise ValueError(
57 "The `_custom_read_partition` code path is not intended "
58 "for use on local filesystems."
59 )
60
61 # Unpack contents of the single piece
62 if isinstance(pieces[0], str):
63 path = pieces[0]
64 row_group = None
65 partition_keys = []
66 else:
67 (path, row_group, partition_keys) = pieces[0]
68
69 # Call optimized read utility
70 df = _optimized_read_remote(path, row_group, columns, fs, **kwargs)
71
72 #
73 # Code below is directly copied from cudf-21.08
74 #
75
76 if index and (index[0] in df.columns):
77 df = df.set_index(index[0])
78 elif index is False and set(df.index.names).issubset(columns):
79 # If index=False, we need to make sure all of the
80 # names in `columns` are actually in `df.columns`
81 df.reset_index(inplace=True)
82
83 if partition_keys:
84 if partitions is None:
85 raise ValueError("Must pass partition sets")
86 for i, (name, index2) in enumerate(partition_keys):
87 categories = [val.as_py() for val in partitions.levels[i].dictionary]
88
89 col = as_column(index2).as_frame().repeat(len(df))._data[None]
90 df[name] = build_categorical_column(
91 categories=categories,
92 codes=as_column(col.base_data, dtype=col.dtype),
93 size=col.size,
94 offset=col.offset,
95 ordered=False,
96 )
97
98 return df
99
100
101 def _optimized_read_remote(path, row_groups, columns, fs, **kwargs):
102
103 if row_groups is not None and not isinstance(row_groups, list):
104 row_groups = [row_groups]
105
106 # Get byte-ranges that are known to contain the
107 # required data for this read
108 byte_ranges, footer, file_size = _get_parquet_byte_ranges(
109 path, row_groups, columns, fs, **kwargs
110 )
111
112 # Transfer the required byte-ranges with fsspec.
113 # Store these blocks in a local dummy buffer
114 dummy_buffer = _fsspec_data_transfer(
115 path,
116 fs,
117 byte_ranges=byte_ranges,
118 footer=footer,
119 file_size=file_size,
120 add_par1_magic=True,
121 **kwargs,
122 )
123
124 # Call cudf.read_parquet on the dummy buffer
125 strings_to_cats = kwargs.get("strings_to_categorical", False)
126 df = cudf.read_parquet(
127 io.BytesIO(dummy_buffer),
128 engine="cudf",
129 columns=columns,
130 row_groups=row_groups,
131 strings_to_categorical=strings_to_cats,
132 **kwargs.get("read", {}),
133 )
134 del dummy_buffer
135 return df
136
137
138 def _get_parquet_byte_ranges(
139 path,
140 rgs,
141 columns,
142 fs,
143 bytes_per_thread=256_000_000,
144 **kwargs,
145 ):
146 # The purpose of this utility is to return a list
147 # of byte ranges (in path) that are known to contain
148 # the data needed to read `columns` and `rgs`
149
150 # Step 0 - Get size of file
151 file_size = fs.size(path)
152
153 # Return early if the file is too small to merit
154 # optimized data transfer
155 if file_size <= bytes_per_thread:
156 return None, None, file_size
157
158 # Step 1 - Get 32 KB from tail of file.
159 #
160 # This "sample size" can be tunable, but should
161 # always be >= 8 bytes (so we can read the footer size)
162 tail_size = 32_000
163 footer_sample = fs.tail(path, tail_size)
164
165 # Step 2 - Read the footer size and re-read a larger
166 # tail if necessary
167 footer_size = int.from_bytes(footer_sample[-8:-4], "little")
168 if tail_size < (footer_size + 8):
169 footer_sample = fs.tail(path, footer_size + 8)
170
171 # Step 3 - Collect required byte ranges
172 byte_ranges = []
173 md = pq.ParquetFile(io.BytesIO(footer_sample)).metadata
174 for r in range(md.num_row_groups):
175 # Skip this row-group if we are targeting
176 # specific row-groups
177 if rgs is None or r in rgs:
178 row_group = md.row_group(r)
179 for c in range(row_group.num_columns):
180 column = row_group.column(c)
181 name = column.path_in_schema
182 # Skip this column if we are targeting a
183 # specific columns
184 if columns is None or name in columns:
185 file_offset0 = column.dictionary_page_offset
186 if file_offset0 is None:
187 file_offset0 = column.data_page_offset
188 num_bytes = column.total_uncompressed_size
189 byte_ranges.append((file_offset0, num_bytes))
190
191 return byte_ranges, footer_sample, file_size
192
193
194 #
195 # General Fsspec Data-transfer Optimization Code
196 #
197
198
199 def _fsspec_data_transfer(
200 path_or_fob,
201 fs,
202 byte_ranges=None,
203 footer=None,
204 file_size=None,
205 add_par1_magic=None,
206 bytes_per_thread=256_000_000,
207 max_gap=64_000,
208 mode="rb",
209 **kwargs,
210 ):
211
212 # Calculate total file size
213 file_size = file_size or fs.size(path_or_fob)
214
215 # Check if a direct read makes the most sense
216 if not byte_ranges and bytes_per_thread >= file_size:
217 return fs.open(path_or_fob, mode=mode, cache_type="none").read()
218
219 # Threaded read into "dummy" buffer
220 buf = np.zeros(file_size, dtype="b")
221 if byte_ranges:
222
223 # Optimize/merge the ranges
224 byte_ranges = _merge_ranges(
225 byte_ranges,
226 max_block=bytes_per_thread,
227 max_gap=max_gap,
228 )
229
230 # Call multi-threaded data transfer of
231 # remote byte-ranges to local buffer
232 _read_byte_ranges(
233 path_or_fob,
234 byte_ranges,
235 buf,
236 fs,
237 **kwargs,
238 )
239
240 # Add Header & Footer bytes
241 if footer is not None:
242 footer_size = len(footer)
243 buf[-footer_size:] = np.frombuffer(footer[-footer_size:], dtype="b")
244
245 # Add parquet magic bytes (optional)
246 if add_par1_magic:
247 buf[:4] = np.frombuffer(b"PAR1", dtype="b")
248 if footer is None:
249 buf[-4:] = np.frombuffer(b"PAR1", dtype="b")
250
251 else:
252 byte_ranges = [
253 (b, min(bytes_per_thread, file_size - b)) for b in range(0, file_size, bytes_per_thread)
254 ]
255 _read_byte_ranges(
256 path_or_fob,
257 byte_ranges,
258 buf,
259 fs,
260 **kwargs,
261 )
262
263 return buf.tobytes()
264
265
266 def _merge_ranges(byte_ranges, max_block=256_000_000, max_gap=64_000):
267 # Simple utility to merge small/adjacent byte ranges
268 new_ranges = []
269 if not byte_ranges:
270 # Early return
271 return new_ranges
272
273 offset, size = byte_ranges[0]
274 for (new_offset, new_size) in byte_ranges[1:]:
275 gap = new_offset - (offset + size)
276 if gap > max_gap or (size + new_size + gap) > max_block:
277 # Gap is too large or total read is too large
278 new_ranges.append((offset, size))
279 offset = new_offset
280 size = new_size
281 continue
282 size += new_size + gap
283 new_ranges.append((offset, size))
284 return new_ranges
285
286
287 def _assign_block(fs, path_or_fob, local_buffer, offset, nbytes):
288 with fs.open(path_or_fob, mode="rb", cache_type="none") as fob:
289 fob.seek(offset)
290 local_buffer[offset : offset + nbytes] = np.frombuffer(
291 fob.read(nbytes),
292 dtype="b",
293 )
294
295
296 def _read_byte_ranges(
297 path_or_fob,
298 ranges,
299 local_buffer,
300 fs,
301 **kwargs,
302 ):
303
304 workers = []
305 for (offset, nbytes) in ranges:
306 if len(ranges) > 1:
307 workers.append(
308 Thread(target=_assign_block, args=(fs, path_or_fob, local_buffer, offset, nbytes))
309 )
310 workers[-1].start()
311 else:
312 _assign_block(fs, path_or_fob, local_buffer, offset, nbytes)
313
314 for worker in workers:
315 worker.join()
316
[end of nvtabular/io/fsspec_utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nvtabular/io/fsspec_utils.py b/nvtabular/io/fsspec_utils.py
--- a/nvtabular/io/fsspec_utils.py
+++ b/nvtabular/io/fsspec_utils.py
@@ -179,13 +179,20 @@
for c in range(row_group.num_columns):
column = row_group.column(c)
name = column.path_in_schema
- # Skip this column if we are targeting a
- # specific columns
- if columns is None or name in columns:
+ # Skip this column if we are targeting
+ # specific columns, and this name is not
+ # in the list.
+ #
+ # Note that `column.path_in_schema` may
+ # modify the column name for list and struct
+ # columns. For example, a column named "a"
+ # may become "a.list.element"
+ split_name = name.split(".")[0]
+ if columns is None or name in columns or split_name in columns:
file_offset0 = column.dictionary_page_offset
if file_offset0 is None:
file_offset0 = column.data_page_offset
- num_bytes = column.total_uncompressed_size
+ num_bytes = column.total_compressed_size
byte_ranges.append((file_offset0, num_bytes))
return byte_ranges, footer_sample, file_size
|
{"golden_diff": "diff --git a/nvtabular/io/fsspec_utils.py b/nvtabular/io/fsspec_utils.py\n--- a/nvtabular/io/fsspec_utils.py\n+++ b/nvtabular/io/fsspec_utils.py\n@@ -179,13 +179,20 @@\n for c in range(row_group.num_columns):\n column = row_group.column(c)\n name = column.path_in_schema\n- # Skip this column if we are targeting a\n- # specific columns\n- if columns is None or name in columns:\n+ # Skip this column if we are targeting\n+ # specific columns, and this name is not\n+ # in the list.\n+ #\n+ # Note that `column.path_in_schema` may\n+ # modify the column name for list and struct\n+ # columns. For example, a column named \"a\"\n+ # may become \"a.list.element\"\n+ split_name = name.split(\".\")[0]\n+ if columns is None or name in columns or split_name in columns:\n file_offset0 = column.dictionary_page_offset\n if file_offset0 is None:\n file_offset0 = column.data_page_offset\n- num_bytes = column.total_uncompressed_size\n+ num_bytes = column.total_compressed_size\n byte_ranges.append((file_offset0, num_bytes))\n \n return byte_ranges, footer_sample, file_size\n", "issue": "[BUG] Reading data from GCS creates issue\n**Describe the bug**\r\nReading parquet file from Google Cloud Storage does not work.\r\n\r\n**Steps/Code to reproduce bug**\r\n```\r\ndataset = nvt.Dataset(\"gs://bucket/file.parquet\")\r\ndataset.to_ddf().head()\r\n```\r\n\r\nError:\r\n```\r\ncuDF failure at: ../src/table/table.cpp:42: Column size mismatch:\r\n```\r\n\r\nIf the data is copied to the local disk, the code will work.\r\ncuDF / dask_cudf can read from GCS.\r\nThis is with the latest NVTabular\r\n\n", "before_files": [{"content": "#\n# Copyright (c) 2021, NVIDIA CORPORATION.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\nimport io\nfrom threading import Thread\n\nimport numpy as np\nfrom pyarrow import parquet as pq\n\ntry:\n import cudf\n from cudf.core.column import as_column, build_categorical_column\nexcept ImportError:\n cudf = None\n\n#\n# Parquet-Specific Utilities\n#\n\n\ndef _optimized_read_partition_remote(\n fs, pieces, columns, index, categories=(), partitions=(), **kwargs\n):\n # This is a specialized version of `CudfEngine.read_partition`\n # for remote filesystems. This implementation is intended to\n # replace the upstream `read_partition` classmethod until\n # remote-filesystem handling is optimized in cudf/dask-cudf\n\n if columns is not None:\n columns = list(columns)\n if isinstance(index, list):\n columns += index\n\n # Check that this is a single-piece read on a non-local filesystem\n if not isinstance(pieces, list):\n pieces = [pieces]\n if len(pieces) > 1:\n raise ValueError(\n \"The `_custom_read_partition` code path is not designed to \"\n \"handle a multi-element `pieces` argument.\"\n )\n if cudf.utils.ioutils._is_local_filesystem(fs):\n raise ValueError(\n \"The `_custom_read_partition` code path is not intended \"\n \"for use on local filesystems.\"\n )\n\n # Unpack contents of the single piece\n if isinstance(pieces[0], str):\n path = pieces[0]\n row_group = None\n partition_keys = []\n else:\n (path, row_group, partition_keys) = pieces[0]\n\n # Call optimized read utility\n df = _optimized_read_remote(path, row_group, columns, fs, **kwargs)\n\n #\n # Code below is directly copied from cudf-21.08\n #\n\n if index and (index[0] in df.columns):\n df = df.set_index(index[0])\n elif index is False and set(df.index.names).issubset(columns):\n # If index=False, we need to make sure all of the\n # names in `columns` are actually in `df.columns`\n df.reset_index(inplace=True)\n\n if partition_keys:\n if partitions is None:\n raise ValueError(\"Must pass partition sets\")\n for i, (name, index2) in enumerate(partition_keys):\n categories = [val.as_py() for val in partitions.levels[i].dictionary]\n\n col = as_column(index2).as_frame().repeat(len(df))._data[None]\n df[name] = build_categorical_column(\n categories=categories,\n codes=as_column(col.base_data, dtype=col.dtype),\n size=col.size,\n offset=col.offset,\n ordered=False,\n )\n\n return df\n\n\ndef _optimized_read_remote(path, row_groups, columns, fs, **kwargs):\n\n if row_groups is not None and not isinstance(row_groups, list):\n row_groups = [row_groups]\n\n # Get byte-ranges that are known to contain the\n # required data for this read\n byte_ranges, footer, file_size = _get_parquet_byte_ranges(\n path, row_groups, columns, fs, **kwargs\n )\n\n # Transfer the required byte-ranges with fsspec.\n # Store these blocks in a local dummy buffer\n dummy_buffer = _fsspec_data_transfer(\n path,\n fs,\n byte_ranges=byte_ranges,\n footer=footer,\n file_size=file_size,\n add_par1_magic=True,\n **kwargs,\n )\n\n # Call cudf.read_parquet on the dummy buffer\n strings_to_cats = kwargs.get(\"strings_to_categorical\", False)\n df = cudf.read_parquet(\n io.BytesIO(dummy_buffer),\n engine=\"cudf\",\n columns=columns,\n row_groups=row_groups,\n strings_to_categorical=strings_to_cats,\n **kwargs.get(\"read\", {}),\n )\n del dummy_buffer\n return df\n\n\ndef _get_parquet_byte_ranges(\n path,\n rgs,\n columns,\n fs,\n bytes_per_thread=256_000_000,\n **kwargs,\n):\n # The purpose of this utility is to return a list\n # of byte ranges (in path) that are known to contain\n # the data needed to read `columns` and `rgs`\n\n # Step 0 - Get size of file\n file_size = fs.size(path)\n\n # Return early if the file is too small to merit\n # optimized data transfer\n if file_size <= bytes_per_thread:\n return None, None, file_size\n\n # Step 1 - Get 32 KB from tail of file.\n #\n # This \"sample size\" can be tunable, but should\n # always be >= 8 bytes (so we can read the footer size)\n tail_size = 32_000\n footer_sample = fs.tail(path, tail_size)\n\n # Step 2 - Read the footer size and re-read a larger\n # tail if necessary\n footer_size = int.from_bytes(footer_sample[-8:-4], \"little\")\n if tail_size < (footer_size + 8):\n footer_sample = fs.tail(path, footer_size + 8)\n\n # Step 3 - Collect required byte ranges\n byte_ranges = []\n md = pq.ParquetFile(io.BytesIO(footer_sample)).metadata\n for r in range(md.num_row_groups):\n # Skip this row-group if we are targeting\n # specific row-groups\n if rgs is None or r in rgs:\n row_group = md.row_group(r)\n for c in range(row_group.num_columns):\n column = row_group.column(c)\n name = column.path_in_schema\n # Skip this column if we are targeting a\n # specific columns\n if columns is None or name in columns:\n file_offset0 = column.dictionary_page_offset\n if file_offset0 is None:\n file_offset0 = column.data_page_offset\n num_bytes = column.total_uncompressed_size\n byte_ranges.append((file_offset0, num_bytes))\n\n return byte_ranges, footer_sample, file_size\n\n\n#\n# General Fsspec Data-transfer Optimization Code\n#\n\n\ndef _fsspec_data_transfer(\n path_or_fob,\n fs,\n byte_ranges=None,\n footer=None,\n file_size=None,\n add_par1_magic=None,\n bytes_per_thread=256_000_000,\n max_gap=64_000,\n mode=\"rb\",\n **kwargs,\n):\n\n # Calculate total file size\n file_size = file_size or fs.size(path_or_fob)\n\n # Check if a direct read makes the most sense\n if not byte_ranges and bytes_per_thread >= file_size:\n return fs.open(path_or_fob, mode=mode, cache_type=\"none\").read()\n\n # Threaded read into \"dummy\" buffer\n buf = np.zeros(file_size, dtype=\"b\")\n if byte_ranges:\n\n # Optimize/merge the ranges\n byte_ranges = _merge_ranges(\n byte_ranges,\n max_block=bytes_per_thread,\n max_gap=max_gap,\n )\n\n # Call multi-threaded data transfer of\n # remote byte-ranges to local buffer\n _read_byte_ranges(\n path_or_fob,\n byte_ranges,\n buf,\n fs,\n **kwargs,\n )\n\n # Add Header & Footer bytes\n if footer is not None:\n footer_size = len(footer)\n buf[-footer_size:] = np.frombuffer(footer[-footer_size:], dtype=\"b\")\n\n # Add parquet magic bytes (optional)\n if add_par1_magic:\n buf[:4] = np.frombuffer(b\"PAR1\", dtype=\"b\")\n if footer is None:\n buf[-4:] = np.frombuffer(b\"PAR1\", dtype=\"b\")\n\n else:\n byte_ranges = [\n (b, min(bytes_per_thread, file_size - b)) for b in range(0, file_size, bytes_per_thread)\n ]\n _read_byte_ranges(\n path_or_fob,\n byte_ranges,\n buf,\n fs,\n **kwargs,\n )\n\n return buf.tobytes()\n\n\ndef _merge_ranges(byte_ranges, max_block=256_000_000, max_gap=64_000):\n # Simple utility to merge small/adjacent byte ranges\n new_ranges = []\n if not byte_ranges:\n # Early return\n return new_ranges\n\n offset, size = byte_ranges[0]\n for (new_offset, new_size) in byte_ranges[1:]:\n gap = new_offset - (offset + size)\n if gap > max_gap or (size + new_size + gap) > max_block:\n # Gap is too large or total read is too large\n new_ranges.append((offset, size))\n offset = new_offset\n size = new_size\n continue\n size += new_size + gap\n new_ranges.append((offset, size))\n return new_ranges\n\n\ndef _assign_block(fs, path_or_fob, local_buffer, offset, nbytes):\n with fs.open(path_or_fob, mode=\"rb\", cache_type=\"none\") as fob:\n fob.seek(offset)\n local_buffer[offset : offset + nbytes] = np.frombuffer(\n fob.read(nbytes),\n dtype=\"b\",\n )\n\n\ndef _read_byte_ranges(\n path_or_fob,\n ranges,\n local_buffer,\n fs,\n **kwargs,\n):\n\n workers = []\n for (offset, nbytes) in ranges:\n if len(ranges) > 1:\n workers.append(\n Thread(target=_assign_block, args=(fs, path_or_fob, local_buffer, offset, nbytes))\n )\n workers[-1].start()\n else:\n _assign_block(fs, path_or_fob, local_buffer, offset, nbytes)\n\n for worker in workers:\n worker.join()\n", "path": "nvtabular/io/fsspec_utils.py"}]}
| 3,824 | 306 |
gh_patches_debug_2228
|
rasdani/github-patches
|
git_diff
|
rucio__rucio-2492
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Issue in client_extract download
Motivation
----------
Modification
------------
</issue>
<code>
[start of lib/rucio/vcsversion.py]
1
2 '''
3 This file is automatically generated; Do not edit it. :)
4 '''
5 VERSION_INFO = {
6 'final': True,
7 'version': '1.19.5',
8 'branch_nick': 'patch-0-1_19_5_preparation',
9 'revision_id': '9e14d56c9d958e5348b19ddc7e5fa45d4a778807',
10 'revno': 7951
11 }
12
[end of lib/rucio/vcsversion.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lib/rucio/vcsversion.py b/lib/rucio/vcsversion.py
--- a/lib/rucio/vcsversion.py
+++ b/lib/rucio/vcsversion.py
@@ -4,8 +4,8 @@
'''
VERSION_INFO = {
'final': True,
- 'version': '1.19.5',
- 'branch_nick': 'patch-0-1_19_5_preparation',
- 'revision_id': '9e14d56c9d958e5348b19ddc7e5fa45d4a778807',
- 'revno': 7951
+ 'version': '1.19.6',
+ 'branch_nick': 'patch-0-Release__Rucio_1_19_6_preparation',
+ 'revision_id': 'a8c639a7a70a9e605ad90535d28d2eab04d89cce',
+ 'revno': 7992
}
|
{"golden_diff": "diff --git a/lib/rucio/vcsversion.py b/lib/rucio/vcsversion.py\n--- a/lib/rucio/vcsversion.py\n+++ b/lib/rucio/vcsversion.py\n@@ -4,8 +4,8 @@\n '''\n VERSION_INFO = {\n 'final': True,\n- 'version': '1.19.5',\n- 'branch_nick': 'patch-0-1_19_5_preparation',\n- 'revision_id': '9e14d56c9d958e5348b19ddc7e5fa45d4a778807',\n- 'revno': 7951\n+ 'version': '1.19.6',\n+ 'branch_nick': 'patch-0-Release__Rucio_1_19_6_preparation',\n+ 'revision_id': 'a8c639a7a70a9e605ad90535d28d2eab04d89cce',\n+ 'revno': 7992\n }\n", "issue": "Issue in client_extract download \nMotivation\r\n----------\r\n\r\n\r\n\r\nModification\r\n------------\r\n\r\n\r\n\n", "before_files": [{"content": "\n'''\nThis file is automatically generated; Do not edit it. :)\n'''\nVERSION_INFO = {\n 'final': True,\n 'version': '1.19.5',\n 'branch_nick': 'patch-0-1_19_5_preparation',\n 'revision_id': '9e14d56c9d958e5348b19ddc7e5fa45d4a778807',\n 'revno': 7951\n}\n", "path": "lib/rucio/vcsversion.py"}]}
| 686 | 252 |
gh_patches_debug_16416
|
rasdani/github-patches
|
git_diff
|
pre-commit__pre-commit-1094
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Docker language fails on Windows - os.getuid()
[`docker_cmd`](https://github.com/pre-commit/pre-commit/blob/0cf2638b3b6a2cfde89cb7013e61b2d4a3e12875/pre_commit/languages/docker.py#L80) in languages/docker.py uses `os.getuid()` and `os.getgid()` that don't exist in Python on Windows.
A hook that uses Docker on Windows fails to execute with
```
An unexpected error has occurred: AttributeError: module 'os' has no attribute 'getuid'
Traceback (most recent call last):
File "C:\Python36\lib\site-packages\pre_commit\error_handler.py", line 46, in error_handler
yield
File "C:\Python36\lib\site-packages\pre_commit\main.py", line 294, in main
return run(args.config, store, args)
File "C:\Python36\lib\site-packages\pre_commit\commands\run.py", line 293, in run
return _run_hooks(config, hooks, args, environ)
File "C:\Python36\lib\site-packages\pre_commit\commands\run.py", line 214, in _run_hooks
retval |= _run_single_hook(classifier, hook, args, skips, cols)
File "C:\Python36\lib\site-packages\pre_commit\commands\run.py", line 124, in _run_single_hook
tuple(filenames) if hook.pass_filenames else (),
File "C:\Python36\lib\site-packages\pre_commit\repository.py", line 100, in run
return lang.run_hook(self, file_args)
File "C:\Python36\lib\site-packages\pre_commit\languages\docker.py", line 99, in run_hook
cmd = docker_cmd() + entry_tag + cmd_rest
File "C:\Python36\lib\site-packages\pre_commit\languages\docker.py", line 80, in docker_cmd
'-u', '{}:{}'.format(os.getuid(), os.getgid()),
AttributeError: module 'os' has no attribute 'getuid'
```
The same hook works fine in Windows Subsystem for Linux.
</issue>
<code>
[start of pre_commit/languages/docker.py]
1 from __future__ import absolute_import
2 from __future__ import unicode_literals
3
4 import hashlib
5 import os
6
7 import pre_commit.constants as C
8 from pre_commit import five
9 from pre_commit.languages import helpers
10 from pre_commit.util import CalledProcessError
11 from pre_commit.util import clean_path_on_failure
12 from pre_commit.util import cmd_output
13
14
15 ENVIRONMENT_DIR = 'docker'
16 PRE_COMMIT_LABEL = 'PRE_COMMIT'
17 get_default_version = helpers.basic_get_default_version
18 healthy = helpers.basic_healthy
19
20
21 def md5(s): # pragma: windows no cover
22 return hashlib.md5(five.to_bytes(s)).hexdigest()
23
24
25 def docker_tag(prefix): # pragma: windows no cover
26 md5sum = md5(os.path.basename(prefix.prefix_dir)).lower()
27 return 'pre-commit-{}'.format(md5sum)
28
29
30 def docker_is_running(): # pragma: windows no cover
31 try:
32 return cmd_output('docker', 'ps')[0] == 0
33 except CalledProcessError:
34 return False
35
36
37 def assert_docker_available(): # pragma: windows no cover
38 assert docker_is_running(), (
39 'Docker is either not running or not configured in this environment'
40 )
41
42
43 def build_docker_image(prefix, **kwargs): # pragma: windows no cover
44 pull = kwargs.pop('pull')
45 assert not kwargs, kwargs
46 cmd = (
47 'docker', 'build',
48 '--tag', docker_tag(prefix),
49 '--label', PRE_COMMIT_LABEL,
50 )
51 if pull:
52 cmd += ('--pull',)
53 # This must come last for old versions of docker. See #477
54 cmd += ('.',)
55 helpers.run_setup_cmd(prefix, cmd)
56
57
58 def install_environment(
59 prefix, version, additional_dependencies,
60 ): # pragma: windows no cover
61 helpers.assert_version_default('docker', version)
62 helpers.assert_no_additional_deps('docker', additional_dependencies)
63 assert_docker_available()
64
65 directory = prefix.path(
66 helpers.environment_dir(ENVIRONMENT_DIR, C.DEFAULT),
67 )
68
69 # Docker doesn't really have relevant disk environment, but pre-commit
70 # still needs to cleanup it's state files on failure
71 with clean_path_on_failure(directory):
72 build_docker_image(prefix, pull=True)
73 os.mkdir(directory)
74
75
76 def docker_cmd(): # pragma: windows no cover
77 return (
78 'docker', 'run',
79 '--rm',
80 '-u', '{}:{}'.format(os.getuid(), os.getgid()),
81 # https://docs.docker.com/engine/reference/commandline/run/#mount-volumes-from-container-volumes-from
82 # The `Z` option tells Docker to label the content with a private
83 # unshared label. Only the current container can use a private volume.
84 '-v', '{}:/src:rw,Z'.format(os.getcwd()),
85 '--workdir', '/src',
86 )
87
88
89 def run_hook(hook, file_args): # pragma: windows no cover
90 assert_docker_available()
91 # Rebuild the docker image in case it has gone missing, as many people do
92 # automated cleanup of docker images.
93 build_docker_image(hook.prefix, pull=False)
94
95 hook_cmd = helpers.to_cmd(hook)
96 entry_exe, cmd_rest = hook_cmd[0], hook_cmd[1:]
97
98 entry_tag = ('--entrypoint', entry_exe, docker_tag(hook.prefix))
99 cmd = docker_cmd() + entry_tag + cmd_rest
100 return helpers.run_xargs(hook, cmd, file_args)
101
[end of pre_commit/languages/docker.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pre_commit/languages/docker.py b/pre_commit/languages/docker.py
--- a/pre_commit/languages/docker.py
+++ b/pre_commit/languages/docker.py
@@ -73,11 +73,18 @@
os.mkdir(directory)
+def get_docker_user(): # pragma: windows no cover
+ try:
+ return '{}:{}'.format(os.getuid(), os.getgid())
+ except AttributeError:
+ return '1000:1000'
+
+
def docker_cmd(): # pragma: windows no cover
return (
'docker', 'run',
'--rm',
- '-u', '{}:{}'.format(os.getuid(), os.getgid()),
+ '-u', get_docker_user(),
# https://docs.docker.com/engine/reference/commandline/run/#mount-volumes-from-container-volumes-from
# The `Z` option tells Docker to label the content with a private
# unshared label. Only the current container can use a private volume.
|
{"golden_diff": "diff --git a/pre_commit/languages/docker.py b/pre_commit/languages/docker.py\n--- a/pre_commit/languages/docker.py\n+++ b/pre_commit/languages/docker.py\n@@ -73,11 +73,18 @@\n os.mkdir(directory)\n \n \n+def get_docker_user(): # pragma: windows no cover\n+ try:\n+ return '{}:{}'.format(os.getuid(), os.getgid())\n+ except AttributeError:\n+ return '1000:1000'\n+\n+\n def docker_cmd(): # pragma: windows no cover\n return (\n 'docker', 'run',\n '--rm',\n- '-u', '{}:{}'.format(os.getuid(), os.getgid()),\n+ '-u', get_docker_user(),\n # https://docs.docker.com/engine/reference/commandline/run/#mount-volumes-from-container-volumes-from\n # The `Z` option tells Docker to label the content with a private\n # unshared label. Only the current container can use a private volume.\n", "issue": "Docker language fails on Windows - os.getuid()\n[`docker_cmd`](https://github.com/pre-commit/pre-commit/blob/0cf2638b3b6a2cfde89cb7013e61b2d4a3e12875/pre_commit/languages/docker.py#L80) in languages/docker.py uses `os.getuid()` and `os.getgid()` that don't exist in Python on Windows.\r\n\r\nA hook that uses Docker on Windows fails to execute with\r\n\r\n```\r\nAn unexpected error has occurred: AttributeError: module 'os' has no attribute 'getuid'\r\nTraceback (most recent call last):\r\n File \"C:\\Python36\\lib\\site-packages\\pre_commit\\error_handler.py\", line 46, in error_handler\r\n yield\r\n File \"C:\\Python36\\lib\\site-packages\\pre_commit\\main.py\", line 294, in main\r\n return run(args.config, store, args)\r\n File \"C:\\Python36\\lib\\site-packages\\pre_commit\\commands\\run.py\", line 293, in run\r\n return _run_hooks(config, hooks, args, environ)\r\n File \"C:\\Python36\\lib\\site-packages\\pre_commit\\commands\\run.py\", line 214, in _run_hooks\r\n retval |= _run_single_hook(classifier, hook, args, skips, cols)\r\n File \"C:\\Python36\\lib\\site-packages\\pre_commit\\commands\\run.py\", line 124, in _run_single_hook\r\n tuple(filenames) if hook.pass_filenames else (),\r\n File \"C:\\Python36\\lib\\site-packages\\pre_commit\\repository.py\", line 100, in run\r\n return lang.run_hook(self, file_args)\r\n File \"C:\\Python36\\lib\\site-packages\\pre_commit\\languages\\docker.py\", line 99, in run_hook\r\n cmd = docker_cmd() + entry_tag + cmd_rest\r\n File \"C:\\Python36\\lib\\site-packages\\pre_commit\\languages\\docker.py\", line 80, in docker_cmd\r\n '-u', '{}:{}'.format(os.getuid(), os.getgid()),\r\nAttributeError: module 'os' has no attribute 'getuid'\r\n```\r\n\r\nThe same hook works fine in Windows Subsystem for Linux.\n", "before_files": [{"content": "from __future__ import absolute_import\nfrom __future__ import unicode_literals\n\nimport hashlib\nimport os\n\nimport pre_commit.constants as C\nfrom pre_commit import five\nfrom pre_commit.languages import helpers\nfrom pre_commit.util import CalledProcessError\nfrom pre_commit.util import clean_path_on_failure\nfrom pre_commit.util import cmd_output\n\n\nENVIRONMENT_DIR = 'docker'\nPRE_COMMIT_LABEL = 'PRE_COMMIT'\nget_default_version = helpers.basic_get_default_version\nhealthy = helpers.basic_healthy\n\n\ndef md5(s): # pragma: windows no cover\n return hashlib.md5(five.to_bytes(s)).hexdigest()\n\n\ndef docker_tag(prefix): # pragma: windows no cover\n md5sum = md5(os.path.basename(prefix.prefix_dir)).lower()\n return 'pre-commit-{}'.format(md5sum)\n\n\ndef docker_is_running(): # pragma: windows no cover\n try:\n return cmd_output('docker', 'ps')[0] == 0\n except CalledProcessError:\n return False\n\n\ndef assert_docker_available(): # pragma: windows no cover\n assert docker_is_running(), (\n 'Docker is either not running or not configured in this environment'\n )\n\n\ndef build_docker_image(prefix, **kwargs): # pragma: windows no cover\n pull = kwargs.pop('pull')\n assert not kwargs, kwargs\n cmd = (\n 'docker', 'build',\n '--tag', docker_tag(prefix),\n '--label', PRE_COMMIT_LABEL,\n )\n if pull:\n cmd += ('--pull',)\n # This must come last for old versions of docker. See #477\n cmd += ('.',)\n helpers.run_setup_cmd(prefix, cmd)\n\n\ndef install_environment(\n prefix, version, additional_dependencies,\n): # pragma: windows no cover\n helpers.assert_version_default('docker', version)\n helpers.assert_no_additional_deps('docker', additional_dependencies)\n assert_docker_available()\n\n directory = prefix.path(\n helpers.environment_dir(ENVIRONMENT_DIR, C.DEFAULT),\n )\n\n # Docker doesn't really have relevant disk environment, but pre-commit\n # still needs to cleanup it's state files on failure\n with clean_path_on_failure(directory):\n build_docker_image(prefix, pull=True)\n os.mkdir(directory)\n\n\ndef docker_cmd(): # pragma: windows no cover\n return (\n 'docker', 'run',\n '--rm',\n '-u', '{}:{}'.format(os.getuid(), os.getgid()),\n # https://docs.docker.com/engine/reference/commandline/run/#mount-volumes-from-container-volumes-from\n # The `Z` option tells Docker to label the content with a private\n # unshared label. Only the current container can use a private volume.\n '-v', '{}:/src:rw,Z'.format(os.getcwd()),\n '--workdir', '/src',\n )\n\n\ndef run_hook(hook, file_args): # pragma: windows no cover\n assert_docker_available()\n # Rebuild the docker image in case it has gone missing, as many people do\n # automated cleanup of docker images.\n build_docker_image(hook.prefix, pull=False)\n\n hook_cmd = helpers.to_cmd(hook)\n entry_exe, cmd_rest = hook_cmd[0], hook_cmd[1:]\n\n entry_tag = ('--entrypoint', entry_exe, docker_tag(hook.prefix))\n cmd = docker_cmd() + entry_tag + cmd_rest\n return helpers.run_xargs(hook, cmd, file_args)\n", "path": "pre_commit/languages/docker.py"}]}
| 1,997 | 219 |
gh_patches_debug_24309
|
rasdani/github-patches
|
git_diff
|
openstates__openstates-scrapers-1356
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
WV: subcommittees treated as full committees
Hello,
So, with WV, the subcommittees (e.g., Finance subcommittees A, B, C) are not identified as a subcommittee.
I know WV is a [round C state](https://github.com/openstates/planning/issues/11), but I thought it was worth mentioning...if only for a "TODO later" note.
Best,
Alex
</issue>
<code>
[start of openstates/wv/committees.py]
1 import re
2
3 from billy.scrape.committees import CommitteeScraper, Committee
4
5 import lxml.html
6
7
8 class WVCommitteeScraper(CommitteeScraper):
9 jurisdiction = "wv"
10
11 def scrape(self, chamber, term):
12 getattr(self, 'scrape_' + chamber)()
13
14 def scrape_lower(self):
15 url = 'http://www.legis.state.wv.us/committees/house/main.cfm'
16 html = self.get(url).text
17 doc = lxml.html.fromstring(html)
18 doc.make_links_absolute(url)
19
20 xpath = '//a[contains(@href, "HouseCommittee")]'
21 for link in doc.xpath(xpath):
22 text = link.text_content().strip()
23 if text == '-':
24 continue
25 committee = self.scrape_lower_committee(link=link, name=text)
26 committee.add_source(url)
27 self.save_committee(committee)
28
29 url = 'http://www.legis.state.wv.us/committees/interims/interims.cfm'
30 html = self.get(url).text
31 doc = lxml.html.fromstring(html)
32 doc.make_links_absolute(url)
33 xpath = '//a[contains(@href, "committee.cfm")]'
34 for link in doc.xpath(xpath):
35 text = link.text_content().strip()
36 if text == '-':
37 continue
38 committee = self.scrape_interim_committee(link=link, name=text)
39 committee.add_source(url)
40 self.save_committee(committee)
41
42 def scrape_lower_committee(self, link, name):
43 url = re.sub(r'\s+', '', link.attrib['href'])
44 html = self.get(url).text
45 doc = lxml.html.fromstring(html)
46 doc.make_links_absolute(url)
47
48 comm = Committee('lower', name)
49 comm.add_source(url)
50
51 xpath = '//a[contains(@href, "?member=")]'
52 for link in doc.xpath(xpath):
53 name = link.text_content().strip()
54 name = re.sub(r'^Delegate\s+', '', name)
55 role = link.getnext().text or 'member'
56 comm.add_member(name, role.strip())
57
58 return comm
59
60 def scrape_interim_committee(self, link, name):
61 url = re.sub(r'\s+', '', link.attrib['href'])
62 html = self.get(url).text
63 doc = lxml.html.fromstring(html)
64 doc.make_links_absolute(url)
65
66 comm = Committee('joint', name)
67 comm.add_source(url)
68
69 xpath = '//a[contains(@href, "?member=")]'
70 for link in doc.xpath(xpath):
71 name = link.text_content().strip()
72 name = re.sub(r'^Delegate\s+', '', name)
73 name = re.sub(r'^Senator\s+', '', name)
74 role = link.getnext().text or 'member'
75 comm.add_member(name, role.strip())
76
77 return comm
78
79 def scrape_upper(self):
80 url = 'http://www.legis.state.wv.us/committees/senate/main.cfm'
81 html = self.get(url).text
82 doc = lxml.html.fromstring(html)
83 doc.make_links_absolute(url)
84
85 xpath = '//a[contains(@href, "SenateCommittee")]'
86 for link in doc.xpath(xpath):
87 text = link.text_content().strip()
88 if text == '-':
89 continue
90 committee = self.scrape_upper_committee(link=link, name=text)
91 committee.add_source(url)
92 self.save_committee(committee)
93
94 def scrape_upper_committee(self, link, name):
95 url = re.sub(r'\s+', '', link.attrib['href'])
96 html = self.get(url).text
97 doc = lxml.html.fromstring(html)
98 doc.make_links_absolute(url)
99
100 comm = Committee('upper', name)
101 comm.add_source(url)
102
103 xpath = '//a[contains(@href, "?member=")]'
104 for link in doc.xpath(xpath):
105 name = link.text_content().strip()
106 name = re.sub(r'^Delegate\s+', '', name)
107 role = link.getnext().text or 'member'
108 comm.add_member(name, role.strip())
109
110 return comm
111
[end of openstates/wv/committees.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/openstates/wv/committees.py b/openstates/wv/committees.py
--- a/openstates/wv/committees.py
+++ b/openstates/wv/committees.py
@@ -8,6 +8,14 @@
class WVCommitteeScraper(CommitteeScraper):
jurisdiction = "wv"
+ # Manually resolved links between subcommittees and parent committees.
+ subcommittee_parent_map = {
+ 'Post Audits Subcommittee': 'Government and Finance',
+ 'Parks, Recreation and Natural Resources Subcommittee': \
+ 'Government and Finance',
+ 'Tax Reform Subcommittee A': 'Joint Tax Reform',
+ }
+
def scrape(self, chamber, term):
getattr(self, 'scrape_' + chamber)()
@@ -63,7 +71,16 @@
doc = lxml.html.fromstring(html)
doc.make_links_absolute(url)
- comm = Committee('joint', name)
+ if 'Subcommittee' in name:
+ # Check whether the parent committee is manually defined first
+ # before attempting to automatically resolve it.
+ parent = WVCommitteeScraper.subcommittee_parent_map.get(name, None)
+ if parent is None:
+ parent = name.partition('Subcommittee')[0].strip()
+
+ comm = Committee('joint', parent, subcommittee=name)
+ else:
+ comm = Committee('joint', name)
comm.add_source(url)
xpath = '//a[contains(@href, "?member=")]'
|
{"golden_diff": "diff --git a/openstates/wv/committees.py b/openstates/wv/committees.py\n--- a/openstates/wv/committees.py\n+++ b/openstates/wv/committees.py\n@@ -8,6 +8,14 @@\n class WVCommitteeScraper(CommitteeScraper):\n jurisdiction = \"wv\"\n \n+ # Manually resolved links between subcommittees and parent committees.\n+ subcommittee_parent_map = {\n+ 'Post Audits Subcommittee': 'Government and Finance',\n+ 'Parks, Recreation and Natural Resources Subcommittee': \\\n+ 'Government and Finance',\n+ 'Tax Reform Subcommittee A': 'Joint Tax Reform',\n+ }\n+\n def scrape(self, chamber, term):\n getattr(self, 'scrape_' + chamber)()\n \n@@ -63,7 +71,16 @@\n doc = lxml.html.fromstring(html)\n doc.make_links_absolute(url)\n \n- comm = Committee('joint', name)\n+ if 'Subcommittee' in name:\n+ # Check whether the parent committee is manually defined first\n+ # before attempting to automatically resolve it.\n+ parent = WVCommitteeScraper.subcommittee_parent_map.get(name, None)\n+ if parent is None:\n+ parent = name.partition('Subcommittee')[0].strip()\n+\n+ comm = Committee('joint', parent, subcommittee=name)\n+ else:\n+ comm = Committee('joint', name)\n comm.add_source(url)\n \n xpath = '//a[contains(@href, \"?member=\")]'\n", "issue": "WV: subcommittees treated as full committees\nHello,\r\n\r\nSo, with WV, the subcommittees (e.g., Finance subcommittees A, B, C) are not identified as a subcommittee.\r\n\r\nI know WV is a [round C state](https://github.com/openstates/planning/issues/11), but I thought it was worth mentioning...if only for a \"TODO later\" note.\r\n\r\nBest,\r\nAlex\n", "before_files": [{"content": "import re\n\nfrom billy.scrape.committees import CommitteeScraper, Committee\n\nimport lxml.html\n\n\nclass WVCommitteeScraper(CommitteeScraper):\n jurisdiction = \"wv\"\n\n def scrape(self, chamber, term):\n getattr(self, 'scrape_' + chamber)()\n\n def scrape_lower(self):\n url = 'http://www.legis.state.wv.us/committees/house/main.cfm'\n html = self.get(url).text\n doc = lxml.html.fromstring(html)\n doc.make_links_absolute(url)\n\n xpath = '//a[contains(@href, \"HouseCommittee\")]'\n for link in doc.xpath(xpath):\n text = link.text_content().strip()\n if text == '-':\n continue\n committee = self.scrape_lower_committee(link=link, name=text)\n committee.add_source(url)\n self.save_committee(committee)\n\n url = 'http://www.legis.state.wv.us/committees/interims/interims.cfm'\n html = self.get(url).text\n doc = lxml.html.fromstring(html)\n doc.make_links_absolute(url)\n xpath = '//a[contains(@href, \"committee.cfm\")]'\n for link in doc.xpath(xpath):\n text = link.text_content().strip()\n if text == '-':\n continue\n committee = self.scrape_interim_committee(link=link, name=text)\n committee.add_source(url)\n self.save_committee(committee)\n\n def scrape_lower_committee(self, link, name):\n url = re.sub(r'\\s+', '', link.attrib['href'])\n html = self.get(url).text\n doc = lxml.html.fromstring(html)\n doc.make_links_absolute(url)\n\n comm = Committee('lower', name)\n comm.add_source(url)\n\n xpath = '//a[contains(@href, \"?member=\")]'\n for link in doc.xpath(xpath):\n name = link.text_content().strip()\n name = re.sub(r'^Delegate\\s+', '', name)\n role = link.getnext().text or 'member'\n comm.add_member(name, role.strip())\n\n return comm\n\n def scrape_interim_committee(self, link, name):\n url = re.sub(r'\\s+', '', link.attrib['href'])\n html = self.get(url).text\n doc = lxml.html.fromstring(html)\n doc.make_links_absolute(url)\n\n comm = Committee('joint', name)\n comm.add_source(url)\n\n xpath = '//a[contains(@href, \"?member=\")]'\n for link in doc.xpath(xpath):\n name = link.text_content().strip()\n name = re.sub(r'^Delegate\\s+', '', name)\n name = re.sub(r'^Senator\\s+', '', name)\n role = link.getnext().text or 'member'\n comm.add_member(name, role.strip())\n\n return comm\n\n def scrape_upper(self):\n url = 'http://www.legis.state.wv.us/committees/senate/main.cfm'\n html = self.get(url).text\n doc = lxml.html.fromstring(html)\n doc.make_links_absolute(url)\n\n xpath = '//a[contains(@href, \"SenateCommittee\")]'\n for link in doc.xpath(xpath):\n text = link.text_content().strip()\n if text == '-':\n continue\n committee = self.scrape_upper_committee(link=link, name=text)\n committee.add_source(url)\n self.save_committee(committee)\n\n def scrape_upper_committee(self, link, name):\n url = re.sub(r'\\s+', '', link.attrib['href'])\n html = self.get(url).text\n doc = lxml.html.fromstring(html)\n doc.make_links_absolute(url)\n\n comm = Committee('upper', name)\n comm.add_source(url)\n\n xpath = '//a[contains(@href, \"?member=\")]'\n for link in doc.xpath(xpath):\n name = link.text_content().strip()\n name = re.sub(r'^Delegate\\s+', '', name)\n role = link.getnext().text or 'member'\n comm.add_member(name, role.strip())\n\n return comm\n", "path": "openstates/wv/committees.py"}]}
| 1,733 | 332 |
gh_patches_debug_17942
|
rasdani/github-patches
|
git_diff
|
open-mmlab__mmocr-334
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
When I want to train a fcenet, I met a problem

It did run, but several epoch,there note that data not on the gpu.
how to solve it?
</issue>
<code>
[start of mmocr/models/textdet/losses/fce_loss.py]
1 import numpy as np
2 import torch
3 import torch.nn.functional as F
4 from mmdet.core import multi_apply
5 from mmdet.models.builder import LOSSES
6 from torch import nn
7
8
9 @LOSSES.register_module()
10 class FCELoss(nn.Module):
11 """The class for implementing FCENet loss
12 FCENet(CVPR2021): Fourier Contour Embedding for Arbitrary-shaped
13 Text Detection
14
15 [https://arxiv.org/abs/2104.10442]
16
17 Args:
18 fourier_degree (int) : The maximum Fourier transform degree k.
19 num_sample (int) : The sampling points number of regression
20 loss. If it is too small, fcenet tends to be overfitting.
21 ohem_ratio (float): the negative/positive ratio in OHEM.
22 """
23
24 def __init__(self, fourier_degree, num_sample, ohem_ratio=3.):
25 super().__init__()
26 self.fourier_degree = fourier_degree
27 self.num_sample = num_sample
28 self.ohem_ratio = ohem_ratio
29
30 def forward(self, preds, _, p3_maps, p4_maps, p5_maps):
31 assert isinstance(preds, list)
32 assert p3_maps[0].shape[0] == 4 * self.fourier_degree + 5,\
33 'fourier degree not equal in FCEhead and FCEtarget'
34
35 device = preds[0][0].device
36 # to tensor
37 gts = [p3_maps, p4_maps, p5_maps]
38 for idx, maps in enumerate(gts):
39 gts[idx] = torch.from_numpy(np.stack(maps)).float().to(device)
40
41 losses = multi_apply(self.forward_single, preds, gts)
42
43 loss_tr = torch.tensor(0., device=device).float()
44 loss_tcl = torch.tensor(0., device=device).float()
45 loss_reg_x = torch.tensor(0., device=device).float()
46 loss_reg_y = torch.tensor(0., device=device).float()
47
48 for idx, loss in enumerate(losses):
49 if idx == 0:
50 loss_tr += sum(loss)
51 elif idx == 1:
52 loss_tcl += sum(loss)
53 elif idx == 2:
54 loss_reg_x += sum(loss)
55 else:
56 loss_reg_y += sum(loss)
57
58 results = dict(
59 loss_text=loss_tr,
60 loss_center=loss_tcl,
61 loss_reg_x=loss_reg_x,
62 loss_reg_y=loss_reg_y,
63 )
64
65 return results
66
67 def forward_single(self, pred, gt):
68 cls_pred = pred[0].permute(0, 2, 3, 1).contiguous()
69 reg_pred = pred[1].permute(0, 2, 3, 1).contiguous()
70 gt = gt.permute(0, 2, 3, 1).contiguous()
71
72 k = 2 * self.fourier_degree + 1
73 tr_pred = cls_pred[:, :, :, :2].view(-1, 2)
74 tcl_pred = cls_pred[:, :, :, 2:].view(-1, 2)
75 x_pred = reg_pred[:, :, :, 0:k].view(-1, k)
76 y_pred = reg_pred[:, :, :, k:2 * k].view(-1, k)
77
78 tr_mask = gt[:, :, :, :1].view(-1)
79 tcl_mask = gt[:, :, :, 1:2].view(-1)
80 train_mask = gt[:, :, :, 2:3].view(-1)
81 x_map = gt[:, :, :, 3:3 + k].view(-1, k)
82 y_map = gt[:, :, :, 3 + k:].view(-1, k)
83
84 tr_train_mask = train_mask * tr_mask
85 device = x_map.device
86 # tr loss
87 loss_tr = self.ohem(tr_pred, tr_mask.long(), train_mask.long())
88
89 # tcl loss
90 loss_tcl = torch.tensor(0.).float().to(device)
91 tr_neg_mask = 1 - tr_train_mask
92 if tr_train_mask.sum().item() > 0:
93 loss_tcl_pos = F.cross_entropy(
94 tcl_pred[tr_train_mask.bool()],
95 tcl_mask[tr_train_mask.bool()].long())
96 loss_tcl_neg = F.cross_entropy(tcl_pred[tr_neg_mask.bool()],
97 tcl_mask[tr_neg_mask.bool()].long())
98 loss_tcl = loss_tcl_pos + 0.5 * loss_tcl_neg
99
100 # regression loss
101 loss_reg_x = torch.tensor(0.).float().to(device)
102 loss_reg_y = torch.tensor(0.).float().to(device)
103 if tr_train_mask.sum().item() > 0:
104 weight = (tr_mask[tr_train_mask.bool()].float() +
105 tcl_mask[tr_train_mask.bool()].float()) / 2
106 weight = weight.contiguous().view(-1, 1)
107
108 ft_x, ft_y = self.fourier2poly(x_map, y_map)
109 ft_x_pre, ft_y_pre = self.fourier2poly(x_pred, y_pred)
110
111 loss_reg_x = torch.mean(weight * F.smooth_l1_loss(
112 ft_x_pre[tr_train_mask.bool()],
113 ft_x[tr_train_mask.bool()],
114 reduction='none'))
115 loss_reg_y = torch.mean(weight * F.smooth_l1_loss(
116 ft_y_pre[tr_train_mask.bool()],
117 ft_y[tr_train_mask.bool()],
118 reduction='none'))
119
120 return loss_tr, loss_tcl, loss_reg_x, loss_reg_y
121
122 def ohem(self, predict, target, train_mask):
123 pos = (target * train_mask).bool()
124 neg = ((1 - target) * train_mask).bool()
125
126 n_pos = pos.float().sum()
127
128 if n_pos.item() > 0:
129 loss_pos = F.cross_entropy(
130 predict[pos], target[pos], reduction='sum')
131 loss_neg = F.cross_entropy(
132 predict[neg], target[neg], reduction='none')
133 n_neg = min(
134 int(neg.float().sum().item()),
135 int(self.ohem_ratio * n_pos.float()))
136 else:
137 loss_pos = torch.tensor(0.)
138 loss_neg = F.cross_entropy(
139 predict[neg], target[neg], reduction='none')
140 n_neg = 100
141 if len(loss_neg) > n_neg:
142 loss_neg, _ = torch.topk(loss_neg, n_neg)
143
144 return (loss_pos + loss_neg.sum()) / (n_pos + n_neg).float()
145
146 def fourier2poly(self, real_maps, imag_maps):
147 """Transform Fourier coefficient maps to polygon maps.
148
149 Args:
150 real_maps (tensor): A map composed of the real parts of the
151 Fourier coefficients, whose shape is (-1, 2k+1)
152 imag_maps (tensor):A map composed of the imag parts of the
153 Fourier coefficients, whose shape is (-1, 2k+1)
154
155 Returns
156 x_maps (tensor): A map composed of the x value of the polygon
157 represented by n sample points (xn, yn), whose shape is (-1, n)
158 y_maps (tensor): A map composed of the y value of the polygon
159 represented by n sample points (xn, yn), whose shape is (-1, n)
160 """
161
162 device = real_maps.device
163
164 k_vect = torch.arange(
165 -self.fourier_degree,
166 self.fourier_degree + 1,
167 dtype=torch.float,
168 device=device).view(-1, 1)
169 i_vect = torch.arange(
170 0, self.num_sample, dtype=torch.float, device=device).view(1, -1)
171
172 transform_matrix = 2 * np.pi / self.num_sample * torch.mm(
173 k_vect, i_vect)
174
175 x1 = torch.einsum('ak, kn-> an', real_maps,
176 torch.cos(transform_matrix))
177 x2 = torch.einsum('ak, kn-> an', imag_maps,
178 torch.sin(transform_matrix))
179 y1 = torch.einsum('ak, kn-> an', real_maps,
180 torch.sin(transform_matrix))
181 y2 = torch.einsum('ak, kn-> an', imag_maps,
182 torch.cos(transform_matrix))
183
184 x_maps = x1 - x2
185 y_maps = y1 + y2
186
187 return x_maps, y_maps
188
[end of mmocr/models/textdet/losses/fce_loss.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mmocr/models/textdet/losses/fce_loss.py b/mmocr/models/textdet/losses/fce_loss.py
--- a/mmocr/models/textdet/losses/fce_loss.py
+++ b/mmocr/models/textdet/losses/fce_loss.py
@@ -120,6 +120,7 @@
return loss_tr, loss_tcl, loss_reg_x, loss_reg_y
def ohem(self, predict, target, train_mask):
+ device = train_mask.device
pos = (target * train_mask).bool()
neg = ((1 - target) * train_mask).bool()
@@ -134,7 +135,7 @@
int(neg.float().sum().item()),
int(self.ohem_ratio * n_pos.float()))
else:
- loss_pos = torch.tensor(0.)
+ loss_pos = torch.tensor(0.).to(device)
loss_neg = F.cross_entropy(
predict[neg], target[neg], reduction='none')
n_neg = 100
|
{"golden_diff": "diff --git a/mmocr/models/textdet/losses/fce_loss.py b/mmocr/models/textdet/losses/fce_loss.py\n--- a/mmocr/models/textdet/losses/fce_loss.py\n+++ b/mmocr/models/textdet/losses/fce_loss.py\n@@ -120,6 +120,7 @@\n return loss_tr, loss_tcl, loss_reg_x, loss_reg_y\n \n def ohem(self, predict, target, train_mask):\n+ device = train_mask.device\n pos = (target * train_mask).bool()\n neg = ((1 - target) * train_mask).bool()\n \n@@ -134,7 +135,7 @@\n int(neg.float().sum().item()),\n int(self.ohem_ratio * n_pos.float()))\n else:\n- loss_pos = torch.tensor(0.)\n+ loss_pos = torch.tensor(0.).to(device)\n loss_neg = F.cross_entropy(\n predict[neg], target[neg], reduction='none')\n n_neg = 100\n", "issue": "When I want to train a fcenet, I met a problem\n\r\nIt did run, but several epoch,there note that data not on the gpu.\r\nhow to solve it?\n", "before_files": [{"content": "import numpy as np\nimport torch\nimport torch.nn.functional as F\nfrom mmdet.core import multi_apply\nfrom mmdet.models.builder import LOSSES\nfrom torch import nn\n\n\[email protected]_module()\nclass FCELoss(nn.Module):\n \"\"\"The class for implementing FCENet loss\n FCENet(CVPR2021): Fourier Contour Embedding for Arbitrary-shaped\n Text Detection\n\n [https://arxiv.org/abs/2104.10442]\n\n Args:\n fourier_degree (int) : The maximum Fourier transform degree k.\n num_sample (int) : The sampling points number of regression\n loss. If it is too small, fcenet tends to be overfitting.\n ohem_ratio (float): the negative/positive ratio in OHEM.\n \"\"\"\n\n def __init__(self, fourier_degree, num_sample, ohem_ratio=3.):\n super().__init__()\n self.fourier_degree = fourier_degree\n self.num_sample = num_sample\n self.ohem_ratio = ohem_ratio\n\n def forward(self, preds, _, p3_maps, p4_maps, p5_maps):\n assert isinstance(preds, list)\n assert p3_maps[0].shape[0] == 4 * self.fourier_degree + 5,\\\n 'fourier degree not equal in FCEhead and FCEtarget'\n\n device = preds[0][0].device\n # to tensor\n gts = [p3_maps, p4_maps, p5_maps]\n for idx, maps in enumerate(gts):\n gts[idx] = torch.from_numpy(np.stack(maps)).float().to(device)\n\n losses = multi_apply(self.forward_single, preds, gts)\n\n loss_tr = torch.tensor(0., device=device).float()\n loss_tcl = torch.tensor(0., device=device).float()\n loss_reg_x = torch.tensor(0., device=device).float()\n loss_reg_y = torch.tensor(0., device=device).float()\n\n for idx, loss in enumerate(losses):\n if idx == 0:\n loss_tr += sum(loss)\n elif idx == 1:\n loss_tcl += sum(loss)\n elif idx == 2:\n loss_reg_x += sum(loss)\n else:\n loss_reg_y += sum(loss)\n\n results = dict(\n loss_text=loss_tr,\n loss_center=loss_tcl,\n loss_reg_x=loss_reg_x,\n loss_reg_y=loss_reg_y,\n )\n\n return results\n\n def forward_single(self, pred, gt):\n cls_pred = pred[0].permute(0, 2, 3, 1).contiguous()\n reg_pred = pred[1].permute(0, 2, 3, 1).contiguous()\n gt = gt.permute(0, 2, 3, 1).contiguous()\n\n k = 2 * self.fourier_degree + 1\n tr_pred = cls_pred[:, :, :, :2].view(-1, 2)\n tcl_pred = cls_pred[:, :, :, 2:].view(-1, 2)\n x_pred = reg_pred[:, :, :, 0:k].view(-1, k)\n y_pred = reg_pred[:, :, :, k:2 * k].view(-1, k)\n\n tr_mask = gt[:, :, :, :1].view(-1)\n tcl_mask = gt[:, :, :, 1:2].view(-1)\n train_mask = gt[:, :, :, 2:3].view(-1)\n x_map = gt[:, :, :, 3:3 + k].view(-1, k)\n y_map = gt[:, :, :, 3 + k:].view(-1, k)\n\n tr_train_mask = train_mask * tr_mask\n device = x_map.device\n # tr loss\n loss_tr = self.ohem(tr_pred, tr_mask.long(), train_mask.long())\n\n # tcl loss\n loss_tcl = torch.tensor(0.).float().to(device)\n tr_neg_mask = 1 - tr_train_mask\n if tr_train_mask.sum().item() > 0:\n loss_tcl_pos = F.cross_entropy(\n tcl_pred[tr_train_mask.bool()],\n tcl_mask[tr_train_mask.bool()].long())\n loss_tcl_neg = F.cross_entropy(tcl_pred[tr_neg_mask.bool()],\n tcl_mask[tr_neg_mask.bool()].long())\n loss_tcl = loss_tcl_pos + 0.5 * loss_tcl_neg\n\n # regression loss\n loss_reg_x = torch.tensor(0.).float().to(device)\n loss_reg_y = torch.tensor(0.).float().to(device)\n if tr_train_mask.sum().item() > 0:\n weight = (tr_mask[tr_train_mask.bool()].float() +\n tcl_mask[tr_train_mask.bool()].float()) / 2\n weight = weight.contiguous().view(-1, 1)\n\n ft_x, ft_y = self.fourier2poly(x_map, y_map)\n ft_x_pre, ft_y_pre = self.fourier2poly(x_pred, y_pred)\n\n loss_reg_x = torch.mean(weight * F.smooth_l1_loss(\n ft_x_pre[tr_train_mask.bool()],\n ft_x[tr_train_mask.bool()],\n reduction='none'))\n loss_reg_y = torch.mean(weight * F.smooth_l1_loss(\n ft_y_pre[tr_train_mask.bool()],\n ft_y[tr_train_mask.bool()],\n reduction='none'))\n\n return loss_tr, loss_tcl, loss_reg_x, loss_reg_y\n\n def ohem(self, predict, target, train_mask):\n pos = (target * train_mask).bool()\n neg = ((1 - target) * train_mask).bool()\n\n n_pos = pos.float().sum()\n\n if n_pos.item() > 0:\n loss_pos = F.cross_entropy(\n predict[pos], target[pos], reduction='sum')\n loss_neg = F.cross_entropy(\n predict[neg], target[neg], reduction='none')\n n_neg = min(\n int(neg.float().sum().item()),\n int(self.ohem_ratio * n_pos.float()))\n else:\n loss_pos = torch.tensor(0.)\n loss_neg = F.cross_entropy(\n predict[neg], target[neg], reduction='none')\n n_neg = 100\n if len(loss_neg) > n_neg:\n loss_neg, _ = torch.topk(loss_neg, n_neg)\n\n return (loss_pos + loss_neg.sum()) / (n_pos + n_neg).float()\n\n def fourier2poly(self, real_maps, imag_maps):\n \"\"\"Transform Fourier coefficient maps to polygon maps.\n\n Args:\n real_maps (tensor): A map composed of the real parts of the\n Fourier coefficients, whose shape is (-1, 2k+1)\n imag_maps (tensor):A map composed of the imag parts of the\n Fourier coefficients, whose shape is (-1, 2k+1)\n\n Returns\n x_maps (tensor): A map composed of the x value of the polygon\n represented by n sample points (xn, yn), whose shape is (-1, n)\n y_maps (tensor): A map composed of the y value of the polygon\n represented by n sample points (xn, yn), whose shape is (-1, n)\n \"\"\"\n\n device = real_maps.device\n\n k_vect = torch.arange(\n -self.fourier_degree,\n self.fourier_degree + 1,\n dtype=torch.float,\n device=device).view(-1, 1)\n i_vect = torch.arange(\n 0, self.num_sample, dtype=torch.float, device=device).view(1, -1)\n\n transform_matrix = 2 * np.pi / self.num_sample * torch.mm(\n k_vect, i_vect)\n\n x1 = torch.einsum('ak, kn-> an', real_maps,\n torch.cos(transform_matrix))\n x2 = torch.einsum('ak, kn-> an', imag_maps,\n torch.sin(transform_matrix))\n y1 = torch.einsum('ak, kn-> an', real_maps,\n torch.sin(transform_matrix))\n y2 = torch.einsum('ak, kn-> an', imag_maps,\n torch.cos(transform_matrix))\n\n x_maps = x1 - x2\n y_maps = y1 + y2\n\n return x_maps, y_maps\n", "path": "mmocr/models/textdet/losses/fce_loss.py"}]}
| 2,969 | 230 |
gh_patches_debug_43238
|
rasdani/github-patches
|
git_diff
|
openvinotoolkit__datumaro-689
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[WIP]Fix yolo format output path
### Summary
delete 'data' folder from path because it is not generated
### Checklist
<!-- Put an 'x' in all the boxes that apply -->
- [ ] I submit my changes into the `develop` branch
- [ ] I have added description of my changes into [CHANGELOG](https://github.com/openvinotoolkit/datumaro/blob/develop/CHANGELOG.md)
- [ ] I have updated the [documentation](
https://github.com/openvinotoolkit/datumaro/tree/develop/docs) accordingly
- [ ] I have added tests to cover my changes
- [ ] I have [linked related issues](
https://help.github.com/en/github/managing-your-work-on-github/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword)
### License
- [ ] I submit _my code changes_ under the same [MIT License](
https://github.com/openvinotoolkit/datumaro/blob/develop/LICENSE) that covers the project.
Feel free to contact the maintainers if that's a concern.
- [ ] I have updated the license header for each file (see an example below)
```python
# Copyright (C) 2021 Intel Corporation
#
# SPDX-License-Identifier: MIT
```
</issue>
<code>
[start of datumaro/plugins/yolo_format/converter.py]
1 # Copyright (C) 2019-2022 Intel Corporation
2 #
3 # SPDX-License-Identifier: MIT
4
5 import logging as log
6 import os
7 import os.path as osp
8 from collections import OrderedDict
9
10 from datumaro.components.annotation import AnnotationType, Bbox
11 from datumaro.components.converter import Converter
12 from datumaro.components.dataset import ItemStatus
13 from datumaro.components.errors import MediaTypeError
14 from datumaro.components.extractor import DEFAULT_SUBSET_NAME, DatasetItem
15 from datumaro.components.media import Image
16
17 from .format import YoloPath
18
19
20 def _make_yolo_bbox(img_size, box):
21 # https://github.com/pjreddie/darknet/blob/master/scripts/voc_label.py
22 # <x> <y> <width> <height> - values relative to width and height of image
23 # <x> <y> - are center of rectangle
24 x = (box[0] + box[2]) / 2 / img_size[0]
25 y = (box[1] + box[3]) / 2 / img_size[1]
26 w = (box[2] - box[0]) / img_size[0]
27 h = (box[3] - box[1]) / img_size[1]
28 return x, y, w, h
29
30
31 class YoloConverter(Converter):
32 # https://github.com/AlexeyAB/darknet#how-to-train-to-detect-your-custom-objects
33 DEFAULT_IMAGE_EXT = ".jpg"
34
35 def apply(self):
36 extractor = self._extractor
37 save_dir = self._save_dir
38
39 if self._extractor.media_type() and not issubclass(self._extractor.media_type(), Image):
40 raise MediaTypeError("Media type is not an image")
41
42 os.makedirs(save_dir, exist_ok=True)
43
44 if self._save_dataset_meta:
45 self._save_meta_file(self._save_dir)
46
47 label_categories = extractor.categories()[AnnotationType.label]
48 label_ids = {label.name: idx for idx, label in enumerate(label_categories.items)}
49 with open(osp.join(save_dir, "obj.names"), "w", encoding="utf-8") as f:
50 f.writelines("%s\n" % l[0] for l in sorted(label_ids.items(), key=lambda x: x[1]))
51
52 subset_lists = OrderedDict()
53
54 subsets = self._extractor.subsets()
55 pbars = self._ctx.progress_reporter.split(len(subsets))
56 for (subset_name, subset), pbar in zip(subsets.items(), pbars):
57 if not subset_name or subset_name == DEFAULT_SUBSET_NAME:
58 subset_name = YoloPath.DEFAULT_SUBSET_NAME
59 elif subset_name not in YoloPath.SUBSET_NAMES:
60 log.warning(
61 "Skipping subset export '%s'. "
62 "If specified, the only valid names are %s"
63 % (subset_name, ", ".join("'%s'" % s for s in YoloPath.SUBSET_NAMES))
64 )
65 continue
66
67 subset_dir = osp.join(save_dir, "obj_%s_data" % subset_name)
68 os.makedirs(subset_dir, exist_ok=True)
69
70 image_paths = OrderedDict()
71 for item in pbar.iter(subset, desc=f"Exporting '{subset_name}'"):
72 try:
73 if not item.media or not (item.media.has_data or item.media.has_size):
74 raise Exception(
75 "Failed to export item '%s': " "item has no image info" % item.id
76 )
77
78 image_name = self._make_image_filename(item)
79 if self._save_media:
80 if item.media:
81 self._save_image(item, osp.join(subset_dir, image_name))
82 else:
83 log.warning("Item '%s' has no image" % item.id)
84 image_paths[item.id] = osp.join("data", osp.basename(subset_dir), image_name)
85
86 yolo_annotation = self._export_item_annotation(item)
87 annotation_path = osp.join(subset_dir, "%s.txt" % item.id)
88 os.makedirs(osp.dirname(annotation_path), exist_ok=True)
89 with open(annotation_path, "w", encoding="utf-8") as f:
90 f.write(yolo_annotation)
91 except Exception as e:
92 self._report_item_error(e, item_id=(item.id, item.subset))
93
94 subset_list_name = "%s.txt" % subset_name
95 subset_list_path = osp.join(save_dir, subset_list_name)
96 if self._patch and subset_name in self._patch.updated_subsets and not image_paths:
97 if osp.isfile(subset_list_path):
98 os.remove(subset_list_path)
99 continue
100
101 subset_lists[subset_name] = subset_list_name
102 with open(subset_list_path, "w", encoding="utf-8") as f:
103 f.writelines("%s\n" % s for s in image_paths.values())
104
105 with open(osp.join(save_dir, "obj.data"), "w", encoding="utf-8") as f:
106 f.write("classes = %s\n" % len(label_ids))
107
108 for subset_name, subset_list_name in subset_lists.items():
109 f.write("%s = %s\n" % (subset_name, osp.join("data", subset_list_name)))
110
111 f.write("names = %s\n" % osp.join("data", "obj.names"))
112 f.write("backup = backup/\n")
113
114 def _export_item_annotation(self, item):
115 height, width = item.media.size
116
117 yolo_annotation = ""
118
119 for bbox in item.annotations:
120 if not isinstance(bbox, Bbox) or bbox.label is None:
121 continue
122
123 yolo_bb = _make_yolo_bbox((width, height), bbox.points)
124 yolo_bb = " ".join("%.6f" % p for p in yolo_bb)
125 yolo_annotation += "%s %s\n" % (bbox.label, yolo_bb)
126
127 return yolo_annotation
128
129 @classmethod
130 def patch(cls, dataset, patch, save_dir, **kwargs):
131 conv = cls(dataset, save_dir=save_dir, **kwargs)
132 conv._patch = patch
133 conv.apply()
134
135 for (item_id, subset), status in patch.updated_items.items():
136 if status != ItemStatus.removed:
137 item = patch.data.get(item_id, subset)
138 else:
139 item = DatasetItem(item_id, subset=subset)
140
141 if not (status == ItemStatus.removed or not item.media):
142 continue
143
144 if subset == DEFAULT_SUBSET_NAME:
145 subset = YoloPath.DEFAULT_SUBSET_NAME
146 subset_dir = osp.join(save_dir, "obj_%s_data" % subset)
147
148 image_path = osp.join(subset_dir, conv._make_image_filename(item))
149 if osp.isfile(image_path):
150 os.remove(image_path)
151
152 ann_path = osp.join(subset_dir, "%s.txt" % item.id)
153 if osp.isfile(ann_path):
154 os.remove(ann_path)
155
[end of datumaro/plugins/yolo_format/converter.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/datumaro/plugins/yolo_format/converter.py b/datumaro/plugins/yolo_format/converter.py
--- a/datumaro/plugins/yolo_format/converter.py
+++ b/datumaro/plugins/yolo_format/converter.py
@@ -11,8 +11,9 @@
from datumaro.components.converter import Converter
from datumaro.components.dataset import ItemStatus
from datumaro.components.errors import MediaTypeError
-from datumaro.components.extractor import DEFAULT_SUBSET_NAME, DatasetItem
+from datumaro.components.extractor import DEFAULT_SUBSET_NAME, DatasetItem, IExtractor
from datumaro.components.media import Image
+from datumaro.util import str_to_bool
from .format import YoloPath
@@ -32,6 +33,24 @@
# https://github.com/AlexeyAB/darknet#how-to-train-to-detect-your-custom-objects
DEFAULT_IMAGE_EXT = ".jpg"
+ @classmethod
+ def build_cmdline_parser(cls, **kwargs):
+ parser = super().build_cmdline_parser(**kwargs)
+ parser.add_argument(
+ "--add-path-prefix",
+ default=True,
+ type=str_to_bool,
+ help="Add the 'data/' prefix for paths in the dataset info (default: %(default)s)",
+ )
+ return parser
+
+ def __init__(
+ self, extractor: IExtractor, save_dir: str, *, add_path_prefix: bool = True, **kwargs
+ ) -> None:
+ super().__init__(extractor, save_dir, **kwargs)
+
+ self._prefix = "data" if add_path_prefix else ""
+
def apply(self):
extractor = self._extractor
save_dir = self._save_dir
@@ -81,7 +100,9 @@
self._save_image(item, osp.join(subset_dir, image_name))
else:
log.warning("Item '%s' has no image" % item.id)
- image_paths[item.id] = osp.join("data", osp.basename(subset_dir), image_name)
+ image_paths[item.id] = osp.join(
+ self._prefix, osp.basename(subset_dir), image_name
+ )
yolo_annotation = self._export_item_annotation(item)
annotation_path = osp.join(subset_dir, "%s.txt" % item.id)
@@ -91,7 +112,7 @@
except Exception as e:
self._report_item_error(e, item_id=(item.id, item.subset))
- subset_list_name = "%s.txt" % subset_name
+ subset_list_name = f"{subset_name}.txt"
subset_list_path = osp.join(save_dir, subset_list_name)
if self._patch and subset_name in self._patch.updated_subsets and not image_paths:
if osp.isfile(subset_list_path):
@@ -100,15 +121,18 @@
subset_lists[subset_name] = subset_list_name
with open(subset_list_path, "w", encoding="utf-8") as f:
- f.writelines("%s\n" % s for s in image_paths.values())
+ f.writelines("%s\n" % s.replace("\\", "/") for s in image_paths.values())
with open(osp.join(save_dir, "obj.data"), "w", encoding="utf-8") as f:
- f.write("classes = %s\n" % len(label_ids))
+ f.write(f"classes = {len(label_ids)}\n")
for subset_name, subset_list_name in subset_lists.items():
- f.write("%s = %s\n" % (subset_name, osp.join("data", subset_list_name)))
+ f.write(
+ "%s = %s\n"
+ % (subset_name, osp.join(self._prefix, subset_list_name).replace("\\", "/"))
+ )
- f.write("names = %s\n" % osp.join("data", "obj.names"))
+ f.write("names = %s\n" % osp.join(self._prefix, "obj.names"))
f.write("backup = backup/\n")
def _export_item_annotation(self, item):
|
{"golden_diff": "diff --git a/datumaro/plugins/yolo_format/converter.py b/datumaro/plugins/yolo_format/converter.py\n--- a/datumaro/plugins/yolo_format/converter.py\n+++ b/datumaro/plugins/yolo_format/converter.py\n@@ -11,8 +11,9 @@\n from datumaro.components.converter import Converter\n from datumaro.components.dataset import ItemStatus\n from datumaro.components.errors import MediaTypeError\n-from datumaro.components.extractor import DEFAULT_SUBSET_NAME, DatasetItem\n+from datumaro.components.extractor import DEFAULT_SUBSET_NAME, DatasetItem, IExtractor\n from datumaro.components.media import Image\n+from datumaro.util import str_to_bool\n \n from .format import YoloPath\n \n@@ -32,6 +33,24 @@\n # https://github.com/AlexeyAB/darknet#how-to-train-to-detect-your-custom-objects\n DEFAULT_IMAGE_EXT = \".jpg\"\n \n+ @classmethod\n+ def build_cmdline_parser(cls, **kwargs):\n+ parser = super().build_cmdline_parser(**kwargs)\n+ parser.add_argument(\n+ \"--add-path-prefix\",\n+ default=True,\n+ type=str_to_bool,\n+ help=\"Add the 'data/' prefix for paths in the dataset info (default: %(default)s)\",\n+ )\n+ return parser\n+\n+ def __init__(\n+ self, extractor: IExtractor, save_dir: str, *, add_path_prefix: bool = True, **kwargs\n+ ) -> None:\n+ super().__init__(extractor, save_dir, **kwargs)\n+\n+ self._prefix = \"data\" if add_path_prefix else \"\"\n+\n def apply(self):\n extractor = self._extractor\n save_dir = self._save_dir\n@@ -81,7 +100,9 @@\n self._save_image(item, osp.join(subset_dir, image_name))\n else:\n log.warning(\"Item '%s' has no image\" % item.id)\n- image_paths[item.id] = osp.join(\"data\", osp.basename(subset_dir), image_name)\n+ image_paths[item.id] = osp.join(\n+ self._prefix, osp.basename(subset_dir), image_name\n+ )\n \n yolo_annotation = self._export_item_annotation(item)\n annotation_path = osp.join(subset_dir, \"%s.txt\" % item.id)\n@@ -91,7 +112,7 @@\n except Exception as e:\n self._report_item_error(e, item_id=(item.id, item.subset))\n \n- subset_list_name = \"%s.txt\" % subset_name\n+ subset_list_name = f\"{subset_name}.txt\"\n subset_list_path = osp.join(save_dir, subset_list_name)\n if self._patch and subset_name in self._patch.updated_subsets and not image_paths:\n if osp.isfile(subset_list_path):\n@@ -100,15 +121,18 @@\n \n subset_lists[subset_name] = subset_list_name\n with open(subset_list_path, \"w\", encoding=\"utf-8\") as f:\n- f.writelines(\"%s\\n\" % s for s in image_paths.values())\n+ f.writelines(\"%s\\n\" % s.replace(\"\\\\\", \"/\") for s in image_paths.values())\n \n with open(osp.join(save_dir, \"obj.data\"), \"w\", encoding=\"utf-8\") as f:\n- f.write(\"classes = %s\\n\" % len(label_ids))\n+ f.write(f\"classes = {len(label_ids)}\\n\")\n \n for subset_name, subset_list_name in subset_lists.items():\n- f.write(\"%s = %s\\n\" % (subset_name, osp.join(\"data\", subset_list_name)))\n+ f.write(\n+ \"%s = %s\\n\"\n+ % (subset_name, osp.join(self._prefix, subset_list_name).replace(\"\\\\\", \"/\"))\n+ )\n \n- f.write(\"names = %s\\n\" % osp.join(\"data\", \"obj.names\"))\n+ f.write(\"names = %s\\n\" % osp.join(self._prefix, \"obj.names\"))\n f.write(\"backup = backup/\\n\")\n \n def _export_item_annotation(self, item):\n", "issue": "[WIP]Fix yolo format output path\n\r\n\r\n### Summary\r\ndelete 'data' folder from path because it is not generated\r\n\r\n\r\n\r\n### Checklist\r\n<!-- Put an 'x' in all the boxes that apply -->\r\n- [ ] I submit my changes into the `develop` branch\r\n- [ ] I have added description of my changes into [CHANGELOG](https://github.com/openvinotoolkit/datumaro/blob/develop/CHANGELOG.md)\r\n- [ ] I have updated the [documentation](\r\n https://github.com/openvinotoolkit/datumaro/tree/develop/docs) accordingly\r\n- [ ] I have added tests to cover my changes\r\n- [ ] I have [linked related issues](\r\n https://help.github.com/en/github/managing-your-work-on-github/linking-a-pull-request-to-an-issue#linking-a-pull-request-to-an-issue-using-a-keyword)\r\n\r\n### License\r\n\r\n- [ ] I submit _my code changes_ under the same [MIT License](\r\n https://github.com/openvinotoolkit/datumaro/blob/develop/LICENSE) that covers the project.\r\n Feel free to contact the maintainers if that's a concern.\r\n- [ ] I have updated the license header for each file (see an example below)\r\n\r\n```python\r\n# Copyright (C) 2021 Intel Corporation\r\n#\r\n# SPDX-License-Identifier: MIT\r\n```\r\n\n", "before_files": [{"content": "# Copyright (C) 2019-2022 Intel Corporation\n#\n# SPDX-License-Identifier: MIT\n\nimport logging as log\nimport os\nimport os.path as osp\nfrom collections import OrderedDict\n\nfrom datumaro.components.annotation import AnnotationType, Bbox\nfrom datumaro.components.converter import Converter\nfrom datumaro.components.dataset import ItemStatus\nfrom datumaro.components.errors import MediaTypeError\nfrom datumaro.components.extractor import DEFAULT_SUBSET_NAME, DatasetItem\nfrom datumaro.components.media import Image\n\nfrom .format import YoloPath\n\n\ndef _make_yolo_bbox(img_size, box):\n # https://github.com/pjreddie/darknet/blob/master/scripts/voc_label.py\n # <x> <y> <width> <height> - values relative to width and height of image\n # <x> <y> - are center of rectangle\n x = (box[0] + box[2]) / 2 / img_size[0]\n y = (box[1] + box[3]) / 2 / img_size[1]\n w = (box[2] - box[0]) / img_size[0]\n h = (box[3] - box[1]) / img_size[1]\n return x, y, w, h\n\n\nclass YoloConverter(Converter):\n # https://github.com/AlexeyAB/darknet#how-to-train-to-detect-your-custom-objects\n DEFAULT_IMAGE_EXT = \".jpg\"\n\n def apply(self):\n extractor = self._extractor\n save_dir = self._save_dir\n\n if self._extractor.media_type() and not issubclass(self._extractor.media_type(), Image):\n raise MediaTypeError(\"Media type is not an image\")\n\n os.makedirs(save_dir, exist_ok=True)\n\n if self._save_dataset_meta:\n self._save_meta_file(self._save_dir)\n\n label_categories = extractor.categories()[AnnotationType.label]\n label_ids = {label.name: idx for idx, label in enumerate(label_categories.items)}\n with open(osp.join(save_dir, \"obj.names\"), \"w\", encoding=\"utf-8\") as f:\n f.writelines(\"%s\\n\" % l[0] for l in sorted(label_ids.items(), key=lambda x: x[1]))\n\n subset_lists = OrderedDict()\n\n subsets = self._extractor.subsets()\n pbars = self._ctx.progress_reporter.split(len(subsets))\n for (subset_name, subset), pbar in zip(subsets.items(), pbars):\n if not subset_name or subset_name == DEFAULT_SUBSET_NAME:\n subset_name = YoloPath.DEFAULT_SUBSET_NAME\n elif subset_name not in YoloPath.SUBSET_NAMES:\n log.warning(\n \"Skipping subset export '%s'. \"\n \"If specified, the only valid names are %s\"\n % (subset_name, \", \".join(\"'%s'\" % s for s in YoloPath.SUBSET_NAMES))\n )\n continue\n\n subset_dir = osp.join(save_dir, \"obj_%s_data\" % subset_name)\n os.makedirs(subset_dir, exist_ok=True)\n\n image_paths = OrderedDict()\n for item in pbar.iter(subset, desc=f\"Exporting '{subset_name}'\"):\n try:\n if not item.media or not (item.media.has_data or item.media.has_size):\n raise Exception(\n \"Failed to export item '%s': \" \"item has no image info\" % item.id\n )\n\n image_name = self._make_image_filename(item)\n if self._save_media:\n if item.media:\n self._save_image(item, osp.join(subset_dir, image_name))\n else:\n log.warning(\"Item '%s' has no image\" % item.id)\n image_paths[item.id] = osp.join(\"data\", osp.basename(subset_dir), image_name)\n\n yolo_annotation = self._export_item_annotation(item)\n annotation_path = osp.join(subset_dir, \"%s.txt\" % item.id)\n os.makedirs(osp.dirname(annotation_path), exist_ok=True)\n with open(annotation_path, \"w\", encoding=\"utf-8\") as f:\n f.write(yolo_annotation)\n except Exception as e:\n self._report_item_error(e, item_id=(item.id, item.subset))\n\n subset_list_name = \"%s.txt\" % subset_name\n subset_list_path = osp.join(save_dir, subset_list_name)\n if self._patch and subset_name in self._patch.updated_subsets and not image_paths:\n if osp.isfile(subset_list_path):\n os.remove(subset_list_path)\n continue\n\n subset_lists[subset_name] = subset_list_name\n with open(subset_list_path, \"w\", encoding=\"utf-8\") as f:\n f.writelines(\"%s\\n\" % s for s in image_paths.values())\n\n with open(osp.join(save_dir, \"obj.data\"), \"w\", encoding=\"utf-8\") as f:\n f.write(\"classes = %s\\n\" % len(label_ids))\n\n for subset_name, subset_list_name in subset_lists.items():\n f.write(\"%s = %s\\n\" % (subset_name, osp.join(\"data\", subset_list_name)))\n\n f.write(\"names = %s\\n\" % osp.join(\"data\", \"obj.names\"))\n f.write(\"backup = backup/\\n\")\n\n def _export_item_annotation(self, item):\n height, width = item.media.size\n\n yolo_annotation = \"\"\n\n for bbox in item.annotations:\n if not isinstance(bbox, Bbox) or bbox.label is None:\n continue\n\n yolo_bb = _make_yolo_bbox((width, height), bbox.points)\n yolo_bb = \" \".join(\"%.6f\" % p for p in yolo_bb)\n yolo_annotation += \"%s %s\\n\" % (bbox.label, yolo_bb)\n\n return yolo_annotation\n\n @classmethod\n def patch(cls, dataset, patch, save_dir, **kwargs):\n conv = cls(dataset, save_dir=save_dir, **kwargs)\n conv._patch = patch\n conv.apply()\n\n for (item_id, subset), status in patch.updated_items.items():\n if status != ItemStatus.removed:\n item = patch.data.get(item_id, subset)\n else:\n item = DatasetItem(item_id, subset=subset)\n\n if not (status == ItemStatus.removed or not item.media):\n continue\n\n if subset == DEFAULT_SUBSET_NAME:\n subset = YoloPath.DEFAULT_SUBSET_NAME\n subset_dir = osp.join(save_dir, \"obj_%s_data\" % subset)\n\n image_path = osp.join(subset_dir, conv._make_image_filename(item))\n if osp.isfile(image_path):\n os.remove(image_path)\n\n ann_path = osp.join(subset_dir, \"%s.txt\" % item.id)\n if osp.isfile(ann_path):\n os.remove(ann_path)\n", "path": "datumaro/plugins/yolo_format/converter.py"}]}
| 2,680 | 906 |
gh_patches_debug_18222
|
rasdani/github-patches
|
git_diff
|
streamlit__streamlit-1908
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
st.map() fails with zoom error for small number of points
# Summary
In this [forum post](https://discuss.streamlit.io/t/plot-map-with-address-from-user-input/2950), the user highlights that `st.map()` does not plot a single point for the map. To troubleshoot, I opened up the Chrome console, saw a "Zoom must be set error" message in regards to the map.
# Solution
Adding a non `None` zoom value in the `st.map()` call [resolves the issue](https://discuss.streamlit.io/t/plot-map-with-address-from-user-input/2950/3?u=randyzwitch). Need a heuristic for a "small" number of points where `st.map()` automatically adds an integer value for the `zoom` parameter. At larger volumes of data, `zoom =None` seems to be ok, and deck.gl infers the proper zoom level based on the bounding box of data points.
st.map() fails with zoom error for small number of points
# Summary
In this [forum post](https://discuss.streamlit.io/t/plot-map-with-address-from-user-input/2950), the user highlights that `st.map()` does not plot a single point for the map. To troubleshoot, I opened up the Chrome console, saw a "Zoom must be set error" message in regards to the map.
# Solution
Adding a non `None` zoom value in the `st.map()` call [resolves the issue](https://discuss.streamlit.io/t/plot-map-with-address-from-user-input/2950/3?u=randyzwitch). Need a heuristic for a "small" number of points where `st.map()` automatically adds an integer value for the `zoom` parameter. At larger volumes of data, `zoom =None` seems to be ok, and deck.gl infers the proper zoom level based on the bounding box of data points.
</issue>
<code>
[start of lib/streamlit/elements/map.py]
1 # Copyright 2018-2020 Streamlit Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """A wrapper for simple PyDeck scatter charts."""
16
17 import copy
18 import json
19 from typing import Any, Dict
20
21 import pandas as pd
22
23 from streamlit.proto.DeckGlJsonChart_pb2 import DeckGlJsonChart as DeckGlJsonChartProto
24 import streamlit.elements.deck_gl_json_chart as deck_gl_json_chart
25 from streamlit.errors import StreamlitAPIException
26
27
28 class MapMixin:
29 def map(dg, data=None, zoom=None, use_container_width=True):
30 """Display a map with points on it.
31
32 This is a wrapper around st.pydeck_chart to quickly create scatterplot
33 charts on top of a map, with auto-centering and auto-zoom.
34
35 When using this command, we advise all users to use a personal Mapbox
36 token. This ensures the map tiles used in this chart are more
37 robust. You can do this with the mapbox.token config option.
38
39 To get a token for yourself, create an account at
40 https://mapbox.com. It's free! (for moderate usage levels) See
41 https://docs.streamlit.io/en/latest/cli.html#view-all-config-options for more
42 info on how to set config options.
43
44 Parameters
45 ----------
46 data : pandas.DataFrame, pandas.Styler, numpy.ndarray, Iterable, dict,
47 or None
48 The data to be plotted. Must have columns called 'lat', 'lon',
49 'latitude', or 'longitude'.
50 zoom : int
51 Zoom level as specified in
52 https://wiki.openstreetmap.org/wiki/Zoom_levels
53
54 Example
55 -------
56 >>> import pandas as pd
57 >>> import numpy as np
58 >>>
59 >>> df = pd.DataFrame(
60 ... np.random.randn(1000, 2) / [50, 50] + [37.76, -122.4],
61 ... columns=['lat', 'lon'])
62 >>>
63 >>> st.map(df)
64
65 .. output::
66 https://share.streamlit.io/0.53.0-SULT/index.html?id=9gTiomqPEbvHY2huTLoQtH
67 height: 600px
68
69 """
70 map_proto = DeckGlJsonChartProto()
71 map_proto.json = to_deckgl_json(data, zoom)
72 map_proto.use_container_width = use_container_width
73 return dg._enqueue("deck_gl_json_chart", map_proto) # type: ignore
74
75
76 # Map used as the basis for st.map.
77 _DEFAULT_MAP = dict(deck_gl_json_chart.EMPTY_MAP) # type: Dict[str, Any]
78 _DEFAULT_MAP["mapStyle"] = "mapbox://styles/mapbox/light-v10"
79
80 # Other default parameters for st.map.
81 _DEFAULT_COLOR = [200, 30, 0, 160]
82 _ZOOM_LEVELS = [
83 360,
84 180,
85 90,
86 45,
87 22.5,
88 11.25,
89 5.625,
90 2.813,
91 1.406,
92 0.703,
93 0.352,
94 0.176,
95 0.088,
96 0.044,
97 0.022,
98 0.011,
99 0.005,
100 0.003,
101 0.001,
102 0.0005,
103 ]
104
105
106 def _get_zoom_level(distance):
107 """Get the zoom level for a given distance in degrees.
108
109 See https://wiki.openstreetmap.org/wiki/Zoom_levels for reference.
110
111 Parameters
112 ----------
113 distance : float
114 How many degrees of longitude should fit in the map.
115
116 Returns
117 -------
118 int
119 The zoom level, from 0 to 29.
120
121 """
122
123 for i in range(len(_ZOOM_LEVELS) - 1):
124 if _ZOOM_LEVELS[i + 1] < distance <= _ZOOM_LEVELS[i]:
125 return i
126
127
128 def to_deckgl_json(data, zoom):
129
130 if data is None or data.empty:
131 return json.dumps(_DEFAULT_MAP)
132
133 if "lat" in data:
134 lat = "lat"
135 elif "latitude" in data:
136 lat = "latitude"
137 else:
138 raise StreamlitAPIException(
139 'Map data must contain a column named "latitude" or "lat".'
140 )
141
142 if "lon" in data:
143 lon = "lon"
144 elif "longitude" in data:
145 lon = "longitude"
146 else:
147 raise StreamlitAPIException(
148 'Map data must contain a column called "longitude" or "lon".'
149 )
150
151 if data[lon].isnull().values.any() or data[lat].isnull().values.any():
152 raise StreamlitAPIException("Latitude and longitude data must be numeric.")
153
154 data = pd.DataFrame(data)
155
156 min_lat = data[lat].min()
157 max_lat = data[lat].max()
158 min_lon = data[lon].min()
159 max_lon = data[lon].max()
160 center_lat = (max_lat + min_lat) / 2.0
161 center_lon = (max_lon + min_lon) / 2.0
162 range_lon = abs(max_lon - min_lon)
163 range_lat = abs(max_lat - min_lat)
164
165 if zoom == None:
166 if range_lon > range_lat:
167 longitude_distance = range_lon
168 else:
169 longitude_distance = range_lat
170 zoom = _get_zoom_level(longitude_distance)
171
172 # "+1" because itertuples includes the row index.
173 lon_col_index = data.columns.get_loc(lon) + 1
174 lat_col_index = data.columns.get_loc(lat) + 1
175 final_data = []
176 for row in data.itertuples():
177 final_data.append(
178 {"lon": float(row[lon_col_index]), "lat": float(row[lat_col_index])}
179 )
180
181 default = copy.deepcopy(_DEFAULT_MAP)
182 default["initialViewState"]["latitude"] = center_lat
183 default["initialViewState"]["longitude"] = center_lon
184 default["initialViewState"]["zoom"] = zoom
185 default["layers"] = [
186 {
187 "@@type": "ScatterplotLayer",
188 "getPosition": "@@=[lon, lat]",
189 "getRadius": 10,
190 "radiusScale": 10,
191 "radiusMinPixels": 3,
192 "getFillColor": _DEFAULT_COLOR,
193 "data": final_data,
194 }
195 ]
196 return json.dumps(default)
197
[end of lib/streamlit/elements/map.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lib/streamlit/elements/map.py b/lib/streamlit/elements/map.py
--- a/lib/streamlit/elements/map.py
+++ b/lib/streamlit/elements/map.py
@@ -79,6 +79,7 @@
# Other default parameters for st.map.
_DEFAULT_COLOR = [200, 30, 0, 160]
+_DEFAULT_ZOOM_LEVEL = 12
_ZOOM_LEVELS = [
360,
180,
@@ -100,6 +101,7 @@
0.003,
0.001,
0.0005,
+ 0.00025,
]
@@ -116,10 +118,14 @@
Returns
-------
int
- The zoom level, from 0 to 29.
+ The zoom level, from 0 to 20.
"""
+ # For small number of points the default zoom level will be used.
+ if distance < _ZOOM_LEVELS[-1]:
+ return _DEFAULT_ZOOM_LEVEL
+
for i in range(len(_ZOOM_LEVELS) - 1):
if _ZOOM_LEVELS[i + 1] < distance <= _ZOOM_LEVELS[i]:
return i
|
{"golden_diff": "diff --git a/lib/streamlit/elements/map.py b/lib/streamlit/elements/map.py\n--- a/lib/streamlit/elements/map.py\n+++ b/lib/streamlit/elements/map.py\n@@ -79,6 +79,7 @@\n \n # Other default parameters for st.map.\n _DEFAULT_COLOR = [200, 30, 0, 160]\n+_DEFAULT_ZOOM_LEVEL = 12\n _ZOOM_LEVELS = [\n 360,\n 180,\n@@ -100,6 +101,7 @@\n 0.003,\n 0.001,\n 0.0005,\n+ 0.00025,\n ]\n \n \n@@ -116,10 +118,14 @@\n Returns\n -------\n int\n- The zoom level, from 0 to 29.\n+ The zoom level, from 0 to 20.\n \n \"\"\"\n \n+ # For small number of points the default zoom level will be used.\n+ if distance < _ZOOM_LEVELS[-1]:\n+ return _DEFAULT_ZOOM_LEVEL\n+\n for i in range(len(_ZOOM_LEVELS) - 1):\n if _ZOOM_LEVELS[i + 1] < distance <= _ZOOM_LEVELS[i]:\n return i\n", "issue": "st.map() fails with zoom error for small number of points\n# Summary\r\n\r\nIn this [forum post](https://discuss.streamlit.io/t/plot-map-with-address-from-user-input/2950), the user highlights that `st.map()` does not plot a single point for the map. To troubleshoot, I opened up the Chrome console, saw a \"Zoom must be set error\" message in regards to the map.\r\n\r\n# Solution\r\n\r\nAdding a non `None` zoom value in the `st.map()` call [resolves the issue](https://discuss.streamlit.io/t/plot-map-with-address-from-user-input/2950/3?u=randyzwitch). Need a heuristic for a \"small\" number of points where `st.map()` automatically adds an integer value for the `zoom` parameter. At larger volumes of data, `zoom =None` seems to be ok, and deck.gl infers the proper zoom level based on the bounding box of data points.\nst.map() fails with zoom error for small number of points\n# Summary\r\n\r\nIn this [forum post](https://discuss.streamlit.io/t/plot-map-with-address-from-user-input/2950), the user highlights that `st.map()` does not plot a single point for the map. To troubleshoot, I opened up the Chrome console, saw a \"Zoom must be set error\" message in regards to the map.\r\n\r\n# Solution\r\n\r\nAdding a non `None` zoom value in the `st.map()` call [resolves the issue](https://discuss.streamlit.io/t/plot-map-with-address-from-user-input/2950/3?u=randyzwitch). Need a heuristic for a \"small\" number of points where `st.map()` automatically adds an integer value for the `zoom` parameter. At larger volumes of data, `zoom =None` seems to be ok, and deck.gl infers the proper zoom level based on the bounding box of data points.\n", "before_files": [{"content": "# Copyright 2018-2020 Streamlit Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"A wrapper for simple PyDeck scatter charts.\"\"\"\n\nimport copy\nimport json\nfrom typing import Any, Dict\n\nimport pandas as pd\n\nfrom streamlit.proto.DeckGlJsonChart_pb2 import DeckGlJsonChart as DeckGlJsonChartProto\nimport streamlit.elements.deck_gl_json_chart as deck_gl_json_chart\nfrom streamlit.errors import StreamlitAPIException\n\n\nclass MapMixin:\n def map(dg, data=None, zoom=None, use_container_width=True):\n \"\"\"Display a map with points on it.\n\n This is a wrapper around st.pydeck_chart to quickly create scatterplot\n charts on top of a map, with auto-centering and auto-zoom.\n\n When using this command, we advise all users to use a personal Mapbox\n token. This ensures the map tiles used in this chart are more\n robust. You can do this with the mapbox.token config option.\n\n To get a token for yourself, create an account at\n https://mapbox.com. It's free! (for moderate usage levels) See\n https://docs.streamlit.io/en/latest/cli.html#view-all-config-options for more\n info on how to set config options.\n\n Parameters\n ----------\n data : pandas.DataFrame, pandas.Styler, numpy.ndarray, Iterable, dict,\n or None\n The data to be plotted. Must have columns called 'lat', 'lon',\n 'latitude', or 'longitude'.\n zoom : int\n Zoom level as specified in\n https://wiki.openstreetmap.org/wiki/Zoom_levels\n\n Example\n -------\n >>> import pandas as pd\n >>> import numpy as np\n >>>\n >>> df = pd.DataFrame(\n ... np.random.randn(1000, 2) / [50, 50] + [37.76, -122.4],\n ... columns=['lat', 'lon'])\n >>>\n >>> st.map(df)\n\n .. output::\n https://share.streamlit.io/0.53.0-SULT/index.html?id=9gTiomqPEbvHY2huTLoQtH\n height: 600px\n\n \"\"\"\n map_proto = DeckGlJsonChartProto()\n map_proto.json = to_deckgl_json(data, zoom)\n map_proto.use_container_width = use_container_width\n return dg._enqueue(\"deck_gl_json_chart\", map_proto) # type: ignore\n\n\n# Map used as the basis for st.map.\n_DEFAULT_MAP = dict(deck_gl_json_chart.EMPTY_MAP) # type: Dict[str, Any]\n_DEFAULT_MAP[\"mapStyle\"] = \"mapbox://styles/mapbox/light-v10\"\n\n# Other default parameters for st.map.\n_DEFAULT_COLOR = [200, 30, 0, 160]\n_ZOOM_LEVELS = [\n 360,\n 180,\n 90,\n 45,\n 22.5,\n 11.25,\n 5.625,\n 2.813,\n 1.406,\n 0.703,\n 0.352,\n 0.176,\n 0.088,\n 0.044,\n 0.022,\n 0.011,\n 0.005,\n 0.003,\n 0.001,\n 0.0005,\n]\n\n\ndef _get_zoom_level(distance):\n \"\"\"Get the zoom level for a given distance in degrees.\n\n See https://wiki.openstreetmap.org/wiki/Zoom_levels for reference.\n\n Parameters\n ----------\n distance : float\n How many degrees of longitude should fit in the map.\n\n Returns\n -------\n int\n The zoom level, from 0 to 29.\n\n \"\"\"\n\n for i in range(len(_ZOOM_LEVELS) - 1):\n if _ZOOM_LEVELS[i + 1] < distance <= _ZOOM_LEVELS[i]:\n return i\n\n\ndef to_deckgl_json(data, zoom):\n\n if data is None or data.empty:\n return json.dumps(_DEFAULT_MAP)\n\n if \"lat\" in data:\n lat = \"lat\"\n elif \"latitude\" in data:\n lat = \"latitude\"\n else:\n raise StreamlitAPIException(\n 'Map data must contain a column named \"latitude\" or \"lat\".'\n )\n\n if \"lon\" in data:\n lon = \"lon\"\n elif \"longitude\" in data:\n lon = \"longitude\"\n else:\n raise StreamlitAPIException(\n 'Map data must contain a column called \"longitude\" or \"lon\".'\n )\n\n if data[lon].isnull().values.any() or data[lat].isnull().values.any():\n raise StreamlitAPIException(\"Latitude and longitude data must be numeric.\")\n\n data = pd.DataFrame(data)\n\n min_lat = data[lat].min()\n max_lat = data[lat].max()\n min_lon = data[lon].min()\n max_lon = data[lon].max()\n center_lat = (max_lat + min_lat) / 2.0\n center_lon = (max_lon + min_lon) / 2.0\n range_lon = abs(max_lon - min_lon)\n range_lat = abs(max_lat - min_lat)\n\n if zoom == None:\n if range_lon > range_lat:\n longitude_distance = range_lon\n else:\n longitude_distance = range_lat\n zoom = _get_zoom_level(longitude_distance)\n\n # \"+1\" because itertuples includes the row index.\n lon_col_index = data.columns.get_loc(lon) + 1\n lat_col_index = data.columns.get_loc(lat) + 1\n final_data = []\n for row in data.itertuples():\n final_data.append(\n {\"lon\": float(row[lon_col_index]), \"lat\": float(row[lat_col_index])}\n )\n\n default = copy.deepcopy(_DEFAULT_MAP)\n default[\"initialViewState\"][\"latitude\"] = center_lat\n default[\"initialViewState\"][\"longitude\"] = center_lon\n default[\"initialViewState\"][\"zoom\"] = zoom\n default[\"layers\"] = [\n {\n \"@@type\": \"ScatterplotLayer\",\n \"getPosition\": \"@@=[lon, lat]\",\n \"getRadius\": 10,\n \"radiusScale\": 10,\n \"radiusMinPixels\": 3,\n \"getFillColor\": _DEFAULT_COLOR,\n \"data\": final_data,\n }\n ]\n return json.dumps(default)\n", "path": "lib/streamlit/elements/map.py"}]}
| 3,013 | 300 |
gh_patches_debug_21737
|
rasdani/github-patches
|
git_diff
|
openmc-dev__openmc-1254
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add method to get total material density
For multiphysics coupling, convergence between successive iterations of OpenMC with a T/H solver may be based on the densities, in which case we will need to make the initial density used in OpenMC available to a multiphysics driver.
There is an `openmc_material_get_densities()` method to get the density of each nuclide in a material, but it would be cleaner for a multiphysics driver to avoid doing a summation on this density and instead directly get the density in g/cm^3.
</issue>
<code>
[start of openmc/capi/material.py]
1 from collections.abc import Mapping
2 from ctypes import c_int, c_int32, c_double, c_char_p, POINTER, c_size_t
3 from weakref import WeakValueDictionary
4
5 import numpy as np
6 from numpy.ctypeslib import as_array
7
8 from openmc.exceptions import AllocationError, InvalidIDError, OpenMCError
9 from . import _dll, Nuclide
10 from .core import _FortranObjectWithID
11 from .error import _error_handler
12
13
14 __all__ = ['Material', 'materials']
15
16 # Material functions
17 _dll.openmc_extend_materials.argtypes = [c_int32, POINTER(c_int32), POINTER(c_int32)]
18 _dll.openmc_extend_materials.restype = c_int
19 _dll.openmc_extend_materials.errcheck = _error_handler
20 _dll.openmc_get_material_index.argtypes = [c_int32, POINTER(c_int32)]
21 _dll.openmc_get_material_index.restype = c_int
22 _dll.openmc_get_material_index.errcheck = _error_handler
23 _dll.openmc_material_add_nuclide.argtypes = [
24 c_int32, c_char_p, c_double]
25 _dll.openmc_material_add_nuclide.restype = c_int
26 _dll.openmc_material_add_nuclide.errcheck = _error_handler
27 _dll.openmc_material_get_id.argtypes = [c_int32, POINTER(c_int32)]
28 _dll.openmc_material_get_id.restype = c_int
29 _dll.openmc_material_get_id.errcheck = _error_handler
30 _dll.openmc_material_get_densities.argtypes = [
31 c_int32, POINTER(POINTER(c_int)), POINTER(POINTER(c_double)),
32 POINTER(c_int)]
33 _dll.openmc_material_get_densities.restype = c_int
34 _dll.openmc_material_get_densities.errcheck = _error_handler
35 _dll.openmc_material_get_volume.argtypes = [c_int32, POINTER(c_double)]
36 _dll.openmc_material_get_volume.restype = c_int
37 _dll.openmc_material_get_volume.errcheck = _error_handler
38 _dll.openmc_material_set_density.argtypes = [c_int32, c_double, c_char_p]
39 _dll.openmc_material_set_density.restype = c_int
40 _dll.openmc_material_set_density.errcheck = _error_handler
41 _dll.openmc_material_set_densities.argtypes = [
42 c_int32, c_int, POINTER(c_char_p), POINTER(c_double)]
43 _dll.openmc_material_set_densities.restype = c_int
44 _dll.openmc_material_set_densities.errcheck = _error_handler
45 _dll.openmc_material_set_id.argtypes = [c_int32, c_int32]
46 _dll.openmc_material_set_id.restype = c_int
47 _dll.openmc_material_set_id.errcheck = _error_handler
48 _dll.openmc_material_set_volume.argtypes = [c_int32, c_double]
49 _dll.openmc_material_set_volume.restype = c_int
50 _dll.openmc_material_set_volume.errcheck = _error_handler
51 _dll.n_materials.argtypes = []
52 _dll.n_materials.restype = c_size_t
53
54
55 class Material(_FortranObjectWithID):
56 """Material stored internally.
57
58 This class exposes a material that is stored internally in the OpenMC
59 library. To obtain a view of a material with a given ID, use the
60 :data:`openmc.capi.materials` mapping.
61
62 Parameters
63 ----------
64 uid : int or None
65 Unique ID of the tally
66 new : bool
67 When `index` is None, this argument controls whether a new object is
68 created or a view to an existing object is returned.
69 index : int or None
70 Index in the `materials` array.
71
72 Attributes
73 ----------
74 id : int
75 ID of the material
76 nuclides : list of str
77 List of nuclides in the material
78 densities : numpy.ndarray
79 Array of densities in atom/b-cm
80
81 """
82 __instances = WeakValueDictionary()
83
84 def __new__(cls, uid=None, new=True, index=None):
85 mapping = materials
86 if index is None:
87 if new:
88 # Determine ID to assign
89 if uid is None:
90 uid = max(mapping, default=0) + 1
91 else:
92 if uid in mapping:
93 raise AllocationError('A material with ID={} has already '
94 'been allocated.'.format(uid))
95
96 index = c_int32()
97 _dll.openmc_extend_materials(1, index, None)
98 index = index.value
99 else:
100 index = mapping[uid]._index
101 elif index == -1:
102 # Special value indicates void material
103 return None
104
105 if index not in cls.__instances:
106 instance = super(Material, cls).__new__(cls)
107 instance._index = index
108 if uid is not None:
109 instance.id = uid
110 cls.__instances[index] = instance
111
112 return cls.__instances[index]
113
114 @property
115 def id(self):
116 mat_id = c_int32()
117 _dll.openmc_material_get_id(self._index, mat_id)
118 return mat_id.value
119
120 @id.setter
121 def id(self, mat_id):
122 _dll.openmc_material_set_id(self._index, mat_id)
123
124 @property
125 def volume(self):
126 volume = c_double()
127 try:
128 _dll.openmc_material_get_volume(self._index, volume)
129 except OpenMCError:
130 return None
131 return volume.value
132
133 @volume.setter
134 def volume(self, volume):
135 _dll.openmc_material_set_volume(self._index, volume)
136
137 @property
138 def nuclides(self):
139 return self._get_densities()[0]
140 return nuclides
141
142 @property
143 def densities(self):
144 return self._get_densities()[1]
145
146 def _get_densities(self):
147 """Get atom densities in a material.
148
149 Returns
150 -------
151 list of string
152 List of nuclide names
153 numpy.ndarray
154 Array of densities in atom/b-cm
155
156 """
157 # Allocate memory for arguments that are written to
158 nuclides = POINTER(c_int)()
159 densities = POINTER(c_double)()
160 n = c_int()
161
162 # Get nuclide names and densities
163 _dll.openmc_material_get_densities(self._index, nuclides, densities, n)
164
165 # Convert to appropriate types and return
166 nuclide_list = [Nuclide(nuclides[i]).name for i in range(n.value)]
167 density_array = as_array(densities, (n.value,))
168 return nuclide_list, density_array
169
170 def add_nuclide(self, name, density):
171 """Add a nuclide to a material.
172
173 Parameters
174 ----------
175 name : str
176 Name of nuclide, e.g. 'U235'
177 density : float
178 Density in atom/b-cm
179
180 """
181 _dll.openmc_material_add_nuclide(self._index, name.encode(), density)
182
183 def set_density(self, density, units='atom/b-cm'):
184 """Set density of a material.
185
186 Parameters
187 ----------
188 density : float
189 Density
190 units : {'atom/b-cm', 'g/cm3'}
191 Units for density
192
193 """
194 _dll.openmc_material_set_density(self._index, density, units.encode())
195
196 def set_densities(self, nuclides, densities):
197 """Set the densities of a list of nuclides in a material
198
199 Parameters
200 ----------
201 nuclides : iterable of str
202 Nuclide names
203 densities : iterable of float
204 Corresponding densities in atom/b-cm
205
206 """
207 # Convert strings to an array of char*
208 nucs = (c_char_p * len(nuclides))()
209 nucs[:] = [x.encode() for x in nuclides]
210
211 # Get numpy array as a double*
212 d = np.asarray(densities)
213 dp = d.ctypes.data_as(POINTER(c_double))
214
215 _dll.openmc_material_set_densities(self._index, len(nuclides), nucs, dp)
216
217
218 class _MaterialMapping(Mapping):
219 def __getitem__(self, key):
220 index = c_int32()
221 try:
222 _dll.openmc_get_material_index(key, index)
223 except (AllocationError, InvalidIDError) as e:
224 # __contains__ expects a KeyError to work correctly
225 raise KeyError(str(e))
226 return Material(index=index.value)
227
228 def __iter__(self):
229 for i in range(len(self)):
230 yield Material(index=i).id
231
232 def __len__(self):
233 return _dll.n_materials()
234
235 def __repr__(self):
236 return repr(dict(self))
237
238 materials = _MaterialMapping()
239
[end of openmc/capi/material.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/openmc/capi/material.py b/openmc/capi/material.py
--- a/openmc/capi/material.py
+++ b/openmc/capi/material.py
@@ -32,6 +32,9 @@
POINTER(c_int)]
_dll.openmc_material_get_densities.restype = c_int
_dll.openmc_material_get_densities.errcheck = _error_handler
+_dll.openmc_material_get_density.argtypes = [c_int32, POINTER(c_double)]
+_dll.openmc_material_get_density.restype = c_int
+_dll.openmc_material_get_density.errcheck = _error_handler
_dll.openmc_material_get_volume.argtypes = [c_int32, POINTER(c_double)]
_dll.openmc_material_get_volume.restype = c_int
_dll.openmc_material_get_volume.errcheck = _error_handler
@@ -139,6 +142,15 @@
return self._get_densities()[0]
return nuclides
+ @property
+ def density(self):
+ density = c_double()
+ try:
+ _dll.openmc_material_get_density(self._index, density)
+ except OpenMCError:
+ return None
+ return density.value
+
@property
def densities(self):
return self._get_densities()[1]
|
{"golden_diff": "diff --git a/openmc/capi/material.py b/openmc/capi/material.py\n--- a/openmc/capi/material.py\n+++ b/openmc/capi/material.py\n@@ -32,6 +32,9 @@\n POINTER(c_int)]\n _dll.openmc_material_get_densities.restype = c_int\n _dll.openmc_material_get_densities.errcheck = _error_handler\n+_dll.openmc_material_get_density.argtypes = [c_int32, POINTER(c_double)]\n+_dll.openmc_material_get_density.restype = c_int\n+_dll.openmc_material_get_density.errcheck = _error_handler\n _dll.openmc_material_get_volume.argtypes = [c_int32, POINTER(c_double)]\n _dll.openmc_material_get_volume.restype = c_int\n _dll.openmc_material_get_volume.errcheck = _error_handler\n@@ -139,6 +142,15 @@\n return self._get_densities()[0]\n return nuclides\n \n+ @property\n+ def density(self):\n+ density = c_double()\n+ try:\n+ _dll.openmc_material_get_density(self._index, density)\n+ except OpenMCError:\n+ return None\n+ return density.value\n+\n @property\n def densities(self):\n return self._get_densities()[1]\n", "issue": "Add method to get total material density\nFor multiphysics coupling, convergence between successive iterations of OpenMC with a T/H solver may be based on the densities, in which case we will need to make the initial density used in OpenMC available to a multiphysics driver. \r\n\r\nThere is an `openmc_material_get_densities()` method to get the density of each nuclide in a material, but it would be cleaner for a multiphysics driver to avoid doing a summation on this density and instead directly get the density in g/cm^3.\n", "before_files": [{"content": "from collections.abc import Mapping\nfrom ctypes import c_int, c_int32, c_double, c_char_p, POINTER, c_size_t\nfrom weakref import WeakValueDictionary\n\nimport numpy as np\nfrom numpy.ctypeslib import as_array\n\nfrom openmc.exceptions import AllocationError, InvalidIDError, OpenMCError\nfrom . import _dll, Nuclide\nfrom .core import _FortranObjectWithID\nfrom .error import _error_handler\n\n\n__all__ = ['Material', 'materials']\n\n# Material functions\n_dll.openmc_extend_materials.argtypes = [c_int32, POINTER(c_int32), POINTER(c_int32)]\n_dll.openmc_extend_materials.restype = c_int\n_dll.openmc_extend_materials.errcheck = _error_handler\n_dll.openmc_get_material_index.argtypes = [c_int32, POINTER(c_int32)]\n_dll.openmc_get_material_index.restype = c_int\n_dll.openmc_get_material_index.errcheck = _error_handler\n_dll.openmc_material_add_nuclide.argtypes = [\n c_int32, c_char_p, c_double]\n_dll.openmc_material_add_nuclide.restype = c_int\n_dll.openmc_material_add_nuclide.errcheck = _error_handler\n_dll.openmc_material_get_id.argtypes = [c_int32, POINTER(c_int32)]\n_dll.openmc_material_get_id.restype = c_int\n_dll.openmc_material_get_id.errcheck = _error_handler\n_dll.openmc_material_get_densities.argtypes = [\n c_int32, POINTER(POINTER(c_int)), POINTER(POINTER(c_double)),\n POINTER(c_int)]\n_dll.openmc_material_get_densities.restype = c_int\n_dll.openmc_material_get_densities.errcheck = _error_handler\n_dll.openmc_material_get_volume.argtypes = [c_int32, POINTER(c_double)]\n_dll.openmc_material_get_volume.restype = c_int\n_dll.openmc_material_get_volume.errcheck = _error_handler\n_dll.openmc_material_set_density.argtypes = [c_int32, c_double, c_char_p]\n_dll.openmc_material_set_density.restype = c_int\n_dll.openmc_material_set_density.errcheck = _error_handler\n_dll.openmc_material_set_densities.argtypes = [\n c_int32, c_int, POINTER(c_char_p), POINTER(c_double)]\n_dll.openmc_material_set_densities.restype = c_int\n_dll.openmc_material_set_densities.errcheck = _error_handler\n_dll.openmc_material_set_id.argtypes = [c_int32, c_int32]\n_dll.openmc_material_set_id.restype = c_int\n_dll.openmc_material_set_id.errcheck = _error_handler\n_dll.openmc_material_set_volume.argtypes = [c_int32, c_double]\n_dll.openmc_material_set_volume.restype = c_int\n_dll.openmc_material_set_volume.errcheck = _error_handler\n_dll.n_materials.argtypes = []\n_dll.n_materials.restype = c_size_t\n\n\nclass Material(_FortranObjectWithID):\n \"\"\"Material stored internally.\n\n This class exposes a material that is stored internally in the OpenMC\n library. To obtain a view of a material with a given ID, use the\n :data:`openmc.capi.materials` mapping.\n\n Parameters\n ----------\n uid : int or None\n Unique ID of the tally\n new : bool\n When `index` is None, this argument controls whether a new object is\n created or a view to an existing object is returned.\n index : int or None\n Index in the `materials` array.\n\n Attributes\n ----------\n id : int\n ID of the material\n nuclides : list of str\n List of nuclides in the material\n densities : numpy.ndarray\n Array of densities in atom/b-cm\n\n \"\"\"\n __instances = WeakValueDictionary()\n\n def __new__(cls, uid=None, new=True, index=None):\n mapping = materials\n if index is None:\n if new:\n # Determine ID to assign\n if uid is None:\n uid = max(mapping, default=0) + 1\n else:\n if uid in mapping:\n raise AllocationError('A material with ID={} has already '\n 'been allocated.'.format(uid))\n\n index = c_int32()\n _dll.openmc_extend_materials(1, index, None)\n index = index.value\n else:\n index = mapping[uid]._index\n elif index == -1:\n # Special value indicates void material\n return None\n\n if index not in cls.__instances:\n instance = super(Material, cls).__new__(cls)\n instance._index = index\n if uid is not None:\n instance.id = uid\n cls.__instances[index] = instance\n\n return cls.__instances[index]\n\n @property\n def id(self):\n mat_id = c_int32()\n _dll.openmc_material_get_id(self._index, mat_id)\n return mat_id.value\n\n @id.setter\n def id(self, mat_id):\n _dll.openmc_material_set_id(self._index, mat_id)\n\n @property\n def volume(self):\n volume = c_double()\n try:\n _dll.openmc_material_get_volume(self._index, volume)\n except OpenMCError:\n return None\n return volume.value\n\n @volume.setter\n def volume(self, volume):\n _dll.openmc_material_set_volume(self._index, volume)\n\n @property\n def nuclides(self):\n return self._get_densities()[0]\n return nuclides\n\n @property\n def densities(self):\n return self._get_densities()[1]\n\n def _get_densities(self):\n \"\"\"Get atom densities in a material.\n\n Returns\n -------\n list of string\n List of nuclide names\n numpy.ndarray\n Array of densities in atom/b-cm\n\n \"\"\"\n # Allocate memory for arguments that are written to\n nuclides = POINTER(c_int)()\n densities = POINTER(c_double)()\n n = c_int()\n\n # Get nuclide names and densities\n _dll.openmc_material_get_densities(self._index, nuclides, densities, n)\n\n # Convert to appropriate types and return\n nuclide_list = [Nuclide(nuclides[i]).name for i in range(n.value)]\n density_array = as_array(densities, (n.value,))\n return nuclide_list, density_array\n\n def add_nuclide(self, name, density):\n \"\"\"Add a nuclide to a material.\n\n Parameters\n ----------\n name : str\n Name of nuclide, e.g. 'U235'\n density : float\n Density in atom/b-cm\n\n \"\"\"\n _dll.openmc_material_add_nuclide(self._index, name.encode(), density)\n\n def set_density(self, density, units='atom/b-cm'):\n \"\"\"Set density of a material.\n\n Parameters\n ----------\n density : float\n Density\n units : {'atom/b-cm', 'g/cm3'}\n Units for density\n\n \"\"\"\n _dll.openmc_material_set_density(self._index, density, units.encode())\n\n def set_densities(self, nuclides, densities):\n \"\"\"Set the densities of a list of nuclides in a material\n\n Parameters\n ----------\n nuclides : iterable of str\n Nuclide names\n densities : iterable of float\n Corresponding densities in atom/b-cm\n\n \"\"\"\n # Convert strings to an array of char*\n nucs = (c_char_p * len(nuclides))()\n nucs[:] = [x.encode() for x in nuclides]\n\n # Get numpy array as a double*\n d = np.asarray(densities)\n dp = d.ctypes.data_as(POINTER(c_double))\n\n _dll.openmc_material_set_densities(self._index, len(nuclides), nucs, dp)\n\n\nclass _MaterialMapping(Mapping):\n def __getitem__(self, key):\n index = c_int32()\n try:\n _dll.openmc_get_material_index(key, index)\n except (AllocationError, InvalidIDError) as e:\n # __contains__ expects a KeyError to work correctly\n raise KeyError(str(e))\n return Material(index=index.value)\n\n def __iter__(self):\n for i in range(len(self)):\n yield Material(index=i).id\n\n def __len__(self):\n return _dll.n_materials()\n\n def __repr__(self):\n return repr(dict(self))\n\nmaterials = _MaterialMapping()\n", "path": "openmc/capi/material.py"}]}
| 3,178 | 286 |
gh_patches_debug_1015
|
rasdani/github-patches
|
git_diff
|
mkdocs__mkdocs-2366
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
build --no-directory-urls feature not working
Hello.
I created new project using
```
mkdocs new .
mkdocs build --no-directory-urls
```
Still when I try to visit home page I am brought to . directory instead of .\index.html
Sorry for some russian text :D

I also tried to modife .yml file like this
`use_directory_urls: false`
Still not working in "offline" mode
```
pip show mkdocs
Name: mkdocs
Version: 1.1.2
Summary: Project documentation with Markdown.
Home-page: https://www.mkdocs.org
Author: Tom Christie
Author-email: [email protected]
License: BSD
Location: /home/demaunt/.local/lib/python3.8/site-packages
Requires: Markdown, lunr, Jinja2, PyYAML, click, livereload, tornado
Required-by: mkdocs-redirects, mkdocs-minify-plugin, mkdocs-material
```
</issue>
<code>
[start of mkdocs/structure/pages.py]
1 import os
2 import logging
3 from urllib.parse import urlparse, urlunparse, urljoin
4 from urllib.parse import unquote as urlunquote
5
6 import markdown
7 from markdown.extensions import Extension
8 from markdown.treeprocessors import Treeprocessor
9 from markdown.util import AMP_SUBSTITUTE
10
11 from mkdocs.structure.toc import get_toc
12 from mkdocs.utils import meta, get_build_date, get_markdown_title
13
14 log = logging.getLogger(__name__)
15
16
17 class Page:
18 def __init__(self, title, file, config):
19 file.page = self
20 self.file = file
21 self.title = title
22
23 # Navigation attributes
24 self.parent = None
25 self.children = None
26 self.previous_page = None
27 self.next_page = None
28 self.active = False
29
30 self.is_section = False
31 self.is_page = True
32 self.is_link = False
33
34 self.update_date = get_build_date()
35
36 self._set_canonical_url(config.get('site_url', None))
37 self._set_edit_url(config.get('repo_url', None), config.get('edit_uri', None))
38
39 # Placeholders to be filled in later in the build process.
40 self.markdown = None
41 self.content = None
42 self.toc = []
43 self.meta = {}
44
45 def __eq__(self, other):
46 return (
47 isinstance(other, self.__class__) and
48 self.title == other.title and
49 self.file == other.file
50 )
51
52 def __ne__(self, other):
53 return not self.__eq__(other)
54
55 def __repr__(self):
56 title = "'{}'".format(self.title) if (self.title is not None) else '[blank]'
57 return "Page(title={}, url='{}')".format(title, self.abs_url or self.file.url)
58
59 def _indent_print(self, depth=0):
60 return '{}{}'.format(' ' * depth, repr(self))
61
62 def _get_active(self):
63 """ Return active status of page. """
64 return self.__active
65
66 def _set_active(self, value):
67 """ Set active status of page and ancestors. """
68 self.__active = bool(value)
69 if self.parent is not None:
70 self.parent.active = bool(value)
71
72 active = property(_get_active, _set_active)
73
74 @property
75 def is_index(self):
76 return self.file.name == 'index'
77
78 @property
79 def is_top_level(self):
80 return self.parent is None
81
82 @property
83 def is_homepage(self):
84 return self.is_top_level and self.is_index and self.file.url == '.'
85
86 @property
87 def url(self):
88 return '' if self.file.url == '.' else self.file.url
89
90 @property
91 def ancestors(self):
92 if self.parent is None:
93 return []
94 return [self.parent] + self.parent.ancestors
95
96 def _set_canonical_url(self, base):
97 if base:
98 if not base.endswith('/'):
99 base += '/'
100 self.canonical_url = urljoin(base, self.url)
101 self.abs_url = urlparse(self.canonical_url).path
102 else:
103 self.canonical_url = None
104 self.abs_url = None
105
106 def _set_edit_url(self, repo_url, edit_uri):
107 if repo_url and edit_uri:
108 src_path = self.file.src_path.replace('\\', '/')
109 self.edit_url = urljoin(repo_url, edit_uri + src_path)
110 else:
111 self.edit_url = None
112
113 def read_source(self, config):
114 source = config['plugins'].run_event(
115 'page_read_source', page=self, config=config
116 )
117 if source is None:
118 try:
119 with open(self.file.abs_src_path, 'r', encoding='utf-8-sig', errors='strict') as f:
120 source = f.read()
121 except OSError:
122 log.error('File not found: {}'.format(self.file.src_path))
123 raise
124 except ValueError:
125 log.error('Encoding error reading file: {}'.format(self.file.src_path))
126 raise
127
128 self.markdown, self.meta = meta.get_data(source)
129 self._set_title()
130
131 def _set_title(self):
132 """
133 Set the title for a Markdown document.
134
135 Check these in order and use the first that returns a valid title:
136 - value provided on init (passed in from config)
137 - value of metadata 'title'
138 - content of the first H1 in Markdown content
139 - convert filename to title
140 """
141 if self.title is not None:
142 return
143
144 if 'title' in self.meta:
145 self.title = self.meta['title']
146 return
147
148 title = get_markdown_title(self.markdown)
149
150 if title is None:
151 if self.is_homepage:
152 title = 'Home'
153 else:
154 title = self.file.name.replace('-', ' ').replace('_', ' ')
155 # Capitalize if the filename was all lowercase, otherwise leave it as-is.
156 if title.lower() == title:
157 title = title.capitalize()
158
159 self.title = title
160
161 def render(self, config, files):
162 """
163 Convert the Markdown source file to HTML as per the config.
164 """
165
166 extensions = [
167 _RelativePathExtension(self.file, files)
168 ] + config['markdown_extensions']
169
170 md = markdown.Markdown(
171 extensions=extensions,
172 extension_configs=config['mdx_configs'] or {}
173 )
174 self.content = md.convert(self.markdown)
175 self.toc = get_toc(getattr(md, 'toc_tokens', []))
176
177
178 class _RelativePathTreeprocessor(Treeprocessor):
179 def __init__(self, file, files):
180 self.file = file
181 self.files = files
182
183 def run(self, root):
184 """
185 Update urls on anchors and images to make them relative
186
187 Iterates through the full document tree looking for specific
188 tags and then makes them relative based on the site navigation
189 """
190 for element in root.iter():
191 if element.tag == 'a':
192 key = 'href'
193 elif element.tag == 'img':
194 key = 'src'
195 else:
196 continue
197
198 url = element.get(key)
199 new_url = self.path_to_url(url)
200 element.set(key, new_url)
201
202 return root
203
204 def path_to_url(self, url):
205 scheme, netloc, path, params, query, fragment = urlparse(url)
206
207 if (scheme or netloc or not path or url.startswith('/') or url.startswith('\\')
208 or AMP_SUBSTITUTE in url or '.' not in os.path.split(path)[-1]):
209 # Ignore URLs unless they are a relative link to a source file.
210 # AMP_SUBSTITUTE is used internally by Markdown only for email.
211 # No '.' in the last part of a path indicates path does not point to a file.
212 return url
213
214 # Determine the filepath of the target.
215 target_path = os.path.join(os.path.dirname(self.file.src_path), urlunquote(path))
216 target_path = os.path.normpath(target_path).lstrip(os.sep)
217
218 # Validate that the target exists in files collection.
219 if target_path not in self.files:
220 log.warning(
221 "Documentation file '{}' contains a link to '{}' which is not found "
222 "in the documentation files.".format(self.file.src_path, target_path)
223 )
224 return url
225 target_file = self.files.get_file_from_path(target_path)
226 path = target_file.url_relative_to(self.file)
227 components = (scheme, netloc, path, params, query, fragment)
228 return urlunparse(components)
229
230
231 class _RelativePathExtension(Extension):
232 """
233 The Extension class is what we pass to markdown, it then
234 registers the Treeprocessor.
235 """
236
237 def __init__(self, file, files):
238 self.file = file
239 self.files = files
240
241 def extendMarkdown(self, md):
242 relpath = _RelativePathTreeprocessor(self.file, self.files)
243 md.treeprocessors.register(relpath, "relpath", 0)
244
[end of mkdocs/structure/pages.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mkdocs/structure/pages.py b/mkdocs/structure/pages.py
--- a/mkdocs/structure/pages.py
+++ b/mkdocs/structure/pages.py
@@ -81,7 +81,7 @@
@property
def is_homepage(self):
- return self.is_top_level and self.is_index and self.file.url == '.'
+ return self.is_top_level and self.is_index and self.file.url in ['.', 'index.html']
@property
def url(self):
|
{"golden_diff": "diff --git a/mkdocs/structure/pages.py b/mkdocs/structure/pages.py\n--- a/mkdocs/structure/pages.py\n+++ b/mkdocs/structure/pages.py\n@@ -81,7 +81,7 @@\n \n @property\n def is_homepage(self):\n- return self.is_top_level and self.is_index and self.file.url == '.'\n+ return self.is_top_level and self.is_index and self.file.url in ['.', 'index.html']\n \n @property\n def url(self):\n", "issue": "build --no-directory-urls feature not working\nHello. \r\nI created new project using \r\n```\r\nmkdocs new .\r\nmkdocs build --no-directory-urls\r\n```\r\n\r\nStill when I try to visit home page I am brought to . directory instead of .\\index.html\r\n\r\nSorry for some russian text :D\r\n\r\n\r\nI also tried to modife .yml file like this \r\n`use_directory_urls: false`\r\n\r\nStill not working in \"offline\" mode\r\n\r\n```\r\npip show mkdocs\r\nName: mkdocs\r\nVersion: 1.1.2\r\nSummary: Project documentation with Markdown.\r\nHome-page: https://www.mkdocs.org\r\nAuthor: Tom Christie\r\nAuthor-email: [email protected]\r\nLicense: BSD\r\nLocation: /home/demaunt/.local/lib/python3.8/site-packages\r\nRequires: Markdown, lunr, Jinja2, PyYAML, click, livereload, tornado\r\nRequired-by: mkdocs-redirects, mkdocs-minify-plugin, mkdocs-material\r\n```\r\n\r\n\n", "before_files": [{"content": "import os\nimport logging\nfrom urllib.parse import urlparse, urlunparse, urljoin\nfrom urllib.parse import unquote as urlunquote\n\nimport markdown\nfrom markdown.extensions import Extension\nfrom markdown.treeprocessors import Treeprocessor\nfrom markdown.util import AMP_SUBSTITUTE\n\nfrom mkdocs.structure.toc import get_toc\nfrom mkdocs.utils import meta, get_build_date, get_markdown_title\n\nlog = logging.getLogger(__name__)\n\n\nclass Page:\n def __init__(self, title, file, config):\n file.page = self\n self.file = file\n self.title = title\n\n # Navigation attributes\n self.parent = None\n self.children = None\n self.previous_page = None\n self.next_page = None\n self.active = False\n\n self.is_section = False\n self.is_page = True\n self.is_link = False\n\n self.update_date = get_build_date()\n\n self._set_canonical_url(config.get('site_url', None))\n self._set_edit_url(config.get('repo_url', None), config.get('edit_uri', None))\n\n # Placeholders to be filled in later in the build process.\n self.markdown = None\n self.content = None\n self.toc = []\n self.meta = {}\n\n def __eq__(self, other):\n return (\n isinstance(other, self.__class__) and\n self.title == other.title and\n self.file == other.file\n )\n\n def __ne__(self, other):\n return not self.__eq__(other)\n\n def __repr__(self):\n title = \"'{}'\".format(self.title) if (self.title is not None) else '[blank]'\n return \"Page(title={}, url='{}')\".format(title, self.abs_url or self.file.url)\n\n def _indent_print(self, depth=0):\n return '{}{}'.format(' ' * depth, repr(self))\n\n def _get_active(self):\n \"\"\" Return active status of page. \"\"\"\n return self.__active\n\n def _set_active(self, value):\n \"\"\" Set active status of page and ancestors. \"\"\"\n self.__active = bool(value)\n if self.parent is not None:\n self.parent.active = bool(value)\n\n active = property(_get_active, _set_active)\n\n @property\n def is_index(self):\n return self.file.name == 'index'\n\n @property\n def is_top_level(self):\n return self.parent is None\n\n @property\n def is_homepage(self):\n return self.is_top_level and self.is_index and self.file.url == '.'\n\n @property\n def url(self):\n return '' if self.file.url == '.' else self.file.url\n\n @property\n def ancestors(self):\n if self.parent is None:\n return []\n return [self.parent] + self.parent.ancestors\n\n def _set_canonical_url(self, base):\n if base:\n if not base.endswith('/'):\n base += '/'\n self.canonical_url = urljoin(base, self.url)\n self.abs_url = urlparse(self.canonical_url).path\n else:\n self.canonical_url = None\n self.abs_url = None\n\n def _set_edit_url(self, repo_url, edit_uri):\n if repo_url and edit_uri:\n src_path = self.file.src_path.replace('\\\\', '/')\n self.edit_url = urljoin(repo_url, edit_uri + src_path)\n else:\n self.edit_url = None\n\n def read_source(self, config):\n source = config['plugins'].run_event(\n 'page_read_source', page=self, config=config\n )\n if source is None:\n try:\n with open(self.file.abs_src_path, 'r', encoding='utf-8-sig', errors='strict') as f:\n source = f.read()\n except OSError:\n log.error('File not found: {}'.format(self.file.src_path))\n raise\n except ValueError:\n log.error('Encoding error reading file: {}'.format(self.file.src_path))\n raise\n\n self.markdown, self.meta = meta.get_data(source)\n self._set_title()\n\n def _set_title(self):\n \"\"\"\n Set the title for a Markdown document.\n\n Check these in order and use the first that returns a valid title:\n - value provided on init (passed in from config)\n - value of metadata 'title'\n - content of the first H1 in Markdown content\n - convert filename to title\n \"\"\"\n if self.title is not None:\n return\n\n if 'title' in self.meta:\n self.title = self.meta['title']\n return\n\n title = get_markdown_title(self.markdown)\n\n if title is None:\n if self.is_homepage:\n title = 'Home'\n else:\n title = self.file.name.replace('-', ' ').replace('_', ' ')\n # Capitalize if the filename was all lowercase, otherwise leave it as-is.\n if title.lower() == title:\n title = title.capitalize()\n\n self.title = title\n\n def render(self, config, files):\n \"\"\"\n Convert the Markdown source file to HTML as per the config.\n \"\"\"\n\n extensions = [\n _RelativePathExtension(self.file, files)\n ] + config['markdown_extensions']\n\n md = markdown.Markdown(\n extensions=extensions,\n extension_configs=config['mdx_configs'] or {}\n )\n self.content = md.convert(self.markdown)\n self.toc = get_toc(getattr(md, 'toc_tokens', []))\n\n\nclass _RelativePathTreeprocessor(Treeprocessor):\n def __init__(self, file, files):\n self.file = file\n self.files = files\n\n def run(self, root):\n \"\"\"\n Update urls on anchors and images to make them relative\n\n Iterates through the full document tree looking for specific\n tags and then makes them relative based on the site navigation\n \"\"\"\n for element in root.iter():\n if element.tag == 'a':\n key = 'href'\n elif element.tag == 'img':\n key = 'src'\n else:\n continue\n\n url = element.get(key)\n new_url = self.path_to_url(url)\n element.set(key, new_url)\n\n return root\n\n def path_to_url(self, url):\n scheme, netloc, path, params, query, fragment = urlparse(url)\n\n if (scheme or netloc or not path or url.startswith('/') or url.startswith('\\\\')\n or AMP_SUBSTITUTE in url or '.' not in os.path.split(path)[-1]):\n # Ignore URLs unless they are a relative link to a source file.\n # AMP_SUBSTITUTE is used internally by Markdown only for email.\n # No '.' in the last part of a path indicates path does not point to a file.\n return url\n\n # Determine the filepath of the target.\n target_path = os.path.join(os.path.dirname(self.file.src_path), urlunquote(path))\n target_path = os.path.normpath(target_path).lstrip(os.sep)\n\n # Validate that the target exists in files collection.\n if target_path not in self.files:\n log.warning(\n \"Documentation file '{}' contains a link to '{}' which is not found \"\n \"in the documentation files.\".format(self.file.src_path, target_path)\n )\n return url\n target_file = self.files.get_file_from_path(target_path)\n path = target_file.url_relative_to(self.file)\n components = (scheme, netloc, path, params, query, fragment)\n return urlunparse(components)\n\n\nclass _RelativePathExtension(Extension):\n \"\"\"\n The Extension class is what we pass to markdown, it then\n registers the Treeprocessor.\n \"\"\"\n\n def __init__(self, file, files):\n self.file = file\n self.files = files\n\n def extendMarkdown(self, md):\n relpath = _RelativePathTreeprocessor(self.file, self.files)\n md.treeprocessors.register(relpath, \"relpath\", 0)\n", "path": "mkdocs/structure/pages.py"}]}
| 3,170 | 114 |
gh_patches_debug_28233
|
rasdani/github-patches
|
git_diff
|
iterative__dvc-8069
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`dvc.api.params_show()`: returns all params for stage with no params
# Bug Report
## Description
When using `dvc.api.params_show(stages="train")`, if there are no `params` for stage `train`, all of `params.yaml` will be returned.
### Reproduce
Use the following files:
```yaml
# dvc.yaml
stages:
train:
cmd: python train.py
deps:
- train.py
```
```yaml
#params.yaml
batch_size: 64
lr: 0.2
```
```python
# train.py
import dvc.api
print(dvc.api.params_show(stages="train"))
```
Running `python train.py` or `dvc repro/exp run` outputs `{'batch_size': 64, 'lr': 0.2}`.
### Expected
An error for no params found or an empty dict.
</issue>
<code>
[start of dvc/repo/params/show.py]
1 import logging
2 import os
3 from collections import defaultdict
4 from copy import copy
5 from typing import (
6 TYPE_CHECKING,
7 Callable,
8 Dict,
9 Iterable,
10 List,
11 Optional,
12 Tuple,
13 )
14
15 from scmrepo.exceptions import SCMError
16
17 from dvc.dependency.param import ParamsDependency
18 from dvc.repo import locked
19 from dvc.repo.collect import collect
20 from dvc.scm import NoSCMError
21 from dvc.stage import PipelineStage
22 from dvc.ui import ui
23 from dvc.utils import error_handler, errored_revisions, onerror_collect
24 from dvc.utils.collections import ensure_list
25 from dvc.utils.serialize import LOADERS
26
27 if TYPE_CHECKING:
28 from dvc.output import Output
29 from dvc.repo import Repo
30
31 logger = logging.getLogger(__name__)
32
33
34 def _is_params(dep: "Output"):
35 return isinstance(dep, ParamsDependency)
36
37
38 def _collect_configs(
39 repo: "Repo", rev, targets=None, duplicates=False
40 ) -> Tuple[List["Output"], List[str]]:
41
42 params, fs_paths = collect(
43 repo,
44 targets=targets or [],
45 deps=True,
46 output_filter=_is_params,
47 rev=rev,
48 duplicates=duplicates,
49 )
50 all_fs_paths = fs_paths + [p.fs_path for p in params]
51 if not targets:
52 default_params = repo.fs.path.join(
53 repo.root_dir, ParamsDependency.DEFAULT_PARAMS_FILE
54 )
55 if default_params not in all_fs_paths and repo.fs.exists(
56 default_params
57 ):
58 fs_paths.append(default_params)
59 return params, fs_paths
60
61
62 @error_handler
63 def _read_fs_path(fs, fs_path, **kwargs):
64 suffix = fs.path.suffix(fs_path).lower()
65 loader = LOADERS[suffix]
66 return loader(fs_path, fs=fs)
67
68
69 def _read_params(
70 repo,
71 params,
72 params_fs_paths,
73 deps=False,
74 onerror: Optional[Callable] = None,
75 stages: Optional[Iterable[str]] = None,
76 ):
77 res: Dict[str, Dict] = defaultdict(lambda: defaultdict(dict))
78 fs_paths = copy(params_fs_paths)
79
80 if deps or stages:
81 for param in params:
82 if stages and param.stage.addressing not in stages:
83 continue
84 params_dict = error_handler(param.read_params)(
85 onerror=onerror, flatten=False
86 )
87 if params_dict:
88 name = os.sep.join(repo.fs.path.relparts(param.fs_path))
89 res[name]["data"].update(params_dict["data"])
90 if name in fs_paths:
91 fs_paths.remove(name)
92 else:
93 fs_paths += [param.fs_path for param in params]
94
95 for fs_path in fs_paths:
96 from_path = _read_fs_path(repo.fs, fs_path, onerror=onerror)
97 if from_path:
98 name = os.sep.join(repo.fs.path.relparts(fs_path))
99 res[name] = from_path
100
101 return res
102
103
104 def _collect_vars(repo, params, stages=None) -> Dict:
105 vars_params: Dict[str, Dict] = defaultdict(dict)
106
107 for stage in repo.index.stages:
108 if isinstance(stage, PipelineStage) and stage.tracked_vars:
109 if stages and stage.addressing not in stages:
110 continue
111 for file, vars_ in stage.tracked_vars.items():
112 # `params` file are shown regardless of `tracked` or not
113 # to reduce noise and duplication, they are skipped
114 if file in params:
115 continue
116
117 name = os.sep.join(repo.fs.path.parts(file))
118 vars_params[name].update(vars_)
119 return vars_params
120
121
122 @locked
123 def show(
124 repo,
125 revs=None,
126 targets=None,
127 deps=False,
128 onerror: Callable = None,
129 stages=None,
130 ):
131 if onerror is None:
132 onerror = onerror_collect
133 res = {}
134
135 targets = ensure_list(targets)
136 targets = [repo.dvcfs.from_os_path(target) for target in targets]
137
138 for branch in repo.brancher(revs=revs):
139 params = error_handler(_gather_params)(
140 repo=repo,
141 rev=branch,
142 targets=targets,
143 deps=deps,
144 onerror=onerror,
145 stages=stages,
146 )
147
148 if params:
149 res[branch] = params
150
151 # Hide workspace params if they are the same as in the active branch
152 try:
153 active_branch = repo.scm.active_branch()
154 except (SCMError, NoSCMError):
155 # SCMError - detached head
156 # NoSCMError - no repo case
157 pass
158 else:
159 if res.get("workspace") == res.get(active_branch):
160 res.pop("workspace", None)
161
162 errored = errored_revisions(res)
163 if errored:
164 ui.error_write(
165 "DVC failed to load some parameters for following revisions:"
166 f" '{', '.join(errored)}'."
167 )
168
169 return res
170
171
172 def _gather_params(
173 repo, rev, targets=None, deps=False, onerror=None, stages=None
174 ):
175 param_outs, params_fs_paths = _collect_configs(
176 repo, rev, targets=targets, duplicates=deps or stages
177 )
178 params = _read_params(
179 repo,
180 params=param_outs,
181 params_fs_paths=params_fs_paths,
182 deps=deps,
183 onerror=onerror,
184 stages=stages,
185 )
186 vars_params = _collect_vars(repo, params, stages=stages)
187
188 # NOTE: only those that are not added as a ParamDependency are
189 # included so we don't need to recursively merge them yet.
190 for key, vals in vars_params.items():
191 params[key]["data"] = vals
192 return params
193
[end of dvc/repo/params/show.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/dvc/repo/params/show.py b/dvc/repo/params/show.py
--- a/dvc/repo/params/show.py
+++ b/dvc/repo/params/show.py
@@ -36,7 +36,7 @@
def _collect_configs(
- repo: "Repo", rev, targets=None, duplicates=False
+ repo: "Repo", rev, targets=None, deps=False, stages=None
) -> Tuple[List["Output"], List[str]]:
params, fs_paths = collect(
@@ -45,10 +45,10 @@
deps=True,
output_filter=_is_params,
rev=rev,
- duplicates=duplicates,
+ duplicates=deps or stages is not None,
)
all_fs_paths = fs_paths + [p.fs_path for p in params]
- if not targets:
+ if not any([deps, targets, stages]):
default_params = repo.fs.path.join(
repo.root_dir, ParamsDependency.DEFAULT_PARAMS_FILE
)
@@ -56,6 +56,7 @@
default_params
):
fs_paths.append(default_params)
+
return params, fs_paths
@@ -173,7 +174,7 @@
repo, rev, targets=None, deps=False, onerror=None, stages=None
):
param_outs, params_fs_paths = _collect_configs(
- repo, rev, targets=targets, duplicates=deps or stages
+ repo, rev, targets=targets, deps=deps, stages=stages
)
params = _read_params(
repo,
|
{"golden_diff": "diff --git a/dvc/repo/params/show.py b/dvc/repo/params/show.py\n--- a/dvc/repo/params/show.py\n+++ b/dvc/repo/params/show.py\n@@ -36,7 +36,7 @@\n \n \n def _collect_configs(\n- repo: \"Repo\", rev, targets=None, duplicates=False\n+ repo: \"Repo\", rev, targets=None, deps=False, stages=None\n ) -> Tuple[List[\"Output\"], List[str]]:\n \n params, fs_paths = collect(\n@@ -45,10 +45,10 @@\n deps=True,\n output_filter=_is_params,\n rev=rev,\n- duplicates=duplicates,\n+ duplicates=deps or stages is not None,\n )\n all_fs_paths = fs_paths + [p.fs_path for p in params]\n- if not targets:\n+ if not any([deps, targets, stages]):\n default_params = repo.fs.path.join(\n repo.root_dir, ParamsDependency.DEFAULT_PARAMS_FILE\n )\n@@ -56,6 +56,7 @@\n default_params\n ):\n fs_paths.append(default_params)\n+\n return params, fs_paths\n \n \n@@ -173,7 +174,7 @@\n repo, rev, targets=None, deps=False, onerror=None, stages=None\n ):\n param_outs, params_fs_paths = _collect_configs(\n- repo, rev, targets=targets, duplicates=deps or stages\n+ repo, rev, targets=targets, deps=deps, stages=stages\n )\n params = _read_params(\n repo,\n", "issue": "`dvc.api.params_show()`: returns all params for stage with no params\n# Bug Report\r\n\r\n## Description\r\n\r\nWhen using `dvc.api.params_show(stages=\"train\")`, if there are no `params` for stage `train`, all of `params.yaml` will be returned.\r\n\r\n### Reproduce\r\n\r\nUse the following files:\r\n\r\n```yaml\r\n# dvc.yaml\r\nstages:\r\n train:\r\n cmd: python train.py\r\n deps:\r\n - train.py\r\n```\r\n\r\n```yaml\r\n#params.yaml\r\nbatch_size: 64\r\nlr: 0.2\r\n```\r\n\r\n```python\r\n# train.py\r\nimport dvc.api\r\n\r\nprint(dvc.api.params_show(stages=\"train\"))\r\n```\r\n\r\nRunning `python train.py` or `dvc repro/exp run` outputs `{'batch_size': 64, 'lr': 0.2}`.\r\n\r\n### Expected\r\n\r\nAn error for no params found or an empty dict.\r\n\n", "before_files": [{"content": "import logging\nimport os\nfrom collections import defaultdict\nfrom copy import copy\nfrom typing import (\n TYPE_CHECKING,\n Callable,\n Dict,\n Iterable,\n List,\n Optional,\n Tuple,\n)\n\nfrom scmrepo.exceptions import SCMError\n\nfrom dvc.dependency.param import ParamsDependency\nfrom dvc.repo import locked\nfrom dvc.repo.collect import collect\nfrom dvc.scm import NoSCMError\nfrom dvc.stage import PipelineStage\nfrom dvc.ui import ui\nfrom dvc.utils import error_handler, errored_revisions, onerror_collect\nfrom dvc.utils.collections import ensure_list\nfrom dvc.utils.serialize import LOADERS\n\nif TYPE_CHECKING:\n from dvc.output import Output\n from dvc.repo import Repo\n\nlogger = logging.getLogger(__name__)\n\n\ndef _is_params(dep: \"Output\"):\n return isinstance(dep, ParamsDependency)\n\n\ndef _collect_configs(\n repo: \"Repo\", rev, targets=None, duplicates=False\n) -> Tuple[List[\"Output\"], List[str]]:\n\n params, fs_paths = collect(\n repo,\n targets=targets or [],\n deps=True,\n output_filter=_is_params,\n rev=rev,\n duplicates=duplicates,\n )\n all_fs_paths = fs_paths + [p.fs_path for p in params]\n if not targets:\n default_params = repo.fs.path.join(\n repo.root_dir, ParamsDependency.DEFAULT_PARAMS_FILE\n )\n if default_params not in all_fs_paths and repo.fs.exists(\n default_params\n ):\n fs_paths.append(default_params)\n return params, fs_paths\n\n\n@error_handler\ndef _read_fs_path(fs, fs_path, **kwargs):\n suffix = fs.path.suffix(fs_path).lower()\n loader = LOADERS[suffix]\n return loader(fs_path, fs=fs)\n\n\ndef _read_params(\n repo,\n params,\n params_fs_paths,\n deps=False,\n onerror: Optional[Callable] = None,\n stages: Optional[Iterable[str]] = None,\n):\n res: Dict[str, Dict] = defaultdict(lambda: defaultdict(dict))\n fs_paths = copy(params_fs_paths)\n\n if deps or stages:\n for param in params:\n if stages and param.stage.addressing not in stages:\n continue\n params_dict = error_handler(param.read_params)(\n onerror=onerror, flatten=False\n )\n if params_dict:\n name = os.sep.join(repo.fs.path.relparts(param.fs_path))\n res[name][\"data\"].update(params_dict[\"data\"])\n if name in fs_paths:\n fs_paths.remove(name)\n else:\n fs_paths += [param.fs_path for param in params]\n\n for fs_path in fs_paths:\n from_path = _read_fs_path(repo.fs, fs_path, onerror=onerror)\n if from_path:\n name = os.sep.join(repo.fs.path.relparts(fs_path))\n res[name] = from_path\n\n return res\n\n\ndef _collect_vars(repo, params, stages=None) -> Dict:\n vars_params: Dict[str, Dict] = defaultdict(dict)\n\n for stage in repo.index.stages:\n if isinstance(stage, PipelineStage) and stage.tracked_vars:\n if stages and stage.addressing not in stages:\n continue\n for file, vars_ in stage.tracked_vars.items():\n # `params` file are shown regardless of `tracked` or not\n # to reduce noise and duplication, they are skipped\n if file in params:\n continue\n\n name = os.sep.join(repo.fs.path.parts(file))\n vars_params[name].update(vars_)\n return vars_params\n\n\n@locked\ndef show(\n repo,\n revs=None,\n targets=None,\n deps=False,\n onerror: Callable = None,\n stages=None,\n):\n if onerror is None:\n onerror = onerror_collect\n res = {}\n\n targets = ensure_list(targets)\n targets = [repo.dvcfs.from_os_path(target) for target in targets]\n\n for branch in repo.brancher(revs=revs):\n params = error_handler(_gather_params)(\n repo=repo,\n rev=branch,\n targets=targets,\n deps=deps,\n onerror=onerror,\n stages=stages,\n )\n\n if params:\n res[branch] = params\n\n # Hide workspace params if they are the same as in the active branch\n try:\n active_branch = repo.scm.active_branch()\n except (SCMError, NoSCMError):\n # SCMError - detached head\n # NoSCMError - no repo case\n pass\n else:\n if res.get(\"workspace\") == res.get(active_branch):\n res.pop(\"workspace\", None)\n\n errored = errored_revisions(res)\n if errored:\n ui.error_write(\n \"DVC failed to load some parameters for following revisions:\"\n f\" '{', '.join(errored)}'.\"\n )\n\n return res\n\n\ndef _gather_params(\n repo, rev, targets=None, deps=False, onerror=None, stages=None\n):\n param_outs, params_fs_paths = _collect_configs(\n repo, rev, targets=targets, duplicates=deps or stages\n )\n params = _read_params(\n repo,\n params=param_outs,\n params_fs_paths=params_fs_paths,\n deps=deps,\n onerror=onerror,\n stages=stages,\n )\n vars_params = _collect_vars(repo, params, stages=stages)\n\n # NOTE: only those that are not added as a ParamDependency are\n # included so we don't need to recursively merge them yet.\n for key, vals in vars_params.items():\n params[key][\"data\"] = vals\n return params\n", "path": "dvc/repo/params/show.py"}]}
| 2,447 | 347 |
gh_patches_debug_9551
|
rasdani/github-patches
|
git_diff
|
airctic__icevision-539
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
EfficientDet images_size has to be divisible by 128
## 📓 Documentation Update
**What part of documentation was unclear or wrong?**
It has to be clear that the image size for the efficientdet model has to be divisible by 128
**Describe the solution you'd like**
Add this information to the `efficientdet/model.py` docstring and also make it explicit in the tutorials that use efficientdet.
</issue>
<code>
[start of icevision/models/efficientdet/model.py]
1 __all__ = ["model"]
2
3 from icevision.imports import *
4 from icevision.utils import *
5 from effdet import get_efficientdet_config, EfficientDet, DetBenchTrain, unwrap_bench
6 from effdet import create_model_from_config
7 from effdet.efficientdet import HeadNet
8
9
10 def model(
11 model_name: str, num_classes: int, img_size: int, pretrained: bool = True
12 ) -> nn.Module:
13 """Creates the efficientdet model specified by `model_name`.
14
15 The model implementation is by Ross Wightman, original repo
16 [here](https://github.com/rwightman/efficientdet-pytorch).
17
18 # Arguments
19 model_name: Specifies the model to create. For pretrained models, check
20 [this](https://github.com/rwightman/efficientdet-pytorch#models) table.
21 num_classes: Number of classes of your dataset (including background).
22 img_size: Image size that will be fed to the model. Must be squared and
23 divisible by 64.
24 pretrained: If True, use a pretrained backbone (on COCO).
25
26 # Returns
27 A PyTorch model.
28 """
29 config = get_efficientdet_config(model_name=model_name)
30 config.image_size = (img_size, img_size) if isinstance(img_size, int) else img_size
31
32 model_bench = create_model_from_config(
33 config,
34 bench_task="train",
35 bench_labeler=True,
36 num_classes=num_classes,
37 pretrained=pretrained,
38 )
39
40 # TODO: Break down param groups for backbone
41 def param_groups_fn(model: nn.Module) -> List[List[nn.Parameter]]:
42 unwrapped = unwrap_bench(model)
43
44 layers = [
45 unwrapped.backbone,
46 unwrapped.fpn,
47 nn.Sequential(unwrapped.class_net, unwrapped.box_net),
48 ]
49 param_groups = [list(layer.parameters()) for layer in layers]
50 check_all_model_params_in_groups2(model, param_groups)
51
52 return param_groups
53
54 model_bench.param_groups = MethodType(param_groups_fn, model_bench)
55
56 return model_bench
57
[end of icevision/models/efficientdet/model.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/icevision/models/efficientdet/model.py b/icevision/models/efficientdet/model.py
--- a/icevision/models/efficientdet/model.py
+++ b/icevision/models/efficientdet/model.py
@@ -20,7 +20,7 @@
[this](https://github.com/rwightman/efficientdet-pytorch#models) table.
num_classes: Number of classes of your dataset (including background).
img_size: Image size that will be fed to the model. Must be squared and
- divisible by 64.
+ divisible by 128.
pretrained: If True, use a pretrained backbone (on COCO).
# Returns
|
{"golden_diff": "diff --git a/icevision/models/efficientdet/model.py b/icevision/models/efficientdet/model.py\n--- a/icevision/models/efficientdet/model.py\n+++ b/icevision/models/efficientdet/model.py\n@@ -20,7 +20,7 @@\n [this](https://github.com/rwightman/efficientdet-pytorch#models) table.\n num_classes: Number of classes of your dataset (including background).\n img_size: Image size that will be fed to the model. Must be squared and\n- divisible by 64.\n+ divisible by 128.\n pretrained: If True, use a pretrained backbone (on COCO).\n \n # Returns\n", "issue": "EfficientDet images_size has to be divisible by 128\n## \ud83d\udcd3 Documentation Update\r\n**What part of documentation was unclear or wrong?**\r\nIt has to be clear that the image size for the efficientdet model has to be divisible by 128\r\n\r\n**Describe the solution you'd like**\r\nAdd this information to the `efficientdet/model.py` docstring and also make it explicit in the tutorials that use efficientdet.\r\n\r\n\r\n\n", "before_files": [{"content": "__all__ = [\"model\"]\n\nfrom icevision.imports import *\nfrom icevision.utils import *\nfrom effdet import get_efficientdet_config, EfficientDet, DetBenchTrain, unwrap_bench\nfrom effdet import create_model_from_config\nfrom effdet.efficientdet import HeadNet\n\n\ndef model(\n model_name: str, num_classes: int, img_size: int, pretrained: bool = True\n) -> nn.Module:\n \"\"\"Creates the efficientdet model specified by `model_name`.\n\n The model implementation is by Ross Wightman, original repo\n [here](https://github.com/rwightman/efficientdet-pytorch).\n\n # Arguments\n model_name: Specifies the model to create. For pretrained models, check\n [this](https://github.com/rwightman/efficientdet-pytorch#models) table.\n num_classes: Number of classes of your dataset (including background).\n img_size: Image size that will be fed to the model. Must be squared and\n divisible by 64.\n pretrained: If True, use a pretrained backbone (on COCO).\n\n # Returns\n A PyTorch model.\n \"\"\"\n config = get_efficientdet_config(model_name=model_name)\n config.image_size = (img_size, img_size) if isinstance(img_size, int) else img_size\n\n model_bench = create_model_from_config(\n config,\n bench_task=\"train\",\n bench_labeler=True,\n num_classes=num_classes,\n pretrained=pretrained,\n )\n\n # TODO: Break down param groups for backbone\n def param_groups_fn(model: nn.Module) -> List[List[nn.Parameter]]:\n unwrapped = unwrap_bench(model)\n\n layers = [\n unwrapped.backbone,\n unwrapped.fpn,\n nn.Sequential(unwrapped.class_net, unwrapped.box_net),\n ]\n param_groups = [list(layer.parameters()) for layer in layers]\n check_all_model_params_in_groups2(model, param_groups)\n\n return param_groups\n\n model_bench.param_groups = MethodType(param_groups_fn, model_bench)\n\n return model_bench\n", "path": "icevision/models/efficientdet/model.py"}]}
| 1,198 | 153 |
gh_patches_debug_22145
|
rasdani/github-patches
|
git_diff
|
huggingface__transformers-7035
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
non-interactive transformers-cli upload?
# 🚀 Feature request
Currently, `transformers-cli upload` works only interactively due to its prompt:
`Proceed? [Y/n]`
After running the updated model conversion, I would like to be able to do:
```
cd data
transformers-cli upload fsmt-wmt19-ru-en
transformers-cli upload fsmt-wmt19-en-ru
transformers-cli upload fsmt-wmt19-de-en
transformers-cli upload fsmt-wmt19-en-de
cd -
```
But this won't work:
Would it be possible to add a `-y` override?
Alternatively, would it be possible to give it all dirs to upload in one command?
```
transformers-cli upload fsmt-wmt19-ru-en fsmt-wmt19-en-ru fsmt-wmt19-de-en fsmt-wmt19-en-de
```
## Motivation
I have been re-uploading 4 x 1.1GB models on a relatively slow connection, and I have to be around to hit Y for each one of them, which is very counter-productive, as I have to go back and re-check whether each upload has been completed. I can probably code some shell expect script to feed it automatically, but this defeats the purpose.
Thank you!
</issue>
<code>
[start of src/transformers/commands/user.py]
1 import os
2 import sys
3 from argparse import ArgumentParser
4 from getpass import getpass
5 from typing import List, Union
6
7 from requests.exceptions import HTTPError
8 from transformers.commands import BaseTransformersCLICommand
9 from transformers.hf_api import HfApi, HfFolder
10
11
12 UPLOAD_MAX_FILES = 15
13
14
15 class UserCommands(BaseTransformersCLICommand):
16 @staticmethod
17 def register_subcommand(parser: ArgumentParser):
18 login_parser = parser.add_parser("login", help="Log in using the same credentials as on huggingface.co")
19 login_parser.set_defaults(func=lambda args: LoginCommand(args))
20 whoami_parser = parser.add_parser("whoami", help="Find out which huggingface.co account you are logged in as.")
21 whoami_parser.set_defaults(func=lambda args: WhoamiCommand(args))
22 logout_parser = parser.add_parser("logout", help="Log out")
23 logout_parser.set_defaults(func=lambda args: LogoutCommand(args))
24 # s3
25 s3_parser = parser.add_parser("s3", help="{ls, rm} Commands to interact with the files you upload on S3.")
26 s3_subparsers = s3_parser.add_subparsers(help="s3 related commands")
27 ls_parser = s3_subparsers.add_parser("ls")
28 ls_parser.add_argument("--organization", type=str, help="Optional: organization namespace.")
29 ls_parser.set_defaults(func=lambda args: ListObjsCommand(args))
30 rm_parser = s3_subparsers.add_parser("rm")
31 rm_parser.add_argument("filename", type=str, help="individual object filename to delete from S3.")
32 rm_parser.add_argument("--organization", type=str, help="Optional: organization namespace.")
33 rm_parser.set_defaults(func=lambda args: DeleteObjCommand(args))
34 # upload
35 upload_parser = parser.add_parser("upload", help="Upload a model to S3.")
36 upload_parser.add_argument(
37 "path", type=str, help="Local path of the model folder or individual file to upload."
38 )
39 upload_parser.add_argument("--organization", type=str, help="Optional: organization namespace.")
40 upload_parser.add_argument(
41 "--filename", type=str, default=None, help="Optional: override individual object filename on S3."
42 )
43 upload_parser.set_defaults(func=lambda args: UploadCommand(args))
44
45
46 class ANSI:
47 """
48 Helper for en.wikipedia.org/wiki/ANSI_escape_code
49 """
50
51 _bold = "\u001b[1m"
52 _red = "\u001b[31m"
53 _reset = "\u001b[0m"
54
55 @classmethod
56 def bold(cls, s):
57 return "{}{}{}".format(cls._bold, s, cls._reset)
58
59 @classmethod
60 def red(cls, s):
61 return "{}{}{}".format(cls._bold + cls._red, s, cls._reset)
62
63
64 class BaseUserCommand:
65 def __init__(self, args):
66 self.args = args
67 self._api = HfApi()
68
69
70 class LoginCommand(BaseUserCommand):
71 def run(self):
72 print(
73 """
74 _| _| _| _| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _|_|_|_| _|_| _|_|_| _|_|_|_|
75 _| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
76 _|_|_|_| _| _| _| _|_| _| _|_| _| _| _| _| _| _|_| _|_|_| _|_|_|_| _| _|_|_|
77 _| _| _| _| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
78 _| _| _|_| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _| _| _| _|_|_| _|_|_|_|
79
80 """
81 )
82 username = input("Username: ")
83 password = getpass()
84 try:
85 token = self._api.login(username, password)
86 except HTTPError as e:
87 # probably invalid credentials, display error message.
88 print(e)
89 print(ANSI.red(e.response.text))
90 exit(1)
91 HfFolder.save_token(token)
92 print("Login successful")
93 print("Your token:", token, "\n")
94 print("Your token has been saved to", HfFolder.path_token)
95
96
97 class WhoamiCommand(BaseUserCommand):
98 def run(self):
99 token = HfFolder.get_token()
100 if token is None:
101 print("Not logged in")
102 exit()
103 try:
104 user, orgs = self._api.whoami(token)
105 print(user)
106 if orgs:
107 print(ANSI.bold("orgs: "), ",".join(orgs))
108 except HTTPError as e:
109 print(e)
110 print(ANSI.red(e.response.text))
111 exit(1)
112
113
114 class LogoutCommand(BaseUserCommand):
115 def run(self):
116 token = HfFolder.get_token()
117 if token is None:
118 print("Not logged in")
119 exit()
120 HfFolder.delete_token()
121 self._api.logout(token)
122 print("Successfully logged out.")
123
124
125 class ListObjsCommand(BaseUserCommand):
126 def tabulate(self, rows: List[List[Union[str, int]]], headers: List[str]) -> str:
127 """
128 Inspired by:
129 stackoverflow.com/a/8356620/593036
130 stackoverflow.com/questions/9535954/printing-lists-as-tabular-data
131 """
132 col_widths = [max(len(str(x)) for x in col) for col in zip(*rows, headers)]
133 row_format = ("{{:{}}} " * len(headers)).format(*col_widths)
134 lines = []
135 lines.append(row_format.format(*headers))
136 lines.append(row_format.format(*["-" * w for w in col_widths]))
137 for row in rows:
138 lines.append(row_format.format(*row))
139 return "\n".join(lines)
140
141 def run(self):
142 token = HfFolder.get_token()
143 if token is None:
144 print("Not logged in")
145 exit(1)
146 try:
147 objs = self._api.list_objs(token, organization=self.args.organization)
148 except HTTPError as e:
149 print(e)
150 print(ANSI.red(e.response.text))
151 exit(1)
152 if len(objs) == 0:
153 print("No shared file yet")
154 exit()
155 rows = [[obj.filename, obj.LastModified, obj.ETag, obj.Size] for obj in objs]
156 print(self.tabulate(rows, headers=["Filename", "LastModified", "ETag", "Size"]))
157
158
159 class DeleteObjCommand(BaseUserCommand):
160 def run(self):
161 token = HfFolder.get_token()
162 if token is None:
163 print("Not logged in")
164 exit(1)
165 try:
166 self._api.delete_obj(token, filename=self.args.filename, organization=self.args.organization)
167 except HTTPError as e:
168 print(e)
169 print(ANSI.red(e.response.text))
170 exit(1)
171 print("Done")
172
173
174 class UploadCommand(BaseUserCommand):
175 def walk_dir(self, rel_path):
176 """
177 Recursively list all files in a folder.
178 """
179 entries: List[os.DirEntry] = list(os.scandir(rel_path))
180 files = [(os.path.join(os.getcwd(), f.path), f.path) for f in entries if f.is_file()] # (filepath, filename)
181 for f in entries:
182 if f.is_dir():
183 files += self.walk_dir(f.path)
184 return files
185
186 def run(self):
187 token = HfFolder.get_token()
188 if token is None:
189 print("Not logged in")
190 exit(1)
191 local_path = os.path.abspath(self.args.path)
192 if os.path.isdir(local_path):
193 if self.args.filename is not None:
194 raise ValueError("Cannot specify a filename override when uploading a folder.")
195 rel_path = os.path.basename(local_path)
196 files = self.walk_dir(rel_path)
197 elif os.path.isfile(local_path):
198 filename = self.args.filename if self.args.filename is not None else os.path.basename(local_path)
199 files = [(local_path, filename)]
200 else:
201 raise ValueError("Not a valid file or directory: {}".format(local_path))
202
203 if sys.platform == "win32":
204 files = [(filepath, filename.replace(os.sep, "/")) for filepath, filename in files]
205
206 if len(files) > UPLOAD_MAX_FILES:
207 print(
208 "About to upload {} files to S3. This is probably wrong. Please filter files before uploading.".format(
209 ANSI.bold(len(files))
210 )
211 )
212 exit(1)
213
214 user, _ = self._api.whoami(token)
215 namespace = self.args.organization if self.args.organization is not None else user
216
217 for filepath, filename in files:
218 print(
219 "About to upload file {} to S3 under filename {} and namespace {}".format(
220 ANSI.bold(filepath), ANSI.bold(filename), ANSI.bold(namespace)
221 )
222 )
223
224 choice = input("Proceed? [Y/n] ").lower()
225 if not (choice == "" or choice == "y" or choice == "yes"):
226 print("Abort")
227 exit()
228 print(ANSI.bold("Uploading... This might take a while if files are large"))
229 for filepath, filename in files:
230 try:
231 access_url = self._api.presign_and_upload(
232 token=token, filename=filename, filepath=filepath, organization=self.args.organization
233 )
234 except HTTPError as e:
235 print(e)
236 print(ANSI.red(e.response.text))
237 exit(1)
238 print("Your file now lives at:")
239 print(access_url)
240
[end of src/transformers/commands/user.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/transformers/commands/user.py b/src/transformers/commands/user.py
--- a/src/transformers/commands/user.py
+++ b/src/transformers/commands/user.py
@@ -40,6 +40,7 @@
upload_parser.add_argument(
"--filename", type=str, default=None, help="Optional: override individual object filename on S3."
)
+ upload_parser.add_argument("-y", "--yes", action="store_true", help="Optional: answer Yes to the prompt")
upload_parser.set_defaults(func=lambda args: UploadCommand(args))
@@ -221,10 +222,11 @@
)
)
- choice = input("Proceed? [Y/n] ").lower()
- if not (choice == "" or choice == "y" or choice == "yes"):
- print("Abort")
- exit()
+ if not self.args.yes:
+ choice = input("Proceed? [Y/n] ").lower()
+ if not (choice == "" or choice == "y" or choice == "yes"):
+ print("Abort")
+ exit()
print(ANSI.bold("Uploading... This might take a while if files are large"))
for filepath, filename in files:
try:
|
{"golden_diff": "diff --git a/src/transformers/commands/user.py b/src/transformers/commands/user.py\n--- a/src/transformers/commands/user.py\n+++ b/src/transformers/commands/user.py\n@@ -40,6 +40,7 @@\n upload_parser.add_argument(\n \"--filename\", type=str, default=None, help=\"Optional: override individual object filename on S3.\"\n )\n+ upload_parser.add_argument(\"-y\", \"--yes\", action=\"store_true\", help=\"Optional: answer Yes to the prompt\")\n upload_parser.set_defaults(func=lambda args: UploadCommand(args))\n \n \n@@ -221,10 +222,11 @@\n )\n )\n \n- choice = input(\"Proceed? [Y/n] \").lower()\n- if not (choice == \"\" or choice == \"y\" or choice == \"yes\"):\n- print(\"Abort\")\n- exit()\n+ if not self.args.yes:\n+ choice = input(\"Proceed? [Y/n] \").lower()\n+ if not (choice == \"\" or choice == \"y\" or choice == \"yes\"):\n+ print(\"Abort\")\n+ exit()\n print(ANSI.bold(\"Uploading... This might take a while if files are large\"))\n for filepath, filename in files:\n try:\n", "issue": "non-interactive transformers-cli upload?\n# \ud83d\ude80 Feature request\r\n\r\nCurrently, `transformers-cli upload` works only interactively due to its prompt:\r\n`Proceed? [Y/n]`\r\n\r\nAfter running the updated model conversion, I would like to be able to do:\r\n```\r\ncd data\r\ntransformers-cli upload fsmt-wmt19-ru-en\r\ntransformers-cli upload fsmt-wmt19-en-ru\r\ntransformers-cli upload fsmt-wmt19-de-en\r\ntransformers-cli upload fsmt-wmt19-en-de\r\ncd -\r\n```\r\nBut this won't work:\r\n\r\nWould it be possible to add a `-y` override?\r\n\r\nAlternatively, would it be possible to give it all dirs to upload in one command?\r\n```\r\ntransformers-cli upload fsmt-wmt19-ru-en fsmt-wmt19-en-ru fsmt-wmt19-de-en fsmt-wmt19-en-de\r\n```\r\n\r\n## Motivation\r\n\r\nI have been re-uploading 4 x 1.1GB models on a relatively slow connection, and I have to be around to hit Y for each one of them, which is very counter-productive, as I have to go back and re-check whether each upload has been completed. I can probably code some shell expect script to feed it automatically, but this defeats the purpose.\r\n\r\nThank you!\r\n\n", "before_files": [{"content": "import os\nimport sys\nfrom argparse import ArgumentParser\nfrom getpass import getpass\nfrom typing import List, Union\n\nfrom requests.exceptions import HTTPError\nfrom transformers.commands import BaseTransformersCLICommand\nfrom transformers.hf_api import HfApi, HfFolder\n\n\nUPLOAD_MAX_FILES = 15\n\n\nclass UserCommands(BaseTransformersCLICommand):\n @staticmethod\n def register_subcommand(parser: ArgumentParser):\n login_parser = parser.add_parser(\"login\", help=\"Log in using the same credentials as on huggingface.co\")\n login_parser.set_defaults(func=lambda args: LoginCommand(args))\n whoami_parser = parser.add_parser(\"whoami\", help=\"Find out which huggingface.co account you are logged in as.\")\n whoami_parser.set_defaults(func=lambda args: WhoamiCommand(args))\n logout_parser = parser.add_parser(\"logout\", help=\"Log out\")\n logout_parser.set_defaults(func=lambda args: LogoutCommand(args))\n # s3\n s3_parser = parser.add_parser(\"s3\", help=\"{ls, rm} Commands to interact with the files you upload on S3.\")\n s3_subparsers = s3_parser.add_subparsers(help=\"s3 related commands\")\n ls_parser = s3_subparsers.add_parser(\"ls\")\n ls_parser.add_argument(\"--organization\", type=str, help=\"Optional: organization namespace.\")\n ls_parser.set_defaults(func=lambda args: ListObjsCommand(args))\n rm_parser = s3_subparsers.add_parser(\"rm\")\n rm_parser.add_argument(\"filename\", type=str, help=\"individual object filename to delete from S3.\")\n rm_parser.add_argument(\"--organization\", type=str, help=\"Optional: organization namespace.\")\n rm_parser.set_defaults(func=lambda args: DeleteObjCommand(args))\n # upload\n upload_parser = parser.add_parser(\"upload\", help=\"Upload a model to S3.\")\n upload_parser.add_argument(\n \"path\", type=str, help=\"Local path of the model folder or individual file to upload.\"\n )\n upload_parser.add_argument(\"--organization\", type=str, help=\"Optional: organization namespace.\")\n upload_parser.add_argument(\n \"--filename\", type=str, default=None, help=\"Optional: override individual object filename on S3.\"\n )\n upload_parser.set_defaults(func=lambda args: UploadCommand(args))\n\n\nclass ANSI:\n \"\"\"\n Helper for en.wikipedia.org/wiki/ANSI_escape_code\n \"\"\"\n\n _bold = \"\\u001b[1m\"\n _red = \"\\u001b[31m\"\n _reset = \"\\u001b[0m\"\n\n @classmethod\n def bold(cls, s):\n return \"{}{}{}\".format(cls._bold, s, cls._reset)\n\n @classmethod\n def red(cls, s):\n return \"{}{}{}\".format(cls._bold + cls._red, s, cls._reset)\n\n\nclass BaseUserCommand:\n def __init__(self, args):\n self.args = args\n self._api = HfApi()\n\n\nclass LoginCommand(BaseUserCommand):\n def run(self):\n print(\n \"\"\"\n _| _| _| _| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _|_|_|_| _|_| _|_|_| _|_|_|_|\n _| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|\n _|_|_|_| _| _| _| _|_| _| _|_| _| _| _| _| _| _|_| _|_|_| _|_|_|_| _| _|_|_|\n _| _| _| _| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|\n _| _| _|_| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _| _| _| _|_|_| _|_|_|_|\n\n \"\"\"\n )\n username = input(\"Username: \")\n password = getpass()\n try:\n token = self._api.login(username, password)\n except HTTPError as e:\n # probably invalid credentials, display error message.\n print(e)\n print(ANSI.red(e.response.text))\n exit(1)\n HfFolder.save_token(token)\n print(\"Login successful\")\n print(\"Your token:\", token, \"\\n\")\n print(\"Your token has been saved to\", HfFolder.path_token)\n\n\nclass WhoamiCommand(BaseUserCommand):\n def run(self):\n token = HfFolder.get_token()\n if token is None:\n print(\"Not logged in\")\n exit()\n try:\n user, orgs = self._api.whoami(token)\n print(user)\n if orgs:\n print(ANSI.bold(\"orgs: \"), \",\".join(orgs))\n except HTTPError as e:\n print(e)\n print(ANSI.red(e.response.text))\n exit(1)\n\n\nclass LogoutCommand(BaseUserCommand):\n def run(self):\n token = HfFolder.get_token()\n if token is None:\n print(\"Not logged in\")\n exit()\n HfFolder.delete_token()\n self._api.logout(token)\n print(\"Successfully logged out.\")\n\n\nclass ListObjsCommand(BaseUserCommand):\n def tabulate(self, rows: List[List[Union[str, int]]], headers: List[str]) -> str:\n \"\"\"\n Inspired by:\n stackoverflow.com/a/8356620/593036\n stackoverflow.com/questions/9535954/printing-lists-as-tabular-data\n \"\"\"\n col_widths = [max(len(str(x)) for x in col) for col in zip(*rows, headers)]\n row_format = (\"{{:{}}} \" * len(headers)).format(*col_widths)\n lines = []\n lines.append(row_format.format(*headers))\n lines.append(row_format.format(*[\"-\" * w for w in col_widths]))\n for row in rows:\n lines.append(row_format.format(*row))\n return \"\\n\".join(lines)\n\n def run(self):\n token = HfFolder.get_token()\n if token is None:\n print(\"Not logged in\")\n exit(1)\n try:\n objs = self._api.list_objs(token, organization=self.args.organization)\n except HTTPError as e:\n print(e)\n print(ANSI.red(e.response.text))\n exit(1)\n if len(objs) == 0:\n print(\"No shared file yet\")\n exit()\n rows = [[obj.filename, obj.LastModified, obj.ETag, obj.Size] for obj in objs]\n print(self.tabulate(rows, headers=[\"Filename\", \"LastModified\", \"ETag\", \"Size\"]))\n\n\nclass DeleteObjCommand(BaseUserCommand):\n def run(self):\n token = HfFolder.get_token()\n if token is None:\n print(\"Not logged in\")\n exit(1)\n try:\n self._api.delete_obj(token, filename=self.args.filename, organization=self.args.organization)\n except HTTPError as e:\n print(e)\n print(ANSI.red(e.response.text))\n exit(1)\n print(\"Done\")\n\n\nclass UploadCommand(BaseUserCommand):\n def walk_dir(self, rel_path):\n \"\"\"\n Recursively list all files in a folder.\n \"\"\"\n entries: List[os.DirEntry] = list(os.scandir(rel_path))\n files = [(os.path.join(os.getcwd(), f.path), f.path) for f in entries if f.is_file()] # (filepath, filename)\n for f in entries:\n if f.is_dir():\n files += self.walk_dir(f.path)\n return files\n\n def run(self):\n token = HfFolder.get_token()\n if token is None:\n print(\"Not logged in\")\n exit(1)\n local_path = os.path.abspath(self.args.path)\n if os.path.isdir(local_path):\n if self.args.filename is not None:\n raise ValueError(\"Cannot specify a filename override when uploading a folder.\")\n rel_path = os.path.basename(local_path)\n files = self.walk_dir(rel_path)\n elif os.path.isfile(local_path):\n filename = self.args.filename if self.args.filename is not None else os.path.basename(local_path)\n files = [(local_path, filename)]\n else:\n raise ValueError(\"Not a valid file or directory: {}\".format(local_path))\n\n if sys.platform == \"win32\":\n files = [(filepath, filename.replace(os.sep, \"/\")) for filepath, filename in files]\n\n if len(files) > UPLOAD_MAX_FILES:\n print(\n \"About to upload {} files to S3. This is probably wrong. Please filter files before uploading.\".format(\n ANSI.bold(len(files))\n )\n )\n exit(1)\n\n user, _ = self._api.whoami(token)\n namespace = self.args.organization if self.args.organization is not None else user\n\n for filepath, filename in files:\n print(\n \"About to upload file {} to S3 under filename {} and namespace {}\".format(\n ANSI.bold(filepath), ANSI.bold(filename), ANSI.bold(namespace)\n )\n )\n\n choice = input(\"Proceed? [Y/n] \").lower()\n if not (choice == \"\" or choice == \"y\" or choice == \"yes\"):\n print(\"Abort\")\n exit()\n print(ANSI.bold(\"Uploading... This might take a while if files are large\"))\n for filepath, filename in files:\n try:\n access_url = self._api.presign_and_upload(\n token=token, filename=filename, filepath=filepath, organization=self.args.organization\n )\n except HTTPError as e:\n print(e)\n print(ANSI.red(e.response.text))\n exit(1)\n print(\"Your file now lives at:\")\n print(access_url)\n", "path": "src/transformers/commands/user.py"}]}
| 3,569 | 278 |
gh_patches_debug_18239
|
rasdani/github-patches
|
git_diff
|
pymodbus-dev__pymodbus-413
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Pymodbus 2.2.0rc2 failing to read registers/coils
<!--
Please use the Pymodbus gitter channel at https://gitter.im/pymodbus_dev/Lobby or Stack Overflow(tag [pymodbus](https://stackoverflow.com/questions/tagged/pymodbus) for
support questions.
Before opening a new issue, make sure you do the following:
* check that your issue isn't already filed: https://github.com/riptideio/pymodbus/issues
* prepare a short, runnable example that reproduce the issue with the latest development version of Pymodbus
-->
### Versions
* Python: 2.7.12
* OS: OSX
* Pymodbus: 2.2.0rc2
* Modbus Hardware (if used): NA
### Pymodbus Specific
* Server: tcp/rtu/ascii - sync/async --> all
* Client: tcp/rtu/ascii - sync/async --> all
### Description
Basic operations on TCP to read coils/registers failing with `[Input/Output] No Response received from the remote unit/Unable to decode response`.
The same code works just fine in earlier versions of pymodbus (2.2.0rc1 and below)
### Code and Logs
```python
# code and logs here.
```
</issue>
<code>
[start of doc/conf.py]
1 # -*- coding: utf-8 -*-
2 #
3 # PyModbus documentation build configuration file, created by
4 # sphinx-quickstart on Wed Dec 20 12:31:10 2017.
5 #
6 # This file is execfile()d with the current directory set to its
7 # containing dir.
8 #
9 # Note that not all possible configuration values are present in this
10 # autogenerated file.
11 #
12 # All configuration values have a default; values that are commented out
13 # serve to show the default.
14
15 # If extensions (or modules to document with autodoc) are in another directory,
16 # add these directories to sys.path here. If the directory is relative to the
17 # documentation root, use os.path.abspath to make it absolute, like shown here.
18 #
19 import os
20 import sys
21 import recommonmark
22 from recommonmark.parser import CommonMarkParser
23 from recommonmark.transform import AutoStructify
24 from pymodbus import __version__
25 parent_dir = os.path.abspath(os.pardir)
26 # examples = os.path.join(parent_dir, "examples")
27 example_contrib = os.path.join(parent_dir, "examples/contrib")
28 example_common = os.path.join(parent_dir, "examples/common")
29 example_gui = os.path.join(parent_dir, "examples/gui")
30
31 sys.path.insert(0, os.path.abspath(os.pardir))
32 sys.path.append(example_common)
33 sys.path.append(example_contrib)
34 sys.path.append(example_gui)
35 # sys.path.extend([examples, example_common, example_contrib, example_gui])
36 # sys.path.insert(0, os.path.abspath('../'))
37
38 github_doc_root = 'https://github.com/riptideio/pymodbus/tree/master/doc/'
39 # -- General configuration ------------------------------------------------
40
41 # If your documentation needs a minimal Sphinx version, state it here.
42 #
43 # needs_sphinx = '1.0'
44
45 # Add any Sphinx extension module names here, as strings. They can be
46 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
47 # ones.
48
49 #extensions = ['sphinx.ext.autodoc', 'm2r', 'recommonmark']
50 extensions = ['sphinx.ext.autodoc', 'm2r']
51
52 # Add any paths that contain templates here, relative to this directory.
53 templates_path = ['_templates']
54
55 # The suffix(es) of source filenames.
56 # You can specify multiple suffix as a list of string:
57 #
58 #source_parsers = {
59 # '.md': CommonMarkParser,
60 #}
61
62 source_suffix = ['.rst', '.md']
63 # source_suffix = '.rst'
64
65 # The master toctree document.
66 master_doc = 'index'
67
68 # General information about the project.
69 project = u'PyModbus'
70 copyright = u'2017, Sanjay'
71 author = u'Sanjay'
72
73 # The version info for the project you're documenting, acts as replacement for
74 # |version| and |release|, also used in various other places throughout the
75 # built documents.
76 #
77 # The short X.Y version.
78 version = __version__
79 # The full version, including alpha/beta/rc tags.
80 release = __version__
81
82 # The language for content autogenerated by Sphinx. Refer to documentation
83 # for a list of supported languages.
84 #
85 # This is also used if you do content translation via gettext catalogs.
86 # Usually you set "language" from the command line for these cases.
87 language = None
88
89 # List of patterns, relative to source directory, that match files and
90 # directories to ignore when looking for source files.
91 # This patterns also effect to html_static_path and html_extra_path
92 exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
93
94 # The name of the Pygments (syntax highlighting) style to use.
95 pygments_style = 'sphinx'
96
97 # If true, `todo` and `todoList` produce output, else they produce nothing.
98 todo_include_todos = False
99
100
101 # -- Options for HTML output ----------------------------------------------
102
103 # The theme to use for HTML and HTML Help pages. See the documentation for
104 # a list of builtin themes.
105 #
106 html_theme = 'sphinx_rtd_theme'
107
108 # Theme options are theme-specific and customize the look and feel of a theme
109 # further. For a list of options available for each theme, see the
110 # documentation.
111 #
112 # html_theme_options = {}
113
114 # Add any paths that contain custom static files (such as style sheets) here,
115 # relative to this directory. They are copied after the builtin static files,
116 # so a file named "default.css" will overwrite the builtin "default.css".
117 # html_static_path = ['_static']
118 html_static_path = []
119
120 # Custom sidebar templates, must be a dictionary that maps document names
121 # to template names.
122 #
123 # This is required for the alabaster theme
124 # refs: http://alabaster.readthedocs.io/en/latest/installation.html#sidebars
125 html_sidebars = {
126 '**': [
127 'relations.html', # needs 'show_related': True theme option to display
128 'searchbox.html',
129 ]
130 }
131
132
133 # -- Options for HTMLHelp output ------------------------------------------
134
135 # Output file base name for HTML help builder.
136 htmlhelp_basename = 'PyModbusdoc'
137
138
139 # -- Options for LaTeX output ---------------------------------------------
140
141 latex_elements = {
142 # The paper size ('letterpaper' or 'a4paper').
143 #
144 # 'papersize': 'letterpaper',
145
146 # The font size ('10pt', '11pt' or '12pt').
147 #
148 # 'pointsize': '10pt',
149
150 # Additional stuff for the LaTeX preamble.
151 #
152 # 'preamble': '',
153
154 # Latex figure (float) alignment
155 #
156 # 'figure_align': 'htbp',
157 }
158
159 # Grouping the document tree into LaTeX files. List of tuples
160 # (source start file, target name, title,
161 # author, documentclass [howto, manual, or own class]).
162 latex_documents = [
163 (master_doc, 'PyModbus.tex', u'PyModbus Documentation',
164 u'Sanjay', 'manual'),
165 ]
166
167
168 # -- Options for manual page output ---------------------------------------
169
170 # One entry per manual page. List of tuples
171 # (source start file, name, description, authors, manual section).
172 man_pages = [
173 (master_doc, 'pymodbus', u'PyModbus Documentation',
174 [author], 1)
175 ]
176
177
178 # -- Options for Texinfo output -------------------------------------------
179
180 # Grouping the document tree into Texinfo files. List of tuples
181 # (source start file, target name, title, author,
182 # dir menu entry, description, category)
183 texinfo_documents = [
184 (master_doc, 'PyModbus', u'PyModbus Documentation',
185 author, 'PyModbus', 'One line description of project.',
186 'Miscellaneous'),
187 ]
188
189
190 def setup(app):
191 app.add_config_value('recommonmark_config', {
192 'url_resolver': lambda url: github_doc_root + url,
193 'auto_toc_tree_section': 'Contents',
194 }, True)
195 app.add_transform(AutoStructify)
196
197
[end of doc/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/doc/conf.py b/doc/conf.py
--- a/doc/conf.py
+++ b/doc/conf.py
@@ -45,7 +45,9 @@
# Add any Sphinx extension module names here, as strings. They can be
# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
# ones.
-extensions = ['sphinx.ext.autodoc', 'm2r', 'recommonmark']
+
+#extensions = ['sphinx.ext.autodoc', 'm2r', 'recommonmark']
+extensions = ['sphinx.ext.autodoc', 'm2r']
# Add any paths that contain templates here, relative to this directory.
templates_path = ['_templates']
@@ -53,9 +55,9 @@
# The suffix(es) of source filenames.
# You can specify multiple suffix as a list of string:
#
-source_parsers = {
- '.md': CommonMarkParser,
-}
+#source_parsers = {
+# '.md': CommonMarkParser,
+#}
source_suffix = ['.rst', '.md']
# source_suffix = '.rst'
|
{"golden_diff": "diff --git a/doc/conf.py b/doc/conf.py\n--- a/doc/conf.py\n+++ b/doc/conf.py\n@@ -45,7 +45,9 @@\n # Add any Sphinx extension module names here, as strings. They can be\n # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n # ones.\n-extensions = ['sphinx.ext.autodoc', 'm2r', 'recommonmark']\n+\n+#extensions = ['sphinx.ext.autodoc', 'm2r', 'recommonmark']\n+extensions = ['sphinx.ext.autodoc', 'm2r']\n \n # Add any paths that contain templates here, relative to this directory.\n templates_path = ['_templates']\n@@ -53,9 +55,9 @@\n # The suffix(es) of source filenames.\n # You can specify multiple suffix as a list of string:\n #\n-source_parsers = {\n- '.md': CommonMarkParser,\n-}\n+#source_parsers = {\n+# '.md': CommonMarkParser,\n+#}\n \n source_suffix = ['.rst', '.md']\n # source_suffix = '.rst'\n", "issue": "Pymodbus 2.2.0rc2 failing to read registers/coils\n<!--\r\nPlease use the Pymodbus gitter channel at https://gitter.im/pymodbus_dev/Lobby or Stack Overflow(tag [pymodbus](https://stackoverflow.com/questions/tagged/pymodbus) for\r\nsupport questions.\r\n\r\nBefore opening a new issue, make sure you do the following:\r\n * check that your issue isn't already filed: https://github.com/riptideio/pymodbus/issues\r\n * prepare a short, runnable example that reproduce the issue with the latest development version of Pymodbus\r\n-->\r\n\r\n### Versions\r\n\r\n* Python: 2.7.12\r\n* OS: OSX\r\n* Pymodbus: 2.2.0rc2\r\n* Modbus Hardware (if used): NA\r\n\r\n### Pymodbus Specific\r\n* Server: tcp/rtu/ascii - sync/async --> all\r\n* Client: tcp/rtu/ascii - sync/async --> all\r\n\r\n### Description\r\nBasic operations on TCP to read coils/registers failing with `[Input/Output] No Response received from the remote unit/Unable to decode response`.\r\n The same code works just fine in earlier versions of pymodbus (2.2.0rc1 and below)\r\n### Code and Logs\r\n\r\n```python\r\n # code and logs here.\r\n\r\n```\r\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# PyModbus documentation build configuration file, created by\n# sphinx-quickstart on Wed Dec 20 12:31:10 2017.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\nimport sys\nimport recommonmark\nfrom recommonmark.parser import CommonMarkParser\nfrom recommonmark.transform import AutoStructify\nfrom pymodbus import __version__\nparent_dir = os.path.abspath(os.pardir)\n# examples = os.path.join(parent_dir, \"examples\")\nexample_contrib = os.path.join(parent_dir, \"examples/contrib\")\nexample_common = os.path.join(parent_dir, \"examples/common\")\nexample_gui = os.path.join(parent_dir, \"examples/gui\")\n\nsys.path.insert(0, os.path.abspath(os.pardir))\nsys.path.append(example_common)\nsys.path.append(example_contrib)\nsys.path.append(example_gui)\n# sys.path.extend([examples, example_common, example_contrib, example_gui])\n# sys.path.insert(0, os.path.abspath('../'))\n\ngithub_doc_root = 'https://github.com/riptideio/pymodbus/tree/master/doc/'\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\n\n#extensions = ['sphinx.ext.autodoc', 'm2r', 'recommonmark']\nextensions = ['sphinx.ext.autodoc', 'm2r']\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n#source_parsers = {\n# '.md': CommonMarkParser,\n#}\n\nsource_suffix = ['.rst', '.md']\n# source_suffix = '.rst'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = u'PyModbus'\ncopyright = u'2017, Sanjay'\nauthor = u'Sanjay'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = __version__\n# The full version, including alpha/beta/rc tags.\nrelease = __version__\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This patterns also effect to html_static_path and html_extra_path\nexclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = False\n\n\n# -- Options for HTML output ----------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = 'sphinx_rtd_theme'\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#\n# html_theme_options = {}\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\n# html_static_path = ['_static']\nhtml_static_path = []\n\n# Custom sidebar templates, must be a dictionary that maps document names\n# to template names.\n#\n# This is required for the alabaster theme\n# refs: http://alabaster.readthedocs.io/en/latest/installation.html#sidebars\nhtml_sidebars = {\n '**': [\n 'relations.html', # needs 'show_related': True theme option to display\n 'searchbox.html',\n ]\n}\n\n\n# -- Options for HTMLHelp output ------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'PyModbusdoc'\n\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, 'PyModbus.tex', u'PyModbus Documentation',\n u'Sanjay', 'manual'),\n]\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (master_doc, 'pymodbus', u'PyModbus Documentation',\n [author], 1)\n]\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (master_doc, 'PyModbus', u'PyModbus Documentation',\n author, 'PyModbus', 'One line description of project.',\n 'Miscellaneous'),\n]\n\n\ndef setup(app):\n app.add_config_value('recommonmark_config', {\n 'url_resolver': lambda url: github_doc_root + url,\n 'auto_toc_tree_section': 'Contents',\n }, True)\n app.add_transform(AutoStructify)\n\n", "path": "doc/conf.py"}]}
| 2,811 | 237 |
gh_patches_debug_17672
|
rasdani/github-patches
|
git_diff
|
facebookresearch__hydra-234
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Better error message if config structure passed to instantiate is invalid.
# 🐛 Bug
In [common patterns#creating objects](https://cli.dev/docs/patterns/objects), if the `params` are mistakenly valued with a single string, the [`instantiate`](https://github.com/facebookresearch/hydra/blob/cb7904c666b34a53e09194993a0dd7b10fd97c99/hydra/utils.py#L44-L53) function exists with the error mentioned in "Stack trace/error messages":
This is fine to some extent, which is do you (Hydra team) aim at providing this kind of output messages?
<!-- A clear and concise description of what the bug is. -->
## To reproduce
** Minimal Code/Config snippet to reproduce **
Set `params` to `bug_report` as in:
```YAML
class: ...
params: bug_report
```
** Stack trace/error message **
```
> AttributeError: 'str' object has no attribute 'merge_with'
[2019-10-16 02:25:21,592][hydra.utils][ERROR] - Error instantiating [[OBJECT_NAME]] : 'str' object has no attribute 'merge_with'
```
**Optional video**
If applicable, record a short [video](https://asciinema.org) with to help explain your problem.
You can also
## Expected Behavior
<!-- A clear and concise description of what you expected to happen. -->
I expect to have some sort of an error message explaining that `params` should be a collection of values where [[TYPE]] was provided.
## System information
- <!-- Hydra Version --> Hydra Version: 0.9.0
- <!-- Operating system --> Operating System: Arch Linux
## Additional context
If you confirm that this should be fixed, I've already implemented the solution (IMO).
Better error message if config structure passed to instantiate is invalid.
# 🐛 Bug
In [common patterns#creating objects](https://cli.dev/docs/patterns/objects), if the `params` are mistakenly valued with a single string, the [`instantiate`](https://github.com/facebookresearch/hydra/blob/cb7904c666b34a53e09194993a0dd7b10fd97c99/hydra/utils.py#L44-L53) function exists with the error mentioned in "Stack trace/error messages":
This is fine to some extent, which is do you (Hydra team) aim at providing this kind of output messages?
<!-- A clear and concise description of what the bug is. -->
## To reproduce
** Minimal Code/Config snippet to reproduce **
Set `params` to `bug_report` as in:
```YAML
class: ...
params: bug_report
```
** Stack trace/error message **
```
> AttributeError: 'str' object has no attribute 'merge_with'
[2019-10-16 02:25:21,592][hydra.utils][ERROR] - Error instantiating [[OBJECT_NAME]] : 'str' object has no attribute 'merge_with'
```
**Optional video**
If applicable, record a short [video](https://asciinema.org) with to help explain your problem.
You can also
## Expected Behavior
<!-- A clear and concise description of what you expected to happen. -->
I expect to have some sort of an error message explaining that `params` should be a collection of values where [[TYPE]] was provided.
## System information
- <!-- Hydra Version --> Hydra Version: 0.9.0
- <!-- Operating system --> Operating System: Arch Linux
## Additional context
If you confirm that this should be fixed, I've already implemented the solution (IMO).
</issue>
<code>
[start of hydra/utils.py]
1 # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
2 import logging.config
3
4 from omegaconf import OmegaConf
5
6 # pylint: disable=C0103
7 log = logging.getLogger(__name__)
8
9
10 def get_method(path):
11 return get_class(path)
12
13
14 def get_class(path):
15 try:
16 from importlib import import_module
17
18 module_path, _, class_name = path.rpartition(".")
19 mod = import_module(module_path)
20 try:
21 klass = getattr(mod, class_name)
22 except AttributeError:
23 raise ImportError(
24 "Class {} is not in module {}".format(class_name, module_path)
25 )
26 return klass
27 except ValueError as e:
28 log.error("Error initializing class " + path)
29 raise e
30
31
32 def get_static_method(full_method_name):
33 try:
34 spl = full_method_name.split(".")
35 method_name = spl.pop()
36 class_name = ".".join(spl)
37 clz = get_class(class_name)
38 return getattr(clz, method_name)
39 except Exception as e:
40 log.error("Error getting static method {} : {}".format(full_method_name, e))
41 raise e
42
43
44 def instantiate(config, *args, **kwargs):
45 assert config is not None, "Input config is None"
46 try:
47 clazz = get_class(config["class"])
48 params = config.params if "params" in config else OmegaConf.create()
49 params.merge_with(OmegaConf.create(kwargs))
50 return clazz(*args, **params)
51 except Exception as e:
52 log.error("Error instantiating {} : {}".format(config["class"], e))
53 raise e
54
[end of hydra/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/hydra/utils.py b/hydra/utils.py
--- a/hydra/utils.py
+++ b/hydra/utils.py
@@ -1,7 +1,7 @@
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
import logging.config
-from omegaconf import OmegaConf
+from omegaconf import OmegaConf, DictConfig
# pylint: disable=C0103
log = logging.getLogger(__name__)
@@ -46,6 +46,11 @@
try:
clazz = get_class(config["class"])
params = config.params if "params" in config else OmegaConf.create()
+ assert isinstance(
+ params, DictConfig
+ ), "Input config params are expected to be a mapping, found {}".format(
+ type(config.params)
+ )
params.merge_with(OmegaConf.create(kwargs))
return clazz(*args, **params)
except Exception as e:
|
{"golden_diff": "diff --git a/hydra/utils.py b/hydra/utils.py\n--- a/hydra/utils.py\n+++ b/hydra/utils.py\n@@ -1,7 +1,7 @@\n # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\n import logging.config\n \n-from omegaconf import OmegaConf\n+from omegaconf import OmegaConf, DictConfig\n \n # pylint: disable=C0103\n log = logging.getLogger(__name__)\n@@ -46,6 +46,11 @@\n try:\n clazz = get_class(config[\"class\"])\n params = config.params if \"params\" in config else OmegaConf.create()\n+ assert isinstance(\n+ params, DictConfig\n+ ), \"Input config params are expected to be a mapping, found {}\".format(\n+ type(config.params)\n+ )\n params.merge_with(OmegaConf.create(kwargs))\n return clazz(*args, **params)\n except Exception as e:\n", "issue": "Better error message if config structure passed to instantiate is invalid.\n# \ud83d\udc1b Bug\r\n\r\nIn [common patterns#creating objects](https://cli.dev/docs/patterns/objects), if the `params` are mistakenly valued with a single string, the [`instantiate`](https://github.com/facebookresearch/hydra/blob/cb7904c666b34a53e09194993a0dd7b10fd97c99/hydra/utils.py#L44-L53) function exists with the error mentioned in \"Stack trace/error messages\":\r\n\r\nThis is fine to some extent, which is do you (Hydra team) aim at providing this kind of output messages? \r\n\r\n<!-- A clear and concise description of what the bug is. -->\r\n\r\n## To reproduce\r\n\r\n** Minimal Code/Config snippet to reproduce **\r\n\r\nSet `params` to `bug_report` as in:\r\n\r\n```YAML\r\nclass: ...\r\nparams: bug_report\r\n```\r\n\r\n** Stack trace/error message **\r\n```\r\n> AttributeError: 'str' object has no attribute 'merge_with'\r\n[2019-10-16 02:25:21,592][hydra.utils][ERROR] - Error instantiating [[OBJECT_NAME]] : 'str' object has no attribute 'merge_with'\r\n```\r\n**Optional video**\r\nIf applicable, record a short [video](https://asciinema.org) with to help explain your problem.\r\nYou can also \r\n\r\n## Expected Behavior\r\n<!-- A clear and concise description of what you expected to happen. -->\r\n\r\nI expect to have some sort of an error message explaining that `params` should be a collection of values where [[TYPE]] was provided. \r\n \r\n## System information\r\n- <!-- Hydra Version --> Hydra Version: 0.9.0\r\n\r\n- <!-- Operating system --> Operating System: Arch Linux\r\n\r\n## Additional context\r\nIf you confirm that this should be fixed, I've already implemented the solution (IMO). \r\n\nBetter error message if config structure passed to instantiate is invalid.\n# \ud83d\udc1b Bug\r\n\r\nIn [common patterns#creating objects](https://cli.dev/docs/patterns/objects), if the `params` are mistakenly valued with a single string, the [`instantiate`](https://github.com/facebookresearch/hydra/blob/cb7904c666b34a53e09194993a0dd7b10fd97c99/hydra/utils.py#L44-L53) function exists with the error mentioned in \"Stack trace/error messages\":\r\n\r\nThis is fine to some extent, which is do you (Hydra team) aim at providing this kind of output messages? \r\n\r\n<!-- A clear and concise description of what the bug is. -->\r\n\r\n## To reproduce\r\n\r\n** Minimal Code/Config snippet to reproduce **\r\n\r\nSet `params` to `bug_report` as in:\r\n\r\n```YAML\r\nclass: ...\r\nparams: bug_report\r\n```\r\n\r\n** Stack trace/error message **\r\n```\r\n> AttributeError: 'str' object has no attribute 'merge_with'\r\n[2019-10-16 02:25:21,592][hydra.utils][ERROR] - Error instantiating [[OBJECT_NAME]] : 'str' object has no attribute 'merge_with'\r\n```\r\n**Optional video**\r\nIf applicable, record a short [video](https://asciinema.org) with to help explain your problem.\r\nYou can also \r\n\r\n## Expected Behavior\r\n<!-- A clear and concise description of what you expected to happen. -->\r\n\r\nI expect to have some sort of an error message explaining that `params` should be a collection of values where [[TYPE]] was provided. \r\n \r\n## System information\r\n- <!-- Hydra Version --> Hydra Version: 0.9.0\r\n\r\n- <!-- Operating system --> Operating System: Arch Linux\r\n\r\n## Additional context\r\nIf you confirm that this should be fixed, I've already implemented the solution (IMO). \r\n\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\nimport logging.config\n\nfrom omegaconf import OmegaConf\n\n# pylint: disable=C0103\nlog = logging.getLogger(__name__)\n\n\ndef get_method(path):\n return get_class(path)\n\n\ndef get_class(path):\n try:\n from importlib import import_module\n\n module_path, _, class_name = path.rpartition(\".\")\n mod = import_module(module_path)\n try:\n klass = getattr(mod, class_name)\n except AttributeError:\n raise ImportError(\n \"Class {} is not in module {}\".format(class_name, module_path)\n )\n return klass\n except ValueError as e:\n log.error(\"Error initializing class \" + path)\n raise e\n\n\ndef get_static_method(full_method_name):\n try:\n spl = full_method_name.split(\".\")\n method_name = spl.pop()\n class_name = \".\".join(spl)\n clz = get_class(class_name)\n return getattr(clz, method_name)\n except Exception as e:\n log.error(\"Error getting static method {} : {}\".format(full_method_name, e))\n raise e\n\n\ndef instantiate(config, *args, **kwargs):\n assert config is not None, \"Input config is None\"\n try:\n clazz = get_class(config[\"class\"])\n params = config.params if \"params\" in config else OmegaConf.create()\n params.merge_with(OmegaConf.create(kwargs))\n return clazz(*args, **params)\n except Exception as e:\n log.error(\"Error instantiating {} : {}\".format(config[\"class\"], e))\n raise e\n", "path": "hydra/utils.py"}]}
| 1,814 | 203 |
gh_patches_debug_64358
|
rasdani/github-patches
|
git_diff
|
PyGithub__PyGithub-1922
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Hashable classes
Hello people!
I wonder if entities like Repository, Issue, PullRequest and etc. could be hashable in future, i.e. using them in structures like dictionary or sets would be possible?
</issue>
<code>
[start of github/GithubObject.py]
1 ############################ Copyrights and license ############################
2 # #
3 # Copyright 2012 Vincent Jacques <[email protected]> #
4 # Copyright 2012 Zearin <[email protected]> #
5 # Copyright 2013 AKFish <[email protected]> #
6 # Copyright 2013 Vincent Jacques <[email protected]> #
7 # Copyright 2014 Andrew Scheller <[email protected]> #
8 # Copyright 2014 Vincent Jacques <[email protected]> #
9 # Copyright 2016 Jakub Wilk <[email protected]> #
10 # Copyright 2016 Jannis Gebauer <[email protected]> #
11 # Copyright 2016 Peter Buckley <[email protected]> #
12 # Copyright 2016 Sam Corbett <[email protected]> #
13 # Copyright 2018 sfdye <[email protected]> #
14 # #
15 # This file is part of PyGithub. #
16 # http://pygithub.readthedocs.io/ #
17 # #
18 # PyGithub is free software: you can redistribute it and/or modify it under #
19 # the terms of the GNU Lesser General Public License as published by the Free #
20 # Software Foundation, either version 3 of the License, or (at your option) #
21 # any later version. #
22 # #
23 # PyGithub is distributed in the hope that it will be useful, but WITHOUT ANY #
24 # WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS #
25 # FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public License for more #
26 # details. #
27 # #
28 # You should have received a copy of the GNU Lesser General Public License #
29 # along with PyGithub. If not, see <http://www.gnu.org/licenses/>. #
30 # #
31 ################################################################################
32
33 import datetime
34 from operator import itemgetter
35
36 from . import Consts, GithubException
37
38
39 class _NotSetType:
40 def __repr__(self):
41 return "NotSet"
42
43 value = None
44
45
46 NotSet = _NotSetType()
47
48
49 class _ValuedAttribute:
50 def __init__(self, value):
51 self.value = value
52
53
54 class _BadAttribute:
55 def __init__(self, value, expectedType, exception=None):
56 self.__value = value
57 self.__expectedType = expectedType
58 self.__exception = exception
59
60 @property
61 def value(self):
62 raise GithubException.BadAttributeException(
63 self.__value, self.__expectedType, self.__exception
64 )
65
66
67 class GithubObject:
68 """
69 Base class for all classes representing objects returned by the API.
70 """
71
72 """
73 A global debug flag to enable header validation by requester for all objects
74 """
75 CHECK_AFTER_INIT_FLAG = False
76
77 @classmethod
78 def setCheckAfterInitFlag(cls, flag):
79 cls.CHECK_AFTER_INIT_FLAG = flag
80
81 def __init__(self, requester, headers, attributes, completed):
82 self._requester = requester
83 self._initAttributes()
84 self._storeAndUseAttributes(headers, attributes)
85
86 # Ask requester to do some checking, for debug and test purpose
87 # Since it's most handy to access and kinda all-knowing
88 if self.CHECK_AFTER_INIT_FLAG: # pragma no branch (Flag always set in tests)
89 requester.check_me(self)
90
91 def _storeAndUseAttributes(self, headers, attributes):
92 # Make sure headers are assigned before calling _useAttributes
93 # (Some derived classes will use headers in _useAttributes)
94 self._headers = headers
95 self._rawData = attributes
96 self._useAttributes(attributes)
97
98 @property
99 def raw_data(self):
100 """
101 :type: dict
102 """
103 self._completeIfNeeded()
104 return self._rawData
105
106 @property
107 def raw_headers(self):
108 """
109 :type: dict
110 """
111 self._completeIfNeeded()
112 return self._headers
113
114 @staticmethod
115 def _parentUrl(url):
116 return "/".join(url.split("/")[:-1])
117
118 @staticmethod
119 def __makeSimpleAttribute(value, type):
120 if value is None or isinstance(value, type):
121 return _ValuedAttribute(value)
122 else:
123 return _BadAttribute(value, type)
124
125 @staticmethod
126 def __makeSimpleListAttribute(value, type):
127 if isinstance(value, list) and all(
128 isinstance(element, type) for element in value
129 ):
130 return _ValuedAttribute(value)
131 else:
132 return _BadAttribute(value, [type])
133
134 @staticmethod
135 def __makeTransformedAttribute(value, type, transform):
136 if value is None:
137 return _ValuedAttribute(None)
138 elif isinstance(value, type):
139 try:
140 return _ValuedAttribute(transform(value))
141 except Exception as e:
142 return _BadAttribute(value, type, e)
143 else:
144 return _BadAttribute(value, type)
145
146 @staticmethod
147 def _makeStringAttribute(value):
148 return GithubObject.__makeSimpleAttribute(value, str)
149
150 @staticmethod
151 def _makeIntAttribute(value):
152 return GithubObject.__makeSimpleAttribute(value, int)
153
154 @staticmethod
155 def _makeFloatAttribute(value):
156 return GithubObject.__makeSimpleAttribute(value, float)
157
158 @staticmethod
159 def _makeBoolAttribute(value):
160 return GithubObject.__makeSimpleAttribute(value, bool)
161
162 @staticmethod
163 def _makeDictAttribute(value):
164 return GithubObject.__makeSimpleAttribute(value, dict)
165
166 @staticmethod
167 def _makeTimestampAttribute(value):
168 return GithubObject.__makeTransformedAttribute(
169 value, int, datetime.datetime.utcfromtimestamp
170 )
171
172 @staticmethod
173 def _makeDatetimeAttribute(value):
174 def parseDatetime(s):
175 if (
176 len(s) == 24
177 ): # pragma no branch (This branch was used only when creating a download)
178 # The Downloads API has been removed. I'm keeping this branch because I have no mean
179 # to check if it's really useless now.
180 return datetime.datetime.strptime(
181 s, "%Y-%m-%dT%H:%M:%S.000Z"
182 ) # pragma no cover (This branch was used only when creating a download)
183 elif len(s) >= 25:
184 return datetime.datetime.strptime(s[:19], "%Y-%m-%dT%H:%M:%S") + (
185 1 if s[19] == "-" else -1
186 ) * datetime.timedelta(hours=int(s[20:22]), minutes=int(s[23:25]))
187 else:
188 return datetime.datetime.strptime(s, "%Y-%m-%dT%H:%M:%SZ")
189
190 return GithubObject.__makeTransformedAttribute(value, str, parseDatetime)
191
192 def _makeClassAttribute(self, klass, value):
193 return GithubObject.__makeTransformedAttribute(
194 value,
195 dict,
196 lambda value: klass(self._requester, self._headers, value, completed=False),
197 )
198
199 @staticmethod
200 def _makeListOfStringsAttribute(value):
201 return GithubObject.__makeSimpleListAttribute(value, str)
202
203 @staticmethod
204 def _makeListOfIntsAttribute(value):
205 return GithubObject.__makeSimpleListAttribute(value, int)
206
207 @staticmethod
208 def _makeListOfDictsAttribute(value):
209 return GithubObject.__makeSimpleListAttribute(value, dict)
210
211 @staticmethod
212 def _makeListOfListOfStringsAttribute(value):
213 return GithubObject.__makeSimpleListAttribute(value, list)
214
215 def _makeListOfClassesAttribute(self, klass, value):
216 if isinstance(value, list) and all(
217 isinstance(element, dict) for element in value
218 ):
219 return _ValuedAttribute(
220 [
221 klass(self._requester, self._headers, element, completed=False)
222 for element in value
223 ]
224 )
225 else:
226 return _BadAttribute(value, [dict])
227
228 def _makeDictOfStringsToClassesAttribute(self, klass, value):
229 if isinstance(value, dict) and all(
230 isinstance(key, str) and isinstance(element, dict)
231 for key, element in value.items()
232 ):
233 return _ValuedAttribute(
234 {
235 key: klass(self._requester, self._headers, element, completed=False)
236 for key, element in value.items()
237 }
238 )
239 else:
240 return _BadAttribute(value, {str: dict})
241
242 @property
243 def etag(self):
244 """
245 :type: str
246 """
247 return self._headers.get(Consts.RES_ETAG)
248
249 @property
250 def last_modified(self):
251 """
252 :type: str
253 """
254 return self._headers.get(Consts.RES_LAST_MODIFIED)
255
256 def get__repr__(self, params):
257 """
258 Converts the object to a nicely printable string.
259 """
260
261 def format_params(params):
262 items = list(params.items())
263 for k, v in sorted(items, key=itemgetter(0), reverse=True):
264 if isinstance(v, bytes):
265 v = v.decode("utf-8")
266 if isinstance(v, str):
267 v = f'"{v}"'
268 yield f"{k}={v}"
269
270 return "{class_name}({params})".format(
271 class_name=self.__class__.__name__,
272 params=", ".join(list(format_params(params))),
273 )
274
275
276 class NonCompletableGithubObject(GithubObject):
277 def _completeIfNeeded(self):
278 pass
279
280
281 class CompletableGithubObject(GithubObject):
282 def __init__(self, requester, headers, attributes, completed):
283 super().__init__(requester, headers, attributes, completed)
284 self.__completed = completed
285
286 def __eq__(self, other):
287 return other.__class__ is self.__class__ and other._url.value == self._url.value
288
289 def __ne__(self, other):
290 return not self == other
291
292 def _completeIfNotSet(self, value):
293 if value is NotSet:
294 self._completeIfNeeded()
295
296 def _completeIfNeeded(self):
297 if not self.__completed:
298 self.__complete()
299
300 def __complete(self):
301 if self._url.value is None:
302 raise GithubException.IncompletableObject(
303 400, "Returned object contains no URL", None
304 )
305 headers, data = self._requester.requestJsonAndCheck("GET", self._url.value)
306 self._storeAndUseAttributes(headers, data)
307 self.__completed = True
308
309 def update(self, additional_headers=None):
310 """
311 Check and update the object with conditional request
312 :rtype: Boolean value indicating whether the object is changed
313 """
314 conditionalRequestHeader = dict()
315 if self.etag is not None:
316 conditionalRequestHeader[Consts.REQ_IF_NONE_MATCH] = self.etag
317 if self.last_modified is not None:
318 conditionalRequestHeader[Consts.REQ_IF_MODIFIED_SINCE] = self.last_modified
319 if additional_headers is not None:
320 conditionalRequestHeader.update(additional_headers)
321
322 status, responseHeaders, output = self._requester.requestJson(
323 "GET", self._url.value, headers=conditionalRequestHeader
324 )
325 if status == 304:
326 return False
327 else:
328 headers, data = self._requester._Requester__check(
329 status, responseHeaders, output
330 )
331 self._storeAndUseAttributes(headers, data)
332 self.__completed = True
333 return True
334
[end of github/GithubObject.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/github/GithubObject.py b/github/GithubObject.py
--- a/github/GithubObject.py
+++ b/github/GithubObject.py
@@ -286,6 +286,9 @@
def __eq__(self, other):
return other.__class__ is self.__class__ and other._url.value == self._url.value
+ def __hash__(self):
+ return hash(self._url.value)
+
def __ne__(self, other):
return not self == other
|
{"golden_diff": "diff --git a/github/GithubObject.py b/github/GithubObject.py\n--- a/github/GithubObject.py\n+++ b/github/GithubObject.py\n@@ -286,6 +286,9 @@\n def __eq__(self, other):\n return other.__class__ is self.__class__ and other._url.value == self._url.value\n \n+ def __hash__(self):\n+ return hash(self._url.value)\n+\n def __ne__(self, other):\n return not self == other\n", "issue": "Hashable classes\nHello people!\r\n\r\nI wonder if entities like Repository, Issue, PullRequest and etc. could be hashable in future, i.e. using them in structures like dictionary or sets would be possible?\n", "before_files": [{"content": "############################ Copyrights and license ############################\n# #\n# Copyright 2012 Vincent Jacques <[email protected]> #\n# Copyright 2012 Zearin <[email protected]> #\n# Copyright 2013 AKFish <[email protected]> #\n# Copyright 2013 Vincent Jacques <[email protected]> #\n# Copyright 2014 Andrew Scheller <[email protected]> #\n# Copyright 2014 Vincent Jacques <[email protected]> #\n# Copyright 2016 Jakub Wilk <[email protected]> #\n# Copyright 2016 Jannis Gebauer <[email protected]> #\n# Copyright 2016 Peter Buckley <[email protected]> #\n# Copyright 2016 Sam Corbett <[email protected]> #\n# Copyright 2018 sfdye <[email protected]> #\n# #\n# This file is part of PyGithub. #\n# http://pygithub.readthedocs.io/ #\n# #\n# PyGithub is free software: you can redistribute it and/or modify it under #\n# the terms of the GNU Lesser General Public License as published by the Free #\n# Software Foundation, either version 3 of the License, or (at your option) #\n# any later version. #\n# #\n# PyGithub is distributed in the hope that it will be useful, but WITHOUT ANY #\n# WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS #\n# FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public License for more #\n# details. #\n# #\n# You should have received a copy of the GNU Lesser General Public License #\n# along with PyGithub. If not, see <http://www.gnu.org/licenses/>. #\n# #\n################################################################################\n\nimport datetime\nfrom operator import itemgetter\n\nfrom . import Consts, GithubException\n\n\nclass _NotSetType:\n def __repr__(self):\n return \"NotSet\"\n\n value = None\n\n\nNotSet = _NotSetType()\n\n\nclass _ValuedAttribute:\n def __init__(self, value):\n self.value = value\n\n\nclass _BadAttribute:\n def __init__(self, value, expectedType, exception=None):\n self.__value = value\n self.__expectedType = expectedType\n self.__exception = exception\n\n @property\n def value(self):\n raise GithubException.BadAttributeException(\n self.__value, self.__expectedType, self.__exception\n )\n\n\nclass GithubObject:\n \"\"\"\n Base class for all classes representing objects returned by the API.\n \"\"\"\n\n \"\"\"\n A global debug flag to enable header validation by requester for all objects\n \"\"\"\n CHECK_AFTER_INIT_FLAG = False\n\n @classmethod\n def setCheckAfterInitFlag(cls, flag):\n cls.CHECK_AFTER_INIT_FLAG = flag\n\n def __init__(self, requester, headers, attributes, completed):\n self._requester = requester\n self._initAttributes()\n self._storeAndUseAttributes(headers, attributes)\n\n # Ask requester to do some checking, for debug and test purpose\n # Since it's most handy to access and kinda all-knowing\n if self.CHECK_AFTER_INIT_FLAG: # pragma no branch (Flag always set in tests)\n requester.check_me(self)\n\n def _storeAndUseAttributes(self, headers, attributes):\n # Make sure headers are assigned before calling _useAttributes\n # (Some derived classes will use headers in _useAttributes)\n self._headers = headers\n self._rawData = attributes\n self._useAttributes(attributes)\n\n @property\n def raw_data(self):\n \"\"\"\n :type: dict\n \"\"\"\n self._completeIfNeeded()\n return self._rawData\n\n @property\n def raw_headers(self):\n \"\"\"\n :type: dict\n \"\"\"\n self._completeIfNeeded()\n return self._headers\n\n @staticmethod\n def _parentUrl(url):\n return \"/\".join(url.split(\"/\")[:-1])\n\n @staticmethod\n def __makeSimpleAttribute(value, type):\n if value is None or isinstance(value, type):\n return _ValuedAttribute(value)\n else:\n return _BadAttribute(value, type)\n\n @staticmethod\n def __makeSimpleListAttribute(value, type):\n if isinstance(value, list) and all(\n isinstance(element, type) for element in value\n ):\n return _ValuedAttribute(value)\n else:\n return _BadAttribute(value, [type])\n\n @staticmethod\n def __makeTransformedAttribute(value, type, transform):\n if value is None:\n return _ValuedAttribute(None)\n elif isinstance(value, type):\n try:\n return _ValuedAttribute(transform(value))\n except Exception as e:\n return _BadAttribute(value, type, e)\n else:\n return _BadAttribute(value, type)\n\n @staticmethod\n def _makeStringAttribute(value):\n return GithubObject.__makeSimpleAttribute(value, str)\n\n @staticmethod\n def _makeIntAttribute(value):\n return GithubObject.__makeSimpleAttribute(value, int)\n\n @staticmethod\n def _makeFloatAttribute(value):\n return GithubObject.__makeSimpleAttribute(value, float)\n\n @staticmethod\n def _makeBoolAttribute(value):\n return GithubObject.__makeSimpleAttribute(value, bool)\n\n @staticmethod\n def _makeDictAttribute(value):\n return GithubObject.__makeSimpleAttribute(value, dict)\n\n @staticmethod\n def _makeTimestampAttribute(value):\n return GithubObject.__makeTransformedAttribute(\n value, int, datetime.datetime.utcfromtimestamp\n )\n\n @staticmethod\n def _makeDatetimeAttribute(value):\n def parseDatetime(s):\n if (\n len(s) == 24\n ): # pragma no branch (This branch was used only when creating a download)\n # The Downloads API has been removed. I'm keeping this branch because I have no mean\n # to check if it's really useless now.\n return datetime.datetime.strptime(\n s, \"%Y-%m-%dT%H:%M:%S.000Z\"\n ) # pragma no cover (This branch was used only when creating a download)\n elif len(s) >= 25:\n return datetime.datetime.strptime(s[:19], \"%Y-%m-%dT%H:%M:%S\") + (\n 1 if s[19] == \"-\" else -1\n ) * datetime.timedelta(hours=int(s[20:22]), minutes=int(s[23:25]))\n else:\n return datetime.datetime.strptime(s, \"%Y-%m-%dT%H:%M:%SZ\")\n\n return GithubObject.__makeTransformedAttribute(value, str, parseDatetime)\n\n def _makeClassAttribute(self, klass, value):\n return GithubObject.__makeTransformedAttribute(\n value,\n dict,\n lambda value: klass(self._requester, self._headers, value, completed=False),\n )\n\n @staticmethod\n def _makeListOfStringsAttribute(value):\n return GithubObject.__makeSimpleListAttribute(value, str)\n\n @staticmethod\n def _makeListOfIntsAttribute(value):\n return GithubObject.__makeSimpleListAttribute(value, int)\n\n @staticmethod\n def _makeListOfDictsAttribute(value):\n return GithubObject.__makeSimpleListAttribute(value, dict)\n\n @staticmethod\n def _makeListOfListOfStringsAttribute(value):\n return GithubObject.__makeSimpleListAttribute(value, list)\n\n def _makeListOfClassesAttribute(self, klass, value):\n if isinstance(value, list) and all(\n isinstance(element, dict) for element in value\n ):\n return _ValuedAttribute(\n [\n klass(self._requester, self._headers, element, completed=False)\n for element in value\n ]\n )\n else:\n return _BadAttribute(value, [dict])\n\n def _makeDictOfStringsToClassesAttribute(self, klass, value):\n if isinstance(value, dict) and all(\n isinstance(key, str) and isinstance(element, dict)\n for key, element in value.items()\n ):\n return _ValuedAttribute(\n {\n key: klass(self._requester, self._headers, element, completed=False)\n for key, element in value.items()\n }\n )\n else:\n return _BadAttribute(value, {str: dict})\n\n @property\n def etag(self):\n \"\"\"\n :type: str\n \"\"\"\n return self._headers.get(Consts.RES_ETAG)\n\n @property\n def last_modified(self):\n \"\"\"\n :type: str\n \"\"\"\n return self._headers.get(Consts.RES_LAST_MODIFIED)\n\n def get__repr__(self, params):\n \"\"\"\n Converts the object to a nicely printable string.\n \"\"\"\n\n def format_params(params):\n items = list(params.items())\n for k, v in sorted(items, key=itemgetter(0), reverse=True):\n if isinstance(v, bytes):\n v = v.decode(\"utf-8\")\n if isinstance(v, str):\n v = f'\"{v}\"'\n yield f\"{k}={v}\"\n\n return \"{class_name}({params})\".format(\n class_name=self.__class__.__name__,\n params=\", \".join(list(format_params(params))),\n )\n\n\nclass NonCompletableGithubObject(GithubObject):\n def _completeIfNeeded(self):\n pass\n\n\nclass CompletableGithubObject(GithubObject):\n def __init__(self, requester, headers, attributes, completed):\n super().__init__(requester, headers, attributes, completed)\n self.__completed = completed\n\n def __eq__(self, other):\n return other.__class__ is self.__class__ and other._url.value == self._url.value\n\n def __ne__(self, other):\n return not self == other\n\n def _completeIfNotSet(self, value):\n if value is NotSet:\n self._completeIfNeeded()\n\n def _completeIfNeeded(self):\n if not self.__completed:\n self.__complete()\n\n def __complete(self):\n if self._url.value is None:\n raise GithubException.IncompletableObject(\n 400, \"Returned object contains no URL\", None\n )\n headers, data = self._requester.requestJsonAndCheck(\"GET\", self._url.value)\n self._storeAndUseAttributes(headers, data)\n self.__completed = True\n\n def update(self, additional_headers=None):\n \"\"\"\n Check and update the object with conditional request\n :rtype: Boolean value indicating whether the object is changed\n \"\"\"\n conditionalRequestHeader = dict()\n if self.etag is not None:\n conditionalRequestHeader[Consts.REQ_IF_NONE_MATCH] = self.etag\n if self.last_modified is not None:\n conditionalRequestHeader[Consts.REQ_IF_MODIFIED_SINCE] = self.last_modified\n if additional_headers is not None:\n conditionalRequestHeader.update(additional_headers)\n\n status, responseHeaders, output = self._requester.requestJson(\n \"GET\", self._url.value, headers=conditionalRequestHeader\n )\n if status == 304:\n return False\n else:\n headers, data = self._requester._Requester__check(\n status, responseHeaders, output\n )\n self._storeAndUseAttributes(headers, data)\n self.__completed = True\n return True\n", "path": "github/GithubObject.py"}]}
| 3,993 | 111 |
gh_patches_debug_29306
|
rasdani/github-patches
|
git_diff
|
saleor__saleor-2827
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CustomJsonEncoder drops currency information from Money instance
Usually, we are using `settings.DEFAULT_CURRENCY` all over the place, however, there can be a bug, where `Money` is saved into `JSONField`, and `settings.DEFAULT_CURRENCY` changed meanwhile.
</issue>
<code>
[start of saleor/core/utils/json_serializer.py]
1 from django.core.serializers.json import (
2 Deserializer as JsonDeserializer, DjangoJSONEncoder,
3 Serializer as JsonSerializer)
4 from prices import Money
5
6
7 class Serializer(JsonSerializer):
8 def _init_options(self):
9 super()._init_options()
10 self.json_kwargs['cls'] = CustomJsonEncoder
11
12
13 class CustomJsonEncoder(DjangoJSONEncoder):
14 def default(self, obj):
15 if isinstance(obj, Money):
16 return obj.amount
17 return super().default(obj)
18
19
20 Deserializer = JsonDeserializer
21
[end of saleor/core/utils/json_serializer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/saleor/core/utils/json_serializer.py b/saleor/core/utils/json_serializer.py
--- a/saleor/core/utils/json_serializer.py
+++ b/saleor/core/utils/json_serializer.py
@@ -1,8 +1,12 @@
+import json
+
+from django.core.serializers.base import DeserializationError
from django.core.serializers.json import (
- Deserializer as JsonDeserializer, DjangoJSONEncoder,
- Serializer as JsonSerializer)
+ DjangoJSONEncoder, PythonDeserializer, Serializer as JsonSerializer)
from prices import Money
+MONEY_TYPE = 'Money'
+
class Serializer(JsonSerializer):
def _init_options(self):
@@ -13,8 +17,32 @@
class CustomJsonEncoder(DjangoJSONEncoder):
def default(self, obj):
if isinstance(obj, Money):
- return obj.amount
+ return {
+ '_type': MONEY_TYPE, 'amount': obj.amount,
+ 'currency': obj.currency}
return super().default(obj)
-Deserializer = JsonDeserializer
+def object_hook(obj):
+ if '_type' in obj and obj['_type'] == MONEY_TYPE:
+ return Money(obj['amount'], obj['currency'])
+ return obj
+
+
+def Deserializer(stream_or_string, **options):
+ """Deserialize a stream or string of JSON data. This is a slightly modified
+ copy of Django implementation with additional argument <object_hook> in
+ json.loads"""
+ if not isinstance(stream_or_string, (bytes, str)):
+ stream_or_string = stream_or_string.read()
+ if isinstance(stream_or_string, bytes):
+ stream_or_string = stream_or_string.decode()
+ try:
+ objects = json.loads(stream_or_string, object_hook=object_hook)
+ yield from PythonDeserializer(objects, **options)
+ except Exception as exc:
+ # ugly construction to overcome pylint's warning
+ # "The except handler raises immediately"
+ if isinstance(exc, (GeneratorExit, DeserializationError)):
+ raise
+ raise DeserializationError() from exc
|
{"golden_diff": "diff --git a/saleor/core/utils/json_serializer.py b/saleor/core/utils/json_serializer.py\n--- a/saleor/core/utils/json_serializer.py\n+++ b/saleor/core/utils/json_serializer.py\n@@ -1,8 +1,12 @@\n+import json\n+\n+from django.core.serializers.base import DeserializationError\n from django.core.serializers.json import (\n- Deserializer as JsonDeserializer, DjangoJSONEncoder,\n- Serializer as JsonSerializer)\n+ DjangoJSONEncoder, PythonDeserializer, Serializer as JsonSerializer)\n from prices import Money\n \n+MONEY_TYPE = 'Money'\n+\n \n class Serializer(JsonSerializer):\n def _init_options(self):\n@@ -13,8 +17,32 @@\n class CustomJsonEncoder(DjangoJSONEncoder):\n def default(self, obj):\n if isinstance(obj, Money):\n- return obj.amount\n+ return {\n+ '_type': MONEY_TYPE, 'amount': obj.amount,\n+ 'currency': obj.currency}\n return super().default(obj)\n \n \n-Deserializer = JsonDeserializer\n+def object_hook(obj):\n+ if '_type' in obj and obj['_type'] == MONEY_TYPE:\n+ return Money(obj['amount'], obj['currency'])\n+ return obj\n+\n+\n+def Deserializer(stream_or_string, **options):\n+ \"\"\"Deserialize a stream or string of JSON data. This is a slightly modified\n+ copy of Django implementation with additional argument <object_hook> in\n+ json.loads\"\"\"\n+ if not isinstance(stream_or_string, (bytes, str)):\n+ stream_or_string = stream_or_string.read()\n+ if isinstance(stream_or_string, bytes):\n+ stream_or_string = stream_or_string.decode()\n+ try:\n+ objects = json.loads(stream_or_string, object_hook=object_hook)\n+ yield from PythonDeserializer(objects, **options)\n+ except Exception as exc:\n+ # ugly construction to overcome pylint's warning\n+ # \"The except handler raises immediately\"\n+ if isinstance(exc, (GeneratorExit, DeserializationError)):\n+ raise\n+ raise DeserializationError() from exc\n", "issue": "CustomJsonEncoder drops currency information from Money instance\nUsually, we are using `settings.DEFAULT_CURRENCY` all over the place, however, there can be a bug, where `Money` is saved into `JSONField`, and `settings.DEFAULT_CURRENCY` changed meanwhile.\r\n\r\n\n", "before_files": [{"content": "from django.core.serializers.json import (\n Deserializer as JsonDeserializer, DjangoJSONEncoder,\n Serializer as JsonSerializer)\nfrom prices import Money\n\n\nclass Serializer(JsonSerializer):\n def _init_options(self):\n super()._init_options()\n self.json_kwargs['cls'] = CustomJsonEncoder\n\n\nclass CustomJsonEncoder(DjangoJSONEncoder):\n def default(self, obj):\n if isinstance(obj, Money):\n return obj.amount\n return super().default(obj)\n\n\nDeserializer = JsonDeserializer\n", "path": "saleor/core/utils/json_serializer.py"}]}
| 735 | 444 |
gh_patches_debug_36537
|
rasdani/github-patches
|
git_diff
|
scikit-image__scikit-image-1783
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
plot_hog.py results in strangely-looking figure in the gallery
Compare http://scikit-image.org/docs/dev/_images/plot_hog_1.png and http://scikit-image.org/docs/0.11.x/_images/plot_hog_1.png
I don't think the example changed, so it must be inside the hog functions or in one of the functions called by this function.
</issue>
<code>
[start of skimage/feature/_hog.py]
1 from __future__ import division
2 import numpy as np
3 from .._shared.utils import assert_nD
4 from . import _hoghistogram
5
6
7 def hog(image, orientations=9, pixels_per_cell=(8, 8),
8 cells_per_block=(3, 3), visualise=False, normalise=False):
9 """Extract Histogram of Oriented Gradients (HOG) for a given image.
10
11 Compute a Histogram of Oriented Gradients (HOG) by
12
13 1. (optional) global image normalisation
14 2. computing the gradient image in x and y
15 3. computing gradient histograms
16 4. normalising across blocks
17 5. flattening into a feature vector
18
19 Parameters
20 ----------
21 image : (M, N) ndarray
22 Input image (greyscale).
23 orientations : int
24 Number of orientation bins.
25 pixels_per_cell : 2 tuple (int, int)
26 Size (in pixels) of a cell.
27 cells_per_block : 2 tuple (int,int)
28 Number of cells in each block.
29 visualise : bool, optional
30 Also return an image of the HOG.
31 normalise : bool, optional
32 Apply power law compression to normalise the image before
33 processing.
34
35 Returns
36 -------
37 newarr : ndarray
38 HOG for the image as a 1D (flattened) array.
39 hog_image : ndarray (if visualise=True)
40 A visualisation of the HOG image.
41
42 References
43 ----------
44 * http://en.wikipedia.org/wiki/Histogram_of_oriented_gradients
45
46 * Dalal, N and Triggs, B, Histograms of Oriented Gradients for
47 Human Detection, IEEE Computer Society Conference on Computer
48 Vision and Pattern Recognition 2005 San Diego, CA, USA
49
50 """
51 image = np.atleast_2d(image)
52
53 """
54 The first stage applies an optional global image normalisation
55 equalisation that is designed to reduce the influence of illumination
56 effects. In practice we use gamma (power law) compression, either
57 computing the square root or the log of each colour channel.
58 Image texture strength is typically proportional to the local surface
59 illumination so this compression helps to reduce the effects of local
60 shadowing and illumination variations.
61 """
62
63 assert_nD(image, 2)
64
65 if normalise:
66 image = np.sqrt(image)
67
68 """
69 The second stage computes first order image gradients. These capture
70 contour, silhouette and some texture information, while providing
71 further resistance to illumination variations. The locally dominant
72 colour channel is used, which provides colour invariance to a large
73 extent. Variant methods may also include second order image derivatives,
74 which act as primitive bar detectors - a useful feature for capturing,
75 e.g. bar like structures in bicycles and limbs in humans.
76 """
77
78 if image.dtype.kind == 'u':
79 # convert uint image to float
80 # to avoid problems with subtracting unsigned numbers in np.diff()
81 image = image.astype('float')
82
83 gx = np.empty(image.shape, dtype=np.double)
84 gx[:, 0] = 0
85 gx[:, -1] = 0
86 gx[:, 1:-1] = image[:, 2:] - image[:, :-2]
87 gy = np.empty(image.shape, dtype=np.double)
88 gy[0, :] = 0
89 gy[-1, :] = 0
90 gy[1:-1, :] = image[2:, :] - image[:-2, :]
91
92 """
93 The third stage aims to produce an encoding that is sensitive to
94 local image content while remaining resistant to small changes in
95 pose or appearance. The adopted method pools gradient orientation
96 information locally in the same way as the SIFT [Lowe 2004]
97 feature. The image window is divided into small spatial regions,
98 called "cells". For each cell we accumulate a local 1-D histogram
99 of gradient or edge orientations over all the pixels in the
100 cell. This combined cell-level 1-D histogram forms the basic
101 "orientation histogram" representation. Each orientation histogram
102 divides the gradient angle range into a fixed number of
103 predetermined bins. The gradient magnitudes of the pixels in the
104 cell are used to vote into the orientation histogram.
105 """
106
107 sy, sx = image.shape
108 cx, cy = pixels_per_cell
109 bx, by = cells_per_block
110
111 n_cellsx = int(np.floor(sx // cx)) # number of cells in x
112 n_cellsy = int(np.floor(sy // cy)) # number of cells in y
113
114 # compute orientations integral images
115 orientation_histogram = np.zeros((n_cellsy, n_cellsx, orientations))
116
117 _hoghistogram.hog_histograms(gx, gy, cx, cy, sx, sy, n_cellsx, n_cellsy,
118 orientations, orientation_histogram)
119
120 # now for each cell, compute the histogram
121 hog_image = None
122
123 if visualise:
124 from .. import draw
125
126 radius = min(cx, cy) // 2 - 1
127 orientations_arr = np.arange(orientations)
128 dx_arr = radius * np.cos(orientations_arr / orientations * np.pi)
129 dy_arr = radius * np.sin(orientations_arr / orientations * np.pi)
130 cr2 = cy + cy
131 cc2 = cx + cx
132 hog_image = np.zeros((sy, sx), dtype=float)
133 for x in range(n_cellsx):
134 for y in range(n_cellsy):
135 for o, dx, dy in zip(orientations_arr, dx_arr, dy_arr):
136 centre = tuple([y * cr2 // 2, x * cc2 // 2])
137 rr, cc = draw.line(int(centre[0] - dx),
138 int(centre[1] + dy),
139 int(centre[0] + dx),
140 int(centre[1] - dy))
141 hog_image[rr, cc] += orientation_histogram[y, x, o]
142
143 """
144 The fourth stage computes normalisation, which takes local groups of
145 cells and contrast normalises their overall responses before passing
146 to next stage. Normalisation introduces better invariance to illumination,
147 shadowing, and edge contrast. It is performed by accumulating a measure
148 of local histogram "energy" over local groups of cells that we call
149 "blocks". The result is used to normalise each cell in the block.
150 Typically each individual cell is shared between several blocks, but
151 its normalisations are block dependent and thus different. The cell
152 thus appears several times in the final output vector with different
153 normalisations. This may seem redundant but it improves the performance.
154 We refer to the normalised block descriptors as Histogram of Oriented
155 Gradient (HOG) descriptors.
156 """
157
158 n_blocksx = (n_cellsx - bx) + 1
159 n_blocksy = (n_cellsy - by) + 1
160 normalised_blocks = np.zeros((n_blocksy, n_blocksx,
161 by, bx, orientations))
162
163 for x in range(n_blocksx):
164 for y in range(n_blocksy):
165 block = orientation_histogram[y:y + by, x:x + bx, :]
166 eps = 1e-5
167 normalised_blocks[y, x, :] = block / np.sqrt(block.sum() ** 2 + eps)
168
169 """
170 The final step collects the HOG descriptors from all blocks of a dense
171 overlapping grid of blocks covering the detection window into a combined
172 feature vector for use in the window classifier.
173 """
174
175 if visualise:
176 return normalised_blocks.ravel(), hog_image
177 else:
178 return normalised_blocks.ravel()
179
[end of skimage/feature/_hog.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/skimage/feature/_hog.py b/skimage/feature/_hog.py
--- a/skimage/feature/_hog.py
+++ b/skimage/feature/_hog.py
@@ -5,7 +5,8 @@
def hog(image, orientations=9, pixels_per_cell=(8, 8),
- cells_per_block=(3, 3), visualise=False, normalise=False):
+ cells_per_block=(3, 3), visualise=False, normalise=False,
+ feature_vector=True):
"""Extract Histogram of Oriented Gradients (HOG) for a given image.
Compute a Histogram of Oriented Gradients (HOG) by
@@ -31,6 +32,9 @@
normalise : bool, optional
Apply power law compression to normalise the image before
processing.
+ feature_vector : bool, optional
+ Return the data as a feature vector by calling .ravel() on the result
+ just before returning.
Returns
-------
@@ -127,13 +131,11 @@
orientations_arr = np.arange(orientations)
dx_arr = radius * np.cos(orientations_arr / orientations * np.pi)
dy_arr = radius * np.sin(orientations_arr / orientations * np.pi)
- cr2 = cy + cy
- cc2 = cx + cx
hog_image = np.zeros((sy, sx), dtype=float)
for x in range(n_cellsx):
for y in range(n_cellsy):
for o, dx, dy in zip(orientations_arr, dx_arr, dy_arr):
- centre = tuple([y * cr2 // 2, x * cc2 // 2])
+ centre = tuple([y * cy + cy // 2, x * cx + cx // 2])
rr, cc = draw.line(int(centre[0] - dx),
int(centre[1] + dy),
int(centre[0] + dx),
@@ -171,8 +173,11 @@
overlapping grid of blocks covering the detection window into a combined
feature vector for use in the window classifier.
"""
+
+ if feature_vector:
+ normalised_blocks = normalised_blocks.ravel()
if visualise:
- return normalised_blocks.ravel(), hog_image
+ return normalised_blocks, hog_image
else:
- return normalised_blocks.ravel()
+ return normalised_blocks
|
{"golden_diff": "diff --git a/skimage/feature/_hog.py b/skimage/feature/_hog.py\n--- a/skimage/feature/_hog.py\n+++ b/skimage/feature/_hog.py\n@@ -5,7 +5,8 @@\n \n \n def hog(image, orientations=9, pixels_per_cell=(8, 8),\n- cells_per_block=(3, 3), visualise=False, normalise=False):\n+ cells_per_block=(3, 3), visualise=False, normalise=False,\n+ feature_vector=True):\n \"\"\"Extract Histogram of Oriented Gradients (HOG) for a given image.\n \n Compute a Histogram of Oriented Gradients (HOG) by\n@@ -31,6 +32,9 @@\n normalise : bool, optional\n Apply power law compression to normalise the image before\n processing.\n+ feature_vector : bool, optional\n+ Return the data as a feature vector by calling .ravel() on the result\n+ just before returning.\n \n Returns\n -------\n@@ -127,13 +131,11 @@\n orientations_arr = np.arange(orientations)\n dx_arr = radius * np.cos(orientations_arr / orientations * np.pi)\n dy_arr = radius * np.sin(orientations_arr / orientations * np.pi)\n- cr2 = cy + cy\n- cc2 = cx + cx\n hog_image = np.zeros((sy, sx), dtype=float)\n for x in range(n_cellsx):\n for y in range(n_cellsy):\n for o, dx, dy in zip(orientations_arr, dx_arr, dy_arr):\n- centre = tuple([y * cr2 // 2, x * cc2 // 2])\n+ centre = tuple([y * cy + cy // 2, x * cx + cx // 2])\n rr, cc = draw.line(int(centre[0] - dx),\n int(centre[1] + dy),\n int(centre[0] + dx),\n@@ -171,8 +173,11 @@\n overlapping grid of blocks covering the detection window into a combined\n feature vector for use in the window classifier.\n \"\"\"\n+ \n+ if feature_vector:\n+ normalised_blocks = normalised_blocks.ravel()\n \n if visualise:\n- return normalised_blocks.ravel(), hog_image\n+ return normalised_blocks, hog_image\n else:\n- return normalised_blocks.ravel()\n+ return normalised_blocks\n", "issue": "plot_hog.py results in strangely-looking figure in the gallery\nCompare http://scikit-image.org/docs/dev/_images/plot_hog_1.png and http://scikit-image.org/docs/0.11.x/_images/plot_hog_1.png\n\nI don't think the example changed, so it must be inside the hog functions or in one of the functions called by this function.\n\n", "before_files": [{"content": "from __future__ import division\nimport numpy as np\nfrom .._shared.utils import assert_nD\nfrom . import _hoghistogram\n\n\ndef hog(image, orientations=9, pixels_per_cell=(8, 8),\n cells_per_block=(3, 3), visualise=False, normalise=False):\n \"\"\"Extract Histogram of Oriented Gradients (HOG) for a given image.\n\n Compute a Histogram of Oriented Gradients (HOG) by\n\n 1. (optional) global image normalisation\n 2. computing the gradient image in x and y\n 3. computing gradient histograms\n 4. normalising across blocks\n 5. flattening into a feature vector\n\n Parameters\n ----------\n image : (M, N) ndarray\n Input image (greyscale).\n orientations : int\n Number of orientation bins.\n pixels_per_cell : 2 tuple (int, int)\n Size (in pixels) of a cell.\n cells_per_block : 2 tuple (int,int)\n Number of cells in each block.\n visualise : bool, optional\n Also return an image of the HOG.\n normalise : bool, optional\n Apply power law compression to normalise the image before\n processing.\n\n Returns\n -------\n newarr : ndarray\n HOG for the image as a 1D (flattened) array.\n hog_image : ndarray (if visualise=True)\n A visualisation of the HOG image.\n\n References\n ----------\n * http://en.wikipedia.org/wiki/Histogram_of_oriented_gradients\n\n * Dalal, N and Triggs, B, Histograms of Oriented Gradients for\n Human Detection, IEEE Computer Society Conference on Computer\n Vision and Pattern Recognition 2005 San Diego, CA, USA\n\n \"\"\"\n image = np.atleast_2d(image)\n\n \"\"\"\n The first stage applies an optional global image normalisation\n equalisation that is designed to reduce the influence of illumination\n effects. In practice we use gamma (power law) compression, either\n computing the square root or the log of each colour channel.\n Image texture strength is typically proportional to the local surface\n illumination so this compression helps to reduce the effects of local\n shadowing and illumination variations.\n \"\"\"\n\n assert_nD(image, 2)\n\n if normalise:\n image = np.sqrt(image)\n\n \"\"\"\n The second stage computes first order image gradients. These capture\n contour, silhouette and some texture information, while providing\n further resistance to illumination variations. The locally dominant\n colour channel is used, which provides colour invariance to a large\n extent. Variant methods may also include second order image derivatives,\n which act as primitive bar detectors - a useful feature for capturing,\n e.g. bar like structures in bicycles and limbs in humans.\n \"\"\"\n\n if image.dtype.kind == 'u':\n # convert uint image to float\n # to avoid problems with subtracting unsigned numbers in np.diff()\n image = image.astype('float')\n\n gx = np.empty(image.shape, dtype=np.double)\n gx[:, 0] = 0\n gx[:, -1] = 0\n gx[:, 1:-1] = image[:, 2:] - image[:, :-2]\n gy = np.empty(image.shape, dtype=np.double)\n gy[0, :] = 0\n gy[-1, :] = 0\n gy[1:-1, :] = image[2:, :] - image[:-2, :]\n\n \"\"\"\n The third stage aims to produce an encoding that is sensitive to\n local image content while remaining resistant to small changes in\n pose or appearance. The adopted method pools gradient orientation\n information locally in the same way as the SIFT [Lowe 2004]\n feature. The image window is divided into small spatial regions,\n called \"cells\". For each cell we accumulate a local 1-D histogram\n of gradient or edge orientations over all the pixels in the\n cell. This combined cell-level 1-D histogram forms the basic\n \"orientation histogram\" representation. Each orientation histogram\n divides the gradient angle range into a fixed number of\n predetermined bins. The gradient magnitudes of the pixels in the\n cell are used to vote into the orientation histogram.\n \"\"\"\n\n sy, sx = image.shape\n cx, cy = pixels_per_cell\n bx, by = cells_per_block\n\n n_cellsx = int(np.floor(sx // cx)) # number of cells in x\n n_cellsy = int(np.floor(sy // cy)) # number of cells in y\n\n # compute orientations integral images\n orientation_histogram = np.zeros((n_cellsy, n_cellsx, orientations))\n\n _hoghistogram.hog_histograms(gx, gy, cx, cy, sx, sy, n_cellsx, n_cellsy,\n orientations, orientation_histogram)\n\n # now for each cell, compute the histogram\n hog_image = None\n\n if visualise:\n from .. import draw\n\n radius = min(cx, cy) // 2 - 1\n orientations_arr = np.arange(orientations)\n dx_arr = radius * np.cos(orientations_arr / orientations * np.pi)\n dy_arr = radius * np.sin(orientations_arr / orientations * np.pi)\n cr2 = cy + cy\n cc2 = cx + cx\n hog_image = np.zeros((sy, sx), dtype=float)\n for x in range(n_cellsx):\n for y in range(n_cellsy):\n for o, dx, dy in zip(orientations_arr, dx_arr, dy_arr):\n centre = tuple([y * cr2 // 2, x * cc2 // 2])\n rr, cc = draw.line(int(centre[0] - dx),\n int(centre[1] + dy),\n int(centre[0] + dx),\n int(centre[1] - dy))\n hog_image[rr, cc] += orientation_histogram[y, x, o]\n\n \"\"\"\n The fourth stage computes normalisation, which takes local groups of\n cells and contrast normalises their overall responses before passing\n to next stage. Normalisation introduces better invariance to illumination,\n shadowing, and edge contrast. It is performed by accumulating a measure\n of local histogram \"energy\" over local groups of cells that we call\n \"blocks\". The result is used to normalise each cell in the block.\n Typically each individual cell is shared between several blocks, but\n its normalisations are block dependent and thus different. The cell\n thus appears several times in the final output vector with different\n normalisations. This may seem redundant but it improves the performance.\n We refer to the normalised block descriptors as Histogram of Oriented\n Gradient (HOG) descriptors.\n \"\"\"\n\n n_blocksx = (n_cellsx - bx) + 1\n n_blocksy = (n_cellsy - by) + 1\n normalised_blocks = np.zeros((n_blocksy, n_blocksx,\n by, bx, orientations))\n\n for x in range(n_blocksx):\n for y in range(n_blocksy):\n block = orientation_histogram[y:y + by, x:x + bx, :]\n eps = 1e-5\n normalised_blocks[y, x, :] = block / np.sqrt(block.sum() ** 2 + eps)\n\n \"\"\"\n The final step collects the HOG descriptors from all blocks of a dense\n overlapping grid of blocks covering the detection window into a combined\n feature vector for use in the window classifier.\n \"\"\"\n\n if visualise:\n return normalised_blocks.ravel(), hog_image\n else:\n return normalised_blocks.ravel()\n", "path": "skimage/feature/_hog.py"}]}
| 2,725 | 543 |
gh_patches_debug_28746
|
rasdani/github-patches
|
git_diff
|
kymatio__kymatio-226
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Make inputs dimension-agnostic (1D/2D)
In other words, make `Scattering*D` operators act only on last dimension without forcing a specific convention on previous dimensions. The output would have the same shape, but this the time/spatial dimension subsampled and another (scattering) dimension added right before it. So we'd have
- in 1D, `batch_shape + (T,)` input gives `batch_shape + (C, T/2**J)` output, and
- in 2D, `batch_shape + (N, M)` input gives `batch_shape + (C, N/2**J, M/2**J)` output,
where `batch_shape` is some (possibly empty) tuple specifying the batch dimensions that are not to be processed and `C` is the number of scattering coefficients.
The 3D case is more complicated since it follows a different output schema compared to the 1D and 2D, which will be addressed in a separate issue. That being said, it would be good if it could mimic the above behavior.
</issue>
<code>
[start of kymatio/scattering2d/scattering2d.py]
1 # Authors: Edouard Oyallon
2 # Scientific Ancestry: Edouard Oyallon, Laurent Sifre, Joan Bruna
3
4
5 __all__ = ['Scattering2D']
6
7 import torch
8 from .backend import cdgmm, Modulus, SubsampleFourier, fft, Pad, unpad
9 from .filter_bank import filter_bank
10 from .utils import compute_padding
11
12
13 class Scattering2D(object):
14 """Main module implementing the scattering transform in 2D.
15 The scattering transform computes two wavelet transform followed
16 by modulus non-linearity.
17 It can be summarized as::
18
19 S_J x = [S_J^0 x, S_J^1 x, S_J^2 x]
20
21 where::
22
23 S_J^0 x = x * phi_J
24 S_J^1 x = [|x * psi^1_lambda| * phi_J]_lambda
25 S_J^2 x = [||x * psi^1_lambda| * psi^2_mu| * phi_J]_{lambda, mu}
26
27 where * denotes the convolution (in space), phi_J is a low pass
28 filter, psi^1_lambda is a family of band pass
29 filters and psi^2_mu is another family of band pass filters.
30 Only Morlet filters are used in this implementation.
31 Convolutions are efficiently performed in the Fourier domain
32 with this implementation.
33
34 Example
35 -------
36 # 1) Define a Scattering object as:
37 s = Scattering2D(J, M, N)
38 # where (M, N) are the image sizes and 2**J the scale of the scattering
39 # 2) Forward on an input Variable x of shape B x 1 x M x N,
40 # where B is the batch size.
41 result_s = s(x)
42
43 Parameters
44 ----------
45 J : int
46 logscale of the scattering
47 shape : tuple of int
48 spatial support (M, N) of the input
49 L : int, optional
50 number of angles used for the wavelet transform
51 max_order : int, optional
52 The maximum order of scattering coefficients to compute. Must be either
53 `1` or `2`. Defaults to `2`.
54 pre_pad : boolean, optional
55 controls the padding: if set to False, a symmetric padding is applied
56 on the signal. If set to true, the software will assume the signal was
57 padded externally.
58
59 Attributes
60 ----------
61 J : int
62 logscale of the scattering
63 shape : tuple of int
64 spatial support (M, N) of the input
65 L : int, optional
66 number of angles used for the wavelet transform
67 max_order : int, optional
68 The maximum order of scattering coefficients to compute.
69 Must be either equal to `1` or `2`. Defaults to `2`.
70 pre_pad : boolean
71 controls the padding
72 Psi : dictionary
73 containing the wavelets filters at all resolutions. See
74 filter_bank.filter_bank for an exact description.
75 Phi : dictionary
76 containing the low-pass filters at all resolutions. See
77 filter_bank.filter_bank for an exact description.
78 M_padded, N_padded : int
79 spatial support of the padded input
80
81 Notes
82 -----
83 The design of the filters is optimized for the value L = 8
84
85 pre_pad is particularly useful when doing crops of a bigger
86 image because the padding is then extremely accurate. Defaults
87 to False.
88
89 """
90 def __init__(self, J, shape, L=8, max_order=2, pre_pad=False):
91 self.J, self.L = J, L
92 self.pre_pad = pre_pad
93 self.max_order = max_order
94 self.shape = shape
95
96 self.build()
97
98 def build(self):
99 self.M, self.N = self.shape
100 self.modulus = Modulus()
101 self.pad = Pad(2**self.J, pre_pad = self.pre_pad)
102 self.subsample_fourier = SubsampleFourier()
103 # Create the filters
104 self.M_padded, self.N_padded = compute_padding(self.M, self.N, self.J)
105 filters = filter_bank(self.M_padded, self.N_padded, self.J, self.L)
106 self.Psi = filters['psi']
107 self.Phi = [filters['phi'][j] for j in range(self.J)]
108
109 def _type(self, _type):
110 for key, item in enumerate(self.Psi):
111 for key2, item2 in self.Psi[key].items():
112 if torch.is_tensor(item2):
113 self.Psi[key][key2] = item2.type(_type)
114 self.Phi = [v.type(_type) for v in self.Phi]
115 self.pad.padding_module.type(_type)
116 return self
117
118 def cuda(self):
119 """
120 Moves the parameters of the scattering to the GPU
121 """
122 return self._type(torch.cuda.FloatTensor)
123
124 def cpu(self):
125 """
126 Moves the parameters of the scattering to the CPU
127 """
128 return self._type(torch.FloatTensor)
129
130 def forward(self, input):
131 """Forward pass of the scattering.
132
133 Parameters
134 ----------
135 input : tensor
136 tensor with 3 dimensions :math:`(B, C, M, N)` where :math:`(B, C)` are arbitrary.
137 :math:`B` typically is the batch size, whereas :math:`C` is the number of input channels.
138
139 Returns
140 -------
141 S : tensor
142 scattering of the input, a 4D tensor :math:`(B, C, D, Md, Nd)` where :math:`D` corresponds
143 to a new channel dimension and :math:`(Md, Nd)` are downsampled sizes by a factor :math:`2^J`.
144
145 """
146 if not torch.is_tensor(input):
147 raise(TypeError('The input should be a torch.cuda.FloatTensor, a torch.FloatTensor or a torch.DoubleTensor'))
148
149 if (not input.is_contiguous()):
150 raise (RuntimeError('Tensor must be contiguous!'))
151
152 if((input.size(-1)!=self.N or input.size(-2)!=self.M) and not self.pre_pad):
153 raise (RuntimeError('Tensor must be of spatial size (%i,%i)!'%(self.M,self.N)))
154
155 if ((input.size(-1) != self.N_padded or input.size(-2) != self.M_padded) and self.pre_pad):
156 raise (RuntimeError('Padded tensor must be of spatial size (%i,%i)!' % (self.M_padded, self.N_padded)))
157
158 if (input.dim() != 4):
159 raise (RuntimeError('Input tensor must be 4D'))
160
161 J = self.J
162 phi = self.Phi
163 psi = self.Psi
164 n = 0
165
166 subsample_fourier = self.subsample_fourier
167 modulus = self.modulus
168 pad = self.pad
169 output_size = 1 + self.L*J
170 if self.max_order == 2:
171 output_size += self.L*self.L*J*(J - 1) // 2
172
173 S = input.new(input.size(0),
174 input.size(1),
175 output_size,
176 self.M_padded//(2**J)-2,
177 self.N_padded//(2**J)-2)
178 U_r = pad(input)
179 U_0_c = fft(U_r, 'C2C') # We trick here with U_r and U_2_c
180
181 # First low pass filter
182 U_1_c = subsample_fourier(cdgmm(U_0_c, phi[0]), k=2**J)
183
184 U_J_r = fft(U_1_c, 'C2R')
185
186 S[..., n, :, :] = unpad(U_J_r)
187 n = n + 1
188
189 for n1 in range(len(psi)):
190 j1 = psi[n1]['j']
191 U_1_c = cdgmm(U_0_c, psi[n1][0])
192 if(j1 > 0):
193 U_1_c = subsample_fourier(U_1_c, k=2 ** j1)
194 U_1_c = fft(U_1_c, 'C2C', inverse=True)
195 U_1_c = fft(modulus(U_1_c), 'C2C')
196
197 # Second low pass filter
198 U_2_c = subsample_fourier(cdgmm(U_1_c, phi[j1]), k=2**(J-j1))
199 U_J_r = fft(U_2_c, 'C2R')
200 S[..., n, :, :] = unpad(U_J_r)
201 n = n + 1
202
203 if self.max_order == 2:
204 for n2 in range(len(psi)):
205 j2 = psi[n2]['j']
206 if(j1 < j2):
207 U_2_c = subsample_fourier(cdgmm(U_1_c, psi[n2][j1]), k=2 ** (j2-j1))
208 U_2_c = fft(U_2_c, 'C2C', inverse=True)
209 U_2_c = fft(modulus(U_2_c), 'C2C')
210
211 # Third low pass filter
212 U_2_c = subsample_fourier(cdgmm(U_2_c, phi[j2]), k=2 ** (J-j2))
213 U_J_r = fft(U_2_c, 'C2R')
214
215 S[..., n, :, :] = unpad(U_J_r)
216 n = n + 1
217
218 return S
219
220 def __call__(self, input):
221 return self.forward(input)
222
[end of kymatio/scattering2d/scattering2d.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kymatio/scattering2d/scattering2d.py b/kymatio/scattering2d/scattering2d.py
--- a/kymatio/scattering2d/scattering2d.py
+++ b/kymatio/scattering2d/scattering2d.py
@@ -146,6 +146,10 @@
if not torch.is_tensor(input):
raise(TypeError('The input should be a torch.cuda.FloatTensor, a torch.FloatTensor or a torch.DoubleTensor'))
+ if len(input.shape) < 2:
+ raise (RuntimeError('Input tensor must have at least two '
+ 'dimensions'))
+
if (not input.is_contiguous()):
raise (RuntimeError('Tensor must be contiguous!'))
@@ -155,8 +159,10 @@
if ((input.size(-1) != self.N_padded or input.size(-2) != self.M_padded) and self.pre_pad):
raise (RuntimeError('Padded tensor must be of spatial size (%i,%i)!' % (self.M_padded, self.N_padded)))
- if (input.dim() != 4):
- raise (RuntimeError('Input tensor must be 4D'))
+ batch_shape = input.shape[:-2]
+ signal_shape = input.shape[-2:]
+
+ input = input.reshape((-1, 1) + signal_shape)
J = self.J
phi = self.Phi
@@ -215,6 +221,9 @@
S[..., n, :, :] = unpad(U_J_r)
n = n + 1
+ scattering_shape = S.shape[-3:]
+ S = S.reshape(batch_shape + scattering_shape)
+
return S
def __call__(self, input):
|
{"golden_diff": "diff --git a/kymatio/scattering2d/scattering2d.py b/kymatio/scattering2d/scattering2d.py\n--- a/kymatio/scattering2d/scattering2d.py\n+++ b/kymatio/scattering2d/scattering2d.py\n@@ -146,6 +146,10 @@\n if not torch.is_tensor(input):\n raise(TypeError('The input should be a torch.cuda.FloatTensor, a torch.FloatTensor or a torch.DoubleTensor'))\n \n+ if len(input.shape) < 2:\n+ raise (RuntimeError('Input tensor must have at least two '\n+ 'dimensions'))\n+\n if (not input.is_contiguous()):\n raise (RuntimeError('Tensor must be contiguous!'))\n \n@@ -155,8 +159,10 @@\n if ((input.size(-1) != self.N_padded or input.size(-2) != self.M_padded) and self.pre_pad):\n raise (RuntimeError('Padded tensor must be of spatial size (%i,%i)!' % (self.M_padded, self.N_padded)))\n \n- if (input.dim() != 4):\n- raise (RuntimeError('Input tensor must be 4D'))\n+ batch_shape = input.shape[:-2]\n+ signal_shape = input.shape[-2:]\n+\n+ input = input.reshape((-1, 1) + signal_shape)\n \n J = self.J\n phi = self.Phi\n@@ -215,6 +221,9 @@\n S[..., n, :, :] = unpad(U_J_r)\n n = n + 1\n \n+ scattering_shape = S.shape[-3:]\n+ S = S.reshape(batch_shape + scattering_shape)\n+\n return S\n \n def __call__(self, input):\n", "issue": "Make inputs dimension-agnostic (1D/2D)\nIn other words, make `Scattering*D` operators act only on last dimension without forcing a specific convention on previous dimensions. The output would have the same shape, but this the time/spatial dimension subsampled and another (scattering) dimension added right before it. So we'd have\r\n\r\n- in 1D, `batch_shape + (T,)` input gives `batch_shape + (C, T/2**J)` output, and\r\n- in 2D, `batch_shape + (N, M)` input gives `batch_shape + (C, N/2**J, M/2**J)` output,\r\n\r\nwhere `batch_shape` is some (possibly empty) tuple specifying the batch dimensions that are not to be processed and `C` is the number of scattering coefficients.\r\n\r\nThe 3D case is more complicated since it follows a different output schema compared to the 1D and 2D, which will be addressed in a separate issue. That being said, it would be good if it could mimic the above behavior.\n", "before_files": [{"content": "# Authors: Edouard Oyallon\n# Scientific Ancestry: Edouard Oyallon, Laurent Sifre, Joan Bruna\n\n\n__all__ = ['Scattering2D']\n\nimport torch\nfrom .backend import cdgmm, Modulus, SubsampleFourier, fft, Pad, unpad\nfrom .filter_bank import filter_bank\nfrom .utils import compute_padding\n\n\nclass Scattering2D(object):\n \"\"\"Main module implementing the scattering transform in 2D.\n The scattering transform computes two wavelet transform followed\n by modulus non-linearity.\n It can be summarized as::\n\n S_J x = [S_J^0 x, S_J^1 x, S_J^2 x]\n\n where::\n\n S_J^0 x = x * phi_J\n S_J^1 x = [|x * psi^1_lambda| * phi_J]_lambda\n S_J^2 x = [||x * psi^1_lambda| * psi^2_mu| * phi_J]_{lambda, mu}\n\n where * denotes the convolution (in space), phi_J is a low pass\n filter, psi^1_lambda is a family of band pass\n filters and psi^2_mu is another family of band pass filters.\n Only Morlet filters are used in this implementation.\n Convolutions are efficiently performed in the Fourier domain\n with this implementation.\n\n Example\n -------\n # 1) Define a Scattering object as:\n s = Scattering2D(J, M, N)\n # where (M, N) are the image sizes and 2**J the scale of the scattering\n # 2) Forward on an input Variable x of shape B x 1 x M x N,\n # where B is the batch size.\n result_s = s(x)\n\n Parameters\n ----------\n J : int\n logscale of the scattering\n shape : tuple of int\n spatial support (M, N) of the input\n L : int, optional\n number of angles used for the wavelet transform\n max_order : int, optional\n The maximum order of scattering coefficients to compute. Must be either\n `1` or `2`. Defaults to `2`.\n pre_pad : boolean, optional\n controls the padding: if set to False, a symmetric padding is applied\n on the signal. If set to true, the software will assume the signal was\n padded externally.\n\n Attributes\n ----------\n J : int\n logscale of the scattering\n shape : tuple of int\n spatial support (M, N) of the input\n L : int, optional\n number of angles used for the wavelet transform\n max_order : int, optional\n The maximum order of scattering coefficients to compute.\n Must be either equal to `1` or `2`. Defaults to `2`.\n pre_pad : boolean\n controls the padding\n Psi : dictionary\n containing the wavelets filters at all resolutions. See\n filter_bank.filter_bank for an exact description.\n Phi : dictionary\n containing the low-pass filters at all resolutions. See\n filter_bank.filter_bank for an exact description.\n M_padded, N_padded : int\n spatial support of the padded input\n\n Notes\n -----\n The design of the filters is optimized for the value L = 8\n\n pre_pad is particularly useful when doing crops of a bigger\n image because the padding is then extremely accurate. Defaults\n to False.\n\n \"\"\"\n def __init__(self, J, shape, L=8, max_order=2, pre_pad=False):\n self.J, self.L = J, L\n self.pre_pad = pre_pad\n self.max_order = max_order\n self.shape = shape\n\n self.build()\n\n def build(self):\n self.M, self.N = self.shape\n self.modulus = Modulus()\n self.pad = Pad(2**self.J, pre_pad = self.pre_pad)\n self.subsample_fourier = SubsampleFourier()\n # Create the filters\n self.M_padded, self.N_padded = compute_padding(self.M, self.N, self.J)\n filters = filter_bank(self.M_padded, self.N_padded, self.J, self.L)\n self.Psi = filters['psi']\n self.Phi = [filters['phi'][j] for j in range(self.J)]\n\n def _type(self, _type):\n for key, item in enumerate(self.Psi):\n for key2, item2 in self.Psi[key].items():\n if torch.is_tensor(item2):\n self.Psi[key][key2] = item2.type(_type)\n self.Phi = [v.type(_type) for v in self.Phi]\n self.pad.padding_module.type(_type)\n return self\n\n def cuda(self):\n \"\"\"\n Moves the parameters of the scattering to the GPU\n \"\"\"\n return self._type(torch.cuda.FloatTensor)\n\n def cpu(self):\n \"\"\"\n Moves the parameters of the scattering to the CPU\n \"\"\"\n return self._type(torch.FloatTensor)\n\n def forward(self, input):\n \"\"\"Forward pass of the scattering.\n\n Parameters\n ----------\n input : tensor\n tensor with 3 dimensions :math:`(B, C, M, N)` where :math:`(B, C)` are arbitrary.\n :math:`B` typically is the batch size, whereas :math:`C` is the number of input channels.\n\n Returns\n -------\n S : tensor\n scattering of the input, a 4D tensor :math:`(B, C, D, Md, Nd)` where :math:`D` corresponds\n to a new channel dimension and :math:`(Md, Nd)` are downsampled sizes by a factor :math:`2^J`.\n\n \"\"\"\n if not torch.is_tensor(input):\n raise(TypeError('The input should be a torch.cuda.FloatTensor, a torch.FloatTensor or a torch.DoubleTensor'))\n\n if (not input.is_contiguous()):\n raise (RuntimeError('Tensor must be contiguous!'))\n\n if((input.size(-1)!=self.N or input.size(-2)!=self.M) and not self.pre_pad):\n raise (RuntimeError('Tensor must be of spatial size (%i,%i)!'%(self.M,self.N)))\n\n if ((input.size(-1) != self.N_padded or input.size(-2) != self.M_padded) and self.pre_pad):\n raise (RuntimeError('Padded tensor must be of spatial size (%i,%i)!' % (self.M_padded, self.N_padded)))\n\n if (input.dim() != 4):\n raise (RuntimeError('Input tensor must be 4D'))\n\n J = self.J\n phi = self.Phi\n psi = self.Psi\n n = 0\n\n subsample_fourier = self.subsample_fourier\n modulus = self.modulus\n pad = self.pad\n output_size = 1 + self.L*J\n if self.max_order == 2:\n output_size += self.L*self.L*J*(J - 1) // 2\n\n S = input.new(input.size(0),\n input.size(1),\n output_size,\n self.M_padded//(2**J)-2,\n self.N_padded//(2**J)-2)\n U_r = pad(input)\n U_0_c = fft(U_r, 'C2C') # We trick here with U_r and U_2_c\n\n # First low pass filter\n U_1_c = subsample_fourier(cdgmm(U_0_c, phi[0]), k=2**J)\n\n U_J_r = fft(U_1_c, 'C2R')\n\n S[..., n, :, :] = unpad(U_J_r)\n n = n + 1\n\n for n1 in range(len(psi)):\n j1 = psi[n1]['j']\n U_1_c = cdgmm(U_0_c, psi[n1][0])\n if(j1 > 0):\n U_1_c = subsample_fourier(U_1_c, k=2 ** j1)\n U_1_c = fft(U_1_c, 'C2C', inverse=True)\n U_1_c = fft(modulus(U_1_c), 'C2C')\n\n # Second low pass filter\n U_2_c = subsample_fourier(cdgmm(U_1_c, phi[j1]), k=2**(J-j1))\n U_J_r = fft(U_2_c, 'C2R')\n S[..., n, :, :] = unpad(U_J_r)\n n = n + 1\n\n if self.max_order == 2:\n for n2 in range(len(psi)):\n j2 = psi[n2]['j']\n if(j1 < j2):\n U_2_c = subsample_fourier(cdgmm(U_1_c, psi[n2][j1]), k=2 ** (j2-j1))\n U_2_c = fft(U_2_c, 'C2C', inverse=True)\n U_2_c = fft(modulus(U_2_c), 'C2C')\n \n # Third low pass filter\n U_2_c = subsample_fourier(cdgmm(U_2_c, phi[j2]), k=2 ** (J-j2))\n U_J_r = fft(U_2_c, 'C2R')\n \n S[..., n, :, :] = unpad(U_J_r)\n n = n + 1\n\n return S\n\n def __call__(self, input):\n return self.forward(input)\n", "path": "kymatio/scattering2d/scattering2d.py"}]}
| 3,436 | 387 |
gh_patches_debug_13540
|
rasdani/github-patches
|
git_diff
|
bokeh__bokeh-7939
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Using on_event with string names in Python2.7
As discovered in #7893, trying to set `on_event` with a string (i.e. `"tap"` instead of `events.Tap`) currently fails with:
``` python
=================================== FAILURES ===================================
Test_standalone_docs_json_and_render_items.test_log_warning_if_python_event_callback
self = <bokeh.embed.tests.test_util.Test_standalone_docs_json_and_render_items object at 0x7f6f7a9a5950>
caplog = <_pytest.logging.LogCaptureFixture object at 0x7f6f7a9a57d0>
def test_log_warning_if_python_event_callback(self, caplog):
d = Document()
m1 = EmbedTestUtilModel()
c1 = _GoodEventCallback()
d.add_root(m1)
> m1.on_event('tap', c1)
bokeh/embed/tests/test_util.py:155:
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
self = EmbedTestUtilModel(id='b0037dfa-87fa-48d7-82ea-df2b14d2aff4', ...)
event = 'tap'
callbacks = (<bokeh.embed.tests.test_util._GoodEventCallback object at 0x7f6f7a9a5d90>,)
def on_event(self, event, *callbacks):
> if not isinstance(event, str) and issubclass(event, Event):
E TypeError: issubclass() arg 1 must be a class
bokeh/util/callback_manager.py:31: TypeError
```
We should:
- [ ] Add tests that check setting `on_event` with a string
- [ ] Fix `bokeh/util/callback_manager.py` to accept strings in Python2.7
</issue>
<code>
[start of bokeh/util/callback_manager.py]
1 ''' Provides ``PropertyCallbackManager`` and ``EventCallbackManager``
2 mixin classes for adding ``on_change`` and ``on_event`` callback
3 interfaces to classes.
4 '''
5 from __future__ import absolute_import
6
7 from ..events import Event
8 from ..util.future import get_param_info, format_signature, signature
9
10 def _check_callback(callback, fargs, what="Callback functions"):
11 '''Bokeh-internal function to check callback signature'''
12 sig = signature(callback)
13 formatted_args = format_signature(sig)
14 error_msg = what + " must have signature func(%s), got func%s"
15
16 all_names, default_values = get_param_info(sig)
17
18 if len(all_names) - len(default_values) != len(fargs):
19 raise ValueError(error_msg % (", ".join(fargs), formatted_args))
20
21 class EventCallbackManager(object):
22 ''' A mixin class to provide an interface for registering and
23 triggering event callbacks on the Python side.
24
25 '''
26 def __init__(self, *args, **kw):
27 super(EventCallbackManager, self).__init__(*args, **kw)
28 self._event_callbacks = dict()
29
30 def on_event(self, event, *callbacks):
31 if not isinstance(event, str) and issubclass(event, Event):
32 event = event.event_name
33
34 for callback in callbacks:
35 _check_callback(callback, ('event',), what='Event callback')
36
37 if event not in self._event_callbacks:
38 self._event_callbacks[event] = [cb for cb in callbacks]
39 else:
40 self._event_callbacks[event].extend(callbacks)
41
42 if event not in self.subscribed_events:
43 self.subscribed_events.append(event)
44
45 def _trigger_event(self, event):
46 for callback in self._event_callbacks.get(event.event_name,[]):
47 if event._model_id is not None and self._id == event._model_id:
48 callback(event)
49
50 def _update_event_callbacks(self):
51 if self.document is None:
52 return
53
54 for key in self._event_callbacks:
55 self.document._subscribed_models[key].add(self)
56
57
58 class PropertyCallbackManager(object):
59 ''' A mixin class to provide an interface for registering and
60 triggering callbacks.
61
62 '''
63
64 def __init__(self, *args, **kw):
65 super(PropertyCallbackManager, self).__init__(*args, **kw)
66 self._callbacks = dict()
67
68 def on_change(self, attr, *callbacks):
69 ''' Add a callback on this object to trigger when ``attr`` changes.
70
71 Args:
72 attr (str) : an attribute name on this object
73 callback (callable) : a callback function to register
74
75 Returns:
76 None
77
78 '''
79 if len(callbacks) == 0:
80 raise ValueError("on_change takes an attribute name and one or more callbacks, got only one parameter")
81
82 _callbacks = self._callbacks.setdefault(attr, [])
83 for callback in callbacks:
84
85 if callback in _callbacks:
86 continue
87
88 _check_callback(callback, ('attr', 'old', 'new'))
89
90 _callbacks.append(callback)
91
92 def remove_on_change(self, attr, *callbacks):
93 ''' Remove a callback from this object '''
94 if len(callbacks) == 0:
95 raise ValueError("remove_on_change takes an attribute name and one or more callbacks, got only one parameter")
96 _callbacks = self._callbacks.setdefault(attr, [])
97 for callback in callbacks:
98 _callbacks.remove(callback)
99
100 def trigger(self, attr, old, new, hint=None, setter=None):
101 ''' Trigger callbacks for ``attr`` on this object.
102
103 Args:
104 attr (str) :
105 old (object) :
106 new (object) :
107
108 Returns:
109 None
110
111 '''
112 def invoke():
113 callbacks = self._callbacks.get(attr)
114 if callbacks:
115 for callback in callbacks:
116 callback(attr, old, new)
117 if hasattr(self, '_document') and self._document is not None:
118 self._document._notify_change(self, attr, old, new, hint, setter, invoke)
119 else:
120 invoke()
121
[end of bokeh/util/callback_manager.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bokeh/util/callback_manager.py b/bokeh/util/callback_manager.py
--- a/bokeh/util/callback_manager.py
+++ b/bokeh/util/callback_manager.py
@@ -4,6 +4,8 @@
'''
from __future__ import absolute_import
+from six import string_types
+
from ..events import Event
from ..util.future import get_param_info, format_signature, signature
@@ -28,7 +30,7 @@
self._event_callbacks = dict()
def on_event(self, event, *callbacks):
- if not isinstance(event, str) and issubclass(event, Event):
+ if not isinstance(event, string_types) and issubclass(event, Event):
event = event.event_name
for callback in callbacks:
|
{"golden_diff": "diff --git a/bokeh/util/callback_manager.py b/bokeh/util/callback_manager.py\n--- a/bokeh/util/callback_manager.py\n+++ b/bokeh/util/callback_manager.py\n@@ -4,6 +4,8 @@\n '''\n from __future__ import absolute_import\n \n+from six import string_types\n+\n from ..events import Event\n from ..util.future import get_param_info, format_signature, signature\n \n@@ -28,7 +30,7 @@\n self._event_callbacks = dict()\n \n def on_event(self, event, *callbacks):\n- if not isinstance(event, str) and issubclass(event, Event):\n+ if not isinstance(event, string_types) and issubclass(event, Event):\n event = event.event_name\n \n for callback in callbacks:\n", "issue": "Using on_event with string names in Python2.7\nAs discovered in #7893, trying to set `on_event` with a string (i.e. `\"tap\"` instead of `events.Tap`) currently fails with:\r\n\r\n``` python\r\n=================================== FAILURES ===================================\r\n Test_standalone_docs_json_and_render_items.test_log_warning_if_python_event_callback \r\nself = <bokeh.embed.tests.test_util.Test_standalone_docs_json_and_render_items object at 0x7f6f7a9a5950>\r\ncaplog = <_pytest.logging.LogCaptureFixture object at 0x7f6f7a9a57d0>\r\n def test_log_warning_if_python_event_callback(self, caplog):\r\n d = Document()\r\n m1 = EmbedTestUtilModel()\r\n c1 = _GoodEventCallback()\r\n d.add_root(m1)\r\n \r\n> m1.on_event('tap', c1)\r\nbokeh/embed/tests/test_util.py:155: \r\n_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ \r\nself = EmbedTestUtilModel(id='b0037dfa-87fa-48d7-82ea-df2b14d2aff4', ...)\r\nevent = 'tap'\r\ncallbacks = (<bokeh.embed.tests.test_util._GoodEventCallback object at 0x7f6f7a9a5d90>,)\r\n def on_event(self, event, *callbacks):\r\n> if not isinstance(event, str) and issubclass(event, Event):\r\nE TypeError: issubclass() arg 1 must be a class\r\nbokeh/util/callback_manager.py:31: TypeError\r\n```\r\n\r\nWe should:\r\n- [ ] Add tests that check setting `on_event` with a string\r\n- [ ] Fix `bokeh/util/callback_manager.py` to accept strings in Python2.7\n", "before_files": [{"content": "''' Provides ``PropertyCallbackManager`` and ``EventCallbackManager``\nmixin classes for adding ``on_change`` and ``on_event`` callback\ninterfaces to classes.\n'''\nfrom __future__ import absolute_import\n\nfrom ..events import Event\nfrom ..util.future import get_param_info, format_signature, signature\n\ndef _check_callback(callback, fargs, what=\"Callback functions\"):\n '''Bokeh-internal function to check callback signature'''\n sig = signature(callback)\n formatted_args = format_signature(sig)\n error_msg = what + \" must have signature func(%s), got func%s\"\n\n all_names, default_values = get_param_info(sig)\n\n if len(all_names) - len(default_values) != len(fargs):\n raise ValueError(error_msg % (\", \".join(fargs), formatted_args))\n\nclass EventCallbackManager(object):\n ''' A mixin class to provide an interface for registering and\n triggering event callbacks on the Python side.\n\n '''\n def __init__(self, *args, **kw):\n super(EventCallbackManager, self).__init__(*args, **kw)\n self._event_callbacks = dict()\n\n def on_event(self, event, *callbacks):\n if not isinstance(event, str) and issubclass(event, Event):\n event = event.event_name\n\n for callback in callbacks:\n _check_callback(callback, ('event',), what='Event callback')\n\n if event not in self._event_callbacks:\n self._event_callbacks[event] = [cb for cb in callbacks]\n else:\n self._event_callbacks[event].extend(callbacks)\n\n if event not in self.subscribed_events:\n self.subscribed_events.append(event)\n\n def _trigger_event(self, event):\n for callback in self._event_callbacks.get(event.event_name,[]):\n if event._model_id is not None and self._id == event._model_id:\n callback(event)\n\n def _update_event_callbacks(self):\n if self.document is None:\n return\n\n for key in self._event_callbacks:\n self.document._subscribed_models[key].add(self)\n\n\nclass PropertyCallbackManager(object):\n ''' A mixin class to provide an interface for registering and\n triggering callbacks.\n\n '''\n\n def __init__(self, *args, **kw):\n super(PropertyCallbackManager, self).__init__(*args, **kw)\n self._callbacks = dict()\n\n def on_change(self, attr, *callbacks):\n ''' Add a callback on this object to trigger when ``attr`` changes.\n\n Args:\n attr (str) : an attribute name on this object\n callback (callable) : a callback function to register\n\n Returns:\n None\n\n '''\n if len(callbacks) == 0:\n raise ValueError(\"on_change takes an attribute name and one or more callbacks, got only one parameter\")\n\n _callbacks = self._callbacks.setdefault(attr, [])\n for callback in callbacks:\n\n if callback in _callbacks:\n continue\n\n _check_callback(callback, ('attr', 'old', 'new'))\n\n _callbacks.append(callback)\n\n def remove_on_change(self, attr, *callbacks):\n ''' Remove a callback from this object '''\n if len(callbacks) == 0:\n raise ValueError(\"remove_on_change takes an attribute name and one or more callbacks, got only one parameter\")\n _callbacks = self._callbacks.setdefault(attr, [])\n for callback in callbacks:\n _callbacks.remove(callback)\n\n def trigger(self, attr, old, new, hint=None, setter=None):\n ''' Trigger callbacks for ``attr`` on this object.\n\n Args:\n attr (str) :\n old (object) :\n new (object) :\n\n Returns:\n None\n\n '''\n def invoke():\n callbacks = self._callbacks.get(attr)\n if callbacks:\n for callback in callbacks:\n callback(attr, old, new)\n if hasattr(self, '_document') and self._document is not None:\n self._document._notify_change(self, attr, old, new, hint, setter, invoke)\n else:\n invoke()\n", "path": "bokeh/util/callback_manager.py"}]}
| 2,080 | 165 |
gh_patches_debug_6987
|
rasdani/github-patches
|
git_diff
|
rasterio__rasterio-750
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
-f does not work as expected in rio-warp
Running on a preexisting file
```
» rio warp tests/data/RGB.byte.tif /tmp/hi.tif
Error: Could not open file : file exists and won't be overwritten without use of the `-f` or `-o` options.
```
Then
```
» rio warp tests/data/RGB.byte.tif /tmp/hi.tif -f
Error: -f option requires an argument
```
But
```
rio warp tests/data/RGB.byte.tif /tmp/hi.tif --force-overwrite
```
Works.
</issue>
<code>
[start of rasterio/rio/helpers.py]
1 """
2 Helper objects used by multiple CLI commands.
3 """
4
5 import json
6 import os
7
8 from rasterio.errors import FileOverwriteError
9
10
11 def coords(obj):
12 """Yield all coordinate coordinate tuples from a geometry or feature.
13 From python-geojson package."""
14 if isinstance(obj, (tuple, list)):
15 coordinates = obj
16 elif 'geometry' in obj:
17 coordinates = obj['geometry']['coordinates']
18 else:
19 coordinates = obj.get('coordinates', obj)
20 for e in coordinates:
21 if isinstance(e, (float, int)):
22 yield tuple(coordinates)
23 break
24 else:
25 for f in coords(e):
26 yield f
27
28
29 def write_features(
30 fobj, collection, sequence=False, geojson_type='feature', use_rs=False,
31 **dump_kwds):
32 """Read an iterator of (feat, bbox) pairs and write to file using
33 the selected modes."""
34 # Sequence of features expressed as bbox, feature, or collection.
35 if sequence:
36 for feat in collection():
37 xs, ys = zip(*coords(feat))
38 bbox = (min(xs), min(ys), max(xs), max(ys))
39 if use_rs:
40 fobj.write(u'\u001e')
41 if geojson_type == 'feature':
42 fobj.write(json.dumps(feat, **dump_kwds))
43 elif geojson_type == 'bbox':
44 fobj.write(json.dumps(bbox, **dump_kwds))
45 else:
46 fobj.write(
47 json.dumps({
48 'type': 'FeatureCollection',
49 'bbox': bbox,
50 'features': [feat]}, **dump_kwds))
51 fobj.write('\n')
52 # Aggregate all features into a single object expressed as
53 # bbox or collection.
54 else:
55 features = list(collection())
56 if geojson_type == 'bbox':
57 fobj.write(json.dumps(collection.bbox, **dump_kwds))
58 elif geojson_type == 'feature':
59 fobj.write(json.dumps(features[0], **dump_kwds))
60 else:
61 fobj.write(json.dumps({
62 'bbox': collection.bbox,
63 'type': 'FeatureCollection',
64 'features': features},
65 **dump_kwds))
66 fobj.write('\n')
67
68
69 def resolve_inout(input=None, output=None, files=None, force_overwrite=False):
70 """Resolves inputs and outputs from standard args and options.
71
72 :param input: a single input filename, optional.
73 :param output: a single output filename, optional.
74 :param files: a sequence of filenames in which the last is the
75 output filename.
76 :param force_overwrite: whether to force overwriting the output
77 file, bool.
78 :return: the resolved output filename and input filenames as a
79 tuple of length 2.
80
81 If provided, the :param:`output` file may be overwritten. An output
82 file extracted from :param:`files` will not be overwritten unless
83 :param:`force_overwrite` is `True`.
84 """
85 resolved_output = output or (files[-1] if files else None)
86 force_overwrite = output is not None or force_overwrite
87 if not force_overwrite and resolved_output and os.path.exists(
88 resolved_output):
89 raise FileOverwriteError(
90 "file exists and won't be overwritten without use of the "
91 "`-f` or `-o` options.")
92 resolved_inputs = (
93 [input] if input else [] +
94 list(files[:-1 if not output else None]) if files else [])
95 return resolved_output, resolved_inputs
96
97
98 def to_lower(ctx, param, value):
99 """Click callback, converts values to lowercase."""
100 return value.lower()
101
[end of rasterio/rio/helpers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/rasterio/rio/helpers.py b/rasterio/rio/helpers.py
--- a/rasterio/rio/helpers.py
+++ b/rasterio/rio/helpers.py
@@ -88,7 +88,7 @@
resolved_output):
raise FileOverwriteError(
"file exists and won't be overwritten without use of the "
- "`-f` or `-o` options.")
+ "`--force-overwrite` or `--output` options.")
resolved_inputs = (
[input] if input else [] +
list(files[:-1 if not output else None]) if files else [])
|
{"golden_diff": "diff --git a/rasterio/rio/helpers.py b/rasterio/rio/helpers.py\n--- a/rasterio/rio/helpers.py\n+++ b/rasterio/rio/helpers.py\n@@ -88,7 +88,7 @@\n resolved_output):\n raise FileOverwriteError(\n \"file exists and won't be overwritten without use of the \"\n- \"`-f` or `-o` options.\")\n+ \"`--force-overwrite` or `--output` options.\")\n resolved_inputs = (\n [input] if input else [] +\n list(files[:-1 if not output else None]) if files else [])\n", "issue": "-f does not work as expected in rio-warp\nRunning on a preexisting file\n\n```\n\u00bb rio warp tests/data/RGB.byte.tif /tmp/hi.tif\nError: Could not open file : file exists and won't be overwritten without use of the `-f` or `-o` options.\n```\n\nThen\n\n```\n\u00bb rio warp tests/data/RGB.byte.tif /tmp/hi.tif -f\nError: -f option requires an argument\n```\n\nBut\n\n```\nrio warp tests/data/RGB.byte.tif /tmp/hi.tif --force-overwrite\n```\n\nWorks.\n\n", "before_files": [{"content": "\"\"\"\nHelper objects used by multiple CLI commands.\n\"\"\"\n\nimport json\nimport os\n\nfrom rasterio.errors import FileOverwriteError\n\n\ndef coords(obj):\n \"\"\"Yield all coordinate coordinate tuples from a geometry or feature.\n From python-geojson package.\"\"\"\n if isinstance(obj, (tuple, list)):\n coordinates = obj\n elif 'geometry' in obj:\n coordinates = obj['geometry']['coordinates']\n else:\n coordinates = obj.get('coordinates', obj)\n for e in coordinates:\n if isinstance(e, (float, int)):\n yield tuple(coordinates)\n break\n else:\n for f in coords(e):\n yield f\n\n\ndef write_features(\n fobj, collection, sequence=False, geojson_type='feature', use_rs=False,\n **dump_kwds):\n \"\"\"Read an iterator of (feat, bbox) pairs and write to file using\n the selected modes.\"\"\"\n # Sequence of features expressed as bbox, feature, or collection.\n if sequence:\n for feat in collection():\n xs, ys = zip(*coords(feat))\n bbox = (min(xs), min(ys), max(xs), max(ys))\n if use_rs:\n fobj.write(u'\\u001e')\n if geojson_type == 'feature':\n fobj.write(json.dumps(feat, **dump_kwds))\n elif geojson_type == 'bbox':\n fobj.write(json.dumps(bbox, **dump_kwds))\n else:\n fobj.write(\n json.dumps({\n 'type': 'FeatureCollection',\n 'bbox': bbox,\n 'features': [feat]}, **dump_kwds))\n fobj.write('\\n')\n # Aggregate all features into a single object expressed as\n # bbox or collection.\n else:\n features = list(collection())\n if geojson_type == 'bbox':\n fobj.write(json.dumps(collection.bbox, **dump_kwds))\n elif geojson_type == 'feature':\n fobj.write(json.dumps(features[0], **dump_kwds))\n else:\n fobj.write(json.dumps({\n 'bbox': collection.bbox,\n 'type': 'FeatureCollection',\n 'features': features},\n **dump_kwds))\n fobj.write('\\n')\n\n\ndef resolve_inout(input=None, output=None, files=None, force_overwrite=False):\n \"\"\"Resolves inputs and outputs from standard args and options.\n\n :param input: a single input filename, optional.\n :param output: a single output filename, optional.\n :param files: a sequence of filenames in which the last is the\n output filename.\n :param force_overwrite: whether to force overwriting the output\n file, bool.\n :return: the resolved output filename and input filenames as a\n tuple of length 2.\n\n If provided, the :param:`output` file may be overwritten. An output\n file extracted from :param:`files` will not be overwritten unless\n :param:`force_overwrite` is `True`.\n \"\"\"\n resolved_output = output or (files[-1] if files else None)\n force_overwrite = output is not None or force_overwrite\n if not force_overwrite and resolved_output and os.path.exists(\n resolved_output):\n raise FileOverwriteError(\n \"file exists and won't be overwritten without use of the \"\n \"`-f` or `-o` options.\")\n resolved_inputs = (\n [input] if input else [] +\n list(files[:-1 if not output else None]) if files else [])\n return resolved_output, resolved_inputs\n\n\ndef to_lower(ctx, param, value):\n \"\"\"Click callback, converts values to lowercase.\"\"\"\n return value.lower()\n", "path": "rasterio/rio/helpers.py"}]}
| 1,637 | 133 |
gh_patches_debug_8115
|
rasdani/github-patches
|
git_diff
|
ocadotechnology__aimmo-51
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Submitting empty code leads to server error
When sending empty program, we are getting:
Traceback:
File "/Library/Python/2.7/site-packages/django/core/handlers/base.py" in get_response
1. response = wrapped_callback(request, _callback_args, *_callback_kwargs)
File "/Library/Python/2.7/site-packages/django/contrib/auth/decorators.py" in _wrapped_view
2. return view_func(request, _args, *_kwargs)
File "/Users/paulina.koch/Documents/C4L/forks/aimmo/ui/players/views.py" in code
3. world.player_changed_code(request.user.id, request.user.player.code)
File "/Users/paulina.koch/Documents/C4L/forks/aimmo/simulation/game_state.py" in player_changed_code
4. avatar.set_code(code)
File "/Users/paulina.koch/Documents/C4L/forks/aimmo/simulation/avatar/avatar_wrapper.py" in set_code
5. self.avatar = Avatar()
Exception Type: TypeError at /api/code/
Exception Value: 'NoneType' object is not callable
Simple check should be enough, but we could use it as a chance to implement an extension of validation or error handling/printing when submitting code.
</issue>
<code>
[start of simulation/avatar/avatar_wrapper.py]
1 import traceback
2 import sys
3
4 from simulation.action import WaitAction
5
6
7 # This class will be implemented by the player
8 Avatar = None
9
10
11 class UserCodeException(Exception):
12 def __init__(self, *args, **kwargs):
13 super(Exception, self).__init__(*args, **kwargs)
14 self.exc_type, self.exc_value, self.exc_traceback = sys.exc_info()
15
16 def to_user_string(self):
17 lines = traceback.format_exception(self.exc_type, self.exc_value, self.exc_traceback)
18 return '<br/>'.join(lines)
19
20
21 class AvatarWrapper(object):
22 """
23 The application's view of a character, not to be confused with "Avatar", the player-supplied code.
24 """
25
26 def __init__(self, initial_location, initial_code, player_id, avatar_appearance):
27 self.location = initial_location
28 self.health = 5
29 self.score = 0
30 self.events = []
31 self.player_id = player_id
32 self.avatar_appearance = avatar_appearance
33 self.avatar = None
34
35 self.set_code(initial_code)
36
37 def handle_turn(self, state):
38 try:
39 next_action = self.avatar.handle_turn(state, self.events)
40 except Exception as e:
41 # TODO: tell user their program threw an exception during execution somehow...
42 print('avatar threw exception during handle_turn:', e)
43 traceback.print_exc()
44 next_action = WaitAction()
45 # Reset event log
46 self.events = []
47
48 return next_action
49
50 def die(self, respawn_location):
51 # TODO: extract settings for health and score loss on death
52 self.health = 5
53 self.score = max(0, self.score - 2)
54 self.location = respawn_location
55
56 def add_event(self, event):
57 self.events.append(event)
58
59 def set_code(self, code):
60 self.code = code
61 try:
62 exec(code)
63 except Exception as ex:
64 raise UserCodeException("Exception in user code", ex)
65 self.avatar = Avatar()
66
67 def __repr__(self):
68 return 'Avatar(id={}, location={}, health={}, score={})'.format(self.player_id, self.location,
69 self.health, self.score)
70
71
[end of simulation/avatar/avatar_wrapper.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/simulation/avatar/avatar_wrapper.py b/simulation/avatar/avatar_wrapper.py
--- a/simulation/avatar/avatar_wrapper.py
+++ b/simulation/avatar/avatar_wrapper.py
@@ -60,9 +60,9 @@
self.code = code
try:
exec(code)
+ self.avatar = Avatar()
except Exception as ex:
raise UserCodeException("Exception in user code", ex)
- self.avatar = Avatar()
def __repr__(self):
return 'Avatar(id={}, location={}, health={}, score={})'.format(self.player_id, self.location,
|
{"golden_diff": "diff --git a/simulation/avatar/avatar_wrapper.py b/simulation/avatar/avatar_wrapper.py\n--- a/simulation/avatar/avatar_wrapper.py\n+++ b/simulation/avatar/avatar_wrapper.py\n@@ -60,9 +60,9 @@\n self.code = code\n try:\n exec(code)\n+ self.avatar = Avatar()\n except Exception as ex:\n raise UserCodeException(\"Exception in user code\", ex)\n- self.avatar = Avatar()\n \n def __repr__(self):\n return 'Avatar(id={}, location={}, health={}, score={})'.format(self.player_id, self.location,\n", "issue": "Submitting empty code leads to server error\nWhen sending empty program, we are getting:\n\nTraceback:\nFile \"/Library/Python/2.7/site-packages/django/core/handlers/base.py\" in get_response\n1. response = wrapped_callback(request, _callback_args, *_callback_kwargs)\n File \"/Library/Python/2.7/site-packages/django/contrib/auth/decorators.py\" in _wrapped_view\n2. return view_func(request, _args, *_kwargs)\n File \"/Users/paulina.koch/Documents/C4L/forks/aimmo/ui/players/views.py\" in code\n3. world.player_changed_code(request.user.id, request.user.player.code)\n File \"/Users/paulina.koch/Documents/C4L/forks/aimmo/simulation/game_state.py\" in player_changed_code\n4. avatar.set_code(code)\n File \"/Users/paulina.koch/Documents/C4L/forks/aimmo/simulation/avatar/avatar_wrapper.py\" in set_code\n5. self.avatar = Avatar()\n\nException Type: TypeError at /api/code/\nException Value: 'NoneType' object is not callable\n\nSimple check should be enough, but we could use it as a chance to implement an extension of validation or error handling/printing when submitting code.\n\n", "before_files": [{"content": "import traceback\nimport sys\n\nfrom simulation.action import WaitAction\n\n\n# This class will be implemented by the player\nAvatar = None\n\n\nclass UserCodeException(Exception):\n def __init__(self, *args, **kwargs):\n super(Exception, self).__init__(*args, **kwargs)\n self.exc_type, self.exc_value, self.exc_traceback = sys.exc_info()\n\n def to_user_string(self):\n lines = traceback.format_exception(self.exc_type, self.exc_value, self.exc_traceback)\n return '<br/>'.join(lines)\n\n\nclass AvatarWrapper(object):\n \"\"\"\n The application's view of a character, not to be confused with \"Avatar\", the player-supplied code.\n \"\"\"\n\n def __init__(self, initial_location, initial_code, player_id, avatar_appearance):\n self.location = initial_location\n self.health = 5\n self.score = 0\n self.events = []\n self.player_id = player_id\n self.avatar_appearance = avatar_appearance\n self.avatar = None\n\n self.set_code(initial_code)\n\n def handle_turn(self, state):\n try:\n next_action = self.avatar.handle_turn(state, self.events)\n except Exception as e:\n # TODO: tell user their program threw an exception during execution somehow...\n print('avatar threw exception during handle_turn:', e)\n traceback.print_exc()\n next_action = WaitAction()\n # Reset event log\n self.events = []\n\n return next_action\n\n def die(self, respawn_location):\n # TODO: extract settings for health and score loss on death\n self.health = 5\n self.score = max(0, self.score - 2)\n self.location = respawn_location\n\n def add_event(self, event):\n self.events.append(event)\n\n def set_code(self, code):\n self.code = code\n try:\n exec(code)\n except Exception as ex:\n raise UserCodeException(\"Exception in user code\", ex)\n self.avatar = Avatar()\n\n def __repr__(self):\n return 'Avatar(id={}, location={}, health={}, score={})'.format(self.player_id, self.location,\n self.health, self.score)\n\n", "path": "simulation/avatar/avatar_wrapper.py"}]}
| 1,406 | 124 |
gh_patches_debug_1611
|
rasdani/github-patches
|
git_diff
|
google__mobly-311
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Exceptions in `setup_test` should leave the test in `ERROR` status
Regardless of the type of the exception, `setup_test` error should cause `ERROR` status.
This is different from a test method.
In a test method, an exception based on signals.TestFailure should cause the test to exit with `FAILED` status.
This is to be consistent with pyunit's behavior.
</issue>
<code>
[start of mobly/signals.py]
1 # Copyright 2016 Google Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """This module is where all the test signal classes and related utilities live.
15 """
16
17 import functools
18 import json
19
20
21 class TestSignalError(Exception):
22 """Raised when an error occurs inside a test signal."""
23
24
25 class TestSignal(Exception):
26 """Base class for all test result control signals. This is used to signal
27 the result of a test.
28
29 Attribute:
30 details: A string that describes the reason for raising this signal.
31 extras: A json-serializable data type to convey extra information about
32 a test result.
33 """
34
35 def __init__(self, details, extras=None):
36 super(TestSignal, self).__init__(details)
37 self.details = str(details)
38 try:
39 json.dumps(extras)
40 self.extras = extras
41 except TypeError:
42 raise TestSignalError('Extras must be json serializable. %s '
43 'is not.' % extras)
44
45 def __str__(self):
46 return 'Details=%s, Extras=%s' % (self.details, self.extras)
47
48
49 class TestFailure(TestSignal):
50 """Raised when a test has failed."""
51
52
53 class TestPass(TestSignal):
54 """Raised when a test has passed."""
55
56
57 class TestSkip(TestSignal):
58 """Raised when a test has been skipped."""
59
60
61 class TestAbortClass(TestSignal):
62 """Raised when all subsequent tests within the same test class should
63 be aborted.
64 """
65
66
67 class TestAbortAll(TestSignal):
68 """Raised when all subsequent tests should be aborted."""
69
70
71 class ControllerError(Exception):
72 """Raised when an error occured in controller classes."""
73
[end of mobly/signals.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mobly/signals.py b/mobly/signals.py
--- a/mobly/signals.py
+++ b/mobly/signals.py
@@ -46,6 +46,10 @@
return 'Details=%s, Extras=%s' % (self.details, self.extras)
+class TestError(TestSignal):
+ """Raised when a test has an unexpected error."""
+
+
class TestFailure(TestSignal):
"""Raised when a test has failed."""
|
{"golden_diff": "diff --git a/mobly/signals.py b/mobly/signals.py\n--- a/mobly/signals.py\n+++ b/mobly/signals.py\n@@ -46,6 +46,10 @@\n return 'Details=%s, Extras=%s' % (self.details, self.extras)\n \n \n+class TestError(TestSignal):\n+ \"\"\"Raised when a test has an unexpected error.\"\"\"\n+\n+\n class TestFailure(TestSignal):\n \"\"\"Raised when a test has failed.\"\"\"\n", "issue": "Exceptions in `setup_test` should leave the test in `ERROR` status\nRegardless of the type of the exception, `setup_test` error should cause `ERROR` status.\r\n\r\nThis is different from a test method.\r\nIn a test method, an exception based on signals.TestFailure should cause the test to exit with `FAILED` status.\r\n\r\nThis is to be consistent with pyunit's behavior.\n", "before_files": [{"content": "# Copyright 2016 Google Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"This module is where all the test signal classes and related utilities live.\n\"\"\"\n\nimport functools\nimport json\n\n\nclass TestSignalError(Exception):\n \"\"\"Raised when an error occurs inside a test signal.\"\"\"\n\n\nclass TestSignal(Exception):\n \"\"\"Base class for all test result control signals. This is used to signal\n the result of a test.\n\n Attribute:\n details: A string that describes the reason for raising this signal.\n extras: A json-serializable data type to convey extra information about\n a test result.\n \"\"\"\n\n def __init__(self, details, extras=None):\n super(TestSignal, self).__init__(details)\n self.details = str(details)\n try:\n json.dumps(extras)\n self.extras = extras\n except TypeError:\n raise TestSignalError('Extras must be json serializable. %s '\n 'is not.' % extras)\n\n def __str__(self):\n return 'Details=%s, Extras=%s' % (self.details, self.extras)\n\n\nclass TestFailure(TestSignal):\n \"\"\"Raised when a test has failed.\"\"\"\n\n\nclass TestPass(TestSignal):\n \"\"\"Raised when a test has passed.\"\"\"\n\n\nclass TestSkip(TestSignal):\n \"\"\"Raised when a test has been skipped.\"\"\"\n\n\nclass TestAbortClass(TestSignal):\n \"\"\"Raised when all subsequent tests within the same test class should\n be aborted.\n \"\"\"\n\n\nclass TestAbortAll(TestSignal):\n \"\"\"Raised when all subsequent tests should be aborted.\"\"\"\n\n\nclass ControllerError(Exception):\n \"\"\"Raised when an error occured in controller classes.\"\"\"\n", "path": "mobly/signals.py"}]}
| 1,218 | 106 |
gh_patches_debug_31916
|
rasdani/github-patches
|
git_diff
|
jazzband__pip-tools-557
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
NotADirectoryError when running --generate-hashes
Running `pip-compile` works flawless, but pip-compile `--generate-hashes` produces the following error:
> Traceback (most recent call last):
> File "/home/ric/.local/bin/pip-compile", line 11, in <module>
> sys.exit(cli())
> File "/home/ric/.local/lib/python3.5/site-packages/click/core.py", line 722, in __call__
> return self.main(*args, **kwargs)
> File "/home/ric/.local/lib/python3.5/site-packages/click/core.py", line 697, in main
> rv = self.invoke(ctx)
> File "/home/ric/.local/lib/python3.5/site-packages/click/core.py", line 895, in invoke
> return ctx.invoke(self.callback, **ctx.params)
> File "/home/ric/.local/lib/python3.5/site-packages/click/core.py", line 535, in invoke
> return callback(*args, **kwargs)
> File "/home/ric/.local/lib/python3.5/site-packages/piptools/scripts/compile.py", line 186, in cli
> hashes = resolver.resolve_hashes(results)
> File "/home/ric/.local/lib/python3.5/site-packages/piptools/resolver.py", line 77, in resolve_hashes
> return {ireq: self.repository.get_hashes(ireq) for ireq in ireqs}
> File "/home/ric/.local/lib/python3.5/site-packages/piptools/resolver.py", line 77, in <dictcomp>
> return {ireq: self.repository.get_hashes(ireq) for ireq in ireqs}
> File "/home/ric/.local/lib/python3.5/site-packages/piptools/repositories/pypi.py", line 169, in get_hashes
> for candidate in matching_candidates
> File "/home/ric/.local/lib/python3.5/site-packages/piptools/repositories/pypi.py", line 169, in <setcomp>
> for candidate in matching_candidates
> File "/home/ric/.local/lib/python3.5/site-packages/piptools/repositories/pypi.py", line 176, in _get_file_hash
> download_dir=tmpdir, only_download=True, session=self.session
> File "/usr/lib/python3/dist-packages/pip/download.py", line 821, in unpack_url
> hashes=hashes
> File "/usr/lib/python3/dist-packages/pip/download.py", line 663, in unpack_http_url
> unpack_file(from_path, location, content_type, link)
> File "/usr/lib/python3/dist-packages/pip/utils/__init__.py", line 623, in unpack_file
> untar_file(filename, location)
> File "/usr/lib/python3/dist-packages/pip/utils/__init__.py", line 595, in untar_file
> with open(path, 'wb') as destfp:
> NotADirectoryError: [Errno 20] Not a directory: '/tmp/tmprk7taktxbuild/LICENSE/LICENSE_STIX'
>
##### Environment Versions
1. Ubuntu 16.04
1. Python 3.5.3
1. pip 9.0.1
1. pip-compile 1.9.0
This is my `requirements.in` file:
>
> seaborn==0.7.1
> pandas==0.20.1
> numpy==1.12.1
> scipy==0.19.0
> tqdm==4.11.2
> matplotlib==2.0.2
>
</issue>
<code>
[start of piptools/repositories/pypi.py]
1 # coding: utf-8
2 from __future__ import (absolute_import, division, print_function,
3 unicode_literals)
4
5 import hashlib
6 import os
7 from shutil import rmtree
8
9 from pip.download import unpack_url
10 from pip.index import PackageFinder
11 from pip.req.req_set import RequirementSet
12 from pip.wheel import Wheel
13 try:
14 from pip.utils.hashes import FAVORITE_HASH
15 except ImportError:
16 FAVORITE_HASH = 'sha256'
17
18 from ..cache import CACHE_DIR
19 from ..exceptions import NoCandidateFound
20 from ..utils import (fs_str, is_pinned_requirement, lookup_table,
21 make_install_requirement, pip_version_info)
22 from .base import BaseRepository
23
24 try:
25 from tempfile import TemporaryDirectory # added in 3.2
26 except ImportError:
27 from .._compat import TemporaryDirectory
28
29
30 # Monkey patch pip's Wheel class to support all platform tags. This allows
31 # pip-tools to generate hashes for all available distributions, not only the
32 # one for the current platform.
33
34 def _wheel_supported(self, tags=None):
35 # Ignore current platform. Support everything.
36 return True
37
38
39 def _wheel_support_index_min(self, tags=None):
40 # All wheels are equal priority for sorting.
41 return 0
42
43
44 Wheel.supported = _wheel_supported
45 Wheel.support_index_min = _wheel_support_index_min
46
47
48 class PyPIRepository(BaseRepository):
49 DEFAULT_INDEX_URL = 'https://pypi.python.org/simple'
50
51 """
52 The PyPIRepository will use the provided Finder instance to lookup
53 packages. Typically, it looks up packages on PyPI (the default implicit
54 config), but any other PyPI mirror can be used if index_urls is
55 changed/configured on the Finder.
56 """
57 def __init__(self, pip_options, session):
58 self.session = session
59
60 index_urls = [pip_options.index_url] + pip_options.extra_index_urls
61 if pip_options.no_index:
62 index_urls = []
63
64 self.finder = PackageFinder(
65 find_links=pip_options.find_links,
66 index_urls=index_urls,
67 trusted_hosts=pip_options.trusted_hosts,
68 allow_all_prereleases=pip_options.pre,
69 process_dependency_links=pip_options.process_dependency_links,
70 session=self.session,
71 )
72
73 # Caches
74 # stores project_name => InstallationCandidate mappings for all
75 # versions reported by PyPI, so we only have to ask once for each
76 # project
77 self._available_candidates_cache = {}
78
79 # stores InstallRequirement => list(InstallRequirement) mappings
80 # of all secondary dependencies for the given requirement, so we
81 # only have to go to disk once for each requirement
82 self._dependencies_cache = {}
83
84 # Setup file paths
85 self.freshen_build_caches()
86 self._download_dir = fs_str(os.path.join(CACHE_DIR, 'pkgs'))
87 self._wheel_download_dir = fs_str(os.path.join(CACHE_DIR, 'wheels'))
88
89 def freshen_build_caches(self):
90 """
91 Start with fresh build/source caches. Will remove any old build
92 caches from disk automatically.
93 """
94 self._build_dir = TemporaryDirectory(fs_str('build'))
95 self._source_dir = TemporaryDirectory(fs_str('source'))
96
97 @property
98 def build_dir(self):
99 return self._build_dir.name
100
101 @property
102 def source_dir(self):
103 return self._source_dir.name
104
105 def clear_caches(self):
106 rmtree(self._download_dir, ignore_errors=True)
107 rmtree(self._wheel_download_dir, ignore_errors=True)
108
109 def find_all_candidates(self, req_name):
110 if req_name not in self._available_candidates_cache:
111 # pip 8 changed the internal API, making this a public method
112 if pip_version_info >= (8, 0):
113 candidates = self.finder.find_all_candidates(req_name)
114 else:
115 candidates = self.finder._find_all_versions(req_name)
116 self._available_candidates_cache[req_name] = candidates
117 return self._available_candidates_cache[req_name]
118
119 def find_best_match(self, ireq, prereleases=None):
120 """
121 Returns a Version object that indicates the best match for the given
122 InstallRequirement according to the external repository.
123 """
124 if ireq.editable:
125 return ireq # return itself as the best match
126
127 all_candidates = self.find_all_candidates(ireq.name)
128 candidates_by_version = lookup_table(all_candidates, key=lambda c: c.version, unique=True)
129 matching_versions = ireq.specifier.filter((candidate.version for candidate in all_candidates),
130 prereleases=prereleases)
131
132 # Reuses pip's internal candidate sort key to sort
133 matching_candidates = [candidates_by_version[ver] for ver in matching_versions]
134 if not matching_candidates:
135 raise NoCandidateFound(ireq, all_candidates)
136 best_candidate = max(matching_candidates, key=self.finder._candidate_sort_key)
137
138 # Turn the candidate into a pinned InstallRequirement
139 return make_install_requirement(
140 best_candidate.project, best_candidate.version, ireq.extras, constraint=ireq.constraint
141 )
142
143 def get_dependencies(self, ireq):
144 """
145 Given a pinned or an editable InstallRequirement, returns a set of
146 dependencies (also InstallRequirements, but not necessarily pinned).
147 They indicate the secondary dependencies for the given requirement.
148 """
149 if not (ireq.editable or is_pinned_requirement(ireq)):
150 raise TypeError('Expected pinned or editable InstallRequirement, got {}'.format(ireq))
151
152 if ireq not in self._dependencies_cache:
153 if ireq.link and not ireq.link.is_artifact:
154 # No download_dir for VCS sources. This also works around pip
155 # using git-checkout-index, which gets rid of the .git dir.
156 download_dir = None
157 else:
158 download_dir = self._download_dir
159 if not os.path.isdir(download_dir):
160 os.makedirs(download_dir)
161 if not os.path.isdir(self._wheel_download_dir):
162 os.makedirs(self._wheel_download_dir)
163
164 reqset = RequirementSet(self.build_dir,
165 self.source_dir,
166 download_dir=download_dir,
167 wheel_download_dir=self._wheel_download_dir,
168 session=self.session)
169 self._dependencies_cache[ireq] = reqset._prepare_file(self.finder, ireq)
170 return set(self._dependencies_cache[ireq])
171
172 def get_hashes(self, ireq):
173 """
174 Given a pinned InstallRequire, returns a set of hashes that represent
175 all of the files for a given requirement. It is not acceptable for an
176 editable or unpinned requirement to be passed to this function.
177 """
178 if not is_pinned_requirement(ireq):
179 raise TypeError(
180 "Expected pinned requirement, not unpinned or editable, got {}".format(ireq))
181
182 # We need to get all of the candidates that match our current version
183 # pin, these will represent all of the files that could possibly
184 # satisify this constraint.
185 all_candidates = self.find_all_candidates(ireq.name)
186 candidates_by_version = lookup_table(all_candidates, key=lambda c: c.version)
187 matching_versions = list(
188 ireq.specifier.filter((candidate.version for candidate in all_candidates)))
189 matching_candidates = candidates_by_version[matching_versions[0]]
190
191 return {
192 self._get_file_hash(candidate.location)
193 for candidate in matching_candidates
194 }
195
196 def _get_file_hash(self, location):
197 with TemporaryDirectory() as tmpdir:
198 unpack_url(
199 location, self.build_dir,
200 download_dir=tmpdir, only_download=True, session=self.session
201 )
202 files = os.listdir(tmpdir)
203 assert len(files) == 1
204 filename = os.path.abspath(os.path.join(tmpdir, files[0]))
205
206 h = hashlib.new(FAVORITE_HASH)
207 with open(filename, "rb") as fp:
208 for chunk in iter(lambda: fp.read(8096), b""):
209 h.update(chunk)
210
211 return ":".join([FAVORITE_HASH, h.hexdigest()])
212
[end of piptools/repositories/pypi.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/piptools/repositories/pypi.py b/piptools/repositories/pypi.py
--- a/piptools/repositories/pypi.py
+++ b/piptools/repositories/pypi.py
@@ -4,9 +4,10 @@
import hashlib
import os
+from contextlib import contextmanager
from shutil import rmtree
-from pip.download import unpack_url
+from pip.download import is_file_url, url_to_path
from pip.index import PackageFinder
from pip.req.req_set import RequirementSet
from pip.wheel import Wheel
@@ -194,18 +195,38 @@
}
def _get_file_hash(self, location):
- with TemporaryDirectory() as tmpdir:
- unpack_url(
- location, self.build_dir,
- download_dir=tmpdir, only_download=True, session=self.session
- )
- files = os.listdir(tmpdir)
- assert len(files) == 1
- filename = os.path.abspath(os.path.join(tmpdir, files[0]))
-
- h = hashlib.new(FAVORITE_HASH)
- with open(filename, "rb") as fp:
- for chunk in iter(lambda: fp.read(8096), b""):
- h.update(chunk)
-
+ h = hashlib.new(FAVORITE_HASH)
+ with open_local_or_remote_file(location, self.session) as fp:
+ for chunk in iter(lambda: fp.read(8096), b""):
+ h.update(chunk)
return ":".join([FAVORITE_HASH, h.hexdigest()])
+
+
+@contextmanager
+def open_local_or_remote_file(link, session):
+ """
+ Open local or remote file for reading.
+
+ :type link: pip.index.Link
+ :type session: requests.Session
+ :raises ValueError: If link points to a local directory.
+ :return: a context manager to the opened file-like object
+ """
+ url = link.url_without_fragment
+
+ if is_file_url(link):
+ # Local URL
+ local_path = url_to_path(url)
+ if os.path.isdir(local_path):
+ raise ValueError("Cannot open directory for read: {}".format(url))
+ else:
+ with open(local_path, 'rb') as local_file:
+ yield local_file
+ else:
+ # Remote URL
+ headers = {"Accept-Encoding": "identity"}
+ response = session.get(url, headers=headers, stream=True)
+ try:
+ yield response.raw
+ finally:
+ response.close()
|
{"golden_diff": "diff --git a/piptools/repositories/pypi.py b/piptools/repositories/pypi.py\n--- a/piptools/repositories/pypi.py\n+++ b/piptools/repositories/pypi.py\n@@ -4,9 +4,10 @@\n \n import hashlib\n import os\n+from contextlib import contextmanager\n from shutil import rmtree\n \n-from pip.download import unpack_url\n+from pip.download import is_file_url, url_to_path\n from pip.index import PackageFinder\n from pip.req.req_set import RequirementSet\n from pip.wheel import Wheel\n@@ -194,18 +195,38 @@\n }\n \n def _get_file_hash(self, location):\n- with TemporaryDirectory() as tmpdir:\n- unpack_url(\n- location, self.build_dir,\n- download_dir=tmpdir, only_download=True, session=self.session\n- )\n- files = os.listdir(tmpdir)\n- assert len(files) == 1\n- filename = os.path.abspath(os.path.join(tmpdir, files[0]))\n-\n- h = hashlib.new(FAVORITE_HASH)\n- with open(filename, \"rb\") as fp:\n- for chunk in iter(lambda: fp.read(8096), b\"\"):\n- h.update(chunk)\n-\n+ h = hashlib.new(FAVORITE_HASH)\n+ with open_local_or_remote_file(location, self.session) as fp:\n+ for chunk in iter(lambda: fp.read(8096), b\"\"):\n+ h.update(chunk)\n return \":\".join([FAVORITE_HASH, h.hexdigest()])\n+\n+\n+@contextmanager\n+def open_local_or_remote_file(link, session):\n+ \"\"\"\n+ Open local or remote file for reading.\n+\n+ :type link: pip.index.Link\n+ :type session: requests.Session\n+ :raises ValueError: If link points to a local directory.\n+ :return: a context manager to the opened file-like object\n+ \"\"\"\n+ url = link.url_without_fragment\n+\n+ if is_file_url(link):\n+ # Local URL\n+ local_path = url_to_path(url)\n+ if os.path.isdir(local_path):\n+ raise ValueError(\"Cannot open directory for read: {}\".format(url))\n+ else:\n+ with open(local_path, 'rb') as local_file:\n+ yield local_file\n+ else:\n+ # Remote URL\n+ headers = {\"Accept-Encoding\": \"identity\"}\n+ response = session.get(url, headers=headers, stream=True)\n+ try:\n+ yield response.raw\n+ finally:\n+ response.close()\n", "issue": "NotADirectoryError when running --generate-hashes\nRunning `pip-compile` works flawless, but pip-compile `--generate-hashes` produces the following error:\r\n\r\n> Traceback (most recent call last):\r\n> File \"/home/ric/.local/bin/pip-compile\", line 11, in <module>\r\n> sys.exit(cli())\r\n> File \"/home/ric/.local/lib/python3.5/site-packages/click/core.py\", line 722, in __call__\r\n> return self.main(*args, **kwargs)\r\n> File \"/home/ric/.local/lib/python3.5/site-packages/click/core.py\", line 697, in main\r\n> rv = self.invoke(ctx)\r\n> File \"/home/ric/.local/lib/python3.5/site-packages/click/core.py\", line 895, in invoke\r\n> return ctx.invoke(self.callback, **ctx.params)\r\n> File \"/home/ric/.local/lib/python3.5/site-packages/click/core.py\", line 535, in invoke\r\n> return callback(*args, **kwargs)\r\n> File \"/home/ric/.local/lib/python3.5/site-packages/piptools/scripts/compile.py\", line 186, in cli\r\n> hashes = resolver.resolve_hashes(results)\r\n> File \"/home/ric/.local/lib/python3.5/site-packages/piptools/resolver.py\", line 77, in resolve_hashes\r\n> return {ireq: self.repository.get_hashes(ireq) for ireq in ireqs}\r\n> File \"/home/ric/.local/lib/python3.5/site-packages/piptools/resolver.py\", line 77, in <dictcomp>\r\n> return {ireq: self.repository.get_hashes(ireq) for ireq in ireqs}\r\n> File \"/home/ric/.local/lib/python3.5/site-packages/piptools/repositories/pypi.py\", line 169, in get_hashes\r\n> for candidate in matching_candidates\r\n> File \"/home/ric/.local/lib/python3.5/site-packages/piptools/repositories/pypi.py\", line 169, in <setcomp>\r\n> for candidate in matching_candidates\r\n> File \"/home/ric/.local/lib/python3.5/site-packages/piptools/repositories/pypi.py\", line 176, in _get_file_hash\r\n> download_dir=tmpdir, only_download=True, session=self.session\r\n> File \"/usr/lib/python3/dist-packages/pip/download.py\", line 821, in unpack_url\r\n> hashes=hashes\r\n> File \"/usr/lib/python3/dist-packages/pip/download.py\", line 663, in unpack_http_url\r\n> unpack_file(from_path, location, content_type, link)\r\n> File \"/usr/lib/python3/dist-packages/pip/utils/__init__.py\", line 623, in unpack_file\r\n> untar_file(filename, location)\r\n> File \"/usr/lib/python3/dist-packages/pip/utils/__init__.py\", line 595, in untar_file\r\n> with open(path, 'wb') as destfp:\r\n> NotADirectoryError: [Errno 20] Not a directory: '/tmp/tmprk7taktxbuild/LICENSE/LICENSE_STIX'\r\n> \r\n\r\n##### Environment Versions\r\n\r\n1. Ubuntu 16.04\r\n1. Python 3.5.3\r\n1. pip 9.0.1\r\n1. pip-compile 1.9.0\r\n\r\nThis is my `requirements.in` file:\r\n\r\n> \r\n> seaborn==0.7.1\r\n> pandas==0.20.1\r\n> numpy==1.12.1\r\n> scipy==0.19.0\r\n> tqdm==4.11.2\r\n> matplotlib==2.0.2\r\n> \n", "before_files": [{"content": "# coding: utf-8\nfrom __future__ import (absolute_import, division, print_function,\n unicode_literals)\n\nimport hashlib\nimport os\nfrom shutil import rmtree\n\nfrom pip.download import unpack_url\nfrom pip.index import PackageFinder\nfrom pip.req.req_set import RequirementSet\nfrom pip.wheel import Wheel\ntry:\n from pip.utils.hashes import FAVORITE_HASH\nexcept ImportError:\n FAVORITE_HASH = 'sha256'\n\nfrom ..cache import CACHE_DIR\nfrom ..exceptions import NoCandidateFound\nfrom ..utils import (fs_str, is_pinned_requirement, lookup_table,\n make_install_requirement, pip_version_info)\nfrom .base import BaseRepository\n\ntry:\n from tempfile import TemporaryDirectory # added in 3.2\nexcept ImportError:\n from .._compat import TemporaryDirectory\n\n\n# Monkey patch pip's Wheel class to support all platform tags. This allows\n# pip-tools to generate hashes for all available distributions, not only the\n# one for the current platform.\n\ndef _wheel_supported(self, tags=None):\n # Ignore current platform. Support everything.\n return True\n\n\ndef _wheel_support_index_min(self, tags=None):\n # All wheels are equal priority for sorting.\n return 0\n\n\nWheel.supported = _wheel_supported\nWheel.support_index_min = _wheel_support_index_min\n\n\nclass PyPIRepository(BaseRepository):\n DEFAULT_INDEX_URL = 'https://pypi.python.org/simple'\n\n \"\"\"\n The PyPIRepository will use the provided Finder instance to lookup\n packages. Typically, it looks up packages on PyPI (the default implicit\n config), but any other PyPI mirror can be used if index_urls is\n changed/configured on the Finder.\n \"\"\"\n def __init__(self, pip_options, session):\n self.session = session\n\n index_urls = [pip_options.index_url] + pip_options.extra_index_urls\n if pip_options.no_index:\n index_urls = []\n\n self.finder = PackageFinder(\n find_links=pip_options.find_links,\n index_urls=index_urls,\n trusted_hosts=pip_options.trusted_hosts,\n allow_all_prereleases=pip_options.pre,\n process_dependency_links=pip_options.process_dependency_links,\n session=self.session,\n )\n\n # Caches\n # stores project_name => InstallationCandidate mappings for all\n # versions reported by PyPI, so we only have to ask once for each\n # project\n self._available_candidates_cache = {}\n\n # stores InstallRequirement => list(InstallRequirement) mappings\n # of all secondary dependencies for the given requirement, so we\n # only have to go to disk once for each requirement\n self._dependencies_cache = {}\n\n # Setup file paths\n self.freshen_build_caches()\n self._download_dir = fs_str(os.path.join(CACHE_DIR, 'pkgs'))\n self._wheel_download_dir = fs_str(os.path.join(CACHE_DIR, 'wheels'))\n\n def freshen_build_caches(self):\n \"\"\"\n Start with fresh build/source caches. Will remove any old build\n caches from disk automatically.\n \"\"\"\n self._build_dir = TemporaryDirectory(fs_str('build'))\n self._source_dir = TemporaryDirectory(fs_str('source'))\n\n @property\n def build_dir(self):\n return self._build_dir.name\n\n @property\n def source_dir(self):\n return self._source_dir.name\n\n def clear_caches(self):\n rmtree(self._download_dir, ignore_errors=True)\n rmtree(self._wheel_download_dir, ignore_errors=True)\n\n def find_all_candidates(self, req_name):\n if req_name not in self._available_candidates_cache:\n # pip 8 changed the internal API, making this a public method\n if pip_version_info >= (8, 0):\n candidates = self.finder.find_all_candidates(req_name)\n else:\n candidates = self.finder._find_all_versions(req_name)\n self._available_candidates_cache[req_name] = candidates\n return self._available_candidates_cache[req_name]\n\n def find_best_match(self, ireq, prereleases=None):\n \"\"\"\n Returns a Version object that indicates the best match for the given\n InstallRequirement according to the external repository.\n \"\"\"\n if ireq.editable:\n return ireq # return itself as the best match\n\n all_candidates = self.find_all_candidates(ireq.name)\n candidates_by_version = lookup_table(all_candidates, key=lambda c: c.version, unique=True)\n matching_versions = ireq.specifier.filter((candidate.version for candidate in all_candidates),\n prereleases=prereleases)\n\n # Reuses pip's internal candidate sort key to sort\n matching_candidates = [candidates_by_version[ver] for ver in matching_versions]\n if not matching_candidates:\n raise NoCandidateFound(ireq, all_candidates)\n best_candidate = max(matching_candidates, key=self.finder._candidate_sort_key)\n\n # Turn the candidate into a pinned InstallRequirement\n return make_install_requirement(\n best_candidate.project, best_candidate.version, ireq.extras, constraint=ireq.constraint\n )\n\n def get_dependencies(self, ireq):\n \"\"\"\n Given a pinned or an editable InstallRequirement, returns a set of\n dependencies (also InstallRequirements, but not necessarily pinned).\n They indicate the secondary dependencies for the given requirement.\n \"\"\"\n if not (ireq.editable or is_pinned_requirement(ireq)):\n raise TypeError('Expected pinned or editable InstallRequirement, got {}'.format(ireq))\n\n if ireq not in self._dependencies_cache:\n if ireq.link and not ireq.link.is_artifact:\n # No download_dir for VCS sources. This also works around pip\n # using git-checkout-index, which gets rid of the .git dir.\n download_dir = None\n else:\n download_dir = self._download_dir\n if not os.path.isdir(download_dir):\n os.makedirs(download_dir)\n if not os.path.isdir(self._wheel_download_dir):\n os.makedirs(self._wheel_download_dir)\n\n reqset = RequirementSet(self.build_dir,\n self.source_dir,\n download_dir=download_dir,\n wheel_download_dir=self._wheel_download_dir,\n session=self.session)\n self._dependencies_cache[ireq] = reqset._prepare_file(self.finder, ireq)\n return set(self._dependencies_cache[ireq])\n\n def get_hashes(self, ireq):\n \"\"\"\n Given a pinned InstallRequire, returns a set of hashes that represent\n all of the files for a given requirement. It is not acceptable for an\n editable or unpinned requirement to be passed to this function.\n \"\"\"\n if not is_pinned_requirement(ireq):\n raise TypeError(\n \"Expected pinned requirement, not unpinned or editable, got {}\".format(ireq))\n\n # We need to get all of the candidates that match our current version\n # pin, these will represent all of the files that could possibly\n # satisify this constraint.\n all_candidates = self.find_all_candidates(ireq.name)\n candidates_by_version = lookup_table(all_candidates, key=lambda c: c.version)\n matching_versions = list(\n ireq.specifier.filter((candidate.version for candidate in all_candidates)))\n matching_candidates = candidates_by_version[matching_versions[0]]\n\n return {\n self._get_file_hash(candidate.location)\n for candidate in matching_candidates\n }\n\n def _get_file_hash(self, location):\n with TemporaryDirectory() as tmpdir:\n unpack_url(\n location, self.build_dir,\n download_dir=tmpdir, only_download=True, session=self.session\n )\n files = os.listdir(tmpdir)\n assert len(files) == 1\n filename = os.path.abspath(os.path.join(tmpdir, files[0]))\n\n h = hashlib.new(FAVORITE_HASH)\n with open(filename, \"rb\") as fp:\n for chunk in iter(lambda: fp.read(8096), b\"\"):\n h.update(chunk)\n\n return \":\".join([FAVORITE_HASH, h.hexdigest()])\n", "path": "piptools/repositories/pypi.py"}]}
| 3,636 | 566 |
gh_patches_debug_37219
|
rasdani/github-patches
|
git_diff
|
streamlink__streamlink-3290
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
bfmtv - No playable streams found on this URL
<!--
Thanks for reporting a plugin issue!
USE THE TEMPLATE. Otherwise your plugin issue may be rejected.
First, see the contribution guidelines:
https://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink
Also check the list of open and closed plugin issues:
https://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22
Please see the text preview to avoid unnecessary formatting errors.
-->
## Plugin Issue
<!-- Replace [ ] with [x] in order to check the box -->
- [x] This is a plugin issue and I have read the contribution guidelines.
### Description
<!-- Explain the plugin issue as thoroughly as you can. -->
There is no playable streams for bfmtv
### Reproduction steps / Explicit stream URLs to test
<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->
`streamlink https://www.bfmtv.com/en-direct/ best`
or `streamlink https://www.bfmtv.com/paris/en-direct/ best`
or any other channels supported by this plugin
### Log output
<!--
TEXT LOG OUTPUT IS REQUIRED for a plugin issue!
Use the `--loglevel debug` parameter and avoid using parameters which suppress log output.
https://streamlink.github.io/cli.html#cmdoption-l
Make sure to **remove usernames and passwords**
You can copy the output to https://gist.github.com/ or paste it below.
Don't post screenshots of the log output and instead copy the text from your terminal application.
-->
```
streamlink --loglevel debug https://www.bfmtv.com/en-direct/ best
[cli][debug] OS: Linux-5.8.15-201.fc32.x86_64-x86_64-with-glibc2.2.5
[cli][debug] Python: 3.8.6
[cli][debug] Streamlink: 1.7.0
[cli][debug] Requests(2.24.0), Socks(1.7.1), Websocket(0.57.0)
[cli][info] Found matching plugin bfmtv for URL https://www.bfmtv.com/en-direct/
error: No playable streams found on this URL: https://www.bfmtv.com/en-direct/
```
### Additional comments, etc.
As a workaround you can use their dailymotion stream: `streamlink https://www.dailymotion.com/embed/video/xgz4t1 best`
</issue>
<code>
[start of src/streamlink/plugins/bfmtv.py]
1 import re
2
3 from streamlink.plugin import Plugin
4 from streamlink.plugins.brightcove import BrightcovePlayer
5 from streamlink.stream import HLSStream
6
7
8 class BFMTV(Plugin):
9 _url_re = re.compile(r'https://.+\.(?:bfmtv|01net)\.com')
10 _brightcove_video_re = re.compile(
11 r'data-holder="video(?P<video_id>[0-9]+)" data-account="(?P<account_id>[0-9]+)"'
12 )
13 _brightcove_video_alt_re = re.compile(
14 r'data-account="(?P<account_id>[0-9]+).*?data-video-id="(?P<video_id>[0-9]+)"',
15 re.DOTALL
16 )
17 _embed_video_url_re = re.compile(
18 r"\$YOPLAYER\('liveStitching', {.+?file: '(?P<video_url>[^\"]+?)'.+?}\);",
19 re.DOTALL
20 )
21
22 @classmethod
23 def can_handle_url(cls, url):
24 return BFMTV._url_re.match(url)
25
26 def _get_streams(self):
27 # Retrieve URL page and search for Brightcove video data
28 res = self.session.http.get(self.url)
29 match = self._brightcove_video_re.search(res.text) or self._brightcove_video_alt_re.search(res.text)
30 if match is not None:
31 account_id = match.group('account_id')
32 video_id = match.group('video_id')
33 player = BrightcovePlayer(self.session, account_id)
34 for stream in player.get_streams(video_id):
35 yield stream
36 else:
37 # Try to get the stream URL in the page
38 match = self._embed_video_url_re.search(res.text)
39 if match is not None:
40 video_url = match.group('video_url')
41 if '.m3u8' in video_url:
42 yield from HLSStream.parse_variant_playlist(self.session, video_url).items()
43
44
45 __plugin__ = BFMTV
46
[end of src/streamlink/plugins/bfmtv.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/streamlink/plugins/bfmtv.py b/src/streamlink/plugins/bfmtv.py
--- a/src/streamlink/plugins/bfmtv.py
+++ b/src/streamlink/plugins/bfmtv.py
@@ -1,45 +1,46 @@
+import logging
import re
from streamlink.plugin import Plugin
from streamlink.plugins.brightcove import BrightcovePlayer
-from streamlink.stream import HLSStream
+
+log = logging.getLogger(__name__)
class BFMTV(Plugin):
_url_re = re.compile(r'https://.+\.(?:bfmtv|01net)\.com')
+ _dailymotion_url = 'https://www.dailymotion.com/embed/video/{}'
_brightcove_video_re = re.compile(
- r'data-holder="video(?P<video_id>[0-9]+)" data-account="(?P<account_id>[0-9]+)"'
- )
- _brightcove_video_alt_re = re.compile(
- r'data-account="(?P<account_id>[0-9]+).*?data-video-id="(?P<video_id>[0-9]+)"',
+ r'accountid="(?P<account_id>[0-9]+).*?videoid="(?P<video_id>[0-9]+)"',
re.DOTALL
)
- _embed_video_url_re = re.compile(
- r"\$YOPLAYER\('liveStitching', {.+?file: '(?P<video_url>[^\"]+?)'.+?}\);",
+ _embed_video_id_re = re.compile(
+ r'<iframe.*?src=".*?/(?P<video_id>\w+)"',
re.DOTALL
)
@classmethod
def can_handle_url(cls, url):
- return BFMTV._url_re.match(url)
+ return cls._url_re.match(url) is not None
def _get_streams(self):
# Retrieve URL page and search for Brightcove video data
res = self.session.http.get(self.url)
- match = self._brightcove_video_re.search(res.text) or self._brightcove_video_alt_re.search(res.text)
+ match = self._brightcove_video_re.search(res.text)
if match is not None:
account_id = match.group('account_id')
+ log.debug(f'Account ID: {account_id}')
video_id = match.group('video_id')
+ log.debug(f'Video ID: {video_id}')
player = BrightcovePlayer(self.session, account_id)
- for stream in player.get_streams(video_id):
- yield stream
+ yield from player.get_streams(video_id)
else:
- # Try to get the stream URL in the page
- match = self._embed_video_url_re.search(res.text)
+ # Try to find the Dailymotion video ID
+ match = self._embed_video_id_re.search(res.text)
if match is not None:
- video_url = match.group('video_url')
- if '.m3u8' in video_url:
- yield from HLSStream.parse_variant_playlist(self.session, video_url).items()
+ video_id = match.group('video_id')
+ log.debug(f'Video ID: {video_id}')
+ yield from self.session.streams(self._dailymotion_url.format(video_id)).items()
__plugin__ = BFMTV
|
{"golden_diff": "diff --git a/src/streamlink/plugins/bfmtv.py b/src/streamlink/plugins/bfmtv.py\n--- a/src/streamlink/plugins/bfmtv.py\n+++ b/src/streamlink/plugins/bfmtv.py\n@@ -1,45 +1,46 @@\n+import logging\n import re\n \n from streamlink.plugin import Plugin\n from streamlink.plugins.brightcove import BrightcovePlayer\n-from streamlink.stream import HLSStream\n+\n+log = logging.getLogger(__name__)\n \n \n class BFMTV(Plugin):\n _url_re = re.compile(r'https://.+\\.(?:bfmtv|01net)\\.com')\n+ _dailymotion_url = 'https://www.dailymotion.com/embed/video/{}'\n _brightcove_video_re = re.compile(\n- r'data-holder=\"video(?P<video_id>[0-9]+)\" data-account=\"(?P<account_id>[0-9]+)\"'\n- )\n- _brightcove_video_alt_re = re.compile(\n- r'data-account=\"(?P<account_id>[0-9]+).*?data-video-id=\"(?P<video_id>[0-9]+)\"',\n+ r'accountid=\"(?P<account_id>[0-9]+).*?videoid=\"(?P<video_id>[0-9]+)\"',\n re.DOTALL\n )\n- _embed_video_url_re = re.compile(\n- r\"\\$YOPLAYER\\('liveStitching', {.+?file: '(?P<video_url>[^\\\"]+?)'.+?}\\);\",\n+ _embed_video_id_re = re.compile(\n+ r'<iframe.*?src=\".*?/(?P<video_id>\\w+)\"',\n re.DOTALL\n )\n \n @classmethod\n def can_handle_url(cls, url):\n- return BFMTV._url_re.match(url)\n+ return cls._url_re.match(url) is not None\n \n def _get_streams(self):\n # Retrieve URL page and search for Brightcove video data\n res = self.session.http.get(self.url)\n- match = self._brightcove_video_re.search(res.text) or self._brightcove_video_alt_re.search(res.text)\n+ match = self._brightcove_video_re.search(res.text)\n if match is not None:\n account_id = match.group('account_id')\n+ log.debug(f'Account ID: {account_id}')\n video_id = match.group('video_id')\n+ log.debug(f'Video ID: {video_id}')\n player = BrightcovePlayer(self.session, account_id)\n- for stream in player.get_streams(video_id):\n- yield stream\n+ yield from player.get_streams(video_id)\n else:\n- # Try to get the stream URL in the page\n- match = self._embed_video_url_re.search(res.text)\n+ # Try to find the Dailymotion video ID\n+ match = self._embed_video_id_re.search(res.text)\n if match is not None:\n- video_url = match.group('video_url')\n- if '.m3u8' in video_url:\n- yield from HLSStream.parse_variant_playlist(self.session, video_url).items()\n+ video_id = match.group('video_id')\n+ log.debug(f'Video ID: {video_id}')\n+ yield from self.session.streams(self._dailymotion_url.format(video_id)).items()\n \n \n __plugin__ = BFMTV\n", "issue": "bfmtv - No playable streams found on this URL\n<!--\r\nThanks for reporting a plugin issue!\r\nUSE THE TEMPLATE. Otherwise your plugin issue may be rejected.\r\n\r\nFirst, see the contribution guidelines:\r\nhttps://github.com/streamlink/streamlink/blob/master/CONTRIBUTING.md#contributing-to-streamlink\r\n\r\nAlso check the list of open and closed plugin issues:\r\nhttps://github.com/streamlink/streamlink/issues?q=is%3Aissue+label%3A%22plugin+issue%22\r\n\r\nPlease see the text preview to avoid unnecessary formatting errors.\r\n-->\r\n\r\n\r\n## Plugin Issue\r\n\r\n<!-- Replace [ ] with [x] in order to check the box -->\r\n- [x] This is a plugin issue and I have read the contribution guidelines.\r\n\r\n\r\n### Description\r\n\r\n<!-- Explain the plugin issue as thoroughly as you can. -->\r\nThere is no playable streams for bfmtv\r\n\r\n### Reproduction steps / Explicit stream URLs to test\r\n\r\n<!-- How can we reproduce this? Please note the exact steps below using the list format supplied. If you need more steps please add them. -->\r\n\r\n`streamlink https://www.bfmtv.com/en-direct/ best`\r\n\r\nor `streamlink https://www.bfmtv.com/paris/en-direct/ best`\r\nor any other channels supported by this plugin\r\n\r\n\r\n### Log output\r\n\r\n<!--\r\nTEXT LOG OUTPUT IS REQUIRED for a plugin issue!\r\nUse the `--loglevel debug` parameter and avoid using parameters which suppress log output.\r\nhttps://streamlink.github.io/cli.html#cmdoption-l\r\n\r\nMake sure to **remove usernames and passwords**\r\nYou can copy the output to https://gist.github.com/ or paste it below.\r\n\r\nDon't post screenshots of the log output and instead copy the text from your terminal application.\r\n-->\r\n\r\n```\r\nstreamlink --loglevel debug https://www.bfmtv.com/en-direct/ best\r\n[cli][debug] OS: Linux-5.8.15-201.fc32.x86_64-x86_64-with-glibc2.2.5\r\n[cli][debug] Python: 3.8.6\r\n[cli][debug] Streamlink: 1.7.0\r\n[cli][debug] Requests(2.24.0), Socks(1.7.1), Websocket(0.57.0)\r\n[cli][info] Found matching plugin bfmtv for URL https://www.bfmtv.com/en-direct/\r\nerror: No playable streams found on this URL: https://www.bfmtv.com/en-direct/\r\n```\r\n\r\n\r\n### Additional comments, etc.\r\n\r\nAs a workaround you can use their dailymotion stream: `streamlink https://www.dailymotion.com/embed/video/xgz4t1 best`\n", "before_files": [{"content": "import re\n\nfrom streamlink.plugin import Plugin\nfrom streamlink.plugins.brightcove import BrightcovePlayer\nfrom streamlink.stream import HLSStream\n\n\nclass BFMTV(Plugin):\n _url_re = re.compile(r'https://.+\\.(?:bfmtv|01net)\\.com')\n _brightcove_video_re = re.compile(\n r'data-holder=\"video(?P<video_id>[0-9]+)\" data-account=\"(?P<account_id>[0-9]+)\"'\n )\n _brightcove_video_alt_re = re.compile(\n r'data-account=\"(?P<account_id>[0-9]+).*?data-video-id=\"(?P<video_id>[0-9]+)\"',\n re.DOTALL\n )\n _embed_video_url_re = re.compile(\n r\"\\$YOPLAYER\\('liveStitching', {.+?file: '(?P<video_url>[^\\\"]+?)'.+?}\\);\",\n re.DOTALL\n )\n\n @classmethod\n def can_handle_url(cls, url):\n return BFMTV._url_re.match(url)\n\n def _get_streams(self):\n # Retrieve URL page and search for Brightcove video data\n res = self.session.http.get(self.url)\n match = self._brightcove_video_re.search(res.text) or self._brightcove_video_alt_re.search(res.text)\n if match is not None:\n account_id = match.group('account_id')\n video_id = match.group('video_id')\n player = BrightcovePlayer(self.session, account_id)\n for stream in player.get_streams(video_id):\n yield stream\n else:\n # Try to get the stream URL in the page\n match = self._embed_video_url_re.search(res.text)\n if match is not None:\n video_url = match.group('video_url')\n if '.m3u8' in video_url:\n yield from HLSStream.parse_variant_playlist(self.session, video_url).items()\n\n\n__plugin__ = BFMTV\n", "path": "src/streamlink/plugins/bfmtv.py"}]}
| 1,632 | 748 |
gh_patches_debug_29059
|
rasdani/github-patches
|
git_diff
|
pypa__setuptools-1477
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
get_requires_for_build_sdist should not require wheel
[get_requires_for_build_sdist](https://github.com/pypa/setuptools/blob/master/setuptools/build_meta.py#L120) also implies [wheel](https://github.com/pypa/setuptools/blob/master/setuptools/build_meta.py#L96) as dependency, even though a wheel is not required to build a source distribution.
</issue>
<code>
[start of setuptools/build_meta.py]
1 """A PEP 517 interface to setuptools
2
3 Previously, when a user or a command line tool (let's call it a "frontend")
4 needed to make a request of setuptools to take a certain action, for
5 example, generating a list of installation requirements, the frontend would
6 would call "setup.py egg_info" or "setup.py bdist_wheel" on the command line.
7
8 PEP 517 defines a different method of interfacing with setuptools. Rather
9 than calling "setup.py" directly, the frontend should:
10
11 1. Set the current directory to the directory with a setup.py file
12 2. Import this module into a safe python interpreter (one in which
13 setuptools can potentially set global variables or crash hard).
14 3. Call one of the functions defined in PEP 517.
15
16 What each function does is defined in PEP 517. However, here is a "casual"
17 definition of the functions (this definition should not be relied on for
18 bug reports or API stability):
19
20 - `build_wheel`: build a wheel in the folder and return the basename
21 - `get_requires_for_build_wheel`: get the `setup_requires` to build
22 - `prepare_metadata_for_build_wheel`: get the `install_requires`
23 - `build_sdist`: build an sdist in the folder and return the basename
24 - `get_requires_for_build_sdist`: get the `setup_requires` to build
25
26 Again, this is not a formal definition! Just a "taste" of the module.
27 """
28
29 import os
30 import sys
31 import tokenize
32 import shutil
33 import contextlib
34
35 import setuptools
36 import distutils
37
38
39 class SetupRequirementsError(BaseException):
40 def __init__(self, specifiers):
41 self.specifiers = specifiers
42
43
44 class Distribution(setuptools.dist.Distribution):
45 def fetch_build_eggs(self, specifiers):
46 raise SetupRequirementsError(specifiers)
47
48 @classmethod
49 @contextlib.contextmanager
50 def patch(cls):
51 """
52 Replace
53 distutils.dist.Distribution with this class
54 for the duration of this context.
55 """
56 orig = distutils.core.Distribution
57 distutils.core.Distribution = cls
58 try:
59 yield
60 finally:
61 distutils.core.Distribution = orig
62
63
64 def _to_str(s):
65 """
66 Convert a filename to a string (on Python 2, explicitly
67 a byte string, not Unicode) as distutils checks for the
68 exact type str.
69 """
70 if sys.version_info[0] == 2 and not isinstance(s, str):
71 # Assume it's Unicode, as that's what the PEP says
72 # should be provided.
73 return s.encode(sys.getfilesystemencoding())
74 return s
75
76
77 def _run_setup(setup_script='setup.py'):
78 # Note that we can reuse our build directory between calls
79 # Correctness comes first, then optimization later
80 __file__ = setup_script
81 __name__ = '__main__'
82 f = getattr(tokenize, 'open', open)(__file__)
83 code = f.read().replace('\\r\\n', '\\n')
84 f.close()
85 exec(compile(code, __file__, 'exec'), locals())
86
87
88 def _fix_config(config_settings):
89 config_settings = config_settings or {}
90 config_settings.setdefault('--global-option', [])
91 return config_settings
92
93
94 def _get_build_requires(config_settings):
95 config_settings = _fix_config(config_settings)
96 requirements = ['setuptools', 'wheel']
97
98 sys.argv = sys.argv[:1] + ['egg_info'] + \
99 config_settings["--global-option"]
100 try:
101 with Distribution.patch():
102 _run_setup()
103 except SetupRequirementsError as e:
104 requirements += e.specifiers
105
106 return requirements
107
108
109 def _get_immediate_subdirectories(a_dir):
110 return [name for name in os.listdir(a_dir)
111 if os.path.isdir(os.path.join(a_dir, name))]
112
113
114 def get_requires_for_build_wheel(config_settings=None):
115 config_settings = _fix_config(config_settings)
116 return _get_build_requires(config_settings)
117
118
119 def get_requires_for_build_sdist(config_settings=None):
120 config_settings = _fix_config(config_settings)
121 return _get_build_requires(config_settings)
122
123
124 def prepare_metadata_for_build_wheel(metadata_directory, config_settings=None):
125 sys.argv = sys.argv[:1] + ['dist_info', '--egg-base', _to_str(metadata_directory)]
126 _run_setup()
127
128 dist_info_directory = metadata_directory
129 while True:
130 dist_infos = [f for f in os.listdir(dist_info_directory)
131 if f.endswith('.dist-info')]
132
133 if len(dist_infos) == 0 and \
134 len(_get_immediate_subdirectories(dist_info_directory)) == 1:
135 dist_info_directory = os.path.join(
136 dist_info_directory, os.listdir(dist_info_directory)[0])
137 continue
138
139 assert len(dist_infos) == 1
140 break
141
142 # PEP 517 requires that the .dist-info directory be placed in the
143 # metadata_directory. To comply, we MUST copy the directory to the root
144 if dist_info_directory != metadata_directory:
145 shutil.move(
146 os.path.join(dist_info_directory, dist_infos[0]),
147 metadata_directory)
148 shutil.rmtree(dist_info_directory, ignore_errors=True)
149
150 return dist_infos[0]
151
152
153 def build_wheel(wheel_directory, config_settings=None,
154 metadata_directory=None):
155 config_settings = _fix_config(config_settings)
156 wheel_directory = os.path.abspath(wheel_directory)
157 sys.argv = sys.argv[:1] + ['bdist_wheel'] + \
158 config_settings["--global-option"]
159 _run_setup()
160 if wheel_directory != 'dist':
161 shutil.rmtree(wheel_directory)
162 shutil.copytree('dist', wheel_directory)
163
164 wheels = [f for f in os.listdir(wheel_directory)
165 if f.endswith('.whl')]
166
167 assert len(wheels) == 1
168 return wheels[0]
169
170
171 def build_sdist(sdist_directory, config_settings=None):
172 config_settings = _fix_config(config_settings)
173 sdist_directory = os.path.abspath(sdist_directory)
174 sys.argv = sys.argv[:1] + ['sdist'] + \
175 config_settings["--global-option"]
176 _run_setup()
177 if sdist_directory != 'dist':
178 shutil.rmtree(sdist_directory)
179 shutil.copytree('dist', sdist_directory)
180
181 sdists = [f for f in os.listdir(sdist_directory)
182 if f.endswith('.tar.gz')]
183
184 assert len(sdists) == 1
185 return sdists[0]
186
[end of setuptools/build_meta.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setuptools/build_meta.py b/setuptools/build_meta.py
--- a/setuptools/build_meta.py
+++ b/setuptools/build_meta.py
@@ -91,9 +91,8 @@
return config_settings
-def _get_build_requires(config_settings):
+def _get_build_requires(config_settings, requirements):
config_settings = _fix_config(config_settings)
- requirements = ['setuptools', 'wheel']
sys.argv = sys.argv[:1] + ['egg_info'] + \
config_settings["--global-option"]
@@ -113,20 +112,20 @@
def get_requires_for_build_wheel(config_settings=None):
config_settings = _fix_config(config_settings)
- return _get_build_requires(config_settings)
+ return _get_build_requires(config_settings, requirements=['setuptools', 'wheel'])
def get_requires_for_build_sdist(config_settings=None):
config_settings = _fix_config(config_settings)
- return _get_build_requires(config_settings)
+ return _get_build_requires(config_settings, requirements=['setuptools'])
def prepare_metadata_for_build_wheel(metadata_directory, config_settings=None):
sys.argv = sys.argv[:1] + ['dist_info', '--egg-base', _to_str(metadata_directory)]
_run_setup()
-
+
dist_info_directory = metadata_directory
- while True:
+ while True:
dist_infos = [f for f in os.listdir(dist_info_directory)
if f.endswith('.dist-info')]
|
{"golden_diff": "diff --git a/setuptools/build_meta.py b/setuptools/build_meta.py\n--- a/setuptools/build_meta.py\n+++ b/setuptools/build_meta.py\n@@ -91,9 +91,8 @@\n return config_settings\n \n \n-def _get_build_requires(config_settings):\n+def _get_build_requires(config_settings, requirements):\n config_settings = _fix_config(config_settings)\n- requirements = ['setuptools', 'wheel']\n \n sys.argv = sys.argv[:1] + ['egg_info'] + \\\n config_settings[\"--global-option\"]\n@@ -113,20 +112,20 @@\n \n def get_requires_for_build_wheel(config_settings=None):\n config_settings = _fix_config(config_settings)\n- return _get_build_requires(config_settings)\n+ return _get_build_requires(config_settings, requirements=['setuptools', 'wheel'])\n \n \n def get_requires_for_build_sdist(config_settings=None):\n config_settings = _fix_config(config_settings)\n- return _get_build_requires(config_settings)\n+ return _get_build_requires(config_settings, requirements=['setuptools'])\n \n \n def prepare_metadata_for_build_wheel(metadata_directory, config_settings=None):\n sys.argv = sys.argv[:1] + ['dist_info', '--egg-base', _to_str(metadata_directory)]\n _run_setup()\n- \n+\n dist_info_directory = metadata_directory\n- while True: \n+ while True:\n dist_infos = [f for f in os.listdir(dist_info_directory)\n if f.endswith('.dist-info')]\n", "issue": "get_requires_for_build_sdist should not require wheel\n[get_requires_for_build_sdist](https://github.com/pypa/setuptools/blob/master/setuptools/build_meta.py#L120) also implies [wheel](https://github.com/pypa/setuptools/blob/master/setuptools/build_meta.py#L96) as dependency, even though a wheel is not required to build a source distribution.\n", "before_files": [{"content": "\"\"\"A PEP 517 interface to setuptools\n\nPreviously, when a user or a command line tool (let's call it a \"frontend\")\nneeded to make a request of setuptools to take a certain action, for\nexample, generating a list of installation requirements, the frontend would\nwould call \"setup.py egg_info\" or \"setup.py bdist_wheel\" on the command line.\n\nPEP 517 defines a different method of interfacing with setuptools. Rather\nthan calling \"setup.py\" directly, the frontend should:\n\n 1. Set the current directory to the directory with a setup.py file\n 2. Import this module into a safe python interpreter (one in which\n setuptools can potentially set global variables or crash hard).\n 3. Call one of the functions defined in PEP 517.\n\nWhat each function does is defined in PEP 517. However, here is a \"casual\"\ndefinition of the functions (this definition should not be relied on for\nbug reports or API stability):\n\n - `build_wheel`: build a wheel in the folder and return the basename\n - `get_requires_for_build_wheel`: get the `setup_requires` to build\n - `prepare_metadata_for_build_wheel`: get the `install_requires`\n - `build_sdist`: build an sdist in the folder and return the basename\n - `get_requires_for_build_sdist`: get the `setup_requires` to build\n\nAgain, this is not a formal definition! Just a \"taste\" of the module.\n\"\"\"\n\nimport os\nimport sys\nimport tokenize\nimport shutil\nimport contextlib\n\nimport setuptools\nimport distutils\n\n\nclass SetupRequirementsError(BaseException):\n def __init__(self, specifiers):\n self.specifiers = specifiers\n\n\nclass Distribution(setuptools.dist.Distribution):\n def fetch_build_eggs(self, specifiers):\n raise SetupRequirementsError(specifiers)\n\n @classmethod\n @contextlib.contextmanager\n def patch(cls):\n \"\"\"\n Replace\n distutils.dist.Distribution with this class\n for the duration of this context.\n \"\"\"\n orig = distutils.core.Distribution\n distutils.core.Distribution = cls\n try:\n yield\n finally:\n distutils.core.Distribution = orig\n\n\ndef _to_str(s):\n \"\"\"\n Convert a filename to a string (on Python 2, explicitly\n a byte string, not Unicode) as distutils checks for the\n exact type str.\n \"\"\"\n if sys.version_info[0] == 2 and not isinstance(s, str):\n # Assume it's Unicode, as that's what the PEP says\n # should be provided.\n return s.encode(sys.getfilesystemencoding())\n return s\n\n\ndef _run_setup(setup_script='setup.py'):\n # Note that we can reuse our build directory between calls\n # Correctness comes first, then optimization later\n __file__ = setup_script\n __name__ = '__main__'\n f = getattr(tokenize, 'open', open)(__file__)\n code = f.read().replace('\\\\r\\\\n', '\\\\n')\n f.close()\n exec(compile(code, __file__, 'exec'), locals())\n\n\ndef _fix_config(config_settings):\n config_settings = config_settings or {}\n config_settings.setdefault('--global-option', [])\n return config_settings\n\n\ndef _get_build_requires(config_settings):\n config_settings = _fix_config(config_settings)\n requirements = ['setuptools', 'wheel']\n\n sys.argv = sys.argv[:1] + ['egg_info'] + \\\n config_settings[\"--global-option\"]\n try:\n with Distribution.patch():\n _run_setup()\n except SetupRequirementsError as e:\n requirements += e.specifiers\n\n return requirements\n\n\ndef _get_immediate_subdirectories(a_dir):\n return [name for name in os.listdir(a_dir)\n if os.path.isdir(os.path.join(a_dir, name))]\n\n\ndef get_requires_for_build_wheel(config_settings=None):\n config_settings = _fix_config(config_settings)\n return _get_build_requires(config_settings)\n\n\ndef get_requires_for_build_sdist(config_settings=None):\n config_settings = _fix_config(config_settings)\n return _get_build_requires(config_settings)\n\n\ndef prepare_metadata_for_build_wheel(metadata_directory, config_settings=None):\n sys.argv = sys.argv[:1] + ['dist_info', '--egg-base', _to_str(metadata_directory)]\n _run_setup()\n \n dist_info_directory = metadata_directory\n while True: \n dist_infos = [f for f in os.listdir(dist_info_directory)\n if f.endswith('.dist-info')]\n\n if len(dist_infos) == 0 and \\\n len(_get_immediate_subdirectories(dist_info_directory)) == 1:\n dist_info_directory = os.path.join(\n dist_info_directory, os.listdir(dist_info_directory)[0])\n continue\n\n assert len(dist_infos) == 1\n break\n\n # PEP 517 requires that the .dist-info directory be placed in the\n # metadata_directory. To comply, we MUST copy the directory to the root\n if dist_info_directory != metadata_directory:\n shutil.move(\n os.path.join(dist_info_directory, dist_infos[0]),\n metadata_directory)\n shutil.rmtree(dist_info_directory, ignore_errors=True)\n\n return dist_infos[0]\n\n\ndef build_wheel(wheel_directory, config_settings=None,\n metadata_directory=None):\n config_settings = _fix_config(config_settings)\n wheel_directory = os.path.abspath(wheel_directory)\n sys.argv = sys.argv[:1] + ['bdist_wheel'] + \\\n config_settings[\"--global-option\"]\n _run_setup()\n if wheel_directory != 'dist':\n shutil.rmtree(wheel_directory)\n shutil.copytree('dist', wheel_directory)\n\n wheels = [f for f in os.listdir(wheel_directory)\n if f.endswith('.whl')]\n\n assert len(wheels) == 1\n return wheels[0]\n\n\ndef build_sdist(sdist_directory, config_settings=None):\n config_settings = _fix_config(config_settings)\n sdist_directory = os.path.abspath(sdist_directory)\n sys.argv = sys.argv[:1] + ['sdist'] + \\\n config_settings[\"--global-option\"]\n _run_setup()\n if sdist_directory != 'dist':\n shutil.rmtree(sdist_directory)\n shutil.copytree('dist', sdist_directory)\n\n sdists = [f for f in os.listdir(sdist_directory)\n if f.endswith('.tar.gz')]\n\n assert len(sdists) == 1\n return sdists[0]\n", "path": "setuptools/build_meta.py"}]}
| 2,478 | 315 |
gh_patches_debug_31993
|
rasdani/github-patches
|
git_diff
|
nonebot__nonebot2-149
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
自动生成 api 文档
**是否在使用中遇到某些问题而需要新的特性?请描述:**
```python
self._server_app = FastAPI(
debug=config.debug,
openapi_url=None,
docs_url=None,
redoc_url=None,
)
```
源码好像禁止了API文档自动生成的功能,能否改为根据配置决定?例如添加一个配置项。
因为开发时要进行 API 请求调试,所以感觉这个功能还是挺有必要的
</issue>
<code>
[start of nonebot/drivers/fastapi.py]
1 """
2 FastAPI 驱动适配
3 ================
4
5 后端使用方法请参考: `FastAPI 文档`_
6
7 .. _FastAPI 文档:
8 https://fastapi.tiangolo.com/
9 """
10
11 import json
12 import asyncio
13 import logging
14 from typing import Optional, Callable
15
16 import uvicorn
17 from fastapi.responses import Response
18 from fastapi import Body, status, Request, FastAPI, HTTPException
19 from starlette.websockets import WebSocketDisconnect, WebSocket as FastAPIWebSocket
20
21 from nonebot.log import logger
22 from nonebot.typing import overrides
23 from nonebot.config import Env, Config
24 from nonebot.utils import DataclassEncoder
25 from nonebot.exception import RequestDenied
26 from nonebot.drivers import Driver as BaseDriver, WebSocket as BaseWebSocket
27
28
29 class Driver(BaseDriver):
30 """
31 FastAPI 驱动框架
32
33 :上报地址:
34
35 * ``/{adapter name}/``: HTTP POST 上报
36 * ``/{adapter name}/http/``: HTTP POST 上报
37 * ``/{adapter name}/ws``: WebSocket 上报
38 * ``/{adapter name}/ws/``: WebSocket 上报
39 """
40
41 def __init__(self, env: Env, config: Config):
42 super().__init__(env, config)
43
44 self._server_app = FastAPI(
45 debug=config.debug,
46 openapi_url=None,
47 docs_url=None,
48 redoc_url=None,
49 )
50
51 self._server_app.post("/{adapter}/")(self._handle_http)
52 self._server_app.post("/{adapter}/http")(self._handle_http)
53 self._server_app.websocket("/{adapter}/ws")(self._handle_ws_reverse)
54 self._server_app.websocket("/{adapter}/ws/")(self._handle_ws_reverse)
55
56 @property
57 @overrides(BaseDriver)
58 def type(self) -> str:
59 """驱动名称: ``fastapi``"""
60 return "fastapi"
61
62 @property
63 @overrides(BaseDriver)
64 def server_app(self) -> FastAPI:
65 """``FastAPI APP`` 对象"""
66 return self._server_app
67
68 @property
69 @overrides(BaseDriver)
70 def asgi(self):
71 """``FastAPI APP`` 对象"""
72 return self._server_app
73
74 @property
75 @overrides(BaseDriver)
76 def logger(self) -> logging.Logger:
77 """fastapi 使用的 logger"""
78 return logging.getLogger("fastapi")
79
80 @overrides(BaseDriver)
81 def on_startup(self, func: Callable) -> Callable:
82 """参考文档: `Events <https://fastapi.tiangolo.com/advanced/events/#startup-event>`_"""
83 return self.server_app.on_event("startup")(func)
84
85 @overrides(BaseDriver)
86 def on_shutdown(self, func: Callable) -> Callable:
87 """参考文档: `Events <https://fastapi.tiangolo.com/advanced/events/#startup-event>`_"""
88 return self.server_app.on_event("shutdown")(func)
89
90 @overrides(BaseDriver)
91 def run(self,
92 host: Optional[str] = None,
93 port: Optional[int] = None,
94 *,
95 app: Optional[str] = None,
96 **kwargs):
97 """使用 ``uvicorn`` 启动 FastAPI"""
98 super().run(host, port, app, **kwargs)
99 LOGGING_CONFIG = {
100 "version": 1,
101 "disable_existing_loggers": False,
102 "handlers": {
103 "default": {
104 "class": "nonebot.log.LoguruHandler",
105 },
106 },
107 "loggers": {
108 "uvicorn.error": {
109 "handlers": ["default"],
110 "level": "INFO"
111 },
112 "uvicorn.access": {
113 "handlers": ["default"],
114 "level": "INFO",
115 },
116 },
117 }
118 uvicorn.run(app or self.server_app,
119 host=host or str(self.config.host),
120 port=port or self.config.port,
121 reload=bool(app) and self.config.debug,
122 debug=self.config.debug,
123 log_config=LOGGING_CONFIG,
124 **kwargs)
125
126 @overrides(BaseDriver)
127 async def _handle_http(self,
128 adapter: str,
129 request: Request,
130 data: dict = Body(...)):
131 if not isinstance(data, dict):
132 logger.warning("Data received is invalid")
133 raise HTTPException(status_code=status.HTTP_400_BAD_REQUEST)
134
135 if adapter not in self._adapters:
136 logger.warning(
137 f"Unknown adapter {adapter}. Please register the adapter before use."
138 )
139 raise HTTPException(status_code=status.HTTP_404_NOT_FOUND,
140 detail="adapter not found")
141
142 # 创建 Bot 对象
143 BotClass = self._adapters[adapter]
144 headers = dict(request.headers)
145 try:
146 x_self_id = await BotClass.check_permission(self, "http", headers,
147 data)
148 except RequestDenied as e:
149 raise HTTPException(status_code=e.status_code,
150 detail=e.reason) from None
151
152 if x_self_id in self._clients:
153 logger.warning("There's already a reverse websocket connection,"
154 "so the event may be handled twice.")
155
156 bot = BotClass(self, "http", self.config, x_self_id)
157
158 asyncio.create_task(bot.handle_message(data))
159 return Response("", 204)
160
161 @overrides(BaseDriver)
162 async def _handle_ws_reverse(self, adapter: str,
163 websocket: FastAPIWebSocket):
164 ws = WebSocket(websocket)
165
166 if adapter not in self._adapters:
167 logger.warning(
168 f"Unknown adapter {adapter}. Please register the adapter before use."
169 )
170 await ws.close(code=status.WS_1008_POLICY_VIOLATION)
171 return
172
173 # Create Bot Object
174 BotClass = self._adapters[adapter]
175 headers = dict(websocket.headers)
176 try:
177 x_self_id = await BotClass.check_permission(self, "websocket",
178 headers, None)
179 except RequestDenied:
180 await ws.close(code=status.WS_1008_POLICY_VIOLATION)
181 return
182
183 if x_self_id in self._clients:
184 logger.warning("There's already a reverse websocket connection, "
185 f"<y>{adapter.upper()} Bot {x_self_id}</y> ignored.")
186 await ws.close(code=status.WS_1008_POLICY_VIOLATION)
187 return
188
189 bot = BotClass(self, "websocket", self.config, x_self_id, websocket=ws)
190
191 await ws.accept()
192 logger.opt(colors=True).info(
193 f"WebSocket Connection from <y>{adapter.upper()} "
194 f"Bot {x_self_id}</y> Accepted!")
195
196 self._bot_connect(bot)
197
198 try:
199 while not ws.closed:
200 data = await ws.receive()
201
202 if not data:
203 continue
204
205 asyncio.create_task(bot.handle_message(data))
206 finally:
207 self._bot_disconnect(bot)
208
209
210 class WebSocket(BaseWebSocket):
211
212 def __init__(self, websocket: FastAPIWebSocket):
213 super().__init__(websocket)
214 self._closed = False
215
216 @property
217 @overrides(BaseWebSocket)
218 def closed(self):
219 return self._closed
220
221 @overrides(BaseWebSocket)
222 async def accept(self):
223 await self.websocket.accept()
224 self._closed = False
225
226 @overrides(BaseWebSocket)
227 async def close(self, code: int = status.WS_1000_NORMAL_CLOSURE):
228 await self.websocket.close(code=code)
229 self._closed = True
230
231 @overrides(BaseWebSocket)
232 async def receive(self) -> Optional[dict]:
233 data = None
234 try:
235 data = await self.websocket.receive_json()
236 if not isinstance(data, dict):
237 data = None
238 raise ValueError
239 except ValueError:
240 logger.warning("Received an invalid json message.")
241 except WebSocketDisconnect:
242 self._closed = True
243 logger.error("WebSocket disconnected by peer.")
244
245 return data
246
247 @overrides(BaseWebSocket)
248 async def send(self, data: dict) -> None:
249 text = json.dumps(data, cls=DataclassEncoder)
250 await self.websocket.send({"type": "websocket.send", "text": text})
251
[end of nonebot/drivers/fastapi.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/nonebot/drivers/fastapi.py b/nonebot/drivers/fastapi.py
--- a/nonebot/drivers/fastapi.py
+++ b/nonebot/drivers/fastapi.py
@@ -14,18 +14,28 @@
from typing import Optional, Callable
import uvicorn
+from pydantic import BaseSettings
from fastapi.responses import Response
from fastapi import Body, status, Request, FastAPI, HTTPException
from starlette.websockets import WebSocketDisconnect, WebSocket as FastAPIWebSocket
from nonebot.log import logger
from nonebot.typing import overrides
-from nonebot.config import Env, Config
from nonebot.utils import DataclassEncoder
from nonebot.exception import RequestDenied
+from nonebot.config import Env, Config as NoneBotConfig
from nonebot.drivers import Driver as BaseDriver, WebSocket as BaseWebSocket
+class Config(BaseSettings):
+ fastapi_openapi_url: Optional[str] = None
+ fastapi_docs_url: Optional[str] = None
+ fastapi_redoc_url: Optional[str] = None
+
+ class Config:
+ extra = "ignore"
+
+
class Driver(BaseDriver):
"""
FastAPI 驱动框架
@@ -38,14 +48,16 @@
* ``/{adapter name}/ws/``: WebSocket 上报
"""
- def __init__(self, env: Env, config: Config):
+ def __init__(self, env: Env, config: NoneBotConfig):
super().__init__(env, config)
+ self.fastapi_config = Config(**config.dict())
+
self._server_app = FastAPI(
debug=config.debug,
- openapi_url=None,
- docs_url=None,
- redoc_url=None,
+ openapi_url=self.fastapi_config.fastapi_openapi_url,
+ docs_url=self.fastapi_config.fastapi_docs_url,
+ redoc_url=self.fastapi_config.fastapi_redoc_url,
)
self._server_app.post("/{adapter}/")(self._handle_http)
|
{"golden_diff": "diff --git a/nonebot/drivers/fastapi.py b/nonebot/drivers/fastapi.py\n--- a/nonebot/drivers/fastapi.py\n+++ b/nonebot/drivers/fastapi.py\n@@ -14,18 +14,28 @@\n from typing import Optional, Callable\n \n import uvicorn\n+from pydantic import BaseSettings\n from fastapi.responses import Response\n from fastapi import Body, status, Request, FastAPI, HTTPException\n from starlette.websockets import WebSocketDisconnect, WebSocket as FastAPIWebSocket\n \n from nonebot.log import logger\n from nonebot.typing import overrides\n-from nonebot.config import Env, Config\n from nonebot.utils import DataclassEncoder\n from nonebot.exception import RequestDenied\n+from nonebot.config import Env, Config as NoneBotConfig\n from nonebot.drivers import Driver as BaseDriver, WebSocket as BaseWebSocket\n \n \n+class Config(BaseSettings):\n+ fastapi_openapi_url: Optional[str] = None\n+ fastapi_docs_url: Optional[str] = None\n+ fastapi_redoc_url: Optional[str] = None\n+\n+ class Config:\n+ extra = \"ignore\"\n+\n+\n class Driver(BaseDriver):\n \"\"\"\n FastAPI \u9a71\u52a8\u6846\u67b6\n@@ -38,14 +48,16 @@\n * ``/{adapter name}/ws/``: WebSocket \u4e0a\u62a5\n \"\"\"\n \n- def __init__(self, env: Env, config: Config):\n+ def __init__(self, env: Env, config: NoneBotConfig):\n super().__init__(env, config)\n \n+ self.fastapi_config = Config(**config.dict())\n+\n self._server_app = FastAPI(\n debug=config.debug,\n- openapi_url=None,\n- docs_url=None,\n- redoc_url=None,\n+ openapi_url=self.fastapi_config.fastapi_openapi_url,\n+ docs_url=self.fastapi_config.fastapi_docs_url,\n+ redoc_url=self.fastapi_config.fastapi_redoc_url,\n )\n \n self._server_app.post(\"/{adapter}/\")(self._handle_http)\n", "issue": "\u81ea\u52a8\u751f\u6210 api \u6587\u6863\n**\u662f\u5426\u5728\u4f7f\u7528\u4e2d\u9047\u5230\u67d0\u4e9b\u95ee\u9898\u800c\u9700\u8981\u65b0\u7684\u7279\u6027\uff1f\u8bf7\u63cf\u8ff0\uff1a**\r\n\r\n```python\r\nself._server_app = FastAPI(\r\n debug=config.debug,\r\n openapi_url=None,\r\n docs_url=None,\r\n redoc_url=None,\r\n )\r\n```\r\n\r\n\u6e90\u7801\u597d\u50cf\u7981\u6b62\u4e86API\u6587\u6863\u81ea\u52a8\u751f\u6210\u7684\u529f\u80fd\uff0c\u80fd\u5426\u6539\u4e3a\u6839\u636e\u914d\u7f6e\u51b3\u5b9a\uff1f\u4f8b\u5982\u6dfb\u52a0\u4e00\u4e2a\u914d\u7f6e\u9879\u3002\r\n\r\n\u56e0\u4e3a\u5f00\u53d1\u65f6\u8981\u8fdb\u884c API \u8bf7\u6c42\u8c03\u8bd5\uff0c\u6240\u4ee5\u611f\u89c9\u8fd9\u4e2a\u529f\u80fd\u8fd8\u662f\u633a\u6709\u5fc5\u8981\u7684\r\n\n", "before_files": [{"content": "\"\"\"\nFastAPI \u9a71\u52a8\u9002\u914d\n================\n\n\u540e\u7aef\u4f7f\u7528\u65b9\u6cd5\u8bf7\u53c2\u8003: `FastAPI \u6587\u6863`_\n\n.. _FastAPI \u6587\u6863:\n https://fastapi.tiangolo.com/\n\"\"\"\n\nimport json\nimport asyncio\nimport logging\nfrom typing import Optional, Callable\n\nimport uvicorn\nfrom fastapi.responses import Response\nfrom fastapi import Body, status, Request, FastAPI, HTTPException\nfrom starlette.websockets import WebSocketDisconnect, WebSocket as FastAPIWebSocket\n\nfrom nonebot.log import logger\nfrom nonebot.typing import overrides\nfrom nonebot.config import Env, Config\nfrom nonebot.utils import DataclassEncoder\nfrom nonebot.exception import RequestDenied\nfrom nonebot.drivers import Driver as BaseDriver, WebSocket as BaseWebSocket\n\n\nclass Driver(BaseDriver):\n \"\"\"\n FastAPI \u9a71\u52a8\u6846\u67b6\n\n :\u4e0a\u62a5\u5730\u5740:\n\n * ``/{adapter name}/``: HTTP POST \u4e0a\u62a5\n * ``/{adapter name}/http/``: HTTP POST \u4e0a\u62a5\n * ``/{adapter name}/ws``: WebSocket \u4e0a\u62a5\n * ``/{adapter name}/ws/``: WebSocket \u4e0a\u62a5\n \"\"\"\n\n def __init__(self, env: Env, config: Config):\n super().__init__(env, config)\n\n self._server_app = FastAPI(\n debug=config.debug,\n openapi_url=None,\n docs_url=None,\n redoc_url=None,\n )\n\n self._server_app.post(\"/{adapter}/\")(self._handle_http)\n self._server_app.post(\"/{adapter}/http\")(self._handle_http)\n self._server_app.websocket(\"/{adapter}/ws\")(self._handle_ws_reverse)\n self._server_app.websocket(\"/{adapter}/ws/\")(self._handle_ws_reverse)\n\n @property\n @overrides(BaseDriver)\n def type(self) -> str:\n \"\"\"\u9a71\u52a8\u540d\u79f0: ``fastapi``\"\"\"\n return \"fastapi\"\n\n @property\n @overrides(BaseDriver)\n def server_app(self) -> FastAPI:\n \"\"\"``FastAPI APP`` \u5bf9\u8c61\"\"\"\n return self._server_app\n\n @property\n @overrides(BaseDriver)\n def asgi(self):\n \"\"\"``FastAPI APP`` \u5bf9\u8c61\"\"\"\n return self._server_app\n\n @property\n @overrides(BaseDriver)\n def logger(self) -> logging.Logger:\n \"\"\"fastapi \u4f7f\u7528\u7684 logger\"\"\"\n return logging.getLogger(\"fastapi\")\n\n @overrides(BaseDriver)\n def on_startup(self, func: Callable) -> Callable:\n \"\"\"\u53c2\u8003\u6587\u6863: `Events <https://fastapi.tiangolo.com/advanced/events/#startup-event>`_\"\"\"\n return self.server_app.on_event(\"startup\")(func)\n\n @overrides(BaseDriver)\n def on_shutdown(self, func: Callable) -> Callable:\n \"\"\"\u53c2\u8003\u6587\u6863: `Events <https://fastapi.tiangolo.com/advanced/events/#startup-event>`_\"\"\"\n return self.server_app.on_event(\"shutdown\")(func)\n\n @overrides(BaseDriver)\n def run(self,\n host: Optional[str] = None,\n port: Optional[int] = None,\n *,\n app: Optional[str] = None,\n **kwargs):\n \"\"\"\u4f7f\u7528 ``uvicorn`` \u542f\u52a8 FastAPI\"\"\"\n super().run(host, port, app, **kwargs)\n LOGGING_CONFIG = {\n \"version\": 1,\n \"disable_existing_loggers\": False,\n \"handlers\": {\n \"default\": {\n \"class\": \"nonebot.log.LoguruHandler\",\n },\n },\n \"loggers\": {\n \"uvicorn.error\": {\n \"handlers\": [\"default\"],\n \"level\": \"INFO\"\n },\n \"uvicorn.access\": {\n \"handlers\": [\"default\"],\n \"level\": \"INFO\",\n },\n },\n }\n uvicorn.run(app or self.server_app,\n host=host or str(self.config.host),\n port=port or self.config.port,\n reload=bool(app) and self.config.debug,\n debug=self.config.debug,\n log_config=LOGGING_CONFIG,\n **kwargs)\n\n @overrides(BaseDriver)\n async def _handle_http(self,\n adapter: str,\n request: Request,\n data: dict = Body(...)):\n if not isinstance(data, dict):\n logger.warning(\"Data received is invalid\")\n raise HTTPException(status_code=status.HTTP_400_BAD_REQUEST)\n\n if adapter not in self._adapters:\n logger.warning(\n f\"Unknown adapter {adapter}. Please register the adapter before use.\"\n )\n raise HTTPException(status_code=status.HTTP_404_NOT_FOUND,\n detail=\"adapter not found\")\n\n # \u521b\u5efa Bot \u5bf9\u8c61\n BotClass = self._adapters[adapter]\n headers = dict(request.headers)\n try:\n x_self_id = await BotClass.check_permission(self, \"http\", headers,\n data)\n except RequestDenied as e:\n raise HTTPException(status_code=e.status_code,\n detail=e.reason) from None\n\n if x_self_id in self._clients:\n logger.warning(\"There's already a reverse websocket connection,\"\n \"so the event may be handled twice.\")\n\n bot = BotClass(self, \"http\", self.config, x_self_id)\n\n asyncio.create_task(bot.handle_message(data))\n return Response(\"\", 204)\n\n @overrides(BaseDriver)\n async def _handle_ws_reverse(self, adapter: str,\n websocket: FastAPIWebSocket):\n ws = WebSocket(websocket)\n\n if adapter not in self._adapters:\n logger.warning(\n f\"Unknown adapter {adapter}. Please register the adapter before use.\"\n )\n await ws.close(code=status.WS_1008_POLICY_VIOLATION)\n return\n\n # Create Bot Object\n BotClass = self._adapters[adapter]\n headers = dict(websocket.headers)\n try:\n x_self_id = await BotClass.check_permission(self, \"websocket\",\n headers, None)\n except RequestDenied:\n await ws.close(code=status.WS_1008_POLICY_VIOLATION)\n return\n\n if x_self_id in self._clients:\n logger.warning(\"There's already a reverse websocket connection, \"\n f\"<y>{adapter.upper()} Bot {x_self_id}</y> ignored.\")\n await ws.close(code=status.WS_1008_POLICY_VIOLATION)\n return\n\n bot = BotClass(self, \"websocket\", self.config, x_self_id, websocket=ws)\n\n await ws.accept()\n logger.opt(colors=True).info(\n f\"WebSocket Connection from <y>{adapter.upper()} \"\n f\"Bot {x_self_id}</y> Accepted!\")\n\n self._bot_connect(bot)\n\n try:\n while not ws.closed:\n data = await ws.receive()\n\n if not data:\n continue\n\n asyncio.create_task(bot.handle_message(data))\n finally:\n self._bot_disconnect(bot)\n\n\nclass WebSocket(BaseWebSocket):\n\n def __init__(self, websocket: FastAPIWebSocket):\n super().__init__(websocket)\n self._closed = False\n\n @property\n @overrides(BaseWebSocket)\n def closed(self):\n return self._closed\n\n @overrides(BaseWebSocket)\n async def accept(self):\n await self.websocket.accept()\n self._closed = False\n\n @overrides(BaseWebSocket)\n async def close(self, code: int = status.WS_1000_NORMAL_CLOSURE):\n await self.websocket.close(code=code)\n self._closed = True\n\n @overrides(BaseWebSocket)\n async def receive(self) -> Optional[dict]:\n data = None\n try:\n data = await self.websocket.receive_json()\n if not isinstance(data, dict):\n data = None\n raise ValueError\n except ValueError:\n logger.warning(\"Received an invalid json message.\")\n except WebSocketDisconnect:\n self._closed = True\n logger.error(\"WebSocket disconnected by peer.\")\n\n return data\n\n @overrides(BaseWebSocket)\n async def send(self, data: dict) -> None:\n text = json.dumps(data, cls=DataclassEncoder)\n await self.websocket.send({\"type\": \"websocket.send\", \"text\": text})\n", "path": "nonebot/drivers/fastapi.py"}]}
| 3,030 | 446 |
gh_patches_debug_29603
|
rasdani/github-patches
|
git_diff
|
bridgecrewio__checkov-3976
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Suppression comment in Dockerfile skips more checks than it should
**Describe the issue**
I tried to skip CKV_DOCKER_9 by adding a suppression comment into my Dockerfile, but it turned out that CKV_DOCKER_5 was also skipped.
**Examples**
Here's my Dockerfile with comment to skip CKV_DOCKER_9:
```dockerfile
#checkov:skip=CKV_DOCKER_9
FROM alpine:3.16
RUN ls
```
As you can see, CKV_DOCKER_5 is also marked as SKIPPED in the results:
```
$ docker run -it --rm -v "$(pwd):$(pwd)" -w "$(pwd)" bridgecrew/checkov:2.2.104 --framework dockerfile --skip-download --file Dockerfile
_ _
___| |__ ___ ___| | _______ __
/ __| '_ \ / _ \/ __| |/ / _ \ \ / /
| (__| | | | __/ (__| < (_) \ V /
\___|_| |_|\___|\___|_|\_\___/ \_/
By bridgecrew.io | version: 2.2.104
dockerfile scan results:
Passed checks: 2, Failed checks: 2, Skipped checks: 2
Check: CKV_DOCKER_11: "Ensure From Alias are unique for multistage builds."
PASSED for resource: Dockerfile.
File: Dockerfile:1-4
Check: CKV_DOCKER_7: "Ensure the base image uses a non latest version tag"
PASSED for resource: Dockerfile.
File: Dockerfile:1-4
Check: CKV_DOCKER_2: "Ensure that HEALTHCHECK instructions have been added to container images"
FAILED for resource: Dockerfile.
File: Dockerfile:1-4
1 | #checkov:skip=CKV_DOCKER_9
2 | FROM alpine:3.16
3 | RUN ls
4 |
Check: CKV_DOCKER_3: "Ensure that a user for the container has been created"
FAILED for resource: Dockerfile.
File: Dockerfile:1-4
1 | #checkov:skip=CKV_DOCKER_9
2 | FROM alpine:3.16
3 | RUN ls
4 |
Check: CKV_DOCKER_9: "Ensure that APT isn't used"
SKIPPED for resource: Dockerfile.
Suppress comment: No comment provided
File: Dockerfile:1-4
Check: CKV_DOCKER_5: "Ensure update instructions are not use alone in the Dockerfile"
SKIPPED for resource: Dockerfile.
Suppress comment: No comment provided
File: Dockerfile:1-4
```
**Version (please complete the following information):**
- Checkov Version: 2.2.104
</issue>
<code>
[start of checkov/dockerfile/base_registry.py]
1 from __future__ import annotations
2
3 from typing import TYPE_CHECKING, Any, cast
4
5 from checkov.common.bridgecrew.check_type import CheckType
6 from checkov.common.checks.base_check_registry import BaseCheckRegistry
7 from checkov.common.models.enums import CheckResult
8
9 if TYPE_CHECKING:
10 from dockerfile_parse.parser import _Instruction # only in extra_stubs
11 from checkov.common.checks.base_check import BaseCheck
12 from checkov.common.typing import _SkippedCheck, _CheckResult
13 from checkov.runner_filter import RunnerFilter
14
15
16 class Registry(BaseCheckRegistry):
17 def __init__(self) -> None:
18 super().__init__(CheckType.DOCKERFILE)
19
20 def extract_entity_details(self, entity: dict[str, Any]) -> tuple[str, str, dict[str, Any]]:
21 # not needed
22 return "", "", {}
23
24 def scan(
25 self,
26 scanned_file: str,
27 entity: dict[str, list[_Instruction]],
28 skipped_checks: list[_SkippedCheck],
29 runner_filter: RunnerFilter,
30 report_type: str | None = None,
31 ) -> dict[BaseCheck, _CheckResult]:
32
33 results: "dict[BaseCheck, _CheckResult]" = {}
34 if not entity:
35 return results
36 for instruction, checks in self.checks.items():
37 skip_info: _SkippedCheck = {}
38 if instruction in entity:
39
40 for check in checks:
41 if check.id in [x['id'] for x in skipped_checks]:
42 skip_info = [x for x in skipped_checks if x['id'] == check.id][0]
43
44 if runner_filter.should_run_check(check, report_type=CheckType.DOCKERFILE):
45 self.update_result(
46 check=check,
47 entity_configuration=entity[instruction],
48 entity_name=instruction,
49 entity_type=instruction,
50 results=results,
51 scanned_file=scanned_file,
52 skip_info=skip_info,
53 )
54
55 for check in self.wildcard_checks["*"]:
56 skip_info = {}
57 if skipped_checks:
58 if check.id in [x['id'] for x in skipped_checks]:
59 skip_info = [x for x in skipped_checks if x['id'] == check.id][0]
60
61 if runner_filter.should_run_check(check, report_type=CheckType.DOCKERFILE):
62 self.update_result(
63 check=check,
64 entity_configuration=entity,
65 entity_name=scanned_file,
66 entity_type="*",
67 results=results,
68 scanned_file=scanned_file,
69 skip_info=skip_info,
70 )
71 return results
72
73 def update_result(
74 self,
75 check: BaseCheck,
76 entity_configuration: list[_Instruction] | dict[str, list[_Instruction]],
77 entity_name: str,
78 entity_type: str,
79 results: dict[BaseCheck, _CheckResult],
80 scanned_file: str,
81 skip_info: _SkippedCheck
82 ) -> None:
83 result = self.run_check(
84 check=check,
85 entity_configuration=entity_configuration, # type:ignore[arg-type] # special Dockerfile runner behaviour
86 entity_name=entity_name,
87 entity_type=entity_type,
88 scanned_file=scanned_file,
89 skip_info=skip_info,
90 )
91 results[check] = {}
92 if result['result'] == CheckResult.SKIPPED:
93 results[check]['result'] = result['result']
94 results[check]['suppress_comment'] = result['suppress_comment']
95 results[check]['results_configuration'] = None
96 else:
97 results[check]['result'] = cast("CheckResult", result['result'][0])
98 results[check]['results_configuration'] = cast("dict[str, Any]", result['result'][1])
99
[end of checkov/dockerfile/base_registry.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/checkov/dockerfile/base_registry.py b/checkov/dockerfile/base_registry.py
--- a/checkov/dockerfile/base_registry.py
+++ b/checkov/dockerfile/base_registry.py
@@ -33,13 +33,16 @@
results: "dict[BaseCheck, _CheckResult]" = {}
if not entity:
return results
+
+ skipped_check_ids = {skipped_check["id"]: skipped_check for skipped_check in skipped_checks}
+
for instruction, checks in self.checks.items():
- skip_info: _SkippedCheck = {}
if instruction in entity:
-
for check in checks:
- if check.id in [x['id'] for x in skipped_checks]:
- skip_info = [x for x in skipped_checks if x['id'] == check.id][0]
+ skip_info: "_SkippedCheck" = {}
+ if skipped_check_ids:
+ if check.id in skipped_check_ids:
+ skip_info = skipped_check_ids[check.id]
if runner_filter.should_run_check(check, report_type=CheckType.DOCKERFILE):
self.update_result(
@@ -54,9 +57,9 @@
for check in self.wildcard_checks["*"]:
skip_info = {}
- if skipped_checks:
- if check.id in [x['id'] for x in skipped_checks]:
- skip_info = [x for x in skipped_checks if x['id'] == check.id][0]
+ if skipped_check_ids:
+ if check.id in skipped_check_ids:
+ skip_info = skipped_check_ids[check.id]
if runner_filter.should_run_check(check, report_type=CheckType.DOCKERFILE):
self.update_result(
|
{"golden_diff": "diff --git a/checkov/dockerfile/base_registry.py b/checkov/dockerfile/base_registry.py\n--- a/checkov/dockerfile/base_registry.py\n+++ b/checkov/dockerfile/base_registry.py\n@@ -33,13 +33,16 @@\n results: \"dict[BaseCheck, _CheckResult]\" = {}\n if not entity:\n return results\n+\n+ skipped_check_ids = {skipped_check[\"id\"]: skipped_check for skipped_check in skipped_checks}\n+\n for instruction, checks in self.checks.items():\n- skip_info: _SkippedCheck = {}\n if instruction in entity:\n-\n for check in checks:\n- if check.id in [x['id'] for x in skipped_checks]:\n- skip_info = [x for x in skipped_checks if x['id'] == check.id][0]\n+ skip_info: \"_SkippedCheck\" = {}\n+ if skipped_check_ids:\n+ if check.id in skipped_check_ids:\n+ skip_info = skipped_check_ids[check.id]\n \n if runner_filter.should_run_check(check, report_type=CheckType.DOCKERFILE):\n self.update_result(\n@@ -54,9 +57,9 @@\n \n for check in self.wildcard_checks[\"*\"]:\n skip_info = {}\n- if skipped_checks:\n- if check.id in [x['id'] for x in skipped_checks]:\n- skip_info = [x for x in skipped_checks if x['id'] == check.id][0]\n+ if skipped_check_ids:\n+ if check.id in skipped_check_ids:\n+ skip_info = skipped_check_ids[check.id]\n \n if runner_filter.should_run_check(check, report_type=CheckType.DOCKERFILE):\n self.update_result(\n", "issue": "Suppression comment in Dockerfile skips more checks than it should\n**Describe the issue**\r\nI tried to skip CKV_DOCKER_9 by adding a suppression comment into my Dockerfile, but it turned out that CKV_DOCKER_5 was also skipped.\r\n\r\n**Examples**\r\nHere's my Dockerfile with comment to skip CKV_DOCKER_9:\r\n```dockerfile\r\n#checkov:skip=CKV_DOCKER_9\r\nFROM alpine:3.16\r\nRUN ls\r\n```\r\nAs you can see, CKV_DOCKER_5 is also marked as SKIPPED in the results:\r\n```\r\n$ docker run -it --rm -v \"$(pwd):$(pwd)\" -w \"$(pwd)\" bridgecrew/checkov:2.2.104 --framework dockerfile --skip-download --file Dockerfile\r\n\r\n _ _ \r\n ___| |__ ___ ___| | _______ __\r\n / __| '_ \\ / _ \\/ __| |/ / _ \\ \\ / /\r\n | (__| | | | __/ (__| < (_) \\ V / \r\n \\___|_| |_|\\___|\\___|_|\\_\\___/ \\_/ \r\n \r\nBy bridgecrew.io | version: 2.2.104 \r\n\r\ndockerfile scan results:\r\n\r\nPassed checks: 2, Failed checks: 2, Skipped checks: 2\r\n\r\nCheck: CKV_DOCKER_11: \"Ensure From Alias are unique for multistage builds.\"\r\n\tPASSED for resource: Dockerfile.\r\n\tFile: Dockerfile:1-4\r\nCheck: CKV_DOCKER_7: \"Ensure the base image uses a non latest version tag\"\r\n\tPASSED for resource: Dockerfile.\r\n\tFile: Dockerfile:1-4\r\nCheck: CKV_DOCKER_2: \"Ensure that HEALTHCHECK instructions have been added to container images\"\r\n\tFAILED for resource: Dockerfile.\r\n\tFile: Dockerfile:1-4\r\n\r\n\t\t1 | #checkov:skip=CKV_DOCKER_9\r\n\t\t2 | FROM alpine:3.16\r\n\t\t3 | RUN ls\r\n\t\t4 | \r\n\r\nCheck: CKV_DOCKER_3: \"Ensure that a user for the container has been created\"\r\n\tFAILED for resource: Dockerfile.\r\n\tFile: Dockerfile:1-4\r\n\r\n\t\t1 | #checkov:skip=CKV_DOCKER_9\r\n\t\t2 | FROM alpine:3.16\r\n\t\t3 | RUN ls\r\n\t\t4 | \r\n\r\nCheck: CKV_DOCKER_9: \"Ensure that APT isn't used\"\r\n\tSKIPPED for resource: Dockerfile.\r\n\tSuppress comment: No comment provided\r\n\tFile: Dockerfile:1-4\r\nCheck: CKV_DOCKER_5: \"Ensure update instructions are not use alone in the Dockerfile\"\r\n\tSKIPPED for resource: Dockerfile.\r\n\tSuppress comment: No comment provided\r\n\tFile: Dockerfile:1-4\r\n```\r\n\r\n**Version (please complete the following information):**\r\n - Checkov Version: 2.2.104\r\n\n", "before_files": [{"content": "from __future__ import annotations\n\nfrom typing import TYPE_CHECKING, Any, cast\n\nfrom checkov.common.bridgecrew.check_type import CheckType\nfrom checkov.common.checks.base_check_registry import BaseCheckRegistry\nfrom checkov.common.models.enums import CheckResult\n\nif TYPE_CHECKING:\n from dockerfile_parse.parser import _Instruction # only in extra_stubs\n from checkov.common.checks.base_check import BaseCheck\n from checkov.common.typing import _SkippedCheck, _CheckResult\n from checkov.runner_filter import RunnerFilter\n\n\nclass Registry(BaseCheckRegistry):\n def __init__(self) -> None:\n super().__init__(CheckType.DOCKERFILE)\n\n def extract_entity_details(self, entity: dict[str, Any]) -> tuple[str, str, dict[str, Any]]:\n # not needed\n return \"\", \"\", {}\n\n def scan(\n self,\n scanned_file: str,\n entity: dict[str, list[_Instruction]],\n skipped_checks: list[_SkippedCheck],\n runner_filter: RunnerFilter,\n report_type: str | None = None,\n ) -> dict[BaseCheck, _CheckResult]:\n\n results: \"dict[BaseCheck, _CheckResult]\" = {}\n if not entity:\n return results\n for instruction, checks in self.checks.items():\n skip_info: _SkippedCheck = {}\n if instruction in entity:\n\n for check in checks:\n if check.id in [x['id'] for x in skipped_checks]:\n skip_info = [x for x in skipped_checks if x['id'] == check.id][0]\n\n if runner_filter.should_run_check(check, report_type=CheckType.DOCKERFILE):\n self.update_result(\n check=check,\n entity_configuration=entity[instruction],\n entity_name=instruction,\n entity_type=instruction,\n results=results,\n scanned_file=scanned_file,\n skip_info=skip_info,\n )\n\n for check in self.wildcard_checks[\"*\"]:\n skip_info = {}\n if skipped_checks:\n if check.id in [x['id'] for x in skipped_checks]:\n skip_info = [x for x in skipped_checks if x['id'] == check.id][0]\n\n if runner_filter.should_run_check(check, report_type=CheckType.DOCKERFILE):\n self.update_result(\n check=check,\n entity_configuration=entity,\n entity_name=scanned_file,\n entity_type=\"*\",\n results=results,\n scanned_file=scanned_file,\n skip_info=skip_info,\n )\n return results\n\n def update_result(\n self,\n check: BaseCheck,\n entity_configuration: list[_Instruction] | dict[str, list[_Instruction]],\n entity_name: str,\n entity_type: str,\n results: dict[BaseCheck, _CheckResult],\n scanned_file: str,\n skip_info: _SkippedCheck\n ) -> None:\n result = self.run_check(\n check=check,\n entity_configuration=entity_configuration, # type:ignore[arg-type] # special Dockerfile runner behaviour\n entity_name=entity_name,\n entity_type=entity_type,\n scanned_file=scanned_file,\n skip_info=skip_info,\n )\n results[check] = {}\n if result['result'] == CheckResult.SKIPPED:\n results[check]['result'] = result['result']\n results[check]['suppress_comment'] = result['suppress_comment']\n results[check]['results_configuration'] = None\n else:\n results[check]['result'] = cast(\"CheckResult\", result['result'][0])\n results[check]['results_configuration'] = cast(\"dict[str, Any]\", result['result'][1])\n", "path": "checkov/dockerfile/base_registry.py"}]}
| 2,186 | 373 |
gh_patches_debug_38791
|
rasdani/github-patches
|
git_diff
|
StackStorm__st2-2994
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Sensor fails to retrieve kv object after some time.
st2 2.0.1
mongo 3.2.10
I have a polling sensor that queries an ES database and when a datapoint crosses a threshold, it sends an alert. Once alerted, it stores a key with a 24-hour ttl so that the sensor knows to skip alerts for the rest of the day. I also have a mechanism for silencing alerts with the same approach. This used to work well before I upgraded st2, but now after a few days of running st2 the sensor keeps alerting even though there’s an `alerted` key in the keystore. When I restart st2 everything goes back to normal for a few days then the problem comes back.
I can probably get permission to publish my entire pack, but here's the gist of the dispatch_trigger logic in my sensor:
https://gist.github.com/pixelrebel/240ca95c480d1377175b3667de0411cb
And here's the gist of my action chain that sets the `alerted` key.
https://gist.github.com/pixelrebel/6def658dfd2ee43fe71ce7735db76b29
</issue>
<code>
[start of st2common/st2common/services/datastore.py]
1 # Licensed to the StackStorm, Inc ('StackStorm') under one or more
2 # contributor license agreements. See the NOTICE file distributed with
3 # this work for additional information regarding copyright ownership.
4 # The ASF licenses this file to You under the Apache License, Version 2.0
5 # (the "License"); you may not use this file except in compliance with
6 # the License. You may obtain a copy of the License at
7 #
8 # http://www.apache.org/licenses/LICENSE-2.0
9 #
10 # Unless required by applicable law or agreed to in writing, software
11 # distributed under the License is distributed on an "AS IS" BASIS,
12 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
13 # See the License for the specific language governing permissions and
14 # limitations under the License.
15
16 from st2client.client import Client
17 from st2client.models import KeyValuePair
18 from st2common.services.access import create_token
19 from st2common.util.api import get_full_public_api_url
20 from st2common.constants.keyvalue import DATASTORE_KEY_SEPARATOR, SYSTEM_SCOPE
21
22
23 class DatastoreService(object):
24 """
25 Class provides public methods for accessing datastore items.
26 """
27
28 DATASTORE_NAME_SEPARATOR = DATASTORE_KEY_SEPARATOR
29
30 def __init__(self, logger, pack_name, class_name, api_username):
31 self._api_username = api_username
32 self._pack_name = pack_name
33 self._class_name = class_name
34 self._logger = logger
35
36 self._client = None
37
38 ##################################
39 # Methods for datastore management
40 ##################################
41
42 def list_values(self, local=True, prefix=None):
43 """
44 Retrieve all the datastores items.
45
46 :param local: List values from a namespace local to this pack/class. Defaults to True.
47 :type: local: ``bool``
48
49 :param prefix: Optional key name prefix / startswith filter.
50 :type prefix: ``str``
51
52 :rtype: ``list`` of :class:`KeyValuePair`
53 """
54 client = self._get_api_client()
55 self._logger.audit('Retrieving all the value from the datastore')
56
57 key_prefix = self._get_full_key_prefix(local=local, prefix=prefix)
58 kvps = client.keys.get_all(prefix=key_prefix)
59 return kvps
60
61 def get_value(self, name, local=True, scope=SYSTEM_SCOPE, decrypt=False):
62 """
63 Retrieve a value from the datastore for the provided key.
64
65 By default, value is retrieved from the namespace local to the pack/class. If you want to
66 retrieve a global value from a datastore, pass local=False to this method.
67
68 :param name: Key name.
69 :type name: ``str``
70
71 :param local: Retrieve value from a namespace local to the pack/class. Defaults to True.
72 :type: local: ``bool``
73
74 :param scope: Scope under which item is saved. Defaults to system scope.
75 :type: local: ``str``
76
77 :param encrypt: Return the decrypted value. Defaults to False.
78 :type: local: ``bool``
79
80 :rtype: ``str`` or ``None``
81 """
82 if scope != SYSTEM_SCOPE:
83 raise ValueError('Scope %s is unsupported.' % scope)
84
85 name = self._get_full_key_name(name=name, local=local)
86
87 client = self._get_api_client()
88 self._logger.audit('Retrieving value from the datastore (name=%s)', name)
89
90 try:
91 params = {'decrypt': str(decrypt).lower(), 'scope': scope}
92 kvp = client.keys.get_by_id(id=name, params=params)
93 except Exception:
94 return None
95
96 if kvp:
97 return kvp.value
98
99 return None
100
101 def set_value(self, name, value, ttl=None, local=True, scope=SYSTEM_SCOPE, encrypt=False):
102 """
103 Set a value for the provided key.
104
105 By default, value is set in a namespace local to the pack/class. If you want to
106 set a global value, pass local=False to this method.
107
108 :param name: Key name.
109 :type name: ``str``
110
111 :param value: Key value.
112 :type value: ``str``
113
114 :param ttl: Optional TTL (in seconds).
115 :type ttl: ``int``
116
117 :param local: Set value in a namespace local to the pack/class. Defaults to True.
118 :type: local: ``bool``
119
120 :param scope: Scope under which to place the item. Defaults to system scope.
121 :type: local: ``str``
122
123 :param encrypt: Encrypyt the value when saving. Defaults to False.
124 :type: local: ``bool``
125
126 :return: ``True`` on success, ``False`` otherwise.
127 :rtype: ``bool``
128 """
129 if scope != SYSTEM_SCOPE:
130 raise ValueError('Scope %s is unsupported.', scope)
131
132 name = self._get_full_key_name(name=name, local=local)
133
134 value = str(value)
135 client = self._get_api_client()
136
137 self._logger.audit('Setting value in the datastore (name=%s)', name)
138
139 instance = KeyValuePair()
140 instance.id = name
141 instance.name = name
142 instance.value = value
143 instance.scope = scope
144 if encrypt:
145 instance.secret = True
146
147 if ttl:
148 instance.ttl = ttl
149
150 client.keys.update(instance=instance)
151 return True
152
153 def delete_value(self, name, local=True, scope=SYSTEM_SCOPE):
154 """
155 Delete the provided key.
156
157 By default, value is deleted from a namespace local to the pack/class. If you want to
158 delete a global value, pass local=False to this method.
159
160 :param name: Name of the key to delete.
161 :type name: ``str``
162
163 :param local: Delete a value in a namespace local to the pack/class. Defaults to True.
164 :type: local: ``bool``
165
166 :param scope: Scope under which item is saved. Defaults to system scope.
167 :type: local: ``str``
168
169 :return: ``True`` on success, ``False`` otherwise.
170 :rtype: ``bool``
171 """
172 if scope != SYSTEM_SCOPE:
173 raise ValueError('Scope %s is unsupported.', scope)
174
175 name = self._get_full_key_name(name=name, local=local)
176
177 client = self._get_api_client()
178
179 instance = KeyValuePair()
180 instance.id = name
181 instance.name = name
182
183 self._logger.audit('Deleting value from the datastore (name=%s)', name)
184
185 try:
186 params = {'scope': scope}
187 client.keys.delete(instance=instance, params=params)
188 except Exception:
189 return False
190
191 return True
192
193 def _get_api_client(self):
194 """
195 Retrieve API client instance.
196 """
197 if not self._client:
198 ttl = (24 * 60 * 60)
199 temporary_token = create_token(username=self._api_username, ttl=ttl)
200 api_url = get_full_public_api_url()
201 self._client = Client(api_url=api_url, token=temporary_token.token)
202
203 return self._client
204
205 def _get_full_key_name(self, name, local):
206 """
207 Retrieve a full key name.
208
209 :rtype: ``str``
210 """
211 if local:
212 name = self._get_key_name_with_prefix(name=name)
213
214 return name
215
216 def _get_full_key_prefix(self, local, prefix=None):
217 if local:
218 key_prefix = self._get_local_key_name_prefix()
219
220 if prefix:
221 key_prefix += prefix
222 else:
223 key_prefix = prefix
224
225 return key_prefix
226
227 def _get_local_key_name_prefix(self):
228 """
229 Retrieve key prefix which is local to this pack/class.
230 """
231 key_prefix = self._get_datastore_key_prefix() + self.DATASTORE_NAME_SEPARATOR
232 return key_prefix
233
234 def _get_key_name_with_prefix(self, name):
235 """
236 Retrieve a full key name which is local to the current pack/class.
237
238 :param name: Base datastore key name.
239 :type name: ``str``
240
241 :rtype: ``str``
242 """
243 prefix = self._get_datastore_key_prefix()
244 full_name = prefix + self.DATASTORE_NAME_SEPARATOR + name
245 return full_name
246
247 def _get_datastore_key_prefix(self):
248 prefix = '%s.%s' % (self._pack_name, self._class_name)
249 return prefix
250
[end of st2common/st2common/services/datastore.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/st2common/st2common/services/datastore.py b/st2common/st2common/services/datastore.py
--- a/st2common/st2common/services/datastore.py
+++ b/st2common/st2common/services/datastore.py
@@ -13,10 +13,12 @@
# See the License for the specific language governing permissions and
# limitations under the License.
+from datetime import timedelta
from st2client.client import Client
from st2client.models import KeyValuePair
from st2common.services.access import create_token
from st2common.util.api import get_full_public_api_url
+from st2common.util.date import get_datetime_utc_now
from st2common.constants.keyvalue import DATASTORE_KEY_SEPARATOR, SYSTEM_SCOPE
@@ -34,6 +36,7 @@
self._logger = logger
self._client = None
+ self._token_expire = get_datetime_utc_now()
##################################
# Methods for datastore management
@@ -90,7 +93,12 @@
try:
params = {'decrypt': str(decrypt).lower(), 'scope': scope}
kvp = client.keys.get_by_id(id=name, params=params)
- except Exception:
+ except Exception as e:
+ self._logger.exception(
+ 'Exception retrieving value from datastore (name=%s): %s',
+ name,
+ e
+ )
return None
if kvp:
@@ -185,7 +193,12 @@
try:
params = {'scope': scope}
client.keys.delete(instance=instance, params=params)
- except Exception:
+ except Exception as e:
+ self._logger.exception(
+ 'Exception deleting value from datastore (name=%s): %s',
+ name,
+ e
+ )
return False
return True
@@ -194,8 +207,12 @@
"""
Retrieve API client instance.
"""
- if not self._client:
+ token_expire = self._token_expire <= get_datetime_utc_now()
+
+ if not self._client or token_expire:
+ self._logger.audit('Creating new Client object.')
ttl = (24 * 60 * 60)
+ self._token_expire = get_datetime_utc_now() + timedelta(seconds=ttl)
temporary_token = create_token(username=self._api_username, ttl=ttl)
api_url = get_full_public_api_url()
self._client = Client(api_url=api_url, token=temporary_token.token)
|
{"golden_diff": "diff --git a/st2common/st2common/services/datastore.py b/st2common/st2common/services/datastore.py\n--- a/st2common/st2common/services/datastore.py\n+++ b/st2common/st2common/services/datastore.py\n@@ -13,10 +13,12 @@\n # See the License for the specific language governing permissions and\n # limitations under the License.\n \n+from datetime import timedelta\n from st2client.client import Client\n from st2client.models import KeyValuePair\n from st2common.services.access import create_token\n from st2common.util.api import get_full_public_api_url\n+from st2common.util.date import get_datetime_utc_now\n from st2common.constants.keyvalue import DATASTORE_KEY_SEPARATOR, SYSTEM_SCOPE\n \n \n@@ -34,6 +36,7 @@\n self._logger = logger\n \n self._client = None\n+ self._token_expire = get_datetime_utc_now()\n \n ##################################\n # Methods for datastore management\n@@ -90,7 +93,12 @@\n try:\n params = {'decrypt': str(decrypt).lower(), 'scope': scope}\n kvp = client.keys.get_by_id(id=name, params=params)\n- except Exception:\n+ except Exception as e:\n+ self._logger.exception(\n+ 'Exception retrieving value from datastore (name=%s): %s',\n+ name,\n+ e\n+ )\n return None\n \n if kvp:\n@@ -185,7 +193,12 @@\n try:\n params = {'scope': scope}\n client.keys.delete(instance=instance, params=params)\n- except Exception:\n+ except Exception as e:\n+ self._logger.exception(\n+ 'Exception deleting value from datastore (name=%s): %s',\n+ name,\n+ e\n+ )\n return False\n \n return True\n@@ -194,8 +207,12 @@\n \"\"\"\n Retrieve API client instance.\n \"\"\"\n- if not self._client:\n+ token_expire = self._token_expire <= get_datetime_utc_now()\n+\n+ if not self._client or token_expire:\n+ self._logger.audit('Creating new Client object.')\n ttl = (24 * 60 * 60)\n+ self._token_expire = get_datetime_utc_now() + timedelta(seconds=ttl)\n temporary_token = create_token(username=self._api_username, ttl=ttl)\n api_url = get_full_public_api_url()\n self._client = Client(api_url=api_url, token=temporary_token.token)\n", "issue": "Sensor fails to retrieve kv object after some time.\nst2 2.0.1\r\nmongo 3.2.10\r\n\r\nI have a polling sensor that queries an ES database and when a datapoint crosses a threshold, it sends an alert. Once alerted, it stores a key with a 24-hour ttl so that the sensor knows to skip alerts for the rest of the day. I also have a mechanism for silencing alerts with the same approach. This used to work well before I upgraded st2, but now after a few days of running st2 the sensor keeps alerting even though there\u2019s an `alerted` key in the keystore. When I restart st2 everything goes back to normal for a few days then the problem comes back. \r\n\r\nI can probably get permission to publish my entire pack, but here's the gist of the dispatch_trigger logic in my sensor:\r\n\r\nhttps://gist.github.com/pixelrebel/240ca95c480d1377175b3667de0411cb\r\n\r\nAnd here's the gist of my action chain that sets the `alerted` key.\r\n\r\nhttps://gist.github.com/pixelrebel/6def658dfd2ee43fe71ce7735db76b29\n", "before_files": [{"content": "# Licensed to the StackStorm, Inc ('StackStorm') under one or more\n# contributor license agreements. See the NOTICE file distributed with\n# this work for additional information regarding copyright ownership.\n# The ASF licenses this file to You under the Apache License, Version 2.0\n# (the \"License\"); you may not use this file except in compliance with\n# the License. You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nfrom st2client.client import Client\nfrom st2client.models import KeyValuePair\nfrom st2common.services.access import create_token\nfrom st2common.util.api import get_full_public_api_url\nfrom st2common.constants.keyvalue import DATASTORE_KEY_SEPARATOR, SYSTEM_SCOPE\n\n\nclass DatastoreService(object):\n \"\"\"\n Class provides public methods for accessing datastore items.\n \"\"\"\n\n DATASTORE_NAME_SEPARATOR = DATASTORE_KEY_SEPARATOR\n\n def __init__(self, logger, pack_name, class_name, api_username):\n self._api_username = api_username\n self._pack_name = pack_name\n self._class_name = class_name\n self._logger = logger\n\n self._client = None\n\n ##################################\n # Methods for datastore management\n ##################################\n\n def list_values(self, local=True, prefix=None):\n \"\"\"\n Retrieve all the datastores items.\n\n :param local: List values from a namespace local to this pack/class. Defaults to True.\n :type: local: ``bool``\n\n :param prefix: Optional key name prefix / startswith filter.\n :type prefix: ``str``\n\n :rtype: ``list`` of :class:`KeyValuePair`\n \"\"\"\n client = self._get_api_client()\n self._logger.audit('Retrieving all the value from the datastore')\n\n key_prefix = self._get_full_key_prefix(local=local, prefix=prefix)\n kvps = client.keys.get_all(prefix=key_prefix)\n return kvps\n\n def get_value(self, name, local=True, scope=SYSTEM_SCOPE, decrypt=False):\n \"\"\"\n Retrieve a value from the datastore for the provided key.\n\n By default, value is retrieved from the namespace local to the pack/class. If you want to\n retrieve a global value from a datastore, pass local=False to this method.\n\n :param name: Key name.\n :type name: ``str``\n\n :param local: Retrieve value from a namespace local to the pack/class. Defaults to True.\n :type: local: ``bool``\n\n :param scope: Scope under which item is saved. Defaults to system scope.\n :type: local: ``str``\n\n :param encrypt: Return the decrypted value. Defaults to False.\n :type: local: ``bool``\n\n :rtype: ``str`` or ``None``\n \"\"\"\n if scope != SYSTEM_SCOPE:\n raise ValueError('Scope %s is unsupported.' % scope)\n\n name = self._get_full_key_name(name=name, local=local)\n\n client = self._get_api_client()\n self._logger.audit('Retrieving value from the datastore (name=%s)', name)\n\n try:\n params = {'decrypt': str(decrypt).lower(), 'scope': scope}\n kvp = client.keys.get_by_id(id=name, params=params)\n except Exception:\n return None\n\n if kvp:\n return kvp.value\n\n return None\n\n def set_value(self, name, value, ttl=None, local=True, scope=SYSTEM_SCOPE, encrypt=False):\n \"\"\"\n Set a value for the provided key.\n\n By default, value is set in a namespace local to the pack/class. If you want to\n set a global value, pass local=False to this method.\n\n :param name: Key name.\n :type name: ``str``\n\n :param value: Key value.\n :type value: ``str``\n\n :param ttl: Optional TTL (in seconds).\n :type ttl: ``int``\n\n :param local: Set value in a namespace local to the pack/class. Defaults to True.\n :type: local: ``bool``\n\n :param scope: Scope under which to place the item. Defaults to system scope.\n :type: local: ``str``\n\n :param encrypt: Encrypyt the value when saving. Defaults to False.\n :type: local: ``bool``\n\n :return: ``True`` on success, ``False`` otherwise.\n :rtype: ``bool``\n \"\"\"\n if scope != SYSTEM_SCOPE:\n raise ValueError('Scope %s is unsupported.', scope)\n\n name = self._get_full_key_name(name=name, local=local)\n\n value = str(value)\n client = self._get_api_client()\n\n self._logger.audit('Setting value in the datastore (name=%s)', name)\n\n instance = KeyValuePair()\n instance.id = name\n instance.name = name\n instance.value = value\n instance.scope = scope\n if encrypt:\n instance.secret = True\n\n if ttl:\n instance.ttl = ttl\n\n client.keys.update(instance=instance)\n return True\n\n def delete_value(self, name, local=True, scope=SYSTEM_SCOPE):\n \"\"\"\n Delete the provided key.\n\n By default, value is deleted from a namespace local to the pack/class. If you want to\n delete a global value, pass local=False to this method.\n\n :param name: Name of the key to delete.\n :type name: ``str``\n\n :param local: Delete a value in a namespace local to the pack/class. Defaults to True.\n :type: local: ``bool``\n\n :param scope: Scope under which item is saved. Defaults to system scope.\n :type: local: ``str``\n\n :return: ``True`` on success, ``False`` otherwise.\n :rtype: ``bool``\n \"\"\"\n if scope != SYSTEM_SCOPE:\n raise ValueError('Scope %s is unsupported.', scope)\n\n name = self._get_full_key_name(name=name, local=local)\n\n client = self._get_api_client()\n\n instance = KeyValuePair()\n instance.id = name\n instance.name = name\n\n self._logger.audit('Deleting value from the datastore (name=%s)', name)\n\n try:\n params = {'scope': scope}\n client.keys.delete(instance=instance, params=params)\n except Exception:\n return False\n\n return True\n\n def _get_api_client(self):\n \"\"\"\n Retrieve API client instance.\n \"\"\"\n if not self._client:\n ttl = (24 * 60 * 60)\n temporary_token = create_token(username=self._api_username, ttl=ttl)\n api_url = get_full_public_api_url()\n self._client = Client(api_url=api_url, token=temporary_token.token)\n\n return self._client\n\n def _get_full_key_name(self, name, local):\n \"\"\"\n Retrieve a full key name.\n\n :rtype: ``str``\n \"\"\"\n if local:\n name = self._get_key_name_with_prefix(name=name)\n\n return name\n\n def _get_full_key_prefix(self, local, prefix=None):\n if local:\n key_prefix = self._get_local_key_name_prefix()\n\n if prefix:\n key_prefix += prefix\n else:\n key_prefix = prefix\n\n return key_prefix\n\n def _get_local_key_name_prefix(self):\n \"\"\"\n Retrieve key prefix which is local to this pack/class.\n \"\"\"\n key_prefix = self._get_datastore_key_prefix() + self.DATASTORE_NAME_SEPARATOR\n return key_prefix\n\n def _get_key_name_with_prefix(self, name):\n \"\"\"\n Retrieve a full key name which is local to the current pack/class.\n\n :param name: Base datastore key name.\n :type name: ``str``\n\n :rtype: ``str``\n \"\"\"\n prefix = self._get_datastore_key_prefix()\n full_name = prefix + self.DATASTORE_NAME_SEPARATOR + name\n return full_name\n\n def _get_datastore_key_prefix(self):\n prefix = '%s.%s' % (self._pack_name, self._class_name)\n return prefix\n", "path": "st2common/st2common/services/datastore.py"}]}
| 3,298 | 551 |
gh_patches_debug_59115
|
rasdani/github-patches
|
git_diff
|
fedora-infra__bodhi-268
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
requests not shown on updates page
The https://bodhi.fedoraproject.org/updates/?user=xxx page show all updates and their status, but not the requests (e.g. "submitted to stable") made for an update.
</issue>
<code>
[start of bodhi/services/updates.py]
1 # This program is free software; you can redistribute it and/or
2 # modify it under the terms of the GNU General Public License
3 # as published by the Free Software Foundation; either version 2
4 # of the License, or (at your option) any later version.
5 #
6 # This program is distributed in the hope that it will be useful,
7 # but WITHOUT ANY WARRANTY; without even the implied warranty of
8 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
9 # GNU General Public License for more details.
10 #
11 # You should have received a copy of the GNU General Public License
12 # along with this program; if not, write to the Free Software
13 # Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.
14
15 import math
16
17 from cornice import Service
18 from pyramid.security import has_permission
19 from sqlalchemy import func, distinct
20 from sqlalchemy.sql import or_
21
22 from bodhi import log
23 from bodhi.exceptions import BodhiException, LockedUpdateException
24 from bodhi.models import Update, Build, Bug, CVE, Package, UpdateRequest
25 import bodhi.schemas
26 import bodhi.security
27 from bodhi.validators import (
28 validate_nvrs,
29 validate_uniqueness,
30 validate_build_tags,
31 validate_acls,
32 validate_builds,
33 validate_enums,
34 validate_releases,
35 validate_release,
36 validate_username,
37 validate_update_id,
38 validate_requirements,
39 )
40
41
42 update = Service(name='update', path='/updates/{id}',
43 validators=(validate_update_id,),
44 description='Update submission service',
45 # This acl only checks if the user is an admin or a commiters to the packages,
46 # where as the validate_acls method which is attached to the @post on this
47 # services does this as well as checking against the groups. So, this acl
48 # should be unnecessary at the moment.
49 #acl=bodhi.security.package_maintainers_only_acl,
50 acl=bodhi.security.packagers_allowed_acl,
51 cors_origins=bodhi.security.cors_origins_ro)
52
53 update_edit = Service(name='update_edit', path='/updates/{id}/edit',
54 validators=(validate_update_id,),
55 description='Update submission service',
56 #acl=bodhi.security.package_maintainers_only_acl,
57 acl=bodhi.security.packagers_allowed_acl,
58 cors_origins=bodhi.security.cors_origins_rw)
59
60 updates = Service(name='updates', path='/updates/',
61 acl=bodhi.security.packagers_allowed_acl,
62 description='Update submission service',
63 cors_origins=bodhi.security.cors_origins_ro)
64
65 update_request = Service(name='update_request', path='/updates/{id}/request',
66 description='Update request service',
67 #acl=bodhi.security.package_maintainers_only_acl,
68 acl=bodhi.security.packagers_allowed_acl,
69 cors_origins=bodhi.security.cors_origins_rw)
70
71
72 @update.get(accept=('application/json', 'text/json'), renderer='json')
73 @update.get(accept=('application/javascript'), renderer='jsonp')
74 @update.get(accept="text/html", renderer="update.html")
75 def get_update(request):
76 """Return a single update from an id, title, or alias"""
77 can_edit = has_permission('edit', request.context, request)
78 return dict(update=request.validated['update'], can_edit=can_edit)
79
80
81 @update_edit.get(accept="text/html", renderer="new_update.html")
82 def get_update_for_editing(request):
83 """Return a single update from an id, title, or alias for the edit form"""
84 return dict(
85 update=request.validated['update'],
86 types=reversed(bodhi.models.UpdateType.values()),
87 severities=reversed(bodhi.models.UpdateSeverity.values()),
88 suggestions=reversed(bodhi.models.UpdateSuggestion.values()),
89 )
90
91
92 @update_request.post(schema=bodhi.schemas.UpdateRequestSchema,
93 validators=(
94 validate_enums,
95 validate_update_id,
96 validate_build_tags,
97 validate_acls,
98 ),
99 permission='edit', renderer='json')
100 def set_request(request):
101 """Sets a specific :class:`bodhi.models.UpdateRequest` on a given update"""
102 update = request.validated['update']
103 action = request.validated['request']
104
105 if update.locked:
106 request.errors.add('body', 'request',
107 "Can't change request on a locked update")
108 return
109
110 if action is UpdateRequest.stable:
111 settings = request.registry.settings
112 result, reason = update.check_requirements(request.db, settings)
113 if not result:
114 request.errors.add('body', 'request',
115 'Requirement not met %s' % reason)
116 return
117
118 try:
119 update.set_request(action, request.user.name)
120 except BodhiException as e:
121 request.errors.add('body', 'request', e.message)
122
123 return dict(update=update)
124
125
126 @updates.get(schema=bodhi.schemas.ListUpdateSchema,
127 accept=('application/json', 'text/json'), renderer='json',
128 validators=(validate_release, validate_releases,
129 validate_enums, validate_username))
130 @updates.get(schema=bodhi.schemas.ListUpdateSchema,
131 accept=('application/javascript'), renderer='jsonp',
132 validators=(validate_release, validate_releases,
133 validate_enums, validate_username))
134 @updates.get(schema=bodhi.schemas.ListUpdateSchema,
135 accept=('application/atom+xml'), renderer='rss',
136 validators=(validate_release, validate_releases,
137 validate_enums, validate_username))
138 @updates.get(schema=bodhi.schemas.ListUpdateSchema,
139 accept=('text/html'), renderer='updates.html',
140 validators=(validate_release, validate_releases,
141 validate_enums, validate_username))
142 def query_updates(request):
143 db = request.db
144 data = request.validated
145 query = db.query(Update)
146
147 log.debug('query(%s)' % data)
148
149 approved_since = data.get('approved_since')
150 if approved_since is not None:
151 query = query.filter(Update.date_approved >= approved_since)
152
153 bugs = data.get('bugs')
154 if bugs is not None:
155 query = query.join(Update.bugs)
156 query = query.filter(or_(*[Bug.bug_id==bug_id for bug_id in bugs]))
157
158 critpath = data.get('critpath')
159 if critpath is not None:
160 query = query.filter(Update.critpath==critpath)
161
162 cves = data.get('cves')
163 if cves is not None:
164 query = query.join(Update.cves)
165 query = query.filter(or_(*[CVE.cve_id==cve_id for cve_id in cves]))
166
167 like = data.get('like')
168 if like is not None:
169 query = query.filter(or_(*[
170 Update.title.like('%%%s%%' % like)
171 ]))
172
173 locked = data.get('locked')
174 if locked is not None:
175 query = query.filter(Update.locked==locked)
176
177 modified_since = data.get('modified_since')
178 if modified_since is not None:
179 query = query.filter(Update.date_modified >= modified_since)
180
181 packages = data.get('packages')
182 if packages is not None:
183 query = query.join(Update.builds).join(Build.package)
184 query = query.filter(or_(*[Package.name==pkg for pkg in packages]))
185
186 builds = data.get('builds')
187 if builds is not None:
188 query = query.join(Update.builds)
189 query = query.filter(or_(*[Build.nvr==build for build in builds]))
190
191 pushed = data.get('pushed')
192 if pushed is not None:
193 query = query.filter(Update.pushed==pushed)
194
195 pushed_since = data.get('pushed_since')
196 if pushed_since is not None:
197 query = query.filter(Update.date_pushed >= pushed_since)
198
199 releases = data.get('releases')
200 if releases is not None:
201 query = query.filter(or_(*[Update.release==r for r in releases]))
202
203 # This singular version of the plural "releases" is purely for bodhi1
204 # backwards compat (mostly for RSS feeds) - threebean
205 release = data.get('release')
206 if release is not None:
207 query = query.filter(Update.release==release)
208
209 req = data.get('request')
210 if req is not None:
211 query = query.filter(Update.request==req)
212
213 severity = data.get('severity')
214 if severity is not None:
215 query = query.filter(Update.severity==severity)
216
217 status = data.get('status')
218 if status is not None:
219 query = query.filter(Update.status==status)
220
221 submitted_since = data.get('submitted_since')
222 if submitted_since is not None:
223 query = query.filter(Update.date_submitted >= submitted_since)
224
225 suggest = data.get('suggest')
226 if suggest is not None:
227 query = query.filter(Update.suggest==suggest)
228
229 type = data.get('type')
230 if type is not None:
231 query = query.filter(Update.type==type)
232
233 user = data.get('user')
234 if user is not None:
235 query = query.filter(Update.user==user)
236
237 updateid = data.get('updateid')
238 if updateid is not None:
239 query = query.filter(or_(*[Update.alias==uid for uid in updateid]))
240 alias = data.get('alias')
241 if alias is not None:
242 query = query.filter(or_(*[Update.alias==a for a in alias]))
243
244 query = query.order_by(Update.date_submitted.desc())
245
246 # We can't use ``query.count()`` here because it is naive with respect to
247 # all the joins that we're doing above.
248 count_query = query.statement\
249 .with_only_columns([func.count(distinct(Update.id))])\
250 .order_by(None)
251 total = db.execute(count_query).scalar()
252
253 page = data.get('page')
254 rows_per_page = data.get('rows_per_page')
255 pages = int(math.ceil(total / float(rows_per_page)))
256 query = query.offset(rows_per_page * (page - 1)).limit(rows_per_page)
257
258 return dict(
259 updates=query.all(),
260 page=page,
261 pages=pages,
262 rows_per_page=rows_per_page,
263 total=total,
264 chrome=data.get('chrome'),
265 display_user=data.get('display_user'),
266 )
267
268
269 @updates.post(schema=bodhi.schemas.SaveUpdateSchema,
270 permission='create', renderer='json',
271 validators=(
272 validate_nvrs,
273 validate_builds,
274 validate_uniqueness,
275 validate_build_tags,
276 validate_acls,
277 validate_enums,
278 validate_requirements,
279 ))
280 def new_update(request):
281 """ Save an update.
282
283 This entails either creating a new update, or editing an existing one. To
284 edit an existing update, the update's original title must be specified in
285 the ``edited`` parameter.
286 """
287 data = request.validated
288 log.debug('validated = %s' % data)
289
290 # This has already been validated at this point, but we need to ditch
291 # it since the models don't care about a csrf argument.
292 data.pop('csrf_token')
293
294 try:
295 if data.get('edited'):
296 log.info('Editing update: %s' % data['edited'])
297 up = Update.edit(request, data)
298 else:
299 log.info('Creating new update: %s' % ' '.join(data['builds']))
300 up = Update.new(request, data)
301 log.debug('update = %r' % up)
302
303 except LockedUpdateException as e:
304 request.errors.add('body', 'builds', "%s" % e)
305 return
306
307 except Exception as e:
308 log.exception(e)
309 request.errors.add('body', 'builds', 'Unable to create update')
310 return
311
312 up.obsolete_older_updates(request)
313
314 return up
315
[end of bodhi/services/updates.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bodhi/services/updates.py b/bodhi/services/updates.py
--- a/bodhi/services/updates.py
+++ b/bodhi/services/updates.py
@@ -262,7 +262,8 @@
rows_per_page=rows_per_page,
total=total,
chrome=data.get('chrome'),
- display_user=data.get('display_user'),
+ display_user=data.get('display_user', False),
+ display_request=data.get('display_request', True),
)
|
{"golden_diff": "diff --git a/bodhi/services/updates.py b/bodhi/services/updates.py\n--- a/bodhi/services/updates.py\n+++ b/bodhi/services/updates.py\n@@ -262,7 +262,8 @@\n rows_per_page=rows_per_page,\n total=total,\n chrome=data.get('chrome'),\n- display_user=data.get('display_user'),\n+ display_user=data.get('display_user', False),\n+ display_request=data.get('display_request', True),\n )\n", "issue": "requests not shown on updates page\nThe https://bodhi.fedoraproject.org/updates/?user=xxx page show all updates and their status, but not the requests (e.g. \"submitted to stable\") made for an update.\n\n", "before_files": [{"content": "# This program is free software; you can redistribute it and/or\n# modify it under the terms of the GNU General Public License\n# as published by the Free Software Foundation; either version 2\n# of the License, or (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program; if not, write to the Free Software\n# Foundation, Inc., 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301, USA.\n\nimport math\n\nfrom cornice import Service\nfrom pyramid.security import has_permission\nfrom sqlalchemy import func, distinct\nfrom sqlalchemy.sql import or_\n\nfrom bodhi import log\nfrom bodhi.exceptions import BodhiException, LockedUpdateException\nfrom bodhi.models import Update, Build, Bug, CVE, Package, UpdateRequest\nimport bodhi.schemas\nimport bodhi.security\nfrom bodhi.validators import (\n validate_nvrs,\n validate_uniqueness,\n validate_build_tags,\n validate_acls,\n validate_builds,\n validate_enums,\n validate_releases,\n validate_release,\n validate_username,\n validate_update_id,\n validate_requirements,\n)\n\n\nupdate = Service(name='update', path='/updates/{id}',\n validators=(validate_update_id,),\n description='Update submission service',\n # This acl only checks if the user is an admin or a commiters to the packages,\n # where as the validate_acls method which is attached to the @post on this\n # services does this as well as checking against the groups. So, this acl\n # should be unnecessary at the moment.\n #acl=bodhi.security.package_maintainers_only_acl,\n acl=bodhi.security.packagers_allowed_acl,\n cors_origins=bodhi.security.cors_origins_ro)\n\nupdate_edit = Service(name='update_edit', path='/updates/{id}/edit',\n validators=(validate_update_id,),\n description='Update submission service',\n #acl=bodhi.security.package_maintainers_only_acl,\n acl=bodhi.security.packagers_allowed_acl,\n cors_origins=bodhi.security.cors_origins_rw)\n\nupdates = Service(name='updates', path='/updates/',\n acl=bodhi.security.packagers_allowed_acl,\n description='Update submission service',\n cors_origins=bodhi.security.cors_origins_ro)\n\nupdate_request = Service(name='update_request', path='/updates/{id}/request',\n description='Update request service',\n #acl=bodhi.security.package_maintainers_only_acl,\n acl=bodhi.security.packagers_allowed_acl,\n cors_origins=bodhi.security.cors_origins_rw)\n\n\[email protected](accept=('application/json', 'text/json'), renderer='json')\[email protected](accept=('application/javascript'), renderer='jsonp')\[email protected](accept=\"text/html\", renderer=\"update.html\")\ndef get_update(request):\n \"\"\"Return a single update from an id, title, or alias\"\"\"\n can_edit = has_permission('edit', request.context, request)\n return dict(update=request.validated['update'], can_edit=can_edit)\n\n\n@update_edit.get(accept=\"text/html\", renderer=\"new_update.html\")\ndef get_update_for_editing(request):\n \"\"\"Return a single update from an id, title, or alias for the edit form\"\"\"\n return dict(\n update=request.validated['update'],\n types=reversed(bodhi.models.UpdateType.values()),\n severities=reversed(bodhi.models.UpdateSeverity.values()),\n suggestions=reversed(bodhi.models.UpdateSuggestion.values()),\n )\n\n\n@update_request.post(schema=bodhi.schemas.UpdateRequestSchema,\n validators=(\n validate_enums,\n validate_update_id,\n validate_build_tags,\n validate_acls,\n ),\n permission='edit', renderer='json')\ndef set_request(request):\n \"\"\"Sets a specific :class:`bodhi.models.UpdateRequest` on a given update\"\"\"\n update = request.validated['update']\n action = request.validated['request']\n\n if update.locked:\n request.errors.add('body', 'request',\n \"Can't change request on a locked update\")\n return\n\n if action is UpdateRequest.stable:\n settings = request.registry.settings\n result, reason = update.check_requirements(request.db, settings)\n if not result:\n request.errors.add('body', 'request',\n 'Requirement not met %s' % reason)\n return\n\n try:\n update.set_request(action, request.user.name)\n except BodhiException as e:\n request.errors.add('body', 'request', e.message)\n\n return dict(update=update)\n\n\[email protected](schema=bodhi.schemas.ListUpdateSchema,\n accept=('application/json', 'text/json'), renderer='json',\n validators=(validate_release, validate_releases,\n validate_enums, validate_username))\[email protected](schema=bodhi.schemas.ListUpdateSchema,\n accept=('application/javascript'), renderer='jsonp',\n validators=(validate_release, validate_releases,\n validate_enums, validate_username))\[email protected](schema=bodhi.schemas.ListUpdateSchema,\n accept=('application/atom+xml'), renderer='rss',\n validators=(validate_release, validate_releases,\n validate_enums, validate_username))\[email protected](schema=bodhi.schemas.ListUpdateSchema,\n accept=('text/html'), renderer='updates.html',\n validators=(validate_release, validate_releases,\n validate_enums, validate_username))\ndef query_updates(request):\n db = request.db\n data = request.validated\n query = db.query(Update)\n\n log.debug('query(%s)' % data)\n\n approved_since = data.get('approved_since')\n if approved_since is not None:\n query = query.filter(Update.date_approved >= approved_since)\n\n bugs = data.get('bugs')\n if bugs is not None:\n query = query.join(Update.bugs)\n query = query.filter(or_(*[Bug.bug_id==bug_id for bug_id in bugs]))\n\n critpath = data.get('critpath')\n if critpath is not None:\n query = query.filter(Update.critpath==critpath)\n\n cves = data.get('cves')\n if cves is not None:\n query = query.join(Update.cves)\n query = query.filter(or_(*[CVE.cve_id==cve_id for cve_id in cves]))\n\n like = data.get('like')\n if like is not None:\n query = query.filter(or_(*[\n Update.title.like('%%%s%%' % like)\n ]))\n\n locked = data.get('locked')\n if locked is not None:\n query = query.filter(Update.locked==locked)\n\n modified_since = data.get('modified_since')\n if modified_since is not None:\n query = query.filter(Update.date_modified >= modified_since)\n\n packages = data.get('packages')\n if packages is not None:\n query = query.join(Update.builds).join(Build.package)\n query = query.filter(or_(*[Package.name==pkg for pkg in packages]))\n\n builds = data.get('builds')\n if builds is not None:\n query = query.join(Update.builds)\n query = query.filter(or_(*[Build.nvr==build for build in builds]))\n\n pushed = data.get('pushed')\n if pushed is not None:\n query = query.filter(Update.pushed==pushed)\n\n pushed_since = data.get('pushed_since')\n if pushed_since is not None:\n query = query.filter(Update.date_pushed >= pushed_since)\n\n releases = data.get('releases')\n if releases is not None:\n query = query.filter(or_(*[Update.release==r for r in releases]))\n\n # This singular version of the plural \"releases\" is purely for bodhi1\n # backwards compat (mostly for RSS feeds) - threebean\n release = data.get('release')\n if release is not None:\n query = query.filter(Update.release==release)\n\n req = data.get('request')\n if req is not None:\n query = query.filter(Update.request==req)\n\n severity = data.get('severity')\n if severity is not None:\n query = query.filter(Update.severity==severity)\n\n status = data.get('status')\n if status is not None:\n query = query.filter(Update.status==status)\n\n submitted_since = data.get('submitted_since')\n if submitted_since is not None:\n query = query.filter(Update.date_submitted >= submitted_since)\n\n suggest = data.get('suggest')\n if suggest is not None:\n query = query.filter(Update.suggest==suggest)\n\n type = data.get('type')\n if type is not None:\n query = query.filter(Update.type==type)\n\n user = data.get('user')\n if user is not None:\n query = query.filter(Update.user==user)\n\n updateid = data.get('updateid')\n if updateid is not None:\n query = query.filter(or_(*[Update.alias==uid for uid in updateid]))\n alias = data.get('alias')\n if alias is not None:\n query = query.filter(or_(*[Update.alias==a for a in alias]))\n\n query = query.order_by(Update.date_submitted.desc())\n\n # We can't use ``query.count()`` here because it is naive with respect to\n # all the joins that we're doing above.\n count_query = query.statement\\\n .with_only_columns([func.count(distinct(Update.id))])\\\n .order_by(None)\n total = db.execute(count_query).scalar()\n\n page = data.get('page')\n rows_per_page = data.get('rows_per_page')\n pages = int(math.ceil(total / float(rows_per_page)))\n query = query.offset(rows_per_page * (page - 1)).limit(rows_per_page)\n\n return dict(\n updates=query.all(),\n page=page,\n pages=pages,\n rows_per_page=rows_per_page,\n total=total,\n chrome=data.get('chrome'),\n display_user=data.get('display_user'),\n )\n\n\[email protected](schema=bodhi.schemas.SaveUpdateSchema,\n permission='create', renderer='json',\n validators=(\n validate_nvrs,\n validate_builds,\n validate_uniqueness,\n validate_build_tags,\n validate_acls,\n validate_enums,\n validate_requirements,\n ))\ndef new_update(request):\n \"\"\" Save an update.\n\n This entails either creating a new update, or editing an existing one. To\n edit an existing update, the update's original title must be specified in\n the ``edited`` parameter.\n \"\"\"\n data = request.validated\n log.debug('validated = %s' % data)\n\n # This has already been validated at this point, but we need to ditch\n # it since the models don't care about a csrf argument.\n data.pop('csrf_token')\n\n try:\n if data.get('edited'):\n log.info('Editing update: %s' % data['edited'])\n up = Update.edit(request, data)\n else:\n log.info('Creating new update: %s' % ' '.join(data['builds']))\n up = Update.new(request, data)\n log.debug('update = %r' % up)\n\n except LockedUpdateException as e:\n request.errors.add('body', 'builds', \"%s\" % e)\n return\n\n except Exception as e:\n log.exception(e)\n request.errors.add('body', 'builds', 'Unable to create update')\n return\n\n up.obsolete_older_updates(request)\n\n return up\n", "path": "bodhi/services/updates.py"}]}
| 3,986 | 111 |
gh_patches_debug_3860
|
rasdani/github-patches
|
git_diff
|
freedomofpress__securedrop-1336
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
update_version.sh should update new documentation
Currently the "set_up_admin_tails" documentation looks like this, I suspect that between every release FPF just increments the number (from .3.6 to .3.7). Luckily we have computers to automate small tasks for us :-) Is there a programmatic way to do this?
```
cd securedrop/
git checkout 0.3.6
git tag -v 0.3.6
```
</issue>
<code>
[start of docs/conf.py]
1 # -*- coding: utf-8 -*-
2 #
3 # SecureDrop documentation build configuration file, created by
4 # sphinx-quickstart on Tue Oct 13 12:08:52 2015.
5 #
6 # This file is execfile()d with the current directory set to its
7 # containing dir.
8 #
9 # Note that not all possible configuration values are present in this
10 # autogenerated file.
11 #
12 # All configuration values have a default; values that are commented out
13 # serve to show the default.
14
15 import sys
16 import os
17 import shlex
18
19 # Detect if we're being built by Read the Docs
20 # https://docs.readthedocs.org/en/latest/faq.html#how-do-i-change-behavior-for-read-the-docs
21 on_rtd = os.environ.get('READTHEDOCS', None) == 'True'
22
23 # If extensions (or modules to document with autodoc) are in another directory,
24 # add these directories to sys.path here. If the directory is relative to the
25 # documentation root, use os.path.abspath to make it absolute, like shown here.
26 #sys.path.insert(0, os.path.abspath('.'))
27
28 # -- General configuration ------------------------------------------------
29
30 # If your documentation needs a minimal Sphinx version, state it here.
31 #needs_sphinx = '1.0'
32
33 # Add any Sphinx extension module names here, as strings. They can be
34 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
35 # ones.
36 extensions = ['sphinx.ext.todo', ]
37
38 # Add any paths that contain templates here, relative to this directory.
39 templates_path = ['_templates']
40
41 # The suffix(es) of source filenames.
42 # You can specify multiple suffix as a list of string:
43 # source_suffix = ['.rst', '.md']
44 source_suffix = '.rst'
45
46 # The encoding of source files.
47 #source_encoding = 'utf-8-sig'
48
49 # The master toctree document.
50 master_doc = 'index'
51
52 # General information about the project.
53 project = u'SecureDrop'
54 copyright = u'2015, Freedom of the Press Foundation'
55 author = u'SecureDrop Team and Contributors'
56
57 # The version info for the project you're documenting, acts as replacement for
58 # |version| and |release|, also used in various other places throughout the
59 # built documents.
60 #
61 # The short X.Y version.
62 version = '0.3.5'
63 # The full version, including alpha/beta/rc tags.
64 release = '0.3.5'
65
66 # The language for content autogenerated by Sphinx. Refer to documentation
67 # for a list of supported languages.
68 #
69 # This is also used if you do content translation via gettext catalogs.
70 # Usually you set "language" from the command line for these cases.
71 language = None
72
73 # There are two options for replacing |today|: either, you set today to some
74 # non-false value, then it is used:
75 #today = ''
76 # Else, today_fmt is used as the format for a strftime call.
77 #today_fmt = '%B %d, %Y'
78
79 # List of patterns, relative to source directory, that match files and
80 # directories to ignore when looking for source files.
81 exclude_patterns = ['_build']
82
83 # The reST default role (used for this markup: `text`) to use for all
84 # documents.
85 #default_role = None
86
87 # If true, '()' will be appended to :func: etc. cross-reference text.
88 #add_function_parentheses = True
89
90 # If true, the current module name will be prepended to all description
91 # unit titles (such as .. function::).
92 #add_module_names = True
93
94 # If true, sectionauthor and moduleauthor directives will be shown in the
95 # output. They are ignored by default.
96 #show_authors = False
97
98 # The name of the Pygments (syntax highlighting) style to use.
99 pygments_style = 'sphinx'
100
101 # A list of ignored prefixes for module index sorting.
102 #modindex_common_prefix = []
103
104 # If true, keep warnings as "system message" paragraphs in the built documents.
105 #keep_warnings = False
106
107 # If true, `todo` and `todoList` produce output, else they produce nothing.
108 todo_include_todos = False
109
110
111 # -- Options for HTML output ----------------------------------------------
112
113 # The theme to use for HTML and HTML Help pages. See the documentation for
114 # a list of builtin themes.
115 if on_rtd:
116 html_theme = 'default'
117 else:
118 try:
119 # If you want to build the docs locally using the RTD theme,
120 # you may need to install it: ``pip install sphinx_rtd_theme``.
121 # https://github.com/snide/sphinx_rtd_theme#via-package
122 import sphinx_rtd_theme
123 html_theme = "sphinx_rtd_theme"
124 html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]
125 except ImportError:
126 # This theme is included with Sphinx and is quite nice (based
127 # on the Pocoo themes), but since we're using the RTD theme
128 # for the production docs, it's best to use that to avoid
129 # issues due to discrepancies between the themes.
130 html_theme = 'alabaster'
131
132 # Theme options are theme-specific and customize the look and feel of a theme
133 # further. For a list of options available for each theme, see the
134 # documentation.
135 #html_theme_options = {}
136
137 # Add any paths that contain custom themes here, relative to this directory.
138 #html_theme_path = []
139
140 # The name for this set of Sphinx documents. If None, it defaults to
141 # "<project> v<release> documentation".
142 #html_title = None
143
144 # A shorter title for the navigation bar. Default is the same as html_title.
145 #html_short_title = None
146
147 # The name of an image file (relative to this directory) to place at the top
148 # of the sidebar.
149 #html_logo = None
150
151 # The name of an image file (within the static path) to use as favicon of the
152 # docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32
153 # pixels large.
154 #html_favicon = None
155
156 # Add any paths that contain custom static files (such as style sheets) here,
157 # relative to this directory. They are copied after the builtin static files,
158 # so a file named "default.css" will overwrite the builtin "default.css".
159 html_static_path = ['_static']
160
161 # Add any extra paths that contain custom files (such as robots.txt or
162 # .htaccess) here, relative to this directory. These files are copied
163 # directly to the root of the documentation.
164 #html_extra_path = []
165
166 # If not '', a 'Last updated on:' timestamp is inserted at every page bottom,
167 # using the given strftime format.
168 #html_last_updated_fmt = '%b %d, %Y'
169
170 # If true, SmartyPants will be used to convert quotes and dashes to
171 # typographically correct entities.
172 #html_use_smartypants = True
173
174 # Custom sidebar templates, maps document names to template names.
175 #html_sidebars = {}
176
177 # Additional templates that should be rendered to pages, maps page names to
178 # template names.
179 #html_additional_pages = {}
180
181 # If false, no module index is generated.
182 #html_domain_indices = True
183
184 # If false, no index is generated.
185 #html_use_index = True
186
187 # If true, the index is split into individual pages for each letter.
188 #html_split_index = False
189
190 # If true, links to the reST sources are added to the pages.
191 #html_show_sourcelink = True
192
193 # If true, "Created using Sphinx" is shown in the HTML footer. Default is True.
194 #html_show_sphinx = True
195
196 # If true, "(C) Copyright ..." is shown in the HTML footer. Default is True.
197 #html_show_copyright = True
198
199 # If true, an OpenSearch description file will be output, and all pages will
200 # contain a <link> tag referring to it. The value of this option must be the
201 # base URL from which the finished HTML is served.
202 #html_use_opensearch = ''
203
204 # This is the file name suffix for HTML files (e.g. ".xhtml").
205 #html_file_suffix = None
206
207 # Language to be used for generating the HTML full-text search index.
208 # Sphinx supports the following languages:
209 # 'da', 'de', 'en', 'es', 'fi', 'fr', 'hu', 'it', 'ja'
210 # 'nl', 'no', 'pt', 'ro', 'ru', 'sv', 'tr'
211 #html_search_language = 'en'
212
213 # A dictionary with options for the search language support, empty by default.
214 # Now only 'ja' uses this config value
215 #html_search_options = {'type': 'default'}
216
217 # The name of a javascript file (relative to the configuration directory) that
218 # implements a search results scorer. If empty, the default will be used.
219 #html_search_scorer = 'scorer.js'
220
221 # Output file base name for HTML help builder.
222 htmlhelp_basename = 'SecureDropdoc'
223
224 # -- Options for LaTeX output ---------------------------------------------
225
226 latex_elements = {
227 # The paper size ('letterpaper' or 'a4paper').
228 #'papersize': 'letterpaper',
229
230 # The font size ('10pt', '11pt' or '12pt').
231 #'pointsize': '10pt',
232
233 # Additional stuff for the LaTeX preamble.
234 #'preamble': '',
235
236 # Latex figure (float) alignment
237 #'figure_align': 'htbp',
238 }
239
240 # Grouping the document tree into LaTeX files. List of tuples
241 # (source start file, target name, title,
242 # author, documentclass [howto, manual, or own class]).
243 latex_documents = [
244 (master_doc, 'SecureDrop.tex', u'SecureDrop Documentation',
245 author, 'manual'),
246 ]
247
248 # The name of an image file (relative to this directory) to place at the top of
249 # the title page.
250 #latex_logo = None
251
252 # For "manual" documents, if this is true, then toplevel headings are parts,
253 # not chapters.
254 #latex_use_parts = False
255
256 # If true, show page references after internal links.
257 #latex_show_pagerefs = False
258
259 # If true, show URL addresses after external links.
260 #latex_show_urls = False
261
262 # Documents to append as an appendix to all manuals.
263 #latex_appendices = []
264
265 # If false, no module index is generated.
266 #latex_domain_indices = True
267
268
269 # -- Options for manual page output ---------------------------------------
270
271 # One entry per manual page. List of tuples
272 # (source start file, name, description, authors, manual section).
273 man_pages = [
274 (master_doc, 'securedrop', u'SecureDrop Documentation',
275 [author], 1)
276 ]
277
278 # If true, show URL addresses after external links.
279 #man_show_urls = False
280
281
282 # -- Options for Texinfo output -------------------------------------------
283
284 # Grouping the document tree into Texinfo files. List of tuples
285 # (source start file, target name, title, author,
286 # dir menu entry, description, category)
287 texinfo_documents = [
288 (master_doc, 'SecureDrop', u'SecureDrop Documentation',
289 author, 'SecureDrop', 'One line description of project.',
290 'Miscellaneous'),
291 ]
292
293 # Documents to append as an appendix to all manuals.
294 #texinfo_appendices = []
295
296 # If false, no module index is generated.
297 #texinfo_domain_indices = True
298
299 # How to display URL addresses: 'footnote', 'no', or 'inline'.
300 #texinfo_show_urls = 'footnote'
301
302 # If true, do not generate a @detailmenu in the "Top" node's menu.
303 #texinfo_no_detailmenu = False
304
[end of docs/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -59,9 +59,9 @@
# built documents.
#
# The short X.Y version.
-version = '0.3.5'
+version = '0.3.7'
# The full version, including alpha/beta/rc tags.
-release = '0.3.5'
+release = '0.3.7'
# The language for content autogenerated by Sphinx. Refer to documentation
# for a list of supported languages.
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -59,9 +59,9 @@\n # built documents.\n #\n # The short X.Y version.\n-version = '0.3.5'\n+version = '0.3.7'\n # The full version, including alpha/beta/rc tags.\n-release = '0.3.5'\n+release = '0.3.7'\n \n # The language for content autogenerated by Sphinx. Refer to documentation\n # for a list of supported languages.\n", "issue": "update_version.sh should update new documentation\nCurrently the \"set_up_admin_tails\" documentation looks like this, I suspect that between every release FPF just increments the number (from .3.6 to .3.7). Luckily we have computers to automate small tasks for us :-) Is there a programmatic way to do this? \n\n```\ncd securedrop/\ngit checkout 0.3.6\ngit tag -v 0.3.6\n```\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\n#\n# SecureDrop documentation build configuration file, created by\n# sphinx-quickstart on Tue Oct 13 12:08:52 2015.\n#\n# This file is execfile()d with the current directory set to its\n# containing dir.\n#\n# Note that not all possible configuration values are present in this\n# autogenerated file.\n#\n# All configuration values have a default; values that are commented out\n# serve to show the default.\n\nimport sys\nimport os\nimport shlex\n\n# Detect if we're being built by Read the Docs\n# https://docs.readthedocs.org/en/latest/faq.html#how-do-i-change-behavior-for-read-the-docs\non_rtd = os.environ.get('READTHEDOCS', None) == 'True'\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#sys.path.insert(0, os.path.abspath('.'))\n\n# -- General configuration ------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = ['sphinx.ext.todo', ]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = ['_templates']\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n# source_suffix = ['.rst', '.md']\nsource_suffix = '.rst'\n\n# The encoding of source files.\n#source_encoding = 'utf-8-sig'\n\n# The master toctree document.\nmaster_doc = 'index'\n\n# General information about the project.\nproject = u'SecureDrop'\ncopyright = u'2015, Freedom of the Press Foundation'\nauthor = u'SecureDrop Team and Contributors'\n\n# The version info for the project you're documenting, acts as replacement for\n# |version| and |release|, also used in various other places throughout the\n# built documents.\n#\n# The short X.Y version.\nversion = '0.3.5'\n# The full version, including alpha/beta/rc tags.\nrelease = '0.3.5'\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# There are two options for replacing |today|: either, you set today to some\n# non-false value, then it is used:\n#today = ''\n# Else, today_fmt is used as the format for a strftime call.\n#today_fmt = '%B %d, %Y'\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\nexclude_patterns = ['_build']\n\n# The reST default role (used for this markup: `text`) to use for all\n# documents.\n#default_role = None\n\n# If true, '()' will be appended to :func: etc. cross-reference text.\n#add_function_parentheses = True\n\n# If true, the current module name will be prepended to all description\n# unit titles (such as .. function::).\n#add_module_names = True\n\n# If true, sectionauthor and moduleauthor directives will be shown in the\n# output. They are ignored by default.\n#show_authors = False\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = 'sphinx'\n\n# A list of ignored prefixes for module index sorting.\n#modindex_common_prefix = []\n\n# If true, keep warnings as \"system message\" paragraphs in the built documents.\n#keep_warnings = False\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = False\n\n\n# -- Options for HTML output ----------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\nif on_rtd:\n html_theme = 'default'\nelse:\n try:\n # If you want to build the docs locally using the RTD theme,\n # you may need to install it: ``pip install sphinx_rtd_theme``.\n # https://github.com/snide/sphinx_rtd_theme#via-package\n import sphinx_rtd_theme\n html_theme = \"sphinx_rtd_theme\"\n html_theme_path = [sphinx_rtd_theme.get_html_theme_path()]\n except ImportError:\n # This theme is included with Sphinx and is quite nice (based\n # on the Pocoo themes), but since we're using the RTD theme\n # for the production docs, it's best to use that to avoid\n # issues due to discrepancies between the themes.\n html_theme = 'alabaster'\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#html_theme_options = {}\n\n# Add any paths that contain custom themes here, relative to this directory.\n#html_theme_path = []\n\n# The name for this set of Sphinx documents. If None, it defaults to\n# \"<project> v<release> documentation\".\n#html_title = None\n\n# A shorter title for the navigation bar. Default is the same as html_title.\n#html_short_title = None\n\n# The name of an image file (relative to this directory) to place at the top\n# of the sidebar.\n#html_logo = None\n\n# The name of an image file (within the static path) to use as favicon of the\n# docs. This file should be a Windows icon file (.ico) being 16x16 or 32x32\n# pixels large.\n#html_favicon = None\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = ['_static']\n\n# Add any extra paths that contain custom files (such as robots.txt or\n# .htaccess) here, relative to this directory. These files are copied\n# directly to the root of the documentation.\n#html_extra_path = []\n\n# If not '', a 'Last updated on:' timestamp is inserted at every page bottom,\n# using the given strftime format.\n#html_last_updated_fmt = '%b %d, %Y'\n\n# If true, SmartyPants will be used to convert quotes and dashes to\n# typographically correct entities.\n#html_use_smartypants = True\n\n# Custom sidebar templates, maps document names to template names.\n#html_sidebars = {}\n\n# Additional templates that should be rendered to pages, maps page names to\n# template names.\n#html_additional_pages = {}\n\n# If false, no module index is generated.\n#html_domain_indices = True\n\n# If false, no index is generated.\n#html_use_index = True\n\n# If true, the index is split into individual pages for each letter.\n#html_split_index = False\n\n# If true, links to the reST sources are added to the pages.\n#html_show_sourcelink = True\n\n# If true, \"Created using Sphinx\" is shown in the HTML footer. Default is True.\n#html_show_sphinx = True\n\n# If true, \"(C) Copyright ...\" is shown in the HTML footer. Default is True.\n#html_show_copyright = True\n\n# If true, an OpenSearch description file will be output, and all pages will\n# contain a <link> tag referring to it. The value of this option must be the\n# base URL from which the finished HTML is served.\n#html_use_opensearch = ''\n\n# This is the file name suffix for HTML files (e.g. \".xhtml\").\n#html_file_suffix = None\n\n# Language to be used for generating the HTML full-text search index.\n# Sphinx supports the following languages:\n# 'da', 'de', 'en', 'es', 'fi', 'fr', 'hu', 'it', 'ja'\n# 'nl', 'no', 'pt', 'ro', 'ru', 'sv', 'tr'\n#html_search_language = 'en'\n\n# A dictionary with options for the search language support, empty by default.\n# Now only 'ja' uses this config value\n#html_search_options = {'type': 'default'}\n\n# The name of a javascript file (relative to the configuration directory) that\n# implements a search results scorer. If empty, the default will be used.\n#html_search_scorer = 'scorer.js'\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = 'SecureDropdoc'\n\n# -- Options for LaTeX output ---------------------------------------------\n\nlatex_elements = {\n# The paper size ('letterpaper' or 'a4paper').\n#'papersize': 'letterpaper',\n\n# The font size ('10pt', '11pt' or '12pt').\n#'pointsize': '10pt',\n\n# Additional stuff for the LaTeX preamble.\n#'preamble': '',\n\n# Latex figure (float) alignment\n#'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (master_doc, 'SecureDrop.tex', u'SecureDrop Documentation',\n author, 'manual'),\n]\n\n# The name of an image file (relative to this directory) to place at the top of\n# the title page.\n#latex_logo = None\n\n# For \"manual\" documents, if this is true, then toplevel headings are parts,\n# not chapters.\n#latex_use_parts = False\n\n# If true, show page references after internal links.\n#latex_show_pagerefs = False\n\n# If true, show URL addresses after external links.\n#latex_show_urls = False\n\n# Documents to append as an appendix to all manuals.\n#latex_appendices = []\n\n# If false, no module index is generated.\n#latex_domain_indices = True\n\n\n# -- Options for manual page output ---------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [\n (master_doc, 'securedrop', u'SecureDrop Documentation',\n [author], 1)\n]\n\n# If true, show URL addresses after external links.\n#man_show_urls = False\n\n\n# -- Options for Texinfo output -------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (master_doc, 'SecureDrop', u'SecureDrop Documentation',\n author, 'SecureDrop', 'One line description of project.',\n 'Miscellaneous'),\n]\n\n# Documents to append as an appendix to all manuals.\n#texinfo_appendices = []\n\n# If false, no module index is generated.\n#texinfo_domain_indices = True\n\n# How to display URL addresses: 'footnote', 'no', or 'inline'.\n#texinfo_show_urls = 'footnote'\n\n# If true, do not generate a @detailmenu in the \"Top\" node's menu.\n#texinfo_no_detailmenu = False\n", "path": "docs/conf.py"}]}
| 3,985 | 120 |
gh_patches_debug_37522
|
rasdani/github-patches
|
git_diff
|
mindsdb__mindsdb-915
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
KeyError: 'typing' when creating new Datasource from MySQL
Using [airplane_satisfaction dataset](https://www.kaggle.com/teejmahal20/airline-passenger-satisfaction?select=train.csv) to create a data source from Scout through MySQL throws bellow error:
```
Traceback (most recent call last):
File "/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/flask/app.py", line 1950, in full_dispatch_request
rv = self.dispatch_request()
File "/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/flask/app.py", line 1936, in dispatch_request
return self.view_functions[rule.endpoint](**req.view_args)
File "/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/flask_restx/api.py", line 375, in wrapper
resp = resource(*args, **kwargs)
File "/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/flask/views.py", line 89, in view
return self.dispatch_request(*args, **kwargs)
File "/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/flask_restx/resource.py", line 44, in dispatch_request
resp = meth(*args, **kwargs)
File "/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/flask_restx/marshalling.py", line 248, in wrapper
resp = f(*args, **kwargs)
File "/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/mindsdb/api/http/namespaces/datasource.py", line 113, in put
ca.default_store.save_datasource(name, source_type, request.json)
File "/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/mindsdb/interfaces/datastore/datastore.py", line 185, in save_datasource
df_with_types = cast_df_columns_types(df, self.get_analysis(df)['data_analysis_v2'])
File "/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/mindsdb/interfaces/datastore/sqlite_helpers.py", line 54, in cast_df_columns_types
print(f'Error: cant convert type of DS column {name} to {new_type}')
UnboundLocalError: local variable 'new_type' referenced before assignment
ERROR:mindsdb.api.http.initialize:Exception on /api/datasources/AirplaneData [PUT]
Traceback (most recent call last):
File "/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/mindsdb/interfaces/datastore/sqlite_helpers.py", line 44, in cast_df_columns_types
col_type = stats[name]['typing']['data_type']
KeyError: 'typing'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/flask/app.py", line 1950, in full_dispatch_request
rv = self.dispatch_request()
File "/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/flask/app.py", line 1936, in dispatch_request
return self.view_functions[rule.endpoint](**req.view_args)
File "/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/flask_restx/api.py", line 375, in wrapper
resp = resource(*args, **kwargs)
File "/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/flask/views.py", line 89, in view
return self.dispatch_request(*args, **kwargs)
File "/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/flask_restx/resource.py", line 44, in dispatch_request
resp = meth(*args, **kwargs)
File "/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/flask_restx/marshalling.py", line 248, in wrapper
resp = f(*args, **kwargs)
File "/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/mindsdb/api/http/namespaces/datasource.py", line 113, in put
ca.default_store.save_datasource(name, source_type, request.json)
File "/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/mindsdb/interfaces/datastore/datastore.py", line 185, in save_datasource
df_with_types = cast_df_columns_types(df, self.get_analysis(df)['data_analysis_v2'])
File "/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/mindsdb/interfaces/datastore/sqlite_helpers.py", line 54, in cast_df_columns_types
print(f'Error: cant convert type of DS column {name} to {new_type}')
UnboundLocalError: local variable 'new_type' referenced before assignment
```
</issue>
<code>
[start of mindsdb/interfaces/datastore/sqlite_helpers.py]
1 import sqlite3
2 from mindsdb_native.libs.constants.mindsdb import DATA_TYPES, DATA_SUBTYPES
3 import re
4
5 def create_sqlite_db(path, data_frame):
6 con = sqlite3.connect(path)
7 data_frame.to_sql(name='data', con=con, index=False)
8 con.close()
9
10 def cast_df_columns_types(df, stats):
11 types_map = {
12 DATA_TYPES.NUMERIC: {
13 DATA_SUBTYPES.INT: 'int64',
14 DATA_SUBTYPES.FLOAT: 'float64',
15 DATA_SUBTYPES.BINARY: 'bool'
16 },
17 DATA_TYPES.DATE: {
18 DATA_SUBTYPES.DATE: 'datetime64', # YYYY-MM-DD
19 DATA_SUBTYPES.TIMESTAMP: 'datetime64' # YYYY-MM-DD hh:mm:ss or 1852362464
20 },
21 DATA_TYPES.CATEGORICAL: {
22 DATA_SUBTYPES.SINGLE: 'category',
23 DATA_SUBTYPES.MULTIPLE: 'category'
24 },
25 DATA_TYPES.FILE_PATH: {
26 DATA_SUBTYPES.IMAGE: 'object',
27 DATA_SUBTYPES.VIDEO: 'object',
28 DATA_SUBTYPES.AUDIO: 'object'
29 },
30 DATA_TYPES.SEQUENTIAL: {
31 DATA_SUBTYPES.ARRAY: 'object'
32 },
33 DATA_TYPES.TEXT: {
34 DATA_SUBTYPES.SHORT: 'object',
35 DATA_SUBTYPES.RICH: 'object'
36 }
37 }
38
39 columns = [dict(name=x) for x in list(df.keys())]
40
41 for column in columns:
42 try:
43 name = column['name']
44 col_type = stats[name]['typing']['data_type']
45 col_subtype = stats[name]['typing']['data_subtype']
46 new_type = types_map[col_type][col_subtype]
47 if new_type == 'int64' or new_type == 'float64':
48 df[name] = df[name].apply(lambda x: x.replace(',','.') if isinstance(x, str) else x)
49 if new_type == 'int64':
50 df = df.astype({name: 'float64'})
51 df = df.astype({name: new_type})
52 except Exception as e:
53 print(e)
54 print(f'Error: cant convert type of DS column {name} to {new_type}')
55
56 return df
57
58 def parse_filter(key, value):
59 result = re.search(r'filter(_*.*)\[(.*)\]', key)
60 operator = result.groups()[0].strip('_') or 'like'
61 field = result.groups()[1]
62 operators_map = {
63 'like': 'like',
64 'in': 'in',
65 'nin': 'not in',
66 'gt': '>',
67 'lt': '<',
68 'gte': '>=',
69 'lte': '<=',
70 'eq': '=',
71 'neq': '!='
72 }
73 if operator not in operators_map:
74 return None
75 operator = operators_map[operator]
76 return {'field': field, 'value': value, 'operator': operator}
77
78
79 def prepare_sql_where(where):
80 marks = {}
81 if len(where) > 0:
82 for i in range(len(where)):
83 field = where[i]['field'].replace('"', '""')
84 operator = where[i]['operator']
85 value = where[i]['value']
86 var_name = f'var{i}'
87 if ' ' in field:
88 field = f'"{field}"'
89 if operator == 'like':
90 marks[var_name] = '%' + value + '%'
91 else:
92 marks[var_name] = value
93 where[i] = f'{field} {operator} :var{i}'
94 where = 'where ' + ' and '.join(where)
95 else:
96 where = ''
97 return where, marks
98
99 def get_sqlite_columns_names(cursor):
100 cursor.execute('pragma table_info(data);')
101 column_name_index = [x[0] for x in cursor.description].index('name')
102 columns = cursor.fetchall()
103 return [x[column_name_index] for x in columns]
104
105 def get_sqlite_data(db_path, where, limit, offset):
106 where = [] if where is None else where
107
108 con = sqlite3.connect(db_path)
109 cur = con.cursor()
110
111 offset = '' if limit is None or offset is None else f'offset {offset}'
112 limit = '' if limit is None else f'limit {limit}'
113
114 columns_names = get_sqlite_columns_names(cur)
115 where = [x for x in where if x['field'] in columns_names]
116 where, marks = prepare_sql_where(where)
117
118 count_query = ' '.join(['select count(1) from data', where])
119 cur.execute(count_query, marks)
120 rowcount = cur.fetchone()[0]
121
122 query = ' '.join(['select * from data', where, limit, offset])
123 cur.execute(query, marks)
124 data = cur.fetchall()
125 data = [dict(zip(columns_names, x)) for x in data]
126
127 cur.close()
128 con.close()
129
130 return {
131 'data': data,
132 'rowcount': rowcount,
133 'columns_names': columns_names
134 }
135
[end of mindsdb/interfaces/datastore/sqlite_helpers.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mindsdb/interfaces/datastore/sqlite_helpers.py b/mindsdb/interfaces/datastore/sqlite_helpers.py
--- a/mindsdb/interfaces/datastore/sqlite_helpers.py
+++ b/mindsdb/interfaces/datastore/sqlite_helpers.py
@@ -2,11 +2,13 @@
from mindsdb_native.libs.constants.mindsdb import DATA_TYPES, DATA_SUBTYPES
import re
+
def create_sqlite_db(path, data_frame):
con = sqlite3.connect(path)
data_frame.to_sql(name='data', con=con, index=False)
con.close()
+
def cast_df_columns_types(df, stats):
types_map = {
DATA_TYPES.NUMERIC: {
@@ -41,11 +43,14 @@
for column in columns:
try:
name = column['name']
- col_type = stats[name]['typing']['data_type']
- col_subtype = stats[name]['typing']['data_subtype']
- new_type = types_map[col_type][col_subtype]
+ if stats[name].get('empty', {}).get('is_empty', False):
+ new_type = types_map[DATA_TYPES.NUMERIC][DATA_SUBTYPES.INT]
+ else:
+ col_type = stats[name]['typing']['data_type']
+ col_subtype = stats[name]['typing']['data_subtype']
+ new_type = types_map[col_type][col_subtype]
if new_type == 'int64' or new_type == 'float64':
- df[name] = df[name].apply(lambda x: x.replace(',','.') if isinstance(x, str) else x)
+ df[name] = df[name].apply(lambda x: x.replace(',', '.') if isinstance(x, str) else x)
if new_type == 'int64':
df = df.astype({name: 'float64'})
df = df.astype({name: new_type})
@@ -55,6 +60,7 @@
return df
+
def parse_filter(key, value):
result = re.search(r'filter(_*.*)\[(.*)\]', key)
operator = result.groups()[0].strip('_') or 'like'
@@ -96,12 +102,14 @@
where = ''
return where, marks
+
def get_sqlite_columns_names(cursor):
cursor.execute('pragma table_info(data);')
column_name_index = [x[0] for x in cursor.description].index('name')
columns = cursor.fetchall()
return [x[column_name_index] for x in columns]
+
def get_sqlite_data(db_path, where, limit, offset):
where = [] if where is None else where
|
{"golden_diff": "diff --git a/mindsdb/interfaces/datastore/sqlite_helpers.py b/mindsdb/interfaces/datastore/sqlite_helpers.py\n--- a/mindsdb/interfaces/datastore/sqlite_helpers.py\n+++ b/mindsdb/interfaces/datastore/sqlite_helpers.py\n@@ -2,11 +2,13 @@\n from mindsdb_native.libs.constants.mindsdb import DATA_TYPES, DATA_SUBTYPES\n import re\n \n+\n def create_sqlite_db(path, data_frame):\n con = sqlite3.connect(path)\n data_frame.to_sql(name='data', con=con, index=False)\n con.close()\n \n+\n def cast_df_columns_types(df, stats):\n types_map = {\n DATA_TYPES.NUMERIC: {\n@@ -41,11 +43,14 @@\n for column in columns:\n try:\n name = column['name']\n- col_type = stats[name]['typing']['data_type']\n- col_subtype = stats[name]['typing']['data_subtype']\n- new_type = types_map[col_type][col_subtype]\n+ if stats[name].get('empty', {}).get('is_empty', False):\n+ new_type = types_map[DATA_TYPES.NUMERIC][DATA_SUBTYPES.INT]\n+ else:\n+ col_type = stats[name]['typing']['data_type']\n+ col_subtype = stats[name]['typing']['data_subtype']\n+ new_type = types_map[col_type][col_subtype]\n if new_type == 'int64' or new_type == 'float64':\n- df[name] = df[name].apply(lambda x: x.replace(',','.') if isinstance(x, str) else x)\n+ df[name] = df[name].apply(lambda x: x.replace(',', '.') if isinstance(x, str) else x)\n if new_type == 'int64':\n df = df.astype({name: 'float64'})\n df = df.astype({name: new_type})\n@@ -55,6 +60,7 @@\n \n return df\n \n+\n def parse_filter(key, value):\n result = re.search(r'filter(_*.*)\\[(.*)\\]', key)\n operator = result.groups()[0].strip('_') or 'like'\n@@ -96,12 +102,14 @@\n where = ''\n return where, marks\n \n+\n def get_sqlite_columns_names(cursor):\n cursor.execute('pragma table_info(data);')\n column_name_index = [x[0] for x in cursor.description].index('name')\n columns = cursor.fetchall()\n return [x[column_name_index] for x in columns]\n \n+\n def get_sqlite_data(db_path, where, limit, offset):\n where = [] if where is None else where\n", "issue": "KeyError: 'typing' when creating new Datasource from MySQL\nUsing [airplane_satisfaction dataset](https://www.kaggle.com/teejmahal20/airline-passenger-satisfaction?select=train.csv) to create a data source from Scout through MySQL throws bellow error:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/flask/app.py\", line 1950, in full_dispatch_request\r\n rv = self.dispatch_request()\r\n File \"/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/flask/app.py\", line 1936, in dispatch_request\r\n return self.view_functions[rule.endpoint](**req.view_args)\r\n File \"/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/flask_restx/api.py\", line 375, in wrapper\r\n resp = resource(*args, **kwargs)\r\n File \"/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/flask/views.py\", line 89, in view\r\n return self.dispatch_request(*args, **kwargs)\r\n File \"/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/flask_restx/resource.py\", line 44, in dispatch_request\r\n resp = meth(*args, **kwargs)\r\n File \"/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/flask_restx/marshalling.py\", line 248, in wrapper\r\n resp = f(*args, **kwargs)\r\n File \"/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/mindsdb/api/http/namespaces/datasource.py\", line 113, in put\r\n ca.default_store.save_datasource(name, source_type, request.json)\r\n File \"/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/mindsdb/interfaces/datastore/datastore.py\", line 185, in save_datasource\r\n df_with_types = cast_df_columns_types(df, self.get_analysis(df)['data_analysis_v2'])\r\n File \"/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/mindsdb/interfaces/datastore/sqlite_helpers.py\", line 54, in cast_df_columns_types\r\n print(f'Error: cant convert type of DS column {name} to {new_type}')\r\nUnboundLocalError: local variable 'new_type' referenced before assignment\r\nERROR:mindsdb.api.http.initialize:Exception on /api/datasources/AirplaneData [PUT]\r\nTraceback (most recent call last):\r\n File \"/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/mindsdb/interfaces/datastore/sqlite_helpers.py\", line 44, in cast_df_columns_types\r\n col_type = stats[name]['typing']['data_type']\r\nKeyError: 'typing'\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/flask/app.py\", line 1950, in full_dispatch_request\r\n rv = self.dispatch_request()\r\n File \"/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/flask/app.py\", line 1936, in dispatch_request\r\n return self.view_functions[rule.endpoint](**req.view_args)\r\n File \"/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/flask_restx/api.py\", line 375, in wrapper\r\n resp = resource(*args, **kwargs)\r\n File \"/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/flask/views.py\", line 89, in view\r\n return self.dispatch_request(*args, **kwargs)\r\n File \"/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/flask_restx/resource.py\", line 44, in dispatch_request\r\n resp = meth(*args, **kwargs)\r\n File \"/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/flask_restx/marshalling.py\", line 248, in wrapper\r\n resp = f(*args, **kwargs)\r\n File \"/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/mindsdb/api/http/namespaces/datasource.py\", line 113, in put\r\n ca.default_store.save_datasource(name, source_type, request.json)\r\n File \"/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/mindsdb/interfaces/datastore/datastore.py\", line 185, in save_datasource\r\n df_with_types = cast_df_columns_types(df, self.get_analysis(df)['data_analysis_v2'])\r\n File \"/home/zoran/MyProjects/mindsdb-examples/mdb/lib/python3.7/site-packages/mindsdb/interfaces/datastore/sqlite_helpers.py\", line 54, in cast_df_columns_types\r\n print(f'Error: cant convert type of DS column {name} to {new_type}')\r\nUnboundLocalError: local variable 'new_type' referenced before assignment\r\n\r\n```\n", "before_files": [{"content": "import sqlite3\nfrom mindsdb_native.libs.constants.mindsdb import DATA_TYPES, DATA_SUBTYPES\nimport re\n\ndef create_sqlite_db(path, data_frame):\n con = sqlite3.connect(path)\n data_frame.to_sql(name='data', con=con, index=False)\n con.close()\n\ndef cast_df_columns_types(df, stats):\n types_map = {\n DATA_TYPES.NUMERIC: {\n DATA_SUBTYPES.INT: 'int64',\n DATA_SUBTYPES.FLOAT: 'float64',\n DATA_SUBTYPES.BINARY: 'bool'\n },\n DATA_TYPES.DATE: {\n DATA_SUBTYPES.DATE: 'datetime64', # YYYY-MM-DD\n DATA_SUBTYPES.TIMESTAMP: 'datetime64' # YYYY-MM-DD hh:mm:ss or 1852362464\n },\n DATA_TYPES.CATEGORICAL: {\n DATA_SUBTYPES.SINGLE: 'category',\n DATA_SUBTYPES.MULTIPLE: 'category'\n },\n DATA_TYPES.FILE_PATH: {\n DATA_SUBTYPES.IMAGE: 'object',\n DATA_SUBTYPES.VIDEO: 'object',\n DATA_SUBTYPES.AUDIO: 'object'\n },\n DATA_TYPES.SEQUENTIAL: {\n DATA_SUBTYPES.ARRAY: 'object'\n },\n DATA_TYPES.TEXT: {\n DATA_SUBTYPES.SHORT: 'object',\n DATA_SUBTYPES.RICH: 'object'\n }\n }\n\n columns = [dict(name=x) for x in list(df.keys())]\n\n for column in columns:\n try:\n name = column['name']\n col_type = stats[name]['typing']['data_type']\n col_subtype = stats[name]['typing']['data_subtype']\n new_type = types_map[col_type][col_subtype]\n if new_type == 'int64' or new_type == 'float64':\n df[name] = df[name].apply(lambda x: x.replace(',','.') if isinstance(x, str) else x)\n if new_type == 'int64':\n df = df.astype({name: 'float64'})\n df = df.astype({name: new_type})\n except Exception as e:\n print(e)\n print(f'Error: cant convert type of DS column {name} to {new_type}')\n\n return df\n\ndef parse_filter(key, value):\n result = re.search(r'filter(_*.*)\\[(.*)\\]', key)\n operator = result.groups()[0].strip('_') or 'like'\n field = result.groups()[1]\n operators_map = {\n 'like': 'like',\n 'in': 'in',\n 'nin': 'not in',\n 'gt': '>',\n 'lt': '<',\n 'gte': '>=',\n 'lte': '<=',\n 'eq': '=',\n 'neq': '!='\n }\n if operator not in operators_map:\n return None\n operator = operators_map[operator]\n return {'field': field, 'value': value, 'operator': operator}\n\n\ndef prepare_sql_where(where):\n marks = {}\n if len(where) > 0:\n for i in range(len(where)):\n field = where[i]['field'].replace('\"', '\"\"')\n operator = where[i]['operator']\n value = where[i]['value']\n var_name = f'var{i}'\n if ' ' in field:\n field = f'\"{field}\"'\n if operator == 'like':\n marks[var_name] = '%' + value + '%'\n else:\n marks[var_name] = value\n where[i] = f'{field} {operator} :var{i}'\n where = 'where ' + ' and '.join(where)\n else:\n where = ''\n return where, marks\n\ndef get_sqlite_columns_names(cursor):\n cursor.execute('pragma table_info(data);')\n column_name_index = [x[0] for x in cursor.description].index('name')\n columns = cursor.fetchall()\n return [x[column_name_index] for x in columns]\n\ndef get_sqlite_data(db_path, where, limit, offset):\n where = [] if where is None else where\n\n con = sqlite3.connect(db_path)\n cur = con.cursor()\n\n offset = '' if limit is None or offset is None else f'offset {offset}'\n limit = '' if limit is None else f'limit {limit}'\n\n columns_names = get_sqlite_columns_names(cur)\n where = [x for x in where if x['field'] in columns_names]\n where, marks = prepare_sql_where(where)\n\n count_query = ' '.join(['select count(1) from data', where])\n cur.execute(count_query, marks)\n rowcount = cur.fetchone()[0]\n\n query = ' '.join(['select * from data', where, limit, offset])\n cur.execute(query, marks)\n data = cur.fetchall()\n data = [dict(zip(columns_names, x)) for x in data]\n\n cur.close()\n con.close()\n\n return {\n 'data': data,\n 'rowcount': rowcount,\n 'columns_names': columns_names\n }\n", "path": "mindsdb/interfaces/datastore/sqlite_helpers.py"}]}
| 3,120 | 568 |
gh_patches_debug_27707
|
rasdani/github-patches
|
git_diff
|
alltheplaces__alltheplaces-8345
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
puregym_gb spider broken
It looks like the PureGym spider (puregym_gb.py) is broken. For the last few weeks it was consistently returning 303 results, but then on 2024-05-04 the number dropped to 1. Looking at the Spider stats, I think it's found 401 branches, but then dropped all but one of them for having duplicate refs.
If I've understood what's going on correctly, the spider code is obtaining a ref from a "gymId" parameter on each individual branch page. However, I don't think this parameter exists any more on those pages. Hence each branch gets the same null ref value, and then all the duplicates are dropped.
Hopefully removing the custom ref code will fix the spider. I think there should be around 400 branches in total. (There's currently 399 unique https://www.puregym.com/gyms/*/ URLs in the sitemap.) So probably even the 303 results being returned consistently before was as a result of incorrectly dropping ~100 gyms.
I've just checked a sample of 15 of the URLs from the sitemap. I found one "temporarily closed" https://www.puregym.com/gyms/tonbridge/ and one "coming soon" https://www.puregym.com/gyms/washington/ . I don't know if it's worth trying to catch these cases or not.
</issue>
<code>
[start of locations/spiders/puregym_gb.py]
1 from scrapy.spiders import SitemapSpider
2
3 from locations.google_url import extract_google_position
4 from locations.structured_data_spider import StructuredDataSpider
5
6
7 class PureGymGBSpider(SitemapSpider, StructuredDataSpider):
8 name = "puregym_gb"
9 item_attributes = {
10 "brand": "PureGym",
11 "brand_wikidata": "Q18345898",
12 "country": "GB",
13 }
14 allowed_domains = ["www.puregym.com"]
15 sitemap_urls = ["https://www.puregym.com/sitemap.xml"]
16 sitemap_rules = [
17 (
18 r"https:\/\/www\.puregym\.com\/gyms\/([\w-]+)\/$",
19 "parse_sd",
20 ),
21 ]
22 wanted_types = ["HealthClub"]
23
24 def inspect_item(self, item, response):
25 item["ref"] = response.xpath('//meta[@itemprop="gymId"]/@content').get()
26 extract_google_position(item, response)
27
28 yield item
29
[end of locations/spiders/puregym_gb.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/locations/spiders/puregym_gb.py b/locations/spiders/puregym_gb.py
--- a/locations/spiders/puregym_gb.py
+++ b/locations/spiders/puregym_gb.py
@@ -1,28 +1,28 @@
+from urllib.parse import parse_qs, urlparse
+
from scrapy.spiders import SitemapSpider
-from locations.google_url import extract_google_position
from locations.structured_data_spider import StructuredDataSpider
class PureGymGBSpider(SitemapSpider, StructuredDataSpider):
name = "puregym_gb"
- item_attributes = {
- "brand": "PureGym",
- "brand_wikidata": "Q18345898",
- "country": "GB",
- }
+ item_attributes = {"brand": "PureGym", "brand_wikidata": "Q18345898", "country": "GB"}
allowed_domains = ["www.puregym.com"]
sitemap_urls = ["https://www.puregym.com/sitemap.xml"]
- sitemap_rules = [
- (
- r"https:\/\/www\.puregym\.com\/gyms\/([\w-]+)\/$",
- "parse_sd",
- ),
- ]
+ sitemap_rules = [(r"/gyms/([^/]+)/$", "parse_sd")]
wanted_types = ["HealthClub"]
- def inspect_item(self, item, response):
- item["ref"] = response.xpath('//meta[@itemprop="gymId"]/@content').get()
- extract_google_position(item, response)
+ def pre_process_data(self, ld_data, **kwargs):
+ ld_data["address"] = ld_data.get("location", {}).get("address")
+
+ def post_process_item(self, item, response, ld_data, **kwargs):
+ item["branch"] = item.pop("name")
+ item["image"] = None
+
+ if img := response.xpath('//img[contains(@src, "tiles.stadiamaps.com")]/@src').get():
+ q = parse_qs(urlparse(img)[4])
+ if "center" in q:
+ item["lat"], item["lon"] = q["center"][0].split(",", 1)
yield item
|
{"golden_diff": "diff --git a/locations/spiders/puregym_gb.py b/locations/spiders/puregym_gb.py\n--- a/locations/spiders/puregym_gb.py\n+++ b/locations/spiders/puregym_gb.py\n@@ -1,28 +1,28 @@\n+from urllib.parse import parse_qs, urlparse\n+\n from scrapy.spiders import SitemapSpider\n \n-from locations.google_url import extract_google_position\n from locations.structured_data_spider import StructuredDataSpider\n \n \n class PureGymGBSpider(SitemapSpider, StructuredDataSpider):\n name = \"puregym_gb\"\n- item_attributes = {\n- \"brand\": \"PureGym\",\n- \"brand_wikidata\": \"Q18345898\",\n- \"country\": \"GB\",\n- }\n+ item_attributes = {\"brand\": \"PureGym\", \"brand_wikidata\": \"Q18345898\", \"country\": \"GB\"}\n allowed_domains = [\"www.puregym.com\"]\n sitemap_urls = [\"https://www.puregym.com/sitemap.xml\"]\n- sitemap_rules = [\n- (\n- r\"https:\\/\\/www\\.puregym\\.com\\/gyms\\/([\\w-]+)\\/$\",\n- \"parse_sd\",\n- ),\n- ]\n+ sitemap_rules = [(r\"/gyms/([^/]+)/$\", \"parse_sd\")]\n wanted_types = [\"HealthClub\"]\n \n- def inspect_item(self, item, response):\n- item[\"ref\"] = response.xpath('//meta[@itemprop=\"gymId\"]/@content').get()\n- extract_google_position(item, response)\n+ def pre_process_data(self, ld_data, **kwargs):\n+ ld_data[\"address\"] = ld_data.get(\"location\", {}).get(\"address\")\n+\n+ def post_process_item(self, item, response, ld_data, **kwargs):\n+ item[\"branch\"] = item.pop(\"name\")\n+ item[\"image\"] = None\n+\n+ if img := response.xpath('//img[contains(@src, \"tiles.stadiamaps.com\")]/@src').get():\n+ q = parse_qs(urlparse(img)[4])\n+ if \"center\" in q:\n+ item[\"lat\"], item[\"lon\"] = q[\"center\"][0].split(\",\", 1)\n \n yield item\n", "issue": "puregym_gb spider broken\nIt looks like the PureGym spider (puregym_gb.py) is broken. For the last few weeks it was consistently returning 303 results, but then on 2024-05-04 the number dropped to 1. Looking at the Spider stats, I think it's found 401 branches, but then dropped all but one of them for having duplicate refs.\r\n\r\nIf I've understood what's going on correctly, the spider code is obtaining a ref from a \"gymId\" parameter on each individual branch page. However, I don't think this parameter exists any more on those pages. Hence each branch gets the same null ref value, and then all the duplicates are dropped.\r\n\r\nHopefully removing the custom ref code will fix the spider. I think there should be around 400 branches in total. (There's currently 399 unique https://www.puregym.com/gyms/*/ URLs in the sitemap.) So probably even the 303 results being returned consistently before was as a result of incorrectly dropping ~100 gyms.\r\n\r\nI've just checked a sample of 15 of the URLs from the sitemap. I found one \"temporarily closed\" https://www.puregym.com/gyms/tonbridge/ and one \"coming soon\" https://www.puregym.com/gyms/washington/ . I don't know if it's worth trying to catch these cases or not.\n", "before_files": [{"content": "from scrapy.spiders import SitemapSpider\n\nfrom locations.google_url import extract_google_position\nfrom locations.structured_data_spider import StructuredDataSpider\n\n\nclass PureGymGBSpider(SitemapSpider, StructuredDataSpider):\n name = \"puregym_gb\"\n item_attributes = {\n \"brand\": \"PureGym\",\n \"brand_wikidata\": \"Q18345898\",\n \"country\": \"GB\",\n }\n allowed_domains = [\"www.puregym.com\"]\n sitemap_urls = [\"https://www.puregym.com/sitemap.xml\"]\n sitemap_rules = [\n (\n r\"https:\\/\\/www\\.puregym\\.com\\/gyms\\/([\\w-]+)\\/$\",\n \"parse_sd\",\n ),\n ]\n wanted_types = [\"HealthClub\"]\n\n def inspect_item(self, item, response):\n item[\"ref\"] = response.xpath('//meta[@itemprop=\"gymId\"]/@content').get()\n extract_google_position(item, response)\n\n yield item\n", "path": "locations/spiders/puregym_gb.py"}]}
| 1,128 | 511 |
gh_patches_debug_15301
|
rasdani/github-patches
|
git_diff
|
conda__conda-5404
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
`cli.python_api` captures `stdout` from `cli.common.confirm_yn`
`cli.python_api.run_command` captures any output to `stdout`/`stderr` via `common.io.captured`. This causes the user confirmation messages from `cli.common.confirm_yn`, i.e.,
```bash
Proceed ([y]/n)?
```
to also be captured, i.e., not being output/accessible until the command finishes (which might be never if the user does not interact). The examples in the doc string are
```python
Examples:
>> run_command(Commands.CREATE, "-n newenv python=3 flask", use_exception_handler=True)
>> run_command(Commands.CREATE, "-n newenv", "python=3", "flask")
>> run_command(Commands.CREATE, ["-n newenv", "python=3", "flask"], search_path=())
```
and show exactly such use cases.
Due to this, `run_command` is only generally usable if any of `--json`, `--yes` or `--dry-run` is supplied.
There could be two solutions to this:
1. Force the user to include at least one of those arguments.
2. Instead of only capturing the output, it could be recorded but also forwarded to `stdout`/`stderr`. This could/should be made optional via some `kwarg` for `run_command`.
Possibility 1. is of course much simpler and could at least serve as a temporary solution.
`cli.python_api` captures `stdout` from `cli.common.confirm_yn`
`cli.python_api.run_command` captures any output to `stdout`/`stderr` via `common.io.captured`. This causes the user confirmation messages from `cli.common.confirm_yn`, i.e.,
```bash
Proceed ([y]/n)?
```
to also be captured, i.e., not being output/accessible until the command finishes (which might be never if the user does not interact). The examples in the doc string are
```python
Examples:
>> run_command(Commands.CREATE, "-n newenv python=3 flask", use_exception_handler=True)
>> run_command(Commands.CREATE, "-n newenv", "python=3", "flask")
>> run_command(Commands.CREATE, ["-n newenv", "python=3", "flask"], search_path=())
```
and show exactly such use cases.
Due to this, `run_command` is only generally usable if any of `--json`, `--yes` or `--dry-run` is supplied.
There could be two solutions to this:
1. Force the user to include at least one of those arguments.
2. Instead of only capturing the output, it could be recorded but also forwarded to `stdout`/`stderr`. This could/should be made optional via some `kwarg` for `run_command`.
Possibility 1. is of course much simpler and could at least serve as a temporary solution.
</issue>
<code>
[start of conda/cli/python_api.py]
1 # -*- coding: utf-8 -*-
2 from __future__ import absolute_import, division, print_function, unicode_literals
3
4 from importlib import import_module
5 from logging import getLogger
6 from shlex import split
7
8 from ..base.constants import APP_NAME, SEARCH_PATH
9 from ..base.context import context
10 from ..cli.main import generate_parser
11 from ..common.io import captured, replace_log_streams
12 from ..common.path import win_path_double_escape
13 from ..exceptions import conda_exception_handler
14 from ..gateways import initialize_logging
15
16 initialize_logging()
17 log = getLogger(__name__)
18
19
20 class Commands:
21 CONFIG = "config"
22 CLEAN = "clean"
23 CREATE = "create"
24 INFO = "info"
25 INSTALL = "install"
26 LIST = "list"
27 REMOVE = "remove"
28 SEARCH = "search"
29 UPDATE = "update"
30
31
32 def get_configure_parser_function(command):
33 module = 'conda.cli.main_' + command
34 return import_module(module).configure_parser
35
36
37 def run_command(command, *arguments, **kwargs):
38 """
39
40 Args:
41 command: one of the Commands.X
42 *arguments: instructions you would normally pass to the conda comamnd on the command line
43 see below for examples
44 **kwargs: special instructions for programmatic overrides
45 use_exception_handler: defaults to False. False will let the code calling
46 `run_command` handle all exceptions. True won't raise when an exception
47 has occured, and instead give a non-zero return code
48 search_path: an optional non-standard search path for configuration information
49 that overrides the default SEARCH_PATH
50
51 Returns: a tuple of stdout, stderr, and return_code
52
53 Examples:
54 >> run_command(Commands.CREATE, "-n newenv python=3 flask", use_exception_handler=True)
55 >> run_command(Commands.CREATE, "-n newenv", "python=3", "flask")
56 >> run_command(Commands.CREATE, ["-n newenv", "python=3", "flask"], search_path=())
57
58
59 """
60 use_exception_handler = kwargs.get('use_exception_handler', False)
61 configuration_search_path = kwargs.get('search_path', SEARCH_PATH)
62 p, sub_parsers = generate_parser()
63 get_configure_parser_function(command)(sub_parsers)
64
65 arguments = map(win_path_double_escape, arguments)
66 command_line = "%s %s" % (command, " ".join(arguments))
67 split_command_line = split(command_line)
68
69 args = p.parse_args(split_command_line)
70 context.__init__(
71 search_path=configuration_search_path,
72 app_name=APP_NAME,
73 argparse_args=args,
74 )
75 log.debug("executing command >>> conda %s", command_line)
76 try:
77 with captured() as c, replace_log_streams():
78 if use_exception_handler:
79 return_code = conda_exception_handler(args.func, args, p)
80 else:
81 return_code = args.func(args, p)
82 except Exception as e:
83 log.debug("\n stdout: %s\n stderr: %s", c.stdout, c.stderr)
84 e.stdout, e.stderr = c.stdout, c.stderr
85 raise e
86 log.debug("\n stdout: %s\n stderr: %s\n return_code: %s", c.stdout, c.stderr, return_code)
87 return c.stdout, c.stderr, return_code
88
[end of conda/cli/python_api.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/conda/cli/python_api.py b/conda/cli/python_api.py
--- a/conda/cli/python_api.py
+++ b/conda/cli/python_api.py
@@ -35,7 +35,10 @@
def run_command(command, *arguments, **kwargs):
- """
+ """Runs a conda command in-process with a given set of command-line interface arguments.
+
+ Differences from the command-line interface:
+ Always uses --yes flag, thus does not ask for confirmation.
Args:
command: one of the Commands.X
@@ -67,6 +70,7 @@
split_command_line = split(command_line)
args = p.parse_args(split_command_line)
+ args.yes = True # always skip user confirmation, force setting context.always_yes
context.__init__(
search_path=configuration_search_path,
app_name=APP_NAME,
|
{"golden_diff": "diff --git a/conda/cli/python_api.py b/conda/cli/python_api.py\n--- a/conda/cli/python_api.py\n+++ b/conda/cli/python_api.py\n@@ -35,7 +35,10 @@\n \n \n def run_command(command, *arguments, **kwargs):\n- \"\"\"\n+ \"\"\"Runs a conda command in-process with a given set of command-line interface arguments.\n+\n+ Differences from the command-line interface:\n+ Always uses --yes flag, thus does not ask for confirmation.\n \n Args:\n command: one of the Commands.X\n@@ -67,6 +70,7 @@\n split_command_line = split(command_line)\n \n args = p.parse_args(split_command_line)\n+ args.yes = True # always skip user confirmation, force setting context.always_yes\n context.__init__(\n search_path=configuration_search_path,\n app_name=APP_NAME,\n", "issue": "`cli.python_api` captures `stdout` from `cli.common.confirm_yn`\n`cli.python_api.run_command` captures any output to `stdout`/`stderr` via `common.io.captured`. This causes the user confirmation messages from `cli.common.confirm_yn`, i.e.,\r\n```bash\r\nProceed ([y]/n)? \r\n```\r\nto also be captured, i.e., not being output/accessible until the command finishes (which might be never if the user does not interact). The examples in the doc string are\r\n```python\r\n Examples:\r\n >> run_command(Commands.CREATE, \"-n newenv python=3 flask\", use_exception_handler=True)\r\n >> run_command(Commands.CREATE, \"-n newenv\", \"python=3\", \"flask\")\r\n >> run_command(Commands.CREATE, [\"-n newenv\", \"python=3\", \"flask\"], search_path=())\r\n```\r\nand show exactly such use cases.\r\n\r\nDue to this, `run_command` is only generally usable if any of `--json`, `--yes` or `--dry-run` is supplied.\r\nThere could be two solutions to this:\r\n 1. Force the user to include at least one of those arguments.\r\n 2. Instead of only capturing the output, it could be recorded but also forwarded to `stdout`/`stderr`. This could/should be made optional via some `kwarg` for `run_command`.\r\n\r\nPossibility 1. is of course much simpler and could at least serve as a temporary solution.\n`cli.python_api` captures `stdout` from `cli.common.confirm_yn`\n`cli.python_api.run_command` captures any output to `stdout`/`stderr` via `common.io.captured`. This causes the user confirmation messages from `cli.common.confirm_yn`, i.e.,\r\n```bash\r\nProceed ([y]/n)? \r\n```\r\nto also be captured, i.e., not being output/accessible until the command finishes (which might be never if the user does not interact). The examples in the doc string are\r\n```python\r\n Examples:\r\n >> run_command(Commands.CREATE, \"-n newenv python=3 flask\", use_exception_handler=True)\r\n >> run_command(Commands.CREATE, \"-n newenv\", \"python=3\", \"flask\")\r\n >> run_command(Commands.CREATE, [\"-n newenv\", \"python=3\", \"flask\"], search_path=())\r\n```\r\nand show exactly such use cases.\r\n\r\nDue to this, `run_command` is only generally usable if any of `--json`, `--yes` or `--dry-run` is supplied.\r\nThere could be two solutions to this:\r\n 1. Force the user to include at least one of those arguments.\r\n 2. Instead of only capturing the output, it could be recorded but also forwarded to `stdout`/`stderr`. This could/should be made optional via some `kwarg` for `run_command`.\r\n\r\nPossibility 1. is of course much simpler and could at least serve as a temporary solution.\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom __future__ import absolute_import, division, print_function, unicode_literals\n\nfrom importlib import import_module\nfrom logging import getLogger\nfrom shlex import split\n\nfrom ..base.constants import APP_NAME, SEARCH_PATH\nfrom ..base.context import context\nfrom ..cli.main import generate_parser\nfrom ..common.io import captured, replace_log_streams\nfrom ..common.path import win_path_double_escape\nfrom ..exceptions import conda_exception_handler\nfrom ..gateways import initialize_logging\n\ninitialize_logging()\nlog = getLogger(__name__)\n\n\nclass Commands:\n CONFIG = \"config\"\n CLEAN = \"clean\"\n CREATE = \"create\"\n INFO = \"info\"\n INSTALL = \"install\"\n LIST = \"list\"\n REMOVE = \"remove\"\n SEARCH = \"search\"\n UPDATE = \"update\"\n\n\ndef get_configure_parser_function(command):\n module = 'conda.cli.main_' + command\n return import_module(module).configure_parser\n\n\ndef run_command(command, *arguments, **kwargs):\n \"\"\"\n\n Args:\n command: one of the Commands.X\n *arguments: instructions you would normally pass to the conda comamnd on the command line\n see below for examples\n **kwargs: special instructions for programmatic overrides\n use_exception_handler: defaults to False. False will let the code calling\n `run_command` handle all exceptions. True won't raise when an exception\n has occured, and instead give a non-zero return code\n search_path: an optional non-standard search path for configuration information\n that overrides the default SEARCH_PATH\n\n Returns: a tuple of stdout, stderr, and return_code\n\n Examples:\n >> run_command(Commands.CREATE, \"-n newenv python=3 flask\", use_exception_handler=True)\n >> run_command(Commands.CREATE, \"-n newenv\", \"python=3\", \"flask\")\n >> run_command(Commands.CREATE, [\"-n newenv\", \"python=3\", \"flask\"], search_path=())\n\n\n \"\"\"\n use_exception_handler = kwargs.get('use_exception_handler', False)\n configuration_search_path = kwargs.get('search_path', SEARCH_PATH)\n p, sub_parsers = generate_parser()\n get_configure_parser_function(command)(sub_parsers)\n\n arguments = map(win_path_double_escape, arguments)\n command_line = \"%s %s\" % (command, \" \".join(arguments))\n split_command_line = split(command_line)\n\n args = p.parse_args(split_command_line)\n context.__init__(\n search_path=configuration_search_path,\n app_name=APP_NAME,\n argparse_args=args,\n )\n log.debug(\"executing command >>> conda %s\", command_line)\n try:\n with captured() as c, replace_log_streams():\n if use_exception_handler:\n return_code = conda_exception_handler(args.func, args, p)\n else:\n return_code = args.func(args, p)\n except Exception as e:\n log.debug(\"\\n stdout: %s\\n stderr: %s\", c.stdout, c.stderr)\n e.stdout, e.stderr = c.stdout, c.stderr\n raise e\n log.debug(\"\\n stdout: %s\\n stderr: %s\\n return_code: %s\", c.stdout, c.stderr, return_code)\n return c.stdout, c.stderr, return_code\n", "path": "conda/cli/python_api.py"}]}
| 2,062 | 195 |
gh_patches_debug_3476
|
rasdani/github-patches
|
git_diff
|
qutebrowser__qutebrowser-980
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
platform.dist() deprecated
```
WARNING py.warnings platform:dist:380 /usr/lib/python3.5/site-packages/qutebrowser/utils/version.py:165: PendingDeprecationWarning: dist() and linux_distribution() functions are deprecated in Python 3.5 and will be removed in Python 3.7
osver = ', '.join([e for e in platform.dist() if e])
```
</issue>
<code>
[start of qutebrowser/utils/version.py]
1 # vim: ft=python fileencoding=utf-8 sts=4 sw=4 et:
2
3 # Copyright 2014-2015 Florian Bruhin (The Compiler) <[email protected]>
4 #
5 # This file is part of qutebrowser.
6 #
7 # qutebrowser is free software: you can redistribute it and/or modify
8 # it under the terms of the GNU General Public License as published by
9 # the Free Software Foundation, either version 3 of the License, or
10 # (at your option) any later version.
11 #
12 # qutebrowser is distributed in the hope that it will be useful,
13 # but WITHOUT ANY WARRANTY; without even the implied warranty of
14 # MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
15 # GNU General Public License for more details.
16 #
17 # You should have received a copy of the GNU General Public License
18 # along with qutebrowser. If not, see <http://www.gnu.org/licenses/>.
19
20 """Utilities to show various version informations."""
21
22 import sys
23 import glob
24 import os.path
25 import platform
26 import subprocess
27 import importlib
28 import collections
29
30 from PyQt5.QtCore import QT_VERSION_STR, PYQT_VERSION_STR, qVersion
31 from PyQt5.QtWebKit import qWebKitVersion
32 from PyQt5.QtNetwork import QSslSocket
33 from PyQt5.QtWidgets import QApplication
34
35 import qutebrowser
36 from qutebrowser.utils import log, utils
37
38
39 GPL_BOILERPLATE = """
40 This program is free software: you can redistribute it and/or modify
41 it under the terms of the GNU General Public License as published by
42 the Free Software Foundation, either version 3 of the License, or
43 (at your option) any later version.
44
45 This program is distributed in the hope that it will be useful,
46 but WITHOUT ANY WARRANTY; without even the implied warranty of
47 MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
48 GNU General Public License for more details.
49
50 You should have received a copy of the GNU General Public License
51 along with this program. If not, see <http://www.gnu.org/licenses/> or use
52 :open qute:gpl.
53 """
54
55
56 def _git_str():
57 """Try to find out git version.
58
59 Return:
60 string containing the git commit ID.
61 None if there was an error or we're not in a git repo.
62 """
63 # First try via subprocess if possible
64 commit = None
65 if not hasattr(sys, "frozen"):
66 try:
67 gitpath = os.path.join(os.path.dirname(os.path.realpath(__file__)),
68 os.path.pardir, os.path.pardir)
69 except (NameError, OSError):
70 log.misc.exception("Error while getting git path")
71 else:
72 commit = _git_str_subprocess(gitpath)
73 if commit is not None:
74 return commit
75 # If that fails, check the git-commit-id file.
76 try:
77 return utils.read_file('git-commit-id')
78 except (OSError, ImportError):
79 return None
80
81
82 def _git_str_subprocess(gitpath):
83 """Try to get the git commit ID and timestamp by calling git.
84
85 Args:
86 gitpath: The path where the .git folder is.
87
88 Return:
89 The ID/timestamp on success, None on failure.
90 """
91 if not os.path.isdir(os.path.join(gitpath, ".git")):
92 return None
93 try:
94 cid = subprocess.check_output(
95 ['git', 'describe', '--tags', '--dirty', '--always'],
96 cwd=gitpath).decode('UTF-8').strip()
97 date = subprocess.check_output(
98 ['git', 'show', '-s', '--format=%ci', 'HEAD'],
99 cwd=gitpath).decode('UTF-8').strip()
100 return '{} ({})'.format(cid, date)
101 except (subprocess.CalledProcessError, OSError):
102 return None
103
104
105 def _release_info():
106 """Try to gather distribution release informations.
107
108 Return:
109 list of (filename, content) tuples.
110 """
111 data = []
112 for fn in glob.glob("/etc/*-release"):
113 try:
114 with open(fn, 'r', encoding='utf-8') as f:
115 data.append((fn, ''.join(f.readlines()))) # pragma: no branch
116 except OSError:
117 log.misc.exception("Error while reading {}.".format(fn))
118 return data
119
120
121 def _module_versions():
122 """Get versions of optional modules.
123
124 Return:
125 A list of lines with version info.
126 """
127 lines = []
128 modules = collections.OrderedDict([
129 ('sip', ['SIP_VERSION_STR']),
130 ('colorlog', []),
131 ('colorama', ['VERSION', '__version__']),
132 ('pypeg2', ['__version__']),
133 ('jinja2', ['__version__']),
134 ('pygments', ['__version__']),
135 ('yaml', ['__version__']),
136 ])
137 for name, attributes in modules.items():
138 try:
139 module = importlib.import_module(name)
140 except ImportError:
141 text = '{}: no'.format(name)
142 else:
143 for attr in attributes:
144 try:
145 text = '{}: {}'.format(name, getattr(module, attr))
146 except AttributeError:
147 pass
148 else:
149 break
150 else:
151 text = '{}: yes'.format(name)
152 lines.append(text)
153 return lines
154
155
156 def _os_info():
157 """Get operating system info.
158
159 Return:
160 A list of lines with version info.
161 """
162 lines = []
163 releaseinfo = None
164 if sys.platform == 'linux':
165 osver = ', '.join([e for e in platform.dist() if e])
166 releaseinfo = _release_info()
167 elif sys.platform == 'win32':
168 osver = ', '.join(platform.win32_ver())
169 elif sys.platform == 'darwin':
170 # pylint: disable=unpacking-non-sequence
171 # See https://bitbucket.org/logilab/pylint/issue/165/
172 release, versioninfo, machine = platform.mac_ver()
173 if all(not e for e in versioninfo):
174 versioninfo = ''
175 else:
176 versioninfo = '.'.join(versioninfo)
177 osver = ', '.join([e for e in (release, versioninfo, machine) if e])
178 else:
179 osver = '?'
180 lines.append('OS Version: {}'.format(osver))
181 if releaseinfo is not None:
182 for (fn, data) in releaseinfo:
183 lines += ['', '--- {} ---'.format(fn), data]
184 return lines
185
186
187 def version(short=False):
188 """Return a string with various version informations.
189
190 Args:
191 short: Return a shortened output.
192 """
193 lines = ["qutebrowser v{}".format(qutebrowser.__version__)]
194 gitver = _git_str()
195 if gitver is not None:
196 lines.append("Git commit: {}".format(gitver))
197 lines += [
198 '',
199 '{}: {}'.format(platform.python_implementation(),
200 platform.python_version()),
201 'Qt: {}, runtime: {}'.format(QT_VERSION_STR, qVersion()),
202 'PyQt: {}'.format(PYQT_VERSION_STR),
203 ]
204
205 if not short:
206 style = QApplication.instance().style()
207 lines += [
208 'Style: {}'.format(style.metaObject().className()),
209 'Desktop: {}'.format(os.environ.get('DESKTOP_SESSION')),
210 ]
211
212 lines += _module_versions()
213
214 lines += [
215 'Webkit: {}'.format(qWebKitVersion()),
216 'Harfbuzz: {}'.format(os.environ.get('QT_HARFBUZZ', 'system')),
217 'SSL: {}'.format(QSslSocket.sslLibraryVersionString()),
218 '',
219 'Frozen: {}'.format(hasattr(sys, 'frozen')),
220 'Platform: {}, {}'.format(platform.platform(),
221 platform.architecture()[0]),
222 ]
223 lines += _os_info()
224 return '\n'.join(lines)
225
[end of qutebrowser/utils/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/qutebrowser/utils/version.py b/qutebrowser/utils/version.py
--- a/qutebrowser/utils/version.py
+++ b/qutebrowser/utils/version.py
@@ -162,7 +162,7 @@
lines = []
releaseinfo = None
if sys.platform == 'linux':
- osver = ', '.join([e for e in platform.dist() if e])
+ osver = ''
releaseinfo = _release_info()
elif sys.platform == 'win32':
osver = ', '.join(platform.win32_ver())
|
{"golden_diff": "diff --git a/qutebrowser/utils/version.py b/qutebrowser/utils/version.py\n--- a/qutebrowser/utils/version.py\n+++ b/qutebrowser/utils/version.py\n@@ -162,7 +162,7 @@\n lines = []\n releaseinfo = None\n if sys.platform == 'linux':\n- osver = ', '.join([e for e in platform.dist() if e])\n+ osver = ''\n releaseinfo = _release_info()\n elif sys.platform == 'win32':\n osver = ', '.join(platform.win32_ver())\n", "issue": "platform.dist() deprecated\n```\nWARNING py.warnings platform:dist:380 /usr/lib/python3.5/site-packages/qutebrowser/utils/version.py:165: PendingDeprecationWarning: dist() and linux_distribution() functions are deprecated in Python 3.5 and will be removed in Python 3.7\n osver = ', '.join([e for e in platform.dist() if e])\n```\n\n", "before_files": [{"content": "# vim: ft=python fileencoding=utf-8 sts=4 sw=4 et:\n\n# Copyright 2014-2015 Florian Bruhin (The Compiler) <[email protected]>\n#\n# This file is part of qutebrowser.\n#\n# qutebrowser is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# qutebrowser is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with qutebrowser. If not, see <http://www.gnu.org/licenses/>.\n\n\"\"\"Utilities to show various version informations.\"\"\"\n\nimport sys\nimport glob\nimport os.path\nimport platform\nimport subprocess\nimport importlib\nimport collections\n\nfrom PyQt5.QtCore import QT_VERSION_STR, PYQT_VERSION_STR, qVersion\nfrom PyQt5.QtWebKit import qWebKitVersion\nfrom PyQt5.QtNetwork import QSslSocket\nfrom PyQt5.QtWidgets import QApplication\n\nimport qutebrowser\nfrom qutebrowser.utils import log, utils\n\n\nGPL_BOILERPLATE = \"\"\"\nThis program is free software: you can redistribute it and/or modify\nit under the terms of the GNU General Public License as published by\nthe Free Software Foundation, either version 3 of the License, or\n(at your option) any later version.\n\nThis program is distributed in the hope that it will be useful,\nbut WITHOUT ANY WARRANTY; without even the implied warranty of\nMERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\nGNU General Public License for more details.\n\nYou should have received a copy of the GNU General Public License\nalong with this program. If not, see <http://www.gnu.org/licenses/> or use\n:open qute:gpl.\n\"\"\"\n\n\ndef _git_str():\n \"\"\"Try to find out git version.\n\n Return:\n string containing the git commit ID.\n None if there was an error or we're not in a git repo.\n \"\"\"\n # First try via subprocess if possible\n commit = None\n if not hasattr(sys, \"frozen\"):\n try:\n gitpath = os.path.join(os.path.dirname(os.path.realpath(__file__)),\n os.path.pardir, os.path.pardir)\n except (NameError, OSError):\n log.misc.exception(\"Error while getting git path\")\n else:\n commit = _git_str_subprocess(gitpath)\n if commit is not None:\n return commit\n # If that fails, check the git-commit-id file.\n try:\n return utils.read_file('git-commit-id')\n except (OSError, ImportError):\n return None\n\n\ndef _git_str_subprocess(gitpath):\n \"\"\"Try to get the git commit ID and timestamp by calling git.\n\n Args:\n gitpath: The path where the .git folder is.\n\n Return:\n The ID/timestamp on success, None on failure.\n \"\"\"\n if not os.path.isdir(os.path.join(gitpath, \".git\")):\n return None\n try:\n cid = subprocess.check_output(\n ['git', 'describe', '--tags', '--dirty', '--always'],\n cwd=gitpath).decode('UTF-8').strip()\n date = subprocess.check_output(\n ['git', 'show', '-s', '--format=%ci', 'HEAD'],\n cwd=gitpath).decode('UTF-8').strip()\n return '{} ({})'.format(cid, date)\n except (subprocess.CalledProcessError, OSError):\n return None\n\n\ndef _release_info():\n \"\"\"Try to gather distribution release informations.\n\n Return:\n list of (filename, content) tuples.\n \"\"\"\n data = []\n for fn in glob.glob(\"/etc/*-release\"):\n try:\n with open(fn, 'r', encoding='utf-8') as f:\n data.append((fn, ''.join(f.readlines()))) # pragma: no branch\n except OSError:\n log.misc.exception(\"Error while reading {}.\".format(fn))\n return data\n\n\ndef _module_versions():\n \"\"\"Get versions of optional modules.\n\n Return:\n A list of lines with version info.\n \"\"\"\n lines = []\n modules = collections.OrderedDict([\n ('sip', ['SIP_VERSION_STR']),\n ('colorlog', []),\n ('colorama', ['VERSION', '__version__']),\n ('pypeg2', ['__version__']),\n ('jinja2', ['__version__']),\n ('pygments', ['__version__']),\n ('yaml', ['__version__']),\n ])\n for name, attributes in modules.items():\n try:\n module = importlib.import_module(name)\n except ImportError:\n text = '{}: no'.format(name)\n else:\n for attr in attributes:\n try:\n text = '{}: {}'.format(name, getattr(module, attr))\n except AttributeError:\n pass\n else:\n break\n else:\n text = '{}: yes'.format(name)\n lines.append(text)\n return lines\n\n\ndef _os_info():\n \"\"\"Get operating system info.\n\n Return:\n A list of lines with version info.\n \"\"\"\n lines = []\n releaseinfo = None\n if sys.platform == 'linux':\n osver = ', '.join([e for e in platform.dist() if e])\n releaseinfo = _release_info()\n elif sys.platform == 'win32':\n osver = ', '.join(platform.win32_ver())\n elif sys.platform == 'darwin':\n # pylint: disable=unpacking-non-sequence\n # See https://bitbucket.org/logilab/pylint/issue/165/\n release, versioninfo, machine = platform.mac_ver()\n if all(not e for e in versioninfo):\n versioninfo = ''\n else:\n versioninfo = '.'.join(versioninfo)\n osver = ', '.join([e for e in (release, versioninfo, machine) if e])\n else:\n osver = '?'\n lines.append('OS Version: {}'.format(osver))\n if releaseinfo is not None:\n for (fn, data) in releaseinfo:\n lines += ['', '--- {} ---'.format(fn), data]\n return lines\n\n\ndef version(short=False):\n \"\"\"Return a string with various version informations.\n\n Args:\n short: Return a shortened output.\n \"\"\"\n lines = [\"qutebrowser v{}\".format(qutebrowser.__version__)]\n gitver = _git_str()\n if gitver is not None:\n lines.append(\"Git commit: {}\".format(gitver))\n lines += [\n '',\n '{}: {}'.format(platform.python_implementation(),\n platform.python_version()),\n 'Qt: {}, runtime: {}'.format(QT_VERSION_STR, qVersion()),\n 'PyQt: {}'.format(PYQT_VERSION_STR),\n ]\n\n if not short:\n style = QApplication.instance().style()\n lines += [\n 'Style: {}'.format(style.metaObject().className()),\n 'Desktop: {}'.format(os.environ.get('DESKTOP_SESSION')),\n ]\n\n lines += _module_versions()\n\n lines += [\n 'Webkit: {}'.format(qWebKitVersion()),\n 'Harfbuzz: {}'.format(os.environ.get('QT_HARFBUZZ', 'system')),\n 'SSL: {}'.format(QSslSocket.sslLibraryVersionString()),\n '',\n 'Frozen: {}'.format(hasattr(sys, 'frozen')),\n 'Platform: {}, {}'.format(platform.platform(),\n platform.architecture()[0]),\n ]\n lines += _os_info()\n return '\\n'.join(lines)\n", "path": "qutebrowser/utils/version.py"}]}
| 2,880 | 124 |
gh_patches_debug_66311
|
rasdani/github-patches
|
git_diff
|
sql-machine-learning__elasticdl-2130
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Make the path of `elasticdl_ps` compatible with various Python versions and OS in the Dockerfile.
</issue>
<code>
[start of elasticdl_client/api.py]
1 # Copyright 2020 The ElasticDL Authors. All rights reserved.
2 # Licensed under the Apache License, Version 2.0 (the "License");
3 # you may not use this file except in compliance with the License.
4 # You may obtain a copy of the License at
5 #
6 # http://www.apache.org/licenses/LICENSE-2.0
7 #
8 # Unless required by applicable law or agreed to in writing, software
9 # distributed under the License is distributed on an "AS IS" BASIS,
10 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
11 # See the License for the specific language governing permissions and
12 # limitations under the License.
13
14 import os
15 import shutil
16
17 import docker
18 from jinja2 import Template
19
20 from elasticdl_client.common import k8s_client as k8s
21 from elasticdl_client.common.args import (
22 build_arguments_from_parsed_result,
23 parse_envs,
24 wrap_python_args_with_string,
25 )
26 from elasticdl_client.common.constants import BashCommandTemplate
27 from elasticdl_client.common.log_utils import default_logger as logger
28
29
30 def init_zoo(args):
31 logger.info("Create the Dockerfile for the model zoo.")
32
33 # Copy cluster spec file to the current directory if specified
34 cluster_spec_path = args.cluster_spec
35 cluster_spec_name = None
36 if cluster_spec_path:
37 if not os.path.exists(cluster_spec_path):
38 raise RuntimeError(
39 "The cluster spec {} doesn't exist".format(cluster_spec_path)
40 )
41 try:
42 shutil.copy2(cluster_spec_path, os.getcwd())
43 except shutil.SameFileError:
44 pass
45 cluster_spec_name = os.path.basename(cluster_spec_path)
46
47 # Create the docker file
48 # Build the content from the template and arguments
49 tmpl_str = """\
50 FROM {{ BASE_IMAGE }} as base
51
52 RUN pip install elasticdl_preprocessing\
53 --extra-index-url={{ EXTRA_PYPI_INDEX }}
54
55 RUN pip install elasticdl --extra-index-url={{ EXTRA_PYPI_INDEX }}
56 ENV PATH /usr/local/lib/python3.6/site-packages/elasticdl/go/bin:$PATH
57
58 COPY . /model_zoo
59 RUN pip install -r /model_zoo/requirements.txt\
60 --extra-index-url={{ EXTRA_PYPI_INDEX }}
61
62 {% if CLUSTER_SPEC_NAME %}\
63 COPY ./{{ CLUSTER_SPEC_NAME }} /cluster_spec/{{ CLUSTER_SPEC_NAME }}\
64 {% endif %}
65 """
66 template = Template(tmpl_str)
67 docker_file_content = template.render(
68 BASE_IMAGE=args.base_image,
69 EXTRA_PYPI_INDEX=args.extra_pypi_index,
70 CLUSTER_SPEC_NAME=cluster_spec_name,
71 )
72
73 with open("./Dockerfile", mode="w") as f:
74 f.write(docker_file_content)
75
76
77 def build_zoo(args):
78 logger.info("Build the image for the model zoo.")
79 # Call docker api to build the image
80 # Validate the image name schema
81 client = docker.DockerClient.from_env()
82 for line in client.api.build(
83 dockerfile="./Dockerfile",
84 path=args.path,
85 rm=True,
86 tag=args.image,
87 decode=True,
88 ):
89 _print_docker_progress(line)
90
91
92 def push_zoo(args):
93 logger.info("Push the image for the model zoo.")
94 # Call docker api to push the image to remote registry
95 client = docker.DockerClient.from_env()
96 for line in client.api.push(args.image, stream=True, decode=True):
97 _print_docker_progress(line)
98
99
100 def train(args):
101 container_args = [
102 "--worker_image",
103 args.image_name,
104 "--model_zoo",
105 args.model_zoo,
106 "--cluster_spec",
107 args.cluster_spec,
108 ]
109
110 container_args.extend(
111 build_arguments_from_parsed_result(
112 args,
113 filter_args=[
114 "model_zoo",
115 "cluster_spec",
116 "worker_image",
117 "force_use_kube_config_file",
118 "func",
119 ],
120 )
121 )
122
123 _submit_job(args.image_name, args, container_args)
124
125
126 def evaluate(args):
127 container_args = [
128 "--worker_image",
129 args.image_name,
130 "--model_zoo",
131 args.model_zoo,
132 "--cluster_spec",
133 args.cluster_spec,
134 ]
135 container_args.extend(
136 build_arguments_from_parsed_result(
137 args,
138 filter_args=[
139 "model_zoo",
140 "cluster_spec",
141 "worker_image",
142 "force_use_kube_config_file",
143 "func",
144 ],
145 )
146 )
147
148 _submit_job(args.image_name, args, container_args)
149
150
151 def predict(args):
152 container_args = [
153 "--worker_image",
154 args.image_name,
155 "--model_zoo",
156 args.model_zoo,
157 "--cluster_spec",
158 args.cluster_spec,
159 ]
160
161 container_args.extend(
162 build_arguments_from_parsed_result(
163 args,
164 filter_args=[
165 "model_zoo",
166 "cluster_spec",
167 "worker_image",
168 "force_use_kube_config_file",
169 "func",
170 ],
171 )
172 )
173
174 _submit_job(args.image_name, args, container_args)
175
176
177 def _submit_job(image_name, client_args, container_args):
178 client = k8s.Client(
179 image_name=image_name,
180 namespace=client_args.namespace,
181 job_name=client_args.job_name,
182 cluster_spec=client_args.cluster_spec,
183 force_use_kube_config_file=client_args.force_use_kube_config_file,
184 )
185
186 container_args = wrap_python_args_with_string(container_args)
187
188 master_client_command = (
189 BashCommandTemplate.SET_PIPEFAIL
190 + " python -m elasticdl.python.master.main"
191 )
192 container_args.insert(0, master_client_command)
193 if client_args.log_file_path:
194 container_args.append(
195 BashCommandTemplate.REDIRECTION.format(client_args.log_file_path)
196 )
197
198 python_command = " ".join(container_args)
199 container_args = ["-c", python_command]
200
201 if client_args.yaml:
202 client.dump_master_yaml(
203 resource_requests=client_args.master_resource_request,
204 resource_limits=client_args.master_resource_limit,
205 args=container_args,
206 pod_priority=client_args.master_pod_priority,
207 image_pull_policy=client_args.image_pull_policy,
208 restart_policy=client_args.restart_policy,
209 volume=client_args.volume,
210 envs=parse_envs(client_args.envs),
211 yaml=client_args.yaml,
212 )
213 logger.info(
214 "ElasticDL job %s YAML has been dumped into file %s."
215 % (client_args.job_name, client_args.yaml)
216 )
217 else:
218 client.create_master(
219 resource_requests=client_args.master_resource_request,
220 resource_limits=client_args.master_resource_limit,
221 args=container_args,
222 pod_priority=client_args.master_pod_priority,
223 image_pull_policy=client_args.image_pull_policy,
224 restart_policy=client_args.restart_policy,
225 volume=client_args.volume,
226 envs=parse_envs(client_args.envs),
227 )
228 logger.info(
229 "ElasticDL job %s was successfully submitted. "
230 "The master pod is: %s."
231 % (client_args.job_name, client.get_master_pod_name())
232 )
233
234
235 def _get_docker_client(docker_base_url, docker_tlscert, docker_tlskey):
236 if docker_tlscert and docker_tlskey:
237 tls_config = docker.tls.TLSConfig(
238 client_cert=(docker_tlscert, docker_tlskey)
239 )
240 return docker.APIClient(base_url=docker_base_url, tls=tls_config)
241 else:
242 return docker.APIClient(base_url=docker_base_url)
243
244
245 def _print_docker_progress(line):
246 error = line.get("error", None)
247 if error:
248 raise RuntimeError("Docker image build: " + error)
249 stream = line.get("stream", None)
250 if stream:
251 print(stream, end="")
252 else:
253 print(line)
254
[end of elasticdl_client/api.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/elasticdl_client/api.py b/elasticdl_client/api.py
--- a/elasticdl_client/api.py
+++ b/elasticdl_client/api.py
@@ -53,7 +53,9 @@
--extra-index-url={{ EXTRA_PYPI_INDEX }}
RUN pip install elasticdl --extra-index-url={{ EXTRA_PYPI_INDEX }}
-ENV PATH /usr/local/lib/python3.6/site-packages/elasticdl/go/bin:$PATH
+RUN /bin/bash -c\
+ 'PYTHON_PKG_PATH=$(pip3 show elasticdl | grep "Location:" | cut -d " " -f2);\
+ echo "PATH=${PYTHON_PKG_PATH}/elasticdl/go/bin:$PATH" >> /root/.bashrc'
COPY . /model_zoo
RUN pip install -r /model_zoo/requirements.txt\
|
{"golden_diff": "diff --git a/elasticdl_client/api.py b/elasticdl_client/api.py\n--- a/elasticdl_client/api.py\n+++ b/elasticdl_client/api.py\n@@ -53,7 +53,9 @@\n --extra-index-url={{ EXTRA_PYPI_INDEX }}\n \n RUN pip install elasticdl --extra-index-url={{ EXTRA_PYPI_INDEX }}\n-ENV PATH /usr/local/lib/python3.6/site-packages/elasticdl/go/bin:$PATH\n+RUN /bin/bash -c\\\n+ 'PYTHON_PKG_PATH=$(pip3 show elasticdl | grep \"Location:\" | cut -d \" \" -f2);\\\n+ echo \"PATH=${PYTHON_PKG_PATH}/elasticdl/go/bin:$PATH\" >> /root/.bashrc'\n \n COPY . /model_zoo\n RUN pip install -r /model_zoo/requirements.txt\\\n", "issue": "Make the path of `elasticdl_ps` compatible with various Python versions and OS in the Dockerfile. \n\n", "before_files": [{"content": "# Copyright 2020 The ElasticDL Authors. All rights reserved.\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport os\nimport shutil\n\nimport docker\nfrom jinja2 import Template\n\nfrom elasticdl_client.common import k8s_client as k8s\nfrom elasticdl_client.common.args import (\n build_arguments_from_parsed_result,\n parse_envs,\n wrap_python_args_with_string,\n)\nfrom elasticdl_client.common.constants import BashCommandTemplate\nfrom elasticdl_client.common.log_utils import default_logger as logger\n\n\ndef init_zoo(args):\n logger.info(\"Create the Dockerfile for the model zoo.\")\n\n # Copy cluster spec file to the current directory if specified\n cluster_spec_path = args.cluster_spec\n cluster_spec_name = None\n if cluster_spec_path:\n if not os.path.exists(cluster_spec_path):\n raise RuntimeError(\n \"The cluster spec {} doesn't exist\".format(cluster_spec_path)\n )\n try:\n shutil.copy2(cluster_spec_path, os.getcwd())\n except shutil.SameFileError:\n pass\n cluster_spec_name = os.path.basename(cluster_spec_path)\n\n # Create the docker file\n # Build the content from the template and arguments\n tmpl_str = \"\"\"\\\nFROM {{ BASE_IMAGE }} as base\n\nRUN pip install elasticdl_preprocessing\\\n --extra-index-url={{ EXTRA_PYPI_INDEX }}\n\nRUN pip install elasticdl --extra-index-url={{ EXTRA_PYPI_INDEX }}\nENV PATH /usr/local/lib/python3.6/site-packages/elasticdl/go/bin:$PATH\n\nCOPY . /model_zoo\nRUN pip install -r /model_zoo/requirements.txt\\\n --extra-index-url={{ EXTRA_PYPI_INDEX }}\n\n{% if CLUSTER_SPEC_NAME %}\\\nCOPY ./{{ CLUSTER_SPEC_NAME }} /cluster_spec/{{ CLUSTER_SPEC_NAME }}\\\n{% endif %}\n\"\"\"\n template = Template(tmpl_str)\n docker_file_content = template.render(\n BASE_IMAGE=args.base_image,\n EXTRA_PYPI_INDEX=args.extra_pypi_index,\n CLUSTER_SPEC_NAME=cluster_spec_name,\n )\n\n with open(\"./Dockerfile\", mode=\"w\") as f:\n f.write(docker_file_content)\n\n\ndef build_zoo(args):\n logger.info(\"Build the image for the model zoo.\")\n # Call docker api to build the image\n # Validate the image name schema\n client = docker.DockerClient.from_env()\n for line in client.api.build(\n dockerfile=\"./Dockerfile\",\n path=args.path,\n rm=True,\n tag=args.image,\n decode=True,\n ):\n _print_docker_progress(line)\n\n\ndef push_zoo(args):\n logger.info(\"Push the image for the model zoo.\")\n # Call docker api to push the image to remote registry\n client = docker.DockerClient.from_env()\n for line in client.api.push(args.image, stream=True, decode=True):\n _print_docker_progress(line)\n\n\ndef train(args):\n container_args = [\n \"--worker_image\",\n args.image_name,\n \"--model_zoo\",\n args.model_zoo,\n \"--cluster_spec\",\n args.cluster_spec,\n ]\n\n container_args.extend(\n build_arguments_from_parsed_result(\n args,\n filter_args=[\n \"model_zoo\",\n \"cluster_spec\",\n \"worker_image\",\n \"force_use_kube_config_file\",\n \"func\",\n ],\n )\n )\n\n _submit_job(args.image_name, args, container_args)\n\n\ndef evaluate(args):\n container_args = [\n \"--worker_image\",\n args.image_name,\n \"--model_zoo\",\n args.model_zoo,\n \"--cluster_spec\",\n args.cluster_spec,\n ]\n container_args.extend(\n build_arguments_from_parsed_result(\n args,\n filter_args=[\n \"model_zoo\",\n \"cluster_spec\",\n \"worker_image\",\n \"force_use_kube_config_file\",\n \"func\",\n ],\n )\n )\n\n _submit_job(args.image_name, args, container_args)\n\n\ndef predict(args):\n container_args = [\n \"--worker_image\",\n args.image_name,\n \"--model_zoo\",\n args.model_zoo,\n \"--cluster_spec\",\n args.cluster_spec,\n ]\n\n container_args.extend(\n build_arguments_from_parsed_result(\n args,\n filter_args=[\n \"model_zoo\",\n \"cluster_spec\",\n \"worker_image\",\n \"force_use_kube_config_file\",\n \"func\",\n ],\n )\n )\n\n _submit_job(args.image_name, args, container_args)\n\n\ndef _submit_job(image_name, client_args, container_args):\n client = k8s.Client(\n image_name=image_name,\n namespace=client_args.namespace,\n job_name=client_args.job_name,\n cluster_spec=client_args.cluster_spec,\n force_use_kube_config_file=client_args.force_use_kube_config_file,\n )\n\n container_args = wrap_python_args_with_string(container_args)\n\n master_client_command = (\n BashCommandTemplate.SET_PIPEFAIL\n + \" python -m elasticdl.python.master.main\"\n )\n container_args.insert(0, master_client_command)\n if client_args.log_file_path:\n container_args.append(\n BashCommandTemplate.REDIRECTION.format(client_args.log_file_path)\n )\n\n python_command = \" \".join(container_args)\n container_args = [\"-c\", python_command]\n\n if client_args.yaml:\n client.dump_master_yaml(\n resource_requests=client_args.master_resource_request,\n resource_limits=client_args.master_resource_limit,\n args=container_args,\n pod_priority=client_args.master_pod_priority,\n image_pull_policy=client_args.image_pull_policy,\n restart_policy=client_args.restart_policy,\n volume=client_args.volume,\n envs=parse_envs(client_args.envs),\n yaml=client_args.yaml,\n )\n logger.info(\n \"ElasticDL job %s YAML has been dumped into file %s.\"\n % (client_args.job_name, client_args.yaml)\n )\n else:\n client.create_master(\n resource_requests=client_args.master_resource_request,\n resource_limits=client_args.master_resource_limit,\n args=container_args,\n pod_priority=client_args.master_pod_priority,\n image_pull_policy=client_args.image_pull_policy,\n restart_policy=client_args.restart_policy,\n volume=client_args.volume,\n envs=parse_envs(client_args.envs),\n )\n logger.info(\n \"ElasticDL job %s was successfully submitted. \"\n \"The master pod is: %s.\"\n % (client_args.job_name, client.get_master_pod_name())\n )\n\n\ndef _get_docker_client(docker_base_url, docker_tlscert, docker_tlskey):\n if docker_tlscert and docker_tlskey:\n tls_config = docker.tls.TLSConfig(\n client_cert=(docker_tlscert, docker_tlskey)\n )\n return docker.APIClient(base_url=docker_base_url, tls=tls_config)\n else:\n return docker.APIClient(base_url=docker_base_url)\n\n\ndef _print_docker_progress(line):\n error = line.get(\"error\", None)\n if error:\n raise RuntimeError(\"Docker image build: \" + error)\n stream = line.get(\"stream\", None)\n if stream:\n print(stream, end=\"\")\n else:\n print(line)\n", "path": "elasticdl_client/api.py"}]}
| 2,871 | 174 |
gh_patches_debug_23424
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-8496
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[bug] Path expansion in virtualrunenv generator adds extra colon for empty path
### Environment Details
* Operating System+version: Debian GNU/Linux 10
* Conan version: 1.34.0-dev
* Python version: 3.7.0
* Shell: GNU bash, version 5.0.3(1)-release (x86_64-pc-linux-gnu)
### Steps to reproduce (Include if Applicable)
~~~bash
export LD_LIBRARY_PATH=
# install a recipe with "-g virtualrunenv"
source activate.sh
echo $LD_LIBRARY_PATH
~~~
The last echo prints path with extra ":" at the end.
### Explanation
According to [Bash expansion](https://www.gnu.org/software/bash/manual/html_node/Shell-Parameter-Expansion.html):
> **${parameter:+word}**
> If parameter is null or unset, nothing is substituted, otherwise the expansion of word is substituted.
Conan uses:
~~~bash
PATH="..."${PATH+:$PATH}
~~~
Using `${var+:$var}`:
~~~bash
export DEFINED_EMPTY_VAR=
echo "xxx"${DEFINED_EMPTY_VAR+:$DEFINED_EMPTY_VAR}
echo "xxx"${UNDEFINED_VAR+:$UNDEFINED_VAR}
~~~
Results
~~~
xxx:
xxx
~~~
Correct form `${var:+:$var}`:
~~~bash
export DEFINED_EMPTY_VAR=
echo "xxx"${DEFINED_EMPTY_VAR:+:$DEFINED_EMPTY_VAR}
echo "xxx"${UNDEFINED_VAR:+:$UNDEFINED_VAR}
~~~
Results
~~~
xxx
xxx
~~~
</issue>
<code>
[start of conans/client/envvars/environment.py]
1 import os
2 import platform
3 import textwrap
4 from collections import OrderedDict
5
6 from jinja2 import Template
7
8 from conans.errors import ConanException
9 from conans.util.files import normalize
10
11 sh_activate = textwrap.dedent("""\
12 #!/usr/bin/env sh
13
14 {%- for it in modified_vars %}
15 export CONAN_OLD_{{it}}="${{it}}"
16 {%- endfor %}
17
18 while read -r line; do
19 LINE="$(eval echo $line)";
20 export "$LINE";
21 done < "{{ environment_file }}"
22
23 export CONAN_OLD_PS1="$PS1"
24 export PS1="({{venv_name}}) $PS1"
25 """)
26
27 sh_deactivate = textwrap.dedent("""\
28 #!/usr/bin/env sh
29 export PS1="$CONAN_OLD_PS1"
30 unset CONAN_OLD_PS1
31
32 {% for it in modified_vars %}
33 export {{it}}="$CONAN_OLD_{{it}}"
34 unset CONAN_OLD_{{it}}
35 {%- endfor %}
36 {%- for it in new_vars %}
37 unset {{it}}
38 {%- endfor %}
39 """)
40
41 bat_activate = textwrap.dedent("""\
42 @echo off
43
44 {%- for it in modified_vars %}
45 SET "CONAN_OLD_{{it}}=%{{it}}%"
46 {%- endfor %}
47
48 FOR /F "usebackq tokens=1,* delims==" %%i IN ("{{ environment_file }}") DO (
49 CALL SET "%%i=%%j"
50 )
51
52 SET "CONAN_OLD_PROMPT=%PROMPT%"
53 SET "PROMPT=({{venv_name}}) %PROMPT%"
54 """)
55
56 bat_deactivate = textwrap.dedent("""\
57 @echo off
58
59 SET "PROMPT=%CONAN_OLD_PROMPT%"
60 SET "CONAN_OLD_PROMPT="
61
62 {% for it in modified_vars %}
63 SET "{{it}}=%CONAN_OLD_{{it}}%"
64 SET "CONAN_OLD_{{it}}="
65 {%- endfor %}
66 {%- for it in new_vars %}
67 SET "{{it}}="
68 {%- endfor %}
69 """)
70
71 ps1_activate = textwrap.dedent("""\
72 {%- for it in modified_vars %}
73 $env:CONAN_OLD_{{venv_name}}_{{it}}=$env:{{it}}
74 {%- endfor %}
75
76 foreach ($line in Get-Content "{{ environment_file }}") {
77 $var,$value = $line -split '=',2
78 $value_expanded = $ExecutionContext.InvokeCommand.ExpandString($value)
79 Set-Item env:\\$var -Value "$value_expanded"
80 }
81
82 function global:_old_conan_{{venv_name}}_prompt {""}
83 $function:_old_conan_{{venv_name}}_prompt = $function:prompt
84 function global:prompt {
85 write-host "({{venv_name}}) " -nonewline; & $function:_old_conan_{{venv_name}}_prompt
86 }
87 """)
88
89 ps1_deactivate = textwrap.dedent("""\
90 $function:prompt = $function:_old_conan_{{venv_name}}_prompt
91 remove-item function:_old_conan_{{venv_name}}_prompt
92
93 {% for it in modified_vars %}
94 $env:{{it}}=$env:CONAN_OLD_{{venv_name}}_{{it}}
95 Remove-Item env:CONAN_OLD_{{venv_name}}_{{it}}
96 {%- endfor %}
97 {%- for it in new_vars %}
98 Remove-Item env:{{it}}
99 {%- endfor %}
100 """)
101
102
103 BAT_FLAVOR = "bat"
104 PS1_FLAVOR = "ps1"
105 SH_FLAVOR = "sh"
106
107
108 def _variable_placeholder(flavor, name, append_with_spaces):
109 """
110 :param flavor: flavor of the execution environment
111 :param name: variable name
112 :return: placeholder for the variable name formatted for a certain execution environment.
113 (e.g., cmd, ps1, sh).
114 """
115 if flavor == BAT_FLAVOR:
116 return "%{}%".format(name)
117 if flavor == PS1_FLAVOR:
118 return "$env:%s" % name
119 # flavor == sh
120 return "${%s+ $%s}" % (name, name) if append_with_spaces else "${%s+:$%s}" % (name, name)
121
122
123 def _format_values(flavor, variables, append_with_spaces):
124 """
125 Formats the values for the different supported script language flavors.
126 :param flavor: flavor of the execution environment
127 :param variables: variables to be formatted
128 :return:
129 """
130
131 if flavor in [BAT_FLAVOR, PS1_FLAVOR] and platform.system() == "Windows":
132 path_sep, quote_elements = ";", False
133 elif flavor == PS1_FLAVOR:
134 path_sep, quote_elements = ":", False
135 else:
136 path_sep, quote_elements = ":", True
137
138 for name, value in variables:
139 # activate values
140 if isinstance(value, list):
141 value = list(OrderedDict.fromkeys(value)) # Avoid repeated entries, while keeping order
142 append_space = name in append_with_spaces
143 placeholder = _variable_placeholder(flavor, name, append_space)
144 if append_space:
145 # Variables joined with spaces look like: CPPFLAGS="one two three"
146 value = " ".join(value+[placeholder])
147 value = "\"%s\"" % value if quote_elements else value
148 else:
149 # Quoted variables joined with pathset may look like:
150 # PATH="one path":"two paths"
151 # Unquoted variables joined with pathset may look like: PATH=one path;two paths
152 value = ["\"%s\"" % v for v in value] if quote_elements else value
153 if flavor == SH_FLAVOR:
154 value = path_sep.join(value) + placeholder
155 else:
156 value = path_sep.join(value + [placeholder])
157 else:
158 # single value
159 value = "\"%s\"" % value if quote_elements else value
160 if platform.system() != "Windows":
161 value = value.replace("\\", "\\\\")
162
163 # deactivate values
164 existing = name in os.environ
165 yield name, value, existing
166
167
168 def _files(env_vars, vars_with_spaces, flavor, activate_tpl, deactivate_tpl, venv_name,
169 env_filepath):
170 ret = list(_format_values(flavor, env_vars.items(), vars_with_spaces))
171 modified_vars = [name for name, _, existing in ret if existing]
172 new_vars = [name for name, _, existing in ret if not existing]
173
174 activate_content = activate_tpl.render(environment_file=env_filepath,
175 modified_vars=modified_vars, new_vars=new_vars,
176 venv_name=venv_name)
177 deactivate_content = deactivate_tpl.render(modified_vars=modified_vars, new_vars=new_vars,
178 venv_name=venv_name)
179
180 environment_lines = ["{}={}".format(name, value) for name, value, _ in ret]
181 # This blank line is important, otherwise the script doens't process last line
182 environment_lines.append('')
183
184 if flavor == SH_FLAVOR:
185 # replace CRLF->LF guarantee it is always LF, irrespective of current .py file
186 activate_content = activate_content.replace("\r\n", "\n")
187 deactivate_content = deactivate_content.replace("\r\n", "\n")
188 environment = "\n".join(environment_lines)
189 else:
190 activate_content = normalize(activate_content)
191 deactivate_content = normalize(deactivate_content)
192 environment = os.linesep.join(environment_lines)
193
194 return activate_content, deactivate_content, environment
195
196
197 def env_files(env_vars, vars_with_spaces, flavor, folder, name, venv_name):
198 env_filename = "environment{}.{}.env".format(name, flavor)
199 activate_filename = "activate{}.{}".format(name, flavor)
200 deactivate_filename = "deactivate{}.{}".format(name, flavor)
201
202 templates = {SH_FLAVOR: (sh_activate, sh_deactivate),
203 BAT_FLAVOR: (bat_activate, bat_deactivate),
204 PS1_FLAVOR: (ps1_activate, ps1_deactivate)}
205 try:
206 activate, deactivate = templates[flavor]
207 except KeyError:
208 raise ConanException("Unrecognized flavor: %s" % flavor)
209 activate_tpl, deactivate_tpl = Template(activate), Template(deactivate)
210
211 env_filepath = os.path.abspath(os.path.join(folder, env_filename))
212 activate, deactivate, envfile = _files(env_vars, vars_with_spaces, flavor, activate_tpl,
213 deactivate_tpl, venv_name, env_filepath)
214
215 result = {activate_filename: activate,
216 deactivate_filename: deactivate,
217 env_filename: envfile}
218 return result
219
[end of conans/client/envvars/environment.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/conans/client/envvars/environment.py b/conans/client/envvars/environment.py
--- a/conans/client/envvars/environment.py
+++ b/conans/client/envvars/environment.py
@@ -117,7 +117,7 @@
if flavor == PS1_FLAVOR:
return "$env:%s" % name
# flavor == sh
- return "${%s+ $%s}" % (name, name) if append_with_spaces else "${%s+:$%s}" % (name, name)
+ return "${%s:+ $%s}" % (name, name) if append_with_spaces else "${%s:+:$%s}" % (name, name)
def _format_values(flavor, variables, append_with_spaces):
@@ -143,7 +143,10 @@
placeholder = _variable_placeholder(flavor, name, append_space)
if append_space:
# Variables joined with spaces look like: CPPFLAGS="one two three"
- value = " ".join(value+[placeholder])
+ if flavor == SH_FLAVOR:
+ value = " ".join(value) + placeholder
+ else:
+ value = " ".join(value + [placeholder])
value = "\"%s\"" % value if quote_elements else value
else:
# Quoted variables joined with pathset may look like:
|
{"golden_diff": "diff --git a/conans/client/envvars/environment.py b/conans/client/envvars/environment.py\n--- a/conans/client/envvars/environment.py\n+++ b/conans/client/envvars/environment.py\n@@ -117,7 +117,7 @@\n if flavor == PS1_FLAVOR:\n return \"$env:%s\" % name\n # flavor == sh\n- return \"${%s+ $%s}\" % (name, name) if append_with_spaces else \"${%s+:$%s}\" % (name, name)\n+ return \"${%s:+ $%s}\" % (name, name) if append_with_spaces else \"${%s:+:$%s}\" % (name, name)\n \n \n def _format_values(flavor, variables, append_with_spaces):\n@@ -143,7 +143,10 @@\n placeholder = _variable_placeholder(flavor, name, append_space)\n if append_space:\n # Variables joined with spaces look like: CPPFLAGS=\"one two three\"\n- value = \" \".join(value+[placeholder])\n+ if flavor == SH_FLAVOR:\n+ value = \" \".join(value) + placeholder\n+ else:\n+ value = \" \".join(value + [placeholder])\n value = \"\\\"%s\\\"\" % value if quote_elements else value\n else:\n # Quoted variables joined with pathset may look like:\n", "issue": "[bug] Path expansion in virtualrunenv generator adds extra colon for empty path\n### Environment Details\r\n * Operating System+version: Debian GNU/Linux 10\r\n * Conan version: 1.34.0-dev\r\n * Python version: 3.7.0\r\n * Shell: GNU bash, version 5.0.3(1)-release (x86_64-pc-linux-gnu)\r\n\r\n### Steps to reproduce (Include if Applicable)\r\n~~~bash\r\nexport LD_LIBRARY_PATH=\r\n# install a recipe with \"-g virtualrunenv\"\r\nsource activate.sh\r\necho $LD_LIBRARY_PATH\r\n~~~\r\nThe last echo prints path with extra \":\" at the end.\r\n\r\n### Explanation\r\n\r\nAccording to [Bash expansion](https://www.gnu.org/software/bash/manual/html_node/Shell-Parameter-Expansion.html):\r\n> **${parameter:+word}**\r\n> If parameter is null or unset, nothing is substituted, otherwise the expansion of word is substituted.\r\n\r\nConan uses:\r\n~~~bash\r\nPATH=\"...\"${PATH+:$PATH}\r\n~~~\r\n\r\nUsing `${var+:$var}`:\r\n~~~bash\r\nexport DEFINED_EMPTY_VAR=\r\necho \"xxx\"${DEFINED_EMPTY_VAR+:$DEFINED_EMPTY_VAR}\r\necho \"xxx\"${UNDEFINED_VAR+:$UNDEFINED_VAR}\r\n~~~\r\nResults\r\n~~~\r\nxxx:\r\nxxx\r\n~~~\r\n\r\nCorrect form `${var:+:$var}`:\r\n~~~bash\r\nexport DEFINED_EMPTY_VAR=\r\necho \"xxx\"${DEFINED_EMPTY_VAR:+:$DEFINED_EMPTY_VAR}\r\necho \"xxx\"${UNDEFINED_VAR:+:$UNDEFINED_VAR}\r\n~~~\r\nResults\r\n~~~\r\nxxx\r\nxxx\r\n~~~\n", "before_files": [{"content": "import os\nimport platform\nimport textwrap\nfrom collections import OrderedDict\n\nfrom jinja2 import Template\n\nfrom conans.errors import ConanException\nfrom conans.util.files import normalize\n\nsh_activate = textwrap.dedent(\"\"\"\\\n #!/usr/bin/env sh\n\n {%- for it in modified_vars %}\n export CONAN_OLD_{{it}}=\"${{it}}\"\n {%- endfor %}\n\n while read -r line; do\n LINE=\"$(eval echo $line)\";\n export \"$LINE\";\n done < \"{{ environment_file }}\"\n\n export CONAN_OLD_PS1=\"$PS1\"\n export PS1=\"({{venv_name}}) $PS1\"\n\"\"\")\n\nsh_deactivate = textwrap.dedent(\"\"\"\\\n #!/usr/bin/env sh\n export PS1=\"$CONAN_OLD_PS1\"\n unset CONAN_OLD_PS1\n\n {% for it in modified_vars %}\n export {{it}}=\"$CONAN_OLD_{{it}}\"\n unset CONAN_OLD_{{it}}\n {%- endfor %}\n {%- for it in new_vars %}\n unset {{it}}\n {%- endfor %}\n\"\"\")\n\nbat_activate = textwrap.dedent(\"\"\"\\\n @echo off\n\n {%- for it in modified_vars %}\n SET \"CONAN_OLD_{{it}}=%{{it}}%\"\n {%- endfor %}\n\n FOR /F \"usebackq tokens=1,* delims==\" %%i IN (\"{{ environment_file }}\") DO (\n CALL SET \"%%i=%%j\"\n )\n\n SET \"CONAN_OLD_PROMPT=%PROMPT%\"\n SET \"PROMPT=({{venv_name}}) %PROMPT%\"\n\"\"\")\n\nbat_deactivate = textwrap.dedent(\"\"\"\\\n @echo off\n\n SET \"PROMPT=%CONAN_OLD_PROMPT%\"\n SET \"CONAN_OLD_PROMPT=\"\n\n {% for it in modified_vars %}\n SET \"{{it}}=%CONAN_OLD_{{it}}%\"\n SET \"CONAN_OLD_{{it}}=\"\n {%- endfor %}\n {%- for it in new_vars %}\n SET \"{{it}}=\"\n {%- endfor %}\n\"\"\")\n\nps1_activate = textwrap.dedent(\"\"\"\\\n {%- for it in modified_vars %}\n $env:CONAN_OLD_{{venv_name}}_{{it}}=$env:{{it}}\n {%- endfor %}\n\n foreach ($line in Get-Content \"{{ environment_file }}\") {\n $var,$value = $line -split '=',2\n $value_expanded = $ExecutionContext.InvokeCommand.ExpandString($value)\n Set-Item env:\\\\$var -Value \"$value_expanded\"\n }\n\n function global:_old_conan_{{venv_name}}_prompt {\"\"}\n $function:_old_conan_{{venv_name}}_prompt = $function:prompt\n function global:prompt {\n write-host \"({{venv_name}}) \" -nonewline; & $function:_old_conan_{{venv_name}}_prompt\n }\n\"\"\")\n\nps1_deactivate = textwrap.dedent(\"\"\"\\\n $function:prompt = $function:_old_conan_{{venv_name}}_prompt\n remove-item function:_old_conan_{{venv_name}}_prompt\n\n {% for it in modified_vars %}\n $env:{{it}}=$env:CONAN_OLD_{{venv_name}}_{{it}}\n Remove-Item env:CONAN_OLD_{{venv_name}}_{{it}}\n {%- endfor %}\n {%- for it in new_vars %}\n Remove-Item env:{{it}}\n {%- endfor %}\n\"\"\")\n\n\nBAT_FLAVOR = \"bat\"\nPS1_FLAVOR = \"ps1\"\nSH_FLAVOR = \"sh\"\n\n\ndef _variable_placeholder(flavor, name, append_with_spaces):\n \"\"\"\n :param flavor: flavor of the execution environment\n :param name: variable name\n :return: placeholder for the variable name formatted for a certain execution environment.\n (e.g., cmd, ps1, sh).\n \"\"\"\n if flavor == BAT_FLAVOR:\n return \"%{}%\".format(name)\n if flavor == PS1_FLAVOR:\n return \"$env:%s\" % name\n # flavor == sh\n return \"${%s+ $%s}\" % (name, name) if append_with_spaces else \"${%s+:$%s}\" % (name, name)\n\n\ndef _format_values(flavor, variables, append_with_spaces):\n \"\"\"\n Formats the values for the different supported script language flavors.\n :param flavor: flavor of the execution environment\n :param variables: variables to be formatted\n :return:\n \"\"\"\n\n if flavor in [BAT_FLAVOR, PS1_FLAVOR] and platform.system() == \"Windows\":\n path_sep, quote_elements = \";\", False\n elif flavor == PS1_FLAVOR:\n path_sep, quote_elements = \":\", False\n else:\n path_sep, quote_elements = \":\", True\n\n for name, value in variables:\n # activate values\n if isinstance(value, list):\n value = list(OrderedDict.fromkeys(value)) # Avoid repeated entries, while keeping order\n append_space = name in append_with_spaces\n placeholder = _variable_placeholder(flavor, name, append_space)\n if append_space:\n # Variables joined with spaces look like: CPPFLAGS=\"one two three\"\n value = \" \".join(value+[placeholder])\n value = \"\\\"%s\\\"\" % value if quote_elements else value\n else:\n # Quoted variables joined with pathset may look like:\n # PATH=\"one path\":\"two paths\"\n # Unquoted variables joined with pathset may look like: PATH=one path;two paths\n value = [\"\\\"%s\\\"\" % v for v in value] if quote_elements else value\n if flavor == SH_FLAVOR:\n value = path_sep.join(value) + placeholder\n else:\n value = path_sep.join(value + [placeholder])\n else:\n # single value\n value = \"\\\"%s\\\"\" % value if quote_elements else value\n if platform.system() != \"Windows\":\n value = value.replace(\"\\\\\", \"\\\\\\\\\")\n\n # deactivate values\n existing = name in os.environ\n yield name, value, existing\n\n\ndef _files(env_vars, vars_with_spaces, flavor, activate_tpl, deactivate_tpl, venv_name,\n env_filepath):\n ret = list(_format_values(flavor, env_vars.items(), vars_with_spaces))\n modified_vars = [name for name, _, existing in ret if existing]\n new_vars = [name for name, _, existing in ret if not existing]\n\n activate_content = activate_tpl.render(environment_file=env_filepath,\n modified_vars=modified_vars, new_vars=new_vars,\n venv_name=venv_name)\n deactivate_content = deactivate_tpl.render(modified_vars=modified_vars, new_vars=new_vars, \n venv_name=venv_name)\n\n environment_lines = [\"{}={}\".format(name, value) for name, value, _ in ret]\n # This blank line is important, otherwise the script doens't process last line\n environment_lines.append('')\n\n if flavor == SH_FLAVOR:\n # replace CRLF->LF guarantee it is always LF, irrespective of current .py file\n activate_content = activate_content.replace(\"\\r\\n\", \"\\n\")\n deactivate_content = deactivate_content.replace(\"\\r\\n\", \"\\n\")\n environment = \"\\n\".join(environment_lines)\n else:\n activate_content = normalize(activate_content)\n deactivate_content = normalize(deactivate_content)\n environment = os.linesep.join(environment_lines)\n\n return activate_content, deactivate_content, environment\n\n\ndef env_files(env_vars, vars_with_spaces, flavor, folder, name, venv_name):\n env_filename = \"environment{}.{}.env\".format(name, flavor)\n activate_filename = \"activate{}.{}\".format(name, flavor)\n deactivate_filename = \"deactivate{}.{}\".format(name, flavor)\n\n templates = {SH_FLAVOR: (sh_activate, sh_deactivate),\n BAT_FLAVOR: (bat_activate, bat_deactivate),\n PS1_FLAVOR: (ps1_activate, ps1_deactivate)}\n try:\n activate, deactivate = templates[flavor]\n except KeyError:\n raise ConanException(\"Unrecognized flavor: %s\" % flavor)\n activate_tpl, deactivate_tpl = Template(activate), Template(deactivate)\n\n env_filepath = os.path.abspath(os.path.join(folder, env_filename))\n activate, deactivate, envfile = _files(env_vars, vars_with_spaces, flavor, activate_tpl,\n deactivate_tpl, venv_name, env_filepath)\n\n result = {activate_filename: activate,\n deactivate_filename: deactivate,\n env_filename: envfile}\n return result\n", "path": "conans/client/envvars/environment.py"}]}
| 3,330 | 296 |
gh_patches_debug_34298
|
rasdani/github-patches
|
git_diff
|
electricitymaps__electricitymaps-contrib-1398
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add price to Turkey
I am not sure which of the ticker [prices](https://www.epias.com.tr/en) to use but section 6.7.3 BLOCK ORDER BOOK in [this guide](https://www.epias.com.tr/wp-content/uploads/2017/06/INTRADAY_MARKET_USER_GUIDE_ENG_18.09.2017.pdf) may help.
</issue>
<code>
[start of parsers/TR.py]
1 #!/usr/bin/env python3
2
3 import requests
4 import re
5 import json
6 import arrow
7
8 SEARCH_DATA = re.compile(r'var gunlukUretimEgrisiData = (?P<data>.*);')
9 TIMEZONE = 'Europe/Istanbul'
10 URL = 'https://ytbs.teias.gov.tr/ytbs/frm_login.jsf'
11 EMPTY_DAY = -1
12
13 MAP_GENERATION = {
14 'akarsu': 'hydro',
15 'barajli': 'hydro',
16 'dogalgaz': 'gas',
17 'lng': 'gas',
18 'lpg': 'gas',
19 'jeotermal': 'geothermal',
20 'taskomur': 'coal',
21 'asfaltitkomur': 'coal',
22 'linyit': 'coal',
23 'ithalkomur': 'coal',
24 'ruzgar': 'wind',
25 'fueloil': 'oil',
26 'biyokutle': 'biomass',
27 'nafta': 'oil',
28 'gunes': 'solar',
29 'nukleer': 'nuclear',
30 'kojenerasyon': 'unknown',
31 'motorin': 'oil',
32 }
33
34
35 def as_float(prod):
36 """Convert json values to float and sum all production for a further use"""
37 prod['total'] = 0.0
38 if isinstance(prod, dict) and 'yuk' not in prod.keys():
39 for prod_type, prod_val in prod.items():
40 prod[prod_type] = float(prod_val)
41 prod['total'] += prod[prod_type]
42 return prod
43
44
45 def get_last_data_idx(productions):
46 """
47 Find index of the last production
48 :param productions: list of 24 production dict objects
49 :return: (int) index of the newest data or -1 if no data (empty day)
50 """
51 for i in range(len(productions)):
52 if productions[i]['total'] < 1000:
53 return i - 1
54 return len(productions) - 1 # full day
55
56
57 def fetch_production(zone_key='TR', session=None, target_datetime=None, logger=None):
58 """
59 Requests the last known production mix (in MW) of a given country
60 Arguments:
61 zone_key (optional) -- used in case a parser is able to fetch multiple countries
62 session (optional) -- request session passed in order to re-use an existing session
63 Return:
64 A list of dictionaries in the form:
65 {
66 'zoneKey': 'FR',
67 'datetime': '2017-01-01T00:00:00Z',
68 'production': {
69 'biomass': 0.0,
70 'coal': 0.0,
71 'gas': 0.0,
72 'hydro': 0.0,
73 'nuclear': null,
74 'oil': 0.0,
75 'solar': 0.0,
76 'wind': 0.0,
77 'geothermal': 0.0,
78 'unknown': 0.0
79 },
80 'storage': {
81 'hydro': -10.0,
82 },
83 'source': 'mysource.com'
84 }
85 """
86 if target_datetime:
87 raise NotImplementedError('This parser is not yet able to parse past dates')
88
89 session = None # Explicitely make a new session to avoid caching from their server...
90 r = session or requests.session()
91 tr_datetime = arrow.now().to('Europe/Istanbul').floor('day')
92 response = r.get(URL, verify=False)
93 str_data = re.search(SEARCH_DATA, response.text)
94
95 production_by_hour = []
96 if str_data:
97 productions = json.loads(str_data.group('data'), object_hook=as_float)
98 last_data_index = get_last_data_idx(productions)
99 valid_production = productions[:last_data_index + 1]
100 if last_data_index != EMPTY_DAY:
101 for datapoint in valid_production:
102 data = {
103 'zoneKey': zone_key,
104 'production': {},
105 'storage': {},
106 'source': 'ytbs.teias.gov.tr',
107 'datetime': None
108 }
109 data['production'] = dict(zip(MAP_GENERATION.values(), [0] * len(MAP_GENERATION)))
110 for prod_type, prod_val in datapoint.items():
111 if prod_type in MAP_GENERATION.keys():
112 data['production'][MAP_GENERATION[prod_type]] += prod_val
113 elif prod_type not in ['total', 'uluslarasi', 'saat']:
114 logger.warning('Warning: %s (%d) is missing in mapping!' % (prod_type, prod_val))
115
116 try:
117 data['datetime'] = tr_datetime.replace(hour=int(datapoint['saat'])).datetime
118 except ValueError:
119 # 24 is not a valid hour!
120 data['datetime'] = tr_datetime.datetime
121
122 production_by_hour.append(data)
123 else:
124 raise Exception('Extracted data was None')
125
126 return production_by_hour
127
128
129 if __name__ == '__main__':
130 """Main method, never used by the Electricity Map backend, but handy for testing."""
131
132 print('fetch_production() ->')
133 print(fetch_production())
134
[end of parsers/TR.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/parsers/TR.py b/parsers/TR.py
--- a/parsers/TR.py
+++ b/parsers/TR.py
@@ -4,12 +4,17 @@
import re
import json
import arrow
+from bs4 import BeautifulSoup
+import datetime as dt
SEARCH_DATA = re.compile(r'var gunlukUretimEgrisiData = (?P<data>.*);')
TIMEZONE = 'Europe/Istanbul'
URL = 'https://ytbs.teias.gov.tr/ytbs/frm_login.jsf'
EMPTY_DAY = -1
+PRICE_URL = 'https://seffaflik.epias.com.tr/transparency/piyasalar/' \
+ 'gop/ptf.xhtml'
+
MAP_GENERATION = {
'akarsu': 'hydro',
'barajli': 'hydro',
@@ -54,6 +59,35 @@
return len(productions) - 1 # full day
+def fetch_price():
+ soup = BeautifulSoup(requests.get(PRICE_URL).text, 'html.parser')
+ cells = soup.select('.TexAlCenter')
+
+ # data is in td elements with class "TexAlCenter" and role "gridcell"
+ data = list()
+ for cell in cells:
+ if cell.attrs.get('role', '') != 'gridcell':
+ continue
+ data.append(cell.text)
+
+ dates = [dt.datetime.strptime(val, '%d/%m/%Y').date()
+ for i, val in enumerate(data) if i % 3 == 0]
+ times = [dt.datetime.strptime(val, '%H:%M').time()
+ for i, val in enumerate(data) if i % 3 == 1]
+ prices = [float(val.replace(',', '.'))
+ for i, val in enumerate(data) if i % 3 == 2]
+
+ datapoints = [{
+ 'zoneKey': 'TR',
+ 'currency': 'TRY',
+ 'datetime': arrow.get(
+ dt.datetime.combine(date, time)).to('Europe/Istanbul').datetime,
+ 'price': price,
+ 'source': 'epias.com.tr'
+ } for date, time, price in zip(dates, times, prices)]
+ return datapoints
+
+
def fetch_production(zone_key='TR', session=None, target_datetime=None, logger=None):
"""
Requests the last known production mix (in MW) of a given country
@@ -127,7 +161,10 @@
if __name__ == '__main__':
- """Main method, never used by the Electricity Map backend, but handy for testing."""
+ """Main method, never used by the Electricity Map backend, but handy for
+ testing."""
print('fetch_production() ->')
print(fetch_production())
+ print('fetch_price() ->')
+ print(fetch_price())
|
{"golden_diff": "diff --git a/parsers/TR.py b/parsers/TR.py\n--- a/parsers/TR.py\n+++ b/parsers/TR.py\n@@ -4,12 +4,17 @@\n import re\n import json\n import arrow\n+from bs4 import BeautifulSoup\n+import datetime as dt\n \n SEARCH_DATA = re.compile(r'var gunlukUretimEgrisiData = (?P<data>.*);')\n TIMEZONE = 'Europe/Istanbul'\n URL = 'https://ytbs.teias.gov.tr/ytbs/frm_login.jsf'\n EMPTY_DAY = -1\n \n+PRICE_URL = 'https://seffaflik.epias.com.tr/transparency/piyasalar/' \\\n+ 'gop/ptf.xhtml'\n+\n MAP_GENERATION = {\n 'akarsu': 'hydro',\n 'barajli': 'hydro',\n@@ -54,6 +59,35 @@\n return len(productions) - 1 # full day\n \n \n+def fetch_price():\n+ soup = BeautifulSoup(requests.get(PRICE_URL).text, 'html.parser')\n+ cells = soup.select('.TexAlCenter')\n+\n+ # data is in td elements with class \"TexAlCenter\" and role \"gridcell\"\n+ data = list()\n+ for cell in cells:\n+ if cell.attrs.get('role', '') != 'gridcell':\n+ continue\n+ data.append(cell.text)\n+\n+ dates = [dt.datetime.strptime(val, '%d/%m/%Y').date()\n+ for i, val in enumerate(data) if i % 3 == 0]\n+ times = [dt.datetime.strptime(val, '%H:%M').time()\n+ for i, val in enumerate(data) if i % 3 == 1]\n+ prices = [float(val.replace(',', '.'))\n+ for i, val in enumerate(data) if i % 3 == 2]\n+\n+ datapoints = [{\n+ 'zoneKey': 'TR',\n+ 'currency': 'TRY',\n+ 'datetime': arrow.get(\n+ dt.datetime.combine(date, time)).to('Europe/Istanbul').datetime,\n+ 'price': price,\n+ 'source': 'epias.com.tr'\n+ } for date, time, price in zip(dates, times, prices)]\n+ return datapoints\n+\n+\n def fetch_production(zone_key='TR', session=None, target_datetime=None, logger=None):\n \"\"\"\n Requests the last known production mix (in MW) of a given country\n@@ -127,7 +161,10 @@\n \n \n if __name__ == '__main__':\n- \"\"\"Main method, never used by the Electricity Map backend, but handy for testing.\"\"\"\n+ \"\"\"Main method, never used by the Electricity Map backend, but handy for\n+ testing.\"\"\"\n \n print('fetch_production() ->')\n print(fetch_production())\n+ print('fetch_price() ->')\n+ print(fetch_price())\n", "issue": "Add price to Turkey\nI am not sure which of the ticker [prices](https://www.epias.com.tr/en) to use but section 6.7.3 BLOCK ORDER BOOK in [this guide](https://www.epias.com.tr/wp-content/uploads/2017/06/INTRADAY_MARKET_USER_GUIDE_ENG_18.09.2017.pdf) may help.\n", "before_files": [{"content": "#!/usr/bin/env python3\n\nimport requests\nimport re\nimport json\nimport arrow\n\nSEARCH_DATA = re.compile(r'var gunlukUretimEgrisiData = (?P<data>.*);')\nTIMEZONE = 'Europe/Istanbul'\nURL = 'https://ytbs.teias.gov.tr/ytbs/frm_login.jsf'\nEMPTY_DAY = -1\n\nMAP_GENERATION = {\n 'akarsu': 'hydro',\n 'barajli': 'hydro',\n 'dogalgaz': 'gas',\n 'lng': 'gas',\n 'lpg': 'gas',\n 'jeotermal': 'geothermal',\n 'taskomur': 'coal',\n 'asfaltitkomur': 'coal',\n 'linyit': 'coal',\n 'ithalkomur': 'coal',\n 'ruzgar': 'wind',\n 'fueloil': 'oil',\n 'biyokutle': 'biomass',\n 'nafta': 'oil',\n 'gunes': 'solar',\n 'nukleer': 'nuclear',\n 'kojenerasyon': 'unknown',\n 'motorin': 'oil',\n}\n\n\ndef as_float(prod):\n \"\"\"Convert json values to float and sum all production for a further use\"\"\"\n prod['total'] = 0.0\n if isinstance(prod, dict) and 'yuk' not in prod.keys():\n for prod_type, prod_val in prod.items():\n prod[prod_type] = float(prod_val)\n prod['total'] += prod[prod_type]\n return prod\n\n\ndef get_last_data_idx(productions):\n \"\"\"\n Find index of the last production\n :param productions: list of 24 production dict objects\n :return: (int) index of the newest data or -1 if no data (empty day)\n \"\"\"\n for i in range(len(productions)):\n if productions[i]['total'] < 1000:\n return i - 1\n return len(productions) - 1 # full day\n\n\ndef fetch_production(zone_key='TR', session=None, target_datetime=None, logger=None):\n \"\"\"\n Requests the last known production mix (in MW) of a given country\n Arguments:\n zone_key (optional) -- used in case a parser is able to fetch multiple countries\n session (optional) -- request session passed in order to re-use an existing session\n Return:\n A list of dictionaries in the form:\n {\n 'zoneKey': 'FR',\n 'datetime': '2017-01-01T00:00:00Z',\n 'production': {\n 'biomass': 0.0,\n 'coal': 0.0,\n 'gas': 0.0,\n 'hydro': 0.0,\n 'nuclear': null,\n 'oil': 0.0,\n 'solar': 0.0,\n 'wind': 0.0,\n 'geothermal': 0.0,\n 'unknown': 0.0\n },\n 'storage': {\n 'hydro': -10.0,\n },\n 'source': 'mysource.com'\n }\n \"\"\"\n if target_datetime:\n raise NotImplementedError('This parser is not yet able to parse past dates')\n\n session = None # Explicitely make a new session to avoid caching from their server...\n r = session or requests.session()\n tr_datetime = arrow.now().to('Europe/Istanbul').floor('day')\n response = r.get(URL, verify=False)\n str_data = re.search(SEARCH_DATA, response.text)\n\n production_by_hour = []\n if str_data:\n productions = json.loads(str_data.group('data'), object_hook=as_float)\n last_data_index = get_last_data_idx(productions)\n valid_production = productions[:last_data_index + 1]\n if last_data_index != EMPTY_DAY:\n for datapoint in valid_production:\n data = {\n 'zoneKey': zone_key,\n 'production': {},\n 'storage': {},\n 'source': 'ytbs.teias.gov.tr',\n 'datetime': None\n }\n data['production'] = dict(zip(MAP_GENERATION.values(), [0] * len(MAP_GENERATION)))\n for prod_type, prod_val in datapoint.items():\n if prod_type in MAP_GENERATION.keys():\n data['production'][MAP_GENERATION[prod_type]] += prod_val\n elif prod_type not in ['total', 'uluslarasi', 'saat']:\n logger.warning('Warning: %s (%d) is missing in mapping!' % (prod_type, prod_val))\n\n try:\n data['datetime'] = tr_datetime.replace(hour=int(datapoint['saat'])).datetime\n except ValueError:\n # 24 is not a valid hour!\n data['datetime'] = tr_datetime.datetime\n\n production_by_hour.append(data)\n else:\n raise Exception('Extracted data was None')\n\n return production_by_hour\n\n\nif __name__ == '__main__':\n \"\"\"Main method, never used by the Electricity Map backend, but handy for testing.\"\"\"\n\n print('fetch_production() ->')\n print(fetch_production())\n", "path": "parsers/TR.py"}]}
| 2,046 | 630 |
gh_patches_debug_19028
|
rasdani/github-patches
|
git_diff
|
coala__coala-319
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Multiple dots irritating in console table
```
| . |
| . |
| . |
| 32| 32| if not isinstance(file_diff_dict, dict):
| 33| 33| raise TypeError("file_diff_dict has to be of type dict.")
| 34| 34|
| 35| 35| return self.apply(result, original_file_dict, file_diff_dict, **self.get_metadata().create_params_from_section(section))
| | | [NORMAL] LineLengthBear:
| | | Line is longer than allowed. (129 > 120)
| | | The following options are applicable to this result (choose 0 for no action):
```
The dots in the first three lines are irritating. Putting in the line above the code `...` or `[...]` (or even something else).
So it should look for example like:
```
| 31| 31| [...]
| 32| 32| if not isinstance(file_diff_dict, dict):
| 33| 33| raise TypeError("file_diff_dict has to be of type dict.")
| 34| 34|
| 35| 35| return self.apply(result, original_file_dict, file_diff_dict, **self.get_metadata().create_params_from_section(section))
| | | [NORMAL] LineLengthBear:
| | | Line is longer than allowed. (129 > 120)
| | | The following options are applicable to this result (choose 0 for no action):
```
or maybe put the dots inside the table like this:
```
| ...| ...|
| 32| 32| if not isinstance(file_diff_dict, dict):
| 33| 33| raise TypeError("file_diff_dict has to be of type dict.")
| 34| 34|
| 35| 35| return self.apply(result, original_file_dict, file_diff_dict, **self.get_metadata().create_params_from_section(section))
| | | [NORMAL] LineLengthBear:
| | | Line is longer than allowed. (129 > 120)
| | | The following options are applicable to this result (choose 0 for no action):
```
Or if that's too complicated just leave them out.
```
| 32| 32| if not isinstance(file_diff_dict, dict):
| 33| 33| raise TypeError("file_diff_dict has to be of type dict.")
| 34| 34|
| 35| 35| return self.apply(result, original_file_dict, file_diff_dict, **self.get_metadata().create_params_from_section(section))
| | | [NORMAL] LineLengthBear:
| | | Line is longer than allowed. (129 > 120)
| | | The following options are applicable to this result (choose 0 for no action):
```
</issue>
<code>
[start of bears/misc/KeywordBear.py]
1 from coalib.results.Result import Result
2 from coalib.bears.LocalBear import LocalBear
3 from coalib.misc.i18n import _
4
5
6 class KeywordBear(LocalBear):
7 def run(self,
8 filename,
9 file,
10 cs_keywords: list,
11 ci_keywords: list):
12 """
13 Checks the code files for given keywords.
14
15 :param cs_keywords: A list of keywords to search for case sensitively. Usual examples are TODO and FIXME.
16 :param ci_keywords: A list of keywords to search for case insensitively.
17 """
18 results = []
19
20 for i in range(len(ci_keywords)):
21 ci_keywords[i] = ci_keywords[i].lower()
22
23 for line_number, line in enumerate(file):
24 found_kws = []
25 for kw in cs_keywords:
26 if kw in line:
27 found_kws.append(kw)
28
29 for kw in ci_keywords:
30 if kw in line.lower():
31 found_kws.append(kw)
32
33 if found_kws != []:
34 results.append(Result(origin=self,
35 message=_("Line contains the following keywords:") + "\n" + ", ".join(found_kws),
36 file=filename,
37 line_nr=line_number + 1))
38
39 return results
40
[end of bears/misc/KeywordBear.py]
[start of coalib/output/ConsoleInteractor.py]
1 from coalib.output.printers.ConsolePrinter import ConsolePrinter
2 from coalib.results.RESULT_SEVERITY import RESULT_SEVERITY
3 from coalib.output.printers.LOG_LEVEL import LOG_LEVEL
4 from coalib.output.Interactor import Interactor
5 from coalib.misc.i18n import _
6
7
8 class ConsoleInteractor(Interactor, ConsolePrinter):
9 STR_GET_VAL_FOR_SETTING = _("Please enter a value for the setting \"{}\" ({}) needed by {}: ")
10 STR_LINE_DOESNT_EXIST = _("The line belonging to the following result cannot be printed because it refers to a "
11 "line that doesn't seem to exist in the given file.")
12 STR_PROJECT_WIDE = _("Project wide:")
13
14 def __init__(self,
15 pre_padding: int=3,
16 log_printer=ConsolePrinter()):
17 """
18 A ConsoleInteractor uses the Console to interact with the user.
19
20 :param output: "stdout" or "stderr".
21 :param pre_padding: Number of code lines to show before a result as context.
22 """
23 Interactor.__init__(self, log_printer=log_printer)
24 ConsolePrinter.__init__(self)
25
26 self.pre_padding = pre_padding
27
28 def acquire_settings(self, settings_names_dict):
29 if not isinstance(settings_names_dict, dict):
30 raise TypeError("The settings_names_dict parameter has to be a dictionary.")
31
32 result = {}
33 for setting_name, arr in settings_names_dict.items():
34 value = self._require_setting(setting_name, arr)
35 if value is not None:
36 result[setting_name] = value
37
38 return result
39
40 def _require_setting(self, setting_name, arr):
41 if not isinstance(arr, list) or len(arr) < 2:
42 self.log_printer.log(LOG_LEVEL.WARNING,
43 _("One of the given settings ({}) is not "
44 "properly described.").
45 format(str(setting_name)))
46
47 return None
48
49 if len(arr) == 2:
50 needed = arr[1]
51 else: # Translators: this is the and that connects the last two items of an enumeration (1st, 2nd AND 3rd)
52 needed = ", ".join(arr[1:-1]) + _(" and ") + arr[-1]
53
54 return input(self.STR_GET_VAL_FOR_SETTING.format(str(setting_name),
55 str(arr[0]),
56 needed))
57
58 def _format_line(self, line, real_nr="", sign="|", mod_nr="", symbol="", ):
59 return "|{:>4}{}{:>4}|{:1}{}".format(real_nr, sign, mod_nr, symbol, line.rstrip("\n"))
60
61 def _print_result(self, result):
62 message_string_list = "[{sev}] {bear}:\n{msg}".format(sev=RESULT_SEVERITY.__str__(result.severity),
63 bear=result.origin,
64 msg=result.message).split("\n")
65
66 return self.print("\n".join([self._format_line(line) for line in message_string_list]))
67
68 def _print_actions(self, actions):
69 self.print(self._format_line(
70 _("The following options are applicable to this result (choose "
71 "0 for no action):")))
72
73 choice = self._choose_action(actions)
74
75 if choice == 0:
76 return None, None
77
78 return self._get_action_info(actions[choice - 1])
79
80 def _choose_action(self, actions):
81 while True:
82 for i, action in enumerate(actions):
83 self.print(self._format_line("{:>2}: {}".format(i + 1, action.desc)))
84
85 try:
86 line = self._format_line(_("Please enter the number of the "
87 "action you want to execute. "))
88 choice = int(input(line))
89 if 0 <= choice <= len(actions):
90 return choice
91 except ValueError:
92 pass
93
94 self.print(self._format_line(_("Please enter a valid number.")))
95
96 def _get_action_info(self, action):
97 # Otherwise we have a recursive import
98 from coalib.settings.Section import Section
99 from coalib.settings.Setting import Setting
100
101 params = action.non_optional_params
102 section = Section("")
103
104 for param_name in params:
105 question = self._format_line(
106 _("Please enter a value for the parameter '{}' ({}): ")
107 .format(param_name, params[param_name][0]))
108 section.append(Setting(param_name, input(question)))
109
110 return action.name, section
111
112 def _print_segregation(self, n=3):
113 self.print("\n".join(self._format_line(line="", sign=".") for i in range(n)))
114
115 def _print_lines(self, file_dict, current_line, result_line, result_file):
116 """
117 Prints the lines between the current and the result line. If needed they will be shortened.
118 """
119 line_delta = result_line - current_line
120
121 if line_delta > self.pre_padding:
122 self._print_segregation()
123
124 for i in range(max(result_line - self.pre_padding, 1), result_line + 1):
125 self.print(self._format_line(line=file_dict[result_file][i - 1],
126 real_nr=i,
127 mod_nr=i))
128 else:
129 for i in range(1, line_delta + 1):
130 self.print(self._format_line(line=file_dict[result_file][current_line + i - 1],
131 real_nr=current_line + i,
132 mod_nr=current_line + i))
133
134 def print_results(self, result_list, file_dict):
135 if not isinstance(result_list, list):
136 raise TypeError("result_list should be of type list")
137 if not isinstance(file_dict, dict):
138 raise TypeError("file_dict should be of type dict")
139
140 current_file = False # We can't use None since we need line 109 be executed if file of first result is None
141 current_line = 0
142
143 for result in sorted(result_list):
144 if result.file != current_file:
145 if result.file in file_dict or result.file is None:
146 current_file = result.file
147 current_line = 0
148 self.print("\n\n{}".format(current_file if current_file is not None else self.STR_PROJECT_WIDE))
149 else:
150 self.log_printer.warn(_("A result ({}) cannot be printed because it refers to a file that doesn't"
151 " seem to exist.").format(str(result)))
152 continue
153
154 if result.line_nr is not None:
155 if current_file is None:
156 raise AssertionError("A result with a line_nr should also have a file.")
157 if result.line_nr < current_line: # pragma: no cover
158 raise AssertionError("The sorting of the results doesn't work correctly.")
159 if len(file_dict[result.file]) < result.line_nr - 1:
160 self.print(self._format_line(line=self.STR_LINE_DOESNT_EXIST))
161 else:
162 self._print_lines(file_dict, current_line, result.line_nr, result.file)
163 current_line = result.line_nr
164
165 self.print_result(result, file_dict)
166
167 def begin_section(self, name):
168 self.print(_("Executing section {name}...").format(name=name))
169
170 def did_nothing(self):
171 self.print(_("No existent section was targeted or enabled. Nothing "
172 "to do."))
173
[end of coalib/output/ConsoleInteractor.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bears/misc/KeywordBear.py b/bears/misc/KeywordBear.py
--- a/bears/misc/KeywordBear.py
+++ b/bears/misc/KeywordBear.py
@@ -12,8 +12,8 @@
"""
Checks the code files for given keywords.
- :param cs_keywords: A list of keywords to search for case sensitively. Usual examples are TODO and FIXME.
- :param ci_keywords: A list of keywords to search for case insensitively.
+ :param cs_keywords: A list of keywords to search for (case sensitive). Usual examples are TODO and FIXME.
+ :param ci_keywords: A list of keywords to search for (case insensitive).
"""
results = []
diff --git a/coalib/output/ConsoleInteractor.py b/coalib/output/ConsoleInteractor.py
--- a/coalib/output/ConsoleInteractor.py
+++ b/coalib/output/ConsoleInteractor.py
@@ -109,8 +109,8 @@
return action.name, section
- def _print_segregation(self, n=3):
- self.print("\n".join(self._format_line(line="", sign=".") for i in range(n)))
+ def _print_segregation(self):
+ self.print(self._format_line(line="", real_nr="...", sign="|", mod_nr="..."))
def _print_lines(self, file_dict, current_line, result_line, result_file):
"""
|
{"golden_diff": "diff --git a/bears/misc/KeywordBear.py b/bears/misc/KeywordBear.py\n--- a/bears/misc/KeywordBear.py\n+++ b/bears/misc/KeywordBear.py\n@@ -12,8 +12,8 @@\n \"\"\"\n Checks the code files for given keywords.\n \n- :param cs_keywords: A list of keywords to search for case sensitively. Usual examples are TODO and FIXME.\n- :param ci_keywords: A list of keywords to search for case insensitively.\n+ :param cs_keywords: A list of keywords to search for (case sensitive). Usual examples are TODO and FIXME.\n+ :param ci_keywords: A list of keywords to search for (case insensitive).\n \"\"\"\n results = []\n \ndiff --git a/coalib/output/ConsoleInteractor.py b/coalib/output/ConsoleInteractor.py\n--- a/coalib/output/ConsoleInteractor.py\n+++ b/coalib/output/ConsoleInteractor.py\n@@ -109,8 +109,8 @@\n \n return action.name, section\n \n- def _print_segregation(self, n=3):\n- self.print(\"\\n\".join(self._format_line(line=\"\", sign=\".\") for i in range(n)))\n+ def _print_segregation(self):\n+ self.print(self._format_line(line=\"\", real_nr=\"...\", sign=\"|\", mod_nr=\"...\"))\n \n def _print_lines(self, file_dict, current_line, result_line, result_file):\n \"\"\"\n", "issue": "Multiple dots irritating in console table\n```\n| . | \n| . | \n| . | \n| 32| 32| if not isinstance(file_diff_dict, dict):\n| 33| 33| raise TypeError(\"file_diff_dict has to be of type dict.\")\n| 34| 34| \n| 35| 35| return self.apply(result, original_file_dict, file_diff_dict, **self.get_metadata().create_params_from_section(section))\n| | | [NORMAL] LineLengthBear:\n| | | Line is longer than allowed. (129 > 120)\n| | | The following options are applicable to this result (choose 0 for no action):\n```\n\nThe dots in the first three lines are irritating. Putting in the line above the code `...` or `[...]` (or even something else).\nSo it should look for example like:\n\n```\n| 31| 31| [...]\n| 32| 32| if not isinstance(file_diff_dict, dict):\n| 33| 33| raise TypeError(\"file_diff_dict has to be of type dict.\")\n| 34| 34| \n| 35| 35| return self.apply(result, original_file_dict, file_diff_dict, **self.get_metadata().create_params_from_section(section))\n| | | [NORMAL] LineLengthBear:\n| | | Line is longer than allowed. (129 > 120)\n| | | The following options are applicable to this result (choose 0 for no action):\n```\n\nor maybe put the dots inside the table like this:\n\n```\n| ...| ...|\n| 32| 32| if not isinstance(file_diff_dict, dict):\n| 33| 33| raise TypeError(\"file_diff_dict has to be of type dict.\")\n| 34| 34| \n| 35| 35| return self.apply(result, original_file_dict, file_diff_dict, **self.get_metadata().create_params_from_section(section))\n| | | [NORMAL] LineLengthBear:\n| | | Line is longer than allowed. (129 > 120)\n| | | The following options are applicable to this result (choose 0 for no action):\n```\n\nOr if that's too complicated just leave them out.\n\n```\n| 32| 32| if not isinstance(file_diff_dict, dict):\n| 33| 33| raise TypeError(\"file_diff_dict has to be of type dict.\")\n| 34| 34| \n| 35| 35| return self.apply(result, original_file_dict, file_diff_dict, **self.get_metadata().create_params_from_section(section))\n| | | [NORMAL] LineLengthBear:\n| | | Line is longer than allowed. (129 > 120)\n| | | The following options are applicable to this result (choose 0 for no action):\n```\n\n", "before_files": [{"content": "from coalib.results.Result import Result\nfrom coalib.bears.LocalBear import LocalBear\nfrom coalib.misc.i18n import _\n\n\nclass KeywordBear(LocalBear):\n def run(self,\n filename,\n file,\n cs_keywords: list,\n ci_keywords: list):\n \"\"\"\n Checks the code files for given keywords.\n\n :param cs_keywords: A list of keywords to search for case sensitively. Usual examples are TODO and FIXME.\n :param ci_keywords: A list of keywords to search for case insensitively.\n \"\"\"\n results = []\n\n for i in range(len(ci_keywords)):\n ci_keywords[i] = ci_keywords[i].lower()\n\n for line_number, line in enumerate(file):\n found_kws = []\n for kw in cs_keywords:\n if kw in line:\n found_kws.append(kw)\n\n for kw in ci_keywords:\n if kw in line.lower():\n found_kws.append(kw)\n\n if found_kws != []:\n results.append(Result(origin=self,\n message=_(\"Line contains the following keywords:\") + \"\\n\" + \", \".join(found_kws),\n file=filename,\n line_nr=line_number + 1))\n\n return results\n", "path": "bears/misc/KeywordBear.py"}, {"content": "from coalib.output.printers.ConsolePrinter import ConsolePrinter\nfrom coalib.results.RESULT_SEVERITY import RESULT_SEVERITY\nfrom coalib.output.printers.LOG_LEVEL import LOG_LEVEL\nfrom coalib.output.Interactor import Interactor\nfrom coalib.misc.i18n import _\n\n\nclass ConsoleInteractor(Interactor, ConsolePrinter):\n STR_GET_VAL_FOR_SETTING = _(\"Please enter a value for the setting \\\"{}\\\" ({}) needed by {}: \")\n STR_LINE_DOESNT_EXIST = _(\"The line belonging to the following result cannot be printed because it refers to a \"\n \"line that doesn't seem to exist in the given file.\")\n STR_PROJECT_WIDE = _(\"Project wide:\")\n\n def __init__(self,\n pre_padding: int=3,\n log_printer=ConsolePrinter()):\n \"\"\"\n A ConsoleInteractor uses the Console to interact with the user.\n\n :param output: \"stdout\" or \"stderr\".\n :param pre_padding: Number of code lines to show before a result as context.\n \"\"\"\n Interactor.__init__(self, log_printer=log_printer)\n ConsolePrinter.__init__(self)\n\n self.pre_padding = pre_padding\n\n def acquire_settings(self, settings_names_dict):\n if not isinstance(settings_names_dict, dict):\n raise TypeError(\"The settings_names_dict parameter has to be a dictionary.\")\n\n result = {}\n for setting_name, arr in settings_names_dict.items():\n value = self._require_setting(setting_name, arr)\n if value is not None:\n result[setting_name] = value\n\n return result\n\n def _require_setting(self, setting_name, arr):\n if not isinstance(arr, list) or len(arr) < 2:\n self.log_printer.log(LOG_LEVEL.WARNING,\n _(\"One of the given settings ({}) is not \"\n \"properly described.\").\n format(str(setting_name)))\n\n return None\n\n if len(arr) == 2:\n needed = arr[1]\n else: # Translators: this is the and that connects the last two items of an enumeration (1st, 2nd AND 3rd)\n needed = \", \".join(arr[1:-1]) + _(\" and \") + arr[-1]\n\n return input(self.STR_GET_VAL_FOR_SETTING.format(str(setting_name),\n str(arr[0]),\n needed))\n\n def _format_line(self, line, real_nr=\"\", sign=\"|\", mod_nr=\"\", symbol=\"\", ):\n return \"|{:>4}{}{:>4}|{:1}{}\".format(real_nr, sign, mod_nr, symbol, line.rstrip(\"\\n\"))\n\n def _print_result(self, result):\n message_string_list = \"[{sev}] {bear}:\\n{msg}\".format(sev=RESULT_SEVERITY.__str__(result.severity),\n bear=result.origin,\n msg=result.message).split(\"\\n\")\n\n return self.print(\"\\n\".join([self._format_line(line) for line in message_string_list]))\n\n def _print_actions(self, actions):\n self.print(self._format_line(\n _(\"The following options are applicable to this result (choose \"\n \"0 for no action):\")))\n\n choice = self._choose_action(actions)\n\n if choice == 0:\n return None, None\n\n return self._get_action_info(actions[choice - 1])\n\n def _choose_action(self, actions):\n while True:\n for i, action in enumerate(actions):\n self.print(self._format_line(\"{:>2}: {}\".format(i + 1, action.desc)))\n\n try:\n line = self._format_line(_(\"Please enter the number of the \"\n \"action you want to execute. \"))\n choice = int(input(line))\n if 0 <= choice <= len(actions):\n return choice\n except ValueError:\n pass\n\n self.print(self._format_line(_(\"Please enter a valid number.\")))\n\n def _get_action_info(self, action):\n # Otherwise we have a recursive import\n from coalib.settings.Section import Section\n from coalib.settings.Setting import Setting\n\n params = action.non_optional_params\n section = Section(\"\")\n\n for param_name in params:\n question = self._format_line(\n _(\"Please enter a value for the parameter '{}' ({}): \")\n .format(param_name, params[param_name][0]))\n section.append(Setting(param_name, input(question)))\n\n return action.name, section\n\n def _print_segregation(self, n=3):\n self.print(\"\\n\".join(self._format_line(line=\"\", sign=\".\") for i in range(n)))\n\n def _print_lines(self, file_dict, current_line, result_line, result_file):\n \"\"\"\n Prints the lines between the current and the result line. If needed they will be shortened.\n \"\"\"\n line_delta = result_line - current_line\n\n if line_delta > self.pre_padding:\n self._print_segregation()\n\n for i in range(max(result_line - self.pre_padding, 1), result_line + 1):\n self.print(self._format_line(line=file_dict[result_file][i - 1],\n real_nr=i,\n mod_nr=i))\n else:\n for i in range(1, line_delta + 1):\n self.print(self._format_line(line=file_dict[result_file][current_line + i - 1],\n real_nr=current_line + i,\n mod_nr=current_line + i))\n\n def print_results(self, result_list, file_dict):\n if not isinstance(result_list, list):\n raise TypeError(\"result_list should be of type list\")\n if not isinstance(file_dict, dict):\n raise TypeError(\"file_dict should be of type dict\")\n\n current_file = False # We can't use None since we need line 109 be executed if file of first result is None\n current_line = 0\n\n for result in sorted(result_list):\n if result.file != current_file:\n if result.file in file_dict or result.file is None:\n current_file = result.file\n current_line = 0\n self.print(\"\\n\\n{}\".format(current_file if current_file is not None else self.STR_PROJECT_WIDE))\n else:\n self.log_printer.warn(_(\"A result ({}) cannot be printed because it refers to a file that doesn't\"\n \" seem to exist.\").format(str(result)))\n continue\n\n if result.line_nr is not None:\n if current_file is None:\n raise AssertionError(\"A result with a line_nr should also have a file.\")\n if result.line_nr < current_line: # pragma: no cover\n raise AssertionError(\"The sorting of the results doesn't work correctly.\")\n if len(file_dict[result.file]) < result.line_nr - 1:\n self.print(self._format_line(line=self.STR_LINE_DOESNT_EXIST))\n else:\n self._print_lines(file_dict, current_line, result.line_nr, result.file)\n current_line = result.line_nr\n\n self.print_result(result, file_dict)\n\n def begin_section(self, name):\n self.print(_(\"Executing section {name}...\").format(name=name))\n\n def did_nothing(self):\n self.print(_(\"No existent section was targeted or enabled. Nothing \"\n \"to do.\"))\n", "path": "coalib/output/ConsoleInteractor.py"}]}
| 3,551 | 321 |
gh_patches_debug_34370
|
rasdani/github-patches
|
git_diff
|
learningequality__kolibri-5413
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Select all not working in groups
### Observed behavior
In the coach tab, while enrolling learners in the group first select single user and then select select all option and then enroll. It will enroll only one user in the group.
### Expected behavior
When we select select all, it must enroll all users in the group.
### Steps to reproduce
1. Create the group.
2. Select one user while enrolling.
3. Then select select all in groups.
4. Click on enroll.
5. It will enroll only one user in the group.
### Context
* Kolibri version : Kolibri 0.12.2
* Operating system : Ubuntu 14.04
* Browser : Chrome
### Screenshots
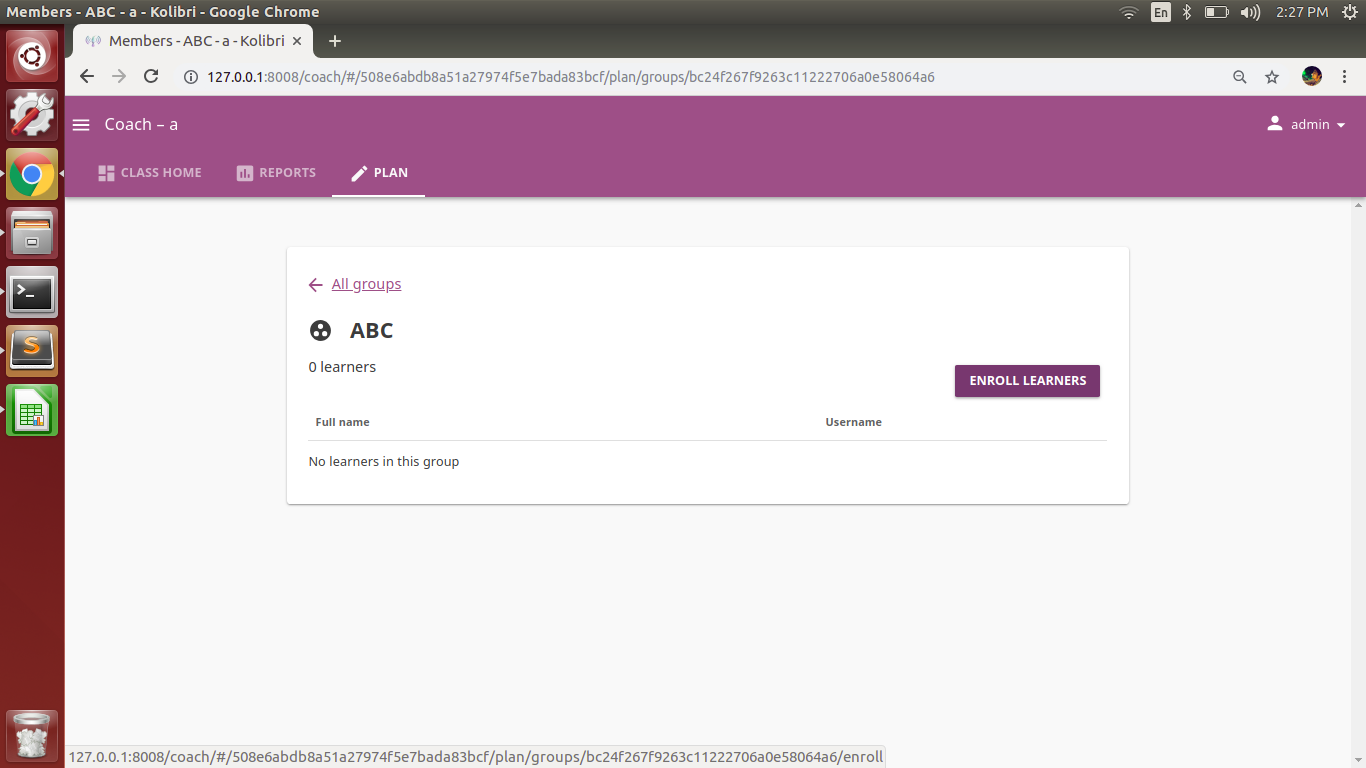
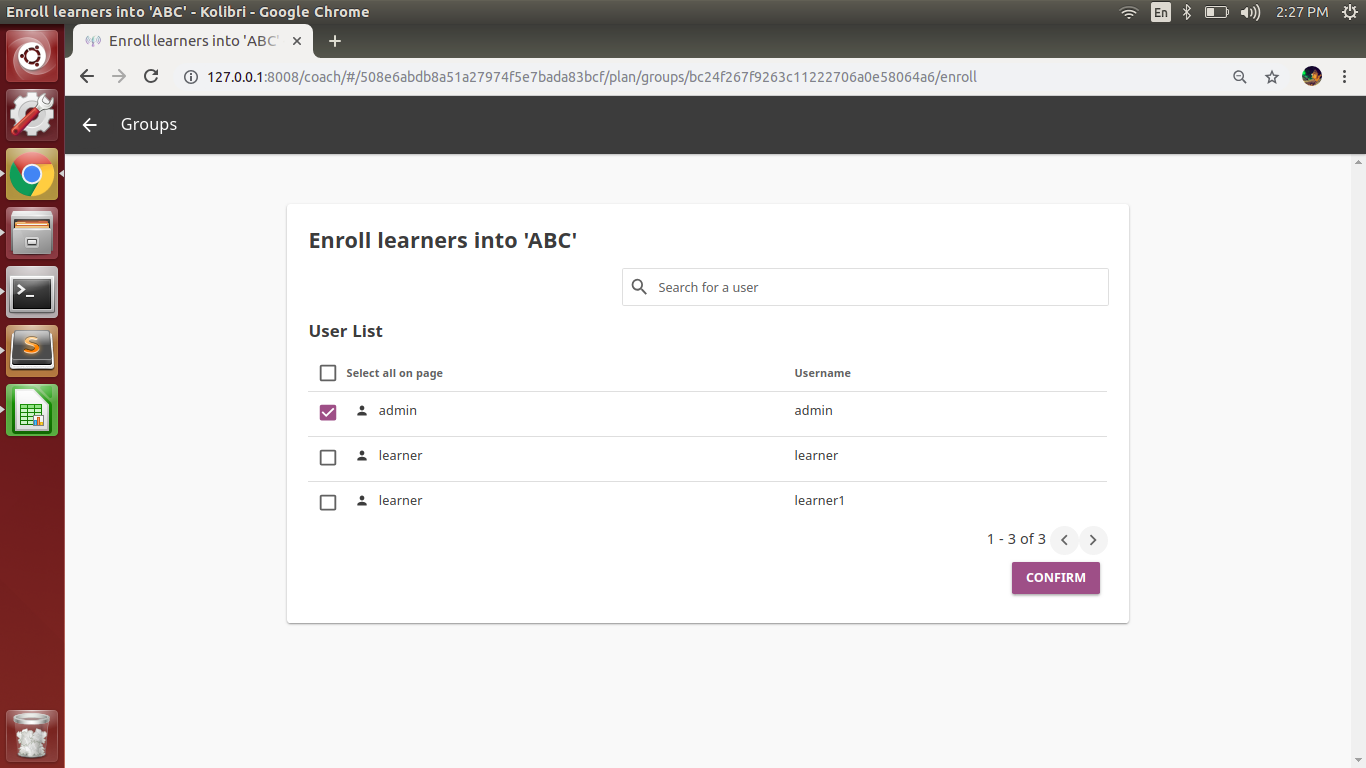
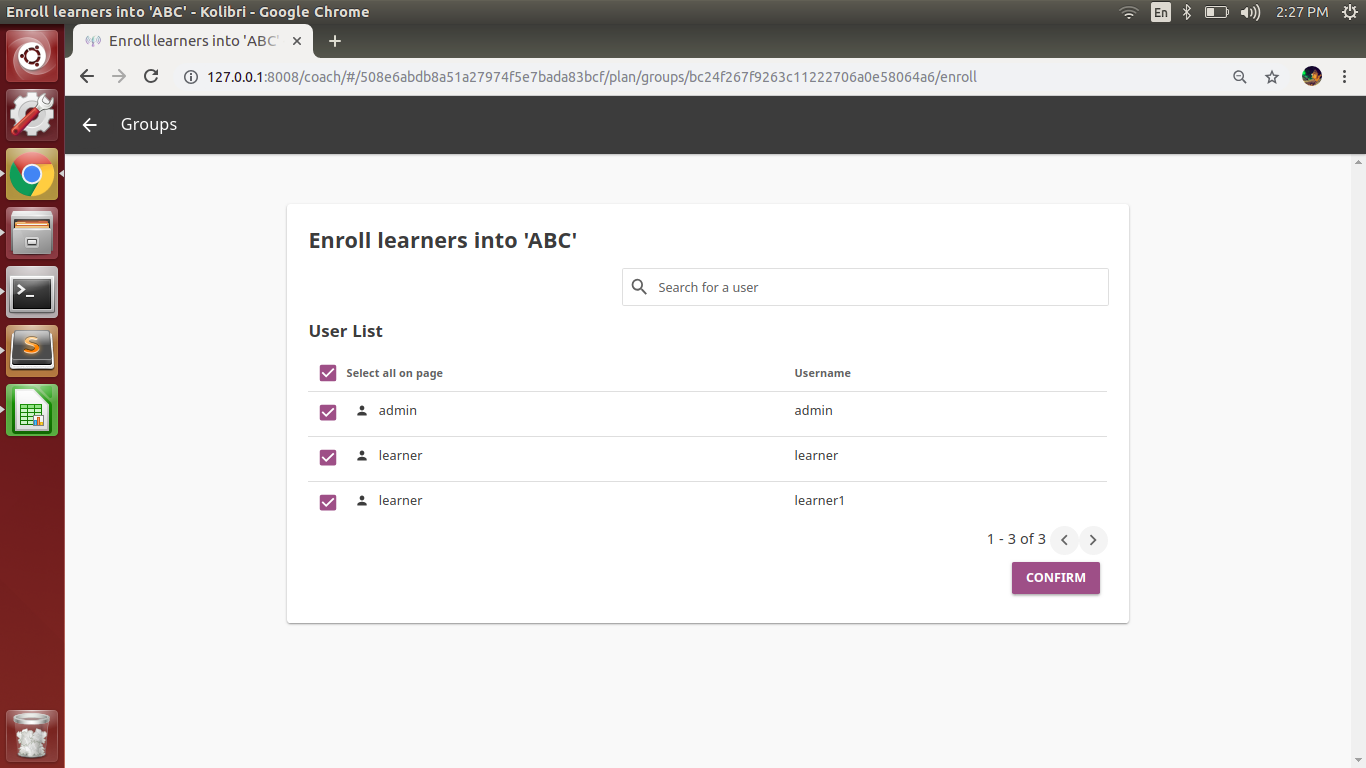
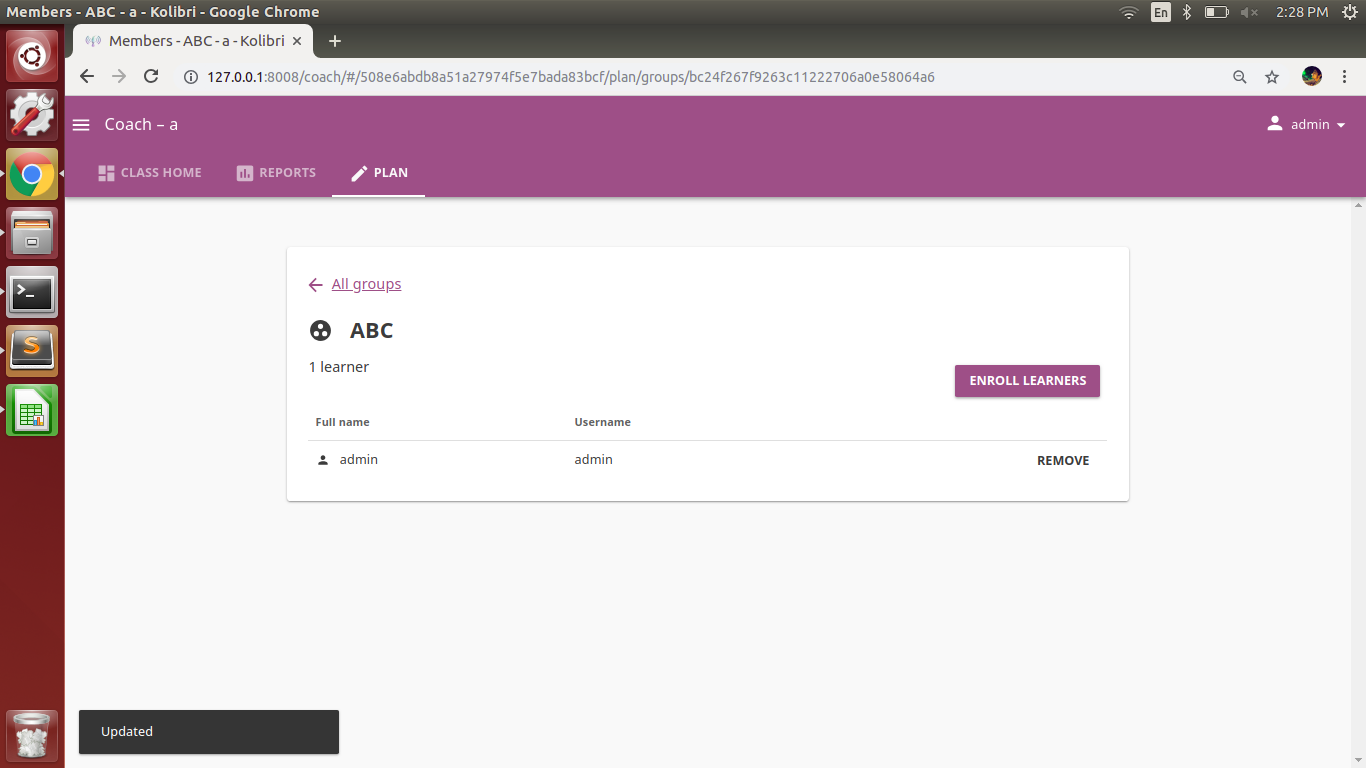
</issue>
<code>
[start of kolibri/core/logger/api.py]
1 from django.core.exceptions import ObjectDoesNotExist
2 from django.db.models.query import F
3 from django.http import Http404
4 from django_filters import ModelChoiceFilter
5 from django_filters.rest_framework import CharFilter
6 from django_filters.rest_framework import DjangoFilterBackend
7 from django_filters.rest_framework import FilterSet
8 from rest_framework import filters
9 from rest_framework import viewsets
10 from rest_framework.response import Response
11
12 from .models import AttemptLog
13 from .models import ContentSessionLog
14 from .models import ContentSummaryLog
15 from .models import ExamAttemptLog
16 from .models import ExamLog
17 from .models import MasteryLog
18 from .models import UserSessionLog
19 from .permissions import ExamActivePermissions
20 from .serializers import AttemptLogSerializer
21 from .serializers import ContentSessionLogSerializer
22 from .serializers import ContentSummaryLogSerializer
23 from .serializers import ExamAttemptLogSerializer
24 from .serializers import ExamLogSerializer
25 from .serializers import MasteryLogSerializer
26 from .serializers import TotalContentProgressSerializer
27 from .serializers import UserSessionLogSerializer
28 from kolibri.core.auth.api import KolibriAuthPermissions
29 from kolibri.core.auth.api import KolibriAuthPermissionsFilter
30 from kolibri.core.auth.filters import HierarchyRelationsFilter
31 from kolibri.core.auth.models import Classroom
32 from kolibri.core.auth.models import Collection
33 from kolibri.core.auth.models import Facility
34 from kolibri.core.auth.models import FacilityUser
35 from kolibri.core.auth.models import LearnerGroup
36 from kolibri.core.content.api import OptionalPageNumberPagination
37 from kolibri.core.exams.models import Exam
38
39
40 class BaseLogFilter(FilterSet):
41 facility = ModelChoiceFilter(
42 method="filter_facility", queryset=Facility.objects.all()
43 )
44 classroom = ModelChoiceFilter(
45 method="filter_classroom", queryset=Classroom.objects.all()
46 )
47 learner_group = ModelChoiceFilter(
48 method="filter_learner_group", queryset=LearnerGroup.objects.all()
49 )
50
51 # Only a superuser can filter by facilities
52 def filter_facility(self, queryset, name, value):
53 return queryset.filter(user__facility=value)
54
55 def filter_classroom(self, queryset, name, value):
56 return HierarchyRelationsFilter(queryset).filter_by_hierarchy(
57 ancestor_collection=value, target_user=F("user")
58 )
59
60 def filter_learner_group(self, queryset, name, value):
61 return HierarchyRelationsFilter(queryset).filter_by_hierarchy(
62 ancestor_collection=value, target_user=F("user")
63 )
64
65
66 class LoggerViewSet(viewsets.ModelViewSet):
67 def update(self, request, *args, **kwargs):
68 partial = kwargs.pop("partial", False)
69 model = self.queryset.model
70 lookup_url_kwarg = self.lookup_url_kwarg or self.lookup_field
71 try:
72 instance = model.objects.get(id=self.kwargs[lookup_url_kwarg])
73 self.check_object_permissions(request, instance)
74 except (ValueError, ObjectDoesNotExist):
75 raise Http404
76 serializer = self.get_serializer(instance, data=request.data, partial=partial)
77 serializer.is_valid(raise_exception=True)
78 self.perform_update(serializer)
79
80 if getattr(instance, "_prefetched_objects_cache", None):
81 # If 'prefetch_related' has been applied to a queryset, we need to
82 # forcibly invalidate the prefetch cache on the instance.
83 instance._prefetched_objects_cache = {}
84 default_response = dict(request.data)
85 # First look if the computed fields to be updated are listed:
86 updating_fields = getattr(serializer.root, "update_fields", None)
87 # If not, fetch all the fields that are computed methods:
88 if updating_fields is None:
89 updating_fields = [
90 field
91 for field in serializer.fields
92 if getattr(serializer.fields[field], "method_name", None)
93 ]
94 for field in updating_fields:
95 method_name = getattr(serializer.fields[field], "method_name", None)
96 if method_name:
97 method = getattr(serializer.root, method_name)
98 default_response[field] = method(instance)
99 return Response(default_response)
100
101
102 class ContentSessionLogFilter(BaseLogFilter):
103 class Meta:
104 model = ContentSessionLog
105 fields = ["user_id", "content_id"]
106
107
108 class ContentSessionLogViewSet(LoggerViewSet):
109 permission_classes = (KolibriAuthPermissions,)
110 filter_backends = (KolibriAuthPermissionsFilter, DjangoFilterBackend)
111 queryset = ContentSessionLog.objects.all()
112 serializer_class = ContentSessionLogSerializer
113 pagination_class = OptionalPageNumberPagination
114 filter_class = ContentSessionLogFilter
115
116
117 class ContentSummaryLogFilter(BaseLogFilter):
118 class Meta:
119 model = ContentSummaryLog
120 fields = ["user_id", "content_id"]
121
122
123 class ContentSummaryLogViewSet(LoggerViewSet):
124 permission_classes = (KolibriAuthPermissions,)
125 filter_backends = (KolibriAuthPermissionsFilter, DjangoFilterBackend)
126 queryset = ContentSummaryLog.objects.all()
127 serializer_class = ContentSummaryLogSerializer
128 pagination_class = OptionalPageNumberPagination
129 filter_class = ContentSummaryLogFilter
130
131
132 class TotalContentProgressViewSet(viewsets.ModelViewSet):
133 permission_classes = (KolibriAuthPermissions,)
134 filter_backends = (KolibriAuthPermissionsFilter,)
135 queryset = FacilityUser.objects.all()
136 serializer_class = TotalContentProgressSerializer
137
138
139 class UserSessionLogFilter(BaseLogFilter):
140 class Meta:
141 model = UserSessionLog
142 fields = ["user_id"]
143
144
145 class UserSessionLogViewSet(LoggerViewSet):
146 permission_classes = (KolibriAuthPermissions,)
147 filter_backends = (KolibriAuthPermissionsFilter, DjangoFilterBackend)
148 queryset = UserSessionLog.objects.all()
149 serializer_class = UserSessionLogSerializer
150 pagination_class = OptionalPageNumberPagination
151 filter_class = UserSessionLogFilter
152
153
154 class MasteryFilter(FilterSet):
155 class Meta:
156 model = MasteryLog
157 fields = ["summarylog"]
158
159
160 class MasteryLogViewSet(LoggerViewSet):
161 permission_classes = (KolibriAuthPermissions,)
162 filter_backends = (KolibriAuthPermissionsFilter, DjangoFilterBackend)
163 queryset = MasteryLog.objects.all()
164 serializer_class = MasteryLogSerializer
165 pagination_class = OptionalPageNumberPagination
166 filter_class = MasteryFilter
167
168
169 class AttemptFilter(BaseLogFilter):
170 content = CharFilter(method="filter_content")
171
172 def filter_content(self, queryset, name, value):
173 return queryset.filter(masterylog__summarylog__content_id=value)
174
175 class Meta:
176 model = AttemptLog
177 fields = ["masterylog", "complete", "user", "content", "item"]
178
179
180 class AttemptLogViewSet(LoggerViewSet):
181 permission_classes = (KolibriAuthPermissions,)
182 filter_backends = (
183 KolibriAuthPermissionsFilter,
184 DjangoFilterBackend,
185 filters.OrderingFilter,
186 )
187 queryset = AttemptLog.objects.all()
188 serializer_class = AttemptLogSerializer
189 pagination_class = OptionalPageNumberPagination
190 filter_class = AttemptFilter
191 ordering_fields = ("end_timestamp",)
192 ordering = ("end_timestamp",)
193
194
195 class ExamAttemptFilter(BaseLogFilter):
196 exam = ModelChoiceFilter(method="filter_exam", queryset=Exam.objects.all())
197 user = ModelChoiceFilter(method="filter_user", queryset=FacilityUser.objects.all())
198 content = CharFilter(field_name="content_id")
199
200 def filter_exam(self, queryset, name, value):
201 return queryset.filter(examlog__exam=value)
202
203 def filter_user(self, queryset, name, value):
204 return queryset.filter(examlog__user=value)
205
206 class Meta:
207 model = ExamAttemptLog
208 fields = ["examlog", "exam", "user", "content", "item"]
209
210
211 class ExamAttemptLogViewSet(LoggerViewSet):
212 permission_classes = (ExamActivePermissions, KolibriAuthPermissions)
213 filter_backends = (
214 KolibriAuthPermissionsFilter,
215 DjangoFilterBackend,
216 filters.OrderingFilter,
217 )
218 queryset = ExamAttemptLog.objects.all()
219 serializer_class = ExamAttemptLogSerializer
220 pagination_class = OptionalPageNumberPagination
221 filter_class = ExamAttemptFilter
222
223
224 class ExamLogFilter(BaseLogFilter):
225
226 collection = ModelChoiceFilter(
227 method="filter_collection", queryset=Collection.objects.all()
228 )
229
230 def filter_collection(self, queryset, name, collection):
231 return HierarchyRelationsFilter(queryset).filter_by_hierarchy(
232 target_user=F("user"), ancestor_collection=collection
233 )
234
235 class Meta:
236 model = ExamLog
237 fields = ["user", "exam"]
238
239
240 class ExamLogViewSet(viewsets.ModelViewSet):
241 permission_classes = (KolibriAuthPermissions,)
242 filter_backends = (KolibriAuthPermissionsFilter, DjangoFilterBackend)
243 queryset = ExamLog.objects.all()
244 serializer_class = ExamLogSerializer
245 pagination_class = OptionalPageNumberPagination
246 filter_class = ExamLogFilter
247
[end of kolibri/core/logger/api.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/kolibri/core/logger/api.py b/kolibri/core/logger/api.py
--- a/kolibri/core/logger/api.py
+++ b/kolibri/core/logger/api.py
@@ -1,12 +1,17 @@
+import logging
+
from django.core.exceptions import ObjectDoesNotExist
from django.db.models.query import F
+from django.db.utils import IntegrityError
from django.http import Http404
from django_filters import ModelChoiceFilter
from django_filters.rest_framework import CharFilter
from django_filters.rest_framework import DjangoFilterBackend
from django_filters.rest_framework import FilterSet
from rest_framework import filters
+from rest_framework import status
from rest_framework import viewsets
+from rest_framework.exceptions import ValidationError
from rest_framework.response import Response
from .models import AttemptLog
@@ -36,6 +41,8 @@
from kolibri.core.content.api import OptionalPageNumberPagination
from kolibri.core.exams.models import Exam
+logger = logging.getLogger(__name__)
+
class BaseLogFilter(FilterSet):
facility = ModelChoiceFilter(
@@ -98,6 +105,21 @@
default_response[field] = method(instance)
return Response(default_response)
+ def create(self, request, *args, **kwargs):
+ try:
+ return super(LoggerViewSet, self).create(request, *args, **kwargs)
+ except IntegrityError:
+ # The object has been created previously: let's calculate its id and return it
+ serializer = self.get_serializer(data=request.data)
+ serializer.is_valid(raise_exception=True)
+ obj = serializer.Meta.model(**serializer.validated_data)
+ obj.id = obj.calculate_uuid()
+ final_obj = self.get_serializer(obj)
+ return Response(final_obj.data)
+ except ValidationError as e:
+ logger.error("Failed to validate data: {}".format(e))
+ return Response(request.data, status.HTTP_400_BAD_REQUEST)
+
class ContentSessionLogFilter(BaseLogFilter):
class Meta:
|
{"golden_diff": "diff --git a/kolibri/core/logger/api.py b/kolibri/core/logger/api.py\n--- a/kolibri/core/logger/api.py\n+++ b/kolibri/core/logger/api.py\n@@ -1,12 +1,17 @@\n+import logging\n+\n from django.core.exceptions import ObjectDoesNotExist\n from django.db.models.query import F\n+from django.db.utils import IntegrityError\n from django.http import Http404\n from django_filters import ModelChoiceFilter\n from django_filters.rest_framework import CharFilter\n from django_filters.rest_framework import DjangoFilterBackend\n from django_filters.rest_framework import FilterSet\n from rest_framework import filters\n+from rest_framework import status\n from rest_framework import viewsets\n+from rest_framework.exceptions import ValidationError\n from rest_framework.response import Response\n \n from .models import AttemptLog\n@@ -36,6 +41,8 @@\n from kolibri.core.content.api import OptionalPageNumberPagination\n from kolibri.core.exams.models import Exam\n \n+logger = logging.getLogger(__name__)\n+\n \n class BaseLogFilter(FilterSet):\n facility = ModelChoiceFilter(\n@@ -98,6 +105,21 @@\n default_response[field] = method(instance)\n return Response(default_response)\n \n+ def create(self, request, *args, **kwargs):\n+ try:\n+ return super(LoggerViewSet, self).create(request, *args, **kwargs)\n+ except IntegrityError:\n+ # The object has been created previously: let's calculate its id and return it\n+ serializer = self.get_serializer(data=request.data)\n+ serializer.is_valid(raise_exception=True)\n+ obj = serializer.Meta.model(**serializer.validated_data)\n+ obj.id = obj.calculate_uuid()\n+ final_obj = self.get_serializer(obj)\n+ return Response(final_obj.data)\n+ except ValidationError as e:\n+ logger.error(\"Failed to validate data: {}\".format(e))\n+ return Response(request.data, status.HTTP_400_BAD_REQUEST)\n+\n \n class ContentSessionLogFilter(BaseLogFilter):\n class Meta:\n", "issue": "Select all not working in groups\n### Observed behavior\r\nIn the coach tab, while enrolling learners in the group first select single user and then select select all option and then enroll. It will enroll only one user in the group.\r\n\r\n### Expected behavior\r\nWhen we select select all, it must enroll all users in the group.\r\n\r\n### Steps to reproduce\r\n1. Create the group.\r\n2. Select one user while enrolling.\r\n3. Then select select all in groups.\r\n4. Click on enroll.\r\n5. It will enroll only one user in the group.\r\n\r\n### Context\r\n * Kolibri version : Kolibri 0.12.2\r\n * Operating system : Ubuntu 14.04\r\n * Browser : Chrome\r\n\r\n### Screenshots\r\n\r\n\r\n\r\n\r\n\r\n\r\n\n", "before_files": [{"content": "from django.core.exceptions import ObjectDoesNotExist\nfrom django.db.models.query import F\nfrom django.http import Http404\nfrom django_filters import ModelChoiceFilter\nfrom django_filters.rest_framework import CharFilter\nfrom django_filters.rest_framework import DjangoFilterBackend\nfrom django_filters.rest_framework import FilterSet\nfrom rest_framework import filters\nfrom rest_framework import viewsets\nfrom rest_framework.response import Response\n\nfrom .models import AttemptLog\nfrom .models import ContentSessionLog\nfrom .models import ContentSummaryLog\nfrom .models import ExamAttemptLog\nfrom .models import ExamLog\nfrom .models import MasteryLog\nfrom .models import UserSessionLog\nfrom .permissions import ExamActivePermissions\nfrom .serializers import AttemptLogSerializer\nfrom .serializers import ContentSessionLogSerializer\nfrom .serializers import ContentSummaryLogSerializer\nfrom .serializers import ExamAttemptLogSerializer\nfrom .serializers import ExamLogSerializer\nfrom .serializers import MasteryLogSerializer\nfrom .serializers import TotalContentProgressSerializer\nfrom .serializers import UserSessionLogSerializer\nfrom kolibri.core.auth.api import KolibriAuthPermissions\nfrom kolibri.core.auth.api import KolibriAuthPermissionsFilter\nfrom kolibri.core.auth.filters import HierarchyRelationsFilter\nfrom kolibri.core.auth.models import Classroom\nfrom kolibri.core.auth.models import Collection\nfrom kolibri.core.auth.models import Facility\nfrom kolibri.core.auth.models import FacilityUser\nfrom kolibri.core.auth.models import LearnerGroup\nfrom kolibri.core.content.api import OptionalPageNumberPagination\nfrom kolibri.core.exams.models import Exam\n\n\nclass BaseLogFilter(FilterSet):\n facility = ModelChoiceFilter(\n method=\"filter_facility\", queryset=Facility.objects.all()\n )\n classroom = ModelChoiceFilter(\n method=\"filter_classroom\", queryset=Classroom.objects.all()\n )\n learner_group = ModelChoiceFilter(\n method=\"filter_learner_group\", queryset=LearnerGroup.objects.all()\n )\n\n # Only a superuser can filter by facilities\n def filter_facility(self, queryset, name, value):\n return queryset.filter(user__facility=value)\n\n def filter_classroom(self, queryset, name, value):\n return HierarchyRelationsFilter(queryset).filter_by_hierarchy(\n ancestor_collection=value, target_user=F(\"user\")\n )\n\n def filter_learner_group(self, queryset, name, value):\n return HierarchyRelationsFilter(queryset).filter_by_hierarchy(\n ancestor_collection=value, target_user=F(\"user\")\n )\n\n\nclass LoggerViewSet(viewsets.ModelViewSet):\n def update(self, request, *args, **kwargs):\n partial = kwargs.pop(\"partial\", False)\n model = self.queryset.model\n lookup_url_kwarg = self.lookup_url_kwarg or self.lookup_field\n try:\n instance = model.objects.get(id=self.kwargs[lookup_url_kwarg])\n self.check_object_permissions(request, instance)\n except (ValueError, ObjectDoesNotExist):\n raise Http404\n serializer = self.get_serializer(instance, data=request.data, partial=partial)\n serializer.is_valid(raise_exception=True)\n self.perform_update(serializer)\n\n if getattr(instance, \"_prefetched_objects_cache\", None):\n # If 'prefetch_related' has been applied to a queryset, we need to\n # forcibly invalidate the prefetch cache on the instance.\n instance._prefetched_objects_cache = {}\n default_response = dict(request.data)\n # First look if the computed fields to be updated are listed:\n updating_fields = getattr(serializer.root, \"update_fields\", None)\n # If not, fetch all the fields that are computed methods:\n if updating_fields is None:\n updating_fields = [\n field\n for field in serializer.fields\n if getattr(serializer.fields[field], \"method_name\", None)\n ]\n for field in updating_fields:\n method_name = getattr(serializer.fields[field], \"method_name\", None)\n if method_name:\n method = getattr(serializer.root, method_name)\n default_response[field] = method(instance)\n return Response(default_response)\n\n\nclass ContentSessionLogFilter(BaseLogFilter):\n class Meta:\n model = ContentSessionLog\n fields = [\"user_id\", \"content_id\"]\n\n\nclass ContentSessionLogViewSet(LoggerViewSet):\n permission_classes = (KolibriAuthPermissions,)\n filter_backends = (KolibriAuthPermissionsFilter, DjangoFilterBackend)\n queryset = ContentSessionLog.objects.all()\n serializer_class = ContentSessionLogSerializer\n pagination_class = OptionalPageNumberPagination\n filter_class = ContentSessionLogFilter\n\n\nclass ContentSummaryLogFilter(BaseLogFilter):\n class Meta:\n model = ContentSummaryLog\n fields = [\"user_id\", \"content_id\"]\n\n\nclass ContentSummaryLogViewSet(LoggerViewSet):\n permission_classes = (KolibriAuthPermissions,)\n filter_backends = (KolibriAuthPermissionsFilter, DjangoFilterBackend)\n queryset = ContentSummaryLog.objects.all()\n serializer_class = ContentSummaryLogSerializer\n pagination_class = OptionalPageNumberPagination\n filter_class = ContentSummaryLogFilter\n\n\nclass TotalContentProgressViewSet(viewsets.ModelViewSet):\n permission_classes = (KolibriAuthPermissions,)\n filter_backends = (KolibriAuthPermissionsFilter,)\n queryset = FacilityUser.objects.all()\n serializer_class = TotalContentProgressSerializer\n\n\nclass UserSessionLogFilter(BaseLogFilter):\n class Meta:\n model = UserSessionLog\n fields = [\"user_id\"]\n\n\nclass UserSessionLogViewSet(LoggerViewSet):\n permission_classes = (KolibriAuthPermissions,)\n filter_backends = (KolibriAuthPermissionsFilter, DjangoFilterBackend)\n queryset = UserSessionLog.objects.all()\n serializer_class = UserSessionLogSerializer\n pagination_class = OptionalPageNumberPagination\n filter_class = UserSessionLogFilter\n\n\nclass MasteryFilter(FilterSet):\n class Meta:\n model = MasteryLog\n fields = [\"summarylog\"]\n\n\nclass MasteryLogViewSet(LoggerViewSet):\n permission_classes = (KolibriAuthPermissions,)\n filter_backends = (KolibriAuthPermissionsFilter, DjangoFilterBackend)\n queryset = MasteryLog.objects.all()\n serializer_class = MasteryLogSerializer\n pagination_class = OptionalPageNumberPagination\n filter_class = MasteryFilter\n\n\nclass AttemptFilter(BaseLogFilter):\n content = CharFilter(method=\"filter_content\")\n\n def filter_content(self, queryset, name, value):\n return queryset.filter(masterylog__summarylog__content_id=value)\n\n class Meta:\n model = AttemptLog\n fields = [\"masterylog\", \"complete\", \"user\", \"content\", \"item\"]\n\n\nclass AttemptLogViewSet(LoggerViewSet):\n permission_classes = (KolibriAuthPermissions,)\n filter_backends = (\n KolibriAuthPermissionsFilter,\n DjangoFilterBackend,\n filters.OrderingFilter,\n )\n queryset = AttemptLog.objects.all()\n serializer_class = AttemptLogSerializer\n pagination_class = OptionalPageNumberPagination\n filter_class = AttemptFilter\n ordering_fields = (\"end_timestamp\",)\n ordering = (\"end_timestamp\",)\n\n\nclass ExamAttemptFilter(BaseLogFilter):\n exam = ModelChoiceFilter(method=\"filter_exam\", queryset=Exam.objects.all())\n user = ModelChoiceFilter(method=\"filter_user\", queryset=FacilityUser.objects.all())\n content = CharFilter(field_name=\"content_id\")\n\n def filter_exam(self, queryset, name, value):\n return queryset.filter(examlog__exam=value)\n\n def filter_user(self, queryset, name, value):\n return queryset.filter(examlog__user=value)\n\n class Meta:\n model = ExamAttemptLog\n fields = [\"examlog\", \"exam\", \"user\", \"content\", \"item\"]\n\n\nclass ExamAttemptLogViewSet(LoggerViewSet):\n permission_classes = (ExamActivePermissions, KolibriAuthPermissions)\n filter_backends = (\n KolibriAuthPermissionsFilter,\n DjangoFilterBackend,\n filters.OrderingFilter,\n )\n queryset = ExamAttemptLog.objects.all()\n serializer_class = ExamAttemptLogSerializer\n pagination_class = OptionalPageNumberPagination\n filter_class = ExamAttemptFilter\n\n\nclass ExamLogFilter(BaseLogFilter):\n\n collection = ModelChoiceFilter(\n method=\"filter_collection\", queryset=Collection.objects.all()\n )\n\n def filter_collection(self, queryset, name, collection):\n return HierarchyRelationsFilter(queryset).filter_by_hierarchy(\n target_user=F(\"user\"), ancestor_collection=collection\n )\n\n class Meta:\n model = ExamLog\n fields = [\"user\", \"exam\"]\n\n\nclass ExamLogViewSet(viewsets.ModelViewSet):\n permission_classes = (KolibriAuthPermissions,)\n filter_backends = (KolibriAuthPermissionsFilter, DjangoFilterBackend)\n queryset = ExamLog.objects.all()\n serializer_class = ExamLogSerializer\n pagination_class = OptionalPageNumberPagination\n filter_class = ExamLogFilter\n", "path": "kolibri/core/logger/api.py"}]}
| 3,509 | 432 |
gh_patches_debug_1225
|
rasdani/github-patches
|
git_diff
|
mindsdb__mindsdb-28
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
IndexError: list index out of range when missing predict value
**Is your feature request related to a problem? Please describe.**
When there is empty string provided as predict value e.g:
```
result = mdb.predict(predict=' ', model_name='home_rentals')
```
IndexError: list index out of range error is thrown
**Describe the solution you'd like**
User friendly message should be thrown e.g
ValueError: Please provide valid predict value
**Additional context**
We can check for empty predict values in https://github.com/mindsdb/main/blob/76c691c4b18a4723626dfcbff8228da614d93e8b/mindsdb/libs/controllers/mindsdb_controller.py#L170 and raise Value error if predict not provided.
</issue>
<code>
[start of mindsdb/libs/controllers/mindsdb_controller.py]
1 import sqlite3
2 import pandas
3 import requests
4 import logging
5 import os
6 import platform
7 import _thread
8 import uuid
9 import traceback
10 import urllib
11
12 from mindsdb.libs.helpers.sqlite_helpers import *
13 from mindsdb.libs.helpers.multi_data_source import getDS
14 from mindsdb.config import SQLITE_FILE
15 import mindsdb.config as CONFIG
16
17 from mindsdb.libs.data_types.transaction_metadata import TransactionMetadata
18 from mindsdb.libs.controllers.session_controller import SessionController
19 from mindsdb.libs.constants.mindsdb import *
20
21 from mindsdb.version import mindsdb_version as MINDSDB_VERSION
22
23 from pathlib import Path
24
25 class MindsDBController:
26
27 def __init__(self, file=SQLITE_FILE):
28 """
29
30 :param file:
31 """
32
33 self.setConfigs()
34
35 _thread.start_new_thread(MindsDBController.checkForUpdates, ())
36 self.session = SessionController()
37 self.storage_file = file
38 self.conn = sqlite3.connect(file)
39 self.conn.create_aggregate("first_value", 1, FirstValueAgg)
40 self.conn.create_aggregate("array_agg_json", 2, ArrayAggJSON)
41
42 def setConfigs(self):
43 """
44 This sets the config settings for this mindsdb instance
45 :return:
46 """
47 # set logging settings
48 logging.basicConfig(**CONFIG.PROXY_LOG_CONFIG)
49
50 # set the mindsdb storage folder
51 storage_ok = True # default state
52
53 # if it does not exist try to create it
54 if not os.path.exists(CONFIG.MINDSDB_STORAGE_PATH):
55 try:
56 logging.info('{folder} does not exist, creating it now'.format(folder=CONFIG.MINDSDB_STORAGE_PATH))
57 path = Path(CONFIG.MINDSDB_STORAGE_PATH)
58 path.mkdir(exist_ok=True, parents=True)
59 except:
60 logging.info(traceback.format_exc())
61 storage_ok = False
62 logging.error('MindsDB storate foldler: {folder} does not exist and could not be created'.format(folder=CONFIG.MINDSDB_STORAGE_PATH))
63
64 # If storage path is not writable, raise an exception as this can no longer be
65 if not os.access(CONFIG.MINDSDB_STORAGE_PATH, os.W_OK) or storage_ok == False:
66 error_message = '''Cannot write into storage path, please either set the config variable mindsdb.config.set('MINDSDB_STORAGE_PATH',<path>) or give write access to {folder}'''
67 raise ValueError(error_message.format(folder=CONFIG.MINDSDB_STORAGE_PATH))
68
69
70 def addTable(self, ds, as_table):
71 """
72
73 :param ds:
74 :param as_table:
75 :return:
76 """
77
78 ds.df.to_sql(as_table, self.conn, if_exists='replace', index=False)
79
80 def query(self, query):
81 """
82
83 :param query:
84 :return:
85 """
86
87 cur = self.conn.cursor()
88 return cur.execute(query)
89
90 def queryToDF(self, query):
91 """
92
93 :param query:
94 :return:
95 """
96
97 return pandas.read_sql_query(query, self.conn)
98
99
100 def setUserEmail(self, email):
101 """
102
103 :param email:
104 :return:
105 """
106 email_file = CONFIG.MINDSDB_STORAGE_PATH + '/../email.mdb_base'
107
108
109 try:
110 open(email_file, 'w').write(email)
111 return True
112 except:
113 logging.warning('Cannot store token, Please add write permissions to file:' + email_file)
114 return False
115
116 def getUserEmail(self):
117 """
118
119 :return:
120 """
121 email_file = CONFIG.MINDSDB_STORAGE_PATH + '/../email.mdb_base'
122 email_file_path = Path(email_file)
123
124 try:
125 if email_file_path.is_file():
126 email = open(email_file, 'r').read()
127 return email
128 else:
129 return None
130 except:
131 logging.warning('Cannot read email, Please add write permissions to file:' + email_file)
132 return None
133
134 def learn(self, predict, from_file=None, from_data = None, model_name='mdsb_model', test_from_data=None, group_by = None, window_size = MODEL_GROUP_BY_DEAFAULT_LIMIT, order_by = [], breakpoint = PHASE_END, ignore_columns = []):
135 """
136
137 :param from_query:
138 :param predict:
139 :param model_name:
140 :param test_query:
141 :return:
142 """
143
144 from_ds = getDS(from_data) if from_file is None else getDS(from_file)
145 test_from_ds = test_from_data if test_from_data is None else getDS(test_from_data)
146
147 transaction_type = TRANSACTION_LEARN
148
149 predict_columns = [predict] if type(predict) != type([]) else predict
150
151 transaction_metadata = TransactionMetadata()
152 transaction_metadata.model_name = model_name
153 transaction_metadata.model_predict_columns = predict_columns
154 transaction_metadata.model_group_by = group_by
155 transaction_metadata.model_order_by = order_by if type(order_by) == type([]) else [order_by]
156 transaction_metadata.window_size = window_size
157 transaction_metadata.type = transaction_type
158 transaction_metadata.from_data = from_ds
159 transaction_metadata.test_from_data = test_from_ds
160 transaction_metadata.ignore_columns = ignore_columns
161
162 self.startInfoServer()
163 self.session.newTransaction(transaction_metadata, breakpoint)
164
165
166 def startInfoServer(self):
167 pass
168
169 def predict(self, predict, from_data = None, when={}, model_name='mdsb_model', breakpoint= PHASE_END):
170 """
171
172 :param predict:
173 :param when:
174 :param model_name:
175 :return:
176 """
177
178 transaction_type = TRANSACTION_PREDICT
179
180 from_ds = None if from_data is None else getDS(from_data)
181
182 predict_columns = [predict] if type(predict) != type([]) else predict
183
184 transaction_metadata = TransactionMetadata()
185 transaction_metadata.model_name = model_name
186 transaction_metadata.model_predict_columns = predict_columns
187 transaction_metadata.model_when_conditions = when
188 transaction_metadata.type = transaction_type
189 transaction_metadata.storage_file = self.storage_file
190 transaction_metadata.from_data = from_ds
191
192 transaction = self.session.newTransaction(transaction_metadata, breakpoint)
193
194 return transaction.output_data
195
196 @staticmethod
197 def checkForUpdates():
198 # tmp files
199 uuid_file = CONFIG.MINDSDB_STORAGE_PATH + '/../uuid.mdb_base'
200 mdb_file = CONFIG.MINDSDB_STORAGE_PATH + '/start.mdb_base'
201
202 uuid_file_path = Path(uuid_file)
203 if uuid_file_path.is_file():
204 uuid_str = open(uuid_file).read()
205 else:
206 uuid_str = str(uuid.uuid4())
207 try:
208 open(uuid_file, 'w').write(uuid_str)
209 except:
210 logging.warning('Cannot store token, Please add write permissions to file:' + uuid_file)
211 uuid_str = uuid_str + '.NO_WRITE'
212
213 file_path = Path(mdb_file)
214 if file_path.is_file():
215 token = open(mdb_file).read()
216 else:
217 token = '{system}|{version}|{uid}'.format(system=platform.system(), version=MINDSDB_VERSION, uid=uuid_str)
218 try:
219 open(mdb_file,'w').write(token)
220 except:
221 logging.warning('Cannot store token, Please add write permissions to file:'+mdb_file)
222 token = token+'.NO_WRITE'
223 extra = urllib.parse.quote_plus(token)
224 try:
225 r = requests.get('http://mindsdb.com/updates/check/{extra}'.format(extra=extra), headers={'referer': 'http://check.mindsdb.com/?token={token}'.format(token=token)})
226 except:
227 logging.warning('Could not check for updates')
228 return
229 try:
230 # TODO: Extract version, compare with version in version.py
231 ret = r.json()
232
233 if 'version' in ret and ret['version']!= MINDSDB_VERSION:
234 logging.warning("There is a new version of MindsDB {version}, please do:\n pip3 uninstall mindsdb\n pip2 install mindsdb --user".format(version=ret['version']))
235 else:
236 logging.debug('MindsDB is up to date!')
237
238 except:
239
240 logging.warning('could not check for MindsDB updates')
241
242
243
[end of mindsdb/libs/controllers/mindsdb_controller.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mindsdb/libs/controllers/mindsdb_controller.py b/mindsdb/libs/controllers/mindsdb_controller.py
--- a/mindsdb/libs/controllers/mindsdb_controller.py
+++ b/mindsdb/libs/controllers/mindsdb_controller.py
@@ -174,6 +174,9 @@
:param model_name:
:return:
"""
+
+ if not predict:
+ raise ValueError('Please provide valid predict value.')
transaction_type = TRANSACTION_PREDICT
|
{"golden_diff": "diff --git a/mindsdb/libs/controllers/mindsdb_controller.py b/mindsdb/libs/controllers/mindsdb_controller.py\n--- a/mindsdb/libs/controllers/mindsdb_controller.py\n+++ b/mindsdb/libs/controllers/mindsdb_controller.py\n@@ -174,6 +174,9 @@\n :param model_name:\n :return:\n \"\"\"\n+ \n+ if not predict:\n+ raise ValueError('Please provide valid predict value.')\n \n transaction_type = TRANSACTION_PREDICT\n", "issue": "IndexError: list index out of range when missing predict value\n**Is your feature request related to a problem? Please describe.**\r\nWhen there is empty string provided as predict value e.g:\r\n``` \r\nresult = mdb.predict(predict=' ', model_name='home_rentals')\r\n```\r\nIndexError: list index out of range error is thrown\r\n\r\n**Describe the solution you'd like**\r\nUser friendly message should be thrown e.g \r\nValueError: Please provide valid predict value\r\n\r\n**Additional context**\r\nWe can check for empty predict values in https://github.com/mindsdb/main/blob/76c691c4b18a4723626dfcbff8228da614d93e8b/mindsdb/libs/controllers/mindsdb_controller.py#L170 and raise Value error if predict not provided.\n", "before_files": [{"content": "import sqlite3\nimport pandas\nimport requests\nimport logging\nimport os\nimport platform\nimport _thread\nimport uuid\nimport traceback\nimport urllib\n\nfrom mindsdb.libs.helpers.sqlite_helpers import *\nfrom mindsdb.libs.helpers.multi_data_source import getDS\nfrom mindsdb.config import SQLITE_FILE\nimport mindsdb.config as CONFIG\n\nfrom mindsdb.libs.data_types.transaction_metadata import TransactionMetadata\nfrom mindsdb.libs.controllers.session_controller import SessionController\nfrom mindsdb.libs.constants.mindsdb import *\n\nfrom mindsdb.version import mindsdb_version as MINDSDB_VERSION\n\nfrom pathlib import Path\n\nclass MindsDBController:\n\n def __init__(self, file=SQLITE_FILE):\n \"\"\"\n\n :param file:\n \"\"\"\n\n self.setConfigs()\n\n _thread.start_new_thread(MindsDBController.checkForUpdates, ())\n self.session = SessionController()\n self.storage_file = file\n self.conn = sqlite3.connect(file)\n self.conn.create_aggregate(\"first_value\", 1, FirstValueAgg)\n self.conn.create_aggregate(\"array_agg_json\", 2, ArrayAggJSON)\n\n def setConfigs(self):\n \"\"\"\n This sets the config settings for this mindsdb instance\n :return:\n \"\"\"\n # set logging settings\n logging.basicConfig(**CONFIG.PROXY_LOG_CONFIG)\n\n # set the mindsdb storage folder\n storage_ok = True # default state\n\n # if it does not exist try to create it\n if not os.path.exists(CONFIG.MINDSDB_STORAGE_PATH):\n try:\n logging.info('{folder} does not exist, creating it now'.format(folder=CONFIG.MINDSDB_STORAGE_PATH))\n path = Path(CONFIG.MINDSDB_STORAGE_PATH)\n path.mkdir(exist_ok=True, parents=True)\n except:\n logging.info(traceback.format_exc())\n storage_ok = False\n logging.error('MindsDB storate foldler: {folder} does not exist and could not be created'.format(folder=CONFIG.MINDSDB_STORAGE_PATH))\n\n # If storage path is not writable, raise an exception as this can no longer be\n if not os.access(CONFIG.MINDSDB_STORAGE_PATH, os.W_OK) or storage_ok == False:\n error_message = '''Cannot write into storage path, please either set the config variable mindsdb.config.set('MINDSDB_STORAGE_PATH',<path>) or give write access to {folder}'''\n raise ValueError(error_message.format(folder=CONFIG.MINDSDB_STORAGE_PATH))\n\n\n def addTable(self, ds, as_table):\n \"\"\"\n\n :param ds:\n :param as_table:\n :return:\n \"\"\"\n\n ds.df.to_sql(as_table, self.conn, if_exists='replace', index=False)\n\n def query(self, query):\n \"\"\"\n\n :param query:\n :return:\n \"\"\"\n\n cur = self.conn.cursor()\n return cur.execute(query)\n\n def queryToDF(self, query):\n \"\"\"\n\n :param query:\n :return:\n \"\"\"\n\n return pandas.read_sql_query(query, self.conn)\n\n\n def setUserEmail(self, email):\n \"\"\"\n\n :param email:\n :return:\n \"\"\"\n email_file = CONFIG.MINDSDB_STORAGE_PATH + '/../email.mdb_base'\n\n\n try:\n open(email_file, 'w').write(email)\n return True\n except:\n logging.warning('Cannot store token, Please add write permissions to file:' + email_file)\n return False\n\n def getUserEmail(self):\n \"\"\"\n\n :return:\n \"\"\"\n email_file = CONFIG.MINDSDB_STORAGE_PATH + '/../email.mdb_base'\n email_file_path = Path(email_file)\n\n try:\n if email_file_path.is_file():\n email = open(email_file, 'r').read()\n return email\n else:\n return None\n except:\n logging.warning('Cannot read email, Please add write permissions to file:' + email_file)\n return None\n\n def learn(self, predict, from_file=None, from_data = None, model_name='mdsb_model', test_from_data=None, group_by = None, window_size = MODEL_GROUP_BY_DEAFAULT_LIMIT, order_by = [], breakpoint = PHASE_END, ignore_columns = []):\n \"\"\"\n\n :param from_query:\n :param predict:\n :param model_name:\n :param test_query:\n :return:\n \"\"\"\n\n from_ds = getDS(from_data) if from_file is None else getDS(from_file)\n test_from_ds = test_from_data if test_from_data is None else getDS(test_from_data)\n\n transaction_type = TRANSACTION_LEARN\n\n predict_columns = [predict] if type(predict) != type([]) else predict\n\n transaction_metadata = TransactionMetadata()\n transaction_metadata.model_name = model_name\n transaction_metadata.model_predict_columns = predict_columns\n transaction_metadata.model_group_by = group_by\n transaction_metadata.model_order_by = order_by if type(order_by) == type([]) else [order_by]\n transaction_metadata.window_size = window_size\n transaction_metadata.type = transaction_type\n transaction_metadata.from_data = from_ds\n transaction_metadata.test_from_data = test_from_ds\n transaction_metadata.ignore_columns = ignore_columns\n\n self.startInfoServer()\n self.session.newTransaction(transaction_metadata, breakpoint)\n\n\n def startInfoServer(self):\n pass\n\n def predict(self, predict, from_data = None, when={}, model_name='mdsb_model', breakpoint= PHASE_END):\n \"\"\"\n\n :param predict:\n :param when:\n :param model_name:\n :return:\n \"\"\"\n\n transaction_type = TRANSACTION_PREDICT\n\n from_ds = None if from_data is None else getDS(from_data)\n\n predict_columns = [predict] if type(predict) != type([]) else predict\n\n transaction_metadata = TransactionMetadata()\n transaction_metadata.model_name = model_name\n transaction_metadata.model_predict_columns = predict_columns\n transaction_metadata.model_when_conditions = when\n transaction_metadata.type = transaction_type\n transaction_metadata.storage_file = self.storage_file\n transaction_metadata.from_data = from_ds\n\n transaction = self.session.newTransaction(transaction_metadata, breakpoint)\n\n return transaction.output_data\n\n @staticmethod\n def checkForUpdates():\n # tmp files\n uuid_file = CONFIG.MINDSDB_STORAGE_PATH + '/../uuid.mdb_base'\n mdb_file = CONFIG.MINDSDB_STORAGE_PATH + '/start.mdb_base'\n\n uuid_file_path = Path(uuid_file)\n if uuid_file_path.is_file():\n uuid_str = open(uuid_file).read()\n else:\n uuid_str = str(uuid.uuid4())\n try:\n open(uuid_file, 'w').write(uuid_str)\n except:\n logging.warning('Cannot store token, Please add write permissions to file:' + uuid_file)\n uuid_str = uuid_str + '.NO_WRITE'\n\n file_path = Path(mdb_file)\n if file_path.is_file():\n token = open(mdb_file).read()\n else:\n token = '{system}|{version}|{uid}'.format(system=platform.system(), version=MINDSDB_VERSION, uid=uuid_str)\n try:\n open(mdb_file,'w').write(token)\n except:\n logging.warning('Cannot store token, Please add write permissions to file:'+mdb_file)\n token = token+'.NO_WRITE'\n extra = urllib.parse.quote_plus(token)\n try:\n r = requests.get('http://mindsdb.com/updates/check/{extra}'.format(extra=extra), headers={'referer': 'http://check.mindsdb.com/?token={token}'.format(token=token)})\n except:\n logging.warning('Could not check for updates')\n return\n try:\n # TODO: Extract version, compare with version in version.py\n ret = r.json()\n\n if 'version' in ret and ret['version']!= MINDSDB_VERSION:\n logging.warning(\"There is a new version of MindsDB {version}, please do:\\n pip3 uninstall mindsdb\\n pip2 install mindsdb --user\".format(version=ret['version']))\n else:\n logging.debug('MindsDB is up to date!')\n\n except:\n\n logging.warning('could not check for MindsDB updates')\n\n\n", "path": "mindsdb/libs/controllers/mindsdb_controller.py"}]}
| 3,101 | 106 |
gh_patches_debug_13560
|
rasdani/github-patches
|
git_diff
|
ydataai__ydata-profiling-1109
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Cramer correlation matrix is not computed
/usr/local/lib/python3.7/dist-packages/pandas_profiling/model/correlations.py:61: UserWarning:There was an attempt to calculate the cramers correlation, but this failed.
To hide this warning, disable the calculation
(using `df.profile_report(correlations={"cramers": {"calculate": False}})`
If this is problematic for your use case, please report this as an issue:
https://github.com/ydataai/pandas-profiling/issues
(include the error message: 'No data; `observed` has size 0.')
pls help. My dataset is https://busan302.mycourses.work/data/house_price_train.csv
</issue>
<code>
[start of src/pandas_profiling/model/pandas/correlations_pandas.py]
1 """Correlations between variables."""
2 import itertools
3 import warnings
4 from typing import Optional
5
6 import numpy as np
7 import pandas as pd
8 from scipy import stats
9
10 from pandas_profiling.config import Settings
11 from pandas_profiling.model.correlations import (
12 Cramers,
13 Kendall,
14 Pearson,
15 PhiK,
16 Spearman,
17 )
18
19
20 @Spearman.compute.register(Settings, pd.DataFrame, dict)
21 def pandas_spearman_compute(
22 config: Settings, df: pd.DataFrame, summary: dict
23 ) -> Optional[pd.DataFrame]:
24 return df.corr(method="spearman")
25
26
27 @Pearson.compute.register(Settings, pd.DataFrame, dict)
28 def pandas_pearson_compute(
29 config: Settings, df: pd.DataFrame, summary: dict
30 ) -> Optional[pd.DataFrame]:
31 return df.corr(method="pearson")
32
33
34 @Kendall.compute.register(Settings, pd.DataFrame, dict)
35 def pandas_kendall_compute(
36 config: Settings, df: pd.DataFrame, summary: dict
37 ) -> Optional[pd.DataFrame]:
38 return df.corr(method="kendall")
39
40
41 def _cramers_corrected_stat(confusion_matrix: pd.DataFrame, correction: bool) -> float:
42 """Calculate the Cramer's V corrected stat for two variables.
43
44 Args:
45 confusion_matrix: Crosstab between two variables.
46 correction: Should the correction be applied?
47
48 Returns:
49 The Cramer's V corrected stat for the two variables.
50 """
51 chi2 = stats.chi2_contingency(confusion_matrix, correction=correction)[0]
52 n = confusion_matrix.sum().sum()
53 phi2 = chi2 / n
54 r = confusion_matrix.shape[0]
55 k = confusion_matrix.shape[1] if len(confusion_matrix.shape) > 1 else 1
56
57 # Deal with NaNs later on
58 with np.errstate(divide="ignore", invalid="ignore"):
59 phi2corr = max(0.0, phi2 - ((k - 1.0) * (r - 1.0)) / (n - 1.0))
60 rcorr = r - ((r - 1.0) ** 2.0) / (n - 1.0)
61 kcorr = k - ((k - 1.0) ** 2.0) / (n - 1.0)
62 rkcorr = min((kcorr - 1.0), (rcorr - 1.0))
63 if rkcorr == 0.0:
64 corr = 1.0
65 else:
66 corr = np.sqrt(phi2corr / rkcorr)
67 return corr
68
69
70 @Cramers.compute.register(Settings, pd.DataFrame, dict)
71 def pandas_cramers_compute(
72 config: Settings, df: pd.DataFrame, summary: dict
73 ) -> Optional[pd.DataFrame]:
74 threshold = config.categorical_maximum_correlation_distinct
75
76 # `index` and `columns` must not be a set since Pandas 1.5,
77 # so convert it to a list. The order of the list is arbitrary.
78 categoricals = list(
79 {
80 key
81 for key, value in summary.items()
82 if value["type"] in {"Categorical", "Boolean"}
83 and value["n_distinct"] <= threshold
84 }
85 )
86
87 if len(categoricals) <= 1:
88 return None
89
90 matrix = np.zeros((len(categoricals), len(categoricals)))
91 np.fill_diagonal(matrix, 1.0)
92 correlation_matrix = pd.DataFrame(
93 matrix,
94 index=categoricals,
95 columns=categoricals,
96 )
97
98 for name1, name2 in itertools.combinations(categoricals, 2):
99 confusion_matrix = pd.crosstab(df[name1], df[name2])
100 correlation_matrix.loc[name2, name1] = _cramers_corrected_stat(
101 confusion_matrix, correction=True
102 )
103 correlation_matrix.loc[name1, name2] = correlation_matrix.loc[name2, name1]
104 return correlation_matrix
105
106
107 @PhiK.compute.register(Settings, pd.DataFrame, dict)
108 def pandas_phik_compute(
109 config: Settings, df: pd.DataFrame, summary: dict
110 ) -> Optional[pd.DataFrame]:
111 df_cols_dict = {i: list(df.columns).index(i) for i in df.columns}
112
113 intcols = {
114 key
115 for key, value in summary.items()
116 # DateTime currently excluded
117 # In some use cases, it makes sense to convert it to interval
118 # See https://github.com/KaveIO/PhiK/issues/7
119 if value["type"] == "Numeric" and 1 < value["n_distinct"]
120 }
121
122 selcols = {
123 key
124 for key, value in summary.items()
125 if value["type"] != "Unsupported"
126 and 1 < value["n_distinct"] <= config.categorical_maximum_correlation_distinct
127 }
128 selcols = selcols.union(intcols)
129 selected_cols = sorted(selcols, key=lambda i: df_cols_dict[i])
130
131 if len(selected_cols) <= 1:
132 return None
133
134 with warnings.catch_warnings():
135 warnings.simplefilter("ignore")
136 from phik import phik_matrix
137
138 correlation = phik_matrix(df[selected_cols], interval_cols=list(intcols))
139
140 return correlation
141
[end of src/pandas_profiling/model/pandas/correlations_pandas.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/pandas_profiling/model/pandas/correlations_pandas.py b/src/pandas_profiling/model/pandas/correlations_pandas.py
--- a/src/pandas_profiling/model/pandas/correlations_pandas.py
+++ b/src/pandas_profiling/model/pandas/correlations_pandas.py
@@ -97,9 +97,12 @@
for name1, name2 in itertools.combinations(categoricals, 2):
confusion_matrix = pd.crosstab(df[name1], df[name2])
- correlation_matrix.loc[name2, name1] = _cramers_corrected_stat(
- confusion_matrix, correction=True
- )
+ if confusion_matrix.empty:
+ correlation_matrix.loc[name2, name1] = np.nan
+ else:
+ correlation_matrix.loc[name2, name1] = _cramers_corrected_stat(
+ confusion_matrix, correction=True
+ )
correlation_matrix.loc[name1, name2] = correlation_matrix.loc[name2, name1]
return correlation_matrix
|
{"golden_diff": "diff --git a/src/pandas_profiling/model/pandas/correlations_pandas.py b/src/pandas_profiling/model/pandas/correlations_pandas.py\n--- a/src/pandas_profiling/model/pandas/correlations_pandas.py\n+++ b/src/pandas_profiling/model/pandas/correlations_pandas.py\n@@ -97,9 +97,12 @@\n \n for name1, name2 in itertools.combinations(categoricals, 2):\n confusion_matrix = pd.crosstab(df[name1], df[name2])\n- correlation_matrix.loc[name2, name1] = _cramers_corrected_stat(\n- confusion_matrix, correction=True\n- )\n+ if confusion_matrix.empty:\n+ correlation_matrix.loc[name2, name1] = np.nan\n+ else:\n+ correlation_matrix.loc[name2, name1] = _cramers_corrected_stat(\n+ confusion_matrix, correction=True\n+ )\n correlation_matrix.loc[name1, name2] = correlation_matrix.loc[name2, name1]\n return correlation_matrix\n", "issue": "Cramer correlation matrix is not computed\n/usr/local/lib/python3.7/dist-packages/pandas_profiling/model/correlations.py:61: UserWarning:There was an attempt to calculate the cramers correlation, but this failed.\r\nTo hide this warning, disable the calculation\r\n(using `df.profile_report(correlations={\"cramers\": {\"calculate\": False}})`\r\nIf this is problematic for your use case, please report this as an issue:\r\nhttps://github.com/ydataai/pandas-profiling/issues\r\n(include the error message: 'No data; `observed` has size 0.')\r\n pls help. My dataset is https://busan302.mycourses.work/data/house_price_train.csv\n", "before_files": [{"content": "\"\"\"Correlations between variables.\"\"\"\nimport itertools\nimport warnings\nfrom typing import Optional\n\nimport numpy as np\nimport pandas as pd\nfrom scipy import stats\n\nfrom pandas_profiling.config import Settings\nfrom pandas_profiling.model.correlations import (\n Cramers,\n Kendall,\n Pearson,\n PhiK,\n Spearman,\n)\n\n\[email protected](Settings, pd.DataFrame, dict)\ndef pandas_spearman_compute(\n config: Settings, df: pd.DataFrame, summary: dict\n) -> Optional[pd.DataFrame]:\n return df.corr(method=\"spearman\")\n\n\[email protected](Settings, pd.DataFrame, dict)\ndef pandas_pearson_compute(\n config: Settings, df: pd.DataFrame, summary: dict\n) -> Optional[pd.DataFrame]:\n return df.corr(method=\"pearson\")\n\n\[email protected](Settings, pd.DataFrame, dict)\ndef pandas_kendall_compute(\n config: Settings, df: pd.DataFrame, summary: dict\n) -> Optional[pd.DataFrame]:\n return df.corr(method=\"kendall\")\n\n\ndef _cramers_corrected_stat(confusion_matrix: pd.DataFrame, correction: bool) -> float:\n \"\"\"Calculate the Cramer's V corrected stat for two variables.\n\n Args:\n confusion_matrix: Crosstab between two variables.\n correction: Should the correction be applied?\n\n Returns:\n The Cramer's V corrected stat for the two variables.\n \"\"\"\n chi2 = stats.chi2_contingency(confusion_matrix, correction=correction)[0]\n n = confusion_matrix.sum().sum()\n phi2 = chi2 / n\n r = confusion_matrix.shape[0]\n k = confusion_matrix.shape[1] if len(confusion_matrix.shape) > 1 else 1\n\n # Deal with NaNs later on\n with np.errstate(divide=\"ignore\", invalid=\"ignore\"):\n phi2corr = max(0.0, phi2 - ((k - 1.0) * (r - 1.0)) / (n - 1.0))\n rcorr = r - ((r - 1.0) ** 2.0) / (n - 1.0)\n kcorr = k - ((k - 1.0) ** 2.0) / (n - 1.0)\n rkcorr = min((kcorr - 1.0), (rcorr - 1.0))\n if rkcorr == 0.0:\n corr = 1.0\n else:\n corr = np.sqrt(phi2corr / rkcorr)\n return corr\n\n\[email protected](Settings, pd.DataFrame, dict)\ndef pandas_cramers_compute(\n config: Settings, df: pd.DataFrame, summary: dict\n) -> Optional[pd.DataFrame]:\n threshold = config.categorical_maximum_correlation_distinct\n\n # `index` and `columns` must not be a set since Pandas 1.5,\n # so convert it to a list. The order of the list is arbitrary.\n categoricals = list(\n {\n key\n for key, value in summary.items()\n if value[\"type\"] in {\"Categorical\", \"Boolean\"}\n and value[\"n_distinct\"] <= threshold\n }\n )\n\n if len(categoricals) <= 1:\n return None\n\n matrix = np.zeros((len(categoricals), len(categoricals)))\n np.fill_diagonal(matrix, 1.0)\n correlation_matrix = pd.DataFrame(\n matrix,\n index=categoricals,\n columns=categoricals,\n )\n\n for name1, name2 in itertools.combinations(categoricals, 2):\n confusion_matrix = pd.crosstab(df[name1], df[name2])\n correlation_matrix.loc[name2, name1] = _cramers_corrected_stat(\n confusion_matrix, correction=True\n )\n correlation_matrix.loc[name1, name2] = correlation_matrix.loc[name2, name1]\n return correlation_matrix\n\n\[email protected](Settings, pd.DataFrame, dict)\ndef pandas_phik_compute(\n config: Settings, df: pd.DataFrame, summary: dict\n) -> Optional[pd.DataFrame]:\n df_cols_dict = {i: list(df.columns).index(i) for i in df.columns}\n\n intcols = {\n key\n for key, value in summary.items()\n # DateTime currently excluded\n # In some use cases, it makes sense to convert it to interval\n # See https://github.com/KaveIO/PhiK/issues/7\n if value[\"type\"] == \"Numeric\" and 1 < value[\"n_distinct\"]\n }\n\n selcols = {\n key\n for key, value in summary.items()\n if value[\"type\"] != \"Unsupported\"\n and 1 < value[\"n_distinct\"] <= config.categorical_maximum_correlation_distinct\n }\n selcols = selcols.union(intcols)\n selected_cols = sorted(selcols, key=lambda i: df_cols_dict[i])\n\n if len(selected_cols) <= 1:\n return None\n\n with warnings.catch_warnings():\n warnings.simplefilter(\"ignore\")\n from phik import phik_matrix\n\n correlation = phik_matrix(df[selected_cols], interval_cols=list(intcols))\n\n return correlation\n", "path": "src/pandas_profiling/model/pandas/correlations_pandas.py"}]}
| 2,161 | 229 |
gh_patches_debug_477
|
rasdani/github-patches
|
git_diff
|
scrapy__scrapy-5786
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
pypy3-pinned OpenSSL error
Yet another CI issue, visible in https://github.com/scrapy/scrapy/actions/runs/3849823417/jobs/6559259481
> /home/runner/work/scrapy/scrapy/.tox/pypy3-pinned/site-packages/cryptography/hazmat/bindings/_openssl.pypy37-pp73-x86_64-linux-gnu.so: undefined symbol: FIPS_mode
This may be a problem with that specific binary distribution (it's `cryptography==3.3`), not sure why it worked before, maybe something was rebuilt recently.
</issue>
<code>
[start of setup.py]
1 from pathlib import Path
2 from pkg_resources import parse_version
3 from setuptools import setup, find_packages, __version__ as setuptools_version
4
5
6 version = (Path(__file__).parent / 'scrapy/VERSION').read_text('ascii').strip()
7
8
9 def has_environment_marker_platform_impl_support():
10 """Code extracted from 'pytest/setup.py'
11 https://github.com/pytest-dev/pytest/blob/7538680c/setup.py#L31
12
13 The first known release to support environment marker with range operators
14 it is 18.5, see:
15 https://setuptools.readthedocs.io/en/latest/history.html#id235
16 """
17 return parse_version(setuptools_version) >= parse_version('18.5')
18
19
20 install_requires = [
21 'Twisted>=18.9.0',
22 'cryptography>=3.3',
23 'cssselect>=0.9.1',
24 'itemloaders>=1.0.1',
25 'parsel>=1.5.0',
26 'pyOpenSSL>=21.0.0',
27 'queuelib>=1.4.2',
28 'service_identity>=18.1.0',
29 'w3lib>=1.17.0',
30 'zope.interface>=5.1.0',
31 'protego>=0.1.15',
32 'itemadapter>=0.1.0',
33 'setuptools',
34 'packaging',
35 'tldextract',
36 'lxml>=4.3.0',
37 ]
38 extras_require = {}
39 cpython_dependencies = [
40 'PyDispatcher>=2.0.5',
41 ]
42 if has_environment_marker_platform_impl_support():
43 extras_require[':platform_python_implementation == "CPython"'] = cpython_dependencies
44 extras_require[':platform_python_implementation == "PyPy"'] = [
45 'PyPyDispatcher>=2.1.0',
46 ]
47 else:
48 install_requires.extend(cpython_dependencies)
49
50
51 setup(
52 name='Scrapy',
53 version=version,
54 url='https://scrapy.org',
55 project_urls={
56 'Documentation': 'https://docs.scrapy.org/',
57 'Source': 'https://github.com/scrapy/scrapy',
58 'Tracker': 'https://github.com/scrapy/scrapy/issues',
59 },
60 description='A high-level Web Crawling and Web Scraping framework',
61 long_description=open('README.rst', encoding="utf-8").read(),
62 author='Scrapy developers',
63 author_email='[email protected]',
64 maintainer='Pablo Hoffman',
65 maintainer_email='[email protected]',
66 license='BSD',
67 packages=find_packages(exclude=('tests', 'tests.*')),
68 include_package_data=True,
69 zip_safe=False,
70 entry_points={
71 'console_scripts': ['scrapy = scrapy.cmdline:execute']
72 },
73 classifiers=[
74 'Framework :: Scrapy',
75 'Development Status :: 5 - Production/Stable',
76 'Environment :: Console',
77 'Intended Audience :: Developers',
78 'License :: OSI Approved :: BSD License',
79 'Operating System :: OS Independent',
80 'Programming Language :: Python',
81 'Programming Language :: Python :: 3',
82 'Programming Language :: Python :: 3.7',
83 'Programming Language :: Python :: 3.8',
84 'Programming Language :: Python :: 3.9',
85 'Programming Language :: Python :: 3.10',
86 'Programming Language :: Python :: 3.11',
87 'Programming Language :: Python :: Implementation :: CPython',
88 'Programming Language :: Python :: Implementation :: PyPy',
89 'Topic :: Internet :: WWW/HTTP',
90 'Topic :: Software Development :: Libraries :: Application Frameworks',
91 'Topic :: Software Development :: Libraries :: Python Modules',
92 ],
93 python_requires='>=3.7',
94 install_requires=install_requires,
95 extras_require=extras_require,
96 )
97
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -19,7 +19,7 @@
install_requires = [
'Twisted>=18.9.0',
- 'cryptography>=3.3',
+ 'cryptography>=3.4.6',
'cssselect>=0.9.1',
'itemloaders>=1.0.1',
'parsel>=1.5.0',
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -19,7 +19,7 @@\n \n install_requires = [\n 'Twisted>=18.9.0',\n- 'cryptography>=3.3',\n+ 'cryptography>=3.4.6',\n 'cssselect>=0.9.1',\n 'itemloaders>=1.0.1',\n 'parsel>=1.5.0',\n", "issue": "pypy3-pinned OpenSSL error\nYet another CI issue, visible in https://github.com/scrapy/scrapy/actions/runs/3849823417/jobs/6559259481\r\n\r\n> /home/runner/work/scrapy/scrapy/.tox/pypy3-pinned/site-packages/cryptography/hazmat/bindings/_openssl.pypy37-pp73-x86_64-linux-gnu.so: undefined symbol: FIPS_mode\r\n\r\nThis may be a problem with that specific binary distribution (it's `cryptography==3.3`), not sure why it worked before, maybe something was rebuilt recently. \n", "before_files": [{"content": "from pathlib import Path\nfrom pkg_resources import parse_version\nfrom setuptools import setup, find_packages, __version__ as setuptools_version\n\n\nversion = (Path(__file__).parent / 'scrapy/VERSION').read_text('ascii').strip()\n\n\ndef has_environment_marker_platform_impl_support():\n \"\"\"Code extracted from 'pytest/setup.py'\n https://github.com/pytest-dev/pytest/blob/7538680c/setup.py#L31\n\n The first known release to support environment marker with range operators\n it is 18.5, see:\n https://setuptools.readthedocs.io/en/latest/history.html#id235\n \"\"\"\n return parse_version(setuptools_version) >= parse_version('18.5')\n\n\ninstall_requires = [\n 'Twisted>=18.9.0',\n 'cryptography>=3.3',\n 'cssselect>=0.9.1',\n 'itemloaders>=1.0.1',\n 'parsel>=1.5.0',\n 'pyOpenSSL>=21.0.0',\n 'queuelib>=1.4.2',\n 'service_identity>=18.1.0',\n 'w3lib>=1.17.0',\n 'zope.interface>=5.1.0',\n 'protego>=0.1.15',\n 'itemadapter>=0.1.0',\n 'setuptools',\n 'packaging',\n 'tldextract',\n 'lxml>=4.3.0',\n]\nextras_require = {}\ncpython_dependencies = [\n 'PyDispatcher>=2.0.5',\n]\nif has_environment_marker_platform_impl_support():\n extras_require[':platform_python_implementation == \"CPython\"'] = cpython_dependencies\n extras_require[':platform_python_implementation == \"PyPy\"'] = [\n 'PyPyDispatcher>=2.1.0',\n ]\nelse:\n install_requires.extend(cpython_dependencies)\n\n\nsetup(\n name='Scrapy',\n version=version,\n url='https://scrapy.org',\n project_urls={\n 'Documentation': 'https://docs.scrapy.org/',\n 'Source': 'https://github.com/scrapy/scrapy',\n 'Tracker': 'https://github.com/scrapy/scrapy/issues',\n },\n description='A high-level Web Crawling and Web Scraping framework',\n long_description=open('README.rst', encoding=\"utf-8\").read(),\n author='Scrapy developers',\n author_email='[email protected]',\n maintainer='Pablo Hoffman',\n maintainer_email='[email protected]',\n license='BSD',\n packages=find_packages(exclude=('tests', 'tests.*')),\n include_package_data=True,\n zip_safe=False,\n entry_points={\n 'console_scripts': ['scrapy = scrapy.cmdline:execute']\n },\n classifiers=[\n 'Framework :: Scrapy',\n 'Development Status :: 5 - Production/Stable',\n 'Environment :: Console',\n 'Intended Audience :: Developers',\n 'License :: OSI Approved :: BSD License',\n 'Operating System :: OS Independent',\n 'Programming Language :: Python',\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n 'Programming Language :: Python :: 3.9',\n 'Programming Language :: Python :: 3.10',\n 'Programming Language :: Python :: 3.11',\n 'Programming Language :: Python :: Implementation :: CPython',\n 'Programming Language :: Python :: Implementation :: PyPy',\n 'Topic :: Internet :: WWW/HTTP',\n 'Topic :: Software Development :: Libraries :: Application Frameworks',\n 'Topic :: Software Development :: Libraries :: Python Modules',\n ],\n python_requires='>=3.7',\n install_requires=install_requires,\n extras_require=extras_require,\n)\n", "path": "setup.py"}]}
| 1,694 | 105 |
gh_patches_debug_28254
|
rasdani/github-patches
|
git_diff
|
airctic__icevision-722
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Rename EfficientDet Backbones
rename EfficientDet Backbones by deleting the `efficientdet_` part from the names: no need to reference that because the model already suggests that
</issue>
<code>
[start of icevision/models/ross/efficientdet/backbones.py]
1 __all__ = [
2 "tf_efficientdet_lite0",
3 "efficientdet_d0",
4 "efficientdet_d1",
5 "efficientdet_d2",
6 "efficientdet_d3",
7 "efficientdet_d4",
8 "efficientdet_d5",
9 "efficientdet_d6",
10 "efficientdet_d7",
11 "efficientdet_d7x",
12 ]
13
14 from icevision.models.ross.efficientdet.utils import *
15
16
17 tf_efficientdet_lite0 = EfficientDetBackboneConfig(model_name="tf_efficientdet_lite0")
18
19 efficientdet_d0 = EfficientDetBackboneConfig(model_name="efficientdet_d0")
20
21 efficientdet_d1 = EfficientDetBackboneConfig(model_name="efficientdet_d1")
22
23 efficientdet_d2 = EfficientDetBackboneConfig(model_name="efficientdet_d2")
24
25 efficientdet_d3 = EfficientDetBackboneConfig(model_name="efficientdet_d3")
26
27 efficientdet_d4 = EfficientDetBackboneConfig(model_name="efficientdet_d4")
28
29 efficientdet_d5 = EfficientDetBackboneConfig(model_name="efficientdet_d5")
30
31 efficientdet_d6 = EfficientDetBackboneConfig(model_name="efficientdet_d6")
32
33 efficientdet_d7 = EfficientDetBackboneConfig(model_name="efficientdet_d7")
34
35 efficientdet_d7x = EfficientDetBackboneConfig(model_name="efficientdet_d7x")
36
[end of icevision/models/ross/efficientdet/backbones.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/icevision/models/ross/efficientdet/backbones.py b/icevision/models/ross/efficientdet/backbones.py
--- a/icevision/models/ross/efficientdet/backbones.py
+++ b/icevision/models/ross/efficientdet/backbones.py
@@ -1,35 +1,35 @@
__all__ = [
- "tf_efficientdet_lite0",
- "efficientdet_d0",
- "efficientdet_d1",
- "efficientdet_d2",
- "efficientdet_d3",
- "efficientdet_d4",
- "efficientdet_d5",
- "efficientdet_d6",
- "efficientdet_d7",
- "efficientdet_d7x",
+ "tf_lite0",
+ "d0",
+ "d1",
+ "d2",
+ "d3",
+ "d4",
+ "d5",
+ "d6",
+ "d7",
+ "d7x",
]
from icevision.models.ross.efficientdet.utils import *
-tf_efficientdet_lite0 = EfficientDetBackboneConfig(model_name="tf_efficientdet_lite0")
+tf_lite0 = EfficientDetBackboneConfig(model_name="tf_efficientdet_lite0")
-efficientdet_d0 = EfficientDetBackboneConfig(model_name="efficientdet_d0")
+d0 = EfficientDetBackboneConfig(model_name="efficientdet_d0")
-efficientdet_d1 = EfficientDetBackboneConfig(model_name="efficientdet_d1")
+d1 = EfficientDetBackboneConfig(model_name="efficientdet_d1")
-efficientdet_d2 = EfficientDetBackboneConfig(model_name="efficientdet_d2")
+d2 = EfficientDetBackboneConfig(model_name="efficientdet_d2")
-efficientdet_d3 = EfficientDetBackboneConfig(model_name="efficientdet_d3")
+d3 = EfficientDetBackboneConfig(model_name="efficientdet_d3")
-efficientdet_d4 = EfficientDetBackboneConfig(model_name="efficientdet_d4")
+d4 = EfficientDetBackboneConfig(model_name="efficientdet_d4")
-efficientdet_d5 = EfficientDetBackboneConfig(model_name="efficientdet_d5")
+d5 = EfficientDetBackboneConfig(model_name="efficientdet_d5")
-efficientdet_d6 = EfficientDetBackboneConfig(model_name="efficientdet_d6")
+d6 = EfficientDetBackboneConfig(model_name="efficientdet_d6")
-efficientdet_d7 = EfficientDetBackboneConfig(model_name="efficientdet_d7")
+d7 = EfficientDetBackboneConfig(model_name="efficientdet_d7")
-efficientdet_d7x = EfficientDetBackboneConfig(model_name="efficientdet_d7x")
+d7x = EfficientDetBackboneConfig(model_name="efficientdet_d7x")
|
{"golden_diff": "diff --git a/icevision/models/ross/efficientdet/backbones.py b/icevision/models/ross/efficientdet/backbones.py\n--- a/icevision/models/ross/efficientdet/backbones.py\n+++ b/icevision/models/ross/efficientdet/backbones.py\n@@ -1,35 +1,35 @@\n __all__ = [\n- \"tf_efficientdet_lite0\",\n- \"efficientdet_d0\",\n- \"efficientdet_d1\",\n- \"efficientdet_d2\",\n- \"efficientdet_d3\",\n- \"efficientdet_d4\",\n- \"efficientdet_d5\",\n- \"efficientdet_d6\",\n- \"efficientdet_d7\",\n- \"efficientdet_d7x\",\n+ \"tf_lite0\",\n+ \"d0\",\n+ \"d1\",\n+ \"d2\",\n+ \"d3\",\n+ \"d4\",\n+ \"d5\",\n+ \"d6\",\n+ \"d7\",\n+ \"d7x\",\n ]\n \n from icevision.models.ross.efficientdet.utils import *\n \n \n-tf_efficientdet_lite0 = EfficientDetBackboneConfig(model_name=\"tf_efficientdet_lite0\")\n+tf_lite0 = EfficientDetBackboneConfig(model_name=\"tf_efficientdet_lite0\")\n \n-efficientdet_d0 = EfficientDetBackboneConfig(model_name=\"efficientdet_d0\")\n+d0 = EfficientDetBackboneConfig(model_name=\"efficientdet_d0\")\n \n-efficientdet_d1 = EfficientDetBackboneConfig(model_name=\"efficientdet_d1\")\n+d1 = EfficientDetBackboneConfig(model_name=\"efficientdet_d1\")\n \n-efficientdet_d2 = EfficientDetBackboneConfig(model_name=\"efficientdet_d2\")\n+d2 = EfficientDetBackboneConfig(model_name=\"efficientdet_d2\")\n \n-efficientdet_d3 = EfficientDetBackboneConfig(model_name=\"efficientdet_d3\")\n+d3 = EfficientDetBackboneConfig(model_name=\"efficientdet_d3\")\n \n-efficientdet_d4 = EfficientDetBackboneConfig(model_name=\"efficientdet_d4\")\n+d4 = EfficientDetBackboneConfig(model_name=\"efficientdet_d4\")\n \n-efficientdet_d5 = EfficientDetBackboneConfig(model_name=\"efficientdet_d5\")\n+d5 = EfficientDetBackboneConfig(model_name=\"efficientdet_d5\")\n \n-efficientdet_d6 = EfficientDetBackboneConfig(model_name=\"efficientdet_d6\")\n+d6 = EfficientDetBackboneConfig(model_name=\"efficientdet_d6\")\n \n-efficientdet_d7 = EfficientDetBackboneConfig(model_name=\"efficientdet_d7\")\n+d7 = EfficientDetBackboneConfig(model_name=\"efficientdet_d7\")\n \n-efficientdet_d7x = EfficientDetBackboneConfig(model_name=\"efficientdet_d7x\")\n+d7x = EfficientDetBackboneConfig(model_name=\"efficientdet_d7x\")\n", "issue": "Rename EfficientDet Backbones\nrename EfficientDet Backbones by deleting the `efficientdet_` part from the names: no need to reference that because the model already suggests that\r\n\n", "before_files": [{"content": "__all__ = [\n \"tf_efficientdet_lite0\",\n \"efficientdet_d0\",\n \"efficientdet_d1\",\n \"efficientdet_d2\",\n \"efficientdet_d3\",\n \"efficientdet_d4\",\n \"efficientdet_d5\",\n \"efficientdet_d6\",\n \"efficientdet_d7\",\n \"efficientdet_d7x\",\n]\n\nfrom icevision.models.ross.efficientdet.utils import *\n\n\ntf_efficientdet_lite0 = EfficientDetBackboneConfig(model_name=\"tf_efficientdet_lite0\")\n\nefficientdet_d0 = EfficientDetBackboneConfig(model_name=\"efficientdet_d0\")\n\nefficientdet_d1 = EfficientDetBackboneConfig(model_name=\"efficientdet_d1\")\n\nefficientdet_d2 = EfficientDetBackboneConfig(model_name=\"efficientdet_d2\")\n\nefficientdet_d3 = EfficientDetBackboneConfig(model_name=\"efficientdet_d3\")\n\nefficientdet_d4 = EfficientDetBackboneConfig(model_name=\"efficientdet_d4\")\n\nefficientdet_d5 = EfficientDetBackboneConfig(model_name=\"efficientdet_d5\")\n\nefficientdet_d6 = EfficientDetBackboneConfig(model_name=\"efficientdet_d6\")\n\nefficientdet_d7 = EfficientDetBackboneConfig(model_name=\"efficientdet_d7\")\n\nefficientdet_d7x = EfficientDetBackboneConfig(model_name=\"efficientdet_d7x\")\n", "path": "icevision/models/ross/efficientdet/backbones.py"}]}
| 937 | 600 |
gh_patches_debug_32768
|
rasdani/github-patches
|
git_diff
|
cisagov__manage.get.gov-972
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Fixtures loads 8 times on docker-compose up
### Current Behavior
When starting up the application, the console log shows that the fixtures file is executed 8 times in a row. However, current logic on the fixtures file is preventing duplicate entries in the database.
### Expected Behavior
Data should just be loaded into the db once when using fixtures.
### Steps to Reproduce
1. locally run docker-compose up
2. observe the logs
3. see that the logs for loading domain application, users, etc are repeated 8 times each. Also note the warning messages that show an attempt was made to enter data that already exists in the db.
### Environment
local & on sandbox (see the deploy logs)
### Additional Context
see this [slack thread](https://cisa-corp.slack.com/archives/C05BGB4L5NF/p1687988129781299)
### Issue Links
_No response_
</issue>
<code>
[start of src/registrar/management/commands/load.py]
1 import logging
2
3 from django.core.management.base import BaseCommand
4 from auditlog.context import disable_auditlog # type: ignore
5
6 from registrar.fixtures import UserFixture, DomainApplicationFixture, DomainFixture
7
8 logger = logging.getLogger(__name__)
9
10
11 class Command(BaseCommand):
12 def handle(self, *args, **options):
13 # django-auditlog has some bugs with fixtures
14 # https://github.com/jazzband/django-auditlog/issues/17
15 with disable_auditlog():
16 UserFixture.load()
17 DomainApplicationFixture.load()
18 DomainFixture.load()
19 logger.info("All fixtures loaded.")
20
[end of src/registrar/management/commands/load.py]
[start of src/registrar/signals.py]
1 import logging
2
3 from django.conf import settings
4 from django.core.management import call_command
5 from django.db.models.signals import post_save, post_migrate
6 from django.dispatch import receiver
7
8 from .models import User, Contact
9
10
11 logger = logging.getLogger(__name__)
12
13
14 @receiver(post_save, sender=User)
15 def handle_profile(sender, instance, **kwargs):
16 """Method for when a User is saved.
17
18 A first time registrant may have been invited, so we'll search for a matching
19 Contact record, by email address, and associate them, if possible.
20
21 A first time registrant may not have a matching Contact, so we'll create one,
22 copying the contact values we received from Login.gov in order to initialize it.
23
24 During subsequent login, a User record may be updated with new data from Login.gov,
25 but in no case will we update contact values on an existing Contact record.
26 """
27
28 first_name = getattr(instance, "first_name", "")
29 last_name = getattr(instance, "last_name", "")
30 email = getattr(instance, "email", "")
31 phone = getattr(instance, "phone", "")
32
33 is_new_user = kwargs.get("created", False)
34
35 if is_new_user:
36 contacts = Contact.objects.filter(email=email)
37 else:
38 contacts = Contact.objects.filter(user=instance)
39
40 if len(contacts) == 0: # no matching contact
41 Contact.objects.create(
42 user=instance,
43 first_name=first_name,
44 last_name=last_name,
45 email=email,
46 phone=phone,
47 )
48
49 if len(contacts) >= 1 and is_new_user: # a matching contact
50 contacts[0].user = instance
51 contacts[0].save()
52
53 if len(contacts) > 1: # multiple matches
54 logger.warning(
55 "There are multiple Contacts with the same email address."
56 f" Picking #{contacts[0].id} for User #{instance.id}."
57 )
58
59
60 @receiver(post_migrate)
61 def handle_loaddata(**kwargs):
62 """Attempt to load test fixtures when in DEBUG mode."""
63 if settings.DEBUG:
64 try:
65 call_command("load")
66 except Exception as e:
67 logger.warning(e)
68
[end of src/registrar/signals.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/registrar/management/commands/load.py b/src/registrar/management/commands/load.py
--- a/src/registrar/management/commands/load.py
+++ b/src/registrar/management/commands/load.py
@@ -2,6 +2,7 @@
from django.core.management.base import BaseCommand
from auditlog.context import disable_auditlog # type: ignore
+from django.conf import settings
from registrar.fixtures import UserFixture, DomainApplicationFixture, DomainFixture
@@ -12,8 +13,11 @@
def handle(self, *args, **options):
# django-auditlog has some bugs with fixtures
# https://github.com/jazzband/django-auditlog/issues/17
- with disable_auditlog():
- UserFixture.load()
- DomainApplicationFixture.load()
- DomainFixture.load()
- logger.info("All fixtures loaded.")
+ if settings.DEBUG:
+ with disable_auditlog():
+ UserFixture.load()
+ DomainApplicationFixture.load()
+ DomainFixture.load()
+ logger.info("All fixtures loaded.")
+ else:
+ logger.warn("Refusing to load fixture data in a non DEBUG env")
diff --git a/src/registrar/signals.py b/src/registrar/signals.py
--- a/src/registrar/signals.py
+++ b/src/registrar/signals.py
@@ -1,8 +1,6 @@
import logging
-from django.conf import settings
-from django.core.management import call_command
-from django.db.models.signals import post_save, post_migrate
+from django.db.models.signals import post_save
from django.dispatch import receiver
from .models import User, Contact
@@ -55,13 +53,3 @@
"There are multiple Contacts with the same email address."
f" Picking #{contacts[0].id} for User #{instance.id}."
)
-
-
-@receiver(post_migrate)
-def handle_loaddata(**kwargs):
- """Attempt to load test fixtures when in DEBUG mode."""
- if settings.DEBUG:
- try:
- call_command("load")
- except Exception as e:
- logger.warning(e)
|
{"golden_diff": "diff --git a/src/registrar/management/commands/load.py b/src/registrar/management/commands/load.py\n--- a/src/registrar/management/commands/load.py\n+++ b/src/registrar/management/commands/load.py\n@@ -2,6 +2,7 @@\n \n from django.core.management.base import BaseCommand\n from auditlog.context import disable_auditlog # type: ignore\n+from django.conf import settings\n \n from registrar.fixtures import UserFixture, DomainApplicationFixture, DomainFixture\n \n@@ -12,8 +13,11 @@\n def handle(self, *args, **options):\n # django-auditlog has some bugs with fixtures\n # https://github.com/jazzband/django-auditlog/issues/17\n- with disable_auditlog():\n- UserFixture.load()\n- DomainApplicationFixture.load()\n- DomainFixture.load()\n- logger.info(\"All fixtures loaded.\")\n+ if settings.DEBUG:\n+ with disable_auditlog():\n+ UserFixture.load()\n+ DomainApplicationFixture.load()\n+ DomainFixture.load()\n+ logger.info(\"All fixtures loaded.\")\n+ else:\n+ logger.warn(\"Refusing to load fixture data in a non DEBUG env\")\ndiff --git a/src/registrar/signals.py b/src/registrar/signals.py\n--- a/src/registrar/signals.py\n+++ b/src/registrar/signals.py\n@@ -1,8 +1,6 @@\n import logging\n \n-from django.conf import settings\n-from django.core.management import call_command\n-from django.db.models.signals import post_save, post_migrate\n+from django.db.models.signals import post_save\n from django.dispatch import receiver\n \n from .models import User, Contact\n@@ -55,13 +53,3 @@\n \"There are multiple Contacts with the same email address.\"\n f\" Picking #{contacts[0].id} for User #{instance.id}.\"\n )\n-\n-\n-@receiver(post_migrate)\n-def handle_loaddata(**kwargs):\n- \"\"\"Attempt to load test fixtures when in DEBUG mode.\"\"\"\n- if settings.DEBUG:\n- try:\n- call_command(\"load\")\n- except Exception as e:\n- logger.warning(e)\n", "issue": "Fixtures loads 8 times on docker-compose up\n### Current Behavior\n\nWhen starting up the application, the console log shows that the fixtures file is executed 8 times in a row. However, current logic on the fixtures file is preventing duplicate entries in the database.\n\n### Expected Behavior\n\nData should just be loaded into the db once when using fixtures.\n\n### Steps to Reproduce\n\n1. locally run docker-compose up\r\n2. observe the logs\r\n3. see that the logs for loading domain application, users, etc are repeated 8 times each. Also note the warning messages that show an attempt was made to enter data that already exists in the db.\r\n\n\n### Environment\n\nlocal & on sandbox (see the deploy logs)\n\n### Additional Context\n\nsee this [slack thread](https://cisa-corp.slack.com/archives/C05BGB4L5NF/p1687988129781299)\n\n### Issue Links\n\n_No response_\n", "before_files": [{"content": "import logging\n\nfrom django.core.management.base import BaseCommand\nfrom auditlog.context import disable_auditlog # type: ignore\n\nfrom registrar.fixtures import UserFixture, DomainApplicationFixture, DomainFixture\n\nlogger = logging.getLogger(__name__)\n\n\nclass Command(BaseCommand):\n def handle(self, *args, **options):\n # django-auditlog has some bugs with fixtures\n # https://github.com/jazzband/django-auditlog/issues/17\n with disable_auditlog():\n UserFixture.load()\n DomainApplicationFixture.load()\n DomainFixture.load()\n logger.info(\"All fixtures loaded.\")\n", "path": "src/registrar/management/commands/load.py"}, {"content": "import logging\n\nfrom django.conf import settings\nfrom django.core.management import call_command\nfrom django.db.models.signals import post_save, post_migrate\nfrom django.dispatch import receiver\n\nfrom .models import User, Contact\n\n\nlogger = logging.getLogger(__name__)\n\n\n@receiver(post_save, sender=User)\ndef handle_profile(sender, instance, **kwargs):\n \"\"\"Method for when a User is saved.\n\n A first time registrant may have been invited, so we'll search for a matching\n Contact record, by email address, and associate them, if possible.\n\n A first time registrant may not have a matching Contact, so we'll create one,\n copying the contact values we received from Login.gov in order to initialize it.\n\n During subsequent login, a User record may be updated with new data from Login.gov,\n but in no case will we update contact values on an existing Contact record.\n \"\"\"\n\n first_name = getattr(instance, \"first_name\", \"\")\n last_name = getattr(instance, \"last_name\", \"\")\n email = getattr(instance, \"email\", \"\")\n phone = getattr(instance, \"phone\", \"\")\n\n is_new_user = kwargs.get(\"created\", False)\n\n if is_new_user:\n contacts = Contact.objects.filter(email=email)\n else:\n contacts = Contact.objects.filter(user=instance)\n\n if len(contacts) == 0: # no matching contact\n Contact.objects.create(\n user=instance,\n first_name=first_name,\n last_name=last_name,\n email=email,\n phone=phone,\n )\n\n if len(contacts) >= 1 and is_new_user: # a matching contact\n contacts[0].user = instance\n contacts[0].save()\n\n if len(contacts) > 1: # multiple matches\n logger.warning(\n \"There are multiple Contacts with the same email address.\"\n f\" Picking #{contacts[0].id} for User #{instance.id}.\"\n )\n\n\n@receiver(post_migrate)\ndef handle_loaddata(**kwargs):\n \"\"\"Attempt to load test fixtures when in DEBUG mode.\"\"\"\n if settings.DEBUG:\n try:\n call_command(\"load\")\n except Exception as e:\n logger.warning(e)\n", "path": "src/registrar/signals.py"}]}
| 1,527 | 461 |
gh_patches_debug_32366
|
rasdani/github-patches
|
git_diff
|
Lightning-Universe__lightning-flash-343
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
flash.Trainer.add_argparse_args(parser) doesn't register args to arg parse
## 🐛 Bug
```
parser = ArgumentParser()
parser = flash.Trainer.add_argparse_args(parser)
args = parser.parse_args()
```
Does not register any of the trainer args but the following code does
```
parser = ArgumentParser()
parser = pl.Trainer.add_argparse_args(parser)
args = parser.parse_args()
```
Since Flash wraps the PL trainer this should work the same way
</issue>
<code>
[start of flash/core/trainer.py]
1 # Copyright The PyTorch Lightning team.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 import warnings
15 from functools import wraps
16 from typing import Callable, List, Optional, Union
17
18 import torch
19 from pytorch_lightning import LightningDataModule, LightningModule, Trainer
20 from pytorch_lightning.callbacks import BaseFinetuning
21 from pytorch_lightning.utilities import rank_zero_warn
22 from pytorch_lightning.utilities.argparse import get_init_arguments_and_types, parse_env_variables
23 from pytorch_lightning.utilities.exceptions import MisconfigurationException
24 from torch.utils.data import DataLoader
25
26 import flash
27 from flash.core.finetuning import _DEFAULTS_FINETUNE_STRATEGIES, instantiate_default_finetuning_callbacks
28
29
30 def _defaults_from_env_vars(fn: Callable) -> Callable:
31 """Copy of ``pytorch_lightning.trainer.connectors.env_vars_connector._defaults_from_env_vars``. Required to fix
32 build error in readthedocs."""
33
34 @wraps(fn)
35 def insert_env_defaults(self, *args, **kwargs):
36 cls = self.__class__ # get the class
37 if args: # inace any args passed move them to kwargs
38 # parse only the argument names
39 cls_arg_names = [arg[0] for arg in get_init_arguments_and_types(cls)]
40 # convert args to kwargs
41 kwargs.update({k: v for k, v in zip(cls_arg_names, args)})
42 env_variables = vars(parse_env_variables(cls))
43 # update the kwargs by env variables
44 kwargs = dict(list(env_variables.items()) + list(kwargs.items()))
45
46 # all args were already moved to kwargs
47 return fn(self, **kwargs)
48
49 return insert_env_defaults
50
51
52 class Trainer(Trainer):
53
54 @_defaults_from_env_vars
55 def __init__(self, *args, **kwargs):
56 if flash._IS_TESTING:
57 if torch.cuda.is_available():
58 kwargs["gpus"] = 1
59 kwargs["max_epochs"] = 3
60 kwargs["limit_train_batches"] = 1.0
61 kwargs["limit_val_batches"] = 1.0
62 kwargs["limit_test_batches"] = 1.0
63 kwargs["fast_dev_run"] = False
64 else:
65 kwargs["fast_dev_run"] = True
66 super().__init__(*args, **kwargs)
67
68 def fit(
69 self,
70 model: LightningModule,
71 train_dataloader: Optional[DataLoader] = None,
72 val_dataloaders: Optional[Union[DataLoader, List[DataLoader]]] = None,
73 datamodule: Optional[LightningDataModule] = None,
74 ):
75 r"""
76 Runs the full optimization routine. Same as :meth:`pytorch_lightning.Trainer.fit`
77
78 Args:
79 datamodule: A instance of :class:`LightningDataModule`.
80
81 model: Model to fit.
82
83 train_dataloader: A Pytorch DataLoader with training samples. If the model has
84 a predefined train_dataloader method this will be skipped.
85
86 val_dataloaders: Either a single Pytorch Dataloader or a list of them, specifying validation samples.
87 If the model has a predefined val_dataloaders method this will be skipped
88 """
89 if any(isinstance(c, BaseFinetuning) for c in self.callbacks):
90 # TODO: if we find a finetuning callback in the trainer should we remove it? or just warn the user?
91 warnings.warn("Warning: You are calling fit(), but your trainer is using a fine-tuning callback")
92 return super().fit(model, train_dataloader, val_dataloaders, datamodule)
93
94 def finetune(
95 self,
96 model: LightningModule,
97 train_dataloader: Optional[DataLoader] = None,
98 val_dataloaders: Optional[Union[DataLoader, List[DataLoader]]] = None,
99 datamodule: Optional[LightningDataModule] = None,
100 strategy: Optional[Union[str, BaseFinetuning]] = None,
101 ):
102 r"""
103
104 Runs the full optimization routine. Same as :meth:`pytorch_lightning.Trainer.fit`, but unfreezes layers
105 of the backbone throughout training layers of the backbone throughout training.
106
107 Args:
108 datamodule: A instance of :class:`LightningDataModule`.
109
110 model: Model to fit.
111
112 train_dataloader: A PyTorch DataLoader with training samples. If the model has
113 a predefined train_dataloader method this will be skipped.
114
115 val_dataloaders: Either a single PyTorch Dataloader or a list of them, specifying validation samples.
116 If the model has a predefined val_dataloaders method this will be skipped
117
118 strategy: Should either be a string or a finetuning callback subclassing
119 :class:`pytorch_lightning.callbacks.BaseFinetuning`.
120
121 Default strategies can be enabled with these strings:
122
123 - ``"no_freeze"``,
124 - ``"freeze"``,
125 - ``"freeze_unfreeze"``,
126 - ``"unfreeze_milestones"``.
127 """
128 self._resolve_callbacks(model, strategy)
129 return super().fit(model, train_dataloader, val_dataloaders, datamodule)
130
131 def _resolve_callbacks(self, model, strategy):
132 """
133 This function is used to select the `BaseFinetuning` to be used for finetuning.
134 """
135 if strategy is not None and not isinstance(strategy, (str, BaseFinetuning)):
136 raise MisconfigurationException(
137 "strategy should be a ``pytorch_lightning.callbacks.BaseFinetuning``"
138 f"callback or a str within {list(_DEFAULTS_FINETUNE_STRATEGIES.keys())}"
139 )
140
141 if isinstance(strategy, BaseFinetuning):
142 callback = [strategy]
143 else:
144 # todo: change to ``configure_callbacks`` when merged to Lightning.
145 model_callback = model.configure_finetune_callback()
146 if len(model_callback) > 1:
147 raise MisconfigurationException(
148 f"{model} configure_finetune_callback should create a list with only 1 callback"
149 )
150 if len(model_callback) == 1:
151 if strategy is not None:
152 rank_zero_warn(
153 "The model contains a default finetune callback. The provided {strategy} will be overriden.\n"
154 " HINT: Provide a `BaseFinetuning` callback as strategy to make it prioritized. ", UserWarning
155 )
156 callback = model_callback
157 else:
158 callback = instantiate_default_finetuning_callbacks(strategy)
159
160 self.callbacks = self._merge_callbacks(self.callbacks, callback)
161
162 @staticmethod
163 def _merge_callbacks(old_callbacks: List, new_callbacks: List) -> List:
164 """
165 This function keeps only 1 instance of each callback type,
166 extending new_callbacks with old_callbacks
167 """
168 if len(new_callbacks) == 0:
169 return old_callbacks
170 new_callbacks_types = set(type(c) for c in new_callbacks)
171 old_callbacks_types = set(type(c) for c in old_callbacks)
172 override_types = new_callbacks_types.intersection(old_callbacks_types)
173 new_callbacks.extend(c for c in old_callbacks if type(c) not in override_types)
174 return new_callbacks
175
[end of flash/core/trainer.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/flash/core/trainer.py b/flash/core/trainer.py
--- a/flash/core/trainer.py
+++ b/flash/core/trainer.py
@@ -12,14 +12,16 @@
# See the License for the specific language governing permissions and
# limitations under the License.
import warnings
+from argparse import ArgumentParser
from functools import wraps
from typing import Callable, List, Optional, Union
import torch
-from pytorch_lightning import LightningDataModule, LightningModule, Trainer
+from pytorch_lightning import LightningDataModule, LightningModule
+from pytorch_lightning import Trainer as PlTrainer
from pytorch_lightning.callbacks import BaseFinetuning
from pytorch_lightning.utilities import rank_zero_warn
-from pytorch_lightning.utilities.argparse import get_init_arguments_and_types, parse_env_variables
+from pytorch_lightning.utilities.argparse import add_argparse_args, get_init_arguments_and_types, parse_env_variables
from pytorch_lightning.utilities.exceptions import MisconfigurationException
from torch.utils.data import DataLoader
@@ -49,7 +51,7 @@
return insert_env_defaults
-class Trainer(Trainer):
+class Trainer(PlTrainer):
@_defaults_from_env_vars
def __init__(self, *args, **kwargs):
@@ -172,3 +174,9 @@
override_types = new_callbacks_types.intersection(old_callbacks_types)
new_callbacks.extend(c for c in old_callbacks if type(c) not in override_types)
return new_callbacks
+
+ @classmethod
+ def add_argparse_args(cls, *args, **kwargs) -> ArgumentParser:
+ # the lightning trainer implementation does not support subclasses.
+ # context: https://github.com/PyTorchLightning/lightning-flash/issues/342#issuecomment-848892447
+ return add_argparse_args(PlTrainer, *args, **kwargs)
|
{"golden_diff": "diff --git a/flash/core/trainer.py b/flash/core/trainer.py\n--- a/flash/core/trainer.py\n+++ b/flash/core/trainer.py\n@@ -12,14 +12,16 @@\n # See the License for the specific language governing permissions and\n # limitations under the License.\n import warnings\n+from argparse import ArgumentParser\n from functools import wraps\n from typing import Callable, List, Optional, Union\n \n import torch\n-from pytorch_lightning import LightningDataModule, LightningModule, Trainer\n+from pytorch_lightning import LightningDataModule, LightningModule\n+from pytorch_lightning import Trainer as PlTrainer\n from pytorch_lightning.callbacks import BaseFinetuning\n from pytorch_lightning.utilities import rank_zero_warn\n-from pytorch_lightning.utilities.argparse import get_init_arguments_and_types, parse_env_variables\n+from pytorch_lightning.utilities.argparse import add_argparse_args, get_init_arguments_and_types, parse_env_variables\n from pytorch_lightning.utilities.exceptions import MisconfigurationException\n from torch.utils.data import DataLoader\n \n@@ -49,7 +51,7 @@\n return insert_env_defaults\n \n \n-class Trainer(Trainer):\n+class Trainer(PlTrainer):\n \n @_defaults_from_env_vars\n def __init__(self, *args, **kwargs):\n@@ -172,3 +174,9 @@\n override_types = new_callbacks_types.intersection(old_callbacks_types)\n new_callbacks.extend(c for c in old_callbacks if type(c) not in override_types)\n return new_callbacks\n+\n+ @classmethod\n+ def add_argparse_args(cls, *args, **kwargs) -> ArgumentParser:\n+ # the lightning trainer implementation does not support subclasses.\n+ # context: https://github.com/PyTorchLightning/lightning-flash/issues/342#issuecomment-848892447\n+ return add_argparse_args(PlTrainer, *args, **kwargs)\n", "issue": " flash.Trainer.add_argparse_args(parser) doesn't register args to arg parse\n## \ud83d\udc1b Bug\r\n\r\n```\r\n parser = ArgumentParser()\r\n parser = flash.Trainer.add_argparse_args(parser)\r\n args = parser.parse_args()\r\n```\r\n\r\nDoes not register any of the trainer args but the following code does\r\n\r\n```\r\n parser = ArgumentParser()\r\n parser = pl.Trainer.add_argparse_args(parser)\r\n args = parser.parse_args()\r\n```\r\n\r\nSince Flash wraps the PL trainer this should work the same way\r\n\r\n\n", "before_files": [{"content": "# Copyright The PyTorch Lightning team.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\nimport warnings\nfrom functools import wraps\nfrom typing import Callable, List, Optional, Union\n\nimport torch\nfrom pytorch_lightning import LightningDataModule, LightningModule, Trainer\nfrom pytorch_lightning.callbacks import BaseFinetuning\nfrom pytorch_lightning.utilities import rank_zero_warn\nfrom pytorch_lightning.utilities.argparse import get_init_arguments_and_types, parse_env_variables\nfrom pytorch_lightning.utilities.exceptions import MisconfigurationException\nfrom torch.utils.data import DataLoader\n\nimport flash\nfrom flash.core.finetuning import _DEFAULTS_FINETUNE_STRATEGIES, instantiate_default_finetuning_callbacks\n\n\ndef _defaults_from_env_vars(fn: Callable) -> Callable:\n \"\"\"Copy of ``pytorch_lightning.trainer.connectors.env_vars_connector._defaults_from_env_vars``. Required to fix\n build error in readthedocs.\"\"\"\n\n @wraps(fn)\n def insert_env_defaults(self, *args, **kwargs):\n cls = self.__class__ # get the class\n if args: # inace any args passed move them to kwargs\n # parse only the argument names\n cls_arg_names = [arg[0] for arg in get_init_arguments_and_types(cls)]\n # convert args to kwargs\n kwargs.update({k: v for k, v in zip(cls_arg_names, args)})\n env_variables = vars(parse_env_variables(cls))\n # update the kwargs by env variables\n kwargs = dict(list(env_variables.items()) + list(kwargs.items()))\n\n # all args were already moved to kwargs\n return fn(self, **kwargs)\n\n return insert_env_defaults\n\n\nclass Trainer(Trainer):\n\n @_defaults_from_env_vars\n def __init__(self, *args, **kwargs):\n if flash._IS_TESTING:\n if torch.cuda.is_available():\n kwargs[\"gpus\"] = 1\n kwargs[\"max_epochs\"] = 3\n kwargs[\"limit_train_batches\"] = 1.0\n kwargs[\"limit_val_batches\"] = 1.0\n kwargs[\"limit_test_batches\"] = 1.0\n kwargs[\"fast_dev_run\"] = False\n else:\n kwargs[\"fast_dev_run\"] = True\n super().__init__(*args, **kwargs)\n\n def fit(\n self,\n model: LightningModule,\n train_dataloader: Optional[DataLoader] = None,\n val_dataloaders: Optional[Union[DataLoader, List[DataLoader]]] = None,\n datamodule: Optional[LightningDataModule] = None,\n ):\n r\"\"\"\n Runs the full optimization routine. Same as :meth:`pytorch_lightning.Trainer.fit`\n\n Args:\n datamodule: A instance of :class:`LightningDataModule`.\n\n model: Model to fit.\n\n train_dataloader: A Pytorch DataLoader with training samples. If the model has\n a predefined train_dataloader method this will be skipped.\n\n val_dataloaders: Either a single Pytorch Dataloader or a list of them, specifying validation samples.\n If the model has a predefined val_dataloaders method this will be skipped\n \"\"\"\n if any(isinstance(c, BaseFinetuning) for c in self.callbacks):\n # TODO: if we find a finetuning callback in the trainer should we remove it? or just warn the user?\n warnings.warn(\"Warning: You are calling fit(), but your trainer is using a fine-tuning callback\")\n return super().fit(model, train_dataloader, val_dataloaders, datamodule)\n\n def finetune(\n self,\n model: LightningModule,\n train_dataloader: Optional[DataLoader] = None,\n val_dataloaders: Optional[Union[DataLoader, List[DataLoader]]] = None,\n datamodule: Optional[LightningDataModule] = None,\n strategy: Optional[Union[str, BaseFinetuning]] = None,\n ):\n r\"\"\"\n\n Runs the full optimization routine. Same as :meth:`pytorch_lightning.Trainer.fit`, but unfreezes layers\n of the backbone throughout training layers of the backbone throughout training.\n\n Args:\n datamodule: A instance of :class:`LightningDataModule`.\n\n model: Model to fit.\n\n train_dataloader: A PyTorch DataLoader with training samples. If the model has\n a predefined train_dataloader method this will be skipped.\n\n val_dataloaders: Either a single PyTorch Dataloader or a list of them, specifying validation samples.\n If the model has a predefined val_dataloaders method this will be skipped\n\n strategy: Should either be a string or a finetuning callback subclassing\n :class:`pytorch_lightning.callbacks.BaseFinetuning`.\n\n Default strategies can be enabled with these strings:\n\n - ``\"no_freeze\"``,\n - ``\"freeze\"``,\n - ``\"freeze_unfreeze\"``,\n - ``\"unfreeze_milestones\"``.\n \"\"\"\n self._resolve_callbacks(model, strategy)\n return super().fit(model, train_dataloader, val_dataloaders, datamodule)\n\n def _resolve_callbacks(self, model, strategy):\n \"\"\"\n This function is used to select the `BaseFinetuning` to be used for finetuning.\n \"\"\"\n if strategy is not None and not isinstance(strategy, (str, BaseFinetuning)):\n raise MisconfigurationException(\n \"strategy should be a ``pytorch_lightning.callbacks.BaseFinetuning``\"\n f\"callback or a str within {list(_DEFAULTS_FINETUNE_STRATEGIES.keys())}\"\n )\n\n if isinstance(strategy, BaseFinetuning):\n callback = [strategy]\n else:\n # todo: change to ``configure_callbacks`` when merged to Lightning.\n model_callback = model.configure_finetune_callback()\n if len(model_callback) > 1:\n raise MisconfigurationException(\n f\"{model} configure_finetune_callback should create a list with only 1 callback\"\n )\n if len(model_callback) == 1:\n if strategy is not None:\n rank_zero_warn(\n \"The model contains a default finetune callback. The provided {strategy} will be overriden.\\n\"\n \" HINT: Provide a `BaseFinetuning` callback as strategy to make it prioritized. \", UserWarning\n )\n callback = model_callback\n else:\n callback = instantiate_default_finetuning_callbacks(strategy)\n\n self.callbacks = self._merge_callbacks(self.callbacks, callback)\n\n @staticmethod\n def _merge_callbacks(old_callbacks: List, new_callbacks: List) -> List:\n \"\"\"\n This function keeps only 1 instance of each callback type,\n extending new_callbacks with old_callbacks\n \"\"\"\n if len(new_callbacks) == 0:\n return old_callbacks\n new_callbacks_types = set(type(c) for c in new_callbacks)\n old_callbacks_types = set(type(c) for c in old_callbacks)\n override_types = new_callbacks_types.intersection(old_callbacks_types)\n new_callbacks.extend(c for c in old_callbacks if type(c) not in override_types)\n return new_callbacks\n", "path": "flash/core/trainer.py"}]}
| 2,718 | 421 |
gh_patches_debug_12464
|
rasdani/github-patches
|
git_diff
|
pre-commit__pre-commit-1700
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Rbenv default ruby issue on install
I am trying to install MDL v0.11.0
i get the following error during install
```
pre-commit
[INFO] Installing environment for git://github.com/markdownlint/markdownlint.
[INFO] Once installed this environment will be reused.
[INFO] This may take a few minutes...
An unexpected error has occurred: CalledProcessError: command: ('/usr/local/bin/bash', '/Users/abuxton/.rbenv/shims/gem', 'build', 'mdl.gemspec')
return code: 1
expected return code: 0
stdout: (none)
stderr:
rbenv: version `default' is not installed (set by RBENV_VERSION environment variable)
```
seems to be the same issue as https://github.com/pre-commit/pre-commit/issues/369 on a previous version of pre-commit
pre-commit.log https://gist.github.com/abuxton/d29e6265f3230f838a746d7a5defd5e3
i have tried, ensuring local rbenv, I have tried pre-commit clean/uninstall and reinstall to no success, mdl will `brew install mdl` successfully and works fine.
</issue>
<code>
[start of pre_commit/languages/ruby.py]
1 import contextlib
2 import functools
3 import os.path
4 import shutil
5 import tarfile
6 from typing import Generator
7 from typing import Sequence
8 from typing import Tuple
9
10 import pre_commit.constants as C
11 from pre_commit.envcontext import envcontext
12 from pre_commit.envcontext import PatchesT
13 from pre_commit.envcontext import UNSET
14 from pre_commit.envcontext import Var
15 from pre_commit.hook import Hook
16 from pre_commit.languages import helpers
17 from pre_commit.prefix import Prefix
18 from pre_commit.util import CalledProcessError
19 from pre_commit.util import clean_path_on_failure
20 from pre_commit.util import resource_bytesio
21
22 ENVIRONMENT_DIR = 'rbenv'
23 healthy = helpers.basic_healthy
24
25
26 @functools.lru_cache(maxsize=1)
27 def get_default_version() -> str:
28 if all(helpers.exe_exists(exe) for exe in ('ruby', 'gem')):
29 return 'system'
30 else:
31 return C.DEFAULT
32
33
34 def get_env_patch(
35 venv: str,
36 language_version: str,
37 ) -> PatchesT:
38 patches: PatchesT = (
39 ('GEM_HOME', os.path.join(venv, 'gems')),
40 ('GEM_PATH', UNSET),
41 ('BUNDLE_IGNORE_CONFIG', '1'),
42 )
43 if language_version == 'system':
44 patches += (
45 (
46 'PATH', (
47 os.path.join(venv, 'gems', 'bin'), os.pathsep,
48 Var('PATH'),
49 ),
50 ),
51 )
52 else: # pragma: win32 no cover
53 patches += (
54 ('RBENV_ROOT', venv),
55 ('RBENV_VERSION', language_version),
56 (
57 'PATH', (
58 os.path.join(venv, 'gems', 'bin'), os.pathsep,
59 os.path.join(venv, 'shims'), os.pathsep,
60 os.path.join(venv, 'bin'), os.pathsep, Var('PATH'),
61 ),
62 ),
63 )
64 return patches
65
66
67 @contextlib.contextmanager
68 def in_env(
69 prefix: Prefix,
70 language_version: str,
71 ) -> Generator[None, None, None]:
72 envdir = prefix.path(
73 helpers.environment_dir(ENVIRONMENT_DIR, language_version),
74 )
75 with envcontext(get_env_patch(envdir, language_version)):
76 yield
77
78
79 def _extract_resource(filename: str, dest: str) -> None:
80 with resource_bytesio(filename) as bio:
81 with tarfile.open(fileobj=bio) as tf:
82 tf.extractall(dest)
83
84
85 def _install_rbenv(
86 prefix: Prefix,
87 version: str,
88 ) -> None: # pragma: win32 no cover
89 directory = helpers.environment_dir(ENVIRONMENT_DIR, version)
90
91 _extract_resource('rbenv.tar.gz', prefix.path('.'))
92 shutil.move(prefix.path('rbenv'), prefix.path(directory))
93
94 # Only install ruby-build if the version is specified
95 if version != C.DEFAULT:
96 plugins_dir = prefix.path(directory, 'plugins')
97 _extract_resource('ruby-download.tar.gz', plugins_dir)
98 _extract_resource('ruby-build.tar.gz', plugins_dir)
99
100
101 def _install_ruby(
102 prefix: Prefix,
103 version: str,
104 ) -> None: # pragma: win32 no cover
105 try:
106 helpers.run_setup_cmd(prefix, ('rbenv', 'download', version))
107 except CalledProcessError: # pragma: no cover (usually find with download)
108 # Failed to download from mirror for some reason, build it instead
109 helpers.run_setup_cmd(prefix, ('rbenv', 'install', version))
110
111
112 def install_environment(
113 prefix: Prefix, version: str, additional_dependencies: Sequence[str],
114 ) -> None:
115 additional_dependencies = tuple(additional_dependencies)
116 directory = helpers.environment_dir(ENVIRONMENT_DIR, version)
117 with clean_path_on_failure(prefix.path(directory)):
118 if version != 'system': # pragma: win32 no cover
119 _install_rbenv(prefix, version)
120 with in_env(prefix, version):
121 # Need to call this before installing so rbenv's directories
122 # are set up
123 helpers.run_setup_cmd(prefix, ('rbenv', 'init', '-'))
124 if version != C.DEFAULT:
125 _install_ruby(prefix, version)
126 # Need to call this after installing to set up the shims
127 helpers.run_setup_cmd(prefix, ('rbenv', 'rehash'))
128
129 with in_env(prefix, version):
130 helpers.run_setup_cmd(
131 prefix, ('gem', 'build', *prefix.star('.gemspec')),
132 )
133 helpers.run_setup_cmd(
134 prefix,
135 (
136 'gem', 'install',
137 '--no-document', '--no-format-executable',
138 *prefix.star('.gem'), *additional_dependencies,
139 ),
140 )
141
142
143 def run_hook(
144 hook: Hook,
145 file_args: Sequence[str],
146 color: bool,
147 ) -> Tuple[int, bytes]:
148 with in_env(hook.prefix, hook.language_version):
149 return helpers.run_xargs(hook, hook.cmd, file_args, color=color)
150
[end of pre_commit/languages/ruby.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pre_commit/languages/ruby.py b/pre_commit/languages/ruby.py
--- a/pre_commit/languages/ruby.py
+++ b/pre_commit/languages/ruby.py
@@ -52,7 +52,6 @@
else: # pragma: win32 no cover
patches += (
('RBENV_ROOT', venv),
- ('RBENV_VERSION', language_version),
(
'PATH', (
os.path.join(venv, 'gems', 'bin'), os.pathsep,
@@ -61,6 +60,9 @@
),
),
)
+ if language_version not in {'system', 'default'}: # pragma: win32 no cover
+ patches += (('RBENV_VERSION', language_version),)
+
return patches
|
{"golden_diff": "diff --git a/pre_commit/languages/ruby.py b/pre_commit/languages/ruby.py\n--- a/pre_commit/languages/ruby.py\n+++ b/pre_commit/languages/ruby.py\n@@ -52,7 +52,6 @@\n else: # pragma: win32 no cover\n patches += (\n ('RBENV_ROOT', venv),\n- ('RBENV_VERSION', language_version),\n (\n 'PATH', (\n os.path.join(venv, 'gems', 'bin'), os.pathsep,\n@@ -61,6 +60,9 @@\n ),\n ),\n )\n+ if language_version not in {'system', 'default'}: # pragma: win32 no cover\n+ patches += (('RBENV_VERSION', language_version),)\n+\n return patches\n", "issue": "Rbenv default ruby issue on install\nI am trying to install MDL v0.11.0\r\n\r\ni get the following error during install \r\n```\r\npre-commit\r\n[INFO] Installing environment for git://github.com/markdownlint/markdownlint.\r\n[INFO] Once installed this environment will be reused.\r\n[INFO] This may take a few minutes...\r\nAn unexpected error has occurred: CalledProcessError: command: ('/usr/local/bin/bash', '/Users/abuxton/.rbenv/shims/gem', 'build', 'mdl.gemspec')\r\nreturn code: 1\r\nexpected return code: 0\r\nstdout: (none)\r\nstderr:\r\n rbenv: version `default' is not installed (set by RBENV_VERSION environment variable)\r\n```\r\n\r\nseems to be the same issue as https://github.com/pre-commit/pre-commit/issues/369 on a previous version of pre-commit\r\npre-commit.log https://gist.github.com/abuxton/d29e6265f3230f838a746d7a5defd5e3 \r\n\r\ni have tried, ensuring local rbenv, I have tried pre-commit clean/uninstall and reinstall to no success, mdl will `brew install mdl` successfully and works fine. \r\n\n", "before_files": [{"content": "import contextlib\nimport functools\nimport os.path\nimport shutil\nimport tarfile\nfrom typing import Generator\nfrom typing import Sequence\nfrom typing import Tuple\n\nimport pre_commit.constants as C\nfrom pre_commit.envcontext import envcontext\nfrom pre_commit.envcontext import PatchesT\nfrom pre_commit.envcontext import UNSET\nfrom pre_commit.envcontext import Var\nfrom pre_commit.hook import Hook\nfrom pre_commit.languages import helpers\nfrom pre_commit.prefix import Prefix\nfrom pre_commit.util import CalledProcessError\nfrom pre_commit.util import clean_path_on_failure\nfrom pre_commit.util import resource_bytesio\n\nENVIRONMENT_DIR = 'rbenv'\nhealthy = helpers.basic_healthy\n\n\[email protected]_cache(maxsize=1)\ndef get_default_version() -> str:\n if all(helpers.exe_exists(exe) for exe in ('ruby', 'gem')):\n return 'system'\n else:\n return C.DEFAULT\n\n\ndef get_env_patch(\n venv: str,\n language_version: str,\n) -> PatchesT:\n patches: PatchesT = (\n ('GEM_HOME', os.path.join(venv, 'gems')),\n ('GEM_PATH', UNSET),\n ('BUNDLE_IGNORE_CONFIG', '1'),\n )\n if language_version == 'system':\n patches += (\n (\n 'PATH', (\n os.path.join(venv, 'gems', 'bin'), os.pathsep,\n Var('PATH'),\n ),\n ),\n )\n else: # pragma: win32 no cover\n patches += (\n ('RBENV_ROOT', venv),\n ('RBENV_VERSION', language_version),\n (\n 'PATH', (\n os.path.join(venv, 'gems', 'bin'), os.pathsep,\n os.path.join(venv, 'shims'), os.pathsep,\n os.path.join(venv, 'bin'), os.pathsep, Var('PATH'),\n ),\n ),\n )\n return patches\n\n\[email protected]\ndef in_env(\n prefix: Prefix,\n language_version: str,\n) -> Generator[None, None, None]:\n envdir = prefix.path(\n helpers.environment_dir(ENVIRONMENT_DIR, language_version),\n )\n with envcontext(get_env_patch(envdir, language_version)):\n yield\n\n\ndef _extract_resource(filename: str, dest: str) -> None:\n with resource_bytesio(filename) as bio:\n with tarfile.open(fileobj=bio) as tf:\n tf.extractall(dest)\n\n\ndef _install_rbenv(\n prefix: Prefix,\n version: str,\n) -> None: # pragma: win32 no cover\n directory = helpers.environment_dir(ENVIRONMENT_DIR, version)\n\n _extract_resource('rbenv.tar.gz', prefix.path('.'))\n shutil.move(prefix.path('rbenv'), prefix.path(directory))\n\n # Only install ruby-build if the version is specified\n if version != C.DEFAULT:\n plugins_dir = prefix.path(directory, 'plugins')\n _extract_resource('ruby-download.tar.gz', plugins_dir)\n _extract_resource('ruby-build.tar.gz', plugins_dir)\n\n\ndef _install_ruby(\n prefix: Prefix,\n version: str,\n) -> None: # pragma: win32 no cover\n try:\n helpers.run_setup_cmd(prefix, ('rbenv', 'download', version))\n except CalledProcessError: # pragma: no cover (usually find with download)\n # Failed to download from mirror for some reason, build it instead\n helpers.run_setup_cmd(prefix, ('rbenv', 'install', version))\n\n\ndef install_environment(\n prefix: Prefix, version: str, additional_dependencies: Sequence[str],\n) -> None:\n additional_dependencies = tuple(additional_dependencies)\n directory = helpers.environment_dir(ENVIRONMENT_DIR, version)\n with clean_path_on_failure(prefix.path(directory)):\n if version != 'system': # pragma: win32 no cover\n _install_rbenv(prefix, version)\n with in_env(prefix, version):\n # Need to call this before installing so rbenv's directories\n # are set up\n helpers.run_setup_cmd(prefix, ('rbenv', 'init', '-'))\n if version != C.DEFAULT:\n _install_ruby(prefix, version)\n # Need to call this after installing to set up the shims\n helpers.run_setup_cmd(prefix, ('rbenv', 'rehash'))\n\n with in_env(prefix, version):\n helpers.run_setup_cmd(\n prefix, ('gem', 'build', *prefix.star('.gemspec')),\n )\n helpers.run_setup_cmd(\n prefix,\n (\n 'gem', 'install',\n '--no-document', '--no-format-executable',\n *prefix.star('.gem'), *additional_dependencies,\n ),\n )\n\n\ndef run_hook(\n hook: Hook,\n file_args: Sequence[str],\n color: bool,\n) -> Tuple[int, bytes]:\n with in_env(hook.prefix, hook.language_version):\n return helpers.run_xargs(hook, hook.cmd, file_args, color=color)\n", "path": "pre_commit/languages/ruby.py"}]}
| 2,226 | 173 |
gh_patches_debug_11775
|
rasdani/github-patches
|
git_diff
|
AUTOMATIC1111__stable-diffusion-webui-14186
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Bug]: ModuleNotFoundError: No module named 'torchvision.transforms.functional_tensor' torchvision 0.17 promblem
### Is there an existing issue for this?
- [X] I have searched the existing issues and checked the recent builds/commits
### What happened?
ModuleNotFoundError: No module named 'torchvision.transforms.functional_tensor'
crash
https://github.com/pytorch/pytorch/issues/103973#issuecomment-1813303128
### Steps to reproduce the problem
1. Install
https://github.com/pytorch/pytorch/issues/103973#issuecomment-1813214452
2. Run webui
### What should have happened?
Run normaly
### Sysinfo
AMD Radeon VII
AMD® Fx(tm)-9590 eight-core processor × 8 (not supporting pci atomics)
32 gb ram
Ubuntu 22.04.3 LTS x64
### What browsers do you use to access the UI ?
Mozilla Firefox
### Console logs
```Shell
(venv) b_cansin@b-cansin-ubuntu:/media/b_cansin/ai/ai/stable-diffusion-webui$ ./webui.sh
################################################################
Install script for stable-diffusion + Web UI
Tested on Debian 11 (Bullseye)
################################################################
################################################################
Running on b_cansin user
################################################################
################################################################
Repo already cloned, using it as install directory
################################################################
################################################################
python venv already activate or run without venv: /media/b_cansin/ai/ai/stable-diffusion-webui/venv
################################################################
################################################################
Launching launch.py...
################################################################
Using TCMalloc: libtcmalloc_minimal.so.4
fatal: No names found, cannot describe anything.
Python 3.10.12 (main, Jun 11 2023, 05:26:28) [GCC 11.4.0]
Version: 1.6.1
Commit hash: 7ba3923d5b494b7756d0b12f33acb3716d830b9a
Launching Web UI with arguments:
2023-11-16 00:38:11.762329: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
no module 'xformers'. Processing without...
no module 'xformers'. Processing without...
No module 'xformers'. Proceeding without it.
*** Error setting up CodeFormer
Traceback (most recent call last):
File "/media/b_cansin/ai/ai/stable-diffusion-webui/modules/codeformer_model.py", line 30, in setup_model
from modules.codeformer.codeformer_arch import CodeFormer
File "/media/b_cansin/ai/ai/stable-diffusion-webui/modules/codeformer/codeformer_arch.py", line 9, in <module>
from modules.codeformer.vqgan_arch import VQAutoEncoder, ResBlock
File "/media/b_cansin/ai/ai/stable-diffusion-webui/modules/codeformer/vqgan_arch.py", line 11, in <module>
from basicsr.utils import get_root_logger
File "/media/b_cansin/ai/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/basicsr/__init__.py", line 4, in <module>
from .data import *
File "/media/b_cansin/ai/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/basicsr/data/__init__.py", line 22, in <module>
_dataset_modules = [importlib.import_module(f'basicsr.data.{file_name}') for file_name in dataset_filenames]
File "/media/b_cansin/ai/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/basicsr/data/__init__.py", line 22, in <listcomp>
_dataset_modules = [importlib.import_module(f'basicsr.data.{file_name}') for file_name in dataset_filenames]
File "/usr/lib/python3.10/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "/media/b_cansin/ai/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/basicsr/data/realesrgan_dataset.py", line 11, in <module>
from basicsr.data.degradations import circular_lowpass_kernel, random_mixed_kernels
File "/media/b_cansin/ai/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/basicsr/data/degradations.py", line 8, in <module>
from torchvision.transforms.functional_tensor import rgb_to_grayscale
ModuleNotFoundError: No module named 'torchvision.transforms.functional_tensor'
---
Traceback (most recent call last):
File "/media/b_cansin/ai/ai/stable-diffusion-webui/launch.py", line 48, in <module>
main()
File "/media/b_cansin/ai/ai/stable-diffusion-webui/launch.py", line 44, in main
start()
File "/media/b_cansin/ai/ai/stable-diffusion-webui/modules/launch_utils.py", line 436, in start
webui.webui()
File "/media/b_cansin/ai/ai/stable-diffusion-webui/webui.py", line 52, in webui
initialize.initialize()
File "/media/b_cansin/ai/ai/stable-diffusion-webui/modules/initialize.py", line 71, in initialize
from modules import gfpgan_model
File "/media/b_cansin/ai/ai/stable-diffusion-webui/modules/gfpgan_model.py", line 4, in <module>
import gfpgan
File "/media/b_cansin/ai/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/gfpgan/__init__.py", line 3, in <module>
from .data import *
File "/media/b_cansin/ai/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/gfpgan/data/__init__.py", line 10, in <module>
_dataset_modules = [importlib.import_module(f'gfpgan.data.{file_name}') for file_name in dataset_filenames]
File "/media/b_cansin/ai/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/gfpgan/data/__init__.py", line 10, in <listcomp>
_dataset_modules = [importlib.import_module(f'gfpgan.data.{file_name}') for file_name in dataset_filenames]
File "/usr/lib/python3.10/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "/media/b_cansin/ai/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/gfpgan/data/ffhq_degradation_dataset.py", line 7, in <module>
from basicsr.data import degradations as degradations
File "/media/b_cansin/ai/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/basicsr/__init__.py", line 4, in <module>
from .data import *
File "/media/b_cansin/ai/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/basicsr/data/__init__.py", line 22, in <module>
_dataset_modules = [importlib.import_module(f'basicsr.data.{file_name}') for file_name in dataset_filenames]
File "/media/b_cansin/ai/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/basicsr/data/__init__.py", line 22, in <listcomp>
_dataset_modules = [importlib.import_module(f'basicsr.data.{file_name}') for file_name in dataset_filenames]
File "/usr/lib/python3.10/importlib/__init__.py", line 126, in import_module
return _bootstrap._gcd_import(name[level:], package, level)
File "/media/b_cansin/ai/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/basicsr/data/realesrgan_dataset.py", line 11, in <module>
from basicsr.data.degradations import circular_lowpass_kernel, random_mixed_kernels
File "/media/b_cansin/ai/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/basicsr/data/degradations.py", line 8, in <module>
from torchvision.transforms.functional_tensor import rgb_to_grayscale
ModuleNotFoundError: No module named 'torchvision.transforms.functional_tensor'
(venv) b_cansin@b-cansin-ubuntu:/media/b_cansin/ai/ai/stable-diffusion-webui$
```
### Additional information
As @hongxiayang said in here:
https://github.com/pytorch/pytorch/issues/103973#issuecomment-1813380169
Need support torchvision 0.17 because of torchvision.transforms.functional deprecated and removed in 0.17. Could we get dev version that support 0.17?
After than we will test if this wheel fix non pci atomics problem of ROCM
</issue>
<code>
[start of modules/import_hook.py]
1 import sys
2
3 # this will break any attempt to import xformers which will prevent stability diffusion repo from trying to use it
4 if "--xformers" not in "".join(sys.argv):
5 sys.modules["xformers"] = None
6
[end of modules/import_hook.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/modules/import_hook.py b/modules/import_hook.py
--- a/modules/import_hook.py
+++ b/modules/import_hook.py
@@ -3,3 +3,14 @@
# this will break any attempt to import xformers which will prevent stability diffusion repo from trying to use it
if "--xformers" not in "".join(sys.argv):
sys.modules["xformers"] = None
+
+# Hack to fix a changed import in torchvision 0.17+, which otherwise breaks
+# basicsr; see https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/13985
+try:
+ import torchvision.transforms.functional_tensor # noqa: F401
+except ImportError:
+ try:
+ import torchvision.transforms.functional as functional
+ sys.modules["torchvision.transforms.functional_tensor"] = functional
+ except ImportError:
+ pass # shrug...
|
{"golden_diff": "diff --git a/modules/import_hook.py b/modules/import_hook.py\n--- a/modules/import_hook.py\n+++ b/modules/import_hook.py\n@@ -3,3 +3,14 @@\n # this will break any attempt to import xformers which will prevent stability diffusion repo from trying to use it\n if \"--xformers\" not in \"\".join(sys.argv):\n sys.modules[\"xformers\"] = None\n+\n+# Hack to fix a changed import in torchvision 0.17+, which otherwise breaks\n+# basicsr; see https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/13985\n+try:\n+ import torchvision.transforms.functional_tensor # noqa: F401\n+except ImportError:\n+ try:\n+ import torchvision.transforms.functional as functional\n+ sys.modules[\"torchvision.transforms.functional_tensor\"] = functional\n+ except ImportError:\n+ pass # shrug...\n", "issue": "[Bug]: ModuleNotFoundError: No module named 'torchvision.transforms.functional_tensor' torchvision 0.17 promblem\n### Is there an existing issue for this?\n\n- [X] I have searched the existing issues and checked the recent builds/commits\n\n### What happened?\n\nModuleNotFoundError: No module named 'torchvision.transforms.functional_tensor'\r\ncrash\r\nhttps://github.com/pytorch/pytorch/issues/103973#issuecomment-1813303128\n\n### Steps to reproduce the problem\n\n1. Install\r\nhttps://github.com/pytorch/pytorch/issues/103973#issuecomment-1813214452\r\n2. Run webui\n\n### What should have happened?\n\nRun normaly\n\n### Sysinfo\n\nAMD Radeon VII\r\nAMD\u00ae Fx(tm)-9590 eight-core processor \u00d7 8 (not supporting pci atomics)\r\n32 gb ram\r\nUbuntu 22.04.3 LTS x64\n\n### What browsers do you use to access the UI ?\n\nMozilla Firefox\n\n### Console logs\n\n```Shell\n(venv) b_cansin@b-cansin-ubuntu:/media/b_cansin/ai/ai/stable-diffusion-webui$ ./webui.sh\r\n\r\n################################################################\r\nInstall script for stable-diffusion + Web UI\r\nTested on Debian 11 (Bullseye)\r\n################################################################\r\n\r\n################################################################\r\nRunning on b_cansin user\r\n################################################################\r\n\r\n################################################################\r\nRepo already cloned, using it as install directory\r\n################################################################\r\n\r\n################################################################\r\npython venv already activate or run without venv: /media/b_cansin/ai/ai/stable-diffusion-webui/venv\r\n################################################################\r\n\r\n################################################################\r\nLaunching launch.py...\r\n################################################################\r\nUsing TCMalloc: libtcmalloc_minimal.so.4\r\nfatal: No names found, cannot describe anything.\r\nPython 3.10.12 (main, Jun 11 2023, 05:26:28) [GCC 11.4.0]\r\nVersion: 1.6.1\r\nCommit hash: 7ba3923d5b494b7756d0b12f33acb3716d830b9a\r\nLaunching Web UI with arguments: \r\n2023-11-16 00:38:11.762329: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.\r\nTo enable the following instructions: FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.\r\nno module 'xformers'. Processing without...\r\nno module 'xformers'. Processing without...\r\nNo module 'xformers'. Proceeding without it.\r\n*** Error setting up CodeFormer\r\n Traceback (most recent call last):\r\n File \"/media/b_cansin/ai/ai/stable-diffusion-webui/modules/codeformer_model.py\", line 30, in setup_model\r\n from modules.codeformer.codeformer_arch import CodeFormer\r\n File \"/media/b_cansin/ai/ai/stable-diffusion-webui/modules/codeformer/codeformer_arch.py\", line 9, in <module>\r\n from modules.codeformer.vqgan_arch import VQAutoEncoder, ResBlock\r\n File \"/media/b_cansin/ai/ai/stable-diffusion-webui/modules/codeformer/vqgan_arch.py\", line 11, in <module>\r\n from basicsr.utils import get_root_logger\r\n File \"/media/b_cansin/ai/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/basicsr/__init__.py\", line 4, in <module>\r\n from .data import *\r\n File \"/media/b_cansin/ai/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/basicsr/data/__init__.py\", line 22, in <module>\r\n _dataset_modules = [importlib.import_module(f'basicsr.data.{file_name}') for file_name in dataset_filenames]\r\n File \"/media/b_cansin/ai/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/basicsr/data/__init__.py\", line 22, in <listcomp>\r\n _dataset_modules = [importlib.import_module(f'basicsr.data.{file_name}') for file_name in dataset_filenames]\r\n File \"/usr/lib/python3.10/importlib/__init__.py\", line 126, in import_module\r\n return _bootstrap._gcd_import(name[level:], package, level)\r\n File \"/media/b_cansin/ai/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/basicsr/data/realesrgan_dataset.py\", line 11, in <module>\r\n from basicsr.data.degradations import circular_lowpass_kernel, random_mixed_kernels\r\n File \"/media/b_cansin/ai/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/basicsr/data/degradations.py\", line 8, in <module>\r\n from torchvision.transforms.functional_tensor import rgb_to_grayscale\r\n ModuleNotFoundError: No module named 'torchvision.transforms.functional_tensor'\r\n\r\n---\r\nTraceback (most recent call last):\r\n File \"/media/b_cansin/ai/ai/stable-diffusion-webui/launch.py\", line 48, in <module>\r\n main()\r\n File \"/media/b_cansin/ai/ai/stable-diffusion-webui/launch.py\", line 44, in main\r\n start()\r\n File \"/media/b_cansin/ai/ai/stable-diffusion-webui/modules/launch_utils.py\", line 436, in start\r\n webui.webui()\r\n File \"/media/b_cansin/ai/ai/stable-diffusion-webui/webui.py\", line 52, in webui\r\n initialize.initialize()\r\n File \"/media/b_cansin/ai/ai/stable-diffusion-webui/modules/initialize.py\", line 71, in initialize\r\n from modules import gfpgan_model\r\n File \"/media/b_cansin/ai/ai/stable-diffusion-webui/modules/gfpgan_model.py\", line 4, in <module>\r\n import gfpgan\r\n File \"/media/b_cansin/ai/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/gfpgan/__init__.py\", line 3, in <module>\r\n from .data import *\r\n File \"/media/b_cansin/ai/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/gfpgan/data/__init__.py\", line 10, in <module>\r\n _dataset_modules = [importlib.import_module(f'gfpgan.data.{file_name}') for file_name in dataset_filenames]\r\n File \"/media/b_cansin/ai/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/gfpgan/data/__init__.py\", line 10, in <listcomp>\r\n _dataset_modules = [importlib.import_module(f'gfpgan.data.{file_name}') for file_name in dataset_filenames]\r\n File \"/usr/lib/python3.10/importlib/__init__.py\", line 126, in import_module\r\n return _bootstrap._gcd_import(name[level:], package, level)\r\n File \"/media/b_cansin/ai/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/gfpgan/data/ffhq_degradation_dataset.py\", line 7, in <module>\r\n from basicsr.data import degradations as degradations\r\n File \"/media/b_cansin/ai/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/basicsr/__init__.py\", line 4, in <module>\r\n from .data import *\r\n File \"/media/b_cansin/ai/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/basicsr/data/__init__.py\", line 22, in <module>\r\n _dataset_modules = [importlib.import_module(f'basicsr.data.{file_name}') for file_name in dataset_filenames]\r\n File \"/media/b_cansin/ai/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/basicsr/data/__init__.py\", line 22, in <listcomp>\r\n _dataset_modules = [importlib.import_module(f'basicsr.data.{file_name}') for file_name in dataset_filenames]\r\n File \"/usr/lib/python3.10/importlib/__init__.py\", line 126, in import_module\r\n return _bootstrap._gcd_import(name[level:], package, level)\r\n File \"/media/b_cansin/ai/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/basicsr/data/realesrgan_dataset.py\", line 11, in <module>\r\n from basicsr.data.degradations import circular_lowpass_kernel, random_mixed_kernels\r\n File \"/media/b_cansin/ai/ai/stable-diffusion-webui/venv/lib/python3.10/site-packages/basicsr/data/degradations.py\", line 8, in <module>\r\n from torchvision.transforms.functional_tensor import rgb_to_grayscale\r\nModuleNotFoundError: No module named 'torchvision.transforms.functional_tensor'\r\n(venv) b_cansin@b-cansin-ubuntu:/media/b_cansin/ai/ai/stable-diffusion-webui$\n```\n\n\n### Additional information\n\nAs @hongxiayang said in here:\r\nhttps://github.com/pytorch/pytorch/issues/103973#issuecomment-1813380169\r\nNeed support torchvision 0.17 because of torchvision.transforms.functional deprecated and removed in 0.17. Could we get dev version that support 0.17?\r\nAfter than we will test if this wheel fix non pci atomics problem of ROCM\n", "before_files": [{"content": "import sys\n\n# this will break any attempt to import xformers which will prevent stability diffusion repo from trying to use it\nif \"--xformers\" not in \"\".join(sys.argv):\n sys.modules[\"xformers\"] = None\n", "path": "modules/import_hook.py"}]}
| 2,809 | 200 |
gh_patches_debug_18436
|
rasdani/github-patches
|
git_diff
|
scalableminds__webknossos-libs-857
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Converting Knossos dataset fails, chunk_shape must be multiple of mag*chunk_shape*chunks_per_shard of the view
## Context
- Affected library: wkcuber
## Expected Behavior
Should output wkw dataset
## Current Behavior
```
2023-01-13 23:33:20,047 INFO Converting KNOSSOS dataset
2023-01-13 23:33:20,048 INFO Assumed data type is uint8
2023-01-13 23:33:21,125 INFO Using pool of 2 workers.
Converting knossos layer my_layer ━━━━━━━━━━━━━━━━━ 100% 0:01:17 | 0:00:002023-01-13 23:34:39,207 INFO Using pool of 2 workers.
Traceback (most recent call last):
File "/usr/local/lib/python3.9/runpy.py", line 197, in _run_module_as_main
return _run_code(code, main_globals, None,
File "/usr/local/lib/python3.9/runpy.py", line 87, in _run_code
exec(code, run_globals)
File "/usr/local/lib/python3.9/site-packages/wkcuber/__main__.py", line 117, in <module>
main()
File "/usr/local/lib/python3.9/site-packages/wkcuber/__main__.py", line 113, in main
cube_with_args(args)
File "/usr/local/lib/python3.9/site-packages/wkcuber/__main__.py", line 81, in cube_with_args
auto_detect_and_run_conversion(args)
File "/usr/local/lib/python3.9/site-packages/wkcuber/converter.py", line 567, in main
should_write_metadata = matching_converters[0].convert_input(args)
File "/usr/local/lib/python3.9/site-packages/wkcuber/converter.py", line 258, in convert_input
convert_knossos(args)
File "/usr/local/lib/python3.9/site-packages/wkcuber/convert_knossos.py", line 144, in main
convert_knossos(
File "/usr/local/lib/python3.9/site-packages/wkcuber/convert_knossos.py", line 135, in convert_knossos
target_mag.for_each_chunk(
File "/usr/local/lib/python3.9/site-packages/webknossos/dataset/view.py", line 742, in for_each_chunk
self._check_chunk_shape(chunk_shape, read_only=self.read_only)
File "/usr/local/lib/python3.9/site-packages/webknossos/dataset/view.py", line 944, in _check_chunk_shape
assert chunk_shape % divisor == Vec3Int.zeros(), (
AssertionError: The chunk_shape Vec3Int(1024,1024,1024) must be a multiple of mag*chunk_shape*chunks_per_shard of the view, which is Vec3Int(8192,8192,8192)).
```
## Steps to Reproduce the bug
Got this for two knossos datasets recently, tested no other. Talk to me for sample data.
## Your Environment for bug
linux, python 3.9, wkcuber 0.11.1
</issue>
<code>
[start of wkcuber/wkcuber/convert_knossos.py]
1 import logging
2 from argparse import ArgumentParser, Namespace
3 from functools import partial
4 from pathlib import Path
5 from typing import Optional, Tuple, cast
6
7 import numpy as np
8 from webknossos import COLOR_CATEGORY, BoundingBox, DataFormat, Dataset, Vec3Int, View
9 from webknossos.utils import time_start, time_stop
10
11 from ._internal.knossos import CUBE_EDGE_LEN
12 from ._internal.utils import (
13 KnossosDatasetInfo,
14 add_data_format_flags,
15 add_distribution_flags,
16 add_verbose_flag,
17 add_voxel_size_flag,
18 get_executor_for_args,
19 open_knossos,
20 parse_path,
21 setup_logging,
22 setup_warnings,
23 )
24
25
26 def create_parser() -> ArgumentParser:
27 parser = ArgumentParser()
28
29 parser.add_argument(
30 "source_path",
31 help="Directory containing the source KNOSSOS dataset.",
32 type=Path,
33 )
34
35 parser.add_argument(
36 "target_path",
37 help="Output directory for the generated WKW dataset.",
38 type=parse_path,
39 )
40
41 parser.add_argument(
42 "--layer_name",
43 "-l",
44 help="Name of the cubed layer (color or segmentation)",
45 default="color",
46 )
47
48 parser.add_argument(
49 "--dtype",
50 "-d",
51 help="Target datatype (e.g. uint8, uint16, uint32)",
52 default="uint8",
53 )
54
55 add_voxel_size_flag(parser)
56
57 parser.add_argument("--mag", "-m", help="Magnification level", type=int, default=1)
58
59 add_verbose_flag(parser)
60 add_distribution_flags(parser)
61 add_data_format_flags(parser)
62
63 return parser
64
65
66 def convert_cube_job(
67 source_knossos_info: KnossosDatasetInfo, args: Tuple[View, int]
68 ) -> None:
69 target_view, _ = args
70
71 time_start(f"Converting of {target_view.bounding_box}")
72 cube_size = cast(Tuple[int, int, int], (CUBE_EDGE_LEN,) * 3)
73
74 offset = target_view.bounding_box.in_mag(target_view.mag).topleft
75 size = target_view.bounding_box.in_mag(target_view.mag).size
76 buffer = np.zeros(size.to_tuple(), dtype=target_view.get_dtype())
77 with open_knossos(source_knossos_info) as source_knossos:
78 for x in range(0, size.x, CUBE_EDGE_LEN):
79 for y in range(0, size.y, CUBE_EDGE_LEN):
80 for z in range(0, size.z, CUBE_EDGE_LEN):
81 cube_data = source_knossos.read(
82 (offset + Vec3Int(x, y, z)).to_tuple(), cube_size
83 )
84 buffer[
85 x : (x + CUBE_EDGE_LEN),
86 y : (y + CUBE_EDGE_LEN),
87 z : (z + CUBE_EDGE_LEN),
88 ] = cube_data
89 target_view.write(buffer)
90
91 time_stop(f"Converting of {target_view.bounding_box}")
92
93
94 def convert_knossos(
95 source_path: Path,
96 target_path: Path,
97 layer_name: str,
98 dtype: str,
99 voxel_size: Tuple[float, float, float],
100 data_format: DataFormat,
101 chunk_shape: Vec3Int,
102 chunks_per_shard: Vec3Int,
103 mag: int = 1,
104 args: Optional[Namespace] = None,
105 ) -> None:
106 source_knossos_info = KnossosDatasetInfo(source_path, dtype)
107
108 target_dataset = Dataset(target_path, voxel_size, exist_ok=True)
109 target_layer = target_dataset.get_or_add_layer(
110 layer_name,
111 COLOR_CATEGORY,
112 data_format=data_format,
113 dtype_per_channel=dtype,
114 )
115
116 with open_knossos(source_knossos_info) as source_knossos:
117 knossos_cubes = np.array(list(source_knossos.list_cubes()))
118 if len(knossos_cubes) == 0:
119 logging.error(
120 "No input KNOSSOS cubes found. Make sure to pass the path which points to a KNOSSOS magnification (e.g., testdata/knossos/color/1)."
121 )
122 exit(1)
123
124 min_xyz = knossos_cubes.min(axis=0) * CUBE_EDGE_LEN
125 max_xyz = (knossos_cubes.max(axis=0) + 1) * CUBE_EDGE_LEN
126 target_layer.bounding_box = BoundingBox(
127 Vec3Int(min_xyz), Vec3Int(max_xyz - min_xyz)
128 )
129
130 target_mag = target_layer.get_or_add_mag(
131 mag, chunk_shape=chunk_shape, chunks_per_shard=chunks_per_shard
132 )
133
134 with get_executor_for_args(args) as executor:
135 target_mag.for_each_chunk(
136 partial(convert_cube_job, source_knossos_info),
137 chunk_shape=chunk_shape * chunks_per_shard,
138 executor=executor,
139 progress_desc=f"Converting knossos layer {layer_name}",
140 )
141
142
143 def main(args: Namespace) -> None:
144 convert_knossos(
145 args.source_path,
146 args.target_path,
147 args.layer_name,
148 args.dtype,
149 args.voxel_size,
150 args.data_format,
151 args.chunk_shape,
152 args.chunks_per_shard,
153 args.mag,
154 args,
155 )
156
157
158 if __name__ == "__main__":
159 setup_warnings()
160 args = create_parser().parse_args()
161 setup_logging(args)
162
163 main(args)
164
[end of wkcuber/wkcuber/convert_knossos.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/wkcuber/wkcuber/convert_knossos.py b/wkcuber/wkcuber/convert_knossos.py
--- a/wkcuber/wkcuber/convert_knossos.py
+++ b/wkcuber/wkcuber/convert_knossos.py
@@ -98,7 +98,7 @@
dtype: str,
voxel_size: Tuple[float, float, float],
data_format: DataFormat,
- chunk_shape: Vec3Int,
+ chunk_shape: Vec3Int, # in target-mag
chunks_per_shard: Vec3Int,
mag: int = 1,
args: Optional[Namespace] = None,
@@ -134,7 +134,7 @@
with get_executor_for_args(args) as executor:
target_mag.for_each_chunk(
partial(convert_cube_job, source_knossos_info),
- chunk_shape=chunk_shape * chunks_per_shard,
+ chunk_shape=chunk_shape * mag * chunks_per_shard,
executor=executor,
progress_desc=f"Converting knossos layer {layer_name}",
)
|
{"golden_diff": "diff --git a/wkcuber/wkcuber/convert_knossos.py b/wkcuber/wkcuber/convert_knossos.py\n--- a/wkcuber/wkcuber/convert_knossos.py\n+++ b/wkcuber/wkcuber/convert_knossos.py\n@@ -98,7 +98,7 @@\n dtype: str,\n voxel_size: Tuple[float, float, float],\n data_format: DataFormat,\n- chunk_shape: Vec3Int,\n+ chunk_shape: Vec3Int, # in target-mag\n chunks_per_shard: Vec3Int,\n mag: int = 1,\n args: Optional[Namespace] = None,\n@@ -134,7 +134,7 @@\n with get_executor_for_args(args) as executor:\n target_mag.for_each_chunk(\n partial(convert_cube_job, source_knossos_info),\n- chunk_shape=chunk_shape * chunks_per_shard,\n+ chunk_shape=chunk_shape * mag * chunks_per_shard,\n executor=executor,\n progress_desc=f\"Converting knossos layer {layer_name}\",\n )\n", "issue": "Converting Knossos dataset fails, chunk_shape must be multiple of mag*chunk_shape*chunks_per_shard of the view\n## Context\r\n- Affected library: wkcuber\r\n\r\n## Expected Behavior\r\nShould output wkw dataset\r\n\r\n## Current Behavior\r\n```\r\n2023-01-13 23:33:20,047 INFO Converting KNOSSOS dataset\r\n2023-01-13 23:33:20,048 INFO Assumed data type is uint8\r\n2023-01-13 23:33:21,125 INFO Using pool of 2 workers.\r\nConverting knossos layer my_layer \u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501\u2501 100% 0:01:17 | 0:00:002023-01-13 23:34:39,207 INFO Using pool of 2 workers.\r\nTraceback (most recent call last):\r\n File \"/usr/local/lib/python3.9/runpy.py\", line 197, in _run_module_as_main\r\n return _run_code(code, main_globals, None,\r\n File \"/usr/local/lib/python3.9/runpy.py\", line 87, in _run_code\r\n exec(code, run_globals)\r\n File \"/usr/local/lib/python3.9/site-packages/wkcuber/__main__.py\", line 117, in <module>\r\n main()\r\n File \"/usr/local/lib/python3.9/site-packages/wkcuber/__main__.py\", line 113, in main\r\n cube_with_args(args)\r\n File \"/usr/local/lib/python3.9/site-packages/wkcuber/__main__.py\", line 81, in cube_with_args\r\n auto_detect_and_run_conversion(args)\r\n File \"/usr/local/lib/python3.9/site-packages/wkcuber/converter.py\", line 567, in main\r\n should_write_metadata = matching_converters[0].convert_input(args)\r\n File \"/usr/local/lib/python3.9/site-packages/wkcuber/converter.py\", line 258, in convert_input\r\n convert_knossos(args)\r\n File \"/usr/local/lib/python3.9/site-packages/wkcuber/convert_knossos.py\", line 144, in main\r\n convert_knossos(\r\n File \"/usr/local/lib/python3.9/site-packages/wkcuber/convert_knossos.py\", line 135, in convert_knossos\r\n target_mag.for_each_chunk(\r\n File \"/usr/local/lib/python3.9/site-packages/webknossos/dataset/view.py\", line 742, in for_each_chunk\r\n self._check_chunk_shape(chunk_shape, read_only=self.read_only)\r\n File \"/usr/local/lib/python3.9/site-packages/webknossos/dataset/view.py\", line 944, in _check_chunk_shape\r\n assert chunk_shape % divisor == Vec3Int.zeros(), (\r\nAssertionError: The chunk_shape Vec3Int(1024,1024,1024) must be a multiple of mag*chunk_shape*chunks_per_shard of the view, which is Vec3Int(8192,8192,8192)).\r\n```\r\n\r\n## Steps to Reproduce the bug\r\nGot this for two knossos datasets recently, tested no other. Talk to me for sample data.\r\n\r\n## Your Environment for bug\r\nlinux, python 3.9, wkcuber 0.11.1\n", "before_files": [{"content": "import logging\nfrom argparse import ArgumentParser, Namespace\nfrom functools import partial\nfrom pathlib import Path\nfrom typing import Optional, Tuple, cast\n\nimport numpy as np\nfrom webknossos import COLOR_CATEGORY, BoundingBox, DataFormat, Dataset, Vec3Int, View\nfrom webknossos.utils import time_start, time_stop\n\nfrom ._internal.knossos import CUBE_EDGE_LEN\nfrom ._internal.utils import (\n KnossosDatasetInfo,\n add_data_format_flags,\n add_distribution_flags,\n add_verbose_flag,\n add_voxel_size_flag,\n get_executor_for_args,\n open_knossos,\n parse_path,\n setup_logging,\n setup_warnings,\n)\n\n\ndef create_parser() -> ArgumentParser:\n parser = ArgumentParser()\n\n parser.add_argument(\n \"source_path\",\n help=\"Directory containing the source KNOSSOS dataset.\",\n type=Path,\n )\n\n parser.add_argument(\n \"target_path\",\n help=\"Output directory for the generated WKW dataset.\",\n type=parse_path,\n )\n\n parser.add_argument(\n \"--layer_name\",\n \"-l\",\n help=\"Name of the cubed layer (color or segmentation)\",\n default=\"color\",\n )\n\n parser.add_argument(\n \"--dtype\",\n \"-d\",\n help=\"Target datatype (e.g. uint8, uint16, uint32)\",\n default=\"uint8\",\n )\n\n add_voxel_size_flag(parser)\n\n parser.add_argument(\"--mag\", \"-m\", help=\"Magnification level\", type=int, default=1)\n\n add_verbose_flag(parser)\n add_distribution_flags(parser)\n add_data_format_flags(parser)\n\n return parser\n\n\ndef convert_cube_job(\n source_knossos_info: KnossosDatasetInfo, args: Tuple[View, int]\n) -> None:\n target_view, _ = args\n\n time_start(f\"Converting of {target_view.bounding_box}\")\n cube_size = cast(Tuple[int, int, int], (CUBE_EDGE_LEN,) * 3)\n\n offset = target_view.bounding_box.in_mag(target_view.mag).topleft\n size = target_view.bounding_box.in_mag(target_view.mag).size\n buffer = np.zeros(size.to_tuple(), dtype=target_view.get_dtype())\n with open_knossos(source_knossos_info) as source_knossos:\n for x in range(0, size.x, CUBE_EDGE_LEN):\n for y in range(0, size.y, CUBE_EDGE_LEN):\n for z in range(0, size.z, CUBE_EDGE_LEN):\n cube_data = source_knossos.read(\n (offset + Vec3Int(x, y, z)).to_tuple(), cube_size\n )\n buffer[\n x : (x + CUBE_EDGE_LEN),\n y : (y + CUBE_EDGE_LEN),\n z : (z + CUBE_EDGE_LEN),\n ] = cube_data\n target_view.write(buffer)\n\n time_stop(f\"Converting of {target_view.bounding_box}\")\n\n\ndef convert_knossos(\n source_path: Path,\n target_path: Path,\n layer_name: str,\n dtype: str,\n voxel_size: Tuple[float, float, float],\n data_format: DataFormat,\n chunk_shape: Vec3Int,\n chunks_per_shard: Vec3Int,\n mag: int = 1,\n args: Optional[Namespace] = None,\n) -> None:\n source_knossos_info = KnossosDatasetInfo(source_path, dtype)\n\n target_dataset = Dataset(target_path, voxel_size, exist_ok=True)\n target_layer = target_dataset.get_or_add_layer(\n layer_name,\n COLOR_CATEGORY,\n data_format=data_format,\n dtype_per_channel=dtype,\n )\n\n with open_knossos(source_knossos_info) as source_knossos:\n knossos_cubes = np.array(list(source_knossos.list_cubes()))\n if len(knossos_cubes) == 0:\n logging.error(\n \"No input KNOSSOS cubes found. Make sure to pass the path which points to a KNOSSOS magnification (e.g., testdata/knossos/color/1).\"\n )\n exit(1)\n\n min_xyz = knossos_cubes.min(axis=0) * CUBE_EDGE_LEN\n max_xyz = (knossos_cubes.max(axis=0) + 1) * CUBE_EDGE_LEN\n target_layer.bounding_box = BoundingBox(\n Vec3Int(min_xyz), Vec3Int(max_xyz - min_xyz)\n )\n\n target_mag = target_layer.get_or_add_mag(\n mag, chunk_shape=chunk_shape, chunks_per_shard=chunks_per_shard\n )\n\n with get_executor_for_args(args) as executor:\n target_mag.for_each_chunk(\n partial(convert_cube_job, source_knossos_info),\n chunk_shape=chunk_shape * chunks_per_shard,\n executor=executor,\n progress_desc=f\"Converting knossos layer {layer_name}\",\n )\n\n\ndef main(args: Namespace) -> None:\n convert_knossos(\n args.source_path,\n args.target_path,\n args.layer_name,\n args.dtype,\n args.voxel_size,\n args.data_format,\n args.chunk_shape,\n args.chunks_per_shard,\n args.mag,\n args,\n )\n\n\nif __name__ == \"__main__\":\n setup_warnings()\n args = create_parser().parse_args()\n setup_logging(args)\n\n main(args)\n", "path": "wkcuber/wkcuber/convert_knossos.py"}]}
| 2,914 | 247 |
gh_patches_debug_1646
|
rasdani/github-patches
|
git_diff
|
dotkom__onlineweb4-2553
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Cant delete mails through REST API endpoints
The endpoint to remove mails are fucked :)
</issue>
<code>
[start of apps/authentication/api/views.py]
1 from django.contrib.auth.models import Group
2 from rest_framework import mixins, status, viewsets
3 from rest_framework.decorators import action
4 from rest_framework.permissions import AllowAny, IsAuthenticated
5 from rest_framework.response import Response
6
7 from apps.authentication.models import Email, GroupMember, GroupRole, OnlineGroup
8 from apps.authentication.models import OnlineUser as User
9 from apps.authentication.models import Position, SpecialPosition
10 from apps.authentication.serializers import (
11 AnonymizeUserSerializer,
12 EmailCreateSerializer,
13 EmailReadOnlySerializer,
14 EmailUpdateSerializer,
15 GroupMemberCreateSerializer,
16 GroupMemberReadOnlySerializer,
17 GroupMemberUpdateSerializer,
18 GroupReadOnlySerializer,
19 GroupRoleReadOnlySerializer,
20 OnlineGroupCreateOrUpdateSerializer,
21 OnlineGroupReadOnlySerializer,
22 PasswordUpdateSerializer,
23 PositionCreateAndUpdateSerializer,
24 PositionReadOnlySerializer,
25 SpecialPositionSerializer,
26 UserCreateSerializer,
27 UserReadOnlySerializer,
28 UserUpdateSerializer,
29 )
30 from apps.common.rest_framework.mixins import MultiSerializerMixin
31 from apps.permissions.drf_permissions import DjangoObjectPermissionOrAnonReadOnly
32
33 from .filters import UserFilter
34 from .permissions import IsSelfOrSuperUser
35 from .serializers.user_data import UserDataSerializer
36
37
38 class UserViewSet(
39 MultiSerializerMixin,
40 viewsets.GenericViewSet,
41 mixins.ListModelMixin,
42 mixins.RetrieveModelMixin,
43 mixins.CreateModelMixin,
44 mixins.UpdateModelMixin,
45 ):
46 """
47 Viewset for User serializer. Supports filtering on 'first_name', 'last_name', 'email'
48 """
49
50 permission_classes = (IsSelfOrSuperUser,)
51 filterset_class = UserFilter
52 queryset = User.objects.all()
53 serializer_classes = {
54 "create": UserCreateSerializer,
55 "update": UserUpdateSerializer,
56 "read": UserReadOnlySerializer,
57 "change_password": PasswordUpdateSerializer,
58 "anonymize_user": AnonymizeUserSerializer,
59 "dump_data": UserDataSerializer,
60 }
61
62 @action(detail=True, methods=["put"])
63 def change_password(self, request, pk=None):
64 user: User = self.get_object()
65 serializer = self.get_serializer(user, data=request.data)
66 serializer.is_valid(raise_exception=True)
67 serializer.save()
68
69 return Response(data=None, status=status.HTTP_204_NO_CONTENT)
70
71 @action(detail=True, methods=["put"])
72 def anonymize_user(self, request, pk=None):
73 user: User = self.get_object()
74 serializer = self.get_serializer(user, data=request.data)
75 serializer.is_valid(raise_exception=True)
76 serializer.save()
77
78 return Response(data=None, status=status.HTTP_204_NO_CONTENT)
79
80 @action(detail=True, methods=["get"], url_path="dump-data")
81 def dump_data(self, request, pk: int):
82 user: User = self.get_object()
83 serializer = self.get_serializer(user)
84 return Response(data=serializer.data, status=status.HTTP_200_OK)
85
86
87 class EmailViewSet(MultiSerializerMixin, viewsets.ModelViewSet):
88 permission_classes = (IsAuthenticated,)
89 serializer_classes = {
90 "create": EmailCreateSerializer,
91 "update": EmailUpdateSerializer,
92 "read": EmailReadOnlySerializer,
93 }
94
95 def get_queryset(self):
96 return Email.objects.filter(user=self.request.user)
97
98 def destroy(self, request, *args, **kwargs):
99 instance: Email = self.get_object()
100 if instance.primary:
101 return Response(
102 {
103 "message": "Du kan ikke slette en primær-epost. Du må først velge en annen epost som "
104 "primær for å kunne slette denne."
105 },
106 status=status.HTTP_400_BAD_REQUEST,
107 )
108
109
110 class PositionViewSet(MultiSerializerMixin, viewsets.ModelViewSet):
111 permission_classes = (IsAuthenticated,)
112 serializer_classes = {
113 "read": PositionReadOnlySerializer,
114 "write": PositionCreateAndUpdateSerializer,
115 }
116
117 def get_queryset(self):
118 user = self.request.user
119 return Position.objects.filter(user=user)
120
121
122 class SpecialPositionViewSet(viewsets.ReadOnlyModelViewSet):
123 serializer_class = SpecialPositionSerializer
124 permission_classes = (IsAuthenticated,)
125
126 def get_queryset(self):
127 user = self.request.user
128 return SpecialPosition.objects.filter(user=user)
129
130
131 class GroupViewSet(viewsets.ReadOnlyModelViewSet):
132 permission_classes = (AllowAny,)
133 queryset = Group.objects.all()
134 serializer_class = GroupReadOnlySerializer
135 ordering = ("name",)
136
137
138 class OnlineGroupViewSet(MultiSerializerMixin, viewsets.ModelViewSet):
139 permission_classes = (DjangoObjectPermissionOrAnonReadOnly,)
140 queryset = OnlineGroup.objects.all()
141 serializer_classes = {
142 "write": OnlineGroupCreateOrUpdateSerializer,
143 "read": OnlineGroupReadOnlySerializer,
144 }
145
146
147 class GroupMemberViewSet(MultiSerializerMixin, viewsets.ModelViewSet):
148 permission_classes = (DjangoObjectPermissionOrAnonReadOnly,)
149 queryset = GroupMember.objects.all()
150 serializer_classes = {
151 "create": GroupMemberCreateSerializer,
152 "update": GroupMemberUpdateSerializer,
153 "read": GroupMemberReadOnlySerializer,
154 }
155
156
157 class GroupRoleViewSet(viewsets.ReadOnlyModelViewSet):
158 permission_classes = (AllowAny,)
159 serializer_class = GroupRoleReadOnlySerializer
160 queryset = GroupRole.objects.all()
161
[end of apps/authentication/api/views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/apps/authentication/api/views.py b/apps/authentication/api/views.py
--- a/apps/authentication/api/views.py
+++ b/apps/authentication/api/views.py
@@ -105,6 +105,7 @@
},
status=status.HTTP_400_BAD_REQUEST,
)
+ super().destroy(request, *args, **kwargs)
class PositionViewSet(MultiSerializerMixin, viewsets.ModelViewSet):
|
{"golden_diff": "diff --git a/apps/authentication/api/views.py b/apps/authentication/api/views.py\n--- a/apps/authentication/api/views.py\n+++ b/apps/authentication/api/views.py\n@@ -105,6 +105,7 @@\n },\n status=status.HTTP_400_BAD_REQUEST,\n )\n+ super().destroy(request, *args, **kwargs)\n \n \n class PositionViewSet(MultiSerializerMixin, viewsets.ModelViewSet):\n", "issue": "Cant delete mails through REST API endpoints\nThe endpoint to remove mails are fucked :)\n", "before_files": [{"content": "from django.contrib.auth.models import Group\nfrom rest_framework import mixins, status, viewsets\nfrom rest_framework.decorators import action\nfrom rest_framework.permissions import AllowAny, IsAuthenticated\nfrom rest_framework.response import Response\n\nfrom apps.authentication.models import Email, GroupMember, GroupRole, OnlineGroup\nfrom apps.authentication.models import OnlineUser as User\nfrom apps.authentication.models import Position, SpecialPosition\nfrom apps.authentication.serializers import (\n AnonymizeUserSerializer,\n EmailCreateSerializer,\n EmailReadOnlySerializer,\n EmailUpdateSerializer,\n GroupMemberCreateSerializer,\n GroupMemberReadOnlySerializer,\n GroupMemberUpdateSerializer,\n GroupReadOnlySerializer,\n GroupRoleReadOnlySerializer,\n OnlineGroupCreateOrUpdateSerializer,\n OnlineGroupReadOnlySerializer,\n PasswordUpdateSerializer,\n PositionCreateAndUpdateSerializer,\n PositionReadOnlySerializer,\n SpecialPositionSerializer,\n UserCreateSerializer,\n UserReadOnlySerializer,\n UserUpdateSerializer,\n)\nfrom apps.common.rest_framework.mixins import MultiSerializerMixin\nfrom apps.permissions.drf_permissions import DjangoObjectPermissionOrAnonReadOnly\n\nfrom .filters import UserFilter\nfrom .permissions import IsSelfOrSuperUser\nfrom .serializers.user_data import UserDataSerializer\n\n\nclass UserViewSet(\n MultiSerializerMixin,\n viewsets.GenericViewSet,\n mixins.ListModelMixin,\n mixins.RetrieveModelMixin,\n mixins.CreateModelMixin,\n mixins.UpdateModelMixin,\n):\n \"\"\"\n Viewset for User serializer. Supports filtering on 'first_name', 'last_name', 'email'\n \"\"\"\n\n permission_classes = (IsSelfOrSuperUser,)\n filterset_class = UserFilter\n queryset = User.objects.all()\n serializer_classes = {\n \"create\": UserCreateSerializer,\n \"update\": UserUpdateSerializer,\n \"read\": UserReadOnlySerializer,\n \"change_password\": PasswordUpdateSerializer,\n \"anonymize_user\": AnonymizeUserSerializer,\n \"dump_data\": UserDataSerializer,\n }\n\n @action(detail=True, methods=[\"put\"])\n def change_password(self, request, pk=None):\n user: User = self.get_object()\n serializer = self.get_serializer(user, data=request.data)\n serializer.is_valid(raise_exception=True)\n serializer.save()\n\n return Response(data=None, status=status.HTTP_204_NO_CONTENT)\n\n @action(detail=True, methods=[\"put\"])\n def anonymize_user(self, request, pk=None):\n user: User = self.get_object()\n serializer = self.get_serializer(user, data=request.data)\n serializer.is_valid(raise_exception=True)\n serializer.save()\n\n return Response(data=None, status=status.HTTP_204_NO_CONTENT)\n\n @action(detail=True, methods=[\"get\"], url_path=\"dump-data\")\n def dump_data(self, request, pk: int):\n user: User = self.get_object()\n serializer = self.get_serializer(user)\n return Response(data=serializer.data, status=status.HTTP_200_OK)\n\n\nclass EmailViewSet(MultiSerializerMixin, viewsets.ModelViewSet):\n permission_classes = (IsAuthenticated,)\n serializer_classes = {\n \"create\": EmailCreateSerializer,\n \"update\": EmailUpdateSerializer,\n \"read\": EmailReadOnlySerializer,\n }\n\n def get_queryset(self):\n return Email.objects.filter(user=self.request.user)\n\n def destroy(self, request, *args, **kwargs):\n instance: Email = self.get_object()\n if instance.primary:\n return Response(\n {\n \"message\": \"Du kan ikke slette en prim\u00e6r-epost. Du m\u00e5 f\u00f8rst velge en annen epost som \"\n \"prim\u00e6r for \u00e5 kunne slette denne.\"\n },\n status=status.HTTP_400_BAD_REQUEST,\n )\n\n\nclass PositionViewSet(MultiSerializerMixin, viewsets.ModelViewSet):\n permission_classes = (IsAuthenticated,)\n serializer_classes = {\n \"read\": PositionReadOnlySerializer,\n \"write\": PositionCreateAndUpdateSerializer,\n }\n\n def get_queryset(self):\n user = self.request.user\n return Position.objects.filter(user=user)\n\n\nclass SpecialPositionViewSet(viewsets.ReadOnlyModelViewSet):\n serializer_class = SpecialPositionSerializer\n permission_classes = (IsAuthenticated,)\n\n def get_queryset(self):\n user = self.request.user\n return SpecialPosition.objects.filter(user=user)\n\n\nclass GroupViewSet(viewsets.ReadOnlyModelViewSet):\n permission_classes = (AllowAny,)\n queryset = Group.objects.all()\n serializer_class = GroupReadOnlySerializer\n ordering = (\"name\",)\n\n\nclass OnlineGroupViewSet(MultiSerializerMixin, viewsets.ModelViewSet):\n permission_classes = (DjangoObjectPermissionOrAnonReadOnly,)\n queryset = OnlineGroup.objects.all()\n serializer_classes = {\n \"write\": OnlineGroupCreateOrUpdateSerializer,\n \"read\": OnlineGroupReadOnlySerializer,\n }\n\n\nclass GroupMemberViewSet(MultiSerializerMixin, viewsets.ModelViewSet):\n permission_classes = (DjangoObjectPermissionOrAnonReadOnly,)\n queryset = GroupMember.objects.all()\n serializer_classes = {\n \"create\": GroupMemberCreateSerializer,\n \"update\": GroupMemberUpdateSerializer,\n \"read\": GroupMemberReadOnlySerializer,\n }\n\n\nclass GroupRoleViewSet(viewsets.ReadOnlyModelViewSet):\n permission_classes = (AllowAny,)\n serializer_class = GroupRoleReadOnlySerializer\n queryset = GroupRole.objects.all()\n", "path": "apps/authentication/api/views.py"}]}
| 2,032 | 88 |
gh_patches_debug_30213
|
rasdani/github-patches
|
git_diff
|
lutris__lutris-528
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Lutris 0.4.5 doesn’t launch (AssertionError)
I'm using Linux Mint 18.1 (my de is Mate if that's any help) and I received the update for Lutris 0.4.5. I tried to launch Lutris after that and nothing seemed to happen. I then tried to launch it from the terminal with the command "lutris" and saw the following:
```python
Traceback (most recent call last):
File "/usr/lib/python3/dist-packages/lutris/gui/application.py", line 152, in do_activate
self.window = LutrisWindow(application=self)
File "/usr/lib/python3/dist-packages/lutris/gui/lutriswindow.py", line 84, in init
desktopapps.sync_with_lutris()
File "/usr/lib/python3/dist-packages/lutris/util/desktopapps.py", line 87, in sync_with_lutris
mark_as_installed(appid, 'linux', game_info)
File "/usr/lib/python3/dist-packages/lutris/util/desktopapps.py", line 32, in mark_as_installed
assert game_info[key]
AssertionError
```
I do hope you fix it, as I run quite a few dosbox/scummvm games, and a Wine game with it, so I kind of need it for gaming. Thanks for the understanding.
P.S. I had also posted it on the forum, but overcame my reluctance to not creating many accounts online, as it's kind of important that this gets resolved.
</issue>
<code>
[start of lutris/util/desktopapps.py]
1 """Get games installed as desktop applications."""
2
3 import os
4 import shutil
5 import shlex
6 import subprocess
7 import re
8
9 from gi.repository import Gio
10 from lutris import pga
11 from lutris.util.log import logger
12 from lutris.util.strings import slugify
13 from lutris.config import make_game_config_id, LutrisConfig
14
15 IGNORED_GAMES = (
16 "lutris", "mame", "dosbox", "playonlinux", "org.gnome.Games", "retroarch",
17 "steam", "steam-runtime", "steam-valve", "steam-native", "PlayOnLinux",
18 "fs-uae-arcade", "PCSX2", "ppsspp", "qchdman", "qmc2-sdlmame", "qmc2-arcade",
19 "sc-controller", "epsxe"
20 )
21 IGNORED_EXECUTABLES = (
22 "lutris", "steam"
23 )
24
25 IGNORED_CATEGORIES = (
26 "Emulator", "Development", "Utility"
27 )
28
29
30 def mark_as_installed(appid, runner_name, game_info):
31 for key in ['name', 'slug']:
32 assert game_info[key]
33 logger.info("Setting %s as installed" % game_info['name'])
34 config_id = (game_info.get('config_path') or make_game_config_id(game_info['slug']))
35 game_id = pga.add_or_update(
36 name=game_info['name'],
37 runner=runner_name,
38 slug=game_info['slug'],
39 installed=1,
40 configpath=config_id,
41 installer_slug=game_info['installer_slug']
42 )
43
44 game_config = LutrisConfig(
45 runner_slug=runner_name,
46 game_config_id=config_id,
47 )
48 game_config.raw_game_config.update({'appid': appid, 'exe': game_info['exe'], 'args': game_info['args']})
49 game_config.save()
50 return game_id
51
52
53 def mark_as_uninstalled(game_info):
54 assert 'id' in game_info
55 assert 'name' in game_info
56 logger.info('Setting %s as uninstalled' % game_info['name'])
57 game_id = pga.add_or_update(
58 id=game_info['id'],
59 runner='',
60 installed=0
61 )
62 return game_id
63
64
65 def sync_with_lutris():
66 apps = get_games()
67 desktop_games_in_lutris = pga.get_desktop_games()
68 slugs_in_lutris = set([str(game['slug']) for game in desktop_games_in_lutris])
69
70 seen_slugs = set()
71 for app in apps:
72 game_info = None
73 name = app[0]
74 slug = slugify(name)
75 appid = app[1]
76 seen_slugs.add(slug)
77
78 if slug not in slugs_in_lutris:
79 game_info = {
80 'name': name,
81 'slug': slug,
82 'config_path': slug + '-desktopapp',
83 'installer_slug': 'desktopapp',
84 'exe': app[2],
85 'args': app[3]
86 }
87 mark_as_installed(appid, 'linux', game_info)
88
89 unavailable_slugs = slugs_in_lutris.difference(seen_slugs)
90 for slug in unavailable_slugs:
91 for game in desktop_games_in_lutris:
92 if game['slug'] == slug:
93 mark_as_uninstalled(game)
94
95
96 def get_games():
97 """Return the list of games stored in the XDG menu."""
98 game_list = []
99
100 apps = Gio.AppInfo.get_all()
101 for app in apps:
102 if app.get_nodisplay() or app.get_is_hidden():
103 continue
104 appid = os.path.splitext(app.get_id())[0]
105 exe = None
106 args = []
107
108 # must be in Game category
109 categories = app.get_categories()
110 if not categories:
111 continue
112 categories = filter(None, categories.lower().split(';'))
113 if 'game' not in categories:
114 continue
115
116 # contains a blacklisted category
117 ok = True
118 for c in categories:
119 if c in map(str.lower, IGNORED_CATEGORIES):
120 ok = False
121 if not ok:
122 continue
123
124 # game is blacklisted
125 if appid.lower() in map(str.lower, IGNORED_GAMES):
126 continue
127
128 # executable is blacklisted
129 if app.get_executable().lower() in IGNORED_EXECUTABLES:
130 continue
131
132 cli = shlex.split(app.get_commandline())
133 exe = cli[0]
134 args = cli[1:]
135 # remove %U etc. and change %% to % in arguments
136 args = list(map(lambda arg: re.sub('%[^%]', '', arg).replace('%%', '%'), args))
137
138 args = subprocess.list2cmdline(args)
139
140 if not exe.startswith('/'):
141 exe = shutil.which(exe)
142 game_list.append((app.get_display_name(), appid, exe, args))
143 return game_list
144
[end of lutris/util/desktopapps.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lutris/util/desktopapps.py b/lutris/util/desktopapps.py
--- a/lutris/util/desktopapps.py
+++ b/lutris/util/desktopapps.py
@@ -18,6 +18,7 @@
"fs-uae-arcade", "PCSX2", "ppsspp", "qchdman", "qmc2-sdlmame", "qmc2-arcade",
"sc-controller", "epsxe"
)
+
IGNORED_EXECUTABLES = (
"lutris", "steam"
)
@@ -41,12 +42,19 @@
installer_slug=game_info['installer_slug']
)
- game_config = LutrisConfig(
+ config = LutrisConfig(
runner_slug=runner_name,
game_config_id=config_id,
)
- game_config.raw_game_config.update({'appid': appid, 'exe': game_info['exe'], 'args': game_info['args']})
- game_config.save()
+ config.raw_game_config.update({
+ 'appid': appid,
+ 'exe': game_info['exe'],
+ 'args': game_info['args']
+ })
+ config.raw_system_config.update({
+ 'disable_runtime': True
+ })
+ config.save()
return game_id
@@ -71,8 +79,23 @@
for app in apps:
game_info = None
name = app[0]
- slug = slugify(name)
appid = app[1]
+ slug = slugify(name)
+
+ # if it fails to get slug from the name
+ if not slug:
+ slug = slugify(appid)
+
+ if not name or not slug or not appid:
+ logger.error("Failed to load desktop game "
+ "\"" + str(name) + "\" "
+ "(app: " + str(appid) + ", slug: " + slug + ")")
+ continue
+ else:
+ logger.debug("Found desktop game "
+ "\"" + str(name) + "\" "
+ "(app: " + str(appid) + ", slug: " + slug + ")")
+
seen_slugs.add(slug)
if slug not in slugs_in_lutris:
|
{"golden_diff": "diff --git a/lutris/util/desktopapps.py b/lutris/util/desktopapps.py\n--- a/lutris/util/desktopapps.py\n+++ b/lutris/util/desktopapps.py\n@@ -18,6 +18,7 @@\n \"fs-uae-arcade\", \"PCSX2\", \"ppsspp\", \"qchdman\", \"qmc2-sdlmame\", \"qmc2-arcade\",\n \"sc-controller\", \"epsxe\"\n )\n+\n IGNORED_EXECUTABLES = (\n \"lutris\", \"steam\"\n )\n@@ -41,12 +42,19 @@\n installer_slug=game_info['installer_slug']\n )\n \n- game_config = LutrisConfig(\n+ config = LutrisConfig(\n runner_slug=runner_name,\n game_config_id=config_id,\n )\n- game_config.raw_game_config.update({'appid': appid, 'exe': game_info['exe'], 'args': game_info['args']})\n- game_config.save()\n+ config.raw_game_config.update({\n+ 'appid': appid,\n+ 'exe': game_info['exe'],\n+ 'args': game_info['args']\n+ })\n+ config.raw_system_config.update({\n+ 'disable_runtime': True\n+ })\n+ config.save()\n return game_id\n \n \n@@ -71,8 +79,23 @@\n for app in apps:\n game_info = None\n name = app[0]\n- slug = slugify(name)\n appid = app[1]\n+ slug = slugify(name)\n+\n+ # if it fails to get slug from the name\n+ if not slug:\n+ slug = slugify(appid)\n+\n+ if not name or not slug or not appid:\n+ logger.error(\"Failed to load desktop game \"\n+ \"\\\"\" + str(name) + \"\\\" \"\n+ \"(app: \" + str(appid) + \", slug: \" + slug + \")\")\n+ continue\n+ else:\n+ logger.debug(\"Found desktop game \"\n+ \"\\\"\" + str(name) + \"\\\" \"\n+ \"(app: \" + str(appid) + \", slug: \" + slug + \")\")\n+\n seen_slugs.add(slug)\n \n if slug not in slugs_in_lutris:\n", "issue": "Lutris 0.4.5 doesn\u2019t launch (AssertionError)\nI'm using Linux Mint 18.1 (my de is Mate if that's any help) and I received the update for Lutris 0.4.5. I tried to launch Lutris after that and nothing seemed to happen. I then tried to launch it from the terminal with the command \"lutris\" and saw the following:\r\n\r\n```python\r\nTraceback (most recent call last):\r\nFile \"/usr/lib/python3/dist-packages/lutris/gui/application.py\", line 152, in do_activate\r\nself.window = LutrisWindow(application=self)\r\nFile \"/usr/lib/python3/dist-packages/lutris/gui/lutriswindow.py\", line 84, in init\r\ndesktopapps.sync_with_lutris()\r\nFile \"/usr/lib/python3/dist-packages/lutris/util/desktopapps.py\", line 87, in sync_with_lutris\r\nmark_as_installed(appid, 'linux', game_info)\r\nFile \"/usr/lib/python3/dist-packages/lutris/util/desktopapps.py\", line 32, in mark_as_installed\r\nassert game_info[key]\r\nAssertionError\r\n```\r\n\r\nI do hope you fix it, as I run quite a few dosbox/scummvm games, and a Wine game with it, so I kind of need it for gaming. Thanks for the understanding.\r\nP.S. I had also posted it on the forum, but overcame my reluctance to not creating many accounts online, as it's kind of important that this gets resolved.\n", "before_files": [{"content": "\"\"\"Get games installed as desktop applications.\"\"\"\n\nimport os\nimport shutil\nimport shlex\nimport subprocess\nimport re\n\nfrom gi.repository import Gio\nfrom lutris import pga\nfrom lutris.util.log import logger\nfrom lutris.util.strings import slugify\nfrom lutris.config import make_game_config_id, LutrisConfig\n\nIGNORED_GAMES = (\n \"lutris\", \"mame\", \"dosbox\", \"playonlinux\", \"org.gnome.Games\", \"retroarch\",\n \"steam\", \"steam-runtime\", \"steam-valve\", \"steam-native\", \"PlayOnLinux\",\n \"fs-uae-arcade\", \"PCSX2\", \"ppsspp\", \"qchdman\", \"qmc2-sdlmame\", \"qmc2-arcade\",\n \"sc-controller\", \"epsxe\"\n)\nIGNORED_EXECUTABLES = (\n \"lutris\", \"steam\"\n)\n\nIGNORED_CATEGORIES = (\n \"Emulator\", \"Development\", \"Utility\"\n)\n\n\ndef mark_as_installed(appid, runner_name, game_info):\n for key in ['name', 'slug']:\n assert game_info[key]\n logger.info(\"Setting %s as installed\" % game_info['name'])\n config_id = (game_info.get('config_path') or make_game_config_id(game_info['slug']))\n game_id = pga.add_or_update(\n name=game_info['name'],\n runner=runner_name,\n slug=game_info['slug'],\n installed=1,\n configpath=config_id,\n installer_slug=game_info['installer_slug']\n )\n\n game_config = LutrisConfig(\n runner_slug=runner_name,\n game_config_id=config_id,\n )\n game_config.raw_game_config.update({'appid': appid, 'exe': game_info['exe'], 'args': game_info['args']})\n game_config.save()\n return game_id\n\n\ndef mark_as_uninstalled(game_info):\n assert 'id' in game_info\n assert 'name' in game_info\n logger.info('Setting %s as uninstalled' % game_info['name'])\n game_id = pga.add_or_update(\n id=game_info['id'],\n runner='',\n installed=0\n )\n return game_id\n\n\ndef sync_with_lutris():\n apps = get_games()\n desktop_games_in_lutris = pga.get_desktop_games()\n slugs_in_lutris = set([str(game['slug']) for game in desktop_games_in_lutris])\n\n seen_slugs = set()\n for app in apps:\n game_info = None\n name = app[0]\n slug = slugify(name)\n appid = app[1]\n seen_slugs.add(slug)\n\n if slug not in slugs_in_lutris:\n game_info = {\n 'name': name,\n 'slug': slug,\n 'config_path': slug + '-desktopapp',\n 'installer_slug': 'desktopapp',\n 'exe': app[2],\n 'args': app[3]\n }\n mark_as_installed(appid, 'linux', game_info)\n\n unavailable_slugs = slugs_in_lutris.difference(seen_slugs)\n for slug in unavailable_slugs:\n for game in desktop_games_in_lutris:\n if game['slug'] == slug:\n mark_as_uninstalled(game)\n\n\ndef get_games():\n \"\"\"Return the list of games stored in the XDG menu.\"\"\"\n game_list = []\n\n apps = Gio.AppInfo.get_all()\n for app in apps:\n if app.get_nodisplay() or app.get_is_hidden():\n continue\n appid = os.path.splitext(app.get_id())[0]\n exe = None\n args = []\n\n # must be in Game category\n categories = app.get_categories()\n if not categories:\n continue\n categories = filter(None, categories.lower().split(';'))\n if 'game' not in categories:\n continue\n\n # contains a blacklisted category\n ok = True\n for c in categories:\n if c in map(str.lower, IGNORED_CATEGORIES):\n ok = False\n if not ok:\n continue\n\n # game is blacklisted\n if appid.lower() in map(str.lower, IGNORED_GAMES):\n continue\n\n # executable is blacklisted\n if app.get_executable().lower() in IGNORED_EXECUTABLES:\n continue\n\n cli = shlex.split(app.get_commandline())\n exe = cli[0]\n args = cli[1:]\n # remove %U etc. and change %% to % in arguments\n args = list(map(lambda arg: re.sub('%[^%]', '', arg).replace('%%', '%'), args))\n\n args = subprocess.list2cmdline(args)\n\n if not exe.startswith('/'):\n exe = shutil.which(exe)\n game_list.append((app.get_display_name(), appid, exe, args))\n return game_list\n", "path": "lutris/util/desktopapps.py"}]}
| 2,251 | 500 |
gh_patches_debug_5467
|
rasdani/github-patches
|
git_diff
|
openstates__openstates-scrapers-1173
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
TN: 109th Session, Legislators, Upper - Senator name extraction fails for district 19
Trying to run the scraper locally, I encountered the following exception for TN's [19th senate district in the 109th general assembly](http://www.capitol.tn.gov/senate/archives/109GA/members/s19.html) (Sen. Thelma Hale):
```
File "/usr/local/bin/billy-update", line 9, in <module>
load_entry_point('billy==1.8.4', 'console_scripts', 'billy-update')()
File "/opt/sunlightfoundation.com/billy/billy/bin/update.py", line 377, in main
run_record += _run_scraper(stype, args, metadata)
File "/opt/sunlightfoundation.com/billy/billy/bin/update.py", line 101, in _run_scraper
scraper.scrape(chamber, time)
File "/srv/openstates-web/openstates/tn/legislators.py", line 81, in scrape
name = member_page.xpath('//div[@id="membertitle"]/h2/text()')[0]
IndexError: list index out of range
```
</issue>
<code>
[start of openstates/tn/legislators.py]
1 import HTMLParser
2
3 from billy.scrape.legislators import LegislatorScraper, Legislator
4 import lxml.html
5 from scrapelib import HTTPError
6 from openstates.utils import LXMLMixin
7
8 class TNLegislatorScraper(LegislatorScraper, LXMLMixin):
9 jurisdiction = 'tn'
10
11 def scrape(self, chamber, term):
12 self.validate_term(term, latest_only=False)
13 root_url = 'http://www.capitol.tn.gov/'
14 parties = {'D': 'Democratic', 'R': 'Republican',
15 'CCR': 'Carter County Republican',
16 'I': 'Independent'}
17
18 #testing for chamber
19 if chamber == 'upper':
20 url_chamber_name = 'senate'
21 abbr = 's'
22 else:
23 url_chamber_name = 'house'
24 abbr = 'h'
25 if term != self.metadata["terms"][-1]["sessions"][0]:
26 chamber_url = root_url + url_chamber_name
27 chamber_url += '/archives/' + term + 'GA/Members/index.html'
28 else:
29 chamber_url = root_url + url_chamber_name + '/members/'
30
31 page = self.lxmlize(chamber_url)
32
33 for row in page.xpath("//tr"):
34
35 # Skip any a header row.
36 if set(child.tag for child in row) == set(['th']):
37 continue
38
39 vacancy_check = row.xpath('./td/text()')[1]
40 if 'Vacant' in vacancy_check:
41 self.logger.warning("Vacant Seat")
42 continue
43
44 partyInit = row.xpath('td[3]')[0].text.split()[0]
45 party = parties[partyInit]
46 district = row.xpath('td[5]/a')[0].text.split()[1]
47 address = row.xpath('td[6]')[0].text_content()
48 # 301 6th Avenue North Suite
49 address = address.replace('LP',
50 'Legislative Plaza\nNashville, TN 37243')
51 address = address.replace('WMB',
52 'War Memorial Building\nNashville, TN 37243')
53 address = '301 6th Avenue North\nSuite ' + address
54 phone = [
55 x.strip() for x in
56 row.xpath('td[7]//text()')
57 if x.strip()
58 ][0]
59
60 email = HTMLParser.HTMLParser().unescape(
61 row.xpath('td[1]/a/@href')[0][len("mailto:"): ])
62 member_url = (root_url + url_chamber_name + '/members/' + abbr +
63 district + '.html')
64 member_photo_url = (root_url + url_chamber_name +
65 '/members/images/' + abbr + district + '.jpg')
66
67 try:
68 member_page = self.get(member_url, allow_redirects=False).text
69 except (TypeError, HTTPError):
70 try:
71 member_url = row.xpath('td[2]/a/@href')[0]
72 member_page = self.get(member_url, allow_redirects=False).text
73 except (TypeError, HTTPError):
74 self.logger.warning("Valid member page does not exist.")
75 continue
76
77 member_page = lxml.html.fromstring(member_page)
78 try:
79 name = member_page.xpath('body/div/div/h1/text()')[0]
80 except IndexError:
81 name = member_page.xpath('//div[@id="membertitle"]/h2/text()')[0]
82
83 if 'Speaker' in name:
84 full_name = name[8:len(name)]
85 elif 'Lt.' in name:
86 full_name = name[13:len(name)]
87 elif abbr == 'h':
88 full_name = name[len("Representative "): len(name)]
89 else:
90 full_name = name[8:len(name)]
91
92 leg = Legislator(term, chamber, district, full_name.strip(),
93 party=party, url=member_url,
94 photo_url=member_photo_url)
95 leg.add_source(chamber_url)
96 leg.add_source(member_url)
97
98 # TODO: add district address from this page
99
100 leg.add_office('capitol', 'Nashville Address',
101 address=address, phone=phone, email=email)
102
103 self.save_legislator(leg)
104
[end of openstates/tn/legislators.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/openstates/tn/legislators.py b/openstates/tn/legislators.py
--- a/openstates/tn/legislators.py
+++ b/openstates/tn/legislators.py
@@ -76,7 +76,7 @@
member_page = lxml.html.fromstring(member_page)
try:
- name = member_page.xpath('body/div/div/h1/text()')[0]
+ name = member_page.xpath('//div/div/h1/text()')[0]
except IndexError:
name = member_page.xpath('//div[@id="membertitle"]/h2/text()')[0]
|
{"golden_diff": "diff --git a/openstates/tn/legislators.py b/openstates/tn/legislators.py\n--- a/openstates/tn/legislators.py\n+++ b/openstates/tn/legislators.py\n@@ -76,7 +76,7 @@\n \n member_page = lxml.html.fromstring(member_page)\n try:\n- name = member_page.xpath('body/div/div/h1/text()')[0]\n+ name = member_page.xpath('//div/div/h1/text()')[0]\n except IndexError:\n name = member_page.xpath('//div[@id=\"membertitle\"]/h2/text()')[0]\n", "issue": "TN: 109th Session, Legislators, Upper - Senator name extraction fails for district 19\nTrying to run the scraper locally, I encountered the following exception for TN's [19th senate district in the 109th general assembly](http://www.capitol.tn.gov/senate/archives/109GA/members/s19.html) (Sen. Thelma Hale):\r\n\r\n```\r\nFile \"/usr/local/bin/billy-update\", line 9, in <module>\r\n load_entry_point('billy==1.8.4', 'console_scripts', 'billy-update')()\r\n File \"/opt/sunlightfoundation.com/billy/billy/bin/update.py\", line 377, in main\r\n run_record += _run_scraper(stype, args, metadata)\r\n File \"/opt/sunlightfoundation.com/billy/billy/bin/update.py\", line 101, in _run_scraper\r\n scraper.scrape(chamber, time)\r\n File \"/srv/openstates-web/openstates/tn/legislators.py\", line 81, in scrape\r\n name = member_page.xpath('//div[@id=\"membertitle\"]/h2/text()')[0]\r\nIndexError: list index out of range\r\n```\n", "before_files": [{"content": "import HTMLParser\n\nfrom billy.scrape.legislators import LegislatorScraper, Legislator\nimport lxml.html\nfrom scrapelib import HTTPError\nfrom openstates.utils import LXMLMixin\n\nclass TNLegislatorScraper(LegislatorScraper, LXMLMixin):\n jurisdiction = 'tn'\n\n def scrape(self, chamber, term):\n self.validate_term(term, latest_only=False)\n root_url = 'http://www.capitol.tn.gov/'\n parties = {'D': 'Democratic', 'R': 'Republican',\n 'CCR': 'Carter County Republican',\n 'I': 'Independent'}\n\n #testing for chamber\n if chamber == 'upper':\n url_chamber_name = 'senate'\n abbr = 's'\n else:\n url_chamber_name = 'house'\n abbr = 'h'\n if term != self.metadata[\"terms\"][-1][\"sessions\"][0]:\n chamber_url = root_url + url_chamber_name\n chamber_url += '/archives/' + term + 'GA/Members/index.html'\n else:\n chamber_url = root_url + url_chamber_name + '/members/'\n\n page = self.lxmlize(chamber_url)\n\n for row in page.xpath(\"//tr\"):\n\n # Skip any a header row.\n if set(child.tag for child in row) == set(['th']):\n continue\n\n vacancy_check = row.xpath('./td/text()')[1]\n if 'Vacant' in vacancy_check:\n self.logger.warning(\"Vacant Seat\")\n continue\n\n partyInit = row.xpath('td[3]')[0].text.split()[0]\n party = parties[partyInit]\n district = row.xpath('td[5]/a')[0].text.split()[1]\n address = row.xpath('td[6]')[0].text_content()\n # 301 6th Avenue North Suite\n address = address.replace('LP',\n 'Legislative Plaza\\nNashville, TN 37243')\n address = address.replace('WMB',\n 'War Memorial Building\\nNashville, TN 37243')\n address = '301 6th Avenue North\\nSuite ' + address\n phone = [\n x.strip() for x in\n row.xpath('td[7]//text()')\n if x.strip()\n ][0]\n\n email = HTMLParser.HTMLParser().unescape(\n row.xpath('td[1]/a/@href')[0][len(\"mailto:\"): ])\n member_url = (root_url + url_chamber_name + '/members/' + abbr +\n district + '.html')\n member_photo_url = (root_url + url_chamber_name +\n '/members/images/' + abbr + district + '.jpg')\n\n try:\n member_page = self.get(member_url, allow_redirects=False).text\n except (TypeError, HTTPError):\n try:\n member_url = row.xpath('td[2]/a/@href')[0]\n member_page = self.get(member_url, allow_redirects=False).text\n except (TypeError, HTTPError):\n self.logger.warning(\"Valid member page does not exist.\")\n continue\n\n member_page = lxml.html.fromstring(member_page)\n try:\n name = member_page.xpath('body/div/div/h1/text()')[0]\n except IndexError:\n name = member_page.xpath('//div[@id=\"membertitle\"]/h2/text()')[0]\n \n if 'Speaker' in name:\n full_name = name[8:len(name)]\n elif 'Lt.' in name:\n full_name = name[13:len(name)]\n elif abbr == 'h':\n full_name = name[len(\"Representative \"): len(name)]\n else:\n full_name = name[8:len(name)]\n\n leg = Legislator(term, chamber, district, full_name.strip(),\n party=party, url=member_url,\n photo_url=member_photo_url)\n leg.add_source(chamber_url)\n leg.add_source(member_url)\n\n # TODO: add district address from this page\n\n leg.add_office('capitol', 'Nashville Address',\n address=address, phone=phone, email=email)\n\n self.save_legislator(leg)\n", "path": "openstates/tn/legislators.py"}]}
| 1,933 | 137 |
gh_patches_debug_30388
|
rasdani/github-patches
|
git_diff
|
facebookresearch__hydra-185
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
move hydra generated files into an output directory relative to the job dir
automatically generated files like config.yaml, overrides.yaml, and others can go here.
Also additional debug information about the hydra config composition order.
</issue>
<code>
[start of hydra/plugins/common/utils.py]
1 # Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved
2
3 import copy
4 import logging
5 import os
6 import re
7 import sys
8 from time import strftime, localtime
9
10 import six
11 from omegaconf import OmegaConf, DictConfig, ListConfig
12
13 # pylint: disable=C0103
14 log = logging.getLogger(__name__)
15
16
17 def configure_log(log_config, verbose_config):
18 assert isinstance(verbose_config, (bool, str, ListConfig))
19 if log_config is not None:
20 conf = log_config.to_container(resolve=True)
21 logging.config.dictConfig(conf)
22 else:
23 # default logging to stdout
24 root = logging.getLogger()
25 root.setLevel(logging.INFO)
26 handler = logging.StreamHandler(sys.stdout)
27 formatter = logging.Formatter(
28 "[%(asctime)s][%(name)s][%(levelname)s] - %(message)s"
29 )
30 handler.setFormatter(formatter)
31 root.addHandler(handler)
32 if isinstance(verbose_config, bool):
33 if verbose_config:
34 logging.getLogger().setLevel(logging.DEBUG)
35 else:
36 if isinstance(verbose_config, str):
37 verbose_config = OmegaConf.create([verbose_config])
38 for logger in verbose_config:
39 logging.getLogger(logger).setLevel(logging.DEBUG)
40
41
42 def save_config(cfg, filename):
43 with open(os.path.join(filename), "w") as file:
44 file.write(cfg.pretty())
45
46
47 def get_overrides_dirname(lst, exclude_keys=[]):
48 lst = [x for x in lst if x not in exclude_keys]
49 lst.sort()
50 return re.sub(pattern="[=]", repl="=", string=",".join(lst))
51
52
53 def filter_overrides(overrides):
54 """
55 :param overrides: overrides list
56 :return: returning a new overrides list with all the keys starting with hydra. fitlered.
57 """
58 return [x for x in overrides if not x.startswith("hydra.")]
59
60
61 def run_job(config, task_function, job_dir_key, job_subdir_key):
62 old_cwd = os.getcwd()
63 working_dir = str(config.select(job_dir_key))
64 if job_subdir_key is not None:
65 # evaluate job_subdir_key lazily.
66 # this is running on the client side in sweep and contains things such as job:id which
67 # are only available there.
68 subdir = str(config.select(job_subdir_key))
69 working_dir = os.path.join(working_dir, subdir)
70 try:
71 ret = JobReturn()
72 ret.working_dir = working_dir
73 task_cfg = copy.deepcopy(config)
74 # TODO: update this after https://github.com/omry/omegaconf/issues/42 is resolved
75 hydra_cfg = OmegaConf.create({"hydra": task_cfg["hydra"]})
76 del task_cfg["hydra"]
77 ret.cfg = task_cfg
78 ret.hydra_cfg = copy.deepcopy(HydraConfig())
79 ret.overrides = config.hydra.overrides.task.to_container()
80 if not os.path.exists(working_dir):
81 os.makedirs(working_dir)
82 os.chdir(working_dir)
83 configure_log(hydra_cfg.hydra.job_logging, hydra_cfg.hydra.verbose)
84
85 save_config(task_cfg, "config.yaml")
86 save_config(hydra_cfg, "hydra.yaml")
87 save_config(config.hydra.overrides.task, "overrides.yaml")
88 ret.return_value = task_function(task_cfg)
89 ret.task_name = JobRuntime().get("name")
90 return ret
91 finally:
92 os.chdir(old_cwd)
93
94
95 def get_valid_filename(s):
96 s = str(s).strip().replace(" ", "_")
97 return re.sub(r"(?u)[^-\w.]", "", s)
98
99
100 def setup_globals():
101 try:
102 OmegaConf.register_resolver(
103 "now", lambda pattern: strftime(pattern, localtime())
104 )
105
106 def job_error(x):
107 raise Exception(
108 "job:{} is no longer available. use hydra.job.{}".format(x, x)
109 )
110
111 OmegaConf.register_resolver("job", job_error)
112
113 except AssertionError:
114 # calling it again in no_workers mode will throw. safe to ignore.
115 pass
116
117
118 class JobReturn:
119 def __init__(self):
120 self.overrides = None
121 self.return_value = None
122 self.cfg = None
123 self.hydra_cfg = None
124 self.working_dir = None
125 self.task_name = None
126
127
128 class Singleton(type):
129 _instances = {}
130
131 def __call__(cls, *args, **kwargs):
132 if cls not in cls._instances:
133 cls._instances[cls] = super(Singleton, cls).__call__(*args, **kwargs)
134 return cls._instances[cls]
135
136 @staticmethod
137 def get_state():
138 return Singleton._instances
139
140 @staticmethod
141 def set_state(instances):
142 Singleton._instances = instances
143
144
145 @six.add_metaclass(Singleton)
146 class JobRuntime:
147 def __init__(self):
148 self.conf = OmegaConf.create()
149 self.set("name", "UNKNOWN_NAME")
150
151 def get(self, key):
152 ret = self.conf.select(key)
153 if ret is None:
154 raise KeyError("Key not found in {}: {}".format(type(self).__name__, key))
155 return ret
156
157 def set(self, key, value):
158 log.debug("Setting {}:{}={}".format(type(self).__name__, key, value))
159 self.conf[key] = value
160
161
162 @six.add_metaclass(Singleton)
163 class HydraConfig(DictConfig):
164 def __init__(self):
165 super(HydraConfig, self).__init__(content={})
166 self.hydra = None
167
168 def set_config(self, cfg):
169 try:
170 OmegaConf.set_readonly(self, False)
171 self.hydra = copy.deepcopy(cfg.hydra)
172 finally:
173 OmegaConf.set_readonly(self, True)
174
[end of hydra/plugins/common/utils.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/hydra/plugins/common/utils.py b/hydra/plugins/common/utils.py
--- a/hydra/plugins/common/utils.py
+++ b/hydra/plugins/common/utils.py
@@ -5,6 +5,7 @@
import os
import re
import sys
+from hydra._internal.pathlib import Path
from time import strftime, localtime
import six
@@ -39,8 +40,9 @@
logging.getLogger(logger).setLevel(logging.DEBUG)
-def save_config(cfg, filename):
- with open(os.path.join(filename), "w") as file:
+def _save_config(cfg, filename, output_dir):
+ Path(str(output_dir)).mkdir(parents=True, exist_ok=True)
+ with open(str(output_dir / filename), "w") as file:
file.write(cfg.pretty())
@@ -77,14 +79,15 @@
ret.cfg = task_cfg
ret.hydra_cfg = copy.deepcopy(HydraConfig())
ret.overrides = config.hydra.overrides.task.to_container()
- if not os.path.exists(working_dir):
- os.makedirs(working_dir)
+ # handle output directories here
+ Path(str(working_dir)).mkdir(parents=True, exist_ok=True)
os.chdir(working_dir)
- configure_log(hydra_cfg.hydra.job_logging, hydra_cfg.hydra.verbose)
+ hydra_output = Path(hydra_cfg.hydra.output_subdir)
- save_config(task_cfg, "config.yaml")
- save_config(hydra_cfg, "hydra.yaml")
- save_config(config.hydra.overrides.task, "overrides.yaml")
+ configure_log(hydra_cfg.hydra.job_logging, hydra_cfg.hydra.verbose)
+ _save_config(task_cfg, "config.yaml", hydra_output)
+ _save_config(hydra_cfg, "hydra.yaml", hydra_output)
+ _save_config(config.hydra.overrides.task, "overrides.yaml", hydra_output)
ret.return_value = task_function(task_cfg)
ret.task_name = JobRuntime().get("name")
return ret
|
{"golden_diff": "diff --git a/hydra/plugins/common/utils.py b/hydra/plugins/common/utils.py\n--- a/hydra/plugins/common/utils.py\n+++ b/hydra/plugins/common/utils.py\n@@ -5,6 +5,7 @@\n import os\n import re\n import sys\n+from hydra._internal.pathlib import Path\n from time import strftime, localtime\n \n import six\n@@ -39,8 +40,9 @@\n logging.getLogger(logger).setLevel(logging.DEBUG)\n \n \n-def save_config(cfg, filename):\n- with open(os.path.join(filename), \"w\") as file:\n+def _save_config(cfg, filename, output_dir):\n+ Path(str(output_dir)).mkdir(parents=True, exist_ok=True)\n+ with open(str(output_dir / filename), \"w\") as file:\n file.write(cfg.pretty())\n \n \n@@ -77,14 +79,15 @@\n ret.cfg = task_cfg\n ret.hydra_cfg = copy.deepcopy(HydraConfig())\n ret.overrides = config.hydra.overrides.task.to_container()\n- if not os.path.exists(working_dir):\n- os.makedirs(working_dir)\n+ # handle output directories here\n+ Path(str(working_dir)).mkdir(parents=True, exist_ok=True)\n os.chdir(working_dir)\n- configure_log(hydra_cfg.hydra.job_logging, hydra_cfg.hydra.verbose)\n+ hydra_output = Path(hydra_cfg.hydra.output_subdir)\n \n- save_config(task_cfg, \"config.yaml\")\n- save_config(hydra_cfg, \"hydra.yaml\")\n- save_config(config.hydra.overrides.task, \"overrides.yaml\")\n+ configure_log(hydra_cfg.hydra.job_logging, hydra_cfg.hydra.verbose)\n+ _save_config(task_cfg, \"config.yaml\", hydra_output)\n+ _save_config(hydra_cfg, \"hydra.yaml\", hydra_output)\n+ _save_config(config.hydra.overrides.task, \"overrides.yaml\", hydra_output)\n ret.return_value = task_function(task_cfg)\n ret.task_name = JobRuntime().get(\"name\")\n return ret\n", "issue": "move hydra generated files into an output directory relative to the job dir\nautomatically generated files like config.yaml, overrides.yaml, and others can go here.\r\nAlso additional debug information about the hydra config composition order.\n", "before_files": [{"content": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\n\nimport copy\nimport logging\nimport os\nimport re\nimport sys\nfrom time import strftime, localtime\n\nimport six\nfrom omegaconf import OmegaConf, DictConfig, ListConfig\n\n# pylint: disable=C0103\nlog = logging.getLogger(__name__)\n\n\ndef configure_log(log_config, verbose_config):\n assert isinstance(verbose_config, (bool, str, ListConfig))\n if log_config is not None:\n conf = log_config.to_container(resolve=True)\n logging.config.dictConfig(conf)\n else:\n # default logging to stdout\n root = logging.getLogger()\n root.setLevel(logging.INFO)\n handler = logging.StreamHandler(sys.stdout)\n formatter = logging.Formatter(\n \"[%(asctime)s][%(name)s][%(levelname)s] - %(message)s\"\n )\n handler.setFormatter(formatter)\n root.addHandler(handler)\n if isinstance(verbose_config, bool):\n if verbose_config:\n logging.getLogger().setLevel(logging.DEBUG)\n else:\n if isinstance(verbose_config, str):\n verbose_config = OmegaConf.create([verbose_config])\n for logger in verbose_config:\n logging.getLogger(logger).setLevel(logging.DEBUG)\n\n\ndef save_config(cfg, filename):\n with open(os.path.join(filename), \"w\") as file:\n file.write(cfg.pretty())\n\n\ndef get_overrides_dirname(lst, exclude_keys=[]):\n lst = [x for x in lst if x not in exclude_keys]\n lst.sort()\n return re.sub(pattern=\"[=]\", repl=\"=\", string=\",\".join(lst))\n\n\ndef filter_overrides(overrides):\n \"\"\"\n :param overrides: overrides list\n :return: returning a new overrides list with all the keys starting with hydra. fitlered.\n \"\"\"\n return [x for x in overrides if not x.startswith(\"hydra.\")]\n\n\ndef run_job(config, task_function, job_dir_key, job_subdir_key):\n old_cwd = os.getcwd()\n working_dir = str(config.select(job_dir_key))\n if job_subdir_key is not None:\n # evaluate job_subdir_key lazily.\n # this is running on the client side in sweep and contains things such as job:id which\n # are only available there.\n subdir = str(config.select(job_subdir_key))\n working_dir = os.path.join(working_dir, subdir)\n try:\n ret = JobReturn()\n ret.working_dir = working_dir\n task_cfg = copy.deepcopy(config)\n # TODO: update this after https://github.com/omry/omegaconf/issues/42 is resolved\n hydra_cfg = OmegaConf.create({\"hydra\": task_cfg[\"hydra\"]})\n del task_cfg[\"hydra\"]\n ret.cfg = task_cfg\n ret.hydra_cfg = copy.deepcopy(HydraConfig())\n ret.overrides = config.hydra.overrides.task.to_container()\n if not os.path.exists(working_dir):\n os.makedirs(working_dir)\n os.chdir(working_dir)\n configure_log(hydra_cfg.hydra.job_logging, hydra_cfg.hydra.verbose)\n\n save_config(task_cfg, \"config.yaml\")\n save_config(hydra_cfg, \"hydra.yaml\")\n save_config(config.hydra.overrides.task, \"overrides.yaml\")\n ret.return_value = task_function(task_cfg)\n ret.task_name = JobRuntime().get(\"name\")\n return ret\n finally:\n os.chdir(old_cwd)\n\n\ndef get_valid_filename(s):\n s = str(s).strip().replace(\" \", \"_\")\n return re.sub(r\"(?u)[^-\\w.]\", \"\", s)\n\n\ndef setup_globals():\n try:\n OmegaConf.register_resolver(\n \"now\", lambda pattern: strftime(pattern, localtime())\n )\n\n def job_error(x):\n raise Exception(\n \"job:{} is no longer available. use hydra.job.{}\".format(x, x)\n )\n\n OmegaConf.register_resolver(\"job\", job_error)\n\n except AssertionError:\n # calling it again in no_workers mode will throw. safe to ignore.\n pass\n\n\nclass JobReturn:\n def __init__(self):\n self.overrides = None\n self.return_value = None\n self.cfg = None\n self.hydra_cfg = None\n self.working_dir = None\n self.task_name = None\n\n\nclass Singleton(type):\n _instances = {}\n\n def __call__(cls, *args, **kwargs):\n if cls not in cls._instances:\n cls._instances[cls] = super(Singleton, cls).__call__(*args, **kwargs)\n return cls._instances[cls]\n\n @staticmethod\n def get_state():\n return Singleton._instances\n\n @staticmethod\n def set_state(instances):\n Singleton._instances = instances\n\n\[email protected]_metaclass(Singleton)\nclass JobRuntime:\n def __init__(self):\n self.conf = OmegaConf.create()\n self.set(\"name\", \"UNKNOWN_NAME\")\n\n def get(self, key):\n ret = self.conf.select(key)\n if ret is None:\n raise KeyError(\"Key not found in {}: {}\".format(type(self).__name__, key))\n return ret\n\n def set(self, key, value):\n log.debug(\"Setting {}:{}={}\".format(type(self).__name__, key, value))\n self.conf[key] = value\n\n\[email protected]_metaclass(Singleton)\nclass HydraConfig(DictConfig):\n def __init__(self):\n super(HydraConfig, self).__init__(content={})\n self.hydra = None\n\n def set_config(self, cfg):\n try:\n OmegaConf.set_readonly(self, False)\n self.hydra = copy.deepcopy(cfg.hydra)\n finally:\n OmegaConf.set_readonly(self, True)\n", "path": "hydra/plugins/common/utils.py"}]}
| 2,228 | 454 |
gh_patches_debug_3144
|
rasdani/github-patches
|
git_diff
|
cupy__cupy-2588
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Stream in the context-manager form is not used in `ElementwiseKernel` or `ReductionKernel`
This is actually a bug reported back in #1695 that unfortunately went unnoticed.
In `examples/stream/map_reduce.py`, a list of streams was created for executing `cupy.matmul()` in parallel, which is backed by a `ReductionKernel` in this case: https://github.com/cupy/cupy/blob/1af22f57fda92ae35bde806d0c4d110faf4fed52/cupy/core/core.pyx#L2513-L2516
However, inspecting the implementation I found that `ReductionKernel` only accepts an explicit `stream` argument; it does not pick up any current stream: https://github.com/cupy/cupy/blob/32718607a7808ec6bc3a24cf9231a9351f8fc95e/cupy/core/reduction.pxi#L396
In other words, that example was misleading because those streams were not used at all and so all executions were serialized, as can be checked from nvprof + nvvp (see the circle in red):
<img width="972" alt="螢幕快照 2019-10-03 上午11 24 27" src="https://user-images.githubusercontent.com/5534781/66140715-978bf180-e5d0-11e9-8228-f613a3eba6fd.png">
The same bug also appears in `ElementwiseKernel`:
https://github.com/cupy/cupy/blob/1af22f57fda92ae35bde806d0c4d110faf4fed52/cupy/core/_kernel.pyx#L537
In my opinion, unlike `RawKernel` which is not used by any CuPy core functionalities, `ElementwiseKernel` and `ReductionKernel` should honor the current stream by checking the current stream pointer if no stream argument is explicitly given, since many CuPy functions like `cupy.matmul()` do not support passing in a stream. A similar approach is already adopted in the FFT module, see #2362.
</issue>
<code>
[start of examples/stream/map_reduce.py]
1 import cupy
2 import time
3
4 device = cupy.cuda.Device()
5 memory_pool = cupy.cuda.MemoryPool()
6 cupy.cuda.set_allocator(memory_pool.malloc)
7 rand = cupy.random.generator.RandomState(seed=1)
8
9 n = 10
10 zs = []
11 map_streams = []
12 stop_events = []
13 reduce_stream = cupy.cuda.stream.Stream()
14 for i in range(n):
15 map_streams.append(cupy.cuda.stream.Stream())
16
17 start_time = time.time()
18
19 # Map
20 for stream in map_streams:
21 with stream:
22 x = rand.normal(size=(1, 1024 * 256))
23 y = rand.normal(size=(1024 * 256, 1))
24 z = cupy.matmul(x, y)
25 zs.append(z)
26 stop_event = stream.record()
27 stop_events.append(stop_event)
28
29 # Block the `reduce_stream` until all events occur. This does not block host.
30 # This is not required when reduction is performed in the default (Stream.null)
31 # stream unless streams are created with `non_blocking=True` flag.
32 for i in range(n):
33 reduce_stream.wait_event(stop_events[i])
34
35 # Reduce
36 with reduce_stream:
37 z = sum(zs)
38
39 device.synchronize()
40 elapsed_time = time.time() - start_time
41 print('elapsed time', elapsed_time)
42 print('total bytes', memory_pool.total_bytes())
43
44 # Free all blocks in the memory pool of streams
45 for stream in map_streams:
46 memory_pool.free_all_blocks(stream=stream)
47 print('total bytes', memory_pool.total_bytes())
48
[end of examples/stream/map_reduce.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/examples/stream/map_reduce.py b/examples/stream/map_reduce.py
--- a/examples/stream/map_reduce.py
+++ b/examples/stream/map_reduce.py
@@ -19,8 +19,8 @@
# Map
for stream in map_streams:
with stream:
- x = rand.normal(size=(1, 1024 * 256))
- y = rand.normal(size=(1024 * 256, 1))
+ x = rand.normal(size=(1, 1024**2))
+ y = rand.normal(size=(1024**2, 1))
z = cupy.matmul(x, y)
zs.append(z)
stop_event = stream.record()
|
{"golden_diff": "diff --git a/examples/stream/map_reduce.py b/examples/stream/map_reduce.py\n--- a/examples/stream/map_reduce.py\n+++ b/examples/stream/map_reduce.py\n@@ -19,8 +19,8 @@\n # Map\n for stream in map_streams:\n with stream:\n- x = rand.normal(size=(1, 1024 * 256))\n- y = rand.normal(size=(1024 * 256, 1))\n+ x = rand.normal(size=(1, 1024**2))\n+ y = rand.normal(size=(1024**2, 1))\n z = cupy.matmul(x, y)\n zs.append(z)\n stop_event = stream.record()\n", "issue": "Stream in the context-manager form is not used in `ElementwiseKernel` or `ReductionKernel`\nThis is actually a bug reported back in #1695 that unfortunately went unnoticed. \r\n\r\nIn `examples/stream/map_reduce.py`, a list of streams was created for executing `cupy.matmul()` in parallel, which is backed by a `ReductionKernel` in this case: https://github.com/cupy/cupy/blob/1af22f57fda92ae35bde806d0c4d110faf4fed52/cupy/core/core.pyx#L2513-L2516\r\nHowever, inspecting the implementation I found that `ReductionKernel` only accepts an explicit `stream` argument; it does not pick up any current stream: https://github.com/cupy/cupy/blob/32718607a7808ec6bc3a24cf9231a9351f8fc95e/cupy/core/reduction.pxi#L396\r\nIn other words, that example was misleading because those streams were not used at all and so all executions were serialized, as can be checked from nvprof + nvvp (see the circle in red):\r\n<img width=\"972\" alt=\"\u87a2\u5e55\u5feb\u7167 2019-10-03 \u4e0a\u534811 24 27\" src=\"https://user-images.githubusercontent.com/5534781/66140715-978bf180-e5d0-11e9-8228-f613a3eba6fd.png\">\r\n\r\nThe same bug also appears in `ElementwiseKernel`:\r\nhttps://github.com/cupy/cupy/blob/1af22f57fda92ae35bde806d0c4d110faf4fed52/cupy/core/_kernel.pyx#L537\r\n\r\nIn my opinion, unlike `RawKernel` which is not used by any CuPy core functionalities, `ElementwiseKernel` and `ReductionKernel` should honor the current stream by checking the current stream pointer if no stream argument is explicitly given, since many CuPy functions like `cupy.matmul()` do not support passing in a stream. A similar approach is already adopted in the FFT module, see #2362.\n", "before_files": [{"content": "import cupy\nimport time\n\ndevice = cupy.cuda.Device()\nmemory_pool = cupy.cuda.MemoryPool()\ncupy.cuda.set_allocator(memory_pool.malloc)\nrand = cupy.random.generator.RandomState(seed=1)\n\nn = 10\nzs = []\nmap_streams = []\nstop_events = []\nreduce_stream = cupy.cuda.stream.Stream()\nfor i in range(n):\n map_streams.append(cupy.cuda.stream.Stream())\n\nstart_time = time.time()\n\n# Map\nfor stream in map_streams:\n with stream:\n x = rand.normal(size=(1, 1024 * 256))\n y = rand.normal(size=(1024 * 256, 1))\n z = cupy.matmul(x, y)\n zs.append(z)\n stop_event = stream.record()\n stop_events.append(stop_event)\n\n# Block the `reduce_stream` until all events occur. This does not block host.\n# This is not required when reduction is performed in the default (Stream.null)\n# stream unless streams are created with `non_blocking=True` flag.\nfor i in range(n):\n reduce_stream.wait_event(stop_events[i])\n\n# Reduce\nwith reduce_stream:\n z = sum(zs)\n\ndevice.synchronize()\nelapsed_time = time.time() - start_time\nprint('elapsed time', elapsed_time)\nprint('total bytes', memory_pool.total_bytes())\n\n# Free all blocks in the memory pool of streams\nfor stream in map_streams:\n memory_pool.free_all_blocks(stream=stream)\nprint('total bytes', memory_pool.total_bytes())\n", "path": "examples/stream/map_reduce.py"}]}
| 1,468 | 157 |
gh_patches_debug_38311
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-center-index-3991
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[package] resiprocate/1.12.0: Error in autotools configuration
There are several errors in the recipe, especially in autotools configuration step.
https://github.com/conan-io/conan-center-index/blob/c68b60af3de84cf460c7512efce75290f1b395cb/recipes/resiprocate/all/conanfile.py#L50-L58
First, in the lines 54~57, values passed to each options are the inverse of what a consumer actually gave. For example, if `with_ssl` is true, then configuration option is passed as `--with-ssl=no`.
Second, the configure script of the project doesn't understand value assignments to the following options : ssl, mysql, postgresql. In other words, `--with-ssl=yes` and `--with-ssl=no` would make no difference in the configuration step and eventually the library is built with ssl feature on in both cases. You can check this out either from resiprocate project's [`configure.ac` file](https://github.com/resiprocate/resiprocate/blob/6b2756ba8516726cfb04e2b2fa5f4e3e67598a31/configure.ac#L113-L119), or from `configure` file autogenerated from `configure.ac` as below.
```
# Check whether --with-ssl was given.
if test "${with_ssl+set}" = set; then :
withval=$with_ssl;
cat >>confdefs.h <<_ACEOF
#define USE_SSL /**/
_ACEOF
LIBSSL_LIBADD="-lssl -lcrypto"
if true; then
USE_SSL_TRUE=
USE_SSL_FALSE='#'
else
USE_SSL_TRUE='#'
USE_SSL_FALSE=
fi
else
LIBSSL_LIBADD=""
fi
```
And lastly, the project requires pthread, and the recipe didn't include that. When I turn off ssl, mysql, postgresql options, linking the library causes pthread missing error. I guess pthread happened to be secondary dependency from ssl or mysql or postgresql library, and that's why it worked when the options were on even though the recipe didn't explicitly include pthread. I suggest we add pthread in `cpp_info.system_libs`
I'm really thankful to those who had worked in this package. I didn't expect it to be on conan ever, but now it's so nice and easy to use. Happy holidays guys!
</issue>
<code>
[start of recipes/resiprocate/all/conanfile.py]
1 import os
2 from conans import ConanFile, AutoToolsBuildEnvironment, tools
3 from conans.errors import ConanInvalidConfiguration
4
5
6 required_conan_version = ">=1.29.1"
7
8 class ResiprocateConan(ConanFile):
9 name = "resiprocate"
10 description = "The project is dedicated to maintaining a complete, correct, and commercially usable implementation of SIP and a few related protocols. "
11 topics = ("sip", "voip", "communication", "signaling")
12 url = "https://github.com/conan-io/conan-center-index"
13 homepage = "http://www.resiprocate.org"
14 license = "VSL-1.0"
15 settings = "os", "compiler", "build_type", "arch"
16 options = {"fPIC": [True, False],
17 "shared": [True, False],
18 "with_ssl": [True, False],
19 "with_postgresql": [True, False],
20 "with_mysql": [True, False]}
21 default_options = {"fPIC": True,
22 "shared": False,
23 "with_ssl": True,
24 "with_postgresql": True,
25 "with_mysql": True}
26 _autotools = None
27
28 @property
29 def _source_subfolder(self):
30 return "source_subfolder"
31
32 def requirements(self):
33 if self.settings.os in ("Windows", "Macos"):
34 raise ConanInvalidConfiguration("reSIProcate is not support on {}.".format(self.settings.os))
35 if self.options.with_ssl:
36 self.requires("openssl/1.1.1h")
37 if self.options.with_postgresql:
38 self.requires("libpq/11.5")
39 if self.options.with_mysql:
40 self.requires("libmysqlclient/8.0.17")
41
42 def source(self):
43 tools.get(**self.conan_data["sources"][self.version])
44 os.rename("{}-{}".format(self.name, self.version), self._source_subfolder)
45
46 def _configure_autotools(self):
47 if self._autotools:
48 return self._autotools
49 self._autotools = AutoToolsBuildEnvironment(self)
50 yes_no = lambda v: "yes" if v else "no"
51 configure_args = [
52 "--enable-shared={}".format(yes_no(self.options.shared)),
53 "--enable-static={}".format(yes_no(not self.options.shared)),
54 "--with-ssl={}".format(yes_no(not self.options.with_ssl)),
55 "--with-mysql={}".format(yes_no(not self.options.with_mysql)),
56 "--with-postgresql={}".format(yes_no(not self.options.with_postgresql)),
57 "--with-pic={}".format(yes_no(not self.options.fPIC))
58 ]
59
60 self._autotools.configure(configure_dir=self._source_subfolder, args=configure_args)
61 return self._autotools
62
63 def build(self):
64 autotools = self._configure_autotools()
65 autotools.make()
66
67 def package(self):
68 self.copy("COPYING", src=self._source_subfolder, dst="licenses")
69 autotools = self._configure_autotools()
70 autotools.install()
71 tools.rmdir(os.path.join(os.path.join(self.package_folder, "share")))
72 tools.remove_files_by_mask(os.path.join(self.package_folder), "*.la")
73
74 def package_info(self):
75 self.cpp_info.libs = ["resip", "rutil", "dum", "resipares"]
76 bin_path = os.path.join(self.package_folder, "bin")
77 self.output.info("Appending PATH environment variable: {}".format(bin_path))
78 self.env_info.PATH.append(os.path.join(self.package_folder, "bin"))
79
[end of recipes/resiprocate/all/conanfile.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/recipes/resiprocate/all/conanfile.py b/recipes/resiprocate/all/conanfile.py
--- a/recipes/resiprocate/all/conanfile.py
+++ b/recipes/resiprocate/all/conanfile.py
@@ -29,13 +29,22 @@
def _source_subfolder(self):
return "source_subfolder"
- def requirements(self):
+ def config_options(self):
+ if self.settings.os == 'Windows':
+ del self.options.fPIC
+
+ def configure(self):
if self.settings.os in ("Windows", "Macos"):
- raise ConanInvalidConfiguration("reSIProcate is not support on {}.".format(self.settings.os))
+ # FIXME: Visual Studio project & Mac support seems available in resiprocate
+ raise ConanInvalidConfiguration("reSIProcate recipe does not currently support {}.".format(self.settings.os))
+ if self.options.shared:
+ del self.options.fPIC
+
+ def requirements(self):
if self.options.with_ssl:
- self.requires("openssl/1.1.1h")
+ self.requires("openssl/1.1.1i")
if self.options.with_postgresql:
- self.requires("libpq/11.5")
+ self.requires("libpq/11.9")
if self.options.with_mysql:
self.requires("libmysqlclient/8.0.17")
@@ -51,12 +60,17 @@
configure_args = [
"--enable-shared={}".format(yes_no(self.options.shared)),
"--enable-static={}".format(yes_no(not self.options.shared)),
- "--with-ssl={}".format(yes_no(not self.options.with_ssl)),
- "--with-mysql={}".format(yes_no(not self.options.with_mysql)),
- "--with-postgresql={}".format(yes_no(not self.options.with_postgresql)),
- "--with-pic={}".format(yes_no(not self.options.fPIC))
+ "--with-pic={}".format(yes_no(self.options.get_safe("fPIC", True)))
]
+ # These options do not support yes/no
+ if self.options.with_ssl:
+ configure_args.append("--with-ssl")
+ if self.options.with_mysql:
+ configure_args.append("--with-mysql")
+ if self.options.with_postgresql:
+ configure_args.append("--with-postgresql")
+
self._autotools.configure(configure_dir=self._source_subfolder, args=configure_args)
return self._autotools
@@ -73,6 +87,8 @@
def package_info(self):
self.cpp_info.libs = ["resip", "rutil", "dum", "resipares"]
+ if self.settings.os in ("Linux", "FreeBSD"):
+ self.cpp_info.system_libs = ["pthread"]
bin_path = os.path.join(self.package_folder, "bin")
self.output.info("Appending PATH environment variable: {}".format(bin_path))
self.env_info.PATH.append(os.path.join(self.package_folder, "bin"))
|
{"golden_diff": "diff --git a/recipes/resiprocate/all/conanfile.py b/recipes/resiprocate/all/conanfile.py\n--- a/recipes/resiprocate/all/conanfile.py\n+++ b/recipes/resiprocate/all/conanfile.py\n@@ -29,13 +29,22 @@\n def _source_subfolder(self):\n return \"source_subfolder\"\n \n- def requirements(self):\n+ def config_options(self):\n+ if self.settings.os == 'Windows':\n+ del self.options.fPIC\n+\n+ def configure(self):\n if self.settings.os in (\"Windows\", \"Macos\"):\n- raise ConanInvalidConfiguration(\"reSIProcate is not support on {}.\".format(self.settings.os))\n+ # FIXME: Visual Studio project & Mac support seems available in resiprocate\n+ raise ConanInvalidConfiguration(\"reSIProcate recipe does not currently support {}.\".format(self.settings.os))\n+ if self.options.shared:\n+ del self.options.fPIC\n+\n+ def requirements(self):\n if self.options.with_ssl:\n- self.requires(\"openssl/1.1.1h\")\n+ self.requires(\"openssl/1.1.1i\")\n if self.options.with_postgresql:\n- self.requires(\"libpq/11.5\")\n+ self.requires(\"libpq/11.9\")\n if self.options.with_mysql:\n self.requires(\"libmysqlclient/8.0.17\")\n \n@@ -51,12 +60,17 @@\n configure_args = [\n \"--enable-shared={}\".format(yes_no(self.options.shared)),\n \"--enable-static={}\".format(yes_no(not self.options.shared)),\n- \"--with-ssl={}\".format(yes_no(not self.options.with_ssl)),\n- \"--with-mysql={}\".format(yes_no(not self.options.with_mysql)),\n- \"--with-postgresql={}\".format(yes_no(not self.options.with_postgresql)),\n- \"--with-pic={}\".format(yes_no(not self.options.fPIC))\n+ \"--with-pic={}\".format(yes_no(self.options.get_safe(\"fPIC\", True)))\n ]\n \n+ # These options do not support yes/no\n+ if self.options.with_ssl:\n+ configure_args.append(\"--with-ssl\")\n+ if self.options.with_mysql:\n+ configure_args.append(\"--with-mysql\")\n+ if self.options.with_postgresql:\n+ configure_args.append(\"--with-postgresql\")\n+ \n self._autotools.configure(configure_dir=self._source_subfolder, args=configure_args)\n return self._autotools\n \n@@ -73,6 +87,8 @@\n \n def package_info(self):\n self.cpp_info.libs = [\"resip\", \"rutil\", \"dum\", \"resipares\"]\n+ if self.settings.os in (\"Linux\", \"FreeBSD\"):\n+ self.cpp_info.system_libs = [\"pthread\"]\n bin_path = os.path.join(self.package_folder, \"bin\")\n self.output.info(\"Appending PATH environment variable: {}\".format(bin_path))\n self.env_info.PATH.append(os.path.join(self.package_folder, \"bin\"))\n", "issue": "[package] resiprocate/1.12.0: Error in autotools configuration\nThere are several errors in the recipe, especially in autotools configuration step.\r\n\r\nhttps://github.com/conan-io/conan-center-index/blob/c68b60af3de84cf460c7512efce75290f1b395cb/recipes/resiprocate/all/conanfile.py#L50-L58\r\n\r\nFirst, in the lines 54~57, values passed to each options are the inverse of what a consumer actually gave. For example, if `with_ssl` is true, then configuration option is passed as `--with-ssl=no`.\r\n\r\nSecond, the configure script of the project doesn't understand value assignments to the following options : ssl, mysql, postgresql. In other words, `--with-ssl=yes` and `--with-ssl=no` would make no difference in the configuration step and eventually the library is built with ssl feature on in both cases. You can check this out either from resiprocate project's [`configure.ac` file](https://github.com/resiprocate/resiprocate/blob/6b2756ba8516726cfb04e2b2fa5f4e3e67598a31/configure.ac#L113-L119), or from `configure` file autogenerated from `configure.ac` as below. \r\n\r\n```\r\n# Check whether --with-ssl was given.\r\nif test \"${with_ssl+set}\" = set; then :\r\n withval=$with_ssl;\r\ncat >>confdefs.h <<_ACEOF\r\n#define USE_SSL /**/\r\n_ACEOF\r\n\r\n LIBSSL_LIBADD=\"-lssl -lcrypto\"\r\n\r\n if true; then\r\n USE_SSL_TRUE=\r\n USE_SSL_FALSE='#'\r\nelse\r\n USE_SSL_TRUE='#'\r\n USE_SSL_FALSE=\r\nfi\r\n\r\nelse\r\n LIBSSL_LIBADD=\"\"\r\n\r\nfi\r\n```\r\n\r\nAnd lastly, the project requires pthread, and the recipe didn't include that. When I turn off ssl, mysql, postgresql options, linking the library causes pthread missing error. I guess pthread happened to be secondary dependency from ssl or mysql or postgresql library, and that's why it worked when the options were on even though the recipe didn't explicitly include pthread. I suggest we add pthread in `cpp_info.system_libs`\r\n\r\nI'm really thankful to those who had worked in this package. I didn't expect it to be on conan ever, but now it's so nice and easy to use. Happy holidays guys! \n", "before_files": [{"content": "import os\nfrom conans import ConanFile, AutoToolsBuildEnvironment, tools\nfrom conans.errors import ConanInvalidConfiguration\n\n\nrequired_conan_version = \">=1.29.1\"\n\nclass ResiprocateConan(ConanFile):\n name = \"resiprocate\"\n description = \"The project is dedicated to maintaining a complete, correct, and commercially usable implementation of SIP and a few related protocols. \"\n topics = (\"sip\", \"voip\", \"communication\", \"signaling\")\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \"http://www.resiprocate.org\"\n license = \"VSL-1.0\"\n settings = \"os\", \"compiler\", \"build_type\", \"arch\"\n options = {\"fPIC\": [True, False],\n \"shared\": [True, False],\n \"with_ssl\": [True, False],\n \"with_postgresql\": [True, False],\n \"with_mysql\": [True, False]}\n default_options = {\"fPIC\": True,\n \"shared\": False,\n \"with_ssl\": True,\n \"with_postgresql\": True,\n \"with_mysql\": True}\n _autotools = None\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n def requirements(self):\n if self.settings.os in (\"Windows\", \"Macos\"):\n raise ConanInvalidConfiguration(\"reSIProcate is not support on {}.\".format(self.settings.os))\n if self.options.with_ssl:\n self.requires(\"openssl/1.1.1h\")\n if self.options.with_postgresql:\n self.requires(\"libpq/11.5\")\n if self.options.with_mysql:\n self.requires(\"libmysqlclient/8.0.17\")\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version])\n os.rename(\"{}-{}\".format(self.name, self.version), self._source_subfolder)\n\n def _configure_autotools(self):\n if self._autotools:\n return self._autotools\n self._autotools = AutoToolsBuildEnvironment(self)\n yes_no = lambda v: \"yes\" if v else \"no\"\n configure_args = [\n \"--enable-shared={}\".format(yes_no(self.options.shared)),\n \"--enable-static={}\".format(yes_no(not self.options.shared)),\n \"--with-ssl={}\".format(yes_no(not self.options.with_ssl)),\n \"--with-mysql={}\".format(yes_no(not self.options.with_mysql)),\n \"--with-postgresql={}\".format(yes_no(not self.options.with_postgresql)),\n \"--with-pic={}\".format(yes_no(not self.options.fPIC))\n ]\n\n self._autotools.configure(configure_dir=self._source_subfolder, args=configure_args)\n return self._autotools\n\n def build(self):\n autotools = self._configure_autotools()\n autotools.make()\n\n def package(self):\n self.copy(\"COPYING\", src=self._source_subfolder, dst=\"licenses\")\n autotools = self._configure_autotools()\n autotools.install()\n tools.rmdir(os.path.join(os.path.join(self.package_folder, \"share\")))\n tools.remove_files_by_mask(os.path.join(self.package_folder), \"*.la\")\n\n def package_info(self):\n self.cpp_info.libs = [\"resip\", \"rutil\", \"dum\", \"resipares\"]\n bin_path = os.path.join(self.package_folder, \"bin\")\n self.output.info(\"Appending PATH environment variable: {}\".format(bin_path))\n self.env_info.PATH.append(os.path.join(self.package_folder, \"bin\"))\n", "path": "recipes/resiprocate/all/conanfile.py"}]}
| 2,041 | 670 |
gh_patches_debug_20750
|
rasdani/github-patches
|
git_diff
|
streamlit__streamlit-4973
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Certain float values not allowed with select_slider
### Summary
Certain values are not allowed when defining `select_slider` of floats due to float precision errors.
### Steps to reproduce
Code snippet:
```
import numpy as np
import streamlit as st
st.select_slider(
label="Select slider of floats",
options=np.arange(0.0, 0.25, 0.05),
value=(0.1, 0.15),
)
```
**Expected behavior:**
A `select_slider` widget where options are float numbers: `[0.0, 0.05, 0.1, 0.15, 0.2]`, and default values are float numbers: `[0.1, 0.15]`.
**Actual behavior:**
The following traceback:
```
2022-04-28 21:47:19.181 Traceback (most recent call last):
File "/home/rguedes/.virtualenvs/streamlit/lib/python3.8/site-packages/streamlit/scriptrunner/script_runner.py", line 443, in _run_script
exec(code, module.__dict__)
File "/source/streamlit/app-report-port-taranaki/app/test.py", line 5, in <module>
st.select_slider(
File "/home/rguedes/.virtualenvs/streamlit/lib/python3.8/site-packages/streamlit/elements/select_slider.py", line 122, in select_slider
return self._select_slider(
File "/home/rguedes/.virtualenvs/streamlit/lib/python3.8/site-packages/streamlit/elements/select_slider.py", line 180, in _select_slider
slider_value = as_index_list(value)
File "/home/rguedes/.virtualenvs/streamlit/lib/python3.8/site-packages/streamlit/elements/select_slider.py", line 164, in as_index_list
slider_value = [index_(opt, val) for val in v]
File "/home/rguedes/.virtualenvs/streamlit/lib/python3.8/site-packages/streamlit/elements/select_slider.py", line 164, in <listcomp>
slider_value = [index_(opt, val) for val in v]
File "/home/rguedes/.virtualenvs/streamlit/lib/python3.8/site-packages/streamlit/util.py", line 130, in index_
raise ValueError("{} is not in iterable".format(str(x)))
ValueError: 0.15 is not in iterable
```
Inspection from [utils.py](https://github.com/streamlit/streamlit/blob/develop/lib/streamlit/util.py#L110-L129) shows that `x` does not match values in `iterable` due to float precision:
```
> /home/rguedes/.virtualenvs/streamlit/lib/python3.8/site-packages/streamlit/util.py(130)index_()
129 import ipdb; ipdb.set_trace()
--> 130 raise ValueError("{} is not in iterable".format(str(x)))
131
ipdb> p x
0.15
ipdb> p iterable
[0.0, 0.05, 0.1, 0.15000000000000002, 0.2]
```
### Is this a regression?
Don't know
### Debug info
- Streamlit version: 1.8.1
- Python version: 3.8.10
- Using Python virtualenv
- OS version: Ubuntu 20.04
- Browser version: Google Chrome 100.0.4896.127
</issue>
<code>
[start of lib/streamlit/util.py]
1 # Copyright 2018-2022 Streamlit Inc.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 """A bunch of useful utilities."""
16
17 import functools
18 import hashlib
19 import os
20 import subprocess
21
22 from typing import Any, Dict, List, Mapping, TypeVar
23 from typing_extensions import Final
24
25 from streamlit import env_util
26
27 # URL of Streamlit's help page.
28 HELP_DOC: Final = "https://docs.streamlit.io/"
29
30
31 def memoize(func):
32 """Decorator to memoize the result of a no-args func."""
33 result = [] # type: List[Any]
34
35 @functools.wraps(func)
36 def wrapped_func():
37 if not result:
38 result.append(func())
39 return result[0]
40
41 return wrapped_func
42
43
44 def open_browser(url):
45 """Open a web browser pointing to a given URL.
46
47 We use this function instead of Python's `webbrowser` module because this
48 way we can capture stdout/stderr to avoid polluting the terminal with the
49 browser's messages. For example, Chrome always prints things like "Created
50 new window in existing browser session", and those get on the user's way.
51
52 url : str
53 The URL. Must include the protocol.
54
55 """
56
57 # Treat Windows separately because:
58 # 1. /dev/null doesn't exist.
59 # 2. subprocess.Popen(['start', url]) doesn't actually pop up the
60 # browser even though 'start url' works from the command prompt.
61 # Fun!
62 # Also, use webbrowser if we are on Linux and xdg-open is not installed.
63 #
64 # We don't use the webbrowser module on Linux and Mac because some browsers
65 # (ahem... Chrome) always print "Opening in existing browser session" to
66 # the terminal, which is spammy and annoying. So instead we start the
67 # browser ourselves and send all its output to /dev/null.
68
69 if env_util.IS_WINDOWS:
70 _open_browser_with_webbrowser(url)
71 return
72 if env_util.IS_LINUX_OR_BSD:
73 if env_util.is_executable_in_path("xdg-open"):
74 _open_browser_with_command("xdg-open", url)
75 return
76 _open_browser_with_webbrowser(url)
77 return
78 if env_util.IS_DARWIN:
79 _open_browser_with_command("open", url)
80 return
81
82 import platform
83
84 raise Error('Cannot open browser in platform "%s"' % platform.system())
85
86
87 def _open_browser_with_webbrowser(url):
88 import webbrowser
89
90 webbrowser.open(url)
91
92
93 def _open_browser_with_command(command, url):
94 cmd_line = [command, url]
95 with open(os.devnull, "w") as devnull:
96 subprocess.Popen(cmd_line, stdout=devnull, stderr=subprocess.STDOUT)
97
98
99 def _maybe_tuple_to_list(item: Any) -> Any:
100 """Convert a tuple to a list. Leave as is if it's not a tuple."""
101 if isinstance(item, tuple):
102 return list(item)
103 return item
104
105
106 def repr_(cls) -> str:
107 classname = cls.__class__.__name__
108 args = ", ".join([f"{k}={repr(v)}" for (k, v) in cls.__dict__.items()])
109 return f"{classname}({args})"
110
111
112 def index_(iterable, x) -> int:
113 """Return zero-based index of the first item whose value is equal to x.
114 Raises a ValueError if there is no such item.
115
116 We need a custom implementation instead of the built-in list .index() to
117 be compatible with NumPy array and Pandas Series.
118
119 Parameters
120 ----------
121 iterable : list, tuple, numpy.ndarray, pandas.Series
122
123 Returns
124 -------
125 int
126 """
127
128 for i, value in enumerate(iterable):
129 if x == value:
130 return i
131 raise ValueError("{} is not in iterable".format(str(x)))
132
133
134 _Key = TypeVar("_Key", bound=str)
135 _Value = TypeVar("_Value")
136
137
138 def lower_clean_dict_keys(dict: Mapping[_Key, _Value]) -> Dict[str, _Value]:
139 return {k.lower().strip(): v for k, v in dict.items()}
140
141
142 # TODO: Move this into errors.py? Replace with StreamlitAPIException?
143 class Error(Exception):
144 pass
145
146
147 def calc_md5(s: str) -> str:
148 """Return the md5 hash of the given string."""
149 h = hashlib.new("md5")
150 h.update(s.encode("utf-8"))
151 return h.hexdigest()
152
[end of lib/streamlit/util.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lib/streamlit/util.py b/lib/streamlit/util.py
--- a/lib/streamlit/util.py
+++ b/lib/streamlit/util.py
@@ -18,6 +18,7 @@
import hashlib
import os
import subprocess
+import numpy as np
from typing import Any, Dict, List, Mapping, TypeVar
from typing_extensions import Final
@@ -26,6 +27,7 @@
# URL of Streamlit's help page.
HELP_DOC: Final = "https://docs.streamlit.io/"
+FLOAT_EQUALITY_EPSILON: Final = 0.000000000005
def memoize(func):
@@ -126,6 +128,11 @@
"""
for i, value in enumerate(iterable):
+ # https://stackoverflow.com/questions/588004/is-floating-point-math-broken
+ # https://github.com/streamlit/streamlit/issues/4663
+ if isinstance(iterable, np.ndarray):
+ if abs(x - value) < FLOAT_EQUALITY_EPSILON:
+ return i
if x == value:
return i
raise ValueError("{} is not in iterable".format(str(x)))
|
{"golden_diff": "diff --git a/lib/streamlit/util.py b/lib/streamlit/util.py\n--- a/lib/streamlit/util.py\n+++ b/lib/streamlit/util.py\n@@ -18,6 +18,7 @@\n import hashlib\n import os\n import subprocess\n+import numpy as np\n \n from typing import Any, Dict, List, Mapping, TypeVar\n from typing_extensions import Final\n@@ -26,6 +27,7 @@\n \n # URL of Streamlit's help page.\n HELP_DOC: Final = \"https://docs.streamlit.io/\"\n+FLOAT_EQUALITY_EPSILON: Final = 0.000000000005\n \n \n def memoize(func):\n@@ -126,6 +128,11 @@\n \"\"\"\n \n for i, value in enumerate(iterable):\n+ # https://stackoverflow.com/questions/588004/is-floating-point-math-broken\n+ # https://github.com/streamlit/streamlit/issues/4663\n+ if isinstance(iterable, np.ndarray):\n+ if abs(x - value) < FLOAT_EQUALITY_EPSILON:\n+ return i\n if x == value:\n return i\n raise ValueError(\"{} is not in iterable\".format(str(x)))\n", "issue": "Certain float values not allowed with select_slider\n### Summary\r\n\r\nCertain values are not allowed when defining `select_slider` of floats due to float precision errors.\r\n\r\n### Steps to reproduce\r\n\r\nCode snippet:\r\n\r\n```\r\nimport numpy as np\r\nimport streamlit as st\r\n\r\n\r\nst.select_slider(\r\n label=\"Select slider of floats\",\r\n options=np.arange(0.0, 0.25, 0.05),\r\n value=(0.1, 0.15),\r\n)\r\n```\r\n\r\n**Expected behavior:**\r\n\r\nA `select_slider` widget where options are float numbers: `[0.0, 0.05, 0.1, 0.15, 0.2]`, and default values are float numbers: `[0.1, 0.15]`.\r\n\r\n**Actual behavior:**\r\n\r\nThe following traceback:\r\n\r\n```\r\n2022-04-28 21:47:19.181 Traceback (most recent call last):\r\n File \"/home/rguedes/.virtualenvs/streamlit/lib/python3.8/site-packages/streamlit/scriptrunner/script_runner.py\", line 443, in _run_script\r\n exec(code, module.__dict__)\r\n File \"/source/streamlit/app-report-port-taranaki/app/test.py\", line 5, in <module>\r\n st.select_slider(\r\n File \"/home/rguedes/.virtualenvs/streamlit/lib/python3.8/site-packages/streamlit/elements/select_slider.py\", line 122, in select_slider\r\n return self._select_slider(\r\n File \"/home/rguedes/.virtualenvs/streamlit/lib/python3.8/site-packages/streamlit/elements/select_slider.py\", line 180, in _select_slider\r\n slider_value = as_index_list(value)\r\n File \"/home/rguedes/.virtualenvs/streamlit/lib/python3.8/site-packages/streamlit/elements/select_slider.py\", line 164, in as_index_list\r\n slider_value = [index_(opt, val) for val in v]\r\n File \"/home/rguedes/.virtualenvs/streamlit/lib/python3.8/site-packages/streamlit/elements/select_slider.py\", line 164, in <listcomp>\r\n slider_value = [index_(opt, val) for val in v]\r\n File \"/home/rguedes/.virtualenvs/streamlit/lib/python3.8/site-packages/streamlit/util.py\", line 130, in index_\r\n raise ValueError(\"{} is not in iterable\".format(str(x)))\r\nValueError: 0.15 is not in iterable\r\n```\r\n\r\nInspection from [utils.py](https://github.com/streamlit/streamlit/blob/develop/lib/streamlit/util.py#L110-L129) shows that `x` does not match values in `iterable` due to float precision:\r\n\r\n```\r\n> /home/rguedes/.virtualenvs/streamlit/lib/python3.8/site-packages/streamlit/util.py(130)index_()\r\n 129 import ipdb; ipdb.set_trace()\r\n--> 130 raise ValueError(\"{} is not in iterable\".format(str(x)))\r\n 131 \r\n\r\nipdb> p x\r\n0.15\r\nipdb> p iterable\r\n[0.0, 0.05, 0.1, 0.15000000000000002, 0.2]\r\n```\r\n### Is this a regression?\r\n\r\nDon't know\r\n\r\n### Debug info\r\n\r\n- Streamlit version: 1.8.1\r\n- Python version: 3.8.10\r\n- Using Python virtualenv\r\n- OS version: Ubuntu 20.04\r\n- Browser version: Google Chrome 100.0.4896.127\r\n\n", "before_files": [{"content": "# Copyright 2018-2022 Streamlit Inc.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"A bunch of useful utilities.\"\"\"\n\nimport functools\nimport hashlib\nimport os\nimport subprocess\n\nfrom typing import Any, Dict, List, Mapping, TypeVar\nfrom typing_extensions import Final\n\nfrom streamlit import env_util\n\n# URL of Streamlit's help page.\nHELP_DOC: Final = \"https://docs.streamlit.io/\"\n\n\ndef memoize(func):\n \"\"\"Decorator to memoize the result of a no-args func.\"\"\"\n result = [] # type: List[Any]\n\n @functools.wraps(func)\n def wrapped_func():\n if not result:\n result.append(func())\n return result[0]\n\n return wrapped_func\n\n\ndef open_browser(url):\n \"\"\"Open a web browser pointing to a given URL.\n\n We use this function instead of Python's `webbrowser` module because this\n way we can capture stdout/stderr to avoid polluting the terminal with the\n browser's messages. For example, Chrome always prints things like \"Created\n new window in existing browser session\", and those get on the user's way.\n\n url : str\n The URL. Must include the protocol.\n\n \"\"\"\n\n # Treat Windows separately because:\n # 1. /dev/null doesn't exist.\n # 2. subprocess.Popen(['start', url]) doesn't actually pop up the\n # browser even though 'start url' works from the command prompt.\n # Fun!\n # Also, use webbrowser if we are on Linux and xdg-open is not installed.\n #\n # We don't use the webbrowser module on Linux and Mac because some browsers\n # (ahem... Chrome) always print \"Opening in existing browser session\" to\n # the terminal, which is spammy and annoying. So instead we start the\n # browser ourselves and send all its output to /dev/null.\n\n if env_util.IS_WINDOWS:\n _open_browser_with_webbrowser(url)\n return\n if env_util.IS_LINUX_OR_BSD:\n if env_util.is_executable_in_path(\"xdg-open\"):\n _open_browser_with_command(\"xdg-open\", url)\n return\n _open_browser_with_webbrowser(url)\n return\n if env_util.IS_DARWIN:\n _open_browser_with_command(\"open\", url)\n return\n\n import platform\n\n raise Error('Cannot open browser in platform \"%s\"' % platform.system())\n\n\ndef _open_browser_with_webbrowser(url):\n import webbrowser\n\n webbrowser.open(url)\n\n\ndef _open_browser_with_command(command, url):\n cmd_line = [command, url]\n with open(os.devnull, \"w\") as devnull:\n subprocess.Popen(cmd_line, stdout=devnull, stderr=subprocess.STDOUT)\n\n\ndef _maybe_tuple_to_list(item: Any) -> Any:\n \"\"\"Convert a tuple to a list. Leave as is if it's not a tuple.\"\"\"\n if isinstance(item, tuple):\n return list(item)\n return item\n\n\ndef repr_(cls) -> str:\n classname = cls.__class__.__name__\n args = \", \".join([f\"{k}={repr(v)}\" for (k, v) in cls.__dict__.items()])\n return f\"{classname}({args})\"\n\n\ndef index_(iterable, x) -> int:\n \"\"\"Return zero-based index of the first item whose value is equal to x.\n Raises a ValueError if there is no such item.\n\n We need a custom implementation instead of the built-in list .index() to\n be compatible with NumPy array and Pandas Series.\n\n Parameters\n ----------\n iterable : list, tuple, numpy.ndarray, pandas.Series\n\n Returns\n -------\n int\n \"\"\"\n\n for i, value in enumerate(iterable):\n if x == value:\n return i\n raise ValueError(\"{} is not in iterable\".format(str(x)))\n\n\n_Key = TypeVar(\"_Key\", bound=str)\n_Value = TypeVar(\"_Value\")\n\n\ndef lower_clean_dict_keys(dict: Mapping[_Key, _Value]) -> Dict[str, _Value]:\n return {k.lower().strip(): v for k, v in dict.items()}\n\n\n# TODO: Move this into errors.py? Replace with StreamlitAPIException?\nclass Error(Exception):\n pass\n\n\ndef calc_md5(s: str) -> str:\n \"\"\"Return the md5 hash of the given string.\"\"\"\n h = hashlib.new(\"md5\")\n h.update(s.encode(\"utf-8\"))\n return h.hexdigest()\n", "path": "lib/streamlit/util.py"}]}
| 2,810 | 267 |
gh_patches_debug_19580
|
rasdani/github-patches
|
git_diff
|
pyjanitor-devs__pyjanitor-445
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[DOC] Adding context about method chaining
# Brief Description of Fix
<!-- Please describe the fix in terms of a "before" and "after". In other words, what's not so good about the current docs
page, and what you would like to see it become.
Example starter wording is provided. -->
Currently, the docs don't explain what method chaining is. A beginner would benefit from reading about it.
I would like to propose a change, such that now the docs include a link to a medium post explaining the topic.
# Relevant Context
<!-- Please put here, in bullet points, links to the relevant docs page. A few starting template points are available
to get you started. -->
- [Link to documentation page](http://pyjanitor.readthedocs.io)
- [Link to exact file to be edited](https://github.com/ericmjl/pyjanitor/README.rst)
</issue>
<code>
[start of docs/conf.py]
1 """Sphinx configuration."""
2
3 # -*- coding: utf-8 -*-
4 #
5 # Configuration file for the Sphinx documentation builder.
6 #
7 # This file does only contain a selection of the most common options. For a
8 # full list see the documentation:
9 # http://www.sphinx-doc.org/en/stable/config
10
11 # -- Path setup --------------------------------------------------------------
12
13 # If extensions (or modules to document with autodoc) are in another directory,
14 # add these directories to sys.path here. If the directory is relative to the
15 # documentation root, use os.path.abspath to make it absolute, like shown here.
16 #
17 import os
18 import sys
19 import datetime
20 from pathlib import Path
21
22 sys.path.insert(0, os.path.abspath("."))
23 sys.path.insert(0, os.path.abspath("../examples"))
24
25 # Make a symlink in our sphinx source directory to the top-level
26 # examples/notebooks directory so we can include notebooks in the doc
27 notebooks = Path("./notebooks")
28 if not notebooks.exists():
29 print("Making symlink to ../examples/notebooks")
30 notebooks.symlink_to("../examples/notebooks")
31
32
33 # -- Project information -----------------------------------------------------
34
35 project = "pyjanitor"
36
37
38 now = datetime.datetime.now()
39 CurrentYear = str(now.year)
40 copyright = CurrentYear+", PyJanitor devs"
41 author = "Eric J. Ma"
42
43 # The short X.Y version
44 version = "0.1.0"
45 # The full version, including alpha/beta/rc tags
46 release = ""
47
48
49 # -- General configuration ---------------------------------------------------
50
51 # If your documentation needs a minimal Sphinx version, state it here.
52 #
53 # needs_sphinx = '1.0'
54
55 # Add any Sphinx extension module names here, as strings. They can be
56 # extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
57 # ones.
58 extensions = [
59 "sphinx.ext.autodoc",
60 "sphinx.ext.doctest",
61 "sphinx.ext.intersphinx",
62 "sphinx.ext.todo",
63 "sphinx.ext.coverage",
64 "sphinx.ext.viewcode",
65 "sphinx.ext.githubpages",
66 "sphinxcontrib.fulltoc",
67 "nbsphinx",
68 "sphinx.ext.autosummary",
69 ]
70
71 # Add any paths that contain templates here, relative to this directory.
72 templates_path = ["_templates"]
73
74 # The suffix(es) of source filenames.
75 # You can specify multiple suffix as a list of string:
76 #
77 # source_suffix = ['.rst', '.md']
78 source_suffix = [".md", ".rst", ".ipynb"]
79
80 # The master toctree document.
81 master_doc = "index"
82
83 # The language for content autogenerated by Sphinx. Refer to documentation
84 # for a list of supported languages.
85 #
86 # This is also used if you do content translation via gettext catalogs.
87 # Usually you set "language" from the command line for these cases.
88 language = None
89
90 # List of patterns, relative to source directory, that match files and
91 # directories to ignore when looking for source files.
92 # This pattern also affects html_static_path and html_extra_path .
93 exclude_patterns = ["_build", "Thumbs.db", ".DS_Store", "**.ipynb_checkpoints"]
94
95 # The name of the Pygments (syntax highlighting) style to use.
96 pygments_style = "sphinx"
97
98
99 # -- Options for HTML output -------------------------------------------------
100
101 # The theme to use for HTML and HTML Help pages. See the documentation for
102 # a list of builtin themes.
103 #
104 html_theme = "alabaster"
105
106 # Theme options are theme-specific and customize the look and feel of a theme
107 # further. For a list of options available for each theme, see the
108 # documentation.
109 #
110 html_theme_options = {"logo": "logo_title.svg"}
111
112 # Add any paths that contain custom static files (such as style sheets) here,
113 # relative to this directory. They are copied after the builtin static files,
114 # so a file named "default.css" will overwrite the builtin "default.css".
115 html_static_path = ["_static"]
116
117 # Custom sidebar templates, must be a dictionary that maps document names
118 # to template names.
119 #
120 # The default sidebars (for documents that don't match any pattern) are
121 # defined by theme itself. Builtin themes are using these templates by
122 # default: ``['localtoc.html', 'relations.html', 'sourcelink.html',
123 # 'searchbox.html']``.
124 #
125 html_sidebars = {
126 "**": ["about.html", "navigation.html", "relations.html", "searchbox.html"]
127 }
128
129
130 # -- Options for HTMLHelp output ---------------------------------------------
131
132 # Output file base name for HTML help builder.
133 htmlhelp_basename = "pyjanitordoc"
134
135
136 # -- Options for LaTeX output ------------------------------------------------
137
138 latex_elements = {
139 # The paper size ('letterpaper' or 'a4paper').
140 #
141 # 'papersize': 'letterpaper',
142 # The font size ('10pt', '11pt' or '12pt').
143 #
144 # 'pointsize': '10pt',
145 # Additional stuff for the LaTeX preamble.
146 #
147 # 'preamble': '',
148 # Latex figure (float) alignment
149 #
150 # 'figure_align': 'htbp',
151 }
152
153 # Grouping the document tree into LaTeX files. List of tuples
154 # (source start file, target name, title,
155 # author, documentclass [howto, manual, or own class]).
156 latex_documents = [
157 (
158 master_doc,
159 "pyjanitor.tex",
160 "pyjanitor Documentation",
161 "Eric J. Ma",
162 "manual",
163 )
164 ]
165
166
167 # -- Options for manual page output ------------------------------------------
168
169 # One entry per manual page. List of tuples
170 # (source start file, name, description, authors, manual section).
171 man_pages = [(master_doc, "pyjanitor", "pyjanitor Documentation", [author], 1)]
172
173
174 # -- Options for Texinfo output ----------------------------------------------
175
176 # Grouping the document tree into Texinfo files. List of tuples
177 # (source start file, target name, title, author,
178 # dir menu entry, description, category)
179 texinfo_documents = [
180 (
181 master_doc,
182 "pyjanitor",
183 "pyjanitor Documentation",
184 author,
185 "pyjanitor",
186 "One line description of project.",
187 "Miscellaneous",
188 )
189 ]
190
191
192 # -- Extension configuration -------------------------------------------------
193
194 # -- Options for intersphinx extension ---------------------------------------
195
196 # Example configuration for intersphinx: refer to the Python standard library.
197 intersphinx_mapping = {
198 "https://docs.python.org/": None,
199 "https://pandas.pydata.org/pandas-docs/stable": None,
200 }
201
202 # -- Options for todo extension ----------------------------------------------
203
204 # If true, `todo` and `todoList` produce output, else they produce nothing.
205 todo_include_todos = True
206
207
208 # -- Other options -----------------------------------------------------------
209
210 autosummary_generate = True # Make _autosummary files and include them
211
[end of docs/conf.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/docs/conf.py b/docs/conf.py
--- a/docs/conf.py
+++ b/docs/conf.py
@@ -10,13 +10,14 @@
# -- Path setup --------------------------------------------------------------
+import datetime
+
# If extensions (or modules to document with autodoc) are in another directory,
# add these directories to sys.path here. If the directory is relative to the
# documentation root, use os.path.abspath to make it absolute, like shown here.
#
import os
import sys
-import datetime
from pathlib import Path
sys.path.insert(0, os.path.abspath("."))
@@ -37,7 +38,7 @@
now = datetime.datetime.now()
CurrentYear = str(now.year)
-copyright = CurrentYear+", PyJanitor devs"
+copyright = CurrentYear + ", PyJanitor devs"
author = "Eric J. Ma"
# The short X.Y version
|
{"golden_diff": "diff --git a/docs/conf.py b/docs/conf.py\n--- a/docs/conf.py\n+++ b/docs/conf.py\n@@ -10,13 +10,14 @@\n \n # -- Path setup --------------------------------------------------------------\n \n+import datetime\n+\n # If extensions (or modules to document with autodoc) are in another directory,\n # add these directories to sys.path here. If the directory is relative to the\n # documentation root, use os.path.abspath to make it absolute, like shown here.\n #\n import os\n import sys\n-import datetime\n from pathlib import Path\n \n sys.path.insert(0, os.path.abspath(\".\"))\n@@ -37,7 +38,7 @@\n \n now = datetime.datetime.now()\n CurrentYear = str(now.year)\n-copyright = CurrentYear+\", PyJanitor devs\"\n+copyright = CurrentYear + \", PyJanitor devs\"\n author = \"Eric J. Ma\"\n \n # The short X.Y version\n", "issue": "[DOC] Adding context about method chaining \n# Brief Description of Fix\r\n\r\n<!-- Please describe the fix in terms of a \"before\" and \"after\". In other words, what's not so good about the current docs\r\npage, and what you would like to see it become. \r\n\r\nExample starter wording is provided. -->\r\n\r\nCurrently, the docs don't explain what method chaining is. A beginner would benefit from reading about it.\r\n\r\nI would like to propose a change, such that now the docs include a link to a medium post explaining the topic.\r\n\r\n# Relevant Context\r\n\r\n<!-- Please put here, in bullet points, links to the relevant docs page. A few starting template points are available\r\nto get you started. -->\r\n\r\n- [Link to documentation page](http://pyjanitor.readthedocs.io)\r\n- [Link to exact file to be edited](https://github.com/ericmjl/pyjanitor/README.rst)\r\n\n", "before_files": [{"content": "\"\"\"Sphinx configuration.\"\"\"\n\n# -*- coding: utf-8 -*-\n#\n# Configuration file for the Sphinx documentation builder.\n#\n# This file does only contain a selection of the most common options. For a\n# full list see the documentation:\n# http://www.sphinx-doc.org/en/stable/config\n\n# -- Path setup --------------------------------------------------------------\n\n# If extensions (or modules to document with autodoc) are in another directory,\n# add these directories to sys.path here. If the directory is relative to the\n# documentation root, use os.path.abspath to make it absolute, like shown here.\n#\nimport os\nimport sys\nimport datetime\nfrom pathlib import Path\n\nsys.path.insert(0, os.path.abspath(\".\"))\nsys.path.insert(0, os.path.abspath(\"../examples\"))\n\n# Make a symlink in our sphinx source directory to the top-level\n# examples/notebooks directory so we can include notebooks in the doc\nnotebooks = Path(\"./notebooks\")\nif not notebooks.exists():\n print(\"Making symlink to ../examples/notebooks\")\n notebooks.symlink_to(\"../examples/notebooks\")\n\n\n# -- Project information -----------------------------------------------------\n\nproject = \"pyjanitor\"\n\n\nnow = datetime.datetime.now()\nCurrentYear = str(now.year)\ncopyright = CurrentYear+\", PyJanitor devs\"\nauthor = \"Eric J. Ma\"\n\n# The short X.Y version\nversion = \"0.1.0\"\n# The full version, including alpha/beta/rc tags\nrelease = \"\"\n\n\n# -- General configuration ---------------------------------------------------\n\n# If your documentation needs a minimal Sphinx version, state it here.\n#\n# needs_sphinx = '1.0'\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.doctest\",\n \"sphinx.ext.intersphinx\",\n \"sphinx.ext.todo\",\n \"sphinx.ext.coverage\",\n \"sphinx.ext.viewcode\",\n \"sphinx.ext.githubpages\",\n \"sphinxcontrib.fulltoc\",\n \"nbsphinx\",\n \"sphinx.ext.autosummary\",\n]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\"_templates\"]\n\n# The suffix(es) of source filenames.\n# You can specify multiple suffix as a list of string:\n#\n# source_suffix = ['.rst', '.md']\nsource_suffix = [\".md\", \".rst\", \".ipynb\"]\n\n# The master toctree document.\nmaster_doc = \"index\"\n\n# The language for content autogenerated by Sphinx. Refer to documentation\n# for a list of supported languages.\n#\n# This is also used if you do content translation via gettext catalogs.\n# Usually you set \"language\" from the command line for these cases.\nlanguage = None\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path .\nexclude_patterns = [\"_build\", \"Thumbs.db\", \".DS_Store\", \"**.ipynb_checkpoints\"]\n\n# The name of the Pygments (syntax highlighting) style to use.\npygments_style = \"sphinx\"\n\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = \"alabaster\"\n\n# Theme options are theme-specific and customize the look and feel of a theme\n# further. For a list of options available for each theme, see the\n# documentation.\n#\nhtml_theme_options = {\"logo\": \"logo_title.svg\"}\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = [\"_static\"]\n\n# Custom sidebar templates, must be a dictionary that maps document names\n# to template names.\n#\n# The default sidebars (for documents that don't match any pattern) are\n# defined by theme itself. Builtin themes are using these templates by\n# default: ``['localtoc.html', 'relations.html', 'sourcelink.html',\n# 'searchbox.html']``.\n#\nhtml_sidebars = {\n \"**\": [\"about.html\", \"navigation.html\", \"relations.html\", \"searchbox.html\"]\n}\n\n\n# -- Options for HTMLHelp output ---------------------------------------------\n\n# Output file base name for HTML help builder.\nhtmlhelp_basename = \"pyjanitordoc\"\n\n\n# -- Options for LaTeX output ------------------------------------------------\n\nlatex_elements = {\n # The paper size ('letterpaper' or 'a4paper').\n #\n # 'papersize': 'letterpaper',\n # The font size ('10pt', '11pt' or '12pt').\n #\n # 'pointsize': '10pt',\n # Additional stuff for the LaTeX preamble.\n #\n # 'preamble': '',\n # Latex figure (float) alignment\n #\n # 'figure_align': 'htbp',\n}\n\n# Grouping the document tree into LaTeX files. List of tuples\n# (source start file, target name, title,\n# author, documentclass [howto, manual, or own class]).\nlatex_documents = [\n (\n master_doc,\n \"pyjanitor.tex\",\n \"pyjanitor Documentation\",\n \"Eric J. Ma\",\n \"manual\",\n )\n]\n\n\n# -- Options for manual page output ------------------------------------------\n\n# One entry per manual page. List of tuples\n# (source start file, name, description, authors, manual section).\nman_pages = [(master_doc, \"pyjanitor\", \"pyjanitor Documentation\", [author], 1)]\n\n\n# -- Options for Texinfo output ----------------------------------------------\n\n# Grouping the document tree into Texinfo files. List of tuples\n# (source start file, target name, title, author,\n# dir menu entry, description, category)\ntexinfo_documents = [\n (\n master_doc,\n \"pyjanitor\",\n \"pyjanitor Documentation\",\n author,\n \"pyjanitor\",\n \"One line description of project.\",\n \"Miscellaneous\",\n )\n]\n\n\n# -- Extension configuration -------------------------------------------------\n\n# -- Options for intersphinx extension ---------------------------------------\n\n# Example configuration for intersphinx: refer to the Python standard library.\nintersphinx_mapping = {\n \"https://docs.python.org/\": None,\n \"https://pandas.pydata.org/pandas-docs/stable\": None,\n}\n\n# -- Options for todo extension ----------------------------------------------\n\n# If true, `todo` and `todoList` produce output, else they produce nothing.\ntodo_include_todos = True\n\n\n# -- Other options -----------------------------------------------------------\n\nautosummary_generate = True # Make _autosummary files and include them\n", "path": "docs/conf.py"}]}
| 2,722 | 194 |
gh_patches_debug_19930
|
rasdani/github-patches
|
git_diff
|
matrix-org__synapse-11757
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
sample doc in #11561 is malformatted
see https://github.com/matrix-org/synapse/pull/11561#pullrequestreview-851817482
</issue>
<code>
[start of synapse/config/api.py]
1 # Copyright 2015-2021 The Matrix.org Foundation C.I.C.
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # http://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14
15 import logging
16 from typing import Iterable
17
18 from synapse.api.constants import EventTypes
19 from synapse.config._base import Config, ConfigError
20 from synapse.config._util import validate_config
21 from synapse.types import JsonDict
22
23 logger = logging.getLogger(__name__)
24
25
26 class ApiConfig(Config):
27 section = "api"
28
29 def read_config(self, config: JsonDict, **kwargs):
30 validate_config(_MAIN_SCHEMA, config, ())
31 self.room_prejoin_state = list(self._get_prejoin_state_types(config))
32 self.track_puppeted_user_ips = config.get("track_puppeted_user_ips", False)
33
34 def generate_config_section(cls, **kwargs) -> str:
35 formatted_default_state_types = "\n".join(
36 " # - %s" % (t,) for t in _DEFAULT_PREJOIN_STATE_TYPES
37 )
38
39 return """\
40 ## API Configuration ##
41
42 # Controls for the state that is shared with users who receive an invite
43 # to a room
44 #
45 room_prejoin_state:
46 # By default, the following state event types are shared with users who
47 # receive invites to the room:
48 #
49 %(formatted_default_state_types)s
50 #
51 # Uncomment the following to disable these defaults (so that only the event
52 # types listed in 'additional_event_types' are shared). Defaults to 'false'.
53 #
54 #disable_default_event_types: true
55
56 # Additional state event types to share with users when they are invited
57 # to a room.
58 #
59 # By default, this list is empty (so only the default event types are shared).
60 #
61 #additional_event_types:
62 # - org.example.custom.event.type
63
64 # By default when puppeting another user, the user who has created the
65 # access token for puppeting is tracked. If this is enabled, both
66 # requests are tracked. Implicitly enables MAU tracking for puppeted users.
67 # Uncomment to also track puppeted user IP's.
68 #
69 #track_puppeted_user_ips: true
70 """ % {
71 "formatted_default_state_types": formatted_default_state_types
72 }
73
74 def _get_prejoin_state_types(self, config: JsonDict) -> Iterable[str]:
75 """Get the event types to include in the prejoin state
76
77 Parses the config and returns an iterable of the event types to be included.
78 """
79 room_prejoin_state_config = config.get("room_prejoin_state") or {}
80
81 # backwards-compatibility support for room_invite_state_types
82 if "room_invite_state_types" in config:
83 # if both "room_invite_state_types" and "room_prejoin_state" are set, then
84 # we don't really know what to do.
85 if room_prejoin_state_config:
86 raise ConfigError(
87 "Can't specify both 'room_invite_state_types' and 'room_prejoin_state' "
88 "in config"
89 )
90
91 logger.warning(_ROOM_INVITE_STATE_TYPES_WARNING)
92
93 yield from config["room_invite_state_types"]
94 return
95
96 if not room_prejoin_state_config.get("disable_default_event_types"):
97 yield from _DEFAULT_PREJOIN_STATE_TYPES
98
99 yield from room_prejoin_state_config.get("additional_event_types", [])
100
101
102 _ROOM_INVITE_STATE_TYPES_WARNING = """\
103 WARNING: The 'room_invite_state_types' configuration setting is now deprecated,
104 and replaced with 'room_prejoin_state'. New features may not work correctly
105 unless 'room_invite_state_types' is removed. See the sample configuration file for
106 details of 'room_prejoin_state'.
107 --------------------------------------------------------------------------------
108 """
109
110 _DEFAULT_PREJOIN_STATE_TYPES = [
111 EventTypes.JoinRules,
112 EventTypes.CanonicalAlias,
113 EventTypes.RoomAvatar,
114 EventTypes.RoomEncryption,
115 EventTypes.Name,
116 # Per MSC1772.
117 EventTypes.Create,
118 # Per MSC3173.
119 EventTypes.Topic,
120 ]
121
122
123 # room_prejoin_state can either be None (as it is in the default config), or
124 # an object containing other config settings
125 _ROOM_PREJOIN_STATE_CONFIG_SCHEMA = {
126 "oneOf": [
127 {
128 "type": "object",
129 "properties": {
130 "disable_default_event_types": {"type": "boolean"},
131 "additional_event_types": {
132 "type": "array",
133 "items": {"type": "string"},
134 },
135 },
136 },
137 {"type": "null"},
138 ]
139 }
140
141 # the legacy room_invite_state_types setting
142 _ROOM_INVITE_STATE_TYPES_SCHEMA = {"type": "array", "items": {"type": "string"}}
143
144 _MAIN_SCHEMA = {
145 "type": "object",
146 "properties": {
147 "room_prejoin_state": _ROOM_PREJOIN_STATE_CONFIG_SCHEMA,
148 "room_invite_state_types": _ROOM_INVITE_STATE_TYPES_SCHEMA,
149 "track_puppeted_user_ips": {
150 "type": "boolean",
151 },
152 },
153 }
154
[end of synapse/config/api.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/synapse/config/api.py b/synapse/config/api.py
--- a/synapse/config/api.py
+++ b/synapse/config/api.py
@@ -61,10 +61,18 @@
#additional_event_types:
# - org.example.custom.event.type
- # By default when puppeting another user, the user who has created the
- # access token for puppeting is tracked. If this is enabled, both
- # requests are tracked. Implicitly enables MAU tracking for puppeted users.
- # Uncomment to also track puppeted user IP's.
+ # We record the IP address of clients used to access the API for various
+ # reasons, including displaying it to the user in the "Where you're signed in"
+ # dialog.
+ #
+ # By default, when puppeting another user via the admin API, the client IP
+ # address is recorded against the user who created the access token (ie, the
+ # admin user), and *not* the puppeted user.
+ #
+ # Uncomment the following to also record the IP address against the puppeted
+ # user. (This also means that the puppeted user will count as an "active" user
+ # for the purpose of monthly active user tracking - see 'limit_usage_by_mau' etc
+ # above.)
#
#track_puppeted_user_ips: true
""" % {
|
{"golden_diff": "diff --git a/synapse/config/api.py b/synapse/config/api.py\n--- a/synapse/config/api.py\n+++ b/synapse/config/api.py\n@@ -61,10 +61,18 @@\n #additional_event_types:\n # - org.example.custom.event.type\n \n- # By default when puppeting another user, the user who has created the\n- # access token for puppeting is tracked. If this is enabled, both\n- # requests are tracked. Implicitly enables MAU tracking for puppeted users.\n- # Uncomment to also track puppeted user IP's.\n+ # We record the IP address of clients used to access the API for various\n+ # reasons, including displaying it to the user in the \"Where you're signed in\"\n+ # dialog.\n+ #\n+ # By default, when puppeting another user via the admin API, the client IP\n+ # address is recorded against the user who created the access token (ie, the\n+ # admin user), and *not* the puppeted user.\n+ #\n+ # Uncomment the following to also record the IP address against the puppeted\n+ # user. (This also means that the puppeted user will count as an \"active\" user\n+ # for the purpose of monthly active user tracking - see 'limit_usage_by_mau' etc\n+ # above.)\n #\n #track_puppeted_user_ips: true\n \"\"\" % {\n", "issue": "sample doc in #11561 is malformatted\nsee https://github.com/matrix-org/synapse/pull/11561#pullrequestreview-851817482\n", "before_files": [{"content": "# Copyright 2015-2021 The Matrix.org Foundation C.I.C.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\nimport logging\nfrom typing import Iterable\n\nfrom synapse.api.constants import EventTypes\nfrom synapse.config._base import Config, ConfigError\nfrom synapse.config._util import validate_config\nfrom synapse.types import JsonDict\n\nlogger = logging.getLogger(__name__)\n\n\nclass ApiConfig(Config):\n section = \"api\"\n\n def read_config(self, config: JsonDict, **kwargs):\n validate_config(_MAIN_SCHEMA, config, ())\n self.room_prejoin_state = list(self._get_prejoin_state_types(config))\n self.track_puppeted_user_ips = config.get(\"track_puppeted_user_ips\", False)\n\n def generate_config_section(cls, **kwargs) -> str:\n formatted_default_state_types = \"\\n\".join(\n \" # - %s\" % (t,) for t in _DEFAULT_PREJOIN_STATE_TYPES\n )\n\n return \"\"\"\\\n ## API Configuration ##\n\n # Controls for the state that is shared with users who receive an invite\n # to a room\n #\n room_prejoin_state:\n # By default, the following state event types are shared with users who\n # receive invites to the room:\n #\n%(formatted_default_state_types)s\n #\n # Uncomment the following to disable these defaults (so that only the event\n # types listed in 'additional_event_types' are shared). Defaults to 'false'.\n #\n #disable_default_event_types: true\n\n # Additional state event types to share with users when they are invited\n # to a room.\n #\n # By default, this list is empty (so only the default event types are shared).\n #\n #additional_event_types:\n # - org.example.custom.event.type\n\n # By default when puppeting another user, the user who has created the\n # access token for puppeting is tracked. If this is enabled, both\n # requests are tracked. Implicitly enables MAU tracking for puppeted users.\n # Uncomment to also track puppeted user IP's.\n #\n #track_puppeted_user_ips: true\n \"\"\" % {\n \"formatted_default_state_types\": formatted_default_state_types\n }\n\n def _get_prejoin_state_types(self, config: JsonDict) -> Iterable[str]:\n \"\"\"Get the event types to include in the prejoin state\n\n Parses the config and returns an iterable of the event types to be included.\n \"\"\"\n room_prejoin_state_config = config.get(\"room_prejoin_state\") or {}\n\n # backwards-compatibility support for room_invite_state_types\n if \"room_invite_state_types\" in config:\n # if both \"room_invite_state_types\" and \"room_prejoin_state\" are set, then\n # we don't really know what to do.\n if room_prejoin_state_config:\n raise ConfigError(\n \"Can't specify both 'room_invite_state_types' and 'room_prejoin_state' \"\n \"in config\"\n )\n\n logger.warning(_ROOM_INVITE_STATE_TYPES_WARNING)\n\n yield from config[\"room_invite_state_types\"]\n return\n\n if not room_prejoin_state_config.get(\"disable_default_event_types\"):\n yield from _DEFAULT_PREJOIN_STATE_TYPES\n\n yield from room_prejoin_state_config.get(\"additional_event_types\", [])\n\n\n_ROOM_INVITE_STATE_TYPES_WARNING = \"\"\"\\\nWARNING: The 'room_invite_state_types' configuration setting is now deprecated,\nand replaced with 'room_prejoin_state'. New features may not work correctly\nunless 'room_invite_state_types' is removed. See the sample configuration file for\ndetails of 'room_prejoin_state'.\n--------------------------------------------------------------------------------\n\"\"\"\n\n_DEFAULT_PREJOIN_STATE_TYPES = [\n EventTypes.JoinRules,\n EventTypes.CanonicalAlias,\n EventTypes.RoomAvatar,\n EventTypes.RoomEncryption,\n EventTypes.Name,\n # Per MSC1772.\n EventTypes.Create,\n # Per MSC3173.\n EventTypes.Topic,\n]\n\n\n# room_prejoin_state can either be None (as it is in the default config), or\n# an object containing other config settings\n_ROOM_PREJOIN_STATE_CONFIG_SCHEMA = {\n \"oneOf\": [\n {\n \"type\": \"object\",\n \"properties\": {\n \"disable_default_event_types\": {\"type\": \"boolean\"},\n \"additional_event_types\": {\n \"type\": \"array\",\n \"items\": {\"type\": \"string\"},\n },\n },\n },\n {\"type\": \"null\"},\n ]\n}\n\n# the legacy room_invite_state_types setting\n_ROOM_INVITE_STATE_TYPES_SCHEMA = {\"type\": \"array\", \"items\": {\"type\": \"string\"}}\n\n_MAIN_SCHEMA = {\n \"type\": \"object\",\n \"properties\": {\n \"room_prejoin_state\": _ROOM_PREJOIN_STATE_CONFIG_SCHEMA,\n \"room_invite_state_types\": _ROOM_INVITE_STATE_TYPES_SCHEMA,\n \"track_puppeted_user_ips\": {\n \"type\": \"boolean\",\n },\n },\n}\n", "path": "synapse/config/api.py"}]}
| 2,124 | 320 |
gh_patches_debug_44351
|
rasdani/github-patches
|
git_diff
|
mitmproxy__mitmproxy-4725
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
"Cannot assemble flow with missing content" when exporting streamed flow in raw format
#### Problem Description
When a response (and possibly request, haven't checked that) is streamed and user tries to command `:export.clip raw @focus`, there is an exception:
```
Traceback (most recent call last):
File "/Users/korran/Projects/mitmproxy/mitmproxy/master.py", line 54, in run_loop
loop()
File "/Users/korran/Projects/mitmproxy/venv/lib/python3.9/site-packages/urwid/main_loop.py", line 287, in run
self._run()
File "/Users/korran/Projects/mitmproxy/venv/lib/python3.9/site-packages/urwid/main_loop.py", line 385, in _run
self.event_loop.run()
File "/Users/korran/Projects/mitmproxy/venv/lib/python3.9/site-packages/urwid/main_loop.py", line 1494, in run
reraise(*exc_info)
File "/Users/korran/Projects/mitmproxy/venv/lib/python3.9/site-packages/urwid/compat.py", line 58, in reraise
raise value
File "/usr/local/Cellar/[email protected]/3.9.6/Frameworks/Python.framework/Versions/3.9/lib/python3.9/asyncio/events.py", line 80, in _run
self._context.run(self._callback, *self._args)
File "/Users/korran/Projects/mitmproxy/venv/lib/python3.9/site-packages/urwid/raw_display.py", line 416, in <lambda>
wrapper = lambda: self.parse_input(
File "/Users/korran/Projects/mitmproxy/venv/lib/python3.9/site-packages/urwid/raw_display.py", line 515, in parse_input
callback(processed, processed_codes)
File "/Users/korran/Projects/mitmproxy/venv/lib/python3.9/site-packages/urwid/main_loop.py", line 412, in _update
self.process_input(keys)
File "/Users/korran/Projects/mitmproxy/venv/lib/python3.9/site-packages/urwid/main_loop.py", line 513, in process_input
k = self._topmost_widget.keypress(self.screen_size, k)
File "/Users/korran/Projects/mitmproxy/mitmproxy/tools/console/window.py", line 316, in keypress
k = super().keypress(size, k)
File "/Users/korran/Projects/mitmproxy/venv/lib/python3.9/site-packages/urwid/container.py", line 1123, in keypress
return self.footer.keypress((maxcol,),key)
File "/Users/korran/Projects/mitmproxy/mitmproxy/tools/console/statusbar.py", line 201, in keypress
return self.ab.keypress(*args, **kwargs)
File "/Users/korran/Projects/mitmproxy/mitmproxy/tools/console/statusbar.py", line 149, in keypress
self.prompt_execute(text)
File "/Users/korran/Projects/mitmproxy/mitmproxy/tools/console/statusbar.py", line 169, in prompt_execute
msg = p(txt)
File "/Users/korran/Projects/mitmproxy/mitmproxy/tools/console/statusbar.py", line 115, in execute_command
execute(txt)
File "/Users/korran/Projects/mitmproxy/mitmproxy/tools/console/commandexecutor.py", line 18, in __call__
ret = self.master.commands.execute(cmd)
File "/Users/korran/Projects/mitmproxy/mitmproxy/command.py", line 273, in execute
return self.call_strings(command_name, args)
File "/Users/korran/Projects/mitmproxy/mitmproxy/command.py", line 259, in call_strings
return self.commands[command_name].call(args)
File "/Users/korran/Projects/mitmproxy/mitmproxy/command.py", line 129, in call
ret = self.func(*bound_args.args, **bound_args.kwargs)
File "/Users/korran/Projects/mitmproxy/mitmproxy/command.py", line 303, in wrapper
return function(*args, **kwargs)
File "/Users/korran/Projects/mitmproxy/mitmproxy/addons/export.py", line 189, in clip
v = strutils.always_str(func(flow))
File "/Users/korran/Projects/mitmproxy/mitmproxy/addons/export.py", line 121, in raw
return b"".join([raw_request(f), separator, raw_response(f)])
File "/Users/korran/Projects/mitmproxy/mitmproxy/addons/export.py", line 109, in raw_response
return assemble.assemble_response(cleanup_response(f))
File "/Users/korran/Projects/mitmproxy/mitmproxy/net/http/http1/assemble.py", line 17, in assemble_response
raise ValueError("Cannot assemble flow with missing content")
ValueError: Cannot assemble flow with missing content
```
#### Steps to reproduce the behavior:
1. Run mitmproxy with `--set stream_large_bodies=10k`
2. `curl -x 127.0.0.1 www.google.com 1>/dev/null`
3. `:export.clip raw @focus`
#### System Information
```
Mitmproxy: 8.0.0.dev (+17, commit 13131e2)
Python: 3.9.6
OpenSSL: OpenSSL 1.1.1i 8 Dec 2020
Platform: macOS-11.5.1-x86_64-i386-64bit
```
This exception is explicitly raised when `flow.response.content` is `None`, but I think it's still valuable to export whatever is available in a flow. I was thinking about setting some artificial content (or `b''`) for streamed request/response, but it doesn't seem like a good idea.
</issue>
<code>
[start of mitmproxy/addons/export.py]
1 import shlex
2 import typing
3
4 import pyperclip
5
6 import mitmproxy.types
7 from mitmproxy import command
8 from mitmproxy import ctx, http
9 from mitmproxy import exceptions
10 from mitmproxy import flow
11 from mitmproxy.net.http.http1 import assemble
12 from mitmproxy.utils import strutils
13
14
15 def cleanup_request(f: flow.Flow) -> http.Request:
16 if not getattr(f, "request", None):
17 raise exceptions.CommandError("Can't export flow with no request.")
18 assert isinstance(f, http.HTTPFlow)
19 request = f.request.copy()
20 request.decode(strict=False)
21 return request
22
23
24 def pop_headers(request: http.Request) -> http.Request:
25 # Remove some headers that are redundant for curl/httpie export
26 request.headers.pop('content-length')
27 if request.headers.get("host", "") == request.host:
28 request.headers.pop("host")
29 if request.headers.get(":authority", "") == request.host:
30 request.headers.pop(":authority")
31 return request
32
33
34 def cleanup_response(f: flow.Flow) -> http.Response:
35 if not getattr(f, "response", None):
36 raise exceptions.CommandError("Can't export flow with no response.")
37 assert isinstance(f, http.HTTPFlow)
38 response = f.response.copy() # type: ignore
39 response.decode(strict=False)
40 return response
41
42
43 def request_content_for_console(request: http.Request) -> str:
44 try:
45 text = request.get_text(strict=True)
46 assert text
47 except ValueError:
48 # shlex.quote doesn't support a bytes object
49 # see https://github.com/python/cpython/pull/10871
50 raise exceptions.CommandError("Request content must be valid unicode")
51 escape_control_chars = {chr(i): f"\\x{i:02x}" for i in range(32)}
52 return "".join(
53 escape_control_chars.get(x, x)
54 for x in text
55 )
56
57
58 def curl_command(f: flow.Flow, preserve_ip: bool = False) -> str:
59 request = cleanup_request(f)
60 request = pop_headers(request)
61 args = ["curl"]
62
63 server_addr = f.server_conn.peername[0] if f.server_conn.peername else None
64
65 if preserve_ip and server_addr and request.pretty_host != server_addr:
66 resolve = "{}:{}:[{}]".format(request.pretty_host, request.port, server_addr)
67 args.append("--resolve")
68 args.append(resolve)
69
70 for k, v in request.headers.items(multi=True):
71 if k.lower() == "accept-encoding":
72 args.append("--compressed")
73 else:
74 args += ["-H", f"{k}: {v}"]
75
76 if request.method != "GET":
77 args += ["-X", request.method]
78
79 args.append(request.pretty_url)
80
81 if request.content:
82 args += ["-d", request_content_for_console(request)]
83 return ' '.join(shlex.quote(arg) for arg in args)
84
85
86 def httpie_command(f: flow.Flow) -> str:
87 request = cleanup_request(f)
88 request = pop_headers(request)
89
90 # TODO: Once https://github.com/httpie/httpie/issues/414 is implemented, we
91 # should ensure we always connect to the IP address specified in the flow,
92 # similar to how it's done in curl_command.
93 url = request.pretty_url
94
95 args = ["http", request.method, url]
96 for k, v in request.headers.items(multi=True):
97 args.append(f"{k}: {v}")
98 cmd = ' '.join(shlex.quote(arg) for arg in args)
99 if request.content:
100 cmd += " <<< " + shlex.quote(request_content_for_console(request))
101 return cmd
102
103
104 def raw_request(f: flow.Flow) -> bytes:
105 return assemble.assemble_request(cleanup_request(f))
106
107
108 def raw_response(f: flow.Flow) -> bytes:
109 return assemble.assemble_response(cleanup_response(f))
110
111
112 def raw(f: flow.Flow, separator=b"\r\n\r\n") -> bytes:
113 """Return either the request or response if only one exists, otherwise return both"""
114 request_present = hasattr(f, "request") and f.request # type: ignore
115 response_present = hasattr(f, "response") and f.response # type: ignore
116
117 if not (request_present or response_present):
118 raise exceptions.CommandError("Can't export flow with no request or response.")
119
120 if request_present and response_present:
121 return b"".join([raw_request(f), separator, raw_response(f)])
122 elif not request_present:
123 return raw_response(f)
124 else:
125 return raw_request(f)
126
127
128 formats = dict(
129 curl=curl_command,
130 httpie=httpie_command,
131 raw=raw,
132 raw_request=raw_request,
133 raw_response=raw_response,
134 )
135
136
137 class Export():
138 def load(self, loader):
139 loader.add_option(
140 "export_preserve_original_ip", bool, False,
141 """
142 When exporting a request as an external command, make an effort to
143 connect to the same IP as in the original request. This helps with
144 reproducibility in cases where the behaviour depends on the
145 particular host we are connecting to. Currently this only affects
146 curl exports.
147 """
148 )
149
150 @command.command("export.formats")
151 def formats(self) -> typing.Sequence[str]:
152 """
153 Return a list of the supported export formats.
154 """
155 return list(sorted(formats.keys()))
156
157 @command.command("export.file")
158 def file(self, format: str, flow: flow.Flow, path: mitmproxy.types.Path) -> None:
159 """
160 Export a flow to path.
161 """
162 if format not in formats:
163 raise exceptions.CommandError("No such export format: %s" % format)
164 func: typing.Any = formats[format]
165 if format == "curl":
166 v = func(flow, preserve_ip=ctx.options.export_preserve_original_ip)
167 else:
168 v = func(flow)
169 try:
170 with open(path, "wb") as fp:
171 if isinstance(v, bytes):
172 fp.write(v)
173 else:
174 fp.write(v.encode("utf-8"))
175 except OSError as e:
176 ctx.log.error(str(e))
177
178 @command.command("export.clip")
179 def clip(self, format: str, flow: flow.Flow) -> None:
180 """
181 Export a flow to the system clipboard.
182 """
183 if format not in formats:
184 raise exceptions.CommandError("No such export format: %s" % format)
185 func: typing.Any = formats[format]
186 if format == "curl":
187 v = strutils.always_str(func(flow, preserve_ip=ctx.options.export_preserve_original_ip))
188 else:
189 v = strutils.always_str(func(flow))
190 try:
191 pyperclip.copy(v)
192 except pyperclip.PyperclipException as e:
193 ctx.log.error(str(e))
194
[end of mitmproxy/addons/export.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mitmproxy/addons/export.py b/mitmproxy/addons/export.py
--- a/mitmproxy/addons/export.py
+++ b/mitmproxy/addons/export.py
@@ -55,14 +55,14 @@
)
-def curl_command(f: flow.Flow, preserve_ip: bool = False) -> str:
+def curl_command(f: flow.Flow) -> str:
request = cleanup_request(f)
request = pop_headers(request)
args = ["curl"]
server_addr = f.server_conn.peername[0] if f.server_conn.peername else None
- if preserve_ip and server_addr and request.pretty_host != server_addr:
+ if ctx.options.export_preserve_original_ip and server_addr and request.pretty_host != server_addr:
resolve = "{}:{}:[{}]".format(request.pretty_host, request.port, server_addr)
args.append("--resolve")
args.append(resolve)
@@ -102,30 +102,35 @@
def raw_request(f: flow.Flow) -> bytes:
- return assemble.assemble_request(cleanup_request(f))
+ request = cleanup_request(f)
+ if request.raw_content is None:
+ raise exceptions.CommandError("Request content missing.")
+ return assemble.assemble_request(request)
def raw_response(f: flow.Flow) -> bytes:
- return assemble.assemble_response(cleanup_response(f))
+ response = cleanup_response(f)
+ if response.raw_content is None:
+ raise exceptions.CommandError("Response content missing.")
+ return assemble.assemble_response(response)
def raw(f: flow.Flow, separator=b"\r\n\r\n") -> bytes:
"""Return either the request or response if only one exists, otherwise return both"""
- request_present = hasattr(f, "request") and f.request # type: ignore
- response_present = hasattr(f, "response") and f.response # type: ignore
-
- if not (request_present or response_present):
- raise exceptions.CommandError("Can't export flow with no request or response.")
+ request_present = isinstance(f, http.HTTPFlow) and f.request and f.request.raw_content is not None
+ response_present = isinstance(f, http.HTTPFlow) and f.response and f.response.raw_content is not None
if request_present and response_present:
return b"".join([raw_request(f), separator, raw_response(f)])
- elif not request_present:
+ elif request_present:
+ return raw_request(f)
+ elif response_present:
return raw_response(f)
else:
- return raw_request(f)
+ raise exceptions.CommandError("Can't export flow with no request or response.")
-formats = dict(
+formats: typing.Dict[str, typing.Callable[[flow.Flow], typing.Union[str, bytes]]] = dict(
curl=curl_command,
httpie=httpie_command,
raw=raw,
@@ -134,7 +139,7 @@
)
-class Export():
+class Export:
def load(self, loader):
loader.add_option(
"export_preserve_original_ip", bool, False,
@@ -162,10 +167,7 @@
if format not in formats:
raise exceptions.CommandError("No such export format: %s" % format)
func: typing.Any = formats[format]
- if format == "curl":
- v = func(flow, preserve_ip=ctx.options.export_preserve_original_ip)
- else:
- v = func(flow)
+ v = func(flow)
try:
with open(path, "wb") as fp:
if isinstance(v, bytes):
@@ -176,18 +178,16 @@
ctx.log.error(str(e))
@command.command("export.clip")
- def clip(self, format: str, flow: flow.Flow) -> None:
+ def clip(self, format: str, f: flow.Flow) -> None:
"""
Export a flow to the system clipboard.
"""
if format not in formats:
raise exceptions.CommandError("No such export format: %s" % format)
- func: typing.Any = formats[format]
- if format == "curl":
- v = strutils.always_str(func(flow, preserve_ip=ctx.options.export_preserve_original_ip))
- else:
- v = strutils.always_str(func(flow))
+ func = formats[format]
+
+ val = strutils.always_str(func(f), "utf8", "backslashreplace")
try:
- pyperclip.copy(v)
+ pyperclip.copy(val)
except pyperclip.PyperclipException as e:
ctx.log.error(str(e))
|
{"golden_diff": "diff --git a/mitmproxy/addons/export.py b/mitmproxy/addons/export.py\n--- a/mitmproxy/addons/export.py\n+++ b/mitmproxy/addons/export.py\n@@ -55,14 +55,14 @@\n )\n \n \n-def curl_command(f: flow.Flow, preserve_ip: bool = False) -> str:\n+def curl_command(f: flow.Flow) -> str:\n request = cleanup_request(f)\n request = pop_headers(request)\n args = [\"curl\"]\n \n server_addr = f.server_conn.peername[0] if f.server_conn.peername else None\n \n- if preserve_ip and server_addr and request.pretty_host != server_addr:\n+ if ctx.options.export_preserve_original_ip and server_addr and request.pretty_host != server_addr:\n resolve = \"{}:{}:[{}]\".format(request.pretty_host, request.port, server_addr)\n args.append(\"--resolve\")\n args.append(resolve)\n@@ -102,30 +102,35 @@\n \n \n def raw_request(f: flow.Flow) -> bytes:\n- return assemble.assemble_request(cleanup_request(f))\n+ request = cleanup_request(f)\n+ if request.raw_content is None:\n+ raise exceptions.CommandError(\"Request content missing.\")\n+ return assemble.assemble_request(request)\n \n \n def raw_response(f: flow.Flow) -> bytes:\n- return assemble.assemble_response(cleanup_response(f))\n+ response = cleanup_response(f)\n+ if response.raw_content is None:\n+ raise exceptions.CommandError(\"Response content missing.\")\n+ return assemble.assemble_response(response)\n \n \n def raw(f: flow.Flow, separator=b\"\\r\\n\\r\\n\") -> bytes:\n \"\"\"Return either the request or response if only one exists, otherwise return both\"\"\"\n- request_present = hasattr(f, \"request\") and f.request # type: ignore\n- response_present = hasattr(f, \"response\") and f.response # type: ignore\n-\n- if not (request_present or response_present):\n- raise exceptions.CommandError(\"Can't export flow with no request or response.\")\n+ request_present = isinstance(f, http.HTTPFlow) and f.request and f.request.raw_content is not None\n+ response_present = isinstance(f, http.HTTPFlow) and f.response and f.response.raw_content is not None\n \n if request_present and response_present:\n return b\"\".join([raw_request(f), separator, raw_response(f)])\n- elif not request_present:\n+ elif request_present:\n+ return raw_request(f)\n+ elif response_present:\n return raw_response(f)\n else:\n- return raw_request(f)\n+ raise exceptions.CommandError(\"Can't export flow with no request or response.\")\n \n \n-formats = dict(\n+formats: typing.Dict[str, typing.Callable[[flow.Flow], typing.Union[str, bytes]]] = dict(\n curl=curl_command,\n httpie=httpie_command,\n raw=raw,\n@@ -134,7 +139,7 @@\n )\n \n \n-class Export():\n+class Export:\n def load(self, loader):\n loader.add_option(\n \"export_preserve_original_ip\", bool, False,\n@@ -162,10 +167,7 @@\n if format not in formats:\n raise exceptions.CommandError(\"No such export format: %s\" % format)\n func: typing.Any = formats[format]\n- if format == \"curl\":\n- v = func(flow, preserve_ip=ctx.options.export_preserve_original_ip)\n- else:\n- v = func(flow)\n+ v = func(flow)\n try:\n with open(path, \"wb\") as fp:\n if isinstance(v, bytes):\n@@ -176,18 +178,16 @@\n ctx.log.error(str(e))\n \n @command.command(\"export.clip\")\n- def clip(self, format: str, flow: flow.Flow) -> None:\n+ def clip(self, format: str, f: flow.Flow) -> None:\n \"\"\"\n Export a flow to the system clipboard.\n \"\"\"\n if format not in formats:\n raise exceptions.CommandError(\"No such export format: %s\" % format)\n- func: typing.Any = formats[format]\n- if format == \"curl\":\n- v = strutils.always_str(func(flow, preserve_ip=ctx.options.export_preserve_original_ip))\n- else:\n- v = strutils.always_str(func(flow))\n+ func = formats[format]\n+\n+ val = strutils.always_str(func(f), \"utf8\", \"backslashreplace\")\n try:\n- pyperclip.copy(v)\n+ pyperclip.copy(val)\n except pyperclip.PyperclipException as e:\n ctx.log.error(str(e))\n", "issue": "\"Cannot assemble flow with missing content\" when exporting streamed flow in raw format\n#### Problem Description\r\nWhen a response (and possibly request, haven't checked that) is streamed and user tries to command `:export.clip raw @focus`, there is an exception:\r\n\r\n```\r\nTraceback (most recent call last):\r\n File \"/Users/korran/Projects/mitmproxy/mitmproxy/master.py\", line 54, in run_loop\r\n loop()\r\n File \"/Users/korran/Projects/mitmproxy/venv/lib/python3.9/site-packages/urwid/main_loop.py\", line 287, in run\r\n self._run()\r\n File \"/Users/korran/Projects/mitmproxy/venv/lib/python3.9/site-packages/urwid/main_loop.py\", line 385, in _run\r\n self.event_loop.run()\r\n File \"/Users/korran/Projects/mitmproxy/venv/lib/python3.9/site-packages/urwid/main_loop.py\", line 1494, in run\r\n reraise(*exc_info)\r\n File \"/Users/korran/Projects/mitmproxy/venv/lib/python3.9/site-packages/urwid/compat.py\", line 58, in reraise\r\n raise value\r\n File \"/usr/local/Cellar/[email protected]/3.9.6/Frameworks/Python.framework/Versions/3.9/lib/python3.9/asyncio/events.py\", line 80, in _run\r\n self._context.run(self._callback, *self._args)\r\n File \"/Users/korran/Projects/mitmproxy/venv/lib/python3.9/site-packages/urwid/raw_display.py\", line 416, in <lambda>\r\n wrapper = lambda: self.parse_input(\r\n File \"/Users/korran/Projects/mitmproxy/venv/lib/python3.9/site-packages/urwid/raw_display.py\", line 515, in parse_input\r\n callback(processed, processed_codes)\r\n File \"/Users/korran/Projects/mitmproxy/venv/lib/python3.9/site-packages/urwid/main_loop.py\", line 412, in _update\r\n self.process_input(keys)\r\n File \"/Users/korran/Projects/mitmproxy/venv/lib/python3.9/site-packages/urwid/main_loop.py\", line 513, in process_input\r\n k = self._topmost_widget.keypress(self.screen_size, k)\r\n File \"/Users/korran/Projects/mitmproxy/mitmproxy/tools/console/window.py\", line 316, in keypress\r\n k = super().keypress(size, k)\r\n File \"/Users/korran/Projects/mitmproxy/venv/lib/python3.9/site-packages/urwid/container.py\", line 1123, in keypress\r\n return self.footer.keypress((maxcol,),key)\r\n File \"/Users/korran/Projects/mitmproxy/mitmproxy/tools/console/statusbar.py\", line 201, in keypress\r\n return self.ab.keypress(*args, **kwargs)\r\n File \"/Users/korran/Projects/mitmproxy/mitmproxy/tools/console/statusbar.py\", line 149, in keypress\r\n self.prompt_execute(text)\r\n File \"/Users/korran/Projects/mitmproxy/mitmproxy/tools/console/statusbar.py\", line 169, in prompt_execute\r\n msg = p(txt)\r\n File \"/Users/korran/Projects/mitmproxy/mitmproxy/tools/console/statusbar.py\", line 115, in execute_command\r\n execute(txt)\r\n File \"/Users/korran/Projects/mitmproxy/mitmproxy/tools/console/commandexecutor.py\", line 18, in __call__\r\n ret = self.master.commands.execute(cmd)\r\n File \"/Users/korran/Projects/mitmproxy/mitmproxy/command.py\", line 273, in execute\r\n return self.call_strings(command_name, args)\r\n File \"/Users/korran/Projects/mitmproxy/mitmproxy/command.py\", line 259, in call_strings\r\n return self.commands[command_name].call(args)\r\n File \"/Users/korran/Projects/mitmproxy/mitmproxy/command.py\", line 129, in call\r\n ret = self.func(*bound_args.args, **bound_args.kwargs)\r\n File \"/Users/korran/Projects/mitmproxy/mitmproxy/command.py\", line 303, in wrapper\r\n return function(*args, **kwargs)\r\n File \"/Users/korran/Projects/mitmproxy/mitmproxy/addons/export.py\", line 189, in clip\r\n v = strutils.always_str(func(flow))\r\n File \"/Users/korran/Projects/mitmproxy/mitmproxy/addons/export.py\", line 121, in raw\r\n return b\"\".join([raw_request(f), separator, raw_response(f)])\r\n File \"/Users/korran/Projects/mitmproxy/mitmproxy/addons/export.py\", line 109, in raw_response\r\n return assemble.assemble_response(cleanup_response(f))\r\n File \"/Users/korran/Projects/mitmproxy/mitmproxy/net/http/http1/assemble.py\", line 17, in assemble_response\r\n raise ValueError(\"Cannot assemble flow with missing content\")\r\nValueError: Cannot assemble flow with missing content\r\n```\r\n#### Steps to reproduce the behavior:\r\n1. Run mitmproxy with `--set stream_large_bodies=10k`\r\n2. `curl -x 127.0.0.1 www.google.com 1>/dev/null`\r\n3. `:export.clip raw @focus`\r\n\r\n#### System Information\r\n```\r\nMitmproxy: 8.0.0.dev (+17, commit 13131e2)\r\nPython: 3.9.6\r\nOpenSSL: OpenSSL 1.1.1i 8 Dec 2020\r\nPlatform: macOS-11.5.1-x86_64-i386-64bit\r\n```\r\nThis exception is explicitly raised when `flow.response.content` is `None`, but I think it's still valuable to export whatever is available in a flow. I was thinking about setting some artificial content (or `b''`) for streamed request/response, but it doesn't seem like a good idea.\n", "before_files": [{"content": "import shlex\nimport typing\n\nimport pyperclip\n\nimport mitmproxy.types\nfrom mitmproxy import command\nfrom mitmproxy import ctx, http\nfrom mitmproxy import exceptions\nfrom mitmproxy import flow\nfrom mitmproxy.net.http.http1 import assemble\nfrom mitmproxy.utils import strutils\n\n\ndef cleanup_request(f: flow.Flow) -> http.Request:\n if not getattr(f, \"request\", None):\n raise exceptions.CommandError(\"Can't export flow with no request.\")\n assert isinstance(f, http.HTTPFlow)\n request = f.request.copy()\n request.decode(strict=False)\n return request\n\n\ndef pop_headers(request: http.Request) -> http.Request:\n # Remove some headers that are redundant for curl/httpie export\n request.headers.pop('content-length')\n if request.headers.get(\"host\", \"\") == request.host:\n request.headers.pop(\"host\")\n if request.headers.get(\":authority\", \"\") == request.host:\n request.headers.pop(\":authority\")\n return request\n\n\ndef cleanup_response(f: flow.Flow) -> http.Response:\n if not getattr(f, \"response\", None):\n raise exceptions.CommandError(\"Can't export flow with no response.\")\n assert isinstance(f, http.HTTPFlow)\n response = f.response.copy() # type: ignore\n response.decode(strict=False)\n return response\n\n\ndef request_content_for_console(request: http.Request) -> str:\n try:\n text = request.get_text(strict=True)\n assert text\n except ValueError:\n # shlex.quote doesn't support a bytes object\n # see https://github.com/python/cpython/pull/10871\n raise exceptions.CommandError(\"Request content must be valid unicode\")\n escape_control_chars = {chr(i): f\"\\\\x{i:02x}\" for i in range(32)}\n return \"\".join(\n escape_control_chars.get(x, x)\n for x in text\n )\n\n\ndef curl_command(f: flow.Flow, preserve_ip: bool = False) -> str:\n request = cleanup_request(f)\n request = pop_headers(request)\n args = [\"curl\"]\n\n server_addr = f.server_conn.peername[0] if f.server_conn.peername else None\n\n if preserve_ip and server_addr and request.pretty_host != server_addr:\n resolve = \"{}:{}:[{}]\".format(request.pretty_host, request.port, server_addr)\n args.append(\"--resolve\")\n args.append(resolve)\n\n for k, v in request.headers.items(multi=True):\n if k.lower() == \"accept-encoding\":\n args.append(\"--compressed\")\n else:\n args += [\"-H\", f\"{k}: {v}\"]\n\n if request.method != \"GET\":\n args += [\"-X\", request.method]\n\n args.append(request.pretty_url)\n\n if request.content:\n args += [\"-d\", request_content_for_console(request)]\n return ' '.join(shlex.quote(arg) for arg in args)\n\n\ndef httpie_command(f: flow.Flow) -> str:\n request = cleanup_request(f)\n request = pop_headers(request)\n\n # TODO: Once https://github.com/httpie/httpie/issues/414 is implemented, we\n # should ensure we always connect to the IP address specified in the flow,\n # similar to how it's done in curl_command.\n url = request.pretty_url\n\n args = [\"http\", request.method, url]\n for k, v in request.headers.items(multi=True):\n args.append(f\"{k}: {v}\")\n cmd = ' '.join(shlex.quote(arg) for arg in args)\n if request.content:\n cmd += \" <<< \" + shlex.quote(request_content_for_console(request))\n return cmd\n\n\ndef raw_request(f: flow.Flow) -> bytes:\n return assemble.assemble_request(cleanup_request(f))\n\n\ndef raw_response(f: flow.Flow) -> bytes:\n return assemble.assemble_response(cleanup_response(f))\n\n\ndef raw(f: flow.Flow, separator=b\"\\r\\n\\r\\n\") -> bytes:\n \"\"\"Return either the request or response if only one exists, otherwise return both\"\"\"\n request_present = hasattr(f, \"request\") and f.request # type: ignore\n response_present = hasattr(f, \"response\") and f.response # type: ignore\n\n if not (request_present or response_present):\n raise exceptions.CommandError(\"Can't export flow with no request or response.\")\n\n if request_present and response_present:\n return b\"\".join([raw_request(f), separator, raw_response(f)])\n elif not request_present:\n return raw_response(f)\n else:\n return raw_request(f)\n\n\nformats = dict(\n curl=curl_command,\n httpie=httpie_command,\n raw=raw,\n raw_request=raw_request,\n raw_response=raw_response,\n)\n\n\nclass Export():\n def load(self, loader):\n loader.add_option(\n \"export_preserve_original_ip\", bool, False,\n \"\"\"\n When exporting a request as an external command, make an effort to\n connect to the same IP as in the original request. This helps with\n reproducibility in cases where the behaviour depends on the\n particular host we are connecting to. Currently this only affects\n curl exports.\n \"\"\"\n )\n\n @command.command(\"export.formats\")\n def formats(self) -> typing.Sequence[str]:\n \"\"\"\n Return a list of the supported export formats.\n \"\"\"\n return list(sorted(formats.keys()))\n\n @command.command(\"export.file\")\n def file(self, format: str, flow: flow.Flow, path: mitmproxy.types.Path) -> None:\n \"\"\"\n Export a flow to path.\n \"\"\"\n if format not in formats:\n raise exceptions.CommandError(\"No such export format: %s\" % format)\n func: typing.Any = formats[format]\n if format == \"curl\":\n v = func(flow, preserve_ip=ctx.options.export_preserve_original_ip)\n else:\n v = func(flow)\n try:\n with open(path, \"wb\") as fp:\n if isinstance(v, bytes):\n fp.write(v)\n else:\n fp.write(v.encode(\"utf-8\"))\n except OSError as e:\n ctx.log.error(str(e))\n\n @command.command(\"export.clip\")\n def clip(self, format: str, flow: flow.Flow) -> None:\n \"\"\"\n Export a flow to the system clipboard.\n \"\"\"\n if format not in formats:\n raise exceptions.CommandError(\"No such export format: %s\" % format)\n func: typing.Any = formats[format]\n if format == \"curl\":\n v = strutils.always_str(func(flow, preserve_ip=ctx.options.export_preserve_original_ip))\n else:\n v = strutils.always_str(func(flow))\n try:\n pyperclip.copy(v)\n except pyperclip.PyperclipException as e:\n ctx.log.error(str(e))\n", "path": "mitmproxy/addons/export.py"}]}
| 3,851 | 1,011 |
gh_patches_debug_10999
|
rasdani/github-patches
|
git_diff
|
privacyidea__privacyidea-1021
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Problematic ldap3 / pyasn1 version combinations
This is an issue to keep track of problematic combinations of ldap3 / pyasn1 versions. See #887, #911.
Functionality I check for each combination:
* STARTTLS
* Complete user info on /validate/check
* Size Limit < number of users
Everything tested on a62fd9b3d0555b43cf31be3c4092a549fd73f724
<table>
<tr>
<th></th><th>pyasn 0.1.9</th><th>pyasn 0.4.2</th>
<tr><td>ldap3 2.1.1</td><td>ok</td><td><ul><li>STARTTLS fails (#885)</li></ul></td></tr>
<tr><td>ldap3 2.3</td><td colspan="2">
<ul><li>Empty user list (#887)</li></ul></td></tr>
<tr><td>ldap3 2.4</td><td colspan="2">
<ul><li>Empty user list (#887)</li><li>Empty user info (#911)</li></ul></td></tr>
<tr><td>ldap3 2.4.1</td><td colspan=2">
<ul><li>Empty user list (#887)</li>
<li><b>Error on /validate/check and resolver error</b> in token list (#911)</li>
<li>cannot search for unicode users (#980)</li></td></tr>
</table>
Combinations in current 2.21.4 packages:
* ``pip install privacyidea``:
```
ldap3==2.1.1
privacyIDEA==2.21.4
pyasn1==0.4.2
```
* CentOS:
```
ldap3==2.3
privacyIDEA==2.21.4
pyasn1==0.4.2
```
* Ubuntu (Launchpad):
```
ldap3==2.1.1
privacyIDEA==2.21.4
pyasn1==0.1.9
```
</issue>
<code>
[start of setup.py]
1 # -*- coding: utf-8 -*-
2 from setuptools import setup, find_packages
3 import os
4 import stat
5 import sys
6
7 #VERSION="2.1dev4"
8 VERSION="2.22"
9
10 # Taken from kennethreitz/requests/setup.py
11 package_directory = os.path.realpath(os.path.dirname(__file__))
12
13
14 def get_file_contents(file_path):
15 """Get the context of the file using full path name."""
16 content = ""
17 try:
18 full_path = os.path.join(package_directory, file_path)
19 content = open(full_path, 'r').read()
20 except:
21 print >> sys.stderr, "### could not open file {0!r}".format(file_path)
22 return content
23
24 def get_file_list(file_path):
25 full_path = os.path.join(package_directory, file_path)
26 file_list = os.listdir(full_path)
27 # now we need to add the path to the files
28 return [ file_path + f for f in file_list ]
29
30
31 install_requires = ["Flask>=0.10.1",
32 "Flask-Migrate>=1.2.0",
33 "Flask-SQLAlchemy>=2.0",
34 "Flask-Script>=2.0.5",
35 "Jinja2>=2.7.3",
36 "Mako>=0.9.1",
37 "MarkupSafe>=0.23",
38 "PyMySQL>=0.6.6",
39 "Pillow>=2.6.1",
40 "PyJWT>=1.3.0",
41 "PyYAML>=3.11",
42 "Pygments>=2.0.2",
43 "SQLAlchemy>=1.0.5",
44 "Werkzeug>=0.10.4",
45 "alembic>=0.6.7",
46 "argparse>=1.2.1",
47 "bcrypt>=1.1.0",
48 "beautifulsoup4>=4.3.2",
49 "cffi>=0.8.6",
50 "configobj>=5.0.6",
51 "docutils>=0.12",
52 "funcparserlib>=0.3.6",
53 "itsdangerous>=0.24",
54 "ldap3==2.1.1",
55 "netaddr>=0.7.12",
56 "passlib>=1.6.2",
57 "pyasn1>=0.1.7",
58 "pyOpenSSL>=0.15.1",
59 "pycparser>=2.10",
60 "pycrypto>=2.6.1",
61 "pyrad>=2.0",
62 "pyusb>=1.0.0b2",
63 "qrcode>=5.1",
64 "requests>=2.7.0",
65 "sqlsoup>=0.9.0",
66 "ecdsa>=0.13",
67 "lxml>=3.3",
68 "python-gnupg>=0.3.8",
69 "defusedxml>=0.4.1",
70 "flask-babel>=0.9"
71 ]
72
73 # For python 2.6 we need additional dependency importlib
74 try:
75 import importlib
76 except ImportError:
77 install_requires.append('importlib')
78
79
80 def get_man_pages(dir):
81 """
82 Get man pages in a directory.
83 :param dir:
84 :return: list of file names
85 """
86 files = os.listdir(dir)
87 r_files = []
88 for file in files:
89 if file.endswith(".1"):
90 r_files.append(dir + "/" + file)
91 return r_files
92
93
94 def get_scripts(dir):
95 """
96 Get files that are executable
97 :param dir:
98 :return: list of file names
99 """
100 files = os.listdir(dir)
101 r_files = []
102 for file in files:
103 if os.stat(dir + "/" + file)[stat.ST_MODE] & stat.S_IEXEC:
104 r_files.append(dir + "/" + file)
105 return r_files
106
107
108 setup(
109 name='privacyIDEA',
110 version=VERSION,
111 description='privacyIDEA: identity, multifactor authentication (OTP), '
112 'authorization, audit',
113 author='privacyidea.org',
114 license='AGPLv3',
115 author_email='[email protected]',
116 url='http://www.privacyidea.org',
117 keywords='OTP, two factor authentication, management, security',
118 packages=find_packages(),
119 scripts=["pi-manage"] + get_scripts("tools"),
120 extras_require={
121 'dev': ["Sphinx>=1.3.1",
122 "sphinxcontrib-httpdomain>=1.3.0"],
123 'test': ["coverage>=3.7.1",
124 "mock>=1.0.1",
125 "pyparsing>=2.0.3",
126 "nose>=1.3.4",
127 "responses>=0.4.0",
128 "six>=1.8.0"],
129 },
130 install_requires=install_requires,
131 include_package_data=True,
132 data_files=[('etc/privacyidea/',
133 ['deploy/apache/privacyideaapp.wsgi',
134 'deploy/privacyidea/dictionary',
135 'deploy/privacyidea/enckey',
136 'deploy/privacyidea/private.pem',
137 'deploy/privacyidea/public.pem']),
138 ('share/man/man1', get_man_pages("tools")),
139 ('lib/privacyidea/authmodules/FreeRADIUS',
140 ["authmodules/FreeRADIUS/LICENSE",
141 "authmodules/FreeRADIUS/privacyidea_radius.pm"]),
142 ('lib/privacyidea/authmodules/OTRS',
143 ["authmodules/OTRS/privacyIDEA.pm"]),
144 ('lib/privacyidea/migrations',
145 ["migrations/alembic.ini",
146 "migrations/env.py",
147 "migrations/README",
148 "migrations/script.py.mako"]),
149 ('lib/privacyidea/migrations/versions',
150 get_file_list("migrations/versions/"))
151 ],
152 classifiers=["Framework :: Flask",
153 "License :: OSI Approved :: "
154 "GNU Affero General Public License v3",
155 "Programming Language :: Python",
156 "Development Status :: 5 - Production/Stable",
157 "Topic :: Internet",
158 "Topic :: Security",
159 "Topic :: System ::"
160 " Systems Administration :: Authentication/Directory"
161 ],
162 #message_extractors={'privacyidea': [
163 # ('**.py', 'python', None),
164 # ('static/**.html', 'html', {'input_encoding': 'utf-8'})]},
165 zip_safe=False,
166 long_description=get_file_contents('README.rst')
167 )
168
[end of setup.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/setup.py b/setup.py
--- a/setup.py
+++ b/setup.py
@@ -51,10 +51,10 @@
"docutils>=0.12",
"funcparserlib>=0.3.6",
"itsdangerous>=0.24",
- "ldap3==2.1.1",
+ "ldap3>=2.5",
"netaddr>=0.7.12",
"passlib>=1.6.2",
- "pyasn1>=0.1.7",
+ "pyasn1>=0.4.2",
"pyOpenSSL>=0.15.1",
"pycparser>=2.10",
"pycrypto>=2.6.1",
|
{"golden_diff": "diff --git a/setup.py b/setup.py\n--- a/setup.py\n+++ b/setup.py\n@@ -51,10 +51,10 @@\n \"docutils>=0.12\",\n \"funcparserlib>=0.3.6\",\n \"itsdangerous>=0.24\",\n- \"ldap3==2.1.1\",\n+ \"ldap3>=2.5\",\n \"netaddr>=0.7.12\",\n \"passlib>=1.6.2\",\n- \"pyasn1>=0.1.7\",\n+ \"pyasn1>=0.4.2\",\n \"pyOpenSSL>=0.15.1\",\n \"pycparser>=2.10\",\n \"pycrypto>=2.6.1\",\n", "issue": "Problematic ldap3 / pyasn1 version combinations\nThis is an issue to keep track of problematic combinations of ldap3 / pyasn1 versions. See #887, #911.\r\n\r\nFunctionality I check for each combination:\r\n* STARTTLS\r\n* Complete user info on /validate/check\r\n* Size Limit < number of users\r\n\r\nEverything tested on a62fd9b3d0555b43cf31be3c4092a549fd73f724\r\n\r\n<table>\r\n<tr>\r\n<th></th><th>pyasn 0.1.9</th><th>pyasn 0.4.2</th>\r\n<tr><td>ldap3 2.1.1</td><td>ok</td><td><ul><li>STARTTLS fails (#885)</li></ul></td></tr>\r\n<tr><td>ldap3 2.3</td><td colspan=\"2\">\r\n<ul><li>Empty user list (#887)</li></ul></td></tr>\r\n<tr><td>ldap3 2.4</td><td colspan=\"2\">\r\n<ul><li>Empty user list (#887)</li><li>Empty user info (#911)</li></ul></td></tr>\r\n<tr><td>ldap3 2.4.1</td><td colspan=2\">\r\n<ul><li>Empty user list (#887)</li>\r\n<li><b>Error on /validate/check and resolver error</b> in token list (#911)</li>\r\n<li>cannot search for unicode users (#980)</li></td></tr>\r\n</table>\r\n\r\nCombinations in current 2.21.4 packages:\r\n* ``pip install privacyidea``:\r\n```\r\nldap3==2.1.1\r\nprivacyIDEA==2.21.4\r\npyasn1==0.4.2\r\n```\r\n* CentOS:\r\n```\r\nldap3==2.3\r\nprivacyIDEA==2.21.4\r\npyasn1==0.4.2\r\n```\r\n* Ubuntu (Launchpad):\r\n```\r\nldap3==2.1.1\r\nprivacyIDEA==2.21.4\r\npyasn1==0.1.9\r\n```\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nfrom setuptools import setup, find_packages\nimport os\nimport stat\nimport sys\n\n#VERSION=\"2.1dev4\"\nVERSION=\"2.22\"\n\n# Taken from kennethreitz/requests/setup.py\npackage_directory = os.path.realpath(os.path.dirname(__file__))\n\n\ndef get_file_contents(file_path):\n \"\"\"Get the context of the file using full path name.\"\"\"\n content = \"\"\n try:\n full_path = os.path.join(package_directory, file_path)\n content = open(full_path, 'r').read()\n except:\n print >> sys.stderr, \"### could not open file {0!r}\".format(file_path)\n return content\n\ndef get_file_list(file_path):\n full_path = os.path.join(package_directory, file_path)\n file_list = os.listdir(full_path)\n # now we need to add the path to the files\n return [ file_path + f for f in file_list ]\n\n\ninstall_requires = [\"Flask>=0.10.1\",\n \"Flask-Migrate>=1.2.0\",\n \"Flask-SQLAlchemy>=2.0\",\n \"Flask-Script>=2.0.5\",\n \"Jinja2>=2.7.3\",\n \"Mako>=0.9.1\",\n \"MarkupSafe>=0.23\",\n \"PyMySQL>=0.6.6\",\n \"Pillow>=2.6.1\",\n \"PyJWT>=1.3.0\",\n \"PyYAML>=3.11\",\n \"Pygments>=2.0.2\",\n \"SQLAlchemy>=1.0.5\",\n \"Werkzeug>=0.10.4\",\n \"alembic>=0.6.7\",\n \"argparse>=1.2.1\",\n \"bcrypt>=1.1.0\",\n \"beautifulsoup4>=4.3.2\",\n \"cffi>=0.8.6\",\n \"configobj>=5.0.6\",\n \"docutils>=0.12\",\n \"funcparserlib>=0.3.6\",\n \"itsdangerous>=0.24\",\n \"ldap3==2.1.1\",\n \"netaddr>=0.7.12\",\n \"passlib>=1.6.2\",\n \"pyasn1>=0.1.7\",\n \"pyOpenSSL>=0.15.1\",\n \"pycparser>=2.10\",\n \"pycrypto>=2.6.1\",\n \"pyrad>=2.0\",\n \"pyusb>=1.0.0b2\",\n \"qrcode>=5.1\",\n \"requests>=2.7.0\",\n \"sqlsoup>=0.9.0\",\n \"ecdsa>=0.13\",\n \"lxml>=3.3\",\n \"python-gnupg>=0.3.8\",\n \"defusedxml>=0.4.1\",\n \"flask-babel>=0.9\"\n ]\n\n# For python 2.6 we need additional dependency importlib\ntry:\n import importlib\nexcept ImportError:\n install_requires.append('importlib')\n\n\ndef get_man_pages(dir):\n \"\"\"\n Get man pages in a directory.\n :param dir: \n :return: list of file names\n \"\"\"\n files = os.listdir(dir)\n r_files = []\n for file in files:\n if file.endswith(\".1\"):\n r_files.append(dir + \"/\" + file)\n return r_files\n\n\ndef get_scripts(dir):\n \"\"\"\n Get files that are executable\n :param dir: \n :return: list of file names\n \"\"\"\n files = os.listdir(dir)\n r_files = []\n for file in files:\n if os.stat(dir + \"/\" + file)[stat.ST_MODE] & stat.S_IEXEC:\n r_files.append(dir + \"/\" + file)\n return r_files\n\n\nsetup(\n name='privacyIDEA',\n version=VERSION,\n description='privacyIDEA: identity, multifactor authentication (OTP), '\n 'authorization, audit',\n author='privacyidea.org',\n license='AGPLv3',\n author_email='[email protected]',\n url='http://www.privacyidea.org',\n keywords='OTP, two factor authentication, management, security',\n packages=find_packages(),\n scripts=[\"pi-manage\"] + get_scripts(\"tools\"),\n extras_require={\n 'dev': [\"Sphinx>=1.3.1\",\n \"sphinxcontrib-httpdomain>=1.3.0\"],\n 'test': [\"coverage>=3.7.1\",\n \"mock>=1.0.1\",\n \"pyparsing>=2.0.3\",\n \"nose>=1.3.4\",\n \"responses>=0.4.0\",\n \"six>=1.8.0\"],\n },\n install_requires=install_requires,\n include_package_data=True,\n data_files=[('etc/privacyidea/',\n ['deploy/apache/privacyideaapp.wsgi',\n 'deploy/privacyidea/dictionary',\n 'deploy/privacyidea/enckey',\n 'deploy/privacyidea/private.pem',\n 'deploy/privacyidea/public.pem']),\n ('share/man/man1', get_man_pages(\"tools\")),\n ('lib/privacyidea/authmodules/FreeRADIUS',\n [\"authmodules/FreeRADIUS/LICENSE\",\n \"authmodules/FreeRADIUS/privacyidea_radius.pm\"]),\n ('lib/privacyidea/authmodules/OTRS',\n [\"authmodules/OTRS/privacyIDEA.pm\"]),\n ('lib/privacyidea/migrations',\n [\"migrations/alembic.ini\",\n \"migrations/env.py\",\n \"migrations/README\",\n \"migrations/script.py.mako\"]),\n ('lib/privacyidea/migrations/versions',\n get_file_list(\"migrations/versions/\"))\n ],\n classifiers=[\"Framework :: Flask\",\n \"License :: OSI Approved :: \"\n \"GNU Affero General Public License v3\",\n \"Programming Language :: Python\",\n \"Development Status :: 5 - Production/Stable\",\n \"Topic :: Internet\",\n \"Topic :: Security\",\n \"Topic :: System ::\"\n \" Systems Administration :: Authentication/Directory\"\n ],\n #message_extractors={'privacyidea': [\n # ('**.py', 'python', None),\n # ('static/**.html', 'html', {'input_encoding': 'utf-8'})]},\n zip_safe=False,\n long_description=get_file_contents('README.rst')\n)\n", "path": "setup.py"}]}
| 2,820 | 173 |
gh_patches_debug_4573
|
rasdani/github-patches
|
git_diff
|
pre-commit__pre-commit-235
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Some versions of git don't create .git/hooks directory
Noticed here: https://github.com/victorlin/bugbuzz-python/pull/1#issuecomment-104971132
</issue>
<code>
[start of pre_commit/commands/install_uninstall.py]
1 from __future__ import print_function
2 from __future__ import unicode_literals
3
4 import io
5 import logging
6 import os
7 import os.path
8 import stat
9 import sys
10
11 from pre_commit.logging_handler import LoggingHandler
12 from pre_commit.util import resource_filename
13
14
15 logger = logging.getLogger('pre_commit')
16
17
18 # This is used to identify the hook file we install
19 PREVIOUS_IDENTIFYING_HASHES = (
20 '4d9958c90bc262f47553e2c073f14cfe',
21 'd8ee923c46731b42cd95cc869add4062',
22 '49fd668cb42069aa1b6048464be5d395',
23 )
24
25
26 IDENTIFYING_HASH = '79f09a650522a87b0da915d0d983b2de'
27
28
29 def is_our_pre_commit(filename):
30 return IDENTIFYING_HASH in io.open(filename).read()
31
32
33 def is_previous_pre_commit(filename):
34 contents = io.open(filename).read()
35 return any(hash in contents for hash in PREVIOUS_IDENTIFYING_HASHES)
36
37
38 def make_executable(filename):
39 original_mode = os.stat(filename).st_mode
40 os.chmod(
41 filename,
42 original_mode | stat.S_IXUSR | stat.S_IXGRP | stat.S_IXOTH,
43 )
44
45
46 def install(runner, overwrite=False, hooks=False, hook_type='pre-commit'):
47 """Install the pre-commit hooks."""
48 hook_path = runner.get_hook_path(hook_type)
49 legacy_path = hook_path + '.legacy'
50
51 # If we have an existing hook, move it to pre-commit.legacy
52 if (
53 os.path.exists(hook_path) and
54 not is_our_pre_commit(hook_path) and
55 not is_previous_pre_commit(hook_path)
56 ):
57 os.rename(hook_path, legacy_path)
58
59 # If we specify overwrite, we simply delete the legacy file
60 if overwrite and os.path.exists(legacy_path):
61 os.remove(legacy_path)
62 elif os.path.exists(legacy_path):
63 print(
64 'Running in migration mode with existing hooks at {0}\n'
65 'Use -f to use only pre-commit.'.format(
66 legacy_path,
67 )
68 )
69
70 with io.open(hook_path, 'w') as pre_commit_file_obj:
71 if hook_type == 'pre-push':
72 with io.open(resource_filename('pre-push-tmpl')) as fp:
73 pre_push_contents = fp.read()
74 else:
75 pre_push_contents = ''
76
77 contents = io.open(resource_filename('hook-tmpl')).read().format(
78 sys_executable=sys.executable,
79 hook_type=hook_type,
80 pre_push=pre_push_contents,
81 )
82 pre_commit_file_obj.write(contents)
83 make_executable(hook_path)
84
85 print('pre-commit installed at {0}'.format(hook_path))
86
87 # If they requested we install all of the hooks, do so.
88 if hooks:
89 # Set up our logging handler
90 logger.addHandler(LoggingHandler(False))
91 logger.setLevel(logging.INFO)
92 for repository in runner.repositories:
93 repository.require_installed()
94
95 return 0
96
97
98 def uninstall(runner, hook_type='pre-commit'):
99 """Uninstall the pre-commit hooks."""
100 hook_path = runner.get_hook_path(hook_type)
101 legacy_path = hook_path + '.legacy'
102 # If our file doesn't exist or it isn't ours, gtfo.
103 if (
104 not os.path.exists(hook_path) or (
105 not is_our_pre_commit(hook_path) and
106 not is_previous_pre_commit(hook_path)
107 )
108 ):
109 return 0
110
111 os.remove(hook_path)
112 print('{0} uninstalled'.format(hook_type))
113
114 if os.path.exists(legacy_path):
115 os.rename(legacy_path, hook_path)
116 print('Restored previous hooks to {0}'.format(hook_path))
117
118 return 0
119
[end of pre_commit/commands/install_uninstall.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pre_commit/commands/install_uninstall.py b/pre_commit/commands/install_uninstall.py
--- a/pre_commit/commands/install_uninstall.py
+++ b/pre_commit/commands/install_uninstall.py
@@ -48,6 +48,9 @@
hook_path = runner.get_hook_path(hook_type)
legacy_path = hook_path + '.legacy'
+ if not os.path.exists(os.path.dirname(hook_path)):
+ os.makedirs(os.path.dirname(hook_path))
+
# If we have an existing hook, move it to pre-commit.legacy
if (
os.path.exists(hook_path) and
|
{"golden_diff": "diff --git a/pre_commit/commands/install_uninstall.py b/pre_commit/commands/install_uninstall.py\n--- a/pre_commit/commands/install_uninstall.py\n+++ b/pre_commit/commands/install_uninstall.py\n@@ -48,6 +48,9 @@\n hook_path = runner.get_hook_path(hook_type)\n legacy_path = hook_path + '.legacy'\n \n+ if not os.path.exists(os.path.dirname(hook_path)):\n+ os.makedirs(os.path.dirname(hook_path))\n+\n # If we have an existing hook, move it to pre-commit.legacy\n if (\n os.path.exists(hook_path) and\n", "issue": "Some versions of git don't create .git/hooks directory\nNoticed here: https://github.com/victorlin/bugbuzz-python/pull/1#issuecomment-104971132\n\n", "before_files": [{"content": "from __future__ import print_function\nfrom __future__ import unicode_literals\n\nimport io\nimport logging\nimport os\nimport os.path\nimport stat\nimport sys\n\nfrom pre_commit.logging_handler import LoggingHandler\nfrom pre_commit.util import resource_filename\n\n\nlogger = logging.getLogger('pre_commit')\n\n\n# This is used to identify the hook file we install\nPREVIOUS_IDENTIFYING_HASHES = (\n '4d9958c90bc262f47553e2c073f14cfe',\n 'd8ee923c46731b42cd95cc869add4062',\n '49fd668cb42069aa1b6048464be5d395',\n)\n\n\nIDENTIFYING_HASH = '79f09a650522a87b0da915d0d983b2de'\n\n\ndef is_our_pre_commit(filename):\n return IDENTIFYING_HASH in io.open(filename).read()\n\n\ndef is_previous_pre_commit(filename):\n contents = io.open(filename).read()\n return any(hash in contents for hash in PREVIOUS_IDENTIFYING_HASHES)\n\n\ndef make_executable(filename):\n original_mode = os.stat(filename).st_mode\n os.chmod(\n filename,\n original_mode | stat.S_IXUSR | stat.S_IXGRP | stat.S_IXOTH,\n )\n\n\ndef install(runner, overwrite=False, hooks=False, hook_type='pre-commit'):\n \"\"\"Install the pre-commit hooks.\"\"\"\n hook_path = runner.get_hook_path(hook_type)\n legacy_path = hook_path + '.legacy'\n\n # If we have an existing hook, move it to pre-commit.legacy\n if (\n os.path.exists(hook_path) and\n not is_our_pre_commit(hook_path) and\n not is_previous_pre_commit(hook_path)\n ):\n os.rename(hook_path, legacy_path)\n\n # If we specify overwrite, we simply delete the legacy file\n if overwrite and os.path.exists(legacy_path):\n os.remove(legacy_path)\n elif os.path.exists(legacy_path):\n print(\n 'Running in migration mode with existing hooks at {0}\\n'\n 'Use -f to use only pre-commit.'.format(\n legacy_path,\n )\n )\n\n with io.open(hook_path, 'w') as pre_commit_file_obj:\n if hook_type == 'pre-push':\n with io.open(resource_filename('pre-push-tmpl')) as fp:\n pre_push_contents = fp.read()\n else:\n pre_push_contents = ''\n\n contents = io.open(resource_filename('hook-tmpl')).read().format(\n sys_executable=sys.executable,\n hook_type=hook_type,\n pre_push=pre_push_contents,\n )\n pre_commit_file_obj.write(contents)\n make_executable(hook_path)\n\n print('pre-commit installed at {0}'.format(hook_path))\n\n # If they requested we install all of the hooks, do so.\n if hooks:\n # Set up our logging handler\n logger.addHandler(LoggingHandler(False))\n logger.setLevel(logging.INFO)\n for repository in runner.repositories:\n repository.require_installed()\n\n return 0\n\n\ndef uninstall(runner, hook_type='pre-commit'):\n \"\"\"Uninstall the pre-commit hooks.\"\"\"\n hook_path = runner.get_hook_path(hook_type)\n legacy_path = hook_path + '.legacy'\n # If our file doesn't exist or it isn't ours, gtfo.\n if (\n not os.path.exists(hook_path) or (\n not is_our_pre_commit(hook_path) and\n not is_previous_pre_commit(hook_path)\n )\n ):\n return 0\n\n os.remove(hook_path)\n print('{0} uninstalled'.format(hook_type))\n\n if os.path.exists(legacy_path):\n os.rename(legacy_path, hook_path)\n print('Restored previous hooks to {0}'.format(hook_path))\n\n return 0\n", "path": "pre_commit/commands/install_uninstall.py"}]}
| 1,725 | 135 |
gh_patches_debug_9953
|
rasdani/github-patches
|
git_diff
|
bookwyrm-social__bookwyrm-2447
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Server error on some book imports
**Describe the bug**
When importing some books the application crashes, with "Server Error Something went wrong! Sorry about that."
```
Internal Server Error: /resolve-book
Traceback (most recent call last):
File "/opt/bookwyrm/venv/lib/python3.10/site-packages/django/core/handlers/exception.py", line 47, in inner
response = get_response(request)
File "/opt/bookwyrm/venv/lib/python3.10/site-packages/django/core/handlers/base.py", line 181, in _get_response
response = wrapped_callback(request, *callback_args, **callback_kwargs)
File "/opt/bookwyrm/venv/lib/python3.10/site-packages/django/contrib/auth/decorators.py", line 21, in _wrapped_view
return view_func(request, *args, **kwargs)
File "/opt/bookwyrm/venv/lib/python3.10/site-packages/django/views/decorators/http.py", line 40, in inner
return func(request, *args, **kwargs)
File "/opt/bookwyrm/bookwyrm/views/books/books.py", line 190, in resolve_book
return redirect("book", book.id)
AttributeError: 'NoneType' object has no attribute 'id'
```
</issue>
<code>
[start of bookwyrm/connectors/inventaire.py]
1 """ inventaire data connector """
2 import re
3
4 from bookwyrm import models
5 from bookwyrm.book_search import SearchResult
6 from .abstract_connector import AbstractConnector, Mapping
7 from .abstract_connector import get_data
8 from .connector_manager import ConnectorException, create_edition_task
9
10
11 class Connector(AbstractConnector):
12 """instantiate a connector for inventaire"""
13
14 generated_remote_link_field = "inventaire_id"
15
16 def __init__(self, identifier):
17 super().__init__(identifier)
18
19 get_first = lambda a: a[0]
20 shared_mappings = [
21 Mapping("id", remote_field="uri", formatter=self.get_remote_id),
22 Mapping("bnfId", remote_field="wdt:P268", formatter=get_first),
23 Mapping("openlibraryKey", remote_field="wdt:P648", formatter=get_first),
24 ]
25 self.book_mappings = [
26 Mapping("title", remote_field="wdt:P1476", formatter=get_first),
27 Mapping("title", remote_field="labels", formatter=get_language_code),
28 Mapping("subtitle", remote_field="wdt:P1680", formatter=get_first),
29 Mapping("inventaireId", remote_field="uri"),
30 Mapping(
31 "description", remote_field="sitelinks", formatter=self.get_description
32 ),
33 Mapping("cover", remote_field="image", formatter=self.get_cover_url),
34 Mapping("isbn13", remote_field="wdt:P212", formatter=get_first),
35 Mapping("isbn10", remote_field="wdt:P957", formatter=get_first),
36 Mapping("oclcNumber", remote_field="wdt:P5331", formatter=get_first),
37 Mapping("goodreadsKey", remote_field="wdt:P2969", formatter=get_first),
38 Mapping("librarythingKey", remote_field="wdt:P1085", formatter=get_first),
39 Mapping("languages", remote_field="wdt:P407", formatter=self.resolve_keys),
40 Mapping("publishers", remote_field="wdt:P123", formatter=self.resolve_keys),
41 Mapping("publishedDate", remote_field="wdt:P577", formatter=get_first),
42 Mapping("pages", remote_field="wdt:P1104", formatter=get_first),
43 Mapping(
44 "subjectPlaces", remote_field="wdt:P840", formatter=self.resolve_keys
45 ),
46 Mapping("subjects", remote_field="wdt:P921", formatter=self.resolve_keys),
47 Mapping("asin", remote_field="wdt:P5749", formatter=get_first),
48 ] + shared_mappings
49 # TODO: P136: genre, P674 characters, P950 bne
50
51 self.author_mappings = [
52 Mapping("id", remote_field="uri", formatter=self.get_remote_id),
53 Mapping("name", remote_field="labels", formatter=get_language_code),
54 Mapping("bio", remote_field="sitelinks", formatter=self.get_description),
55 Mapping("goodreadsKey", remote_field="wdt:P2963", formatter=get_first),
56 Mapping("isni", remote_field="wdt:P213", formatter=get_first),
57 Mapping("viafId", remote_field="wdt:P214", formatter=get_first),
58 Mapping("gutenberg_id", remote_field="wdt:P1938", formatter=get_first),
59 Mapping("born", remote_field="wdt:P569", formatter=get_first),
60 Mapping("died", remote_field="wdt:P570", formatter=get_first),
61 ] + shared_mappings
62
63 def get_remote_id(self, value):
64 """convert an id/uri into a url"""
65 return f"{self.books_url}?action=by-uris&uris={value}"
66
67 def get_book_data(self, remote_id):
68 data = get_data(remote_id)
69 extracted = list(data.get("entities").values())
70 try:
71 data = extracted[0]
72 except (KeyError, IndexError):
73 raise ConnectorException("Invalid book data")
74 # flatten the data so that images, uri, and claims are on the same level
75 return {
76 **data.get("claims", {}),
77 **{k: data.get(k) for k in ["uri", "image", "labels", "sitelinks", "type"]},
78 }
79
80 def parse_search_data(self, data, min_confidence):
81 for search_result in data.get("results", []):
82 images = search_result.get("image")
83 cover = f"{self.covers_url}/img/entities/{images[0]}" if images else None
84 # a deeply messy translation of inventaire's scores
85 confidence = float(search_result.get("_score", 0.1))
86 confidence = 0.1 if confidence < 150 else 0.999
87 if confidence < min_confidence:
88 continue
89 yield SearchResult(
90 title=search_result.get("label"),
91 key=self.get_remote_id(search_result.get("uri")),
92 author=search_result.get("description"),
93 view_link=f"{self.base_url}/entity/{search_result.get('uri')}",
94 cover=cover,
95 confidence=confidence,
96 connector=self,
97 )
98
99 def parse_isbn_search_data(self, data):
100 """got some daaaata"""
101 results = data.get("entities")
102 if not results:
103 return
104 for search_result in list(results.values()):
105 title = search_result.get("claims", {}).get("wdt:P1476", [])
106 if not title:
107 continue
108 yield SearchResult(
109 title=title[0],
110 key=self.get_remote_id(search_result.get("uri")),
111 author=search_result.get("description"),
112 view_link=f"{self.base_url}/entity/{search_result.get('uri')}",
113 cover=self.get_cover_url(search_result.get("image")),
114 connector=self,
115 )
116
117 def is_work_data(self, data):
118 return data.get("type") == "work"
119
120 def load_edition_data(self, work_uri):
121 """get a list of editions for a work"""
122 # pylint: disable=line-too-long
123 url = f"{self.books_url}?action=reverse-claims&property=wdt:P629&value={work_uri}&sort=true"
124 return get_data(url)
125
126 def get_edition_from_work_data(self, data):
127 data = self.load_edition_data(data.get("uri"))
128 try:
129 uri = data.get("uris", [])[0]
130 except IndexError:
131 raise ConnectorException("Invalid book data")
132 return self.get_book_data(self.get_remote_id(uri))
133
134 def get_work_from_edition_data(self, data):
135 uri = data.get("wdt:P629", [None])[0]
136 if not uri:
137 raise ConnectorException("Invalid book data")
138 return self.get_book_data(self.get_remote_id(uri))
139
140 def get_authors_from_data(self, data):
141 authors = data.get("wdt:P50", [])
142 for author in authors:
143 yield self.get_or_create_author(self.get_remote_id(author))
144
145 def expand_book_data(self, book):
146 work = book
147 # go from the edition to the work, if necessary
148 if isinstance(book, models.Edition):
149 work = book.parent_work
150
151 try:
152 edition_options = self.load_edition_data(work.inventaire_id)
153 except ConnectorException:
154 # who knows, man
155 return
156
157 for edition_uri in edition_options.get("uris"):
158 remote_id = self.get_remote_id(edition_uri)
159 create_edition_task.delay(self.connector.id, work.id, remote_id)
160
161 def create_edition_from_data(self, work, edition_data, instance=None):
162 """pass in the url as data and then call the version in abstract connector"""
163 if isinstance(edition_data, str):
164 try:
165 edition_data = self.get_book_data(edition_data)
166 except ConnectorException:
167 # who, indeed, knows
168 return
169 super().create_edition_from_data(work, edition_data, instance=instance)
170
171 def get_cover_url(self, cover_blob, *_):
172 """format the relative cover url into an absolute one:
173 {"url": "/img/entities/e794783f01b9d4f897a1ea9820b96e00d346994f"}
174 """
175 # covers may or may not be a list
176 if isinstance(cover_blob, list) and len(cover_blob) > 0:
177 cover_blob = cover_blob[0]
178 cover_id = cover_blob.get("url")
179 if not cover_id:
180 return None
181 # cover may or may not be an absolute url already
182 if re.match(r"^http", cover_id):
183 return cover_id
184 return f"{self.covers_url}{cover_id}"
185
186 def resolve_keys(self, keys):
187 """cool, it's "wd:Q3156592" now what the heck does that mean"""
188 results = []
189 for uri in keys:
190 try:
191 data = self.get_book_data(self.get_remote_id(uri))
192 except ConnectorException:
193 continue
194 results.append(get_language_code(data.get("labels")))
195 return results
196
197 def get_description(self, links):
198 """grab an extracted excerpt from wikipedia"""
199 link = links.get("enwiki")
200 if not link:
201 return ""
202 url = f"{self.base_url}/api/data?action=wp-extract&lang=en&title={link}"
203 try:
204 data = get_data(url)
205 except ConnectorException:
206 return ""
207 return data.get("extract")
208
209 def get_remote_id_from_model(self, obj):
210 """use get_remote_id to figure out the link from a model obj"""
211 remote_id_value = obj.inventaire_id
212 return self.get_remote_id(remote_id_value)
213
214
215 def get_language_code(options, code="en"):
216 """when there are a bunch of translation but we need a single field"""
217 result = options.get(code)
218 if result:
219 return result
220 values = list(options.values())
221 return values[0] if values else None
222
[end of bookwyrm/connectors/inventaire.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/bookwyrm/connectors/inventaire.py b/bookwyrm/connectors/inventaire.py
--- a/bookwyrm/connectors/inventaire.py
+++ b/bookwyrm/connectors/inventaire.py
@@ -165,8 +165,8 @@
edition_data = self.get_book_data(edition_data)
except ConnectorException:
# who, indeed, knows
- return
- super().create_edition_from_data(work, edition_data, instance=instance)
+ return None
+ return super().create_edition_from_data(work, edition_data, instance=instance)
def get_cover_url(self, cover_blob, *_):
"""format the relative cover url into an absolute one:
|
{"golden_diff": "diff --git a/bookwyrm/connectors/inventaire.py b/bookwyrm/connectors/inventaire.py\n--- a/bookwyrm/connectors/inventaire.py\n+++ b/bookwyrm/connectors/inventaire.py\n@@ -165,8 +165,8 @@\n edition_data = self.get_book_data(edition_data)\n except ConnectorException:\n # who, indeed, knows\n- return\n- super().create_edition_from_data(work, edition_data, instance=instance)\n+ return None\n+ return super().create_edition_from_data(work, edition_data, instance=instance)\n \n def get_cover_url(self, cover_blob, *_):\n \"\"\"format the relative cover url into an absolute one:\n", "issue": "Server error on some book imports\n**Describe the bug**\r\nWhen importing some books the application crashes, with \"Server Error Something went wrong! Sorry about that.\"\r\n```\r\nInternal Server Error: /resolve-book\r\nTraceback (most recent call last):\r\n File \"/opt/bookwyrm/venv/lib/python3.10/site-packages/django/core/handlers/exception.py\", line 47, in inner\r\n response = get_response(request)\r\n File \"/opt/bookwyrm/venv/lib/python3.10/site-packages/django/core/handlers/base.py\", line 181, in _get_response\r\n response = wrapped_callback(request, *callback_args, **callback_kwargs)\r\n File \"/opt/bookwyrm/venv/lib/python3.10/site-packages/django/contrib/auth/decorators.py\", line 21, in _wrapped_view\r\n return view_func(request, *args, **kwargs)\r\n File \"/opt/bookwyrm/venv/lib/python3.10/site-packages/django/views/decorators/http.py\", line 40, in inner\r\n return func(request, *args, **kwargs)\r\n File \"/opt/bookwyrm/bookwyrm/views/books/books.py\", line 190, in resolve_book\r\n return redirect(\"book\", book.id)\r\nAttributeError: 'NoneType' object has no attribute 'id'\r\n```\r\n\n", "before_files": [{"content": "\"\"\" inventaire data connector \"\"\"\nimport re\n\nfrom bookwyrm import models\nfrom bookwyrm.book_search import SearchResult\nfrom .abstract_connector import AbstractConnector, Mapping\nfrom .abstract_connector import get_data\nfrom .connector_manager import ConnectorException, create_edition_task\n\n\nclass Connector(AbstractConnector):\n \"\"\"instantiate a connector for inventaire\"\"\"\n\n generated_remote_link_field = \"inventaire_id\"\n\n def __init__(self, identifier):\n super().__init__(identifier)\n\n get_first = lambda a: a[0]\n shared_mappings = [\n Mapping(\"id\", remote_field=\"uri\", formatter=self.get_remote_id),\n Mapping(\"bnfId\", remote_field=\"wdt:P268\", formatter=get_first),\n Mapping(\"openlibraryKey\", remote_field=\"wdt:P648\", formatter=get_first),\n ]\n self.book_mappings = [\n Mapping(\"title\", remote_field=\"wdt:P1476\", formatter=get_first),\n Mapping(\"title\", remote_field=\"labels\", formatter=get_language_code),\n Mapping(\"subtitle\", remote_field=\"wdt:P1680\", formatter=get_first),\n Mapping(\"inventaireId\", remote_field=\"uri\"),\n Mapping(\n \"description\", remote_field=\"sitelinks\", formatter=self.get_description\n ),\n Mapping(\"cover\", remote_field=\"image\", formatter=self.get_cover_url),\n Mapping(\"isbn13\", remote_field=\"wdt:P212\", formatter=get_first),\n Mapping(\"isbn10\", remote_field=\"wdt:P957\", formatter=get_first),\n Mapping(\"oclcNumber\", remote_field=\"wdt:P5331\", formatter=get_first),\n Mapping(\"goodreadsKey\", remote_field=\"wdt:P2969\", formatter=get_first),\n Mapping(\"librarythingKey\", remote_field=\"wdt:P1085\", formatter=get_first),\n Mapping(\"languages\", remote_field=\"wdt:P407\", formatter=self.resolve_keys),\n Mapping(\"publishers\", remote_field=\"wdt:P123\", formatter=self.resolve_keys),\n Mapping(\"publishedDate\", remote_field=\"wdt:P577\", formatter=get_first),\n Mapping(\"pages\", remote_field=\"wdt:P1104\", formatter=get_first),\n Mapping(\n \"subjectPlaces\", remote_field=\"wdt:P840\", formatter=self.resolve_keys\n ),\n Mapping(\"subjects\", remote_field=\"wdt:P921\", formatter=self.resolve_keys),\n Mapping(\"asin\", remote_field=\"wdt:P5749\", formatter=get_first),\n ] + shared_mappings\n # TODO: P136: genre, P674 characters, P950 bne\n\n self.author_mappings = [\n Mapping(\"id\", remote_field=\"uri\", formatter=self.get_remote_id),\n Mapping(\"name\", remote_field=\"labels\", formatter=get_language_code),\n Mapping(\"bio\", remote_field=\"sitelinks\", formatter=self.get_description),\n Mapping(\"goodreadsKey\", remote_field=\"wdt:P2963\", formatter=get_first),\n Mapping(\"isni\", remote_field=\"wdt:P213\", formatter=get_first),\n Mapping(\"viafId\", remote_field=\"wdt:P214\", formatter=get_first),\n Mapping(\"gutenberg_id\", remote_field=\"wdt:P1938\", formatter=get_first),\n Mapping(\"born\", remote_field=\"wdt:P569\", formatter=get_first),\n Mapping(\"died\", remote_field=\"wdt:P570\", formatter=get_first),\n ] + shared_mappings\n\n def get_remote_id(self, value):\n \"\"\"convert an id/uri into a url\"\"\"\n return f\"{self.books_url}?action=by-uris&uris={value}\"\n\n def get_book_data(self, remote_id):\n data = get_data(remote_id)\n extracted = list(data.get(\"entities\").values())\n try:\n data = extracted[0]\n except (KeyError, IndexError):\n raise ConnectorException(\"Invalid book data\")\n # flatten the data so that images, uri, and claims are on the same level\n return {\n **data.get(\"claims\", {}),\n **{k: data.get(k) for k in [\"uri\", \"image\", \"labels\", \"sitelinks\", \"type\"]},\n }\n\n def parse_search_data(self, data, min_confidence):\n for search_result in data.get(\"results\", []):\n images = search_result.get(\"image\")\n cover = f\"{self.covers_url}/img/entities/{images[0]}\" if images else None\n # a deeply messy translation of inventaire's scores\n confidence = float(search_result.get(\"_score\", 0.1))\n confidence = 0.1 if confidence < 150 else 0.999\n if confidence < min_confidence:\n continue\n yield SearchResult(\n title=search_result.get(\"label\"),\n key=self.get_remote_id(search_result.get(\"uri\")),\n author=search_result.get(\"description\"),\n view_link=f\"{self.base_url}/entity/{search_result.get('uri')}\",\n cover=cover,\n confidence=confidence,\n connector=self,\n )\n\n def parse_isbn_search_data(self, data):\n \"\"\"got some daaaata\"\"\"\n results = data.get(\"entities\")\n if not results:\n return\n for search_result in list(results.values()):\n title = search_result.get(\"claims\", {}).get(\"wdt:P1476\", [])\n if not title:\n continue\n yield SearchResult(\n title=title[0],\n key=self.get_remote_id(search_result.get(\"uri\")),\n author=search_result.get(\"description\"),\n view_link=f\"{self.base_url}/entity/{search_result.get('uri')}\",\n cover=self.get_cover_url(search_result.get(\"image\")),\n connector=self,\n )\n\n def is_work_data(self, data):\n return data.get(\"type\") == \"work\"\n\n def load_edition_data(self, work_uri):\n \"\"\"get a list of editions for a work\"\"\"\n # pylint: disable=line-too-long\n url = f\"{self.books_url}?action=reverse-claims&property=wdt:P629&value={work_uri}&sort=true\"\n return get_data(url)\n\n def get_edition_from_work_data(self, data):\n data = self.load_edition_data(data.get(\"uri\"))\n try:\n uri = data.get(\"uris\", [])[0]\n except IndexError:\n raise ConnectorException(\"Invalid book data\")\n return self.get_book_data(self.get_remote_id(uri))\n\n def get_work_from_edition_data(self, data):\n uri = data.get(\"wdt:P629\", [None])[0]\n if not uri:\n raise ConnectorException(\"Invalid book data\")\n return self.get_book_data(self.get_remote_id(uri))\n\n def get_authors_from_data(self, data):\n authors = data.get(\"wdt:P50\", [])\n for author in authors:\n yield self.get_or_create_author(self.get_remote_id(author))\n\n def expand_book_data(self, book):\n work = book\n # go from the edition to the work, if necessary\n if isinstance(book, models.Edition):\n work = book.parent_work\n\n try:\n edition_options = self.load_edition_data(work.inventaire_id)\n except ConnectorException:\n # who knows, man\n return\n\n for edition_uri in edition_options.get(\"uris\"):\n remote_id = self.get_remote_id(edition_uri)\n create_edition_task.delay(self.connector.id, work.id, remote_id)\n\n def create_edition_from_data(self, work, edition_data, instance=None):\n \"\"\"pass in the url as data and then call the version in abstract connector\"\"\"\n if isinstance(edition_data, str):\n try:\n edition_data = self.get_book_data(edition_data)\n except ConnectorException:\n # who, indeed, knows\n return\n super().create_edition_from_data(work, edition_data, instance=instance)\n\n def get_cover_url(self, cover_blob, *_):\n \"\"\"format the relative cover url into an absolute one:\n {\"url\": \"/img/entities/e794783f01b9d4f897a1ea9820b96e00d346994f\"}\n \"\"\"\n # covers may or may not be a list\n if isinstance(cover_blob, list) and len(cover_blob) > 0:\n cover_blob = cover_blob[0]\n cover_id = cover_blob.get(\"url\")\n if not cover_id:\n return None\n # cover may or may not be an absolute url already\n if re.match(r\"^http\", cover_id):\n return cover_id\n return f\"{self.covers_url}{cover_id}\"\n\n def resolve_keys(self, keys):\n \"\"\"cool, it's \"wd:Q3156592\" now what the heck does that mean\"\"\"\n results = []\n for uri in keys:\n try:\n data = self.get_book_data(self.get_remote_id(uri))\n except ConnectorException:\n continue\n results.append(get_language_code(data.get(\"labels\")))\n return results\n\n def get_description(self, links):\n \"\"\"grab an extracted excerpt from wikipedia\"\"\"\n link = links.get(\"enwiki\")\n if not link:\n return \"\"\n url = f\"{self.base_url}/api/data?action=wp-extract&lang=en&title={link}\"\n try:\n data = get_data(url)\n except ConnectorException:\n return \"\"\n return data.get(\"extract\")\n\n def get_remote_id_from_model(self, obj):\n \"\"\"use get_remote_id to figure out the link from a model obj\"\"\"\n remote_id_value = obj.inventaire_id\n return self.get_remote_id(remote_id_value)\n\n\ndef get_language_code(options, code=\"en\"):\n \"\"\"when there are a bunch of translation but we need a single field\"\"\"\n result = options.get(code)\n if result:\n return result\n values = list(options.values())\n return values[0] if values else None\n", "path": "bookwyrm/connectors/inventaire.py"}]}
| 3,560 | 158 |
gh_patches_debug_33227
|
rasdani/github-patches
|
git_diff
|
rasterio__rasterio-1910
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Should rio clip fill nodata at borders?
Hello lovely people :hugs:,
I'm using `rio clip` to quickly cut out z10 tiles for raster image. The raster image is not divisible by the z10 tiles, so I expect the border tiles to contain nodata. But more importantly I expect all z10 tiles I cut out to be of the same dimension. This is not the case with rio clip right now.
Here is an example where I first convert my raster image to WGS84 and then cut it into z10 tiles where the file name is the z10 quad key id.
```
rio warp in.tif wgs84.tif --dst-crs EPSG:4326
rio bounds wgs84.tif | mercantile tiles 10 > z10.txt
while read tile; do
rio clip wgs84.tif $(mercantile quadkey "$tile").tif --bounds "$(mercantile shapes --extents "$tile")"
done < z10.txt
```
This results in
- many raster images of pixel size 2857x1744
- some raster images (at the borders) with smaller dimensions; the bounds are not filled with nodata
Should rio clip use boundless windows and fill with nodata, to respect the user's bounds?
(rio 1.1.3, tested in ubuntu 18.04 docker container with python 3.6)
</issue>
<code>
[start of rasterio/rio/clip.py]
1 """File translation command"""
2
3 import logging
4
5 import click
6 from cligj import format_opt
7
8 from .helpers import resolve_inout
9 from . import options
10 import rasterio
11 from rasterio.coords import disjoint_bounds
12 from rasterio.crs import CRS
13 from rasterio.windows import Window
14
15
16 logger = logging.getLogger(__name__)
17
18
19 # Geographic (default), projected, or Mercator switch.
20 projection_geographic_opt = click.option(
21 '--geographic',
22 'projection',
23 flag_value='geographic',
24 help="Bounds in geographic coordinates.")
25
26 projection_projected_opt = click.option(
27 '--projected',
28 'projection',
29 flag_value='projected',
30 default=True,
31 help="Bounds in input's own projected coordinates (the default).")
32
33
34 # Clip command
35 @click.command(short_help='Clip a raster to given bounds.')
36 @click.argument(
37 'files',
38 nargs=-1,
39 type=click.Path(),
40 required=True,
41 metavar="INPUT OUTPUT")
42 @options.output_opt
43 @options.bounds_opt
44 @click.option(
45 '--like',
46 type=click.Path(exists=True),
47 help='Raster dataset to use as a template for bounds')
48 @format_opt
49 @projection_geographic_opt
50 @projection_projected_opt
51 @options.overwrite_opt
52 @options.creation_options
53 @click.pass_context
54 def clip(ctx, files, output, bounds, like, driver, projection,
55 overwrite, creation_options):
56 """Clips a raster using projected or geographic bounds.
57
58 \b
59 $ rio clip input.tif output.tif --bounds xmin ymin xmax ymax
60 $ rio clip input.tif output.tif --like template.tif
61
62 The values of --bounds are presumed to be from the coordinate
63 reference system of the input dataset unless the --geographic option
64 is used, in which case the values may be longitude and latitude
65 bounds. Either JSON, for example "[west, south, east, north]", or
66 plain text "west south east north" representations of a bounding box
67 are acceptable.
68
69 If using --like, bounds will automatically be transformed to match the
70 coordinate reference system of the input.
71
72 It can also be combined to read bounds of a feature dataset using Fiona:
73
74 \b
75 $ rio clip input.tif output.tif --bounds $(fio info features.shp --bounds)
76
77 """
78 from rasterio.warp import transform_bounds
79
80 with ctx.obj['env']:
81
82 output, files = resolve_inout(files=files, output=output, overwrite=overwrite)
83 input = files[0]
84
85 with rasterio.open(input) as src:
86 if bounds:
87 if projection == 'geographic':
88 bounds = transform_bounds(CRS.from_epsg(4326), src.crs, *bounds)
89 if disjoint_bounds(bounds, src.bounds):
90 raise click.BadParameter('must overlap the extent of '
91 'the input raster',
92 param='--bounds',
93 param_hint='--bounds')
94 elif like:
95 with rasterio.open(like) as template_ds:
96 bounds = template_ds.bounds
97 if template_ds.crs != src.crs:
98 bounds = transform_bounds(template_ds.crs, src.crs,
99 *bounds)
100
101 if disjoint_bounds(bounds, src.bounds):
102 raise click.BadParameter('must overlap the extent of '
103 'the input raster',
104 param='--like',
105 param_hint='--like')
106
107 else:
108 raise click.UsageError('--bounds or --like required')
109
110 bounds_window = src.window(*bounds)
111 bounds_window = bounds_window.intersection(
112 Window(0, 0, src.width, src.height))
113
114 # Get the window with integer height
115 # and width that contains the bounds window.
116 out_window = bounds_window.round_lengths(op='ceil')
117
118 height = int(out_window.height)
119 width = int(out_window.width)
120
121 out_kwargs = src.profile
122 out_kwargs.update({
123 'driver': driver,
124 'height': height,
125 'width': width,
126 'transform': src.window_transform(out_window)})
127 out_kwargs.update(**creation_options)
128
129 if 'blockxsize' in out_kwargs and out_kwargs['blockxsize'] > width:
130 del out_kwargs['blockxsize']
131 logger.warning("Blockxsize removed from creation options to accomodate small output width")
132 if 'blockysize' in out_kwargs and out_kwargs['blockysize'] > height:
133 del out_kwargs['blockysize']
134 logger.warning("Blockysize removed from creation options to accomodate small output height")
135
136 with rasterio.open(output, 'w', **out_kwargs) as out:
137 out.write(src.read(window=out_window,
138 out_shape=(src.count, height, width)))
139
[end of rasterio/rio/clip.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/rasterio/rio/clip.py b/rasterio/rio/clip.py
--- a/rasterio/rio/clip.py
+++ b/rasterio/rio/clip.py
@@ -50,9 +50,24 @@
@projection_projected_opt
@options.overwrite_opt
@options.creation_options
[email protected](
+ "--with-complement/--without-complement",
+ default=False,
+ help="Include the relative complement of the raster in the given bounds (giving a larger result), else return results only from the intersection of the raster and the bounds (the default).",
+)
@click.pass_context
-def clip(ctx, files, output, bounds, like, driver, projection,
- overwrite, creation_options):
+def clip(
+ ctx,
+ files,
+ output,
+ bounds,
+ like,
+ driver,
+ projection,
+ overwrite,
+ creation_options,
+ with_complement,
+):
"""Clips a raster using projected or geographic bounds.
\b
@@ -108,8 +123,11 @@
raise click.UsageError('--bounds or --like required')
bounds_window = src.window(*bounds)
- bounds_window = bounds_window.intersection(
- Window(0, 0, src.width, src.height))
+
+ if not with_complement:
+ bounds_window = bounds_window.intersection(
+ Window(0, 0, src.width, src.height)
+ )
# Get the window with integer height
# and width that contains the bounds window.
@@ -133,6 +151,11 @@
del out_kwargs['blockysize']
logger.warning("Blockysize removed from creation options to accomodate small output height")
- with rasterio.open(output, 'w', **out_kwargs) as out:
- out.write(src.read(window=out_window,
- out_shape=(src.count, height, width)))
+ with rasterio.open(output, "w", **out_kwargs) as out:
+ out.write(
+ src.read(
+ window=out_window,
+ out_shape=(src.count, height, width),
+ boundless=True,
+ )
+ )
|
{"golden_diff": "diff --git a/rasterio/rio/clip.py b/rasterio/rio/clip.py\n--- a/rasterio/rio/clip.py\n+++ b/rasterio/rio/clip.py\n@@ -50,9 +50,24 @@\n @projection_projected_opt\n @options.overwrite_opt\n @options.creation_options\[email protected](\n+ \"--with-complement/--without-complement\",\n+ default=False,\n+ help=\"Include the relative complement of the raster in the given bounds (giving a larger result), else return results only from the intersection of the raster and the bounds (the default).\",\n+)\n @click.pass_context\n-def clip(ctx, files, output, bounds, like, driver, projection,\n- overwrite, creation_options):\n+def clip(\n+ ctx,\n+ files,\n+ output,\n+ bounds,\n+ like,\n+ driver,\n+ projection,\n+ overwrite,\n+ creation_options,\n+ with_complement,\n+):\n \"\"\"Clips a raster using projected or geographic bounds.\n \n \\b\n@@ -108,8 +123,11 @@\n raise click.UsageError('--bounds or --like required')\n \n bounds_window = src.window(*bounds)\n- bounds_window = bounds_window.intersection(\n- Window(0, 0, src.width, src.height))\n+\n+ if not with_complement:\n+ bounds_window = bounds_window.intersection(\n+ Window(0, 0, src.width, src.height)\n+ )\n \n # Get the window with integer height\n # and width that contains the bounds window.\n@@ -133,6 +151,11 @@\n del out_kwargs['blockysize']\n logger.warning(\"Blockysize removed from creation options to accomodate small output height\")\n \n- with rasterio.open(output, 'w', **out_kwargs) as out:\n- out.write(src.read(window=out_window,\n- out_shape=(src.count, height, width)))\n+ with rasterio.open(output, \"w\", **out_kwargs) as out:\n+ out.write(\n+ src.read(\n+ window=out_window,\n+ out_shape=(src.count, height, width),\n+ boundless=True,\n+ )\n+ )\n", "issue": "Should rio clip fill nodata at borders?\nHello lovely people :hugs:,\r\n\r\nI'm using `rio clip` to quickly cut out z10 tiles for raster image. The raster image is not divisible by the z10 tiles, so I expect the border tiles to contain nodata. But more importantly I expect all z10 tiles I cut out to be of the same dimension. This is not the case with rio clip right now.\r\n\r\nHere is an example where I first convert my raster image to WGS84 and then cut it into z10 tiles where the file name is the z10 quad key id.\r\n\r\n```\r\nrio warp in.tif wgs84.tif --dst-crs EPSG:4326\r\nrio bounds wgs84.tif | mercantile tiles 10 > z10.txt\r\n \r\nwhile read tile; do\r\n rio clip wgs84.tif $(mercantile quadkey \"$tile\").tif --bounds \"$(mercantile shapes --extents \"$tile\")\"\r\ndone < z10.txt\r\n```\r\n\r\nThis results in\r\n- many raster images of pixel size 2857x1744\r\n- some raster images (at the borders) with smaller dimensions; the bounds are not filled with nodata\r\n\r\nShould rio clip use boundless windows and fill with nodata, to respect the user's bounds?\r\n\r\n(rio 1.1.3, tested in ubuntu 18.04 docker container with python 3.6)\n", "before_files": [{"content": "\"\"\"File translation command\"\"\"\n\nimport logging\n\nimport click\nfrom cligj import format_opt\n\nfrom .helpers import resolve_inout\nfrom . import options\nimport rasterio\nfrom rasterio.coords import disjoint_bounds\nfrom rasterio.crs import CRS\nfrom rasterio.windows import Window\n\n\nlogger = logging.getLogger(__name__)\n\n\n# Geographic (default), projected, or Mercator switch.\nprojection_geographic_opt = click.option(\n '--geographic',\n 'projection',\n flag_value='geographic',\n help=\"Bounds in geographic coordinates.\")\n\nprojection_projected_opt = click.option(\n '--projected',\n 'projection',\n flag_value='projected',\n default=True,\n help=\"Bounds in input's own projected coordinates (the default).\")\n\n\n# Clip command\[email protected](short_help='Clip a raster to given bounds.')\[email protected](\n 'files',\n nargs=-1,\n type=click.Path(),\n required=True,\n metavar=\"INPUT OUTPUT\")\[email protected]_opt\[email protected]_opt\[email protected](\n '--like',\n type=click.Path(exists=True),\n help='Raster dataset to use as a template for bounds')\n@format_opt\n@projection_geographic_opt\n@projection_projected_opt\[email protected]_opt\[email protected]_options\[email protected]_context\ndef clip(ctx, files, output, bounds, like, driver, projection,\n overwrite, creation_options):\n \"\"\"Clips a raster using projected or geographic bounds.\n\n \\b\n $ rio clip input.tif output.tif --bounds xmin ymin xmax ymax\n $ rio clip input.tif output.tif --like template.tif\n\n The values of --bounds are presumed to be from the coordinate\n reference system of the input dataset unless the --geographic option\n is used, in which case the values may be longitude and latitude\n bounds. Either JSON, for example \"[west, south, east, north]\", or\n plain text \"west south east north\" representations of a bounding box\n are acceptable.\n\n If using --like, bounds will automatically be transformed to match the\n coordinate reference system of the input.\n\n It can also be combined to read bounds of a feature dataset using Fiona:\n\n \\b\n $ rio clip input.tif output.tif --bounds $(fio info features.shp --bounds)\n\n \"\"\"\n from rasterio.warp import transform_bounds\n\n with ctx.obj['env']:\n\n output, files = resolve_inout(files=files, output=output, overwrite=overwrite)\n input = files[0]\n\n with rasterio.open(input) as src:\n if bounds:\n if projection == 'geographic':\n bounds = transform_bounds(CRS.from_epsg(4326), src.crs, *bounds)\n if disjoint_bounds(bounds, src.bounds):\n raise click.BadParameter('must overlap the extent of '\n 'the input raster',\n param='--bounds',\n param_hint='--bounds')\n elif like:\n with rasterio.open(like) as template_ds:\n bounds = template_ds.bounds\n if template_ds.crs != src.crs:\n bounds = transform_bounds(template_ds.crs, src.crs,\n *bounds)\n\n if disjoint_bounds(bounds, src.bounds):\n raise click.BadParameter('must overlap the extent of '\n 'the input raster',\n param='--like',\n param_hint='--like')\n\n else:\n raise click.UsageError('--bounds or --like required')\n\n bounds_window = src.window(*bounds)\n bounds_window = bounds_window.intersection(\n Window(0, 0, src.width, src.height))\n\n # Get the window with integer height\n # and width that contains the bounds window.\n out_window = bounds_window.round_lengths(op='ceil')\n\n height = int(out_window.height)\n width = int(out_window.width)\n\n out_kwargs = src.profile\n out_kwargs.update({\n 'driver': driver,\n 'height': height,\n 'width': width,\n 'transform': src.window_transform(out_window)})\n out_kwargs.update(**creation_options)\n\n if 'blockxsize' in out_kwargs and out_kwargs['blockxsize'] > width:\n del out_kwargs['blockxsize']\n logger.warning(\"Blockxsize removed from creation options to accomodate small output width\")\n if 'blockysize' in out_kwargs and out_kwargs['blockysize'] > height:\n del out_kwargs['blockysize']\n logger.warning(\"Blockysize removed from creation options to accomodate small output height\")\n\n with rasterio.open(output, 'w', **out_kwargs) as out:\n out.write(src.read(window=out_window,\n out_shape=(src.count, height, width)))\n", "path": "rasterio/rio/clip.py"}]}
| 2,161 | 487 |
gh_patches_debug_25125
|
rasdani/github-patches
|
git_diff
|
mlcommons__GaNDLF-646
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add another optimizer (or 2) as option
**Is your feature request related to a problem? Please describe.**
Currently, GaNDLF only offers Adam and SGD as options for optimizers, which could sometimes be a bit limiting.
**Describe the solution you'd like**
Add ~[RMSProp](https://pytorch.org/docs/stable/generated/torch.optim.RMSprop.html#torch.optim.RMSprop), and optionally~ one or more of the following:
- [LBFGS](https://pytorch.org/docs/1.13/generated/torch.optim.LBFGS.html#torch.optim.LBFGS)
- [RAdam](https://pytorch.org/docs/1.13/generated/torch.optim.RAdam.html#torch.optim.RAdam)
- ~[Rprop](https://pytorch.org/docs/1.11/generated/torch.optim.Rprop.html#torch.optim.Rprop)~
- ~[ASGD](https://pytorch.org/docs/1.11/generated/torch.optim.ASGD.html#torch.optim.ASGD)~
**Describe alternatives you've considered**
N.A.
**Additional context**
N.A.
EDIT [2023/03/20]: updated to the optimizers that are actually missing.
</issue>
<code>
[start of GANDLF/optimizers/__init__.py]
1 from .wrap_torch import (
2 sgd,
3 asgd,
4 adam,
5 adamw,
6 adamax,
7 # sparseadam,
8 rprop,
9 adadelta,
10 adagrad,
11 rmsprop,
12 )
13
14 global_optimizer_dict = {
15 "sgd": sgd,
16 "asgd": asgd,
17 "adam": adam,
18 "adamw": adamw,
19 "adamax": adamax,
20 # "sparseadam": sparseadam,
21 "rprop": rprop,
22 "adadelta": adadelta,
23 "adagrad": adagrad,
24 "rmsprop": rmsprop,
25 }
26
27
28 def get_optimizer(params):
29 """
30 Returns an instance of the specified optimizer from the PyTorch `torch.optim` module.
31
32 Args:
33 params (dict): A dictionary containing the input parameters for the optimizer.
34
35 Returns:
36 optimizer (torch.optim.Optimizer): An instance of the specified optimizer.
37
38 """
39 # Retrieve the optimizer type from the input parameters
40 optimizer_type = params["optimizer"]["type"]
41
42 # Create the optimizer instance using the specified type and input parameters
43 if optimizer_type in global_optimizer_dict:
44 optimizer_function = global_optimizer_dict[optimizer_type]
45 return optimizer_function(params)
46 else:
47 raise ValueError("Optimizer type %s not found" % optimizer_type)
48
[end of GANDLF/optimizers/__init__.py]
[start of GANDLF/optimizers/wrap_torch.py]
1 from torch.optim import (
2 SGD,
3 ASGD,
4 Rprop,
5 Adam,
6 AdamW,
7 # SparseAdam,
8 Adamax,
9 Adadelta,
10 Adagrad,
11 RMSprop,
12 )
13
14
15 def sgd(parameters):
16 """
17 Creates a Stochastic Gradient Descent optimizer from the PyTorch `torch.optim` module using the input parameters.
18
19 Args:
20 parameters (dict): A dictionary containing the input parameters for the optimizer.
21
22 Returns:
23 optimizer (torch.optim.SGD): A Stochastic Gradient Descent optimizer.
24
25 """
26 # Create the optimizer using the input parameters
27 optimizer = SGD(
28 parameters["model_parameters"],
29 lr=parameters.get("learning_rate"),
30 momentum=parameters["optimizer"].get("momentum", 0.9),
31 weight_decay=parameters["optimizer"].get("weight_decay", 0),
32 dampening=parameters["optimizer"].get("dampening", 0),
33 nesterov=parameters["optimizer"].get("Nesterov", False),
34 )
35
36 return optimizer
37
38
39 def asgd(parameters):
40 """
41 Creates an Averaged Stochastic Gradient Descent optimizer from the PyTorch `torch.optim` module using the input parameters.
42
43 Args:
44 parameters (dict): A dictionary containing the input parameters for the optimizer.
45
46 Returns:
47 optimizer (torch.optim.ASGD): An Averaged Stochastic Gradient Descent optimizer.
48
49 """
50 # Create the optimizer using the input parameters
51 return ASGD(
52 parameters["model_parameters"],
53 lr=parameters.get("learning_rate"),
54 alpha=parameters["optimizer"].get("alpha", 0.75),
55 t0=parameters["optimizer"].get("t0", 1e6),
56 lambd=parameters["optimizer"].get("lambd", 1e-4),
57 weight_decay=parameters["optimizer"].get("weight_decay", 0),
58 )
59
60
61 def adam(parameters, opt_type="normal"):
62 """
63 Creates an Adam or AdamW optimizer from the PyTorch `torch.optim` module using the input parameters.
64
65 Args:
66 parameters (dict): A dictionary containing the input parameters for the optimizer.
67 opt_type (str): A string indicating the type of optimizer to create (either "normal" for Adam or "AdamW" for AdamW).
68
69 Returns:
70 optimizer (torch.optim.Adam or torch.optim.AdamW): An Adam or AdamW optimizer.
71
72 """
73 # Determine which optimizer to create based on opt_type
74 if opt_type == "normal":
75 optimizer_fn = Adam
76 elif opt_type == "AdamW":
77 optimizer_fn = AdamW
78 else:
79 raise ValueError(f"Invalid optimizer type: {opt_type}")
80
81 # Create the optimizer using the input parameters
82 return optimizer_fn(
83 parameters["model_parameters"],
84 lr=parameters.get("learning_rate"),
85 betas=parameters["optimizer"].get("betas", (0.9, 0.999)),
86 weight_decay=parameters["optimizer"].get("weight_decay", 0.00005),
87 eps=parameters["optimizer"].get("eps", 1e-8),
88 amsgrad=parameters["optimizer"].get("amsgrad", False),
89 )
90
91
92 def adamw(parameters):
93 """
94 Creates an AdamW optimizer from the PyTorch `torch.optim` module using the input parameters.
95
96 Args:
97 parameters (dict): A dictionary containing the input parameters for the optimizer.
98
99 Returns:
100 optimizer (torch.optim.AdamW): An AdamW optimizer.
101
102 """
103 return adam(parameters, opt_type="AdamW")
104
105 def adamax(parameters):
106 """
107 Creates an Adamax optimizer from the PyTorch `torch.optim` module using the input parameters.
108
109 Args:
110 parameters (dict): A dictionary containing the input parameters for the optimizer.
111
112 Returns:
113 optimizer (torch.optim.Adamax): An Adamax optimizer.
114
115 """
116 # Create the optimizer using the input parameters
117 return Adamax(
118 parameters["model_parameters"],
119 lr=parameters.get("learning_rate"),
120 betas=parameters["optimizer"].get("betas", (0.9, 0.999)),
121 weight_decay=parameters["optimizer"].get("weight_decay", 0.00005),
122 eps=parameters["optimizer"].get("eps", 1e-8),
123 )
124
125
126 # def sparseadam(parameters):
127 # # pick defaults
128 # if not ("betas" in parameters["optimizer"]):
129 # parameters["optimizer"]["betas"] = (0.9, 0.999)
130 # if not ("eps" in parameters["optimizer"]):
131 # parameters["optimizer"]["eps"] = 1e-8
132
133 # return SparseAdam(
134 # parameters["model_parameters"],
135 # lr=parameters["learning_rate"],
136 # betas=parameters["optimizer"]["betas"],
137 # eps=parameters["optimizer"]["eps"],
138 # )
139
140
141 def rprop(parameters):
142 """
143 Creates a Resilient Backpropagation optimizer from the PyTorch `torch.optim` module using the input parameters.
144
145 Args:
146 parameters (dict): A dictionary containing the input parameters for the optimizer.
147
148 Returns:
149 optimizer (torch.optim.Rprop): A Resilient Backpropagation optimizer.
150
151 """
152 # Create the optimizer using the input parameters
153 return Rprop(
154 parameters["model_parameters"],
155 lr=parameters.get("learning_rate"),
156 etas=parameters["optimizer"].get("etas", (0.5, 1.2)),
157 step_sizes=parameters["optimizer"].get("step_sizes", (1e-7, 50)),
158 )
159
160
161 def adadelta(parameters):
162 """
163 Creates an Adadelta optimizer from the PyTorch `torch.optim` module using the input parameters.
164
165 Args:
166 parameters (dict): A dictionary containing the input parameters for the optimizer.
167
168 Returns:
169 optimizer (torch.optim.Adadelta): An Adadelta optimizer.
170
171 """
172 # Create the optimizer using the input parameters
173 return Adadelta(
174 parameters["model_parameters"],
175 lr=parameters.get("learning_rate"),
176 rho=parameters["optimizer"].get("rho", 0.9),
177 eps=parameters["optimizer"].get("eps", 1e-6),
178 weight_decay=parameters["optimizer"].get("weight_decay", 0),
179 )
180
181
182 def adagrad(parameters):
183 """
184 Creates an Adagrad optimizer from the PyTorch `torch.optim` module using the input parameters.
185
186 Args:
187 parameters (dict): A dictionary containing the input parameters for the optimizer.
188
189 Returns:
190 optimizer (torch.optim.Adagrad): An Adagrad optimizer.
191
192 """
193
194 # Create the optimizer using the input parameters
195 return Adagrad(
196 parameters["model_parameters"],
197 lr=parameters.get("learning_rate"),
198 lr_decay=parameters["optimizer"].get("lr_decay", 0),
199 eps=parameters["optimizer"].get("eps", 1e-6),
200 weight_decay=parameters["optimizer"].get("weight_decay", 0),
201 )
202
203
204 def rmsprop(parameters):
205 """
206 Creates an RMSprop optimizer from the PyTorch `torch.optim` module using the input parameters.
207
208 Args:
209 parameters (dict): A dictionary containing the input parameters for the optimizer.
210
211 Returns:
212 optimizer (torch.optim.RMSprop): An RMSprop optimizer.
213
214 """
215 # Create the optimizer using the input parameters
216 return RMSprop(
217 parameters["model_parameters"],
218 lr=parameters.get("learning_rate"),
219 alpha=parameters["optimizer"].get("alpha", 0.99),
220 eps=parameters["optimizer"].get("eps", 1e-8),
221 centered=parameters["optimizer"].get("centered", False),
222 momentum=parameters["optimizer"].get("momentum", 0),
223 weight_decay=parameters["optimizer"].get("weight_decay", 0),
224 )
225
226
[end of GANDLF/optimizers/wrap_torch.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/GANDLF/optimizers/__init__.py b/GANDLF/optimizers/__init__.py
--- a/GANDLF/optimizers/__init__.py
+++ b/GANDLF/optimizers/__init__.py
@@ -9,6 +9,7 @@
adadelta,
adagrad,
rmsprop,
+ radam,
)
global_optimizer_dict = {
@@ -22,6 +23,7 @@
"adadelta": adadelta,
"adagrad": adagrad,
"rmsprop": rmsprop,
+ "radam": radam,
}
diff --git a/GANDLF/optimizers/wrap_torch.py b/GANDLF/optimizers/wrap_torch.py
--- a/GANDLF/optimizers/wrap_torch.py
+++ b/GANDLF/optimizers/wrap_torch.py
@@ -9,6 +9,7 @@
Adadelta,
Adagrad,
RMSprop,
+ RAdam
)
@@ -223,3 +224,23 @@
weight_decay=parameters["optimizer"].get("weight_decay", 0),
)
+def radam(parameters):
+ """
+ Creates a RAdam optimizer from the PyTorch `torch.optim` module using the input parameters.
+
+ Args:
+ parameters (dict): A dictionary containing the input parameters for the optimizer.
+
+ Returns:
+ optimizer (torch.optim.RAdam): A RAdam optimizer.
+ """
+ # Create the optimizer using the input parameters
+ return RAdam(
+ parameters["model_parameters"],
+ lr=parameters.get("learning_rate"),
+ betas=parameters["optimizer"].get("betas", (0.9, 0.999)),
+ eps=parameters["optimizer"].get("eps", 1e-8),
+ weight_decay=parameters["optimizer"].get("weight_decay", 0),
+ foreach=parameters["optimizer"].get("foreach", None),
+ )
+
|
{"golden_diff": "diff --git a/GANDLF/optimizers/__init__.py b/GANDLF/optimizers/__init__.py\n--- a/GANDLF/optimizers/__init__.py\n+++ b/GANDLF/optimizers/__init__.py\n@@ -9,6 +9,7 @@\n adadelta,\n adagrad,\n rmsprop,\n+ radam,\n )\n \n global_optimizer_dict = {\n@@ -22,6 +23,7 @@\n \"adadelta\": adadelta,\n \"adagrad\": adagrad,\n \"rmsprop\": rmsprop,\n+ \"radam\": radam,\n }\n \n \ndiff --git a/GANDLF/optimizers/wrap_torch.py b/GANDLF/optimizers/wrap_torch.py\n--- a/GANDLF/optimizers/wrap_torch.py\n+++ b/GANDLF/optimizers/wrap_torch.py\n@@ -9,6 +9,7 @@\n Adadelta,\n Adagrad,\n RMSprop,\n+ RAdam\n )\n \n \n@@ -223,3 +224,23 @@\n weight_decay=parameters[\"optimizer\"].get(\"weight_decay\", 0),\n )\n \n+def radam(parameters):\n+ \"\"\"\n+ Creates a RAdam optimizer from the PyTorch `torch.optim` module using the input parameters. \n+ \n+ Args: \n+ parameters (dict): A dictionary containing the input parameters for the optimizer.\n+ \n+ Returns: \n+ optimizer (torch.optim.RAdam): A RAdam optimizer.\n+ \"\"\"\n+ # Create the optimizer using the input parameters\n+ return RAdam(\n+ parameters[\"model_parameters\"],\n+ lr=parameters.get(\"learning_rate\"),\n+ betas=parameters[\"optimizer\"].get(\"betas\", (0.9, 0.999)),\n+ eps=parameters[\"optimizer\"].get(\"eps\", 1e-8),\n+ weight_decay=parameters[\"optimizer\"].get(\"weight_decay\", 0),\n+ foreach=parameters[\"optimizer\"].get(\"foreach\", None),\n+ )\n+\n", "issue": "Add another optimizer (or 2) as option\n**Is your feature request related to a problem? Please describe.**\r\nCurrently, GaNDLF only offers Adam and SGD as options for optimizers, which could sometimes be a bit limiting.\r\n\r\n**Describe the solution you'd like**\r\nAdd ~[RMSProp](https://pytorch.org/docs/stable/generated/torch.optim.RMSprop.html#torch.optim.RMSprop), and optionally~ one or more of the following:\r\n- [LBFGS](https://pytorch.org/docs/1.13/generated/torch.optim.LBFGS.html#torch.optim.LBFGS) \r\n- [RAdam](https://pytorch.org/docs/1.13/generated/torch.optim.RAdam.html#torch.optim.RAdam)\r\n- ~[Rprop](https://pytorch.org/docs/1.11/generated/torch.optim.Rprop.html#torch.optim.Rprop)~\r\n- ~[ASGD](https://pytorch.org/docs/1.11/generated/torch.optim.ASGD.html#torch.optim.ASGD)~\r\n\r\n**Describe alternatives you've considered**\r\nN.A.\r\n\r\n**Additional context**\r\nN.A.\r\n\r\nEDIT [2023/03/20]: updated to the optimizers that are actually missing.\n", "before_files": [{"content": "from .wrap_torch import (\n sgd,\n asgd,\n adam,\n adamw,\n adamax,\n # sparseadam,\n rprop,\n adadelta,\n adagrad,\n rmsprop,\n)\n\nglobal_optimizer_dict = {\n \"sgd\": sgd,\n \"asgd\": asgd,\n \"adam\": adam,\n \"adamw\": adamw,\n \"adamax\": adamax,\n # \"sparseadam\": sparseadam,\n \"rprop\": rprop,\n \"adadelta\": adadelta,\n \"adagrad\": adagrad,\n \"rmsprop\": rmsprop,\n}\n\n\ndef get_optimizer(params):\n \"\"\"\n Returns an instance of the specified optimizer from the PyTorch `torch.optim` module.\n\n Args:\n params (dict): A dictionary containing the input parameters for the optimizer.\n\n Returns:\n optimizer (torch.optim.Optimizer): An instance of the specified optimizer.\n\n \"\"\"\n # Retrieve the optimizer type from the input parameters\n optimizer_type = params[\"optimizer\"][\"type\"]\n\n # Create the optimizer instance using the specified type and input parameters\n if optimizer_type in global_optimizer_dict:\n optimizer_function = global_optimizer_dict[optimizer_type]\n return optimizer_function(params)\n else:\n raise ValueError(\"Optimizer type %s not found\" % optimizer_type)\n", "path": "GANDLF/optimizers/__init__.py"}, {"content": "from torch.optim import (\n SGD,\n ASGD,\n Rprop,\n Adam,\n AdamW,\n # SparseAdam,\n Adamax,\n Adadelta,\n Adagrad,\n RMSprop,\n)\n\n\ndef sgd(parameters):\n \"\"\"\n Creates a Stochastic Gradient Descent optimizer from the PyTorch `torch.optim` module using the input parameters.\n\n Args:\n parameters (dict): A dictionary containing the input parameters for the optimizer.\n\n Returns:\n optimizer (torch.optim.SGD): A Stochastic Gradient Descent optimizer.\n\n \"\"\"\n # Create the optimizer using the input parameters\n optimizer = SGD(\n parameters[\"model_parameters\"],\n lr=parameters.get(\"learning_rate\"),\n momentum=parameters[\"optimizer\"].get(\"momentum\", 0.9),\n weight_decay=parameters[\"optimizer\"].get(\"weight_decay\", 0),\n dampening=parameters[\"optimizer\"].get(\"dampening\", 0),\n nesterov=parameters[\"optimizer\"].get(\"Nesterov\", False),\n )\n\n return optimizer\n\n\ndef asgd(parameters):\n \"\"\"\n Creates an Averaged Stochastic Gradient Descent optimizer from the PyTorch `torch.optim` module using the input parameters.\n\n Args:\n parameters (dict): A dictionary containing the input parameters for the optimizer.\n\n Returns:\n optimizer (torch.optim.ASGD): An Averaged Stochastic Gradient Descent optimizer.\n\n \"\"\"\n # Create the optimizer using the input parameters\n return ASGD(\n parameters[\"model_parameters\"],\n lr=parameters.get(\"learning_rate\"),\n alpha=parameters[\"optimizer\"].get(\"alpha\", 0.75),\n t0=parameters[\"optimizer\"].get(\"t0\", 1e6),\n lambd=parameters[\"optimizer\"].get(\"lambd\", 1e-4),\n weight_decay=parameters[\"optimizer\"].get(\"weight_decay\", 0),\n )\n\n\ndef adam(parameters, opt_type=\"normal\"):\n \"\"\"\n Creates an Adam or AdamW optimizer from the PyTorch `torch.optim` module using the input parameters.\n\n Args:\n parameters (dict): A dictionary containing the input parameters for the optimizer.\n opt_type (str): A string indicating the type of optimizer to create (either \"normal\" for Adam or \"AdamW\" for AdamW).\n\n Returns:\n optimizer (torch.optim.Adam or torch.optim.AdamW): An Adam or AdamW optimizer.\n\n \"\"\"\n # Determine which optimizer to create based on opt_type\n if opt_type == \"normal\":\n optimizer_fn = Adam\n elif opt_type == \"AdamW\":\n optimizer_fn = AdamW\n else:\n raise ValueError(f\"Invalid optimizer type: {opt_type}\")\n\n # Create the optimizer using the input parameters\n return optimizer_fn(\n parameters[\"model_parameters\"],\n lr=parameters.get(\"learning_rate\"),\n betas=parameters[\"optimizer\"].get(\"betas\", (0.9, 0.999)),\n weight_decay=parameters[\"optimizer\"].get(\"weight_decay\", 0.00005),\n eps=parameters[\"optimizer\"].get(\"eps\", 1e-8),\n amsgrad=parameters[\"optimizer\"].get(\"amsgrad\", False),\n )\n\n\ndef adamw(parameters):\n \"\"\"\n Creates an AdamW optimizer from the PyTorch `torch.optim` module using the input parameters.\n\n Args:\n parameters (dict): A dictionary containing the input parameters for the optimizer.\n\n Returns:\n optimizer (torch.optim.AdamW): An AdamW optimizer.\n\n \"\"\"\n return adam(parameters, opt_type=\"AdamW\")\n\ndef adamax(parameters):\n \"\"\"\n Creates an Adamax optimizer from the PyTorch `torch.optim` module using the input parameters.\n\n Args:\n parameters (dict): A dictionary containing the input parameters for the optimizer.\n\n Returns:\n optimizer (torch.optim.Adamax): An Adamax optimizer.\n\n \"\"\"\n # Create the optimizer using the input parameters\n return Adamax(\n parameters[\"model_parameters\"],\n lr=parameters.get(\"learning_rate\"),\n betas=parameters[\"optimizer\"].get(\"betas\", (0.9, 0.999)),\n weight_decay=parameters[\"optimizer\"].get(\"weight_decay\", 0.00005),\n eps=parameters[\"optimizer\"].get(\"eps\", 1e-8),\n )\n\n\n# def sparseadam(parameters):\n# # pick defaults\n# if not (\"betas\" in parameters[\"optimizer\"]):\n# parameters[\"optimizer\"][\"betas\"] = (0.9, 0.999)\n# if not (\"eps\" in parameters[\"optimizer\"]):\n# parameters[\"optimizer\"][\"eps\"] = 1e-8\n\n# return SparseAdam(\n# parameters[\"model_parameters\"],\n# lr=parameters[\"learning_rate\"],\n# betas=parameters[\"optimizer\"][\"betas\"],\n# eps=parameters[\"optimizer\"][\"eps\"],\n# )\n\n\ndef rprop(parameters):\n \"\"\"\n Creates a Resilient Backpropagation optimizer from the PyTorch `torch.optim` module using the input parameters.\n\n Args:\n parameters (dict): A dictionary containing the input parameters for the optimizer.\n\n Returns:\n optimizer (torch.optim.Rprop): A Resilient Backpropagation optimizer.\n\n \"\"\"\n # Create the optimizer using the input parameters\n return Rprop(\n parameters[\"model_parameters\"],\n lr=parameters.get(\"learning_rate\"),\n etas=parameters[\"optimizer\"].get(\"etas\", (0.5, 1.2)),\n step_sizes=parameters[\"optimizer\"].get(\"step_sizes\", (1e-7, 50)),\n )\n\n\ndef adadelta(parameters):\n \"\"\"\n Creates an Adadelta optimizer from the PyTorch `torch.optim` module using the input parameters.\n\n Args:\n parameters (dict): A dictionary containing the input parameters for the optimizer.\n\n Returns:\n optimizer (torch.optim.Adadelta): An Adadelta optimizer.\n\n \"\"\"\n # Create the optimizer using the input parameters\n return Adadelta(\n parameters[\"model_parameters\"],\n lr=parameters.get(\"learning_rate\"),\n rho=parameters[\"optimizer\"].get(\"rho\", 0.9),\n eps=parameters[\"optimizer\"].get(\"eps\", 1e-6),\n weight_decay=parameters[\"optimizer\"].get(\"weight_decay\", 0),\n )\n\n\ndef adagrad(parameters):\n \"\"\"\n Creates an Adagrad optimizer from the PyTorch `torch.optim` module using the input parameters.\n\n Args:\n parameters (dict): A dictionary containing the input parameters for the optimizer.\n\n Returns:\n optimizer (torch.optim.Adagrad): An Adagrad optimizer.\n\n \"\"\"\n\n # Create the optimizer using the input parameters\n return Adagrad(\n parameters[\"model_parameters\"],\n lr=parameters.get(\"learning_rate\"),\n lr_decay=parameters[\"optimizer\"].get(\"lr_decay\", 0),\n eps=parameters[\"optimizer\"].get(\"eps\", 1e-6),\n weight_decay=parameters[\"optimizer\"].get(\"weight_decay\", 0),\n )\n\n\ndef rmsprop(parameters):\n \"\"\"\n Creates an RMSprop optimizer from the PyTorch `torch.optim` module using the input parameters.\n\n Args:\n parameters (dict): A dictionary containing the input parameters for the optimizer.\n\n Returns:\n optimizer (torch.optim.RMSprop): An RMSprop optimizer.\n\n \"\"\"\n # Create the optimizer using the input parameters\n return RMSprop(\n parameters[\"model_parameters\"],\n lr=parameters.get(\"learning_rate\"),\n alpha=parameters[\"optimizer\"].get(\"alpha\", 0.99),\n eps=parameters[\"optimizer\"].get(\"eps\", 1e-8),\n centered=parameters[\"optimizer\"].get(\"centered\", False),\n momentum=parameters[\"optimizer\"].get(\"momentum\", 0),\n weight_decay=parameters[\"optimizer\"].get(\"weight_decay\", 0),\n )\n\n", "path": "GANDLF/optimizers/wrap_torch.py"}]}
| 3,499 | 452 |
gh_patches_debug_34072
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-center-index-20842
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[request] geographiclib/2.1.1
### Package Details
* Package Name/Version: **geographiclib/2.1.1**
* Changelog: **https://geographiclib.sourceforge.io/C++/doc/changes.html**
* Source-Link: https://github.com/geographiclib/geographiclib/tree/v2.1.1
The above mentioned version is newly released by the upstream project and not yet available as a recipe. Please add this version.
</issue>
<code>
[start of recipes/geographiclib/all/conanfile.py]
1 from conan import ConanFile
2 from conan.errors import ConanInvalidConfiguration
3 from conan.tools.build import check_min_cppstd
4 from conan.tools.cmake import CMake, CMakeToolchain, cmake_layout
5 from conan.tools.files import (
6 apply_conandata_patches, collect_libs, copy, export_conandata_patches, get,
7 replace_in_file, rm, rmdir
8 )
9 from conan.tools.scm import Version
10 import os
11
12 required_conan_version = ">=1.53.0"
13
14
15 class GeographiclibConan(ConanFile):
16 name = "geographiclib"
17 description = "Convert geographic units and solve geodesic problems"
18 topics = ("geographiclib", "geodesic")
19 url = "https://github.com/conan-io/conan-center-index"
20 homepage = "https://geographiclib.sourceforge.io"
21 license = "MIT"
22
23 settings = "os", "arch", "compiler", "build_type"
24 options = {
25 "shared": [True, False],
26 "fPIC": [True, False],
27 "precision": ["float", "double", "extended", "quadruple", "variable"],
28 "tools": [True, False],
29 }
30 default_options = {
31 "shared": False,
32 "fPIC": True,
33 "precision": "double",
34 "tools": True,
35 }
36
37 def export_sources(self):
38 export_conandata_patches(self)
39
40 def config_options(self):
41 if self.settings.os == "Windows":
42 del self.options.fPIC
43
44 def configure(self):
45 if self.options.shared:
46 self.options.rm_safe("fPIC")
47
48 def layout(self):
49 cmake_layout(self, src_folder="src")
50
51 @property
52 def _compilers_minimum_version(self):
53 # Minimum compiler version having C++11 math functions
54 return {
55 "apple-clang": "3.3",
56 "gcc": "4.9",
57 "clang": "6",
58 "Visual Studio": "14", # guess
59 "msvc": "190",
60 }
61
62 def validate(self):
63 if Version(self.version) >= "1.51":
64 if self.settings.compiler.get_safe("cppstd"):
65 check_min_cppstd(self, 11)
66
67 def loose_lt_semver(v1, v2):
68 lv1 = [int(v) for v in v1.split(".")]
69 lv2 = [int(v) for v in v2.split(".")]
70 min_length = min(len(lv1), len(lv2))
71 return lv1[:min_length] < lv2[:min_length]
72
73 minimum_version = self._compilers_minimum_version.get(str(self.settings.compiler), False)
74 if minimum_version and loose_lt_semver(str(self.settings.compiler.version), minimum_version):
75 raise ConanInvalidConfiguration(
76 f"{self.ref} requires C++11 math functions, which your compiler does not support."
77 )
78
79 if self.options.precision not in ["float", "double"]:
80 # FIXME: add support for extended, quadruple and variable precisions
81 # (may require external libs: boost multiprecision for quadruple, mpfr for variable)
82 raise ConanInvalidConfiguration("extended, quadruple and variable precisions not yet supported in this recipe")
83
84 def source(self):
85 get(self, **self.conan_data["sources"][self.version], strip_root=True)
86
87 @property
88 def _cmake_option_precision(self):
89 return {
90 "float": 1,
91 "double": 2,
92 "extended": 3,
93 "quadruple": 4,
94 "variable": 5,
95 }.get(str(self.options.precision))
96
97 def generate(self):
98 tc = CMakeToolchain(self)
99 tc.variables["GEOGRAPHICLIB_LIB_TYPE"] = "SHARED" if self.options.shared else "STATIC"
100 tc.variables["GEOGRAPHICLIB_PRECISION"] = self._cmake_option_precision
101 tc.generate()
102
103 def _patch_sources(self):
104 apply_conandata_patches(self)
105 cmakelists = os.path.join(self.source_folder, "CMakeLists.txt")
106 # it does not work on Windows but is not needed
107 replace_in_file(self, cmakelists, "add_subdirectory (js)", "")
108 # Don't install system libs
109 replace_in_file(self, cmakelists, "include (InstallRequiredSystemLibraries)", "")
110 # Don't build tools if asked
111 if not self.options.tools:
112 replace_in_file(self, cmakelists, "add_subdirectory (tools)", "")
113 replace_in_file(self, os.path.join(self.source_folder, "cmake", "CMakeLists.txt"),
114 "${TOOLS}", "")
115
116 def build(self):
117 self._patch_sources()
118 cmake = CMake(self)
119 cmake.configure()
120 cmake.build()
121
122 def package(self):
123 copy(self, "LICENSE.txt", src=self.source_folder, dst=os.path.join(self.package_folder, "licenses"))
124 cmake = CMake(self)
125 cmake.install()
126 for folder in [
127 "share", "sbin", "python", "matlab", "doc", "cmake",
128 os.path.join("lib", "python"),
129 os.path.join("lib", "pkgconfig"),
130 os.path.join("lib", "cmake"),
131 ]:
132 rmdir(self, os.path.join(os.path.join(self.package_folder, folder)))
133 rm(self, "*.pdb", os.path.join(self.package_folder, "bin"))
134
135 def package_info(self):
136 self.cpp_info.set_property("cmake_file_name", "geographiclib")
137 self.cpp_info.set_property("cmake_target_name", "GeographicLib::GeographicLib")
138 self.cpp_info.set_property("pkg_config_name", "geographiclib")
139 self.cpp_info.libs = collect_libs(self)
140 self.cpp_info.defines.append("GEOGRAPHICLIB_SHARED_LIB={}".format("1" if self.options.shared else "0"))
141
142 # TODO: to remove in conan v2 once cmake_find_package_* generators removed
143 self.cpp_info.filenames["cmake_find_package"] = "geographiclib"
144 self.cpp_info.filenames["cmake_find_package_multi"] = "geographiclib"
145 self.cpp_info.names["cmake_find_package"] = "GeographicLib"
146 self.cpp_info.names["cmake_find_package_multi"] = "GeographicLib"
147 if self.options.tools:
148 self.env_info.PATH.append(os.path.join(self.package_folder, "bin"))
149
[end of recipes/geographiclib/all/conanfile.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/recipes/geographiclib/all/conanfile.py b/recipes/geographiclib/all/conanfile.py
--- a/recipes/geographiclib/all/conanfile.py
+++ b/recipes/geographiclib/all/conanfile.py
@@ -65,10 +65,7 @@
check_min_cppstd(self, 11)
def loose_lt_semver(v1, v2):
- lv1 = [int(v) for v in v1.split(".")]
- lv2 = [int(v) for v in v2.split(".")]
- min_length = min(len(lv1), len(lv2))
- return lv1[:min_length] < lv2[:min_length]
+ return all(int(p1) < int(p2) for p1, p2 in zip(str(v1).split("."), str(v2).split(".")))
minimum_version = self._compilers_minimum_version.get(str(self.settings.compiler), False)
if minimum_version and loose_lt_semver(str(self.settings.compiler.version), minimum_version):
@@ -103,8 +100,9 @@
def _patch_sources(self):
apply_conandata_patches(self)
cmakelists = os.path.join(self.source_folder, "CMakeLists.txt")
- # it does not work on Windows but is not needed
- replace_in_file(self, cmakelists, "add_subdirectory (js)", "")
+ if Version(self.version) < "2":
+ # it does not work on Windows but is not needed
+ replace_in_file(self, cmakelists, "add_subdirectory (js)", "")
# Don't install system libs
replace_in_file(self, cmakelists, "include (InstallRequiredSystemLibraries)", "")
# Don't build tools if asked
@@ -112,6 +110,9 @@
replace_in_file(self, cmakelists, "add_subdirectory (tools)", "")
replace_in_file(self, os.path.join(self.source_folder, "cmake", "CMakeLists.txt"),
"${TOOLS}", "")
+ # Disable -Werror
+ replace_in_file(self, cmakelists, "-Werror", "")
+ replace_in_file(self, cmakelists, "/WX", "")
def build(self):
self._patch_sources()
|
{"golden_diff": "diff --git a/recipes/geographiclib/all/conanfile.py b/recipes/geographiclib/all/conanfile.py\n--- a/recipes/geographiclib/all/conanfile.py\n+++ b/recipes/geographiclib/all/conanfile.py\n@@ -65,10 +65,7 @@\n check_min_cppstd(self, 11)\n \n def loose_lt_semver(v1, v2):\n- lv1 = [int(v) for v in v1.split(\".\")]\n- lv2 = [int(v) for v in v2.split(\".\")]\n- min_length = min(len(lv1), len(lv2))\n- return lv1[:min_length] < lv2[:min_length]\n+ return all(int(p1) < int(p2) for p1, p2 in zip(str(v1).split(\".\"), str(v2).split(\".\")))\n \n minimum_version = self._compilers_minimum_version.get(str(self.settings.compiler), False)\n if minimum_version and loose_lt_semver(str(self.settings.compiler.version), minimum_version):\n@@ -103,8 +100,9 @@\n def _patch_sources(self):\n apply_conandata_patches(self)\n cmakelists = os.path.join(self.source_folder, \"CMakeLists.txt\")\n- # it does not work on Windows but is not needed\n- replace_in_file(self, cmakelists, \"add_subdirectory (js)\", \"\")\n+ if Version(self.version) < \"2\":\n+ # it does not work on Windows but is not needed\n+ replace_in_file(self, cmakelists, \"add_subdirectory (js)\", \"\")\n # Don't install system libs\n replace_in_file(self, cmakelists, \"include (InstallRequiredSystemLibraries)\", \"\")\n # Don't build tools if asked\n@@ -112,6 +110,9 @@\n replace_in_file(self, cmakelists, \"add_subdirectory (tools)\", \"\")\n replace_in_file(self, os.path.join(self.source_folder, \"cmake\", \"CMakeLists.txt\"),\n \"${TOOLS}\", \"\")\n+ # Disable -Werror\n+ replace_in_file(self, cmakelists, \"-Werror\", \"\")\n+ replace_in_file(self, cmakelists, \"/WX\", \"\")\n \n def build(self):\n self._patch_sources()\n", "issue": "[request] geographiclib/2.1.1\n### Package Details\r\n * Package Name/Version: **geographiclib/2.1.1**\r\n * Changelog: **https://geographiclib.sourceforge.io/C++/doc/changes.html**\r\n\r\n* Source-Link: https://github.com/geographiclib/geographiclib/tree/v2.1.1\r\n\r\nThe above mentioned version is newly released by the upstream project and not yet available as a recipe. Please add this version.\r\n\n", "before_files": [{"content": "from conan import ConanFile\nfrom conan.errors import ConanInvalidConfiguration\nfrom conan.tools.build import check_min_cppstd\nfrom conan.tools.cmake import CMake, CMakeToolchain, cmake_layout\nfrom conan.tools.files import (\n apply_conandata_patches, collect_libs, copy, export_conandata_patches, get,\n replace_in_file, rm, rmdir\n)\nfrom conan.tools.scm import Version\nimport os\n\nrequired_conan_version = \">=1.53.0\"\n\n\nclass GeographiclibConan(ConanFile):\n name = \"geographiclib\"\n description = \"Convert geographic units and solve geodesic problems\"\n topics = (\"geographiclib\", \"geodesic\")\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \"https://geographiclib.sourceforge.io\"\n license = \"MIT\"\n\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n options = {\n \"shared\": [True, False],\n \"fPIC\": [True, False],\n \"precision\": [\"float\", \"double\", \"extended\", \"quadruple\", \"variable\"],\n \"tools\": [True, False],\n }\n default_options = {\n \"shared\": False,\n \"fPIC\": True,\n \"precision\": \"double\",\n \"tools\": True,\n }\n\n def export_sources(self):\n export_conandata_patches(self)\n\n def config_options(self):\n if self.settings.os == \"Windows\":\n del self.options.fPIC\n\n def configure(self):\n if self.options.shared:\n self.options.rm_safe(\"fPIC\")\n\n def layout(self):\n cmake_layout(self, src_folder=\"src\")\n\n @property\n def _compilers_minimum_version(self):\n # Minimum compiler version having C++11 math functions\n return {\n \"apple-clang\": \"3.3\",\n \"gcc\": \"4.9\",\n \"clang\": \"6\",\n \"Visual Studio\": \"14\", # guess\n \"msvc\": \"190\",\n }\n\n def validate(self):\n if Version(self.version) >= \"1.51\":\n if self.settings.compiler.get_safe(\"cppstd\"):\n check_min_cppstd(self, 11)\n\n def loose_lt_semver(v1, v2):\n lv1 = [int(v) for v in v1.split(\".\")]\n lv2 = [int(v) for v in v2.split(\".\")]\n min_length = min(len(lv1), len(lv2))\n return lv1[:min_length] < lv2[:min_length]\n\n minimum_version = self._compilers_minimum_version.get(str(self.settings.compiler), False)\n if minimum_version and loose_lt_semver(str(self.settings.compiler.version), minimum_version):\n raise ConanInvalidConfiguration(\n f\"{self.ref} requires C++11 math functions, which your compiler does not support.\"\n )\n\n if self.options.precision not in [\"float\", \"double\"]:\n # FIXME: add support for extended, quadruple and variable precisions\n # (may require external libs: boost multiprecision for quadruple, mpfr for variable)\n raise ConanInvalidConfiguration(\"extended, quadruple and variable precisions not yet supported in this recipe\")\n\n def source(self):\n get(self, **self.conan_data[\"sources\"][self.version], strip_root=True)\n\n @property\n def _cmake_option_precision(self):\n return {\n \"float\": 1,\n \"double\": 2,\n \"extended\": 3,\n \"quadruple\": 4,\n \"variable\": 5,\n }.get(str(self.options.precision))\n\n def generate(self):\n tc = CMakeToolchain(self)\n tc.variables[\"GEOGRAPHICLIB_LIB_TYPE\"] = \"SHARED\" if self.options.shared else \"STATIC\"\n tc.variables[\"GEOGRAPHICLIB_PRECISION\"] = self._cmake_option_precision\n tc.generate()\n\n def _patch_sources(self):\n apply_conandata_patches(self)\n cmakelists = os.path.join(self.source_folder, \"CMakeLists.txt\")\n # it does not work on Windows but is not needed\n replace_in_file(self, cmakelists, \"add_subdirectory (js)\", \"\")\n # Don't install system libs\n replace_in_file(self, cmakelists, \"include (InstallRequiredSystemLibraries)\", \"\")\n # Don't build tools if asked\n if not self.options.tools:\n replace_in_file(self, cmakelists, \"add_subdirectory (tools)\", \"\")\n replace_in_file(self, os.path.join(self.source_folder, \"cmake\", \"CMakeLists.txt\"),\n \"${TOOLS}\", \"\")\n\n def build(self):\n self._patch_sources()\n cmake = CMake(self)\n cmake.configure()\n cmake.build()\n\n def package(self):\n copy(self, \"LICENSE.txt\", src=self.source_folder, dst=os.path.join(self.package_folder, \"licenses\"))\n cmake = CMake(self)\n cmake.install()\n for folder in [\n \"share\", \"sbin\", \"python\", \"matlab\", \"doc\", \"cmake\",\n os.path.join(\"lib\", \"python\"),\n os.path.join(\"lib\", \"pkgconfig\"),\n os.path.join(\"lib\", \"cmake\"),\n ]:\n rmdir(self, os.path.join(os.path.join(self.package_folder, folder)))\n rm(self, \"*.pdb\", os.path.join(self.package_folder, \"bin\"))\n\n def package_info(self):\n self.cpp_info.set_property(\"cmake_file_name\", \"geographiclib\")\n self.cpp_info.set_property(\"cmake_target_name\", \"GeographicLib::GeographicLib\")\n self.cpp_info.set_property(\"pkg_config_name\", \"geographiclib\")\n self.cpp_info.libs = collect_libs(self)\n self.cpp_info.defines.append(\"GEOGRAPHICLIB_SHARED_LIB={}\".format(\"1\" if self.options.shared else \"0\"))\n\n # TODO: to remove in conan v2 once cmake_find_package_* generators removed\n self.cpp_info.filenames[\"cmake_find_package\"] = \"geographiclib\"\n self.cpp_info.filenames[\"cmake_find_package_multi\"] = \"geographiclib\"\n self.cpp_info.names[\"cmake_find_package\"] = \"GeographicLib\"\n self.cpp_info.names[\"cmake_find_package_multi\"] = \"GeographicLib\"\n if self.options.tools:\n self.env_info.PATH.append(os.path.join(self.package_folder, \"bin\"))\n", "path": "recipes/geographiclib/all/conanfile.py"}]}
| 2,381 | 506 |
gh_patches_debug_12577
|
rasdani/github-patches
|
git_diff
|
vyperlang__vyper-1537
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Types not always enforced on events
Haven't dug deeply on this one but something equivalent to this is compiling for me:
```python
Sale: event({eth_sold: indexed(uint256(wei))})
@public
def logSale(amount: uint256):
log.Sale(amount)
```
</issue>
<code>
[start of vyper/parser/events.py]
1 from vyper import ast
2 from vyper.exceptions import (
3 InvalidLiteralException,
4 TypeMismatchException,
5 )
6 from vyper.parser.expr import (
7 Expr,
8 )
9 from vyper.parser.lll_node import (
10 LLLnode,
11 )
12 from vyper.parser.parser_utils import (
13 base_type_conversion,
14 byte_array_to_num,
15 getpos,
16 make_byte_array_copier,
17 make_setter,
18 unwrap_location,
19 )
20 from vyper.types.types import (
21 BaseType,
22 ByteArrayLike,
23 ListType,
24 get_size_of_type,
25 )
26 from vyper.utils import (
27 bytes_to_int,
28 ceil32,
29 string_to_bytes,
30 )
31
32
33 def pack_logging_topics(event_id, args, expected_topics, context, pos):
34 topics = [event_id]
35 code_pos = pos
36 for pos, expected_topic in enumerate(expected_topics):
37 expected_type = expected_topic.typ
38 arg = args[pos]
39 value = Expr(arg, context).lll_node
40 arg_type = value.typ
41
42 if isinstance(arg_type, ByteArrayLike) and isinstance(expected_type, ByteArrayLike):
43 if arg_type.maxlen > expected_type.maxlen:
44 raise TypeMismatchException(
45 "Topic input bytes are too big: %r %r" % (arg_type, expected_type), code_pos
46 )
47 if isinstance(arg, ast.Str):
48 bytez, bytez_length = string_to_bytes(arg.s)
49 if len(bytez) > 32:
50 raise InvalidLiteralException(
51 "Can only log a maximum of 32 bytes at a time.", code_pos
52 )
53 topics.append(bytes_to_int(bytez + b'\x00' * (32 - bytez_length)))
54 else:
55 if value.location == "memory":
56 size = ['mload', value]
57 elif value.location == "storage":
58 size = ['sload', ['sha3_32', value]]
59 topics.append(byte_array_to_num(value, arg, 'uint256', size))
60 else:
61 value = unwrap_location(value)
62 value = base_type_conversion(value, arg_type, expected_type, pos=code_pos)
63 topics.append(value)
64
65 return topics
66
67
68 def pack_args_by_32(holder, maxlen, arg, typ, context, placeholder,
69 dynamic_offset_counter=None, datamem_start=None, zero_pad_i=None, pos=None):
70 """
71 Copy necessary variables to pre-allocated memory section.
72
73 :param holder: Complete holder for all args
74 :param maxlen: Total length in bytes of the full arg section (static + dynamic).
75 :param arg: Current arg to pack
76 :param context: Context of arg
77 :param placeholder: Static placeholder for static argument part.
78 :param dynamic_offset_counter: position counter stored in static args.
79 :param dynamic_placeholder: pointer to current position in memory to write dynamic values to.
80 :param datamem_start: position where the whole datemem section starts.
81 """
82
83 if isinstance(typ, BaseType):
84 if isinstance(arg, LLLnode):
85 value = unwrap_location(arg)
86 else:
87 value = Expr(arg, context).lll_node
88 value = base_type_conversion(value, value.typ, typ, pos)
89 holder.append(LLLnode.from_list(['mstore', placeholder, value], typ=typ, location='memory'))
90 elif isinstance(typ, ByteArrayLike):
91
92 if isinstance(arg, LLLnode): # Is prealloacted variable.
93 source_lll = arg
94 else:
95 source_lll = Expr(arg, context).lll_node
96
97 # Set static offset, in arg slot.
98 holder.append(LLLnode.from_list(['mstore', placeholder, ['mload', dynamic_offset_counter]]))
99 # Get the biginning to write the ByteArray to.
100 dest_placeholder = LLLnode.from_list(
101 ['add', datamem_start, ['mload', dynamic_offset_counter]],
102 typ=typ, location='memory', annotation="pack_args_by_32:dest_placeholder")
103 copier = make_byte_array_copier(dest_placeholder, source_lll, pos=pos)
104 holder.append(copier)
105 # Add zero padding.
106 new_maxlen = ceil32(source_lll.typ.maxlen)
107
108 holder.append([
109 'with', '_ceil32_end', ['ceil32', ['mload', dest_placeholder]], [
110 'seq', ['with', '_bytearray_loc', dest_placeholder, [
111 'seq', ['repeat', zero_pad_i, ['mload', '_bytearray_loc'], new_maxlen, [
112 'seq',
113 # stay within allocated bounds
114 ['if', ['ge', ['mload', zero_pad_i], '_ceil32_end'], 'break'],
115 [
116 'mstore8',
117 ['add', ['add', '_bytearray_loc', 32], ['mload', zero_pad_i]],
118 0,
119 ],
120 ]],
121 ]],
122 ]
123 ])
124
125 # Increment offset counter.
126 increment_counter = LLLnode.from_list([
127 'mstore', dynamic_offset_counter,
128 [
129 'add',
130 ['add', ['mload', dynamic_offset_counter], ['ceil32', ['mload', dest_placeholder]]],
131 32,
132 ],
133 ], annotation='Increment dynamic offset counter')
134 holder.append(increment_counter)
135 elif isinstance(typ, ListType):
136 maxlen += (typ.count - 1) * 32
137 typ = typ.subtype
138
139 def check_list_type_match(provided): # Check list types match.
140 if provided != typ:
141 raise TypeMismatchException(
142 "Log list type '%s' does not match provided, expected '%s'" % (provided, typ)
143 )
144
145 # NOTE: Below code could be refactored into iterators/getter functions for each type of
146 # repetitive loop. But seeing how each one is a unique for loop, and in which way
147 # the sub value makes the difference in each type of list clearer.
148
149 # List from storage
150 if isinstance(arg, ast.Attribute) and arg.value.id == 'self':
151 stor_list = context.globals[arg.attr]
152 check_list_type_match(stor_list.typ.subtype)
153 size = stor_list.typ.count
154 mem_offset = 0
155 for i in range(0, size):
156 storage_offset = i
157 arg2 = LLLnode.from_list(
158 ['sload', ['add', ['sha3_32', Expr(arg, context).lll_node], storage_offset]],
159 typ=typ,
160 )
161 holder, maxlen = pack_args_by_32(
162 holder,
163 maxlen,
164 arg2,
165 typ,
166 context,
167 placeholder + mem_offset,
168 pos=pos,
169 )
170 mem_offset += get_size_of_type(typ) * 32
171
172 # List from variable.
173 elif isinstance(arg, ast.Name):
174 size = context.vars[arg.id].size
175 pos = context.vars[arg.id].pos
176 check_list_type_match(context.vars[arg.id].typ.subtype)
177 mem_offset = 0
178 for _ in range(0, size):
179 arg2 = LLLnode.from_list(
180 pos + mem_offset,
181 typ=typ,
182 location=context.vars[arg.id].location
183 )
184 holder, maxlen = pack_args_by_32(
185 holder,
186 maxlen,
187 arg2,
188 typ,
189 context,
190 placeholder + mem_offset,
191 pos=pos,
192 )
193 mem_offset += get_size_of_type(typ) * 32
194
195 # List from list literal.
196 else:
197 mem_offset = 0
198 for arg2 in arg.elts:
199 holder, maxlen = pack_args_by_32(
200 holder,
201 maxlen,
202 arg2,
203 typ,
204 context,
205 placeholder + mem_offset,
206 pos=pos,
207 )
208 mem_offset += get_size_of_type(typ) * 32
209 return holder, maxlen
210
211
212 # Pack logging data arguments
213 def pack_logging_data(expected_data, args, context, pos):
214 # Checks to see if there's any data
215 if not args:
216 return ['seq'], 0, None, 0
217 holder = ['seq']
218 maxlen = len(args) * 32 # total size of all packed args (upper limit)
219
220 # Unroll any function calls, to temp variables.
221 prealloacted = {}
222 for idx, (arg, _expected_arg) in enumerate(zip(args, expected_data)):
223
224 if isinstance(arg, (ast.Str, ast.Call)):
225 expr = Expr(arg, context)
226 source_lll = expr.lll_node
227 typ = source_lll.typ
228
229 if isinstance(arg, ast.Str):
230 if len(arg.s) > typ.maxlen:
231 raise TypeMismatchException(
232 "Data input bytes are to big: %r %r" % (len(arg.s), typ), pos
233 )
234
235 tmp_variable = context.new_variable(
236 '_log_pack_var_%i_%i' % (arg.lineno, arg.col_offset),
237 source_lll.typ,
238 )
239 tmp_variable_node = LLLnode.from_list(
240 tmp_variable,
241 typ=source_lll.typ,
242 pos=getpos(arg),
243 location="memory",
244 annotation='log_prealloacted %r' % source_lll.typ,
245 )
246 # Store len.
247 # holder.append(['mstore', len_placeholder, ['mload', unwrap_location(source_lll)]])
248 # Copy bytes.
249
250 holder.append(
251 make_setter(tmp_variable_node, source_lll, pos=getpos(arg), location='memory')
252 )
253 prealloacted[idx] = tmp_variable_node
254
255 requires_dynamic_offset = any([isinstance(data.typ, ByteArrayLike) for data in expected_data])
256 if requires_dynamic_offset:
257 # Iterator used to zero pad memory.
258 zero_pad_i = context.new_placeholder(BaseType('uint256'))
259 dynamic_offset_counter = context.new_placeholder(BaseType(32))
260 dynamic_placeholder = context.new_placeholder(BaseType(32))
261 else:
262 dynamic_offset_counter = None
263 zero_pad_i = None
264
265 # Create placeholder for static args. Note: order of new_*() is important.
266 placeholder_map = {}
267 for i, (_arg, data) in enumerate(zip(args, expected_data)):
268 typ = data.typ
269 if not isinstance(typ, ByteArrayLike):
270 placeholder = context.new_placeholder(typ)
271 else:
272 placeholder = context.new_placeholder(BaseType(32))
273 placeholder_map[i] = placeholder
274
275 # Populate static placeholders.
276 for i, (arg, data) in enumerate(zip(args, expected_data)):
277 typ = data.typ
278 placeholder = placeholder_map[i]
279 if not isinstance(typ, ByteArrayLike):
280 holder, maxlen = pack_args_by_32(
281 holder,
282 maxlen,
283 prealloacted.get(i, arg),
284 typ,
285 context,
286 placeholder,
287 zero_pad_i=zero_pad_i,
288 pos=pos,
289 )
290
291 # Dynamic position starts right after the static args.
292 if requires_dynamic_offset:
293 holder.append(LLLnode.from_list(['mstore', dynamic_offset_counter, maxlen]))
294
295 # Calculate maximum dynamic offset placeholders, used for gas estimation.
296 for _arg, data in zip(args, expected_data):
297 typ = data.typ
298 if isinstance(typ, ByteArrayLike):
299 maxlen += 32 + ceil32(typ.maxlen)
300
301 if requires_dynamic_offset:
302 datamem_start = dynamic_placeholder + 32
303 else:
304 datamem_start = placeholder_map[0]
305
306 # Copy necessary data into allocated dynamic section.
307 for i, (arg, data) in enumerate(zip(args, expected_data)):
308 typ = data.typ
309 if isinstance(typ, ByteArrayLike):
310 pack_args_by_32(
311 holder=holder,
312 maxlen=maxlen,
313 arg=prealloacted.get(i, arg),
314 typ=typ,
315 context=context,
316 placeholder=placeholder_map[i],
317 datamem_start=datamem_start,
318 dynamic_offset_counter=dynamic_offset_counter,
319 zero_pad_i=zero_pad_i,
320 pos=pos
321 )
322
323 return holder, maxlen, dynamic_offset_counter, datamem_start
324
[end of vyper/parser/events.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/vyper/parser/events.py b/vyper/parser/events.py
--- a/vyper/parser/events.py
+++ b/vyper/parser/events.py
@@ -58,6 +58,11 @@
size = ['sload', ['sha3_32', value]]
topics.append(byte_array_to_num(value, arg, 'uint256', size))
else:
+ if arg_type != expected_type:
+ raise TypeMismatchException(
+ f"Invalid type for logging topic, got {arg_type} expected {expected_type}",
+ value.pos
+ )
value = unwrap_location(value)
value = base_type_conversion(value, arg_type, expected_type, pos=code_pos)
topics.append(value)
|
{"golden_diff": "diff --git a/vyper/parser/events.py b/vyper/parser/events.py\n--- a/vyper/parser/events.py\n+++ b/vyper/parser/events.py\n@@ -58,6 +58,11 @@\n size = ['sload', ['sha3_32', value]]\n topics.append(byte_array_to_num(value, arg, 'uint256', size))\n else:\n+ if arg_type != expected_type:\n+ raise TypeMismatchException(\n+ f\"Invalid type for logging topic, got {arg_type} expected {expected_type}\",\n+ value.pos\n+ )\n value = unwrap_location(value)\n value = base_type_conversion(value, arg_type, expected_type, pos=code_pos)\n topics.append(value)\n", "issue": "Types not always enforced on events\nHaven't dug deeply on this one but something equivalent to this is compiling for me:\r\n\r\n```python\r\nSale: event({eth_sold: indexed(uint256(wei))})\r\n\r\n@public\r\ndef logSale(amount: uint256):\r\n log.Sale(amount)\r\n```\n", "before_files": [{"content": "from vyper import ast\nfrom vyper.exceptions import (\n InvalidLiteralException,\n TypeMismatchException,\n)\nfrom vyper.parser.expr import (\n Expr,\n)\nfrom vyper.parser.lll_node import (\n LLLnode,\n)\nfrom vyper.parser.parser_utils import (\n base_type_conversion,\n byte_array_to_num,\n getpos,\n make_byte_array_copier,\n make_setter,\n unwrap_location,\n)\nfrom vyper.types.types import (\n BaseType,\n ByteArrayLike,\n ListType,\n get_size_of_type,\n)\nfrom vyper.utils import (\n bytes_to_int,\n ceil32,\n string_to_bytes,\n)\n\n\ndef pack_logging_topics(event_id, args, expected_topics, context, pos):\n topics = [event_id]\n code_pos = pos\n for pos, expected_topic in enumerate(expected_topics):\n expected_type = expected_topic.typ\n arg = args[pos]\n value = Expr(arg, context).lll_node\n arg_type = value.typ\n\n if isinstance(arg_type, ByteArrayLike) and isinstance(expected_type, ByteArrayLike):\n if arg_type.maxlen > expected_type.maxlen:\n raise TypeMismatchException(\n \"Topic input bytes are too big: %r %r\" % (arg_type, expected_type), code_pos\n )\n if isinstance(arg, ast.Str):\n bytez, bytez_length = string_to_bytes(arg.s)\n if len(bytez) > 32:\n raise InvalidLiteralException(\n \"Can only log a maximum of 32 bytes at a time.\", code_pos\n )\n topics.append(bytes_to_int(bytez + b'\\x00' * (32 - bytez_length)))\n else:\n if value.location == \"memory\":\n size = ['mload', value]\n elif value.location == \"storage\":\n size = ['sload', ['sha3_32', value]]\n topics.append(byte_array_to_num(value, arg, 'uint256', size))\n else:\n value = unwrap_location(value)\n value = base_type_conversion(value, arg_type, expected_type, pos=code_pos)\n topics.append(value)\n\n return topics\n\n\ndef pack_args_by_32(holder, maxlen, arg, typ, context, placeholder,\n dynamic_offset_counter=None, datamem_start=None, zero_pad_i=None, pos=None):\n \"\"\"\n Copy necessary variables to pre-allocated memory section.\n\n :param holder: Complete holder for all args\n :param maxlen: Total length in bytes of the full arg section (static + dynamic).\n :param arg: Current arg to pack\n :param context: Context of arg\n :param placeholder: Static placeholder for static argument part.\n :param dynamic_offset_counter: position counter stored in static args.\n :param dynamic_placeholder: pointer to current position in memory to write dynamic values to.\n :param datamem_start: position where the whole datemem section starts.\n \"\"\"\n\n if isinstance(typ, BaseType):\n if isinstance(arg, LLLnode):\n value = unwrap_location(arg)\n else:\n value = Expr(arg, context).lll_node\n value = base_type_conversion(value, value.typ, typ, pos)\n holder.append(LLLnode.from_list(['mstore', placeholder, value], typ=typ, location='memory'))\n elif isinstance(typ, ByteArrayLike):\n\n if isinstance(arg, LLLnode): # Is prealloacted variable.\n source_lll = arg\n else:\n source_lll = Expr(arg, context).lll_node\n\n # Set static offset, in arg slot.\n holder.append(LLLnode.from_list(['mstore', placeholder, ['mload', dynamic_offset_counter]]))\n # Get the biginning to write the ByteArray to.\n dest_placeholder = LLLnode.from_list(\n ['add', datamem_start, ['mload', dynamic_offset_counter]],\n typ=typ, location='memory', annotation=\"pack_args_by_32:dest_placeholder\")\n copier = make_byte_array_copier(dest_placeholder, source_lll, pos=pos)\n holder.append(copier)\n # Add zero padding.\n new_maxlen = ceil32(source_lll.typ.maxlen)\n\n holder.append([\n 'with', '_ceil32_end', ['ceil32', ['mload', dest_placeholder]], [\n 'seq', ['with', '_bytearray_loc', dest_placeholder, [\n 'seq', ['repeat', zero_pad_i, ['mload', '_bytearray_loc'], new_maxlen, [\n 'seq',\n # stay within allocated bounds\n ['if', ['ge', ['mload', zero_pad_i], '_ceil32_end'], 'break'],\n [\n 'mstore8',\n ['add', ['add', '_bytearray_loc', 32], ['mload', zero_pad_i]],\n 0,\n ],\n ]],\n ]],\n ]\n ])\n\n # Increment offset counter.\n increment_counter = LLLnode.from_list([\n 'mstore', dynamic_offset_counter,\n [\n 'add',\n ['add', ['mload', dynamic_offset_counter], ['ceil32', ['mload', dest_placeholder]]],\n 32,\n ],\n ], annotation='Increment dynamic offset counter')\n holder.append(increment_counter)\n elif isinstance(typ, ListType):\n maxlen += (typ.count - 1) * 32\n typ = typ.subtype\n\n def check_list_type_match(provided): # Check list types match.\n if provided != typ:\n raise TypeMismatchException(\n \"Log list type '%s' does not match provided, expected '%s'\" % (provided, typ)\n )\n\n # NOTE: Below code could be refactored into iterators/getter functions for each type of\n # repetitive loop. But seeing how each one is a unique for loop, and in which way\n # the sub value makes the difference in each type of list clearer.\n\n # List from storage\n if isinstance(arg, ast.Attribute) and arg.value.id == 'self':\n stor_list = context.globals[arg.attr]\n check_list_type_match(stor_list.typ.subtype)\n size = stor_list.typ.count\n mem_offset = 0\n for i in range(0, size):\n storage_offset = i\n arg2 = LLLnode.from_list(\n ['sload', ['add', ['sha3_32', Expr(arg, context).lll_node], storage_offset]],\n typ=typ,\n )\n holder, maxlen = pack_args_by_32(\n holder,\n maxlen,\n arg2,\n typ,\n context,\n placeholder + mem_offset,\n pos=pos,\n )\n mem_offset += get_size_of_type(typ) * 32\n\n # List from variable.\n elif isinstance(arg, ast.Name):\n size = context.vars[arg.id].size\n pos = context.vars[arg.id].pos\n check_list_type_match(context.vars[arg.id].typ.subtype)\n mem_offset = 0\n for _ in range(0, size):\n arg2 = LLLnode.from_list(\n pos + mem_offset,\n typ=typ,\n location=context.vars[arg.id].location\n )\n holder, maxlen = pack_args_by_32(\n holder,\n maxlen,\n arg2,\n typ,\n context,\n placeholder + mem_offset,\n pos=pos,\n )\n mem_offset += get_size_of_type(typ) * 32\n\n # List from list literal.\n else:\n mem_offset = 0\n for arg2 in arg.elts:\n holder, maxlen = pack_args_by_32(\n holder,\n maxlen,\n arg2,\n typ,\n context,\n placeholder + mem_offset,\n pos=pos,\n )\n mem_offset += get_size_of_type(typ) * 32\n return holder, maxlen\n\n\n# Pack logging data arguments\ndef pack_logging_data(expected_data, args, context, pos):\n # Checks to see if there's any data\n if not args:\n return ['seq'], 0, None, 0\n holder = ['seq']\n maxlen = len(args) * 32 # total size of all packed args (upper limit)\n\n # Unroll any function calls, to temp variables.\n prealloacted = {}\n for idx, (arg, _expected_arg) in enumerate(zip(args, expected_data)):\n\n if isinstance(arg, (ast.Str, ast.Call)):\n expr = Expr(arg, context)\n source_lll = expr.lll_node\n typ = source_lll.typ\n\n if isinstance(arg, ast.Str):\n if len(arg.s) > typ.maxlen:\n raise TypeMismatchException(\n \"Data input bytes are to big: %r %r\" % (len(arg.s), typ), pos\n )\n\n tmp_variable = context.new_variable(\n '_log_pack_var_%i_%i' % (arg.lineno, arg.col_offset),\n source_lll.typ,\n )\n tmp_variable_node = LLLnode.from_list(\n tmp_variable,\n typ=source_lll.typ,\n pos=getpos(arg),\n location=\"memory\",\n annotation='log_prealloacted %r' % source_lll.typ,\n )\n # Store len.\n # holder.append(['mstore', len_placeholder, ['mload', unwrap_location(source_lll)]])\n # Copy bytes.\n\n holder.append(\n make_setter(tmp_variable_node, source_lll, pos=getpos(arg), location='memory')\n )\n prealloacted[idx] = tmp_variable_node\n\n requires_dynamic_offset = any([isinstance(data.typ, ByteArrayLike) for data in expected_data])\n if requires_dynamic_offset:\n # Iterator used to zero pad memory.\n zero_pad_i = context.new_placeholder(BaseType('uint256'))\n dynamic_offset_counter = context.new_placeholder(BaseType(32))\n dynamic_placeholder = context.new_placeholder(BaseType(32))\n else:\n dynamic_offset_counter = None\n zero_pad_i = None\n\n # Create placeholder for static args. Note: order of new_*() is important.\n placeholder_map = {}\n for i, (_arg, data) in enumerate(zip(args, expected_data)):\n typ = data.typ\n if not isinstance(typ, ByteArrayLike):\n placeholder = context.new_placeholder(typ)\n else:\n placeholder = context.new_placeholder(BaseType(32))\n placeholder_map[i] = placeholder\n\n # Populate static placeholders.\n for i, (arg, data) in enumerate(zip(args, expected_data)):\n typ = data.typ\n placeholder = placeholder_map[i]\n if not isinstance(typ, ByteArrayLike):\n holder, maxlen = pack_args_by_32(\n holder,\n maxlen,\n prealloacted.get(i, arg),\n typ,\n context,\n placeholder,\n zero_pad_i=zero_pad_i,\n pos=pos,\n )\n\n # Dynamic position starts right after the static args.\n if requires_dynamic_offset:\n holder.append(LLLnode.from_list(['mstore', dynamic_offset_counter, maxlen]))\n\n # Calculate maximum dynamic offset placeholders, used for gas estimation.\n for _arg, data in zip(args, expected_data):\n typ = data.typ\n if isinstance(typ, ByteArrayLike):\n maxlen += 32 + ceil32(typ.maxlen)\n\n if requires_dynamic_offset:\n datamem_start = dynamic_placeholder + 32\n else:\n datamem_start = placeholder_map[0]\n\n # Copy necessary data into allocated dynamic section.\n for i, (arg, data) in enumerate(zip(args, expected_data)):\n typ = data.typ\n if isinstance(typ, ByteArrayLike):\n pack_args_by_32(\n holder=holder,\n maxlen=maxlen,\n arg=prealloacted.get(i, arg),\n typ=typ,\n context=context,\n placeholder=placeholder_map[i],\n datamem_start=datamem_start,\n dynamic_offset_counter=dynamic_offset_counter,\n zero_pad_i=zero_pad_i,\n pos=pos\n )\n\n return holder, maxlen, dynamic_offset_counter, datamem_start\n", "path": "vyper/parser/events.py"}]}
| 4,067 | 158 |
gh_patches_debug_5269
|
rasdani/github-patches
|
git_diff
|
freedomofpress__securedrop-354
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Stuck in "Sorry, we couldn't locate what you requested" state
As a source, after generating a code and clicking the "Continue..." button and going back, then refreshing you get stuck on a page that says "Sorry, we couldn't locate what you requested". Going to any URL causes the same message to be displayed and you have to close the browser to be able to get back to a normal state.
</issue>
<code>
[start of securedrop/source.py]
1 # -*- coding: utf-8 -*-
2 import os
3 from datetime import datetime
4 import uuid
5 from functools import wraps
6 import zipfile
7 from cStringIO import StringIO
8 import subprocess
9
10 import logging
11 # This module's logger is explicitly labeled so the correct logger is used,
12 # even when this is run from the command line (e.g. during development)
13 log = logging.getLogger('source')
14
15 from flask import (Flask, request, render_template, session, redirect, url_for,
16 flash, abort, g, send_file)
17 from flask_wtf.csrf import CsrfProtect
18
19 from sqlalchemy.orm.exc import MultipleResultsFound, NoResultFound
20
21 import config
22 import version
23 import crypto_util
24 import store
25 import background
26 from db import db_session, Source, Submission
27
28 app = Flask(__name__, template_folder=config.SOURCE_TEMPLATES_DIR)
29 app.config.from_object(config.FlaskConfig)
30 CsrfProtect(app)
31
32 app.jinja_env.globals['version'] = version.__version__
33 if getattr(config, 'CUSTOM_HEADER_IMAGE', None):
34 app.jinja_env.globals['header_image'] = config.CUSTOM_HEADER_IMAGE
35 app.jinja_env.globals['use_custom_header_image'] = True
36 else:
37 app.jinja_env.globals['header_image'] = 'securedrop.png'
38 app.jinja_env.globals['use_custom_header_image'] = False
39
40
41 @app.teardown_appcontext
42 def shutdown_session(exception=None):
43 """Automatically remove database sessions at the end of the request, or
44 when the application shuts down"""
45 db_session.remove()
46
47
48 def logged_in():
49 if 'logged_in' in session:
50 return True
51
52
53 def login_required(f):
54 @wraps(f)
55 def decorated_function(*args, **kwargs):
56 if not logged_in():
57 return redirect(url_for('lookup'))
58 return f(*args, **kwargs)
59 return decorated_function
60
61
62 def ignore_static(f):
63 """Only executes the wrapped function if we're not loading a static resource."""
64 @wraps(f)
65 def decorated_function(*args, **kwargs):
66 if request.path.startswith('/static'):
67 return # don't execute the decorated function
68 return f(*args, **kwargs)
69 return decorated_function
70
71
72 @app.before_request
73 @ignore_static
74 def setup_g():
75 """Store commonly used values in Flask's special g object"""
76 # ignore_static here because `crypto_util.hash_codename` is scrypt (very
77 # time consuming), and we don't need to waste time running if we're just
78 # serving a static resource that won't need to access these common values.
79 if logged_in():
80 g.codename = session['codename']
81 g.sid = crypto_util.hash_codename(g.codename)
82 try:
83 g.source = Source.query.filter(Source.filesystem_id == g.sid).one()
84 except MultipleResultsFound as e:
85 app.logger.error("Found multiple Sources when one was expected: %s" % (e,))
86 abort(500)
87 except NoResultFound as e:
88 app.logger.error("Found no Sources when one was expected: %s" % (e,))
89 abort(404)
90 g.loc = store.path(g.sid)
91
92
93 @app.before_request
94 @ignore_static
95 def check_tor2web():
96 # ignore_static here so we only flash a single message warning about Tor2Web,
97 # corresponding to the intial page load.
98 if 'X-tor2web' in request.headers:
99 flash('<strong>WARNING:</strong> You appear to be using Tor2Web. '
100 'This <strong>does not</strong> provide anonymity. '
101 '<a href="/tor2web-warning">Why is this dangerous?</a>',
102 "header-warning")
103
104
105 @app.route('/')
106 def index():
107 return render_template('index.html')
108
109
110 @app.route('/generate', methods=('GET', 'POST'))
111 def generate():
112 number_words = 8
113 if request.method == 'POST':
114 number_words = int(request.form['number-words'])
115 if number_words not in range(7, 11):
116 abort(403)
117 session['codename'] = crypto_util.genrandomid(number_words)
118 # TODO: make sure this codename isn't a repeat
119 return render_template('generate.html', codename=session['codename'])
120
121
122 @app.route('/create', methods=['POST'])
123 def create():
124 sid = crypto_util.hash_codename(session['codename'])
125
126 source = Source(sid, crypto_util.display_id())
127 db_session.add(source)
128 db_session.commit()
129
130 if os.path.exists(store.path(sid)):
131 # if this happens, we're not using very secure crypto
132 log.warning("Got a duplicate ID '%s'" % sid)
133 else:
134 os.mkdir(store.path(sid))
135
136 session['logged_in'] = True
137 return redirect(url_for('lookup'))
138
139
140 @app.route('/lookup', methods=('GET',))
141 @login_required
142 def lookup():
143 replies = []
144 for fn in os.listdir(g.loc):
145 if fn.startswith('reply-'):
146 try:
147 msg = crypto_util.decrypt(g.sid, g.codename,
148 file(store.path(g.sid, fn)).read()).decode("utf-8")
149 except UnicodeDecodeError:
150 app.logger.error("Could not decode reply %s" % fn)
151 else:
152 date = str(datetime.fromtimestamp(
153 os.stat(store.path(g.sid, fn)).st_mtime))
154 replies.append(dict(id=fn, date=date, msg=msg))
155
156 def async_genkey(sid, codename):
157 with app.app_context():
158 background.execute(lambda: crypto_util.genkeypair(sid, codename))
159
160 # Generate a keypair to encrypt replies from the journalist
161 # Only do this if the journalist has flagged the source as one
162 # that they would like to reply to. (Issue #140.)
163 if not crypto_util.getkey(g.sid) and g.source.flagged:
164 async_genkey(g.sid, g.codename)
165
166 return render_template('lookup.html', codename=g.codename, msgs=replies,
167 flagged=g.source.flagged, haskey=crypto_util.getkey(g.sid))
168
169
170 def normalize_timestamps(sid):
171 """
172 Update the timestamps on all of the source's submissions to match that of
173 the latest submission. This minimizes metadata that could be useful to
174 investigators. See #301.
175 """
176 sub_paths = [ store.path(sid, submission.filename)
177 for submission in g.source.submissions ]
178 if len(sub_paths) > 1:
179 args = ["touch"]
180 args.extend(sub_paths[:-1])
181 rc = subprocess.call(args)
182 if rc != 0:
183 app.logger.warning("Couldn't normalize submission timestamps (touch exited with %d)" % rc)
184
185
186 @app.route('/submit', methods=('POST',))
187 @login_required
188 def submit():
189 msg = request.form['msg']
190 fh = request.files['fh']
191 strip_metadata = True if 'notclean' in request.form else False
192
193 fnames = []
194
195 if msg:
196 fnames.append(store.save_message_submission(g.sid, msg))
197 flash("Thanks! We received your message.", "notification")
198 if fh:
199 fnames.append(store.save_file_submission(g.sid, fh.filename,
200 fh.stream, fh.content_type, strip_metadata))
201 flash("Thanks! We received your document '%s'."
202 % fh.filename or '[unnamed]', "notification")
203
204 for fname in fnames:
205 submission = Submission(g.source, fname)
206 db_session.add(submission)
207
208 if g.source.pending:
209 g.source.pending = False
210
211 # Generate a keypair now, if there's enough entropy (issue #303)
212 entropy_avail = int(open('/proc/sys/kernel/random/entropy_avail').read())
213 if entropy_avail >= 2400:
214 crypto_util.genkeypair(g.sid, g.codename)
215
216 g.source.last_updated = datetime.now()
217 db_session.commit()
218 normalize_timestamps(g.sid)
219
220 return redirect(url_for('lookup'))
221
222
223 @app.route('/delete', methods=('POST',))
224 @login_required
225 def delete():
226 msgid = request.form['msgid']
227 assert '/' not in msgid
228 potential_files = os.listdir(g.loc)
229 if msgid not in potential_files:
230 abort(404) # TODO are the checks necessary?
231 store.secure_unlink(store.path(g.sid, msgid))
232 flash("Reply deleted.", "notification")
233
234 return redirect(url_for('lookup'))
235
236
237 def valid_codename(codename):
238 return os.path.exists(store.path(crypto_util.hash_codename(codename)))
239
240 @app.route('/login', methods=('GET', 'POST'))
241 def login():
242 if request.method == 'POST':
243 codename = request.form['codename']
244 if valid_codename(codename):
245 session.update(codename=codename, logged_in=True)
246 return redirect(url_for('lookup'))
247 else:
248 flash("Sorry, that is not a recognized codename.", "error")
249 return render_template('login.html')
250
251
252 @app.route('/howto-disable-js')
253 def howto_disable_js():
254 return render_template("howto-disable-js.html")
255
256
257 @app.route('/tor2web-warning')
258 def tor2web_warning():
259 return render_template("tor2web-warning.html")
260
261
262 @app.route('/journalist-key')
263 def download_journalist_pubkey():
264 journalist_pubkey = crypto_util.gpg.export_keys(config.JOURNALIST_KEY)
265 return send_file(StringIO(journalist_pubkey),
266 mimetype="application/pgp-keys",
267 attachment_filename=config.JOURNALIST_KEY + ".asc",
268 as_attachment=True)
269
270
271 @app.route('/why-journalist-key')
272 def why_download_journalist_pubkey():
273 return render_template("why-journalist-key.html")
274
275
276 _REDIRECT_URL_WHITELIST = ["http://tor2web.org/",
277 "https://www.torproject.org/download.html.en",
278 "https://tails.boum.org/",
279 "http://www.wired.com/threatlevel/2013/09/freedom-hosting-fbi/",
280 "http://www.theguardian.com/world/interactive/2013/oct/04/egotistical-giraffe-nsa-tor-document",
281 "https://addons.mozilla.org/en-US/firefox/addon/noscript/",
282 "http://noscript.net"]
283
284
285 @app.route('/redirect/<path:redirect_url>')
286 def redirect_hack(redirect_url):
287 # A hack to avoid referer leakage when a user clicks on an external link.
288 # TODO: Most likely will want to share this between source.py and
289 # journalist.py in the future.
290 if redirect_url not in _REDIRECT_URL_WHITELIST:
291 return 'Redirect not allowed'
292 else:
293 return render_template("redirect.html", redirect_url=redirect_url)
294
295
296 @app.errorhandler(404)
297 def page_not_found(error):
298 return render_template('notfound.html'), 404
299
300 @app.errorhandler(500)
301 def internal_error(error):
302 return render_template('error.html'), 500
303
304 if __name__ == "__main__":
305 # TODO make sure debug is not on in production
306 app.run(debug=True, host='0.0.0.0', port=8080)
307
[end of securedrop/source.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/securedrop/source.py b/securedrop/source.py
--- a/securedrop/source.py
+++ b/securedrop/source.py
@@ -115,6 +115,7 @@
if number_words not in range(7, 11):
abort(403)
session['codename'] = crypto_util.genrandomid(number_words)
+ session.pop('logged_in', None)
# TODO: make sure this codename isn't a repeat
return render_template('generate.html', codename=session['codename'])
|
{"golden_diff": "diff --git a/securedrop/source.py b/securedrop/source.py\n--- a/securedrop/source.py\n+++ b/securedrop/source.py\n@@ -115,6 +115,7 @@\n if number_words not in range(7, 11):\n abort(403)\n session['codename'] = crypto_util.genrandomid(number_words)\n+ session.pop('logged_in', None)\n # TODO: make sure this codename isn't a repeat\n return render_template('generate.html', codename=session['codename'])\n", "issue": "Stuck in \"Sorry, we couldn't locate what you requested\" state\nAs a source, after generating a code and clicking the \"Continue...\" button and going back, then refreshing you get stuck on a page that says \"Sorry, we couldn't locate what you requested\". Going to any URL causes the same message to be displayed and you have to close the browser to be able to get back to a normal state.\n\n", "before_files": [{"content": "# -*- coding: utf-8 -*-\nimport os\nfrom datetime import datetime\nimport uuid\nfrom functools import wraps\nimport zipfile\nfrom cStringIO import StringIO\nimport subprocess\n\nimport logging\n# This module's logger is explicitly labeled so the correct logger is used,\n# even when this is run from the command line (e.g. during development)\nlog = logging.getLogger('source')\n\nfrom flask import (Flask, request, render_template, session, redirect, url_for,\n flash, abort, g, send_file)\nfrom flask_wtf.csrf import CsrfProtect\n\nfrom sqlalchemy.orm.exc import MultipleResultsFound, NoResultFound\n\nimport config\nimport version\nimport crypto_util\nimport store\nimport background\nfrom db import db_session, Source, Submission\n\napp = Flask(__name__, template_folder=config.SOURCE_TEMPLATES_DIR)\napp.config.from_object(config.FlaskConfig)\nCsrfProtect(app)\n\napp.jinja_env.globals['version'] = version.__version__\nif getattr(config, 'CUSTOM_HEADER_IMAGE', None):\n app.jinja_env.globals['header_image'] = config.CUSTOM_HEADER_IMAGE\n app.jinja_env.globals['use_custom_header_image'] = True\nelse:\n app.jinja_env.globals['header_image'] = 'securedrop.png'\n app.jinja_env.globals['use_custom_header_image'] = False\n\n\[email protected]_appcontext\ndef shutdown_session(exception=None):\n \"\"\"Automatically remove database sessions at the end of the request, or\n when the application shuts down\"\"\"\n db_session.remove()\n\n\ndef logged_in():\n if 'logged_in' in session:\n return True\n\n\ndef login_required(f):\n @wraps(f)\n def decorated_function(*args, **kwargs):\n if not logged_in():\n return redirect(url_for('lookup'))\n return f(*args, **kwargs)\n return decorated_function\n\n\ndef ignore_static(f):\n \"\"\"Only executes the wrapped function if we're not loading a static resource.\"\"\"\n @wraps(f)\n def decorated_function(*args, **kwargs):\n if request.path.startswith('/static'):\n return # don't execute the decorated function\n return f(*args, **kwargs)\n return decorated_function\n\n\[email protected]_request\n@ignore_static\ndef setup_g():\n \"\"\"Store commonly used values in Flask's special g object\"\"\"\n # ignore_static here because `crypto_util.hash_codename` is scrypt (very\n # time consuming), and we don't need to waste time running if we're just\n # serving a static resource that won't need to access these common values.\n if logged_in():\n g.codename = session['codename']\n g.sid = crypto_util.hash_codename(g.codename)\n try:\n g.source = Source.query.filter(Source.filesystem_id == g.sid).one()\n except MultipleResultsFound as e:\n app.logger.error(\"Found multiple Sources when one was expected: %s\" % (e,))\n abort(500)\n except NoResultFound as e:\n app.logger.error(\"Found no Sources when one was expected: %s\" % (e,))\n abort(404)\n g.loc = store.path(g.sid)\n\n\[email protected]_request\n@ignore_static\ndef check_tor2web():\n # ignore_static here so we only flash a single message warning about Tor2Web,\n # corresponding to the intial page load.\n if 'X-tor2web' in request.headers:\n flash('<strong>WARNING:</strong> You appear to be using Tor2Web. '\n 'This <strong>does not</strong> provide anonymity. '\n '<a href=\"/tor2web-warning\">Why is this dangerous?</a>',\n \"header-warning\")\n\n\[email protected]('/')\ndef index():\n return render_template('index.html')\n\n\[email protected]('/generate', methods=('GET', 'POST'))\ndef generate():\n number_words = 8\n if request.method == 'POST':\n number_words = int(request.form['number-words'])\n if number_words not in range(7, 11):\n abort(403)\n session['codename'] = crypto_util.genrandomid(number_words)\n # TODO: make sure this codename isn't a repeat\n return render_template('generate.html', codename=session['codename'])\n\n\[email protected]('/create', methods=['POST'])\ndef create():\n sid = crypto_util.hash_codename(session['codename'])\n\n source = Source(sid, crypto_util.display_id())\n db_session.add(source)\n db_session.commit()\n\n if os.path.exists(store.path(sid)):\n # if this happens, we're not using very secure crypto\n log.warning(\"Got a duplicate ID '%s'\" % sid)\n else:\n os.mkdir(store.path(sid))\n\n session['logged_in'] = True\n return redirect(url_for('lookup'))\n\n\[email protected]('/lookup', methods=('GET',))\n@login_required\ndef lookup():\n replies = []\n for fn in os.listdir(g.loc):\n if fn.startswith('reply-'):\n try:\n msg = crypto_util.decrypt(g.sid, g.codename,\n file(store.path(g.sid, fn)).read()).decode(\"utf-8\")\n except UnicodeDecodeError:\n app.logger.error(\"Could not decode reply %s\" % fn)\n else:\n date = str(datetime.fromtimestamp(\n os.stat(store.path(g.sid, fn)).st_mtime))\n replies.append(dict(id=fn, date=date, msg=msg))\n\n def async_genkey(sid, codename):\n with app.app_context():\n background.execute(lambda: crypto_util.genkeypair(sid, codename))\n\n # Generate a keypair to encrypt replies from the journalist\n # Only do this if the journalist has flagged the source as one\n # that they would like to reply to. (Issue #140.)\n if not crypto_util.getkey(g.sid) and g.source.flagged:\n async_genkey(g.sid, g.codename)\n\n return render_template('lookup.html', codename=g.codename, msgs=replies,\n flagged=g.source.flagged, haskey=crypto_util.getkey(g.sid))\n\n\ndef normalize_timestamps(sid):\n \"\"\"\n Update the timestamps on all of the source's submissions to match that of\n the latest submission. This minimizes metadata that could be useful to\n investigators. See #301.\n \"\"\"\n sub_paths = [ store.path(sid, submission.filename)\n for submission in g.source.submissions ]\n if len(sub_paths) > 1:\n args = [\"touch\"]\n args.extend(sub_paths[:-1])\n rc = subprocess.call(args)\n if rc != 0:\n app.logger.warning(\"Couldn't normalize submission timestamps (touch exited with %d)\" % rc)\n\n\[email protected]('/submit', methods=('POST',))\n@login_required\ndef submit():\n msg = request.form['msg']\n fh = request.files['fh']\n strip_metadata = True if 'notclean' in request.form else False\n\n fnames = []\n\n if msg:\n fnames.append(store.save_message_submission(g.sid, msg))\n flash(\"Thanks! We received your message.\", \"notification\")\n if fh:\n fnames.append(store.save_file_submission(g.sid, fh.filename,\n fh.stream, fh.content_type, strip_metadata))\n flash(\"Thanks! We received your document '%s'.\"\n % fh.filename or '[unnamed]', \"notification\")\n\n for fname in fnames:\n submission = Submission(g.source, fname)\n db_session.add(submission)\n\n if g.source.pending:\n g.source.pending = False\n\n # Generate a keypair now, if there's enough entropy (issue #303)\n entropy_avail = int(open('/proc/sys/kernel/random/entropy_avail').read())\n if entropy_avail >= 2400:\n crypto_util.genkeypair(g.sid, g.codename)\n\n g.source.last_updated = datetime.now()\n db_session.commit()\n normalize_timestamps(g.sid)\n\n return redirect(url_for('lookup'))\n\n\[email protected]('/delete', methods=('POST',))\n@login_required\ndef delete():\n msgid = request.form['msgid']\n assert '/' not in msgid\n potential_files = os.listdir(g.loc)\n if msgid not in potential_files:\n abort(404) # TODO are the checks necessary?\n store.secure_unlink(store.path(g.sid, msgid))\n flash(\"Reply deleted.\", \"notification\")\n\n return redirect(url_for('lookup'))\n\n\ndef valid_codename(codename):\n return os.path.exists(store.path(crypto_util.hash_codename(codename)))\n\[email protected]('/login', methods=('GET', 'POST'))\ndef login():\n if request.method == 'POST':\n codename = request.form['codename']\n if valid_codename(codename):\n session.update(codename=codename, logged_in=True)\n return redirect(url_for('lookup'))\n else:\n flash(\"Sorry, that is not a recognized codename.\", \"error\")\n return render_template('login.html')\n\n\[email protected]('/howto-disable-js')\ndef howto_disable_js():\n return render_template(\"howto-disable-js.html\")\n\n\[email protected]('/tor2web-warning')\ndef tor2web_warning():\n return render_template(\"tor2web-warning.html\")\n\n\[email protected]('/journalist-key')\ndef download_journalist_pubkey():\n journalist_pubkey = crypto_util.gpg.export_keys(config.JOURNALIST_KEY)\n return send_file(StringIO(journalist_pubkey),\n mimetype=\"application/pgp-keys\",\n attachment_filename=config.JOURNALIST_KEY + \".asc\",\n as_attachment=True)\n\n\[email protected]('/why-journalist-key')\ndef why_download_journalist_pubkey():\n return render_template(\"why-journalist-key.html\")\n\n\n_REDIRECT_URL_WHITELIST = [\"http://tor2web.org/\",\n \"https://www.torproject.org/download.html.en\",\n \"https://tails.boum.org/\",\n \"http://www.wired.com/threatlevel/2013/09/freedom-hosting-fbi/\",\n \"http://www.theguardian.com/world/interactive/2013/oct/04/egotistical-giraffe-nsa-tor-document\",\n \"https://addons.mozilla.org/en-US/firefox/addon/noscript/\",\n \"http://noscript.net\"]\n\n\[email protected]('/redirect/<path:redirect_url>')\ndef redirect_hack(redirect_url):\n # A hack to avoid referer leakage when a user clicks on an external link.\n # TODO: Most likely will want to share this between source.py and\n # journalist.py in the future.\n if redirect_url not in _REDIRECT_URL_WHITELIST:\n return 'Redirect not allowed'\n else:\n return render_template(\"redirect.html\", redirect_url=redirect_url)\n\n\[email protected](404)\ndef page_not_found(error):\n return render_template('notfound.html'), 404\n\[email protected](500)\ndef internal_error(error):\n return render_template('error.html'), 500\n\nif __name__ == \"__main__\":\n # TODO make sure debug is not on in production\n app.run(debug=True, host='0.0.0.0', port=8080)\n", "path": "securedrop/source.py"}]}
| 3,864 | 121 |
gh_patches_debug_17750
|
rasdani/github-patches
|
git_diff
|
canonical__microk8s-2195
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Indentation error in yaml output of microk8s.status
The output of `microk8s.status` is
```
microk8s:
running: False
high-availability:
enabled: False
message: microk8s is not running. Use microk8s inspect for a deeper inspection.
```
which confuses some parsers (e.g. the built-in Python 3.8) due to the extraneous space before `message`.
</issue>
<code>
[start of scripts/wrappers/status.py]
1 #!/usr/bin/python3
2 import os
3 import argparse
4
5 from common.utils import (
6 exit_if_no_permission,
7 exit_if_stopped,
8 is_cluster_locked,
9 is_ha_enabled,
10 get_dqlite_info,
11 wait_for_ready,
12 is_cluster_ready,
13 get_available_addons,
14 get_current_arch,
15 get_addon_by_name,
16 kubectl_get,
17 kubectl_get_clusterroles,
18 )
19
20
21 def is_enabled(addon, item):
22 if addon in item:
23 return True
24 else:
25 filepath = os.path.expandvars(addon)
26 return os.path.isfile(filepath)
27
28 return False
29
30
31 def print_short(isReady, enabled_addons, disabled_addons):
32 if isReady:
33 print("microk8s is running")
34 print("addons:")
35 if enabled_addons and len(enabled_addons) > 0:
36 for enabled in enabled_addons:
37 print("{}: enabled".format(enabled["name"]))
38 if disabled_addons and len(disabled_addons) > 0:
39 for disabled in disabled_addons:
40 print("{}: disabled".format(disabled["name"]))
41 else:
42 print("microk8s is not running. Use microk8s inspect for a deeper inspection.")
43
44
45 def print_pretty(isReady, enabled_addons, disabled_addons):
46 console_formatter = "{:>3} {:<20} # {}"
47 if isReady:
48 print("microk8s is running")
49 if not is_ha_enabled():
50 print("high-availability: no")
51 else:
52 info = get_dqlite_info()
53 if ha_cluster_formed(info):
54 print("high-availability: yes")
55 else:
56 print("high-availability: no")
57
58 masters = "none"
59 standby = "none"
60 for node in info:
61 if node[1] == "voter":
62 if masters == "none":
63 masters = "{}".format(node[0])
64 else:
65 masters = "{} {}".format(masters, node[0])
66 if node[1] == "standby":
67 if standby == "none":
68 standby = "{}".format(node[0])
69 else:
70 standby = "{} {}".format(standby, node[0])
71
72 print("{:>2}{} {}".format("", "datastore master nodes:", masters))
73 print("{:>2}{} {}".format("", "datastore standby nodes:", standby))
74
75 print("addons:")
76 if enabled_addons and len(enabled_addons) > 0:
77 print('{:>2}{}'.format("", "enabled:"))
78 for enabled in enabled_addons:
79 print(console_formatter.format("", enabled["name"], enabled["description"]))
80 if disabled_addons and len(disabled_addons) > 0:
81 print('{:>2}{}'.format("", "disabled:"))
82 for disabled in disabled_addons:
83 print(console_formatter.format("", disabled["name"], disabled["description"]))
84 else:
85 print("microk8s is not running. Use microk8s inspect for a deeper inspection.")
86
87
88 def print_short_yaml(isReady, enabled_addons, disabled_addons):
89 print("microk8s:")
90 print("{:>2}{} {}".format("", "running:", isReady))
91
92 if isReady:
93 print("addons:")
94 for enabled in enabled_addons:
95 print(" {}: enabled".format(enabled["name"]))
96
97 for disabled in disabled_addons:
98 print(" {}: disabled".format(disabled["name"]))
99 else:
100 print(
101 "{:>2} {} {}".format(
102 "",
103 "message:",
104 "microk8s is not running. Use microk8s inspect for a deeper inspection.",
105 )
106 )
107
108
109 def print_yaml(isReady, enabled_addons, disabled_addons):
110 print("microk8s:")
111 print("{:>2}{} {}".format("", "running:", isReady))
112
113 print("{:>2}".format("high-availability:"))
114 ha_enabled = is_ha_enabled()
115 print("{:>2}{} {}".format("", "enabled:", ha_enabled))
116 if ha_enabled:
117 info = get_dqlite_info()
118 print("{:>2}{}".format("", "nodes:"))
119 for node in info:
120 print("{:>6}address: {:<1}".format("- ", node[0]))
121 print("{:>6}role: {:<1}".format("", node[1]))
122
123 if isReady:
124 print("{:>2}".format("addons:"))
125 for enabled in enabled_addons:
126 print("{:>4}name: {:<1}".format("- ", enabled["name"]))
127 print("{:>4}description: {:<1}".format("", enabled["description"]))
128 print("{:>4}version: {:<1}".format("", enabled["version"]))
129 print("{:>4}status: enabled".format(""))
130
131 for disabled in disabled_addons:
132 print("{:>4}name: {:<1}".format("- ", disabled["name"]))
133 print("{:>4}description: {:<1}".format("", disabled["description"]))
134 print("{:>4}version: {:<1}".format("", disabled["version"]))
135 print("{:>4}status: disabled".format(""))
136 else:
137 print(
138 "{:>2} {} {}".format(
139 "",
140 "message:",
141 "microk8s is not running. Use microk8s inspect for a deeper inspection.",
142 )
143 )
144
145
146 def print_addon_status(enabled):
147 if len(enabled) > 0:
148 print("enabled")
149 else:
150 print("disabled")
151
152
153 def get_status(available_addons, isReady):
154 enabled = []
155 disabled = []
156 if isReady:
157 kube_output = kubectl_get("all")
158 cluster_output = kubectl_get_clusterroles()
159 kube_output = kube_output + cluster_output
160 for addon in available_addons:
161 found = False
162 for row in kube_output.split('\n'):
163 if is_enabled(addon["check_status"], row):
164 enabled.append(addon)
165 found = True
166 break
167 if not found:
168 disabled.append(addon)
169
170 return enabled, disabled
171
172
173 def ha_cluster_formed(info):
174 voters = 0
175 for node in info:
176 if node[1] == "voter":
177 voters += 1
178 ha_formed = False
179 if voters > 2:
180 ha_formed = True
181 return ha_formed
182
183
184 if __name__ == '__main__':
185 exit_if_no_permission()
186 exit_if_stopped()
187 is_cluster_locked()
188
189 # initiate the parser with a description
190 parser = argparse.ArgumentParser(
191 description='Microk8s cluster status check.', prog='microk8s status'
192 )
193 parser.add_argument(
194 "--format",
195 help="print cluster and addon status, output can be in yaml, pretty or short",
196 default="pretty",
197 choices={"pretty", "yaml", "short"},
198 )
199 parser.add_argument(
200 "-w", "--wait-ready", action='store_true', help="wait until the cluster is in ready state"
201 )
202 parser.add_argument(
203 "-t",
204 "--timeout",
205 help="specify a timeout in seconds when waiting for the cluster to be ready.",
206 type=int,
207 default=0,
208 )
209 parser.add_argument("-a", "--addon", help="check the status of an addon.", default="all")
210 parser.add_argument(
211 "--yaml", action='store_true', help="DEPRECATED, use '--format yaml' instead"
212 )
213
214 # read arguments from the command line
215 args = parser.parse_args()
216
217 wait_ready = args.wait_ready
218 timeout = args.timeout
219 yaml_short = args.yaml
220
221 if wait_ready:
222 isReady = wait_for_ready(wait_ready, timeout)
223 else:
224 isReady = is_cluster_ready()
225
226 available_addons = get_available_addons(get_current_arch())
227
228 if args.addon != "all":
229 available_addons = get_addon_by_name(available_addons, args.addon)
230
231 enabled, disabled = get_status(available_addons, isReady)
232
233 if args.addon != "all":
234 print_addon_status(enabled)
235 else:
236 if args.format == "yaml":
237 print_yaml(isReady, enabled, disabled)
238 elif args.format == "short":
239 print_short(isReady, enabled, disabled)
240 else:
241 if yaml_short:
242 print_short_yaml(isReady, enabled, disabled)
243 else:
244 print_pretty(isReady, enabled, disabled)
245
[end of scripts/wrappers/status.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/scripts/wrappers/status.py b/scripts/wrappers/status.py
--- a/scripts/wrappers/status.py
+++ b/scripts/wrappers/status.py
@@ -98,7 +98,7 @@
print(" {}: disabled".format(disabled["name"]))
else:
print(
- "{:>2} {} {}".format(
+ "{:>2}{} {}".format(
"",
"message:",
"microk8s is not running. Use microk8s inspect for a deeper inspection.",
@@ -135,7 +135,7 @@
print("{:>4}status: disabled".format(""))
else:
print(
- "{:>2} {} {}".format(
+ "{:>2}{} {}".format(
"",
"message:",
"microk8s is not running. Use microk8s inspect for a deeper inspection.",
|
{"golden_diff": "diff --git a/scripts/wrappers/status.py b/scripts/wrappers/status.py\n--- a/scripts/wrappers/status.py\n+++ b/scripts/wrappers/status.py\n@@ -98,7 +98,7 @@\n print(\" {}: disabled\".format(disabled[\"name\"]))\n else:\n print(\n- \"{:>2} {} {}\".format(\n+ \"{:>2}{} {}\".format(\n \"\",\n \"message:\",\n \"microk8s is not running. Use microk8s inspect for a deeper inspection.\",\n@@ -135,7 +135,7 @@\n print(\"{:>4}status: disabled\".format(\"\"))\n else:\n print(\n- \"{:>2} {} {}\".format(\n+ \"{:>2}{} {}\".format(\n \"\",\n \"message:\",\n \"microk8s is not running. Use microk8s inspect for a deeper inspection.\",\n", "issue": "Indentation error in yaml output of microk8s.status\nThe output of `microk8s.status` is\r\n\r\n```\r\nmicrok8s:\r\n running: False\r\nhigh-availability:\r\n enabled: False\r\n message: microk8s is not running. Use microk8s inspect for a deeper inspection.\r\n```\r\n\r\nwhich confuses some parsers (e.g. the built-in Python 3.8) due to the extraneous space before `message`.\n", "before_files": [{"content": "#!/usr/bin/python3\nimport os\nimport argparse\n\nfrom common.utils import (\n exit_if_no_permission,\n exit_if_stopped,\n is_cluster_locked,\n is_ha_enabled,\n get_dqlite_info,\n wait_for_ready,\n is_cluster_ready,\n get_available_addons,\n get_current_arch,\n get_addon_by_name,\n kubectl_get,\n kubectl_get_clusterroles,\n)\n\n\ndef is_enabled(addon, item):\n if addon in item:\n return True\n else:\n filepath = os.path.expandvars(addon)\n return os.path.isfile(filepath)\n\n return False\n\n\ndef print_short(isReady, enabled_addons, disabled_addons):\n if isReady:\n print(\"microk8s is running\")\n print(\"addons:\")\n if enabled_addons and len(enabled_addons) > 0:\n for enabled in enabled_addons:\n print(\"{}: enabled\".format(enabled[\"name\"]))\n if disabled_addons and len(disabled_addons) > 0:\n for disabled in disabled_addons:\n print(\"{}: disabled\".format(disabled[\"name\"]))\n else:\n print(\"microk8s is not running. Use microk8s inspect for a deeper inspection.\")\n\n\ndef print_pretty(isReady, enabled_addons, disabled_addons):\n console_formatter = \"{:>3} {:<20} # {}\"\n if isReady:\n print(\"microk8s is running\")\n if not is_ha_enabled():\n print(\"high-availability: no\")\n else:\n info = get_dqlite_info()\n if ha_cluster_formed(info):\n print(\"high-availability: yes\")\n else:\n print(\"high-availability: no\")\n\n masters = \"none\"\n standby = \"none\"\n for node in info:\n if node[1] == \"voter\":\n if masters == \"none\":\n masters = \"{}\".format(node[0])\n else:\n masters = \"{} {}\".format(masters, node[0])\n if node[1] == \"standby\":\n if standby == \"none\":\n standby = \"{}\".format(node[0])\n else:\n standby = \"{} {}\".format(standby, node[0])\n\n print(\"{:>2}{} {}\".format(\"\", \"datastore master nodes:\", masters))\n print(\"{:>2}{} {}\".format(\"\", \"datastore standby nodes:\", standby))\n\n print(\"addons:\")\n if enabled_addons and len(enabled_addons) > 0:\n print('{:>2}{}'.format(\"\", \"enabled:\"))\n for enabled in enabled_addons:\n print(console_formatter.format(\"\", enabled[\"name\"], enabled[\"description\"]))\n if disabled_addons and len(disabled_addons) > 0:\n print('{:>2}{}'.format(\"\", \"disabled:\"))\n for disabled in disabled_addons:\n print(console_formatter.format(\"\", disabled[\"name\"], disabled[\"description\"]))\n else:\n print(\"microk8s is not running. Use microk8s inspect for a deeper inspection.\")\n\n\ndef print_short_yaml(isReady, enabled_addons, disabled_addons):\n print(\"microk8s:\")\n print(\"{:>2}{} {}\".format(\"\", \"running:\", isReady))\n\n if isReady:\n print(\"addons:\")\n for enabled in enabled_addons:\n print(\" {}: enabled\".format(enabled[\"name\"]))\n\n for disabled in disabled_addons:\n print(\" {}: disabled\".format(disabled[\"name\"]))\n else:\n print(\n \"{:>2} {} {}\".format(\n \"\",\n \"message:\",\n \"microk8s is not running. Use microk8s inspect for a deeper inspection.\",\n )\n )\n\n\ndef print_yaml(isReady, enabled_addons, disabled_addons):\n print(\"microk8s:\")\n print(\"{:>2}{} {}\".format(\"\", \"running:\", isReady))\n\n print(\"{:>2}\".format(\"high-availability:\"))\n ha_enabled = is_ha_enabled()\n print(\"{:>2}{} {}\".format(\"\", \"enabled:\", ha_enabled))\n if ha_enabled:\n info = get_dqlite_info()\n print(\"{:>2}{}\".format(\"\", \"nodes:\"))\n for node in info:\n print(\"{:>6}address: {:<1}\".format(\"- \", node[0]))\n print(\"{:>6}role: {:<1}\".format(\"\", node[1]))\n\n if isReady:\n print(\"{:>2}\".format(\"addons:\"))\n for enabled in enabled_addons:\n print(\"{:>4}name: {:<1}\".format(\"- \", enabled[\"name\"]))\n print(\"{:>4}description: {:<1}\".format(\"\", enabled[\"description\"]))\n print(\"{:>4}version: {:<1}\".format(\"\", enabled[\"version\"]))\n print(\"{:>4}status: enabled\".format(\"\"))\n\n for disabled in disabled_addons:\n print(\"{:>4}name: {:<1}\".format(\"- \", disabled[\"name\"]))\n print(\"{:>4}description: {:<1}\".format(\"\", disabled[\"description\"]))\n print(\"{:>4}version: {:<1}\".format(\"\", disabled[\"version\"]))\n print(\"{:>4}status: disabled\".format(\"\"))\n else:\n print(\n \"{:>2} {} {}\".format(\n \"\",\n \"message:\",\n \"microk8s is not running. Use microk8s inspect for a deeper inspection.\",\n )\n )\n\n\ndef print_addon_status(enabled):\n if len(enabled) > 0:\n print(\"enabled\")\n else:\n print(\"disabled\")\n\n\ndef get_status(available_addons, isReady):\n enabled = []\n disabled = []\n if isReady:\n kube_output = kubectl_get(\"all\")\n cluster_output = kubectl_get_clusterroles()\n kube_output = kube_output + cluster_output\n for addon in available_addons:\n found = False\n for row in kube_output.split('\\n'):\n if is_enabled(addon[\"check_status\"], row):\n enabled.append(addon)\n found = True\n break\n if not found:\n disabled.append(addon)\n\n return enabled, disabled\n\n\ndef ha_cluster_formed(info):\n voters = 0\n for node in info:\n if node[1] == \"voter\":\n voters += 1\n ha_formed = False\n if voters > 2:\n ha_formed = True\n return ha_formed\n\n\nif __name__ == '__main__':\n exit_if_no_permission()\n exit_if_stopped()\n is_cluster_locked()\n\n # initiate the parser with a description\n parser = argparse.ArgumentParser(\n description='Microk8s cluster status check.', prog='microk8s status'\n )\n parser.add_argument(\n \"--format\",\n help=\"print cluster and addon status, output can be in yaml, pretty or short\",\n default=\"pretty\",\n choices={\"pretty\", \"yaml\", \"short\"},\n )\n parser.add_argument(\n \"-w\", \"--wait-ready\", action='store_true', help=\"wait until the cluster is in ready state\"\n )\n parser.add_argument(\n \"-t\",\n \"--timeout\",\n help=\"specify a timeout in seconds when waiting for the cluster to be ready.\",\n type=int,\n default=0,\n )\n parser.add_argument(\"-a\", \"--addon\", help=\"check the status of an addon.\", default=\"all\")\n parser.add_argument(\n \"--yaml\", action='store_true', help=\"DEPRECATED, use '--format yaml' instead\"\n )\n\n # read arguments from the command line\n args = parser.parse_args()\n\n wait_ready = args.wait_ready\n timeout = args.timeout\n yaml_short = args.yaml\n\n if wait_ready:\n isReady = wait_for_ready(wait_ready, timeout)\n else:\n isReady = is_cluster_ready()\n\n available_addons = get_available_addons(get_current_arch())\n\n if args.addon != \"all\":\n available_addons = get_addon_by_name(available_addons, args.addon)\n\n enabled, disabled = get_status(available_addons, isReady)\n\n if args.addon != \"all\":\n print_addon_status(enabled)\n else:\n if args.format == \"yaml\":\n print_yaml(isReady, enabled, disabled)\n elif args.format == \"short\":\n print_short(isReady, enabled, disabled)\n else:\n if yaml_short:\n print_short_yaml(isReady, enabled, disabled)\n else:\n print_pretty(isReady, enabled, disabled)\n", "path": "scripts/wrappers/status.py"}]}
| 3,083 | 193 |
gh_patches_debug_2733
|
rasdani/github-patches
|
git_diff
|
GeotrekCE__Geotrek-admin-805
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
ADMIN - Tronçon bouclant sur lui-même
Impossible de saisir le CIRCUIT DES LACS correctement.
Renvoie souvent une 504 BAD GATEWAY quand on enregistre. L'itinéraire a pourtant été modifié mais différemment de la façon dont il a été saisi. A creuser.
</issue>
<code>
[start of geotrek/core/forms.py]
1 from django.utils.translation import ugettext_lazy as _
2
3 import floppyforms as forms
4
5 from geotrek.common.forms import CommonForm
6 from .models import Path
7 from .helpers import PathHelper
8 from .fields import TopologyField, SnappedLineStringField
9
10
11 class TopologyForm(CommonForm):
12 """
13 This form is a bit specific :
14
15 We use a field (topology) in order to edit the whole instance.
16 Thus, at init, we load the instance into field, and at save, we
17 save the field into the instance.
18
19 The geom field is fully ignored, since we edit a topology.
20 """
21 topology = TopologyField(label="")
22
23 def __init__(self, *args, **kwargs):
24 super(TopologyForm, self).__init__(*args, **kwargs)
25 if self.instance and self.instance.pk:
26 self.fields['topology'].initial = self.instance
27
28 def clean(self, *args, **kwargs):
29 data = super(TopologyForm, self).clean()
30 # geom is computed at db-level and never edited
31 if 'geom' in self.errors:
32 del self.errors['geom']
33 return data
34
35 def save(self, *args, **kwargs):
36 topology = self.cleaned_data.pop('topology')
37 instance = super(TopologyForm, self).save(*args, **kwargs)
38 instance.mutate(topology)
39 return instance
40
41 geomfields = ['topology']
42
43 class Meta(CommonForm.Meta):
44 fields = CommonForm.Meta.fields + ['topology']
45
46 MEDIA_JS = ("core/dijkstra.js",
47 "core/leaflet-geomutils.js",
48 "core/multipath.js",
49 "core/topology_helper.js") + CommonForm.MEDIA_JS
50
51
52 class PathForm(CommonForm):
53 geom = SnappedLineStringField()
54
55 reverse_geom = forms.BooleanField(required=False,
56 label=_("Reverse path"),
57 help_text=_("The path will be reversed once saved"))
58
59 geomfields = ['geom']
60
61 class Meta(CommonForm.Meta):
62 model = Path
63 fields = CommonForm.Meta.fields + \
64 ['structure',
65 'name', 'stake', 'comfort', 'trail', 'departure', 'arrival', 'comments',
66 'datasource', 'networks', 'usages', 'valid', 'reverse_geom', 'geom']
67
68 def __init__(self, *args, **kwargs):
69 super(PathForm, self).__init__(*args, **kwargs)
70 self.fields['geom'].label = ''
71
72 def clean_geom(self):
73 geom = self.cleaned_data['geom']
74 if geom is None:
75 raise forms.ValidationError(_("Invalid snapped geometry."))
76 if not geom.simple:
77 raise forms.ValidationError(_("Geometry is not simple."))
78 if not PathHelper.disjoint(geom, self.cleaned_data.get('pk') or -1):
79 raise forms.ValidationError(_("Geometry overlaps another."))
80 return geom
81
82 def save(self, commit=True):
83 path = super(PathForm, self).save(commit=False)
84
85 if self.cleaned_data.get('reverse_geom'):
86 path.reverse()
87
88 if commit:
89 path.save()
90 self.save_m2m()
91
92 return path
93
[end of geotrek/core/forms.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/geotrek/core/forms.py b/geotrek/core/forms.py
--- a/geotrek/core/forms.py
+++ b/geotrek/core/forms.py
@@ -44,7 +44,6 @@
fields = CommonForm.Meta.fields + ['topology']
MEDIA_JS = ("core/dijkstra.js",
- "core/leaflet-geomutils.js",
"core/multipath.js",
"core/topology_helper.js") + CommonForm.MEDIA_JS
|
{"golden_diff": "diff --git a/geotrek/core/forms.py b/geotrek/core/forms.py\n--- a/geotrek/core/forms.py\n+++ b/geotrek/core/forms.py\n@@ -44,7 +44,6 @@\n fields = CommonForm.Meta.fields + ['topology']\n \n MEDIA_JS = (\"core/dijkstra.js\",\n- \"core/leaflet-geomutils.js\",\n \"core/multipath.js\",\n \"core/topology_helper.js\") + CommonForm.MEDIA_JS\n", "issue": "ADMIN - Tron\u00e7on bouclant sur lui-m\u00eame\nImpossible de saisir le CIRCUIT DES LACS correctement.\nRenvoie souvent une 504 BAD GATEWAY quand on enregistre. L'itin\u00e9raire a pourtant \u00e9t\u00e9 modifi\u00e9 mais diff\u00e9remment de la fa\u00e7on dont il a \u00e9t\u00e9 saisi. A creuser.\n\n", "before_files": [{"content": "from django.utils.translation import ugettext_lazy as _\n\nimport floppyforms as forms\n\nfrom geotrek.common.forms import CommonForm\nfrom .models import Path\nfrom .helpers import PathHelper\nfrom .fields import TopologyField, SnappedLineStringField\n\n\nclass TopologyForm(CommonForm):\n \"\"\"\n This form is a bit specific :\n\n We use a field (topology) in order to edit the whole instance.\n Thus, at init, we load the instance into field, and at save, we\n save the field into the instance.\n\n The geom field is fully ignored, since we edit a topology.\n \"\"\"\n topology = TopologyField(label=\"\")\n\n def __init__(self, *args, **kwargs):\n super(TopologyForm, self).__init__(*args, **kwargs)\n if self.instance and self.instance.pk:\n self.fields['topology'].initial = self.instance\n\n def clean(self, *args, **kwargs):\n data = super(TopologyForm, self).clean()\n # geom is computed at db-level and never edited\n if 'geom' in self.errors:\n del self.errors['geom']\n return data\n\n def save(self, *args, **kwargs):\n topology = self.cleaned_data.pop('topology')\n instance = super(TopologyForm, self).save(*args, **kwargs)\n instance.mutate(topology)\n return instance\n\n geomfields = ['topology']\n\n class Meta(CommonForm.Meta):\n fields = CommonForm.Meta.fields + ['topology']\n\n MEDIA_JS = (\"core/dijkstra.js\",\n \"core/leaflet-geomutils.js\",\n \"core/multipath.js\",\n \"core/topology_helper.js\") + CommonForm.MEDIA_JS\n\n\nclass PathForm(CommonForm):\n geom = SnappedLineStringField()\n\n reverse_geom = forms.BooleanField(required=False,\n label=_(\"Reverse path\"),\n help_text=_(\"The path will be reversed once saved\"))\n\n geomfields = ['geom']\n\n class Meta(CommonForm.Meta):\n model = Path\n fields = CommonForm.Meta.fields + \\\n ['structure',\n 'name', 'stake', 'comfort', 'trail', 'departure', 'arrival', 'comments',\n 'datasource', 'networks', 'usages', 'valid', 'reverse_geom', 'geom']\n\n def __init__(self, *args, **kwargs):\n super(PathForm, self).__init__(*args, **kwargs)\n self.fields['geom'].label = ''\n\n def clean_geom(self):\n geom = self.cleaned_data['geom']\n if geom is None:\n raise forms.ValidationError(_(\"Invalid snapped geometry.\"))\n if not geom.simple:\n raise forms.ValidationError(_(\"Geometry is not simple.\"))\n if not PathHelper.disjoint(geom, self.cleaned_data.get('pk') or -1):\n raise forms.ValidationError(_(\"Geometry overlaps another.\"))\n return geom\n\n def save(self, commit=True):\n path = super(PathForm, self).save(commit=False)\n\n if self.cleaned_data.get('reverse_geom'):\n path.reverse()\n\n if commit:\n path.save()\n self.save_m2m()\n\n return path\n", "path": "geotrek/core/forms.py"}]}
| 1,471 | 104 |
gh_patches_debug_32674
|
rasdani/github-patches
|
git_diff
|
mitmproxy__mitmproxy-2268
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
crash when export flow to 'r' curl
##### Steps to reproduce the problem:
1. enter a flow view
2. press E and choose r
3. crash
##### Any other comments? What have you tried so far?
##### System information
Traceback (most recent call last):
File "/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/mitmproxy/tools/console/master.py", line 281, in run
self.loop.run()
File "/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/urwid/main_loop.py", line 278, in run
self._run()
File "/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/urwid/main_loop.py", line 376, in _run
self.event_loop.run()
File "/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/urwid/main_loop.py", line 682, in run
self._loop()
File "/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/urwid/main_loop.py", line 719, in _loop
self._watch_files[fd]()
File "/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/urwid/raw_display.py", line 393, in <lambda>
event_loop, callback, self.get_available_raw_input())
File "/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/urwid/raw_display.py", line 493, in parse_input
callback(processed, processed_codes)
File "/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/urwid/main_loop.py", line 403, in _update
self.process_input(keys)
File "/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/urwid/main_loop.py", line 503, in process_input
k = self._topmost_widget.keypress(self.screen_size, k)
File "/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/mitmproxy/tools/console/window.py", line 84, in keypress
k = super().keypress(size, k)
File "/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/urwid/container.py", line 1116, in keypress
return self.footer.keypress((maxcol,),key)
File "/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/mitmproxy/tools/console/statusbar.py", line 155, in keypress
return self.master.ab.keypress(*args, **kwargs)
File "/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/mitmproxy/tools/console/statusbar.py", line 108, in keypress
self.prompt_execute(k)
File "/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/mitmproxy/tools/console/statusbar.py", line 133, in prompt_execute
msg = p(txt)
File "/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/mitmproxy/tools/console/statusbar.py", line 31, in __call__
return self.callback(txt, *self.args)
File "/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/mitmproxy/tools/console/common.py", line 328, in export_to_clip_or_file
writer(exporter(flow))
File "/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/mitmproxy/export.py", line 39, in curl_command
data += " --data-binary '%s'" % _native(request.content)
File "/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/mitmproxy/export.py", line 13, in _native
return s.decode()
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x88 in position 188: invalid start byte
<!--
Cut and paste the output of "mitmproxy --version".
If you're using an older version if mitmproxy, please specify the version
and OS.
-->
Mitmproxy version: 2.0.1 (release version)
Python version: 3.6.1
Platform: Darwin-16.1.0-x86_64-i386-64bit
SSL version: OpenSSL 1.1.0e 16 Feb 2017
Mac version: 10.12.1 ('', '', '') x86_64
</issue>
<code>
[start of mitmproxy/export.py]
1 import io
2 import json
3 import pprint
4 import re
5 import textwrap
6 from typing import Any
7
8 from mitmproxy import http
9
10
11 def _native(s):
12 if isinstance(s, bytes):
13 return s.decode()
14 return s
15
16
17 def dictstr(items, indent: str) -> str:
18 lines = []
19 for k, v in items:
20 lines.append(indent + "%s: %s,\n" % (repr(_native(k)), repr(_native(v))))
21 return "{\n%s}\n" % "".join(lines)
22
23
24 def curl_command(flow: http.HTTPFlow) -> str:
25 data = "curl "
26
27 request = flow.request.copy()
28 request.decode(strict=False)
29
30 for k, v in request.headers.items(multi=True):
31 data += "-H '%s:%s' " % (k, v)
32
33 if request.method != "GET":
34 data += "-X %s " % request.method
35
36 data += "'%s'" % request.url
37
38 if request.content:
39 data += " --data-binary '%s'" % _native(request.content)
40
41 return data
42
43
44 def python_arg(arg: str, val: Any) -> str:
45 if not val:
46 return ""
47 if arg:
48 arg += "="
49 arg_str = "{}{},\n".format(
50 arg,
51 pprint.pformat(val, 79 - len(arg))
52 )
53 return textwrap.indent(arg_str, " " * 4)
54
55
56 def python_code(flow: http.HTTPFlow):
57 code = io.StringIO()
58
59 def writearg(arg, val):
60 code.write(python_arg(arg, val))
61
62 code.write("import requests\n")
63 code.write("\n")
64 if flow.request.method.lower() in ("get", "post", "put", "head", "delete", "patch"):
65 code.write("response = requests.{}(\n".format(flow.request.method.lower()))
66 else:
67 code.write("response = requests.request(\n")
68 writearg("", flow.request.method)
69 url_without_query = flow.request.url.split("?", 1)[0]
70 writearg("", url_without_query)
71
72 writearg("params", list(flow.request.query.fields))
73
74 headers = flow.request.headers.copy()
75 # requests adds those by default.
76 for x in (":authority", "host", "content-length"):
77 headers.pop(x, None)
78 writearg("headers", dict(headers))
79 try:
80 if "json" not in flow.request.headers.get("content-type", ""):
81 raise ValueError()
82 writearg("json", json.loads(flow.request.text))
83 except ValueError:
84 writearg("data", flow.request.content)
85
86 code.seek(code.tell() - 2) # remove last comma
87 code.write("\n)\n")
88 code.write("\n")
89 code.write("print(response.text)")
90
91 return code.getvalue()
92
93
94 def locust_code(flow):
95 code = textwrap.dedent("""
96 from locust import HttpLocust, TaskSet, task
97
98 class UserBehavior(TaskSet):
99 def on_start(self):
100 ''' on_start is called when a Locust start before any task is scheduled '''
101 self.{name}()
102
103 @task()
104 def {name}(self):
105 url = self.locust.host + '{path}'
106 {headers}{params}{data}
107 self.response = self.client.request(
108 method='{method}',
109 url=url,{args}
110 )
111
112 ### Additional tasks can go here ###
113
114
115 class WebsiteUser(HttpLocust):
116 task_set = UserBehavior
117 min_wait = 1000
118 max_wait = 3000
119 """).strip()
120
121 name = re.sub('\W|^(?=\d)', '_', flow.request.path.strip("/").split("?", 1)[0])
122 if not name:
123 new_name = "_".join([str(flow.request.host), str(flow.request.timestamp_start)])
124 name = re.sub('\W|^(?=\d)', '_', new_name)
125
126 path_without_query = flow.request.path.split("?")[0]
127
128 args = ""
129 headers = ""
130 if flow.request.headers:
131 lines = [
132 (_native(k), _native(v)) for k, v in flow.request.headers.fields
133 if _native(k).lower() not in [":authority", "host", "cookie"]
134 ]
135 lines = [" '%s': '%s',\n" % (k, v) for k, v in lines]
136 headers += "\n headers = {\n%s }\n" % "".join(lines)
137 args += "\n headers=headers,"
138
139 params = ""
140 if flow.request.query:
141 lines = [
142 " %s: %s,\n" % (repr(k), repr(v))
143 for k, v in
144 flow.request.query.collect()
145 ]
146 params = "\n params = {\n%s }\n" % "".join(lines)
147 args += "\n params=params,"
148
149 data = ""
150 if flow.request.content:
151 data = "\n data = '''%s'''\n" % _native(flow.request.content)
152 args += "\n data=data,"
153
154 code = code.format(
155 name=name,
156 path=path_without_query,
157 headers=headers,
158 params=params,
159 data=data,
160 method=flow.request.method,
161 args=args,
162 )
163
164 return code
165
166
167 def locust_task(flow):
168 code = locust_code(flow)
169 start_task = len(code.split('@task')[0]) - 4
170 end_task = -19 - len(code.split('### Additional')[1])
171 task_code = code[start_task:end_task]
172
173 return task_code
174
175
176 def url(flow):
177 return flow.request.url
178
179
180 EXPORTERS = [
181 ("content", "c", None),
182 ("headers+content", "h", None),
183 ("url", "u", url),
184 ("as curl command", "r", curl_command),
185 ("as python code", "p", python_code),
186 ("as locust code", "l", locust_code),
187 ("as locust task", "t", locust_task),
188 ]
189
[end of mitmproxy/export.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mitmproxy/export.py b/mitmproxy/export.py
--- a/mitmproxy/export.py
+++ b/mitmproxy/export.py
@@ -6,19 +6,7 @@
from typing import Any
from mitmproxy import http
-
-
-def _native(s):
- if isinstance(s, bytes):
- return s.decode()
- return s
-
-
-def dictstr(items, indent: str) -> str:
- lines = []
- for k, v in items:
- lines.append(indent + "%s: %s,\n" % (repr(_native(k)), repr(_native(v))))
- return "{\n%s}\n" % "".join(lines)
+from mitmproxy.utils import strutils
def curl_command(flow: http.HTTPFlow) -> str:
@@ -36,7 +24,10 @@
data += "'%s'" % request.url
if request.content:
- data += " --data-binary '%s'" % _native(request.content)
+ data += " --data-binary '%s'" % strutils.bytes_to_escaped_str(
+ request.content,
+ escape_single_quotes=True
+ )
return data
@@ -127,10 +118,14 @@
args = ""
headers = ""
+
+ def conv(x):
+ return strutils.bytes_to_escaped_str(x, escape_single_quotes=True)
+
if flow.request.headers:
lines = [
- (_native(k), _native(v)) for k, v in flow.request.headers.fields
- if _native(k).lower() not in [":authority", "host", "cookie"]
+ (conv(k), conv(v)) for k, v in flow.request.headers.fields
+ if conv(k).lower() not in [":authority", "host", "cookie"]
]
lines = [" '%s': '%s',\n" % (k, v) for k, v in lines]
headers += "\n headers = {\n%s }\n" % "".join(lines)
@@ -148,7 +143,7 @@
data = ""
if flow.request.content:
- data = "\n data = '''%s'''\n" % _native(flow.request.content)
+ data = "\n data = '''%s'''\n" % conv(flow.request.content)
args += "\n data=data,"
code = code.format(
|
{"golden_diff": "diff --git a/mitmproxy/export.py b/mitmproxy/export.py\n--- a/mitmproxy/export.py\n+++ b/mitmproxy/export.py\n@@ -6,19 +6,7 @@\n from typing import Any\n \n from mitmproxy import http\n-\n-\n-def _native(s):\n- if isinstance(s, bytes):\n- return s.decode()\n- return s\n-\n-\n-def dictstr(items, indent: str) -> str:\n- lines = []\n- for k, v in items:\n- lines.append(indent + \"%s: %s,\\n\" % (repr(_native(k)), repr(_native(v))))\n- return \"{\\n%s}\\n\" % \"\".join(lines)\n+from mitmproxy.utils import strutils\n \n \n def curl_command(flow: http.HTTPFlow) -> str:\n@@ -36,7 +24,10 @@\n data += \"'%s'\" % request.url\n \n if request.content:\n- data += \" --data-binary '%s'\" % _native(request.content)\n+ data += \" --data-binary '%s'\" % strutils.bytes_to_escaped_str(\n+ request.content,\n+ escape_single_quotes=True\n+ )\n \n return data\n \n@@ -127,10 +118,14 @@\n \n args = \"\"\n headers = \"\"\n+\n+ def conv(x):\n+ return strutils.bytes_to_escaped_str(x, escape_single_quotes=True)\n+\n if flow.request.headers:\n lines = [\n- (_native(k), _native(v)) for k, v in flow.request.headers.fields\n- if _native(k).lower() not in [\":authority\", \"host\", \"cookie\"]\n+ (conv(k), conv(v)) for k, v in flow.request.headers.fields\n+ if conv(k).lower() not in [\":authority\", \"host\", \"cookie\"]\n ]\n lines = [\" '%s': '%s',\\n\" % (k, v) for k, v in lines]\n headers += \"\\n headers = {\\n%s }\\n\" % \"\".join(lines)\n@@ -148,7 +143,7 @@\n \n data = \"\"\n if flow.request.content:\n- data = \"\\n data = '''%s'''\\n\" % _native(flow.request.content)\n+ data = \"\\n data = '''%s'''\\n\" % conv(flow.request.content)\n args += \"\\n data=data,\"\n \n code = code.format(\n", "issue": "crash when export flow to 'r' curl\n##### Steps to reproduce the problem:\r\n\r\n1. enter a flow view\r\n2. press E and choose r\r\n3. crash\r\n\r\n\r\n##### Any other comments? What have you tried so far?\r\n\r\n\r\n\r\n##### System information\r\nTraceback (most recent call last):\r\n File \"/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/mitmproxy/tools/console/master.py\", line 281, in run\r\n self.loop.run()\r\n File \"/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/urwid/main_loop.py\", line 278, in run\r\n self._run()\r\n File \"/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/urwid/main_loop.py\", line 376, in _run\r\n self.event_loop.run()\r\n File \"/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/urwid/main_loop.py\", line 682, in run\r\n self._loop()\r\n File \"/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/urwid/main_loop.py\", line 719, in _loop\r\n self._watch_files[fd]()\r\n File \"/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/urwid/raw_display.py\", line 393, in <lambda>\r\n event_loop, callback, self.get_available_raw_input())\r\n File \"/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/urwid/raw_display.py\", line 493, in parse_input\r\n callback(processed, processed_codes)\r\n File \"/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/urwid/main_loop.py\", line 403, in _update\r\n self.process_input(keys)\r\n File \"/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/urwid/main_loop.py\", line 503, in process_input\r\n k = self._topmost_widget.keypress(self.screen_size, k)\r\n File \"/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/mitmproxy/tools/console/window.py\", line 84, in keypress\r\n k = super().keypress(size, k)\r\n File \"/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/urwid/container.py\", line 1116, in keypress\r\n return self.footer.keypress((maxcol,),key)\r\n File \"/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/mitmproxy/tools/console/statusbar.py\", line 155, in keypress\r\n return self.master.ab.keypress(*args, **kwargs)\r\n File \"/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/mitmproxy/tools/console/statusbar.py\", line 108, in keypress\r\n self.prompt_execute(k)\r\n File \"/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/mitmproxy/tools/console/statusbar.py\", line 133, in prompt_execute\r\n msg = p(txt)\r\n File \"/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/mitmproxy/tools/console/statusbar.py\", line 31, in __call__\r\n return self.callback(txt, *self.args)\r\n File \"/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/mitmproxy/tools/console/common.py\", line 328, in export_to_clip_or_file\r\n writer(exporter(flow))\r\n File \"/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/mitmproxy/export.py\", line 39, in curl_command\r\n data += \" --data-binary '%s'\" % _native(request.content)\r\n File \"/usr/local/Cellar/mitmproxy/2.0.1/libexec/lib/python3.6/site-packages/mitmproxy/export.py\", line 13, in _native\r\n return s.decode()\r\nUnicodeDecodeError: 'utf-8' codec can't decode byte 0x88 in position 188: invalid start byte\r\n\r\n<!--\r\n Cut and paste the output of \"mitmproxy --version\".\r\n\r\n If you're using an older version if mitmproxy, please specify the version\r\n and OS.\r\n-->\r\nMitmproxy version: 2.0.1 (release version)\r\nPython version: 3.6.1\r\nPlatform: Darwin-16.1.0-x86_64-i386-64bit\r\nSSL version: OpenSSL 1.1.0e 16 Feb 2017\r\nMac version: 10.12.1 ('', '', '') x86_64\n", "before_files": [{"content": "import io\nimport json\nimport pprint\nimport re\nimport textwrap\nfrom typing import Any\n\nfrom mitmproxy import http\n\n\ndef _native(s):\n if isinstance(s, bytes):\n return s.decode()\n return s\n\n\ndef dictstr(items, indent: str) -> str:\n lines = []\n for k, v in items:\n lines.append(indent + \"%s: %s,\\n\" % (repr(_native(k)), repr(_native(v))))\n return \"{\\n%s}\\n\" % \"\".join(lines)\n\n\ndef curl_command(flow: http.HTTPFlow) -> str:\n data = \"curl \"\n\n request = flow.request.copy()\n request.decode(strict=False)\n\n for k, v in request.headers.items(multi=True):\n data += \"-H '%s:%s' \" % (k, v)\n\n if request.method != \"GET\":\n data += \"-X %s \" % request.method\n\n data += \"'%s'\" % request.url\n\n if request.content:\n data += \" --data-binary '%s'\" % _native(request.content)\n\n return data\n\n\ndef python_arg(arg: str, val: Any) -> str:\n if not val:\n return \"\"\n if arg:\n arg += \"=\"\n arg_str = \"{}{},\\n\".format(\n arg,\n pprint.pformat(val, 79 - len(arg))\n )\n return textwrap.indent(arg_str, \" \" * 4)\n\n\ndef python_code(flow: http.HTTPFlow):\n code = io.StringIO()\n\n def writearg(arg, val):\n code.write(python_arg(arg, val))\n\n code.write(\"import requests\\n\")\n code.write(\"\\n\")\n if flow.request.method.lower() in (\"get\", \"post\", \"put\", \"head\", \"delete\", \"patch\"):\n code.write(\"response = requests.{}(\\n\".format(flow.request.method.lower()))\n else:\n code.write(\"response = requests.request(\\n\")\n writearg(\"\", flow.request.method)\n url_without_query = flow.request.url.split(\"?\", 1)[0]\n writearg(\"\", url_without_query)\n\n writearg(\"params\", list(flow.request.query.fields))\n\n headers = flow.request.headers.copy()\n # requests adds those by default.\n for x in (\":authority\", \"host\", \"content-length\"):\n headers.pop(x, None)\n writearg(\"headers\", dict(headers))\n try:\n if \"json\" not in flow.request.headers.get(\"content-type\", \"\"):\n raise ValueError()\n writearg(\"json\", json.loads(flow.request.text))\n except ValueError:\n writearg(\"data\", flow.request.content)\n\n code.seek(code.tell() - 2) # remove last comma\n code.write(\"\\n)\\n\")\n code.write(\"\\n\")\n code.write(\"print(response.text)\")\n\n return code.getvalue()\n\n\ndef locust_code(flow):\n code = textwrap.dedent(\"\"\"\n from locust import HttpLocust, TaskSet, task\n\n class UserBehavior(TaskSet):\n def on_start(self):\n ''' on_start is called when a Locust start before any task is scheduled '''\n self.{name}()\n\n @task()\n def {name}(self):\n url = self.locust.host + '{path}'\n {headers}{params}{data}\n self.response = self.client.request(\n method='{method}',\n url=url,{args}\n )\n\n ### Additional tasks can go here ###\n\n\n class WebsiteUser(HttpLocust):\n task_set = UserBehavior\n min_wait = 1000\n max_wait = 3000\n\"\"\").strip()\n\n name = re.sub('\\W|^(?=\\d)', '_', flow.request.path.strip(\"/\").split(\"?\", 1)[0])\n if not name:\n new_name = \"_\".join([str(flow.request.host), str(flow.request.timestamp_start)])\n name = re.sub('\\W|^(?=\\d)', '_', new_name)\n\n path_without_query = flow.request.path.split(\"?\")[0]\n\n args = \"\"\n headers = \"\"\n if flow.request.headers:\n lines = [\n (_native(k), _native(v)) for k, v in flow.request.headers.fields\n if _native(k).lower() not in [\":authority\", \"host\", \"cookie\"]\n ]\n lines = [\" '%s': '%s',\\n\" % (k, v) for k, v in lines]\n headers += \"\\n headers = {\\n%s }\\n\" % \"\".join(lines)\n args += \"\\n headers=headers,\"\n\n params = \"\"\n if flow.request.query:\n lines = [\n \" %s: %s,\\n\" % (repr(k), repr(v))\n for k, v in\n flow.request.query.collect()\n ]\n params = \"\\n params = {\\n%s }\\n\" % \"\".join(lines)\n args += \"\\n params=params,\"\n\n data = \"\"\n if flow.request.content:\n data = \"\\n data = '''%s'''\\n\" % _native(flow.request.content)\n args += \"\\n data=data,\"\n\n code = code.format(\n name=name,\n path=path_without_query,\n headers=headers,\n params=params,\n data=data,\n method=flow.request.method,\n args=args,\n )\n\n return code\n\n\ndef locust_task(flow):\n code = locust_code(flow)\n start_task = len(code.split('@task')[0]) - 4\n end_task = -19 - len(code.split('### Additional')[1])\n task_code = code[start_task:end_task]\n\n return task_code\n\n\ndef url(flow):\n return flow.request.url\n\n\nEXPORTERS = [\n (\"content\", \"c\", None),\n (\"headers+content\", \"h\", None),\n (\"url\", \"u\", url),\n (\"as curl command\", \"r\", curl_command),\n (\"as python code\", \"p\", python_code),\n (\"as locust code\", \"l\", locust_code),\n (\"as locust task\", \"t\", locust_task),\n]\n", "path": "mitmproxy/export.py"}]}
| 3,473 | 534 |
gh_patches_debug_29336
|
rasdani/github-patches
|
git_diff
|
AnalogJ__lexicon-270
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[Regression on #PR-203] CloudNS authentication broken when `auth-id` supplied
Provider CloudNS fails to authenticate when using auth-id for authentication, rather than auth-subid or auth-subuser.
Line 146 in lexicon/providers/cloudns.py reads `if self.is_given_option(self.options['auth_id']):`. It should instead should read `if self.is_given_option('auth_id'):`.
I've inlined a patch below which fixes this. Sorry if this is more effort for you than a PR.
--- cloudns.py
+++ cloudns.pr203fix.py
@@ -143,7 +143,7 @@
if not self.options['auth_password']:
raise Exception('No valid authentication data passed, expected: auth-password')
- if self._is_given_option(self.options['auth_id']):
+ if self._is_given_option('auth_id'):
return {'auth-id': self.options['auth_id'], 'auth-password': self.options['auth_password']}
elif self._is_given_option('auth_subid'):
return {'sub-auth-id': self.options['auth_subid'], 'auth-password': self.options['auth_password']}
</issue>
<code>
[start of lexicon/providers/cloudns.py]
1 from __future__ import absolute_import
2 from __future__ import print_function
3
4 import logging
5 import requests
6
7 from .base import Provider as BaseProvider
8
9 logger = logging.getLogger(__name__)
10
11
12 def ProviderParser(subparser):
13 identity_group = subparser.add_mutually_exclusive_group()
14 identity_group.add_argument("--auth-id", help="specify user id used to authenticate")
15 identity_group.add_argument("--auth-subid", help="specify subuser id used to authenticate")
16 identity_group.add_argument("--auth-subuser", help="specify subuser name used to authenticate")
17 subparser.add_argument("--auth-password", help="specify password used to authenticate")
18 subparser.add_argument("--weight", help="specify the SRV record weight")
19 subparser.add_argument("--port", help="specify the SRV record port")
20
21
22 class Provider(BaseProvider):
23 def __init__(self, options, engine_overrides=None):
24 super(Provider, self).__init__(options, engine_overrides)
25 self.domain_id = None
26 self.api_endpoint = self.engine_overrides.get('api_endpoint', 'https://api.cloudns.net')
27
28 def authenticate(self):
29 payload = self._get('/dns/get-zone-info.json', {'domain-name': self.options['domain']})
30 self.domain_id = payload['name']
31 logger.debug('authenticate: %s', payload)
32
33 def create_record(self, type, name, content):
34 # Skip execution if such a record already exists
35 existing_records = self.list_records(type, name, content)
36 if len(existing_records) > 0:
37 return True
38
39 # Build parameters for adding a new record
40 params = {
41 'domain-name': self.domain_id,
42 'record-type': type,
43 'host': self._relative_name(name),
44 'record': content
45 }
46 if self.options['ttl']:
47 params['ttl'] = self.options['ttl']
48 if self.options['priority']:
49 params['priority'] = self.options['priority']
50 if self.options['weight']:
51 params['weight'] = self.options['weight']
52 if self.options['port']:
53 params['port'] = self.options['port']
54
55 # Add new record by calling the ClouDNS API
56 payload = self._post('/dns/add-record.json', params)
57 logger.debug('create_record: %s', payload)
58
59 # Error handling is already covered by self._request
60 return True
61
62 def list_records(self, type=None, name=None, content=None):
63 # Build parameters to make use of the built-in API filtering
64 params = {'domain-name': self.domain_id}
65 if type:
66 params['type'] = type
67 if name:
68 params['host'] = self._relative_name(name)
69
70 # Fetch and parse all records for the given zone
71 payload = self._get('/dns/records.json', params)
72 payload = payload if not isinstance(payload, list) else {}
73 records = []
74 for record in payload.values():
75 records.append({
76 'type': record['type'],
77 'name': self._full_name(record['host']),
78 'ttl': record['ttl'],
79 'content': record['record'],
80 'id': record['id']
81 })
82
83 # Filter by content manually as API does not support that
84 if content:
85 records = [record for record in records if record['content'] == content]
86
87 # Print records as debug output and return them
88 logger.debug('list_records: %s', records)
89 return records
90
91 def update_record(self, identifier, type=None, name=None, content=None):
92 # Try to find record if no identifier was specified
93 if not identifier:
94 identifier = self._find_record_identifier(type, name, None)
95
96 # Build parameters for updating an existing record
97 params = {'domain-name': self.domain_id, 'record-id': identifier}
98 if name:
99 params['host'] = self._relative_name(name)
100 if content:
101 params['record'] = content
102 if self.options.get('ttl'):
103 params['ttl'] = self.options.get('ttl')
104 if self.options['priority']:
105 params['priority'] = self.options['priority']
106 if self.options['weight']:
107 params['weight'] = self.options['weight']
108 if self.options['port']:
109 params['port'] = self.options['port']
110
111 # Update existing record by calling the ClouDNS API
112 payload = self._post('/dns/mod-record.json', params)
113 logger.debug('update_record: %s', payload)
114
115 # Error handling is already covered by self._request
116 return True
117
118 def delete_record(self, identifier=None, type=None, name=None, content=None):
119 # Try to find record if no identifier was specified
120 delete_record_id = []
121 if not identifier:
122 records = self.list_records(type, name, content)
123 delete_record_id = [record['id'] for record in records]
124 else:
125 delete_record_id.append(identifier)
126
127 logger.debug('delete_records: %s', delete_record_id)
128
129 for record_id in delete_record_id:
130 # Delete existing record by calling the ClouDNS API
131 payload = self._post('/dns/delete-record.json', {'domain-name': self.domain_id, 'record-id': record_id})
132
133 logger.debug('delete_record: %s', True)
134
135 # Error handling is already covered by self._request
136 return True
137
138 def _is_given_option(self, key):
139 fallback_fn = self.engine_overrides.get('fallbackFn', (lambda x: None))
140 return self.options[key] and self.options[key] != fallback_fn(key)
141
142 def _build_authentication_data(self):
143 if not self.options['auth_password']:
144 raise Exception('No valid authentication data passed, expected: auth-password')
145
146 if self._is_given_option(self.options['auth_id']):
147 return {'auth-id': self.options['auth_id'], 'auth-password': self.options['auth_password']}
148 elif self._is_given_option('auth_subid'):
149 return {'sub-auth-id': self.options['auth_subid'], 'auth-password': self.options['auth_password']}
150 elif self._is_given_option('auth_subuser'):
151 return {'sub-auth-user': self.options['auth_subuser'], 'auth-password': self.options['auth_password']}
152 elif self.options['auth_id'] or self.options['auth_subid'] or self.options['auth_subuser']:
153 # All the options were passed with a fallback value, return an empty dictionary.
154 return {}
155 else:
156 raise Exception('No valid authentication data passed, expected: auth-id, auth-subid, auth-subuser')
157
158 def _find_record_identifier(self, type, name, content):
159 records = self.list_records(type, name, content)
160 logger.debug('records: %s', records)
161 if len(records) == 1:
162 return records[0]['id']
163 else:
164 raise Exception('Record identifier could not be found.')
165
166 def _request(self, action='GET', url='/', data=None, query_params=None):
167 # Set default values for missing arguments
168 data = data if data else {}
169 query_params = query_params if query_params else {}
170
171 # Merge authentication data into request
172 if action == 'GET':
173 query_params.update(self._build_authentication_data())
174 else:
175 data.update(self._build_authentication_data())
176
177 # Fire request against ClouDNS API and parse result as JSON
178 r = requests.request(action, self.api_endpoint + url, params=query_params, data=data)
179 r.raise_for_status()
180 payload = r.json()
181
182 # Check ClouDNS specific status code and description
183 if 'status' in payload and 'statusDescription' in payload and payload['status'] != 'Success':
184 raise Exception('ClouDNS API request has failed: ' + payload['statusDescription'])
185
186 # Return payload
187 return payload
188
[end of lexicon/providers/cloudns.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/lexicon/providers/cloudns.py b/lexicon/providers/cloudns.py
--- a/lexicon/providers/cloudns.py
+++ b/lexicon/providers/cloudns.py
@@ -123,13 +123,13 @@
delete_record_id = [record['id'] for record in records]
else:
delete_record_id.append(identifier)
-
+
logger.debug('delete_records: %s', delete_record_id)
-
+
for record_id in delete_record_id:
# Delete existing record by calling the ClouDNS API
payload = self._post('/dns/delete-record.json', {'domain-name': self.domain_id, 'record-id': record_id})
-
+
logger.debug('delete_record: %s', True)
# Error handling is already covered by self._request
@@ -143,7 +143,7 @@
if not self.options['auth_password']:
raise Exception('No valid authentication data passed, expected: auth-password')
- if self._is_given_option(self.options['auth_id']):
+ if self._is_given_option('auth_id'):
return {'auth-id': self.options['auth_id'], 'auth-password': self.options['auth_password']}
elif self._is_given_option('auth_subid'):
return {'sub-auth-id': self.options['auth_subid'], 'auth-password': self.options['auth_password']}
|
{"golden_diff": "diff --git a/lexicon/providers/cloudns.py b/lexicon/providers/cloudns.py\n--- a/lexicon/providers/cloudns.py\n+++ b/lexicon/providers/cloudns.py\n@@ -123,13 +123,13 @@\n delete_record_id = [record['id'] for record in records]\n else:\n delete_record_id.append(identifier)\n- \n+\n logger.debug('delete_records: %s', delete_record_id)\n- \n+\n for record_id in delete_record_id:\n # Delete existing record by calling the ClouDNS API\n payload = self._post('/dns/delete-record.json', {'domain-name': self.domain_id, 'record-id': record_id})\n- \n+\n logger.debug('delete_record: %s', True)\n \n # Error handling is already covered by self._request\n@@ -143,7 +143,7 @@\n if not self.options['auth_password']:\n raise Exception('No valid authentication data passed, expected: auth-password')\n \n- if self._is_given_option(self.options['auth_id']):\n+ if self._is_given_option('auth_id'):\n return {'auth-id': self.options['auth_id'], 'auth-password': self.options['auth_password']}\n elif self._is_given_option('auth_subid'):\n return {'sub-auth-id': self.options['auth_subid'], 'auth-password': self.options['auth_password']}\n", "issue": "[Regression on #PR-203] CloudNS authentication broken when `auth-id` supplied\nProvider CloudNS fails to authenticate when using auth-id for authentication, rather than auth-subid or auth-subuser.\r\n\r\nLine 146 in lexicon/providers/cloudns.py reads `if self.is_given_option(self.options['auth_id']):`. It should instead should read `if self.is_given_option('auth_id'):`.\r\n\r\nI've inlined a patch below which fixes this. Sorry if this is more effort for you than a PR.\r\n\r\n --- cloudns.py\r\n +++ cloudns.pr203fix.py\r\n @@ -143,7 +143,7 @@ \r\n if not self.options['auth_password']:\r\n raise Exception('No valid authentication data passed, expected: auth-password')\r\n \r\n - if self._is_given_option(self.options['auth_id']):\r\n + if self._is_given_option('auth_id'):\r\n return {'auth-id': self.options['auth_id'], 'auth-password': self.options['auth_password']}\r\n elif self._is_given_option('auth_subid'):\r\n return {'sub-auth-id': self.options['auth_subid'], 'auth-password': self.options['auth_password']}\n", "before_files": [{"content": "from __future__ import absolute_import\nfrom __future__ import print_function\n\nimport logging\nimport requests\n\nfrom .base import Provider as BaseProvider\n\nlogger = logging.getLogger(__name__)\n\n\ndef ProviderParser(subparser):\n identity_group = subparser.add_mutually_exclusive_group()\n identity_group.add_argument(\"--auth-id\", help=\"specify user id used to authenticate\")\n identity_group.add_argument(\"--auth-subid\", help=\"specify subuser id used to authenticate\")\n identity_group.add_argument(\"--auth-subuser\", help=\"specify subuser name used to authenticate\")\n subparser.add_argument(\"--auth-password\", help=\"specify password used to authenticate\")\n subparser.add_argument(\"--weight\", help=\"specify the SRV record weight\")\n subparser.add_argument(\"--port\", help=\"specify the SRV record port\")\n\n\nclass Provider(BaseProvider):\n def __init__(self, options, engine_overrides=None):\n super(Provider, self).__init__(options, engine_overrides)\n self.domain_id = None\n self.api_endpoint = self.engine_overrides.get('api_endpoint', 'https://api.cloudns.net')\n\n def authenticate(self):\n payload = self._get('/dns/get-zone-info.json', {'domain-name': self.options['domain']})\n self.domain_id = payload['name']\n logger.debug('authenticate: %s', payload)\n\n def create_record(self, type, name, content):\n # Skip execution if such a record already exists\n existing_records = self.list_records(type, name, content)\n if len(existing_records) > 0:\n return True\n\n # Build parameters for adding a new record\n params = {\n 'domain-name': self.domain_id,\n 'record-type': type,\n 'host': self._relative_name(name),\n 'record': content\n }\n if self.options['ttl']:\n params['ttl'] = self.options['ttl']\n if self.options['priority']:\n params['priority'] = self.options['priority']\n if self.options['weight']:\n params['weight'] = self.options['weight']\n if self.options['port']:\n params['port'] = self.options['port']\n\n # Add new record by calling the ClouDNS API\n payload = self._post('/dns/add-record.json', params)\n logger.debug('create_record: %s', payload)\n\n # Error handling is already covered by self._request\n return True\n\n def list_records(self, type=None, name=None, content=None):\n # Build parameters to make use of the built-in API filtering\n params = {'domain-name': self.domain_id}\n if type:\n params['type'] = type\n if name:\n params['host'] = self._relative_name(name)\n\n # Fetch and parse all records for the given zone\n payload = self._get('/dns/records.json', params)\n payload = payload if not isinstance(payload, list) else {}\n records = []\n for record in payload.values():\n records.append({\n 'type': record['type'],\n 'name': self._full_name(record['host']),\n 'ttl': record['ttl'],\n 'content': record['record'],\n 'id': record['id']\n })\n\n # Filter by content manually as API does not support that\n if content:\n records = [record for record in records if record['content'] == content]\n\n # Print records as debug output and return them\n logger.debug('list_records: %s', records)\n return records\n\n def update_record(self, identifier, type=None, name=None, content=None):\n # Try to find record if no identifier was specified\n if not identifier:\n identifier = self._find_record_identifier(type, name, None)\n\n # Build parameters for updating an existing record\n params = {'domain-name': self.domain_id, 'record-id': identifier}\n if name:\n params['host'] = self._relative_name(name)\n if content:\n params['record'] = content\n if self.options.get('ttl'):\n params['ttl'] = self.options.get('ttl')\n if self.options['priority']:\n params['priority'] = self.options['priority']\n if self.options['weight']:\n params['weight'] = self.options['weight']\n if self.options['port']:\n params['port'] = self.options['port']\n\n # Update existing record by calling the ClouDNS API\n payload = self._post('/dns/mod-record.json', params)\n logger.debug('update_record: %s', payload)\n\n # Error handling is already covered by self._request\n return True\n\n def delete_record(self, identifier=None, type=None, name=None, content=None):\n # Try to find record if no identifier was specified\n delete_record_id = []\n if not identifier:\n records = self.list_records(type, name, content)\n delete_record_id = [record['id'] for record in records]\n else:\n delete_record_id.append(identifier)\n \n logger.debug('delete_records: %s', delete_record_id)\n \n for record_id in delete_record_id:\n # Delete existing record by calling the ClouDNS API\n payload = self._post('/dns/delete-record.json', {'domain-name': self.domain_id, 'record-id': record_id})\n \n logger.debug('delete_record: %s', True)\n\n # Error handling is already covered by self._request\n return True\n\n def _is_given_option(self, key):\n fallback_fn = self.engine_overrides.get('fallbackFn', (lambda x: None))\n return self.options[key] and self.options[key] != fallback_fn(key)\n\n def _build_authentication_data(self):\n if not self.options['auth_password']:\n raise Exception('No valid authentication data passed, expected: auth-password')\n\n if self._is_given_option(self.options['auth_id']):\n return {'auth-id': self.options['auth_id'], 'auth-password': self.options['auth_password']}\n elif self._is_given_option('auth_subid'):\n return {'sub-auth-id': self.options['auth_subid'], 'auth-password': self.options['auth_password']}\n elif self._is_given_option('auth_subuser'):\n return {'sub-auth-user': self.options['auth_subuser'], 'auth-password': self.options['auth_password']}\n elif self.options['auth_id'] or self.options['auth_subid'] or self.options['auth_subuser']:\n # All the options were passed with a fallback value, return an empty dictionary.\n return {}\n else:\n raise Exception('No valid authentication data passed, expected: auth-id, auth-subid, auth-subuser')\n\n def _find_record_identifier(self, type, name, content):\n records = self.list_records(type, name, content)\n logger.debug('records: %s', records)\n if len(records) == 1:\n return records[0]['id']\n else:\n raise Exception('Record identifier could not be found.')\n\n def _request(self, action='GET', url='/', data=None, query_params=None):\n # Set default values for missing arguments\n data = data if data else {}\n query_params = query_params if query_params else {}\n\n # Merge authentication data into request\n if action == 'GET':\n query_params.update(self._build_authentication_data())\n else:\n data.update(self._build_authentication_data())\n\n # Fire request against ClouDNS API and parse result as JSON\n r = requests.request(action, self.api_endpoint + url, params=query_params, data=data)\n r.raise_for_status()\n payload = r.json()\n\n # Check ClouDNS specific status code and description\n if 'status' in payload and 'statusDescription' in payload and payload['status'] != 'Success':\n raise Exception('ClouDNS API request has failed: ' + payload['statusDescription'])\n\n # Return payload\n return payload\n", "path": "lexicon/providers/cloudns.py"}]}
| 2,941 | 301 |
gh_patches_debug_4559
|
rasdani/github-patches
|
git_diff
|
netbox-community__netbox-6790
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
/32 IP's not automatically represented in /32 subnet.
### NetBox version
v2.11.7
### Python version
3.7
### Steps to Reproduce
1) Have a /32 IP address,
2) Create a /32 Subnet for that IP address
3) In the new subnet on the IP addresses tab observe IP's.
### Expected Behavior
IP address reference should be observed and not the ability to assign an IP address in the subnet.
### Observed Behavior
'Available IP' Button is present instead of a reference to the IP address as per 1).
</issue>
<code>
[start of netbox/ipam/lookups.py]
1 from django.db.models import IntegerField, Lookup, Transform, lookups
2
3
4 class NetFieldDecoratorMixin(object):
5
6 def process_lhs(self, qn, connection, lhs=None):
7 lhs = lhs or self.lhs
8 lhs_string, lhs_params = qn.compile(lhs)
9 lhs_string = 'TEXT(%s)' % lhs_string
10 return lhs_string, lhs_params
11
12
13 class IExact(NetFieldDecoratorMixin, lookups.IExact):
14
15 def get_rhs_op(self, connection, rhs):
16 return '= LOWER(%s)' % rhs
17
18
19 class EndsWith(NetFieldDecoratorMixin, lookups.EndsWith):
20 pass
21
22
23 class IEndsWith(NetFieldDecoratorMixin, lookups.IEndsWith):
24 pass
25
26 def get_rhs_op(self, connection, rhs):
27 return 'LIKE LOWER(%s)' % rhs
28
29
30 class StartsWith(NetFieldDecoratorMixin, lookups.StartsWith):
31 lookup_name = 'startswith'
32
33
34 class IStartsWith(NetFieldDecoratorMixin, lookups.IStartsWith):
35 pass
36
37 def get_rhs_op(self, connection, rhs):
38 return 'LIKE LOWER(%s)' % rhs
39
40
41 class Regex(NetFieldDecoratorMixin, lookups.Regex):
42 pass
43
44
45 class IRegex(NetFieldDecoratorMixin, lookups.IRegex):
46 pass
47
48
49 class NetContainsOrEquals(Lookup):
50 lookup_name = 'net_contains_or_equals'
51
52 def as_sql(self, qn, connection):
53 lhs, lhs_params = self.process_lhs(qn, connection)
54 rhs, rhs_params = self.process_rhs(qn, connection)
55 params = lhs_params + rhs_params
56 return '%s >>= %s' % (lhs, rhs), params
57
58
59 class NetContains(Lookup):
60 lookup_name = 'net_contains'
61
62 def as_sql(self, qn, connection):
63 lhs, lhs_params = self.process_lhs(qn, connection)
64 rhs, rhs_params = self.process_rhs(qn, connection)
65 params = lhs_params + rhs_params
66 return '%s >> %s' % (lhs, rhs), params
67
68
69 class NetContained(Lookup):
70 lookup_name = 'net_contained'
71
72 def as_sql(self, qn, connection):
73 lhs, lhs_params = self.process_lhs(qn, connection)
74 rhs, rhs_params = self.process_rhs(qn, connection)
75 params = lhs_params + rhs_params
76 return '%s << %s' % (lhs, rhs), params
77
78
79 class NetContainedOrEqual(Lookup):
80 lookup_name = 'net_contained_or_equal'
81
82 def as_sql(self, qn, connection):
83 lhs, lhs_params = self.process_lhs(qn, connection)
84 rhs, rhs_params = self.process_rhs(qn, connection)
85 params = lhs_params + rhs_params
86 return '%s <<= %s' % (lhs, rhs), params
87
88
89 class NetHost(Lookup):
90 lookup_name = 'net_host'
91
92 def as_sql(self, qn, connection):
93 lhs, lhs_params = self.process_lhs(qn, connection)
94 rhs, rhs_params = self.process_rhs(qn, connection)
95 # Query parameters are automatically converted to IPNetwork objects, which are then turned to strings. We need
96 # to omit the mask portion of the object's string representation to match PostgreSQL's HOST() function.
97 if rhs_params:
98 rhs_params[0] = rhs_params[0].split('/')[0]
99 params = lhs_params + rhs_params
100 return 'HOST(%s) = %s' % (lhs, rhs), params
101
102
103 class NetIn(Lookup):
104 lookup_name = 'net_in'
105
106 def get_prep_lookup(self):
107 # Don't cast the query value to a netaddr object, since it may or may not include a mask.
108 return self.rhs
109
110 def as_sql(self, qn, connection):
111 lhs, lhs_params = self.process_lhs(qn, connection)
112 rhs, rhs_params = self.process_rhs(qn, connection)
113 with_mask, without_mask = [], []
114 for address in rhs_params[0]:
115 if '/' in address:
116 with_mask.append(address)
117 else:
118 without_mask.append(address)
119
120 address_in_clause = self.create_in_clause('{} IN ('.format(lhs), len(with_mask))
121 host_in_clause = self.create_in_clause('HOST({}) IN ('.format(lhs), len(without_mask))
122
123 if with_mask and not without_mask:
124 return address_in_clause, with_mask
125 elif not with_mask and without_mask:
126 return host_in_clause, without_mask
127
128 in_clause = '({}) OR ({})'.format(address_in_clause, host_in_clause)
129 with_mask.extend(without_mask)
130 return in_clause, with_mask
131
132 @staticmethod
133 def create_in_clause(clause_part, max_size):
134 clause_elements = [clause_part]
135 for offset in range(0, max_size):
136 if offset > 0:
137 clause_elements.append(', ')
138 clause_elements.append('%s')
139 clause_elements.append(')')
140 return ''.join(clause_elements)
141
142
143 class NetHostContained(Lookup):
144 """
145 Check for the host portion of an IP address without regard to its mask. This allows us to find e.g. 192.0.2.1/24
146 when specifying a parent prefix of 192.0.2.0/26.
147 """
148 lookup_name = 'net_host_contained'
149
150 def as_sql(self, qn, connection):
151 lhs, lhs_params = self.process_lhs(qn, connection)
152 rhs, rhs_params = self.process_rhs(qn, connection)
153 params = lhs_params + rhs_params
154 return 'CAST(HOST(%s) AS INET) << %s' % (lhs, rhs), params
155
156
157 class NetFamily(Transform):
158 lookup_name = 'family'
159 function = 'FAMILY'
160
161 @property
162 def output_field(self):
163 return IntegerField()
164
165
166 class NetMaskLength(Transform):
167 function = 'MASKLEN'
168 lookup_name = 'net_mask_length'
169
170 @property
171 def output_field(self):
172 return IntegerField()
173
174
175 class Host(Transform):
176 function = 'HOST'
177 lookup_name = 'host'
178
179
180 class Inet(Transform):
181 function = 'INET'
182 lookup_name = 'inet'
183
[end of netbox/ipam/lookups.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/netbox/ipam/lookups.py b/netbox/ipam/lookups.py
--- a/netbox/ipam/lookups.py
+++ b/netbox/ipam/lookups.py
@@ -151,7 +151,7 @@
lhs, lhs_params = self.process_lhs(qn, connection)
rhs, rhs_params = self.process_rhs(qn, connection)
params = lhs_params + rhs_params
- return 'CAST(HOST(%s) AS INET) << %s' % (lhs, rhs), params
+ return 'CAST(HOST(%s) AS INET) <<= %s' % (lhs, rhs), params
class NetFamily(Transform):
|
{"golden_diff": "diff --git a/netbox/ipam/lookups.py b/netbox/ipam/lookups.py\n--- a/netbox/ipam/lookups.py\n+++ b/netbox/ipam/lookups.py\n@@ -151,7 +151,7 @@\n lhs, lhs_params = self.process_lhs(qn, connection)\n rhs, rhs_params = self.process_rhs(qn, connection)\n params = lhs_params + rhs_params\n- return 'CAST(HOST(%s) AS INET) << %s' % (lhs, rhs), params\n+ return 'CAST(HOST(%s) AS INET) <<= %s' % (lhs, rhs), params\n \n \n class NetFamily(Transform):\n", "issue": "/32 IP's not automatically represented in /32 subnet.\n### NetBox version\n\nv2.11.7\n\n### Python version\n\n3.7\n\n### Steps to Reproduce\n\n1) Have a /32 IP address,\r\n\r\n2) Create a /32 Subnet for that IP address\r\n\r\n3) In the new subnet on the IP addresses tab observe IP's. \n\n### Expected Behavior\n\nIP address reference should be observed and not the ability to assign an IP address in the subnet.\n\n### Observed Behavior\n\n'Available IP' Button is present instead of a reference to the IP address as per 1).\n", "before_files": [{"content": "from django.db.models import IntegerField, Lookup, Transform, lookups\n\n\nclass NetFieldDecoratorMixin(object):\n\n def process_lhs(self, qn, connection, lhs=None):\n lhs = lhs or self.lhs\n lhs_string, lhs_params = qn.compile(lhs)\n lhs_string = 'TEXT(%s)' % lhs_string\n return lhs_string, lhs_params\n\n\nclass IExact(NetFieldDecoratorMixin, lookups.IExact):\n\n def get_rhs_op(self, connection, rhs):\n return '= LOWER(%s)' % rhs\n\n\nclass EndsWith(NetFieldDecoratorMixin, lookups.EndsWith):\n pass\n\n\nclass IEndsWith(NetFieldDecoratorMixin, lookups.IEndsWith):\n pass\n\n def get_rhs_op(self, connection, rhs):\n return 'LIKE LOWER(%s)' % rhs\n\n\nclass StartsWith(NetFieldDecoratorMixin, lookups.StartsWith):\n lookup_name = 'startswith'\n\n\nclass IStartsWith(NetFieldDecoratorMixin, lookups.IStartsWith):\n pass\n\n def get_rhs_op(self, connection, rhs):\n return 'LIKE LOWER(%s)' % rhs\n\n\nclass Regex(NetFieldDecoratorMixin, lookups.Regex):\n pass\n\n\nclass IRegex(NetFieldDecoratorMixin, lookups.IRegex):\n pass\n\n\nclass NetContainsOrEquals(Lookup):\n lookup_name = 'net_contains_or_equals'\n\n def as_sql(self, qn, connection):\n lhs, lhs_params = self.process_lhs(qn, connection)\n rhs, rhs_params = self.process_rhs(qn, connection)\n params = lhs_params + rhs_params\n return '%s >>= %s' % (lhs, rhs), params\n\n\nclass NetContains(Lookup):\n lookup_name = 'net_contains'\n\n def as_sql(self, qn, connection):\n lhs, lhs_params = self.process_lhs(qn, connection)\n rhs, rhs_params = self.process_rhs(qn, connection)\n params = lhs_params + rhs_params\n return '%s >> %s' % (lhs, rhs), params\n\n\nclass NetContained(Lookup):\n lookup_name = 'net_contained'\n\n def as_sql(self, qn, connection):\n lhs, lhs_params = self.process_lhs(qn, connection)\n rhs, rhs_params = self.process_rhs(qn, connection)\n params = lhs_params + rhs_params\n return '%s << %s' % (lhs, rhs), params\n\n\nclass NetContainedOrEqual(Lookup):\n lookup_name = 'net_contained_or_equal'\n\n def as_sql(self, qn, connection):\n lhs, lhs_params = self.process_lhs(qn, connection)\n rhs, rhs_params = self.process_rhs(qn, connection)\n params = lhs_params + rhs_params\n return '%s <<= %s' % (lhs, rhs), params\n\n\nclass NetHost(Lookup):\n lookup_name = 'net_host'\n\n def as_sql(self, qn, connection):\n lhs, lhs_params = self.process_lhs(qn, connection)\n rhs, rhs_params = self.process_rhs(qn, connection)\n # Query parameters are automatically converted to IPNetwork objects, which are then turned to strings. We need\n # to omit the mask portion of the object's string representation to match PostgreSQL's HOST() function.\n if rhs_params:\n rhs_params[0] = rhs_params[0].split('/')[0]\n params = lhs_params + rhs_params\n return 'HOST(%s) = %s' % (lhs, rhs), params\n\n\nclass NetIn(Lookup):\n lookup_name = 'net_in'\n\n def get_prep_lookup(self):\n # Don't cast the query value to a netaddr object, since it may or may not include a mask.\n return self.rhs\n\n def as_sql(self, qn, connection):\n lhs, lhs_params = self.process_lhs(qn, connection)\n rhs, rhs_params = self.process_rhs(qn, connection)\n with_mask, without_mask = [], []\n for address in rhs_params[0]:\n if '/' in address:\n with_mask.append(address)\n else:\n without_mask.append(address)\n\n address_in_clause = self.create_in_clause('{} IN ('.format(lhs), len(with_mask))\n host_in_clause = self.create_in_clause('HOST({}) IN ('.format(lhs), len(without_mask))\n\n if with_mask and not without_mask:\n return address_in_clause, with_mask\n elif not with_mask and without_mask:\n return host_in_clause, without_mask\n\n in_clause = '({}) OR ({})'.format(address_in_clause, host_in_clause)\n with_mask.extend(without_mask)\n return in_clause, with_mask\n\n @staticmethod\n def create_in_clause(clause_part, max_size):\n clause_elements = [clause_part]\n for offset in range(0, max_size):\n if offset > 0:\n clause_elements.append(', ')\n clause_elements.append('%s')\n clause_elements.append(')')\n return ''.join(clause_elements)\n\n\nclass NetHostContained(Lookup):\n \"\"\"\n Check for the host portion of an IP address without regard to its mask. This allows us to find e.g. 192.0.2.1/24\n when specifying a parent prefix of 192.0.2.0/26.\n \"\"\"\n lookup_name = 'net_host_contained'\n\n def as_sql(self, qn, connection):\n lhs, lhs_params = self.process_lhs(qn, connection)\n rhs, rhs_params = self.process_rhs(qn, connection)\n params = lhs_params + rhs_params\n return 'CAST(HOST(%s) AS INET) << %s' % (lhs, rhs), params\n\n\nclass NetFamily(Transform):\n lookup_name = 'family'\n function = 'FAMILY'\n\n @property\n def output_field(self):\n return IntegerField()\n\n\nclass NetMaskLength(Transform):\n function = 'MASKLEN'\n lookup_name = 'net_mask_length'\n\n @property\n def output_field(self):\n return IntegerField()\n\n\nclass Host(Transform):\n function = 'HOST'\n lookup_name = 'host'\n\n\nclass Inet(Transform):\n function = 'INET'\n lookup_name = 'inet'\n", "path": "netbox/ipam/lookups.py"}]}
| 2,478 | 153 |
gh_patches_debug_11542
|
rasdani/github-patches
|
git_diff
|
open-mmlab__mmdetection-1404
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
assert len(indices) == self.total_size error during multiple GPU training
I am trying to train my dataset on 8 GPU's. However, after calling `./dist_train.sh` this error assertion appeares:
Traceback (most recent call last):
File "./tools/train.py", line 113, in <module>
main()
File "./tools/train.py", line 109, in main
logger=logger)
File "/mmdetection/mmdet/apis/train.py", line 58, in train_detector
_dist_train(model, dataset, cfg, validate=validate)
File "/mmdetection/mmdet/apis/train.py", line 186, in _dist_train
runner.run(data_loaders, cfg.workflow, cfg.total_epochs)
File "/opt/conda/lib/python3.6/site-packages/mmcv/runner/runner.py", line 358, in run
epoch_runner(data_loaders[i], **kwargs)
File "/opt/conda/lib/python3.6/site-packages/mmcv/runner/runner.py", line 260, in train
for i, data_batch in enumerate(data_loader):
File "/opt/conda/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 193, in __iter__ return _DataLoaderIter(self)
File "/opt/conda/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 493, in __init__
self._put_indices()
File "/opt/conda/lib/python3.6/site-packages/torch/utils/data/dataloader.py", line 591, in _put_indices
indices = next(self.sample_iter, None)
File "/opt/conda/lib/python3.6/site-packages/torch/utils/data/sampler.py", line 172, in __iter__
for idx in self.sampler:
File "/mmdetection/mmdet/datasets/loader/sampler.py", line 138, in __iter__
assert len(indices) == self.total_size
...
in the config I tried various values for `imgs_per_gpu` and `workers_per_gpu`, currently it is:
`imgs_per_gpu=2,
workers_per_gpu=2,`
no settings was working though. Single-GPU training works well.
What is the meaning of this assert?
Thanks!
</issue>
<code>
[start of mmdet/datasets/loader/sampler.py]
1 from __future__ import division
2 import math
3
4 import numpy as np
5 import torch
6 from mmcv.runner.utils import get_dist_info
7 from torch.utils.data import DistributedSampler as _DistributedSampler
8 from torch.utils.data import Sampler
9
10
11 class DistributedSampler(_DistributedSampler):
12
13 def __init__(self, dataset, num_replicas=None, rank=None, shuffle=True):
14 super().__init__(dataset, num_replicas=num_replicas, rank=rank)
15 self.shuffle = shuffle
16
17 def __iter__(self):
18 # deterministically shuffle based on epoch
19 if self.shuffle:
20 g = torch.Generator()
21 g.manual_seed(self.epoch)
22 indices = torch.randperm(len(self.dataset), generator=g).tolist()
23 else:
24 indices = torch.arange(len(self.dataset)).tolist()
25
26 # add extra samples to make it evenly divisible
27 indices += indices[:(self.total_size - len(indices))]
28 assert len(indices) == self.total_size
29
30 # subsample
31 indices = indices[self.rank:self.total_size:self.num_replicas]
32 assert len(indices) == self.num_samples
33
34 return iter(indices)
35
36
37 class GroupSampler(Sampler):
38
39 def __init__(self, dataset, samples_per_gpu=1):
40 assert hasattr(dataset, 'flag')
41 self.dataset = dataset
42 self.samples_per_gpu = samples_per_gpu
43 self.flag = dataset.flag.astype(np.int64)
44 self.group_sizes = np.bincount(self.flag)
45 self.num_samples = 0
46 for i, size in enumerate(self.group_sizes):
47 self.num_samples += int(np.ceil(
48 size / self.samples_per_gpu)) * self.samples_per_gpu
49
50 def __iter__(self):
51 indices = []
52 for i, size in enumerate(self.group_sizes):
53 if size == 0:
54 continue
55 indice = np.where(self.flag == i)[0]
56 assert len(indice) == size
57 np.random.shuffle(indice)
58 num_extra = int(np.ceil(size / self.samples_per_gpu)
59 ) * self.samples_per_gpu - len(indice)
60 indice = np.concatenate([indice, indice[:num_extra]])
61 indices.append(indice)
62 indices = np.concatenate(indices)
63 indices = [
64 indices[i * self.samples_per_gpu:(i + 1) * self.samples_per_gpu]
65 for i in np.random.permutation(
66 range(len(indices) // self.samples_per_gpu))
67 ]
68 indices = np.concatenate(indices)
69 indices = indices.astype(np.int64).tolist()
70 assert len(indices) == self.num_samples
71 return iter(indices)
72
73 def __len__(self):
74 return self.num_samples
75
76
77 class DistributedGroupSampler(Sampler):
78 """Sampler that restricts data loading to a subset of the dataset.
79 It is especially useful in conjunction with
80 :class:`torch.nn.parallel.DistributedDataParallel`. In such case, each
81 process can pass a DistributedSampler instance as a DataLoader sampler,
82 and load a subset of the original dataset that is exclusive to it.
83 .. note::
84 Dataset is assumed to be of constant size.
85 Arguments:
86 dataset: Dataset used for sampling.
87 num_replicas (optional): Number of processes participating in
88 distributed training.
89 rank (optional): Rank of the current process within num_replicas.
90 """
91
92 def __init__(self,
93 dataset,
94 samples_per_gpu=1,
95 num_replicas=None,
96 rank=None):
97 _rank, _num_replicas = get_dist_info()
98 if num_replicas is None:
99 num_replicas = _num_replicas
100 if rank is None:
101 rank = _rank
102 self.dataset = dataset
103 self.samples_per_gpu = samples_per_gpu
104 self.num_replicas = num_replicas
105 self.rank = rank
106 self.epoch = 0
107
108 assert hasattr(self.dataset, 'flag')
109 self.flag = self.dataset.flag
110 self.group_sizes = np.bincount(self.flag)
111
112 self.num_samples = 0
113 for i, j in enumerate(self.group_sizes):
114 self.num_samples += int(
115 math.ceil(self.group_sizes[i] * 1.0 / self.samples_per_gpu /
116 self.num_replicas)) * self.samples_per_gpu
117 self.total_size = self.num_samples * self.num_replicas
118
119 def __iter__(self):
120 # deterministically shuffle based on epoch
121 g = torch.Generator()
122 g.manual_seed(self.epoch)
123
124 indices = []
125 for i, size in enumerate(self.group_sizes):
126 if size > 0:
127 indice = np.where(self.flag == i)[0]
128 assert len(indice) == size
129 indice = indice[list(torch.randperm(int(size),
130 generator=g))].tolist()
131 extra = int(
132 math.ceil(
133 size * 1.0 / self.samples_per_gpu / self.num_replicas)
134 ) * self.samples_per_gpu * self.num_replicas - len(indice)
135 indice += indice[:extra]
136 indices += indice
137
138 assert len(indices) == self.total_size
139
140 indices = [
141 indices[j] for i in list(
142 torch.randperm(
143 len(indices) // self.samples_per_gpu, generator=g))
144 for j in range(i * self.samples_per_gpu, (i + 1) *
145 self.samples_per_gpu)
146 ]
147
148 # subsample
149 offset = self.num_samples * self.rank
150 indices = indices[offset:offset + self.num_samples]
151 assert len(indices) == self.num_samples
152
153 return iter(indices)
154
155 def __len__(self):
156 return self.num_samples
157
158 def set_epoch(self, epoch):
159 self.epoch = epoch
160
[end of mmdet/datasets/loader/sampler.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/mmdet/datasets/loader/sampler.py b/mmdet/datasets/loader/sampler.py
--- a/mmdet/datasets/loader/sampler.py
+++ b/mmdet/datasets/loader/sampler.py
@@ -132,8 +132,12 @@
math.ceil(
size * 1.0 / self.samples_per_gpu / self.num_replicas)
) * self.samples_per_gpu * self.num_replicas - len(indice)
- indice += indice[:extra]
- indices += indice
+ # pad indice
+ tmp = indice.copy()
+ for _ in range(extra // size):
+ indice.extend(tmp)
+ indice.extend(tmp[:extra % size])
+ indices.extend(indice)
assert len(indices) == self.total_size
|
{"golden_diff": "diff --git a/mmdet/datasets/loader/sampler.py b/mmdet/datasets/loader/sampler.py\n--- a/mmdet/datasets/loader/sampler.py\n+++ b/mmdet/datasets/loader/sampler.py\n@@ -132,8 +132,12 @@\n math.ceil(\n size * 1.0 / self.samples_per_gpu / self.num_replicas)\n ) * self.samples_per_gpu * self.num_replicas - len(indice)\n- indice += indice[:extra]\n- indices += indice\n+ # pad indice\n+ tmp = indice.copy()\n+ for _ in range(extra // size):\n+ indice.extend(tmp)\n+ indice.extend(tmp[:extra % size])\n+ indices.extend(indice)\n \n assert len(indices) == self.total_size\n", "issue": "assert len(indices) == self.total_size error during multiple GPU training\nI am trying to train my dataset on 8 GPU's. However, after calling `./dist_train.sh` this error assertion appeares:\r\n\r\nTraceback (most recent call last): \r\n File \"./tools/train.py\", line 113, in <module> \r\n main() \r\n File \"./tools/train.py\", line 109, in main \r\n logger=logger) \r\n File \"/mmdetection/mmdet/apis/train.py\", line 58, in train_detector \r\n _dist_train(model, dataset, cfg, validate=validate) \r\n File \"/mmdetection/mmdet/apis/train.py\", line 186, in _dist_train \r\n runner.run(data_loaders, cfg.workflow, cfg.total_epochs) \r\n File \"/opt/conda/lib/python3.6/site-packages/mmcv/runner/runner.py\", line 358, in run\r\n epoch_runner(data_loaders[i], **kwargs) \r\n File \"/opt/conda/lib/python3.6/site-packages/mmcv/runner/runner.py\", line 260, in train\r\n for i, data_batch in enumerate(data_loader): \r\n File \"/opt/conda/lib/python3.6/site-packages/torch/utils/data/dataloader.py\", line 193, in __iter__ return _DataLoaderIter(self) \r\n File \"/opt/conda/lib/python3.6/site-packages/torch/utils/data/dataloader.py\", line 493, in __init__\r\n self._put_indices() \r\n File \"/opt/conda/lib/python3.6/site-packages/torch/utils/data/dataloader.py\", line 591, in _put_indices\r\n indices = next(self.sample_iter, None) \r\n File \"/opt/conda/lib/python3.6/site-packages/torch/utils/data/sampler.py\", line 172, in __iter__\r\n for idx in self.sampler: \r\n File \"/mmdetection/mmdet/datasets/loader/sampler.py\", line 138, in __iter__ \r\n assert len(indices) == self.total_size \r\n...\r\n\r\nin the config I tried various values for `imgs_per_gpu` and `workers_per_gpu`, currently it is:\r\n`imgs_per_gpu=2,\r\nworkers_per_gpu=2,`\r\nno settings was working though. Single-GPU training works well.\r\n\r\nWhat is the meaning of this assert?\r\nThanks!\n", "before_files": [{"content": "from __future__ import division\nimport math\n\nimport numpy as np\nimport torch\nfrom mmcv.runner.utils import get_dist_info\nfrom torch.utils.data import DistributedSampler as _DistributedSampler\nfrom torch.utils.data import Sampler\n\n\nclass DistributedSampler(_DistributedSampler):\n\n def __init__(self, dataset, num_replicas=None, rank=None, shuffle=True):\n super().__init__(dataset, num_replicas=num_replicas, rank=rank)\n self.shuffle = shuffle\n\n def __iter__(self):\n # deterministically shuffle based on epoch\n if self.shuffle:\n g = torch.Generator()\n g.manual_seed(self.epoch)\n indices = torch.randperm(len(self.dataset), generator=g).tolist()\n else:\n indices = torch.arange(len(self.dataset)).tolist()\n\n # add extra samples to make it evenly divisible\n indices += indices[:(self.total_size - len(indices))]\n assert len(indices) == self.total_size\n\n # subsample\n indices = indices[self.rank:self.total_size:self.num_replicas]\n assert len(indices) == self.num_samples\n\n return iter(indices)\n\n\nclass GroupSampler(Sampler):\n\n def __init__(self, dataset, samples_per_gpu=1):\n assert hasattr(dataset, 'flag')\n self.dataset = dataset\n self.samples_per_gpu = samples_per_gpu\n self.flag = dataset.flag.astype(np.int64)\n self.group_sizes = np.bincount(self.flag)\n self.num_samples = 0\n for i, size in enumerate(self.group_sizes):\n self.num_samples += int(np.ceil(\n size / self.samples_per_gpu)) * self.samples_per_gpu\n\n def __iter__(self):\n indices = []\n for i, size in enumerate(self.group_sizes):\n if size == 0:\n continue\n indice = np.where(self.flag == i)[0]\n assert len(indice) == size\n np.random.shuffle(indice)\n num_extra = int(np.ceil(size / self.samples_per_gpu)\n ) * self.samples_per_gpu - len(indice)\n indice = np.concatenate([indice, indice[:num_extra]])\n indices.append(indice)\n indices = np.concatenate(indices)\n indices = [\n indices[i * self.samples_per_gpu:(i + 1) * self.samples_per_gpu]\n for i in np.random.permutation(\n range(len(indices) // self.samples_per_gpu))\n ]\n indices = np.concatenate(indices)\n indices = indices.astype(np.int64).tolist()\n assert len(indices) == self.num_samples\n return iter(indices)\n\n def __len__(self):\n return self.num_samples\n\n\nclass DistributedGroupSampler(Sampler):\n \"\"\"Sampler that restricts data loading to a subset of the dataset.\n It is especially useful in conjunction with\n :class:`torch.nn.parallel.DistributedDataParallel`. In such case, each\n process can pass a DistributedSampler instance as a DataLoader sampler,\n and load a subset of the original dataset that is exclusive to it.\n .. note::\n Dataset is assumed to be of constant size.\n Arguments:\n dataset: Dataset used for sampling.\n num_replicas (optional): Number of processes participating in\n distributed training.\n rank (optional): Rank of the current process within num_replicas.\n \"\"\"\n\n def __init__(self,\n dataset,\n samples_per_gpu=1,\n num_replicas=None,\n rank=None):\n _rank, _num_replicas = get_dist_info()\n if num_replicas is None:\n num_replicas = _num_replicas\n if rank is None:\n rank = _rank\n self.dataset = dataset\n self.samples_per_gpu = samples_per_gpu\n self.num_replicas = num_replicas\n self.rank = rank\n self.epoch = 0\n\n assert hasattr(self.dataset, 'flag')\n self.flag = self.dataset.flag\n self.group_sizes = np.bincount(self.flag)\n\n self.num_samples = 0\n for i, j in enumerate(self.group_sizes):\n self.num_samples += int(\n math.ceil(self.group_sizes[i] * 1.0 / self.samples_per_gpu /\n self.num_replicas)) * self.samples_per_gpu\n self.total_size = self.num_samples * self.num_replicas\n\n def __iter__(self):\n # deterministically shuffle based on epoch\n g = torch.Generator()\n g.manual_seed(self.epoch)\n\n indices = []\n for i, size in enumerate(self.group_sizes):\n if size > 0:\n indice = np.where(self.flag == i)[0]\n assert len(indice) == size\n indice = indice[list(torch.randperm(int(size),\n generator=g))].tolist()\n extra = int(\n math.ceil(\n size * 1.0 / self.samples_per_gpu / self.num_replicas)\n ) * self.samples_per_gpu * self.num_replicas - len(indice)\n indice += indice[:extra]\n indices += indice\n\n assert len(indices) == self.total_size\n\n indices = [\n indices[j] for i in list(\n torch.randperm(\n len(indices) // self.samples_per_gpu, generator=g))\n for j in range(i * self.samples_per_gpu, (i + 1) *\n self.samples_per_gpu)\n ]\n\n # subsample\n offset = self.num_samples * self.rank\n indices = indices[offset:offset + self.num_samples]\n assert len(indices) == self.num_samples\n\n return iter(indices)\n\n def __len__(self):\n return self.num_samples\n\n def set_epoch(self, epoch):\n self.epoch = epoch\n", "path": "mmdet/datasets/loader/sampler.py"}]}
| 2,640 | 173 |
gh_patches_debug_13229
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-center-index-1921
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[libselinux] libselinux/:3.0 Missing symlinks=True in recipe
## Package and Environment Details
* Package Name/Version: **libselinux/3.0**
* Operating System+version: **Linux Fedora 31**
* Compiler+version: **GCC 9**
* Conan version: **conan 1.26.0**
* Python version: **Python 3.7.7**
## Conan profile
```
[settings]
os=Linux
os_build=Linux
arch=x86_64
arch_build=x86_64
compiler=gcc
compiler.version=9
compiler.libcxx=libstdc++11
build_type=Release
[options]
[build_requires]
[env]
```
### Steps to reproduce
`conan install -o shared=True libselinux/3.0@`
```
$ ls -lh ~/.conan/data/libselinux/3.0/_/_/package/7a5a46e61ac4a00adf1fe45a7ed646d200a7c49b/lib/
total 3.0M
-rwxr-xr-x. 1 forbinn forbinn 733K Jun 13 09:26 libselinux.so
-rwxr-xr-x. 1 forbinn forbinn 733K Jun 13 09:26 libselinux.so.1
-rwxr-xr-x. 1 forbinn forbinn 749K Jun 13 09:26 libsepol.so
-rwxr-xr-x. 1 forbinn forbinn 749K Jun 13 09:26 libsepol.so.1
```
### Logs
<details><summary>Click to expand log</summary>
```
Configuration:
[settings]
arch=x86_64
arch_build=x86_64
build_type=Release
compiler=gcc
compiler.libcxx=libstdc++11
compiler.version=9
os=Linux
os_build=Linux
[options]
shared=True
[build_requires]
[env]
Installing package: libselinux/3.0
Requirements
bzip2/1.0.8 from 'conan-center' - Cache
libselinux/3.0 from 'conan-center' - Cache
pcre2/10.33 from 'conan-center' - Cache
zlib/1.2.11 from 'conan-center' - Cache
Packages
bzip2/1.0.8:da606cf731e334010b0bf6e85a2a6f891b9f36b0 - Cache
libselinux/3.0:7a5a46e61ac4a00adf1fe45a7ed646d200a7c49b - Download
pcre2/10.33:18903774d26ee0498535ef95198a1c997e4ca9ba - Cache
zlib/1.2.11:6af9cc7cb931c5ad942174fd7838eb655717c709 - Cache
Installing (downloading, building) binaries...
libselinux/3.0: Retrieving package 7a5a46e61ac4a00adf1fe45a7ed646d200a7c49b from remote 'conan-center'
Downloading conanmanifest.txt completed [3.71k]
Downloading conaninfo.txt completed [0.88k]
Downloading conan_package.tgz completed [1249.37k]
Decompressing conan_package.tgz completed [0.00k]
libselinux/3.0: Package installed 7a5a46e61ac4a00adf1fe45a7ed646d200a7c49b
libselinux/3.0: Downloaded package revision 0
bzip2/1.0.8: Already installed!
zlib/1.2.11: Already installed!
pcre2/10.33: Already installed!
```
</details>
## Notes
As you can see in the `ls` command output the `libselinux` and `libsepol` appears 2 times without symlinks. This is due to the fact that the current recipe do not set set `symlinks` flag to `True` inside the `package()` method.
Current [conanfile.py](https://github.com/conan-io/conan-center-index/blob/master/recipes/libselinux/all/conanfile.py#L59)
`self.copy(pattern="*.so*", dst="lib", src=library, keep_path=False)`
Expected:
`self.copy(pattern="*.so*", dst="lib", src=library, keep_path=False, symlinks=True)`
</issue>
<code>
[start of recipes/libselinux/all/conanfile.py]
1 from conans import ConanFile, tools, AutoToolsBuildEnvironment
2 from conans.errors import ConanInvalidConfiguration
3 import os
4 import glob
5
6
7 class LibSELinuxConan(ConanFile):
8 name = "libselinux"
9 description = "Security-enhanced Linux is a patch of the Linux kernel and a number of utilities with enhanced security functionality designed to add mandatory access controls to Linux"
10 topics = ("conan", "selinux", "security-enhanced linux")
11 url = "https://github.com/conan-io/conan-center-index"
12 homepage = "https://github.com/SELinuxProject/selinux"
13 license = "Unlicense" # This library (libselinux) is public domain software, i.e. not copyrighted
14 settings = "os", "arch", "compiler", "build_type"
15 options = {"shared": [True, False], "fPIC": [True, False]}
16 default_options = {"shared": False, "fPIC": True}
17 requires = ("pcre2/10.33",)
18
19 def _get_subfolders(self):
20 _sepol_subfolder = "libsepol-%s" % self.version
21 _selinux_subfolder = "libselinux-%s" % self.version
22 return _sepol_subfolder, _selinux_subfolder
23
24 def configure(self):
25 del self.settings.compiler.libcxx
26 del self.settings.compiler.cppstd
27 if self.settings.os != "Linux":
28 raise ConanInvalidConfiguration("Only Linux is supported")
29
30 def build_requirements(self):
31 self.build_requires("flex/2.6.4")
32
33 def source(self):
34 for download in self.conan_data["sources"][self.version]:
35 tools.get(**download)
36
37 def build(self):
38 _sepol_subfolder, _selinux_subfolder = self._get_subfolders()
39 pcre_inc = os.path.join(self.deps_cpp_info["pcre2"].rootpath,
40 self.deps_cpp_info["pcre2"].includedirs[0])
41 pcre_libs = ' '.join(["-l%s" % lib for lib in self.deps_cpp_info["pcre2"].libs])
42 sepol_inc = os.path.join(self.source_folder, _sepol_subfolder, "include")
43 with tools.chdir(os.path.join(_sepol_subfolder, "src")):
44 args = ["libsepol.so.1" if self.options.shared else "libsepol.a"]
45 env_build = AutoToolsBuildEnvironment(self)
46 env_build.make(args=args)
47 with tools.chdir(os.path.join(_selinux_subfolder, "src")):
48 args = ["libselinux.so.1" if self.options.shared else "libselinux.a",
49 'PCRE_CFLAGS=-DPCRE2_CODE_UNIT_WIDTH=8 -DUSE_PCRE2=1 -I%s -I%s' % (pcre_inc, sepol_inc),
50 'PCRE_LDLIBS=%s' % pcre_libs]
51 env_build = AutoToolsBuildEnvironment(self)
52 env_build.make(args=args)
53
54 def package(self):
55 _sepol_subfolder, _selinux_subfolder = self._get_subfolders()
56 self.copy(pattern="LICENSE", dst="licenses", src=_selinux_subfolder)
57 for library in [_sepol_subfolder, _selinux_subfolder]:
58 self.copy(pattern="*.h", dst="include", src=os.path.join(library, "include"), keep_path=True)
59 self.copy(pattern="*.so*", dst="lib", src=library, keep_path=False)
60 self.copy(pattern="*.a", dst="lib", src=library, keep_path=False)
61
62 def package_info(self):
63 self.cpp_info.libs = ["selinux", "sepol"]
64
[end of recipes/libselinux/all/conanfile.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/recipes/libselinux/all/conanfile.py b/recipes/libselinux/all/conanfile.py
--- a/recipes/libselinux/all/conanfile.py
+++ b/recipes/libselinux/all/conanfile.py
@@ -56,7 +56,7 @@
self.copy(pattern="LICENSE", dst="licenses", src=_selinux_subfolder)
for library in [_sepol_subfolder, _selinux_subfolder]:
self.copy(pattern="*.h", dst="include", src=os.path.join(library, "include"), keep_path=True)
- self.copy(pattern="*.so*", dst="lib", src=library, keep_path=False)
+ self.copy(pattern="*.so*", dst="lib", src=library, keep_path=False, symlinks=True)
self.copy(pattern="*.a", dst="lib", src=library, keep_path=False)
def package_info(self):
|
{"golden_diff": "diff --git a/recipes/libselinux/all/conanfile.py b/recipes/libselinux/all/conanfile.py\n--- a/recipes/libselinux/all/conanfile.py\n+++ b/recipes/libselinux/all/conanfile.py\n@@ -56,7 +56,7 @@\n self.copy(pattern=\"LICENSE\", dst=\"licenses\", src=_selinux_subfolder)\n for library in [_sepol_subfolder, _selinux_subfolder]:\n self.copy(pattern=\"*.h\", dst=\"include\", src=os.path.join(library, \"include\"), keep_path=True)\n- self.copy(pattern=\"*.so*\", dst=\"lib\", src=library, keep_path=False)\n+ self.copy(pattern=\"*.so*\", dst=\"lib\", src=library, keep_path=False, symlinks=True)\n self.copy(pattern=\"*.a\", dst=\"lib\", src=library, keep_path=False)\n \n def package_info(self):\n", "issue": "[libselinux] libselinux/:3.0 Missing symlinks=True in recipe\n## Package and Environment Details\r\n * Package Name/Version: **libselinux/3.0**\r\n * Operating System+version: **Linux Fedora 31**\r\n * Compiler+version: **GCC 9**\r\n * Conan version: **conan 1.26.0**\r\n * Python version: **Python 3.7.7**\r\n\r\n## Conan profile\r\n```\r\n[settings]\r\nos=Linux\r\nos_build=Linux\r\narch=x86_64\r\narch_build=x86_64\r\ncompiler=gcc\r\ncompiler.version=9\r\ncompiler.libcxx=libstdc++11\r\nbuild_type=Release\r\n[options]\r\n[build_requires]\r\n[env]\r\n```\r\n\r\n### Steps to reproduce\r\n\r\n`conan install -o shared=True libselinux/3.0@`\r\n```\r\n$ ls -lh ~/.conan/data/libselinux/3.0/_/_/package/7a5a46e61ac4a00adf1fe45a7ed646d200a7c49b/lib/\r\n\r\ntotal 3.0M\r\n-rwxr-xr-x. 1 forbinn forbinn 733K Jun 13 09:26 libselinux.so\r\n-rwxr-xr-x. 1 forbinn forbinn 733K Jun 13 09:26 libselinux.so.1\r\n-rwxr-xr-x. 1 forbinn forbinn 749K Jun 13 09:26 libsepol.so\r\n-rwxr-xr-x. 1 forbinn forbinn 749K Jun 13 09:26 libsepol.so.1\r\n```\r\n\r\n\r\n### Logs\r\n<details><summary>Click to expand log</summary>\r\n\r\n```\r\nConfiguration:\r\n[settings]\r\narch=x86_64\r\narch_build=x86_64\r\nbuild_type=Release\r\ncompiler=gcc\r\ncompiler.libcxx=libstdc++11\r\ncompiler.version=9\r\nos=Linux\r\nos_build=Linux\r\n[options]\r\nshared=True\r\n[build_requires]\r\n[env]\r\n\r\nInstalling package: libselinux/3.0\r\nRequirements\r\n bzip2/1.0.8 from 'conan-center' - Cache\r\n libselinux/3.0 from 'conan-center' - Cache\r\n pcre2/10.33 from 'conan-center' - Cache\r\n zlib/1.2.11 from 'conan-center' - Cache\r\nPackages\r\n bzip2/1.0.8:da606cf731e334010b0bf6e85a2a6f891b9f36b0 - Cache\r\n libselinux/3.0:7a5a46e61ac4a00adf1fe45a7ed646d200a7c49b - Download\r\n pcre2/10.33:18903774d26ee0498535ef95198a1c997e4ca9ba - Cache\r\n zlib/1.2.11:6af9cc7cb931c5ad942174fd7838eb655717c709 - Cache\r\n\r\nInstalling (downloading, building) binaries...\r\nlibselinux/3.0: Retrieving package 7a5a46e61ac4a00adf1fe45a7ed646d200a7c49b from remote 'conan-center' \r\nDownloading conanmanifest.txt completed [3.71k] \r\nDownloading conaninfo.txt completed [0.88k] \r\nDownloading conan_package.tgz completed [1249.37k] \r\nDecompressing conan_package.tgz completed [0.00k] \r\nlibselinux/3.0: Package installed 7a5a46e61ac4a00adf1fe45a7ed646d200a7c49b\r\nlibselinux/3.0: Downloaded package revision 0\r\nbzip2/1.0.8: Already installed!\r\nzlib/1.2.11: Already installed!\r\npcre2/10.33: Already installed!\r\n```\r\n\r\n</details>\r\n\r\n## Notes\r\n\r\nAs you can see in the `ls` command output the `libselinux` and `libsepol` appears 2 times without symlinks. This is due to the fact that the current recipe do not set set `symlinks` flag to `True` inside the `package()` method.\r\n\r\nCurrent [conanfile.py](https://github.com/conan-io/conan-center-index/blob/master/recipes/libselinux/all/conanfile.py#L59)\r\n`self.copy(pattern=\"*.so*\", dst=\"lib\", src=library, keep_path=False)`\r\nExpected:\r\n`self.copy(pattern=\"*.so*\", dst=\"lib\", src=library, keep_path=False, symlinks=True)`\n", "before_files": [{"content": "from conans import ConanFile, tools, AutoToolsBuildEnvironment\nfrom conans.errors import ConanInvalidConfiguration\nimport os\nimport glob\n\n\nclass LibSELinuxConan(ConanFile):\n name = \"libselinux\"\n description = \"Security-enhanced Linux is a patch of the Linux kernel and a number of utilities with enhanced security functionality designed to add mandatory access controls to Linux\"\n topics = (\"conan\", \"selinux\", \"security-enhanced linux\")\n url = \"https://github.com/conan-io/conan-center-index\"\n homepage = \"https://github.com/SELinuxProject/selinux\"\n license = \"Unlicense\" # This library (libselinux) is public domain software, i.e. not copyrighted\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n options = {\"shared\": [True, False], \"fPIC\": [True, False]}\n default_options = {\"shared\": False, \"fPIC\": True}\n requires = (\"pcre2/10.33\",)\n\n def _get_subfolders(self):\n _sepol_subfolder = \"libsepol-%s\" % self.version\n _selinux_subfolder = \"libselinux-%s\" % self.version\n return _sepol_subfolder, _selinux_subfolder\n\n def configure(self):\n del self.settings.compiler.libcxx\n del self.settings.compiler.cppstd\n if self.settings.os != \"Linux\":\n raise ConanInvalidConfiguration(\"Only Linux is supported\")\n\n def build_requirements(self):\n self.build_requires(\"flex/2.6.4\")\n\n def source(self):\n for download in self.conan_data[\"sources\"][self.version]:\n tools.get(**download)\n\n def build(self):\n _sepol_subfolder, _selinux_subfolder = self._get_subfolders()\n pcre_inc = os.path.join(self.deps_cpp_info[\"pcre2\"].rootpath,\n self.deps_cpp_info[\"pcre2\"].includedirs[0])\n pcre_libs = ' '.join([\"-l%s\" % lib for lib in self.deps_cpp_info[\"pcre2\"].libs])\n sepol_inc = os.path.join(self.source_folder, _sepol_subfolder, \"include\")\n with tools.chdir(os.path.join(_sepol_subfolder, \"src\")):\n args = [\"libsepol.so.1\" if self.options.shared else \"libsepol.a\"]\n env_build = AutoToolsBuildEnvironment(self)\n env_build.make(args=args)\n with tools.chdir(os.path.join(_selinux_subfolder, \"src\")):\n args = [\"libselinux.so.1\" if self.options.shared else \"libselinux.a\",\n 'PCRE_CFLAGS=-DPCRE2_CODE_UNIT_WIDTH=8 -DUSE_PCRE2=1 -I%s -I%s' % (pcre_inc, sepol_inc),\n 'PCRE_LDLIBS=%s' % pcre_libs]\n env_build = AutoToolsBuildEnvironment(self)\n env_build.make(args=args)\n\n def package(self):\n _sepol_subfolder, _selinux_subfolder = self._get_subfolders()\n self.copy(pattern=\"LICENSE\", dst=\"licenses\", src=_selinux_subfolder)\n for library in [_sepol_subfolder, _selinux_subfolder]:\n self.copy(pattern=\"*.h\", dst=\"include\", src=os.path.join(library, \"include\"), keep_path=True)\n self.copy(pattern=\"*.so*\", dst=\"lib\", src=library, keep_path=False)\n self.copy(pattern=\"*.a\", dst=\"lib\", src=library, keep_path=False)\n\n def package_info(self):\n self.cpp_info.libs = [\"selinux\", \"sepol\"]\n", "path": "recipes/libselinux/all/conanfile.py"}]}
| 2,616 | 197 |
gh_patches_debug_7307
|
rasdani/github-patches
|
git_diff
|
conan-io__conan-center-index-9895
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[package] freeimage/3.18.0: Plugins aren't enabled
The preprocessor symbols used in the patches (WITH_JPEG etc.) are not defined by cmake.
### Package and Environment Details (include every applicable attribute)
* Package Name/Version: **freeimage/3.18.0**
* Operating System+version: **Windows 11**
* Compiler+version: **Visual Studio 2019**
* Conan version: **conan 1.46.2**
* Python version: **Python 3.10.3**
### Conan profile (output of `conan profile show default` or `conan profile show <profile>` if custom profile is in use)
```
[settings]
os=Windows
os_build=Windows
arch=x86_64
arch_build=x86_64
compiler=Visual Studio
compiler.version=16
```
### Steps to reproduce (Include if Applicable)
Load image with any optional plugin (JPEG, PNG, TIFF, etc). The test package didn't check for errors.
### Logs (Include/Attach if Applicable)
<details><summary>Click to expand log</summary>
```
freeimage/3.18.0 (test package): Running test()
FreeImage 3.18.0, with:
- bmp
- ico
- jng
- koa
- iff,lbm
- mng
- pbm
- pbm
- pcd
- pcx
- pgm
- pgm
- ppm
- ppm
- ras
- tga,targa
- wap,wbmp,wbm
- psd,psb
- cut
- xbm
- xpm
- dds
- gif
- hdr
- sgi,rgb,rgba,bw
- pfm
- pct,pict,pic
```
Should be:
```
freeimage/3.18.0 (test package): Running test()
FreeImage 3.18.0, with:
- bmp
- ico
- jpg,jif,jpeg,jpe
- jng
- koa
- iff,lbm
- mng
- pbm
- pbm
- pcd
- pcx
- pgm
- pgm
- png
- ppm
- ppm
- ras
- tga,targa
- tif,tiff
- wap,wbmp,wbm
- psd,psb
- cut
- xbm
- xpm
- dds
- gif
- hdr
- sgi,rgb,rgba,bw
- exr
- j2k,j2c
- jp2
- pfm
- pct,pict,pic
- 3fr,arw,bay,bmq,cap,cine,cr2,crw,cs1,dc2,dcr,drf,dsc,dng,erf,fff,ia,iiq,k25,kc2,kdc,mdc,mef,mos,mrw,nef,nrw,orf,pef,ptx,pxn,qtk,raf,raw,rdc,rw2,rwl,rwz,sr2,srf,srw,sti,x3f
- webp
- jxr,wdp,hdp
```
</details>
</issue>
<code>
[start of recipes/freeimage/all/conanfile.py]
1 from conans import ConanFile, CMake, tools
2 import os
3 import shutil
4
5 required_conan_version = ">=1.43.0"
6
7
8 class FreeImageConan(ConanFile):
9 name = "freeimage"
10 description = "Open Source library project for developers who would like to support popular graphics image formats"\
11 "like PNG, BMP, JPEG, TIFF and others as needed by today's multimedia applications."
12 homepage = "https://freeimage.sourceforge.io"
13 url = "https://github.com/conan-io/conan-center-index"
14 license = "FreeImage", "GPL-3.0-or-later", "GPL-2.0-or-later"
15 topics = ("freeimage", "image", "decoding", "graphics")
16 generators = "cmake", "cmake_find_package"
17 settings = "os", "arch", "compiler", "build_type"
18 options = {
19 "shared": [True, False],
20 "fPIC": [True, False],
21 "with_jpeg": [False, "libjpeg", "libjpeg-turbo"],
22 "with_png": [True, False],
23 "with_tiff": [True, False],
24 "with_jpeg2000": [True, False],
25 "with_openexr": [True, False],
26 "with_eigen": [True, False],
27 "with_webp": [True, False],
28 "with_raw": [True, False],
29 "with_jxr": [True, False],
30 }
31 default_options = {
32 "shared": False,
33 "fPIC": True,
34 "with_jpeg": "libjpeg",
35 "with_png": True,
36 "with_tiff": True,
37 "with_jpeg2000": True,
38 "with_openexr": True,
39 "with_eigen": True,
40 "with_webp": True,
41 "with_raw": True,
42 "with_jxr": True,
43 }
44
45 _cmake = None
46
47 @property
48 def _source_subfolder(self):
49 return "source_subfolder"
50
51 @property
52 def _build_subfolder(self):
53 return "build_subfolder"
54
55 def export_sources(self):
56 self.copy("CMakeLists.txt")
57 for patch in self.conan_data.get("patches", {}).get(self.version, []):
58 self.copy(patch["patch_file"])
59
60 def config_options(self):
61 if self.settings.os == "Windows":
62 del self.options.fPIC
63
64 def configure(self):
65 tools.check_min_cppstd(self, "11")
66 if self.options.shared:
67 del self.options.fPIC
68 self.output.warn("G3 plugin and JPEGTransform are disabled.")
69 if self.options.with_jpeg is not None:
70 if self.options.with_tiff:
71 self.options["libtiff"].jpeg = self.options.with_jpeg
72
73 def requirements(self):
74 self.requires("zlib/1.2.11")
75 if self.options.with_jpeg == "libjpeg":
76 self.requires("libjpeg/9d")
77 elif self.options.with_jpeg == "libjpeg-turbo":
78 self.requires("libjpeg-turbo/2.1.2")
79 if self.options.with_jpeg2000:
80 self.requires("openjpeg/2.4.0")
81 if self.options.with_png:
82 self.requires("libpng/1.6.37")
83 if self.options.with_webp:
84 self.requires("libwebp/1.2.2")
85 if self.options.with_openexr:
86 self.requires("openexr/2.5.7")
87 if self.options.with_raw:
88 self.requires("libraw/0.20.2")
89 if self.options.with_jxr:
90 self.requires("jxrlib/cci.20170615")
91 if self.options.with_tiff:
92 self.requires("libtiff/4.3.0")
93
94 def source(self):
95 tools.get(**self.conan_data["sources"][self.version],
96 destination=self._source_subfolder, strip_root=True)
97
98 def _configure_cmake(self):
99 if self._cmake:
100 return self._cmake
101 self._cmake = CMake(self)
102 self._cmake.definitions["WITH_JPEG"] = self.options.with_jpeg != False
103 self._cmake.definitions["WITH_OPENJPEG"] = self.options.with_jpeg2000
104 self._cmake.definitions["WITH_PNG"] = self.options.with_png
105 self._cmake.definitions["WITH_WEBP"] = self.options.with_webp
106 self._cmake.definitions["WITH_OPENEXR"] = self.options.with_openexr
107 self._cmake.definitions["WITH_RAW"] = self.options.with_raw
108 self._cmake.definitions["WITH_JXR"] = self.options.with_jxr
109 self._cmake.definitions["WITH_TIFF"] = self.options.with_tiff
110 self._cmake.configure(build_dir=self._build_subfolder)
111 return self._cmake
112
113 def build(self):
114 tools.rmdir(os.path.join(self._source_subfolder, "Source", "LibPNG"))
115 tools.rmdir(os.path.join(self._source_subfolder, "Source", "LibTIFF4"))
116 tools.rmdir(os.path.join(self._source_subfolder, "Source", "LibOpenJPEG"))
117 tools.rmdir(os.path.join(self._source_subfolder, "Source", "LibJXR"))
118 tools.rmdir(os.path.join(self._source_subfolder, "Source", "LibWebP"))
119 tools.rmdir(os.path.join(self._source_subfolder, "Source", "LibRawLite"))
120 tools.rmdir(os.path.join(self._source_subfolder, "Source", "OpenEXR"))
121
122 for patch in self.conan_data.get("patches", {}).get(self.version, {}):
123 tools.patch(**patch)
124 cmake = self._configure_cmake()
125 cmake.build()
126
127 def package(self):
128 cmake = self._configure_cmake()
129 cmake.install()
130 self.copy("license-fi.txt", dst="licenses", src=self._source_subfolder)
131 self.copy("license-gplv3.txt", dst="licenses", src=self._source_subfolder)
132 self.copy("license-gplv2.txt", dst="licenses", src=self._source_subfolder)
133
134 def package_info(self):
135 def imageformats_deps():
136 components = []
137 components.append("zlib::zlib")
138 if self.options.with_jpeg:
139 components.append("{0}::{0}".format(self.options.with_jpeg))
140 if self.options.with_jpeg2000:
141 components.append("openjpeg::openjpeg")
142 if self.options.with_png:
143 components.append("libpng::libpng")
144 if self.options.with_webp:
145 components.append("libwebp::libwebp")
146 if self.options.with_openexr:
147 components.append("openexr::openexr")
148 if self.options.with_raw:
149 components.append("libraw::libraw")
150 if self.options.with_jxr:
151 components.append("jxrlib::jxrlib")
152 if self.options.with_tiff:
153 components.append("libtiff::libtiff")
154 return components
155
156 self.cpp_info.names["pkg_config"] = "freeimage"
157 self.cpp_info.names["cmake_find_package"] = "FreeImage"
158 self.cpp_info.names["cmake_find_package_multi"] = "FreeImage"
159 self.cpp_info.components["FreeImage"].libs = ["freeimage"]
160 self.cpp_info.components["FreeImage"].requires = imageformats_deps()
161 self.cpp_info.components["FreeImagePlus"].libs = ["freeimageplus"]
162 self.cpp_info.components["FreeImagePlus"].requires = ["FreeImage"]
163
164 if not self.options.shared:
165 self.cpp_info.components["FreeImage"].defines.append("FREEIMAGE_LIB")
166
[end of recipes/freeimage/all/conanfile.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/recipes/freeimage/all/conanfile.py b/recipes/freeimage/all/conanfile.py
--- a/recipes/freeimage/all/conanfile.py
+++ b/recipes/freeimage/all/conanfile.py
@@ -13,6 +13,7 @@
url = "https://github.com/conan-io/conan-center-index"
license = "FreeImage", "GPL-3.0-or-later", "GPL-2.0-or-later"
topics = ("freeimage", "image", "decoding", "graphics")
+ short_paths = True
generators = "cmake", "cmake_find_package"
settings = "os", "arch", "compiler", "build_type"
options = {
|
{"golden_diff": "diff --git a/recipes/freeimage/all/conanfile.py b/recipes/freeimage/all/conanfile.py\n--- a/recipes/freeimage/all/conanfile.py\n+++ b/recipes/freeimage/all/conanfile.py\n@@ -13,6 +13,7 @@\n url = \"https://github.com/conan-io/conan-center-index\"\n license = \"FreeImage\", \"GPL-3.0-or-later\", \"GPL-2.0-or-later\"\n topics = (\"freeimage\", \"image\", \"decoding\", \"graphics\")\n+ short_paths = True\n generators = \"cmake\", \"cmake_find_package\"\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n options = {\n", "issue": "[package] freeimage/3.18.0: Plugins aren't enabled\nThe preprocessor symbols used in the patches (WITH_JPEG etc.) are not defined by cmake.\r\n\r\n### Package and Environment Details (include every applicable attribute)\r\n * Package Name/Version: **freeimage/3.18.0**\r\n * Operating System+version: **Windows 11**\r\n * Compiler+version: **Visual Studio 2019**\r\n * Conan version: **conan 1.46.2**\r\n * Python version: **Python 3.10.3**\r\n\r\n\r\n### Conan profile (output of `conan profile show default` or `conan profile show <profile>` if custom profile is in use)\r\n```\r\n[settings]\r\nos=Windows\r\nos_build=Windows\r\narch=x86_64\r\narch_build=x86_64\r\ncompiler=Visual Studio\r\ncompiler.version=16\r\n```\r\n\r\n\r\n### Steps to reproduce (Include if Applicable)\r\n\r\nLoad image with any optional plugin (JPEG, PNG, TIFF, etc). The test package didn't check for errors.\r\n\r\n### Logs (Include/Attach if Applicable)\r\n<details><summary>Click to expand log</summary>\r\n\r\n```\r\nfreeimage/3.18.0 (test package): Running test()\r\nFreeImage 3.18.0, with:\r\n\t- bmp\r\n\t- ico\r\n\t- jng\r\n\t- koa\r\n\t- iff,lbm\r\n\t- mng\r\n\t- pbm\r\n\t- pbm\r\n\t- pcd\r\n\t- pcx\r\n\t- pgm\r\n\t- pgm\r\n\t- ppm\r\n\t- ppm\r\n\t- ras\r\n\t- tga,targa\r\n\t- wap,wbmp,wbm\r\n\t- psd,psb\r\n\t- cut\r\n\t- xbm\r\n\t- xpm\r\n\t- dds\r\n\t- gif\r\n\t- hdr\r\n\t- sgi,rgb,rgba,bw\r\n\t- pfm\r\n\t- pct,pict,pic\r\n```\r\n\r\nShould be:\r\n\r\n```\r\nfreeimage/3.18.0 (test package): Running test()\r\nFreeImage 3.18.0, with:\r\n\t- bmp\r\n\t- ico\r\n\t- jpg,jif,jpeg,jpe\r\n\t- jng\r\n\t- koa\r\n\t- iff,lbm\r\n\t- mng\r\n\t- pbm\r\n\t- pbm\r\n\t- pcd\r\n\t- pcx\r\n\t- pgm\r\n\t- pgm\r\n\t- png\r\n\t- ppm\r\n\t- ppm\r\n\t- ras\r\n\t- tga,targa\r\n\t- tif,tiff\r\n\t- wap,wbmp,wbm\r\n\t- psd,psb\r\n\t- cut\r\n\t- xbm\r\n\t- xpm\r\n\t- dds\r\n\t- gif\r\n\t- hdr\r\n\t- sgi,rgb,rgba,bw\r\n\t- exr\r\n\t- j2k,j2c\r\n\t- jp2\r\n\t- pfm\r\n\t- pct,pict,pic\r\n\t- 3fr,arw,bay,bmq,cap,cine,cr2,crw,cs1,dc2,dcr,drf,dsc,dng,erf,fff,ia,iiq,k25,kc2,kdc,mdc,mef,mos,mrw,nef,nrw,orf,pef,ptx,pxn,qtk,raf,raw,rdc,rw2,rwl,rwz,sr2,srf,srw,sti,x3f\r\n\t- webp\r\n\t- jxr,wdp,hdp\r\n```\r\n\r\n</details>\r\n\n", "before_files": [{"content": "from conans import ConanFile, CMake, tools\nimport os\nimport shutil\n\nrequired_conan_version = \">=1.43.0\"\n\n\nclass FreeImageConan(ConanFile):\n name = \"freeimage\"\n description = \"Open Source library project for developers who would like to support popular graphics image formats\"\\\n \"like PNG, BMP, JPEG, TIFF and others as needed by today's multimedia applications.\"\n homepage = \"https://freeimage.sourceforge.io\"\n url = \"https://github.com/conan-io/conan-center-index\"\n license = \"FreeImage\", \"GPL-3.0-or-later\", \"GPL-2.0-or-later\"\n topics = (\"freeimage\", \"image\", \"decoding\", \"graphics\")\n generators = \"cmake\", \"cmake_find_package\"\n settings = \"os\", \"arch\", \"compiler\", \"build_type\"\n options = {\n \"shared\": [True, False],\n \"fPIC\": [True, False],\n \"with_jpeg\": [False, \"libjpeg\", \"libjpeg-turbo\"],\n \"with_png\": [True, False],\n \"with_tiff\": [True, False],\n \"with_jpeg2000\": [True, False],\n \"with_openexr\": [True, False],\n \"with_eigen\": [True, False],\n \"with_webp\": [True, False],\n \"with_raw\": [True, False],\n \"with_jxr\": [True, False],\n }\n default_options = {\n \"shared\": False,\n \"fPIC\": True,\n \"with_jpeg\": \"libjpeg\",\n \"with_png\": True,\n \"with_tiff\": True,\n \"with_jpeg2000\": True,\n \"with_openexr\": True,\n \"with_eigen\": True,\n \"with_webp\": True,\n \"with_raw\": True,\n \"with_jxr\": True,\n }\n\n _cmake = None\n\n @property\n def _source_subfolder(self):\n return \"source_subfolder\"\n\n @property\n def _build_subfolder(self):\n return \"build_subfolder\"\n\n def export_sources(self):\n self.copy(\"CMakeLists.txt\")\n for patch in self.conan_data.get(\"patches\", {}).get(self.version, []):\n self.copy(patch[\"patch_file\"])\n\n def config_options(self):\n if self.settings.os == \"Windows\":\n del self.options.fPIC\n\n def configure(self):\n tools.check_min_cppstd(self, \"11\")\n if self.options.shared:\n del self.options.fPIC\n self.output.warn(\"G3 plugin and JPEGTransform are disabled.\")\n if self.options.with_jpeg is not None:\n if self.options.with_tiff:\n self.options[\"libtiff\"].jpeg = self.options.with_jpeg\n\n def requirements(self):\n self.requires(\"zlib/1.2.11\")\n if self.options.with_jpeg == \"libjpeg\":\n self.requires(\"libjpeg/9d\")\n elif self.options.with_jpeg == \"libjpeg-turbo\":\n self.requires(\"libjpeg-turbo/2.1.2\")\n if self.options.with_jpeg2000:\n self.requires(\"openjpeg/2.4.0\")\n if self.options.with_png:\n self.requires(\"libpng/1.6.37\")\n if self.options.with_webp:\n self.requires(\"libwebp/1.2.2\")\n if self.options.with_openexr:\n self.requires(\"openexr/2.5.7\")\n if self.options.with_raw:\n self.requires(\"libraw/0.20.2\")\n if self.options.with_jxr:\n self.requires(\"jxrlib/cci.20170615\")\n if self.options.with_tiff:\n self.requires(\"libtiff/4.3.0\")\n\n def source(self):\n tools.get(**self.conan_data[\"sources\"][self.version],\n destination=self._source_subfolder, strip_root=True)\n\n def _configure_cmake(self):\n if self._cmake:\n return self._cmake\n self._cmake = CMake(self)\n self._cmake.definitions[\"WITH_JPEG\"] = self.options.with_jpeg != False\n self._cmake.definitions[\"WITH_OPENJPEG\"] = self.options.with_jpeg2000\n self._cmake.definitions[\"WITH_PNG\"] = self.options.with_png\n self._cmake.definitions[\"WITH_WEBP\"] = self.options.with_webp\n self._cmake.definitions[\"WITH_OPENEXR\"] = self.options.with_openexr\n self._cmake.definitions[\"WITH_RAW\"] = self.options.with_raw\n self._cmake.definitions[\"WITH_JXR\"] = self.options.with_jxr\n self._cmake.definitions[\"WITH_TIFF\"] = self.options.with_tiff\n self._cmake.configure(build_dir=self._build_subfolder)\n return self._cmake\n\n def build(self):\n tools.rmdir(os.path.join(self._source_subfolder, \"Source\", \"LibPNG\"))\n tools.rmdir(os.path.join(self._source_subfolder, \"Source\", \"LibTIFF4\"))\n tools.rmdir(os.path.join(self._source_subfolder, \"Source\", \"LibOpenJPEG\"))\n tools.rmdir(os.path.join(self._source_subfolder, \"Source\", \"LibJXR\"))\n tools.rmdir(os.path.join(self._source_subfolder, \"Source\", \"LibWebP\"))\n tools.rmdir(os.path.join(self._source_subfolder, \"Source\", \"LibRawLite\"))\n tools.rmdir(os.path.join(self._source_subfolder, \"Source\", \"OpenEXR\"))\n\n for patch in self.conan_data.get(\"patches\", {}).get(self.version, {}):\n tools.patch(**patch)\n cmake = self._configure_cmake()\n cmake.build()\n\n def package(self):\n cmake = self._configure_cmake()\n cmake.install()\n self.copy(\"license-fi.txt\", dst=\"licenses\", src=self._source_subfolder)\n self.copy(\"license-gplv3.txt\", dst=\"licenses\", src=self._source_subfolder)\n self.copy(\"license-gplv2.txt\", dst=\"licenses\", src=self._source_subfolder)\n\n def package_info(self):\n def imageformats_deps():\n components = []\n components.append(\"zlib::zlib\")\n if self.options.with_jpeg:\n components.append(\"{0}::{0}\".format(self.options.with_jpeg))\n if self.options.with_jpeg2000:\n components.append(\"openjpeg::openjpeg\")\n if self.options.with_png:\n components.append(\"libpng::libpng\")\n if self.options.with_webp:\n components.append(\"libwebp::libwebp\")\n if self.options.with_openexr:\n components.append(\"openexr::openexr\")\n if self.options.with_raw:\n components.append(\"libraw::libraw\")\n if self.options.with_jxr:\n components.append(\"jxrlib::jxrlib\")\n if self.options.with_tiff:\n components.append(\"libtiff::libtiff\")\n return components\n\n self.cpp_info.names[\"pkg_config\"] = \"freeimage\"\n self.cpp_info.names[\"cmake_find_package\"] = \"FreeImage\"\n self.cpp_info.names[\"cmake_find_package_multi\"] = \"FreeImage\"\n self.cpp_info.components[\"FreeImage\"].libs = [\"freeimage\"]\n self.cpp_info.components[\"FreeImage\"].requires = imageformats_deps()\n self.cpp_info.components[\"FreeImagePlus\"].libs = [\"freeimageplus\"]\n self.cpp_info.components[\"FreeImagePlus\"].requires = [\"FreeImage\"]\n\n if not self.options.shared:\n self.cpp_info.components[\"FreeImage\"].defines.append(\"FREEIMAGE_LIB\")\n", "path": "recipes/freeimage/all/conanfile.py"}]}
| 3,425 | 160 |
gh_patches_debug_3385
|
rasdani/github-patches
|
git_diff
|
svthalia__concrexit-1601
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
CSRF in /admin/payments/batch/new_filled/
### Describe the bug
The admin page to create a new batch is on the url /admin/payments/batch/new_filled/, but this works with a GET request and is thus vulnerable to cross site request forgery. I believe no csrf token is checked
### How to reproduce
Steps to reproduce the behaviour:
1. Go to /admin/payments/batch/new_filled/
2. A new batch is created without user action
### Expected behaviour
Some action on the concrexit site should create a POST request, preferably including a csrf token
</issue>
<code>
[start of website/payments/admin_views.py]
1 """Admin views provided by the payments package."""
2 import csv
3
4 from django.apps import apps
5 from django.contrib import messages
6 from django.contrib.admin.utils import model_ngettext
7 from django.contrib.admin.views.decorators import staff_member_required
8 from django.contrib.auth.decorators import permission_required
9 from django.db.models import Sum, Count, Min, Max
10 from django.http import HttpResponse
11 from django.core.exceptions import SuspiciousOperation, DisallowedRedirect
12 from django.shortcuts import redirect, get_object_or_404, render
13 from django.utils import timezone
14 from django.utils.text import capfirst
15 from django.utils.decorators import method_decorator
16 from django.utils.http import url_has_allowed_host_and_scheme
17 from django.utils.translation import gettext_lazy as _
18 from django.views import View
19
20 from payments import services
21 from .models import Payment, Batch, PaymentUser
22
23
24 @method_decorator(staff_member_required, name="dispatch")
25 @method_decorator(
26 permission_required("payments.process_payments"), name="dispatch",
27 )
28 class PaymentAdminView(View):
29 """View that creates a payment."""
30
31 def post(self, request, *args, app_label, model_name, payable, **kwargs):
32 if "type" not in request.POST:
33 raise SuspiciousOperation("Missing POST parameters")
34
35 if "next" in request.POST and not url_has_allowed_host_and_scheme(
36 request.POST.get("next"), allowed_hosts={request.get_host()}
37 ):
38 raise DisallowedRedirect
39
40 payable_model = apps.get_model(app_label=app_label, model_name=model_name)
41 payable_obj = payable_model.objects.get(pk=payable)
42
43 result = services.create_payment(
44 payable_obj, self.request.member, request.POST["type"],
45 )
46 payable_obj.save()
47
48 if result:
49 messages.success(
50 request, _("Successfully paid %s.") % model_ngettext(payable_obj, 1),
51 )
52 else:
53 messages.error(
54 request, _("Could not pay %s.") % model_ngettext(payable_obj, 1),
55 )
56 return redirect(f"admin:{app_label}_{model_name}_change", payable_obj.pk)
57
58 if "next" in request.POST:
59 return redirect(request.POST["next"])
60
61 return redirect("admin:payments_payment_change", result.pk)
62
63
64 @method_decorator(staff_member_required, name="dispatch")
65 @method_decorator(
66 permission_required("payments.process_batches"), name="dispatch",
67 )
68 class BatchProcessAdminView(View):
69 """View that processes a batch."""
70
71 def post(self, request, *args, **kwargs):
72 batch = Batch.objects.get(pk=kwargs["pk"])
73
74 if "next" in request.POST and not url_has_allowed_host_and_scheme(
75 request.POST.get("next"), allowed_hosts={request.get_host()}
76 ):
77 raise DisallowedRedirect
78
79 if batch.processed:
80 messages.error(
81 request, _("{} already processed.").format(model_ngettext(batch, 1))
82 )
83 else:
84 services.process_batch(batch)
85 messages.success(
86 request,
87 _("Successfully processed {}.").format(model_ngettext(batch, 1)),
88 )
89
90 if "next" in request.POST:
91 return redirect(request.POST["next"])
92
93 return redirect("admin:payments_batch_change", kwargs["pk"])
94
95
96 @method_decorator(staff_member_required, name="dispatch")
97 @method_decorator(
98 permission_required("payments.process_batches"), name="dispatch",
99 )
100 class BatchExportAdminView(View):
101 """View that exports a batch."""
102
103 def post(self, request, *args, **kwargs):
104 batch = Batch.objects.get(pk=kwargs["pk"])
105
106 response = HttpResponse(content_type="text/csv")
107 response["Content-Disposition"] = 'attachment;filename="batch.csv"'
108 writer = csv.writer(response)
109 headers = [
110 _("Account holder"),
111 _("IBAN"),
112 _("Mandate Reference"),
113 _("Amount"),
114 _("Description"),
115 _("Mandate Date"),
116 ]
117 writer.writerow([capfirst(x) for x in headers])
118
119 member_rows = batch.payments_set.values("paid_by").annotate(total=Sum("amount"))
120
121 for row in member_rows:
122 member = PaymentUser.objects.get(id=row["paid_by"])
123 bankaccount = member.bank_accounts.last()
124 writer.writerow(
125 [
126 bankaccount.name,
127 bankaccount.iban,
128 bankaccount.mandate_no,
129 f"{row['total']:.2f}",
130 batch.description,
131 bankaccount.valid_from,
132 ]
133 )
134 return response
135
136
137 @method_decorator(staff_member_required, name="dispatch")
138 @method_decorator(
139 permission_required("payments.process_batches"), name="dispatch",
140 )
141 class BatchTopicExportAdminView(View):
142 """View that exports a batch per topic."""
143
144 def post(self, request, *args, **kwargs):
145 batch = Batch.objects.get(pk=kwargs["pk"])
146
147 response = HttpResponse(content_type="text/csv")
148 response["Content-Disposition"] = 'attachment;filename="batch-topic.csv"'
149 writer = csv.writer(response)
150 headers = [
151 _("Topic"),
152 _("No. of payments"),
153 _("First payment"),
154 _("Last payment"),
155 _("Total amount"),
156 ]
157 writer.writerow([capfirst(x) for x in headers])
158
159 topic_rows = (
160 batch.payments_set.values("topic")
161 .annotate(
162 total=Sum("amount"),
163 count=Count("paid_by"),
164 min_date=Min("created_at"),
165 max_date=Max("created_at"),
166 )
167 .order_by("topic")
168 )
169
170 for row in topic_rows:
171 writer.writerow(
172 [
173 row["topic"],
174 row["count"],
175 timezone.localtime(row["min_date"]).date(),
176 timezone.localtime(row["max_date"]).date(),
177 f"{row['total']:.2f}",
178 ]
179 )
180 return response
181
182
183 @method_decorator(staff_member_required, name="dispatch")
184 @method_decorator(
185 permission_required("payments.process_batches"), name="dispatch",
186 )
187 class BatchTopicDescriptionAdminView(View):
188 """Shows the topic export as plain text."""
189
190 template_name = "admin/payments/batch_topic.html"
191
192 def post(self, request, *args, **kwargs):
193 context = {}
194 batch = get_object_or_404(Batch, pk=kwargs["pk"])
195 topic_rows = (
196 batch.payments_set.values("topic")
197 .annotate(
198 total=Sum("amount"),
199 count=Count("paid_by"),
200 min_date=Min("created_at"),
201 max_date=Max("created_at"),
202 )
203 .order_by("topic")
204 )
205
206 description = f"Batch {batch.id} - {batch.processing_date if batch.processing_date else timezone.now().date()}:\n"
207 for row in topic_rows:
208 description += f"- {row['topic']} ({row['count']}x) [{timezone.localtime(row['min_date']).date()} -- {timezone.localtime(row['max_date']).date()}], total €{row['total']:.2f}\n"
209 description += f"\n{batch.description}"
210
211 context["batch"] = batch
212 context["description"] = description
213 return render(request, self.template_name, context)
214
215
216 @method_decorator(staff_member_required, name="dispatch")
217 @method_decorator(
218 permission_required("payments.process_batches"), name="dispatch",
219 )
220 class BatchNewFilledAdminView(View):
221 """View that adds a new batch filled with all payments that where not already in a batch."""
222
223 def get(self, request, *args, **kwargs):
224 batch = Batch()
225 batch.save()
226
227 payments = Payment.objects.filter(type=Payment.TPAY, batch=None,)
228
229 payments.update(batch=batch)
230
231 return redirect("admin:payments_batch_change", object_id=batch.id)
232
[end of website/payments/admin_views.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/website/payments/admin_views.py b/website/payments/admin_views.py
--- a/website/payments/admin_views.py
+++ b/website/payments/admin_views.py
@@ -220,7 +220,7 @@
class BatchNewFilledAdminView(View):
"""View that adds a new batch filled with all payments that where not already in a batch."""
- def get(self, request, *args, **kwargs):
+ def post(self, request, *args, **kwargs):
batch = Batch()
batch.save()
|
{"golden_diff": "diff --git a/website/payments/admin_views.py b/website/payments/admin_views.py\n--- a/website/payments/admin_views.py\n+++ b/website/payments/admin_views.py\n@@ -220,7 +220,7 @@\n class BatchNewFilledAdminView(View):\n \"\"\"View that adds a new batch filled with all payments that where not already in a batch.\"\"\"\n \n- def get(self, request, *args, **kwargs):\n+ def post(self, request, *args, **kwargs):\n batch = Batch()\n batch.save()\n", "issue": "CSRF in /admin/payments/batch/new_filled/\n### Describe the bug\r\nThe admin page to create a new batch is on the url /admin/payments/batch/new_filled/, but this works with a GET request and is thus vulnerable to cross site request forgery. I believe no csrf token is checked\r\n\r\n### How to reproduce\r\nSteps to reproduce the behaviour:\r\n1. Go to /admin/payments/batch/new_filled/\r\n2. A new batch is created without user action\r\n\r\n### Expected behaviour\r\nSome action on the concrexit site should create a POST request, preferably including a csrf token\r\n\n", "before_files": [{"content": "\"\"\"Admin views provided by the payments package.\"\"\"\nimport csv\n\nfrom django.apps import apps\nfrom django.contrib import messages\nfrom django.contrib.admin.utils import model_ngettext\nfrom django.contrib.admin.views.decorators import staff_member_required\nfrom django.contrib.auth.decorators import permission_required\nfrom django.db.models import Sum, Count, Min, Max\nfrom django.http import HttpResponse\nfrom django.core.exceptions import SuspiciousOperation, DisallowedRedirect\nfrom django.shortcuts import redirect, get_object_or_404, render\nfrom django.utils import timezone\nfrom django.utils.text import capfirst\nfrom django.utils.decorators import method_decorator\nfrom django.utils.http import url_has_allowed_host_and_scheme\nfrom django.utils.translation import gettext_lazy as _\nfrom django.views import View\n\nfrom payments import services\nfrom .models import Payment, Batch, PaymentUser\n\n\n@method_decorator(staff_member_required, name=\"dispatch\")\n@method_decorator(\n permission_required(\"payments.process_payments\"), name=\"dispatch\",\n)\nclass PaymentAdminView(View):\n \"\"\"View that creates a payment.\"\"\"\n\n def post(self, request, *args, app_label, model_name, payable, **kwargs):\n if \"type\" not in request.POST:\n raise SuspiciousOperation(\"Missing POST parameters\")\n\n if \"next\" in request.POST and not url_has_allowed_host_and_scheme(\n request.POST.get(\"next\"), allowed_hosts={request.get_host()}\n ):\n raise DisallowedRedirect\n\n payable_model = apps.get_model(app_label=app_label, model_name=model_name)\n payable_obj = payable_model.objects.get(pk=payable)\n\n result = services.create_payment(\n payable_obj, self.request.member, request.POST[\"type\"],\n )\n payable_obj.save()\n\n if result:\n messages.success(\n request, _(\"Successfully paid %s.\") % model_ngettext(payable_obj, 1),\n )\n else:\n messages.error(\n request, _(\"Could not pay %s.\") % model_ngettext(payable_obj, 1),\n )\n return redirect(f\"admin:{app_label}_{model_name}_change\", payable_obj.pk)\n\n if \"next\" in request.POST:\n return redirect(request.POST[\"next\"])\n\n return redirect(\"admin:payments_payment_change\", result.pk)\n\n\n@method_decorator(staff_member_required, name=\"dispatch\")\n@method_decorator(\n permission_required(\"payments.process_batches\"), name=\"dispatch\",\n)\nclass BatchProcessAdminView(View):\n \"\"\"View that processes a batch.\"\"\"\n\n def post(self, request, *args, **kwargs):\n batch = Batch.objects.get(pk=kwargs[\"pk\"])\n\n if \"next\" in request.POST and not url_has_allowed_host_and_scheme(\n request.POST.get(\"next\"), allowed_hosts={request.get_host()}\n ):\n raise DisallowedRedirect\n\n if batch.processed:\n messages.error(\n request, _(\"{} already processed.\").format(model_ngettext(batch, 1))\n )\n else:\n services.process_batch(batch)\n messages.success(\n request,\n _(\"Successfully processed {}.\").format(model_ngettext(batch, 1)),\n )\n\n if \"next\" in request.POST:\n return redirect(request.POST[\"next\"])\n\n return redirect(\"admin:payments_batch_change\", kwargs[\"pk\"])\n\n\n@method_decorator(staff_member_required, name=\"dispatch\")\n@method_decorator(\n permission_required(\"payments.process_batches\"), name=\"dispatch\",\n)\nclass BatchExportAdminView(View):\n \"\"\"View that exports a batch.\"\"\"\n\n def post(self, request, *args, **kwargs):\n batch = Batch.objects.get(pk=kwargs[\"pk\"])\n\n response = HttpResponse(content_type=\"text/csv\")\n response[\"Content-Disposition\"] = 'attachment;filename=\"batch.csv\"'\n writer = csv.writer(response)\n headers = [\n _(\"Account holder\"),\n _(\"IBAN\"),\n _(\"Mandate Reference\"),\n _(\"Amount\"),\n _(\"Description\"),\n _(\"Mandate Date\"),\n ]\n writer.writerow([capfirst(x) for x in headers])\n\n member_rows = batch.payments_set.values(\"paid_by\").annotate(total=Sum(\"amount\"))\n\n for row in member_rows:\n member = PaymentUser.objects.get(id=row[\"paid_by\"])\n bankaccount = member.bank_accounts.last()\n writer.writerow(\n [\n bankaccount.name,\n bankaccount.iban,\n bankaccount.mandate_no,\n f\"{row['total']:.2f}\",\n batch.description,\n bankaccount.valid_from,\n ]\n )\n return response\n\n\n@method_decorator(staff_member_required, name=\"dispatch\")\n@method_decorator(\n permission_required(\"payments.process_batches\"), name=\"dispatch\",\n)\nclass BatchTopicExportAdminView(View):\n \"\"\"View that exports a batch per topic.\"\"\"\n\n def post(self, request, *args, **kwargs):\n batch = Batch.objects.get(pk=kwargs[\"pk\"])\n\n response = HttpResponse(content_type=\"text/csv\")\n response[\"Content-Disposition\"] = 'attachment;filename=\"batch-topic.csv\"'\n writer = csv.writer(response)\n headers = [\n _(\"Topic\"),\n _(\"No. of payments\"),\n _(\"First payment\"),\n _(\"Last payment\"),\n _(\"Total amount\"),\n ]\n writer.writerow([capfirst(x) for x in headers])\n\n topic_rows = (\n batch.payments_set.values(\"topic\")\n .annotate(\n total=Sum(\"amount\"),\n count=Count(\"paid_by\"),\n min_date=Min(\"created_at\"),\n max_date=Max(\"created_at\"),\n )\n .order_by(\"topic\")\n )\n\n for row in topic_rows:\n writer.writerow(\n [\n row[\"topic\"],\n row[\"count\"],\n timezone.localtime(row[\"min_date\"]).date(),\n timezone.localtime(row[\"max_date\"]).date(),\n f\"{row['total']:.2f}\",\n ]\n )\n return response\n\n\n@method_decorator(staff_member_required, name=\"dispatch\")\n@method_decorator(\n permission_required(\"payments.process_batches\"), name=\"dispatch\",\n)\nclass BatchTopicDescriptionAdminView(View):\n \"\"\"Shows the topic export as plain text.\"\"\"\n\n template_name = \"admin/payments/batch_topic.html\"\n\n def post(self, request, *args, **kwargs):\n context = {}\n batch = get_object_or_404(Batch, pk=kwargs[\"pk\"])\n topic_rows = (\n batch.payments_set.values(\"topic\")\n .annotate(\n total=Sum(\"amount\"),\n count=Count(\"paid_by\"),\n min_date=Min(\"created_at\"),\n max_date=Max(\"created_at\"),\n )\n .order_by(\"topic\")\n )\n\n description = f\"Batch {batch.id} - {batch.processing_date if batch.processing_date else timezone.now().date()}:\\n\"\n for row in topic_rows:\n description += f\"- {row['topic']} ({row['count']}x) [{timezone.localtime(row['min_date']).date()} -- {timezone.localtime(row['max_date']).date()}], total \u20ac{row['total']:.2f}\\n\"\n description += f\"\\n{batch.description}\"\n\n context[\"batch\"] = batch\n context[\"description\"] = description\n return render(request, self.template_name, context)\n\n\n@method_decorator(staff_member_required, name=\"dispatch\")\n@method_decorator(\n permission_required(\"payments.process_batches\"), name=\"dispatch\",\n)\nclass BatchNewFilledAdminView(View):\n \"\"\"View that adds a new batch filled with all payments that where not already in a batch.\"\"\"\n\n def get(self, request, *args, **kwargs):\n batch = Batch()\n batch.save()\n\n payments = Payment.objects.filter(type=Payment.TPAY, batch=None,)\n\n payments.update(batch=batch)\n\n return redirect(\"admin:payments_batch_change\", object_id=batch.id)\n", "path": "website/payments/admin_views.py"}]}
| 2,879 | 120 |
gh_patches_debug_943
|
rasdani/github-patches
|
git_diff
|
microsoft__ptvsd-259
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Debugging of modules using -m is broken
Used to be able to debug Flask & other code using the `-m` flag.
</issue>
<code>
[start of ptvsd/debugger.py]
1 # Copyright (c) Microsoft Corporation. All rights reserved.
2 # Licensed under the MIT License. See LICENSE in the project root
3 # for license information.
4
5 import sys
6
7 # import the wrapper first, so that it gets a chance
8 # to detour pydevd socket functionality.
9 import ptvsd.wrapper
10
11
12 __author__ = "Microsoft Corporation <[email protected]>"
13 __version__ = "4.0.0a4"
14
15 DONT_DEBUG = []
16
17
18 def debug(filename, port_num, debug_id, debug_options, run_as):
19 # TODO: docstring
20 address = (None, port_num)
21 if run_as == 'module':
22 _run_module(address, filename)
23 else:
24 _run_file(address, filename)
25
26
27 def _run_module(address, modname):
28 filename = modname + ':'
29 argv = _run_argv(address, filename)
30 argv.append('--module')
31 _run(argv)
32
33
34 def _run_file(address, filename):
35 argv = _run_argv(address, filename)
36 _run(argv)
37
38
39 def _run_argv(address, filename):
40 host, port = address
41 if host is None:
42 host = '127.0.0.1'
43 return [
44 '--port', str(port),
45 '--client', host,
46 '--file', filename,
47 ]
48
49
50 def _run(argv):
51 import pydevd
52 sys.argv[1:0] = argv
53 try:
54 pydevd.main()
55 except SystemExit as ex:
56 ptvsd.wrapper.ptvsd_sys_exit_code = int(ex.code)
57 raise
58
[end of ptvsd/debugger.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ptvsd/debugger.py b/ptvsd/debugger.py
--- a/ptvsd/debugger.py
+++ b/ptvsd/debugger.py
@@ -27,7 +27,7 @@
def _run_module(address, modname):
filename = modname + ':'
argv = _run_argv(address, filename)
- argv.append('--module')
+ argv.insert(argv.index('--file'), '--module')
_run(argv)
|
{"golden_diff": "diff --git a/ptvsd/debugger.py b/ptvsd/debugger.py\n--- a/ptvsd/debugger.py\n+++ b/ptvsd/debugger.py\n@@ -27,7 +27,7 @@\n def _run_module(address, modname):\n filename = modname + ':'\n argv = _run_argv(address, filename)\n- argv.append('--module')\n+ argv.insert(argv.index('--file'), '--module')\n _run(argv)\n", "issue": "Debugging of modules using -m is broken\nUsed to be able to debug Flask & other code using the `-m` flag.\r\n\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License. See LICENSE in the project root\n# for license information.\n\nimport sys\n\n# import the wrapper first, so that it gets a chance\n# to detour pydevd socket functionality.\nimport ptvsd.wrapper\n\n\n__author__ = \"Microsoft Corporation <[email protected]>\"\n__version__ = \"4.0.0a4\"\n\nDONT_DEBUG = []\n\n\ndef debug(filename, port_num, debug_id, debug_options, run_as):\n # TODO: docstring\n address = (None, port_num)\n if run_as == 'module':\n _run_module(address, filename)\n else:\n _run_file(address, filename)\n\n\ndef _run_module(address, modname):\n filename = modname + ':'\n argv = _run_argv(address, filename)\n argv.append('--module')\n _run(argv)\n\n\ndef _run_file(address, filename):\n argv = _run_argv(address, filename)\n _run(argv)\n\n\ndef _run_argv(address, filename):\n host, port = address\n if host is None:\n host = '127.0.0.1'\n return [\n '--port', str(port),\n '--client', host,\n '--file', filename,\n ]\n\n\ndef _run(argv):\n import pydevd\n sys.argv[1:0] = argv\n try:\n pydevd.main()\n except SystemExit as ex:\n ptvsd.wrapper.ptvsd_sys_exit_code = int(ex.code)\n raise\n", "path": "ptvsd/debugger.py"}]}
| 1,021 | 103 |
gh_patches_debug_8163
|
rasdani/github-patches
|
git_diff
|
microsoft__ptvsd-84
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Debugging modules (using -m switch)
This is currently not supported
</issue>
<code>
[start of ptvsd/debugger.py]
1 # Copyright (c) Microsoft Corporation. All rights reserved.
2 # Licensed under the MIT License. See LICENSE in the project root
3 # for license information.
4
5 import sys
6
7
8 __author__ = "Microsoft Corporation <[email protected]>"
9 __version__ = "4.0.0a1"
10
11 DONT_DEBUG = []
12
13
14 def debug(filename, port_num, debug_id, debug_options, run_as):
15 # TODO: docstring
16
17 # import the wrapper first, so that it gets a chance
18 # to detour pydevd socket functionality.
19 import ptvsd.wrapper
20 import pydevd
21
22 sys.argv[1:0] = [
23 '--port', str(port_num),
24 '--client', '127.0.0.1',
25 '--file', filename,
26 ]
27 try:
28 pydevd.main()
29 except SystemExit as ex:
30 ptvsd.wrapper.ptvsd_sys_exit_code = ex.code
31 raise
32
[end of ptvsd/debugger.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/ptvsd/debugger.py b/ptvsd/debugger.py
--- a/ptvsd/debugger.py
+++ b/ptvsd/debugger.py
@@ -19,11 +19,16 @@
import ptvsd.wrapper
import pydevd
- sys.argv[1:0] = [
+ args = [
'--port', str(port_num),
'--client', '127.0.0.1',
- '--file', filename,
]
+ if run_as == 'module':
+ args.append('--module')
+ args.extend(('--file', filename + ":"))
+ else:
+ args.extend(('--file', filename))
+ sys.argv[1:0] = args
try:
pydevd.main()
except SystemExit as ex:
|
{"golden_diff": "diff --git a/ptvsd/debugger.py b/ptvsd/debugger.py\n--- a/ptvsd/debugger.py\n+++ b/ptvsd/debugger.py\n@@ -19,11 +19,16 @@\n import ptvsd.wrapper\n import pydevd\n \n- sys.argv[1:0] = [\n+ args = [\n '--port', str(port_num),\n '--client', '127.0.0.1',\n- '--file', filename,\n ]\n+ if run_as == 'module':\n+ args.append('--module')\n+ args.extend(('--file', filename + \":\"))\n+ else:\n+ args.extend(('--file', filename))\n+ sys.argv[1:0] = args\n try:\n pydevd.main()\n except SystemExit as ex:\n", "issue": "Debugging modules (using -m switch)\nThis is currently not supported\n", "before_files": [{"content": "# Copyright (c) Microsoft Corporation. All rights reserved.\n# Licensed under the MIT License. See LICENSE in the project root\n# for license information.\n\nimport sys\n\n\n__author__ = \"Microsoft Corporation <[email protected]>\"\n__version__ = \"4.0.0a1\"\n\nDONT_DEBUG = []\n\n\ndef debug(filename, port_num, debug_id, debug_options, run_as):\n # TODO: docstring\n\n # import the wrapper first, so that it gets a chance\n # to detour pydevd socket functionality.\n import ptvsd.wrapper\n import pydevd\n\n sys.argv[1:0] = [\n '--port', str(port_num),\n '--client', '127.0.0.1',\n '--file', filename,\n ]\n try:\n pydevd.main()\n except SystemExit as ex:\n ptvsd.wrapper.ptvsd_sys_exit_code = ex.code\n raise\n", "path": "ptvsd/debugger.py"}]}
| 819 | 185 |
gh_patches_debug_33624
|
rasdani/github-patches
|
git_diff
|
yt-dlp__yt-dlp-2375
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
[TVer] Extractor error (caused by KeyError('publisher_id')) for some video URLs
### Checklist
- [X] I'm reporting a broken site
- [X] I've verified that I'm running yt-dlp version **2021.12.27**. ([update instructions](https://github.com/yt-dlp/yt-dlp#update))
- [X] I've checked that all provided URLs are alive and playable in a browser
- [X] I've checked that all URLs and arguments with special characters are [properly quoted or escaped](https://github.com/ytdl-org/youtube-dl#video-url-contains-an-ampersand-and-im-getting-some-strange-output-1-2839-or-v-is-not-recognized-as-an-internal-or-external-command)
- [X] I've searched the [bugtracker](https://github.com/yt-dlp/yt-dlp/issues?q=) for similar issues including closed ones. DO NOT post duplicates
- [X] I've read the [guidelines for opening an issue](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#opening-an-issue)
- [x] I've read about [sharing account credentials](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#are-you-willing-to-share-account-details-if-needed) and I'm willing to share it if required
### Region
Japan
### Description
I get extractor errors when downloading certain videos from TVer. There are some video URLs (such as https://tver.jp/corner/f0095338) that can be downloaded successfully, but there are also some live video URLs (such as https://tver.jp/feature/f0095053) that are now videos, but instead is a LIVE broadcast prepared for the future. The URLs I just introduced have an expiration date for viewing, so please be careful.
### Verbose log
```shell
[debug] Command-line config: ['-Uv', 'https://tver.jp/feature/f0095053']
[debug] Encodings: locale cp932, fs utf-8, out utf-8, err utf-8, pref cp932
[debug] yt-dlp version 2021.12.27 [6223f67a8]
[debug] Python version 3.8.12 (CPython 64bit) - Windows-10-10.0.19044-SP0
[debug] exe versions: ffmpeg 4.4-full_build-www.gyan.dev (setts), ffprobe 4.4-full_build-www.gyan.dev
[debug] Optional libraries: Cryptodome, mutagen, sqlite, websockets
[debug] Proxy map: {}
Latest version: 2021.12.27, Current version: 2021.12.27
yt-dlp is up to date (2021.12.27)
[TVer] Downloading JSON metadata
[debug] [TVer] Extracting URL: https://tver.jp/feature/f0095053
[TVer] f0095053: Downloading JSON metadata
ERROR: f0095053: An extractor error has occurred. (caused by KeyError('publisher_id')); please report this issue on https://github.com/yt-dlp/yt-dlp . Make sure you are using the latest version; see https://github.com/yt-dlp/yt-dlp on how to update. Be sure to call yt-dlp with the --verbose flag and include its complete output.
Traceback (most recent call last):
File "C:\Users\User\anaconda3\lib\site-packages\yt_dlp\extractor\common.py", line 599, in extract
ie_result = self._real_extract(url)
File "C:\Users\User\anaconda3\lib\site-packages\yt_dlp\extractor\tver.py", line 44, in _real_extract
p_id = main['publisher_id']
KeyError: 'publisher_id'
Traceback (most recent call last):
File "C:\Users\User\anaconda3\lib\site-packages\yt_dlp\extractor\common.py", line 599, in extract
ie_result = self._real_extract(url)
File "C:\Users\User\anaconda3\lib\site-packages\yt_dlp\extractor\tver.py", line 44, in _real_extract
p_id = main['publisher_id']
KeyError: 'publisher_id'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:\Users\User\anaconda3\lib\site-packages\yt_dlp\YoutubeDL.py", line 1353, in wrapper
return func(self, *args, **kwargs)
File "C:\Users\User\anaconda3\lib\site-packages\yt_dlp\YoutubeDL.py", line 1423, in __extract_info
ie_result = ie.extract(url)
File "C:\Users\User\anaconda3\lib\site-packages\yt_dlp\extractor\common.py", line 629, in extract
raise ExtractorError('An extractor error has occurred.', cause=e, video_id=self.get_temp_id(url))
yt_dlp.utils.ExtractorError: f0095053: An extractor error has occurred. (caused by KeyError('publisher_id')); please report this issue on https://github.com/yt-dlp/yt-dlp . Make sure you are using the latest version; see https://github.com/yt-dlp/yt-dlp on how to update. Be sure to call yt-dlp with the --verbose flag and include its complete output.
```
[TVer] Extractor error (caused by KeyError('publisher_id')) for some video URLs
### Checklist
- [X] I'm reporting a broken site
- [X] I've verified that I'm running yt-dlp version **2021.12.27**. ([update instructions](https://github.com/yt-dlp/yt-dlp#update))
- [X] I've checked that all provided URLs are alive and playable in a browser
- [X] I've checked that all URLs and arguments with special characters are [properly quoted or escaped](https://github.com/ytdl-org/youtube-dl#video-url-contains-an-ampersand-and-im-getting-some-strange-output-1-2839-or-v-is-not-recognized-as-an-internal-or-external-command)
- [X] I've searched the [bugtracker](https://github.com/yt-dlp/yt-dlp/issues?q=) for similar issues including closed ones. DO NOT post duplicates
- [X] I've read the [guidelines for opening an issue](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#opening-an-issue)
- [x] I've read about [sharing account credentials](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#are-you-willing-to-share-account-details-if-needed) and I'm willing to share it if required
### Region
Japan
### Description
I get extractor errors when downloading certain videos from TVer. There are some video URLs (such as https://tver.jp/corner/f0095338) that can be downloaded successfully, but there are also some live video URLs (such as https://tver.jp/feature/f0095053) that are now videos, but instead is a LIVE broadcast prepared for the future. The URLs I just introduced have an expiration date for viewing, so please be careful.
### Verbose log
```shell
[debug] Command-line config: ['-Uv', 'https://tver.jp/feature/f0095053']
[debug] Encodings: locale cp932, fs utf-8, out utf-8, err utf-8, pref cp932
[debug] yt-dlp version 2021.12.27 [6223f67a8]
[debug] Python version 3.8.12 (CPython 64bit) - Windows-10-10.0.19044-SP0
[debug] exe versions: ffmpeg 4.4-full_build-www.gyan.dev (setts), ffprobe 4.4-full_build-www.gyan.dev
[debug] Optional libraries: Cryptodome, mutagen, sqlite, websockets
[debug] Proxy map: {}
Latest version: 2021.12.27, Current version: 2021.12.27
yt-dlp is up to date (2021.12.27)
[TVer] Downloading JSON metadata
[debug] [TVer] Extracting URL: https://tver.jp/feature/f0095053
[TVer] f0095053: Downloading JSON metadata
ERROR: f0095053: An extractor error has occurred. (caused by KeyError('publisher_id')); please report this issue on https://github.com/yt-dlp/yt-dlp . Make sure you are using the latest version; see https://github.com/yt-dlp/yt-dlp on how to update. Be sure to call yt-dlp with the --verbose flag and include its complete output.
Traceback (most recent call last):
File "C:\Users\User\anaconda3\lib\site-packages\yt_dlp\extractor\common.py", line 599, in extract
ie_result = self._real_extract(url)
File "C:\Users\User\anaconda3\lib\site-packages\yt_dlp\extractor\tver.py", line 44, in _real_extract
p_id = main['publisher_id']
KeyError: 'publisher_id'
Traceback (most recent call last):
File "C:\Users\User\anaconda3\lib\site-packages\yt_dlp\extractor\common.py", line 599, in extract
ie_result = self._real_extract(url)
File "C:\Users\User\anaconda3\lib\site-packages\yt_dlp\extractor\tver.py", line 44, in _real_extract
p_id = main['publisher_id']
KeyError: 'publisher_id'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:\Users\User\anaconda3\lib\site-packages\yt_dlp\YoutubeDL.py", line 1353, in wrapper
return func(self, *args, **kwargs)
File "C:\Users\User\anaconda3\lib\site-packages\yt_dlp\YoutubeDL.py", line 1423, in __extract_info
ie_result = ie.extract(url)
File "C:\Users\User\anaconda3\lib\site-packages\yt_dlp\extractor\common.py", line 629, in extract
raise ExtractorError('An extractor error has occurred.', cause=e, video_id=self.get_temp_id(url))
yt_dlp.utils.ExtractorError: f0095053: An extractor error has occurred. (caused by KeyError('publisher_id')); please report this issue on https://github.com/yt-dlp/yt-dlp . Make sure you are using the latest version; see https://github.com/yt-dlp/yt-dlp on how to update. Be sure to call yt-dlp with the --verbose flag and include its complete output.
```
</issue>
<code>
[start of yt_dlp/extractor/tver.py]
1 # coding: utf-8
2 from __future__ import unicode_literals
3
4
5 from .common import InfoExtractor
6 from ..compat import compat_str
7 from ..utils import (
8 int_or_none,
9 remove_start,
10 smuggle_url,
11 try_get,
12 )
13
14
15 class TVerIE(InfoExtractor):
16 _VALID_URL = r'https?://(?:www\.)?tver\.jp/(?P<path>(?:corner|episode|feature)/(?P<id>f?\d+))'
17 # videos are only available for 7 days
18 _TESTS = [{
19 'url': 'https://tver.jp/corner/f0062178',
20 'only_matching': True,
21 }, {
22 'url': 'https://tver.jp/feature/f0062413',
23 'only_matching': True,
24 }, {
25 'url': 'https://tver.jp/episode/79622438',
26 'only_matching': True,
27 }, {
28 # subtitle = ' '
29 'url': 'https://tver.jp/corner/f0068870',
30 'only_matching': True,
31 }]
32 _TOKEN = None
33 BRIGHTCOVE_URL_TEMPLATE = 'http://players.brightcove.net/%s/default_default/index.html?videoId=%s'
34
35 def _real_initialize(self):
36 self._TOKEN = self._download_json(
37 'https://tver.jp/api/access_token.php', None)['token']
38
39 def _real_extract(self, url):
40 path, video_id = self._match_valid_url(url).groups()
41 main = self._download_json(
42 'https://api.tver.jp/v4/' + path, video_id,
43 query={'token': self._TOKEN})['main']
44 p_id = main['publisher_id']
45 service = remove_start(main['service'], 'ts_')
46
47 r_id = main['reference_id']
48 if service not in ('tx', 'russia2018', 'sebare2018live', 'gorin'):
49 r_id = 'ref:' + r_id
50 bc_url = smuggle_url(
51 self.BRIGHTCOVE_URL_TEMPLATE % (p_id, r_id),
52 {'geo_countries': ['JP']})
53
54 return {
55 '_type': 'url_transparent',
56 'description': try_get(main, lambda x: x['note'][0]['text'], compat_str),
57 'episode_number': int_or_none(try_get(main, lambda x: x['ext']['episode_number'])),
58 'url': bc_url,
59 'ie_key': 'BrightcoveNew',
60 }
61
[end of yt_dlp/extractor/tver.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/yt_dlp/extractor/tver.py b/yt_dlp/extractor/tver.py
--- a/yt_dlp/extractor/tver.py
+++ b/yt_dlp/extractor/tver.py
@@ -5,10 +5,11 @@
from .common import InfoExtractor
from ..compat import compat_str
from ..utils import (
+ ExtractorError,
int_or_none,
remove_start,
smuggle_url,
- try_get,
+ traverse_obj,
)
@@ -38,13 +39,18 @@
def _real_extract(self, url):
path, video_id = self._match_valid_url(url).groups()
- main = self._download_json(
+ api_response = self._download_json(
'https://api.tver.jp/v4/' + path, video_id,
- query={'token': self._TOKEN})['main']
- p_id = main['publisher_id']
- service = remove_start(main['service'], 'ts_')
+ query={'token': self._TOKEN})
+ p_id = traverse_obj(api_response, ('main', 'publisher_id'))
+ if not p_id:
+ error_msg, expected = traverse_obj(api_response, ('episode', 0, 'textbar', 0, ('text', 'longer')), get_all=False), True
+ if not error_msg:
+ error_msg, expected = 'Failed to extract publisher ID', False
+ raise ExtractorError(error_msg, expected=expected)
+ service = remove_start(traverse_obj(api_response, ('main', 'service')), 'ts_')
- r_id = main['reference_id']
+ r_id = traverse_obj(api_response, ('main', 'reference_id'))
if service not in ('tx', 'russia2018', 'sebare2018live', 'gorin'):
r_id = 'ref:' + r_id
bc_url = smuggle_url(
@@ -53,8 +59,8 @@
return {
'_type': 'url_transparent',
- 'description': try_get(main, lambda x: x['note'][0]['text'], compat_str),
- 'episode_number': int_or_none(try_get(main, lambda x: x['ext']['episode_number'])),
+ 'description': traverse_obj(api_response, ('main', 'note', 0, 'text'), expected_type=compat_str),
+ 'episode_number': int_or_none(traverse_obj(api_response, ('main', 'ext', 'episode_number'), expected_type=compat_str)),
'url': bc_url,
'ie_key': 'BrightcoveNew',
}
|
{"golden_diff": "diff --git a/yt_dlp/extractor/tver.py b/yt_dlp/extractor/tver.py\n--- a/yt_dlp/extractor/tver.py\n+++ b/yt_dlp/extractor/tver.py\n@@ -5,10 +5,11 @@\n from .common import InfoExtractor\n from ..compat import compat_str\n from ..utils import (\n+ ExtractorError,\n int_or_none,\n remove_start,\n smuggle_url,\n- try_get,\n+ traverse_obj,\n )\n \n \n@@ -38,13 +39,18 @@\n \n def _real_extract(self, url):\n path, video_id = self._match_valid_url(url).groups()\n- main = self._download_json(\n+ api_response = self._download_json(\n 'https://api.tver.jp/v4/' + path, video_id,\n- query={'token': self._TOKEN})['main']\n- p_id = main['publisher_id']\n- service = remove_start(main['service'], 'ts_')\n+ query={'token': self._TOKEN})\n+ p_id = traverse_obj(api_response, ('main', 'publisher_id'))\n+ if not p_id:\n+ error_msg, expected = traverse_obj(api_response, ('episode', 0, 'textbar', 0, ('text', 'longer')), get_all=False), True\n+ if not error_msg:\n+ error_msg, expected = 'Failed to extract publisher ID', False\n+ raise ExtractorError(error_msg, expected=expected)\n+ service = remove_start(traverse_obj(api_response, ('main', 'service')), 'ts_')\n \n- r_id = main['reference_id']\n+ r_id = traverse_obj(api_response, ('main', 'reference_id'))\n if service not in ('tx', 'russia2018', 'sebare2018live', 'gorin'):\n r_id = 'ref:' + r_id\n bc_url = smuggle_url(\n@@ -53,8 +59,8 @@\n \n return {\n '_type': 'url_transparent',\n- 'description': try_get(main, lambda x: x['note'][0]['text'], compat_str),\n- 'episode_number': int_or_none(try_get(main, lambda x: x['ext']['episode_number'])),\n+ 'description': traverse_obj(api_response, ('main', 'note', 0, 'text'), expected_type=compat_str),\n+ 'episode_number': int_or_none(traverse_obj(api_response, ('main', 'ext', 'episode_number'), expected_type=compat_str)),\n 'url': bc_url,\n 'ie_key': 'BrightcoveNew',\n }\n", "issue": "[TVer] Extractor error (caused by KeyError('publisher_id')) for some video URLs\n### Checklist\r\n\r\n- [X] I'm reporting a broken site\r\n- [X] I've verified that I'm running yt-dlp version **2021.12.27**. ([update instructions](https://github.com/yt-dlp/yt-dlp#update))\r\n- [X] I've checked that all provided URLs are alive and playable in a browser\r\n- [X] I've checked that all URLs and arguments with special characters are [properly quoted or escaped](https://github.com/ytdl-org/youtube-dl#video-url-contains-an-ampersand-and-im-getting-some-strange-output-1-2839-or-v-is-not-recognized-as-an-internal-or-external-command)\r\n- [X] I've searched the [bugtracker](https://github.com/yt-dlp/yt-dlp/issues?q=) for similar issues including closed ones. DO NOT post duplicates\r\n- [X] I've read the [guidelines for opening an issue](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#opening-an-issue)\r\n- [x] I've read about [sharing account credentials](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#are-you-willing-to-share-account-details-if-needed) and I'm willing to share it if required\r\n\r\n### Region\r\n\r\nJapan\r\n\r\n### Description\r\n\r\nI get extractor errors when downloading certain videos from TVer. There are some video URLs (such as https://tver.jp/corner/f0095338) that can be downloaded successfully, but there are also some live video URLs (such as https://tver.jp/feature/f0095053) that are now videos, but instead is a LIVE broadcast prepared for the future. The URLs I just introduced have an expiration date for viewing, so please be careful.\r\n\r\n### Verbose log\r\n\r\n```shell\r\n[debug] Command-line config: ['-Uv', 'https://tver.jp/feature/f0095053']\r\n[debug] Encodings: locale cp932, fs utf-8, out utf-8, err utf-8, pref cp932\r\n[debug] yt-dlp version 2021.12.27 [6223f67a8]\r\n[debug] Python version 3.8.12 (CPython 64bit) - Windows-10-10.0.19044-SP0\r\n[debug] exe versions: ffmpeg 4.4-full_build-www.gyan.dev (setts), ffprobe 4.4-full_build-www.gyan.dev\r\n[debug] Optional libraries: Cryptodome, mutagen, sqlite, websockets\r\n[debug] Proxy map: {}\r\nLatest version: 2021.12.27, Current version: 2021.12.27\r\nyt-dlp is up to date (2021.12.27)\r\n[TVer] Downloading JSON metadata\r\n[debug] [TVer] Extracting URL: https://tver.jp/feature/f0095053\r\n[TVer] f0095053: Downloading JSON metadata\r\nERROR: f0095053: An extractor error has occurred. (caused by KeyError('publisher_id')); please report this issue on https://github.com/yt-dlp/yt-dlp . Make sure you are using the latest version; see https://github.com/yt-dlp/yt-dlp on how to update. Be sure to call yt-dlp with the --verbose flag and include its complete output.\r\nTraceback (most recent call last):\r\n File \"C:\\Users\\User\\anaconda3\\lib\\site-packages\\yt_dlp\\extractor\\common.py\", line 599, in extract\r\n ie_result = self._real_extract(url)\r\n File \"C:\\Users\\User\\anaconda3\\lib\\site-packages\\yt_dlp\\extractor\\tver.py\", line 44, in _real_extract\r\n p_id = main['publisher_id']\r\nKeyError: 'publisher_id'\r\nTraceback (most recent call last):\r\n File \"C:\\Users\\User\\anaconda3\\lib\\site-packages\\yt_dlp\\extractor\\common.py\", line 599, in extract\r\n ie_result = self._real_extract(url)\r\n File \"C:\\Users\\User\\anaconda3\\lib\\site-packages\\yt_dlp\\extractor\\tver.py\", line 44, in _real_extract\r\n p_id = main['publisher_id']\r\nKeyError: 'publisher_id'\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"C:\\Users\\User\\anaconda3\\lib\\site-packages\\yt_dlp\\YoutubeDL.py\", line 1353, in wrapper\r\n return func(self, *args, **kwargs)\r\n File \"C:\\Users\\User\\anaconda3\\lib\\site-packages\\yt_dlp\\YoutubeDL.py\", line 1423, in __extract_info\r\n ie_result = ie.extract(url)\r\n File \"C:\\Users\\User\\anaconda3\\lib\\site-packages\\yt_dlp\\extractor\\common.py\", line 629, in extract\r\n raise ExtractorError('An extractor error has occurred.', cause=e, video_id=self.get_temp_id(url))\r\nyt_dlp.utils.ExtractorError: f0095053: An extractor error has occurred. (caused by KeyError('publisher_id')); please report this issue on https://github.com/yt-dlp/yt-dlp . Make sure you are using the latest version; see https://github.com/yt-dlp/yt-dlp on how to update. Be sure to call yt-dlp with the --verbose flag and include its complete output.\r\n```\r\n\n[TVer] Extractor error (caused by KeyError('publisher_id')) for some video URLs\n### Checklist\r\n\r\n- [X] I'm reporting a broken site\r\n- [X] I've verified that I'm running yt-dlp version **2021.12.27**. ([update instructions](https://github.com/yt-dlp/yt-dlp#update))\r\n- [X] I've checked that all provided URLs are alive and playable in a browser\r\n- [X] I've checked that all URLs and arguments with special characters are [properly quoted or escaped](https://github.com/ytdl-org/youtube-dl#video-url-contains-an-ampersand-and-im-getting-some-strange-output-1-2839-or-v-is-not-recognized-as-an-internal-or-external-command)\r\n- [X] I've searched the [bugtracker](https://github.com/yt-dlp/yt-dlp/issues?q=) for similar issues including closed ones. DO NOT post duplicates\r\n- [X] I've read the [guidelines for opening an issue](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#opening-an-issue)\r\n- [x] I've read about [sharing account credentials](https://github.com/yt-dlp/yt-dlp/blob/master/CONTRIBUTING.md#are-you-willing-to-share-account-details-if-needed) and I'm willing to share it if required\r\n\r\n### Region\r\n\r\nJapan\r\n\r\n### Description\r\n\r\nI get extractor errors when downloading certain videos from TVer. There are some video URLs (such as https://tver.jp/corner/f0095338) that can be downloaded successfully, but there are also some live video URLs (such as https://tver.jp/feature/f0095053) that are now videos, but instead is a LIVE broadcast prepared for the future. The URLs I just introduced have an expiration date for viewing, so please be careful.\r\n\r\n### Verbose log\r\n\r\n```shell\r\n[debug] Command-line config: ['-Uv', 'https://tver.jp/feature/f0095053']\r\n[debug] Encodings: locale cp932, fs utf-8, out utf-8, err utf-8, pref cp932\r\n[debug] yt-dlp version 2021.12.27 [6223f67a8]\r\n[debug] Python version 3.8.12 (CPython 64bit) - Windows-10-10.0.19044-SP0\r\n[debug] exe versions: ffmpeg 4.4-full_build-www.gyan.dev (setts), ffprobe 4.4-full_build-www.gyan.dev\r\n[debug] Optional libraries: Cryptodome, mutagen, sqlite, websockets\r\n[debug] Proxy map: {}\r\nLatest version: 2021.12.27, Current version: 2021.12.27\r\nyt-dlp is up to date (2021.12.27)\r\n[TVer] Downloading JSON metadata\r\n[debug] [TVer] Extracting URL: https://tver.jp/feature/f0095053\r\n[TVer] f0095053: Downloading JSON metadata\r\nERROR: f0095053: An extractor error has occurred. (caused by KeyError('publisher_id')); please report this issue on https://github.com/yt-dlp/yt-dlp . Make sure you are using the latest version; see https://github.com/yt-dlp/yt-dlp on how to update. Be sure to call yt-dlp with the --verbose flag and include its complete output.\r\nTraceback (most recent call last):\r\n File \"C:\\Users\\User\\anaconda3\\lib\\site-packages\\yt_dlp\\extractor\\common.py\", line 599, in extract\r\n ie_result = self._real_extract(url)\r\n File \"C:\\Users\\User\\anaconda3\\lib\\site-packages\\yt_dlp\\extractor\\tver.py\", line 44, in _real_extract\r\n p_id = main['publisher_id']\r\nKeyError: 'publisher_id'\r\nTraceback (most recent call last):\r\n File \"C:\\Users\\User\\anaconda3\\lib\\site-packages\\yt_dlp\\extractor\\common.py\", line 599, in extract\r\n ie_result = self._real_extract(url)\r\n File \"C:\\Users\\User\\anaconda3\\lib\\site-packages\\yt_dlp\\extractor\\tver.py\", line 44, in _real_extract\r\n p_id = main['publisher_id']\r\nKeyError: 'publisher_id'\r\n\r\nDuring handling of the above exception, another exception occurred:\r\n\r\nTraceback (most recent call last):\r\n File \"C:\\Users\\User\\anaconda3\\lib\\site-packages\\yt_dlp\\YoutubeDL.py\", line 1353, in wrapper\r\n return func(self, *args, **kwargs)\r\n File \"C:\\Users\\User\\anaconda3\\lib\\site-packages\\yt_dlp\\YoutubeDL.py\", line 1423, in __extract_info\r\n ie_result = ie.extract(url)\r\n File \"C:\\Users\\User\\anaconda3\\lib\\site-packages\\yt_dlp\\extractor\\common.py\", line 629, in extract\r\n raise ExtractorError('An extractor error has occurred.', cause=e, video_id=self.get_temp_id(url))\r\nyt_dlp.utils.ExtractorError: f0095053: An extractor error has occurred. (caused by KeyError('publisher_id')); please report this issue on https://github.com/yt-dlp/yt-dlp . Make sure you are using the latest version; see https://github.com/yt-dlp/yt-dlp on how to update. Be sure to call yt-dlp with the --verbose flag and include its complete output.\r\n```\r\n\n", "before_files": [{"content": "# coding: utf-8\nfrom __future__ import unicode_literals\n\n\nfrom .common import InfoExtractor\nfrom ..compat import compat_str\nfrom ..utils import (\n int_or_none,\n remove_start,\n smuggle_url,\n try_get,\n)\n\n\nclass TVerIE(InfoExtractor):\n _VALID_URL = r'https?://(?:www\\.)?tver\\.jp/(?P<path>(?:corner|episode|feature)/(?P<id>f?\\d+))'\n # videos are only available for 7 days\n _TESTS = [{\n 'url': 'https://tver.jp/corner/f0062178',\n 'only_matching': True,\n }, {\n 'url': 'https://tver.jp/feature/f0062413',\n 'only_matching': True,\n }, {\n 'url': 'https://tver.jp/episode/79622438',\n 'only_matching': True,\n }, {\n # subtitle = ' '\n 'url': 'https://tver.jp/corner/f0068870',\n 'only_matching': True,\n }]\n _TOKEN = None\n BRIGHTCOVE_URL_TEMPLATE = 'http://players.brightcove.net/%s/default_default/index.html?videoId=%s'\n\n def _real_initialize(self):\n self._TOKEN = self._download_json(\n 'https://tver.jp/api/access_token.php', None)['token']\n\n def _real_extract(self, url):\n path, video_id = self._match_valid_url(url).groups()\n main = self._download_json(\n 'https://api.tver.jp/v4/' + path, video_id,\n query={'token': self._TOKEN})['main']\n p_id = main['publisher_id']\n service = remove_start(main['service'], 'ts_')\n\n r_id = main['reference_id']\n if service not in ('tx', 'russia2018', 'sebare2018live', 'gorin'):\n r_id = 'ref:' + r_id\n bc_url = smuggle_url(\n self.BRIGHTCOVE_URL_TEMPLATE % (p_id, r_id),\n {'geo_countries': ['JP']})\n\n return {\n '_type': 'url_transparent',\n 'description': try_get(main, lambda x: x['note'][0]['text'], compat_str),\n 'episode_number': int_or_none(try_get(main, lambda x: x['ext']['episode_number'])),\n 'url': bc_url,\n 'ie_key': 'BrightcoveNew',\n }\n", "path": "yt_dlp/extractor/tver.py"}]}
| 3,811 | 585 |
gh_patches_debug_16822
|
rasdani/github-patches
|
git_diff
|
tough-dev-school__education-backend-560
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
User.DoesNotExist: User matching query does not exist.
Sentry Issue: [EDUCATION-BACKEND-23](https://sentry.io/organizations/f213/issues/2200858697/?referrer=github_integration)
```
User.DoesNotExist: User matching query does not exist.
File "celery/app/autoretry.py", line 34, in run
return task._orig_run(*args, **kwargs)
File "app/tasks.py", line 77, in subscribe_to_mailchimp
user=apps.get_model('users.User').objects.get(pk=user_id),
File "django/db/models/manager.py", line 85, in manager_method
return getattr(self.get_queryset(), name)(*args, **kwargs)
File "django/db/models/query.py", line 435, in get
raise self.model.DoesNotExist(
```
</issue>
<code>
[start of src/app/tasks.py]
1 from typing import List, Union
2
3 from anymail.exceptions import AnymailRequestsAPIError
4 from django.apps import apps
5 from django.conf import settings
6 from requests.exceptions import RequestException
7
8 from app.celery import celery
9 from app.integrations import tg
10 from app.integrations.clickmeeting import ClickMeetingClient, ClickMeetingHTTPException
11 from app.integrations.mailchimp import AppMailchimp, MailchimpException
12 from app.integrations.zoomus import ZoomusClient, ZoomusHTTPException
13 from app.mail.owl import TemplOwl
14
15
16 @celery.task(
17 autoretry_for=[AnymailRequestsAPIError],
18 retry_kwargs={
19 'max_retries': 10,
20 'countdown': 5,
21 },
22 )
23 def send_mail(to: Union[List, str], template_id, subject: str = '', ctx: dict = None, disable_antispam=False):
24 TemplOwl(
25 to=to,
26 template_id=template_id,
27 subject=subject,
28 ctx=ctx,
29 disable_antispam=disable_antispam,
30 ).send()
31
32
33 @celery.task(
34 autoretry_for=[RequestException, ClickMeetingHTTPException],
35 retry_kwargs={
36 'max_retries': 10,
37 'countdown': 5,
38 },
39 )
40 def invite_to_clickmeeting(room_url: str, email: str):
41 client = ClickMeetingClient()
42 client.invite(room_url, email)
43
44
45 @celery.task(
46 autoretry_for=[RequestException, ZoomusHTTPException],
47 retry_kwargs={
48 'max_retries': 10,
49 'countdown': 5,
50 },
51 )
52 def invite_to_zoomus(webinar_id: str, user_id: int):
53 user = apps.get_model('users.User').objects.get(pk=user_id)
54
55 client = ZoomusClient()
56 client.invite(webinar_id, user)
57
58
59 @celery.task(
60 autoretry_for=[RequestException, MailchimpException],
61 retry_kwargs={
62 'max_retries': 10,
63 'countdown': 5,
64 },
65 )
66 def subscribe_to_mailchimp(user_id: int, list_id=None, tags=None):
67 if list_id is None:
68 list_id = settings.MAILCHIMP_CONTACT_LIST_ID
69
70 if not list_id:
71 return
72
73 mailchimp = AppMailchimp()
74
75 mailchimp.subscribe_django_user(
76 list_id=list_id,
77 user=apps.get_model('users.User').objects.get(pk=user_id),
78 tags=tags,
79 )
80
81
82 @celery.task
83 def send_happiness_message(text):
84 tg.send_happiness_message(text)
85
[end of src/app/tasks.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/src/app/tasks.py b/src/app/tasks.py
--- a/src/app/tasks.py
+++ b/src/app/tasks.py
@@ -3,6 +3,7 @@
from anymail.exceptions import AnymailRequestsAPIError
from django.apps import apps
from django.conf import settings
+from django.core.exceptions import ObjectDoesNotExist
from requests.exceptions import RequestException
from app.celery import celery
@@ -57,11 +58,12 @@
@celery.task(
- autoretry_for=[RequestException, MailchimpException],
+ autoretry_for=[RequestException, MailchimpException, ObjectDoesNotExist],
retry_kwargs={
'max_retries': 10,
'countdown': 5,
},
+ rate_limit='1/s',
)
def subscribe_to_mailchimp(user_id: int, list_id=None, tags=None):
if list_id is None:
|
{"golden_diff": "diff --git a/src/app/tasks.py b/src/app/tasks.py\n--- a/src/app/tasks.py\n+++ b/src/app/tasks.py\n@@ -3,6 +3,7 @@\n from anymail.exceptions import AnymailRequestsAPIError\n from django.apps import apps\n from django.conf import settings\n+from django.core.exceptions import ObjectDoesNotExist\n from requests.exceptions import RequestException\n \n from app.celery import celery\n@@ -57,11 +58,12 @@\n \n \n @celery.task(\n- autoretry_for=[RequestException, MailchimpException],\n+ autoretry_for=[RequestException, MailchimpException, ObjectDoesNotExist],\n retry_kwargs={\n 'max_retries': 10,\n 'countdown': 5,\n },\n+ rate_limit='1/s',\n )\n def subscribe_to_mailchimp(user_id: int, list_id=None, tags=None):\n if list_id is None:\n", "issue": "User.DoesNotExist: User matching query does not exist.\nSentry Issue: [EDUCATION-BACKEND-23](https://sentry.io/organizations/f213/issues/2200858697/?referrer=github_integration)\n\n```\nUser.DoesNotExist: User matching query does not exist.\n File \"celery/app/autoretry.py\", line 34, in run\n return task._orig_run(*args, **kwargs)\n File \"app/tasks.py\", line 77, in subscribe_to_mailchimp\n user=apps.get_model('users.User').objects.get(pk=user_id),\n File \"django/db/models/manager.py\", line 85, in manager_method\n return getattr(self.get_queryset(), name)(*args, **kwargs)\n File \"django/db/models/query.py\", line 435, in get\n raise self.model.DoesNotExist(\n```\n", "before_files": [{"content": "from typing import List, Union\n\nfrom anymail.exceptions import AnymailRequestsAPIError\nfrom django.apps import apps\nfrom django.conf import settings\nfrom requests.exceptions import RequestException\n\nfrom app.celery import celery\nfrom app.integrations import tg\nfrom app.integrations.clickmeeting import ClickMeetingClient, ClickMeetingHTTPException\nfrom app.integrations.mailchimp import AppMailchimp, MailchimpException\nfrom app.integrations.zoomus import ZoomusClient, ZoomusHTTPException\nfrom app.mail.owl import TemplOwl\n\n\[email protected](\n autoretry_for=[AnymailRequestsAPIError],\n retry_kwargs={\n 'max_retries': 10,\n 'countdown': 5,\n },\n)\ndef send_mail(to: Union[List, str], template_id, subject: str = '', ctx: dict = None, disable_antispam=False):\n TemplOwl(\n to=to,\n template_id=template_id,\n subject=subject,\n ctx=ctx,\n disable_antispam=disable_antispam,\n ).send()\n\n\[email protected](\n autoretry_for=[RequestException, ClickMeetingHTTPException],\n retry_kwargs={\n 'max_retries': 10,\n 'countdown': 5,\n },\n)\ndef invite_to_clickmeeting(room_url: str, email: str):\n client = ClickMeetingClient()\n client.invite(room_url, email)\n\n\[email protected](\n autoretry_for=[RequestException, ZoomusHTTPException],\n retry_kwargs={\n 'max_retries': 10,\n 'countdown': 5,\n },\n)\ndef invite_to_zoomus(webinar_id: str, user_id: int):\n user = apps.get_model('users.User').objects.get(pk=user_id)\n\n client = ZoomusClient()\n client.invite(webinar_id, user)\n\n\[email protected](\n autoretry_for=[RequestException, MailchimpException],\n retry_kwargs={\n 'max_retries': 10,\n 'countdown': 5,\n },\n)\ndef subscribe_to_mailchimp(user_id: int, list_id=None, tags=None):\n if list_id is None:\n list_id = settings.MAILCHIMP_CONTACT_LIST_ID\n\n if not list_id:\n return\n\n mailchimp = AppMailchimp()\n\n mailchimp.subscribe_django_user(\n list_id=list_id,\n user=apps.get_model('users.User').objects.get(pk=user_id),\n tags=tags,\n )\n\n\[email protected]\ndef send_happiness_message(text):\n tg.send_happiness_message(text)\n", "path": "src/app/tasks.py"}]}
| 1,450 | 196 |
gh_patches_debug_21052
|
rasdani/github-patches
|
git_diff
|
svthalia__concrexit-1251
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
0008_migrate_processing_date cannot be run when existing Payables have payments
### Describe the bug
Inside the `0008_migrate_processing_date` migration we delete payments. However, the payables they belong to protect them so the migration fails.
### How to reproduce
Steps to reproduce the behaviour:
1. Have an existing pizza order or membership renewal with a non-processed payment
2. Execute migration
### Expected behaviour
Successful migration.
### Additional context
```
web_1 | Running migrations:
web_1 | Traceback (most recent call last):
web_1 | File "./manage.py", line 19, in <module>
web_1 | execute_from_command_line(sys.argv)
web_1 | File "/usr/local/lib/python3.8/site-packages/django/core/management/__init__.py", line 401, in execute_from_command_line
web_1 | utility.execute()
web_1 | File "/usr/local/lib/python3.8/site-packages/django/core/management/__init__.py", line 395, in execute
web_1 | self.fetch_command(subcommand).run_from_argv(self.argv)
web_1 | File "/usr/local/lib/python3.8/site-packages/django/core/management/base.py", line 330, in run_from_argv
web_1 | self.execute(*args, **cmd_options)
web_1 | File "/usr/local/lib/python3.8/site-packages/django/core/management/base.py", line 371, in execute
web_1 | output = self.handle(*args, **options)
web_1 | File "/usr/local/lib/python3.8/site-packages/django/core/management/base.py", line 85, in wrapped
web_1 | res = handle_func(*args, **kwargs)
web_1 | File "/usr/local/lib/python3.8/site-packages/django/core/management/commands/migrate.py", line 243, in handle
web_1 | post_migrate_state = executor.migrate(
web_1 | File "/usr/local/lib/python3.8/site-packages/django/db/migrations/executor.py", line 117, in migrate
web_1 | state = self._migrate_all_forwards(state, plan, full_plan, fake=fake, fake_initial=fake_initial)
web_1 | File "/usr/local/lib/python3.8/site-packages/django/db/migrations/executor.py", line 147, in _migrate_all_forwards
web_1 | state = self.apply_migration(state, migration, fake=fake, fake_initial=fake_initial)
web_1 | File "/usr/local/lib/python3.8/site-packages/django/db/migrations/executor.py", line 227, in apply_migration
web_1 | state = migration.apply(state, schema_editor)
web_1 | File "/usr/local/lib/python3.8/site-packages/django/db/migrations/migration.py", line 124, in apply
web_1 | operation.database_forwards(self.app_label, schema_editor, old_state, project_state)
web_1 | File "/usr/local/lib/python3.8/site-packages/django/db/migrations/operations/special.py", line 190, in database_forwards
web_1 | self.code(from_state.apps, schema_editor)
web_1 | File "/usr/src/app/website/payments/migrations/0008_migrate_processing_date.py", line 11, in set_created_at
web_1 | payment.delete()
web_1 | File "/usr/local/lib/python3.8/site-packages/django/db/models/base.py", line 946, in delete
web_1 | collector.collect([self], keep_parents=keep_parents)
web_1 | File "/usr/local/lib/python3.8/site-packages/django/db/models/deletion.py", line 302, in collect
web_1 | raise ProtectedError(
web_1 | django.db.models.deletion.ProtectedError: ("Cannot delete some instances of model 'Payment' because they are referenced through protected foreign keys: 'Entry.payment'.", <itertools.chain object at 0x7f087b01aa00>)
```
```
web_1 | Running migrations:
web_1 | Traceback (most recent call last):
web_1 | File "./manage.py", line 19, in <module>
web_1 | execute_from_command_line(sys.argv)
web_1 | File "/usr/local/lib/python3.8/site-packages/django/core/management/__init__.py", line 401, in execute_from_command_line
web_1 | utility.execute()
web_1 | File "/usr/local/lib/python3.8/site-packages/django/core/management/__init__.py", line 395, in execute
web_1 | self.fetch_command(subcommand).run_from_argv(self.argv)
web_1 | File "/usr/local/lib/python3.8/site-packages/django/core/management/base.py", line 330, in run_from_argv
web_1 | self.execute(*args, **cmd_options)
web_1 | File "/usr/local/lib/python3.8/site-packages/django/core/management/base.py", line 371, in execute
web_1 | output = self.handle(*args, **options)
web_1 | File "/usr/local/lib/python3.8/site-packages/django/core/management/base.py", line 85, in wrapped
web_1 | res = handle_func(*args, **kwargs)
web_1 | File "/usr/local/lib/python3.8/site-packages/django/core/management/commands/migrate.py", line 243, in handle
web_1 | post_migrate_state = executor.migrate(
web_1 | File "/usr/local/lib/python3.8/site-packages/django/db/migrations/executor.py", line 117, in migrate
web_1 | state = self._migrate_all_forwards(state, plan, full_plan, fake=fake, fake_initial=fake_initial)
web_1 | File "/usr/local/lib/python3.8/site-packages/django/db/migrations/executor.py", line 147, in _migrate_all_forwards
web_1 | state = self.apply_migration(state, migration, fake=fake, fake_initial=fake_initial)
web_1 | File "/usr/local/lib/python3.8/site-packages/django/db/migrations/executor.py", line 227, in apply_migration
web_1 | state = migration.apply(state, schema_editor)
web_1 | File "/usr/local/lib/python3.8/site-packages/django/db/migrations/migration.py", line 124, in apply
web_1 | operation.database_forwards(self.app_label, schema_editor, old_state, project_state)
web_1 | File "/usr/local/lib/python3.8/site-packages/django/db/migrations/operations/special.py", line 190, in database_forwards
web_1 | self.code(from_state.apps, schema_editor)
web_1 | File "/usr/src/app/website/payments/migrations/0008_migrate_processing_date.py", line 11, in set_created_at
web_1 | payment.delete()
web_1 | File "/usr/local/lib/python3.8/site-packages/django/db/models/base.py", line 946, in delete
web_1 | collector.collect([self], keep_parents=keep_parents)
web_1 | File "/usr/local/lib/python3.8/site-packages/django/db/models/deletion.py", line 302, in collect
web_1 | raise ProtectedError(
web_1 | django.db.models.deletion.ProtectedError: ("Cannot delete some instances of model 'Payment' because they are referenced through protected foreign keys: 'Order.payment'.", <itertools.chain object at 0x7f5e652bcaf0>)
```
</issue>
<code>
[start of website/payments/migrations/0008_migrate_processing_date.py]
1 from django.db import migrations
2
3
4 def set_created_at(apps, schema_editor):
5 """On this migration, set the created at to the processing date."""
6 Payment = apps.get_model('payments', 'Payment')
7 for payment in Payment.objects.all():
8 if payment.processing_date:
9 payment.created_at = payment.processing_date
10 else:
11 payment.delete()
12
13
14 class Migration(migrations.Migration):
15
16 dependencies = [
17 ('payments', '0007_auto_20200510_2042'),
18 ]
19
20 operations = [
21 migrations.RunPython(set_created_at)
22 ]
23
[end of website/payments/migrations/0008_migrate_processing_date.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/website/payments/migrations/0008_migrate_processing_date.py b/website/payments/migrations/0008_migrate_processing_date.py
--- a/website/payments/migrations/0008_migrate_processing_date.py
+++ b/website/payments/migrations/0008_migrate_processing_date.py
@@ -8,9 +8,26 @@
if payment.processing_date:
payment.created_at = payment.processing_date
else:
+ if hasattr(payment, 'pizzas_order'):
+ order = payment.pizzas_order
+ order.payment = None
+ order.save()
+
+ if hasattr(payment, 'registrations_entry'):
+ entry = payment.registrations_entry
+ entry.payment = None
+ entry.save()
+
payment.delete()
+def set_processed_date(apps, schema_editor):
+ """Revert sets the processing date to the created_at value."""
+ Payment = apps.get_model('payments', 'Payment')
+ for payment in Payment.objects.all():
+ payment.processing_date = payment.created_at
+
+
class Migration(migrations.Migration):
dependencies = [
@@ -18,5 +35,5 @@
]
operations = [
- migrations.RunPython(set_created_at)
+ migrations.RunPython(set_created_at, set_processed_date)
]
|
{"golden_diff": "diff --git a/website/payments/migrations/0008_migrate_processing_date.py b/website/payments/migrations/0008_migrate_processing_date.py\n--- a/website/payments/migrations/0008_migrate_processing_date.py\n+++ b/website/payments/migrations/0008_migrate_processing_date.py\n@@ -8,9 +8,26 @@\n if payment.processing_date:\n payment.created_at = payment.processing_date\n else:\n+ if hasattr(payment, 'pizzas_order'):\n+ order = payment.pizzas_order\n+ order.payment = None\n+ order.save()\n+\n+ if hasattr(payment, 'registrations_entry'):\n+ entry = payment.registrations_entry\n+ entry.payment = None\n+ entry.save()\n+\n payment.delete()\n \n \n+def set_processed_date(apps, schema_editor):\n+ \"\"\"Revert sets the processing date to the created_at value.\"\"\"\n+ Payment = apps.get_model('payments', 'Payment')\n+ for payment in Payment.objects.all():\n+ payment.processing_date = payment.created_at\n+\n+\n class Migration(migrations.Migration):\n \n dependencies = [\n@@ -18,5 +35,5 @@\n ]\n \n operations = [\n- migrations.RunPython(set_created_at)\n+ migrations.RunPython(set_created_at, set_processed_date)\n ]\n", "issue": "0008_migrate_processing_date cannot be run when existing Payables have payments\n### Describe the bug\r\n\r\nInside the `0008_migrate_processing_date` migration we delete payments. However, the payables they belong to protect them so the migration fails.\r\n\r\n\r\n### How to reproduce\r\nSteps to reproduce the behaviour:\r\n1. Have an existing pizza order or membership renewal with a non-processed payment\r\n2. Execute migration\r\n\r\n### Expected behaviour\r\nSuccessful migration.\r\n\r\n### Additional context\r\n```\r\nweb_1 | Running migrations:\r\nweb_1 | Traceback (most recent call last):\r\nweb_1 | File \"./manage.py\", line 19, in <module>\r\nweb_1 | execute_from_command_line(sys.argv)\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/django/core/management/__init__.py\", line 401, in execute_from_command_line\r\nweb_1 | utility.execute()\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/django/core/management/__init__.py\", line 395, in execute\r\nweb_1 | self.fetch_command(subcommand).run_from_argv(self.argv)\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/django/core/management/base.py\", line 330, in run_from_argv\r\nweb_1 | self.execute(*args, **cmd_options)\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/django/core/management/base.py\", line 371, in execute\r\nweb_1 | output = self.handle(*args, **options)\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/django/core/management/base.py\", line 85, in wrapped\r\nweb_1 | res = handle_func(*args, **kwargs)\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/django/core/management/commands/migrate.py\", line 243, in handle\r\nweb_1 | post_migrate_state = executor.migrate(\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/django/db/migrations/executor.py\", line 117, in migrate\r\nweb_1 | state = self._migrate_all_forwards(state, plan, full_plan, fake=fake, fake_initial=fake_initial)\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/django/db/migrations/executor.py\", line 147, in _migrate_all_forwards\r\nweb_1 | state = self.apply_migration(state, migration, fake=fake, fake_initial=fake_initial)\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/django/db/migrations/executor.py\", line 227, in apply_migration\r\nweb_1 | state = migration.apply(state, schema_editor)\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/django/db/migrations/migration.py\", line 124, in apply\r\nweb_1 | operation.database_forwards(self.app_label, schema_editor, old_state, project_state)\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/django/db/migrations/operations/special.py\", line 190, in database_forwards\r\nweb_1 | self.code(from_state.apps, schema_editor)\r\nweb_1 | File \"/usr/src/app/website/payments/migrations/0008_migrate_processing_date.py\", line 11, in set_created_at\r\nweb_1 | payment.delete()\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/django/db/models/base.py\", line 946, in delete\r\nweb_1 | collector.collect([self], keep_parents=keep_parents)\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/django/db/models/deletion.py\", line 302, in collect\r\nweb_1 | raise ProtectedError(\r\nweb_1 | django.db.models.deletion.ProtectedError: (\"Cannot delete some instances of model 'Payment' because they are referenced through protected foreign keys: 'Entry.payment'.\", <itertools.chain object at 0x7f087b01aa00>)\r\n```\r\n\r\n```\r\nweb_1 | Running migrations:\r\nweb_1 | Traceback (most recent call last):\r\nweb_1 | File \"./manage.py\", line 19, in <module>\r\nweb_1 | execute_from_command_line(sys.argv)\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/django/core/management/__init__.py\", line 401, in execute_from_command_line\r\nweb_1 | utility.execute()\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/django/core/management/__init__.py\", line 395, in execute\r\nweb_1 | self.fetch_command(subcommand).run_from_argv(self.argv)\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/django/core/management/base.py\", line 330, in run_from_argv\r\nweb_1 | self.execute(*args, **cmd_options)\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/django/core/management/base.py\", line 371, in execute\r\nweb_1 | output = self.handle(*args, **options)\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/django/core/management/base.py\", line 85, in wrapped\r\nweb_1 | res = handle_func(*args, **kwargs)\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/django/core/management/commands/migrate.py\", line 243, in handle\r\nweb_1 | post_migrate_state = executor.migrate(\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/django/db/migrations/executor.py\", line 117, in migrate\r\nweb_1 | state = self._migrate_all_forwards(state, plan, full_plan, fake=fake, fake_initial=fake_initial)\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/django/db/migrations/executor.py\", line 147, in _migrate_all_forwards\r\nweb_1 | state = self.apply_migration(state, migration, fake=fake, fake_initial=fake_initial)\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/django/db/migrations/executor.py\", line 227, in apply_migration\r\nweb_1 | state = migration.apply(state, schema_editor)\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/django/db/migrations/migration.py\", line 124, in apply\r\nweb_1 | operation.database_forwards(self.app_label, schema_editor, old_state, project_state)\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/django/db/migrations/operations/special.py\", line 190, in database_forwards\r\nweb_1 | self.code(from_state.apps, schema_editor)\r\nweb_1 | File \"/usr/src/app/website/payments/migrations/0008_migrate_processing_date.py\", line 11, in set_created_at\r\nweb_1 | payment.delete()\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/django/db/models/base.py\", line 946, in delete\r\nweb_1 | collector.collect([self], keep_parents=keep_parents)\r\nweb_1 | File \"/usr/local/lib/python3.8/site-packages/django/db/models/deletion.py\", line 302, in collect\r\nweb_1 | raise ProtectedError(\r\nweb_1 | django.db.models.deletion.ProtectedError: (\"Cannot delete some instances of model 'Payment' because they are referenced through protected foreign keys: 'Order.payment'.\", <itertools.chain object at 0x7f5e652bcaf0>)\r\n```\n", "before_files": [{"content": "from django.db import migrations\n\n\ndef set_created_at(apps, schema_editor):\n \"\"\"On this migration, set the created at to the processing date.\"\"\"\n Payment = apps.get_model('payments', 'Payment')\n for payment in Payment.objects.all():\n if payment.processing_date:\n payment.created_at = payment.processing_date\n else:\n payment.delete()\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('payments', '0007_auto_20200510_2042'),\n ]\n\n operations = [\n migrations.RunPython(set_created_at)\n ]\n", "path": "website/payments/migrations/0008_migrate_processing_date.py"}]}
| 2,540 | 295 |
gh_patches_debug_18093
|
rasdani/github-patches
|
git_diff
|
keras-team__keras-nlp-835
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Add compilation defaults for the MaskedLM task models
In https://github.com/keras-team/keras-nlp/issues/709 we added compilation defaults to all classification tasks. We should also do the same for all `XXMaskedLM` models. E.g. [bert](https://github.com/keras-team/keras-nlp/blob/master/keras_nlp/models/bert/bert_masked_lm.py). Here's the full list of models.
- [ ] `AlbertMaskedLM`
- [ ] `BertMaskedLM`
- [ ] `DebertV3MaskedLM`
- [ ] `DistilBertMaskedLM`
- [ ] `FNetMaskedLM`
- [ ] `RobertaMaskedLM`
https://github.com/keras-team/keras-nlp/pull/714 is a good template PR. We can probably just use Adam and `1e-5` or `2e-5` as a learning rate for now. Though a little experimentation for each model to make sure the task does converge would be helpful. This [colab](https://gist.github.com/mattdangerw/b16c257973762a0b4ab9a34f6a932cc1) may be a helpful starting place.
</issue>
<code>
[start of keras_nlp/models/deberta_v3/deberta_v3_masked_lm.py]
1 # Copyright 2022 The KerasNLP Authors
2 #
3 # Licensed under the Apache License, Version 2.0 (the "License");
4 # you may not use this file except in compliance with the License.
5 # You may obtain a copy of the License at
6 #
7 # https://www.apache.org/licenses/LICENSE-2.0
8 #
9 # Unless required by applicable law or agreed to in writing, software
10 # distributed under the License is distributed on an "AS IS" BASIS,
11 # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
12 # See the License for the specific language governing permissions and
13 # limitations under the License.
14 """DeBERTaV3 masked lm model."""
15
16 import copy
17
18 from tensorflow import keras
19
20 from keras_nlp.api_export import keras_nlp_export
21 from keras_nlp.layers.masked_lm_head import MaskedLMHead
22 from keras_nlp.models.deberta_v3.deberta_v3_backbone import DebertaV3Backbone
23 from keras_nlp.models.deberta_v3.deberta_v3_backbone import (
24 deberta_kernel_initializer,
25 )
26 from keras_nlp.models.deberta_v3.deberta_v3_masked_lm_preprocessor import (
27 DebertaV3MaskedLMPreprocessor,
28 )
29 from keras_nlp.models.deberta_v3.deberta_v3_presets import backbone_presets
30 from keras_nlp.models.task import Task
31 from keras_nlp.utils.python_utils import classproperty
32
33
34 @keras_nlp_export("keras_nlp.models.DebertaV3MaskedLM")
35 class DebertaV3MaskedLM(Task):
36 """An end-to-end DeBERTaV3 model for the masked language modeling task.
37
38 This model will train DeBERTaV3 on a masked language modeling task.
39 The model will predict labels for a number of masked tokens in the
40 input data. For usage of this model with pre-trained weights, see the
41 `from_preset()` method.
42
43 This model can optionally be configured with a `preprocessor` layer, in
44 which case inputs can be raw string features during `fit()`, `predict()`,
45 and `evaluate()`. Inputs will be tokenized and dynamically masked during
46 training and evaluation. This is done by default when creating the model
47 with `from_preset()`.
48
49 Disclaimer: Pre-trained models are provided on an "as is" basis, without
50 warranties or conditions of any kind. The underlying model is provided by a
51 third party and subject to a separate license, available
52 [here](https://github.com/microsoft/DeBERTa).
53
54 Args:
55 backbone: A `keras_nlp.models.DebertaV3Backbone` instance.
56 preprocessor: A `keras_nlp.models.DebertaV3MaskedLMPreprocessor` or
57 `None`. If `None`, this model will not apply preprocessing, and
58 inputs should be preprocessed before calling the model.
59
60 Example usage:
61
62 Raw string inputs and pretrained backbone.
63 ```python
64 # Create a dataset with raw string features. Labels are inferred.
65 features = ["The quick brown fox jumped.", "I forgot my homework."]
66
67 # Create a DebertaV3MaskedLM with a pretrained backbone and further train
68 # on an MLM task.
69 masked_lm = keras_nlp.models.DebertaV3MaskedLM.from_preset(
70 "deberta_v3_base_en",
71 )
72 masked_lm.compile(
73 loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
74 )
75 masked_lm.fit(x=features, batch_size=2)
76 ```
77
78 Preprocessed inputs and custom backbone.
79 ```python
80 # Create a preprocessed dataset where 0 is the mask token.
81 preprocessed_features = {
82 "token_ids": tf.constant(
83 [[1, 2, 0, 4, 0, 6, 7, 8]] * 2, shape=(2, 8)
84 ),
85 "padding_mask": tf.constant(
86 [[1, 1, 1, 1, 1, 1, 1, 1]] * 2, shape=(2, 8)
87 ),
88 "mask_positions": tf.constant([[2, 4]] * 2, shape=(2, 2))
89 }
90 # Labels are the original masked values.
91 labels = [[3, 5]] * 2
92
93 # Randomly initialize a DeBERTaV3 encoder
94 backbone = keras_nlp.models.DebertaV3Backbone(
95 vocabulary_size=50265,
96 num_layers=12,
97 num_heads=12,
98 hidden_dim=768,
99 intermediate_dim=3072,
100 max_sequence_length=12
101 )
102 # Create a DeBERTaV3 masked_lm and fit the data.
103 masked_lm = keras_nlp.models.DebertaV3MaskedLM(
104 backbone,
105 preprocessor=None,
106 )
107 masked_lm.compile(
108 loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
109 )
110 masked_lm.fit(x=preprocessed_features, y=labels, batch_size=2)
111 ```
112 """
113
114 def __init__(
115 self,
116 backbone,
117 preprocessor=None,
118 **kwargs,
119 ):
120 inputs = {
121 **backbone.input,
122 "mask_positions": keras.Input(
123 shape=(None,), dtype="int32", name="mask_positions"
124 ),
125 }
126 backbone_outputs = backbone(backbone.input)
127 outputs = MaskedLMHead(
128 vocabulary_size=backbone.vocabulary_size,
129 embedding_weights=backbone.token_embedding.embeddings,
130 intermediate_activation=lambda x: keras.activations.gelu(
131 x, approximate=False
132 ),
133 kernel_initializer=deberta_kernel_initializer(),
134 name="mlm_head",
135 )(backbone_outputs, inputs["mask_positions"])
136
137 # Instantiate using Functional API Model constructor
138 super().__init__(
139 inputs=inputs,
140 outputs=outputs,
141 include_preprocessing=preprocessor is not None,
142 **kwargs,
143 )
144 # All references to `self` below this line
145 self.backbone = backbone
146 self.preprocessor = preprocessor
147
148 @classproperty
149 def backbone_cls(cls):
150 return DebertaV3Backbone
151
152 @classproperty
153 def preprocessor_cls(cls):
154 return DebertaV3MaskedLMPreprocessor
155
156 @classproperty
157 def presets(cls):
158 return copy.deepcopy(backbone_presets)
159
[end of keras_nlp/models/deberta_v3/deberta_v3_masked_lm.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/keras_nlp/models/deberta_v3/deberta_v3_masked_lm.py b/keras_nlp/models/deberta_v3/deberta_v3_masked_lm.py
--- a/keras_nlp/models/deberta_v3/deberta_v3_masked_lm.py
+++ b/keras_nlp/models/deberta_v3/deberta_v3_masked_lm.py
@@ -28,6 +28,7 @@
)
from keras_nlp.models.deberta_v3.deberta_v3_presets import backbone_presets
from keras_nlp.models.task import Task
+from keras_nlp.utils.keras_utils import is_xla_compatible
from keras_nlp.utils.python_utils import classproperty
@@ -145,6 +146,13 @@
self.backbone = backbone
self.preprocessor = preprocessor
+ self.compile(
+ loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),
+ optimizer=keras.optimizers.Adam(5e-5),
+ weighted_metrics=keras.metrics.SparseCategoricalAccuracy(),
+ jit_compile=is_xla_compatible(self),
+ )
+
@classproperty
def backbone_cls(cls):
return DebertaV3Backbone
|
{"golden_diff": "diff --git a/keras_nlp/models/deberta_v3/deberta_v3_masked_lm.py b/keras_nlp/models/deberta_v3/deberta_v3_masked_lm.py\n--- a/keras_nlp/models/deberta_v3/deberta_v3_masked_lm.py\n+++ b/keras_nlp/models/deberta_v3/deberta_v3_masked_lm.py\n@@ -28,6 +28,7 @@\n )\n from keras_nlp.models.deberta_v3.deberta_v3_presets import backbone_presets\n from keras_nlp.models.task import Task\n+from keras_nlp.utils.keras_utils import is_xla_compatible\n from keras_nlp.utils.python_utils import classproperty\n \n \n@@ -145,6 +146,13 @@\n self.backbone = backbone\n self.preprocessor = preprocessor\n \n+ self.compile(\n+ loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n+ optimizer=keras.optimizers.Adam(5e-5),\n+ weighted_metrics=keras.metrics.SparseCategoricalAccuracy(),\n+ jit_compile=is_xla_compatible(self),\n+ )\n+\n @classproperty\n def backbone_cls(cls):\n return DebertaV3Backbone\n", "issue": "Add compilation defaults for the MaskedLM task models\nIn https://github.com/keras-team/keras-nlp/issues/709 we added compilation defaults to all classification tasks. We should also do the same for all `XXMaskedLM` models. E.g. [bert](https://github.com/keras-team/keras-nlp/blob/master/keras_nlp/models/bert/bert_masked_lm.py). Here's the full list of models.\r\n\r\n- [ ] `AlbertMaskedLM`\r\n- [ ] `BertMaskedLM`\r\n- [ ] `DebertV3MaskedLM`\r\n- [ ] `DistilBertMaskedLM`\r\n- [ ] `FNetMaskedLM`\r\n- [ ] `RobertaMaskedLM`\r\n\r\nhttps://github.com/keras-team/keras-nlp/pull/714 is a good template PR. We can probably just use Adam and `1e-5` or `2e-5` as a learning rate for now. Though a little experimentation for each model to make sure the task does converge would be helpful. This [colab](https://gist.github.com/mattdangerw/b16c257973762a0b4ab9a34f6a932cc1) may be a helpful starting place.\n", "before_files": [{"content": "# Copyright 2022 The KerasNLP Authors\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\"\"\"DeBERTaV3 masked lm model.\"\"\"\n\nimport copy\n\nfrom tensorflow import keras\n\nfrom keras_nlp.api_export import keras_nlp_export\nfrom keras_nlp.layers.masked_lm_head import MaskedLMHead\nfrom keras_nlp.models.deberta_v3.deberta_v3_backbone import DebertaV3Backbone\nfrom keras_nlp.models.deberta_v3.deberta_v3_backbone import (\n deberta_kernel_initializer,\n)\nfrom keras_nlp.models.deberta_v3.deberta_v3_masked_lm_preprocessor import (\n DebertaV3MaskedLMPreprocessor,\n)\nfrom keras_nlp.models.deberta_v3.deberta_v3_presets import backbone_presets\nfrom keras_nlp.models.task import Task\nfrom keras_nlp.utils.python_utils import classproperty\n\n\n@keras_nlp_export(\"keras_nlp.models.DebertaV3MaskedLM\")\nclass DebertaV3MaskedLM(Task):\n \"\"\"An end-to-end DeBERTaV3 model for the masked language modeling task.\n\n This model will train DeBERTaV3 on a masked language modeling task.\n The model will predict labels for a number of masked tokens in the\n input data. For usage of this model with pre-trained weights, see the\n `from_preset()` method.\n\n This model can optionally be configured with a `preprocessor` layer, in\n which case inputs can be raw string features during `fit()`, `predict()`,\n and `evaluate()`. Inputs will be tokenized and dynamically masked during\n training and evaluation. This is done by default when creating the model\n with `from_preset()`.\n\n Disclaimer: Pre-trained models are provided on an \"as is\" basis, without\n warranties or conditions of any kind. The underlying model is provided by a\n third party and subject to a separate license, available\n [here](https://github.com/microsoft/DeBERTa).\n\n Args:\n backbone: A `keras_nlp.models.DebertaV3Backbone` instance.\n preprocessor: A `keras_nlp.models.DebertaV3MaskedLMPreprocessor` or\n `None`. If `None`, this model will not apply preprocessing, and\n inputs should be preprocessed before calling the model.\n\n Example usage:\n\n Raw string inputs and pretrained backbone.\n ```python\n # Create a dataset with raw string features. Labels are inferred.\n features = [\"The quick brown fox jumped.\", \"I forgot my homework.\"]\n\n # Create a DebertaV3MaskedLM with a pretrained backbone and further train\n # on an MLM task.\n masked_lm = keras_nlp.models.DebertaV3MaskedLM.from_preset(\n \"deberta_v3_base_en\",\n )\n masked_lm.compile(\n loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n )\n masked_lm.fit(x=features, batch_size=2)\n ```\n\n Preprocessed inputs and custom backbone.\n ```python\n # Create a preprocessed dataset where 0 is the mask token.\n preprocessed_features = {\n \"token_ids\": tf.constant(\n [[1, 2, 0, 4, 0, 6, 7, 8]] * 2, shape=(2, 8)\n ),\n \"padding_mask\": tf.constant(\n [[1, 1, 1, 1, 1, 1, 1, 1]] * 2, shape=(2, 8)\n ),\n \"mask_positions\": tf.constant([[2, 4]] * 2, shape=(2, 2))\n }\n # Labels are the original masked values.\n labels = [[3, 5]] * 2\n\n # Randomly initialize a DeBERTaV3 encoder\n backbone = keras_nlp.models.DebertaV3Backbone(\n vocabulary_size=50265,\n num_layers=12,\n num_heads=12,\n hidden_dim=768,\n intermediate_dim=3072,\n max_sequence_length=12\n )\n # Create a DeBERTaV3 masked_lm and fit the data.\n masked_lm = keras_nlp.models.DebertaV3MaskedLM(\n backbone,\n preprocessor=None,\n )\n masked_lm.compile(\n loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True),\n )\n masked_lm.fit(x=preprocessed_features, y=labels, batch_size=2)\n ```\n \"\"\"\n\n def __init__(\n self,\n backbone,\n preprocessor=None,\n **kwargs,\n ):\n inputs = {\n **backbone.input,\n \"mask_positions\": keras.Input(\n shape=(None,), dtype=\"int32\", name=\"mask_positions\"\n ),\n }\n backbone_outputs = backbone(backbone.input)\n outputs = MaskedLMHead(\n vocabulary_size=backbone.vocabulary_size,\n embedding_weights=backbone.token_embedding.embeddings,\n intermediate_activation=lambda x: keras.activations.gelu(\n x, approximate=False\n ),\n kernel_initializer=deberta_kernel_initializer(),\n name=\"mlm_head\",\n )(backbone_outputs, inputs[\"mask_positions\"])\n\n # Instantiate using Functional API Model constructor\n super().__init__(\n inputs=inputs,\n outputs=outputs,\n include_preprocessing=preprocessor is not None,\n **kwargs,\n )\n # All references to `self` below this line\n self.backbone = backbone\n self.preprocessor = preprocessor\n\n @classproperty\n def backbone_cls(cls):\n return DebertaV3Backbone\n\n @classproperty\n def preprocessor_cls(cls):\n return DebertaV3MaskedLMPreprocessor\n\n @classproperty\n def presets(cls):\n return copy.deepcopy(backbone_presets)\n", "path": "keras_nlp/models/deberta_v3/deberta_v3_masked_lm.py"}]}
| 2,623 | 281 |
gh_patches_debug_26342
|
rasdani/github-patches
|
git_diff
|
zalando__patroni-1535
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
features/steps/standby_cluster.py produces error under Windows
Trying to execute:
`>behave -i standby_cluster.feature`
will produce error:
```
2020-05-07 19:27:19,407 ERROR: Failed to execute ['c:userspashaappdatalocalprogramspythonpython37-32python.exe', 'features/callback.py', '5362', 'on_role_change', 'master', 'batman']
Traceback (most recent call last):
File "C:\Users\pasha\Code\zalando-patroni\patroni\postgresql\cancellable.py", line 28, in _start_process
self._process = psutil.Popen(cmd, *args, **kwargs)
File "c:\users\pasha\appdata\local\programs\python\python37-32\lib\site-packages\psutil\__init__.py", line 1431, in __init__
self.__subproc = subprocess.Popen(*args, **kwargs)
File "c:\users\pasha\appdata\local\programs\python\python37-32\lib\subprocess.py", line 775, in __init__
restore_signals, start_new_session)
File "c:\users\pasha\appdata\local\programs\python\python37-32\lib\subprocess.py", line 1178, in _execute_child
startupinfo)
FileNotFoundError: [WinError 2] The system cannot find the file specified
```
This error produced by `postgresql/cancellable.py`:
```
def _start_process(self, cmd, *args, **kwargs):
"""This method must be executed only when the `_lock` is acquired"""
try:
self._process_children = []
self._process_cmd = cmd
self._process = psutil.Popen(cmd, *args, **kwargs)
^^^^^^^^^^^^^^^^^
except Exception:
return logger.exception('Failed to execute %s', cmd)
return True
```
</issue>
<code>
[start of features/steps/standby_cluster.py]
1 import os
2 import sys
3 import time
4
5 from behave import step
6
7
8 select_replication_query = """
9 SELECT * FROM pg_catalog.pg_stat_replication
10 WHERE application_name = '{0}'
11 """
12
13 callback = sys.executable + " features/callback2.py "
14
15
16 @step('I start {name:w} with callback configured')
17 def start_patroni_with_callbacks(context, name):
18 return context.pctl.start(name, custom_config={
19 "postgresql": {
20 "callbacks": {
21 "on_role_change": sys.executable + " features/callback.py"
22 }
23 }
24 })
25
26
27 @step('I start {name:w} in a cluster {cluster_name:w}')
28 def start_patroni(context, name, cluster_name):
29 return context.pctl.start(name, custom_config={
30 "scope": cluster_name,
31 "postgresql": {
32 "callbacks": {c: callback + name for c in ('on_start', 'on_stop', 'on_restart', 'on_role_change')},
33 "backup_restore": {
34 "command": (sys.executable + " features/backup_restore.py --sourcedir=" +
35 os.path.join(context.pctl.patroni_path, 'data', 'basebackup'))}
36 }
37 })
38
39
40 @step('I start {name:w} in a standby cluster {cluster_name:w} as a clone of {name2:w}')
41 def start_patroni_standby_cluster(context, name, cluster_name, name2):
42 # we need to remove patroni.dynamic.json in order to "bootstrap" standby cluster with existing PGDATA
43 os.unlink(os.path.join(context.pctl._processes[name]._data_dir, 'patroni.dynamic.json'))
44 port = context.pctl._processes[name2]._connkwargs.get('port')
45 context.pctl._processes[name].update_config({
46 "scope": cluster_name,
47 "bootstrap": {
48 "dcs": {
49 "ttl": 20,
50 "loop_wait": 2,
51 "retry_timeout": 5,
52 "standby_cluster": {
53 "host": "localhost",
54 "port": port,
55 "primary_slot_name": "pm_1",
56 "create_replica_methods": ["backup_restore", "basebackup"]
57 }
58 }
59 },
60 "postgresql": {
61 "callbacks": {c: callback + name for c in ('on_start', 'on_stop', 'on_restart', 'on_role_change')}
62 }
63 })
64 return context.pctl.start(name)
65
66
67 @step('{pg_name1:w} is replicating from {pg_name2:w} after {timeout:d} seconds')
68 def check_replication_status(context, pg_name1, pg_name2, timeout):
69 bound_time = time.time() + timeout
70
71 while time.time() < bound_time:
72 cur = context.pctl.query(
73 pg_name2,
74 select_replication_query.format(pg_name1),
75 fail_ok=True
76 )
77
78 if cur and len(cur.fetchall()) != 0:
79 break
80
81 time.sleep(1)
82 else:
83 assert False, "{0} is not replicating from {1} after {2} seconds".format(pg_name1, pg_name2, timeout)
84
[end of features/steps/standby_cluster.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/features/steps/standby_cluster.py b/features/steps/standby_cluster.py
--- a/features/steps/standby_cluster.py
+++ b/features/steps/standby_cluster.py
@@ -10,7 +10,8 @@
WHERE application_name = '{0}'
"""
-callback = sys.executable + " features/callback2.py "
+executable = sys.executable if os.name != 'nt' else sys.executable.replace('\\', '/')
+callback = executable + " features/callback2.py "
@step('I start {name:w} with callback configured')
@@ -18,7 +19,7 @@
return context.pctl.start(name, custom_config={
"postgresql": {
"callbacks": {
- "on_role_change": sys.executable + " features/callback.py"
+ "on_role_change": executable + " features/callback.py"
}
}
})
@@ -31,7 +32,7 @@
"postgresql": {
"callbacks": {c: callback + name for c in ('on_start', 'on_stop', 'on_restart', 'on_role_change')},
"backup_restore": {
- "command": (sys.executable + " features/backup_restore.py --sourcedir=" +
+ "command": (executable + " features/backup_restore.py --sourcedir=" +
os.path.join(context.pctl.patroni_path, 'data', 'basebackup'))}
}
})
|
{"golden_diff": "diff --git a/features/steps/standby_cluster.py b/features/steps/standby_cluster.py\n--- a/features/steps/standby_cluster.py\n+++ b/features/steps/standby_cluster.py\n@@ -10,7 +10,8 @@\n WHERE application_name = '{0}'\n \"\"\"\n \n-callback = sys.executable + \" features/callback2.py \"\n+executable = sys.executable if os.name != 'nt' else sys.executable.replace('\\\\', '/')\n+callback = executable + \" features/callback2.py \"\n \n \n @step('I start {name:w} with callback configured')\n@@ -18,7 +19,7 @@\n return context.pctl.start(name, custom_config={\n \"postgresql\": {\n \"callbacks\": {\n- \"on_role_change\": sys.executable + \" features/callback.py\"\n+ \"on_role_change\": executable + \" features/callback.py\"\n }\n }\n })\n@@ -31,7 +32,7 @@\n \"postgresql\": {\n \"callbacks\": {c: callback + name for c in ('on_start', 'on_stop', 'on_restart', 'on_role_change')},\n \"backup_restore\": {\n- \"command\": (sys.executable + \" features/backup_restore.py --sourcedir=\" +\n+ \"command\": (executable + \" features/backup_restore.py --sourcedir=\" +\n os.path.join(context.pctl.patroni_path, 'data', 'basebackup'))}\n }\n })\n", "issue": "features/steps/standby_cluster.py produces error under Windows\nTrying to execute:\r\n`>behave -i standby_cluster.feature`\r\nwill produce error:\r\n```\r\n2020-05-07 19:27:19,407 ERROR: Failed to execute ['c:userspashaappdatalocalprogramspythonpython37-32python.exe', 'features/callback.py', '5362', 'on_role_change', 'master', 'batman']\r\nTraceback (most recent call last):\r\n File \"C:\\Users\\pasha\\Code\\zalando-patroni\\patroni\\postgresql\\cancellable.py\", line 28, in _start_process\r\n self._process = psutil.Popen(cmd, *args, **kwargs)\r\n File \"c:\\users\\pasha\\appdata\\local\\programs\\python\\python37-32\\lib\\site-packages\\psutil\\__init__.py\", line 1431, in __init__\r\n self.__subproc = subprocess.Popen(*args, **kwargs)\r\n File \"c:\\users\\pasha\\appdata\\local\\programs\\python\\python37-32\\lib\\subprocess.py\", line 775, in __init__\r\n restore_signals, start_new_session)\r\n File \"c:\\users\\pasha\\appdata\\local\\programs\\python\\python37-32\\lib\\subprocess.py\", line 1178, in _execute_child\r\n startupinfo)\r\nFileNotFoundError: [WinError 2] The system cannot find the file specified\r\n```\r\n\r\nThis error produced by `postgresql/cancellable.py`: \r\n```\r\n def _start_process(self, cmd, *args, **kwargs):\r\n \"\"\"This method must be executed only when the `_lock` is acquired\"\"\"\r\n\r\n try:\r\n self._process_children = []\r\n self._process_cmd = cmd\r\n self._process = psutil.Popen(cmd, *args, **kwargs)\r\n ^^^^^^^^^^^^^^^^^\r\n except Exception:\r\n return logger.exception('Failed to execute %s', cmd)\r\n return True\r\n```\r\n\n", "before_files": [{"content": "import os\nimport sys\nimport time\n\nfrom behave import step\n\n\nselect_replication_query = \"\"\"\nSELECT * FROM pg_catalog.pg_stat_replication\nWHERE application_name = '{0}'\n\"\"\"\n\ncallback = sys.executable + \" features/callback2.py \"\n\n\n@step('I start {name:w} with callback configured')\ndef start_patroni_with_callbacks(context, name):\n return context.pctl.start(name, custom_config={\n \"postgresql\": {\n \"callbacks\": {\n \"on_role_change\": sys.executable + \" features/callback.py\"\n }\n }\n })\n\n\n@step('I start {name:w} in a cluster {cluster_name:w}')\ndef start_patroni(context, name, cluster_name):\n return context.pctl.start(name, custom_config={\n \"scope\": cluster_name,\n \"postgresql\": {\n \"callbacks\": {c: callback + name for c in ('on_start', 'on_stop', 'on_restart', 'on_role_change')},\n \"backup_restore\": {\n \"command\": (sys.executable + \" features/backup_restore.py --sourcedir=\" +\n os.path.join(context.pctl.patroni_path, 'data', 'basebackup'))}\n }\n })\n\n\n@step('I start {name:w} in a standby cluster {cluster_name:w} as a clone of {name2:w}')\ndef start_patroni_standby_cluster(context, name, cluster_name, name2):\n # we need to remove patroni.dynamic.json in order to \"bootstrap\" standby cluster with existing PGDATA\n os.unlink(os.path.join(context.pctl._processes[name]._data_dir, 'patroni.dynamic.json'))\n port = context.pctl._processes[name2]._connkwargs.get('port')\n context.pctl._processes[name].update_config({\n \"scope\": cluster_name,\n \"bootstrap\": {\n \"dcs\": {\n \"ttl\": 20,\n \"loop_wait\": 2,\n \"retry_timeout\": 5,\n \"standby_cluster\": {\n \"host\": \"localhost\",\n \"port\": port,\n \"primary_slot_name\": \"pm_1\",\n \"create_replica_methods\": [\"backup_restore\", \"basebackup\"]\n }\n }\n },\n \"postgresql\": {\n \"callbacks\": {c: callback + name for c in ('on_start', 'on_stop', 'on_restart', 'on_role_change')}\n }\n })\n return context.pctl.start(name)\n\n\n@step('{pg_name1:w} is replicating from {pg_name2:w} after {timeout:d} seconds')\ndef check_replication_status(context, pg_name1, pg_name2, timeout):\n bound_time = time.time() + timeout\n\n while time.time() < bound_time:\n cur = context.pctl.query(\n pg_name2,\n select_replication_query.format(pg_name1),\n fail_ok=True\n )\n\n if cur and len(cur.fetchall()) != 0:\n break\n\n time.sleep(1)\n else:\n assert False, \"{0} is not replicating from {1} after {2} seconds\".format(pg_name1, pg_name2, timeout)\n", "path": "features/steps/standby_cluster.py"}]}
| 1,834 | 313 |
gh_patches_debug_654
|
rasdani/github-patches
|
git_diff
|
pex-tool__pex-2123
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Release 2.1.133
On the docket:
+ [x] python<=3.8 symlink with a suffix (eg 3.7m) can create a venv without a pythonX.Y symlink which breaks pex assumptions that pythonX.Y is always available #2119
</issue>
<code>
[start of pex/version.py]
1 # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
2 # Licensed under the Apache License, Version 2.0 (see LICENSE).
3
4 __version__ = "2.1.132"
5
[end of pex/version.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/pex/version.py b/pex/version.py
--- a/pex/version.py
+++ b/pex/version.py
@@ -1,4 +1,4 @@
# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).
# Licensed under the Apache License, Version 2.0 (see LICENSE).
-__version__ = "2.1.132"
+__version__ = "2.1.133"
|
{"golden_diff": "diff --git a/pex/version.py b/pex/version.py\n--- a/pex/version.py\n+++ b/pex/version.py\n@@ -1,4 +1,4 @@\n # Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n # Licensed under the Apache License, Version 2.0 (see LICENSE).\n \n-__version__ = \"2.1.132\"\n+__version__ = \"2.1.133\"\n", "issue": "Release 2.1.133\nOn the docket:\r\n+ [x] python<=3.8 symlink with a suffix (eg 3.7m) can create a venv without a pythonX.Y symlink which breaks pex assumptions that pythonX.Y is always available #2119\n", "before_files": [{"content": "# Copyright 2015 Pants project contributors (see CONTRIBUTORS.md).\n# Licensed under the Apache License, Version 2.0 (see LICENSE).\n\n__version__ = \"2.1.132\"\n", "path": "pex/version.py"}]}
| 648 | 98 |
gh_patches_debug_8786
|
rasdani/github-patches
|
git_diff
|
Flexget__Flexget-1369
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Discover from iptorrents: 'NoneType' object has no attribute 'findAll'
The `iptorrents` plugin is unable to find and produce entries from searches.
### Expected behaviour:
Expected search plugin `iptorrents` to produce entries when used with `discover`.
### Actual behaviour:
Critical error was returned, see below:
```
2016-08-25 02:59 VERBOSE discover search_movies Searching for `The Dark Knight Rises (2012)` with plugin `iptorrents` (1 of 1)
2016-08-25 02:59 CRITICAL task search_movies BUG: Unhandled error in plugin discover: 'NoneType' object has no attribute 'findAll'
Traceback (most recent call last):
File "/usr/local/python/lib/python2.7/site-packages/flexget/task.py", line 472, in __run_plugin
return method(*args, **kwargs)
File "/usr/local/python/lib/python2.7/site-packages/flexget/event.py", line 23, in __call__
return self.func(*args, **kwargs)
File "/usr/local/python/lib/python2.7/site-packages/flexget/plugins/input/discover.py", line 290, in on_task_input
return self.execute_searches(config, entries, task)
File "/usr/local/python/lib/python2.7/site-packages/flexget/plugins/input/discover.py", line 155, in execute_searches
search_results = search.search(task=task, entry=entry, config=plugin_config)
File "/usr/local/python/lib/python2.7/site-packages/flexget/plugin.py", line 118, in wrapped_func
return func(*args, **kwargs)
File "/usr/local/python/lib/python2.7/site-packages/flexget/plugins/sites/iptorrents.py", line 146, in search
for torrent in torrents.findAll('a', href=re.compile('\.torrent$')):
AttributeError: 'NoneType' object has no attribute 'findAll'
```
#### Config:
```
...
search_movies:
discover:
what:
- movie_list: movies
from:
- iptorrents:
rss_key: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
uid: xxxxxxx
password: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
category:
- Movie-HD-Bluray
...
```
### Additional information:
- Flexget Version: 2.3.5
- Python Version: 2.7.12
Discover from iptorrents: 'NoneType' object has no attribute 'findAll'
The `iptorrents` plugin is unable to find and produce entries from searches.
### Expected behaviour:
Expected search plugin `iptorrents` to produce entries when used with `discover`.
### Actual behaviour:
Critical error was returned, see below:
```
2016-08-25 02:59 VERBOSE discover search_movies Searching for `The Dark Knight Rises (2012)` with plugin `iptorrents` (1 of 1)
2016-08-25 02:59 CRITICAL task search_movies BUG: Unhandled error in plugin discover: 'NoneType' object has no attribute 'findAll'
Traceback (most recent call last):
File "/usr/local/python/lib/python2.7/site-packages/flexget/task.py", line 472, in __run_plugin
return method(*args, **kwargs)
File "/usr/local/python/lib/python2.7/site-packages/flexget/event.py", line 23, in __call__
return self.func(*args, **kwargs)
File "/usr/local/python/lib/python2.7/site-packages/flexget/plugins/input/discover.py", line 290, in on_task_input
return self.execute_searches(config, entries, task)
File "/usr/local/python/lib/python2.7/site-packages/flexget/plugins/input/discover.py", line 155, in execute_searches
search_results = search.search(task=task, entry=entry, config=plugin_config)
File "/usr/local/python/lib/python2.7/site-packages/flexget/plugin.py", line 118, in wrapped_func
return func(*args, **kwargs)
File "/usr/local/python/lib/python2.7/site-packages/flexget/plugins/sites/iptorrents.py", line 146, in search
for torrent in torrents.findAll('a', href=re.compile('\.torrent$')):
AttributeError: 'NoneType' object has no attribute 'findAll'
```
#### Config:
```
...
search_movies:
discover:
what:
- movie_list: movies
from:
- iptorrents:
rss_key: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
uid: xxxxxxx
password: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
category:
- Movie-HD-Bluray
...
```
### Additional information:
- Flexget Version: 2.3.5
- Python Version: 2.7.12
</issue>
<code>
[start of flexget/plugins/sites/iptorrents.py]
1 from __future__ import unicode_literals, division, absolute_import
2 from builtins import * # pylint: disable=unused-import, redefined-builtin
3 from future.moves.urllib.parse import quote_plus
4
5 import re
6 import logging
7
8 from flexget import plugin
9 from flexget.config_schema import one_or_more
10 from flexget.entry import Entry
11 from flexget.event import event
12 from flexget.plugins.internal.urlrewriting import UrlRewritingError
13 from flexget.utils import requests
14 from flexget.utils.soup import get_soup
15 from flexget.utils.search import torrent_availability, normalize_unicode
16 from flexget.utils.tools import parse_filesize
17
18 log = logging.getLogger('iptorrents')
19
20 CATEGORIES = {
21
22 # Movies
23 'Movie-all': 72,
24 'Movie-3D': 87,
25 'Movie-480p': 77,
26 'Movie-BD-R': 89,
27 'Movie-BD-Rip': 90,
28 'Movie-DVD-R': 6,
29 'Movie-HD-Bluray': 48,
30 'Movie-Kids': 54,
31 'Movie-MP4': 62,
32 'Movie-Non-English': 38,
33 'Movie-Packs': 68,
34 'Movie-XviD': 17,
35
36 # TV
37 'TV-all': 73,
38 'TV-Sports': 55,
39 'TV-480p': 78,
40 'TV-MP4': 66,
41 'TV-Non-English': 82,
42 'TV-Packs': 65,
43 'TV-Packs-Non-English': 83,
44 'TV-SD-x264': 79,
45 'TV-x264': 5,
46 'TV-XVID': 4,
47 'TV-Web-DL': 22
48 }
49
50 BASE_URL = 'https://iptorrents.com'
51
52
53 class UrlRewriteIPTorrents(object):
54 """
55 IpTorrents urlrewriter and search plugin.
56
57 iptorrents:
58 rss_key: xxxxxxxxx (required)
59 uid: xxxxxxxx (required)
60 password: xxxxxxxx (required)
61 category: HD
62
63 Category is any combination of: all, Movie-3D, Movie-480p, Movie-3D,
64 Movie-480p, Movie-BD-R, Movie-BD-Rip, Movie-DVD-R,
65 Movie-HD-Bluray, Movie-Kids, Movie-MP4,
66 Movie-Non-English, Movie-Packs, Movie-XviD,
67
68 TV-all, TV-Sports, TV-480p, TV-MP4, TV-Non-English, TV-Packs,
69 TV-Packs-Non-English, TV-SD-x264, TV-x264, TV-XVID, TV-Web-DL
70 """
71
72 schema = {
73 'type': 'object',
74 'properties': {
75 'rss_key': {'type': 'string'},
76 'uid': {'oneOf': [
77 {'type': 'integer'},
78 {'type': 'string'}
79 ]},
80 'password': {'type': 'string'},
81 'category': one_or_more({
82 'oneOf': [
83 {'type': 'integer'},
84 {'type': 'string', 'enum': list(CATEGORIES)},
85 ]}),
86 },
87 'required': ['rss_key', 'uid', 'password'],
88 'additionalProperties': False
89 }
90
91 # urlrewriter API
92 def url_rewritable(self, task, entry):
93 url = entry['url']
94 if url.startswith(BASE_URL + '/download.php/'):
95 return False
96 if url.startswith(BASE_URL + '/'):
97 return True
98 return False
99
100 # urlrewriter API
101 def url_rewrite(self, task, entry):
102 if 'url' not in entry:
103 log.error("Didn't actually get a URL...")
104 else:
105 log.debug("Got the URL: %s" % entry['url'])
106 if entry['url'].startswith(BASE_URL + '/t?'):
107 # use search
108 results = self.search(task, entry)
109 if not results:
110 raise UrlRewritingError("No search results found")
111 # TODO: Search doesn't enforce close match to title, be more picky
112 entry['url'] = results[0]['url']
113
114 @plugin.internet(log)
115 def search(self, task, entry, config=None):
116 """
117 Search for name from iptorrents
118 """
119
120 categories = config.get('category', 'all')
121 # Make sure categories is a list
122 if not isinstance(categories, list):
123 categories = [categories]
124
125 # If there are any text categories, turn them into their id number
126 categories = [c if isinstance(c, int) else CATEGORIES[c]
127 for c in categories]
128 filter_url = '&'.join((str(c) + '=') for c in categories)
129
130 entries = set()
131
132 for search_string in entry.get('search_strings', [entry['title']]):
133 query = normalize_unicode(search_string)
134 query = quote_plus(query.encode('utf8'))
135
136 url = "{base_url}/t?{filter}&q={query}&qf=".format(base_url=BASE_URL, filter=filter_url, query=query)
137 log.debug('searching with url: %s' % url)
138 req = requests.get(url, cookies={'uid': str(config['uid']), 'pass': config['password']})
139
140 if '/u/' + str(config.get('uid')) not in req.content:
141 raise plugin.PluginError("Invalid cookies (user not logged in)...")
142
143 soup = get_soup(req.content, parser="html.parser")
144 torrents = soup.find('table', {'class': 'torrents'})
145
146 for torrent in torrents.findAll('a', href=re.compile('\.torrent$')):
147 entry = Entry()
148 entry['url'] = "{base}{link}?torrent_pass={key}".format(
149 base=BASE_URL, link=torrent['href'], key=config.get('rss_key'))
150 entry['title'] = torrent.findPrevious("a", attrs={'class': 't_title'}).text
151
152 seeders = torrent.findNext('td', {'class': 'ac t_seeders'}).text
153 leechers = torrent.findNext('td', {'class': 'ac t_leechers'}).text
154 entry['torrent_seeds'] = int(seeders)
155 entry['torrent_leeches'] = int(leechers)
156 entry['search_sort'] = torrent_availability(entry['torrent_seeds'],
157 entry['torrent_leeches'])
158
159 size = torrent.findNext(text=re.compile('^([\.\d]+) ([GMK]?)B$'))
160 size = re.search('^([\.\d]+) ([GMK]?)B$', size)
161
162 entry['content_size'] = parse_filesize(size.group(0))
163
164 entries.add(entry)
165
166 return entries
167
168
169 @event('plugin.register')
170 def register_plugin():
171 plugin.register(UrlRewriteIPTorrents, 'iptorrents', groups=['urlrewriter', 'search'], api_ver=2)
172
[end of flexget/plugins/sites/iptorrents.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/flexget/plugins/sites/iptorrents.py b/flexget/plugins/sites/iptorrents.py
--- a/flexget/plugins/sites/iptorrents.py
+++ b/flexget/plugins/sites/iptorrents.py
@@ -141,7 +141,7 @@
raise plugin.PluginError("Invalid cookies (user not logged in)...")
soup = get_soup(req.content, parser="html.parser")
- torrents = soup.find('table', {'class': 'torrents'})
+ torrents = soup.find('table', {'id': 'torrents'})
for torrent in torrents.findAll('a', href=re.compile('\.torrent$')):
entry = Entry()
|
{"golden_diff": "diff --git a/flexget/plugins/sites/iptorrents.py b/flexget/plugins/sites/iptorrents.py\n--- a/flexget/plugins/sites/iptorrents.py\n+++ b/flexget/plugins/sites/iptorrents.py\n@@ -141,7 +141,7 @@\n raise plugin.PluginError(\"Invalid cookies (user not logged in)...\")\n \n soup = get_soup(req.content, parser=\"html.parser\")\n- torrents = soup.find('table', {'class': 'torrents'})\n+ torrents = soup.find('table', {'id': 'torrents'})\n \n for torrent in torrents.findAll('a', href=re.compile('\\.torrent$')):\n entry = Entry()\n", "issue": "Discover from iptorrents: 'NoneType' object has no attribute 'findAll'\nThe `iptorrents` plugin is unable to find and produce entries from searches.\n### Expected behaviour:\n\nExpected search plugin `iptorrents` to produce entries when used with `discover`.\n### Actual behaviour:\n\nCritical error was returned, see below:\n\n```\n2016-08-25 02:59 VERBOSE discover search_movies Searching for `The Dark Knight Rises (2012)` with plugin `iptorrents` (1 of 1)\n2016-08-25 02:59 CRITICAL task search_movies BUG: Unhandled error in plugin discover: 'NoneType' object has no attribute 'findAll'\nTraceback (most recent call last):\n File \"/usr/local/python/lib/python2.7/site-packages/flexget/task.py\", line 472, in __run_plugin\n return method(*args, **kwargs)\n File \"/usr/local/python/lib/python2.7/site-packages/flexget/event.py\", line 23, in __call__\n return self.func(*args, **kwargs)\n File \"/usr/local/python/lib/python2.7/site-packages/flexget/plugins/input/discover.py\", line 290, in on_task_input\n return self.execute_searches(config, entries, task)\n File \"/usr/local/python/lib/python2.7/site-packages/flexget/plugins/input/discover.py\", line 155, in execute_searches\n search_results = search.search(task=task, entry=entry, config=plugin_config)\n File \"/usr/local/python/lib/python2.7/site-packages/flexget/plugin.py\", line 118, in wrapped_func\n return func(*args, **kwargs)\n File \"/usr/local/python/lib/python2.7/site-packages/flexget/plugins/sites/iptorrents.py\", line 146, in search\n for torrent in torrents.findAll('a', href=re.compile('\\.torrent$')):\nAttributeError: 'NoneType' object has no attribute 'findAll'\n```\n#### Config:\n\n```\n...\n search_movies:\n discover:\n what:\n - movie_list: movies\n from:\n - iptorrents:\n rss_key: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx\n uid: xxxxxxx\n password: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx\n category:\n - Movie-HD-Bluray\n... \n```\n### Additional information:\n- Flexget Version: 2.3.5\n- Python Version: 2.7.12\n\nDiscover from iptorrents: 'NoneType' object has no attribute 'findAll'\nThe `iptorrents` plugin is unable to find and produce entries from searches.\n### Expected behaviour:\n\nExpected search plugin `iptorrents` to produce entries when used with `discover`.\n### Actual behaviour:\n\nCritical error was returned, see below:\n\n```\n2016-08-25 02:59 VERBOSE discover search_movies Searching for `The Dark Knight Rises (2012)` with plugin `iptorrents` (1 of 1)\n2016-08-25 02:59 CRITICAL task search_movies BUG: Unhandled error in plugin discover: 'NoneType' object has no attribute 'findAll'\nTraceback (most recent call last):\n File \"/usr/local/python/lib/python2.7/site-packages/flexget/task.py\", line 472, in __run_plugin\n return method(*args, **kwargs)\n File \"/usr/local/python/lib/python2.7/site-packages/flexget/event.py\", line 23, in __call__\n return self.func(*args, **kwargs)\n File \"/usr/local/python/lib/python2.7/site-packages/flexget/plugins/input/discover.py\", line 290, in on_task_input\n return self.execute_searches(config, entries, task)\n File \"/usr/local/python/lib/python2.7/site-packages/flexget/plugins/input/discover.py\", line 155, in execute_searches\n search_results = search.search(task=task, entry=entry, config=plugin_config)\n File \"/usr/local/python/lib/python2.7/site-packages/flexget/plugin.py\", line 118, in wrapped_func\n return func(*args, **kwargs)\n File \"/usr/local/python/lib/python2.7/site-packages/flexget/plugins/sites/iptorrents.py\", line 146, in search\n for torrent in torrents.findAll('a', href=re.compile('\\.torrent$')):\nAttributeError: 'NoneType' object has no attribute 'findAll'\n```\n#### Config:\n\n```\n...\n search_movies:\n discover:\n what:\n - movie_list: movies\n from:\n - iptorrents:\n rss_key: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx\n uid: xxxxxxx\n password: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx\n category:\n - Movie-HD-Bluray\n... \n```\n### Additional information:\n- Flexget Version: 2.3.5\n- Python Version: 2.7.12\n\n", "before_files": [{"content": "from __future__ import unicode_literals, division, absolute_import\nfrom builtins import * # pylint: disable=unused-import, redefined-builtin\nfrom future.moves.urllib.parse import quote_plus\n\nimport re\nimport logging\n\nfrom flexget import plugin\nfrom flexget.config_schema import one_or_more\nfrom flexget.entry import Entry\nfrom flexget.event import event\nfrom flexget.plugins.internal.urlrewriting import UrlRewritingError\nfrom flexget.utils import requests\nfrom flexget.utils.soup import get_soup\nfrom flexget.utils.search import torrent_availability, normalize_unicode\nfrom flexget.utils.tools import parse_filesize\n\nlog = logging.getLogger('iptorrents')\n\nCATEGORIES = {\n\n # Movies\n 'Movie-all': 72,\n 'Movie-3D': 87,\n 'Movie-480p': 77,\n 'Movie-BD-R': 89,\n 'Movie-BD-Rip': 90,\n 'Movie-DVD-R': 6,\n 'Movie-HD-Bluray': 48,\n 'Movie-Kids': 54,\n 'Movie-MP4': 62,\n 'Movie-Non-English': 38,\n 'Movie-Packs': 68,\n 'Movie-XviD': 17,\n\n # TV\n 'TV-all': 73,\n 'TV-Sports': 55,\n 'TV-480p': 78,\n 'TV-MP4': 66,\n 'TV-Non-English': 82,\n 'TV-Packs': 65,\n 'TV-Packs-Non-English': 83,\n 'TV-SD-x264': 79,\n 'TV-x264': 5,\n 'TV-XVID': 4,\n 'TV-Web-DL': 22\n}\n\nBASE_URL = 'https://iptorrents.com'\n\n\nclass UrlRewriteIPTorrents(object):\n \"\"\"\n IpTorrents urlrewriter and search plugin.\n\n iptorrents:\n rss_key: xxxxxxxxx (required)\n uid: xxxxxxxx (required)\n password: xxxxxxxx (required)\n category: HD\n\n Category is any combination of: all, Movie-3D, Movie-480p, Movie-3D,\n Movie-480p, Movie-BD-R, Movie-BD-Rip, Movie-DVD-R,\n Movie-HD-Bluray, Movie-Kids, Movie-MP4,\n Movie-Non-English, Movie-Packs, Movie-XviD,\n\n TV-all, TV-Sports, TV-480p, TV-MP4, TV-Non-English, TV-Packs,\n TV-Packs-Non-English, TV-SD-x264, TV-x264, TV-XVID, TV-Web-DL\n \"\"\"\n\n schema = {\n 'type': 'object',\n 'properties': {\n 'rss_key': {'type': 'string'},\n 'uid': {'oneOf': [\n {'type': 'integer'},\n {'type': 'string'}\n ]},\n 'password': {'type': 'string'},\n 'category': one_or_more({\n 'oneOf': [\n {'type': 'integer'},\n {'type': 'string', 'enum': list(CATEGORIES)},\n ]}),\n },\n 'required': ['rss_key', 'uid', 'password'],\n 'additionalProperties': False\n }\n\n # urlrewriter API\n def url_rewritable(self, task, entry):\n url = entry['url']\n if url.startswith(BASE_URL + '/download.php/'):\n return False\n if url.startswith(BASE_URL + '/'):\n return True\n return False\n\n # urlrewriter API\n def url_rewrite(self, task, entry):\n if 'url' not in entry:\n log.error(\"Didn't actually get a URL...\")\n else:\n log.debug(\"Got the URL: %s\" % entry['url'])\n if entry['url'].startswith(BASE_URL + '/t?'):\n # use search\n results = self.search(task, entry)\n if not results:\n raise UrlRewritingError(\"No search results found\")\n # TODO: Search doesn't enforce close match to title, be more picky\n entry['url'] = results[0]['url']\n\n @plugin.internet(log)\n def search(self, task, entry, config=None):\n \"\"\"\n Search for name from iptorrents\n \"\"\"\n\n categories = config.get('category', 'all')\n # Make sure categories is a list\n if not isinstance(categories, list):\n categories = [categories]\n\n # If there are any text categories, turn them into their id number\n categories = [c if isinstance(c, int) else CATEGORIES[c]\n for c in categories]\n filter_url = '&'.join((str(c) + '=') for c in categories)\n\n entries = set()\n\n for search_string in entry.get('search_strings', [entry['title']]):\n query = normalize_unicode(search_string)\n query = quote_plus(query.encode('utf8'))\n\n url = \"{base_url}/t?{filter}&q={query}&qf=\".format(base_url=BASE_URL, filter=filter_url, query=query)\n log.debug('searching with url: %s' % url)\n req = requests.get(url, cookies={'uid': str(config['uid']), 'pass': config['password']})\n\n if '/u/' + str(config.get('uid')) not in req.content:\n raise plugin.PluginError(\"Invalid cookies (user not logged in)...\")\n\n soup = get_soup(req.content, parser=\"html.parser\")\n torrents = soup.find('table', {'class': 'torrents'})\n\n for torrent in torrents.findAll('a', href=re.compile('\\.torrent$')):\n entry = Entry()\n entry['url'] = \"{base}{link}?torrent_pass={key}\".format(\n base=BASE_URL, link=torrent['href'], key=config.get('rss_key'))\n entry['title'] = torrent.findPrevious(\"a\", attrs={'class': 't_title'}).text\n\n seeders = torrent.findNext('td', {'class': 'ac t_seeders'}).text\n leechers = torrent.findNext('td', {'class': 'ac t_leechers'}).text\n entry['torrent_seeds'] = int(seeders)\n entry['torrent_leeches'] = int(leechers)\n entry['search_sort'] = torrent_availability(entry['torrent_seeds'],\n entry['torrent_leeches'])\n\n size = torrent.findNext(text=re.compile('^([\\.\\d]+) ([GMK]?)B$'))\n size = re.search('^([\\.\\d]+) ([GMK]?)B$', size)\n\n entry['content_size'] = parse_filesize(size.group(0))\n\n entries.add(entry)\n\n return entries\n\n\n@event('plugin.register')\ndef register_plugin():\n plugin.register(UrlRewriteIPTorrents, 'iptorrents', groups=['urlrewriter', 'search'], api_ver=2)\n", "path": "flexget/plugins/sites/iptorrents.py"}]}
| 3,612 | 150 |
gh_patches_debug_67097
|
rasdani/github-patches
|
git_diff
|
celery__celery-5356
|
You will be provided with a partial code base and an issue statement explaining a problem to resolve.
<issue>
Prepend to sys.path in the Django fixup instead of appending.
This makes sure that project modules have precedence over system ones.
Closes #5347.
## Description
This follows @Phyks's suggestion of a fix for #5347, by prepending instead of appending to the system path, to ensure that the project modules are not hidden by system-wide ones.
</issue>
<code>
[start of celery/fixups/django.py]
1 """Django-specific customization."""
2 from __future__ import absolute_import, unicode_literals
3
4 import os
5 import sys
6 import warnings
7 from datetime import datetime
8 from importlib import import_module
9
10 from kombu.utils.imports import symbol_by_name
11 from kombu.utils.objects import cached_property
12
13 from celery import _state, signals
14 from celery.exceptions import FixupWarning, ImproperlyConfigured
15
16 __all__ = ('DjangoFixup', 'fixup')
17
18 ERR_NOT_INSTALLED = """\
19 Environment variable DJANGO_SETTINGS_MODULE is defined
20 but Django isn't installed. Won't apply Django fix-ups!
21 """
22
23
24 def _maybe_close_fd(fh):
25 try:
26 os.close(fh.fileno())
27 except (AttributeError, OSError, TypeError):
28 # TypeError added for celery#962
29 pass
30
31
32 def _verify_django_version(django):
33 if django.VERSION < (1, 11):
34 raise ImproperlyConfigured('Celery 4.x requires Django 1.11 or later.')
35
36
37 def fixup(app, env='DJANGO_SETTINGS_MODULE'):
38 """Install Django fixup if settings module environment is set."""
39 SETTINGS_MODULE = os.environ.get(env)
40 if SETTINGS_MODULE and 'django' not in app.loader_cls.lower():
41 try:
42 import django # noqa
43 except ImportError:
44 warnings.warn(FixupWarning(ERR_NOT_INSTALLED))
45 else:
46 _verify_django_version(django)
47 return DjangoFixup(app).install()
48
49
50 class DjangoFixup(object):
51 """Fixup installed when using Django."""
52
53 def __init__(self, app):
54 self.app = app
55 if _state.default_app is None:
56 self.app.set_default()
57 self._worker_fixup = None
58
59 def install(self):
60 # Need to add project directory to path.
61 # The project directory has precedence over system modules,
62 # so we prepend it to the path.
63 sys.path.prepend(os.getcwd())
64
65 self._settings = symbol_by_name('django.conf:settings')
66 self.app.loader.now = self.now
67
68 signals.import_modules.connect(self.on_import_modules)
69 signals.worker_init.connect(self.on_worker_init)
70 return self
71
72 @property
73 def worker_fixup(self):
74 if self._worker_fixup is None:
75 self._worker_fixup = DjangoWorkerFixup(self.app)
76 return self._worker_fixup
77
78 @worker_fixup.setter
79 def worker_fixup(self, value):
80 self._worker_fixup = value
81
82 def on_import_modules(self, **kwargs):
83 # call django.setup() before task modules are imported
84 self.worker_fixup.validate_models()
85
86 def on_worker_init(self, **kwargs):
87 self.worker_fixup.install()
88
89 def now(self, utc=False):
90 return datetime.utcnow() if utc else self._now()
91
92 def autodiscover_tasks(self):
93 from django.apps import apps
94 return [config.name for config in apps.get_app_configs()]
95
96 @cached_property
97 def _now(self):
98 return symbol_by_name('django.utils.timezone:now')
99
100
101 class DjangoWorkerFixup(object):
102 _db_recycles = 0
103
104 def __init__(self, app):
105 self.app = app
106 self.db_reuse_max = self.app.conf.get('CELERY_DB_REUSE_MAX', None)
107 self._db = import_module('django.db')
108 self._cache = import_module('django.core.cache')
109 self._settings = symbol_by_name('django.conf:settings')
110
111 self.interface_errors = (
112 symbol_by_name('django.db.utils.InterfaceError'),
113 )
114 self.DatabaseError = symbol_by_name('django.db:DatabaseError')
115
116 def django_setup(self):
117 import django
118 django.setup()
119
120 def validate_models(self):
121 from django.core.checks import run_checks
122 self.django_setup()
123 run_checks()
124
125 def install(self):
126 signals.beat_embedded_init.connect(self.close_database)
127 signals.worker_ready.connect(self.on_worker_ready)
128 signals.task_prerun.connect(self.on_task_prerun)
129 signals.task_postrun.connect(self.on_task_postrun)
130 signals.worker_process_init.connect(self.on_worker_process_init)
131 self.close_database()
132 self.close_cache()
133 return self
134
135 def on_worker_process_init(self, **kwargs):
136 # Child process must validate models again if on Windows,
137 # or if they were started using execv.
138 if os.environ.get('FORKED_BY_MULTIPROCESSING'):
139 self.validate_models()
140
141 # close connections:
142 # the parent process may have established these,
143 # so need to close them.
144
145 # calling db.close() on some DB connections will cause
146 # the inherited DB conn to also get broken in the parent
147 # process so we need to remove it without triggering any
148 # network IO that close() might cause.
149 for c in self._db.connections.all():
150 if c and c.connection:
151 self._maybe_close_db_fd(c.connection)
152
153 # use the _ version to avoid DB_REUSE preventing the conn.close() call
154 self._close_database()
155 self.close_cache()
156
157 def _maybe_close_db_fd(self, fd):
158 try:
159 _maybe_close_fd(fd)
160 except self.interface_errors:
161 pass
162
163 def on_task_prerun(self, sender, **kwargs):
164 """Called before every task."""
165 if not getattr(sender.request, 'is_eager', False):
166 self.close_database()
167
168 def on_task_postrun(self, sender, **kwargs):
169 # See https://groups.google.com/group/django-users/
170 # browse_thread/thread/78200863d0c07c6d/
171 if not getattr(sender.request, 'is_eager', False):
172 self.close_database()
173 self.close_cache()
174
175 def close_database(self, **kwargs):
176 if not self.db_reuse_max:
177 return self._close_database()
178 if self._db_recycles >= self.db_reuse_max * 2:
179 self._db_recycles = 0
180 self._close_database()
181 self._db_recycles += 1
182
183 def _close_database(self):
184 for conn in self._db.connections.all():
185 try:
186 conn.close_if_unusable_or_obsolete()
187 except self.interface_errors:
188 pass
189 except self.DatabaseError as exc:
190 str_exc = str(exc)
191 if 'closed' not in str_exc and 'not connected' not in str_exc:
192 raise
193
194 def close_cache(self):
195 try:
196 self._cache.close_caches()
197 except (TypeError, AttributeError):
198 pass
199
200 def on_worker_ready(self, **kwargs):
201 if self._settings.DEBUG:
202 warnings.warn('Using settings.DEBUG leads to a memory leak, never '
203 'use this setting in production environments!')
204
[end of celery/fixups/django.py]
</code>
I need you to solve this issue by generating a single patch file that I can apply directly to this repository using git apply. Please respond with a single patch file in the following format.
<patch>
diff --git a/file.py b/file.py
--- a/file.py
+++ b/file.py
@@ -1,27 +1,35 @@
def euclidean(a, b):
- while b:
- a, b = b, a % b
- return a
+ if b == 0:
+ return a
+ return euclidean(b, a % b)
def bresenham(x0, y0, x1, y1):
points = []
dx = abs(x1 - x0)
dy = abs(y1 - y0)
- sx = 1 if x0 < x1 else -1
- sy = 1 if y0 < y1 else -1
- err = dx - dy
+ x, y = x0, y0
+ sx = -1 if x0 > x1 else 1
+ sy = -1 if y0 > y1 else 1
- while True:
- points.append((x0, y0))
- if x0 == x1 and y0 == y1:
- break
- e2 = 2 * err
- if e2 > -dy:
- err -= dy
- x0 += sx
- if e2 < dx:
- err += dx
- y0 += sy
+ if dx > dy:
+ err = dx / 2.0
+ while x != x1:
+ points.append((x, y))
+ err -= dy
+ if err < 0:
+ y += sy
+ err += dx
+ x += sx
+ else:
+ err = dy / 2.0
+ while y != y1:
+ points.append((x, y))
+ err -= dx
+ if err < 0:
+ x += sx
+ err += dy
+ y += sy
+
+ points.append((x, y))
return points
</patch>
|
diff --git a/celery/fixups/django.py b/celery/fixups/django.py
--- a/celery/fixups/django.py
+++ b/celery/fixups/django.py
@@ -60,7 +60,7 @@
# Need to add project directory to path.
# The project directory has precedence over system modules,
# so we prepend it to the path.
- sys.path.prepend(os.getcwd())
+ sys.path.insert(0, os.getcwd())
self._settings = symbol_by_name('django.conf:settings')
self.app.loader.now = self.now
|
{"golden_diff": "diff --git a/celery/fixups/django.py b/celery/fixups/django.py\n--- a/celery/fixups/django.py\n+++ b/celery/fixups/django.py\n@@ -60,7 +60,7 @@\n # Need to add project directory to path.\n # The project directory has precedence over system modules,\n # so we prepend it to the path.\n- sys.path.prepend(os.getcwd())\n+ sys.path.insert(0, os.getcwd())\n \n self._settings = symbol_by_name('django.conf:settings')\n self.app.loader.now = self.now\n", "issue": "Prepend to sys.path in the Django fixup instead of appending.\nThis makes sure that project modules have precedence over system ones.\r\nCloses #5347.\r\n\r\n## Description\r\n\r\nThis follows @Phyks's suggestion of a fix for #5347, by prepending instead of appending to the system path, to ensure that the project modules are not hidden by system-wide ones.\r\n\n", "before_files": [{"content": "\"\"\"Django-specific customization.\"\"\"\nfrom __future__ import absolute_import, unicode_literals\n\nimport os\nimport sys\nimport warnings\nfrom datetime import datetime\nfrom importlib import import_module\n\nfrom kombu.utils.imports import symbol_by_name\nfrom kombu.utils.objects import cached_property\n\nfrom celery import _state, signals\nfrom celery.exceptions import FixupWarning, ImproperlyConfigured\n\n__all__ = ('DjangoFixup', 'fixup')\n\nERR_NOT_INSTALLED = \"\"\"\\\nEnvironment variable DJANGO_SETTINGS_MODULE is defined\nbut Django isn't installed. Won't apply Django fix-ups!\n\"\"\"\n\n\ndef _maybe_close_fd(fh):\n try:\n os.close(fh.fileno())\n except (AttributeError, OSError, TypeError):\n # TypeError added for celery#962\n pass\n\n\ndef _verify_django_version(django):\n if django.VERSION < (1, 11):\n raise ImproperlyConfigured('Celery 4.x requires Django 1.11 or later.')\n\n\ndef fixup(app, env='DJANGO_SETTINGS_MODULE'):\n \"\"\"Install Django fixup if settings module environment is set.\"\"\"\n SETTINGS_MODULE = os.environ.get(env)\n if SETTINGS_MODULE and 'django' not in app.loader_cls.lower():\n try:\n import django # noqa\n except ImportError:\n warnings.warn(FixupWarning(ERR_NOT_INSTALLED))\n else:\n _verify_django_version(django)\n return DjangoFixup(app).install()\n\n\nclass DjangoFixup(object):\n \"\"\"Fixup installed when using Django.\"\"\"\n\n def __init__(self, app):\n self.app = app\n if _state.default_app is None:\n self.app.set_default()\n self._worker_fixup = None\n\n def install(self):\n # Need to add project directory to path.\n # The project directory has precedence over system modules,\n # so we prepend it to the path.\n sys.path.prepend(os.getcwd())\n\n self._settings = symbol_by_name('django.conf:settings')\n self.app.loader.now = self.now\n\n signals.import_modules.connect(self.on_import_modules)\n signals.worker_init.connect(self.on_worker_init)\n return self\n\n @property\n def worker_fixup(self):\n if self._worker_fixup is None:\n self._worker_fixup = DjangoWorkerFixup(self.app)\n return self._worker_fixup\n\n @worker_fixup.setter\n def worker_fixup(self, value):\n self._worker_fixup = value\n\n def on_import_modules(self, **kwargs):\n # call django.setup() before task modules are imported\n self.worker_fixup.validate_models()\n\n def on_worker_init(self, **kwargs):\n self.worker_fixup.install()\n\n def now(self, utc=False):\n return datetime.utcnow() if utc else self._now()\n\n def autodiscover_tasks(self):\n from django.apps import apps\n return [config.name for config in apps.get_app_configs()]\n\n @cached_property\n def _now(self):\n return symbol_by_name('django.utils.timezone:now')\n\n\nclass DjangoWorkerFixup(object):\n _db_recycles = 0\n\n def __init__(self, app):\n self.app = app\n self.db_reuse_max = self.app.conf.get('CELERY_DB_REUSE_MAX', None)\n self._db = import_module('django.db')\n self._cache = import_module('django.core.cache')\n self._settings = symbol_by_name('django.conf:settings')\n\n self.interface_errors = (\n symbol_by_name('django.db.utils.InterfaceError'),\n )\n self.DatabaseError = symbol_by_name('django.db:DatabaseError')\n\n def django_setup(self):\n import django\n django.setup()\n\n def validate_models(self):\n from django.core.checks import run_checks\n self.django_setup()\n run_checks()\n\n def install(self):\n signals.beat_embedded_init.connect(self.close_database)\n signals.worker_ready.connect(self.on_worker_ready)\n signals.task_prerun.connect(self.on_task_prerun)\n signals.task_postrun.connect(self.on_task_postrun)\n signals.worker_process_init.connect(self.on_worker_process_init)\n self.close_database()\n self.close_cache()\n return self\n\n def on_worker_process_init(self, **kwargs):\n # Child process must validate models again if on Windows,\n # or if they were started using execv.\n if os.environ.get('FORKED_BY_MULTIPROCESSING'):\n self.validate_models()\n\n # close connections:\n # the parent process may have established these,\n # so need to close them.\n\n # calling db.close() on some DB connections will cause\n # the inherited DB conn to also get broken in the parent\n # process so we need to remove it without triggering any\n # network IO that close() might cause.\n for c in self._db.connections.all():\n if c and c.connection:\n self._maybe_close_db_fd(c.connection)\n\n # use the _ version to avoid DB_REUSE preventing the conn.close() call\n self._close_database()\n self.close_cache()\n\n def _maybe_close_db_fd(self, fd):\n try:\n _maybe_close_fd(fd)\n except self.interface_errors:\n pass\n\n def on_task_prerun(self, sender, **kwargs):\n \"\"\"Called before every task.\"\"\"\n if not getattr(sender.request, 'is_eager', False):\n self.close_database()\n\n def on_task_postrun(self, sender, **kwargs):\n # See https://groups.google.com/group/django-users/\n # browse_thread/thread/78200863d0c07c6d/\n if not getattr(sender.request, 'is_eager', False):\n self.close_database()\n self.close_cache()\n\n def close_database(self, **kwargs):\n if not self.db_reuse_max:\n return self._close_database()\n if self._db_recycles >= self.db_reuse_max * 2:\n self._db_recycles = 0\n self._close_database()\n self._db_recycles += 1\n\n def _close_database(self):\n for conn in self._db.connections.all():\n try:\n conn.close_if_unusable_or_obsolete()\n except self.interface_errors:\n pass\n except self.DatabaseError as exc:\n str_exc = str(exc)\n if 'closed' not in str_exc and 'not connected' not in str_exc:\n raise\n\n def close_cache(self):\n try:\n self._cache.close_caches()\n except (TypeError, AttributeError):\n pass\n\n def on_worker_ready(self, **kwargs):\n if self._settings.DEBUG:\n warnings.warn('Using settings.DEBUG leads to a memory leak, never '\n 'use this setting in production environments!')\n", "path": "celery/fixups/django.py"}]}
| 2,587 | 134 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.